[docs] Redesign (#31757)
* toctree * not-doctested.txt * collapse sections * feedback * update * rewrite get started sections * fixes * fix * loading models * fix * customize models * share * fix link * contribute part 1 * contribute pt 2 * fix toctree * tokenization pt 1 * Add new model (#32615) * v1 - working version * fix * fix * fix * fix * rename to correct name * fix title * fixup * rename files * fix * add copied from on tests * rename to `FalconMamba` everywhere and fix bugs * fix quantization + accelerate * fix copies * add `torch.compile` support * fix tests * fix tests and add slow tests * copies on config * merge the latest changes * fix tests * add few lines about instruct * Apply suggestions from code review Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * fix * fix tests --------- Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * "to be not" -> "not to be" (#32636) * "to be not" -> "not to be" * Update sam.md * Update trainer.py * Update modeling_utils.py * Update test_modeling_utils.py * Update test_modeling_utils.py * fix hfoption tag * tokenization pt. 2 * image processor * fix toctree * backbones * feature extractor * fix file name * processor * update not-doctested * update * make style * fix toctree * revision * make fixup * fix toctree * fix * make style * fix hfoption tag * pipeline * pipeline gradio * pipeline web server * add pipeline * fix toctree * not-doctested * prompting * llm optims * fix toctree * fixes * cache * text generation * fix * chat pipeline * chat stuff * xla * torch.compile * cpu inference * toctree * gpu inference * agents and tools * gguf/tiktoken * finetune * toctree * trainer * trainer pt 2 * optims * optimizers * accelerate * parallelism * fsdp * update * distributed cpu * hardware training * gpu training * gpu training 2 * peft * distrib debug * deepspeed 1 * deepspeed 2 * chat toctree * quant pt 1 * quant pt 2 * fix toctree * fix * fix * quant pt 3 * quant pt 4 * serialization * torchscript * scripts * tpu * review * model addition timeline * modular * more reviews * reviews * fix toctree * reviews reviews * continue reviews * more reviews * modular transformers * more review * zamba2 * fix * all frameworks * pytorch * supported model frameworks * flashattention * rm check_table * not-doctested.txt * rm check_support_list.py * feedback * updates/feedback * review * feedback * fix * update * feedback * updates * update --------- Co-authored-by: Younes Belkada <49240599+younesbelkada@users.noreply.github.com> Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> Co-authored-by: Quentin Gallouédec <45557362+qgallouedec@users.noreply.github.com>
This commit is contained in:
@@ -1,4 +1,4 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
@@ -13,353 +13,59 @@ rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Optimize inference using torch.compile()
|
||||
# torch.compile
|
||||
|
||||
This guide aims to provide a benchmark on the inference speed-ups introduced with [`torch.compile()`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) for [computer vision models in 🤗 Transformers](https://huggingface.co/models?pipeline_tag=image-classification&library=transformers&sort=trending).
|
||||
[torch.compile](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) compiles PyTorch code into optimized kernels that significantly speed up inference. This feature relies on [TorchDynamo](https://pytorch.org/docs/stable/torch.compiler_dynamo_overview.html) to compile the code into graphs and [TorchInductor](https://dev-discuss.pytorch.org/t/torchinductor-a-pytorch-native-compiler-with-define-by-run-ir-and-symbolic-shapes/747) to further compile the graphs into optimized kernels. It is a powerful optimization tool, and in many cases, only requires adding a single line of code.
|
||||
|
||||
## Benefits of torch.compile
|
||||
|
||||
Depending on the model and the GPU, `torch.compile()` yields up to 30% speed-up during inference. To use `torch.compile()`, simply install any version of `torch` above 2.0.
|
||||
Wrap a model with torch.compile to compile and return an optimized model.
|
||||
|
||||
Compiling a model takes time, so it's useful if you are compiling the model only once instead of every time you infer.
|
||||
To compile any computer vision model of your choice, call `torch.compile()` on the model as shown below:
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM
|
||||
|
||||
```diff
|
||||
from transformers import AutoModelForImageClassification
|
||||
|
||||
model = AutoModelForImageClassification.from_pretrained(MODEL_ID).to(DEVICE)
|
||||
+ model = torch.compile(model)
|
||||
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", device_map="auto")
|
||||
compiled_model = torch.compile(model)
|
||||
```
|
||||
|
||||
`compile()` comes with multiple modes for compiling, which essentially differ in compilation time and inference overhead. `max-autotune` takes longer than `reduce-overhead` but results in faster inference. Default mode is fastest for compilation but is not as efficient compared to `reduce-overhead` for inference time. In this guide, we used the default mode. You can learn more about it [here](https://pytorch.org/get-started/pytorch-2.0/#user-experience).
