Compare commits
482 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
bffac926ca | ||
|
|
0e2cf025fa | ||
|
|
c9b9d87e93 | ||
|
|
7c9a1b6ade | ||
|
|
6da93f5580 | ||
|
|
b033d1a679 | ||
|
|
2ba46c140b | ||
|
|
8160e4270b | ||
|
|
118c676ef3 | ||
|
|
5a4f340df7 | ||
|
|
5a6fa3ef09 | ||
|
|
19a323ee4a | ||
|
|
49b69fe0d4 | ||
|
|
22a69f1d7d | ||
|
|
040c4613c2 | ||
|
|
44d2c199f6 | ||
|
|
3a479672ea | ||
|
|
034bc5d26a | ||
|
|
d750eff627 | ||
|
|
7cd01d4e38 | ||
|
|
bfb1895e33 | ||
|
|
eb984418e2 | ||
|
|
f435003e0c | ||
|
|
604a6c51ae | ||
|
|
d4407a3bd1 | ||
|
|
51e1e8120b | ||
|
|
0f0e1a2c2b | ||
|
|
b1d475f6d2 | ||
|
|
ab8cba824e | ||
|
|
0afa5071bd | ||
|
|
a4dd53d88e | ||
|
|
3587769c08 | ||
|
|
1fa2d89a9b | ||
|
|
b439129e74 | ||
|
|
be0e189bd3 | ||
|
|
69c5b8f186 | ||
|
|
16d6e3087c | ||
|
|
53e2fd785b | ||
|
|
024acd271b | ||
|
|
4ece3b9433 | ||
|
|
ef10dbce5c | ||
|
|
0f08cd205a | ||
|
|
3fb1535b09 | ||
|
|
eaf5e98ec0 | ||
|
|
9c5acca002 | ||
|
|
2be8a9098e | ||
|
|
a39ebbf879 | ||
|
|
3b39b90618 | ||
|
|
99fc3ac8ac | ||
|
|
e95bcaeef0 | ||
|
|
f8468b4fac | ||
|
|
716bb2e391 | ||
|
|
1c6f072db0 | ||
|
|
9219d1427b | ||
|
|
459bc6738c | ||
|
|
72298178bc | ||
|
|
f73c20970c | ||
|
|
ed290b0837 | ||
|
|
09dc99517f | ||
|
|
62399d6f35 | ||
|
|
52574026b6 | ||
|
|
1bf2f36daf | ||
|
|
07998ef399 | ||
|
|
8c75cfdaee | ||
|
|
dbc16f4404 | ||
|
|
ce2d4bc6a1 | ||
|
|
0daeeb40a1 | ||
|
|
0e59c93983 | ||
|
|
245dcc49ef | ||
|
|
aade754b27 | ||
|
|
d97fd871e5 | ||
|
|
a35f889acc | ||
|
|
483861d52d | ||
|
|
33aa0af70c | ||
|
|
173fa7da9c | ||
|
|
2ee60b757e | ||
|
|
5b5ee235f3 | ||
|
|
9525515cd4 | ||
|
|
3dd030d264 | ||
|
|
dc0c102954 | ||
|
|
c9bae84eb5 | ||
|
|
77713d11f6 | ||
|
|
4c21da5e34 | ||
|
|
99c3d44906 | ||
|
|
39c37fe45c | ||
|
|
738ecd17d8 | ||
|
|
50573c648a | ||
|
|
886b6be081 | ||
|
|
ed915cff97 | ||
|
|
cb91ec67b5 | ||
|
|
de139702a1 | ||
|
|
686c68f64c | ||
|
|
960807f62e | ||
|
|
015f8e110d | ||
|
|
74081cb5fa | ||
|
|
0040469bb8 | ||
|
|
4b79697865 | ||
|
|
4d9e45f3ef | ||
|
|
8b0a7bfcdc | ||
|
|
35c570c80e | ||
|
|
dd8b7d28ae | ||
|
|
0770ce6cfb | ||
|
|
494e96d8d6 | ||
|
|
c6a84b7202 | ||
|
|
85cf90a1c9 | ||
|
|
cb8e3ee25f | ||
|
|
8968fface4 | ||
|
|
ae320fa53f | ||
|
|
f26099e7b5 | ||
|
|
0218876822 | ||
|
|
fd0b94fd7b | ||
|
|
1b2381c46b | ||
|
|
7a6efe1e9f | ||
|
|
fecf08560c | ||
|
|
0a365c3e6a | ||
|
|
584eeb5387 | ||
|
|
2febd50614 | ||
|
|
70b49f023c | ||
|
|
8fff61b9db | ||
|
|
f01459c75d | ||
|
|
c2123626aa | ||
|
|
6e6da5e4b8 | ||
|
|
b85b88069a | ||
|
|
68fa9a5937 | ||
|
|
4d40109c3a | ||
|
|
3c2383b1c6 | ||
|
|
656e17f6f7 | ||
|
|
6add3b313d | ||
|
|
2189a7f54a | ||
|
|
8657ec68fc | ||
|
|
77cb2ab792 | ||
|
|
2cf87e2bbb | ||
|
|
b413e0610b | ||
|
|
3d1edb6c5d | ||
|
|
db58722084 | ||
|
|
51794bf21e | ||
|
|
57943630e2 | ||
|
|
40a0cabd93 | ||
|
|
977b2f05d5 | ||
|
|
908f853688 | ||
|
|
5eeaef921f | ||
|
|
fd56f7f081 | ||
|
|
e20fab0bbe | ||
|
|
62396cff46 | ||
|
|
3629190689 | ||
|
|
edb28722c2 | ||
|
|
88e51ba306 | ||
|
|
6a314ea7cd | ||
|
|
182b83749a | ||
|
|
58c36bea74 | ||
|
|
450a181d8b | ||
|
|
6f041fcbb8 | ||
|
|
8608bf2049 | ||
|
|
2df24228d6 | ||
|
|
2582bbde2e | ||
|
|
2c1bcbf5ed | ||
|
|
e769ca3d28 | ||
|
|
5c67682b16 | ||
|
|
2f8acfea1c | ||
|
|
f09db47a71 | ||
|
|
9627c3da4a | ||
|
|
f92cc7034a | ||
|
|
1982dd3b15 | ||
|
|
6b82d936d4 | ||
|
|
6c811a322f | ||
|
|
4d64157ed3 | ||
|
|
6f4424bb08 | ||
|
|
faed2ca46f | ||
|
|
ef1534252f | ||
|
|
636acc75b0 | ||
|
|
8d2f953f4a | ||
|
|
bc3e20dcf0 | ||
|
|
30b3c46ff5 | ||
|
|
9d7afd2536 | ||
|
|
c45aab7535 | ||
|
|
940d1a76b0 | ||
|
|
08e32519f8 | ||
|
|
659ab0423e | ||
|
|
4a27c13f1e | ||
|
|
427adc898a | ||
|
|
b8f69d0d10 | ||
|
|
c4c0ceff09 | ||
|
|
4e1dee0e8e | ||
|
|
d4c0aa1443 | ||
|
|
181d778f83 | ||
|
|
9264fc915a | ||
|
|
b4d5548800 | ||
|
|
5347d00092 | ||
|
|
d6bf08f7f6 | ||
|
|
d2871b2975 | ||
|
|
1791ef8df6 | ||
|
|
e7e9261a20 | ||
|
|
8992589dd6 | ||
|
|
e50c9253f3 | ||
|
|
c8346cb267 | ||
|
|
8fd6561981 | ||
|
|
ec25306b39 | ||
|
|
297a6a7aea | ||
|
|
d1832dd808 | ||
|
|
db816c6e02 | ||
|
|
2defb6b048 | ||
|
|
36f183ebab | ||
|
|
6bca43bb90 | ||
|
|
a6609caf4e | ||
|
|
f61f072b61 | ||
|
|
0ed23e4db2 | ||
|
|
3f9cb33504 | ||
|
|
e13d5b6048 | ||
|
|
0b568291d7 | ||
|
|
5ccf343aeb | ||
|
|
c385de2441 | ||
|
|
eec5841e9f | ||
|
|
ca51499248 | ||
|
|
f11518a542 | ||
|
|
7a94ea4c64 | ||
|
|
2552b8c5bd | ||
|
|
df91ff5314 | ||
|
|
b42010bb1d | ||
|
|
c41291965f | ||
|
|
06a1d75bd5 | ||
|
|
80f29a25a7 | ||
|
|
ee7d6694ed | ||
|
|
87c9d8a10f | ||
|
|
b1b0fc4f56 | ||
|
|
e97deca9a3 | ||
|
|
0ebe7ae160 | ||
|
|
2b22cde71e | ||
|
|
892f9ea0db | ||
|
|
fe3c8ab1af | ||
|
|
5e5fa0d88c | ||
|
|
11757e2bbd | ||
|
|
0acf56224b | ||
|
|
1d75768695 | ||
|
|
4692d26194 | ||
|
|
41d56ea6dd | ||
|
|
454957c9bb | ||
|
|
55db70c63d | ||
|
|
347001237a | ||
|
|
a7da2996a0 | ||
|
|
2d6839eaa6 | ||
|
|
e7b001db4f | ||
|
|
3e41cf13fc | ||
|
|
d0839f1a74 | ||
|
|
123ad5363f | ||
|
|
16edf4d9fd | ||
|
|
b14d4641f6 | ||
|
|
b175fc39d9 | ||
|
|
d0c1aebea4 | ||
|
|
944ddce8bf | ||
|
|
cb3c821cb7 | ||
|
|
704bf595eb | ||
|
|
cf84738d2e | ||
|
|
133aac09b0 | ||
|
|
f2a43c7383 | ||
|
|
eb3ded16f7 | ||
|
|
ef74da6582 | ||
|
|
f456b4d10b | ||
|
|
00b93cda21 | ||
|
|
3deed1f97e | ||
|
|
d59b872c9e | ||
|
|
ea5dda2290 | ||
|
|
599377161b | ||
|
|
85447bb22e | ||
|
|
1564a81ac5 | ||
|
|
1367142afd | ||
|
|
41c5f45bfe | ||
|
|
3a05e010e0 | ||
|
|
e3490104da | ||
|
|
5b517e1764 | ||
|
|
9c7b744795 | ||
|
|
5bd8c011bb | ||
|
|
9e57e0c063 | ||
|
|
6247d1b2b6 | ||
|
|
26ce4dd8b7 | ||
|
|
5744482abc | ||
|
|
01ab39b65f | ||
|
|
36d5b8b06c | ||
|
|
dedd11160d | ||
|
|
5ea2595ecd | ||
|
|
6ea3ee3cd2 | ||
|
|
d4bd33cc9f | ||
|
|
a23ac36f8c | ||
|
|
080a97119c | ||
|
|
5ee9693a1c | ||
|
|
676247fd6b | ||
|
|
5fe36970e5 | ||
|
|
baf1daa58e | ||
|
|
c177606fb4 | ||
|
|
7d65697da7 | ||
|
|
145109382a | ||
|
|
65001cb1c8 | ||
|
|
d6bfba76be | ||
|
|
b0f23036f1 | ||
|
|
b9da44bd3e | ||
|
|
d533465150 | ||
|
|
a6e6b1c622 | ||
|
|
fdd81aea12 | ||
|
|
fdaef3368b | ||
|
|
ce6d153a53 | ||
|
|
f0fd73a2de | ||
|
|
29f04002e6 | ||
|
|
aeb5a08abd | ||
|
|
bff4313b37 | ||
|
|
fab1a0aa82 | ||
|
|
67683095a6 | ||
|
|
641adca558 | ||
|
|
33da2db5ea | ||
|
|
66c240f3c9 | ||
|
|
d114a6b71f | ||
|
|
6d3f9c1e2e | ||
|
|
8455346c5c | ||
|
|
a8817371c9 | ||
|
|
30409af6e1 | ||
|
|
15082a9dc6 | ||
|
|
2bd7a27a67 | ||
|
|
bd90cda9a6 | ||
|
|
b28ebb2655 | ||
|
|
ad8321512d | ||
|
|
bef02fd6b9 | ||
|
|
8edd0da960 | ||
|
|
1baeed5bdf | ||
|
|
eec0d84e6a | ||
|
|
8021c684ec | ||
|
|
1b35409768 | ||
|
|
904e7e0f3c | ||
|
|
149cb0cce2 | ||
|
|
c6a8768dab | ||
|
|
2230d149f0 | ||
|
|
f6f567d0be | ||
|
|
d27e4c18fe | ||
|
|
3170af71e1 | ||
|
|
05ebb0264e | ||
|
|
972fdcc778 | ||
|
|
77c3973e8f | ||
|
|
4033ea7167 | ||
|
|
0fd8d2aa2c | ||
|
|
1b4f6199c6 | ||
|
|
e0c50b274a | ||
|
|
5220606607 | ||
|
|
9ca3aa0156 | ||
|
|
59dcea3fe4 | ||
|
|
67b85f24de | ||
|
|
4a564490e1 | ||
|
|
05cda5df34 | ||
|
|
03f98f9683 | ||
|
|
c90e14fb0f | ||
|
|
31f137c04f | ||
|
|
dd9d45b6ec | ||
|
|
add0895dd9 | ||
|
|
d53b8ad780 | ||
|
|
3cbc560d03 | ||
|
|
afa96fffdf | ||
|
|
d23d2c27c2 | ||
|
|
2a78720104 | ||
|
|
c1dba1111b | ||
|
|
6232c380f2 | ||
|
|
400e76ef11 | ||
|
|
e93103632b | ||
|
|
0c790ddbd1 | ||
|
|
0b92ae3489 | ||
|
|
9cea3e7b80 | ||
|
|
a1c4954d25 | ||
|
|
9a220ce30c | ||
|
|
9429642e2d | ||
|
|
de9e3b5945 | ||
|
|
a004237926 | ||
|
|
1689aea733 | ||
|
|
659829b6ae | ||
|
|
b914ec9847 | ||
|
|
1486d2aec2 | ||
|
|
d30cf3d02f | ||
|
|
224da5df69 | ||
|
|
c53c8e490c | ||
|
|
04a5c859b0 | ||
|
|
31acba5697 | ||
|
|
ee63520a7b | ||
|
|
277d3aed0a | ||
|
|
a5cc30d72a | ||
|
|
f1deb21fce | ||
|
|
45bde362d2 | ||
|
|
6b8dbc283c | ||
|
|
da5ff18a4a | ||
|
|
8f36ab3e22 | ||
|
|
21150cb0f3 | ||
|
|
f9cc333805 | ||
|
|
0779fc8eb8 | ||
|
|
2fac342238 | ||
|
|
f104522718 | ||
|
|
1e662f0f07 | ||
|
|
b51312e24d | ||
|
|
b99f7bd4fc | ||
|
|
dcb183f4bd | ||
|
|
1dbc1440a7 | ||
|
|
cb8abee511 | ||
|
|
f2c1df93f5 | ||
|
|
c879318cc5 | ||
|
|
25e443c0d4 | ||
|
|
6bc61aa7af | ||
|
|
5dba88b2d2 | ||
|
|
f295fc8a16 | ||
|
|
ee1eb3b325 | ||
|
|
f6fe1d5514 | ||
|
|
faf25c040d | ||
|
|
c0742b15cb | ||
|
|
c53a6eae74 | ||
|
|
d2295708a6 | ||
|
|
c0d1c33022 | ||
|
|
b08f41e62a | ||
|
|
3611fc90e0 | ||
|
|
a03d13c83d | ||
|
|
afe8bfc075 | ||
|
|
42571f6eb8 | ||
|
|
8f1f0bf50f | ||
|
|
3b734f5042 | ||
|
|
9d2b983ed0 | ||
|
|
383be1b763 | ||
|
|
efb2ba666d | ||
|
|
6704923107 | ||
|
|
75317aefb3 | ||
|
|
54ba8608d0 | ||
|
|
0906d21203 | ||
|
|
c9a82be592 | ||
|
|
b257c46a07 | ||
|
|
87fba947a5 | ||
|
|
ea41e18cfc | ||
|
|
95f96b45ff | ||
|
|
d3ce048c20 | ||
|
|
f1a1eb4ae1 | ||
|
|
a7d213189d | ||
|
|
a6484c89b9 | ||
|
|
5b7ffd5492 | ||
|
|
640e1b6c6f | ||
|
|
0511369a8b | ||
|
|
f74560d007 | ||
|
|
f4eb459ef2 | ||
|
|
ec3dfe5e24 | ||
|
|
83f9314d10 | ||
|
|
1c7e5e2368 | ||
|
|
9ef5256dfb | ||
|
|
caf5e369fc | ||
|
|
aa1b09c5d1 | ||
|
|
89a1f34271 | ||
|
|
9f912ef62a | ||
|
|
e75cb0cb3c | ||
|
|
0c41765df4 | ||
|
|
35c04596f8 | ||
|
|
85514c17d1 | ||
|
|
9859806608 | ||
|
|
89136ff7f8 | ||
|
|
37d8611ac9 | ||
|
|
79444f370f | ||
|
|
8fd8c8e49e | ||
|
|
7381987f90 | ||
|
|
6112b1c644 | ||
|
|
ee4250a35f | ||
|
|
3a43794dd6 | ||
|
|
99c1268e0a | ||
|
|
aa4afa67f3 | ||
|
|
243b2ea3fd | ||
|
|
c035970212 | ||
|
|
129cb6d523 | ||
|
|
476be08c4a | ||
|
|
a982c0225e | ||
|
|
07360b6c9c | ||
|
|
30c172fc20 | ||
|
|
dd49404a89 | ||
|
|
5c5cb4eeb2 | ||
|
|
a9e067a45c | ||
|
|
3ec10e6c76 | ||
|
|
57da42ad05 | ||
|
|
9c875839c0 | ||
|
|
f14c7f999d | ||
|
|
ca974aff0f | ||
|
|
2ab75add4b | ||
|
|
d561408cc3 | ||
|
|
870dfc15b2 | ||
|
|
9dc965bb40 | ||
|
|
0f4502d335 | ||
|
|
eeaa9c016a | ||
|
|
d0154015f7 | ||
|
|
12b908c659 | ||
|
|
e9ad51306f |
@@ -136,20 +136,20 @@ jobs:
|
||||
- checkout
|
||||
- restore_cache:
|
||||
keys:
|
||||
- v0.7-code_quality-{{ checksum "setup.py" }}
|
||||
- v0.7-code-quality
|
||||
- v0.7-code_quality-pip-{{ checksum "setup.py" }}
|
||||
- v0.7-code-quality-pip
|
||||
- restore_cache:
|
||||
keys:
|
||||
- v0.7-code_quality-{{ checksum "setup.py" }}-site-packages
|
||||
- v0.7-code_quality-site-packages-{{ checksum "setup.py" }}
|
||||
- v0.7-code-quality-site-packages
|
||||
- run: pip install --upgrade --upgrade-strategy eager pip
|
||||
- run: pip install -U --upgrade-strategy eager .[all,quality]
|
||||
- save_cache:
|
||||
key: v0.7-code_quality-{{ checksum "setup.py" }}
|
||||
key: v0.7-code_quality-pip-{{ checksum "setup.py" }}
|
||||
paths:
|
||||
- '~/.cache/pip'
|
||||
- save_cache:
|
||||
key: v0.7-code_quality-{{ checksum "setup.py" }}-site-packages
|
||||
key: v0.7-code_quality-site-packages-{{ checksum "setup.py" }}
|
||||
paths:
|
||||
- '~/.pyenv/versions/'
|
||||
- run:
|
||||
@@ -177,20 +177,20 @@ jobs:
|
||||
- checkout
|
||||
- restore_cache:
|
||||
keys:
|
||||
- v0.7-repository_consistency-{{ checksum "setup.py" }}
|
||||
- v0.7-repository_consistency
|
||||
- v0.7-repository_consistency-pip-{{ checksum "setup.py" }}
|
||||
- v0.7-repository_consistency-pip
|
||||
- restore_cache:
|
||||
keys:
|
||||
- v0.7-repository_consistency-{{ checksum "setup.py" }}-site-packages
|
||||
- v0.7-repository_consistency-site-packages-{{ checksum "setup.py" }}
|
||||
- v0.7-repository_consistency-site-packages
|
||||
- run: pip install --upgrade --upgrade-strategy eager pip
|
||||
- run: pip install -U --upgrade-strategy eager .[all,quality]
|
||||
- save_cache:
|
||||
key: v0.7-repository_consistency-{{ checksum "setup.py" }}
|
||||
key: v0.7-repository_consistency-pip-{{ checksum "setup.py" }}
|
||||
paths:
|
||||
- '~/.cache/pip'
|
||||
- save_cache:
|
||||
key: v0.7-repository_consistency-{{ checksum "setup.py" }}-site-packages
|
||||
key: v0.7-repository_consistency-site-packages-{{ checksum "setup.py" }}
|
||||
paths:
|
||||
- '~/.pyenv/versions/'
|
||||
- run:
|
||||
|
||||
@@ -32,7 +32,8 @@ COMMON_ENV_VARIABLES = {
|
||||
"RUN_PT_TF_CROSS_TESTS": False,
|
||||
"RUN_PT_FLAX_CROSS_TESTS": False,
|
||||
}
|
||||
COMMON_PYTEST_OPTIONS = {"max-worker-restart": 0, "dist": "loadfile", "s": None}
|
||||
# Disable the use of {"s": None} as the output is way too long, causing the navigation on CircleCI impractical
|
||||
COMMON_PYTEST_OPTIONS = {"max-worker-restart": 0, "dist": "loadfile"}
|
||||
DEFAULT_DOCKER_IMAGE = [{"image": "cimg/python:3.8.12"}]
|
||||
|
||||
|
||||
@@ -86,6 +87,11 @@ class CircleCIJob:
|
||||
def to_dict(self):
|
||||
env = COMMON_ENV_VARIABLES.copy()
|
||||
env.update(self.additional_env)
|
||||
|
||||
cache_branch_prefix = os.environ.get("CIRCLE_BRANCH", "pull")
|
||||
if cache_branch_prefix != "main":
|
||||
cache_branch_prefix = "pull"
|
||||
|
||||
job = {
|
||||
"working_directory": self.working_directory,
|
||||
"docker": self.docker_image,
|
||||
@@ -101,16 +107,21 @@ class CircleCIJob:
|
||||
{
|
||||
"restore_cache": {
|
||||
"keys": [
|
||||
f"v{self.cache_version}-{self.cache_name}-" + '{{ checksum "setup.py" }}',
|
||||
f"v{self.cache_version}-{self.cache_name}-",
|
||||
# check the fully-matched cache first
|
||||
f"v{self.cache_version}-{self.cache_name}-{cache_branch_prefix}-pip-" + '{{ checksum "setup.py" }}',
|
||||
# try the partially-matched cache from `main`
|
||||
f"v{self.cache_version}-{self.cache_name}-main-pip-",
|
||||
# try the general partially-matched cache
|
||||
f"v{self.cache_version}-{self.cache_name}-{cache_branch_prefix}-pip-",
|
||||
]
|
||||
}
|
||||
},
|
||||
{
|
||||
"restore_cache": {
|
||||
"keys": [
|
||||
f"v{self.cache_version}-{self.cache_name}-" + '{{ checksum "setup.py" }}-site-packages',
|
||||
f"v{self.cache_version}-{self.cache_name}-site-packages",
|
||||
f"v{self.cache_version}-{self.cache_name}-{cache_branch_prefix}-site-packages-" + '{{ checksum "setup.py" }}',
|
||||
f"v{self.cache_version}-{self.cache_name}-main-site-packages-",
|
||||
f"v{self.cache_version}-{self.cache_name}-{cache_branch_prefix}-site-packages-",
|
||||
]
|
||||
}
|
||||
},
|
||||
@@ -119,7 +130,7 @@ class CircleCIJob:
|
||||
steps.append(
|
||||
{
|
||||
"save_cache": {
|
||||
"key": f"v{self.cache_version}-{self.cache_name}-" + '{{ checksum "setup.py" }}',
|
||||
"key": f"v{self.cache_version}-{self.cache_name}-{cache_branch_prefix}-pip-" + '{{ checksum "setup.py" }}',
|
||||
"paths": ["~/.cache/pip"],
|
||||
}
|
||||
}
|
||||
@@ -127,7 +138,7 @@ class CircleCIJob:
|
||||
steps.append(
|
||||
{
|
||||
"save_cache": {
|
||||
"key": f"v{self.cache_version}-{self.cache_name}-" + '{{ checksum "setup.py" }}-site-packages',
|
||||
"key": f"v{self.cache_version}-{self.cache_name}-{cache_branch_prefix}-site-packages-" + '{{ checksum "setup.py" }}',
|
||||
"paths": ["~/.pyenv/versions/"],
|
||||
}
|
||||
}
|
||||
@@ -275,7 +286,7 @@ torch_job = CircleCIJob(
|
||||
"pip install -U --upgrade-strategy eager git+https://github.com/huggingface/accelerate",
|
||||
],
|
||||
parallelism=1,
|
||||
pytest_num_workers=3,
|
||||
pytest_num_workers=8,
|
||||
)
|
||||
|
||||
|
||||
@@ -288,8 +299,6 @@ tf_job = CircleCIJob(
|
||||
"pip install -U --upgrade-strategy eager tensorflow_probability",
|
||||
],
|
||||
parallelism=1,
|
||||
pytest_num_workers=6,
|
||||
pytest_options={"rA": None},
|
||||
)
|
||||
|
||||
|
||||
@@ -301,7 +310,6 @@ flax_job = CircleCIJob(
|
||||
"pip install -U --upgrade-strategy eager .[flax,testing,sentencepiece,flax-speech,vision]",
|
||||
],
|
||||
parallelism=1,
|
||||
pytest_options={"rA": None},
|
||||
)
|
||||
|
||||
|
||||
@@ -313,7 +321,6 @@ pipelines_torch_job = CircleCIJob(
|
||||
"pip install --upgrade --upgrade-strategy eager pip",
|
||||
"pip install -U --upgrade-strategy eager .[sklearn,torch,testing,sentencepiece,torch-speech,vision,timm,video]",
|
||||
],
|
||||
pytest_options={"rA": None},
|
||||
marker="is_pipeline_test",
|
||||
)
|
||||
|
||||
@@ -327,7 +334,6 @@ pipelines_tf_job = CircleCIJob(
|
||||
"pip install -U --upgrade-strategy eager .[sklearn,tf-cpu,testing,sentencepiece,vision]",
|
||||
"pip install -U --upgrade-strategy eager tensorflow_probability",
|
||||
],
|
||||
pytest_options={"rA": None},
|
||||
marker="is_pipeline_test",
|
||||
)
|
||||
|
||||
@@ -581,13 +587,13 @@ def create_circleci_config(folder=None):
|
||||
example_file = os.path.join(folder, "examples_test_list.txt")
|
||||
if os.path.exists(example_file) and os.path.getsize(example_file) > 0:
|
||||
with open(example_file, "r", encoding="utf-8") as f:
|
||||
example_tests = f.read().split(" ")
|
||||
example_tests = f.read()
|
||||
for job in EXAMPLES_TESTS:
|
||||
framework = job.name.replace("examples_", "").replace("torch", "pytorch")
|
||||
if example_tests == "all":
|
||||
job.tests_to_run = [f"examples/{framework}"]
|
||||
else:
|
||||
job.tests_to_run = [f for f in example_tests if f.startswith(f"examples/{framework}")]
|
||||
job.tests_to_run = [f for f in example_tests.split(" ") if f.startswith(f"examples/{framework}")]
|
||||
|
||||
if len(job.tests_to_run) > 0:
|
||||
jobs.append(job)
|
||||
|
||||
9
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
9
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
@@ -37,15 +37,16 @@ body:
|
||||
- pipelines: @Narsil
|
||||
- tensorflow: @gante and @Rocketknight1
|
||||
- tokenizers: @ArthurZucker
|
||||
- trainer: @sgugger
|
||||
- trainer: @muellerz and @pacman100
|
||||
|
||||
Integrations:
|
||||
|
||||
- deepspeed: HF Trainer/Accelerate: @pacman100
|
||||
- ray/raytune: @richardliaw, @amogkam
|
||||
- Big Model Inference: @sgugger @muellerzr
|
||||
- Big Model Inference: @SunMarc
|
||||
- quantization (bitsandbytes, autogpt): @SunMarc and @younesbelkada
|
||||
|
||||
Documentation: @sgugger, @stevhliu and @MKhalusova
|
||||
Documentation: @stevhliu and @MKhalusova
|
||||
|
||||
Model hub:
|
||||
|
||||
@@ -61,7 +62,7 @@ body:
|
||||
Maintained examples (not research project or legacy):
|
||||
|
||||
- Flax: @sanchit-gandhi
|
||||
- PyTorch: @sgugger
|
||||
- PyTorch: See Models above and tag the person corresponding to the modality of the example.
|
||||
- TensorFlow: @Rocketknight1
|
||||
|
||||
Research projects are not maintained and should be taken as is.
|
||||
|
||||
2
.github/ISSUE_TEMPLATE/i18n.md
vendored
2
.github/ISSUE_TEMPLATE/i18n.md
vendored
@@ -23,7 +23,7 @@ Some notes:
|
||||
* Please translate in a gender-neutral way.
|
||||
* Add your translations to the folder called `<languageCode>` inside the [source folder](https://github.com/huggingface/transformers/tree/main/docs/source).
|
||||
* Register your translation in `<languageCode>/_toctree.yml`; please follow the order of the [English version](https://github.com/huggingface/transformers/blob/main/docs/source/en/_toctree.yml).
|
||||
* Once you're finished, open a pull request and tag this issue by including #issue-number in the description, where issue-number is the number of this issue. Please ping @ArthurZucker, @sgugger for review.
|
||||
* Once you're finished, open a pull request and tag this issue by including #issue-number in the description, where issue-number is the number of this issue. Please ping @stevhliu and @MKhalusova for review.
|
||||
* 🙋 If you'd like others to help you with the translation, you can also post in the 🤗 [forums](https://discuss.huggingface.co/).
|
||||
|
||||
## Get Started section
|
||||
|
||||
8
.github/PULL_REQUEST_TEMPLATE.md
vendored
8
.github/PULL_REQUEST_TEMPLATE.md
vendored
@@ -51,14 +51,16 @@ Library:
|
||||
- pipelines: @Narsil
|
||||
- tensorflow: @gante and @Rocketknight1
|
||||
- tokenizers: @ArthurZucker
|
||||
- trainer: @sgugger
|
||||
- trainer: @muellerz and @pacman100
|
||||
|
||||
Integrations:
|
||||
|
||||
- deepspeed: HF Trainer/Accelerate: @pacman100
|
||||
- ray/raytune: @richardliaw, @amogkam
|
||||
- Big Model Inference: @SunMarc
|
||||
- quantization (bitsandbytes, autogpt): @SunMarc and @younesbelkada
|
||||
|
||||
Documentation: @sgugger, @stevhliu and @MKhalusova
|
||||
Documentation: @stevhliu and @MKhalusova
|
||||
|
||||
HF projects:
|
||||
|
||||
@@ -70,7 +72,7 @@ HF projects:
|
||||
Maintained examples (not research project or legacy):
|
||||
|
||||
- Flax: @sanchit-gandhi
|
||||
- PyTorch: @sgugger
|
||||
- PyTorch: See Models above and tag the person corresponding to the modality of the example.
|
||||
- TensorFlow: @Rocketknight1
|
||||
|
||||
-->
|
||||
|
||||
4
.github/conda/meta.yaml
vendored
4
.github/conda/meta.yaml
vendored
@@ -26,6 +26,8 @@ requirements:
|
||||
- protobuf
|
||||
- tokenizers >=0.11.1,!=0.11.3,<0.13
|
||||
- pyyaml >=5.1
|
||||
- safetensors
|
||||
- fsspec
|
||||
run:
|
||||
- python
|
||||
- numpy >=1.17
|
||||
@@ -40,6 +42,8 @@ requirements:
|
||||
- protobuf
|
||||
- tokenizers >=0.11.1,!=0.11.3,<0.13
|
||||
- pyyaml >=5.1
|
||||
- safetensors
|
||||
- fsspec
|
||||
|
||||
test:
|
||||
imports:
|
||||
|
||||
14
.github/workflows/add-model-like.yml
vendored
14
.github/workflows/add-model-like.yml
vendored
@@ -3,13 +3,13 @@ name: Add model like runner
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
pull_request:
|
||||
paths:
|
||||
- "src/**"
|
||||
- "tests/**"
|
||||
- ".github/**"
|
||||
types: [opened, synchronize, reopened]
|
||||
- none # put main here when this is fixed
|
||||
#pull_request:
|
||||
# paths:
|
||||
# - "src/**"
|
||||
# - "tests/**"
|
||||
# - ".github/**"
|
||||
# types: [opened, synchronize, reopened]
|
||||
|
||||
jobs:
|
||||
run_tests_templates_like:
|
||||
|
||||
8
.github/workflows/doctests.yml
vendored
8
.github/workflows/doctests.yml
vendored
@@ -34,7 +34,7 @@ jobs:
|
||||
nvidia-smi
|
||||
|
||||
- name: Install transformers in edit mode
|
||||
run: python3 -m pip install -e .
|
||||
run: python3 -m pip install -e .[flax]
|
||||
|
||||
- name: GPU visibility
|
||||
run: |
|
||||
@@ -43,9 +43,13 @@ jobs:
|
||||
- name: Show installed libraries and their versions
|
||||
run: pip freeze
|
||||
|
||||
- name: Get doctest files
|
||||
run: |
|
||||
$(python3 -c 'from utils.tests_fetcher import get_all_doctest_files; to_test = get_all_doctest_files(); to_test = " ".join(to_test); fp = open("doc_tests.txt", "w"); fp.write(to_test); fp.close()')
|
||||
|
||||
- name: Run doctests
|
||||
run: |
|
||||
python3 -m pytest -v --make-reports doc_tests_gpu --doctest-modules $(cat utils/documentation_tests.txt) -sv --doctest-continue-on-failure --doctest-glob="*.md"
|
||||
python3 -m pytest -v --make-reports doc_tests_gpu --doctest-modules $(cat doc_tests.txt) -sv --doctest-continue-on-failure --doctest-glob="*.md"
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
|
||||
2
.github/workflows/stale.yml
vendored
2
.github/workflows/stale.yml
vendored
@@ -2,7 +2,7 @@ name: Stale Bot
|
||||
|
||||
on:
|
||||
schedule:
|
||||
- cron: "0 15 * * *"
|
||||
- cron: "0 8 * * *"
|
||||
|
||||
jobs:
|
||||
close_stale_issues:
|
||||
|
||||
4
.github/workflows/update_metdata.yml
vendored
4
.github/workflows/update_metdata.yml
vendored
@@ -19,9 +19,9 @@ jobs:
|
||||
- name: Setup environment
|
||||
run: |
|
||||
pip install --upgrade pip
|
||||
pip install datasets pandas
|
||||
pip install datasets pandas==2.0.3
|
||||
pip install .[torch,tf,flax]
|
||||
|
||||
- name: Update metadata
|
||||
run: |
|
||||
python utils/update_metadata.py --token ${{ secrets.SYLVAIN_HF_TOKEN }} --commit_sha ${{ github.sha }}
|
||||
python utils/update_metadata.py --token ${{ secrets.LYSANDRE_HF_TOKEN }} --commit_sha ${{ github.sha }}
|
||||
|
||||
1
Makefile
1
Makefile
@@ -80,6 +80,7 @@ fix-copies:
|
||||
python utils/check_copies.py --fix_and_overwrite
|
||||
python utils/check_table.py --fix_and_overwrite
|
||||
python utils/check_dummies.py --fix_and_overwrite
|
||||
python utils/check_doctest_list.py --fix_and_overwrite
|
||||
python utils/check_task_guides.py --fix_and_overwrite
|
||||
|
||||
# Run tests for the library
|
||||
|
||||
33
README.md
33
README.md
@@ -116,8 +116,8 @@ In Multimodal tasks:
|
||||
|
||||
## 100 projects using Transformers
|
||||
|
||||
Transformers is more than a toolkit to use pretrained models: it's a community of projects built around it and the
|
||||
Hugging Face Hub. We want Transformers to enable developers, researchers, students, professors, engineers, and anyone
|
||||
Transformers is more than a toolkit to use pretrained models: it's a community of projects built around it and the
|
||||
Hugging Face Hub. We want Transformers to enable developers, researchers, students, professors, engineers, and anyone
|
||||
else to build their dream projects.
|
||||
|
||||
In order to celebrate the 100,000 stars of transformers, we have decided to put the spotlight on the
|
||||
@@ -247,7 +247,7 @@ The model itself is a regular [Pytorch `nn.Module`](https://pytorch.org/docs/sta
|
||||
|
||||
### With pip
|
||||
|
||||
This repository is tested on Python 3.7+, Flax 0.4.1+, PyTorch 1.9+ and TensorFlow 2.4+.
|
||||
This repository is tested on Python 3.8+, Flax 0.4.1+, PyTorch 1.10+ and TensorFlow 2.6+.
|
||||
|
||||
You should install 🤗 Transformers in a [virtual environment](https://docs.python.org/3/library/venv.html). If you're unfamiliar with Python virtual environments, check out the [user guide](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
|
||||
|
||||
@@ -291,7 +291,7 @@ Current number of checkpoints: ** (from BAAI) released with the paper [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) by Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell.
|
||||
1. **[Audio Spectrogram Transformer](https://huggingface.co/docs/transformers/model_doc/audio-spectrogram-transformer)** (from MIT) released with the paper [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
|
||||
1. **[Autoformer](https://huggingface.co/docs/transformers/model_doc/autoformer)** (from Tsinghua University) released with the paper [Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008) by Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long.
|
||||
1. **[Bark](https://huggingface.co/docs/transformers/main/model_doc/bark)** (from Suno) released in the repository [suno-ai/bark](https://github.com/suno-ai/bark) by Suno AI team.
|
||||
1. **[Bark](https://huggingface.co/docs/transformers/model_doc/bark)** (from Suno) released in the repository [suno-ai/bark](https://github.com/suno-ai/bark) by Suno AI team.
|
||||
1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
|
||||
1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
|
||||
1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
|
||||
@@ -318,6 +318,7 @@ Current number of checkpoints: ** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
|
||||
1. **[CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
|
||||
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
|
||||
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (from MetaAI) released with the paper [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) by Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.
|
||||
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
|
||||
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
|
||||
1. **[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
|
||||
@@ -337,6 +338,7 @@ Current number of checkpoints: ** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
|
||||
1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
|
||||
1. **[DiNAT](https://huggingface.co/docs/transformers/model_doc/dinat)** (from SHI Labs) released with the paper [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) by Ali Hassani and Humphrey Shi.
|
||||
1. **[DINOv2](https://huggingface.co/docs/transformers/model_doc/dinov2)** (from Meta AI) released with the paper [DINOv2: Learning Robust Visual Features without Supervision](https://arxiv.org/abs/2304.07193) by Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski.
|
||||
1. **[DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation) and a German version of DistilBERT.
|
||||
1. **[DiT](https://huggingface.co/docs/transformers/model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
|
||||
1. **[Donut](https://huggingface.co/docs/transformers/model_doc/donut)** (from NAVER), released together with the paper [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) by Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park.
|
||||
@@ -345,12 +347,12 @@ Current number of checkpoints: ** (from Snap Research) released with the paper [EfficientFormer: Vision Transformers at MobileNetSpeed](https://arxiv.org/abs/2206.01191) by Yanyu Li, Geng Yuan, Yang Wen, Ju Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren.
|
||||
1. **[EfficientNet](https://huggingface.co/docs/transformers/model_doc/efficientnet)** (from Google Brain) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan, Quoc V. Le.
|
||||
1. **[ELECTRA](https://huggingface.co/docs/transformers/model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
|
||||
1. **[EnCodec](https://huggingface.co/docs/transformers/main/model_doc/encodec)** (from Meta AI) released with the paper [High Fidelity Neural Audio Compression](https://arxiv.org/abs/2210.13438) by Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi.
|
||||
1. **[EnCodec](https://huggingface.co/docs/transformers/model_doc/encodec)** (from Meta AI) released with the paper [High Fidelity Neural Audio Compression](https://arxiv.org/abs/2210.13438) by Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi.
|
||||
1. **[EncoderDecoder](https://huggingface.co/docs/transformers/model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
|
||||
1. **[ERNIE](https://huggingface.co/docs/transformers/model_doc/ernie)** (from Baidu) released with the paper [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223) by Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu.
|
||||
1. **[ErnieM](https://huggingface.co/docs/transformers/model_doc/ernie_m)** (from Baidu) released with the paper [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang.
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2 and ESMFold** were released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/main/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
|
||||
@@ -373,9 +375,10 @@ Current number of checkpoints: ** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
|
||||
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
|
||||
1. **[I-BERT](https://huggingface.co/docs/transformers/model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
|
||||
1. **[IDEFICS](https://huggingface.co/docs/transformers/model_doc/idefics)** (from HuggingFace) released with the paper [OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents](https://huggingface.co/papers/2306.16527) by Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander M. Rush, Douwe Kiela, Matthieu Cord, Victor Sanh.
|
||||
1. **[ImageGPT](https://huggingface.co/docs/transformers/model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
|
||||
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
|
||||
1. **[InstructBLIP](https://huggingface.co/docs/transformers/main/model_doc/instructblip)** (from Salesforce) released with the paper [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
|
||||
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (from Salesforce) released with the paper [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
|
||||
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
|
||||
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
|
||||
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
|
||||
@@ -385,6 +388,7 @@ Current number of checkpoints: ** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
|
||||
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
|
||||
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (from The FAIR team of Meta AI) released with the paper [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.
|
||||
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (from The FAIR team of Meta AI) released with the paper [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX) by Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom.
|
||||
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
|
||||
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
|
||||
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
|
||||
@@ -410,9 +414,10 @@ Current number of checkpoints: ** (from Apple) released with the paper [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari.
|
||||
1. **[MobileViTV2](https://huggingface.co/docs/transformers/model_doc/mobilevitv2)** (from Apple) released with the paper [Separable Self-attention for Mobile Vision Transformers](https://arxiv.org/abs/2206.02680) by Sachin Mehta and Mohammad Rastegari.
|
||||
1. **[MPNet](https://huggingface.co/docs/transformers/model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/main/model_doc/mra)** (from the University of Wisconsin - Madison) released with the paper [Multi Resolution Analysis (MRA) for Approximate Self-Attention](https://arxiv.org/abs/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh.
|
||||
1. **[MPT](https://huggingface.co/docs/transformers/model_doc/mpt)** (from MosaiML) released with the repository [llm-foundry](https://github.com/mosaicml/llm-foundry/) by the MosaicML NLP Team.
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (from the University of Wisconsin - Madison) released with the paper [Multi Resolution Analysis (MRA) for Approximate Self-Attention](https://arxiv.org/abs/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh.
|
||||
1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
|
||||
1. **[MusicGen](https://huggingface.co/docs/transformers/main/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MusicGen](https://huggingface.co/docs/transformers/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
|
||||
1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (from SHI Labs) released with the paper [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
|
||||
1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
|
||||
@@ -420,7 +425,7 @@ Current number of checkpoints: ** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
|
||||
1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
|
||||
1. **[OneFormer](https://huggingface.co/docs/transformers/model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
|
||||
1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released in [Open-Llama](https://github.com/s-JoL/Open-Llama).
|
||||
1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released in [Open-Llama](https://github.com/s-JoL/Open-Llama).
|
||||
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
|
||||
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
|
||||
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
|
||||
@@ -430,7 +435,9 @@ Current number of checkpoints: ** (from Google) released with the paper [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
|
||||
1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
|
||||
1. **[PoolFormer](https://huggingface.co/docs/transformers/model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
|
||||
1. **[Pop2Piano](https://huggingface.co/docs/transformers/model_doc/pop2piano)** released with the paper [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi and Kyogu Lee.
|
||||
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
|
||||
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (from Nanjing University, The University of Hong Kong etc.) released with the paper [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
|
||||
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
|
||||
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
|
||||
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
|
||||
@@ -469,7 +476,7 @@ Current number of checkpoints: ** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
|
||||
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill) released with the paper [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
|
||||
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
|
||||
1. **[UMT5](https://huggingface.co/docs/transformers/main/model_doc/umt5)** (from Google Research) released with the paper [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
|
||||
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (from Google Research) released with the paper [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
|
||||
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
|
||||
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
|
||||
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
|
||||
@@ -479,9 +486,11 @@ Current number of checkpoints: ](https://huggingface.co/docs/transformers/model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
|
||||
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
|
||||
1. **[ViT Hybrid](https://huggingface.co/docs/transformers/model_doc/vit_hybrid)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
|
||||
1. **[VitDet](https://huggingface.co/docs/transformers/model_doc/vitdet)** (from Meta AI) released with the paper [Exploring Plain Vision Transformer Backbones for Object Detection](https://arxiv.org/abs/2203.16527) by Yanghao Li, Hanzi Mao, Ross Girshick, Kaiming He.
|
||||
1. **[ViTMAE](https://huggingface.co/docs/transformers/model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
|
||||
1. **[ViTMSN](https://huggingface.co/docs/transformers/model_doc/vit_msn)** (from Meta AI) released with the paper [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas.
|
||||
1. **[ViViT](https://huggingface.co/docs/transformers/main/model_doc/vivit)** (from Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
|
||||
1. **[VITS](https://huggingface.co/docs/transformers/model_doc/vits)** (from Kakao Enterprise) released with the paper [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103) by Jaehyeon Kim, Jungil Kong, Juhee Son.
|
||||
1. **[ViViT](https://huggingface.co/docs/transformers/model_doc/vivit)** (from Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
|
||||
1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
|
||||
1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
|
||||
1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
|
||||
|
||||
29
README_es.md
29
README_es.md
@@ -224,7 +224,7 @@ El modelo en si es un [Pytorch `nn.Module`](https://pytorch.org/docs/stable/nn.h
|
||||
|
||||
### Con pip
|
||||
|
||||
Este repositorio está probado en Python 3.6+, Flax 0.3.2+, PyTorch 1.3.1+ y TensorFlow 2.3+.
|
||||
Este repositorio está probado en Python 3.8+, Flax 0.4.1+, PyTorch 1.10+ y TensorFlow 2.6+.
|
||||
|
||||
Deberías instalar 🤗 Transformers en un [ambiente virtual](https://docs.python.org/3/library/venv.html). Si no estas familiarizado con los entornos virtuales de Python, consulta la [guía de usuario](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
|
||||
|
||||
@@ -268,7 +268,7 @@ Número actual de puntos de control: ** (from BAAI) released with the paper [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) by Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell.
|
||||
1. **[Audio Spectrogram Transformer](https://huggingface.co/docs/transformers/model_doc/audio-spectrogram-transformer)** (from MIT) released with the paper [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
|
||||
1. **[Autoformer](https://huggingface.co/docs/transformers/model_doc/autoformer)** (from Tsinghua University) released with the paper [Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008) by Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long.
|
||||
1. **[Bark](https://huggingface.co/docs/transformers/main/model_doc/bark)** (from Suno) released in the repository [suno-ai/bark](https://github.com/suno-ai/bark) by Suno AI team.
|
||||
1. **[Bark](https://huggingface.co/docs/transformers/model_doc/bark)** (from Suno) released in the repository [suno-ai/bark](https://github.com/suno-ai/bark) by Suno AI team.
|
||||
1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
|
||||
1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
|
||||
1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
|
||||
@@ -295,6 +295,7 @@ Número actual de puntos de control: ** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
|
||||
1. **[CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
|
||||
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
|
||||
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (from MetaAI) released with the paper [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) by Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.
|
||||
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
|
||||
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
|
||||
1. **[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
|
||||
@@ -314,6 +315,7 @@ Número actual de puntos de control: ** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
|
||||
1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
|
||||
1. **[DiNAT](https://huggingface.co/docs/transformers/model_doc/dinat)** (from SHI Labs) released with the paper [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) by Ali Hassani and Humphrey Shi.
|
||||
1. **[DINOv2](https://huggingface.co/docs/transformers/model_doc/dinov2)** (from Meta AI) released with the paper [DINOv2: Learning Robust Visual Features without Supervision](https://arxiv.org/abs/2304.07193) by Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski.
|
||||
1. **[DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation) and a German version of DistilBERT.
|
||||
1. **[DiT](https://huggingface.co/docs/transformers/model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
|
||||
1. **[Donut](https://huggingface.co/docs/transformers/model_doc/donut)** (from NAVER), released together with the paper [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) by Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park.
|
||||
@@ -322,12 +324,12 @@ Número actual de puntos de control: ** (from Snap Research) released with the paper [EfficientFormer: Vision Transformers at MobileNetSpeed](https://arxiv.org/abs/2206.01191) by Yanyu Li, Geng Yuan, Yang Wen, Ju Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren.
|
||||
1. **[EfficientNet](https://huggingface.co/docs/transformers/model_doc/efficientnet)** (from Google Brain) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan, Quoc V. Le.
|
||||
1. **[ELECTRA](https://huggingface.co/docs/transformers/model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
|
||||
1. **[EnCodec](https://huggingface.co/docs/transformers/main/model_doc/encodec)** (from Meta AI) released with the paper [High Fidelity Neural Audio Compression](https://arxiv.org/abs/2210.13438) by Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi.
|
||||
1. **[EnCodec](https://huggingface.co/docs/transformers/model_doc/encodec)** (from Meta AI) released with the paper [High Fidelity Neural Audio Compression](https://arxiv.org/abs/2210.13438) by Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi.
|
||||
1. **[EncoderDecoder](https://huggingface.co/docs/transformers/model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
|
||||
1. **[ERNIE](https://huggingface.co/docs/transformers/model_doc/ernie)** (from Baidu) released with the paper [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223) by Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu.
|
||||
1. **[ErnieM](https://huggingface.co/docs/transformers/model_doc/ernie_m)** (from Baidu) released with the paper [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang.
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2** was released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/main/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
|
||||
@@ -350,9 +352,10 @@ Número actual de puntos de control: ** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
|
||||
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
|
||||
1. **[I-BERT](https://huggingface.co/docs/transformers/model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
|
||||
1. **[IDEFICS](https://huggingface.co/docs/transformers/model_doc/idefics)** (from HuggingFace) released with the paper [OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents](https://huggingface.co/papers/2306.16527) by Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander M. Rush, Douwe Kiela, Matthieu Cord, Victor Sanh.
|
||||
1. **[ImageGPT](https://huggingface.co/docs/transformers/model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
|
||||
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
|
||||
1. **[InstructBLIP](https://huggingface.co/docs/transformers/main/model_doc/instructblip)** (from Salesforce) released with the paper [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
|
||||
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (from Salesforce) released with the paper [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
|
||||
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
|
||||
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
|
||||
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
|
||||
@@ -362,6 +365,7 @@ Número actual de puntos de control: ** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
|
||||
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
|
||||
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (from The FAIR team of Meta AI) released with the paper [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.
|
||||
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (from The FAIR team of Meta AI) released with the paper [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX) by Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom..
|
||||
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
|
||||
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
|
||||
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
|
||||
@@ -387,9 +391,10 @@ Número actual de puntos de control: ** (from Apple) released with the paper [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari.
|
||||
1. **[MobileViTV2](https://huggingface.co/docs/transformers/model_doc/mobilevitv2)** (from Apple) released with the paper [Separable Self-attention for Mobile Vision Transformers](https://arxiv.org/abs/2206.02680) by Sachin Mehta and Mohammad Rastegari.
|
||||
1. **[MPNet](https://huggingface.co/docs/transformers/model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/main/model_doc/mra)** (from the University of Wisconsin - Madison) released with the paper [Multi Resolution Analysis (MRA)](https://arxiv.org/abs/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh.
|
||||
1. **[MPT](https://huggingface.co/docs/transformers/model_doc/mpt)** (from MosaiML) released with the repository [llm-foundry](https://github.com/mosaicml/llm-foundry/) by the MosaicML NLP Team.
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (from the University of Wisconsin - Madison) released with the paper [Multi Resolution Analysis (MRA)](https://arxiv.org/abs/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh.
|
||||
1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
|
||||
1. **[MusicGen](https://huggingface.co/docs/transformers/main/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MusicGen](https://huggingface.co/docs/transformers/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
|
||||
1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (from SHI Labs) released with the paper [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
|
||||
1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
|
||||
@@ -407,7 +412,9 @@ Número actual de puntos de control: ** (from Google) released with the paper [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
|
||||
1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
|
||||
1. **[PoolFormer](https://huggingface.co/docs/transformers/model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
|
||||
1. **[Pop2Piano](https://huggingface.co/docs/transformers/model_doc/pop2piano)** released with the paper [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi, Kyogu Lee.
|
||||
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
|
||||
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (from Nanjing University, The University of Hong Kong etc.) released with the paper [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
|
||||
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
|
||||
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
|
||||
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
|
||||
@@ -446,7 +453,7 @@ Número actual de puntos de control: ** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
|
||||
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill) released with the paper [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
|
||||
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
|
||||
1. **[UMT5](https://huggingface.co/docs/transformers/main/model_doc/umt5)** (from Google Research) released with the paper [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
|
||||
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (from Google Research) released with the paper [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
|
||||
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
|
||||
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
|
||||
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
|
||||
@@ -456,9 +463,11 @@ Número actual de puntos de control: ](https://huggingface.co/docs/transformers/model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
|
||||
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
|
||||
1. **[ViT Hybrid](https://huggingface.co/docs/transformers/model_doc/vit_hybrid)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
|
||||
1. **[VitDet](https://huggingface.co/docs/transformers/model_doc/vitdet)** (from Meta AI) released with the paper [Exploring Plain Vision Transformer Backbones for Object Detection](https://arxiv.org/abs/2203.16527) by Yanghao Li, Hanzi Mao, Ross Girshick, Kaiming He.
|
||||
1. **[ViTMAE](https://huggingface.co/docs/transformers/model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
|
||||
1. **[ViTMSN](https://huggingface.co/docs/transformers/model_doc/vit_msn)** (from Meta AI) released with the paper [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas.
|
||||
1. **[ViViT](https://huggingface.co/docs/transformers/main/model_doc/vivit)** (from Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
|
||||
1. **[VITS](https://huggingface.co/docs/transformers/model_doc/vits)** (from Kakao Enterprise) released with the paper [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103) by Jaehyeon Kim, Jungil Kong, Juhee Son.
|
||||
1. **[ViViT](https://huggingface.co/docs/transformers/model_doc/vivit)** (from Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
|
||||
1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
|
||||
1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
|
||||
1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
|
||||
@@ -511,4 +520,4 @@ Ahora nosotros tenemos un [papel](https://www.aclweb.org/anthology/2020.emnlp-de
|
||||
url = "https://www.aclweb.org/anthology/2020.emnlp-demos.6",
|
||||
pages = "38--45"
|
||||
}
|
||||
```
|
||||
```
|
||||
31
README_hd.md
31
README_hd.md
@@ -200,7 +200,7 @@ checkpoint: जाँच बिंदु
|
||||
|
||||
### पिप का उपयोग करना
|
||||
|
||||
इस रिपॉजिटरी का परीक्षण Python 3.6+, Flax 0.3.2+, PyTorch 1.3.1+ और TensorFlow 2.3+ के तहत किया गया है।
|
||||
इस रिपॉजिटरी का परीक्षण Python 3.8+, Flax 0.4.1+, PyTorch 1.10+ और TensorFlow 2.6+ के तहत किया गया है।
|
||||
|
||||
आप [वर्चुअल एनवायरनमेंट] (https://docs.python.org/3/library/venv.html) में 🤗 ट्रांसफॉर्मर इंस्टॉल कर सकते हैं। यदि आप अभी तक पायथन के वर्चुअल एनवायरनमेंट से परिचित नहीं हैं, तो कृपया इसे [उपयोगकर्ता निर्देश] (https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/) पढ़ें।
|
||||
|
||||
@@ -240,7 +240,7 @@ conda install -c huggingface transformers
|
||||
1. **[AltCLIP](https://huggingface.co/docs/transformers/model_doc/altclip)** (from BAAI) released with the paper [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) by Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell.
|
||||
1. **[Audio Spectrogram Transformer](https://huggingface.co/docs/transformers/model_doc/audio-spectrogram-transformer)** (from MIT) released with the paper [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
|
||||
1. **[Autoformer](https://huggingface.co/docs/transformers/model_doc/autoformer)** (from Tsinghua University) released with the paper [Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008) by Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long.
|
||||
1. **[Bark](https://huggingface.co/docs/transformers/main/model_doc/bark)** (from Suno) released in the repository [suno-ai/bark](https://github.com/suno-ai/bark) by Suno AI team.
|
||||
1. **[Bark](https://huggingface.co/docs/transformers/model_doc/bark)** (from Suno) released in the repository [suno-ai/bark](https://github.com/suno-ai/bark) by Suno AI team.
|
||||
1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (फेसबुक) साथ थीसिस [बार्ट: प्राकृतिक भाषा निर्माण, अनुवाद के लिए अनुक्रम-से-अनुक्रम पूर्व प्रशिक्षण , और समझ] (https://arxiv.org/pdf/1910.13461.pdf) पर निर्भर माइक लुईस, यिनहान लियू, नमन गोयल, मार्जन ग़ज़विनिनेजाद, अब्देलरहमान मोहम्मद, ओमर लेवी, वेस स्टोयानोव और ल्यूक ज़ेटलमॉयर
|
||||
1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (से École polytechnique) साथ थीसिस [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) पर निर्भर Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis रिहाई।
|
||||
1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (VinAI Research से) साथ में पेपर [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701)गुयेन लुओंग ट्रान, डुओंग मिन्ह ले और डाट क्वोक गुयेन द्वारा पोस्ट किया गया।
|
||||
@@ -267,6 +267,7 @@ conda install -c huggingface transformers
|
||||
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (OpenAI से) साथ वाला पेपर [लर्निंग ट्रांसफरेबल विजुअल मॉडल फ्रॉम नेचुरल लैंग्वेज सुपरविजन](https://arxiv.org /abs/2103.00020) एलेक रैडफोर्ड, जोंग वूक किम, क्रिस हैलासी, आदित्य रमेश, गेब्रियल गोह, संध्या अग्रवाल, गिरीश शास्त्री, अमांडा एस्केल, पामेला मिश्किन, जैक क्लार्क, ग्रेचेन क्रुएगर, इल्या सुत्स्केवर द्वारा।
|
||||
1. **[CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
|
||||
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (सेल्सफोर्स से) साथ में पेपर [प्रोग्राम सिंथेसिस के लिए एक संवादात्मक प्रतिमान](https://arxiv.org/abs/2203.13474) एरिक निजकैंप, बो पैंग, हिरोआकी हयाशी, लिफू तू, हुआन वांग, यिंगबो झोउ, सिल्वियो सावरेस, कैमिंग जिओंग रिलीज।
|
||||
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (MetaAI से) Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve. द्वाराअनुसंधान पत्र [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) के साथ जारी किया गया
|
||||
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (माइक्रोसॉफ्ट रिसर्च एशिया से) कागज के साथ [फास्ट ट्रेनिंग कन्वर्जेंस के लिए सशर्त डीईटीआर](https://arxiv. org/abs/2108.06152) डेपू मेंग, ज़ियाओकांग चेन, ज़ेजिया फैन, गैंग ज़ेंग, होउकियांग ली, युहुई युआन, लेई सन, जिंगडोंग वांग द्वारा।
|
||||
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (YituTech से) साथ में कागज [ConvBERT: स्पैन-आधारित डायनेमिक कनवल्शन के साथ BERT में सुधार](https://arxiv .org/abs/2008.02496) जिहांग जियांग, वीहाओ यू, डाकान झोउ, युनपेंग चेन, जियाशी फेंग, शुइचेंग यान द्वारा।
|
||||
1. **[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)** (Facebook AI से) साथ वाला पेपर [A ConvNet for the 2020s](https://arxiv.org/abs /2201.03545) ज़ुआंग लियू, हेंज़ी माओ, चाओ-युआन वू, क्रिस्टोफ़ फीचटेनहोफ़र, ट्रेवर डेरेल, सैनिंग ज़ी द्वारा।
|
||||
@@ -286,6 +287,7 @@ conda install -c huggingface transformers
|
||||
1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (फेसबुक से) साथ में कागज [ट्रांसफॉर्मर्स के साथ एंड-टू-एंड ऑब्जेक्ट डिटेक्शन](https://arxiv. org/abs/2005.12872) निकोलस कैरियन, फ़्रांसिस्को मस्सा, गेब्रियल सिनेव, निकोलस उसुनियर, अलेक्जेंडर किरिलोव, सर्गेई ज़ागोरुयको द्वारा।
|
||||
1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (माइक्रोसॉफ्ट रिसर्च से) कागज के साथ [DialoGPT: बड़े पैमाने पर जनरेटिव प्री-ट्रेनिंग फॉर कन्वर्सेशनल रिस्पांस जेनरेशन](https ://arxiv.org/abs/1911.00536) यिज़े झांग, सिकी सन, मिशेल गैली, येन-चुन चेन, क्रिस ब्रोकेट, जियांग गाओ, जियानफेंग गाओ, जिंगजिंग लियू, बिल डोलन द्वारा।
|
||||
1. **[DiNAT](https://huggingface.co/docs/transformers/model_doc/dinat)** (from SHI Labs) released with the paper [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) by Ali Hassani and Humphrey Shi.
|
||||
1. **[DINOv2](https://huggingface.co/docs/transformers/model_doc/dinov2)** (Meta AI से) Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski. द्वाराअनुसंधान पत्र [DINOv2: Learning Robust Visual Features without Supervision](https://arxiv.org/abs/2304.07193) के साथ जारी किया गया
|
||||
1. **[DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)** (हगिंगफेस से), साथ में कागज [डिस्टिलबर्ट, बीईआरटी का डिस्टिल्ड वर्जन: छोटा, तेज, सस्ता और हल्का] (https://arxiv.org/abs/1910.01108) विक्टर सनह, लिसांड्रे डेब्यू और थॉमस वुल्फ द्वारा पोस्ट किया गया। यही तरीका GPT-2 को [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/distillation), RoBERta से [DistilRoBERta](https://github.com) पर कंप्रेस करने के लिए भी लागू किया जाता है। / हगिंगफेस/ट्रांसफॉर्मर्स/ट्री/मेन/उदाहरण/डिस्टिलेशन), बहुभाषी BERT से [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/distillation) और डिस्टिलबर्ट का जर्मन संस्करण।
|
||||
1. **[DiT](https://huggingface.co/docs/transformers/model_doc/dit)** (माइक्रोसॉफ्ट रिसर्च से) साथ में पेपर [DiT: सेल्फ सुपरवाइज्ड प्री-ट्रेनिंग फॉर डॉक्यूमेंट इमेज ट्रांसफॉर्मर](https://arxiv.org/abs/2203.02378) जुनलॉन्ग ली, यिहेंग जू, टेंगचाओ लव, लेई कुई, चा झांग द्वारा फुरु वेई द्वारा पोस्ट किया गया।
|
||||
1. **[Donut](https://huggingface.co/docs/transformers/model_doc/donut)** (NAVER से) साथ में कागज [OCR-मुक्त डॉक्यूमेंट अंडरस्टैंडिंग ट्रांसफॉर्मर](https://arxiv.org/abs /2111.15664) गीवूक किम, टीकग्यू होंग, मूनबिन यिम, जियोंग्योन नाम, जिनयॉन्ग पार्क, जिनयॉन्ग यिम, वोनसेओक ह्वांग, सांगडू यूं, डोंगयून हान, सेउंग्युन पार्क द्वारा।
|
||||
@@ -294,12 +296,12 @@ conda install -c huggingface transformers
|
||||
1. **[EfficientFormer](https://huggingface.co/docs/transformers/model_doc/efficientformer)** (from Snap Research) released with the paper [EfficientFormer: Vision Transformers at MobileNetSpeed](https://arxiv.org/abs/2206.01191) by Yanyu Li, Geng Yuan, Yang Wen, Ju Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren.
|
||||
1. **[EfficientNet](https://huggingface.co/docs/transformers/model_doc/efficientnet)** (from Google Brain) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan, Quoc V. Le.
|
||||
1. **[ELECTRA](https://huggingface.co/docs/transformers/model_doc/electra)** (Google रिसर्च/स्टैनफोर्ड यूनिवर्सिटी से) साथ में दिया गया पेपर [इलेक्ट्रा: जेनरेटर के बजाय भेदभाव करने वाले के रूप में टेक्स्ट एन्कोडर्स का पूर्व-प्रशिक्षण] (https://arxiv.org/abs/2003.10555) केविन क्लार्क, मिन्ह-थांग लुओंग, क्वोक वी. ले, क्रिस्टोफर डी. मैनिंग द्वारा पोस्ट किया गया।
|
||||
1. **[EnCodec](https://huggingface.co/docs/transformers/main/model_doc/encodec)** (Meta AI से) Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi. द्वाराअनुसंधान पत्र [High Fidelity Neural Audio Compression](https://arxiv.org/abs/2210.13438) के साथ जारी किया गया
|
||||
1. **[EnCodec](https://huggingface.co/docs/transformers/model_doc/encodec)** (Meta AI से) Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi. द्वाराअनुसंधान पत्र [High Fidelity Neural Audio Compression](https://arxiv.org/abs/2210.13438) के साथ जारी किया गया
|
||||
1. **[EncoderDecoder](https://huggingface.co/docs/transformers/model_doc/encoder-decoder)** (Google रिसर्च से) साथ में दिया गया पेपर [सीक्वेंस जेनरेशन टास्क के लिए प्री-ट्रेंड चेकपॉइंट का इस्तेमाल करना](https:/ /arxiv.org/abs/1907.12461) साशा रोठे, शशि नारायण, अलियाक्सि सेवेरिन द्वारा।
|
||||
1. **[ERNIE](https://huggingface.co/docs/transformers/model_doc/ernie)**(Baidu से) साथ देने वाला पेपर [ERNIE: एन्हांस्ड रिप्रेजेंटेशन थ्रू नॉलेज इंटीग्रेशन](https://arxiv.org/abs/1904.09223) यू सन, शुओहुआन वांग, युकुन ली, शिकुन फेंग, ज़ुई चेन, हान झांग, शिन तियान, डैनक्सियांग झू, हाओ तियान, हुआ वू द्वारा पोस्ट किया गया।
|
||||
1. **[ErnieM](https://huggingface.co/docs/transformers/model_doc/ernie_m)** (Baidu से) Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang. द्वाराअनुसंधान पत्र [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) के साथ जारी किया गया
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (मेटा AI से) ट्रांसफॉर्मर प्रोटीन भाषा मॉडल हैं। **ESM-1b** पेपर के साथ जारी किया गया था [ अलेक्जेंडर राइव्स, जोशुआ मेयर, टॉम सर्कु, सिद्धार्थ गोयल, ज़ेमिंग लिन द्वारा जैविक संरचना और कार्य असुरक्षित सीखने को 250 मिलियन प्रोटीन अनुक्रमों तक स्केल करने से उभरता है] (https://www.pnas.org/content/118/15/e2016239118) जेसन लियू, डेमी गुओ, मायल ओट, सी. लॉरेंस ज़िटनिक, जेरी मा और रॉब फर्गस। **ESM-1v** को पेपर के साथ जारी किया गया था [भाषा मॉडल प्रोटीन फ़ंक्शन पर उत्परिवर्तन के प्रभावों की शून्य-शॉट भविष्यवाणी को सक्षम करते हैं] (https://doi.org/10.1101/2021.07.09.450648) जोशुआ मेयर, रोशन राव, रॉबर्ट वेरकुइल, जेसन लियू, टॉम सर्कु और अलेक्जेंडर राइव्स द्वारा। **ESM-2** को पेपर के साथ जारी किया गया था [भाषा मॉडल विकास के पैमाने पर प्रोटीन अनुक्रम सटीक संरचना भविष्यवाणी को सक्षम करते हैं](https://doi.org/10.1101/2022.07.20.500902) ज़ेमिंग लिन, हलील अकिन, रोशन राव, ब्रायन ही, झोंगकाई झू, वेंटिंग लू, ए द्वारा लान डॉस सैंटोस कोस्टा, मरियम फ़ज़ल-ज़रंडी, टॉम सर्कू, साल कैंडिडो, अलेक्जेंडर राइव्स।
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/main/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (CNRS से) साथ वाला पेपर [FlauBERT: Unsupervised Language Model Pre-training for फ़्रेंच](https://arxiv .org/abs/1912.05372) Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, बेंजामिन लेकोउटेक्स, अलेक्जेंड्रे अल्लाउज़ेन, बेनोइट क्रैबे, लॉरेंट बेसेसियर, डिडिएर श्वाब द्वारा।
|
||||
@@ -322,9 +324,10 @@ conda install -c huggingface transformers
|
||||
1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (UCSD, NVIDIA से) साथ में कागज [GroupViT: टेक्स्ट सुपरविजन से सिमेंटिक सेगमेंटेशन इमर्जेस](https://arxiv .org/abs/2202.11094) जियारुई जू, शालिनी डी मेलो, सिफ़ी लियू, वोनमिन बायन, थॉमस ब्रेउएल, जान कौट्ज़, ज़ियाओलोंग वांग द्वारा।
|
||||
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (फेसबुक से) साथ में पेपर [ह्यूबर्ट: सेल्फ सुपरवाइज्ड स्पीच रिप्रेजेंटेशन लर्निंग बाय मास्क्ड प्रेडिक्शन ऑफ हिडन यूनिट्स](https ://arxiv.org/abs/2106.07447) वेई-निंग सू, बेंजामिन बोल्टे, याओ-हंग ह्यूबर्ट त्साई, कुशाल लखोटिया, रुस्लान सालाखुतदीनोव, अब्देलरहमान मोहम्मद द्वारा।
|
||||
1. **[I-BERT](https://huggingface.co/docs/transformers/model_doc/ibert)** (बर्कले से) साथ में कागज [I-BERT: Integer-only BERT Quantization](https:// arxiv.org/abs/2101.01321) सेहून किम, अमीर घोलमी, ज़ेवेई याओ, माइकल डब्ल्यू महोनी, कर्ट केटज़र द्वारा।
|
||||
1. **[IDEFICS](https://huggingface.co/docs/transformers/model_doc/idefics)** (from HuggingFace) released with the paper [OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents](https://huggingface.co/papers/2306.16527) by Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander M. Rush, Douwe Kiela, Matthieu Cord, Victor Sanh.
