Compare commits
96 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
11c3257a18 | ||
|
|
36bffc81b3 | ||
|
|
2ee410560e | ||
|
|
1789c7daf1 | ||
|
|
b809d2f073 | ||
|
|
4ab8ab4f50 | ||
|
|
ac40eed1a5 | ||
|
|
fd9995ebc5 | ||
|
|
5d912e7ed4 | ||
|
|
94eb68d742 | ||
|
|
243e687be6 | ||
|
|
3e4b4dd190 | ||
|
|
c6acd246ec | ||
|
|
d5d7d88612 | ||
|
|
8594dd80dd | ||
|
|
216e167ce6 | ||
|
|
1ac6a246d8 | ||
|
|
e91692f4a3 | ||
|
|
8e287d507d | ||
|
|
81484b447b | ||
|
|
9f6349aba9 | ||
|
|
ddb1ce7418 | ||
|
|
f68d22850c | ||
|
|
c50aa67bff | ||
|
|
1b10159950 | ||
|
|
390c128592 | ||
|
|
ab5d06a094 | ||
|
|
a4ee4da18a | ||
|
|
06dd597552 | ||
|
|
9de9ceb6c5 | ||
|
|
b815edf69f | ||
|
|
8538ce9044 | ||
|
|
c1a6252be1 | ||
|
|
50e15c825c | ||
|
|
b38d552a92 | ||
|
|
ae6834e028 | ||
|
|
0373b60c4c | ||
|
|
83d1fbcff6 | ||
|
|
55bcae7f25 | ||
|
|
42e1e3c67f | ||
|
|
57b0fab692 | ||
|
|
a8d4dff0a1 | ||
|
|
4a5663568f | ||
|
|
bbedb59675 | ||
|
|
c2cf192943 | ||
|
|
c82ef72158 | ||
|
|
b48a1f08c1 | ||
|
|
99833a9cbf | ||
|
|
ebceeeacda | ||
|
|
a6c4ee27fd | ||
|
|
e5c393dceb | ||
|
|
8deff3acf2 | ||
|
|
1f72865726 | ||
|
|
cc598b312b | ||
|
|
d38bbb225f | ||
|
|
eff757f2e3 | ||
|
|
a009d751c2 | ||
|
|
6f5a12a583 | ||
|
|
296252c49e | ||
|
|
75ec6c9e3a | ||
|
|
5b44e0a31b | ||
|
|
33ef7002e1 | ||
|
|
f6a23d1911 | ||
|
|
601ac5b1dc | ||
|
|
17dceae7a1 | ||
|
|
00ea100e96 | ||
|
|
b08259a120 | ||
|
|
f4f4946836 | ||
|
|
fa9af2468a | ||
|
|
ff80b73157 | ||
|
|
e2c05f06ef | ||
|
|
3ee431dd4c | ||
|
|
53fe733805 | ||
|
|
c10decf7a0 | ||
|
|
63f4d8cad0 | ||
|
|
2b2a2f8df2 | ||
|
|
1a5aefc95c | ||
|
|
39371ee454 | ||
|
|
5ad2ea06af | ||
|
|
b4fb94fe6d | ||
|
|
e703e923ca | ||
|
|
1a6c546c6f | ||
|
|
311970546f | ||
|
|
7420a6a9cc | ||
|
|
022e8fab97 | ||
|
|
3c5c567507 | ||
|
|
9c683ef01e | ||
|
|
ffcffebe85 | ||
|
|
010e0460b2 | ||
|
|
ffa17fe322 | ||
|
|
83272a3853 | ||
|
|
ccbe839ee0 | ||
|
|
3d76df3a12 | ||
|
|
eaabaaf750 | ||
|
|
f8823bad9a | ||
|
|
d0c36a7b72 |
@@ -85,6 +85,8 @@ jobs:
|
||||
parallelism: 1
|
||||
steps:
|
||||
- checkout
|
||||
# we need a version of isort with https://github.com/timothycrosley/isort/pull/1000
|
||||
- run: sudo pip install git+git://github.com/timothycrosley/isort.git@e63ae06ec7d70b06df9e528357650281a3d3ec22#egg=isort
|
||||
- run: sudo pip install .[tf,torch,quality]
|
||||
- run: black --check --line-length 119 --target-version py35 examples templates tests src utils
|
||||
- run: isort --check-only --recursive examples templates tests src utils
|
||||
|
||||
@@ -164,8 +164,9 @@ At some point in the future, you'll be able to seamlessly move from pre-training
|
||||
14. **[MMBT](https://github.com/facebookresearch/mmbt/)** (from Facebook), released together with the paper a [Supervised Multimodal Bitransformers for Classifying Images and Text](https://arxiv.org/pdf/1909.02950.pdf) by Douwe Kiela, Suvrat Bhooshan, Hamed Firooz, Davide Testuggine.
|
||||
15. **[FlauBERT](https://github.com/getalp/Flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
|
||||
16. **[BART](https://github.com/pytorch/fairseq/tree/master/examples/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/pdf/1910.13461.pdf) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
|
||||
17. **[Other community models](https://huggingface.co/models)**, contributed by the [community](https://huggingface.co/users).
|
||||
18. Want to contribute a new model? We have added a **detailed guide and templates** to guide you in the process of adding a new model. You can find them in the [`templates`](./templates) folder of the repository. Be sure to check the [contributing guidelines](./CONTRIBUTING.md) and contact the maintainers or open an issue to collect feedbacks before starting your PR.
|
||||
17. **[ELECTRA](https://github.com/google-research/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
|
||||
18. **[Other community models](https://huggingface.co/models)**, contributed by the [community](https://huggingface.co/users).
|
||||
19. Want to contribute a new model? We have added a **detailed guide and templates** to guide you in the process of adding a new model. You can find them in the [`templates`](./templates) folder of the repository. Be sure to check the [contributing guidelines](./CONTRIBUTING.md) and contact the maintainers or open an issue to collect feedbacks before starting your PR.
|
||||
|
||||
These implementations have been tested on several datasets (see the example scripts) and should match the performances of the original implementations (e.g. ~93 F1 on SQuAD for BERT Whole-Word-Masking, ~88 F1 on RocStories for OpenAI GPT, ~18.3 perplexity on WikiText 103 for Transformer-XL, ~0.916 Peason R coefficient on STS-B for XLNet). You can find more details on the performances in the Examples section of the [documentation](https://huggingface.co/transformers/examples.html).
|
||||
|
||||
|
||||
@@ -47,6 +47,8 @@ Once you have setup `sphinx`, you can build the documentation by running the fol
|
||||
make html
|
||||
```
|
||||
|
||||
A folder called ``_build/html`` should have been created. You can now open the file ``_build/html/index.html`` in your browser.
|
||||
|
||||
---
|
||||
**NOTE**
|
||||
|
||||
|
||||
@@ -26,7 +26,7 @@ author = u'huggingface'
|
||||
# The short X.Y version
|
||||
version = u''
|
||||
# The full version, including alpha/beta/rc tags
|
||||
release = u'2.6.0'
|
||||
release = u'2.8.0'
|
||||
|
||||
|
||||
# -- General configuration ---------------------------------------------------
|
||||
|
||||
@@ -103,3 +103,5 @@ The library currently contains PyTorch and Tensorflow implementations, pre-train
|
||||
model_doc/xlmroberta
|
||||
model_doc/flaubert
|
||||
model_doc/bart
|
||||
model_doc/t5
|
||||
model_doc/electra
|
||||
@@ -27,7 +27,7 @@ loss = outputs[0]
|
||||
# In transformers you can also have access to the logits:
|
||||
loss, logits = outputs[:2]
|
||||
|
||||
# And even the attention weigths if you configure the model to output them (and other outputs too, see the docstrings and documentation)
|
||||
# And even the attention weights if you configure the model to output them (and other outputs too, see the docstrings and documentation)
|
||||
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', output_attentions=True)
|
||||
outputs = model(input_ids, labels=labels)
|
||||
loss, logits, attentions = outputs
|
||||
|
||||
115
docs/source/model_doc/electra.rst
Normal file
115
docs/source/model_doc/electra.rst
Normal file
@@ -0,0 +1,115 @@
|
||||
ELECTRA
|
||||
----------------------------------------------------
|
||||
|
||||
The ELECTRA model was proposed in the paper.
|
||||
`ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators <https://openreview.net/pdf?id=r1xMH1BtvB>`__.
|
||||
ELECTRA is a new pre-training approach which trains two transformer models: the generator and the discriminator. The
|
||||
generator's role is to replace tokens in a sequence, and is therefore trained as a masked language model. The discriminator,
|
||||
which is the model we're interested in, tries to identify which tokens were replaced by the generator in the sequence.
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
*Masked language modeling (MLM) pre-training methods such as BERT corrupt
|
||||
the input by replacing some tokens with [MASK] and then train a model to
|
||||
reconstruct the original tokens. While they produce good results when transferred
|
||||
to downstream NLP tasks, they generally require large amounts of compute to be
|
||||
effective. As an alternative, we propose a more sample-efficient pre-training task
|
||||
called replaced token detection. Instead of masking the input, our approach
|
||||
corrupts it by replacing some tokens with plausible alternatives sampled from a small
|
||||
generator network. Then, instead of training a model that predicts the original
|
||||
identities of the corrupted tokens, we train a discriminative model that predicts
|
||||
whether each token in the corrupted input was replaced by a generator sample
|
||||
or not. Thorough experiments demonstrate this new pre-training task is more
|
||||
efficient than MLM because the task is defined over all input tokens rather than
|
||||
just the small subset that was masked out. As a result, the contextual representations
|
||||
learned by our approach substantially outperform the ones learned by BERT
|
||||
given the same model size, data, and compute. The gains are particularly strong
|
||||
for small models; for example, we train a model on one GPU for 4 days that
|
||||
outperforms GPT (trained using 30x more compute) on the GLUE natural language
|
||||
understanding benchmark. Our approach also works well at scale, where it
|
||||
performs comparably to RoBERTa and XLNet while using less than 1/4 of their
|
||||
compute and outperforms them when using the same amount of compute.*
|
||||
|
||||
Tips:
|
||||
|
||||
- ELECTRA is the pre-training approach, therefore there is nearly no changes done to the underlying model: BERT. The
|
||||
only change is the separation of the embedding size and the hidden size -> The embedding size is generally smaller,
|
||||
while the hidden size is larger. An additional projection layer (linear) is used to project the embeddings from
|
||||
their embedding size to the hidden size. In the case where the embedding size is the same as the hidden size, no
|
||||
projection layer is used.
|
||||
- The ELECTRA checkpoints saved using `Google Research's implementation <https://github.com/google-research/electra>`__
|
||||
contain both the generator and discriminator. The conversion script requires the user to name which model to export
|
||||
into the correct architecture. Once converted to the HuggingFace format, these checkpoints may be loaded into all
|
||||
available ELECTRA models, however. This means that the discriminator may be loaded in the `ElectraForMaskedLM` model,
|
||||
and the generator may be loaded in the `ElectraForPreTraining` model (the classification head will be randomly
|
||||
initialized as it doesn't exist in the generator).
|
||||
|
||||
|
||||
ElectraConfig
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.ElectraConfig
|
||||
:members:
|
||||
|
||||
|
||||
ElectraTokenizer
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.ElectraTokenizer
|
||||
:members:
|
||||
|
||||
|
||||
ElectraModel
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.ElectraModel
|
||||
:members:
|
||||
|
||||
|
||||
ElectraForPreTraining
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.ElectraForPreTraining
|
||||
:members:
|
||||
|
||||
|
||||
ElectraForMaskedLM
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.ElectraForMaskedLM
|
||||
:members:
|
||||
|
||||
|
||||
ElectraForTokenClassification
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.ElectraForTokenClassification
|
||||
:members:
|
||||
|
||||
|
||||
TFElectraModel
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.TFElectraModel
|
||||
:members:
|
||||
|
||||
|
||||
TFElectraForPreTraining
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.TFElectraForPreTraining
|
||||
:members:
|
||||
|
||||
|
||||
TFElectraForMaskedLM
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.TFElectraForMaskedLM
|
||||
:members:
|
||||
|
||||
|
||||
TFElectraForTokenClassification
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.TFElectraForTokenClassification
|
||||
:members:
|
||||
101
docs/source/model_doc/t5.rst
Normal file
101
docs/source/model_doc/t5.rst
Normal file
@@ -0,0 +1,101 @@
|
||||
T5
|
||||
----------------------------------------------------
|
||||
**DISCLAIMER:** This model is still a work in progress, if you see something strange,
|
||||
file a `Github Issue <https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title>`_
|
||||
|
||||
Overview
|
||||
~~~~~
|
||||
The T5 model was presented in `Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer <https://arxiv.org/pdf/1910.10683.pdf>`_ by Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu in
|
||||
Here the abstract:
|
||||
|
||||
*Transfer learning, where a model is first pre-trained on a data-rich task before being fine-tuned on a downstream task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning has given rise to a diversity of approaches, methodology, and practice.
|
||||
In this paper, we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts every language problem into a text-to-text format.
|
||||
Our systematic study compares pre-training objectives, architectures, unlabeled datasets, transfer approaches, and other factors on dozens of language understanding tasks.
|
||||
By combining the insights from our exploration with scale and our new "Colossal Clean Crawled Corpus", we achieve state-of-the-art results on many benchmarks covering summarization, question answering, text classification, and more.
|
||||
To facilitate future work on transfer learning for NLP, we release our dataset, pre-trained models, and code.*
|
||||
|
||||
The Authors' code can be found `here <https://github.com/google-research/text-to-text-transfer-transformer>`_ .
|
||||
|
||||
Training
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
T5 is an encoder-decoder model and converts all NLP problems into a text-to-text format. It is trained using teacher forcing.
|
||||
This means that for training we always need an input sequence and a target sequence.
|
||||
The input sequence is fed to the model using ``input_ids``. The target sequence is shifted to the right, *i.e.* perprended by a start-sequence token and fed to the decoder using the `decoder_input_ids`. In teacher-forcing style, the target sequence is then appended by the EOS token and corresponds to the ``lm_labels``. The PAD token is hereby used as the start-sequence token.
|
||||
T5 can be trained / fine-tuned both in a supervised and unsupervised fashion.
|
||||
|
||||
- Unsupervised denoising training
|
||||
In this setup spans of the input sequence are masked by so-called sentinel tokens (*a.k.a* unique mask tokens)
|
||||
and the output sequence is formed as a concatenation of the same sentinel tokens and the *real* masked tokens.
|
||||
Each sentinel tokens represents a unique mask token for this sentence and should start with ``<extra_id_1>``, ``<extrac_id_2>``, ... up to ``<extra_id_100>``. As a default 100 sentinel tokens are available in ``T5Tokenizer``.
|
||||
*E.g.* the sentence "The cute dog walks in the park" with the masks put on "cute dog" and "the" should be processed as follows:
|
||||
|
||||
::
|
||||
|
||||
input_ids = tokenizer.encode('The <extra_id_1> walks in <extra_id_2> park', return_tensors='pt')
|
||||
lm_labels = tokenizer.encode('<extra_id_1> cute dog <extra_id_2> the <extra_id_3> </s>', return_tensors='pt')
|
||||
# the forward function automatically creates the correct decoder_input_ids
|
||||
model(input_ids=input_ids, lm_labels=lm_labels)
|
||||
|
||||
- Supervised training
|
||||
In this setup the input sequence and output sequence are standard sequence to sequence input output mapping.
|
||||
In translation, *e.g.* the input sequence "The house is wonderful." and output sequence "Das Haus ist wunderbar." should
|
||||
be processed as follows:
|
||||
|
||||
::
|
||||
|
||||
input_ids = tokenizer.encode('translate English to German: The house is wonderful. </s>', return_tensors='pt')
|
||||
lm_labels = tokenizer.encode('Das Haus ist wunderbar. </s>', return_tensors='pt')
|
||||
# the forward function automatically creates the correct decoder_input_ids
|
||||
model(input_ids=input_ids, lm_labels=lm_labels)
|
||||
|
||||
Tips
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
- T5 is an encoder-decoder model pre-trained on a multi-task mixture of unsupervised
|
||||
and supervised tasks and for which each task is converted into a text-to-text format.
|
||||
T5 works well on a variety of tasks out-of-the-box by prepending a different prefix to the input corresponding to each task, e.g.: for translation: *translate English to German: ..., summarize: ...*.
|
||||
For more information about which prefix to use, it is easiest to look into Appendix D of the `paper <https://arxiv.org/pdf/1910.10683.pdf>`_ .
|
||||
- For sequence to sequence generation, it is recommended to use ``T5ForConditionalGeneration.generate()``. The method takes care of feeding the encoded input via cross-attention layers to the decoder and auto-regressively generates the decoder output.
|
||||
- T5 uses relative scalar embeddings. Encoder input padding can be done on the left and on the right.
|
||||
|
||||
|
||||
T5Config
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.T5Config
|
||||
:members:
|
||||
|
||||
|
||||
T5Tokenizer
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.T5Tokenizer
|
||||
:members: build_inputs_with_special_tokens, get_special_tokens_mask,
|
||||
create_token_type_ids_from_sequences, save_vocabulary
|
||||
|
||||
|
||||
T5Model
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.T5Model
|
||||
:members:
|
||||
|
||||
|
||||
T5ForConditionalGeneration
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.T5ForConditionalGeneration
|
||||
:members:
|
||||
|
||||
|
||||
TFT5Model
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.TFT5Model
|
||||
:members:
|
||||
|
||||
|
||||
TFT5ForConditionalGeneration
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.TFT5ForConditionalGeneration
|
||||
:members:
|
||||
@@ -275,7 +275,6 @@ For a list that includes community-uploaded models, refer to `https://huggingfac
|
||||
| | | | FlauBERT large architecture |
|
||||
| | | (see `details <https://github.com/getalp/Flaubert>`__) |
|
||||
+-------------------+------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------+
|
||||
+-------------------+------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| Bart | ``bart-large`` | | 12-layer, 1024-hidden, 16-heads, 406M parameters |
|
||||
| | | (see `details <https://github.com/pytorch/fairseq/tree/master/examples/bart>`_) |
|
||||
| +------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------+
|
||||
@@ -285,6 +284,3 @@ For a list that includes community-uploaded models, refer to `https://huggingfac
|
||||
| | ``bart-large-cnn`` | | 12-layer, 1024-hidden, 16-heads, 406M parameters (same as base) |
|
||||
| | | | bart-large base architecture finetuned on cnn summarization task |
|
||||
+-------------------+------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------+
|
||||
|
||||
|
||||
.. <https://huggingface.co/transformers/examples.html>`__
|
||||
|
||||
@@ -420,7 +420,7 @@ to generate the tokens following the initial sequence in PyTorch, and creating a
|
||||
sequence = f"Hugging Face is based in DUMBO, New York City, and is"
|
||||
|
||||
input = tokenizer.encode(sequence, return_tensors="pt")
|
||||
generated = model.generate(input, max_length=50)
|
||||
generated = model.generate(input, max_length=50, do_sample=True)
|
||||
|
||||
resulting_string = tokenizer.decode(generated.tolist()[0])
|
||||
print(resulting_string)
|
||||
@@ -432,14 +432,10 @@ to generate the tokens following the initial sequence in PyTorch, and creating a
|
||||
model = TFAutoModelWithLMHead.from_pretrained("gpt2")
|
||||
|
||||
sequence = f"Hugging Face is based in DUMBO, New York City, and is"
|
||||
generated = tokenizer.encode(sequence)
|
||||
input = tokenizer.encode(sequence, return_tensors="tf")
|
||||
generated = model.generate(input, max_length=50, do_sample=True)
|
||||
|
||||
for i in range(50):
|
||||
predictions = model(tf.constant([generated]))[0]
|
||||
token = tf.argmax(predictions[0], axis=1)[-1].numpy()
|
||||
generated += [token]
|
||||
|
||||
resulting_string = tokenizer.decode(generated)
|
||||
resulting_string = tokenizer.decode(generated.tolist()[0])
|
||||
print(resulting_string)
|
||||
|
||||
|
||||
@@ -594,4 +590,138 @@ following array should be the output:
|
||||
|
||||
::
|
||||
|
||||
[('[CLS]', 'O'), ('Hu', 'I-ORG'), ('##gging', 'I-ORG'), ('Face', 'I-ORG'), ('Inc', 'I-ORG'), ('.', 'O'), ('is', 'O'), ('a', 'O'), ('company', 'O'), ('based', 'O'), ('in', 'O'), ('New', 'I-LOC'), ('York', 'I-LOC'), ('City', 'I-LOC'), ('.', 'O'), ('Its', 'O'), ('headquarters', 'O'), ('are', 'O'), ('in', 'O'), ('D', 'I-LOC'), ('##UM', 'I-LOC'), ('##BO', 'I-LOC'), (',', 'O'), ('therefore', 'O'), ('very', 'O'), ('##c', 'O'), ('##lose', 'O'), ('to', 'O'), ('the', 'O'), ('Manhattan', 'I-LOC'), ('Bridge', 'I-LOC'), ('.', 'O'), ('[SEP]', 'O')]
|
||||
[('[CLS]', 'O'), ('Hu', 'I-ORG'), ('##gging', 'I-ORG'), ('Face', 'I-ORG'), ('Inc', 'I-ORG'), ('.', 'O'), ('is', 'O'), ('a', 'O'), ('company', 'O'), ('based', 'O'), ('in', 'O'), ('New', 'I-LOC'), ('York', 'I-LOC'), ('City', 'I-LOC'), ('.', 'O'), ('Its', 'O'), ('headquarters', 'O'), ('are', 'O'), ('in', 'O'), ('D', 'I-LOC'), ('##UM', 'I-LOC'), ('##BO', 'I-LOC'), (',', 'O'), ('therefore', 'O'), ('very', 'O'), ('##c', 'O'), ('##lose', 'O'), ('to', 'O'), ('the', 'O'), ('Manhattan', 'I-LOC'), ('Bridge', 'I-LOC'), ('.', 'O'), ('[SEP]', 'O')]
|
||||
Summarization
|
||||
----------------------------------------------------
|
||||
|
||||
Summarization is the task of summarizing a text / an article into a shorter text.
|
||||
|
||||
An example of a summarization dataset is the CNN / Daily Mail dataset, which consists of long news articles and was created for the task of summarization.
|
||||
If you would like to fine-tune a model on a summarization task, you may leverage the ``examples/summarization/bart/run_train.sh`` (leveraging pytorch-lightning) script.
|
||||
|
||||
Here is an example using the pipelines do to summarization.
|
||||
It leverages a Bart model that was fine-tuned on the CNN / Daily Mail data set.
|
||||
|
||||
::
|
||||
|
||||
from transformers import pipeline
|
||||
|
||||
summarizer = pipeline("summarization")
|
||||
|
||||
ARTICLE = """ New York (CNN)When Liana Barrientos was 23 years old, she got married in Westchester County, New York.
|
||||
A year later, she got married again in Westchester County, but to a different man and without divorcing her first husband.
|
||||
Only 18 days after that marriage, she got hitched yet again. Then, Barrientos declared "I do" five more times, sometimes only within two weeks of each other.
|
||||
In 2010, she married once more, this time in the Bronx. In an application for a marriage license, she stated it was her "first and only" marriage.
|
||||
Barrientos, now 39, is facing two criminal counts of "offering a false instrument for filing in the first degree," referring to her false statements on the
|
||||
2010 marriage license application, according to court documents.
|
||||
Prosecutors said the marriages were part of an immigration scam.
|
||||
On Friday, she pleaded not guilty at State Supreme Court in the Bronx, according to her attorney, Christopher Wright, who declined to comment further.
|
||||
After leaving court, Barrientos was arrested and charged with theft of service and criminal trespass for allegedly sneaking into the New York subway through an emergency exit, said Detective
|
||||
Annette Markowski, a police spokeswoman. In total, Barrientos has been married 10 times, with nine of her marriages occurring between 1999 and 2002.
|
||||
All occurred either in Westchester County, Long Island, New Jersey or the Bronx. She is believed to still be married to four men, and at one time, she was married to eight men at once, prosecutors say.
|
||||
Prosecutors said the immigration scam involved some of her husbands, who filed for permanent residence status shortly after the marriages.
|
||||
Any divorces happened only after such filings were approved. It was unclear whether any of the men will be prosecuted.
|
||||
The case was referred to the Bronx District Attorney\'s Office by Immigration and Customs Enforcement and the Department of Homeland Security\'s
|
||||
Investigation Division. Seven of the men are from so-called "red-flagged" countries, including Egypt, Turkey, Georgia, Pakistan and Mali.
|
||||
Her eighth husband, Rashid Rajput, was deported in 2006 to his native Pakistan after an investigation by the Joint Terrorism Task Force.
|
||||
If convicted, Barrientos faces up to four years in prison. Her next court appearance is scheduled for May 18.
