Compare commits
57 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
11c3257a18 | ||
|
|
36bffc81b3 | ||
|
|
2ee410560e | ||
|
|
1789c7daf1 | ||
|
|
b809d2f073 | ||
|
|
4ab8ab4f50 | ||
|
|
ac40eed1a5 | ||
|
|
fd9995ebc5 | ||
|
|
5d912e7ed4 | ||
|
|
94eb68d742 | ||
|
|
243e687be6 | ||
|
|
3e4b4dd190 | ||
|
|
c6acd246ec | ||
|
|
d5d7d88612 | ||
|
|
8594dd80dd | ||
|
|
216e167ce6 | ||
|
|
1ac6a246d8 | ||
|
|
e91692f4a3 | ||
|
|
8e287d507d | ||
|
|
81484b447b | ||
|
|
9f6349aba9 | ||
|
|
ddb1ce7418 | ||
|
|
f68d22850c | ||
|
|
c50aa67bff | ||
|
|
1b10159950 | ||
|
|
390c128592 | ||
|
|
ab5d06a094 | ||
|
|
a4ee4da18a | ||
|
|
06dd597552 | ||
|
|
9de9ceb6c5 | ||
|
|
b815edf69f | ||
|
|
8538ce9044 | ||
|
|
c1a6252be1 | ||
|
|
50e15c825c | ||
|
|
b38d552a92 | ||
|
|
ae6834e028 | ||
|
|
0373b60c4c | ||
|
|
83d1fbcff6 | ||
|
|
55bcae7f25 | ||
|
|
42e1e3c67f | ||
|
|
57b0fab692 | ||
|
|
a8d4dff0a1 | ||
|
|
4a5663568f | ||
|
|
bbedb59675 | ||
|
|
c2cf192943 | ||
|
|
c82ef72158 | ||
|
|
b48a1f08c1 | ||
|
|
99833a9cbf | ||
|
|
ebceeeacda | ||
|
|
a6c4ee27fd | ||
|
|
e5c393dceb | ||
|
|
8deff3acf2 | ||
|
|
1f72865726 | ||
|
|
cc598b312b | ||
|
|
d38bbb225f | ||
|
|
eff757f2e3 | ||
|
|
a009d751c2 |
@@ -164,8 +164,9 @@ At some point in the future, you'll be able to seamlessly move from pre-training
|
||||
14. **[MMBT](https://github.com/facebookresearch/mmbt/)** (from Facebook), released together with the paper a [Supervised Multimodal Bitransformers for Classifying Images and Text](https://arxiv.org/pdf/1909.02950.pdf) by Douwe Kiela, Suvrat Bhooshan, Hamed Firooz, Davide Testuggine.
|
||||
15. **[FlauBERT](https://github.com/getalp/Flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
|
||||
16. **[BART](https://github.com/pytorch/fairseq/tree/master/examples/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/pdf/1910.13461.pdf) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
|
||||
17. **[Other community models](https://huggingface.co/models)**, contributed by the [community](https://huggingface.co/users).
|
||||
18. Want to contribute a new model? We have added a **detailed guide and templates** to guide you in the process of adding a new model. You can find them in the [`templates`](./templates) folder of the repository. Be sure to check the [contributing guidelines](./CONTRIBUTING.md) and contact the maintainers or open an issue to collect feedbacks before starting your PR.
|
||||
17. **[ELECTRA](https://github.com/google-research/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
|
||||
18. **[Other community models](https://huggingface.co/models)**, contributed by the [community](https://huggingface.co/users).
|
||||
19. Want to contribute a new model? We have added a **detailed guide and templates** to guide you in the process of adding a new model. You can find them in the [`templates`](./templates) folder of the repository. Be sure to check the [contributing guidelines](./CONTRIBUTING.md) and contact the maintainers or open an issue to collect feedbacks before starting your PR.
|
||||
|
||||
These implementations have been tested on several datasets (see the example scripts) and should match the performances of the original implementations (e.g. ~93 F1 on SQuAD for BERT Whole-Word-Masking, ~88 F1 on RocStories for OpenAI GPT, ~18.3 perplexity on WikiText 103 for Transformer-XL, ~0.916 Peason R coefficient on STS-B for XLNet). You can find more details on the performances in the Examples section of the [documentation](https://huggingface.co/transformers/examples.html).
|
||||
|
||||
|
||||
@@ -47,6 +47,8 @@ Once you have setup `sphinx`, you can build the documentation by running the fol
|
||||
make html
|
||||
```
|
||||
|
||||
A folder called ``_build/html`` should have been created. You can now open the file ``_build/html/index.html`` in your browser.
|
||||
|
||||
---
|
||||
**NOTE**
|
||||
|
||||
|
||||
@@ -26,7 +26,7 @@ author = u'huggingface'
|
||||
# The short X.Y version
|
||||
version = u''
|
||||
# The full version, including alpha/beta/rc tags
|
||||
release = u'2.7.0'
|
||||
release = u'2.8.0'
|
||||
|
||||
|
||||
# -- General configuration ---------------------------------------------------
|
||||
|
||||
@@ -104,3 +104,4 @@ The library currently contains PyTorch and Tensorflow implementations, pre-train
|
||||
model_doc/flaubert
|
||||
model_doc/bart
|
||||
model_doc/t5
|
||||
model_doc/electra
|
||||
@@ -27,7 +27,7 @@ loss = outputs[0]
|
||||
# In transformers you can also have access to the logits:
|
||||
loss, logits = outputs[:2]
|
||||
|
||||
# And even the attention weigths if you configure the model to output them (and other outputs too, see the docstrings and documentation)
|
||||
# And even the attention weights if you configure the model to output them (and other outputs too, see the docstrings and documentation)
|
||||
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', output_attentions=True)
|
||||
outputs = model(input_ids, labels=labels)
|
||||
loss, logits, attentions = outputs
|
||||
|
||||
115
docs/source/model_doc/electra.rst
Normal file
115
docs/source/model_doc/electra.rst
Normal file
@@ -0,0 +1,115 @@
|
||||
ELECTRA
|
||||
----------------------------------------------------
|
||||
|
||||
The ELECTRA model was proposed in the paper.
|
||||
`ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators <https://openreview.net/pdf?id=r1xMH1BtvB>`__.
|
||||
ELECTRA is a new pre-training approach which trains two transformer models: the generator and the discriminator. The
|
||||
generator's role is to replace tokens in a sequence, and is therefore trained as a masked language model. The discriminator,
|
||||
which is the model we're interested in, tries to identify which tokens were replaced by the generator in the sequence.
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
*Masked language modeling (MLM) pre-training methods such as BERT corrupt
|
||||
the input by replacing some tokens with [MASK] and then train a model to
|
||||
reconstruct the original tokens. While they produce good results when transferred
|
||||
to downstream NLP tasks, they generally require large amounts of compute to be
|
||||
effective. As an alternative, we propose a more sample-efficient pre-training task
|
||||
called replaced token detection. Instead of masking the input, our approach
|
||||
corrupts it by replacing some tokens with plausible alternatives sampled from a small
|
||||
generator network. Then, instead of training a model that predicts the original
|
||||
identities of the corrupted tokens, we train a discriminative model that predicts
|
||||
whether each token in the corrupted input was replaced by a generator sample
|
||||
or not. Thorough experiments demonstrate this new pre-training task is more
|
||||
efficient than MLM because the task is defined over all input tokens rather than
|
||||
just the small subset that was masked out. As a result, the contextual representations
|
||||
learned by our approach substantially outperform the ones learned by BERT
|
||||
given the same model size, data, and compute. The gains are particularly strong
|
||||
for small models; for example, we train a model on one GPU for 4 days that
|
||||
outperforms GPT (trained using 30x more compute) on the GLUE natural language
|
||||
understanding benchmark. Our approach also works well at scale, where it
|
||||
performs comparably to RoBERTa and XLNet while using less than 1/4 of their
|
||||
compute and outperforms them when using the same amount of compute.*
|
||||
|
||||
Tips:
|
||||
|
||||
- ELECTRA is the pre-training approach, therefore there is nearly no changes done to the underlying model: BERT. The
|
||||
only change is the separation of the embedding size and the hidden size -> The embedding size is generally smaller,
|
||||
while the hidden size is larger. An additional projection layer (linear) is used to project the embeddings from
|
||||
their embedding size to the hidden size. In the case where the embedding size is the same as the hidden size, no
|
||||
projection layer is used.
|
||||
- The ELECTRA checkpoints saved using `Google Research's implementation <https://github.com/google-research/electra>`__
|
||||
contain both the generator and discriminator. The conversion script requires the user to name which model to export
|
||||
into the correct architecture. Once converted to the HuggingFace format, these checkpoints may be loaded into all
|
||||
available ELECTRA models, however. This means that the discriminator may be loaded in the `ElectraForMaskedLM` model,
|
||||
and the generator may be loaded in the `ElectraForPreTraining` model (the classification head will be randomly
|
||||
initialized as it doesn't exist in the generator).
|
||||
|
||||
|
||||
ElectraConfig
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.ElectraConfig
|
||||
:members:
|
||||
|
||||
|
||||
ElectraTokenizer
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.ElectraTokenizer
|
||||
:members:
|
||||
|
||||
|
||||
ElectraModel
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.ElectraModel
|
||||
:members:
|
||||
|
||||
|
||||
ElectraForPreTraining
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.ElectraForPreTraining
|
||||
:members:
|
||||
|
||||
|
||||
ElectraForMaskedLM
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.ElectraForMaskedLM
|
||||
:members:
|
||||
|
||||
|
||||
ElectraForTokenClassification
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.ElectraForTokenClassification
|
||||
:members:
|
||||
|
||||
|
||||
TFElectraModel
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.TFElectraModel
|
||||
:members:
|
||||
|
||||
|
||||
TFElectraForPreTraining
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.TFElectraForPreTraining
|
||||
:members:
|
||||
|
||||
|
||||
TFElectraForMaskedLM
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.TFElectraForMaskedLM
|
||||
:members:
|
||||
|
||||
|
||||
TFElectraForTokenClassification
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.TFElectraForTokenClassification
|
||||
:members:
|
||||
@@ -420,7 +420,7 @@ to generate the tokens following the initial sequence in PyTorch, and creating a
|
||||
sequence = f"Hugging Face is based in DUMBO, New York City, and is"
|
||||
|
||||
input = tokenizer.encode(sequence, return_tensors="pt")
|
||||
generated = model.generate(input, max_length=50)
|
||||
generated = model.generate(input, max_length=50, do_sample=True)
|
||||
|
||||
resulting_string = tokenizer.decode(generated.tolist()[0])
|
||||
print(resulting_string)
|
||||
@@ -432,14 +432,10 @@ to generate the tokens following the initial sequence in PyTorch, and creating a
|
||||
model = TFAutoModelWithLMHead.from_pretrained("gpt2")
|
||||
|
||||
sequence = f"Hugging Face is based in DUMBO, New York City, and is"
|
||||
generated = tokenizer.encode(sequence)
|
||||
input = tokenizer.encode(sequence, return_tensors="tf")
|
||||
generated = model.generate(input, max_length=50, do_sample=True)
|
||||
|
||||
for i in range(50):
|
||||
predictions = model(tf.constant([generated]))[0]
|
||||
token = tf.argmax(predictions[0], axis=1)[-1].numpy()
|
||||
generated += [token]
|
||||
|
||||
resulting_string = tokenizer.decode(generated)
|
||||
resulting_string = tokenizer.decode(generated.tolist()[0])
|
||||
print(resulting_string)
|
||||
|
||||
|
||||
@@ -594,4 +590,138 @@ following array should be the output:
|
||||
|
||||
::
|
||||
|
||||
[('[CLS]', 'O'), ('Hu', 'I-ORG'), ('##gging', 'I-ORG'), ('Face', 'I-ORG'), ('Inc', 'I-ORG'), ('.', 'O'), ('is', 'O'), ('a', 'O'), ('company', 'O'), ('based', 'O'), ('in', 'O'), ('New', 'I-LOC'), ('York', 'I-LOC'), ('City', 'I-LOC'), ('.', 'O'), ('Its', 'O'), ('headquarters', 'O'), ('are', 'O'), ('in', 'O'), ('D', 'I-LOC'), ('##UM', 'I-LOC'), ('##BO', 'I-LOC'), (',', 'O'), ('therefore', 'O'), ('very', 'O'), ('##c', 'O'), ('##lose', 'O'), ('to', 'O'), ('the', 'O'), ('Manhattan', 'I-LOC'), ('Bridge', 'I-LOC'), ('.', 'O'), ('[SEP]', 'O')]
|
||||
[('[CLS]', 'O'), ('Hu', 'I-ORG'), ('##gging', 'I-ORG'), ('Face', 'I-ORG'), ('Inc', 'I-ORG'), ('.', 'O'), ('is', 'O'), ('a', 'O'), ('company', 'O'), ('based', 'O'), ('in', 'O'), ('New', 'I-LOC'), ('York', 'I-LOC'), ('City', 'I-LOC'), ('.', 'O'), ('Its', 'O'), ('headquarters', 'O'), ('are', 'O'), ('in', 'O'), ('D', 'I-LOC'), ('##UM', 'I-LOC'), ('##BO', 'I-LOC'), (',', 'O'), ('therefore', 'O'), ('very', 'O'), ('##c', 'O'), ('##lose', 'O'), ('to', 'O'), ('the', 'O'), ('Manhattan', 'I-LOC'), ('Bridge', 'I-LOC'), ('.', 'O'), ('[SEP]', 'O')]
|
||||
Summarization
|
||||
----------------------------------------------------
|
||||
|
||||
Summarization is the task of summarizing a text / an article into a shorter text.
|
||||
|
||||
An example of a summarization dataset is the CNN / Daily Mail dataset, which consists of long news articles and was created for the task of summarization.
|
||||
If you would like to fine-tune a model on a summarization task, you may leverage the ``examples/summarization/bart/run_train.sh`` (leveraging pytorch-lightning) script.
|
||||
|
||||
Here is an example using the pipelines do to summarization.
|
||||
It leverages a Bart model that was fine-tuned on the CNN / Daily Mail data set.
|
||||
|
||||
::
|
||||
|
||||
from transformers import pipeline
|
||||
|
||||
summarizer = pipeline("summarization")
|
||||
|
||||
ARTICLE = """ New York (CNN)When Liana Barrientos was 23 years old, she got married in Westchester County, New York.
|
||||
A year later, she got married again in Westchester County, but to a different man and without divorcing her first husband.
|
||||
Only 18 days after that marriage, she got hitched yet again. Then, Barrientos declared "I do" five more times, sometimes only within two weeks of each other.
|
||||
In 2010, she married once more, this time in the Bronx. In an application for a marriage license, she stated it was her "first and only" marriage.
|
||||
Barrientos, now 39, is facing two criminal counts of "offering a false instrument for filing in the first degree," referring to her false statements on the
|
||||
2010 marriage license application, according to court documents.
|
||||
Prosecutors said the marriages were part of an immigration scam.
|
||||
On Friday, she pleaded not guilty at State Supreme Court in the Bronx, according to her attorney, Christopher Wright, who declined to comment further.
|
||||
After leaving court, Barrientos was arrested and charged with theft of service and criminal trespass for allegedly sneaking into the New York subway through an emergency exit, said Detective
|
||||
Annette Markowski, a police spokeswoman. In total, Barrientos has been married 10 times, with nine of her marriages occurring between 1999 and 2002.
|
||||
All occurred either in Westchester County, Long Island, New Jersey or the Bronx. She is believed to still be married to four men, and at one time, she was married to eight men at once, prosecutors say.
|
||||
Prosecutors said the immigration scam involved some of her husbands, who filed for permanent residence status shortly after the marriages.
|
||||
Any divorces happened only after such filings were approved. It was unclear whether any of the men will be prosecuted.
|
||||
The case was referred to the Bronx District Attorney\'s Office by Immigration and Customs Enforcement and the Department of Homeland Security\'s
|
||||
Investigation Division. Seven of the men are from so-called "red-flagged" countries, including Egypt, Turkey, Georgia, Pakistan and Mali.
|
||||
Her eighth husband, Rashid Rajput, was deported in 2006 to his native Pakistan after an investigation by the Joint Terrorism Task Force.
|
||||
If convicted, Barrientos faces up to four years in prison. Her next court appearance is scheduled for May 18.
|
||||
"""
|
||||
|
||||
print(summarizer(ARTICLE, max_length=130, min_length=30))
|
||||
|
||||
Because the summarization pipeline depends on the ``PretrainedModel.generate()`` method, we can override the default arguments
|
||||
of ``PretrainedModel.generate()`` directly in the pipeline as is shown for ``max_length`` and ``min_length`` above.
|
||||
This outputs the following summary:
|
||||
|
||||
::
|
||||
|
||||
Liana Barrientos has been married 10 times, sometimes within two weeks of each other. Prosecutors say the marriages were part of an immigration scam. She pleaded not guilty at State Supreme Court in the Bronx on Friday.
|
||||
|
||||
Here is an example doing summarization using a model and a tokenizer. The process is the following:
|
||||
|
||||
- Instantiate a tokenizer and a model from the checkpoint name. Summarization is usually done using an encoder-decoder model, such as ``Bart`` or ``T5``.
|
||||
- Define the article that should be summarizaed.
|
||||
- Leverage the ``PretrainedModel.generate()`` method.
|
||||
- Add the T5 specific prefix "summarize: ".
|
||||
|
||||
Here Google`s T5 model is used that was only pre-trained on a multi-task mixed data set (including CNN / Daily Mail), but nevertheless yields very good results.
|
||||
::
|
||||
|
||||
## PYTORCH CODE
|
||||
from transformers import AutoModelWithLMHead, AutoTokenizer
|
||||
|
||||
model = AutoModelWithLMHead.from_pretrained("t5-base")
|
||||
tokenizer = AutoTokenizer.from_pretrained("t5-base")
|
||||
|
||||
# T5 uses a max_length of 512 so we cut the article to 512 tokens.
|
||||
inputs = tokenizer.encode("summarize: " + ARTICLE, return_tensors="pt", max_length=512)
|
||||
outputs = model.generate(inputs, max_length=150, min_length=40, length_penalty=2.0, num_beams=4, early_stopping=True)
|
||||
print(outputs)
|
||||
|
||||
## TENSORFLOW CODE
|
||||
from transformers import TFAutoModelWithLMHead, AutoTokenizer
|
||||
|
||||
model = TFAutoModelWithLMHead.from_pretrained("t5-base")
|
||||
tokenizer = AutoTokenizer.from_pretrained("t5-base")
|
||||
|
||||
# T5 uses a max_length of 512 so we cut the article to 512 tokens.
|
||||
inputs = tokenizer.encode("summarize: " + ARTICLE, return_tensors="tf", max_length=512)
|
||||
outputs = model.generate(inputs, max_length=150, min_length=40, length_penalty=2.0, num_beams=4, early_stopping=True)
|
||||
print(outputs)
|
||||
Translation
|
||||
----------------------------------------------------
|
||||
|
||||
Translation is the task of translating a text from one language to another.
|
||||
|
||||
An example of a translation dataset is the WMT English to German dataset, which has English sentences as the input data
|
||||
and German sentences as the target data.
|
||||
|
||||
Here is an example using the pipelines do to translation.
|
||||
It leverages a T5 model that was only pre-trained on a multi-task mixture dataset (including WMT), but yields impressive
|
||||
translation results nevertheless.
|
||||
|
||||
::
|
||||
|
||||
from transformers import pipeline
|
||||
|
||||
translator = pipeline("translation_en_to_de")
|
||||
print(translator("Hugging Face is a technology company based in New York and Paris", max_length=40))
|
||||
|
||||
Because the translation pipeline depends on the ``PretrainedModel.generate()`` method, we can override the default arguments
|
||||
of ``PretrainedModel.generate()`` directly in the pipeline as is shown for ``max_length`` above.
|
||||
This outputs the following translation into German:
|
||||
|
||||
::
|
||||
|
||||
Hugging Face ist ein Technologieunternehmen mit Sitz in New York und Paris.
|
||||
|
||||
Here is an example doing translation using a model and a tokenizer. The process is the following:
|
||||
|
||||
- Instantiate a tokenizer and a model from the checkpoint name. Summarization is usually done using an encoder-decoder model, such as ``Bart`` or ``T5``.
|
||||
- Define the article that should be summarizaed.
|
||||
- Leverage the ``PretrainedModel.generate()`` method.
|
||||
- Add the T5 specific prefix "translate English to German: "
|
||||
|
||||
::
|
||||
|
||||
## PYTORCH CODE
|
||||
from transformers import AutoModelWithLMHead, AutoTokenizer
|
||||
|
||||
model = AutoModelWithLMHead.from_pretrained("t5-base")
|
||||
tokenizer = AutoTokenizer.from_pretrained("t5-base")
|
||||
|
||||
inputs = tokenizer.encode("translate English to German: Hugging Face is a technology company based in New York and Paris", return_tensors="pt")
|
||||
outputs = model.generate(inputs, max_length=40, num_beams=4, early_stopping=True)
|
||||
|
||||
print(outputs)
|
||||
|
||||
## TENSORFLOW CODE
|
||||
from transformers import TFAutoModelWithLMHead, AutoTokenizer
|
||||
|
||||
model = TFAutoModelWithLMHead.from_pretrained("t5-base")
|
||||
tokenizer = AutoTokenizer.from_pretrained("t5-base")
|
||||
|
||||
inputs = tokenizer.encode("translate English to German: Hugging Face is a technology company based in New York and Paris", return_tensors="tf")
|
||||
outputs = model.generate(inputs, max_length=40, num_beams=4, early_stopping=True)
|
||||
|
||||
print(outputs)
|
||||
|
||||
@@ -68,7 +68,7 @@ class GLUETransformer(BaseTransformer):
|
||||
output_mode=args.glue_output_mode,
|
||||
pad_on_left=bool(args.model_type in ["xlnet"]), # pad on the left for xlnet
|
||||
pad_token=self.tokenizer.convert_tokens_to_ids([self.tokenizer.pad_token])[0],
|
||||
pad_token_segment_id=4 if args.model_type in ["xlnet"] else 0,
|
||||
pad_token_segment_id=self.tokenizer.pad_token_type_id,
|
||||
)
|
||||
logger.info("Saving features into cached file %s", cached_features_file)
|
||||
torch.save(features, cached_features_file)
|
||||
@@ -192,5 +192,5 @@ if __name__ == "__main__":
|
||||
# Optionally, predict on dev set and write to output_dir
|
||||
if args.do_predict:
|
||||
checkpoints = list(sorted(glob.glob(os.path.join(args.output_dir, "checkpointepoch=*.ckpt"), recursive=True)))
|
||||
GLUETransformer.load_from_checkpoint(checkpoints[-1])
|
||||
model = model.load_from_checkpoint(checkpoints[-1])
|
||||
trainer.test(model)
|
||||
|
||||
@@ -342,8 +342,8 @@ def load_and_cache_examples(args, task, tokenizer, evaluate=False):
|
||||
max_length=args.max_seq_length,
|
||||
output_mode=output_mode,
|
||||
pad_on_left=bool(args.model_type in ["xlnet"]), # pad on the left for xlnet
|
||||
pad_token=tokenizer.convert_tokens_to_ids([tokenizer.pad_token])[0],
|
||||
pad_token_segment_id=4 if args.model_type in ["xlnet"] else 0,
|
||||
pad_token=tokenizer.pad_token_id,
|
||||
pad_token_segment_id=tokenizer.pad_token_type_id,
|
||||
)
|
||||
if args.local_rank in [-1, 0]:
|
||||
logger.info("Saving features into cached file %s", cached_features_file)
|
||||
|
||||
@@ -348,8 +348,8 @@ def load_and_cache_examples(args, tokenizer, labels, pad_token_label_id, mode):
|
||||
# roberta uses an extra separator b/w pairs of sentences, cf. github.com/pytorch/fairseq/commit/1684e166e3da03f5b600dbb7855cb98ddfcd0805
|
||||
pad_on_left=bool(args.model_type in ["xlnet"]),
|
||||
# pad on the left for xlnet
|
||||
pad_token=tokenizer.convert_tokens_to_ids([tokenizer.pad_token])[0],
|
||||
pad_token_segment_id=4 if args.model_type in ["xlnet"] else 0,
|
||||
pad_token=tokenizer.pad_token_id,
|
||||
pad_token_segment_id=tokenizer.pad_token_type_id,
|
||||
pad_token_label_id=pad_token_label_id,
|
||||
)
|
||||
if args.local_rank in [-1, 0]:
|
||||
|
||||
@@ -64,8 +64,8 @@ class NERTransformer(BaseTransformer):
|
||||
sep_token=self.tokenizer.sep_token,
|
||||
sep_token_extra=bool(args.model_type in ["roberta"]),
|
||||
pad_on_left=bool(args.model_type in ["xlnet"]),
|
||||
pad_token=self.tokenizer.convert_tokens_to_ids([self.tokenizer.pad_token])[0],
|
||||
pad_token_segment_id=4 if args.model_type in ["xlnet"] else 0,
|
||||
pad_token=self.tokenizer.pad_token_id,
|
||||
pad_token_segment_id=self.tokenizer.pad_token_type_id,
|
||||
pad_token_label_id=self.pad_token_label_id,
|
||||
)
|
||||
logger.info("Saving features into cached file %s", cached_features_file)
|
||||
@@ -192,5 +192,5 @@ if __name__ == "__main__":
|
||||
# https://github.com/PyTorchLightning/pytorch-lightning/blob/master\
|
||||
# /pytorch_lightning/callbacks/model_checkpoint.py#L169
|
||||
checkpoints = list(sorted(glob.glob(os.path.join(args.output_dir, "checkpointepoch=*.ckpt"), recursive=True)))
|
||||
NERTransformer.load_from_checkpoint(checkpoints[-1])
|
||||
model = model.load_from_checkpoint(checkpoints[-1])
|
||||
trainer.test(model)
|
||||
|
||||
@@ -157,7 +157,9 @@ def train(
|
||||
writer = tf.summary.create_file_writer("/tmp/mylogs")
|
||||
|
||||
with strategy.scope():
|
||||
loss_fct = tf.keras.losses.SparseCategoricalCrossentropy(reduction=tf.keras.losses.Reduction.NONE)
|
||||
loss_fct = tf.keras.losses.SparseCategoricalCrossentropy(
|
||||
from_logits=True, reduction=tf.keras.losses.Reduction.NONE
|
||||
)
|
||||
optimizer = create_optimizer(args["learning_rate"], num_train_steps, args["warmup_steps"])
|
||||
|
||||
if args["fp16"]:
|
||||
@@ -205,11 +207,9 @@ def train(
|
||||
|
||||
with tf.GradientTape() as tape:
|
||||
logits = model(train_features["input_ids"], **inputs)[0]
|
||||
logits = tf.reshape(logits, (-1, len(labels) + 1))
|
||||
active_loss = tf.reshape(train_features["input_mask"], (-1,))
|
||||
active_logits = tf.boolean_mask(logits, active_loss)
|
||||
train_labels = tf.reshape(train_labels, (-1,))
|
||||
active_labels = tf.boolean_mask(train_labels, active_loss)
|
||||
active_loss = tf.reshape(train_labels, (-1,)) != pad_token_label_id
|
||||
active_logits = tf.boolean_mask(tf.reshape(logits, (-1, len(labels))), active_loss)
|
||||
active_labels = tf.boolean_mask(tf.reshape(train_labels, (-1,)), active_loss)
|
||||
cross_entropy = loss_fct(active_labels, active_logits)
|
||||
loss = tf.reduce_sum(cross_entropy) * (1.0 / train_batch_size)
|
||||
grads = tape.gradient(loss, model.trainable_variables)
|
||||
@@ -329,11 +329,9 @@ def evaluate(args, strategy, model, tokenizer, labels, pad_token_label_id, mode)
|
||||
|
||||
with strategy.scope():
|
||||
logits = model(eval_features["input_ids"], **inputs)[0]
|
||||
tmp_logits = tf.reshape(logits, (-1, len(labels) + 1))
|
||||
active_loss = tf.reshape(eval_features["input_mask"], (-1,))
|
||||
active_logits = tf.boolean_mask(tmp_logits, active_loss)
|
||||
tmp_eval_labels = tf.reshape(eval_labels, (-1,))
|
||||
active_labels = tf.boolean_mask(tmp_eval_labels, active_loss)
|
||||
active_loss = tf.reshape(eval_labels, (-1,)) != pad_token_label_id
|
||||
active_logits = tf.boolean_mask(tf.reshape(logits, (-1, len(labels))), active_loss)
|
||||
active_labels = tf.boolean_mask(tf.reshape(eval_labels, (-1,)), active_loss)
|
||||
cross_entropy = loss_fct(active_labels, active_logits)
|
||||
loss += tf.reduce_sum(cross_entropy) * (1.0 / eval_batch_size)
|
||||
|
||||
@@ -436,8 +434,8 @@ def load_and_cache_examples(args, tokenizer, labels, pad_token_label_id, batch_s
|
||||
# roberta uses an extra separator b/w pairs of sentences, cf. github.com/pytorch/fairseq/commit/1684e166e3da03f5b600dbb7855cb98ddfcd0805
|
||||
pad_on_left=bool(args["model_type"] in ["xlnet"]),
|
||||
# pad on the left for xlnet
|
||||
pad_token=tokenizer.convert_tokens_to_ids([tokenizer.pad_token])[0],
|
||||
pad_token_segment_id=4 if args["model_type"] in ["xlnet"] else 0,
|
||||
pad_token=tokenizer.pad_token_id,
|
||||
pad_token_segment_id=tokenizer.pad_token_type_id,
|
||||
pad_token_label_id=pad_token_label_id,
|
||||
)
|
||||
logging.info("Saving features into cached file %s", cached_features_file)
|
||||
@@ -497,8 +495,8 @@ def main(_):
|
||||
)
|
||||
|
||||
labels = get_labels(args["labels"])
|
||||
num_labels = len(labels) + 1
|
||||
pad_token_label_id = 0
|
||||
num_labels = len(labels)
|
||||
pad_token_label_id = -1
|
||||
config = AutoConfig.from_pretrained(
|
||||
args["config_name"] if args["config_name"] else args["model_name_or_path"],
|
||||
num_labels=num_labels,
|
||||
@@ -522,7 +520,6 @@ def main(_):
|
||||
config=config,
|
||||
cache_dir=args["cache_dir"] if args["cache_dir"] else None,
|
||||
)
|
||||
model.layers[-1].activation = tf.keras.activations.softmax
|
||||
|
||||
train_batch_size = args["per_device_train_batch_size"] * args["n_device"]
|
||||
train_dataset, num_train_examples = load_and_cache_examples(
|
||||
|
||||
@@ -360,8 +360,8 @@ def load_and_cache_examples(args, task, tokenizer, evaluate=False):
|
||||
max_length=args.max_seq_length,
|
||||
output_mode=output_mode,
|
||||
pad_on_left=bool(args.model_type in ["xlnet"]), # pad on the left for xlnet
|
||||
pad_token=tokenizer.convert_tokens_to_ids([tokenizer.pad_token])[0],
|
||||
pad_token_segment_id=4 if args.model_type in ["xlnet"] else 0,
|
||||
pad_token=tokenizer.pad_token_id,
|
||||
pad_token_segment_id=tokenizer.pad_token_type_id,
|
||||
)
|
||||
if args.local_rank in [-1, 0]:
|
||||
logger.info("Saving features into cached file %s", cached_features_file)
|
||||
|
||||
@@ -233,6 +233,9 @@ def train(args, train_dataset, model: PreTrainedModel, tokenizer: PreTrainedToke
|
||||
else:
|
||||
t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
|
||||
|
||||
model = model.module if hasattr(model, "module") else model # Take care of distributed/parallel training
|
||||
model.resize_token_embeddings(len(tokenizer))
|
||||
|
||||
# Prepare optimizer and schedule (linear warmup and decay)
|
||||
no_decay = ["bias", "LayerNorm.weight"]
|
||||
optimizer_grouped_parameters = [
|
||||
@@ -309,9 +312,6 @@ def train(args, train_dataset, model: PreTrainedModel, tokenizer: PreTrainedToke
|
||||
|
||||
tr_loss, logging_loss = 0.0, 0.0
|
||||
|
||||
model_to_resize = model.module if hasattr(model, "module") else model # Take care of distributed/parallel training
|
||||
model_to_resize.resize_token_embeddings(len(tokenizer))
|
||||
|
||||
model.zero_grad()
|
||||
train_iterator = trange(
|
||||
epochs_trained, int(args.num_train_epochs), desc="Epoch", disable=args.local_rank not in [-1, 0]
|
||||
@@ -624,6 +624,7 @@ def main():
|
||||
and os.listdir(args.output_dir)
|
||||
and args.do_train
|
||||
and not args.overwrite_output_dir
|
||||
and not args.should_continue
|
||||
):
|
||||
raise ValueError(
|
||||
"Output directory ({}) already exists and is not empty. Use --overwrite_output_dir to overcome.".format(
|
||||
|
||||
@@ -361,7 +361,7 @@ def load_and_cache_examples(args, task, tokenizer, evaluate=False, test=False):
|
||||
args.max_seq_length,
|
||||
tokenizer,
|
||||
pad_on_left=bool(args.model_type in ["xlnet"]), # pad on the left for xlnet
|
||||
pad_token_segment_id=4 if args.model_type in ["xlnet"] else 0,
|
||||
pad_token_segment_id=tokenizer.pad_token_type_id,
|
||||
)
|
||||
if args.local_rank in [-1, 0]:
|
||||
logger.info("Saving features into cached file %s", cached_features_file)
|
||||
|
||||
@@ -350,8 +350,8 @@ def load_and_cache_examples(args, task, tokenizer, evaluate=False):
|
||||
max_length=args.max_seq_length,
|
||||
output_mode=output_mode,
|
||||
pad_on_left=False,
|
||||
pad_token=tokenizer.convert_tokens_to_ids([tokenizer.pad_token])[0],
|
||||
pad_token_segment_id=0,
|
||||
pad_token=tokenizer.pad_token_id,
|
||||
pad_token_segment_id=tokenizer.pad_token_type_id,
|
||||
)
|
||||
if args.local_rank in [-1, 0]:
|
||||
logger.info("Saving features into cached file %s", cached_features_file)
|
||||
|
||||
@@ -16,15 +16,17 @@ def chunks(lst, n):
|
||||
yield lst[i : i + n]
|
||||
|
||||
|
||||
def generate_summaries(lns, out_file, batch_size=8, device=DEFAULT_DEVICE):
|
||||
def generate_summaries(
|
||||
examples: list, out_file: str, model_name: str, batch_size: int = 8, device: str = DEFAULT_DEVICE
|
||||
):
|
||||
fout = Path(out_file).open("w")
|
||||
model = BartForConditionalGeneration.from_pretrained("bart-large-cnn", output_past=True,).to(device)
|
||||
model = BartForConditionalGeneration.from_pretrained(model_name, output_past=True,).to(device)
|
||||
tokenizer = BartTokenizer.from_pretrained("bart-large")
|
||||
|
||||
max_length = 140
|
||||
min_length = 55
|
||||
|
||||
for batch in tqdm(list(chunks(lns, batch_size))):
|
||||
for batch in tqdm(list(chunks(examples, batch_size))):
|
||||
dct = tokenizer.batch_encode_plus(batch, max_length=1024, return_tensors="pt", pad_to_max_length=True)
|
||||
summaries = model.generate(
|
||||
input_ids=dct["input_ids"].to(device),
|
||||
@@ -43,7 +45,7 @@ def generate_summaries(lns, out_file, batch_size=8, device=DEFAULT_DEVICE):
|
||||
fout.flush()
|
||||
|
||||
|
||||
def _run_generate():
|
||||
def run_generate():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument(
|
||||
"source_path", type=str, help="like cnn_dm/test.source",
|
||||
@@ -51,6 +53,9 @@ def _run_generate():
|
||||
parser.add_argument(
|
||||
"output_path", type=str, help="where to save summaries",
|
||||
)
|
||||
parser.add_argument(
|
||||
"model_name", type=str, default="bart-large-cnn", help="like bart-large-cnn",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--device", type=str, required=False, default=DEFAULT_DEVICE, help="cuda, cuda:1, cpu etc.",
|
||||
)
|
||||
@@ -58,9 +63,9 @@ def _run_generate():
|
||||
"--bs", type=int, default=8, required=False, help="batch size: how many to summarize at a time",
|
||||
)
|
||||
args = parser.parse_args()
|
||||
lns = [" " + x.rstrip() for x in open(args.source_path).readlines()]
|
||||
generate_summaries(lns, args.output_path, batch_size=args.bs, device=args.device)
|
||||
examples = [" " + x.rstrip() for x in open(args.source_path).readlines()]
|
||||
generate_summaries(examples, args.output_path, args.model_name, batch_size=args.bs, device=args.device)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
_run_generate()
|
||||
run_generate()
|
||||
|
||||
@@ -1,16 +1,13 @@
|
||||
import logging
|
||||
import os
|
||||
import sys
|
||||
import tempfile
|
||||
import unittest
|
||||
from pathlib import Path
|
||||
from unittest.mock import patch
|
||||
|
||||
from .evaluate_cnn import _run_generate
|
||||
from .evaluate_cnn import run_generate
|
||||
|
||||
|
||||
output_file_name = "output_bart_sum.txt"
|
||||
|
||||
articles = [" New York (CNN)When Liana Barrientos was 23 years old, she got married in Westchester County."]