|
||||
1. **[ImageGPT](https://huggingface.co/docs/transformers/model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
|
||||
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
|
||||
1. **[InstructBLIP](https://huggingface.co/docs/transformers/main/model_doc/instructblip)** (Salesforce से) Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi. द्वाराअनुसंधान पत्र [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) के साथ जारी किया गया
|
||||
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (Salesforce से) Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi. द्वाराअनुसंधान पत्र [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) के साथ जारी किया गया
|
||||
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
|
||||
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
|
||||
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
|
||||
@@ -334,6 +337,7 @@ conda install -c huggingface transformers
|
||||
1. **[LeViT](https://huggingface.co/docs/transformers/model_doc/levit)** (मेटा AI से) साथ वाला पेपर [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https:/ /arxiv.org/abs/2104.01136) बेन ग्राहम, अलाएल्डिन एल-नौबी, ह्यूगो टौवरन, पियरे स्टॉक, आर्मंड जौलिन, हर्वे जेगौ, मैथिज डूज़ द्वारा।
|
||||
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (दक्षिण चीन प्रौद्योगिकी विश्वविद्यालय से) साथ में कागज [LiLT: एक सरल लेकिन प्रभावी भाषा-स्वतंत्र लेआउट ट्रांसफार्मर संरचित दस्तावेज़ समझ के लिए](https://arxiv.org/abs/2202.13669) जियापेंग वांग, लियानवेन जिन, काई डिंग द्वारा पोस्ट किया गया।
|
||||
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (The FAIR team of Meta AI से) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample. द्वाराअनुसंधान पत्र [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) के साथ जारी किया गया
|
||||
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (The FAIR team of Meta AI से) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom.. द्वाराअनुसंधान पत्र [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX) के साथ जारी किया गया
|
||||
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
|
||||
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (मैंडी गुओ, जोशुआ आइंस्ली, डेविड यूथस, सैंटियागो ओंटानन, जियानमो नि, यूं-हुआन सुंग, यिनफेई यांग द्वारा पोस्ट किया गया।
|
||||
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (स्टूडियो औसिया से) साथ में पेपर [LUKE: डीप कॉन्टेक्स्टुअलाइज्ड एंटिटी रिप्रेजेंटेशन विद एंटिटी-अवेयर सेल्फ-अटेंशन](https ://arxiv.org/abs/2010.01057) Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto द्वारा।
|
||||
@@ -359,9 +363,10 @@ conda install -c huggingface transformers
|
||||
1. **[MobileViT](https://huggingface.co/docs/transformers/model_doc/mobilevit)** (Apple से) साथ में कागज [MobileViT: लाइट-वेट, जनरल-पर्पस, और मोबाइल-फ्रेंडली विजन ट्रांसफॉर्मर] (https://arxiv.org/abs/2110.02178) सचिन मेहता और मोहम्मद रस्तगरी द्वारा पोस्ट किया गया।
|
||||
1. **[MobileViTV2](https://huggingface.co/docs/transformers/model_doc/mobilevitv2)** (Apple से) Sachin Mehta and Mohammad Rastegari. द्वाराअनुसंधान पत्र [Separable Self-attention for Mobile Vision Transformers](https://arxiv.org/abs/2206.02680) के साथ जारी किया गया
|
||||
1. **[MPNet](https://huggingface.co/docs/transformers/model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/main/model_doc/mra)** (the University of Wisconsin - Madison से) Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh. द्वाराअनुसंधान पत्र [Multi Resolution Analysis (MRA)](https://arxiv.org/abs/2207.10284) के साथ जारी किया गया
|
||||
1. **[MPT](https://huggingface.co/docs/transformers/model_doc/mpt)** (MosaiML से) the MosaicML NLP Team. द्वाराअनुसंधान पत्र [llm-foundry](https://github.com/mosaicml/llm-foundry/) के साथ जारी किया गया
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (the University of Wisconsin - Madison से) Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh. द्वाराअनुसंधान पत्र [Multi Resolution Analysis (MRA)](https://arxiv.org/abs/2207.10284) के साथ जारी किया गया
|
||||
1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (Google AI से) साथ वाला पेपर [mT5: एक व्यापक बहुभाषी पूर्व-प्रशिक्षित टेक्स्ट-टू-टेक्स्ट ट्रांसफॉर्मर]( https://arxiv.org/abs/2010.11934) लिंटिंग ज़ू, नोआ कॉन्सटेंट, एडम रॉबर्ट्स, मिहिर काले, रामी अल-रफू, आदित्य सिद्धांत, आदित्य बरुआ, कॉलिन रैफेल द्वारा पोस्ट किया गया।
|
||||
1. **[MusicGen](https://huggingface.co/docs/transformers/main/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MusicGen](https://huggingface.co/docs/transformers/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
|
||||
1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (from SHI Labs) released with the paper [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
|
||||
1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (हुआवेई नूह के आर्क लैब से) साथ में कागज़ [NEZHA: चीनी भाषा समझ के लिए तंत्रिका प्रासंगिक प्रतिनिधित्व](https :/ /arxiv.org/abs/1909.00204) जुन्किउ वेई, ज़ियाओज़े रेन, ज़िआओगुआंग ली, वेनयोंग हुआंग, यी लियाओ, याशेंग वांग, जियाशू लिन, शिन जियांग, जिओ चेन और कुन लियू द्वारा।
|
||||
@@ -369,7 +374,7 @@ conda install -c huggingface transformers
|
||||
1. **[NLLB-MOE](https://huggingface.co/docs/transformers/model_doc/nllb-moe)** (Meta से) the NLLB team. द्वाराअनुसंधान पत्र [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) के साथ जारी किया गया
|
||||
1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (विस्कॉन्सिन विश्वविद्यालय - मैडिसन से) साथ में कागज [Nyströmformer: A Nyström- आधारित एल्गोरिथम आत्म-ध्यान का अनुमान लगाने के लिए ](https://arxiv.org/abs/2102.03902) युनयांग ज़िओंग, झानपेंग ज़ेंग, रुद्रसिस चक्रवर्ती, मिंगक्सिंग टैन, ग्लेन फंग, यिन ली, विकास सिंह द्वारा पोस्ट किया गया।
|
||||
1. **[OneFormer](https://huggingface.co/docs/transformers/model_doc/oneformer)** (SHI Labs से) पेपर [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) जितेश जैन, जिआचेन ली, मांगटिक चिउ, अली हसनी, निकिता ओरलोव, हम्फ्री शि के द्वारा जारी किया गया है।
|
||||
1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released in [Open-Llama](https://github.com/s-JoL/Open-Llama).
|
||||
1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released in [Open-Llama](https://github.com/s-JoL/Open-Llama).
|
||||
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
|
||||
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (Google AI से) साथ में कागज [विज़न ट्रांसफॉर्मर्स के साथ सिंपल ओपन-वोकैबुलरी ऑब्जेक्ट डिटेक्शन](https:/ /arxiv.org/abs/2205.06230) मैथियास मिंडरर, एलेक्सी ग्रिट्सेंको, ऑस्टिन स्टोन, मैक्सिम न्यूमैन, डिर्क वीसेनबोर्न, एलेक्सी डोसोवित्स्की, अरविंद महेंद्रन, अनुराग अर्नब, मुस्तफा देहघानी, ज़ुओरन शेन, जिओ वांग, ज़ियाओहुआ झाई, थॉमस किफ़, और नील हॉल्सबी द्वारा पोस्ट किया गया।
|
||||
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
|
||||
@@ -379,7 +384,9 @@ conda install -c huggingface transformers
|
||||
1. **[Pix2Struct](https://huggingface.co/docs/transformers/model_doc/pix2struct)** (Google से) Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova. द्वाराअनुसंधान पत्र [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) के साथ जारी किया गया
|
||||
1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (UCLA NLP से) साथ वाला पेपर [प्रोग्राम अंडरस्टैंडिंग एंड जेनरेशन के लिए यूनिफाइड प्री-ट्रेनिंग](https://arxiv .org/abs/2103.06333) वसी उद्दीन अहमद, सैकत चक्रवर्ती, बैशाखी रे, काई-वेई चांग द्वारा।
|
||||
1. **[PoolFormer](https://huggingface.co/docs/transformers/model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
|
||||
1. **[Pop2Piano](https://huggingface.co/docs/transformers/model_doc/pop2piano)** released with the paper [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi, Kyogu Lee.
|
||||
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (माइक्रोसॉफ्ट रिसर्च से) साथ में पेपर [ProphetNet: प्रेडिक्टिंग फ्यूचर एन-ग्राम फॉर सीक्वेंस-टू-सीक्वेंस प्री-ट्रेनिंग ](https://arxiv.org/abs/2001.04063) यू यान, वीज़ेन क्यूई, येयुन गोंग, दयाहेंग लियू, नान डुआन, जिउशेंग चेन, रुओफ़ेई झांग और मिंग झोउ द्वारा पोस्ट किया गया।
|
||||
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (Nanjing University, The University of Hong Kong etc. से) Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao. द्वाराअनुसंधान पत्र [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf) के साथ जारी किया गया
|
||||
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (NVIDIA से) साथ वाला पेपर [डीप लर्निंग इंफ़ेक्शन के लिए इंटीजर क्वांटिज़ेशन: प्रिंसिपल्स एंड एम्पिरिकल इवैल्यूएशन](https:// arxiv.org/abs/2004.09602) हाओ वू, पैट्रिक जुड, जिआओजी झांग, मिखाइल इसेव और पॉलियस माइकेविसियस द्वारा।
|
||||
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (फेसबुक से) साथ में कागज [रिट्रीवल-ऑगमेंटेड जेनरेशन फॉर नॉलेज-इंटेंसिव एनएलपी टास्क](https://arxiv .org/abs/2005.11401) पैट्रिक लुईस, एथन पेरेज़, अलेक्जेंड्रा पिक्टस, फैबियो पेट्रोनी, व्लादिमीर कारपुखिन, नमन गोयल, हेनरिक कुटलर, माइक लुईस, वेन-ताउ यिह, टिम रॉकटाशेल, सेबस्टियन रिडेल, डौवे कीला द्वारा।
|
||||
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (Google अनुसंधान से) केल्विन गु, केंटन ली, ज़ोरा तुंग, पानुपोंग पसुपत और मिंग-वेई चांग द्वारा साथ में दिया गया पेपर [REALM: रिट्रीवल-ऑगमेंटेड लैंग्वेज मॉडल प्री-ट्रेनिंग](https://arxiv.org/abs/2002.08909)।
|
||||
@@ -418,7 +425,7 @@ conda install -c huggingface transformers
|
||||
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (from Microsoft) released with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
|
||||
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill) released with the paper [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
|
||||
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
|
||||
1. **[UMT5](https://huggingface.co/docs/transformers/main/model_doc/umt5)** (Google Research से) Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant. द्वाराअनुसंधान पत्र [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) के साथ जारी किया गया
|
||||
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (Google Research से) Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant. द्वाराअनुसंधान पत्र [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) के साथ जारी किया गया
|
||||
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (माइक्रोसॉफ्ट रिसर्च से) साथ में दिया गया पेपर [UniSpeech: यूनिफाइड स्पीच रिप्रेजेंटेशन लर्निंग विद लेबलेड एंड अनलेबल्ड डेटा](https:/ /arxiv.org/abs/2101.07597) चेंगई वांग, यू वू, याओ कियान, केनिची कुमातानी, शुजी लियू, फुरु वेई, माइकल ज़ेंग, ज़ुएदोंग हुआंग द्वारा।
|
||||
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (माइक्रोसॉफ्ट रिसर्च से) कागज के साथ [UNISPEECH-SAT: यूनिवर्सल स्पीच रिप्रेजेंटेशन लर्निंग विद स्पीकर अवेयर प्री-ट्रेनिंग ](https://arxiv.org/abs/2110.05752) सानयुआन चेन, यू वू, चेंग्यी वांग, झेंगयांग चेन, झूओ चेन, शुजी लियू, जियान वू, याओ कियान, फुरु वेई, जिन्यु ली, जियांगज़ान यू द्वारा पोस्ट किया गया।
|
||||
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
|
||||
@@ -428,9 +435,11 @@ conda install -c huggingface transformers
|
||||
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (गूगल एआई से) कागज के साथ [एक इमेज इज़ वर्थ 16x16 वर्ड्स: ट्रांसफॉर्मर्स फॉर इमेज रिकॉग्निशन एट स्केल](https://arxiv.org/abs/2010.11929) एलेक्सी डोसोवित्स्की, लुकास बेयर, अलेक्जेंडर कोलेसनिकोव, डिर्क वीसेनबोर्न, शियाओहुआ झाई, थॉमस अनटरथिनर, मुस्तफा देहघानी, मैथियास मिंडरर, जॉर्ज हेगोल्ड, सिल्वेन गेली, जैकब उस्ज़कोरेइट द्वारा हॉल्सबी द्वारा पोस्ट किया गया।
|
||||
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (UCLA NLP से) साथ वाला पेपर [VisualBERT: A Simple and Performant Baseline for Vision and Language](https:/ /arxiv.org/pdf/1908.03557) लियुनियन हेरोल्ड ली, मार्क यात्स्कर, दा यिन, चो-जुई हसीह, काई-वेई चांग द्वारा।
|
||||
1. **[ViT Hybrid](https://huggingface.co/docs/transformers/model_doc/vit_hybrid)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
|
||||
1. **[VitDet](https://huggingface.co/docs/transformers/model_doc/vitdet)** (Meta AI से) Yanghao Li, Hanzi Mao, Ross Girshick, Kaiming He. द्वाराअनुसंधान पत्र [Exploring Plain Vision Transformer Backbones for Object Detection](https://arxiv.org/abs/2203.16527) के साथ जारी किया गया
|
||||
1. **[ViTMAE](https://huggingface.co/docs/transformers/model_doc/vit_mae)** (मेटा एआई से) साथ में कागज [मास्कड ऑटोएन्कोडर स्केलेबल विजन लर्नर्स हैं](https://arxiv.org/ एब्स/2111.06377) कैमिंग हे, ज़िनेली चेन, सेनिंग ज़ी, यांगहो ली, पिओट्र डॉलर, रॉस गिर्शिक द्वारा।
|
||||
1. **[ViTMSN](https://huggingface.co/docs/transformers/model_doc/vit_msn)** (मेटा एआई से) साथ में कागज [लेबल-कुशल सीखने के लिए मास्क्ड स्याम देश के नेटवर्क](https://arxiv. org/abs/2204.07141) महमूद असरान, मथिल्डे कैरन, ईशान मिश्रा, पियोट्र बोजानोवस्की, फ्लोरियन बोर्डेस, पास्कल विंसेंट, आर्मंड जौलिन, माइकल रब्बत, निकोलस बल्लास द्वारा।
|
||||
1. **[ViViT](https://huggingface.co/docs/transformers/main/model_doc/vivit)** (from Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
|
||||
1. **[VITS](https://huggingface.co/docs/transformers/model_doc/vits)** (Kakao Enterprise से) Jaehyeon Kim, Jungil Kong, Juhee Son. द्वाराअनुसंधान पत्र [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103) के साथ जारी किया गया
|
||||
1. **[ViViT](https://huggingface.co/docs/transformers/model_doc/vivit)** (from Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
|
||||
1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (फेसबुक एआई से) साथ में पेपर [wav2vec 2.0: ए फ्रेमवर्क फॉर सेल्फ-सुपरवाइज्ड लर्निंग ऑफ स्पीच रिप्रेजेंटेशन] (https://arxiv.org/abs/2006.11477) एलेक्सी बेवस्की, हेनरी झोउ, अब्देलरहमान मोहम्मद, माइकल औली द्वारा।
|
||||
1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (Facebook AI से) साथ वाला पेपर [FAIRSEQ S2T: FAIRSEQ के साथ फास्ट स्पीच-टू-टेक्स्ट मॉडलिंग ](https://arxiv.org/abs/2010.05171) चांगहान वांग, यूं तांग, जुताई मा, ऐनी वू, सरव्या पोपुरी, दिमित्रो ओखोनको, जुआन पिनो द्वारा पोस्ट किया गया।
|
||||
1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (Facebook AI से) साथ वाला पेपर [सरल और प्रभावी जीरो-शॉट क्रॉस-लिंगुअल फोनेम रिकॉग्निशन](https:/ /arxiv.org/abs/2109.11680) कियानटोंग जू, एलेक्सी बाएव्स्की, माइकल औली द्वारा।
|
||||
@@ -451,7 +460,7 @@ conda install -c huggingface transformers
|
||||
1. **[YOSO](https://huggingface.co/docs/transformers/model_doc/yoso)** (विस्कॉन्सिन विश्वविद्यालय - मैडिसन से) साथ में पेपर [यू ओनली सैंपल (लगभग) ज़ानपेंग ज़ेंग, युनयांग ज़िओंग द्वारा , सत्य एन. रवि, शैलेश आचार्य, ग्लेन फंग, विकास सिंह द्वारा पोस्ट किया गया।
|
||||
1. एक नए मॉडल में योगदान देना चाहते हैं? नए मॉडल जोड़ने में आपका मार्गदर्शन करने के लिए हमारे पास एक **विस्तृत मार्गदर्शिका और टेम्प्लेट** है। आप उन्हें [`टेम्पलेट्स`](./templates) निर्देशिका में पा सकते हैं। पीआर शुरू करने से पहले [योगदान दिशानिर्देश] (./CONTRIBUTING.md) देखना और अनुरक्षकों से संपर्क करना या प्रतिक्रिया प्राप्त करने के लिए एक नया मुद्दा खोलना याद रखें।
|
||||
|
||||
यह जांचने के लिए कि क्या किसी मॉडल में पहले से ही Flax, PyTorch या TensorFlow का कार्यान्वयन है, या यदि उसके पास Tokenizers लाइब्रेरी में संबंधित टोकन है, तो [यह तालिका] (https://huggingface.co/ docs/transformers/index#supported) देखें। -फ्रेमवर्क)।
|
||||
यह जांचने के लिए कि क्या किसी मॉडल में पहले से ही Flax, PyTorch या TensorFlow का कार्यान्वयन है, या यदि उसके पास Tokenizers लाइब्रेरी में संबंधित टोकन है, तो [यह तालिका](https://huggingface.co/docs/transformers/index#supported) देखें। -फ्रेमवर्क)।
|
||||
|
||||
इन कार्यान्वयनों का परीक्षण कई डेटासेट पर किया गया है (देखें केस स्क्रिप्ट का उपयोग करें) और वैनिला कार्यान्वयन के लिए तुलनात्मक रूप से प्रदर्शन करना चाहिए। आप उपयोग के मामले के दस्तावेज़ [इस अनुभाग](https://huggingface.co/docs/transformers/examples) में व्यवहार का विवरण पढ़ सकते हैं।
|
||||
|
||||
|
||||
29
README_ja.md
29
README_ja.md
@@ -258,7 +258,7 @@ And here is the equivalent code for TensorFlow:
|
||||
|
||||
### pipにて
|
||||
|
||||
このリポジトリは、Python 3.6+, Flax 0.3.2+, PyTorch 1.3.1+, TensorFlow 2.3+ でテストされています。
|
||||
このリポジトリは、Python 3.8+, Flax 0.4.1+, PyTorch 1.10+, TensorFlow 2.6+ でテストされています。
|
||||
|
||||
🤗Transformersは[仮想環境](https://docs.python.org/3/library/venv.html)にインストールする必要があります。Pythonの仮想環境に慣れていない場合は、[ユーザーガイド](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/)を確認してください。
|
||||
|
||||
@@ -302,7 +302,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
|
||||
1. **[AltCLIP](https://huggingface.co/docs/transformers/model_doc/altclip)** (BAAI から) Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell から公開された研究論文: [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679)
|
||||
1. **[Audio Spectrogram Transformer](https://huggingface.co/docs/transformers/model_doc/audio-spectrogram-transformer)** (MIT から) Yuan Gong, Yu-An Chung, James Glass から公開された研究論文: [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778)
|
||||
1. **[Autoformer](https://huggingface.co/docs/transformers/model_doc/autoformer)** (from Tsinghua University) released with the paper [Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008) by Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long.
|
||||
1. **[Bark](https://huggingface.co/docs/transformers/main/model_doc/bark)** (from Suno) released in the repository [suno-ai/bark](https://github.com/suno-ai/bark) by Suno AI team.
|
||||
1. **[Bark](https://huggingface.co/docs/transformers/model_doc/bark)** (from Suno) released in the repository [suno-ai/bark](https://github.com/suno-ai/bark) by Suno AI team.
|
||||
1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (Facebook から) Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer から公開された研究論文: [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461)
|
||||
1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (École polytechnique から) Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis から公開された研究論文: [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321)
|
||||
1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (VinAI Research から) Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen から公開された研究論文: [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701)
|
||||
@@ -329,6 +329,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
|
||||
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (OpenAI から) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever から公開された研究論文: [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020)
|
||||
1. **[CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)** (University of Göttingen から) Timo Lüddecke and Alexander Ecker から公開された研究論文: [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003)
|
||||
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (Salesforce から) Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong から公開された研究論文: [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474)
|
||||
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (MetaAI から) Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve. から公開された研究論文 [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/)
|
||||
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (Microsoft Research Asia から) Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang から公開された研究論文: [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152)
|
||||
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (YituTech から) Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan から公開された研究論文: [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496)
|
||||
1. **[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)** (Facebook AI から) Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie から公開された研究論文: [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545)
|
||||
@@ -348,6 +349,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
|
||||
1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (Facebook から) Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko から公開された研究論文: [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872)
|
||||
1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (Microsoft Research から) Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan から公開された研究論文: [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536)
|
||||
1. **[DiNAT](https://huggingface.co/docs/transformers/model_doc/dinat)** (SHI Labs から) Ali Hassani and Humphrey Shi から公開された研究論文: [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001)
|
||||
1. **[DINOv2](https://huggingface.co/docs/transformers/model_doc/dinov2)** (Meta AI から) Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski. から公開された研究論文 [DINOv2: Learning Robust Visual Features without Supervision](https://arxiv.org/abs/2304.07193)
|
||||
1. **[DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)** (HuggingFace から), Victor Sanh, Lysandre Debut and Thomas Wolf. 同じ手法で GPT2, RoBERTa と Multilingual BERT の圧縮を行いました.圧縮されたモデルはそれぞれ [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation)、[DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation)、[DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation) と名付けられました. 公開された研究論文: [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108)
|
||||
1. **[DiT](https://huggingface.co/docs/transformers/model_doc/dit)** (Microsoft Research から) Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei から公開された研究論文: [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378)
|
||||
1. **[Donut](https://huggingface.co/docs/transformers/model_doc/donut)** (NAVER から), Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park から公開された研究論文: [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664)
|
||||
@@ -356,12 +358,12 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
|
||||
1. **[EfficientFormer](https://huggingface.co/docs/transformers/model_doc/efficientformer)** (Snap Research から) Yanyu Li, Geng Yuan, Yang Wen, Ju Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren. から公開された研究論文 [EfficientFormer: Vision Transformers at MobileNetSpeed](https://arxiv.org/abs/2206.01191)
|
||||
1. **[EfficientNet](https://huggingface.co/docs/transformers/model_doc/efficientnet)** (from Google Brain) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan, Quoc V. Le.
|
||||
1. **[ELECTRA](https://huggingface.co/docs/transformers/model_doc/electra)** (Google Research/Stanford University から) Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning から公開された研究論文: [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555)
|
||||
1. **[EnCodec](https://huggingface.co/docs/transformers/main/model_doc/encodec)** (Meta AI から) Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi. から公開された研究論文 [High Fidelity Neural Audio Compression](https://arxiv.org/abs/2210.13438)
|
||||
1. **[EnCodec](https://huggingface.co/docs/transformers/model_doc/encodec)** (Meta AI から) Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi. から公開された研究論文 [High Fidelity Neural Audio Compression](https://arxiv.org/abs/2210.13438)
|
||||
1. **[EncoderDecoder](https://huggingface.co/docs/transformers/model_doc/encoder-decoder)** (Google Research から) Sascha Rothe, Shashi Narayan, Aliaksei Severyn から公開された研究論文: [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461)
|
||||
1. **[ERNIE](https://huggingface.co/docs/transformers/model_doc/ernie)** (Baidu から) Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu から公開された研究論文: [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223)
|
||||
1. **[ErnieM](https://huggingface.co/docs/transformers/model_doc/ernie_m)** (Baidu から) Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang. から公開された研究論文 [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674)
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (Meta AI から) はトランスフォーマープロテイン言語モデルです. **ESM-1b** は Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus から公開された研究論文: [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118). **ESM-1v** は Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives から公開された研究論文: [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648). **ESM-2** と **ESMFold** は Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives から公開された研究論文: [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902)
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/main/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (Google AI から) Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V から公開されたレポジトリー [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) Le, and Jason Wei
|
||||
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (CNRS から) Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab から公開された研究論文: [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372)
|
||||
@@ -384,9 +386,10 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
|
||||
1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (UCSD, NVIDIA から) Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang から公開された研究論文: [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094)
|
||||
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (Facebook から) Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed から公開された研究論文: [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447)
|
||||
1. **[I-BERT](https://huggingface.co/docs/transformers/model_doc/ibert)** (Berkeley から) Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer から公開された研究論文: [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321)
|
||||
1. **[IDEFICS](https://huggingface.co/docs/transformers/model_doc/idefics)** (from HuggingFace) released with the paper [OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents](https://huggingface.co/papers/2306.16527) by Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander M. Rush, Douwe Kiela, Matthieu Cord, Victor Sanh.
|
||||
1. **[ImageGPT](https://huggingface.co/docs/transformers/model_doc/imagegpt)** (OpenAI から) Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever から公開された研究論文: [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/)
|
||||
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
|
||||
1. **[InstructBLIP](https://huggingface.co/docs/transformers/main/model_doc/instructblip)** (Salesforce から) Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi. から公開された研究論文 [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500)
|
||||
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (Salesforce から) Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi. から公開された研究論文 [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500)
|
||||
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (OpenAI から) Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever から公開された研究論文: [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf)
|
||||
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (Microsoft Research Asia から) Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou から公開された研究論文: [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318)
|
||||
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (Microsoft Research Asia から) Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou から公開された研究論文: [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740)
|
||||
@@ -396,6 +399,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
|
||||
1. **[LeViT](https://huggingface.co/docs/transformers/model_doc/levit)** (Meta AI から) Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze から公開された研究論文: [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136)
|
||||
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (South China University of Technology から) Jiapeng Wang, Lianwen Jin, Kai Ding から公開された研究論文: [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669)
|
||||
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (The FAIR team of Meta AI から) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample. から公開された研究論文 [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971)
|
||||
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (The FAIR team of Meta AI から) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom.. から公開された研究論文 [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX)
|
||||
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (AllenAI から) Iz Beltagy, Matthew E. Peters, Arman Cohan から公開された研究論文: [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150)
|
||||
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (Google AI から) Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang から公開された研究論文: [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916)
|
||||
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (Studio Ousia から) Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto から公開された研究論文: [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057)
|
||||
@@ -421,9 +425,10 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
|
||||
1. **[MobileViT](https://huggingface.co/docs/transformers/model_doc/mobilevit)** (Apple から) Sachin Mehta and Mohammad Rastegari から公開された研究論文: [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178)
|
||||
1. **[MobileViTV2](https://huggingface.co/docs/transformers/model_doc/mobilevitv2)** (Apple から) Sachin Mehta and Mohammad Rastegari. から公開された研究論文 [Separable Self-attention for Mobile Vision Transformers](https://arxiv.org/abs/2206.02680)
|
||||
1. **[MPNet](https://huggingface.co/docs/transformers/model_doc/mpnet)** (Microsoft Research から) Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu から公開された研究論文: [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297)
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/main/model_doc/mra)** (the University of Wisconsin - Madison から) Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh. から公開された研究論文 [Multi Resolution Analysis (MRA)](https://arxiv.org/abs/2207.10284)
|
||||
1. **[MPT](https://huggingface.co/docs/transformers/model_doc/mpt)** (MosaiML から) the MosaicML NLP Team. から公開された研究論文 [llm-foundry](https://github.com/mosaicml/llm-foundry/)
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (the University of Wisconsin - Madison から) Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh. から公開された研究論文 [Multi Resolution Analysis (MRA)](https://arxiv.org/abs/2207.10284)
|
||||
1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (Google AI から) Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel から公開された研究論文: [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934)
|
||||
1. **[MusicGen](https://huggingface.co/docs/transformers/main/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MusicGen](https://huggingface.co/docs/transformers/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (RUC AI Box から) Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen から公開された研究論文: [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131)
|
||||
1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (SHI Labs から) Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi から公開された研究論文: [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143)
|
||||
1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (Huawei Noah’s Ark Lab から) Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu から公開された研究論文: [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204)
|
||||
@@ -431,7 +436,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
|
||||
1. **[NLLB-MOE](https://huggingface.co/docs/transformers/model_doc/nllb-moe)** (Meta から) the NLLB team. から公開された研究論文 [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672)
|
||||
1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (the University of Wisconsin - Madison から) Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh から公開された研究論文: [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902)
|
||||
1. **[OneFormer](https://huggingface.co/docs/transformers/model_doc/oneformer)** (SHI Labs から) Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi から公開された研究論文: [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220)
|
||||
1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released in [Open-Llama](https://github.com/s-JoL/Open-Llama).
|
||||
1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released in [Open-Llama](https://github.com/s-JoL/Open-Llama).
|
||||
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (Meta AI から) Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al から公開された研究論文: [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068)
|
||||
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (Google AI から) Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby から公開された研究論文: [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230)
|
||||
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (Google から) Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu から公開された研究論文: [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777)
|
||||
@@ -441,7 +446,9 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
|
||||
1. **[Pix2Struct](https://huggingface.co/docs/transformers/model_doc/pix2struct)** (Google から) Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova. から公開された研究論文 [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347)
|
||||
1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (UCLA NLP から) Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang から公開された研究論文: [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333)
|
||||
1. **[PoolFormer](https://huggingface.co/docs/transformers/model_doc/poolformer)** (Sea AI Labs から) Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng から公開された研究論文: [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418)
|
||||
1. **[Pop2Piano](https://huggingface.co/docs/transformers/model_doc/pop2piano)** released with the paper [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi, Kyogu Lee.
|
||||
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (Microsoft Research から) Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou から公開された研究論文: [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063)
|
||||
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (Nanjing University, The University of Hong Kong etc. から) Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao. から公開された研究論文 [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf)
|
||||
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (NVIDIA から) Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius から公開された研究論文: [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602)
|
||||
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (Facebook から) Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela から公開された研究論文: [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401)
|
||||
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (Google Research から) Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang から公開された研究論文: [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909)
|
||||
@@ -480,7 +487,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
|
||||
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (Microsoft から), Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei から公開された研究論文: [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282)
|
||||
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill から), Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal から公開された研究論文: [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156)
|
||||
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (Google Research から) Yi Tay, Mostafa Dehghani, Vinh Q から公開された研究論文: [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
|
||||
1. **[UMT5](https://huggingface.co/docs/transformers/main/model_doc/umt5)** (Google Research から) Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant. から公開された研究論文 [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi)
|
||||
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (Google Research から) Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant. から公開された研究論文 [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi)
|
||||
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (Microsoft Research から) Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang から公開された研究論文: [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597)
|
||||
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (Microsoft Research から) Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu から公開された研究論文: [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752)
|
||||
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (Peking University から) Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun. から公開された研究論文 [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221)
|
||||
@@ -490,9 +497,11 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
|
||||
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (Google AI から) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby から公開された研究論文: [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929)
|
||||
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (UCLA NLP から) Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang から公開された研究論文: [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557)
|
||||
1. **[ViT Hybrid](https://huggingface.co/docs/transformers/model_doc/vit_hybrid)** (Google AI から) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby から公開された研究論文: [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929)
|
||||
1. **[VitDet](https://huggingface.co/docs/transformers/model_doc/vitdet)** (Meta AI から) Yanghao Li, Hanzi Mao, Ross Girshick, Kaiming He. から公開された研究論文 [Exploring Plain Vision Transformer Backbones for Object Detection](https://arxiv.org/abs/2203.16527)
|
||||
1. **[ViTMAE](https://huggingface.co/docs/transformers/model_doc/vit_mae)** (Meta AI から) Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick から公開された研究論文: [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377)
|
||||
1. **[ViTMSN](https://huggingface.co/docs/transformers/model_doc/vit_msn)** (Meta AI から) Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas から公開された研究論文: [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141)
|
||||
1. **[ViViT](https://huggingface.co/docs/transformers/main/model_doc/vivit)** (from Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
|
||||
1. **[VITS](https://huggingface.co/docs/transformers/model_doc/vits)** (Kakao Enterprise から) Jaehyeon Kim, Jungil Kong, Juhee Son. から公開された研究論文 [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103)
|
||||
1. **[ViViT](https://huggingface.co/docs/transformers/model_doc/vivit)** (from Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
|
||||
1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (Facebook AI から) Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli から公開された研究論文: [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477)
|
||||
1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (Facebook AI から) Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino から公開された研究論文: [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171)
|
||||
1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (Facebook AI から) Qiantong Xu, Alexei Baevski, Michael Auli から公開された研究論文: [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680)
|
||||
|
||||
29
README_ko.md
29
README_ko.md
@@ -175,7 +175,7 @@ limitations under the License.
|
||||
|
||||
### pip로 설치하기
|
||||
|
||||
이 저장소는 Python 3.6+, Flax 0.3.2+, PyTorch 1.3.1+, TensorFlow 2.3+에서 테스트 되었습니다.
|
||||
이 저장소는 Python 3.8+, Flax 0.4.1+, PyTorch 1.10+, TensorFlow 2.6+에서 테스트 되었습니다.
|
||||
|
||||
[가상 환경](https://docs.python.org/3/library/venv.html)에 🤗 Transformers를 설치하세요. Python 가상 환경에 익숙하지 않다면, [사용자 가이드](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/)를 확인하세요.
|
||||
|
||||
@@ -217,7 +217,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[AltCLIP](https://huggingface.co/docs/transformers/model_doc/altclip)** (from BAAI) released with the paper [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) by Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell.
|
||||
1. **[Audio Spectrogram Transformer](https://huggingface.co/docs/transformers/model_doc/audio-spectrogram-transformer)** (from MIT) released with the paper [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
|
||||
1. **[Autoformer](https://huggingface.co/docs/transformers/model_doc/autoformer)** (from Tsinghua University) released with the paper [Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008) by Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long.
|
||||
1. **[Bark](https://huggingface.co/docs/transformers/main/model_doc/bark)** (from Suno) released in the repository [suno-ai/bark](https://github.com/suno-ai/bark) by Suno AI team.
|
||||
1. **[Bark](https://huggingface.co/docs/transformers/model_doc/bark)** (from Suno) released in the repository [suno-ai/bark](https://github.com/suno-ai/bark) by Suno AI team.
|
||||
1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/pdf/1910.13461.pdf) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
|
||||
1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
|
||||
1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
|
||||
@@ -244,6 +244,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (OpenAI 에서) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever 의 [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) 논문과 함께 발표했습니다.
|
||||
1. **[CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)** (University of Göttingen 에서) Timo Lüddecke and Alexander Ecker 의 [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) 논문과 함께 발표했습니다.
|
||||
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (Salesforce 에서) Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong 의 [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) 논문과 함께 발표했습니다.
|
||||
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (MetaAI 에서 제공)은 Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.의 [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/)논문과 함께 발표했습니다.
|
||||
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (Microsoft Research Asia 에서) Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang 의 [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) 논문과 함께 발표했습니다.
|
||||
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (YituTech 에서) Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan 의 [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) 논문과 함께 발표했습니다.
|
||||
1. **[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)** (Facebook AI 에서) Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie 의 [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) 논문과 함께 발표했습니다.
|
||||
@@ -263,6 +264,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (Facebook 에서) Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko 의 [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) 논문과 함께 발표했습니다.
|
||||
1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (Microsoft Research 에서) Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan 의 [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) 논문과 함께 발표했습니다.
|
||||
1. **[DiNAT](https://huggingface.co/docs/transformers/model_doc/dinat)** (SHI Labs 에서) Ali Hassani and Humphrey Shi 의 [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) 논문과 함께 발표했습니다.
|
||||
1. **[DINOv2](https://huggingface.co/docs/transformers/model_doc/dinov2)** (Meta AI 에서 제공)은 Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski.의 [DINOv2: Learning Robust Visual Features without Supervision](https://arxiv.org/abs/2304.07193)논문과 함께 발표했습니다.
|
||||
1. **[DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)** (HuggingFace 에서) Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/distillation) and a German version of DistilBERT 의 [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) 논문과 함께 발표했습니다.
|
||||
1. **[DiT](https://huggingface.co/docs/transformers/model_doc/dit)** (Microsoft Research 에서) Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei 의 [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) 논문과 함께 발표했습니다.
|
||||
1. **[Donut](https://huggingface.co/docs/transformers/model_doc/donut)** (NAVER 에서) Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park 의 [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) 논문과 함께 발표했습니다.
|
||||
@@ -271,12 +273,12 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[EfficientFormer](https://huggingface.co/docs/transformers/model_doc/efficientformer)** (from Snap Research) released with the paper [EfficientFormer: Vision Transformers at MobileNetSpeed](https://arxiv.org/abs/2206.01191) by Yanyu Li, Geng Yuan, Yang Wen, Ju Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren.
|
||||
1. **[EfficientNet](https://huggingface.co/docs/transformers/model_doc/efficientnet)** (from Google Brain) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan, Quoc V. Le.
|
||||
1. **[ELECTRA](https://huggingface.co/docs/transformers/model_doc/electra)** (Google Research/Stanford University 에서) Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning 의 [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) 논문과 함께 발표했습니다.
|
||||
1. **[EnCodec](https://huggingface.co/docs/transformers/main/model_doc/encodec)** (Meta AI 에서 제공)은 Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi.의 [High Fidelity Neural Audio Compression](https://arxiv.org/abs/2210.13438)논문과 함께 발표했습니다.
|
||||
1. **[EnCodec](https://huggingface.co/docs/transformers/model_doc/encodec)** (Meta AI 에서 제공)은 Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi.의 [High Fidelity Neural Audio Compression](https://arxiv.org/abs/2210.13438)논문과 함께 발표했습니다.
|
||||
1. **[EncoderDecoder](https://huggingface.co/docs/transformers/model_doc/encoder-decoder)** (Google Research 에서) Sascha Rothe, Shashi Narayan, Aliaksei Severyn 의 [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) 논문과 함께 발표했습니다.
|
||||
1. **[ERNIE](https://huggingface.co/docs/transformers/model_doc/ernie)** (Baidu 에서) Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu 의 [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223) 논문과 함께 발표했습니다.
|
||||
1. **[ErnieM](https://huggingface.co/docs/transformers/model_doc/ernie_m)** (Baidu 에서 제공)은 Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang.의 [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674)논문과 함께 발표했습니다.
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2** was released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/main/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
|
||||
@@ -299,9 +301,10 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (UCSD, NVIDIA 에서) Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang 의 [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) 논문과 함께 발표했습니다.
|
||||
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (Facebook 에서) Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed 의 [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) 논문과 함께 발표했습니다.
|
||||
1. **[I-BERT](https://huggingface.co/docs/transformers/model_doc/ibert)** (Berkeley 에서) Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer 의 [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) 논문과 함께 발표했습니다.
|
||||
1. **[IDEFICS](https://huggingface.co/docs/transformers/model_doc/idefics)** (from HuggingFace) released with the paper [OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents](https://huggingface.co/papers/2306.16527) by Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander M. Rush, Douwe Kiela, Matthieu Cord, Victor Sanh.
|
||||
1. **[ImageGPT](https://huggingface.co/docs/transformers/model_doc/imagegpt)** (OpenAI 에서) Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever 의 [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) 논문과 함께 발표했습니다.
|
||||
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
|
||||
1. **[InstructBLIP](https://huggingface.co/docs/transformers/main/model_doc/instructblip)** (Salesforce 에서 제공)은 Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.의 [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500)논문과 함께 발표했습니다.
|
||||
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (Salesforce 에서 제공)은 Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.의 [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500)논문과 함께 발표했습니다.
|
||||
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (OpenAI 에서) Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever 의 [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) 논문과 함께 발표했습니다.
|
||||
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (Microsoft Research Asia 에서) Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou 의 [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) 논문과 함께 발표했습니다.
|
||||
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (Microsoft Research Asia 에서) Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou 의 [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) 논문과 함께 발표했습니다.
|
||||
@@ -311,6 +314,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[LeViT](https://huggingface.co/docs/transformers/model_doc/levit)** (Meta AI 에서) Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze 의 [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) 논문과 함께 발표했습니다.
|
||||
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (South China University of Technology 에서) Jiapeng Wang, Lianwen Jin, Kai Ding 의 [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) 논문과 함께 발표했습니다.
|
||||
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (The FAIR team of Meta AI 에서 제공)은 Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.의 [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971)논문과 함께 발표했습니다.
|
||||
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (The FAIR team of Meta AI 에서 제공)은 Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom..의 [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX)논문과 함께 발표했습니다.
|
||||
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (AllenAI 에서) Iz Beltagy, Matthew E. Peters, Arman Cohan 의 [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) 논문과 함께 발표했습니다.
|
||||
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (Google AI 에서) Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang 의 [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) 논문과 함께 발표했습니다.
|
||||
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (Studio Ousia 에서) Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto 의 [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) 논문과 함께 발표했습니다.
|
||||
@@ -336,9 +340,10 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[MobileViT](https://huggingface.co/docs/transformers/model_doc/mobilevit)** (Apple 에서) Sachin Mehta and Mohammad Rastegari 의 [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) 논문과 함께 발표했습니다.
|
||||
1. **[MobileViTV2](https://huggingface.co/docs/transformers/model_doc/mobilevitv2)** (Apple 에서 제공)은 Sachin Mehta and Mohammad Rastegari.의 [Separable Self-attention for Mobile Vision Transformers](https://arxiv.org/abs/2206.02680)논문과 함께 발표했습니다.
|
||||
1. **[MPNet](https://huggingface.co/docs/transformers/model_doc/mpnet)** (Microsoft Research 에서) Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu 의 [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) 논문과 함께 발표했습니다.
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/main/model_doc/mra)** (the University of Wisconsin - Madison 에서 제공)은 Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh.의 [Multi Resolution Analysis (MRA)](https://arxiv.org/abs/2207.10284) 논문과 함께 발표했습니다.
|
||||
1. **[MPT](https://huggingface.co/docs/transformers/model_doc/mpt)** (MosaiML 에서 제공)은 the MosaicML NLP Team.의 [llm-foundry](https://github.com/mosaicml/llm-foundry/)논문과 함께 발표했습니다.
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (the University of Wisconsin - Madison 에서 제공)은 Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh.의 [Multi Resolution Analysis (MRA)](https://arxiv.org/abs/2207.10284) 논문과 함께 발표했습니다.
|
||||
1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (Google AI 에서) Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel 의 [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) 논문과 함께 발표했습니다.
|
||||
1. **[MusicGen](https://huggingface.co/docs/transformers/main/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MusicGen](https://huggingface.co/docs/transformers/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (RUC AI Box 에서) Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen 의 [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) 논문과 함께 발표했습니다.
|
||||
1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (SHI Labs 에서) Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi 의 [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) 논문과 함께 발표했습니다.
|
||||
1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (Huawei Noah’s Ark Lab 에서) Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu 의 [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) 논문과 함께 발표했습니다.
|
||||
@@ -346,7 +351,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[NLLB-MOE](https://huggingface.co/docs/transformers/model_doc/nllb-moe)** (Meta 에서 제공)은 the NLLB team.의 [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672)논문과 함께 발표했습니다.
|
||||
1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (the University of Wisconsin - Madison 에서) Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh 의 [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) 논문과 함께 발표했습니다.
|
||||
1. **[OneFormer](https://huggingface.co/docs/transformers/model_doc/oneformer)** (SHI Labs 에서) Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi 의 [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) 논문과 함께 발표했습니다.
|
||||
1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released in [Open-Llama](https://github.com/s-JoL/Open-Llama).
|
||||
1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released in [Open-Llama](https://github.com/s-JoL/Open-Llama).
|
||||
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (Meta AI 에서) Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al 의 [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) 논문과 함께 발표했습니다.
|
||||
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (Google AI 에서) Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby 의 [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) 논문과 함께 발표했습니다.
|
||||
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (Google 에서) Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu 의 [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) 논문과 함께 발표했습니다.
|
||||
@@ -356,7 +361,9 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[Pix2Struct](https://huggingface.co/docs/transformers/model_doc/pix2struct)** (Google 에서 제공)은 Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.의 [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347)논문과 함께 발표했습니다.
|
||||
1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (UCLA NLP 에서) Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang 의 [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) 논문과 함께 발표했습니다.
|
||||
1. **[PoolFormer](https://huggingface.co/docs/transformers/model_doc/poolformer)** (Sea AI Labs 에서) Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng 의 [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) 논문과 함께 발표했습니다.
|
||||
1. **[Pop2Piano](https://huggingface.co/docs/transformers/model_doc/pop2piano)** released with the paper [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi, Kyogu Lee.
|
||||
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (Microsoft Research 에서) Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou 의 [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) 논문과 함께 발표했습니다.
|
||||
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (Nanjing University, The University of Hong Kong etc. 에서 제공)은 Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.의 [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf)논문과 함께 발표했습니다.
|
||||
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (NVIDIA 에서) Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius 의 [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) 논문과 함께 발표했습니다.
|
||||
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (Facebook 에서) Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela 의 [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) 논문과 함께 발표했습니다.
|
||||
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (Google Research 에서) Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang 의 [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) 논문과 함께 발표했습니다.
|
||||
@@ -395,7 +402,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (Microsoft 에서) Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei 의 [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) 논문과 함께 발표했습니다.
|
||||
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill 에서) Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal 의 [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) 논문과 함께 발표했습니다.
|
||||
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (Google Research 에서) Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzle 의 [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) 논문과 함께 발표했습니다.
|
||||
1. **[UMT5](https://huggingface.co/docs/transformers/main/model_doc/umt5)** (Google Research 에서 제공)은 Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.의 [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi)논문과 함께 발표했습니다.
|
||||
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (Google Research 에서 제공)은 Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.의 [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi)논문과 함께 발표했습니다.
|
||||
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (Microsoft Research 에서) Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang 의 [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) 논문과 함께 발표했습니다.
|
||||
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (Microsoft Research 에서) Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu 의 [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) 논문과 함께 발표했습니다.
|
||||
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (Peking University 에서 제공)은 Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.의 [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221)논문과 함께 발표했습니다.
|
||||
@@ -405,9 +412,11 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (Google AI 에서) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby 의 [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) 논문과 함께 발표했습니다.
|
||||
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (UCLA NLP 에서) Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang 의 [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) 논문과 함께 발표했습니다.
|
||||
1. **[ViT Hybrid](https://huggingface.co/docs/transformers/model_doc/vit_hybrid)** (Google AI 에서) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby 의 [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) 논문과 함께 발표했습니다.
|
||||
1. **[VitDet](https://huggingface.co/docs/transformers/model_doc/vitdet)** (Meta AI 에서 제공)은 Yanghao Li, Hanzi Mao, Ross Girshick, Kaiming He.의 [Exploring Plain Vision Transformer Backbones for Object Detection](https://arxiv.org/abs/2203.16527)논문과 함께 발표했습니다.
|
||||
1. **[ViTMAE](https://huggingface.co/docs/transformers/model_doc/vit_mae)** (Meta AI 에서) Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick 의 [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) 논문과 함께 발표했습니다.
|
||||
1. **[ViTMSN](https://huggingface.co/docs/transformers/model_doc/vit_msn)** (Meta AI 에서) Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas 의 [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) 논문과 함께 발표했습니다.
|
||||
1. **[ViViT](https://huggingface.co/docs/transformers/main/model_doc/vivit)** (from Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
|
||||
1. **[VITS](https://huggingface.co/docs/transformers/model_doc/vits)** (Kakao Enterprise 에서 제공)은 Jaehyeon Kim, Jungil Kong, Juhee Son.의 [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103)논문과 함께 발표했습니다.
|
||||
1. **[ViViT](https://huggingface.co/docs/transformers/model_doc/vivit)** (from Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
|
||||
1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (Facebook AI 에서) Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli 의 [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) 논문과 함께 발표했습니다.
|
||||
1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (Facebook AI 에서) Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino 의 [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) 논문과 함께 발표했습니다.
|
||||
1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (Facebook AI 에서) Qiantong Xu, Alexei Baevski, Michael Auli 의 [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) 논문과 함께 발표했습니다.
|
||||
|
||||
@@ -200,7 +200,7 @@ checkpoint: 检查点
|
||||
|
||||
### 使用 pip
|
||||
|
||||
这个仓库已在 Python 3.6+、Flax 0.3.2+、PyTorch 1.3.1+ 和 TensorFlow 2.3+ 下经过测试。
|
||||
这个仓库已在 Python 3.8+、Flax 0.4.1+、PyTorch 1.10+ 和 TensorFlow 2.6+ 下经过测试。
|
||||
|
||||
你可以在[虚拟环境](https://docs.python.org/3/library/venv.html)中安装 🤗 Transformers。如果你还不熟悉 Python 的虚拟环境,请阅此[用户说明](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/)。
|
||||
|
||||
@@ -241,7 +241,7 @@ conda install -c huggingface transformers
|
||||
1. **[AltCLIP](https://huggingface.co/docs/transformers/model_doc/altclip)** (来自 BAAI) 伴随论文 [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) 由 Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell 发布。
|
||||
1. **[Audio Spectrogram Transformer](https://huggingface.co/docs/transformers/model_doc/audio-spectrogram-transformer)** (来自 MIT) 伴随论文 [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) 由 Yuan Gong, Yu-An Chung, James Glass 发布。
|
||||
1. **[Autoformer](https://huggingface.co/docs/transformers/model_doc/autoformer)** (from Tsinghua University) released with the paper [Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008) by Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long.
|
||||
1. **[Bark](https://huggingface.co/docs/transformers/main/model_doc/bark)** (from Suno) released in the repository [suno-ai/bark](https://github.com/suno-ai/bark) by Suno AI team.
|
||||
1. **[Bark](https://huggingface.co/docs/transformers/model_doc/bark)** (from Suno) released in the repository [suno-ai/bark](https://github.com/suno-ai/bark) by Suno AI team.
|
||||
1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (来自 Facebook) 伴随论文 [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/pdf/1910.13461.pdf) 由 Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer 发布。
|
||||
1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (来自 École polytechnique) 伴随论文 [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) 由 Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis 发布。
|
||||
1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (来自 VinAI Research) 伴随论文 [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) 由 Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen 发布。
|
||||
@@ -268,6 +268,7 @@ conda install -c huggingface transformers
|
||||
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (来自 OpenAI) 伴随论文 [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) 由 Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever 发布。
|
||||
1. **[CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)** (来自 University of Göttingen) 伴随论文 [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) 由 Timo Lüddecke and Alexander Ecker 发布。
|
||||
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (来自 Salesforce) 伴随论文 [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) 由 Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong 发布。
|
||||
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (来自 MetaAI) 伴随论文 [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) 由 Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve 发布。
|
||||
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (来自 Microsoft Research Asia) 伴随论文 [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) 由 Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang 发布。
|
||||
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (来自 YituTech) 伴随论文 [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) 由 Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan 发布。
|
||||
1. **[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)** (来自 Facebook AI) 伴随论文 [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) 由 Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie 发布。
|
||||
@@ -287,6 +288,7 @@ conda install -c huggingface transformers
|
||||
1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (来自 Facebook) 伴随论文 [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) 由 Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko 发布。
|
||||
1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (来自 Microsoft Research) 伴随论文 [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) 由 Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan 发布。
|
||||
1. **[DiNAT](https://huggingface.co/docs/transformers/model_doc/dinat)** (来自 SHI Labs) 伴随论文 [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) 由 Ali Hassani and Humphrey Shi 发布。
|
||||
1. **[DINOv2](https://huggingface.co/docs/transformers/model_doc/dinov2)** (来自 Meta AI) 伴随论文 [DINOv2: Learning Robust Visual Features without Supervision](https://arxiv.org/abs/2304.07193) 由 Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski 发布。
|
||||
1. **[DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)** (来自 HuggingFace), 伴随论文 [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) 由 Victor Sanh, Lysandre Debut and Thomas Wolf 发布。 同样的方法也应用于压缩 GPT-2 到 [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/distillation), RoBERTa 到 [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/distillation), Multilingual BERT 到 [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/distillation) 和德语版 DistilBERT。
|
||||
1. **[DiT](https://huggingface.co/docs/transformers/model_doc/dit)** (来自 Microsoft Research) 伴随论文 [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) 由 Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei 发布。
|
||||
1. **[Donut](https://huggingface.co/docs/transformers/model_doc/donut)** (来自 NAVER) 伴随论文 [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) 由 Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park 发布。
|
||||
@@ -295,12 +297,12 @@ conda install -c huggingface transformers
|
||||
1. **[EfficientFormer](https://huggingface.co/docs/transformers/model_doc/efficientformer)** (来自 Snap Research) 伴随论文 [EfficientFormer: Vision Transformers at MobileNetSpeed](https://arxiv.org/abs/2206.01191) 由 Yanyu Li, Geng Yuan, Yang Wen, Ju Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren 发布。
|
||||
1. **[EfficientNet](https://huggingface.co/docs/transformers/model_doc/efficientnet)** (from Google Brain) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan, Quoc V. Le.
|
||||
1. **[ELECTRA](https://huggingface.co/docs/transformers/model_doc/electra)** (来自 Google Research/Stanford University) 伴随论文 [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) 由 Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning 发布。
|
||||
1. **[EnCodec](https://huggingface.co/docs/transformers/main/model_doc/encodec)** (来自 Meta AI) 伴随论文 [High Fidelity Neural Audio Compression](https://arxiv.org/abs/2210.13438) 由 Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi 发布。
|
||||
1. **[EnCodec](https://huggingface.co/docs/transformers/model_doc/encodec)** (来自 Meta AI) 伴随论文 [High Fidelity Neural Audio Compression](https://arxiv.org/abs/2210.13438) 由 Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi 发布。
|
||||
1. **[EncoderDecoder](https://huggingface.co/docs/transformers/model_doc/encoder-decoder)** (来自 Google Research) 伴随论文 [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) 由 Sascha Rothe, Shashi Narayan, Aliaksei Severyn 发布。
|
||||
1. **[ERNIE](https://huggingface.co/docs/transformers/model_doc/ernie)** (来自 Baidu) 伴随论文 [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223) by Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu 发布。
|
||||
1. **[ErnieM](https://huggingface.co/docs/transformers/model_doc/ernie_m)** (来自 Baidu) 伴随论文 [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) 由 Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang 发布。
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2** was released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/main/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (来自 CNRS) 伴随论文 [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) 由 Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab 发布。
|
||||
@@ -323,9 +325,10 @@ conda install -c huggingface transformers
|
||||
1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (来自 UCSD, NVIDIA) 伴随论文 [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) 由 Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang 发布。
|
||||
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (来自 Facebook) 伴随论文 [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) 由 Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed 发布。
|
||||
1. **[I-BERT](https://huggingface.co/docs/transformers/model_doc/ibert)** (来自 Berkeley) 伴随论文 [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) 由 Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer 发布。
|
||||
1. **[IDEFICS](https://huggingface.co/docs/transformers/model_doc/idefics)** (from HuggingFace) released with the paper [OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents](https://huggingface.co/papers/2306.16527) by Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander M. Rush, Douwe Kiela, Matthieu Cord, Victor Sanh.
|
||||
1. **[ImageGPT](https://huggingface.co/docs/transformers/model_doc/imagegpt)** (来自 OpenAI) 伴随论文 [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) 由 Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever 发布。
|
||||
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
|
||||
1. **[InstructBLIP](https://huggingface.co/docs/transformers/main/model_doc/instructblip)** (来自 Salesforce) 伴随论文 [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) 由 Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi 发布。
|
||||
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (来自 Salesforce) 伴随论文 [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) 由 Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi 发布。
|
||||
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
|
||||
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (来自 Microsoft Research Asia) 伴随论文 [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) 由 Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou 发布。
|
||||
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (来自 Microsoft Research Asia) 伴随论文 [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) 由 Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou 发布。
|
||||
@@ -335,6 +338,7 @@ conda install -c huggingface transformers
|
||||
1. **[LeViT](https://huggingface.co/docs/transformers/model_doc/levit)** (来自 Meta AI) 伴随论文 [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) 由 Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze 发布。
|
||||
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (来自 South China University of Technology) 伴随论文 [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) 由 Jiapeng Wang, Lianwen Jin, Kai Ding 发布。
|
||||
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (来自 The FAIR team of Meta AI) 伴随论文 [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) 由 Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample 发布。
|
||||
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (来自 The FAIR team of Meta AI) 伴随论文 [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX) 由 Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom. 发布。
|
||||
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (来自 AllenAI) 伴随论文 [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) 由 Iz Beltagy, Matthew E. Peters, Arman Cohan 发布。
|
||||
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (来自 Google AI) released 伴随论文 [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) 由 Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang 发布。
|
||||
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (来自 Studio Ousia) 伴随论文 [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) 由 Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto 发布。
|
||||
@@ -344,7 +348,7 @@ conda install -c huggingface transformers
|
||||
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** 用 [OPUS](http://opus.nlpl.eu/) 数据训练的机器翻译模型由 Jörg Tiedemann 发布。[Marian Framework](https://marian-nmt.github.io/) 由微软翻译团队开发。
|
||||
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (来自 Microsoft Research Asia) 伴随论文 [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) 由 Junlong Li, Yiheng Xu, Lei Cui, Furu Wei 发布。
|
||||
1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (来自 FAIR and UIUC) 伴随论文 [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) 由 Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar 发布。
|
||||
1. **[MaskFormer](https://huggingface.co/docs/transformers/model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov
|
||||
1. **[MaskFormer](https://huggingface.co/docs/transformers/model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov
|
||||
1. **[MatCha](https://huggingface.co/docs/transformers/model_doc/matcha)** (来自 Google AI) 伴随论文 [MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering](https://arxiv.org/abs/2212.09662) 由 Fangyu Liu, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Yasemin Altun, Nigel Collier, Julian Martin Eisenschlos 发布。
|
||||
1. **[mBART](https://huggingface.co/docs/transformers/model_doc/mbart)** (来自 Facebook) 伴随论文 [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) 由 Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer 发布。
|
||||
1. **[mBART-50](https://huggingface.co/docs/transformers/model_doc/mbart)** (来自 Facebook) 伴随论文 [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) 由 Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan 发布。
|
||||
@@ -360,9 +364,10 @@ conda install -c huggingface transformers
|
||||
1. **[MobileViT](https://huggingface.co/docs/transformers/model_doc/mobilevit)** (来自 Apple) 伴随论文 [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) 由 Sachin Mehta and Mohammad Rastegari 发布。
|
||||
1. **[MobileViTV2](https://huggingface.co/docs/transformers/model_doc/mobilevitv2)** (来自 Apple) 伴随论文 [Separable Self-attention for Mobile Vision Transformers](https://arxiv.org/abs/2206.02680) 由 Sachin Mehta and Mohammad Rastegari 发布。
|
||||
1. **[MPNet](https://huggingface.co/docs/transformers/model_doc/mpnet)** (来自 Microsoft Research) 伴随论文 [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) 由 Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu 发布。
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/main/model_doc/mra)** (来自 the University of Wisconsin - Madison) 伴随论文 [Multi Resolution Analysis (MRA)](https://arxiv.org/abs/2207.10284) 由 Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh 发布。
|
||||
1. **[MPT](https://huggingface.co/docs/transformers/model_doc/mpt)** (来自 MosaiML) 伴随论文 [llm-foundry](https://github.com/mosaicml/llm-foundry/) 由 the MosaicML NLP Team 发布。
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (来自 the University of Wisconsin - Madison) 伴随论文 [Multi Resolution Analysis (MRA)](https://arxiv.org/abs/2207.10284) 由 Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh 发布。
|
||||
1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (来自 Google AI) 伴随论文 [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) 由 Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel 发布。
|
||||
1. **[MusicGen](https://huggingface.co/docs/transformers/main/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MusicGen](https://huggingface.co/docs/transformers/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (来自 中国人民大学 AI Box) 伴随论文 [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) 由 Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen 发布。
|
||||
1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (来自 SHI Labs) 伴随论文 [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) 由 Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi 发布。
|
||||
1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (来自华为诺亚方舟实验室) 伴随论文 [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) 由 Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu 发布。
|
||||
@@ -370,7 +375,7 @@ conda install -c huggingface transformers
|
||||
1. **[NLLB-MOE](https://huggingface.co/docs/transformers/model_doc/nllb-moe)** (来自 Meta) 伴随论文 [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) 由 the NLLB team 发布。
|
||||
1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (来自 the University of Wisconsin - Madison) 伴随论文 [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) 由 Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh 发布。
|
||||
1. **[OneFormer](https://huggingface.co/docs/transformers/model_doc/oneformer)** (来自 SHI Labs) 伴随论文 [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) 由 Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi 发布。
|
||||
1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (来自 [s-JoL](https://huggingface.co/s-JoL)) 由 [Open-Llama](https://github.com/s-JoL/Open-Llama) 发布.
|
||||
1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (来自 [s-JoL](https://huggingface.co/s-JoL)) 由 [Open-Llama](https://github.com/s-JoL/Open-Llama) 发布.
|
||||
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (来自 Meta AI) 伴随论文 [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) 由 Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al 发布。
|
||||
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (来自 Google AI) 伴随论文 [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) 由 Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby 发布。
|
||||
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (来自 Google) 伴随论文 [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) 由 Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu 发布。
|
||||
@@ -380,7 +385,9 @@ conda install -c huggingface transformers
|
||||
1. **[Pix2Struct](https://huggingface.co/docs/transformers/model_doc/pix2struct)** (来自 Google) 伴随论文 [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) 由 Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova 发布。
|
||||
1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (来自 UCLA NLP) 伴随论文 [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) 由 Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang 发布。
|
||||
1. **[PoolFormer](https://huggingface.co/docs/transformers/model_doc/poolformer)** (来自 Sea AI Labs) 伴随论文 [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) 由 Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng 发布。
|
||||
1. **[Pop2Piano](https://huggingface.co/docs/transformers/model_doc/pop2piano)** released with the paper [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi, Kyogu Lee.
|
||||
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (来自 Microsoft Research) 伴随论文 [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) 由 Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou 发布。
|
||||
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (来自 Nanjing University, The University of Hong Kong etc.) 伴随论文 [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf) 由 Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao 发布。
|
||||
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (来自 NVIDIA) 伴随论文 [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) 由 Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius 发布。
|
||||
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (来自 Facebook) 伴随论文 [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) 由 Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela 发布。
|
||||
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (来自 Google Research) 伴随论文 [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) 由 Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang 发布。
|
||||
@@ -419,7 +426,7 @@ conda install -c huggingface transformers
|
||||
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (来自 Microsoft) 伴随论文 [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) 由 Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei 发布。
|
||||
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (来自 UNC Chapel Hill) 伴随论文 [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) 由 Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal 发布。
|
||||
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
|
||||
1. **[UMT5](https://huggingface.co/docs/transformers/main/model_doc/umt5)** (来自 Google Research) 伴随论文 [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) 由 Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant 发布。
|
||||
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (来自 Google Research) 伴随论文 [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) 由 Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant 发布。
|
||||
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (来自 Microsoft Research) 伴随论文 [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) 由 Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang 发布。
|
||||
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (来自 Microsoft Research) 伴随论文 [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) 由 Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu 发布。
|
||||
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (来自 Peking University) 伴随论文 [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) 由 Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun 发布。
|
||||
@@ -429,9 +436,11 @@ conda install -c huggingface transformers
|
||||
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (来自 Google AI) 伴随论文 [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) 由 Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby 发布。
|
||||
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (来自 UCLA NLP) 伴随论文 [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) 由 Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang 发布。
|
||||
1. **[ViT Hybrid](https://huggingface.co/docs/transformers/model_doc/vit_hybrid)** (来自 Google AI) 伴随论文 [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) 由 Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby 发布。
|
||||
1. **[VitDet](https://huggingface.co/docs/transformers/model_doc/vitdet)** (来自 Meta AI) 伴随论文 [Exploring Plain Vision Transformer Backbones for Object Detection](https://arxiv.org/abs/2203.16527) 由 Yanghao Li, Hanzi Mao, Ross Girshick, Kaiming He 发布。
|
||||
1. **[ViTMAE](https://huggingface.co/docs/transformers/model_doc/vit_mae)** (来自 Meta AI) 伴随论文 [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) 由 Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick 发布。
|
||||
1. **[ViTMSN](https://huggingface.co/docs/transformers/model_doc/vit_msn)** (来自 Meta AI) 伴随论文 [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas 发布.
|
||||
1. **[ViViT](https://huggingface.co/docs/transformers/main/model_doc/vivit)** (来自 Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) 由 Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
|
||||
1. **[VITS](https://huggingface.co/docs/transformers/model_doc/vits)** (来自 Kakao Enterprise) 伴随论文 [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103) 由 Jaehyeon Kim, Jungil Kong, Juhee Son 发布。
|
||||
1. **[ViViT](https://huggingface.co/docs/transformers/model_doc/vivit)** (来自 Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) 由 Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
|
||||
1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (来自 Facebook AI) 伴随论文 [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) 由 Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli 发布。
|
||||
1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (来自 Facebook AI) 伴随论文 [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) 由 Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino 发布。
|
||||
1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (来自 Facebook AI) 伴随论文 [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) 由 Qiantong Xu, Alexei Baevski, Michael Auli 发布。
|
||||
|
||||
@@ -212,7 +212,7 @@ Tokenizer 為所有的預訓練模型提供了預處理,並可以直接轉換
|
||||
|
||||
### 使用 pip
|
||||
|
||||
這個 Repository 已在 Python 3.6+、Flax 0.3.2+、PyTorch 1.3.1+ 和 TensorFlow 2.3+ 下經過測試。
|
||||
這個 Repository 已在 Python 3.8+、Flax 0.4.1+、PyTorch 1.10+ 和 TensorFlow 2.6+ 下經過測試。
|
||||
|
||||
你可以在[虛擬環境](https://docs.python.org/3/library/venv.html)中安裝 🤗 Transformers。如果你還不熟悉 Python 的虛擬環境,請閱此[使用者指引](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/)。
|
||||
|
||||
@@ -253,7 +253,7 @@ conda install -c huggingface transformers
|
||||
1. **[AltCLIP](https://huggingface.co/docs/transformers/model_doc/altclip)** (from BAAI) released with the paper [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) by Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell.
|
||||
1. **[Audio Spectrogram Transformer](https://huggingface.co/docs/transformers/model_doc/audio-spectrogram-transformer)** (from MIT) released with the paper [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
|
||||
1. **[Autoformer](https://huggingface.co/docs/transformers/model_doc/autoformer)** (from Tsinghua University) released with the paper [Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008) by Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long.
|
||||
1. **[Bark](https://huggingface.co/docs/transformers/main/model_doc/bark)** (from Suno) released in the repository [suno-ai/bark](https://github.com/suno-ai/bark) by Suno AI team.
|
||||
1. **[Bark](https://huggingface.co/docs/transformers/model_doc/bark)** (from Suno) released in the repository [suno-ai/bark](https://github.com/suno-ai/bark) by Suno AI team.
|
||||
1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/pdf/1910.13461.pdf) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
|
||||
1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
|
||||
1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
|
||||
@@ -280,6 +280,7 @@ conda install -c huggingface transformers
|
||||
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
|
||||
1. **[CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
|
||||
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
|
||||
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (from MetaAI) released with the paper [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) by Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.
|
||||
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
|
||||
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
|
||||
1. **[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
|
||||
@@ -299,6 +300,7 @@ conda install -c huggingface transformers
|
||||
1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
|
||||
1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
|
||||
1. **[DiNAT](https://huggingface.co/docs/transformers/model_doc/dinat)** (from SHI Labs) released with the paper [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) by Ali Hassani and Humphrey Shi.
|
||||
1. **[DINOv2](https://huggingface.co/docs/transformers/model_doc/dinov2)** (from Meta AI) released with the paper [DINOv2: Learning Robust Visual Features without Supervision](https://arxiv.org/abs/2304.07193) by Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski.
|
||||
1. **[DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/distillation) and a German version of DistilBERT.
|
||||
1. **[DiT](https://huggingface.co/docs/transformers/model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
|
||||
1. **[Donut](https://huggingface.co/docs/transformers/model_doc/donut)** (from NAVER) released with the paper [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) by Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park.
|
||||
@@ -307,12 +309,12 @@ conda install -c huggingface transformers
|
||||
1. **[EfficientFormer](https://huggingface.co/docs/transformers/model_doc/efficientformer)** (from Snap Research) released with the paper [EfficientFormer: Vision Transformers at MobileNetSpeed](https://arxiv.org/abs/2206.01191) by Yanyu Li, Geng Yuan, Yang Wen, Ju Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren.
|
||||
1. **[EfficientNet](https://huggingface.co/docs/transformers/model_doc/efficientnet)** (from Google Brain) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan, Quoc V. Le.
|
||||
1. **[ELECTRA](https://huggingface.co/docs/transformers/model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
|
||||
1. **[EnCodec](https://huggingface.co/docs/transformers/main/model_doc/encodec)** (from Meta AI) released with the paper [High Fidelity Neural Audio Compression](https://arxiv.org/abs/2210.13438) by Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi.
|
||||
1. **[EnCodec](https://huggingface.co/docs/transformers/model_doc/encodec)** (from Meta AI) released with the paper [High Fidelity Neural Audio Compression](https://arxiv.org/abs/2210.13438) by Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi.
|
||||
1. **[EncoderDecoder](https://huggingface.co/docs/transformers/model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
|
||||
1. **[ERNIE](https://huggingface.co/docs/transformers/model_doc/ernie)** (from Baidu) released with the paper [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223) by Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu.
|
||||
1. **[ErnieM](https://huggingface.co/docs/transformers/model_doc/ernie_m)** (from Baidu) released with the paper [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang.