|
||||
"""
|
||||
|
||||
print(summarizer(ARTICLE, max_length=130, min_length=30))
|
||||
|
||||
Because the summarization pipeline depends on the ``PretrainedModel.generate()`` method, we can override the default arguments
|
||||
of ``PretrainedModel.generate()`` directly in the pipeline as is shown for ``max_length`` and ``min_length`` above.
|
||||
This outputs the following summary:
|
||||
|
||||
::
|
||||
|
||||
Liana Barrientos has been married 10 times, sometimes within two weeks of each other. Prosecutors say the marriages were part of an immigration scam. She pleaded not guilty at State Supreme Court in the Bronx on Friday.
|
||||
|
||||
Here is an example doing summarization using a model and a tokenizer. The process is the following:
|
||||
|
||||
- Instantiate a tokenizer and a model from the checkpoint name. Summarization is usually done using an encoder-decoder model, such as ``Bart`` or ``T5``.
|
||||
- Define the article that should be summarizaed.
|
||||
- Leverage the ``PretrainedModel.generate()`` method.
|
||||
- Add the T5 specific prefix "summarize: ".
|
||||
|
||||
Here Google`s T5 model is used that was only pre-trained on a multi-task mixed data set (including CNN / Daily Mail), but nevertheless yields very good results.
|
||||
::
|
||||
|
||||
## PYTORCH CODE
|
||||
from transformers import AutoModelWithLMHead, AutoTokenizer
|
||||
|
||||
model = AutoModelWithLMHead.from_pretrained("t5-base")
|
||||
tokenizer = AutoTokenizer.from_pretrained("t5-base")
|
||||
|
||||
# T5 uses a max_length of 512 so we cut the article to 512 tokens.
|
||||
inputs = tokenizer.encode("summarize: " + ARTICLE, return_tensors="pt", max_length=512)
|
||||
outputs = model.generate(inputs, max_length=150, min_length=40, length_penalty=2.0, num_beams=4, early_stopping=True)
|
||||
print(outputs)
|
||||
|
||||
## TENSORFLOW CODE
|
||||
from transformers import TFAutoModelWithLMHead, AutoTokenizer
|
||||
|
||||
model = TFAutoModelWithLMHead.from_pretrained("t5-base")
|
||||
tokenizer = AutoTokenizer.from_pretrained("t5-base")
|
||||
|
||||
# T5 uses a max_length of 512 so we cut the article to 512 tokens.
|
||||
inputs = tokenizer.encode("summarize: " + ARTICLE, return_tensors="tf", max_length=512)
|
||||
outputs = model.generate(inputs, max_length=150, min_length=40, length_penalty=2.0, num_beams=4, early_stopping=True)
|
||||
print(outputs)
|
||||
Translation
|
||||
----------------------------------------------------
|
||||
|
||||
Translation is the task of translating a text from one language to another.
|
||||
|
||||
An example of a translation dataset is the WMT English to German dataset, which has English sentences as the input data
|
||||
and German sentences as the target data.
|
||||
|
||||
Here is an example using the pipelines do to translation.
|
||||
It leverages a T5 model that was only pre-trained on a multi-task mixture dataset (including WMT), but yields impressive
|
||||
translation results nevertheless.
|
||||
|
||||
::
|
||||
|
||||
from transformers import pipeline
|
||||
|
||||
translator = pipeline("translation_en_to_de")
|
||||
print(translator("Hugging Face is a technology company based in New York and Paris", max_length=40))
|
||||
|
||||
Because the translation pipeline depends on the ``PretrainedModel.generate()`` method, we can override the default arguments
|
||||
of ``PretrainedModel.generate()`` directly in the pipeline as is shown for ``max_length`` above.
|
||||
This outputs the following translation into German:
|
||||
|
||||
::
|
||||
|
||||
Hugging Face ist ein Technologieunternehmen mit Sitz in New York und Paris.
|
||||
|
||||
Here is an example doing translation using a model and a tokenizer. The process is the following:
|
||||
|
||||
- Instantiate a tokenizer and a model from the checkpoint name. Summarization is usually done using an encoder-decoder model, such as ``Bart`` or ``T5``.
|
||||
- Define the article that should be summarizaed.
|
||||
- Leverage the ``PretrainedModel.generate()`` method.
|
||||
- Add the T5 specific prefix "translate English to German: "
|
||||
|
||||
::
|
||||
|
||||
## PYTORCH CODE
|
||||
from transformers import AutoModelWithLMHead, AutoTokenizer
|
||||
|
||||
model = AutoModelWithLMHead.from_pretrained("t5-base")
|
||||
tokenizer = AutoTokenizer.from_pretrained("t5-base")
|
||||
|
||||
inputs = tokenizer.encode("translate English to German: Hugging Face is a technology company based in New York and Paris", return_tensors="pt")
|
||||
outputs = model.generate(inputs, max_length=40, num_beams=4, early_stopping=True)
|
||||
|
||||
print(outputs)
|
||||
|
||||
## TENSORFLOW CODE
|
||||
from transformers import TFAutoModelWithLMHead, AutoTokenizer
|
||||
|
||||
model = TFAutoModelWithLMHead.from_pretrained("t5-base")
|
||||
tokenizer = AutoTokenizer.from_pretrained("t5-base")
|
||||
|
||||
inputs = tokenizer.encode("translate English to German: Hugging Face is a technology company based in New York and Paris", return_tensors="tf")
|
||||
outputs = model.generate(inputs, max_length=40, num_beams=4, early_stopping=True)
|
||||
|
||||
print(outputs)
|
||||
|
||||
@@ -68,7 +68,7 @@ class GLUETransformer(BaseTransformer):
|
||||
output_mode=args.glue_output_mode,
|
||||
pad_on_left=bool(args.model_type in ["xlnet"]), # pad on the left for xlnet
|
||||
pad_token=self.tokenizer.convert_tokens_to_ids([self.tokenizer.pad_token])[0],
|
||||
pad_token_segment_id=4 if args.model_type in ["xlnet"] else 0,
|
||||
pad_token_segment_id=self.tokenizer.pad_token_type_id,
|
||||
)
|
||||
logger.info("Saving features into cached file %s", cached_features_file)
|
||||
torch.save(features, cached_features_file)
|
||||
@@ -192,5 +192,5 @@ if __name__ == "__main__":
|
||||
# Optionally, predict on dev set and write to output_dir
|
||||
if args.do_predict:
|
||||
checkpoints = list(sorted(glob.glob(os.path.join(args.output_dir, "checkpointepoch=*.ckpt"), recursive=True)))
|
||||
GLUETransformer.load_from_checkpoint(checkpoints[-1])
|
||||
model = model.load_from_checkpoint(checkpoints[-1])
|
||||
trainer.test(model)
|
||||
|
||||
@@ -342,8 +342,8 @@ def load_and_cache_examples(args, task, tokenizer, evaluate=False):
|
||||
max_length=args.max_seq_length,
|
||||
output_mode=output_mode,
|
||||
pad_on_left=bool(args.model_type in ["xlnet"]), # pad on the left for xlnet
|
||||
pad_token=tokenizer.convert_tokens_to_ids([tokenizer.pad_token])[0],
|
||||
pad_token_segment_id=4 if args.model_type in ["xlnet"] else 0,
|
||||
pad_token=tokenizer.pad_token_id,
|
||||
pad_token_segment_id=tokenizer.pad_token_type_id,
|
||||
)
|
||||
if args.local_rank in [-1, 0]:
|
||||
logger.info("Saving features into cached file %s", cached_features_file)
|
||||
|
||||
@@ -348,8 +348,8 @@ def load_and_cache_examples(args, tokenizer, labels, pad_token_label_id, mode):
|
||||
# roberta uses an extra separator b/w pairs of sentences, cf. github.com/pytorch/fairseq/commit/1684e166e3da03f5b600dbb7855cb98ddfcd0805
|
||||
pad_on_left=bool(args.model_type in ["xlnet"]),
|
||||
# pad on the left for xlnet
|
||||
pad_token=tokenizer.convert_tokens_to_ids([tokenizer.pad_token])[0],
|
||||
pad_token_segment_id=4 if args.model_type in ["xlnet"] else 0,
|
||||
pad_token=tokenizer.pad_token_id,
|
||||
pad_token_segment_id=tokenizer.pad_token_type_id,
|
||||
pad_token_label_id=pad_token_label_id,
|
||||
)
|
||||
if args.local_rank in [-1, 0]:
|
||||
|
||||
@@ -64,8 +64,8 @@ class NERTransformer(BaseTransformer):
|
||||
sep_token=self.tokenizer.sep_token,
|
||||
sep_token_extra=bool(args.model_type in ["roberta"]),
|
||||
pad_on_left=bool(args.model_type in ["xlnet"]),
|
||||
pad_token=self.tokenizer.convert_tokens_to_ids([self.tokenizer.pad_token])[0],
|
||||
pad_token_segment_id=4 if args.model_type in ["xlnet"] else 0,
|
||||
pad_token=self.tokenizer.pad_token_id,
|
||||
pad_token_segment_id=self.tokenizer.pad_token_type_id,
|
||||
pad_token_label_id=self.pad_token_label_id,
|
||||
)
|
||||
logger.info("Saving features into cached file %s", cached_features_file)
|
||||
@@ -192,5 +192,5 @@ if __name__ == "__main__":
|
||||
# https://github.com/PyTorchLightning/pytorch-lightning/blob/master\
|
||||
# /pytorch_lightning/callbacks/model_checkpoint.py#L169
|
||||
checkpoints = list(sorted(glob.glob(os.path.join(args.output_dir, "checkpointepoch=*.ckpt"), recursive=True)))
|
||||
NERTransformer.load_from_checkpoint(checkpoints[-1])
|
||||
model = model.load_from_checkpoint(checkpoints[-1])
|
||||
trainer.test(model)
|
||||
|
||||
@@ -157,7 +157,9 @@ def train(
|
||||
writer = tf.summary.create_file_writer("/tmp/mylogs")
|
||||
|
||||
with strategy.scope():
|
||||
loss_fct = tf.keras.losses.SparseCategoricalCrossentropy(reduction=tf.keras.losses.Reduction.NONE)
|
||||
loss_fct = tf.keras.losses.SparseCategoricalCrossentropy(
|
||||
from_logits=True, reduction=tf.keras.losses.Reduction.NONE
|
||||
)
|
||||
optimizer = create_optimizer(args["learning_rate"], num_train_steps, args["warmup_steps"])
|
||||
|
||||
if args["fp16"]:
|
||||
@@ -205,11 +207,9 @@ def train(
|
||||
|
||||
with tf.GradientTape() as tape:
|
||||
logits = model(train_features["input_ids"], **inputs)[0]
|
||||
logits = tf.reshape(logits, (-1, len(labels) + 1))
|
||||
active_loss = tf.reshape(train_features["input_mask"], (-1,))
|
||||
active_logits = tf.boolean_mask(logits, active_loss)
|
||||
train_labels = tf.reshape(train_labels, (-1,))
|
||||
active_labels = tf.boolean_mask(train_labels, active_loss)
|
||||
active_loss = tf.reshape(train_labels, (-1,)) != pad_token_label_id
|
||||
active_logits = tf.boolean_mask(tf.reshape(logits, (-1, len(labels))), active_loss)
|
||||
active_labels = tf.boolean_mask(tf.reshape(train_labels, (-1,)), active_loss)
|
||||
cross_entropy = loss_fct(active_labels, active_logits)
|
||||
loss = tf.reduce_sum(cross_entropy) * (1.0 / train_batch_size)
|
||||
grads = tape.gradient(loss, model.trainable_variables)
|
||||
@@ -329,11 +329,9 @@ def evaluate(args, strategy, model, tokenizer, labels, pad_token_label_id, mode)
|
||||
|
||||
with strategy.scope():
|
||||
logits = model(eval_features["input_ids"], **inputs)[0]
|
||||
tmp_logits = tf.reshape(logits, (-1, len(labels) + 1))
|
||||
active_loss = tf.reshape(eval_features["input_mask"], (-1,))
|
||||
active_logits = tf.boolean_mask(tmp_logits, active_loss)
|
||||
tmp_eval_labels = tf.reshape(eval_labels, (-1,))
|
||||
active_labels = tf.boolean_mask(tmp_eval_labels, active_loss)
|
||||
active_loss = tf.reshape(eval_labels, (-1,)) != pad_token_label_id
|
||||
active_logits = tf.boolean_mask(tf.reshape(logits, (-1, len(labels))), active_loss)
|
||||
active_labels = tf.boolean_mask(tf.reshape(eval_labels, (-1,)), active_loss)
|
||||
cross_entropy = loss_fct(active_labels, active_logits)
|
||||
loss += tf.reduce_sum(cross_entropy) * (1.0 / eval_batch_size)
|
||||
|
||||
@@ -436,8 +434,8 @@ def load_and_cache_examples(args, tokenizer, labels, pad_token_label_id, batch_s
|
||||
# roberta uses an extra separator b/w pairs of sentences, cf. github.com/pytorch/fairseq/commit/1684e166e3da03f5b600dbb7855cb98ddfcd0805
|
||||
pad_on_left=bool(args["model_type"] in ["xlnet"]),
|
||||
# pad on the left for xlnet
|
||||
pad_token=tokenizer.convert_tokens_to_ids([tokenizer.pad_token])[0],
|
||||
pad_token_segment_id=4 if args["model_type"] in ["xlnet"] else 0,
|
||||
pad_token=tokenizer.pad_token_id,
|
||||
pad_token_segment_id=tokenizer.pad_token_type_id,
|
||||
pad_token_label_id=pad_token_label_id,
|
||||
)
|
||||
logging.info("Saving features into cached file %s", cached_features_file)
|
||||
@@ -497,8 +495,8 @@ def main(_):
|
||||
)
|
||||
|
||||
labels = get_labels(args["labels"])
|
||||
num_labels = len(labels) + 1
|
||||
pad_token_label_id = 0
|
||||
num_labels = len(labels)
|
||||
pad_token_label_id = -1
|
||||
config = AutoConfig.from_pretrained(
|
||||
args["config_name"] if args["config_name"] else args["model_name_or_path"],
|
||||
num_labels=num_labels,
|
||||
@@ -522,7 +520,6 @@ def main(_):
|
||||
config=config,
|
||||
cache_dir=args["cache_dir"] if args["cache_dir"] else None,
|
||||
)
|
||||
model.layers[-1].activation = tf.keras.activations.softmax
|
||||
|
||||
train_batch_size = args["per_device_train_batch_size"] * args["n_device"]
|
||||
train_dataset, num_train_examples = load_and_cache_examples(
|
||||
|
||||
@@ -112,12 +112,15 @@ def convert_examples_to_features(
|
||||
label_ids = []
|
||||
for word, label in zip(example.words, example.labels):
|
||||
word_tokens = tokenizer.tokenize(word)
|
||||
tokens.extend(word_tokens)
|
||||
# Use the real label id for the first token of the word, and padding ids for the remaining tokens
|
||||
label_ids.extend([label_map[label]] + [pad_token_label_id] * (len(word_tokens) - 1))
|
||||
|
||||
# bert-base-multilingual-cased sometimes output "nothing ([]) when calling tokenize with just a space.
|
||||
if len(word_tokens) > 0:
|
||||
tokens.extend(word_tokens)
|
||||
# Use the real label id for the first token of the word, and padding ids for the remaining tokens
|
||||
label_ids.extend([label_map[label]] + [pad_token_label_id] * (len(word_tokens) - 1))
|
||||
|
||||
# Account for [CLS] and [SEP] with "- 2" and with "- 3" for RoBERTa.
|
||||
special_tokens_count = 3 if sep_token_extra else 2
|
||||
special_tokens_count = tokenizer.num_added_tokens()
|
||||
if len(tokens) > max_seq_length - special_tokens_count:
|
||||
tokens = tokens[: (max_seq_length - special_tokens_count)]
|
||||
label_ids = label_ids[: (max_seq_length - special_tokens_count)]
|
||||
|
||||
@@ -3,3 +3,6 @@ tensorboard
|
||||
scikit-learn
|
||||
seqeval
|
||||
psutil
|
||||
sacrebleu
|
||||
rouge-score
|
||||
tensorflow_datasets
|
||||
@@ -360,8 +360,8 @@ def load_and_cache_examples(args, task, tokenizer, evaluate=False):
|
||||
max_length=args.max_seq_length,
|
||||
output_mode=output_mode,
|
||||
pad_on_left=bool(args.model_type in ["xlnet"]), # pad on the left for xlnet
|
||||
pad_token=tokenizer.convert_tokens_to_ids([tokenizer.pad_token])[0],
|
||||
pad_token_segment_id=4 if args.model_type in ["xlnet"] else 0,
|
||||
pad_token=tokenizer.pad_token_id,
|
||||
pad_token_segment_id=tokenizer.pad_token_type_id,
|
||||
)
|
||||
if args.local_rank in [-1, 0]:
|
||||
logger.info("Saving features into cached file %s", cached_features_file)
|
||||
|
||||
@@ -38,7 +38,6 @@ from torch.utils.data.distributed import DistributedSampler
|
||||
from tqdm import tqdm, trange
|
||||
|
||||
from transformers import (
|
||||
CONFIG_MAPPING,
|
||||
MODEL_WITH_LM_HEAD_MAPPING,
|
||||
WEIGHTS_NAME,
|
||||
AdamW,
|
||||
@@ -234,6 +233,9 @@ def train(args, train_dataset, model: PreTrainedModel, tokenizer: PreTrainedToke
|
||||
else:
|
||||
t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
|
||||
|
||||
model = model.module if hasattr(model, "module") else model # Take care of distributed/parallel training
|
||||
model.resize_token_embeddings(len(tokenizer))
|
||||
|
||||
# Prepare optimizer and schedule (linear warmup and decay)
|
||||
no_decay = ["bias", "LayerNorm.weight"]
|
||||
optimizer_grouped_parameters = [
|
||||
@@ -310,9 +312,6 @@ def train(args, train_dataset, model: PreTrainedModel, tokenizer: PreTrainedToke
|
||||
|
||||
tr_loss, logging_loss = 0.0, 0.0
|
||||
|
||||
model_to_resize = model.module if hasattr(model, "module") else model # Take care of distributed/parallel training
|
||||
model_to_resize.resize_token_embeddings(len(tokenizer))
|
||||
|
||||
model.zero_grad()
|
||||
train_iterator = trange(
|
||||
epochs_trained, int(args.num_train_epochs), desc="Epoch", disable=args.local_rank not in [-1, 0]
|
||||
@@ -625,6 +624,7 @@ def main():
|
||||
and os.listdir(args.output_dir)
|
||||
and args.do_train
|
||||
and not args.overwrite_output_dir
|
||||
and not args.should_continue
|
||||
):
|
||||
raise ValueError(
|
||||
"Output directory ({}) already exists and is not empty. Use --overwrite_output_dir to overcome.".format(
|
||||
@@ -679,7 +679,12 @@ def main():
|
||||
elif args.model_name_or_path:
|
||||
config = AutoConfig.from_pretrained(args.model_name_or_path, cache_dir=args.cache_dir)
|
||||
else:
|
||||
config = CONFIG_MAPPING[args.model_type]()
|
||||
# When we release a pip version exposing CONFIG_MAPPING,
|
||||
# we can do `config = CONFIG_MAPPING[args.model_type]()`.
|
||||
raise ValueError(
|
||||
"You are instantiating a new config instance from scratch. This is not supported, but you can do it from another script, save it,"
|
||||
"and load it from here, using --config_name"
|
||||
)
|
||||
|
||||
if args.tokenizer_name:
|
||||
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_name, cache_dir=args.cache_dir)
|
||||
@@ -687,8 +692,8 @@ def main():
|
||||
tokenizer = AutoTokenizer.from_pretrained(args.model_name_or_path, cache_dir=args.cache_dir)
|
||||
else:
|
||||
raise ValueError(
|
||||
"You are instantiating a new {} tokenizer. This is not supported, but you can do it from another script, save it,"
|
||||
"and load it from here, using --tokenizer_name".format(AutoTokenizer.__name__)
|
||||
"You are instantiating a new tokenizer from scratch. This is not supported, but you can do it from another script, save it,"
|
||||
"and load it from here, using --tokenizer_name"
|
||||
)
|
||||
|
||||
if args.block_size <= 0:
|
||||
@@ -706,7 +711,7 @@ def main():
|
||||
)
|
||||
else:
|
||||
logger.info("Training new model from scratch")
|
||||
model = AutoModelWithLMHead(config=config)
|
||||
model = AutoModelWithLMHead.from_config(config)
|
||||
|
||||
model.to(args.device)
|
||||
|
||||
|
||||
@@ -361,7 +361,7 @@ def load_and_cache_examples(args, task, tokenizer, evaluate=False, test=False):
|
||||
args.max_seq_length,
|
||||
tokenizer,
|
||||
pad_on_left=bool(args.model_type in ["xlnet"]), # pad on the left for xlnet
|
||||
pad_token_segment_id=4 if args.model_type in ["xlnet"] else 0,
|
||||
pad_token_segment_id=tokenizer.pad_token_type_id,
|
||||
)
|
||||
if args.local_rank in [-1, 0]:
|
||||
logger.info("Saving features into cached file %s", cached_features_file)
|
||||
|
||||
@@ -350,8 +350,8 @@ def load_and_cache_examples(args, task, tokenizer, evaluate=False):
|
||||
max_length=args.max_seq_length,
|
||||
output_mode=output_mode,
|
||||
pad_on_left=False,
|
||||
pad_token=tokenizer.convert_tokens_to_ids([tokenizer.pad_token])[0],
|
||||
pad_token_segment_id=0,
|
||||
pad_token=tokenizer.pad_token_id,
|
||||
pad_token_segment_id=tokenizer.pad_token_type_id,
|
||||
)
|
||||
if args.local_rank in [-1, 0]:
|
||||
logger.info("Saving features into cached file %s", cached_features_file)
|
||||
|
||||
@@ -1,23 +1,29 @@
|
||||
### Get the CNN Data
|
||||
### Get Preprocessed CNN Data
|
||||
To be able to reproduce the authors' results on the CNN/Daily Mail dataset you first need to download both CNN and Daily Mail datasets [from Kyunghyun Cho's website](https://cs.nyu.edu/~kcho/DMQA/) (the links next to "Stories") in the same folder. Then uncompress the archives by running:
|
||||
|
||||
```bash
|
||||
tar -xvf cnn_stories.tgz && tar -xvf dailymail_stories.tgz
|
||||
wget https://s3.amazonaws.com/datasets.huggingface.co/summarization/cnn_dm.tgz
|
||||
tar -xzvf cnn_dm.tgz
|
||||
```
|
||||
|
||||
this should make a directory called cnn_dm/ with files like `test.source`.
|
||||
To use your own data, copy that files format. Each article to be summarized is on its own line.
|
||||
|
||||
### Usage
|
||||
### Evaluation
|
||||
To create summaries for each article in dataset, run:
|
||||
```bash
|
||||
python evaluate_cnn.py <path_to_test.source> cnn_test_summaries.txt
|
||||
```
|
||||
the default batch size, 8, fits in 16GB GPU memory, but may need to be adjusted to fit your system.
|
||||
|
||||
|
||||
### Training
|
||||
Run/modify `run_train.sh`
|
||||
|
||||
### Where is the code?
|
||||
The core model is in `src/transformers/modeling_bart.py`. This directory only contains examples.