|
||||
> [!TIP]
|
||||
> The initial call to torch.compile is slow because the model needs to be compiled. Subsequent calls to the compiled model are much faster because it doesn't need to compile again.
|
||||
|
||||
We benchmarked `torch.compile` with different computer vision models, tasks, types of hardware, and batch sizes on `torch` version 2.0.1.
|
||||
There are several parameters to customize the compilation process. Two of the more important ones are listed below. For a full list of parameters, refer to the torch.compile [documentation](https://pytorch.org/docs/stable/generated/torch.compile.html).
|
||||
|
||||
## Benchmarking code
|
||||
## Modes
|
||||
|
||||
Below you can find the benchmarking code for each task. We warm up the GPU before inference and take the mean time of 300 inferences, using the same image each time.
|
||||
The `mode` parameter offers several performance options for compiling. Try different modes to see which one works best for your use case.
|
||||
|
||||
### Image Classification with ViT
|
||||
- `default` is a balanced option between speed and memory.
|
||||
- `reduce-overhead` reduces the Python overhead at the expense of a little more memory, but it can be faster.
|
||||
- `max-autotune` offers the fastest speed, but compilation takes longer.
|
||||
|
||||
```python
|
||||
import torch
|
||||
from PIL import Image
|
||||
import requests
|
||||
import numpy as np
|
||||
from transformers import AutoImageProcessor, AutoModelForImageClassification
|
||||
from accelerate.test_utils.testing import get_backend
|
||||
|
||||
device, _, _ = get_backend() # automatically detects the underlying device type (CUDA, CPU, XPU, MPS, etc.)
|
||||
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
|
||||
image = Image.open(requests.get(url, stream=True).raw)
|
||||
|
||||
processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
|
||||
model = AutoModelForImageClassification.from_pretrained("google/vit-base-patch16-224").to(device)
|
||||
model = torch.compile(model)
|
||||
|
||||
processed_input = processor(image, return_tensors='pt').to(device)
|
||||
|
||||
with torch.no_grad():
|
||||
_ = model(**processed_input)
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", device_map="auto")
|
||||
compiled_model = torch.compile(model, mode="reduce-overhead")
|
||||
```
|
||||
|
||||
#### Object Detection with DETR
|
||||
## Fullgraph
|
||||
|
||||
```python
|
||||
from transformers import AutoImageProcessor, AutoModelForObjectDetection
|
||||
from accelerate.test_utils.testing import get_backend
|
||||
Fullgraph attempts to compile the entire model into a single graph to maximize performance. torch.compile raises an error if it encounters a graph break, which means it can't compile the model into a single graph.
|
||||
|
||||
device, _, _ = get_backend() # automatically detects the underlying device type (CUDA, CPU, XPU, MPS, etc.)
|
||||
processor = AutoImageProcessor.from_pretrained("facebook/detr-resnet-50")
|
||||
model = AutoModelForObjectDetection.from_pretrained("facebook/detr-resnet-50").to(device)
|
||||
model = torch.compile(model)
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM
|
||||
|
||||
texts = ["a photo of a cat", "a photo of a dog"]
|
||||
inputs = processor(text=texts, images=image, return_tensors="pt").to(device)
|
||||
|
||||
with torch.no_grad():
|
||||
_ = model(**inputs)
|
||||
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", device_map="auto")
|
||||
compiled_model = torch.compile(model, mode="reduce-overhead", fullgraph=True)
|
||||
```
|
||||
|
||||
#### Image Segmentation with Segformer
|
||||
## Benchmarks
|
||||
|
||||
```python
|
||||
from transformers import SegformerImageProcessor, SegformerForSemanticSegmentation
|
||||
from accelerate.test_utils.testing import get_backend
|
||||
|
||||
device, _, _ = get_backend() # automatically detects the underlying device type (CUDA, CPU, XPU, MPS, etc.)
|
||||
processor = SegformerImageProcessor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
|
||||
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512").to(device)
|
||||
model = torch.compile(model)
|
||||
seg_inputs = processor(images=image, return_tensors="pt").to(device)
|
||||
|
||||
with torch.no_grad():
|
||||
_ = model(**seg_inputs)
|
||||
```
|
||||
|
||||
Below you can find the list of the models we benchmarked.
