Compare commits
107 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
fb560dcb07 | ||
|
|
3f3fa7f7da | ||
|
|
ffb93ec0cc | ||
|
|
20fc18fbda | ||
|
|
2ae98336d1 | ||
|
|
0dbddba6d2 | ||
|
|
29ab4b7f40 | ||
|
|
c88ed74ccf | ||
|
|
5b2d4f2657 | ||
|
|
fb4d8d0832 | ||
|
|
6083c1566e | ||
|
|
73028c5df0 | ||
|
|
81fb8d3251 | ||
|
|
4e69104a1f | ||
|
|
73d79d42b4 | ||
|
|
47b735f994 | ||
|
|
7d22fefd37 | ||
|
|
61a2b7dc9d | ||
|
|
6e261d3a22 | ||
|
|
4e597c8e4d | ||
|
|
925a13ced1 | ||
|
|
575a3b7aa1 | ||
|
|
4d36472b96 | ||
|
|
8514018300 | ||
|
|
1eec69a900 | ||
|
|
8744402f1e | ||
|
|
7f98edd7e3 | ||
|
|
f1e8a51f08 | ||
|
|
0ed630f139 | ||
|
|
ef74b0f07a | ||
|
|
f54a5bd37f | ||
|
|
569897ce2c | ||
|
|
21da895013 | ||
|
|
9a70910d47 | ||
|
|
9274734a0d | ||
|
|
69f948461f | ||
|
|
e0b6247cf7 | ||
|
|
5f2dd71d1b | ||
|
|
31158af57c | ||
|
|
5dd61fb9a9 | ||
|
|
ee5de0ba44 | ||
|
|
bed38d3afe | ||
|
|
498d06e914 | ||
|
|
3e3a9e2c01 | ||
|
|
1f5db9a13c | ||
|
|
95bac8dabb | ||
|
|
ba498eac38 | ||
|
|
68ccc04ee6 | ||
|
|
539f601be7 | ||
|
|
cfb7d108bd | ||
|
|
b4691a438d | ||
|
|
fc325e97cd | ||
|
|
fd639e5be3 | ||
|
|
63a5399bc4 | ||
|
|
125a75a121 | ||
|
|
9c64d1da35 | ||
|
|
bf99014c46 | ||
|
|
92e974196f | ||
|
|
6aa7973aec | ||
|
|
520e7f2119 | ||
|
|
dd28830327 | ||
|
|
db97930122 | ||
|
|
7046de2991 | ||
|
|
0d3aa3c04c | ||
|
|
d8b43600fd | ||
|
|
ee5a6856ca | ||
|
|
73368963b2 | ||
|
|
d7dabfeff5 | ||
|
|
42f08e596f | ||
|
|
4f7bdb0958 | ||
|
|
c6c5c3fd4e | ||
|
|
961c69776f | ||
|
|
d311f87bca | ||
|
|
7d99e05f76 | ||
|
|
2c12464a20 | ||
|
|
6fc3d34abd | ||
|
|
7748cbbe7d | ||
|
|
432c12521e | ||
|
|
c069932f5d | ||
|
|
33d3072e1c | ||
|
|
eae8ee0389 | ||
|
|
6bb6a01765 | ||
|
|
ada24def22 | ||
|
|
2184f87003 | ||
|
|
e615269cb8 | ||
|
|
5f96ebc0be | ||
|
|
950c6a4f09 | ||
|
|
d28b81dc29 | ||
|
|
d1ab1fab1b | ||
|
|
9e5b549b4d | ||
|
|
25848a6094 | ||
|
|
cbcb83f21d | ||
|
|
3bf5417258 | ||
|
|
1ebfeb7946 | ||
|
|
9c67196b83 | ||
|
|
90ab15cb7a | ||
|
|
9a50828b5c | ||
|
|
6c1b23554f | ||
|
|
239dd23f64 | ||
|
|
522c5b5533 | ||
|
|
9329e59700 | ||
|
|
2ba147ecff | ||
|
|
9773e5e0d9 | ||
|
|
ddb6f9476b | ||
|
|
6636826f04 | ||
|
|
98dadc98e1 | ||
|
|
d6fc34b459 |
@@ -10,7 +10,7 @@ jobs:
|
||||
parallelism: 1
|
||||
steps:
|
||||
- checkout
|
||||
- run: sudo pip install .[sklearn,tf,torch,testing]
|
||||
- run: sudo pip install .[sklearn,tf-cpu,torch,testing]
|
||||
- run: sudo pip install codecov pytest-cov
|
||||
- run: python -m pytest -n 8 --dist=loadfile -s -v ./tests/ --cov
|
||||
- run: codecov
|
||||
@@ -26,8 +26,10 @@ jobs:
|
||||
parallelism: 1
|
||||
steps:
|
||||
- checkout
|
||||
- run: sudo pip install .[mecab,sklearn,tf,torch,testing]
|
||||
- run: sudo pip install .[mecab,sklearn,tf-cpu,torch,testing]
|
||||
- run: python -m pytest -n 8 --dist=loadfile -s -v ./tests/
|
||||
- no_output_timeout: 4h
|
||||
|
||||
run_tests_torch:
|
||||
working_directory: ~/transformers
|
||||
docker:
|
||||
@@ -52,7 +54,7 @@ jobs:
|
||||
parallelism: 1
|
||||
steps:
|
||||
- checkout
|
||||
- run: sudo pip install .[sklearn,tf,testing]
|
||||
- run: sudo pip install .[sklearn,tf-cpu,testing]
|
||||
- run: sudo pip install codecov pytest-cov
|
||||
- run: python -m pytest -n 8 --dist=loadfile -s -v ./tests/ --cov
|
||||
- run: codecov
|
||||
|
||||
20
.github/ISSUE_TEMPLATE/bug-report.md
vendored
20
.github/ISSUE_TEMPLATE/bug-report.md
vendored
@@ -39,12 +39,14 @@ Steps to reproduce the behavior:
|
||||
|
||||
<!-- A clear and concise description of what you would expect to happen. -->
|
||||
|
||||
## Environment
|
||||
|
||||
* OS:
|
||||
* Python version:
|
||||
* PyTorch version:
|
||||
* `transformers` version (or branch):
|
||||
* Using GPU ?
|
||||
* Distributed or parallel setup ?
|
||||
* Any other relevant information:
|
||||
## Environment info
|
||||
<!-- You can run the command `python transformers-cli env` and copy-and-paste its output below.
|
||||
Don't forget to fill out the missing fields in that output! -->
|
||||
|
||||
- `transformers` version:
|
||||
- Platform:
|
||||
- Python version:
|
||||
- PyTorch version (GPU?):
|
||||
- Tensorflow version (GPU?):
|
||||
- Using GPU in script?:
|
||||
- Using distributed or parallel set-up in script?:
|
||||
|
||||
21
.github/ISSUE_TEMPLATE/migration.md
vendored
21
.github/ISSUE_TEMPLATE/migration.md
vendored
@@ -33,16 +33,21 @@ The tasks I am working on is:
|
||||
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.
|
||||
-->
|
||||
|
||||
## Environment
|
||||
## Environment info
|
||||
<!-- You can run the command `python transformers-cli env` and copy-and-paste its output below.
|
||||
Don't forget to fill out the missing fields in that output! -->
|
||||
|
||||
- `transformers` version:
|
||||
- Platform:
|
||||
- Python version:
|
||||
- PyTorch version (GPU?):
|
||||
- Tensorflow version (GPU?):
|
||||
- Using GPU in script?:
|
||||
- Using distributed or parallel set-up in script?:
|
||||
|
||||
* OS:
|
||||
* Python version:
|
||||
* PyTorch version:
|
||||
<!-- IMPORTANT: which version of the former library do you use? -->
|
||||
* `pytorch-transformers` or `pytorch-pretrained-bert` version (or branch):
|
||||
* `transformers` version (or branch):
|
||||
* Using GPU?
|
||||
* Distributed or parallel setup?
|
||||
* Any other relevant information:
|
||||
|
||||
|
||||
## Checklist
|
||||
|
||||
|
||||
3
.gitignore
vendored
3
.gitignore
vendored
@@ -139,3 +139,6 @@ serialization_dir
|
||||
# emacs
|
||||
*.*~
|
||||
debug.env
|
||||
|
||||
# vim
|
||||
.*.swp
|
||||
|
||||
@@ -41,14 +41,10 @@ Did not find it? :( So we can act quickly on it, please follow these steps:
|
||||
less than 30s;
|
||||
* Provide the *full* traceback if an exception is raised.
|
||||
|
||||
To get the OS and software versions, execute the following code and copy-paste
|
||||
the output:
|
||||
To get the OS and software versions automatically, you can run the following command:
|
||||
|
||||
```
|
||||
import platform; print("Platform", platform.platform())
|
||||
import sys; print("Python", sys.version)
|
||||
import torch; print("PyTorch", torch.__version__)
|
||||
import tensorflow; print("Tensorflow", tensorflow.__version__)
|
||||
```bash
|
||||
python transformers-cli env
|
||||
```
|
||||
|
||||
### Do you want to implement a new model?
|
||||
@@ -202,11 +198,13 @@ Follow these steps to start contributing:
|
||||
3. To indicate a work in progress please prefix the title with `[WIP]`. These
|
||||
are useful to avoid duplicated work, and to differentiate it from PRs ready
|
||||
to be merged;
|
||||
4. Make sure pre-existing tests still pass;
|
||||
5. Add high-coverage tests. No quality test, no merge;
|
||||
4. Make sure existing tests pass;
|
||||
5. Add high-coverage tests. No quality test, no merge.
|
||||
- If you are adding a new model, make sure that you use `ModelTester.all_model_classes = (MyModel, MyModelWithLMHead,...)`, which triggers the common tests.
|
||||
- If you are adding new `@slow` tests, make sure they pass using `RUN_SLOW=1 python -m pytest tests/test_my_new_model.py`.
|
||||
CircleCI does not run them.
|
||||
6. All public methods must have informative docstrings;
|
||||
|
||||
|
||||
### Tests
|
||||
|
||||
You can run 🤗 Transformers tests with `unittest` or `pytest`.
|
||||
|
||||
13
README.md
13
README.md
@@ -24,6 +24,8 @@
|
||||
|
||||
🤗 Transformers (formerly known as `pytorch-transformers` and `pytorch-pretrained-bert`) provides state-of-the-art general-purpose architectures (BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet, CTRL...) for Natural Language Understanding (NLU) and Natural Language Generation (NLG) with over 32+ pretrained models in 100+ languages and deep interoperability between TensorFlow 2.0 and PyTorch.
|
||||
|
||||
[](https://sourcerer.io/fame/clmnt/huggingface/transformers/links/0)[](https://sourcerer.io/fame/clmnt/huggingface/transformers/links/1)[](https://sourcerer.io/fame/clmnt/huggingface/transformers/links/2)[](https://sourcerer.io/fame/clmnt/huggingface/transformers/links/3)[](https://sourcerer.io/fame/clmnt/huggingface/transformers/links/4)[](https://sourcerer.io/fame/clmnt/huggingface/transformers/links/5)[](https://sourcerer.io/fame/clmnt/huggingface/transformers/links/6)[](https://sourcerer.io/fame/clmnt/huggingface/transformers/links/7)
|
||||
|
||||
### Features
|
||||
|
||||
- As easy to use as pytorch-transformers
|
||||
@@ -193,7 +195,7 @@ MODELS = [(BertModel, BertTokenizer, 'bert-base-uncased'),
|
||||
(TransfoXLModel, TransfoXLTokenizer, 'transfo-xl-wt103'),
|
||||
(XLNetModel, XLNetTokenizer, 'xlnet-base-cased'),
|
||||
(XLMModel, XLMTokenizer, 'xlm-mlm-enfr-1024'),
|
||||
(DistilBertModel, DistilBertTokenizer, 'distilbert-base-uncased'),
|
||||
(DistilBertModel, DistilBertTokenizer, 'distilbert-base-cased'),
|
||||
(RobertaModel, RobertaTokenizer, 'roberta-base'),
|
||||
(XLMRobertaModel, XLMRobertaTokenizer, 'xlm-roberta-base'),
|
||||
]
|
||||
@@ -493,19 +495,22 @@ Your model will then be accessible through its identifier, a concatenation of yo
|
||||
"username/pretrained_model"
|
||||
```
|
||||
|
||||
**Please add a README.md model card** to the repo under `model_cards/` with: model description, training params (dataset, preprocessing, hyperparameters), evaluation results, intended uses & limitations, etc.
|
||||
|
||||
Your model now has a page on huggingface.co/models 🔥
|
||||
|
||||
Anyone can load it from code:
|
||||
```python
|
||||
tokenizer = AutoTokenizer.from_pretrained("username/pretrained_model")
|
||||
model = AutoModel.from_pretrained("username/pretrained_model")
|
||||
```
|
||||
|
||||
Finally, list all your files on S3:
|
||||
List all your files on S3:
|
||||
```shell
|
||||
transformers-cli s3 ls
|
||||
# List all your S3 objects.
|
||||
```
|
||||
|
||||
You can also delete files:
|
||||
You can also delete unneeded files:
|
||||
|
||||
```shell
|
||||
transformers-cli s3 rm …
|
||||
|
||||
@@ -194,3 +194,41 @@ h2, .rst-content .toctree-wrapper p.caption, h3, h4, h5, h6, legend{
|
||||
src: url(./Calibre-Thin.otf);
|
||||
font-weight:400;
|
||||
}
|
||||
|
||||
|
||||
/**
|
||||
* Nav Links to other parts of huggingface.co
|
||||
*/
|
||||
div.menu {
|
||||
position: absolute;
|
||||
top: 0;
|
||||
right: 0;
|
||||
padding-top: 20px;
|
||||
padding-right: 20px;
|
||||
z-index: 1000;
|
||||
}
|
||||
div.menu a {
|
||||
font-size: 14px;
|
||||
letter-spacing: 0.3px;
|
||||
text-transform: uppercase;
|
||||
color: white;
|
||||
-webkit-font-smoothing: antialiased;
|
||||
background: linear-gradient(0deg, #6671ffb8, #9a66ffb8 50%);
|
||||
padding: 10px 16px 6px 16px;
|
||||
border-radius: 3px;
|
||||
margin-left: 12px;
|
||||
position: relative;
|
||||
}
|
||||
div.menu a:active {
|
||||
top: 1px;
|
||||
}
|
||||
@media (min-width: 768px) and (max-width: 1750px) {
|
||||
.wy-breadcrumbs {
|
||||
margin-top: 32px;
|
||||
}
|
||||
}
|
||||
@media (max-width: 768px) {
|
||||
div.menu {
|
||||
display: none;
|
||||
}
|
||||
}
|
||||
|
||||
@@ -58,6 +58,16 @@ function addGithubButton() {
|
||||
document.querySelector(".wy-side-nav-search .icon-home").insertAdjacentHTML('afterend', div);
|
||||
}
|
||||
|
||||
function addHfMenu() {
|
||||
const div = `
|
||||
<div class="menu">
|
||||
<a href="/welcome">🔥 Sign in</a>
|
||||
<a href="/models">🚀 Models</a>
|
||||
</div>
|
||||
`;
|
||||
document.body.insertAdjacentHTML('afterbegin', div);
|
||||
}
|
||||
|
||||
/*!
|
||||
* github-buttons v2.2.10
|
||||
* (c) 2019 なつき
|
||||
@@ -74,6 +84,7 @@ function onLoad() {
|
||||
addCustomFooter();
|
||||
addGithubButton();
|
||||
parseGithubButtons();
|
||||
addHfMenu();
|
||||
}
|
||||
|
||||
window.addEventListener("load", onLoad);
|
||||
|
||||
@@ -26,7 +26,7 @@ author = u'huggingface'
|
||||
# The short X.Y version
|
||||
version = u''
|
||||
# The full version, including alpha/beta/rc tags
|
||||
release = u'2.4.1'
|
||||
release = u'2.5.0'
|
||||
|
||||
|
||||
# -- General configuration ---------------------------------------------------
|
||||
|
||||
@@ -63,7 +63,7 @@ XNLI
|
||||
`The Cross-Lingual NLI Corpus (XNLI) <https://www.nyu.edu/projects/bowman/xnli/>`__ is a benchmark that evaluates
|
||||
the quality of cross-lingual text representations.
|
||||
XNLI is crowd-sourced dataset based on `MultiNLI <http://www.nyu.edu/projects/bowman/multinli/>`: pairs of text are labeled with textual entailment
|
||||
annotations for 15 different languages (including both high-ressource language such as English and low-ressource languages such as Swahili).
|
||||
annotations for 15 different languages (including both high-resource language such as English and low-resource languages such as Swahili).
|
||||
|
||||
It was released together with the paper
|
||||
`XNLI: Evaluating Cross-lingual Sentence Representations <https://arxiv.org/abs/1809.05053>`__
|
||||
|
||||
@@ -23,6 +23,9 @@ Tips:
|
||||
|
||||
- This implementation is the same as :class:`~transformers.BertModel` with a tiny embeddings tweak as well as a
|
||||
setup for Roberta pretrained models.
|
||||
- RoBERTa has the same architecture as BERT, but uses a byte-level BPE as a tokenizer (same as GPT-2) and uses a
|
||||
different pre-training scheme.
|
||||
- RoBERTa doesn't have `token_type_ids`, you don't need to indicate which token belongs to which segment. Just separate your segments with the separation token `tokenizer.sep_token` (or `</s>`)
|
||||
- `Camembert <./camembert.html>`__ is a wrapper around RoBERTa. Refer to this page for usage examples.
|
||||
|
||||
RobertaConfig
|
||||
|
||||
@@ -22,6 +22,9 @@ and XNLI benchmarks. We will make XLM-R code, data, and models publicly availabl
|
||||
|
||||
Tips:
|
||||
|
||||
- XLM-R is a multilingual model trained on 100 different languages. Unlike some XLM multilingual models, it does
|
||||
not require `lang` tensors to understand which language is used, and should be able to determine the correct
|
||||
language from the input ids.
|
||||
- This implementation is the same as RoBERTa. Refer to the `documentation of RoBERTa <./roberta.html>`__ for usage
|
||||
examples as well as the information relative to the inputs and outputs.
|
||||
|
||||
|
||||
@@ -26,19 +26,22 @@ Your model will then be accessible through its identifier, a concatenation of yo
|
||||
"username/pretrained_model"
|
||||
```
|
||||
|
||||
**Please add a README.md model card** to the repo under `model_cards/` with: model description, training params (dataset, preprocessing, hyperparameters), evaluation results, intended uses & limitations, etc.
|
||||
|
||||
Your model now has a page on huggingface.co/models 🔥
|
||||
|
||||
Anyone can load it from code:
|
||||
```python
|
||||
tokenizer = AutoTokenizer.from_pretrained("username/pretrained_model")
|
||||
model = AutoModel.from_pretrained("username/pretrained_model")
|
||||
```
|
||||
|
||||
Finally, list all your files on S3:
|
||||
List all your files on S3:
|
||||
```shell
|
||||
transformers-cli s3 ls
|
||||
# List all your S3 objects.
|
||||
```
|
||||
|
||||
You can also delete files:
|
||||
You can also delete unneeded files:
|
||||
|
||||
```shell
|
||||
transformers-cli s3 rm …
|
||||
|
||||
@@ -179,6 +179,14 @@ For a list that includes community-uploaded models, refer to `https://huggingfac
|
||||
| | | | The DistilBERT model distilled from the BERT model `bert-base-uncased` checkpoint, with an additional linear layer. |
|
||||
| | | (see `details <https://github.com/huggingface/transformers/tree/master/examples/distillation>`__) |
|
||||
| +------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| | ``distilbert-base-cased`` | | 6-layer, 768-hidden, 12-heads, 65M parameters |
|
||||
| | | | The DistilBERT model distilled from the BERT model `bert-base-cased` checkpoint |
|
||||
| | | (see `details <https://github.com/huggingface/transformers/tree/master/examples/distillation>`__) |
|
||||
| +------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| | ``distilbert-base-cased-distilled-squad`` | | 6-layer, 768-hidden, 12-heads, 65M parameters |
|
||||
| | | | The DistilBERT model distilled from the BERT model `bert-base-cased` checkpoint, with an additional question answering layer. |
|
||||
| | | (see `details <https://github.com/huggingface/transformers/tree/master/examples/distillation>`__) |
|
||||
| +------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| | ``distilgpt2`` | | 6-layer, 768-hidden, 12-heads, 82M parameters |
|
||||
| | | | The DistilGPT2 model distilled from the GPT2 model `gpt2` checkpoint. |
|
||||
| | | (see `details <https://github.com/huggingface/transformers/tree/master/examples/distillation>`__) |
|
||||
|
||||
@@ -209,7 +209,7 @@ past = None
|
||||
for i in range(100):
|
||||
print(i)
|
||||
output, past = model(context, past=past)
|
||||
token = torch.argmax(output[0, :])
|
||||
token = torch.argmax(output[..., -1, :])
|
||||
|
||||
generated += [token.tolist()]
|
||||
context = token.unsqueeze(0)
|
||||
@@ -299,8 +299,8 @@ model = Model2Model.from_pretrained('fine-tuned-weights')
|
||||
model.eval()
|
||||
|
||||
# If you have a GPU, put everything on cuda
|
||||
question_tensor = encoded_question.to('cuda')
|
||||
answer_tensor = encoded_answer.to('cuda')
|
||||
question_tensor = question_tensor.to('cuda')
|
||||
answer_tensor = answer_tensor.to('cuda')
|
||||
model.to('cuda')
|
||||
|
||||
# Predict all tokens
|
||||
|
||||
@@ -17,15 +17,14 @@ pip install -r ./examples/requirements.txt
|
||||
| Section | Description |
|
||||
|----------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| [TensorFlow 2.0 models on GLUE](#TensorFlow-2.0-Bert-models-on-GLUE) | Examples running BERT TensorFlow 2.0 model on the GLUE tasks.
|
||||
| [Language Model fine-tuning](#language-model-fine-tuning) | Fine-tuning the library models for language modeling on a text dataset. Causal language modeling for GPT/GPT-2, masked language modeling for BERT/RoBERTa. |
|
||||
| [Language Generation](#language-generation) | Conditional text generation using the auto-regressive models of the library: GPT, GPT-2, Transformer-XL and XLNet. |
|
||||
| [GLUE](#glue) | Examples running BERT/XLM/XLNet/RoBERTa on the 9 GLUE tasks. Examples feature distributed training as well as half-precision. |
|
||||
| [SQuAD](#squad) | Using BERT/RoBERTa/XLNet/XLM for question answering, examples with distributed training. |
|
||||
| [Multiple Choice](#multiple-choice) | Examples running BERT/XLNet/RoBERTa on the SWAG/RACE/ARC tasks.
|
||||
| [Named Entity Recognition](#named-entity-recognition) | Using BERT for Named Entity Recognition (NER) on the CoNLL 2003 dataset, examples with distributed training. |
|
||||
| [Language Model training](#language-model-training) | Fine-tuning (or training from scratch) the library models for language modeling on a text dataset. Causal language modeling for GPT/GPT-2, masked language modeling for BERT/RoBERTa. |
|
||||
| [Language Generation](#language-generation) | Conditional text generation using the auto-regressive models of the library: GPT, GPT-2, Transformer-XL and XLNet. |
|
||||
| [GLUE](#glue) | Examples running BERT/XLM/XLNet/RoBERTa on the 9 GLUE tasks. Examples feature distributed training as well as half-precision. |
|
||||
| [SQuAD](#squad) | Using BERT/RoBERTa/XLNet/XLM for question answering, examples with distributed training. |
|
||||
| [Multiple Choice](#multiple-choice) | Examples running BERT/XLNet/RoBERTa on the SWAG/RACE/ARC tasks. |
|
||||
| [Named Entity Recognition](#named-entity-recognition) | Using BERT for Named Entity Recognition (NER) on the CoNLL 2003 dataset, examples with distributed training. |
|
||||
| [XNLI](#xnli) | Examples running BERT/XLM on the XNLI benchmark. |
|
||||
| [Adversarial evaluation of model performances](#adversarial-evaluation-of-model-performances) | Testing a model with adversarial evaluation of natural language
|
||||
inference on the Heuristic Analysis for NLI Systems (HANS) dataset (McCoy et al., 2019.) |
|
||||
| [Adversarial evaluation of model performances](#adversarial-evaluation-of-model-performances) | Testing a model with adversarial evaluation of natural language inference on the Heuristic Analysis for NLI Systems (HANS) dataset (McCoy et al., 2019.) |
|
||||
|
||||
## TensorFlow 2.0 Bert models on GLUE
|
||||
|
||||
@@ -49,16 +48,16 @@ Quick benchmarks from the script (no other modifications):
|
||||
|
||||
Mixed precision (AMP) reduces the training time considerably for the same hardware and hyper-parameters (same batch size was used).
|
||||
|
||||
## Language model fine-tuning
|
||||
## Language model training
|
||||
|
||||
Based on the script [`run_lm_finetuning.py`](https://github.com/huggingface/transformers/blob/master/examples/run_lm_finetuning.py).
|
||||
Based on the script [`run_language_modeling.py`](https://github.com/huggingface/transformers/blob/master/examples/run_language_modeling.py).
|
||||
|
||||
Fine-tuning the library models for language modeling on a text dataset for GPT, GPT-2, BERT and RoBERTa (DistilBERT
|
||||
Fine-tuning (or training from scratch) the library models for language modeling on a text dataset for GPT, GPT-2, BERT and RoBERTa (DistilBERT
|
||||
to be added soon). GPT and GPT-2 are fine-tuned using a causal language modeling (CLM) loss while BERT and RoBERTa
|
||||
are fine-tuned using a masked language modeling (MLM) loss.
|
||||
|
||||
Before running the following example, you should get a file that contains text on which the language model will be
|
||||
fine-tuned. A good example of such text is the [WikiText-2 dataset](https://blog.einstein.ai/the-wikitext-long-term-dependency-language-modeling-dataset/).
|
||||
trained or fine-tuned. A good example of such text is the [WikiText-2 dataset](https://blog.einstein.ai/the-wikitext-long-term-dependency-language-modeling-dataset/).
|
||||
|
||||
We will refer to two different files: `$TRAIN_FILE`, which contains text for training, and `$TEST_FILE`, which contains
|
||||
text that will be used for evaluation.
|
||||
@@ -72,7 +71,7 @@ the tokenization). The loss here is that of causal language modeling.
|
||||
export TRAIN_FILE=/path/to/dataset/wiki.train.raw
|
||||
export TEST_FILE=/path/to/dataset/wiki.test.raw
|
||||
|
||||
python run_lm_finetuning.py \
|
||||
python run_language_modeling.py \
|
||||
--output_dir=output \
|
||||
--model_type=gpt2 \
|
||||
--model_name_or_path=gpt2 \
|
||||
@@ -100,7 +99,7 @@ We use the `--mlm` flag so that the script may change its loss function.
|
||||
export TRAIN_FILE=/path/to/dataset/wiki.train.raw
|
||||
export TEST_FILE=/path/to/dataset/wiki.test.raw
|
||||
|
||||
python run_lm_finetuning.py \
|
||||
python run_language_modeling.py \
|
||||
--output_dir=output \
|
||||
--model_type=roberta \
|
||||
--model_name_or_path=roberta-base \
|
||||
@@ -154,7 +153,7 @@ between different runs. We report the median on 5 runs (with different seeds) fo
|
||||
Some of these results are significantly different from the ones reported on the test set
|
||||
of GLUE benchmark on the website. For QQP and WNLI, please refer to [FAQ #12](https://gluebenchmark.com/faq) on the webite.
|
||||
|
||||
Before running anyone of these GLUE tasks you should download the
|
||||
Before running any one of these GLUE tasks you should download the
|
||||
[GLUE data](https://gluebenchmark.com/tasks) by running
|
||||
[this script](https://gist.github.com/W4ngatang/60c2bdb54d156a41194446737ce03e2e)
|
||||
and unpack it to some directory `$GLUE_DIR`.
|
||||
@@ -196,7 +195,7 @@ since the data processor for each task inherits from the base class DataProcesso
|
||||
The following examples fine-tune BERT on the Microsoft Research Paraphrase Corpus (MRPC) corpus and runs in less
|
||||
than 10 minutes on a single K-80 and in 27 seconds (!) on single tesla V100 16GB with apex installed.
|
||||
|
||||
Before running anyone of these GLUE tasks you should download the
|
||||
Before running any one of these GLUE tasks you should download the
|
||||
[GLUE data](https://gluebenchmark.com/tasks) by running
|
||||
[this script](https://gist.github.com/W4ngatang/60c2bdb54d156a41194446737ce03e2e)
|
||||
and unpack it to some directory `$GLUE_DIR`.
|
||||
@@ -701,7 +700,7 @@ macro avg 0.8712 0.8774 0.8740 13869
|
||||
|
||||
Based on the script [`run_xnli.py`](https://github.com/huggingface/transformers/blob/master/examples/run_xnli.py).
|
||||
|
||||
[XNLI](https://www.nyu.edu/projects/bowman/xnli/) is crowd-sourced dataset based on [MultiNLI](http://www.nyu.edu/projects/bowman/multinli/). It is an evaluation benchmark for cross-lingual text representations. Pairs of text are labeled with textual entailment annotations for 15 different languages (including both high-ressource language such as English and low-ressource languages such as Swahili).
|
||||
[XNLI](https://www.nyu.edu/projects/bowman/xnli/) is crowd-sourced dataset based on [MultiNLI](http://www.nyu.edu/projects/bowman/multinli/). It is an evaluation benchmark for cross-lingual text representations. Pairs of text are labeled with textual entailment annotations for 15 different languages (including both high-resource language such as English and low-resource languages such as Swahili).
|
||||
|
||||
#### Fine-tuning on XNLI
|
||||
|
||||
@@ -773,7 +772,7 @@ export HANS_DIR=path-to-hans
|
||||
export MODEL_TYPE=type-of-the-model-e.g.-bert-roberta-xlnet-etc
|
||||
export MODEL_PATH=path-to-the-model-directory-that-is-trained-on-NLI-e.g.-by-using-run_glue.py
|
||||
|
||||
python examples/test_hans.py \
|
||||
python examples/hans/test_hans.py \
|
||||
--task_name hans \
|
||||
--model_type $MODEL_TYPE \
|
||||
--do_eval \
|
||||
@@ -781,7 +780,7 @@ python examples/test_hans.py \
|
||||
--data_dir $HANS_DIR \
|
||||
--model_name_or_path $MODEL_PATH \
|
||||
--max_seq_length 128 \
|
||||
-output_dir $MODEL_PATH \
|
||||
--output_dir $MODEL_PATH \
|
||||
```
|
||||
|
||||
This will create the hans_predictions.txt file in MODEL_PATH, which can then be evaluated using hans/evaluate_heur_output.py from the HANS dataset.
|
||||
|
||||
@@ -31,8 +31,10 @@ Here are the results on the dev sets of GLUE:
|
||||
|
||||
| Model | Macro-score | CoLA | MNLI | MRPC | QNLI | QQP | RTE | SST-2| STS-B| WNLI |
|
||||
| :---: | :---: | :---:| :---:| :---:| :---:| :---:| :---:| :---:| :---:| :---: |
|
||||
| BERT-base-uncased | **77.6** | 49.2 | 80.8 | 87.4 | 87.5 | 86.4 | 61.7 | 92.0 | 83.8 | 45.1 |
|
||||
| DistilBERT-base-uncased | **76.8** | 43.6 | 79.0 | 87.5 | 85.3 | 84.9 | 59.9 | 90.7 | 81.2 | 56.3 |
|
||||
| BERT-base-uncased | **74.9** | 49.2 | 80.8 | 87.4 | 87.5 | 86.4 | 61.7 | 92.0 | 83.8 | 45.1 |
|
||||
| DistilBERT-base-uncased | **74.3** | 43.6 | 79.0 | 87.5 | 85.3 | 84.9 | 59.9 | 90.7 | 81.2 | 56.3 |
|
||||
| BERT-base-cased | **78.2** | 58.2 | 83.9 | 87.8 | 91.0 | 89.2 | 66.1 | 91.7 | 89.2 | 46.5 |
|
||||
| DistilBERT-base-cased | **75.9** | 47.2 | 81.5 | 85.6 | 88.2 | 87.8 | 60.6 | 90.4 | 85.5 | 56.3 |
|
||||
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
|
||||
| RoBERTa-base (reported) | **83.2**/**86.4**<sup>2</sup> | 63.6 | 87.6 | 90.2 | 92.8 | 91.9 | 78.7 | 94.8 | 91.2 | 57.7<sup>3</sup> |
|
||||
| DistilRoBERTa<sup>1</sup> | **79.0**/**82.3**<sup>2</sup> | 59.3 | 84.0 | 86.6 | 90.8 | 89.4 | 67.9 | 92.5 | 88.3 | 52.1 |
|
||||
@@ -63,7 +65,9 @@ This part of the library has only be tested with Python3.6+. There are few speci
|
||||
Transformers includes five pre-trained Distil* models, currently only provided for English and German (we are investigating the possibility to train and release a multilingual version of DistilBERT):
|
||||
|
||||
- `distilbert-base-uncased`: DistilBERT English language model pretrained on the same data used to pretrain Bert (concatenation of the Toronto Book Corpus and full English Wikipedia) using distillation with the supervision of the `bert-base-uncased` version of Bert. The model has 6 layers, 768 dimension and 12 heads, totalizing 66M parameters.
|
||||
- `distilbert-base-uncased-distilled-squad`: A finetuned version of `distilbert-base-uncased` finetuned using (a second step of) knwoledge distillation on SQuAD 1.0. This model reaches a F1 score of 86.9 on the dev set (for comparison, Bert `bert-base-uncased` version reaches a 88.5 F1 score).
|
||||
- `distilbert-base-uncased-distilled-squad`: A finetuned version of `distilbert-base-uncased` finetuned using (a second step of) knwoledge distillation on SQuAD 1.0. This model reaches a F1 score of 79.8 on the dev set (for comparison, Bert `bert-base-uncased` version reaches a 82.3 F1 score).
|
||||
- `distilbert-base-cased`: DistilBERT English language model pretrained on the same data used to pretrain Bert (concatenation of the Toronto Book Corpus and full English Wikipedia) using distillation with the supervision of the `bert-base-cased` version of Bert. The model has 6 layers, 768 dimension and 12 heads, totalizing 65M parameters.
|
||||
- `distilbert-base-cased-distilled-squad`: A finetuned version of `distilbert-base-cased` finetuned using (a second step of) knwoledge distillation on SQuAD 1.0. This model reaches a F1 score of 87.1 on the dev set (for comparison, Bert `bert-base-cased` version reaches a 88.7 F1 score).
|
||||
- `distilbert-base-german-cased`: DistilBERT German language model pretrained on 1/2 of the data used to pretrain Bert using distillation with the supervision of the `bert-base-german-dbmdz-cased` version of German DBMDZ Bert. For NER tasks the model reaches a F1 score of 83.49 on the CoNLL-2003 test set (for comparison, `bert-base-german-dbmdz-cased` reaches a 84.52 F1 score), and a F1 score of 85.23 on the GermEval 2014 test set (`bert-base-german-dbmdz-cased` reaches a 86.89 F1 score).
|
||||
- `distilgpt2`: DistilGPT2 English language model pretrained with the supervision of `gpt2` (the smallest version of GPT2) on [OpenWebTextCorpus](https://skylion007.github.io/OpenWebTextCorpus/), a reproduction of OpenAI's WebText dataset. The model has 6 layers, 768 dimension and 12 heads, totalizing 82M parameters (compared to 124M parameters for GPT2). On average, DistilGPT2 is two times faster than GPT2.
|
||||
- `distilroberta-base`: DistilRoBERTa English language model pretrained with the supervision of `roberta-base` solely on [OpenWebTextCorpus](https://skylion007.github.io/OpenWebTextCorpus/), a reproduction of OpenAI's WebText dataset (it is ~4 times less training data than the teacher RoBERTa). The model has 6 layers, 768 dimension and 12 heads, totalizing 82M parameters (compared to 125M parameters for RoBERTa-base). On average DistilRoBERTa is twice as fast as Roberta-base.
|
||||
@@ -72,8 +76,8 @@ Transformers includes five pre-trained Distil* models, currently only provided f
|
||||
Using DistilBERT is very similar to using BERT. DistilBERT share the same tokenizer as BERT's `bert-base-uncased` even though we provide a link to this tokenizer under the `DistilBertTokenizer` name to have a consistent naming between the library models.
|
||||
|
||||
```python
|
||||
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
|
||||
model = DistilBertModel.from_pretrained('distilbert-base-uncased')
|
||||
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-cased')
|
||||
model = DistilBertModel.from_pretrained('distilbert-base-cased')
|
||||
|
||||
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute")).unsqueeze(0)
|
||||
outputs = model(input_ids)
|
||||
@@ -81,6 +85,7 @@ last_hidden_states = outputs[0] # The last hidden-state is the first element of
|
||||
```
|
||||
|
||||
Similarly, using the other Distil* models simply consists in calling the base classes with a different pretrained checkpoint:
|
||||
- DistilBERT uncased: `model = DistilBertModel.from_pretrained('distilbert-base-uncased')`
|
||||
- DistilGPT2: `model = GPT2Model.from_pretrained('distilgpt2')`
|
||||
- DistilRoBERTa: `model = RobertaModel.from_pretrained('distilroberta-base')`
|
||||
- DistilmBERT: `model = DistilBertModel.from_pretrained('distilbert-base-multilingual-cased')`
|
||||
@@ -174,7 +179,7 @@ Happy distillation!
