Compare commits
46 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
b90745c590 | ||
|
|
3716c3d8af | ||
|
|
f9ec5ca90b | ||
|
|
4cd9c0971c | ||
|
|
ee60840ee6 | ||
|
|
6a50d501ec | ||
|
|
65d74c4965 | ||
|
|
a143d9479e | ||
|
|
286d1ec746 | ||
|
|
7984a70ee4 | ||
|
|
21d8b6a33e | ||
|
|
17c45c39ed | ||
|
|
8194df8e0c | ||
|
|
38f5fe9e02 | ||
|
|
129f0604ac | ||
|
|
0e84559d64 | ||
|
|
92487a1dc0 | ||
|
|
c36416e53c | ||
|
|
cafc4dfc7c | ||
|
|
34b4b5a9ed | ||
|
|
7df12d7bf8 | ||
|
|
cc6775cdf5 | ||
|
|
94ff2d6ee8 | ||
|
|
b5b3445c4f | ||
|
|
fc38d4c86f | ||
|
|
c749a543fa | ||
|
|
5211d333bb | ||
|
|
3e98f27e4a | ||
|
|
4452b44b90 | ||
|
|
53ce3854a1 | ||
|
|
564fd75d65 | ||
|
|
889d3bfdbb | ||
|
|
197d74f988 | ||
|
|
ea8eba35e2 | ||
|
|
e2a6445ebb | ||
|
|
9b3093311f | ||
|
|
b662f0e625 | ||
|
|
ab1238393c | ||
|
|
976e9afece | ||
|
|
cbc5705541 | ||
|
|
d490b5d500 | ||
|
|
2708b44ee9 | ||
|
|
1abd53b1aa | ||
|
|
e676764241 | ||
|
|
59c23ad9c9 | ||
|
|
22b2b5790e |
@@ -25,4 +25,5 @@ deploy_doc "fc9faa8" v2.0.0
|
||||
deploy_doc "3ddce1d" v2.1.1
|
||||
deploy_doc "3616209" v2.2.0
|
||||
deploy_doc "d0f8b9a" v2.3.0
|
||||
deploy_doc "6664ea9" v2.4.0
|
||||
deploy_doc "6664ea9" v2.4.0
|
||||
deploy_doc "fb560dc" v2.5.0
|
||||
|
||||
3
.gitignore
vendored
3
.gitignore
vendored
@@ -142,3 +142,6 @@ debug.env
|
||||
|
||||
# vim
|
||||
.*.swp
|
||||
|
||||
#ctags
|
||||
tags
|
||||
|
||||
@@ -62,7 +62,7 @@ Choose the right framework for every part of a model's lifetime
|
||||
| [Quick tour: Share your models ](#Quick-tour-of-model-sharing) | Upload and share your fine-tuned models with the community |
|
||||
| [Migrating from pytorch-transformers to transformers](#Migrating-from-pytorch-transformers-to-transformers) | Migrating your code from pytorch-transformers to transformers |
|
||||
| [Migrating from pytorch-pretrained-bert to pytorch-transformers](#Migrating-from-pytorch-pretrained-bert-to-transformers) | Migrating your code from pytorch-pretrained-bert to transformers |
|
||||
| [Documentation][(v2.4.0)](https://huggingface.co/transformers/v2.4.0)[(v2.3.0)](https://huggingface.co/transformers/v2.3.0)[(v2.2.0/v2.2.1/v2.2.2)](https://huggingface.co/transformers/v2.2.0) [(v2.1.1)](https://huggingface.co/transformers/v2.1.1) [(v2.0.0)](https://huggingface.co/transformers/v2.0.0) [(v1.2.0)](https://huggingface.co/transformers/v1.2.0) [(v1.1.0)](https://huggingface.co/transformers/v1.1.0) [(v1.0.0)](https://huggingface.co/transformers/v1.0.0) [(master)](https://huggingface.co/transformers) | Full API documentation and more |
|
||||
| [Documentation][(v2.5.0)](https://huggingface.co/transformers/v2.5.0)[(v2.4.0/v2.4.1)](https://huggingface.co/transformers/v2.4.0)[(v2.3.0)](https://huggingface.co/transformers/v2.3.0)[(v2.2.0/v2.2.1/v2.2.2)](https://huggingface.co/transformers/v2.2.0) [(v2.1.1)](https://huggingface.co/transformers/v2.1.1) [(v2.0.0)](https://huggingface.co/transformers/v2.0.0) [(v1.2.0)](https://huggingface.co/transformers/v1.2.0) [(v1.1.0)](https://huggingface.co/transformers/v1.1.0) [(v1.0.0)](https://huggingface.co/transformers/v1.0.0) [(master)](https://huggingface.co/transformers) | Full API documentation and more |
|
||||
|
||||
## Installation
|
||||
|
||||
@@ -678,7 +678,7 @@ for batch in train_data:
|
||||
## Citation
|
||||
|
||||
We now have a paper you can cite for the 🤗 Transformers library:
|
||||
```
|
||||
```bibtex
|
||||
@article{Wolf2019HuggingFacesTS,
|
||||
title={HuggingFace's Transformers: State-of-the-art Natural Language Processing},
|
||||
author={Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and R'emi Louf and Morgan Funtowicz and Jamie Brew},
|
||||
|
||||
@@ -26,7 +26,7 @@ author = u'huggingface'
|
||||
# The short X.Y version
|
||||
version = u''
|
||||
# The full version, including alpha/beta/rc tags
|
||||
release = u'2.5.0'
|
||||
release = u'2.5.1'
|
||||
|
||||
|
||||
# -- General configuration ---------------------------------------------------
|
||||
|
||||
@@ -99,4 +99,5 @@ The library currently contains PyTorch and Tensorflow implementations, pre-train
|
||||
model_doc/camembert
|
||||
model_doc/albert
|
||||
model_doc/xlmroberta
|
||||
model_doc/flaubert
|
||||
model_doc/flaubert
|
||||
model_doc/bart
|
||||
|
||||
52
docs/source/model_doc/bart.rst
Normal file
52
docs/source/model_doc/bart.rst
Normal file
@@ -0,0 +1,52 @@
|
||||
Bart
|
||||
----------------------------------------------------
|
||||
**DISCLAIMER:** This model is still a work in progress, if you see something strange,
|
||||
file a `Github Issue <https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title>`__ and assign
|
||||
@sshleifer
|
||||
|
||||
The Bart model was `proposed <https://arxiv.org/abs/1910.13461>`_ by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, Luke Zettlemoyer on 29 Oct, 2019.
|
||||
It is a sequence to sequence model where both encoder and decoder are transformers. The paper also introduces a novel pretraining objective, and demonstrates excellent summarization results.
|
||||
The authors released their code `here <https://github.com/pytorch/fairseq/tree/master/examples/bart>`_
|
||||
|
||||
**Abstract:**
|
||||
|
||||
*We present BART, a denoising autoencoder for pretraining sequence-to-sequence models. BART is trained by (1) corrupting text with an arbitrary noising function, and (2) learning a model to reconstruct the original text. It uses a standard Tranformer-based neural machine translation architecture which, despite its simplicity, can be seen as generalizing BERT (due to the bidirectional encoder), GPT (with the left-to-right decoder), and many other more recent pretraining schemes. We evaluate a number of noising approaches, finding the best performance by both randomly shuffling the order of the original sentences and using a novel in-filling scheme, where spans of text are replaced with a single mask token. BART is particularly effective when fine tuned for text generation but also works well for comprehension tasks. It matches the performance of RoBERTa with comparable training resources on GLUE and SQuAD, achieves new state-of-the-art results on a range of abstractive dialogue, question answering, and summarization tasks, with gains of up to 6 ROUGE. BART also provides a 1.1 BLEU increase over a back-translation system for machine translation, with only target language pretraining. We also report ablation experiments that replicate other pretraining schemes within the BART framework, to better measure which factors most influence end-task performance.*
|
||||
`BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension`
|
||||
|
||||
|
||||
Notes:
|
||||
- Bart doesn't use :obj:`token_type_ids`, for sequence classification just use BartTokenizer.encode to get the proper splitting.
|
||||
- Inputs to the decoder are created by BartModel.forward if they are not passed. This is different than some other model APIs.
|
||||
- Model predictions are intended to be identical to the original implementation. This only works, however, if the string you pass to fairseq.encode starts with a space.
|
||||
|
||||
BartModel
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.BartModel
|
||||
:members: forward
|
||||
|
||||
|
||||
BartForMaskedLM
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.BartForMaskedLM
|
||||
:members: forward
|
||||
|
||||
|
||||
BartForSequenceClassification
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.BartForSequenceClassification
|
||||
:members: forward
|
||||
|
||||
BartConfig
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: transformers.BartConfig
|
||||
:members:
|
||||
|
||||
Automatic Creation of Decoder Inputs
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
This is enabled by default
|
||||
|
||||
.. autofunction:: transformers.modeling_bart._prepare_bart_decoder_inputs
|
||||
@@ -275,6 +275,13 @@ For a list that includes community-uploaded models, refer to `https://huggingfac
|
||||
| | | | FlauBERT large architecture |
|
||||
| | | (see `details <https://github.com/getalp/Flaubert>`__) |
|
||||
+-------------------+------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------+
|
||||
+-------------------+------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| Bart | ``bart-large`` | | 12-layer, 1024-hidden, 16-heads, 406M parameters |
|
||||
| | | (see `details <https://github.com/pytorch/fairseq/tree/master/examples/bart>`_) |
|
||||
| +------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| | ``bart-large-mnli`` | | Adds a 2 layer classification head with 1 million parameters |
|
||||
| | | | bart-large base architecture with a classification head |
|
||||
+-------------------+------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------+
|
||||
|
||||
|
||||
.. <https://huggingface.co/transformers/examples.html>`__
|
||||
|
||||
@@ -3,7 +3,7 @@
|
||||
In this section a few examples are put together. All of these examples work for several models, making use of the very
|
||||
similar API between the different models.
|
||||
|
||||
**Important**
|
||||
**Important**
|
||||
To run the latest versions of the examples, you have to install from source and install some specific requirements for the examples.
|
||||
Execute the following steps in a new virtual environment:
|
||||
|
||||
@@ -15,8 +15,8 @@ pip install -r ./examples/requirements.txt
|
||||
```
|
||||
|
||||
| Section | Description |
|
||||
|----------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| [TensorFlow 2.0 models on GLUE](#TensorFlow-2.0-Bert-models-on-GLUE) | Examples running BERT TensorFlow 2.0 model on the GLUE tasks.
|
||||
|----------------------------|------------------------------------------------------------------------------------------------------------------------------------------
|
||||
| [TensorFlow 2.0 models on GLUE](#TensorFlow-2.0-Bert-models-on-GLUE) | Examples running BERT TensorFlow 2.0 model on the GLUE tasks. |
|
||||
| [Language Model training](#language-model-training) | Fine-tuning (or training from scratch) the library models for language modeling on a text dataset. Causal language modeling for GPT/GPT-2, masked language modeling for BERT/RoBERTa. |
|
||||
| [Language Generation](#language-generation) | Conditional text generation using the auto-regressive models of the library: GPT, GPT-2, Transformer-XL and XLNet. |
|
||||
| [GLUE](#glue) | Examples running BERT/XLM/XLNet/RoBERTa on the 9 GLUE tasks. Examples feature distributed training as well as half-precision. |
|
||||
@@ -88,7 +88,7 @@ a score of ~20 perplexity once fine-tuned on the dataset.
|
||||
|
||||
The following example fine-tunes RoBERTa on WikiText-2. Here too, we're using the raw WikiText-2. The loss is different
|
||||
as BERT/RoBERTa have a bidirectional mechanism; we're therefore using the same loss that was used during their
|
||||
pre-training: masked language modeling.
|
||||
pre-training: masked language modeling.
|
||||
|
||||
In accordance to the RoBERTa paper, we use dynamic masking rather than static masking. The model may, therefore, converge
|
||||
slightly slower (over-fitting takes more epochs).
|
||||
@@ -130,8 +130,8 @@ python run_generation.py \
|
||||
|
||||
Based on the script [`run_glue.py`](https://github.com/huggingface/transformers/blob/master/examples/run_glue.py).
|
||||
|
||||
Fine-tuning the library models for sequence classification on the GLUE benchmark: [General Language Understanding
|
||||
Evaluation](https://gluebenchmark.com/). This script can fine-tune the following models: BERT, XLM, XLNet and RoBERTa.
|
||||
Fine-tuning the library models for sequence classification on the GLUE benchmark: [General Language Understanding
|
||||
Evaluation](https://gluebenchmark.com/). This script can fine-tune the following models: BERT, XLM, XLNet and RoBERTa.
|
||||
|
||||
GLUE is made up of a total of 9 different tasks. We get the following results on the dev set of the benchmark with an
|
||||
uncased BERT base model (the checkpoint `bert-base-uncased`). All experiments ran single V100 GPUs with a total train
|
||||
@@ -179,20 +179,20 @@ python run_glue.py \
|
||||
|
||||
where task name can be one of CoLA, SST-2, MRPC, STS-B, QQP, MNLI, QNLI, RTE, WNLI.
|
||||
|
||||
The dev set results will be present within the text file `eval_results.txt` in the specified output_dir.
|
||||
In case of MNLI, since there are two separate dev sets (matched and mismatched), there will be a separate
|
||||
The dev set results will be present within the text file `eval_results.txt` in the specified output_dir.
|
||||
In case of MNLI, since there are two separate dev sets (matched and mismatched), there will be a separate
|
||||
output folder called `/tmp/MNLI-MM/` in addition to `/tmp/MNLI/`.
|
||||
|
||||
The code has not been tested with half-precision training with apex on any GLUE task apart from MRPC, MNLI,
|
||||
CoLA, SST-2. The following section provides details on how to run half-precision training with MRPC. With that being
|
||||
said, there shouldn’t be any issues in running half-precision training with the remaining GLUE tasks as well,
|
||||
The code has not been tested with half-precision training with apex on any GLUE task apart from MRPC, MNLI,
|
||||
CoLA, SST-2. The following section provides details on how to run half-precision training with MRPC. With that being
|
||||
said, there shouldn’t be any issues in running half-precision training with the remaining GLUE tasks as well,
|
||||
since the data processor for each task inherits from the base class DataProcessor.
|
||||
|
||||
### MRPC
|
||||
|
||||
#### Fine-tuning example
|
||||
|
||||
The following examples fine-tune BERT on the Microsoft Research Paraphrase Corpus (MRPC) corpus and runs in less
|
||||
The following examples fine-tune BERT on the Microsoft Research Paraphrase Corpus (MRPC) corpus and runs in less
|
||||
than 10 minutes on a single K-80 and in 27 seconds (!) on single tesla V100 16GB with apex installed.
|
||||
|
||||
Before running any one of these GLUE tasks you should download the
|
||||
@@ -219,12 +219,12 @@ python run_glue.py \
|
||||
```
|
||||
|
||||
Our test ran on a few seeds with [the original implementation hyper-
|
||||
parameters](https://github.com/google-research/bert#sentence-and-sentence-pair-classification-tasks) gave evaluation
|
||||
parameters](https://github.com/google-research/bert#sentence-and-sentence-pair-classification-tasks) gave evaluation
|
||||
results between 84% and 88%.
|
||||
|
||||
#### Using Apex and mixed-precision
|
||||
|
||||
Using Apex and 16 bit precision, the fine-tuning on MRPC only takes 27 seconds. First install
|
||||
Using Apex and 16 bit precision, the fine-tuning on MRPC only takes 27 seconds. First install
|
||||
[apex](https://github.com/NVIDIA/apex), then run the following example:
|
||||
|
||||
```bash
|
||||
@@ -360,8 +360,8 @@ Based on the script [`run_squad.py`](https://github.com/huggingface/transformers
|
||||
|
||||
#### Fine-tuning BERT on SQuAD1.0
|
||||
|
||||
This example code fine-tunes BERT on the SQuAD1.0 dataset. It runs in 24 min (with BERT-base) or 68 min (with BERT-large)
|
||||
on a single tesla V100 16GB. The data for SQuAD can be downloaded with the following links and should be saved in a
|
||||
This example code fine-tunes BERT on the SQuAD1.0 dataset. It runs in 24 min (with BERT-base) or 68 min (with BERT-large)
|
||||
on a single tesla V100 16GB. The data for SQuAD can be downloaded with the following links and should be saved in a
|
||||
$SQUAD_DIR directory.
|
||||
|
||||
* [train-v1.1.json](https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v1.1.json)
|
||||
@@ -442,14 +442,14 @@ This example code fine-tunes XLNet on both SQuAD1.0 and SQuAD2.0 dataset. See ab
|
||||
```bash
|
||||
export SQUAD_DIR=/path/to/SQUAD
|
||||
|
||||
python /data/home/hlu/transformers/examples/run_squad.py \
|
||||
python run_squad.py \
|
||||
--model_type xlnet \
|
||||
--model_name_or_path xlnet-large-cased \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--do_lower_case \
|
||||
--train_file /data/home/hlu/notebooks/NLP/examples/question_answering/train-v1.1.json \
|
||||
--predict_file /data/home/hlu/notebooks/NLP/examples/question_answering/dev-v1.1.json \
|
||||
--train_file $SQUAD_DIR/train-v1.1.json \
|
||||
--predict_file $SQUAD_DIR/dev-v1.1.json \
|
||||
--learning_rate 3e-5 \
|
||||
--num_train_epochs 2 \
|
||||
--max_seq_length 384 \
|
||||
@@ -516,185 +516,6 @@ Larger batch size may improve the performance while costing more memory.
|
||||
|
||||
|
||||
|
||||
## Named Entity Recognition
|
||||
|
||||
Based on the scripts [`run_ner.py`](https://github.com/huggingface/transformers/blob/master/examples/run_ner.py) for Pytorch and
|
||||
[`run_tf_ner.py`](https://github.com/huggingface/transformers/blob/master/examples/run_tf_ner.py) for Tensorflow 2.
|
||||
This example fine-tune Bert Multilingual on GermEval 2014 (German NER).
|
||||
Details and results for the fine-tuning provided by @stefan-it.
|
||||
|
||||
### Data (Download and pre-processing steps)
|
||||
|
||||
Data can be obtained from the [GermEval 2014](https://sites.google.com/site/germeval2014ner/data) shared task page.
|
||||
|
||||
Here are the commands for downloading and pre-processing train, dev and test datasets. The original data format has four (tab-separated) columns, in a pre-processing step only the two relevant columns (token and outer span NER annotation) are extracted:
|
||||
|
||||
```bash
|
||||
curl -L 'https://sites.google.com/site/germeval2014ner/data/NER-de-train.tsv?attredirects=0&d=1' \
|
||||
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > train.txt.tmp
|
||||
curl -L 'https://sites.google.com/site/germeval2014ner/data/NER-de-dev.tsv?attredirects=0&d=1' \
|
||||
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > dev.txt.tmp
|
||||
curl -L 'https://sites.google.com/site/germeval2014ner/data/NER-de-test.tsv?attredirects=0&d=1' \
|
||||
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > test.txt.tmp
|
||||
```
|
||||
|
||||
The GermEval 2014 dataset contains some strange "control character" tokens like `'\x96', '\u200e', '\x95', '\xad' or '\x80'`. One problem with these tokens is, that `BertTokenizer` returns an empty token for them, resulting in misaligned `InputExample`s. I wrote a script that a) filters these tokens and b) splits longer sentences into smaller ones (once the max. subtoken length is reached).
|
||||
|
||||
```bash
|
||||
wget "https://raw.githubusercontent.com/stefan-it/fine-tuned-berts-seq/master/scripts/preprocess.py"
|
||||
```
|
||||
Let's define some variables that we need for further pre-processing steps and training the model:
|
||||
|
||||
```bash
|
||||
export MAX_LENGTH=128
|
||||
export BERT_MODEL=bert-base-multilingual-cased
|
||||
```
|
||||
|
||||
Run the pre-processing script on training, dev and test datasets:
|
||||
|
||||
```bash
|
||||
python3 preprocess.py train.txt.tmp $BERT_MODEL $MAX_LENGTH > train.txt
|
||||
python3 preprocess.py dev.txt.tmp $BERT_MODEL $MAX_LENGTH > dev.txt
|
||||
python3 preprocess.py test.txt.tmp $BERT_MODEL $MAX_LENGTH > test.txt
|
||||
```
|
||||
|
||||
The GermEval 2014 dataset has much more labels than CoNLL-2002/2003 datasets, so an own set of labels must be used:
|
||||
|
||||
```bash
|
||||
cat train.txt dev.txt test.txt | cut -d " " -f 2 | grep -v "^$"| sort | uniq > labels.txt
|
||||
```
|
||||
|
||||
### Prepare the run
|
||||
|
||||
Additional environment variables must be set:
|
||||
|
||||
```bash
|
||||
export OUTPUT_DIR=germeval-model
|
||||
export BATCH_SIZE=32
|
||||
export NUM_EPOCHS=3
|
||||
export SAVE_STEPS=750
|
||||
export SEED=1
|
||||
```
|
||||
|
||||
### Run the Pytorch version
|
||||
|
||||
To start training, just run:
|
||||
|
||||
```bash
|
||||
python3 run_ner.py --data_dir ./ \
|
||||
--model_type bert \
|
||||
--labels ./labels.txt \
|
||||
--model_name_or_path $BERT_MODEL \
|
||||
--output_dir $OUTPUT_DIR \
|
||||
--max_seq_length $MAX_LENGTH \
|
||||
--num_train_epochs $NUM_EPOCHS \
|
||||
--per_gpu_train_batch_size $BATCH_SIZE \
|
||||
--save_steps $SAVE_STEPS \
|
||||
--seed $SEED \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--do_predict
|
||||
```
|
||||
|
||||
If your GPU supports half-precision training, just add the `--fp16` flag. After training, the model will be both evaluated on development and test datasets.
|
||||
|
||||
#### Evaluation
|
||||
|
||||
Evaluation on development dataset outputs the following for our example:
|
||||
|
||||
```bash
|
||||
10/04/2019 00:42:06 - INFO - __main__ - ***** Eval results *****
|
||||
10/04/2019 00:42:06 - INFO - __main__ - f1 = 0.8623348017621146
|
||||
10/04/2019 00:42:06 - INFO - __main__ - loss = 0.07183869666975543
|
||||
10/04/2019 00:42:06 - INFO - __main__ - precision = 0.8467916366258111
|
||||
10/04/2019 00:42:06 - INFO - __main__ - recall = 0.8784592370979806
|
||||
```
|
||||
|
||||
On the test dataset the following results could be achieved:
|
||||
|
||||
```bash
|
||||
10/04/2019 00:42:42 - INFO - __main__ - ***** Eval results *****
|
||||
10/04/2019 00:42:42 - INFO - __main__ - f1 = 0.8614389652384803
|
||||
10/04/2019 00:42:42 - INFO - __main__ - loss = 0.07064602487454782
|
||||
10/04/2019 00:42:42 - INFO - __main__ - precision = 0.8604651162790697
|
||||
10/04/2019 00:42:42 - INFO - __main__ - recall = 0.8624150210424085
|
||||
```
|
||||
|
||||
#### Comparing BERT (large, cased), RoBERTa (large, cased) and DistilBERT (base, uncased)
|
||||
|
||||
Here is a small comparison between BERT (large, cased), RoBERTa (large, cased) and DistilBERT (base, uncased) with the same hyperparameters as specified in the [example documentation](https://huggingface.co/transformers/examples.html#named-entity-recognition) (one run):
|
||||
|
||||
| Model | F-Score Dev | F-Score Test
|
||||
| --------------------------------- | ------- | --------
|
||||
| `bert-large-cased` | 95.59 | 91.70
|
||||
| `roberta-large` | 95.96 | 91.87
|
||||
| `distilbert-base-uncased` | 94.34 | 90.32
|
||||
|
||||
### Run the Tensorflow 2 version
|
||||
|
||||
To start training, just run:
|
||||
|
||||
```bash
|
||||
python3 run_tf_ner.py --data_dir ./ \
|
||||
--model_type bert \
|
||||
--labels ./labels.txt \
|
||||
--model_name_or_path $BERT_MODEL \
|
||||
--output_dir $OUTPUT_DIR \
|
||||
--max_seq_length $MAX_LENGTH \
|
||||
--num_train_epochs $NUM_EPOCHS \
|
||||
--per_device_train_batch_size $BATCH_SIZE \
|
||||
--save_steps $SAVE_STEPS \
|
||||
--seed $SEED \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--do_predict
|
||||
```
|
||||
|
||||
Such as the Pytorch version, if your GPU supports half-precision training, just add the `--fp16` flag. After training, the model will be both evaluated on development and test datasets.
|
||||
|
||||
#### Evaluation
|
||||
|
||||
Evaluation on development dataset outputs the following for our example:
|
||||
```bash
|
||||
precision recall f1-score support
|
||||
|
||||
LOCderiv 0.7619 0.6154 0.6809 52
|
||||
PERpart 0.8724 0.8997 0.8858 4057
|
||||
OTHpart 0.9360 0.9466 0.9413 711
|
||||
ORGpart 0.7015 0.6989 0.7002 269
|
||||
LOCpart 0.7668 0.8488 0.8057 496
|
||||
LOC 0.8745 0.9191 0.8963 235
|
||||
ORGderiv 0.7723 0.8571 0.8125 91
|
||||
OTHderiv 0.4800 0.6667 0.5581 18
|
||||
OTH 0.5789 0.6875 0.6286 16
|
||||
PERderiv 0.5385 0.3889 0.4516 18
|
||||
PER 0.5000 0.5000 0.5000 2
|
||||
ORG 0.0000 0.0000 0.0000 3
|
||||
|
||||
micro avg 0.8574 0.8862 0.8715 5968
|
||||
macro avg 0.8575 0.8862 0.8713 5968
|
||||
```
|
||||
|
||||
On the test dataset the following results could be achieved:
|
||||
```bash
|
||||
precision recall f1-score support
|
||||
|
||||
PERpart 0.8847 0.8944 0.8896 9397
|
||||
OTHpart 0.9376 0.9353 0.9365 1639
|
||||
ORGpart 0.7307 0.7044 0.7173 697
|
||||
LOC 0.9133 0.9394 0.9262 561
|
||||
LOCpart 0.8058 0.8157 0.8107 1150
|
||||
ORG 0.0000 0.0000 0.0000 8
|
||||
OTHderiv 0.5882 0.4762 0.5263 42
|
||||
PERderiv 0.6571 0.5227 0.5823 44
|
||||
OTH 0.4906 0.6667 0.5652 39
|
||||
ORGderiv 0.7016 0.7791 0.7383 172
|
||||
LOCderiv 0.8256 0.6514 0.7282 109
|
||||
PER 0.0000 0.0000 0.0000 11
|
||||
|
||||
micro avg 0.8722 0.8774 0.8748 13869
|
||||
macro avg 0.8712 0.8774 0.8740 13869
|
||||
```
|
||||
|
||||
## XNLI
|
||||
|
||||
@@ -705,7 +526,7 @@ Based on the script [`run_xnli.py`](https://github.com/huggingface/transformers/
|
||||
#### Fine-tuning on XNLI
|
||||
|
||||
This example code fine-tunes mBERT (multi-lingual BERT) on the XNLI dataset. It runs in 106 mins
|
||||
on a single tesla V100 16GB. The data for XNLI can be downloaded with the following links and should be both saved (and un-zipped) in a
|
||||
on a single tesla V100 16GB. The data for XNLI can be downloaded with the following links and should be both saved (and un-zipped) in a
|
||||
`$XNLI_DIR` directory.
|
||||
|
||||
* [XNLI 1.0](https://www.nyu.edu/projects/bowman/xnli/XNLI-1.0.zip)
|
||||
|
||||
179
examples/ner/README.md
Normal file
179
examples/ner/README.md
Normal file
@@ -0,0 +1,179 @@
|
||||
## Named Entity Recognition
|
||||
|
||||
Based on the scripts [`run_ner.py`](https://github.com/huggingface/transformers/blob/master/examples/ner/run_ner.py) for Pytorch and
|
||||
[`run_tf_ner.py`](https://github.com/huggingface/transformers/blob/master/examples/ner/run_tf_ner.py) for Tensorflow 2.
|
||||
This example fine-tune Bert Multilingual on GermEval 2014 (German NER).
|
||||
Details and results for the fine-tuning provided by @stefan-it.
|
||||
|
||||
### Data (Download and pre-processing steps)
|
||||
|
||||
Data can be obtained from the [GermEval 2014](https://sites.google.com/site/germeval2014ner/data) shared task page.
|
||||
|
||||
Here are the commands for downloading and pre-processing train, dev and test datasets. The original data format has four (tab-separated) columns, in a pre-processing step only the two relevant columns (token and outer span NER annotation) are extracted:
|
||||
|
||||
```bash
|
||||
curl -L 'https://sites.google.com/site/germeval2014ner/data/NER-de-train.tsv?attredirects=0&d=1' \
|
||||
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > train.txt.tmp
|
||||
curl -L 'https://sites.google.com/site/germeval2014ner/data/NER-de-dev.tsv?attredirects=0&d=1' \
|
||||
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > dev.txt.tmp
|
||||
curl -L 'https://sites.google.com/site/germeval2014ner/data/NER-de-test.tsv?attredirects=0&d=1' \
|
||||
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > test.txt.tmp
|
||||
```
|
||||
|
||||
The GermEval 2014 dataset contains some strange "control character" tokens like `'\x96', '\u200e', '\x95', '\xad' or '\x80'`. One problem with these tokens is, that `BertTokenizer` returns an empty token for them, resulting in misaligned `InputExample`s. I wrote a script that a) filters these tokens and b) splits longer sentences into smaller ones (once the max. subtoken length is reached).
|
||||
|
||||
```bash
|
||||
wget "https://raw.githubusercontent.com/stefan-it/fine-tuned-berts-seq/master/scripts/preprocess.py"
|
||||
```
|
||||
Let's define some variables that we need for further pre-processing steps and training the model:
|
||||
|
||||
```bash
|
||||
export MAX_LENGTH=128
|
||||
export BERT_MODEL=bert-base-multilingual-cased
|
||||
```
|
||||
|
||||
Run the pre-processing script on training, dev and test datasets:
|
||||
|
||||
```bash
|
||||
python3 preprocess.py train.txt.tmp $BERT_MODEL $MAX_LENGTH > train.txt
|
||||
python3 preprocess.py dev.txt.tmp $BERT_MODEL $MAX_LENGTH > dev.txt
|
||||
python3 preprocess.py test.txt.tmp $BERT_MODEL $MAX_LENGTH > test.txt
|
||||
```
|
||||
|
||||
The GermEval 2014 dataset has much more labels than CoNLL-2002/2003 datasets, so an own set of labels must be used:
|
||||
|
||||
```bash
|
||||
cat train.txt dev.txt test.txt | cut -d " " -f 2 | grep -v "^$"| sort | uniq > labels.txt
|
||||
```
|
||||
|
||||
### Prepare the run
|
||||
|
||||
Additional environment variables must be set:
|
||||
|
||||
```bash
|
||||
export OUTPUT_DIR=germeval-model
|
||||
export BATCH_SIZE=32
|
||||
export NUM_EPOCHS=3
|
||||
export SAVE_STEPS=750
|
||||
export SEED=1
|
||||
```
|
||||
|
||||
### Run the Pytorch version
|
||||
|
||||
To start training, just run:
|
||||
|
||||
```bash
|
||||
python3 run_ner.py --data_dir ./ \
|
||||
--model_type bert \
|
||||
--labels ./labels.txt \
|
||||
--model_name_or_path $BERT_MODEL \
|
||||
--output_dir $OUTPUT_DIR \
|
||||
--max_seq_length $MAX_LENGTH \
|
||||
--num_train_epochs $NUM_EPOCHS \
|
||||
--per_gpu_train_batch_size $BATCH_SIZE \
|
||||
--save_steps $SAVE_STEPS \
|
||||
--seed $SEED \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--do_predict
|
||||
```
|
||||
|
||||
If your GPU supports half-precision training, just add the `--fp16` flag. After training, the model will be both evaluated on development and test datasets.
|
||||
|
||||
#### Evaluation
|
||||
|
||||
Evaluation on development dataset outputs the following for our example:
|
||||
|
||||
```bash
|
||||
10/04/2019 00:42:06 - INFO - __main__ - ***** Eval results *****
|
||||
10/04/2019 00:42:06 - INFO - __main__ - f1 = 0.8623348017621146
|
||||
10/04/2019 00:42:06 - INFO - __main__ - loss = 0.07183869666975543
|
||||
10/04/2019 00:42:06 - INFO - __main__ - precision = 0.8467916366258111
|
||||
10/04/2019 00:42:06 - INFO - __main__ - recall = 0.8784592370979806
|
||||
```
|
||||
|
||||
On the test dataset the following results could be achieved:
|
||||
|
||||
```bash
|
||||
10/04/2019 00:42:42 - INFO - __main__ - ***** Eval results *****
|
||||
10/04/2019 00:42:42 - INFO - __main__ - f1 = 0.8614389652384803
|
||||
10/04/2019 00:42:42 - INFO - __main__ - loss = 0.07064602487454782
|
||||
10/04/2019 00:42:42 - INFO - __main__ - precision = 0.8604651162790697
|
||||
10/04/2019 00:42:42 - INFO - __main__ - recall = 0.8624150210424085
|
||||
```
|
||||
|
||||
#### Comparing BERT (large, cased), RoBERTa (large, cased) and DistilBERT (base, uncased)
|
||||
|
||||
Here is a small comparison between BERT (large, cased), RoBERTa (large, cased) and DistilBERT (base, uncased) with the same hyperparameters as specified in the [example documentation](https://huggingface.co/transformers/examples.html#named-entity-recognition) (one run):
|
||||
|
||||
| Model | F-Score Dev | F-Score Test
|
||||
| --------------------------------- | ------- | --------
|
||||
| `bert-large-cased` | 95.59 | 91.70
|
||||
| `roberta-large` | 95.96 | 91.87
|
||||
| `distilbert-base-uncased` | 94.34 | 90.32
|
||||
|
||||
### Run the Tensorflow 2 version
|
||||
|
||||
To start training, just run:
|
||||
|
||||
```bash
|
||||
python3 run_tf_ner.py --data_dir ./ \
|
||||
--model_type bert \
|
||||
--labels ./labels.txt \
|
||||
--model_name_or_path $BERT_MODEL \
|
||||
--output_dir $OUTPUT_DIR \
|
||||
--max_seq_length $MAX_LENGTH \
|
||||
--num_train_epochs $NUM_EPOCHS \
|
||||
--per_device_train_batch_size $BATCH_SIZE \
|
||||
--save_steps $SAVE_STEPS \
|
||||
--seed $SEED \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--do_predict
|
||||
```
|
||||
|
||||
Such as the Pytorch version, if your GPU supports half-precision training, just add the `--fp16` flag. After training, the model will be both evaluated on development and test datasets.