|
||||
|
||||
### (WIP) Rouge Scores
|
||||
## (WIP) Rouge Scores
|
||||
|
||||
### Stanford CoreNLP Setup
|
||||
```
|
||||
|
||||
@@ -16,15 +16,17 @@ def chunks(lst, n):
|
||||
yield lst[i : i + n]
|
||||
|
||||
|
||||
def generate_summaries(lns, out_file, batch_size=8, device=DEFAULT_DEVICE):
|
||||
def generate_summaries(
|
||||
examples: list, out_file: str, model_name: str, batch_size: int = 8, device: str = DEFAULT_DEVICE
|
||||
):
|
||||
fout = Path(out_file).open("w")
|
||||
model = BartForConditionalGeneration.from_pretrained("bart-large-cnn", output_past=True,).to(device)
|
||||
model = BartForConditionalGeneration.from_pretrained(model_name, output_past=True,).to(device)
|
||||
tokenizer = BartTokenizer.from_pretrained("bart-large")
|
||||
|
||||
max_length = 140
|
||||
min_length = 55
|
||||
|
||||
for batch in tqdm(list(chunks(lns, batch_size))):
|
||||
for batch in tqdm(list(chunks(examples, batch_size))):
|
||||
dct = tokenizer.batch_encode_plus(batch, max_length=1024, return_tensors="pt", pad_to_max_length=True)
|
||||
summaries = model.generate(
|
||||
input_ids=dct["input_ids"].to(device),
|
||||
@@ -43,7 +45,7 @@ def generate_summaries(lns, out_file, batch_size=8, device=DEFAULT_DEVICE):
|
||||
fout.flush()
|
||||
|
||||
|
||||
def _run_generate():
|
||||
def run_generate():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument(
|
||||
"source_path", type=str, help="like cnn_dm/test.source",
|
||||
@@ -51,6 +53,9 @@ def _run_generate():
|
||||
parser.add_argument(
|
||||
"output_path", type=str, help="where to save summaries",
|
||||
)
|
||||
parser.add_argument(
|
||||
"model_name", type=str, default="bart-large-cnn", help="like bart-large-cnn",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--device", type=str, required=False, default=DEFAULT_DEVICE, help="cuda, cuda:1, cpu etc.",
|
||||
)
|
||||
@@ -58,9 +63,9 @@ def _run_generate():
|
||||
"--bs", type=int, default=8, required=False, help="batch size: how many to summarize at a time",
|
||||
)
|
||||
args = parser.parse_args()
|
||||
lns = [" " + x.rstrip() for x in open(args.source_path).readlines()]
|
||||
generate_summaries(lns, args.output_path, batch_size=args.bs, device=args.device)
|
||||
examples = [" " + x.rstrip() for x in open(args.source_path).readlines()]
|
||||
generate_summaries(examples, args.output_path, args.model_name, batch_size=args.bs, device=args.device)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
_run_generate()
|
||||
run_generate()
|
||||
|
||||
172
examples/summarization/bart/run_bart_sum.py
Normal file
172
examples/summarization/bart/run_bart_sum.py
Normal file
@@ -0,0 +1,172 @@
|
||||
import argparse
|
||||
import glob
|
||||
import logging
|
||||
import os
|
||||
import time
|
||||
|
||||
import torch
|
||||
from torch.utils.data import DataLoader
|
||||
|
||||
from transformer_base import BaseTransformer, add_generic_args, generic_train, get_linear_schedule_with_warmup
|
||||
from utils import SummarizationDataset
|
||||
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
class BartSystem(BaseTransformer):
|
||||
|
||||
mode = "language-modeling"
|
||||
|
||||
def __init__(self, hparams):
|
||||
super(BartSystem, self).__init__(hparams, num_labels=None, mode=self.mode)
|
||||
|
||||
def forward(
|
||||
self, input_ids, attention_mask=None, decoder_input_ids=None, decoder_attention_mask=None, lm_labels=None
|
||||
):
|
||||
return self.model(
|
||||
input_ids,
|
||||
attention_mask=attention_mask,
|
||||
decoder_input_ids=decoder_input_ids,
|
||||
decoder_attention_mask=decoder_attention_mask,
|
||||
lm_labels=lm_labels,
|
||||
)
|
||||
|
||||
def _step(self, batch):
|
||||
y = batch["target_ids"]
|
||||
y_ids = y[:, :-1].contiguous()
|
||||
lm_labels = y[:, 1:].clone()
|
||||
lm_labels[y[:, 1:] == self.tokenizer.pad_token_id] = -100
|
||||
outputs = self(
|
||||
input_ids=batch["source_ids"],
|
||||
attention_mask=batch["source_mask"],
|
||||
decoder_input_ids=y_ids,
|
||||
lm_labels=lm_labels,
|
||||
)
|
||||
|
||||
loss = outputs[0]
|
||||
|
||||
return loss
|
||||
|
||||
def training_step(self, batch, batch_idx):
|
||||
loss = self._step(batch)
|
||||
|
||||
tensorboard_logs = {"train_loss": loss}
|
||||
return {"loss": loss, "log": tensorboard_logs}
|
||||
|
||||
def validation_step(self, batch, batch_idx):
|
||||
loss = self._step(batch)
|
||||
return {"val_loss": loss}
|
||||
|
||||
def validation_end(self, outputs):
|
||||
avg_loss = torch.stack([x["val_loss"] for x in outputs]).mean()
|
||||
tensorboard_logs = {"val_loss": avg_loss}
|
||||
return {"avg_val_loss": avg_loss, "log": tensorboard_logs}
|
||||
|
||||
def test_step(self, batch, batch_idx):
|
||||
generated_ids = self.model.generate(
|
||||
batch["source_ids"],
|
||||
attention_mask=batch["source_mask"],
|
||||
num_beams=1,
|
||||
max_length=80,
|
||||
repetition_penalty=2.5,
|
||||
length_penalty=1.0,
|
||||
early_stopping=True,
|
||||
)
|
||||
preds = [
|
||||
self.tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=True)
|
||||
for g in generated_ids
|
||||
]
|
||||
target = [
|
||||
self.tokenizer.decode(t, skip_special_tokens=True, clean_up_tokenization_spaces=True)
|
||||
for t in batch["target_ids"]
|
||||
]
|
||||
loss = self._step(batch)
|
||||
|
||||
return {"val_loss": loss, "preds": preds, "target": target}
|
||||
|
||||
def test_end(self, outputs):
|
||||
return self.validation_end(outputs)
|
||||
|
||||
def test_epoch_end(self, outputs):
|
||||
output_test_predictions_file = os.path.join(self.hparams.output_dir, "test_predictions.txt")
|
||||
output_test_targets_file = os.path.join(self.hparams.output_dir, "test_targets.txt")
|
||||
# write predictions and targets for later rouge evaluation.
|
||||
with open(output_test_predictions_file, "w+") as p_writer, open(output_test_targets_file, "w+") as t_writer:
|
||||
for output_batch in outputs:
|
||||
p_writer.writelines(s + "\n" for s in output_batch["preds"])
|
||||
t_writer.writelines(s + "\n" for s in output_batch["target"])
|
||||
p_writer.close()
|
||||
t_writer.close()
|
||||
|
||||
return self.test_end(outputs)
|
||||
|
||||
def train_dataloader(self):
|
||||
train_dataset = SummarizationDataset(
|
||||
self.tokenizer, data_dir=self.hparams.data_dir, type_path="train", block_size=self.hparams.max_seq_length
|
||||
)
|
||||
dataloader = DataLoader(train_dataset, batch_size=self.hparams.train_batch_size)
|
||||
t_total = (
|
||||
(len(dataloader.dataset) // (self.hparams.train_batch_size * max(1, self.hparams.n_gpu)))
|
||||
// self.hparams.gradient_accumulation_steps
|
||||
* float(self.hparams.num_train_epochs)
|
||||
)
|
||||
scheduler = get_linear_schedule_with_warmup(
|
||||
self.opt, num_warmup_steps=self.hparams.warmup_steps, num_training_steps=t_total
|
||||
)
|
||||
self.lr_scheduler = scheduler
|
||||
return dataloader
|
||||
|
||||
def val_dataloader(self):
|
||||
val_dataset = SummarizationDataset(
|
||||
self.tokenizer, data_dir=self.hparams.data_dir, type_path="val", block_size=self.hparams.max_seq_length
|
||||
)
|
||||
return DataLoader(val_dataset, batch_size=self.hparams.eval_batch_size)
|
||||
|
||||
def test_dataloader(self):
|
||||
test_dataset = SummarizationDataset(
|
||||
self.tokenizer, data_dir=self.hparams.data_dir, type_path="test", block_size=self.hparams.max_seq_length
|
||||
)
|
||||
return DataLoader(test_dataset, batch_size=self.hparams.eval_batch_size)
|
||||
|
||||
@staticmethod
|
||||
def add_model_specific_args(parser, root_dir):
|
||||
BaseTransformer.add_model_specific_args(parser, root_dir)
|
||||
# Add BART specific options
|
||||
parser.add_argument(
|
||||
"--max_seq_length",
|
||||
default=1024,
|
||||
type=int,
|
||||
help="The maximum total input sequence length after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded.",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--data_dir",
|
||||
default=None,
|
||||
type=str,
|
||||
required=True,
|
||||
help="The input data dir. Should contain the dataset files for the CNN/DM summarization task.",
|
||||
)
|
||||
return parser
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
add_generic_args(parser, os.getcwd())
|
||||
parser = BartSystem.add_model_specific_args(parser, os.getcwd())
|
||||
args = parser.parse_args()
|
||||
|
||||
# If output_dir not provided, a folder will be generated in pwd
|
||||
if args.output_dir is None:
|
||||
args.output_dir = os.path.join("./results", f"{args.task}_{args.model_type}_{time.strftime('%Y%m%d_%H%M%S')}",)
|
||||
os.makedirs(args.output_dir)
|
||||
|
||||
model = BartSystem(args)
|
||||
trainer = generic_train(model, args)
|
||||
|
||||
# Optionally, predict on dev set and write to output_dir
|
||||
if args.do_predict:
|
||||
checkpoints = list(sorted(glob.glob(os.path.join(args.output_dir, "checkpointepoch=*.ckpt"), recursive=True)))
|
||||
BartSystem.load_from_checkpoint(checkpoints[-1])
|
||||
trainer.test(model)
|
||||
23
examples/summarization/bart/run_train.sh
Executable file
23
examples/summarization/bart/run_train.sh
Executable file
@@ -0,0 +1,23 @@
|
||||
# Install newest ptl.
|
||||
pip install -U git+http://github.com/PyTorchLightning/pytorch-lightning/
|
||||
|
||||
|
||||
export OUTPUT_DIR_NAME=bart_sum
|
||||
export CURRENT_DIR=${PWD}
|
||||
export OUTPUT_DIR=${CURRENT_DIR}/${OUTPUT_DIR_NAME}
|
||||
|
||||
# Make output directory if it doesn't exist
|
||||
mkdir -p $OUTPUT_DIR
|
||||
|
||||
# Add parent directory to python path to access transformer_base.py
|
||||
export PYTHONPATH="../../":"${PYTHONPATH}"
|
||||
|
||||
python run_bart_sum.py \
|
||||
--data_dir=./cnn-dailymail/cnn_dm \
|
||||
--model_type=bart \
|
||||
--model_name_or_path=bart-large \
|
||||
--learning_rate=3e-5 \
|
||||
--train_batch_size=4 \
|
||||
--eval_batch_size=4 \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--do_train
|
||||
@@ -5,7 +5,7 @@ import unittest
|
||||
from pathlib import Path
|
||||
from unittest.mock import patch
|
||||
|
||||
from .evaluate_cnn import _run_generate
|
||||
from .evaluate_cnn import run_generate
|
||||
|
||||
|
||||
articles = [" New York (CNN)When Liana Barrientos was 23 years old, she got married in Westchester County."]
|
||||
@@ -19,10 +19,14 @@ class TestBartExamples(unittest.TestCase):
|
||||
def test_bart_cnn_cli(self):
|
||||
stream_handler = logging.StreamHandler(sys.stdout)
|
||||
logger.addHandler(stream_handler)
|
||||
tmp = Path(tempfile.gettempdir()) / "utest_generations.hypo"
|
||||
tmp = Path(tempfile.gettempdir()) / "utest_generations_bart_sum.hypo"
|
||||
with tmp.open("w") as f:
|
||||
f.write("\n".join(articles))
|
||||
testargs = ["evaluate_cnn.py", str(tmp), "output.txt"]
|
||||
|
||||
output_file_name = Path(tempfile.gettempdir()) / "utest_output_bart_sum.hypo"
|
||||
|
||||
testargs = ["evaluate_cnn.py", str(tmp), str(output_file_name), "sshleifer/bart-tiny-random"]
|
||||
|
||||
with patch.object(sys, "argv", testargs):
|
||||
_run_generate()
|
||||
self.assertTrue(Path("output.txt").exists())
|
||||
run_generate()
|
||||
self.assertTrue(Path(output_file_name).exists())
|
||||
|
||||
43
examples/summarization/bart/utils.py
Normal file
43
examples/summarization/bart/utils.py
Normal file
@@ -0,0 +1,43 @@
|
||||
import os
|
||||
|
||||
from torch.utils.data import Dataset
|
||||
|
||||
|
||||
class SummarizationDataset(Dataset):
|
||||
def __init__(self, tokenizer, data_dir="./cnn-dailymail/cnn_dm/", type_path="train", block_size=1024):
|
||||
super(SummarizationDataset,).__init__()
|
||||
self.tokenizer = tokenizer
|
||||
|
||||
self.source = []
|
||||
self.target = []
|
||||
|
||||
print("loading " + type_path + " source.")
|
||||
|
||||
with open(os.path.join(data_dir, type_path + ".source"), "r") as f:
|
||||
for text in f.readlines(): # each text is a line and a full story
|
||||
tokenized = tokenizer.batch_encode_plus(
|
||||
[text], max_length=block_size, pad_to_max_length=True, return_tensors="pt"
|
||||
)
|
||||
self.source.append(tokenized)
|
||||
f.close()
|
||||
|
||||
print("loading " + type_path + " target.")
|
||||
|
||||
with open(os.path.join(data_dir, type_path + ".target"), "r") as f:
|
||||
for text in f.readlines(): # each text is a line and a summary
|
||||
tokenized = tokenizer.batch_encode_plus(
|
||||
[text], max_length=56, pad_to_max_length=True, return_tensors="pt"
|
||||
)
|
||||
self.target.append(tokenized)
|
||||
f.close()
|
||||
|
||||
def __len__(self):
|
||||
return len(self.source)
|
||||
|
||||
def __getitem__(self, index):
|
||||
source_ids = self.source[index]["input_ids"].squeeze()
|
||||
target_ids = self.target[index]["input_ids"].squeeze()
|
||||
|
||||
src_mask = self.source[index]["attention_mask"].squeeze() # might need to squeeze
|
||||
|
||||
return {"source_ids": source_ids, "source_mask": src_mask, "target_ids": target_ids}
|
||||
25
examples/summarization/t5/README.md
Normal file
25
examples/summarization/t5/README.md
Normal file
@@ -0,0 +1,25 @@
|
||||
***This script evaluates the the multitask pre-trained checkpoint for ``t5-base`` (see paper [here](https://arxiv.org/pdf/1910.10683.pdf)) on the CNN/Daily Mail test dataset. Please note that the results in the paper were attained using a model fine-tuned on summarization, so that results will be worse here by approx. 0.5 ROUGE points***
|
||||
|
||||
### Get the CNN Data
|
||||
First, you need to download the CNN data. It's about ~400 MB and can be downloaded by
|
||||
running
|
||||
|
||||
```bash
|
||||
python download_cnn_daily_mail.py cnn_articles_input_data.txt cnn_articles_reference_summaries.txt
|
||||
```
|
||||
|
||||
You should confirm that each file has 11490 lines:
|
||||
|
||||
```bash
|
||||
wc -l cnn_articles_input_data.txt # should print 11490
|
||||
wc -l cnn_articles_reference_summaries.txt # should print 11490
|
||||
```
|
||||
|
||||
### Usage
|
||||
|
||||
To create summaries for each article in dataset, run:
|
||||
```bash
|
||||
python evaluate_cnn.py cnn_articles_input_data.txt cnn_generated_articles_summaries.txt cnn_articles_reference_summaries.txt rouge_score.txt
|
||||
```
|
||||
The default batch size, 8, fits in 16GB GPU memory, but may need to be adjusted to fit your system.
|
||||
The rouge scores "rouge1, rouge2, rougeL" are automatically created and saved in ``rouge_score.txt``.
|
||||
0
examples/summarization/t5/__init__.py
Normal file
0
examples/summarization/t5/__init__.py
Normal file
31
examples/summarization/t5/download_cnn_daily_mail.py
Normal file
31
examples/summarization/t5/download_cnn_daily_mail.py
Normal file
@@ -0,0 +1,31 @@
|
||||
import argparse
|
||||
from pathlib import Path
|
||||
|
||||
import tensorflow_datasets as tfds
|
||||
|
||||
|
||||
def main(input_path, reference_path, data_dir):
|
||||
cnn_ds = tfds.load("cnn_dailymail", split="test", shuffle_files=False, data_dir=data_dir)
|
||||
cnn_ds_iter = tfds.as_numpy(cnn_ds)
|
||||
|
||||
test_articles_file = Path(input_path).open("w")
|
||||
test_summaries_file = Path(reference_path).open("w")
|
||||
|
||||
for example in cnn_ds_iter:
|
||||
test_articles_file.write(example["article"].decode("utf-8") + "\n")
|
||||
test_articles_file.flush()
|
||||
test_summaries_file.write(example["highlights"].decode("utf-8").replace("\n", " ") + "\n")
|
||||
test_summaries_file.flush()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("input_path", type=str, help="where to save the articles input data")
|
||||
parser.add_argument(
|
||||
"reference_path", type=str, help="where to save the reference summaries",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--data_dir", type=str, default="~/tensorflow_datasets", help="where to save the tensorflow datasets.",
|
||||
)
|
||||
args = parser.parse_args()
|
||||
main(args.input_path, args.reference_path, args.data_dir)
|
||||
101
examples/summarization/t5/evaluate_cnn.py
Normal file
101
examples/summarization/t5/evaluate_cnn.py
Normal file
@@ -0,0 +1,101 @@
|
||||
import argparse
|
||||
from pathlib import Path
|
||||
|
||||
import torch
|
||||
from tqdm import tqdm
|
||||
|
||||
from rouge_score import rouge_scorer, scoring
|
||||
from transformers import T5ForConditionalGeneration, T5Tokenizer
|
||||
|
||||
|
||||
def chunks(lst, n):
|
||||
"""Yield successive n-sized chunks from lst."""
|
||||
for i in range(0, len(lst), n):
|
||||
yield lst[i : i + n]
|
||||
|
||||
|
||||
def generate_summaries(lns, output_file_path, model_size, batch_size, device):
|
||||
output_file = Path(output_file_path).open("w")
|
||||
|
||||
model = T5ForConditionalGeneration.from_pretrained(model_size)
|
||||
model.to(device)
|
||||
|
||||
tokenizer = T5Tokenizer.from_pretrained(model_size)
|
||||
|
||||
# update config with summarization specific params
|
||||
task_specific_params = model.config.task_specific_params
|
||||
if task_specific_params is not None:
|
||||
model.config.update(task_specific_params.get("summarization", {}))
|
||||
|
||||
for batch in tqdm(list(chunks(lns, batch_size))):
|
||||
batch = [model.config.prefix + text for text in batch]
|
||||
|
||||
dct = tokenizer.batch_encode_plus(batch, max_length=512, return_tensors="pt", pad_to_max_length=True)
|
||||
input_ids = dct["input_ids"].to(device)
|
||||
attention_mask = dct["attention_mask"].to(device)
|
||||
|
||||
summaries = model.generate(input_ids=input_ids, attention_mask=attention_mask)
|
||||
dec = [tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=False) for g in summaries]
|
||||
|
||||
for hypothesis in dec:
|
||||
output_file.write(hypothesis + "\n")
|
||||
output_file.flush()
|
||||
|
||||
|
||||
def calculate_rouge(output_lns, reference_lns, score_path):
|
||||
score_file = Path(score_path).open("w")
|
||||
scorer = rouge_scorer.RougeScorer(["rouge1", "rouge2", "rougeL"], use_stemmer=True)
|
||||
aggregator = scoring.BootstrapAggregator()
|
||||
|
||||
for reference_ln, output_ln in zip(reference_lns, output_lns):
|
||||
scores = scorer.score(reference_ln, output_ln)
|
||||
aggregator.add_scores(scores)
|
||||
|
||||
result = aggregator.aggregate()
|
||||
score_file.write(
|
||||
"ROUGE_1: \n{} \n\n ROUGE_2: \n{} \n\n ROUGE_L: \n{} \n\n".format(
|
||||
result["rouge1"], result["rouge2"], result["rougeL"]
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
def run_generate():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument(
|
||||
"model_size",
|
||||
type=str,
|
||||
help="T5 model size, either 't5-small', 't5-base', 't5-large', 't5-3b', 't5-11b'. Defaults to 't5-base'.",
|
||||
default="t5-base",
|
||||
)
|
||||
parser.add_argument(
|
||||
"input_path", type=str, help="like cnn_dm/test_articles_input.txt",
|
||||
)
|
||||
parser.add_argument(
|
||||
"output_path", type=str, help="where to save summaries",
|
||||
)
|
||||
parser.add_argument("reference_path", type=str, help="like cnn_dm/test_reference_summaries.txt")
|
||||
parser.add_argument(
|
||||
"score_path", type=str, help="where to save the rouge score",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--batch_size", type=int, default=8, required=False, help="batch size: how many to summarize at a time",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--no_cuda", default=False, type=bool, help="Whether to force the execution on CPU.",
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
args.device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
|
||||
|
||||
source_lns = [x.rstrip() for x in open(args.input_path).readlines()]
|
||||
|
||||
generate_summaries(source_lns, args.output_path, args.model_size, args.batch_size, args.device)
|
||||
|
||||
output_lns = [x.rstrip() for x in open(args.output_path).readlines()]
|
||||
reference_lns = [x.rstrip() for x in open(args.reference_path).readlines()]
|
||||
|
||||
calculate_rouge(output_lns, reference_lns, args.score_path)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
run_generate()
|
||||
44
examples/summarization/t5/test_t5_examples.py
Normal file
44
examples/summarization/t5/test_t5_examples.py
Normal file
@@ -0,0 +1,44 @@
|
||||
import logging
|
||||
import sys
|
||||
import tempfile
|
||||
import unittest
|
||||
from pathlib import Path
|
||||
from unittest.mock import patch
|
||||
|
||||
from .evaluate_cnn import run_generate
|
||||
|
||||
|
||||
output_file_name = "output_t5_sum.txt"
|
||||
score_file_name = "score_t5_sum.txt"
|
||||
|
||||
articles = ["New York (CNN)When Liana Barrientos was 23 years old, she got married in Westchester County."]
|
||||
|
||||
logging.basicConfig(level=logging.DEBUG)
|
||||
|
||||
logger = logging.getLogger()
|
||||
|
||||
|
||||
class TestT5Examples(unittest.TestCase):
|
||||
def test_t5_cli(self):
|
||||
stream_handler = logging.StreamHandler(sys.stdout)
|
||||
logger.addHandler(stream_handler)
|
||||
tmp = Path(tempfile.gettempdir()) / "utest_generations_t5_sum.hypo"
|
||||
with tmp.open("w") as f:
|
||||
f.write("\n".join(articles))
|
||||
|
||||
output_file_name = Path(tempfile.gettempdir()) / "utest_output_t5_sum.hypo"
|
||||
score_file_name = Path(tempfile.gettempdir()) / "utest_score_t5_sum.hypo"
|
||||
|
||||
testargs = [
|
||||
"evaluate_cnn.py",
|
||||
"patrickvonplaten/t5-tiny-random",
|
||||
str(tmp),
|
||||
str(output_file_name),
|
||||
str(tmp),
|
||||
str(score_file_name),
|
||||
]
|
||||
|
||||
with patch.object(sys, "argv", testargs):
|
||||
run_generate()
|
||||
self.assertTrue(Path(output_file_name).exists())
|
||||
self.assertTrue(Path(score_file_name).exists())
|
||||
@@ -53,10 +53,9 @@ class BaseTransformer(pl.LightningModule):
|
||||
super(BaseTransformer, self).__init__()
|
||||
self.hparams = hparams
|
||||
self.hparams.model_type = self.hparams.model_type.lower()
|
||||
|
||||
config = AutoConfig.from_pretrained(
|
||||
self.hparams.config_name if self.hparams.config_name else self.hparams.model_name_or_path,
|
||||
num_labels=num_labels,
|
||||
**({"num_labels": num_labels} if num_labels is not None else {}),
|
||||
cache_dir=self.hparams.cache_dir if self.hparams.cache_dir else None,
|
||||
)
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
|
||||
51
examples/translation/t5/README.md
Normal file
51
examples/translation/t5/README.md
Normal file
@@ -0,0 +1,51 @@
|
||||
***This script evaluates the multitask pre-trained checkpoint for ``t5-base`` (see paper [here](https://arxiv.org/pdf/1910.10683.pdf)) on the English to German WMT dataset. Please note that the results in the paper were attained using a model fine-tuned on translation, so that results will be worse here by approx. 1.5 BLEU points***
|
||||
|
||||
### Intro
|
||||
|
||||
This example shows how T5 (here the official [paper](https://arxiv.org/abs/1910.10683)) can be
|
||||
evaluated on the WMT English-German dataset.
|
||||
|
||||
### Get the WMT Data
|
||||
|
||||
To be able to reproduce the authors' results on WMT English to German, you first need to download
|
||||
the WMT14 en-de news datasets.
|
||||
Go on Stanford's official NLP [website](https://nlp.stanford.edu/projects/nmt/) and find "newstest2013.en" and "newstest2013.de" under WMT'14 English-German data or download the dataset directly via:
|
||||
|
||||
```bash
|
||||
curl https://nlp.stanford.edu/projects/nmt/data/wmt14.en-de/newstest2013.en > newstest2013.en
|
||||
curl https://nlp.stanford.edu/projects/nmt/data/wmt14.en-de/newstest2013.de > newstest2013.de
|
||||
```
|
||||
|
||||
You should have 3000 sentence in each file. You can verify this by running:
|
||||
|
||||
```bash
|
||||
wc -l newstest2013.en # should give 3000
|
||||
```
|
||||
|
||||
### Usage
|
||||
|
||||
Let's check the longest and shortest sentence in our file to find reasonable decoding hyperparameters:
|
||||
|
||||
Get the longest and shortest sentence:
|
||||
|
||||
```bash
|
||||
awk '{print NF}' newstest2013.en | sort -n | head -1 # shortest sentence has 1 word
|
||||
awk '{print NF}' newstest2013.en | sort -n | tail -1 # longest sentence has 106 words
|
||||
```
|
||||
|
||||
We will set our `max_length` to ~3 times the longest sentence and leave `min_length` to its default value of 0.