|
||||
|
||||
logging.basicConfig(level=logging.DEBUG)
|
||||
@@ -25,8 +22,11 @@ class TestBartExamples(unittest.TestCase):
|
||||
tmp = Path(tempfile.gettempdir()) / "utest_generations_bart_sum.hypo"
|
||||
with tmp.open("w") as f:
|
||||
f.write("\n".join(articles))
|
||||
testargs = ["evaluate_cnn.py", str(tmp), output_file_name]
|
||||
|
||||
output_file_name = Path(tempfile.gettempdir()) / "utest_output_bart_sum.hypo"
|
||||
|
||||
testargs = ["evaluate_cnn.py", str(tmp), str(output_file_name), "sshleifer/bart-tiny-random"]
|
||||
|
||||
with patch.object(sys, "argv", testargs):
|
||||
_run_generate()
|
||||
run_generate()
|
||||
self.assertTrue(Path(output_file_name).exists())
|
||||
os.remove(Path(output_file_name))
|
||||
|
||||
@@ -64,7 +64,7 @@ def run_generate():
|
||||
parser.add_argument(
|
||||
"model_size",
|
||||
type=str,
|
||||
help="T5 model size, either 't5-small', 't5-base' or 't5-large'. Defaults to base.",
|
||||
help="T5 model size, either 't5-small', 't5-base', 't5-large', 't5-3b', 't5-11b'. Defaults to 't5-base'.",
|
||||
default="t5-base",
|
||||
)
|
||||
parser.add_argument(
|
||||
|
||||
@@ -1,5 +1,4 @@
|
||||
import logging
|
||||
import os
|
||||
import sys
|
||||
import tempfile
|
||||
import unittest
|
||||
@@ -26,10 +25,20 @@ class TestT5Examples(unittest.TestCase):
|
||||
tmp = Path(tempfile.gettempdir()) / "utest_generations_t5_sum.hypo"
|
||||
with tmp.open("w") as f:
|
||||
f.write("\n".join(articles))
|
||||
testargs = ["evaluate_cnn.py", "t5-small", str(tmp), output_file_name, str(tmp), score_file_name]
|
||||
|
||||
output_file_name = Path(tempfile.gettempdir()) / "utest_output_t5_sum.hypo"
|
||||
score_file_name = Path(tempfile.gettempdir()) / "utest_score_t5_sum.hypo"
|
||||
|
||||
testargs = [
|
||||
"evaluate_cnn.py",
|
||||
"patrickvonplaten/t5-tiny-random",
|
||||
str(tmp),
|
||||
str(output_file_name),
|
||||
str(tmp),
|
||||
str(score_file_name),
|
||||
]
|
||||
|
||||
with patch.object(sys, "argv", testargs):
|
||||
run_generate()
|
||||
self.assertTrue(Path(output_file_name).exists())
|
||||
self.assertTrue(Path(score_file_name).exists())
|
||||
os.remove(Path(output_file_name))
|
||||
os.remove(Path(score_file_name))
|
||||
|
||||
@@ -14,13 +14,13 @@ def chunks(lst, n):
|
||||
yield lst[i : i + n]
|
||||
|
||||
|
||||
def generate_translations(lns, output_file_path, batch_size, device):
|
||||
def generate_translations(lns, output_file_path, model_size, batch_size, device):
|
||||
output_file = Path(output_file_path).open("w")
|
||||
|
||||
model = T5ForConditionalGeneration.from_pretrained("t5-base")
|
||||
model = T5ForConditionalGeneration.from_pretrained(model_size)
|
||||
model.to(device)
|
||||
|
||||
tokenizer = T5Tokenizer.from_pretrained("t5-base")
|
||||
tokenizer = T5Tokenizer.from_pretrained(model_size)
|
||||
|
||||
# update config with summarization specific params
|
||||
task_specific_params = model.config.task_specific_params
|
||||
@@ -52,6 +52,12 @@ def calculate_bleu_score(output_lns, refs_lns, score_path):
|
||||
|
||||
def run_generate():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument(
|
||||
"model_size",
|
||||
type=str,
|
||||
help="T5 model size, either 't5-small', 't5-base', 't5-large', 't5-3b', 't5-11b'. Defaults to 't5-base'.",
|
||||
default="t5-base",
|
||||
)
|
||||
parser.add_argument(
|
||||
"input_path", type=str, help="like wmt/newstest2013.en",
|
||||
)
|
||||
@@ -78,7 +84,7 @@ def run_generate():
|
||||
|
||||
input_lns = [x.strip().replace(dash_pattern[0], dash_pattern[1]) for x in open(args.input_path).readlines()]
|
||||
|
||||
generate_translations(input_lns, args.output_path, args.batch_size, args.device)
|
||||
generate_translations(input_lns, args.output_path, args.model_size, args.batch_size, args.device)
|
||||
|
||||
output_lns = [x.strip() for x in open(args.output_path).readlines()]
|
||||
refs_lns = [x.strip().replace(dash_pattern[0], dash_pattern[1]) for x in open(args.reference_path).readlines()]
|
||||
|
||||
@@ -1,5 +1,4 @@
|
||||
import logging
|
||||
import os
|
||||
import sys
|
||||
import tempfile
|
||||
import unittest
|
||||
@@ -33,11 +32,19 @@ class TestT5Examples(unittest.TestCase):
|
||||
with tmp_target.open("w") as f:
|
||||
f.write("\n".join(translation))
|
||||
|
||||
testargs = ["evaluate_wmt.py", str(tmp_source), output_file_name, str(tmp_target), score_file_name]
|
||||
output_file_name = Path(tempfile.gettempdir()) / "utest_output_trans.hypo"
|
||||
score_file_name = Path(tempfile.gettempdir()) / "utest_score.hypo"
|
||||
|
||||
testargs = [
|
||||
"evaluate_wmt.py",
|
||||
"patrickvonplaten/t5-tiny-random",
|
||||
str(tmp_source),
|
||||
str(output_file_name),
|
||||
str(tmp_target),
|
||||
str(score_file_name),
|
||||
]
|
||||
|
||||
with patch.object(sys, "argv", testargs):
|
||||
run_generate()
|
||||
self.assertTrue(Path(output_file_name).exists())
|
||||
self.assertTrue(Path(score_file_name).exists())
|
||||
os.remove(Path(output_file_name))
|
||||
os.remove(Path(score_file_name))
|
||||
|
||||
@@ -64,27 +64,8 @@ TensorFlow: 2.1.0
|
||||
Python: 3.7.6
|
||||
```
|
||||
|
||||
### Inferencing / prediction works with the current Transformers v2.4.1
|
||||
|
||||
### Access this albert_xxlargev1_sqd2_512 fine-tuned model with "tried & true" code:
|
||||
### Access this albert_xxlargev1_sqd2_512 fine-tuned model with:
|
||||
|
||||
```python
|
||||
config_class, model_class, tokenizer_class = \
|
||||
AlbertConfig, AlbertForQuestionAnswering, AlbertTokenizer
|
||||
|
||||
model_name_or_path = "ahotrod/albert_xxlargev1_squad2_512"
|
||||
config = config_class.from_pretrained(model_name_or_path)
|
||||
tokenizer = tokenizer_class.from_pretrained(model_name_or_path, do_lower_case=True)
|
||||
model = model_class.from_pretrained(model_name_or_path, config=config)
|
||||
```
|
||||
|
||||
### or the AutoModels (AutoConfig, AutoTokenizer & AutoModel) should also work, however I have yet to use them in my app & confirm:
|
||||
|
||||
```python
|
||||
from transformers import AutoConfig, AutoTokenizer, AutoModel
|
||||
|
||||
model_name_or_path = "ahotrod/albert_xxlargev1_squad2_512"
|
||||
config = AutoConfig.from_pretrained(model_name_or_path)
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, do_lower_case=True)
|
||||
model = AutoModel.from_pretrained(model_name_or_path, config=config)
|
||||
```
|
||||
tokenizer = AutoTokenizer.from_pretrained("ahotrod/albert_xxlargev1_squad2_512")
|
||||
model = AutoModelForQuestionAnswering.from_pretrained("ahotrod/albert_xxlargev1_squad2_512")
|
||||
|
||||
68
model_cards/ahotrod/roberta_large_squad2/README.md
Normal file
68
model_cards/ahotrod/roberta_large_squad2/README.md
Normal file
@@ -0,0 +1,68 @@
|
||||
## RoBERTa-large language model fine-tuned on SQuAD2.0
|
||||
|
||||
### with the following results:
|
||||
|
||||
```
|
||||
"exact": 84.02257222269014,
|
||||
"f1": 87.47063479332766,
|
||||
"total": 11873,
|
||||
"HasAns_exact": 81.19095816464238,
|
||||
"HasAns_f1": 88.0969714745582,
|
||||
"HasAns_total": 5928,
|
||||
"NoAns_exact": 86.84608915054667,
|
||||
"NoAns_f1": 86.84608915054667,
|
||||
"NoAns_total": 5945,
|
||||
"best_exact": 84.02257222269014,
|
||||
"best_exact_thresh": 0.0,
|
||||
"best_f1": 87.47063479332759,
|
||||
"best_f1_thresh": 0.0
|
||||
```
|
||||
### from script:
|
||||
```
|
||||
python -m torch.distributed.launch --nproc_per_node=2 ${RUN_SQUAD_DIR}/run_squad.py \
|
||||
--model_type roberta \
|
||||
--model_name_or_path roberta-large \
|
||||
--do_train \
|
||||
--train_file ${SQUAD_DIR}/train-v2.0.json \
|
||||
--predict_file ${SQUAD_DIR}/dev-v2.0.json \
|
||||
--version_2_with_negative \
|
||||
--num_train_epochs 2 \
|
||||
--warmup_steps 328 \
|
||||
--weight_decay 0.01 \
|
||||
--do_lower_case \
|
||||
--learning_rate 1.5e-5 \
|
||||
--max_seq_length 512 \
|
||||
--doc_stride 128 \
|
||||
--save_steps 1000 \
|
||||
--per_gpu_train_batch_size 1 \
|
||||
--gradient_accumulation_steps 24 \
|
||||
--logging_steps 50 \
|
||||
--threads 10 \
|
||||
--overwrite_cache \
|
||||
--overwrite_output_dir \
|
||||
--output_dir ${MODEL_PATH}
|
||||
|
||||
python ${RUN_SQUAD_DIR}/run_squad.py \
|
||||
--model_type roberta \
|
||||
--model_name_or_path ${MODEL_PATH} \
|
||||
--do_eval \
|
||||
--train_file ${SQUAD_DIR}/train-v2.0.json \
|
||||
--predict_file ${SQUAD_DIR}/dev-v2.0.json \
|
||||
--version_2_with_negative \
|
||||
--do_lower_case \
|
||||
--max_seq_length 512 \
|
||||
--per_gpu_eval_batch_size 24 \
|
||||
--eval_all_checkpoints \
|
||||
--overwrite_output_dir \
|
||||
--output_dir ${MODEL_PATH}
|
||||
$@
|
||||
```
|
||||
### using the following system & software:
|
||||
```
|
||||
OS/Platform: Linux-4.15.0-91-generic-x86_64-with-debian-buster-sid
|
||||
GPU/CPU: 2 x NVIDIA 1080Ti / Intel i7-8700
|
||||
Transformers: 2.7.0
|
||||
PyTorch: 1.4.0
|
||||
TensorFlow: 2.1.0
|
||||
Python: 3.7.7
|
||||
```
|
||||
@@ -56,22 +56,8 @@ PyTorch: 1.4.0
|
||||
TensorFlow: 2.1.0
|
||||
Python: 3.7.6
|
||||
```
|
||||
### Inferencing / prediction works with Transformers v2.4.1, the latest version tested
|
||||
|
||||
### Utilize this xlnet_large_squad2_512 fine-tuned model with:
|
||||
```python
|
||||
config_class, model_class, tokenizer_class = \
|
||||
XLNetConfig, XLNetforQuestionAnswering, XLNetTokenizer
|
||||
model_name_or_path = "ahotrod/xlnet_large_squad2_512"
|
||||
config = config_class.from_pretrained(model_name_or_path)
|
||||
tokenizer = tokenizer_class.from_pretrained(model_name_or_path, do_lower_case=True)
|
||||
model = model_class.from_pretrained(model_name_or_path, config=config)
|
||||
```
|
||||
### or the AutoModels (AutoConfig, AutoTokenizer & AutoModel) should also work, however I have yet to use them in my apps & confirm:
|
||||
```python
|
||||
from transformers import AutoConfig, AutoTokenizer, AutoModel
|
||||
model_name_or_path = "ahotrod/xlnet_large_squad2_512"
|
||||
config = AutoConfig.from_pretrained(model_name_or_path)
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, do_lower_case=True)
|
||||
model = AutoModel.from_pretrained(model_name_or_path, config=config)
|
||||
tokenizer = AutoTokenizer.from_pretrained("ahotrod/xlnet_large_squad2_512")
|
||||
model = AutoModelForQuestionAnswering.from_pretrained("ahotrod/xlnet_large_squad2_512")
|
||||
```
|
||||
|
||||
6
model_cards/albert-base-v1-README.md
Normal file
6
model_cards/albert-base-v1-README.md
Normal file
@@ -0,0 +1,6 @@
|
||||
---
|
||||
tags:
|
||||
- exbert
|
||||
---
|
||||
|
||||
[](https://huggingface.co/exbert/?model=albert-base-v1)
|
||||
6
model_cards/albert-xxlarge-v2-README.md
Normal file
6
model_cards/albert-xxlarge-v2-README.md
Normal file
@@ -0,0 +1,6 @@
|
||||
---
|
||||
tags:
|
||||
- exbert
|
||||
---
|
||||
|
||||
[](https://huggingface.co/exbert/?model=albert-xxlarge-v2)
|
||||
6
model_cards/bert-base-cased-README.md
Normal file
6
model_cards/bert-base-cased-README.md
Normal file
@@ -0,0 +1,6 @@
|
||||
---
|
||||
tags:
|
||||
- exbert
|
||||
---
|
||||
|
||||
[](https://huggingface.co/exbert/?model=bert-base-cased)
|
||||
@@ -1,8 +1,12 @@
|
||||
---
|
||||
language: german
|
||||
thumbnail: https://static.tildacdn.com/tild6438-3730-4164-b266-613634323466/german_bert.png
|
||||
tags:
|
||||
- exbert
|
||||
---
|
||||
|
||||
[](https://huggingface.co/exbert/?model=bert-base-german-cased)
|
||||
|
||||
# German BERT
|
||||

|
||||
## Overview
|
||||
@@ -18,6 +22,7 @@ thumbnail: https://static.tildacdn.com/tild6438-3730-4164-b266-613634323466/germ
|
||||
- We trained 810k steps with a batch size of 1024 for sequence length 128 and 30k steps with sequence length 512. Training took about 9 days.
|
||||
- As training data we used the latest German Wikipedia dump (6GB of raw txt files), the OpenLegalData dump (2.4 GB) and news articles (3.6 GB).
|
||||
- We cleaned the data dumps with tailored scripts and segmented sentences with spacy v2.1. To create tensorflow records we used the recommended sentencepiece library for creating the word piece vocabulary and tensorflow scripts to convert the text to data usable by BERT.
|
||||
- Update April 3rd, 2020: updated the vocab file on deepset s3 to adjust tokenization of punctuation.
|
||||
|
||||
See https://deepset.ai/german-bert for more details
|
||||
|
||||
|
||||
6
model_cards/bert-base-uncased-README.md
Normal file
6
model_cards/bert-base-uncased-README.md
Normal file
@@ -0,0 +1,6 @@
|
||||
---
|
||||
tags:
|
||||
- exbert
|
||||
---
|
||||
|
||||
[](https://huggingface.co/exbert/?model=bert-base-uncased)
|
||||
@@ -1,3 +1,7 @@
|
||||
---
|
||||
language: french
|
||||
---
|
||||
|
||||
# CamemBERT
|
||||
|
||||
CamemBERT is a state-of-the-art language model for French based on the RoBERTa architecture pretrained on the French subcorpus of the newly available multilingual corpus OSCAR.
|
||||
|
||||
59
model_cards/deepset/quora_dedup_bert_base/README.md
Normal file
59
model_cards/deepset/quora_dedup_bert_base/README.md
Normal file
@@ -0,0 +1,59 @@
|
||||
This language model is trained using sentence_transformers (https://github.com/UKPLab/sentence-transformers)
|
||||
Started with bert-base-nli-stsb-mean-tokens
|
||||
Continue training on quora questions deduplication dataset (https://www.kaggle.com/c/quora-question-pairs)
|
||||
See train_script.py for script used
|
||||
|
||||
Below is the performance over the course of training
|
||||
epoch,steps,cosine_pearson,cosine_spearman,euclidean_pearson,euclidean_spearman,manhattan_pearson,manhattan_spearman,dot_pearson,dot_spearman
|
||||
0,1000,0.5944576426835938,0.6010801382777033,0.5942803776859142,0.5934485776801595,0.5939676679774666,0.593162725602328,0.5905591590826669,0.5921674789994058
|
||||
0,2000,0.6404080440207146,0.6416811632113405,0.6384419354012121,0.6352050423100778,0.6379917744471867,0.6347884067391001,0.6410544760582826,0.6379252046791412
|
||||
0,3000,0.6710168301884945,0.6676529324662036,0.6660195209784969,0.6618423144808695,0.6656461098096684,0.6615366331956389,0.6724401903484759,0.666073727723655
|
||||
0,4000,0.6886373265097949,0.6808948140300153,0.67907655686838,0.6714218133850957,0.6786809551564443,0.6711577956884357,0.6926435869763303,0.68190855298609
|
||||
0,5000,0.6991409753700026,0.6919630610321864,0.6991041519437052,0.6868961486499775,0.6987076032270729,0.6865385550504007,0.7035518148330993,0.6916275246101342
|
||||
0,6000,0.7120367327025509,0.6975005265298305,0.7065567493967201,0.6922375503495235,0.7060005509843024,0.6916475765570651,0.7147094303373102,0.6981390706722722
|
||||
0,7000,0.7254672394728687,0.7130118465900485,0.7261844956277705,0.7086213543110718,0.7257479964972307,0.7079315661881832,0.728729909455115,0.7122743793160531
|
||||
0,8000,0.7402421930101399,0.7216774208330149,0.7367901914441078,0.7166256588352043,0.7362607046874481,0.7158881916281887,0.7433902441373252,0.7220998491980078
|
||||
0,9000,0.7381005358120434,0.7197216844469877,0.7343228719349923,0.7139462687943793,0.7345247569255238,0.7145106206467152,0.7421843672419275,0.720686853053079
|
||||
0,10000,0.7465436564646095,0.7260327107480364,0.7467524239596304,0.7230195666847953,0.7467721566237211,0.7231367593302213,0.749792199122442,0.7263143296580317
|
||||
0,11000,0.7521805421706547,0.7323771570146701,0.7530672061250105,0.729223203496722,0.7530616532823367,0.7293818369675622,0.7552399002305836,0.7320808333541338
|
||||
0,12000,0.7579359969644401,0.7340677616737238,0.7570017235719905,0.7305965412825544,0.7570601853520393,0.730718189957289,0.7611254136080384,0.7351501229591327
|
||||
0,-1,0.7573407371218097,0.7329952035782198,0.755595312163209,0.7291445551777086,0.7557737117990928,0.7295404703700227,0.7607276219361719,0.7342415455980179
|
||||
1,1000,0.7619907683805341,0.7374667949734767,0.7629820517114324,0.7330364216044966,0.7628369522755882,0.7331912674450544,0.7658583898073758,0.7381503446695727
|
||||
1,2000,0.7618972640071228,0.7362151058969478,0.764582212425539,0.7335856230046062,0.7643125513700815,0.7334501607097152,0.7652852805583232,0.7369104639809163
|
||||
1,3000,0.7687362955240467,0.7404674623181671,0.7708304819979073,0.7380959815601529,0.7707835692712482,0.7379796800453193,0.772074854759756,0.7414513460702766
|
||||
1,4000,0.7685047787908202,0.7403088288815168,0.7703522257474043,0.7379787888808298,0.7701221475099808,0.7377898546753812,0.7713755359045312,0.7409415801952219
|
||||
1,5000,0.7696438109797803,0.7410393893292365,0.773270389327895,0.7392953127251652,0.7729880866533291,0.7389853982789335,0.7726236305835863,0.7416278035580925
|
||||
1,6000,0.7749538363837081,0.7436499342062207,0.774879168058157,0.7401827241766746,0.7745754601165837,0.739763415043146,0.7788801166152383,0.7446249060022169
|
||||
1,7000,0.7794560817870597,0.7480970176267153,0.7803506944510302,0.7453305130502859,0.7799867949176531,0.7447100155494814,0.7828208193123926,0.7486740690324809
|
||||
1,8000,0.7855844359073243,0.7496742172376921,0.7828816645965887,0.747176409009761,0.7827584875358967,0.7471037762845532,0.7879159073496309,0.7507349669102151
|
||||
1,9000,0.7844110753729492,0.7507746252693759,0.7847208586489722,0.7485172180290892,0.7846408087474059,0.748491818820158,0.7872061334510225,0.7514470349769437
|
||||
1,10000,0.7881311227435004,0.7530048509727403,0.7886917756879734,0.7508018068765787,0.7883332502188707,0.7505037008187275,0.7910707228932787,0.7537200382362567
|
||||
1,11000,0.7883300109606874,0.7513494487126553,0.7879329130497712,0.749818368689255,0.7876525616593218,0.7494872882301785,0.7911454269743292,0.7522843165147303
|
||||
1,12000,0.7853334933336618,0.7516809747712728,0.7893895316714998,0.749780492728257,0.7890075986655403,0.7494079715118533,0.7885959664070629,0.7523827940133203
|
||||
1,-1,0.7887529238148887,0.7534076729932393,0.7896864404801204,0.7513080079201105,0.7894077512343298,0.7510009899066772,0.7919617393746149,0.7542173273241598
|
||||
2,1000,0.7919209063905188,0.7550167329363414,0.7917464066515253,0.7523043685293455,0.7914371703225378,0.7520285423781206,0.7950297421784158,0.7562599556207076
|
||||
2,2000,0.7924507768792486,0.7542908512484463,0.7934519001953887,0.7517491515010692,0.7931885648751081,0.751521004535999,0.7951637852162545,0.7551495215642072
|
||||
2,3000,0.7937606244038364,0.755599577136169,0.7933633347508111,0.7527922999916203,0.7931581019714242,0.7527132061436363,0.797275652800117,0.7569827180764233
|
||||
2,4000,0.7938389298721445,0.7578716892320315,0.7963783770097079,0.7555928931784702,0.796150381773947,0.7555438771581088,0.7972911620482322,0.759178632650707
|
||||
2,5000,0.7935330563129844,0.7551129824372304,0.7970775059297484,0.7527285792572385,0.7967359830546507,0.7524478515463257,0.7966395126138969,0.756319220359678
|
||||
2,6000,0.7929852776759999,0.7525490026774382,0.7952484474454824,0.7503695753216607,0.7950784132079611,0.7503677929234961,0.7956152082976395,0.7535275392698093
|
||||
2,7000,0.794956504054517,0.756119591765251,0.7982025041673655,0.7532521587180684,0.7980261618830962,0.7532107179960499,0.7983222918908033,0.7571226363678287
|
||||
2,8000,0.7934568432535339,0.7538336661192452,0.797015698241178,0.7514773358161916,0.7968076980315735,0.7513458838811067,0.7960694134685949,0.754143803399873
|
||||
2,9000,0.7970040626682157,0.7576497805894974,0.7987855332059015,0.7550996144509958,0.7984693921009676,0.7548260162973456,0.7999509314900626,0.758347143906916
|
||||
2,10000,0.7979442987735523,0.7585338500791028,0.8018677081664496,0.7557412777548302,0.8015397301245205,0.7552916678886369,0.8007921348414564,0.7589772216225288
|
||||
2,11000,0.7985519561040211,0.7579986850302035,0.8021236875460913,0.7555826443181872,0.8019861620475348,0.7553763317660516,0.8009230128897853,0.7586541619907702
|
||||
2,12000,0.7986842143860736,0.7599570950134775,0.8029131054823838,0.7577678644678973,0.8027922603736795,0.7575152095990927,0.8020896747930555,0.7608540869254408
|
||||
2,-1,0.7994135319568432,0.7596286881516635,0.8022087183675333,0.7570593611974978,0.8020218401019292,0.7567291719729909,0.8026346812258125,0.7603928913647044
|
||||
3,1000,0.7985505039929134,0.7592588405681144,0.8023296699449267,0.7569345933969436,0.8023622066009718,0.7570237132696928,0.8013054275981851,0.759643838536062
|
||||
3,2000,0.7995482191699455,0.759205368623176,0.8026859405513612,0.7565709841358819,0.8024845263367439,0.7562920388231202,0.8021318586127523,0.7596496313300967
|
||||
3,3000,0.7991070423195897,0.7582027696555826,0.8016352550470427,0.7555585819429662,0.8014268261947898,0.7551838327642736,0.8013136081494014,0.7584429477727118
|
||||
3,4000,0.7999188836884763,0.7586764419322649,0.802987646214278,0.7561111254802977,0.8026549791861386,0.7556463650525692,0.8024068858366156,0.7591238238715613
|
||||
3,5000,0.7988075932525881,0.7583533823004922,0.8019498750207454,0.755792967372457,0.8016459824731964,0.7553834613587099,0.8015528810821693,0.7589527136833425
|
||||
3,6000,0.8003341798460688,0.7585432077405799,0.8032464035902267,0.7563722467405277,0.8028695045742804,0.7557626665682309,0.8027937010871594,0.7590404967573696
|
||||
3,7000,0.799187592384933,0.7579358555659604,0.8028413548398412,0.7555875459131398,0.8025187078191003,0.7551196665011402,0.8018680475193432,0.7585565756912578
|
||||
3,8000,0.797725037202641,0.757439012042047,0.802048241301358,0.7548888458326453,0.8017608103042271,0.7544606246736175,0.8005479449399782,0.758037452190282
|
||||
3,9000,0.7990232649360067,0.7573703896772077,0.8021375332910405,0.754873027155089,0.8018733796679427,0.7545680141630304,0.8016400687760605,0.7579461042843499
|
||||
3,10000,0.7994934439260372,0.758368978248884,0.8035693504115055,0.75619400688862,0.8032990505007025,0.7559016935896375,0.8022819185772518,0.7589558328445544
|
||||
3,11000,0.8002954591825011,0.758710753096932,0.8043310859792212,0.7566387152306694,0.8040865016706966,0.7564221538891368,0.8030873114870971,0.7592722085543488
|
||||
3,12000,0.8003726616196549,0.7588056657991931,0.8044000317617518,0.7566146528909147,0.8041705213966136,0.7563419459362758,0.8031760015719815,0.7593194421057111
|
||||
3,-1,0.8004926728141455,0.7587192194882135,0.8043340929890026,0.756546030526114,0.8041028559910275,0.7563103085106637,0.8032542493776693,0.7592325501951863
|
||||
6
model_cards/distilbert-base-uncased-README.md
Normal file
6
model_cards/distilbert-base-uncased-README.md
Normal file
@@ -0,0 +1,6 @@
|
||||
---
|
||||
tags:
|
||||
- exbert
|
||||
---
|
||||
|
||||
[](https://huggingface.co/exbert/?model=distilbert-base-uncased)
|
||||
6
model_cards/distilgpt2-README.md
Normal file
6
model_cards/distilgpt2-README.md
Normal file
@@ -0,0 +1,6 @@
|
||||
---
|
||||
tags:
|
||||
- exbert
|
||||
---
|
||||
|
||||
[](https://huggingface.co/exbert/?model=distilgpt2)
|
||||
6
model_cards/distilroberta-base-README.md
Normal file
6
model_cards/distilroberta-base-README.md
Normal file
@@ -0,0 +1,6 @@
|
||||
---
|
||||
tags:
|
||||
- exbert
|
||||
---
|
||||
|
||||
[](https://huggingface.co/exbert/?model=distilroberta-base)
|
||||
6
model_cards/gpt2-README.md
Normal file
6
model_cards/gpt2-README.md
Normal file
@@ -0,0 +1,6 @@
|
||||
---
|
||||
tags:
|
||||
- exbert
|
||||
---
|
||||
|
||||
[](https://huggingface.co/exbert/?model=gpt2)
|
||||
38
model_cards/gsarti/covidbert-nli/README.md
Normal file
38
model_cards/gsarti/covidbert-nli/README.md
Normal file
@@ -0,0 +1,38 @@
|
||||
# CovidBERT-NLI
|
||||
|
||||
This is the model **CovidBERT** trained by DeepSet on AllenAI's [CORD19 Dataset](https://pages.semanticscholar.org/coronavirus-research) of scientific articles about coronaviruses.
|
||||
|
||||
The model uses the original BERT wordpiece vocabulary and was subsequently fine-tuned on the [SNLI](https://nlp.stanford.edu/projects/snli/) and the [MultiNLI](https://www.nyu.edu/projects/bowman/multinli/) datasets using the [`sentence-transformers` library](https://github.com/UKPLab/sentence-transformers/) to produce universal sentence embeddings [1] using the **average pooling strategy** and a **softmax loss**.
|
||||
|
||||
Parameter details for the original training on CORD-19 are available on [DeepSet's MLFlow](https://public-mlflow.deepset.ai/#/experiments/2/runs/ba27d00c30044ef6a33b1d307b4a6cba)
|
||||
|
||||
**Base model**: `deepset/covid_bert_base` from HuggingFace's `AutoModel`.
|
||||
|
||||
**Training time**: ~6 hours on the NVIDIA Tesla P100 GPU provided in Kaggle Notebooks.
|
||||
|
||||
**Parameters**:
|
||||
|
||||
| Parameter | Value |
|
||||
|------------------|-------|
|
||||
| Batch size | 64 |
|
||||
| Training steps | 23000 |
|
||||
| Warmup steps | 1450 |
|
||||
| Lowercasing | True |
|
||||
| Max. Seq. Length | 128 |
|
||||
|
||||
**Performances**: The performance was evaluated on the test portion of the [STS dataset](http://ixa2.si.ehu.es/stswiki/index.php/STSbenchmark) using Spearman rank correlation and compared to the performances of similar models obtained with the same procedure to verify its performances.
|
||||
|
||||
| Model | Score |
|
||||
|-------------------------------|-------------|
|
||||
| `covidbert-nli` (this) | 67.52 |
|
||||
| `gsarti/biobert-nli` | 73.40 |
|
||||
| `gsarti/scibert-nli` | 74.50 |
|
||||
| `bert-base-nli-mean-tokens`[2]| 77.12 |
|
||||
|
||||
An example usage for similarity-based scientific paper retrieval is provided in the [Covid-19 Semantic Browser](https://github.com/gsarti/covid-papers-browser) repository.
|
||||
|
||||
**References:**
|
||||
|
||||
[1] A. Conneau et al., [Supervised Learning of Universal Sentence Representations from Natural Language Inference Data](https://www.aclweb.org/anthology/D17-1070/)
|
||||
|
||||
[2] N. Reimers et I. Gurevych, [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://www.aclweb.org/anthology/D19-1410/)
|
||||
@@ -0,0 +1,94 @@
|
||||
---
|
||||
language: polish
|
||||
---
|
||||
|
||||
# Multilingual + Polish SQuAD1.1
|
||||
|
||||
This model is the multilingual model provided by the Google research team with a fine-tuned polish Q&A downstream task.
|
||||
|
||||
## Details of the language model
|
||||
|
||||
Language model ([**bert-base-multilingual-cased**](https://github.com/google-research/bert/blob/master/multilingual.md)):
|
||||
12-layer, 768-hidden, 12-heads, 110M parameters.
|
||||
Trained on cased text in the top 104 languages with the largest Wikipedias.
|
||||
|
||||
## Details of the downstream task
|
||||
Using the `mtranslate` Python module, [**SQuAD1.1**](https://rajpurkar.github.io/SQuAD-explorer/) was machine-translated. In order to find the start tokens, the direct translations of the answers were searched in the corresponding paragraphs. Due to the different translations depending on the context (missing context in the pure answer), the answer could not always be found in the text, and thus a loss of question-answer examples occurred. This is a potential problem where errors can occur in the data set.
|
||||
|
||||
| Dataset | # Q&A |
|
||||
| ---------------------- | ----- |
|
||||
| SQuAD1.1 Train | 87.7 K |
|
||||
| Polish SQuAD1.1 Train | 39.5 K |
|
||||
| SQuAD1.1 Dev | 10.6 K |
|
||||
| Polish SQuAD1.1 Dev | 2.6 K |
|
||||
|
||||
|
||||
## Model benchmark
|
||||
|
||||
| Model | EM | F1 |
|
||||
| ---------------------- | ----- | ----- |
|
||||
| [SlavicBERT](https://huggingface.co/DeepPavlov/bert-base-bg-cs-pl-ru-cased) | **60.89** | 71.68 |
|
||||
| [polBERT](https://huggingface.co/dkleczek/bert-base-polish-uncased-v1) | 57.46 | 68.87 |
|
||||
| [multiBERT](https://huggingface.co/bert-base-multilingual-cased) | 60.67 | **71.89** |
|
||||
| [xlm](https://huggingface.co/xlm-mlm-100-1280) | 47.98 | 59.42 |
|
||||
## Model training
|
||||
|
||||
The model was trained on a **Tesla V100** GPU with the following command:
|
||||
|
||||
```python
|
||||
export SQUAD_DIR=path/to/pl_squad
|
||||
|
||||
python run_squad.py
|
||||
--model_type bert \
|
||||
--model_name_or_path bert-base-multilingual-cased \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--train_file $SQUAD_DIR/pl_squadv1_train_clean.json \
|
||||
--predict_file $SQUAD_DIR/pl_squadv1_dev_clean.json \
|
||||
--num_train_epochs 2 \
|
||||
--max_seq_length 384 \
|
||||
--doc_stride 128 \
|
||||
--save_steps=8000 \
|
||||
--output_dir ../../output \
|
||||
--overwrite_cache \
|
||||
--overwrite_output_dir
|
||||
```
|
||||
|
||||
**Results**:
|
||||
|
||||
{'exact': 60.670731707317074, 'f1': 71.8952193697293, 'total': 2624, 'HasAns_exact': 60.670731707317074, 'HasAns_f1': 71.8952193697293,
|
||||
'HasAns_total': 2624, 'best_exact': 60.670731707317074, 'best_exact_thresh': 0.0, 'best_f1': 71.8952193697293, 'best_f1_thresh': 0.0}
|
||||
|
||||
## Model in action
|
||||
|
||||
Fast usage with **pipelines**:
|
||||
|
||||
```python
|
||||
from transformers import pipeline
|
||||
|
||||
qa_pipeline = pipeline(
|
||||
"question-answering",
|
||||
model="henryk/bert-base-multilingual-cased-finetuned-polish-squad1",
|
||||
tokenizer="henryk/bert-base-multilingual-cased-finetuned-polish-squad1"
|
||||
)
|
||||
|
||||
qa_pipeline({
|
||||
'context': "Warszawa jest największym miastem w Polsce pod względem liczby ludności i powierzchni",
|
||||
'question': "Jakie jest największe miasto w Polsce?"})
|
||||
|
||||
```
|
||||
|
||||
# Output:
|
||||
|
||||
```json
|
||||
{
|
||||
"score": 0.9988,
|
||||
"start": 0,
|
||||
"end": 8,
|
||||
"answer": "Warszawa"
|
||||
}
|
||||
```
|
||||
|
||||
## Contact
|
||||
|
||||
Please do not hesitate to contact me via [LinkedIn](https://www.linkedin.com/in/henryk-borzymowski-0755a2167/) if you want to discuss or get access to the Polish version of SQuAD.
|
||||
@@ -0,0 +1,96 @@
|
||||
---
|
||||
language: polish
|
||||
---
|
||||
|
||||
# Multilingual + Polish SQuAD2.0
|
||||
|
||||
This model is the multilingual model provided by the Google research team with a fine-tuned polish Q&A downstream task.
|
||||
|
||||
## Details of the language model
|
||||
|
||||
Language model ([**bert-base-multilingual-cased**](https://github.com/google-research/bert/blob/master/multilingual.md)):
|
||||
12-layer, 768-hidden, 12-heads, 110M parameters.
|
||||
Trained on cased text in the top 104 languages with the largest Wikipedias.
|
||||
|
||||
## Details of the downstream task
|
||||
Using the `mtranslate` Python module, [**SQuAD2.0**](https://rajpurkar.github.io/SQuAD-explorer/) was machine-translated. In order to find the start tokens, the direct translations of the answers were searched in the corresponding paragraphs. Due to the different translations depending on the context (missing context in the pure answer), the answer could not always be found in the text, and thus a loss of question-answer examples occurred. This is a potential problem where errors can occur in the data set.
|
||||
|
||||
| Dataset | # Q&A |
|
||||
| ---------------------- | ----- |
|
||||
| SQuAD2.0 Train | 130 K |
|
||||
| Polish SQuAD2.0 Train | 83.1 K |
|
||||
| SQuAD2.0 Dev | 12 K |
|
||||
| Polish SQuAD2.0 Dev | 8.5 K |
|
||||
|
||||
|
||||
## Model benchmark
|
||||
|
||||
| Model | EM/F1 |HasAns (EM/F1) | NoAns |
|
||||
| ---------------------- | ----- | ----- | ----- |
|
||||
| [SlavicBERT](https://huggingface.co/DeepPavlov/bert-base-bg-cs-pl-ru-cased) | 69.35/71.51 | 47.02/54.09 | 79.20 |
|
||||
| [polBERT](https://huggingface.co/dkleczek/bert-base-polish-uncased-v1) | 67.33/69.80| 45.73/53.80 | 76.87 |
|
||||
| [multiBERT](https://huggingface.co/bert-base-multilingual-cased) | **70.76**/**72.92** |45.00/52.04 | 82.13 |
|
||||
|
||||
## Model training
|
||||
|
||||
The model was trained on a **Tesla V100** GPU with the following command:
|
||||
|
||||
```python
|
||||
export SQUAD_DIR=path/to/pl_squad
|
||||
|
||||
python run_squad.py
|
||||
--model_type bert \
|
||||
--model_name_or_path bert-base-multilingual-cased \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--version_2_with_negative \
|
||||
--train_file $SQUAD_DIR/pl_squadv2_train.json \
|
||||
--predict_file $SQUAD_DIR/pl_squadv2_dev.json \
|
||||
--num_train_epochs 2 \
|
||||
--max_seq_length 384 \
|
||||
--doc_stride 128 \
|
||||
--save_steps=8000 \
|
||||
--output_dir ../../output \
|
||||
--overwrite_cache \
|
||||
--overwrite_output_dir
|
||||
```
|
||||
|
||||
**Results**:
|
||||
|
||||
{'exact': 70.76671723655035, 'f1': 72.92156947155917, 'total': 8569, 'HasAns_exact': 45.00762195121951, 'HasAns_f1': 52.04456128116991, 'HasAns_total': 2624, 'NoAns_exact': 82.13624894869638, '
|
||||
NoAns_f1': 82.13624894869638, 'NoAns_total': 5945, 'best_exact': 71.72365503559342, 'best_exact_thresh': 0.0, 'best_f1': 73.62662512059369, 'best_f1_thresh': 0.0}
|
||||
|
||||
|
||||
## Model in action
|
||||
|
||||
Fast usage with **pipelines**:
|
||||
|
||||
```python
|
||||
from transformers import pipeline
|
||||
|
||||
qa_pipeline = pipeline(
|
||||
"question-answering",
|
||||
model="henryk/bert-base-multilingual-cased-finetuned-polish-squad2",
|
||||
tokenizer="henryk/bert-base-multilingual-cased-finetuned-polish-squad2"
|
||||
)
|
||||
|
||||
qa_pipeline({
|
||||
'context': "Warszawa jest największym miastem w Polsce pod względem liczby ludności i powierzchni",
|
||||
'question': "Jakie jest największe miasto w Polsce?"})
|
||||
|
||||
```
|
||||
|
||||
# Output:
|
||||
|
||||
```json
|
||||
{
|
||||
"score": 0.9986,
|
||||
"start": 0,
|
||||
"end": 8,
|
||||
"answer": "Warszawa"
|
||||
}
|
||||
```
|
||||
|
||||
## Contact
|
||||
|
||||
Please do not hesitate to contact me via [LinkedIn](https://www.linkedin.com/in/henryk-borzymowski-0755a2167/) if you want to discuss or get access to the Polish version of SQuAD.
|
||||
86
model_cards/huseinzol05/albert-base-bahasa-cased/README.md
Normal file
86
model_cards/huseinzol05/albert-base-bahasa-cased/README.md
Normal file
@@ -0,0 +1,86 @@
|
||||
---
|
||||
language: malay
|
||||
---
|
||||
|
||||
# Bahasa Albert Model
|
||||
|
||||
Pretrained Albert base language model for Malay and Indonesian.
|
||||
|
||||
## Pretraining Corpus
|
||||
|
||||
`albert-base-bahasa-cased` model was pretrained on ~1.8 Billion words. We trained on both standard and social media language structures, and below is list of data we trained on,
|
||||
|
||||
1. [dumping wikipedia](https://github.com/huseinzol05/Malaya-Dataset#wikipedia-1).
|
||||
2. [local instagram](https://github.com/huseinzol05/Malaya-Dataset#instagram).
|
||||
3. [local twitter](https://github.com/huseinzol05/Malaya-Dataset#twitter-1).
|
||||
4. [local news](https://github.com/huseinzol05/Malaya-Dataset#public-news).
|
||||
5. [local parliament text](https://github.com/huseinzol05/Malaya-Dataset#parliament).
|
||||
6. [local singlish/manglish text](https://github.com/huseinzol05/Malaya-Dataset#singlish-text).
|
||||
7. [IIUM Confession](https://github.com/huseinzol05/Malaya-Dataset#iium-confession).
|
||||
8. [Wattpad](https://github.com/huseinzol05/Malaya-Dataset#wattpad).
|
||||
9. [Academia PDF](https://github.com/huseinzol05/Malaya-Dataset#academia-pdf).
|
||||
|
||||
Preprocessing steps can reproduce from here, [Malaya/pretrained-model/preprocess](https://github.com/huseinzol05/Malaya/tree/master/pretrained-model/preprocess).
|
||||
|
||||
## Pretraining details
|
||||
|
||||
- This model was trained using Google Albert's github [repository](https://github.com/google-research/ALBERT) on v3-8 TPU.
|
||||
- All steps can reproduce from here, [Malaya/pretrained-model/albert](https://github.com/huseinzol05/Malaya/tree/master/pretrained-model/albert).
