- 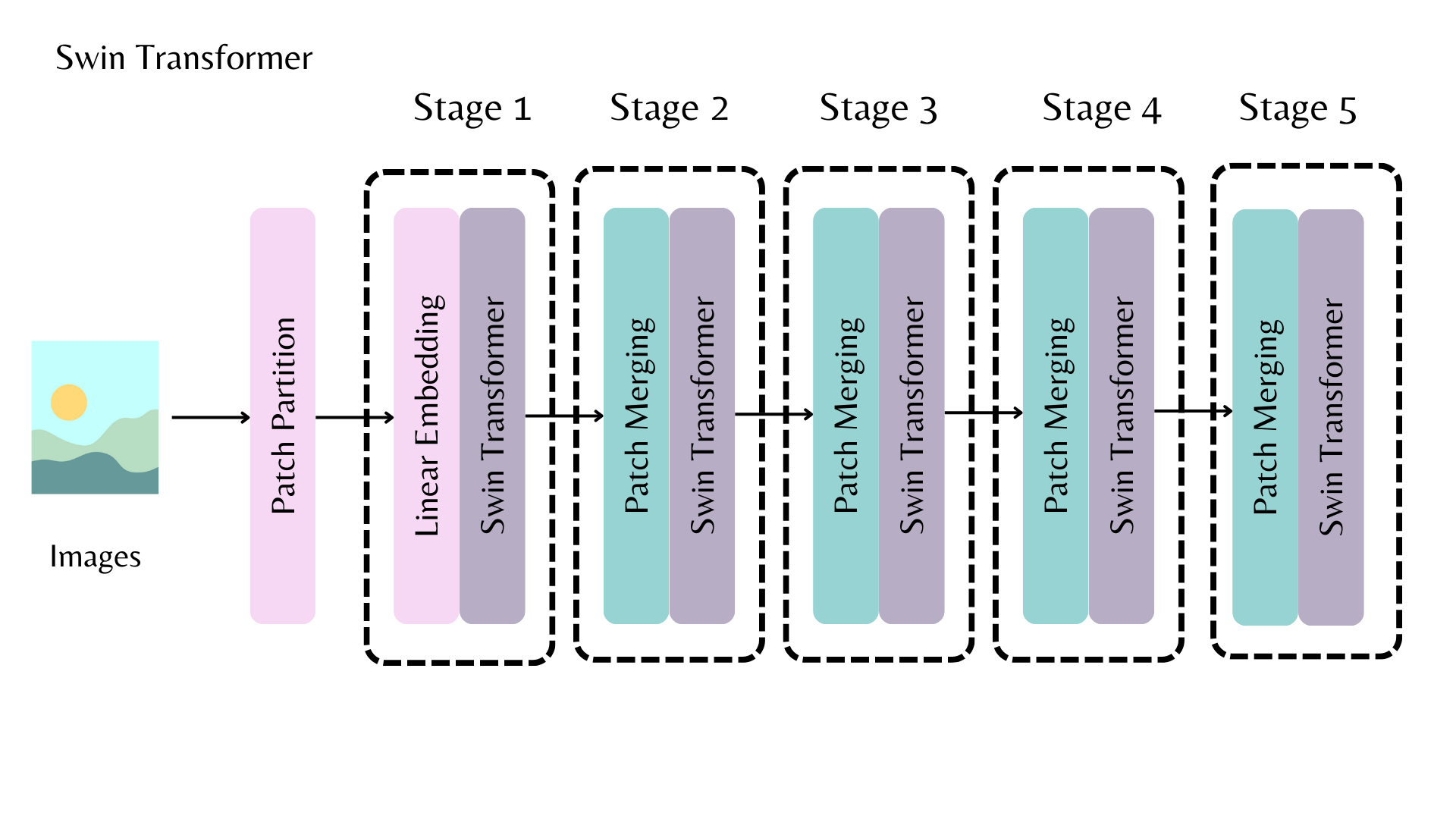 -
- A Swin backbone with multiple stages for outputting a feature map.
-
-
-The [`AutoBackbone`] lets you use pretrained models as backbones to get feature maps from different stages of the backbone. You should specify one of the following parameters in [`~PretrainedConfig.from_pretrained`]:
-
-* `out_indices` is the index of the layer you'd like to get the feature map from
-* `out_features` is the name of the layer you'd like to get the feature map from
-
-These parameters can be used interchangeably, but if you use both, make sure they're aligned with each other! If you don't pass any of these parameters, the backbone returns the feature map from the last layer.
-
-
-
- 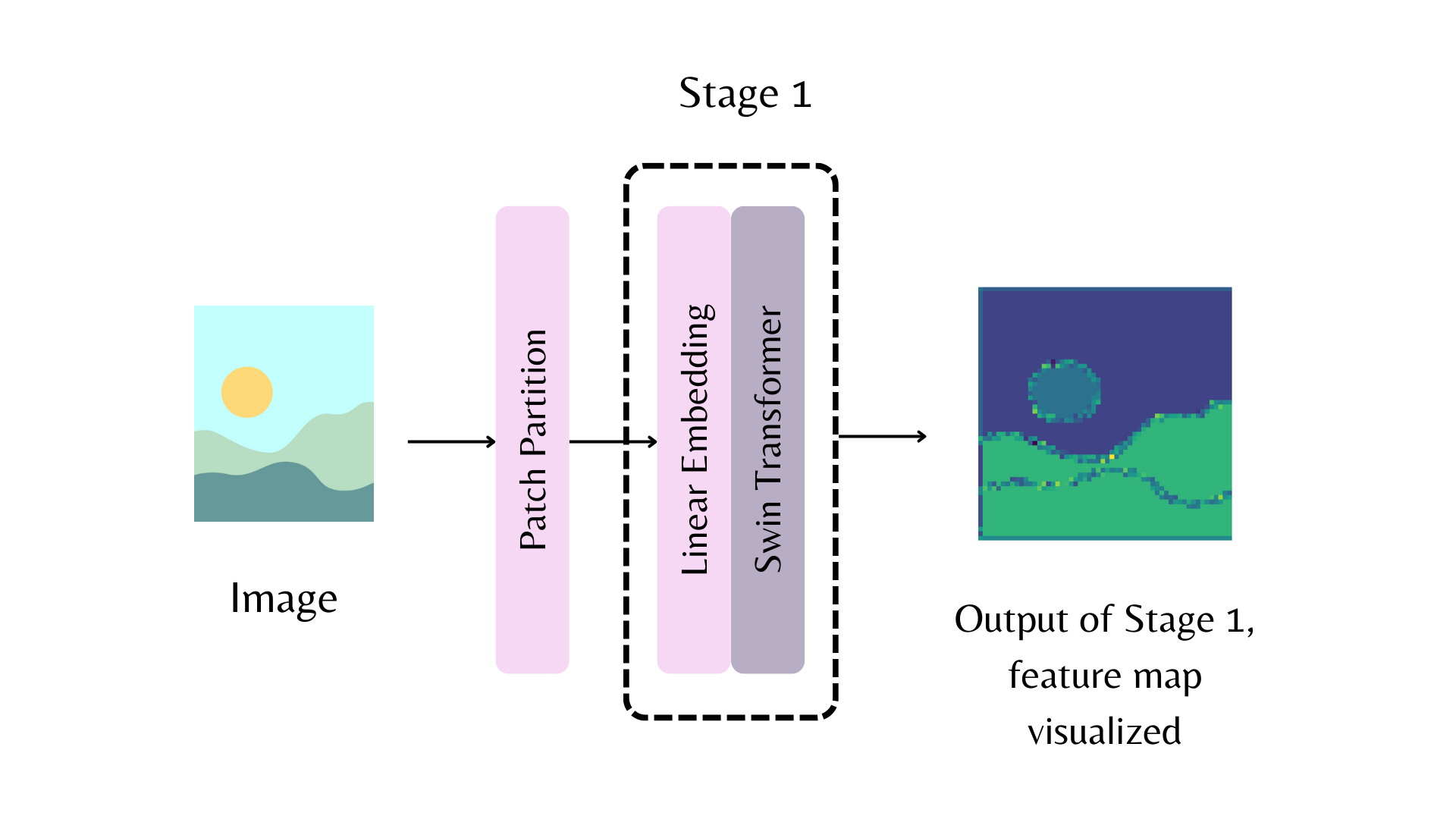 -
- A feature map from the first stage of the backbone. The patch partition refers to the model stem.
-
-
-For example, in the above diagram, to return the feature map from the first stage of the Swin backbone, you can set `out_indices=(1,)`:
-
-```py
->>> from transformers import AutoImageProcessor, AutoBackbone
->>> import torch
->>> from PIL import Image
->>> import requests
->>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
->>> image = Image.open(requests.get(url, stream=True).raw)
->>> processor = AutoImageProcessor.from_pretrained("microsoft/swin-tiny-patch4-window7-224")
->>> model = AutoBackbone.from_pretrained("microsoft/swin-tiny-patch4-window7-224", out_indices=(1,))
-
->>> inputs = processor(image, return_tensors="pt")
->>> outputs = model(**inputs)
->>> feature_maps = outputs.feature_maps
-```
-
-Now you can access the `feature_maps` object from the first stage of the backbone:
-
-```py
->>> list(feature_maps[0].shape)
-[1, 96, 56, 56]
-```
-
-## AutoFeatureExtractor
-
-For audio tasks, a feature extractor processes the audio signal into the correct input format.
-
-Load a feature extractor with [`AutoFeatureExtractor.from_pretrained`]:
-
-```py
->>> from transformers import AutoFeatureExtractor
-
->>> feature_extractor = AutoFeatureExtractor.from_pretrained(
-... "ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
-... )
-```
-
-## AutoProcessor
-
-Multimodal tasks require a processor that combines two types of preprocessing tools. For example, the [LayoutLMV2](model_doc/layoutlmv2) model requires an image processor to handle images and a tokenizer to handle text; a processor combines both of them.
-
-Load a processor with [`AutoProcessor.from_pretrained`]:
-
-```py
->>> from transformers import AutoProcessor
-
->>> processor = AutoProcessor.from_pretrained("microsoft/layoutlmv2-base-uncased")
-```
-
-## AutoModel
-
-
-
+  +
+
+
+Load a backbone with [`~PretrainedConfig.from_pretrained`] and use the `out_indices` parameter to determine which layer, given by the index, to extract a feature map from.
+
+```py
+from transformers import AutoBackbone
+
+model = AutoBackbone.from_pretrained("microsoft/swin-tiny-patch4-window7-224", out_indices=(1,))
+```
+
+This guide describes the backbone class, backbones from the [timm](https://hf.co/docs/timm/index) library, and how to extract features with them.
+
+## Backbone classes
+
+There are two backbone classes.
+
+- [`~transformers.utils.BackboneMixin`] allows you to load a backbone and includes functions for extracting the feature maps and indices.
+- [`~transformers.utils.BackboneConfigMixin`] allows you to set the feature map and indices of a backbone configuration.
+
+Refer to the [Backbone](./main_classes/backbones) API documentation to check which models support a backbone.
+
+There are two ways to load a Transformers backbone, [`AutoBackbone`] and a model-specific backbone class.
+
+
+
+
+
+
+```py
+from transformers import AutoImageProcessor, AutoBackbone
+
+model = AutoBackbone.from_pretrained("microsoft/swin-tiny-patch4-window7-224", out_indices=(1,))
+```
+
+
+
+  +
+
+
+For a full list of options, run the command below.
+
+```bash
+transformers-cli chat -h
+```
+
+The chat is implemented on top of the [AutoClass](./model_doc/auto), using tooling from [text generation](./llm_tutorial) and [chat](./chat_templating).
+
+## TextGenerationPipeline
+
+[`TextGenerationPipeline`] is a high-level text generation class with a "chat mode". Chat mode is enabled when a conversational model is detected and the chat prompt is [properly formatted](./llm_tutorial#wrong-prompt-format).
+
+To start, build a chat history with the following two roles.
+
+- `system` describes how the model should behave and respond when you're chatting with it. This role isn't supported by all chat models.
+- `user` is where you enter your first message to the model.
+
+```py
chat = [
{"role": "system", "content": "You are a sassy, wise-cracking robot as imagined by Hollywood circa 1986."},
{"role": "user", "content": "Hey, can you tell me any fun things to do in New York?"}
]
```
-Notice that in addition to the user's message, we added a **system** message at the start of the conversation. Not all
-chat models support system messages, but when they do, they represent high-level directives about how the model
-should behave in the conversation. You can use this to guide the model - whether you want short or long responses,
-lighthearted or serious ones, and so on. If you want the model to do useful work instead of
-practicing its improv routine, you can either omit the system message or try a terse one such as "You are a helpful and intelligent
-AI assistant who responds to user queries."
+Create the [`TextGenerationPipeline`] and pass `chat` to it. For large models, setting [device_map="auto"](./models#big-model-inference) helps load the model quicker and automatically places it on the fastest device available. Changing the data type to [torch.bfloat16](./models#model-data-type) also helps save memory.
-Once you have a chat, the quickest way to continue it is using the [`TextGenerationPipeline`].
-Let's see this in action with `LLaMA-3`. Note that `LLaMA-3` is a gated model, which means you will need to
-[apply for access](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) and log in with your Hugging Face
-account to use it. We'll also use `device_map="auto"`, which will load the model on GPU if there's enough memory
-for it, and set the dtype to `torch.bfloat16` to save memory:
-
-```python
+```py
import torch
from transformers import pipeline
-pipe = pipeline("text-generation", "meta-llama/Meta-Llama-3-8B-Instruct", torch_dtype=torch.bfloat16, device_map="auto")
-response = pipe(chat, max_new_tokens=512)
-print(response[0]['generated_text'][-1]['content'])
+pipeline = pipeline(task="text-generation", model="meta-llama/Meta-Llama-3-8B-Instruct", torch_dtype=torch.bfloat16, device_map="auto")
+response = pipeline(chat, max_new_tokens=512)
+print(response[0]["generated_text"][-1]["content"])
```
-And you'll get:
-
-```text
-(sigh) Oh boy, you're asking me for advice? You're gonna need a map, pal! Alright,
+```txt
+(sigh) Oh boy, you're asking me for advice? You're gonna need a map, pal! Alright,
alright, I'll give you the lowdown. But don't say I didn't warn you, I'm a robot, not a tour guide!
So, you wanna know what's fun to do in the Big Apple? Well, let me tell you, there's a million
@@ -91,22 +95,18 @@ So, there you have it, pal! That's my expert advice on what to do in New York. N
excuse me, I've got some oil changes to attend to. (winks)
```
-You can continue the chat by appending your own response to it. The
-`response` object returned by the pipeline actually contains the entire chat so far, so we can simply append
-a message and pass it back:
+Use the `append` method on `chat` to respond to the models message.
-```python
-chat = response[0]['generated_text']
+```py
+chat = response[0]["generated_text"]
chat.append(
{"role": "user", "content": "Wait, what's so wild about soup cans?"}
)
-response = pipe(chat, max_new_tokens=512)
-print(response[0]['generated_text'][-1]['content'])
+response = pipeline(chat, max_new_tokens=512)
+print(response[0]["generated_text"][-1]["content"])
```
-And you'll get:
-
-```text
+```txt
(laughs) Oh, you're killin' me, pal! You don't get it, do you? Warhol's soup cans are like, art, man!
It's like, he took something totally mundane, like a can of soup, and turned it into a masterpiece. It's
like, "Hey, look at me, I'm a can of soup, but I'm also a work of art!"
@@ -120,171 +120,35 @@ But, hey, you're not alone, pal. I mean, I'm a robot, and even I don't get it. (
But, hey, that's what makes art, art, right? (laughs)
```
-The remainder of this tutorial will cover specific topics such
-as performance and memory, or how to select a chat model for your needs.
+## Performance
-## Choosing a chat model
+Transformers load models in full precision by default, and for a 8B model, this requires ~32GB of memory! Reduce memory usage by loading a model in half-precision or bfloat16 (only uses ~2 bytes per parameter). You can even quantize the model to a lower precision like 8-bit or 4-bit with [bitsandbytes](https://hf.co/docs/bitsandbytes/index).
-There are an enormous number of different chat models available on the [Hugging Face Hub](https://huggingface.co/models?pipeline_tag=text-generation&sort=trending),
-and new users often feel very overwhelmed by the selection offered. Don't be, though! You really need to just focus on
-two important considerations:
-- The model's size, which will determine if you can fit it in memory and how quickly it will
-run.
-- The quality of the model's chat output.
+> [!TIP]
+> Refer to the [Quantization](./quantization/overview) docs for more information about the different quantization backends available.
-In general, these are correlated - bigger models tend to be
-more capable, but even so there's a lot of variation at a given size point!
+Create a [`BitsAndBytesConfig`] with your desired quantization settings and pass it to the pipelines `model_kwargs` parameter. The example below quantizes a model to 8-bits.
-### Size and model naming
-The size of a model is easy to spot - it's the number in the model name, like "8B" or "70B". This is the number of
-**parameters** in the model. Without quantization, you should expect to need about 2 bytes of memory per parameter.