|
||||
|
||||
## Citation
|
||||
|
||||
If you find the ressource useful, you should cite the following paper:
|
||||
If you find the resource useful, you should cite the following paper:
|
||||
|
||||
```
|
||||
@inproceedings{sanh2019distilbert,
|
||||
|
||||
@@ -75,13 +75,17 @@ def main():
|
||||
iter += 1
|
||||
if iter % interval == 0:
|
||||
end = time.time()
|
||||
logger.info(f"{iter} examples processed. - {(end-start)/interval:.2f}s/expl")
|
||||
logger.info(f"{iter} examples processed. - {(end-start):.2f}s/{interval}expl")
|
||||
start = time.time()
|
||||
logger.info("Finished binarization")
|
||||
logger.info(f"{len(data)} examples processed.")
|
||||
|
||||
dp_file = f"{args.dump_file}.{args.tokenizer_name}.pickle"
|
||||
rslt_ = [np.uint16(d) for d in rslt]
|
||||
vocab_size = tokenizer.vocab_size
|
||||
if vocab_size < (1 << 16):
|
||||
rslt_ = [np.uint16(d) for d in rslt]
|
||||
else:
|
||||
rslt_ = [np.int32(d) for d in rslt]
|
||||
random.shuffle(rslt_)
|
||||
logger.info(f"Dump to {dp_file}")
|
||||
with open(dp_file, "wb") as handle:
|
||||
|
||||
@@ -0,0 +1,15 @@
|
||||
{
|
||||
"activation": "gelu",
|
||||
"attention_dropout": 0.1,
|
||||
"dim": 768,
|
||||
"dropout": 0.1,
|
||||
"hidden_dim": 3072,
|
||||
"initializer_range": 0.02,
|
||||
"max_position_embeddings": 512,
|
||||
"n_heads": 12,
|
||||
"n_layers": 6,
|
||||
"sinusoidal_pos_embds": true,
|
||||
"tie_weights_": true,
|
||||
"vocab_size": 28996
|
||||
}
|
||||
|
||||
@@ -310,7 +310,7 @@ def evaluate(args, model, tokenizer, prefix=""):
|
||||
eval_dataloader = DataLoader(eval_dataset, sampler=eval_sampler, batch_size=args.eval_batch_size)
|
||||
|
||||
# multi-gpu eval
|
||||
if args.n_gpu > 1:
|
||||
if args.n_gpu > 1 and not isinstance(model, torch.nn.DataParallel):
|
||||
model = torch.nn.DataParallel(model)
|
||||
|
||||
# Eval!
|
||||
|
||||
@@ -86,6 +86,9 @@ MODEL_CLASSES = {
|
||||
class TextDataset(Dataset):
|
||||
def __init__(self, tokenizer: PreTrainedTokenizer, args, file_path: str, block_size=512):
|
||||
assert os.path.isfile(file_path)
|
||||
|
||||
block_size = block_size - (tokenizer.max_len - tokenizer.max_len_single_sentence)
|
||||
|
||||
directory, filename = os.path.split(file_path)
|
||||
cached_features_file = os.path.join(
|
||||
directory, args.model_type + "_cached_lm_" + str(block_size) + "_" + filename
|
||||
@@ -118,7 +121,7 @@ class TextDataset(Dataset):
|
||||
return len(self.examples)
|
||||
|
||||
def __getitem__(self, item):
|
||||
return torch.tensor(self.examples[item])
|
||||
return torch.tensor(self.examples[item], dtype=torch.long)
|
||||
|
||||
|
||||
class LineByLineTextDataset(Dataset):
|
||||
@@ -130,15 +133,15 @@ class LineByLineTextDataset(Dataset):
|
||||
logger.info("Creating features from dataset file at %s", file_path)
|
||||
|
||||
with open(file_path, encoding="utf-8") as f:
|
||||
lines = [line for line in f.read().splitlines() if len(line) > 0]
|
||||
lines = [line for line in f.read().splitlines() if (len(line) > 0 and not line.isspace())]
|
||||
|
||||
self.examples = tokenizer.batch_encode_plus(lines, max_length=block_size)["input_ids"]
|
||||
self.examples = tokenizer.batch_encode_plus(lines, add_special_tokens=True, max_length=block_size)["input_ids"]
|
||||
|
||||
def __len__(self):
|
||||
return len(self.examples)
|
||||
|
||||
def __getitem__(self, i):
|
||||
return torch.tensor(self.examples[i])
|
||||
return torch.tensor(self.examples[i], dtype=torch.long)
|
||||
|
||||
|
||||
def load_and_cache_examples(args, tokenizer, evaluate=False):
|
||||
@@ -195,6 +198,12 @@ def _rotate_checkpoints(args, checkpoint_prefix="checkpoint", use_mtime=False) -
|
||||
|
||||
def mask_tokens(inputs: torch.Tensor, tokenizer: PreTrainedTokenizer, args) -> Tuple[torch.Tensor, torch.Tensor]:
|
||||
""" Prepare masked tokens inputs/labels for masked language modeling: 80% MASK, 10% random, 10% original. """
|
||||
|
||||
if tokenizer.mask_token is None:
|
||||
raise ValueError(
|
||||
"This tokenizer does not have a mask token which is necessary for masked language modeling. Remove the --mlm flag if you want to use this tokenizer."
|
||||
)
|
||||
|
||||
labels = inputs.clone()
|
||||
# We sample a few tokens in each sequence for masked-LM training (with probability args.mlm_probability defaults to 0.15 in Bert/RoBERTa)
|
||||
probability_matrix = torch.full(labels.shape, args.mlm_probability)
|
||||
@@ -704,10 +713,10 @@ def main():
|
||||
)
|
||||
|
||||
if args.block_size <= 0:
|
||||
args.block_size = tokenizer.max_len_single_sentence
|
||||
args.block_size = tokenizer.max_len
|
||||
# Our input block size will be the max possible for the model
|
||||
else:
|
||||
args.block_size = min(args.block_size, tokenizer.max_len_single_sentence)
|
||||
args.block_size = min(args.block_size, tokenizer.max_len)
|
||||
|
||||
if args.model_name_or_path:
|
||||
model = model_class.from_pretrained(
|
||||
@@ -160,7 +160,10 @@ def train(args, train_dataset, model, tokenizer, labels, pad_token_label_id):
|
||||
# Check if continuing training from a checkpoint
|
||||
if os.path.exists(args.model_name_or_path):
|
||||
# set global_step to gobal_step of last saved checkpoint from model path
|
||||
global_step = int(args.model_name_or_path.split("-")[-1].split("/")[0])
|
||||
try:
|
||||
global_step = int(args.model_name_or_path.split("-")[-1].split("/")[0])
|
||||
except ValueError:
|
||||
global_step = 0
|
||||
epochs_trained = global_step // (len(train_dataloader) // args.gradient_accumulation_steps)
|
||||
steps_trained_in_current_epoch = global_step % (len(train_dataloader) // args.gradient_accumulation_steps)
|
||||
|
||||
|
||||
@@ -219,6 +219,11 @@ def train(args, train_dataset, model, tokenizer):
|
||||
inputs.update({"cls_index": batch[5], "p_mask": batch[6]})
|
||||
if args.version_2_with_negative:
|
||||
inputs.update({"is_impossible": batch[7]})
|
||||
if hasattr(model, "config") and hasattr(model.config, "lang2id"):
|
||||
inputs.update(
|
||||
{"langs": (torch.ones(batch[0].shape, dtype=torch.int64) * args.lang_id).to(args.device)}
|
||||
)
|
||||
|
||||
outputs = model(**inputs)
|
||||
# model outputs are always tuple in transformers (see doc)
|
||||
loss = outputs[0]
|
||||
@@ -330,6 +335,11 @@ def evaluate(args, model, tokenizer, prefix=""):
|
||||
# XLNet and XLM use more arguments for their predictions
|
||||
if args.model_type in ["xlnet", "xlm"]:
|
||||
inputs.update({"cls_index": batch[4], "p_mask": batch[5]})
|
||||
# for lang_id-sensitive xlm models
|
||||
if hasattr(model, "config") and hasattr(model.config, "lang2id"):
|
||||
inputs.update(
|
||||
{"langs": (torch.ones(batch[0].shape, dtype=torch.int64) * args.lang_id).to(args.device)}
|
||||
)
|
||||
|
||||
outputs = model(**inputs)
|
||||
|
||||
@@ -635,6 +645,12 @@ def main():
|
||||
help="If true, all of the warnings related to data processing will be printed. "
|
||||
"A number of warnings are expected for a normal SQuAD evaluation.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--lang_id",
|
||||
default=0,
|
||||
type=int,
|
||||
help="language id of input for language-specific xlm models (see tokenization_xlm.PRETRAINED_INIT_CONFIGURATION)",
|
||||
)
|
||||
|
||||
parser.add_argument("--logging_steps", type=int, default=500, help="Log every X updates steps.")
|
||||
parser.add_argument("--save_steps", type=int, default=500, help="Save checkpoint every X updates steps.")
|
||||
|
||||
@@ -459,7 +459,7 @@ def main():
|
||||
help="Number of updates steps to accumulate before performing a backward/update pass.",
|
||||
)
|
||||
parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
|
||||
parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight deay if we apply some.")
|
||||
parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
|
||||
parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
|
||||
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
|
||||
parser.add_argument(
|
||||
|
||||
@@ -73,7 +73,7 @@ def read_examples_from_file(data_dir, mode):
|
||||
# Examples could have no label for mode = "test"
|
||||
labels.append("O")
|
||||
if words:
|
||||
examples.append(InputExample(guid="%s-%d".format(mode, guid_index), words=words, labels=labels))
|
||||
examples.append(InputExample(guid="{}-{}".format(mode, guid_index), words=words, labels=labels))
|
||||
return examples
|
||||
|
||||
|
||||
|
||||
121
model_cards/KB/albert-base-swedish-cased-alpha/README.md
Normal file
121
model_cards/KB/albert-base-swedish-cased-alpha/README.md
Normal file
@@ -0,0 +1,121 @@
|
||||
---
|
||||
language: swedish
|
||||
---
|
||||
|
||||
# Swedish BERT Models
|
||||
|
||||
The National Library of Sweden / KBLab releases three pretrained language models based on BERT and ALBERT. The models are trained on aproximately 15-20GB of text (200M sentences, 3000M tokens) from various sources (books, news, government publications, swedish wikipedia and internet forums) aiming to provide a representative BERT model for Swedish text. A more complete description will be published later on.
|
||||
|
||||
The following three models are currently available:
|
||||
|
||||
- **bert-base-swedish-cased** (*v1*) - A BERT trained with the same hyperparameters as first published by Google.
|
||||
- **bert-base-swedish-cased-ner** (*experimental*) - a BERT fine-tuned for NER using SUC 3.0.
|
||||
- **albert-base-swedish-cased-alpha** (*alpha*) - A first attempt at an ALBERT for Swedish.
|
||||
|
||||
All models are cased and trained with whole word masking.
|
||||
|
||||
## Files
|
||||
|
||||
| **name** | **files** |
|
||||
|---------------------------------|-----------|
|
||||
| bert-base-swedish-cased | [config](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased/config.json), [vocab](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased/vocab.txt), [pytorch_model.bin](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased/pytorch_model.bin) |
|
||||
| bert-base-swedish-cased-ner | [config](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased-ner/config.json), [vocab](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased-ner/vocab.txt) [pytorch_model.bin](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased-ner/pytorch_model.bin) |
|
||||
| albert-base-swedish-cased-alpha | [config](https://s3.amazonaws.com/models.huggingface.co/bert/KB/albert-base-swedish-cased-alpha/config.json), [sentencepiece model](https://s3.amazonaws.com/models.huggingface.co/bert/KB/albert-base-swedish-cased-alpha/spiece.model), [pytorch_model.bin](https://s3.amazonaws.com/models.huggingface.co/bert/KB/albert-base-swedish-cased-alpha/pytorch_model.bin) |
|
||||
|
||||
TensorFlow model weights will be released soon.
|
||||
|
||||
## Usage requirements / installation instructions
|
||||
|
||||
The examples below require Huggingface Transformers 2.4.1 and Pytorch 1.3.1 or greater. For Transformers<2.4.0 the tokenizer must be instantiated manually and the `do_lower_case` flag parameter set to `False` and `keep_accents` to `True` (for ALBERT).
|
||||
|
||||
To create an environment where the examples can be run, run the following in an terminal on your OS of choice.
|
||||
|
||||
```
|
||||
# git clone https://github.com/Kungbib/swedish-bert-models
|
||||
# cd swedish-bert-models
|
||||
# python3 -m venv venv
|
||||
# source venv/bin/activate
|
||||
# pip install --upgrade pip
|
||||
# pip install -r requirements.txt
|
||||
```
|
||||
|
||||
### BERT Base Swedish
|
||||
|
||||
A standard BERT base for Swedish trained on a variety of sources. Vocabulary size is ~50k. Using Huggingface Transformers the model can be loaded in Python as follows:
|
||||
|
||||
```python
|
||||
from transformers import AutoModel,AutoTokenizer
|
||||
|
||||
tok = AutoTokenizer.from_pretrained('KB/bert-base-swedish-cased')
|
||||
model = AutoModel.from_pretrained('KB/bert-base-swedish-cased')
|
||||
```
|
||||
|
||||
|
||||
### BERT base fine-tuned for Swedish NER
|
||||
|
||||
This model is fine-tuned on the SUC 3.0 dataset. Using the Huggingface pipeline the model can be easily instantiated. For Transformer<2.4.1 it seems the tokenizer must be loaded separately to disable lower-casing of input strings:
|
||||
|
||||
```python
|
||||
from transformers import pipeline
|
||||
|
||||
nlp = pipeline('ner', model='KB/bert-base-swedish-cased-ner', tokenizer='KB/bert-base-swedish-cased-ner')
|
||||
|
||||
nlp('Idag släpper KB tre språkmodeller.')
|
||||
```
|
||||
|
||||
Running the Python code above should produce in something like the result below. Entity types used are `TME` for time, `PRS` for personal names, `LOC` for locations, `EVN` for events and `ORG` for organisations. These labels are subject to change.
|
||||
|
||||
```python
|
||||
[ { 'word': 'Idag', 'score': 0.9998126029968262, 'entity': 'TME' },
|
||||
{ 'word': 'KB', 'score': 0.9814832210540771, 'entity': 'ORG' } ]
|
||||
```
|
||||
|
||||
The BERT tokenizer often splits words into multiple tokens, with the subparts starting with `##`, for example the string `Engelbert kör Volvo till Herrängens fotbollsklubb` gets tokenized as `Engel ##bert kör Volvo till Herr ##ängens fotbolls ##klubb`. To glue parts back together one can use something like this:
|
||||
|
||||
```python
|
||||
text = 'Engelbert tar Volvon till Tele2 Arena för att titta på Djurgården IF ' +\
|
||||
'som spelar fotboll i VM klockan två på kvällen.'
|
||||
|
||||
l = []
|
||||
for token in nlp(text):
|
||||
if token['word'].startswith('##'):
|
||||
l[-1]['word'] += token['word'][2:]
|
||||
else:
|
||||
l += [ token ]
|
||||
|
||||
print(l)
|
||||
```
|
||||
|
||||
Which should result in the following (though less cleanly formated):
|
||||
|
||||
```python
|
||||
[ { 'word': 'Engelbert', 'score': 0.99..., 'entity': 'PRS'},
|
||||
{ 'word': 'Volvon', 'score': 0.99..., 'entity': 'OBJ'},
|
||||
{ 'word': 'Tele2', 'score': 0.99..., 'entity': 'LOC'},
|
||||
{ 'word': 'Arena', 'score': 0.99..., 'entity': 'LOC'},
|
||||
{ 'word': 'Djurgården', 'score': 0.99..., 'entity': 'ORG'},
|
||||
{ 'word': 'IF', 'score': 0.99..., 'entity': 'ORG'},
|
||||
{ 'word': 'VM', 'score': 0.99..., 'entity': 'EVN'},
|
||||
{ 'word': 'klockan', 'score': 0.99..., 'entity': 'TME'},
|
||||
{ 'word': 'två', 'score': 0.99..., 'entity': 'TME'},
|
||||
{ 'word': 'på', 'score': 0.99..., 'entity': 'TME'},
|
||||
{ 'word': 'kvällen', 'score': 0.54..., 'entity': 'TME'} ]
|
||||
```
|
||||
|
||||
### ALBERT base
|
||||
|
||||
The easisest way to do this is, again, using Huggingface Transformers:
|
||||
|
||||
```python
|
||||
from transformers import AutoModel,AutoTokenizer
|
||||
|
||||
tok = AutoTokenizer.from_pretrained('KB/albert-base-swedish-cased-alpha'),
|
||||
model = AutoModel.from_pretrained('KB/albert-base-swedish-cased-alpha')
|
||||
```
|
||||
|
||||
## Acknowledgements ❤️
|
||||
|
||||
- Resources from Stockholms University, Umeå University and Swedish Language Bank at Gothenburg University were used when fine-tuning BERT for NER.
|
||||
- Model pretraining was made partly in-house at the KBLab and partly (for material without active copyright) with the support of Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
|
||||
- Models are hosted on S3 by Huggingface 🤗
|
||||
|
||||
121
model_cards/KB/bert-base-swedish-cased-ner/README.md
Normal file
121
model_cards/KB/bert-base-swedish-cased-ner/README.md
Normal file
@@ -0,0 +1,121 @@
|
||||
---
|
||||
language: swedish
|
||||
---
|
||||
|
||||
# Swedish BERT Models
|
||||
|
||||
The National Library of Sweden / KBLab releases three pretrained language models based on BERT and ALBERT. The models are trained on aproximately 15-20GB of text (200M sentences, 3000M tokens) from various sources (books, news, government publications, swedish wikipedia and internet forums) aiming to provide a representative BERT model for Swedish text. A more complete description will be published later on.
|
||||
|
||||
The following three models are currently available:
|
||||
|
||||
- **bert-base-swedish-cased** (*v1*) - A BERT trained with the same hyperparameters as first published by Google.
|
||||
- **bert-base-swedish-cased-ner** (*experimental*) - a BERT fine-tuned for NER using SUC 3.0.
|
||||
- **albert-base-swedish-cased-alpha** (*alpha*) - A first attempt at an ALBERT for Swedish.
|
||||
|
||||
All models are cased and trained with whole word masking.
|
||||
|
||||
## Files
|
||||
|
||||
| **name** | **files** |
|
||||
|---------------------------------|-----------|
|
||||
| bert-base-swedish-cased | [config](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased/config.json), [vocab](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased/vocab.txt), [pytorch_model.bin](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased/pytorch_model.bin) |
|
||||
| bert-base-swedish-cased-ner | [config](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased-ner/config.json), [vocab](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased-ner/vocab.txt) [pytorch_model.bin](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased-ner/pytorch_model.bin) |
|
||||
| albert-base-swedish-cased-alpha | [config](https://s3.amazonaws.com/models.huggingface.co/bert/KB/albert-base-swedish-cased-alpha/config.json), [sentencepiece model](https://s3.amazonaws.com/models.huggingface.co/bert/KB/albert-base-swedish-cased-alpha/spiece.model), [pytorch_model.bin](https://s3.amazonaws.com/models.huggingface.co/bert/KB/albert-base-swedish-cased-alpha/pytorch_model.bin) |
|
||||
|
||||
TensorFlow model weights will be released soon.
|
||||
|
||||
## Usage requirements / installation instructions
|
||||
|
||||
The examples below require Huggingface Transformers 2.4.1 and Pytorch 1.3.1 or greater. For Transformers<2.4.0 the tokenizer must be instantiated manually and the `do_lower_case` flag parameter set to `False` and `keep_accents` to `True` (for ALBERT).
|
||||
|
||||
To create an environment where the examples can be run, run the following in an terminal on your OS of choice.
|
||||
|
||||
```
|
||||
# git clone https://github.com/Kungbib/swedish-bert-models
|
||||
# cd swedish-bert-models
|
||||
# python3 -m venv venv
|
||||
# source venv/bin/activate
|
||||
# pip install --upgrade pip
|
||||
# pip install -r requirements.txt
|
||||
```
|
||||
|
||||
### BERT Base Swedish
|
||||
|
||||
A standard BERT base for Swedish trained on a variety of sources. Vocabulary size is ~50k. Using Huggingface Transformers the model can be loaded in Python as follows:
|
||||
|
||||
```python
|
||||
from transformers import AutoModel,AutoTokenizer
|
||||
|
||||
tok = AutoTokenizer.from_pretrained('KB/bert-base-swedish-cased')
|
||||
model = AutoModel.from_pretrained('KB/bert-base-swedish-cased')
|
||||
```
|
||||
|
||||
|
||||
### BERT base fine-tuned for Swedish NER
|
||||
|
||||
This model is fine-tuned on the SUC 3.0 dataset. Using the Huggingface pipeline the model can be easily instantiated. For Transformer<2.4.1 it seems the tokenizer must be loaded separately to disable lower-casing of input strings:
|
||||
|
||||
```python
|
||||
from transformers import pipeline
|
||||
|
||||
nlp = pipeline('ner', model='KB/bert-base-swedish-cased-ner', tokenizer='KB/bert-base-swedish-cased-ner')
|
||||
|
||||
nlp('Idag släpper KB tre språkmodeller.')
|
||||
```
|
||||
|
||||
Running the Python code above should produce in something like the result below. Entity types used are `TME` for time, `PRS` for personal names, `LOC` for locations, `EVN` for events and `ORG` for organisations. These labels are subject to change.
|
||||
|
||||
```python
|
||||
[ { 'word': 'Idag', 'score': 0.9998126029968262, 'entity': 'TME' },
|
||||
{ 'word': 'KB', 'score': 0.9814832210540771, 'entity': 'ORG' } ]
|
||||
```
|
||||
|
||||
The BERT tokenizer often splits words into multiple tokens, with the subparts starting with `##`, for example the string `Engelbert kör Volvo till Herrängens fotbollsklubb` gets tokenized as `Engel ##bert kör Volvo till Herr ##ängens fotbolls ##klubb`. To glue parts back together one can use something like this:
|
||||
|
||||
```python
|
||||
text = 'Engelbert tar Volvon till Tele2 Arena för att titta på Djurgården IF ' +\
|
||||
'som spelar fotboll i VM klockan två på kvällen.'
|
||||
|
||||
l = []
|
||||
for token in nlp(text):
|
||||
if token['word'].startswith('##'):
|
||||
l[-1]['word'] += token['word'][2:]
|
||||
else:
|
||||
l += [ token ]
|
||||
|
||||
print(l)
|
||||
```
|
||||
|
||||
Which should result in the following (though less cleanly formated):
|
||||
|
||||
```python
|
||||
[ { 'word': 'Engelbert', 'score': 0.99..., 'entity': 'PRS'},
|
||||
{ 'word': 'Volvon', 'score': 0.99..., 'entity': 'OBJ'},
|
||||
{ 'word': 'Tele2', 'score': 0.99..., 'entity': 'LOC'},
|
||||
{ 'word': 'Arena', 'score': 0.99..., 'entity': 'LOC'},
|
||||
{ 'word': 'Djurgården', 'score': 0.99..., 'entity': 'ORG'},
|
||||
{ 'word': 'IF', 'score': 0.99..., 'entity': 'ORG'},
|
||||
{ 'word': 'VM', 'score': 0.99..., 'entity': 'EVN'},
|
||||
{ 'word': 'klockan', 'score': 0.99..., 'entity': 'TME'},
|
||||
{ 'word': 'två', 'score': 0.99..., 'entity': 'TME'},
|
||||
{ 'word': 'på', 'score': 0.99..., 'entity': 'TME'},
|
||||
{ 'word': 'kvällen', 'score': 0.54..., 'entity': 'TME'} ]
|
||||
```
|
||||
|
||||
### ALBERT base
|
||||
|
||||
The easisest way to do this is, again, using Huggingface Transformers:
|
||||
|
||||
```python
|
||||
from transformers import AutoModel,AutoTokenizer
|
||||
|
||||
tok = AutoTokenizer.from_pretrained('KB/albert-base-swedish-cased-alpha'),
|
||||
model = AutoModel.from_pretrained('KB/albert-base-swedish-cased-alpha')
|
||||
```
|
||||
|
||||
## Acknowledgements ❤️
|
||||
|
||||
- Resources from Stockholms University, Umeå University and Swedish Language Bank at Gothenburg University were used when fine-tuning BERT for NER.
|
||||
- Model pretraining was made partly in-house at the KBLab and partly (for material without active copyright) with the support of Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
|
||||
- Models are hosted on S3 by Huggingface 🤗
|
||||
|
||||
121
model_cards/KB/bert-base-swedish-cased/README.md
Normal file
121
model_cards/KB/bert-base-swedish-cased/README.md
Normal file
@@ -0,0 +1,121 @@
|
||||
---
|
||||
language: swedish
|
||||
---
|
||||
|
||||
# Swedish BERT Models
|
||||
|
||||
The National Library of Sweden / KBLab releases three pretrained language models based on BERT and ALBERT. The models are trained on aproximately 15-20GB of text (200M sentences, 3000M tokens) from various sources (books, news, government publications, swedish wikipedia and internet forums) aiming to provide a representative BERT model for Swedish text. A more complete description will be published later on.
|
||||
|
||||
The following three models are currently available:
|
||||
|
||||
- **bert-base-swedish-cased** (*v1*) - A BERT trained with the same hyperparameters as first published by Google.
|
||||
- **bert-base-swedish-cased-ner** (*experimental*) - a BERT fine-tuned for NER using SUC 3.0.
|
||||
- **albert-base-swedish-cased-alpha** (*alpha*) - A first attempt at an ALBERT for Swedish.
|
||||
|
||||
All models are cased and trained with whole word masking.
|
||||
|
||||
## Files
|
||||
|
||||
| **name** | **files** |
|
||||
|---------------------------------|-----------|
|
||||
| bert-base-swedish-cased | [config](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased/config.json), [vocab](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased/vocab.txt), [pytorch_model.bin](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased/pytorch_model.bin) |
|
||||
| bert-base-swedish-cased-ner | [config](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased-ner/config.json), [vocab](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased-ner/vocab.txt) [pytorch_model.bin](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased-ner/pytorch_model.bin) |
|
||||
| albert-base-swedish-cased-alpha | [config](https://s3.amazonaws.com/models.huggingface.co/bert/KB/albert-base-swedish-cased-alpha/config.json), [sentencepiece model](https://s3.amazonaws.com/models.huggingface.co/bert/KB/albert-base-swedish-cased-alpha/spiece.model), [pytorch_model.bin](https://s3.amazonaws.com/models.huggingface.co/bert/KB/albert-base-swedish-cased-alpha/pytorch_model.bin) |
|
||||
|
||||
TensorFlow model weights will be released soon.
|
||||
|
||||
## Usage requirements / installation instructions
|
||||
|
||||
The examples below require Huggingface Transformers 2.4.1 and Pytorch 1.3.1 or greater. For Transformers<2.4.0 the tokenizer must be instantiated manually and the `do_lower_case` flag parameter set to `False` and `keep_accents` to `True` (for ALBERT).
|
||||
|
||||
To create an environment where the examples can be run, run the following in an terminal on your OS of choice.
|
||||
|
||||
```
|
||||
# git clone https://github.com/Kungbib/swedish-bert-models
|
||||
# cd swedish-bert-models
|
||||
# python3 -m venv venv
|
||||
# source venv/bin/activate
|
||||
# pip install --upgrade pip
|
||||
# pip install -r requirements.txt
|
||||
```
|
||||
|
||||
### BERT Base Swedish
|
||||
|
||||
A standard BERT base for Swedish trained on a variety of sources. Vocabulary size is ~50k. Using Huggingface Transformers the model can be loaded in Python as follows:
|
||||
|
||||
```python
|
||||
from transformers import AutoModel,AutoTokenizer
|
||||
|
||||
tok = AutoTokenizer.from_pretrained('KB/bert-base-swedish-cased')
|
||||
model = AutoModel.from_pretrained('KB/bert-base-swedish-cased')
|
||||
```
|
||||
|
||||
|
||||
### BERT base fine-tuned for Swedish NER
|
||||
|
||||
This model is fine-tuned on the SUC 3.0 dataset. Using the Huggingface pipeline the model can be easily instantiated. For Transformer<2.4.1 it seems the tokenizer must be loaded separately to disable lower-casing of input strings:
|
||||
|
||||
```python
|
||||
from transformers import pipeline
|
||||
|
||||
nlp = pipeline('ner', model='KB/bert-base-swedish-cased-ner', tokenizer='KB/bert-base-swedish-cased-ner')
|
||||
|
||||
nlp('Idag släpper KB tre språkmodeller.')
|
||||
```
|
||||
|
||||
Running the Python code above should produce in something like the result below. Entity types used are `TME` for time, `PRS` for personal names, `LOC` for locations, `EVN` for events and `ORG` for organisations. These labels are subject to change.
|
||||
|
||||
```python
|
||||
[ { 'word': 'Idag', 'score': 0.9998126029968262, 'entity': 'TME' },
|
||||
{ 'word': 'KB', 'score': 0.9814832210540771, 'entity': 'ORG' } ]
|
||||
```
|
||||
|
||||
The BERT tokenizer often splits words into multiple tokens, with the subparts starting with `##`, for example the string `Engelbert kör Volvo till Herrängens fotbollsklubb` gets tokenized as `Engel ##bert kör Volvo till Herr ##ängens fotbolls ##klubb`. To glue parts back together one can use something like this:
|
||||
|
||||
```python
|
||||
text = 'Engelbert tar Volvon till Tele2 Arena för att titta på Djurgården IF ' +\
|
||||
'som spelar fotboll i VM klockan två på kvällen.'
|
||||
|
||||
l = []
|
||||
for token in nlp(text):
|
||||
if token['word'].startswith('##'):
|
||||
l[-1]['word'] += token['word'][2:]
|
||||
else:
|
||||
l += [ token ]
|
||||
|
||||
print(l)
|
||||
```
|
||||
|
||||
Which should result in the following (though less cleanly formated):
|
||||
|
||||
```python
|
||||
[ { 'word': 'Engelbert', 'score': 0.99..., 'entity': 'PRS'},
|
||||
{ 'word': 'Volvon', 'score': 0.99..., 'entity': 'OBJ'},
|
||||
{ 'word': 'Tele2', 'score': 0.99..., 'entity': 'LOC'},
|
||||
{ 'word': 'Arena', 'score': 0.99..., 'entity': 'LOC'},
|
||||
{ 'word': 'Djurgården', 'score': 0.99..., 'entity': 'ORG'},
|
||||
{ 'word': 'IF', 'score': 0.99..., 'entity': 'ORG'},
|
||||
{ 'word': 'VM', 'score': 0.99..., 'entity': 'EVN'},
|
||||
{ 'word': 'klockan', 'score': 0.99..., 'entity': 'TME'},
|
||||
{ 'word': 'två', 'score': 0.99..., 'entity': 'TME'},
|
||||
{ 'word': 'på', 'score': 0.99..., 'entity': 'TME'},
|
||||
{ 'word': 'kvällen', 'score': 0.54..., 'entity': 'TME'} ]
|
||||
```
|
||||
|
||||
### ALBERT base
|
||||
|
||||
The easisest way to do this is, again, using Huggingface Transformers:
|
||||
|
||||
```python
|
||||
from transformers import AutoModel,AutoTokenizer
|
||||
|
||||
tok = AutoTokenizer.from_pretrained('KB/albert-base-swedish-cased-alpha'),
|
||||
model = AutoModel.from_pretrained('KB/albert-base-swedish-cased-alpha')
|
||||
```
|
||||
|
||||
## Acknowledgements ❤️
|
||||
|
||||
- Resources from Stockholms University, Umeå University and Swedish Language Bank at Gothenburg University were used when fine-tuning BERT for NER.
|
||||
- Model pretraining was made partly in-house at the KBLab and partly (for material without active copyright) with the support of Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
|
||||
- Models are hosted on S3 by Huggingface 🤗
|
||||
|
||||
118
model_cards/Musixmatch/umberto-commoncrawl-cased-v1/README.md
Normal file
118
model_cards/Musixmatch/umberto-commoncrawl-cased-v1/README.md
Normal file
@@ -0,0 +1,118 @@
|
||||
---
|
||||
language: italian
|
||||
---
|
||||
|
||||
# UmBERTo Commoncrawl Cased
|
||||
|
||||
[UmBERTo](https://github.com/musixmatchresearch/umberto) is a Roberta-based Language Model trained on large Italian Corpora and uses two innovative approaches: SentencePiece and Whole Word Masking. Now available at [github.com/huggingface/transformers](https://huggingface.co/Musixmatch/umberto-commoncrawl-cased-v1)
|
||||
|
||||
<p align="center">
|
||||
<img src="https://user-images.githubusercontent.com/7140210/72913702-d55a8480-3d3d-11ea-99fc-f2ef29af4e72.jpg" width="700"> </br>
|
||||
Marco Lodola, Monument to Umberto Eco, Alessandria 2019
|
||||
</p>
|
||||
|
||||
## Dataset
|
||||
UmBERTo-Commoncrawl-Cased utilizes the Italian subcorpus of [OSCAR](https://traces1.inria.fr/oscar/) as training set of the language model. We used deduplicated version of the Italian corpus that consists in 70 GB of plain text data, 210M sentences with 11B words where the sentences have been filtered and shuffled at line level in order to be used for NLP research.
|
||||
|
||||
## Pre-trained model
|
||||
|
||||
| Model | WWM | Cased | Tokenizer | Vocab Size | Train Steps | Download |
|
||||
| ------ | ------ | ------ | ------ | ------ |------ | ------ |
|
||||
| `umberto-commoncrawl-cased-v1` | YES | YES | SPM | 32K | 125k | [Link](http://bit.ly/35zO7GH) |
|
||||
|
||||
This model was trained with [SentencePiece](https://github.com/google/sentencepiece) and Whole Word Masking.
|
||||
|
||||
## Downstream Tasks
|
||||
These results refers to umberto-commoncrawl-cased model. All details are at [Umberto](https://github.com/musixmatchresearch/umberto) Official Page.
|
||||
|
||||
#### Named Entity Recognition (NER)
|
||||
|
||||
| Dataset | F1 | Precision | Recall | Accuracy |
|
||||
| ------ | ------ | ------ | ------ | ------ |
|
||||
| **ICAB-EvalITA07** | **87.565** | 86.596 | 88.556 | 98.690 |
|
||||
| **WikiNER-ITA** | **92.531** | 92.509 | 92.553 | 99.136 |
|
||||
|
||||
#### Part of Speech (POS)
|
||||
|
||||
| Dataset | F1 | Precision | Recall | Accuracy |
|
||||
| ------ | ------ | ------ | ------ | ------ |
|
||||
| **UD_Italian-ISDT** | 98.870 | 98.861 | 98.879 | **98.977** |
|
||||
| **UD_Italian-ParTUT** | 98.786 | 98.812 | 98.760 | **98.903** |
|
||||
|
||||
|
||||
|
||||
## Usage
|
||||
|
||||
##### Load UmBERTo with AutoModel, Autotokenizer:
|
||||
|
||||
```python
|
||||
|
||||
import torch
|
||||
from transformers import AutoTokenizer, AutoModel
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("Musixmatch/umberto-commoncrawl-cased-v1")
|
||||
umberto = AutoModel.from_pretrained("Musixmatch/umberto-commoncrawl-cased-v1")
|
||||
|
||||
encoded_input = tokenizer.encode("Umberto Eco è stato un grande scrittore")
|
||||
input_ids = torch.tensor(encoded_input).unsqueeze(0) # Batch size 1
|
||||
outputs = umberto(input_ids)
|
||||
last_hidden_states = outputs[0] # The last hidden-state is the first element of the output
|
||||
```
|
||||
|
||||
##### Predict masked token:
|
||||
|
||||
```python
|
||||
from transformers import pipeline
|
||||
|
||||
fill_mask = pipeline(
|
||||
"fill-mask",
|
||||
model="Musixmatch/umberto-commoncrawl-cased-v1",
|
||||
tokenizer="Musixmatch/umberto-commoncrawl-cased-v1"
|
||||
)
|
||||
|
||||
result = fill_mask("Umberto Eco è <mask> un grande scrittore")
|
||||
# {'sequence': '<s> Umberto Eco è considerato un grande scrittore</s>', 'score': 0.18599839508533478, 'token': 5032}
|
||||
# {'sequence': '<s> Umberto Eco è stato un grande scrittore</s>', 'score': 0.17816807329654694, 'token': 471}
|
||||
# {'sequence': '<s> Umberto Eco è sicuramente un grande scrittore</s>', 'score': 0.16565583646297455, 'token': 2654}
|
||||
# {'sequence': '<s> Umberto Eco è indubbiamente un grande scrittore</s>', 'score': 0.0932890921831131, 'token': 17908}
|
||||
# {'sequence': '<s> Umberto Eco è certamente un grande scrittore</s>', 'score': 0.054701317101716995, 'token': 5269}
|
||||
```
|
||||
|
||||
|
||||
## Citation
|
||||
All of the original datasets are publicly available or were released with the owners' grant. The datasets are all released under a CC0 or CCBY license.