|
||||
|
||||
## Load Pretrained Model
|
||||
|
||||
You can use this model by installing `torch` or `tensorflow` and Huggingface library `transformers`. And you can use it directly by initializing it like this:
|
||||
|
||||
```python
|
||||
from transformers import AlbertTokenizer, AlbertModel
|
||||
|
||||
model = BertModel.from_pretrained('huseinzol05/albert-base-bahasa-cased')
|
||||
tokenizer = AlbertTokenizer.from_pretrained(
|
||||
'huseinzol05/albert-base-bahasa-cased',
|
||||
do_lower_case = False,
|
||||
)
|
||||
```
|
||||
|
||||
## Example using AutoModelWithLMHead
|
||||
|
||||
```python
|
||||
from transformers import AlbertTokenizer, AutoModelWithLMHead, pipeline
|
||||
|
||||
model = AutoModelWithLMHead.from_pretrained('huseinzol05/albert-base-bahasa-cased')
|
||||
tokenizer = AlbertTokenizer.from_pretrained(
|
||||
'huseinzol05/albert-base-bahasa-cased',
|
||||
do_lower_case = False,
|
||||
)
|
||||
fill_mask = pipeline('fill-mask', model = model, tokenizer = tokenizer)
|
||||
print(fill_mask('makan ayam dengan [MASK]'))
|
||||
```
|
||||
|
||||
Output is,
|
||||
|
||||
```text
|
||||
[{'sequence': '[CLS] makan ayam dengan ayam[SEP]',
|
||||
'score': 0.044952988624572754,
|
||||
'token': 629},
|
||||
{'sequence': '[CLS] makan ayam dengan sayur[SEP]',
|
||||
'score': 0.03621877357363701,
|
||||
'token': 1639},
|
||||
{'sequence': '[CLS] makan ayam dengan ikan[SEP]',
|
||||
'score': 0.034429922699928284,
|
||||
'token': 758},
|
||||
{'sequence': '[CLS] makan ayam dengan nasi[SEP]',
|
||||
'score': 0.032447945326566696,
|
||||
'token': 453},
|
||||
{'sequence': '[CLS] makan ayam dengan rendang[SEP]',
|
||||
'score': 0.028885239735245705,
|
||||
'token': 2451}]
|
||||
```
|
||||
|
||||
## Results
|
||||
|
||||
For further details on the model performance, simply checkout accuracy page from Malaya, https://malaya.readthedocs.io/en/latest/Accuracy.html, we compared with traditional models.
|
||||
|
||||
## Acknowledgement
|
||||
|
||||
Thanks to [Im Big](https://www.facebook.com/imbigofficial/), [LigBlou](https://www.facebook.com/ligblou), [Mesolitica](https://mesolitica.com/) and [KeyReply](https://www.keyreply.com/) for sponsoring AWS, Google and GPU clouds to train Albert for Bahasa.
|
||||
|
||||
|
||||
92
model_cards/huseinzol05/tiny-bert-bahasa-cased/README.md
Normal file
92
model_cards/huseinzol05/tiny-bert-bahasa-cased/README.md
Normal file
@@ -0,0 +1,92 @@
|
||||
---
|
||||
language: malay
|
||||
---
|
||||
|
||||
# Bahasa Tiny-BERT Model
|
||||
|
||||
General Distilled Tiny BERT language model for Malay and Indonesian.
|
||||
|
||||
## Pretraining Corpus
|
||||
|
||||
`tiny-bert-bahasa-cased` model was distilled on ~1.8 Billion words. We distilled on both standard and social media language structures, and below is list of data we distilled on,
|
||||
|
||||
1. [dumping wikipedia](https://github.com/huseinzol05/Malaya-Dataset#wikipedia-1).
|
||||
2. [local instagram](https://github.com/huseinzol05/Malaya-Dataset#instagram).
|
||||
3. [local twitter](https://github.com/huseinzol05/Malaya-Dataset#twitter-1).
|
||||
4. [local news](https://github.com/huseinzol05/Malaya-Dataset#public-news).
|
||||
5. [local parliament text](https://github.com/huseinzol05/Malaya-Dataset#parliament).
|
||||
6. [local singlish/manglish text](https://github.com/huseinzol05/Malaya-Dataset#singlish-text).
|
||||
7. [IIUM Confession](https://github.com/huseinzol05/Malaya-Dataset#iium-confession).
|
||||
8. [Wattpad](https://github.com/huseinzol05/Malaya-Dataset#wattpad).
|
||||
9. [Academia PDF](https://github.com/huseinzol05/Malaya-Dataset#academia-pdf).
|
||||
|
||||
Preprocessing steps can reproduce from here, [Malaya/pretrained-model/preprocess](https://github.com/huseinzol05/Malaya/tree/master/pretrained-model/preprocess).
|
||||
|
||||
## Distilling details
|
||||
|
||||
- This model was distilled using huawei-noah Tiny-BERT's github [repository](https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/TinyBERT) on 3 Titan V100 32GB VRAM.
|
||||
- All steps can reproduce from here, [Malaya/pretrained-model/tiny-bert](https://github.com/huseinzol05/Malaya/tree/master/pretrained-model/tiny-bert).
|
||||
|
||||
## Load Distilled Model
|
||||
|
||||
You can use this model by installing `torch` or `tensorflow` and Huggingface library `transformers`. And you can use it directly by initializing it like this:
|
||||
|
||||
```python
|
||||
from transformers import AlbertTokenizer, BertModel
|
||||
|
||||
model = BertModel.from_pretrained('huseinzol05/tiny-bert-bahasa-cased')
|
||||
tokenizer = AlbertTokenizer.from_pretrained(
|
||||
'huseinzol05/tiny-bert-bahasa-cased',
|
||||
unk_token = '[UNK]',
|
||||
pad_token = '[PAD]',
|
||||
do_lower_case = False,
|
||||
)
|
||||
```
|
||||
|
||||
We use [google/sentencepiece](https://github.com/google/sentencepiece) to train the tokenizer, so to use it, need to load from `AlbertTokenizer`.
|
||||
|
||||
## Example using AutoModelWithLMHead
|
||||
|
||||
```python
|
||||
from transformers import AlbertTokenizer, AutoModelWithLMHead, pipeline
|
||||
|
||||
model = AutoModelWithLMHead.from_pretrained('huseinzol05/tiny-bert-bahasa-cased')
|
||||
tokenizer = AlbertTokenizer.from_pretrained(
|
||||
'huseinzol05/tiny-bert-bahasa-cased',
|
||||
unk_token = '[UNK]',
|
||||
pad_token = '[PAD]',
|
||||
do_lower_case = False,
|
||||
)
|
||||
fill_mask = pipeline('fill-mask', model = model, tokenizer = tokenizer)
|
||||
print(fill_mask('makan ayam dengan [MASK]'))
|
||||
```
|
||||
|
||||
Output is,
|
||||
|
||||
```text
|
||||
[{'sequence': '[CLS] makan ayam dengan berbual[SEP]',
|
||||
'score': 0.00015769545279908925,
|
||||
'token': 17859},
|
||||
{'sequence': '[CLS] makan ayam dengan kembar[SEP]',
|
||||
'score': 0.0001448775001335889,
|
||||
'token': 8289},
|
||||
{'sequence': '[CLS] makan ayam dengan memaklumkan[SEP]',
|
||||
'score': 0.00013484008377417922,
|
||||
'token': 6881},
|
||||
{'sequence': '[CLS] makan ayam dengan Senarai[SEP]',
|
||||
'score': 0.00013061291247140616,
|
||||
'token': 11698},
|
||||
{'sequence': '[CLS] makan ayam dengan Tiga[SEP]',
|
||||
'score': 0.00012453157978598028,
|
||||
'token': 4232}]
|
||||
```
|
||||
|
||||
## Results
|
||||
|
||||
For further details on the model performance, simply checkout accuracy page from Malaya, https://malaya.readthedocs.io/en/latest/Accuracy.html, we compared with traditional models.
|
||||
|
||||
## Acknowledgement
|
||||
|
||||
Thanks to [Im Big](https://www.facebook.com/imbigofficial/), [LigBlou](https://www.facebook.com/ligblou), [Mesolitica](https://mesolitica.com/) and [KeyReply](https://www.keyreply.com/) for sponsoring AWS, Google and GPU clouds to train BERT for Bahasa.
|
||||
|
||||
|
||||
@@ -50,7 +50,7 @@ tokenizer = XLNetTokenizer.from_pretrained(
|
||||
'huseinzol05/xlnet-base-bahasa-cased', do_lower_case = False
|
||||
)
|
||||
fill_mask = pipeline('fill-mask', model = model, tokenizer = tokenizer)
|
||||
print(fill_mask('makan ayam dengan [MASK]'))
|
||||
print(fill_mask('makan ayam dengan <mask>'))
|
||||
```
|
||||
|
||||
## Results
|
||||
|
||||
61
model_cards/ktrapeznikov/albert-xlarge-v2-squad-v2/README.md
Normal file
61
model_cards/ktrapeznikov/albert-xlarge-v2-squad-v2/README.md
Normal file
@@ -0,0 +1,61 @@
|
||||
### Model
|
||||
**[`albert-xlarge-v2`](https://huggingface.co/albert-xlarge-v2)** fine-tuned on **[`SQuAD V2`](https://rajpurkar.github.io/SQuAD-explorer/)** using **[`run_squad.py`](https://github.com/huggingface/transformers/blob/master/examples/run_squad.py)**
|
||||
|
||||
### Training Parameters
|
||||
Trained on 4 NVIDIA GeForce RTX 2080 Ti 11Gb
|
||||
```bash
|
||||
BASE_MODEL=albert-xlarge-v2
|
||||
python run_squad.py \
|
||||
--version_2_with_negative \
|
||||
--model_type albert \
|
||||
--model_name_or_path $BASE_MODEL \
|
||||
--output_dir $OUTPUT_MODEL \
|
||||
--do_eval \
|
||||
--do_lower_case \
|
||||
--train_file $SQUAD_DIR/train-v2.0.json \
|
||||
--predict_file $SQUAD_DIR/dev-v2.0.json \
|
||||
--per_gpu_train_batch_size 3 \
|
||||
--per_gpu_eval_batch_size 64 \
|
||||
--learning_rate 3e-5 \
|
||||
--num_train_epochs 3.0 \
|
||||
--max_seq_length 384 \
|
||||
--doc_stride 128 \
|
||||
--save_steps 2000 \
|
||||
--threads 24 \
|
||||
--warmup_steps 814 \
|
||||
--gradient_accumulation_steps 4 \
|
||||
--fp16 \
|
||||
--do_train
|
||||
```
|
||||
|
||||
### Evaluation
|
||||
|
||||
Evaluation on the dev set. I did not sweep for best threshold.
|
||||
|
||||
| | val |
|
||||
|-------------------|-------------------|
|
||||
| exact | 84.41842836688285 |
|
||||
| f1 | 87.4628460501696 |
|
||||
| total | 11873.0 |
|
||||
| HasAns_exact | 80.68488529014844 |
|
||||
| HasAns_f1 | 86.78245127423482 |
|
||||
| HasAns_total | 5928.0 |
|
||||
| NoAns_exact | 88.1412952060555 |
|
||||
| NoAns_f1 | 88.1412952060555 |
|
||||
| NoAns_total | 5945.0 |
|
||||
| best_exact | 84.41842836688285 |
|
||||
| best_exact_thresh | 0.0 |
|
||||
| best_f1 | 87.46284605016956 |
|
||||
| best_f1_thresh | 0.0 |
|
||||
|
||||
|
||||
### Usage
|
||||
|
||||
See [huggingface documentation](https://huggingface.co/transformers/model_doc/albert.html#albertforquestionanswering). Training on `SQuAD V2` allows the model to score if a paragraph contains an answer:
|
||||
```python
|
||||
start_scores, end_scores = model(input_ids)
|
||||
span_scores = start_scores.softmax(dim=1).log()[:,:,None] + end_scores.softmax(dim=1).log()[:,None,:]
|
||||
ignore_score = span_scores[:,0,0] #no answer scores
|
||||
|
||||
```
|
||||
|
||||
@@ -0,0 +1,61 @@
|
||||
### Model
|
||||
**[`allenai/scibert_scivocab_uncased`](https://huggingface.co/allenai/scibert_scivocab_uncased)** fine-tuned on **[`SQuAD V2`](https://rajpurkar.github.io/SQuAD-explorer/)** using **[`run_squad.py`](https://github.com/huggingface/transformers/blob/master/examples/run_squad.py)**
|
||||
|
||||
### Training Parameters
|
||||
Trained on 4 NVIDIA GeForce RTX 2080 Ti 11Gb
|
||||
```bash
|
||||
BASE_MODEL=allenai/scibert_scivocab_uncased
|
||||
python run_squad.py \
|
||||
--version_2_with_negative \
|
||||
--model_type albert \
|
||||
--model_name_or_path $BASE_MODEL \
|
||||
--output_dir $OUTPUT_MODEL \
|
||||
--do_eval \
|
||||
--do_lower_case \
|
||||
--train_file $SQUAD_DIR/train-v2.0.json \
|
||||
--predict_file $SQUAD_DIR/dev-v2.0.json \
|
||||
--per_gpu_train_batch_size 18 \
|
||||
--per_gpu_eval_batch_size 64 \
|
||||
--learning_rate 3e-5 \
|
||||
--num_train_epochs 3.0 \
|
||||
--max_seq_length 384 \
|
||||
--doc_stride 128 \
|
||||
--save_steps 2000 \
|
||||
--threads 24 \
|
||||
--warmup_steps 550 \
|
||||
--gradient_accumulation_steps 1 \
|
||||
--fp16 \
|
||||
--logging_steps 50 \
|
||||
--do_train
|
||||
```
|
||||
|
||||
### Evaluation
|
||||
|
||||
Evaluation on the dev set. I did not sweep for best threshold.
|
||||
|
||||
| | val |
|
||||
|-------------------|-------------------|
|
||||
| exact | 75.07790785816559 |
|
||||
| f1 | 78.47735207283013 |
|
||||
| total | 11873.0 |
|
||||
| HasAns_exact | 70.76585695006747 |
|
||||
| HasAns_f1 | 77.57449412292718 |
|
||||
| HasAns_total | 5928.0 |
|
||||
| NoAns_exact | 79.37762825904122 |
|
||||
| NoAns_f1 | 79.37762825904122 |
|
||||
| NoAns_total | 5945.0 |
|
||||
| best_exact | 75.08633032931863 |
|
||||
| best_exact_thresh | 0.0 |
|
||||
| best_f1 | 78.48577454398324 |
|
||||
| best_f1_thresh | 0.0 |
|
||||
|
||||
### Usage
|
||||
|
||||
See [huggingface documentation](https://huggingface.co/transformers/model_doc/bert.html#bertforquestionanswering). Training on `SQuAD V2` allows the model to score if a paragraph contains an answer:
|
||||
```python
|
||||
start_scores, end_scores = model(input_ids)
|
||||
span_scores = start_scores.softmax(dim=1).log()[:,:,None] + end_scores.softmax(dim=1).log()[:,None,:]
|
||||
ignore_score = span_scores[:,0,0] #no answer scores
|
||||
|
||||
```
|
||||
|
||||
14
model_cards/lvwerra/bert-imdb/README.md
Normal file
14
model_cards/lvwerra/bert-imdb/README.md
Normal file
@@ -0,0 +1,14 @@
|
||||
# BERT-IMDB
|
||||
|
||||
## What is it?
|
||||
BERT (`bert-large-cased`) trained for sentiment classification on the [IMDB dataset](https://www.kaggle.com/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews).
|
||||
|
||||
## Training setting
|
||||
|
||||
The model was trained on 80% of the IMDB dataset for sentiment classification for three epochs with a learning rate of `1e-5` with the `simpletransformers` library. The library uses a learning rate schedule.
|
||||
|
||||
## Result
|
||||
The model achieved 90% classification accuracy on the validation set.
|
||||
|
||||
## Reference
|
||||
The full experiment is available in the [tlr repo](https://lvwerra.github.io/trl/03-bert-imdb-training/).
|
||||
18
model_cards/lvwerra/gpt2-imdb-pos/README.md
Normal file
18
model_cards/lvwerra/gpt2-imdb-pos/README.md
Normal file
@@ -0,0 +1,18 @@
|
||||
# GPT2-IMDB-pos
|
||||
|
||||
## What is it?
|
||||
A small GPT2 (`lvwerra/gpt2-imdb`) language model fine-tuned to produce positive movie reviews based the [IMDB dataset](https://www.kaggle.com/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews). The model is trained with rewards from a BERT sentiment classifier (`lvwerra/gpt2-imdb`) via PPO.
|
||||
|
||||
## Training setting
|
||||
The model was trained for `100` optimisation steps with a batch size of `256` which corresponds to `25600` training samples. The full experiment setup can be found in the Jupyter notebook in the [trl repo](https://lvwerra.github.io/trl/04-gpt2-sentiment-ppo-training/).
|
||||
|
||||
## Examples
|
||||
A few examples of the model response to a query before and after optimisation:
|
||||
|
||||
| query | response (before) | response (after) | rewards (before) | rewards (after) |
|
||||
|-------|-------------------|------------------|------------------|-----------------|
|
||||
|I'd never seen a |heavier, woodier example of Victorian archite... |film of this caliber, and I think it's wonder... |3.297736 |4.158653|
|
||||
|I love John's work |but I actually have to write language as in w... |and I hereby recommend this film. I am really... |-1.904006 |4.159198 |
|
||||
|I's a big struggle |to see anyone who acts in that way. by Jim Th... |, but overall I'm happy with the changes even ... |-1.595925 |2.651260|
|
||||
|
||||
|
||||
27
model_cards/lvwerra/gpt2-imdb/README.md
Normal file
27
model_cards/lvwerra/gpt2-imdb/README.md
Normal file
@@ -0,0 +1,27 @@
|
||||
# GPT2-IMDB
|
||||
|
||||
## What is it?
|
||||
A GPT2 (`gpt2`) language model fine-tuned on the [IMDB dataset](https://www.kaggle.com/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews).
|
||||
|
||||
## Training setting
|
||||
|
||||
The GPT2 language model was fine-tuned for 1 epoch on the IMDB dataset. All comments were joined into a single text file separated by the EOS token:
|
||||
|
||||
```
|
||||
import pandas as pd
|
||||
df = pd.read_csv("imdb-dataset.csv")
|
||||
imdb_str = " <|endoftext|> ".join(df['review'].tolist())
|
||||
|
||||
with open ('imdb.txt', 'w') as f:
|
||||
f.write(imdb_str)
|
||||
```
|
||||
|
||||
To train the model the `run_language_modeling.py` script in the `transformer` library was used:
|
||||
|
||||
```
|
||||
python run_language_modeling.py
|
||||
--train_data_file imdb.txt
|
||||
--output_dir gpt2-imdb
|
||||
--model_type gpt2
|
||||
--model_name_or_path gpt2
|
||||
```
|
||||
@@ -5,15 +5,16 @@ thumbnail:
|
||||
|
||||
# GPT-2 + CORD19 dataset : 🦠 ✍ ⚕
|
||||
|
||||
**GPT-2** fine-tuned on **biorxiv_medrxiv** and **comm_use_subset files** from [CORD-19](https://www.kaggle.com/allen-institute-for-ai/CORD-19-research-challenge) dataset.
|
||||
**GPT-2** fine-tuned on **biorxiv_medrxiv**, **comm_use_subset** and **custom_license** files from [CORD-19](https://www.kaggle.com/allen-institute-for-ai/CORD-19-research-challenge) dataset.
|
||||
|
||||
|
||||
## Datasets details:
|
||||
## Datasets details
|
||||
|
||||
| Dataset | # Files |
|
||||
| ---------------------- | ----- |
|
||||
| biorxiv_medrxiv | 885 |
|
||||
| comm_use_subse | 9K |
|
||||
| comm_use_subset | 9K |
|
||||
| custom_license | 20.6K |
|
||||
|
||||
## Model training
|
||||
|
||||
@@ -37,7 +38,7 @@ python run_language_modeling.py \
|
||||
|
||||
<img alt="training loss" src="https://svgshare.com/i/JTf.svg' title='GTP-2-finetuned-CORDS19-loss" width="600" height="300" />
|
||||
|
||||
## Model in action / Example of usage: ✒
|
||||
## Model in action / Example of usage ✒
|
||||
|
||||
You can get the following script [here](https://github.com/huggingface/transformers/blob/master/examples/run_generation.py)
|
||||
|
||||
|
||||
@@ -0,0 +1,62 @@
|
||||
---
|
||||
language: english
|
||||
thumbnail:
|
||||
---
|
||||
|
||||
# GPT-2 + bio/medrxiv files from CORD19: 🦠 ✍ ⚕
|
||||
|
||||
**GPT-2** fine-tuned on **biorxiv_medrxiv** files from [CORD-19](https://www.kaggle.com/allen-institute-for-ai/CORD-19-research-challenge) dataset.
|
||||
|
||||
|
||||
## Datasets details:
|
||||
|
||||
| Dataset | # Files |
|
||||
| ---------------------- | ----- |
|
||||
| biorxiv_medrxiv | 885 |
|
||||
|
||||
|
||||
## Model training:
|
||||
|
||||
The model was trained on a Tesla P100 GPU and 25GB of RAM with the following command:
|
||||
|
||||
```bash
|
||||
|
||||
export TRAIN_FILE=/path/to/dataset/train.txt
|
||||
|
||||
python run_language_modeling.py \
|
||||
--model_type gpt2 \
|
||||
--model_name_or_path gpt2 \
|
||||
--do_train \
|
||||
--train_data_file $TRAIN_FILE \
|
||||
--num_train_epochs 4 \
|
||||
--output_dir model_output \
|
||||
--overwrite_output_dir \
|
||||
--save_steps 2000 \
|
||||
--per_gpu_train_batch_size 3
|
||||
```
|
||||
|
||||
## Model in action / Example of usage: ✒
|
||||
|
||||
You can get the following script [here](https://github.com/huggingface/transformers/blob/master/examples/run_generation.py)
|
||||
|
||||
```bash
|
||||
python run_generation.py \
|
||||
--model_type gpt2 \
|
||||
--model_name_or_path mrm8488/GPT-2-finetuned-CORD19 \
|
||||
--length 200
|
||||
```
|
||||
```txt
|
||||
👵👴🦠
|
||||
# Input: Old people with COVID-19 tends to suffer
|
||||
# Output: === GENERATED SEQUENCE 1 ===
|
||||
Old people with COVID-19 tends to suffer more symptom onset time and death. It is well known that many people with COVID-19 have high homozygous ZIKV infection in the face of severe symptoms in both severe and severe cases.
|
||||
The origin of Wuhan Fever was investigated by Prof. Shen Jiang at the outbreak of Wuhan Fever [34]. As Huanan Province is the epicenter of this outbreak, Huanan, the epicenter of epidemic Wuhan Fever, is the most potential location for the direct transmission of infection (source: Zhongzhen et al., 2020). A negative risk ratio indicates more frequent underlying signs in the people in Huanan Province with COVID-19 patients. Further analysis of reported Huanan Fever onset data in the past two years indicated that the intensity of exposure is the key risk factor for developing MERS-CoV infection in this region, especially among children and elderly. To be continued to develop infected patients would be a very important area for
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
|
||||
|
||||
> Made with <span style="color: #e25555;">♥</span> in Spain
|
||||
@@ -66,6 +66,8 @@ nlp_ner = pipeline(
|
||||
{"use_fast": False}
|
||||
))
|
||||
|
||||
text = 'Mis amigos están pensando viajar a Londres este verano'
|
||||
|
||||
nlp_ner(text)
|
||||
|
||||
#Output: [{'entity': 'B-LOC', 'score': 0.9998720288276672, 'word': 'Londres'}]
|
||||
|
||||
@@ -0,0 +1,83 @@
|
||||
---
|
||||
language: spanish
|
||||
thumbnail:
|
||||
---
|
||||
|
||||
# Spanish BERT (BETO) + Syntax POS tagging ✍🏷
|
||||
|
||||
This model is a fine-tuned version of the Spanish BERT [(BETO)](https://github.com/dccuchile/beto) on Spanish **syntax** annotations in [CONLL CORPORA](https://www.kaggle.com/nltkdata/conll-corpora) dataset for **syntax POS** (Part of Speech tagging) downstream task.
|
||||
|
||||
## Details of the downstream task (Syntax POS) - Dataset
|
||||
|
||||
- [Dataset: CONLL Corpora ES](https://www.kaggle.com/nltkdata/conll-corpora)
|
||||
|
||||
#### [Fine-tune script on NER dataset provided by Huggingface](https://github.com/huggingface/transformers/blob/master/examples/run_ner.py)
|
||||
|
||||
#### 21 Syntax annotations (Labels) covered:
|
||||
|
||||
- \_
|
||||
- ATR
|
||||
- ATR.d
|
||||
- CAG
|
||||
- CC
|
||||
- CD
|
||||
- CD.Q
|
||||
- CI
|
||||
- CPRED
|
||||
- CPRED.CD
|
||||
- CPRED.SUJ
|
||||
- CREG
|
||||
- ET
|
||||
- IMPERS
|
||||
- MOD
|
||||
- NEG
|
||||
- PASS
|
||||
- PUNC
|
||||
- ROOT
|
||||
- SUJ
|
||||
- VOC
|
||||
|
||||
## Metrics on test set 📋
|
||||
|
||||
| Metric | # score |
|
||||
| :-------: | :-------: |
|
||||
| F1 | **89.27** |
|
||||
| Precision | **89.44** |
|
||||
| Recall | **89.11** |
|
||||
|
||||
## Model in action 🔨
|
||||
|
||||
Fast usage with **pipelines** 🧪
|
||||
|
||||
```python
|
||||
from transformers import pipeline
|
||||
|
||||
nlp_pos_syntax = pipeline(
|
||||
"ner",
|
||||
model="mrm8488/bert-spanish-cased-finetuned-pos-syntax",
|
||||
tokenizer="mrm8488/bert-spanish-cased-finetuned-pos-syntax"
|
||||
)
|
||||
|
||||
text = 'Mis amigos están pensando viajar a Londres este verano.'
|
||||
|
||||
nlp_pos_syntax(text)[1:len(nlp_pos_syntax(text))-1]
|
||||
```
|
||||
|
||||
```json
|
||||
[
|
||||
{ "entity": "_", "score": 0.9999216794967651, "word": "Mis" },
|
||||
{ "entity": "SUJ", "score": 0.999882698059082, "word": "amigos" },
|
||||
{ "entity": "_", "score": 0.9998869299888611, "word": "están" },
|
||||
{ "entity": "ROOT", "score": 0.9980518221855164, "word": "pensando" },
|
||||
{ "entity": "_", "score": 0.9998420476913452, "word": "viajar" },
|
||||
{ "entity": "CD", "score": 0.999351978302002, "word": "a" },
|
||||
{ "entity": "_", "score": 0.999959409236908, "word": "Londres" },
|
||||
{ "entity": "_", "score": 0.9998968839645386, "word": "este" },
|
||||
{ "entity": "CC", "score": 0.99931401014328, "word": "verano" },
|
||||
{ "entity": "PUNC", "score": 0.9998534917831421, "word": "." }
|
||||
]
|
||||
```
|
||||
|
||||
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
|
||||
|
||||
> Made with <span style="color: #e25555;">♥</span> in Spain
|
||||
@@ -21,7 +21,7 @@ I preprocessed the dataset and splitted it as train / dev (80/20)
|
||||
|
||||
- [Fine-tune on NER script provided by Huggingface](https://github.com/huggingface/transformers/blob/master/examples/run_ner.py)
|
||||
|
||||
- Labels covered:
|
||||
- **60** Labels covered:
|
||||
|
||||
```
|
||||
AO, AQ, CC, CS, DA, DD, DE, DI, DN, DP, DT, Faa, Fat, Fc, Fd, Fe, Fg, Fh, Fia, Fit, Fp, Fpa, Fpt, Fs, Ft, Fx, Fz, I, NC, NP, P0, PD, PI, PN, PP, PR, PT, PX, RG, RN, SP, VAI, VAM, VAN, VAP, VAS, VMG, VMI, VMM, VMN, VMP, VMS, VSG, VSI, VSM, VSN, VSP, VSS, Y and Z
|
||||
@@ -74,6 +74,8 @@ nlp_pos(text)
|
||||
```
|
||||
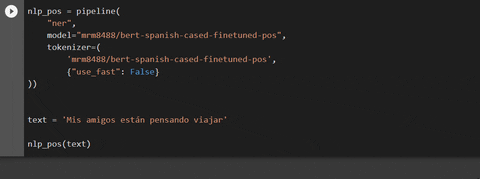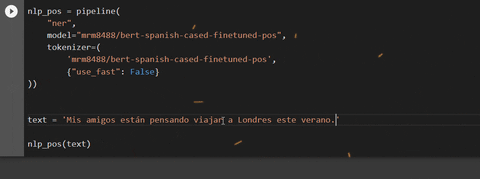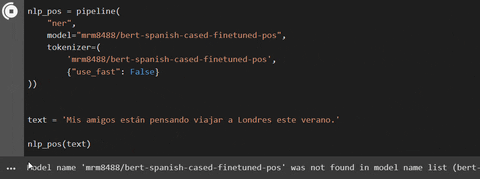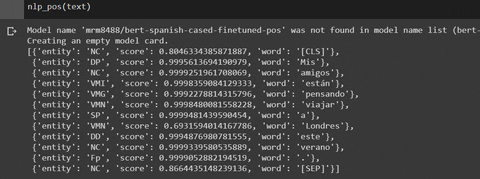
|
||||
|
||||
16 POS tags version also available [here](https://huggingface.co/mrm8488/bert-spanish-cased-finetuned-pos-16-tags)
|
||||
|
||||
|
||||
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
|
||||
|
||||
|
||||
@@ -0,0 +1,82 @@
|
||||
---
|
||||
language: multilingual
|
||||
thumbnail:
|
||||
---
|
||||
|
||||
# DistilBERT multilingual fine-tuned on TydiQA (GoldP task) dataset for multilingual Q&A 😛🌍❓
|
||||
|
||||
|
||||
## Details of the language model
|
||||
|
||||
[distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased)
|
||||
|
||||
|
||||
## Details of the Tydi QA dataset
|
||||
|
||||
TyDi QA contains 200k human-annotated question-answer pairs in 11 Typologically Diverse languages, written without seeing the answer and without the use of translation, and is designed for the **training and evaluation** of automatic question answering systems. This repository provides evaluation code and a baseline system for the dataset. https://ai.google.com/research/tydiqa
|
||||
|
||||
|
||||
## Details of the downstream task (Gold Passage or GoldP aka the secondary task)
|
||||
|
||||
Given a passage that is guaranteed to contain the answer, predict the single contiguous span of characters that answers the question. the gold passage task differs from the [primary task](https://github.com/google-research-datasets/tydiqa/blob/master/README.md#the-tasks) in several ways:
|
||||
* only the gold answer passage is provided rather than the entire Wikipedia article;
|
||||
* unanswerable questions have been discarded, similar to MLQA and XQuAD;
|
||||
* we evaluate with the SQuAD 1.1 metrics like XQuAD; and
|
||||
* Thai and Japanese are removed since the lack of whitespace breaks some tools.
|
||||
|
||||
|
||||
## Model training 💪🏋️
|
||||
|
||||
The model was fine-tuned on a Tesla P100 GPU and 25GB of RAM.
|
||||
The script is the following:
|
||||
|
||||
```python
|
||||
python transformers/examples/run_squad.py \
|
||||
--model_type distilbert \
|
||||
--model_name_or_path distilbert-base-multilingual-cased \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--train_file /path/to/dataset/train.json \
|
||||
--predict_file /path/to/dataset/dev.json \
|
||||
--per_gpu_train_batch_size 24 \
|
||||
--per_gpu_eval_batch_size 24 \
|
||||
--learning_rate 3e-5 \
|
||||
--num_train_epochs 5 \
|
||||
--max_seq_length 384 \
|
||||
--doc_stride 128 \
|
||||
--output_dir /content/model_output \
|
||||
--overwrite_output_dir \
|
||||
--save_steps 1000 \
|
||||
--threads 400
|
||||
```
|
||||
|
||||
## Global Results (dev set) 📝
|
||||
|
||||
| Metric | # Value |
|
||||
| --------- | ----------- |
|
||||
| **EM** | **63.85** |
|
||||
| **F1** | **75.70** |
|
||||
|
||||
## Specific Results (per language) 🌍📝
|
||||
|
||||
| Language | # Samples | # EM | # F1 |
|
||||
| --------- | ----------- |--------| ------ |
|
||||
| Arabic | 1314 | 66.66 | 80.02 |
|
||||
| Bengali | 180 | 53.09 | 63.50 |
|
||||
| English | 654 | 62.42 | 73.12 |
|
||||
| Finnish | 1031 | 64.57 | 75.15 |
|
||||
| Indonesian| 773 | 67.89 | 79.70 |
|
||||
| Korean | 414 | 51.29 | 61.73 |
|
||||
| Russian | 1079 | 55.42 | 70.08 |
|
||||
| Swahili | 596 | 74.51 | 81.15 |
|
||||
| Telegu | 874 | 66.21 | 79.85 |
|
||||
|
||||
|
||||
## Similar models
|
||||
|
||||
You can also try [bert-multi-cased-finedtuned-xquad-tydiqa-goldp](https://huggingface.co/mrm8488/bert-multi-cased-finedtuned-xquad-tydiqa-goldp) that achieves **F1 = 82.16** and **EM = 71.06** (And of course better marks per language).
|
||||
|
||||
|
||||
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
|
||||
|
||||
> Made with <span style="color: #e25555;">♥</span> in Spain
|
||||
27
model_cards/mrm8488/gpt2-imdb-neg/README.md
Normal file
27
model_cards/mrm8488/gpt2-imdb-neg/README.md
Normal file
@@ -0,0 +1,27 @@
|
||||
# GPT2-IMDB-neg (LM + RL) 🎞😡✍
|
||||
|
||||
All credits to [@lvwerra](https://twitter.com/lvwerra)
|
||||
|
||||
## What is it?
|
||||
A small GPT2 (`lvwerra/gpt2-imdb`) language model fine-tuned to produce **negative** movie reviews based the [IMDB dataset](https://www.kaggle.com/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews). The model is trained with rewards from a BERT sentiment classifier (`lvwerra/gpt2-imdb`) via **PPO**.
|
||||
|
||||
## Why?
|
||||
I wanted to reproduce the experiment [lvwerra/gpt2-imdb-pos](https://huggingface.co/lvwerra/gpt2-imdb-pos) but for generating **negative** movie reviews.
|
||||
|
||||
## Training setting
|
||||
The model was trained for `100` optimisation steps with a batch size of `256` which corresponds to `25600` training samples. The full experiment setup (for positive samples) in [trl repo](https://lvwerra.github.io/trl/04-gpt2-sentiment-ppo-training/).
|
||||
|
||||
## Examples
|
||||
A few examples of the model response to a query before and after optimisation:
|
||||
|
||||
| query | response (before) | response (after) | rewards (before) | rewards (after) |
|
||||
|-------|-------------------|------------------|------------------|-----------------|
|
||||
|This movie is a fine | attempt as far as live action is concerned, n...|example of how bad Hollywood in theatrics pla...| 2.118391 | -3.31625|
|
||||
|I have watched 3 episodes |with this guy and he is such a talented actor...| but the show is just plain awful and there ne...| 2.681171| -4.512792|
|
||||
|We know that firefighters and| police officers are forced to become populari...| other chains have going to get this disaster ...| 1.367811| -3.34017|
|
||||
|
||||
|
||||
|
||||
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
|
||||
|
||||
> Made with <span style="color: #e25555;">♥</span> in Spain
|
||||
@@ -0,0 +1,57 @@
|
||||
---
|
||||
language: german
|
||||
---
|
||||
|
||||
# Model description
|
||||
## Dataset
|
||||
Trained on fictional and non-fictional German texts written between 1840 and 1920:
|
||||
* Narrative texts from Digitale Bibliothek (https://textgrid.de/digitale-bibliothek)
|
||||
* Fairy tales and sagas from Grimm Korpus (https://www1.ids-mannheim.de/kl/projekte/korpora/archiv/gri.html)
|
||||
* Newspaper and magazine article from Mannheimer Korpus Historischer Zeitungen und Zeitschriften (https://repos.ids-mannheim.de/mkhz-beschreibung.html)
|
||||
* Magazine article from the journal „Die Grenzboten“ (http://www.deutschestextarchiv.de/doku/textquellen#grenzboten)
|
||||
* Fictional and non-fictional texts from Projekt Gutenberg (https://www.projekt-gutenberg.org)
|
||||
|
||||
## Hardware used
|
||||
1 Tesla P4 GPU
|
||||
|
||||
## Hyperparameters
|
||||
|
||||
| Parameter | Value |
|
||||
|-------------------------------|----------|
|
||||
| Epochs | 3 |
|
||||
| Gradient_accumulation_steps | 1 |
|
||||
| Train_batch_size | 32 |
|
||||
| Learning_rate | 0.00003 |
|
||||
| Max_seq_len | 128 |
|
||||
|
||||
## Evaluation results: Automatic tagging of four forms of speech/thought/writing representation in historical fictional and non-fictional German texts
|
||||
|
||||
The language model was used in the task to tag direct, indirect, reported and free indirect speech/thought/writing representation in fictional and non-fictional German texts. The tagger is available and described in detail at https://github.com/redewiedergabe/tagger.
|
||||
|
||||
The tagging model was trained using the SequenceTagger Class of the Flair framework ([Akbik et al., 2019](https://www.aclweb.org/anthology/N19-4010)) which implements a BiLSTM-CRF architecture on top of a language embedding (as proposed by [Huang et al. (2015)](https://arxiv.org/abs/1508.01991)).
|
||||
|
||||
|
||||
Hyperparameters
|
||||
|
||||
| Parameter | Value |
|
||||
|-------------------------------|------------|
|
||||
| Hidden_size | 256 |
|
||||
| Learning_rate | 0.1 |
|
||||
| Mini_batch_size | 8 |
|
||||
| Max_epochs | 150 |
|
||||
|
||||
Results are reported below in comparison to a custom trained flair embedding, which was stacked onto a custom trained fastText-model. Both models were trained on the same dataset.
|
||||
|
||||
| | BERT ||| FastText+Flair |||Test data|
|
||||
|----------------|----------|-----------|----------|------|-----------|--------|--------|
|
||||
| | F1 | Precision | Recall | F1 | Precision | Recall ||
|
||||
| Direct | 0.80 | 0.86 | 0.74 | 0.84 | 0.90 | 0.79 |historical German, fictional & non-fictional|
|
||||
| Indirect | **0.76** | **0.79** | **0.73** | 0.73 | 0.78 | 0.68 |historical German, fictional & non-fictional|
|
||||
| Reported | **0.58** | **0.69** | **0.51** | 0.56 | 0.68 | 0.48 |historical German, fictional & non-fictional|
|
||||
| Free indirect | **0.57** | **0.80** | **0.44** | 0.47 | 0.78 | 0.34 |modern German, fictional|
|
||||
|
||||
## Intended use:
|
||||
Historical German Texts (1840 to 1920)
|
||||
|
||||
(Showed good performance with modern German fictional texts as well)
|
||||
|
||||
6
model_cards/roberta-base-README.md
Normal file
6
model_cards/roberta-base-README.md
Normal file
@@ -0,0 +1,6 @@
|
||||
---
|
||||
tags:
|
||||
- exbert
|
||||
---
|
||||
|
||||
[](https://huggingface.co/exbert/?model=roberta-base)
|
||||
60
model_cards/shoarora/alectra-small-owt/README.md
Normal file
60
model_cards/shoarora/alectra-small-owt/README.md
Normal file
@@ -0,0 +1,60 @@
|
||||
# ALECTRA-small-OWT
|
||||
|
||||
This is an extension of
|
||||
[ELECTRA](https://openreview.net/forum?id=r1xMH1BtvB) small model, trained on the
|
||||
[OpenWebText corpus](https://skylion007.github.io/OpenWebTextCorpus/).
|
||||
The training task (discriminative LM / replaced-token-detection) can be generalized to any transformer type. Here, we train an ALBERT model under the same scheme.
|
||||
|
||||
## Pretraining task
|
||||

|
||||
(figure from [Clark et al. 2020](https://openreview.net/pdf?id=r1xMH1BtvB))
|
||||
|
||||
ELECTRA uses discriminative LM / replaced-token-detection for pretraining.
|
||||
This involves a generator (a Masked LM model) creating examples for a discriminator
|
||||
to classify as original or replaced for each token.
|
||||
|
||||
The generator generalizes to any `*ForMaskedLM` model and the discriminator could be
|
||||
any `*ForTokenClassification` model. Therefore, we can extend the task to ALBERT models,
|
||||
not just BERT as in the original paper.
|
||||
|
||||
## Usage
|
||||
```python
|
||||
from transformers import AlbertForSequenceClassification, BertTokenizer
|
||||
|
||||
# Both models use the bert-base-uncased tokenizer and vocab.
|
||||
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
|
||||
alectra = AlbertForSequenceClassification.from_pretrained('shoarora/alectra-small-owt')
|
||||
```
|
||||
NOTE: this ALBERT model uses a BERT WordPiece tokenizer.