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2** was released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/main/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
|
||||
@@ -335,9 +337,10 @@ conda install -c huggingface transformers
|
||||
1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
|
||||
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
|
||||
1. **[I-BERT](https://huggingface.co/docs/transformers/model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
|
||||
1. **[IDEFICS](https://huggingface.co/docs/transformers/model_doc/idefics)** (from HuggingFace) released with the paper [OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents](https://huggingface.co/papers/2306.16527) by Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander M. Rush, Douwe Kiela, Matthieu Cord, Victor Sanh.
|
||||
1. **[ImageGPT](https://huggingface.co/docs/transformers/model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
|
||||
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
|
||||
1. **[InstructBLIP](https://huggingface.co/docs/transformers/main/model_doc/instructblip)** (from Salesforce) released with the paper [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
|
||||
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (from Salesforce) released with the paper [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
|
||||
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
|
||||
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
|
||||
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
|
||||
@@ -347,6 +350,7 @@ conda install -c huggingface transformers
|
||||
1. **[LeViT](https://huggingface.co/docs/transformers/model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
|
||||
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
|
||||
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (from The FAIR team of Meta AI) released with the paper [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.
|
||||
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (from The FAIR team of Meta AI) released with the paper [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX) by Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom..
|
||||
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
|
||||
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
|
||||
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
|
||||
@@ -372,9 +376,10 @@ conda install -c huggingface transformers
|
||||
1. **[MobileViT](https://huggingface.co/docs/transformers/model_doc/mobilevit)** (from Apple) released with the paper [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari.
|
||||
1. **[MobileViTV2](https://huggingface.co/docs/transformers/model_doc/mobilevitv2)** (from Apple) released with the paper [Separable Self-attention for Mobile Vision Transformers](https://arxiv.org/abs/2206.02680) by Sachin Mehta and Mohammad Rastegari.
|
||||
1. **[MPNet](https://huggingface.co/docs/transformers/model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/main/model_doc/mra)** (from the University of Wisconsin - Madison) released with the paper [Multi Resolution Analysis (MRA)](https://arxiv.org/abs/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh.
|
||||
1. **[MPT](https://huggingface.co/docs/transformers/model_doc/mpt)** (from MosaiML) released with the paper [llm-foundry](https://github.com/mosaicml/llm-foundry/) by the MosaicML NLP Team.
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (from the University of Wisconsin - Madison) released with the paper [Multi Resolution Analysis (MRA)](https://arxiv.org/abs/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh.
|
||||
1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
|
||||
1. **[MusicGen](https://huggingface.co/docs/transformers/main/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MusicGen](https://huggingface.co/docs/transformers/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
|
||||
1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (from SHI Labs) released with the paper [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
|
||||
1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
|
||||
@@ -382,7 +387,7 @@ conda install -c huggingface transformers
|
||||
1. **[NLLB-MOE](https://huggingface.co/docs/transformers/model_doc/nllb-moe)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
|
||||
1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
|
||||
1. **[OneFormer](https://huggingface.co/docs/transformers/model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
|
||||
1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released in [Open-Llama](https://github.com/s-JoL/Open-Llama).
|
||||
1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released in [Open-Llama](https://github.com/s-JoL/Open-Llama).
|
||||
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
|
||||
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
|
||||
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
|
||||
@@ -392,7 +397,9 @@ conda install -c huggingface transformers
|
||||
1. **[Pix2Struct](https://huggingface.co/docs/transformers/model_doc/pix2struct)** (from Google) released with the paper [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
|
||||
1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
|
||||
1. **[PoolFormer](https://huggingface.co/docs/transformers/model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
|
||||
1. **[Pop2Piano](https://huggingface.co/docs/transformers/model_doc/pop2piano)** released with the paper [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi, Kyogu Lee.
|
||||
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
|
||||
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (from Nanjing University, The University of Hong Kong etc.) released with the paper [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
|
||||
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
|
||||
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
|
||||
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
|
||||
@@ -431,7 +438,7 @@ conda install -c huggingface transformers
|
||||
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (from Microsoft) released with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
|
||||
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill) released with the paper [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
|
||||
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
|
||||
1. **[UMT5](https://huggingface.co/docs/transformers/main/model_doc/umt5)** (from Google Research) released with the paper [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
|
||||
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (from Google Research) released with the paper [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
|
||||
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
|
||||
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
|
||||
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
|
||||
@@ -441,9 +448,11 @@ conda install -c huggingface transformers
|
||||
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
|
||||
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
|
||||
1. **[ViT Hybrid](https://huggingface.co/docs/transformers/model_doc/vit_hybrid)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
|
||||
1. **[VitDet](https://huggingface.co/docs/transformers/model_doc/vitdet)** (from Meta AI) released with the paper [Exploring Plain Vision Transformer Backbones for Object Detection](https://arxiv.org/abs/2203.16527) by Yanghao Li, Hanzi Mao, Ross Girshick, Kaiming He.
|
||||
1. **[ViTMAE](https://huggingface.co/docs/transformers/model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
|
||||
1. **[ViTMSN](https://huggingface.co/docs/transformers/model_doc/vit_msn)** (from Meta AI) released with the paper [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas.
|
||||
1. **[ViViT](https://huggingface.co/docs/transformers/main/model_doc/vivit)** (from Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
|
||||
1. **[VITS](https://huggingface.co/docs/transformers/model_doc/vits)** (from Kakao Enterprise) released with the paper [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103) by Jaehyeon Kim, Jungil Kong, Juhee Son.
|
||||
1. **[ViViT](https://huggingface.co/docs/transformers/model_doc/vivit)** (from Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
|
||||
1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
|
||||
1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
|
||||
1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
|
||||
|
||||
@@ -601,3 +601,9 @@ All Hugging Face models and pipelines can be seamlessly integrated into BentoML
|
||||
|
||||
Keywords: BentoML, Framework, Deployment, AI Applications
|
||||
|
||||
## [LLaMA-Efficient-Tuning](https://github.com/hiyouga/LLaMA-Efficient-Tuning)
|
||||
|
||||
[LLaMA-Efficient-Tuning](https://github.com/hiyouga/LLaMA-Efficient-Tuning) offers a user-friendly fine-tuning framework that incorporates PEFT. The repository includes training(fine-tuning) and inference examples for LLaMA-2, BLOOM, Falcon, Baichuan, Qwen, and other LLMs. A ChatGLM version is also available in [ChatGLM-Efficient-Tuning](https://github.com/hiyouga/ChatGLM-Efficient-Tuning).
|
||||
|
||||
Keywords: PEFT, fine-tuning, LLaMA-2, ChatGLM, Qwen
|
||||
|
||||
|
||||
@@ -22,7 +22,6 @@ RUN python3 -m pip install --no-cache-dir --upgrade pip
|
||||
|
||||
ARG REF=main
|
||||
RUN git clone https://github.com/huggingface/transformers && cd transformers && git checkout $REF
|
||||
RUN python3 -m pip install --no-cache-dir -e ./transformers[dev,onnxruntime]
|
||||
|
||||
# TODO: Handle these in a python utility script
|
||||
RUN [ ${#PYTORCH} -gt 0 -a "$PYTORCH" != "pre" ] && VERSION='torch=='$PYTORCH'.*' || VERSION='torch'; echo "export VERSION='$VERSION'" >> ~/.profile
|
||||
@@ -32,7 +31,10 @@ RUN echo torch=$VERSION
|
||||
# TODO: We might need to specify proper versions that work with a specific torch version (especially for past CI).
|
||||
RUN [ "$PYTORCH" != "pre" ] && python3 -m pip install --no-cache-dir -U $VERSION torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/$CUDA || python3 -m pip install --no-cache-dir -U --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/$CUDA
|
||||
|
||||
RUN python3 -m pip install --no-cache-dir -U tensorflow==2.12 protobuf==3.20.3 tensorflow_text tensorflow_probability
|
||||
RUN python3 -m pip install --no-cache-dir -U tensorflow==2.13 protobuf==3.20.3 tensorflow_text tensorflow_probability
|
||||
|
||||
RUN python3 -m pip install --no-cache-dir -e ./transformers[dev,onnxruntime]
|
||||
|
||||
RUN python3 -m pip uninstall -y flax jax
|
||||
|
||||
RUN python3 -m pip install --no-cache-dir intel_extension_for_pytorch==$INTEL_TORCH_EXT+cpu -f https://developer.intel.com/ipex-whl-stable-cpu
|
||||
@@ -42,11 +44,19 @@ RUN python3 -m pip install -U "itsdangerous<2.1.0"
|
||||
|
||||
RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/accelerate@main#egg=accelerate
|
||||
|
||||
RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/peft@main#egg=peft
|
||||
|
||||
# Add bitsandbytes for mixed int8 testing
|
||||
RUN python3 -m pip install --no-cache-dir bitsandbytes
|
||||
|
||||
# For bettertransformer
|
||||
RUN python3 -m pip install --no-cache-dir optimum
|
||||
# Add auto-gptq for gtpq quantization testing
|
||||
RUN python3 -m pip install --no-cache-dir auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/
|
||||
|
||||
# Add einops for additional model testing
|
||||
RUN python3 -m pip install --no-cache-dir einops
|
||||
|
||||
# For bettertransformer + gptq
|
||||
RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/optimum@main#egg=optimum
|
||||
|
||||
# For video model testing
|
||||
RUN python3 -m pip install --no-cache-dir decord av==9.2.0
|
||||
|
||||
@@ -12,7 +12,7 @@ RUN git clone https://github.com/huggingface/transformers && cd transformers &&
|
||||
RUN python3 -m pip install --no-cache-dir -e ./transformers[dev-tensorflow,testing]
|
||||
|
||||
# If set to nothing, will install the latest version
|
||||
ARG TENSORFLOW='2.12'
|
||||
ARG TENSORFLOW='2.13'
|
||||
|
||||
RUN [ ${#TENSORFLOW} -gt 0 ] && VERSION='tensorflow=='$TENSORFLOW'.*' || VERSION='tensorflow'; python3 -m pip install --no-cache-dir -U $VERSION
|
||||
RUN python3 -m pip uninstall -y torch flax
|
||||
|
||||
@@ -84,7 +84,7 @@ The `preview` command only works with existing doc files. When you add a complet
|
||||
Accepted files are Markdown (.md or .md).
|
||||
|
||||
Create a file with its extension and put it in the source directory. You can then link it to the toc-tree by putting
|
||||
the filename without the extension in the [`_toctree.yml`](https://github.com/huggingface/transformers/blob/main/docs/source/_toctree.yml) file.
|
||||
the filename without the extension in the [`_toctree.yml`](https://github.com/huggingface/transformers/blob/main/docs/source/en/_toctree.yml) file.
|
||||
|
||||
## Renaming section headers and moving sections
|
||||
|
||||
@@ -147,7 +147,7 @@ When adding a new model:
|
||||
- Add the classes that should be linked in the model. This generally includes the configuration, the tokenizer, and
|
||||
every model of that class (the base model, alongside models with additional heads), both in PyTorch and TensorFlow.
|
||||
The order is generally:
|
||||
- Configuration,
|
||||
- Configuration
|
||||
- Tokenizer
|
||||
- PyTorch base model
|
||||
- PyTorch head models
|
||||
|
||||
@@ -54,4 +54,4 @@ The fields you should add are `local` (with the name of the file containing the
|
||||
|
||||
Once you have translated the `_toctree.yml` file, you can start translating the [MDX](https://mdxjs.com/) files associated with your docs chapter.
|
||||
|
||||
> 🙋 If you'd like others to help you with the translation, you should [open an issue](https://github.com/huggingface/transformers/issues) and tag @sgugger.
|
||||
> 🙋 If you'd like others to help you with the translation, you should [open an issue](https://github.com/huggingface/transformers/issues) and tag @stevhliu and @MKhalusova.
|
||||
|
||||
@@ -218,7 +218,7 @@ Flax), PyTorch, und/oder TensorFlow haben.
|
||||
| BigBird-Pegasus | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Blenderbot | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| BlenderbotSmall | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| BLOOM | ❌ | ✅ | ✅ | ❌ | ❌ |
|
||||
| BLOOM | ❌ | ✅ | ✅ | ❌ | ✅ |
|
||||
| CamemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
|
||||
| CANINE | ✅ | ❌ | ✅ | ❌ | ❌ |
|
||||
| CLIP | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
|
||||
@@ -68,11 +68,13 @@ Installieren Sie die folgenden Abhängigkeiten, falls Sie dies nicht bereits get
|
||||
|
||||
<frameworkcontent>
|
||||
<pt>
|
||||
|
||||
```bash
|
||||
pip install torch
|
||||
```
|
||||
</pt>
|
||||
<tf>
|
||||
|
||||
```bash
|
||||
pip install tensorflow
|
||||
```
|
||||
@@ -226,6 +228,7 @@ Genau wie die [`pipeline`] akzeptiert der Tokenizer eine Liste von Eingaben. Dar
|
||||
|
||||
<frameworkcontent>
|
||||
<pt>
|
||||
|
||||
```py
|
||||
>>> pt_batch = tokenizer(
|
||||
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
|
||||
@@ -237,6 +240,7 @@ Genau wie die [`pipeline`] akzeptiert der Tokenizer eine Liste von Eingaben. Dar
|
||||
```
|
||||
</pt>
|
||||
<tf>
|
||||
|
||||
```py
|
||||
>>> tf_batch = tokenizer(
|
||||
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
|
||||
@@ -375,6 +379,7 @@ Ein besonders cooles 🤗 Transformers-Feature ist die Möglichkeit, ein Modell
|
||||
|
||||
<frameworkcontent>
|
||||
<pt>
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModel
|
||||
|
||||
@@ -383,6 +388,7 @@ Ein besonders cooles 🤗 Transformers-Feature ist die Möglichkeit, ein Modell
|
||||
```
|
||||
</pt>
|
||||
<tf>
|
||||
|
||||
```py
|
||||
>>> from transformers import TFAutoModel
|
||||
|
||||
|
||||
@@ -19,112 +19,128 @@
|
||||
title: Train with a script
|
||||
- local: accelerate
|
||||
title: Set up distributed training with 🤗 Accelerate
|
||||
- local: peft
|
||||
title: Load and train adapters with 🤗 PEFT
|
||||
- local: model_sharing
|
||||
title: Share your model
|
||||
- local: transformers_agents
|
||||
title: Agents
|
||||
- local: llm_tutorial
|
||||
title: Generation with LLMs
|
||||
title: Tutorials
|
||||
- sections:
|
||||
- sections:
|
||||
- local: tasks/sequence_classification
|
||||
title: Text classification
|
||||
- local: tasks/token_classification
|
||||
title: Token classification
|
||||
- local: tasks/question_answering
|
||||
title: Question answering
|
||||
- local: tasks/language_modeling
|
||||
title: Causal language modeling
|
||||
- local: tasks/masked_language_modeling
|
||||
title: Masked language modeling
|
||||
- local: tasks/translation
|
||||
title: Translation
|
||||
- local: tasks/summarization
|
||||
title: Summarization
|
||||
- local: tasks/multiple_choice
|
||||
title: Multiple choice
|
||||
- isExpanded: false
|
||||
sections:
|
||||
- local: tasks/sequence_classification
|
||||
title: Text classification
|
||||
- local: tasks/token_classification
|
||||
title: Token classification
|
||||
- local: tasks/question_answering
|
||||
title: Question answering
|
||||
- local: tasks/language_modeling
|
||||
title: Causal language modeling
|
||||
- local: tasks/masked_language_modeling
|
||||
title: Masked language modeling
|
||||
- local: tasks/translation
|
||||
title: Translation
|
||||
- local: tasks/summarization
|
||||
title: Summarization
|
||||
- local: tasks/multiple_choice
|
||||
title: Multiple choice
|
||||
title: Natural Language Processing
|
||||
isExpanded: false
|
||||
- sections:
|
||||
- local: tasks/audio_classification
|
||||
title: Audio classification
|
||||
- local: tasks/asr
|
||||
title: Automatic speech recognition
|
||||
- isExpanded: false
|
||||
sections:
|
||||
- local: tasks/audio_classification
|
||||
title: Audio classification
|
||||
- local: tasks/asr
|
||||
title: Automatic speech recognition
|
||||
title: Audio
|
||||
isExpanded: false
|
||||
- sections:
|
||||
- local: tasks/image_classification
|
||||
title: Image classification
|
||||
- local: tasks/semantic_segmentation
|
||||
title: Semantic segmentation
|
||||
- local: tasks/video_classification
|
||||
title: Video classification
|
||||
- local: tasks/object_detection
|
||||
title: Object detection
|
||||
- local: tasks/zero_shot_object_detection
|
||||
title: Zero-shot object detection
|
||||
- local: tasks/zero_shot_image_classification
|
||||
title: Zero-shot image classification
|
||||
- local: tasks/monocular_depth_estimation
|
||||
title: Depth estimation
|
||||
- isExpanded: false
|
||||
sections:
|
||||
- local: tasks/image_classification
|
||||
title: Image classification
|
||||
- local: tasks/semantic_segmentation
|
||||
title: Semantic segmentation
|
||||
- local: tasks/video_classification
|
||||
title: Video classification
|
||||
- local: tasks/object_detection
|
||||
title: Object detection
|
||||
- local: tasks/zero_shot_object_detection
|
||||
title: Zero-shot object detection
|
||||
- local: tasks/zero_shot_image_classification
|
||||
title: Zero-shot image classification
|
||||
- local: tasks/monocular_depth_estimation
|
||||
title: Depth estimation
|
||||
title: Computer Vision
|
||||
isExpanded: false
|
||||
- sections:
|
||||
- local: tasks/image_captioning
|
||||
title: Image captioning
|
||||
- local: tasks/document_question_answering
|
||||
title: Document Question Answering
|
||||
- local: tasks/text-to-speech
|
||||
title: Text to speech
|
||||
- isExpanded: false
|
||||
sections:
|
||||
- local: tasks/image_captioning
|
||||
title: Image captioning
|
||||
- local: tasks/document_question_answering
|
||||
title: Document Question Answering
|
||||
- local: tasks/visual_question_answering
|
||||
title: Visual Question Answering
|
||||
- local: tasks/text-to-speech
|
||||
title: Text to speech
|
||||
title: Multimodal
|
||||
isExpanded: false
|
||||
- isExpanded: false
|
||||
sections:
|
||||
- local: generation_strategies
|
||||
title: Customize the generation strategy
|
||||
title: Generation
|
||||
title: Task Guides
|
||||
- sections:
|
||||
- local: fast_tokenizers
|
||||
title: Use fast tokenizers from 🤗 Tokenizers
|
||||
- local: multilingual
|
||||
title: Run inference with multilingual models
|
||||
- local: generation_strategies
|
||||
title: Customize text generation strategy
|
||||
- local: create_a_model
|
||||
title: Use model-specific APIs
|
||||
- local: custom_models
|
||||
title: Share a custom model
|
||||
- local: sagemaker
|
||||
title: Run training on Amazon SageMaker
|
||||
- local: serialization
|
||||
title: Export to ONNX
|
||||
- local: tflite
|
||||
title: Export to TFLite
|
||||
- local: torchscript
|
||||
title: Export to TorchScript
|
||||
- local: benchmarks
|
||||
title: Benchmarks
|
||||
- local: notebooks
|
||||
title: Notebooks with examples
|
||||
- local: community
|
||||
title: Community resources
|
||||
- local: custom_tools
|
||||
title: Custom Tools and Prompts
|
||||
- local: troubleshooting
|
||||
title: Troubleshoot
|
||||
- local: fast_tokenizers
|
||||
title: Use fast tokenizers from 🤗 Tokenizers
|
||||
- local: multilingual
|
||||
title: Run inference with multilingual models
|
||||
- local: create_a_model
|
||||
title: Use model-specific APIs
|
||||
- local: custom_models
|
||||
title: Share a custom model
|
||||
- local: sagemaker
|
||||
title: Run training on Amazon SageMaker
|
||||
- local: serialization
|
||||
title: Export to ONNX
|
||||
- local: tflite
|
||||
title: Export to TFLite
|
||||
- local: torchscript
|
||||
title: Export to TorchScript
|
||||
- local: benchmarks
|
||||
title: Benchmarks
|
||||
- local: notebooks
|
||||
title: Notebooks with examples
|
||||
- local: community
|
||||
title: Community resources
|
||||
- local: custom_tools
|
||||
title: Custom Tools and Prompts
|
||||
- local: troubleshooting
|
||||
title: Troubleshoot
|
||||
title: Developer guides
|
||||
- sections:
|
||||
- local: performance
|
||||
title: Overview
|
||||
- local: performance
|
||||
title: Overview
|
||||
- sections:
|
||||
- local: perf_train_gpu_one
|
||||
title: Training on one GPU
|
||||
title: Methods and tools for efficient training on a single GPU
|
||||
- local: perf_train_gpu_many
|
||||
title: Training on many GPUs
|
||||
title: Multiple GPUs and parallelism
|
||||
- local: perf_train_cpu
|
||||
title: Training on CPU
|
||||
title: Efficient training on CPU
|
||||
- local: perf_train_cpu_many
|
||||
title: Training on many CPUs
|
||||
title: Distributed CPU training
|
||||
- local: perf_train_tpu
|
||||
title: Training on TPUs
|
||||
- local: perf_train_tpu_tf
|
||||
title: Training on TPU with TensorFlow
|
||||
- local: perf_train_special
|
||||
title: Training on Specialized Hardware
|
||||
- local: perf_hardware
|
||||
title: Custom hardware for training
|
||||
- local: hpo_train
|
||||
title: Hyperparameter Search using Trainer API
|
||||
title: Efficient training techniques
|
||||
- sections:
|
||||
- local: perf_infer_cpu
|
||||
title: Inference on CPU
|
||||
- local: perf_infer_gpu_one
|
||||
@@ -133,32 +149,30 @@
|
||||
title: Inference on many GPUs
|
||||
- local: perf_infer_special
|
||||
title: Inference on Specialized Hardware
|
||||
- local: perf_hardware
|
||||
title: Custom hardware for training
|
||||
- local: big_models
|
||||
title: Instantiating a big model
|
||||
- local: debugging
|
||||
title: Debugging
|
||||
- local: hpo_train
|
||||
title: Hyperparameter Search using Trainer API
|
||||
- local: tf_xla
|
||||
title: XLA Integration for TensorFlow Models
|
||||
title: Optimizing inference
|
||||
- local: big_models
|
||||
title: Instantiating a big model
|
||||
- local: debugging
|
||||
title: Troubleshooting
|
||||
- local: tf_xla
|
||||
title: XLA Integration for TensorFlow Models
|
||||
- local: perf_torch_compile
|
||||
title: Optimize inference using `torch.compile()`
|
||||
title: Performance and scalability
|
||||
- sections:
|
||||
- local: contributing
|
||||
title: How to contribute to transformers?
|
||||
- local: add_new_model
|
||||
title: How to add a model to 🤗 Transformers?
|
||||
- local: add_tensorflow_model
|
||||
title: How to convert a 🤗 Transformers model to TensorFlow?
|
||||
- local: add_new_pipeline
|
||||
title: How to add a pipeline to 🤗 Transformers?
|
||||
- local: testing
|
||||
title: Testing
|
||||
- local: pr_checks
|
||||
title: Checks on a Pull Request
|
||||
- local: contributing
|
||||
title: How to contribute to transformers?
|
||||
- local: add_new_model
|
||||
title: How to add a model to 🤗 Transformers?
|
||||
- local: add_tensorflow_model
|
||||
title: How to convert a 🤗 Transformers model to TensorFlow?
|
||||
- local: add_new_pipeline
|
||||
title: How to add a pipeline to 🤗 Transformers?
|
||||
- local: testing
|
||||
title: Testing
|
||||
- local: pr_checks
|
||||
title: Checks on a Pull Request
|
||||
title: Contribute
|
||||
|
||||
- sections:
|
||||
- local: philosophy
|
||||
title: Philosophy
|
||||
@@ -182,6 +196,8 @@
|
||||
title: Perplexity of fixed-length models
|
||||
- local: pipeline_webserver
|
||||
title: Pipelines for webserver inference
|
||||
- local: model_memory_anatomy
|
||||
title: Model training anatomy
|
||||
title: Conceptual guides
|
||||
- sections:
|
||||
- sections:
|
||||
@@ -267,6 +283,8 @@
|
||||
title: CANINE
|
||||
- local: model_doc/codegen
|
||||
title: CodeGen
|
||||
- local: model_doc/code_llama
|
||||
title: CodeLlama
|
||||
- local: model_doc/convbert
|
||||
title: ConvBERT
|
||||
- local: model_doc/cpm
|
||||
@@ -295,6 +313,8 @@
|
||||
title: ErnieM
|
||||
- local: model_doc/esm
|
||||
title: ESM
|
||||
- local: model_doc/falcon
|
||||
title: Falcon
|
||||
- local: model_doc/flan-t5
|
||||
title: FLAN-T5
|
||||
- local: model_doc/flan-ul2
|
||||
@@ -335,6 +355,8 @@
|
||||
title: LED
|
||||
- local: model_doc/llama
|
||||
title: LLaMA
|
||||
- local: model_doc/llama2
|
||||
title: Llama2
|
||||
- local: model_doc/longformer
|
||||
title: Longformer
|
||||
- local: model_doc/longt5
|
||||
@@ -361,6 +383,8 @@
|
||||
title: MobileBERT
|
||||
- local: model_doc/mpnet
|
||||
title: MPNet
|
||||
- local: model_doc/mpt
|
||||
title: MPT
|
||||
- local: model_doc/mra
|
||||
title: MRA
|
||||
- local: model_doc/mt5
|
||||
@@ -472,6 +496,8 @@
|
||||
title: DETR
|
||||
- local: model_doc/dinat
|
||||
title: DiNAT
|
||||
- local: model_doc/dinov2
|
||||
title: DINO V2
|
||||
- local: model_doc/dit
|
||||
title: DiT
|
||||
- local: model_doc/dpt
|
||||
@@ -504,6 +530,8 @@
|
||||
title: NAT
|
||||
- local: model_doc/poolformer
|
||||
title: PoolFormer
|
||||
- local: model_doc/pvt
|
||||
title: Pyramid Vision Transformer (PVT)
|
||||
- local: model_doc/regnet
|
||||
title: RegNet
|
||||
- local: model_doc/resnet
|
||||
@@ -532,6 +560,8 @@
|
||||
title: Vision Transformer (ViT)
|
||||
- local: model_doc/vit_hybrid
|
||||
title: ViT Hybrid
|
||||
- local: model_doc/vitdet
|
||||
title: ViTDet
|
||||
- local: model_doc/vit_mae
|
||||
title: ViTMAE
|
||||
- local: model_doc/vit_msn
|
||||
@@ -559,6 +589,8 @@
|
||||
title: MMS
|
||||
- local: model_doc/musicgen
|
||||
title: MusicGen
|
||||
- local: model_doc/pop2piano
|
||||
title: Pop2Piano
|
||||
- local: model_doc/sew
|
||||
title: SEW
|
||||
- local: model_doc/sew-d
|
||||
@@ -573,6 +605,8 @@
|
||||
title: UniSpeech
|
||||
- local: model_doc/unispeech-sat
|
||||
title: UniSpeech-SAT
|
||||
- local: model_doc/vits
|
||||
title: VITS
|
||||
- local: model_doc/wav2vec2
|
||||
title: Wav2Vec2
|
||||
- local: model_doc/wav2vec2-conformer
|
||||
@@ -618,6 +652,8 @@
|
||||
title: GIT
|
||||
- local: model_doc/groupvit
|
||||
title: GroupViT
|
||||
- local: model_doc/idefics
|
||||
title: IDEFICS
|
||||
- local: model_doc/instructblip
|
||||
title: InstructBLIP
|
||||
- local: model_doc/layoutlm
|
||||
|
||||
@@ -133,4 +133,4 @@ accelerate launch train.py
|
||||
>>> notebook_launcher(training_function)
|
||||
```
|
||||
|
||||
For more information about 🤗 Accelerate and it's rich features, refer to the [documentation](https://huggingface.co/docs/accelerate).
|
||||
For more information about 🤗 Accelerate and its rich features, refer to the [documentation](https://huggingface.co/docs/accelerate).
|
||||
|
||||
@@ -101,7 +101,7 @@ own regarding how code should be written :-)
|
||||
1. The forward pass of your model should be fully written in the modeling file while being fully independent of other
|
||||
models in the library. If you want to reuse a block from another model, copy the code and paste it with a
|
||||
`# Copied from` comment on top (see [here](https://github.com/huggingface/transformers/blob/v4.17.0/src/transformers/models/roberta/modeling_roberta.py#L160)
|
||||
for a good example).
|
||||
for a good example and [there](pr_checks#check-copies) for more documentation on Copied from).
|
||||
2. The code should be fully understandable, even by a non-native English speaker. This means you should pick
|
||||
descriptive variable names and avoid abbreviations. As an example, `activation` is preferred to `act`.
|
||||
One-letter variable names are strongly discouraged unless it's an index in a for loop.
|
||||
@@ -361,7 +361,7 @@ We expect that every model added to 🤗 Transformers passes a couple of integra
|
||||
model and the reimplemented version in 🤗 Transformers have to give the exact same output up to a precision of 0.001!
|
||||
Since it is normal that the exact same model written in different libraries can give a slightly different output
|
||||
depending on the library framework, we accept an error tolerance of 1e-3 (0.001). It is not enough if the model gives
|
||||
nearly the same output, they have to be the almost identical. Therefore, you will certainly compare the intermediate
|
||||
nearly the same output, they have to be almost identical. Therefore, you will certainly compare the intermediate
|
||||
outputs of the 🤗 Transformers version multiple times against the intermediate outputs of the original implementation of
|
||||
*brand_new_bert* in which case an **efficient** debugging environment of the original repository is absolutely
|
||||
important. Here is some advice is to make your debugging environment as efficient as possible.
|
||||
|
||||
@@ -56,7 +56,7 @@ you might recall from our [general overview of 🤗 Transformers](add_new_model#
|
||||
that we are an opinionated bunch - the ease of use of 🤗 Transformers relies on consistent design choices. From
|
||||
experience, we can tell you a few important things about adding TensorFlow models:
|
||||
|
||||
- Don't reinvent the wheel! More often that not, there are at least two reference implementations you should check: the
|
||||
- Don't reinvent the wheel! More often than not, there are at least two reference implementations you should check: the
|
||||
PyTorch equivalent of the model you are implementing and other TensorFlow models for the same class of problems.
|
||||
- Great model implementations survive the test of time. This doesn't happen because the code is pretty, but rather
|
||||
because the code is clear, easy to debug and build upon. If you make the life of the maintainers easy with your
|
||||
@@ -101,7 +101,7 @@ TensorFlow-related pull request.
|
||||
|
||||
**2. Prepare transformers dev environment**
|
||||
|
||||
Having selected the model architecture, open an draft PR to signal your intention to work on it. Follow the
|
||||
Having selected the model architecture, open a draft PR to signal your intention to work on it. Follow the
|
||||
instructions below to set up your environment and open a draft PR.
|
||||
|
||||
1. Fork the [repository](https://github.com/huggingface/transformers) by clicking on the 'Fork' button on the
|
||||
@@ -328,7 +328,7 @@ That's it! 🎉
|
||||
## Debugging mismatches across ML frameworks 🐛
|
||||
|
||||
At some point, when adding a new architecture or when creating TensorFlow weights for an existing architecture, you
|
||||
might come across errors compaining about mismatches between PyTorch and TensorFlow. You might even decide to open the
|
||||
might come across errors complaining about mismatches between PyTorch and TensorFlow. You might even decide to open the
|
||||
model architecture code for the two frameworks, and find that they look identical. What's going on? 🤔
|
||||
|
||||
First of all, let's talk about why understanding these mismatches matters. Many community members will use 🤗
|
||||
@@ -351,7 +351,7 @@ ingredient here is patience. Here is our suggested workflow for when you come ac
|
||||
that you'll have to venture into the source implementation of said instruction. In some cases, you might find an
|
||||
issue with a reference implementation - don't abstain from opening an issue in the upstream repository.
|
||||
|
||||
In some cases, in dicussion with the 🤗 Transformers team, we might find that the fixing the mismatch is infeasible.
|
||||
In some cases, in discussion with the 🤗 Transformers team, we might find that fixing the mismatch is infeasible.
|
||||
When the mismatch is very small in the output layers of the model (but potentially large in the hidden states), we
|
||||
might decide to ignore it in favor of distributing the model. The `pt-to-tf` CLI mentioned above has a `--max-error`
|
||||
flag to override the error message at weight conversion time.
|
||||
|
||||
@@ -16,7 +16,7 @@ rendered properly in your Markdown viewer.
|
||||
|
||||
# Load pretrained instances with an AutoClass
|
||||
|
||||
With so many different Transformer architectures, it can be challenging to create one for your checkpoint. As a part of 🤗 Transformers core philosophy to make the library easy, simple and flexible to use, an `AutoClass` automatically infer and load the correct architecture from a given checkpoint. The `from_pretrained()` method lets you quickly load a pretrained model for any architecture so you don't have to devote time and resources to train a model from scratch. Producing this type of checkpoint-agnostic code means if your code works for one checkpoint, it will work with another checkpoint - as long as it was trained for a similar task - even if the architecture is different.
|
||||
With so many different Transformer architectures, it can be challenging to create one for your checkpoint. As a part of 🤗 Transformers core philosophy to make the library easy, simple and flexible to use, an `AutoClass` automatically infers and loads the correct architecture from a given checkpoint. The `from_pretrained()` method lets you quickly load a pretrained model for any architecture so you don't have to devote time and resources to train a model from scratch. Producing this type of checkpoint-agnostic code means if your code works for one checkpoint, it will work with another checkpoint - as long as it was trained for a similar task - even if the architecture is different.
|
||||
|
||||
<Tip>
|
||||
|
||||
|
||||
@@ -23,11 +23,11 @@ from PyTorch is:
|
||||
2. Load your pretrained weights.
|
||||
3. Put those pretrained weights in your random model.
|
||||
|
||||
Step 1 and 2 both require a full version of the model in memory, which is not a problem in most cases, but if your model starts weighing several GigaBytes, those two copies can make you got our of RAM. Even worse, if you are using `torch.distributed` to launch a distributed training, each process will load the pretrained model and store these two copies in RAM.
|
||||
Step 1 and 2 both require a full version of the model in memory, which is not a problem in most cases, but if your model starts weighing several GigaBytes, those two copies can make you get out of RAM. Even worse, if you are using `torch.distributed` to launch a distributed training, each process will load the pretrained model and store these two copies in RAM.
|
||||
|
||||
<Tip>
|
||||
|
||||
Note that the randomly created model is initialized with "empty" tensors, which take the space in memory without filling it (thus the random values are whatever was in this chunk of memory at a given time). The random initialization following the appropriate distribution for the kind of model/parameters instatiated (like a normal distribution for instance) is only performed after step 3 on the non-initialized weights, to be as fast as possible!
|
||||
Note that the randomly created model is initialized with "empty" tensors, which take the space in memory without filling it (thus the random values are whatever was in this chunk of memory at a given time). The random initialization following the appropriate distribution for the kind of model/parameters instantiated (like a normal distribution for instance) is only performed after step 3 on the non-initialized weights, to be as fast as possible!
|
||||
|
||||
</Tip>
|
||||
|
||||
@@ -120,4 +120,4 @@ If you want to directly load such a sharded checkpoint inside a model without us
|
||||
|
||||
Sharded checkpoints reduce the memory usage during step 2 of the workflow mentioned above, but in order to use that model in a low memory setting, we recommend leveraging our tools based on the Accelerate library.
|
||||
|
||||
Please read the following guide for more information: [Large model loading using Accelerate](./main_classes/model#large-model-loading)
|
||||
Please read the following guide for more information: [Large model loading using Accelerate](./main_classes/model#large-model-loading)
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
<!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
<!--⚠️ Note that this file is in Markdown but contains specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
-->
|
||||
|
||||
@@ -10,7 +10,7 @@ This page regroups resources around 🤗 Transformers developed by the community
|
||||
|
||||
| Resource | Description | Author |
|
||||
|:----------|:-------------|------:|
|
||||
| [Hugging Face Transformers Glossary Flashcards](https://www.darigovresearch.com/huggingface-transformers-glossary-flashcards) | A set of flashcards based on the [Transformers Docs Glossary](glossary) that has been put into a form which can be easily learnt/revised using [Anki ](https://apps.ankiweb.net/) an open source, cross platform app specifically designed for long term knowledge retention. See this [Introductory video on how to use the flashcards](https://www.youtube.com/watch?v=Dji_h7PILrw). | [Darigov Research](https://www.darigovresearch.com/) |
|
||||
| [Hugging Face Transformers Glossary Flashcards](https://www.darigovresearch.com/huggingface-transformers-glossary-flashcards) | A set of flashcards based on the [Transformers Docs Glossary](glossary) that has been put into a form which can be easily learned/revised using [Anki ](https://apps.ankiweb.net/) an open source, cross platform app specifically designed for long term knowledge retention. See this [Introductory video on how to use the flashcards](https://www.youtube.com/watch?v=Dji_h7PILrw). | [Darigov Research](https://www.darigovresearch.com/) |
|
||||
|
||||
## Community notebooks:
|
||||
|
||||
@@ -35,7 +35,7 @@ This page regroups resources around 🤗 Transformers developed by the community
|
||||
|[Speed up Fine-Tuning in Transformers with Dynamic Padding / Bucketing](https://github.com/ELS-RD/transformers-notebook/blob/master/Divide_Hugging_Face_Transformers_training_time_by_2_or_more.ipynb)|How to speed up fine-tuning by a factor of 2 using dynamic padding / bucketing|[Michael Benesty](https://github.com/pommedeterresautee) |[](https://colab.research.google.com/drive/1CBfRU1zbfu7-ijiOqAAQUA-RJaxfcJoO?usp=sharing)|
|
||||
|[Pretrain Reformer for Masked Language Modeling](https://github.com/patrickvonplaten/notebooks/blob/master/Reformer_For_Masked_LM.ipynb)| How to train a Reformer model with bi-directional self-attention layers | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/drive/1tzzh0i8PgDQGV3SMFUGxM7_gGae3K-uW?usp=sharing)|
|
||||
|[Expand and Fine Tune Sci-BERT](https://github.com/lordtt13/word-embeddings/blob/master/COVID-19%20Research%20Data/COVID-SciBERT.ipynb)| How to increase vocabulary of a pretrained SciBERT model from AllenAI on the CORD dataset and pipeline it. | [Tanmay Thakur](https://github.com/lordtt13) | [](https://colab.research.google.com/drive/1rqAR40goxbAfez1xvF3hBJphSCsvXmh8)|
|
||||
|[Fine Tune BlenderBotSmall for Summarization using the Trainer API](https://github.com/lordtt13/transformers-experiments/blob/master/Custom%20Tasks/fine-tune-blenderbot_small-for-summarization.ipynb)| How to fine tune BlenderBotSmall for summarization on a custom dataset, using the Trainer API. | [Tanmay Thakur](https://github.com/lordtt13) | [](https://colab.research.google.com/drive/19Wmupuls7mykSGyRN_Qo6lPQhgp56ymq?usp=sharing)|
|
||||
|[Fine Tune BlenderBotSmall for Summarization using the Trainer API](https://github.com/lordtt13/transformers-experiments/blob/master/Custom%20Tasks/fine-tune-blenderbot_small-for-summarization.ipynb)| How to fine-tune BlenderBotSmall for summarization on a custom dataset, using the Trainer API. | [Tanmay Thakur](https://github.com/lordtt13) | [](https://colab.research.google.com/drive/19Wmupuls7mykSGyRN_Qo6lPQhgp56ymq?usp=sharing)|
|
||||
|[Fine-tune Electra and interpret with Integrated Gradients](https://github.com/elsanns/xai-nlp-notebooks/blob/master/electra_fine_tune_interpret_captum_ig.ipynb) | How to fine-tune Electra for sentiment analysis and interpret predictions with Captum Integrated Gradients | [Eliza Szczechla](https://elsanns.github.io) | [](https://colab.research.google.com/github/elsanns/xai-nlp-notebooks/blob/master/electra_fine_tune_interpret_captum_ig.ipynb)|
|
||||
|[fine-tune a non-English GPT-2 Model with Trainer class](https://github.com/philschmid/fine-tune-GPT-2/blob/master/Fine_tune_a_non_English_GPT_2_Model_with_Huggingface.ipynb) | How to fine-tune a non-English GPT-2 Model with Trainer class | [Philipp Schmid](https://www.philschmid.de) | [](https://colab.research.google.com/github/philschmid/fine-tune-GPT-2/blob/master/Fine_tune_a_non_English_GPT_2_Model_with_Huggingface.ipynb)|
|
||||
|[Fine-tune a DistilBERT Model for Multi Label Classification task](https://github.com/DhavalTaunk08/Transformers_scripts/blob/master/Transformers_multilabel_distilbert.ipynb) | How to fine-tune a DistilBERT Model for Multi Label Classification task | [Dhaval Taunk](https://github.com/DhavalTaunk08) | [](https://colab.research.google.com/github/DhavalTaunk08/Transformers_scripts/blob/master/Transformers_multilabel_distilbert.ipynb)|
|
||||
|
||||
@@ -209,7 +209,7 @@ Easily reuse this checkpoint for another task by switching to a different model
|
||||
The last base class you need before using a model for textual data is a [tokenizer](main_classes/tokenizer) to convert raw text to tensors. There are two types of tokenizers you can use with 🤗 Transformers:
|
||||
|
||||
- [`PreTrainedTokenizer`]: a Python implementation of a tokenizer.
|
||||
- [`PreTrainedTokenizerFast`]: a tokenizer from our Rust-based [🤗 Tokenizer](https://huggingface.co/docs/tokenizers/python/latest/) library. This tokenizer type is significantly faster - especially during batch tokenization - due to it's Rust implementation. The fast tokenizer also offers additional methods like *offset mapping* which maps tokens to their original words or characters.
|
||||
- [`PreTrainedTokenizerFast`]: a tokenizer from our Rust-based [🤗 Tokenizer](https://huggingface.co/docs/tokenizers/python/latest/) library. This tokenizer type is significantly faster - especially during batch tokenization - due to its Rust implementation. The fast tokenizer also offers additional methods like *offset mapping* which maps tokens to their original words or characters.
|
||||
|
||||
Both tokenizers support common methods such as encoding and decoding, adding new tokens, and managing special tokens.
|
||||
|
||||
|
||||
@@ -341,7 +341,7 @@ model. This is different from pushing the code to the Hub in the sense that user
|
||||
get the custom models (contrarily to automatically downloading the model code from the Hub).
|
||||
|
||||
As long as your config has a `model_type` attribute that is different from existing model types, and that your model
|
||||
classes have the right `config_class` attributes, you can just add them to the auto classes likes this:
|
||||
classes have the right `config_class` attributes, you can just add them to the auto classes like this:
|
||||
|
||||
```py
|
||||
from transformers import AutoConfig, AutoModel, AutoModelForImageClassification
|
||||
|
||||
@@ -25,7 +25,7 @@ If you are not aware of what tools and agents are in the context of transformers
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
Transformers Agent is an experimental API that is subject to change at any time. Results returned by the agents
|
||||
Transformers Agents is an experimental API that is subject to change at any time. Results returned by the agents
|
||||
can vary as the APIs or underlying models are prone to change.
|
||||
|
||||
</Tip>
|
||||
|
||||
@@ -55,7 +55,7 @@ When you load a model explicitly, you can inspect the generation configuration t
|
||||
>>> from transformers import AutoModelForCausalLM
|
||||
|
||||
>>> model = AutoModelForCausalLM.from_pretrained("distilgpt2")
|
||||
>>> model.generation_config
|
||||
>>> model.generation_config # doctest: +IGNORE_RESULT
|
||||
GenerationConfig {
|
||||
"_from_model_config": true,
|
||||
"bos_token_id": 50256,
|
||||
@@ -77,7 +77,7 @@ producing highly repetitive results.
|
||||
You can override any `generation_config` by passing the parameters and their values directly to the [`generate`] method:
|
||||
|
||||
```python
|
||||
>>> my_model.generate(**inputs, num_beams=4, do_sample=True)
|
||||
>>> my_model.generate(**inputs, num_beams=4, do_sample=True) # doctest: +SKIP
|
||||
```
|
||||
|
||||
Even if the default decoding strategy mostly works for your task, you can still tweak a few things. Some of the
|
||||
@@ -92,7 +92,7 @@ sequences that start with a lower probability initial tokens and would've been i
|
||||
- `do_sample`: if set to `True`, this parameter enables decoding strategies such as multinomial sampling, beam-search
|
||||
multinomial sampling, Top-K sampling and Top-p sampling. All these strategies select the next token from the probability
|
||||
distribution over the entire vocabulary with various strategy-specific adjustments.
|
||||
- `num_return_sequences`: the number of sequence candidates to return for each input. This options is only available for
|
||||
- `num_return_sequences`: the number of sequence candidates to return for each input. This option is only available for
|
||||
the decoding strategies that support multiple sequence candidates, e.g. variations of beam search and sampling. Decoding
|
||||
strategies like greedy search and contrastive search return a single output sequence.
|
||||
|
||||
@@ -107,11 +107,11 @@ If you would like to share your fine-tuned model with a specific generation conf
|
||||
```python
|
||||
>>> from transformers import AutoModelForCausalLM, GenerationConfig
|
||||
|
||||
>>> model = AutoModelForCausalLM.from_pretrained("my_account/my_model")
|
||||
>>> model = AutoModelForCausalLM.from_pretrained("my_account/my_model") # doctest: +SKIP
|
||||
>>> generation_config = GenerationConfig(
|
||||
... max_new_tokens=50, do_sample=True, top_k=50, eos_token_id=model.config.eos_token_id
|
||||
... )
|
||||
>>> generation_config.save_pretrained("my_account/my_model", push_to_hub=True)
|
||||
>>> generation_config.save_pretrained("my_account/my_model", push_to_hub=True) # doctest: +SKIP
|
||||
```
|
||||
|
||||
You can also store several generation configurations in a single directory, making use of the `config_file_name`
|
||||
@@ -133,19 +133,20 @@ one for summarization with beam search). You must have the right Hub permissions
|
||||
... pad_token=model.config.pad_token_id,
|
||||
... )
|
||||
|
||||
>>> translation_generation_config.save_pretrained("t5-small", "translation_generation_config.json", push_to_hub=True)
|
||||
>>> # Tip: add `push_to_hub=True` to push to the Hub
|
||||
>>> translation_generation_config.save_pretrained("/tmp", "translation_generation_config.json")
|
||||
|
||||
>>> # You could then use the named generation config file to parameterize generation
|
||||
>>> generation_config = GenerationConfig.from_pretrained("t5-small", "translation_generation_config.json")
|
||||
>>> generation_config = GenerationConfig.from_pretrained("/tmp", "translation_generation_config.json")
|
||||
>>> inputs = tokenizer("translate English to French: Configuration files are easy to use!", return_tensors="pt")
|
||||
>>> outputs = model.generate(**inputs, generation_config=generation_config)
|
||||
>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
|
||||
['Les fichiers de configuration sont faciles à utiliser !']
|
||||
['Les fichiers de configuration sont faciles à utiliser!']
|
||||
```
|
||||
|
||||
## Streaming
|
||||
|
||||
The `generate()` supports streaming, through its `streamer` input. The `streamer` input is compatible any instance
|
||||
The `generate()` supports streaming, through its `streamer` input. The `streamer` input is compatible with any instance
|
||||
from a class that has the following methods: `put()` and `end()`. Internally, `put()` is used to push new tokens and
|
||||
`end()` is used to flag the end of text generation.
|
||||
|
||||
@@ -217,10 +218,9 @@ The two main parameters that enable and control the behavior of contrastive sear
|
||||
|
||||
>>> outputs = model.generate(**inputs, penalty_alpha=0.6, top_k=4, max_new_tokens=100)
|
||||
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
|
||||
['Hugging Face Company is a family owned and operated business. \
|
||||
We pride ourselves on being the best in the business and our customer service is second to none.\
|
||||
\n\nIf you have any questions about our products or services, feel free to contact us at any time.\
|
||||
We look forward to hearing from you!']
|
||||
['Hugging Face Company is a family owned and operated business. We pride ourselves on being the best
|
||||
in the business and our customer service is second to none.\n\nIf you have any questions about our
|
||||
products or services, feel free to contact us at any time. We look forward to hearing from you!']
|
||||
```
|
||||
|
||||
### Multinomial sampling
|
||||
@@ -233,7 +233,8 @@ risk of repetition.
|
||||
To enable multinomial sampling set `do_sample=True` and `num_beams=1`.
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoTokenizer, AutoModelForCausalLM
|
||||
>>> from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
|
||||
>>> set_seed(0) # For reproducibility
|
||||
|
||||
>>> checkpoint = "gpt2-large"
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
|
||||
@@ -244,11 +245,8 @@ To enable multinomial sampling set `do_sample=True` and `num_beams=1`.
|
||||
|
||||
>>> outputs = model.generate(**inputs, do_sample=True, num_beams=1, max_new_tokens=100)
|
||||
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
|
||||
['Today was an amazing day because we are now in the final stages of our trip to New York City which was very tough. \
|
||||
It is a difficult schedule and a challenging part of the year but still worth it. I have been taking things easier and \
|
||||
I feel stronger and more motivated to be out there on their tour. Hopefully, that experience is going to help them with \
|
||||
their upcoming events which are currently scheduled in Australia.\n\nWe love that they are here. They want to make a \
|
||||
name for themselves and become famous for what they']
|
||||
['Today was an amazing day because when you go to the World Cup and you don\'t, or when you don\'t get invited,
|
||||
that\'s a terrible feeling."']
|
||||
```
|
||||
|
||||
### Beam-search decoding
|
||||
@@ -272,7 +270,7 @@ To enable this decoding strategy, specify the `num_beams` (aka number of hypothe
|
||||
|
||||
>>> outputs = model.generate(**inputs, num_beams=5, max_new_tokens=50)
|
||||
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
|
||||
['It is astonishing how one can have such a profound impact on the lives of so many people in such a short period of \
|
||||
['It is astonishing how one can have such a profound impact on the lives of so many people in such a short period of
|
||||
time."\n\nHe added: "I am very proud of the work I have been able to do in the last few years.\n\n"I have']
|
||||
```
|
||||
|
||||
@@ -282,7 +280,8 @@ As the name implies, this decoding strategy combines beam search with multinomia
|
||||
the `num_beams` greater than 1, and set `do_sample=True` to use this decoding strategy.
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
|
||||
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, set_seed
|
||||
>>> set_seed(0) # For reproducibility
|
||||
|
||||
>>> prompt = "translate English to German: The house is wonderful."
|
||||
>>> checkpoint = "t5-small"
|
||||
@@ -302,27 +301,29 @@ the `num_beams` greater than 1, and set `do_sample=True` to use this decoding st
|
||||
The diverse beam search decoding strategy is an extension of the beam search strategy that allows for generating a more diverse
|
||||
set of beam sequences to choose from. To learn how it works, refer to [Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models](https://arxiv.org/pdf/1610.02424.pdf).
|
||||
This approach has three main parameters: `num_beams`, `num_beam_groups`, and `diversity_penalty`.
|
||||
The diversily penalty ensures the outputs are distinct across groups, and beam search is used within each group.
|
||||
The diversity penalty ensures the outputs are distinct across groups, and beam search is used within each group.
|
||||
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
|
||||
|
||||
>>> checkpoint = "google/pegasus-xsum"
|
||||
>>> prompt = "The Permaculture Design Principles are a set of universal design principles \
|
||||
>>> that can be applied to any location, climate and culture, and they allow us to design \
|
||||
>>> the most efficient and sustainable human habitation and food production systems. \
|
||||
>>> Permaculture is a design system that encompasses a wide variety of disciplines, such \
|
||||
>>> as ecology, landscape design, environmental science and energy conservation, and the \
|
||||
>>> Permaculture design principles are drawn from these various disciplines. Each individual \
|
||||
>>> design principle itself embodies a complete conceptual framework based on sound \
|
||||
>>> scientific principles. When we bring all these separate principles together, we can \
|
||||
>>> create a design system that both looks at whole systems, the parts that these systems \
|
||||
>>> consist of, and how those parts interact with each other to create a complex, dynamic, \
|
||||
>>> living system. Each design principle serves as a tool that allows us to integrate all \
|
||||
>>> the separate parts of a design, referred to as elements, into a functional, synergistic, \
|
||||
>>> whole system, where the elements harmoniously interact and work together in the most \
|
||||
>>> efficient way possible."
|
||||
>>> prompt = (
|
||||
... "The Permaculture Design Principles are a set of universal design principles "
|
||||
... "that can be applied to any location, climate and culture, and they allow us to design "
|
||||
... "the most efficient and sustainable human habitation and food production systems. "
|
||||
... "Permaculture is a design system that encompasses a wide variety of disciplines, such "
|
||||
... "as ecology, landscape design, environmental science and energy conservation, and the "
|
||||
... "Permaculture design principles are drawn from these various disciplines. Each individual "
|
||||
... "design principle itself embodies a complete conceptual framework based on sound "
|
||||
... "scientific principles. When we bring all these separate principles together, we can "
|
||||
... "create a design system that both looks at whole systems, the parts that these systems "
|
||||
... "consist of, and how those parts interact with each other to create a complex, dynamic, "
|
||||
... "living system. Each design principle serves as a tool that allows us to integrate all "
|
||||
... "the separate parts of a design, referred to as elements, into a functional, synergistic, "
|
||||
... "whole system, where the elements harmoniously interact and work together in the most "
|
||||
... "efficient way possible."
|
||||
... )
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
|
||||
>>> inputs = tokenizer(prompt, return_tensors="pt")
|
||||
@@ -331,7 +332,8 @@ The diversily penalty ensures the outputs are distinct across groups, and beam s
|
||||
|
||||
>>> outputs = model.generate(**inputs, num_beams=5, num_beam_groups=5, max_new_tokens=30, diversity_penalty=1.0)
|
||||
>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
|
||||
'The aim of this project is to create a new type of living system, one that is more sustainable and efficient than the current one.'
|
||||
'The Design Principles are a set of universal design principles that can be applied to any location, climate and
|
||||
culture, and they allow us to design the'
|
||||
```
|
||||
|
||||
This guide illustrates the main parameters that enable various decoding strategies. More advanced parameters exist for the
|
||||
@@ -365,11 +367,12 @@ To enable assisted decoding, set the `assistant_model` argument with a model.
|
||||
['Alice and Bob are sitting in a bar. Alice is drinking a beer and Bob is drinking a']
|
||||
```
|
||||
|
||||
When using assisted decoding with sampling methods, you can use the `temperarure` argument to control the randomness
|
||||
When using assisted decoding with sampling methods, you can use the `temperature` argument to control the randomness
|
||||
just like in multinomial sampling. However, in assisted decoding, reducing the temperature will help improving latency.