-This means that an "8B" model with 8 billion parameters will need about 16GB of memory just to fit the parameters,
-plus a little extra for other overhead. It's a good fit for a high-end consumer GPU with 24GB of memory, such as a 3090
-or 4090.
-
-Some chat models are "Mixture of Experts" models. These may list their sizes in different ways, such as "8x7B" or
-"141B-A35B". The numbers are a little fuzzier here, but in general you can read this as saying that the model
-has approximately 56 (8x7) billion parameters in the first case, or 141 billion parameters in the second case.
-
-Note that it is very common to use quantization techniques to reduce the memory usage per parameter to 8 bits, 4 bits,
-or even less. This topic is discussed in more detail in the [Memory considerations](#memory-considerations) section below.
-
-### But which chat model is best?
-Even once you know the size of chat model you can run, there's still a lot of choice out there. One way to sift through
-it all is to consult **leaderboards**. Two of the most popular leaderboards are the [OpenLLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
-and the [LMSys Chatbot Arena Leaderboard](https://chat.lmsys.org/?leaderboard). Note that the LMSys leaderboard
-also includes proprietary models - look at the `licence` column to identify open-source ones that you can download, then
-search for them on the [Hugging Face Hub](https://huggingface.co/models?pipeline_tag=text-generation&sort=trending).
-
-### Specialist domains
-Some models may be specialized for certain domains, such as medical or legal text, or non-English languages.
-If you're working in these domains, you may find that a specialized model will give you big performance benefits.
-Don't automatically assume that, though! Particularly when specialized models are smaller or older than the current
-cutting-edge, a top-end general-purpose model may still outclass them. Thankfully, we are beginning to see
-[domain-specific leaderboards](https://huggingface.co/blog/leaderboard-medicalllm) that should make it easier to locate
-the best models for specialized domains.
-
-## What happens inside the pipeline?
-
-The quickstart above used a high-level pipeline to chat with a chat model, which is convenient, but not the
-most flexible. Let's take a more low-level approach, to see each of the steps involved in chat. Let's start with
-a code sample, and then break it down:
-
-```python
-from transformers import AutoModelForCausalLM, AutoTokenizer
-import torch
-
-# Prepare the input as before
-chat = [
- {"role": "system", "content": "You are a sassy, wise-cracking robot as imagined by Hollywood circa 1986."},
- {"role": "user", "content": "Hey, can you tell me any fun things to do in New York?"}
-]
-
-# 1: Load the model and tokenizer
-model = AutoModelForCausalLM.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct", device_map="auto", torch_dtype=torch.bfloat16)
-tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct")
-
-# 2: Apply the chat template
-formatted_chat = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
-print("Formatted chat:\n", formatted_chat)
-
-# 3: Tokenize the chat (This can be combined with the previous step using tokenize=True)
-inputs = tokenizer(formatted_chat, return_tensors="pt", add_special_tokens=False)
-# Move the tokenized inputs to the same device the model is on (GPU/CPU)
-inputs = {key: tensor.to(model.device) for key, tensor in inputs.items()}
-print("Tokenized inputs:\n", inputs)
-
-# 4: Generate text from the model
-outputs = model.generate(**inputs, max_new_tokens=512, temperature=0.1)
-print("Generated tokens:\n", outputs)
-
-# 5: Decode the output back to a string
-decoded_output = tokenizer.decode(outputs[0][inputs['input_ids'].size(1):], skip_special_tokens=True)
-print("Decoded output:\n", decoded_output)
-```
-
-There's a lot in here, each piece of which could be its own document! Rather than going into too much detail, I'll cover
-the broad ideas, and leave the details for the linked documents. The key steps are:
-
-1. [Models](https://huggingface.co/learn/nlp-course/en/chapter2/3) and [Tokenizers](https://huggingface.co/learn/nlp-course/en/chapter2/4?fw=pt) are loaded from the Hugging Face Hub.
-2. The chat is formatted using the tokenizer's [chat template](https://huggingface.co/docs/transformers/main/en/chat_templating)
-3. The formatted chat is [tokenized](https://huggingface.co/learn/nlp-course/en/chapter2/4) using the tokenizer.
-4. We [generate](https://huggingface.co/docs/transformers/en/llm_tutorial) a response from the model.
-5. The tokens output by the model are decoded back to a string
-
-## Performance, memory and hardware
-
-You probably know by now that most machine learning tasks are run on GPUs. However, it is entirely possible
-to generate text from a chat model or language model on a CPU, albeit somewhat more slowly. If you can fit
-the model in GPU memory, though, this will usually be the preferable option.
-
-### Memory considerations
-
-By default, Hugging Face classes like [`TextGenerationPipeline`] or [`AutoModelForCausalLM`] will load the model in
-`float32` precision. This means that it will need 4 bytes (32 bits) per parameter, so an "8B" model with 8 billion
-parameters will need ~32GB of memory. However, this can be wasteful! Most modern language models are trained in
-"bfloat16" precision, which uses only 2 bytes per parameter. If your hardware supports it (Nvidia 30xx/Axxx
-or newer), you can load the model in `bfloat16` precision, using the `torch_dtype` argument as we did above.
-
-It is possible to go even lower than 16-bits using "quantization", a method to lossily compress model weights. This
-allows each parameter to be squeezed down to 8 bits, 4 bits or even less. Note that, especially at 4 bits,
-the model's outputs may be negatively affected, but often this is a tradeoff worth making to fit a larger and more
-capable chat model in memory. Let's see this in action with `bitsandbytes`:
-
-```python
-from transformers import AutoModelForCausalLM, BitsAndBytesConfig
-
-quantization_config = BitsAndBytesConfig(load_in_8bit=True) # You can also try load_in_4bit
-model = AutoModelForCausalLM.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct", device_map="auto", quantization_config=quantization_config)
-```
-
-Or we can do the same thing using the `pipeline` API:
-
-```python
+```py
from transformers import pipeline, BitsAndBytesConfig
-quantization_config = BitsAndBytesConfig(load_in_8bit=True) # You can also try load_in_4bit
-pipe = pipeline("text-generation", "meta-llama/Meta-Llama-3-8B-Instruct", device_map="auto", model_kwargs={"quantization_config": quantization_config})
+quantization_config = BitsAndBytesConfig(load_in_8bit=True)
+pipeline = pipeline(task="text-generation", model="meta-llama/Meta-Llama-3-8B-Instruct", device_map="auto", model_kwargs={"quantization_config": quantization_config})
```
-There are several other options for quantizing models besides `bitsandbytes` - please see the [Quantization guide](./quantization)
-for more information.
+In general, larger models are slower in addition to requiring more memory because text generation is bottlenecked by **memory bandwidth** instead of compute power. Each active parameter must be read from memory for every generated token. For a 16GB model, 16GB must be read from memory for every generated token.
-### Performance considerations
+The number of generated tokens/sec is proportional to the total memory bandwidth of the system divided by the model size. Depending on your hardware, total memory bandwidth can vary. Refer to the table below for approximate generation speeds for different hardware types.
-
-
-
-
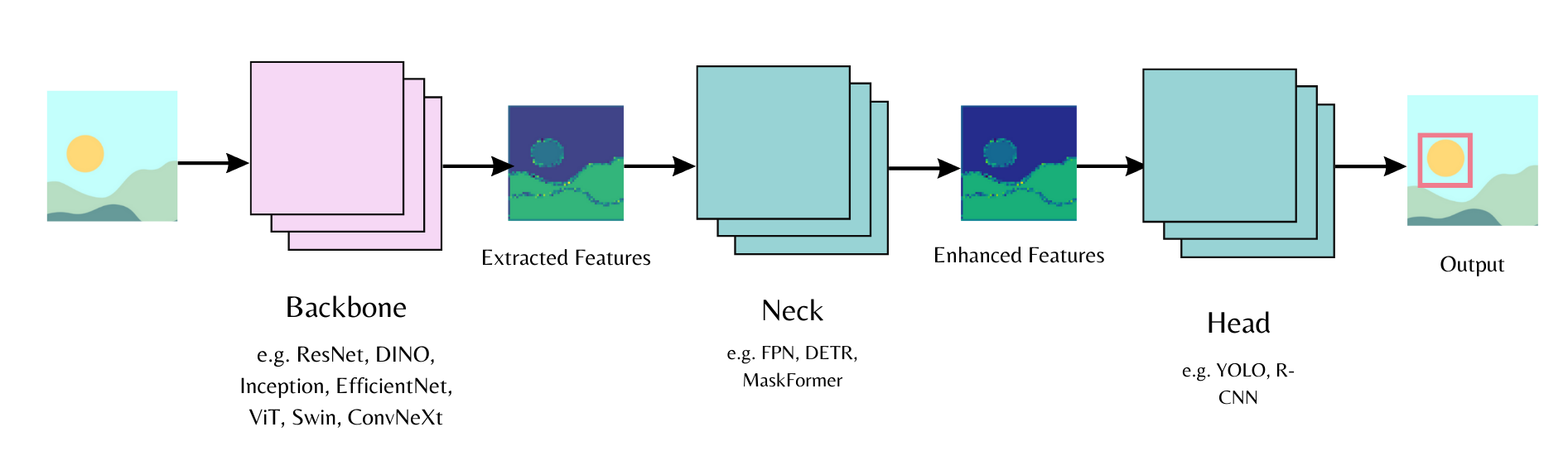
-Computer vision models consist of a backbone, neck, and head. The backbone extracts features from an input image, the neck combines and enhances the extracted features, and the head is used for the main task (e.g., object detection). Start by initializing a backbone in the model config and specify whether you want to load pretrained weights or load randomly initialized weights. Then you can pass the model config to the model head.
-
-For example, to load a [ResNet](../model_doc/resnet) backbone into a [MaskFormer](../model_doc/maskformer) model with an instance segmentation head:
-
-
-
+  +
+
+
+> [!TIP]
+> Learn more about streaming in the [Text Generation Inference](https://huggingface.co/docs/text-generation-inference/en/conceptual/streaming) docs.
+
+Create an instance of [`TextStreamer`] with the tokenizer. Pass [`TextStreamer`] to the `streamer` parameter in [`~GenerationMixin.generate`] to stream the output one word at a time.
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
+
+tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2")
+model = AutoModelForCausalLM.from_pretrained("openai-community/gpt2")
+inputs = tokenizer(["The secret to baking a good cake is "], return_tensors="pt")
+streamer = TextStreamer(tokenizer)
+
+_ = model.generate(**inputs, streamer=streamer, max_new_tokens=20)
+```
+
+The `streamer` parameter is compatible with any class with a [`~TextStreamer.put`] and [`~TextStreamer.end`] method. [`~TextStreamer.put`] pushes new tokens and [`~TextStreamer.end`] flags the end of generation. You can create your own streamer class as long as they include these two methods, or you can use Transformers' basic streamer classes.
+
+## Watermarking
+
+Watermarking is useful for detecting whether text is generated. The [watermarking strategy](https://hf.co/papers/2306.04634) in Transformers randomly "colors" a subset of the tokens green. When green tokens are generated, they have a small bias added to their logits, and a higher probability of being generated. You can detect generated text by comparing the proportion of green tokens to the amount of green tokens typically found in human-generated text.
+
+Watermarking is supported for any generative model in Transformers and doesn't require an extra classfication model to detect the watermarked text.
+
+Create a [`WatermarkingConfig`] with the bias value to add to the logits and watermarking algorithm. The example below uses the `"selfhash"` algorithm, where the green token selection only depends on the current token. Pass the [`WatermarkingConfig`] to [`~GenerationMixin.generate`].
+
+> [!TIP]
+> The [`WatermarkDetector`] class detects the proportion of green tokens in generated text, which is why it is recommended to strip the prompt text, if it is much longer than the generated text. Padding can also have an effect on [`WatermarkDetector`].
+
+```py
+from transformers import AutoTokenizer, AutoModelForCausalLM, WatermarkDetector, WatermarkingConfig
+
+model = AutoModelForCausalLM.from_pretrained("openai-community/gpt2")
+tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2")
+tokenizer.pad_token_id = tokenizer.eos_token_id
+tokenizer.padding_side = "left"
+
+inputs = tokenizer(["This is the beginning of a long story", "Alice and Bob are"], padding=True, return_tensors="pt")
+input_len = inputs["input_ids"].shape[-1]
+
+watermarking_config = WatermarkingConfig(bias=2.5, seeding_scheme="selfhash")
+out = model.generate(**inputs, watermarking_config=watermarking_config, do_sample=False, max_length=20)
+```
+
+Create an instance of [`WatermarkDetector`] and pass the model output to it to detect whether the text is machine-generated. The [`WatermarkDetector`] must have the same [`WatermarkingConfig`] used during generation.
+
+```py
+detector = WatermarkDetector(model_config=model.config, device="cpu", watermarking_config=watermarking_config)
+detection_out = detector(out, return_dict=True)
+detection_out.prediction
+array([True, True])
+```
diff --git a/docs/source/en/generation_strategies.md b/docs/source/en/generation_strategies.md
index 99049cceef..706443906a 100644
--- a/docs/source/en/generation_strategies.md
+++ b/docs/source/en/generation_strategies.md
@@ -1,4 +1,4 @@
-
-# Text generation strategies
+# Generation strategies
-Text generation is essential to many NLP tasks, such as open-ended text generation, summarization, translation, and
-more. It also plays a role in a variety of mixed-modality applications that have text as an output like speech-to-text
-and vision-to-text. Some of the models that can generate text include
-GPT2, XLNet, OpenAI GPT, CTRL, TransformerXL, XLM, Bart, T5, GIT, Whisper.
+A decoding strategy informs how a model should select the next generated token. There are many types of decoding strategies, and choosing the appropriate one has a significant impact on the quality of the generated text.
-Check out a few examples that use [`~generation.GenerationMixin.generate`] method to produce
-text outputs for different tasks:
-* [Text summarization](./tasks/summarization#inference)
-* [Image captioning](./model_doc/git#transformers.GitForCausalLM.forward.example)
-* [Audio transcription](./model_doc/whisper#transformers.WhisperForConditionalGeneration.forward.example)
+This guide will help you understand the different decoding strategies available in Transformers and how and when to use them.
-Note that the inputs to the generate method depend on the model's modality. They are returned by the model's preprocessor
-class, such as AutoTokenizer or AutoProcessor. If a model's preprocessor creates more than one kind of input, pass all
-the inputs to generate(). You can learn more about the individual model's preprocessor in the corresponding model's documentation.
+## Greedy search
-The process of selecting output tokens to generate text is known as decoding, and you can customize the decoding strategy
-that the `generate()` method will use. Modifying a decoding strategy does not change the values of any trainable parameters.
-However, it can have a noticeable impact on the quality of the generated output. It can help reduce repetition in the text
-and make it more coherent.
+Greedy search is the default decoding strategy. It selects the next most likely token at each step. Unless specified in [`GenerationConfig`], this strategy generates a maximum of 20 tokens.
-This guide describes:
-* default generation configuration
-* common decoding strategies and their main parameters
-* saving and sharing custom generation configurations with your fine-tuned model on 🤗 Hub
+Greedy search works well for tasks with relatively short outputs. However, it breaks down when generating longer sequences because it begins to repeat itself.
-
+ -
+[Prompt lookup decoding](./llm_optims#prompt-lookup-decoding) is a variant of speculative decoding that uses overlapping n-grams as the candidate tokens. It works well for input-grounded tasks such as summarization. Refer to the [prompt lookup decoding](./llm_optims#prompt-lookup-decoding) guide to learn more.
-You can visualize how beam-search decoding works in [this interactive demo](https://huggingface.co/spaces/m-ric/beam_search_visualizer): type your input sentence, and play with the parameters to see how the decoding beams change.
+Enable prompt lookup decoding with the `prompt_lookup_num_tokens` parameter.
-To enable this decoding strategy, specify the `num_beams` (aka number of hypotheses to keep track of) that is greater than 1.
+```py
+import torch
+from transformers import AutoModelForCausalLM, AutoTokenizer
-```python
->>> from transformers import AutoModelForCausalLM, AutoTokenizer
+tokenizer = AutoTokenizer.from_pretrained("HuggingFaceTB/SmolLM-1.7B")
+model = AutoModelForCausalLM.from_pretrained("HuggingFaceTB/SmolLM-1.7B", torch_dtype=torch.float16).to("cuda")
+assistant_model = AutoModelForCausalLM.from_pretrained("HuggingFaceTB/SmolLM-135M", torch_dtype=torch.float16).to("cuda")
+inputs = tokenizer("Hugging Face is an open-source company", return_tensors="pt").to("cuda")
->>> prompt = "It is astonishing how one can"
->>> checkpoint = "openai-community/gpt2-medium"
-
->>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
->>> inputs = tokenizer(prompt, return_tensors="pt")
-
->>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
-
->>> outputs = model.generate(**inputs, num_beams=5, max_new_tokens=50)
->>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
-['It is astonishing how one can have such a profound impact on the lives of so many people in such a short period of
-time."\n\nHe added: "I am very proud of the work I have been able to do in the last few years.\n\n"I have']
+outputs = model.generate(**inputs, assistant_model=assistant_model, max_new_tokens=20, prompt_lookup_num_tokens=5)
+tokenizer.batch_decode(outputs, skip_special_tokens=True)
+'Hugging Face is an open-source company that provides a platform for developers to build and deploy machine learning models. It offers a variety of tools'
```
-### Beam-search multinomial sampling
+### Self-speculative decoding
-As the name implies, this decoding strategy combines beam search with multinomial sampling. You need to specify
-the `num_beams` greater than 1, and set `do_sample=True` to use this decoding strategy.