|
||||
|
||||
* UD Italian-ISDT Dataset [Github](https://github.com/UniversalDependencies/UD_Italian-ISDT)
|
||||
* UD Italian-ParTUT Dataset [Github](https://github.com/UniversalDependencies/UD_Italian-ParTUT)
|
||||
* I-CAB (Italian Content Annotation Bank), EvalITA [Page](http://www.evalita.it/)
|
||||
* WIKINER [Page](https://figshare.com/articles/Learning_multilingual_named_entity_recognition_from_Wikipedia/5462500) , [Paper](https://www.sciencedirect.com/science/article/pii/S0004370212000276?via%3Dihub)
|
||||
|
||||
```
|
||||
@inproceedings {magnini2006annotazione,
|
||||
title = {Annotazione di contenuti concettuali in un corpus italiano: I - CAB},
|
||||
author = {Magnini,Bernardo and Cappelli,Amedeo and Pianta,Emanuele and Speranza,Manuela and Bartalesi Lenzi,V and Sprugnoli,Rachele and Romano,Lorenza and Girardi,Christian and Negri,Matteo},
|
||||
booktitle = {Proc.of SILFI 2006},
|
||||
year = {2006}
|
||||
}
|
||||
@inproceedings {magnini2006cab,
|
||||
title = {I - CAB: the Italian Content Annotation Bank.},
|
||||
author = {Magnini,Bernardo and Pianta,Emanuele and Girardi,Christian and Negri,Matteo and Romano,Lorenza and Speranza,Manuela and Lenzi,Valentina Bartalesi and Sprugnoli,Rachele},
|
||||
booktitle = {LREC},
|
||||
pages = {963--968},
|
||||
year = {2006},
|
||||
organization = {Citeseer}
|
||||
}
|
||||
```
|
||||
|
||||
## Authors
|
||||
|
||||
**Loreto Parisi**: `loreto at musixmatch dot com`, [loretoparisi](https://github.com/loretoparisi)
|
||||
**Simone Francia**: `simone.francia at musixmatch dot com`, [simonefrancia](https://github.com/simonefrancia)
|
||||
**Paolo Magnani**: `paul.magnani95 at gmail dot com`, [paulthemagno](https://github.com/paulthemagno)
|
||||
|
||||
## About Musixmatch AI
|
||||

|
||||
We do Machine Learning and Artificial Intelligence @[musixmatch](https://twitter.com/Musixmatch)
|
||||
Follow us on [Twitter](https://twitter.com/musixmatchai) [Github](https://github.com/musixmatchresearch)
|
||||
|
||||
|
||||
117
model_cards/Musixmatch/umberto-wikipedia-uncased-v1/README.md
Normal file
117
model_cards/Musixmatch/umberto-wikipedia-uncased-v1/README.md
Normal file
@@ -0,0 +1,117 @@
|
||||
---
|
||||
language: italian
|
||||
---
|
||||
|
||||
# UmBERTo Wikipedia Uncased
|
||||
|
||||
[UmBERTo](https://github.com/musixmatchresearch/umberto) is a Roberta-based Language Model trained on large Italian Corpora and uses two innovative approaches: SentencePiece and Whole Word Masking. Now available at [github.com/huggingface/transformers](https://huggingface.co/Musixmatch/umberto-commoncrawl-cased-v1)
|
||||
|
||||
<p align="center">
|
||||
<img src="https://user-images.githubusercontent.com/7140210/72913702-d55a8480-3d3d-11ea-99fc-f2ef29af4e72.jpg" width="700"> </br>
|
||||
Marco Lodola, Monument to Umberto Eco, Alessandria 2019
|
||||
</p>
|
||||
|
||||
## Dataset
|
||||
UmBERTo-Wikipedia-Uncased Training is trained on a relative small corpus (~7GB) extracted from [Wikipedia-ITA](https://linguatools.org/tools/corpora/wikipedia-monolingual-corpora/).
|
||||
|
||||
## Pre-trained model
|
||||
|
||||
| Model | WWM | Cased | Tokenizer | Vocab Size | Train Steps | Download |
|
||||
| ------ | ------ | ------ | ------ | ------ |------ | ------ |
|
||||
| `umberto-wikipedia-uncased-v1` | YES | YES | SPM | 32K | 100k | [Link](http://bit.ly/35wbSj6) |
|
||||
|
||||
This model was trained with [SentencePiece](https://github.com/google/sentencepiece) and Whole Word Masking.
|
||||
|
||||
## Downstream Tasks
|
||||
These results refers to umberto-wikipedia-uncased model. All details are at [Umberto](https://github.com/musixmatchresearch/umberto) Official Page.
|
||||
|
||||
#### Named Entity Recognition (NER)
|
||||
|
||||
| Dataset | F1 | Precision | Recall | Accuracy |
|
||||
| ------ | ------ | ------ | ------ | ----- |
|
||||
| **ICAB-EvalITA07** | **86.240** | 85.939 | 86.544 | 98.534 |
|
||||
| **WikiNER-ITA** | **90.483** | 90.328 | 90.638 | 98.661 |
|
||||
|
||||
#### Part of Speech (POS)
|
||||
|
||||
| Dataset | F1 | Precision | Recall | Accuracy |
|
||||
| ------ | ------ | ------ | ------ | ------ |
|
||||
| **UD_Italian-ISDT** | 98.563 | 98.508 | 98.618 | **98.717** |
|
||||
| **UD_Italian-ParTUT** | 97.810 | 97.835 | 97.784 | **98.060** |
|
||||
|
||||
|
||||
|
||||
## Usage
|
||||
|
||||
##### Load UmBERTo Wikipedia Uncased with AutoModel, Autotokenizer:
|
||||
|
||||
```python
|
||||
|
||||
import torch
|
||||
from transformers import AutoTokenizer, AutoModel
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("Musixmatch/umberto-wikipedia-uncased-v1")
|
||||
umberto = AutoModel.from_pretrained("Musixmatch/umberto-wikipedia-uncased-v1")
|
||||
|
||||
encoded_input = tokenizer.encode("Umberto Eco è stato un grande scrittore")
|
||||
input_ids = torch.tensor(encoded_input).unsqueeze(0) # Batch size 1
|
||||
outputs = umberto(input_ids)
|
||||
last_hidden_states = outputs[0] # The last hidden-state is the first element of the output
|
||||
```
|
||||
|
||||
##### Predict masked token:
|
||||
|
||||
```python
|
||||
from transformers import pipeline
|
||||
|
||||
fill_mask = pipeline(
|
||||
"fill-mask",
|
||||
model="Musixmatch/umberto-wikipedia-uncased-v1",
|
||||
tokenizer="Musixmatch/umberto-wikipedia-uncased-v1"
|
||||
)
|
||||
|
||||
result = fill_mask("Umberto Eco è <mask> un grande scrittore")
|
||||
# {'sequence': '<s> umberto eco è stato un grande scrittore</s>', 'score': 0.5784581303596497, 'token': 361}
|
||||
# {'sequence': '<s> umberto eco è anche un grande scrittore</s>', 'score': 0.33813193440437317, 'token': 269}
|
||||
# {'sequence': '<s> umberto eco è considerato un grande scrittore</s>', 'score': 0.027196012437343597, 'token': 3236}
|
||||
# {'sequence': '<s> umberto eco è diventato un grande scrittore</s>', 'score': 0.013716378249228, 'token': 5742}
|
||||
# {'sequence': '<s> umberto eco è inoltre un grande scrittore</s>', 'score': 0.010662357322871685, 'token': 1030}
|
||||
```
|
||||
|
||||
|
||||
## Citation
|
||||
All of the original datasets are publicly available or were released with the owners' grant. The datasets are all released under a CC0 or CCBY license.
|
||||
|
||||
* UD Italian-ISDT Dataset [Github](https://github.com/UniversalDependencies/UD_Italian-ISDT)
|
||||
* UD Italian-ParTUT Dataset [Github](https://github.com/UniversalDependencies/UD_Italian-ParTUT)
|
||||
* I-CAB (Italian Content Annotation Bank), EvalITA [Page](http://www.evalita.it/)
|
||||
* WIKINER [Page](https://figshare.com/articles/Learning_multilingual_named_entity_recognition_from_Wikipedia/5462500) , [Paper](https://www.sciencedirect.com/science/article/pii/S0004370212000276?via%3Dihub)
|
||||
|
||||
```
|
||||
@inproceedings {magnini2006annotazione,
|
||||
title = {Annotazione di contenuti concettuali in un corpus italiano: I - CAB},
|
||||
author = {Magnini,Bernardo and Cappelli,Amedeo and Pianta,Emanuele and Speranza,Manuela and Bartalesi Lenzi,V and Sprugnoli,Rachele and Romano,Lorenza and Girardi,Christian and Negri,Matteo},
|
||||
booktitle = {Proc.of SILFI 2006},
|
||||
year = {2006}
|
||||
}
|
||||
@inproceedings {magnini2006cab,
|
||||
title = {I - CAB: the Italian Content Annotation Bank.},
|
||||
author = {Magnini,Bernardo and Pianta,Emanuele and Girardi,Christian and Negri,Matteo and Romano,Lorenza and Speranza,Manuela and Lenzi,Valentina Bartalesi and Sprugnoli,Rachele},
|
||||
booktitle = {LREC},
|
||||
pages = {963--968},
|
||||
year = {2006},
|
||||
organization = {Citeseer}
|
||||
}
|
||||
```
|
||||
|
||||
## Authors
|
||||
|
||||
**Loreto Parisi**: `loreto at musixmatch dot com`, [loretoparisi](https://github.com/loretoparisi)
|
||||
**Simone Francia**: `simone.francia at musixmatch dot com`, [simonefrancia](https://github.com/simonefrancia)
|
||||
**Paolo Magnani**: `paul.magnani95 at gmail dot com`, [paulthemagno](https://github.com/paulthemagno)
|
||||
|
||||
## About Musixmatch AI
|
||||

|
||||
We do Machine Learning and Artificial Intelligence @[musixmatch](https://twitter.com/Musixmatch)
|
||||
Follow us on [Twitter](https://twitter.com/musixmatchai) [Github](https://github.com/musixmatchresearch)
|
||||
|
||||
90
model_cards/ahotrod/albert_xxlargev1_squad2_512/README.md
Normal file
90
model_cards/ahotrod/albert_xxlargev1_squad2_512/README.md
Normal file
@@ -0,0 +1,90 @@
|
||||
## Albert xxlarge version 1 language model fine-tuned on SQuAD2.0
|
||||
|
||||
### with the following results:
|
||||
|
||||
```
|
||||
exact: 85.65653162637918
|
||||
f1: 89.260458954177
|
||||
total': 11873
|
||||
HasAns_exact': 82.6417004048583
|
||||
HasAns_f1': 89.8598902096736
|
||||
HasAns_total': 5928
|
||||
NoAns_exact': 88.66274179983179
|
||||
NoAns_f1': 88.66274179983179
|
||||
NoAns_total': 5945
|
||||
best_exact': 85.65653162637918
|
||||
best_exact_thresh': 0.0
|
||||
best_f1': 89.2604589541768
|
||||
best_f1_thresh': 0.0
|
||||
```
|
||||
|
||||
### from script:
|
||||
|
||||
```
|
||||
python -m torch.distributed.launch --nproc_per_node=2 ${RUN_SQUAD_DIR}/run_squad.py \
|
||||
--model_type albert \
|
||||
--model_name_or_path albert-xxlarge-v1 \
|
||||
--do_train \
|
||||
--train_file ${SQUAD_DIR}/train-v2.0.json \
|
||||
--predict_file ${SQUAD_DIR}/dev-v2.0.json \
|
||||
--version_2_with_negative \
|
||||
--num_train_epochs 3 \
|
||||
--max_steps 8144 \
|
||||
--warmup_steps 814 \
|
||||
--do_lower_case \
|
||||
--learning_rate 3e-5 \
|
||||
--max_seq_length 512 \
|
||||
--doc_stride 128 \
|
||||
--save_steps 2000 \
|
||||
--per_gpu_train_batch_size 1 \
|
||||
--gradient_accumulation_steps 24 \
|
||||
--output_dir ${MODEL_PATH}
|
||||
|
||||
CUDA_VISIBLE_DEVICES=0 python ${RUN_SQUAD_DIR}/run_squad.py \
|
||||
--model_type albert \
|
||||
--model_name_or_path ${MODEL_PATH} \
|
||||
--do_eval \
|
||||
--train_file ${SQUAD_DIR}/train-v2.0.json \
|
||||
--predict_file ${SQUAD_DIR}/dev-v2.0.json \
|
||||
--version_2_with_negative \
|
||||
--do_lower_case \
|
||||
--max_seq_length 512 \
|
||||
--per_gpu_eval_batch_size 48 \
|
||||
--output_dir ${MODEL_PATH}
|
||||
```
|
||||
|
||||
### using the following system & software:
|
||||
|
||||
```
|
||||
OS/Platform: Linux-4.15.0-76-generic-x86_64-with-debian-buster-sid
|
||||
GPU/CPU: 2 x NVIDIA 1080Ti / Intel i7-8700
|
||||
Transformers: 2.3.0
|
||||
PyTorch: 1.4.0
|
||||
TensorFlow: 2.1.0
|
||||
Python: 3.7.6
|
||||
```
|
||||
|
||||
### Inferencing / prediction works with the current Transformers v2.4.1
|
||||
|
||||
### Access this albert_xxlargev1_sqd2_512 fine-tuned model with "tried & true" code:
|
||||
|
||||
```python
|
||||
config_class, model_class, tokenizer_class = \
|
||||
AlbertConfig, AlbertForQuestionAnswering, AlbertTokenizer
|
||||
|
||||
model_name_or_path = "ahotrod/albert_xxlargev1_squad2_512"
|
||||
config = config_class.from_pretrained(model_name_or_path)
|
||||
tokenizer = tokenizer_class.from_pretrained(model_name_or_path, do_lower_case=True)
|
||||
model = model_class.from_pretrained(model_name_or_path, config=config)
|
||||
```
|
||||
|
||||
### or the AutoModels (AutoConfig, AutoTokenizer & AutoModel) should also work, however I have yet to use them in my app & confirm:
|
||||
|
||||
```python
|
||||
from transformers import AutoConfig, AutoTokenizer, AutoModel
|
||||
|
||||
model_name_or_path = "ahotrod/albert_xxlargev1_squad2_512"
|
||||
config = AutoConfig.from_pretrained(model_name_or_path)
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, do_lower_case=True)
|
||||
model = AutoModel.from_pretrained(model_name_or_path, config=config)
|
||||
```
|
||||
71
model_cards/bert-base-german-cased-README.md
Normal file
71
model_cards/bert-base-german-cased-README.md
Normal file
@@ -0,0 +1,71 @@
|
||||
---
|
||||
language: german
|
||||
thumbnail: https://thumb.tildacdn.com/tild3162-6462-4566-b663-376630376138/-/format/webp/Screenshot_from_2020.png
|
||||
---
|
||||
|
||||
# German BERT
|
||||
|
||||
## Overview
|
||||
**Language model:** bert-base-cased
|
||||
**Language:** German
|
||||
**Training data:** Wiki, OpenLegalData, News (~ 12GB)
|
||||
**Eval data:** Conll03 (NER), GermEval14 (NER), GermEval18 (Classification), GNAD (Classification)
|
||||
**Infrastructure**: 1x TPU v2
|
||||
**Published**: Jun 14th, 2019
|
||||
|
||||
## Details
|
||||
- We trained using Google's Tensorflow code on a single cloud TPU v2 with standard settings.
|
||||
- We trained 810k steps with a batch size of 1024 for sequence length 128 and 30k steps with sequence length 512. Training took about 9 days.
|
||||
- As training data we used the latest German Wikipedia dump (6GB of raw txt files), the OpenLegalData dump (2.4 GB) and news articles (3.6 GB).
|
||||
- We cleaned the data dumps with tailored scripts and segmented sentences with spacy v2.1. To create tensorflow records we used the recommended sentencepiece library for creating the word piece vocabulary and tensorflow scripts to convert the text to data usable by BERT.
|
||||
|
||||
See https://deepset.ai/german-bert for more details
|
||||
|
||||
## Hyperparameters
|
||||
|
||||
```
|
||||
batch_size = 1024
|
||||
n_steps = 810_000
|
||||
max_seq_len = 128 (and 512 later)
|
||||
learning_rate = 1e-4
|
||||
lr_schedule = LinearWarmup
|
||||
num_warmup_steps = 10_000
|
||||
```
|
||||
|
||||
## Performance
|
||||
|
||||
During training we monitored the loss and evaluated different model checkpoints on the following German datasets:
|
||||
|
||||
- germEval18Fine: Macro f1 score for multiclass sentiment classification
|
||||
- germEval18coarse: Macro f1 score for binary sentiment classification
|
||||
- germEval14: Seq f1 score for NER (file names deuutf.\*)
|
||||
- CONLL03: Seq f1 score for NER
|
||||
- 10kGNAD: Accuracy for document classification
|
||||
|
||||
Even without thorough hyperparameter tuning, we observed quite stable learning especially for our German model. Multiple restarts with different seeds produced quite similar results.
|
||||
|
||||

|
||||
|
||||
We further evaluated different points during the 9 days of pre-training and were astonished how fast the model converges to the maximally reachable performance. We ran all 5 downstream tasks on 7 different model checkpoints - taken at 0 up to 840k training steps (x-axis in figure below). Most checkpoints are taken from early training where we expected most performance changes. Surprisingly, even a randomly initialized BERT can be trained only on labeled downstream datasets and reach good performance (blue line, GermEval 2018 Coarse task, 795 kB trainset size).
|
||||
|
||||
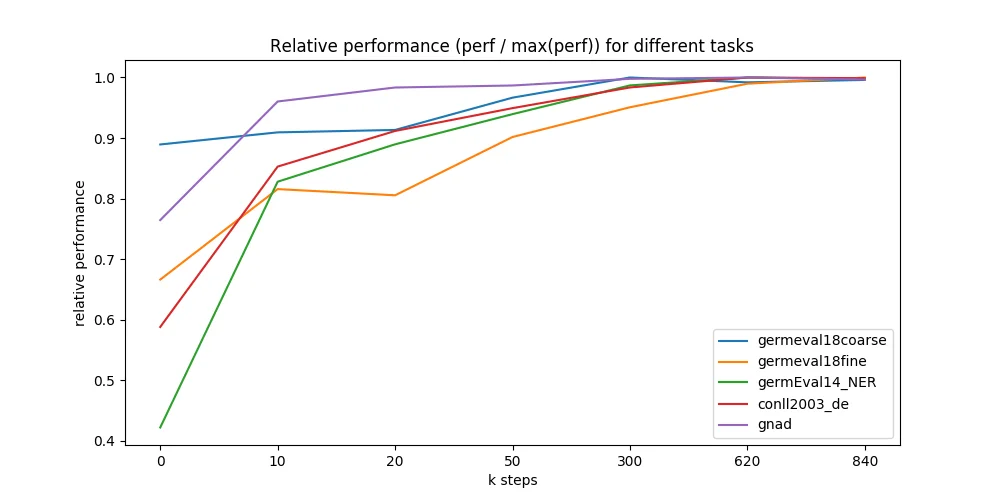
|
||||
|
||||
## Authors
|
||||
Branden Chan: `branden.chan [at] deepset.ai`
|
||||
Timo Möller: `timo.moeller [at] deepset.ai`
|
||||
Malte Pietsch: `malte.pietsch [at] deepset.ai`
|
||||
Tanay Soni: `tanay.soni [at] deepset.ai`
|
||||
|
||||
## About us
|
||||

|
||||
|
||||
We bring NLP to the industry via open source!
|
||||
Our focus: Industry specific language models & large scale QA systems.
|
||||
|
||||
Some of our work:
|
||||
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
|
||||
- [FARM](https://github.com/deepset-ai/FARM)
|
||||
- [Haystack](https://github.com/deepset-ai/haystack/)
|
||||
|
||||
Get in touch:
|
||||
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Website](https://deepset.ai)
|
||||
5
model_cards/binwang/xlnet-base-cased/README.md
Normal file
5
model_cards/binwang/xlnet-base-cased/README.md
Normal file
@@ -0,0 +1,5 @@
|
||||
This model is pre-trained **XLNET** with 12 layers.
|
||||
|
||||
It comes with paper: SBERT-WK: A Sentence Embedding Method By Dissecting BERT-based Word Models
|
||||
|
||||
Project Page: [SBERT-WK](https://github.com/BinWang28/SBERT-WK-Sentence-Embedding)
|
||||
20
model_cards/canwenxu/BERT-of-Theseus-MNLI/README.md
Normal file
20
model_cards/canwenxu/BERT-of-Theseus-MNLI/README.md
Normal file
@@ -0,0 +1,20 @@
|
||||
---
|
||||
thumbnail: https://raw.githubusercontent.com/JetRunner/BERT-of-Theseus/master/bert-of-theseus.png
|
||||
---
|
||||
|
||||
# BERT-of-Theseus
|
||||
See our paper ["BERT-of-Theseus: Compressing BERT by Progressive Module Replacing"](http://arxiv.org/abs/2002.02925).
|
||||
|
||||
BERT-of-Theseus is a new compressed BERT by progressively replacing the components of the original BERT.
|
||||
|
||||

|
||||
|
||||
## Load Pretrained Model on MNLI
|
||||
|
||||
We provide a 6-layer pretrained model on MNLI as a general-purpose model, which can transfer to other sentence classification tasks, outperforming DistillBERT (with the same 6-layer structure) on six tasks of GLUE (dev set).
|
||||
|
||||
| Method | MNLI | MRPC | QNLI | QQP | RTE | SST-2 | STS-B |
|
||||
|-----------------|------|------|------|------|------|-------|-------|
|
||||
| BERT-base | 83.5 | 89.5 | 91.2 | 89.8 | 71.1 | 91.5 | 88.9 |
|
||||
| DistillBERT | 79.0 | 87.5 | 85.3 | 84.9 | 59.9 | 90.7 | 81.2 |
|
||||
| BERT-of-Theseus | 82.1 | 87.5 | 88.8 | 88.8 | 70.1 | 91.8 | 87.8 |
|
||||
70
model_cards/dbmdz/bert-base-german-cased/README.md
Normal file
70
model_cards/dbmdz/bert-base-german-cased/README.md
Normal file
@@ -0,0 +1,70 @@
|
||||
---
|
||||
language: german
|
||||
---
|
||||
|
||||
# 🤗 + 📚 dbmdz German BERT models
|
||||
|
||||
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
|
||||
Library open sources another German BERT models 🎉
|
||||
|
||||
# German BERT
|
||||
|
||||
## Stats
|
||||
|
||||
In addition to the recently released [German BERT](https://deepset.ai/german-bert)
|
||||
model by [deepset](https://deepset.ai/) we provide another German-language model.
|
||||
|
||||
The source data for the model consists of a recent Wikipedia dump, EU Bookshop corpus,
|
||||
Open Subtitles, CommonCrawl, ParaCrawl and News Crawl. This results in a dataset with
|
||||
a size of 16GB and 2,350,234,427 tokens.
|
||||
|
||||
For sentence splitting, we use [spacy](https://spacy.io/). Our preprocessing steps
|
||||
(sentence piece model for vocab generation) follow those used for training
|
||||
[SciBERT](https://github.com/allenai/scibert). The model is trained with an initial
|
||||
sequence length of 512 subwords and was performed for 1.5M steps.
|
||||
|
||||
This release includes both cased and uncased models.
|
||||
|
||||
## Model weights
|
||||
|
||||
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
|
||||
compatible weights are available. If you need access to TensorFlow checkpoints,
|
||||
please raise an issue!
|
||||
|
||||
| Model | Downloads
|
||||
| -------------------------------- | ---------------------------------------------------------------------------------------------------------------
|
||||
| `bert-base-german-dbmdz-cased` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-german-dbmdz-cased-config.json) • [`pytorch_model.bin`](https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-german-dbmdz-cased-pytorch_model.bin) • [`vocab.txt`](https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-german-dbmdz-cased-vocab.txt)
|
||||
| `bert-base-german-dbmdz-uncased` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-german-dbmdz-uncased-config.json) • [`pytorch_model.bin`](https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-german-dbmdz-uncased-pytorch_model.bin) • [`vocab.txt`](https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-german-dbmdz-uncased-vocab.txt)
|
||||
|
||||
## Usage
|
||||
|
||||
With Transformers >= 2.3 our German BERT models can be loaded like:
|
||||
|
||||
```python
|
||||
from transformers import AutoModel, AutoTokenizer
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-german-cased")
|
||||
model = AutoModel.from_pretrained("dbmdz/bert-base-german-cased")
|
||||
```
|
||||
|
||||
## Results
|
||||
|
||||
For results on downstream tasks like NER or PoS tagging, please refer to
|
||||
[this repository](https://github.com/stefan-it/fine-tuned-berts-seq).
|
||||
|
||||
# Huggingface model hub
|
||||
|
||||
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
|
||||
|
||||
# Contact (Bugs, Feedback, Contribution and more)
|
||||
|
||||
For questions about our BERT models just open an issue
|
||||
[here](https://github.com/dbmdz/berts/issues/new) 🤗
|
||||
|
||||
# Acknowledgments
|
||||
|
||||
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
|
||||
Thanks for providing access to the TFRC ❤️
|
||||
|
||||
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
|
||||
it is possible to download both cased and uncased models from their S3 storage 🤗
|
||||
61
model_cards/dbmdz/bert-base-german-europeana-cased/README.md
Normal file
61
model_cards/dbmdz/bert-base-german-europeana-cased/README.md
Normal file
@@ -0,0 +1,61 @@
|
||||
---
|
||||
language: german
|
||||
tags:
|
||||
- "historic german"
|
||||
---
|
||||
|
||||
# 🤗 + 📚 dbmdz BERT models
|
||||
|
||||
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
|
||||
Library open sources German Europeana BERT models 🎉
|
||||
|
||||
# German Europeana BERT
|
||||
|
||||
We use the open source [Europeana newspapers](http://www.europeana-newspapers.eu/)
|
||||
that were provided by *The European Library*. The final
|
||||
training corpus has a size of 51GB and consists of 8,035,986,369 tokens.
|
||||
|
||||
Detailed information about the data and pretraining steps can be found in
|
||||
[this repository](https://github.com/stefan-it/europeana-bert).
|
||||
|
||||
## Model weights
|
||||
|
||||
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
|
||||
compatible weights are available. If you need access to TensorFlow checkpoints,
|
||||
please raise an issue!
|
||||
|
||||
| Model | Downloads
|
||||
| ------------------------------------------ | ---------------------------------------------------------------------------------------------------------------
|
||||
| `dbmdz/bert-base-german-europeana-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-german-europeana-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-german-europeana-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-german-europeana-cased/vocab.txt)
|
||||
|
||||
## Results
|
||||
|
||||
For results on Historic NER, please refer to [this repository](https://github.com/stefan-it/europeana-bert).
|
||||
|
||||
## Usage
|
||||
|
||||
With Transformers >= 2.3 our German Europeana BERT models can be loaded like:
|
||||
|
||||
```python
|
||||
from transformers import AutoModel, AutoTokenizer
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-german-europeana-cased")
|
||||
model = AutoModel.from_pretrained("dbmdz/bert-base-german-europeana-cased")
|
||||
```
|
||||
|
||||
# Huggingface model hub
|
||||
|
||||
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
|
||||
|
||||
# Contact (Bugs, Feedback, Contribution and more)
|
||||
|
||||
For questions about our BERT models just open an issue
|
||||
[here](https://github.com/dbmdz/berts/issues/new) 🤗
|
||||
|
||||
# Acknowledgments
|
||||
|
||||
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
|
||||
Thanks for providing access to the TFRC ❤️
|
||||
|
||||
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
|
||||
it is possible to download both cased and uncased models from their S3 storage 🤗
|
||||
@@ -0,0 +1,61 @@
|
||||
---
|
||||
language: german
|
||||
tags:
|
||||
- "historic german"
|
||||
---
|
||||
|
||||
# 🤗 + 📚 dbmdz BERT models
|
||||
|
||||
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
|
||||
Library open sources German Europeana BERT models 🎉
|
||||
|
||||
# German Europeana BERT
|
||||
|
||||
We use the open source [Europeana newspapers](http://www.europeana-newspapers.eu/)
|
||||
that were provided by *The European Library*. The final
|
||||
training corpus has a size of 51GB and consists of 8,035,986,369 tokens.
|
||||
|
||||
Detailed information about the data and pretraining steps can be found in
|
||||
[this repository](https://github.com/stefan-it/europeana-bert).
|
||||
|
||||
## Model weights
|
||||
|
||||
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
|
||||
compatible weights are available. If you need access to TensorFlow checkpoints,
|
||||
please raise an issue!
|
||||
|
||||
| Model | Downloads
|
||||
| ------------------------------------------ | ---------------------------------------------------------------------------------------------------------------
|
||||
| `dbmdz/bert-base-german-europeana-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-german-europeana-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-german-europeana-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-german-europeana-uncased/vocab.txt)
|
||||
|
||||
## Results
|
||||
|
||||
For results on Historic NER, please refer to [this repository](https://github.com/stefan-it/europeana-bert).
|
||||
|
||||
## Usage
|
||||
|
||||
With Transformers >= 2.3 our German Europeana BERT models can be loaded like:
|
||||
|
||||
```python
|
||||
from transformers import AutoModel, AutoTokenizer
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-german-europeana-uncased")
|
||||
model = AutoModel.from_pretrained("dbmdz/bert-base-german-europeana-uncased")
|
||||
```
|
||||
|
||||
# Huggingface model hub
|
||||
|
||||
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
|
||||
|
||||
# Contact (Bugs, Feedback, Contribution and more)
|
||||
|
||||
For questions about our BERT models just open an issue
|
||||
[here](https://github.com/dbmdz/berts/issues/new) 🤗
|
||||
|
||||
# Acknowledgments
|
||||
|
||||
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
|
||||
Thanks for providing access to the TFRC ❤️
|
||||
|
||||
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
|
||||
it is possible to download both cased and uncased models from their S3 storage 🤗
|
||||
70
model_cards/dbmdz/bert-base-german-uncased/README.md
Normal file
70
model_cards/dbmdz/bert-base-german-uncased/README.md
Normal file
@@ -0,0 +1,70 @@
|
||||
---
|
||||
language: german
|
||||
---
|
||||
|
||||
# 🤗 + 📚 dbmdz German BERT models
|
||||
|
||||
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
|
||||
Library open sources another German BERT models 🎉
|
||||
|
||||
# German BERT
|
||||
|
||||
## Stats
|
||||
|
||||
In addition to the recently released [German BERT](https://deepset.ai/german-bert)
|
||||
model by [deepset](https://deepset.ai/) we provide another German-language model.
|
||||
|
||||
The source data for the model consists of a recent Wikipedia dump, EU Bookshop corpus,
|
||||
Open Subtitles, CommonCrawl, ParaCrawl and News Crawl. This results in a dataset with
|
||||
a size of 16GB and 2,350,234,427 tokens.
|
||||
|
||||
For sentence splitting, we use [spacy](https://spacy.io/). Our preprocessing steps
|
||||
(sentence piece model for vocab generation) follow those used for training
|
||||
[SciBERT](https://github.com/allenai/scibert). The model is trained with an initial
|
||||
sequence length of 512 subwords and was performed for 1.5M steps.
|
||||
|
||||
This release includes both cased and uncased models.
|
||||
|
||||
## Model weights
|
||||
|
||||
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
|
||||
compatible weights are available. If you need access to TensorFlow checkpoints,
|
||||
please raise an issue!
|
||||
|
||||
| Model | Downloads
|
||||
| -------------------------------- | ---------------------------------------------------------------------------------------------------------------
|
||||
| `bert-base-german-dbmdz-cased` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-german-dbmdz-cased-config.json) • [`pytorch_model.bin`](https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-german-dbmdz-cased-pytorch_model.bin) • [`vocab.txt`](https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-german-dbmdz-cased-vocab.txt)
|
||||
| `bert-base-german-dbmdz-uncased` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-german-dbmdz-uncased-config.json) • [`pytorch_model.bin`](https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-german-dbmdz-uncased-pytorch_model.bin) • [`vocab.txt`](https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-german-dbmdz-uncased-vocab.txt)
|
||||
|
||||
## Usage
|
||||
|
||||
With Transformers >= 2.3 our German BERT models can be loaded like:
|
||||
|
||||
```python
|
||||
from transformers import AutoModel, AutoTokenizer
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-german-cased")
|
||||
model = AutoModel.from_pretrained("dbmdz/bert-base-german-cased")
|
||||
```
|
||||
|
||||
## Results
|
||||
|
||||
For results on downstream tasks like NER or PoS tagging, please refer to
|
||||
[this repository](https://github.com/stefan-it/fine-tuned-berts-seq).
|
||||
|
||||
# Huggingface model hub
|
||||
|
||||
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
|
||||
|
||||
# Contact (Bugs, Feedback, Contribution and more)
|
||||
|
||||
For questions about our BERT models just open an issue
|
||||
[here](https://github.com/dbmdz/berts/issues/new) 🤗
|
||||
|
||||
# Acknowledgments
|
||||
|
||||
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
|
||||
Thanks for providing access to the TFRC ❤️
|
||||
|
||||
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
|
||||
it is possible to download both cased and uncased models from their S3 storage 🤗
|
||||
77
model_cards/dbmdz/bert-base-italian-cased/README.md
Normal file
77
model_cards/dbmdz/bert-base-italian-cased/README.md
Normal file
@@ -0,0 +1,77 @@
|
||||
---
|
||||
language: italian
|
||||
---
|
||||
|
||||
# 🤗 + 📚 dbmdz BERT models
|
||||
|
||||
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
|
||||
Library open sources Italian BERT models 🎉
|
||||
|
||||
# Italian BERT
|
||||
|
||||
The source data for the Italian BERT model consists of a recent Wikipedia dump and
|
||||
various texts from the [OPUS corpora](http://opus.nlpl.eu/) collection. The final
|
||||
training corpus has a size of 13GB and 2,050,057,573 tokens.
|
||||
|
||||
For sentence splitting, we use NLTK (faster compared to spacy).
|
||||
Our cased and uncased models are training with an initial sequence length of 512
|
||||
subwords for ~2-3M steps.
|
||||
|
||||
For the XXL Italian models, we use the same training data from OPUS and extend
|
||||
it with data from the Italian part of the [OSCAR corpus](https://traces1.inria.fr/oscar/).
|
||||
Thus, the final training corpus has a size of 81GB and 13,138,379,147 tokens.
|
||||
|
||||
## Model weights
|
||||
|
||||
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
|
||||
compatible weights are available. If you need access to TensorFlow checkpoints,
|
||||
please raise an issue!
|
||||
|
||||
| Model | Downloads
|
||||
| --------------------------------------- | ---------------------------------------------------------------------------------------------------------------
|
||||
| `dbmdz/bert-base-italian-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/vocab.txt)
|
||||
| `dbmdz/bert-base-italian-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/vocab.txt)
|
||||
| `dbmdz/bert-base-italian-xxl-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/vocab.txt)
|
||||
| `dbmdz/bert-base-italian-xxl-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/vocab.txt)
|
||||
|
||||
## Results
|
||||
|
||||
For results on downstream tasks like NER or PoS tagging, please refer to
|
||||
[this repository](https://github.com/stefan-it/fine-tuned-berts-seq).
|
||||
|
||||
## Usage
|
||||
|
||||
With Transformers >= 2.3 our Italian BERT models can be loaded like:
|
||||
|
||||
```python
|
||||
from transformers import AutoModel, AutoTokenizer
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-italian-cased")
|
||||
model = AutoModel.from_pretrained("dbmdz/bert-base-italian-cased")
|
||||
```
|
||||
|
||||
To load the (recommended) Italian XXL BERT models, just use:
|
||||
|
||||
```python
|
||||
from transformers import AutoModel, AutoTokenizer
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-italian-xxl-cased")
|
||||
model = AutoModel.from_pretrained("dbmdz/bert-base-italian-xxl-cased")
|
||||
```
|
||||
|
||||
# Huggingface model hub
|
||||
|
||||
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
|
||||
|
||||
# Contact (Bugs, Feedback, Contribution and more)
|
||||
|
||||
For questions about our BERT models just open an issue
|
||||
[here](https://github.com/dbmdz/berts/issues/new) 🤗
|
||||
|
||||
# Acknowledgments
|
||||
|
||||
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
|
||||
Thanks for providing access to the TFRC ❤️
|
||||
|
||||
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
|
||||
it is possible to download both cased and uncased models from their S3 storage 🤗
|
||||
77
model_cards/dbmdz/bert-base-italian-uncased/README.md
Normal file
77
model_cards/dbmdz/bert-base-italian-uncased/README.md
Normal file
@@ -0,0 +1,77 @@
|
||||
---
|
||||
language: italian
|
||||
---
|
||||
|
||||
# 🤗 + 📚 dbmdz BERT models
|
||||
|
||||
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
|
||||
Library open sources Italian BERT models 🎉
|
||||
|
||||
# Italian BERT
|
||||
|
||||
The source data for the Italian BERT model consists of a recent Wikipedia dump and
|
||||
various texts from the [OPUS corpora](http://opus.nlpl.eu/) collection. The final
|
||||
training corpus has a size of 13GB and 2,050,057,573 tokens.
|
||||
|
||||
For sentence splitting, we use NLTK (faster compared to spacy).
|
||||
Our cased and uncased models are training with an initial sequence length of 512
|
||||
subwords for ~2-3M steps.
|
||||
|
||||
For the XXL Italian models, we use the same training data from OPUS and extend
|
||||
it with data from the Italian part of the [OSCAR corpus](https://traces1.inria.fr/oscar/).
|
||||
Thus, the final training corpus has a size of 81GB and 13,138,379,147 tokens.
|
||||
|
||||
## Model weights
|
||||
|
||||
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
|
||||
compatible weights are available. If you need access to TensorFlow checkpoints,
|
||||
please raise an issue!