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
|
||||
>>> set_seed(42) # For reproducibility
|
||||
|
||||
>>> prompt = "Alice and Bob"
|
||||
>>> checkpoint = "EleutherAI/pythia-1.4b-deduped"
|
||||
@@ -382,5 +385,5 @@ just like in multinomial sampling. However, in assisted decoding, reducing the t
|
||||
>>> assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
|
||||
>>> outputs = model.generate(**inputs, assistant_model=assistant_model, do_sample=True, temperature=0.5)
|
||||
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
|
||||
["Alice and Bob are sitting on the sofa. Alice says, 'I'm going to my room"]
|
||||
['Alice and Bob are going to the same party. It is a small party, in a small']
|
||||
```
|
||||
|
||||
@@ -187,7 +187,7 @@ The model head refers to the last layer of a neural network that accepts the raw
|
||||
|
||||
### image patch
|
||||
|
||||
Vision-based Transformers models split an image into smaller patches which are linearly embedded, and then passed as a sequence to the model. You can find the `patch_size` - or resolution - of the model in it's configuration.
|
||||
Vision-based Transformers models split an image into smaller patches which are linearly embedded, and then passed as a sequence to the model. You can find the `patch_size` - or resolution - of the model in its configuration.
|
||||
|
||||
### inference
|
||||
|
||||
|
||||
@@ -84,6 +84,7 @@ The documentation is organized into five sections:
|
||||
1. **[CLIP](model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
|
||||
1. **[CLIPSeg](model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
|
||||
1. **[CodeGen](model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
|
||||
1. **[CodeLlama](model_doc/llama_code)** (from MetaAI) released with the paper [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) by Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.
|
||||
1. **[Conditional DETR](model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
|
||||
1. **[ConvBERT](model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
|
||||
1. **[ConvNeXT](model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
|
||||
@@ -103,6 +104,7 @@ The documentation is organized into five sections:
|
||||
1. **[DETR](model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
|
||||
1. **[DialoGPT](model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
|
||||
1. **[DiNAT](model_doc/dinat)** (from SHI Labs) released with the paper [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) by Ali Hassani and Humphrey Shi.
|
||||
1. **[DINOv2](model_doc/dinov2)** (from Meta AI) released with the paper [DINOv2: Learning Robust Visual Features without Supervision](https://arxiv.org/abs/2304.07193) by Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski.
|
||||
1. **[DistilBERT](model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation) and a German version of DistilBERT.
|
||||
1. **[DiT](model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
|
||||
1. **[Donut](model_doc/donut)** (from NAVER), released together with the paper [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) by Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park.
|
||||
@@ -139,6 +141,7 @@ The documentation is organized into five sections:
|
||||
1. **[GroupViT](model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
|
||||
1. **[Hubert](model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
|
||||
1. **[I-BERT](model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
|
||||
1. **[IDEFICS](model_doc/idefics)** (from HuggingFace) released with the paper [OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents](https://huggingface.co/papers/2306.16527) by Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander M. Rush, Douwe Kiela, Matthieu Cord, Victor Sanh.
|
||||
1. **[ImageGPT](model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
|
||||
1. **[Informer](model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
|
||||
1. **[InstructBLIP](model_doc/instructblip)** (from Salesforce) released with the paper [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
|
||||
@@ -151,6 +154,7 @@ The documentation is organized into five sections:
|
||||
1. **[LeViT](model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
|
||||
1. **[LiLT](model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
|
||||
1. **[LLaMA](model_doc/llama)** (from The FAIR team of Meta AI) released with the paper [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.
|
||||
1. **[Llama2](model_doc/llama2)** (from The FAIR team of Meta AI) released with the paper [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX) by Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom.
|
||||
1. **[Longformer](model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
|
||||
1. **[LongT5](model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
|
||||
1. **[LUKE](model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
|
||||
@@ -176,9 +180,10 @@ The documentation is organized into five sections:
|
||||
1. **[MobileViT](model_doc/mobilevit)** (from Apple) released with the paper [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari.
|
||||
1. **[MobileViTV2](model_doc/mobilevitv2)** (from Apple) released with the paper [Separable Self-attention for Mobile Vision Transformers](https://arxiv.org/abs/2206.02680) by Sachin Mehta and Mohammad Rastegari.
|
||||
1. **[MPNet](model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
|
||||
1. **[MPT](model_doc/mpt)** (from MosaiML) released with the repository [llm-foundry](https://github.com/mosaicml/llm-foundry/) by the MosaicML NLP Team.
|
||||
1. **[MRA](model_doc/mra)** (from the University of Wisconsin - Madison) released with the paper [Multi Resolution Analysis (MRA) for Approximate Self-Attention](https://arxiv.org/abs/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh.
|
||||
1. **[MT5](model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
|
||||
1. **[MusicGen](model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MusicGen](model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MVP](model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
|
||||
1. **[NAT](model_doc/nat)** (from SHI Labs) released with the paper [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
|
||||
1. **[Nezha](model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
|
||||
@@ -186,7 +191,7 @@ The documentation is organized into five sections:
|
||||
1. **[NLLB-MOE](model_doc/nllb-moe)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
|
||||
1. **[Nyströmformer](model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
|
||||
1. **[OneFormer](model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
|
||||
1. **[OpenLlama](model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released in [Open-Llama](https://github.com/s-JoL/Open-Llama).
|
||||
1. **[OpenLlama](model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released in [Open-Llama](https://github.com/s-JoL/Open-Llama).
|
||||
1. **[OPT](master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
|
||||
1. **[OWL-ViT](model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
|
||||
1. **[Pegasus](model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
|
||||
@@ -196,7 +201,9 @@ The documentation is organized into five sections:
|
||||
1. **[Pix2Struct](model_doc/pix2struct)** (from Google) released with the paper [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
|
||||
1. **[PLBart](model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
|
||||
1. **[PoolFormer](model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
|
||||
1. **[Pop2Piano](model_doc/pop2piano)** released with the paper [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi and Kyogu Lee.
|
||||
1. **[ProphetNet](model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
|
||||
1. **[PVT](model_doc/pvt)** (from Nanjing University, The University of Hong Kong etc.) released with the paper [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
|
||||
1. **[QDQBert](model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
|
||||
1. **[RAG](model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
|
||||
1. **[REALM](model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
|
||||
@@ -245,8 +252,10 @@ The documentation is organized into five sections:
|
||||
1. **[Vision Transformer (ViT)](model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
|
||||
1. **[VisualBERT](model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
|
||||
1. **[ViT Hybrid](model_doc/vit_hybrid)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
|
||||
1. **[VitDet](model_doc/vitdet)** (from Meta AI) released with the paper [Exploring Plain Vision Transformer Backbones for Object Detection](https://arxiv.org/abs/2203.16527) by Yanghao Li, Hanzi Mao, Ross Girshick, Kaiming He.
|
||||
1. **[ViTMAE](model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
|
||||
1. **[ViTMSN](model_doc/vit_msn)** (from Meta AI) released with the paper [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas.
|
||||
1. **[VITS](model_doc/vits)** (from Kakao Enterprise) released with the paper [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103) by Jaehyeon Kim, Jungil Kong, Juhee Son.
|
||||
1. **[ViViT](model_doc/vivit)** (from Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
|
||||
1. **[Wav2Vec2](model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
|
||||
1. **[Wav2Vec2-Conformer](model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
|
||||
@@ -276,204 +285,212 @@ Flax), PyTorch, and/or TensorFlow.
|
||||
|
||||
<!--This table is updated automatically from the auto modules with _make fix-copies_. Do not update manually!-->
|
||||
|
||||
| Model | Tokenizer slow | Tokenizer fast | PyTorch support | TensorFlow support | Flax Support |
|
||||
|:-----------------------------:|:--------------:|:--------------:|:---------------:|:------------------:|:------------:|
|
||||
| ALBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| ALIGN | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| AltCLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Audio Spectrogram Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Autoformer | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Bark | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| BART | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| BEiT | ❌ | ❌ | ✅ | ❌ | ✅ |
|
||||
| BERT | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| Bert Generation | ✅ | ❌ | ✅ | ❌ | ❌ |
|
||||
| BigBird | ✅ | ✅ | ✅ | ❌ | ✅ |
|
||||
| BigBird-Pegasus | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| BioGpt | ✅ | ❌ | ✅ | ❌ | ❌ |
|
||||
| BiT | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Blenderbot | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| BlenderbotSmall | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| BLIP | ❌ | ❌ | ✅ | ✅ | ❌ |
|
||||
| BLIP-2 | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| BLOOM | ❌ | ✅ | ✅ | ❌ | ❌ |
|
||||
| BridgeTower | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| CamemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
|
||||
| CANINE | ✅ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Chinese-CLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| CLAP | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| CLIP | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| CLIPSeg | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| CodeGen | ✅ | ✅ | ✅ | ❌ | ❌ |
|
||||
| Conditional DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| ConvBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
|
||||
| ConvNeXT | ❌ | ❌ | ✅ | ✅ | ❌ |
|
||||
| ConvNeXTV2 | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| CPM-Ant | ✅ | ❌ | ✅ | ❌ | ❌ |
|
||||
| CTRL | ✅ | ❌ | ✅ | ✅ | ❌ |
|
||||
| CvT | ❌ | ❌ | ✅ | ✅ | ❌ |
|
||||
| Data2VecAudio | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Data2VecText | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Data2VecVision | ❌ | ❌ | ✅ | ✅ | ❌ |
|
||||
| DeBERTa | ✅ | ✅ | ✅ | ✅ | ❌ |
|
||||
| DeBERTa-v2 | ✅ | ✅ | ✅ | ✅ | ❌ |
|
||||
| Decision Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Deformable DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| DeiT | ❌ | ❌ | ✅ | ✅ | ❌ |
|
||||
| DETA | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| DiNAT | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| DistilBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| DonutSwin | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| DPR | ✅ | ✅ | ✅ | ✅ | ❌ |
|
||||
| DPT | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| EfficientFormer | ❌ | ❌ | ✅ | ✅ | ❌ |
|
||||
| EfficientNet | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| ELECTRA | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| EnCodec | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
|
||||
| ERNIE | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| ErnieM | ✅ | ❌ | ✅ | ❌ | ❌ |
|
||||
| ESM | ✅ | ❌ | ✅ | ✅ | ❌ |
|
||||
| FairSeq Machine-Translation | ✅ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Falcon | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| FlauBERT | ✅ | ❌ | ✅ | ✅ | ❌ |
|
||||
| FLAVA | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| FNet | ✅ | ✅ | ✅ | ❌ | ❌ |
|
||||
| FocalNet | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Funnel Transformer | ✅ | ✅ | ✅ | ✅ | ❌ |
|
||||
| GIT | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| GLPN | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| GPT Neo | ❌ | ❌ | ✅ | ❌ | ✅ |
|
||||
| GPT NeoX | ❌ | ✅ | ✅ | ❌ | ❌ |
|
||||
| GPT NeoX Japanese | ✅ | ❌ | ✅ | ❌ | ❌ |
|
||||
| GPT-J | ❌ | ❌ | ✅ | ✅ | ✅ |
|
||||
| GPT-Sw3 | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| GPTBigCode | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| GPTSAN-japanese | ✅ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Graphormer | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| GroupViT | ❌ | ❌ | ✅ | ✅ | ❌ |
|
||||
| Hubert | ❌ | ❌ | ✅ | ✅ | ❌ |
|
||||
| I-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| ImageGPT | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Informer | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| InstructBLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Jukebox | ✅ | ❌ | ✅ | ❌ | ❌ |
|
||||
| LayoutLM | ✅ | ✅ | ✅ | ✅ | ❌ |
|
||||
| LayoutLMv2 | ✅ | ✅ | ✅ | ❌ | ❌ |
|
||||
| LayoutLMv3 | ✅ | ✅ | ✅ | ✅ | ❌ |
|
||||
| LED | ✅ | ✅ | ✅ | ✅ | ❌ |
|
||||
| LeViT | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| LiLT | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| LLaMA | ✅ | ✅ | ✅ | ❌ | ❌ |
|
||||
| Longformer | ✅ | ✅ | ✅ | ✅ | ❌ |
|
||||
| LongT5 | ❌ | ❌ | ✅ | ❌ | ✅ |
|
||||
| LUKE | ✅ | ❌ | ✅ | ❌ | ❌ |
|
||||
| LXMERT | ✅ | ✅ | ✅ | ✅ | ❌ |
|
||||
| M-CTC-T | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| M2M100 | ✅ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Marian | ✅ | ❌ | ✅ | ✅ | ✅ |
|
||||
| MarkupLM | ✅ | ✅ | ✅ | ❌ | ❌ |
|
||||
| Mask2Former | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| MaskFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| MaskFormerSwin | ❌ | ❌ | ❌ | ❌ | ❌ |
|
||||
| mBART | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| MEGA | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Megatron-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| MGP-STR | ✅ | ❌ | ✅ | ❌ | ❌ |
|
||||
| MobileBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
|
||||
| MobileNetV1 | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| MobileNetV2 | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| MobileViT | ❌ | ❌ | ✅ | ✅ | ❌ |
|
||||
| MobileViTV2 | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| MPNet | ✅ | ✅ | ✅ | ✅ | ❌ |
|
||||
| MRA | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| MT5 | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| MusicGen | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| MVP | ✅ | ✅ | ✅ | ❌ | ❌ |
|
||||
| NAT | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Nezha | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| NLLB-MOE | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Nyströmformer | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| OneFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| OpenAI GPT | ✅ | ✅ | ✅ | ✅ | ❌ |
|
||||
| OpenAI GPT-2 | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| OpenLlama | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| OPT | ❌ | ❌ | ✅ | ✅ | ✅ |
|
||||
| OWL-ViT | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Pegasus | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| PEGASUS-X | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Perceiver | ✅ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Pix2Struct | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| PLBart | ✅ | ❌ | ✅ | ❌ | ❌ |
|
||||
| PoolFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
|
||||
| QDQBert | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| RAG | ✅ | ❌ | ✅ | ✅ | ❌ |
|
||||
| REALM | ✅ | ✅ | ✅ | ❌ | ❌ |
|
||||
| Reformer | ✅ | ✅ | ✅ | ❌ | ❌ |
|
||||
| RegNet | ❌ | ❌ | ✅ | ✅ | ✅ |
|
||||
| RemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
|
||||
| ResNet | ❌ | ❌ | ✅ | ✅ | ✅ |
|
||||
| RetriBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
|
||||
| RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| RoBERTa-PreLayerNorm | ❌ | ❌ | ✅ | ✅ | ✅ |
|
||||
| RoCBert | ✅ | ❌ | ✅ | ❌ | ❌ |
|
||||
| RoFormer | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| RWKV | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| SAM | ❌ | ❌ | ✅ | ✅ | ❌ |
|
||||
| SegFormer | ❌ | ❌ | ✅ | ✅ | ❌ |
|
||||
| SEW | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| SEW-D | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Speech Encoder decoder | ❌ | ❌ | ✅ | ❌ | ✅ |
|
||||
| Speech2Text | ✅ | ❌ | ✅ | ✅ | ❌ |
|
||||
| Speech2Text2 | ✅ | ❌ | ❌ | ❌ | ❌ |
|
||||
| SpeechT5 | ✅ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Splinter | ✅ | ✅ | ✅ | ❌ | ❌ |
|
||||
| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
|
||||
| SwiftFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Swin Transformer | ❌ | ❌ | ✅ | ✅ | ❌ |
|
||||
| Swin Transformer V2 | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Swin2SR | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| SwitchTransformers | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| T5 | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| Table Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| TAPAS | ✅ | ❌ | ✅ | ✅ | ❌ |
|
||||
| Time Series Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| TimeSformer | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| TimmBackbone | ❌ | ❌ | ❌ | ❌ | ❌ |
|
||||
| Trajectory Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Transformer-XL | ✅ | ❌ | ✅ | ✅ | ❌ |
|
||||
| TrOCR | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| TVLT | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| UMT5 | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| UniSpeech | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| UniSpeechSat | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| UPerNet | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| VAN | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| VideoMAE | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| ViLT | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Vision Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
|
||||
| VisionTextDualEncoder | ❌ | ❌ | ✅ | ✅ | ✅ |
|
||||
| VisualBERT | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| ViT | ❌ | ❌ | ✅ | ✅ | ✅ |
|
||||
| ViT Hybrid | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| ViTMAE | ❌ | ❌ | ✅ | ✅ | ❌ |
|
||||
| ViTMSN | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| ViViT | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Wav2Vec2 | ✅ | ❌ | ✅ | ✅ | ✅ |
|
||||
| Wav2Vec2-Conformer | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| WavLM | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Whisper | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| X-CLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| X-MOD | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| XGLM | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| XLM | ✅ | ❌ | ✅ | ✅ | ❌ |
|
||||
| XLM-ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
|
||||
| XLM-RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| XLM-RoBERTa-XL | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| XLNet | ✅ | ✅ | ✅ | ✅ | ❌ |
|
||||
| YOLOS | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| YOSO | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Model | PyTorch support | TensorFlow support | Flax Support |
|
||||
|:-----------------------------:|:---------------:|:------------------:|:------------:|
|
||||
| ALBERT | ✅ | ✅ | ✅ |
|
||||
| ALIGN | ✅ | ❌ | ❌ |
|
||||
| AltCLIP | ✅ | ❌ | ❌ |
|
||||
| Audio Spectrogram Transformer | ✅ | ❌ | ❌ |
|
||||
| Autoformer | ✅ | ❌ | ❌ |
|
||||
| Bark | ✅ | ❌ | ❌ |
|
||||
| BART | ✅ | ✅ | ✅ |
|
||||
| BEiT | ✅ | ❌ | ✅ |
|
||||
| BERT | ✅ | ✅ | ✅ |
|
||||
| Bert Generation | ✅ | ❌ | ❌ |
|
||||
| BigBird | ✅ | ❌ | ✅ |
|
||||
| BigBird-Pegasus | ✅ | ❌ | ❌ |
|
||||
| BioGpt | ✅ | ❌ | ❌ |
|
||||
| BiT | ✅ | ❌ | ❌ |
|
||||
| Blenderbot | ✅ | ✅ | ✅ |
|
||||
| BlenderbotSmall | ✅ | ✅ | ✅ |
|
||||
| BLIP | ✅ | ✅ | ❌ |
|
||||
| BLIP-2 | ✅ | ❌ | ❌ |
|
||||
| BLOOM | ✅ | ❌ | ✅ |
|
||||
| BridgeTower | ✅ | ❌ | ❌ |
|
||||
| CamemBERT | ✅ | ✅ | ❌ |
|
||||
| CANINE | ✅ | ❌ | ❌ |
|
||||
| Chinese-CLIP | ✅ | ❌ | ❌ |
|
||||
| CLAP | ✅ | ❌ | ❌ |
|
||||
| CLIP | ✅ | ✅ | ✅ |
|
||||
| CLIPSeg | ✅ | ❌ | ❌ |
|
||||
| CodeGen | ✅ | ❌ | ❌ |
|
||||
| CodeLlama | ✅ | ❌ | ❌ |
|
||||
| Conditional DETR | ✅ | ❌ | ❌ |
|
||||
| ConvBERT | ✅ | ✅ | ❌ |
|
||||
| ConvNeXT | ✅ | ✅ | ❌ |
|
||||
| ConvNeXTV2 | ✅ | ❌ | ❌ |
|
||||
| CPM-Ant | ✅ | ❌ | ❌ |
|
||||
| CTRL | ✅ | ✅ | ❌ |
|
||||
| CvT | ✅ | ✅ | ❌ |
|
||||
| Data2VecAudio | ✅ | ❌ | ❌ |
|
||||
| Data2VecText | ✅ | ❌ | ❌ |
|
||||
| Data2VecVision | ✅ | ✅ | ❌ |
|
||||
| DeBERTa | ✅ | ✅ | ❌ |
|
||||
| DeBERTa-v2 | ✅ | ✅ | ❌ |
|
||||
| Decision Transformer | ✅ | ❌ | ❌ |
|
||||
| Deformable DETR | ✅ | ❌ | ❌ |
|
||||
| DeiT | ✅ | ✅ | ❌ |
|
||||
| DETA | ✅ | ❌ | ❌ |
|
||||
| DETR | ✅ | ❌ | ❌ |
|
||||
| DiNAT | ✅ | ❌ | ❌ |
|
||||
| DINOv2 | ✅ | ❌ | ❌ |
|
||||
| DistilBERT | ✅ | ✅ | ✅ |
|
||||
| DonutSwin | ✅ | ❌ | ❌ |
|
||||
| DPR | ✅ | ✅ | ❌ |
|
||||
| DPT | ✅ | ❌ | ❌ |
|
||||
| EfficientFormer | ✅ | ✅ | ❌ |
|
||||
| EfficientNet | ✅ | ❌ | ❌ |
|
||||
| ELECTRA | ✅ | ✅ | ✅ |
|
||||
| EnCodec | ✅ | ❌ | ❌ |
|
||||
| Encoder decoder | ✅ | ✅ | ✅ |
|
||||
| ERNIE | ✅ | ❌ | ❌ |
|
||||
| ErnieM | ✅ | ❌ | ❌ |
|
||||
| ESM | ✅ | ✅ | ❌ |
|
||||
| FairSeq Machine-Translation | ✅ | ❌ | ❌ |
|
||||
| Falcon | ✅ | ❌ | ❌ |
|
||||
| FlauBERT | ✅ | ✅ | ❌ |
|
||||
| FLAVA | ✅ | ❌ | ❌ |
|
||||
| FNet | ✅ | ❌ | ❌ |
|
||||
| FocalNet | ✅ | ❌ | ❌ |
|
||||
| Funnel Transformer | ✅ | ✅ | ❌ |
|
||||
| GIT | ✅ | ❌ | ❌ |
|
||||
| GLPN | ✅ | ❌ | ❌ |
|
||||
| GPT Neo | ✅ | ❌ | ✅ |
|
||||
| GPT NeoX | ✅ | ❌ | ❌ |
|
||||
| GPT NeoX Japanese | ✅ | ❌ | ❌ |
|
||||
| GPT-J | ✅ | ✅ | ✅ |
|
||||
| GPT-Sw3 | ✅ | ✅ | ✅ |
|
||||
| GPTBigCode | ✅ | ❌ | ❌ |
|
||||
| GPTSAN-japanese | ✅ | ❌ | ❌ |
|
||||
| Graphormer | ✅ | ❌ | ❌ |
|
||||
| GroupViT | ✅ | ✅ | ❌ |
|
||||
| Hubert | ✅ | ✅ | ❌ |
|
||||
| I-BERT | ✅ | ❌ | ❌ |
|
||||
| IDEFICS | ✅ | ❌ | ❌ |
|
||||
| ImageGPT | ✅ | ❌ | ❌ |
|
||||
| Informer | ✅ | ❌ | ❌ |
|
||||
| InstructBLIP | ✅ | ❌ | ❌ |
|
||||
| Jukebox | ✅ | ❌ | ❌ |
|
||||
| LayoutLM | ✅ | ✅ | ❌ |
|
||||
| LayoutLMv2 | ✅ | ❌ | ❌ |
|
||||
| LayoutLMv3 | ✅ | ✅ | ❌ |
|
||||
| LED | ✅ | ✅ | ❌ |
|
||||
| LeViT | ✅ | ❌ | ❌ |
|
||||
| LiLT | ✅ | ❌ | ❌ |
|
||||
| LLaMA | ✅ | ❌ | ❌ |
|
||||
| Longformer | ✅ | ✅ | ❌ |
|
||||
| LongT5 | ✅ | ❌ | ✅ |
|
||||
| LUKE | ✅ | ❌ | ❌ |
|
||||
| LXMERT | ✅ | ✅ | ❌ |
|
||||
| M-CTC-T | ✅ | ❌ | ❌ |
|
||||
| M2M100 | ✅ | ❌ | ❌ |
|
||||
| Marian | ✅ | ✅ | ✅ |
|
||||
| MarkupLM | ✅ | ❌ | ❌ |
|
||||
| Mask2Former | ✅ | ❌ | ❌ |
|
||||
| MaskFormer | ✅ | ❌ | ❌ |
|
||||
| MaskFormerSwin | ❌ | ❌ | ❌ |
|
||||
| mBART | ✅ | ✅ | ✅ |
|
||||
| MEGA | ✅ | ❌ | ❌ |
|
||||
| Megatron-BERT | ✅ | ❌ | ❌ |
|
||||
| MGP-STR | ✅ | ❌ | ❌ |
|
||||
| MobileBERT | ✅ | ✅ | ❌ |
|
||||
| MobileNetV1 | ✅ | ❌ | ❌ |
|
||||
| MobileNetV2 | ✅ | ❌ | ❌ |
|
||||
| MobileViT | ✅ | ✅ | ❌ |
|
||||
| MobileViTV2 | ✅ | ❌ | ❌ |
|
||||
| MPNet | ✅ | ✅ | ❌ |
|
||||
| MPT | ✅ | ❌ | ❌ |
|
||||
| MRA | ✅ | ❌ | ❌ |
|
||||
| MT5 | ✅ | ✅ | ✅ |
|
||||
| MusicGen | ✅ | ❌ | ❌ |
|
||||
| MVP | ✅ | ❌ | ❌ |
|
||||
| NAT | ✅ | ❌ | ❌ |
|
||||
| Nezha | ✅ | ❌ | ❌ |
|
||||
| NLLB-MOE | ✅ | ❌ | ❌ |
|
||||
| Nyströmformer | ✅ | ❌ | ❌ |
|
||||
| OneFormer | ✅ | ❌ | ❌ |
|
||||
| OpenAI GPT | ✅ | ✅ | ❌ |
|
||||
| OpenAI GPT-2 | ✅ | ✅ | ✅ |
|
||||
| OpenLlama | ✅ | ❌ | ❌ |
|
||||
| OPT | ✅ | ✅ | ✅ |
|
||||
| OWL-ViT | ✅ | ❌ | ❌ |
|
||||
| Pegasus | ✅ | ✅ | ✅ |
|
||||
| PEGASUS-X | ✅ | ❌ | ❌ |
|
||||
| Perceiver | ✅ | ❌ | ❌ |
|
||||
| Pix2Struct | ✅ | ❌ | ❌ |
|
||||
| PLBart | ✅ | ❌ | ❌ |
|
||||
| PoolFormer | ✅ | ❌ | ❌ |
|
||||
| Pop2Piano | ✅ | ❌ | ❌ |
|
||||
| ProphetNet | ✅ | ❌ | ❌ |
|
||||
| PVT | ✅ | ❌ | ❌ |
|
||||
| QDQBert | ✅ | ❌ | ❌ |
|
||||
| RAG | ✅ | ✅ | ❌ |
|
||||
| REALM | ✅ | ❌ | ❌ |
|
||||
| Reformer | ✅ | ❌ | ❌ |
|
||||
| RegNet | ✅ | ✅ | ✅ |
|
||||
| RemBERT | ✅ | ✅ | ❌ |
|
||||
| ResNet | ✅ | ✅ | ✅ |
|
||||
| RetriBERT | ✅ | ❌ | ❌ |
|
||||
| RoBERTa | ✅ | ✅ | ✅ |
|
||||
| RoBERTa-PreLayerNorm | ✅ | ✅ | ✅ |
|
||||
| RoCBert | ✅ | ❌ | ❌ |
|
||||
| RoFormer | ✅ | ✅ | ✅ |
|
||||
| RWKV | ✅ | ❌ | ❌ |
|
||||
| SAM | ✅ | ✅ | ❌ |
|
||||
| SegFormer | ✅ | ✅ | ❌ |
|
||||
| SEW | ✅ | ❌ | ❌ |
|
||||
| SEW-D | ✅ | ❌ | ❌ |
|
||||
| Speech Encoder decoder | ✅ | ❌ | ✅ |
|
||||
| Speech2Text | ✅ | ✅ | ❌ |
|
||||
| Speech2Text2 | ❌ | ❌ | ❌ |
|
||||
| SpeechT5 | ✅ | ❌ | ❌ |
|
||||
| Splinter | ✅ | ❌ | ❌ |
|
||||
| SqueezeBERT | ✅ | ❌ | ❌ |
|
||||
| SwiftFormer | ✅ | ❌ | ❌ |
|
||||
| Swin Transformer | ✅ | ✅ | ❌ |
|
||||
| Swin Transformer V2 | ✅ | ❌ | ❌ |
|
||||
| Swin2SR | ✅ | ❌ | ❌ |
|
||||
| SwitchTransformers | ✅ | ❌ | ❌ |
|
||||
| T5 | ✅ | ✅ | ✅ |
|
||||
| Table Transformer | ✅ | ❌ | ❌ |
|
||||
| TAPAS | ✅ | ✅ | ❌ |
|
||||
| Time Series Transformer | ✅ | ❌ | ❌ |
|
||||
| TimeSformer | ✅ | ❌ | ❌ |
|
||||
| TimmBackbone | ❌ | ❌ | ❌ |
|
||||
| Trajectory Transformer | ✅ | ❌ | ❌ |
|
||||
| Transformer-XL | ✅ | ✅ | ❌ |
|
||||
| TrOCR | ✅ | ❌ | ❌ |
|
||||
| TVLT | ✅ | ❌ | ❌ |
|
||||
| UMT5 | ✅ | ❌ | ❌ |
|
||||
| UniSpeech | ✅ | ❌ | ❌ |
|
||||
| UniSpeechSat | ✅ | ❌ | ❌ |
|
||||
| UPerNet | ✅ | ❌ | ❌ |
|
||||
| VAN | ✅ | ❌ | ❌ |
|
||||
| VideoMAE | ✅ | ❌ | ❌ |
|
||||
| ViLT | ✅ | ❌ | ❌ |
|
||||
| Vision Encoder decoder | ✅ | ✅ | ✅ |
|
||||
| VisionTextDualEncoder | ✅ | ✅ | ✅ |
|
||||
| VisualBERT | ✅ | ❌ | ❌ |
|
||||
| ViT | ✅ | ✅ | ✅ |
|
||||
| ViT Hybrid | ✅ | ❌ | ❌ |
|
||||
| VitDet | ✅ | ❌ | ❌ |
|
||||
| ViTMAE | ✅ | ✅ | ❌ |
|
||||
| ViTMSN | ✅ | ❌ | ❌ |
|
||||
| VITS | ✅ | ❌ | ❌ |
|
||||
| ViViT | ✅ | ❌ | ❌ |
|
||||
| Wav2Vec2 | ✅ | ✅ | ✅ |
|
||||
| Wav2Vec2-Conformer | ✅ | ❌ | ❌ |
|
||||
| WavLM | ✅ | ❌ | ❌ |
|
||||
| Whisper | ✅ | ✅ | ✅ |
|
||||
| X-CLIP | ✅ | ❌ | ❌ |
|
||||
| X-MOD | ✅ | ❌ | ❌ |
|
||||
| XGLM | ✅ | ✅ | ✅ |
|
||||
| XLM | ✅ | ✅ | ❌ |
|
||||
| XLM-ProphetNet | ✅ | ❌ | ❌ |
|
||||
| XLM-RoBERTa | ✅ | ✅ | ✅ |
|
||||
| XLM-RoBERTa-XL | ✅ | ❌ | ❌ |
|
||||
| XLNet | ✅ | ✅ | ❌ |
|
||||
| YOLOS | ✅ | ❌ | ❌ |
|
||||
| YOSO | ✅ | ❌ | ❌ |
|
||||
|
||||
<!-- End table-->
|
||||
|
||||
@@ -75,39 +75,104 @@ values. Here, for instance, it has two keys that are `sequences` and `scores`.
|
||||
We document here all output types.
|
||||
|
||||
|
||||
### GreedySearchOutput
|
||||
|
||||
[[autodoc]] generation.GreedySearchDecoderOnlyOutput
|
||||
### PyTorch
|
||||
|
||||
[[autodoc]] generation.GreedySearchEncoderDecoderOutput
|
||||
|
||||
[[autodoc]] generation.FlaxGreedySearchOutput
|
||||
|
||||
### SampleOutput
|
||||
|
||||
[[autodoc]] generation.SampleDecoderOnlyOutput
|
||||
[[autodoc]] generation.GreedySearchDecoderOnlyOutput
|
||||
|
||||
[[autodoc]] generation.SampleEncoderDecoderOutput
|
||||
|
||||
[[autodoc]] generation.FlaxSampleOutput
|
||||
|
||||
### BeamSearchOutput
|
||||
|
||||
[[autodoc]] generation.BeamSearchDecoderOnlyOutput
|
||||
[[autodoc]] generation.SampleDecoderOnlyOutput
|
||||
|
||||
[[autodoc]] generation.BeamSearchEncoderDecoderOutput
|
||||
|
||||
### BeamSampleOutput
|
||||
[[autodoc]] generation.BeamSearchDecoderOnlyOutput
|
||||
|
||||
[[autodoc]] generation.BeamSampleEncoderDecoderOutput
|
||||
|
||||
[[autodoc]] generation.BeamSampleDecoderOnlyOutput
|
||||
|
||||
[[autodoc]] generation.BeamSampleEncoderDecoderOutput
|
||||
[[autodoc]] generation.ContrastiveSearchEncoderDecoderOutput
|
||||
|
||||
[[autodoc]] generation.ContrastiveSearchDecoderOnlyOutput
|
||||
|
||||
### TensorFlow
|
||||
|
||||
[[autodoc]] generation.TFGreedySearchEncoderDecoderOutput
|
||||
|
||||
[[autodoc]] generation.TFGreedySearchDecoderOnlyOutput
|
||||
|
||||
[[autodoc]] generation.TFSampleEncoderDecoderOutput
|
||||
|
||||
[[autodoc]] generation.TFSampleDecoderOnlyOutput
|
||||
|
||||
[[autodoc]] generation.TFBeamSearchEncoderDecoderOutput
|
||||
|
||||
[[autodoc]] generation.TFBeamSearchDecoderOnlyOutput
|
||||
|
||||
[[autodoc]] generation.TFBeamSampleEncoderDecoderOutput
|
||||
|
||||
[[autodoc]] generation.TFBeamSampleDecoderOnlyOutput
|
||||
|
||||
[[autodoc]] generation.TFContrastiveSearchEncoderDecoderOutput
|
||||
|
||||
[[autodoc]] generation.TFContrastiveSearchDecoderOnlyOutput
|
||||
|
||||
### FLAX
|
||||
|
||||
[[autodoc]] generation.FlaxSampleOutput
|
||||
|
||||
[[autodoc]] generation.FlaxGreedySearchOutput
|
||||
|
||||
[[autodoc]] generation.FlaxBeamSearchOutput
|
||||
|
||||
## LogitsProcessor
|
||||
|
||||
A [`LogitsProcessor`] can be used to modify the prediction scores of a language model head for
|
||||
generation.
|
||||
|
||||
### PyTorch
|
||||
|
||||
[[autodoc]] AlternatingCodebooksLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] ClassifierFreeGuidanceLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] EncoderNoRepeatNGramLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] EncoderRepetitionPenaltyLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] EpsilonLogitsWarper
|
||||
- __call__
|
||||
|
||||
[[autodoc]] EtaLogitsWarper
|
||||
- __call__
|
||||
|
||||
[[autodoc]] ExponentialDecayLengthPenalty
|
||||
- __call__
|
||||
|
||||
[[autodoc]] ForcedBOSTokenLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] ForcedEOSTokenLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] ForceTokensLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] HammingDiversityLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] InfNanRemoveLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] LogitNormalization
|
||||
- __call__
|
||||
|
||||
[[autodoc]] LogitsProcessor
|
||||
- __call__
|
||||
|
||||
@@ -123,43 +188,54 @@ generation.
|
||||
[[autodoc]] MinNewTokensLengthLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] TemperatureLogitsWarper
|
||||
- __call__
|
||||
|
||||
[[autodoc]] RepetitionPenaltyLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] TopPLogitsWarper
|
||||
- __call__
|
||||
|
||||
[[autodoc]] TopKLogitsWarper
|
||||
- __call__
|
||||
|
||||
[[autodoc]] TypicalLogitsWarper
|
||||
[[autodoc]] NoBadWordsLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] NoRepeatNGramLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] SequenceBiasLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] NoBadWordsLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] PrefixConstrainedLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] HammingDiversityLogitsProcessor
|
||||
[[autodoc]] RepetitionPenaltyLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] ForcedBOSTokenLogitsProcessor
|
||||
[[autodoc]] SequenceBiasLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] ForcedEOSTokenLogitsProcessor
|
||||
[[autodoc]] SuppressTokensAtBeginLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] InfNanRemoveLogitsProcessor
|
||||
[[autodoc]] SuppressTokensLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] TemperatureLogitsWarper
|
||||
- __call__
|
||||
|
||||
[[autodoc]] TopKLogitsWarper
|
||||
- __call__
|
||||
|
||||
[[autodoc]] TopPLogitsWarper
|
||||
- __call__
|
||||
|
||||
[[autodoc]] TypicalLogitsWarper
|
||||
- __call__
|
||||
|
||||
[[autodoc]] UnbatchedClassifierFreeGuidanceLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] WhisperTimeStampLogitsProcessor
|
||||
- __call__
|
||||
|
||||
### TensorFlow
|
||||
|
||||
[[autodoc]] TFForcedBOSTokenLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] TFForcedEOSTokenLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] TFForceTokensLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] TFLogitsProcessor
|
||||
@@ -171,15 +247,6 @@ generation.
|
||||
[[autodoc]] TFLogitsWarper
|
||||
- __call__
|
||||
|
||||
[[autodoc]] TFTemperatureLogitsWarper
|
||||
- __call__
|
||||
|
||||
[[autodoc]] TFTopPLogitsWarper
|
||||
- __call__
|
||||
|
||||
[[autodoc]] TFTopKLogitsWarper
|
||||
- __call__
|
||||
|
||||
[[autodoc]] TFMinLengthLogitsProcessor
|
||||
- __call__
|
||||
|
||||
@@ -192,10 +259,30 @@ generation.
|
||||
[[autodoc]] TFRepetitionPenaltyLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] TFForcedBOSTokenLogitsProcessor
|
||||
[[autodoc]] TFSuppressTokensAtBeginLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] TFForcedEOSTokenLogitsProcessor
|
||||
[[autodoc]] TFSuppressTokensLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] TFTemperatureLogitsWarper
|
||||
- __call__
|
||||
|
||||
[[autodoc]] TFTopKLogitsWarper
|
||||
- __call__
|
||||
|
||||
[[autodoc]] TFTopPLogitsWarper
|
||||
- __call__
|
||||
|
||||
### FLAX
|
||||
|
||||
[[autodoc]] FlaxForcedBOSTokenLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] FlaxForcedEOSTokenLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] FlaxForceTokensLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] FlaxLogitsProcessor
|
||||
@@ -207,27 +294,30 @@ generation.
|
||||
[[autodoc]] FlaxLogitsWarper
|
||||
- __call__
|
||||
|
||||
[[autodoc]] FlaxTemperatureLogitsWarper
|
||||
[[autodoc]] FlaxMinLengthLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] FlaxTopPLogitsWarper
|
||||
[[autodoc]] FlaxSuppressTokensAtBeginLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] FlaxSuppressTokensLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] FlaxTemperatureLogitsWarper
|
||||
- __call__
|
||||
|
||||
[[autodoc]] FlaxTopKLogitsWarper
|
||||
- __call__
|
||||
|
||||
[[autodoc]] FlaxForcedBOSTokenLogitsProcessor
|
||||
[[autodoc]] FlaxTopPLogitsWarper
|
||||
- __call__
|
||||
|
||||
[[autodoc]] FlaxForcedEOSTokenLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] FlaxMinLengthLogitsProcessor
|
||||
[[autodoc]] FlaxWhisperTimeStampLogitsProcessor
|
||||
- __call__
|
||||
|
||||
## StoppingCriteria
|
||||
|
||||
A [`StoppingCriteria`] can be used to change when to stop generation (other than EOS token).
|
||||
A [`StoppingCriteria`] can be used to change when to stop generation (other than EOS token). Please note that this is exclusivelly available to our PyTorch implementations.
|
||||
|
||||
[[autodoc]] StoppingCriteria
|
||||
- __call__
|
||||
@@ -243,7 +333,7 @@ A [`StoppingCriteria`] can be used to change when to stop generation (other than
|
||||
|
||||
## Constraints
|
||||
|
||||
A [`Constraint`] can be used to force the generation to include specific tokens or sequences in the output.
|
||||
A [`Constraint`] can be used to force the generation to include specific tokens or sequences in the output. Please note that this is exclusivelly available to our PyTorch implementations.
|
||||
|
||||
[[autodoc]] Constraint
|
||||
|
||||
|
||||
221
docs/source/en/llm_tutorial.md
Normal file
221
docs/source/en/llm_tutorial.md
Normal file
@@ -0,0 +1,221 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
|
||||
# Generation with LLMs
|
||||
|
||||
[[open-in-colab]]
|
||||
|
||||
LLMs, or Large Language Models, are the key component behind text generation. In a nutshell, they consist of large pretrained transformer models trained to predict the next word (or, more precisely, token) given some input text. Since they predict one token at a time, you need to do something more elaborate to generate new sentences other than just calling the model -- you need to do autoregressive generation.
|
||||
|
||||
Autoregressive generation is the inference-time procedure of iteratively calling a model with its own generated outputs, given a few initial inputs. In 🤗 Transformers, this is handled by the [`~generation.GenerationMixin.generate`] method, which is available to all models with generative capabilities.
|
||||
|
||||
This tutorial will show you how to:
|
||||
|
||||
* Generate text with an LLM
|
||||
* Avoid common pitfalls
|
||||
* Next steps to help you get the most out of your LLM
|
||||
|
||||
Before you begin, make sure you have all the necessary libraries installed:
|
||||
|
||||
```bash
|
||||
pip install transformers bitsandbytes>=0.39.0 -q
|
||||
```
|
||||
|
||||
|
||||
## Generate text
|
||||
|
||||
A language model trained for [causal language modeling](tasks/language_modeling) takes a sequence of text tokens as input and returns the probability distribution for the next token.
|
||||
|
||||
<!-- [GIF 1 -- FWD PASS] -->
|
||||
<figure class="image table text-center m-0 w-full">
|
||||
<video
|
||||
style="max-width: 90%; margin: auto;"
|
||||
autoplay loop muted playsinline
|
||||
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_1_1080p.mov"
|
||||
></video>
|
||||
<figcaption>"Forward pass of an LLM"</figcaption>
|
||||
</figure>
|
||||
|
||||
A critical aspect of autoregressive generation with LLMs is how to select the next token from this probability distribution. Anything goes in this step as long as you end up with a token for the next iteration. This means it can be as simple as selecting the most likely token from the probability distribution or as complex as applying a dozen transformations before sampling from the resulting distribution.
|
||||
|
||||
<!-- [GIF 2 -- TEXT GENERATION] -->
|
||||
<figure class="image table text-center m-0 w-full">
|
||||
<video
|
||||
style="max-width: 90%; margin: auto;"
|
||||
autoplay loop muted playsinline
|
||||
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_2_1080p.mov"
|
||||
></video>
|
||||
<figcaption>"Autoregressive generation iteratively selects the next token from a probability distribution to generate text"</figcaption>
|
||||
</figure>
|
||||
|
||||
The process depicted above is repeated iteratively until some stopping condition is reached. Ideally, the stopping condition is dictated by the model, which should learn when to output an end-of-sequence (`EOS`) token. If this is not the case, generation stops when some predefined maximum length is reached.
|
||||
|
||||
Properly setting up the token selection step and the stopping condition is essential to make your model behave as you'd expect on your task. That is why we have a [`~generation.GenerationConfig`] file associated with each model, which contains a good default generative parameterization and is loaded alongside your model.
|
||||
|
||||
Let's talk code!
|
||||
|
||||
<Tip>
|
||||
|
||||
If you're interested in basic LLM usage, our high-level [`Pipeline`](pipeline_tutorial) interface is a great starting point. However, LLMs often require advanced features like quantization and fine control of the token selection step, which is best done through [`~generation.GenerationMixin.generate`]. Autoregressive generation with LLMs is also resource-intensive and should be executed on a GPU for adequate throughput.
|
||||
|
||||
</Tip>
|
||||
|
||||
<!-- TODO: update example to llama 2 (or a newer popular baseline) when it becomes ungated -->
|
||||
First, you need to load the model.
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModelForCausalLM
|
||||
|
||||
>>> model = AutoModelForCausalLM.from_pretrained(
|
||||
... "openlm-research/open_llama_7b", device_map="auto", load_in_4bit=True
|
||||
... )
|
||||
```
|
||||
|
||||
You'll notice two flags in the `from_pretrained` call:
|
||||
|
||||
- `device_map` ensures the model is moved to your GPU(s)
|
||||
- `load_in_4bit` applies [4-bit dynamic quantization](main_classes/quantization) to massively reduce the resource requirements
|
||||
|
||||
There are other ways to initialize a model, but this is a good baseline to begin with an LLM.
|
||||
|
||||
Next, you need to preprocess your text input with a [tokenizer](tokenizer_summary).
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoTokenizer
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("openlm-research/open_llama_7b")
|
||||
>>> model_inputs = tokenizer(["A list of colors: red, blue"], return_tensors="pt").to("cuda")
|
||||
```
|
||||
|
||||
The `model_inputs` variable holds the tokenized text input, as well as the attention mask. While [`~generation.GenerationMixin.generate`] does its best effort to infer the attention mask when it is not passed, we recommend passing it whenever possible for optimal results.
|
||||
|
||||
Finally, call the [`~generation.GenerationMixin.generate`] method to returns the generated tokens, which should be converted to text before printing.
|
||||
|
||||
```py
|
||||
>>> generated_ids = model.generate(**model_inputs)
|
||||
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
||||
'A list of colors: red, blue, green, yellow, black, white, and brown'
|
||||
```
|
||||
|
||||
And that's it! In a few lines of code, you can harness the power of an LLM.
|
||||
|
||||
|
||||
## Common pitfalls
|
||||
|
||||
There are many [generation strategies](generation_strategies), and sometimes the default values may not be appropriate for your use case. If your outputs aren't aligned with what you're expecting, we've created a list of the most common pitfalls and how to avoid them.
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("openlm-research/open_llama_7b")
|
||||
>>> tokenizer.pad_token = tokenizer.eos_token # Llama has no pad token by default
|
||||
>>> model = AutoModelForCausalLM.from_pretrained(
|
||||
... "openlm-research/open_llama_7b", device_map="auto", load_in_4bit=True
|
||||
... )
|
||||
```
|
||||
|
||||
### Generated output is too short/long
|
||||
|
||||
If not specified in the [`~generation.GenerationConfig`] file, `generate` returns up to 20 tokens by default. We highly recommend manually setting `max_new_tokens` in your `generate` call to control the maximum number of new tokens it can return. Keep in mind LLMs (more precisely, [decoder-only models](https://huggingface.co/learn/nlp-course/chapter1/6?fw=pt)) also return the input prompt as part of the output.
|
||||
|
||||
|
||||
```py
|
||||
>>> model_inputs = tokenizer(["A sequence of numbers: 1, 2"], return_tensors="pt").to("cuda")
|
||||
|
||||
>>> # By default, the output will contain up to 20 tokens
|
||||
>>> generated_ids = model.generate(**model_inputs)
|
||||
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
||||
'A sequence of numbers: 1, 2, 3, 4, 5'
|
||||
|
||||
>>> # Setting `max_new_tokens` allows you to control the maximum length
|
||||
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=50)
|
||||
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
||||
'A sequence of numbers: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,'
|
||||
```
|
||||
|
||||
### Incorrect generation mode
|
||||
|
||||
By default, and unless specified in the [`~generation.GenerationConfig`] file, `generate` selects the most likely token at each iteration (greedy decoding). Depending on your task, this may be undesirable; creative tasks like chatbots or writing an essay benefit from sampling. On the other hand, input-grounded tasks like audio transcription or translation benefit from greedy decoding. Enable sampling with `do_sample=True`, and you can learn more about this topic in this [blog post](https://huggingface.co/blog/how-to-generate).
|
||||
|
||||
```py
|
||||
>>> # Set seed or reproducibility -- you don't need this unless you want full reproducibility
|
||||
>>> from transformers import set_seed
|
||||
>>> set_seed(0)
|
||||
|
||||
>>> model_inputs = tokenizer(["I am a cat."], return_tensors="pt").to("cuda")
|
||||
|
||||
>>> # LLM + greedy decoding = repetitive, boring output
|
||||
>>> generated_ids = model.generate(**model_inputs)
|
||||
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
||||
'I am a cat. I am a cat. I am a cat. I am a cat'
|
||||
|
||||
>>> # With sampling, the output becomes more creative!
|
||||
>>> generated_ids = model.generate(**model_inputs, do_sample=True)
|
||||
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
||||
'I am a cat.\nI just need to be. I am always.\nEvery time'
|
||||
```
|
||||
|
||||
### Wrong padding side
|
||||
|
||||
LLMs are [decoder-only](https://huggingface.co/learn/nlp-course/chapter1/6?fw=pt) architectures, meaning they continue to iterate on your input prompt. If your inputs do not have the same length, they need to be padded. Since LLMs are not trained to continue from pad tokens, your input needs to be left-padded. Make sure you also don't forget to pass the attention mask to generate!
|
||||
|
||||
```py
|
||||
>>> # The tokenizer initialized above has right-padding active by default: the 1st sequence,
|
||||
>>> # which is shorter, has padding on the right side. Generation fails.
|
||||
>>> model_inputs = tokenizer(
|
||||
... ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
|
||||
... ).to("cuda")
|
||||
>>> generated_ids = model.generate(**model_inputs)
|
||||
>>> tokenizer.batch_decode(generated_ids[0], skip_special_tokens=True)[0]
|
||||
''
|
||||
|
||||
>>> # With left-padding, it works as expected!
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("openlm-research/open_llama_7b", padding_side="left")
|
||||
>>> tokenizer.pad_token = tokenizer.eos_token # Llama has no pad token by default
|
||||
>>> model_inputs = tokenizer(
|
||||
... ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
|
||||
... ).to("cuda")
|
||||
>>> generated_ids = model.generate(**model_inputs)
|
||||
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
||||
'1, 2, 3, 4, 5, 6,'
|
||||
```
|
||||
|
||||
<!-- TODO: when the prompting guide is ready, mention the importance of setting the right prompt in this section -->
|
||||
|
||||
## Further resources
|
||||
|
||||
While the autoregressive generation process is relatively straightforward, making the most out of your LLM can be a challenging endeavor because there are many moving parts. For your next steps to help you dive deeper into LLM usage and understanding:
|
||||
|
||||
<!-- TODO: complete with new guides -->
|
||||
### Advanced generate usage
|
||||
|
||||
1. [Guide](generation_strategies) on how to control different generation methods, how to set up the generation configuration file, and how to stream the output;
|
||||
2. API reference on [`~generation.GenerationConfig`], [`~generation.GenerationMixin.generate`], and [generate-related classes](internal/generation_utils).
|
||||
|
||||
### LLM leaderboards
|
||||
|
||||
1. [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard), which focuses on the quality of the open-source models;
|
||||
2. [Open LLM-Perf Leaderboard](https://huggingface.co/spaces/optimum/llm-perf-leaderboard), which focuses on LLM throughput.
|
||||
|
||||
### Latency and throughput
|
||||
|
||||
1. [Guide](main_classes/quantization) on dynamic quantization, which shows you how to drastically reduce your memory requirements.
|
||||
|
||||
### Related libraries
|
||||
|
||||
1. [`text-generation-inference`](https://github.com/huggingface/text-generation-inference), a production-ready server for LLMs;
|
||||
2. [`optimum`](https://github.com/huggingface/optimum), an extension of 🤗 Transformers that optimizes for specific hardware devices.
|
||||
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
Transformers Agent is an experimental API which is subject to change at any time. Results returned by the agents
|
||||
Transformers Agents is an experimental API which is subject to change at any time. Results returned by the agents
|
||||
can vary as the APIs or underlying models are prone to change.
|
||||
|
||||
</Tip>
|
||||
|
||||
@@ -168,6 +168,8 @@ If after trying everything suggested you still encounter build issues, please, p
|
||||
|
||||
To deploy the DeepSpeed integration adjust the [`Trainer`] command line arguments to include a new argument `--deepspeed ds_config.json`, where `ds_config.json` is the DeepSpeed configuration file as
|
||||
documented [here](https://www.deepspeed.ai/docs/config-json/). The file naming is up to you.
|
||||
It's recommended to use DeepSpeed's `add_config_arguments` utility to add the necessary command line arguments to your code.
|
||||
For more information please see [DeepSpeed's Argument Parsing](https://deepspeed.readthedocs.io/en/latest/initialize.html#argument-parsing) doc.
|
||||
|
||||
You can use a launcher of your choice here. You can continue using the pytorch launcher:
|
||||
|
||||
@@ -1410,7 +1412,7 @@ the full fp32 mode, by explicitly disabling the otherwise default fp16 mixed pre
|
||||
```json
|
||||
{
|
||||
"fp16": {
|
||||
"enabled": "false",
|
||||
"enabled": false,
|
||||
}
|
||||
}
|
||||
```
|
||||
@@ -2063,20 +2065,20 @@ In this case you usually need to raise the value of `initial_scale_power`. Setti
|
||||
|
||||
## Non-Trainer Deepspeed Integration
|
||||
|
||||
The [`~deepspeed.HfDeepSpeedConfig`] is used to integrate Deepspeed into the 🤗 Transformers core
|
||||
The [`~integrations.HfDeepSpeedConfig`] is used to integrate Deepspeed into the 🤗 Transformers core
|
||||
functionality, when [`Trainer`] is not used. The only thing that it does is handling Deepspeed ZeRO-3 param gathering and automatically splitting the model onto multiple gpus during `from_pretrained` call. Everything else you have to do by yourself.
|
||||
|
||||
When using [`Trainer`] everything is automatically taken care of.
|
||||
|
||||
When not using [`Trainer`], to efficiently deploy DeepSpeed ZeRO-3, you must instantiate the
|
||||
[`~deepspeed.HfDeepSpeedConfig`] object before instantiating the model and keep that object alive.
|
||||
[`~integrations.HfDeepSpeedConfig`] object before instantiating the model and keep that object alive.
|
||||
|
||||
If you're using Deepspeed ZeRO-1 or ZeRO-2 you don't need to use `HfDeepSpeedConfig` at all.
|
||||
|
||||
For example for a pretrained model:
|
||||
|
||||
```python
|
||||
from transformers.deepspeed import HfDeepSpeedConfig
|
||||
from transformers.integrations import HfDeepSpeedConfig
|
||||
from transformers import AutoModel
|
||||
import deepspeed
|
||||
|
||||
@@ -2090,7 +2092,7 @@ engine = deepspeed.initialize(model=model, config_params=ds_config, ...)
|
||||
or for non-pretrained model:
|
||||
|
||||
```python
|
||||
from transformers.deepspeed import HfDeepSpeedConfig
|
||||
from transformers.integrations import HfDeepSpeedConfig
|
||||
from transformers import AutoModel, AutoConfig
|
||||
import deepspeed
|
||||
|
||||
@@ -2106,7 +2108,7 @@ Please note that if you're not using the [`Trainer`] integration, you're complet
|
||||
|
||||
## HfDeepSpeedConfig
|
||||
|
||||
[[autodoc]] deepspeed.HfDeepSpeedConfig
|
||||
[[autodoc]] integrations.HfDeepSpeedConfig
|
||||
- all
|
||||
|
||||
### Custom DeepSpeed ZeRO Inference
|
||||
@@ -2159,7 +2161,7 @@ Make sure to:
|
||||
|
||||
|
||||
from transformers import AutoTokenizer, AutoConfig, AutoModelForSeq2SeqLM
|
||||
from transformers.deepspeed import HfDeepSpeedConfig
|
||||
from transformers.integrations import HfDeepSpeedConfig
|
||||
import deepspeed
|
||||
import os
|
||||
import torch
|
||||
|
||||
@@ -318,6 +318,13 @@ Pipelines available for audio tasks include the following.
|
||||
- __call__
|
||||
- all
|
||||
|
||||
### TextToAudioPipeline
|
||||
|
||||
[[autodoc]] TextToAudioPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
|
||||
### ZeroShotAudioClassificationPipeline
|
||||
|
||||
[[autodoc]] ZeroShotAudioClassificationPipeline
|
||||
|
||||
@@ -16,6 +16,138 @@ rendered properly in your Markdown viewer.
|
||||
|
||||
# Quantize 🤗 Transformers models
|
||||
|
||||
## `AutoGPTQ` Integration
|
||||
|
||||
🤗 Transformers has integrated `optimum` API to perform GPTQ quantization on language models. You can load and quantize your model in 8, 4, 3 or even 2 bits without a big drop of performance and faster inference speed! This is supported by most GPU hardwares.
|
||||
|
||||
To learn more about the the quantization model, check out:
|
||||
- the [GPTQ](https://arxiv.org/pdf/2210.17323.pdf) paper
|
||||
- the `optimum` [guide](https://huggingface.co/docs/optimum/llm_quantization/usage_guides/quantization) on GPTQ quantization
|
||||
- the [`AutoGPTQ`](https://github.com/PanQiWei/AutoGPTQ) library used as the backend
|
||||
|
||||
### Requirements
|
||||
|
||||
You need to have the following requirements installed to run the code below:
|
||||
|
||||
- Install latest `AutoGPTQ` library
|
||||
`pip install auto-gptq`
|
||||
|
||||
- Install latest `optimum` from source
|
||||
`pip install git+https://github.com/huggingface/optimum.git`
|
||||
|
||||
- Install latest `transformers` from source
|
||||
`pip install git+https://github.com/huggingface/transformers.git`
|
||||
|
||||
- Install latest `accelerate` library
|
||||
`pip install --upgrade accelerate`
|
||||
|
||||
Note that GPTQ integration supports for now only text models and you may encounter unexpected behaviour for vision, speech or multi-modal models.
|
||||
|
||||
### Load and quantize a model
|
||||
|
||||
GPTQ is a quantization method that requires weights calibration before using the quantized models. If you want to quantize transformers model from scratch, it might take some time before producing the quantized model (~5 min on a Google colab for `facebook/opt-350m` model).
|
||||
|
||||
Hence, there are two different scenarios where you want to use GPTQ-quantized models. The first use case would be to load models that has been already quantized by other users that are available on the Hub, the second use case would be to quantize your model from scratch and save it or push it on the Hub so that other users can also use it.
|
||||
#### GPTQ Configuration
|
||||
|
||||
In order to load and quantize a model, you need to create a [`GPTQConfig`]. You need to pass the number of `bits`, a `dataset` in order to calibrate the quantization and the `tokenizer` of the model in order prepare the dataset.
|
||||
|
||||
```python
|
||||
model_id = "facebook/opt-125m"
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
||||
gptq_config = GPTQConfig(bits=4, dataset = "c4", tokenizer=tokenizer)
|
||||
```
|
||||
|
||||
Note that you can pass your own dataset as a list of string. However, it is highly recommended to use the dataset from the GPTQ paper.
|
||||
```python
|
||||
dataset = ["auto-gptq is an easy-to-use model quantization library with user-friendly apis, based on GPTQ algorithm."]
|
||||
quantization = GPTQConfig(bits=4, dataset = dataset, tokenizer=tokenizer)
|
||||
```
|
||||
|
||||
#### Quantization
|
||||
|
||||
You can quantize a model by using `from_pretrained` and setting the `quantization_config`.
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM
|
||||
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=gptq_config)
|
||||
```
|
||||
Note that you will need a GPU to quantize a model. We will put the model in the cpu and move the modules back and forth to the gpu in order to quantize them.
|
||||
|
||||
If you want to maximize your gpus usage while using cpu offload, you can set `device_map = "auto"`.
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM
|
||||
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", quantization_config=gptq_config)
|
||||
```
|
||||
Note that disk offload is not supported. Furthermore, if you are out of memory because of the dataset, you may have to pass `max_memory` in `from_pretained`. Checkout this [guide](https://huggingface.co/docs/accelerate/usage_guides/big_modeling#designing-a-device-map) to learn more about `device_map` and `max_memory`.
|
||||
|
||||
<Tip warning={true}>
|
||||
GPTQ quantization only works for text model for now. Futhermore, the quantization process can a lot of time depending on one's hardware (175B model = 4 gpu hours using NVIDIA A100). Please check on the hub if there is not a GPTQ quantized version of the model. If not, you can submit a demand on github.
|
||||
</Tip>
|
||||
|
||||
### Push quantized model to 🤗 Hub
|
||||
|
||||
You can push the quantized model like any 🤗 model to Hub with `push_to_hub`. The quantization config will be saved and pushed along the model.
|
||||
|
||||
```python
|
||||
quantized_model.push_to_hub("opt-125m-gptq")
|
||||
tokenizer.push_to_hub("opt-125m-gptq")
|
||||
```
|
||||
|
||||
If you want to save your quantized model on your local machine, you can also do it with `save_pretrained`:
|
||||
```python
|
||||
quantized_model.save_pretrained("opt-125m-gptq")
|
||||
tokenizer.save_pretrained("opt-125m-gptq")
|
||||
```
|
||||
|
||||
Note that if you have quantized your model with a `device_map`, make sure to move the entire model to one of your gpus or the `cpu` before saving it.
|
||||
```python
|
||||
quantized_model.to("cpu")
|
||||
quantized_model.save_pretrained("opt-125m-gptq")
|
||||
```
|
||||
|
||||
### Load a quantized model from the 🤗 Hub
|
||||
|
||||
You can load a quantized model from the Hub by using `from_pretrained`.
|
||||
Make sure that the pushed weights are quantized, by checking that the attribute `quantization_config` is present in the model configuration object.
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM
|
||||
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq")
|
||||
```
|
||||
|
||||
If you want to load a model faster and without allocating more memory than needed, the `device_map` argument also works with quantized model. Make sure that you have `accelerate` library installed.
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM
|
||||
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto")
|
||||
```
|
||||
|
||||
### Exllama kernels for faster inference
|
||||
|
||||
For 4-bit model, you can use the exllama kernels in order to a faster inference speed. It is activated by default. You can change that behavior by passing `disable_exllama` in [`GPTQConfig`]. This will overwrite the quantization config stored in the config. Note that you will only be able to overwrite the attributes related to the kernels. Furthermore, you need to have the entire model on gpus if you want to use exllama kernels.
|
||||
|
||||
```py
|
||||
import torch
|
||||
gptq_config = GPTQConfig(bits=4, disable_exllama=False)
|
||||
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto", quantization_config = gptq_config)
|
||||
```
|
||||
|
||||
Note that only 4-bit models are supported for now. Furthermore, it is recommended to deactivate the exllama kernels if you are finetuning a quantized model with peft.
|
||||
|
||||
#### Fine-tune a quantized model
|
||||
|
||||
With the official support of adapters in the Hugging Face ecosystem, you can fine-tune models that have been quantized with GPTQ.
|
||||
Please have a look at [`peft`](https://github.com/huggingface/peft) library for more details.
|
||||
|
||||
### Example demo
|
||||
|
||||
Check out the Google Colab [notebook](https://colab.research.google.com/drive/1_TIrmuKOFhuRRiTWN94iLKUFu6ZX4ceb?usp=sharing) to learn how to quantize your model with GPTQ and how finetune the quantized model with peft.
|
||||
|
||||
### GPTQConfig
|
||||
|
||||
[[autodoc]] GPTQConfig
|
||||
|
||||
|
||||
## `bitsandbytes` Integration
|
||||
|
||||
🤗 Transformers is closely integrated with most used modules on `bitsandbytes`. You can load your model in 8-bit precision with few lines of code.
|
||||
@@ -29,6 +161,29 @@ If you want to quantize your own pytorch model, check out this [documentation](h
|
||||
|
||||
Here are the things you can do using `bitsandbytes` integration
|
||||
|
||||
### General usage
|
||||
|
||||
You can quantize a model by using the `load_in_8bit` or `load_in_4bit` argument when calling the [`~PreTrainedModel.from_pretrained`] method as long as your model supports loading with 🤗 Accelerate and contains `torch.nn.Linear` layers. This should work for any modality as well.
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM
|
||||
|
||||
model_8bit = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_8bit=True)
|
||||
model_4bit = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_4bit=True)
|
||||
```
|
||||
|
||||
By default all other modules (e.g. `torch.nn.LayerNorm`) will be converted in `torch.float16`, but if you want to change their `dtype` you can overwrite the `torch_dtype` argument:
|
||||
|
||||
```python
|
||||
>>> import torch
|
||||
>>> from transformers import AutoModelForCausalLM
|
||||
|
||||
>>> model_8bit = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_8bit=True, torch_dtype=torch.float32)
|
||||
>>> model_8bit.model.decoder.layers[-1].final_layer_norm.weight.dtype
|
||||
torch.float32
|
||||
```
|
||||
|
||||
|
||||
### FP4 quantization
|
||||
|
||||
#### Requirements
|
||||
@@ -38,11 +193,21 @@ Make sure that you have installed the requirements below before running any of t
|
||||
- Latest `bitsandbytes` library
|
||||
`pip install bitsandbytes>=0.39.0`
|
||||
|
||||
- Install latest `accelerate` from source
|
||||
`pip install git+https://github.com/huggingface/accelerate.git`
|
||||
- Install latest `accelerate`
|
||||
`pip install --upgrade accelerate`
|
||||
|
||||
- Install latest `transformers` from source
|
||||
`pip install git+https://github.com/huggingface/transformers.git`
|
||||
- Install latest `transformers`
|
||||
`pip install --upgrade transformers`
|
||||
|
||||
#### Tips and best practices
|
||||
|
||||
- **Advanced usage:** Refer to [this Google Colab notebook](https://colab.research.google.com/drive/1ge2F1QSK8Q7h0hn3YKuBCOAS0bK8E0wf) for advanced usage of 4-bit quantization with all the possible options.
|
||||
|
||||
- **Faster inference with `batch_size=1` :** Since the `0.40.0` release of bitsandbytes, for `batch_size=1` you can benefit from fast inference. Check out [these release notes](https://github.com/TimDettmers/bitsandbytes/releases/tag/0.40.0) and make sure to have a version that is greater than `0.40.0` to benefit from this feature out of the box.
|
||||
|
||||
- **Training:** According to [QLoRA paper](https://arxiv.org/abs/2305.14314), for training 4-bit base models (e.g. using LoRA adapters) one should use `bnb_4bit_quant_type='nf4'`.
|
||||
|
||||
- **Inference:** For inference, `bnb_4bit_quant_type` does not have a huge impact on the performance. However for consistency with the model's weights, make sure you use the same `bnb_4bit_compute_dtype` and `torch_dtype` arguments.
|
||||
|
||||
#### Load a large model in 4bit
|
||||
|
||||
@@ -96,9 +261,9 @@ Note also that `device_map` is optional but setting `device_map = 'auto'` is pre
|
||||
|
||||
</Tip>
|
||||
|
||||
#### Advanced usecases
|
||||
#### Advanced use cases
|
||||
|
||||
Here we will cover some advanced usecases you can perform with FP4 quantization
|
||||
Here we will cover some advanced use cases you can perform with FP4 quantization
|
||||
|
||||
##### Change the compute dtype
|
||||
|
||||
@@ -174,15 +339,15 @@ model = AutoModelForCausalLM.from_pretrained("{your_username}/bloom-560m-8bit",
|
||||
Note that in this case, you don't need to specify the arguments `load_in_8bit=True`, but you need to make sure that `bitsandbytes` and `accelerate` are installed.
|
||||
Note also that `device_map` is optional but setting `device_map = 'auto'` is prefered for inference as it will dispatch efficiently the model on the available ressources.
|
||||
|
||||
### Advanced usecases
|
||||
### Advanced use cases
|
||||
|
||||
This section is intended to advanced users, that want to explore what it is possible to do beyond loading and running 8-bit models.
|
||||
|
||||
#### Offload between `cpu` and `gpu`
|
||||
|
||||
One of the advanced usecase of this is being able to load a model and dispatch the weights between `CPU` and `GPU`. Note that the weights that will be dispatched on CPU **will not** be converted in 8-bit, thus kept in `float32`. This feature is intended for users that want to fit a very large model and dispatch the model between GPU and CPU.
|
||||
One of the advanced use case of this is being able to load a model and dispatch the weights between `CPU` and `GPU`. Note that the weights that will be dispatched on CPU **will not** be converted in 8-bit, thus kept in `float32`. This feature is intended for users that want to fit a very large model and dispatch the model between GPU and CPU.
|
||||
|
||||
First, load a `BitsAndBytesConfig` from `transformers` and set the attribute `llm_int8_enable_fp32_cpu_offload` to `True`:
|
||||
First, load a [`BitsAndBytesConfig`] from `transformers` and set the attribute `llm_int8_enable_fp32_cpu_offload` to `True`:
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
|
||||
@@ -216,7 +381,7 @@ And that's it! Enjoy your model!
|
||||
|
||||
You can play with the `llm_int8_threshold` argument to change the threshold of the outliers. An "outlier" is a hidden state value that is greater than a certain threshold.
|
||||
This corresponds to the outlier threshold for outlier detection as described in `LLM.int8()` paper. Any hidden states value that is above this threshold will be considered an outlier and the operation on those values will be done in fp16. Values are usually normally distributed, that is, most values are in the range [-3.5, 3.5], but there are some exceptional systematic outliers that are very differently distributed for large models. These outliers are often in the interval [-60, -6] or [6, 60]. Int8 quantization works well for values of magnitude ~5, but beyond that, there is a significant performance penalty. A good default threshold is 6, but a lower threshold might be needed for more unstable models (small models, fine-tuning).
|
||||
This argument can impact the inference speed of the model. We suggest to play with this parameter to find which one is the best for your usecase.
|
||||
This argument can impact the inference speed of the model. We suggest to play with this parameter to find which one is the best for your use case.