+Early exiting uses the earlier hidden states from the language modeling head as inputs, effectively skipping layers to yield a lower quality output. The lower quality output is used as the assistant output and self-speculation is applied to fix the output using the remaining layers. The final generated result from this self-speculative method is the same (or has the same distribution) as the original models generation.
-```python
->>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, set_seed
->>> set_seed(0) # For reproducibility
+The assistant model is also part of the target model, so the caches and weights can be shared, resulting in lower memory requirements.
->>> prompt = "translate English to German: The house is wonderful."
->>> checkpoint = "google-t5/t5-small"
+For a model trained with early exit, pass `assistant_early_exit` to [`~GenerationMixin.generate`].
->>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
->>> inputs = tokenizer(prompt, return_tensors="pt")
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer
->>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
+prompt = "Alice and Bob"
+checkpoint = "facebook/layerskip-llama3.2-1B"
->>> outputs = model.generate(**inputs, num_beams=5, do_sample=True)
->>> tokenizer.decode(outputs[0], skip_special_tokens=True)
-'Das Haus ist wunderbar.'
+tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+inputs = tokenizer(prompt, return_tensors="pt")
+
+model = AutoModelForCausalLM.from_pretrained(checkpoint)
+outputs = model.generate(**inputs, assistant_early_exit=4, do_sample=False, max_new_tokens=20)
+tokenizer.batch_decode(outputs, skip_special_tokens=True)
```
-### Diverse beam search decoding
+### Universal assisted decoding
-The diverse beam search decoding strategy is an extension of the beam search strategy that allows for generating a more diverse
-set of beam sequences to choose from. To learn how it works, refer to [Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models](https://arxiv.org/pdf/1610.02424.pdf).
-This approach has three main parameters: `num_beams`, `num_beam_groups`, and `diversity_penalty`.
-The diversity penalty ensures the outputs are distinct across groups, and beam search is used within each group.
+Universal assisted decoding (UAD) enables the main and assistant models to use different tokenizers. The main models input tokens are re-encoded into assistant model tokens. Candidate tokens are generated in the assistant encoding which are re-encoded into the main model candidate tokens. The candidate tokens are verified as explained in [speculative decoding](#speculative-decoding).
+Re-encoding involves decoding token ids into text and encoding the text with a different tokenizer. To prevent tokenization discrepancies during re-encoding, UAD finds the longest common sub-sequence between the source and target encodings to ensure the new tokens include the correct prompt suffix.
-```python
->>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
+Add the `tokenizer` and `assistant_tokenizer` parameters to [`~GenerationMixin.generate`] to enable UAD.
->>> checkpoint = "google/pegasus-xsum"
->>> prompt = (
-... "The Permaculture Design Principles are a set of universal design principles "
-... "that can be applied to any location, climate and culture, and they allow us to design "
-... "the most efficient and sustainable human habitation and food production systems. "
-... "Permaculture is a design system that encompasses a wide variety of disciplines, such "
-... "as ecology, landscape design, environmental science and energy conservation, and the "
-... "Permaculture design principles are drawn from these various disciplines. Each individual "
-... "design principle itself embodies a complete conceptual framework based on sound "
-... "scientific principles. When we bring all these separate principles together, we can "
-... "create a design system that both looks at whole systems, the parts that these systems "
-... "consist of, and how those parts interact with each other to create a complex, dynamic, "
-... "living system. Each design principle serves as a tool that allows us to integrate all "
-... "the separate parts of a design, referred to as elements, into a functional, synergistic, "
-... "whole system, where the elements harmoniously interact and work together in the most "
-... "efficient way possible."
-... )
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer
->>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
->>> inputs = tokenizer(prompt, return_tensors="pt")
+prompt = "Alice and Bob"
->>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
+assistant_tokenizer = AutoTokenizer.from_pretrained("double7/vicuna-68m")
+tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-9b")
+inputs = tokenizer(prompt, return_tensors="pt")
->>> outputs = model.generate(**inputs, num_beams=5, num_beam_groups=5, max_new_tokens=30, diversity_penalty=1.0)
->>> tokenizer.decode(outputs[0], skip_special_tokens=True)
-'The Design Principles are a set of universal design principles that can be applied to any location, climate and
-culture, and they allow us to design the'
+model = AutoModelForCausalLM.from_pretrained("google/gemma-2-9b")
+assistant_model = AutoModelForCausalLM.from_pretrained("double7/vicuna-68m")
+outputs = model.generate(**inputs, assistant_model=assistant_model, tokenizer=tokenizer, assistant_tokenizer=assistant_tokenizer)
+tokenizer.batch_decode(outputs, skip_special_tokens=True)
+['Alice and Bob are sitting in a bar. Alice is drinking a beer and Bob is drinking a']
```
-This guide illustrates the main parameters that enable various decoding strategies. More advanced parameters exist for the
-[`generate`] method, which gives you even further control over the [`generate`] method's behavior.
-For the complete list of the available parameters, refer to the [API documentation](./main_classes/text_generation).
+## DoLa
-### Speculative Decoding
+[Decoding by Contrasting Layers (DoLa)](https://hf.co/papers/2309.03883) is a contrastive decoding strategy for improving factuality and reducing hallucination. This strategy works by contrasting the logit diffferences between the final and early layers. As a result, factual knowledge localized to particular layers are amplified. DoLa is not recommended for smaller models like GPT-2.
-Speculative decoding (also known as assisted decoding) is a modification of the decoding strategies above, that uses an
-assistant model (ideally a much smaller one), to generate a few candidate tokens. The main model then validates the candidate
-tokens in a single forward pass, which speeds up the decoding process. If `do_sample=True`, then the token validation with
-resampling introduced in the [speculative decoding paper](https://arxiv.org/pdf/2211.17192.pdf) is used.
-Assisted decoding assumes the main and assistant models have the same tokenizer, otherwise, see Universal Assisted Decoding below.
+Enable DoLa with the following parameters.
-Currently, only greedy search and sampling are supported with assisted decoding, and assisted decoding doesn't support batched inputs.
-To learn more about assisted decoding, check [this blog post](https://huggingface.co/blog/assisted-generation).
+- `dola_layers` are the candidate layers to be contrasted with the final layer. It can be a string (`low` or `high`) to contrast the lower or higher parts of a layer. `high` is recommended for short-answer tasks like TruthfulQA. `low` is recommended for long-answer reasoning tasks like GSM8K, StrategyQA, FACTOR, and VicunaQA.
-To enable assisted decoding, set the `assistant_model` argument with a model.
+ When a model has tied word embeddings, layer 0 is skipped and it begins from layer 2.
-```python
->>> from transformers import AutoModelForCausalLM, AutoTokenizer
+ It can also be a list of integers that represent the layer indices between 0 and the total number of layers. Layer 0 is the word embedding, 1 is the first transformer layer, and so on. Refer to the table below for the range of layer indices depending on the number of model layers.
->>> prompt = "Alice and Bob"
->>> checkpoint = "EleutherAI/pythia-1.4b-deduped"
->>> assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
+ | layers | low | high |
+ |---|---|---|
+ | > 40 | (0, 20, 2) | (N - 20, N, 2) |
+ | <= 40 | range(0, N // 2, 2) | range(N // 2, N, 2) |
->>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
->>> inputs = tokenizer(prompt, return_tensors="pt")
+- `repetition_penalty` reduces repetition and it is recommended to set it to 1.2.
->>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
->>> assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
->>> outputs = model.generate(**inputs, assistant_model=assistant_model)
->>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
-['Alice and Bob are sitting in a bar. Alice is drinking a beer and Bob is drinking a glass of wine.']
+
-
+[Prompt lookup decoding](./llm_optims#prompt-lookup-decoding) is a variant of speculative decoding that uses overlapping n-grams as the candidate tokens. It works well for input-grounded tasks such as summarization. Refer to the [prompt lookup decoding](./llm_optims#prompt-lookup-decoding) guide to learn more.
-You can visualize how beam-search decoding works in [this interactive demo](https://huggingface.co/spaces/m-ric/beam_search_visualizer): type your input sentence, and play with the parameters to see how the decoding beams change.
+Enable prompt lookup decoding with the `prompt_lookup_num_tokens` parameter.
-To enable this decoding strategy, specify the `num_beams` (aka number of hypotheses to keep track of) that is greater than 1.
+```py
+import torch
+from transformers import AutoModelForCausalLM, AutoTokenizer
-```python
->>> from transformers import AutoModelForCausalLM, AutoTokenizer
+tokenizer = AutoTokenizer.from_pretrained("HuggingFaceTB/SmolLM-1.7B")
+model = AutoModelForCausalLM.from_pretrained("HuggingFaceTB/SmolLM-1.7B", torch_dtype=torch.float16).to("cuda")
+assistant_model = AutoModelForCausalLM.from_pretrained("HuggingFaceTB/SmolLM-135M", torch_dtype=torch.float16).to("cuda")
+inputs = tokenizer("Hugging Face is an open-source company", return_tensors="pt").to("cuda")
->>> prompt = "It is astonishing how one can"
->>> checkpoint = "openai-community/gpt2-medium"
-
->>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
->>> inputs = tokenizer(prompt, return_tensors="pt")
-
->>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
-
->>> outputs = model.generate(**inputs, num_beams=5, max_new_tokens=50)
->>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
-['It is astonishing how one can have such a profound impact on the lives of so many people in such a short period of
-time."\n\nHe added: "I am very proud of the work I have been able to do in the last few years.\n\n"I have']
+outputs = model.generate(**inputs, assistant_model=assistant_model, max_new_tokens=20, prompt_lookup_num_tokens=5)
+tokenizer.batch_decode(outputs, skip_special_tokens=True)
+'Hugging Face is an open-source company that provides a platform for developers to build and deploy machine learning models. It offers a variety of tools'
```
-### Beam-search multinomial sampling
+### Self-speculative decoding
-As the name implies, this decoding strategy combines beam search with multinomial sampling. You need to specify
-the `num_beams` greater than 1, and set `do_sample=True` to use this decoding strategy.
+Early exiting uses the earlier hidden states from the language modeling head as inputs, effectively skipping layers to yield a lower quality output. The lower quality output is used as the assistant output and self-speculation is applied to fix the output using the remaining layers. The final generated result from this self-speculative method is the same (or has the same distribution) as the original models generation.
-```python
->>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, set_seed
->>> set_seed(0) # For reproducibility
+The assistant model is also part of the target model, so the caches and weights can be shared, resulting in lower memory requirements.
->>> prompt = "translate English to German: The house is wonderful."
->>> checkpoint = "google-t5/t5-small"
+For a model trained with early exit, pass `assistant_early_exit` to [`~GenerationMixin.generate`].
->>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
->>> inputs = tokenizer(prompt, return_tensors="pt")
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer
->>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
+prompt = "Alice and Bob"
+checkpoint = "facebook/layerskip-llama3.2-1B"
->>> outputs = model.generate(**inputs, num_beams=5, do_sample=True)
->>> tokenizer.decode(outputs[0], skip_special_tokens=True)
-'Das Haus ist wunderbar.'
+tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+inputs = tokenizer(prompt, return_tensors="pt")
+
+model = AutoModelForCausalLM.from_pretrained(checkpoint)
+outputs = model.generate(**inputs, assistant_early_exit=4, do_sample=False, max_new_tokens=20)
+tokenizer.batch_decode(outputs, skip_special_tokens=True)
```
-### Diverse beam search decoding
+### Universal assisted decoding
-The diverse beam search decoding strategy is an extension of the beam search strategy that allows for generating a more diverse
-set of beam sequences to choose from. To learn how it works, refer to [Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models](https://arxiv.org/pdf/1610.02424.pdf).
-This approach has three main parameters: `num_beams`, `num_beam_groups`, and `diversity_penalty`.
-The diversity penalty ensures the outputs are distinct across groups, and beam search is used within each group.
+Universal assisted decoding (UAD) enables the main and assistant models to use different tokenizers. The main models input tokens are re-encoded into assistant model tokens. Candidate tokens are generated in the assistant encoding which are re-encoded into the main model candidate tokens. The candidate tokens are verified as explained in [speculative decoding](#speculative-decoding).
+Re-encoding involves decoding token ids into text and encoding the text with a different tokenizer. To prevent tokenization discrepancies during re-encoding, UAD finds the longest common sub-sequence between the source and target encodings to ensure the new tokens include the correct prompt suffix.
-```python
->>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
+Add the `tokenizer` and `assistant_tokenizer` parameters to [`~GenerationMixin.generate`] to enable UAD.
->>> checkpoint = "google/pegasus-xsum"
->>> prompt = (
-... "The Permaculture Design Principles are a set of universal design principles "
-... "that can be applied to any location, climate and culture, and they allow us to design "
-... "the most efficient and sustainable human habitation and food production systems. "
-... "Permaculture is a design system that encompasses a wide variety of disciplines, such "
-... "as ecology, landscape design, environmental science and energy conservation, and the "
-... "Permaculture design principles are drawn from these various disciplines. Each individual "
-... "design principle itself embodies a complete conceptual framework based on sound "
-... "scientific principles. When we bring all these separate principles together, we can "
-... "create a design system that both looks at whole systems, the parts that these systems "
-... "consist of, and how those parts interact with each other to create a complex, dynamic, "
-... "living system. Each design principle serves as a tool that allows us to integrate all "
-... "the separate parts of a design, referred to as elements, into a functional, synergistic, "
-... "whole system, where the elements harmoniously interact and work together in the most "
-... "efficient way possible."
-... )
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer
->>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
->>> inputs = tokenizer(prompt, return_tensors="pt")
+prompt = "Alice and Bob"
->>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
+assistant_tokenizer = AutoTokenizer.from_pretrained("double7/vicuna-68m")
+tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-9b")
+inputs = tokenizer(prompt, return_tensors="pt")
->>> outputs = model.generate(**inputs, num_beams=5, num_beam_groups=5, max_new_tokens=30, diversity_penalty=1.0)
->>> tokenizer.decode(outputs[0], skip_special_tokens=True)
-'The Design Principles are a set of universal design principles that can be applied to any location, climate and
-culture, and they allow us to design the'
+model = AutoModelForCausalLM.from_pretrained("google/gemma-2-9b")
+assistant_model = AutoModelForCausalLM.from_pretrained("double7/vicuna-68m")
+outputs = model.generate(**inputs, assistant_model=assistant_model, tokenizer=tokenizer, assistant_tokenizer=assistant_tokenizer)
+tokenizer.batch_decode(outputs, skip_special_tokens=True)
+['Alice and Bob are sitting in a bar. Alice is drinking a beer and Bob is drinking a']
```
-This guide illustrates the main parameters that enable various decoding strategies. More advanced parameters exist for the
-[`generate`] method, which gives you even further control over the [`generate`] method's behavior.
-For the complete list of the available parameters, refer to the [API documentation](./main_classes/text_generation).
+## DoLa
-### Speculative Decoding
+[Decoding by Contrasting Layers (DoLa)](https://hf.co/papers/2309.03883) is a contrastive decoding strategy for improving factuality and reducing hallucination. This strategy works by contrasting the logit diffferences between the final and early layers. As a result, factual knowledge localized to particular layers are amplified. DoLa is not recommended for smaller models like GPT-2.
-Speculative decoding (also known as assisted decoding) is a modification of the decoding strategies above, that uses an
-assistant model (ideally a much smaller one), to generate a few candidate tokens. The main model then validates the candidate
-tokens in a single forward pass, which speeds up the decoding process. If `do_sample=True`, then the token validation with
-resampling introduced in the [speculative decoding paper](https://arxiv.org/pdf/2211.17192.pdf) is used.
-Assisted decoding assumes the main and assistant models have the same tokenizer, otherwise, see Universal Assisted Decoding below.
+Enable DoLa with the following parameters.
-Currently, only greedy search and sampling are supported with assisted decoding, and assisted decoding doesn't support batched inputs.
-To learn more about assisted decoding, check [this blog post](https://huggingface.co/blog/assisted-generation).
+- `dola_layers` are the candidate layers to be contrasted with the final layer. It can be a string (`low` or `high`) to contrast the lower or higher parts of a layer. `high` is recommended for short-answer tasks like TruthfulQA. `low` is recommended for long-answer reasoning tasks like GSM8K, StrategyQA, FACTOR, and VicunaQA.
-To enable assisted decoding, set the `assistant_model` argument with a model.
+ When a model has tied word embeddings, layer 0 is skipped and it begins from layer 2.