|
||||
We decode with beam search `num_beams=4` as proposed in the paper. Also as is common in beam search we set `early_stopping=True` and `length_penalty=2.0`.
|
||||
|
||||
To create translation for each in dataset and get a final BLEU score, run:
|
||||
```bash
|
||||
python evaluate_wmt.py <path_to_newstest2013.en> newstest2013_de_translations.txt <path_to_newstest2013.de> newsstest2013_en_de_bleu.txt
|
||||
```
|
||||
the default batch size, 16, fits in 16GB GPU memory, but may need to be adjusted to fit your system.
|
||||
|
||||
### Where is the code?
|
||||
The core model is in `src/transformers/modeling_t5.py`. This directory only contains examples.
|
||||
|
||||
### BLEU Scores
|
||||
|
||||
The BLEU score is calculated using [sacrebleu](https://github.com/mjpost/sacreBLEU) by mjpost.
|
||||
To get the BLEU score we used
|
||||
0
examples/translation/t5/__init__.py
Normal file
0
examples/translation/t5/__init__.py
Normal file
96
examples/translation/t5/evaluate_wmt.py
Normal file
96
examples/translation/t5/evaluate_wmt.py
Normal file
@@ -0,0 +1,96 @@
|
||||
import argparse
|
||||
from pathlib import Path
|
||||
|
||||
import torch
|
||||
from tqdm import tqdm
|
||||
|
||||
from sacrebleu import corpus_bleu
|
||||
from transformers import T5ForConditionalGeneration, T5Tokenizer
|
||||
|
||||
|
||||
def chunks(lst, n):
|
||||
"""Yield successive n-sized chunks from lst."""
|
||||
for i in range(0, len(lst), n):
|
||||
yield lst[i : i + n]
|
||||
|
||||
|
||||
def generate_translations(lns, output_file_path, model_size, batch_size, device):
|
||||
output_file = Path(output_file_path).open("w")
|
||||
|
||||
model = T5ForConditionalGeneration.from_pretrained(model_size)
|
||||
model.to(device)
|
||||
|
||||
tokenizer = T5Tokenizer.from_pretrained(model_size)
|
||||
|
||||
# update config with summarization specific params
|
||||
task_specific_params = model.config.task_specific_params
|
||||
if task_specific_params is not None:
|
||||
model.config.update(task_specific_params.get("translation_en_to_de", {}))
|
||||
|
||||
for batch in tqdm(list(chunks(lns, batch_size))):
|
||||
batch = [model.config.prefix + text for text in batch]
|
||||
|
||||
dct = tokenizer.batch_encode_plus(batch, max_length=512, return_tensors="pt", pad_to_max_length=True)
|
||||
|
||||
input_ids = dct["input_ids"].to(device)
|
||||
attention_mask = dct["attention_mask"].to(device)
|
||||
|
||||
translations = model.generate(input_ids=input_ids, attention_mask=attention_mask)
|
||||
dec = [tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=False) for g in translations]
|
||||
|
||||
for hypothesis in dec:
|
||||
output_file.write(hypothesis + "\n")
|
||||
output_file.flush()
|
||||
|
||||
|
||||
def calculate_bleu_score(output_lns, refs_lns, score_path):
|
||||
bleu = corpus_bleu(output_lns, [refs_lns])
|
||||
result = "BLEU score: {}".format(bleu.score)
|
||||
score_file = Path(score_path).open("w")
|
||||
score_file.write(result)
|
||||
|
||||
|
||||
def run_generate():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument(
|
||||
"model_size",
|
||||
type=str,
|
||||
help="T5 model size, either 't5-small', 't5-base', 't5-large', 't5-3b', 't5-11b'. Defaults to 't5-base'.",
|
||||
default="t5-base",
|
||||
)
|
||||
parser.add_argument(
|
||||
"input_path", type=str, help="like wmt/newstest2013.en",
|
||||
)
|
||||
parser.add_argument(
|
||||
"output_path", type=str, help="where to save translation",
|
||||
)
|
||||
parser.add_argument(
|
||||
"reference_path", type=str, help="like wmt/newstest2013.de",
|
||||
)
|
||||
parser.add_argument(
|
||||
"score_path", type=str, help="where to save the bleu score",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--batch_size", type=int, default=16, required=False, help="batch size: how many to summarize at a time",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--no_cuda", default=False, type=bool, help="Whether to force the execution on CPU.",
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
args.device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
|
||||
|
||||
dash_pattern = (" ##AT##-##AT## ", "-")
|
||||
|
||||
input_lns = [x.strip().replace(dash_pattern[0], dash_pattern[1]) for x in open(args.input_path).readlines()]
|
||||
|
||||
generate_translations(input_lns, args.output_path, args.model_size, args.batch_size, args.device)
|
||||
|
||||
output_lns = [x.strip() for x in open(args.output_path).readlines()]
|
||||
refs_lns = [x.strip().replace(dash_pattern[0], dash_pattern[1]) for x in open(args.reference_path).readlines()]
|
||||
|
||||
calculate_bleu_score(output_lns, refs_lns, args.score_path)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
run_generate()
|
||||
50
examples/translation/t5/test_t5_examples.py
Normal file
50
examples/translation/t5/test_t5_examples.py
Normal file
@@ -0,0 +1,50 @@
|
||||
import logging
|
||||
import sys
|
||||
import tempfile
|
||||
import unittest
|
||||
from pathlib import Path
|
||||
from unittest.mock import patch
|
||||
|
||||
from .evaluate_wmt import run_generate
|
||||
|
||||
|
||||
text = ["When Liana Barrientos was 23 years old, she got married in Westchester County."]
|
||||
translation = ["Als Liana Barrientos 23 Jahre alt war, heiratete sie in Westchester County."]
|
||||
|
||||
output_file_name = "output_t5_trans.txt"
|
||||
score_file_name = "score_t5_trans.txt"
|
||||
|
||||
logging.basicConfig(level=logging.DEBUG)
|
||||
|
||||
logger = logging.getLogger()
|
||||
|
||||
|
||||
class TestT5Examples(unittest.TestCase):
|
||||
def test_t5_cli(self):
|
||||
stream_handler = logging.StreamHandler(sys.stdout)
|
||||
logger.addHandler(stream_handler)
|
||||
|
||||
tmp_source = Path(tempfile.gettempdir()) / "utest_generations_t5_trans.hypo"
|
||||
with tmp_source.open("w") as f:
|
||||
f.write("\n".join(text))
|
||||
|
||||
tmp_target = Path(tempfile.gettempdir()) / "utest_generations_t5_trans.target"
|
||||
with tmp_target.open("w") as f:
|
||||
f.write("\n".join(translation))
|
||||
|
||||
output_file_name = Path(tempfile.gettempdir()) / "utest_output_trans.hypo"
|
||||
score_file_name = Path(tempfile.gettempdir()) / "utest_score.hypo"
|
||||
|
||||
testargs = [
|
||||
"evaluate_wmt.py",
|
||||
"patrickvonplaten/t5-tiny-random",
|
||||
str(tmp_source),
|
||||
str(output_file_name),
|
||||
str(tmp_target),
|
||||
str(score_file_name),
|
||||
]
|
||||
|
||||
with patch.object(sys, "argv", testargs):
|
||||
run_generate()
|
||||
self.assertTrue(Path(output_file_name).exists())
|
||||
self.assertTrue(Path(score_file_name).exists())
|
||||
@@ -320,7 +320,9 @@ def convert_examples_to_features(
|
||||
else:
|
||||
text_b = example.question + " " + ending
|
||||
|
||||
inputs = tokenizer.encode_plus(text_a, text_b, add_special_tokens=True, max_length=max_length,)
|
||||
inputs = tokenizer.encode_plus(
|
||||
text_a, text_b, add_special_tokens=True, max_length=max_length, return_token_type_ids=True
|
||||
)
|
||||
if "num_truncated_tokens" in inputs and inputs["num_truncated_tokens"] > 0:
|
||||
logger.info(
|
||||
"Attention! you are cropping tokens (swag task is ok). "
|
||||
|
||||
@@ -64,27 +64,8 @@ TensorFlow: 2.1.0
|
||||
Python: 3.7.6
|
||||
```
|
||||
|
||||
### Inferencing / prediction works with the current Transformers v2.4.1
|
||||
|
||||
### Access this albert_xxlargev1_sqd2_512 fine-tuned model with "tried & true" code:
|
||||
### Access this albert_xxlargev1_sqd2_512 fine-tuned model with:
|
||||
|
||||
```python
|
||||
config_class, model_class, tokenizer_class = \
|
||||
AlbertConfig, AlbertForQuestionAnswering, AlbertTokenizer
|
||||
|
||||
model_name_or_path = "ahotrod/albert_xxlargev1_squad2_512"
|
||||
config = config_class.from_pretrained(model_name_or_path)
|
||||
tokenizer = tokenizer_class.from_pretrained(model_name_or_path, do_lower_case=True)
|
||||
model = model_class.from_pretrained(model_name_or_path, config=config)
|
||||
```
|
||||
|
||||
### or the AutoModels (AutoConfig, AutoTokenizer & AutoModel) should also work, however I have yet to use them in my app & confirm:
|
||||
|
||||
```python
|
||||
from transformers import AutoConfig, AutoTokenizer, AutoModel
|
||||
|
||||
model_name_or_path = "ahotrod/albert_xxlargev1_squad2_512"
|
||||
config = AutoConfig.from_pretrained(model_name_or_path)
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, do_lower_case=True)
|
||||
model = AutoModel.from_pretrained(model_name_or_path, config=config)
|
||||
```
|
||||
tokenizer = AutoTokenizer.from_pretrained("ahotrod/albert_xxlargev1_squad2_512")
|
||||
model = AutoModelForQuestionAnswering.from_pretrained("ahotrod/albert_xxlargev1_squad2_512")
|
||||
|
||||
68
model_cards/ahotrod/roberta_large_squad2/README.md
Normal file
68
model_cards/ahotrod/roberta_large_squad2/README.md
Normal file
@@ -0,0 +1,68 @@
|
||||
## RoBERTa-large language model fine-tuned on SQuAD2.0
|
||||
|
||||
### with the following results:
|
||||
|
||||
```
|
||||
"exact": 84.02257222269014,
|
||||
"f1": 87.47063479332766,
|
||||
"total": 11873,
|
||||
"HasAns_exact": 81.19095816464238,
|
||||
"HasAns_f1": 88.0969714745582,
|
||||
"HasAns_total": 5928,
|
||||
"NoAns_exact": 86.84608915054667,
|
||||
"NoAns_f1": 86.84608915054667,
|
||||
"NoAns_total": 5945,
|
||||
"best_exact": 84.02257222269014,
|
||||
"best_exact_thresh": 0.0,
|
||||
"best_f1": 87.47063479332759,
|
||||
"best_f1_thresh": 0.0
|
||||
```
|
||||
### from script:
|
||||
```
|
||||
python -m torch.distributed.launch --nproc_per_node=2 ${RUN_SQUAD_DIR}/run_squad.py \
|
||||
--model_type roberta \
|
||||
--model_name_or_path roberta-large \
|
||||
--do_train \
|
||||
--train_file ${SQUAD_DIR}/train-v2.0.json \
|
||||
--predict_file ${SQUAD_DIR}/dev-v2.0.json \
|
||||
--version_2_with_negative \
|
||||
--num_train_epochs 2 \
|
||||
--warmup_steps 328 \
|
||||
--weight_decay 0.01 \
|
||||
--do_lower_case \
|
||||
--learning_rate 1.5e-5 \
|
||||
--max_seq_length 512 \
|
||||
--doc_stride 128 \
|
||||
--save_steps 1000 \
|
||||
--per_gpu_train_batch_size 1 \
|
||||
--gradient_accumulation_steps 24 \
|
||||
--logging_steps 50 \
|
||||
--threads 10 \
|
||||
--overwrite_cache \
|
||||
--overwrite_output_dir \
|
||||
--output_dir ${MODEL_PATH}
|
||||
|
||||
python ${RUN_SQUAD_DIR}/run_squad.py \
|
||||
--model_type roberta \
|
||||
--model_name_or_path ${MODEL_PATH} \
|
||||
--do_eval \
|
||||
--train_file ${SQUAD_DIR}/train-v2.0.json \
|
||||
--predict_file ${SQUAD_DIR}/dev-v2.0.json \
|
||||
--version_2_with_negative \
|
||||
--do_lower_case \
|
||||
--max_seq_length 512 \
|
||||
--per_gpu_eval_batch_size 24 \
|
||||
--eval_all_checkpoints \
|
||||
--overwrite_output_dir \
|
||||
--output_dir ${MODEL_PATH}
|
||||
$@
|
||||
```
|
||||
### using the following system & software:
|
||||
```
|
||||
OS/Platform: Linux-4.15.0-91-generic-x86_64-with-debian-buster-sid
|
||||
GPU/CPU: 2 x NVIDIA 1080Ti / Intel i7-8700
|
||||
Transformers: 2.7.0
|
||||
PyTorch: 1.4.0
|
||||
TensorFlow: 2.1.0
|
||||
Python: 3.7.7
|
||||
```
|
||||
@@ -56,22 +56,8 @@ PyTorch: 1.4.0
|
||||
TensorFlow: 2.1.0
|
||||
Python: 3.7.6
|
||||
```
|
||||
### Inferencing / prediction works with Transformers v2.4.1, the latest version tested
|
||||
|
||||
### Utilize this xlnet_large_squad2_512 fine-tuned model with:
|
||||
```python
|
||||
config_class, model_class, tokenizer_class = \
|
||||
XLNetConfig, XLNetforQuestionAnswering, XLNetTokenizer
|
||||
model_name_or_path = "ahotrod/xlnet_large_squad2_512"
|
||||
config = config_class.from_pretrained(model_name_or_path)
|
||||
tokenizer = tokenizer_class.from_pretrained(model_name_or_path, do_lower_case=True)
|
||||
model = model_class.from_pretrained(model_name_or_path, config=config)
|
||||
```
|
||||
### or the AutoModels (AutoConfig, AutoTokenizer & AutoModel) should also work, however I have yet to use them in my apps & confirm:
|
||||
```python
|
||||
from transformers import AutoConfig, AutoTokenizer, AutoModel
|
||||
model_name_or_path = "ahotrod/xlnet_large_squad2_512"
|
||||
config = AutoConfig.from_pretrained(model_name_or_path)
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, do_lower_case=True)
|
||||
model = AutoModel.from_pretrained(model_name_or_path, config=config)
|
||||
tokenizer = AutoTokenizer.from_pretrained("ahotrod/xlnet_large_squad2_512")
|
||||
model = AutoModelForQuestionAnswering.from_pretrained("ahotrod/xlnet_large_squad2_512")
|
||||
```
|
||||
|
||||
6
model_cards/albert-base-v1-README.md
Normal file
6
model_cards/albert-base-v1-README.md
Normal file
@@ -0,0 +1,6 @@
|
||||
---
|
||||
tags:
|
||||
- exbert
|
||||
---
|
||||
|
||||
[](https://huggingface.co/exbert/?model=albert-base-v1)
|
||||
6
model_cards/albert-xxlarge-v2-README.md
Normal file
6
model_cards/albert-xxlarge-v2-README.md
Normal file
@@ -0,0 +1,6 @@
|
||||
---
|
||||
tags:
|
||||
- exbert
|
||||
---
|
||||
|
||||
[](https://huggingface.co/exbert/?model=albert-xxlarge-v2)
|
||||
6
model_cards/bert-base-cased-README.md
Normal file
6
model_cards/bert-base-cased-README.md
Normal file
@@ -0,0 +1,6 @@
|
||||
---
|
||||
tags:
|
||||
- exbert
|
||||
---
|
||||
|
||||
[](https://huggingface.co/exbert/?model=bert-base-cased)
|
||||
@@ -1,8 +1,12 @@
|
||||
---
|
||||
language: german
|
||||
thumbnail: https://static.tildacdn.com/tild6438-3730-4164-b266-613634323466/german_bert.png
|
||||
tags:
|
||||
- exbert
|
||||
---
|
||||
|
||||
[](https://huggingface.co/exbert/?model=bert-base-german-cased)
|
||||
|
||||
# German BERT
|
||||

|
||||
## Overview
|
||||
@@ -18,6 +22,7 @@ thumbnail: https://static.tildacdn.com/tild6438-3730-4164-b266-613634323466/germ
|
||||
- We trained 810k steps with a batch size of 1024 for sequence length 128 and 30k steps with sequence length 512. Training took about 9 days.
|
||||
- As training data we used the latest German Wikipedia dump (6GB of raw txt files), the OpenLegalData dump (2.4 GB) and news articles (3.6 GB).
|
||||
- We cleaned the data dumps with tailored scripts and segmented sentences with spacy v2.1. To create tensorflow records we used the recommended sentencepiece library for creating the word piece vocabulary and tensorflow scripts to convert the text to data usable by BERT.
|
||||
- Update April 3rd, 2020: updated the vocab file on deepset s3 to adjust tokenization of punctuation.
|
||||
|
||||
See https://deepset.ai/german-bert for more details
|
||||
|
||||
|
||||
6
model_cards/bert-base-uncased-README.md
Normal file
6
model_cards/bert-base-uncased-README.md
Normal file
@@ -0,0 +1,6 @@
|
||||
---
|
||||
tags:
|
||||
- exbert
|
||||
---
|
||||
|
||||
[](https://huggingface.co/exbert/?model=bert-base-uncased)
|
||||
@@ -1,3 +1,7 @@
|
||||
---
|
||||
language: french
|
||||
---
|
||||
|
||||
# CamemBERT
|
||||
|
||||
CamemBERT is a state-of-the-art language model for French based on the RoBERTa architecture pretrained on the French subcorpus of the newly available multilingual corpus OSCAR.