|
||||
|
||||
#### Evaluation
|
||||
|
||||
Evaluation on development dataset outputs the following for our example:
|
||||
```bash
|
||||
precision recall f1-score support
|
||||
|
||||
LOCderiv 0.7619 0.6154 0.6809 52
|
||||
PERpart 0.8724 0.8997 0.8858 4057
|
||||
OTHpart 0.9360 0.9466 0.9413 711
|
||||
ORGpart 0.7015 0.6989 0.7002 269
|
||||
LOCpart 0.7668 0.8488 0.8057 496
|
||||
LOC 0.8745 0.9191 0.8963 235
|
||||
ORGderiv 0.7723 0.8571 0.8125 91
|
||||
OTHderiv 0.4800 0.6667 0.5581 18
|
||||
OTH 0.5789 0.6875 0.6286 16
|
||||
PERderiv 0.5385 0.3889 0.4516 18
|
||||
PER 0.5000 0.5000 0.5000 2
|
||||
ORG 0.0000 0.0000 0.0000 3
|
||||
|
||||
micro avg 0.8574 0.8862 0.8715 5968
|
||||
macro avg 0.8575 0.8862 0.8713 5968
|
||||
```
|
||||
|
||||
On the test dataset the following results could be achieved:
|
||||
```bash
|
||||
precision recall f1-score support
|
||||
|
||||
PERpart 0.8847 0.8944 0.8896 9397
|
||||
OTHpart 0.9376 0.9353 0.9365 1639
|
||||
ORGpart 0.7307 0.7044 0.7173 697
|
||||
LOC 0.9133 0.9394 0.9262 561
|
||||
LOCpart 0.8058 0.8157 0.8107 1150
|
||||
ORG 0.0000 0.0000 0.0000 8
|
||||
OTHderiv 0.5882 0.4762 0.5263 42
|
||||
PERderiv 0.6571 0.5227 0.5823 44
|
||||
OTH 0.4906 0.6667 0.5652 39
|
||||
ORGderiv 0.7016 0.7791 0.7383 172
|
||||
LOCderiv 0.8256 0.6514 0.7282 109
|
||||
PER 0.0000 0.0000 0.0000 11
|
||||
|
||||
micro avg 0.8722 0.8774 0.8748 13869
|
||||
macro avg 0.8712 0.8774 0.8740 13869
|
||||
```
|
||||
32
examples/ner/run.sh
Normal file
32
examples/ner/run.sh
Normal file
@@ -0,0 +1,32 @@
|
||||
curl -L 'https://sites.google.com/site/germeval2014ner/data/NER-de-train.tsv?attredirects=0&d=1' \
|
||||
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > train.txt.tmp
|
||||
curl -L 'https://sites.google.com/site/germeval2014ner/data/NER-de-dev.tsv?attredirects=0&d=1' \
|
||||
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > dev.txt.tmp
|
||||
curl -L 'https://sites.google.com/site/germeval2014ner/data/NER-de-test.tsv?attredirects=0&d=1' \
|
||||
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > test.txt.tmp
|
||||
wget "https://raw.githubusercontent.com/stefan-it/fine-tuned-berts-seq/master/scripts/preprocess.py"
|
||||
export MAX_LENGTH=128
|
||||
export BERT_MODEL=bert-base-multilingual-cased
|
||||
python3 preprocess.py train.txt.tmp $BERT_MODEL $MAX_LENGTH > train.txt
|
||||
python3 preprocess.py dev.txt.tmp $BERT_MODEL $MAX_LENGTH > dev.txt
|
||||
python3 preprocess.py test.txt.tmp $BERT_MODEL $MAX_LENGTH > test.txt
|
||||
cat train.txt dev.txt test.txt | cut -d " " -f 2 | grep -v "^$"| sort | uniq > labels.txt
|
||||
export OUTPUT_DIR=germeval-model
|
||||
export BATCH_SIZE=32
|
||||
export NUM_EPOCHS=3
|
||||
export SAVE_STEPS=750
|
||||
export SEED=1
|
||||
|
||||
python3 run_ner.py --data_dir ./ \
|
||||
--model_type bert \
|
||||
--labels ./labels.txt \
|
||||
--model_name_or_path $BERT_MODEL \
|
||||
--output_dir $OUTPUT_DIR \
|
||||
--max_seq_length $MAX_LENGTH \
|
||||
--num_train_epochs $NUM_EPOCHS \
|
||||
--per_gpu_train_batch_size $BATCH_SIZE \
|
||||
--save_steps $SAVE_STEPS \
|
||||
--seed $SEED \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--do_predict
|
||||
@@ -586,6 +586,8 @@ def main():
|
||||
config = config_class.from_pretrained(
|
||||
args.config_name if args.config_name else args.model_name_or_path,
|
||||
num_labels=num_labels,
|
||||
id2label={str(i): label for i, label in enumerate(labels)},
|
||||
label2id={label: i for i, label in enumerate(labels)},
|
||||
cache_dir=args.cache_dir if args.cache_dir else None,
|
||||
)
|
||||
tokenizer = tokenizer_class.from_pretrained(
|
||||
21
examples/ner/run_pl.sh
Normal file
21
examples/ner/run_pl.sh
Normal file
@@ -0,0 +1,21 @@
|
||||
# Require pytorch-lightning=0.6
|
||||
export MAX_LENGTH=128
|
||||
export BERT_MODEL=bert-base-multilingual-cased
|
||||
export OUTPUT_DIR=germeval-model
|
||||
export BATCH_SIZE=32
|
||||
export NUM_EPOCHS=3
|
||||
export SAVE_STEPS=750
|
||||
export SEED=1
|
||||
|
||||
python3 run_pl_ner.py --data_dir ./ \
|
||||
--model_type bert \
|
||||
--labels ./labels.txt \
|
||||
--model_name_or_path $BERT_MODEL \
|
||||
--output_dir $OUTPUT_DIR \
|
||||
--max_seq_length $MAX_LENGTH \
|
||||
--num_train_epochs $NUM_EPOCHS \
|
||||
--train_batch_size 32 \
|
||||
--save_steps $SAVE_STEPS \
|
||||
--seed $SEED \
|
||||
--do_train \
|
||||
--do_predict
|
||||
238
examples/ner/run_pl_ner.py
Normal file
238
examples/ner/run_pl_ner.py
Normal file
@@ -0,0 +1,238 @@
|
||||
import argparse
|
||||
import glob
|
||||
import logging
|
||||
import os
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from seqeval.metrics import f1_score, precision_score, recall_score
|
||||
from torch.nn import CrossEntropyLoss
|
||||
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler, TensorDataset
|
||||
from torch.utils.data.distributed import DistributedSampler
|
||||
|
||||
from transformer_base import BaseTransformer, add_generic_args, generic_train
|
||||
from utils_ner import convert_examples_to_features, get_labels, read_examples_from_file
|
||||
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
class NERTransformer(BaseTransformer):
|
||||
"""
|
||||
A training module for NER. See BaseTransformer for the core options.
|
||||
"""
|
||||
|
||||
def __init__(self, hparams):
|
||||
self.labels = get_labels(hparams.labels)
|
||||
num_labels = len(self.labels)
|
||||
super(NERTransformer, self).__init__(hparams, num_labels)
|
||||
|
||||
def forward(self, **inputs):
|
||||
return self.model(**inputs)
|
||||
|
||||
def training_step(self, batch, batch_num):
|
||||
"Compute loss"
|
||||
inputs = {"input_ids": batch[0], "attention_mask": batch[1], "labels": batch[3]}
|
||||
if self.hparams.model_type != "distilbert":
|
||||
inputs["token_type_ids"] = (
|
||||
batch[2] if self.hparams.model_type in ["bert", "xlnet"] else None
|
||||
) # XLM and RoBERTa don"t use segment_ids
|
||||
|
||||
outputs = self.forward(**inputs)
|
||||
loss = outputs[0]
|
||||
|
||||
tensorboard_logs = {"loss": loss, "rate": self.lr_scheduler.get_last_lr()[-1]}
|
||||
return {"loss": loss, "log": tensorboard_logs}
|
||||
|
||||
def load_dataset(self, mode, batch_size):
|
||||
labels = get_labels(self.hparams.labels)
|
||||
self.pad_token_label_id = CrossEntropyLoss().ignore_index
|
||||
dataset = self.load_and_cache_examples(labels, self.pad_token_label_id, mode)
|
||||
if mode == "train":
|
||||
if self.hparams.n_gpu > 1:
|
||||
sampler = DistributedSampler(dataset)
|
||||
else:
|
||||
sampler = RandomSampler(dataset)
|
||||
else:
|
||||
sampler = SequentialSampler(dataset)
|
||||
dataloader = DataLoader(dataset, sampler=sampler, batch_size=batch_size)
|
||||
return dataloader
|
||||
|
||||
def validation_step(self, batch, batch_nb):
|
||||
inputs = {"input_ids": batch[0], "attention_mask": batch[1], "labels": batch[3]}
|
||||
if self.hparams.model_type != "distilbert":
|
||||
inputs["token_type_ids"] = (
|
||||
batch[2] if self.hparams.model_type in ["bert", "xlnet"] else None
|
||||
) # XLM and RoBERTa don"t use segment_ids
|
||||
outputs = self.forward(**inputs)
|
||||
tmp_eval_loss, logits = outputs[:2]
|
||||
preds = logits.detach().cpu().numpy()
|
||||
out_label_ids = inputs["labels"].detach().cpu().numpy()
|
||||
|
||||
return {"val_loss": tmp_eval_loss, "pred": preds, "target": out_label_ids}
|
||||
|
||||
def _eval_end(self, outputs):
|
||||
"Task specific validation"
|
||||
val_loss_mean = torch.stack([x["val_loss"] for x in outputs]).mean()
|
||||
preds = np.concatenate([x["pred"] for x in outputs], axis=0)
|
||||
preds = np.argmax(preds, axis=2)
|
||||
out_label_ids = np.concatenate([x["target"] for x in outputs], axis=0)
|
||||
|
||||
label_map = {i: label for i, label in enumerate(self.labels)}
|
||||
out_label_list = [[] for _ in range(out_label_ids.shape[0])]
|
||||
preds_list = [[] for _ in range(out_label_ids.shape[0])]
|
||||
|
||||
for i in range(out_label_ids.shape[0]):
|
||||
for j in range(out_label_ids.shape[1]):
|
||||
if out_label_ids[i, j] != self.pad_token_label_id:
|
||||
out_label_list[i].append(label_map[out_label_ids[i][j]])
|
||||
preds_list[i].append(label_map[preds[i][j]])
|
||||
|
||||
results = {
|
||||
"val_loss": val_loss_mean,
|
||||
"precision": precision_score(out_label_list, preds_list),
|
||||
"recall": recall_score(out_label_list, preds_list),
|
||||
"f1": f1_score(out_label_list, preds_list),
|
||||
}
|
||||
|
||||
if self.is_logger():
|
||||
logger.info(self.proc_rank)
|
||||
logger.info("***** Eval results *****")
|
||||
for key in sorted(results.keys()):
|
||||
logger.info(" %s = %s", key, str(results[key]))
|
||||
|
||||
tensorboard_logs = results
|
||||
ret = {k: v for k, v in results.items()}
|
||||
ret["log"] = tensorboard_logs
|
||||
return ret, preds_list, out_label_list
|
||||
|
||||
def validation_end(self, outputs):
|
||||
ret, preds, targets = self._eval_end(outputs)
|
||||
return ret
|
||||
|
||||
def test_end(self, outputs):
|
||||
ret, predictions, targets = self._eval_end(outputs)
|
||||
|
||||
if self.is_logger():
|
||||
# Write output to a file:
|
||||
# Save results
|
||||
output_test_results_file = os.path.join(self.hparams.output_dir, "test_results.txt")
|
||||
with open(output_test_results_file, "w") as writer:
|
||||
for key in sorted(ret.keys()):
|
||||
if key != "log":
|
||||
writer.write("{} = {}\n".format(key, str(ret[key])))
|
||||
# Save predictions
|
||||
output_test_predictions_file = os.path.join(self.hparams.output_dir, "test_predictions.txt")
|
||||
with open(output_test_predictions_file, "w") as writer:
|
||||
with open(os.path.join(self.hparams.data_dir, "test.txt"), "r") as f:
|
||||
example_id = 0
|
||||
for line in f:
|
||||
if line.startswith("-DOCSTART-") or line == "" or line == "\n":
|
||||
writer.write(line)
|
||||
if not predictions[example_id]:
|
||||
example_id += 1
|
||||
elif predictions[example_id]:
|
||||
output_line = line.split()[0] + " " + predictions[example_id].pop(0) + "\n"
|
||||
writer.write(output_line)
|
||||
else:
|
||||
logger.warning(
|
||||
"Maximum sequence length exceeded: No prediction for '%s'.", line.split()[0]
|
||||
)
|
||||
return ret
|
||||
|
||||
def load_and_cache_examples(self, labels, pad_token_label_id, mode):
|
||||
args = self.hparams
|
||||
tokenizer = self.tokenizer
|
||||
if self.proc_rank not in [-1, 0] and mode == "train":
|
||||
torch.distributed.barrier() # Make sure only the first process in distributed training process the dataset, and the others will use the cache
|
||||
|
||||
# Load data features from cache or dataset file
|
||||
cached_features_file = os.path.join(
|
||||
args.data_dir,
|
||||
"cached_{}_{}_{}".format(
|
||||
mode, list(filter(None, args.model_name_or_path.split("/"))).pop(), str(args.max_seq_length)
|
||||
),
|
||||
)
|
||||
if os.path.exists(cached_features_file) and not args.overwrite_cache:
|
||||
logger.info("Loading features from cached file %s", cached_features_file)
|
||||
features = torch.load(cached_features_file)
|
||||
else:
|
||||
logger.info("Creating features from dataset file at %s", args.data_dir)
|
||||
examples = read_examples_from_file(args.data_dir, mode)
|
||||
features = convert_examples_to_features(
|
||||
examples,
|
||||
labels,
|
||||
args.max_seq_length,
|
||||
tokenizer,
|
||||
cls_token_at_end=bool(args.model_type in ["xlnet"]),
|
||||
cls_token=tokenizer.cls_token,
|
||||
cls_token_segment_id=2 if args.model_type in ["xlnet"] else 0,
|
||||
sep_token=tokenizer.sep_token,
|
||||
sep_token_extra=bool(args.model_type in ["roberta"]),
|
||||
pad_on_left=bool(args.model_type in ["xlnet"]),
|
||||
pad_token=tokenizer.convert_tokens_to_ids([tokenizer.pad_token])[0],
|
||||
pad_token_segment_id=4 if args.model_type in ["xlnet"] else 0,
|
||||
pad_token_label_id=pad_token_label_id,
|
||||
)
|
||||
if self.proc_rank in [-1, 0]:
|
||||
logger.info("Saving features into cached file %s", cached_features_file)
|
||||
torch.save(features, cached_features_file)
|
||||
|
||||
if self.proc_rank == 0 and mode == "train":
|
||||
torch.distributed.barrier() # Make sure only the first process in distributed training process the dataset, and the others will use the cache
|
||||
|
||||
# Convert to Tensors and build dataset
|
||||
all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long)
|
||||
all_input_mask = torch.tensor([f.input_mask for f in features], dtype=torch.long)
|
||||
all_segment_ids = torch.tensor([f.segment_ids for f in features], dtype=torch.long)
|
||||
all_label_ids = torch.tensor([f.label_ids for f in features], dtype=torch.long)
|
||||
|
||||
dataset = TensorDataset(all_input_ids, all_input_mask, all_segment_ids, all_label_ids)
|
||||
return dataset
|
||||
|
||||
@staticmethod
|
||||
def add_model_specific_args(parser, root_dir):
|
||||
# Add NER specific options
|
||||
BaseTransformer.add_model_specific_args(parser, root_dir)
|
||||
parser.add_argument(
|
||||
"--max_seq_length",
|
||||
default=128,
|
||||
type=int,
|
||||
help="The maximum total input sequence length after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded.",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--labels",
|
||||
default="",
|
||||
type=str,
|
||||
help="Path to a file containing all labels. If not specified, CoNLL-2003 labels are used.",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--data_dir",
|
||||
default=None,
|
||||
type=str,
|
||||
required=True,
|
||||
help="The input data dir. Should contain the training files for the CoNLL-2003 NER task.",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
|
||||
)
|
||||
|
||||
return parser
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
add_generic_args(parser, os.getcwd())
|
||||
parser = NERTransformer.add_model_specific_args(parser, os.getcwd())
|
||||
args = parser.parse_args()
|
||||
model = NERTransformer(args)
|
||||
trainer = generic_train(model, args)
|
||||
|
||||
if args.do_predict:
|
||||
checkpoints = list(sorted(glob.glob(args.output_dir + "/checkpoint_*.ckpt", recursive=True)))
|
||||
NERTransformer.load_from_checkpoint(checkpoints[-1])
|
||||
trainer.test(model)
|
||||
270
examples/ner/transformer_base.py
Normal file
270
examples/ner/transformer_base.py
Normal file
@@ -0,0 +1,270 @@
|
||||
import os
|
||||
import random
|
||||
|
||||
import numpy as np
|
||||
import pytorch_lightning as pl
|
||||
import torch
|
||||
|
||||
from transformers import (
|
||||
AdamW,
|
||||
BertConfig,
|
||||
BertForTokenClassification,
|
||||
BertTokenizer,
|
||||
CamembertConfig,
|
||||
CamembertForTokenClassification,
|
||||
CamembertTokenizer,
|
||||
DistilBertConfig,
|
||||
DistilBertForTokenClassification,
|
||||
DistilBertTokenizer,
|
||||
RobertaConfig,
|
||||
RobertaForTokenClassification,
|
||||
RobertaTokenizer,
|
||||
XLMRobertaConfig,
|
||||
XLMRobertaForTokenClassification,
|
||||
XLMRobertaTokenizer,
|
||||
get_linear_schedule_with_warmup,
|
||||
)
|
||||
|
||||
|
||||
ALL_MODELS = sum(
|
||||
(
|
||||
tuple(conf.pretrained_config_archive_map.keys())
|
||||
for conf in (BertConfig, RobertaConfig, DistilBertConfig, CamembertConfig, XLMRobertaConfig)
|
||||
),
|
||||
(),
|
||||
)
|
||||
|
||||
MODEL_CLASSES = {
|
||||
"bert": (BertConfig, BertForTokenClassification, BertTokenizer),
|
||||
"roberta": (RobertaConfig, RobertaForTokenClassification, RobertaTokenizer),
|
||||
"distilbert": (DistilBertConfig, DistilBertForTokenClassification, DistilBertTokenizer),
|
||||
"camembert": (CamembertConfig, CamembertForTokenClassification, CamembertTokenizer),
|
||||
"xlmroberta": (XLMRobertaConfig, XLMRobertaForTokenClassification, XLMRobertaTokenizer),
|
||||
}
|
||||
|
||||
|
||||
def set_seed(args):
|
||||
random.seed(args.seed)
|
||||
np.random.seed(args.seed)
|
||||
torch.manual_seed(args.seed)
|
||||
if args.n_gpu > 0:
|
||||
torch.cuda.manual_seed_all(args.seed)
|
||||
|
||||
|
||||
class BaseTransformer(pl.LightningModule):
|
||||
def __init__(self, hparams, num_labels=None):
|
||||
"Initialize a model."
|
||||
|
||||
super(BaseTransformer, self).__init__()
|
||||
self.hparams = hparams
|
||||
self.hparams.model_type = self.hparams.model_type.lower()
|
||||
|
||||
config_class, model_class, tokenizer_class = MODEL_CLASSES[self.hparams.model_type]
|
||||
config = config_class.from_pretrained(
|
||||
self.hparams.config_name if self.hparams.config_name else self.hparams.model_name_or_path,
|
||||
num_labels=num_labels,
|
||||
cache_dir=self.hparams.cache_dir if self.hparams.cache_dir else None,
|
||||
)
|
||||
tokenizer = tokenizer_class.from_pretrained(
|
||||
self.hparams.tokenizer_name if self.hparams.tokenizer_name else self.hparams.model_name_or_path,
|
||||
do_lower_case=self.hparams.do_lower_case,
|
||||
cache_dir=self.hparams.cache_dir if self.hparams.cache_dir else None,
|
||||
)
|
||||
model = model_class.from_pretrained(
|
||||
self.hparams.model_name_or_path,
|
||||
from_tf=bool(".ckpt" in self.hparams.model_name_or_path),
|
||||
config=config,
|
||||
cache_dir=self.hparams.cache_dir if self.hparams.cache_dir else None,
|
||||
)
|
||||
self.config, self.tokenizer, self.model = config, tokenizer, model
|
||||
self.proc_rank = -1
|
||||
|
||||
def is_logger(self):
|
||||
return self.proc_rank <= 0
|
||||
|
||||
def configure_optimizers(self):
|
||||
"Prepare optimizer and schedule (linear warmup and decay)"
|
||||
model = self.model
|
||||
|
||||
t_total = (
|
||||
len(self.train_dataloader())
|
||||
// self.hparams.gradient_accumulation_steps
|
||||
* float(self.hparams.num_train_epochs)
|
||||
)
|
||||
no_decay = ["bias", "LayerNorm.weight"]
|
||||
optimizer_grouped_parameters = [
|
||||
{
|
||||
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
|
||||
"weight_decay": self.hparams.weight_decay,
|
||||
},
|
||||
{
|
||||
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
|
||||
"weight_decay": 0.0,
|
||||
},
|
||||
]
|
||||
optimizer = AdamW(optimizer_grouped_parameters, lr=self.hparams.learning_rate, eps=self.hparams.adam_epsilon)
|
||||
scheduler = get_linear_schedule_with_warmup(
|
||||
optimizer, num_warmup_steps=self.hparams.warmup_steps, num_training_steps=t_total
|
||||
)
|
||||
self.lr_scheduler = scheduler
|
||||
return [optimizer]
|
||||
|
||||
def optimizer_step(self, epoch, batch_idx, optimizer, optimizer_idx, second_order_closure=None):
|
||||
|
||||
# Step each time.
|
||||
optimizer.step()
|
||||
self.lr_scheduler.step()
|
||||
optimizer.zero_grad()
|
||||
|
||||
def get_tqdm_dict(self):
|
||||
tqdm_dict = {"loss": "{:.3f}".format(self.trainer.avg_loss), "lr": self.lr_scheduler.get_last_lr()[-1]}
|
||||
|
||||
return tqdm_dict
|
||||
|
||||
def test_step(self, batch, batch_nb):
|
||||
return self.validation_step(batch, batch_nb)
|
||||
|
||||
def test_end(self, outputs):
|
||||
return self.validation_end(outputs)
|
||||
|
||||
@pl.data_loader
|
||||
def train_dataloader(self):
|
||||
return self.load_dataset("train", self.hparams.train_batch_size)
|
||||
|
||||
@pl.data_loader
|
||||
def val_dataloader(self):
|
||||
return self.load_dataset("dev", self.hparams.eval_batch_size)
|
||||
|
||||
@pl.data_loader
|
||||
def test_dataloader(self):
|
||||
return self.load_dataset("test", self.hparams.eval_batch_size)
|
||||
|
||||
def init_ddp_connection(self, proc_rank, world_size):
|
||||
self.proc_rank = proc_rank
|
||||
super(BaseTransformer, self).init_ddp_connection(proc_rank, world_size)
|
||||
|
||||
@staticmethod
|
||||
def add_model_specific_args(parser, root_dir):
|
||||
parser.add_argument(
|
||||
"--model_type",
|
||||
default=None,
|
||||
type=str,
|
||||
required=True,
|
||||
help="Model type selected in the list: " + ", ".join(MODEL_CLASSES.keys()),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--model_name_or_path",
|
||||
default=None,
|
||||
type=str,
|
||||
required=True,
|
||||
help="Path to pre-trained model or shortcut name selected in the list: " + ", ".join(ALL_MODELS),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--config_name", default="", type=str, help="Pretrained config name or path if not the same as model_name"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--tokenizer_name",
|
||||
default="",
|
||||
type=str,
|
||||
help="Pretrained tokenizer name or path if not the same as model_name",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--cache_dir",
|
||||
default="",
|
||||
type=str,
|
||||
help="Where do you want to store the pre-trained models downloaded from s3",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--do_lower_case", action="store_true", help="Set this flag if you are using an uncased model."
|
||||
)
|
||||
parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
|
||||
parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
|
||||
parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
|
||||
parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
|
||||
parser.add_argument(
|
||||
"--num_train_epochs", default=3, type=int, help="Total number of training epochs to perform."
|
||||
)
|
||||
|
||||
parser.add_argument("--train_batch_size", default=32, type=int)
|
||||
parser.add_argument("--eval_batch_size", default=32, type=int)
|
||||
|
||||
|
||||
def add_generic_args(parser, root_dir):
|
||||
parser.add_argument(
|
||||
"--output_dir",
|
||||
default=None,
|
||||
type=str,
|
||||
required=True,
|
||||
help="The output directory where the model predictions and checkpoints will be written.",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--fp16",
|
||||
action="store_true",
|
||||
help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--fp16_opt_level",
|
||||
type=str,
|
||||
default="O1",
|
||||
help="For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']."
|
||||
"See details at https://nvidia.github.io/apex/amp.html",
|
||||
)
|
||||
|
||||
parser.add_argument("--n_gpu", type=int, default=1)
|
||||
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
|
||||
parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
|
||||
parser.add_argument("--do_predict", action="store_true", help="Whether to run predictions on the test set.")
|
||||
parser.add_argument(
|
||||
"--gradient_accumulation_steps",
|
||||
type=int,
|
||||
default=1,
|
||||
help="Number of updates steps to accumulate before performing a backward/update pass.",
|
||||
)
|
||||
|
||||
parser.add_argument("--server_ip", type=str, default="", help="For distant debugging.")
|
||||
parser.add_argument("--server_port", type=str, default="", help="For distant debugging.")
|
||||
parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
|
||||
|
||||
|
||||
def generic_train(model, args):
|
||||
# init model
|
||||
set_seed(args)
|
||||
|
||||
# Setup distant debugging if needed
|
||||
if args.server_ip and args.server_port:
|
||||
# Distant debugging - see https://code.visualstudio.com/docs/python/debugging#_attach-to-a-local-script
|
||||
import ptvsd
|
||||
|
||||
print("Waiting for debugger attach")
|
||||
ptvsd.enable_attach(address=(args.server_ip, args.server_port), redirect_output=True)
|
||||
ptvsd.wait_for_attach()
|
||||
|
||||
if os.path.exists(args.output_dir) and os.listdir(args.output_dir) and args.do_train:
|
||||
raise ValueError("Output directory ({}) already exists and is not empty.".format(args.output_dir))
|
||||
|
||||
checkpoint_callback = pl.callbacks.ModelCheckpoint(
|
||||
filepath=args.output_dir, prefix="checkpoint", monitor="val_loss", mode="min", save_top_k=5
|
||||
)
|
||||
|
||||
train_params = dict(
|
||||
accumulate_grad_batches=args.gradient_accumulation_steps,
|
||||
gpus=args.n_gpu,
|
||||
max_epochs=args.num_train_epochs,
|
||||
gradient_clip_val=args.max_grad_norm,
|
||||
checkpoint_callback=checkpoint_callback,
|
||||
)
|
||||
if args.fp16:
|
||||
train_params["use_amp"] = args.fp16
|
||||
train_params["amp_level"] = args.fp16_opt_level
|
||||
|
||||
if args.n_gpu > 1:
|
||||
train_params["distributed_backend"] = "ddp"
|
||||
|
||||
trainer = pl.Trainer(**train_params)
|
||||
|
||||
if args.do_train:
|
||||
trainer.fit(model)
|
||||
|
||||
return trainer
|
||||
@@ -59,7 +59,7 @@ MODEL_CLASSES = {
|
||||
# Padding text to help Transformer-XL and XLNet with short prompts as proposed by Aman Rusia
|
||||
# in https://github.com/rusiaaman/XLNet-gen#methodology
|
||||
# and https://medium.com/@amanrusia/xlnet-speaks-comparison-to-gpt-2-ea1a4e9ba39e
|
||||
PADDING_TEXT = """ In 1991, the remains of Russian Tsar Nicholas II and his family
|
||||
PADDING_TEXT = """In 1991, the remains of Russian Tsar Nicholas II and his family
|
||||
(except for Alexei and Maria) are discovered.
|
||||
The voice of Nicholas's young son, Tsarevich Alexei Nikolaevich, narrates the
|
||||
remainder of the story. 1883 Western Siberia,
|
||||
@@ -106,6 +106,8 @@ def prepare_xlm_input(args, model, tokenizer, prompt_text):
|
||||
language = None
|
||||
while language not in available_languages:
|
||||
language = input("Using XLM. Select language in " + str(list(available_languages)) + " >>> ")
|
||||
|
||||
model.config.lang_id = model.config.lang2id[language]
|
||||
# kwargs["language"] = tokenizer.lang2id[language]
|
||||
|
||||
# TODO fix mask_token_id setup when configurations will be synchronized between models and tokenizers
|
||||
@@ -119,12 +121,12 @@ def prepare_xlm_input(args, model, tokenizer, prompt_text):
|
||||
|
||||
def prepare_xlnet_input(args, _, tokenizer, prompt_text):
|
||||
prompt_text = (args.padding_text if args.padding_text else PADDING_TEXT) + prompt_text
|
||||
return prompt_text, {}
|
||||
return prompt_text
|
||||
|
||||
|
||||
def prepare_transfoxl_input(args, _, tokenizer, prompt_text):
|
||||
prompt_text = (args.padding_text if args.padding_text else PADDING_TEXT) + prompt_text
|
||||
return prompt_text, {}
|
||||
return prompt_text
|
||||
|
||||
|
||||
PREPROCESSING_FUNCTIONS = {
|
||||
@@ -183,6 +185,7 @@ def main():
|
||||
|
||||
parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
|
||||
parser.add_argument("--no_cuda", action="store_true", help="Avoid using CUDA when available")
|
||||
parser.add_argument("--num_return_sequences", type=int, default=1, help="The number of samples to generate.")
|
||||
args = parser.parse_args()
|
||||
|
||||
args.device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
|
||||
@@ -210,28 +213,50 @@ def main():
|
||||
requires_preprocessing = args.model_type in PREPROCESSING_FUNCTIONS.keys()
|
||||
if requires_preprocessing:
|
||||
prepare_input = PREPROCESSING_FUNCTIONS.get(args.model_type)
|
||||
prompt_text = prepare_input(args, model, tokenizer, prompt_text)
|
||||
encoded_prompt = tokenizer.encode(prompt_text, add_special_tokens=False, return_tensors="pt")
|
||||
preprocessed_prompt_text = prepare_input(args, model, tokenizer, prompt_text)
|
||||
encoded_prompt = tokenizer.encode(
|
||||
preprocessed_prompt_text, add_special_tokens=False, return_tensors="pt", add_space_before_punct_symbol=True
|
||||
)
|
||||
else:
|
||||
encoded_prompt = tokenizer.encode(prompt_text, add_special_tokens=False, return_tensors="pt")
|
||||
encoded_prompt = encoded_prompt.to(args.device)
|
||||
|
||||
output_sequences = model.generate(
|
||||
input_ids=encoded_prompt,
|
||||
max_length=args.length,
|
||||
max_length=args.length + len(encoded_prompt[0]),
|
||||
temperature=args.temperature,
|
||||
top_k=args.k,
|
||||
top_p=args.p,
|
||||
repetition_penalty=args.repetition_penalty,
|
||||
do_sample=True,
|
||||
num_return_sequences=args.num_return_sequences,
|
||||
)
|
||||
|
||||
# Batch size == 1. to add more examples please use num_return_sequences > 1
|
||||
generated_sequence = output_sequences[0].tolist()
|
||||
text = tokenizer.decode(generated_sequence, clean_up_tokenization_spaces=True)
|
||||
text = text[: text.find(args.stop_token) if args.stop_token else None]
|
||||
# Remove the batch dimension when returning multiple sequences
|
||||
if len(output_sequences.shape) > 2:
|
||||
output_sequences.squeeze_()
|
||||
|
||||
print(text)
|
||||
generated_sequences = []
|
||||
|
||||
return text
|
||||
for generated_sequence_idx, generated_sequence in enumerate(output_sequences):
|
||||
print("=== GENERATED SEQUENCE {} ===".format(generated_sequence_idx + 1))
|
||||
generated_sequence = generated_sequence.tolist()
|
||||
|
||||
# Decode text
|
||||
text = tokenizer.decode(generated_sequence, clean_up_tokenization_spaces=True)
|
||||
|
||||
# Remove all text after the stop token
|
||||
text = text[: text.find(args.stop_token) if args.stop_token else None]
|
||||
|
||||
# Add the prompt at the beginning of the sequence. Remove the excess text that was used for pre-processing
|
||||
total_sequence = (
|
||||
prompt_text + text[len(tokenizer.decode(encoded_prompt[0], clean_up_tokenization_spaces=True)) :]
|
||||
)
|
||||
|
||||
generated_sequences.append(total_sequence)
|
||||
print(total_sequence)
|
||||
|
||||
return generated_sequences
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
||||
@@ -38,6 +38,9 @@ from transformers import (
|
||||
BertConfig,
|
||||
BertForQuestionAnswering,
|
||||
BertTokenizer,
|
||||
CamembertConfig,
|
||||
CamembertForQuestionAnswering,
|
||||
CamembertTokenizer,
|
||||
DistilBertConfig,
|
||||
DistilBertForQuestionAnswering,
|
||||
DistilBertTokenizer,
|
||||
@@ -70,12 +73,16 @@ except ImportError:
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
ALL_MODELS = sum(
|
||||
(tuple(conf.pretrained_config_archive_map.keys()) for conf in (BertConfig, RobertaConfig, XLNetConfig, XLMConfig)),
|
||||
(
|
||||
tuple(conf.pretrained_config_archive_map.keys())
|
||||
for conf in (BertConfig, CamembertConfig, RobertaConfig, XLNetConfig, XLMConfig)
|
||||
),
|
||||
(),
|
||||
)
|
||||
|
||||
MODEL_CLASSES = {
|
||||
"bert": (BertConfig, BertForQuestionAnswering, BertTokenizer),
|
||||
"camembert": (CamembertConfig, CamembertForQuestionAnswering, CamembertTokenizer),
|
||||
"roberta": (RobertaConfig, RobertaForQuestionAnswering, RobertaTokenizer),
|
||||
"xlnet": (XLNetConfig, XLNetForQuestionAnswering, XLNetTokenizer),
|
||||
"xlm": (XLMConfig, XLMForQuestionAnswering, XLMTokenizer),
|
||||
@@ -212,7 +219,7 @@ def train(args, train_dataset, model, tokenizer):
|
||||
"end_positions": batch[4],
|
||||
}
|
||||
|
||||
if args.model_type in ["xlm", "roberta", "distilbert"]:
|
||||
if args.model_type in ["xlm", "roberta", "distilbert", "camembert"]:
|
||||
del inputs["token_type_ids"]
|
||||
|
||||
if args.model_type in ["xlnet", "xlm"]:
|
||||
@@ -327,7 +334,7 @@ def evaluate(args, model, tokenizer, prefix=""):
|
||||
"token_type_ids": batch[2],
|
||||
}
|
||||
|
||||
if args.model_type in ["xlm", "roberta", "distilbert"]:
|
||||
if args.model_type in ["xlm", "roberta", "distilbert", "camembert"]:
|
||||
del inputs["token_type_ids"]
|
||||
|
||||
example_indices = batch[3]
|
||||
|
||||
@@ -303,7 +303,7 @@ class TransformerDecoderLayer(nn.Module):
|
||||
self.layer_norm_2 = nn.LayerNorm(d_model, eps=1e-6)
|
||||
self.drop = nn.Dropout(dropout)
|
||||
mask = self._get_attn_subsequent_mask(MAX_SIZE)
|
||||
# Register self.mask as a buffer in TransformerDecoderLayer, so
|
||||
# Register self.mask as a saved_state in TransformerDecoderLayer, so
|
||||
# it gets TransformerDecoderLayer's cuda behavior automatically.
|
||||
self.register_buffer("mask", mask)
|
||||
|
||||
|
||||
@@ -97,4 +97,4 @@ class ExamplesTests(unittest.TestCase):
|
||||
model_type, model_name = ("--model_type=openai-gpt", "--model_name_or_path=openai-gpt")
|
||||
with patch.object(sys, "argv", testargs + [model_type, model_name]):
|
||||
result = run_generation.main()
|
||||
self.assertGreaterEqual(len(result), 10)
|
||||
self.assertGreaterEqual(len(result[0]), 10)
|
||||
|
||||
77
model_cards/ahotrod/xlnet_large_squad2_512/README.md
Normal file
77
model_cards/ahotrod/xlnet_large_squad2_512/README.md
Normal file
@@ -0,0 +1,77 @@
|
||||
## XLNet large language model fine-tuned on SQuAD2.0
|
||||
|
||||
### with the following results:
|
||||
|
||||
```
|
||||
"exact": 82.07698138633876,
|
||||
"f1": 85.898874470488,
|
||||
"total": 11873,
|
||||
"HasAns_exact": 79.60526315789474,
|
||||
"HasAns_f1": 87.26000954590184,
|
||||
"HasAns_total": 5928,
|
||||
"NoAns_exact": 84.54163162321278,
|
||||
"NoAns_f1": 84.54163162321278,
|
||||
"NoAns_total": 5945,
|
||||
"best_exact": 83.22243746315169,
|
||||
"best_exact_thresh": -11.112004280090332,
|
||||
"best_f1": 86.88541353813282,
|
||||
"best_f1_thresh": -11.112004280090332
|
||||
```
|
||||
### from script:
|
||||
```
|
||||
python -m torch.distributed.launch --nproc_per_node=2 ${RUN_SQUAD_DIR}/run_squad.py \
|
||||
--model_type xlnet \
|
||||
--model_name_or_path xlnet-large-cased \
|
||||
--do_train \
|
||||
--train_file ${SQUAD_DIR}/train-v2.0.json \
|
||||
--predict_file ${SQUAD_DIR}/dev-v2.0.json \
|
||||
--version_2_with_negative \
|
||||
--num_train_epochs 3 \
|
||||
--learning_rate 3e-5 \
|
||||
--adam_epsilon 1e-6 \
|
||||
--max_seq_length 512 \
|
||||
--doc_stride 128 \
|
||||
--save_steps 2000 \
|
||||
--per_gpu_train_batch_size 1 \
|
||||
--gradient_accumulation_steps 24 \
|
||||
--output_dir ${MODEL_PATH}
|
||||
|
||||
CUDA_VISIBLE_DEVICES=0 python ${RUN_SQUAD_DIR}/run_squad_II.py \
|
||||
--model_type xlnet \
|
||||
--model_name_or_path ${MODEL_PATH} \
|
||||
--do_eval \
|
||||
--train_file ${SQUAD_DIR}/train-v2.0.json \
|
||||
--predict_file ${SQUAD_DIR}/dev-v2.0.json \
|
||||
--version_2_with_negative \
|
||||
--max_seq_length 512 \
|
||||
--per_gpu_eval_batch_size 48 \
|
||||
--output_dir ${MODEL_PATH}
|
||||
```
|
||||
### using the following system & software:
|
||||
```
|
||||
OS/Platform: Linux-4.15.0-76-generic-x86_64-with-debian-buster-sid
|
||||
GPU/CPU: 2 x NVIDIA 1080Ti / Intel i7-8700
|
||||
Transformers: 2.1.1
|
||||
PyTorch: 1.4.0
|
||||
TensorFlow: 2.1.0
|
||||
Python: 3.7.6
|
||||
```
|
||||
### Inferencing / prediction works with Transformers v2.4.1, the latest version tested
|
||||
|
||||
### Utilize this xlnet_large_squad2_512 fine-tuned model with:
|
||||
```python
|
||||
config_class, model_class, tokenizer_class = \
|
||||
XLNetConfig, XLNetforQuestionAnswering, XLNetTokenizer
|
||||
model_name_or_path = "ahotrod/xlnet_large_squad2_512"
|
||||
config = config_class.from_pretrained(model_name_or_path)
|
||||
tokenizer = tokenizer_class.from_pretrained(model_name_or_path, do_lower_case=True)
|
||||
model = model_class.from_pretrained(model_name_or_path, config=config)
|
||||
```
|
||||
### or the AutoModels (AutoConfig, AutoTokenizer & AutoModel) should also work, however I have yet to use them in my apps & confirm:
|
||||
```python
|
||||
from transformers import AutoConfig, AutoTokenizer, AutoModel
|
||||
model_name_or_path = "ahotrod/xlnet_large_squad2_512"
|
||||
config = AutoConfig.from_pretrained(model_name_or_path)
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, do_lower_case=True)
|
||||
model = AutoModel.from_pretrained(model_name_or_path, config=config)
|
||||
```
|
||||
@@ -1,10 +1,10 @@
|
||||
---
|
||||
language: german
|
||||
thumbnail: https://thumb.tildacdn.com/tild3162-6462-4566-b663-376630376138/-/format/webp/Screenshot_from_2020.png
|
||||
thumbnail: https://static.tildacdn.com/tild6438-3730-4164-b266-613634323466/german_bert.png
|
||||
---
|
||||
|
||||
# German BERT
|
||||
|
||||

|
||||
## Overview
|
||||
**Language model:** bert-base-cased
|
||||
**Language:** German
|
||||
@@ -68,4 +68,4 @@ Some of our work:
|
||||
- [Haystack](https://github.com/deepset-ai/haystack/)
|
||||
|
||||
Get in touch:
|
||||
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Website](https://deepset.ai)
|
||||
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Website](https://deepset.ai)
|
||||
|
||||
@@ -22,8 +22,8 @@ from transformers import pipeline
|
||||
|
||||
fill_mask = pipeline(
|
||||
"fill-mask",
|
||||
model="julien-c/EspertBERTo-small",
|
||||
tokenizer="julien-c/EspertBERTo-small"
|
||||
model="julien-c/EsperBERTo-small",
|
||||
tokenizer="julien-c/EsperBERTo-small"
|
||||
)
|
||||
|
||||
fill_mask("Jen la komenco de bela <mask>.")