|
||||
|
||||
**Image Classification**
|
||||
- [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224)
|
||||
- [microsoft/beit-base-patch16-224-pt22k-ft22k](https://huggingface.co/microsoft/beit-base-patch16-224-pt22k-ft22k)
|
||||
- [facebook/convnext-large-224](https://huggingface.co/facebook/convnext-large-224)
|
||||
- [microsoft/resnet-50](https://huggingface.co/microsoft/resnet-50)
|
||||
|
||||
**Image Segmentation**
|
||||
- [nvidia/segformer-b0-finetuned-ade-512-512](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
|
||||
- [facebook/mask2former-swin-tiny-coco-panoptic](https://huggingface.co/facebook/mask2former-swin-tiny-coco-panoptic)
|
||||
- [facebook/maskformer-swin-base-ade](https://huggingface.co/facebook/maskformer-swin-base-ade)
|
||||
- [google/deeplabv3_mobilenet_v2_1.0_513](https://huggingface.co/google/deeplabv3_mobilenet_v2_1.0_513)
|
||||
|
||||
**Object Detection**
|
||||
- [google/owlvit-base-patch32](https://huggingface.co/google/owlvit-base-patch32)
|
||||
- [facebook/detr-resnet-101](https://huggingface.co/facebook/detr-resnet-101)
|
||||
- [microsoft/conditional-detr-resnet-50](https://huggingface.co/microsoft/conditional-detr-resnet-50)
|
||||
|
||||
Below you can find visualization of inference durations with and without `torch.compile()` and percentage improvements for each model in different hardware and batch sizes.
|
||||
|
||||
<div class="flex">
|
||||
<div>
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/a100_batch_comp.png" />
|
||||
</div>
|
||||
<div>
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/v100_batch_comp.png" />
|
||||
</div>
|
||||
<div>
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/t4_batch_comp.png" />
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<div class="flex">
|
||||
<div>
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/A100_1_duration.png" />
|
||||
</div>
|
||||
<div>
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/A100_1_percentage.png" />
|
||||
</div>
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Below you can find inference durations in milliseconds for each model with and without `compile()`. Note that OwlViT results in OOM in larger batch sizes.
|
||||
|
||||
### A100 (batch size: 1)
|
||||
|
||||
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|
|
||||
| Image Classification/ViT | 9.325 | 7.584 |
|
||||
| Image Segmentation/Segformer | 11.759 | 10.500 |
|
||||
| Object Detection/OwlViT | 24.978 | 18.420 |
|
||||
| Image Classification/BeiT | 11.282 | 8.448 |
|
||||
| Object Detection/DETR | 34.619 | 19.040 |
|
||||
| Image Classification/ConvNeXT | 10.410 | 10.208 |
|
||||
| Image Classification/ResNet | 6.531 | 4.124 |
|
||||
| Image Segmentation/Mask2former | 60.188 | 49.117 |
|
||||
| Image Segmentation/Maskformer | 75.764 | 59.487 |
|
||||
| Image Segmentation/MobileNet | 8.583 | 3.974 |
|
||||
| Object Detection/Resnet-101 | 36.276 | 18.197 |
|
||||
| Object Detection/Conditional-DETR | 31.219 | 17.993 |
|
||||
|
||||
|
||||
### A100 (batch size: 4)
|
||||
|
||||
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|
|
||||