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
---
|
||||
language: german
|
||||
license: mit
|
||||
---
|
||||
|
||||
# 🤗 + 📚 dbmdz German BERT models
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
---
|
||||
language: german
|
||||
license: mit
|
||||
tags:
|
||||
- "historic german"
|
||||
---
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
---
|
||||
language: german
|
||||
license: mit
|
||||
tags:
|
||||
- "historic german"
|
||||
---
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
---
|
||||
language: german
|
||||
license: mit
|
||||
---
|
||||
|
||||
# 🤗 + 📚 dbmdz German BERT models
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
---
|
||||
language: italian
|
||||
license: mit
|
||||
---
|
||||
|
||||
# 🤗 + 📚 dbmdz BERT models
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
---
|
||||
language: italian
|
||||
license: mit
|
||||
---
|
||||
|
||||
# 🤗 + 📚 dbmdz BERT models
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
---
|
||||
language: italian
|
||||
license: mit
|
||||
---
|
||||
|
||||
# 🤗 + 📚 dbmdz BERT models
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
---
|
||||
language: italian
|
||||
license: mit
|
||||
---
|
||||
|
||||
# 🤗 + 📚 dbmdz BERT models
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
---
|
||||
language: turkish
|
||||
license: mit
|
||||
---
|
||||
|
||||
# 🤗 + 📚 dbmdz Turkish BERT model
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
---
|
||||
language: turkish
|
||||
license: mit
|
||||
---
|
||||
|
||||
# 🤗 + 📚 dbmdz Turkish BERT model
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
---
|
||||
language: turkish
|
||||
license: mit
|
||||
---
|
||||
|
||||
# 🤗 + 📚 dbmdz Turkish BERT model
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
---
|
||||
language: turkish
|
||||
license: mit
|
||||
---
|
||||
|
||||
# 🤗 + 📚 dbmdz Turkish BERT model
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
---
|
||||
language: turkish
|
||||
license: mit
|
||||
---
|
||||
|
||||
# 🤗 + 📚 dbmdz Distilled Turkish BERT model
|
||||
|
||||
59
model_cards/deepset/quora_dedup_bert_base/README.md
Normal file
59
model_cards/deepset/quora_dedup_bert_base/README.md
Normal file
@@ -0,0 +1,59 @@
|
||||
This language model is trained using sentence_transformers (https://github.com/UKPLab/sentence-transformers)
|
||||
Started with bert-base-nli-stsb-mean-tokens
|
||||
Continue training on quora questions deduplication dataset (https://www.kaggle.com/c/quora-question-pairs)
|
||||
See train_script.py for script used
|
||||
|
||||
Below is the performance over the course of training
|
||||
epoch,steps,cosine_pearson,cosine_spearman,euclidean_pearson,euclidean_spearman,manhattan_pearson,manhattan_spearman,dot_pearson,dot_spearman
|
||||
0,1000,0.5944576426835938,0.6010801382777033,0.5942803776859142,0.5934485776801595,0.5939676679774666,0.593162725602328,0.5905591590826669,0.5921674789994058
|
||||
0,2000,0.6404080440207146,0.6416811632113405,0.6384419354012121,0.6352050423100778,0.6379917744471867,0.6347884067391001,0.6410544760582826,0.6379252046791412
|
||||
0,3000,0.6710168301884945,0.6676529324662036,0.6660195209784969,0.6618423144808695,0.6656461098096684,0.6615366331956389,0.6724401903484759,0.666073727723655
|
||||
0,4000,0.6886373265097949,0.6808948140300153,0.67907655686838,0.6714218133850957,0.6786809551564443,0.6711577956884357,0.6926435869763303,0.68190855298609
|
||||
0,5000,0.6991409753700026,0.6919630610321864,0.6991041519437052,0.6868961486499775,0.6987076032270729,0.6865385550504007,0.7035518148330993,0.6916275246101342
|
||||
0,6000,0.7120367327025509,0.6975005265298305,0.7065567493967201,0.6922375503495235,0.7060005509843024,0.6916475765570651,0.7147094303373102,0.6981390706722722
|
||||
0,7000,0.7254672394728687,0.7130118465900485,0.7261844956277705,0.7086213543110718,0.7257479964972307,0.7079315661881832,0.728729909455115,0.7122743793160531
|
||||
0,8000,0.7402421930101399,0.7216774208330149,0.7367901914441078,0.7166256588352043,0.7362607046874481,0.7158881916281887,0.7433902441373252,0.7220998491980078
|
||||
0,9000,0.7381005358120434,0.7197216844469877,0.7343228719349923,0.7139462687943793,0.7345247569255238,0.7145106206467152,0.7421843672419275,0.720686853053079
|
||||
0,10000,0.7465436564646095,0.7260327107480364,0.7467524239596304,0.7230195666847953,0.7467721566237211,0.7231367593302213,0.749792199122442,0.7263143296580317
|
||||
0,11000,0.7521805421706547,0.7323771570146701,0.7530672061250105,0.729223203496722,0.7530616532823367,0.7293818369675622,0.7552399002305836,0.7320808333541338
|
||||
0,12000,0.7579359969644401,0.7340677616737238,0.7570017235719905,0.7305965412825544,0.7570601853520393,0.730718189957289,0.7611254136080384,0.7351501229591327
|
||||
0,-1,0.7573407371218097,0.7329952035782198,0.755595312163209,0.7291445551777086,0.7557737117990928,0.7295404703700227,0.7607276219361719,0.7342415455980179
|
||||
1,1000,0.7619907683805341,0.7374667949734767,0.7629820517114324,0.7330364216044966,0.7628369522755882,0.7331912674450544,0.7658583898073758,0.7381503446695727
|
||||
1,2000,0.7618972640071228,0.7362151058969478,0.764582212425539,0.7335856230046062,0.7643125513700815,0.7334501607097152,0.7652852805583232,0.7369104639809163
|
||||
1,3000,0.7687362955240467,0.7404674623181671,0.7708304819979073,0.7380959815601529,0.7707835692712482,0.7379796800453193,0.772074854759756,0.7414513460702766
|
||||
1,4000,0.7685047787908202,0.7403088288815168,0.7703522257474043,0.7379787888808298,0.7701221475099808,0.7377898546753812,0.7713755359045312,0.7409415801952219
|
||||
1,5000,0.7696438109797803,0.7410393893292365,0.773270389327895,0.7392953127251652,0.7729880866533291,0.7389853982789335,0.7726236305835863,0.7416278035580925
|
||||
1,6000,0.7749538363837081,0.7436499342062207,0.774879168058157,0.7401827241766746,0.7745754601165837,0.739763415043146,0.7788801166152383,0.7446249060022169
|
||||
1,7000,0.7794560817870597,0.7480970176267153,0.7803506944510302,0.7453305130502859,0.7799867949176531,0.7447100155494814,0.7828208193123926,0.7486740690324809
|
||||
1,8000,0.7855844359073243,0.7496742172376921,0.7828816645965887,0.747176409009761,0.7827584875358967,0.7471037762845532,0.7879159073496309,0.7507349669102151
|
||||
1,9000,0.7844110753729492,0.7507746252693759,0.7847208586489722,0.7485172180290892,0.7846408087474059,0.748491818820158,0.7872061334510225,0.7514470349769437
|
||||
1,10000,0.7881311227435004,0.7530048509727403,0.7886917756879734,0.7508018068765787,0.7883332502188707,0.7505037008187275,0.7910707228932787,0.7537200382362567
|
||||
1,11000,0.7883300109606874,0.7513494487126553,0.7879329130497712,0.749818368689255,0.7876525616593218,0.7494872882301785,0.7911454269743292,0.7522843165147303
|
||||
1,12000,0.7853334933336618,0.7516809747712728,0.7893895316714998,0.749780492728257,0.7890075986655403,0.7494079715118533,0.7885959664070629,0.7523827940133203
|
||||
1,-1,0.7887529238148887,0.7534076729932393,0.7896864404801204,0.7513080079201105,0.7894077512343298,0.7510009899066772,0.7919617393746149,0.7542173273241598
|
||||
2,1000,0.7919209063905188,0.7550167329363414,0.7917464066515253,0.7523043685293455,0.7914371703225378,0.7520285423781206,0.7950297421784158,0.7562599556207076
|
||||
2,2000,0.7924507768792486,0.7542908512484463,0.7934519001953887,0.7517491515010692,0.7931885648751081,0.751521004535999,0.7951637852162545,0.7551495215642072
|
||||
2,3000,0.7937606244038364,0.755599577136169,0.7933633347508111,0.7527922999916203,0.7931581019714242,0.7527132061436363,0.797275652800117,0.7569827180764233
|
||||
2,4000,0.7938389298721445,0.7578716892320315,0.7963783770097079,0.7555928931784702,0.796150381773947,0.7555438771581088,0.7972911620482322,0.759178632650707
|
||||
2,5000,0.7935330563129844,0.7551129824372304,0.7970775059297484,0.7527285792572385,0.7967359830546507,0.7524478515463257,0.7966395126138969,0.756319220359678
|
||||
2,6000,0.7929852776759999,0.7525490026774382,0.7952484474454824,0.7503695753216607,0.7950784132079611,0.7503677929234961,0.7956152082976395,0.7535275392698093
|
||||
2,7000,0.794956504054517,0.756119591765251,0.7982025041673655,0.7532521587180684,0.7980261618830962,0.7532107179960499,0.7983222918908033,0.7571226363678287
|
||||
2,8000,0.7934568432535339,0.7538336661192452,0.797015698241178,0.7514773358161916,0.7968076980315735,0.7513458838811067,0.7960694134685949,0.754143803399873
|
||||
2,9000,0.7970040626682157,0.7576497805894974,0.7987855332059015,0.7550996144509958,0.7984693921009676,0.7548260162973456,0.7999509314900626,0.758347143906916
|
||||
2,10000,0.7979442987735523,0.7585338500791028,0.8018677081664496,0.7557412777548302,0.8015397301245205,0.7552916678886369,0.8007921348414564,0.7589772216225288
|
||||
2,11000,0.7985519561040211,0.7579986850302035,0.8021236875460913,0.7555826443181872,0.8019861620475348,0.7553763317660516,0.8009230128897853,0.7586541619907702
|
||||
2,12000,0.7986842143860736,0.7599570950134775,0.8029131054823838,0.7577678644678973,0.8027922603736795,0.7575152095990927,0.8020896747930555,0.7608540869254408
|
||||
2,-1,0.7994135319568432,0.7596286881516635,0.8022087183675333,0.7570593611974978,0.8020218401019292,0.7567291719729909,0.8026346812258125,0.7603928913647044
|
||||
3,1000,0.7985505039929134,0.7592588405681144,0.8023296699449267,0.7569345933969436,0.8023622066009718,0.7570237132696928,0.8013054275981851,0.759643838536062
|
||||
3,2000,0.7995482191699455,0.759205368623176,0.8026859405513612,0.7565709841358819,0.8024845263367439,0.7562920388231202,0.8021318586127523,0.7596496313300967
|
||||
3,3000,0.7991070423195897,0.7582027696555826,0.8016352550470427,0.7555585819429662,0.8014268261947898,0.7551838327642736,0.8013136081494014,0.7584429477727118
|
||||
3,4000,0.7999188836884763,0.7586764419322649,0.802987646214278,0.7561111254802977,0.8026549791861386,0.7556463650525692,0.8024068858366156,0.7591238238715613
|
||||
3,5000,0.7988075932525881,0.7583533823004922,0.8019498750207454,0.755792967372457,0.8016459824731964,0.7553834613587099,0.8015528810821693,0.7589527136833425
|
||||
3,6000,0.8003341798460688,0.7585432077405799,0.8032464035902267,0.7563722467405277,0.8028695045742804,0.7557626665682309,0.8027937010871594,0.7590404967573696
|
||||
3,7000,0.799187592384933,0.7579358555659604,0.8028413548398412,0.7555875459131398,0.8025187078191003,0.7551196665011402,0.8018680475193432,0.7585565756912578
|
||||
3,8000,0.797725037202641,0.757439012042047,0.802048241301358,0.7548888458326453,0.8017608103042271,0.7544606246736175,0.8005479449399782,0.758037452190282
|
||||
3,9000,0.7990232649360067,0.7573703896772077,0.8021375332910405,0.754873027155089,0.8018733796679427,0.7545680141630304,0.8016400687760605,0.7579461042843499
|
||||
3,10000,0.7994934439260372,0.758368978248884,0.8035693504115055,0.75619400688862,0.8032990505007025,0.7559016935896375,0.8022819185772518,0.7589558328445544
|
||||
3,11000,0.8002954591825011,0.758710753096932,0.8043310859792212,0.7566387152306694,0.8040865016706966,0.7564221538891368,0.8030873114870971,0.7592722085543488
|
||||
3,12000,0.8003726616196549,0.7588056657991931,0.8044000317617518,0.7566146528909147,0.8041705213966136,0.7563419459362758,0.8031760015719815,0.7593194421057111
|
||||
3,-1,0.8004926728141455,0.7587192194882135,0.8043340929890026,0.756546030526114,0.8041028559910275,0.7563103085106637,0.8032542493776693,0.7592325501951863
|
||||
6
model_cards/distilbert-base-uncased-README.md
Normal file
6
model_cards/distilbert-base-uncased-README.md
Normal file
@@ -0,0 +1,6 @@
|
||||
---
|
||||
tags:
|
||||
- exbert
|
||||
---
|
||||
|
||||
[](https://huggingface.co/exbert/?model=distilbert-base-uncased)
|
||||
6
model_cards/distilgpt2-README.md
Normal file
6
model_cards/distilgpt2-README.md
Normal file
@@ -0,0 +1,6 @@
|
||||
---
|
||||
tags:
|
||||
- exbert
|
||||
---
|
||||
|
||||
[](https://huggingface.co/exbert/?model=distilgpt2)
|
||||
6
model_cards/distilroberta-base-README.md
Normal file
6
model_cards/distilroberta-base-README.md
Normal file
@@ -0,0 +1,6 @@
|
||||
---
|
||||
tags:
|
||||
- exbert
|
||||
---
|
||||
|
||||
[](https://huggingface.co/exbert/?model=distilroberta-base)
|
||||
6
model_cards/gpt2-README.md
Normal file
6
model_cards/gpt2-README.md
Normal file
@@ -0,0 +1,6 @@
|
||||
---
|
||||
tags:
|
||||
- exbert
|
||||
---
|
||||
|
||||
[](https://huggingface.co/exbert/?model=gpt2)
|
||||
37
model_cards/gsarti/biobert-nli/README.md
Normal file
37
model_cards/gsarti/biobert-nli/README.md
Normal file
@@ -0,0 +1,37 @@
|
||||
# BioBERT-NLI
|
||||
|
||||
This is the model [BioBERT](https://github.com/dmis-lab/biobert) [1] fine-tuned on the [SNLI](https://nlp.stanford.edu/projects/snli/) and the [MultiNLI](https://www.nyu.edu/projects/bowman/multinli/) datasets using the [`sentence-transformers` library](https://github.com/UKPLab/sentence-transformers/) to produce universal sentence embeddings [2].
|
||||
|
||||
The model uses the original BERT wordpiece vocabulary and was trained using the **average pooling strategy** and a **softmax loss**.
|
||||
|
||||
**Base model**: `monologg/biobert_v1.1_pubmed` from HuggingFace's `AutoModel`.
|
||||
|
||||
**Training time**: ~6 hours on the NVIDIA Tesla P100 GPU provided in Kaggle Notebooks.
|
||||
|
||||
**Parameters**:
|
||||
|
||||
| Parameter | Value |
|
||||
|------------------|-------|
|
||||
| Batch size | 64 |
|
||||
| Training steps | 30000 |
|
||||
| Warmup steps | 1450 |
|
||||
| Lowercasing | False |
|
||||
| Max. Seq. Length | 128 |
|
||||
|
||||
**Performances**: The performance was evaluated on the test portion of the [STS dataset](http://ixa2.si.ehu.es/stswiki/index.php/STSbenchmark) using Spearman rank correlation and compared to the performances of a general BERT base model obtained with the same procedure to verify their similarity.
|
||||
|
||||
| Model | Score |
|
||||
|-------------------------------|-------------|
|
||||
| `biobert-nli` (this) | 73.40 |
|
||||
| `gsarti/scibert-nli` | 74.50 |
|
||||
| `bert-base-nli-mean-tokens`[3]| 77.12 |
|
||||
|
||||
An example usage for similarity-based scientific paper retrieval is provided in the [Covid Papers Browser](https://github.com/gsarti/covid-papers-browser) repository.
|
||||
|
||||
**References:**
|
||||
|
||||
[1] J. Lee et al, [BioBERT: a pre-trained biomedical language representation model for biomedical text mining](https://academic.oup.com/bioinformatics/article/36/4/1234/5566506)
|
||||
|
||||
[2] A. Conneau et al., [Supervised Learning of Universal Sentence Representations from Natural Language Inference Data](https://www.aclweb.org/anthology/D17-1070/)
|
||||
|
||||
[3] N. Reimers et I. Gurevych, [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://www.aclweb.org/anthology/D19-1410/)
|
||||
38
model_cards/gsarti/covidbert-nli/README.md
Normal file
38
model_cards/gsarti/covidbert-nli/README.md
Normal file
@@ -0,0 +1,38 @@
|
||||
# CovidBERT-NLI
|
||||
|
||||
This is the model **CovidBERT** trained by DeepSet on AllenAI's [CORD19 Dataset](https://pages.semanticscholar.org/coronavirus-research) of scientific articles about coronaviruses.
|
||||
|
||||
The model uses the original BERT wordpiece vocabulary and was subsequently fine-tuned on the [SNLI](https://nlp.stanford.edu/projects/snli/) and the [MultiNLI](https://www.nyu.edu/projects/bowman/multinli/) datasets using the [`sentence-transformers` library](https://github.com/UKPLab/sentence-transformers/) to produce universal sentence embeddings [1] using the **average pooling strategy** and a **softmax loss**.
|
||||
|
||||
Parameter details for the original training on CORD-19 are available on [DeepSet's MLFlow](https://public-mlflow.deepset.ai/#/experiments/2/runs/ba27d00c30044ef6a33b1d307b4a6cba)
|
||||
|
||||
**Base model**: `deepset/covid_bert_base` from HuggingFace's `AutoModel`.
|
||||
|
||||
**Training time**: ~6 hours on the NVIDIA Tesla P100 GPU provided in Kaggle Notebooks.
|
||||
|
||||
**Parameters**:
|
||||
|
||||
| Parameter | Value |
|
||||
|------------------|-------|
|
||||
| Batch size | 64 |
|
||||
| Training steps | 23000 |
|
||||
| Warmup steps | 1450 |
|
||||
| Lowercasing | True |
|
||||
| Max. Seq. Length | 128 |
|
||||
|
||||
**Performances**: The performance was evaluated on the test portion of the [STS dataset](http://ixa2.si.ehu.es/stswiki/index.php/STSbenchmark) using Spearman rank correlation and compared to the performances of similar models obtained with the same procedure to verify its performances.
|
||||
|
||||
| Model | Score |
|
||||
|-------------------------------|-------------|
|
||||
| `covidbert-nli` (this) | 67.52 |
|
||||
| `gsarti/biobert-nli` | 73.40 |
|
||||
| `gsarti/scibert-nli` | 74.50 |
|
||||
| `bert-base-nli-mean-tokens`[2]| 77.12 |
|
||||
|
||||
An example usage for similarity-based scientific paper retrieval is provided in the [Covid-19 Semantic Browser](https://github.com/gsarti/covid-papers-browser) repository.
|
||||
|
||||
**References:**
|
||||
|
||||
[1] A. Conneau et al., [Supervised Learning of Universal Sentence Representations from Natural Language Inference Data](https://www.aclweb.org/anthology/D17-1070/)
|
||||
|
||||
[2] N. Reimers et I. Gurevych, [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://www.aclweb.org/anthology/D19-1410/)
|
||||
@@ -0,0 +1,94 @@
|
||||
---
|
||||
language: polish
|
||||
---
|
||||
|
||||
# Multilingual + Polish SQuAD1.1
|
||||
|
||||
This model is the multilingual model provided by the Google research team with a fine-tuned polish Q&A downstream task.
|
||||
|
||||
## Details of the language model
|
||||
|
||||
Language model ([**bert-base-multilingual-cased**](https://github.com/google-research/bert/blob/master/multilingual.md)):
|
||||
12-layer, 768-hidden, 12-heads, 110M parameters.
|
||||
Trained on cased text in the top 104 languages with the largest Wikipedias.
|
||||
|
||||
## Details of the downstream task
|
||||
Using the `mtranslate` Python module, [**SQuAD1.1**](https://rajpurkar.github.io/SQuAD-explorer/) was machine-translated. In order to find the start tokens, the direct translations of the answers were searched in the corresponding paragraphs. Due to the different translations depending on the context (missing context in the pure answer), the answer could not always be found in the text, and thus a loss of question-answer examples occurred. This is a potential problem where errors can occur in the data set.
|
||||
|
||||
| Dataset | # Q&A |
|
||||
| ---------------------- | ----- |
|
||||
| SQuAD1.1 Train | 87.7 K |
|
||||
| Polish SQuAD1.1 Train | 39.5 K |
|
||||
| SQuAD1.1 Dev | 10.6 K |
|
||||
| Polish SQuAD1.1 Dev | 2.6 K |
|
||||
|
||||
|
||||
## Model benchmark
|
||||
|
||||
| Model | EM | F1 |
|
||||
| ---------------------- | ----- | ----- |
|
||||
| [SlavicBERT](https://huggingface.co/DeepPavlov/bert-base-bg-cs-pl-ru-cased) | **60.89** | 71.68 |
|
||||
| [polBERT](https://huggingface.co/dkleczek/bert-base-polish-uncased-v1) | 57.46 | 68.87 |
|
||||
| [multiBERT](https://huggingface.co/bert-base-multilingual-cased) | 60.67 | **71.89** |
|
||||
| [xlm](https://huggingface.co/xlm-mlm-100-1280) | 47.98 | 59.42 |
|
||||
## Model training
|
||||
|
||||
The model was trained on a **Tesla V100** GPU with the following command:
|
||||
|
||||
```python
|
||||
export SQUAD_DIR=path/to/pl_squad
|
||||
|
||||
python run_squad.py
|
||||
--model_type bert \
|
||||
--model_name_or_path bert-base-multilingual-cased \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--train_file $SQUAD_DIR/pl_squadv1_train_clean.json \
|
||||
--predict_file $SQUAD_DIR/pl_squadv1_dev_clean.json \
|
||||
--num_train_epochs 2 \
|
||||
--max_seq_length 384 \
|
||||
--doc_stride 128 \
|
||||
--save_steps=8000 \
|
||||
--output_dir ../../output \
|
||||
--overwrite_cache \
|
||||
--overwrite_output_dir
|
||||
```
|
||||
|
||||
**Results**:
|
||||
|
||||
{'exact': 60.670731707317074, 'f1': 71.8952193697293, 'total': 2624, 'HasAns_exact': 60.670731707317074, 'HasAns_f1': 71.8952193697293,
|
||||
'HasAns_total': 2624, 'best_exact': 60.670731707317074, 'best_exact_thresh': 0.0, 'best_f1': 71.8952193697293, 'best_f1_thresh': 0.0}
|
||||
|
||||
## Model in action
|
||||
|
||||
Fast usage with **pipelines**:
|
||||
|
||||
```python
|
||||
from transformers import pipeline
|
||||
|
||||
qa_pipeline = pipeline(
|
||||
"question-answering",
|
||||
model="henryk/bert-base-multilingual-cased-finetuned-polish-squad1",
|
||||
tokenizer="henryk/bert-base-multilingual-cased-finetuned-polish-squad1"
|
||||
)
|
||||
|
||||
qa_pipeline({
|
||||
'context': "Warszawa jest największym miastem w Polsce pod względem liczby ludności i powierzchni",
|
||||
'question': "Jakie jest największe miasto w Polsce?"})
|
||||
|
||||
```
|
||||
|
||||
# Output:
|
||||
|
||||
```json
|
||||
{
|
||||
"score": 0.9988,
|
||||
"start": 0,
|
||||
"end": 8,
|
||||
"answer": "Warszawa"
|
||||
}
|
||||
```
|
||||
|
||||
## Contact
|
||||
|
||||
Please do not hesitate to contact me via [LinkedIn](https://www.linkedin.com/in/henryk-borzymowski-0755a2167/) if you want to discuss or get access to the Polish version of SQuAD.
|
||||
@@ -0,0 +1,96 @@
|
||||
---
|
||||
language: polish
|
||||
---
|
||||
|
||||
# Multilingual + Polish SQuAD2.0
|
||||
|
||||
This model is the multilingual model provided by the Google research team with a fine-tuned polish Q&A downstream task.
|
||||
|
||||
## Details of the language model
|
||||
|
||||
Language model ([**bert-base-multilingual-cased**](https://github.com/google-research/bert/blob/master/multilingual.md)):
|
||||
12-layer, 768-hidden, 12-heads, 110M parameters.
|
||||
Trained on cased text in the top 104 languages with the largest Wikipedias.
|
||||
|
||||
## Details of the downstream task
|
||||
Using the `mtranslate` Python module, [**SQuAD2.0**](https://rajpurkar.github.io/SQuAD-explorer/) was machine-translated. In order to find the start tokens, the direct translations of the answers were searched in the corresponding paragraphs. Due to the different translations depending on the context (missing context in the pure answer), the answer could not always be found in the text, and thus a loss of question-answer examples occurred. This is a potential problem where errors can occur in the data set.
|
||||
|
||||
| Dataset | # Q&A |
|
||||
| ---------------------- | ----- |
|
||||
| SQuAD2.0 Train | 130 K |
|
||||
| Polish SQuAD2.0 Train | 83.1 K |
|
||||
| SQuAD2.0 Dev | 12 K |
|
||||
| Polish SQuAD2.0 Dev | 8.5 K |
|
||||
|
||||
|
||||
## Model benchmark
|
||||
|
||||
| Model | EM/F1 |HasAns (EM/F1) | NoAns |
|
||||
| ---------------------- | ----- | ----- | ----- |
|
||||
| [SlavicBERT](https://huggingface.co/DeepPavlov/bert-base-bg-cs-pl-ru-cased) | 69.35/71.51 | 47.02/54.09 | 79.20 |
|
||||
| [polBERT](https://huggingface.co/dkleczek/bert-base-polish-uncased-v1) | 67.33/69.80| 45.73/53.80 | 76.87 |
|
||||
| [multiBERT](https://huggingface.co/bert-base-multilingual-cased) | **70.76**/**72.92** |45.00/52.04 | 82.13 |
|
||||
|
||||
## Model training
|
||||
|
||||
The model was trained on a **Tesla V100** GPU with the following command:
|
||||
|
||||
```python
|
||||
export SQUAD_DIR=path/to/pl_squad
|
||||
|
||||
python run_squad.py
|
||||
--model_type bert \
|
||||
--model_name_or_path bert-base-multilingual-cased \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--version_2_with_negative \
|
||||
--train_file $SQUAD_DIR/pl_squadv2_train.json \
|
||||
--predict_file $SQUAD_DIR/pl_squadv2_dev.json \
|
||||
--num_train_epochs 2 \
|
||||
--max_seq_length 384 \
|
||||
--doc_stride 128 \
|
||||
--save_steps=8000 \
|
||||
--output_dir ../../output \
|
||||
--overwrite_cache \
|
||||
--overwrite_output_dir
|
||||
```
|
||||
|
||||
**Results**:
|
||||
|
||||
{'exact': 70.76671723655035, 'f1': 72.92156947155917, 'total': 8569, 'HasAns_exact': 45.00762195121951, 'HasAns_f1': 52.04456128116991, 'HasAns_total': 2624, 'NoAns_exact': 82.13624894869638, '
|
||||
NoAns_f1': 82.13624894869638, 'NoAns_total': 5945, 'best_exact': 71.72365503559342, 'best_exact_thresh': 0.0, 'best_f1': 73.62662512059369, 'best_f1_thresh': 0.0}
|
||||
|
||||
|
||||
## Model in action
|
||||
|
||||
Fast usage with **pipelines**:
|
||||
|
||||
```python
|
||||
from transformers import pipeline
|
||||
|
||||
qa_pipeline = pipeline(
|
||||
"question-answering",
|
||||
model="henryk/bert-base-multilingual-cased-finetuned-polish-squad2",
|
||||
tokenizer="henryk/bert-base-multilingual-cased-finetuned-polish-squad2"
|
||||
)
|
||||
|
||||
qa_pipeline({
|
||||
'context': "Warszawa jest największym miastem w Polsce pod względem liczby ludności i powierzchni",
|
||||
'question': "Jakie jest największe miasto w Polsce?"})
|
||||
|
||||
```
|
||||
|
||||
# Output:
|
||||
|
||||
```json
|
||||
{
|
||||
"score": 0.9986,
|
||||
"start": 0,
|
||||
"end": 8,
|
||||
"answer": "Warszawa"
|
||||
}
|
||||
```
|
||||
|
||||
## Contact
|
||||
|
||||
Please do not hesitate to contact me via [LinkedIn](https://www.linkedin.com/in/henryk-borzymowski-0755a2167/) if you want to discuss or get access to the Polish version of SQuAD.
|
||||
86
model_cards/huseinzol05/albert-base-bahasa-cased/README.md
Normal file
86
model_cards/huseinzol05/albert-base-bahasa-cased/README.md
Normal file
@@ -0,0 +1,86 @@
|
||||
---
|
||||
language: malay
|
||||
---
|
||||
|
||||
# Bahasa Albert Model
|
||||
|
||||
Pretrained Albert base language model for Malay and Indonesian.
|
||||
|
||||
## Pretraining Corpus
|
||||
|
||||
`albert-base-bahasa-cased` model was pretrained on ~1.8 Billion words. We trained on both standard and social media language structures, and below is list of data we trained on,
|
||||
|
||||
1. [dumping wikipedia](https://github.com/huseinzol05/Malaya-Dataset#wikipedia-1).
|
||||
2. [local instagram](https://github.com/huseinzol05/Malaya-Dataset#instagram).
|
||||
3. [local twitter](https://github.com/huseinzol05/Malaya-Dataset#twitter-1).
|
||||
4. [local news](https://github.com/huseinzol05/Malaya-Dataset#public-news).
|
||||
5. [local parliament text](https://github.com/huseinzol05/Malaya-Dataset#parliament).
|
||||
6. [local singlish/manglish text](https://github.com/huseinzol05/Malaya-Dataset#singlish-text).
|
||||
7. [IIUM Confession](https://github.com/huseinzol05/Malaya-Dataset#iium-confession).
|
||||
8. [Wattpad](https://github.com/huseinzol05/Malaya-Dataset#wattpad).
|
||||
9. [Academia PDF](https://github.com/huseinzol05/Malaya-Dataset#academia-pdf).
|
||||
|
||||
Preprocessing steps can reproduce from here, [Malaya/pretrained-model/preprocess](https://github.com/huseinzol05/Malaya/tree/master/pretrained-model/preprocess).
|
||||
|
||||
## Pretraining details
|
||||
|
||||
- This model was trained using Google Albert's github [repository](https://github.com/google-research/ALBERT) on v3-8 TPU.
|
||||
- All steps can reproduce from here, [Malaya/pretrained-model/albert](https://github.com/huseinzol05/Malaya/tree/master/pretrained-model/albert).