|
||||
@@ -56,4 +56,4 @@ fill_mask("Jen la komenco de bela <mask>.")
|
||||
# 'sequence':'<s> Jen la komenco de bela festo.</s>'
|
||||
# 'token':4580
|
||||
# }
|
||||
```
|
||||
```
|
||||
|
||||
@@ -0,0 +1,80 @@
|
||||
---
|
||||
language: spanish
|
||||
thumbnail: https://i.imgur.com/jgBdimh.png
|
||||
---
|
||||
|
||||
# Spanish BERT (BETO) + POS
|
||||
|
||||
This model is a fine-tuned on [NER-C](https://www.kaggle.com/nltkdata/conll-corpora) Of the Spanish BERT cased [(BETO)](https://github.com/dccuchile/beto) for **POS** (Part of Speech tagging) downstream task.
|
||||
|
||||
## Details of the downstream task (POS) - Dataset
|
||||
|
||||
- [Dataset: CONLL Corpora ES](https://www.kaggle.com/nltkdata/conll-corpora) with data augmentation techniques
|
||||
|
||||
I preprocessed the dataset and splitted it as train / dev (80/20)
|
||||
|
||||
| Dataset | # Examples |
|
||||
| ---------------------- | ----- |
|
||||
| Train | 340 K |
|
||||
| Dev | 50 K |
|
||||
|
||||
|
||||
- [Fine-tune on NER script provided by Huggingface](https://github.com/huggingface/transformers/blob/master/examples/run_ner.py)
|
||||
|
||||
- Labels covered:
|
||||
|
||||
```
|
||||
AO, AQ, CC, CS, DA, DD, DE, DI, DN, DP, DT, Faa, Fat, Fc, Fd, Fe, Fg, Fh, Fia, Fit, Fp, Fpa, Fpt, Fs, Ft, Fx, Fz, I, NC, NP, P0, PD, PI, PN, PP, PR, PT, PX, RG, RN, SP, VAI, VAM, VAN, VAP, VAS, VMG, VMI, VMM, VMN, VMP, VMS, VSG, VSI, VSM, VSN, VSP, VSS, Y and Z
|
||||
```
|
||||
|
||||
|
||||
## Metrics on evaluation set:
|
||||
|
||||
| Metric | # score |
|
||||
| :------------------------------------------------------------------------------------: | :-------: |
|
||||
| F1 | **90.06**
|
||||
| Precision | **89.46** |
|
||||
| Recall | **90.67** |
|
||||
|
||||
## Model in action
|
||||
|
||||
Fast usage with **pipelines**:
|
||||
|
||||
```python
|
||||
from transformers import pipeline
|
||||
|
||||
nlp_pos = pipeline(
|
||||
"ner",
|
||||
model="mrm8488/bert-spanish-cased-finetuned-pos",
|
||||
tokenizer=(
|
||||
'mrm8488/bert-spanish-cased-finetuned-pos',
|
||||
{"use_fast": False}
|
||||
))
|
||||
|
||||
|
||||
text = 'Mis amigos están pensando en viajar a Londres este verano'
|
||||
|
||||
nlp_pos(text)
|
||||
|
||||
#Output:
|
||||
'''
|
||||
[{'entity': 'NC', 'score': 0.7792173624038696, 'word': '[CLS]'},
|
||||
{'entity': 'DP', 'score': 0.9996283650398254, 'word': 'Mis'},
|
||||
{'entity': 'NC', 'score': 0.9999253749847412, 'word': 'amigos'},
|
||||
{'entity': 'VMI', 'score': 0.9998560547828674, 'word': 'están'},
|
||||
{'entity': 'VMG', 'score': 0.9992249011993408, 'word': 'pensando'},
|
||||
{'entity': 'SP', 'score': 0.9999602437019348, 'word': 'en'},
|
||||
{'entity': 'VMN', 'score': 0.9998666048049927, 'word': 'viajar'},
|
||||
{'entity': 'SP', 'score': 0.9999545216560364, 'word': 'a'},
|
||||
{'entity': 'VMN', 'score': 0.8722310662269592, 'word': 'Londres'},
|
||||
{'entity': 'DD', 'score': 0.9995203614234924, 'word': 'este'},
|
||||
{'entity': 'NC', 'score': 0.9999248385429382, 'word': 'verano'},
|
||||
{'entity': 'NC', 'score': 0.8802427649497986, 'word': '[SEP]'}]
|
||||
'''
|
||||
```
|
||||
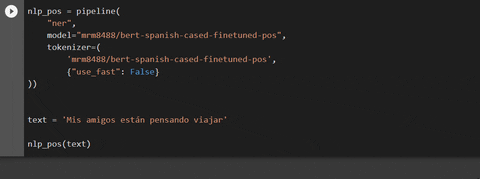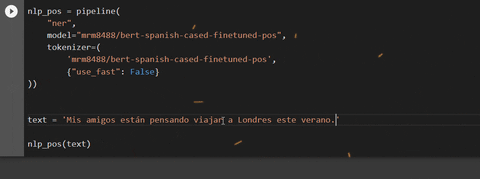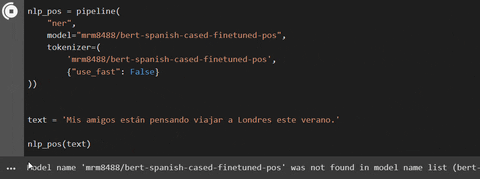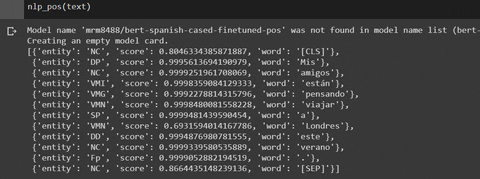
|
||||
|
||||
|
||||
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
|
||||
|
||||
> Made with <span style="color: #e25555;">♥</span> in Spain
|
||||
@@ -89,7 +89,37 @@ The model was trained on a Tesla P100 GPU and 25GB of RAM with the following com
|
||||
|
||||
So, yes, this version is even more accurate.
|
||||
|
||||
### Model in action (in a Colab Notebook)
|
||||
### Model in action
|
||||
|
||||
Fast usage with **pipelines**:
|
||||
|
||||
```python
|
||||
from transformers import *
|
||||
|
||||
# Important!: By now the QA pipeline is not compatible with fast tokenizer, but they are working on it. So that pass the object to the tokenizer {"use_fast": False} as in the following example:
|
||||
|
||||
nlp = pipeline(
|
||||
'question-answering',
|
||||
model='mrm8488/distill-bert-base-spanish-wwm-cased-finetuned-spa-squad2-es',
|
||||
tokenizer=(
|
||||
'mrm8488/distill-bert-base-spanish-wwm-cased-finetuned-spa-squad2-es',
|
||||
{"use_fast": False}
|
||||
)
|
||||
)
|
||||
|
||||
nlp(
|
||||
{
|
||||
'question': '¿Para qué lenguaje está trabajando?',
|
||||
'context': 'Manuel Romero está colaborando activamente con huggingface/transformers ' +
|
||||
'para traer el poder de las últimas técnicas de procesamiento de lenguaje natural al idioma español'
|
||||
}
|
||||
)
|
||||
# Output: {'answer': 'español', 'end': 169, 'score': 0.67530957344621, 'start': 163}
|
||||
```
|
||||
|
||||
Play with this model and ```pipelines``` in a Colab:
|
||||
|
||||
<a href="https://colab.research.google.com/github/mrm8488/shared_colab_notebooks/blob/master/Using_Spanish_BERT_fine_tuned_for_Q%26A_pipelines.ipynb" target="_parent"><img src="https://camo.githubusercontent.com/52feade06f2fecbf006889a904d221e6a730c194/68747470733a2f2f636f6c61622e72657365617263682e676f6f676c652e636f6d2f6173736574732f636f6c61622d62616467652e737667" alt="Open In Colab" data-canonical-src="https://colab.research.google.com/assets/colab-badge.svg"></a>
|
||||
|
||||
<details>
|
||||
|
||||
@@ -100,13 +130,12 @@ So, yes, this version is even more accurate.
|
||||
2. Run predictions:
|
||||
|
||||

|
||||
|
||||
3. Using **Pipelines**
|
||||
|
||||
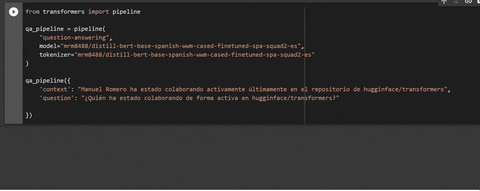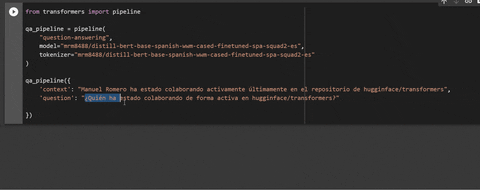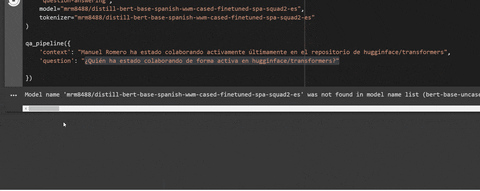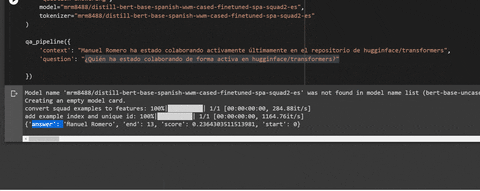
|
||||
|
||||
</details>
|
||||
|
||||
More about ``` Huggingface pipelines```? check this Colab out:
|
||||
|
||||
<a href="https://colab.research.google.com/github/mrm8488/shared_colab_notebooks/blob/master/Huggingface_pipelines_demo.ipynb" target="_parent"><img src="https://camo.githubusercontent.com/52feade06f2fecbf006889a904d221e6a730c194/68747470733a2f2f636f6c61622e72657365617263682e676f6f676c652e636f6d2f6173736574732f636f6c61622d62616467652e737667" alt="Open In Colab" data-canonical-src="https://colab.research.google.com/assets/colab-badge.svg"></a>
|
||||
|
||||
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
|
||||
|
||||
> Made with <span style="color: #e25555;">♥</span> in Spain
|
||||
|
||||
@@ -68,6 +68,47 @@ tokenizer = AutoTokenizer.from_pretrained("nlpaueb/bert-base-greek-uncased-v1")
|
||||
model = AutoModel.from_pretrained("nlpaueb/bert-base-greek-uncased-v1")
|
||||
```
|
||||
|
||||
## Use Pretrained Model as a Language Model
|
||||
|
||||
```python
|
||||
import torch
|
||||
from transformers import *
|
||||
|
||||
# Load model and tokenizer
|
||||
tokenizer_greek = AutoTokenizer.from_pretrained('nlpaueb/bert-base-greek-uncased-v1')
|
||||
lm_model_greek = AutoModelWithLMHead.from_pretrained('nlpaueb/bert-base-greek-uncased-v1')
|
||||
|
||||
# ================ EXAMPLE 1 ================
|
||||
text_1 = 'O ποιητής έγραψε ένα [MASK] .'
|
||||
# EN: 'The poet wrote a [MASK].'
|
||||
input_ids = tokenizer_greek.encode(text_1)
|
||||
print(tokenizer_greek.convert_ids_to_tokens(input_ids))
|
||||
# ['[CLS]', 'o', 'ποιητης', 'εγραψε', 'ενα', '[MASK]', '.', '[SEP]']
|
||||
outputs = lm_model_greek(torch.tensor([input_ids]))[0]
|
||||
print(tokenizer_greek.convert_ids_to_tokens(outputs[0, 5].max(0)[1].item()))
|
||||
# the most plausible prediction for [MASK] is "song"
|
||||
|
||||
# ================ EXAMPLE 2 ================
|
||||
text_2 = 'Είναι ένας [MASK] άνθρωπος.'
|
||||
# EN: 'He is a [MASK] person.'
|
||||
input_ids = tokenizer_greek.encode(text_1)
|
||||
print(tokenizer_greek.convert_ids_to_tokens(input_ids))
|
||||
# ['[CLS]', 'ειναι', 'ενας', '[MASK]', 'ανθρωπος', '.', '[SEP]']
|
||||
outputs = lm_model_greek(torch.tensor([input_ids]))[0]
|
||||
print(tokenizer_greek.convert_ids_to_tokens(outputs[0, 3].max(0)[1].item()))
|
||||
# the most plausible prediction for [MASK] is "good"
|
||||
|
||||
# ================ EXAMPLE 3 ================
|
||||
text_3 = 'Είναι ένας [MASK] άνθρωπος και κάνει συχνά [MASK].'
|
||||
# EN: 'He is a [MASK] person he does frequently [MASK].'
|
||||
input_ids = tokenizer_greek.encode(text_3)
|
||||
print(tokenizer_greek.convert_ids_to_tokens(input_ids))
|
||||
# ['[CLS]', 'ειναι', 'ενας', '[MASK]', 'ανθρωπος', 'και', 'κανει', 'συχνα', '[MASK]', '.', '[SEP]']
|
||||
outputs = lm_model_greek(torch.tensor([input_ids]))[0]
|
||||
print(tokenizer_greek.convert_ids_to_tokens(outputs[0, 8].max(0)[1].item()))
|
||||
# the most plausible prediction for the second [MASK] is "trips"
|
||||
```
|
||||
|
||||
## Evaluation on downstream tasks
|
||||
|
||||
TBA
|
||||
|
||||
@@ -15,6 +15,7 @@ known_third_party =
|
||||
packaging
|
||||
PIL
|
||||
psutil
|
||||
pytorch_lightning
|
||||
seqeval
|
||||
sklearn
|
||||
tensorboardX
|
||||
@@ -23,6 +24,7 @@ known_third_party =
|
||||
torch
|
||||
torchtext
|
||||
torchvision
|
||||
torch_xla
|
||||
|
||||
line_length = 119
|
||||
lines_after_imports = 2
|
||||
|
||||
7
setup.py
7
setup.py
@@ -34,6 +34,9 @@ To create the package for pypi.
|
||||
|
||||
7. Copy the release notes from RELEASE.md to the tag in github once everything is looking hunky-dory.
|
||||
|
||||
8. Update the documentation commit in .circleci/deploy.sh for the accurate documentation to be displayed
|
||||
|
||||
9. Update README.md to redirect to correct documentation.
|
||||
"""
|
||||
|
||||
import shutil
|
||||
@@ -76,7 +79,7 @@ extras["dev"] = extras["testing"] + extras["quality"] + ["mecab-python3", "sciki
|
||||
|
||||
setup(
|
||||
name="transformers",
|
||||
version="2.5.0",
|
||||
version="2.5.1",
|
||||
author="Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Sam Shleifer, Google AI Language Team Authors, Open AI team Authors, Facebook AI Authors, Carnegie Mellon University Authors",
|
||||
author_email="thomas@huggingface.co",
|
||||
description="State-of-the-art Natural Language Processing for TensorFlow 2.0 and PyTorch",
|
||||
@@ -89,7 +92,7 @@ setup(
|
||||
packages=find_packages("src"),
|
||||
install_requires=[
|
||||
"numpy",
|
||||
"tokenizers == 0.5.0",
|
||||
"tokenizers == 0.5.2",
|
||||
# accessing files from S3 directly
|
||||
"boto3",
|
||||
# filesystem locks e.g. to prevent parallel downloads
|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
# There's no way to ignore "F401 '...' imported but unused" warnings in this
|
||||
# module, but to preserve other warnings. So, don't check this module at all.
|
||||
|
||||
__version__ = "2.5.0"
|
||||
__version__ = "2.5.1"
|
||||
|
||||
# Work around to update TensorFlow's absl.logging threshold which alters the
|
||||
# default Python logging output behavior when present.
|
||||
@@ -21,6 +21,7 @@ import logging
|
||||
|
||||
from .configuration_albert import ALBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, AlbertConfig
|
||||
from .configuration_auto import ALL_PRETRAINED_CONFIG_ARCHIVE_MAP, AutoConfig
|
||||
from .configuration_bart import BartConfig
|
||||
from .configuration_bert import BERT_PRETRAINED_CONFIG_ARCHIVE_MAP, BertConfig
|
||||
from .configuration_camembert import CAMEMBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, CamembertConfig
|
||||
from .configuration_ctrl import CTRL_PRETRAINED_CONFIG_ARCHIVE_MAP, CTRLConfig
|
||||
@@ -106,6 +107,7 @@ from .pipelines import (
|
||||
)
|
||||
from .tokenization_albert import AlbertTokenizer
|
||||
from .tokenization_auto import AutoTokenizer
|
||||
from .tokenization_bart import BartTokenizer
|
||||
from .tokenization_bert import BasicTokenizer, BertTokenizer, BertTokenizerFast, WordpieceTokenizer
|
||||
from .tokenization_bert_japanese import BertJapaneseTokenizer, CharacterTokenizer, MecabTokenizer
|
||||
from .tokenization_camembert import CamembertTokenizer
|
||||
@@ -204,6 +206,7 @@ if is_torch_available():
|
||||
XLMForQuestionAnsweringSimple,
|
||||
XLM_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
)
|
||||
from .modeling_bart import BartForSequenceClassification, BartModel, BartForMaskedLM
|
||||
from .modeling_roberta import (
|
||||
RobertaForMaskedLM,
|
||||
RobertaModel,
|
||||
@@ -218,6 +221,7 @@ if is_torch_available():
|
||||
CamembertModel,
|
||||
CamembertForSequenceClassification,
|
||||
CamembertForTokenClassification,
|
||||
CamembertForQuestionAnswering,
|
||||
CAMEMBERT_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
)
|
||||
from .modeling_distilbert import (
|
||||
|
||||
@@ -18,7 +18,10 @@ def _gelu_python(x):
|
||||
return x * 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))
|
||||
|
||||
|
||||
gelu = getattr(F, "gelu", _gelu_python)
|
||||
if torch.__version__ < "1.4.0":
|
||||
gelu = _gelu_python
|
||||
else:
|
||||
gelu = F.gelu
|
||||
|
||||
|
||||
def gelu_new(x):
|
||||
|
||||
@@ -19,6 +19,7 @@ import logging
|
||||
from collections import OrderedDict
|
||||
|
||||
from .configuration_albert import ALBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, AlbertConfig
|
||||
from .configuration_bart import BART_PRETRAINED_CONFIG_ARCHIVE_MAP, BartConfig
|
||||
from .configuration_bert import BERT_PRETRAINED_CONFIG_ARCHIVE_MAP, BertConfig
|
||||
from .configuration_camembert import CAMEMBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, CamembertConfig
|
||||
from .configuration_ctrl import CTRL_PRETRAINED_CONFIG_ARCHIVE_MAP, CTRLConfig
|
||||
@@ -42,6 +43,7 @@ ALL_PRETRAINED_CONFIG_ARCHIVE_MAP = dict(
|
||||
(key, value)
|
||||
for pretrained_map in [
|
||||
BERT_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
BART_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
OPENAI_GPT_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
TRANSFO_XL_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
@@ -67,6 +69,7 @@ CONFIG_MAPPING = OrderedDict(
|
||||
("albert", AlbertConfig,),
|
||||
("camembert", CamembertConfig,),
|
||||
("xlm-roberta", XLMRobertaConfig,),
|
||||
("bart", BartConfig,),
|
||||
("roberta", RobertaConfig,),
|
||||
("flaubert", FlaubertConfig,),
|
||||
("bert", BertConfig,),
|
||||
|
||||
101
src/transformers/configuration_bart.py
Normal file
101
src/transformers/configuration_bart.py
Normal file
@@ -0,0 +1,101 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2020 The Fairseq Authors and The HuggingFace Inc. team.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
""" BART configuration """
|
||||
|
||||
|
||||
import logging
|
||||
|
||||
from .configuration_utils import PretrainedConfig
|
||||
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
_bart_large_url = "https://s3.amazonaws.com/models.huggingface.co/bert/facebook/bart-large/config.json"
|
||||
BART_PRETRAINED_CONFIG_ARCHIVE_MAP = {
|
||||
"bart-large": _bart_large_url,
|
||||
"bart-large-mnli": _bart_large_url, # fine as same
|
||||
"bart-cnn": None, # not done
|
||||
}
|
||||
|
||||
|
||||
class BartConfig(PretrainedConfig):
|
||||
r"""
|
||||
Configuration class for Bart. Parameters are renamed from the fairseq implementation
|
||||
"""
|
||||
model_type = "bart"
|
||||
pretrained_config_archive_map = BART_PRETRAINED_CONFIG_ARCHIVE_MAP
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
activation_dropout=0.0,
|
||||
vocab_size=50265,
|
||||
pad_token_id=1,
|
||||
eos_token_id=2,
|
||||
d_model=1024,
|
||||
encoder_ffn_dim=4096,
|
||||
encoder_layers=12,
|
||||
encoder_attention_heads=16,
|
||||
decoder_ffn_dim=4096,
|
||||
decoder_layers=12,
|
||||
decoder_attention_heads=16,
|
||||
encoder_layerdrop=0.0,
|
||||
decoder_layerdrop=0.0,
|
||||
attention_dropout=0.0,
|
||||
dropout=0.1,
|
||||
max_position_embeddings=1024,
|
||||
init_std=0.02,
|
||||
classifier_dropout=0.0,
|
||||
output_past=False,
|
||||
num_labels=3,
|
||||
**common_kwargs
|
||||
):
|
||||
r"""
|
||||
:class:`~transformers.BartConfig` is the configuration class for `BartModel`.
|
||||
Examples:
|
||||
config = BartConfig.from_pretrained('bart-large')
|
||||
model = BartModel(config)
|
||||
"""
|
||||
super().__init__(num_labels=num_labels, output_past=output_past, pad_token_id=pad_token_id, **common_kwargs)
|
||||
|
||||
self.vocab_size = vocab_size
|
||||
self.d_model = d_model # encoder_embed_dim and decoder_embed_dim
|
||||
self.eos_token_id = eos_token_id
|
||||
|
||||
self.encoder_ffn_dim = encoder_ffn_dim
|
||||
self.encoder_layers = self.num_hidden_layers = encoder_layers
|
||||
self.encoder_attention_heads = encoder_attention_heads
|
||||
self.encoder_layerdrop = encoder_layerdrop
|
||||
self.decoder_layerdrop = decoder_layerdrop
|
||||
self.decoder_ffn_dim = decoder_ffn_dim
|
||||
self.decoder_layers = decoder_layers
|
||||
self.decoder_attention_heads = decoder_attention_heads
|
||||
self.max_position_embeddings = max_position_embeddings
|
||||
self.init_std = init_std # Normal(0, this parameter)
|
||||
|
||||
# 3 Types of Dropout
|
||||
self.attention_dropout = attention_dropout
|
||||
self.activation_dropout = activation_dropout
|
||||
self.dropout = dropout
|
||||
|
||||
# Classifier stuff
|
||||
self.classif_dropout = classifier_dropout
|
||||
|
||||
@property
|
||||
def num_attention_heads(self):
|
||||
return self.encoder_attention_heads
|
||||
|
||||
@property
|
||||
def hidden_size(self):
|
||||
return self.d_model
|
||||
@@ -75,9 +75,9 @@ class PretrainedConfig(object):
|
||||
self.top_k = kwargs.pop("top_k", 50)
|
||||
self.top_p = kwargs.pop("top_p", 1.0)
|
||||
self.repetition_penalty = kwargs.pop("repetition_penalty", 1.0)
|
||||
self.bos_token_id = kwargs.pop("bos_token_id", 0)
|
||||
self.pad_token_id = kwargs.pop("pad_token_id", 0)
|
||||
self.eos_token_ids = kwargs.pop("eos_token_ids", 0)
|
||||
self.bos_token_id = kwargs.pop("bos_token_id", None)
|
||||
self.pad_token_id = kwargs.pop("pad_token_id", None)
|
||||
self.eos_token_ids = kwargs.pop("eos_token_ids", None)
|
||||
self.length_penalty = kwargs.pop("length_penalty", 1.0)
|
||||
self.num_return_sequences = kwargs.pop("num_return_sequences", 1)
|
||||
|
||||
@@ -198,6 +198,7 @@ class PretrainedConfig(object):
|
||||
force_download = kwargs.pop("force_download", False)
|
||||
resume_download = kwargs.pop("resume_download", False)
|
||||
proxies = kwargs.pop("proxies", None)
|
||||
local_files_only = kwargs.pop("local_files_only", False)
|
||||
|
||||
if pretrained_config_archive_map is None:
|
||||
pretrained_config_archive_map = cls.pretrained_config_archive_map
|
||||
@@ -219,6 +220,7 @@ class PretrainedConfig(object):
|
||||
force_download=force_download,
|
||||
proxies=proxies,
|
||||
resume_download=resume_download,
|
||||
local_files_only=local_files_only,
|
||||
)
|
||||
# Load config dict
|
||||
if resolved_config_file is None:
|
||||
|
||||
@@ -0,0 +1,100 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2020 The HuggingFace Inc. team.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""Convert BART checkpoint."""
|
||||
|
||||
|
||||
import argparse
|
||||
import logging
|
||||
from pathlib import Path
|
||||
|
||||
import fairseq
|
||||
import torch
|
||||
from packaging import version
|
||||
|
||||
from transformers import BartConfig, BartForSequenceClassification, BartModel, BartTokenizer
|
||||
|
||||
|
||||
if version.parse(fairseq.__version__) < version.parse("0.9.0"):
|
||||
raise Exception("requires fairseq >= 0.9.0")
|
||||
|
||||
|
||||
logging.basicConfig(level=logging.INFO)
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
SAMPLE_TEXT = "Hello world! cécé herlolip"
|
||||
|
||||
rename_keys = [
|
||||
("model.classification_heads.mnli.dense.weight", "classification_head.dense.weight"),
|
||||
("model.classification_heads.mnli.dense.bias", "classification_head.dense.bias"),
|
||||
("model.classification_heads.mnli.out_proj.weight", "classification_head.out_proj.weight"),
|
||||
("model.classification_heads.mnli.out_proj.bias", "classification_head.out_proj.bias"),
|
||||
]
|
||||
IGNORE_KEYS = ["encoder.version", "decoder.version", "model.encoder.version", "model.decoder.version"]
|
||||
|
||||
|
||||
def rename_key(dct, old, new):
|
||||
val = dct.pop(old)
|
||||
dct[new] = val
|
||||
|
||||
|
||||
def convert_bart_checkpoint(checkpoint_path, pytorch_dump_folder_path):
|
||||
"""
|
||||
Copy/paste/tweak model's weights to our BERT structure.
|
||||
"""
|
||||
b2 = torch.hub.load("pytorch/fairseq", checkpoint_path)
|
||||
b2.eval() # disable dropout
|
||||
b2.model.upgrade_state_dict(b2.model.state_dict())
|
||||
config = BartConfig()
|
||||
tokens = b2.encode(SAMPLE_TEXT).unsqueeze(0)
|
||||
tokens2 = BartTokenizer.from_pretrained("bart-large").encode(SAMPLE_TEXT).unsqueeze(0)
|
||||
assert torch.eq(tokens, tokens2).all()
|
||||
|
||||
# assert their_output.size() == (1, 11, 1024)
|
||||
|
||||
if checkpoint_path == "bart.large":
|
||||
state_dict = b2.model.state_dict()
|
||||
state_dict["shared.weight"] = state_dict["decoder.embed_tokens.weight"]
|
||||
model = BartModel(config)
|
||||
their_output = b2.extract_features(tokens)
|
||||
|
||||
else: # MNLI Case
|
||||
state_dict = b2.state_dict()
|
||||
state_dict["model.shared.weight"] = state_dict["model.decoder.embed_tokens.weight"]
|
||||
for src, dest in rename_keys:
|
||||
rename_key(state_dict, src, dest)
|
||||
state_dict.pop("_float_tensor", None)
|
||||
model = BartForSequenceClassification(config)
|
||||
their_output = b2.predict("mnli", tokens, return_logits=True)
|
||||
for k in IGNORE_KEYS:
|
||||
state_dict.pop(k, None)
|
||||
model.load_state_dict(state_dict)
|
||||
model.eval()
|
||||
our_outputs = model.forward(tokens)[0]
|
||||
|
||||
assert their_output.shape == our_outputs.shape
|
||||
assert (their_output == our_outputs).all().item()
|
||||
Path(pytorch_dump_folder_path).mkdir(exist_ok=True)
|
||||
model.save_pretrained(pytorch_dump_folder_path)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
# Required parameters
|
||||
parser.add_argument("fairseq_path", choices=["bart.large", "bart.large.mnli"], type=str, help="")
|
||||
parser.add_argument("pytorch_dump_folder_path", default=None, type=str, help="Path to the output PyTorch model.")
|
||||
args = parser.parse_args()
|
||||
convert_bart_checkpoint(
|
||||
args.fairseq_path, args.pytorch_dump_folder_path,
|
||||
)
|
||||
@@ -123,7 +123,7 @@ def squad_convert_example_to_features(example, max_seq_length, doc_stride, max_q
|
||||
truncated_query = tokenizer.encode(example.question_text, add_special_tokens=False, max_length=max_query_length)
|
||||
sequence_added_tokens = (
|
||||
tokenizer.max_len - tokenizer.max_len_single_sentence + 1
|
||||
if "roberta" in str(type(tokenizer))
|
||||
if "roberta" in str(type(tokenizer)) or "camembert" in str(type(tokenizer))
|
||||
else tokenizer.max_len - tokenizer.max_len_single_sentence
|
||||
)
|
||||
sequence_pair_added_tokens = tokenizer.max_len - tokenizer.max_len_sentences_pair
|
||||
|
||||
@@ -32,11 +32,11 @@ class InputExample(object):
|
||||
Args:
|
||||
guid: Unique id for the example.
|
||||
text_a: string. The untokenized text of the first sequence. For single
|
||||
sequence tasks, only this sequence must be specified.
|
||||
sequence tasks, only this sequence must be specified.
|
||||
text_b: (Optional) string. The untokenized text of the second sequence.
|
||||
Only must be specified for sequence pair tasks.
|
||||
Only must be specified for sequence pair tasks.
|
||||
label: (Optional) string. The label of the example. This should be
|
||||
specified for train and dev examples, but not for test examples.
|
||||
specified for train and dev examples, but not for test examples.
|
||||
"""
|
||||
|
||||
def __init__(self, guid, text_a, text_b=None, label=None):
|
||||
|
||||
@@ -214,6 +214,7 @@ def cached_path(
|
||||
user_agent=None,
|
||||
extract_compressed_file=False,
|
||||
force_extract=False,
|
||||
local_files_only=False,
|
||||
) -> Optional[str]:
|
||||
"""
|
||||
Given something that might be a URL (or might be a local path),
|
||||
@@ -250,6 +251,7 @@ def cached_path(
|
||||
proxies=proxies,
|
||||
resume_download=resume_download,
|
||||
user_agent=user_agent,
|
||||
local_files_only=local_files_only,
|
||||
)
|
||||
elif os.path.exists(url_or_filename):
|
||||
# File, and it exists.
|
||||
@@ -378,7 +380,14 @@ def http_get(url, temp_file, proxies=None, resume_size=0, user_agent=None):
|
||||
|
||||
|
||||
def get_from_cache(
|
||||
url, cache_dir=None, force_download=False, proxies=None, etag_timeout=10, resume_download=False, user_agent=None
|
||||
url,
|
||||
cache_dir=None,
|
||||
force_download=False,
|
||||
proxies=None,
|
||||
etag_timeout=10,
|
||||
resume_download=False,
|
||||
user_agent=None,
|
||||
local_files_only=False,
|
||||
) -> Optional[str]:
|
||||
"""
|
||||
Given a URL, look for the corresponding file in the local cache.
|
||||
@@ -395,18 +404,19 @@ def get_from_cache(
|
||||
|
||||
os.makedirs(cache_dir, exist_ok=True)
|
||||
|
||||
# Get eTag to add to filename, if it exists.
|
||||
if url.startswith("s3://"):
|
||||
etag = s3_etag(url, proxies=proxies)
|
||||
else:
|
||||
try:
|
||||
response = requests.head(url, allow_redirects=True, proxies=proxies, timeout=etag_timeout)
|
||||
if response.status_code != 200:
|
||||
etag = None
|
||||
else:
|
||||
etag = response.headers.get("ETag")
|
||||
except (EnvironmentError, requests.exceptions.Timeout):
|
||||
etag = None
|
||||
etag = None
|
||||
if not local_files_only:
|
||||
# Get eTag to add to filename, if it exists.
|
||||
if url.startswith("s3://"):
|
||||
etag = s3_etag(url, proxies=proxies)
|
||||
else:
|
||||
try:
|
||||
response = requests.head(url, allow_redirects=True, proxies=proxies, timeout=etag_timeout)
|
||||
if response.status_code == 200:
|
||||
etag = response.headers.get("ETag")
|
||||
except (EnvironmentError, requests.exceptions.Timeout):
|
||||
# etag is already None
|
||||
pass
|
||||
|
||||
filename = url_to_filename(url, etag)
|
||||
|
||||
@@ -427,6 +437,15 @@ def get_from_cache(
|
||||
if len(matching_files) > 0:
|
||||
return os.path.join(cache_dir, matching_files[-1])
|
||||
else:
|
||||
# If files cannot be found and local_files_only=True,
|
||||
# the models might've been found if local_files_only=False
|
||||
# Notify the user about that
|
||||
if local_files_only:
|
||||
raise ValueError(
|
||||
"Cannot find the requested files in the cached path and outgoing traffic has been"
|
||||
" disabled. To enable model look-ups and downloads online, set 'local_files_only'"
|
||||
" to False."
|
||||
)
|
||||
return None
|
||||
|
||||
# From now on, etag is not None.
|
||||
|
||||
@@ -600,7 +600,7 @@ class AlbertMLMHead(nn.Module):
|
||||
hidden_states = self.LayerNorm(hidden_states)
|
||||
hidden_states = self.decoder(hidden_states)
|
||||
|
||||
prediction_scores = hidden_states + self.bias
|
||||
prediction_scores = hidden_states
|
||||
|
||||
return prediction_scores
|
||||
|
||||
|
||||
@@ -21,6 +21,7 @@ from collections import OrderedDict
|
||||
from .configuration_auto import (
|
||||
AlbertConfig,
|
||||
AutoConfig,
|
||||
BartConfig,
|
||||
BertConfig,
|
||||
CamembertConfig,
|
||||
CTRLConfig,
|
||||
@@ -43,6 +44,7 @@ from .modeling_albert import (
|
||||
AlbertForSequenceClassification,
|
||||
AlbertModel,
|
||||
)
|
||||
from .modeling_bart import BART_PRETRAINED_MODEL_ARCHIVE_MAP, BartForMaskedLM, BartForSequenceClassification, BartModel
|
||||
from .modeling_bert import (
|
||||
BERT_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
BertForMaskedLM,
|
||||
@@ -118,6 +120,7 @@ ALL_PRETRAINED_MODEL_ARCHIVE_MAP = dict(
|
||||
(key, value)
|
||||
for pretrained_map in [
|
||||
BERT_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
BART_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
OPENAI_GPT_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
TRANSFO_XL_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
GPT2_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
@@ -142,6 +145,7 @@ MODEL_MAPPING = OrderedDict(
|
||||
(AlbertConfig, AlbertModel),
|
||||
(CamembertConfig, CamembertModel),
|
||||
(XLMRobertaConfig, XLMRobertaModel),
|
||||
(BartConfig, BartModel),
|
||||
(RobertaConfig, RobertaModel),
|
||||
(BertConfig, BertModel),
|
||||
(OpenAIGPTConfig, OpenAIGPTModel),
|
||||
@@ -161,6 +165,7 @@ MODEL_FOR_PRETRAINING_MAPPING = OrderedDict(
|
||||
(AlbertConfig, AlbertForMaskedLM),
|
||||
(CamembertConfig, CamembertForMaskedLM),
|
||||
(XLMRobertaConfig, XLMRobertaForMaskedLM),
|
||||
(BartConfig, BartForMaskedLM),
|
||||
(RobertaConfig, RobertaForMaskedLM),
|
||||
(BertConfig, BertForPreTraining),
|
||||
(OpenAIGPTConfig, OpenAIGPTLMHeadModel),
|
||||
@@ -180,6 +185,7 @@ MODEL_WITH_LM_HEAD_MAPPING = OrderedDict(
|
||||
(AlbertConfig, AlbertForMaskedLM),
|
||||
(CamembertConfig, CamembertForMaskedLM),
|
||||
(XLMRobertaConfig, XLMRobertaForMaskedLM),
|
||||
(BartConfig, BartForMaskedLM),
|
||||
(RobertaConfig, RobertaForMaskedLM),
|
||||
(BertConfig, BertForMaskedLM),
|
||||
(OpenAIGPTConfig, OpenAIGPTLMHeadModel),
|
||||
@@ -198,6 +204,7 @@ MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING = OrderedDict(
|
||||
(AlbertConfig, AlbertForSequenceClassification),
|
||||
(CamembertConfig, CamembertForSequenceClassification),
|
||||
(XLMRobertaConfig, XLMRobertaForSequenceClassification),
|
||||
(BartConfig, BartForSequenceClassification),
|
||||
(RobertaConfig, RobertaForSequenceClassification),
|
||||
(BertConfig, BertForSequenceClassification),
|
||||
(XLNetConfig, XLNetForSequenceClassification),
|
||||
@@ -352,16 +359,12 @@ class AutoModel(object):
|
||||
Set to ``True`` to also return a dictionnary containing missing keys, unexpected keys and error messages.