-```python
->>> from transformers import AutoModelForCausalLM, AutoTokenizer
+ It can also be a list of integers that represent the layer indices between 0 and the total number of layers. Layer 0 is the word embedding, 1 is the first transformer layer, and so on. Refer to the table below for the range of layer indices depending on the number of model layers.
->>> prompt = "Alice and Bob"
->>> checkpoint = "EleutherAI/pythia-1.4b-deduped"
->>> assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
+ | layers | low | high |
+ |---|---|---|
+ | > 40 | (0, 20, 2) | (N - 20, N, 2) |
+ | <= 40 | range(0, N // 2, 2) | range(N // 2, N, 2) |
->>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
->>> inputs = tokenizer(prompt, return_tensors="pt")
+- `repetition_penalty` reduces repetition and it is recommended to set it to 1.2.
->>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
->>> assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
->>> outputs = model.generate(**inputs, assistant_model=assistant_model)
->>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
-['Alice and Bob are sitting in a bar. Alice is drinking a beer and Bob is drinking a glass of wine.']
+
+  +
+
-This file format is designed as a "single-file-format" where a single file usually contains both the configuration
-attributes, the tokenizer vocabulary and other attributes, as well as all tensors to be loaded in the model. These
-files come in different formats according to the quantization type of the file. We briefly go over some of them
-[here](https://huggingface.co/docs/hub/en/gguf#quantization-types).
+The GGUF format also supports many quantized data types (refer to [quantization type table](https://hf.co/docs/hub/en/gguf#quantization-types) for a complete list of supported quantization types) which saves a significant amount of memory, making inference with large models like Whisper and Llama feasible on local and edge devices.
-## Support within Transformers
+Transformers supports loading models stored in the GGUF format for further training or finetuning. The GGUF format is dequantized to fp32 where the full model weights are available and compatible with PyTorch.
-We have added the ability to load `gguf` files within `transformers` in order to offer further training/fine-tuning
-capabilities to gguf models, before converting back those models to `gguf` to use within the `ggml` ecosystem. When
-loading a model, we first dequantize it to fp32, before loading the weights to be used in PyTorch.
+> [!TIP]
+> Models that support GGUF include Llama, Mistral, Qwen2, Qwen2Moe, Phi3, Bloom, Falcon, StableLM, GPT2, and Starcoder2.
-> [!NOTE]
-> The support is still very exploratory and we welcome contributions in order to solidify it across quantization types
-> and model architectures.
-
-For now, here are the supported model architectures and quantization types:
-
-### Supported quantization types
-
-The initial supported quantization types are decided according to the popular quantized files that have been shared
-on the Hub.
-
-- F32
-- F16
-- BF16
-- Q4_0
-- Q4_1
-- Q5_0
-- Q5_1
-- Q8_0
-- Q2_K
-- Q3_K
-- Q4_K
-- Q5_K
-- Q6_K
-- IQ1_S
-- IQ1_M
-- IQ2_XXS
-- IQ2_XS
-- IQ2_S
-- IQ3_XXS
-- IQ3_S
-- IQ4_XS
-- IQ4_NL
-
-> [!NOTE]
-> To support gguf dequantization, `gguf>=0.10.0` installation is required.
-
-### Supported model architectures
-
-For now the supported model architectures are the architectures that have been very popular on the Hub, namely:
-
-- LLaMa
-- Mistral
-- Qwen2
-- Qwen2Moe
-- Phi3
-- Bloom
-- Falcon
-- StableLM
-- GPT2
-- Starcoder2
-- T5
-- Mamba
-- Nemotron
-- Gemma2
-
-## Example usage
-
-In order to load `gguf` files in `transformers`, you should specify the `gguf_file` argument to the `from_pretrained`
-methods of both tokenizers and models. Here is how one would load a tokenizer and a model, which can be loaded
-from the exact same file:
+Add the `gguf_file` parameter to [`~PreTrainedModel.from_pretrained`] to specify the GGUF file to load.
```py
from transformers import AutoTokenizer, AutoModelForCausalLM
@@ -106,17 +41,11 @@ tokenizer = AutoTokenizer.from_pretrained(model_id, gguf_file=filename)
model = AutoModelForCausalLM.from_pretrained(model_id, gguf_file=filename)
```
-Now you have access to the full, unquantized version of the model in the PyTorch ecosystem, where you can combine it
-with a plethora of other tools.
-
-In order to convert back to a `gguf` file, we recommend using the
-[`convert-hf-to-gguf.py` file](https://github.com/ggerganov/llama.cpp/blob/master/convert_hf_to_gguf.py) from llama.cpp.
-
-Here's how you would complete the script above to save the model and export it back to `gguf`:
+Once you're done tinkering with the model, save and convert it back to the GGUF format with the [convert-hf-to-gguf.py](https://github.com/ggerganov/llama.cpp/blob/master/convert_hf_to_gguf.py) script.
```py
-tokenizer.save_pretrained('directory')
-model.save_pretrained('directory')
+tokenizer.save_pretrained("directory")
+model.save_pretrained("directory")
!python ${path_to_llama_cpp}/convert-hf-to-gguf.py ${directory}
```
diff --git a/docs/source/en/gpu_selection.md b/docs/source/en/gpu_selection.md
new file mode 100644
index 0000000000..749fcf3c2d
--- /dev/null
+++ b/docs/source/en/gpu_selection.md
@@ -0,0 +1,94 @@
+
+
+# GPU selection
+
+During distributed training, you can specify the number of GPUs to use and in what order. This can be useful when you have GPUs with different computing power and you want to use the faster GPU first. Or you could only use a subset of the available GPUs. The selection process works for both [DistributedDataParallel](https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html) and [DataParallel](https://pytorch.org/docs/stable/generated/torch.nn.DataParallel.html). You don't need Accelerate or [DeepSpeed integration](./main_classes/deepspeed).
+
+This guide will show you how to select the number of GPUs to use and the order to use them in.
+
+## Number of GPUs
+
+For example, if there are 4 GPUs and you only want to use the first 2, run the command below.
+
+
+
+
+
+## Preprocess
+
+Transformers' vision models expects the input as PyTorch tensors of pixel values. An image processor handles the conversion of images to pixel values, which is represented by the batch size, number of channels, height, and width. To achieve this, an image is resized (center cropped) and the pixel values are normalized and rescaled to the models expected values.
+
+Image preprocessing is not the same as *image augmentation*. Image augmentation makes changes (brightness, colors, rotatation, etc.) to an image for the purpose of either creating new training examples or prevent overfitting. Image preprocessing makes changes to an image for the purpose of matching a pretrained model's expected input format.
+
+Typically, images are augmented (to increase performance) and then preprocessed before being passed to a model. You can use any library ([Albumentations](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_albumentations.ipynb), [Kornia](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_kornia.ipynb)) for augmentation and an image processor for preprocessing.
+
+This guide uses the torchvision [transforms](https://pytorch.org/vision/stable/transforms.html) module for augmentation.
+
+Start by loading a small sample of the [food101](https://hf.co/datasets/food101) dataset.
+
+```py
+from datasets import load_dataset
+
+dataset = load_dataset("food101", split="train[:100]")
+```
+
+From the [transforms](https://pytorch.org/vision/stable/transforms.html) module, use the [Compose](https://pytorch.org/vision/master/generated/torchvision.transforms.Compose.html) API to chain together [RandomResizedCrop](https://pytorch.org/vision/main/generated/torchvision.transforms.RandomResizedCrop.html) and [ColorJitter](https://pytorch.org/vision/main/generated/torchvision.transforms.ColorJitter.html). These transforms randomly crop and resize an image, and randomly adjusts an images colors.
+
+The image size to randomly crop to can be retrieved from the image processor. For some models, an exact height and width are expected while for others, only the `shortest_edge` is required.
+
+```py
+from torchvision.transforms import RandomResizedCrop, ColorJitter, Compose
+
+size = (
+ image_processor.size["shortest_edge"]
+ if "shortest_edge" in image_processor.size
+ else (image_processor.size["height"], image_processor.size["width"])
+)
+_transforms = Compose([RandomResizedCrop(size), ColorJitter(brightness=0.5, hue=0.5)])
+```
+
+Apply the transforms to the images and convert them to the RGB format. Then pass the augmented images to the image processor to return the pixel values.
+
+The `do_resize` parameter is set to `False` because the images have already been resized in the augmentation step by [RandomResizedCrop](https://pytorch.org/vision/main/generated/torchvision.transforms.RandomResizedCrop.html). If you don't augment the images, then the image processor automatically resizes and normalizes the images with the `image_mean` and `image_std` values. These values are found in the preprocessor configuration file.
+
+```py
+def transforms(examples):
+ images = [_transforms(img.convert("RGB")) for img in examples["image"]]
+ examples["pixel_values"] = image_processor(images, do_resize=False, return_tensors="pt")["pixel_values"]
+ return examples
+```
+
+Apply the combined augmentation and preprocessing function to the entire dataset on the fly with [`~datasets.Dataset.set_transform`].
+
+```py
+dataset.set_transform(transforms)
+```
+
+Convert the pixel values back into an image to see how the image has been augmented and preprocessed.
+
+```py
+import numpy as np
+import matplotlib.pyplot as plt
+
+img = dataset[0]["pixel_values"]
+plt.imshow(img.permute(1, 2, 0))
+```
+
+Benchmarks
+ +The benchmarks are obtained from an [AWS EC2 g5.2xlarge](https://aws.amazon.com/ec2/instance-types/g5/) instance with a NVIDIA A10G Tensor Core GPU. + +
+  +
+
+
+
+  +
+
+
+
+  +
+
+
+
+  +
+
+
+
+
+
+For other vision tasks like object detection or segmentation, the image processor includes post-processing methods to convert a models raw output into meaningful predictions like bounding boxes or segmentation maps.
+
+### Padding
+
+Some models, like [DETR](./model_doc/detr), applies [scale augmentation](https://paperswithcode.com/method/image-scale-augmentation) during training which can cause images in a batch to have different sizes. Images with different sizes can't be batched together.
+
+To fix this, pad the images with the special padding token `0`. Use the [pad](https://github.com/huggingface/transformers/blob/9578c2597e2d88b6f0b304b5a05864fd613ddcc1/src/transformers/models/detr/image_processing_detr.py#L1151) method to pad the images, and define a custom collate function to batch them together.
+
+```py
+def collate_fn(batch):
+ pixel_values = [item["pixel_values"] for item in batch]
+ encoding = image_processor.pad(pixel_values, return_tensors="pt")
+ labels = [item["labels"] for item in batch]
+ batch = {}
+ batch["pixel_values"] = encoding["pixel_values"]
+ batch["pixel_mask"] = encoding["pixel_mask"]
+ batch["labels"] = labels
+ return batch
+```
diff --git a/docs/source/en/index.md b/docs/source/en/index.md
index a6961b06a4..8120e12937 100644
--- a/docs/source/en/index.md
+++ b/docs/source/en/index.md
@@ -1,4 +1,4 @@
-
-# 🤗 Transformers
+# Transformers
-State-of-the-art Machine Learning for [PyTorch](https://pytorch.org/), [TensorFlow](https://www.tensorflow.org/), and [JAX](https://jax.readthedocs.io/en/latest/).
+Transformers is a library of pretrained natural language processing, computer vision, audio, and multimodal models for inference and training. Use Transformers to train models on your data, build inference applications, and generate text with large language models.
-🤗 Transformers provides APIs and tools to easily download and train state-of-the-art pretrained models. Using pretrained models can reduce your compute costs, carbon footprint, and save you the time and resources required to train a model from scratch. These models support common tasks in different modalities, such as:
+Explore the [Hugging Face Hub](https://huggingface.com) today to find a model and use Transformers to help you get started right away.
-📝 **Natural Language Processing**: text classification, named entity recognition, question answering, language modeling, code generation, summarization, translation, multiple choice, and text generation.
+  +
+ before
+
+
+
+  +
+ after
+
+
+ -🖼️ **Computer Vision**: image classification, object detection, and segmentation.
-🗣️ **Audio**: automatic speech recognition and audio classification.
-🐙 **Multimodal**: table question answering, optical character recognition, information extraction from scanned documents, video classification, and visual question answering. +## Features -🤗 Transformers support framework interoperability between PyTorch, TensorFlow, and JAX. This provides the flexibility to use a different framework at each stage of a model's life; train a model in three lines of code in one framework, and load it for inference in another. Models can also be exported to a format like ONNX and TorchScript for deployment in production environments. +Transformers provides everything you need for inference or training with state-of-the-art pretrained models. Some of the main features include: -Join the growing community on the [Hub](https://huggingface.co/models), [forum](https://discuss.huggingface.co/), or [Discord](https://discord.com/invite/JfAtkvEtRb) today! +- [Pipeline](./pipeline_tutorial): Simple and optimized inference class for many machine learning tasks like text generation, image segmentation, automatic speech recognition, document question answering, and more. +- [Trainer](./trainer): A comprehensive trainer that supports features such as mixed precision, torch.compile, and FlashAttention for training and distributed training for PyTorch models. +- [generate](./llm_tutorial): Fast text generation with large language models (LLMs) and vision language models (VLMs), including support for streaming and multiple decoding strategies. -## If you are looking for custom support from the Hugging Face team +## Design - -
 -
+> [!TIP]
+> Read our [Philosophy](./philosophy) to learn more about Transformers' design principles.
-## Contents
+Transformers is designed for developers and machine learning engineers and researchers. Its main design principles are:
-The documentation is organized into five sections:
+1. Fast and easy to use: Every model is implemented from only three main classes (configuration, model, and preprocessor) and can be quickly used for inference or training with [`Pipeline`] or [`Trainer`].
+2. Pretrained models: Reduce your carbon footprint, compute cost and time by using a pretrained model instead of training an entirely new one. Each pretrained model is reproduced as closely as possible to the original model and offers state-of-the-art performance.
-- **GET STARTED** provides a quick tour of the library and installation instructions to get up and running.
-- **TUTORIALS** are a great place to start if you're a beginner. This section will help you gain the basic skills you need to start using the library.
-- **HOW-TO GUIDES** show you how to achieve a specific goal, like finetuning a pretrained model for language modeling or how to write and share a custom model.
-- **CONCEPTUAL GUIDES** offers more discussion and explanation of the underlying concepts and ideas behind models, tasks, and the design philosophy of 🤗 Transformers.
-- **API** describes all classes and functions:
+
-
+> [!TIP]
+> Read our [Philosophy](./philosophy) to learn more about Transformers' design principles.
-## Contents
+Transformers is designed for developers and machine learning engineers and researchers. Its main design principles are:
-The documentation is organized into five sections:
+1. Fast and easy to use: Every model is implemented from only three main classes (configuration, model, and preprocessor) and can be quickly used for inference or training with [`Pipeline`] or [`Trainer`].
+2. Pretrained models: Reduce your carbon footprint, compute cost and time by using a pretrained model instead of training an entirely new one. Each pretrained model is reproduced as closely as possible to the original model and offers state-of-the-art performance.
-- **GET STARTED** provides a quick tour of the library and installation instructions to get up and running.
-- **TUTORIALS** are a great place to start if you're a beginner. This section will help you gain the basic skills you need to start using the library.
-- **HOW-TO GUIDES** show you how to achieve a specific goal, like finetuning a pretrained model for language modeling or how to write and share a custom model.
-- **CONCEPTUAL GUIDES** offers more discussion and explanation of the underlying concepts and ideas behind models, tasks, and the design philosophy of 🤗 Transformers.
-- **API** describes all classes and functions:
+
+
+  +
+
+
+
- - **MAIN CLASSES** details the most important classes like configuration, model, tokenizer, and pipeline.
- - **MODELS** details the classes and functions related to each model implemented in the library.
- - **INTERNAL HELPERS** details utility classes and functions used internally.
-
-
-## Supported models and frameworks
-
-The table below represents the current support in the library for each of those models, whether they have a Python
-tokenizer (called "slow"). A "fast" tokenizer backed by the 🤗 Tokenizers library, whether they have support in Jax (via
-Flax), PyTorch, and/or TensorFlow.