| Image Classification/ViT | 14.832 | 14.499 |
|
||||
| Image Segmentation/Segformer | 18.838 | 16.476 |
|
||||
| Image Classification/BeiT | 13.205 | 13.048 |
|
||||
| Object Detection/DETR | 48.657 | 32.418|
|
||||
| Image Classification/ConvNeXT | 22.940 | 21.631 |
|
||||
| Image Classification/ResNet | 6.657 | 4.268 |
|
||||
| Image Segmentation/Mask2former | 74.277 | 61.781 |
|
||||
| Image Segmentation/Maskformer | 180.700 | 159.116 |
|
||||
| Image Segmentation/MobileNet | 14.174 | 8.515 |
|
||||
| Object Detection/Resnet-101 | 68.101 | 44.998 |
|
||||
| Object Detection/Conditional-DETR | 56.470 | 35.552 |
|
||||
|
||||
### A100 (batch size: 16)
|
||||
|
||||
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|
|
||||
| Image Classification/ViT | 40.944 | 40.010 |
|
||||
| Image Segmentation/Segformer | 37.005 | 31.144 |
|
||||
| Image Classification/BeiT | 41.854 | 41.048 |
|
||||
| Object Detection/DETR | 164.382 | 161.902 |
|
||||
| Image Classification/ConvNeXT | 82.258 | 75.561 |
|
||||
| Image Classification/ResNet | 7.018 | 5.024 |
|
||||
| Image Segmentation/Mask2former | 178.945 | 154.814 |
|
||||
| Image Segmentation/Maskformer | 638.570 | 579.826 |
|
||||
| Image Segmentation/MobileNet | 51.693 | 30.310 |
|
||||
| Object Detection/Resnet-101 | 232.887 | 155.021 |
|
||||
| Object Detection/Conditional-DETR | 180.491 | 124.032 |
|
||||
|
||||
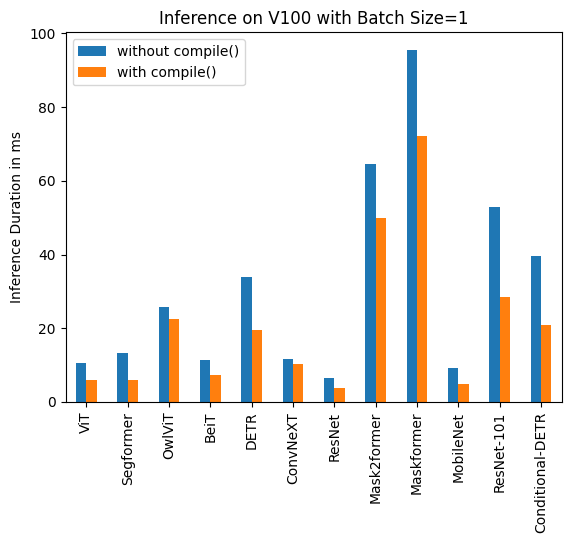
### V100 (batch size: 1)
|
||||
|
||||
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|
|
||||
| Image Classification/ViT | 10.495 | 6.00 |
|
||||
| Image Segmentation/Segformer | 13.321 | 5.862 |
|
||||
| Object Detection/OwlViT | 25.769 | 22.395 |
|
||||
| Image Classification/BeiT | 11.347 | 7.234 |
|
||||
| Object Detection/DETR | 33.951 | 19.388 |
|
||||
| Image Classification/ConvNeXT | 11.623 | 10.412 |
|
||||
| Image Classification/ResNet | 6.484 | 3.820 |
|
||||
| Image Segmentation/Mask2former | 64.640 | 49.873 |
|
||||
| Image Segmentation/Maskformer | 95.532 | 72.207 |
|
||||
| Image Segmentation/MobileNet | 9.217 | 4.753 |
|
||||
| Object Detection/Resnet-101 | 52.818 | 28.367 |
|
||||
| Object Detection/Conditional-DETR | 39.512 | 20.816 |
|
||||
|
||||
### V100 (batch size: 4)
|
||||
|
||||
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|
|
||||
| Image Classification/ViT | 15.181 | 14.501 |
|
||||
| Image Segmentation/Segformer | 16.787 | 16.188 |
|
||||
| Image Classification/BeiT | 15.171 | 14.753 |
|
||||
| Object Detection/DETR | 88.529 | 64.195 |
|
||||
| Image Classification/ConvNeXT | 29.574 | 27.085 |
|
||||
| Image Classification/ResNet | 6.109 | 4.731 |
|
||||
| Image Segmentation/Mask2former | 90.402 | 76.926 |
|
||||
| Image Segmentation/Maskformer | 234.261 | 205.456 |
|
||||
| Image Segmentation/MobileNet | 24.623 | 14.816 |
|
||||
| Object Detection/Resnet-101 | 134.672 | 101.304 |
|
||||
| Object Detection/Conditional-DETR | 97.464 | 69.739 |
|
||||
|
||||
### V100 (batch size: 16)
|
||||
|
||||
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|
|
||||
| Image Classification/ViT | 52.209 | 51.633 |
|
||||