|
||||
|
||||
## Code
|
||||
The pytorch module that implements this task is available [here](https://github.com/shoarora/lmtuners/blob/master/lmtuners/lightning_modules/discriminative_lm.py).
|
||||
|
||||
Further implementation information [here](https://github.com/shoarora/lmtuners/tree/master/experiments/disc_lm_small),
|
||||
and [here](https://github.com/shoarora/lmtuners/blob/master/experiments/disc_lm_small/train_alectra_small.py) is the script that created this model.
|
||||
|
||||
This specific model was trained with the following params:
|
||||
- `batch_size: 512`
|
||||
- `training_steps: 5e5`
|
||||
- `warmup_steps: 4e4`
|
||||
- `learning_rate: 2e-3`
|
||||
|
||||
|
||||
## Downstream tasks
|
||||
#### GLUE Dev results
|
||||
| Model | # Params | CoLA | SST | MRPC | STS | QQP | MNLI | QNLI | RTE |
|
||||
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
|
||||
| ELECTRA-Small++ | 14M | 57.0 | 91. | 88.0 | 87.5 | 89.0 | 81.3 | 88.4 | 66.7|
|
||||
| ELECTRA-Small-OWT | 14M | 56.8 | 88.3| 87.4 | 86.8 | 88.3 | 78.9 | 87.9 | 68.5|
|
||||
| ELECTRA-Small-OWT (ours) | 17M | 56.3 | 88.4| 75.0 | 86.1 | 89.1 | 77.9 | 83.0 | 67.1|
|
||||
| ALECTRA-Small-OWT (ours) | 4M | 50.6 | 89.1| 86.3 | 87.2 | 89.1 | 78.2 | 85.9 | 69.6|
|
||||
|
||||
|
||||
#### GLUE Test results
|
||||
| Model | # Params | CoLA | SST | MRPC | STS | QQP | MNLI | QNLI | RTE |
|
||||
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
|
||||
| BERT-Base | 110M | 52.1 | 93.5| 84.8 | 85.9 | 89.2 | 84.6 | 90.5 | 66.4|
|
||||
| GPT | 117M | 45.4 | 91.3| 75.7 | 80.0 | 88.5 | 82.1 | 88.1 | 56.0|
|
||||
| ELECTRA-Small++ | 14M | 57.0 | 91.2| 88.0 | 87.5 | 89.0 | 81.3 | 88.4 | 66.7|
|
||||
| ELECTRA-Small-OWT (ours) | 17M | 57.4 | 89.3| 76.2 | 81.9 | 87.5 | 78.1 | 82.4 | 68.1|
|
||||
| ALECTRA-Small-OWT (ours) | 4M | 43.9 | 87.9| 82.1 | 82.0 | 87.6 | 77.9 | 85.8 | 67.5|
|
||||
59
model_cards/shoarora/electra-small-owt/README.md
Normal file
59
model_cards/shoarora/electra-small-owt/README.md
Normal file
@@ -0,0 +1,59 @@
|
||||
# ELECTRA-small-OWT
|
||||
|
||||
This is an unnoficial implementation of an
|
||||
[ELECTRA](https://openreview.net/forum?id=r1xMH1BtvB) small model, trained on the
|
||||
[OpenWebText corpus](https://skylion007.github.io/OpenWebTextCorpus/).
|
||||
|
||||
Differences from official ELECTRA models:
|
||||
- we use a `BertForMaskedLM` as the generator and `BertForTokenClassification` as the discriminator
|
||||
- they use an embedding projection layer, but Bert doesn't have one
|
||||
|
||||
## Pretraining ttask
|
||||

|
||||
(figure from [Clark et al. 2020](https://openreview.net/pdf?id=r1xMH1BtvB))
|
||||
|
||||
ELECTRA uses discriminative LM / replaced-token-detection for pretraining.
|
||||
This involves a generator (a Masked LM model) creating examples for a discriminator
|
||||
to classify as original or replaced for each token.
|
||||
|
||||
|
||||
## Usage
|
||||
```python
|
||||
from transformers import BertForSequenceClassification, BertTokenizer
|
||||
|
||||
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
|
||||
electra = BertForSequenceClassification.from_pretrained('shoarora/electra-small-owt')
|
||||
```
|
||||
|
||||
## Code
|
||||
The pytorch module that implements this task is available [here](https://github.com/shoarora/lmtuners/blob/master/lmtuners/lightning_modules/discriminative_lm.py).
|
||||
|
||||
Further implementation information [here](https://github.com/shoarora/lmtuners/tree/master/experiments/disc_lm_small),
|
||||
and [here](https://github.com/shoarora/lmtuners/blob/master/experiments/disc_lm_small/train_electra_small.py) is the script that created this model.
|
||||
|
||||
This specific model was trained with the following params:
|
||||
- `batch_size: 512`
|
||||
- `training_steps: 5e5`
|
||||
- `warmup_steps: 4e4`
|
||||
- `learning_rate: 2e-3`
|
||||
|
||||
|
||||
## Downstream tasks
|
||||
#### GLUE Dev results
|
||||
| Model | # Params | CoLA | SST | MRPC | STS | QQP | MNLI | QNLI | RTE |
|
||||
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
|
||||
| ELECTRA-Small++ | 14M | 57.0 | 91. | 88.0 | 87.5 | 89.0 | 81.3 | 88.4 | 66.7|
|
||||
| ELECTRA-Small-OWT | 14M | 56.8 | 88.3| 87.4 | 86.8 | 88.3 | 78.9 | 87.9 | 68.5|
|
||||
| ELECTRA-Small-OWT (ours) | 17M | 56.3 | 88.4| 75.0 | 86.1 | 89.1 | 77.9 | 83.0 | 67.1|
|
||||
| ALECTRA-Small-OWT (ours) | 4M | 50.6 | 89.1| 86.3 | 87.2 | 89.1 | 78.2 | 85.9 | 69.6|
|
||||
|
||||
- Table initialized from [ELECTRA github repo](https://github.com/google-research/electra)
|
||||
|
||||
#### GLUE Test results
|
||||
| Model | # Params | CoLA | SST | MRPC | STS | QQP | MNLI | QNLI | RTE |
|
||||
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
|
||||
| BERT-Base | 110M | 52.1 | 93.5| 84.8 | 85.9 | 89.2 | 84.6 | 90.5 | 66.4|
|
||||
| GPT | 117M | 45.4 | 91.3| 75.7 | 80.0 | 88.5 | 82.1 | 88.1 | 56.0|
|
||||
| ELECTRA-Small++ | 14M | 57.0 | 91.2| 88.0 | 87.5 | 89.0 | 81.3 | 88.4 | 66.7|
|
||||
| ELECTRA-Small-OWT (ours) | 17M | 57.4 | 89.3| 76.2 | 81.9 | 87.5 | 78.1 | 82.4 | 68.1|
|
||||
| ALECTRA-Small-OWT (ours) | 4M | 43.9 | 87.9| 82.1 | 82.0 | 87.6 | 77.9 | 85.8 | 67.5|
|
||||
6
model_cards/xlm-mlm-en-2048-README.md
Normal file
6
model_cards/xlm-mlm-en-2048-README.md
Normal file
@@ -0,0 +1,6 @@
|
||||
---
|
||||
tags:
|
||||
- exbert
|
||||
---
|
||||
|
||||
[](https://huggingface.co/exbert/?model=xlm-mlm-en-2048)
|
||||
6
model_cards/xlm-roberta-base-README.md
Normal file
6
model_cards/xlm-roberta-base-README.md
Normal file
@@ -0,0 +1,6 @@
|
||||
---
|
||||
tags:
|
||||
- exbert
|
||||
---
|
||||
|
||||
[](https://huggingface.co/exbert/?model=xlm-roberta-base)
|
||||
4
setup.py
4
setup.py
@@ -76,14 +76,14 @@ extras["testing"] = ["pytest", "pytest-xdist"]
|
||||
extras["docs"] = ["recommonmark", "sphinx", "sphinx-markdown-tables", "sphinx-rtd-theme"]
|
||||
extras["quality"] = [
|
||||
"black",
|
||||
"isort @ git+git://github.com/timothycrosley/isort.git@e63ae06ec7d70b06df9e528357650281a3d3ec22#egg=isort",
|
||||
"isort",
|
||||
"flake8",
|
||||
]
|
||||
extras["dev"] = extras["testing"] + extras["quality"] + ["mecab-python3", "scikit-learn", "tensorflow", "torch"]
|
||||
|
||||
setup(
|
||||
name="transformers",
|
||||
version="2.7.0",
|
||||
version="2.8.0",
|
||||
author="Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Sam Shleifer, Google AI Language Team Authors, Open AI team Authors, Facebook AI Authors, Carnegie Mellon University Authors",
|
||||
author_email="thomas@huggingface.co",
|
||||
description="State-of-the-art Natural Language Processing for TensorFlow 2.0 and PyTorch",
|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
# There's no way to ignore "F401 '...' imported but unused" warnings in this
|
||||
# module, but to preserve other warnings. So, don't check this module at all.
|
||||
|
||||
__version__ = "2.7.0"
|
||||
__version__ = "2.8.0"
|
||||
|
||||
# Work around to update TensorFlow's absl.logging threshold which alters the
|
||||
# default Python logging output behavior when present.
|
||||
@@ -38,6 +38,7 @@ from .configuration_bert import BERT_PRETRAINED_CONFIG_ARCHIVE_MAP, BertConfig
|
||||
from .configuration_camembert import CAMEMBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, CamembertConfig
|
||||
from .configuration_ctrl import CTRL_PRETRAINED_CONFIG_ARCHIVE_MAP, CTRLConfig
|
||||
from .configuration_distilbert import DISTILBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, DistilBertConfig
|
||||
from .configuration_electra import ELECTRA_PRETRAINED_CONFIG_ARCHIVE_MAP, ElectraConfig
|
||||
from .configuration_flaubert import FLAUBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, FlaubertConfig
|
||||
from .configuration_gpt2 import GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP, GPT2Config
|
||||
from .configuration_mmbt import MMBTConfig
|
||||
@@ -127,6 +128,7 @@ from .tokenization_bert_japanese import BertJapaneseTokenizer, CharacterTokenize
|
||||
from .tokenization_camembert import CamembertTokenizer
|
||||
from .tokenization_ctrl import CTRLTokenizer
|
||||
from .tokenization_distilbert import DistilBertTokenizer, DistilBertTokenizerFast
|
||||
from .tokenization_electra import ElectraTokenizer, ElectraTokenizerFast
|
||||
from .tokenization_flaubert import FlaubertTokenizer
|
||||
from .tokenization_gpt2 import GPT2Tokenizer, GPT2TokenizerFast
|
||||
from .tokenization_openai import OpenAIGPTTokenizer, OpenAIGPTTokenizerFast
|
||||
@@ -297,6 +299,15 @@ if is_torch_available():
|
||||
FLAUBERT_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
)
|
||||
|
||||
from .modeling_electra import (
|
||||
ElectraForPreTraining,
|
||||
ElectraForMaskedLM,
|
||||
ElectraForTokenClassification,
|
||||
ElectraModel,
|
||||
load_tf_weights_in_electra,
|
||||
ELECTRA_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
)
|
||||
|
||||
# Optimization
|
||||
from .optimization import (
|
||||
AdamW,
|
||||
@@ -463,6 +474,15 @@ if is_tf_available():
|
||||
TF_T5_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
)
|
||||
|
||||
from .modeling_tf_electra import (
|
||||
TFElectraPreTrainedModel,
|
||||
TFElectraModel,
|
||||
TFElectraForPreTraining,
|
||||
TFElectraForMaskedLM,
|
||||
TFElectraForTokenClassification,
|
||||
TF_ELECTRA_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
)
|
||||
|
||||
# Optimization
|
||||
from .optimization_tf import WarmUp, create_optimizer, AdamWeightDecay, GradientAccumulator
|
||||
|
||||
|
||||
@@ -18,12 +18,6 @@ def _gelu_python(x):
|
||||
return x * 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))
|
||||
|
||||
|
||||
if torch.__version__ < "1.4.0":
|
||||
gelu = _gelu_python
|
||||
else:
|
||||
gelu = F.gelu
|
||||
|
||||
|
||||
def gelu_new(x):
|
||||
""" Implementation of the gelu activation function currently in Google Bert repo (identical to OpenAI GPT).
|
||||
Also see https://arxiv.org/abs/1606.08415
|
||||
@@ -31,6 +25,12 @@ def gelu_new(x):
|
||||
return 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
|
||||
|
||||
|
||||
if torch.__version__ < "1.4.0":
|
||||
gelu = _gelu_python
|
||||
else:
|
||||
gelu = F.gelu
|
||||
gelu_new = torch.jit.script(gelu_new)
|
||||
|
||||
ACT2FN = {
|
||||
"relu": F.relu,
|
||||
"swish": swish,
|
||||
|
||||
@@ -24,6 +24,7 @@ from .configuration_bert import BERT_PRETRAINED_CONFIG_ARCHIVE_MAP, BertConfig
|
||||
from .configuration_camembert import CAMEMBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, CamembertConfig
|
||||
from .configuration_ctrl import CTRL_PRETRAINED_CONFIG_ARCHIVE_MAP, CTRLConfig
|
||||
from .configuration_distilbert import DISTILBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, DistilBertConfig
|
||||
from .configuration_electra import ELECTRA_PRETRAINED_CONFIG_ARCHIVE_MAP, ElectraConfig
|
||||
from .configuration_flaubert import FLAUBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, FlaubertConfig
|
||||
from .configuration_gpt2 import GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP, GPT2Config
|
||||
from .configuration_openai import OPENAI_GPT_PRETRAINED_CONFIG_ARCHIVE_MAP, OpenAIGPTConfig
|
||||
@@ -57,6 +58,7 @@ ALL_PRETRAINED_CONFIG_ARCHIVE_MAP = dict(
|
||||
T5_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
XLM_ROBERTA_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
FLAUBERT_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
ELECTRA_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
]
|
||||
for key, value, in pretrained_map.items()
|
||||
)
|
||||
@@ -79,6 +81,7 @@ CONFIG_MAPPING = OrderedDict(
|
||||
("xlnet", XLNetConfig,),
|
||||
("xlm", XLMConfig,),
|
||||
("ctrl", CTRLConfig,),
|
||||
("electra", ElectraConfig,),
|
||||
]
|
||||
)
|
||||
|
||||
@@ -133,6 +136,7 @@ class AutoConfig:
|
||||
- contains `xlm`: :class:`~transformers.XLMConfig` (XLM model)
|
||||
- contains `ctrl` : :class:`~transformers.CTRLConfig` (CTRL model)
|
||||
- contains `flaubert` : :class:`~transformers.FlaubertConfig` (Flaubert model)
|
||||
- contains `electra` : :class:`~transformers.ElectraConfig` (ELECTRA model)
|
||||
|
||||
|
||||
Args:
|
||||
|
||||
132
src/transformers/configuration_electra.py
Normal file
132
src/transformers/configuration_electra.py
Normal file
@@ -0,0 +1,132 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
|
||||
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
""" ELECTRA model configuration """
|
||||
|
||||
|
||||
import logging
|
||||
|
||||
from .configuration_utils import PretrainedConfig
|
||||
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
ELECTRA_PRETRAINED_CONFIG_ARCHIVE_MAP = {
|
||||
"google/electra-small-generator": "https://s3.amazonaws.com/models.huggingface.co/bert/google/electra-small-generator/config.json",
|
||||
"google/electra-base-generator": "https://s3.amazonaws.com/models.huggingface.co/bert/google/electra-base-generator/config.json",
|
||||
"google/electra-large-generator": "https://s3.amazonaws.com/models.huggingface.co/bert/google/electra-large-generator/config.json",
|
||||
"google/electra-small-discriminator": "https://s3.amazonaws.com/models.huggingface.co/bert/google/electra-small-discriminator/config.json",
|
||||
"google/electra-base-discriminator": "https://s3.amazonaws.com/models.huggingface.co/bert/google/electra-base-discriminator/config.json",
|
||||
"google/electra-large-discriminator": "https://s3.amazonaws.com/models.huggingface.co/bert/google/electra-large-discriminator/config.json",
|
||||
}
|
||||
|
||||
|
||||
class ElectraConfig(PretrainedConfig):
|
||||
r"""
|
||||
This is the configuration class to store the configuration of a :class:`~transformers.ElectraModel`.
|
||||
It is used to instantiate an ELECTRA model according to the specified arguments, defining the model
|
||||
architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of
|
||||
the ELECTRA `google/electra-small-discriminator <https://huggingface.co/google/electra-small-discriminator>`__
|
||||
architecture.
|
||||
|
||||
Configuration objects inherit from :class:`~transformers.PretrainedConfig` and can be used
|
||||
to control the model outputs. Read the documentation from :class:`~transformers.PretrainedConfig`
|
||||
for more information.
|
||||
|
||||
|
||||
Args:
|
||||
vocab_size (:obj:`int`, optional, defaults to 30522):
|
||||
Vocabulary size of the ELECTRA model. Defines the different tokens that
|
||||
can be represented by the `inputs_ids` passed to the forward method of :class:`~transformers.ElectraModel`.
|
||||
embedding_size (:obj:`int`, optional, defaults to 128):
|
||||
Dimensionality of the encoder layers and the pooler layer.
|
||||
hidden_size (:obj:`int`, optional, defaults to 256):
|
||||
Dimensionality of the encoder layers and the pooler layer.
|
||||
num_hidden_layers (:obj:`int`, optional, defaults to 12):
|
||||
Number of hidden layers in the Transformer encoder.
|
||||
num_attention_heads (:obj:`int`, optional, defaults to 4):
|
||||
Number of attention heads for each attention layer in the Transformer encoder.
|
||||
intermediate_size (:obj:`int`, optional, defaults to 1024):
|
||||
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
|
||||
hidden_act (:obj:`str` or :obj:`function`, optional, defaults to "gelu"):
|
||||
The non-linear activation function (function or string) in the encoder and pooler.
|
||||
If string, "gelu", "relu", "swish" and "gelu_new" are supported.
|
||||
hidden_dropout_prob (:obj:`float`, optional, defaults to 0.1):
|
||||
The dropout probabilitiy for all fully connected layers in the embeddings, encoder, and pooler.
|
||||
attention_probs_dropout_prob (:obj:`float`, optional, defaults to 0.1):
|
||||
The dropout ratio for the attention probabilities.
|
||||
max_position_embeddings (:obj:`int`, optional, defaults to 512):
|
||||
The maximum sequence length that this model might ever be used with.
|
||||
Typically set this to something large just in case (e.g., 512 or 1024 or 2048).
|
||||
type_vocab_size (:obj:`int`, optional, defaults to 2):
|
||||
The vocabulary size of the `token_type_ids` passed into :class:`~transformers.ElectraModel`.
|
||||
initializer_range (:obj:`float`, optional, defaults to 0.02):
|
||||
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
||||
layer_norm_eps (:obj:`float`, optional, defaults to 1e-12):
|
||||
The epsilon used by the layer normalization layers.
|
||||
|
||||
Example::
|
||||
|
||||
from transformers import ElectraModel, ElectraConfig
|
||||
|
||||
# Initializing a ELECTRA electra-base-uncased style configuration
|
||||
configuration = ElectraConfig()
|
||||
|
||||
# Initializing a model from the electra-base-uncased style configuration
|
||||
model = ElectraModel(configuration)
|
||||
|
||||
# Accessing the model configuration
|
||||
configuration = model.config
|
||||
|
||||
Attributes:
|
||||
pretrained_config_archive_map (Dict[str, str]):
|
||||
A dictionary containing all the available pre-trained checkpoints.
|
||||
"""
|
||||
pretrained_config_archive_map = ELECTRA_PRETRAINED_CONFIG_ARCHIVE_MAP
|
||||
model_type = "electra"
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
vocab_size=30522,
|
||||
embedding_size=128,
|
||||
hidden_size=256,
|
||||
num_hidden_layers=12,
|
||||
num_attention_heads=4,
|
||||
intermediate_size=1024,
|
||||
hidden_act="gelu",
|
||||
hidden_dropout_prob=0.1,
|
||||
attention_probs_dropout_prob=0.1,
|
||||
max_position_embeddings=512,
|
||||
type_vocab_size=2,
|
||||
initializer_range=0.02,
|
||||
layer_norm_eps=1e-12,
|
||||
pad_token_id=0,
|
||||
**kwargs
|
||||
):
|
||||
super().__init__(pad_token_id=pad_token_id, **kwargs)
|
||||
|
||||
self.vocab_size = vocab_size
|
||||
self.embedding_size = embedding_size
|
||||
self.hidden_size = hidden_size
|
||||
self.num_hidden_layers = num_hidden_layers
|
||||
self.num_attention_heads = num_attention_heads
|
||||
self.intermediate_size = intermediate_size
|
||||
self.hidden_act = hidden_act
|
||||
self.hidden_dropout_prob = hidden_dropout_prob
|
||||
self.attention_probs_dropout_prob = attention_probs_dropout_prob
|
||||
self.max_position_embeddings = max_position_embeddings
|
||||
self.type_vocab_size = type_vocab_size
|
||||
self.initializer_range = initializer_range
|
||||
self.layer_norm_eps = layer_norm_eps
|
||||
@@ -80,6 +80,7 @@ class PretrainedConfig(object):
|
||||
self.repetition_penalty = kwargs.pop("repetition_penalty", 1.0)
|
||||
self.length_penalty = kwargs.pop("length_penalty", 1.0)
|
||||
self.no_repeat_ngram_size = kwargs.pop("no_repeat_ngram_size", 0)
|
||||
self.bad_words_ids = kwargs.pop("bad_words_ids", None)
|
||||
self.num_return_sequences = kwargs.pop("num_return_sequences", 1)
|
||||
|
||||
# Fine-tuning task arguments
|
||||
|
||||
@@ -0,0 +1,79 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2018 The HuggingFace Inc. team.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""Convert ELECTRA checkpoint."""
|
||||
|
||||
|
||||
import argparse
|
||||
import logging
|
||||
|
||||
import torch
|
||||
|
||||
from transformers import ElectraConfig, ElectraForMaskedLM, ElectraForPreTraining, load_tf_weights_in_electra
|
||||
|
||||
|
||||
logging.basicConfig(level=logging.INFO)
|
||||
|
||||
|
||||
def convert_tf_checkpoint_to_pytorch(tf_checkpoint_path, config_file, pytorch_dump_path, discriminator_or_generator):
|
||||
# Initialise PyTorch model
|
||||
config = ElectraConfig.from_json_file(config_file)
|
||||
print("Building PyTorch model from configuration: {}".format(str(config)))
|
||||
|
||||
if discriminator_or_generator == "discriminator":
|
||||
model = ElectraForPreTraining(config)
|
||||
elif discriminator_or_generator == "generator":
|
||||
model = ElectraForMaskedLM(config)
|
||||
else:
|
||||
raise ValueError("The discriminator_or_generator argument should be either 'discriminator' or 'generator'")
|
||||
|
||||
# Load weights from tf checkpoint
|
||||
load_tf_weights_in_electra(
|
||||
model, config, tf_checkpoint_path, discriminator_or_generator=discriminator_or_generator
|
||||
)
|
||||
|
||||
# Save pytorch-model
|
||||
print("Save PyTorch model to {}".format(pytorch_dump_path))
|
||||
torch.save(model.state_dict(), pytorch_dump_path)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
# Required parameters
|
||||
parser.add_argument(
|
||||
"--tf_checkpoint_path", default=None, type=str, required=True, help="Path to the TensorFlow checkpoint path."
|
||||
)
|
||||
parser.add_argument(
|
||||
"--config_file",
|
||||
default=None,
|
||||
type=str,
|
||||
required=True,
|
||||
help="The config json file corresponding to the pre-trained model. \n"
|
||||
"This specifies the model architecture.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--pytorch_dump_path", default=None, type=str, required=True, help="Path to the output PyTorch model."
|
||||
)
|
||||
parser.add_argument(
|
||||
"--discriminator_or_generator",
|
||||
default=None,
|
||||
type=str,
|
||||
required=True,
|
||||
help="Whether to export the generator or the discriminator. Should be a string, either 'discriminator' or "
|
||||
"'generator'.",
|
||||
)
|
||||
args = parser.parse_args()
|
||||
convert_tf_checkpoint_to_pytorch(
|
||||
args.tf_checkpoint_path, args.config_file, args.pytorch_dump_path, args.discriminator_or_generator
|
||||
)
|
||||
@@ -25,6 +25,7 @@ from transformers import (
|
||||
CAMEMBERT_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
CTRL_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
DISTILBERT_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
ELECTRA_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
FLAUBERT_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
OPENAI_GPT_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
@@ -39,6 +40,7 @@ from transformers import (
|
||||
CamembertConfig,
|
||||
CTRLConfig,
|
||||
DistilBertConfig,
|
||||
ElectraConfig,
|
||||
FlaubertConfig,
|
||||
GPT2Config,
|
||||
OpenAIGPTConfig,
|
||||
@@ -52,6 +54,7 @@ from transformers import (
|
||||
TFCTRLLMHeadModel,
|
||||
TFDistilBertForMaskedLM,
|
||||
TFDistilBertForQuestionAnswering,
|
||||
TFElectraForPreTraining,
|
||||
TFFlaubertWithLMHeadModel,
|
||||
TFGPT2LMHeadModel,
|
||||
TFOpenAIGPTLMHeadModel,
|
||||
@@ -110,6 +113,8 @@ if is_torch_available():
|
||||
ALBERT_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
T5ForConditionalGeneration,
|
||||
T5_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
ElectraForPreTraining,
|
||||
ELECTRA_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
)
|
||||
else:
|
||||
(
|
||||
@@ -147,6 +152,8 @@ else:
|
||||
ALBERT_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
T5ForConditionalGeneration,
|
||||
T5_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
ElectraForPreTraining,
|
||||
ELECTRA_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
) = (
|
||||
None,
|
||||
None,
|
||||
@@ -182,6 +189,8 @@ else:
|
||||
None,
|
||||
None,
|
||||
None,
|
||||
None,
|
||||
None,
|
||||
)
|
||||
|
||||
|
||||
@@ -321,6 +330,13 @@ MODEL_CLASSES = {
|
||||
T5_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
T5_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
),
|
||||
"electra": (
|
||||
ElectraConfig,
|
||||
TFElectraForPreTraining,
|
||||
ElectraForPreTraining,
|
||||
ELECTRA_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
ELECTRA_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
),
|
||||
}
|
||||
|
||||
|
||||
|
||||
@@ -28,7 +28,7 @@ from ...file_utils import is_tf_available, is_torch_available
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
@dataclass(frozen=True)
|
||||
@dataclass(frozen=False)
|
||||
class InputExample:
|
||||
"""
|
||||
A single training/test example for simple sequence classification.
|
||||
|
||||
@@ -26,6 +26,7 @@ from .configuration_auto import (
|
||||
CamembertConfig,
|
||||
CTRLConfig,
|
||||
DistilBertConfig,
|
||||
ElectraConfig,
|
||||
FlaubertConfig,
|
||||
GPT2Config,
|
||||
OpenAIGPTConfig,
|
||||
@@ -76,6 +77,13 @@ from .modeling_distilbert import (
|
||||
DistilBertForTokenClassification,
|
||||
DistilBertModel,
|
||||
)
|
||||
from .modeling_electra import (
|
||||
ELECTRA_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
ElectraForMaskedLM,
|
||||
ElectraForPreTraining,
|
||||
ElectraForTokenClassification,
|
||||
ElectraModel,
|
||||
)
|
||||
from .modeling_flaubert import (
|
||||
FLAUBERT_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
FlaubertForQuestionAnsweringSimple,
|
||||
@@ -141,6 +149,7 @@ ALL_PRETRAINED_MODEL_ARCHIVE_MAP = dict(
|
||||
T5_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
FLAUBERT_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
XLM_ROBERTA_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
ELECTRA_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
]
|
||||
for key, value, in pretrained_map.items()
|
||||
)
|
||||
@@ -162,6 +171,7 @@ MODEL_MAPPING = OrderedDict(
|
||||
(FlaubertConfig, FlaubertModel),
|
||||
(XLMConfig, XLMModel),
|
||||
(CTRLConfig, CTRLModel),
|
||||
(ElectraConfig, ElectraModel),
|
||||
]
|
||||
)
|
||||
|
||||
@@ -182,6 +192,7 @@ MODEL_FOR_PRETRAINING_MAPPING = OrderedDict(
|
||||
(FlaubertConfig, FlaubertWithLMHeadModel),
|
||||
(XLMConfig, XLMWithLMHeadModel),
|
||||
(CTRLConfig, CTRLLMHeadModel),
|
||||
(ElectraConfig, ElectraForPreTraining),
|
||||
]
|
||||
)
|
||||
|
||||
@@ -202,6 +213,7 @@ MODEL_WITH_LM_HEAD_MAPPING = OrderedDict(
|
||||
(FlaubertConfig, FlaubertWithLMHeadModel),
|
||||
(XLMConfig, XLMWithLMHeadModel),
|
||||
(CTRLConfig, CTRLLMHeadModel),
|
||||
(ElectraConfig, ElectraForMaskedLM),
|
||||
]
|
||||
)
|
||||
|
||||
@@ -242,6 +254,7 @@ MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING = OrderedDict(
|
||||
(BertConfig, BertForTokenClassification),
|
||||
(XLNetConfig, XLNetForTokenClassification),
|
||||
(AlbertConfig, AlbertForTokenClassification),
|
||||
(ElectraConfig, ElectraForTokenClassification),
|
||||
]
|
||||
)
|
||||
|
||||
@@ -281,7 +294,8 @@ class AutoModel(object):
|
||||
- isInstance of `transfo-xl` configuration class: :class:`~transformers.TransfoXLModel` (Transformer-XL model)
|
||||
- isInstance of `xlnet` configuration class: :class:`~transformers.XLNetModel` (XLNet model)
|
||||
- isInstance of `xlm` configuration class: :class:`~transformers.XLMModel` (XLM model)
|
||||
- isInstance of `flaubert` configuration class: :class:`~transformers.FlaubertModel` (XLM model)
|
||||
- isInstance of `flaubert` configuration class: :class:`~transformers.FlaubertModel` (Flaubert model)
|
||||
- isInstance of `electra` configuration class: :class:`~transformers.ElectraModel` (Electra model)
|
||||
|
||||
Examples::
|
||||
|
||||
@@ -322,7 +336,8 @@ class AutoModel(object):
|
||||
- contains `xlnet`: :class:`~transformers.XLNetModel` (XLNet model)
|
||||
- contains `xlm`: :class:`~transformers.XLMModel` (XLM model)
|
||||
- contains `ctrl`: :class:`~transformers.CTRLModel` (Salesforce CTRL model)
|
||||
- contains `flaubert`: :class:`~transformers.Flaubert` (Flaubert model)
|
||||
- contains `flaubert`: :class:`~transformers.FlaubertModel` (Flaubert model)
|
||||
- contains `electra`: :class:`~transformers.ElectraModel` (Electra model)
|
||||
|
||||
The model is set in evaluation mode by default using `model.eval()` (Dropout modules are deactivated)
|
||||
To train the model, you should first set it back in training mode with `model.train()`
|
||||
@@ -430,6 +445,7 @@ class AutoModelForPreTraining(object):
|
||||
- isInstance of `xlnet` configuration class: :class:`~transformers.XLNetLMHeadModel` (XLNet model)
|
||||
- isInstance of `xlm` configuration class: :class:`~transformers.XLMWithLMHeadModel` (XLM model)
|
||||
- isInstance of `flaubert` configuration class: :class:`~transformers.FlaubertWithLMHeadModel` (Flaubert model)
|
||||
- isInstance of `electra` configuration class: :class:`~transformers.ElectraForPreTraining` (Electra model)
|
||||
|
||||
Examples::
|
||||
|
||||
@@ -470,6 +486,7 @@ class AutoModelForPreTraining(object):
|
||||
- contains `xlm`: :class:`~transformers.XLMWithLMHeadModel` (XLM model)
|
||||
- contains `ctrl`: :class:`~transformers.CTRLLMHeadModel` (Salesforce CTRL model)
|
||||
- contains `flaubert`: :class:`~transformers.FlaubertWithLMHeadModel` (Flaubert model)
|
||||
- contains `electra`: :class:`~transformers.ElectraForPreTraining` (Electra model)
|
||||
|
||||
The model is set in evaluation mode by default using `model.eval()` (Dropout modules are deactivated)
|
||||
To train the model, you should first set it back in training mode with `model.train()`
|
||||
@@ -571,6 +588,7 @@ class AutoModelWithLMHead(object):
|
||||
- isInstance of `xlnet` configuration class: :class:`~transformers.XLNetLMHeadModel` (XLNet model)
|
||||
- isInstance of `xlm` configuration class: :class:`~transformers.XLMWithLMHeadModel` (XLM model)
|
||||
- isInstance of `flaubert` configuration class: :class:`~transformers.FlaubertWithLMHeadModel` (Flaubert model)
|
||||
- isInstance of `electra` configuration class: :class:`~transformers.ElectraForMaskedLM` (Electra model)
|
||||
|
||||
Examples::
|
||||
|
||||
@@ -612,6 +630,7 @@ class AutoModelWithLMHead(object):
|
||||
- contains `xlm`: :class:`~transformers.XLMWithLMHeadModel` (XLM model)
|
||||
- contains `ctrl`: :class:`~transformers.CTRLLMHeadModel` (Salesforce CTRL model)
|
||||
- contains `flaubert`: :class:`~transformers.FlaubertWithLMHeadModel` (Flaubert model)
|
||||
- contains `electra`: :class:`~transformers.ElectraForMaskedLM` (Electra model)
|
||||
|
||||
The model is set in evaluation mode by default using `model.eval()` (Dropout modules are deactivated)
|
||||
To train the model, you should first set it back in training mode with `model.train()`
|
||||
@@ -998,6 +1017,7 @@ class AutoModelForTokenClassification:
|
||||
- isInstance of `xlnet` configuration class: :class:`~transformers.XLNetModelForTokenClassification` (XLNet model)
|
||||
- isInstance of `camembert` configuration class: :class:`~transformers.CamembertModelForTokenClassification` (Camembert model)
|
||||
- isInstance of `roberta` configuration class: :class:`~transformers.RobertaModelForTokenClassification` (Roberta model)
|
||||
- isInstance of `electra` configuration class: :class:`~transformers.ElectraForTokenClassification` (Electra model)
|
||||
|
||||
Examples::
|
||||
|
||||
@@ -1035,6 +1055,7 @@ class AutoModelForTokenClassification:
|
||||
- contains `bert`: :class:`~transformers.BertForTokenClassification` (Bert model)
|
||||
- contains `xlnet`: :class:`~transformers.XLNetForTokenClassification` (XLNet model)
|
||||
- contains `roberta`: :class:`~transformers.RobertaForTokenClassification` (Roberta model)
|
||||
- contains `electra`: :class:`~transformers.ElectraForTokenClassification` (Electra model)
|
||||
|
||||
The model is set in evaluation mode by default using `model.eval()` (Dropout modules are deactivated)
|
||||
To train the model, you should first set it back in training mode with `model.train()`
|
||||
|
||||
@@ -116,7 +116,6 @@ class PretrainedBartModel(PreTrainedModel):
|
||||
config_class = BartConfig
|
||||
base_model_prefix = "model"
|
||||
pretrained_model_archive_map = BART_PRETRAINED_MODEL_ARCHIVE_MAP
|
||||
encoder_outputs_batch_dim_idx = 1 # outputs shaped (seq_len, bs, ...)
|
||||
|
||||
def _init_weights(self, module):
|
||||
std = self.config.init_std
|
||||
@@ -294,7 +293,10 @@ class BartEncoder(nn.Module):
|
||||
if self.output_hidden_states:
|
||||
encoder_states.append(x)
|
||||
|
||||
# T x B x C -> B x T x C
|
||||
encoder_states = [hidden_state.transpose(0, 1) for hidden_state in encoder_states]
|
||||
x = x.transpose(0, 1)
|
||||
|
||||
return x, encoder_states, all_attentions
|
||||
|
||||
|
||||
@@ -448,7 +450,11 @@ class BartDecoder(nn.Module):
|
||||
|
||||
x = self.layernorm_embedding(x)
|
||||
x = F.dropout(x, p=self.dropout, training=self.training)
|
||||
x = x.transpose(0, 1) # (seq_len, BS, model_dim)
|
||||
|
||||
# Convert to Bart output format: (seq_len, BS, model_dim) -> (BS, seq_len, model_dim)
|
||||
x = x.transpose(0, 1)
|
||||
encoder_hidden_states = encoder_hidden_states.transpose(0, 1)
|
||||
|
||||
# decoder layers
|
||||
all_hidden_states = ()
|
||||
all_self_attns = ()
|
||||
@@ -477,9 +483,10 @@ class BartDecoder(nn.Module):
|
||||
if self.output_attentions:
|
||||
all_self_attns += (layer_self_attn,)
|
||||
|
||||
# Convert shapes from (seq_len, BS, model_dim) to (BS, seq_len, model_dim)
|
||||
# Convert to standart output format: (seq_len, BS, model_dim) -> (BS, seq_len, model_dim)
|
||||
all_hidden_states = [hidden_state.transpose(0, 1) for hidden_state in all_hidden_states]
|
||||
x = x.transpose(0, 1)
|
||||
encoder_hidden_states = encoder_hidden_states.transpose(0, 1)
|
||||
|
||||
if self.output_past:
|
||||
next_cache = ((encoder_hidden_states, encoder_padding_mask), next_decoder_cache)
|
||||
@@ -805,6 +812,8 @@ class BartModel(PretrainedBartModel):
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.shared = value
|
||||
self.encoder.embed_tokens = self.shared
|
||||
self.decoder.embed_tokens = self.shared
|
||||
|
||||
def get_output_embeddings(self):
|
||||
return _make_linear_from_emb(self.shared) # make it on the fly
|
||||
@@ -928,10 +937,9 @@ class BartForConditionalGeneration(PretrainedBartModel):
|
||||
layer_past_new = {
|
||||
attn_key: _reorder_buffer(attn_cache, beam_idx) for attn_key, attn_cache in layer_past.items()
|
||||
}
|
||||
# reordered_layer_past = [layer_past[:, i].unsqueeze(1).clone().detach() for i in beam_idx]
|
||||
# reordered_layer_past = torch.cat(reordered_layer_past, dim=1)
|
||||
reordered_past.append(layer_past_new)
|
||||
new_enc_out = enc_out if enc_out is None else enc_out.index_select(1, beam_idx)
|
||||
|
||||
new_enc_out = enc_out if enc_out is None else enc_out.index_select(0, beam_idx)
|
||||
new_enc_mask = enc_mask if enc_mask is None else enc_mask.index_select(0, beam_idx)
|
||||
|
||||
past = ((new_enc_out, new_enc_mask), reordered_past)
|
||||
|
||||
@@ -183,7 +183,7 @@ class BertEmbeddings(nn.Module):
|
||||
class BertSelfAttention(nn.Module):
|
||||
def __init__(self, config):
|
||||
super().__init__()
|
||||
if config.hidden_size % config.num_attention_heads != 0:
|
||||
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
|
||||
raise ValueError(
|
||||
"The hidden size (%d) is not a multiple of the number of attention "
|
||||
"heads (%d)" % (config.hidden_size, config.num_attention_heads)
|
||||
@@ -845,7 +845,7 @@ class BertForPreTraining(BertPreTrainedModel):
|
||||
Total loss as the sum of the masked language modeling loss and the next sequence prediction (classification) loss.
|
||||
prediction_scores (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, config.vocab_size)`)
|
||||
Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
|
||||
seq_relationship_scores (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, 2)`):
|
||||
seq_relationship_scores (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, 2)`):
|
||||
Prediction scores of the next sequence prediction (classification) head (scores of True/False
|
||||
continuation before SoftMax).
|
||||
hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when :obj:`config.output_hidden_states=True`):
|
||||
@@ -1048,7 +1048,7 @@ class BertForNextSentencePrediction(BertPreTrainedModel):
|
||||
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.BertConfig`) and inputs:
|
||||
loss (:obj:`torch.FloatTensor` of shape :obj:`(1,)`, `optional`, returned when :obj:`next_sentence_label` is provided):
|
||||
Next sequence prediction (classification) loss.
|
||||
seq_relationship_scores (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, 2)`):
|
||||
seq_relationship_scores (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, 2)`):
|
||||
Prediction scores of the next sequence prediction (classification) head (scores of True/False continuation before SoftMax).