-
-
-
-| Model | PyTorch support | TensorFlow support | Flax Support |
-|:------------------------------------------------------------------------:|:---------------:|:------------------:|:------------:|
-| [ALBERT](model_doc/albert) | ✅ | ✅ | ✅ |
-| [ALIGN](model_doc/align) | ✅ | ❌ | ❌ |
-| [AltCLIP](model_doc/altclip) | ✅ | ❌ | ❌ |
-| [Aria](model_doc/aria) | ✅ | ❌ | ❌ |
-| [AriaText](model_doc/aria_text) | ✅ | ❌ | ❌ |
-| [Audio Spectrogram Transformer](model_doc/audio-spectrogram-transformer) | ✅ | ❌ | ❌ |
-| [Autoformer](model_doc/autoformer) | ✅ | ❌ | ❌ |
-| [Bamba](model_doc/bamba) | ✅ | ❌ | ❌ |
-| [Bark](model_doc/bark) | ✅ | ❌ | ❌ |
-| [BART](model_doc/bart) | ✅ | ✅ | ✅ |
-| [BARThez](model_doc/barthez) | ✅ | ✅ | ✅ |
-| [BARTpho](model_doc/bartpho) | ✅ | ✅ | ✅ |
-| [BEiT](model_doc/beit) | ✅ | ❌ | ✅ |
-| [BERT](model_doc/bert) | ✅ | ✅ | ✅ |
-| [Bert Generation](model_doc/bert-generation) | ✅ | ❌ | ❌ |
-| [BertJapanese](model_doc/bert-japanese) | ✅ | ✅ | ✅ |
-| [BERTweet](model_doc/bertweet) | ✅ | ✅ | ✅ |
-| [BigBird](model_doc/big_bird) | ✅ | ❌ | ✅ |
-| [BigBird-Pegasus](model_doc/bigbird_pegasus) | ✅ | ❌ | ❌ |
-| [BioGpt](model_doc/biogpt) | ✅ | ❌ | ❌ |
-| [BiT](model_doc/bit) | ✅ | ❌ | ❌ |
-| [Blenderbot](model_doc/blenderbot) | ✅ | ✅ | ✅ |
-| [BlenderbotSmall](model_doc/blenderbot-small) | ✅ | ✅ | ✅ |
-| [BLIP](model_doc/blip) | ✅ | ✅ | ❌ |
-| [BLIP-2](model_doc/blip-2) | ✅ | ❌ | ❌ |
-| [BLOOM](model_doc/bloom) | ✅ | ❌ | ✅ |
-| [BORT](model_doc/bort) | ✅ | ✅ | ✅ |
-| [BridgeTower](model_doc/bridgetower) | ✅ | ❌ | ❌ |
-| [BROS](model_doc/bros) | ✅ | ❌ | ❌ |
-| [ByT5](model_doc/byt5) | ✅ | ✅ | ✅ |
-| [CamemBERT](model_doc/camembert) | ✅ | ✅ | ❌ |
-| [CANINE](model_doc/canine) | ✅ | ❌ | ❌ |
-| [Chameleon](model_doc/chameleon) | ✅ | ❌ | ❌ |
-| [Chinese-CLIP](model_doc/chinese_clip) | ✅ | ❌ | ❌ |
-| [CLAP](model_doc/clap) | ✅ | ❌ | ❌ |
-| [CLIP](model_doc/clip) | ✅ | ✅ | ✅ |
-| [CLIPSeg](model_doc/clipseg) | ✅ | ❌ | ❌ |
-| [CLVP](model_doc/clvp) | ✅ | ❌ | ❌ |
-| [CodeGen](model_doc/codegen) | ✅ | ❌ | ❌ |
-| [CodeLlama](model_doc/code_llama) | ✅ | ❌ | ✅ |
-| [Cohere](model_doc/cohere) | ✅ | ❌ | ❌ |
-| [Cohere2](model_doc/cohere2) | ✅ | ❌ | ❌ |
-| [ColPali](model_doc/colpali) | ✅ | ❌ | ❌ |
-| [Conditional DETR](model_doc/conditional_detr) | ✅ | ❌ | ❌ |
-| [ConvBERT](model_doc/convbert) | ✅ | ✅ | ❌ |
-| [ConvNeXT](model_doc/convnext) | ✅ | ✅ | ❌ |
-| [ConvNeXTV2](model_doc/convnextv2) | ✅ | ✅ | ❌ |
-| [CPM](model_doc/cpm) | ✅ | ✅ | ✅ |
-| [CPM-Ant](model_doc/cpmant) | ✅ | ❌ | ❌ |
-| [CTRL](model_doc/ctrl) | ✅ | ✅ | ❌ |
-| [CvT](model_doc/cvt) | ✅ | ✅ | ❌ |
-| [DAB-DETR](model_doc/dab-detr) | ✅ | ❌ | ❌ |
-| [DAC](model_doc/dac) | ✅ | ❌ | ❌ |
-| [Data2VecAudio](model_doc/data2vec) | ✅ | ❌ | ❌ |
-| [Data2VecText](model_doc/data2vec) | ✅ | ❌ | ❌ |
-| [Data2VecVision](model_doc/data2vec) | ✅ | ✅ | ❌ |
-| [DBRX](model_doc/dbrx) | ✅ | ❌ | ❌ |
-| [DeBERTa](model_doc/deberta) | ✅ | ✅ | ❌ |
-| [DeBERTa-v2](model_doc/deberta-v2) | ✅ | ✅ | ❌ |
-| [Decision Transformer](model_doc/decision_transformer) | ✅ | ❌ | ❌ |
-| [Deformable DETR](model_doc/deformable_detr) | ✅ | ❌ | ❌ |
-| [DeiT](model_doc/deit) | ✅ | ✅ | ❌ |
-| [DePlot](model_doc/deplot) | ✅ | ❌ | ❌ |
-| [Depth Anything](model_doc/depth_anything) | ✅ | ❌ | ❌ |
-| [DepthPro](model_doc/depth_pro) | ✅ | ❌ | ❌ |
-| [DETA](model_doc/deta) | ✅ | ❌ | ❌ |
-| [DETR](model_doc/detr) | ✅ | ❌ | ❌ |
-| [DialoGPT](model_doc/dialogpt) | ✅ | ✅ | ✅ |
-| [DiffLlama](model_doc/diffllama) | ✅ | ❌ | ❌ |
-| [DiNAT](model_doc/dinat) | ✅ | ❌ | ❌ |
-| [DINOv2](model_doc/dinov2) | ✅ | ❌ | ✅ |
-| [DINOv2 with Registers](model_doc/dinov2_with_registers) | ✅ | ❌ | ❌ |
-| [DistilBERT](model_doc/distilbert) | ✅ | ✅ | ✅ |
-| [DiT](model_doc/dit) | ✅ | ❌ | ✅ |
-| [DonutSwin](model_doc/donut) | ✅ | ❌ | ❌ |
-| [DPR](model_doc/dpr) | ✅ | ✅ | ❌ |
-| [DPT](model_doc/dpt) | ✅ | ❌ | ❌ |
-| [EfficientFormer](model_doc/efficientformer) | ✅ | ✅ | ❌ |
-| [EfficientNet](model_doc/efficientnet) | ✅ | ❌ | ❌ |
-| [ELECTRA](model_doc/electra) | ✅ | ✅ | ✅ |
-| [Emu3](model_doc/emu3) | ✅ | ❌ | ❌ |
-| [EnCodec](model_doc/encodec) | ✅ | ❌ | ❌ |
-| [Encoder decoder](model_doc/encoder-decoder) | ✅ | ✅ | ✅ |
-| [ERNIE](model_doc/ernie) | ✅ | ❌ | ❌ |
-| [ErnieM](model_doc/ernie_m) | ✅ | ❌ | ❌ |
-| [ESM](model_doc/esm) | ✅ | ✅ | ❌ |
-| [FairSeq Machine-Translation](model_doc/fsmt) | ✅ | ❌ | ❌ |
-| [Falcon](model_doc/falcon) | ✅ | ❌ | ❌ |
-| [Falcon3](model_doc/falcon3) | ✅ | ❌ | ✅ |
-| [FalconMamba](model_doc/falcon_mamba) | ✅ | ❌ | ❌ |
-| [FastSpeech2Conformer](model_doc/fastspeech2_conformer) | ✅ | ❌ | ❌ |
-| [FLAN-T5](model_doc/flan-t5) | ✅ | ✅ | ✅ |
-| [FLAN-UL2](model_doc/flan-ul2) | ✅ | ✅ | ✅ |
-| [FlauBERT](model_doc/flaubert) | ✅ | ✅ | ❌ |
-| [FLAVA](model_doc/flava) | ✅ | ❌ | ❌ |
-| [FNet](model_doc/fnet) | ✅ | ❌ | ❌ |
-| [FocalNet](model_doc/focalnet) | ✅ | ❌ | ❌ |
-| [Funnel Transformer](model_doc/funnel) | ✅ | ✅ | ❌ |
-| [Fuyu](model_doc/fuyu) | ✅ | ❌ | ❌ |
-| [Gemma](model_doc/gemma) | ✅ | ❌ | ✅ |
-| [Gemma2](model_doc/gemma2) | ✅ | ❌ | ❌ |
-| [GIT](model_doc/git) | ✅ | ❌ | ❌ |
-| [GLM](model_doc/glm) | ✅ | ❌ | ❌ |
-| [GLPN](model_doc/glpn) | ✅ | ❌ | ❌ |
-| [GOT-OCR2](model_doc/got_ocr2) | ✅ | ❌ | ❌ |
-| [GPT Neo](model_doc/gpt_neo) | ✅ | ❌ | ✅ |
-| [GPT NeoX](model_doc/gpt_neox) | ✅ | ❌ | ❌ |
-| [GPT NeoX Japanese](model_doc/gpt_neox_japanese) | ✅ | ❌ | ❌ |
-| [GPT-J](model_doc/gptj) | ✅ | ✅ | ✅ |
-| [GPT-Sw3](model_doc/gpt-sw3) | ✅ | ✅ | ✅ |
-| [GPTBigCode](model_doc/gpt_bigcode) | ✅ | ❌ | ❌ |
-| [GPTSAN-japanese](model_doc/gptsan-japanese) | ✅ | ❌ | ❌ |
-| [Granite](model_doc/granite) | ✅ | ❌ | ❌ |
-| [GraniteMoeMoe](model_doc/granitemoe) | ✅ | ❌ | ❌ |
-| [GraniteMoeSharedMoe](model_doc/granitemoeshared) | ✅ | ❌ | ❌ |
-| [Graphormer](model_doc/graphormer) | ✅ | ❌ | ❌ |
-| [Grounding DINO](model_doc/grounding-dino) | ✅ | ❌ | ❌ |
-| [GroupViT](model_doc/groupvit) | ✅ | ✅ | ❌ |
-| [Helium](model_doc/helium) | ✅ | ❌ | ❌ |
-| [HerBERT](model_doc/herbert) | ✅ | ✅ | ✅ |
-| [Hiera](model_doc/hiera) | ✅ | ❌ | ❌ |
-| [Hubert](model_doc/hubert) | ✅ | ✅ | ❌ |
-| [I-BERT](model_doc/ibert) | ✅ | ❌ | ❌ |
-| [I-JEPA](model_doc/ijepa) | ✅ | ❌ | ❌ |
-| [IDEFICS](model_doc/idefics) | ✅ | ✅ | ❌ |
-| [Idefics2](model_doc/idefics2) | ✅ | ❌ | ❌ |
-| [Idefics3](model_doc/idefics3) | ✅ | ❌ | ❌ |
-| [Idefics3VisionTransformer](model_doc/idefics3_vision) | ❌ | ❌ | ❌ |
-| [ImageGPT](model_doc/imagegpt) | ✅ | ❌ | ❌ |
-| [Informer](model_doc/informer) | ✅ | ❌ | ❌ |
-| [InstructBLIP](model_doc/instructblip) | ✅ | ❌ | ❌ |
-| [InstructBlipVideo](model_doc/instructblipvideo) | ✅ | ❌ | ❌ |
-| [Jamba](model_doc/jamba) | ✅ | ❌ | ❌ |
-| [JetMoe](model_doc/jetmoe) | ✅ | ❌ | ❌ |
-| [Jukebox](model_doc/jukebox) | ✅ | ❌ | ❌ |
-| [KOSMOS-2](model_doc/kosmos-2) | ✅ | ❌ | ❌ |
-| [LayoutLM](model_doc/layoutlm) | ✅ | ✅ | ❌ |
-| [LayoutLMv2](model_doc/layoutlmv2) | ✅ | ❌ | ❌ |
-| [LayoutLMv3](model_doc/layoutlmv3) | ✅ | ✅ | ❌ |
-| [LayoutXLM](model_doc/layoutxlm) | ✅ | ❌ | ❌ |
-| [LED](model_doc/led) | ✅ | ✅ | ❌ |
-| [LeViT](model_doc/levit) | ✅ | ❌ | ❌ |
-| [LiLT](model_doc/lilt) | ✅ | ❌ | ❌ |
-| [LLaMA](model_doc/llama) | ✅ | ❌ | ✅ |
-| [Llama2](model_doc/llama2) | ✅ | ❌ | ✅ |
-| [Llama3](model_doc/llama3) | ✅ | ❌ | ✅ |
-| [LLaVa](model_doc/llava) | ✅ | ❌ | ❌ |
-| [LLaVA-NeXT](model_doc/llava_next) | ✅ | ❌ | ❌ |
-| [LLaVa-NeXT-Video](model_doc/llava_next_video) | ✅ | ❌ | ❌ |
-| [LLaVA-Onevision](model_doc/llava_onevision) | ✅ | ❌ | ❌ |
-| [Longformer](model_doc/longformer) | ✅ | ✅ | ❌ |
-| [LongT5](model_doc/longt5) | ✅ | ❌ | ✅ |
-| [LUKE](model_doc/luke) | ✅ | ❌ | ❌ |
-| [LXMERT](model_doc/lxmert) | ✅ | ✅ | ❌ |
-| [M-CTC-T](model_doc/mctct) | ✅ | ❌ | ❌ |
-| [M2M100](model_doc/m2m_100) | ✅ | ❌ | ❌ |
-| [MADLAD-400](model_doc/madlad-400) | ✅ | ✅ | ✅ |
-| [Mamba](model_doc/mamba) | ✅ | ❌ | ❌ |
-| [mamba2](model_doc/mamba2) | ✅ | ❌ | ❌ |
-| [Marian](model_doc/marian) | ✅ | ✅ | ✅ |
-| [MarkupLM](model_doc/markuplm) | ✅ | ❌ | ❌ |
-| [Mask2Former](model_doc/mask2former) | ✅ | ❌ | ❌ |
-| [MaskFormer](model_doc/maskformer) | ✅ | ❌ | ❌ |
-| [MatCha](model_doc/matcha) | ✅ | ❌ | ❌ |
-| [mBART](model_doc/mbart) | ✅ | ✅ | ✅ |
-| [mBART-50](model_doc/mbart50) | ✅ | ✅ | ✅ |
-| [MEGA](model_doc/mega) | ✅ | ❌ | ❌ |
-| [Megatron-BERT](model_doc/megatron-bert) | ✅ | ❌ | ❌ |
-| [Megatron-GPT2](model_doc/megatron_gpt2) | ✅ | ✅ | ✅ |
-| [MGP-STR](model_doc/mgp-str) | ✅ | ❌ | ❌ |
-| [Mimi](model_doc/mimi) | ✅ | ❌ | ❌ |
-| [Mistral](model_doc/mistral) | ✅ | ✅ | ✅ |
-| [Mixtral](model_doc/mixtral) | ✅ | ❌ | ❌ |
-| [Mllama](model_doc/mllama) | ✅ | ❌ | ❌ |
-| [mLUKE](model_doc/mluke) | ✅ | ❌ | ❌ |
-| [MMS](model_doc/mms) | ✅ | ✅ | ✅ |
-| [MobileBERT](model_doc/mobilebert) | ✅ | ✅ | ❌ |
-| [MobileNetV1](model_doc/mobilenet_v1) | ✅ | ❌ | ❌ |
-| [MobileNetV2](model_doc/mobilenet_v2) | ✅ | ❌ | ❌ |
-| [MobileViT](model_doc/mobilevit) | ✅ | ✅ | ❌ |
-| [MobileViTV2](model_doc/mobilevitv2) | ✅ | ❌ | ❌ |
-| [ModernBERT](model_doc/modernbert) | ✅ | ❌ | ❌ |
-| [Moonshine](model_doc/moonshine) | ✅ | ❌ | ❌ |
-| [Moshi](model_doc/moshi) | ✅ | ❌ | ❌ |
-| [MPNet](model_doc/mpnet) | ✅ | ✅ | ❌ |
-| [MPT](model_doc/mpt) | ✅ | ❌ | ❌ |
-| [MRA](model_doc/mra) | ✅ | ❌ | ❌ |
-| [MT5](model_doc/mt5) | ✅ | ✅ | ✅ |
-| [MusicGen](model_doc/musicgen) | ✅ | ❌ | ❌ |
-| [MusicGen Melody](model_doc/musicgen_melody) | ✅ | ❌ | ❌ |
-| [MVP](model_doc/mvp) | ✅ | ❌ | ❌ |
-| [NAT](model_doc/nat) | ✅ | ❌ | ❌ |
-| [Nemotron](model_doc/nemotron) | ✅ | ❌ | ❌ |
-| [Nezha](model_doc/nezha) | ✅ | ❌ | ❌ |
-| [NLLB](model_doc/nllb) | ✅ | ❌ | ❌ |
-| [NLLB-MOE](model_doc/nllb-moe) | ✅ | ❌ | ❌ |
-| [Nougat](model_doc/nougat) | ✅ | ✅ | ✅ |
-| [Nyströmformer](model_doc/nystromformer) | ✅ | ❌ | ❌ |
-| [OLMo](model_doc/olmo) | ✅ | ❌ | ❌ |
-| [OLMo2](model_doc/olmo2) | ✅ | ❌ | ❌ |
-| [OLMoE](model_doc/olmoe) | ✅ | ❌ | ❌ |
-| [OmDet-Turbo](model_doc/omdet-turbo) | ✅ | ❌ | ❌ |
-| [OneFormer](model_doc/oneformer) | ✅ | ❌ | ❌ |
-| [OpenAI GPT](model_doc/openai-gpt) | ✅ | ✅ | ❌ |
-| [OpenAI GPT-2](model_doc/gpt2) | ✅ | ✅ | ✅ |
-| [OpenLlama](model_doc/open-llama) | ✅ | ❌ | ❌ |
-| [OPT](model_doc/opt) | ✅ | ✅ | ✅ |
-| [OWL-ViT](model_doc/owlvit) | ✅ | ❌ | ❌ |
-| [OWLv2](model_doc/owlv2) | ✅ | ❌ | ❌ |
-| [PaliGemma](model_doc/paligemma) | ✅ | ❌ | ❌ |
-| [PatchTSMixer](model_doc/patchtsmixer) | ✅ | ❌ | ❌ |
-| [PatchTST](model_doc/patchtst) | ✅ | ❌ | ❌ |
-| [Pegasus](model_doc/pegasus) | ✅ | ✅ | ✅ |
-| [PEGASUS-X](model_doc/pegasus_x) | ✅ | ❌ | ❌ |
-| [Perceiver](model_doc/perceiver) | ✅ | ❌ | ❌ |
-| [Persimmon](model_doc/persimmon) | ✅ | ❌ | ❌ |
-| [Phi](model_doc/phi) | ✅ | ❌ | ❌ |
-| [Phi3](model_doc/phi3) | ✅ | ❌ | ❌ |
-| [Phimoe](model_doc/phimoe) | ✅ | ❌ | ❌ |
-| [PhoBERT](model_doc/phobert) | ✅ | ✅ | ✅ |
-| [Pix2Struct](model_doc/pix2struct) | ✅ | ❌ | ❌ |
-| [Pixtral](model_doc/pixtral) | ✅ | ❌ | ❌ |
-| [PLBart](model_doc/plbart) | ✅ | ❌ | ❌ |
-| [PoolFormer](model_doc/poolformer) | ✅ | ❌ | ❌ |
-| [Pop2Piano](model_doc/pop2piano) | ✅ | ❌ | ❌ |
-| [ProphetNet](model_doc/prophetnet) | ✅ | ❌ | ❌ |
-| [PVT](model_doc/pvt) | ✅ | ❌ | ❌ |
-| [PVTv2](model_doc/pvt_v2) | ✅ | ❌ | ❌ |
-| [QDQBert](model_doc/qdqbert) | ✅ | ❌ | ❌ |
-| [Qwen2](model_doc/qwen2) | ✅ | ❌ | ❌ |
-| [Qwen2_5_VL](model_doc/qwen2_5_vl) | ✅ | ❌ | ❌ |
-| [Qwen2Audio](model_doc/qwen2_audio) | ✅ | ❌ | ❌ |