|
||||
|
||||
| Model | Downloads
|
||||
| --------------------------------------- | ---------------------------------------------------------------------------------------------------------------
|
||||
| `dbmdz/bert-base-italian-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/vocab.txt)
|
||||
| `dbmdz/bert-base-italian-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/vocab.txt)
|
||||
| `dbmdz/bert-base-italian-xxl-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/vocab.txt)
|
||||
| `dbmdz/bert-base-italian-xxl-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/vocab.txt)
|
||||
|
||||
## Results
|
||||
|
||||
For results on downstream tasks like NER or PoS tagging, please refer to
|
||||
[this repository](https://github.com/stefan-it/fine-tuned-berts-seq).
|
||||
|
||||
## Usage
|
||||
|
||||
With Transformers >= 2.3 our Italian BERT models can be loaded like:
|
||||
|
||||
```python
|
||||
from transformers import AutoModel, AutoTokenizer
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-italian-cased")
|
||||
model = AutoModel.from_pretrained("dbmdz/bert-base-italian-cased")
|
||||
```
|
||||
|
||||
To load the (recommended) Italian XXL BERT models, just use:
|
||||
|
||||
```python
|
||||
from transformers import AutoModel, AutoTokenizer
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-italian-xxl-cased")
|
||||
model = AutoModel.from_pretrained("dbmdz/bert-base-italian-xxl-cased")
|
||||
```
|
||||
|
||||
# Huggingface model hub
|
||||
|
||||
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
|
||||
|
||||
# Contact (Bugs, Feedback, Contribution and more)
|
||||
|
||||
For questions about our BERT models just open an issue
|
||||
[here](https://github.com/dbmdz/berts/issues/new) 🤗
|
||||
|
||||
# Acknowledgments
|
||||
|
||||
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
|
||||
Thanks for providing access to the TFRC ❤️
|
||||
|
||||
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
|
||||
it is possible to download both cased and uncased models from their S3 storage 🤗
|
||||
77
model_cards/dbmdz/bert-base-italian-xxl-cased/README.md
Normal file
77
model_cards/dbmdz/bert-base-italian-xxl-cased/README.md
Normal file
@@ -0,0 +1,77 @@
|
||||
---
|
||||
language: italian
|
||||
---
|
||||
|
||||
# 🤗 + 📚 dbmdz BERT models
|
||||
|
||||
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
|
||||
Library open sources Italian BERT models 🎉
|
||||
|
||||
# Italian BERT
|
||||
|
||||
The source data for the Italian BERT model consists of a recent Wikipedia dump and
|
||||
various texts from the [OPUS corpora](http://opus.nlpl.eu/) collection. The final
|
||||
training corpus has a size of 13GB and 2,050,057,573 tokens.
|
||||
|
||||
For sentence splitting, we use NLTK (faster compared to spacy).
|
||||
Our cased and uncased models are training with an initial sequence length of 512
|
||||
subwords for ~2-3M steps.
|
||||
|
||||
For the XXL Italian models, we use the same training data from OPUS and extend
|
||||
it with data from the Italian part of the [OSCAR corpus](https://traces1.inria.fr/oscar/).
|
||||
Thus, the final training corpus has a size of 81GB and 13,138,379,147 tokens.
|
||||
|
||||
## Model weights
|
||||
|
||||
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
|
||||
compatible weights are available. If you need access to TensorFlow checkpoints,
|
||||
please raise an issue!
|
||||
|
||||
| Model | Downloads
|
||||
| --------------------------------------- | ---------------------------------------------------------------------------------------------------------------
|
||||
| `dbmdz/bert-base-italian-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/vocab.txt)
|
||||
| `dbmdz/bert-base-italian-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/vocab.txt)
|
||||
| `dbmdz/bert-base-italian-xxl-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/vocab.txt)
|
||||
| `dbmdz/bert-base-italian-xxl-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/vocab.txt)
|
||||
|
||||
## Results
|
||||
|
||||
For results on downstream tasks like NER or PoS tagging, please refer to
|
||||
[this repository](https://github.com/stefan-it/fine-tuned-berts-seq).
|
||||
|
||||
## Usage
|
||||
|
||||
With Transformers >= 2.3 our Italian BERT models can be loaded like:
|
||||
|
||||
```python
|
||||
from transformers import AutoModel, AutoTokenizer
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-italian-cased")
|
||||
model = AutoModel.from_pretrained("dbmdz/bert-base-italian-cased")
|
||||
```
|
||||
|
||||
To load the (recommended) Italian XXL BERT models, just use:
|
||||
|
||||
```python
|
||||
from transformers import AutoModel, AutoTokenizer
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-italian-xxl-cased")
|
||||
model = AutoModel.from_pretrained("dbmdz/bert-base-italian-xxl-cased")
|
||||
```
|
||||
|
||||
# Huggingface model hub
|
||||
|
||||
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
|
||||
|
||||
# Contact (Bugs, Feedback, Contribution and more)
|
||||
|
||||
For questions about our BERT models just open an issue
|
||||
[here](https://github.com/dbmdz/berts/issues/new) 🤗
|
||||
|
||||
# Acknowledgments
|
||||
|
||||
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
|
||||
Thanks for providing access to the TFRC ❤️
|
||||
|
||||
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
|
||||
it is possible to download both cased and uncased models from their S3 storage 🤗
|
||||
77
model_cards/dbmdz/bert-base-italian-xxl-uncased/README.md
Normal file
77
model_cards/dbmdz/bert-base-italian-xxl-uncased/README.md
Normal file
@@ -0,0 +1,77 @@
|
||||
---
|
||||
language: italian
|
||||
---
|
||||
|
||||
# 🤗 + 📚 dbmdz BERT models
|
||||
|
||||
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
|
||||
Library open sources Italian BERT models 🎉
|
||||
|
||||
# Italian BERT
|
||||
|
||||
The source data for the Italian BERT model consists of a recent Wikipedia dump and
|
||||
various texts from the [OPUS corpora](http://opus.nlpl.eu/) collection. The final
|
||||
training corpus has a size of 13GB and 2,050,057,573 tokens.
|
||||
|
||||
For sentence splitting, we use NLTK (faster compared to spacy).
|
||||
Our cased and uncased models are training with an initial sequence length of 512
|
||||
subwords for ~2-3M steps.
|
||||
|
||||
For the XXL Italian models, we use the same training data from OPUS and extend
|
||||
it with data from the Italian part of the [OSCAR corpus](https://traces1.inria.fr/oscar/).
|
||||
Thus, the final training corpus has a size of 81GB and 13,138,379,147 tokens.
|
||||
|
||||
## Model weights
|
||||
|
||||
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
|
||||
compatible weights are available. If you need access to TensorFlow checkpoints,
|
||||
please raise an issue!
|
||||
|
||||
| Model | Downloads
|
||||
| --------------------------------------- | ---------------------------------------------------------------------------------------------------------------
|
||||
| `dbmdz/bert-base-italian-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/vocab.txt)
|
||||
| `dbmdz/bert-base-italian-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/vocab.txt)
|
||||
| `dbmdz/bert-base-italian-xxl-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/vocab.txt)
|
||||
| `dbmdz/bert-base-italian-xxl-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/vocab.txt)
|
||||
|
||||
## Results
|
||||
|
||||
For results on downstream tasks like NER or PoS tagging, please refer to
|
||||
[this repository](https://github.com/stefan-it/fine-tuned-berts-seq).
|
||||
|
||||
## Usage
|
||||
|
||||
With Transformers >= 2.3 our Italian BERT models can be loaded like:
|
||||
|
||||
```python
|
||||
from transformers import AutoModel, AutoTokenizer
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-italian-cased")
|
||||
model = AutoModel.from_pretrained("dbmdz/bert-base-italian-cased")
|
||||
```
|
||||
|
||||
To load the (recommended) Italian XXL BERT models, just use:
|
||||
|
||||
```python
|
||||
from transformers import AutoModel, AutoTokenizer
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-italian-xxl-cased")
|
||||
model = AutoModel.from_pretrained("dbmdz/bert-base-italian-xxl-cased")
|
||||
```
|
||||
|
||||
# Huggingface model hub
|
||||
|
||||
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
|
||||
|
||||
# Contact (Bugs, Feedback, Contribution and more)
|
||||
|
||||
For questions about our BERT models just open an issue
|
||||
[here](https://github.com/dbmdz/berts/issues/new) 🤗
|
||||
|
||||
# Acknowledgments
|
||||
|
||||
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
|
||||
Thanks for providing access to the TFRC ❤️
|
||||
|
||||
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
|
||||
it is possible to download both cased and uncased models from their S3 storage 🤗
|
||||
74
model_cards/dbmdz/bert-base-turkish-cased/README.md
Normal file
74
model_cards/dbmdz/bert-base-turkish-cased/README.md
Normal file
@@ -0,0 +1,74 @@
|
||||
---
|
||||
language: turkish
|
||||
---
|
||||
|
||||
# 🤗 + 📚 dbmdz Turkish BERT model
|
||||
|
||||
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
|
||||
Library open sources a cased model for Turkish 🎉
|
||||
|
||||
# 🇹🇷 BERTurk
|
||||
|
||||
BERTurk is a community-driven cased BERT model for Turkish.
|
||||
|
||||
Some datasets used for pretraining and evaluation are contributed from the
|
||||
awesome Turkish NLP community, as well as the decision for the model name: BERTurk.
|
||||
|
||||
## Stats
|
||||
|
||||
The current version of the model is trained on a filtered and sentence
|
||||
segmented version of the Turkish [OSCAR corpus](https://traces1.inria.fr/oscar/),
|
||||
a recent Wikipedia dump, various [OPUS corpora](http://opus.nlpl.eu/) and a
|
||||
special corpus provided by [Kemal Oflazer](http://www.andrew.cmu.edu/user/ko/).
|
||||
|
||||
The final training corpus has a size of 35GB and 44,04,976,662 tokens.
|
||||
|
||||
Thanks to Google's TensorFlow Research Cloud (TFRC) we could train a cased model
|
||||
on a TPU v3-8 for 2M steps.
|
||||
|
||||
## Model weights
|
||||
|
||||
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
|
||||
compatible weights are available. If you need access to TensorFlow checkpoints,
|
||||
please raise an issue!
|
||||
|
||||
| Model | Downloads
|
||||
| --------------------------------- | ---------------------------------------------------------------------------------------------------------------
|
||||
| `dbmdz/bert-base-turkish-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-turkish-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-turkish-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-turkish-cased/vocab.txt)
|
||||
|
||||
## Usage
|
||||
|
||||
With Transformers >= 2.3 our BERTurk cased model can be loaded like:
|
||||
|
||||
```python
|
||||
from transformers import AutoModel, AutoTokenizer
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-turkish-cased")
|
||||
model = AutoModel.from_pretrained("dbmdz/bert-base-turkish-cased")
|
||||
```
|
||||
|
||||
## Results
|
||||
|
||||
For results on PoS tagging or NER tasks, please refer to
|
||||
[this repository](https://github.com/stefan-it/turkish-bert).
|
||||
|
||||
# Huggingface model hub
|
||||
|
||||
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
|
||||
|
||||
# Contact (Bugs, Feedback, Contribution and more)
|
||||
|
||||
For questions about our BERT models just open an issue
|
||||
[here](https://github.com/dbmdz/berts/issues/new) 🤗
|
||||
|
||||
# Acknowledgments
|
||||
|
||||
Thanks to [Kemal Oflazer](http://www.andrew.cmu.edu/user/ko/) for providing us
|
||||
additional large corpora for Turkish. Many thanks to Reyyan Yeniterzi for providing
|
||||
us the Turkish NER dataset for evaluation.
|
||||
|
||||
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
|
||||
Thanks for providing access to the TFRC ❤️
|
||||
|
||||
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
|
||||
it is possible to download both cased and uncased models from their S3 storage 🤗
|
||||
104
model_cards/deepset/roberta-base-squad2/README.md
Normal file
104
model_cards/deepset/roberta-base-squad2/README.md
Normal file
@@ -0,0 +1,104 @@
|
||||
# roberta-base for QA
|
||||
|
||||
## Overview
|
||||
**Language model:** roberta-base
|
||||
**Language:** English
|
||||
**Downstream-task:** Extractive QA
|
||||
**Training data:** SQuAD 2.0
|
||||
**Eval data:** SQuAD 2.0
|
||||
**Code:** See [example](https://github.com/deepset-ai/FARM/blob/master/examples/question_answering.py) in [FARM](https://github.com/deepset-ai/FARM/blob/master/examples/question_answering.py)
|
||||
**Infrastructure**: 4x Tesla v100
|
||||
|
||||
## Hyperparameters
|
||||
|
||||
```
|
||||
batch_size = 50
|
||||
n_epochs = 3
|
||||
base_LM_model = "roberta-base"
|
||||
max_seq_len = 384
|
||||
learning_rate = 3e-5
|
||||
lr_schedule = LinearWarmup
|
||||
warmup_proportion = 0.2
|
||||
doc_stride=128
|
||||
max_query_length=64
|
||||
```
|
||||
|
||||
## Performance
|
||||
Evaluated on the SQuAD 2.0 dev set with the [official eval script](https://worksheets.codalab.org/rest/bundles/0x6b567e1cf2e041ec80d7098f031c5c9e/contents/blob/).
|
||||
```
|
||||
"exact": 78.49743114629833,
|
||||
"f1": 81.73092721240889
|
||||
```
|
||||
|
||||
## Usage
|
||||
|
||||
### In Transformers
|
||||
```python
|
||||
from transformers.pipelines import pipeline
|
||||
from transformers.modeling_auto import AutoModelForQuestionAnswering
|
||||
from transformers.tokenization_auto import AutoTokenizer
|
||||
|
||||
model_name = "deepset/roberta-base-squad2"
|
||||
|
||||
# a) Get predictions
|
||||
nlp = pipeline('question-answering', model=model_name, tokenizer=model_name)
|
||||
QA_input = {
|
||||
'question': 'Why is model conversion important?',
|
||||
'context': 'The option to convert models between FARM and transformers gives freedom to the user and let people easily switch between frameworks.'
|
||||
}
|
||||
res = nlp(QA_input)
|
||||
|
||||
# b) Load model & tokenizer
|
||||
model = AutoModelForQuestionAnswering.from_pretrained(model_name)
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
||||
```
|
||||
|
||||
### In FARM
|
||||
|
||||
```python
|
||||
from farm.modeling.adaptive_model import AdaptiveModel
|
||||
from farm.modeling.tokenization import Tokenizer
|
||||
from farm.infer import Inferencer
|
||||
|
||||
model_name = "deepset/roberta-base-squad2"
|
||||
|
||||
# a) Get predictions
|
||||
nlp = Inferencer.load(model_name, task_type="question_answering")
|
||||
QA_input = [{"questions": ["Why is model conversion important?"],
|
||||
"text": "The option to convert models between FARM and transformers gives freedom to the user and let people easily switch between frameworks."}]
|
||||
res = nlp.inference_from_dicts(dicts=QA_input, rest_api_schema=True)
|
||||
|
||||
# b) Load model & tokenizer
|
||||
model = AdaptiveModel.convert_from_transformers(model_name, device="cpu", task_type="question_answering")
|
||||
tokenizer = Tokenizer.load(model_name)
|
||||
```
|
||||
|
||||
### In haystack
|
||||
For doing QA at scale (i.e. many docs instead of single paragraph), you can load the model also in [haystack](https://github.com/deepset-ai/haystack/):
|
||||
```python
|
||||
reader = FARMReader(model_name_or_path="deepset/roberta-base-squad2")
|
||||
# or
|
||||
reader = TransformersReader(model="deepset/roberta-base-squad2",tokenizer="deepset/roberta-base-squad2")
|
||||
```
|
||||
|
||||
|
||||
## Authors
|
||||
Branden Chan: `branden.chan [at] deepset.ai`
|
||||
Timo Möller: `timo.moeller [at] deepset.ai`
|
||||
Malte Pietsch: `malte.pietsch [at] deepset.ai`
|
||||
Tanay Soni: `tanay.soni [at] deepset.ai`
|
||||
|
||||
## About us
|
||||

|
||||
|
||||
We bring NLP to the industry via open source!
|
||||
Our focus: Industry specific language models & large scale QA systems.
|
||||
|
||||
Some of our work:
|
||||
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
|
||||
- [FARM](https://github.com/deepset-ai/FARM)
|
||||
- [Haystack](https://github.com/deepset-ai/haystack/)
|
||||
|
||||
Get in touch:
|
||||
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Website](https://deepset.ai)
|
||||
|
||||
48
model_cards/fmikaelian/flaubert-base-uncased-squad/README.md
Normal file
48
model_cards/fmikaelian/flaubert-base-uncased-squad/README.md
Normal file
@@ -0,0 +1,48 @@
|
||||
---
|
||||
language: french
|
||||
---
|
||||
|
||||
# flaubert-base-uncased-squad
|
||||
|
||||
## Description
|
||||
|
||||
A baseline model for question-answering in french ([flaubert](https://github.com/getalp/Flaubert) model fine-tuned on [french-translated SQuAD 1.1 dataset](https://github.com/Alikabbadj/French-SQuAD))
|
||||
|
||||
## Training hyperparameters
|
||||
|
||||
```shell
|
||||
python3 ./examples/run_squad.py \
|
||||
--model_type flaubert \
|
||||
--model_name_or_path flaubert-base-uncased \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--do_lower_case \
|
||||
--train_file SQuAD-v1.1-train_fr_ss999_awstart2_net.json \
|
||||
--predict_file SQuAD-v1.1-dev_fr_ss999_awstart2_net.json \
|
||||
--learning_rate 3e-5 \
|
||||
--num_train_epochs 2 \
|
||||
--max_seq_length 384 \
|
||||
--doc_stride 128 \
|
||||
--output_dir output \
|
||||
--per_gpu_eval_batch_size=3 \
|
||||
--per_gpu_train_batch_size=3
|
||||
```
|
||||
|
||||
## Evaluation results
|
||||
|
||||
```shell
|
||||
{"f1": 68.66174806561969, "exact_match": 49.299692063176714}
|
||||
```
|
||||
|
||||
## Usage
|
||||
|
||||
```python
|
||||
from transformers import pipeline
|
||||
|
||||
nlp = pipeline('question-answering', model='fmikaelian/flaubert-base-uncased-squad', tokenizer='fmikaelian/flaubert-base-uncased-squad')
|
||||
|
||||
nlp({
|
||||
'question': "Qui est Claude Monet?",
|
||||
'context': "Claude Monet, né le 14 novembre 1840 à Paris et mort le 5 décembre 1926 à Giverny, est un peintre français et l’un des fondateurs de l'impressionnisme."
|
||||
})
|
||||
```
|
||||
@@ -0,0 +1,50 @@
|
||||
---
|
||||
language: dutch
|
||||
---
|
||||
|
||||
# Multilingual + Dutch SQuAD2.0
|
||||
|
||||
This model is the multilingual model provided by the Google research team with a fine-tuned dutch Q&A downstream task.
|
||||
|
||||
## Details of the language model(bert-base-multilingual-cased)
|
||||
|
||||
Language model ([**bert-base-multilingual-cased**](https://github.com/google-research/bert/blob/master/multilingual.md)):
|
||||
12-layer, 768-hidden, 12-heads, 110M parameters.
|
||||
Trained on cased text in the top 104 languages with the largest Wikipedias.
|
||||
|
||||
## Details of the downstream task - Dataset
|
||||
Using the `mtranslate` Python module, [**SQuAD2.0**](https://rajpurkar.github.io/SQuAD-explorer/) was machine-translated. In order to find the start tokens the direct translations of the answers were searched in the corresponding paragraphs. Since the answer could not always be found in the text, due to the different translations depending on the context (missing context in the pure answer), a loss of question-answer examples occurred. This is a potential problem where errors can occur in the data set (but in the end it was a quick and dirty solution that worked well enough for my task).
|
||||
|
||||
| Dataset | # Q&A |
|
||||
| ---------------------- | ----- |
|
||||
| SQuAD2.0 Train | 130 K |
|
||||
| Dutch SQuAD2.0 Train | 99 K |
|
||||
| SQuAD2.0 Dev | 12 K |
|
||||
| Dutch SQuAD2.0 Dev | 10 K |
|
||||
|
||||
## Model training
|
||||
|
||||
The model was trained on a Tesla V100 GPU with the following command:
|
||||
|
||||
```python
|
||||
export SQUAD_DIR=path/to/nl_squad
|
||||
|
||||
python run_squad.py \
|
||||
--model_type bert \
|
||||
--model_name_or_path bert-base-multilingual-cased \
|
||||
--version_2_with_negative \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--train_file $SQUAD_DIR/train_nl-v2.0.json \
|
||||
--predict_file $SQUAD_DIR/dev_nl-v2.0.json \
|
||||
--per_gpu_train_batch_size 12 \
|
||||
--learning_rate 3e-5 \
|
||||
--num_train_epochs 2.0 \
|
||||
--max_seq_length 384 \
|
||||
--doc_stride 128 \
|
||||
--output_dir /tmp/output_dir/
|
||||
```
|
||||
|
||||
**Results**:
|
||||
|
||||
{'exact': **67.38**, 'f1': **71.36**}
|
||||
31
model_cards/jplu/tf-camembert-base/README.md
Normal file
31
model_cards/jplu/tf-camembert-base/README.md
Normal file
@@ -0,0 +1,31 @@
|
||||
# Tensorflow CamemBERT
|
||||
|
||||
In this repository you will find different versions of the CamemBERT model for Tensorflow.
|
||||
|
||||
## CamemBERT
|
||||
|
||||
[CamemBERT](https://camembert-model.fr/) is a state-of-the-art language model for French based on the RoBERTa architecture pretrained on the French subcorpus of the newly available multilingual corpus OSCAR.
|
||||
|
||||
## Model Weights
|
||||
|
||||
| Model | Downloads
|
||||
| -------------------------------- | ---------------------------------------------------------------------------------------------------------------
|
||||
| `jplu/tf-camembert-base` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/jplu/tf-camembert-base/config.json) • [`tf_model.h5`](https://s3.amazonaws.com/models.huggingface.co/bert/jplu/tf-camembert-base/tf_model.h5)
|
||||
|
||||
## Usage
|
||||
|
||||
With Transformers >= 2.4 the Tensorflow models of CamemBERT can be loaded like:
|
||||
|
||||
```python
|
||||
from transformers import TFCamembertModel
|
||||
|
||||
model = TFCamembertModel.from_pretrained("jplu/tf-camembert-base")
|
||||
```
|
||||
|
||||
## Huggingface model hub
|
||||
|
||||
All models are available on the [Huggingface model hub](https://huggingface.co/jplu).
|
||||
|
||||
## Acknowledgments
|
||||
|
||||
Thanks to all the Huggingface team for the support and their amazing library!
|
||||
36
model_cards/jplu/tf-xlm-roberta-base/README.md
Normal file
36
model_cards/jplu/tf-xlm-roberta-base/README.md
Normal file
@@ -0,0 +1,36 @@
|
||||
# Tensorflow XLM-RoBERTa
|
||||
|
||||
In this repository you will find different versions of the XLM-RoBERTa model for Tensorflow.
|
||||
|
||||
## XLM-RoBERTa
|
||||
|
||||
[XLM-RoBERTa](https://ai.facebook.com/blog/-xlm-r-state-of-the-art-cross-lingual-understanding-through-self-supervision/) is a scaled cross lingual sentence encoder. It is trained on 2.5T of data across 100 languages data filtered from Common Crawl. XLM-R achieves state-of-the-arts results on multiple cross lingual benchmarks.
|
||||
|
||||
## Model Weights
|
||||
|
||||
| Model | Downloads
|
||||
| -------------------------------- | ---------------------------------------------------------------------------------------------------------------
|
||||
| `jplu/tf-xlm-roberta-base` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/jplu/tf-xlm-roberta-base/config.json) • [`tf_model.h5`](https://s3.amazonaws.com/models.huggingface.co/bert/jplu/tf-xlm-roberta-base/tf_model.h5)
|
||||
| `jplu/tf-xlm-roberta-large` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/jplu/tf-xlm-roberta-large/config.json) • [`tf_model.h5`](https://s3.amazonaws.com/models.huggingface.co/bert/jplu/tf-xlm-roberta-large/tf_model.h5)
|
||||
|
||||
## Usage
|
||||
|
||||
With Transformers >= 2.4 the Tensorflow models of XLM-RoBERTa can be loaded like:
|
||||
|
||||
```python
|
||||
from transformers import TFXLMRobertaModel
|
||||
|
||||
model = TFXLMRobertaModel.from_pretrained("jplu/tf-xlm-roberta-base")
|
||||
```
|
||||
Or
|
||||
```
|
||||
model = TFXLMRobertaModel.from_pretrained("jplu/tf-xlm-roberta-large")
|
||||
```
|
||||
|
||||
## Huggingface model hub
|
||||
|
||||
All models are available on the [Huggingface model hub](https://huggingface.co/jplu).
|
||||
|
||||
## Acknowledgments
|
||||
|
||||
Thanks to all the Huggingface team for the support and their amazing library!
|
||||
36
model_cards/jplu/tf-xlm-roberta-large/README.md
Normal file
36
model_cards/jplu/tf-xlm-roberta-large/README.md
Normal file
@@ -0,0 +1,36 @@
|
||||
# Tensorflow XLM-RoBERTa
|
||||
|
||||
In this repository you will find different versions of the XLM-RoBERTa model for Tensorflow.
|
||||
|
||||
## XLM-RoBERTa
|
||||
|
||||
[XLM-RoBERTa](https://ai.facebook.com/blog/-xlm-r-state-of-the-art-cross-lingual-understanding-through-self-supervision/) is a scaled cross lingual sentence encoder. It is trained on 2.5T of data across 100 languages data filtered from Common Crawl. XLM-R achieves state-of-the-arts results on multiple cross lingual benchmarks.
|
||||
|
||||
## Model Weights
|
||||
|
||||
| Model | Downloads
|
||||
| -------------------------------- | ---------------------------------------------------------------------------------------------------------------
|
||||
| `jplu/tf-xlm-roberta-base` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/jplu/tf-xlm-roberta-base/config.json) • [`tf_model.h5`](https://s3.amazonaws.com/models.huggingface.co/bert/jplu/tf-xlm-roberta-base/tf_model.h5)
|
||||
| `jplu/tf-xlm-roberta-large` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/jplu/tf-xlm-roberta-large/config.json) • [`tf_model.h5`](https://s3.amazonaws.com/models.huggingface.co/bert/jplu/tf-xlm-roberta-large/tf_model.h5)
|
||||
|
||||
## Usage
|
||||
|
||||
With Transformers >= 2.4 the Tensorflow models of XLM-RoBERTa can be loaded like:
|
||||
|
||||
```python
|
||||
from transformers import TFXLMRobertaModel
|
||||
|
||||
model = TFXLMRobertaModel.from_pretrained("jplu/tf-xlm-roberta-base")
|
||||
```
|
||||
Or
|
||||
```
|
||||
model = TFXLMRobertaModel.from_pretrained("jplu/tf-xlm-roberta-large")
|
||||
```
|
||||
|
||||
## Huggingface model hub
|
||||
|
||||
All models are available on the [Huggingface model hub](https://huggingface.co/jplu).
|
||||
|
||||
## Acknowledgments
|
||||
|
||||
Thanks to all the Huggingface team for the support and their amazing library!
|
||||
40
model_cards/julien-c/EsperBERTo-small-pos/README.md
Normal file
40
model_cards/julien-c/EsperBERTo-small-pos/README.md
Normal file
@@ -0,0 +1,40 @@
|
||||
---
|
||||
language: esperanto
|
||||
thumbnail: https://huggingface.co/blog/assets/EsperBERTo-thumbnail-v2.png
|
||||
---
|
||||
|
||||
# EsperBERTo: RoBERTa-like Language model trained on Esperanto
|
||||
|
||||
**Companion model to blog post https://huggingface.co/blog/how-to-train** 🔥
|
||||
|
||||
## Training Details
|
||||
|
||||
- current checkpoint: 566000
|
||||
- machine name: `galinette`
|
||||
|
||||
|
||||

|
||||
|
||||
## Example pipeline
|
||||
|
||||
```python
|
||||
from transformers import TokenClassificationPipeline, pipeline
|
||||
|
||||
|
||||
MODEL_PATH = "./models/EsperBERTo-small-pos/"
|
||||
|
||||
nlp = pipeline(
|
||||
"ner",
|
||||
model=MODEL_PATH,
|
||||
tokenizer=MODEL_PATH,
|
||||
)
|
||||
# or instantiate a TokenClassificationPipeline directly.
|
||||
|
||||
nlp("Mi estas viro kej estas tago varma.")
|
||||
|
||||
# {'entity': 'PRON', 'score': 0.9979867339134216, 'word': ' Mi'}
|
||||
# {'entity': 'VERB', 'score': 0.9683094620704651, 'word': ' estas'}
|
||||
# {'entity': 'VERB', 'score': 0.9797462821006775, 'word': ' estas'}
|
||||
# {'entity': 'NOUN', 'score': 0.8509314060211182, 'word': ' tago'}
|
||||
# {'entity': 'ADJ', 'score': 0.9996201395988464, 'word': ' varma'}
|
||||
```
|
||||
59
model_cards/julien-c/EsperBERTo-small/README.md
Normal file
59
model_cards/julien-c/EsperBERTo-small/README.md
Normal file
@@ -0,0 +1,59 @@
|
||||
---
|
||||
language: esperanto
|
||||
thumbnail: https://huggingface.co/blog/assets/EsperBERTo-thumbnail-v2.png
|
||||
---
|
||||
|
||||
# EsperBERTo: RoBERTa-like Language model trained on Esperanto
|
||||
|
||||
**Companion model to blog post https://huggingface.co/blog/how-to-train** 🔥
|
||||
|
||||
## Training Details
|
||||
|
||||
- current checkpoint: 566000
|
||||
- machine name: `galinette`
|
||||
|
||||
|
||||

|
||||
|
||||
## Example pipeline
|
||||
|
||||
```python
|
||||
from transformers import pipeline
|
||||
|
||||
fill_mask = pipeline(
|
||||
"fill-mask",
|
||||
model="julien-c/EspertBERTo-small",
|
||||
tokenizer="julien-c/EspertBERTo-small"
|
||||
)
|
||||
|
||||
fill_mask("Jen la komenco de bela <mask>.")
|
||||
|
||||
# This is the beginning of a beautiful <mask>.
|
||||
# =>
|
||||
|
||||
# {
|
||||
# 'score':0.06502299010753632
|
||||
# 'sequence':'<s> Jen la komenco de bela vivo.</s>'
|
||||
# 'token':1099
|
||||
# }
|
||||
# {
|
||||
# 'score':0.0421181358397007
|
||||
# 'sequence':'<s> Jen la komenco de bela vespero.</s>'
|
||||
# 'token':5100
|
||||
# }
|
||||
# {
|
||||
# 'score':0.024884626269340515
|
||||
# 'sequence':'<s> Jen la komenco de bela laboro.</s>'
|
||||
# 'token':1570
|
||||
# }
|
||||
# {
|
||||
# 'score':0.02324388362467289
|
||||
# 'sequence':'<s> Jen la komenco de bela tago.</s>'
|
||||
# 'token':1688
|
||||
# }
|
||||
# {
|
||||
# 'score':0.020378097891807556
|
||||
# 'sequence':'<s> Jen la komenco de bela festo.</s>'
|
||||
# 'token':4580
|
||||
# }
|
||||
```
|
||||
25
model_cards/julien-c/bert-xsmall-dummy/README.md
Normal file
25
model_cards/julien-c/bert-xsmall-dummy/README.md
Normal file
@@ -0,0 +1,25 @@
|
||||
## How to build a dummy model
|
||||
|
||||
|
||||
```python
|
||||
from transformers.configuration_bert import BertConfig
|
||||
from transformers.modeling_bert import BertForMaskedLM
|
||||
from transformers.modeling_tf_bert import TFBertForMaskedLM
|
||||
from transformers.tokenization_bert import BertTokenizer
|
||||
|
||||
|
||||
SMALL_MODEL_IDENTIFIER = "julien-c/bert-xsmall-dummy"
|
||||
DIRNAME = "./bert-xsmall-dummy"
|
||||
|
||||
config = BertConfig(10, 20, 1, 1, 40)
|
||||
|
||||
model = BertForMaskedLM(config)
|
||||
model.save_pretrained(DIRNAME)
|
||||
|
||||
tf_model = TFBertForMaskedLM.from_pretrained(DIRNAME, from_pt=True)
|
||||
tf_model.save_pretrained(DIRNAME)
|
||||
|
||||
# Slightly different for tokenizer.
|
||||
# tokenizer = BertTokenizer.from_pretrained(DIRNAME)
|
||||
# tokenizer.save_pretrained()
|
||||
```
|
||||
59
model_cards/julien-c/dummy-unknown/README.md
Normal file
59
model_cards/julien-c/dummy-unknown/README.md
Normal file
@@ -0,0 +1,59 @@
|
||||
---
|
||||
tags:
|
||||
- ci
|
||||
---
|
||||
|
||||
## Dummy model used for unit testing and CI
|
||||
|
||||
|
||||
```python
|
||||
import json
|
||||
import os
|
||||
from transformers.configuration_roberta import RobertaConfig
|
||||
from transformers import RobertaForMaskedLM, TFRobertaForMaskedLM
|
||||
|
||||
DIRNAME = "./dummy-unknown"
|
||||
|
||||
|
||||
config = RobertaConfig(10, 20, 1, 1, 40)
|
||||
|
||||
model = RobertaForMaskedLM(config)
|
||||
model.save_pretrained(DIRNAME)
|
||||
|
||||
tf_model = TFRobertaForMaskedLM.from_pretrained(DIRNAME, from_pt=True)
|
||||
tf_model.save_pretrained(DIRNAME)
|
||||
|
||||
# Tokenizer:
|
||||
|
||||
vocab = [
|
||||
"l",
|
||||
"o",
|
||||
"w",
|
||||
"e",
|
||||
"r",
|
||||
"s",
|
||||
"t",
|
||||
"i",
|
||||
"d",
|
||||
"n",
|
||||
"\u0120",
|
||||
"\u0120l",
|
||||
"\u0120n",
|
||||
"\u0120lo",
|
||||
"\u0120low",
|
||||
"er",
|
||||
"\u0120lowest",
|
||||
"\u0120newer",
|
||||
"\u0120wider",
|
||||
"<unk>",
|
||||
]
|
||||
vocab_tokens = dict(zip(vocab, range(len(vocab))))
|
||||
merges = ["#version: 0.2", "\u0120 l", "\u0120l o", "\u0120lo w", "e r", ""]
|
||||
|
||||
vocab_file = os.path.join(DIRNAME, "vocab.json")
|
||||
merges_file = os.path.join(DIRNAME, "merges.txt")
|
||||
with open(vocab_file, "w", encoding="utf-8") as fp:
|
||||
fp.write(json.dumps(vocab_tokens) + "\n")
|
||||
with open(merges_file, "w", encoding="utf-8") as fp:
|
||||
fp.write("\n".join(merges))
|
||||
```
|
||||
7
model_cards/lysandre/arxiv-nlp/README.md
Normal file
7
model_cards/lysandre/arxiv-nlp/README.md
Normal file
@@ -0,0 +1,7 @@
|
||||
# ArXiv-NLP GPT-2 checkpoint
|
||||
|
||||
This is a GPT-2 small checkpoint for PyTorch. It is the official `gpt2-small` fine-tuned to ArXiv paper on the computational linguistics field.
|
||||
|
||||
## Training data
|
||||
|
||||
This model was trained on a subset of ArXiv papers that were parsed from PDF to txt. The resulting data is made of 80MB of text from the computational linguistics (cs.CL) field.
|
||||
7
model_cards/lysandre/arxiv/README.md
Normal file
7
model_cards/lysandre/arxiv/README.md
Normal file
@@ -0,0 +1,7 @@
|
||||
# ArXiv GPT-2 checkpoint
|
||||
|
||||
This is a GPT-2 small checkpoint for PyTorch. It is the official `gpt2-small` finetuned to ArXiv paper on physics fields.
|
||||
|
||||
## Training data
|
||||
|
||||
This model was trained on a subset of ArXiv papers that were parsed from PDF to txt. The resulting data is made of 130MB of text, mostly from quantum physics (quant-ph) and other physics sub-fields.
|
||||
@@ -0,0 +1,91 @@
|
||||
---
|
||||
language: spanish
|
||||
thumbnail: https://i.imgur.com/jgBdimh.png
|
||||
---
|
||||
|
||||
# BETO (Spanish BERT) + Spanish SQuAD2.0
|
||||
|
||||
This model is provided by [BETO team](https://github.com/dccuchile/beto) and fine-tuned on [SQuAD-es-v2.0](https://github.com/ccasimiro88/TranslateAlignRetrieve) for **Q&A** downstream task.
|
||||
|
||||
## Details of the language model('dccuchile/bert-base-spanish-wwm-cased')
|
||||
|
||||
Language model ([**'dccuchile/bert-base-spanish-wwm-cased'**](https://github.com/dccuchile/beto/blob/master/README.md)):
|
||||
|
||||
BETO is a [BERT model](https://github.com/google-research/bert) trained on a [big Spanish corpus](https://github.com/josecannete/spanish-corpora). BETO is of size similar to a BERT-Base and was trained with the Whole Word Masking technique. Below you find Tensorflow and Pytorch checkpoints for the uncased and cased versions, as well as some results for Spanish benchmarks comparing BETO with [Multilingual BERT](https://github.com/google-research/bert/blob/master/multilingual.md) as well as other (not BERT-based) models.