|
||||
|
||||
## Load Pretrained Model
|
||||
|
||||
You can use this model by installing `torch` or `tensorflow` and Huggingface library `transformers`. And you can use it directly by initializing it like this:
|
||||
|
||||
```python
|
||||
from transformers import AlbertTokenizer, AlbertModel
|
||||
|
||||
model = BertModel.from_pretrained('huseinzol05/albert-base-bahasa-cased')
|
||||
tokenizer = AlbertTokenizer.from_pretrained(
|
||||
'huseinzol05/albert-base-bahasa-cased',
|
||||
do_lower_case = False,
|
||||
)
|
||||
```
|
||||
|
||||
## Example using AutoModelWithLMHead
|
||||
|
||||
```python
|
||||
from transformers import AlbertTokenizer, AutoModelWithLMHead, pipeline
|
||||
|
||||
model = AutoModelWithLMHead.from_pretrained('huseinzol05/albert-base-bahasa-cased')
|
||||
tokenizer = AlbertTokenizer.from_pretrained(
|
||||
'huseinzol05/albert-base-bahasa-cased',
|
||||
do_lower_case = False,
|
||||
)
|
||||
fill_mask = pipeline('fill-mask', model = model, tokenizer = tokenizer)
|
||||
print(fill_mask('makan ayam dengan [MASK]'))
|
||||
```
|
||||
|
||||
Output is,
|
||||
|
||||
```text
|
||||
[{'sequence': '[CLS] makan ayam dengan ayam[SEP]',
|
||||
'score': 0.044952988624572754,
|
||||
'token': 629},
|
||||
{'sequence': '[CLS] makan ayam dengan sayur[SEP]',
|
||||
'score': 0.03621877357363701,
|
||||
'token': 1639},
|
||||
{'sequence': '[CLS] makan ayam dengan ikan[SEP]',
|
||||
'score': 0.034429922699928284,
|
||||
'token': 758},
|
||||
{'sequence': '[CLS] makan ayam dengan nasi[SEP]',
|
||||
'score': 0.032447945326566696,
|
||||
'token': 453},
|
||||
{'sequence': '[CLS] makan ayam dengan rendang[SEP]',
|
||||
'score': 0.028885239735245705,
|
||||
'token': 2451}]
|
||||
```
|
||||
|
||||
## Results
|
||||
|
||||
For further details on the model performance, simply checkout accuracy page from Malaya, https://malaya.readthedocs.io/en/latest/Accuracy.html, we compared with traditional models.
|
||||
|
||||
## Acknowledgement
|
||||
|
||||
Thanks to [Im Big](https://www.facebook.com/imbigofficial/), [LigBlou](https://www.facebook.com/ligblou), [Mesolitica](https://mesolitica.com/) and [KeyReply](https://www.keyreply.com/) for sponsoring AWS, Google and GPU clouds to train Albert for Bahasa.
|
||||
|
||||
|
||||
@@ -32,13 +32,54 @@ Preprocessing steps can reproduce from here, [Malaya/pretrained-model/preprocess
|
||||
You can use this model by installing `torch` or `tensorflow` and Huggingface library `transformers`. And you can use it directly by initializing it like this:
|
||||
|
||||
```python
|
||||
from transformers import XLNetTokenizer, BertModel
|
||||
from transformers import AlbertTokenizer, BertModel
|
||||
|
||||
model = BertModel.from_pretrained('huseinzol05/bert-base-bahasa-cased')
|
||||
tokenizer = XLNetTokenizer.from_pretrained('huseinzol05/bert-base-bahasa-cased')
|
||||
tokenizer = AlbertTokenizer.from_pretrained(
|
||||
'huseinzol05/bert-base-bahasa-cased',
|
||||
unk_token = '[UNK]',
|
||||
pad_token = '[PAD]',
|
||||
do_lower_case = False,
|
||||
)
|
||||
```
|
||||
|
||||
We use [google/sentencepiece](https://github.com/google/sentencepiece) to train the tokenizer, so to use it, need to load from `XLNetTokenizer`.
|
||||
We use [google/sentencepiece](https://github.com/google/sentencepiece) to train the tokenizer, so to use it, need to load from `AlbertTokenizer`.
|
||||
|
||||
## Example using AutoModelWithLMHead
|
||||
|
||||
```python
|
||||
from transformers import AlbertTokenizer, AutoModelWithLMHead, pipeline
|
||||
|
||||
model = AutoModelWithLMHead.from_pretrained('huseinzol05/bert-base-bahasa-cased')
|
||||
tokenizer = AlbertTokenizer.from_pretrained(
|
||||
'huseinzol05/bert-base-bahasa-cased',
|
||||
unk_token = '[UNK]',
|
||||
pad_token = '[PAD]',
|
||||
do_lower_case = False,
|
||||
)
|
||||
fill_mask = pipeline('fill-mask', model = model, tokenizer = tokenizer)
|
||||
print(fill_mask('makan ayam dengan [MASK]'))
|
||||
```
|
||||
|
||||
Output is,
|
||||
|
||||
```text
|
||||
[{'sequence': '[CLS] makan ayam dengan rendang[SEP]',
|
||||
'score': 0.10812027007341385,
|
||||
'token': 2446},
|
||||
{'sequence': '[CLS] makan ayam dengan kicap[SEP]',
|
||||
'score': 0.07653367519378662,
|
||||
'token': 12928},
|
||||
{'sequence': '[CLS] makan ayam dengan nasi[SEP]',
|
||||
'score': 0.06839974224567413,
|
||||
'token': 450},
|
||||
{'sequence': '[CLS] makan ayam dengan ayam[SEP]',
|
||||
'score': 0.059544261544942856,
|
||||
'token': 638},
|
||||
{'sequence': '[CLS] makan ayam dengan sayur[SEP]',
|
||||
'score': 0.05294966697692871,
|
||||
'token': 1639}]
|
||||
```
|
||||
|
||||
## Results
|
||||
|
||||
|
||||
92
model_cards/huseinzol05/tiny-bert-bahasa-cased/README.md
Normal file
92
model_cards/huseinzol05/tiny-bert-bahasa-cased/README.md
Normal file
@@ -0,0 +1,92 @@
|
||||
---
|
||||
language: malay
|
||||
---
|
||||
|
||||
# Bahasa Tiny-BERT Model
|
||||
|
||||
General Distilled Tiny BERT language model for Malay and Indonesian.
|
||||
|
||||
## Pretraining Corpus
|
||||
|
||||
`tiny-bert-bahasa-cased` model was distilled on ~1.8 Billion words. We distilled on both standard and social media language structures, and below is list of data we distilled on,
|
||||
|
||||
1. [dumping wikipedia](https://github.com/huseinzol05/Malaya-Dataset#wikipedia-1).
|
||||
2. [local instagram](https://github.com/huseinzol05/Malaya-Dataset#instagram).
|
||||
3. [local twitter](https://github.com/huseinzol05/Malaya-Dataset#twitter-1).
|
||||
4. [local news](https://github.com/huseinzol05/Malaya-Dataset#public-news).
|
||||
5. [local parliament text](https://github.com/huseinzol05/Malaya-Dataset#parliament).
|
||||
6. [local singlish/manglish text](https://github.com/huseinzol05/Malaya-Dataset#singlish-text).
|
||||
7. [IIUM Confession](https://github.com/huseinzol05/Malaya-Dataset#iium-confession).
|
||||
8. [Wattpad](https://github.com/huseinzol05/Malaya-Dataset#wattpad).
|
||||
9. [Academia PDF](https://github.com/huseinzol05/Malaya-Dataset#academia-pdf).
|
||||
|
||||
Preprocessing steps can reproduce from here, [Malaya/pretrained-model/preprocess](https://github.com/huseinzol05/Malaya/tree/master/pretrained-model/preprocess).
|
||||
|
||||
## Distilling details
|
||||
|
||||
- This model was distilled using huawei-noah Tiny-BERT's github [repository](https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/TinyBERT) on 3 Titan V100 32GB VRAM.
|
||||
- All steps can reproduce from here, [Malaya/pretrained-model/tiny-bert](https://github.com/huseinzol05/Malaya/tree/master/pretrained-model/tiny-bert).
|
||||
|
||||
## Load Distilled Model
|
||||
|
||||
You can use this model by installing `torch` or `tensorflow` and Huggingface library `transformers`. And you can use it directly by initializing it like this:
|
||||
|
||||
```python
|
||||
from transformers import AlbertTokenizer, BertModel
|
||||
|
||||
model = BertModel.from_pretrained('huseinzol05/tiny-bert-bahasa-cased')
|
||||
tokenizer = AlbertTokenizer.from_pretrained(
|
||||
'huseinzol05/tiny-bert-bahasa-cased',
|
||||
unk_token = '[UNK]',
|
||||
pad_token = '[PAD]',
|
||||
do_lower_case = False,
|
||||
)
|
||||
```
|
||||
|
||||
We use [google/sentencepiece](https://github.com/google/sentencepiece) to train the tokenizer, so to use it, need to load from `AlbertTokenizer`.
|
||||
|
||||
## Example using AutoModelWithLMHead
|
||||
|
||||
```python
|
||||
from transformers import AlbertTokenizer, AutoModelWithLMHead, pipeline
|
||||
|
||||
model = AutoModelWithLMHead.from_pretrained('huseinzol05/tiny-bert-bahasa-cased')
|
||||
tokenizer = AlbertTokenizer.from_pretrained(
|
||||
'huseinzol05/tiny-bert-bahasa-cased',
|
||||
unk_token = '[UNK]',
|
||||
pad_token = '[PAD]',
|
||||
do_lower_case = False,
|
||||
)
|
||||
fill_mask = pipeline('fill-mask', model = model, tokenizer = tokenizer)
|
||||
print(fill_mask('makan ayam dengan [MASK]'))
|
||||
```
|
||||
|
||||
Output is,
|
||||
|
||||
```text
|
||||
[{'sequence': '[CLS] makan ayam dengan berbual[SEP]',
|
||||
'score': 0.00015769545279908925,
|
||||
'token': 17859},
|
||||
{'sequence': '[CLS] makan ayam dengan kembar[SEP]',
|
||||
'score': 0.0001448775001335889,
|
||||
'token': 8289},
|
||||
{'sequence': '[CLS] makan ayam dengan memaklumkan[SEP]',
|
||||
'score': 0.00013484008377417922,
|
||||
'token': 6881},
|
||||
{'sequence': '[CLS] makan ayam dengan Senarai[SEP]',
|
||||
'score': 0.00013061291247140616,
|
||||
'token': 11698},
|
||||
{'sequence': '[CLS] makan ayam dengan Tiga[SEP]',
|
||||
'score': 0.00012453157978598028,
|
||||
'token': 4232}]
|
||||
```
|
||||
|
||||
## Results
|
||||
|
||||
For further details on the model performance, simply checkout accuracy page from Malaya, https://malaya.readthedocs.io/en/latest/Accuracy.html, we compared with traditional models.
|
||||
|
||||
## Acknowledgement
|
||||
|
||||
Thanks to [Im Big](https://www.facebook.com/imbigofficial/), [LigBlou](https://www.facebook.com/ligblou), [Mesolitica](https://mesolitica.com/) and [KeyReply](https://www.keyreply.com/) for sponsoring AWS, Google and GPU clouds to train BERT for Bahasa.
|
||||
|
||||
|
||||
64
model_cards/huseinzol05/xlnet-base-bahasa-cased/README.md
Normal file
64
model_cards/huseinzol05/xlnet-base-bahasa-cased/README.md
Normal file
@@ -0,0 +1,64 @@
|
||||
---
|
||||
language: malay
|
||||
---
|
||||
|
||||
# Bahasa XLNet Model
|
||||
|
||||
Pretrained XLNet base language model for Malay and Indonesian.
|
||||
|
||||
## Pretraining Corpus
|
||||
|
||||
`XLNET-base-bahasa-cased` model was pretrained on ~1.8 Billion words. We trained on both standard and social media language structures, and below is list of data we trained on,
|
||||
|
||||
1. [dumping wikipedia](https://github.com/huseinzol05/Malaya-Dataset#wikipedia-1).
|
||||
2. [local instagram](https://github.com/huseinzol05/Malaya-Dataset#instagram).
|
||||
3. [local twitter](https://github.com/huseinzol05/Malaya-Dataset#twitter-1).
|
||||
4. [local news](https://github.com/huseinzol05/Malaya-Dataset#public-news).
|
||||
5. [local parliament text](https://github.com/huseinzol05/Malaya-Dataset#parliament).
|
||||
6. [local singlish/manglish text](https://github.com/huseinzol05/Malaya-Dataset#singlish-text).
|
||||
7. [IIUM Confession](https://github.com/huseinzol05/Malaya-Dataset#iium-confession).
|
||||
8. [Wattpad](https://github.com/huseinzol05/Malaya-Dataset#wattpad).
|
||||
9. [Academia PDF](https://github.com/huseinzol05/Malaya-Dataset#academia-pdf).
|
||||
|
||||
Preprocessing steps can reproduce from here, [Malaya/pretrained-model/preprocess](https://github.com/huseinzol05/Malaya/tree/master/pretrained-model/preprocess).
|
||||
|
||||
## Pretraining details
|
||||
|
||||
- This model was trained using zihangdai XLNet's github [repository](https://github.com/zihangdai/xlnet) on 3 Titan V100 32GB VRAM.
|
||||
- All steps can reproduce from here, [Malaya/pretrained-model/xlnet](https://github.com/huseinzol05/Malaya/tree/master/pretrained-model/xlnet).
|
||||
|
||||
## Load Pretrained Model
|
||||
|
||||
You can use this model by installing `torch` or `tensorflow` and Huggingface library `transformers`. And you can use it directly by initializing it like this:
|
||||
|
||||
```python
|
||||
from transformers import XLNetTokenizer, XLNetModel
|
||||
|
||||
model = XLNetModel.from_pretrained('huseinzol05/xlnet-base-bahasa-cased')
|
||||
tokenizer = XLNetTokenizer.from_pretrained(
|
||||
'huseinzol05/xlnet-base-bahasa-cased', do_lower_case = False
|
||||
)
|
||||
```
|
||||
|
||||
## Example using AutoModelWithLMHead
|
||||
|
||||
```python
|
||||
from transformers import AlbertTokenizer, AutoModelWithLMHead, pipeline
|
||||
|
||||
model = AutoModelWithLMHead.from_pretrained('huseinzol05/xlnet-base-bahasa-cased')
|
||||
tokenizer = XLNetTokenizer.from_pretrained(
|
||||
'huseinzol05/xlnet-base-bahasa-cased', do_lower_case = False
|
||||
)
|
||||
fill_mask = pipeline('fill-mask', model = model, tokenizer = tokenizer)
|
||||
print(fill_mask('makan ayam dengan <mask>'))
|
||||
```
|
||||
|
||||
## Results
|
||||
|
||||
For further details on the model performance, simply checkout accuracy page from Malaya, https://malaya.readthedocs.io/en/latest/Accuracy.html, we compared with traditional models.
|
||||
|
||||
## Acknowledgement
|
||||
|
||||
Thanks to [Im Big](https://www.facebook.com/imbigofficial/), [LigBlou](https://www.facebook.com/ligblou), [Mesolitica](https://mesolitica.com/) and [KeyReply](https://www.keyreply.com/) for sponsoring AWS, Google and GPU clouds to train XLNet for Bahasa.
|
||||
|
||||
|
||||
61
model_cards/ktrapeznikov/albert-xlarge-v2-squad-v2/README.md
Normal file
61
model_cards/ktrapeznikov/albert-xlarge-v2-squad-v2/README.md
Normal file
@@ -0,0 +1,61 @@
|
||||
### Model
|
||||
**[`albert-xlarge-v2`](https://huggingface.co/albert-xlarge-v2)** fine-tuned on **[`SQuAD V2`](https://rajpurkar.github.io/SQuAD-explorer/)** using **[`run_squad.py`](https://github.com/huggingface/transformers/blob/master/examples/run_squad.py)**
|
||||
|
||||
### Training Parameters
|
||||
Trained on 4 NVIDIA GeForce RTX 2080 Ti 11Gb
|
||||
```bash
|
||||
BASE_MODEL=albert-xlarge-v2
|
||||
python run_squad.py \
|
||||
--version_2_with_negative \
|
||||
--model_type albert \
|
||||
--model_name_or_path $BASE_MODEL \
|
||||
--output_dir $OUTPUT_MODEL \
|
||||
--do_eval \
|
||||
--do_lower_case \
|
||||
--train_file $SQUAD_DIR/train-v2.0.json \
|
||||
--predict_file $SQUAD_DIR/dev-v2.0.json \
|
||||
--per_gpu_train_batch_size 3 \
|
||||
--per_gpu_eval_batch_size 64 \
|
||||
--learning_rate 3e-5 \
|
||||
--num_train_epochs 3.0 \
|
||||
--max_seq_length 384 \
|
||||
--doc_stride 128 \
|
||||
--save_steps 2000 \
|
||||
--threads 24 \
|
||||
--warmup_steps 814 \
|
||||
--gradient_accumulation_steps 4 \
|
||||
--fp16 \
|
||||
--do_train
|
||||
```
|
||||
|
||||
### Evaluation
|
||||
|
||||
Evaluation on the dev set. I did not sweep for best threshold.
|
||||
|
||||
| | val |
|
||||
|-------------------|-------------------|
|
||||
| exact | 84.41842836688285 |
|
||||
| f1 | 87.4628460501696 |
|
||||
| total | 11873.0 |
|
||||
| HasAns_exact | 80.68488529014844 |
|
||||
| HasAns_f1 | 86.78245127423482 |
|
||||
| HasAns_total | 5928.0 |
|
||||
| NoAns_exact | 88.1412952060555 |
|
||||
| NoAns_f1 | 88.1412952060555 |
|
||||
| NoAns_total | 5945.0 |
|
||||
| best_exact | 84.41842836688285 |
|
||||
| best_exact_thresh | 0.0 |
|
||||
| best_f1 | 87.46284605016956 |
|
||||
| best_f1_thresh | 0.0 |
|
||||
|
||||
|
||||
### Usage
|
||||
|
||||
See [huggingface documentation](https://huggingface.co/transformers/model_doc/albert.html#albertforquestionanswering). Training on `SQuAD V2` allows the model to score if a paragraph contains an answer:
|
||||
```python
|
||||
start_scores, end_scores = model(input_ids)
|
||||
span_scores = start_scores.softmax(dim=1).log()[:,:,None] + end_scores.softmax(dim=1).log()[:,None,:]
|
||||
ignore_score = span_scores[:,0,0] #no answer scores
|
||||
|
||||
```
|
||||
|
||||
@@ -0,0 +1,61 @@
|
||||
### Model
|
||||
**[`allenai/scibert_scivocab_uncased`](https://huggingface.co/allenai/scibert_scivocab_uncased)** fine-tuned on **[`SQuAD V2`](https://rajpurkar.github.io/SQuAD-explorer/)** using **[`run_squad.py`](https://github.com/huggingface/transformers/blob/master/examples/run_squad.py)**
|
||||
|
||||
### Training Parameters
|
||||
Trained on 4 NVIDIA GeForce RTX 2080 Ti 11Gb
|
||||
```bash
|
||||
BASE_MODEL=allenai/scibert_scivocab_uncased
|
||||
python run_squad.py \
|
||||
--version_2_with_negative \
|
||||
--model_type albert \
|
||||
--model_name_or_path $BASE_MODEL \
|
||||
--output_dir $OUTPUT_MODEL \
|
||||
--do_eval \
|
||||
--do_lower_case \
|
||||
--train_file $SQUAD_DIR/train-v2.0.json \
|
||||
--predict_file $SQUAD_DIR/dev-v2.0.json \
|
||||
--per_gpu_train_batch_size 18 \
|
||||
--per_gpu_eval_batch_size 64 \
|
||||
--learning_rate 3e-5 \
|
||||
--num_train_epochs 3.0 \
|
||||
--max_seq_length 384 \
|
||||
--doc_stride 128 \
|
||||
--save_steps 2000 \
|
||||
--threads 24 \
|
||||
--warmup_steps 550 \
|
||||
--gradient_accumulation_steps 1 \
|
||||
--fp16 \
|
||||
--logging_steps 50 \
|
||||
--do_train
|
||||
```
|
||||
|
||||
### Evaluation
|
||||
|
||||
Evaluation on the dev set. I did not sweep for best threshold.
|
||||
|
||||
| | val |
|
||||
|-------------------|-------------------|
|
||||
| exact | 75.07790785816559 |
|
||||
| f1 | 78.47735207283013 |
|
||||
| total | 11873.0 |
|
||||
| HasAns_exact | 70.76585695006747 |
|
||||
| HasAns_f1 | 77.57449412292718 |
|
||||
| HasAns_total | 5928.0 |
|
||||
| NoAns_exact | 79.37762825904122 |
|
||||
| NoAns_f1 | 79.37762825904122 |
|
||||
| NoAns_total | 5945.0 |
|
||||
| best_exact | 75.08633032931863 |
|
||||
| best_exact_thresh | 0.0 |
|
||||
| best_f1 | 78.48577454398324 |
|
||||
| best_f1_thresh | 0.0 |
|
||||
|
||||
### Usage
|
||||
|
||||
See [huggingface documentation](https://huggingface.co/transformers/model_doc/bert.html#bertforquestionanswering). Training on `SQuAD V2` allows the model to score if a paragraph contains an answer:
|
||||
```python
|
||||
start_scores, end_scores = model(input_ids)
|
||||
span_scores = start_scores.softmax(dim=1).log()[:,:,None] + end_scores.softmax(dim=1).log()[:,None,:]
|
||||
ignore_score = span_scores[:,0,0] #no answer scores
|
||||
|
||||
```
|
||||
|
||||
14
model_cards/lvwerra/bert-imdb/README.md
Normal file
14
model_cards/lvwerra/bert-imdb/README.md
Normal file
@@ -0,0 +1,14 @@
|
||||
# BERT-IMDB
|
||||
|
||||
## What is it?
|
||||
BERT (`bert-large-cased`) trained for sentiment classification on the [IMDB dataset](https://www.kaggle.com/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews).
|
||||
|
||||
## Training setting
|
||||
|
||||
The model was trained on 80% of the IMDB dataset for sentiment classification for three epochs with a learning rate of `1e-5` with the `simpletransformers` library. The library uses a learning rate schedule.
|
||||
|
||||
## Result
|
||||
The model achieved 90% classification accuracy on the validation set.
|
||||
|
||||
## Reference
|
||||
The full experiment is available in the [tlr repo](https://lvwerra.github.io/trl/03-bert-imdb-training/).
|
||||
18
model_cards/lvwerra/gpt2-imdb-pos/README.md
Normal file
18
model_cards/lvwerra/gpt2-imdb-pos/README.md
Normal file
@@ -0,0 +1,18 @@
|
||||
# GPT2-IMDB-pos
|
||||
|
||||
## What is it?
|
||||
A small GPT2 (`lvwerra/gpt2-imdb`) language model fine-tuned to produce positive movie reviews based the [IMDB dataset](https://www.kaggle.com/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews). The model is trained with rewards from a BERT sentiment classifier (`lvwerra/gpt2-imdb`) via PPO.
|
||||
|
||||
## Training setting
|
||||
The model was trained for `100` optimisation steps with a batch size of `256` which corresponds to `25600` training samples. The full experiment setup can be found in the Jupyter notebook in the [trl repo](https://lvwerra.github.io/trl/04-gpt2-sentiment-ppo-training/).
|
||||
|
||||
## Examples
|
||||
A few examples of the model response to a query before and after optimisation:
|
||||
|
||||
| query | response (before) | response (after) | rewards (before) | rewards (after) |
|
||||
|-------|-------------------|------------------|------------------|-----------------|
|
||||
|I'd never seen a |heavier, woodier example of Victorian archite... |film of this caliber, and I think it's wonder... |3.297736 |4.158653|
|
||||
|I love John's work |but I actually have to write language as in w... |and I hereby recommend this film. I am really... |-1.904006 |4.159198 |
|
||||
|I's a big struggle |to see anyone who acts in that way. by Jim Th... |, but overall I'm happy with the changes even ... |-1.595925 |2.651260|
|
||||
|
||||
|
||||
27
model_cards/lvwerra/gpt2-imdb/README.md
Normal file
27
model_cards/lvwerra/gpt2-imdb/README.md
Normal file
@@ -0,0 +1,27 @@
|
||||
# GPT2-IMDB
|
||||
|
||||
## What is it?
|
||||
A GPT2 (`gpt2`) language model fine-tuned on the [IMDB dataset](https://www.kaggle.com/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews).