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
|
||||
@@ -270,4 +435,4 @@ Note that you don't need to pass `device_map` when loading the model for trainin
|
||||
|
||||
## Quantization with 🤗 `optimum`
|
||||
|
||||
Please have a look at [Optimum documentation](https://huggingface.co/docs/optimum/index) to learn more about quantization methods that are supported by `optimum` and see if these are applicable for your usecase.
|
||||
Please have a look at [Optimum documentation](https://huggingface.co/docs/optimum/index) to learn more about quantization methods that are supported by `optimum` and see if these are applicable for your use case.
|
||||
|
||||
@@ -60,7 +60,7 @@ from transformers import Trainer
|
||||
|
||||
class CustomTrainer(Trainer):
|
||||
def compute_loss(self, model, inputs, return_outputs=False):
|
||||
labels = inputs.get("labels")
|
||||
labels = inputs.pop("labels")
|
||||
# forward pass
|
||||
outputs = model(**inputs)
|
||||
logits = outputs.get("logits")
|
||||
@@ -441,7 +441,7 @@ as the model saving with FSDP activated is only available with recent fixes.
|
||||
- Remaining FSDP config is passed via `--fsdp_config <path_to_fsdp_config.json>`. It is either a location of
|
||||
FSDP json config file (e.g., `fsdp_config.json`) or an already loaded json file as `dict`.
|
||||
- If auto wrapping is enabled, you can either use transformer based auto wrap policy or size based auto wrap policy.
|
||||
- For transformer based auto wrap policy, please specify `fsdp_transformer_layer_cls_to_wrap` in the config file.
|
||||
- For transformer based auto wrap policy, it is recommended to specify `fsdp_transformer_layer_cls_to_wrap` in the config file. If not specified, the default value is `model._no_split_modules` when available.
|
||||
This specifies the list of transformer layer class name (case-sensitive) to wrap ,e.g, [`BertLayer`], [`GPTJBlock`], [`T5Block`] ....
|
||||
This is important because submodules that share weights (e.g., embedding layer) should not end up in different FSDP wrapped units.
|
||||
Using this policy, wrapping happens for each block containing Multi-Head Attention followed by couple of MLP layers.
|
||||
@@ -456,6 +456,10 @@ as the model saving with FSDP activated is only available with recent fixes.
|
||||
If `"True"`, FSDP explicitly prefetches the next upcoming all-gather while executing in the forward pass.
|
||||
- `limit_all_gathers` can be specified in the config file.
|
||||
If `"True"`, FSDP explicitly synchronizes the CPU thread to prevent too many in-flight all-gathers.
|
||||
- `activation_checkpointing` can be specified in the config file.
|
||||
If `"True"`, FSDP activation checkpointing is a technique to reduce memory usage by clearing activations of
|
||||
certain layers and recomputing them during a backward pass. Effectively, this trades extra computation time
|
||||
for reduced memory usage.
|
||||
|
||||
**Few caveats to be aware of**
|
||||
- it is incompatible with `generate`, thus is incompatible with `--predict_with_generate`
|
||||
@@ -482,7 +486,7 @@ Pass `--fsdp "full shard"` along with following changes to be made in `--fsdp_co
|
||||
This setting can only be used when the xla flag is set to true, and an auto wrapping policy is specified through
|
||||
`fsdp_min_num_params` or `fsdp_transformer_layer_cls_to_wrap`.
|
||||
- You can either use transformer based auto wrap policy or size based auto wrap policy.
|
||||
- For transformer based auto wrap policy, please specify `fsdp_transformer_layer_cls_to_wrap` in the config file.
|
||||
- For transformer based auto wrap policy, it is recommended to specify `fsdp_transformer_layer_cls_to_wrap` in the config file. If not specified, the default value is `model._no_split_modules` when available.
|
||||
This specifies the list of transformer layer class name (case-sensitive) to wrap ,e.g, [`BertLayer`], [`GPTJBlock`], [`T5Block`] ....
|
||||
This is important because submodules that share weights (e.g., embedding layer) should not end up in different FSDP wrapped units.
|
||||
Using this policy, wrapping happens for each block containing Multi-Head Attention followed by couple of MLP layers.
|
||||
|
||||
@@ -330,6 +330,14 @@ The following auto classes are available for the following audio tasks.
|
||||
|
||||
[[autodoc]] AutoModelForAudioXVector
|
||||
|
||||
### AutoModelForTextToSpectrogram
|
||||
|
||||
[[autodoc]] AutoModelForTextToSpectrogram
|
||||
|
||||
### AutoModelForTextToWaveform
|
||||
|
||||
[[autodoc]] AutoModelForTextToWaveform
|
||||
|
||||
## Multimodal
|
||||
|
||||
The following auto classes are available for the following multimodal tasks.
|
||||
|
||||
@@ -26,8 +26,67 @@ Bark is made of 4 main models:
|
||||
|
||||
It should be noted that each of the first three modules can support conditional speaker embeddings to condition the output sound according to specific predefined voice.
|
||||
|
||||
### Optimizing Bark
|
||||
|
||||
### Tips:
|
||||
Bark can be optimized with just a few extra lines of code, which **significantly reduces its memory footprint** and **accelerates inference**.
|
||||
|
||||
#### Using half-precision
|
||||
|
||||
You can speed up inference and reduce memory footprint by 50% simply by loading the model in half-precision.
|
||||
|
||||
```python
|
||||
from transformers import BarkModel
|
||||
import torch
|
||||
|
||||
device = "cuda" if torch.cuda.is_available() else "cpu"
|
||||
model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16).to(device)
|
||||
```
|
||||
|
||||
#### Using 🤗 Better Transformer
|
||||
|
||||
Better Transformer is an 🤗 Optimum feature that performs kernel fusion under the hood. You can gain 20% to 30% in speed with zero performance degradation. It only requires one line of code to export the model to 🤗 Better Transformer:
|
||||
|
||||
```python
|
||||
model = model.to_bettertransformer()
|
||||
```
|
||||
|
||||
Note that 🤗 Optimum must be installed before using this feature. [Here's how to install it.](https://huggingface.co/docs/optimum/installation)
|
||||
|
||||
#### Using CPU offload
|
||||
|
||||
As mentioned above, Bark is made up of 4 sub-models, which are called up sequentially during audio generation. In other words, while one sub-model is in use, the other sub-models are idle.
|
||||
|
||||
If you're using a CUDA device, a simple solution to benefit from an 80% reduction in memory footprint is to offload the GPU's submodels when they're idle. This operation is called CPU offloading. You can use it with one line of code.
|
||||
|
||||
```python
|
||||
model.enable_cpu_offload()
|
||||
```
|
||||
|
||||
Note that 🤗 Accelerate must be installed before using this feature. [Here's how to install it.](https://huggingface.co/docs/accelerate/basic_tutorials/install)
|
||||
|
||||
#### Combining optimizaton techniques
|
||||
|
||||
You can combine optimization techniques, and use CPU offload, half-precision and 🤗 Better Transformer all at once.
|
||||
|
||||
```python
|
||||
from transformers import BarkModel
|
||||
import torch
|
||||
|
||||
device = "cuda" if torch.cuda.is_available() else "cpu"
|
||||
|
||||
# load in fp16
|
||||
model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16).to(device)
|
||||
|
||||
# convert to bettertransformer
|
||||
model = BetterTransformer.transform(model, keep_original_model=False)
|
||||
|
||||
# enable CPU offload
|
||||
model.enable_cpu_offload()
|
||||
```
|
||||
|
||||
Find out more on inference optimization techniques [here](https://huggingface.co/docs/transformers/perf_infer_gpu_one).
|
||||
|
||||
### Tips
|
||||
|
||||
Suno offers a library of voice presets in a number of languages [here](https://suno-ai.notion.site/8b8e8749ed514b0cbf3f699013548683?v=bc67cff786b04b50b3ceb756fd05f68c).
|
||||
These presets are also uploaded in the hub [here](https://huggingface.co/suno/bark-small/tree/main/speaker_embeddings) or [here](https://huggingface.co/suno/bark/tree/main/speaker_embeddings).
|
||||
@@ -103,6 +162,7 @@ The original code can be found [here](https://github.com/suno-ai/bark).
|
||||
|
||||
[[autodoc]] BarkModel
|
||||
- generate
|
||||
- enable_cpu_offload
|
||||
|
||||
## BarkSemanticModel
|
||||
|
||||
|
||||
@@ -30,7 +30,7 @@ The abstract from the paper is the following:
|
||||
*Vision-Language Pre-training (VLP) has advanced the performance for many vision-language tasks.
|
||||
However, most existing pre-trained models only excel in either understanding-based tasks or generation-based tasks. Furthermore, performance improvement has been largely achieved by scaling up the dataset with noisy image-text pairs collected from the web, which is a suboptimal source of supervision. In this paper, we propose BLIP, a new VLP framework which transfers flexibly to both vision-language understanding and generation tasks. BLIP effectively utilizes the noisy web data by bootstrapping the captions, where a captioner generates synthetic captions and a filter removes the noisy ones. We achieve state-of-the-art results on a wide range of vision-language tasks, such as image-text retrieval (+2.7% in average recall@1), image captioning (+2.8% in CIDEr), and VQA (+1.6% in VQA score). BLIP also demonstrates strong generalization ability when directly transferred to videolanguage tasks in a zero-shot manner. Code, models, and datasets are released.*
|
||||
|
||||

|
||||

|
||||
|
||||
This model was contributed by [ybelkada](https://huggingface.co/ybelkada).
|
||||
The original code can be found [here](https://github.com/salesforce/BLIP).
|
||||
|
||||
@@ -85,3 +85,13 @@ See also:
|
||||
|
||||
[[autodoc]] BloomForQuestionAnswering
|
||||
- forward
|
||||
|
||||
## FlaxBloomModel
|
||||
|
||||
[[autodoc]] FlaxBloomModel
|
||||
- __call__
|
||||
|
||||
## FlaxBloomForCausalLM
|
||||
|
||||
[[autodoc]] FlaxBloomForCausalLM
|
||||
- __call__
|
||||
|
||||
@@ -184,6 +184,11 @@ The resource should ideally demonstrate something new instead of duplicating an
|
||||
[[autodoc]] FlaxCLIPTextModel
|
||||
- __call__
|
||||
|
||||
## FlaxCLIPTextModelWithProjection
|
||||
|
||||
[[autodoc]] FlaxCLIPTextModelWithProjection
|
||||
- __call__
|
||||
|
||||
## FlaxCLIPVisionModel
|
||||
|
||||
[[autodoc]] FlaxCLIPVisionModel
|
||||
|
||||
118
docs/source/en/model_doc/code_llama.md
Normal file
118
docs/source/en/model_doc/code_llama.md
Normal file
@@ -0,0 +1,118 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contains specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# CodeLlama
|
||||
|
||||
## Overview
|
||||
|
||||
The Code Llama model was proposed in [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) by Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
*We release Code Llama, a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models, infilling capabilities, support for large input contexts, and zero-shot instruction following ability for programming tasks. We provide multiple flavors to cover a wide range of applications: foundation models (Code Llama), Python specializations (Code Llama - Python), and instruction-following models (Code Llama - Instruct) with 7B, 13B and 34B parameters each. All models are trained on sequences of 16k tokens and show improvements on inputs with up to 100k tokens. 7B and 13B Code Llama and Code Llama - Instruct variants support infilling based on surrounding content. Code Llama reaches state-of-the-art performance among open models on several code benchmarks, with scores of up to 53% and 55% on HumanEval and MBPP, respectively. Notably, Code Llama - Python 7B outperforms Llama 2 70B on HumanEval and MBPP, and all our models outperform every other publicly available model on MultiPL-E. We release Code Llama under a permissive license that allows for both research and commercial use.*
|
||||
|
||||
Check out all Code Llama models [here](https://huggingface.co/models?search=code_llama) and the officially released ones in the [codellama org](https://huggingface.co/codellama).
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
The `Llama2` family models, on which Code Llama is based, were trained using `bfloat16`, but the original inference uses `float16`. Let's look at the different precisions:
|
||||
|
||||
* `float32`: PyTorch convention on model initialization is to load models in `float32`, no matter with which `dtype` the model weights were stored. `transformers` also follows this convention for consistency with PyTorch. This will be picked by default. If you want the `AutoModel` API to cast the load the checkpoints with the storage weights type, you must specify `torch_dtype="auto"`, e.g. `model = AutoModelForCausalLM.from_pretrained("path", torch_dtype = "auto")`.
|
||||
* `bfloat16`: Code Llama was trained with this precision, so we recommend using it for further training or fine-tuning.
|
||||
* `float16`: We recommend running inference using this precision, as it's usually faster than `bfloat16`, and evaluation metrics show no discernible degradation with respect to `bfloat16`. You can also run inference using `bfloat16`, and we recommend you check inference results with both `float16` and `bfloat16` after fine-tuning.
|
||||
|
||||
As mentioned above, the `dtype` of the storage weights is mostly irrelevant unless you are using `torch_dtype="auto"` when initializing a model using. The reason is that the model will first be downloaded (using the `dtype` of the checkpoints online) and then will be casted to the default `dtype` of `torch` (becomes `torch.float32`). If there is a specified `torch_dtype`, it will be used instead.
|
||||
|
||||
</Tip>
|
||||
|
||||
Tips:
|
||||
|
||||
- These models have the same architecture as the `Llama2` models
|
||||
- The infilling task is supported out of the box. You should be using the `tokenizer.fill_token` where you want your input to be filled.
|
||||
- The model conversion script is the same as for the `Llama2` family:
|
||||
|
||||
Here is a sample usage
|
||||
```bash
|
||||
python src/transformers/models/llama/convert_llama_weights_to_hf.py \
|
||||
--input_dir /path/to/downloaded/llama/weights --model_size 7B --output_dir /output/path
|
||||
```
|
||||
Note that executing the script requires enough CPU RAM to host the whole model in float16 precision (even if the biggest versions
|
||||
come in several checkpoints they each contain a part of each weight of the model, so we need to load them all in RAM).
|
||||
|
||||
- After conversion, the model and tokenizer can be loaded via:
|
||||
|
||||
```python
|
||||
>>> from transformers import LlamaForCausalLM, CodeLlamaTokenizer
|
||||
|
||||
>>> tokenizer = CodeLlamaTokenizer.from_pretrained("codellama/CodeLlama-7b-hf")
|
||||
>>> model = LlamaForCausalLM.from_pretrained("codellama/CodeLlama-7b-hf")
|
||||
>>> PROMPT = '''def remove_non_ascii(s: str) -> str:
|
||||
""" <FILL_ME>
|
||||
return result
|
||||
'''
|
||||
>>> input_ids = tokenizer(PROMPT, return_tensors="pt")["input_ids"]
|
||||
>>> generated_ids = model.generate(input_ids, max_new_tokens=128)
|
||||
|
||||
>>> filling = tokenizer.batch_decode(generated_ids[:, input_ids.shape[1]:], skip_special_tokens = True)[0]
|
||||
>>> print(PROMPT.replace("<FILL_ME>", filling))
|
||||
def remove_non_ascii(s: str) -> str:
|
||||
""" Remove non-ASCII characters from a string.
|
||||
|
||||
Args:
|
||||
s: The string to remove non-ASCII characters from.
|
||||
|
||||
Returns:
|
||||
The string with non-ASCII characters removed.
|
||||
"""
|
||||
result = ""
|
||||
for c in s:
|
||||
if ord(c) < 128:
|
||||
result += c
|
||||
return result
|
||||
```
|
||||
|
||||
If you only want the infilled part:
|
||||
```python
|
||||
>>> from transformers import pipeline
|
||||
>>> import torch
|
||||
|
||||
>>> generator = pipeline("text-generation",model="codellama/CodeLlama-7b-hf",torch_dtype=torch.float16, device_map="auto")
|
||||
>>> generator('def remove_non_ascii(s: str) -> str:\n """ <FILL_ME>\n return result', max_new_tokens = 128, return_type = 1)
|
||||
```
|
||||
|
||||
Under the hood, the tokenizer [automatically splits by `<FILL_ME>`](https://huggingface.co/docs/transformers/main/model_doc/code_llama#transformers.CodeLlamaTokenizer.fill_token) to create a formatted input string that follows [the original training pattern](https://github.com/facebookresearch/codellama/blob/cb51c14ec761370ba2e2bc351374a79265d0465e/llama/generation.py#L402). This is more robust than preparing the pattern yourself: it avoids pitfalls, such as token glueing, that are very hard to debug. To see how much CPU and GPU memory you need for this model or others, try [this calculator](https://huggingface.co/spaces/hf-accelerate/model-memory-usage) which can help determine that value.
|
||||
|
||||
- The LLaMA tokenizer is a BPE model based on [sentencepiece](https://github.com/google/sentencepiece). One quirk of sentencepiece is that when decoding a sequence, if the first token is the start of the word (e.g. "Banana"), the tokenizer does not prepend the prefix space to the string.
|
||||
|
||||
This model was contributed by [ArthurZucker](https://huggingface.co/ArthurZ). The original code of the authors can be found [here](https://github.com/facebookresearch/llama).
|
||||
|
||||
|
||||
## CodeLlamaTokenizer
|
||||
|
||||
[[autodoc]] CodeLlamaTokenizer
|
||||
- build_inputs_with_special_tokens
|
||||
- get_special_tokens_mask
|
||||
- create_token_type_ids_from_sequences
|
||||
- save_vocabulary
|
||||
|
||||
## CodeLlamaTokenizerFast
|
||||
|
||||
[[autodoc]] CodeLlamaTokenizerFast
|
||||
- build_inputs_with_special_tokens
|
||||
- get_special_tokens_mask
|
||||
- create_token_type_ids_from_sequences
|
||||
- update_post_processor
|
||||
- save_vocabulary
|
||||
45
docs/source/en/model_doc/dinov2.md
Normal file
45
docs/source/en/model_doc/dinov2.md
Normal file
@@ -0,0 +1,45 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# DINOv2
|
||||
|
||||
## Overview
|
||||
|
||||
The DINOv2 model was proposed in [DINOv2: Learning Robust Visual Features without Supervision](https://arxiv.org/abs/2304.07193) by
|
||||
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski.
|
||||
DINOv2 is an upgrade of [DINO](https://arxiv.org/abs/2104.14294), a self-supervised method applied on [Vision Transformers](vit). This method enables all-purpose visual features, i.e., features that work across image distributions and tasks without finetuning.
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
*The recent breakthroughs in natural language processing for model pretraining on large quantities of data have opened the way for similar foundation models in computer vision. These models could greatly simplify the use of images in any system by producing all-purpose visual features, i.e., features that work across image distributions and tasks without finetuning. This work shows that existing pretraining methods, especially self-supervised methods, can produce such features if trained on enough curated data from diverse sources. We revisit existing approaches and combine different techniques to scale our pretraining in terms of data and model size. Most of the technical contributions aim at accelerating and stabilizing the training at scale. In terms of data, we propose an automatic pipeline to build a dedicated, diverse, and curated image dataset instead of uncurated data, as typically done in the self-supervised literature. In terms of models, we train a ViT model (Dosovitskiy et al., 2020) with 1B parameters and distill it into a series of smaller models that surpass the best available all-purpose features, OpenCLIP (Ilharco et al., 2021) on most of the benchmarks at image and pixel levels.*
|
||||
|
||||
Tips:
|
||||
|
||||
- One can use [`AutoImageProcessor`] class to prepare images for the model.
|
||||
|
||||
This model was contributed by [nielsr](https://huggingface.co/nielsr).
|
||||
The original code can be found [here](https://github.com/facebookresearch/dinov2).
|
||||
|
||||
|
||||
## Dinov2Config
|
||||
|
||||
[[autodoc]] Dinov2Config
|
||||
|
||||
## Dinov2Model
|
||||
|
||||
[[autodoc]] Dinov2Model
|
||||
- forward
|
||||
|
||||
## Dinov2ForImageClassification
|
||||
|
||||
[[autodoc]] Dinov2ForImageClassification
|
||||
- forward
|
||||
@@ -80,11 +80,9 @@ into a single instance to both extract the input features and decode the predict
|
||||
... pixel_values.to(device),
|
||||
... decoder_input_ids=decoder_input_ids.to(device),
|
||||
... max_length=model.decoder.config.max_position_embeddings,
|
||||
... early_stopping=True,
|
||||
... pad_token_id=processor.tokenizer.pad_token_id,
|
||||
... eos_token_id=processor.tokenizer.eos_token_id,
|
||||
... use_cache=True,
|
||||
... num_beams=1,
|
||||
... bad_words_ids=[[processor.tokenizer.unk_token_id]],
|
||||
... return_dict_in_generate=True,
|
||||
... )
|
||||
@@ -125,11 +123,9 @@ into a single instance to both extract the input features and decode the predict
|
||||
... pixel_values.to(device),
|
||||
... decoder_input_ids=decoder_input_ids.to(device),
|
||||
... max_length=model.decoder.config.max_position_embeddings,
|
||||
... early_stopping=True,
|
||||
... pad_token_id=processor.tokenizer.pad_token_id,
|
||||
... eos_token_id=processor.tokenizer.eos_token_id,
|
||||
... use_cache=True,
|
||||
... num_beams=1,
|
||||
... bad_words_ids=[[processor.tokenizer.unk_token_id]],
|
||||
... return_dict_in_generate=True,
|
||||
... )
|
||||
@@ -172,11 +168,9 @@ into a single instance to both extract the input features and decode the predict
|
||||
... pixel_values.to(device),
|
||||
... decoder_input_ids=decoder_input_ids.to(device),
|
||||
... max_length=model.decoder.config.max_position_embeddings,
|
||||
... early_stopping=True,
|
||||
... pad_token_id=processor.tokenizer.pad_token_id,
|
||||
... eos_token_id=processor.tokenizer.eos_token_id,
|
||||
... use_cache=True,
|
||||
... num_beams=1,
|
||||
... bad_words_ids=[[processor.tokenizer.unk_token_id]],
|
||||
... return_dict_in_generate=True,
|
||||
... )
|
||||
|
||||
84
docs/source/en/model_doc/falcon.md
Normal file
84
docs/source/en/model_doc/falcon.md
Normal file
@@ -0,0 +1,84 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Falcon
|
||||
|
||||
## Overview
|
||||
|
||||
Falcon is a class of causal decoder-only models built by [TII](https://www.tii.ae/). The largest Falcon checkpoints
|
||||
have been trained on >=1T tokens of text, with a particular emphasis on the [RefinedWeb](https://arxiv.org/abs/2306.01116)
|
||||
corpus. They are made available under the Apache 2.0 license.
|
||||
|
||||
|
||||
Falcon's architecture is modern and optimized for inference, with multi-query attention and support for efficient
|
||||
attention variants like `FlashAttention`. Both 'base' models trained only as causal language models as well as
|
||||
'instruct' models that have received further fine-tuning are available.
|
||||
|
||||
|
||||
Falcon models are (as of 2023) some of the largest and most powerful open-source language models,
|
||||
and consistently rank highly in the [OpenLLM leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
|
||||
|
||||
## Converting custom checkpoints
|
||||
|
||||
<Tip>
|
||||
|
||||
Falcon models were initially added to the Hugging Face Hub as custom code checkpoints. However, Falcon is now fully
|
||||
supported in the Transformers library. If you fine-tuned a model from a custom code checkpoint, we recommend converting
|
||||
your checkpoint to the new in-library format, as this should give significant improvements to stability and
|
||||
performance, especially for generation, as well as removing the need to use `trust_remote_code=True`!
|
||||
|
||||
</Tip>
|
||||
|
||||
You can convert custom code checkpoints to full Transformers checkpoints using the `convert_custom_code_checkpoint.py`
|
||||
script located in the
|
||||
[Falcon model directory](https://github.com/huggingface/transformers/tree/main/src/transformers/models/falcon)
|
||||
of the Transformers library. To use this script, simply call it with
|
||||
`python convert_custom_code_checkpoint.py --checkpoint_dir my_model`. This will convert your checkpoint in-place, and
|
||||
you can immediately load it from the directory afterwards with e.g. `from_pretrained()`. If your model hasn't been
|
||||
uploaded to the Hub, we recommend making a backup before attempting the conversion, just in case!
|
||||
|
||||
|
||||
## FalconConfig
|
||||
|
||||
[[autodoc]] FalconConfig
|
||||
- all
|
||||
|
||||
## FalconModel
|
||||
|
||||
[[autodoc]] FalconModel
|
||||
- forward
|
||||
|
||||
## FalconForCausalLM
|
||||
|
||||
[[autodoc]] FalconForCausalLM
|
||||
- forward
|
||||
|
||||
## FalconForSequenceClassification
|
||||
|
||||
[[autodoc]] FalconForSequenceClassification
|
||||
- forward
|
||||
|
||||
## FalconForTokenClassification
|
||||
|
||||
[[autodoc]] FalconForTokenClassification
|
||||
- forward
|
||||
|
||||
## FalconForQuestionAnswering
|
||||
|
||||
[[autodoc]] FalconForQuestionAnswering
|
||||
- forward
|
||||
|
||||
|
||||
63
docs/source/en/model_doc/idefics.md
Normal file
63
docs/source/en/model_doc/idefics.md
Normal file
@@ -0,0 +1,63 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# IDEFICS
|
||||
|
||||
## Overview
|
||||
|
||||
The IDEFICS model was proposed in [OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents
|
||||
](https://huggingface.co/papers/2306.16527
|
||||
) by Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander M. Rush, Douwe Kiela, Matthieu Cord, Victor Sanh
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
*Large multimodal models trained on natural documents, which interleave images and text, outperform models trained on image-text pairs on various multimodal benchmarks that require reasoning over one or multiple images to generate a text. However, the datasets used to train these models have not been released, and the collection process has not been fully specified. We introduce the OBELICS dataset, an open web-scale filtered dataset of interleaved image-text documents comprising 141 million web pages extracted from Common Crawl, 353 million associated images, and 115 billion text tokens. We describe the dataset creation process, present comprehensive filtering rules, and provide an analysis of the dataset's content. To show the viability of OBELISC, we train an 80 billion parameters vision and language model on the dataset and obtain competitive performance on various multimodal benchmarks. We release the code to reproduce the dataset along with the dataset itself.*
|
||||
|
||||
This model was contributed by [HuggingFaceM4](https://huggingface.co/HuggingFaceM4). The original code can be found [here](<INSERT LINK TO GITHUB REPO HERE>). (TODO: don't have a public link yet).
|
||||
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
Idefics modeling code in Transformers is for finetuning and inferencing the pre-trained Idefics models.
|
||||
|
||||
To train a new Idefics model from scratch use the m4 codebase (a link will be provided once it's made public)
|
||||
|
||||
</Tip>
|
||||
|
||||
|
||||
## IdeficsConfig
|
||||
|
||||
[[autodoc]] IdeficsConfig
|
||||
|
||||
## IdeficsModel
|
||||
|
||||
[[autodoc]] IdeficsModel
|
||||
- forward
|
||||
|
||||
## IdeficsForVisionText2Text
|
||||
|
||||
[[autodoc]] IdeficsForVisionText2Text
|
||||
- forward
|
||||
|
||||
## IdeficsImageProcessor
|
||||
|
||||
[[autodoc]] IdeficsImageProcessor
|
||||
- preprocess
|
||||
|
||||
## IdeficsProcessor
|
||||
|
||||
[[autodoc]] IdeficsProcessor
|
||||
- __call__
|
||||
@@ -50,6 +50,12 @@ come in several checkpoints they each contain a part of each weight of the model
|
||||
|
||||
This model was contributed by [zphang](https://huggingface.co/zphang) with contributions from [BlackSamorez](https://huggingface.co/BlackSamorez). The code of the implementation in Hugging Face is based on GPT-NeoX [here](https://github.com/EleutherAI/gpt-neox). The original code of the authors can be found [here](https://github.com/facebookresearch/llama).
|
||||
|
||||
|
||||
Based on the original LLaMA model, Meta AI has released some follow-up works:
|
||||
|
||||
- **Llama2**: Llama2 is an improved version of Llama with some architectural tweaks (Grouped Query Attention), and is pre-trained on 2Trillion tokens. Refer to the documentation of Llama2 which can be found [here](llama2).
|
||||
|
||||
|
||||
## LlamaConfig
|
||||
|
||||
[[autodoc]] LlamaConfig
|
||||
|
||||
132
docs/source/en/model_doc/llama2.md
Normal file
132
docs/source/en/model_doc/llama2.md
Normal file
@@ -0,0 +1,132 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contains specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Llama2
|
||||
|
||||
## Overview
|
||||
|
||||
The Llama2 model was proposed in [LLaMA: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/) by Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom. It is a collection of foundation language models ranging from 7B to 70B parameters, with checkpoints finetuned for chat application!
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
*In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed-source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.*
|
||||
|
||||
Checkout all Llama2 models [here](https://huggingface.co/models?search=llama2)
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
The `Llama2` models were trained using `bfloat16`, but the original inference uses `float16. The checkpoints uploaded on the hub use `torch_dtype = 'float16'` which will be
|
||||
used by the `AutoModel` API to cast the checkpoints from `torch.float32` to `torch.float16`.
|
||||
|
||||
The `dtype` of the online weights is mostly irrelevant, unless you are using `torch_dtype="auto"` when initializing a model using `model = AutoModelForCausalLM.from_pretrained("path", torch_dtype = "auto")`. The reason is that the model will first be downloaded ( using the `dtype` of the checkpoints online) then it will be casted to the default `dtype` of `torch` (becomes `torch.float32`) and finally, if there is a `torch_dtype` provided in the config, it will be used.
|
||||
|
||||
Training the model in `float16` is not recommended and known to produce `nan`, as such the model should be trained in `bfloat16`.
|
||||
|
||||
</Tip>
|
||||
|
||||
Tips:
|
||||
|
||||
- Weights for the Llama2 models can be obtained by filling out [this form](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)
|
||||
- The architecture is very similar to the first Llama, with the addition of Grouped Query Attention (GQA) following this [paper](https://arxiv.org/pdf/2305.13245.pdf)
|
||||
- Setting `config.pretraining_tp` to a value different than 1 will activate the more accurate but slower computation of the linear layers, which should better match the original logits.
|
||||
- The original model uses `pad_id = -1` which means that there is no padding token. We can't have the same logic, make sure to add a padding token using `tokenizer.add_special_tokens({"pad_token":"<pad>"})` and resize the token embedding accordingly. You should also set the `model.config.pad_token_id`. The `embed_tokens` layer of the model is initialized with `self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.config.padding_idx)`, which makes sure that encoding the padding token will output zeros, so passing it when initializing is recommended.
|
||||
- After filling out the form and gaining access to the model checkpoints, you should be able to use the already converted checkpoints. Otherwise, if you are converting your own model, feel free to use the [conversion script](https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/convert_llama_weights_to_hf.py). The script can be called with the following (example) command:
|
||||
|
||||
```bash
|
||||
python src/transformers/models/llama/convert_llama_weights_to_hf.py \
|
||||
--input_dir /path/to/downloaded/llama/weights --model_size 7B --output_dir /output/path
|
||||
```
|
||||
|
||||
- After conversion, the model and tokenizer can be loaded via:
|
||||
|
||||
```python
|
||||
from transformers import LlamaForCausalLM, LlamaTokenizer
|
||||
|
||||
tokenizer = LlamaTokenizer.from_pretrained("/output/path")
|
||||
model = LlamaForCausalLM.from_pretrained("/output/path")
|
||||
```
|
||||
|
||||
Note that executing the script requires enough CPU RAM to host the whole model in float16 precision (even if the biggest versions
|
||||
come in several checkpoints they each contain a part of each weight of the model, so we need to load them all in RAM). For the 75B model, it's thus 145GB of RAM needed.
|
||||
|
||||
- The LLaMA tokenizer is a BPE model based on [sentencepiece](https://github.com/google/sentencepiece). One quirk of sentencepiece is that when decoding a sequence, if the first token is the start of the word (e.g. "Banana"), the tokenizer does not prepend the prefix space to the string.
|
||||
|
||||
This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ) with contributions from [Lysandre Debut](https://huggingface.co/lysandre). The code of the implementation in Hugging Face is based on GPT-NeoX [here](https://github.com/EleutherAI/gpt-neox). The original code of the authors can be found [here](https://github.com/facebookresearch/llama).
|
||||
|
||||
## Resources
|
||||
|
||||
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LLaMA2. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
|
||||
|
||||
- [Llama 2 is here - get it on Hugging Face](https://huggingface.co/blog/llama2), a blog post about Llama 2 and how to use it with 🤗 Transformers and 🤗 PEFT.
|
||||
- [LLaMA 2 - Every Resource you need](https://www.philschmid.de/llama-2), a compilation of relevant resources to learn about LLaMA 2 and how to get started quickly.
|
||||
|
||||
<PipelineTag pipeline="text-generation"/>
|
||||
|
||||
- A [notebook](https://colab.research.google.com/drive/1PEQyJO1-f6j0S_XJ8DV50NkpzasXkrzd?usp=sharing) on how to fine-tune Llama 2 in Google Colab using QLoRA and 4-bit precision. 🌎
|
||||
- A [notebook](https://colab.research.google.com/drive/134o_cXcMe_lsvl15ZE_4Y75Kstepsntu?usp=sharing) on how to fine-tune the "Llama-v2-7b-guanaco" model with 4-bit QLoRA and generate Q&A datasets from PDFs. 🌎
|
||||
|
||||
⚗️ Optimization
|
||||
- [Fine-tune Llama 2 with DPO](https://huggingface.co/blog/dpo-trl), a guide to using the TRL library's DPO method to fine tune Llama 2 on a specific dataset.
|
||||
- [Extended Guide: Instruction-tune Llama 2](https://www.philschmid.de/instruction-tune-llama-2), a guide to training Llama 2 to generate instructions from inputs, transforming the model from instruction-following to instruction-giving.
|
||||
- A [notebook](https://colab.research.google.com/drive/1SYpgFpcmtIUzdE7pxqknrM4ArCASfkFQ?usp=sharing) on how to fine-tune the Llama 2 model on a personal computer using QLoRa and TRL. 🌎
|
||||
|
||||
⚡️ Inference
|
||||
- A [notebook](https://colab.research.google.com/drive/1TC56ArKerXUpbgRy5vM3woRsbTEVNq7h?usp=sharing) on how to quantize the Llama 2 model using GPTQ from the AutoGPTQ library. 🌎
|
||||
- A [notebook](https://colab.research.google.com/drive/1X1z9Q6domMKl2CnEM0QGHNwidLfR4dW2?usp=sharing) on how to run the Llama 2 Chat Model with 4-bit quantization on a local computer or Google Colab. 🌎
|
||||
|
||||
🚀 Deploy
|
||||
- [Fine-tune LLaMA 2 (7-70B) on Amazon SageMaker](https://www.philschmid.de/sagemaker-llama2-qlora), a complete guide from setup to QLoRA fine-tuning and deployment on Amazon SageMaker.
|
||||
- [Deploy Llama 2 7B/13B/70B on Amazon SageMaker](https://www.philschmid.de/sagemaker-llama-llm), a guide on using Hugging Face's LLM DLC container for secure and scalable deployment.
|
||||
|
||||
|
||||
## LlamaConfig
|
||||
|
||||
[[autodoc]] LlamaConfig
|
||||
|
||||
|
||||
## LlamaTokenizer
|
||||
|
||||
[[autodoc]] LlamaTokenizer
|
||||
- build_inputs_with_special_tokens
|
||||
- get_special_tokens_mask
|
||||
- create_token_type_ids_from_sequences
|
||||
- save_vocabulary
|
||||
|
||||
## LlamaTokenizerFast
|
||||
|
||||
[[autodoc]] LlamaTokenizerFast
|
||||
- build_inputs_with_special_tokens
|
||||
- get_special_tokens_mask
|
||||
- create_token_type_ids_from_sequences
|
||||
- update_post_processor
|
||||
- save_vocabulary
|
||||
|
||||
## LlamaModel
|
||||
|
||||
[[autodoc]] LlamaModel
|
||||
- forward
|
||||
|
||||
|
||||
## LlamaForCausalLM
|
||||
|
||||
[[autodoc]] LlamaForCausalLM
|
||||
- forward
|
||||
|
||||
## LlamaForSequenceClassification
|
||||
|
||||
[[autodoc]] LlamaForSequenceClassification
|
||||
- forward
|
||||
|
||||
@@ -165,7 +165,147 @@ To further improve performance from ASR models, language model decoding can be u
|
||||
|
||||
### Speech Synthesis (TTS)
|
||||
|
||||
Individual TTS models are available for each of the 1100+ languages. The models and inference documentation can be found [here](https://huggingface.co/facebook/mms-tts).
|
||||
MMS-TTS uses the same model architecture as VITS, which was added to 🤗 Transformers in v4.33. MMS trains a separate
|
||||
model checkpoint for each of the 1100+ languages in the project. All available checkpoints can be found on the Hugging
|
||||
Face Hub: [facebook/mms-tts](https://huggingface.co/models?sort=trending&search=facebook%2Fmms-tts), and the inference
|
||||
documentation under [VITS](https://huggingface.co/docs/transformers/main/en/model_doc/vits).
|
||||
|
||||
#### Inference
|
||||
|
||||
To use the MMS model, first update to the latest version of the Transformers library:
|
||||
|
||||
```bash
|
||||
pip install --upgrade transformers accelerate
|
||||
```
|
||||
|
||||
Since the flow-based model in VITS is non-deterministic, it is good practice to set a seed to ensure reproducibility of
|
||||
the outputs.
|
||||
|
||||
- For languages with a Roman alphabet, such as English or French, the tokenizer can be used directly to
|
||||
pre-process the text inputs. The following code example runs a forward pass using the MMS-TTS English checkpoint:
|
||||
|
||||
```python
|
||||
import torch
|
||||
from transformers import VitsTokenizer, VitsModel, set_seed
|
||||
|
||||
tokenizer = VitsTokenizer.from_pretrained("facebook/mms-tts-eng")
|
||||
model = VitsModel.from_pretrained("facebook/mms-tts-eng")
|
||||
|
||||
inputs = tokenizer(text="Hello - my dog is cute", return_tensors="pt")
|
||||
|
||||
set_seed(555) # make deterministic
|
||||
|
||||
with torch.no_grad():
|
||||
outputs = model(**inputs)
|
||||
|
||||
waveform = outputs.waveform[0]
|
||||
```
|
||||
|
||||
The resulting waveform can be saved as a `.wav` file:
|
||||
|
||||
```python
|
||||
import scipy
|
||||
|
||||
scipy.io.wavfile.write("synthesized_speech.wav", rate=model.config.sampling_rate, data=waveform)
|
||||
```
|
||||
|
||||
Or displayed in a Jupyter Notebook / Google Colab:
|
||||
|
||||
```python
|
||||
from IPython.display import Audio
|
||||
|
||||
Audio(waveform, rate=model.config.sampling_rate)
|
||||
```
|
||||
|
||||
For certain languages with non-Roman alphabets, such as Arabic, Mandarin or Hindi, the [`uroman`](https://github.com/isi-nlp/uroman)
|
||||
perl package is required to pre-process the text inputs to the Roman alphabet.
|
||||
|
||||
You can check whether you require the `uroman` package for your language by inspecting the `is_uroman` attribute of
|
||||
the pre-trained `tokenizer`:
|
||||
|
||||
```python
|
||||
from transformers import VitsTokenizer
|
||||
|
||||
tokenizer = VitsTokenizer.from_pretrained("facebook/mms-tts-eng")
|
||||
print(tokenizer.is_uroman)
|
||||
```
|
||||
|
||||
If required, you should apply the uroman package to your text inputs **prior** to passing them to the `VitsTokenizer`,
|
||||
since currently the tokenizer does not support performing the pre-processing itself.
|
||||
|
||||
To do this, first clone the uroman repository to your local machine and set the bash variable `UROMAN` to the local path:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/isi-nlp/uroman.git
|
||||
cd uroman
|
||||
export UROMAN=$(pwd)
|
||||
```
|
||||
|
||||
You can then pre-process the text input using the following code snippet. You can either rely on using the bash variable
|
||||
`UROMAN` to point to the uroman repository, or you can pass the uroman directory as an argument to the `uromaize` function:
|
||||
|
||||
```python
|
||||
import torch
|
||||
from transformers import VitsTokenizer, VitsModel, set_seed
|
||||
import os
|
||||
import subprocess
|
||||
|
||||
tokenizer = VitsTokenizer.from_pretrained("facebook/mms-tts-kor")
|
||||
model = VitsModel.from_pretrained("facebook/mms-tts-kor")
|
||||
|
||||
def uromanize(input_string, uroman_path):
|
||||
"""Convert non-Roman strings to Roman using the `uroman` perl package."""
|
||||
script_path = os.path.join(uroman_path, "bin", "uroman.pl")
|
||||
|
||||
command = ["perl", script_path]
|
||||
|
||||
process = subprocess.Popen(command, stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
|
||||
# Execute the perl command
|
||||
stdout, stderr = process.communicate(input=input_string.encode())
|
||||
|
||||
if process.returncode != 0:
|
||||
raise ValueError(f"Error {process.returncode}: {stderr.decode()}")
|
||||
|
||||
# Return the output as a string and skip the new-line character at the end
|
||||
return stdout.decode()[:-1]
|
||||
|
||||
text = "이봐 무슨 일이야"
|
||||
uromaized_text = uromanize(text, uroman_path=os.environ["UROMAN"])
|
||||
|
||||
inputs = tokenizer(text=uromaized_text, return_tensors="pt")
|
||||
|
||||
set_seed(555) # make deterministic
|
||||
with torch.no_grad():
|
||||
outputs = model(inputs["input_ids"])
|
||||
|
||||
waveform = outputs.waveform[0]
|
||||
```
|
||||
|
||||
**Tips:**
|
||||
|
||||
* The MMS-TTS checkpoints are trained on lower-cased, un-punctuated text. By default, the `VitsTokenizer` *normalizes* the inputs by removing any casing and punctuation, to avoid passing out-of-vocabulary characters to the model. Hence, the model is agnostic to casing and punctuation, so these should be avoided in the text prompt. You can disable normalisation by setting `noramlize=False` in the call to the tokenizer, but this will lead to un-expected behaviour and is discouraged.
|
||||
* The speaking rate can be varied by setting the attribute `model.speaking_rate` to a chosen value. Likewise, the randomness of the noise is controlled by `model.noise_scale`:
|
||||
|
||||
```python
|
||||
import torch
|
||||
from transformers import VitsTokenizer, VitsModel, set_seed
|
||||
|
||||
tokenizer = VitsTokenizer.from_pretrained("facebook/mms-tts-eng")
|
||||
model = VitsModel.from_pretrained("facebook/mms-tts-eng")
|
||||
|
||||
inputs = tokenizer(text="Hello - my dog is cute", return_tensors="pt")
|
||||
|
||||
# make deterministic
|
||||
set_seed(555)
|
||||
|
||||
# make speech faster and more noisy
|
||||
model.speaking_rate = 1.5
|
||||
model.noise_scale = 0.8
|
||||
|
||||
with torch.no_grad():
|
||||
outputs = model(**inputs)
|
||||
```
|
||||
|
||||
|
||||
### Language Identification (LID)
|
||||
|
||||
@@ -173,11 +313,12 @@ Different LID models are available based on the number of languages they can rec
|
||||
|
||||
#### Inference
|
||||
First, we install transformers and some other libraries
|
||||
```
|
||||
pip install torch accelerate torchaudio datasets
|
||||
|
||||
```bash
|
||||
pip install torch accelerate datasets[audio]
|
||||
pip install --upgrade transformers
|
||||
````
|
||||
pip install torch datasets[audio]
|
||||
|
||||
Next, we load a couple of audio samples via `datasets`. Make sure that the audio data is sampled to 16000 kHz.
|
||||
|
||||
```py
|
||||
|
||||
69
docs/source/en/model_doc/mpt.md
Normal file
69
docs/source/en/model_doc/mpt.md
Normal file
@@ -0,0 +1,69 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# MPT
|
||||
|
||||
## Overview
|
||||
|
||||
The MPT model was proposed by the [MosaicML](https://www.mosaicml.com/) team and released with multiple sizes and finetuned variants. The MPT models is a series of open source and commercially usable LLMs pre-trained on 1T tokens.
|
||||
|
||||
MPT models are GPT-style decoder-only transformers with several improvements: performance-optimized layer implementations, architecture changes that provide greater training stability, and the elimination of context length limits by replacing positional embeddings with ALiBi.
|
||||
|
||||
- MPT base: MPT base pre-trained models on next token prediction
|
||||
- MPT instruct: MPT base models fine-tuned on instruction based tasks
|
||||
- MPT storywriter: MPT base models fine-tuned for 2500 steps on 65k-token excerpts of fiction books contained in the books3 corpus, this enables the model to handle very long sequences
|
||||
|
||||
The original code is available at the [`llm-foundry`](https://github.com/mosaicml/llm-foundry/tree/main) repository.
|
||||
|
||||
Read more about it [in the release blogpost](https://www.mosaicml.com/blog/mpt-7b)
|
||||
|
||||
Tips:
|
||||
|
||||
- Learn more about some techniques behind training of the model [in this section of llm-foundry repository](https://github.com/mosaicml/llm-foundry/blob/main/TUTORIAL.md#faqs)
|
||||
- If you want to use the advanced version of the model (triton kernels, direct flash attention integration), you can still use the original model implementation by adding `trust_remote_code=True` when calling `from_pretrained`.
|
||||
|
||||
- [Fine-tuning Notebook](https://colab.research.google.com/drive/1HCpQkLL7UXW8xJUJJ29X7QAeNJKO0frZ?usp=sharing) on how to fine-tune MPT-7B on a free Google Colab instance to turn the model into a Chatbot.
|
||||
|
||||
|
||||
## MptConfig
|
||||
|
||||
[[autodoc]] MptConfig
|
||||
- all
|
||||
|
||||
## MptModel
|
||||
|
||||
[[autodoc]] MptModel
|
||||
- forward
|
||||
|
||||
## MptForCausalLM
|
||||
|
||||
[[autodoc]] MptForCausalLM
|
||||
- forward
|
||||
|
||||
## MptForSequenceClassification
|
||||
|
||||
[[autodoc]] MptForSequenceClassification
|
||||
- forward
|
||||
|
||||
## MptForTokenClassification
|
||||
|
||||
[[autodoc]] MptForTokenClassification
|
||||
- forward
|
||||
|
||||
## MptForQuestionAnswering
|
||||
|
||||
[[autodoc]] MptForQuestionAnswering
|
||||
- forward
|
||||
@@ -95,6 +95,10 @@ See [`T5TokenizerFast`] for all details.
|
||||
|
||||
[[autodoc]] MT5EncoderModel
|
||||
|
||||
## MT5ForSequenceClassification
|
||||
|
||||
[[autodoc]] MT5ForSequenceClassification
|
||||
|
||||
## MT5ForQuestionAnswering
|
||||
|
||||
[[autodoc]] MT5ForQuestionAnswering
|
||||
|
||||
@@ -53,6 +53,10 @@ better results than greedy, thus we encourage sampling mode to be used where pos
|
||||
and can be explicitly specified by setting `do_sample=True` in the call to [`MusicgenForConditionalGeneration.generate`],
|
||||
or by overriding the model's generation config (see below).
|
||||
|
||||
Generation is limited by the sinusoidal positional embeddings to 30 second inputs. Meaning, MusicGen cannot generate more
|
||||
than 30 seconds of audio (1503 tokens), and input audio passed by Audio-Prompted Generation contributes to this limit so,
|
||||
given an input of 20 seconds of audio, MusicGen cannot generate more than 10 seconds of additional audio.
|
||||
|
||||
### Unconditional Generation
|
||||
|
||||
The inputs for unconditional (or 'null') generation can be obtained through the method
|
||||
@@ -210,28 +214,7 @@ The MusicGen model can be de-composed into three distinct stages:
|
||||
|
||||
Thus, the MusicGen model can either be used as a standalone decoder model, corresponding to the class [`MusicgenForCausalLM`],
|
||||
or as a composite model that includes the text encoder and audio encoder/decoder, corresponding to the class
|
||||
[`MusicgenForConditionalGeneration`].
|
||||
|
||||
Since the text encoder and audio encoder/decoder models are frozen during training, the MusicGen decoder [`MusicgenForCausalLM`]
|
||||
can be trained standalone on a dataset of encoder hidden-states and audio codes. For inference, the trained decoder can
|
||||
be combined with the frozen text encoder and audio encoder/decoders to recover the composite [`MusicgenForConditionalGeneration`]
|
||||
model.
|
||||
|
||||
Below, we demonstrate how to construct the composite [`MusicgenForConditionalGeneration`] model from its three constituent
|
||||
parts, as would typically be done following training of the MusicGen decoder LM:
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoConfig, AutoModelForTextEncoding, AutoModel, MusicgenForCausalLM, MusicgenForConditionalGeneration
|
||||
|
||||
>>> text_encoder = AutoModelForTextEncoding.from_pretrained("t5-base")
|
||||
>>> audio_encoder = AutoModel.from_pretrained("facebook/encodec_32khz")
|
||||
>>> decoder_config = AutoConfig.from_pretrained("facebook/musicgen-small").decoder
|
||||
>>> decoder = MusicgenForCausalLM.from_pretrained("facebook/musicgen-small", **decoder_config)
|
||||
|
||||
>>> model = MusicgenForConditionalGeneration.from_sub_models_pretrained(text_encoder, audio_encoder, decoder)
|
||||
```
|
||||
|
||||
If only the decoder needs to be loaded from the pre-trained checkpoint for the composite model, it can be loaded by first
|
||||
[`MusicgenForConditionalGeneration`]. If only the decoder needs to be loaded from the pre-trained checkpoint, it can be loaded by first
|
||||
specifying the correct config, or be accessed through the `.decoder` attribute of the composite model:
|
||||
|
||||
```python
|
||||
@@ -245,6 +228,11 @@ specifying the correct config, or be accessed through the `.decoder` attribute o
|
||||
>>> decoder = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small").decoder
|
||||
```
|
||||
|
||||
Since the text encoder and audio encoder/decoder models are frozen during training, the MusicGen decoder [`MusicgenForCausalLM`]
|
||||
can be trained standalone on a dataset of encoder hidden-states and audio codes. For inference, the trained decoder can
|
||||
be combined with the frozen text encoder and audio encoder/decoders to recover the composite [`MusicgenForConditionalGeneration`]
|
||||
model.
|
||||
|
||||
Tips:
|
||||
* MusicGen is trained on the 32kHz checkpoint of Encodec. You should ensure you use a compatible version of the Encodec model.
|
||||
* Sampling mode tends to deliver better results than greedy - you can toggle sampling with the variable `do_sample` in the call to [`MusicgenForConditionalGeneration.generate`]
|
||||
|
||||
@@ -16,6 +16,21 @@ rendered properly in your Markdown viewer.
|
||||
|
||||
# Open-Llama
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This model is in maintenance mode only, so we won't accept any new PRs changing its code.
|
||||
|
||||
If you run into any issues running this model, please reinstall the last version that supported this model: v4.31.0.
|
||||
You can do so by running the following command: `pip install -U transformers==4.31.0`.
|
||||
|
||||
</Tip>
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This model differs from the [OpenLLaMA models](https://huggingface.co/models?search=openllama) on the Hugging Face Hub, which primarily use the [LLaMA](llama) architecture.
|
||||
|
||||
</Tip>
|
||||
|
||||
## Overview
|
||||
|
||||
The Open-Llama model was proposed in [Open-Llama project](https://github.com/s-JoL/Open-Llama) by community developer s-JoL.
|
||||
|
||||
190
docs/source/en/model_doc/pop2piano.md
Normal file
190
docs/source/en/model_doc/pop2piano.md
Normal file
@@ -0,0 +1,190 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Pop2Piano
|
||||
|
||||
## Overview
|
||||
|
||||
The Pop2Piano model was proposed in [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi and Kyogu Lee.
|
||||
|
||||
Piano covers of pop music are widely enjoyed, but generating them from music is not a trivial task. It requires great
|
||||
expertise with playing piano as well as knowing different characteristics and melodies of a song. With Pop2Piano you
|
||||
can directly generate a cover from a song's audio waveform. It is the first model to directly generate a piano cover
|
||||
from pop audio without melody and chord extraction modules.
|
||||
|
||||
Pop2Piano is an encoder-decoder Transformer model based on [T5](https://arxiv.org/pdf/1910.10683.pdf). The input audio
|
||||
is transformed to its waveform and passed to the encoder, which transforms it to a latent representation. The decoder
|
||||
uses these latent representations to generate token ids in an autoregressive way. Each token id corresponds to one of four
|
||||
different token types: time, velocity, note and 'special'. The token ids are then decoded to their equivalent MIDI file.
|
||||
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
*Piano covers of pop music are enjoyed by many people. However, the
|
||||
task of automatically generating piano covers of pop music is still
|
||||
understudied. This is partly due to the lack of synchronized
|
||||
{Pop, Piano Cover} data pairs, which made it challenging to apply
|
||||
the latest data-intensive deep learning-based methods. To leverage
|
||||
the power of the data-driven approach, we make a large amount of
|
||||
paired and synchronized {Pop, Piano Cover} data using an automated
|
||||
pipeline. In this paper, we present Pop2Piano, a Transformer network
|
||||
that generates piano covers given waveforms of pop music. To the best
|
||||
of our knowledge, this is the first model to generate a piano cover
|
||||
directly from pop audio without using melody and chord extraction
|
||||
modules. We show that Pop2Piano, trained with our dataset, is capable
|
||||
of producing plausible piano covers.*
|
||||
|
||||
|
||||
Tips:
|
||||
|
||||
1. To use Pop2Piano, you will need to install the 🤗 Transformers library, as well as the following third party modules:
|
||||
```
|
||||
pip install pretty-midi==0.2.9 essentia==2.1b6.dev1034 librosa scipy
|
||||
```
|
||||
Please note that you may need to restart your runtime after installation.
|
||||
2. Pop2Piano is an Encoder-Decoder based model like T5.
|
||||
3. Pop2Piano can be used to generate midi-audio files for a given audio sequence.
|
||||
4. Choosing different composers in `Pop2PianoForConditionalGeneration.generate()` can lead to variety of different results.
|
||||
5. Setting the sampling rate to 44.1 kHz when loading the audio file can give good performance.
|
||||
6. Though Pop2Piano was mainly trained on Korean Pop music, it also does pretty well on other Western Pop or Hip Hop songs.
|
||||
|
||||
This model was contributed by [Susnato Dhar](https://huggingface.co/susnato).
|
||||
The original code can be found [here](https://github.com/sweetcocoa/pop2piano).
|
||||
|
||||
## Examples
|
||||
|
||||
- Example using HuggingFace Dataset:
|
||||
|
||||
```python
|
||||
>>> from datasets import load_dataset
|
||||
>>> from transformers import Pop2PianoForConditionalGeneration, Pop2PianoProcessor
|
||||
|
||||
>>> model = Pop2PianoForConditionalGeneration.from_pretrained("sweetcocoa/pop2piano")
|
||||
>>> processor = Pop2PianoProcessor.from_pretrained("sweetcocoa/pop2piano")
|
||||
>>> ds = load_dataset("sweetcocoa/pop2piano_ci", split="test")
|
||||
|
||||
>>> inputs = processor(
|
||||
... audio=ds["audio"][0]["array"], sampling_rate=ds["audio"][0]["sampling_rate"], return_tensors="pt"
|
||||
... )
|
||||
>>> model_output = model.generate(input_features=inputs["input_features"], composer="composer1")
|
||||
>>> tokenizer_output = processor.batch_decode(
|
||||
... token_ids=model_output, feature_extractor_output=inputs
|
||||
... )["pretty_midi_objects"][0]
|
||||
>>> tokenizer_output.write("./Outputs/midi_output.mid")
|
||||
```
|
||||
|
||||
- Example using your own audio file:
|
||||
|
||||
```python
|
||||
>>> import librosa
|
||||
>>> from transformers import Pop2PianoForConditionalGeneration, Pop2PianoProcessor
|
||||
|
||||
>>> audio, sr = librosa.load("<your_audio_file_here>", sr=44100) # feel free to change the sr to a suitable value.
|
||||
>>> model = Pop2PianoForConditionalGeneration.from_pretrained("sweetcocoa/pop2piano")
|
||||
>>> processor = Pop2PianoProcessor.from_pretrained("sweetcocoa/pop2piano")
|
||||
|
||||
>>> inputs = processor(audio=audio, sampling_rate=sr, return_tensors="pt")
|
||||
>>> model_output = model.generate(input_features=inputs["input_features"], composer="composer1")
|
||||
>>> tokenizer_output = processor.batch_decode(
|
||||
... token_ids=model_output, feature_extractor_output=inputs
|
||||
... )["pretty_midi_objects"][0]
|
||||
>>> tokenizer_output.write("./Outputs/midi_output.mid")
|
||||
```
|
||||
|
||||
- Example of processing multiple audio files in batch:
|
||||
|
||||
```python
|
||||
>>> import librosa
|
||||
>>> from transformers import Pop2PianoForConditionalGeneration, Pop2PianoProcessor
|
||||
|
||||
>>> # feel free to change the sr to a suitable value.
|
||||
>>> audio1, sr1 = librosa.load("<your_first_audio_file_here>", sr=44100)
|
||||
>>> audio2, sr2 = librosa.load("<your_second_audio_file_here>", sr=44100)
|
||||
>>> model = Pop2PianoForConditionalGeneration.from_pretrained("sweetcocoa/pop2piano")
|
||||
>>> processor = Pop2PianoProcessor.from_pretrained("sweetcocoa/pop2piano")
|
||||
|
||||
>>> inputs = processor(audio=[audio1, audio2], sampling_rate=[sr1, sr2], return_attention_mask=True, return_tensors="pt")
|
||||
>>> # Since we now generating in batch(2 audios) we must pass the attention_mask
|
||||
>>> model_output = model.generate(
|
||||
... input_features=inputs["input_features"],
|
||||
... attention_mask=inputs["attention_mask"],
|
||||
... composer="composer1",
|
||||
... )
|
||||
>>> tokenizer_output = processor.batch_decode(
|
||||
... token_ids=model_output, feature_extractor_output=inputs
|
||||
... )["pretty_midi_objects"]
|
||||
|
||||
>>> # Since we now have 2 generated MIDI files
|
||||
>>> tokenizer_output[0].write("./Outputs/midi_output1.mid")
|
||||
>>> tokenizer_output[1].write("./Outputs/midi_output2.mid")
|
||||
```
|
||||
|
||||
|
||||
- Example of processing multiple audio files in batch (Using `Pop2PianoFeatureExtractor` and `Pop2PianoTokenizer`):
|
||||
|
||||
```python
|
||||
>>> import librosa
|
||||
>>> from transformers import Pop2PianoForConditionalGeneration, Pop2PianoFeatureExtractor, Pop2PianoTokenizer
|
||||
|
||||
>>> # feel free to change the sr to a suitable value.
|
||||
>>> audio1, sr1 = librosa.load("<your_first_audio_file_here>", sr=44100)
|
||||
>>> audio2, sr2 = librosa.load("<your_second_audio_file_here>", sr=44100)
|
||||
>>> model = Pop2PianoForConditionalGeneration.from_pretrained("sweetcocoa/pop2piano")
|
||||
>>> feature_extractor = Pop2PianoFeatureExtractor.from_pretrained("sweetcocoa/pop2piano")
|
||||
>>> tokenizer = Pop2PianoTokenizer.from_pretrained("sweetcocoa/pop2piano")
|
||||
|
||||
>>> inputs = feature_extractor(
|
||||
... audio=[audio1, audio2],
|
||||
... sampling_rate=[sr1, sr2],
|
||||
... return_attention_mask=True,
|
||||
... return_tensors="pt",
|
||||
... )
|
||||
>>> # Since we now generating in batch(2 audios) we must pass the attention_mask
|
||||
>>> model_output = model.generate(
|
||||
... input_features=inputs["input_features"],
|
||||
... attention_mask=inputs["attention_mask"],
|
||||
... composer="composer1",
|
||||
... )
|
||||
>>> tokenizer_output = tokenizer.batch_decode(
|
||||
... token_ids=model_output, feature_extractor_output=inputs
|
||||
... )["pretty_midi_objects"]
|
||||
|
||||
>>> # Since we now have 2 generated MIDI files
|
||||
>>> tokenizer_output[0].write("./Outputs/midi_output1.mid")
|
||||
>>> tokenizer_output[1].write("./Outputs/midi_output2.mid")
|
||||
```
|
||||
|
||||
|
||||
## Pop2PianoConfig
|
||||
|
||||
[[autodoc]] Pop2PianoConfig
|
||||
|
||||
## Pop2PianoFeatureExtractor
|
||||
|
||||
[[autodoc]] Pop2PianoFeatureExtractor
|
||||
- __call__
|
||||
|
||||
## Pop2PianoForConditionalGeneration
|
||||
|
||||
[[autodoc]] Pop2PianoForConditionalGeneration
|
||||
- forward
|
||||
- generate
|
||||
|
||||
## Pop2PianoTokenizer
|
||||
|
||||
[[autodoc]] Pop2PianoTokenizer
|
||||
- __call__
|
||||
|
||||
## Pop2PianoProcessor
|
||||
|
||||
[[autodoc]] Pop2PianoProcessor
|
||||
- __call__
|
||||
71
docs/source/en/model_doc/pvt.md
Normal file
71
docs/source/en/model_doc/pvt.md
Normal file
@@ -0,0 +1,71 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Pyramid Vision Transformer (PVT)
|
||||
|
||||
## Overview
|
||||
|
||||
The PVT model was proposed in
|
||||
[Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/abs/2102.12122)
|
||||
by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao. The PVT is a type of
|
||||
vision transformer that utilizes a pyramid structure to make it an effective backbone for dense prediction tasks. Specifically
|
||||
it allows for more fine-grained inputs (4 x 4 pixels per patch) to be used, while simultaneously shrinking the sequence length
|
||||
of the Transformer as it deepens - reducing the computational cost. Additionally, a spatial-reduction attention (SRA) layer
|
||||
is used to further reduce the resource consumption when learning high-resolution features.
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
*Although convolutional neural networks (CNNs) have achieved great success in computer vision, this work investigates a
|
||||
simpler, convolution-free backbone network useful for many dense prediction tasks. Unlike the recently proposed Vision
|
||||
Transformer (ViT) that was designed for image classification specifically, we introduce the Pyramid Vision Transformer
|
||||
(PVT), which overcomes the difficulties of porting Transformer to various dense prediction tasks. PVT has several
|
||||
merits compared to current state of the arts. Different from ViT that typically yields low resolution outputs and
|
||||
incurs high computational and memory costs, PVT not only can be trained on dense partitions of an image to achieve high
|
||||
output resolution, which is important for dense prediction, but also uses a progressive shrinking pyramid to reduce the
|
||||
computations of large feature maps. PVT inherits the advantages of both CNN and Transformer, making it a unified
|
||||
backbone for various vision tasks without convolutions, where it can be used as a direct replacement for CNN backbones.
|
||||
We validate PVT through extensive experiments, showing that it boosts the performance of many downstream tasks, including
|
||||
object detection, instance and semantic segmentation. For example, with a comparable number of parameters, PVT+RetinaNet
|
||||
achieves 40.4 AP on the COCO dataset, surpassing ResNet50+RetinNet (36.3 AP) by 4.1 absolute AP (see Figure 2). We hope
|
||||
that PVT could serve as an alternative and useful backbone for pixel-level predictions and facilitate future research.*
|
||||
|
||||
This model was contributed by [Xrenya](<https://huggingface.co/Xrenya). The original code can be found [here](https://github.com/whai362/PVT).
|
||||
|
||||
|
||||
- PVTv1 on ImageNet-1K
|
||||
|
||||
| **Model variant** |**Size** |**Acc@1**|**Params (M)**|
|
||||
|--------------------|:-------:|:-------:|:------------:|
|
||||
| PVT-Tiny | 224 | 75.1 | 13.2 |
|
||||
| PVT-Small | 224 | 79.8 | 24.5 |
|
||||
| PVT-Medium | 224 | 81.2 | 44.2 |
|
||||
| PVT-Large | 224 | 81.7 | 61.4 |
|
||||
|
||||
|
||||
## PvtConfig
|
||||
|
||||
[[autodoc]] PvtConfig
|
||||
|
||||
## PvtImageProcessor
|
||||
|
||||
[[autodoc]] PvtImageProcessor
|
||||
- preprocess
|
||||
|
||||
## PvtForImageClassification
|
||||
|
||||
[[autodoc]] PvtForImageClassification
|
||||
- forward
|
||||
|
||||
## PvtModel
|
||||
|
||||
[[autodoc]] PvtModel
|
||||
- forward
|
||||
@@ -51,6 +51,24 @@ output_two = outputs.last_hidden_state
|
||||
torch.allclose(torch.cat([output_one, output_two], dim=1), output_whole, atol=1e-5)
|
||||
```
|
||||
|
||||
If you want to make sure the model stops generating when `'\n\n'` is detected, we recommend using the following stopping criteria:
|
||||
|
||||
```python
|
||||
from transformers import StoppingCriteria
|
||||
|
||||
class RwkvStoppingCriteria(StoppingCriteria):
|
||||
def __init__(self, eos_sequence = [187,187], eos_token_id = 537):
|
||||
self.eos_sequence = eos_sequence
|
||||
self.eos_token_id = eos_token_id
|
||||
|
||||
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
|
||||
last_2_ids = input_ids[:,-2:].tolist()
|
||||
return self.eos_sequence in last_2_ids
|
||||
|
||||
|
||||
output = model.generate(inputs["input_ids"], max_new_tokens=64, stopping_criteria = [RwkvStoppingCriteria()])
|
||||
```
|
||||
|
||||
## RwkvConfig
|
||||
|
||||
[[autodoc]] RwkvConfig
|
||||
|
||||
@@ -111,7 +111,7 @@ speech inputs) and `labels` (which are the `input_ids` of the encoded target seq
|
||||
>>> labels = tokenizer(ds[0]["text"], return_tensors="pt").input_ids
|
||||
|
||||
>>> # the forward function automatically creates the correct decoder_input_ids
|
||||
>>> loss = model(**input_features).loss
|
||||
>>> loss = model(input_values=input_values, labels=labels).loss
|
||||
>>> loss.backward()
|
||||
```
|
||||
|
||||
@@ -129,4 +129,4 @@ speech inputs) and `labels` (which are the `input_ids` of the encoded target seq
|
||||
|
||||
[[autodoc]] FlaxSpeechEncoderDecoderModel
|
||||
- __call__
|
||||
- from_encoder_decoder_pretrained
|
||||
- from_encoder_decoder_pretrained
|
||||
|
||||
@@ -71,7 +71,7 @@ This model was contributed by [Matthijs](https://huggingface.co/Matthijs). The o
|
||||
|
||||
[[autodoc]] SpeechT5ForTextToSpeech
|
||||
- forward
|
||||
- generate_speech
|
||||
- generate
|
||||
|
||||
## SpeechT5ForSpeechToSpeech
|
||||
|
||||
|
||||
@@ -401,6 +401,11 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
|
||||
[[autodoc]] T5EncoderModel
|
||||
- forward
|
||||
|
||||
## T5ForSequenceClassification
|
||||
|
||||
[[autodoc]] T5ForSequenceClassification
|
||||
- forward
|
||||
|
||||
## T5ForQuestionAnswering
|
||||
|
||||
[[autodoc]] T5ForQuestionAnswering
|
||||
|
||||
@@ -92,6 +92,11 @@ The conversion script is also different because the model was saved in t5x's lat
|
||||
[[autodoc]] UMT5EncoderModel
|
||||
- forward
|
||||
|
||||
## UMT5ForSequenceClassification
|
||||
|
||||
[[autodoc]] UMT5ForSequenceClassification
|
||||
- forward
|
||||
|
||||
## UMT5ForQuestionAnswering
|
||||
|
||||
[[autodoc]] UMT5ForQuestionAnswering
|
||||
|
||||
39
docs/source/en/model_doc/vitdet.md
Normal file
39
docs/source/en/model_doc/vitdet.md
Normal file
@@ -0,0 +1,39 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# ViTDet
|
||||
|
||||
## Overview
|
||||
|
||||
The ViTDet model was proposed in [Exploring Plain Vision Transformer Backbones for Object Detection](https://arxiv.org/abs/2203.16527) by Yanghao Li, Hanzi Mao, Ross Girshick, Kaiming He.
|
||||
VitDet leverages the plain [Vision Transformer](vit) for the task of object detection.
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
*We explore the plain, non-hierarchical Vision Transformer (ViT) as a backbone network for object detection. This design enables the original ViT architecture to be fine-tuned for object detection without needing to redesign a hierarchical backbone for pre-training. With minimal adaptations for fine-tuning, our plain-backbone detector can achieve competitive results. Surprisingly, we observe: (i) it is sufficient to build a simple feature pyramid from a single-scale feature map (without the common FPN design) and (ii) it is sufficient to use window attention (without shifting) aided with very few cross-window propagation blocks. With plain ViT backbones pre-trained as Masked Autoencoders (MAE), our detector, named ViTDet, can compete with the previous leading methods that were all based on hierarchical backbones, reaching up to 61.3 AP_box on the COCO dataset using only ImageNet-1K pre-training. We hope our study will draw attention to research on plain-backbone detectors.*
|
||||
|
||||
Tips:
|
||||
|
||||
- For the moment, only the backbone is available.
|
||||
|
||||
This model was contributed by [nielsr](https://huggingface.co/nielsr).
|
||||
The original code can be found [here](https://github.com/facebookresearch/detectron2/tree/main/projects/ViTDet).
|
||||
|
||||
|
||||
## VitDetConfig
|
||||
|
||||
[[autodoc]] VitDetConfig
|
||||
|
||||
## VitDetModel
|
||||
|
||||
[[autodoc]] VitDetModel
|
||||
- forward
|
||||
162
docs/source/en/model_doc/vits.md
Normal file
162
docs/source/en/model_doc/vits.md
Normal file
@@ -0,0 +1,162 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# VITS
|
||||
|
||||
## Overview
|
||||
|
||||
The VITS model was proposed in [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103) by Jaehyeon Kim, Jungil Kong, Juhee Son.
|
||||
|
||||
|
||||
VITS (**V**ariational **I**nference with adversarial learning for end-to-end **T**ext-to-**S**peech) is an end-to-end
|
||||
speech synthesis model that predicts a speech waveform conditional on an input text sequence. It is a conditional variational
|
||||
autoencoder (VAE) comprised of a posterior encoder, decoder, and conditional prior.
|
||||
|
||||
A set of spectrogram-based acoustic features are predicted by the flow-based module, which is formed of a Transformer-based
|
||||
text encoder and multiple coupling layers. The spectrogram is decoded using a stack of transposed convolutional layers,
|
||||
much in the same style as the HiFi-GAN vocoder. Motivated by the one-to-many nature of the TTS problem, where the same text
|
||||
input can be spoken in multiple ways, the model also includes a stochastic duration predictor, which allows the model to
|
||||
synthesise speech with different rhythms from the same input text.
|
||||
|
||||
The model is trained end-to-end with a combination of losses derived from variational lower bound and adversarial training.
|
||||
To improve the expressiveness of the model, normalizing flows are applied to the conditional prior distribution. During
|
||||
inference, the text encodings are up-sampled based on the duration prediction module, and then mapped into the
|
||||
waveform using a cascade of the flow module and HiFi-GAN decoder. Due to the stochastic nature of the duration predictor,
|
||||
the model is non-deterministic, and thus requires a fixed seed to generate the same speech waveform.