|
||||
|
||||
## Details of the downstream task (Q&A) - Dataset
|
||||
[SQuAD-es-v2.0](https://github.com/ccasimiro88/TranslateAlignRetrieve)
|
||||
|
||||
| Dataset | # Q&A |
|
||||
| ---------------------- | ----- |
|
||||
| SQuAD2.0 Train | 130 K |
|
||||
| SQuAD2.0-es-v2.0 | 111 K |
|
||||
| SQuAD2.0 Dev | 12 K |
|
||||
| SQuAD-es-v2.0-small Dev| 69 K |
|
||||
|
||||
## Model training
|
||||
|
||||
The model was trained on a Tesla P100 GPU and 25GB of RAM with the following command:
|
||||
|
||||
```bash
|
||||
export SQUAD_DIR=path/to/nl_squad
|
||||
python transformers/examples/run_squad.py \
|
||||
--model_type bert \
|
||||
--model_name_or_path dccuchile/bert-base-spanish-wwm-cased \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--do_lower_case \
|
||||
--train_file $SQUAD_DIR/train_nl-v2.0.json \
|
||||
--predict_file $SQUAD_DIR/dev_nl-v2.0.json \
|
||||
--per_gpu_train_batch_size 12 \
|
||||
--learning_rate 3e-5 \
|
||||
--num_train_epochs 2.0 \
|
||||
--max_seq_length 384 \
|
||||
--doc_stride 128 \
|
||||
--output_dir /content/model_output \
|
||||
--save_steps 5000 \
|
||||
--threads 4 \
|
||||
--version_2_with_negative
|
||||
```
|
||||
|
||||
## Results:
|
||||
|
||||
|
||||
| Metric | # Value |
|
||||
| ---------------------- | ----- |
|
||||
| **Exact** | **76.50**50 |
|
||||
| **F1** | **86.07**81 |
|
||||
|
||||
```json
|
||||
{
|
||||
"exact": 76.50501430594491,
|
||||
"f1": 86.07818773108252,
|
||||
"total": 69202,
|
||||
"HasAns_exact": 67.93020719738277,
|
||||
"HasAns_f1": 82.37912207996466,
|
||||
"HasAns_total": 45850,
|
||||
"NoAns_exact": 93.34104145255225,
|
||||
"NoAns_f1": 93.34104145255225,
|
||||
"NoAns_total": 23352,
|
||||
"best_exact": 76.51223953064941,
|
||||
"best_exact_thresh": 0.0,
|
||||
"best_f1": 86.08541295578848,
|
||||
"best_f1_thresh": 0.0
|
||||
}
|
||||
```
|
||||
|
||||
### Model in action (in a Colab Notebook)
|
||||
<details>
|
||||
|
||||
1. Set the context and ask some questions:
|
||||
|
||||

|
||||
|
||||
2. Run predictions:
|
||||
|
||||

|
||||
</details>
|
||||
|
||||
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
|
||||
|
||||
> Made with <span style="color: #e25555;">♥</span> in Spain
|
||||
@@ -0,0 +1,58 @@
|
||||
---
|
||||
language: spanish
|
||||
thumbnail: https://i.imgur.com/jgBdimh.png
|
||||
---
|
||||
|
||||
# Spanish BERT (BETO) + NER
|
||||
|
||||
This model is a fine-tuned on [NER-C](https://www.kaggle.com/nltkdata/conll-corpora) of the Spanish BERT cased [(BETO)](https://github.com/dccuchile/beto) for **NER** downstream task.
|
||||
|
||||
## Details of the downstream task (NER) - Dataset
|
||||
|
||||
- [Dataset: CONLL Corpora ES](https://www.kaggle.com/nltkdata/conll-corpora)
|
||||
|
||||
I preprocessed the dataset and splitted it as train / dev (80/20)
|
||||
|
||||
| Dataset | # Examples |
|
||||
| ---------------------- | ----- |
|
||||
| Train | 8.7 K |
|
||||
| Dev | 2.2 K |
|
||||
|
||||
|
||||
- [Fine-tune on NER script](https://github.com/huggingface/transformers/blob/master/examples/run_ner.py)
|
||||
|
||||
```bash
|
||||
!export NER_DIR='/content/ner_dataset'
|
||||
!python /content/transformers/examples/run_ner.py \
|
||||
--model_type bert \
|
||||
--model_name_or_path dccuchile/bert-base-spanish-wwm-cased \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--data_dir '/content/ner_dataset' \
|
||||
--num_train_epochs 15.0 \
|
||||
--max_seq_length 384 \
|
||||
--output_dir /content/model_output \
|
||||
--save_steps 5000 \
|
||||
|
||||
```
|
||||
|
||||
## Comparison:
|
||||
|
||||
| Model | # score |
|
||||
| :--------------------------------------------------------------------------------------------------------------: | :-------: |
|
||||
| bert-base-spanish-wwm-cased (BETO) | 88.43 |
|
||||
| [bert-spanish-cased-finetuned-ner (this one)](https://huggingface.co/mrm8488/bert-spanish-cased-finetuned-ner) | **89.65** |
|
||||
| Best Multilingual BERT | 87.38 |
|
||||
|
||||
```
|
||||
***** All metrics on Eval results *****
|
||||
|
||||
f1 = 0.8965040489828165
|
||||
loss = 0.11504213575173258
|
||||
precision = 0.893679858239811
|
||||
recall = 0.8993461462254805
|
||||
```
|
||||
|
||||
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
|
||||
|
||||
> Made with <span style="color: #e25555;">♥</span> in Spain
|
||||
@@ -0,0 +1,112 @@
|
||||
---
|
||||
language: spanish
|
||||
thumbnail: https://i.imgur.com/jgBdimh.png
|
||||
---
|
||||
|
||||
# BETO (Spanish BERT) + Spanish SQuAD2.0 + distillation using 'bert-base-multilingual-cased' as teacher
|
||||
|
||||
This model is a fine-tuned on [SQuAD-es-v2.0](https://github.com/ccasimiro88/TranslateAlignRetrieve) and **distilled** version of [BETO](https://github.com/dccuchile/beto) for **Q&A**.
|
||||
|
||||
Distillation makes the model **smaller, faster, cheaper and lighter** than [bert-base-spanish-wwm-cased-finetuned-spa-squad2-es](https://github.com/huggingface/transformers/blob/master/model_cards/mrm8488/bert-base-spanish-wwm-cased-finetuned-spa-squad2-es/README.md)
|
||||
|
||||
This model was fine-tuned on the same dataset but using **distillation** during the process as mentioned above (and one more train epoch).
|
||||
|
||||
The **teacher model** for the distillation was `bert-base-multilingual-cased`. It is the same teacher used for `distilbert-base-multilingual-cased` AKA [**DistilmBERT**](https://github.com/huggingface/transformers/tree/master/examples/distillation) (on average is twice as fast as **mBERT-base**).
|
||||
|
||||
## Details of the downstream task (Q&A) - Dataset
|
||||
|
||||
<details>
|
||||
|
||||
[SQuAD-es-v2.0](https://github.com/ccasimiro88/TranslateAlignRetrieve)
|
||||
|
||||
| Dataset | # Q&A |
|
||||
| ----------------------- | ----- |
|
||||
| SQuAD2.0 Train | 130 K |
|
||||
| SQuAD2.0-es-v2.0 | 111 K |
|
||||
| SQuAD2.0 Dev | 12 K |
|
||||
| SQuAD-es-v2.0-small Dev | 69 K |
|
||||
|
||||
</details>
|
||||
|
||||
## Model training
|
||||
|
||||
The model was trained on a Tesla P100 GPU and 25GB of RAM with the following command:
|
||||
|
||||
```bash
|
||||
!export SQUAD_DIR=/path/to/squad-v2_spanish \
|
||||
&& python transformers/examples/distillation/run_squad_w_distillation.py \
|
||||
--model_type bert \
|
||||
--model_name_or_path dccuchile/bert-base-spanish-wwm-cased \
|
||||
--teacher_type bert \
|
||||
--teacher_name_or_path bert-base-multilingual-cased \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--do_lower_case \
|
||||
--train_file $SQUAD_DIR/train-v2.json \
|
||||
--predict_file $SQUAD_DIR/dev-v2.json \
|
||||
--per_gpu_train_batch_size 12 \
|
||||
--learning_rate 3e-5 \
|
||||
--num_train_epochs 5.0 \
|
||||
--max_seq_length 384 \
|
||||
--doc_stride 128 \
|
||||
--output_dir /content/model_output \
|
||||
--save_steps 5000 \
|
||||
--threads 4 \
|
||||
--version_2_with_negative
|
||||
```
|
||||
|
||||
## Results:
|
||||
|
||||
| Metric | # Value |
|
||||
| --------- | ----------- |
|
||||
| **Exact** | **90.77**48 |
|
||||
| **F1** | **94.94**71 |
|
||||
|
||||
```json
|
||||
{
|
||||
"exact": 90.77483309730933,
|
||||
"f1": 94.94714391266254,
|
||||
"total": 69202,
|
||||
"HasAns_exact": 86.60850599781898,
|
||||
"HasAns_f1": 92.90582885592328,
|
||||
"HasAns_total": 45850,
|
||||
"NoAns_exact": 98.95512161699212,
|
||||
"NoAns_f1": 98.95512161699212,
|
||||
"NoAns_total": 23352,
|
||||
"best_exact": 90.77483309730933,
|
||||
"best_exact_thresh": 0.0,
|
||||
"best_f1": 94.94714391266305,
|
||||
"best_f1_thresh": 0.0
|
||||
}
|
||||
```
|
||||
|
||||
## Comparison:
|
||||
|
||||
| Model | f1 score |
|
||||
| :-------------------------------------------------------------: | :-------: |
|
||||
| bert-base-spanish-wwm-cased-finetuned-spa-squad2-es | 86.07 |
|
||||
| **distill**-bert-base-spanish-wwm-cased-finetuned-spa-squad2-es | **94.94** |
|
||||
|
||||
So, yes, this version is even more accurate.
|
||||
|
||||
### Model in action (in a Colab Notebook)
|
||||
|
||||
<details>
|
||||
|
||||
1. Set the context and ask some questions:
|
||||
|
||||

|
||||
|
||||
2. Run predictions:
|
||||
|
||||

|
||||
|
||||
3. Using **Pipelines**
|
||||
|
||||
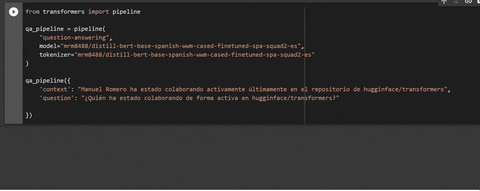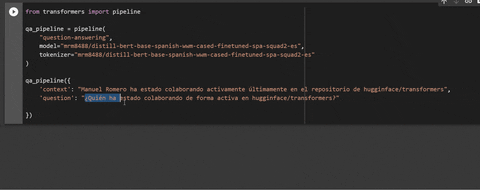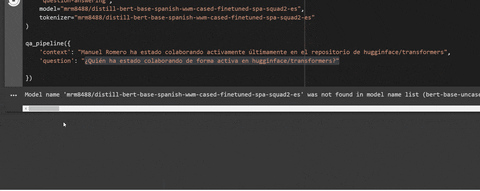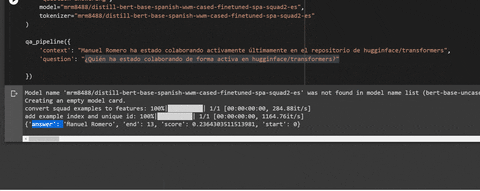
|
||||
|
||||
</details>
|
||||
|
||||
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
|
||||
|
||||
> Made with <span style="color: #e25555;">♥</span> in Spain
|
||||
93
model_cards/nlpaueb/bert-base-greek-uncased-v1/README.md
Normal file
93
model_cards/nlpaueb/bert-base-greek-uncased-v1/README.md
Normal file
@@ -0,0 +1,93 @@
|
||||
---
|
||||
language: greek
|
||||
thumbnail: https://github.com/nlpaueb/GreekBERT/raw/master/greek-bert-logo.png
|
||||
---
|
||||
|
||||
# GreekBERT
|
||||
|
||||
A Greek version of BERT pre-trained language model.
|
||||
|
||||
<img src="https://github.com/nlpaueb/GreekBERT/raw/master/greek-bert-logo.png" width="600"/>
|
||||
|
||||
|
||||
## Pre-training corpora
|
||||
|
||||
The pre-training corpora of `bert-base-greek-uncased-v1` include:
|
||||
|
||||
* The Greek part of [Wikipedia](https://el.wikipedia.org/wiki/Βικιπαίδεια:Αντίγραφα_της_βάσης_δεδομένων),
|
||||
* The Greek part of [European Parliament Proceedings Parallel Corpus](https://www.statmt.org/europarl/), and
|
||||
* The Greek part of [OSCAR](https://traces1.inria.fr/oscar/), a cleansed version of [Common Crawl](https://commoncrawl.org).
|
||||
|
||||
Future release will also include:
|
||||
|
||||
* The entire corpus of Greek legislation, as published by the [National Publication Office](http://www.et.gr),
|
||||
* The entire corpus of EU legislation (Greek translation), as published in [Eur-Lex](https://eur-lex.europa.eu/homepage.html?locale=en).
|
||||
|
||||
## Pre-training details
|
||||
|
||||
* We trained BERT using the official code provided in Google BERT's github repository (https://github.com/google-research/bert). We then used [Hugging Face](https://huggingface.co)'s [Transformers](https://github.com/huggingface/transformers) conversion script to convert the TF checkpoint and vocabulary in the desirable format in order to be able to load the model in two lines of code for both PyTorch and TF2 users.
|
||||
* We released a model similar to the English `bert-base-uncased` model (12-layer, 768-hidden, 12-heads, 110M parameters).
|
||||
* We chose to follow the same training set-up: 1 million training steps with batches of 256 sequences of length 512 with an initial learning rate 1e-4.
|
||||
* We were able to use a single Google Cloud TPU v3-8 provided for free from [TensorFlow Research Cloud (TFRC)](https://www.tensorflow.org/tfrc), while also utilizing [GCP research credits](https://edu.google.com/programs/credits/research). Huge thanks to both Google programs for supporting us!
|
||||
|
||||
|
||||
## Requirements
|
||||
|
||||
We published `bert-base-greek-uncased-v1` as part of [Hugging Face](https://huggingface.co)'s [Transformers](https://github.com/huggingface/transformers) repository. So, you need to install the transfomers library through pip along with PyTorch or Tensorflow 2.
|
||||
|
||||
```
|
||||
pip install transfomers
|
||||
pip install (torch|tensorflow)
|
||||
```
|
||||
|
||||
## Pre-process text (Deaccent - Lower)
|
||||
|
||||
In order to use `bert-base-greek-uncased-v1`, you have to pre-process texts to lowercase letters and remove all Greek diacritics.
|
||||
|
||||
```python
|
||||
|
||||
import unicodedata
|
||||
|
||||
def strip_accents_and_lowercase(s):
|
||||
return ''.join(c for c in unicodedata.normalize('NFD', s)
|
||||
if unicodedata.category(c) != 'Mn').lower()
|
||||
|
||||
accented_string = "Αυτή είναι η Ελληνική έκδοση του BERT."
|
||||
unaccented_string = strip_accents_and_lowercase(accented_string)
|
||||
|
||||
print(unaccented_string) # αυτη ειναι η ελληνικη εκδοση του bert.
|
||||
|
||||
```
|
||||
|
||||
## Load Pretrained Model
|
||||
|
||||
```python
|
||||
from transformers import AutoTokenizer, AutoModel
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("nlpaueb/bert-base-greek-uncased-v1")
|
||||
model = AutoModel.from_pretrained("nlpaueb/bert-base-greek-uncased-v1")
|
||||
```
|
||||
|
||||
## Evaluation on downstream tasks
|
||||
|
||||
TBA
|
||||
|
||||
## Author
|
||||
|
||||
Ilias Chalkidis on behalf of [AUEB's Natural Language Processing Group](http://nlp.cs.aueb.gr)
|
||||
|
||||
| Github: [@ilias.chalkidis](https://github.com/seolhokim) | Twitter: [@KiddoThe2B](https://twitter.com/KiddoThe2B) |
|
||||
|
||||
## About Us
|
||||
|
||||
[AUEB's Natural Language Processing Group](http://nlp.cs.aueb.gr) develops algorithms, models, and systems that allow computers to process and generate natural language texts.
|
||||
|
||||
The group's current research interests include:
|
||||
* question answering systems for databases, ontologies, document collections, and the Web, especially biomedical question answering,
|
||||
* natural language generation from databases and ontologies, especially Semantic Web ontologies,
|
||||
text classification, including filtering spam and abusive content,
|
||||
* information extraction and opinion mining, including legal text analytics and sentiment analysis,
|
||||
* natural language processing tools for Greek, for example parsers and named-entity recognizers,
|
||||
machine learning in natural language processing, especially deep learning.
|
||||
|
||||
The group is part of the Information Processing Laboratory of the Department of Informatics of the Athens University of Economics and Business.
|
||||
@@ -0,0 +1,49 @@
|
||||
---
|
||||
language:
|
||||
- english
|
||||
- dutch
|
||||
- german
|
||||
- french
|
||||
- italian
|
||||
- spanish
|
||||
---
|
||||
|
||||
# bert-base-multilingual-uncased-sentiment
|
||||
|
||||
This a bert-base-multilingual-uncased model finetuned for sentiment analysis on product reviews in six languages: English, Dutch, German, French, Spanish and Italian. It predicts the sentiment of the review as a number of stars (between 1 and 5).
|
||||
|
||||
This model is intended for direct use as a sentiment analysis model for product reviews in any of the six languages above, or for further finetuning on related sentiment analysis tasks.
|
||||
|
||||
## Training data
|
||||
|
||||
Here is the number of product reviews we used for finetuning the model:
|
||||
|
||||
| Language | Number of reviews |
|
||||
| -------- | ----------------- |
|
||||
| English | 150k |
|
||||
| Dutch | 80k |
|
||||
| German | 137k |
|
||||
| French | 140k |
|
||||
| Italian | 72k |
|
||||
| Spanish | 50k |
|
||||
|
||||
## Accuracy
|
||||
|
||||
The finetuned model obtained the following accuracy on 5,000 held-out product reviews in each of the languages:
|
||||
|
||||
- Accuracy (exact) is the exact match on the number of stars.
|
||||
- Accuracy (off-by-1) is the percentage of reviews where the number of stars the model predicts differs by a maximum of 1 from the number given by the human reviewer.
|
||||
|
||||
|
||||
| Language | Accuracy (exact) | Accuracy (off-by-1) |
|
||||
| -------- | ---------------------- | ------------------- |
|
||||
| English | 67% | 95%
|
||||
| Dutch | 57% | 93%
|
||||
| German | 61% | 94%
|
||||
| French | 59% | 94%
|
||||
| Italian | 59% | 95%
|
||||
| Spanish | 58% | 95%
|
||||
|
||||
## Contact
|
||||
|
||||
Contact [NLP Town](https://www.nlp.town) for questions, feedback and/or requests for similar models.
|
||||
51
model_cards/severinsimmler/literary-german-bert/README.md
Normal file
51
model_cards/severinsimmler/literary-german-bert/README.md
Normal file
@@ -0,0 +1,51 @@
|
||||
---
|
||||
language: german
|
||||
thumbnail: kfold.png
|
||||
---
|
||||
|
||||
# German BERT for literary texts
|
||||
|
||||
This German BERT is based on `bert-base-german-dbmdz-cased`, and has been adapted to the domain of literary texts by fine-tuning the language modeling task on the [Corpus of German-Language Fiction](https://figshare.com/articles/Corpus_of_German-Language_Fiction_txt_/4524680/1). Afterwards the model was fine-tuned for named entity recognition on the [DROC](https://gitlab2.informatik.uni-wuerzburg.de/kallimachos/DROC-Release) corpus, so you can use it to recognize protagonists in German novels.
|
||||
|
||||
|
||||
# Stats
|
||||
|
||||
## Language modeling
|
||||
|
||||
The [Corpus of German-Language Fiction](https://figshare.com/articles/Corpus_of_German-Language_Fiction_txt_/4524680/1) consists of 3,194 documents with 203,516,988 tokens or 1,520,855 types. The publication year of the texts ranges from the 18th to the 20th century:
|
||||
|
||||

|
||||
|
||||
|
||||
### Results
|
||||
|
||||
After one epoch:
|
||||
|
||||
| Model | Perplexity |
|
||||
| ---------------- | ---------- |
|
||||
| Vanilla BERT | 6.82 |
|
||||
| Fine-tuned BERT | 4.98 |
|
||||
|
||||
|
||||
## Named entity recognition
|
||||
|
||||
The provided model was also fine-tuned for two epochs on 10,799 sentences for training, validated on 547 and tested on 1,845 with three labels: `B-PER`, `I-PER` and `O`.
|
||||
|
||||
|
||||
## Results
|
||||
|
||||
| Dataset | Precision | Recall | F1 |
|
||||
| ------- | --------- | ------ | ---- |
|
||||
| Dev | 96.4 | 87.3 | 91.6 |
|
||||
| Test | 92.8 | 94.9 | 93.8 |
|
||||
|
||||
The model has also been evaluated using 10-fold cross validation and compared with a classic Conditional Random Field baseline described in [Jannidis et al.](https://opus.bibliothek.uni-wuerzburg.de/opus4-wuerzburg/frontdoor/deliver/index/docId/14333/file/Jannidis_Figurenerkennung_Roman.pdf) (2015):
|
||||
|
||||

|
||||
|
||||
|
||||
# References
|
||||
|
||||
Markus Krug, Lukas Weimer, Isabella Reger, Luisa Macharowsky, Stephan Feldhaus, Frank Puppe, Fotis Jannidis, [Description of a Corpus of Character References in German Novels](http://webdoc.sub.gwdg.de/pub/mon/dariah-de/dwp-2018-27.pdf), 2018.
|
||||
|
||||
Fotis Jannidis, Isabella Reger, Lukas Weimer, Markus Krug, Martin Toepfer, Frank Puppe, [Automatische Erkennung von Figuren in deutschsprachigen Romanen](https://opus.bibliothek.uni-wuerzburg.de/opus4-wuerzburg/frontdoor/deliver/index/docId/14333/file/Jannidis_Figurenerkennung_Roman.pdf), 2015.
|
||||
BIN
model_cards/severinsimmler/literary-german-bert/kfold.png
Normal file
BIN
model_cards/severinsimmler/literary-german-bert/kfold.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 5.6 KiB |
BIN
model_cards/severinsimmler/literary-german-bert/prosa-jahre.png
Normal file
BIN
model_cards/severinsimmler/literary-german-bert/prosa-jahre.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 21 KiB |
7
setup.py
7
setup.py
@@ -63,6 +63,7 @@ extras = {}
|
||||
extras["mecab"] = ["mecab-python3"]
|
||||
extras["sklearn"] = ["scikit-learn"]
|
||||
extras["tf"] = ["tensorflow"]
|
||||
extras["tf-cpu"] = ["tensorflow-cpu"]
|
||||
extras["torch"] = ["torch"]
|
||||
|
||||
extras["serving"] = ["pydantic", "uvicorn", "fastapi", "starlette"]
|
||||
@@ -75,8 +76,8 @@ extras["dev"] = extras["testing"] + extras["quality"] + ["mecab-python3", "sciki
|
||||
|
||||
setup(
|
||||
name="transformers",
|
||||
version="2.4.1",
|
||||
author="Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Google AI Language Team Authors, Open AI team Authors, Facebook AI Authors, Carnegie Mellon University Authors",
|
||||
version="2.5.0",
|
||||
author="Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Sam Shleifer, Google AI Language Team Authors, Open AI team Authors, Facebook AI Authors, Carnegie Mellon University Authors",
|
||||
author_email="thomas@huggingface.co",
|
||||
description="State-of-the-art Natural Language Processing for TensorFlow 2.0 and PyTorch",
|
||||
long_description=open("README.md", "r", encoding="utf-8").read(),
|
||||
@@ -88,7 +89,7 @@ setup(
|
||||
packages=find_packages("src"),
|
||||
install_requires=[
|
||||
"numpy",
|
||||
"tokenizers == 0.0.11",
|
||||
"tokenizers == 0.5.0",
|
||||
# accessing files from S3 directly
|
||||
"boto3",
|
||||
# filesystem locks e.g. to prevent parallel downloads
|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
# There's no way to ignore "F401 '...' imported but unused" warnings in this
|
||||
# module, but to preserve other warnings. So, don't check this module at all.
|
||||
|
||||
__version__ = "2.4.1"
|
||||
__version__ = "2.5.0"
|
||||
|
||||
# Work around to update TensorFlow's absl.logging threshold which alters the
|
||||
# default Python logging output behavior when present.
|
||||
@@ -101,6 +101,7 @@ from .pipelines import (
|
||||
PipelineDataFormat,
|
||||
QuestionAnsweringPipeline,
|
||||
TextClassificationPipeline,
|
||||
TokenClassificationPipeline,
|
||||
pipeline,
|
||||
)
|
||||
from .tokenization_albert import AlbertTokenizer
|
||||
@@ -109,13 +110,13 @@ from .tokenization_bert import BasicTokenizer, BertTokenizer, BertTokenizerFast,
|
||||
from .tokenization_bert_japanese import BertJapaneseTokenizer, CharacterTokenizer, MecabTokenizer
|
||||
from .tokenization_camembert import CamembertTokenizer
|
||||
from .tokenization_ctrl import CTRLTokenizer
|
||||
from .tokenization_distilbert import DistilBertTokenizer
|
||||
from .tokenization_distilbert import DistilBertTokenizer, DistilBertTokenizerFast
|
||||
from .tokenization_flaubert import FlaubertTokenizer
|
||||
from .tokenization_gpt2 import GPT2Tokenizer, GPT2TokenizerFast
|
||||
from .tokenization_openai import OpenAIGPTTokenizer
|
||||
from .tokenization_roberta import RobertaTokenizer
|
||||
from .tokenization_openai import OpenAIGPTTokenizer, OpenAIGPTTokenizerFast
|
||||
from .tokenization_roberta import RobertaTokenizer, RobertaTokenizerFast
|
||||
from .tokenization_t5 import T5Tokenizer
|
||||
from .tokenization_transfo_xl import TransfoXLCorpus, TransfoXLTokenizer
|
||||
from .tokenization_transfo_xl import TransfoXLCorpus, TransfoXLTokenizer, TransfoXLTokenizerFast
|
||||
|
||||
# Tokenizers
|
||||
from .tokenization_utils import PreTrainedTokenizer
|
||||
|
||||
48
src/transformers/activations.py
Normal file
48
src/transformers/activations.py
Normal file
@@ -0,0 +1,48 @@
|
||||
import math
|
||||
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
|
||||
|
||||
def swish(x):
|
||||
return x * torch.sigmoid(x)
|
||||
|
||||
|
||||
def _gelu_python(x):
|
||||
""" Original Implementation of the gelu activation function in Google Bert repo when initially created.
|
||||
For information: OpenAI GPT's gelu is slightly different (and gives slightly different results):
|
||||
0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
|
||||
This is now written in C in torch.nn.functional
|
||||
Also see https://arxiv.org/abs/1606.08415
|
||||
"""
|
||||
return x * 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))
|
||||
|
||||
|
||||
gelu = getattr(F, "gelu", _gelu_python)
|
||||
|
||||
|
||||
def gelu_new(x):
|
||||
""" Implementation of the gelu activation function currently in Google Bert repo (identical to OpenAI GPT).
|
||||
Also see https://arxiv.org/abs/1606.08415
|
||||
"""
|
||||
return 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
|
||||
|
||||
|
||||
ACT2FN = {
|
||||
"relu": F.relu,
|
||||
"swish": swish,
|
||||
"gelu": gelu,
|
||||
"tanh": F.tanh,
|
||||
"gelu_new": gelu_new,
|
||||
}
|
||||
|
||||
|
||||
def get_activation(activation_string):
|
||||
if activation_string in ACT2FN:
|
||||
return ACT2FN[activation_string]
|
||||
else:
|
||||
raise KeyError(
|
||||
"function {} not found in ACT2FN mapping {} or torch.nn.functional".format(
|
||||
activation_string, list(ACT2FN.keys())
|
||||
)
|
||||
)
|
||||
58
src/transformers/commands/env.py
Normal file
58
src/transformers/commands/env.py
Normal file
@@ -0,0 +1,58 @@
|
||||
import platform
|
||||
from argparse import ArgumentParser
|
||||
|
||||
from transformers import __version__ as version
|
||||
from transformers import is_tf_available, is_torch_available
|
||||
from transformers.commands import BaseTransformersCLICommand
|
||||
|
||||
|
||||
def info_command_factory(_):
|
||||
return EnvironmentCommand()
|
||||
|
||||
|
||||
class EnvironmentCommand(BaseTransformersCLICommand):
|
||||
@staticmethod
|
||||
def register_subcommand(parser: ArgumentParser):
|
||||
download_parser = parser.add_parser("env")
|
||||
download_parser.set_defaults(func=info_command_factory)
|
||||
|
||||
def run(self):
|
||||
pt_version = "not installed"
|
||||
pt_cuda_available = "NA"
|
||||
if is_torch_available():
|
||||
import torch
|
||||
|
||||
pt_version = torch.__version__
|
||||
pt_cuda_available = torch.cuda.is_available()
|
||||
|
||||
tf_version = "not installed"
|
||||
tf_cuda_available = "NA"
|
||||
if is_tf_available():
|
||||
import tensorflow as tf
|
||||
|
||||
tf_version = tf.__version__
|
||||
try:
|
||||
# deprecated in v2.1
|
||||
tf_cuda_available = tf.test.is_gpu_available()
|
||||
except AttributeError:
|
||||
# returns list of devices, convert to bool
|
||||
tf_cuda_available = bool(tf.config.list_physical_devices("GPU"))
|
||||
|
||||
info = {
|
||||
"`transformers` version": version,
|
||||
"Platform": platform.platform(),
|
||||
"Python version": platform.python_version(),
|
||||
"PyTorch version (GPU?)": "{} ({})".format(pt_version, pt_cuda_available),
|
||||
"Tensorflow version (GPU?)": "{} ({})".format(tf_version, tf_cuda_available),
|
||||
"Using GPU in script?": "<fill in>",
|
||||
"Using distributed or parallel set-up in script?": "<fill in>",
|
||||
}
|
||||
|
||||
print("\nCopy-and-paste the text below in your GitHub issue and FILL OUT the two last points.\n")
|
||||
print(self.format_dict(info))
|
||||
|
||||
return info
|
||||
|
||||
@staticmethod
|
||||
def format_dict(d):
|
||||
return "\n".join(["- {}: {}".format(prop, val) for prop, val in d.items()]) + "\n"
|
||||
@@ -25,6 +25,8 @@ logger = logging.getLogger(__name__)
|
||||
DISTILBERT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
|
||||
"distilbert-base-uncased": "https://s3.amazonaws.com/models.huggingface.co/bert/distilbert-base-uncased-config.json",
|
||||
"distilbert-base-uncased-distilled-squad": "https://s3.amazonaws.com/models.huggingface.co/bert/distilbert-base-uncased-distilled-squad-config.json",
|
||||
"distilbert-base-cased": "https://s3.amazonaws.com/models.huggingface.co/bert/distilbert-base-cased-config.json",
|
||||
"distilbert-base-cased-distilled-squad": "https://s3.amazonaws.com/models.huggingface.co/bert/distilbert-base-cased-distilled-squad-config.json",
|
||||
"distilbert-base-german-cased": "https://s3.amazonaws.com/models.huggingface.co/bert/distilbert-base-german-cased-config.json",
|
||||
"distilbert-base-multilingual-cased": "https://s3.amazonaws.com/models.huggingface.co/bert/distilbert-base-multilingual-cased-config.json",
|
||||
"distilbert-base-uncased-finetuned-sst-2-english": "https://s3.amazonaws.com/models.huggingface.co/bert/distilbert-base-uncased-finetuned-sst-2-english-config.json",
|
||||
@@ -58,7 +60,7 @@ class DistilBertConfig(PretrainedConfig):
|
||||
Number of attention heads for each attention layer in the Transformer encoder.
|
||||
dim (:obj:`int`, optional, defaults to 768):
|
||||
Dimensionality of the encoder layers and the pooler layer.
|
||||
intermediate_size (:obj:`int`, optional, defaults to 3072):
|
||||
hidden_dim (:obj:`int`, optional, defaults to 3072):
|
||||
The size of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
|
||||
dropout (:obj:`float`, optional, defaults to 0.1):
|
||||
The dropout probabilitiy for all fully connected layers in the embeddings, encoder, and pooler.
|
||||
|
||||
@@ -277,7 +277,7 @@ MODEL_CLASSES = {
|
||||
DISTILBERT_PRETRAINED_MODEL_ARCHIVE_MAP,
|
||||
DISTILBERT_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
),
|
||||
"distilbert-base-uncased-distilled-squad": (
|
||||
"distilbert-base-distilled-squad": (
|
||||
DistilBertConfig,
|
||||
TFDistilBertForQuestionAnswering,
|
||||
DistilBertForQuestionAnswering,
|
||||
|
||||
@@ -147,7 +147,14 @@ def squad_convert_example_to_features(example, max_seq_length, doc_stride, max_q
|
||||
)
|
||||
|
||||
if tokenizer.pad_token_id in encoded_dict["input_ids"]:
|
||||
non_padded_ids = encoded_dict["input_ids"][: encoded_dict["input_ids"].index(tokenizer.pad_token_id)]
|
||||
if tokenizer.padding_side == "right":
|
||||
non_padded_ids = encoded_dict["input_ids"][: encoded_dict["input_ids"].index(tokenizer.pad_token_id)]
|
||||
else:
|
||||
last_padding_id_position = (
|
||||
len(encoded_dict["input_ids"]) - 1 - encoded_dict["input_ids"][::-1].index(tokenizer.pad_token_id)
|
||||
)
|
||||
non_padded_ids = encoded_dict["input_ids"][last_padding_id_position + 1 :]
|
||||
|
||||
else:
|
||||
non_padded_ids = encoded_dict["input_ids"]
|
||||
|
||||
@@ -621,7 +628,7 @@ class SquadExample(object):
|
||||
self.doc_tokens = doc_tokens
|
||||
self.char_to_word_offset = char_to_word_offset
|
||||
|
||||
# Start end end positions only has a value during evaluation.
|
||||
# Start and end positions only has a value during evaluation.
|
||||
if start_position_character is not None and not is_impossible:
|
||||
self.start_position = char_to_word_offset[start_position_character]
|
||||
self.end_position = char_to_word_offset[
|
||||
|
||||
@@ -8,13 +8,16 @@ import fnmatch
|
||||
import json
|
||||
import logging
|
||||
import os
|
||||
import shutil
|
||||
import sys
|
||||
import tarfile
|
||||
import tempfile
|
||||
from contextlib import contextmanager
|
||||
from functools import partial, wraps
|
||||
from hashlib import sha256
|
||||
from typing import Optional
|
||||
from urllib.parse import urlparse
|
||||
from zipfile import ZipFile, is_zipfile
|
||||
|
||||
import boto3
|
||||
import requests
|
||||
@@ -203,7 +206,14 @@ def filename_to_url(filename, cache_dir=None):
|
||||
|
||||
|
||||
def cached_path(
|
||||
url_or_filename, cache_dir=None, force_download=False, proxies=None, resume_download=False, user_agent=None
|
||||
url_or_filename,
|
||||
cache_dir=None,
|
||||
force_download=False,
|
||||
proxies=None,
|
||||
resume_download=False,
|
||||
user_agent=None,
|
||||
extract_compressed_file=False,
|
||||
force_extract=False,
|
||||
) -> Optional[str]:
|
||||
"""
|
||||
Given something that might be a URL (or might be a local path),
|
||||
@@ -215,6 +225,10 @@ def cached_path(
|
||||
force_download: if True, re-dowload the file even if it's already cached in the cache dir.
|
||||
resume_download: if True, resume the download if incompletly recieved file is found.
|
||||
user_agent: Optional string or dict that will be appended to the user-agent on remote requests.
|
||||
extract_compressed_file: if True and the path point to a zip or tar file, extract the compressed
|
||||
file in a folder along the archive.
|
||||
force_extract: if True when extract_compressed_file is True and the archive was already extracted,
|
||||
re-extract the archive and overide the folder where it was extracted.
|
||||
|
||||
Return:
|
||||
None in case of non-recoverable file (non-existent or inaccessible url + no cache on disk).