-| [Qwen2MoE](model_doc/qwen2_moe) | ✅ | ❌ | ❌ |
-| [Qwen2VL](model_doc/qwen2_vl) | ✅ | ❌ | ❌ |
-| [RAG](model_doc/rag) | ✅ | ✅ | ❌ |
-| [REALM](model_doc/realm) | ✅ | ❌ | ❌ |
-| [RecurrentGemma](model_doc/recurrent_gemma) | ✅ | ❌ | ❌ |
-| [Reformer](model_doc/reformer) | ✅ | ❌ | ❌ |
-| [RegNet](model_doc/regnet) | ✅ | ✅ | ✅ |
-| [RemBERT](model_doc/rembert) | ✅ | ✅ | ❌ |
-| [ResNet](model_doc/resnet) | ✅ | ✅ | ✅ |
-| [RetriBERT](model_doc/retribert) | ✅ | ❌ | ❌ |
-| [RoBERTa](model_doc/roberta) | ✅ | ✅ | ✅ |
-| [RoBERTa-PreLayerNorm](model_doc/roberta-prelayernorm) | ✅ | ✅ | ✅ |
-| [RoCBert](model_doc/roc_bert) | ✅ | ❌ | ❌ |
-| [RoFormer](model_doc/roformer) | ✅ | ✅ | ✅ |
-| [RT-DETR](model_doc/rt_detr) | ✅ | ❌ | ❌ |
-| [RT-DETR-ResNet](model_doc/rt_detr_resnet) | ✅ | ❌ | ❌ |
-| [RT-DETRv2](model_doc/rt_detr_v2) | ✅ | ❌ | ❌ |
-| [RWKV](model_doc/rwkv) | ✅ | ❌ | ❌ |
-| [SAM](model_doc/sam) | ✅ | ✅ | ❌ |
-| [SeamlessM4T](model_doc/seamless_m4t) | ✅ | ❌ | ❌ |
-| [SeamlessM4Tv2](model_doc/seamless_m4t_v2) | ✅ | ❌ | ❌ |
-| [SegFormer](model_doc/segformer) | ✅ | ✅ | ❌ |
-| [SegGPT](model_doc/seggpt) | ✅ | ❌ | ❌ |
-| [SEW](model_doc/sew) | ✅ | ❌ | ❌ |
-| [SEW-D](model_doc/sew-d) | ✅ | ❌ | ❌ |
-| [SigLIP](model_doc/siglip) | ✅ | ❌ | ❌ |
-| [SigLIP2](model_doc/siglip2) | ✅ | ❌ | ❌ |
-| [SmolVLM](model_doc/smolvlm) | ✅ | ❌ | ❌ |
-| [Speech Encoder decoder](model_doc/speech-encoder-decoder) | ✅ | ❌ | ✅ |
-| [Speech2Text](model_doc/speech_to_text) | ✅ | ✅ | ❌ |
-| [SpeechT5](model_doc/speecht5) | ✅ | ❌ | ❌ |
-| [Splinter](model_doc/splinter) | ✅ | ❌ | ❌ |
-| [SqueezeBERT](model_doc/squeezebert) | ✅ | ❌ | ❌ |
-| [StableLm](model_doc/stablelm) | ✅ | ❌ | ❌ |
-| [Starcoder2](model_doc/starcoder2) | ✅ | ❌ | ❌ |
-| [SuperGlue](model_doc/superglue) | ✅ | ❌ | ❌ |
-| [SuperPoint](model_doc/superpoint) | ✅ | ❌ | ❌ |
-| [SwiftFormer](model_doc/swiftformer) | ✅ | ✅ | ❌ |
-| [Swin Transformer](model_doc/swin) | ✅ | ✅ | ❌ |
-| [Swin Transformer V2](model_doc/swinv2) | ✅ | ❌ | ❌ |
-| [Swin2SR](model_doc/swin2sr) | ✅ | ❌ | ❌ |
-| [SwitchTransformers](model_doc/switch_transformers) | ✅ | ❌ | ❌ |
-| [T5](model_doc/t5) | ✅ | ✅ | ✅ |
-| [T5v1.1](model_doc/t5v1.1) | ✅ | ✅ | ✅ |
-| [Table Transformer](model_doc/table-transformer) | ✅ | ❌ | ❌ |
-| [TAPAS](model_doc/tapas) | ✅ | ✅ | ❌ |
-| [TAPEX](model_doc/tapex) | ✅ | ✅ | ✅ |
-| [TextNet](model_doc/textnet) | ✅ | ❌ | ❌ |
-| [Time Series Transformer](model_doc/time_series_transformer) | ✅ | ❌ | ❌ |
-| [TimeSformer](model_doc/timesformer) | ✅ | ❌ | ❌ |
-| [TimmWrapperModel](model_doc/timm_wrapper) | ✅ | ❌ | ❌ |
-| [Trajectory Transformer](model_doc/trajectory_transformer) | ✅ | ❌ | ❌ |
-| [Transformer-XL](model_doc/transfo-xl) | ✅ | ✅ | ❌ |
-| [TrOCR](model_doc/trocr) | ✅ | ❌ | ❌ |
-| [TVLT](model_doc/tvlt) | ✅ | ❌ | ❌ |
-| [TVP](model_doc/tvp) | ✅ | ❌ | ❌ |
-| [UDOP](model_doc/udop) | ✅ | ❌ | ❌ |
-| [UL2](model_doc/ul2) | ✅ | ✅ | ✅ |
-| [UMT5](model_doc/umt5) | ✅ | ❌ | ❌ |
-| [UniSpeech](model_doc/unispeech) | ✅ | ❌ | ❌ |
-| [UniSpeechSat](model_doc/unispeech-sat) | ✅ | ❌ | ❌ |
-| [UnivNet](model_doc/univnet) | ✅ | ❌ | ❌ |
-| [UPerNet](model_doc/upernet) | ✅ | ❌ | ❌ |
-| [VAN](model_doc/van) | ✅ | ❌ | ❌ |
-| [VideoLlava](model_doc/video_llava) | ✅ | ❌ | ❌ |
-| [VideoMAE](model_doc/videomae) | ✅ | ❌ | ❌ |
-| [ViLT](model_doc/vilt) | ✅ | ❌ | ❌ |
-| [VipLlava](model_doc/vipllava) | ✅ | ❌ | ❌ |
-| [Vision Encoder decoder](model_doc/vision-encoder-decoder) | ✅ | ✅ | ✅ |
-| [VisionTextDualEncoder](model_doc/vision-text-dual-encoder) | ✅ | ✅ | ✅ |
-| [VisualBERT](model_doc/visual_bert) | ✅ | ❌ | ❌ |
-| [ViT](model_doc/vit) | ✅ | ✅ | ✅ |
-| [ViT Hybrid](model_doc/vit_hybrid) | ✅ | ❌ | ❌ |
-| [VitDet](model_doc/vitdet) | ✅ | ❌ | ❌ |
-| [ViTMAE](model_doc/vit_mae) | ✅ | ✅ | ❌ |
-| [ViTMatte](model_doc/vitmatte) | ✅ | ❌ | ❌ |
-| [ViTMSN](model_doc/vit_msn) | ✅ | ❌ | ❌ |
-| [ViTPose](model_doc/vitpose) | ✅ | ❌ | ❌ |
-| [ViTPoseBackbone](model_doc/vitpose_backbone) | ✅ | ❌ | ❌ |
-| [VITS](model_doc/vits) | ✅ | ❌ | ❌ |
-| [ViViT](model_doc/vivit) | ✅ | ❌ | ❌ |
-| [Wav2Vec2](model_doc/wav2vec2) | ✅ | ✅ | ✅ |
-| [Wav2Vec2-BERT](model_doc/wav2vec2-bert) | ✅ | ❌ | ❌ |
-| [Wav2Vec2-Conformer](model_doc/wav2vec2-conformer) | ✅ | ❌ | ❌ |
-| [Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme) | ✅ | ✅ | ✅ |
-| [WavLM](model_doc/wavlm) | ✅ | ❌ | ❌ |
-| [Whisper](model_doc/whisper) | ✅ | ✅ | ✅ |
-| [X-CLIP](model_doc/xclip) | ✅ | ❌ | ❌ |
-| [X-MOD](model_doc/xmod) | ✅ | ❌ | ❌ |
-| [XGLM](model_doc/xglm) | ✅ | ✅ | ✅ |
-| [XLM](model_doc/xlm) | ✅ | ✅ | ❌ |
-| [XLM-ProphetNet](model_doc/xlm-prophetnet) | ✅ | ❌ | ❌ |
-| [XLM-RoBERTa](model_doc/xlm-roberta) | ✅ | ✅ | ✅ |
-| [XLM-RoBERTa-XL](model_doc/xlm-roberta-xl) | ✅ | ❌ | ❌ |
-| [XLM-V](model_doc/xlm-v) | ✅ | ✅ | ✅ |
-| [XLNet](model_doc/xlnet) | ✅ | ✅ | ❌ |
-| [XLS-R](model_doc/xls_r) | ✅ | ✅ | ✅ |
-| [XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2) | ✅ | ✅ | ✅ |
-| [YOLOS](model_doc/yolos) | ✅ | ❌ | ❌ |
-| [YOSO](model_doc/yoso) | ✅ | ❌ | ❌ |
-| [Zamba](model_doc/zamba) | ✅ | ❌ | ❌ |
-| [Zamba2](model_doc/zamba2) | ✅ | ❌ | ❌ |
-| [ZoeDepth](model_doc/zoedepth) | ✅ | ❌ | ❌ |
-
-
+Join us on the Hugging Face [Hub](https://huggingface.co/), [Discord](https://discord.com/invite/JfAtkvEtRb), or [forum](https://discuss.huggingface.co/) to collaborate and build models, datasets, and applications together.
diff --git a/docs/source/en/installation.md b/docs/source/en/installation.md
index 4573efbb43..2c7ddabb87 100644
--- a/docs/source/en/installation.md
+++ b/docs/source/en/installation.md
@@ -1,5 +1,5 @@
-# Best Practices for Generation with Cache
+# KV cache strategies
-Efficient caching is crucial for optimizing the performance of models in various generative tasks,
-including text generation, translation, summarization and other transformer-based applications.
-Effective caching helps reduce computation time and improve response rates, especially in real-time or resource-intensive applications.
+The key-value (KV) vectors are used to calculate attention scores. For autoregressive models, KV scores are calculated *every* time because the model predicts one token at a time. Each prediction depends on the previous tokens, which means the model performs the same computations each time.
-Transformers support various caching methods, leveraging "Cache" classes to abstract and manage the caching logic.
-This document outlines best practices for using these classes to maximize performance and efficiency.
-Check out all the available `Cache` classes in the [API documentation](./internal/generation_utils).
+A KV *cache* stores these calculations so they can be reused without recomputing them. Efficient caching is crucial for optimizing model performance because it reduces computation time and improves response rates. Refer to the [Caching](./cache_explanation.md) doc for a more detailed explanation about how a cache works.
-## What is Cache and why we should care?
+Transformers offers several [`Cache`] classes that implement different caching mechanisms. Some of these [`Cache`] classes are optimized to save memory while others are designed to maximize generation speed. Refer to the table below to compare cache types and use it to help you select the best cache for your use case.
-Imagine you’re having a conversation with someone, and instead of remembering what was said previously, you have to start from scratch every time you respond. This would be slow and inefficient, right? In the world of Transformer models, a similar concept applies, and that's where Caching keys and values come into play. From now on, I'll refer to the concept as KV Cache.
-
-KV cache is needed to optimize the generation in autoregressive models, where the model predicts text token by token. This process can be slow since the model can generate only one token at a time, and each new prediction is dependent on the previous context. That means, to predict token number 1000 in the generation, you need information from the previous 999 tokens, which comes in the form of some matrix multiplications across the representations of those tokens. But to predict token number 1001, you also need the same information from the first 999 tokens, plus additional information from token number 1000. That is where key-value cache is used to optimize the sequential generation process by storing previous calculations to reuse in subsequent tokens, so they don't need to be computed again.
-
-More concretely, key-value cache acts as a memory bank for these generative models, where the model stores key-value pairs derived from self-attention layers for previously processed tokens. By storing this information, the model can avoid redundant computations and instead retrieve keys and values of previous tokens from the cache. Note that caching can be used only in inference and should be disabled when training, otherwise it might cause unexpected errors.
-
-
+
+
-
-
- One important concept you need to know when writing your own generation loop, is `cache_position`. In case you want to reuse an already filled Cache object by calling `forward()`, you have to pass in a valid `cache_position` which will indicate the positions of inputs in the sequence. Note that `cache_position` is not affected by padding, and always adds one more position for each token. For example, if key/value cache contains 10 tokens (no matter how many of it is a pad token), the cache position for the next token should be `torch.tensor([10])`.
-
-
-
-
- See an example below for how to implement your own generation loop.
-
- ```python
- >>> import torch
- >>> from transformers import AutoTokenizer, AutoModelForCausalLM, DynamicCache
-
- >>> model_id = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
- >>> model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="auto")
- >>> tokenizer = AutoTokenizer.from_pretrained(model_id)
-
- >>> past_key_values = DynamicCache()
- >>> messages = [{"role": "user", "content": "Hello, what's your name."}]
- >>> inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt", return_dict=True).to(model.device)
-
- >>> generated_ids = inputs.input_ids
- >>> cache_position = torch.arange(inputs.input_ids.shape[1], dtype=torch.int64, device=model.device)
- >>> max_new_tokens = 10
-
- >>> for _ in range(max_new_tokens):
- ... outputs = model(**inputs, cache_position=cache_position, past_key_values=past_key_values, use_cache=True)
- ... # Greedily sample one next token
- ... next_token_ids = outputs.logits[:, -1:].argmax(-1)
- ... generated_ids = torch.cat([generated_ids, next_token_ids], dim=-1)
- ...
- ... # Prepare inputs for the next generation step by leaaving unprocessed tokens, in our case we have only one new token
- ... # and expanding attn mask for the new token, as explained above
- ... attention_mask = inputs["attention_mask"]
- ... attention_mask = torch.cat([attention_mask, attention_mask.new_ones((attention_mask.shape[0], 1))], dim=-1)
- ... inputs = {"input_ids": next_token_ids, "attention_mask": attention_mask}
- ... cache_position = cache_position[-1:] + 1 # add one more position for the next token
-
- >>> print(tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0])
- ```
- ```txt
- <|user|>
- Hello, what's your name.