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
*Several recent end-to-end text-to-speech (TTS) models enabling single-stage training and parallel sampling have been proposed, but their sample quality does not match that of two-stage TTS systems. In this work, we present a parallel end-to-end TTS method that generates more natural sounding audio than current two-stage models. Our method adopts variational inference augmented with normalizing flows and an adversarial training process, which improves the expressive power of generative modeling. We also propose a stochastic duration predictor to synthesize speech with diverse rhythms from input text. With the uncertainty modeling over latent variables and the stochastic duration predictor, our method expresses the natural one-to-many relationship in which a text input can be spoken in multiple ways with different pitches and rhythms. A subjective human evaluation (mean opinion score, or MOS) on the LJ Speech, a single speaker dataset, shows that our method outperforms the best publicly available TTS systems and achieves a MOS comparable to ground truth.*
|
||||
|
||||
This model can also be used with TTS checkpoints from [Massively Multilingual Speech (MMS)](https://arxiv.org/abs/2305.13516)
|
||||
as these checkpoints use the same architecture and a slightly modified tokenizer.
|
||||
|
||||
This model was contributed by [Matthijs](https://huggingface.co/Matthijs) and [sanchit-gandhi](https://huggingface.co/sanchit-gandhi). The original code can be found [here](https://github.com/jaywalnut310/vits).
|
||||
|
||||
## Model Usage
|
||||
|
||||
Both the VITS and MMS-TTS checkpoints can be used with the same API. Since the flow-based model is non-deterministic, it
|
||||
is good practice to set a seed to ensure reproducibility of the outputs. For languages with a Roman alphabet,
|
||||
such as English or French, the tokenizer can be used directly to pre-process the text inputs. The following code example
|
||||
runs a forward pass using the MMS-TTS English checkpoint:
|
||||
|
||||
```python
|
||||
import torch
|
||||
from transformers import VitsTokenizer, VitsModel, set_seed
|
||||
|
||||
tokenizer = VitsTokenizer.from_pretrained("facebook/mms-tts-eng")
|
||||
model = VitsModel.from_pretrained("facebook/mms-tts-eng")
|
||||
|
||||
inputs = tokenizer(text="Hello - my dog is cute", return_tensors="pt")
|
||||
|
||||
set_seed(555) # make deterministic
|
||||
|
||||
with torch.no_grad():
|
||||
outputs = model(**inputs)
|
||||
|
||||
waveform = outputs.waveform[0]
|
||||
```
|
||||
|
||||
The resulting waveform can be saved as a `.wav` file:
|
||||
|
||||
```python
|
||||
import scipy
|
||||
|
||||
scipy.io.wavfile.write("techno.wav", rate=model.config.sampling_rate, data=waveform)
|
||||
```
|
||||
|
||||
Or displayed in a Jupyter Notebook / Google Colab:
|
||||
|
||||
```python
|
||||
from IPython.display import Audio
|
||||
|
||||
Audio(waveform, rate=model.config.sampling_rate)
|
||||
```
|
||||
|
||||
For certain languages with a non-Roman alphabet, such as Arabic, Mandarin or Hindi, the [`uroman`](https://github.com/isi-nlp/uroman)
|
||||
perl package is required to pre-process the text inputs to the Roman alphabet.
|
||||
|
||||
You can check whether you require the `uroman` package for your language by inspecting the `is_uroman` attribute of
|
||||
the pre-trained `tokenizer`:
|
||||
|
||||
```python
|
||||
from transformers import VitsTokenizer
|
||||
|
||||
tokenizer = VitsTokenizer.from_pretrained("facebook/mms-tts-eng")
|
||||
print(tokenizer.is_uroman)
|
||||
```
|
||||
|
||||
If required, you should apply the uroman package to your text inputs **prior** to passing them to the `VitsTokenizer`,
|
||||
since currently the tokenizer does not support performing the pre-processing itself.
|
||||
|
||||
To do this, first clone the uroman repository to your local machine and set the bash variable `UROMAN` to the local path:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/isi-nlp/uroman.git
|
||||
cd uroman
|
||||
export UROMAN=$(pwd)
|
||||
```
|
||||
|
||||
You can then pre-process the text input using the following code snippet. You can either rely on using the bash variable
|
||||
`UROMAN` to point to the uroman repository, or you can pass the uroman directory as an argument to the `uromaize` function:
|
||||
|
||||
```python
|
||||
import torch
|
||||
from transformers import VitsTokenizer, VitsModel, set_seed
|
||||
import os
|
||||
import subprocess
|
||||
|
||||
tokenizer = VitsTokenizer.from_pretrained("facebook/mms-tts-kor")
|
||||
model = VitsModel.from_pretrained("facebook/mms-tts-kor")
|
||||
|
||||
def uromanize(input_string, uroman_path):
|
||||
"""Convert non-Roman strings to Roman using the `uroman` perl package."""
|
||||
script_path = os.path.join(uroman_path, "bin", "uroman.pl")
|
||||
|
||||
command = ["perl", script_path]
|
||||
|
||||
process = subprocess.Popen(command, stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
|
||||
# Execute the perl command
|
||||
stdout, stderr = process.communicate(input=input_string.encode())
|
||||
|
||||
if process.returncode != 0:
|
||||
raise ValueError(f"Error {process.returncode}: {stderr.decode()}")
|
||||
|
||||
# Return the output as a string and skip the new-line character at the end
|
||||
return stdout.decode()[:-1]
|
||||
|
||||
text = "이봐 무슨 일이야"
|
||||
uromaized_text = uromanize(text, uroman_path=os.environ["UROMAN"])
|
||||
|
||||
inputs = tokenizer(text=uromaized_text, return_tensors="pt")
|
||||
|
||||
set_seed(555) # make deterministic
|
||||
with torch.no_grad():
|
||||
outputs = model(inputs["input_ids"])
|
||||
|
||||
waveform = outputs.waveform[0]
|
||||
```
|
||||
|
||||
## VitsConfig
|
||||
|
||||
[[autodoc]] VitsConfig
|
||||
|
||||
## VitsTokenizer
|
||||
|
||||
[[autodoc]] VitsTokenizer
|
||||
- __call__
|
||||
- save_vocabulary
|
||||
|
||||
## VitsModel
|
||||
|
||||
[[autodoc]] VitsModel
|
||||
- forward
|
||||
272
docs/source/en/model_memory_anatomy.md
Normal file
272
docs/source/en/model_memory_anatomy.md
Normal file
@@ -0,0 +1,272 @@
|
||||
<!---
|
||||
Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
-->
|
||||
|
||||
# Model training anatomy
|
||||
|
||||
To understand performance optimization techniques that one can apply to improve efficiency of model training
|
||||
speed and memory utilization, it's helpful to get familiar with how GPU is utilized during training, and how compute
|
||||
intensity varies depending on an operation performed.
|
||||
|
||||
Let's start by exploring a motivating example of GPU utilization and the training run of a model. For the demonstration,
|
||||
we'll need to install a few libraries:
|
||||
|
||||
```bash
|
||||
pip install transformers datasets accelerate nvidia-ml-py3
|
||||
```
|
||||
|
||||
The `nvidia-ml-py3` library allows us to monitor the memory usage of the models from within Python. You might be familiar
|
||||
with the `nvidia-smi` command in the terminal - this library allows to access the same information in Python directly.
|
||||
|
||||
Then, we create some dummy data: random token IDs between 100 and 30000 and binary labels for a classifier.
|
||||
In total, we get 512 sequences each with length 512 and store them in a [`~datasets.Dataset`] with PyTorch format.
|
||||
|
||||
|
||||
```py
|
||||
>>> import numpy as np
|
||||
>>> from datasets import Dataset
|
||||
|
||||
|
||||
>>> seq_len, dataset_size = 512, 512
|
||||
>>> dummy_data = {
|
||||
... "input_ids": np.random.randint(100, 30000, (dataset_size, seq_len)),
|
||||
... "labels": np.random.randint(0, 1, (dataset_size)),
|
||||
... }
|
||||
>>> ds = Dataset.from_dict(dummy_data)
|
||||
>>> ds.set_format("pt")
|
||||
```
|
||||
|
||||
To print summary statistics for the GPU utilization and the training run with the [`Trainer`] we define two helper functions:
|
||||
|
||||
```py
|
||||
>>> from pynvml import *
|
||||
|
||||
|
||||
>>> def print_gpu_utilization():
|
||||
... nvmlInit()
|
||||
... handle = nvmlDeviceGetHandleByIndex(0)
|
||||
... info = nvmlDeviceGetMemoryInfo(handle)
|
||||
... print(f"GPU memory occupied: {info.used//1024**2} MB.")
|
||||
|
||||
|
||||
>>> def print_summary(result):
|
||||
... print(f"Time: {result.metrics['train_runtime']:.2f}")
|
||||
... print(f"Samples/second: {result.metrics['train_samples_per_second']:.2f}")
|
||||
... print_gpu_utilization()
|
||||
```
|
||||
|
||||
Let's verify that we start with a free GPU memory:
|
||||
|
||||
```py
|
||||
>>> print_gpu_utilization()
|
||||
GPU memory occupied: 0 MB.
|
||||
```
|
||||
|
||||
That looks good: the GPU memory is not occupied as we would expect before we load any models. If that's not the case on
|
||||
your machine make sure to stop all processes that are using GPU memory. However, not all free GPU memory can be used by
|
||||
the user. When a model is loaded to the GPU the kernels are also loaded, which can take up 1-2GB of memory. To see how
|
||||
much it is we load a tiny tensor into the GPU which triggers the kernels to be loaded as well.
|
||||
|
||||
```py
|
||||
>>> import torch
|
||||
|
||||
|
||||
>>> torch.ones((1, 1)).to("cuda")
|
||||
>>> print_gpu_utilization()
|
||||
GPU memory occupied: 1343 MB.
|
||||
```
|
||||
|
||||
We see that the kernels alone take up 1.3GB of GPU memory. Now let's see how much space the model uses.
|
||||
|
||||
## Load Model
|
||||
|
||||
First, we load the `bert-large-uncased` model. We load the model weights directly to the GPU so that we can check
|
||||
how much space just the weights use.
|
||||
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModelForSequenceClassification
|
||||
|
||||
|
||||
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-large-uncased").to("cuda")
|
||||
>>> print_gpu_utilization()
|
||||
GPU memory occupied: 2631 MB.
|
||||
```
|
||||
|
||||
We can see that the model weights alone take up 1.3 GB of GPU memory. The exact number depends on the specific
|
||||
GPU you are using. Note that on newer GPUs a model can sometimes take up more space since the weights are loaded in an
|
||||
optimized fashion that speeds up the usage of the model. Now we can also quickly check if we get the same result
|
||||
as with `nvidia-smi` CLI:
|
||||
|
||||
|
||||
```bash
|
||||
nvidia-smi
|
||||
```
|
||||
|
||||
```bash
|
||||
Tue Jan 11 08:58:05 2022
|
||||
+-----------------------------------------------------------------------------+
|
||||
| NVIDIA-SMI 460.91.03 Driver Version: 460.91.03 CUDA Version: 11.2 |
|
||||
|-------------------------------+----------------------+----------------------+
|
||||
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
|
||||
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|
||||
| | | MIG M. |
|
||||
|===============================+======================+======================|
|
||||
| 0 Tesla V100-SXM2... On | 00000000:00:04.0 Off | 0 |
|
||||
| N/A 37C P0 39W / 300W | 2631MiB / 16160MiB | 0% Default |
|
||||
| | | N/A |
|
||||
+-------------------------------+----------------------+----------------------+
|
||||
|
||||
+-----------------------------------------------------------------------------+
|
||||
| Processes: |
|
||||
| GPU GI CI PID Type Process name GPU Memory |
|
||||
| ID ID Usage |
|
||||
|=============================================================================|
|
||||
| 0 N/A N/A 3721 C ...nvs/codeparrot/bin/python 2629MiB |
|
||||
+-----------------------------------------------------------------------------+
|
||||
```
|
||||
|
||||
We get the same number as before and you can also see that we are using a V100 GPU with 16GB of memory. So now we can
|
||||
start training the model and see how the GPU memory consumption changes. First, we set up a few standard training
|
||||
arguments:
|
||||
|
||||
```py
|
||||
default_args = {
|
||||
"output_dir": "tmp",
|
||||
"evaluation_strategy": "steps",
|
||||
"num_train_epochs": 1,
|
||||
"log_level": "error",
|
||||
"report_to": "none",
|
||||
}
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
If you plan to run multiple experiments, in order to properly clear the memory between experiments, restart the Python
|
||||
kernel between experiments.
|
||||
|
||||
</Tip>
|
||||
|
||||
## Memory utilization at vanilla training
|
||||
|
||||
Let's use the [`Trainer`] and train the model without using any GPU performance optimization techniques and a batch size of 4:
|
||||
|
||||
```py
|
||||
>>> from transformers import TrainingArguments, Trainer, logging
|
||||
|
||||
>>> logging.set_verbosity_error()
|
||||
|
||||
|
||||
>>> training_args = TrainingArguments(per_device_train_batch_size=4, **default_args)
|
||||
>>> trainer = Trainer(model=model, args=training_args, train_dataset=ds)
|
||||
>>> result = trainer.train()
|
||||
>>> print_summary(result)
|
||||
```
|
||||
|
||||
```
|
||||
Time: 57.82
|
||||
Samples/second: 8.86
|
||||
GPU memory occupied: 14949 MB.
|
||||
```
|
||||
|
||||
We see that already a relatively small batch size almost fills up our GPU's entire memory. However, a larger batch size
|
||||
can often result in faster model convergence or better end performance. So ideally we want to tune the batch size to our
|
||||
model's needs and not to the GPU limitations. What's interesting is that we use much more memory than the size of the model.
|
||||
To understand a bit better why this is the case let's have a look at a model's operations and memory needs.
|
||||
|
||||
## Anatomy of Model's Operations
|
||||
|
||||
Transformers architecture includes 3 main groups of operations grouped below by compute-intensity.
|
||||
|
||||
1. **Tensor Contractions**
|
||||
|
||||
Linear layers and components of Multi-Head Attention all do batched **matrix-matrix multiplications**. These operations are the most compute-intensive part of training a transformer.
|
||||
|
||||
2. **Statistical Normalizations**
|
||||
|
||||
Softmax and layer normalization are less compute-intensive than tensor contractions, and involve one or more **reduction operations**, the result of which is then applied via a map.
|
||||
|
||||
3. **Element-wise Operators**
|
||||
|
||||
These are the remaining operators: **biases, dropout, activations, and residual connections**. These are the least compute-intensive operations.
|
||||
|
||||
This knowledge can be helpful to know when analyzing performance bottlenecks.
|
||||
|
||||
This summary is derived from [Data Movement Is All You Need: A Case Study on Optimizing Transformers 2020](https://arxiv.org/abs/2007.00072)
|
||||
|
||||
|
||||
## Anatomy of Model's Memory
|
||||
|
||||
We've seen that training the model uses much more memory than just putting the model on the GPU. This is because there
|
||||
are many components during training that use GPU memory. The components on GPU memory are the following:
|
||||
|
||||
1. model weights
|
||||
2. optimizer states
|
||||
3. gradients
|
||||
4. forward activations saved for gradient computation
|
||||
5. temporary buffers
|
||||
6. functionality-specific memory
|
||||
|
||||
A typical model trained in mixed precision with AdamW requires 18 bytes per model parameter plus activation memory. For
|
||||
inference there are no optimizer states and gradients, so we can subtract those. And thus we end up with 6 bytes per
|
||||
model parameter for mixed precision inference, plus activation memory.
|
||||
|
||||
Let's look at the details.
|
||||
|
||||
**Model Weights:**
|
||||
|
||||
- 4 bytes * number of parameters for fp32 training
|
||||
- 6 bytes * number of parameters for mixed precision training (maintains a model in fp32 and one in fp16 in memory)
|
||||
|
||||
**Optimizer States:**
|
||||
|
||||
- 8 bytes * number of parameters for normal AdamW (maintains 2 states)
|
||||
- 2 bytes * number of parameters for 8-bit AdamW optimizers like [bitsandbytes](https://github.com/TimDettmers/bitsandbytes)
|
||||
- 4 bytes * number of parameters for optimizers like SGD with momentum (maintains only 1 state)
|
||||
|
||||
**Gradients**
|
||||
|
||||
- 4 bytes * number of parameters for either fp32 or mixed precision training (gradients are always kept in fp32)
|
||||
|
||||
**Forward Activations**
|
||||
|
||||
- size depends on many factors, the key ones being sequence length, hidden size and batch size.
|
||||
|
||||
There are the input and output that are being passed and returned by the forward and the backward functions and the
|
||||
forward activations saved for gradient computation.
|
||||
|
||||
**Temporary Memory**
|
||||
|
||||
Additionally, there are all kinds of temporary variables which get released once the calculation is done, but in the
|
||||
moment these could require additional memory and could push to OOM. Therefore, when coding it's crucial to think
|
||||
strategically about such temporary variables and sometimes to explicitly free those as soon as they are no longer needed.
|
||||
|
||||
**Functionality-specific memory**
|
||||
|
||||
Then, your software could have special memory needs. For example, when generating text using beam search, the software
|
||||
needs to maintain multiple copies of inputs and outputs.
|
||||
|
||||
**`forward` vs `backward` Execution Speed**
|
||||
|
||||
For convolutions and linear layers there are 2x flops in the backward compared to the forward, which generally translates
|
||||
into ~2x slower (sometimes more, because sizes in the backward tend to be more awkward). Activations are usually
|
||||
bandwidth-limited, and it’s typical for an activation to have to read more data in the backward than in the forward
|
||||
(e.g. activation forward reads once, writes once, activation backward reads twice, gradOutput and output of the forward,
|
||||
and writes once, gradInput).
|
||||
|
||||
As you can see, there are potentially a few places where we could save GPU memory or speed up operations.
|
||||
Now that you understand what affects GPU utilization and computation speed, refer to
|
||||
the [Methods and tools for efficient training on a single GPU](perf_train_gpu_one) documentation page to learn about
|
||||
performance optimization techniques.
|
||||
@@ -95,7 +95,7 @@ Specify `from_pt=True` to convert a checkpoint from PyTorch to TensorFlow:
|
||||
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("path/to/awesome-name-you-picked", from_pt=True)
|
||||
```
|
||||
|
||||
Then you can save your new TensorFlow model with it's new checkpoint:
|
||||
Then you can save your new TensorFlow model with its new checkpoint:
|
||||
|
||||
```py
|
||||
>>> tf_model.save_pretrained("path/to/awesome-name-you-picked")
|
||||
@@ -201,7 +201,7 @@ Or perhaps you'd like to add the TensorFlow version of your fine-tuned PyTorch m
|
||||
>>> tf_model.push_to_hub("my-awesome-model")
|
||||
```
|
||||
|
||||
Now when you navigate to the your Hugging Face profile, you should see your newly created model repository. Clicking on the **Files** tab will display all the files you've uploaded to the repository.
|
||||
Now when you navigate to your Hugging Face profile, you should see your newly created model repository. Clicking on the **Files** tab will display all the files you've uploaded to the repository.
|
||||
|
||||
For more details on how to create and upload files to a repository, refer to the Hub documentation [here](https://huggingface.co/docs/hub/how-to-upstream).
|
||||
|
||||
|
||||
@@ -171,9 +171,9 @@ Tokenize the text:
|
||||
MBart forces the target language id as the first generated token to translate to the target language. Set the `forced_bos_token_id` to `en` in the `generate` method to translate to English:
|
||||
|
||||
```py
|
||||
>>> generated_tokens = model.generate(**encoded_en, forced_bos_token_id=tokenizer.lang_code_to_id("en_XX"))
|
||||
>>> generated_tokens = model.generate(**encoded_en, forced_bos_token_id=tokenizer.lang_code_to_id["en_XX"])
|
||||
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
|
||||
"Don't interfere with the wizard's affairs, because they are subtle, will soon get angry."
|
||||
```
|
||||
|
||||
If you are using the `facebook/mbart-large-50-many-to-one-mmt` checkpoint, you don't need to force the target language id as the first generated token otherwise the usage is the same.
|
||||
If you are using the `facebook/mbart-large-50-many-to-one-mmt` checkpoint, you don't need to force the target language id as the first generated token otherwise the usage is the same.
|
||||
|
||||
216
docs/source/en/peft.md
Normal file
216
docs/source/en/peft.md
Normal file
@@ -0,0 +1,216 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
-->
|
||||
|
||||
# Load adapters with 🤗 PEFT
|
||||
|
||||
[[open-in-colab]]
|
||||
|
||||
[Parameter-Efficient Fine Tuning (PEFT)](https://huggingface.co/blog/peft) methods freeze the pretrained model parameters during fine-tuning and add a small number of trainable parameters (the adapters) on top of it. The adapters are trained to learn task-specific information. This approach has been shown to be very memory-efficient with lower compute usage while producing results comparable to a fully fine-tuned model.
|
||||
|
||||
Adapters trained with PEFT are also usually an order of magnitude smaller than the full model, making it convenient to share, store, and load them.
|
||||
|
||||
<div class="flex flex-col justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/PEFT-hub-screenshot.png"/>
|
||||
<figcaption class="text-center">The adapter weights for a OPTForCausalLM model stored on the Hub are only ~6MB compared to the full size of the model weights, which can be ~700MB.</figcaption>
|
||||
</div>
|
||||
|
||||
If you're interested in learning more about the 🤗 PEFT library, check out the [documentation](https://huggingface.co/docs/peft/index).
|
||||
|
||||
## Setup
|
||||
|
||||
Get started by installing 🤗 PEFT:
|
||||
|
||||
```bash
|
||||
pip install peft
|
||||
```
|
||||
|
||||
If you want to try out the brand new features, you might be interested in installing the library from source:
|
||||
|
||||
```bash
|
||||
pip install git+https://github.com/huggingface/peft.git
|
||||
```
|
||||
|
||||
## Supported PEFT models
|
||||
|
||||
🤗 Transformers natively supports some PEFT methods, meaning you can load adapter weights stored locally or on the Hub and easily run or train them with a few lines of code. The following methods are supported:
|
||||
|
||||
- [Low Rank Adapters](https://huggingface.co/docs/peft/conceptual_guides/lora)
|
||||
- [IA3](https://huggingface.co/docs/peft/conceptual_guides/ia3)
|
||||
- [AdaLoRA](https://arxiv.org/abs/2303.10512)
|
||||
|
||||
If you want to use other PEFT methods, such as prompt learning or prompt tuning, or about the 🤗 PEFT library in general, please refer to the [documentation](https://huggingface.co/docs/peft/index).
|
||||
|
||||
|
||||
## Load a PEFT adapter
|
||||
|
||||
To load and use a PEFT adapter model from 🤗 Transformers, make sure the Hub repository or local directory contains an `adapter_config.json` file and the adapter weights, as shown in the example image above. Then you can load the PEFT adapter model using the `AutoModelFor` class. For example, to load a PEFT adapter model for causal language modeling:
|
||||
|
||||
1. specify the PEFT model id
|
||||
2. pass it to the [`AutoModelForCausalLM`] class
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
peft_model_id = "ybelkada/opt-350m-lora"
|
||||
model = AutoModelForCausalLM.from_pretrained(peft_model_id)
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
You can load a PEFT adapter with either an `AutoModelFor` class or the base model class like `OPTForCausalLM` or `LlamaForCausalLM`.
|
||||
|
||||
</Tip>
|
||||
|
||||
You can also load a PEFT adapter by calling the `load_adapter` method:
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
model_id = "facebook/opt-350m"
|
||||
peft_model_id = "ybelkada/opt-350m-lora"
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained(model_id)
|
||||
model.load_adapter(peft_model_id)
|
||||
```
|
||||
|
||||
## Load in 8bit or 4bit
|
||||
|
||||
The `bitsandbytes` integration supports 8bit and 4bit precision data types, which are useful for loading large models because it saves memory (see the `bitsandbytes` integration [guide](./quantization#bitsandbytes-integration) to learn more). Add the `load_in_8bit` or `load_in_4bit` parameters to [`~PreTrainedModel.from_pretrained`] and set `device_map="auto"` to effectively distribute the model to your hardware:
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
peft_model_id = "ybelkada/opt-350m-lora"
|
||||
model = AutoModelForCausalLM.from_pretrained(peft_model_id, device_map="auto", load_in_8bit=True)
|
||||
```
|
||||
|
||||
## Add a new adapter
|
||||
|
||||
You can use [`~peft.PeftModel.add_adapter`] to add a new adapter to a model with an existing adapter as long as the new adapter is the same type as the current one. For example, if you have an existing LoRA adapter attached to a model:
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
|
||||
from peft import PeftConfig
|
||||
|
||||
model_id = "facebook/opt-350m"
|
||||
model = AutoModelForCausalLM.from_pretrained(model_id)
|
||||
|
||||
lora_config = LoraConfig(
|
||||
target_modules=["q_proj", "k_proj"],
|
||||
init_lora_weights=False
|
||||
)
|
||||
|
||||
model.add_adapter(lora_config, adapter_name="adapter_1")
|
||||
```
|
||||
|
||||
To add a new adapter:
|
||||
|
||||
```py
|
||||
# attach new adapter with same config
|
||||
model.add_adapter(lora_config, adapter_name="adapter_2")
|
||||
```
|
||||
|
||||
Now you can use [`~peft.PeftModel.set_adapter`] to set which adapter to use:
|
||||
|
||||
```py
|
||||
# use adapter_1
|
||||
model.set_adapter("adapter_1")
|
||||
output = model.generate(**inputs)
|
||||
print(tokenizer.decode(output_disabled[0], skip_special_tokens=True))
|
||||
|
||||
# use adapter_2
|
||||
model.set_adapter("adapter_2")
|
||||
output_enabled = model.generate(**inputs)
|
||||
print(tokenizer.decode(output_enabled[0], skip_special_tokens=True))
|
||||
```
|
||||
|
||||
## Enable and disable adapters
|
||||
|
||||
Once you've added an adapter to a model, you can enable or disable the adapter module. To enable the adapter module:
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
|
||||
from peft import PeftConfig
|
||||
|
||||
model_id = "facebook/opt-350m"
|
||||
adapter_model_id = "ybelkada/opt-350m-lora"
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
||||
text = "Hello"
|
||||
inputs = tokenizer(text, return_tensors="pt")
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained(model_id)
|
||||
peft_config = PeftConfig.from_pretrained(adapter_model_id)
|
||||
|
||||
# to initiate with random weights
|
||||
peft_config.init_lora_weights = False
|
||||
|
||||
model.add_adapter(peft_config)
|
||||
model.enable_adapters()
|
||||
output = model.generate(**inputs)
|
||||
```
|
||||
|
||||
To disable the adapter module:
|
||||
|
||||
```py
|
||||
model.disable_adapters()
|
||||
output = model.generate(**inputs)
|
||||
```
|
||||
|
||||
## Train a PEFT adapter
|
||||
|
||||
PEFT adapters are supported by the [`Trainer`] class so that you can train an adapter for your specific use case. It only requires adding a few more lines of code. For example, to train a LoRA adapter:
|
||||
|
||||
<Tip>
|
||||
|
||||
If you aren't familiar with fine-tuning a model with [`Trainer`], take a look at the [Fine-tune a pretrained model](training) tutorial.
|
||||
|
||||
</Tip>
|
||||
|
||||
1. Define your adapter configuration with the task type and hyperparameters (see [`~peft.LoraConfig`] for more details about what the hyperparameters do).
|
||||
|
||||
```py
|
||||
from peft import LoraConfig
|
||||
|
||||
peft_config = LoraConfig(
|
||||
lora_alpha=16,
|
||||
lora_dropout=0.1,
|
||||
r=64,
|
||||
bias="none",
|
||||
task_type="CAUSAL_LM",
|
||||
)
|
||||
```
|
||||
|
||||
2. Add adapter to the model.
|
||||
|
||||
```py
|
||||
model.add_adapter(peft_config)
|
||||
```
|
||||
|
||||
3. Now you can pass the model to [`Trainer`]!
|
||||
|
||||
```py
|
||||
trainer = Trainer(model=model, ...)
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
To save your trained adapter and load it back:
|
||||
|
||||
```py
|
||||
model.save_pretrained(save_dir)
|
||||
model = AutoModelForCausalLM.from_pretrained(save_dir)
|
||||
```
|
||||
|
||||
<!--
|
||||
TODO: (@younesbelkada @stevhliu)
|
||||
- Link to PEFT docs for further details
|
||||
- Trainer
|
||||
- 8-bit / 4-bit examples ?
|
||||
-->
|
||||
@@ -27,6 +27,7 @@ Let's have a look at some practical advice for GPU setups.
|
||||
|
||||
## GPU
|
||||
When you train bigger models you have essentially three options:
|
||||
|
||||
- bigger GPUs
|
||||
- more GPUs
|
||||
- more CPU and NVMe (offloaded to by [DeepSpeed-Infinity](main_classes/deepspeed#nvme-support))
|
||||
|
||||
@@ -22,6 +22,99 @@ Note: A multi GPU setup can use the majority of the strategies described in the
|
||||
|
||||
</Tip>
|
||||
|
||||
## `BetterTransformer` for faster inference
|
||||
## BetterTransformer
|
||||
|
||||
We have recently integrated `BetterTransformer` for faster inference on multi-GPU for text, image and audio models. Check the documentation about this integration [here](https://huggingface.co/docs/optimum/bettertransformer/overview) for more details.
|
||||
[BetterTransformer](https://huggingface.co/docs/optimum/bettertransformer/overview) converts 🤗 Transformers models to use the PyTorch-native fastpath execution, which calls optimized kernels like Flash Attention under the hood.
|
||||
|
||||
BetterTransformer is also supported for faster inference on single and multi-GPU for text, image, and audio models.
|
||||
|
||||
<Tip>
|
||||
|
||||
Flash Attention can only be used for models using fp16 or bf16 dtype. Make sure to cast your model to the appropriate dtype before using BetterTransformer.
|
||||
|
||||
</Tip>
|
||||
|
||||
### Decoder models
|
||||
|
||||
For text models, especially decoder-based models (GPT, T5, Llama, etc.), the BetterTransformer API converts all attention operations to use the [`torch.nn.functional.scaled_dot_product_attention` operator](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention) (SDPA) that is only available in PyTorch 2.0 and onwards.
|
||||
|
||||
To convert a model to BetterTransformer:
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
|
||||
# convert the model to BetterTransformer
|
||||
model.to_bettertransformer()
|
||||
|
||||
# Use it for training or inference
|
||||
```
|
||||
|
||||
SDPA can also call [Flash Attention](https://arxiv.org/abs/2205.14135) kernels under the hood. To enable Flash Attention or to check that it is available in a given setting (hardware, problem size), use [`torch.backends.cuda.sdp_kernel`](https://pytorch.org/docs/master/backends.html#torch.backends.cuda.sdp_kernel) as a context manager:
|
||||
|
||||
|
||||
```diff
|
||||
import torch
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
|
||||
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m").to("cuda")
|
||||
# convert the model to BetterTransformer
|
||||
model.to_bettertransformer()
|
||||
|
||||
input_text = "Hello my dog is cute and"
|
||||
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
|
||||
|
||||
+ with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
|
||||
outputs = model.generate(**inputs)
|
||||
|
||||
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
|
||||
```
|
||||
|
||||
If you see a bug with a traceback saying
|
||||
|
||||
```bash
|
||||
RuntimeError: No available kernel. Aborting execution.
|
||||
```
|
||||
|
||||
try using the PyTorch nightly version, which may have a broader coverage for Flash Attention:
|
||||
|
||||
```bash
|
||||
pip3 install -U --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu118
|
||||
```
|
||||
|
||||
Have a look at this [blog post](https://pytorch.org/blog/out-of-the-box-acceleration/) to learn more about what is possible with the BetterTransformer + SDPA API.
|
||||
|
||||
### Encoder models
|
||||
|
||||
For encoder models during inference, BetterTransformer dispatches the forward call of encoder layers to an equivalent of [`torch.nn.TransformerEncoderLayer`](https://pytorch.org/docs/stable/generated/torch.nn.TransformerEncoderLayer.html) that will execute the fastpath implementation of the encoder layers.
|
||||
|
||||
Because `torch.nn.TransformerEncoderLayer` fastpath does not support training, it is dispatched to `torch.nn.functional.scaled_dot_product_attention` instead, which does not leverage nested tensors but can use Flash Attention or Memory-Efficient Attention fused kernels.
|
||||
|
||||
More details about BetterTransformer performance can be found in this [blog post](https://medium.com/pytorch/bettertransformer-out-of-the-box-performance-for-huggingface-transformers-3fbe27d50ab2), and you can learn more about BetterTransformer for encoder models in this [blog](https://pytorch.org/blog/a-better-transformer-for-fast-transformer-encoder-inference/).
|
||||
|
||||
|
||||
## Advanced usage: mixing FP4 (or Int8) and BetterTransformer
|
||||
|
||||
You can combine the different methods described above to get the best performance for your model. For example, you can use BetterTransformer with FP4 mixed-precision inference + flash attention:
|
||||
|
||||
```py
|
||||
import torch
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
|
||||
|
||||
quantization_config = BitsAndBytesConfig(
|
||||
load_in_4bit=True,
|
||||
bnb_4bit_compute_dtype=torch.float16
|
||||
)
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
|
||||
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", quantization_config=quantization_config)
|
||||
|
||||
input_text = "Hello my dog is cute and"
|
||||
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
|
||||
|
||||
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
|
||||
outputs = model.generate(**inputs)
|
||||
|
||||
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
|
||||
```
|
||||
@@ -17,7 +17,19 @@ rendered properly in your Markdown viewer.
|
||||
|
||||
In addition to this guide, relevant information can be found as well in [the guide for training on a single GPU](perf_train_gpu_one) and [the guide for inference on CPUs](perf_infer_cpu).
|
||||
|
||||
## Better Transformer: PyTorch-native transformer fastpath
|
||||
## BetterTransformer
|
||||
|
||||
[BetterTransformer](https://huggingface.co/docs/optimum/bettertransformer/overview) converts 🤗 Transformers models to use the PyTorch-native fastpath execution, which calls optimized kernels like Flash Attention under the hood.
|
||||
|
||||
BetterTransformer is also supported for faster inference on single and multi-GPU for text, image, and audio models.
|
||||
|
||||
<Tip>
|
||||
|
||||
Flash Attention can only be used for models using fp16 or bf16 dtype. Make sure to cast your model to the appropriate dtype before using BetterTransformer.
|
||||
|
||||
</Tip>
|
||||
|
||||
### Encoder models
|
||||
|
||||
PyTorch-native [`nn.MultiHeadAttention`](https://pytorch.org/blog/a-better-transformer-for-fast-transformer-encoder-inference/) attention fastpath, called BetterTransformer, can be used with Transformers through the integration in the [🤗 Optimum library](https://huggingface.co/docs/optimum/bettertransformer/overview).
|
||||
|
||||
@@ -36,7 +48,61 @@ model = model.reverse_bettertransformer()
|
||||
model.save_pretrained("saved_model")
|
||||
```
|
||||
|
||||
As of PyTorch 2.0, the attention fastpath is supported for both encoders and decoders. The list of supported architectures can be found [here](https://huggingface.co/docs/optimum/bettertransformer/overview#supported-models).
|
||||
Have a look at this [blog post](https://medium.com/pytorch/bettertransformer-out-of-the-box-performance-for-huggingface-transformers-3fbe27d50ab2) to learn more about what is possible to do with `BetterTransformer` API for encoder models.
|
||||
|
||||
### Decoder models
|
||||
|
||||
For text models, especially decoder-based models (GPT, T5, Llama, etc.), the BetterTransformer API converts all attention operations to use the [`torch.nn.functional.scaled_dot_product_attention` operator](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention) (SDPA) that is only available in PyTorch 2.0 and onwards.
|
||||
|
||||
To convert a model to BetterTransformer:
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
|
||||
# convert the model to BetterTransformer
|
||||
model.to_bettertransformer()
|
||||
|
||||
# Use it for training or inference
|
||||
```
|
||||
|
||||
SDPA can also call [Flash Attention](https://arxiv.org/abs/2205.14135) kernels under the hood. To enable Flash Attention or to check that it is available in a given setting (hardware, problem size), use [`torch.backends.cuda.sdp_kernel`](https://pytorch.org/docs/master/backends.html#torch.backends.cuda.sdp_kernel) as a context manager:
|
||||
|
||||
|
||||
```diff
|
||||
import torch
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
|
||||
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.float16).to("cuda")
|
||||
# convert the model to BetterTransformer
|
||||
model.to_bettertransformer()
|
||||
|
||||
input_text = "Hello my dog is cute and"
|
||||
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
|
||||
|
||||
+ with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
|
||||
outputs = model.generate(**inputs)
|
||||
|
||||
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
|
||||
```
|
||||
|
||||
If you see a bug with a traceback saying
|
||||
|
||||
```bash
|
||||
RuntimeError: No available kernel. Aborting execution.
|
||||
```
|
||||
|
||||
try using the PyTorch nightly version, which may have a broader coverage for Flash Attention:
|
||||
|
||||
```bash
|
||||
pip3 install -U --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu118
|
||||
```
|
||||
|
||||
Or make sure your model is correctly casted in float16 or bfloat16
|
||||
|
||||
|
||||
Have a look at [this detailed blogpost](https://pytorch.org/blog/out-of-the-box-acceleration/) to read more about what is possible to do with `BetterTransformer` + SDPA API.
|
||||
|
||||
## `bitsandbytes` integration for FP4 mixed-precision inference
|
||||
|
||||
@@ -48,7 +114,7 @@ Note that this feature can also be used in a multi GPU setup.
|
||||
|
||||
</Tip>
|
||||
|
||||
### Requirements
|
||||
### Requirements [[requirements-for-fp4-mixedprecision-inference]]
|
||||
|
||||
- Latest `bitsandbytes` library
|
||||
`pip install bitsandbytes>=0.39.0`
|
||||
@@ -104,17 +170,17 @@ Note that this feature can also be used in a multi GPU setup.
|
||||
From the paper [`LLM.int8() : 8-bit Matrix Multiplication for Transformers at Scale`](https://arxiv.org/abs/2208.07339), we support Hugging Face integration for all models in the Hub with a few lines of code.
|
||||
The method reduces `nn.Linear` size by 2 for `float16` and `bfloat16` weights and by 4 for `float32` weights, with close to no impact to the quality by operating on the outliers in half-precision.
|
||||
|
||||

|
||||

|
||||
|
||||
Int8 mixed-precision matrix decomposition works by separating a matrix multiplication into two streams: (1) a systematic feature outlier stream matrix multiplied in fp16 (0.01%), (2) a regular stream of int8 matrix multiplication (99.9%). With this method, int8 inference with no predictive degradation is possible for very large models.
|
||||
For more details regarding the method, check out the [paper](https://arxiv.org/abs/2208.07339) or our [blogpost about the integration](https://huggingface.co/blog/hf-bitsandbytes-integration).
|
||||
|
||||

|
||||

|
||||
|
||||
Note, that you would require a GPU to run mixed-8bit models as the kernels have been compiled for GPUs only. Make sure that you have enough GPU memory to store the quarter (or half if your model weights are in half precision) of the model before using this feature.
|
||||
Below are some notes to help you use this module, or follow the demos on [Google colab](#colab-demos).
|
||||
|
||||
### Requirements
|
||||
### Requirements [[requirements-for-int8-mixedprecision-matrix-decomposition]]
|
||||
|
||||
- If you have `bitsandbytes<0.37.0`, make sure you run on NVIDIA GPUs that support 8-bit tensor cores (Turing, Ampere or newer architectures - e.g. T4, RTX20s RTX30s, A40-A100). For `bitsandbytes>=0.37.0`, all GPUs should be supported.
|
||||
- Install the correct version of `bitsandbytes` by running:
|
||||
@@ -182,3 +248,28 @@ Check out the demo for running T5-11b (42GB in fp32)! Using 8-bit quantization o
|
||||
Or this demo for BLOOM-3B:
|
||||
|
||||
[](https://colab.research.google.com/drive/1qOjXfQIAULfKvZqwCen8-MoWKGdSatZ4?usp=sharing)
|
||||
|
||||
## Advanced usage: mixing FP4 (or Int8) and BetterTransformer
|
||||
|
||||
You can combine the different methods described above to get the best performance for your model. For example, you can use BetterTransformer with FP4 mixed-precision inference + flash attention:
|
||||
|
||||
```py
|
||||
import torch
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
|
||||
|
||||
quantization_config = BitsAndBytesConfig(
|
||||
load_in_4bit=True,
|
||||
bnb_4bit_compute_dtype=torch.float16
|
||||
)
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
|
||||
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", quantization_config=quantization_config)
|
||||
|
||||
input_text = "Hello my dog is cute and"
|
||||
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
|
||||
|
||||
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
|
||||
outputs = model.generate(**inputs)
|
||||
|
||||
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
|
||||
```
|
||||
|
||||
359
docs/source/en/perf_torch_compile.md
Normal file
359
docs/source/en/perf_torch_compile.md
Normal file
@@ -0,0 +1,359 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Optimize inference using torch.compile()
|
||||
|
||||
This guide aims to provide a benchmark on the inference speed-ups introduced with [`torch.compile()`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) for [computer vision models in 🤗 Transformers](https://huggingface.co/models?pipeline_tag=image-classification&library=transformers&sort=trending).
|
||||
|
||||
## Benefits of torch.compile
|
||||
|
||||
Depending on the model and the GPU, `torch.compile()` yields up to 30% speed-up during inference. To use `torch.compile()`, simply install any version of `torch` above 2.0.
|
||||
|
||||
Compiling a model takes time, so it's useful if you are compiling the model only once instead of every time you infer.
|
||||
To compile any computer vision model of your choice, call `torch.compile()` on the model as shown below:
|
||||
|
||||
```diff
|
||||
from transformers import AutoModelForImageClassification
|
||||
|
||||
model = AutoModelForImageClassification.from_pretrained(MODEL_ID).to("cuda")
|
||||
+ model = torch.compile(model)
|
||||
```
|
||||
|
||||
`compile()` comes with multiple modes for compiling, which essentially differ in compilation time and inference overhead. `max-autotune` takes longer than `reduce-overhead` but results in faster inference. Default mode is fastest for compilation but is not as efficient compared to `reduce-overhead` for inference time. In this guide, we used the default mode. You can learn more about it [here](https://pytorch.org/get-started/pytorch-2.0/#user-experience).
|
||||
|
||||
We benchmarked `torch.compile` with different computer vision models, tasks, types of hardware, and batch sizes on `torch` version 2.0.1.
|
||||
|
||||
## Benchmarking code
|
||||
|
||||
Below you can find the benchmarking code for each task. We warm up the GPU before inference and take the mean time of 300 inferences, using the same image each time.
|
||||
|
||||
### Image Classification with ViT
|
||||
|
||||
```python
|
||||
import torch
|
||||
from PIL import Image
|
||||
import requests
|
||||
import numpy as np
|
||||
from transformers import AutoImageProcessor, AutoModelForImageClassification
|
||||
|
||||
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
|
||||
image = Image.open(requests.get(url, stream=True).raw)
|
||||
|
||||
processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
|
||||
model = AutoModelForImageClassification.from_pretrained("google/vit-base-patch16-224").to("cuda")
|
||||
model = torch.compile(model)
|
||||
|
||||
processed_input = processor(image, return_tensors='pt').to(device="cuda")
|
||||
|
||||
with torch.no_grad():
|
||||
_ = model(**processed_input)
|
||||
|
||||
```
|
||||
|
||||
#### Object Detection with DETR
|
||||
|
||||
```python
|
||||
from transformers import AutoImageProcessor, AutoModelForObjectDetection
|
||||
|
||||
processor = AutoImageProcessor.from_pretrained("facebook/detr-resnet-50")
|
||||
model = AutoModelForObjectDetection.from_pretrained("facebook/detr-resnet-50").to("cuda")
|
||||
model = torch.compile(model)
|
||||
|
||||
texts = ["a photo of a cat", "a photo of a dog"]
|
||||
inputs = processor(text=texts, images=image, return_tensors="pt").to("cuda")
|
||||
|
||||
with torch.no_grad():
|
||||
_ = model(**inputs)
|
||||
```
|
||||
|
||||
#### Image Segmentation with Segformer
|
||||
|
||||
```python
|
||||
from transformers import SegformerImageProcessor, SegformerForSemanticSegmentation
|
||||
|
||||
processor = SegformerImageProcessor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
|
||||
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512").to("cuda")
|
||||
model = torch.compile(model)
|
||||
seg_inputs = processor(images=image, return_tensors="pt").to("cuda")
|
||||
|
||||
with torch.no_grad():
|
||||
_ = model(**seg_inputs)
|
||||
```
|
||||
|
||||
Below you can find the list of the models we benchmarked.
|
||||
|
||||
**Image Classification**
|
||||
- [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224)
|
||||
- [microsoft/beit-base-patch16-224-pt22k-ft22k](https://huggingface.co/microsoft/beit-base-patch16-224-pt22k-ft22k)
|
||||
- [facebook/convnext-large-224](https://huggingface.co/facebook/convnext-large-224)
|
||||
- [microsoft/resnet-50](https://huggingface.co/)
|
||||
|
||||
**Image Segmentation**
|
||||
- [nvidia/segformer-b0-finetuned-ade-512-512](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
|
||||
- [facebook/mask2former-swin-tiny-coco-panoptic](https://huggingface.co/facebook/mask2former-swin-tiny-coco-panoptic)
|
||||
- [facebook/maskformer-swin-base-ade](https://huggingface.co/facebook/maskformer-swin-base-ade)
|
||||
- [google/deeplabv3_mobilenet_v2_1.0_513](https://huggingface.co/google/deeplabv3_mobilenet_v2_1.0_513)
|
||||
|
||||
**Object Detection**
|
||||
- [google/owlvit-base-patch32](https://huggingface.co/google/owlvit-base-patch32)
|
||||
- [facebook/detr-resnet-101](https://huggingface.co/facebook/detr-resnet-101)
|
||||
- [microsoft/conditional-detr-resnet-50](https://huggingface.co/microsoft/conditional-detr-resnet-50)
|
||||
|
||||
Below you can find visualization of inference durations with and without `torch.compile()` and percentage improvements for each model in different hardware and batch sizes.
|
||||
|
||||
<div class="flex">
|
||||
<div>
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/a100_batch_comp.png" />
|
||||
</div>
|
||||
<div>
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/v100_batch_comp.png" />
|
||||
</div>
|
||||
<div>
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/t4_batch_comp.png" />
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<div class="flex">
|
||||
<div>
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/A100_1_duration.png" />
|
||||
</div>
|
||||
<div>
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/A100_1_percentage.png" />
|
||||
</div>
|
||||
</div>
|
||||
|
||||
|
||||
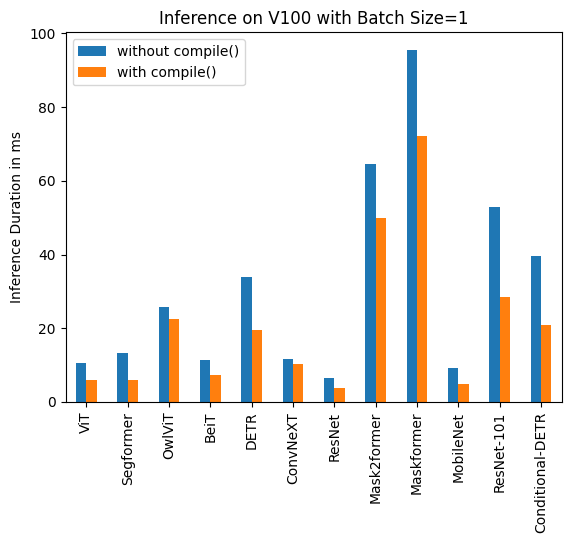
|
||||
|
||||
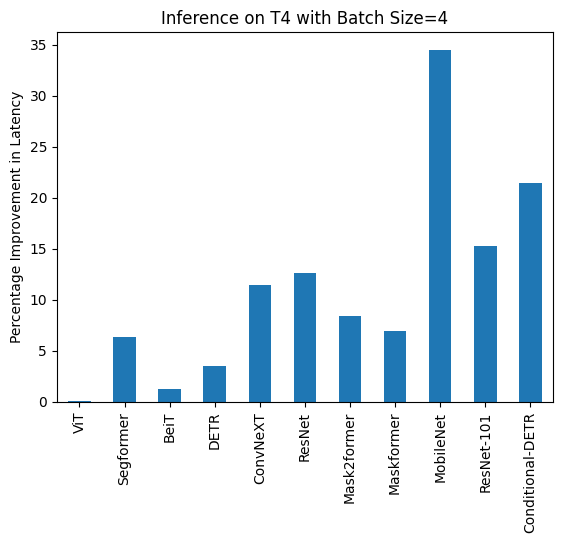
|
||||
|
||||
Below you can find inference durations in milliseconds for each model with and without `compile()`. Note that OwlViT results in OOM in larger batch sizes.
|
||||
|
||||
### A100 (batch size: 1)
|
||||
|
||||
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|
|
||||
| Image Classification/ViT | 9.325 | 7.584 |
|
||||
| Image Segmentation/Segformer | 11.759 | 10.500 |
|
||||
| Object Detection/OwlViT | 24.978 | 18.420 |
|
||||
| Image Classification/BeiT | 11.282 | 8.448 |
|
||||
| Object Detection/DETR | 34.619 | 19.040 |
|
||||
| Image Classification/ConvNeXT | 10.410 | 10.208 |
|
||||
| Image Classification/ResNet | 6.531 | 4.124 |
|
||||
| Image Segmentation/Mask2former | 60.188 | 49.117 |
|
||||
| Image Segmentation/Maskformer | 75.764 | 59.487 |
|
||||
| Image Segmentation/MobileNet | 8.583 | 3.974 |
|
||||
| Object Detection/Resnet-101 | 36.276 | 18.197 |
|
||||
| Object Detection/Conditional-DETR | 31.219 | 17.993 |
|
||||
|
||||
|
||||
### A100 (batch size: 4)
|
||||
|
||||
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|
|
||||
| Image Classification/ViT | 14.832 | 14.499 |
|
||||
| Image Segmentation/Segformer | 18.838 | 16.476 |
|
||||
| Image Classification/BeiT | 13.205 | 13.048 |
|
||||
| Object Detection/DETR | 48.657 | 32.418|
|
||||
| Image Classification/ConvNeXT | 22.940 | 21.631 |
|
||||
| Image Classification/ResNet | 6.657 | 4.268 |
|
||||
| Image Segmentation/Mask2former | 74.277 | 61.781 |
|
||||
| Image Segmentation/Maskformer | 180.700 | 159.116 |
|
||||
| Image Segmentation/MobileNet | 14.174 | 8.515 |
|
||||
| Object Detection/Resnet-101 | 68.101 | 44.998 |
|
||||
| Object Detection/Conditional-DETR | 56.470 | 35.552 |
|
||||
|
||||
### A100 (batch size: 16)
|
||||
|
||||
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|
|
||||
| Image Classification/ViT | 40.944 | 40.010 |
|
||||
| Image Segmentation/Segformer | 37.005 | 31.144 |
|
||||
| Image Classification/BeiT | 41.854 | 41.048 |
|
||||
| Object Detection/DETR | 164.382 | 161.902 |
|
||||
| Image Classification/ConvNeXT | 82.258 | 75.561 |
|
||||
| Image Classification/ResNet | 7.018 | 5.024 |
|
||||
| Image Segmentation/Mask2former | 178.945 | 154.814 |
|
||||
| Image Segmentation/Maskformer | 638.570 | 579.826 |
|
||||
| Image Segmentation/MobileNet | 51.693 | 30.310 |
|
||||
| Object Detection/Resnet-101 | 232.887 | 155.021 |
|
||||
| Object Detection/Conditional-DETR | 180.491 | 124.032 |
|
||||
|
||||
### V100 (batch size: 1)
|
||||
|
||||
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|
|
||||
| Image Classification/ViT | 10.495 | 6.00 |
|
||||
| Image Segmentation/Segformer | 13.321 | 5.862 |
|
||||
| Object Detection/OwlViT | 25.769 | 22.395 |
|
||||
| Image Classification/BeiT | 11.347 | 7.234 |
|
||||
| Object Detection/DETR | 33.951 | 19.388 |
|
||||
| Image Classification/ConvNeXT | 11.623 | 10.412 |
|
||||
| Image Classification/ResNet | 6.484 | 3.820 |
|
||||
| Image Segmentation/Mask2former | 64.640 | 49.873 |
|
||||
| Image Segmentation/Maskformer | 95.532 | 72.207 |
|
||||
| Image Segmentation/MobileNet | 9.217 | 4.753 |
|
||||
| Object Detection/Resnet-101 | 52.818 | 28.367 |
|
||||
| Object Detection/Conditional-DETR | 39.512 | 20.816 |
|
||||
|
||||
### V100 (batch size: 4)
|
||||
|
||||
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|
|
||||
| Image Classification/ViT | 15.181 | 14.501 |
|
||||
| Image Segmentation/Segformer | 16.787 | 16.188 |
|
||||
| Image Classification/BeiT | 15.171 | 14.753 |
|
||||
| Object Detection/DETR | 88.529 | 64.195 |
|
||||
| Image Classification/ConvNeXT | 29.574 | 27.085 |
|
||||
| Image Classification/ResNet | 6.109 | 4.731 |
|
||||
| Image Segmentation/Mask2former | 90.402 | 76.926 |
|
||||
| Image Segmentation/Maskformer | 234.261 | 205.456 |
|
||||
| Image Segmentation/MobileNet | 24.623 | 14.816 |
|
||||
| Object Detection/Resnet-101 | 134.672 | 101.304 |
|
||||
| Object Detection/Conditional-DETR | 97.464 | 69.739 |
|
||||
|
||||
### V100 (batch size: 16)
|
||||
|
||||
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|
|
||||
| Image Classification/ViT | 52.209 | 51.633 |
|
||||
| Image Segmentation/Segformer | 61.013 | 55.499 |
|
||||
| Image Classification/BeiT | 53.938 | 53.581 |
|
||||
| Object Detection/DETR | OOM | OOM |
|
||||
| Image Classification/ConvNeXT | 109.682 | 100.771 |
|
||||
| Image Classification/ResNet | 14.857 | 12.089 |
|
||||
| Image Segmentation/Mask2former | 249.605 | 222.801 |
|
||||
| Image Segmentation/Maskformer | 831.142 | 743.645 |
|
||||
| Image Segmentation/MobileNet | 93.129 | 55.365 |
|
||||
| Object Detection/Resnet-101 | 482.425 | 361.843 |
|
||||
| Object Detection/Conditional-DETR | 344.661 | 255.298 |
|
||||
|
||||
### T4 (batch size: 1)
|
||||
|
||||
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|
|
||||
| Image Classification/ViT | 16.520 | 15.786 |
|
||||
| Image Segmentation/Segformer | 16.116 | 14.205 |
|
||||
| Object Detection/OwlViT | 53.634 | 51.105 |
|
||||
| Image Classification/BeiT | 16.464 | 15.710 |
|
||||
| Object Detection/DETR | 73.100 | 53.99 |
|
||||
| Image Classification/ConvNeXT | 32.932 | 30.845 |
|
||||
| Image Classification/ResNet | 6.031 | 4.321 |
|
||||
| Image Segmentation/Mask2former | 79.192 | 66.815 |
|
||||
| Image Segmentation/Maskformer | 200.026 | 188.268 |
|
||||
| Image Segmentation/MobileNet | 18.908 | 11.997 |
|
||||
| Object Detection/Resnet-101 | 106.622 | 82.566 |
|
||||
| Object Detection/Conditional-DETR | 77.594 | 56.984 |
|
||||
|
||||
### T4 (batch size: 4)
|
||||
|
||||
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|
|
||||
| Image Classification/ViT | 43.653 | 43.626 |
|
||||
| Image Segmentation/Segformer | 45.327 | 42.445 |
|
||||
| Image Classification/BeiT | 52.007 | 51.354 |
|
||||
| Object Detection/DETR | 277.850 | 268.003 |
|
||||
| Image Classification/ConvNeXT | 119.259 | 105.580 |
|
||||
| Image Classification/ResNet | 13.039 | 11.388 |
|
||||
| Image Segmentation/Mask2former | 201.540 | 184.670 |
|
||||
| Image Segmentation/Maskformer | 764.052 | 711.280 |
|
||||
| Image Segmentation/MobileNet | 74.289 | 48.677 |
|
||||
| Object Detection/Resnet-101 | 421.859 | 357.614 |
|
||||
| Object Detection/Conditional-DETR | 289.002 | 226.945 |
|
||||
|
||||
### T4 (batch size: 16)
|
||||
|
||||
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|
|
||||
| Image Classification/ViT | 163.914 | 160.907 |
|
||||
| Image Segmentation/Segformer | 192.412 | 163.620 |
|
||||
| Image Classification/BeiT | 188.978 | 187.976 |
|
||||
| Object Detection/DETR | OOM | OOM |
|
||||
| Image Classification/ConvNeXT | 422.886 | 388.078 |
|
||||
| Image Classification/ResNet | 44.114 | 37.604 |
|
||||
| Image Segmentation/Mask2former | 756.337 | 695.291 |
|
||||
| Image Segmentation/Maskformer | 2842.940 | 2656.88 |
|
||||
| Image Segmentation/MobileNet | 299.003 | 201.942 |
|
||||
| Object Detection/Resnet-101 | 1619.505 | 1262.758 |
|
||||
| Object Detection/Conditional-DETR | 1137.513 | 897.390|
|
||||
|
||||
## PyTorch Nightly
|
||||
We also benchmarked on PyTorch nightly (2.1.0dev, find the wheel [here](https://download.pytorch.org/whl/nightly/cu118)) and observed improvement in latency both for uncompiled and compiled models.
|
||||
|
||||
### A100
|
||||
|
||||
| **Task/Model** | **Batch Size** | **torch 2.0 - no compile** | **torch 2.0 -<br> compile** |
|
||||
|:---:|:---:|:---:|:---:|
|
||||
| Image Classification/BeiT | Unbatched | 12.462 | 6.954 |
|
||||
| Image Classification/BeiT | 4 | 14.109 | 12.851 |
|
||||
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
|
||||
| Object Detection/DETR | Unbatched | 30.484 | 15.221 |
|
||||
| Object Detection/DETR | 4 | 46.816 | 30.942 |
|
||||
| Object Detection/DETR | 16 | 163.749 | 163.706 |
|
||||
|
||||
### T4
|
||||
|
||||
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|:---:|
|
||||
| Image Classification/BeiT | Unbatched | 14.408 | 14.052 |
|
||||
| Image Classification/BeiT | 4 | 47.381 | 46.604 |
|
||||
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
|
||||
| Object Detection/DETR | Unbatched | 68.382 | 53.481 |
|
||||
| Object Detection/DETR | 4 | 269.615 | 204.785 |
|
||||
| Object Detection/DETR | 16 | OOM | OOM |
|
||||
|
||||
### V100
|
||||
|
||||
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|:---:|
|
||||
| Image Classification/BeiT | Unbatched | 13.477 | 7.926 |
|
||||
| Image Classification/BeiT | 4 | 15.103 | 14.378 |
|
||||
| Image Classification/BeiT | 16 | 52.517 | 51.691 |
|
||||
| Object Detection/DETR | Unbatched | 28.706 | 19.077 |
|
||||
| Object Detection/DETR | 4 | 88.402 | 62.949|
|
||||
| Object Detection/DETR | 16 | OOM | OOM |
|
||||
|
||||
|
||||
## Reduce Overhead
|
||||
We benchmarked `reduce-overhead` compilation mode for A100 and T4 in Nightly.
|
||||
|
||||
### A100
|
||||
|
||||
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|:---:|
|
||||
| Image Classification/ConvNeXT | Unbatched | 11.758 | 7.335 |
|
||||
| Image Classification/ConvNeXT | 4 | 23.171 | 21.490 |
|
||||
| Image Classification/ResNet | Unbatched | 7.435 | 3.801 |
|
||||
| Image Classification/ResNet | 4 | 7.261 | 2.187 |
|
||||
| Object Detection/Conditional-DETR | Unbatched | 32.823 | 11.627 |
|
||||
| Object Detection/Conditional-DETR | 4 | 50.622 | 33.831 |
|
||||
| Image Segmentation/MobileNet | Unbatched | 9.869 | 4.244 |
|
||||
| Image Segmentation/MobileNet | 4 | 14.385 | 7.946 |
|
||||
|
||||
|
||||
### T4
|
||||
|
||||
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|:---:|
|
||||
| Image Classification/ConvNeXT | Unbatched | 32.137 | 31.84 |
|
||||
| Image Classification/ConvNeXT | 4 | 120.944 | 110.209 |
|
||||
| Image Classification/ResNet | Unbatched | 9.761 | 7.698 |
|
||||
| Image Classification/ResNet | 4 | 15.215 | 13.871 |
|
||||
| Object Detection/Conditional-DETR | Unbatched | 72.150 | 57.660 |
|
||||
| Object Detection/Conditional-DETR | 4 | 301.494 | 247.543 |
|
||||
| Image Segmentation/MobileNet | Unbatched | 22.266 | 19.339 |
|
||||
| Image Segmentation/MobileNet | 4 | 78.311 | 50.983 |
|
||||
|
||||
|
||||
@@ -13,489 +13,277 @@ rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Efficient Training on a Single GPU
|
||||
# Methods and tools for efficient training on a single GPU
|
||||
|
||||
This guide focuses on training large models efficiently on a single GPU. These approaches are still valid if you have access to a machine with multiple GPUs but you will also have access to additional methods outlined in the [multi-GPU section](perf_train_gpu_many).
|
||||
|
||||
In this section we have a look at a few tricks to reduce the memory footprint and speed up training for large models and how they are integrated in the [`Trainer`] and [🤗 Accelerate](https://huggingface.co/docs/accelerate/). Each method can improve speed or memory usage which is summarized in the table below:
|
||||
|
||||
|Method|Speed|Memory|
|
||||
|:-----|:----|:-----|
|
||||
| Gradient accumulation | No | Yes |
|
||||
| Gradient checkpointing | No| Yes |
|
||||
| Mixed precision training | Yes | (No) |
|
||||
| Batch size | Yes | Yes |
|
||||
| Optimizer choice | Yes | Yes |
|
||||
| DataLoader | Yes | No |
|
||||
| DeepSpeed Zero | No | Yes |
|
||||
|
||||
A bracket means that it might not be strictly the case but is usually either not a main concern or negligible. Before we start make sure you have installed the following libraries:
|
||||
|
||||
```bash
|
||||
pip install transformers datasets accelerate nvidia-ml-py3
|
||||
```
|
||||
|
||||
The `nvidia-ml-py3` library allows us to monitor the memory usage of the models from within Python. You might be familiar with the `nvidia-smi` command in the terminal - this library allows to access the same information in Python directly.
|
||||
|
||||
Then we create some dummy data. We create random token IDs between 100 and 30000 and binary labels for a classifier. In total we get 512 sequences each with length 512 and store them in a [`~datasets.Dataset`] with PyTorch format.
|
||||
|
||||
|
||||
```py
|
||||
import numpy as np
|
||||
from datasets import Dataset
|
||||
|
||||
|
||||
seq_len, dataset_size = 512, 512
|
||||
dummy_data = {
|
||||
"input_ids": np.random.randint(100, 30000, (dataset_size, seq_len)),
|
||||
"labels": np.random.randint(0, 1, (dataset_size)),
|
||||
}
|
||||
ds = Dataset.from_dict(dummy_data)
|
||||
ds.set_format("pt")
|
||||
```
|
||||
|
||||
We want to print some summary statistics for the GPU utilization and the training run with the [`Trainer`]. We setup a two helper functions to do just that:
|
||||
|
||||
```py
|
||||
from pynvml import *
|
||||
|
||||
|
||||
def print_gpu_utilization():
|
||||
nvmlInit()
|
||||
handle = nvmlDeviceGetHandleByIndex(0)
|
||||
info = nvmlDeviceGetMemoryInfo(handle)
|
||||
print(f"GPU memory occupied: {info.used//1024**2} MB.")
|
||||
|
||||
|
||||
def print_summary(result):
|
||||
print(f"Time: {result.metrics['train_runtime']:.2f}")
|
||||
print(f"Samples/second: {result.metrics['train_samples_per_second']:.2f}")
|
||||
print_gpu_utilization()
|
||||
```
|
||||
|
||||
Let's verify that we start with a free GPU memory:
|
||||
|
||||
```py
|
||||
>>> print_gpu_utilization()
|
||||
GPU memory occupied: 0 MB.
|
||||
```
|
||||
|
||||
That looks good: the GPU memory is not occupied as we would expect before we load any models. If that's not the case on your machine make sure to stop all processes that are using GPU memory. However, not all free GPU memory can be used by the user. When a model is loaded to the GPU also the kernels are loaded which can take up 1-2GB of memory. To see how much it is we load a tiny tensor into the GPU which triggers the kernels to be loaded as well.
|
||||
|
||||
```py
|
||||
>>> import torch
|
||||
|
||||
|
||||
>>> torch.ones((1, 1)).to("cuda")
|
||||
>>> print_gpu_utilization()
|
||||
GPU memory occupied: 1343 MB.
|
||||
```
|
||||
|
||||
We see that the kernels alone take up 1.3GB of GPU memory. Now let's see how much space the model uses.
|
||||
|
||||
## Load Model
|
||||
|
||||
First, we load the `bert-large-uncased` model. We load the model weights directly to the GPU so that we can check how much space just weights use.
|
||||
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModelForSequenceClassification
|
||||
|
||||
|
||||
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-large-uncased").to("cuda")
|
||||
>>> print_gpu_utilization()
|
||||
GPU memory occupied: 2631 MB.
|
||||
```
|
||||
|
||||
We can see that the model weights alone take up 1.3 GB of the GPU memory. The exact number depends on the specific GPU you are using. Note that on newer GPUs a model can sometimes take up more space since the weights are loaded in an optimized fashion that speeds up the usage of the model. Now we can also quickly check if we get the same result as with `nvidia-smi` CLI:
|
||||
|
||||
|
||||
```bash
|
||||
nvidia-smi
|
||||
```
|
||||
|
||||
```bash
|
||||
Tue Jan 11 08:58:05 2022
|
||||
+-----------------------------------------------------------------------------+
|
||||
| NVIDIA-SMI 460.91.03 Driver Version: 460.91.03 CUDA Version: 11.2 |
|
||||
|-------------------------------+----------------------+----------------------+
|
||||
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
|
||||
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|
||||
| | | MIG M. |
|
||||
|===============================+======================+======================|
|
||||
| 0 Tesla V100-SXM2... On | 00000000:00:04.0 Off | 0 |
|
||||
| N/A 37C P0 39W / 300W | 2631MiB / 16160MiB | 0% Default |
|
||||
| | | N/A |
|
||||
+-------------------------------+----------------------+----------------------+
|
||||
|
||||
+-----------------------------------------------------------------------------+
|
||||
| Processes: |
|
||||
| GPU GI CI PID Type Process name GPU Memory |
|
||||
| ID ID Usage |
|
||||
|=============================================================================|
|
||||
| 0 N/A N/A 3721 C ...nvs/codeparrot/bin/python 2629MiB |
|
||||
+-----------------------------------------------------------------------------+
|
||||
```
|
||||
|
||||
We get the same number as before and you can also see that we are using a V100 GPU with 16GB of memory. So now we can start training the model and see how the GPU memory consumption changes. First, we set up a few standard training arguments that we will use across all our experiments:
|
||||
|
||||
```py
|
||||
default_args = {
|
||||
"output_dir": "tmp",
|
||||
"evaluation_strategy": "steps",
|
||||
"num_train_epochs": 1,
|
||||
"log_level": "error",
|
||||
"report_to": "none",
|
||||
}
|
||||
```
|
||||
This guide demonstrates practical techniques that you can use to increase the efficiency of your model's training by
|
||||
optimizing memory utilization, speeding up the training, or both. If you'd like to understand how GPU is utilized during
|
||||
training, please refer to the [Model training anatomy](model_memory_anatomy) conceptual guide first. This guide
|
||||
focuses on practical techniques.
|
||||
|
||||
<Tip>
|
||||
|
||||
Note: In order to properly clear the memory after experiments we need restart the Python kernel between experiments. Run all steps above and then just one of the experiments below.
|
||||
If you have access to a machine with multiple GPUs, these approaches are still valid, plus you can leverage additional methods outlined in the [multi-GPU section](perf_train_gpu_many).