|
||||
|
||||
kwargs: (`optional`) Remaining dictionary of keyword arguments:
|
||||
Can be used to update the configuration object (after it being loaded) and initiate the model. (e.g. ``output_attention=True``). Behave differently depending on whether a `config` is provided or automatically loaded:
|
||||
|
||||
- If a configuration is provided with ``config``, ``**kwargs`` will be directly passed to the underlying model's ``__init__`` method (we assume all relevant updates to the configuration have already been done)
|
||||
- If a configuration is not provided, ``kwargs`` will be first passed to the configuration class initialization function (:func:`~transformers.PretrainedConfig.from_pretrained`). Each key of ``kwargs`` that corresponds to a configuration attribute will be used to override said attribute with the supplied ``kwargs`` value. Remaining keys that do not correspond to any configuration attribute will be passed to the underlying model's ``__init__`` function.
|
||||
These arguments will be passed to the configuration and the model.
|
||||
|
||||
Examples::
|
||||
|
||||
model = AutoModel.from_pretrained('bert-base-uncased') # Download model and configuration from S3 and cache.
|
||||
model = AutoModel.from_pretrained('./test/bert_model/') # E.g. model was saved using `save_pretrained('./test/saved_model/')`
|
||||
model = AutoModel.from_pretrained('bert-base-uncased', output_attention=True) # Update configuration during loading
|
||||
assert model.config.output_attention == True
|
||||
# Loading from a TF checkpoint file instead of a PyTorch model (slower)
|
||||
config = AutoConfig.from_json_file('./tf_model/bert_tf_model_config.json')
|
||||
@@ -496,24 +499,12 @@ class AutoModelForPreTraining(object):
|
||||
output_loading_info: (`optional`) boolean:
|
||||
Set to ``True`` to also return a dictionnary containing missing keys, unexpected keys and error messages.
|
||||
kwargs: (`optional`) Remaining dictionary of keyword arguments:
|
||||
Can be used to update the configuration object (after it being loaded) and initiate the model.
|
||||
(e.g. ``output_attention=True``). Behave differently depending on whether a `config` is provided or
|
||||
automatically loaded:
|
||||
|
||||
- If a configuration is provided with ``config``, ``**kwargs`` will be directly passed to the
|
||||
underlying model's ``__init__`` method (we assume all relevant updates to the configuration have
|
||||
already been done)
|
||||
- If a configuration is not provided, ``kwargs`` will be first passed to the configuration class
|
||||
initialization function (:func:`~transformers.PretrainedConfig.from_pretrained`). Each key of
|
||||
``kwargs`` that corresponds to a configuration attribute will be used to override said attribute
|
||||
with the supplied ``kwargs`` value. Remaining keys that do not correspond to any configuration
|
||||
attribute will be passed to the underlying model's ``__init__`` function.
|
||||
These arguments will be passed to the configuration and the model.
|
||||
|
||||
Examples::
|
||||
|
||||
model = AutoModelForPreTraining.from_pretrained('bert-base-uncased') # Download model and configuration from S3 and cache.
|
||||
model = AutoModelForPreTraining.from_pretrained('./test/bert_model/') # E.g. model was saved using `save_pretrained('./test/saved_model/')`
|
||||
model = AutoModelForPreTraining.from_pretrained('bert-base-uncased', output_attention=True) # Update configuration during loading
|
||||
assert model.config.output_attention == True
|
||||
# Loading from a TF checkpoint file instead of a PyTorch model (slower)
|
||||
config = AutoConfig.from_json_file('./tf_model/bert_tf_model_config.json')
|
||||
@@ -650,24 +641,12 @@ class AutoModelWithLMHead(object):
|
||||
output_loading_info: (`optional`) boolean:
|
||||
Set to ``True`` to also return a dictionnary containing missing keys, unexpected keys and error messages.
|
||||
kwargs: (`optional`) Remaining dictionary of keyword arguments:
|
||||
Can be used to update the configuration object (after it being loaded) and initiate the model.
|
||||
(e.g. ``output_attention=True``). Behave differently depending on whether a `config` is provided or
|
||||
automatically loaded:
|
||||
|
||||
- If a configuration is provided with ``config``, ``**kwargs`` will be directly passed to the
|
||||
underlying model's ``__init__`` method (we assume all relevant updates to the configuration have
|
||||
already been done)
|
||||
- If a configuration is not provided, ``kwargs`` will be first passed to the configuration class
|
||||
initialization function (:func:`~transformers.PretrainedConfig.from_pretrained`). Each key of
|
||||
``kwargs`` that corresponds to a configuration attribute will be used to override said attribute
|
||||
with the supplied ``kwargs`` value. Remaining keys that do not correspond to any configuration
|
||||
attribute will be passed to the underlying model's ``__init__`` function.
|
||||
These arguments will be passed to the configuration and the model.
|
||||
|
||||
Examples::
|
||||
|
||||
model = AutoModelWithLMHead.from_pretrained('bert-base-uncased') # Download model and configuration from S3 and cache.
|
||||
model = AutoModelWithLMHead.from_pretrained('./test/bert_model/') # E.g. model was saved using `save_pretrained('./test/saved_model/')`
|
||||
model = AutoModelWithLMHead.from_pretrained('bert-base-uncased', output_attention=True) # Update configuration during loading
|
||||
assert model.config.output_attention == True
|
||||
# Loading from a TF checkpoint file instead of a PyTorch model (slower)
|
||||
config = AutoConfig.from_json_file('./tf_model/bert_tf_model_config.json')
|
||||
@@ -807,16 +786,12 @@ class AutoModelForSequenceClassification(object):
|
||||
Set to ``True`` to also return a dictionnary containing missing keys, unexpected keys and error messages.
|
||||
|
||||
kwargs: (`optional`) Remaining dictionary of keyword arguments:
|
||||
Can be used to update the configuration object (after it being loaded) and initiate the model. (e.g. ``output_attention=True``). Behave differently depending on whether a `config` is provided or automatically loaded:
|
||||
|
||||
- If a configuration is provided with ``config``, ``**kwargs`` will be directly passed to the underlying model's ``__init__`` method (we assume all relevant updates to the configuration have already been done)
|
||||
- If a configuration is not provided, ``kwargs`` will be first passed to the configuration class initialization function (:func:`~transformers.PretrainedConfig.from_pretrained`). Each key of ``kwargs`` that corresponds to a configuration attribute will be used to override said attribute with the supplied ``kwargs`` value. Remaining keys that do not correspond to any configuration attribute will be passed to the underlying model's ``__init__`` function.
|
||||
These arguments will be passed to the configuration and the model.
|
||||
|
||||
Examples::
|
||||
|
||||
model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased') # Download model and configuration from S3 and cache.
|
||||
model = AutoModelForSequenceClassification.from_pretrained('./test/bert_model/') # E.g. model was saved using `save_pretrained('./test/saved_model/')`
|
||||
model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased', output_attention=True) # Update configuration during loading
|
||||
assert model.config.output_attention == True
|
||||
# Loading from a TF checkpoint file instead of a PyTorch model (slower)
|
||||
config = AutoConfig.from_json_file('./tf_model/bert_tf_model_config.json')
|
||||
@@ -950,16 +925,12 @@ class AutoModelForQuestionAnswering(object):
|
||||
Set to ``True`` to also return a dictionnary containing missing keys, unexpected keys and error messages.
|
||||
|
||||
kwargs: (`optional`) Remaining dictionary of keyword arguments:
|
||||
Can be used to update the configuration object (after it being loaded) and initiate the model. (e.g. ``output_attention=True``). Behave differently depending on whether a `config` is provided or automatically loaded:
|
||||
|
||||
- If a configuration is provided with ``config``, ``**kwargs`` will be directly passed to the underlying model's ``__init__`` method (we assume all relevant updates to the configuration have already been done)
|
||||
- If a configuration is not provided, ``kwargs`` will be first passed to the configuration class initialization function (:func:`~transformers.PretrainedConfig.from_pretrained`). Each key of ``kwargs`` that corresponds to a configuration attribute will be used to override said attribute with the supplied ``kwargs`` value. Remaining keys that do not correspond to any configuration attribute will be passed to the underlying model's ``__init__`` function.
|
||||
These arguments will be passed to the configuration and the model.
|
||||
|
||||
Examples::
|
||||
|
||||
model = AutoModelForQuestionAnswering.from_pretrained('bert-base-uncased') # Download model and configuration from S3 and cache.
|
||||
model = AutoModelForQuestionAnswering.from_pretrained('./test/bert_model/') # E.g. model was saved using `save_pretrained('./test/saved_model/')`
|
||||
model = AutoModelForQuestionAnswering.from_pretrained('bert-base-uncased', output_attention=True) # Update configuration during loading
|
||||
assert model.config.output_attention == True
|
||||
# Loading from a TF checkpoint file instead of a PyTorch model (slower)
|
||||
config = AutoConfig.from_json_file('./tf_model/bert_tf_model_config.json')
|
||||
@@ -1094,16 +1065,12 @@ class AutoModelForTokenClassification:
|
||||
Set to ``True`` to also return a dictionnary containing missing keys, unexpected keys and error messages.
|
||||
|
||||
kwargs: (`optional`) Remaining dictionary of keyword arguments:
|
||||
Can be used to update the configuration object (after it being loaded) and initiate the model. (e.g. ``output_attention=True``). Behave differently depending on whether a `config` is provided or automatically loaded:
|
||||
|
||||
- If a configuration is provided with ``config``, ``**kwargs`` will be directly passed to the underlying model's ``__init__`` method (we assume all relevant updates to the configuration have already been done)
|
||||
- If a configuration is not provided, ``kwargs`` will be first passed to the configuration class initialization function (:func:`~transformers.PretrainedConfig.from_pretrained`). Each key of ``kwargs`` that corresponds to a configuration attribute will be used to override said attribute with the supplied ``kwargs`` value. Remaining keys that do not correspond to any configuration attribute will be passed to the underlying model's ``__init__`` function.
|
||||
These arguments will be passed to the configuration and the model.
|
||||
|
||||
Examples::
|
||||
|
||||
model = AutoModelForTokenClassification.from_pretrained('bert-base-uncased') # Download model and configuration from S3 and cache.
|
||||
model = AutoModelForTokenClassification.from_pretrained('./test/bert_model/') # E.g. model was saved using `save_pretrained('./test/saved_model/')`
|
||||
model = AutoModelForTokenClassification.from_pretrained('bert-base-uncased', output_attention=True) # Update configuration during loading
|
||||
assert model.config.output_attention == True
|
||||
# Loading from a TF checkpoint file instead of a PyTorch model (slower)
|
||||
config = AutoConfig.from_json_file('./tf_model/bert_tf_model_config.json')
|
||||
|
||||
1024
src/transformers/modeling_bart.py
Normal file
1024
src/transformers/modeling_bart.py
Normal file
File diff suppressed because it is too large
Load Diff
@@ -471,7 +471,7 @@ class BertLMPredictionHead(nn.Module):
|
||||
|
||||
def forward(self, hidden_states):
|
||||
hidden_states = self.transform(hidden_states)
|
||||
hidden_states = self.decoder(hidden_states) + self.bias
|
||||
hidden_states = self.decoder(hidden_states)
|
||||
return hidden_states
|
||||
|
||||
|
||||
|
||||
@@ -15,7 +15,6 @@
|
||||
# limitations under the License.
|
||||
"""PyTorch CamemBERT model. """
|
||||
|
||||
|
||||
import logging
|
||||
|
||||
from .configuration_camembert import CamembertConfig
|
||||
@@ -23,6 +22,7 @@ from .file_utils import add_start_docstrings
|
||||
from .modeling_roberta import (
|
||||
RobertaForMaskedLM,
|
||||
RobertaForMultipleChoice,
|
||||
RobertaForQuestionAnswering,
|
||||
RobertaForSequenceClassification,
|
||||
RobertaForTokenClassification,
|
||||
RobertaModel,
|
||||
@@ -37,7 +37,6 @@ CAMEMBERT_PRETRAINED_MODEL_ARCHIVE_MAP = {
|
||||
"umberto-wikipedia-uncased-v1": "https://s3.amazonaws.com/models.huggingface.co/bert/Musixmatch/umberto-wikipedia-uncased-v1/pytorch_model.bin",
|
||||
}
|
||||
|
||||
|
||||
CAMEMBERT_START_DOCSTRING = r"""
|
||||
|
||||
This model is a PyTorch `torch.nn.Module <https://pytorch.org/docs/stable/nn.html#torch.nn.Module>`_ sub-class.
|
||||
@@ -46,7 +45,8 @@ CAMEMBERT_START_DOCSTRING = r"""
|
||||
|
||||
Parameters:
|
||||
config (:class:`~transformers.CamembertConfig`): Model configuration class with all the parameters of the
|
||||
model. Initializing with a config file does not load the weights associated with the model, only the configuration.
|
||||
model. Initializing with a config file does not load the weights associated with the model, only the
|
||||
configuration.
|
||||
Check out the :meth:`~transformers.PreTrainedModel.from_pretrained` method to load the model weights.
|
||||
"""
|
||||
|
||||
@@ -121,3 +121,18 @@ class CamembertForTokenClassification(RobertaForTokenClassification):
|
||||
|
||||
config_class = CamembertConfig
|
||||
pretrained_model_archive_map = CAMEMBERT_PRETRAINED_MODEL_ARCHIVE_MAP
|
||||
|
||||
|
||||
@add_start_docstrings(
|
||||
"""CamemBERT Model with a span classification head on top for extractive question-answering tasks like SQuAD
|
||||
(a linear layers on top of the hidden-states output to compute `span start logits` and `span end logits` """,
|
||||
CAMEMBERT_START_DOCSTRING,
|
||||
)
|
||||
class CamembertForQuestionAnswering(RobertaForQuestionAnswering):
|
||||
"""
|
||||
This class overrides :class:`~transformers.RobertaForQuestionAnswering`. Please check the
|
||||
superclass for the appropriate documentation alongside usage examples.
|
||||
"""
|
||||
|
||||
config_class = CamembertConfig
|
||||
pretrained_model_archive_map = CAMEMBERT_PRETRAINED_MODEL_ARCHIVE_MAP
|
||||
|
||||
@@ -217,11 +217,6 @@ class TransformerBlock(nn.Module):
|
||||
def __init__(self, config):
|
||||
super().__init__()
|
||||
|
||||
self.n_heads = config.n_heads
|
||||
self.dim = config.dim
|
||||
self.hidden_dim = config.hidden_dim
|
||||
self.dropout = nn.Dropout(p=config.dropout)
|
||||
self.activation = config.activation
|
||||
self.output_attentions = config.output_attentions
|
||||
|
||||
assert config.dim % config.n_heads == 0
|
||||
|
||||
@@ -18,7 +18,6 @@
|
||||
import logging
|
||||
import os
|
||||
|
||||
import torch
|
||||
from torch import nn
|
||||
|
||||
from .modeling_auto import AutoModel, AutoModelWithLMHead
|
||||
@@ -236,42 +235,6 @@ class PreTrainedEncoderDecoder(nn.Module):
|
||||
|
||||
return decoder_outputs + encoder_outputs
|
||||
|
||||
@staticmethod
|
||||
def prepare_model_kwargs(**kwargs):
|
||||
""" Prepare the encoder and decoder's keyword arguments.
|
||||
|
||||
Keyword arguments come in 3 flavors:
|
||||
- encoder-specific (prefixed by `encoder_`)
|
||||
- decoder-specific (prefixed by `decoder_`)
|
||||
- those that apply to the model as whole.
|
||||
|
||||
We let the specific kwargs override the common ones in case of
|
||||
conflict.
|
||||
"""
|
||||
kwargs_common = {
|
||||
argument: value
|
||||
for argument, value in kwargs.items()
|
||||
if not argument.startswith("encoder_") and not argument.startswith("decoder_")
|
||||
}
|
||||
decoder_kwargs = kwargs_common.copy()
|
||||
encoder_kwargs = kwargs_common.copy()
|
||||
encoder_kwargs.update(
|
||||
{
|
||||
argument[len("encoder_") :]: value
|
||||
for argument, value in kwargs.items()
|
||||
if argument.startswith("encoder_")
|
||||
}
|
||||
)
|
||||
decoder_kwargs.update(
|
||||
{
|
||||
argument[len("decoder_") :]: value
|
||||
for argument, value in kwargs.items()
|
||||
if argument.startswith("decoder_")
|
||||
}
|
||||
)
|
||||
decoder_kwargs["encoder_attention_mask"] = encoder_kwargs.get("attention_mask", None)
|
||||
return encoder_kwargs, decoder_kwargs
|
||||
|
||||
|
||||
class Model2Model(PreTrainedEncoderDecoder):
|
||||
r"""
|
||||
@@ -330,21 +293,3 @@ class Model2Model(PreTrainedEncoderDecoder):
|
||||
)
|
||||
|
||||
return model
|
||||
|
||||
|
||||
class Model2LSTM(PreTrainedEncoderDecoder):
|
||||
@classmethod
|
||||
def from_pretrained(cls, *args, **kwargs):
|
||||
if kwargs.get("decoder_model", None) is None:
|
||||
# We will create a randomly initilized LSTM model as decoder
|
||||
if "decoder_config" not in kwargs:
|
||||
raise ValueError(
|
||||
"To load an LSTM in Encoder-Decoder model, please supply either: "
|
||||
" - a torch.nn.LSTM model as `decoder_model` parameter (`decoder_model=lstm_model`), or"
|
||||
" - a dictionary of configuration parameters that will be used to initialize a"
|
||||
" torch.nn.LSTM model as `decoder_config` keyword argument. "
|
||||
" E.g. `decoder_config={'input_size': 768, 'hidden_size': 768, 'num_layers': 2}`"
|
||||
)
|
||||
kwargs["decoder_model"] = torch.nn.LSTM(kwargs.pop("decoder_config"))
|
||||
model = super().from_pretrained(*args, **kwargs)
|
||||
return model
|
||||
|
||||
@@ -25,6 +25,7 @@ from torch.nn import CrossEntropyLoss, MSELoss
|
||||
from .configuration_roberta import RobertaConfig
|
||||
from .file_utils import add_start_docstrings, add_start_docstrings_to_callable
|
||||
from .modeling_bert import BertEmbeddings, BertLayerNorm, BertModel, BertPreTrainedModel, gelu
|
||||
from .modeling_utils import create_position_ids_from_input_ids
|
||||
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
@@ -56,7 +57,7 @@ class RobertaEmbeddings(BertEmbeddings):
|
||||
if position_ids is None:
|
||||
if input_ids is not None:
|
||||
# Create the position ids from the input token ids. Any padded tokens remain padded.
|
||||
position_ids = self.create_position_ids_from_input_ids(input_ids).to(input_ids.device)
|
||||
position_ids = create_position_ids_from_input_ids(input_ids, self.padding_idx).to(input_ids.device)
|
||||
else:
|
||||
position_ids = self.create_position_ids_from_inputs_embeds(inputs_embeds)
|
||||
|
||||
@@ -64,18 +65,6 @@ class RobertaEmbeddings(BertEmbeddings):
|
||||
input_ids, token_type_ids=token_type_ids, position_ids=position_ids, inputs_embeds=inputs_embeds
|
||||
)
|
||||
|
||||
def create_position_ids_from_input_ids(self, x):
|
||||
""" Replace non-padding symbols with their position numbers. Position numbers begin at
|
||||
padding_idx+1. Padding symbols are ignored. This is modified from fairseq's
|
||||
`utils.make_positions`.
|
||||
|
||||
:param torch.Tensor x:
|
||||
:return torch.Tensor:
|
||||
"""
|
||||
mask = x.ne(self.padding_idx).long()
|
||||
incremental_indicies = torch.cumsum(mask, dim=1) * mask
|
||||
return incremental_indicies + self.padding_idx
|
||||
|
||||
def create_position_ids_from_inputs_embeds(self, inputs_embeds):
|
||||
""" We are provided embeddings directly. We cannot infer which are padded so just generate
|
||||
sequential position ids.
|
||||
@@ -275,7 +264,7 @@ class RobertaLMHead(nn.Module):
|
||||
x = self.layer_norm(x)
|
||||
|
||||
# project back to size of vocabulary with bias
|
||||
x = self.decoder(x) + self.bias
|
||||
x = self.decoder(x)
|
||||
|
||||
return x
|
||||
|
||||
|
||||
@@ -29,14 +29,14 @@ from .modeling_tf_utils import TFPreTrainedModel, get_initializer, shape_list
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
TF_ALBERT_PRETRAINED_MODEL_ARCHIVE_MAP = {
|
||||
"albert-base-v1": "https://s3.amazonaws.com/models.huggingface.co/bert/albert-base-v1-tf_model.h5",
|
||||
"albert-large-v1": "https://s3.amazonaws.com/models.huggingface.co/bert/albert-large-v1-tf_model.h5",
|
||||
"albert-xlarge-v1": "https://s3.amazonaws.com/models.huggingface.co/bert/albert-xlarge-v1-tf_model.h5",
|
||||
"albert-xxlarge-v1": "https://s3.amazonaws.com/models.huggingface.co/bert/albert-xxlarge-v1-tf_model.h5",
|
||||
"albert-base-v2": "https://s3.amazonaws.com/models.huggingface.co/bert/albert-base-v2-tf_model.h5",
|
||||
"albert-large-v2": "https://s3.amazonaws.com/models.huggingface.co/bert/albert-large-v2-tf_model.h5",
|
||||
"albert-xlarge-v2": "https://s3.amazonaws.com/models.huggingface.co/bert/albert-xlarge-v2-tf_model.h5",
|
||||
"albert-xxlarge-v2": "https://s3.amazonaws.com/models.huggingface.co/bert/albert-xxlarge-v2-tf_model.h5",
|
||||
"albert-base-v1": "https://s3.amazonaws.com/models.huggingface.co/bert/albert-base-v1-with-prefix-tf_model.h5",
|
||||
"albert-large-v1": "https://s3.amazonaws.com/models.huggingface.co/bert/albert-large-v1-with-prefix-tf_model.h5",
|
||||
"albert-xlarge-v1": "https://s3.amazonaws.com/models.huggingface.co/bert/albert-xlarge-v1-with-prefix-tf_model.h5",
|
||||
"albert-xxlarge-v1": "https://s3.amazonaws.com/models.huggingface.co/bert/albert-xxlarge-v1-with-prefix-tf_model.h5",
|
||||
"albert-base-v2": "https://s3.amazonaws.com/models.huggingface.co/bert/albert-base-v2-with-prefix-tf_model.h5",
|
||||
"albert-large-v2": "https://s3.amazonaws.com/models.huggingface.co/bert/albert-large-v2-with-prefix-tf_model.h5",
|
||||
"albert-xlarge-v2": "https://s3.amazonaws.com/models.huggingface.co/bert/albert-xlarge-v2-with-prefix-tf_model.h5",
|
||||
"albert-xxlarge-v2": "https://s3.amazonaws.com/models.huggingface.co/bert/albert-xxlarge-v2-with-prefix-tf_model.h5",
|
||||
}
|
||||
|
||||
|
||||
@@ -478,6 +478,115 @@ class TFAlbertMLMHead(tf.keras.layers.Layer):
|
||||
return hidden_states
|
||||
|
||||
|
||||
class TFAlbertMainLayer(tf.keras.layers.Layer):
|
||||
def __init__(self, config, **kwargs):
|
||||
super().__init__(config, **kwargs)
|
||||
self.num_hidden_layers = config.num_hidden_layers
|
||||
|
||||
self.embeddings = TFAlbertEmbeddings(config, name="embeddings")
|
||||
self.encoder = TFAlbertTransformer(config, name="encoder")
|
||||
self.pooler = tf.keras.layers.Dense(
|
||||
config.hidden_size,
|
||||
kernel_initializer=get_initializer(config.initializer_range),
|
||||
activation="tanh",
|
||||
name="pooler",
|
||||
)
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.embeddings
|
||||
|
||||
def _resize_token_embeddings(self, new_num_tokens):
|
||||
raise NotImplementedError
|
||||
|
||||
def _prune_heads(self, heads_to_prune):
|
||||
""" Prunes heads of the model.
|
||||
heads_to_prune: dict of {layer_num: list of heads to prune in this layer}
|
||||
See base class PreTrainedModel
|
||||
"""
|
||||
raise NotImplementedError
|
||||
|
||||
def call(
|
||||
self,
|
||||
inputs,
|
||||
attention_mask=None,
|
||||
token_type_ids=None,
|
||||
position_ids=None,
|
||||
head_mask=None,
|
||||
inputs_embeds=None,
|
||||
training=False,
|
||||
):
|
||||
if isinstance(inputs, (tuple, list)):
|
||||
input_ids = inputs[0]
|
||||
attention_mask = inputs[1] if len(inputs) > 1 else attention_mask
|
||||
token_type_ids = inputs[2] if len(inputs) > 2 else token_type_ids
|
||||
position_ids = inputs[3] if len(inputs) > 3 else position_ids
|
||||
head_mask = inputs[4] if len(inputs) > 4 else head_mask
|
||||
inputs_embeds = inputs[5] if len(inputs) > 5 else inputs_embeds
|
||||
assert len(inputs) <= 6, "Too many inputs."
|
||||
elif isinstance(inputs, dict):
|
||||
input_ids = inputs.get("input_ids")
|
||||
attention_mask = inputs.get("attention_mask", attention_mask)
|
||||
token_type_ids = inputs.get("token_type_ids", token_type_ids)
|
||||
position_ids = inputs.get("position_ids", position_ids)
|
||||
head_mask = inputs.get("head_mask", head_mask)
|
||||
inputs_embeds = inputs.get("inputs_embeds", inputs_embeds)
|
||||
assert len(inputs) <= 6, "Too many inputs."
|
||||
else:
|
||||
input_ids = inputs
|
||||
|
||||
if input_ids is not None and inputs_embeds is not None:
|
||||
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
|
||||
elif input_ids is not None:
|
||||
input_shape = shape_list(input_ids)
|
||||
elif inputs_embeds is not None:
|
||||
input_shape = shape_list(inputs_embeds)[:-1]
|
||||
else:
|
||||
raise ValueError("You have to specify either input_ids or inputs_embeds")
|
||||
|
||||
if attention_mask is None:
|
||||
attention_mask = tf.fill(input_shape, 1)
|
||||
if token_type_ids is None:
|
||||
token_type_ids = tf.fill(input_shape, 0)
|
||||
|
||||
# We create a 3D attention mask from a 2D tensor mask.
|
||||
# Sizes are [batch_size, 1, 1, to_seq_length]
|
||||
# So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
|
||||
# this attention mask is more simple than the triangular masking of causal attention
|
||||
# used in OpenAI GPT, we just need to prepare the broadcast dimension here.
|
||||
extended_attention_mask = attention_mask[:, tf.newaxis, tf.newaxis, :]
|
||||
|
||||
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
|
||||
# masked positions, this operation will create a tensor which is 0.0 for
|
||||
# positions we want to attend and -10000.0 for masked positions.
|
||||
# Since we are adding it to the raw scores before the softmax, this is
|
||||
# effectively the same as removing these entirely.
|
||||
|
||||
extended_attention_mask = tf.cast(extended_attention_mask, tf.float32)
|
||||
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
|
||||
|
||||
# Prepare head mask if needed
|
||||
# 1.0 in head_mask indicate we keep the head
|
||||
# attention_probs has shape bsz x n_heads x N x N
|
||||
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
|
||||
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
|
||||
if head_mask is not None:
|
||||
raise NotImplementedError
|
||||
else:
|
||||
head_mask = [None] * self.num_hidden_layers
|
||||
# head_mask = tf.constant([0] * self.num_hidden_layers)
|
||||
|
||||
embedding_output = self.embeddings([input_ids, position_ids, token_type_ids, inputs_embeds], training=training)
|
||||
encoder_outputs = self.encoder([embedding_output, extended_attention_mask, head_mask], training=training)
|
||||
|
||||
sequence_output = encoder_outputs[0]
|
||||
pooled_output = self.pooler(sequence_output[:, 0])
|
||||
|
||||
# add hidden_states and attentions if they are here
|
||||
outputs = (sequence_output, pooled_output,) + encoder_outputs[1:]
|
||||
# sequence_output, pooled_output, (hidden_states), (attentions)
|
||||
return outputs
|
||||
|
||||
|
||||
ALBERT_START_DOCSTRING = r"""
|
||||
This model is a `tf.keras.Model <https://www.tensorflow.org/api_docs/python/tf/keras/Model>`__ sub-class.
|
||||
Use it as a regular TF 2.0 Keras Model and
|
||||
@@ -560,147 +669,48 @@ ALBERT_INPUTS_DOCSTRING = r"""
|
||||
ALBERT_START_DOCSTRING,
|
||||
)
|
||||
class TFAlbertModel(TFAlbertPreTrainedModel):
|
||||
def __init__(self, config, **kwargs):
|
||||
super().__init__(config, **kwargs)
|
||||
self.num_hidden_layers = config.num_hidden_layers
|
||||
|
||||
self.embeddings = TFAlbertEmbeddings(config, name="embeddings")
|
||||
self.encoder = TFAlbertTransformer(config, name="encoder")
|
||||
self.pooler = tf.keras.layers.Dense(
|
||||
config.hidden_size,
|
||||
kernel_initializer=get_initializer(config.initializer_range),
|
||||
activation="tanh",
|
||||
name="pooler",
|
||||
)
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.embeddings
|
||||
|
||||
def _resize_token_embeddings(self, new_num_tokens):
|
||||
raise NotImplementedError
|
||||
|
||||
def _prune_heads(self, heads_to_prune):
|
||||
""" Prunes heads of the model.
|
||||
heads_to_prune: dict of {layer_num: list of heads to prune in this layer}
|
||||
See base class PreTrainedModel
|
||||
"""
|
||||
raise NotImplementedError
|
||||
def __init__(self, config, *inputs, **kwargs):
|
||||
super().__init__(config, *inputs, **kwargs)
|
||||
self.albert = TFAlbertMainLayer(config, name="albert")
|
||||
|
||||
@add_start_docstrings_to_callable(ALBERT_INPUTS_DOCSTRING)
|
||||
def call(
|
||||
self,
|
||||
inputs,
|
||||
attention_mask=None,
|
||||
token_type_ids=None,
|
||||
position_ids=None,
|
||||
head_mask=None,
|
||||
inputs_embeds=None,
|
||||
training=False,
|
||||
):
|
||||
def call(self, inputs, **kwargs):
|
||||
r"""
|
||||
Returns:
|
||||
:obj:`tuple(tf.Tensor)` comprising various elements depending on the configuration (:class:`~transformers.AlbertConfig`) and inputs:
|
||||
last_hidden_state (:obj:`tf.Tensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`):
|
||||
Sequence of hidden-states at the output of the last layer of the model.
|
||||
pooler_output (:obj:`tf.Tensor` of shape :obj:`(batch_size, hidden_size)`):
|
||||
Last layer hidden-state of the first token of the sequence (classification token)
|
||||
further processed by a Linear layer and a Tanh activation function. The Linear
|
||||
layer weights are trained from the next sentence prediction (classification)
|
||||
objective during Albert pretraining. This output is usually *not* a good summary
|
||||
of the semantic content of the input, you're often better with averaging or pooling
|
||||
the sequence of hidden-states for the whole input sequence.
|
||||
hidden_states (:obj:`tuple(tf.Tensor)`, `optional`, returned when :obj:`config.output_hidden_states=True`):
|
||||
tuple of :obj:`tf.Tensor` (one for the output of the embeddings + one for the output of each layer)
|
||||
of shape :obj:`(batch_size, sequence_length, hidden_size)`.
|
||||
Returns:
|
||||
:obj:`tuple(tf.Tensor)` comprising various elements depending on the configuration (:class:`~transformers.AlbertConfig`) and inputs:
|
||||
last_hidden_state (:obj:`tf.Tensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`):
|
||||
Sequence of hidden-states at the output of the last layer of the model.
|
||||
pooler_output (:obj:`tf.Tensor` of shape :obj:`(batch_size, hidden_size)`):
|
||||
Last layer hidden-state of the first token of the sequence (classification token)
|
||||
further processed by a Linear layer and a Tanh activation function. The Linear
|
||||
layer weights are trained from the next sentence prediction (classification)
|
||||
objective during Albert pretraining. This output is usually *not* a good summary
|
||||
of the semantic content of the input, you're often better with averaging or pooling
|
||||
the sequence of hidden-states for the whole input sequence.
|
||||
hidden_states (:obj:`tuple(tf.Tensor)`, `optional`, returned when :obj:`config.output_hidden_states=True`):
|
||||
tuple of :obj:`tf.Tensor` (one for the output of the embeddings + one for the output of each layer)
|
||||
of shape :obj:`(batch_size, sequence_length, hidden_size)`.
|
||||
|
||||
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
|
||||
attentions (:obj:`tuple(tf.Tensor)`, `optional`, returned when ``config.output_attentions=True``):
|
||||
tuple of :obj:`tf.Tensor` (one for each layer) of shape
|
||||
:obj:`(batch_size, num_heads, sequence_length, sequence_length)`:
|
||||
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
|
||||
attentions (:obj:`tuple(tf.Tensor)`, `optional`, returned when ``config.output_attentions=True``):
|
||||
tuple of :obj:`tf.Tensor` (one for each layer) of shape
|
||||
:obj:`(batch_size, num_heads, sequence_length, sequence_length)`:
|
||||
|
||||
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
|
||||
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
|
||||
|
||||
Examples::
|
||||
Examples::
|
||||
|
||||
import tensorflow as tf
|
||||
from transformers import AlbertTokenizer, TFAlbertModel
|
||||
import tensorflow as tf
|
||||
from transformers import AlbertTokenizer, TFAlbertModel
|
||||
|
||||
tokenizer = AlbertTokenizer.from_pretrained('albert-base-v2')
|
||||
model = TFAlbertModel.from_pretrained('albert-base-v2')
|
||||
input_ids = tf.constant(tokenizer.encode("Hello, my dog is cute"))[None, :] # Batch size 1
|
||||
outputs = model(input_ids)
|
||||
last_hidden_states = outputs[0] # The last hidden-state is the first element of the output tuple
|
||||
tokenizer = AlbertTokenizer.from_pretrained('albert-base-v2')
|
||||
model = TFAlbertModel.from_pretrained('albert-base-v2')
|
||||
input_ids = tf.constant(tokenizer.encode("Hello, my dog is cute"))[None, :] # Batch size 1
|
||||
outputs = model(input_ids)
|
||||
last_hidden_states = outputs[0] # The last hidden-state is the first element of the output tuple
|
||||
|
||||
"""
|
||||
if isinstance(inputs, (tuple, list)):
|
||||
input_ids = inputs[0]
|
||||
attention_mask = inputs[1] if len(inputs) > 1 else attention_mask
|
||||
token_type_ids = inputs[2] if len(inputs) > 2 else token_type_ids
|
||||
position_ids = inputs[3] if len(inputs) > 3 else position_ids
|
||||
head_mask = inputs[4] if len(inputs) > 4 else head_mask
|
||||
inputs_embeds = inputs[5] if len(inputs) > 5 else inputs_embeds
|
||||
assert len(inputs) <= 6, "Too many inputs."
|
||||
elif isinstance(inputs, dict):
|
||||
input_ids = inputs.get("input_ids")
|
||||
attention_mask = inputs.get("attention_mask", attention_mask)
|
||||
token_type_ids = inputs.get("token_type_ids", token_type_ids)
|
||||
position_ids = inputs.get("position_ids", position_ids)
|
||||
head_mask = inputs.get("head_mask", head_mask)
|
||||
inputs_embeds = inputs.get("inputs_embeds", inputs_embeds)
|
||||
assert len(inputs) <= 6, "Too many inputs."