- <|assistant|>
- My name is Sarah.
- <|
- ```
-
-
-
-
-
-## Generate with Cache
-
-In 🤗 Transformers, we support various Cache types to optimize the performance across different models and tasks. By default, all models generate with caching,
-with the [`~DynamicCache`] class being the default cache for most models. It allows us to dynamically grow cache size, by saving more and more keys and values as we generate. If for some reason you don't want to use caches, you can pass `use_cache=False` into the `generate()` method.
-
-Refer to the table below to see the difference between cache types and choose the one that suits best for your use-case. Models for which initialization is recommended should be initialized before calling the model and passed to model as a kwarg. In all other cases you can simply define desired `cache_implementation` and we take care of the rest for you.
-
-| Cache Type | Memory Efficient | Supports torch.compile() | Initialization Recommended | Latency | Long Context Generation |
+| Cache Type | Memory Efficient | Supports torch.compile() | Initialization Recommended | Latency | Long Context Generation |
|------------------------|------------------|--------------------------|----------------------------|---------|-------------------------|
| Dynamic Cache | No | No | No | Mid | No |
| Static Cache | No | Yes | Yes | High | No |
-| Offloaded Cache | Yes | No | No | Low | Yes |
-| Offloaded Static Cache | No | Yes | Yes | High | Yes |
+| Offloaded Cache | Yes | No | No | Low | Yes |
+| Offloaded Static Cache | No | Yes | Yes | High | Yes |
| Quantized Cache | Yes | No | No | Low | Yes |
| Sliding Window Cache | No | Yes | Yes | High | No |
| Sink Cache | Yes | No | Yes | Mid | Yes |
+This guide introduces you to the different [`Cache`] classes and shows you how to use them for generation.
-These cache classes can be set with a `cache_implementation` argument when generating. To learn about the available options for the cache_implementation flag, please refer to the [API Documentation](./main_classes/text_generation#transformers.GenerationConfig). Now, let's explore each cache type in detail and see how to use them. Note that the below examples are for decoder-only Tranformer-based models. We also support ["Model-Specific Cache"] classes for models such as Mamba or Jamba, keep reading for more details.
+## Default cache
-### Quantized Cache
+The [`DynamicCache`] is the default cache class for most models. It allows the cache size to grow dynamically in order to store an increasing number of keys and values as generation progresses.
-The key and value cache can occupy a large portion of memory, becoming a [bottleneck for long-context generation](https://huggingface.co/blog/llama31#inference-memory-requirements), especially for Large Language Models.
-Quantizing the cache when using `generate()` can significantly reduce memory requirements at the cost of speed.
+Disable the cache by configuring `use_cache=False` in [`~GenerationMixin.generate`].
-KV Cache quantization in `transformers` is largely inspired by the paper ["KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache"](https://arxiv.org/abs/2402.02750) and currently supports [`~QuantoQuantizedCache`] and [`~HQQQuantizedCache`] classes. For more information on the inner workings see the paper.
+```py
+import torch
+from transformers import AutoTokenizer, AutoModelForCausalLM
-To enable quantization of the key-value cache, one needs to indicate `cache_implementation="quantized"` in the `generation_config`.
-Quantization related arguments should be passed to the `generation_config` either as a `dict` or an instance of a [`~QuantizedCacheConfig`] class.
-One has to indicate which quantization backend to use in the [`~QuantizedCacheConfig`], the default is `quanto`.
+tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
+model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf", torch_dtype=torch.float16).to("cuda:0")
+inputs = tokenizer("I like rock music because", return_tensors="pt").to(model.device)
-It is recommended to set `axis-key/axis-value` parameters in the cache config to `0` if you're using the `quanto` backend and to `1` if you're using the `HQQ` backend. For other config values, please use the defaults unless you're running out of memory. In that case, you may consider decreasing the residual length.
-
-For the Curious Minds Who Like to Dive Deep
- - ### Under the Hood: How Cache Object Works in Attention Mechanism - - When utilizing a cache object in the input, the Attention module performs several critical steps to integrate past and present information seamlessly. - - The Attention module concatenates the current key-values with the past key-values stored in the cache. This results in attention weights of shape `(new_tokens_length, past_kv_length + new_tokens_length)`. Essentially, the past and current key-values are combined to compute attention scores, ensuring that the model considers both previous context and new input. The concatenated key-values are used to compute the attention scores resulting in attention weights of shape `(new_tokens_length, past_kv_length + new_tokens_length)`. - - Therefore, when iteratively calling `forward()` instead of the `generate()` method, it’s crucial to ensure that the attention mask shape matches the combined length of past and current key-values. The attention mask should have the shape `(batch_size, past_kv_length + new_tokens_length)`. This is usually handled internally when you call `generate()` method. If you want to implement your own generation loop with Cache classes, take this into consideration and prepare the attention mask to hold values to current and past tokens. - -
+ +
+
+
## Overview
The ALIGN model was proposed in [Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://arxiv.org/abs/2102.05918) by Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig. ALIGN is a multi-modal vision and language model. It can be used for image-text similarity and for zero-shot image classification. ALIGN features a dual-encoder architecture with [EfficientNet](efficientnet) as its vision encoder and [BERT](bert) as its text encoder, and learns to align visual and text representations with contrastive learning. Unlike previous work, ALIGN leverages a massive noisy dataset and shows that the scale of the corpus can be used to achieve SOTA representations with a simple recipe.
diff --git a/docs/source/en/model_doc/altclip.md b/docs/source/en/model_doc/altclip.md
index b1fc9b3826..0dfbf797a0 100644
--- a/docs/source/en/model_doc/altclip.md
+++ b/docs/source/en/model_doc/altclip.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# AltCLIP
+
+
+
+
## Overview
The AltCLIP model was proposed in [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679v2) by Zhongzhi Chen, Guang Liu, Bo-Wen Zhang, Fulong Ye, Qinghong Yang, Ledell Wu. AltCLIP
diff --git a/docs/source/en/model_doc/aria.md b/docs/source/en/model_doc/aria.md
index 9ff7a6687a..7b58f59cab 100644
--- a/docs/source/en/model_doc/aria.md
+++ b/docs/source/en/model_doc/aria.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# Aria
+
+
+ +
+ +
+
+
## Overview
The Aria model was proposed in [Aria: An Open Multimodal Native Mixture-of-Experts Model](https://huggingface.co/papers/2410.05993) by Li et al. from the Rhymes.AI team.
diff --git a/docs/source/en/model_doc/audio-spectrogram-transformer.md b/docs/source/en/model_doc/audio-spectrogram-transformer.md
index d83c3bbb6c..4cc07aea75 100644
--- a/docs/source/en/model_doc/audio-spectrogram-transformer.md
+++ b/docs/source/en/model_doc/audio-spectrogram-transformer.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# Audio Spectrogram Transformer
+
+
+
+
+
## Overview
The Audio Spectrogram Transformer model was proposed in [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
diff --git a/docs/source/en/model_doc/autoformer.md b/docs/source/en/model_doc/autoformer.md
index bb423e941c..2c5e27153e 100644
--- a/docs/source/en/model_doc/autoformer.md
+++ b/docs/source/en/model_doc/autoformer.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Autoformer
+
+
+
+
## Overview
The Autoformer model was proposed in [Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008) by Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long.
diff --git a/docs/source/en/model_doc/bamba.md b/docs/source/en/model_doc/bamba.md
index 4ea8475edb..c6e1bcec56 100644
--- a/docs/source/en/model_doc/bamba.md
+++ b/docs/source/en/model_doc/bamba.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# Bamba
+
+
+
+
+
## Overview
diff --git a/docs/source/en/model_doc/bark.md b/docs/source/en/model_doc/bark.md
index 7c02e4be70..912f552fa7 100644
--- a/docs/source/en/model_doc/bark.md
+++ b/docs/source/en/model_doc/bark.md
@@ -12,6 +12,11 @@ specific language governing permissions and limitations under the License.
# Bark
+
+
+
+
+
## Overview
Bark is a transformer-based text-to-speech model proposed by Suno AI in [suno-ai/bark](https://github.com/suno-ai/bark).
diff --git a/docs/source/en/model_doc/bart.md b/docs/source/en/model_doc/bart.md
index 7986228915..aaccd78047 100644
--- a/docs/source/en/model_doc/bart.md
+++ b/docs/source/en/model_doc/bart.md
@@ -17,12 +17,12 @@ rendered properly in your Markdown viewer.
# BART
## Overview
diff --git a/docs/source/en/model_doc/barthez.md b/docs/source/en/model_doc/barthez.md
index 1b571e242f..131b1dd8e1 100644
--- a/docs/source/en/model_doc/barthez.md
+++ b/docs/source/en/model_doc/barthez.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# BARThez
+
+
+ +
+ +
+
+
## Overview
The BARThez model was proposed in [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis on 23 Oct,
diff --git a/docs/source/en/model_doc/bartpho.md b/docs/source/en/model_doc/bartpho.md
index 8f0a5f8bfe..b374951632 100644
--- a/docs/source/en/model_doc/bartpho.md
+++ b/docs/source/en/model_doc/bartpho.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# BARTpho
+
+
+
+
+
+
## Overview
The BARTpho model was proposed in [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
diff --git a/docs/source/en/model_doc/beit.md b/docs/source/en/model_doc/beit.md
index 25b0eafb26..24dfabf682 100644
--- a/docs/source/en/model_doc/beit.md
+++ b/docs/source/en/model_doc/beit.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# BEiT
+
+
+
+
+
+
## Overview
The BEiT model was proposed in [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by
diff --git a/docs/source/en/model_doc/bert-generation.md b/docs/source/en/model_doc/bert-generation.md
index 40c2fbaa21..0c42adbeb5 100644
--- a/docs/source/en/model_doc/bert-generation.md
+++ b/docs/source/en/model_doc/bert-generation.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# BertGeneration
+
+
+
+
## Overview
The BertGeneration model is a BERT model that can be leveraged for sequence-to-sequence tasks using
diff --git a/docs/source/en/model_doc/bert-japanese.md b/docs/source/en/model_doc/bert-japanese.md
index d68bb221d5..33a720318b 100644
--- a/docs/source/en/model_doc/bert-japanese.md
+++ b/docs/source/en/model_doc/bert-japanese.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# BertJapanese
+
+
+
+
+
+
## Overview
The BERT models trained on Japanese text.
diff --git a/docs/source/en/model_doc/bert.md b/docs/source/en/model_doc/bert.md
index b6e99d1031..883fba9a07 100644
--- a/docs/source/en/model_doc/bert.md
+++ b/docs/source/en/model_doc/bert.md
@@ -17,12 +17,11 @@ rendered properly in your Markdown viewer.
# BERT
## Overview
diff --git a/docs/source/en/model_doc/bertweet.md b/docs/source/en/model_doc/bertweet.md
index c4c883b21a..be48964317 100644
--- a/docs/source/en/model_doc/bertweet.md
+++ b/docs/source/en/model_doc/bertweet.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# BERTweet
+
+
+
+
+
+
## Overview
The BERTweet model was proposed in [BERTweet: A pre-trained language model for English Tweets](https://www.aclweb.org/anthology/2020.emnlp-demos.2.pdf) by Dat Quoc Nguyen, Thanh Vu, Anh Tuan Nguyen.
diff --git a/docs/source/en/model_doc/big_bird.md b/docs/source/en/model_doc/big_bird.md
index 3d1ef91d56..32ca5a2062 100644
--- a/docs/source/en/model_doc/big_bird.md
+++ b/docs/source/en/model_doc/big_bird.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# BigBird
+
+
+
+
+
## Overview
The BigBird model was proposed in [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by
diff --git a/docs/source/en/model_doc/bigbird_pegasus.md b/docs/source/en/model_doc/bigbird_pegasus.md
index 003e564371..499d40b314 100644
--- a/docs/source/en/model_doc/bigbird_pegasus.md
+++ b/docs/source/en/model_doc/bigbird_pegasus.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# BigBirdPegasus
+
+
+
+
## Overview
The BigBird model was proposed in [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by
diff --git a/docs/source/en/model_doc/biogpt.md b/docs/source/en/model_doc/biogpt.md
index 7d0943d539..ab8aea6c29 100644
--- a/docs/source/en/model_doc/biogpt.md
+++ b/docs/source/en/model_doc/biogpt.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# BioGPT
+
+
+
+
+
## Overview
The BioGPT model was proposed in [BioGPT: generative pre-trained transformer for biomedical text generation and mining](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9) by Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon and Tie-Yan Liu. BioGPT is a domain-specific generative pre-trained Transformer language model for biomedical text generation and mining. BioGPT follows the Transformer language model backbone, and is pre-trained on 15M PubMed abstracts from scratch.
diff --git a/docs/source/en/model_doc/bit.md b/docs/source/en/model_doc/bit.md
index 7f8a8ea67c..550c07662d 100644
--- a/docs/source/en/model_doc/bit.md
+++ b/docs/source/en/model_doc/bit.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Big Transfer (BiT)
+
+
+
+
## Overview
The BiT model was proposed in [Big Transfer (BiT): General Visual Representation Learning](https://arxiv.org/abs/1912.11370) by Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby.
diff --git a/docs/source/en/model_doc/blenderbot-small.md b/docs/source/en/model_doc/blenderbot-small.md
index d5f4a7d849..647a865de3 100644
--- a/docs/source/en/model_doc/blenderbot-small.md
+++ b/docs/source/en/model_doc/blenderbot-small.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# Blenderbot Small
+
+
+
+
+
+
Note that [`BlenderbotSmallModel`] and
[`BlenderbotSmallForConditionalGeneration`] are only used in combination with the checkpoint
[facebook/blenderbot-90M](https://huggingface.co/facebook/blenderbot-90M). Larger Blenderbot checkpoints should
diff --git a/docs/source/en/model_doc/blenderbot.md b/docs/source/en/model_doc/blenderbot.md
index 42e1710cb2..ec24d5ed74 100644
--- a/docs/source/en/model_doc/blenderbot.md
+++ b/docs/source/en/model_doc/blenderbot.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# Blenderbot
+
+
+
+
+
+
## Overview
The Blender chatbot model was proposed in [Recipes for building an open-domain chatbot](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu,
diff --git a/docs/source/en/model_doc/blip-2.md b/docs/source/en/model_doc/blip-2.md
index 4125d372d5..94331d9a5f 100644
--- a/docs/source/en/model_doc/blip-2.md
+++ b/docs/source/en/model_doc/blip-2.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# BLIP-2
+
+
+
+
## Overview
The BLIP-2 model was proposed in [BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://arxiv.org/abs/2301.12597) by
diff --git a/docs/source/en/model_doc/blip.md b/docs/source/en/model_doc/blip.md
index 0545400b83..1acf172f26 100644
--- a/docs/source/en/model_doc/blip.md
+++ b/docs/source/en/model_doc/blip.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# BLIP
+
+
+
+
+
## Overview
The BLIP model was proposed in [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) by Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
diff --git a/docs/source/en/model_doc/bloom.md b/docs/source/en/model_doc/bloom.md
index a1d39d13ad..9de9870595 100644
--- a/docs/source/en/model_doc/bloom.md
+++ b/docs/source/en/model_doc/bloom.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# BLOOM
+
+
+
+
+
## Overview
The BLOOM model has been proposed with its various versions through the [BigScience Workshop](https://bigscience.huggingface.co/). BigScience is inspired by other open science initiatives where researchers have pooled their time and resources to collectively achieve a higher impact.
diff --git a/docs/source/en/model_doc/bort.md b/docs/source/en/model_doc/bort.md
index 1542d464d9..04cc2feb06 100644
--- a/docs/source/en/model_doc/bort.md
+++ b/docs/source/en/model_doc/bort.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# BORT
+
+
+
+
+
+
+
+
+
## Overview
The BridgeTower model was proposed in [BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning](https://arxiv.org/abs/2206.08657) by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan. The goal of this model is to build a
diff --git a/docs/source/en/model_doc/bros.md b/docs/source/en/model_doc/bros.md
index 419e725e75..baa658e598 100644
--- a/docs/source/en/model_doc/bros.md
+++ b/docs/source/en/model_doc/bros.md
@@ -12,6 +12,10 @@ specific language governing permissions and limitations under the License.