|
||||
hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
|
||||
Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
|
||||
|
||||
671
src/transformers/modeling_electra.py
Normal file
671
src/transformers/modeling_electra.py
Normal file
@@ -0,0 +1,671 @@
|
||||
import logging
|
||||
import os
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from transformers import ElectraConfig, add_start_docstrings
|
||||
from transformers.activations import get_activation
|
||||
|
||||
from .file_utils import add_start_docstrings_to_callable
|
||||
from .modeling_bert import BertEmbeddings, BertEncoder, BertLayerNorm, BertPreTrainedModel
|
||||
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
ELECTRA_PRETRAINED_MODEL_ARCHIVE_MAP = {
|
||||
"google/electra-small-generator": "https://s3.amazonaws.com/models.huggingface.co/bert/google/electra-small-generator/pytorch_model.bin",
|
||||
"google/electra-base-generator": "https://s3.amazonaws.com/models.huggingface.co/bert/google/electra-base-generator/pytorch_model.bin",
|
||||
"google/electra-large-generator": "https://s3.amazonaws.com/models.huggingface.co/bert/google/electra-large-generator/pytorch_model.bin",
|
||||
"google/electra-small-discriminator": "https://s3.amazonaws.com/models.huggingface.co/bert/google/electra-small-discriminator/pytorch_model.bin",
|
||||
"google/electra-base-discriminator": "https://s3.amazonaws.com/models.huggingface.co/bert/google/electra-base-discriminator/pytorch_model.bin",
|
||||
"google/electra-large-discriminator": "https://s3.amazonaws.com/models.huggingface.co/bert/google/electra-large-discriminator/pytorch_model.bin",
|
||||
}
|
||||
|
||||
|
||||
def load_tf_weights_in_electra(model, config, tf_checkpoint_path, discriminator_or_generator="discriminator"):
|
||||
""" Load tf checkpoints in a pytorch model.
|
||||
"""
|
||||
try:
|
||||
import re
|
||||
import numpy as np
|
||||
import tensorflow as tf
|
||||
except ImportError:
|
||||
logger.error(
|
||||
"Loading a TensorFlow model in PyTorch, requires TensorFlow to be installed. Please see "
|
||||
"https://www.tensorflow.org/install/ for installation instructions."
|
||||
)
|
||||
raise
|
||||
tf_path = os.path.abspath(tf_checkpoint_path)
|
||||
logger.info("Converting TensorFlow checkpoint from {}".format(tf_path))
|
||||
# Load weights from TF model
|
||||
init_vars = tf.train.list_variables(tf_path)
|
||||
names = []
|
||||
arrays = []
|
||||
for name, shape in init_vars:
|
||||
logger.info("Loading TF weight {} with shape {}".format(name, shape))
|
||||
array = tf.train.load_variable(tf_path, name)
|
||||
names.append(name)
|
||||
arrays.append(array)
|
||||
for name, array in zip(names, arrays):
|
||||
original_name: str = name
|
||||
|
||||
try:
|
||||
if isinstance(model, ElectraForMaskedLM):
|
||||
name = name.replace("electra/embeddings/", "generator/embeddings/")
|
||||
|
||||
if discriminator_or_generator == "generator":
|
||||
name = name.replace("electra/", "discriminator/")
|
||||
name = name.replace("generator/", "electra/")
|
||||
|
||||
name = name.replace("dense_1", "dense_prediction")
|
||||
name = name.replace("generator_predictions/output_bias", "generator_lm_head/bias")
|
||||
|
||||
name = name.split("/")
|
||||
# print(original_name, name)
|
||||
# adam_v and adam_m are variables used in AdamWeightDecayOptimizer to calculated m and v
|
||||
# which are not required for using pretrained model
|
||||
if any(n in ["global_step", "temperature"] for n in name):
|
||||
logger.info("Skipping {}".format(original_name))
|
||||
continue
|
||||
pointer = model
|
||||
for m_name in name:
|
||||
if re.fullmatch(r"[A-Za-z]+_\d+", m_name):
|
||||
scope_names = re.split(r"_(\d+)", m_name)
|
||||
else:
|
||||
scope_names = [m_name]
|
||||
if scope_names[0] == "kernel" or scope_names[0] == "gamma":
|
||||
pointer = getattr(pointer, "weight")
|
||||
elif scope_names[0] == "output_bias" or scope_names[0] == "beta":
|
||||
pointer = getattr(pointer, "bias")
|
||||
elif scope_names[0] == "output_weights":
|
||||
pointer = getattr(pointer, "weight")
|
||||
elif scope_names[0] == "squad":
|
||||
pointer = getattr(pointer, "classifier")
|
||||
else:
|
||||
pointer = getattr(pointer, scope_names[0])
|
||||
if len(scope_names) >= 2:
|
||||
num = int(scope_names[1])
|
||||
pointer = pointer[num]
|
||||
if m_name.endswith("_embeddings"):
|
||||
pointer = getattr(pointer, "weight")
|
||||
elif m_name == "kernel":
|
||||
array = np.transpose(array)
|
||||
try:
|
||||
assert pointer.shape == array.shape, original_name
|
||||
except AssertionError as e:
|
||||
e.args += (pointer.shape, array.shape)
|
||||
raise
|
||||
print("Initialize PyTorch weight {}".format(name), original_name)
|
||||
pointer.data = torch.from_numpy(array)
|
||||
except AttributeError as e:
|
||||
print("Skipping {}".format(original_name), name, e)
|
||||
continue
|
||||
return model
|
||||
|
||||
|
||||
class ElectraEmbeddings(BertEmbeddings):
|
||||
"""Construct the embeddings from word, position and token_type embeddings."""
|
||||
|
||||
def __init__(self, config):
|
||||
super().__init__(config)
|
||||
self.word_embeddings = nn.Embedding(config.vocab_size, config.embedding_size, padding_idx=config.pad_token_id)
|
||||
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.embedding_size)
|
||||
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.embedding_size)
|
||||
|
||||
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
|
||||
# any TensorFlow checkpoint file
|
||||
self.LayerNorm = BertLayerNorm(config.embedding_size, eps=config.layer_norm_eps)
|
||||
|
||||
|
||||
class ElectraDiscriminatorPredictions(nn.Module):
|
||||
"""Prediction module for the discriminator, made up of two dense layers."""
|
||||
|
||||
def __init__(self, config):
|
||||
super().__init__()
|
||||
|
||||
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
|
||||
self.dense_prediction = nn.Linear(config.hidden_size, 1)
|
||||
self.config = config
|
||||
|
||||
def forward(self, discriminator_hidden_states, attention_mask):
|
||||
hidden_states = self.dense(discriminator_hidden_states)
|
||||
hidden_states = get_activation(self.config.hidden_act)(hidden_states)
|
||||
logits = self.dense_prediction(hidden_states).squeeze()
|
||||
|
||||
return logits
|
||||
|
||||
|
||||
class ElectraGeneratorPredictions(nn.Module):
|
||||
"""Prediction module for the generator, made up of two dense layers."""
|
||||
|
||||
def __init__(self, config):
|
||||
super().__init__()
|
||||
|
||||
self.LayerNorm = BertLayerNorm(config.embedding_size)
|
||||
self.dense = nn.Linear(config.hidden_size, config.embedding_size)
|
||||
|
||||
def forward(self, generator_hidden_states):
|
||||
hidden_states = self.dense(generator_hidden_states)
|
||||
hidden_states = get_activation("gelu")(hidden_states)
|
||||
hidden_states = self.LayerNorm(hidden_states)
|
||||
|
||||
return hidden_states
|
||||
|
||||
|
||||
class ElectraPreTrainedModel(BertPreTrainedModel):
|
||||
""" An abstract class to handle weights initialization and
|
||||
a simple interface for downloading and loading pretrained models.
|
||||
"""
|
||||
|
||||
config_class = ElectraConfig
|
||||
pretrained_model_archive_map = ELECTRA_PRETRAINED_MODEL_ARCHIVE_MAP
|
||||
load_tf_weights = load_tf_weights_in_electra
|
||||
base_model_prefix = "electra"
|
||||
|
||||
def get_extended_attention_mask(self, attention_mask, input_shape, device):
|
||||
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
|
||||
# ourselves in which case we just need to make it broadcastable to all heads.
|
||||
if attention_mask.dim() == 3:
|
||||
extended_attention_mask = attention_mask[:, None, :, :]
|
||||
elif attention_mask.dim() == 2:
|
||||
# Provided a padding mask of dimensions [batch_size, seq_length]
|
||||
# - if the model is a decoder, apply a causal mask in addition to the padding mask
|
||||
# - if the model is an encoder, make the mask broadcastable to [batch_size, num_heads, seq_length, seq_length]
|
||||
if self.config.is_decoder:
|
||||
batch_size, seq_length = input_shape
|
||||
seq_ids = torch.arange(seq_length, device=device)
|
||||
causal_mask = seq_ids[None, None, :].repeat(batch_size, seq_length, 1) <= seq_ids[None, :, None]
|
||||
causal_mask = causal_mask.to(
|
||||
attention_mask.dtype
|
||||
) # causal and attention masks must have same type with pytorch version < 1.3
|
||||
extended_attention_mask = causal_mask[:, None, :, :] * attention_mask[:, None, None, :]
|
||||
else:
|
||||
extended_attention_mask = attention_mask[:, None, None, :]
|
||||
else:
|
||||
raise ValueError(
|
||||
"Wrong shape for input_ids (shape {}) or attention_mask (shape {})".format(
|
||||
input_shape, attention_mask.shape
|
||||
)
|
||||
)
|
||||
|
||||
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
|
||||
# masked positions, this operation will create a tensor which is 0.0 for
|
||||
# positions we want to attend and -10000.0 for masked positions.
|
||||
# Since we are adding it to the raw scores before the softmax, this is
|
||||
# effectively the same as removing these entirely.
|
||||
extended_attention_mask = extended_attention_mask.to(dtype=next(self.parameters()).dtype) # fp16 compatibility
|
||||
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
|
||||
|
||||
return extended_attention_mask
|
||||
|
||||
def get_head_mask(self, head_mask):
|
||||
# Prepare head mask if needed
|
||||
# 1.0 in head_mask indicate we keep the head
|
||||
# attention_probs has shape bsz x n_heads x N x N
|
||||
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
|
||||
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
|
||||
num_hidden_layers = self.config.num_hidden_layers
|
||||
if head_mask is not None:
|
||||
if head_mask.dim() == 1:
|
||||
head_mask = head_mask.unsqueeze(0).unsqueeze(0).unsqueeze(-1).unsqueeze(-1)
|
||||
head_mask = head_mask.expand(num_hidden_layers, -1, -1, -1, -1)
|
||||
elif head_mask.dim() == 2:
|
||||
head_mask = (
|
||||
head_mask.unsqueeze(1).unsqueeze(-1).unsqueeze(-1)
|
||||
) # We can specify head_mask for each layer
|
||||
head_mask = head_mask.to(
|
||||
dtype=next(self.parameters()).dtype
|
||||
) # switch to fload if need + fp16 compatibility
|
||||
else:
|
||||
head_mask = [None] * num_hidden_layers
|
||||
|
||||
return head_mask
|
||||
|
||||
|
||||
ELECTRA_START_DOCSTRING = r"""
|
||||
This model is a PyTorch `torch.nn.Module <https://pytorch.org/docs/stable/nn.html#torch.nn.Module>`_ sub-class.
|
||||
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general
|
||||
usage and behavior.
|
||||
|
||||
Parameters:
|
||||
config (:class:`~transformers.ElectraConfig`): Model configuration class with all the parameters of the model.
|
||||
Initializing with a config file does not load the weights associated with the model, only the configuration.
|
||||
Check out the :meth:`~transformers.PreTrainedModel.from_pretrained` method to load the model weights.
|
||||
"""
|
||||
|
||||
ELECTRA_INPUTS_DOCSTRING = r"""
|
||||
Args:
|
||||
input_ids (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`):
|
||||
Indices of input sequence tokens in the vocabulary.
|
||||
|
||||
Indices can be obtained using :class:`transformers.ElectraTokenizer`.
|
||||
See :func:`transformers.PreTrainedTokenizer.encode` and
|
||||
:func:`transformers.PreTrainedTokenizer.encode_plus` for details.
|
||||
|
||||
`What are input IDs? <../glossary.html#input-ids>`__
|
||||
attention_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`, defaults to :obj:`None`):
|
||||
Mask to avoid performing attention on padding token indices.
|
||||
Mask values selected in ``[0, 1]``:
|
||||
``1`` for tokens that are NOT MASKED, ``0`` for MASKED tokens.
|
||||
|
||||
`What are attention masks? <../glossary.html#attention-mask>`__
|
||||
token_type_ids (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`, defaults to :obj:`None`):
|
||||
Segment token indices to indicate first and second portions of the inputs.
|
||||
Indices are selected in ``[0, 1]``: ``0`` corresponds to a `sentence A` token, ``1``
|
||||
corresponds to a `sentence B` token
|
||||
|
||||
`What are token type IDs? <../glossary.html#token-type-ids>`_
|
||||
position_ids (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`, defaults to :obj:`None`):
|
||||
Indices of positions of each input sequence tokens in the position embeddings.
|
||||
Selected in the range ``[0, config.max_position_embeddings - 1]``.
|
||||
|
||||
`What are position IDs? <../glossary.html#position-ids>`_
|
||||
head_mask (:obj:`torch.FloatTensor` of shape :obj:`(num_heads,)` or :obj:`(num_layers, num_heads)`, `optional`, defaults to :obj:`None`):
|
||||
Mask to nullify selected heads of the self-attention modules.
|
||||
Mask values selected in ``[0, 1]``:
|
||||
:obj:`1` indicates the head is **not masked**, :obj:`0` indicates the head is **masked**.
|
||||
inputs_embeds (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`, defaults to :obj:`None`):
|
||||
Optionally, instead of passing :obj:`input_ids` you can choose to directly pass an embedded representation.
|
||||
This is useful if you want more control over how to convert `input_ids` indices into associated vectors
|
||||
than the model's internal embedding lookup matrix.
|
||||
encoder_hidden_states (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`, defaults to :obj:`None`):
|
||||
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention
|
||||
if the model is configured as a decoder.
|
||||
encoder_attention_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`, defaults to :obj:`None`):
|
||||
Mask to avoid performing attention on the padding token indices of the encoder input. This mask
|
||||
is used in the cross-attention if the model is configured as a decoder.
|
||||
Mask values selected in ``[0, 1]``:
|
||||
``1`` for tokens that are NOT MASKED, ``0`` for MASKED tokens.
|
||||
"""
|
||||
|
||||
|
||||
@add_start_docstrings(
|
||||
"The bare Electra Model transformer outputting raw hidden-states without any specific head on top. Identical to "
|
||||
"the BERT model except that it uses an additional linear layer between the embedding layer and the encoder if the "
|
||||
"hidden size and embedding size are different."
|
||||
""
|
||||
"Both the generator and discriminator checkpoints may be loaded into this model.",
|
||||
ELECTRA_START_DOCSTRING,
|
||||
)
|
||||
class ElectraModel(ElectraPreTrainedModel):
|
||||
|
||||
config_class = ElectraConfig
|
||||
|
||||
def __init__(self, config):
|
||||
super().__init__(config)
|
||||
self.embeddings = ElectraEmbeddings(config)
|
||||
|
||||
if config.embedding_size != config.hidden_size:
|
||||
self.embeddings_project = nn.Linear(config.embedding_size, config.hidden_size)
|
||||
|
||||
self.encoder = BertEncoder(config)
|
||||
self.config = config
|
||||
self.init_weights()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.embeddings.word_embeddings
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.embeddings.word_embeddings = value
|
||||
|
||||
def _prune_heads(self, heads_to_prune):
|
||||
""" Prunes heads of the model.
|
||||
heads_to_prune: dict of {layer_num: list of heads to prune in this layer}
|
||||
See base class PreTrainedModel
|
||||
"""
|
||||
for layer, heads in heads_to_prune.items():
|
||||
self.encoder.layer[layer].attention.prune_heads(heads)
|
||||
|
||||
@add_start_docstrings_to_callable(ELECTRA_INPUTS_DOCSTRING)
|
||||
def forward(
|
||||
self,
|
||||
input_ids=None,
|
||||
attention_mask=None,
|
||||
token_type_ids=None,
|
||||
position_ids=None,
|
||||
head_mask=None,
|
||||
inputs_embeds=None,
|
||||
):
|
||||
r"""
|
||||
Return:
|
||||
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.ElectraConfig`) and inputs:
|
||||
last_hidden_state (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`):
|
||||
Sequence of hidden-states at the output of the last layer of the model.
|
||||
hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
|
||||
Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
|
||||
of shape :obj:`(batch_size, sequence_length, hidden_size)`.
|
||||
|
||||
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
|
||||
attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
|
||||
Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
|
||||
:obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
|
||||
|
||||
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
|
||||
heads.
|
||||
|
||||
Examples::
|
||||
|
||||
from transformers import ElectraModel, ElectraTokenizer
|
||||
import torch
|
||||
|
||||
tokenizer = ElectraTokenizer.from_pretrained('google/electra-small-discriminator')
|
||||
model = ElectraModel.from_pretrained('google/electra-small-discriminator')
|
||||
|
||||
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute", add_special_tokens=True)).unsqueeze(0) # Batch size 1
|
||||
outputs = model(input_ids)
|
||||
|
||||
last_hidden_states = outputs[0] # The last hidden-state is the first element of the output tuple
|
||||
|
||||
"""
|
||||
if input_ids is not None and inputs_embeds is not None:
|
||||
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
|
||||
elif input_ids is not None:
|
||||
input_shape = input_ids.size()
|
||||
elif inputs_embeds is not None:
|
||||
input_shape = inputs_embeds.size()[:-1]
|
||||
else:
|
||||
raise ValueError("You have to specify either input_ids or inputs_embeds")
|
||||
|
||||
device = input_ids.device if input_ids is not None else inputs_embeds.device
|
||||
|
||||
if attention_mask is None:
|
||||
attention_mask = torch.ones(input_shape, device=device)
|
||||
if token_type_ids is None:
|
||||
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
|
||||
|
||||
extended_attention_mask = self.get_extended_attention_mask(attention_mask, input_shape, device)
|
||||
head_mask = self.get_head_mask(head_mask)
|
||||
|
||||
hidden_states = self.embeddings(
|
||||
input_ids=input_ids, position_ids=position_ids, token_type_ids=token_type_ids, inputs_embeds=inputs_embeds
|
||||
)
|
||||
|
||||
if hasattr(self, "embeddings_project"):
|
||||
hidden_states = self.embeddings_project(hidden_states)
|
||||
|
||||
hidden_states = self.encoder(hidden_states, attention_mask=extended_attention_mask, head_mask=head_mask)
|
||||
|
||||
return hidden_states
|
||||
|
||||
|
||||
@add_start_docstrings(
|
||||
"""
|
||||
Electra model with a binary classification head on top as used during pre-training for identifying generated
|
||||
tokens.
|
||||
|
||||
It is recommended to load the discriminator checkpoint into that model.""",
|
||||
ELECTRA_START_DOCSTRING,
|
||||
)
|
||||
class ElectraForPreTraining(ElectraPreTrainedModel):
|
||||
def __init__(self, config):
|
||||
super().__init__(config)
|
||||
|
||||
self.electra = ElectraModel(config)
|
||||
self.discriminator_predictions = ElectraDiscriminatorPredictions(config)
|
||||
self.init_weights()
|
||||
|
||||
@add_start_docstrings_to_callable(ELECTRA_INPUTS_DOCSTRING)
|
||||
def forward(
|
||||
self,
|
||||
input_ids=None,
|
||||
attention_mask=None,
|
||||
token_type_ids=None,
|
||||
position_ids=None,
|
||||
head_mask=None,
|
||||
inputs_embeds=None,
|
||||
labels=None,
|
||||
):
|
||||
r"""
|
||||
labels (``torch.LongTensor`` of shape ``(batch_size, sequence_length)``, `optional`, defaults to :obj:`None`):
|
||||
Labels for computing the ELECTRA loss. Input should be a sequence of tokens (see :obj:`input_ids` docstring)
|
||||
Indices should be in ``[0, 1]``.
|
||||
``0`` indicates the token is an original token,
|
||||
``1`` indicates the token was replaced.
|
||||
|
||||
Returns:
|
||||
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.ElectraConfig`) and inputs:
|
||||
loss (`optional`, returned when ``labels`` is provided) ``torch.FloatTensor`` of shape ``(1,)``:
|
||||
Total loss of the ELECTRA objective.
|
||||
scores (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`)
|
||||
Prediction scores of the head (scores for each token before SoftMax).
|
||||
hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when :obj:`config.output_hidden_states=True`):
|
||||
Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
|
||||
of shape :obj:`(batch_size, sequence_length, hidden_size)`.
|
||||
|
||||
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
|
||||
attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
|
||||
Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
|
||||
:obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
|
||||
|
||||
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
|
||||
heads.
|
||||
|
||||
|
||||
Examples::
|
||||
|
||||
from transformers import ElectraTokenizer, ElectraForPreTraining
|
||||
import torch
|
||||
|
||||
tokenizer = ElectraTokenizer.from_pretrained('google/electra-small-discriminator')
|
||||
model = ElectraForPreTraining.from_pretrained('google/electra-small-discriminator')
|
||||
|
||||
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute", add_special_tokens=True)).unsqueeze(0) # Batch size 1
|
||||
outputs = model(input_ids)
|
||||
|
||||
prediction_scores, seq_relationship_scores = outputs[:2]
|
||||
|
||||
"""
|
||||
|
||||
discriminator_hidden_states = self.electra(
|
||||
input_ids, attention_mask, token_type_ids, position_ids, head_mask, inputs_embeds
|
||||
)
|
||||
discriminator_sequence_output = discriminator_hidden_states[0]
|
||||
|
||||
logits = self.discriminator_predictions(discriminator_sequence_output, attention_mask)
|
||||
|
||||
output = (logits,)
|
||||
|
||||
if labels is not None:
|
||||
loss_fct = nn.BCEWithLogitsLoss()
|
||||
if attention_mask is not None:
|
||||
active_loss = attention_mask.view(-1, discriminator_sequence_output.shape[1]) == 1
|
||||
active_logits = logits.view(-1, discriminator_sequence_output.shape[1])[active_loss]
|
||||
active_labels = labels[active_loss]
|
||||
loss = loss_fct(active_logits, active_labels.float())
|
||||
else:
|
||||
loss = loss_fct(logits.view(-1, discriminator_sequence_output.shape[1]), labels.float())
|
||||
|
||||
output = (loss,) + output
|
||||
|
||||
output += discriminator_hidden_states[1:]
|
||||
|
||||
return output # (loss), scores, (hidden_states), (attentions)
|
||||
|
||||
|
||||
@add_start_docstrings(
|
||||
"""
|
||||
Electra model with a language modeling head on top.
|
||||
|
||||
Even though both the discriminator and generator may be loaded into this model, the generator is
|
||||
the only model of the two to have been trained for the masked language modeling task.""",
|
||||
ELECTRA_START_DOCSTRING,
|
||||
)
|
||||
class ElectraForMaskedLM(ElectraPreTrainedModel):
|
||||
def __init__(self, config):
|
||||
super().__init__(config)
|
||||
|
||||
self.electra = ElectraModel(config)
|
||||
self.generator_predictions = ElectraGeneratorPredictions(config)
|
||||
|
||||
self.generator_lm_head = nn.Linear(config.embedding_size, config.vocab_size)
|
||||
self.init_weights()
|
||||
|
||||
def get_output_embeddings(self):
|
||||
return self.generator_lm_head
|
||||
|
||||
@add_start_docstrings_to_callable(ELECTRA_INPUTS_DOCSTRING)
|
||||
def forward(
|
||||
self,
|
||||
input_ids=None,
|
||||
attention_mask=None,
|
||||
token_type_ids=None,
|
||||
position_ids=None,
|
||||
head_mask=None,
|
||||
inputs_embeds=None,
|
||||
masked_lm_labels=None,
|
||||
):
|
||||
r"""
|
||||
masked_lm_labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`, defaults to :obj:`None`):
|
||||
Labels for computing the masked language modeling loss.
|
||||
Indices should be in ``[-100, 0, ..., config.vocab_size]`` (see ``input_ids`` docstring)
|
||||
Tokens with indices set to ``-100`` are ignored (masked), the loss is only computed for the tokens with labels
|
||||
in ``[0, ..., config.vocab_size]``
|
||||
|
||||
Returns:
|
||||
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.ElectraConfig`) and inputs:
|
||||
masked_lm_loss (`optional`, returned when ``masked_lm_labels`` is provided) ``torch.FloatTensor`` of shape ``(1,)``:
|
||||
Masked language modeling loss.
|
||||
prediction_scores (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, config.vocab_size)`)
|
||||
Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
|
||||
hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
|
||||
Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
|
||||
of shape :obj:`(batch_size, sequence_length, hidden_size)`.
|
||||
|
||||
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
|
||||
attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
|
||||
Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
|
||||
:obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
|
||||
|
||||
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
|
||||
heads.
|
||||
|
||||
Examples::
|
||||
|
||||
from transformers import ElectraTokenizer, ElectraForMaskedLM
|
||||
import torch
|
||||
|
||||
tokenizer = ElectraTokenizer.from_pretrained('google/electra-small-generator')
|
||||
model = ElectraForMaskedLM.from_pretrained('google/electra-small-generator')
|
||||
|
||||
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute", add_special_tokens=True)).unsqueeze(0) # Batch size 1
|
||||
outputs = model(input_ids, masked_lm_labels=input_ids)
|
||||
|
||||
loss, prediction_scores = outputs[:2]
|
||||
|
||||
"""
|
||||
|
||||
generator_hidden_states = self.electra(
|
||||
input_ids, attention_mask, token_type_ids, position_ids, head_mask, inputs_embeds
|
||||
)
|
||||
generator_sequence_output = generator_hidden_states[0]
|
||||
|
||||
prediction_scores = self.generator_predictions(generator_sequence_output)
|
||||
prediction_scores = self.generator_lm_head(prediction_scores)
|
||||
|
||||
output = (prediction_scores,)
|
||||
|
||||
# Masked language modeling softmax layer
|
||||
if masked_lm_labels is not None:
|
||||
loss_fct = nn.CrossEntropyLoss() # -100 index = padding token
|
||||
loss = loss_fct(prediction_scores.view(-1, self.config.vocab_size), masked_lm_labels.view(-1))
|
||||
output = (loss,) + output
|
||||
|
||||
output += generator_hidden_states[1:]
|
||||
|
||||
return output # (masked_lm_loss), prediction_scores, (hidden_states), (attentions)
|
||||
|
||||
|
||||
@add_start_docstrings(
|
||||
"""
|
||||
Electra model with a token classification head on top.
|
||||
|
||||
Both the discriminator and generator may be loaded into this model.""",
|
||||
ELECTRA_START_DOCSTRING,
|
||||
)
|
||||
class ElectraForTokenClassification(ElectraPreTrainedModel):
|
||||
def __init__(self, config):
|
||||
super().__init__(config)
|
||||
|
||||
self.electra = ElectraModel(config)
|
||||
self.dropout = nn.Dropout(config.hidden_dropout_prob)
|
||||
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
|
||||
self.init_weights()
|
||||
|
||||
@add_start_docstrings_to_callable(ELECTRA_INPUTS_DOCSTRING)
|
||||
def forward(
|
||||
self,
|
||||
input_ids=None,
|
||||
attention_mask=None,
|
||||
token_type_ids=None,
|
||||
position_ids=None,
|
||||
head_mask=None,
|
||||
inputs_embeds=None,
|
||||
labels=None,
|
||||
):
|
||||
r"""
|
||||
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`, defaults to :obj:`None`):
|
||||
Labels for computing the token classification loss.
|
||||
Indices should be in ``[0, ..., config.num_labels - 1]``.
|
||||
|
||||
Returns:
|
||||
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.ElectraConfig`) and inputs:
|
||||
loss (:obj:`torch.FloatTensor` of shape :obj:`(1,)`, `optional`, returned when ``labels`` is provided) :
|
||||
Classification loss.
|
||||
scores (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, config.num_labels)`)
|
||||
Classification scores (before SoftMax).
|
||||
hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
|
||||
Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
|
||||
of shape :obj:`(batch_size, sequence_length, hidden_size)`.
|
||||
|
||||
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
|
||||
attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
|
||||
Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
|
||||
:obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
|
||||
|
||||
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
|
||||
heads.
|
||||
|
||||
Examples::
|
||||
|
||||
from transformers import ElectraTokenizer, ElectraForTokenClassification
|
||||
import torch
|
||||
|
||||
tokenizer = ElectraTokenizer.from_pretrained('google/electra-small-discriminator')
|
||||
model = ElectraForTokenClassification.from_pretrained('google/electra-small-discriminator')
|
||||
|
||||
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute", add_special_tokens=True)).unsqueeze(0) # Batch size 1
|
||||
labels = torch.tensor([1] * input_ids.size(1)).unsqueeze(0) # Batch size 1
|
||||
outputs = model(input_ids, labels=labels)
|
||||
|
||||
loss, scores = outputs[:2]
|
||||
|
||||
"""
|
||||
|
||||
discriminator_hidden_states = self.electra(
|
||||
input_ids, attention_mask, token_type_ids, position_ids, head_mask, inputs_embeds
|
||||
)
|
||||
discriminator_sequence_output = discriminator_hidden_states[0]
|
||||
|
||||
discriminator_sequence_output = self.dropout(discriminator_sequence_output)
|
||||
logits = self.classifier(discriminator_sequence_output)
|
||||
|
||||
output = (logits,)
|
||||
|
||||
if labels is not None:
|
||||
loss_fct = nn.CrossEntropyLoss()
|
||||
# Only keep active parts of the loss
|
||||
if attention_mask is not None:
|
||||
active_loss = attention_mask.view(-1) == 1
|
||||
active_logits = logits.view(-1, self.config.num_labels)[active_loss]
|
||||
active_labels = labels.view(-1)[active_loss]
|
||||
loss = loss_fct(active_logits, active_labels)
|
||||
else:
|
||||
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
|
||||
|
||||
output = (loss,) + output
|
||||
|
||||
output += discriminator_hidden_states[1:]
|
||||
|
||||
return output # (loss), scores, (hidden_states), (attentions)
|
||||
@@ -457,7 +457,6 @@ class T5PreTrainedModel(PreTrainedModel):
|
||||
pretrained_model_archive_map = T5_PRETRAINED_MODEL_ARCHIVE_MAP
|
||||
load_tf_weights = load_tf_weights_in_t5
|
||||
base_model_prefix = "transformer"
|
||||
encoder_outputs_batch_dim_idx = 0 # outputs shaped (bs, ...)
|
||||
|
||||
@property
|
||||
def dummy_inputs(self):
|
||||
@@ -901,7 +900,6 @@ class T5ForConditionalGeneration(T5PreTrainedModel):
|
||||
lm_labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`, defaults to :obj:`None`):
|
||||
Labels for computing the sequence classification/regression loss.
|
||||
Indices should be in :obj:`[-100, 0, ..., config.vocab_size - 1]`.
|
||||
If :obj:`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
|
||||
All labels set to ``-100`` are ignored (masked), the loss is only
|
||||
computed for labels in ``[0, ..., config.vocab_size]``
|
||||
|
||||
|
||||
615
src/transformers/modeling_tf_electra.py
Normal file
615
src/transformers/modeling_tf_electra.py
Normal file
@@ -0,0 +1,615 @@
|
||||
import logging
|
||||
|
||||
import tensorflow as tf
|
||||
|
||||
from transformers import ElectraConfig
|
||||
|
||||
from .file_utils import add_start_docstrings, add_start_docstrings_to_callable
|
||||
from .modeling_tf_bert import ACT2FN, TFBertEncoder, TFBertPreTrainedModel
|
||||
from .modeling_tf_utils import get_initializer, shape_list
|
||||
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
TF_ELECTRA_PRETRAINED_MODEL_ARCHIVE_MAP = {
|
||||
"google/electra-small-generator": "https://s3.amazonaws.com/models.huggingface.co/bert/google/electra-small-generator/tf_model.h5",
|
||||
"google/electra-base-generator": "https://s3.amazonaws.com/models.huggingface.co/bert/google/electra-base-generator/tf_model.h5",
|
||||
"google/electra-large-generator": "https://s3.amazonaws.com/models.huggingface.co/bert/google/electra-large-generator/tf_model.h5",
|
||||
"google/electra-small-discriminator": "https://s3.amazonaws.com/models.huggingface.co/bert/google/electra-small-discriminator/tf_model.h5",
|
||||
"google/electra-base-discriminator": "https://s3.amazonaws.com/models.huggingface.co/bert/google/electra-base-discriminator/tf_model.h5",
|
||||
"google/electra-large-discriminator": "https://s3.amazonaws.com/models.huggingface.co/bert/google/electra-large-discriminator/tf_model.h5",
|
||||
}
|
||||
|
||||
|
||||
class TFElectraEmbeddings(tf.keras.layers.Layer):
|
||||
"""Construct the embeddings from word, position and token_type embeddings.
|
||||
"""
|
||||
|
||||
def __init__(self, config, **kwargs):
|
||||
super().__init__(**kwargs)
|
||||
self.vocab_size = config.vocab_size
|
||||
self.embedding_size = config.embedding_size
|
||||
self.initializer_range = config.initializer_range
|
||||
|
||||
self.position_embeddings = tf.keras.layers.Embedding(
|
||||
config.max_position_embeddings,
|
||||
config.embedding_size,
|
||||
embeddings_initializer=get_initializer(self.initializer_range),
|
||||
name="position_embeddings",
|
||||
)
|
||||
self.token_type_embeddings = tf.keras.layers.Embedding(
|
||||
config.type_vocab_size,
|
||||
config.embedding_size,
|
||||
embeddings_initializer=get_initializer(self.initializer_range),
|
||||
name="token_type_embeddings",
|
||||
)
|
||||
|
||||
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
|
||||
# any TensorFlow checkpoint file
|
||||
self.LayerNorm = tf.keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="LayerNorm")
|
||||
self.dropout = tf.keras.layers.Dropout(config.hidden_dropout_prob)
|
||||
|
||||
def build(self, input_shape):
|
||||
"""Build shared word embedding layer """
|
||||
with tf.name_scope("word_embeddings"):
|
||||
# Create and initialize weights. The random normal initializer was chosen
|
||||
# arbitrarily, and works well.
|
||||
self.word_embeddings = self.add_weight(
|
||||
"weight",
|
||||
shape=[self.vocab_size, self.embedding_size],
|
||||
initializer=get_initializer(self.initializer_range),
|
||||
)
|
||||
super().build(input_shape)
|
||||
|
||||
def call(self, inputs, mode="embedding", training=False):
|
||||
"""Get token embeddings of inputs.
|
||||
Args:
|
||||
inputs: list of three int64 tensors with shape [batch_size, length]: (input_ids, position_ids, token_type_ids)
|
||||
mode: string, a valid value is one of "embedding" and "linear".
|
||||
Returns:
|
||||
outputs: (1) If mode == "embedding", output embedding tensor, float32 with
|
||||
shape [batch_size, length, embedding_size]; (2) mode == "linear", output
|
||||
linear tensor, float32 with shape [batch_size, length, vocab_size].
|
||||
Raises:
|
||||
ValueError: if mode is not valid.
|
||||
|
||||
Shared weights logic adapted from
|
||||
https://github.com/tensorflow/models/blob/a009f4fb9d2fc4949e32192a944688925ef78659/official/transformer/v2/embedding_layer.py#L24
|
||||
"""
|
||||
if mode == "embedding":
|
||||
return self._embedding(inputs, training=training)
|
||||
elif mode == "linear":
|
||||
return self._linear(inputs)
|
||||
else:
|
||||
raise ValueError("mode {} is not valid.".format(mode))
|
||||
|
||||
def _embedding(self, inputs, training=False):
|
||||
"""Applies embedding based on inputs tensor."""
|
||||
input_ids, position_ids, token_type_ids, inputs_embeds = inputs
|
||||
|
||||
if input_ids is not None:
|
||||
input_shape = shape_list(input_ids)
|
||||
else:
|
||||
input_shape = shape_list(inputs_embeds)[:-1]
|
||||
|
||||
seq_length = input_shape[1]
|
||||
if position_ids is None:
|
||||
position_ids = tf.range(seq_length, dtype=tf.int32)[tf.newaxis, :]
|
||||
if token_type_ids is None:
|
||||
token_type_ids = tf.fill(input_shape, 0)
|
||||
|
||||
if inputs_embeds is None:
|
||||
inputs_embeds = tf.gather(self.word_embeddings, input_ids)
|
||||
position_embeddings = self.position_embeddings(position_ids)
|
||||
token_type_embeddings = self.token_type_embeddings(token_type_ids)
|
||||
|
||||
embeddings = inputs_embeds + position_embeddings + token_type_embeddings
|
||||
embeddings = self.LayerNorm(embeddings)
|
||||
embeddings = self.dropout(embeddings, training=training)
|
||||
return embeddings
|
||||
|
||||
def _linear(self, inputs):
|
||||
"""Computes logits by running inputs through a linear layer.
|
||||
Args:
|
||||
inputs: A float32 tensor with shape [batch_size, length, hidden_size]
|
||||
Returns:
|
||||
float32 tensor with shape [batch_size, length, vocab_size].
|
||||
"""
|
||||
batch_size = shape_list(inputs)[0]
|
||||
length = shape_list(inputs)[1]
|
||||
|
||||
x = tf.reshape(inputs, [-1, self.embedding_size])
|
||||
logits = tf.matmul(x, self.word_embeddings, transpose_b=True)
|
||||
|
||||
return tf.reshape(logits, [batch_size, length, self.vocab_size])
|
||||
|
||||
|
||||
class TFElectraDiscriminatorPredictions(tf.keras.layers.Layer):
|
||||
def __init__(self, config, **kwargs):
|
||||
super().__init__(**kwargs)
|
||||
|
||||
self.dense = tf.keras.layers.Dense(config.hidden_size, name="dense")
|
||||
self.dense_prediction = tf.keras.layers.Dense(1, name="dense_prediction")
|
||||
self.config = config
|
||||
|
||||
def call(self, discriminator_hidden_states, training=False):
|
||||
hidden_states = self.dense(discriminator_hidden_states)
|
||||
hidden_states = ACT2FN[self.config.hidden_act](hidden_states)
|
||||
logits = tf.squeeze(self.dense_prediction(hidden_states))
|
||||
|
||||
return logits
|
||||
|
||||
|
||||
class TFElectraGeneratorPredictions(tf.keras.layers.Layer):
|
||||
def __init__(self, config, **kwargs):
|
||||
super().__init__(**kwargs)
|
||||
|
||||
self.LayerNorm = tf.keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="LayerNorm")
|
||||
self.dense = tf.keras.layers.Dense(config.embedding_size, name="dense")
|
||||
|
||||
def call(self, generator_hidden_states, training=False):
|
||||
hidden_states = self.dense(generator_hidden_states)
|
||||
hidden_states = ACT2FN["gelu"](hidden_states)
|
||||
hidden_states = self.LayerNorm(hidden_states)
|
||||
|
||||
return hidden_states
|
||||
|
||||
|
||||
class TFElectraPreTrainedModel(TFBertPreTrainedModel):
|
||||
|
||||
config_class = ElectraConfig
|
||||
pretrained_model_archive_map = TF_ELECTRA_PRETRAINED_MODEL_ARCHIVE_MAP
|
||||
base_model_prefix = "electra"
|
||||
|
||||
def get_extended_attention_mask(self, attention_mask, input_shape):
|
||||
if attention_mask is None:
|
||||
attention_mask = tf.fill(input_shape, 1)
|
||||
|
||||
# We create a 3D attention mask from a 2D tensor mask.
|
||||
# Sizes are [batch_size, 1, 1, to_seq_length]
|
||||
# So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
|
||||
# this attention mask is more simple than the triangular masking of causal attention
|
||||
# used in OpenAI GPT, we just need to prepare the broadcast dimension here.
|
||||
extended_attention_mask = attention_mask[:, tf.newaxis, tf.newaxis, :]
|
||||
|
||||
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
|
||||
# masked positions, this operation will create a tensor which is 0.0 for
|
||||
# positions we want to attend and -10000.0 for masked positions.
|
||||
# Since we are adding it to the raw scores before the softmax, this is
|
||||
# effectively the same as removing these entirely.
|
||||
|
||||
extended_attention_mask = tf.cast(extended_attention_mask, tf.float32)
|
||||
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
|
||||
|
||||
return extended_attention_mask
|
||||
|
||||
def get_head_mask(self, head_mask):
|
||||
if head_mask is not None:
|
||||
raise NotImplementedError
|
||||
else:
|
||||
head_mask = [None] * self.config.num_hidden_layers
|
||||
|
||||
return head_mask
|
||||
|
||||
|
||||
class TFElectraMainLayer(TFElectraPreTrainedModel):
|
||||
|
||||
config_class = ElectraConfig
|
||||
|
||||
def __init__(self, config, **kwargs):
|
||||
super().__init__(config, **kwargs)
|
||||
self.embeddings = TFElectraEmbeddings(config, name="embeddings")
|
||||
|
||||
if config.embedding_size != config.hidden_size:
|
||||
self.embeddings_project = tf.keras.layers.Dense(config.hidden_size, name="embeddings_project")
|
||||
self.encoder = TFBertEncoder(config, name="encoder")
|
||||
self.config = config
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.embeddings
|
||||
|
||||
def _resize_token_embeddings(self, new_num_tokens):
|
||||
raise NotImplementedError
|
||||
|
||||
def _prune_heads(self, heads_to_prune):
|
||||
""" Prunes heads of the model.