|
||||
else:
|
||||
input_ids = inputs
|
||||
|
||||
if input_ids is not None and inputs_embeds is not None:
|
||||
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
|
||||
elif input_ids is not None:
|
||||
input_shape = shape_list(input_ids)
|
||||
elif inputs_embeds is not None:
|
||||
input_shape = shape_list(inputs_embeds)[:-1]
|
||||
else:
|
||||
raise ValueError("You have to specify either input_ids or inputs_embeds")
|
||||
|
||||
if attention_mask is None:
|
||||
attention_mask = tf.fill(input_shape, 1)
|
||||
if token_type_ids is None:
|
||||
token_type_ids = tf.fill(input_shape, 0)
|
||||
|
||||
# We create a 3D attention mask from a 2D tensor mask.
|
||||
# Sizes are [batch_size, 1, 1, to_seq_length]
|
||||
# So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
|
||||
# this attention mask is more simple than the triangular masking of causal attention
|
||||
# used in OpenAI GPT, we just need to prepare the broadcast dimension here.
|
||||
extended_attention_mask = attention_mask[:, tf.newaxis, tf.newaxis, :]
|
||||
|
||||
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
|
||||
# masked positions, this operation will create a tensor which is 0.0 for
|
||||
# positions we want to attend and -10000.0 for masked positions.
|
||||
# Since we are adding it to the raw scores before the softmax, this is
|
||||
# effectively the same as removing these entirely.
|
||||
|
||||
extended_attention_mask = tf.cast(extended_attention_mask, tf.float32)
|
||||
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
|
||||
|
||||
# Prepare head mask if needed
|
||||
# 1.0 in head_mask indicate we keep the head
|
||||
# attention_probs has shape bsz x n_heads x N x N
|
||||
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
|
||||
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
|
||||
if head_mask is not None:
|
||||
raise NotImplementedError
|
||||
else:
|
||||
head_mask = [None] * self.num_hidden_layers
|
||||
# head_mask = tf.constant([0] * self.num_hidden_layers)
|
||||
|
||||
embedding_output = self.embeddings([input_ids, position_ids, token_type_ids, inputs_embeds], training=training)
|
||||
encoder_outputs = self.encoder([embedding_output, extended_attention_mask, head_mask], training=training)
|
||||
|
||||
sequence_output = encoder_outputs[0]
|
||||
pooled_output = self.pooler(sequence_output[:, 0])
|
||||
|
||||
# add hidden_states and attentions if they are here
|
||||
outputs = (sequence_output, pooled_output,) + encoder_outputs[1:]
|
||||
# sequence_output, pooled_output, (hidden_states), (attentions)
|
||||
outputs = self.albert(inputs, **kwargs)
|
||||
return outputs
|
||||
|
||||
|
||||
@@ -709,7 +719,7 @@ class TFAlbertForMaskedLM(TFAlbertPreTrainedModel):
|
||||
def __init__(self, config, *inputs, **kwargs):
|
||||
super(TFAlbertForMaskedLM, self).__init__(config, *inputs, **kwargs)
|
||||
|
||||
self.albert = TFAlbertModel(config, name="albert")
|
||||
self.albert = TFAlbertMainLayer(config, name="albert")
|
||||
self.predictions = TFAlbertMLMHead(config, self.albert.embeddings, name="predictions")
|
||||
|
||||
def get_output_embeddings(self):
|
||||
@@ -766,7 +776,7 @@ class TFAlbertForSequenceClassification(TFAlbertPreTrainedModel):
|
||||
super(TFAlbertForSequenceClassification, self).__init__(config, *inputs, **kwargs)
|
||||
self.num_labels = config.num_labels
|
||||
|
||||
self.albert = TFAlbertModel(config, name="albert")
|
||||
self.albert = TFAlbertMainLayer(config, name="albert")
|
||||
self.dropout = tf.keras.layers.Dropout(config.hidden_dropout_prob)
|
||||
self.classifier = tf.keras.layers.Dense(
|
||||
config.num_labels, kernel_initializer=get_initializer(config.initializer_range), name="classifier"
|
||||
|
||||
@@ -192,9 +192,6 @@ class TFPreTrainedModel(tf.keras.Model, TFModelUtilsMixin):
|
||||
def from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs):
|
||||
r"""Instantiate a pretrained TF 2.0 model from a pre-trained model configuration.
|
||||
|
||||
The model is set in evaluation mode by default using ``model.eval()`` (Dropout modules are deactivated)
|
||||
To train the model, you should first set it back in training mode with ``model.train()``
|
||||
|
||||
The warning ``Weights from XXX not initialized from pretrained model`` means that the weights of XXX do not come pre-trained with the rest of the model.
|
||||
It is up to you to train those weights with a downstream fine-tuning task.
|
||||
|
||||
|
||||
@@ -645,7 +645,7 @@ class TransfoXLModel(TransfoXLPreTrainedModel):
|
||||
else:
|
||||
return None
|
||||
|
||||
def _update_mems(self, hids, mems, qlen, mlen):
|
||||
def _update_mems(self, hids, mems, mlen, qlen):
|
||||
# does not deal with None
|
||||
if mems is None:
|
||||
return None
|
||||
|
||||
@@ -376,6 +376,7 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
resume_download = kwargs.pop("resume_download", False)
|
||||
proxies = kwargs.pop("proxies", None)
|
||||
output_loading_info = kwargs.pop("output_loading_info", False)
|
||||
local_files_only = kwargs.pop("local_files_only", False)
|
||||
|
||||
# Load config if we don't provide a configuration
|
||||
if not isinstance(config, PretrainedConfig):
|
||||
@@ -388,6 +389,7 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
force_download=force_download,
|
||||
resume_download=resume_download,
|
||||
proxies=proxies,
|
||||
local_files_only=local_files_only,
|
||||
**kwargs,
|
||||
)
|
||||
else:
|
||||
@@ -435,6 +437,7 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
force_download=force_download,
|
||||
proxies=proxies,
|
||||
resume_download=resume_download,
|
||||
local_files_only=local_files_only,
|
||||
)
|
||||
except EnvironmentError:
|
||||
if pretrained_model_name_or_path in cls.pretrained_model_archive_map:
|
||||
@@ -645,33 +648,39 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
num_return_sequences: (`optional`) int
|
||||
The number of independently computed returned sequences for each element in the batch. Default to 1.
|
||||
|
||||
Return:
|
||||
|
||||
output: `torch.LongTensor` of shape `(batch_size * num_return_sequences, sequence_length)`
|
||||
sequence_length is either equal to max_length or shorter if all batches finished early due to the `eos_token_id`
|
||||
|
||||
Examples::
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained('distilgpt2') # Initialize tokenizer
|
||||
model = AutoModelWithLMHead.from_pretrained('distilgpt2') # Download model and configuration from S3 and cache.
|
||||
outputs = model.generate(max_length=40, bos_token_id=tokenizer.bos_token_id, eos_token_ids=tokenizer.eos_token_id) # do greedy decoding without beam search
|
||||
outputs = model.generate(max_length=40, bos_token_id=tokenizer.bos_token_id, eos_token_ids=tokenizer.eos_token_id, do_sample=False) # do greedy decoding
|
||||
print('Generated: {}'.format(tokenizer.decode(outputs[0], skip_special_tokens=True)))
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained('openai-gpt') # Initialize tokenizer
|
||||
model = AutoModelWithLMHead.from_pretrained('openai-gpt') # Download model and configuration from S3 and cache.
|
||||
input_context = 'The dog'
|
||||
input_ids = torch.tensor(tokenizer.encode(input_context)).unsqueeze(0) # encode input context
|
||||
outputs = model.generate(input_ids=input_ids, do_sample=True, num_beams=5, num_return_sequences=3, temperature=1.5) # generate 3 independent sequences using beam search decoding (5 beams) with sampling from initial context 'The dog'
|
||||
outputs = model.generate(input_ids=input_ids, num_beams=5, num_return_sequences=3, temperature=1.5) # generate 3 independent sequences using beam search decoding (5 beams) with sampling from initial context 'The dog'
|
||||
for i in range(3): # 3 output sequences were generated
|
||||
print('Generated {}: {}'.format(i, tokenizer.decode(outputs[0][i], skip_special_tokens=True)))
|
||||
print('Generated {}: {}'.format(i, tokenizer.decode(outputs[i], skip_special_tokens=True)))
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained('distilgpt2') # Initialize tokenizer
|
||||
model = AutoModelWithLMHead.from_pretrained('distilgpt2') # Download model and configuration from S3 and cache.
|
||||
input_context = 'The dog'
|
||||
input_ids = torch.tensor(tokenizer.encode(input_context)).unsqueeze(0) # encode input context
|
||||
outputs = model.generate(input_ids=input_ids, max_length=40, temperature=0.7, bos_token_id=tokenizer.bos_token_id, eos_token_ids=tokenizer.eos_token_id, num_beams=3) # generate sequences using greedy beam search decoding (3 beams)
|
||||
print('Generated: {}'.format(tokenizer.decode(outputs[0], skip_special_tokens=True)))
|
||||
outputs = model.generate(input_ids=input_ids, max_length=40, temperature=0.7, bos_token_id=tokenizer.bos_token_id, pad_token_id=tokenizer.pad_token_id, eos_token_ids=tokenizer.eos_token_id, num_return_sequences=3) # 3 generate sequences using by sampling
|
||||
for i in range(3): # 3 output sequences were generated
|
||||
print('Generated {}: {}'.format(i, tokenizer.decode(outputs[i], skip_special_tokens=True)))
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained('ctrl') # Initialize tokenizer
|
||||
model = AutoModelWithLMHead.from_pretrained('ctrl') # Download model and configuration from S3 and cache.
|
||||
input_context = 'Legal My neighbor is' # "Legal" is one of the control codes for ctrl
|
||||
input_ids = torch.tensor(tokenizer.encode(input_context)).unsqueeze(0) # encode input context
|
||||
outputs = model.generate(input_ids=input_ids, max_length=50, temperature=0.7, repetition_penalty=1.2) # generate sequences using using greedy search
|
||||
outputs = model.generate(input_ids=input_ids, max_length=50, temperature=0.7, repetition_penalty=1.2) # generate sequences
|
||||
print('Generated: {}'.format(tokenizer.decode(outputs[0], skip_special_tokens=True)))
|
||||
|
||||
"""
|
||||
@@ -712,10 +721,14 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
assert isinstance(top_k, int) and top_k >= 0, "`top_k` should be a positive integer."
|
||||
assert 0 <= top_p <= 1, "`top_p` should be between 0 and 1."
|
||||
assert repetition_penalty >= 1.0, "`repetition_penalty` should be >= 1."
|
||||
assert isinstance(bos_token_id, int) and bos_token_id >= 0, "`bos_token_id` should be a positive integer."
|
||||
assert isinstance(pad_token_id, int) and pad_token_id >= 0, "`pad_token_id` should be a positive integer."
|
||||
assert isinstance(eos_token_ids, (list, tuple)) and (
|
||||
e >= 0 for e in eos_token_ids
|
||||
assert input_ids is not None or (
|
||||
isinstance(bos_token_id, int) and bos_token_id >= 0
|
||||
), "If input_ids is not defined, `bos_token_id` should be a positive integer."
|
||||
assert pad_token_id is None or (
|
||||
isinstance(pad_token_id, int) and (pad_token_id >= 0)
|
||||
), "`pad_token_id` should be a positive integer."
|
||||
assert (eos_token_ids is None) or (
|
||||
isinstance(eos_token_ids, (list, tuple)) and ((isinstance(e, int) and e >= 0) for e in eos_token_ids)
|
||||
), "`eos_token_ids` should be a positive integer or a list/tuple of positive integers."
|
||||
assert length_penalty > 0, "`length_penalty` should be strictely positive."
|
||||
assert (
|
||||
@@ -723,12 +736,22 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
), "`num_return_sequences` should be a strictely positive integer."
|
||||
|
||||
if input_ids is None:
|
||||
assert isinstance(bos_token_id, int) and bos_token_id >= 0, (
|
||||
"you should either supply a context to complete as `input_ids` input "
|
||||
"or a `bos_token_id` (integer >= 0) as a first token to start the generation."
|
||||
)
|
||||
input_ids = torch.full(
|
||||
(batch_size, 1), bos_token_id, dtype=torch.long, device=next(self.parameters()).device
|
||||
)
|
||||
else:
|
||||
assert input_ids.dim() == 2, "Input prompt should be of shape (batch_size, sequence length)."
|
||||
|
||||
if pad_token_id is None and eos_token_ids is not None:
|
||||
logger.warning(
|
||||
"Setting `pad_token_id` to {} (first `eos_token_id`) to generate sequence".format(eos_token_ids[0])
|
||||
)
|
||||
pad_token_id = eos_token_ids[0]
|
||||
|
||||
# current position and vocab size
|
||||
cur_len = input_ids.shape[1]
|
||||
vocab_size = self.config.vocab_size
|
||||
@@ -775,8 +798,6 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
effective_batch_size,
|
||||
)
|
||||
|
||||
if num_return_sequences != 1:
|
||||
output = output.view(batch_size, num_return_sequences, -1)
|
||||
return output
|
||||
|
||||
def _generate_no_beam_search(
|
||||
@@ -798,6 +819,7 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
"""
|
||||
# current position / max lengths / length of generated sentences / unfinished sentences
|
||||
unfinished_sents = input_ids.new(batch_size).fill_(1)
|
||||
sent_lengths = input_ids.new(batch_size).fill_(max_length)
|
||||
|
||||
past = None
|
||||
|
||||
@@ -833,21 +855,41 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
next_token = torch.argmax(next_token_logits, dim=-1)
|
||||
|
||||
# update generations and finished sentences
|
||||
tokens_to_add = next_token * unfinished_sents + pad_token_id * (1 - unfinished_sents)
|
||||
if eos_token_ids is not None:
|
||||
# pad finished sentences if eos_token_ids exist
|
||||
tokens_to_add = next_token * unfinished_sents + (pad_token_id) * (1 - unfinished_sents)
|
||||
else:
|
||||
tokens_to_add = next_token
|
||||
|
||||
input_ids = torch.cat([input_ids, tokens_to_add.unsqueeze(-1)], dim=-1)
|
||||
for eos_token_id in eos_token_ids:
|
||||
unfinished_sents.mul_(tokens_to_add.ne(eos_token_id).long())
|
||||
|
||||
if eos_token_ids is not None:
|
||||
for eos_token_id in eos_token_ids:
|
||||
eos_in_sents = tokens_to_add == eos_token_id
|
||||
# if sentence is unfinished and the token to add is eos, sent_lengths is filled with current length
|
||||
is_sents_unfinished_and_token_to_add_is_eos = unfinished_sents.mul(eos_in_sents.long()).bool()
|
||||
sent_lengths.masked_fill_(is_sents_unfinished_and_token_to_add_is_eos, cur_len + 1)
|
||||
# unfinished_sents is set to zero if eos in sentence
|
||||
unfinished_sents.mul_((~eos_in_sents).long())
|
||||
|
||||
cur_len = cur_len + 1
|
||||
|
||||
# stop when there is a </s> in each sentence, or if we exceed the maximul length
|
||||
if unfinished_sents.max() == 0:
|
||||
break
|
||||
|
||||
# add eos_token_ids to unfinished sentences
|
||||
if cur_len == max_length:
|
||||
input_ids[:, -1].masked_fill_(unfinished_sents.to(dtype=torch.bool), eos_token_ids[0])
|
||||
# if there are different sentences lengths in the batch, some batches have to be padded
|
||||
if sent_lengths.min().item() != sent_lengths.max().item():
|
||||
assert pad_token_id is not None, "`Pad_token_id` has to be defined if batches have different lengths"
|
||||
# finished sents are filled with pad_token
|
||||
decoded = input_ids.new(batch_size, sent_lengths.max().item()).fill_(pad_token_id)
|
||||
else:
|
||||
decoded = input_ids
|
||||
|
||||
return input_ids
|
||||
for hypo_idx, hypo in enumerate(input_ids):
|
||||
decoded[hypo_idx, : sent_lengths[hypo_idx]] = hypo[: sent_lengths[hypo_idx]]
|
||||
|
||||
return decoded
|
||||
|
||||
def _generate_beam_search(
|
||||
self,
|
||||
@@ -941,11 +983,19 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
next_batch_beam = []
|
||||
|
||||
# for each sentence
|
||||
for batch_ex in range(batch_size):
|
||||
for batch_idx in range(batch_size):
|
||||
|
||||
# if we are done with this sentence
|
||||
done[batch_ex] = done[batch_ex] or generated_hyps[batch_ex].is_done(next_scores[batch_ex].max().item())
|
||||
if done[batch_ex]:
|
||||
done[batch_idx] = done[batch_idx] or generated_hyps[batch_idx].is_done(
|
||||
next_scores[batch_idx].max().item()
|
||||
)
|
||||
if done[batch_idx]:
|
||||
assert (
|
||||
len(generated_hyps[batch_idx]) >= num_beams
|
||||
), "Batch can only be done if at least {} beams have been generated".format(num_beams)
|
||||
assert (
|
||||
eos_token_ids is not None and pad_token_id is not None
|
||||
), "generated beams >= num_beams -> eos_token_id and pad_token have to be defined"
|
||||
next_batch_beam.extend([(0, pad_token_id, 0)] * num_beams) # pad the batch
|
||||
continue
|
||||
|
||||
@@ -953,30 +1003,29 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
next_sent_beam = []
|
||||
|
||||
# next words for this sentence
|
||||
for idx, score in zip(next_words[batch_ex], next_scores[batch_ex]):
|
||||
for idx, score in zip(next_words[batch_idx], next_scores[batch_idx]):
|
||||
|
||||
# get beam and word IDs
|
||||
beam_id = idx // vocab_size
|
||||
word_id = idx % vocab_size
|
||||
|
||||
# end of sentence, or next word
|
||||
if word_id.item() in eos_token_ids or cur_len + 1 == max_length:
|
||||
generated_hyps[batch_ex].add(
|
||||
input_ids[batch_ex * num_beams + beam_id, :cur_len].clone(), score.item()
|
||||
# add to generated hypotheses if end of sentence or last iteration
|
||||
if eos_token_ids is not None and word_id.item() in eos_token_ids:
|
||||
generated_hyps[batch_idx].add(
|
||||
input_ids[batch_idx * num_beams + beam_id, :cur_len].clone(), score.item()
|
||||
)
|
||||
else:
|
||||
next_sent_beam.append((score, word_id, batch_ex * num_beams + beam_id))
|
||||
# add next predicted word if it is not eos_token
|
||||
next_sent_beam.append((score, word_id, batch_idx * num_beams + beam_id))
|
||||
|
||||
# the beam for next step is full
|
||||
if len(next_sent_beam) == num_beams:
|
||||
break
|
||||
|
||||
# update next beam content
|
||||
assert len(next_sent_beam) == 0 if cur_len + 1 == max_length else num_beams
|
||||
if len(next_sent_beam) == 0:
|
||||
next_sent_beam = [(0, pad_token_id, 0)] * num_beams # pad the batch
|
||||
assert len(next_sent_beam) == num_beams, "Beam should always be full"
|
||||
next_batch_beam.extend(next_sent_beam)
|
||||
assert len(next_batch_beam) == num_beams * (batch_ex + 1)
|
||||
assert len(next_batch_beam) == num_beams * (batch_idx + 1)
|
||||
|
||||
# sanity check / prepare next batch
|
||||
assert len(next_batch_beam) == batch_size * num_beams
|
||||
@@ -1008,29 +1057,42 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
if all(done):
|
||||
break
|
||||
|
||||
# visualize hypotheses
|
||||
# print([len(x) for x in generated_hyps], cur_len)
|
||||
# globals().update( locals() );
|
||||
# !import code; code.interact(local=vars())
|
||||
# for ii in range(batch_size):
|
||||
# for ss, ww in sorted(generated_hyps[ii].hyp, key=lambda x: x[0], reverse=True):
|
||||
# print("%.3f " % ss + " ".join(self.dico[x] for x in ww.tolist()))
|
||||
# print("")
|
||||
for batch_idx in range(batch_size):
|
||||
# Add all open beam hypothesis to generated_hyps
|
||||
if not done[batch_idx]:
|
||||
for idx, score in zip(next_words[batch_idx], next_scores[batch_idx]):
|
||||
|
||||
# get beam and word IDs
|
||||
beam_id = idx // vocab_size
|
||||
word_id = idx % vocab_size
|
||||
generated_hyps[batch_idx].add(
|
||||
input_ids[batch_idx * num_beams + beam_id, :cur_len].clone(), score.item()
|
||||
)
|
||||
|
||||
# select the best hypotheses
|
||||
tgt_len = input_ids.new(batch_size)
|
||||
sent_lengths = input_ids.new(batch_size)
|
||||
best = []
|
||||
|
||||
for i, hypotheses in enumerate(generated_hyps):
|
||||
best_hyp = max(hypotheses.hyp, key=lambda x: x[0])[1]
|
||||
tgt_len[i] = len(best_hyp) + 1 # +1 for the <EOS> symbol
|
||||
best_hyp = max(hypotheses.beams, key=lambda x: x[0])[1]
|
||||
sent_lengths[i] = len(best_hyp)
|
||||
best.append(best_hyp)
|
||||
|
||||
# generate target batch
|
||||
decoded = input_ids.new(batch_size, tgt_len.max().item()).fill_(pad_token_id)
|
||||
for i, hypo in enumerate(best):
|
||||
decoded[i, : tgt_len[i] - 1] = hypo
|
||||
decoded[i, tgt_len[i] - 1] = eos_token_ids[0]
|
||||
# shorter batches are filled with pad_token
|
||||
if sent_lengths.min().item() != sent_lengths.max().item():
|
||||
assert pad_token_id is not None, "`Pad_token_id` has to be defined"
|
||||
sent_max_len = min(sent_lengths.max().item() + 1, max_length)
|
||||
decoded = input_ids.new(batch_size, sent_max_len).fill_(pad_token_id)
|
||||
|
||||
# fill with hypothesis and eos_token_id if necessary
|
||||
for i, hypo in enumerate(best):
|
||||
decoded[i, : sent_lengths[i]] = hypo
|
||||
if sent_lengths[i] < max_length:
|
||||
decoded[i, sent_lengths[i]] = eos_token_ids[0]
|
||||
else:
|
||||
# none of the hypotheses have an eos_token
|
||||
assert (len(hypo) == max_length for hypo in best)
|
||||
decoded = torch.stack(best).type(torch.long).to(next(self.parameters()).device)
|
||||
|
||||
return decoded
|
||||
|
||||
@@ -1071,33 +1133,33 @@ def top_k_top_p_filtering(logits, top_k=0, top_p=1.0, filter_value=-float("Inf")
|
||||
|
||||
|
||||
class BeamHypotheses(object):
|
||||
def __init__(self, n_hyp, max_length, length_penalty, early_stopping):
|
||||
def __init__(self, num_beams, max_length, length_penalty, early_stopping):
|
||||
"""
|
||||
Initialize n-best list of hypotheses.
|
||||
"""
|
||||
self.max_length = max_length - 1 # ignoring bos_token
|
||||
self.length_penalty = length_penalty
|
||||
self.early_stopping = early_stopping
|
||||
self.n_hyp = n_hyp
|
||||
self.hyp = []
|
||||
self.num_beams = num_beams
|
||||
self.beams = []
|
||||
self.worst_score = 1e9
|
||||
|
||||
def __len__(self):
|
||||
"""
|
||||
Number of hypotheses in the list.
|
||||
"""
|
||||
return len(self.hyp)
|
||||
return len(self.beams)
|
||||
|
||||
def add(self, hyp, sum_logprobs):
|
||||
"""
|
||||
Add a new hypothesis to the list.
|
||||
"""
|
||||
score = sum_logprobs / len(hyp) ** self.length_penalty
|
||||
if len(self) < self.n_hyp or score > self.worst_score:
|
||||
self.hyp.append((score, hyp))
|
||||
if len(self) > self.n_hyp:
|
||||
sorted_scores = sorted([(s, idx) for idx, (s, _) in enumerate(self.hyp)])
|
||||
del self.hyp[sorted_scores[0][1]]
|
||||
if len(self) < self.num_beams or score > self.worst_score:
|
||||
self.beams.append((score, hyp))
|
||||
if len(self) > self.num_beams:
|
||||
sorted_scores = sorted([(s, idx) for idx, (s, _) in enumerate(self.beams)])
|
||||
del self.beams[sorted_scores[0][1]]
|
||||
self.worst_score = sorted_scores[1][0]
|
||||
else:
|
||||
self.worst_score = min(score, self.worst_score)
|
||||
@@ -1107,7 +1169,7 @@ class BeamHypotheses(object):
|
||||
If there are enough hypotheses and that none of the hypotheses being generated
|
||||
can become better than the worst one in the heap, then we are done with this sentence.
|
||||
"""
|
||||
if len(self) < self.n_hyp:
|
||||
if len(self) < self.num_beams:
|
||||
return False
|
||||
elif self.early_stopping:
|
||||
return True
|
||||
@@ -1448,6 +1510,20 @@ class SequenceSummary(nn.Module):
|
||||
return output
|
||||
|
||||
|
||||
def create_position_ids_from_input_ids(input_ids, padding_idx):
|
||||
""" Replace non-padding symbols with their position numbers. Position numbers begin at
|
||||
padding_idx+1. Padding symbols are ignored. This is modified from fairseq's
|
||||
`utils.make_positions`.
|
||||
|
||||
:param torch.Tensor x:
|
||||
:return torch.Tensor:
|
||||
"""
|
||||
# The series of casts and type-conversions here are carefully balanced to both work with ONNX export and XLA.
|
||||
mask = input_ids.ne(padding_idx).int()
|
||||
incremental_indicies = torch.cumsum(mask, dim=1).type_as(mask) * mask
|
||||
return incremental_indicies.long() + padding_idx
|
||||
|
||||
|
||||
def prune_linear_layer(layer, index, dim=0):
|
||||
""" Prune a linear layer (a model parameters) to keep only entries in index.
|
||||
Return the pruned layer as a new layer with requires_grad=True.
|
||||
|
||||
@@ -512,7 +512,7 @@ class XLMModel(XLMPreTrainedModel):
|
||||
inputs_embeds = self.embeddings(input_ids)
|
||||
|
||||
tensor = inputs_embeds + self.position_embeddings(position_ids).expand_as(inputs_embeds)
|
||||
if langs is not None and self.use_lang_emb:
|
||||
if langs is not None and self.use_lang_emb and self.n_langs > 1:
|
||||
tensor = tensor + self.lang_embeddings(langs)
|
||||
if token_type_ids is not None:
|
||||
tensor = tensor + self.embeddings(token_type_ids)
|
||||
|
||||
@@ -702,8 +702,9 @@ class XLNetModel(XLNetPreTrainedModel):
|
||||
r"""
|
||||
Return:
|
||||
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.XLNetConfig`) and inputs:
|
||||
last_hidden_state (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`):
|
||||
last_hidden_state (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, num_predict, hidden_size)`):
|
||||
Sequence of hidden-states at the last layer of the model.
|
||||
`num_predict` corresponds to `target_mapping.shape[1]`. If `target_mapping` is `None`, then `num_predict` corresponds to `sequence_length`.
|
||||
mems (:obj:`List[torch.FloatTensor]` of length :obj:`config.n_layers`):
|
||||
Contains pre-computed hidden-states (key and values in the attention blocks).
|
||||
Can be used (see `mems` input) to speed up sequential decoding. The token ids which have their past given to this model
|
||||
@@ -728,7 +729,7 @@ class XLNetModel(XLNetPreTrainedModel):
|
||||
tokenizer = XLNetTokenizer.from_pretrained('xlnet-large-cased')
|
||||
model = XLNetModel.from_pretrained('xlnet-large-cased')
|
||||
|
||||
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute", add_special_tokens=True)).unsqueeze(0) # Batch size 1
|
||||
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute", add_special_tokens=False)).unsqueeze(0) # Batch size 1
|
||||
|
||||
outputs = model(input_ids)
|
||||
last_hidden_states = outputs[0] # The last hidden-state is the first element of the output tuple
|
||||
@@ -977,19 +978,21 @@ class XLNetLMHeadModel(XLNetPreTrainedModel):
|
||||
labels=None,
|
||||
):
|
||||
r"""
|
||||
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`, defaults to :obj:`None`):
|
||||
Labels for language modeling.
|
||||
Note that the labels **are shifted** inside the model, i.e. you can set ``lm_labels = input_ids``
|
||||
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size, num_predict)`, `optional`, defaults to :obj:`None`):
|
||||
Labels for masked language modeling.
|
||||
`num_predict` corresponds to `target_mapping.shape[1]`. If `target_mapping` is `None`, then `num_predict` corresponds to `sequence_length`.
|
||||
The labels should correspond to the masked input words that should be predicted and depends on `target_mapping`. Note in order to perform standard auto-regressive language modeling a `<mask>` token has to be added to the `input_ids` (see `prepare_inputs_for_generation` fn and examples below)
|
||||
Indices are selected in ``[-100, 0, ..., config.vocab_size]``
|
||||
All labels set to ``-100`` are ignored (masked), the loss is only
|
||||
All labels set to ``-100`` are ignored, the loss is only
|
||||
computed for labels in ``[0, ..., config.vocab_size]``
|
||||
|
||||
Return:
|
||||
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.XLNetConfig`) and inputs:
|
||||
loss (:obj:`torch.FloatTensor` of shape `(1,)`, `optional`, returned when ``labels`` is provided)
|
||||
Language modeling loss.
|
||||
prediction_scores (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, config.vocab_size)`):
|
||||
prediction_scores (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, num_predict, config.vocab_size)`):
|
||||
Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
|
||||
`num_predict` corresponds to `target_mapping.shape[1]`. If `target_mapping` is `None`, then `num_predict` corresponds to `sequence_length`.
|
||||
mems (:obj:`List[torch.FloatTensor]` of length :obj:`config.n_layers`):
|
||||
Contains pre-computed hidden-states (key and values in the attention blocks).
|
||||
Can be used (see `past` input) to speed up sequential decoding. The token ids which have their past given to this model
|
||||
@@ -1015,7 +1018,7 @@ class XLNetLMHeadModel(XLNetPreTrainedModel):
|
||||
model = XLNetLMHeadModel.from_pretrained('xlnet-large-cased')
|
||||
|
||||
# We show how to setup inputs to predict a next token using a bi-directional context.
|
||||
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is very <mask>", add_special_tokens=True)).unsqueeze(0) # We will predict the masked token
|
||||
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is very <mask>", add_special_tokens=False)).unsqueeze(0) # We will predict the masked token
|
||||
perm_mask = torch.zeros((1, input_ids.shape[1], input_ids.shape[1]), dtype=torch.float)
|
||||
perm_mask[:, :, -1] = 1.0 # Previous tokens don't see last token
|
||||
target_mapping = torch.zeros((1, 1, input_ids.shape[1]), dtype=torch.float) # Shape [1, 1, seq_length] => let's predict one token
|
||||
@@ -1024,6 +1027,18 @@ class XLNetLMHeadModel(XLNetPreTrainedModel):
|
||||
outputs = model(input_ids, perm_mask=perm_mask, target_mapping=target_mapping)
|
||||
next_token_logits = outputs[0] # Output has shape [target_mapping.size(0), target_mapping.size(1), config.vocab_size]
|
||||
|
||||
# The same way can the XLNetLMHeadModel be used to be trained by standard auto-regressive language modeling.
|
||||
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is very <mask>", add_special_tokens=False)).unsqueeze(0) # We will predict the masked token
|
||||
labels = torch.tensor(tokenizer.encode("cute", add_special_tokens=False)).unsqueeze(0)
|
||||
assert labels.shape[0] == 1, 'only one word will be predicted'
|
||||
perm_mask = torch.zeros((1, input_ids.shape[1], input_ids.shape[1]), dtype=torch.float)
|
||||
perm_mask[:, :, -1] = 1.0 # Previous tokens don't see last token as is done in standard auto-regressive lm training
|
||||
target_mapping = torch.zeros((1, 1, input_ids.shape[1]), dtype=torch.float) # Shape [1, 1, seq_length] => let's predict one token
|
||||
target_mapping[0, 0, -1] = 1.0 # Our first (and only) prediction will be the last token of the sequence (the masked token)
|
||||
|
||||
outputs = model(input_ids, perm_mask=perm_mask, target_mapping=target_mapping, labels=labels)
|
||||
loss, next_token_logits = outputs[:2] # Output has shape [target_mapping.size(0), target_mapping.size(1), config.vocab_size]
|
||||
|
||||
"""
|
||||
transformer_outputs = self.transformer(
|
||||
input_ids,
|
||||
|
||||
@@ -114,6 +114,11 @@ class AlbertTokenizer(PreTrainedTokenizer):
|
||||
def vocab_size(self):
|
||||
return len(self.sp_model)
|
||||
|
||||
def get_vocab(self):
|
||||
vocab = {self.convert_ids_to_tokens(i): i for i in range(self.vocab_size)}
|
||||
vocab.update(self.added_tokens_encoder)
|
||||
return vocab
|
||||
|
||||
def __getstate__(self):
|
||||
state = self.__dict__.copy()
|
||||
state["sp_model"] = None
|
||||
|
||||
@@ -21,6 +21,7 @@ from collections import OrderedDict
|
||||
from .configuration_auto import (
|
||||
AlbertConfig,
|
||||
AutoConfig,
|
||||
BartConfig,
|
||||
BertConfig,
|
||||
CamembertConfig,
|
||||
CTRLConfig,
|
||||
@@ -37,6 +38,7 @@ from .configuration_auto import (
|
||||
)
|
||||
from .configuration_utils import PretrainedConfig
|
||||
from .tokenization_albert import AlbertTokenizer
|
||||
from .tokenization_bart import BartTokenizer
|
||||
from .tokenization_bert import BertTokenizer, BertTokenizerFast
|
||||
from .tokenization_bert_japanese import BertJapaneseTokenizer
|
||||
from .tokenization_camembert import CamembertTokenizer
|
||||
@@ -63,6 +65,7 @@ TOKENIZER_MAPPING = OrderedDict(
|
||||
(AlbertConfig, (AlbertTokenizer, None)),
|
||||
(CamembertConfig, (CamembertTokenizer, None)),
|
||||
(XLMRobertaConfig, (XLMRobertaTokenizer, None)),
|
||||
(BartConfig, (BartTokenizer, None)),
|
||||
(RobertaConfig, (RobertaTokenizer, RobertaTokenizerFast)),
|
||||
(BertConfig, (BertTokenizer, BertTokenizerFast)),
|
||||
(OpenAIGPTConfig, (OpenAIGPTTokenizer, OpenAIGPTTokenizerFast)),
|
||||
@@ -154,7 +157,7 @@ class AutoTokenizer:
|
||||
A dictionary of proxy servers to use by protocol or endpoint, e.g.: {'http': 'foo.bar:3128', 'http://hostname': 'foo.bar:4012'}.
|
||||
The proxies are used on each request.
|
||||
|
||||
use_fast: (`optional`) boolean, default True:
|
||||
use_fast: (`optional`) boolean, default False:
|
||||
Indicate if transformers should try to load the fast version of the tokenizer (True) or use the Python one (False).
|
||||
|
||||
inputs: (`optional`) positional arguments: will be passed to the Tokenizer ``__init__`` method.
|
||||
@@ -180,7 +183,7 @@ class AutoTokenizer:
|
||||
if "bert-base-japanese" in pretrained_model_name_or_path:
|
||||
return BertJapaneseTokenizer.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)
|
||||
|
||||
use_fast = kwargs.pop("use_fast", True)
|
||||
use_fast = kwargs.pop("use_fast", False)
|
||||
for config_class, (tokenizer_class_py, tokenizer_class_fast) in TOKENIZER_MAPPING.items():
|
||||
if isinstance(config, config_class):
|
||||
if tokenizer_class_fast and use_fast:
|
||||
|
||||
35
src/transformers/tokenization_bart.py
Normal file
35
src/transformers/tokenization_bart.py
Normal file
@@ -0,0 +1,35 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2020 The Facebook AI Research Team Authors and The HuggingFace Inc. team.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from .tokenization_roberta import RobertaTokenizer
|
||||
|
||||
|
||||
# vocab and merges same as roberta
|
||||
vocab_url = "https://s3.amazonaws.com/models.huggingface.co/bert/roberta-large-vocab.json"
|
||||
merges_url = "https://s3.amazonaws.com/models.huggingface.co/bert/roberta-large-merges.txt"
|
||||
_all_bart_models = [
|
||||
"bart-large",
|
||||
"bart-large-mnli",
|
||||
# "bart-large-cnn"
|
||||
]
|
||||
|
||||
|
||||
class BartTokenizer(RobertaTokenizer):
|
||||
# merges and vocab same as Roberta
|
||||
max_model_input_sizes = {m: 1024 for m in _all_bart_models}
|
||||
pretrained_vocab_files_map = {
|
||||
"vocab_file": {m: vocab_url for m in _all_bart_models},
|
||||
"merges_file": {m: merges_url for m in _all_bart_models},
|
||||
}
|
||||
@@ -195,6 +195,9 @@ class BertTokenizer(PreTrainedTokenizer):
|
||||
def vocab_size(self):
|
||||
return len(self.vocab)
|
||||
|
||||
def get_vocab(self):
|
||||
return dict(self.vocab, **self.added_tokens_encoder)
|
||||
|
||||
def _tokenize(self, text):
|
||||
split_tokens = []
|
||||
if self.do_basic_tokenize:
|
||||
@@ -549,8 +552,11 @@ class BertTokenizerFast(PreTrainedTokenizerFast):
|
||||
pad_token="[PAD]",
|
||||
cls_token="[CLS]",
|
||||
mask_token="[MASK]",
|
||||
clean_text=True,
|
||||
tokenize_chinese_chars=True,
|
||||
add_special_tokens=True,
|
||||
strip_accents=True,
|
||||
wordpieces_prefix="##",
|
||||
**kwargs
|
||||
):
|
||||
super().__init__(
|
||||
@@ -560,8 +566,11 @@ class BertTokenizerFast(PreTrainedTokenizerFast):
|
||||
unk_token=unk_token,
|
||||
sep_token=sep_token,
|
||||
cls_token=cls_token,
|
||||
clean_text=clean_text,
|
||||
handle_chinese_chars=tokenize_chinese_chars,
|
||||
strip_accents=strip_accents,
|
||||
lowercase=do_lower_case,
|
||||
wordpieces_prefix=wordpieces_prefix,
|
||||
),
|
||||
unk_token=unk_token,
|
||||
sep_token=sep_token,
|
||||
@@ -572,3 +581,11 @@ class BertTokenizerFast(PreTrainedTokenizerFast):
|
||||
)
|
||||
|
||||
self.do_lower_case = do_lower_case
|
||||
|
||||
def build_inputs_with_special_tokens(self, token_ids_0, token_ids_1=None):
|
||||
output = [self.cls_token_id] + token_ids_0 + [self.sep_token_id]
|
||||
|
||||
if token_ids_1:
|
||||
output += token_ids_1 + [self.sep_token_id]
|
||||
|
||||
return output
|
||||
|
||||
@@ -147,6 +147,9 @@ class CTRLTokenizer(PreTrainedTokenizer):
|
||||
def vocab_size(self):
|
||||
return len(self.encoder)
|
||||
|
||||
def get_vocab(self):
|
||||
return dict(self.encoder, **self.added_tokens_encoder)
|
||||
|
||||
def bpe(self, token):
|
||||
if token in self.cache:
|
||||
return self.cache[token]
|
||||
|
||||
@@ -149,6 +149,9 @@ class GPT2Tokenizer(PreTrainedTokenizer):
|
||||
def vocab_size(self):
|
||||
return len(self.encoder)
|
||||
|
||||
def get_vocab(self):
|
||||
return dict(self.encoder, **self.added_tokens_encoder)
|
||||
|
||||
def bpe(self, token):
|
||||
if token in self.cache:
|
||||
return self.cache[token]
|
||||
@@ -269,9 +272,3 @@ class GPT2TokenizerFast(PreTrainedTokenizerFast):
|
||||
unk_token=unk_token,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
logger.warning(
|
||||
"RobertaTokenizerFast has an issue when working on mask language modeling "
|
||||
"where it introduces an extra encoded space before the mask token."