|
||||
|
||||
</Tip>
|
||||
|
||||
## Vanilla Training
|
||||
When training large models, there are two aspects that should be considered at the same time:
|
||||
|
||||
As a first experiment we will use the [`Trainer`] and train the model without any further modifications and a batch size of 4:
|
||||
* Data throughput/training time
|
||||
* Model performance
|
||||
|
||||
```py
|
||||
from transformers import TrainingArguments, Trainer, logging
|
||||
Maximizing the throughput (samples/second) leads to lower training cost. This is generally achieved by utilizing the GPU
|
||||
as much as possible and thus filling GPU memory to its limit. If the desired batch size exceeds the limits of the GPU memory,
|
||||
the memory optimization techniques, such as gradient accumulation, can help.
|
||||
|
||||
logging.set_verbosity_error()
|
||||
However, if the preferred batch size fits into memory, there's no reason to apply memory-optimizing techniques because they can
|
||||
slow down the training. Just because one can use a large batch size, does not necessarily mean they should. As part of
|
||||
hyperparameter tuning, you should determine which batch size yields the best results and then optimize resources accordingly.
|
||||
|
||||
The methods and tools covered in this guide can be classified based on the effect they have on the training process:
|
||||
|
||||
training_args = TrainingArguments(per_device_train_batch_size=4, **default_args)
|
||||
trainer = Trainer(model=model, args=training_args, train_dataset=ds)
|
||||
result = trainer.train()
|
||||
print_summary(result)
|
||||
```
|
||||
| Method/tool | Improves training speed | Optimizes memory utilization |
|
||||
|:-----------------------------------------------------------|:------------------------|:-----------------------------|
|
||||
| [Batch size choice](#batch-size-choice) | Yes | Yes |
|
||||
| [Gradient accumulation](#gradient-accumulation) | No | Yes |
|
||||
| [Gradient checkpointing](#gradient-checkpointing) | No | Yes |
|
||||
| [Mixed precision training](#mixed-precision-training) | Yes | (No) |
|
||||
| [Optimizer choice](#optimizer-choice) | Yes | Yes |
|
||||
| [Data preloading](#data-preloading) | Yes | No |
|
||||
| [DeepSpeed Zero](#deepspeed-zero) | No | Yes |
|
||||
| [torch.compile](#using-torchcompile) | Yes | No |
|
||||
|
||||
```
|
||||
Time: 57.82
|
||||
Samples/second: 8.86
|
||||
GPU memory occupied: 14949 MB.
|
||||
```
|
||||
<Tip>
|
||||
|
||||
We see that already a relatively small batch size almost fills up our GPU's entire memory. However, a larger batch size can often result in faster model convergence or better end performance. So ideally we want to tune the batch size to our model's needs and not to the GPU limitations. What's interesting is that we use much more memory than the size of the model. To understand a bit better why this is the case let's have look at a model's operations and memory needs.
|
||||
Note: when using mixed precision with a small model and a large batch size, there will be some memory savings but with a
|
||||
large model and a small batch size, the memory use will be larger.
|
||||
|
||||
## Anatomy of Model's Operations
|
||||
</Tip>
|
||||
|
||||
Transformers architecture includes 3 main groups of operations grouped below by compute-intensity.
|
||||
You can combine the above methods to get a cumulative effect. These techniques are available to you whether you are
|
||||
training your model with [`Trainer`] or writing a pure PyTorch loop, in which case you can [configure these optimizations
|
||||
with 🤗 Accelerate](#using-accelerate).
|
||||
|
||||
1. **Tensor Contractions**
|
||||
If these methods do not result in sufficient gains, you can explore the following options:
|
||||
* [Look into building your own custom Docker container with efficient softare prebuilds](#efficient-software-prebuilds)
|
||||
* [Consider a model that uses Mixture of Experts (MoE)](#mixture-of-experts)
|
||||
* [Convert your model to BetterTransformer to leverage PyTorch native attention](#using-pytorch-native-attention)
|
||||
|
||||
Linear layers and components of Multi-Head Attention all do batched **matrix-matrix multiplications**. These operations are the most compute-intensive part of training a transformer.
|
||||
Finally, if all of the above is still not enough, even after switching to a server-grade GPU like A100, consider moving
|
||||
to a multi-GPU setup. All these approaches are still valid in a multi-GPU setup, plus you can leverage additional parallelism
|
||||
techniques outlined in the [multi-GPU section](perf_train_gpu_many).
|
||||
|
||||
2. **Statistical Normalizations**
|
||||
## Batch size choice
|
||||
|
||||
Softmax and layer normalization are less compute-intensive than tensor contractions, and involve one or more **reduction operations**, the result of which is then applied via a map.
|
||||
To achieve optimal performance, start by identifying the appropriate batch size. It is recommended to use batch sizes and
|
||||
input/output neuron counts that are of size 2^N. Often it's a multiple of 8, but it can be
|
||||
higher depending on the hardware being used and the model's dtype.
|
||||
|
||||
3. **Element-wise Operators**
|
||||
For reference, check out NVIDIA's recommendation for [input/output neuron counts](
|
||||
https://docs.nvidia.com/deeplearning/performance/dl-performance-fully-connected/index.html#input-features) and
|
||||
[batch size](https://docs.nvidia.com/deeplearning/performance/dl-performance-fully-connected/index.html#batch-size) for
|
||||
fully connected layers (which are involved in GEMMs (General Matrix Multiplications)).
|
||||
|
||||
These are the remaining operators: **biases, dropout, activations, and residual connections**. These are the least compute-intensive operations.
|
||||
[Tensor Core Requirements](https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc)
|
||||
define the multiplier based on the dtype and the hardware. For instance, for fp16 data type a multiple of 8 is recommended, unless
|
||||
it's an A100 GPU, in which case use multiples of 64.
|
||||
|
||||
This knowledge can be helpful to know when analyzing performance bottlenecks.
|
||||
|
||||
This summary is derived from [Data Movement Is All You Need: A Case Study on Optimizing Transformers 2020](https://arxiv.org/abs/2007.00072)
|
||||
|
||||
|
||||
## Anatomy of Model's Memory
|
||||
We've seen that training the model uses much more memory than just putting the model on the GPU. This is because there are many components during training that use GPU memory. The components on GPU memory are the following:
|
||||
1. model weights
|
||||
2. optimizer states
|
||||
3. gradients
|
||||
4. forward activations saved for gradient computation
|
||||
5. temporary buffers
|
||||
6. functionality-specific memory
|
||||
|
||||
A typical model trained in mixed precision with AdamW requires 18 bytes per model parameter plus activation memory. For inference there are no optimizer states and gradients, so we can subtract those. And thus we end up with 6 bytes per model parameter for mixed precision inference, plus activation memory.
|
||||
|
||||
Let's look at the details.
|
||||
|
||||
**Model Weights:**
|
||||
|
||||
- 4 bytes * number of parameters for fp32 training
|
||||
- 6 bytes * number of parameters for mixed precision training (maintains a model in fp32 and one in fp16 in memory)
|
||||
|
||||
**Optimizer States:**
|
||||
|
||||
- 8 bytes * number of parameters for normal AdamW (maintains 2 states)
|
||||
- 2 bytes * number of parameters for 8-bit AdamW optimizers like [bitsandbytes](https://github.com/TimDettmers/bitsandbytes)
|
||||
- 4 bytes * number of parameters for optimizers like SGD with momentum (maintains only 1 state)
|
||||
|
||||
**Gradients**
|
||||
|
||||
- 4 bytes * number of parameters for either fp32 or mixed precision training (gradients are always kept in fp32)
|
||||
|
||||
**Forward Activations**
|
||||
|
||||
- size depends on many factors, the key ones being sequence length, hidden size and batch size.
|
||||
|
||||
There are the input and output that are being passed and returned by the forward and the backward functions and the forward activations saved for gradient computation.
|
||||
|
||||
**Temporary Memory**
|
||||
|
||||
Additionally there are all kinds of temporary variables which get released once the calculation is done, but in the moment these could require additional memory and could push to OOM. Therefore when coding it's crucial to think strategically about such temporary variables and sometimes to explicitly free those as soon as they are no longer needed.
|
||||
|
||||
**Functionality-specific memory**
|
||||
|
||||
Then your software could have special memory needs. For example, when generating text using beam search, the software needs to maintain multiple copies of inputs and outputs.
|
||||
|
||||
**`forward` vs `backward` Execution Speed**
|
||||
|
||||
For convolutions and linear layers there are 2x flops in the backward compared to the forward, which generally translates into ~2x slower (sometimes more, because sizes in the backward tend to be more awkward). Activations are usually bandwidth-limited, and it’s typical for an activation to have to read more data in the backward than in the forward (e.g. activation forward reads once, writes once, activation backward reads twice, gradOutput and output of the forward, and writes once, gradInput).
|
||||
|
||||
So there are potentially a few places where we could save GPU memory or speed up operations. Let's start with a simple optimization: choosing the right batch size.
|
||||
|
||||
## Batch sizes
|
||||
|
||||
One gets the most efficient performance when batch sizes and input/output neuron counts are divisible by a certain number, which typically starts at 8, but can be much higher as well. That number varies a lot depending on the specific hardware being used and the dtype of the model.
|
||||
|
||||
For example for fully connected layers (which correspond to GEMMs), NVIDIA provides recommendations for [input/output neuron counts](
|
||||
https://docs.nvidia.com/deeplearning/performance/dl-performance-fully-connected/index.html#input-features) and [batch size](https://docs.nvidia.com/deeplearning/performance/dl-performance-fully-connected/index.html#batch-size).
|
||||
|
||||
[Tensor Core Requirements](https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc) define the multiplier based on the dtype and the hardware. For example, for fp16 a multiple of 8 is recommended, but on A100 it's 64!
|
||||
|
||||
For parameters that are small, there is also [Dimension Quantization Effects](https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#dim-quantization) to consider, this is where tiling happens and the right multiplier can have a significant speedup.
|
||||
For parameters that are small, consider also [Dimension Quantization Effects](https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#dim-quantization).
|
||||
This is where tiling happens and the right multiplier can have a significant speedup.
|
||||
|
||||
## Gradient Accumulation
|
||||
|
||||
The idea behind gradient accumulation is to instead of calculating the gradients for the whole batch at once to do it in smaller steps. The way we do that is to calculate the gradients iteratively in smaller batches by doing a forward and backward pass through the model and accumulating the gradients in the process. When enough gradients are accumulated we run the model's optimization step. This way we can easily increase the overall batch size to numbers that would never fit into the GPU's memory. In turn, however, the added forward and backward passes can slow down the training a bit.
|
||||
The **gradient accumulation** method aims to calculate gradients in smaller increments instead of computing them for the
|
||||
entire batch at once. This approach involves iteratively calculating gradients in smaller batches by performing forward
|
||||
and backward passes through the model and accumulating the gradients during the process. Once a sufficient number of
|
||||
gradients have been accumulated, the model's optimization step is executed. By employing gradient accumulation, it
|
||||
becomes possible to increase the **effective batch size** beyond the limitations imposed by the GPU's memory capacity.
|
||||
However, it is important to note that the additional forward and backward passes introduced by gradient accumulation can
|
||||
slow down the training process.
|
||||
|
||||
We can use gradient accumulation in the [`Trainer`] by simply adding the `gradient_accumulation_steps` argument to [`TrainingArguments`]. Let's see how it impacts the models memory footprint:
|
||||
You can enable gradient accumulation by adding the `gradient_accumulation_steps` argument to [`TrainingArguments`]:
|
||||
|
||||
```py
|
||||
training_args = TrainingArguments(per_device_train_batch_size=1, gradient_accumulation_steps=4, **default_args)
|
||||
|
||||
trainer = Trainer(model=model, args=training_args, train_dataset=ds)
|
||||
result = trainer.train()
|
||||
print_summary(result)
|
||||
```
|
||||
|
||||
```
|
||||
Time: 66.03
|
||||
Samples/second: 7.75
|
||||
GPU memory occupied: 8681 MB.
|
||||
```
|
||||
In the above example, your effective batch size becomes 4.
|
||||
|
||||
We can see that the memory footprint was dramatically reduced at the cost of being only slightly slower than the vanilla run. Of course, this would change as you increase the number of accumulation steps. In general you would want to max out the GPU usage as much as possible. So in our case, the batch_size of 4 was already pretty close to the GPU's limit. If we wanted to train with a batch size of 64 we should not use `per_device_train_batch_size=1` and `gradient_accumulation_steps=64` but instead `per_device_train_batch_size=4` and `gradient_accumulation_steps=16` which has the same effective batch size while making better use of the available GPU resources.
|
||||
Alternatively, use 🤗 Accelerate to gain full control over the training loop. Find the 🤗 Accelerate example
|
||||
[further down in this guide](#using-accelerate).
|
||||
|
||||
For more details see the benchmarks for [RTX-3090](https://github.com/huggingface/transformers/issues/14608#issuecomment-1004392537)
|
||||
While it is advised to max out GPU usage as much as possible, a high number of gradient accumulation steps can
|
||||
result in a more pronounced training slowdown. Consider the following example. Let's say, the `per_device_train_batch_size=4`
|
||||
without gradient accumulation hits the GPU's limit. If you would like to train with batches of size 64, do not set the
|
||||
`per_device_train_batch_size` to 1 and `gradient_accumulation_steps` to 64. Instead, keep `per_device_train_batch_size=4`
|
||||
and set `gradient_accumulation_steps=16`. This results in the same effective batch size while making better use of
|
||||
the available GPU resources.
|
||||
|
||||
For additional information, please refer to batch size and gradient accumulation benchmarks for [RTX-3090](https://github.com/huggingface/transformers/issues/14608#issuecomment-1004392537)
|
||||
and [A100](https://github.com/huggingface/transformers/issues/15026#issuecomment-1005033957).
|
||||
|
||||
Next we have a look at another trick to save a little bit more GPU memory called gradient checkpointing.
|
||||
|
||||
## Gradient Checkpointing
|
||||
|
||||
Even when we set the batch size to 1 and use gradient accumulation we can still run out of memory when working with large models. In order to compute the gradients during the backward pass all activations from the forward pass are normally saved. This can create a big memory overhead. Alternatively, one could forget all activations during the forward pass and recompute them on demand during the backward pass. This would however add a significant computational overhead and slow down training.
|
||||
Some large models may still face memory issues even when the batch size is set to 1 and gradient accumulation is used.
|
||||
This is because there are other components that also require memory storage.
|
||||
|
||||
Gradient checkpointing strikes a compromise between the two approaches and saves strategically selected activations throughout the computational graph so only a fraction of the activations need to be re-computed for the gradients. See [this great article](https://medium.com/tensorflow/fitting-larger-networks-into-memory-583e3c758ff9) explaining the ideas behind gradient checkpointing.
|
||||
Saving all activations from the forward pass in order to compute the gradients during the backward pass can result in
|
||||
significant memory overhead. The alternative approach of discarding the activations and recalculating them when needed
|
||||
during the backward pass, would introduce a considerable computational overhead and slow down the training process.
|
||||
|
||||
To enable gradient checkpointing in the [`Trainer`] we only need to pass it as a flag to the [`TrainingArguments`]. Everything else is handled under the hood:
|
||||
**Gradient checkpointing** offers a compromise between these two approaches and saves strategically selected activations
|
||||
throughout the computational graph so only a fraction of the activations need to be re-computed for the gradients. For
|
||||
an in-depth explanation of gradient checkpointing, refer to [this great article](https://medium.com/tensorflow/fitting-larger-networks-into-memory-583e3c758ff9).
|
||||
|
||||
To enable gradient checkpointing in the [`Trainer`], pass the corresponding a flag to [`TrainingArguments`]:
|
||||
|
||||
```py
|
||||
training_args = TrainingArguments(
|
||||
per_device_train_batch_size=1, gradient_accumulation_steps=4, gradient_checkpointing=True, **default_args
|
||||
)
|
||||
|
||||
trainer = Trainer(model=model, args=training_args, train_dataset=ds)
|
||||
result = trainer.train()
|
||||
print_summary(result)
|
||||
```
|
||||
|
||||
```
|
||||
Time: 85.47
|
||||
Samples/second: 5.99
|
||||
GPU memory occupied: 6775 MB.
|
||||
```
|
||||
Alternatively, use 🤗 Accelerate - find the 🤗 Accelerate example [further in this guide](#using-accelerate).
|
||||
|
||||
We can see that this saved some more memory but at the same time training became a bit slower. A general rule of thumb is that gradient checkpointing slows down training by about 20%. Let's have a look at another method with which we can regain some speed: mixed precision training.
|
||||
<Tip>
|
||||
|
||||
While gradient checkpointing may improve memory efficiency, it slows training by approximately 20%.
|
||||
|
||||
## Floating Data Types
|
||||
</Tip>
|
||||
|
||||
The idea of mixed precision training is that not all variables need to be stored in full (32-bit) floating point precision. If we can reduce the precision the variables and their computations are faster. Here are the commonly used floating point data types choice of which impacts both memory usage and throughput:
|
||||
## Mixed precision training
|
||||
|
||||
- fp32 (`float32`)
|
||||
- fp16 (`float16`)
|
||||
- bf16 (`bfloat16`)
|
||||
- tf32 (CUDA internal data type)
|
||||
**Mixed precision training** is a technique that aims to optimize the computational efficiency of training models by
|
||||
utilizing lower-precision numerical formats for certain variables. Traditionally, most models use 32-bit floating point
|
||||
precision (fp32 or float32) to represent and process variables. However, not all variables require this high precision
|
||||
level to achieve accurate results. By reducing the precision of certain variables to lower numerical formats like 16-bit
|
||||
floating point (fp16 or float16), we can speed up the computations. Because in this approach some computations are performed
|
||||
in half-precision, while some are still in full precision, the approach is called mixed precision training.
|
||||
|
||||
Here is a diagram that shows how these data types correlate to each other.
|
||||
Most commonly mixed precision training is achieved by using fp16 (float16) data types, however, some GPU architectures
|
||||
(such as the Ampere architecture) offer bf16 and tf32 (CUDA internal data type) data types. Check
|
||||
out the [NVIDIA Blog](https://developer.nvidia.com/blog/accelerating-ai-training-with-tf32-tensor-cores/) to learn more about
|
||||
the differences between these data types.
|
||||
|
||||
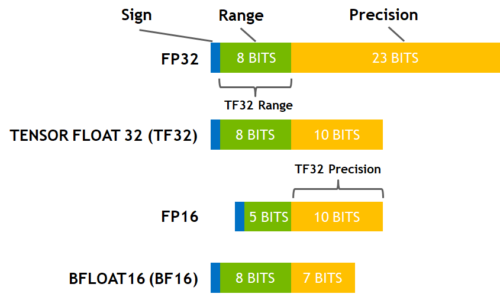
|
||||
(source: [NVIDIA Blog](https://developer.nvidia.com/blog/accelerating-ai-training-with-tf32-tensor-cores/))
|
||||
### fp16
|
||||
|
||||
While fp16 and fp32 have been around for quite some time, bf16 and tf32 are only available on the Ampere architecture GPUS and TPUs support bf16 as well. Let's start with the most commonly used method which is FP16 training/
|
||||
The main advantage of mixed precision training comes from saving the activations in half precision (fp16).
|
||||
Although the gradients are also computed in half precision they are converted back to full precision for the optimization
|
||||
step so no memory is saved here.
|
||||
While mixed precision training results in faster computations, it can also lead to more GPU memory being utilized, especially for small batch sizes.
|
||||
This is because the model is now present on the GPU in both 16-bit and 32-bit precision (1.5x the original model on the GPU).
|
||||
|
||||
|
||||
### FP16 Training
|
||||
|
||||
The idea of mixed precision training is that not all variables need to be stored in full (32-bit) floating point precision. If we can reduce the precision the variales and their computations are faster. The main advantage comes from saving the activations in half (16-bit) precision. Although the gradients are also computed in half precision they are converted back to full precision for the optimization step so no memory is saved here. Since the model is present on the GPU in both 16-bit and 32-bit precision this can use more GPU memory (1.5x the original model is on the GPU), especially for small batch sizes. Since some computations are performed in full and some in half precision this approach is also called mixed precision training. Enabling mixed precision training is also just a matter of setting the `fp16` flag to `True`:
|
||||
To enable mixed precision training, set the `fp16` flag to `True`:
|
||||
|
||||
```py
|
||||
training_args = TrainingArguments(per_device_train_batch_size=4, fp16=True, **default_args)
|
||||
|
||||
trainer = Trainer(model=model, args=training_args, train_dataset=ds)
|
||||
result = trainer.train()
|
||||
print_summary(result)
|
||||
```
|
||||
|
||||
```
|
||||
Time: 27.46
|
||||
Samples/second: 18.64
|
||||
GPU memory occupied: 13939 MB.
|
||||
```
|
||||
|
||||
We can see that this is almost twice as fast as the vanilla training. Let's add it to the mix of the previous methods:
|
||||
|
||||
|
||||
```py
|
||||
training_args = TrainingArguments(
|
||||
per_device_train_batch_size=1,
|
||||
gradient_accumulation_steps=4,
|
||||
gradient_checkpointing=True,
|
||||
fp16=True,
|
||||
**default_args,
|
||||
)
|
||||
|
||||
trainer = Trainer(model=model, args=training_args, train_dataset=ds)
|
||||
result = trainer.train()
|
||||
print_summary(result)
|
||||
```
|
||||
|
||||
```
|
||||
Time: 50.76
|
||||
Samples/second: 10.09
|
||||
GPU memory occupied: 7275 MB.
|
||||
```
|
||||
|
||||
We can see that with these tweaks we use about half the GPU memory as at the beginning while also being slightly faster.
|
||||
If you prefer to use 🤗 Accelerate, find the 🤗 Accelerate example [further in this guide](#using-accelerate).
|
||||
|
||||
### BF16
|
||||
If you have access to a Ampere or newer hardware you can use bf16 for your training and evaluation. While bf16 has a worse precision than fp16, it has a much much bigger dynamic range. Therefore, if in the past you were experiencing overflow issues while training the model, bf16 will prevent this from happening most of the time. Remember that in fp16 the biggest number you can have is `65535` and any number above that will overflow. A bf16 number can be as large as `3.39e+38` (!) which is about the same as fp32 - because both have 8-bits used for the numerical range.
|
||||
|
||||
If you have access to an Ampere or newer hardware you can use bf16 for mixed precision training and evaluation. While
|
||||
bf16 has a worse precision than fp16, it has a much bigger dynamic range. In fp16 the biggest number you can have
|
||||
is `65535` and any number above that will result in an overflow. A bf16 number can be as large as `3.39e+38` (!) which
|
||||
is about the same as fp32 - because both have 8-bits used for the numerical range.
|
||||
|
||||
You can enable BF16 in the 🤗 Trainer with:
|
||||
|
||||
```python
|
||||
TrainingArguments(bf16=True)
|
||||
training_args = TrainingArguments(bf16=True, **default_args)
|
||||
```
|
||||
|
||||
### TF32
|
||||
The Ampere hardware uses a magical data type called tf32. It has the same numerical range as fp32 (8-bits), but instead of 23 bits precision it has only 10 bits (same as fp16) and uses only 19 bits in total.
|
||||
|
||||
It's magical in the sense that you can use the normal fp32 training and/or inference code and by enabling tf32 support you can get up to 3x throughput improvement. All you need to do is to add this to your code:
|
||||
The Ampere hardware uses a magical data type called tf32. It has the same numerical range as fp32 (8-bits), but instead
|
||||
of 23 bits precision it has only 10 bits (same as fp16) and uses only 19 bits in total. It's "magical" in the sense that
|
||||
you can use the normal fp32 training and/or inference code and by enabling tf32 support you can get up to 3x throughput
|
||||
improvement. All you need to do is to add the following to your code:
|
||||
|
||||
```
|
||||
import torch
|
||||
torch.backends.cuda.matmul.allow_tf32 = True
|
||||
torch.backends.cudnn.allow_tf32 = True
|
||||
```
|
||||
|
||||
When this is done CUDA will automatically switch to using tf32 instead of fp32 where it's possible. This, of course, assumes that the used GPU is from the Ampere series.
|
||||
|
||||
Like all cases with reduced precision this may or may not be satisfactory for your needs, so you have to experiment and see. According to [NVIDIA research](https://developer.nvidia.com/blog/accelerating-ai-training-with-tf32-tensor-cores/) the majority of machine learning training shouldn't be impacted and showed the same perplexity and convergence as the fp32 training.
|
||||
CUDA will automatically switch to using tf32 instead of fp32 where possible, assuming that the used GPU is from the Ampere series.
|
||||
|
||||
According to [NVIDIA research](https://developer.nvidia.com/blog/accelerating-ai-training-with-tf32-tensor-cores/), the
|
||||
majority of machine learning training workloads show the same perplexity and convergence with tf32 training as with fp32.
|
||||
If you're already using fp16 or bf16 mixed precision it may help with the throughput as well.
|
||||
|
||||
You can enable this mode in the 🤗 Trainer with:
|
||||
You can enable this mode in the 🤗 Trainer:
|
||||
|
||||
```python
|
||||
TrainingArguments(tf32=True)
|
||||
TrainingArguments(tf32=True, **default_args)
|
||||
```
|
||||
By default the PyTorch default is used.
|
||||
|
||||
Note: tf32 mode is internal to CUDA and can't be accessed directly via `tensor.to(dtype=torch.tf32)` as `torch.tf32` doesn't exist.
|
||||
<Tip>
|
||||
|
||||
Note: you need `torch>=1.7` to enjoy this feature.
|
||||
tf32 can't be accessed directly via `tensor.to(dtype=torch.tf32)` because it is an internal CUDA data type. You need `torch>=1.7` to use tf32 data types.
|
||||
|
||||
You can also see a variety of benchmarks on tf32 vs other precisions:
|
||||
</Tip>
|
||||
|
||||
For additional information on tf32 vs other precisions, please refer to the following benchmarks:
|
||||
[RTX-3090](https://github.com/huggingface/transformers/issues/14608#issuecomment-1004390803) and
|
||||
[A100](https://github.com/huggingface/transformers/issues/15026#issuecomment-1004543189).
|
||||
|
||||
We've now seen how we can change the floating types to increase throughput, but we are not done, yet! There is another area where we can save GPU memory: the optimizer.
|
||||
## Optimizer choice
|
||||
|
||||
## Optimizer
|
||||
The most common optimizer used to train transformer models is Adam or AdamW (Adam with weight decay). Adam achieves
|
||||
good convergence by storing the rolling average of the previous gradients; however, it adds an additional memory
|
||||
footprint of the order of the number of model parameters. To remedy this, you can use an alternative optimizer.
|
||||
For example if you have [NVIDIA/apex](https://github.com/NVIDIA/apex) installed, `adamw_apex_fused` will give you the
|
||||
fastest training experience among all supported AdamW optimizers.
|
||||
|
||||
The most common optimizer used to train transformer model is Adam or AdamW (Adam with weight decay). Adam achieves good convergence by storing the rolling average of the previous gradients which, however, adds an additional memory footprint of the order of the number of model parameters. One remedy to this is to use an alternative optimizer such as Adafactor, which works well for some models but often it has instability issues.
|
||||
[`Trainer`] integrates a variety of optimizers that can be used out of box: `adamw_hf`, `adamw_torch`, `adamw_torch_fused`,
|
||||
`adamw_apex_fused`, `adamw_anyprecision`, `adafactor`, or `adamw_bnb_8bit`. More optimizers can be plugged in via a third-party implementation.
|
||||
|
||||
HF Trainer integrates a variety of optimisers that can be used out of box. To activate the desired optimizer simply pass the `--optim` flag to the command line.
|
||||
Let's take a closer look at two alternatives to AdamW optimizer:
|
||||
1. `adafactor` which is available in [`Trainer`]
|
||||
2. `adamw_bnb_8bit` is also available in Trainer, but a third-party integration is provided below for demonstration.
|
||||
|
||||
To see which optimizers are currently supported:
|
||||
|
||||
```bash
|
||||
$ python examples/pytorch/translation/run_translation.py -h | grep "\-optim"
|
||||
[--optim {adamw_hf,adamw_torch,adamw_torch_xla,adamw_apex_fused,adafactor}]
|
||||
```
|
||||
|
||||
For example, if you have [NVIDIA/apex](https://github.com/NVIDIA/apex) installed `--optim adamw_apex_fused` will give you the fastest training experience among all supported AdamW optimizers.
|
||||
|
||||
On the other hand [8bit BNB optimizer](https://github.com/TimDettmers/bitsandbytes) can save 3/4 of memory normally used by a typical AdamW optimizer if it is configured to quantize all optimizer states, but in some situations only some optimizer states are quintized and then more memory is used.
|
||||
|
||||
Let's get a feel for the numbers and use for example use a 3B-parameter model, like `t5-3b`. Note that since a Gigabyte correpsonds to a billion bytes we can simply multiply the parameters (in billions) with the number of necessary bytes per parameter to get Gigabytes of GPU memory usage:
|
||||
|
||||
- A standard AdamW uses 8 bytes for each parameter, here the optimizer will need (`8*3`) 24GB of GPU memory.
|
||||
- Adafactor uses slightly more than 4 bytes, so (`4*3`) 12GB and then some extra.
|
||||
- 8bit BNB quantized optimizer will use only (`2*3`) 6GB if all optimizer states are quantized.
|
||||
|
||||
Let's have a look at Adafactor first.
|
||||
For comparison, for a 3B-parameter model, like “t5-3b”:
|
||||
* A standard AdamW optimizer will need 24GB of GPU memory because it uses 8 bytes for each parameter (8*3 => 24GB)
|
||||
* Adafactor optimizer will need more than 12GB. It uses slightly more than 4 bytes for each parameter, so 4*3 and then some extra.
|
||||
* 8bit BNB quantized optimizer will use only (2*3) 6GB if all optimizer states are quantized.
|
||||
|
||||
### Adafactor
|
||||
|
||||
Instead of keeping the rolling average for each element in the weight matrices Adafactor only stores aggregated information (row- and column-wise sums of the rolling averages) which reduces the footprint considerably. One downside of Adafactor is that in some instances convergence can be slower than Adam's so some experimentation is advised here. We can use Adafactor simply by setting `optim="adafactor"`:
|
||||
Adafactor doesn't store rolling averages for each element in weight matrices. Instead, it keeps aggregated information
|
||||
(sums of rolling averages row- and column-wise), significantly reducing its footprint. However, compared to Adam,
|
||||
Adafactor may have slower convergence in certain cases.
|
||||
|
||||
You can switch to Adafactor by setting `optim="adafactor"` in [`TrainingArguments`]:
|
||||
|
||||
```py
|
||||
training_args = TrainingArguments(per_device_train_batch_size=4, optim="adafactor", **default_args)
|
||||
|
||||
trainer = Trainer(model=model, args=training_args, train_dataset=ds)
|
||||
result = trainer.train()
|
||||
print_summary(result)
|
||||
```
|
||||
|
||||
```
|
||||
Time: 64.31
|
||||
Samples/second: 7.96
|
||||
GPU memory occupied: 12295 MB.
|
||||
```
|
||||
|
||||
We can see that this saves a few more GB on the GPU. Let's see how it looks when we add it to the other methods we introduced earlier:
|
||||
|
||||
|
||||
```py
|
||||
training_args = TrainingArguments(
|
||||
per_device_train_batch_size=1,
|
||||
gradient_accumulation_steps=4,
|
||||
gradient_checkpointing=True,
|
||||
fp16=True,
|
||||
optim="adafactor",
|
||||
**default_args,
|
||||
)
|
||||
|
||||
trainer = Trainer(model=model, args=training_args, train_dataset=ds)
|
||||
result = trainer.train()
|
||||
print_summary(result)
|
||||
```
|
||||
|
||||
```
|
||||
Time: 56.54
|
||||
Samples/second: 9.06
|
||||
GPU memory occupied: 4847 MB.
|
||||
```
|
||||
|
||||
We went from 15 GB memory usage to 5 GB - a 3x improvement while maintaining the throughput! However, as mentioned before, the convergence of Adafactor can be worse than Adam. There is an alternative to Adafactor called 8-bit Adam that takes a slightly different approach.
|
||||
Combined with other approaches (gradient accumulation, gradient checkpointing, and mixed precision training)
|
||||
you can notice up to 3x improvement while maintaining the throughput! However, as mentioned before, the convergence of
|
||||
Adafactor can be worse than Adam.
|
||||
|
||||
### 8-bit Adam
|
||||
|
||||
Instead of aggregating optimizer states like Adafactor, 8-bit Adam keeps the full state and quantizes it. Quantization means that it stores the state with lower precision and dequantizes it only for the optimization. This is similar to the idea behind FP16 training where using variables with lower precision saves memory.
|
||||
Instead of aggregating optimizer states like Adafactor, 8-bit Adam keeps the full state and quantizes it. Quantization
|
||||
means that it stores the state with lower precision and dequantizes it only for the optimization. This is similar to the
|
||||
idea behind mixed precision training.
|
||||
|
||||
In contrast to the previous approaches is this one not integrated into the [`Trainer`] as a simple flag. We need to install the 8-bit optimizer and then pass it as a custom optimizer to the [`Trainer`]. Follow the installation guide in the Github [repo](https://github.com/TimDettmers/bitsandbytes) to install the `bitsandbytes` library that implements the 8-bit Adam optimizer.
|
||||
To use `adamw_bnb_8bit`, you simply need to set `optim="adamw_bnb_8bit"` in [`TrainingArguments`]:
|
||||
|
||||
Once installed, we just need to initialize the the optimizer. Although this looks like a considerable amount of work it actually just involves two steps: first we need to group the model's parameters into two groups where to one group we apply weight decay and to the other we don't. Usually, biases and layer norm parameters are not weight decayed. Then in a second step we just do some argument housekeeping to use the same parameters as the previously used AdamW optimizer.
|
||||
```py
|
||||
training_args = TrainingArguments(per_device_train_batch_size=4, optim="adamw_bnb_8bit", **default_args)
|
||||
```
|
||||
|
||||
<Tip>
|
||||
Note that in order to use the 8-bit optimizer with an existing pretrained model a change to the embedding layer is needed.
|
||||
Read [this issue](https://github.com/huggingface/transformers/issues/14819) for more information.
|
||||
</Tip>
|
||||
However, we can also use a third-party implementation of the 8-bit optimizer for demonstration purposes to see how that can be integrated.
|
||||
|
||||
First, follow the installation guide in the GitHub [repo](https://github.com/TimDettmers/bitsandbytes) to install the `bitsandbytes` library
|
||||
that implements the 8-bit Adam optimizer.
|
||||
|
||||
Next you need to initialize the optimizer. This involves two steps:
|
||||
* First, group the model's parameters into two groups - one where weight decay should be applied, and the other one where it should not. Usually, biases and layer norm parameters are not weight decayed.
|
||||
* Then do some argument housekeeping to use the same parameters as the previously used AdamW optimizer.
|
||||
|
||||
```py
|
||||
import bitsandbytes as bnb
|
||||
@@ -530,53 +318,90 @@ adam_bnb_optim = bnb.optim.Adam8bit(
|
||||
)
|
||||
```
|
||||
|
||||
We can now pass the custom optimizer as an argument to the `Trainer`:
|
||||
```py
|
||||
trainer = Trainer(model=model, args=training_args, train_dataset=ds, optimizers=(adam_bnb_optim, None))
|
||||
result = trainer.train()
|
||||
print_summary(result)
|
||||
```
|
||||
|
||||
```
|
||||
Time: 55.95
|
||||
Samples/second: 9.15
|
||||
GPU memory occupied: 13085 MB.
|
||||
```
|
||||
|
||||
We can see that we get a similar memory improvement as with Adafactor while keeping the full rolling average of the gradients. Let's repeat the experiment with the full settings:
|
||||
Finally, pass the custom optimizer as an argument to the `Trainer`:
|
||||
|
||||
```py
|
||||
training_args = TrainingArguments(
|
||||
per_device_train_batch_size=1,
|
||||
gradient_accumulation_steps=4,
|
||||
gradient_checkpointing=True,
|
||||
fp16=True,
|
||||
**default_args,
|
||||
)
|
||||
|
||||
trainer = Trainer(model=model, args=training_args, train_dataset=ds, optimizers=(adam_bnb_optim, None))
|
||||
result = trainer.train()
|
||||
print_summary(result)
|
||||
```
|
||||
|
||||
```
|
||||
Time: 49.46
|
||||
Samples/second: 10.35
|
||||
GPU memory occupied: 5363 MB.
|
||||
Combined with other approaches (gradient accumulation, gradient checkpointing, and mixed precision training),
|
||||
you can expect to get about a 3x memory improvement and even slightly higher throughput as using Adafactor.
|
||||
|
||||
### multi_tensor
|
||||
|
||||
pytorch-nightly introduced `torch.optim._multi_tensor` which should significantly speed up the optimizers for situations
|
||||
with lots of small feature tensors. It should eventually become the default, but if you want to experiment with it sooner, take a look at this GitHub [issue](https://github.com/huggingface/transformers/issues/9965).
|
||||
|
||||
## Data preloading
|
||||
|
||||
One of the important requirements to reach great training speed is the ability to feed the GPU at the maximum speed it
|
||||
can handle. By default, everything happens in the main process, and it might not be able to read the data from disk fast
|
||||
enough, and thus create a bottleneck, leading to GPU under-utilization. Configure the following arguments to reduce the bottleneck:
|
||||
|
||||
- `DataLoader(pin_memory=True, ...)` - ensures the data gets preloaded into the pinned memory on CPU and typically leads to much faster transfers from CPU to GPU memory.
|
||||
- `DataLoader(num_workers=4, ...)` - spawn several workers to preload data faster. During training, watch the GPU utilization stats; if it's far from 100%, experiment with increasing the number of workers. Of course, the problem could be elsewhere, so many workers won't necessarily lead to better performance.
|
||||
|
||||
When using [`Trainer`], the corresponding [`TrainingArguments`] are: `dataloader_pin_memory` (`True` by default), and `dataloader_num_workers` (defaults to `0`).
|
||||
|
||||
## DeepSpeed ZeRO
|
||||
|
||||
DeepSpeed is an open-source deep learning optimization library that is integrated with 🤗 Transformers and 🤗 Accelerate.
|
||||
It provides a wide range of features and optimizations designed to improve the efficiency and scalability of large-scale
|
||||
deep learning training.
|
||||
|
||||
If your model fits onto a single GPU and you have enough space to fit a small batch size, you don't need to use DeepSpeed
|
||||
as it'll only slow things down. However, if the model doesn't fit onto a single GPU or you can't fit a small batch, you can
|
||||
leverage DeepSpeed ZeRO + CPU Offload, or NVMe Offload for much larger models. In this case, you need to separately
|
||||
[install the library](main_classes/deepspeed#installation), then follow one of the guides to create a configuration file
|
||||
and launch DeepSpeed:
|
||||
|
||||
* For an in-depth guide on DeepSpeed integration with [`Trainer`], review [the corresponding documentation](main_classes/deepspeed), specifically the
|
||||
[section for a single GPU](main_classes/deepspeed#deployment-with-one-gpu). Some adjustments are required to use DeepSpeed in a notebook; please take a look at the [corresponding guide](main_classes/deepspeed#deployment-in-notebooks).
|
||||
* If you prefer to use 🤗 Accelerate, refer to [🤗 Accelerate DeepSpeed guide](https://huggingface.co/docs/accelerate/en/usage_guides/deepspeed).
|
||||
|
||||
## Using torch.compile
|
||||
|
||||
PyTorch 2.0 introduced a new compile function that doesn't require any modification to existing PyTorch code but can
|
||||
optimize your code by adding a single line of code: `model = torch.compile(model)`.
|
||||
|
||||
If using [`Trainer`], you only need `to` pass the `torch_compile` option in the [`TrainingArguments`]:
|
||||
|
||||
```python
|
||||
training_args = TrainingArguments(torch_compile=True, **default_args)
|
||||
```
|
||||
|
||||
Again, we get about a 3x memory improvement and even slightly higher throughput as using Adafactor. So we have seen how we can optimize the memory footprint of large models. The following plot summarizes all our experiments:
|
||||
`torch.compile` uses Python's frame evaluation API to automatically create a graph from existing PyTorch programs. After
|
||||
capturing the graph, different backends can be deployed to lower the graph to an optimized engine.
|
||||
You can find more details and benchmarks in [PyTorch documentation](https://pytorch.org/get-started/pytorch-2.0/).
|
||||
|
||||
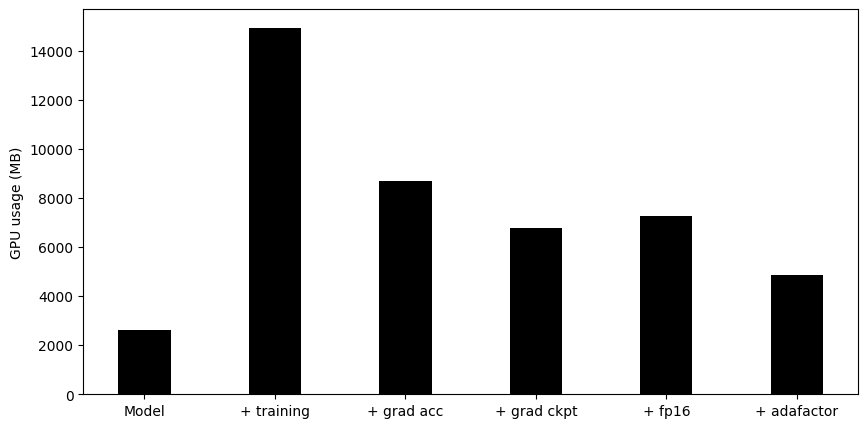
|
||||
`torch.compile` has a growing list of backends, which can be found in by calling `torchdynamo.list_backends()`, each of which with its optional dependencies.
|
||||
|
||||
### `_multi_tensor`
|
||||
pytorch-nightly introduced `torch.optim._multi_tensor` which should significantly speed up the optimizers for situations with lots of small feature tensors. It should eventually become the default, but if you want to experiment with it sooner and don't mind using the bleed-edge, see: https://github.com/huggingface/transformers/issues/9965
|
||||
Choose which backend to use by specifying it via `torch_compile_backend` in the [`TrainingArguments`]. Some of the most commonly used backends are:
|
||||
|
||||
**Debugging backends**:
|
||||
* `dynamo.optimize("eager")` - Uses PyTorch to run the extracted GraphModule. This is quite useful in debugging TorchDynamo issues.
|
||||
* `dynamo.optimize("aot_eager")` - Uses AotAutograd with no compiler, i.e, just using PyTorch eager for the AotAutograd's extracted forward and backward graphs. This is useful for debugging, and unlikely to give speedups.
|
||||
|
||||
**Training & inference backends**:
|
||||
* `dynamo.optimize("inductor")` - Uses TorchInductor backend with AotAutograd and cudagraphs by leveraging codegened Triton kernels [Read more](https://dev-discuss.pytorch.org/t/torchinductor-a-pytorch-native-compiler-with-define-by-run-ir-and-symbolic-shapes/747)
|
||||
* `dynamo.optimize("nvfuser")` - nvFuser with TorchScript. [Read more](https://dev-discuss.pytorch.org/t/tracing-with-primitives-update-1-nvfuser-and-its-primitives/593)
|
||||
* `dynamo.optimize("aot_nvfuser")` - nvFuser with AotAutograd. [Read more](https://dev-discuss.pytorch.org/t/tracing-with-primitives-update-1-nvfuser-and-its-primitives/593)
|
||||
* `dynamo.optimize("aot_cudagraphs")` - cudagraphs with AotAutograd. [Read more](https://github.com/pytorch/torchdynamo/pull/757)
|
||||
|
||||
**Inference-only backend**s:
|
||||
* `dynamo.optimize("ofi")` - Uses Torchscript optimize_for_inference. [Read more](https://pytorch.org/docs/stable/generated/torch.jit.optimize_for_inference.html)
|
||||
* `dynamo.optimize("fx2trt")` - Uses Nvidia TensorRT for inference optimizations. [Read more](https://github.com/pytorch/TensorRT/blob/master/docsrc/tutorials/getting_started_with_fx_path.rst)
|
||||
* `dynamo.optimize("onnxrt")` - Uses ONNXRT for inference on CPU/GPU. [Read more](https://onnxruntime.ai/)
|
||||
* `dynamo.optimize("ipex")` - Uses IPEX for inference on CPU. [Read more](https://github.com/intel/intel-extension-for-pytorch)
|
||||
|
||||
For an example of using `torch.compile` with 🤗 Transformers, check out this [blog post on fine-tuning a BERT model for Text Classification using the newest PyTorch 2.0 features](https://www.philschmid.de/getting-started-pytorch-2-0-transformers)
|
||||
|
||||
## Using 🤗 Accelerate
|
||||
|
||||
So far we have used the [`Trainer`] to run the experiments but a more flexible alternative to that approach is to use 🤗 Accelerate. With 🤗 Accelerate you have full control over the training loop and can essentially write the loop in pure PyTorch with some minor modifications. In turn it allows you to easily scale across different infrastructures such as CPUs, GPUs, TPUs, or distributed multi-GPU setups without changing any code. Let's see what it takes to implement all of the above tweaks in 🤗 Accelerate. We can still use the [`TrainingArguments`] to wrap the training settings:
|
||||
With [🤗 Accelerate](https://huggingface.co/docs/accelerate/index) you can use the above methods while gaining full
|
||||
control over the training loop and can essentially write the loop in pure PyTorch with some minor modifications.
|
||||
|
||||
Suppose you have combined the methods in the [`TrainingArguments`] like so:
|
||||
|
||||
```py
|
||||
training_args = TrainingArguments(
|
||||
@@ -590,7 +415,6 @@ training_args = TrainingArguments(
|
||||
|
||||
The full example training loop with 🤗 Accelerate is only a handful of lines of code long:
|
||||
|
||||
|
||||
```py
|
||||
from accelerate import Accelerator
|
||||
from torch.utils.data.dataloader import DataLoader
|
||||
@@ -613,89 +437,50 @@ for step, batch in enumerate(dataloader, start=1):
|
||||
optimizer.zero_grad()
|
||||
```
|
||||
|
||||
First we wrap the dataset in a [`DataLoader`](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader). Then we can enable gradient checkpointing by calling the model's [`~PreTrainedModel.gradient_checkpointing_enable`] method. When we initialize the [`Accelerator`](https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator) we can specify if we want to use mixed precision training and it will take care of it for us in the [`prepare`] call. During the [`prepare`](https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.prepare) call the dataloader will also be distributed across workers should we use multiple GPUs. We use the same 8-bit optimizer from the earlier experiments.
|
||||
First we wrap the dataset in a [`DataLoader`](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader).
|
||||
Then we can enable gradient checkpointing by calling the model's [`~PreTrainedModel.gradient_checkpointing_enable`] method.
|
||||
When we initialize the [`Accelerator`](https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator)
|
||||
we can specify if we want to use mixed precision training and it will take care of it for us in the [`prepare`] call.
|
||||
During the [`prepare`](https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.prepare)
|
||||
call the dataloader will also be distributed across workers should we use multiple GPUs. We use the same [8-bit optimizer](#8-bit-adam) from the earlier example.
|
||||
|
||||
Finally, we can write the main training loop. Note that the `backward` call is handled by 🤗 Accelerate. We can also see how gradient accumulation works: we normalize the loss so we get the average at the end of accumulation and once we have enough steps we run the optimization. Now the question is: does this use the same amount of memory as the previous steps? Let's check:
|
||||
Finally, we can add the main training loop. Note that the `backward` call is handled by 🤗 Accelerate. We can also see
|
||||
how gradient accumulation works: we normalize the loss, so we get the average at the end of accumulation and once we have
|
||||
enough steps we run the optimization.
|
||||
|
||||
|
||||
```py
|
||||
>>> print_gpu_utilization()
|
||||
GPU memory occupied: 5363 MB.
|
||||
```
|
||||
|
||||
Indeed it does. Implementing these optimization techniques with 🤗 Accelerate only takes a handful of lines of code and comes with the benefit of more flexiblity in the training loop. For a full documentation of all features have a look at the [Accelerate documentation](https://huggingface.co/docs/accelerate/index).
|
||||
|
||||
## DataLoader
|
||||
|
||||
One of the important requirements to reach great training speed is the ability to feed the GPU at the maximum speed it can handle. By default everything happens in the main process and it might not be able to read the data from disk fast enough, and thus create a bottleneck, leading to GPU under-utilization.
|
||||
|
||||
- `DataLoader(pin_memory=True, ...)` which ensures that the data gets preloaded into the pinned memory on CPU and typically leads to much faster transfers from CPU to GPU memory.
|
||||
- `DataLoader(num_workers=4, ...)` - spawn several workers to pre-load data faster - during training watch the GPU utilization stats and if it's far from 100% experiment with raising the number of workers. Of course, the problem could be elsewhere so a very big number of workers won't necessarily lead to a better performance.
|
||||
|
||||
## DeepSpeed ZeRO
|
||||
|
||||
The in-depth details on how to use Deepspeed can be found [here](main_classes/deepspeed).
|
||||
|
||||
First, a quick decision tree:
|
||||
|
||||
1. Model fits onto a single GPU and you have enough space to fit a small batch size - you don't need to use Deepspeed as it'll only slow things down in this use case.
|
||||
2. Model doesn't fit onto a single GPU or you can't fit a small batch - use DeepSpeed ZeRO + CPU Offload and for much larger models NVMe Offload.
|
||||
|
||||
Now if the decision tree suggested you use DeepSpeed first you need to [install it](main_classes/deepspeed#installation), then follow one of the following guides to create a configuration file and launch DeepSpeed.
|
||||
|
||||
Activation:
|
||||
|
||||
- HF Trainer-based examples: see this [guide](main_classes/deepspeed#deployment-with-one-gpu).
|
||||
- Custom HF Trainer-based program: Same as above, but pass:
|
||||
|
||||
```python
|
||||
TrainingArguments(deepspeed="/path/to/ds_config.json")
|
||||
```
|
||||
- Deployment in Notebooks: see this [guide](main_classes/deepspeed#deployment-in-notebooks).
|
||||
|
||||
- Custom training loop: This is somewhat complex but you can study how this is implemented in [HF Trainer](
|
||||
https://github.com/huggingface/transformers/blob/master/src/transformers/trainer.py) - simply search for `deepspeed` in the code.
|
||||
|
||||
|
||||
## Choice of GPU
|
||||
Sometimes, even when applying all the above tweaks the throughput on a given GPU might still not be good enough. One easy solution is to change the type of GPU. For example switching from let's say a K80 (which you typically get on Google Colab) to a fancier GPU such as the V100 or A100. Although they are more expensive they are usually more cost effective than cheaper GPUs due to their larger memory and faster architecture.
|
||||
|
||||
Now, let's take a step back and discuss what we should optimize for when scaling the training of large models.
|
||||
|
||||
## How to scale
|
||||
|
||||
When we train models there are a two aspects we want to optimize at the same time:
|
||||
|
||||
- Data throughput/training time
|
||||
- Model performance
|
||||
|
||||
We have seen that each method changes the memory usage and throughput. In general we want to maximize the throughput (samples/second) to minimize the training cost. This is generally achieved by utilizing the GPU as much as possible and thus filling GPU memory to its limit. For example, as mentioned earlier, we only employ gradient accumulation when we want to use a batch size beyond the size of the GPU memory. If the desired batch size fits into memory then there is no reason to apply gradient accumulation which will only slow down training.
|
||||
|
||||
The second objective is model performance. Just because we can does not mean we should use a large batch size. As part of hyperparameter tuning you should determine which batch size yields the best result and then optimize the throughput accordingly.
|
||||
Implementing these optimization techniques with 🤗 Accelerate only takes a handful of lines of code and comes with the
|
||||
benefit of more flexibility in the training loop. For a full documentation of all features have a look at the
|
||||
[Accelerate documentation](https://huggingface.co/docs/accelerate/index).
|
||||
|
||||
|
||||
## Efficient Software Prebuilds
|
||||
|
||||
PyTorch's [pip and conda builds](https://pytorch.org/get-started/locally/#start-locally) come prebuit with the cuda toolkit which is enough to run PyTorch, but it is insufficient if you need to build cuda extensions.
|
||||
PyTorch's [pip and conda builds](https://pytorch.org/get-started/locally/#start-locally) come prebuilt with the cuda toolkit
|
||||
which is enough to run PyTorch, but it is insufficient if you need to build cuda extensions.
|
||||
|
||||
At times it may take an additional effort to pre-build some components, e.g., if you're using libraries like `apex` that don't come pre-compiled. In other situations figuring out how to install the right cuda toolkit system-wide can be complicated. To address these users' needs PyTorch and NVIDIA release a new version of NGC docker container which already comes with everything prebuilt and you just need to install your programs on it and it will run out of the box.
|
||||
At times, additional efforts may be required to pre-build some components. For instance, if you're using libraries like `apex` that
|
||||
don't come pre-compiled. In other situations figuring out how to install the right cuda toolkit system-wide can be complicated.
|
||||
To address these scenarios PyTorch and NVIDIA released a new version of NGC docker container which already comes with
|
||||
everything prebuilt. You just need to install your programs on it, and it will run out of the box.
|
||||
|
||||
This approach is also useful if you want to tweak the pytorch source and/or make a new customized build.
|
||||
|
||||
To find the docker image version you want start [here](https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/), choose one of the latest monthly releases. Go into the release's notes for the desired release, check that the environment's components are matching your needs (including NVIDIA Driver requirements!) and then at the very top of that document go to the corresponding NGC page. If for some reason you get lost, here is [the index of all PyTorch NGC images](https://ngc.nvidia.com/catalog/containers/nvidia:pytorch).
|
||||
To find the docker image version you want start [with PyTorch release notes](https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/),
|
||||
choose one of the latest monthly releases. Go into the release's notes for the desired release, check that the environment's
|
||||
components are matching your needs (including NVIDIA Driver requirements!) and then at the very top of that document go
|
||||
to the corresponding NGC page. If for some reason you get lost, here is [the index of all PyTorch NGC images](https://ngc.nvidia.com/catalog/containers/nvidia:pytorch).
|
||||
|
||||
Next follow the instructions to download and deploy the docker image.
|
||||
|
||||
## Sparsity
|
||||
## Mixture of Experts
|
||||
|
||||
### Mixture of Experts
|
||||
|
||||
Quite a few of the recent papers reported a 4-5x training speedup and a faster inference by integrating
|
||||
Some recent papers reported a 4-5x training speedup and a faster inference by integrating
|
||||
Mixture of Experts (MoE) into the Transformer models.
|
||||
|
||||
Since it has been discovered that more parameters lead to better performance, this technique allows to increase the number of parameters by an order of magnitude without increasing training costs.
|
||||
Since it has been discovered that more parameters lead to better performance, this technique allows to increase the
|
||||
number of parameters by an order of magnitude without increasing training costs.
|
||||
|
||||
In this approach every other FFN layer is replaced with a MoE Layer which consists of many experts, with a gated function that trains each expert in a balanced way depending on the input token's position in a sequence.
|
||||
In this approach every other FFN layer is replaced with a MoE Layer which consists of many experts, with a gated function
|
||||
that trains each expert in a balanced way depending on the input token's position in a sequence.
|
||||
|
||||

|
||||
|
||||
@@ -703,9 +488,12 @@ In this approach every other FFN layer is replaced with a MoE Layer which consis
|
||||
|
||||
You can find exhaustive details and comparison tables in the papers listed at the end of this section.
|
||||
|
||||
The main drawback of this approach is that it requires staggering amounts of GPU memory - almost an order of magnitude larger than its dense equivalent. Various distillation and approaches are proposed to how to overcome the much higher memory requirements.
|
||||
The main drawback of this approach is that it requires staggering amounts of GPU memory - almost an order of magnitude
|
||||
larger than its dense equivalent. Various distillation and approaches are proposed to how to overcome the much higher memory requirements.
|
||||
|
||||
There is direct trade-off though, you can use just a few experts with a 2-3x smaller base model instead of dozens or hundreds experts leading to a 5x smaller model and thus increase the training speed moderately while increasing the memory requirements moderately as well.
|
||||
There is direct trade-off though, you can use just a few experts with a 2-3x smaller base model instead of dozens or
|
||||
hundreds experts leading to a 5x smaller model and thus increase the training speed moderately while increasing the
|
||||
memory requirements moderately as well.
|
||||
|
||||
Most related papers and implementations are built around Tensorflow/TPUs:
|
||||
|
||||
@@ -715,46 +503,26 @@ Most related papers and implementations are built around Tensorflow/TPUs:
|
||||
|
||||
And for Pytorch DeepSpeed has built one as well: [DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale](https://arxiv.org/abs/2201.05596), [Mixture of Experts](https://www.deepspeed.ai/tutorials/mixture-of-experts/) - blog posts: [1](https://www.microsoft.com/en-us/research/blog/deepspeed-powers-8x-larger-moe-model-training-with-high-performance/), [2](https://www.microsoft.com/en-us/research/publication/scalable-and-efficient-moe-training-for-multitask-multilingual-models/) and specific deployment with large transformer-based natural language generation models: [blog post](https://www.deepspeed.ai/news/2021/12/09/deepspeed-moe-nlg.html), [Megatron-Deepspeed branch](Thttps://github.com/microsoft/Megatron-DeepSpeed/tree/moe-training).
|
||||
|
||||
## Using PyTorch native attention and Flash Attention
|
||||
|
||||
## Scaling beyond a single GPU
|
||||
PyTorch 2.0 released a native [`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html) (SDPA),
|
||||
that allows using fused GPU kernels such as [memory-efficient attention](https://arxiv.org/abs/2112.05682) and [flash attention](https://arxiv.org/abs/2205.14135).
|
||||
|
||||
For some applications, such as pretraining large language models, applying all the approaches above might still not be fast enough. In this case you want to scale your experiment to several GPUs.
|
||||
|
||||
Another use case for training on many GPUs is if the model does not fit on a single GPU with all the mentioned tricks. There are still more methods we can apply although life starts to get a bit more complicated. This usually involves some form of pipeline or tensor parallelism where the model itself is distributed across several GPUs. One can also make use of DeepSpeed which implements some of these parallelism strategies along with some more optimization to reduce the memory footprint such as partitioning the optimizer states. You can read more about this in the ["Multi-GPU training" section](perf_train_gpu_many).
|
||||
|
||||
## Using PyTorch native attention
|
||||
|
||||
PyTorch 2.0 released the native [`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html) (SDPA), that allows to use fused GPU kernels as [memory-efficient attention](https://arxiv.org/abs/2112.05682) and [flash attention](https://arxiv.org/abs/2205.14135).
|
||||
|
||||
After installing the [`optimum`](https://github.com/huggingface/optimum) package, the relevant internal modules can be replaced to use PyTorch's native attention with:
|
||||
After installing the [`optimum`](https://github.com/huggingface/optimum) package, the relevant internal modules can be
|
||||
replaced to use PyTorch's native attention with:
|
||||
|
||||
```python
|
||||
model = model.to_bettertransformer()
|
||||
```
|
||||
|
||||
Training can then be done as usual.
|
||||
Once converted, train the model as usual.
|
||||
|
||||
## Using torch.compile
|
||||
<Tip warning={true}>
|
||||
|
||||
PyTorch 2.0 introduces a new compile function, you can learn more about it [in their documentation](https://pytorch.org/get-started/pytorch-2.0/). It uses Python’s frame evaluation API to automatically create a graph from existing PyTorch programs. After capturing the graph, different backends can be deployed to lower the graph to an optimized engine. You can choose one option below for performance boost.
|
||||
The PyTorch-native `scaled_dot_product_attention` operator can only dispatch to Flash Attention if no `attention_mask` is provided.
|
||||
|
||||
`torch.compile` has a growing list of backends, which can be found in [backends.py](https://github.com/pytorch/pytorch/blob/master/torch/_dynamo/optimizations/backends.py)
|
||||
or `torchdynamo.list_backends()` each of which with its optional dependencies.
|
||||
By default, in training mode, the BetterTransformer integration **drops the mask support and can only be used for training that does not require a padding mask for batched training**. This is the case, for example, during masked language modeling or causal language modeling. BetterTransformer is not suited for fine-tuning models on tasks that require a padding mask.
|
||||
|
||||
Some of the most commonly used backends are
|
||||
</Tip>
|
||||
|
||||
**Debugging backends**:
|
||||
* `dynamo.optimize("eager")` - Uses PyTorch to run the extracted GraphModule. This is quite useful in debugging TorchDynamo issues.
|
||||
* `dynamo.optimize("aot_eager")` - Uses AotAutograd with no compiler, i.e, just using PyTorch eager for the AotAutograd's extracted forward and backward graphs. This is useful for debugging, and unlikely to give speedups.
|
||||
|
||||
**Training & inference backends**:
|
||||
* `dynamo.optimize("inductor")` - Uses TorchInductor backend with AotAutograd and cudagraphs by leveraging codegened Triton kernels [Read more](https://dev-discuss.pytorch.org/t/torchinductor-a-pytorch-native-compiler-with-define-by-run-ir-and-symbolic-shapes/747)
|
||||
* `dynamo.optimize("nvfuser")` - nvFuser with TorchScript. [Read more](https://dev-discuss.pytorch.org/t/tracing-with-primitives-update-1-nvfuser-and-its-primitives/593)
|
||||
* `dynamo.optimize("aot_nvfuser")` - nvFuser with AotAutograd. [Read more](https://dev-discuss.pytorch.org/t/tracing-with-primitives-update-1-nvfuser-and-its-primitives/593)
|
||||
* `dynamo.optimize("aot_cudagraphs")` - cudagraphs with AotAutograd. [Read more](https://github.com/pytorch/torchdynamo/pull/757)
|
||||
|
||||
**Inference-only backend**s:
|
||||
* `dynamo.optimize("ofi")` - Uses Torchscript optimize_for_inference. [Read more](https://pytorch.org/docs/stable/generated/torch.jit.optimize_for_inference.html)
|
||||
* `dynamo.optimize("fx2trt")` - Uses Nvidia TensorRT for inference optimizations. [Read more](https://github.com/pytorch/TensorRT/blob/master/docsrc/tutorials/getting_started_with_fx_path.rst)
|
||||
* `dynamo.optimize("onnxrt")` - Uses ONNXRT for inference on CPU/GPU. [Read more](https://onnxruntime.ai/)
|
||||
* `dynamo.optimize("ipex")` - Uses IPEX for inference on CPU. [Read more](https://github.com/intel/intel-extension-for-pytorch)
|
||||
Check out this [blogpost](https://pytorch.org/blog/out-of-the-box-acceleration/) to learn more about acceleration and memory-savings with SDPA.
|
||||
@@ -20,77 +20,54 @@ rendered properly in your Markdown viewer.
|
||||
|
||||
# Performance and Scalability
|
||||
|
||||
Training larger and larger transformer models and deploying them to production comes with a range of challenges. During training your model can require more GPU memory than is available or be very slow to train and when you deploy it for inference it can be overwhelmed with the throughput that is required in the production environment. This documentation is designed to help you navigate these challenges and find the best setting for your use-case. We split the guides into training and inference as they come with different challenges and solutions. Then within each of them we have separate guides for different kinds of hardware setting (e.g. single vs. multi-GPU for training or CPU vs. GPU for infrence).
|
||||
Training large transformer models and deploying them to production present various challenges.
|
||||
During training, the model may require more GPU memory than available or exhibit slow training speed. In the deployment
|
||||
phase, the model can struggle to handle the required throughput in a production environment.
|
||||
|
||||
|
||||
This documentation aims to assist you in overcoming these challenges and finding the optimal setting for your use-case.
|
||||
The guides are divided into training and inference sections, as each comes with different challenges and solutions.
|
||||
Within each section you'll find separate guides for different hardware configurations, such as single GPU vs. multi-GPU
|
||||
for training or CPU vs. GPU for inference.
|
||||
|
||||
This document serves as an overview and entry point for the methods that could be useful for your scenario.
|
||||
Use this document as your starting point to navigate further to the methods that match your scenario.
|
||||
|
||||
## Training
|
||||
|
||||
Training transformer models efficiently requires an accelerator such as a GPU or TPU. The most common case is where you only have a single GPU, but there is also a section about multi-GPU and CPU training (with more coming soon).
|
||||
Training large transformer models efficiently requires an accelerator such as a GPU or TPU. The most common case is where
|
||||
you have a single GPU. The methods that you can apply to improve training efficiency on a single GPU extend to other setups
|
||||
such as multiple GPU. However, there are also techniques that are specific to multi-GPU or CPU training. We cover them in
|
||||
separate sections.
|
||||
|
||||
<Tip>
|
||||
|
||||
Note: Most of the strategies introduced in the single GPU sections (such as mixed precision training or gradient accumulation) are generic and apply to training models in general so make sure to have a look at it before diving into the following sections such as multi-GPU or CPU training.
|
||||
|
||||
</Tip>
|
||||
|
||||
### Single GPU
|
||||
|
||||
Training large models on a single GPU can be challenging but there are a number of tools and methods that make it feasible. In this section methods such as mixed precision training, gradient accumulation and checkpointing, efficient optimizers, as well as strategies to determine the best batch size are discussed.
|
||||
|
||||
[Go to single GPU training section](perf_train_gpu_one)
|
||||
|
||||
### Multi-GPU
|
||||
|
||||
In some cases training on a single GPU is still too slow or won't fit the large model. Moving to a multi-GPU setup is the logical step, but training on multiple GPUs at once comes with new decisions: does each GPU have a full copy of the model or is the model itself also distributed? In this section we look at data, tensor, and pipeline parallism.
|
||||
|
||||
[Go to multi-GPU training section](perf_train_gpu_many)
|
||||
|
||||
### CPU
|
||||
|
||||
|
||||
[Go to CPU training section](perf_train_cpu)
|
||||
|
||||
|
||||
### TPU
|
||||
|
||||
[_Coming soon_](perf_train_tpu)
|
||||
|
||||
### Specialized Hardware
|
||||
|
||||
[_Coming soon_](perf_train_special)
|
||||
* [Methods and tools for efficient training on a single GPU](perf_train_gpu_one): start here to learn common approaches that can help optimize GPU memory utilization, speed up the training, or both.
|
||||
* [Multi-GPU training section](perf_train_gpu_many): explore this section to learn about further optimization methods that apply to a multi-GPU settings, such as data, tensor, and pipeline parallelism.
|
||||
* [CPU training section](perf_train_cpu): learn about mixed precision training on CPU.
|
||||
* [Efficient Training on Multiple CPUs](perf_train_cpu_many): learn about distributed CPU training.
|
||||
* [Training on TPU with TensorFlow](perf_train_tpu_tf): if you are new to TPUs, refer to this section for an opinionated introduction to training on TPUs and using XLA.
|
||||
* [Custom hardware for training](perf_hardware): find tips and tricks when building your own deep learning rig.
|
||||
* [Hyperparameter Search using Trainer API](hpo_train)
|
||||
|
||||
## Inference
|
||||
|
||||
Efficient inference with large models in a production environment can be as challenging as training them. In the following sections we go through the steps to run inference on CPU and single/multi-GPU setups.
|
||||
Efficient inference with large models in a production environment can be as challenging as training them. In the following
|
||||
sections we go through the steps to run inference on CPU and single/multi-GPU setups.