|
||||
heads_to_prune: dict of {layer_num: list of heads to prune in this layer}
|
||||
See base class PreTrainedModel
|
||||
"""
|
||||
raise NotImplementedError
|
||||
|
||||
def call(
|
||||
self,
|
||||
inputs,
|
||||
attention_mask=None,
|
||||
token_type_ids=None,
|
||||
position_ids=None,
|
||||
head_mask=None,
|
||||
inputs_embeds=None,
|
||||
training=False,
|
||||
):
|
||||
if isinstance(inputs, (tuple, list)):
|
||||
input_ids = inputs[0]
|
||||
attention_mask = inputs[1] if len(inputs) > 1 else attention_mask
|
||||
token_type_ids = inputs[2] if len(inputs) > 2 else token_type_ids
|
||||
position_ids = inputs[3] if len(inputs) > 3 else position_ids
|
||||
head_mask = inputs[4] if len(inputs) > 4 else head_mask
|
||||
inputs_embeds = inputs[5] if len(inputs) > 5 else inputs_embeds
|
||||
assert len(inputs) <= 6, "Too many inputs."
|
||||
elif isinstance(inputs, dict):
|
||||
input_ids = inputs.get("input_ids")
|
||||
attention_mask = inputs.get("attention_mask", attention_mask)
|
||||
token_type_ids = inputs.get("token_type_ids", token_type_ids)
|
||||
position_ids = inputs.get("position_ids", position_ids)
|
||||
head_mask = inputs.get("head_mask", head_mask)
|
||||
inputs_embeds = inputs.get("inputs_embeds", inputs_embeds)
|
||||
assert len(inputs) <= 6, "Too many inputs."
|
||||
else:
|
||||
input_ids = inputs
|
||||
|
||||
if input_ids is not None and inputs_embeds is not None:
|
||||
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
|
||||
elif input_ids is not None:
|
||||
input_shape = shape_list(input_ids)
|
||||
elif inputs_embeds is not None:
|
||||
input_shape = shape_list(inputs_embeds)[:-1]
|
||||
else:
|
||||
raise ValueError("You have to specify either input_ids or inputs_embeds")
|
||||
|
||||
if attention_mask is None:
|
||||
attention_mask = tf.fill(input_shape, 1)
|
||||
if token_type_ids is None:
|
||||
token_type_ids = tf.fill(input_shape, 0)
|
||||
|
||||
extended_attention_mask = self.get_extended_attention_mask(attention_mask, input_shape)
|
||||
head_mask = self.get_head_mask(head_mask)
|
||||
|
||||
hidden_states = self.embeddings([input_ids, position_ids, token_type_ids, inputs_embeds], training=training)
|
||||
|
||||
if hasattr(self, "embeddings_project"):
|
||||
hidden_states = self.embeddings_project(hidden_states, training=training)
|
||||
|
||||
hidden_states = self.encoder([hidden_states, extended_attention_mask, head_mask], training=training)
|
||||
|
||||
return hidden_states
|
||||
|
||||
|
||||
ELECTRA_START_DOCSTRING = r"""
|
||||
This model is a `tf.keras.Model <https://www.tensorflow.org/api_docs/python/tf/keras/Model>`__ sub-class.
|
||||
Use it as a regular TF 2.0 Keras Model and
|
||||
refer to the TF 2.0 documentation for all matter related to general usage and behavior.
|
||||
|
||||
.. note::
|
||||
|
||||
TF 2.0 models accepts two formats as inputs:
|
||||
|
||||
- having all inputs as keyword arguments (like PyTorch models), or
|
||||
- having all inputs as a list, tuple or dict in the first positional arguments.
|
||||
|
||||
This second option is useful when using :obj:`tf.keras.Model.fit()` method which currently requires having
|
||||
all the tensors in the first argument of the model call function: :obj:`model(inputs)`.
|
||||
|
||||
If you choose this second option, there are three possibilities you can use to gather all the input Tensors
|
||||
in the first positional argument :
|
||||
|
||||
- a single Tensor with input_ids only and nothing else: :obj:`model(inputs_ids)`
|
||||
- a list of varying length with one or several input Tensors IN THE ORDER given in the docstring:
|
||||
:obj:`model([input_ids, attention_mask])` or :obj:`model([input_ids, attention_mask, token_type_ids])`
|
||||
- a dictionary with one or several input Tensors associated to the input names given in the docstring:
|
||||
:obj:`model({'input_ids': input_ids, 'token_type_ids': token_type_ids})`
|
||||
|
||||
Parameters:
|
||||
config (:class:`~transformers.ElectraConfig`): Model configuration class with all the parameters of the model.
|
||||
Initializing with a config file does not load the weights associated with the model, only the configuration.
|
||||
Check out the :meth:`~transformers.PreTrainedModel.from_pretrained` method to load the model weights.
|
||||
"""
|
||||
|
||||
ELECTRA_INPUTS_DOCSTRING = r"""
|
||||
Args:
|
||||
input_ids (:obj:`Numpy array` or :obj:`tf.Tensor` of shape :obj:`(batch_size, sequence_length)`):
|
||||
Indices of input sequence tokens in the vocabulary.
|
||||
|
||||
Indices can be obtained using :class:`transformers.ElectraTokenizer`.
|
||||
See :func:`transformers.PreTrainedTokenizer.encode` and
|
||||
:func:`transformers.PreTrainedTokenizer.encode_plus` for details.
|
||||
|
||||
`What are input IDs? <../glossary.html#input-ids>`__
|
||||
attention_mask (:obj:`Numpy array` or :obj:`tf.Tensor` of shape :obj:`(batch_size, sequence_length)`, `optional`, defaults to :obj:`None`):
|
||||
Mask to avoid performing attention on padding token indices.
|
||||
Mask values selected in ``[0, 1]``:
|
||||
``1`` for tokens that are NOT MASKED, ``0`` for MASKED tokens.
|
||||
|
||||
`What are attention masks? <../glossary.html#attention-mask>`__
|
||||
head_mask (:obj:`Numpy array` or :obj:`tf.Tensor` of shape :obj:`(num_heads,)` or :obj:`(num_layers, num_heads)`, `optional`, defaults to :obj:`None`):
|
||||
Mask to nullify selected heads of the self-attention modules.
|
||||
Mask values selected in ``[0, 1]``:
|
||||
:obj:`1` indicates the head is **not masked**, :obj:`0` indicates the head is **masked**.
|
||||
inputs_embeds (:obj:`Numpy array` or :obj:`tf.Tensor` of shape :obj:`(batch_size, sequence_length, embedding_dim)`, `optional`, defaults to :obj:`None`):
|
||||
Optionally, instead of passing :obj:`input_ids` you can choose to directly pass an embedded representation.
|
||||
This is useful if you want more control over how to convert `input_ids` indices into associated vectors
|
||||
than the model's internal embedding lookup matrix.
|
||||
training (:obj:`boolean`, `optional`, defaults to :obj:`False`):
|
||||
Whether to activate dropout modules (if set to :obj:`True`) during training or to de-activate them
|
||||
(if set to :obj:`False`) for evaluation.
|
||||
|
||||
"""
|
||||
|
||||
|
||||
@add_start_docstrings(
|
||||
"The bare Electra Model transformer outputting raw hidden-states without any specific head on top. Identical to "
|
||||
"the BERT model except that it uses an additional linear layer between the embedding layer and the encoder if the "
|
||||
"hidden size and embedding size are different."
|
||||
""
|
||||
"Both the generator and discriminator checkpoints may be loaded into this model.",
|
||||
ELECTRA_START_DOCSTRING,
|
||||
)
|
||||
class TFElectraModel(TFElectraPreTrainedModel):
|
||||
def __init__(self, config, *inputs, **kwargs):
|
||||
super().__init__(config, *inputs, **kwargs)
|
||||
self.electra = TFElectraMainLayer(config, name="electra")
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.electra.embeddings
|
||||
|
||||
@add_start_docstrings_to_callable(ELECTRA_INPUTS_DOCSTRING)
|
||||
def call(self, inputs, **kwargs):
|
||||
r"""
|
||||
Returns:
|
||||
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.ElectraConfig`) and inputs:
|
||||
last_hidden_state (:obj:`tf.Tensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`):
|
||||
Sequence of hidden-states at the output of the last layer of the model.
|
||||
hidden_states (:obj:`tuple(tf.Tensor)`, `optional`, returned when :obj:`config.output_hidden_states=True`):
|
||||
tuple of :obj:`tf.Tensor` (one for the output of the embeddings + one for the output of each layer)
|
||||
of shape :obj:`(batch_size, sequence_length, hidden_size)`.
|
||||
|
||||
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
|
||||
attentions (:obj:`tuple(tf.Tensor)`, `optional`, returned when ``config.output_attentions=True``):
|
||||
tuple of :obj:`tf.Tensor` (one for each layer) of shape
|
||||
:obj:`(batch_size, num_heads, sequence_length, sequence_length)`:
|
||||
|
||||
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
|
||||
|
||||
Examples::
|
||||
|
||||
import tensorflow as tf
|
||||
from transformers import ElectraTokenizer, TFElectraModel
|
||||
|
||||
tokenizer = ElectraTokenizer.from_pretrained('google/electra-small-discriminator')
|
||||
model = TFElectraModel.from_pretrained('google/electra-small-discriminator')
|
||||
input_ids = tf.constant(tokenizer.encode("Hello, my dog is cute"))[None, :] # Batch size 1
|
||||
outputs = model(input_ids)
|
||||
last_hidden_states = outputs[0] # The last hidden-state is the first element of the output tuple
|
||||
"""
|
||||
outputs = self.electra(inputs, **kwargs)
|
||||
return outputs
|
||||
|
||||
|
||||
@add_start_docstrings(
|
||||
"""
|
||||
Electra model with a binary classification head on top as used during pre-training for identifying generated
|
||||
tokens.
|
||||
|
||||
Even though both the discriminator and generator may be loaded into this model, the discriminator is
|
||||
the only model of the two to have the correct classification head to be used for this model.""",
|
||||
ELECTRA_START_DOCSTRING,
|
||||
)
|
||||
class TFElectraForPreTraining(TFElectraPreTrainedModel):
|
||||
def __init__(self, config, **kwargs):
|
||||
super().__init__(config, **kwargs)
|
||||
|
||||
self.electra = TFElectraMainLayer(config, name="electra")
|
||||
self.discriminator_predictions = TFElectraDiscriminatorPredictions(config, name="discriminator_predictions")
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.electra.embeddings
|
||||
|
||||
@add_start_docstrings_to_callable(ELECTRA_INPUTS_DOCSTRING)
|
||||
def call(
|
||||
self,
|
||||
input_ids=None,
|
||||
attention_mask=None,
|
||||
token_type_ids=None,
|
||||
position_ids=None,
|
||||
head_mask=None,
|
||||
inputs_embeds=None,
|
||||
training=False,
|
||||
):
|
||||
r"""
|
||||
Returns:
|
||||
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.ElectraConfig`) and inputs:
|
||||
scores (:obj:`Numpy array` or :obj:`tf.Tensor` of shape :obj:`(batch_size, sequence_length, config.num_labels)`):
|
||||
Prediction scores of the head (scores for each token before SoftMax).
|
||||
hidden_states (:obj:`tuple(tf.Tensor)`, `optional`, returned when :obj:`config.output_hidden_states=True`):
|
||||
tuple of :obj:`tf.Tensor` (one for the output of the embeddings + one for the output of each layer)
|
||||
of shape :obj:`(batch_size, sequence_length, hidden_size)`.
|
||||
|
||||
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
|
||||
attentions (:obj:`tuple(tf.Tensor)`, `optional`, returned when ``config.output_attentions=True``):
|
||||
tuple of :obj:`tf.Tensor` (one for each layer) of shape
|
||||
:obj:`(batch_size, num_heads, sequence_length, sequence_length)`:
|
||||
|
||||
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
|
||||
|
||||
Examples::
|
||||
|
||||
import tensorflow as tf
|
||||
from transformers import ElectraTokenizer, TFElectraForPreTraining
|
||||
|
||||
tokenizer = ElectraTokenizer.from_pretrained('google/electra-small-discriminator')
|
||||
model = TFElectraForPreTraining.from_pretrained('google/electra-small-discriminator')
|
||||
input_ids = tf.constant(tokenizer.encode("Hello, my dog is cute"))[None, :] # Batch size 1
|
||||
outputs = model(input_ids)
|
||||
scores = outputs[0]
|
||||
"""
|
||||
|
||||
discriminator_hidden_states = self.electra(
|
||||
input_ids, attention_mask, token_type_ids, position_ids, head_mask, inputs_embeds, training=training
|
||||
)
|
||||
discriminator_sequence_output = discriminator_hidden_states[0]
|
||||
logits = self.discriminator_predictions(discriminator_sequence_output)
|
||||
output = (logits,)
|
||||
output += discriminator_hidden_states[1:]
|
||||
|
||||
return output # (loss), scores, (hidden_states), (attentions)
|
||||
|
||||
|
||||
class TFElectraMaskedLMHead(tf.keras.layers.Layer):
|
||||
def __init__(self, config, input_embeddings, **kwargs):
|
||||
super().__init__(**kwargs)
|
||||
self.vocab_size = config.vocab_size
|
||||
self.input_embeddings = input_embeddings
|
||||
|
||||
def build(self, input_shape):
|
||||
self.bias = self.add_weight(shape=(self.vocab_size,), initializer="zeros", trainable=True, name="bias")
|
||||
super().build(input_shape)
|
||||
|
||||
def call(self, hidden_states, training=False):
|
||||
hidden_states = self.input_embeddings(hidden_states, mode="linear")
|
||||
hidden_states = hidden_states + self.bias
|
||||
return hidden_states
|
||||
|
||||
|
||||
@add_start_docstrings(
|
||||
"""
|
||||
Electra model with a language modeling head on top.
|
||||
|
||||
Even though both the discriminator and generator may be loaded into this model, the generator is
|
||||
the only model of the two to have been trained for the masked language modeling task.""",
|
||||
ELECTRA_START_DOCSTRING,
|
||||
)
|
||||
class TFElectraForMaskedLM(TFElectraPreTrainedModel):
|
||||
def __init__(self, config, **kwargs):
|
||||
super().__init__(config, **kwargs)
|
||||
|
||||
self.vocab_size = config.vocab_size
|
||||
self.electra = TFElectraMainLayer(config, name="electra")
|
||||
self.generator_predictions = TFElectraGeneratorPredictions(config, name="generator_predictions")
|
||||
if isinstance(config.hidden_act, str):
|
||||
self.activation = ACT2FN[config.hidden_act]
|
||||
else:
|
||||
self.activation = config.hidden_act
|
||||
self.generator_lm_head = TFElectraMaskedLMHead(config, self.electra.embeddings, name="generator_lm_head")
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.electra.embeddings
|
||||
|
||||
def get_output_embeddings(self):
|
||||
return self.generator_lm_head
|
||||
|
||||
@add_start_docstrings_to_callable(ELECTRA_INPUTS_DOCSTRING)
|
||||
def call(
|
||||
self,
|
||||
input_ids=None,
|
||||
attention_mask=None,
|
||||
token_type_ids=None,
|
||||
position_ids=None,
|
||||
head_mask=None,
|
||||
inputs_embeds=None,
|
||||
training=False,
|
||||
):
|
||||
r"""
|
||||
Returns:
|
||||
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.ElectraConfig`) and inputs:
|
||||
prediction_scores (:obj:`Numpy array` or :obj:`tf.Tensor` of shape :obj:`(batch_size, sequence_length, config.vocab_size)`):
|
||||
Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
|
||||
hidden_states (:obj:`tuple(tf.Tensor)`, `optional`, returned when :obj:`config.output_hidden_states=True`):
|
||||
tuple of :obj:`tf.Tensor` (one for the output of the embeddings + one for the output of each layer)
|
||||
of shape :obj:`(batch_size, sequence_length, hidden_size)`.
|
||||
|
||||
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
|
||||
attentions (:obj:`tuple(tf.Tensor)`, `optional`, returned when ``config.output_attentions=True``):
|
||||
tuple of :obj:`tf.Tensor` (one for each layer) of shape
|
||||
:obj:`(batch_size, num_heads, sequence_length, sequence_length)`:
|
||||
|
||||
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
|
||||
|
||||
Examples::
|
||||
|
||||
import tensorflow as tf
|
||||
from transformers import ElectraTokenizer, TFElectraForMaskedLM
|
||||
|
||||
tokenizer = ElectraTokenizer.from_pretrained('google/electra-small-generator')
|
||||
model = TFElectraForMaskedLM.from_pretrained('google/electra-small-generator')
|
||||
input_ids = tf.constant(tokenizer.encode("Hello, my dog is cute"))[None, :] # Batch size 1
|
||||
outputs = model(input_ids)
|
||||
prediction_scores = outputs[0]
|
||||
|
||||
"""
|
||||
|
||||
generator_hidden_states = self.electra(
|
||||
input_ids, attention_mask, token_type_ids, position_ids, head_mask, inputs_embeds, training=training
|
||||
)
|
||||
generator_sequence_output = generator_hidden_states[0]
|
||||
prediction_scores = self.generator_predictions(generator_sequence_output, training=training)
|
||||
prediction_scores = self.generator_lm_head(prediction_scores, training=training)
|
||||
output = (prediction_scores,)
|
||||
output += generator_hidden_states[1:]
|
||||
|
||||
return output # (masked_lm_loss), prediction_scores, (hidden_states), (attentions)
|
||||
|
||||
|
||||
@add_start_docstrings(
|
||||
"""
|
||||
Electra model with a token classification head on top.
|
||||
|
||||
Both the discriminator and generator may be loaded into this model.""",
|
||||
ELECTRA_START_DOCSTRING,
|
||||
)
|
||||
class TFElectraForTokenClassification(TFElectraPreTrainedModel):
|
||||
def __init__(self, config, **kwargs):
|
||||
super().__init__(config, **kwargs)
|
||||
|
||||
self.electra = TFElectraMainLayer(config, name="electra")
|
||||
self.dropout = tf.keras.layers.Dropout(config.hidden_dropout_prob)
|
||||
self.classifier = tf.keras.layers.Dense(config.num_labels, name="classifier")
|
||||
|
||||
@add_start_docstrings_to_callable(ELECTRA_INPUTS_DOCSTRING)
|
||||
def call(
|
||||
self,
|
||||
input_ids=None,
|
||||
attention_mask=None,
|
||||
token_type_ids=None,
|
||||
position_ids=None,
|
||||
head_mask=None,
|
||||
inputs_embeds=None,
|
||||
training=False,
|
||||
):
|
||||
r"""
|
||||
Returns:
|
||||
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.ElectraConfig`) and inputs:
|
||||
scores (:obj:`Numpy array` or :obj:`tf.Tensor` of shape :obj:`(batch_size, sequence_length, config.num_labels)`):
|
||||
Classification scores (before SoftMax).
|
||||
hidden_states (:obj:`tuple(tf.Tensor)`, `optional`, returned when :obj:`config.output_hidden_states=True`):
|
||||
tuple of :obj:`tf.Tensor` (one for the output of the embeddings + one for the output of each layer)
|
||||
of shape :obj:`(batch_size, sequence_length, hidden_size)`.
|
||||
|
||||
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
|
||||
attentions (:obj:`tuple(tf.Tensor)`, `optional`, returned when ``config.output_attentions=True``):
|
||||
tuple of :obj:`tf.Tensor` (one for each layer) of shape
|
||||
:obj:`(batch_size, num_heads, sequence_length, sequence_length)`:
|
||||
|
||||
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
|
||||
|
||||
Examples::
|
||||
|
||||
import tensorflow as tf
|
||||
from transformers import ElectraTokenizer, TFElectraForTokenClassification
|
||||
|
||||
tokenizer = ElectraTokenizer.from_pretrained('google/electra-small-discriminator')
|
||||
model = TFElectraForTokenClassification.from_pretrained('google/electra-small-discriminator')
|
||||
input_ids = tf.constant(tokenizer.encode("Hello, my dog is cute"))[None, :] # Batch size 1
|
||||
outputs = model(input_ids)
|
||||
scores = outputs[0]
|
||||
"""
|
||||
|
||||
discriminator_hidden_states = self.electra(
|
||||
input_ids, attention_mask, token_type_ids, position_ids, head_mask, inputs_embeds, training=training
|
||||
)
|
||||
discriminator_sequence_output = discriminator_hidden_states[0]
|
||||
discriminator_sequence_output = self.dropout(discriminator_sequence_output)
|
||||
logits = self.classifier(discriminator_sequence_output)
|
||||
output = (logits,)
|
||||
output += discriminator_hidden_states[1:]
|
||||
|
||||
return output # (loss), scores, (hidden_states), (attentions)
|
||||
@@ -119,7 +119,7 @@ class TFT5Attention(tf.keras.layers.Layer):
|
||||
|
||||
if self.has_relative_attention_bias:
|
||||
self.relative_attention_bias = tf.keras.layers.Embedding(
|
||||
self.relative_attention_num_buckets, self.n_heads, name="relative_attention_bias"
|
||||
self.relative_attention_num_buckets, self.n_heads, name="relative_attention_bias",
|
||||
)
|
||||
self.pruned_heads = set()
|
||||
|
||||
@@ -178,13 +178,15 @@ class TFT5Attention(tf.keras.layers.Layer):
|
||||
memory_position = tf.range(klen)[None, :]
|
||||
relative_position = memory_position - context_position # shape (qlen, klen)
|
||||
rp_bucket = self._relative_position_bucket(
|
||||
relative_position, bidirectional=not self.is_decoder, num_buckets=self.relative_attention_num_buckets
|
||||
relative_position, bidirectional=not self.is_decoder, num_buckets=self.relative_attention_num_buckets,
|
||||
)
|
||||
values = self.relative_attention_bias(rp_bucket) # shape (qlen, klen, num_heads)
|
||||
values = tf.expand_dims(tf.transpose(values, [2, 0, 1]), axis=0) # shape (1, num_heads, qlen, klen)
|
||||
return values
|
||||
|
||||
def call(self, input, mask=None, kv=None, position_bias=None, cache=None, head_mask=None, training=False):
|
||||
def call(
|
||||
self, input, mask=None, kv=None, position_bias=None, cache=None, head_mask=None, training=False,
|
||||
):
|
||||
"""
|
||||
Self-attention (if kv is None) or attention over source sentence (provided by kv).
|
||||
"""
|
||||
@@ -261,15 +263,17 @@ class TFT5LayerSelfAttention(tf.keras.layers.Layer):
|
||||
def __init__(self, config, has_relative_attention_bias=False, **kwargs):
|
||||
super().__init__(**kwargs)
|
||||
self.SelfAttention = TFT5Attention(
|
||||
config, has_relative_attention_bias=has_relative_attention_bias, name="SelfAttention"
|
||||
config, has_relative_attention_bias=has_relative_attention_bias, name="SelfAttention",
|
||||
)
|
||||
self.layer_norm = TFT5LayerNorm(epsilon=config.layer_norm_epsilon, name="layer_norm")
|
||||
self.dropout = tf.keras.layers.Dropout(config.dropout_rate)
|
||||
|
||||
def call(self, hidden_states, attention_mask=None, position_bias=None, head_mask=None, training=False):
|
||||
def call(
|
||||
self, hidden_states, attention_mask=None, position_bias=None, head_mask=None, training=False,
|
||||
):
|
||||
norm_x = self.layer_norm(hidden_states)
|
||||
attention_output = self.SelfAttention(
|
||||
norm_x, mask=attention_mask, position_bias=position_bias, head_mask=head_mask, training=training
|
||||
norm_x, mask=attention_mask, position_bias=position_bias, head_mask=head_mask, training=training,
|
||||
)
|
||||
y = attention_output[0]
|
||||
layer_output = hidden_states + self.dropout(y, training=training)
|
||||
@@ -281,15 +285,17 @@ class TFT5LayerCrossAttention(tf.keras.layers.Layer):
|
||||
def __init__(self, config, has_relative_attention_bias=False, **kwargs):
|
||||
super().__init__(**kwargs)
|
||||
self.EncDecAttention = TFT5Attention(
|
||||
config, has_relative_attention_bias=has_relative_attention_bias, name="EncDecAttention"
|
||||
config, has_relative_attention_bias=has_relative_attention_bias, name="EncDecAttention",
|
||||
)
|
||||
self.layer_norm = TFT5LayerNorm(epsilon=config.layer_norm_epsilon, name="layer_norm")
|
||||
self.dropout = tf.keras.layers.Dropout(config.dropout_rate)
|
||||
|
||||
def call(self, hidden_states, kv, attention_mask=None, position_bias=None, head_mask=None, training=False):
|
||||
def call(
|
||||
self, hidden_states, kv, attention_mask=None, position_bias=None, head_mask=None, training=False,
|
||||
):
|
||||
norm_x = self.layer_norm(hidden_states)
|
||||
attention_output = self.EncDecAttention(
|
||||
norm_x, mask=attention_mask, kv=kv, position_bias=position_bias, head_mask=head_mask, training=training
|
||||
norm_x, mask=attention_mask, kv=kv, position_bias=position_bias, head_mask=head_mask, training=training,
|
||||
)
|
||||
y = attention_output[0]
|
||||
layer_output = hidden_states + self.dropout(y, training=training)
|
||||
@@ -303,12 +309,12 @@ class TFT5Block(tf.keras.layers.Layer):
|
||||
self.is_decoder = config.is_decoder
|
||||
self.layer = []
|
||||
self.layer.append(
|
||||
TFT5LayerSelfAttention(config, has_relative_attention_bias=has_relative_attention_bias, name="layer_._0")
|
||||
TFT5LayerSelfAttention(config, has_relative_attention_bias=has_relative_attention_bias, name="layer_._0",)
|
||||
)
|
||||
if self.is_decoder:
|
||||
self.layer.append(
|
||||
TFT5LayerCrossAttention(
|
||||
config, has_relative_attention_bias=has_relative_attention_bias, name="layer_._1"
|
||||
config, has_relative_attention_bias=has_relative_attention_bias, name="layer_._1",
|
||||
)
|
||||
)
|
||||
self.layer.append(TFT5LayerFF(config, name="layer_._2"))
|
||||
@@ -402,7 +408,7 @@ class TFT5MainLayer(tf.keras.layers.Layer):
|
||||
self.num_hidden_layers = config.num_layers
|
||||
|
||||
self.block = [
|
||||
TFT5Block(config, has_relative_attention_bias=bool(i == 0), name="block_._{}".format(i))
|
||||
TFT5Block(config, has_relative_attention_bias=bool(i == 0), name="block_._{}".format(i),)
|
||||
for i in range(config.num_layers)
|
||||
]
|
||||
self.final_layer_norm = TFT5LayerNorm(epsilon=config.layer_norm_epsilon, name="final_layer_norm")
|
||||
@@ -469,7 +475,7 @@ class TFT5MainLayer(tf.keras.layers.Layer):
|
||||
if self.config.is_decoder:
|
||||
seq_ids = tf.range(seq_length)
|
||||
causal_mask = tf.less_equal(
|
||||
tf.tile(seq_ids[None, None, :], (batch_size, seq_length, 1)), seq_ids[None, :, None]
|
||||
tf.tile(seq_ids[None, None, :], (batch_size, seq_length, 1)), seq_ids[None, :, None],
|
||||
)
|
||||
causal_mask = tf.cast(causal_mask, dtype=tf.float32)
|
||||
extended_attention_mask = causal_mask[:, None, :, :] * attention_mask[:, None, None, :]
|
||||
@@ -586,8 +592,8 @@ class TFT5PreTrainedModel(TFPreTrainedModel):
|
||||
input_ids = tf.constant(DUMMY_INPUTS)
|
||||
input_mask = tf.constant(DUMMY_MASK)
|
||||
dummy_inputs = {
|
||||
"inputs": input_ids,
|
||||
"decoder_input_ids": input_ids,
|
||||
"input_ids": input_ids,
|
||||
"decoder_attention_mask": input_mask,
|
||||
}
|
||||
return dummy_inputs
|
||||
@@ -631,11 +637,9 @@ T5_START_DOCSTRING = r""" The T5 model was proposed in
|
||||
|
||||
T5_INPUTS_DOCSTRING = r"""
|
||||
Args:
|
||||
decoder_input_ids are usually used as a `dict` (see T5 description above for more information) containing all the following.
|
||||
decoder_input_ids (:obj:`tf.Tensor` of shape :obj:`(batch_size, target_sequence_length)`, `optional`, defaults to :obj:`None`):
|
||||
Provide for sequence to sequence training. T5 uses the pad_token_id as the starting token for decoder_input_ids generation.
|
||||
inputs are usually used as a `dict` (see T5 description above for more information) containing all the following.
|
||||
|
||||
input_ids (:obj:`tf.Tensor` of shape :obj:`(batch_size, sequence_length)`):
|
||||
inputs (:obj:`tf.Tensor` of shape :obj:`(batch_size, sequence_length)`):
|
||||
Indices of input sequence tokens in the vocabulary.
|
||||
T5 is a model with relative position embeddings so you should be able to pad the inputs on
|
||||
the right or the left.
|
||||
@@ -644,6 +648,8 @@ T5_INPUTS_DOCSTRING = r"""
|
||||
`T5 Training <./t5.html#training>`_ .
|
||||
See :func:`transformers.PreTrainedTokenizer.encode` and
|
||||
:func:`transformers.PreTrainedTokenizer.convert_tokens_to_ids` for details.
|
||||
decoder_input_ids (:obj:`tf.Tensor` of shape :obj:`(batch_size, target_sequence_length)`, `optional`, defaults to :obj:`None`):
|
||||
Provide for sequence to sequence training. T5 uses the pad_token_id as the starting token for decoder_input_ids generation.
|
||||
attention_mask (:obj:`tf.Tensor` of shape :obj:`(batch_size, sequence_length)`, `optional`, defaults to :obj:`None`):
|
||||
Mask to avoid performing attention on padding token indices.
|
||||
Mask values selected in ``[0, 1]``:
|
||||
@@ -700,7 +706,7 @@ class TFT5Model(TFT5PreTrainedModel):
|
||||
return self.shared
|
||||
|
||||
@add_start_docstrings_to_callable(T5_INPUTS_DOCSTRING)
|
||||
def call(self, decoder_input_ids, **kwargs):
|
||||
def call(self, inputs, **kwargs):
|
||||
r"""
|
||||
Return:
|
||||
:obj:`tuple(tf.Tensor)` comprising various elements depending on the configuration (:class:`~transformers.T5Config`) and inputs.
|
||||
@@ -725,18 +731,18 @@ class TFT5Model(TFT5PreTrainedModel):
|
||||
tokenizer = T5Tokenizer.from_pretrained('t5-small')
|
||||
model = TFT5Model.from_pretrained('t5-small')
|
||||
input_ids = tokenizer.encode("Hello, my dog is cute", return_tensors="tf") # Batch size 1
|
||||
outputs = model(input_ids, input_ids=input_ids)
|
||||
outputs = model(input_ids, decoder_input_ids=input_ids)
|
||||
last_hidden_states = outputs[0] # The last hidden-state is the first element of the output tuple
|
||||
|
||||
"""
|
||||
|
||||
if isinstance(decoder_input_ids, dict):
|
||||
kwargs.update(decoder_input_ids)
|
||||
if isinstance(inputs, dict):
|
||||
kwargs.update(inputs)
|
||||
else:
|
||||
kwargs["decoder_input_ids"] = decoder_input_ids
|
||||
kwargs["inputs"] = inputs
|
||||
|
||||
# retrieve arguments
|
||||
input_ids = kwargs.get("input_ids", None)
|
||||
input_ids = kwargs.get("inputs", None)
|
||||
decoder_input_ids = kwargs.get("decoder_input_ids", None)
|
||||
attention_mask = kwargs.get("attention_mask", None)
|
||||
encoder_outputs = kwargs.get("encoder_outputs", None)
|
||||
@@ -748,7 +754,7 @@ class TFT5Model(TFT5PreTrainedModel):
|
||||
# Encode if needed (training, first prediction pass)
|
||||
if encoder_outputs is None:
|
||||
encoder_outputs = self.encoder(
|
||||
input_ids, attention_mask=attention_mask, inputs_embeds=inputs_embeds, head_mask=head_mask
|
||||
input_ids, attention_mask=attention_mask, inputs_embeds=inputs_embeds, head_mask=head_mask,
|
||||
)
|
||||
|
||||
hidden_states = encoder_outputs[0]
|
||||
@@ -797,7 +803,7 @@ class TFT5ForConditionalGeneration(TFT5PreTrainedModel):
|
||||
return self.encoder
|
||||
|
||||
@add_start_docstrings_to_callable(T5_INPUTS_DOCSTRING)
|
||||
def call(self, decoder_input_ids, **kwargs):
|
||||
def call(self, inputs, **kwargs):
|
||||
r"""
|
||||
Return:
|
||||
:obj:`tuple(tf.Tensor)` comprising various elements depending on the configuration (:class:`~transformers.T5Config`) and inputs.
|
||||
@@ -823,7 +829,7 @@ class TFT5ForConditionalGeneration(TFT5PreTrainedModel):
|
||||
tokenizer = T5Tokenizer.from_pretrained('t5-small')
|
||||
model = TFT5ForConditionalGeneration.from_pretrained('t5-small')
|
||||
input_ids = tokenizer.encode("Hello, my dog is cute", return_tensors="tf") # Batch size 1
|
||||
outputs = model(input_ids, input_ids=input_ids)
|
||||
outputs = model(input_ids, decoder_input_ids=input_ids)
|
||||
prediction_scores = outputs[0]
|
||||
|
||||
tokenizer = T5Tokenizer.from_pretrained('t5-small')
|
||||
@@ -833,13 +839,13 @@ class TFT5ForConditionalGeneration(TFT5PreTrainedModel):
|
||||
|
||||
"""
|
||||
|
||||
if isinstance(decoder_input_ids, dict):
|
||||
kwargs.update(decoder_input_ids)
|
||||
if isinstance(inputs, dict):
|
||||
kwargs.update(inputs)
|
||||
else:
|
||||
kwargs["decoder_input_ids"] = decoder_input_ids
|
||||
kwargs["inputs"] = inputs
|
||||
|
||||
# retrieve arguments
|
||||
input_ids = kwargs.get("input_ids", None)
|
||||
input_ids = kwargs.get("inputs", None)
|
||||
decoder_input_ids = kwargs.get("decoder_input_ids", None)
|
||||
attention_mask = kwargs.get("attention_mask", None)
|
||||
encoder_outputs = kwargs.get("encoder_outputs", None)
|
||||
@@ -852,7 +858,7 @@ class TFT5ForConditionalGeneration(TFT5PreTrainedModel):
|
||||
if encoder_outputs is None:
|
||||
# Convert encoder inputs in embeddings if needed
|
||||
encoder_outputs = self.encoder(
|
||||
input_ids, attention_mask=attention_mask, inputs_embeds=inputs_embeds, head_mask=head_mask
|
||||
input_ids, attention_mask=attention_mask, inputs_embeds=inputs_embeds, head_mask=head_mask,
|
||||
)
|
||||
|
||||
hidden_states = encoder_outputs[0]
|
||||
@@ -884,7 +890,8 @@ class TFT5ForConditionalGeneration(TFT5PreTrainedModel):
|
||||
encoder_outputs = (past,)
|
||||
|
||||
return {
|
||||
"inputs": input_ids,
|
||||
"inputs": None, # inputs don't have to be defined, but still need to be passed to make Keras.layer.__call__ happy
|
||||
"decoder_input_ids": input_ids, # input_ids are the decoder_input_ids
|
||||
"encoder_outputs": encoder_outputs,
|
||||
"attention_mask": attention_mask,
|
||||
}
|
||||
|
||||
@@ -488,7 +488,7 @@ class TFTransfoXLMainLayer(tf.keras.layers.Layer):
|
||||
else:
|
||||
return None
|
||||
|
||||
def _update_mems(self, hids, mems, qlen, mlen):
|
||||
def _update_mems(self, hids, mems, mlen, qlen):
|
||||
# does not deal with None
|
||||
if mems is None:
|
||||
return None
|
||||
|
||||
@@ -467,6 +467,7 @@ class TFPreTrainedModel(tf.keras.Model, TFModelUtilsMixin):
|
||||
top_k=None,
|
||||
top_p=None,
|
||||
repetition_penalty=None,
|
||||
bad_words_ids=None,
|
||||
bos_token_id=None,
|
||||
pad_token_id=None,
|
||||
eos_token_id=None,
|
||||
@@ -532,6 +533,9 @@ class TFPreTrainedModel(tf.keras.Model, TFModelUtilsMixin):
|
||||
no_repeat_ngram_size: (`optional`) int
|
||||
If set to int > 0, all ngrams of size `no_repeat_ngram_size` can only occur once.
|
||||
|
||||
bad_words_ids: (`optional`) list of lists of int
|
||||
`bad_words_ids` contains tokens that are not allowed to be generated. In order to get the tokens of the words that should not appear in the generated text, use `tokenizer.encode(bad_word, add_prefix_space=True)`.
|
||||
|
||||
num_return_sequences: (`optional`) int
|
||||
The number of independently computed returned sequences for each element in the batch. Default to 1.
|
||||
|
||||
@@ -582,6 +586,12 @@ class TFPreTrainedModel(tf.keras.Model, TFModelUtilsMixin):
|
||||
outputs = model.generate(input_ids=input_ids, max_length=50, temperature=0.7, repetition_penalty=1.2) # generate sequences
|
||||
print('Generated: {}'.format(tokenizer.decode(outputs[0], skip_special_tokens=True)))
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained('gpt2') # Initialize tokenizer
|
||||
model = TFAutoModelWithLMHead.from_pretrained('gpt2') # Download model and configuration from S3 and cache.
|
||||
input_context = 'My cute dog' # "Legal" is one of the control codes for ctrl
|
||||
bad_words_ids = [tokenizer.encode(bad_word, add_prefix_space=True) for bad_word in ['idiot', 'stupid', 'shut up']]
|
||||
input_ids = tokenizer.encode(input_context, return_tensors='tf') # encode input context
|
||||
outputs = model.generate(input_ids=input_ids, max_length=100, do_sample=True, bad_words_ids=bad_words_ids) # generate sequences without allowing bad_words to be generated
|
||||
"""
|
||||
|
||||
# We cannot generate if the model does not have a LM head
|
||||
@@ -607,6 +617,7 @@ class TFPreTrainedModel(tf.keras.Model, TFModelUtilsMixin):
|
||||
no_repeat_ngram_size = (
|
||||
no_repeat_ngram_size if no_repeat_ngram_size is not None else self.config.no_repeat_ngram_size
|
||||
)
|
||||
bad_words_ids = bad_words_ids if bad_words_ids is not None else self.config.bad_words_ids
|
||||
num_return_sequences = (
|
||||
num_return_sequences if num_return_sequences is not None else self.config.num_return_sequences
|
||||
)
|
||||
@@ -641,6 +652,9 @@ class TFPreTrainedModel(tf.keras.Model, TFModelUtilsMixin):
|
||||
assert (
|
||||
isinstance(num_return_sequences, int) and num_return_sequences > 0
|
||||
), "`num_return_sequences` should be a strictely positive integer."