|
||||
"See https://github.com/huggingface/transformers/pull/2778 for more information."
|
||||
)
|
||||
|
||||
@@ -125,6 +125,9 @@ class OpenAIGPTTokenizer(PreTrainedTokenizer):
|
||||
def vocab_size(self):
|
||||
return len(self.encoder)
|
||||
|
||||
def get_vocab(self):
|
||||
return dict(self.encoder, **self.added_tokens_encoder)
|
||||
|
||||
def bpe(self, token):
|
||||
word = tuple(token[:-1]) + (token[-1] + "</w>",)
|
||||
if token in self.cache:
|
||||
|
||||
@@ -210,3 +210,16 @@ class RobertaTokenizerFast(GPT2TokenizerFast):
|
||||
# We need to recompute max_len according to the newly register post_processor to get real values.
|
||||
self.max_len_single_sentence = self.max_len - self.num_added_tokens(False) # take into account special tokens
|
||||
self.max_len_sentences_pair = self.max_len - self.num_added_tokens(True) # take into account special tokens
|
||||
|
||||
logger.warning(
|
||||
"RobertaTokenizerFast has an issue when working on mask language modeling "
|
||||
"where it introduces an extra encoded space before the mask token."
|
||||
"See https://github.com/huggingface/transformers/pull/2778 for more information."
|
||||
)
|
||||
|
||||
def build_inputs_with_special_tokens(self, token_ids_0, token_ids_1=None):
|
||||
output = [self.bos_token_id] + token_ids_0 + [self.eos_token_id]
|
||||
if token_ids_1 is None:
|
||||
return output
|
||||
|
||||
return output + [self.eos_token_id] + token_ids_1 + [self.eos_token_id]
|
||||
|
||||
@@ -98,6 +98,12 @@ class T5Tokenizer(PreTrainedTokenizer):
|
||||
additional_special_tokens=additional_special_tokens,
|
||||
**kwargs,
|
||||
)
|
||||
self.max_len_single_sentence = (
|
||||
self.max_len
|
||||
) # no default special tokens - you can update this value if you add special tokens
|
||||
self.max_len_sentences_pair = (
|
||||
self.max_len
|
||||
) # no default special tokens - you can update this value if you add special tokens
|
||||
|
||||
try:
|
||||
import sentencepiece as spm
|
||||
@@ -119,6 +125,11 @@ class T5Tokenizer(PreTrainedTokenizer):
|
||||
def vocab_size(self):
|
||||
return self.sp_model.get_piece_size() + self._extra_ids
|
||||
|
||||
def get_vocab(self):
|
||||
vocab = {self.convert_ids_to_tokens(i): i for i in range(self.vocab_size)}
|
||||
vocab.update(self.added_tokens_encoder)
|
||||
return vocab
|
||||
|
||||
def __getstate__(self):
|
||||
state = self.__dict__.copy()
|
||||
state["sp_model"] = None
|
||||
|
||||
@@ -22,6 +22,7 @@ import glob
|
||||
import logging
|
||||
import os
|
||||
import pickle
|
||||
import re
|
||||
from collections import Counter, OrderedDict
|
||||
from typing import List, Optional, Tuple, Union
|
||||
|
||||
@@ -44,6 +45,7 @@ if is_torch_available():
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
VOCAB_FILES_NAMES = {"pretrained_vocab_file": "vocab.bin", "vocab_file": "vocab.txt"}
|
||||
VOCAB_FILES_NAMES_FAST = {"pretrained_vocab_file": "vocab.json", "vocab_file": "vocab.json"}
|
||||
|
||||
PRETRAINED_VOCAB_FILES_MAP = {
|
||||
"pretrained_vocab_file": {
|
||||
@@ -114,18 +116,36 @@ class TransfoXLTokenizer(PreTrainedTokenizer):
|
||||
self.delimiter = delimiter
|
||||
self.vocab_file = vocab_file
|
||||
self.never_split = never_split
|
||||
self.punctuation_symbols = '!"#$%&()*+,-./\:;<=>?@[\\]^_`{|}~' # noqa: W605
|
||||
self.punction_without_space_before_pattern = re.compile(r"[^\s][{}]".format(self.punctuation_symbols))
|
||||
self.punctuation_with_space_around_pattern = self._compile_space_around_punctuation_pattern()
|
||||
|
||||
if pretrained_vocab_file is not None:
|
||||
# Hack because, honestly this tokenizer was not made to be used
|
||||
# in a library like ours, at all.
|
||||
vocab_dict = torch.load(pretrained_vocab_file)
|
||||
for key, value in vocab_dict.items():
|
||||
if key not in self.__dict__:
|
||||
self.__dict__[key] = value
|
||||
try:
|
||||
if pretrained_vocab_file is not None:
|
||||
# Hack because, honestly this tokenizer was not made to be used
|
||||
# in a library like ours, at all.
|
||||
vocab_dict = torch.load(pretrained_vocab_file)
|
||||
for key, value in vocab_dict.items():
|
||||
if key not in self.__dict__:
|
||||
self.__dict__[key] = value
|
||||
|
||||
if vocab_file is not None:
|
||||
self.build_vocab()
|
||||
except Exception:
|
||||
raise ValueError(
|
||||
"Unable to parse file {}. Unknown format. "
|
||||
"If you tried to load a model saved through TransfoXLTokenizerFast,"
|
||||
"please note they are not compatible.".format(pretrained_vocab_file)
|
||||
)
|
||||
|
||||
if vocab_file is not None:
|
||||
self.build_vocab()
|
||||
|
||||
def _compile_space_around_punctuation_pattern(self):
|
||||
look_ahead_for_special_token = "(?=[{}])".format(self.punctuation_symbols)
|
||||
look_ahead_to_match_all_except_space = "(?=[^\s])" # noqa: W605
|
||||
return re.compile(r"" + look_ahead_for_special_token + look_ahead_to_match_all_except_space)
|
||||
|
||||
def count_file(self, path, verbose=False, add_eos=False):
|
||||
if verbose:
|
||||
logger.info("counting file {} ...".format(path))
|
||||
@@ -170,6 +190,12 @@ class TransfoXLTokenizer(PreTrainedTokenizer):
|
||||
|
||||
def save_vocabulary(self, vocab_path):
|
||||
"""Save the tokenizer vocabulary to a directory or file."""
|
||||
|
||||
logger.warning(
|
||||
"Please note you will not be able to load the save vocabulary in"
|
||||
" Rust-based TransfoXLTokenizerFast as they don't share the same structure."
|
||||
)
|
||||
|
||||
if os.path.isdir(vocab_path):
|
||||
vocab_file = os.path.join(vocab_path, VOCAB_FILES_NAMES["pretrained_vocab_file"])
|
||||
else:
|
||||
@@ -273,6 +299,9 @@ class TransfoXLTokenizer(PreTrainedTokenizer):
|
||||
def vocab_size(self):
|
||||
return len(self.idx2sym)
|
||||
|
||||
def get_vocab(self):
|
||||
return dict(self.sym2idx, **self.added_tokens_encoder)
|
||||
|
||||
def _tokenize(self, line, add_eos=False, add_double_eos=False):
|
||||
line = line.strip()
|
||||
# convert to lower case
|
||||
@@ -292,6 +321,19 @@ class TransfoXLTokenizer(PreTrainedTokenizer):
|
||||
else:
|
||||
return symbols
|
||||
|
||||
def prepare_for_tokenization(self, text, **kwargs):
|
||||
# add spaces before punctuation symbols as should be done in transfo-xl
|
||||
|
||||
if "add_space_before_punct_symbol" in kwargs and kwargs["add_space_before_punct_symbol"]:
|
||||
text = self.punctuation_with_space_around_pattern.sub(r" ", text)
|
||||
elif self.punction_without_space_before_pattern.search(text):
|
||||
# searches until the first occurence of a punctuation symbol without surrounding spaces
|
||||
logger.warning(
|
||||
"You might want to consider setting `add_space_before_punct_symbol=True` as an argument to the `tokenizer.encode()` to avoid tokenizing words with punctuation symbols to the `<unk>` token"
|
||||
)
|
||||
|
||||
return text
|
||||
|
||||
|
||||
class _TransfoXLDelimiterLookupTokenizer(BaseTokenizer):
|
||||
def __init__(
|
||||
@@ -306,8 +348,15 @@ class _TransfoXLDelimiterLookupTokenizer(BaseTokenizer):
|
||||
normalization: Optional[str] = None,
|
||||
):
|
||||
|
||||
tokenizer = WordLevel.from_files(vocab_file, unk_token=unk_token)
|
||||
tokenizer = Tokenizer(tokenizer)
|
||||
try:
|
||||
tokenizer = WordLevel.from_files(vocab_file, unk_token=unk_token)
|
||||
tokenizer = Tokenizer(tokenizer)
|
||||
except Exception:
|
||||
raise ValueError(
|
||||
"Unable to parse file {}. Unknown format. "
|
||||
"If you tried to load a model saved through TransfoXLTokenizer,"
|
||||
"please note they are not compatible.".format(vocab_file)
|
||||
)
|
||||
|
||||
# Create the correct normalization path
|
||||
normalizer = []
|
||||
@@ -354,7 +403,7 @@ class _TransfoXLDelimiterLookupTokenizer(BaseTokenizer):
|
||||
|
||||
class TransfoXLTokenizerFast(PreTrainedTokenizerFast):
|
||||
|
||||
vocab_files_names = VOCAB_FILES_NAMES
|
||||
vocab_files_names = VOCAB_FILES_NAMES_FAST
|
||||
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP_FAST
|
||||
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
|
||||
|
||||
@@ -394,6 +443,14 @@ class TransfoXLTokenizerFast(PreTrainedTokenizerFast):
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
def save_pretrained(self, save_directory):
|
||||
logger.warning(
|
||||
"Please note you will not be able to load the vocabulary in"
|
||||
" Python-based TransfoXLTokenizer as they don't share the same structure."
|
||||
)
|
||||
|
||||
return super().save_pretrained(save_directory)
|
||||
|
||||
|
||||
class LMOrderedIterator(object):
|
||||
def __init__(self, data, bsz, bptt, device="cpu", ext_len=None):
|
||||
|
||||
@@ -14,7 +14,6 @@
|
||||
# limitations under the License.
|
||||
"""Tokenization classes for OpenAI GPT."""
|
||||
|
||||
|
||||
import copy
|
||||
import itertools
|
||||
import json
|
||||
@@ -79,13 +78,13 @@ def truncate_and_pad(
|
||||
|
||||
if pad_to_max_length and (pad_token and pad_token_id >= 0):
|
||||
tokenizer.enable_padding(
|
||||
max_length=None,
|
||||
max_length=max_length,
|
||||
direction=padding_side,
|
||||
pad_id=pad_token_id,
|
||||
pad_type_id=pad_token_type_id,
|
||||
pad_token=pad_token,
|
||||
)
|
||||
else:
|
||||
elif pad_to_max_length:
|
||||
logger.warning(
|
||||
"Disabled padding because no padding token set (pad_token: {}, pad_token_id: {}).\n"
|
||||
"To remove this error, you can add a new pad token and then resize model embedding:\n"
|
||||
@@ -153,6 +152,18 @@ class PreTrainedTokenizer(object):
|
||||
|
||||
padding_side = "right"
|
||||
|
||||
NO_PAD_TOKEN_FOR_BATCH_MSG = (
|
||||
"No padding token is set for this model, therefore no batch can be made with uneven "
|
||||
"sequences. Set a padding token or adjust the lengths of the sequences building the "
|
||||
"batch so that every sequence is of the same length."
|
||||
)
|
||||
|
||||
UNEVEN_SEQUENCES_FOR_BATCH_MSG = (
|
||||
"The sequences building the batch are not of the same size, no tensor "
|
||||
"can be built. Set `pad_to_max_length=True` to pad the smaller sequences"
|
||||
"up to the larger sequence's length."
|
||||
)
|
||||
|
||||
@property
|
||||
def bos_token(self):
|
||||
""" Beginning of sentence token (string). Log an error if used while not having been set. """
|
||||
@@ -286,6 +297,10 @@ class PreTrainedTokenizer(object):
|
||||
""" Ids of all the additional special tokens in the vocabulary (list of integers). Log an error if used while not having been set. """
|
||||
return self.convert_tokens_to_ids(self.additional_special_tokens)
|
||||
|
||||
def get_vocab(self):
|
||||
""" Returns the vocabulary as a dict of {token: index} pairs. `tokenizer.get_vocab()[token]` is equivalent to `tokenizer.convert_tokens_to_ids(token)` when `token` is in the vocab. """
|
||||
raise NotImplementedError()
|
||||
|
||||
def __init__(self, max_len=None, **kwargs):
|
||||
self._bos_token = None
|
||||
self._eos_token = None
|
||||
@@ -380,6 +395,7 @@ class PreTrainedTokenizer(object):
|
||||
force_download = kwargs.pop("force_download", False)
|
||||
resume_download = kwargs.pop("resume_download", False)
|
||||
proxies = kwargs.pop("proxies", None)
|
||||
local_files_only = kwargs.pop("local_files_only", False)
|
||||
|
||||
s3_models = list(cls.max_model_input_sizes.keys())
|
||||
vocab_files = {}
|
||||
@@ -447,6 +463,7 @@ class PreTrainedTokenizer(object):
|
||||
force_download=force_download,
|
||||
proxies=proxies,
|
||||
resume_download=resume_download,
|
||||
local_files_only=local_files_only,
|
||||
)
|
||||
except EnvironmentError:
|
||||
if pretrained_model_name_or_path in s3_models:
|
||||
@@ -1016,14 +1033,18 @@ class PreTrainedTokenizer(object):
|
||||
def batch_encode_plus(
|
||||
self,
|
||||
batch_text_or_text_pairs=None,
|
||||
add_special_tokens=False,
|
||||
add_special_tokens=True,
|
||||
max_length=None,
|
||||
stride=0,
|
||||
truncation_strategy="longest_first",
|
||||
pad_to_max_length=False,
|
||||
return_tensors=None,
|
||||
return_input_lengths=False,
|
||||
return_attention_masks=False,
|
||||
return_token_type_ids=True,
|
||||
return_attention_masks=True,
|
||||
return_overflowing_tokens=False,
|
||||
return_special_tokens_masks=False,
|
||||
return_offsets_mapping=False,
|
||||
return_input_lengths=False,
|
||||
**kwargs
|
||||
):
|
||||
"""
|
||||
@@ -1046,14 +1067,54 @@ class PreTrainedTokenizer(object):
|
||||
- 'only_first': Only truncate the first sequence
|
||||
- 'only_second': Only truncate the second sequence
|
||||
- 'do_not_truncate': Does not truncate (raise an error if the input sequence is longer than max_length)
|
||||
pad_to_max_length: if set to True, the returned sequences will be padded according to the model's padding side and
|
||||
padding index, up to their max length. If no max length is specified, the padding is done up to the model's max length.
|
||||
The tokenizer padding sides are handled by the class attribute `padding_side` which can be set to the following strings:
|
||||
- 'left': pads on the left of the sequences
|
||||
- 'right': pads on the right of the sequences
|
||||
Defaults to False: no padding.
|
||||
return_tensors: (optional) can be set to 'tf' or 'pt' to return respectively TensorFlow tf.constant
|
||||
or PyTorch torch.Tensor instead of a list of python integers.
|
||||
return_input_lengths: (optional) If set the resulting dictionary will include the length of each sample
|
||||
return_attention_masks: (optional) Set to True to return the attention mask (default False)
|
||||
return_offsets_mapping: (optional) Not available, should be set to False or it will throw NotImplementError
|
||||
**kwargs: passed to the `self.tokenize()` method
|
||||
|
||||
Return:
|
||||
A Dictionary of shape::
|
||||
|
||||
{
|
||||
input_ids: list[List[int]],
|
||||
token_type_ids: list[List[int]] if return_token_type_ids is True (default)
|
||||
attention_mask: list[List[int]] if return_attention_mask is True (default)
|
||||
overflowing_tokens: list[List[int]] if a ``max_length`` is specified and return_overflowing_tokens is True
|
||||
num_truncated_tokens: List[int] if a ``max_length`` is specified and return_overflowing_tokens is True
|
||||
special_tokens_mask: list[List[int]] if ``add_special_tokens`` if set to ``True`` and return_special_tokens_mask is True
|
||||
}
|
||||
|
||||
With the fields:
|
||||
``input_ids``: list of token ids to be fed to a model
|
||||
``token_type_ids``: list of token type ids to be fed to a model
|
||||
``attention_mask``: list of indices specifying which tokens should be attended to by the model
|
||||
``overflowing_tokens``: list of overflowing tokens if a max length is specified.
|
||||
``num_truncated_tokens``: number of overflowing tokens a ``max_length`` is specified
|
||||
``special_tokens_mask``: if adding special tokens, this is a list of [0, 1], with 0 specifying special added
|
||||
tokens and 1 specifying sequence tokens.
|
||||
"""
|
||||
|
||||
def get_input_ids(text):
|
||||
if isinstance(text, str):
|
||||
tokens = self.tokenize(text, add_special_tokens=add_special_tokens, **kwargs)
|
||||
return self.convert_tokens_to_ids(tokens)
|
||||
elif isinstance(text, (list, tuple)) and len(text) > 0 and isinstance(text[0], str):
|
||||
return self.convert_tokens_to_ids(text)
|
||||
elif isinstance(text, (list, tuple)) and len(text) > 0 and isinstance(text[0], int):
|
||||
return text
|
||||
else:
|
||||
raise ValueError(
|
||||
"Input is not valid. Should be a string, a list/tuple of strings or a list/tuple of integers."
|
||||
)
|
||||
|
||||
if return_offsets_mapping:
|
||||
raise NotImplementedError(
|
||||
"return_offset_mapping is not available when using Python tokenizers."
|
||||
@@ -1063,21 +1124,47 @@ class PreTrainedTokenizer(object):
|
||||
"https://github.com/huggingface/transformers/pull/2674"
|
||||
)
|
||||
|
||||
batch_outputs = {}
|
||||
input_ids = []
|
||||
for ids_or_pair_ids in batch_text_or_text_pairs:
|
||||
if isinstance(ids_or_pair_ids, (list, tuple)):
|
||||
assert len(ids_or_pair_ids) == 2
|
||||
ids, pair_ids = ids_or_pair_ids
|
||||
else:
|
||||
ids, pair_ids = ids_or_pair_ids, None
|
||||
outputs = self.encode_plus(
|
||||
ids,
|
||||
pair_ids,
|
||||
add_special_tokens=add_special_tokens,
|
||||
|
||||
first_ids = get_input_ids(ids)
|
||||
second_ids = get_input_ids(pair_ids) if pair_ids is not None else None
|
||||
input_ids.append((first_ids, second_ids))
|
||||
|
||||
if max_length is None and pad_to_max_length:
|
||||
|
||||
def total_sequence_length(input_pairs):
|
||||
first_ids, second_ids = input_pairs
|
||||
return len(first_ids) + (
|
||||
self.num_added_tokens()
|
||||
if second_ids is None
|
||||
else (len(second_ids) + self.num_added_tokens(pair=True))
|
||||
)
|
||||
|
||||
max_length = max([total_sequence_length(ids) for ids in input_ids])
|
||||
|
||||
batch_outputs = {}
|
||||
for first_ids, second_ids in input_ids:
|
||||
# Prepares a sequence of input id, or a pair of sequences of inputs ids so that it can be used by
|
||||
# the model. It adds special tokens, truncates sequences if overflowing while taking into account
|
||||
# the special tokens and manages a window stride for overflowing tokens
|
||||
outputs = self.prepare_for_model(
|
||||
first_ids,
|
||||
pair_ids=second_ids,
|
||||
max_length=max_length,
|
||||
pad_to_max_length=pad_to_max_length,
|
||||
add_special_tokens=add_special_tokens,
|
||||
stride=stride,
|
||||
truncation_strategy=truncation_strategy,
|
||||
return_tensors=None,
|
||||
return_attention_mask=return_attention_masks,
|
||||
return_token_type_ids=return_token_type_ids,
|
||||
return_overflowing_tokens=return_overflowing_tokens,
|
||||
return_special_tokens_mask=return_special_tokens_masks,
|
||||
)
|
||||
|
||||
# Append the non-padded length to the output
|
||||
@@ -1089,31 +1176,28 @@ class PreTrainedTokenizer(object):
|
||||
batch_outputs[key] = []
|
||||
batch_outputs[key].append(value)
|
||||
|
||||
# Compute longest sequence size
|
||||
max_seq_len = max(map(len, batch_outputs["input_ids"]))
|
||||
|
||||
if return_attention_masks:
|
||||
# Allow the model to not give any special attention to padded input
|
||||
batch_outputs["attention_mask"] = [[0] * len(v) for v in batch_outputs["input_ids"]]
|
||||
|
||||
if return_tensors is not None:
|
||||
|
||||
# Do the tensor conversion in batch
|
||||
for key, value in batch_outputs.items():
|
||||
|
||||
padded_value = value
|
||||
# verify that the tokenizer has a pad_token_id
|
||||
if key != "input_len" and self._pad_token is not None:
|
||||
# Padding handle
|
||||
padded_value = [
|
||||
v + [self.pad_token_id if key == "input_ids" else 1] * (max_seq_len - len(v))
|
||||
for v in padded_value
|
||||
]
|
||||
|
||||
if return_tensors == "tf" and is_tf_available():
|
||||
batch_outputs[key] = tf.constant(padded_value)
|
||||
try:
|
||||
batch_outputs[key] = tf.constant(value)
|
||||
except ValueError:
|
||||
if None in [item for sequence in value for item in sequence]:
|
||||
raise ValueError(self.NO_PAD_TOKEN_FOR_BATCH_MSG)
|
||||
else:
|
||||
raise ValueError(self.UNEVEN_SEQUENCES_FOR_BATCH_MSG)
|
||||
elif return_tensors == "pt" and is_torch_available():
|
||||
batch_outputs[key] = torch.tensor(padded_value)
|
||||
try:
|
||||
batch_outputs[key] = torch.tensor(value)
|
||||
except ValueError:
|
||||
raise ValueError(self.UNEVEN_SEQUENCES_FOR_BATCH_MSG)
|
||||
except RuntimeError:
|
||||
if None in [item for sequence in value for item in sequence]:
|
||||
raise ValueError(self.NO_PAD_TOKEN_FOR_BATCH_MSG)
|
||||
else:
|
||||
raise
|
||||
elif return_tensors is not None:
|
||||
logger.warning(
|
||||
"Unable to convert output to tensors format {}, PyTorch or TensorFlow is not available.".format(
|
||||
@@ -1121,13 +1205,6 @@ class PreTrainedTokenizer(object):
|
||||
)
|
||||
)
|
||||
|
||||
# encoder_attention_mask requires 1 for real token, 0 for padding, just invert value
|
||||
if return_attention_masks:
|
||||
if is_tf_available():
|
||||
batch_outputs["attention_mask"] = tf.abs(batch_outputs["attention_mask"] - 1)
|
||||
else:
|
||||
batch_outputs["attention_mask"] = torch.abs(batch_outputs["attention_mask"] - 1)
|
||||
|
||||
return batch_outputs
|
||||
|
||||
def prepare_for_model(
|
||||
@@ -1229,7 +1306,10 @@ class PreTrainedTokenizer(object):
|
||||
token_type_ids = [0] * len(ids) + ([1] * len(pair_ids) if pair else [])
|
||||
|
||||
if return_special_tokens_mask:
|
||||
encoded_inputs["special_tokens_mask"] = self.get_special_tokens_mask(ids, pair_ids)
|
||||
if add_special_tokens:
|
||||
encoded_inputs["special_tokens_mask"] = self.get_special_tokens_mask(ids, pair_ids)
|
||||
else:
|
||||
encoded_inputs["special_tokens_mask"] = [0] * len(sequence)
|
||||
|
||||
encoded_inputs["input_ids"] = sequence
|
||||
if return_token_type_ids:
|
||||
@@ -1669,6 +1749,12 @@ class PreTrainedTokenizerFast(PreTrainedTokenizer):
|
||||
self._update_special_tokens()
|
||||
return added
|
||||
|
||||
def build_inputs_with_special_tokens(self, token_ids_0, token_ids_1=None):
|
||||
if token_ids_1 is None:
|
||||
return token_ids_0
|
||||
else:
|
||||
return token_ids_0 + token_ids_1
|
||||
|
||||
def num_added_tokens(self, pair=False):
|
||||
return self.tokenizer.num_special_tokens_to_add(pair)
|
||||
|
||||
@@ -1691,6 +1777,13 @@ class PreTrainedTokenizerFast(PreTrainedTokenizer):
|
||||
return_offsets_mapping=False,
|
||||
**kwargs
|
||||
):
|
||||
if not add_special_tokens:
|
||||
logger.warning(
|
||||
"Fast tokenizers add special tokens by default. To remove special tokens, please specify"
|
||||
"`add_special_tokens=False` during the initialisation rather than when calling `encode`,"
|
||||
"`encode_plus` or `batch_encode_plus`."
|
||||
)
|
||||
|
||||
# Needed if we have to return a tensor
|
||||
pad_to_max_length = pad_to_max_length or (return_tensors is not None)
|
||||
|
||||
@@ -1813,7 +1906,9 @@ class PreTrainedTokenizerFast(PreTrainedTokenizer):
|
||||
|
||||
def save_vocabulary(self, save_directory):
|
||||
if os.path.isdir(save_directory):
|
||||
folder, file = save_directory, self.vocab_files_names["vocab_file"]
|
||||
files = self._tokenizer.save(save_directory)
|
||||
else:
|
||||
folder, file = os.path.split(os.path.abspath(save_directory))
|
||||
self._tokenizer.save(folder, file)
|
||||
files = self._tokenizer.save(folder, name=file)
|
||||
|
||||
return tuple(files)
|
||||
|
||||
@@ -662,6 +662,9 @@ class XLMTokenizer(PreTrainedTokenizer):
|
||||
def vocab_size(self):
|
||||
return len(self.encoder)
|
||||
|
||||
def get_vocab(self):
|
||||
return dict(self.encoder, **self.added_tokens_encoder)
|
||||
|
||||
def bpe(self, token):
|
||||
word = tuple(token[:-1]) + (token[-1] + "</w>",)
|
||||
if token in self.cache:
|
||||
|
||||
@@ -190,6 +190,11 @@ class XLMRobertaTokenizer(PreTrainedTokenizer):
|
||||
def vocab_size(self):
|
||||
return len(self.sp_model) + len(self.fairseq_tokens_to_ids)
|
||||
|
||||
def get_vocab(self):
|
||||
vocab = {self.convert_ids_to_tokens(i): i for i in range(self.vocab_size)}
|
||||
vocab.update(self.added_tokens_encoder)
|
||||
return vocab
|
||||
|
||||
def _tokenize(self, text):
|
||||
return self.sp_model.EncodeAsPieces(text)
|
||||
|
||||
|
||||
@@ -114,6 +114,11 @@ class XLNetTokenizer(PreTrainedTokenizer):
|
||||
def vocab_size(self):
|
||||
return len(self.sp_model)
|
||||
|
||||
def get_vocab(self):
|
||||
vocab = {self.convert_ids_to_tokens(i): i for i in range(self.vocab_size)}
|
||||
vocab.update(self.added_tokens_encoder)
|
||||
return vocab
|
||||
|
||||
def __getstate__(self):
|
||||
state = self.__dict__.copy()
|
||||
state["sp_model"] = None
|
||||
|
||||
47
src/transformers/utils_encoder_decoder.py
Normal file
47
src/transformers/utils_encoder_decoder.py
Normal file
@@ -0,0 +1,47 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2020 The HuggingFace Inc. team.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
""" Classes to support Encoder-Decoder architectures """
|
||||
|
||||
|
||||
def prepare_encoder_decoder_model_kwargs(**kwargs):
|
||||
""" Prepare the encoder and decoder's keyword arguments.
|
||||
|
||||
Keyword arguments come in 3 flavors:
|
||||
- encoder-specific (prefixed by `encoder_`)
|
||||
- decoder-specific (prefixed by `decoder_`)
|
||||
- those that apply to the model as whole.
|
||||
|
||||
We let the specific kwargs override the common ones in case of
|
||||
conflict.
|
||||
"""
|
||||
|
||||
kwargs_common = {
|
||||
argument: value
|
||||
for argument, value in kwargs.items()
|
||||
if not argument.startswith("encoder_") and not argument.startswith("decoder_")
|
||||
}
|
||||
if "input_ids" in kwargs_common:
|
||||
kwargs["encoder_input_ids"] = kwargs_common.pop("input_ids")
|
||||
|
||||
decoder_kwargs = kwargs_common.copy()
|
||||
encoder_kwargs = kwargs_common.copy()
|
||||
encoder_kwargs.update(
|
||||
{argument[len("encoder_") :]: value for argument, value in kwargs.items() if argument.startswith("encoder_")}
|
||||
)
|
||||
decoder_kwargs.update(
|
||||
{argument[len("decoder_") :]: value for argument, value in kwargs.items() if argument.startswith("decoder_")}
|
||||
)
|
||||
decoder_kwargs["encoder_attention_mask"] = encoder_kwargs.get("attention_mask", None)
|
||||
return encoder_kwargs, decoder_kwargs
|
||||
344
tests/test_modeling_bart.py
Normal file
344
tests/test_modeling_bart.py
Normal file
@@ -0,0 +1,344 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2020 Huggingface
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
|
||||
import tempfile
|
||||
import unittest
|
||||
|
||||
from transformers import is_torch_available
|
||||
|
||||
from .test_configuration_common import ConfigTester
|
||||
from .test_modeling_common import ModelTesterMixin, ids_tensor
|
||||
from .utils import CACHE_DIR, require_torch, slow, torch_device
|
||||
|
||||
|
||||
if is_torch_available():
|
||||
import torch
|
||||
from transformers import (
|
||||
AutoModelForSequenceClassification,
|
||||
BartModel,
|
||||
BartForMaskedLM,
|
||||
BartForSequenceClassification,
|
||||
BartConfig,
|
||||
)
|
||||
from transformers.modeling_bart import (
|
||||
BART_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
shift_tokens_right,
|
||||
_prepare_bart_decoder_inputs,
|
||||
)
|
||||
from transformers.tokenization_bart import BartTokenizer
|
||||
|
||||
|
||||
@require_torch
|
||||
class ModelTester:
|
||||
def __init__(
|
||||
self, parent,
|
||||
):
|
||||
self.parent = parent
|
||||
self.batch_size = 13
|
||||
self.seq_length = 7
|
||||
self.is_training = True
|
||||
self.use_labels = False
|
||||
self.vocab_size = 99
|
||||
self.hidden_size = 32
|
||||
self.num_hidden_layers = 5
|
||||
self.num_attention_heads = 4
|
||||
self.intermediate_size = 37
|
||||
self.hidden_act = "gelu"
|
||||
self.hidden_dropout_prob = 0.1
|
||||
self.attention_probs_dropout_prob = 0.1
|
||||
self.max_position_embeddings = 12
|
||||
torch.manual_seed(0)
|
||||
|
||||
def prepare_config_and_inputs_for_common(self):
|
||||
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size).clamp(3,)
|
||||
input_ids[:, -1] = 2 # Eos Token
|
||||
|
||||
config = BartConfig(
|
||||
vocab_size=self.vocab_size,
|
||||
d_model=self.hidden_size,
|
||||
encoder_layers=self.num_hidden_layers,
|
||||
decoder_layers=self.num_hidden_layers,
|
||||
encoder_attention_heads=self.num_attention_heads,
|
||||
decoder_attention_heads=self.num_attention_heads,
|
||||
encoder_ffn_dim=self.intermediate_size,
|
||||
decoder_ffn_dim=self.intermediate_size,
|
||||
dropout=self.hidden_dropout_prob,
|
||||
attention_dropout=self.attention_probs_dropout_prob,
|
||||
max_position_embeddings=self.max_position_embeddings,
|
||||
)
|
||||
inputs_dict = prepare_bart_inputs_dict(config, input_ids)
|
||||
return config, inputs_dict
|
||||
|
||||
|
||||
def prepare_bart_inputs_dict(
|
||||
config, input_ids, attention_mask=None,
|
||||
):
|
||||
if attention_mask is None:
|
||||
attention_mask = input_ids.ne(config.pad_token_id)
|
||||
return {
|
||||
"input_ids": input_ids,
|
||||
"attention_mask": attention_mask,
|
||||
}
|
||||
|
||||
|
||||
@require_torch
|
||||
class BARTModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
|
||||
all_model_classes = (BartModel, BartForMaskedLM, BartForSequenceClassification) if is_torch_available() else ()
|
||||
is_encoder_decoder = True
|
||||
# TODO(SS): fix the below in a separate PR
|
||||
test_pruning = False
|
||||
test_torchscript = False
|
||||
test_head_masking = False
|
||||
test_resize_embeddings = False # This requires inputs_dict['input_ids']
|
||||
|
||||
def setUp(self):
|
||||
self.model_tester = ModelTester(self)
|
||||
self.config_tester = ConfigTester(self, config_class=BartConfig)
|
||||
|
||||
def test_config(self):
|
||||
self.config_tester.run_common_tests()
|
||||
|
||||
def test_advanced_inputs(self):
|
||||
# (config, input_ids, token_type_ids, input_mask, *unused) = \
|
||||
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
|
||||
decoder_input_ids, decoder_attn_mask = _prepare_bart_decoder_inputs(config, inputs_dict["input_ids"])
|
||||
model = BartModel(config)
|
||||
model.to(torch_device)
|
||||
model.eval()
|
||||
# test init
|
||||
self.assertTrue((model.encoder.embed_tokens.weight == model.shared.weight).all().item())
|
||||
|
||||
def _check_var(module):
|
||||
"""Check that we initialized various parameters from N(0, config.init_std)."""
|
||||
self.assertAlmostEqual(torch.std(module.weight).item(), config.init_std, 2)
|
||||
|
||||
_check_var(model.encoder.embed_tokens)
|
||||
_check_var(model.encoder.layers[0].self_attn.k_proj)
|
||||
_check_var(model.encoder.layers[0].fc1)
|
||||
_check_var(model.encoder.embed_positions)
|
||||
|
||||
decoder_features_with_created_mask = model.forward(**inputs_dict)[0]
|
||||
decoder_features_with_passed_mask = model.forward(
|
||||
decoder_attention_mask=decoder_attn_mask, decoder_input_ids=decoder_input_ids, **inputs_dict
|
||||
)[0]
|
||||
_assert_tensors_equal(decoder_features_with_passed_mask, decoder_features_with_created_mask)
|
||||
useless_mask = torch.zeros_like(decoder_attn_mask)
|
||||
decoder_features = model.forward(decoder_attention_mask=useless_mask, **inputs_dict)[0]
|
||||
self.assertTrue(isinstance(decoder_features, torch.Tensor)) # no hidden states or attentions
|
||||
self.assertEqual(
|
||||
decoder_features.size(), (self.model_tester.batch_size, self.model_tester.seq_length, config.d_model)
|
||||
)
|
||||
if decoder_attn_mask.min().item() < -1e3: # some tokens were masked
|
||||
self.assertFalse((decoder_features_with_created_mask == decoder_features).all().item())
|
||||
|
||||
# Test different encoder attention masks
|
||||
decoder_features_with_long_encoder_mask = model.forward(
|
||||
inputs_dict["input_ids"], attention_mask=inputs_dict["attention_mask"].long()
|
||||
)[0]
|
||||
_assert_tensors_equal(decoder_features_with_long_encoder_mask, decoder_features_with_created_mask)
|
||||
|
||||
def test_save_load_strict(self):
|
||||
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
|
||||
for model_class in self.all_model_classes:
|
||||
model = model_class(config)
|
||||
|
||||
with tempfile.TemporaryDirectory() as tmpdirname:
|
||||
model.save_pretrained(tmpdirname)
|
||||
model2, info = model_class.from_pretrained(tmpdirname, output_loading_info=True)
|
||||
self.assertEqual(info["missing_keys"], [])
|
||||
|
||||
@unittest.skip("Passing inputs_embeds not implemented for Bart.")