| Image Segmentation/Segformer | 61.013 | 55.499 |
|
||||
| Image Classification/BeiT | 53.938 | 53.581 |
|
||||
| Object Detection/DETR | OOM | OOM |
|
||||
| Image Classification/ConvNeXT | 109.682 | 100.771 |
|
||||
| Image Classification/ResNet | 14.857 | 12.089 |
|
||||
| Image Segmentation/Mask2former | 249.605 | 222.801 |
|
||||
| Image Segmentation/Maskformer | 831.142 | 743.645 |
|
||||
| Image Segmentation/MobileNet | 93.129 | 55.365 |
|
||||
| Object Detection/Resnet-101 | 482.425 | 361.843 |
|
||||
| Object Detection/Conditional-DETR | 344.661 | 255.298 |
|
||||
|
||||
### T4 (batch size: 1)
|
||||
|
||||
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|
|
||||
| Image Classification/ViT | 16.520 | 15.786 |
|
||||
| Image Segmentation/Segformer | 16.116 | 14.205 |
|
||||
| Object Detection/OwlViT | 53.634 | 51.105 |
|
||||
| Image Classification/BeiT | 16.464 | 15.710 |
|
||||
| Object Detection/DETR | 73.100 | 53.99 |
|
||||
| Image Classification/ConvNeXT | 32.932 | 30.845 |
|
||||
| Image Classification/ResNet | 6.031 | 4.321 |
|
||||
| Image Segmentation/Mask2former | 79.192 | 66.815 |
|
||||
| Image Segmentation/Maskformer | 200.026 | 188.268 |
|
||||
| Image Segmentation/MobileNet | 18.908 | 11.997 |
|
||||
| Object Detection/Resnet-101 | 106.622 | 82.566 |
|
||||
| Object Detection/Conditional-DETR | 77.594 | 56.984 |
|
||||
|
||||
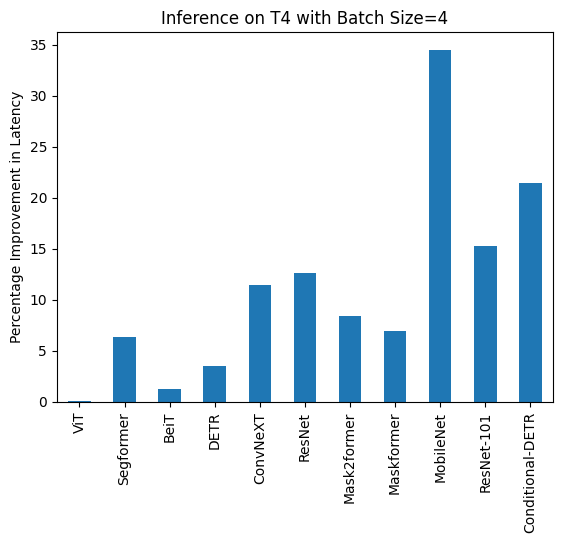
### T4 (batch size: 4)
|
||||
|
||||
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|
|
||||
| Image Classification/ViT | 43.653 | 43.626 |
|
||||
| Image Segmentation/Segformer | 45.327 | 42.445 |
|
||||
| Image Classification/BeiT | 52.007 | 51.354 |
|
||||
| Object Detection/DETR | 277.850 | 268.003 |
|
||||
| Image Classification/ConvNeXT | 119.259 | 105.580 |
|
||||
| Image Classification/ResNet | 13.039 | 11.388 |
|
||||
| Image Segmentation/Mask2former | 201.540 | 184.670 |
|
||||
| Image Segmentation/Maskformer | 764.052 | 711.280 |
|
||||
| Image Segmentation/MobileNet | 74.289 | 48.677 |
|
||||
| Object Detection/Resnet-101 | 421.859 | 357.614 |
|
||||
| Object Detection/Conditional-DETR | 289.002 | 226.945 |
|
||||
|
||||
### T4 (batch size: 16)
|
||||
|
||||
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|
|
||||
| Image Classification/ViT | 163.914 | 160.907 |
|
||||
| Image Segmentation/Segformer | 192.412 | 163.620 |
|
||||
| Image Classification/BeiT | 188.978 | 187.976 |
|
||||
| Object Detection/DETR | OOM | OOM |
|
||||
| Image Classification/ConvNeXT | 422.886 | 388.078 |
|
||||
| Image Classification/ResNet | 44.114 | 37.604 |
|
||||
| Image Segmentation/Mask2former | 756.337 | 695.291 |
|
||||
| Image Segmentation/Maskformer | 2842.940 | 2656.88 |
|
||||
| Image Segmentation/MobileNet | 299.003 | 201.942 |
|
||||
| Object Detection/Resnet-101 | 1619.505 | 1262.758 |
|
||||
| Object Detection/Conditional-DETR | 1137.513 | 897.390|
|
||||
|
||||
## PyTorch Nightly
|
||||
We also benchmarked on PyTorch nightly (2.1.0dev, find the wheel [here](https://download.pytorch.org/whl/nightly/cu118)) and observed improvement in latency both for uncompiled and compiled models.