|
||||
assert (
|
||||
bad_words_ids is None or isinstance(bad_words_ids, list) and isinstance(bad_words_ids[0], list)
|
||||
), "`bad_words_ids` is either `None` or a list of lists of tokens that should not be generated"
|
||||
|
||||
if input_ids is None:
|
||||
assert isinstance(bos_token_id, int) and bos_token_id >= 0, (
|
||||
@@ -742,6 +756,7 @@ class TFPreTrainedModel(tf.keras.Model, TFModelUtilsMixin):
|
||||
top_p=top_p,
|
||||
repetition_penalty=repetition_penalty,
|
||||
no_repeat_ngram_size=no_repeat_ngram_size,
|
||||
bad_words_ids=bad_words_ids,
|
||||
bos_token_id=bos_token_id,
|
||||
pad_token_id=pad_token_id,
|
||||
eos_token_id=eos_token_id,
|
||||
@@ -766,6 +781,7 @@ class TFPreTrainedModel(tf.keras.Model, TFModelUtilsMixin):
|
||||
top_p=top_p,
|
||||
repetition_penalty=repetition_penalty,
|
||||
no_repeat_ngram_size=no_repeat_ngram_size,
|
||||
bad_words_ids=bad_words_ids,
|
||||
bos_token_id=bos_token_id,
|
||||
pad_token_id=pad_token_id,
|
||||
eos_token_id=eos_token_id,
|
||||
@@ -790,6 +806,7 @@ class TFPreTrainedModel(tf.keras.Model, TFModelUtilsMixin):
|
||||
top_p,
|
||||
repetition_penalty,
|
||||
no_repeat_ngram_size,
|
||||
bad_words_ids,
|
||||
bos_token_id,
|
||||
pad_token_id,
|
||||
eos_token_id,
|
||||
@@ -828,7 +845,7 @@ class TFPreTrainedModel(tf.keras.Model, TFModelUtilsMixin):
|
||||
if no_repeat_ngram_size > 0:
|
||||
# calculate a list of banned tokens to prevent repetitively generating the same ngrams
|
||||
# from fairseq: https://github.com/pytorch/fairseq/blob/a07cb6f40480928c9e0548b737aadd36ee66ac76/fairseq/sequence_generator.py#L345
|
||||
banned_tokens = calc_banned_tokens(input_ids, batch_size, no_repeat_ngram_size, cur_len)
|
||||
banned_tokens = calc_banned_ngram_tokens(input_ids, batch_size, no_repeat_ngram_size, cur_len)
|
||||
# create banned_tokens boolean mask
|
||||
banned_tokens_indices_mask = []
|
||||
for banned_tokens_slice in banned_tokens:
|
||||
@@ -840,6 +857,20 @@ class TFPreTrainedModel(tf.keras.Model, TFModelUtilsMixin):
|
||||
next_token_logits, tf.convert_to_tensor(banned_tokens_indices_mask, dtype=tf.bool), -float("inf")
|
||||
)
|
||||
|
||||
if bad_words_ids is not None:
|
||||
# calculate a list of banned tokens according to bad words
|
||||
banned_tokens = calc_banned_bad_words_ids(input_ids, bad_words_ids)
|
||||
|
||||
banned_tokens_indices_mask = []
|
||||
for banned_tokens_slice in banned_tokens:
|
||||
banned_tokens_indices_mask.append(
|
||||
[True if token in banned_tokens_slice else False for token in range(vocab_size)]
|
||||
)
|
||||
|
||||
next_token_logits = set_tensor_by_indices_to_value(
|
||||
next_token_logits, tf.convert_to_tensor(banned_tokens_indices_mask, dtype=tf.bool), -float("inf")
|
||||
)
|
||||
|
||||
# set eos token prob to zero if min_length is not reached
|
||||
if eos_token_id is not None and cur_len < min_length:
|
||||
# create eos_token_id boolean mask
|
||||
@@ -936,6 +967,7 @@ class TFPreTrainedModel(tf.keras.Model, TFModelUtilsMixin):
|
||||
top_p,
|
||||
repetition_penalty,
|
||||
no_repeat_ngram_size,
|
||||
bad_words_ids,
|
||||
bos_token_id,
|
||||
pad_token_id,
|
||||
decoder_start_token_id,
|
||||
@@ -1012,7 +1044,9 @@ class TFPreTrainedModel(tf.keras.Model, TFModelUtilsMixin):
|
||||
# calculate a list of banned tokens to prevent repetitively generating the same ngrams
|
||||
# from fairseq: https://github.com/pytorch/fairseq/blob/a07cb6f40480928c9e0548b737aadd36ee66ac76/fairseq/sequence_generator.py#L345
|
||||
num_batch_hypotheses = batch_size * num_beams
|
||||
banned_tokens = calc_banned_tokens(input_ids, num_batch_hypotheses, no_repeat_ngram_size, cur_len)
|
||||
banned_tokens = calc_banned_ngram_tokens(
|
||||
input_ids, num_batch_hypotheses, no_repeat_ngram_size, cur_len
|
||||
)
|
||||
# create banned_tokens boolean mask
|
||||
banned_tokens_indices_mask = []
|
||||
for banned_tokens_slice in banned_tokens:
|
||||
@@ -1024,6 +1058,20 @@ class TFPreTrainedModel(tf.keras.Model, TFModelUtilsMixin):
|
||||
scores, tf.convert_to_tensor(banned_tokens_indices_mask, dtype=tf.bool), -float("inf")
|
||||
)
|
||||
|
||||
if bad_words_ids is not None:
|
||||
# calculate a list of banned tokens according to bad words
|
||||
banned_tokens = calc_banned_bad_words_ids(input_ids, bad_words_ids)
|
||||
|
||||
banned_tokens_indices_mask = []
|
||||
for banned_tokens_slice in banned_tokens:
|
||||
banned_tokens_indices_mask.append(
|
||||
[True if token in banned_tokens_slice else False for token in range(vocab_size)]
|
||||
)
|
||||
|
||||
scores = set_tensor_by_indices_to_value(
|
||||
scores, tf.convert_to_tensor(banned_tokens_indices_mask, dtype=tf.bool), -float("inf")
|
||||
)
|
||||
|
||||
assert shape_list(scores) == [batch_size * num_beams, vocab_size]
|
||||
|
||||
if do_sample:
|
||||
@@ -1064,12 +1112,12 @@ class TFPreTrainedModel(tf.keras.Model, TFModelUtilsMixin):
|
||||
assert shape_list(next_scores) == shape_list(next_tokens) == [batch_size, 2 * num_beams]
|
||||
|
||||
# next batch beam content
|
||||
# list of (batch_size * num_beams) tuple(next hypothesis score, next token, current position in the batch)
|
||||
next_batch_beam = []
|
||||
|
||||
# for each sentence
|
||||
for batch_idx in range(batch_size):
|
||||
|
||||
# if we are done with this sentence
|
||||
if done[batch_idx]:
|
||||
assert (
|
||||
len(generated_hyps[batch_idx]) >= num_beams
|
||||
@@ -1087,14 +1135,13 @@ class TFPreTrainedModel(tf.keras.Model, TFModelUtilsMixin):
|
||||
for beam_token_rank, (beam_token_id, beam_token_score) in enumerate(
|
||||
zip(next_tokens[batch_idx], next_scores[batch_idx])
|
||||
):
|
||||
|
||||
# get beam and token IDs
|
||||
beam_id = beam_token_id // vocab_size
|
||||
token_id = beam_token_id % vocab_size
|
||||
|
||||
effective_beam_id = batch_idx * num_beams + beam_id
|
||||
# add to generated hypotheses if end of sentence or last iteration
|
||||
if eos_token_id is not None and token_id.numpy() is eos_token_id:
|
||||
if (eos_token_id is not None) and (token_id.numpy() == eos_token_id):
|
||||
# if beam_token does not belong to top num_beams tokens, it should not be added
|
||||
is_beam_token_worse_than_top_num_beams = beam_token_rank >= num_beams
|
||||
if is_beam_token_worse_than_top_num_beams:
|
||||
@@ -1110,9 +1157,9 @@ class TFPreTrainedModel(tf.keras.Model, TFModelUtilsMixin):
|
||||
if len(next_sent_beam) == num_beams:
|
||||
break
|
||||
|
||||
# if we are done with this sentence
|
||||
# Check if were done so that we can save a pad step if all(done)
|
||||
done[batch_idx] = done[batch_idx] or generated_hyps[batch_idx].is_done(
|
||||
tf.reduce_max(next_scores[batch_idx]).numpy()
|
||||
tf.reduce_max(next_scores[batch_idx]).numpy(), cur_len=cur_len
|
||||
)
|
||||
|
||||
# update next beam content
|
||||
@@ -1137,6 +1184,7 @@ class TFPreTrainedModel(tf.keras.Model, TFModelUtilsMixin):
|
||||
if past is not None:
|
||||
past = self._reorder_cache(past, beam_idx)
|
||||
|
||||
# extend attention_mask for new generated input if only decoder
|
||||
if self.config.is_encoder_decoder is False:
|
||||
attention_mask = tf.concat(
|
||||
[attention_mask, tf.ones((shape_list(attention_mask)[0], 1), dtype=tf.int32)], axis=-1
|
||||
@@ -1196,16 +1244,26 @@ class TFPreTrainedModel(tf.keras.Model, TFModelUtilsMixin):
|
||||
|
||||
# fill with hypothesis and eos_token_id if necessary
|
||||
for i, hypo in enumerate(best):
|
||||
padding = tf.ones((sent_max_len - shape_list(hypo)[0],), dtype=tf.int32) * pad_token_id
|
||||
decoded_hypo = tf.concat([hypo, padding], axis=0)
|
||||
assert sent_lengths[i] == shape_list(hypo)[0]
|
||||
# if sent_length is max_len do not pad
|
||||
if sent_lengths[i] == sent_max_len:
|
||||
decoded_slice = hypo
|
||||
else:
|
||||
# else pad to sent_max_len
|
||||
num_pad_tokens = sent_max_len - sent_lengths[i]
|
||||
padding = pad_token_id * tf.ones((num_pad_tokens,), dtype=tf.int32)
|
||||
decoded_slice = tf.concat([hypo, padding], axis=-1)
|
||||
|
||||
# finish sentence with EOS token
|
||||
if sent_lengths[i] < max_length:
|
||||
decoded_slice = tf.where(
|
||||
tf.range(sent_max_len, dtype=tf.int32) == sent_lengths[i],
|
||||
eos_token_id * tf.ones((sent_max_len,), dtype=tf.int32),
|
||||
decoded_slice,
|
||||
)
|
||||
# add to list
|
||||
decoded_list.append(decoded_slice)
|
||||
|
||||
if sent_lengths[i] < max_length:
|
||||
decoded_hypo = tf.where(
|
||||
tf.range(max_length) == sent_lengths[i],
|
||||
eos_token_id * tf.ones((sent_max_len,), dtype=tf.int32),
|
||||
decoded_hypo,
|
||||
)
|
||||
decoded_list.append(decoded_hypo)
|
||||
decoded = tf.stack(decoded_list)
|
||||
else:
|
||||
# none of the hypotheses have an eos_token
|
||||
@@ -1243,7 +1301,7 @@ def _create_next_token_logits_penalties(input_ids, logits, repetition_penalty):
|
||||
return tf.convert_to_tensor(token_penalties, dtype=tf.float32)
|
||||
|
||||
|
||||
def calc_banned_tokens(prev_input_ids, num_hypos, no_repeat_ngram_size, cur_len):
|
||||
def calc_banned_ngram_tokens(prev_input_ids, num_hypos, no_repeat_ngram_size, cur_len):
|
||||
# Copied from fairseq for no_repeat_ngram in beam_search"""
|
||||
if cur_len + 1 < no_repeat_ngram_size:
|
||||
# return no banned tokens if we haven't generated no_repeat_ngram_size tokens yet
|
||||
@@ -1266,6 +1324,42 @@ def calc_banned_tokens(prev_input_ids, num_hypos, no_repeat_ngram_size, cur_len)
|
||||
return banned_tokens
|
||||
|
||||
|
||||
def calc_banned_bad_words_ids(prev_input_ids, bad_words_ids):
|
||||
banned_tokens = []
|
||||
|
||||
def _tokens_match(prev_tokens, tokens):
|
||||
if len(tokens) == 0:
|
||||
# if bad word tokens is just one token always ban it
|
||||
return True
|
||||
if len(tokens) > len(prev_input_ids):
|
||||
# if bad word tokens are longer then prev input_ids they can't be equal
|
||||
return False
|
||||
|
||||
if prev_tokens[-len(tokens) :] == tokens:
|
||||
# if tokens match
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
|
||||
for prev_input_ids_slice in prev_input_ids:
|
||||
banned_tokens_slice = []
|
||||
|
||||
for banned_token_seq in bad_words_ids:
|
||||
assert len(banned_token_seq) > 0, "Banned words token sequences {} cannot have an empty list".format(
|
||||
bad_words_ids
|
||||
)
|
||||
|
||||
if _tokens_match(prev_input_ids_slice.numpy().tolist(), banned_token_seq[:-1]) is False:
|
||||
# if tokens do not match continue
|
||||
continue
|
||||
|
||||
banned_tokens_slice.append(banned_token_seq[-1])
|
||||
|
||||
banned_tokens.append(banned_tokens_slice)
|
||||
|
||||
return banned_tokens
|
||||
|
||||
|
||||
def tf_top_k_top_p_filtering(logits, top_k=0, top_p=1.0, filter_value=-float("Inf"), min_tokens_to_keep=1):
|
||||
""" Filter a distribution of logits using top-k and/or nucleus (top-p) filtering
|
||||
Args:
|
||||
|
||||
@@ -136,7 +136,7 @@ def load_tf_weights_in_transfo_xl(model, config, tf_path):
|
||||
if "kernel" in name or "proj" in name:
|
||||
array = np.transpose(array)
|
||||
if ("r_r_bias" in name or "r_w_bias" in name) and len(pointer) > 1:
|
||||
# Here we will split the TF weigths
|
||||
# Here we will split the TF weights
|
||||
assert len(pointer) == array.shape[0]
|
||||
for i, p_i in enumerate(pointer):
|
||||
arr_i = array[i, ...]
|
||||
|
||||
@@ -667,6 +667,7 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
top_k=None,
|
||||
top_p=None,
|
||||
repetition_penalty=None,
|
||||
bad_words_ids=None,
|
||||
bos_token_id=None,
|
||||
pad_token_id=None,
|
||||
eos_token_id=None,
|
||||
@@ -731,6 +732,8 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
|
||||
no_repeat_ngram_size: (`optional`) int
|
||||
If set to int > 0, all ngrams of size `no_repeat_ngram_size` can only occur once.
|
||||
bad_words_ids: (`optional`) list of lists of int
|
||||
`bad_words_ids` contains tokens that are not allowed to be generated. In order to get the tokens of the words that should not appear in the generated text, use `tokenizer.encode(bad_word, add_prefix_space=True)`.
|
||||
|
||||
num_return_sequences: (`optional`) int
|
||||
The number of independently computed returned sequences for each element in the batch. Default to 1.
|
||||
@@ -782,6 +785,12 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
outputs = model.generate(input_ids=input_ids, max_length=50, temperature=0.7, repetition_penalty=1.2) # generate sequences
|
||||
print('Generated: {}'.format(tokenizer.decode(outputs[0], skip_special_tokens=True)))
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained('gpt2') # Initialize tokenizer
|
||||
model = AutoModelWithLMHead.from_pretrained('gpt2') # Download model and configuration from S3 and cache.
|
||||
input_context = 'My cute dog' # "Legal" is one of the control codes for ctrl
|
||||
bad_words_ids = [tokenizer.encode(bad_word, add_prefix_space=True) for bad_word in ['idiot', 'stupid', 'shut up']]
|
||||
input_ids = tokenizer.encode(input_context, return_tensors='pt') # encode input context
|
||||
outputs = model.generate(input_ids=input_ids, max_length=100, do_sample=True, bad_words_ids=bad_words_ids) # generate sequences without allowing bad_words to be generated
|
||||
"""
|
||||
|
||||
# We cannot generate if the model does not have a LM head
|
||||
@@ -807,6 +816,7 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
no_repeat_ngram_size = (
|
||||
no_repeat_ngram_size if no_repeat_ngram_size is not None else self.config.no_repeat_ngram_size
|
||||
)
|
||||
bad_words_ids = bad_words_ids if bad_words_ids is not None else self.config.bad_words_ids
|
||||
num_return_sequences = (
|
||||
num_return_sequences if num_return_sequences is not None else self.config.num_return_sequences
|
||||
)
|
||||
@@ -844,6 +854,9 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
assert (
|
||||
isinstance(num_return_sequences, int) and num_return_sequences > 0
|
||||
), "`num_return_sequences` should be a strictly positive integer."
|
||||
assert (
|
||||
bad_words_ids is None or isinstance(bad_words_ids, list) and isinstance(bad_words_ids[0], list)
|
||||
), "`bad_words_ids` is either `None` or a list of lists of tokens that should not be generated"
|
||||
|
||||
if input_ids is None:
|
||||
assert isinstance(bos_token_id, int) and bos_token_id >= 0, (
|
||||
@@ -935,18 +948,22 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
device=next(self.parameters()).device,
|
||||
)
|
||||
cur_len = 1
|
||||
batch_idx = self.encoder_outputs_batch_dim_idx
|
||||
|
||||
assert (
|
||||
batch_size == encoder_outputs[0].shape[batch_idx]
|
||||
), f"expected encoder_outputs[0] to have 1st dimension bs={batch_size}, got {encoder_outputs[0].shape[1]} "
|
||||
expanded_idx = (
|
||||
batch_size == encoder_outputs[0].shape[0]
|
||||
), f"expected encoder_outputs[0] to have 1st dimension bs={batch_size}, got {encoder_outputs[0].shape[0]} "
|
||||
|
||||
# expand batch_idx to assign correct encoder output for expanded input_ids (due to num_beams > 1 and num_return_sequences > 1)
|
||||
expanded_batch_idxs = (
|
||||
torch.arange(batch_size)
|
||||
.view(-1, 1)
|
||||
.repeat(1, num_beams * effective_batch_mult)
|
||||
.view(-1)
|
||||
.to(input_ids.device)
|
||||
)
|
||||
encoder_outputs = (encoder_outputs[0].index_select(batch_idx, expanded_idx), *encoder_outputs[1:])
|
||||
# expand encoder_outputs
|
||||
encoder_outputs = (encoder_outputs[0].index_select(0, expanded_batch_idxs), *encoder_outputs[1:])
|
||||
|
||||
else:
|
||||
encoder_outputs = None
|
||||
cur_len = input_ids.shape[-1]
|
||||
@@ -964,6 +981,7 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
top_p=top_p,
|
||||
repetition_penalty=repetition_penalty,
|
||||
no_repeat_ngram_size=no_repeat_ngram_size,
|
||||
bad_words_ids=bad_words_ids,
|
||||
bos_token_id=bos_token_id,
|
||||
pad_token_id=pad_token_id,
|
||||
decoder_start_token_id=decoder_start_token_id,
|
||||
@@ -988,6 +1006,7 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
top_p=top_p,
|
||||
repetition_penalty=repetition_penalty,
|
||||
no_repeat_ngram_size=no_repeat_ngram_size,
|
||||
bad_words_ids=bad_words_ids,
|
||||
bos_token_id=bos_token_id,
|
||||
pad_token_id=pad_token_id,
|
||||
decoder_start_token_id=decoder_start_token_id,
|
||||
@@ -1011,6 +1030,7 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
top_p,
|
||||
repetition_penalty,
|
||||
no_repeat_ngram_size,
|
||||
bad_words_ids,
|
||||
bos_token_id,
|
||||
pad_token_id,
|
||||
eos_token_id,
|
||||
@@ -1045,7 +1065,14 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
if no_repeat_ngram_size > 0:
|
||||
# calculate a list of banned tokens to prevent repetitively generating the same ngrams
|
||||
# from fairseq: https://github.com/pytorch/fairseq/blob/a07cb6f40480928c9e0548b737aadd36ee66ac76/fairseq/sequence_generator.py#L345
|
||||
banned_tokens = calc_banned_tokens(input_ids, batch_size, no_repeat_ngram_size, cur_len)
|
||||
banned_tokens = calc_banned_ngram_tokens(input_ids, batch_size, no_repeat_ngram_size, cur_len)
|
||||
for batch_idx in range(batch_size):
|
||||
next_token_logits[batch_idx, banned_tokens[batch_idx]] = -float("inf")
|
||||
|
||||
if bad_words_ids is not None:
|
||||
# calculate a list of banned tokens according to bad words
|
||||
banned_tokens = calc_banned_bad_words_ids(input_ids, bad_words_ids)
|
||||
|
||||
for batch_idx in range(batch_size):
|
||||
next_token_logits[batch_idx, banned_tokens[batch_idx]] = -float("inf")
|
||||
|
||||
@@ -1121,6 +1148,7 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
top_p,
|
||||
repetition_penalty,
|
||||
no_repeat_ngram_size,
|
||||
bad_words_ids,
|
||||
bos_token_id,
|
||||
pad_token_id,
|
||||
eos_token_id,
|
||||
@@ -1187,12 +1215,19 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
# calculate a list of banned tokens to prevent repetitively generating the same ngrams
|
||||
num_batch_hypotheses = batch_size * num_beams
|
||||
# from fairseq: https://github.com/pytorch/fairseq/blob/a07cb6f40480928c9e0548b737aadd36ee66ac76/fairseq/sequence_generator.py#L345
|
||||
banned_batch_tokens = calc_banned_tokens(
|
||||
banned_batch_tokens = calc_banned_ngram_tokens(
|
||||
input_ids, num_batch_hypotheses, no_repeat_ngram_size, cur_len
|
||||
)
|
||||
for i, banned_tokens in enumerate(banned_batch_tokens):
|
||||
scores[i, banned_tokens] = -float("inf")
|
||||
|
||||
if bad_words_ids is not None:
|
||||
# calculate a list of banned tokens according to bad words
|
||||
banned_tokens = calc_banned_bad_words_ids(input_ids, bad_words_ids)
|
||||
|
||||
for i, banned_tokens in enumerate(banned_tokens):
|
||||
scores[i, banned_tokens] = -float("inf")
|
||||
|
||||
assert scores.shape == (batch_size * num_beams, vocab_size), "Shapes of scores: {} != {}".format(
|
||||
scores.shape, (batch_size * num_beams, vocab_size)
|
||||
)
|
||||
@@ -1253,14 +1288,13 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
for beam_token_rank, (beam_token_id, beam_token_score) in enumerate(
|
||||
zip(next_tokens[batch_idx], next_scores[batch_idx])
|
||||
):
|
||||
# get beam and word IDs
|
||||
# get beam and token IDs
|
||||
beam_id = beam_token_id // vocab_size
|
||||
token_id = beam_token_id % vocab_size
|
||||
|
||||
effective_beam_id = batch_idx * num_beams + beam_id
|
||||
|
||||
# add to generated hypotheses if end of sentence
|
||||
if (eos_token_id is not None) and (token_id.item() is eos_token_id):
|
||||
# add to generated hypotheses if end of sentence or last iteration
|
||||
if (eos_token_id is not None) and (token_id.item() == eos_token_id):
|
||||
# if beam_token does not belong to top num_beams tokens, it should not be added
|
||||
is_beam_token_worse_than_top_num_beams = beam_token_rank >= num_beams
|
||||
if is_beam_token_worse_than_top_num_beams:
|
||||
@@ -1269,7 +1303,7 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
input_ids[effective_beam_id].clone(), beam_token_score.item(),
|
||||
)
|
||||
else:
|
||||
# add next predicted word if it is not eos_token
|
||||
# add next predicted token if it is not eos_token
|
||||
next_sent_beam.append((beam_token_score, token_id, effective_beam_id))
|
||||
|
||||
# the beam for next step is full
|
||||
@@ -1299,7 +1333,6 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
# re-order batch
|
||||
input_ids = input_ids[beam_idx, :]
|
||||
input_ids = torch.cat([input_ids, beam_tokens.unsqueeze(1)], dim=-1)
|
||||
|
||||
# re-order internal states
|
||||
if past is not None:
|
||||
past = self._reorder_cache(past, beam_idx)
|
||||
@@ -1397,7 +1430,7 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
return past
|
||||
|
||||
|
||||
def calc_banned_tokens(prev_input_ids, num_hypos, no_repeat_ngram_size, cur_len):
|
||||
def calc_banned_ngram_tokens(prev_input_ids, num_hypos, no_repeat_ngram_size, cur_len):
|
||||
# Copied from fairseq for no_repeat_ngram in beam_search"""
|
||||
if cur_len + 1 < no_repeat_ngram_size:
|
||||
# return no banned tokens if we haven't generated no_repeat_ngram_size tokens yet
|
||||
@@ -1420,6 +1453,42 @@ def calc_banned_tokens(prev_input_ids, num_hypos, no_repeat_ngram_size, cur_len)
|
||||
return banned_tokens
|
||||
|
||||
|
||||
def calc_banned_bad_words_ids(prev_input_ids, bad_words_ids):
|
||||
banned_tokens = []
|
||||
|
||||
def _tokens_match(prev_tokens, tokens):
|
||||
if len(tokens) == 0:
|
||||
# if bad word tokens is just one token always ban it
|
||||
return True
|
||||
if len(tokens) > len(prev_input_ids):
|
||||
# if bad word tokens are longer then prev input_ids they can't be equal
|
||||
return False
|
||||
|
||||
if prev_tokens[-len(tokens) :] == tokens:
|
||||
# if tokens match
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
|
||||
for prev_input_ids_slice in prev_input_ids:
|
||||
banned_tokens_slice = []
|
||||
|
||||
for banned_token_seq in bad_words_ids:
|
||||
assert len(banned_token_seq) > 0, "Banned words token sequences {} cannot have an empty list".format(
|
||||
bad_words_ids
|
||||
)
|
||||
|
||||
if _tokens_match(prev_input_ids_slice.tolist(), banned_token_seq[:-1]) is False:
|
||||
# if tokens do not match continue
|
||||
continue
|
||||
|
||||
banned_tokens_slice.append(banned_token_seq[-1])
|
||||
|
||||
banned_tokens.append(banned_tokens_slice)
|
||||
|
||||
return banned_tokens
|
||||
|
||||
|
||||
def top_k_top_p_filtering(logits, top_k=0, top_p=1.0, filter_value=-float("Inf"), min_tokens_to_keep=1):
|
||||
""" Filter a distribution of logits using top-k and/or nucleus (top-p) filtering
|
||||
Args:
|
||||
|
||||
@@ -156,7 +156,7 @@ def load_tf_weights_in_xlnet(model, config, tf_path):
|
||||
logger.info("Transposing")
|
||||
array = np.transpose(array)
|
||||
if isinstance(pointer, list):
|
||||
# Here we will split the TF weigths
|
||||
# Here we will split the TF weights
|
||||
assert len(pointer) == array.shape[0]
|
||||
for i, p_i in enumerate(pointer):
|
||||
arr_i = array[i, ...]
|
||||
|
||||
@@ -214,7 +214,7 @@ class GradientAccumulator(object):
|
||||
raise ValueError("Expected %s gradients, but got %d" % (len(self._gradients), len(gradients)))
|
||||
|
||||
for accum_gradient, gradient in zip(self._get_replica_gradients(), gradients):
|
||||
if accum_gradient is not None:
|
||||
if accum_gradient is not None and gradient is not None:
|
||||
accum_gradient.assign_add(gradient)
|
||||
|
||||
self._accum_steps.assign_add(1)
|
||||
@@ -241,6 +241,7 @@ class GradientAccumulator(object):
|
||||
return (
|
||||
gradient.device_map.select_for_current_replica(gradient.values, replica_context)
|
||||
for gradient in self._gradients
|
||||
if gradient is not None
|
||||
)
|
||||
else:
|
||||
return self._gradients
|
||||
|
||||
@@ -1235,17 +1235,19 @@ class SummarizationPipeline(Pipeline):
|
||||
elif self.framework == "tf":
|
||||
input_length = tf.shape(inputs["input_ids"])[-1].numpy()
|
||||
|
||||
if input_length < self.model.config.min_length // 2:
|
||||
min_length = generate_kwargs.get("min_length", self.model.config.min_length)
|
||||
if input_length < min_length // 2:
|
||||
logger.warning(
|
||||
"Your min_length is set to {}, but you input_length is only {}. You might consider decreasing min_length manually, e.g. summarizer('...', min_length=10)".format(
|
||||
self.model.config.min_length, input_length
|
||||
min_length, input_length
|
||||
)
|
||||
)
|
||||
|
||||
if input_length < self.model.config.max_length:
|
||||
max_length = generate_kwargs.get("max_length", self.model.config.max_length)
|
||||
if input_length < max_length:
|
||||
logger.warning(
|
||||
"Your max_length is set to {}, but you input_length is only {}. You might consider decreasing max_length manually, e.g. summarizer('...', max_length=50)".format(
|
||||
self.model.config.max_length, input_length
|
||||
max_length, input_length
|
||||
)
|
||||
)
|
||||
|
||||
@@ -1349,10 +1351,11 @@ class TranslationPipeline(Pipeline):
|
||||
elif self.framework == "tf":
|
||||
input_length = tf.shape(inputs["input_ids"])[-1].numpy()
|
||||
|
||||
if input_length > 0.9 * self.model.config.max_length:
|
||||
max_length = generate_kwargs.get("max_length", self.model.config.max_length)
|
||||
if input_length > 0.9 * max_length:
|
||||
logger.warning(
|
||||
"Your input_length: {} is bigger than 0.9 * max_length: {}. You might consider increasing your max_length manually, e.g. translator('...', max_length=400)".format(
|
||||
input_length, self.model.config.max_length
|
||||
input_length, max_length
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
@@ -26,6 +26,7 @@ from .configuration_auto import (
|
||||
CamembertConfig,
|
||||
CTRLConfig,
|
||||
DistilBertConfig,
|
||||
ElectraConfig,
|
||||
FlaubertConfig,
|
||||
GPT2Config,
|
||||
OpenAIGPTConfig,
|
||||
@@ -44,6 +45,7 @@ from .tokenization_bert_japanese import BertJapaneseTokenizer
|
||||
from .tokenization_camembert import CamembertTokenizer
|
||||
from .tokenization_ctrl import CTRLTokenizer
|
||||
from .tokenization_distilbert import DistilBertTokenizer, DistilBertTokenizerFast
|
||||
from .tokenization_electra import ElectraTokenizer, ElectraTokenizerFast
|
||||
from .tokenization_flaubert import FlaubertTokenizer
|
||||
from .tokenization_gpt2 import GPT2Tokenizer, GPT2TokenizerFast
|
||||
from .tokenization_openai import OpenAIGPTTokenizer, OpenAIGPTTokenizerFast
|
||||
@@ -67,6 +69,7 @@ TOKENIZER_MAPPING = OrderedDict(
|
||||
(XLMRobertaConfig, (XLMRobertaTokenizer, None)),
|
||||
(BartConfig, (BartTokenizer, None)),
|
||||
(RobertaConfig, (RobertaTokenizer, RobertaTokenizerFast)),
|
||||
(ElectraConfig, (ElectraTokenizer, ElectraTokenizerFast)),
|
||||
(BertConfig, (BertTokenizer, BertTokenizerFast)),
|
||||
(OpenAIGPTConfig, (OpenAIGPTTokenizer, OpenAIGPTTokenizerFast)),
|
||||
(GPT2Config, (GPT2Tokenizer, GPT2TokenizerFast)),
|
||||
@@ -104,6 +107,7 @@ class AutoTokenizer:
|
||||
- contains `xlnet`: XLNetTokenizer (XLNet model)
|
||||
- contains `xlm`: XLMTokenizer (XLM model)
|
||||
- contains `ctrl`: CTRLTokenizer (Salesforce CTRL model)
|
||||
- contains `electra`: ElectraTokenizer (Google ELECTRA model)
|
||||
|
||||
This class cannot be instantiated using `__init__()` (throw an error).
|
||||
"""
|
||||
@@ -135,6 +139,7 @@ class AutoTokenizer:
|
||||
- contains `xlnet`: XLNetTokenizer (XLNet model)
|
||||
- contains `xlm`: XLMTokenizer (XLM model)
|
||||
- contains `ctrl`: CTRLTokenizer (Salesforce CTRL model)
|
||||
- contains `electra`: ElectraTokenizer (Google ELECTRA model)
|
||||
|
||||
Params:
|
||||
pretrained_model_name_or_path: either:
|
||||
|
||||
@@ -19,6 +19,7 @@ import collections
|
||||
import logging
|
||||
import os
|
||||
import unicodedata
|
||||
from typing import Optional
|
||||
|
||||
from .tokenization_bert import BasicTokenizer, BertTokenizer, WordpieceTokenizer, load_vocab
|
||||
|
||||
@@ -89,6 +90,7 @@ class BertJapaneseTokenizer(BertTokenizer):
|
||||
pad_token="[PAD]",
|
||||
cls_token="[CLS]",
|
||||
mask_token="[MASK]",
|
||||
mecab_kwargs=None,
|
||||
**kwargs
|
||||
):
|
||||
"""Constructs a MecabBertTokenizer.
|
||||
@@ -106,6 +108,7 @@ class BertJapaneseTokenizer(BertTokenizer):
|
||||
Type of word tokenizer.
|
||||
**subword_tokenizer_type**: (`optional`) string (default "wordpiece")
|
||||
Type of subword tokenizer.
|
||||
**mecab_kwargs**: (`optional`) dict passed to `MecabTokenizer` constructor (default None)
|
||||
"""
|
||||
super(BertTokenizer, self).__init__(
|
||||
unk_token=unk_token,
|
||||
@@ -134,7 +137,9 @@ class BertJapaneseTokenizer(BertTokenizer):
|
||||
do_lower_case=do_lower_case, never_split=never_split, tokenize_chinese_chars=False
|
||||
)
|
||||
elif word_tokenizer_type == "mecab":
|
||||
self.word_tokenizer = MecabTokenizer(do_lower_case=do_lower_case, never_split=never_split)
|
||||
self.word_tokenizer = MecabTokenizer(
|
||||
do_lower_case=do_lower_case, never_split=never_split, **(mecab_kwargs or {})
|
||||
)
|
||||
else:
|
||||
raise ValueError("Invalid word_tokenizer_type '{}' is specified.".format(word_tokenizer_type))
|
||||
|
||||
@@ -161,10 +166,10 @@ class BertJapaneseTokenizer(BertTokenizer):
|
||||
return split_tokens
|
||||
|
||||
|
||||
class MecabTokenizer(object):
|
||||
class MecabTokenizer:
|
||||
"""Runs basic tokenization with MeCab morphological parser."""
|
||||
|
||||
def __init__(self, do_lower_case=False, never_split=None, normalize_text=True):
|
||||
def __init__(self, do_lower_case=False, never_split=None, normalize_text=True, mecab_option: Optional[str] = None):
|
||||
"""Constructs a MecabTokenizer.
|
||||
|
||||
Args:
|
||||
@@ -176,6 +181,7 @@ class MecabTokenizer(object):
|
||||
List of token not to split.
|
||||
**normalize_text**: (`optional`) boolean (default True)
|
||||
Whether to apply unicode normalization to text before tokenization.
|
||||
**mecab_option**: (`optional`) string passed to `MeCab.Tagger` constructor (default "")
|
||||
"""
|
||||
self.do_lower_case = do_lower_case
|
||||
self.never_split = never_split if never_split is not None else []
|
||||
@@ -183,7 +189,7 @@ class MecabTokenizer(object):
|
||||
|
||||
import MeCab
|
||||
|
||||
self.mecab = MeCab.Tagger()
|
||||
self.mecab = MeCab.Tagger(mecab_option) if mecab_option is not None else MeCab.Tagger()
|
||||
|
||||
def tokenize(self, text, never_split=None, **kwargs):
|
||||
"""Tokenizes a piece of text."""
|
||||
|
||||
80
src/transformers/tokenization_electra.py
Normal file
80
src/transformers/tokenization_electra.py
Normal file
@@ -0,0 +1,80 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2020 The Google AI Team, Stanford University and The HuggingFace Inc. team.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from .tokenization_bert import BertTokenizer, BertTokenizerFast
|
||||
|
||||
|
||||
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
|
||||
|
||||
PRETRAINED_VOCAB_FILES_MAP = {
|
||||
"vocab_file": {
|
||||
"google/electra-small-generator": "https://s3.amazonaws.com/models.huggingface.co/bert/google/electra-small-generator/vocab.txt",
|
||||
"google/electra-base-generator": "https://s3.amazonaws.com/models.huggingface.co/bert/google/electra-base-generator/vocab.txt",
|
||||
"google/electra-large-generator": "https://s3.amazonaws.com/models.huggingface.co/bert/google/electra-large-generator/vocab.txt",
|
||||
"google/electra-small-discriminator": "https://s3.amazonaws.com/models.huggingface.co/bert/google/electra-small-discriminator/vocab.txt",
|
||||
"google/electra-base-discriminator": "https://s3.amazonaws.com/models.huggingface.co/bert/google/electra-base-discriminator/vocab.txt",
|
||||
"google/electra-large-discriminator": "https://s3.amazonaws.com/models.huggingface.co/bert/google/electra-large-discriminator/vocab.txt",
|
||||
}
|
||||
}
|
||||
|
||||
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
|
||||
"google/electra-small-generator": 512,
|
||||
"google/electra-base-generator": 512,
|
||||
"google/electra-large-generator": 512,
|
||||
"google/electra-small-discriminator": 512,
|
||||
"google/electra-base-discriminator": 512,
|
||||
"google/electra-large-discriminator": 512,
|
||||
}
|
||||
|
||||
|
||||
PRETRAINED_INIT_CONFIGURATION = {
|
||||
"google/electra-small-generator": {"do_lower_case": True},
|
||||
"google/electra-base-generator": {"do_lower_case": True},
|
||||
"google/electra-large-generator": {"do_lower_case": True},
|
||||
"google/electra-small-discriminator": {"do_lower_case": True},
|
||||
"google/electra-base-discriminator": {"do_lower_case": True},
|
||||
"google/electra-large-discriminator": {"do_lower_case": True},
|
||||
}
|
||||
|
||||
|
||||
class ElectraTokenizer(BertTokenizer):
|
||||
r"""
|
||||
Constructs an Electra tokenizer.
|
||||
:class:`~transformers.ElectraTokenizer` is identical to :class:`~transformers.BertTokenizer` and runs end-to-end
|
||||
tokenization: punctuation splitting + wordpiece.
|
||||
|
||||
Refer to superclass :class:`~transformers.BertTokenizer` for usage examples and documentation concerning
|
||||
parameters.
|
||||
"""
|
||||
|
||||
vocab_files_names = VOCAB_FILES_NAMES
|
||||
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
|
||||
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
|
||||
pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
|
||||
|
||||
|
||||
class ElectraTokenizerFast(BertTokenizerFast):
|
||||
r"""
|
||||
Constructs an Electra Fast tokenizer.
|
||||
:class:`~transformers.ElectraTokenizerFast` is identical to :class:`~transformers.BertTokenizerFast` and runs end-to-end
|
||||
tokenization: punctuation splitting + wordpiece.
|
||||
|
||||
Refer to superclass :class:`~transformers.BertTokenizerFast` for usage examples and documentation concerning
|
||||
parameters.
|
||||
"""
|
||||
vocab_files_names = VOCAB_FILES_NAMES
|
||||
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
|
||||
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
|
||||
pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
|
||||
@@ -59,4 +59,4 @@ You can then finish the addition step by adding imports for your classes in the
|
||||
- [ ] add a link to your conversion script in the main conversion utility (in `commands/convert.py`)
|
||||
- [ ] edit the PyTorch to TF 2.0 conversion script to add your model in the `convert_pytorch_checkpoint_to_tf2.py` file
|
||||
- [ ] add a mention of your model in the doc: `README.md` and the documentation itself at `docs/source/pretrained_models.rst`.
|
||||
- [ ] upload the pretrained weigths, configurations and vocabulary files.
|
||||
- [ ] upload the pretrained weights, configurations and vocabulary files.