|
||||
def test_inputs_embeds(self):
|
||||
pass
|
||||
|
||||
|
||||
@require_torch
|
||||
class BartHeadTests(unittest.TestCase):
|
||||
|
||||
vocab_size = 99
|
||||
|
||||
def test_lm_forward(self):
|
||||
input_ids = torch.Tensor(
|
||||
[
|
||||
[71, 82, 18, 33, 46, 91, 2],
|
||||
[68, 34, 26, 58, 30, 82, 2],
|
||||
[5, 97, 17, 39, 94, 40, 2],
|
||||
[76, 83, 94, 25, 70, 78, 2],
|
||||
[87, 59, 41, 35, 48, 66, 2],
|
||||
[55, 13, 16, 58, 5, 2, 1], # note padding
|
||||
[64, 27, 31, 51, 12, 75, 2],
|
||||
[52, 64, 86, 17, 83, 39, 2],
|
||||
[48, 61, 9, 24, 71, 82, 2],
|
||||
[26, 1, 60, 48, 22, 13, 2],
|
||||
[21, 5, 62, 28, 14, 76, 2],
|
||||
[45, 98, 37, 86, 59, 48, 2],
|
||||
[70, 70, 50, 9, 28, 0, 2],
|
||||
]
|
||||
).long()
|
||||
batch_size = input_ids.shape[0]
|
||||
decoder_lm_labels = ids_tensor([batch_size, input_ids.shape[1]], self.vocab_size)
|
||||
|
||||
config = BartConfig(
|
||||
vocab_size=self.vocab_size,
|
||||
d_model=24,
|
||||
encoder_layers=2,
|
||||
decoder_layers=2,
|
||||
encoder_attention_heads=2,
|
||||
decoder_attention_heads=2,
|
||||
encoder_ffn_dim=32,
|
||||
decoder_ffn_dim=32,
|
||||
max_position_embeddings=48,
|
||||
)
|
||||
model = BartForSequenceClassification(config)
|
||||
outputs = model.forward(input_ids=input_ids, decoder_input_ids=input_ids)
|
||||
logits = outputs[0]
|
||||
expected_shape = torch.Size((batch_size, config.num_labels))
|
||||
self.assertEqual(logits.shape, expected_shape)
|
||||
|
||||
lm_model = BartForMaskedLM(config)
|
||||
loss, logits, enc_features = lm_model.forward(
|
||||
input_ids=input_ids, lm_labels=decoder_lm_labels, decoder_input_ids=input_ids
|
||||
)
|
||||
expected_shape = (batch_size, input_ids.shape[1], config.vocab_size)
|
||||
self.assertEqual(logits.shape, expected_shape)
|
||||
self.assertIsInstance(loss.item(), float)
|
||||
|
||||
def test_lm_uneven_forward(self):
|
||||
config = BartConfig(
|
||||
vocab_size=self.vocab_size,
|
||||
d_model=24,
|
||||
encoder_layers=2,
|
||||
decoder_layers=2,
|
||||
encoder_attention_heads=2,
|
||||
decoder_attention_heads=2,
|
||||
encoder_ffn_dim=32,
|
||||
decoder_ffn_dim=32,
|
||||
max_position_embeddings=48,
|
||||
)
|
||||
lm_model = BartForMaskedLM(config)
|
||||
context = torch.Tensor([[71, 82, 18, 33, 46, 91, 2], [68, 34, 26, 58, 30, 2, 1]]).long()
|
||||
summary = torch.Tensor([[82, 71, 82, 18, 2], [58, 68, 2, 1, 1]]).long()
|
||||
logits, enc_features = lm_model.forward(input_ids=context, decoder_input_ids=summary)
|
||||
expected_shape = (*summary.shape, config.vocab_size)
|
||||
self.assertEqual(logits.shape, expected_shape)
|
||||
|
||||
def test_generate(self):
|
||||
input_ids = torch.Tensor([[71, 82, 2], [68, 34, 2]]).long()
|
||||
config = BartConfig(
|
||||
vocab_size=self.vocab_size,
|
||||
d_model=24,
|
||||
encoder_layers=2,
|
||||
decoder_layers=2,
|
||||
encoder_attention_heads=2,
|
||||
decoder_attention_heads=2,
|
||||
encoder_ffn_dim=32,
|
||||
decoder_ffn_dim=32,
|
||||
max_position_embeddings=48,
|
||||
output_past=True,
|
||||
)
|
||||
lm_model = BartForMaskedLM(config)
|
||||
lm_model.eval()
|
||||
new_input_ids = lm_model.generate(input_ids)
|
||||
self.assertEqual(new_input_ids.shape, (input_ids.shape[0], 20))
|
||||
|
||||
def test_shift_tokens_right(self):
|
||||
input_ids = torch.Tensor([[71, 82, 18, 33, 2, 1, 1], [68, 34, 26, 58, 30, 82, 2]]).long()
|
||||
shifted = shift_tokens_right(input_ids, 1)
|
||||
n_pad_before = input_ids.eq(1).float().sum()
|
||||
n_pad_after = shifted.eq(1).float().sum()
|
||||
self.assertEqual(shifted.shape, input_ids.shape)
|
||||
self.assertEqual(n_pad_after, n_pad_before - 1)
|
||||
self.assertTrue(torch.eq(shifted[:, 0], 2).all())
|
||||
|
||||
@slow
|
||||
def test_tokenization(self):
|
||||
tokenizer = BartTokenizer.from_pretrained("bart-large")
|
||||
examples = [" Hello world", " DomDramg"] # need leading spaces for equality
|
||||
fairseq_results = [
|
||||
torch.Tensor([0, 20920, 232, 2]),
|
||||
torch.Tensor([0, 11349, 495, 4040, 571, 2]),
|
||||
]
|
||||
for ex, desired_result in zip(examples, fairseq_results):
|
||||
bart_toks = tokenizer.encode(ex, return_tensors="pt")
|
||||
_assert_tensors_equal(desired_result.long(), bart_toks, prefix=ex)
|
||||
|
||||
|
||||
def _assert_tensors_equal(a, b, atol=1e-12, prefix=""):
|
||||
"""If tensors not close, or a and b arent both tensors, raise a nice Assertion error."""
|
||||
if a is None and b is None:
|
||||
return True
|
||||
try:
|
||||
if torch.allclose(a, b, atol=atol):
|
||||
return True
|
||||
raise
|
||||
except Exception:
|
||||
msg = "{} != {}".format(a, b)
|
||||
if prefix:
|
||||
msg = prefix + ": " + msg
|
||||
raise AssertionError(msg)
|
||||
|
||||
|
||||
TOLERANCE = 1e-4
|
||||
|
||||
|
||||
@require_torch
|
||||
class BartModelIntegrationTest(unittest.TestCase):
|
||||
@slow
|
||||
def test_inference_no_head(self):
|
||||
model = BartModel.from_pretrained("bart-large")
|
||||
input_ids = torch.Tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]]).long()
|
||||
inputs_dict = prepare_bart_inputs_dict(model.config, input_ids)
|
||||
with torch.no_grad():
|
||||
output = model.forward(**inputs_dict)[0]
|
||||
expected_shape = torch.Size((1, 11, 1024))
|
||||
self.assertEqual(output.shape, expected_shape)
|
||||
expected_slice = torch.Tensor(
|
||||
[[0.7144, 0.8143, -1.2813], [0.7144, 0.8143, -1.2813], [-0.0467, 2.5911, -2.1845]]
|
||||
)
|
||||
self.assertTrue(torch.allclose(output[:, :3, :3], expected_slice, atol=TOLERANCE))
|
||||
|
||||
@slow
|
||||
def test_mnli_inference(self):
|
||||
|
||||
example_b = [0, 31414, 232, 328, 740, 1140, 69, 46078, 1588, 2, 1]
|
||||
input_ids = torch.Tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2], example_b]).long()
|
||||
|
||||
model = AutoModelForSequenceClassification.from_pretrained("bart-large-mnli") # eval called in from_pre
|
||||
inputs_dict = prepare_bart_inputs_dict(model.config, input_ids)
|
||||
# Test that model hasn't changed
|
||||
with torch.no_grad():
|
||||
batched_logits, features = model.forward(**inputs_dict)
|
||||
expected_shape = torch.Size((2, 3))
|
||||
self.assertEqual(batched_logits.shape, expected_shape)
|
||||
expected_slice = torch.Tensor([[0.1907, 1.4342, -1.0289]])
|
||||
logits_arr = batched_logits[0].detach()
|
||||
|
||||
# Test that padding does not change results
|
||||
input_ids_no_pad = torch.Tensor([example_b[:-1]]).long()
|
||||
|
||||
inputs_dict = prepare_bart_inputs_dict(model.config, input_ids=input_ids_no_pad)
|
||||
with torch.no_grad():
|
||||
logits2 = model.forward(**inputs_dict)[0]
|
||||
_assert_tensors_equal(batched_logits[1], logits2, atol=TOLERANCE)
|
||||
_assert_tensors_equal(expected_slice, logits_arr, atol=TOLERANCE)
|
||||
|
||||
@unittest.skip("This is just too slow")
|
||||
def test_model_from_pretrained(self):
|
||||
# Forces 1.6GB download from S3 for each model
|
||||
for model_name in list(BART_PRETRAINED_MODEL_ARCHIVE_MAP.keys()):
|
||||
model = BartModel.from_pretrained(model_name, cache_dir=CACHE_DIR)
|
||||
self.assertIsNotNone(model)
|
||||
@@ -13,7 +13,6 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
|
||||
import copy
|
||||
import logging
|
||||
import os.path
|
||||
@@ -53,6 +52,7 @@ class ModelTesterMixin:
|
||||
|
||||
model_tester = None
|
||||
all_model_classes = ()
|
||||
all_generative_model_classes = ()
|
||||
test_torchscript = True
|
||||
test_pruning = True
|
||||
test_resize_embeddings = True
|
||||
@@ -142,10 +142,17 @@ class ModelTesterMixin:
|
||||
out_len = len(outputs)
|
||||
|
||||
if self.is_encoder_decoder:
|
||||
self.assertEqual(out_len % 2, 0)
|
||||
decoder_attentions = outputs[(out_len // 2) - 1]
|
||||
self.assertEqual(model.config.output_attentions, True)
|
||||
self.assertEqual(model.config.output_hidden_states, False)
|
||||
correct_outlen = (
|
||||
4 # decoder_features_or_logits, decoder_attentions, encoder_features, encoder_attentions
|
||||
)
|
||||
decoder_attention_idx = 1
|
||||
if "lm_labels" in inputs_dict or "decoder_lm_labels" in inputs_dict: # loss will come first
|
||||
correct_outlen += 1 # compute loss
|
||||
decoder_attention_idx += 1
|
||||
self.assertEqual(out_len, correct_outlen)
|
||||
|
||||
decoder_attentions = outputs[decoder_attention_idx]
|
||||
self.assertIsInstance(decoder_attentions, (list, tuple))
|
||||
self.assertEqual(len(decoder_attentions), self.model_tester.num_hidden_layers)
|
||||
self.assertListEqual(
|
||||
list(decoder_attentions[0].shape[-3:]),
|
||||
@@ -562,15 +569,16 @@ class ModelTesterMixin:
|
||||
# self.assertTrue(check_same_values(model.transformer.wte, model.lm_head))
|
||||
|
||||
def test_inputs_embeds(self):
|
||||
|
||||
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
|
||||
if not self.is_encoder_decoder:
|
||||
input_ids = inputs_dict["input_ids"]
|
||||
del inputs_dict["input_ids"]
|
||||
else:
|
||||
encoder_input_ids = inputs_dict["encoder_input_ids"]
|
||||
decoder_input_ids = inputs_dict["decoder_input_ids"]
|
||||
decoder_input_ids = inputs_dict.get("decoder_input_ids", encoder_input_ids)
|
||||
del inputs_dict["encoder_input_ids"]
|
||||
del inputs_dict["decoder_input_ids"]
|
||||
inputs_dict.pop("decoder_input_ids", None)
|
||||
|
||||
for model_class in self.all_model_classes:
|
||||
model = model_class(config)
|
||||
@@ -587,12 +595,53 @@ class ModelTesterMixin:
|
||||
with torch.no_grad():
|
||||
model(**inputs_dict)
|
||||
|
||||
def test_lm_head_model_random_generate(self):
|
||||
|
||||
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
|
||||
input_ids = inputs_dict.get(
|
||||
"input_ids", None
|
||||
) # TODO (PVP): ugly workaround to make code work for t5 for the moment - has to changed when t5 is fixed.
|
||||
|
||||
for model_class in self.all_generative_model_classes:
|
||||
model = model_class(config)
|
||||
model.to(torch_device)
|
||||
model.eval()
|
||||
|
||||
if config.bos_token_id is None:
|
||||
with self.assertRaises(AssertionError):
|
||||
model.generate(max_length=5)
|
||||
# batch_size = 1
|
||||
self._check_generated_tokens(model.generate(input_ids))
|
||||
# batch_size = 1, num_beams > 1
|
||||
self._check_generated_tokens(model.generate(input_ids, num_beams=3))
|
||||
else:
|
||||
# batch_size = 1
|
||||
self._check_generated_tokens(model.generate(max_length=5))
|
||||
# batch_size = 1, num_beams > 1
|
||||
self._check_generated_tokens(model.generate(max_length=5, num_beams=3))
|
||||
|
||||
# batch_size > 1, sample
|
||||
self._check_generated_tokens(model.generate(input_ids, num_return_sequences=3))
|
||||
# batch_size > 1, greedy
|
||||
self._check_generated_tokens(model.generate(input_ids, do_sample=False, num_return_sequences=3))
|
||||
# batch_size > 1, num_beams > 1, sample
|
||||
self._check_generated_tokens(model.generate(input_ids, num_beams=3, num_return_sequences=3,))
|
||||
# batch_size > 1, num_beams > 1, greedy
|
||||
self._check_generated_tokens(
|
||||
model.generate(input_ids, do_sample=False, num_beams=3, num_return_sequences=3)
|
||||
)
|
||||
|
||||
def _check_generated_tokens(self, output_ids):
|
||||
for token_id in output_ids[0].tolist():
|
||||
self.assertGreaterEqual(token_id, 0)
|
||||
self.assertLess(token_id, self.model_tester.vocab_size)
|
||||
|
||||
|
||||
global_rng = random.Random()
|
||||
|
||||
|
||||
def ids_tensor(shape, vocab_size, rng=None, name=None):
|
||||
"""Creates a random int32 tensor of the shape within the vocab size."""
|
||||
# Creates a random int32 tensor of the shape within the vocab size
|
||||
if rng is None:
|
||||
rng = global_rng
|
||||
|
||||
|
||||
@@ -23,6 +23,7 @@ from .utils import CACHE_DIR, require_torch, slow, torch_device
|
||||
|
||||
|
||||
if is_torch_available():
|
||||
import torch
|
||||
from transformers import CTRLConfig, CTRLModel, CTRL_PRETRAINED_MODEL_ARCHIVE_MAP, CTRLLMHeadModel
|
||||
|
||||
|
||||
@@ -30,6 +31,7 @@ if is_torch_available():
|
||||
class CTRLModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
|
||||
all_model_classes = (CTRLModel, CTRLLMHeadModel) if is_torch_available() else ()
|
||||
all_generative_model_classes = (CTRLLMHeadModel,) if is_torch_available() else ()
|
||||
test_pruning = False
|
||||
test_torchscript = False
|
||||
test_resize_embeddings = False
|
||||
@@ -211,3 +213,36 @@ class CTRLModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
for model_name in list(CTRL_PRETRAINED_MODEL_ARCHIVE_MAP.keys())[:1]:
|
||||
model = CTRLModel.from_pretrained(model_name, cache_dir=CACHE_DIR)
|
||||
self.assertIsNotNone(model)
|
||||
|
||||
|
||||
class CTRLModelLanguageGenerationTest(unittest.TestCase):
|
||||
@slow
|
||||
def test_lm_generate_ctrl(self):
|
||||
model = CTRLLMHeadModel.from_pretrained("ctrl")
|
||||
input_ids = torch.Tensor([[11859, 586, 20984, 8]]).long() # Legal My neighbor is
|
||||
expected_output_ids = [
|
||||
11859,
|
||||
586,
|
||||
20984,
|
||||
8,
|
||||
13391,
|
||||
3,
|
||||
980,
|
||||
8258,
|
||||
72,
|
||||
327,
|
||||
148,
|
||||
2,
|
||||
53,
|
||||
29,
|
||||
226,
|
||||
3,
|
||||
780,
|
||||
49,
|
||||
3,
|
||||
980,
|
||||
] # Legal My neighbor is refusing to pay rent after 2 years and we are having to force him to pay
|
||||
torch.manual_seed(0)
|
||||
|
||||
output_ids = model.generate(input_ids)
|
||||
self.assertListEqual(output_ids[0].tolist(), expected_output_ids)
|
||||
|
||||
@@ -24,6 +24,7 @@ from .utils import CACHE_DIR, require_torch, slow, torch_device
|
||||
|
||||
|
||||
if is_torch_available():
|
||||
import torch
|
||||
from transformers import (
|
||||
GPT2Config,
|
||||
GPT2Model,
|
||||
@@ -37,6 +38,9 @@ if is_torch_available():
|
||||
class GPT2ModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
|
||||
all_model_classes = (GPT2Model, GPT2LMHeadModel, GPT2DoubleHeadsModel) if is_torch_available() else ()
|
||||
all_generative_model_classes = (
|
||||
(GPT2LMHeadModel,) if is_torch_available() else ()
|
||||
) # TODO (PVP): Add Double HeadsModel when generate() function is changed accordingly
|
||||
|
||||
class GPT2ModelTester(object):
|
||||
def __init__(
|
||||
@@ -88,6 +92,8 @@ class GPT2ModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
self.num_labels = num_labels
|
||||
self.num_choices = num_choices
|
||||
self.scope = scope
|
||||
self.bos_token_id = vocab_size - 1
|
||||
self.eos_token_id = vocab_size - 1
|
||||
|
||||
def prepare_config_and_inputs(self):
|
||||
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
|
||||
@@ -122,9 +128,11 @@ class GPT2ModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
# hidden_dropout_prob=self.hidden_dropout_prob,
|
||||
# attention_probs_dropout_prob=self.attention_probs_dropout_prob,
|
||||
n_positions=self.max_position_embeddings,
|
||||
n_ctx=self.max_position_embeddings
|
||||
n_ctx=self.max_position_embeddings,
|
||||
# type_vocab_size=self.type_vocab_size,
|
||||
# initializer_range=self.initializer_range
|
||||
bos_token_id=self.bos_token_id,
|
||||
eos_token_ids=self.eos_token_id,
|
||||
)
|
||||
|
||||
head_mask = ids_tensor([self.num_hidden_layers, self.num_attention_heads], 2)
|
||||
@@ -158,7 +166,7 @@ class GPT2ModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
"presents": presents,
|
||||
}
|
||||
self.parent.assertListEqual(
|
||||
list(result["sequence_output"].size()), [self.batch_size, self.seq_length, self.hidden_size]
|
||||
list(result["sequence_output"].size()), [self.batch_size, self.seq_length, self.hidden_size],
|
||||
)
|
||||
self.parent.assertEqual(len(result["presents"]), config.n_layer)
|
||||
|
||||
@@ -173,7 +181,7 @@ class GPT2ModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
|
||||
self.parent.assertListEqual(list(result["loss"].size()), [])
|
||||
self.parent.assertListEqual(
|
||||
list(result["lm_logits"].size()), [self.batch_size, self.seq_length, self.vocab_size]
|
||||
list(result["lm_logits"].size()), [self.batch_size, self.seq_length, self.vocab_size],
|
||||
)
|
||||
|
||||
def create_and_check_double_lm_head_model(
|
||||
@@ -201,7 +209,8 @@ class GPT2ModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
|
||||
self.parent.assertListEqual(list(result["loss"].size()), [])
|
||||
self.parent.assertListEqual(
|
||||
list(result["lm_logits"].size()), [self.batch_size, self.num_choices, self.seq_length, self.vocab_size]
|
||||
list(result["lm_logits"].size()),
|
||||
[self.batch_size, self.num_choices, self.seq_length, self.vocab_size],
|
||||
)
|
||||
self.parent.assertListEqual(list(result["mc_logits"].size()), [self.batch_size, self.num_choices])
|
||||
|
||||
@@ -220,7 +229,11 @@ class GPT2ModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
choice_labels,
|
||||
) = config_and_inputs
|
||||
|
||||
inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "head_mask": head_mask}
|
||||
inputs_dict = {
|
||||
"input_ids": input_ids,
|
||||
"token_type_ids": token_type_ids,
|
||||
"head_mask": head_mask,
|
||||
}
|
||||
|
||||
return config, inputs_dict
|
||||
|
||||
@@ -248,3 +261,84 @@ class GPT2ModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
for model_name in list(GPT2_PRETRAINED_MODEL_ARCHIVE_MAP.keys())[:1]:
|
||||
model = GPT2Model.from_pretrained(model_name, cache_dir=CACHE_DIR)
|
||||
self.assertIsNotNone(model)
|
||||
|
||||
|
||||
def prepare_generation_special_tokens():
|
||||
return {"bos_token_id": 50256, "eos_token_id": 50256}
|
||||
|
||||
|
||||
class GPT2ModelLanguageGenerationTest(unittest.TestCase):
|
||||
|
||||
special_tokens = prepare_generation_special_tokens()
|
||||
|
||||
@slow
|
||||
def test_lm_generate_gpt2(self):
|
||||
model = GPT2LMHeadModel.from_pretrained("gpt2")
|
||||
input_ids = torch.Tensor([[464, 3290, 318, 13779]]).long() # The dog is cute
|
||||
expected_output_ids = [
|
||||
464,
|
||||
3290,
|
||||
318,
|
||||
13779,
|
||||
1165,
|
||||
13,
|
||||
632,
|
||||
7832,
|
||||
284,
|
||||
6437,
|
||||
319,
|
||||
502,
|
||||
290,
|
||||
318,
|
||||
922,
|
||||
329,
|
||||
502,
|
||||
357,
|
||||
1169,
|
||||
3290,
|
||||
] # The dog is cute too. It likes to rub on me and is good for me (the dog
|
||||
torch.manual_seed(0)
|
||||
|
||||
output_ids = model.generate(
|
||||
input_ids,
|
||||
bos_token_id=self.special_tokens["bos_token_id"],
|
||||
eos_token_ids=self.special_tokens["eos_token_id"],
|
||||
)
|
||||
|
||||
self.assertListEqual(output_ids[0].tolist(), expected_output_ids)
|
||||
|
||||
@slow
|
||||
def test_lm_generate_distilgpt2(self):
|
||||
model = GPT2LMHeadModel.from_pretrained("distilgpt2")
|
||||
input_ids = torch.Tensor([[464, 3290, 318, 13779]]).long() # The dog is cute
|
||||
expected_output_ids = [
|
||||
464,
|
||||
3290,
|
||||
318,
|
||||
13779,
|
||||
996,
|
||||
339,
|
||||
460,
|
||||
3360,
|
||||
655,
|
||||
2513,
|
||||
287,
|
||||
262,
|
||||
3952,
|
||||
13,
|
||||
632,
|
||||
318,
|
||||
407,
|
||||
845,
|
||||
3621,
|
||||
284,
|
||||
] # The dog is cute though he can sometimes just walk in the park. It is not very nice to
|
||||
torch.manual_seed(0)
|
||||
|
||||
output_ids = model.generate(
|
||||
input_ids,
|
||||
bos_token_id=self.special_tokens["bos_token_id"],
|
||||
eos_token_ids=self.special_tokens["eos_token_id"],
|
||||
)
|
||||
|
||||
self.assertListEqual(output_ids[0].tolist(), expected_output_ids)
|
||||
|
||||
@@ -24,6 +24,7 @@ from .utils import CACHE_DIR, require_torch, slow, torch_device
|
||||
|
||||
|
||||
if is_torch_available():
|
||||
import torch
|
||||
from transformers import (
|
||||
OpenAIGPTConfig,
|
||||
OpenAIGPTModel,
|
||||
@@ -39,6 +40,9 @@ class OpenAIGPTModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
all_model_classes = (
|
||||
(OpenAIGPTModel, OpenAIGPTLMHeadModel, OpenAIGPTDoubleHeadsModel) if is_torch_available() else ()
|
||||
)
|
||||
all_generative_model_classes = (
|
||||
(OpenAIGPTLMHeadModel,) if is_torch_available() else ()
|
||||
) # TODO (PVP): Add Double HeadsModel when generate() function is changed accordingly
|
||||
|
||||
class OpenAIGPTModelTester(object):
|
||||
def __init__(
|
||||
@@ -205,3 +209,36 @@ class OpenAIGPTModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
for model_name in list(OPENAI_GPT_PRETRAINED_MODEL_ARCHIVE_MAP.keys())[:1]:
|
||||
model = OpenAIGPTModel.from_pretrained(model_name, cache_dir=CACHE_DIR)
|
||||
self.assertIsNotNone(model)
|
||||
|
||||
|
||||
class OPENAIGPTModelLanguageGenerationTest(unittest.TestCase):
|
||||
@slow
|
||||
def test_lm_generate_openai_gpt(self):
|
||||
model = OpenAIGPTLMHeadModel.from_pretrained("openai-gpt")
|
||||
input_ids = torch.Tensor([[481, 2585, 544, 4957]]).long() # The dog is cute
|
||||
expected_output_ids = [
|
||||
481,
|
||||
2585,
|
||||
544,
|
||||
4957,
|
||||
669,
|
||||
512,
|
||||
761,
|
||||
5990,
|
||||
271,
|
||||
645,
|
||||
487,
|
||||
535,
|
||||
976,
|
||||
2479,
|
||||
240,
|
||||
487,
|
||||
804,
|
||||
1296,
|
||||
2891,
|
||||
512,
|
||||
] # the dog is cute when you're annoyed : if he's really stupid, he 'll stop fighting you
|
||||
torch.manual_seed(0)
|
||||
|
||||
output_ids = model.generate(input_ids)
|
||||
self.assertListEqual(output_ids[0].tolist(), expected_output_ids)
|
||||
|
||||
@@ -34,6 +34,7 @@ if is_torch_available():
|
||||
)
|
||||
from transformers.modeling_roberta import RobertaEmbeddings, RobertaForMultipleChoice, RobertaForQuestionAnswering
|
||||
from transformers.modeling_roberta import ROBERTA_PRETRAINED_MODEL_ARCHIVE_MAP
|
||||
from transformers.modeling_utils import create_position_ids_from_input_ids
|
||||
|
||||
|
||||
@require_torch
|
||||
@@ -291,7 +292,7 @@ class RobertaModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
[[0 + model.padding_idx + 1, 1 + model.padding_idx + 1, 2 + model.padding_idx + 1, model.padding_idx]]
|
||||
)
|
||||
|
||||
position_ids = model.create_position_ids_from_input_ids(input_ids)
|
||||
position_ids = create_position_ids_from_input_ids(input_ids, model.padding_idx)
|
||||
self.assertEqual(position_ids.shape, expected_positions.shape)
|
||||
self.assertTrue(torch.all(torch.eq(position_ids, expected_positions)))
|
||||
|
||||
|
||||
@@ -164,7 +164,8 @@ class T5ModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
decoder_attention_mask=decoder_attention_mask,
|
||||
decoder_lm_labels=decoder_lm_labels,
|
||||
)
|
||||
loss, prediction_scores = outputs[0], outputs[1]
|
||||
loss, prediction_scores, encoder_features = outputs
|
||||
self.parent.assertEqual(len(outputs), 3)
|
||||
result = {
|
||||
"loss": loss,
|
||||
"prediction_scores": prediction_scores,
|
||||
|
||||
@@ -34,6 +34,7 @@ if is_torch_available():
|
||||
class TransfoXLModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
|
||||
all_model_classes = (TransfoXLModel, TransfoXLLMHeadModel) if is_torch_available() else ()
|
||||
all_generative_model_classes = (TransfoXLLMHeadModel,) if is_torch_available() else ()
|
||||
test_pruning = False
|
||||
test_torchscript = False
|
||||
test_resize_embeddings = False
|
||||
@@ -59,6 +60,7 @@ class TransfoXLModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
num_hidden_layers=5,
|
||||
scope=None,
|
||||
seed=1,
|
||||
eos_token_id=0,
|
||||
):
|
||||
self.parent = parent
|
||||
self.batch_size = batch_size
|
||||
@@ -79,6 +81,7 @@ class TransfoXLModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
self.num_hidden_layers = num_hidden_layers
|
||||
self.scope = scope
|
||||
self.seed = seed
|
||||
self.eos_token_id = eos_token_id
|
||||
|
||||
def prepare_config_and_inputs(self):
|
||||
input_ids_1 = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
|
||||
@@ -100,6 +103,7 @@ class TransfoXLModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
d_inner=self.d_inner,
|
||||
div_val=self.div_val,
|
||||
n_layer=self.num_hidden_layers,
|
||||
eos_token_ids=self.eos_token_id,
|
||||
)
|
||||
|
||||
return (config, input_ids_1, input_ids_2, lm_labels)
|
||||
@@ -208,3 +212,372 @@ class TransfoXLModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
for model_name in list(TRANSFO_XL_PRETRAINED_MODEL_ARCHIVE_MAP.keys())[:1]:
|
||||
model = TransfoXLModel.from_pretrained(model_name, cache_dir=CACHE_DIR)
|
||||
self.assertIsNotNone(model)
|
||||
|
||||
|
||||
def prepare_generation_special_tokens():
|
||||
return {"eos_token_id": 0}
|
||||
|
||||
|
||||
class TransfoXLModelLanguageGenerationTest(unittest.TestCase):
|
||||
|
||||
special_tokens = prepare_generation_special_tokens()
|
||||
|
||||
@slow
|
||||
def test_lm_generate_transfo_xl_wt103(self):
|
||||
model = TransfoXLLMHeadModel.from_pretrained("transfo-xl-wt103")
|
||||
input_ids = torch.Tensor(
|
||||
[
|
||||
[
|
||||
33,
|
||||
1297,
|
||||
2,
|
||||
1,
|
||||
1009,
|
||||
4,
|
||||
1109,
|
||||
11739,
|
||||
4762,
|
||||
358,
|
||||
5,
|
||||
25,
|
||||
245,
|
||||
22,
|
||||
1706,
|
||||
17,
|
||||
20098,
|
||||
5,
|
||||
3215,
|
||||
21,
|
||||
37,
|
||||
1110,
|
||||
3,
|
||||
13,
|
||||
1041,
|
||||
4,
|
||||
24,
|
||||
603,
|
||||
490,
|
||||
2,
|
||||
71477,
|
||||
20098,
|
||||
104447,
|
||||
2,
|
||||
20961,
|
||||
1,
|
||||
2604,
|
||||
4,
|
||||
1,
|
||||
329,
|
||||
3,
|
||||
6224,
|
||||
831,
|
||||
16002,
|
||||
2,
|
||||
8,
|
||||
603,
|
||||
78967,
|
||||
29546,
|
||||
23,
|
||||
803,
|
||||
20,
|
||||
25,
|
||||
416,
|
||||
5,
|
||||
8,
|
||||
232,
|
||||
4,
|
||||
277,
|
||||
6,
|
||||
1855,
|
||||
4601,
|
||||
3,
|
||||
29546,
|
||||
54,
|
||||
8,
|
||||
3609,
|
||||
5,
|
||||
57211,
|
||||
49,
|
||||
4,
|
||||
1,
|
||||
277,
|
||||
18,
|
||||
8,
|
||||
1755,
|
||||
15691,
|
||||
3,
|
||||
341,
|
||||
25,
|
||||
416,
|
||||
693,
|
||||
42573,
|
||||
71,
|
||||
17,
|
||||
401,
|
||||
94,
|
||||
31,
|
||||
17919,
|
||||
2,
|
||||
29546,
|
||||
7873,
|
||||
18,
|
||||
1,
|
||||
435,
|
||||
23,
|
||||
11011,
|
||||
755,
|
||||
5,
|
||||
5167,
|
||||
3,
|
||||
7983,
|
||||
98,
|
||||
84,
|
||||
2,
|
||||
29546,
|
||||
3267,
|
||||
8,
|
||||
3609,
|
||||
4,
|
||||
1,
|
||||
4865,
|
||||
1075,
|
||||
2,
|
||||
6087,
|
||||
71,
|
||||
6,
|
||||
346,
|
||||
8,
|
||||
5854,
|
||||
3,
|
||||
29546,
|
||||
824,
|
||||
1400,
|
||||
1868,
|
||||
2,
|
||||
19,
|
||||
160,
|
||||
2,
|
||||
311,
|
||||
8,
|
||||
5496,
|
||||
2,
|
||||
20920,
|
||||
17,
|
||||
25,
|
||||
15097,
|
||||
3,
|
||||
24,
|
||||
24,
|
||||
0,
|
||||
]
|
||||
]
|
||||
).long()
|
||||
# In 1991 , the remains of Russian Tsar Nicholas II and his family
|
||||
# ( except for Alexei and Maria ) are discovered .
|
||||
# The voice of Nicholas's young son , Tsarevich Alexei Nikolaevich , narrates the
|
||||
# remainder of the story . 1883 Western Siberia ,
|
||||
# a young Grigori Rasputin is asked by his father and a group of men to perform magic .
|
||||
# Rasputin has a vision and denounces one of the men as a horse thief . Although his
|
||||
# father initially slaps him for making such an accusation , Rasputin watches as the
|
||||
# man is chased outside and beaten . Twenty years later , Rasputin sees a vision of
|
||||
# the Virgin Mary , prompting him to become a priest . Rasputin quickly becomes famous ,
|
||||
# with people , even a bishop , begging for his blessing . <eod> </s> <eos>
|
||||
|
||||
expected_output_ids = [
|
||||
33,
|
||||
1297,
|
||||
2,
|
||||
1,
|
||||
1009,
|
||||
4,
|
||||
1109,
|
||||
11739,
|
||||
4762,
|
||||
358,
|
||||
5,
|
||||
25,
|
||||
245,
|
||||
22,
|
||||
1706,
|
||||
17,
|
||||
20098,
|
||||
5,
|
||||
3215,
|
||||
21,
|
||||
37,
|
||||
1110,
|
||||
3,
|
||||
13,
|
||||
1041,
|
||||
4,
|
||||
24,
|
||||
603,
|
||||
490,
|
||||
2,
|
||||
71477,
|
||||
20098,
|
||||
104447,
|
||||
2,
|
||||
20961,
|
||||
1,
|
||||
2604,
|
||||
4,
|
||||
1,
|
||||
329,
|
||||
3,
|
||||
6224,
|
||||
831,
|
||||
16002,
|
||||
2,
|
||||
8,
|
||||
603,
|
||||
78967,
|
||||
29546,
|
||||
23,
|
||||
803,
|
||||
20,
|
||||
25,
|
||||
416,
|
||||
5,
|
||||
8,
|
||||
232,
|
||||
4,
|
||||
277,
|
||||
6,
|
||||
1855,
|
||||
4601,
|
||||
3,
|
||||
29546,
|
||||
54,
|
||||
8,
|
||||
3609,
|
||||
5,
|
||||
57211,
|
||||
49,
|
||||
4,
|
||||
1,
|
||||
277,
|
||||
18,
|
||||
8,
|
||||
1755,
|
||||
15691,
|
||||
3,
|
||||
341,
|
||||
25,
|
||||
416,
|
||||
693,
|
||||
42573,
|
||||
71,
|
||||
17,
|
||||
401,
|
||||
94,
|
||||
31,
|
||||
17919,
|
||||
2,
|
||||
29546,
|
||||
7873,
|
||||
18,
|
||||
1,
|
||||
435,
|
||||
23,
|
||||
11011,
|
||||
755,
|
||||
5,
|
||||
5167,
|
||||
3,
|
||||
7983,
|
||||
98,
|
||||
84,
|
||||
2,
|
||||
29546,
|
||||
3267,
|
||||
8,
|
||||
3609,
|
||||
4,
|
||||
1,
|
||||
4865,
|
||||
1075,
|
||||
2,
|
||||
6087,
|
||||
71,
|
||||
6,
|
||||
346,
|
||||
8,
|
||||
5854,
|
||||
3,
|
||||
29546,
|
||||
824,
|
||||
1400,
|
||||
1868,
|
||||
2,
|
||||
19,
|
||||
160,
|
||||
2,
|
||||
311,
|
||||
8,
|
||||
5496,
|
||||
2,
|
||||
20920,
|
||||
17,
|
||||
25,
|
||||
15097,
|
||||
3,
|
||||
24,
|
||||
24,
|
||||
0,
|
||||
29546,
|
||||
40,
|
||||
1092,
|
||||
18,
|
||||
8,
|
||||
5854,
|
||||
7,
|
||||
1143,
|
||||
2,
|
||||
7,
|
||||
1,
|
||||
159,
|
||||
99,
|
||||
16,
|
||||
1,
|
||||
1009,
|
||||
4,
|
||||
1109,
|
||||
11739,
|
||||
4762,
|
||||
358,
|
||||
5,
|
||||
25,
|
||||
245,
|
||||
28,
|
||||
1110,
|
||||
3,
|
||||
57,
|
||||
629,
|
||||
38,
|
||||
3493,
|
||||
47,
|
||||
1094,
|
||||
7,
|
||||
1297,
|
||||
3,
|
||||
0,
|
||||
]
|
||||
# In 1991, the remains of Russian Tsar Nicholas II and his family (
|
||||
# except for Alexei and Maria ) are discovered. The voice of young son,
|
||||
# Tsarevich Alexei Nikolaevich, narrates the remainder of the story.
|
||||
# 1883 Western Siberia, a young Grigori Rasputin is asked by his father
|
||||
# and a group of men to perform magic. Rasputin has a vision and
|
||||
# denounces one of the men as a horse thief. Although his father initially
|
||||
# slaps him for making such an accusation, Rasputin watches as the man
|
||||
# is chased outside and beaten. Twenty years later, Rasputin sees a vision
|
||||
# of the Virgin Mary, prompting him to become a priest.
|
||||
# Rasputin quickly becomes famous, with people, even a bishop, begging for
|
||||
# his blessing. Rasputin first appears as a priest in 1996, in the same year
|
||||
# that the remains of Russian Tsar Nicholas II and his family were discovered. H
|
||||
|
||||
torch.manual_seed(0)
|
||||
|
||||
output_ids = model.generate(input_ids, eos_token_ids=self.special_tokens["eos_token_id"], max_length=200)
|
||||
|
||||
self.assertListEqual(output_ids[0].tolist(), expected_output_ids)
|
||||
|
||||
@@ -24,6 +24,7 @@ from .utils import CACHE_DIR, require_torch, slow, torch_device
|
||||
|
||||
|
||||
if is_torch_available():
|
||||
import torch
|
||||
from transformers import (
|
||||
XLMConfig,
|
||||
XLMModel,
|
||||
@@ -49,6 +50,9 @@ class XLMModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
if is_torch_available()
|
||||
else ()
|
||||
)
|
||||
all_generative_model_classes = (
|
||||
(XLMWithLMHeadModel,) if is_torch_available() else ()
|
||||
) # TODO (PVP): Check other models whether language generation is also applicable
|
||||
|
||||
class XLMModelTester(object):
|
||||
def __init__(
|
||||
@@ -81,6 +85,7 @@ class XLMModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
summary_type="last",
|
||||
use_proj=True,
|
||||
scope=None,
|
||||
bos_token_id=0,
|
||||
):
|
||||
self.parent = parent
|
||||
self.batch_size = batch_size
|
||||
@@ -111,6 +116,7 @@ class XLMModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
self.num_labels = num_labels
|
||||
self.num_choices = num_choices
|
||||
self.scope = scope
|
||||
self.bos_token_id = bos_token_id
|
||||
|
||||
def prepare_config_and_inputs(self):
|
||||
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
|
||||
@@ -151,6 +157,7 @@ class XLMModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
initializer_range=self.initializer_range,
|
||||
summary_type=self.summary_type,
|
||||
use_proj=self.use_proj,
|
||||
bos_token_id=self.bos_token_id,
|
||||
)
|
||||
|
||||
return (
|
||||
@@ -390,3 +397,48 @@ class XLMModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
for model_name in list(XLM_PRETRAINED_MODEL_ARCHIVE_MAP.keys())[:1]:
|
||||
model = XLMModel.from_pretrained(model_name, cache_dir=CACHE_DIR)
|
||||
self.assertIsNotNone(model)
|
||||
|
||||
|
||||
def prepare_generation_special_tokens():
|
||||
return {"bos_token_id": 0, "pad_token_id": 2}
|
||||
|
||||
|
||||
class XLMModelLanguageGenerationTest(unittest.TestCase):
|
||||
|
||||
special_tokens = prepare_generation_special_tokens()
|
||||
|
||||
@slow
|
||||
def test_lm_generate_xlm_mlm_en_2048(self):
|
||||
model = XLMWithLMHeadModel.from_pretrained("xlm-mlm-en-2048")
|
||||
input_ids = torch.Tensor([[1, 14, 2232, 26, 1]]).long() # The dog is cute
|
||||
expected_output_ids = [
|
||||
1,
|
||||
14,
|
||||
2232,
|
||||
26,
|
||||
1,
|
||||
567,
|
||||
26,
|
||||
32,
|
||||
149,
|
||||
149,
|
||||
149,
|
||||
149,
|
||||
149,
|
||||
149,
|
||||
149,
|
||||
149,
|
||||
149,
|
||||
149,
|
||||
149,
|
||||
149,
|
||||
] # The dog is nothing is it!!!!!!!!!!!! TODO (PVP): this sentence (and others I tried) does not make much sense, there seems to be a problem with xlm language generation.