|
||||
|
||||
### A100
|
||||
|
||||
| **Task/Model** | **Batch Size** | **torch 2.0 - no compile** | **torch 2.0 -<br> compile** |
|
||||
|:---:|:---:|:---:|:---:|
|
||||
| Image Classification/BeiT | Unbatched | 12.462 | 6.954 |
|
||||
| Image Classification/BeiT | 4 | 14.109 | 12.851 |
|
||||
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
|
||||
| Object Detection/DETR | Unbatched | 30.484 | 15.221 |
|
||||
| Object Detection/DETR | 4 | 46.816 | 30.942 |
|
||||
| Object Detection/DETR | 16 | 163.749 | 163.706 |
|
||||
|
||||
### T4
|
||||
|
||||
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|:---:|
|
||||
| Image Classification/BeiT | Unbatched | 14.408 | 14.052 |
|
||||
| Image Classification/BeiT | 4 | 47.381 | 46.604 |
|
||||
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
|
||||
| Object Detection/DETR | Unbatched | 68.382 | 53.481 |
|
||||
| Object Detection/DETR | 4 | 269.615 | 204.785 |
|
||||
| Object Detection/DETR | 16 | OOM | OOM |
|
||||
|
||||
### V100
|
||||
|
||||
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|:---:|
|
||||
| Image Classification/BeiT | Unbatched | 13.477 | 7.926 |
|
||||
| Image Classification/BeiT | 4 | 15.103 | 14.378 |
|
||||
| Image Classification/BeiT | 16 | 52.517 | 51.691 |
|
||||
| Object Detection/DETR | Unbatched | 28.706 | 19.077 |
|
||||
| Object Detection/DETR | 4 | 88.402 | 62.949|
|
||||
| Object Detection/DETR | 16 | OOM | OOM |
|
||||
|
||||
|
||||
## Reduce Overhead
|
||||
We benchmarked `reduce-overhead` compilation mode for A100 and T4 in Nightly.
|
||||
|
||||
### A100
|
||||
|
||||
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|:---:|
|
||||
| Image Classification/ConvNeXT | Unbatched | 11.758 | 7.335 |
|
||||
| Image Classification/ConvNeXT | 4 | 23.171 | 21.490 |
|
||||
| Image Classification/ResNet | Unbatched | 7.435 | 3.801 |
|
||||
| Image Classification/ResNet | 4 | 7.261 | 2.187 |
|
||||
| Object Detection/Conditional-DETR | Unbatched | 32.823 | 11.627 |
|
||||
| Object Detection/Conditional-DETR | 4 | 50.622 | 33.831 |
|
||||
| Image Segmentation/MobileNet | Unbatched | 9.869 | 4.244 |
|
||||
| Image Segmentation/MobileNet | 4 | 14.385 | 7.946 |
|
||||
|
||||
|
||||
### T4
|
||||
|
||||
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|:---:|
|
||||
| Image Classification/ConvNeXT | Unbatched | 32.137 | 31.84 |
|
||||
| Image Classification/ConvNeXT | 4 | 120.944 | 110.209 |
|
||||
| Image Classification/ResNet | Unbatched | 9.761 | 7.698 |
|
||||
| Image Classification/ResNet | 4 | 15.215 | 13.871 |
|
||||
| Object Detection/Conditional-DETR | Unbatched | 72.150 | 57.660 |
|
||||
| Object Detection/Conditional-DETR | 4 | 301.494 | 247.543 |
|
||||
| Image Segmentation/MobileNet | Unbatched | 22.266 | 19.339 |
|
||||
| Image Segmentation/MobileNet | 4 | 78.311 | 50.983 |
|
||||
Refer to the table below for performance benchmarks comparing the mean inference time in milliseconds with torch.compile enabled and disabled across various GPUs and batch sizes on the same image for different vision tasks.
|
||||
|
||||
Select **Subset** in the table below to switch between different GPUs, as well as benchmarks on [PyTorch nightly](https://download.pytorch.org/whl/nightly/cu118) 2.1.0dev and torch.compile with `reduce-overhead` mode enabled.
|
||||
|
||||
<iframe
|
||||
src="https://huggingface.co/datasets/stevhliu/compile-benchmarks/embed/viewer/t4/train"
|
||||
frameborder="0"
|
||||
width="100%"
|
||||
height="560px"
|
||||
></iframe>
|
||||
|
||||
Reference in New Issue
Block a user