|
||||
|
||||
@@ -27,7 +27,9 @@ from .utils import CACHE_DIR, require_torch, slow, torch_device
|
||||
if is_torch_available():
|
||||
import torch
|
||||
from transformers import (
|
||||
AutoModel,
|
||||
AutoModelForSequenceClassification,
|
||||
AutoTokenizer,
|
||||
BartModel,
|
||||
BartForConditionalGeneration,
|
||||
BartForSequenceClassification,
|
||||
@@ -183,6 +185,15 @@ class BARTModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
def test_inputs_embeds(self):
|
||||
pass
|
||||
|
||||
def test_tiny_model(self):
|
||||
model_name = "sshleifer/bart-tiny-random"
|
||||
tiny = AutoModel.from_pretrained(model_name) # same vocab size
|
||||
tok = AutoTokenizer.from_pretrained(model_name) # same tokenizer
|
||||
inputs_dict = tok.batch_encode_plus(["Hello my friends"], return_tensors="pt")
|
||||
|
||||
with torch.no_grad():
|
||||
tiny(**inputs_dict)
|
||||
|
||||
|
||||
@require_torch
|
||||
class BartHeadTests(unittest.TestCase):
|
||||
|
||||
@@ -624,60 +624,114 @@ class ModelTesterMixin:
|
||||
with torch.no_grad():
|
||||
model(**inputs_dict)
|
||||
|
||||
def test_lm_head_model_random_generate(self):
|
||||
|
||||
def test_lm_head_model_random_no_beam_search_generate(self):
|
||||
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
|
||||
input_ids = inputs_dict.get("input_ids")
|
||||
input_ids = inputs_dict["input_ids"] if "input_ids" in inputs_dict else inputs_dict["inputs"]
|
||||
|
||||
# iterate over all generative models
|
||||
for model_class in self.all_generative_model_classes:
|
||||
model = model_class(config)
|
||||
|
||||
if config.bos_token_id is None:
|
||||
# if bos token id is not defined mobel needs input_ids
|
||||
with self.assertRaises(AssertionError):
|
||||
model.generate(do_sample=True, max_length=5)
|
||||
# num_return_sequences = 1
|
||||
self._check_generated_ids(model.generate(input_ids, do_sample=True))
|
||||
else:
|
||||
# num_return_sequences = 1
|
||||
self._check_generated_ids(model.generate(do_sample=True, max_length=5))
|
||||
|
||||
with self.assertRaises(AssertionError):
|
||||
# generating multiple sequences when no beam search generation
|
||||
# is not allowed as it would always generate the same sequences
|
||||
model.generate(input_ids, do_sample=False, num_return_sequences=2)
|
||||
|
||||
# num_return_sequences > 1, sample
|
||||
self._check_generated_ids(model.generate(input_ids, do_sample=True, num_return_sequences=2))
|
||||
|
||||
# check bad words tokens language generation
|
||||
# create list of 1-seq bad token and list of 2-seq of bad tokens
|
||||
bad_words_ids = [self._generate_random_bad_tokens(1, model), self._generate_random_bad_tokens(2, model)]
|
||||
output_tokens = model.generate(
|
||||
input_ids, do_sample=True, bad_words_ids=bad_words_ids, num_return_sequences=2
|
||||
)
|
||||
# only count generated tokens
|
||||
generated_ids = output_tokens[:, input_ids.shape[-1] :]
|
||||
self.assertFalse(self._check_match_tokens(generated_ids.tolist(), bad_words_ids))
|
||||
|
||||
def test_lm_head_model_random_beam_search_generate(self):
|
||||
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
|
||||
input_ids = inputs_dict["input_ids"] if "input_ids" in inputs_dict else inputs_dict["inputs"]
|
||||
|
||||
if self.is_encoder_decoder:
|
||||
config.output_past = True # needed for Bart TODO: might have to update for other encoder-decoder models
|
||||
# needed for Bart beam search
|
||||
config.output_past = True
|
||||
|
||||
for model_class in self.all_generative_model_classes:
|
||||
model = model_class(config)
|
||||
model.to(torch_device)
|
||||
model.eval()
|
||||
|
||||
if config.bos_token_id is None:
|
||||
with self.assertRaises(AssertionError):
|
||||
model.generate(do_sample=True, max_length=5)
|
||||
# batch_size = 1
|
||||
self._check_generated_tokens(model.generate(input_ids, do_sample=True))
|
||||
# batch_size = 1, num_beams > 1
|
||||
self._check_generated_tokens(model.generate(input_ids, do_sample=True, num_beams=3))
|
||||
# if bos token id is not defined mobel needs input_ids, num_return_sequences = 1
|
||||
self._check_generated_ids(model.generate(input_ids, do_sample=True, num_beams=2))
|
||||
else:
|
||||
# batch_size = 1
|
||||
self._check_generated_tokens(model.generate(do_sample=True, max_length=5))
|
||||
# batch_size = 1, num_beams > 1
|
||||
self._check_generated_tokens(model.generate(do_sample=True, max_length=5, num_beams=3))
|
||||
|
||||
with self.assertRaises(AssertionError):
|
||||
# generating multiple sequences when greedy no beam generation
|
||||
# is not allowed as it would always generate the same sequences
|
||||
model.generate(input_ids, do_sample=False, num_return_sequences=2)
|
||||
# num_return_sequences = 1
|
||||
self._check_generated_ids(model.generate(do_sample=True, max_length=5, num_beams=2))
|
||||
|
||||
with self.assertRaises(AssertionError):
|
||||
# generating more sequences than having beams leads is not possible
|
||||
model.generate(input_ids, do_sample=False, num_return_sequences=3, num_beams=2)
|
||||
|
||||
# batch_size > 1, sample
|
||||
self._check_generated_tokens(model.generate(input_ids, do_sample=True, num_return_sequences=3))
|
||||
# batch_size > 1, greedy
|
||||
self._check_generated_tokens(model.generate(input_ids, do_sample=False))
|
||||
# num_return_sequences > 1, sample
|
||||
self._check_generated_ids(model.generate(input_ids, do_sample=True, num_beams=2, num_return_sequences=2,))
|
||||
# num_return_sequences > 1, greedy
|
||||
self._check_generated_ids(model.generate(input_ids, do_sample=False, num_beams=2, num_return_sequences=2))
|
||||
|
||||
# batch_size > 1, num_beams > 1, sample
|
||||
self._check_generated_tokens(
|
||||
model.generate(input_ids, do_sample=True, num_beams=3, num_return_sequences=3,)
|
||||
)
|
||||
# batch_size > 1, num_beams > 1, greedy
|
||||
self._check_generated_tokens(
|
||||
model.generate(input_ids, do_sample=False, num_beams=3, num_return_sequences=3)
|
||||
# check bad words tokens language generation
|
||||
# create list of 1-seq bad token and list of 2-seq of bad tokens
|
||||
bad_words_ids = [self._generate_random_bad_tokens(1, model), self._generate_random_bad_tokens(2, model)]
|
||||
output_tokens = model.generate(
|
||||
input_ids, do_sample=False, bad_words_ids=bad_words_ids, num_beams=2, num_return_sequences=2
|
||||
)
|
||||
# only count generated tokens
|
||||
generated_ids = output_tokens[:, input_ids.shape[-1] :]
|
||||
self.assertFalse(self._check_match_tokens(generated_ids.tolist(), bad_words_ids))
|
||||
|
||||
def _check_generated_tokens(self, output_ids):
|
||||
def _generate_random_bad_tokens(self, num_bad_tokens, model):
|
||||
# special tokens cannot be bad tokens
|
||||
special_tokens = []
|
||||
if model.config.bos_token_id is not None:
|
||||
special_tokens.append(model.config.bos_token_id)
|
||||
if model.config.pad_token_id is not None:
|
||||
special_tokens.append(model.config.pad_token_id)
|
||||
if model.config.eos_token_id is not None:
|
||||
special_tokens.append(model.config.eos_token_id)
|
||||
|
||||
# create random bad tokens that are not special tokens
|
||||
bad_tokens = []
|
||||
while len(bad_tokens) < num_bad_tokens:
|
||||
token = ids_tensor((1, 1), self.model_tester.vocab_size).squeeze(0).numpy()[0]
|
||||
if token not in special_tokens:
|
||||
bad_tokens.append(token)
|
||||
return bad_tokens
|
||||
|
||||
def _check_generated_ids(self, output_ids):
|
||||
for token_id in output_ids[0].tolist():
|
||||
self.assertGreaterEqual(token_id, 0)
|
||||
self.assertLess(token_id, self.model_tester.vocab_size)
|
||||
|
||||
def _check_match_tokens(self, generated_ids, bad_words_ids):
|
||||
# for all bad word tokens
|
||||
for bad_word_ids in bad_words_ids:
|
||||
# for all slices in batch
|
||||
for generated_ids_slice in generated_ids:
|
||||
# for all word idx
|
||||
for i in range(len(bad_word_ids), len(generated_ids_slice)):
|
||||
# if tokens match
|
||||
if generated_ids_slice[i - len(bad_word_ids) : i] == bad_word_ids:
|
||||
return True
|
||||
return False
|
||||
|
||||
|
||||
global_rng = random.Random()
|
||||
|
||||
|
||||
287
tests/test_modeling_electra.py
Normal file
287
tests/test_modeling_electra.py
Normal file
@@ -0,0 +1,287 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2018 The Google AI Language Team Authors.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
|
||||
import unittest
|
||||
|
||||
from transformers import is_torch_available
|
||||
|
||||
from .test_configuration_common import ConfigTester
|
||||
from .test_modeling_common import ModelTesterMixin, ids_tensor
|
||||
from .utils import CACHE_DIR, require_torch, slow, torch_device
|
||||
|
||||
|
||||
if is_torch_available():
|
||||
from transformers import (
|
||||
ElectraConfig,
|
||||
ElectraModel,
|
||||
ElectraForMaskedLM,
|
||||
ElectraForTokenClassification,
|
||||
ElectraForPreTraining,
|
||||
)
|
||||
from transformers.modeling_electra import ELECTRA_PRETRAINED_MODEL_ARCHIVE_MAP
|
||||
|
||||
|
||||
@require_torch
|
||||
class ElectraModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
|
||||
all_model_classes = (
|
||||
(ElectraModel, ElectraForMaskedLM, ElectraForTokenClassification,) if is_torch_available() else ()
|
||||
)
|
||||
|
||||
class ElectraModelTester(object):
|
||||
def __init__(
|
||||
self,
|
||||
parent,
|
||||
batch_size=13,
|
||||
seq_length=7,
|
||||
is_training=True,
|
||||
use_input_mask=True,
|
||||
use_token_type_ids=True,
|
||||
use_labels=True,
|
||||
vocab_size=99,
|
||||
hidden_size=32,
|
||||
num_hidden_layers=5,
|
||||
num_attention_heads=4,
|
||||
intermediate_size=37,
|
||||
hidden_act="gelu",
|
||||
hidden_dropout_prob=0.1,
|
||||
attention_probs_dropout_prob=0.1,
|
||||
max_position_embeddings=512,
|
||||
type_vocab_size=16,
|
||||
type_sequence_label_size=2,
|
||||
initializer_range=0.02,
|
||||
num_labels=3,
|
||||
num_choices=4,
|
||||
scope=None,
|
||||
):
|
||||
self.parent = parent
|
||||
self.batch_size = batch_size
|
||||
self.seq_length = seq_length
|
||||
self.is_training = is_training
|
||||
self.use_input_mask = use_input_mask
|
||||
self.use_token_type_ids = use_token_type_ids
|
||||
self.use_labels = use_labels
|
||||
self.vocab_size = vocab_size
|
||||
self.hidden_size = hidden_size
|
||||
self.num_hidden_layers = num_hidden_layers
|
||||
self.num_attention_heads = num_attention_heads
|
||||
self.intermediate_size = intermediate_size
|
||||
self.hidden_act = hidden_act
|
||||
self.hidden_dropout_prob = hidden_dropout_prob
|
||||
self.attention_probs_dropout_prob = attention_probs_dropout_prob
|
||||
self.max_position_embeddings = max_position_embeddings
|
||||
self.type_vocab_size = type_vocab_size
|
||||
self.type_sequence_label_size = type_sequence_label_size
|
||||
self.initializer_range = initializer_range
|
||||
self.num_labels = num_labels
|
||||
self.num_choices = num_choices
|
||||
self.scope = scope
|
||||
|
||||
def prepare_config_and_inputs(self):
|
||||
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
|
||||
|
||||
input_mask = None
|
||||
if self.use_input_mask:
|
||||
input_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
|
||||
|
||||
token_type_ids = None
|
||||
if self.use_token_type_ids:
|
||||
token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
|
||||
|
||||
sequence_labels = None
|
||||
token_labels = None
|
||||
choice_labels = None
|
||||
if self.use_labels:
|
||||
sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
|
||||
token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
|
||||
choice_labels = ids_tensor([self.batch_size], self.num_choices)
|
||||
fake_token_labels = ids_tensor([self.batch_size, self.seq_length], 1)
|
||||
|
||||
config = ElectraConfig(
|
||||
vocab_size=self.vocab_size,
|
||||
hidden_size=self.hidden_size,
|
||||
num_hidden_layers=self.num_hidden_layers,
|
||||
num_attention_heads=self.num_attention_heads,
|
||||
intermediate_size=self.intermediate_size,
|
||||
hidden_act=self.hidden_act,
|
||||
hidden_dropout_prob=self.hidden_dropout_prob,
|
||||
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
|
||||
max_position_embeddings=self.max_position_embeddings,
|
||||
type_vocab_size=self.type_vocab_size,
|
||||
is_decoder=False,
|
||||
initializer_range=self.initializer_range,
|
||||
)
|
||||
|
||||
return (
|
||||
config,
|
||||
input_ids,
|
||||
token_type_ids,
|
||||
input_mask,
|
||||
sequence_labels,
|
||||
token_labels,
|
||||
choice_labels,
|
||||
fake_token_labels,
|
||||
)
|
||||
|
||||
def check_loss_output(self, result):
|
||||
self.parent.assertListEqual(list(result["loss"].size()), [])
|
||||
|
||||
def create_and_check_electra_model(
|
||||
self,
|
||||
config,
|
||||
input_ids,
|
||||
token_type_ids,
|
||||
input_mask,
|
||||
sequence_labels,
|
||||
token_labels,
|
||||
choice_labels,
|
||||
fake_token_labels,
|
||||
):
|
||||
model = ElectraModel(config=config)
|
||||
model.to(torch_device)
|
||||
model.eval()
|
||||
(sequence_output,) = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
|
||||
(sequence_output,) = model(input_ids, token_type_ids=token_type_ids)
|
||||
(sequence_output,) = model(input_ids)
|
||||
|
||||
result = {
|
||||
"sequence_output": sequence_output,
|
||||
}
|
||||
self.parent.assertListEqual(
|
||||
list(result["sequence_output"].size()), [self.batch_size, self.seq_length, self.hidden_size]
|
||||
)
|
||||
|
||||
def create_and_check_electra_for_masked_lm(
|
||||
self,
|
||||
config,
|
||||
input_ids,
|
||||
token_type_ids,
|
||||
input_mask,
|
||||
sequence_labels,
|
||||
token_labels,
|
||||
choice_labels,
|
||||
fake_token_labels,
|
||||
):
|
||||
model = ElectraForMaskedLM(config=config)
|
||||
model.to(torch_device)
|
||||
model.eval()
|
||||
loss, prediction_scores = model(
|
||||
input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, masked_lm_labels=token_labels
|
||||
)
|
||||
result = {
|
||||
"loss": loss,
|
||||
"prediction_scores": prediction_scores,
|
||||
}
|
||||
self.parent.assertListEqual(
|
||||
list(result["prediction_scores"].size()), [self.batch_size, self.seq_length, self.vocab_size]
|
||||
)
|
||||
self.check_loss_output(result)
|
||||
|
||||
def create_and_check_electra_for_token_classification(
|
||||
self,
|
||||
config,
|
||||
input_ids,
|
||||
token_type_ids,
|
||||
input_mask,
|
||||
sequence_labels,
|
||||
token_labels,
|
||||
choice_labels,
|
||||
fake_token_labels,
|
||||
):
|
||||
config.num_labels = self.num_labels
|
||||
model = ElectraForTokenClassification(config=config)
|
||||
model.to(torch_device)
|
||||
model.eval()
|
||||
loss, logits = model(
|
||||
input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels
|
||||
)
|
||||
result = {
|
||||
"loss": loss,
|
||||
"logits": logits,
|
||||
}
|
||||
self.parent.assertListEqual(
|
||||
list(result["logits"].size()), [self.batch_size, self.seq_length, self.num_labels]
|
||||
)
|
||||
self.check_loss_output(result)
|
||||
|
||||
def create_and_check_electra_for_pretraining(
|
||||
self,
|
||||
config,
|
||||
input_ids,
|
||||
token_type_ids,
|
||||
input_mask,
|
||||
sequence_labels,
|
||||
token_labels,
|
||||
choice_labels,
|
||||
fake_token_labels,
|
||||
):
|
||||
config.num_labels = self.num_labels
|
||||
model = ElectraForPreTraining(config=config)
|
||||
model.to(torch_device)
|
||||
model.eval()
|
||||
loss, logits = model(
|
||||
input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=fake_token_labels
|
||||
)
|
||||
result = {
|
||||
"loss": loss,
|
||||
"logits": logits,
|
||||
}
|
||||
self.parent.assertListEqual(list(result["logits"].size()), [self.batch_size, self.seq_length])
|
||||
self.check_loss_output(result)
|
||||
|
||||
def prepare_config_and_inputs_for_common(self):
|
||||
config_and_inputs = self.prepare_config_and_inputs()
|
||||
(
|
||||
config,
|
||||
input_ids,
|
||||
token_type_ids,
|
||||
input_mask,
|
||||
sequence_labels,
|
||||
token_labels,
|
||||
choice_labels,
|
||||
fake_token_labels,
|
||||
) = config_and_inputs
|
||||
inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "attention_mask": input_mask}
|
||||
return config, inputs_dict
|
||||
|
||||
def setUp(self):
|
||||
self.model_tester = ElectraModelTest.ElectraModelTester(self)
|
||||
self.config_tester = ConfigTester(self, config_class=ElectraConfig, hidden_size=37)
|
||||
|
||||
def test_config(self):
|
||||
self.config_tester.run_common_tests()
|
||||
|
||||
def test_electra_model(self):
|
||||
config_and_inputs = self.model_tester.prepare_config_and_inputs()
|
||||
self.model_tester.create_and_check_electra_model(*config_and_inputs)
|
||||
|
||||
def test_for_masked_lm(self):
|
||||
config_and_inputs = self.model_tester.prepare_config_and_inputs()
|
||||
self.model_tester.create_and_check_electra_for_masked_lm(*config_and_inputs)
|
||||
|
||||
def test_for_token_classification(self):
|
||||
config_and_inputs = self.model_tester.prepare_config_and_inputs()
|
||||
self.model_tester.create_and_check_electra_for_token_classification(*config_and_inputs)
|
||||
|
||||
def test_for_pre_training(self):
|
||||
config_and_inputs = self.model_tester.prepare_config_and_inputs()
|
||||
self.model_tester.create_and_check_electra_for_pretraining(*config_and_inputs)
|
||||
|
||||
@slow
|
||||
def test_model_from_pretrained(self):
|
||||
for model_name in list(ELECTRA_PRETRAINED_MODEL_ARCHIVE_MAP.keys())[:1]:
|
||||
model = ElectraModel.from_pretrained(model_name, cache_dir=CACHE_DIR)
|
||||
self.assertIsNotNone(model)
|
||||
File diff suppressed because one or more lines are too long
@@ -162,6 +162,10 @@ class TFModelTesterMixin:
|
||||
pt_inputs_dict = dict(
|
||||
(name, torch.from_numpy(key.numpy()).to(torch.long)) for name, key in inputs_dict.items()
|
||||
)
|
||||
# need to rename encoder-decoder "inputs" for PyTorch
|
||||
if "inputs" in pt_inputs_dict and self.is_encoder_decoder:
|
||||
pt_inputs_dict["input_ids"] = pt_inputs_dict.pop("inputs")
|
||||
|
||||
with torch.no_grad():
|
||||
pto = pt_model(**pt_inputs_dict)
|
||||
tfo = tf_model(inputs_dict, training=False)
|
||||
@@ -201,6 +205,10 @@ class TFModelTesterMixin:
|
||||
pt_inputs_dict = dict(
|
||||
(name, torch.from_numpy(key.numpy()).to(torch.long)) for name, key in inputs_dict.items()
|
||||
)
|
||||
# need to rename encoder-decoder "inputs" for PyTorch
|
||||
if "inputs" in pt_inputs_dict and self.is_encoder_decoder:
|
||||
pt_inputs_dict["input_ids"] = pt_inputs_dict.pop("inputs")
|
||||
|
||||
with torch.no_grad():
|
||||
pto = pt_model(**pt_inputs_dict)
|
||||
tfo = tf_model(inputs_dict)
|
||||
@@ -223,7 +231,7 @@ class TFModelTesterMixin:
|
||||
if self.is_encoder_decoder:
|
||||
input_ids = {
|
||||
"decoder_input_ids": tf.keras.Input(batch_shape=(2, 2000), name="decoder_input_ids", dtype="int32"),
|
||||
"input_ids": tf.keras.Input(batch_shape=(2, 2000), name="input_ids", dtype="int32"),
|
||||
"inputs": tf.keras.Input(batch_shape=(2, 2000), name="inputs", dtype="int32"),
|
||||
}
|
||||
else:
|
||||
input_ids = tf.keras.Input(batch_shape=(2, 2000), name="input_ids", dtype="int32")
|
||||
@@ -259,7 +267,7 @@ class TFModelTesterMixin:
|
||||
outputs_dict = model(inputs_dict)
|
||||
|
||||
inputs_keywords = copy.deepcopy(inputs_dict)
|
||||
input_ids = inputs_keywords.pop("input_ids" if not self.is_encoder_decoder else "decoder_input_ids", None,)
|
||||
input_ids = inputs_keywords.pop("input_ids" if not self.is_encoder_decoder else "inputs", None,)
|
||||
outputs_keywords = model(input_ids, **inputs_keywords)
|
||||
|
||||
output_dict = outputs_dict[0].numpy()
|
||||
@@ -395,9 +403,9 @@ class TFModelTesterMixin:
|
||||
input_ids = inputs_dict["input_ids"]
|
||||
del inputs_dict["input_ids"]
|
||||
else:
|
||||
encoder_input_ids = inputs_dict["input_ids"]
|
||||
encoder_input_ids = inputs_dict["inputs"]
|
||||
decoder_input_ids = inputs_dict["decoder_input_ids"]
|
||||
del inputs_dict["input_ids"]
|
||||
del inputs_dict["inputs"]
|
||||
del inputs_dict["decoder_input_ids"]
|
||||
|
||||
for model_class in self.all_model_classes:
|
||||
@@ -412,58 +420,114 @@ class TFModelTesterMixin:
|
||||
|
||||
model(inputs_dict)
|
||||
|
||||
def test_lm_head_model_random_generate(self):
|
||||
|
||||
def test_lm_head_model_random_no_beam_search_generate(self):
|
||||
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
|
||||
input_ids = inputs_dict["input_ids"]
|
||||
input_ids = inputs_dict["input_ids"] if "input_ids" in inputs_dict else inputs_dict["inputs"]
|
||||
|
||||
# iterate over all generative models
|
||||
for model_class in self.all_generative_model_classes:
|
||||
model = model_class(config)
|
||||
|
||||
if config.bos_token_id is None:
|
||||
# if bos token id is not defined mobel needs input_ids
|
||||
with self.assertRaises(AssertionError):
|
||||
model.generate(do_sample=True, max_length=5)
|
||||
# num_return_sequences = 1
|
||||
self._check_generated_ids(model.generate(input_ids, do_sample=True))
|
||||
else:
|
||||
# num_return_sequences = 1
|
||||
self._check_generated_ids(model.generate(do_sample=True, max_length=5))
|
||||
|
||||
with self.assertRaises(AssertionError):
|
||||
# generating multiple sequences when no beam search generation
|
||||
# is not allowed as it would always generate the same sequences
|
||||
model.generate(input_ids, do_sample=False, num_return_sequences=2)
|
||||
|
||||
# num_return_sequences > 1, sample
|
||||
self._check_generated_ids(model.generate(input_ids, do_sample=True, num_return_sequences=2))
|
||||
|
||||
# check bad words tokens language generation
|
||||
# create list of 1-seq bad token and list of 2-seq of bad tokens
|
||||
bad_words_ids = [self._generate_random_bad_tokens(1, model), self._generate_random_bad_tokens(2, model)]
|
||||
output_tokens = model.generate(
|
||||
input_ids, do_sample=True, bad_words_ids=bad_words_ids, num_return_sequences=2
|
||||
)
|
||||
# only count generated tokens
|
||||
generated_ids = output_tokens[:, input_ids.shape[-1] :]
|
||||
self.assertFalse(self._check_match_tokens(generated_ids.numpy().tolist(), bad_words_ids))
|
||||
|
||||
def test_lm_head_model_random_beam_search_generate(self):
|
||||
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
|
||||
input_ids = inputs_dict["input_ids"] if "input_ids" in inputs_dict else inputs_dict["inputs"]
|
||||
|
||||
if self.is_encoder_decoder:
|
||||
config.output_past = True # needed for Bart TODO: might have to update for other encoder-decoder models
|
||||
# needed for Bart beam search
|
||||
config.output_past = True
|
||||
|
||||
for model_class in self.all_generative_model_classes:
|
||||
model = model_class(config)
|
||||
|
||||
if config.bos_token_id is None:
|
||||
with self.assertRaises(AssertionError):
|
||||
model.generate(do_sample=True, max_length=5)
|
||||
# batch_size = 1
|
||||
self._check_generated_tokens(model.generate(input_ids, do_sample=True))
|
||||
# batch_size = 1, num_beams > 1
|
||||
self._check_generated_tokens(model.generate(input_ids, do_sample=True, num_beams=3))
|
||||
# if bos token id is not defined mobel needs input_ids, num_return_sequences = 1
|
||||
self._check_generated_ids(model.generate(input_ids, do_sample=True, num_beams=2))
|
||||
else:
|
||||
# batch_size = 1
|
||||
self._check_generated_tokens(model.generate(do_sample=True, max_length=5))
|
||||
# batch_size = 1, num_beams > 1
|
||||
self._check_generated_tokens(model.generate(do_sample=True, max_length=5, num_beams=3))
|
||||
|
||||
with self.assertRaises(AssertionError):
|
||||
# generating multiple sequences when greedy no beam generation
|
||||
# is not allowed as it would always generate the same sequences
|
||||
model.generate(input_ids, do_sample=False, num_return_sequences=2)
|
||||
# num_return_sequences = 1
|
||||
self._check_generated_ids(model.generate(do_sample=True, max_length=5, num_beams=2))
|
||||
|
||||
with self.assertRaises(AssertionError):
|
||||
# generating more sequences than having beams leads is not possible
|
||||
model.generate(input_ids, do_sample=False, num_return_sequences=3, num_beams=2)
|
||||
|
||||
# batch_size > 1, sample
|
||||
self._check_generated_tokens(model.generate(input_ids, do_sample=True, num_return_sequences=3))
|
||||
# batch_size > 1, greedy
|
||||
self._check_generated_tokens(model.generate(input_ids, do_sample=False))
|
||||
# num_return_sequences > 1, sample
|
||||
self._check_generated_ids(model.generate(input_ids, do_sample=True, num_beams=2, num_return_sequences=2,))
|
||||
# num_return_sequences > 1, greedy
|
||||
self._check_generated_ids(model.generate(input_ids, do_sample=False, num_beams=2, num_return_sequences=2))
|
||||
|
||||
# batch_size > 1, num_beams > 1, sample
|
||||
self._check_generated_tokens(
|
||||
model.generate(input_ids, do_sample=True, num_beams=3, num_return_sequences=3,)
|
||||
)
|
||||
# batch_size > 1, num_beams > 1, greedy
|
||||
self._check_generated_tokens(
|
||||
model.generate(input_ids, do_sample=False, num_beams=3, num_return_sequences=3)
|
||||
# check bad words tokens language generation
|
||||
# create list of 1-seq bad token and list of 2-seq of bad tokens
|
||||
bad_words_ids = [self._generate_random_bad_tokens(1, model), self._generate_random_bad_tokens(2, model)]
|
||||
output_tokens = model.generate(
|
||||
input_ids, do_sample=False, bad_words_ids=bad_words_ids, num_beams=2, num_return_sequences=2
|
||||
)
|
||||
# only count generated tokens
|
||||
generated_ids = output_tokens[:, input_ids.shape[-1] :]
|
||||
self.assertFalse(self._check_match_tokens(generated_ids.numpy().tolist(), bad_words_ids))
|
||||
|
||||
def _check_generated_tokens(self, output_ids):
|
||||
def _generate_random_bad_tokens(self, num_bad_tokens, model):
|
||||
# special tokens cannot be bad tokens
|
||||
special_tokens = []
|
||||
if model.config.bos_token_id is not None:
|
||||
special_tokens.append(model.config.bos_token_id)
|
||||
if model.config.pad_token_id is not None:
|
||||
special_tokens.append(model.config.pad_token_id)
|
||||
if model.config.eos_token_id is not None:
|
||||
special_tokens.append(model.config.eos_token_id)
|
||||
|
||||
# create random bad tokens that are not special tokens
|
||||
bad_tokens = []
|
||||
while len(bad_tokens) < num_bad_tokens:
|
||||
token = tf.squeeze(ids_tensor((1, 1), self.model_tester.vocab_size), 0).numpy()[0]
|
||||
if token not in special_tokens:
|
||||
bad_tokens.append(token)
|
||||
return bad_tokens
|
||||
|
||||
def _check_generated_ids(self, output_ids):
|
||||
for token_id in output_ids[0].numpy().tolist():
|
||||
self.assertGreaterEqual(token_id, 0)
|
||||
self.assertLess(token_id, self.model_tester.vocab_size)
|
||||
|
||||
def _check_match_tokens(self, generated_ids, bad_words_ids):
|
||||
# for all bad word tokens
|
||||
for bad_word_ids in bad_words_ids:
|
||||
# for all slices in batch
|
||||
for generated_ids_slice in generated_ids:
|
||||
# for all word idx
|
||||
for i in range(len(bad_word_ids), len(generated_ids_slice)):
|
||||
# if tokens match
|
||||
if generated_ids_slice[i - len(bad_word_ids) : i] == bad_word_ids:
|
||||
return True
|
||||
return False
|
||||
|
||||
|
||||
def ids_tensor(shape, vocab_size, rng=None, name=None, dtype=None):
|
||||
"""Creates a random int32 tensor of the shape within the vocab size."""
|
||||
|
||||
227
tests/test_modeling_tf_electra.py
Normal file
227
tests/test_modeling_tf_electra.py
Normal file
@@ -0,0 +1,227 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2018 The Google AI Language Team Authors.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
|
||||
import unittest
|
||||
|
||||
from transformers import ElectraConfig, is_tf_available
|
||||
|
||||
from .test_configuration_common import ConfigTester
|
||||
from .test_modeling_tf_common import TFModelTesterMixin, ids_tensor
|
||||
from .utils import CACHE_DIR, require_tf, slow
|
||||
|
||||
|
||||
if is_tf_available():
|
||||
from transformers.modeling_tf_electra import (
|
||||
TFElectraModel,
|
||||
TFElectraForMaskedLM,
|
||||
TFElectraForPreTraining,
|
||||
TFElectraForTokenClassification,
|
||||
)
|
||||
|
||||
|
||||
@require_tf
|
||||
class TFElectraModelTest(TFModelTesterMixin, unittest.TestCase):
|
||||
|
||||
all_model_classes = (
|
||||
(TFElectraModel, TFElectraForMaskedLM, TFElectraForPreTraining, TFElectraForTokenClassification,)
|
||||
if is_tf_available()
|
||||
else ()
|
||||
)
|
||||
|
||||
class TFElectraModelTester(object):
|
||||
def __init__(
|
||||
self,
|
||||
parent,
|
||||
batch_size=13,
|
||||
seq_length=7,
|
||||
is_training=True,
|
||||
use_input_mask=True,
|
||||
use_token_type_ids=True,
|
||||
use_labels=True,
|
||||
vocab_size=99,
|
||||
hidden_size=32,
|
||||
num_hidden_layers=5,
|
||||
num_attention_heads=4,
|
||||
intermediate_size=37,
|
||||
hidden_act="gelu",
|
||||
hidden_dropout_prob=0.1,
|
||||
attention_probs_dropout_prob=0.1,
|
||||
max_position_embeddings=512,
|
||||
type_vocab_size=16,
|
||||
type_sequence_label_size=2,
|
||||
initializer_range=0.02,
|
||||
num_labels=3,
|
||||
num_choices=4,
|
||||
scope=None,
|
||||
):
|
||||
self.parent = parent
|
||||
self.batch_size = batch_size
|
||||
self.seq_length = seq_length
|
||||
self.is_training = is_training
|
||||
self.use_input_mask = use_input_mask
|
||||
self.use_token_type_ids = use_token_type_ids
|
||||
self.use_labels = use_labels
|
||||
self.vocab_size = vocab_size
|
||||
self.hidden_size = hidden_size
|
||||
self.num_hidden_layers = num_hidden_layers
|
||||
self.num_attention_heads = num_attention_heads
|
||||
self.intermediate_size = intermediate_size
|
||||
self.hidden_act = hidden_act
|
||||
self.hidden_dropout_prob = hidden_dropout_prob
|
||||
self.attention_probs_dropout_prob = attention_probs_dropout_prob
|
||||
self.max_position_embeddings = max_position_embeddings
|
||||
self.type_vocab_size = type_vocab_size
|
||||
self.type_sequence_label_size = type_sequence_label_size
|
||||
self.initializer_range = initializer_range
|
||||
self.num_labels = num_labels
|
||||
self.num_choices = num_choices
|
||||
self.scope = scope
|
||||
|
||||
def prepare_config_and_inputs(self):
|
||||
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
|
||||
|
||||
input_mask = None
|
||||
if self.use_input_mask:
|
||||
input_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
|
||||
|
||||
token_type_ids = None
|
||||
if self.use_token_type_ids:
|
||||
token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
|
||||
|
||||
sequence_labels = None
|
||||
token_labels = None
|
||||
choice_labels = None
|
||||
if self.use_labels:
|
||||
sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
|
||||
token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
|
||||
choice_labels = ids_tensor([self.batch_size], self.num_choices)
|
||||
|
||||
config = ElectraConfig(
|
||||
vocab_size=self.vocab_size,
|
||||
hidden_size=self.hidden_size,
|
||||
num_hidden_layers=self.num_hidden_layers,
|
||||
num_attention_heads=self.num_attention_heads,
|
||||
intermediate_size=self.intermediate_size,
|
||||
hidden_act=self.hidden_act,
|
||||
hidden_dropout_prob=self.hidden_dropout_prob,
|
||||
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
|
||||
max_position_embeddings=self.max_position_embeddings,
|
||||
type_vocab_size=self.type_vocab_size,
|
||||
initializer_range=self.initializer_range,
|
||||
)
|
||||
|
||||
return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
|
||||
|
||||
def create_and_check_electra_model(
|
||||
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
|
||||
):
|
||||
model = TFElectraModel(config=config)
|
||||
inputs = {"input_ids": input_ids, "attention_mask": input_mask, "token_type_ids": token_type_ids}
|
||||
(sequence_output,) = model(inputs)
|
||||
|
||||
inputs = [input_ids, input_mask]
|
||||
(sequence_output,) = model(inputs)
|
||||
|
||||
(sequence_output,) = model(input_ids)
|
||||
|
||||
result = {
|
||||
"sequence_output": sequence_output.numpy(),
|
||||
}
|
||||
self.parent.assertListEqual(
|
||||
list(result["sequence_output"].shape), [self.batch_size, self.seq_length, self.hidden_size]
|
||||
)
|
||||
|
||||
def create_and_check_electra_for_masked_lm(
|
||||
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
|
||||
):
|
||||
model = TFElectraForMaskedLM(config=config)
|
||||
inputs = {"input_ids": input_ids, "attention_mask": input_mask, "token_type_ids": token_type_ids}
|
||||
(prediction_scores,) = model(inputs)
|
||||
result = {
|
||||
"prediction_scores": prediction_scores.numpy(),
|
||||
}
|
||||
self.parent.assertListEqual(
|
||||
list(result["prediction_scores"].shape), [self.batch_size, self.seq_length, self.vocab_size]
|
||||
)
|
||||
|
||||
def create_and_check_electra_for_pretraining(
|
||||
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
|
||||
):
|
||||
model = TFElectraForPreTraining(config=config)
|
||||
inputs = {"input_ids": input_ids, "attention_mask": input_mask, "token_type_ids": token_type_ids}
|
||||
(prediction_scores,) = model(inputs)
|
||||
result = {
|
||||
"prediction_scores": prediction_scores.numpy(),
|
||||
}
|
||||
self.parent.assertListEqual(list(result["prediction_scores"].shape), [self.batch_size, self.seq_length])
|
||||
|
||||
def create_and_check_electra_for_token_classification(
|
||||
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
|
||||
):
|
||||
config.num_labels = self.num_labels
|
||||
model = TFElectraForTokenClassification(config=config)
|
||||
inputs = {"input_ids": input_ids, "attention_mask": input_mask, "token_type_ids": token_type_ids}
|
||||
(logits,) = model(inputs)
|
||||
result = {
|
||||
"logits": logits.numpy(),
|
||||
}
|
||||
self.parent.assertListEqual(
|
||||
list(result["logits"].shape), [self.batch_size, self.seq_length, self.num_labels]
|
||||
)
|
||||
|
||||
def prepare_config_and_inputs_for_common(self):
|
||||
config_and_inputs = self.prepare_config_and_inputs()
|
||||
(
|
||||
config,
|
||||
input_ids,
|
||||
token_type_ids,
|
||||
input_mask,
|
||||
sequence_labels,
|
||||
token_labels,
|
||||
choice_labels,
|
||||
) = config_and_inputs
|
||||
inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "attention_mask": input_mask}
|
||||
return config, inputs_dict
|
||||
|
||||
def setUp(self):
|
||||
self.model_tester = TFElectraModelTest.TFElectraModelTester(self)
|
||||
self.config_tester = ConfigTester(self, config_class=ElectraConfig, hidden_size=37)
|
||||
|
||||
def test_config(self):
|
||||
self.config_tester.run_common_tests()
|
||||
|
||||
def test_electra_model(self):
|
||||
config_and_inputs = self.model_tester.prepare_config_and_inputs()
|
||||
self.model_tester.create_and_check_electra_model(*config_and_inputs)
|
||||
|
||||
def test_for_masked_lm(self):
|
||||
config_and_inputs = self.model_tester.prepare_config_and_inputs()
|
||||
self.model_tester.create_and_check_electra_for_masked_lm(*config_and_inputs)
|
||||
|
||||
def test_for_pretraining(self):
|
||||
config_and_inputs = self.model_tester.prepare_config_and_inputs()
|
||||
self.model_tester.create_and_check_electra_for_pretraining(*config_and_inputs)
|
||||
|
||||
def test_for_token_classification(self):
|
||||
config_and_inputs = self.model_tester.prepare_config_and_inputs()
|
||||
self.model_tester.create_and_check_electra_for_token_classification(*config_and_inputs)
|
||||
|
||||
@slow
|
||||
def test_model_from_pretrained(self):
|
||||
# for model_name in list(TF_ELECTRA_PRETRAINED_MODEL_ARCHIVE_MAP.keys())[:1]:
|
||||
for model_name in ["electra-small-discriminator"]:
|
||||
model = TFElectraModel.from_pretrained(model_name, cache_dir=CACHE_DIR)
|
||||
self.assertIsNotNone(model)
|
||||
File diff suppressed because one or more lines are too long
@@ -91,6 +91,20 @@ class BertJapaneseTokenizationTest(TokenizerTesterMixin, unittest.TestCase):
|
||||
["アップルストア", "で", "iphone", "8", "が", "発売", "さ", "れ", "た", "。"],
|
||||
)
|
||||
|
||||
def test_mecab_tokenizer_with_option(self):
|
||||
try:
|
||||
tokenizer = MecabTokenizer(
|
||||
do_lower_case=True, normalize_text=False, mecab_option="-d /usr/local/lib/mecab/dic/jumandic"
|
||||
)
|
||||
except RuntimeError:
|
||||
# if dict doesn't exist in the system, previous code raises this error.
|
||||
return
|
||||
|
||||
self.assertListEqual(
|
||||
tokenizer.tokenize(" \tアップルストアでiPhone8 が \n 発売された 。 "),
|
||||
["アップルストア", "で", "iPhone", "8", "が", "発売", "さ", "れた", "\u3000", "。"],
|
||||
)
|
||||
|
||||
def test_mecab_tokenizer_no_normalize(self):
|
||||
tokenizer = MecabTokenizer(normalize_text=False)
|
||||
|
||||
|
||||
Reference in New Issue
Block a user