|
||||
torch.manual_seed(0)
|
||||
|
||||
output_ids = model.generate(
|
||||
input_ids,
|
||||
bos_token_id=self.special_tokens["bos_token_id"],
|
||||
pad_token_id=self.special_tokens["pad_token_id"],
|
||||
)
|
||||
|
||||
self.assertListEqual(output_ids[0].tolist(), expected_output_ids)
|
||||
|
||||
@@ -52,6 +52,9 @@ class XLNetModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
if is_torch_available()
|
||||
else ()
|
||||
)
|
||||
all_generative_model_classes = (
|
||||
(XLNetLMHeadModel,) if is_torch_available() else ()
|
||||
) # TODO (PVP): Check other models whether language generation is also applicable
|
||||
test_pruning = False
|
||||
|
||||
class XLNetModelTester(object):
|
||||
@@ -78,6 +81,9 @@ class XLNetModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
initializer_range=0.05,
|
||||
seed=1,
|
||||
type_vocab_size=2,
|
||||
bos_token_id=1,
|
||||
eos_token_id=2,
|
||||
pad_token_id=5,
|
||||
):
|
||||
self.parent = parent
|
||||
self.batch_size = batch_size
|
||||
@@ -101,6 +107,9 @@ class XLNetModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
self.seed = seed
|
||||
self.type_vocab_size = type_vocab_size
|
||||
self.type_sequence_label_size = type_sequence_label_size
|
||||
self.bos_token_id = bos_token_id
|
||||
self.pad_token_id = pad_token_id
|
||||
self.eos_token_id = eos_token_id
|
||||
|
||||
def prepare_config_and_inputs(self):
|
||||
input_ids_1 = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
|
||||
@@ -142,6 +151,9 @@ class XLNetModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
bi_data=self.bi_data,
|
||||
initializer_range=self.initializer_range,
|
||||
num_labels=self.type_sequence_label_size,
|
||||
bos_token_id=self.bos_token_id,
|
||||
pad_token_id=self.pad_token_id,
|
||||
eos_token_id=self.eos_token_id,
|
||||
)
|
||||
|
||||
return (
|
||||
@@ -499,3 +511,418 @@ class XLNetModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
for model_name in list(XLNET_PRETRAINED_MODEL_ARCHIVE_MAP.keys())[:1]:
|
||||
model = XLNetModel.from_pretrained(model_name, cache_dir=CACHE_DIR)
|
||||
self.assertIsNotNone(model)
|
||||
|
||||
|
||||
def prepare_generation_special_tokens():
|
||||
return {"bos_token_id": 1, "pad_token_id": 5, "eos_token_id": 2}
|
||||
|
||||
|
||||
class XLNetModelLanguageGenerationTest(unittest.TestCase):
|
||||
|
||||
special_tokens = prepare_generation_special_tokens()
|
||||
|
||||
@slow
|
||||
def test_lm_generate_xlnet_base_cased(self):
|
||||
model = XLNetLMHeadModel.from_pretrained("xlnet-base-cased")
|
||||
input_ids = torch.Tensor(
|
||||
[
|
||||
[
|
||||
67,
|
||||
2840,
|
||||
19,
|
||||
18,
|
||||
1484,
|
||||
20,
|
||||
965,
|
||||
29077,
|
||||
8719,
|
||||
1273,
|
||||
21,
|
||||
45,
|
||||
273,
|
||||
17,
|
||||
10,
|
||||
15048,
|
||||
28,
|
||||
27511,
|
||||
21,
|
||||
4185,
|
||||
11,
|
||||
41,
|
||||
2444,
|
||||
9,
|
||||
32,
|
||||
1025,
|
||||
20,
|
||||
8719,
|
||||
26,
|
||||
23,
|
||||
673,
|
||||
966,
|
||||
19,
|
||||
29077,
|
||||
20643,
|
||||
27511,
|
||||
20822,
|
||||
20643,
|
||||
19,
|
||||
17,
|
||||
6616,
|
||||
17511,
|
||||
18,
|
||||
8978,
|
||||
20,
|
||||
18,
|
||||
777,
|
||||
9,
|
||||
19233,
|
||||
1527,
|
||||
17669,
|
||||
19,
|
||||
24,
|
||||
673,
|
||||
17,
|
||||
28756,
|
||||
150,
|
||||
12943,
|
||||
4354,
|
||||
153,
|
||||
27,
|
||||
442,
|
||||
37,
|
||||
45,
|
||||
668,
|
||||
21,
|
||||
24,
|
||||
256,
|
||||
20,
|
||||
416,
|
||||
22,
|
||||
2771,
|
||||
4901,
|
||||
9,
|
||||
12943,
|
||||
4354,
|
||||
153,
|
||||
51,
|
||||
24,
|
||||
3004,
|
||||
21,
|
||||
28142,
|
||||
23,
|
||||
65,
|
||||
20,
|
||||
18,
|
||||
416,
|
||||
34,
|
||||
24,
|
||||
2958,
|
||||
22947,
|
||||
9,
|
||||
1177,
|
||||
45,
|
||||
668,
|
||||
3097,
|
||||
13768,
|
||||
23,
|
||||
103,
|
||||
28,
|
||||
441,
|
||||
148,
|
||||
48,
|
||||
20522,
|
||||
19,
|
||||
12943,
|
||||
4354,
|
||||
153,
|
||||
12860,
|
||||
34,
|
||||
18,
|
||||
326,
|
||||
27,
|
||||
17492,
|
||||
684,
|
||||
21,
|
||||
6709,
|
||||
9,
|
||||
8585,
|
||||
123,
|
||||
266,
|
||||
19,
|
||||
12943,
|
||||
4354,
|
||||
153,
|
||||
6872,
|
||||
24,
|
||||
3004,
|
||||
20,
|
||||
18,
|
||||
9225,
|
||||
2198,
|
||||
19,
|
||||
12717,
|
||||
103,
|
||||
22,
|
||||
401,
|
||||
24,
|
||||
6348,
|
||||
9,
|
||||
12943,
|
||||
4354,
|
||||
153,
|
||||
1068,
|
||||
2768,
|
||||
2286,
|
||||
19,
|
||||
33,
|
||||
104,
|
||||
19,
|
||||
176,
|
||||
24,
|
||||
9313,
|
||||
19,
|
||||
20086,
|
||||
28,
|
||||
45,
|
||||
10292,
|
||||
9,
|
||||
4,
|
||||
3,
|
||||
]
|
||||
]
|
||||
).long()
|
||||
# In 1991, the remains of Russian Tsar Nicholas II and his family
|
||||
# (except for Alexei and Maria) are discovered.
|
||||
# The voice of Nicholas's young son, Tsarevich Alexei Nikolaevich, narrates the
|
||||
# remainder of the story. 1883 Western Siberia,
|
||||
# a young Grigori Rasputin is asked by his father and a group of men to perform magic.
|
||||
# Rasputin has a vision and denounces one of the men as a horse thief. Although his
|
||||
# father initially slaps him for making such an accusation, Rasputin watches as the
|
||||
# man is chased outside and beaten. Twenty years later, Rasputin sees a vision of
|
||||
# the Virgin Mary, prompting him to become a priest. Rasputin quickly becomes famous,
|
||||
# with people, even a bishop, begging for his blessing. """
|
||||
|
||||
expected_output_ids = [
|
||||
67,
|
||||
2840,
|
||||
19,
|
||||
18,
|
||||
1484,
|
||||
20,
|
||||
965,
|
||||
29077,
|
||||
8719,
|
||||
1273,
|
||||
21,
|
||||
45,
|
||||
273,
|
||||
17,
|
||||
10,
|
||||
15048,
|
||||
28,
|
||||
27511,
|
||||
21,
|
||||
4185,
|
||||
11,
|
||||
41,
|
||||
2444,
|
||||
9,
|
||||
32,
|
||||
1025,
|
||||
20,
|
||||
8719,
|
||||
26,
|
||||
23,
|
||||
673,
|
||||
966,
|
||||
19,
|
||||
29077,
|
||||
20643,
|
||||
27511,
|
||||
20822,
|
||||
20643,
|
||||
19,
|
||||
17,
|
||||
6616,
|
||||
17511,
|
||||
18,
|
||||
8978,
|
||||
20,
|
||||
18,
|
||||
777,
|
||||
9,
|
||||
19233,
|
||||
1527,
|
||||
17669,
|
||||
19,
|
||||
24,
|
||||
673,
|
||||
17,
|
||||
28756,
|
||||
150,
|
||||
12943,
|
||||
4354,
|
||||
153,
|
||||
27,
|
||||
442,
|
||||
37,
|
||||
45,
|
||||
668,
|
||||
21,
|
||||
24,
|
||||
256,
|
||||
20,
|
||||
416,
|
||||
22,
|
||||
2771,
|
||||
4901,
|
||||
9,
|
||||
12943,
|
||||
4354,
|
||||
153,
|
||||
51,
|
||||
24,
|
||||
3004,
|
||||
21,
|
||||
28142,
|
||||
23,
|
||||
65,
|
||||
20,
|
||||
18,
|
||||
416,
|
||||
34,
|
||||
24,
|
||||
2958,
|
||||
22947,
|
||||
9,
|
||||
1177,
|
||||
45,
|
||||
668,
|
||||
3097,
|
||||
13768,
|
||||
23,
|
||||
103,
|
||||
28,
|
||||
441,
|
||||
148,
|
||||
48,
|
||||
20522,
|
||||
19,
|
||||
12943,
|
||||
4354,
|
||||
153,
|
||||
12860,
|
||||
34,
|
||||
18,
|
||||
326,
|
||||
27,
|
||||
17492,
|
||||
684,
|
||||
21,
|
||||
6709,
|
||||
9,
|
||||
8585,
|
||||
123,
|
||||
266,
|
||||
19,
|
||||
12943,
|
||||
4354,
|
||||
153,
|
||||
6872,
|
||||
24,
|
||||
3004,
|
||||
20,
|
||||
18,
|
||||
9225,
|
||||
2198,
|
||||
19,
|
||||
12717,
|
||||
103,
|
||||
22,
|
||||
401,
|
||||
24,
|
||||
6348,
|
||||
9,
|
||||
12943,
|
||||
4354,
|
||||
153,
|
||||
1068,
|
||||
2768,
|
||||
2286,
|
||||
19,
|
||||
33,
|
||||
104,
|
||||
19,
|
||||
176,
|
||||
24,
|
||||
9313,
|
||||
19,
|
||||
20086,
|
||||
28,
|
||||
45,
|
||||
10292,
|
||||
9,
|
||||
4,
|
||||
3,
|
||||
1722,
|
||||
19,
|
||||
24,
|
||||
6348,
|
||||
61,
|
||||
977,
|
||||
176,
|
||||
1772,
|
||||
33,
|
||||
45,
|
||||
970,
|
||||
19,
|
||||
4185,
|
||||
19,
|
||||
27,
|
||||
442,
|
||||
22,
|
||||
2771,
|
||||
4901,
|
||||
25,
|
||||
18,
|
||||
2059,
|
||||
20,
|
||||
24,
|
||||
303,
|
||||
1775,
|
||||
691,
|
||||
9,
|
||||
1147,
|
||||
19,
|
||||
634,
|
||||
19,
|
||||
43,
|
||||
51,
|
||||
54,
|
||||
6157,
|
||||
2999,
|
||||
33,
|
||||
4185,
|
||||
]
|
||||
# In 1991, the remains of Russian Tsar Nicholas II and his family (except for Alexei and Maria)
|
||||
# are discovered. The voice of Nicholas's young son, Tsarevich Alexei Nikolaevich,
|
||||
# narrates the remainder of the story. 1883 Western Siberia, a young Grigori Rasputin
|
||||
# is asked by his father and a group of men to perform magic. Rasputin has a vision and
|
||||
# denounces one of the men as a horse thief. Although his father initially slaps
|
||||
# him for making such an accusation, Rasputin watches as the man is chased outside and beaten.
|
||||
# Twenty years later, Rasputin sees a vision of the Virgin Mary, prompting him to become a priest.
|
||||
# Rasputin quickly becomes famous, with people, even a bishop, begging for his blessing.
|
||||
# 1990, a priest who cannot even walk with his wife, Maria, is asked to perform magic
|
||||
# in the presence of a local religious leader.
|
||||
# Since, however, he has had difficulty walking with Maria
|
||||
|
||||
torch.manual_seed(0)
|
||||
output_ids = model.generate(
|
||||
input_ids,
|
||||
bos_token_id=self.special_tokens["bos_token_id"],
|
||||
pad_token_id=self.special_tokens["pad_token_id"],
|
||||
eos_token_ids=self.special_tokens["eos_token_id"],
|
||||
max_length=200,
|
||||
)
|
||||
|
||||
self.assertListEqual(output_ids[0].tolist(), expected_output_ids)
|
||||
|
||||
@@ -101,5 +101,5 @@ class AutoTokenizerTest(unittest.TestCase):
|
||||
self.assertFalse(issubclass(child_model_fast, parent_model_fast))
|
||||
|
||||
def test_from_pretrained_use_fast_toggle(self):
|
||||
self.assertIsInstance(AutoTokenizer.from_pretrained("bert-base-cased"), BertTokenizerFast)
|
||||
self.assertIsInstance(AutoTokenizer.from_pretrained("bert-base-cased", use_fast=False), BertTokenizer)
|
||||
self.assertIsInstance(AutoTokenizer.from_pretrained("bert-base-cased"), BertTokenizer)
|
||||
self.assertIsInstance(AutoTokenizer.from_pretrained("bert-base-cased", use_fast=True), BertTokenizerFast)
|
||||
|
||||
@@ -19,6 +19,8 @@ import pickle
|
||||
import shutil
|
||||
import tempfile
|
||||
|
||||
from tests.utils import require_tf, require_torch
|
||||
|
||||
|
||||
class TokenizerTesterMixin:
|
||||
|
||||
@@ -40,6 +42,15 @@ class TokenizerTesterMixin:
|
||||
def get_input_output_texts(self):
|
||||
raise NotImplementedError
|
||||
|
||||
@staticmethod
|
||||
def convert_batch_encode_plus_format_to_encode_plus(batch_encode_plus_sequences):
|
||||
# Switch from batch_encode_plus format: {'input_ids': [[...], [...]], ...}
|
||||
# to the concatenated encode_plus format: [{'input_ids': [...], ...}, {'input_ids': [...], ...}]
|
||||
return [
|
||||
{value: batch_encode_plus_sequences[value][i] for value in batch_encode_plus_sequences.keys()}
|
||||
for i in range(len(batch_encode_plus_sequences))
|
||||
]
|
||||
|
||||
def test_tokenizers_common_properties(self):
|
||||
tokenizer = self.get_tokenizer()
|
||||
attributes_list = [
|
||||
@@ -535,10 +546,125 @@ class TokenizerTesterMixin:
|
||||
# we're loading an S3 configuration from a pre-trained identifier, and we have no way of testing those today.
|
||||
|
||||
tokenizer = self.get_tokenizer(random_argument=True)
|
||||
print(tokenizer.init_kwargs)
|
||||
assert tokenizer.init_kwargs["random_argument"] is True
|
||||
new_tokenizer = self.get_tokenizer(random_argument=False)
|
||||
print(tokenizer.init_kwargs)
|
||||
print(new_tokenizer.init_kwargs)
|
||||
assert tokenizer.init_kwargs["random_argument"] is True
|
||||
assert new_tokenizer.init_kwargs["random_argument"] is False
|
||||
|
||||
def test_get_vocab(self):
|
||||
tokenizer = self.get_tokenizer()
|
||||
vocab = tokenizer.get_vocab()
|
||||
|
||||
self.assertIsInstance(vocab, dict)
|
||||
self.assertEqual(len(vocab), len(tokenizer))
|
||||
|
||||
for word, ind in vocab.items():
|
||||
self.assertEqual(tokenizer.convert_tokens_to_ids(word), ind)
|
||||
self.assertEqual(tokenizer.convert_ids_to_tokens(ind), word)
|
||||
|
||||
tokenizer.add_tokens(["asdfasdfasdfasdf"])
|
||||
vocab = tokenizer.get_vocab()
|
||||
self.assertIsInstance(vocab, dict)
|
||||
self.assertEqual(len(vocab), len(tokenizer))
|
||||
|
||||
for word, ind in vocab.items():
|
||||
self.assertEqual(tokenizer.convert_tokens_to_ids(word), ind)
|
||||
self.assertEqual(tokenizer.convert_ids_to_tokens(ind), word)
|
||||
|
||||
def test_batch_encode_plus_batch_sequence_length(self):
|
||||
# Tests that all encoded values have the correct size
|
||||
tokenizer = self.get_tokenizer()
|
||||
sequences = [
|
||||
"Testing batch encode plus",
|
||||
"Testing batch encode plus with different sequence lengths",
|
||||
"Testing batch encode plus with different sequence lengths correctly pads",
|
||||
]
|
||||
|
||||
encoded_sequences = [tokenizer.encode_plus(sequence, pad_to_max_length=False) for sequence in sequences]
|
||||
encoded_sequences_batch = tokenizer.batch_encode_plus(sequences)
|
||||
self.assertListEqual(
|
||||
encoded_sequences, self.convert_batch_encode_plus_format_to_encode_plus(encoded_sequences_batch)
|
||||
)
|
||||
|
||||
maximum_length = len(max([encoded_sequence["input_ids"] for encoded_sequence in encoded_sequences], key=len))
|
||||
|
||||
encoded_sequences_padded = [
|
||||
tokenizer.encode_plus(sequence, pad_to_max_length=True, max_length=maximum_length)
|
||||
for sequence in sequences
|
||||
]
|
||||
encoded_sequences_batch_padded = tokenizer.batch_encode_plus(sequences, pad_to_max_length=True)
|
||||
self.assertListEqual(
|
||||
encoded_sequences_padded,
|
||||
self.convert_batch_encode_plus_format_to_encode_plus(encoded_sequences_batch_padded),
|
||||
)
|
||||
|
||||
def test_batch_encode_plus_padding(self):
|
||||
# Test that padded sequences are equivalent between batch_encode_plus and encode_plus
|
||||
|
||||
# Right padding tests
|
||||
tokenizer = self.get_tokenizer()
|
||||
sequences = [
|
||||
"Testing batch encode plus",
|
||||
"Testing batch encode plus with different sequence lengths",
|
||||
"Testing batch encode plus with different sequence lengths correctly pads",
|
||||
]
|
||||
|
||||
max_length = 100
|
||||
encoded_sequences = [
|
||||
tokenizer.encode_plus(sequence, pad_to_max_length=True, max_length=max_length) for sequence in sequences
|
||||
]
|
||||
encoded_sequences_batch = tokenizer.batch_encode_plus(sequences, pad_to_max_length=True, max_length=max_length)
|
||||
self.assertListEqual(
|
||||
encoded_sequences, self.convert_batch_encode_plus_format_to_encode_plus(encoded_sequences_batch)
|
||||
)
|
||||
|
||||
# Left padding tests
|
||||
tokenizer = self.get_tokenizer()
|
||||
tokenizer.padding_side = "left"
|
||||
sequences = [
|
||||
"Testing batch encode plus",
|
||||
"Testing batch encode plus with different sequence lengths",
|
||||
"Testing batch encode plus with different sequence lengths correctly pads",
|
||||
]
|
||||
|
||||
max_length = 100
|
||||
encoded_sequences = [
|
||||
tokenizer.encode_plus(sequence, pad_to_max_length=True, max_length=max_length) for sequence in sequences
|
||||
]
|
||||
encoded_sequences_batch = tokenizer.batch_encode_plus(sequences, pad_to_max_length=True, max_length=max_length)
|
||||
self.assertListEqual(
|
||||
encoded_sequences, self.convert_batch_encode_plus_format_to_encode_plus(encoded_sequences_batch)
|
||||
)
|
||||
|
||||
@require_torch
|
||||
@require_tf
|
||||
def test_batch_encode_plus_tensors(self):
|
||||
tokenizer = self.get_tokenizer()
|
||||
sequences = [
|
||||
"Testing batch encode plus",
|
||||
"Testing batch encode plus with different sequence lengths",
|
||||
"Testing batch encode plus with different sequence lengths correctly pads",
|
||||
]
|
||||
|
||||
# A Tensor cannot be build by sequences which are not the same size
|
||||
self.assertRaises(ValueError, tokenizer.batch_encode_plus, sequences, return_tensors="pt")
|
||||
self.assertRaises(ValueError, tokenizer.batch_encode_plus, sequences, return_tensors="tf")
|
||||
|
||||
if tokenizer.pad_token_id is None:
|
||||
self.assertRaises(
|
||||
ValueError, tokenizer.batch_encode_plus, sequences, pad_to_max_length=True, return_tensors="pt"
|
||||
)
|
||||
self.assertRaises(
|
||||
ValueError, tokenizer.batch_encode_plus, sequences, pad_to_max_length=True, return_tensors="tf"
|
||||
)
|
||||
else:
|
||||
pytorch_tensor = tokenizer.batch_encode_plus(sequences, pad_to_max_length=True, return_tensors="pt")
|
||||
tensorflow_tensor = tokenizer.batch_encode_plus(sequences, pad_to_max_length=True, return_tensors="tf")
|
||||
encoded_sequences = tokenizer.batch_encode_plus(sequences, pad_to_max_length=True)
|
||||
|
||||
for key in encoded_sequences.keys():
|
||||
pytorch_value = pytorch_tensor[key].tolist()
|
||||
tensorflow_value = tensorflow_tensor[key].numpy().tolist()
|
||||
encoded_value = encoded_sequences[key]
|
||||
|
||||
self.assertEqual(pytorch_value, tensorflow_value, encoded_value)
|
||||
|
||||
@@ -76,6 +76,63 @@ class FastTokenizerMatchingTest(unittest.TestCase):
|
||||
for key in filter(lambda x: x in ["input_ids", "token_type_ids", "attention_mask"], input_p.keys()):
|
||||
self.assert_sequence_almost_equals(input_p[key], input_r[key], threshold)
|
||||
|
||||
def assert_padding(self, tokenizer_r, tokenizer_p):
|
||||
# Simple input
|
||||
input_r = tokenizer_r.encode("This is a simple input", max_length=15, pad_to_max_length=True)
|
||||
input_p = tokenizer_p.encode("This is a simple input", max_length=15, pad_to_max_length=True)
|
||||
|
||||
self.assertSequenceEqual(input_r, input_p)
|
||||
|
||||
# Simple input
|
||||
input_r = tokenizer_r.encode_plus("This is a simple input", max_length=15, pad_to_max_length=True)
|
||||
input_p = tokenizer_p.encode_plus("This is a simple input", max_length=15, pad_to_max_length=True)
|
||||
|
||||
self.assertSequenceEqual(input_r, input_p)
|
||||
|
||||
# Simple input
|
||||
# TODO: Re-enable this test when batch_encode_plus with padding correctly handles padding
|
||||
# input_r = tokenizer_r.batch_encode_plus(
|
||||
# ["This is a simple input 1", "This is a simple input 2"], max_length=15, pad_to_max_length=True
|
||||
# )
|
||||
# input_p = tokenizer_p.batch_encode_plus(
|
||||
# ["This is a simple input 1", "This is a simple input 2"], max_length=15, pad_to_max_length=True
|
||||
# )
|
||||
|
||||
# self.assertSequenceEqual(input_r, input_p)
|
||||
|
||||
# Pair input
|
||||
input_r = tokenizer_r.encode("This is a simple input", "This is a pair", max_length=15, pad_to_max_length=True)
|
||||
input_p = tokenizer_p.encode("This is a simple input", "This is a pair", max_length=15, pad_to_max_length=True)
|
||||
|
||||
self.assertSequenceEqual(input_r, input_p)
|
||||
|
||||
# Pair input
|
||||
input_r = tokenizer_r.encode_plus(
|
||||
"This is a simple input", "This is a pair", max_length=15, pad_to_max_length=True
|
||||
)
|
||||
input_p = tokenizer_p.encode_plus(
|
||||
"This is a simple input", "This is a pair", max_length=15, pad_to_max_length=True
|
||||
)
|
||||
|
||||
self.assertSequenceEqual(input_r, input_p)
|
||||
|
||||
# Pair input
|
||||
# TODO: Re-enable this test when batch_encode_plus with padding correctly handles padding
|
||||
# input_r = tokenizer_r.batch_encode_plus(
|
||||
# ["This is a simple input 1", "This is a simple input 2"],
|
||||
# ["This is a simple pair 1", "This is a simple pair 2"],
|
||||
# max_length=15,
|
||||
# pad_to_max_length=True,
|
||||
# )
|
||||
# input_p = tokenizer_p.batch_encode_plus(
|
||||
# ["This is a simple input 1", "This is a simple input 2"],
|
||||
# ["This is a simple pair 1", "This is a simple pair 2"],
|
||||
# max_length=15,
|
||||
# pad_to_max_length=True,
|
||||
# )
|
||||
|
||||
# self.assertSequenceEqual(input_r, input_p)
|
||||
|
||||
def assert_add_tokens(self, tokenizer_r):
|
||||
vocab_size = tokenizer_r.vocab_size
|
||||
self.assertEqual(tokenizer_r.add_tokens(""), 0)
|
||||
@@ -172,6 +229,49 @@ class FastTokenizerMatchingTest(unittest.TestCase):
|
||||
self.assertEqual(len(tokens[key].shape), 2)
|
||||
self.assertEqual(tokens[key].shape[-1], 6)
|
||||
|
||||
def assert_build_inputs_with_special_tokens(self, tokenizer_r, tokenizer_p):
|
||||
# Input string
|
||||
input_simple = tokenizer_p.tokenize("This is a sample input")
|
||||
input_pair = tokenizer_p.tokenize("This is a sample pair")
|
||||
|
||||
# Generate output
|
||||
output_r = tokenizer_r.build_inputs_with_special_tokens(input_simple)
|
||||
output_p = tokenizer_p.build_inputs_with_special_tokens(input_simple)
|
||||
self.assertEqual(output_p, output_r)
|
||||
|
||||
# Generate pair output
|
||||
output_r = tokenizer_r.build_inputs_with_special_tokens(input_simple, input_pair)
|
||||
output_p = tokenizer_p.build_inputs_with_special_tokens(input_simple, input_pair)
|
||||
self.assertEqual(output_p, output_r)
|
||||
|
||||
# Input tokens id
|
||||
input_simple = tokenizer_p.encode("This is a sample input")
|
||||
input_pair = tokenizer_p.encode("This is a sample pair")
|
||||
|
||||
# Generate output
|
||||
output_r = tokenizer_r.build_inputs_with_special_tokens(input_simple)
|
||||
output_p = tokenizer_p.build_inputs_with_special_tokens(input_simple)
|
||||
self.assertEqual(output_p, output_r)
|
||||
|
||||
# Generate pair output
|
||||
output_r = tokenizer_r.build_inputs_with_special_tokens(input_simple, input_pair)
|
||||
output_p = tokenizer_p.build_inputs_with_special_tokens(input_simple, input_pair)
|
||||
self.assertEqual(output_p, output_r)
|
||||
|
||||
def assert_save_pretrained(self, tokenizer_r, tokenizer_p):
|
||||
|
||||
# Checks it save with the same files
|
||||
self.assertSequenceEqual(tokenizer_r.save_vocabulary("."), tokenizer_p.save_vocabulary("."))
|
||||
|
||||
# Checks everything loads correctly in the same way
|
||||
tokenizer_rp, tokenizer_pp = tokenizer_r.from_pretrained("."), tokenizer_p.from_pretrained(".")
|
||||
|
||||
# Check special tokens are set accordingly on Rust and Python
|
||||
for key in tokenizer_pp.special_tokens_map:
|
||||
self.assertTrue(hasattr(tokenizer_rp, key))
|
||||
# self.assertEqual(getattr(tokenizer_rp, key), getattr(tokenizer_pp, key))
|
||||
# self.assertEqual(getattr(tokenizer_rp, key + "_id"), getattr(tokenizer_pp, key + "_id"))
|
||||
|
||||
def test_bert(self):
|
||||
for tokenizer_name in BertTokenizer.pretrained_vocab_files_map["vocab_file"].keys():
|
||||
tokenizer_p = BertTokenizer.from_pretrained(tokenizer_name)
|
||||
@@ -204,6 +304,15 @@ class FastTokenizerMatchingTest(unittest.TestCase):
|
||||
# Check for dynamic encoding sequence handling in batch_encode_plus
|
||||
self.assert_batch_encode_dynamic_overflowing(tokenizer_r)
|
||||
|
||||
# Check alignment for build_inputs_with_special_tokens
|
||||
self.assert_build_inputs_with_special_tokens(tokenizer_r, tokenizer_p)
|
||||
|
||||
# Check the number of returned files for save_vocabulary
|
||||
self.assert_save_pretrained(tokenizer_r, tokenizer_p)
|
||||
|
||||
# Check for padding
|
||||
self.assert_padding(tokenizer_r, tokenizer_p)
|
||||
|
||||
@require_torch
|
||||
def test_transfoxl(self):
|
||||
for tokenizer_name in TransfoXLTokenizer.pretrained_vocab_files_map["pretrained_vocab_file"].keys():
|
||||
@@ -237,6 +346,29 @@ class FastTokenizerMatchingTest(unittest.TestCase):
|
||||
# Check for dynamic encoding sequence handling in batch_encode_plus
|
||||
self.assertRaises(ValueError, self.assert_batch_encode_dynamic_overflowing, tokenizer_r)
|
||||
|
||||
# Check alignment for build_inputs_with_special_tokens
|
||||
self.assert_build_inputs_with_special_tokens(tokenizer_r, tokenizer_p)
|
||||
|
||||
# Check for padding
|
||||
self.assertRaises(ValueError, self.assert_padding, tokenizer_r, tokenizer_p)
|
||||
|
||||
# Check the number of returned files for save_vocabulary
|
||||
# TransfoXL tokenizers comes in a special format which is not compatible at all
|
||||
# with rust tokenizers. We ensure the errors detection at correctly raised
|
||||
tokenizer_r_files = tokenizer_r.save_pretrained(".")
|
||||
self.assertSequenceEqual(
|
||||
tokenizer_r_files, ["./vocab.json", "./special_tokens_map.json", "./added_tokens.json"]
|
||||
)
|
||||
|
||||
# Check loading Python-tokenizer save through Rust doesnt work (and the opposite)
|
||||
self.assertRaises(ValueError, tokenizer_p.from_pretrained, *tokenizer_r_files)
|
||||
self.assertRaises(ValueError, tokenizer_r.from_pretrained, *tokenizer_p.save_pretrained("."))
|
||||
|
||||
# Check loading works for Python to Python and Rust to Rust
|
||||
# Issue: https://github.com/huggingface/transformers/issues/3000
|
||||
# self.assertIsNotNone(tokenizer_p.__class__.from_pretrained('./'))
|
||||
self.assertIsNotNone(tokenizer_r.__class__.from_pretrained("./"))
|
||||
|
||||
def test_distilbert(self):
|
||||
for tokenizer_name in DistilBertTokenizer.pretrained_vocab_files_map["vocab_file"].keys():
|
||||
tokenizer_p = DistilBertTokenizer.from_pretrained(tokenizer_name)
|
||||
@@ -270,6 +402,15 @@ class FastTokenizerMatchingTest(unittest.TestCase):
|
||||
# Check for dynamic encoding sequence handling in batch_encode_plus
|
||||
self.assert_batch_encode_dynamic_overflowing(tokenizer_r)
|
||||
|
||||
# Check alignment for build_inputs_with_special_tokens
|
||||
self.assert_build_inputs_with_special_tokens(tokenizer_r, tokenizer_p)
|
||||
|
||||
# Check the number of returned files for save_vocabulary
|
||||
self.assert_save_pretrained(tokenizer_r, tokenizer_p)
|
||||
|
||||
# Check for padding
|
||||
self.assert_padding(tokenizer_r, tokenizer_p)
|
||||
|
||||
def test_gpt2(self):
|
||||
for tokenizer_name in GPT2Tokenizer.pretrained_vocab_files_map["vocab_file"].keys():
|
||||
tokenizer_p = GPT2Tokenizer.from_pretrained(tokenizer_name)
|
||||
@@ -302,6 +443,15 @@ class FastTokenizerMatchingTest(unittest.TestCase):
|
||||
# Check for dynamic encoding sequence handling in batch_encode_plus
|
||||
self.assertRaises(ValueError, self.assert_batch_encode_dynamic_overflowing, tokenizer_r)
|
||||
|
||||
# Check alignment for build_inputs_with_special_tokens
|
||||
self.assert_build_inputs_with_special_tokens(tokenizer_r, tokenizer_p)
|
||||
|
||||
# Check the number of returned files for save_vocabulary
|
||||
self.assert_save_pretrained(tokenizer_r, tokenizer_p)
|
||||
|
||||
# Check for padding
|
||||
self.assertRaises(ValueError, self.assert_padding, tokenizer_r, tokenizer_p)
|
||||
|
||||
def test_roberta(self):
|
||||
for tokenizer_name in RobertaTokenizer.pretrained_vocab_files_map["vocab_file"].keys():
|
||||
tokenizer_p = RobertaTokenizer.from_pretrained(tokenizer_name)
|
||||
@@ -334,6 +484,16 @@ class FastTokenizerMatchingTest(unittest.TestCase):
|
||||
# Check for dynamic encoding sequence handling in batch_encode_plus
|
||||
self.assert_batch_encode_dynamic_overflowing(tokenizer_r)
|
||||
|
||||
# Check alignment for build_inputs_with_special_tokens
|
||||
self.assert_build_inputs_with_special_tokens(tokenizer_r, tokenizer_p)
|
||||
|
||||
# Check the number of returned files for save_vocabulary
|
||||
self.assert_save_pretrained(tokenizer_r, tokenizer_p)
|
||||
|
||||
# Check for padding
|
||||
# TODO: Re-enable this test as soon as Roberta align with the python tokenizer.
|
||||
# self.assert_padding(tokenizer_r, tokenizer_p)
|
||||
|
||||
def test_openai(self):
|
||||
for tokenizer_name in OpenAIGPTTokenizer.pretrained_vocab_files_map["vocab_file"].keys():
|
||||
tokenizer_p = OpenAIGPTTokenizer.from_pretrained(tokenizer_name)
|
||||
@@ -366,6 +526,13 @@ class FastTokenizerMatchingTest(unittest.TestCase):
|
||||
# Check for dynamic encoding sequence handling in batch_encode_plus
|
||||
self.assertRaises(ValueError, self.assert_batch_encode_dynamic_overflowing, tokenizer_r)
|
||||
|
||||
# Check alignment for build_inputs_with_special_tokens
|
||||
self.assert_build_inputs_with_special_tokens(tokenizer_r, tokenizer_p)
|
||||
|
||||
if __name__ == "__main__":
|
||||
unittest.main()
|
||||
self.assertEqual(len(tokenizer_r.save_vocabulary(".")), len(tokenizer_p.save_vocabulary(".")))
|
||||
|
||||
# Check for padding
|
||||
self.assertRaises(ValueError, self.assert_padding, tokenizer_r, tokenizer_p)
|
||||
|
||||
# Check the number of returned files for save_vocabulary
|
||||
self.assert_save_pretrained(tokenizer_r, tokenizer_p)
|
||||
|
||||
Reference in New Issue
Block a user