|
||||
|
||||
### CPU
|
||||
* [Inference on a single CPU](perf_infer_cpu)
|
||||
* [Inference on a single GPU](perf_infer_gpu_one)
|
||||
* [Multi-GPU inference](perf_infer_gpu_many)
|
||||
* [XLA Integration for TensorFlow Models](tf_xla)
|
||||
|
||||
[Go to CPU inference section](perf_infer_cpu)
|
||||
|
||||
### Single GPU
|
||||
## Training and inference
|
||||
|
||||
[Go to single GPU inference section](perf_infer_gpu_one)
|
||||
|
||||
### Multi-GPU
|
||||
|
||||
[Go to multi-GPU inference section](perf_infer_gpu_many)
|
||||
|
||||
### Specialized Hardware
|
||||
|
||||
[_Coming soon_](perf_infer_special)
|
||||
|
||||
## Hardware
|
||||
|
||||
In the hardware section you can find tips and tricks when building your own deep learning rig.
|
||||
|
||||
[Go to hardware section](perf_hardware)
|
||||
Here you'll find techniques, tips and tricks that apply whether you are training a model, or running inference with it.
|
||||
|
||||
* [Instantiating a big model](big_models)
|
||||
* [Troubleshooting performance issues](debugging)
|
||||
|
||||
## Contribute
|
||||
|
||||
This document is far from being complete and a lot more needs to be added, so if you have additions or corrections to make please don't hesitate to open a PR or if you aren't sure start an Issue and we can discuss the details there.
|
||||
This document is far from being complete and a lot more needs to be added, so if you have additions or corrections to
|
||||
make please don't hesitate to open a PR or if you aren't sure start an Issue and we can discuss the details there.
|
||||
|
||||
When making contributions that A is better than B, please try to include a reproducible benchmark and/or a link to the source of that information (unless it comes directly from you).
|
||||
When making contributions that A is better than B, please try to include a reproducible benchmark and/or a link to the
|
||||
source of that information (unless it comes directly from you).
|
||||
|
||||
@@ -204,7 +204,7 @@ page.
|
||||
|
||||
Using a [`pipeline`] for vision tasks is practically identical.
|
||||
|
||||
Specify your task and pass your image to the classifier. The image can be a link or a local path to the image. For example, what species of cat is shown below?
|
||||
Specify your task and pass your image to the classifier. The image can be a link, a local path or a base64-encoded image. For example, what species of cat is shown below?
|
||||
|
||||

|
||||
|
||||
|
||||
@@ -87,6 +87,13 @@ of the model on the webserver. This way, no unnecessary RAM is being used.
|
||||
Then the queuing mechanism allows you to do fancy stuff like maybe accumulating a few
|
||||
items before inferring to use dynamic batching:
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
The code sample below is intentionally written like pseudo-code for readability.
|
||||
Do not run this without checking if it makes sense for your system resources!
|
||||
|
||||
</Tip>
|
||||
|
||||
```py
|
||||
(string, rq) = await q.get()
|
||||
strings = []
|
||||
@@ -104,11 +111,7 @@ for rq, out in zip(queues, outs):
|
||||
await rq.put(out)
|
||||
```
|
||||
|
||||
<Tip warning={true}>
|
||||
Do not activate this without checking it makes sense for your load!
|
||||
</Tip>
|
||||
|
||||
The proposed code is optimized for readability, not for being the best code.
|
||||
Again, the proposed code is optimized for readability, not for being the best code.
|
||||
First of all, there's no batch size limit which is usually not a
|
||||
great idea. Next, the timeout is reset on every queue fetch, meaning you could
|
||||
wait much more than 1ms before running the inference (delaying the first request
|
||||
|
||||
@@ -142,3 +142,58 @@ Additional checks concern PRs that add new models, mainly that:
|
||||
- All checkpoints used actually exist on the Hub
|
||||
|
||||
-->
|
||||
|
||||
### Check copies
|
||||
|
||||
Since the Transformers library is very opinionated with respect to model code, and each model should fully be implemented in a single file without relying on other models, we have added a mechanism that checks whether a copy of the code of a layer of a given model stays consistent with the original. This way, when there is a bug fix, we can see all other impacted models and choose to trickle down the modification or break the copy.
|
||||
|
||||
<Tip>
|
||||
|
||||
If a file is a full copy of another file, you should register it in the constant `FULL_COPIES` of `utils/check_copies.py`.
|
||||
|
||||
</Tip>
|
||||
|
||||
This mechanism relies on comments of the form `# Copied from xxx`. The `xxx` should contain the whole path to the class of function which is being copied below. For instance, `RobertaSelfOutput` is a direct copy of the `BertSelfOutput` class, so you can see [here](https://github.com/huggingface/transformers/blob/2bd7a27a671fd1d98059124024f580f8f5c0f3b5/src/transformers/models/roberta/modeling_roberta.py#L289) it has a comment:
|
||||
|
||||
```py
|
||||
# Copied from transformers.models.bert.modeling_bert.BertSelfOutput
|
||||
```
|
||||
|
||||
Note that instead of applying this to a whole class, you can apply it to the relevant methods that are copied from. For instance [here](https://github.com/huggingface/transformers/blob/2bd7a27a671fd1d98059124024f580f8f5c0f3b5/src/transformers/models/roberta/modeling_roberta.py#L598) you can see how `RobertaPreTrainedModel._init_weights` is copied from the same method in `BertPreTrainedModel` with the comment:
|
||||
|
||||
```py
|
||||
# Copied from transformers.models.bert.modeling_bert.BertPreTrainedModel._init_weights
|
||||
```
|
||||
|
||||
Sometimes the copy is exactly the same except for names: for instance in `RobertaAttention`, we use `RobertaSelfAttention` insted of `BertSelfAttention` but other than that, the code is exactly the same. This is why `# Copied from` supports simple string replacements with the follwoing syntax: `Copied from xxx with foo->bar`. This means the code is copied with all instances of `foo` being replaced by `bar`. You can see how it used [here](https://github.com/huggingface/transformers/blob/2bd7a27a671fd1d98059124024f580f8f5c0f3b5/src/transformers/models/roberta/modeling_roberta.py#L304C1-L304C86) in `RobertaAttention` with the comment:
|
||||
|
||||
```py
|
||||
# Copied from transformers.models.bert.modeling_bert.BertAttention with Bert->Roberta
|
||||
```
|
||||
|
||||
Note that there shouldn't be any spaces around the arrow (unless that space is part of the pattern to replace of course).
|
||||
|
||||
You can add several patterns separated by a comma. For instance here `CamemberForMaskedLM` is a direct copy of `RobertaForMaskedLM` with two replacements: `Roberta` to `Camembert` and `ROBERTA` to `CAMEMBERT`. You can see [here](https://github.com/huggingface/transformers/blob/15082a9dc6950ecae63a0d3e5060b2fc7f15050a/src/transformers/models/camembert/modeling_camembert.py#L929) this is done with the comment:
|
||||
|
||||
```py
|
||||
# Copied from transformers.models.roberta.modeling_roberta.RobertaForMaskedLM with Roberta->Camembert, ROBERTA->CAMEMBERT
|
||||
```
|
||||
|
||||
If the order matters (because one of the replacements might conflict with a previous one), the replacements are executed from left to right.
|
||||
|
||||
<Tip>
|
||||
|
||||
If the replacements change the formatting (if you replace a short name by a very long name for instance), the copy is checked after applying the auto-formatter.
|
||||
|
||||
</Tip>
|
||||
|
||||
Another way when the patterns are just different casings of the same replacement (with an uppercased and a lowercased variants) is just to add the option `all-casing`. [Here](https://github.com/huggingface/transformers/blob/15082a9dc6950ecae63a0d3e5060b2fc7f15050a/src/transformers/models/mobilebert/modeling_mobilebert.py#L1237) is an example in `MobileBertForSequenceClassification` with the comment:
|
||||
|
||||
```py
|
||||
# Copied from transformers.models.bert.modeling_bert.BertForSequenceClassification with Bert->MobileBert all-casing
|
||||
```
|
||||
|
||||
In this case, the code is copied from `BertForSequenceClassification` by replacing:
|
||||
- `Bert` by `MobileBert` (for instance when using `MobileBertModel` in the init)
|
||||
- `bert` by `mobilebert` (for instance when defining `self.mobilebert`)
|
||||
- `BERT` by `MOBILEBERT` (in the constant `MOBILEBERT_INPUTS_DOCSTRING`)
|
||||
|
||||
@@ -30,11 +30,13 @@ You'll also need to install your preferred machine learning framework:
|
||||
|
||||
<frameworkcontent>
|
||||
<pt>
|
||||
|
||||
```bash
|
||||
pip install torch
|
||||
```
|
||||
</pt>
|
||||
<tf>
|
||||
|
||||
```bash
|
||||
pip install tensorflow
|
||||
```
|
||||
@@ -64,7 +66,7 @@ For a complete list of available tasks, check out the [pipeline API reference](.
|
||||
| Audio classification | assign a label to some audio data | Audio | pipeline(task=“audio-classification”) |
|
||||
| Automatic speech recognition | transcribe speech into text | Audio | pipeline(task=“automatic-speech-recognition”) |
|
||||
| Visual question answering | answer a question about the image, given an image and a question | Multimodal | pipeline(task=“vqa”) |
|
||||
| Document question answering | answer a question about a document, given an image and a question | Multimodal | pipeline(task="document-question-answering") |
|
||||
| Document question answering | answer a question about the document, given a document and a question | Multimodal | pipeline(task="document-question-answering") |
|
||||
| Image captioning | generate a caption for a given image | Multimodal | pipeline(task="image-to-text") |
|
||||
|
||||
Start by creating an instance of [`pipeline`] and specifying a task you want to use it for. In this guide, you'll use the [`pipeline`] for sentiment analysis as an example:
|
||||
@@ -208,6 +210,7 @@ A tokenizer can also accept a list of inputs, and pad and truncate the text to r
|
||||
|
||||
<frameworkcontent>
|
||||
<pt>
|
||||
|
||||
```py
|
||||
>>> pt_batch = tokenizer(
|
||||
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
|
||||
@@ -219,6 +222,7 @@ A tokenizer can also accept a list of inputs, and pad and truncate the text to r
|
||||
```
|
||||
</pt>
|
||||
<tf>
|
||||
|
||||
```py
|
||||
>>> tf_batch = tokenizer(
|
||||
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
|
||||
@@ -289,7 +293,7 @@ See the [task summary](./task_summary) for tasks supported by an [`AutoModel`] c
|
||||
|
||||
</Tip>
|
||||
|
||||
Now pass your preprocessed batch of inputs directly to the model by passing the dictionary keys directly to the tensors:
|
||||
Now pass your preprocessed batch of inputs directly to the model. You can pass the tensors as-is:
|
||||
|
||||
```py
|
||||
>>> tf_outputs = tf_model(tf_batch)
|
||||
@@ -352,6 +356,7 @@ One particularly cool 🤗 Transformers feature is the ability to save a model a
|
||||
|
||||
<frameworkcontent>
|
||||
<pt>
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModel
|
||||
|
||||
@@ -360,6 +365,7 @@ One particularly cool 🤗 Transformers feature is the ability to save a model a
|
||||
```
|
||||
</pt>
|
||||
<tf>
|
||||
|
||||
```py
|
||||
>>> from transformers import TFAutoModel
|
||||
|
||||
@@ -410,7 +416,7 @@ All models are a standard [`torch.nn.Module`](https://pytorch.org/docs/stable/nn
|
||||
|
||||
Depending on your task, you'll typically pass the following parameters to [`Trainer`]:
|
||||
|
||||
1. A [`PreTrainedModel`] or a [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module):
|
||||
1. You'll start with a [`PreTrainedModel`] or a [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module):
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModelForSequenceClassification
|
||||
@@ -432,7 +438,7 @@ Depending on your task, you'll typically pass the following parameters to [`Trai
|
||||
... )
|
||||
```
|
||||
|
||||
3. A preprocessing class like a tokenizer, image processor, feature extractor, or processor:
|
||||
3. Load a preprocessing class like a tokenizer, image processor, feature extractor, or processor:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoTokenizer
|
||||
@@ -512,7 +518,7 @@ All models are a standard [`tf.keras.Model`](https://www.tensorflow.org/api_docs
|
||||
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
|
||||
```
|
||||
|
||||
2. A preprocessing class like a tokenizer, image processor, feature extractor, or processor:
|
||||
2. Load a preprocessing class like a tokenizer, image processor, feature extractor, or processor:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoTokenizer
|
||||
|
||||
@@ -335,7 +335,7 @@ Document question answering is a task that answers natural language questions fr
|
||||
... image=image,
|
||||
... )
|
||||
>>> preds
|
||||
[{'score': 0.8531239628791809, 'answer': '17,000', 'start': 4, 'end': 4}]
|
||||
[{'score': 0.8531, 'answer': '17,000', 'start': 4, 'end': 4}]
|
||||
```
|
||||
|
||||
Hopefully, this page has given you some more background information about all the types of tasks in each modality and the practical importance of each one. In the next [section](tasks_explained), you'll learn **how** 🤗 Transformers work to solve these tasks.
|
||||
@@ -34,7 +34,8 @@ The task illustrated in this tutorial is supported by the following model archit
|
||||
|
||||
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
|
||||
|
||||
[BEiT](../model_doc/beit), [BiT](../model_doc/bit), [ConvNeXT](../model_doc/convnext), [ConvNeXTV2](../model_doc/convnextv2), [CvT](../model_doc/cvt), [Data2VecVision](../model_doc/data2vec-vision), [DeiT](../model_doc/deit), [DiNAT](../model_doc/dinat), [EfficientFormer](../model_doc/efficientformer), [EfficientNet](../model_doc/efficientnet), [FocalNet](../model_doc/focalnet), [ImageGPT](../model_doc/imagegpt), [LeViT](../model_doc/levit), [MobileNetV1](../model_doc/mobilenet_v1), [MobileNetV2](../model_doc/mobilenet_v2), [MobileViT](../model_doc/mobilevit), [MobileViTV2](../model_doc/mobilevitv2), [NAT](../model_doc/nat), [Perceiver](../model_doc/perceiver), [PoolFormer](../model_doc/poolformer), [RegNet](../model_doc/regnet), [ResNet](../model_doc/resnet), [SegFormer](../model_doc/segformer), [SwiftFormer](../model_doc/swiftformer), [Swin Transformer](../model_doc/swin), [Swin Transformer V2](../model_doc/swinv2), [VAN](../model_doc/van), [ViT](../model_doc/vit), [ViT Hybrid](../model_doc/vit_hybrid), [ViTMSN](../model_doc/vit_msn)
|
||||
[BEiT](../model_doc/beit), [BiT](../model_doc/bit), [ConvNeXT](../model_doc/convnext), [ConvNeXTV2](../model_doc/convnextv2), [CvT](../model_doc/cvt), [Data2VecVision](../model_doc/data2vec-vision), [DeiT](../model_doc/deit), [DiNAT](../model_doc/dinat), [DINOv2](../model_doc/dinov2), [EfficientFormer](../model_doc/efficientformer), [EfficientNet](../model_doc/efficientnet), [FocalNet](../model_doc/focalnet), [ImageGPT](../model_doc/imagegpt), [LeViT](../model_doc/levit), [MobileNetV1](../model_doc/mobilenet_v1), [MobileNetV2](../model_doc/mobilenet_v2), [MobileViT](../model_doc/mobilevit), [MobileViTV2](../model_doc/mobilevitv2), [NAT](../model_doc/nat), [Perceiver](../model_doc/perceiver), [PoolFormer](../model_doc/poolformer), [PVT](../model_doc/pvt), [RegNet](../model_doc/regnet), [ResNet](../model_doc/resnet), [SegFormer](../model_doc/segformer), [SwiftFormer](../model_doc/swiftformer), [Swin Transformer](../model_doc/swin), [Swin Transformer V2](../model_doc/swinv2), [VAN](../model_doc/van), [ViT](../model_doc/vit), [ViT Hybrid](../model_doc/vit_hybrid), [ViTMSN](../model_doc/vit_msn)
|
||||
|
||||
<!--End of the generated tip-->
|
||||
|
||||
</Tip>
|
||||
|
||||
@@ -37,7 +37,8 @@ You can finetune other architectures for causal language modeling following the
|
||||
Choose one of the following architectures:
|
||||
|
||||
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
|
||||
[BART](../model_doc/bart), [BERT](../model_doc/bert), [Bert Generation](../model_doc/bert-generation), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BioGpt](../model_doc/biogpt), [Blenderbot](../model_doc/blenderbot), [BlenderbotSmall](../model_doc/blenderbot-small), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CodeGen](../model_doc/codegen), [CPM-Ant](../model_doc/cpmant), [CTRL](../model_doc/ctrl), [Data2VecText](../model_doc/data2vec-text), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [Falcon](../model_doc/falcon), [GIT](../model_doc/git), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT NeoX Japanese](../model_doc/gpt_neox_japanese), [GPT-J](../model_doc/gptj), [LLaMA](../model_doc/llama), [Marian](../model_doc/marian), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [MusicGen](../model_doc/musicgen), [MVP](../model_doc/mvp), [OpenLlama](../model_doc/open-llama), [OpenAI GPT](../model_doc/openai-gpt), [OPT](../model_doc/opt), [Pegasus](../model_doc/pegasus), [PLBart](../model_doc/plbart), [ProphetNet](../model_doc/prophetnet), [QDQBert](../model_doc/qdqbert), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [RWKV](../model_doc/rwkv), [Speech2Text2](../model_doc/speech_to_text_2), [Transformer-XL](../model_doc/transfo-xl), [TrOCR](../model_doc/trocr), [XGLM](../model_doc/xglm), [XLM](../model_doc/xlm), [XLM-ProphetNet](../model_doc/xlm-prophetnet), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod)
|
||||
[BART](../model_doc/bart), [BERT](../model_doc/bert), [Bert Generation](../model_doc/bert-generation), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BioGpt](../model_doc/biogpt), [Blenderbot](../model_doc/blenderbot), [BlenderbotSmall](../model_doc/blenderbot-small), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CodeLlama](../model_doc/code_llama), [CodeGen](../model_doc/codegen), [CPM-Ant](../model_doc/cpmant), [CTRL](../model_doc/ctrl), [Data2VecText](../model_doc/data2vec-text), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [Falcon](../model_doc/falcon), [GIT](../model_doc/git), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT NeoX Japanese](../model_doc/gpt_neox_japanese), [GPT-J](../model_doc/gptj), [LLaMA](../model_doc/llama), [Marian](../model_doc/marian), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [MPT](../model_doc/mpt), [MusicGen](../model_doc/musicgen), [MVP](../model_doc/mvp), [OpenLlama](../model_doc/open-llama), [OpenAI GPT](../model_doc/openai-gpt), [OPT](../model_doc/opt), [Pegasus](../model_doc/pegasus), [PLBart](../model_doc/plbart), [ProphetNet](../model_doc/prophetnet), [QDQBert](../model_doc/qdqbert), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [RWKV](../model_doc/rwkv), [Speech2Text2](../model_doc/speech_to_text_2), [Transformer-XL](../model_doc/transfo-xl), [TrOCR](../model_doc/trocr), [XGLM](../model_doc/xglm), [XLM](../model_doc/xlm), [XLM-ProphetNet](../model_doc/xlm-prophetnet), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod)
|
||||
|
||||
|
||||
|
||||
<!--End of the generated tip-->
|
||||
@@ -153,7 +154,7 @@ This dataset contains the token sequences, but some of these are longer than the
|
||||
|
||||
You can now use a second preprocessing function to
|
||||
- concatenate all the sequences
|
||||
- split the concatenated sequences into shorter chunks defined by `block_size`, which should be both shorter than the maximum input length and short enough for your GPU RAM.
|
||||
- split the concatenated sequences into shorter chunks defined by `block_size`, which should be both shorter than the maximum input length and short enough for your GPU RAM.
|
||||
|
||||
```py
|
||||
>>> block_size = 128
|
||||
|
||||
@@ -35,7 +35,8 @@ The task illustrated in this tutorial is supported by the following model archit
|
||||
|
||||
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
|
||||
|
||||
[ALBERT](../model_doc/albert), [BART](../model_doc/bart), [BERT](../model_doc/bert), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CANINE](../model_doc/canine), [ConvBERT](../model_doc/convbert), [Data2VecText](../model_doc/data2vec-text), [DeBERTa](../model_doc/deberta), [DeBERTa-v2](../model_doc/deberta-v2), [DistilBERT](../model_doc/distilbert), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [ErnieM](../model_doc/ernie_m), [Falcon](../model_doc/falcon), [FlauBERT](../model_doc/flaubert), [FNet](../model_doc/fnet), [Funnel Transformer](../model_doc/funnel), [OpenAI GPT-2](../model_doc/gpt2), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT-J](../model_doc/gptj), [I-BERT](../model_doc/ibert), [LayoutLMv2](../model_doc/layoutlmv2), [LayoutLMv3](../model_doc/layoutlmv3), [LED](../model_doc/led), [LiLT](../model_doc/lilt), [Longformer](../model_doc/longformer), [LUKE](../model_doc/luke), [LXMERT](../model_doc/lxmert), [MarkupLM](../model_doc/markuplm), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [MobileBERT](../model_doc/mobilebert), [MPNet](../model_doc/mpnet), [MRA](../model_doc/mra), [MT5](../model_doc/mt5), [MVP](../model_doc/mvp), [Nezha](../model_doc/nezha), [Nyströmformer](../model_doc/nystromformer), [OPT](../model_doc/opt), [QDQBert](../model_doc/qdqbert), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [Splinter](../model_doc/splinter), [SqueezeBERT](../model_doc/squeezebert), [T5](../model_doc/t5), [UMT5](../model_doc/umt5), [XLM](../model_doc/xlm), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod), [YOSO](../model_doc/yoso)
|
||||
|
||||
[ALBERT](../model_doc/albert), [BART](../model_doc/bart), [BERT](../model_doc/bert), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CANINE](../model_doc/canine), [ConvBERT](../model_doc/convbert), [Data2VecText](../model_doc/data2vec-text), [DeBERTa](../model_doc/deberta), [DeBERTa-v2](../model_doc/deberta-v2), [DistilBERT](../model_doc/distilbert), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [ErnieM](../model_doc/ernie_m), [Falcon](../model_doc/falcon), [FlauBERT](../model_doc/flaubert), [FNet](../model_doc/fnet), [Funnel Transformer](../model_doc/funnel), [OpenAI GPT-2](../model_doc/gpt2), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT-J](../model_doc/gptj), [I-BERT](../model_doc/ibert), [LayoutLMv2](../model_doc/layoutlmv2), [LayoutLMv3](../model_doc/layoutlmv3), [LED](../model_doc/led), [LiLT](../model_doc/lilt), [Longformer](../model_doc/longformer), [LUKE](../model_doc/luke), [LXMERT](../model_doc/lxmert), [MarkupLM](../model_doc/markuplm), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [MobileBERT](../model_doc/mobilebert), [MPNet](../model_doc/mpnet), [MPT](../model_doc/mpt), [MRA](../model_doc/mra), [MT5](../model_doc/mt5), [MVP](../model_doc/mvp), [Nezha](../model_doc/nezha), [Nyströmformer](../model_doc/nystromformer), [OPT](../model_doc/opt), [QDQBert](../model_doc/qdqbert), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [Splinter](../model_doc/splinter), [SqueezeBERT](../model_doc/squeezebert), [T5](../model_doc/t5), [UMT5](../model_doc/umt5), [XLM](../model_doc/xlm), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod), [YOSO](../model_doc/yoso)
|
||||
|
||||
|
||||
<!--End of the generated tip-->
|
||||
|
||||
@@ -221,6 +221,10 @@ logits first, and then reshaped to match the size of the labels before you can c
|
||||
<pt>
|
||||
|
||||
```py
|
||||
>>> import numpy as np
|
||||
>>> import torch
|
||||
>>> from torch import nn
|
||||
|
||||
>>> def compute_metrics(eval_pred):
|
||||
... with torch.no_grad():
|
||||
... logits, labels = eval_pred
|
||||
|
||||
@@ -32,7 +32,9 @@ The task illustrated in this tutorial is supported by the following model archit
|
||||
|
||||
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
|
||||
|
||||
[ALBERT](../model_doc/albert), [BART](../model_doc/bart), [BERT](../model_doc/bert), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BioGpt](../model_doc/biogpt), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CANINE](../model_doc/canine), [ConvBERT](../model_doc/convbert), [CTRL](../model_doc/ctrl), [Data2VecText](../model_doc/data2vec-text), [DeBERTa](../model_doc/deberta), [DeBERTa-v2](../model_doc/deberta-v2), [DistilBERT](../model_doc/distilbert), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [ErnieM](../model_doc/ernie_m), [ESM](../model_doc/esm), [Falcon](../model_doc/falcon), [FlauBERT](../model_doc/flaubert), [FNet](../model_doc/fnet), [Funnel Transformer](../model_doc/funnel), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT-J](../model_doc/gptj), [I-BERT](../model_doc/ibert), [LayoutLM](../model_doc/layoutlm), [LayoutLMv2](../model_doc/layoutlmv2), [LayoutLMv3](../model_doc/layoutlmv3), [LED](../model_doc/led), [LiLT](../model_doc/lilt), [LLaMA](../model_doc/llama), [Longformer](../model_doc/longformer), [LUKE](../model_doc/luke), [MarkupLM](../model_doc/markuplm), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [MobileBERT](../model_doc/mobilebert), [MPNet](../model_doc/mpnet), [MRA](../model_doc/mra), [MVP](../model_doc/mvp), [Nezha](../model_doc/nezha), [Nyströmformer](../model_doc/nystromformer), [OpenLlama](../model_doc/open-llama), [OpenAI GPT](../model_doc/openai-gpt), [OPT](../model_doc/opt), [Perceiver](../model_doc/perceiver), [PLBart](../model_doc/plbart), [QDQBert](../model_doc/qdqbert), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [SqueezeBERT](../model_doc/squeezebert), [TAPAS](../model_doc/tapas), [Transformer-XL](../model_doc/transfo-xl), [XLM](../model_doc/xlm), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod), [YOSO](../model_doc/yoso)
|
||||
|
||||
[ALBERT](../model_doc/albert), [BART](../model_doc/bart), [BERT](../model_doc/bert), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BioGpt](../model_doc/biogpt), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CANINE](../model_doc/canine), [CodeLlama](../model_doc/code_llama), [ConvBERT](../model_doc/convbert), [CTRL](../model_doc/ctrl), [Data2VecText](../model_doc/data2vec-text), [DeBERTa](../model_doc/deberta), [DeBERTa-v2](../model_doc/deberta-v2), [DistilBERT](../model_doc/distilbert), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [ErnieM](../model_doc/ernie_m), [ESM](../model_doc/esm), [Falcon](../model_doc/falcon), [FlauBERT](../model_doc/flaubert), [FNet](../model_doc/fnet), [Funnel Transformer](../model_doc/funnel), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT-J](../model_doc/gptj), [I-BERT](../model_doc/ibert), [LayoutLM](../model_doc/layoutlm), [LayoutLMv2](../model_doc/layoutlmv2), [LayoutLMv3](../model_doc/layoutlmv3), [LED](../model_doc/led), [LiLT](../model_doc/lilt), [LLaMA](../model_doc/llama), [Longformer](../model_doc/longformer), [LUKE](../model_doc/luke), [MarkupLM](../model_doc/markuplm), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [MobileBERT](../model_doc/mobilebert), [MPNet](../model_doc/mpnet), [MPT](../model_doc/mpt), [MRA](../model_doc/mra), [MT5](../model_doc/mt5), [MVP](../model_doc/mvp), [Nezha](../model_doc/nezha), [Nyströmformer](../model_doc/nystromformer), [OpenLlama](../model_doc/open-llama), [OpenAI GPT](../model_doc/openai-gpt), [OPT](../model_doc/opt), [Perceiver](../model_doc/perceiver), [PLBart](../model_doc/plbart), [QDQBert](../model_doc/qdqbert), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [SqueezeBERT](../model_doc/squeezebert), [T5](../model_doc/t5), [TAPAS](../model_doc/tapas), [Transformer-XL](../model_doc/transfo-xl), [UMT5](../model_doc/umt5), [XLM](../model_doc/xlm), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod), [YOSO](../model_doc/yoso)
|
||||
|
||||
|
||||
|
||||
<!--End of the generated tip-->
|
||||
|
||||
@@ -32,7 +32,8 @@ The task illustrated in this tutorial is supported by the following model archit
|
||||
|
||||
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
|
||||
|
||||
[ALBERT](../model_doc/albert), [BERT](../model_doc/bert), [BigBird](../model_doc/big_bird), [BioGpt](../model_doc/biogpt), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CANINE](../model_doc/canine), [ConvBERT](../model_doc/convbert), [Data2VecText](../model_doc/data2vec-text), [DeBERTa](../model_doc/deberta), [DeBERTa-v2](../model_doc/deberta-v2), [DistilBERT](../model_doc/distilbert), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [ErnieM](../model_doc/ernie_m), [ESM](../model_doc/esm), [Falcon](../model_doc/falcon), [FlauBERT](../model_doc/flaubert), [FNet](../model_doc/fnet), [Funnel Transformer](../model_doc/funnel), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [I-BERT](../model_doc/ibert), [LayoutLM](../model_doc/layoutlm), [LayoutLMv2](../model_doc/layoutlmv2), [LayoutLMv3](../model_doc/layoutlmv3), [LiLT](../model_doc/lilt), [Longformer](../model_doc/longformer), [LUKE](../model_doc/luke), [MarkupLM](../model_doc/markuplm), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [MobileBERT](../model_doc/mobilebert), [MPNet](../model_doc/mpnet), [MRA](../model_doc/mra), [Nezha](../model_doc/nezha), [Nyströmformer](../model_doc/nystromformer), [QDQBert](../model_doc/qdqbert), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [SqueezeBERT](../model_doc/squeezebert), [XLM](../model_doc/xlm), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod), [YOSO](../model_doc/yoso)
|
||||
[ALBERT](../model_doc/albert), [BERT](../model_doc/bert), [BigBird](../model_doc/big_bird), [BioGpt](../model_doc/biogpt), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CANINE](../model_doc/canine), [ConvBERT](../model_doc/convbert), [Data2VecText](../model_doc/data2vec-text), [DeBERTa](../model_doc/deberta), [DeBERTa-v2](../model_doc/deberta-v2), [DistilBERT](../model_doc/distilbert), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [ErnieM](../model_doc/ernie_m), [ESM](../model_doc/esm), [Falcon](../model_doc/falcon), [FlauBERT](../model_doc/flaubert), [FNet](../model_doc/fnet), [Funnel Transformer](../model_doc/funnel), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [I-BERT](../model_doc/ibert), [LayoutLM](../model_doc/layoutlm), [LayoutLMv2](../model_doc/layoutlmv2), [LayoutLMv3](../model_doc/layoutlmv3), [LiLT](../model_doc/lilt), [Longformer](../model_doc/longformer), [LUKE](../model_doc/luke), [MarkupLM](../model_doc/markuplm), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [MobileBERT](../model_doc/mobilebert), [MPNet](../model_doc/mpnet), [MPT](../model_doc/mpt), [MRA](../model_doc/mra), [Nezha](../model_doc/nezha), [Nyströmformer](../model_doc/nystromformer), [QDQBert](../model_doc/qdqbert), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [SqueezeBERT](../model_doc/squeezebert), [XLM](../model_doc/xlm), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod), [YOSO](../model_doc/yoso)
|
||||
|
||||
|
||||
<!--End of the generated tip-->
|
||||
|
||||
|
||||
401
docs/source/en/tasks/visual_question_answering.md
Normal file
401
docs/source/en/tasks/visual_question_answering.md
Normal file
@@ -0,0 +1,401 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Visual Question Answering
|
||||
|
||||
[[open-in-colab]]
|
||||
|
||||
Visual Question Answering (VQA) is the task of answering open-ended questions based on an image.
|
||||
The input to models supporting this task is typically a combination of an image and a question, and the output is an
|
||||
answer expressed in natural language.
|
||||
|
||||
Some noteworthy use case examples for VQA include:
|
||||
* Accessibility applications for visually impaired individuals.
|
||||
* Education: posing questions about visual materials presented in lectures or textbooks. VQA can also be utilized in interactive museum exhibits or historical sites.
|
||||
* Customer service and e-commerce: VQA can enhance user experience by letting users ask questions about products.
|
||||
* Image retrieval: VQA models can be used to retrieve images with specific characteristics. For example, the user can ask "Is there a dog?" to find all images with dogs from a set of images.
|
||||
|
||||
In this guide you'll learn how to:
|
||||
|
||||
- Fine-tune a classification VQA model, specifically [ViLT](../model_doc/vilt), on the [`Graphcore/vqa` dataset](https://huggingface.co/datasets/Graphcore/vqa).
|
||||
- Use your fine-tuned ViLT for inference.
|
||||
- Run zero-shot VQA inference with a generative model, like BLIP-2.
|
||||
|
||||
## Fine-tuning ViLT
|
||||
|
||||
ViLT model incorporates text embeddings into a Vision Transformer (ViT), allowing it to have a minimal design for
|
||||
Vision-and-Language Pre-training (VLP). This model can be used for several downstream tasks. For the VQA task, a classifier
|
||||
head is placed on top (a linear layer on top of the final hidden state of the `[CLS]` token) and randomly initialized.
|
||||
Visual Question Answering is thus treated as a **classification problem**.
|
||||
|
||||
More recent models, such as BLIP, BLIP-2, and InstructBLIP, treat VQA as a generative task. Later in this guide we
|
||||
illustrate how to use them for zero-shot VQA inference.
|
||||
|
||||
Before you begin, make sure you have all the necessary libraries installed.
|
||||
|
||||
```bash
|
||||
pip install -q transformers datasets
|
||||
```
|
||||
|
||||
We encourage you to share your model with the community. Log in to your Hugging Face account to upload it to the 🤗 Hub.
|
||||
When prompted, enter your token to log in:
|
||||
|
||||
```py
|
||||
>>> from huggingface_hub import notebook_login
|
||||
|
||||
>>> notebook_login()
|
||||
```
|
||||
|
||||
Let's define the model checkpoint as a global variable.
|
||||
|
||||
```py
|
||||
>>> model_checkpoint = "dandelin/vilt-b32-mlm"
|
||||
```
|
||||
|
||||
## Load the data
|
||||
|
||||
For illustration purposes, in this guide we use a very small sample of the annotated visual question answering `Graphcore/vqa` dataset.
|
||||
You can find the full dataset on [🤗 Hub](https://huggingface.co/datasets/Graphcore/vqa).
|
||||
|
||||
As an alternative to the [`Graphcore/vqa` dataset](https://huggingface.co/datasets/Graphcore/vqa), you can download the
|
||||
same data manually from the official [VQA dataset page](https://visualqa.org/download.html). If you prefer to follow the
|
||||
tutorial with your custom data, check out how to [Create an image dataset](https://huggingface.co/docs/datasets/image_dataset#loading-script)
|
||||
guide in the 🤗 Datasets documentation.
|
||||
|
||||
Let's load the first 200 examples from the validation split and explore the dataset's features:
|
||||
|
||||
```python
|
||||
>>> from datasets import load_dataset
|
||||
|
||||
>>> dataset = load_dataset("Graphcore/vqa", split="validation[:200]")
|
||||
>>> dataset
|
||||
Dataset({
|
||||
features: ['question', 'question_type', 'question_id', 'image_id', 'answer_type', 'label'],
|
||||
num_rows: 200
|
||||
})
|
||||
```
|
||||
|
||||
Let's take a look at an example to understand the dataset's features:
|
||||
|
||||
```py
|
||||
>>> dataset[0]
|
||||
{'question': 'Where is he looking?',
|
||||
'question_type': 'none of the above',
|
||||
'question_id': 262148000,
|
||||
'image_id': '/root/.cache/huggingface/datasets/downloads/extracted/ca733e0e000fb2d7a09fbcc94dbfe7b5a30750681d0e965f8e0a23b1c2f98c75/val2014/COCO_val2014_000000262148.jpg',
|
||||
'answer_type': 'other',
|
||||
'label': {'ids': ['at table', 'down', 'skateboard', 'table'],
|
||||
'weights': [0.30000001192092896,
|
||||
1.0,
|
||||
0.30000001192092896,
|
||||
0.30000001192092896]}}
|
||||
```
|
||||
|
||||
The features relevant to the task include:
|
||||
* `question`: the question to be answered from the image
|
||||
* `image_id`: the path to the image the question refers to
|
||||
* `label`: the annotations
|
||||
|
||||
We can remove the rest of the features as they won't be necessary:
|
||||
|
||||
```py
|
||||
>>> dataset = dataset.remove_columns(['question_type', 'question_id', 'answer_type'])
|
||||
```
|
||||
|
||||
As you can see, the `label` feature contains several answers to the same question (called `ids` here) collected by different human annotators.
|
||||
This is because the answer to a question can be subjective. In this case, the question is "where is he looking?". Some people
|
||||
annotated this with "down", others with "at table", another one with "skateboard", etc.
|
||||
|
||||
Take a look at the image and consider which answer would you give:
|
||||
|
||||
```python
|
||||
>>> from PIL import Image
|
||||
|
||||
>>> image = Image.open(dataset[0]['image_id'])
|
||||
>>> image
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/vqa-example.png" alt="VQA Image Example"/>
|
||||
</div>
|
||||
|
||||
Due to the questions' and answers' ambiguity, datasets like this are treated as a multi-label classification problem (as
|
||||
multiple answers are possibly valid). Moreover, rather than just creating a one-hot encoded vector, one creates a
|
||||
soft encoding, based on the number of times a certain answer appeared in the annotations.
|
||||
|
||||
For instance, in the example above, because the answer "down" is selected way more often than other answers, it has a
|
||||
score (called `weight` in the dataset) of 1.0, and the rest of the answers have scores < 1.0.
|
||||
|
||||
To later instantiate the model with an appropriate classification head, let's create two dictionaries: one that maps
|
||||
the label name to an integer and vice versa:
|
||||
|
||||
```py
|
||||
>>> import itertools
|
||||
|
||||
>>> labels = [item['ids'] for item in dataset['label']]
|
||||
>>> flattened_labels = list(itertools.chain(*labels))
|
||||
>>> unique_labels = list(set(flattened_labels))
|
||||
|
||||
>>> label2id = {label: idx for idx, label in enumerate(unique_labels)}
|
||||
>>> id2label = {idx: label for label, idx in label2id.items()}
|
||||
```
|
||||
|
||||
Now that we have the mappings, we can replace the string answers with their ids, and flatten the dataset for a more convenient further preprocessing.
|
||||
|
||||
```python
|
||||
>>> def replace_ids(inputs):
|
||||
... inputs["label"]["ids"] = [label2id[x] for x in inputs["label"]["ids"]]
|
||||
... return inputs
|
||||
|
||||
|
||||
>>> dataset = dataset.map(replace_ids)
|
||||
>>> flat_dataset = dataset.flatten()
|
||||
>>> flat_dataset.features
|
||||
{'question': Value(dtype='string', id=None),
|
||||
'image_id': Value(dtype='string', id=None),
|
||||
'label.ids': Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None),
|
||||
'label.weights': Sequence(feature=Value(dtype='float64', id=None), length=-1, id=None)}
|
||||
```
|
||||
|
||||
## Preprocessing data
|
||||
|
||||
The next step is to load a ViLT processor to prepare the image and text data for the model.
|
||||
[`ViltProcessor`] wraps a BERT tokenizer and ViLT image processor into a convenient single processor:
|
||||
|
||||
```py
|
||||
>>> from transformers import ViltProcessor
|
||||
|
||||
>>> processor = ViltProcessor.from_pretrained(model_checkpoint)
|
||||
```
|
||||
|
||||
To preprocess the data we need to encode the images and questions using the [`ViltProcessor`]. The processor will use
|
||||
the [`BertTokenizerFast`] to tokenize the text and create `input_ids`, `attention_mask` and `token_type_ids` for the text data.
|
||||
As for images, the processor will leverage [`ViltImageProcessor`] to resize and normalize the image, and create `pixel_values` and `pixel_mask`.
|
||||
|
||||
All these preprocessing steps are done under the hood, we only need to call the `processor`. However, we still need to
|
||||
prepare the target labels. In this representation, each element corresponds to a possible answer (label). For correct answers, the element holds
|
||||
their respective score (weight), while the remaining elements are set to zero.
|
||||
|
||||
The following function applies the `processor` to the images and questions and formats the labels as described above:
|
||||
|
||||
```py
|
||||
>>> import torch
|
||||
|
||||
>>> def preprocess_data(examples):
|
||||
... image_paths = examples['image_id']
|
||||
... images = [Image.open(image_path) for image_path in image_paths]
|
||||
... texts = examples['question']
|
||||
|
||||
... encoding = processor(images, texts, padding="max_length", truncation=True, return_tensors="pt")
|
||||
|
||||
... for k, v in encoding.items():
|
||||
... encoding[k] = v.squeeze()
|
||||
|
||||
... targets = []
|
||||
|
||||
... for labels, scores in zip(examples['label.ids'], examples['label.weights']):
|
||||
... target = torch.zeros(len(id2label))
|
||||
|
||||
... for label, score in zip(labels, scores):
|
||||
... target[label] = score
|
||||
|
||||
... targets.append(target)
|
||||
|
||||
... encoding["labels"] = targets
|
||||
|
||||
... return encoding
|
||||
```
|
||||
|
||||
To apply the preprocessing function over the entire dataset, use 🤗 Datasets [`~datasets.map`] function. You can speed up `map` by
|
||||
setting `batched=True` to process multiple elements of the dataset at once. At this point, feel free to remove the columns you don't need.
|
||||
|
||||
```py
|
||||
>>> processed_dataset = flat_dataset.map(preprocess_data, batched=True, remove_columns=['question','question_type', 'question_id', 'image_id', 'answer_type', 'label.ids', 'label.weights'])
|
||||
>>> processed_dataset
|
||||
Dataset({
|
||||
features: ['input_ids', 'token_type_ids', 'attention_mask', 'pixel_values', 'pixel_mask', 'labels'],
|
||||
num_rows: 200
|
||||
})
|
||||
```
|
||||
|
||||
As a final step, create a batch of examples using [`DefaultDataCollator`]:
|
||||
|
||||
```py
|
||||
>>> from transformers import DefaultDataCollator
|
||||
|
||||
>>> data_collator = DefaultDataCollator()
|
||||
```
|
||||
|
||||
## Train the model
|
||||
|
||||
You’re ready to start training your model now! Load ViLT with [`ViltForQuestionAnswering`]. Specify the number of labels
|
||||
along with the label mappings:
|
||||
|
||||
```py
|
||||
>>> from transformers import ViltForQuestionAnswering
|
||||
|
||||
>>> model = ViltForQuestionAnswering.from_pretrained(model_checkpoint, num_labels=len(id2label), id2label=id2label, label2id=label2id)
|
||||
```
|
||||
|
||||
At this point, only three steps remain:
|
||||
|
||||
1. Define your training hyperparameters in [`TrainingArguments`]:
|
||||
|
||||
```py
|
||||
>>> from transformers import TrainingArguments
|
||||
|
||||
>>> repo_id = "MariaK/vilt_finetuned_200"
|
||||
|
||||
>>> training_args = TrainingArguments(
|
||||
... output_dir=repo_id,
|
||||
... per_device_train_batch_size=4,
|
||||
... num_train_epochs=20,
|
||||
... save_steps=200,
|
||||
... logging_steps=50,
|
||||
... learning_rate=5e-5,
|
||||
... save_total_limit=2,
|
||||
... remove_unused_columns=False,
|
||||
... push_to_hub=True,
|
||||
... )
|
||||
```
|
||||
|
||||
2. Pass the training arguments to [`Trainer`] along with the model, dataset, processor, and data collator.
|
||||
|
||||
```py
|
||||
>>> from transformers import Trainer
|
||||
|
||||
>>> trainer = Trainer(
|
||||
... model=model,
|
||||
... args=training_args,
|
||||
... data_collator=data_collator,
|
||||
... train_dataset=processed_dataset,
|
||||
... tokenizer=processor,
|
||||
... )
|
||||
```
|
||||
|
||||
3. Call [`~Trainer.train`] to finetune your model.
|
||||
|
||||
```py
|
||||
>>> trainer.train()
|
||||
```
|
||||
|
||||
Once training is completed, share your model to the Hub with the [`~Trainer.push_to_hub`] method to share your final model on the 🤗 Hub:
|
||||
|
||||
```py
|
||||
>>> trainer.push_to_hub()
|
||||
```
|
||||
|
||||
## Inference
|
||||
|
||||
Now that you have fine-tuned a ViLT model, and uploaded it to the 🤗 Hub, you can use it for inference. The simplest
|
||||
way to try out your fine-tuned model for inference is to use it in a [`Pipeline`].
|
||||
|
||||
```py
|
||||
>>> from transformers import pipeline
|
||||
|
||||
>>> pipe = pipeline("visual-question-answering", model="MariaK/vilt_finetuned_200")
|
||||
```
|
||||
|
||||
The model in this guide has only been trained on 200 examples, so don't expect a lot from it. Let's see if it at least
|
||||
learned something from the data and take the first example from the dataset to illustrate inference:
|
||||
|
||||
```py
|
||||
>>> example = dataset[0]
|
||||
>>> image = Image.open(example['image_id'])
|
||||
>>> question = example['question']
|
||||
>>> print(question)
|
||||
>>> pipe(image, question, top_k=1)
|
||||
"Where is he looking?"
|
||||
[{'score': 0.5498199462890625, 'answer': 'down'}]
|
||||
```
|
||||
|
||||
Even though not very confident, the model indeed has learned something. With more examples and longer training, you'll get far better results!
|
||||
|
||||
You can also manually replicate the results of the pipeline if you'd like:
|
||||
1. Take an image and a question, prepare them for the model using the processor from your model.
|
||||
2. Forward the result or preprocessing through the model.
|
||||
3. From the logits, get the most likely answer's id, and find the actual answer in the `id2label`.
|
||||
|
||||
```py
|
||||
>>> processor = ViltProcessor.from_pretrained("MariaK/vilt_finetuned_200")
|
||||
|
||||
>>> image = Image.open(example['image_id'])
|
||||
>>> question = example['question']
|
||||
|
||||
>>> # prepare inputs
|
||||
>>> inputs = processor(image, question, return_tensors="pt")
|
||||
|
||||
>>> model = ViltForQuestionAnswering.from_pretrained("MariaK/vilt_finetuned_200")
|
||||
|
||||
>>> # forward pass
|
||||
>>> with torch.no_grad():
|
||||
... outputs = model(**inputs)
|
||||
|
||||
>>> logits = outputs.logits
|
||||
>>> idx = logits.argmax(-1).item()
|
||||
>>> print("Predicted answer:", model.config.id2label[idx])
|
||||
Predicted answer: down
|
||||
```
|
||||
|
||||
## Zero-shot VQA
|
||||
|
||||
The previous model treated VQA as a classification task. Some recent models, such as BLIP, BLIP-2, and InstructBLIP approach
|
||||
VQA as a generative task. Let's take [BLIP-2](../model_doc/blip-2) as an example. It introduced a new visual-language pre-training
|
||||
paradigm in which any combination of pre-trained vision encoder and LLM can be used (learn more in the [BLIP-2 blog post](https://huggingface.co/blog/blip-2)).
|
||||
This enables achieving state-of-the-art results on multiple visual-language tasks including visual question answering.
|
||||
|
||||
Let's illustrate how you can use this model for VQA. First, let's load the model. Here we'll explicitly send the model to a
|
||||
GPU, if available, which we didn't need to do earlier when training, as [`Trainer`] handles this automatically:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoProcessor, Blip2ForConditionalGeneration
|
||||
>>> import torch
|
||||
|
||||
>>> processor = AutoProcessor.from_pretrained("Salesforce/blip2-opt-2.7b")
|
||||
>>> model = Blip2ForConditionalGeneration.from_pretrained("Salesforce/blip2-opt-2.7b", torch_dtype=torch.float16)
|
||||
>>> device = "cuda" if torch.cuda.is_available() else "cpu"
|
||||
>>> model.to(device)
|
||||
```
|
||||
|
||||
The model takes image and text as input, so let's use the exact same image/question pair from the first example in the VQA dataset:
|
||||
|
||||
```py
|
||||
>>> example = dataset[0]
|
||||
>>> image = Image.open(example['image_id'])
|
||||
>>> question = example['question']
|
||||
```
|
||||
|
||||
To use BLIP-2 for visual question answering task, the textual prompt has to follow a specific format: `Question: {} Answer:`.
|
||||
|
||||
```py
|
||||
>>> prompt = f"Question: {question} Answer:"
|
||||
```
|
||||
|
||||
Now we need to preprocess the image/prompt with the model's processor, pass the processed input through the model, and decode the output:
|
||||
|
||||
```py
|
||||
>>> inputs = processor(image, text=prompt, return_tensors="pt").to(device, torch.float16)
|
||||
|
||||
>>> generated_ids = model.generate(**inputs, max_new_tokens=10)
|
||||
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
|
||||
>>> print(generated_text)
|
||||
"He is looking at the crowd"
|
||||
```
|
||||
|
||||
As you can see, the model recognized the crowd, and the direction of the face (looking down), however, it seems to miss
|
||||
the fact the crowd is behind the skater. Still, in cases where acquiring human-annotated datasets is not feasible, this
|
||||
approach can quickly produce useful results.
|
||||
|
||||
@@ -112,7 +112,7 @@ pytest tests/test_optimization.py --collect-only -q
|
||||
To run an individual test module:
|
||||
|
||||
```bash
|
||||
pytest tests/test_logging.py
|
||||
pytest tests/utils/test_logging.py
|
||||
```
|
||||
|
||||
### Run specific tests
|
||||
@@ -432,14 +432,14 @@ pytest --instafail
|
||||
On a GPU-enabled setup, to test in CPU-only mode add `CUDA_VISIBLE_DEVICES=""`:
|
||||
|
||||
```bash
|
||||
CUDA_VISIBLE_DEVICES="" pytest tests/test_logging.py
|
||||
CUDA_VISIBLE_DEVICES="" pytest tests/utils/test_logging.py
|
||||
```
|
||||
|
||||
or if you have multiple gpus, you can specify which one is to be used by `pytest`. For example, to use only the
|
||||
second gpu if you have gpus `0` and `1`, you can run:
|
||||
|
||||
```bash
|
||||
CUDA_VISIBLE_DEVICES="1" pytest tests/test_logging.py
|
||||
CUDA_VISIBLE_DEVICES="1" pytest tests/utils/test_logging.py
|
||||
```
|
||||
|
||||
This is handy when you want to run different tasks on different GPUs.
|
||||
@@ -511,6 +511,21 @@ from transformers.testing_utils import get_gpu_count
|
||||
n_gpu = get_gpu_count() # works with torch and tf
|
||||
```
|
||||
|
||||
### Testing with a specific PyTorch backend or device
|
||||
|
||||
To run the test suite on a specific torch device add `TRANSFORMERS_TEST_DEVICE="$device"` where `$device` is the target backend. For example, to test on CPU only:
|
||||
```bash
|
||||
TRANSFORMERS_TEST_DEVICE="cpu" pytest tests/utils/test_logging.py
|
||||
```
|
||||
|
||||
This variable is useful for testing custom or less common PyTorch backends such as `mps`. It can also be used to achieve the same effect as `CUDA_VISIBLE_DEVICES` by targeting specific GPUs or testing in CPU-only mode.
|
||||
|
||||
Certain devices will require an additional import after importing `torch` for the first time. This can be specified using the environment variable `TRANSFORMERS_TEST_BACKEND`:
|
||||
```bash
|
||||
TRANSFORMERS_TEST_BACKEND="torch_npu" pytest tests/utils/test_logging.py
|
||||
```
|
||||
|
||||
|
||||
### Distributed training
|
||||
|
||||
`pytest` can't deal with distributed training directly. If this is attempted - the sub-processes don't do the right
|
||||
@@ -538,7 +553,7 @@ according captured output will usually be shown along with the failure traceback
|
||||
To disable output capturing and to get the `stdout` and `stderr` normally, use `-s` or `--capture=no`:
|
||||
|
||||
```bash
|
||||
pytest -s tests/test_logging.py
|
||||
pytest -s tests/utils/test_logging.py
|
||||
```
|
||||
|
||||
To send test results to JUnit format output:
|
||||
@@ -552,7 +567,7 @@ py.test tests --junitxml=result.xml
|
||||
To have no color (e.g., yellow on white background is not readable):
|
||||
|
||||
```bash
|
||||
pytest --color=no tests/test_logging.py
|
||||
pytest --color=no tests/utils/test_logging.py
|
||||
```
|
||||
|
||||
### Sending test report to online pastebin service
|
||||
@@ -560,7 +575,7 @@ pytest --color=no tests/test_logging.py
|
||||
Creating a URL for each test failure:
|
||||
|
||||
```bash
|
||||
pytest --pastebin=failed tests/test_logging.py
|
||||
pytest --pastebin=failed tests/utils/test_logging.py
|
||||
```
|
||||
|
||||
This will submit test run information to a remote Paste service and provide a URL for each failure. You may select
|
||||
@@ -569,7 +584,7 @@ tests as usual or add for example -x if you only want to send one particular fai
|
||||
Creating a URL for a whole test session log:
|
||||
|
||||
```bash
|
||||
pytest --pastebin=all tests/test_logging.py
|
||||
pytest --pastebin=all tests/utils/test_logging.py
|
||||
```
|
||||
|
||||
## Writing tests
|
||||
@@ -1199,7 +1214,7 @@ tf.random.set_seed(seed)
|
||||
To start a debugger at the point of the warning, do this:
|
||||
|
||||
```bash
|
||||
pytest tests/test_logging.py -W error::UserWarning --pdb
|
||||
pytest tests/utils/test_logging.py -W error::UserWarning --pdb
|
||||
```
|
||||
|
||||
## Working with github actions workflows
|
||||
|
||||
@@ -141,7 +141,7 @@ on.
|
||||
|
||||
Byte-Pair Encoding (BPE) was introduced in [Neural Machine Translation of Rare Words with Subword Units (Sennrich et
|
||||
al., 2015)](https://arxiv.org/abs/1508.07909). BPE relies on a pre-tokenizer that splits the training data into
|
||||
words. Pretokenization can be as simple as space tokenization, e.g. [GPT-2](model_doc/gpt2), [Roberta](model_doc/roberta). More advanced pre-tokenization include rule-based tokenization, e.g. [XLM](model_doc/xlm),
|
||||
words. Pretokenization can be as simple as space tokenization, e.g. [GPT-2](model_doc/gpt2), [RoBERTa](model_doc/roberta). More advanced pre-tokenization include rule-based tokenization, e.g. [XLM](model_doc/xlm),
|
||||
[FlauBERT](model_doc/flaubert) which uses Moses for most languages, or [GPT](model_doc/gpt) which uses
|
||||
Spacy and ftfy, to count the frequency of each word in the training corpus.
|
||||
|
||||
|
||||
@@ -14,11 +14,11 @@ rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Transformers Agent
|
||||
# Transformers Agents
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
Transformers Agent is an experimental API which is subject to change at any time. Results returned by the agents
|
||||
Transformers Agents is an experimental API which is subject to change at any time. Results returned by the agents
|
||||
can vary as the APIs or underlying models are prone to change.
|
||||
|
||||
</Tip>
|
||||
@@ -206,25 +206,13 @@ This method can also take arguments if you would like to pass non-text types or
|
||||
|
||||
### ⚠️ Remote execution
|
||||
|
||||
For demonstration purposes and so that this can be used with all setups, we have created remote executors for several
|
||||
of the default tools the agent has access. These are created using
|
||||
[inference endpoints](https://huggingface.co/inference-endpoints). To see how to set up remote executors tools yourself,
|
||||
For demonstration purposes and so that it could be used with all setups, we had created remote executors for several
|
||||
of the default tools the agent has access for the release. These are created using
|
||||
[inference endpoints](https://huggingface.co/inference-endpoints).
|
||||
|
||||
We have turned these off for now, but in order to see how to set up remote executors tools yourself,
|
||||
we recommend reading the [custom tool guide](./custom_tools).
|
||||
|
||||
In order to run with remote tools, specifying `remote=True` to either [`~Agent.run`] or [`~Agent.chat`] is sufficient.
|
||||
|
||||
For example, the following command could be run on any device efficiently, without needing significant RAM or GPU:
|
||||
|
||||
```py
|
||||
agent.run("Draw me a picture of rivers and lakes", remote=True)
|
||||
```
|
||||
|
||||
The same can be said for [`~Agent.chat`]:
|
||||
|
||||
```py
|
||||
agent.chat("Draw me a picture of rivers and lakes", remote=True)
|
||||
```
|
||||
|
||||
### What's happening here? What are tools, and what are agents?
|
||||
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/diagram.png">
|
||||
|
||||
@@ -68,11 +68,13 @@ Instala las siguientes dependencias si aún no lo has hecho:
|
||||
|
||||
<frameworkcontent>
|
||||
<pt>
|
||||
|
||||
```bash
|
||||
pip install torch
|
||||
```
|
||||
</pt>
|
||||
<tf>
|
||||
|
||||
```bash
|
||||
pip install tensorflow
|
||||
```
|
||||
@@ -224,6 +226,7 @@ Como con el [`pipeline`], el tokenizador aceptará una lista de inputs. Además,
|
||||
|
||||
<frameworkcontent>
|
||||
<pt>
|
||||
|
||||
```py
|
||||
>>> pt_batch = tokenizer(
|
||||
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
|
||||
@@ -235,6 +238,7 @@ Como con el [`pipeline`], el tokenizador aceptará una lista de inputs. Además,
|
||||
```
|
||||
</pt>
|
||||
<tf>
|
||||
|
||||
```py
|
||||
>>> tf_batch = tokenizer(
|
||||
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
|
||||
@@ -377,6 +381,7 @@ Una característica particularmente interesante de 🤗 Transformers es la habil
|
||||
|
||||
<frameworkcontent>
|
||||
<pt>
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModel
|
||||
|
||||
@@ -385,6 +390,7 @@ Una característica particularmente interesante de 🤗 Transformers es la habil
|
||||
```
|
||||
</pt>
|
||||
<tf>
|
||||
|
||||
```py
|
||||
>>> from transformers import TFAutoModel
|
||||
|
||||
|
||||
@@ -25,7 +25,7 @@ Apprentissage automatique de pointe pour [PyTorch](https://pytorch.org/), [Tenso
|
||||
🗣️ **Audio**: reconnaissance automatique de la parole et classification audio.<br>
|
||||
🐙 **Multimodalité**: système de question-réponse avec des tableaux ou images, reconnaissance optique de caractères, extraction d'information depuis des documents scannés et classification de vidéo.
|
||||
|
||||
🤗 Transformers prend en charge l'interopérabilité entre PyTorch, TensorFlow et JAX. Cela permet d'utiliser un framework différent à chaque étape de la vie d'un modèle, par example entraîner un modèle en trois lignes de code avec un framework, et le charger pour l'inférence avec un autre. Les modèles peuvent également être exportés dans un format comme ONNX et TorchScript pour être déployés dans des environnements de production.
|
||||
🤗 Transformers prend en charge l'interopérabilité entre PyTorch, TensorFlow et JAX. Cela permet d'utiliser un framework différent à chaque étape de la vie d'un modèle, par exemple entraîner un modèle en trois lignes de code avec un framework, et le charger pour l'inférence avec un autre. Les modèles peuvent également être exportés dans un format comme ONNX et TorchScript pour être déployés dans des environnements de production.
|
||||
|
||||
Rejoignez la communauté grandissante sur le [Hub](https://huggingface.co/models), le [forum](https://discuss.huggingface.co/) ou [Discord](https://discord.com/invite/JfAtkvEtRb) dès aujourd'hui !
|
||||
|
||||
@@ -407,4 +407,4 @@ Le tableau ci-dessous représente la prise en charge actuelle dans la bibliothè
|
||||
| YOLOS | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| YOSO | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
|
||||
<!-- End table-->
|
||||
<!-- End table-->
|
||||
|
||||
@@ -30,11 +30,13 @@ Vous aurez aussi besoin d'installer votre bibliothèque d'apprentissage profond
|
||||
|
||||
<frameworkcontent>
|
||||
<pt>
|
||||
|
||||
```bash
|
||||
pip install torch
|
||||
```
|
||||
</pt>
|
||||
<tf>
|
||||
|
||||
```bash
|
||||
pip install tensorflow
|
||||
```
|
||||
@@ -58,7 +60,7 @@ Le [`pipeline`] est le moyen le plus simple d'utiliser un modèle pré-entraîn
|
||||
| Traduction | Traduit du texte d'un langage à un autre | Texte | pipeline(task="translation") |
|
||||
| Classification d'image | Attribue une catégorie à une image | Image | pipeline(task="image-classification") |
|
||||
| Segmentation d'image | Attribue une catégorie à chaque pixel d'une image (supporte la segmentation sémantique, panoptique et d'instance) | Image | pipeline(task="image-segmentation") |
|
||||
| Détection d'objects | Prédit les délimitations et catégories d'objects dans une image | Image | pipeline(task="object-detection") |
|
||||
| Détection d'objets | Prédit les délimitations et catégories d'objets dans une image | Image | pipeline(task="object-detection") |
|
||||
| Classification d'audio | Attribue une catégorie à un fichier audio | Audio | pipeline(task="audio-classification") |
|
||||
| Reconnaissance automatique de la parole | Extrait le discours d'un fichier audio en texte | Audio | pipeline(task="automatic-speech-recognition") |
|
||||
| Question réponse visuels | Etant données une image et une question, répond correctement à une question sur l'image | Modalités multiples | pipeline(task="vqa") |
|
||||
@@ -97,7 +99,7 @@ Le [`pipeline`] peut aussi itérer sur un jeu de données entier pour n'importe
|
||||
>>> speech_recognizer = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h")
|
||||
```
|
||||
|
||||
Chargez un jeu de données audio (voir le 🤗 Datasets [Quick Start](https://huggingface.co/docs/datasets/quickstart#audio) pour plus de détails) sur lequel vous souhaitez itérer. Pour cet example, nous chargons le jeu de données [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) :
|
||||
Chargez un jeu de données audio (voir le 🤗 Datasets [Quick Start](https://huggingface.co/docs/datasets/quickstart#audio) pour plus de détails) sur lequel vous souhaitez itérer. Pour cet exemple, nous chargeons le jeu de données [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) :
|
||||
|
||||
```py
|
||||
>>> from datasets import load_dataset, Audio
|
||||
@@ -153,7 +155,7 @@ Utilisez [`TFAutoModelForSequenceClassification`] et [`AutoTokenizer`] pour char
|
||||
</tf>
|
||||
</frameworkcontent>
|
||||
|
||||
Specifiez le modèle et le tokenizer dans le [`pipeline`], et utilisez le `classifier` sur le texte en français :
|
||||
Spécifiez le modèle et le tokenizer dans le [`pipeline`], et utilisez le `classifier` sur le texte en français :
|
||||
|
||||
```py
|
||||
>>> classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
|
||||
@@ -203,6 +205,7 @@ Un tokenizer peut également accepter une liste de textes, et remplir et tronque
|
||||
|
||||
<frameworkcontent>
|
||||
<pt>
|
||||
|
||||
```py
|
||||
>>> pt_batch = tokenizer(
|
||||
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
|
||||
@@ -214,6 +217,7 @@ Un tokenizer peut également accepter une liste de textes, et remplir et tronque
|
||||
```
|
||||
</pt>
|
||||
<tf>
|
||||
|
||||
```py
|
||||
>>> tf_batch = tokenizer(
|
||||
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
|
||||
@@ -346,6 +350,7 @@ Une fonctionnalité particulièrement cool 🤗 Transformers est la possibilité
|
||||
|
||||
<frameworkcontent>
|
||||
<pt>
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModel
|
||||
|
||||
@@ -354,6 +359,7 @@ Une fonctionnalité particulièrement cool 🤗 Transformers est la possibilité
|
||||
```
|
||||
</pt>
|
||||
<tf>
|
||||
|
||||
```py
|
||||
>>> from transformers import TFAutoModel
|
||||
|
||||
@@ -412,7 +418,7 @@ En fonction de votre tâche, vous passerez généralement les paramètres suivan
|
||||
>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
|
||||
```
|
||||
|
||||
2. [`TrainingArguments`] contient les hyperparamètres du modèle que vous pouvez changer comme le taux d'apprentissage, la taille due l'échantillon, et le nombre d'époques pour s'entraîner. Les valeurs par défaut sont utilisées si vous ne spécifiez pas d'hyperparamètres d'apprentissage :
|
||||
2. [`TrainingArguments`] contient les hyperparamètres du modèle que vous pouvez changer comme le taux d'apprentissage, la taille de l'échantillon, et le nombre d'époques pour s'entraîner. Les valeurs par défaut sont utilisées si vous ne spécifiez pas d'hyperparamètres d'apprentissage :
|
||||
|
||||
```py
|
||||
>>> from transformers import TrainingArguments
|
||||
@@ -541,4 +547,4 @@ Tous les modèles sont des modèles standard [`tf.keras.Model`](https://www.tens
|
||||
|
||||
## Et après ?
|
||||
|
||||
Maintenant que vous avez terminé la visite rapide de 🤗 Transformers, consultez nos guides et apprenez à faire des choses plus spécifiques comme créer un modèle personnalisé, finetuner un modèle pour une tâche, et comment entraîner un modèle avec un script. Si vous souhaitez en savoir plus sur les concepts fondamentaux de 🤗 Transformers, jetez un œil à nos guides conceptuels !
|
||||
Maintenant que vous avez terminé la visite rapide de 🤗 Transformers, consultez nos guides et apprenez à faire des choses plus spécifiques comme créer un modèle personnalisé, finetuner un modèle pour une tâche, et comment entraîner un modèle avec un script. Si vous souhaitez en savoir plus sur les concepts fondamentaux de 🤗 Transformers, jetez un œil à nos guides conceptuels !
|
||||
|
||||
@@ -32,12 +32,12 @@ Nota che questa funzione può essere utilizzata anche nelle configurazioni multi
|
||||
Dal paper [`LLM.int8() : 8-bit Matrix Multiplication for Transformers at Scale`](https://arxiv.org/abs/2208.07339), noi supportiamo l'integrazione di Hugging Face per tutti i modelli dell'Hub con poche righe di codice.
|
||||
Il metodo `nn.Linear` riduce la dimensione di 2 per i pesi `float16` e `bfloat16` e di 4 per i pesi `float32`, con un impatto quasi nullo sulla qualità, operando sugli outlier in half-precision.
|
||||
|
||||

|
||||

|
||||
|
||||
Il metodo Int8 mixed-precision matrix decomposition funziona separando la moltiplicazione tra matrici in due flussi: (1) una matrice di flusso di outlier di caratteristiche sistematiche moltiplicata in fp16, (2) in flusso regolare di moltiplicazione di matrici int8 (99,9%). Con questo metodo, è possibile effettutare inferenza int8 per modelli molto grandi senza degrado predittivo.
|
||||
Per maggiori dettagli sul metodo, consultare il [paper](https://arxiv.org/abs/2208.07339) o il nostro [blogpost sull'integrazione](https://huggingface.co/blog/hf-bitsandbytes-integration).
|
||||
|
||||

|
||||

|
||||
|
||||
Nota che è necessaria una GPU per eseguire modelli di tipo mixed-8bit, poiché i kernel sono stati compilati solo per le GPU. Prima di utilizzare questa funzione, assicurarsi di disporre di memoria sufficiente sulla GPU per memorizzare un quarto del modello (o la metà se i pesi del modello sono in mezza precisione).
|
||||
Di seguito sono riportate alcune note per aiutarvi a utilizzare questo modulo, oppure seguite le dimostrazioni su [Google colab](#colab-demos).
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user