|
||||
@@ -229,7 +243,7 @@ def cached_path(
|
||||
|
||||
if is_remote_url(url_or_filename):
|
||||
# URL, so get it from the cache (downloading if necessary)
|
||||
return get_from_cache(
|
||||
output_path = get_from_cache(
|
||||
url_or_filename,
|
||||
cache_dir=cache_dir,
|
||||
force_download=force_download,
|
||||
@@ -239,7 +253,7 @@ def cached_path(
|
||||
)
|
||||
elif os.path.exists(url_or_filename):
|
||||
# File, and it exists.
|
||||
return url_or_filename
|
||||
output_path = url_or_filename
|
||||
elif urlparse(url_or_filename).scheme == "":
|
||||
# File, but it doesn't exist.
|
||||
raise EnvironmentError("file {} not found".format(url_or_filename))
|
||||
@@ -247,6 +261,39 @@ def cached_path(
|
||||
# Something unknown
|
||||
raise ValueError("unable to parse {} as a URL or as a local path".format(url_or_filename))
|
||||
|
||||
if extract_compressed_file:
|
||||
if not is_zipfile(output_path) and not tarfile.is_tarfile(output_path):
|
||||
return output_path
|
||||
|
||||
# Path where we extract compressed archives
|
||||
# We avoid '.' in dir name and add "-extracted" at the end: "./model.zip" => "./model-zip-extracted/"
|
||||
output_dir, output_file = os.path.split(output_path)
|
||||
output_extract_dir_name = output_file.replace(".", "-") + "-extracted"
|
||||
output_path_extracted = os.path.join(output_dir, output_extract_dir_name)
|
||||
|
||||
if os.path.isdir(output_path_extracted) and os.listdir(output_path_extracted) and not force_extract:
|
||||
return output_path_extracted
|
||||
|
||||
# Prevent parallel extractions
|
||||
lock_path = output_path + ".lock"
|
||||
with FileLock(lock_path):
|
||||
shutil.rmtree(output_path_extracted, ignore_errors=True)
|
||||
os.makedirs(output_path_extracted)
|
||||
if is_zipfile(output_path):
|
||||
with ZipFile(output_path, "r") as zip_file:
|
||||
zip_file.extractall(output_path_extracted)
|
||||
zip_file.close()
|
||||
elif tarfile.is_tarfile(output_path):
|
||||
tar_file = tarfile.open(output_path)
|
||||
tar_file.extractall(output_path_extracted)
|
||||
tar_file.close()
|
||||
else:
|
||||
raise EnvironmentError("Archive format of {} could not be identified".format(output_path))
|
||||
|
||||
return output_path_extracted
|
||||
|
||||
return output_path
|
||||
|
||||
|
||||
def split_s3_path(url):
|
||||
"""Split a full s3 path into the bucket name and path."""
|
||||
|
||||
@@ -117,7 +117,13 @@ def load_tf_weights_in_albert(model, config, tf_checkpoint_path):
|
||||
name = name.split("/")
|
||||
|
||||
# Ignore the gradients applied by the LAMB/ADAM optimizers.
|
||||
if "adam_m" in name or "adam_v" in name or "global_step" in name:
|
||||
if (
|
||||
"adam_m" in name
|
||||
or "adam_v" in name
|
||||
or "AdamWeightDecayOptimizer" in name
|
||||
or "AdamWeightDecayOptimizer_1" in name
|
||||
or "global_step" in name
|
||||
):
|
||||
logger.info("Skipping {}".format("/".join(name)))
|
||||
continue
|
||||
|
||||
|
||||
@@ -24,6 +24,7 @@ import torch
|
||||
from torch import nn
|
||||
from torch.nn import CrossEntropyLoss, MSELoss
|
||||
|
||||
from .activations import gelu, gelu_new, swish
|
||||
from .configuration_bert import BertConfig
|
||||
from .file_utils import add_start_docstrings, add_start_docstrings_to_callable
|
||||
from .modeling_utils import PreTrainedModel, prune_linear_layer
|
||||
@@ -86,7 +87,10 @@ def load_tf_weights_in_bert(model, config, tf_checkpoint_path):
|
||||
name = name.split("/")
|
||||
# adam_v and adam_m are variables used in AdamWeightDecayOptimizer to calculated m and v
|
||||
# which are not required for using pretrained model
|
||||
if any(n in ["adam_v", "adam_m", "global_step"] for n in name):
|
||||
if any(
|
||||
n in ["adam_v", "adam_m", "AdamWeightDecayOptimizer", "AdamWeightDecayOptimizer_1", "global_step"]
|
||||
for n in name
|
||||
):
|
||||
logger.info("Skipping {}".format("/".join(name)))
|
||||
continue
|
||||
pointer = model
|
||||
@@ -126,26 +130,6 @@ def load_tf_weights_in_bert(model, config, tf_checkpoint_path):
|
||||
return model
|
||||
|
||||
|
||||
def gelu(x):
|
||||
""" Original Implementation of the gelu activation function in Google Bert repo when initially created.
|
||||
For information: OpenAI GPT's gelu is slightly different (and gives slightly different results):
|
||||
0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
|
||||
Also see https://arxiv.org/abs/1606.08415
|
||||
"""
|
||||
return x * 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))
|
||||
|
||||
|
||||
def gelu_new(x):
|
||||
""" Implementation of the gelu activation function currently in Google Bert repo (identical to OpenAI GPT).
|
||||
Also see https://arxiv.org/abs/1606.08415
|
||||
"""
|
||||
return 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
|
||||
|
||||
|
||||
def swish(x):
|
||||
return x * torch.sigmoid(x)
|
||||
|
||||
|
||||
def mish(x):
|
||||
return x * torch.tanh(nn.functional.softplus(x))
|
||||
|
||||
@@ -730,8 +714,8 @@ class BertModel(BertPreTrainedModel):
|
||||
seq_ids = torch.arange(seq_length, device=device)
|
||||
causal_mask = seq_ids[None, None, :].repeat(batch_size, seq_length, 1) <= seq_ids[None, :, None]
|
||||
causal_mask = causal_mask.to(
|
||||
torch.long
|
||||
) # not converting to long will cause errors with pytorch version < 1.3
|
||||
attention_mask.dtype
|
||||
) # causal and attention masks must have same type with pytorch version < 1.3
|
||||
extended_attention_mask = causal_mask[:, None, :, :] * attention_mask[:, None, None, :]
|
||||
else:
|
||||
extended_attention_mask = attention_mask[:, None, None, :]
|
||||
|
||||
@@ -27,6 +27,7 @@ import torch
|
||||
import torch.nn as nn
|
||||
from torch.nn import CrossEntropyLoss
|
||||
|
||||
from .activations import gelu
|
||||
from .configuration_distilbert import DistilBertConfig
|
||||
from .file_utils import add_start_docstrings, add_start_docstrings_to_callable
|
||||
from .modeling_utils import PreTrainedModel, prune_linear_layer
|
||||
@@ -38,6 +39,8 @@ logger = logging.getLogger(__name__)
|
||||
DISTILBERT_PRETRAINED_MODEL_ARCHIVE_MAP = {
|
||||
"distilbert-base-uncased": "https://s3.amazonaws.com/models.huggingface.co/bert/distilbert-base-uncased-pytorch_model.bin",
|
||||
"distilbert-base-uncased-distilled-squad": "https://s3.amazonaws.com/models.huggingface.co/bert/distilbert-base-uncased-distilled-squad-pytorch_model.bin",
|
||||
"distilbert-base-cased": "https://s3.amazonaws.com/models.huggingface.co/bert/distilbert-base-cased-pytorch_model.bin",
|
||||
"distilbert-base-cased-distilled-squad": "https://s3.amazonaws.com/models.huggingface.co/bert/distilbert-base-cased-distilled-squad-pytorch_model.bin",
|
||||
"distilbert-base-german-cased": "https://s3.amazonaws.com/models.huggingface.co/bert/distilbert-base-german-cased-pytorch_model.bin",
|
||||
"distilbert-base-multilingual-cased": "https://s3.amazonaws.com/models.huggingface.co/bert/distilbert-base-multilingual-cased-pytorch_model.bin",
|
||||
"distilbert-base-uncased-finetuned-sst-2-english": "https://s3.amazonaws.com/models.huggingface.co/bert/distilbert-base-uncased-finetuned-sst-2-english-pytorch_model.bin",
|
||||
@@ -45,8 +48,6 @@ DISTILBERT_PRETRAINED_MODEL_ARCHIVE_MAP = {
|
||||
|
||||
|
||||
# UTILS AND BUILDING BLOCKS OF THE ARCHITECTURE #
|
||||
def gelu(x):
|
||||
return 0.5 * x * (1.0 + torch.erf(x / math.sqrt(2.0)))
|
||||
|
||||
|
||||
def create_sinusoidal_embeddings(n_pos, dim, out):
|
||||
@@ -440,8 +441,8 @@ class DistilBertModel(DistilBertPreTrainedModel):
|
||||
from transformers import DistilBertTokenizer, DistilBertModel
|
||||
import torch
|
||||
|
||||
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
|
||||
model = DistilBertModel.from_pretrained('distilbert-base-uncased')
|
||||
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-cased')
|
||||
model = DistilBertModel.from_pretrained('distilbert-base-cased')
|
||||
|
||||
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute", add_special_tokens=True)).unsqueeze(0) # Batch size 1
|
||||
outputs = model(input_ids)
|
||||
@@ -544,8 +545,8 @@ class DistilBertForMaskedLM(DistilBertPreTrainedModel):
|
||||
from transformers import DistilBertTokenizer, DistilBertForMaskedLM
|
||||
import torch
|
||||
|
||||
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
|
||||
model = DistilBertForMaskedLM.from_pretrained('distilbert-base-uncased')
|
||||
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-cased')
|
||||
model = DistilBertForMaskedLM.from_pretrained('distilbert-base-cased')
|
||||
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute", add_special_tokens=True)).unsqueeze(0) # Batch size 1
|
||||
outputs = model(input_ids, masked_lm_labels=input_ids)
|
||||
loss, prediction_scores = outputs[:2]
|
||||
@@ -619,8 +620,8 @@ class DistilBertForSequenceClassification(DistilBertPreTrainedModel):
|
||||
from transformers import DistilBertTokenizer, DistilBertForSequenceClassification
|
||||
import torch
|
||||
|
||||
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
|
||||
model = DistilBertForSequenceClassification.from_pretrained('distilbert-base-uncased')
|
||||
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-cased')
|
||||
model = DistilBertForSequenceClassification.from_pretrained('distilbert-base-cased')
|
||||
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute", add_special_tokens=True)).unsqueeze(0) # Batch size 1
|
||||
labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
|
||||
outputs = model(input_ids, labels=labels)
|
||||
@@ -711,8 +712,8 @@ class DistilBertForQuestionAnswering(DistilBertPreTrainedModel):
|
||||
from transformers import DistilBertTokenizer, DistilBertForQuestionAnswering
|
||||
import torch
|
||||
|
||||
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
|
||||
model = DistilBertForQuestionAnswering.from_pretrained('distilbert-base-uncased')
|
||||
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-cased')
|
||||
model = DistilBertForQuestionAnswering.from_pretrained('distilbert-base-cased')
|
||||
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute", add_special_tokens=True)).unsqueeze(0) # Batch size 1
|
||||
start_positions = torch.tensor([1])
|
||||
end_positions = torch.tensor([3])
|
||||
@@ -798,8 +799,8 @@ class DistilBertForTokenClassification(DistilBertPreTrainedModel):
|
||||
from transformers import DistilBertTokenizer, DistilBertForTokenClassification
|
||||
import torch
|
||||
|
||||
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
|
||||
model = DistilBertForTokenClassification.from_pretrained('distilbert-base-uncased')
|
||||
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-cased')
|
||||
model = DistilBertForTokenClassification.from_pretrained('distilbert-base-cased')
|
||||
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute")).unsqueeze(0) # Batch size 1
|
||||
labels = torch.tensor([1] * input_ids.size(1)).unsqueeze(0) # Batch size 1
|
||||
outputs = model(input_ids, labels=labels)
|
||||
|
||||
@@ -232,7 +232,7 @@ class PreTrainedEncoderDecoder(nn.Module):
|
||||
encoder_outputs = ()
|
||||
|
||||
kwargs_decoder["encoder_hidden_states"] = encoder_hidden_states
|
||||
decoder_outputs = self.decoder(decoder_input_ids, encoder_hidden_states, **kwargs_decoder)
|
||||
decoder_outputs = self.decoder(decoder_input_ids, **kwargs_decoder)
|
||||
|
||||
return decoder_outputs + encoder_outputs
|
||||
|
||||
|
||||
@@ -231,7 +231,7 @@ class FlaubertModel(XLMModel):
|
||||
inputs_embeds = self.embeddings(input_ids)
|
||||
|
||||
tensor = inputs_embeds + self.position_embeddings(position_ids).expand_as(inputs_embeds)
|
||||
if langs is not None and self.use_lang_emb:
|
||||
if langs is not None and self.use_lang_emb and self.config.n_langs > 1:
|
||||
tensor = tensor + self.lang_embeddings(langs)
|
||||
if token_type_ids is not None:
|
||||
tensor = tensor + self.embeddings(token_type_ids)
|
||||
|
||||
@@ -24,6 +24,7 @@ import torch
|
||||
import torch.nn as nn
|
||||
from torch.nn import CrossEntropyLoss
|
||||
|
||||
from .activations import gelu_new
|
||||
from .configuration_gpt2 import GPT2Config
|
||||
from .file_utils import add_start_docstrings, add_start_docstrings_to_callable
|
||||
from .modeling_utils import Conv1D, PreTrainedModel, SequenceSummary, prune_conv1d_layer
|
||||
@@ -95,10 +96,6 @@ def load_tf_weights_in_gpt2(model, config, gpt2_checkpoint_path):
|
||||
return model
|
||||
|
||||
|
||||
def gelu(x):
|
||||
return 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
|
||||
|
||||
|
||||
class Attention(nn.Module):
|
||||
def __init__(self, nx, n_ctx, config, scale=False):
|
||||
super().__init__()
|
||||
@@ -206,7 +203,7 @@ class MLP(nn.Module):
|
||||
nx = config.n_embd
|
||||
self.c_fc = Conv1D(n_state, nx)
|
||||
self.c_proj = Conv1D(nx, n_state)
|
||||
self.act = gelu
|
||||
self.act = gelu_new
|
||||
self.dropout = nn.Dropout(config.resid_pdrop)
|
||||
|
||||
def forward(self, x):
|
||||
|
||||
@@ -25,6 +25,7 @@ import torch
|
||||
import torch.nn as nn
|
||||
from torch.nn import CrossEntropyLoss
|
||||
|
||||
from .activations import gelu_new, swish
|
||||
from .configuration_openai import OpenAIGPTConfig
|
||||
from .file_utils import add_start_docstrings, add_start_docstrings_to_callable
|
||||
from .modeling_utils import Conv1D, PreTrainedModel, SequenceSummary, prune_conv1d_layer
|
||||
@@ -114,15 +115,7 @@ def load_tf_weights_in_openai_gpt(model, config, openai_checkpoint_folder_path):
|
||||
return model
|
||||
|
||||
|
||||
def gelu(x):
|
||||
return 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
|
||||
|
||||
|
||||
def swish(x):
|
||||
return x * torch.sigmoid(x)
|
||||
|
||||
|
||||
ACT_FNS = {"relu": nn.ReLU, "swish": swish, "gelu": gelu}
|
||||
ACT_FNS = {"relu": nn.ReLU, "swish": swish, "gelu": gelu_new}
|
||||
|
||||
|
||||
class Attention(nn.Module):
|
||||
|
||||
@@ -79,7 +79,10 @@ def load_tf_weights_in_t5(model, config, tf_checkpoint_path):
|
||||
name = txt_name.split("/")
|
||||
# adam_v and adam_m are variables used in AdamWeightDecayOptimizer to calculated m and v
|
||||
# which are not required for using pretrained model
|
||||
if any(n in ["adam_v", "adam_m", "global_step"] for n in name):
|
||||
if any(
|
||||
n in ["adam_v", "adam_m", "AdamWeightDecayOptimizer", "AdamWeightDecayOptimizer_1", "global_step"]
|
||||
for n in name
|
||||
):
|
||||
logger.info("Skipping {}".format("/".join(name)))
|
||||
tf_weights.pop(txt_name, None)
|
||||
continue
|
||||
|
||||
@@ -33,6 +33,8 @@ logger = logging.getLogger(__name__)
|
||||
TF_DISTILBERT_PRETRAINED_MODEL_ARCHIVE_MAP = {
|
||||
"distilbert-base-uncased": "https://s3.amazonaws.com/models.huggingface.co/bert/distilbert-base-uncased-tf_model.h5",
|
||||
"distilbert-base-uncased-distilled-squad": "https://s3.amazonaws.com/models.huggingface.co/bert/distilbert-base-uncased-distilled-squad-tf_model.h5",
|
||||
"distilbert-base-cased": "https://s3.amazonaws.com/models.huggingface.co/bert/distilbert-base-cased-tf_model.h5",
|
||||
"distilbert-base-cased-distilled-squad": "https://s3.amazonaws.com/models.huggingface.co/bert/distilbert-base-cased-distilled-squad-tf_model.h5",
|
||||
"distilbert-base-multilingual-cased": "https://s3.amazonaws.com/models.huggingface.co/bert/distilbert-base-multilingual-cased-tf_model.h5",
|
||||
"distilbert-base-uncased-finetuned-sst-2-english": "https://s3.amazonaws.com/models.huggingface.co/bert/distilbert-base-uncased-finetuned-sst-2-english-tf_model.h5",
|
||||
}
|
||||
@@ -78,8 +80,6 @@ class TFEmbeddings(tf.keras.layers.Layer):
|
||||
embeddings_initializer=get_initializer(config.initializer_range),
|
||||
name="position_embeddings",
|
||||
)
|
||||
if config.sinusoidal_pos_embds:
|
||||
raise NotImplementedError
|
||||
|
||||
self.LayerNorm = tf.keras.layers.LayerNormalization(epsilon=1e-12, name="LayerNorm")
|
||||
self.dropout = tf.keras.layers.Dropout(config.dropout)
|
||||
@@ -563,8 +563,8 @@ class TFDistilBertModel(TFDistilBertPreTrainedModel):
|
||||
import tensorflow as tf
|
||||
from transformers import DistilBertTokenizer, TFDistilBertModel
|
||||
|
||||
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
|
||||
model = TFDistilBertModel.from_pretrained('distilbert-base-uncased')
|
||||
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-cased')
|
||||
model = TFDistilBertModel.from_pretrained('distilbert-base-cased')
|
||||
input_ids = tf.constant(tokenizer.encode("Hello, my dog is cute"))[None, :] # Batch size 1
|
||||
outputs = model(input_ids)
|
||||
last_hidden_states = outputs[0] # The last hidden-state is the first element of the output tuple
|
||||
@@ -637,8 +637,8 @@ class TFDistilBertForMaskedLM(TFDistilBertPreTrainedModel):
|
||||
import tensorflow as tf
|
||||
from transformers import DistilBertTokenizer, TFDistilBertForMaskedLM
|
||||
|
||||
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
|
||||
model = TFDistilBertForMaskedLM.from_pretrained('distilbert-base-uncased')
|
||||
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-cased')
|
||||
model = TFDistilBertForMaskedLM.from_pretrained('distilbert-base-cased')
|
||||
input_ids = tf.constant(tokenizer.encode("Hello, my dog is cute"))[None, :] # Batch size 1
|
||||
outputs = model(input_ids)
|
||||
prediction_scores = outputs[0]
|
||||
@@ -701,8 +701,8 @@ class TFDistilBertForSequenceClassification(TFDistilBertPreTrainedModel):
|
||||
import tensorflow as tf
|
||||
from transformers import DistilBertTokenizer, TFDistilBertForSequenceClassification
|
||||
|
||||
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
|
||||
model = TFDistilBertForSequenceClassification.from_pretrained('distilbert-base-uncased')
|
||||
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-cased')
|
||||
model = TFDistilBertForSequenceClassification.from_pretrained('distilbert-base-cased')
|
||||
input_ids = tf.constant(tokenizer.encode("Hello, my dog is cute"))[None, :] # Batch size 1
|
||||
outputs = model(input_ids)
|
||||
logits = outputs[0]
|
||||
@@ -759,8 +759,8 @@ class TFDistilBertForTokenClassification(TFDistilBertPreTrainedModel):
|
||||
import tensorflow as tf
|
||||
from transformers import DistilBertTokenizer, TFDistilBertForTokenClassification
|
||||
|
||||
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
|
||||
model = TFDistilBertForTokenClassification.from_pretrained('distilbert-base-uncased')
|
||||
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-cased')
|
||||
model = TFDistilBertForTokenClassification.from_pretrained('distilbert-base-cased')
|
||||
input_ids = tf.constant(tokenizer.encode("Hello, my dog is cute"))[None, :] # Batch size 1
|
||||
outputs = model(input_ids)
|
||||
scores = outputs[0]
|
||||
@@ -818,8 +818,8 @@ class TFDistilBertForQuestionAnswering(TFDistilBertPreTrainedModel):
|
||||
import tensorflow as tf
|
||||
from transformers import DistilBertTokenizer, TFDistilBertForQuestionAnswering
|
||||
|
||||
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
|
||||
model = TFDistilBertForQuestionAnswering.from_pretrained('distilbert-base-uncased')
|
||||
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-cased')
|
||||
model = TFDistilBertForQuestionAnswering.from_pretrained('distilbert-base-cased')
|
||||
input_ids = tf.constant(tokenizer.encode("Hello, my dog is cute"))[None, :] # Batch size 1
|
||||
outputs = model(input_ids)
|
||||
start_scores, end_scores = outputs[:2]
|
||||
|
||||
@@ -198,7 +198,7 @@ class TFBlock(tf.keras.layers.Layer):
|
||||
|
||||
class TFGPT2MainLayer(tf.keras.layers.Layer):
|
||||
def __init__(self, config, *inputs, **kwargs):
|
||||
super().__init__(config, *inputs, **kwargs)
|
||||
super().__init__(*inputs, **kwargs)
|
||||
self.output_hidden_states = config.output_hidden_states
|
||||
self.output_attentions = config.output_attentions
|
||||
self.num_hidden_layers = config.n_layer
|
||||
|
||||
@@ -303,11 +303,9 @@ class TFPreTrainedModel(tf.keras.Model, TFModelUtilsMixin):
|
||||
elif os.path.isfile(pretrained_model_name_or_path + ".index"):
|
||||
archive_file = pretrained_model_name_or_path + ".index"
|
||||
else:
|
||||
archive_file = hf_bucket_url(pretrained_model_name_or_path, postfix=TF2_WEIGHTS_NAME)
|
||||
if from_pt:
|
||||
raise EnvironmentError(
|
||||
"Loading a TF model from a PyTorch checkpoint is not supported when using a model identifier name."
|
||||
)
|
||||
archive_file = hf_bucket_url(
|
||||
pretrained_model_name_or_path, postfix=(WEIGHTS_NAME if from_pt else TF2_WEIGHTS_NAME)
|
||||
)
|
||||
|
||||
# redirect to the cache, if necessary
|
||||
try:
|
||||
|
||||
@@ -90,9 +90,9 @@ class ProjectedAdaptiveLogSoftmax(nn.Module):
|
||||
labels :: [len*bsz]
|
||||
Return:
|
||||
if labels is None:
|
||||
out :: [len*bsz] Negative log likelihood
|
||||
else:
|
||||
out :: [len*bsz x n_tokens] log probabilities of tokens over the vocabulary
|
||||
else:
|
||||
out :: [len*bsz] Negative log likelihood
|
||||
We could replace this implementation by the native PyTorch one
|
||||
if their's had an option to set bias on all clusters in the native one.
|
||||
here: https://github.com/pytorch/pytorch/blob/dbe6a7a9ff1a364a8706bf5df58a1ca96d2fd9da/torch/nn/modules/adaptive.py#L138
|
||||
|
||||
@@ -18,12 +18,14 @@
|
||||
|
||||
import logging
|
||||
import os
|
||||
import typing
|
||||
|
||||
import torch
|
||||
from torch import nn
|
||||
from torch.nn import CrossEntropyLoss
|
||||
from torch.nn import functional as F
|
||||
|
||||
from .activations import get_activation
|
||||
from .configuration_utils import PretrainedConfig
|
||||
from .file_utils import (
|
||||
DUMMY_INPUTS,
|
||||
@@ -421,11 +423,9 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
)
|
||||
archive_file = pretrained_model_name_or_path + ".index"
|
||||
else:
|
||||
archive_file = hf_bucket_url(pretrained_model_name_or_path, postfix=WEIGHTS_NAME)
|
||||
if from_tf:
|
||||
raise EnvironmentError(
|
||||
"Loading a PyTorch model from a TF checkpoint is not supported when using a model identifier name."
|
||||
)
|
||||
archive_file = hf_bucket_url(
|
||||
pretrained_model_name_or_path, postfix=(TF2_WEIGHTS_NAME if from_tf else WEIGHTS_NAME)
|
||||
)
|
||||
|
||||
# redirect to the cache, if necessary
|
||||
try:
|
||||
@@ -586,7 +586,7 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
self,
|
||||
input_ids=None,
|
||||
max_length=None,
|
||||
do_sample=None,
|
||||
do_sample=True,
|
||||
num_beams=None,
|
||||
temperature=None,
|
||||
top_k=None,
|
||||
@@ -617,7 +617,7 @@ class PreTrainedModel(nn.Module, ModuleUtilsMixin):
|
||||
The max length of the sequence to be generated. Between 1 and infinity. Default to 20.
|
||||
|
||||
do_sample: (`optional`) bool
|
||||
If set to `False` greedy decoding is used. Otherwise sampling is used. Default to greedy sampling.
|
||||
If set to `False` greedy decoding is used. Otherwise sampling is used. Defaults to `True`.
|
||||
|
||||
num_beams: (`optional`) int
|
||||
Number of beams for beam search. Must be between 1 and infinity. 1 means no beam search. Default to 1.
|
||||
@@ -1380,15 +1380,15 @@ class SequenceSummary(nn.Module):
|
||||
- 'attn' => Not implemented now, use multi-head attention
|
||||
summary_use_proj: Add a projection after the vector extraction
|
||||
summary_proj_to_labels: If True, the projection outputs to config.num_labels classes (otherwise to hidden_size). Default: False.
|
||||
summary_activation: 'tanh' => add a tanh activation to the output, Other => no activation. Default
|
||||
summary_activation: 'tanh' or another string => add an activation to the output, Other => no activation. Default
|
||||
summary_first_dropout: Add a dropout before the projection and activation
|
||||
summary_last_dropout: Add a dropout after the projection and activation
|
||||
"""
|
||||
|
||||
def __init__(self, config):
|
||||
def __init__(self, config: PretrainedConfig):
|
||||
super().__init__()
|
||||
|
||||
self.summary_type = config.summary_type if hasattr(config, "summary_type") else "last"
|
||||
self.summary_type = getattr(config, "summary_type", "last")
|
||||
if self.summary_type == "attn":
|
||||
# We should use a standard multi-head attention module with absolute positional embedding for that.
|
||||
# Cf. https://github.com/zihangdai/xlnet/blob/master/modeling.py#L253-L276
|
||||
@@ -1403,9 +1403,10 @@ class SequenceSummary(nn.Module):
|
||||
num_classes = config.hidden_size
|
||||
self.summary = nn.Linear(config.hidden_size, num_classes)
|
||||
|
||||
self.activation = Identity()
|
||||
if hasattr(config, "summary_activation") and config.summary_activation == "tanh":
|
||||
self.activation = nn.Tanh()
|
||||
activation_string = getattr(config, "summary_activation", None)
|
||||
self.activation = (
|
||||
get_activation(activation_string) if activation_string else Identity()
|
||||
) # type: typing.Callable
|
||||
|
||||
self.first_dropout = Identity()
|
||||
if hasattr(config, "summary_first_dropout") and config.summary_first_dropout > 0:
|
||||
|
||||
@@ -26,6 +26,7 @@ from torch import nn
|
||||
from torch.nn import CrossEntropyLoss, MSELoss
|
||||
from torch.nn import functional as F
|
||||
|
||||
from .activations import gelu
|
||||
from .configuration_xlm import XLMConfig
|
||||
from .file_utils import add_start_docstrings, add_start_docstrings_to_callable
|
||||
from .modeling_utils import PreTrainedModel, SequenceSummary, SQuADHead, prune_linear_layer
|
||||
@@ -55,17 +56,6 @@ def create_sinusoidal_embeddings(n_pos, dim, out):
|
||||
out.requires_grad = False
|
||||
|
||||
|
||||
def gelu(x):
|
||||
"""
|
||||
GELU activation
|
||||
https://arxiv.org/abs/1606.08415
|
||||
https://github.com/huggingface/pytorch-openai-transformer-lm/blob/master/model_pytorch.py#L14
|
||||
https://github.com/huggingface/transformers/blob/master/modeling.py
|
||||
"""
|
||||
# return 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
|
||||
return 0.5 * x * (1.0 + torch.erf(x / math.sqrt(2.0)))
|
||||
|
||||
|
||||
def get_masks(slen, lengths, causal, padding_mask=None):
|
||||
"""
|
||||
Generate hidden states mask, and optionally an attention mask.
|
||||
|
||||
@@ -18,13 +18,13 @@
|
||||
|
||||
|
||||
import logging
|
||||
import math
|
||||
|
||||
import torch
|
||||
from torch import nn
|
||||
from torch.nn import CrossEntropyLoss, MSELoss
|
||||
from torch.nn import functional as F
|
||||
|
||||
from .activations import gelu_new, swish
|
||||
from .configuration_xlnet import XLNetConfig
|
||||
from .file_utils import add_start_docstrings, add_start_docstrings_to_callable
|
||||
from .modeling_utils import PoolerAnswerClass, PoolerEndLogits, PoolerStartLogits, PreTrainedModel, SequenceSummary
|
||||
@@ -183,20 +183,7 @@ def load_tf_weights_in_xlnet(model, config, tf_path):
|
||||
return model
|
||||
|
||||
|
||||
def gelu(x):
|
||||
""" Implementation of the gelu activation function.
|
||||
XLNet is using OpenAI GPT's gelu (not exactly the same as BERT)
|
||||
Also see https://arxiv.org/abs/1606.08415
|
||||
"""
|
||||
cdf = 0.5 * (1.0 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
|
||||
return x * cdf
|
||||
|
||||
|
||||
def swish(x):
|
||||
return x * torch.sigmoid(x)
|
||||
|
||||
|
||||
ACT2FN = {"gelu": gelu, "relu": torch.nn.functional.relu, "swish": swish}
|
||||
ACT2FN = {"gelu": gelu_new, "relu": torch.nn.functional.relu, "swish": swish}
|
||||
|
||||
|
||||
XLNetLayerNorm = nn.LayerNorm
|
||||
@@ -550,7 +537,7 @@ XLNET_INPUTS_DOCSTRING = r"""
|
||||
token_type_ids (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`, defaults to :obj:`None`):
|
||||
Segment token indices to indicate first and second portions of the inputs.
|
||||
Indices are selected in ``[0, 1]``: ``0`` corresponds to a `sentence A` token, ``1``
|
||||
corresponds to a `sentence B` token
|
||||
corresponds to a `sentence B` token. The classifier token should be represented by a ``2``.
|
||||
|
||||
`What are token type IDs? <../glossary.html#token-type-ids>`_
|
||||
input_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`, defaults to :obj:`None`):
|
||||
|
||||
@@ -326,7 +326,7 @@ class Pipeline(_ScikitCompat):
|
||||
self,
|
||||
model,
|
||||
tokenizer: PreTrainedTokenizer = None,
|
||||
modelcard: ModelCard = None,
|
||||
modelcard: Optional[ModelCard] = None,
|
||||
framework: Optional[str] = None,
|
||||
args_parser: ArgumentHandler = None,
|
||||
device: int = -1,
|
||||
@@ -358,7 +358,8 @@ class Pipeline(_ScikitCompat):
|
||||
|
||||
self.model.save_pretrained(save_directory)
|
||||
self.tokenizer.save_pretrained(save_directory)
|
||||
self.modelcard.save_pretrained(save_directory)
|
||||
if self.modelcard is not None:
|
||||
self.modelcard.save_pretrained(save_directory)
|
||||
|
||||
def transform(self, X):
|
||||
"""
|
||||
@@ -476,7 +477,7 @@ class FeatureExtractionPipeline(Pipeline):
|
||||
self,
|
||||
model,
|
||||
tokenizer: PreTrainedTokenizer = None,
|
||||
modelcard: ModelCard = None,
|
||||
modelcard: Optional[ModelCard] = None,
|
||||
framework: Optional[str] = None,
|
||||
args_parser: ArgumentHandler = None,
|
||||
device: int = -1,
|
||||
@@ -515,7 +516,7 @@ class FillMaskPipeline(Pipeline):
|
||||
self,
|
||||
model,
|
||||
tokenizer: PreTrainedTokenizer = None,
|
||||
modelcard: ModelCard = None,
|
||||
modelcard: Optional[ModelCard] = None,
|
||||
framework: Optional[str] = None,
|
||||
args_parser: ArgumentHandler = None,
|
||||
device: int = -1,
|
||||
@@ -582,7 +583,7 @@ class NerPipeline(Pipeline):
|
||||
self,
|
||||
model,
|
||||
tokenizer: PreTrainedTokenizer = None,
|
||||
modelcard: ModelCard = None,
|
||||
modelcard: Optional[ModelCard] = None,
|
||||
framework: Optional[str] = None,
|
||||
args_parser: ArgumentHandler = None,
|
||||
device: int = -1,
|
||||
@@ -648,6 +649,9 @@ class NerPipeline(Pipeline):
|
||||
return answers
|
||||
|
||||
|
||||
TokenClassificationPipeline = NerPipeline
|
||||
|
||||
|
||||
class QuestionAnsweringArgumentHandler(ArgumentHandler):
|
||||
"""
|
||||
QuestionAnsweringPipeline requires the user to provide multiple arguments (i.e. question & context) to be mapped
|
||||
@@ -721,7 +725,7 @@ class QuestionAnsweringPipeline(Pipeline):
|
||||
self,
|
||||
model,
|
||||
tokenizer: Optional[PreTrainedTokenizer],
|
||||
modelcard: Optional[ModelCard],
|
||||
modelcard: Optional[ModelCard] = None,
|
||||
framework: Optional[str] = None,
|
||||
device: int = -1,
|
||||
**kwargs
|
||||
@@ -940,9 +944,9 @@ SUPPORTED_TASKS = {
|
||||
"tf": TFAutoModel if is_tf_available() else None,
|
||||
"pt": AutoModel if is_torch_available() else None,
|
||||
"default": {
|
||||
"model": {"pt": "distilbert-base-uncased", "tf": "distilbert-base-uncased"},
|
||||
"model": {"pt": "distilbert-base-cased", "tf": "distilbert-base-cased"},
|
||||
"config": None,
|
||||
"tokenizer": "distilbert-base-uncased",
|
||||
"tokenizer": "distilbert-base-cased",
|
||||
},
|
||||
},
|
||||
"sentiment-analysis": {
|
||||
@@ -976,12 +980,9 @@ SUPPORTED_TASKS = {
|
||||
"tf": TFAutoModelForQuestionAnswering if is_tf_available() else None,
|
||||
"pt": AutoModelForQuestionAnswering if is_torch_available() else None,
|
||||
"default": {
|
||||
"model": {
|
||||
"pt": "distilbert-base-uncased-distilled-squad",
|
||||
"tf": "distilbert-base-uncased-distilled-squad",
|
||||
},
|
||||
"model": {"pt": "distilbert-base-cased-distilled-squad", "tf": "distilbert-base-cased-distilled-squad"},
|
||||
"config": None,
|
||||
"tokenizer": "distilbert-base-uncased",
|
||||
"tokenizer": ("distilbert-base-cased", {"use_fast": False}),
|
||||
},
|
||||
},
|
||||
"fill-mask": {
|
||||
@@ -991,7 +992,7 @@ SUPPORTED_TASKS = {
|
||||
"default": {
|
||||
"model": {"pt": "distilroberta-base", "tf": "distilroberta-base"},
|
||||
"config": None,
|
||||
"tokenizer": "distilroberta-base",
|
||||
"tokenizer": ("distilroberta-base", {"use_fast": False}),
|
||||
},
|
||||
},
|
||||
}
|
||||
@@ -1003,6 +1004,7 @@ def pipeline(
|
||||
config: Optional[Union[str, PretrainedConfig]] = None,
|
||||
tokenizer: Optional[Union[str, PreTrainedTokenizer]] = None,
|
||||
modelcard: Optional[Union[str, ModelCard]] = None,
|
||||
framework: Optional[str] = None,
|
||||
**kwargs
|
||||
) -> Pipeline:
|
||||
"""
|
||||
@@ -1014,7 +1016,7 @@ def pipeline(
|
||||
|
||||
Examples:
|
||||
pipeline('sentiment-analysis')
|
||||
pipeline('question-answering', model='distilbert-base-uncased-distilled-squad', tokenizer='bert-base-cased')
|
||||
pipeline('question-answering', model='distilbert-base-cased-distilled-squad', tokenizer='bert-base-cased')
|
||||
pipeline('ner', model=AutoModel.from_pretrained(...), tokenizer=AutoTokenizer.from_pretrained(...)