|
||||
|
||||
## Training setting
|
||||
|
||||
The GPT2 language model was fine-tuned for 1 epoch on the IMDB dataset. All comments were joined into a single text file separated by the EOS token:
|
||||
|
||||
```
|
||||
import pandas as pd
|
||||
df = pd.read_csv("imdb-dataset.csv")
|
||||
imdb_str = " <|endoftext|> ".join(df['review'].tolist())
|
||||
|
||||
with open ('imdb.txt', 'w') as f:
|
||||
f.write(imdb_str)
|
||||
```
|
||||
|
||||
To train the model the `run_language_modeling.py` script in the `transformer` library was used:
|
||||
|
||||
```
|
||||
python run_language_modeling.py
|
||||
--train_data_file imdb.txt
|
||||
--output_dir gpt2-imdb
|
||||
--model_type gpt2
|
||||
--model_name_or_path gpt2
|
||||
```
|
||||
61
model_cards/mrm8488/GPT-2-finetuned-CORD19/README.md
Normal file
61
model_cards/mrm8488/GPT-2-finetuned-CORD19/README.md
Normal file
@@ -0,0 +1,61 @@
|
||||
---
|
||||
language: english
|
||||
thumbnail:
|
||||
---
|
||||
|
||||
# GPT-2 + CORD19 dataset : 🦠 ✍ ⚕
|
||||
|
||||
**GPT-2** fine-tuned on **biorxiv_medrxiv**, **comm_use_subset** and **custom_license** files from [CORD-19](https://www.kaggle.com/allen-institute-for-ai/CORD-19-research-challenge) dataset.
|
||||
|
||||
|
||||
## Datasets details
|
||||
|
||||
| Dataset | # Files |
|
||||
| ---------------------- | ----- |
|
||||
| biorxiv_medrxiv | 885 |
|
||||
| comm_use_subset | 9K |
|
||||
| custom_license | 20.6K |
|
||||
|
||||
## Model training
|
||||
|
||||
The model was trained on a Tesla P100 GPU and 25GB of RAM with the following command:
|
||||
|
||||
```bash
|
||||
|
||||
export TRAIN_FILE=/path/to/dataset/train.txt
|
||||
|
||||
python run_language_modeling.py \
|
||||
--model_type gpt2 \
|
||||
--model_name_or_path gpt2 \
|
||||
--do_train \
|
||||
--train_data_file $TRAIN_FILE \
|
||||
--num_train_epochs 4 \
|
||||
--output_dir model_output \
|
||||
--overwrite_output_dir \
|
||||
--save_steps 10000 \
|
||||
--per_gpu_train_batch_size 3
|
||||
```
|
||||
|
||||
<img alt="training loss" src="https://svgshare.com/i/JTf.svg' title='GTP-2-finetuned-CORDS19-loss" width="600" height="300" />
|
||||
|
||||
## Model in action / Example of usage ✒
|
||||
|
||||
You can get the following script [here](https://github.com/huggingface/transformers/blob/master/examples/run_generation.py)
|
||||
|
||||
```bash
|
||||
python run_generation.py \
|
||||
--model_type gpt2 \
|
||||
--model_name_or_path mrm8488/GPT-2-finetuned-CORD19 \
|
||||
--length 200
|
||||
```
|
||||
```txt
|
||||
# Input: the effects of COVID-19 on the lungs
|
||||
# Output: === GENERATED SEQUENCE 1 ===
|
||||
the effects of COVID-19 on the lungs are currently debated (86). The role of this virus in the pathogenesis of pneumonia and lung cancer is still debated. MERS-CoV is also known to cause acute respiratory distress syndrome (87) and is associated with increased expression of pulmonary fibrosis markers (88). Thus, early airway inflammation may play an important role in the pathogenesis of coronavirus pneumonia and may contribute to the severe disease and/or mortality observed in coronavirus patients.
|
||||
Pneumonia is an acute, often fatal disease characterized by severe edema, leakage of oxygen and bronchiolar inflammation. Viruses include coronaviruses, and the role of oxygen depletion is complicated by lung injury and fibrosis in the lung, in addition to susceptibility to other lung diseases. The progression of the disease may be variable, depending on the lung injury, pathologic role, prognosis, and the immune status of the patient. Inflammatory responses to respiratory viruses cause various pathologies of the respiratory
|
||||
```
|
||||
|
||||
|
||||
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
|
||||
|
||||
> Made with <span style="color: #e25555;">♥</span> in Spain
|
||||
@@ -0,0 +1,62 @@
|
||||
---
|
||||
language: english
|
||||
thumbnail:
|
||||
---
|
||||
|
||||
# GPT-2 + bio/medrxiv files from CORD19: 🦠 ✍ ⚕
|
||||
|
||||
**GPT-2** fine-tuned on **biorxiv_medrxiv** files from [CORD-19](https://www.kaggle.com/allen-institute-for-ai/CORD-19-research-challenge) dataset.
|
||||
|
||||
|
||||
## Datasets details:
|
||||
|
||||
| Dataset | # Files |
|
||||
| ---------------------- | ----- |
|
||||
| biorxiv_medrxiv | 885 |
|
||||
|
||||
|
||||
## Model training:
|
||||
|
||||
The model was trained on a Tesla P100 GPU and 25GB of RAM with the following command:
|
||||
|
||||
```bash
|
||||
|
||||
export TRAIN_FILE=/path/to/dataset/train.txt
|
||||
|
||||
python run_language_modeling.py \
|
||||
--model_type gpt2 \
|
||||
--model_name_or_path gpt2 \
|
||||
--do_train \
|
||||
--train_data_file $TRAIN_FILE \
|
||||
--num_train_epochs 4 \
|
||||
--output_dir model_output \
|
||||
--overwrite_output_dir \
|
||||
--save_steps 2000 \
|
||||
--per_gpu_train_batch_size 3
|
||||
```
|
||||
|
||||
## Model in action / Example of usage: ✒
|
||||
|
||||
You can get the following script [here](https://github.com/huggingface/transformers/blob/master/examples/run_generation.py)
|
||||
|
||||
```bash
|
||||
python run_generation.py \
|
||||
--model_type gpt2 \
|
||||
--model_name_or_path mrm8488/GPT-2-finetuned-CORD19 \
|
||||
--length 200
|
||||
```
|
||||
```txt
|
||||
👵👴🦠
|
||||
# Input: Old people with COVID-19 tends to suffer
|
||||
# Output: === GENERATED SEQUENCE 1 ===
|
||||
Old people with COVID-19 tends to suffer more symptom onset time and death. It is well known that many people with COVID-19 have high homozygous ZIKV infection in the face of severe symptoms in both severe and severe cases.
|
||||
The origin of Wuhan Fever was investigated by Prof. Shen Jiang at the outbreak of Wuhan Fever [34]. As Huanan Province is the epicenter of this outbreak, Huanan, the epicenter of epidemic Wuhan Fever, is the most potential location for the direct transmission of infection (source: Zhongzhen et al., 2020). A negative risk ratio indicates more frequent underlying signs in the people in Huanan Province with COVID-19 patients. Further analysis of reported Huanan Fever onset data in the past two years indicated that the intensity of exposure is the key risk factor for developing MERS-CoV infection in this region, especially among children and elderly. To be continued to develop infected patients would be a very important area for
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
|
||||
|
||||
> Made with <span style="color: #e25555;">♥</span> in Spain
|
||||
@@ -66,6 +66,8 @@ nlp_ner = pipeline(
|
||||
{"use_fast": False}
|
||||
))
|
||||
|
||||
text = 'Mis amigos están pensando viajar a Londres este verano'
|
||||
|
||||
nlp_ner(text)
|
||||
|
||||
#Output: [{'entity': 'B-LOC', 'score': 0.9998720288276672, 'word': 'Londres'}]
|
||||
|
||||
@@ -0,0 +1,83 @@
|
||||
---
|
||||
language: spanish
|
||||
thumbnail:
|
||||
---
|
||||
|
||||
# Spanish BERT (BETO) + Syntax POS tagging ✍🏷
|
||||
|
||||
This model is a fine-tuned version of the Spanish BERT [(BETO)](https://github.com/dccuchile/beto) on Spanish **syntax** annotations in [CONLL CORPORA](https://www.kaggle.com/nltkdata/conll-corpora) dataset for **syntax POS** (Part of Speech tagging) downstream task.
|
||||
|
||||
## Details of the downstream task (Syntax POS) - Dataset
|
||||
|
||||
- [Dataset: CONLL Corpora ES](https://www.kaggle.com/nltkdata/conll-corpora)
|
||||
|
||||
#### [Fine-tune script on NER dataset provided by Huggingface](https://github.com/huggingface/transformers/blob/master/examples/run_ner.py)
|
||||
|
||||
#### 21 Syntax annotations (Labels) covered:
|
||||
|
||||
- \_
|
||||
- ATR
|
||||
- ATR.d
|
||||
- CAG
|
||||
- CC
|
||||
- CD
|
||||
- CD.Q
|
||||
- CI
|
||||
- CPRED
|
||||
- CPRED.CD
|
||||
- CPRED.SUJ
|
||||
- CREG
|
||||
- ET
|
||||
- IMPERS
|
||||
- MOD
|
||||
- NEG
|
||||
- PASS
|
||||
- PUNC
|
||||
- ROOT
|
||||
- SUJ
|
||||
- VOC
|
||||
|
||||
## Metrics on test set 📋
|
||||
|
||||
| Metric | # score |
|
||||
| :-------: | :-------: |
|
||||
| F1 | **89.27** |
|
||||
| Precision | **89.44** |
|
||||
| Recall | **89.11** |
|
||||
|
||||
## Model in action 🔨
|
||||
|
||||
Fast usage with **pipelines** 🧪
|
||||
|
||||
```python
|
||||
from transformers import pipeline
|
||||
|
||||
nlp_pos_syntax = pipeline(
|
||||
"ner",
|
||||
model="mrm8488/bert-spanish-cased-finetuned-pos-syntax",
|
||||
tokenizer="mrm8488/bert-spanish-cased-finetuned-pos-syntax"
|
||||
)
|
||||
|
||||
text = 'Mis amigos están pensando viajar a Londres este verano.'
|
||||
|
||||
nlp_pos_syntax(text)[1:len(nlp_pos_syntax(text))-1]
|
||||
```
|
||||
|
||||
```json
|
||||
[
|
||||
{ "entity": "_", "score": 0.9999216794967651, "word": "Mis" },
|
||||
{ "entity": "SUJ", "score": 0.999882698059082, "word": "amigos" },
|
||||
{ "entity": "_", "score": 0.9998869299888611, "word": "están" },
|
||||
{ "entity": "ROOT", "score": 0.9980518221855164, "word": "pensando" },
|
||||
{ "entity": "_", "score": 0.9998420476913452, "word": "viajar" },
|
||||
{ "entity": "CD", "score": 0.999351978302002, "word": "a" },
|
||||
{ "entity": "_", "score": 0.999959409236908, "word": "Londres" },
|
||||
{ "entity": "_", "score": 0.9998968839645386, "word": "este" },
|
||||
{ "entity": "CC", "score": 0.99931401014328, "word": "verano" },
|
||||
{ "entity": "PUNC", "score": 0.9998534917831421, "word": "." }
|
||||
]
|
||||
```
|
||||
|
||||
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
|
||||
|
||||
> Made with <span style="color: #e25555;">♥</span> in Spain
|
||||
@@ -5,7 +5,7 @@ thumbnail: https://i.imgur.com/jgBdimh.png
|
||||
|
||||
# Spanish BERT (BETO) + POS
|
||||
|
||||
This model is a fine-tuned on [NER-C](https://www.kaggle.com/nltkdata/conll-corpora) Of the Spanish BERT cased [(BETO)](https://github.com/dccuchile/beto) for **POS** (Part of Speech tagging) downstream task.
|
||||
This model is a fine-tuned on Spanish [CONLL CORPORA](https://www.kaggle.com/nltkdata/conll-corpora) version of the Spanish BERT cased [(BETO)](https://github.com/dccuchile/beto) for **POS** (Part of Speech tagging) downstream task.
|
||||
|
||||
## Details of the downstream task (POS) - Dataset
|
||||
|
||||
@@ -21,7 +21,7 @@ I preprocessed the dataset and splitted it as train / dev (80/20)
|
||||
|
||||
- [Fine-tune on NER script provided by Huggingface](https://github.com/huggingface/transformers/blob/master/examples/run_ner.py)
|
||||
|
||||
- Labels covered:
|
||||
- **60** Labels covered:
|
||||
|
||||
```
|
||||
AO, AQ, CC, CS, DA, DD, DE, DI, DN, DP, DT, Faa, Fat, Fc, Fd, Fe, Fg, Fh, Fia, Fit, Fp, Fpa, Fpt, Fs, Ft, Fx, Fz, I, NC, NP, P0, PD, PI, PN, PP, PR, PT, PX, RG, RN, SP, VAI, VAM, VAN, VAP, VAS, VMG, VMI, VMM, VMN, VMP, VMS, VSG, VSI, VSM, VSN, VSP, VSS, Y and Z
|
||||
@@ -74,6 +74,8 @@ nlp_pos(text)
|
||||
```
|
||||
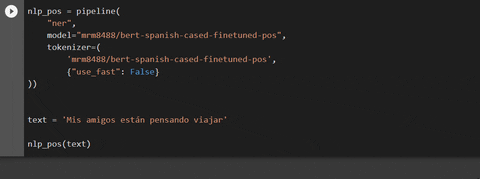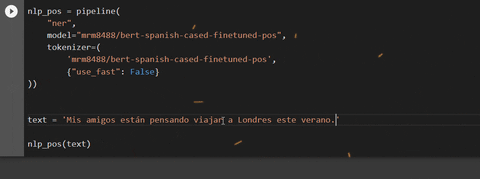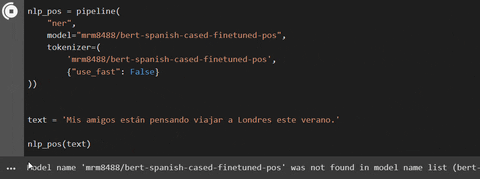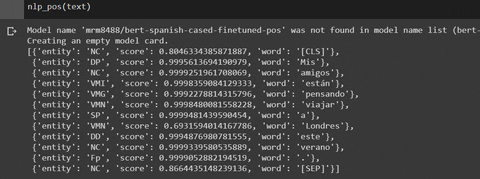
|
||||
|
||||
16 POS tags version also available [here](https://huggingface.co/mrm8488/bert-spanish-cased-finetuned-pos-16-tags)
|
||||
|
||||
|
||||
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
|
||||
|
||||
|
||||
@@ -0,0 +1,82 @@
|
||||
---
|
||||
language: multilingual
|
||||
thumbnail:
|
||||
---
|
||||
|
||||
# DistilBERT multilingual fine-tuned on TydiQA (GoldP task) dataset for multilingual Q&A 😛🌍❓
|
||||
|
||||
|
||||
## Details of the language model
|
||||
|
||||
[distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased)
|
||||
|
||||
|
||||
## Details of the Tydi QA dataset
|
||||
|
||||
TyDi QA contains 200k human-annotated question-answer pairs in 11 Typologically Diverse languages, written without seeing the answer and without the use of translation, and is designed for the **training and evaluation** of automatic question answering systems. This repository provides evaluation code and a baseline system for the dataset. https://ai.google.com/research/tydiqa
|
||||
|
||||
|
||||
## Details of the downstream task (Gold Passage or GoldP aka the secondary task)
|
||||
|
||||
Given a passage that is guaranteed to contain the answer, predict the single contiguous span of characters that answers the question. the gold passage task differs from the [primary task](https://github.com/google-research-datasets/tydiqa/blob/master/README.md#the-tasks) in several ways:
|
||||
* only the gold answer passage is provided rather than the entire Wikipedia article;
|
||||
* unanswerable questions have been discarded, similar to MLQA and XQuAD;
|
||||
* we evaluate with the SQuAD 1.1 metrics like XQuAD; and
|
||||
* Thai and Japanese are removed since the lack of whitespace breaks some tools.
|
||||
|
||||
|
||||
## Model training 💪🏋️
|
||||
|
||||
The model was fine-tuned on a Tesla P100 GPU and 25GB of RAM.
|
||||
The script is the following:
|
||||
|
||||
```python
|
||||
python transformers/examples/run_squad.py \
|
||||
--model_type distilbert \
|
||||
--model_name_or_path distilbert-base-multilingual-cased \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--train_file /path/to/dataset/train.json \
|
||||
--predict_file /path/to/dataset/dev.json \
|
||||
--per_gpu_train_batch_size 24 \
|
||||
--per_gpu_eval_batch_size 24 \
|
||||
--learning_rate 3e-5 \
|
||||
--num_train_epochs 5 \
|
||||
--max_seq_length 384 \
|
||||
--doc_stride 128 \
|
||||
--output_dir /content/model_output \
|
||||
--overwrite_output_dir \
|
||||
--save_steps 1000 \
|
||||
--threads 400
|
||||
```
|
||||
|
||||
## Global Results (dev set) 📝
|
||||
|
||||
| Metric | # Value |
|
||||
| --------- | ----------- |
|
||||
| **EM** | **63.85** |
|
||||
| **F1** | **75.70** |
|
||||
|
||||
## Specific Results (per language) 🌍📝
|
||||
|
||||
| Language | # Samples | # EM | # F1 |
|
||||
| --------- | ----------- |--------| ------ |
|
||||
| Arabic | 1314 | 66.66 | 80.02 |
|
||||
| Bengali | 180 | 53.09 | 63.50 |
|
||||
| English | 654 | 62.42 | 73.12 |
|
||||
| Finnish | 1031 | 64.57 | 75.15 |
|
||||
| Indonesian| 773 | 67.89 | 79.70 |
|
||||
| Korean | 414 | 51.29 | 61.73 |
|
||||
| Russian | 1079 | 55.42 | 70.08 |
|
||||
| Swahili | 596 | 74.51 | 81.15 |
|
||||
| Telegu | 874 | 66.21 | 79.85 |
|
||||
|
||||
|
||||
## Similar models
|
||||
|
||||
You can also try [bert-multi-cased-finedtuned-xquad-tydiqa-goldp](https://huggingface.co/mrm8488/bert-multi-cased-finedtuned-xquad-tydiqa-goldp) that achieves **F1 = 82.16** and **EM = 71.06** (And of course better marks per language).
|
||||
|
||||
|
||||
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
|
||||
|
||||
> Made with <span style="color: #e25555;">♥</span> in Spain
|
||||
27
model_cards/mrm8488/gpt2-imdb-neg/README.md
Normal file
27
model_cards/mrm8488/gpt2-imdb-neg/README.md
Normal file
@@ -0,0 +1,27 @@
|
||||
# GPT2-IMDB-neg (LM + RL) 🎞😡✍
|
||||
|
||||
All credits to [@lvwerra](https://twitter.com/lvwerra)
|
||||
|
||||
## What is it?
|
||||
A small GPT2 (`lvwerra/gpt2-imdb`) language model fine-tuned to produce **negative** movie reviews based the [IMDB dataset](https://www.kaggle.com/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews). The model is trained with rewards from a BERT sentiment classifier (`lvwerra/gpt2-imdb`) via **PPO**.
|
||||
|
||||
## Why?
|
||||
I wanted to reproduce the experiment [lvwerra/gpt2-imdb-pos](https://huggingface.co/lvwerra/gpt2-imdb-pos) but for generating **negative** movie reviews.
|
||||
|
||||
## Training setting
|
||||
The model was trained for `100` optimisation steps with a batch size of `256` which corresponds to `25600` training samples. The full experiment setup (for positive samples) in [trl repo](https://lvwerra.github.io/trl/04-gpt2-sentiment-ppo-training/).
|
||||
|
||||
## Examples
|
||||
A few examples of the model response to a query before and after optimisation:
|
||||
|
||||
| query | response (before) | response (after) | rewards (before) | rewards (after) |
|
||||
|-------|-------------------|------------------|------------------|-----------------|
|
||||
|This movie is a fine | attempt as far as live action is concerned, n...|example of how bad Hollywood in theatrics pla...| 2.118391 | -3.31625|
|
||||
|I have watched 3 episodes |with this guy and he is such a talented actor...| but the show is just plain awful and there ne...| 2.681171| -4.512792|
|
||||
|We know that firefighters and| police officers are forced to become populari...| other chains have going to get this disaster ...| 1.367811| -3.34017|
|
||||
|
||||
|
||||
|
||||
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
|
||||
|
||||
> Made with <span style="color: #e25555;">♥</span> in Spain
|
||||
@@ -0,0 +1,57 @@
|
||||
---
|
||||
language: german
|
||||
---
|
||||
|
||||
# Model description
|
||||
## Dataset
|
||||
Trained on fictional and non-fictional German texts written between 1840 and 1920:
|
||||
* Narrative texts from Digitale Bibliothek (https://textgrid.de/digitale-bibliothek)
|
||||
* Fairy tales and sagas from Grimm Korpus (https://www1.ids-mannheim.de/kl/projekte/korpora/archiv/gri.html)
|
||||
* Newspaper and magazine article from Mannheimer Korpus Historischer Zeitungen und Zeitschriften (https://repos.ids-mannheim.de/mkhz-beschreibung.html)
|
||||
* Magazine article from the journal „Die Grenzboten“ (http://www.deutschestextarchiv.de/doku/textquellen#grenzboten)
|
||||
* Fictional and non-fictional texts from Projekt Gutenberg (https://www.projekt-gutenberg.org)
|
||||
|
||||
## Hardware used
|
||||
1 Tesla P4 GPU
|
||||
|
||||
## Hyperparameters
|
||||
|
||||
| Parameter | Value |
|
||||
|-------------------------------|----------|
|
||||
| Epochs | 3 |
|
||||
| Gradient_accumulation_steps | 1 |
|
||||
| Train_batch_size | 32 |
|
||||
| Learning_rate | 0.00003 |
|
||||
| Max_seq_len | 128 |
|
||||
|
||||
## Evaluation results: Automatic tagging of four forms of speech/thought/writing representation in historical fictional and non-fictional German texts
|
||||
|
||||
The language model was used in the task to tag direct, indirect, reported and free indirect speech/thought/writing representation in fictional and non-fictional German texts. The tagger is available and described in detail at https://github.com/redewiedergabe/tagger.
|
||||
|
||||
The tagging model was trained using the SequenceTagger Class of the Flair framework ([Akbik et al., 2019](https://www.aclweb.org/anthology/N19-4010)) which implements a BiLSTM-CRF architecture on top of a language embedding (as proposed by [Huang et al. (2015)](https://arxiv.org/abs/1508.01991)).
|
||||
|
||||
|
||||
Hyperparameters
|
||||
|
||||
| Parameter | Value |
|
||||
|-------------------------------|------------|
|
||||
| Hidden_size | 256 |
|
||||
| Learning_rate | 0.1 |
|
||||
| Mini_batch_size | 8 |
|
||||
| Max_epochs | 150 |
|
||||
|
||||
Results are reported below in comparison to a custom trained flair embedding, which was stacked onto a custom trained fastText-model. Both models were trained on the same dataset.
|
||||
|
||||
| | BERT ||| FastText+Flair |||Test data|
|
||||
|----------------|----------|-----------|----------|------|-----------|--------|--------|
|
||||
| | F1 | Precision | Recall | F1 | Precision | Recall ||
|
||||
| Direct | 0.80 | 0.86 | 0.74 | 0.84 | 0.90 | 0.79 |historical German, fictional & non-fictional|
|
||||
| Indirect | **0.76** | **0.79** | **0.73** | 0.73 | 0.78 | 0.68 |historical German, fictional & non-fictional|
|
||||
| Reported | **0.58** | **0.69** | **0.51** | 0.56 | 0.68 | 0.48 |historical German, fictional & non-fictional|
|
||||
| Free indirect | **0.57** | **0.80** | **0.44** | 0.47 | 0.78 | 0.34 |modern German, fictional|
|
||||
|
||||
## Intended use:
|
||||
Historical German Texts (1840 to 1920)
|
||||
|
||||
(Showed good performance with modern German fictional texts as well)
|
||||
|
||||
6
model_cards/roberta-base-README.md
Normal file
6
model_cards/roberta-base-README.md
Normal file
@@ -0,0 +1,6 @@
|
||||
---
|
||||
tags:
|
||||
- exbert
|
||||
---
|
||||
|
||||
[](https://huggingface.co/exbert/?model=roberta-base)
|
||||
60
model_cards/shoarora/alectra-small-owt/README.md
Normal file
60
model_cards/shoarora/alectra-small-owt/README.md
Normal file
@@ -0,0 +1,60 @@
|
||||
# ALECTRA-small-OWT
|
||||
|
||||
This is an extension of
|
||||
[ELECTRA](https://openreview.net/forum?id=r1xMH1BtvB) small model, trained on the
|
||||
[OpenWebText corpus](https://skylion007.github.io/OpenWebTextCorpus/).
|
||||
The training task (discriminative LM / replaced-token-detection) can be generalized to any transformer type. Here, we train an ALBERT model under the same scheme.
|
||||
|
||||
## Pretraining task
|
||||

|
||||
(figure from [Clark et al. 2020](https://openreview.net/pdf?id=r1xMH1BtvB))
|
||||
|
||||
ELECTRA uses discriminative LM / replaced-token-detection for pretraining.