|
||||
pipeline('ner', model='dbmdz/bert-large-cased-finetuned-conll03-english', tokenizer='bert-base-cased')
|
||||
pipeline('ner', model='https://...pytorch-model.bin', config='https://...config.json', tokenizer='bert-base-cased')
|
||||
@@ -1023,7 +1025,7 @@ def pipeline(
|
||||
if task not in SUPPORTED_TASKS:
|
||||
raise KeyError("Unknown task {}, available tasks are {}".format(task, list(SUPPORTED_TASKS.keys())))
|
||||
|
||||
framework = get_framework(model)
|
||||
framework = framework or get_framework(model)
|
||||
|
||||
targeted_task = SUPPORTED_TASKS[task]
|
||||
task, model_class = targeted_task["impl"], targeted_task[framework]
|
||||
@@ -1055,8 +1057,12 @@ def pipeline(
|
||||
modelcard = config
|
||||
|
||||
# Instantiate tokenizer if needed
|
||||
if isinstance(tokenizer, str):
|
||||
tokenizer = AutoTokenizer.from_pretrained(tokenizer)
|
||||
if isinstance(tokenizer, (str, tuple)):
|
||||
if isinstance(tokenizer, tuple):
|
||||
# For tuple we have (tokenizer name, {kwargs})
|
||||
tokenizer = AutoTokenizer.from_pretrained(tokenizer[0], **tokenizer[1])
|
||||
else:
|
||||
tokenizer = AutoTokenizer.from_pretrained(tokenizer)
|
||||
|
||||
# Instantiate config if needed
|
||||
if isinstance(config, str):
|
||||
|
||||
@@ -37,17 +37,17 @@ from .configuration_auto import (
|
||||
)
|
||||
from .configuration_utils import PretrainedConfig
|
||||
from .tokenization_albert import AlbertTokenizer
|
||||
from .tokenization_bert import BertTokenizer
|
||||
from .tokenization_bert import BertTokenizer, BertTokenizerFast
|
||||
from .tokenization_bert_japanese import BertJapaneseTokenizer
|
||||
from .tokenization_camembert import CamembertTokenizer
|
||||
from .tokenization_ctrl import CTRLTokenizer
|
||||
from .tokenization_distilbert import DistilBertTokenizer
|
||||
from .tokenization_distilbert import DistilBertTokenizer, DistilBertTokenizerFast
|
||||
from .tokenization_flaubert import FlaubertTokenizer
|
||||
from .tokenization_gpt2 import GPT2Tokenizer
|
||||
from .tokenization_openai import OpenAIGPTTokenizer
|
||||
from .tokenization_roberta import RobertaTokenizer
|
||||
from .tokenization_gpt2 import GPT2Tokenizer, GPT2TokenizerFast
|
||||
from .tokenization_openai import OpenAIGPTTokenizer, OpenAIGPTTokenizerFast
|
||||
from .tokenization_roberta import RobertaTokenizer, RobertaTokenizerFast
|
||||
from .tokenization_t5 import T5Tokenizer
|
||||
from .tokenization_transfo_xl import TransfoXLTokenizer
|
||||
from .tokenization_transfo_xl import TransfoXLTokenizer, TransfoXLTokenizerFast
|
||||
from .tokenization_xlm import XLMTokenizer
|
||||
from .tokenization_xlm_roberta import XLMRobertaTokenizer
|
||||
from .tokenization_xlnet import XLNetTokenizer
|
||||
@@ -58,20 +58,20 @@ logger = logging.getLogger(__name__)
|
||||
|
||||
TOKENIZER_MAPPING = OrderedDict(
|
||||
[
|
||||
(T5Config, T5Tokenizer),
|
||||
(DistilBertConfig, DistilBertTokenizer),
|
||||
(AlbertConfig, AlbertTokenizer),
|
||||
(CamembertConfig, CamembertTokenizer),
|
||||
(XLMRobertaConfig, XLMRobertaTokenizer),
|
||||
(RobertaConfig, RobertaTokenizer),
|
||||
(BertConfig, BertTokenizer),
|
||||
(OpenAIGPTConfig, OpenAIGPTTokenizer),
|
||||
(GPT2Config, GPT2Tokenizer),
|
||||
(TransfoXLConfig, TransfoXLTokenizer),
|
||||
(XLNetConfig, XLNetTokenizer),
|
||||
(FlaubertConfig, FlaubertTokenizer),
|
||||
(XLMConfig, XLMTokenizer),
|
||||
(CTRLConfig, CTRLTokenizer),
|
||||
(T5Config, (T5Tokenizer, None)),
|
||||
(DistilBertConfig, (DistilBertTokenizer, DistilBertTokenizerFast)),
|
||||
(AlbertConfig, (AlbertTokenizer, None)),
|
||||
(CamembertConfig, (CamembertTokenizer, None)),
|
||||
(XLMRobertaConfig, (XLMRobertaTokenizer, None)),
|
||||
(RobertaConfig, (RobertaTokenizer, RobertaTokenizerFast)),
|
||||
(BertConfig, (BertTokenizer, BertTokenizerFast)),
|
||||
(OpenAIGPTConfig, (OpenAIGPTTokenizer, OpenAIGPTTokenizerFast)),
|
||||
(GPT2Config, (GPT2Tokenizer, GPT2TokenizerFast)),
|
||||
(TransfoXLConfig, (TransfoXLTokenizer, TransfoXLTokenizerFast)),
|
||||
(XLNetConfig, (XLNetTokenizer, None)),
|
||||
(FlaubertConfig, (FlaubertTokenizer, None)),
|
||||
(XLMConfig, (XLMTokenizer, None)),
|
||||
(CTRLConfig, (CTRLTokenizer, None)),
|
||||
]
|
||||
)
|
||||
|
||||
@@ -154,6 +154,9 @@ class AutoTokenizer:
|
||||
A dictionary of proxy servers to use by protocol or endpoint, e.g.: {'http': 'foo.bar:3128', 'http://hostname': 'foo.bar:4012'}.
|
||||
The proxies are used on each request.
|
||||
|
||||
use_fast: (`optional`) boolean, default True:
|
||||
Indicate if transformers should try to load the fast version of the tokenizer (True) or use the Python one (False).
|
||||
|
||||
inputs: (`optional`) positional arguments: will be passed to the Tokenizer ``__init__`` method.
|
||||
|
||||
kwargs: (`optional`) keyword arguments: will be passed to the Tokenizer ``__init__`` method. Can be used to set special tokens like ``bos_token``, ``eos_token``, ``unk_token``, ``sep_token``, ``pad_token``, ``cls_token``, ``mask_token``, ``additional_special_tokens``. See parameters in the doc string of :class:`~transformers.PreTrainedTokenizer` for details.
|
||||
@@ -177,9 +180,13 @@ class AutoTokenizer:
|
||||
if "bert-base-japanese" in pretrained_model_name_or_path:
|
||||
return BertJapaneseTokenizer.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)
|
||||
|
||||
for config_class, tokenizer_class in TOKENIZER_MAPPING.items():
|
||||
use_fast = kwargs.pop("use_fast", True)
|
||||
for config_class, (tokenizer_class_py, tokenizer_class_fast) in TOKENIZER_MAPPING.items():
|
||||
if isinstance(config, config_class):
|
||||
return tokenizer_class.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)
|
||||
if tokenizer_class_fast and use_fast:
|
||||
return tokenizer_class_fast.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)
|
||||
else:
|
||||
return tokenizer_class_py.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)
|
||||
|
||||
raise ValueError(
|
||||
"Unrecognized configuration class {} to build an AutoTokenizer.\n"
|
||||
|
||||
@@ -20,7 +20,7 @@ import logging
|
||||
import os
|
||||
import unicodedata
|
||||
|
||||
import tokenizers as tk
|
||||
from tokenizers import BertWordPieceTokenizer
|
||||
|
||||
from .tokenization_utils import PreTrainedTokenizer, PreTrainedTokenizerFast
|
||||
|
||||
@@ -550,14 +550,19 @@ class BertTokenizerFast(PreTrainedTokenizerFast):
|
||||
cls_token="[CLS]",
|
||||
mask_token="[MASK]",
|
||||
tokenize_chinese_chars=True,
|
||||
max_length=None,
|
||||
pad_to_max_length=False,
|
||||
stride=0,
|
||||
truncation_strategy="longest_first",
|
||||
add_special_tokens=True,
|
||||
**kwargs
|
||||
):
|
||||
super().__init__(
|
||||
BertWordPieceTokenizer(
|
||||
vocab_file=vocab_file,
|
||||
add_special_tokens=add_special_tokens,
|
||||
unk_token=unk_token,
|
||||
sep_token=sep_token,
|
||||
cls_token=cls_token,
|
||||
handle_chinese_chars=tokenize_chinese_chars,
|
||||
lowercase=do_lower_case,
|
||||
),
|
||||
unk_token=unk_token,
|
||||
sep_token=sep_token,
|
||||
pad_token=pad_token,
|
||||
@@ -566,32 +571,4 @@ class BertTokenizerFast(PreTrainedTokenizerFast):
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
self._tokenizer = tk.Tokenizer(tk.models.WordPiece.from_files(vocab_file, unk_token=unk_token))
|
||||
self._update_special_tokens()
|
||||
self._tokenizer.with_pre_tokenizer(
|
||||
tk.pre_tokenizers.BertPreTokenizer.new(
|
||||
do_basic_tokenize=do_basic_tokenize,
|
||||
do_lower_case=do_lower_case,
|
||||
tokenize_chinese_chars=tokenize_chinese_chars,
|
||||
never_split=never_split if never_split is not None else [],
|
||||
)
|
||||
)
|
||||
self._tokenizer.with_decoder(tk.decoders.WordPiece.new())
|
||||
|
||||
if add_special_tokens:
|
||||
self._tokenizer.with_post_processor(
|
||||
tk.processors.BertProcessing.new(
|
||||
(sep_token, self._tokenizer.token_to_id(sep_token)),
|
||||
(cls_token, self._tokenizer.token_to_id(cls_token)),
|
||||
)
|
||||
)
|
||||
if max_length is not None:
|
||||
self._tokenizer.with_truncation(max_length, stride=stride, strategy=truncation_strategy)
|
||||
self._tokenizer.with_padding(
|
||||
max_length=max_length if pad_to_max_length else None,
|
||||
direction=self.padding_side,
|
||||
pad_id=self.pad_token_id,
|
||||
pad_type_id=self.pad_token_type_id,
|
||||
pad_token=self.pad_token,
|
||||
)
|
||||
self._decoder = tk.decoders.WordPiece.new()
|
||||
self.do_lower_case = do_lower_case
|
||||
|
||||
@@ -17,7 +17,7 @@
|
||||
|
||||
import logging
|
||||
|
||||
from .tokenization_bert import BertTokenizer
|
||||
from .tokenization_bert import BertTokenizer, BertTokenizerFast
|
||||
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
@@ -28,6 +28,8 @@ PRETRAINED_VOCAB_FILES_MAP = {
|
||||
"vocab_file": {
|
||||
"distilbert-base-uncased": "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-vocab.txt",
|
||||
"distilbert-base-uncased-distilled-squad": "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-uncased-vocab.txt",
|
||||
"distilbert-base-cased": "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-vocab.txt",
|
||||
"distilbert-base-cased-distilled-squad": "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-cased-vocab.txt",
|
||||
"distilbert-base-german-cased": "https://s3.amazonaws.com/models.huggingface.co/bert/distilbert-base-german-cased-vocab.txt",
|
||||
"distilbert-base-multilingual-cased": "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-cased-vocab.txt",
|
||||
}
|
||||
@@ -36,6 +38,8 @@ PRETRAINED_VOCAB_FILES_MAP = {
|
||||
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
|
||||
"distilbert-base-uncased": 512,
|
||||
"distilbert-base-uncased-distilled-squad": 512,
|
||||
"distilbert-base-cased": 512,
|
||||
"distilbert-base-cased-distilled-squad": 512,
|
||||
"distilbert-base-german-cased": 512,
|
||||
"distilbert-base-multilingual-cased": 512,
|
||||
}
|
||||
@@ -44,6 +48,8 @@ PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
|
||||
PRETRAINED_INIT_CONFIGURATION = {
|
||||
"distilbert-base-uncased": {"do_lower_case": True},
|
||||
"distilbert-base-uncased-distilled-squad": {"do_lower_case": True},
|
||||
"distilbert-base-cased": {"do_lower_case": False},
|
||||
"distilbert-base-cased-distilled-squad": {"do_lower_case": False},
|
||||
"distilbert-base-german-cased": {"do_lower_case": False},
|
||||
"distilbert-base-multilingual-cased": {"do_lower_case": False},
|
||||
}
|
||||
@@ -68,3 +74,10 @@ class DistilBertTokenizer(BertTokenizer):
|
||||
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
|
||||
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
|
||||
pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
|
||||
|
||||
|
||||
class DistilBertTokenizerFast(BertTokenizerFast):
|
||||
vocab_files_names = VOCAB_FILES_NAMES
|
||||
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
|
||||
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
|
||||
pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
|
||||
|
||||
@@ -21,7 +21,7 @@ import os
|
||||
from functools import lru_cache
|
||||
|
||||
import regex as re
|
||||
import tokenizers as tk
|
||||
from tokenizers import ByteLevelBPETokenizer
|
||||
|
||||
from .tokenization_utils import PreTrainedTokenizer, PreTrainedTokenizerFast
|
||||
|
||||
@@ -191,15 +191,8 @@ class GPT2Tokenizer(PreTrainedTokenizer):
|
||||
self.cache[token] = word
|
||||
return word
|
||||
|
||||
def _tokenize(self, text, add_prefix_space=False):
|
||||
""" Tokenize a string.
|
||||
Args:
|
||||
- add_prefix_space (boolean, default False):
|
||||
Begin the sentence with at least one space to get invariance to word order in GPT-2 (and RoBERTa) tokenizers.
|
||||
"""
|
||||
if add_prefix_space:
|
||||
text = " " + text
|
||||
|
||||
def _tokenize(self, text):
|
||||
""" Tokenize a string. """
|
||||
bpe_tokens = []
|
||||
for token in re.findall(self.pat, text):
|
||||
token = "".join(
|
||||
@@ -248,6 +241,11 @@ class GPT2Tokenizer(PreTrainedTokenizer):
|
||||
|
||||
return vocab_file, merge_file
|
||||
|
||||
def prepare_for_tokenization(self, text, **kwargs):
|
||||
if "add_prefix_space" in kwargs and kwargs["add_prefix_space"]:
|
||||
return " " + text
|
||||
return text
|
||||
|
||||
|
||||
class GPT2TokenizerFast(PreTrainedTokenizerFast):
|
||||
vocab_files_names = VOCAB_FILES_NAMES
|
||||
@@ -261,26 +259,19 @@ class GPT2TokenizerFast(PreTrainedTokenizerFast):
|
||||
unk_token="<|endoftext|>",
|
||||
bos_token="<|endoftext|>",
|
||||
eos_token="<|endoftext|>",
|
||||
pad_to_max_length=False,
|
||||
add_prefix_space=False,
|
||||
max_length=None,
|
||||
stride=0,
|
||||
truncation_strategy="longest_first",
|
||||
**kwargs
|
||||
):
|
||||
super().__init__(bos_token=bos_token, eos_token=eos_token, unk_token=unk_token, **kwargs)
|
||||
|
||||
self._tokenizer = tk.Tokenizer(tk.models.BPE.from_files(vocab_file, merges_file))
|
||||
self._update_special_tokens()
|
||||
self._tokenizer.with_pre_tokenizer(tk.pre_tokenizers.ByteLevel.new(add_prefix_space=add_prefix_space))
|
||||
self._tokenizer.with_decoder(tk.decoders.ByteLevel.new())
|
||||
if max_length:
|
||||
self._tokenizer.with_truncation(max_length, stride=stride, strategy=truncation_strategy)
|
||||
self._tokenizer.with_padding(
|
||||
max_length=max_length if pad_to_max_length else None,
|
||||
direction=self.padding_side,
|
||||
pad_id=self.pad_token_id if self.pad_token_id is not None else 0,
|
||||
pad_type_id=self.pad_token_type_id,
|
||||
pad_token=self.pad_token if self.pad_token is not None else "",
|
||||
super().__init__(
|
||||
ByteLevelBPETokenizer(vocab_file=vocab_file, merges_file=merges_file, add_prefix_space=add_prefix_space),
|
||||
bos_token=bos_token,
|
||||
eos_token=eos_token,
|
||||
unk_token=unk_token,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
logger.warning(
|
||||
"RobertaTokenizerFast has an issue when working on mask language modeling "
|
||||
"where it introduces an extra encoded space before the mask token."
|
||||
"See https://github.com/huggingface/transformers/pull/2778 for more information."
|
||||
)
|
||||
self._decoder = tk.decoders.ByteLevel.new()
|
||||
|
||||
@@ -19,9 +19,18 @@ import json
|
||||
import logging
|
||||
import os
|
||||
import re
|
||||
from typing import List, Optional, Union
|
||||
|
||||
from tokenizers import Tokenizer
|
||||
from tokenizers.decoders import BPEDecoder
|
||||
from tokenizers.implementations import BaseTokenizer
|
||||
from tokenizers.models import BPE
|
||||
from tokenizers.normalizers import BertNormalizer, Sequence, unicode_normalizer_from_str
|
||||
from tokenizers.pre_tokenizers import BertPreTokenizer
|
||||
from tokenizers.trainers import BpeTrainer
|
||||
|
||||
from .tokenization_bert import BasicTokenizer
|
||||
from .tokenization_utils import PreTrainedTokenizer
|
||||
from .tokenization_utils import PreTrainedTokenizer, PreTrainedTokenizerFast
|
||||
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
@@ -213,3 +222,93 @@ class OpenAIGPTTokenizer(PreTrainedTokenizer):
|
||||
index += 1
|
||||
|
||||
return vocab_file, merge_file
|
||||
|
||||
|
||||
class _OpenAIGPTCharBPETokenizer(BaseTokenizer):
|
||||
"""
|
||||
OpenAI character-level BPE Tokenizer
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
vocab_file: Optional[str] = None,
|
||||
merges_file: Optional[str] = None,
|
||||
unk_token: Optional[str] = "<unk>",
|
||||
suffix: Optional[str] = "</w>",
|
||||
dropout: Optional[float] = None,
|
||||
unicode_normalizer: Optional[str] = None,
|
||||
):
|
||||
if vocab_file is not None and merges_file is not None:
|
||||
tokenizer = Tokenizer(
|
||||
BPE.from_files(
|
||||
vocab_file, merges_file, dropout=dropout, unk_token=unk_token, end_of_word_suffix=suffix
|
||||
)
|
||||
)
|
||||
else:
|
||||
tokenizer = Tokenizer(BPE.empty())
|
||||
|
||||
# Check for Unicode normalization first (before everything else)
|
||||
normalizers = []
|
||||
|
||||
if unicode_normalizer:
|
||||
normalizers += [unicode_normalizer_from_str(unicode_normalizer)]
|
||||
|
||||
# OpenAI normalization is the same as Bert
|
||||
normalizers += [BertNormalizer()]
|
||||
|
||||
# Create the normalizer structure
|
||||
if len(normalizers) > 0:
|
||||
if len(normalizers) > 1:
|
||||
tokenizer.normalizer = Sequence(normalizers)
|
||||
else:
|
||||
tokenizer.normalizer = normalizers[0]
|
||||
|
||||
tokenizer.pre_tokenizer = BertPreTokenizer()
|
||||
tokenizer.decoder = BPEDecoder(suffix=suffix)
|
||||
|
||||
parameters = {
|
||||
"model": "BPE",
|
||||
"unk_token": unk_token,
|
||||
"suffix": suffix,
|
||||
"dropout": dropout,
|
||||
}
|
||||
|
||||
super().__init__(tokenizer, parameters)
|
||||
|
||||
def train(
|
||||
self,
|
||||
files: Union[str, List[str]],
|
||||
vocab_size: int = 30000,
|
||||
min_frequency: int = 2,
|
||||
special_tokens: List[str] = ["<unk>"],
|
||||
limit_alphabet: int = 1000,
|
||||
initial_alphabet: List[str] = [],
|
||||
suffix: Optional[str] = "</w>",
|
||||
show_progress: bool = True,
|
||||
):
|
||||
""" Train the model using the given files """
|
||||
|
||||
trainer = BpeTrainer(
|
||||
vocab_size=vocab_size,
|
||||
min_frequency=min_frequency,
|
||||
special_tokens=special_tokens,
|
||||
limit_alphabet=limit_alphabet,
|
||||
initial_alphabet=initial_alphabet,
|
||||
end_of_word_suffix=suffix,
|
||||
show_progress=show_progress,
|
||||
)
|
||||
if isinstance(files, str):
|
||||
files = [files]
|
||||
self._tokenizer.train(trainer, files)
|
||||
|
||||
|
||||
class OpenAIGPTTokenizerFast(PreTrainedTokenizerFast):
|
||||
vocab_files_names = VOCAB_FILES_NAMES
|
||||
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
|
||||
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
|
||||
|
||||
def __init__(self, vocab_file, merges_file, unk_token="<unk>", **kwargs):
|
||||
kwargs.setdefault("unk_token", unk_token)
|
||||
super().__init__(
|
||||
_OpenAIGPTCharBPETokenizer(vocab_file=vocab_file, merges_file=merges_file, unk_token=unk_token), **kwargs
|
||||
)
|
||||
|
||||
@@ -17,7 +17,9 @@
|
||||
|
||||
import logging
|
||||
|
||||
from .tokenization_gpt2 import GPT2Tokenizer
|
||||
from tokenizers.processors import RobertaProcessing
|
||||
|
||||
from .tokenization_gpt2 import GPT2Tokenizer, GPT2TokenizerFast
|
||||
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
@@ -154,3 +156,57 @@ class RobertaTokenizer(GPT2Tokenizer):
|
||||
if token_ids_1 is None:
|
||||
return len(cls + token_ids_0 + sep) * [0]
|
||||
return len(cls + token_ids_0 + sep + sep + token_ids_1 + sep) * [0]
|
||||
|
||||
def prepare_for_tokenization(self, text, add_special_tokens=False, **kwargs):
|
||||
if "add_prefix_space" in kwargs:
|
||||
add_prefix_space = kwargs["add_prefix_space"]
|
||||
else:
|
||||
add_prefix_space = add_special_tokens
|
||||
if add_prefix_space and not text[0].isspace():
|
||||
text = " " + text
|
||||
return text
|
||||
|
||||
|
||||
class RobertaTokenizerFast(GPT2TokenizerFast):
|
||||
vocab_files_names = VOCAB_FILES_NAMES
|
||||
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
|
||||
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
vocab_file,
|
||||
merges_file,
|
||||
errors="replace",
|
||||
bos_token="<s>",
|
||||
eos_token="</s>",
|
||||
sep_token="</s>",
|
||||
cls_token="<s>",
|
||||
unk_token="<unk>",
|
||||
pad_token="<pad>",
|
||||
mask_token="<mask>",
|
||||
add_prefix_space=False,
|
||||
**kwargs
|
||||
):
|
||||
kwargs.setdefault("pad_token", pad_token)
|
||||
kwargs.setdefault("sep_token", sep_token)
|
||||
kwargs.setdefault("cls_token", cls_token)
|
||||
kwargs.setdefault("mask_token", mask_token)
|
||||
|
||||
super().__init__(
|
||||
vocab_file=vocab_file,
|
||||
merges_file=merges_file,
|
||||
unk_token=unk_token,
|
||||
bos_token=bos_token,
|
||||
eos_token=eos_token,
|
||||
add_prefix_space=add_prefix_space,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
self.tokenizer._tokenizer.post_processor = RobertaProcessing(
|
||||
(sep_token, self.sep_token_id), (cls_token, self.cls_token_id)
|
||||
)
|
||||
|
||||
# As we override the post_processor post super.__init__ the computed num_added_tokens is wrong in super().
|
||||
# We need to recompute max_len according to the newly register post_processor to get real values.
|
||||
self.max_len_single_sentence = self.max_len - self.num_added_tokens(False) # take into account special tokens
|
||||
self.max_len_sentences_pair = self.max_len - self.num_added_tokens(True) # take into account special tokens
|
||||
|
||||
@@ -23,11 +23,18 @@ import logging
|
||||
import os
|
||||
import pickle
|
||||
from collections import Counter, OrderedDict
|
||||
from typing import List, Optional, Tuple, Union
|
||||
|
||||
import numpy as np
|
||||
from tokenizers import Encoding, Tokenizer
|
||||
from tokenizers.implementations import BaseTokenizer
|
||||
from tokenizers.models import WordLevel
|
||||
from tokenizers.normalizers import Lowercase, Sequence, unicode_normalizer_from_str
|
||||
from tokenizers.pre_tokenizers import CharDelimiterSplit, WhitespaceSplit
|
||||
from tokenizers.processors import BertProcessing
|
||||
|
||||
from .file_utils import cached_path, is_torch_available
|
||||
from .tokenization_utils import PreTrainedTokenizer
|
||||
from .tokenization_utils import PreTrainedTokenizer, PreTrainedTokenizerFast
|
||||
|
||||
|
||||
if is_torch_available():
|
||||
@@ -44,6 +51,12 @@ PRETRAINED_VOCAB_FILES_MAP = {
|
||||
}
|
||||
}
|
||||
|
||||
PRETRAINED_VOCAB_FILES_MAP_FAST = {
|
||||
"pretrained_vocab_file": {
|
||||
"transfo-xl-wt103": "https://s3.amazonaws.com/models.huggingface.co/bert/transfo-xl-wt103-vocab.json",
|
||||
}
|
||||
}
|
||||
|
||||
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
|
||||
"transfo-xl-wt103": None,
|
||||
}
|
||||
@@ -159,6 +172,8 @@ class TransfoXLTokenizer(PreTrainedTokenizer):
|
||||
"""Save the tokenizer vocabulary to a directory or file."""
|
||||
if os.path.isdir(vocab_path):
|
||||
vocab_file = os.path.join(vocab_path, VOCAB_FILES_NAMES["pretrained_vocab_file"])
|
||||
else:
|
||||
vocab_file = vocab_path
|
||||
torch.save(self.__dict__, vocab_file)
|
||||
return (vocab_file,)
|
||||
|
||||
@@ -278,6 +293,108 @@ class TransfoXLTokenizer(PreTrainedTokenizer):
|
||||
return symbols
|
||||
|
||||
|
||||
class _TransfoXLDelimiterLookupTokenizer(BaseTokenizer):
|
||||
def __init__(
|
||||
self,
|
||||
vocab_file,
|
||||
delimiter,
|
||||
lowercase,
|
||||
unk_token,
|
||||
eos_token,
|
||||
add_eos=False,
|
||||
add_double_eos=False,
|
||||
normalization: Optional[str] = None,
|
||||
):
|
||||
|
||||
tokenizer = WordLevel.from_files(vocab_file, unk_token=unk_token)
|
||||
tokenizer = Tokenizer(tokenizer)
|
||||
|
||||
# Create the correct normalization path
|
||||
normalizer = []
|
||||
|
||||
# Include unicode normalization
|
||||
if normalization:
|
||||
normalizer += [unicode_normalizer_from_str(normalization)]
|
||||
|
||||
# Include case normalization
|
||||
if lowercase:
|
||||
normalizer += [Lowercase()]
|
||||
|
||||
if len(normalizer) > 0:
|
||||
tokenizer.normalizer = Sequence(normalizer) if len(normalizer) > 1 else normalizer[0]
|
||||
|
||||
# Setup the splitter
|
||||
tokenizer.pre_tokenizer = CharDelimiterSplit(delimiter) if delimiter else WhitespaceSplit()
|
||||
|
||||
if add_double_eos:
|
||||
tokenizer.post_processor = BertProcessing(
|
||||
(eos_token, tokenizer.token_to_id(eos_token)), (eos_token, tokenizer.token_to_id(eos_token))
|
||||
)
|
||||
|
||||
parameters = {
|
||||
"model": "TransfoXLModel",
|
||||
"add_eos": add_eos,
|
||||
"add_double_eos": add_double_eos,
|
||||
"unk_token": unk_token,
|
||||
"eos_token": eos_token,
|
||||
"delimiter": delimiter,
|
||||
"lowercase": lowercase,
|
||||
}
|
||||
|
||||
super().__init__(tokenizer, parameters)
|
||||
|
||||
def encode_batch(self, sequences: List[Union[str, Tuple[str, str]]]) -> List[Encoding]:
|
||||
return super().encode_batch(
|
||||
[seq.strip() if isinstance(seq, str) else (seq[0].strip(), seq[1].strip()) for seq in sequences]
|
||||
)
|
||||
|
||||
def encode(self, sequence: str, pair: Optional[str] = None) -> Encoding:
|
||||
return super().encode(sequence.strip(), pair.strip() if pair else pair)
|
||||
|
||||
|
||||
class TransfoXLTokenizerFast(PreTrainedTokenizerFast):
|
||||
|
||||
vocab_files_names = VOCAB_FILES_NAMES
|
||||
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP_FAST
|
||||
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
special=None,
|
||||
min_freq=0,
|
||||
max_size=None,
|
||||
lower_case=False,
|
||||
delimiter=None,
|
||||
vocab_file=None,
|
||||
pretrained_vocab_file=None,
|
||||
never_split=None,
|
||||
unk_token="<unk>",
|
||||
eos_token="<eos>",
|
||||
additional_special_tokens=["<formula>"],
|
||||
add_eos=False,
|
||||
add_double_eos=False,
|
||||
normalization=None,
|
||||
**kwargs
|
||||
):
|
||||
|
||||
super().__init__(
|
||||
_TransfoXLDelimiterLookupTokenizer(
|
||||
vocab_file=vocab_file or pretrained_vocab_file,
|
||||
delimiter=delimiter,
|
||||
lowercase=lower_case,
|
||||
unk_token=unk_token,
|
||||
eos_token=eos_token,
|
||||
add_eos=add_eos,
|
||||
add_double_eos=add_double_eos,
|
||||
normalization=normalization,
|
||||
),
|
||||
unk_token=unk_token,
|
||||
eos_token=eos_token,
|
||||
additional_special_tokens=additional_special_tokens,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
|
||||
class LMOrderedIterator(object):
|
||||
def __init__(self, data, bsz, bptt, device="cpu", ext_len=None):
|
||||
"""
|
||||
|
||||
@@ -21,6 +21,10 @@ import json
|
||||
import logging
|
||||
import os
|
||||
import re
|
||||
from collections import defaultdict
|
||||
from contextlib import contextmanager
|
||||
|
||||
from tokenizers.implementations import BaseTokenizer
|
||||
|
||||
from .file_utils import cached_path, hf_bucket_url, is_remote_url, is_tf_available, is_torch_available
|
||||
|
||||
@@ -37,6 +41,68 @@ ADDED_TOKENS_FILE = "added_tokens.json"
|
||||
TOKENIZER_CONFIG_FILE = "tokenizer_config.json"
|
||||
|
||||
|
||||
@contextmanager
|
||||
def truncate_and_pad(
|
||||
tokenizer: BaseTokenizer,
|
||||
max_length: int,
|
||||
stride: int,
|
||||
strategy: str,
|
||||
pad_to_max_length: bool,
|
||||
padding_side: str,
|
||||
pad_token_id: int,
|
||||
pad_token_type_id: int,
|
||||
pad_token: str,
|
||||
):
|
||||
"""
|
||||
This contextmanager is in charge of defining the truncation and the padding strategies and then
|
||||
restore the tokenizer settings afterwards.
|
||||
|
||||
This contextmanager assumes the provider tokenizer has no padding / truncation strategy
|
||||
before the managed section. If your tokenizer set a padding / truncation strategy before,
|
||||
then it will be reset to no padding/truncation when exiting the managed section.
|
||||
|
||||
:param tokenizer:
|
||||
:param max_length:
|
||||
:param stride:
|
||||
:param strategy:
|
||||
:param pad_to_max_length:
|
||||
:param padding_side:
|
||||
:param pad_token_id:
|
||||
:param pad_token_type_id:
|
||||
:param pad_token:
|
||||
:return:
|
||||
"""
|
||||
|
||||
# Handle all the truncation and padding stuff
|
||||
if max_length is not None:
|
||||
tokenizer.enable_truncation(max_length, stride=stride, strategy=strategy)
|
||||
|
||||
if pad_to_max_length and (pad_token and pad_token_id >= 0):
|
||||
tokenizer.enable_padding(
|
||||
max_length=None,
|
||||
direction=padding_side,
|
||||
pad_id=pad_token_id,
|
||||
pad_type_id=pad_token_type_id,
|
||||
pad_token=pad_token,
|
||||
)
|
||||
else:
|
||||
logger.warning(
|
||||
"Disabled padding because no padding token set (pad_token: {}, pad_token_id: {}).\n"
|
||||
"To remove this error, you can add a new pad token and then resize model embedding:\n"
|
||||
"\ttokenizer.pad_token = '<PAD>'\n\tmodel.resize_token_embeddings(len(tokenizer))".format(
|
||||
pad_token, pad_token_id
|
||||
)
|
||||
)
|
||||
|
||||
yield
|
||||
|
||||
if max_length is not None:
|
||||
tokenizer.no_truncation()
|
||||
|
||||
if pad_to_max_length and (pad_token and pad_token_id >= 0):
|
||||
tokenizer.no_padding()
|
||||
|
||||
|
||||
class PreTrainedTokenizer(object):
|
||||
""" Base class for all tokenizers.
|
||||
Handle all the shared methods for tokenization and special tokens as well as methods downloading/caching/loading pretrained tokenizers as well as adding tokens to the vocabulary.
|
||||
@@ -542,7 +608,7 @@ class PreTrainedTokenizer(object):
|
||||
vocabulary, they are added to it with indices starting from length of the current vocabulary.
|
||||
|
||||
Args:
|
||||
new_tokens: list of string. Each string is a token to add. Tokens are only added if they are not already in the vocabulary (tested by checking if the tokenizer assign the index of the ``unk_token`` to them).
|
||||
new_tokens: string or list of string. Each string is a token to add. Tokens are only added if they are not already in the vocabulary (tested by checking if the tokenizer assign the index of the ``unk_token`` to them).
|
||||
|
||||
Returns:
|
||||
Number of tokens added to the vocabulary.
|
||||
@@ -560,6 +626,9 @@ class PreTrainedTokenizer(object):
|
||||
if not new_tokens:
|
||||
return 0
|
||||
|
||||
if not isinstance(new_tokens, list):
|
||||
new_tokens = [new_tokens]
|
||||
|
||||
to_add_tokens = []
|
||||
for token in new_tokens:
|
||||
assert isinstance(token, str)
|
||||
@@ -662,9 +731,12 @@ class PreTrainedTokenizer(object):
|
||||
Take care of added tokens.
|
||||
|
||||
text: The sequence to be encoded.
|
||||
**kwargs: passed to the child `self.tokenize()` method
|
||||
add_prefix_space: Only applies to GPT-2 and RoBERTa tokenizers. When `True`, this ensures that the sequence
|
||||
begins with an empty space. False by default except for when using RoBERTa with `add_special_tokens=True`.
|
||||
**kwargs: passed to the `prepare_for_tokenization` preprocessing method.
|
||||
"""
|
||||
all_special_tokens = self.all_special_tokens
|
||||
text = self.prepare_for_tokenization(text, **kwargs)
|
||||
|
||||
def lowercase_text(t):
|
||||
# convert non-special tokens to lowercase
|
||||
@@ -679,7 +751,7 @@ class PreTrainedTokenizer(object):
|
||||
result = []
|
||||
split_text = text.split(tok)
|
||||
for i, sub_text in enumerate(split_text):
|
||||
sub_text = sub_text.strip()
|
||||
sub_text = sub_text.rstrip()
|
||||
if i == 0 and not sub_text:
|
||||
result += [tok]
|
||||
elif i == len(split_text) - 1:
|
||||
@@ -697,7 +769,7 @@ class PreTrainedTokenizer(object):
|
||||
if not text.strip():
|
||||
return []
|
||||
if not tok_list:
|
||||
return self._tokenize(text, **kwargs)
|
||||
return self._tokenize(text)
|
||||
|
||||
tokenized_text = []
|
||||
text_list = [text]
|
||||
@@ -713,7 +785,7 @@ class PreTrainedTokenizer(object):
|
||||
return list(
|
||||
itertools.chain.from_iterable(
|
||||
(
|
||||
self._tokenize(token, **kwargs) if token not in self.unique_added_tokens_encoder else [token]
|
||||
self._tokenize(token) if token not in self.unique_added_tokens_encoder else [token]
|
||||
for token in tokenized_text
|
||||
)
|
||||
)
|
||||
@@ -802,6 +874,8 @@ class PreTrainedTokenizer(object):
|
||||
Defaults to False: no padding.
|
||||
return_tensors: (optional) can be set to 'tf' or 'pt' to return respectively TensorFlow tf.constant
|
||||
or PyTorch torch.Tensor instead of a list of python integers.
|
||||
add_prefix_space: Only applies to GPT-2 and RoBERTa tokenizers. When `True`, this ensures that the sequence
|
||||
begins with an empty space. False by default except for when using RoBERTa with `add_special_tokens=True`.
|
||||
**kwargs: passed to the `self.tokenize()` method
|
||||
"""
|
||||
encoded_inputs = self.encode_plus(
|
||||
@@ -832,6 +906,7 @@ class PreTrainedTokenizer(object):
|
||||
return_attention_mask=True,
|
||||
return_overflowing_tokens=False,
|
||||
return_special_tokens_mask=False,
|
||||
return_offsets_mapping=False,
|
||||
**kwargs
|
||||
):
|
||||
"""
|
||||
@@ -865,10 +940,15 @@ class PreTrainedTokenizer(object):
|
||||
Defaults to False: no padding.
|
||||
return_tensors: (optional) can be set to 'tf' or 'pt' to return respectively TensorFlow tf.constant
|
||||
or PyTorch torch.Tensor instead of a list of python integers.
|
||||
add_prefix_space: Only applies to GPT-2 and RoBERTa tokenizers. When `True`, this ensures that the sequence
|
||||
begins with an empty space. False by default except for when using RoBERTa with `add_special_tokens=True`.
|
||||
return_token_type_ids: (optional) Set to False to avoid returning token_type_ids (default True).
|
||||
return_attention_mask: (optional) Set to False to avoid returning attention mask (default True)
|
||||
return_overflowing_tokens: (optional) Set to True to return overflowing token information (default False).
|
||||
return_special_tokens_mask: (optional) Set to True to return special tokens mask information (default False).
|
||||
return_offsets_mapping: (optional) Set to True to return (char_start, char_end) for each token (default False).
|
||||
If using Python's tokenizer, this method will raise NotImplementedError. This one is only available on
|
||||
Rust-based tokenizers inheriting from PreTrainedTokenizerFast.
|
||||
**kwargs: passed to the `self.tokenize()` method
|
||||
|
||||
Return:
|
||||
@@ -895,7 +975,8 @@ class PreTrainedTokenizer(object):
|
||||
|
||||
def get_input_ids(text):
|
||||
if isinstance(text, str):
|
||||
return self.convert_tokens_to_ids(self.tokenize(text, **kwargs))
|
||||
tokens = self.tokenize(text, add_special_tokens=add_special_tokens, **kwargs)
|
||||
return self.convert_tokens_to_ids(tokens)
|
||||
elif isinstance(text, (list, tuple)) and len(text) > 0 and isinstance(text[0], str):
|
||||
return self.convert_tokens_to_ids(text)
|
||||
elif isinstance(text, (list, tuple)) and len(text) > 0 and isinstance(text[0], int):
|
||||
@@ -905,6 +986,15 @@ class PreTrainedTokenizer(object):
|
||||
"Input is not valid. Should be a string, a list/tuple of strings or a list/tuple of integers."
|
||||
)
|
||||
|
||||
if return_offsets_mapping:
|
||||
raise NotImplementedError(
|
||||
"return_offset_mapping is not available when using Python tokenizers."
|
||||
"To use this feature, change your tokenizer to one deriving from "
|
||||
"transformers.PreTrainedTokenizerFast."
|
||||
"More information on available tokenizers at "
|
||||
"https://github.com/huggingface/transformers/pull/2674"
|
||||
)
|
||||
|
||||
first_ids = get_input_ids(text)
|
||||
second_ids = get_input_ids(text_pair) if text_pair is not None else None
|
||||
|
||||
@@ -933,6 +1023,7 @@ class PreTrainedTokenizer(object):
|
||||
return_tensors=None,
|
||||
return_input_lengths=False,
|
||||
return_attention_masks=False,
|
||||
return_offsets_mapping=False,
|
||||
**kwargs
|
||||
):
|
||||
"""
|
||||
@@ -957,8 +1048,21 @@ class PreTrainedTokenizer(object):
|
||||
- 'do_not_truncate': Does not truncate (raise an error if the input sequence is longer than max_length)
|
||||
return_tensors: (optional) can be set to 'tf' or 'pt' to return respectively TensorFlow tf.constant
|
||||
or PyTorch torch.Tensor instead of a list of python integers.
|
||||
return_input_lengths: (optional) If set the resulting dictionary will include the length of each sample
|
||||
return_attention_masks: (optional) Set to True to return the attention mask (default False)
|
||||
return_offsets_mapping: (optional) Not available, should be set to False or it will throw NotImplementError
|
||||
**kwargs: passed to the `self.tokenize()` method
|
||||
"""
|
||||
|
||||
if return_offsets_mapping:
|
||||
raise NotImplementedError(
|
||||
"return_offset_mapping is not available when using Python tokenizers."
|
||||
"To use this feature, change your tokenizer to one deriving from "
|
||||
"transformers.PreTrainedTokenizerFast."
|
||||
"More information on available tokenizers at "
|
||||
"https://github.com/huggingface/transformers/pull/2674"
|
||||
)
|
||||
|
||||
batch_outputs = {}
|
||||
for ids_or_pair_ids in batch_text_or_text_pairs:
|
||||
if isinstance(ids_or_pair_ids, (list, tuple)):
|
||||
@@ -1215,6 +1319,10 @@ class PreTrainedTokenizer(object):
|
||||
|
||||
return encoded_inputs
|
||||
|
||||
def prepare_for_tokenization(self, text, **kwargs):
|
||||
""" Performs any necessary transformations before tokenization """
|
||||
return text
|
||||
|
||||
def truncate_sequences(
|
||||
self, ids, pair_ids=None, num_tokens_to_remove=0, truncation_strategy="longest_first", stride=0
|
||||
):
|
||||
@@ -1418,30 +1526,29 @@ class PreTrainedTokenizer(object):
|
||||
|
||||
|
||||
class PreTrainedTokenizerFast(PreTrainedTokenizer):
|
||||
_tokenizer = None
|
||||
_decoder = None
|
||||
def __init__(self, tokenizer: BaseTokenizer, **kwargs):
|
||||
if tokenizer is None:
|
||||
raise ValueError("Provided tokenizer cannot be None")
|
||||
self._tokenizer = tokenizer
|
||||
|
||||
def __init__(self, **kwargs):
|
||||
super().__init__(**kwargs)
|
||||
self.max_len_single_sentence = self.max_len - self.num_added_tokens(False) # take into account special tokens
|
||||
self.max_len_sentences_pair = self.max_len - self.num_added_tokens(True) # take into account special tokens
|
||||
|
||||
@property
|
||||
def tokenizer(self):
|
||||
if self._tokenizer is None:
|
||||
raise NotImplementedError
|
||||
return self._tokenizer
|
||||
|
||||
@property
|
||||
def decoder(self):
|
||||
if self._decoder is None:
|
||||
raise NotImplementedError
|
||||
return self._decoder
|
||||
return self._tokenizer._tokenizer.decoder
|
||||
|
||||
@property
|
||||
def vocab_size(self):
|
||||
return self.tokenizer.get_vocab_size(with_added_tokens=False)
|
||||
return self._tokenizer.get_vocab_size(with_added_tokens=False)
|
||||
|
||||
def __len__(self):
|
||||
return self.tokenizer.get_vocab_size(with_added_tokens=True)
|
||||
return self._tokenizer.get_vocab_size(with_added_tokens=True)
|
||||
|
||||
@PreTrainedTokenizer.bos_token.setter
|
||||
def bos_token(self, value):
|
||||
@@ -1495,36 +1602,42 @@ class PreTrainedTokenizerFast(PreTrainedTokenizer):
|
||||
return_attention_mask=True,
|
||||
return_overflowing_tokens=False,
|
||||
return_special_tokens_mask=False,
|
||||
return_offsets_mapping=False,
|
||||
):
|
||||
encoding_dict = {
|
||||
"input_ids": encoding.ids,
|
||||
}
|
||||
if return_token_type_ids:
|
||||
encoding_dict["token_type_ids"] = encoding.type_ids
|
||||
if return_attention_mask:
|
||||
encoding_dict["attention_mask"] = encoding.attention_mask
|
||||
if return_overflowing_tokens:
|
||||
overflowing = encoding.overflowing
|
||||
encoding_dict["overflowing_tokens"] = overflowing.ids if overflowing is not None else []
|
||||
if return_special_tokens_mask:
|
||||
encoding_dict["special_tokens_mask"] = encoding.special_tokens_mask
|
||||
if return_overflowing_tokens and encoding.overflowing is not None:
|
||||
encodings = [encoding] + encoding.overflowing
|
||||
else:
|
||||
encodings = [encoding]
|
||||
|
||||
encoding_dict = defaultdict(list)
|
||||
for e in encodings:
|
||||
encoding_dict["input_ids"].append(e.ids)
|
||||
|
||||
if return_token_type_ids:
|
||||
encoding_dict["token_type_ids"].append(e.type_ids)
|
||||
if return_attention_mask:
|
||||
encoding_dict["attention_mask"].append(e.attention_mask)
|
||||
if return_special_tokens_mask:
|
||||
encoding_dict["special_tokens_mask"].append(e.special_tokens_mask)
|
||||
if return_offsets_mapping:
|
||||
encoding_dict["offset_mapping"].append([e.original_str.offsets(o) for o in e.offsets])
|
||||
|
||||
# Prepare inputs as tensors if asked
|
||||
if return_tensors == "tf" and is_tf_available():
|
||||
encoding_dict["input_ids"] = tf.constant([encoding_dict["input_ids"]])
|
||||
encoding_dict["input_ids"] = tf.constant(encoding_dict["input_ids"])
|
||||
if "token_type_ids" in encoding_dict:
|
||||
encoding_dict["token_type_ids"] = tf.constant([encoding_dict["token_type_ids"]])
|
||||
encoding_dict["token_type_ids"] = tf.constant(encoding_dict["token_type_ids"])
|
||||
|
||||
if "attention_mask" in encoding_dict:
|
||||
encoding_dict["attention_mask"] = tf.constant([encoding_dict["attention_mask"]])
|
||||
encoding_dict["attention_mask"] = tf.constant(encoding_dict["attention_mask"])
|
||||
|
||||
elif return_tensors == "pt" and is_torch_available():
|
||||
encoding_dict["input_ids"] = torch.tensor([encoding_dict["input_ids"]])
|
||||
encoding_dict["input_ids"] = torch.tensor(encoding_dict["input_ids"])
|
||||
if "token_type_ids" in encoding_dict:
|
||||
encoding_dict["token_type_ids"] = torch.tensor([encoding_dict["token_type_ids"]])
|
||||
encoding_dict["token_type_ids"] = torch.tensor(encoding_dict["token_type_ids"])
|
||||
|
||||
if "attention_mask" in encoding_dict:
|
||||
encoding_dict["attention_mask"] = torch.tensor([encoding_dict["attention_mask"]])
|
||||
encoding_dict["attention_mask"] = torch.tensor(encoding_dict["attention_mask"])
|
||||
elif return_tensors is not None:
|
||||
logger.warning(
|
||||
"Unable to convert output to tensors format {}, PyTorch or TensorFlow is not available.".format(
|
||||
@@ -1534,71 +1647,161 @@ class PreTrainedTokenizerFast(PreTrainedTokenizer):
|
||||
|
||||
return encoding_dict
|
||||
|
||||
def encode_plus(
|
||||
self,
|
||||
text,
|
||||
text_pair=None,
|
||||
return_tensors=None,
|
||||
return_token_type_ids=True,
|
||||
return_attention_mask=True,
|
||||
return_overflowing_tokens=False,
|
||||
return_special_tokens_mask=False,
|
||||
**kwargs
|
||||
):
|
||||
encoding = self.tokenizer.encode(text, text_pair)
|
||||
return self._convert_encoding(
|
||||
encoding,
|
||||
return_tensors=return_tensors,
|
||||
return_token_type_ids=return_token_type_ids,
|
||||
return_attention_mask=return_attention_mask,
|
||||
return_overflowing_tokens=return_overflowing_tokens,
|
||||
return_special_tokens_mask=return_special_tokens_mask,
|
||||
)
|
||||
|
||||
def tokenize(self, text):
|
||||
return self.tokenizer.encode(text).tokens
|
||||
|
||||
def _convert_token_to_id_with_added_voc(self, token):
|
||||
id = self.tokenizer.token_to_id(token)
|
||||
id = self._tokenizer.token_to_id(token)
|
||||
if id is None:
|
||||
return self.unk_token_id
|
||||
return id
|
||||
|
||||
def _convert_id_to_token(self, index):
|
||||
return self.tokenizer.id_to_token(int(index))
|
||||
return self._tokenizer.id_to_token(int(index))
|
||||
|
||||
def convert_tokens_to_string(self, tokens):
|
||||
return self.decoder.decode(tokens)
|
||||
return self._tokenizer.decode(tokens)
|
||||
|
||||
def add_tokens(self, new_tokens):
|
||||
self.tokenizer.add_tokens(new_tokens)
|
||||
if isinstance(new_tokens, str):
|
||||
new_tokens = [new_tokens]
|
||||
return self._tokenizer.add_tokens(new_tokens)
|
||||
|
||||
def add_special_tokens(self, special_tokens_dict):
|
||||
added = super().add_special_tokens(special_tokens_dict)
|
||||
self._update_special_tokens()
|
||||
return added
|
||||
|
||||
def encode_batch(
|
||||
def num_added_tokens(self, pair=False):
|
||||
return self.tokenizer.num_special_tokens_to_add(pair)
|
||||
|
||||
def tokenize(self, text, **kwargs):
|
||||
return self.tokenizer.encode(text).tokens
|
||||
|
||||
def batch_encode_plus(
|
||||
self,
|
||||
texts,
|
||||
batch_text_or_text_pairs=None,
|
||||
add_special_tokens=True,
|
||||
max_length=None,
|
||||
stride=0,
|
||||
truncation_strategy="longest_first",
|
||||
pad_to_max_length=False,
|
||||
return_tensors=None,
|
||||
return_token_type_ids=True,
|
||||
return_attention_mask=True,
|
||||
return_overflowing_tokens=False,
|
||||
return_special_tokens_mask=False,
|
||||
return_offsets_mapping=False,
|
||||
**kwargs
|
||||
):
|
||||
return [
|
||||
# Needed if we have to return a tensor
|
||||
pad_to_max_length = pad_to_max_length or (return_tensors is not None)
|
||||
|
||||
# Throw an error if we can pad because there is no padding token
|
||||
if pad_to_max_length and self.pad_token_id is None:
|
||||
raise ValueError("Unable to set proper padding strategy as the tokenizer does have padding token")
|
||||
|
||||
# Set the truncation and padding strategy and restore the initial configuration
|
||||
with truncate_and_pad(
|
||||
tokenizer=self._tokenizer,
|
||||
max_length=max_length,
|
||||
stride=stride,
|
||||
strategy=truncation_strategy,
|
||||
pad_to_max_length=pad_to_max_length,
|
||||
padding_side=self.padding_side,
|
||||
pad_token_id=self.pad_token_id,
|
||||
pad_token_type_id=self.pad_token_type_id,
|
||||
pad_token=self._pad_token,
|
||||
):
|
||||
|
||||
if not isinstance(batch_text_or_text_pairs, list):
|
||||
raise TypeError(
|
||||
"batch_text_or_text_pairs has to be a list (got {})".format(type(batch_text_or_text_pairs))
|
||||
)
|
||||
|
||||
# Avoid thread overhead if only one example.
|
||||
if len(batch_text_or_text_pairs) == 1:
|
||||
if isinstance(batch_text_or_text_pairs[0], (tuple, list)):
|
||||
tokens = self._tokenizer.encode(*batch_text_or_text_pairs[0])
|
||||
else:
|
||||
tokens = self._tokenizer.encode(batch_text_or_text_pairs[0])
|
||||
tokens = [tokens]
|
||||
else:
|
||||
tokens = self._tokenizer.encode_batch(batch_text_or_text_pairs)
|
||||
|
||||
# Convert encoding to dict
|
||||
tokens = [
|
||||
self._convert_encoding(
|
||||
encoding,
|
||||
encoding=encoding,
|
||||
return_tensors=return_tensors,
|
||||
return_token_type_ids=return_token_type_ids,
|
||||
return_attention_mask=return_attention_mask,
|
||||
return_overflowing_tokens=return_overflowing_tokens,
|
||||
return_special_tokens_mask=return_special_tokens_mask,
|
||||
return_offsets_mapping=return_offsets_mapping,
|
||||
)
|
||||
for encoding in self.tokenizer.encode_batch(texts)
|
||||
for encoding in tokens
|
||||
]
|
||||
|
||||
# Sanitize the output to have dict[list] from list[dict]
|
||||
sanitized = {}
|
||||
for key in tokens[0].keys():
|
||||
stack = [e for item in tokens for e in item[key]]
|
||||
if return_tensors == "tf":
|
||||
stack = tf.stack(stack, axis=0)
|
||||
elif return_tensors == "pt":
|
||||
stack = torch.stack(stack, dim=0)
|
||||
elif not return_tensors and len(stack) == 1:
|
||||
stack = stack[0]
|
||||
|
||||
sanitized[key] = stack
|
||||
|
||||
# If returning overflowing tokens, we need to return a mapping
|
||||
# from the batch idx to the original sample
|
||||
if return_overflowing_tokens:
|
||||
overflow_to_sample_mapping = [
|
||||
i if len(item["input_ids"]) == 1 else [i] * len(item["input_ids"]) for i, item in enumerate(tokens)
|
||||
]
|
||||
sanitized["overflow_to_sample_mapping"] = overflow_to_sample_mapping
|
||||
return sanitized
|
||||
|
||||
def encode_plus(
|
||||
self,
|
||||
text,
|
||||
text_pair=None,
|
||||
add_special_tokens=False,
|
||||
max_length=None,
|
||||
pad_to_max_length=False,
|
||||
stride=0,
|
||||
truncation_strategy="longest_first",
|
||||
return_tensors=None,
|
||||
return_token_type_ids=True,
|
||||
return_attention_mask=True,
|
||||
return_overflowing_tokens=False,
|
||||
return_special_tokens_mask=False,
|
||||
return_offsets_mapping=False,
|
||||
**kwargs
|
||||
):
|
||||
batched_input = [(text, text_pair)] if text_pair else [text]
|
||||
batched_output = self.batch_encode_plus(
|
||||
batched_input,
|
||||
add_special_tokens=add_special_tokens,
|
||||
max_length=max_length,
|
||||
stride=stride,
|
||||
truncation_strategy=truncation_strategy,
|
||||
return_tensors=return_tensors,
|
||||
return_token_type_ids=return_token_type_ids,
|
||||
return_attention_mask=return_attention_mask,
|
||||
return_overflowing_tokens=return_overflowing_tokens,
|
||||
return_special_tokens_mask=return_special_tokens_mask,
|
||||
return_offsets_mapping=return_offsets_mapping,
|
||||
pad_to_max_length=pad_to_max_length,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
# Return tensor is None, then we can remove the leading batch axis
|
||||
if not return_tensors:
|
||||
return {key: value[0] if isinstance(value[0], list) else value for key, value in batched_output.items()}
|
||||
else:
|
||||
return batched_output
|
||||
|
||||
def decode(self, token_ids, skip_special_tokens=False, clean_up_tokenization_spaces=True):
|
||||
text = self.tokenizer.decode(token_ids, skip_special_tokens)
|
||||
|
||||
@@ -1608,8 +1811,9 @@ class PreTrainedTokenizerFast(PreTrainedTokenizer):
|
||||
else:
|
||||
return text
|
||||
|
||||
def decode_batch(self, ids_batch, skip_special_tokens=False, clear_up_tokenization_spaces=True):
|
||||
return [
|
||||
self.clean_up_tokenization(text) if clear_up_tokenization_spaces else text
|
||||
for text in self.tokenizer.decode_batch(ids_batch, skip_special_tokens)
|
||||
]
|
||||
def save_vocabulary(self, save_directory):
|
||||
if os.path.isdir(save_directory):
|
||||
folder, file = save_directory, self.vocab_files_names["vocab_file"]
|
||||
else:
|
||||
folder, file = os.path.split(os.path.abspath(save_directory))
|
||||
self._tokenizer.save(folder, file)
|
||||
|
||||
@@ -76,7 +76,10 @@ def load_tf_weights_in_xxx(model, config, tf_checkpoint_path):
|
||||
name = name.split("/")
|
||||
# adam_v and adam_m are variables used in AdamWeightDecayOptimizer to calculated m and v
|
||||
# which are not required for using pretrained model
|
||||
if any(n in ["adam_v", "adam_m", "global_step"] for n in name):
|
||||
if any(
|
||||
n in ["adam_v", "adam_m", "AdamWeightDecayOptimizer", "AdamWeightDecayOptimizer_1", "global_step"]
|
||||
for n in name
|
||||
):
|
||||
logger.info("Skipping {}".format("/".join(name)))
|
||||
continue
|
||||
pointer = model
|
||||
|
||||
28
tests/test_activations.py
Normal file
28
tests/test_activations.py
Normal file
@@ -0,0 +1,28 @@
|
||||
import unittest
|
||||
|
||||
from transformers import is_torch_available
|
||||
|
||||
from .utils import require_torch
|
||||
|
||||
|
||||
if is_torch_available():
|
||||
from transformers.activations import _gelu_python, get_activation, gelu_new
|
||||
import torch
|
||||
|
||||
|
||||
@require_torch
|
||||
class TestActivations(unittest.TestCase):
|
||||
def test_gelu_versions(self):
|
||||
x = torch.Tensor([-100, -1, -0.1, 0, 0.1, 1.0, 100])
|
||||
torch_builtin = get_activation("gelu")
|
||||
self.assertTrue(torch.eq(_gelu_python(x), torch_builtin(x)).all().item())
|
||||
self.assertFalse(torch.eq(_gelu_python(x), gelu_new(x)).all().item())
|
||||
|
||||
def test_get_activation(self):
|
||||
get_activation("swish")
|
||||
get_activation("relu")
|
||||
get_activation("tanh")
|
||||
with self.assertRaises(KeyError):
|
||||
get_activation("bogus")
|
||||
with self.assertRaises(KeyError):
|
||||
get_activation(None)
|
||||
@@ -438,6 +438,34 @@ class BertModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
|
||||
self.model_tester.create_and_check_bert_model_as_decoder(*config_and_inputs)
|
||||
|
||||
def test_bert_model_as_decoder_with_default_input_mask(self):
|
||||
# This regression test was failing with PyTorch < 1.3
|
||||
(
|
||||
config,
|
||||
input_ids,
|
||||
token_type_ids,
|
||||
input_mask,
|
||||
sequence_labels,
|
||||
token_labels,
|
||||
choice_labels,
|
||||
encoder_hidden_states,
|
||||
encoder_attention_mask,
|
||||
) = self.model_tester.prepare_config_and_inputs_for_decoder()
|
||||
|
||||
input_mask = None
|
||||
|
||||
self.model_tester.create_and_check_bert_model_as_decoder(
|
||||
config,
|
||||
input_ids,
|
||||
token_type_ids,
|
||||
input_mask,
|
||||
sequence_labels,
|
||||
token_labels,
|
||||
choice_labels,
|
||||
encoder_hidden_states,
|
||||
encoder_attention_mask,
|
||||
)
|
||||
|
||||
def test_for_masked_lm(self):
|
||||
config_and_inputs = self.model_tester.prepare_config_and_inputs()
|
||||
self.model_tester.create_and_check_bert_for_masked_lm(*config_and_inputs)
|
||||
|
||||
@@ -117,23 +117,11 @@ class ModelTesterMixin:
|
||||
|
||||
def test_attention_outputs(self):
|
||||
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
|
||||
|
||||
decoder_seq_length = (
|
||||
self.model_tester.decoder_seq_length
|
||||
if hasattr(self.model_tester, "decoder_seq_length")
|
||||
else self.model_tester.seq_length
|
||||
)
|
||||
encoder_seq_length = (
|
||||
self.model_tester.encoder_seq_length
|
||||
if hasattr(self.model_tester, "encoder_seq_length")
|
||||
else self.model_tester.seq_length
|
||||
)
|
||||
decoder_key_length = (
|
||||
self.model_tester.key_length if hasattr(self.model_tester, "key_length") else decoder_seq_length
|
||||
)
|
||||
encoder_key_length = (
|
||||
self.model_tester.key_length if hasattr(self.model_tester, "key_length") else encoder_seq_length
|
||||
)
|
||||
seq_len = getattr(self.model_tester, "seq_length", None)
|
||||
decoder_seq_length = getattr(self.model_tester, "decoder_seq_length", seq_len)
|
||||
encoder_seq_length = getattr(self.model_tester, "encoder_seq_length", seq_len)
|
||||
decoder_key_length = getattr(self.model_tester, "key_length", decoder_seq_length)
|
||||
encoder_key_length = getattr(self.model_tester, "key_length", encoder_seq_length)
|
||||
|
||||
for model_class in self.all_model_classes:
|
||||
config.output_attentions = True
|
||||
|
||||
392
tests/test_modeling_flaubert.py
Normal file
392
tests/test_modeling_flaubert.py
Normal file
@@ -0,0 +1,392 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2018 The Google AI Language Team Authors.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
|
||||
import unittest
|
||||
|
||||
from transformers import is_torch_available
|
||||
|
||||
from .test_configuration_common import ConfigTester
|
||||
from .test_modeling_common import ModelTesterMixin, ids_tensor
|
||||
from .utils import CACHE_DIR, require_torch, slow, torch_device
|
||||
|
||||
|
||||
if is_torch_available():
|
||||
from transformers import (
|
||||
FlaubertConfig,
|
||||
FlaubertModel,
|
||||
FlaubertWithLMHeadModel,
|
||||
FlaubertForQuestionAnswering,
|
||||
FlaubertForQuestionAnsweringSimple,
|
||||
FlaubertForSequenceClassification,
|
||||
)
|
||||
from transformers.modeling_flaubert import FLAUBERT_PRETRAINED_MODEL_ARCHIVE_MAP
|
||||
|
||||
|
||||
@require_torch
|
||||
class FlaubertModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
|
||||
all_model_classes = (
|
||||
(
|
||||
FlaubertModel,
|
||||
FlaubertWithLMHeadModel,
|
||||
FlaubertForQuestionAnswering,
|
||||
FlaubertForQuestionAnsweringSimple,
|
||||
FlaubertForSequenceClassification,
|
||||
)
|
||||
if is_torch_available()
|
||||
else ()
|
||||
)
|
||||
|
||||
class FlaubertModelTester(object):
|
||||
def __init__(
|
||||
self,
|
||||
parent,
|
||||
batch_size=13,
|
||||
seq_length=7,
|
||||
is_training=True,
|
||||
use_input_lengths=True,
|
||||
use_token_type_ids=True,
|
||||
use_labels=True,
|
||||
gelu_activation=True,
|
||||
sinusoidal_embeddings=False,
|
||||
causal=False,
|
||||
asm=False,
|
||||
n_langs=2,
|
||||
vocab_size=99,
|
||||
n_special=0,
|
||||
hidden_size=32,
|
||||
num_hidden_layers=5,
|
||||
num_attention_heads=4,
|
||||
hidden_dropout_prob=0.1,
|
||||
attention_probs_dropout_prob=0.1,
|
||||
max_position_embeddings=512,
|
||||
type_vocab_size=16,
|
||||
type_sequence_label_size=2,
|
||||
initializer_range=0.02,
|
||||
num_labels=3,
|
||||
num_choices=4,
|
||||
summary_type="last",
|
||||
use_proj=True,
|
||||
scope=None,
|
||||
):
|
||||
self.parent = parent
|
||||
self.batch_size = batch_size
|
||||
self.seq_length = seq_length
|
||||
self.is_training = is_training
|
||||
self.use_input_lengths = use_input_lengths
|
||||
self.use_token_type_ids = use_token_type_ids
|
||||
self.use_labels = use_labels
|
||||
self.gelu_activation = gelu_activation
|
||||
self.sinusoidal_embeddings = sinusoidal_embeddings
|
||||
self.asm = asm
|
||||
self.n_langs = n_langs
|
||||
self.vocab_size = vocab_size
|
||||
self.n_special = n_special
|
||||
self.summary_type = summary_type
|
||||
self.causal = causal
|
||||
self.use_proj = use_proj
|
||||
self.hidden_size = hidden_size
|
||||
self.num_hidden_layers = num_hidden_layers
|
||||
self.num_attention_heads = num_attention_heads
|
||||
self.hidden_dropout_prob = hidden_dropout_prob
|
||||
self.attention_probs_dropout_prob = attention_probs_dropout_prob
|
||||
self.max_position_embeddings = max_position_embeddings
|
||||
self.n_langs = n_langs
|
||||
self.type_sequence_label_size = type_sequence_label_size
|
||||
self.initializer_range = initializer_range
|
||||
self.summary_type = summary_type
|
||||
self.num_labels = num_labels
|
||||
self.num_choices = num_choices
|
||||
self.scope = scope
|
||||
|
||||
def prepare_config_and_inputs(self):
|
||||
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
|
||||
input_mask = ids_tensor([self.batch_size, self.seq_length], 2).float()
|
||||
|
||||
input_lengths = None
|
||||
if self.use_input_lengths:
|
||||
input_lengths = (
|
||||
ids_tensor([self.batch_size], vocab_size=2) + self.seq_length - 2
|
||||
) # small variation of seq_length
|
||||
|
||||
token_type_ids = None
|
||||
if self.use_token_type_ids:
|
||||
token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.n_langs)
|
||||
|
||||
sequence_labels = None
|
||||
token_labels = None
|
||||
is_impossible_labels = None
|
||||
if self.use_labels:
|
||||
sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
|
||||
token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
|
||||
is_impossible_labels = ids_tensor([self.batch_size], 2).float()
|
||||
|
||||
config = FlaubertConfig(
|
||||
vocab_size=self.vocab_size,
|
||||
n_special=self.n_special,
|
||||
emb_dim=self.hidden_size,
|
||||
n_layers=self.num_hidden_layers,
|
||||
n_heads=self.num_attention_heads,
|
||||
dropout=self.hidden_dropout_prob,
|
||||
attention_dropout=self.attention_probs_dropout_prob,
|
||||
gelu_activation=self.gelu_activation,
|
||||
sinusoidal_embeddings=self.sinusoidal_embeddings,
|
||||
asm=self.asm,
|
||||
causal=self.causal,
|
||||
n_langs=self.n_langs,
|
||||
max_position_embeddings=self.max_position_embeddings,
|
||||
initializer_range=self.initializer_range,
|
||||
summary_type=self.summary_type,
|
||||
use_proj=self.use_proj,
|
||||
)
|
||||
|
||||
return (
|
||||
config,
|
||||
input_ids,
|
||||
token_type_ids,
|
||||
input_lengths,
|
||||
sequence_labels,
|
||||
token_labels,
|
||||
is_impossible_labels,
|
||||
input_mask,
|
||||
)
|
||||
|
||||
def check_loss_output(self, result):
|
||||
self.parent.assertListEqual(list(result["loss"].size()), [])
|
||||
|
||||
def create_and_check_flaubert_model(
|
||||
self,
|
||||
config,
|
||||
input_ids,
|
||||
token_type_ids,
|
||||
input_lengths,
|
||||
sequence_labels,
|
||||
token_labels,
|
||||
is_impossible_labels,
|
||||
input_mask,
|
||||
):
|
||||
model = FlaubertModel(config=config)
|
||||
model.to(torch_device)
|
||||
model.eval()
|
||||
outputs = model(input_ids, lengths=input_lengths, langs=token_type_ids)
|
||||
outputs = model(input_ids, langs=token_type_ids)
|
||||
outputs = model(input_ids)
|
||||
sequence_output = outputs[0]
|
||||
result = {
|
||||
"sequence_output": sequence_output,
|
||||
}
|
||||
self.parent.assertListEqual(
|
||||
list(result["sequence_output"].size()), [self.batch_size, self.seq_length, self.hidden_size]
|
||||
)
|
||||
|
||||
def create_and_check_flaubert_lm_head(
|
||||
self,
|
||||
config,
|
||||
input_ids,
|
||||
token_type_ids,
|
||||
input_lengths,
|
||||
sequence_labels,
|
||||
token_labels,
|
||||
is_impossible_labels,
|
||||
input_mask,
|
||||
):
|
||||
model = FlaubertWithLMHeadModel(config)
|
||||
model.to(torch_device)
|
||||
model.eval()
|
||||
|
||||
loss, logits = model(input_ids, token_type_ids=token_type_ids, labels=token_labels)
|
||||
|
||||
result = {
|
||||
"loss": loss,
|
||||
"logits": logits,
|
||||
}
|
||||
|
||||
self.parent.assertListEqual(list(result["loss"].size()), [])
|
||||
self.parent.assertListEqual(
|
||||
list(result["logits"].size()), [self.batch_size, self.seq_length, self.vocab_size]
|
||||
)
|
||||
|
||||
def create_and_check_flaubert_simple_qa(
|
||||
self,
|
||||
config,
|
||||
input_ids,
|
||||
token_type_ids,
|
||||
input_lengths,
|
||||
sequence_labels,
|
||||
token_labels,
|
||||
is_impossible_labels,
|
||||
input_mask,
|
||||
):
|
||||
model = FlaubertForQuestionAnsweringSimple(config)
|
||||
model.to(torch_device)
|
||||
model.eval()
|
||||
|
||||
outputs = model(input_ids)
|
||||
|
||||
outputs = model(input_ids, start_positions=sequence_labels, end_positions=sequence_labels)
|
||||
loss, start_logits, end_logits = outputs
|
||||
|
||||
result = {
|
||||
"loss": loss,
|
||||
"start_logits": start_logits,
|
||||
"end_logits": end_logits,
|
||||
}
|
||||
self.parent.assertListEqual(list(result["start_logits"].size()), [self.batch_size, self.seq_length])
|
||||
self.parent.assertListEqual(list(result["end_logits"].size()), [self.batch_size, self.seq_length])
|
||||
self.check_loss_output(result)
|
||||
|
||||
def create_and_check_flaubert_qa(
|
||||
self,
|
||||
config,
|
||||
input_ids,
|
||||
token_type_ids,
|
||||
input_lengths,
|
||||
sequence_labels,
|
||||
token_labels,
|
||||
is_impossible_labels,
|
||||
input_mask,
|
||||
):
|
||||
model = FlaubertForQuestionAnswering(config)
|
||||
model.to(torch_device)
|
||||
model.eval()
|
||||
|
||||
outputs = model(input_ids)
|
||||
start_top_log_probs, start_top_index, end_top_log_probs, end_top_index, cls_logits = outputs
|
||||
|
||||
outputs = model(
|
||||
input_ids,
|
||||
start_positions=sequence_labels,
|
||||
end_positions=sequence_labels,
|
||||
cls_index=sequence_labels,
|
||||
is_impossible=is_impossible_labels,
|
||||
p_mask=input_mask,
|
||||
)
|
||||
|
||||
outputs = model(
|
||||
input_ids,
|
||||
start_positions=sequence_labels,
|
||||
end_positions=sequence_labels,
|
||||
cls_index=sequence_labels,
|
||||
is_impossible=is_impossible_labels,
|
||||
)
|
||||
|
||||
(total_loss,) = outputs
|
||||
|
||||
outputs = model(input_ids, start_positions=sequence_labels, end_positions=sequence_labels)
|
||||
|
||||
(total_loss,) = outputs
|
||||
|
||||
result = {
|
||||
"loss": total_loss,
|
||||
"start_top_log_probs": start_top_log_probs,
|
||||
"start_top_index": start_top_index,
|
||||
"end_top_log_probs": end_top_log_probs,
|
||||
"end_top_index": end_top_index,
|
||||
"cls_logits": cls_logits,
|
||||
}
|
||||
|
||||
self.parent.assertListEqual(list(result["loss"].size()), [])
|
||||
self.parent.assertListEqual(
|
||||
list(result["start_top_log_probs"].size()), [self.batch_size, model.config.start_n_top]
|
||||
)
|
||||
self.parent.assertListEqual(
|
||||
list(result["start_top_index"].size()), [self.batch_size, model.config.start_n_top]
|
||||
)
|
||||
self.parent.assertListEqual(
|
||||
list(result["end_top_log_probs"].size()),
|
||||
[self.batch_size, model.config.start_n_top * model.config.end_n_top],
|
||||
)
|
||||
self.parent.assertListEqual(
|
||||
list(result["end_top_index"].size()),
|
||||
[self.batch_size, model.config.start_n_top * model.config.end_n_top],
|
||||
)
|
||||
self.parent.assertListEqual(list(result["cls_logits"].size()), [self.batch_size])
|
||||
|
||||
def create_and_check_flaubert_sequence_classif(
|
||||
self,
|
||||
config,
|
||||
input_ids,
|
||||
token_type_ids,
|
||||
input_lengths,
|
||||
sequence_labels,
|
||||
token_labels,
|
||||
is_impossible_labels,
|
||||
input_mask,
|
||||
):
|
||||
model = FlaubertForSequenceClassification(config)
|
||||
model.to(torch_device)
|
||||
model.eval()
|
||||
|
||||
(logits,) = model(input_ids)
|
||||
loss, logits = model(input_ids, labels=sequence_labels)
|
||||
|
||||
result = {
|
||||
"loss": loss,
|
||||
"logits": logits,
|
||||
}
|
||||
|
||||
self.parent.assertListEqual(list(result["loss"].size()), [])
|
||||
self.parent.assertListEqual(
|
||||
list(result["logits"].size()), [self.batch_size, self.type_sequence_label_size]
|
||||
)
|
||||
|
||||
def prepare_config_and_inputs_for_common(self):
|
||||
config_and_inputs = self.prepare_config_and_inputs()
|
||||
(
|
||||
config,
|
||||
input_ids,
|
||||
token_type_ids,
|
||||
input_lengths,
|
||||
sequence_labels,
|
||||
token_labels,
|
||||
is_impossible_labels,
|
||||
input_mask,
|
||||
) = config_and_inputs
|
||||
inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "lengths": input_lengths}
|
||||
return config, inputs_dict
|
||||
|
||||
def setUp(self):
|
||||
self.model_tester = FlaubertModelTest.FlaubertModelTester(self)
|
||||
self.config_tester = ConfigTester(self, config_class=FlaubertConfig, emb_dim=37)
|
||||
|
||||
def test_config(self):
|
||||
self.config_tester.run_common_tests()
|
||||
|
||||
def test_flaubert_model(self):
|
||||
config_and_inputs = self.model_tester.prepare_config_and_inputs()
|
||||
self.model_tester.create_and_check_flaubert_model(*config_and_inputs)
|
||||
|
||||
def test_flaubert_lm_head(self):
|
||||
config_and_inputs = self.model_tester.prepare_config_and_inputs()
|
||||
self.model_tester.create_and_check_flaubert_lm_head(*config_and_inputs)
|
||||
|
||||
def test_flaubert_simple_qa(self):
|
||||
config_and_inputs = self.model_tester.prepare_config_and_inputs()
|
||||
self.model_tester.create_and_check_flaubert_simple_qa(*config_and_inputs)
|
||||
|
||||
def test_flaubert_qa(self):
|
||||
config_and_inputs = self.model_tester.prepare_config_and_inputs()
|
||||
self.model_tester.create_and_check_flaubert_qa(*config_and_inputs)
|
||||
|
||||
def test_flaubert_sequence_classif(self):
|
||||
config_and_inputs = self.model_tester.prepare_config_and_inputs()
|
||||
self.model_tester.create_and_check_flaubert_sequence_classif(*config_and_inputs)
|
||||
|
||||
@slow
|
||||
def test_model_from_pretrained(self):
|
||||
for model_name in list(FLAUBERT_PRETRAINED_MODEL_ARCHIVE_MAP.keys())[:1]:
|
||||
model = FlaubertModel.from_pretrained(model_name, cache_dir=CACHE_DIR)
|
||||
self.assertIsNotNone(model)
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user