|
||||
This involves a generator (a Masked LM model) creating examples for a discriminator
|
||||
to classify as original or replaced for each token.
|
||||
|
||||
The generator generalizes to any `*ForMaskedLM` model and the discriminator could be
|
||||
any `*ForTokenClassification` model. Therefore, we can extend the task to ALBERT models,
|
||||
not just BERT as in the original paper.
|
||||
|
||||
## Usage
|
||||
```python
|
||||
from transformers import AlbertForSequenceClassification, BertTokenizer
|
||||
|
||||
# Both models use the bert-base-uncased tokenizer and vocab.
|
||||
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
|
||||
alectra = AlbertForSequenceClassification.from_pretrained('shoarora/alectra-small-owt')
|
||||
```
|
||||
NOTE: this ALBERT model uses a BERT WordPiece tokenizer.
|
||||
|
||||
## Code
|
||||
The pytorch module that implements this task is available [here](https://github.com/shoarora/lmtuners/blob/master/lmtuners/lightning_modules/discriminative_lm.py).
|
||||
|
||||
Further implementation information [here](https://github.com/shoarora/lmtuners/tree/master/experiments/disc_lm_small),
|
||||
and [here](https://github.com/shoarora/lmtuners/blob/master/experiments/disc_lm_small/train_alectra_small.py) is the script that created this model.
|
||||
|
||||
This specific model was trained with the following params:
|
||||
- `batch_size: 512`
|
||||
- `training_steps: 5e5`
|
||||
- `warmup_steps: 4e4`
|
||||
- `learning_rate: 2e-3`
|
||||
|
||||
|
||||
## Downstream tasks
|
||||
#### GLUE Dev results
|
||||
| Model | # Params | CoLA | SST | MRPC | STS | QQP | MNLI | QNLI | RTE |
|
||||
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
|
||||
| ELECTRA-Small++ | 14M | 57.0 | 91. | 88.0 | 87.5 | 89.0 | 81.3 | 88.4 | 66.7|
|
||||
| ELECTRA-Small-OWT | 14M | 56.8 | 88.3| 87.4 | 86.8 | 88.3 | 78.9 | 87.9 | 68.5|
|
||||
| ELECTRA-Small-OWT (ours) | 17M | 56.3 | 88.4| 75.0 | 86.1 | 89.1 | 77.9 | 83.0 | 67.1|
|
||||
| ALECTRA-Small-OWT (ours) | 4M | 50.6 | 89.1| 86.3 | 87.2 | 89.1 | 78.2 | 85.9 | 69.6|
|
||||
|
||||
|
||||
#### GLUE Test results
|
||||
| Model | # Params | CoLA | SST | MRPC | STS | QQP | MNLI | QNLI | RTE |
|
||||
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
|
||||
| BERT-Base | 110M | 52.1 | 93.5| 84.8 | 85.9 | 89.2 | 84.6 | 90.5 | 66.4|
|
||||
| GPT | 117M | 45.4 | 91.3| 75.7 | 80.0 | 88.5 | 82.1 | 88.1 | 56.0|
|
||||
| ELECTRA-Small++ | 14M | 57.0 | 91.2| 88.0 | 87.5 | 89.0 | 81.3 | 88.4 | 66.7|
|
||||
| ELECTRA-Small-OWT (ours) | 17M | 57.4 | 89.3| 76.2 | 81.9 | 87.5 | 78.1 | 82.4 | 68.1|
|
||||
| ALECTRA-Small-OWT (ours) | 4M | 43.9 | 87.9| 82.1 | 82.0 | 87.6 | 77.9 | 85.8 | 67.5|
|
||||
59
model_cards/shoarora/electra-small-owt/README.md
Normal file
59
model_cards/shoarora/electra-small-owt/README.md
Normal file
@@ -0,0 +1,59 @@
|
||||
# ELECTRA-small-OWT
|
||||
|
||||
This is an unnoficial implementation of an
|
||||
[ELECTRA](https://openreview.net/forum?id=r1xMH1BtvB) small model, trained on the
|
||||
[OpenWebText corpus](https://skylion007.github.io/OpenWebTextCorpus/).
|
||||
|
||||
Differences from official ELECTRA models:
|
||||
- we use a `BertForMaskedLM` as the generator and `BertForTokenClassification` as the discriminator
|
||||
- they use an embedding projection layer, but Bert doesn't have one
|
||||
|
||||
## Pretraining ttask
|
||||

|
||||
(figure from [Clark et al. 2020](https://openreview.net/pdf?id=r1xMH1BtvB))
|
||||
|
||||
ELECTRA uses discriminative LM / replaced-token-detection for pretraining.
|
||||
This involves a generator (a Masked LM model) creating examples for a discriminator
|
||||
to classify as original or replaced for each token.
|
||||
|
||||
|
||||
## Usage
|
||||
```python
|
||||
from transformers import BertForSequenceClassification, BertTokenizer
|
||||
|
||||
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
|
||||
electra = BertForSequenceClassification.from_pretrained('shoarora/electra-small-owt')
|
||||
```
|
||||
|
||||
## Code
|
||||
The pytorch module that implements this task is available [here](https://github.com/shoarora/lmtuners/blob/master/lmtuners/lightning_modules/discriminative_lm.py).
|
||||
|
||||
Further implementation information [here](https://github.com/shoarora/lmtuners/tree/master/experiments/disc_lm_small),
|
||||
and [here](https://github.com/shoarora/lmtuners/blob/master/experiments/disc_lm_small/train_electra_small.py) is the script that created this model.
|
||||
|
||||
This specific model was trained with the following params:
|
||||
- `batch_size: 512`
|
||||
- `training_steps: 5e5`
|
||||
- `warmup_steps: 4e4`
|
||||
- `learning_rate: 2e-3`
|
||||
|
||||
|
||||
## Downstream tasks
|
||||
#### GLUE Dev results
|
||||
| Model | # Params | CoLA | SST | MRPC | STS | QQP | MNLI | QNLI | RTE |
|
||||
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
|
||||
| ELECTRA-Small++ | 14M | 57.0 | 91. | 88.0 | 87.5 | 89.0 | 81.3 | 88.4 | 66.7|
|
||||
| ELECTRA-Small-OWT | 14M | 56.8 | 88.3| 87.4 | 86.8 | 88.3 | 78.9 | 87.9 | 68.5|
|
||||
| ELECTRA-Small-OWT (ours) | 17M | 56.3 | 88.4| 75.0 | 86.1 | 89.1 | 77.9 | 83.0 | 67.1|
|
||||
| ALECTRA-Small-OWT (ours) | 4M | 50.6 | 89.1| 86.3 | 87.2 | 89.1 | 78.2 | 85.9 | 69.6|
|
||||
|
||||
- Table initialized from [ELECTRA github repo](https://github.com/google-research/electra)
|
||||
|
||||
#### GLUE Test results
|
||||
| Model | # Params | CoLA | SST | MRPC | STS | QQP | MNLI | QNLI | RTE |
|
||||
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
|
||||
| BERT-Base | 110M | 52.1 | 93.5| 84.8 | 85.9 | 89.2 | 84.6 | 90.5 | 66.4|
|
||||
| GPT | 117M | 45.4 | 91.3| 75.7 | 80.0 | 88.5 | 82.1 | 88.1 | 56.0|
|
||||
| ELECTRA-Small++ | 14M | 57.0 | 91.2| 88.0 | 87.5 | 89.0 | 81.3 | 88.4 | 66.7|
|
||||
| ELECTRA-Small-OWT (ours) | 17M | 57.4 | 89.3| 76.2 | 81.9 | 87.5 | 78.1 | 82.4 | 68.1|
|
||||
| ALECTRA-Small-OWT (ours) | 4M | 43.9 | 87.9| 82.1 | 82.0 | 87.6 | 77.9 | 85.8 | 67.5|
|
||||
@@ -1,22 +1,24 @@
|
||||
This model is ALBERT base v2 trained on SQuAD v2 as:
|
||||
This model is [ALBERT base v2](https://huggingface.co/albert-base-v2) trained on SQuAD v2 as:
|
||||
|
||||
```
|
||||
python run_squad.py
|
||||
--model_type albert
|
||||
--model_name_or_path albert-base-v2
|
||||
--do_train
|
||||
--do_eval
|
||||
--overwrite_cache
|
||||
--do_lower_case
|
||||
--version_2_with_negative
|
||||
--train_file $SQUAD_DIR/train-v2.0.json
|
||||
--predict_file $SQUAD_DIR/dev-v2.0.json
|
||||
--per_gpu_train_batch_size 8
|
||||
--num_train_epochs 3
|
||||
--learning_rate 3e-5
|
||||
--max_seq_length 384
|
||||
--doc_stride 128
|
||||
--output_dir ./tmp/albert_base_fine/
|
||||
export SQUAD_DIR=../../squad2
|
||||
python3 run_squad.py
|
||||
--model_type albert
|
||||
--model_name_or_path albert-base-v2
|
||||
--do_train
|
||||
--do_eval
|
||||
--overwrite_cache
|
||||
--do_lower_case
|
||||
--version_2_with_negative
|
||||
--save_steps 100000
|
||||
--train_file $SQUAD_DIR/train-v2.0.json
|
||||
--predict_file $SQUAD_DIR/dev-v2.0.json
|
||||
--per_gpu_train_batch_size 8
|
||||
--num_train_epochs 3
|
||||
--learning_rate 3e-5
|
||||
--max_seq_length 384
|
||||
--doc_stride 128
|
||||
--output_dir ./tmp/albert_fine/
|
||||
```
|
||||
|
||||
Performance on a dev subset is close to the original paper:
|
||||
|
||||
@@ -1,22 +1,24 @@
|
||||
This model is BERT base uncased trained on SQuAD v2 as:
|
||||
This model is [BERT base uncased](https://huggingface.co/bert-base-uncased) trained on SQuAD v2 as:
|
||||
|
||||
```
|
||||
python run_squad.py
|
||||
--model_type bert
|
||||
--model_name_or_path bert-base-uncased
|
||||
--do_train
|
||||
--do_eval
|
||||
--overwrite_cache
|
||||
--do_lower_case
|
||||
--version_2_with_negative
|
||||
--train_file $SQUAD_DIR/train-v2.0.json
|
||||
--predict_file $SQUAD_DIR/dev-v2.0.json
|
||||
--per_gpu_train_batch_size 8
|
||||
--num_train_epochs 3
|
||||
--learning_rate 3e-5
|
||||
--max_seq_length 384
|
||||
--doc_stride 128
|
||||
--output_dir ./tmp/bert_base_fine/
|
||||
export SQUAD_DIR=../../squad2
|
||||
python3 run_squad.py
|
||||
--model_type bert
|
||||
--model_name_or_path bert-base-uncased
|
||||
--do_train
|
||||
--do_eval
|
||||
--overwrite_cache
|
||||
--do_lower_case
|
||||
--version_2_with_negative
|
||||
--save_steps 100000
|
||||
--train_file $SQUAD_DIR/train-v2.0.json
|
||||
--predict_file $SQUAD_DIR/dev-v2.0.json
|
||||
--per_gpu_train_batch_size 8
|
||||
--num_train_epochs 3
|
||||
--learning_rate 3e-5
|
||||
--max_seq_length 384
|
||||
--doc_stride 128
|
||||
--output_dir ./tmp/bert_fine_tuned/
|
||||
```
|
||||
|
||||
Performance on a dev subset is close to the original paper:
|
||||
|
||||
45
model_cards/twmkn9/distilbert-base-uncased-squad2/README.md
Normal file
45
model_cards/twmkn9/distilbert-base-uncased-squad2/README.md
Normal file
@@ -0,0 +1,45 @@
|
||||
This model is [Distilbert base uncased](https://huggingface.co/distilbert-base-uncased) trained on SQuAD v2 as:
|
||||
|
||||
```
|
||||
export SQUAD_DIR=../../squad2
|
||||
python3 run_squad.py
|
||||
--model_type distilbert
|
||||
--model_name_or_path distilbert-base-uncased
|
||||
--do_train
|
||||
--do_eval
|
||||
--overwrite_cache
|
||||
--do_lower_case
|
||||
--version_2_with_negative
|
||||
--save_steps 100000
|
||||
--train_file $SQUAD_DIR/train-v2.0.json
|
||||
--predict_file $SQUAD_DIR/dev-v2.0.json
|
||||
--per_gpu_train_batch_size 8
|
||||
--num_train_epochs 3
|
||||
--learning_rate 3e-5
|
||||
--max_seq_length 384
|
||||
--doc_stride 128
|
||||
--output_dir ./tmp/distilbert_fine_tuned/
|
||||
```
|
||||
|
||||
Performance on a dev subset is close to the original paper:
|
||||
|
||||
```
|
||||
Results:
|
||||
{
|
||||
'exact': 64.88976637051661,
|
||||
'f1': 68.1776176526635,
|
||||
'total': 6078,
|
||||
'HasAns_exact': 69.7594501718213,
|
||||
'HasAns_f1': 76.62665295288285,
|
||||
'HasAns_total': 2910,
|
||||
'NoAns_exact': 60.416666666666664,
|
||||
'NoAns_f1': 60.416666666666664,
|
||||
'NoAns_total': 3168,
|
||||
'best_exact': 64.88976637051661,
|
||||
'best_exact_thresh': 0.0,
|
||||
'best_f1': 68.17761765266337,
|
||||
'best_f1_thresh': 0.0
|
||||
}
|
||||
```
|
||||
|
||||
We are hopeful this might save you time, energy, and compute. Cheers!
|
||||
44
model_cards/twmkn9/distilroberta-base-squad2/README.md
Normal file
44
model_cards/twmkn9/distilroberta-base-squad2/README.md
Normal file
@@ -0,0 +1,44 @@
|
||||
This model is [Distilroberta base](https://huggingface.co/distilroberta-base) trained on SQuAD v2 as:
|
||||
|
||||
```
|
||||
export SQUAD_DIR=../../squad2
|
||||
python3 run_squad.py
|
||||
--model_type robberta
|
||||
--model_name_or_path distilroberta-base
|
||||
--do_train
|
||||
--do_eval
|
||||
--overwrite_cache
|
||||
--do_lower_case
|
||||
--version_2_with_negative
|
||||
--save_steps 100000
|
||||
--train_file $SQUAD_DIR/train-v2.0.json
|
||||
--predict_file $SQUAD_DIR/dev-v2.0.json
|
||||
--per_gpu_train_batch_size 8
|
||||
--num_train_epochs 3
|
||||
--learning_rate 3e-5
|
||||
--max_seq_length 384
|
||||
--doc_stride 128
|
||||
--output_dir ./tmp/distilroberta_fine_tuned/
|
||||
```
|
||||
|
||||
Performance on a dev subset is close to the original paper:
|
||||
|
||||
```
|
||||
Results:
|
||||
{
|
||||
'exact': 70.9279368213228,
|
||||
'f1': 74.60439802429168,
|
||||
'total': 6078,
|
||||
'HasAns_exact': 67.62886597938144,
|
||||
'HasAns_f1': 75.30774267754136,
|
||||
'HasAns_total': 2910,
|
||||
'NoAns_exact': 73.95833333333333,
|
||||
'NoAns_f1': 73.95833333333333, 'NoAns_total': 3168,
|
||||
'best_exact': 70.94438960184272,
|
||||
'best_exact_thresh': 0.0,
|
||||
'best_f1': 74.62085080481161,
|
||||
'best_f1_thresh': 0.0
|
||||
}
|
||||
```
|
||||
|
||||
We are hopeful this might save you time, energy, and compute. Cheers!
|
||||
6
model_cards/xlm-mlm-en-2048-README.md
Normal file
6
model_cards/xlm-mlm-en-2048-README.md
Normal file
@@ -0,0 +1,6 @@
|
||||
---
|
||||
tags:
|
||||
- exbert
|
||||
---
|
||||
|
||||
[](https://huggingface.co/exbert/?model=xlm-mlm-en-2048)
|
||||
6
model_cards/xlm-roberta-base-README.md
Normal file
6
model_cards/xlm-roberta-base-README.md
Normal file
@@ -0,0 +1,6 @@
|
||||
---
|
||||
tags:
|
||||
- exbert
|
||||
---
|
||||
|
||||
[](https://huggingface.co/exbert/?model=xlm-roberta-base)
|
||||
File diff suppressed because it is too large
Load Diff
4
setup.py
4
setup.py
@@ -83,7 +83,7 @@ extras["dev"] = extras["testing"] + extras["quality"] + ["mecab-python3", "sciki
|
||||
|
||||
setup(
|
||||
name="transformers",
|
||||
version="2.6.0",
|
||||
version="2.8.0",
|
||||
author="Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Sam Shleifer, Google AI Language Team Authors, Open AI team Authors, Facebook AI Authors, Carnegie Mellon University Authors",
|
||||
author_email="thomas@huggingface.co",
|
||||
description="State-of-the-art Natural Language Processing for TensorFlow 2.0 and PyTorch",
|
||||
@@ -97,6 +97,8 @@ setup(
|
||||
install_requires=[
|
||||
"numpy",
|
||||
"tokenizers == 0.5.2",
|
||||
# dataclasses for Python versions that don't have it
|
||||
"dataclasses;python_version<'3.7'",
|
||||
# accessing files from S3 directly
|
||||
"boto3",
|
||||
# filesystem locks e.g. to prevent parallel downloads
|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
# There's no way to ignore "F401 '...' imported but unused" warnings in this
|
||||
# module, but to preserve other warnings. So, don't check this module at all.
|
||||
|
||||
__version__ = "2.6.0"
|
||||
__version__ = "2.8.0"
|
||||
|
||||
# Work around to update TensorFlow's absl.logging threshold which alters the
|
||||
# default Python logging output behavior when present.
|
||||
@@ -32,12 +32,13 @@ from .benchmark_utils import (
|
||||
stop_memory_tracing,
|
||||
)
|
||||
from .configuration_albert import ALBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, AlbertConfig
|
||||
from .configuration_auto import ALL_PRETRAINED_CONFIG_ARCHIVE_MAP, AutoConfig
|
||||
from .configuration_auto import ALL_PRETRAINED_CONFIG_ARCHIVE_MAP, CONFIG_MAPPING, AutoConfig
|
||||
from .configuration_bart import BartConfig
|
||||
from .configuration_bert import BERT_PRETRAINED_CONFIG_ARCHIVE_MAP, BertConfig
|
||||
from .configuration_camembert import CAMEMBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, CamembertConfig
|
||||
from .configuration_ctrl import CTRL_PRETRAINED_CONFIG_ARCHIVE_MAP, CTRLConfig
|
||||
from .configuration_distilbert import DISTILBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, DistilBertConfig
|
||||
from .configuration_electra import ELECTRA_PRETRAINED_CONFIG_ARCHIVE_MAP, ElectraConfig
|
||||
from .configuration_flaubert import FLAUBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, FlaubertConfig
|
||||
from .configuration_gpt2 import GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP, GPT2Config
|
||||
from .configuration_mmbt import MMBTConfig
|
||||
@@ -116,16 +117,18 @@ from .pipelines import (
|
||||
SummarizationPipeline,
|
||||
TextClassificationPipeline,
|
||||
TokenClassificationPipeline,
|
||||
TranslationPipeline,
|
||||
pipeline,
|
||||
)
|
||||
from .tokenization_albert import AlbertTokenizer
|
||||
from .tokenization_auto import AutoTokenizer
|
||||
from .tokenization_auto import TOKENIZER_MAPPING, AutoTokenizer
|
||||
from .tokenization_bart import BartTokenizer
|
||||
from .tokenization_bert import BasicTokenizer, BertTokenizer, BertTokenizerFast, WordpieceTokenizer
|
||||
from .tokenization_bert_japanese import BertJapaneseTokenizer, CharacterTokenizer, MecabTokenizer
|
||||
from .tokenization_camembert import CamembertTokenizer
|
||||
from .tokenization_ctrl import CTRLTokenizer
|
||||
from .tokenization_distilbert import DistilBertTokenizer, DistilBertTokenizerFast
|
||||
from .tokenization_electra import ElectraTokenizer, ElectraTokenizerFast
|
||||
from .tokenization_flaubert import FlaubertTokenizer
|
||||
from .tokenization_gpt2 import GPT2Tokenizer, GPT2TokenizerFast
|
||||
from .tokenization_openai import OpenAIGPTTokenizer, OpenAIGPTTokenizerFast
|
||||
@@ -221,6 +224,7 @@ if is_torch_available():
|
||||
XLMModel,
|
||||
XLMWithLMHeadModel,
|
||||
XLMForSequenceClassification,
|
||||
XLMForTokenClassification,
|
||||
XLMForQuestionAnswering,
|
||||
XLMForQuestionAnsweringSimple,
|
||||
XLM_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
@@ -295,6 +299,15 @@ if is_torch_available():
|
||||
FLAUBERT_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
)
|
||||
|
||||
from .modeling_electra import (
|
||||
ElectraForPreTraining,
|
||||
ElectraForMaskedLM,
|
||||
ElectraForTokenClassification,
|
||||
ElectraModel,
|
||||
load_tf_weights_in_electra,
|
||||
ELECTRA_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
)
|
||||
|
||||
# Optimization
|
||||
from .optimization import (
|
||||
AdamW,
|
||||
@@ -461,6 +474,15 @@ if is_tf_available():
|
||||
TF_T5_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
)
|
||||
|
||||
from .modeling_tf_electra import (
|
||||
TFElectraPreTrainedModel,
|
||||
TFElectraModel,
|
||||
TFElectraForPreTraining,
|
||||
TFElectraForMaskedLM,
|
||||
TFElectraForTokenClassification,
|
||||
TF_ELECTRA_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
)
|
||||
|
||||
# Optimization
|
||||
from .optimization_tf import WarmUp, create_optimizer, AdamWeightDecay, GradientAccumulator
|
||||
|
||||
|
||||
@@ -18,12 +18,6 @@ def _gelu_python(x):
|
||||
return x * 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))
|
||||
|
||||
|
||||
if torch.__version__ < "1.4.0":
|
||||
gelu = _gelu_python
|
||||
else:
|
||||
gelu = F.gelu
|
||||
|
||||
|
||||
def gelu_new(x):
|
||||
""" Implementation of the gelu activation function currently in Google Bert repo (identical to OpenAI GPT).
|
||||
Also see https://arxiv.org/abs/1606.08415
|
||||
@@ -31,6 +25,12 @@ def gelu_new(x):
|
||||
return 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
|
||||
|
||||
|
||||
if torch.__version__ < "1.4.0":
|
||||
gelu = _gelu_python
|
||||
else:
|
||||
gelu = F.gelu
|
||||
gelu_new = torch.jit.script(gelu_new)
|
||||
|
||||
ACT2FN = {
|
||||
"relu": F.relu,
|
||||
"swish": swish,
|
||||
|
||||
@@ -24,6 +24,7 @@ from .configuration_bert import BERT_PRETRAINED_CONFIG_ARCHIVE_MAP, BertConfig
|
||||
from .configuration_camembert import CAMEMBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, CamembertConfig
|
||||
from .configuration_ctrl import CTRL_PRETRAINED_CONFIG_ARCHIVE_MAP, CTRLConfig
|
||||
from .configuration_distilbert import DISTILBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, DistilBertConfig
|
||||
from .configuration_electra import ELECTRA_PRETRAINED_CONFIG_ARCHIVE_MAP, ElectraConfig
|
||||
from .configuration_flaubert import FLAUBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, FlaubertConfig
|
||||
from .configuration_gpt2 import GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP, GPT2Config
|
||||
from .configuration_openai import OPENAI_GPT_PRETRAINED_CONFIG_ARCHIVE_MAP, OpenAIGPTConfig
|
||||
@@ -57,6 +58,7 @@ ALL_PRETRAINED_CONFIG_ARCHIVE_MAP = dict(
|
||||
T5_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
XLM_ROBERTA_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
FLAUBERT_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
ELECTRA_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
]
|
||||
for key, value, in pretrained_map.items()
|
||||
)
|
||||
@@ -79,6 +81,7 @@ CONFIG_MAPPING = OrderedDict(
|
||||
("xlnet", XLNetConfig,),
|
||||
("xlm", XLMConfig,),
|
||||
("ctrl", CTRLConfig,),
|
||||
("electra", ElectraConfig,),
|
||||
]
|
||||
)
|
||||
|
||||
@@ -133,6 +136,7 @@ class AutoConfig:
|
||||
- contains `xlm`: :class:`~transformers.XLMConfig` (XLM model)
|
||||
- contains `ctrl` : :class:`~transformers.CTRLConfig` (CTRL model)
|
||||
- contains `flaubert` : :class:`~transformers.FlaubertConfig` (Flaubert model)
|
||||
- contains `electra` : :class:`~transformers.ElectraConfig` (ELECTRA model)
|
||||
|
||||
|
||||
Args:
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user