# BROS
+
+
+
+
## Overview
The BROS model was proposed in [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://arxiv.org/abs/2108.04539) by Teakgyu Hong, Donghyun Kim, Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park.
diff --git a/docs/source/en/model_doc/byt5.md b/docs/source/en/model_doc/byt5.md
index dc2942e33b..7e95bae53e 100644
--- a/docs/source/en/model_doc/byt5.md
+++ b/docs/source/en/model_doc/byt5.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# ByT5
+
+
+
+
+
+
## Overview
The ByT5 model was presented in [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir
diff --git a/docs/source/en/model_doc/camembert.md b/docs/source/en/model_doc/camembert.md
index fd872282d5..9066ee360c 100644
--- a/docs/source/en/model_doc/camembert.md
+++ b/docs/source/en/model_doc/camembert.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# CamemBERT
+
+
+
+
+
+
## Overview
The CamemBERT model was proposed in [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by
diff --git a/docs/source/en/model_doc/canine.md b/docs/source/en/model_doc/canine.md
index 7729d8aa91..cd1cce34c7 100644
--- a/docs/source/en/model_doc/canine.md
+++ b/docs/source/en/model_doc/canine.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# CANINE
+
+
+
+
## Overview
The CANINE model was proposed in [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language
diff --git a/docs/source/en/model_doc/chameleon.md b/docs/source/en/model_doc/chameleon.md
index 6cbbdf3982..3810b3590a 100644
--- a/docs/source/en/model_doc/chameleon.md
+++ b/docs/source/en/model_doc/chameleon.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# Chameleon
+
+
+
+
+
+
## Overview
The Chameleon model was proposed in [Chameleon: Mixed-Modal Early-Fusion Foundation Models
diff --git a/docs/source/en/model_doc/chinese_clip.md b/docs/source/en/model_doc/chinese_clip.md
index b2d27a844e..c73fee0422 100644
--- a/docs/source/en/model_doc/chinese_clip.md
+++ b/docs/source/en/model_doc/chinese_clip.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Chinese-CLIP
+
+
+
+
## Overview
The Chinese-CLIP model was proposed in [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://arxiv.org/abs/2211.01335) by An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou.
diff --git a/docs/source/en/model_doc/clap.md b/docs/source/en/model_doc/clap.md
index 2bd2814e1b..e060662c01 100644
--- a/docs/source/en/model_doc/clap.md
+++ b/docs/source/en/model_doc/clap.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# CLAP
+
+
+
+
## Overview
The CLAP model was proposed in [Large Scale Contrastive Language-Audio pretraining with
diff --git a/docs/source/en/model_doc/clip.md b/docs/source/en/model_doc/clip.md
index cd2d56229b..2e1c5168ce 100644
--- a/docs/source/en/model_doc/clip.md
+++ b/docs/source/en/model_doc/clip.md
@@ -16,6 +16,15 @@ rendered properly in your Markdown viewer.
# CLIP
+
+
+
+
+
+
+
+
## Overview
The CLIP model was proposed in [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh,
diff --git a/docs/source/en/model_doc/clipseg.md b/docs/source/en/model_doc/clipseg.md
index 005e6746d0..f594dbc3e0 100644
--- a/docs/source/en/model_doc/clipseg.md
+++ b/docs/source/en/model_doc/clipseg.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# CLIPSeg
+
+
+
+
## Overview
The CLIPSeg model was proposed in [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke
diff --git a/docs/source/en/model_doc/clvp.md b/docs/source/en/model_doc/clvp.md
index a30269faf9..cfa4f97b82 100644
--- a/docs/source/en/model_doc/clvp.md
+++ b/docs/source/en/model_doc/clvp.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# CLVP
+
+
+
+
## Overview
The CLVP (Contrastive Language-Voice Pretrained Transformer) model was proposed in [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
diff --git a/docs/source/en/model_doc/code_llama.md b/docs/source/en/model_doc/code_llama.md
index 6eb687a728..ff3e66769c 100644
--- a/docs/source/en/model_doc/code_llama.md
+++ b/docs/source/en/model_doc/code_llama.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# CodeLlama
+
+
+
+
+
## Overview
The Code Llama model was proposed in [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) by Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.
diff --git a/docs/source/en/model_doc/codegen.md b/docs/source/en/model_doc/codegen.md
index bee8c8a076..465c8e5445 100644
--- a/docs/source/en/model_doc/codegen.md
+++ b/docs/source/en/model_doc/codegen.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# CodeGen
+
+
+
+
## Overview
The CodeGen model was proposed in [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong.
diff --git a/docs/source/en/model_doc/cohere.md b/docs/source/en/model_doc/cohere.md
index 4275f059c5..2ab75e9d1c 100644
--- a/docs/source/en/model_doc/cohere.md
+++ b/docs/source/en/model_doc/cohere.md
@@ -1,5 +1,11 @@
# Cohere
+
+
+
+
+
+
## Overview
The Cohere Command-R model was proposed in the blogpost [Command-R: Retrieval Augmented Generation at Production Scale](https://txt.cohere.com/command-r/) by the Cohere Team.
diff --git a/docs/source/en/model_doc/cohere2.md b/docs/source/en/model_doc/cohere2.md
index 33e67d48fb..3b0b6e1740 100644
--- a/docs/source/en/model_doc/cohere2.md
+++ b/docs/source/en/model_doc/cohere2.md
@@ -1,5 +1,11 @@
# Cohere
+
+
+
+
+
+
## Overview
[C4AI Command R7B](https://cohere.com/blog/command-r7b) is an open weights research release of a 7B billion parameter model developed by Cohere and Cohere For AI. It has advanced capabilities optimized for various use cases, including reasoning, summarization, question answering, and code. The model is trained to perform sophisticated tasks including Retrieval Augmented Generation (RAG) and tool use. The model also has powerful agentic capabilities that can use and combine multiple tools over multiple steps to accomplish more difficult tasks. It obtains top performance on enterprise-relevant code use cases. C4AI Command R7B is a multilingual model trained on 23 languages.
diff --git a/docs/source/en/model_doc/colpali.md b/docs/source/en/model_doc/colpali.md
index 3f6b0cbc66..07c4b45f14 100644
--- a/docs/source/en/model_doc/colpali.md
+++ b/docs/source/en/model_doc/colpali.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# ColPali
+
+
+
+
## Overview
The *ColPali* model was proposed in [ColPali: Efficient Document Retrieval with Vision Language Models](https://doi.org/10.48550/arXiv.2407.01449) by **Manuel Faysse***, **Hugues Sibille***, **Tony Wu***, Bilel Omrani, Gautier Viaud, Céline Hudelot, Pierre Colombo (* denotes equal contribution). Work lead by ILLUIN Technology.
diff --git a/docs/source/en/model_doc/conditional_detr.md b/docs/source/en/model_doc/conditional_detr.md
index 400c5c2c53..6a03d14d96 100644
--- a/docs/source/en/model_doc/conditional_detr.md
+++ b/docs/source/en/model_doc/conditional_detr.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Conditional DETR
+
+
+
+
## Overview
The Conditional DETR model was proposed in [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang. Conditional DETR presents a conditional cross-attention mechanism for fast DETR training. Conditional DETR converges 6.7× to 10× faster than DETR.
diff --git a/docs/source/en/model_doc/convbert.md b/docs/source/en/model_doc/convbert.md
index 17b5d7920c..e52bbd5c47 100644
--- a/docs/source/en/model_doc/convbert.md
+++ b/docs/source/en/model_doc/convbert.md
@@ -17,12 +17,8 @@ rendered properly in your Markdown viewer.
# ConvBERT
## Overview
diff --git a/docs/source/en/model_doc/convnext.md b/docs/source/en/model_doc/convnext.md
index f3d10d77b1..576e95ee04 100644
--- a/docs/source/en/model_doc/convnext.md
+++ b/docs/source/en/model_doc/convnext.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# ConvNeXT
+
+
+
+
+
## Overview
The ConvNeXT model was proposed in [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
diff --git a/docs/source/en/model_doc/convnextv2.md b/docs/source/en/model_doc/convnextv2.md
index 8cd142c276..87a261b8de 100644
--- a/docs/source/en/model_doc/convnextv2.md
+++ b/docs/source/en/model_doc/convnextv2.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# ConvNeXt V2
+
+
+
+
+
## Overview
The ConvNeXt V2 model was proposed in [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
diff --git a/docs/source/en/model_doc/cpm.md b/docs/source/en/model_doc/cpm.md
index 129c4ed3a3..8a1826a25c 100644
--- a/docs/source/en/model_doc/cpm.md
+++ b/docs/source/en/model_doc/cpm.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# CPM
+
+
+
+
+
+
## Overview
The CPM model was proposed in [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin,
diff --git a/docs/source/en/model_doc/cpmant.md b/docs/source/en/model_doc/cpmant.md
index 4bcf774507..f8e2b3b515 100644
--- a/docs/source/en/model_doc/cpmant.md
+++ b/docs/source/en/model_doc/cpmant.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# CPMAnt
+
+
+
+
## Overview
CPM-Ant is an open-source Chinese pre-trained language model (PLM) with 10B parameters. It is also the first milestone of the live training process of CPM-Live. The training process is cost-effective and environment-friendly. CPM-Ant also achieves promising results with delta tuning on the CUGE benchmark. Besides the full model, we also provide various compressed versions to meet the requirements of different hardware configurations. [See more](https://github.com/OpenBMB/CPM-Live/tree/cpm-ant/cpm-live)
diff --git a/docs/source/en/model_doc/ctrl.md b/docs/source/en/model_doc/ctrl.md
index be9fa85c70..0253d4e007 100644
--- a/docs/source/en/model_doc/ctrl.md
+++ b/docs/source/en/model_doc/ctrl.md
@@ -17,12 +17,8 @@ rendered properly in your Markdown viewer.
# CTRL
## Overview
diff --git a/docs/source/en/model_doc/cvt.md b/docs/source/en/model_doc/cvt.md
index 503f97795c..fec632ed84 100644
--- a/docs/source/en/model_doc/cvt.md
+++ b/docs/source/en/model_doc/cvt.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# Convolutional Vision Transformer (CvT)
+
+
+
+
+
## Overview
The CvT model was proposed in [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan and Lei Zhang. The Convolutional vision Transformer (CvT) improves the [Vision Transformer (ViT)](vit) in performance and efficiency by introducing convolutions into ViT to yield the best of both designs.
diff --git a/docs/source/en/model_doc/dab-detr.md b/docs/source/en/model_doc/dab-detr.md
index 6071ee6ca4..d19b45b486 100644
--- a/docs/source/en/model_doc/dab-detr.md
+++ b/docs/source/en/model_doc/dab-detr.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# DAB-DETR
+
+
+
+
## Overview
The DAB-DETR model was proposed in [DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR](https://arxiv.org/abs/2201.12329) by Shilong Liu, Feng Li, Hao Zhang, Xiao Yang, Xianbiao Qi, Hang Su, Jun Zhu, Lei Zhang.
diff --git a/docs/source/en/model_doc/dac.md b/docs/source/en/model_doc/dac.md
index db54b387b1..3ee4d92b58 100644
--- a/docs/source/en/model_doc/dac.md
+++ b/docs/source/en/model_doc/dac.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# DAC
+
+
+
+
## Overview
diff --git a/docs/source/en/model_doc/data2vec.md b/docs/source/en/model_doc/data2vec.md
index cb1dc675ca..62ddbd8ff1 100644
--- a/docs/source/en/model_doc/data2vec.md
+++ b/docs/source/en/model_doc/data2vec.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# Data2Vec
+
+
+
+
+
+
## Overview
The Data2Vec model was proposed in [data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/pdf/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu and Michael Auli.
diff --git a/docs/source/en/model_doc/dbrx.md b/docs/source/en/model_doc/dbrx.md
index fb53742d05..11463e93d1 100644
--- a/docs/source/en/model_doc/dbrx.md
+++ b/docs/source/en/model_doc/dbrx.md
@@ -12,6 +12,12 @@ specific language governing permissions and limitations under the License.
# DBRX
+
+
+
+
+
+
## Overview
DBRX is a [transformer-based](https://www.isattentionallyouneed.com/) decoder-only large language model (LLM) that was trained using next-token prediction.
diff --git a/docs/source/en/model_doc/deberta-v2.md b/docs/source/en/model_doc/deberta-v2.md
index e3bd91e8e4..2e48a3e9a7 100644
--- a/docs/source/en/model_doc/deberta-v2.md
+++ b/docs/source/en/model_doc/deberta-v2.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# DeBERTa-v2
+
+
+
+
+
## Overview
The DeBERTa model was proposed in [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen It is based on Google's
diff --git a/docs/source/en/model_doc/deberta.md b/docs/source/en/model_doc/deberta.md
index 342a3bc479..39afe83f5f 100644
--- a/docs/source/en/model_doc/deberta.md
+++ b/docs/source/en/model_doc/deberta.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# DeBERTa
+
+
+
+
+
## Overview
The DeBERTa model was proposed in [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen It is based on Google's
diff --git a/docs/source/en/model_doc/decision_transformer.md b/docs/source/en/model_doc/decision_transformer.md
index 07ef2ecbdc..fb932ce3ec 100644
--- a/docs/source/en/model_doc/decision_transformer.md
+++ b/docs/source/en/model_doc/decision_transformer.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Decision Transformer
+
+
+
+
## Overview
The Decision Transformer model was proposed in [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345)
diff --git a/docs/source/en/model_doc/deformable_detr.md b/docs/source/en/model_doc/deformable_detr.md
index 5ed99dfe81..5b83f23cf5 100644
--- a/docs/source/en/model_doc/deformable_detr.md
+++ b/docs/source/en/model_doc/deformable_detr.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Deformable DETR
+
+
+
+
## Overview
The Deformable DETR model was proposed in [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
diff --git a/docs/source/en/model_doc/deit.md b/docs/source/en/model_doc/deit.md
index a24632d5f8..0750d4000a 100644
--- a/docs/source/en/model_doc/deit.md
+++ b/docs/source/en/model_doc/deit.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# DeiT
+
+
+
+
+
+
## Overview
The DeiT model was proposed in [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre
diff --git a/docs/source/en/model_doc/deplot.md b/docs/source/en/model_doc/deplot.md
index a77bee39de..d3c0de7b7f 100644
--- a/docs/source/en/model_doc/deplot.md
+++ b/docs/source/en/model_doc/deplot.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# DePlot
+
+
+
+
## Overview
DePlot was proposed in the paper [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) from Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.
diff --git a/docs/source/en/model_doc/depth_anything.md b/docs/source/en/model_doc/depth_anything.md
index 7cdf72de5c..07bed70880 100644
--- a/docs/source/en/model_doc/depth_anything.md
+++ b/docs/source/en/model_doc/depth_anything.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Depth Anything
+
+
+
+
## Overview
The Depth Anything model was proposed in [Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891) by Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao. Depth Anything is based on the [DPT](dpt) architecture, trained on ~62 million images, obtaining state-of-the-art results for both relative and absolute depth estimation.
diff --git a/docs/source/en/model_doc/depth_pro.md b/docs/source/en/model_doc/depth_pro.md
index 2447b7d93d..91cbb61907 100644
--- a/docs/source/en/model_doc/depth_pro.md
+++ b/docs/source/en/model_doc/depth_pro.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# DepthPro
+
+
+
+
## Overview
The DepthPro model was proposed in [Depth Pro: Sharp Monocular Metric Depth in Less Than a Second](https://arxiv.org/abs/2410.02073) by Aleksei Bochkovskii, Amaël Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan R. Richter, Vladlen Koltun.
diff --git a/docs/source/en/model_doc/deta.md b/docs/source/en/model_doc/deta.md
index 996142bc59..e3859341a7 100644
--- a/docs/source/en/model_doc/deta.md
+++ b/docs/source/en/model_doc/deta.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# DETA
+
+
+
+
+
+
+
## Overview
The DETR model was proposed in [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by
diff --git a/docs/source/en/model_doc/dialogpt.md b/docs/source/en/model_doc/dialogpt.md
index 558b91d76d..33d7e3b16d 100644
--- a/docs/source/en/model_doc/dialogpt.md
+++ b/docs/source/en/model_doc/dialogpt.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# DialoGPT
+
+
+
+
+
+
## Overview
DialoGPT was proposed in [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao,
diff --git a/docs/source/en/model_doc/diffllama.md b/docs/source/en/model_doc/diffllama.md
index 80afcfe433..c4a170c265 100644
--- a/docs/source/en/model_doc/diffllama.md
+++ b/docs/source/en/model_doc/diffllama.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# DiffLlama
+
+
+
+
+
+
## Overview
The DiffLlama model was proposed in [Differential Transformer](https://arxiv.org/abs/2410.05258) by Kazuma Matsumoto and .
diff --git a/docs/source/en/model_doc/dinat.md b/docs/source/en/model_doc/dinat.md
index 23dfa3b74f..cd1d67073b 100644
--- a/docs/source/en/model_doc/dinat.md
+++ b/docs/source/en/model_doc/dinat.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Dilated Neighborhood Attention Transformer
+
+
+
+
## Overview
DiNAT was proposed in [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001)
diff --git a/docs/source/en/model_doc/dinov2.md b/docs/source/en/model_doc/dinov2.md
index 19674907f0..5c130dabda 100644
--- a/docs/source/en/model_doc/dinov2.md
+++ b/docs/source/en/model_doc/dinov2.md
@@ -12,6 +12,13 @@ specific language governing permissions and limitations under the License.
# DINOv2
+
+
+
+
+
+
## Overview
The DINOv2 model was proposed in [DINOv2: Learning Robust Visual Features without Supervision](https://arxiv.org/abs/2304.07193) by
diff --git a/docs/source/en/model_doc/dinov2_with_registers.md b/docs/source/en/model_doc/dinov2_with_registers.md
index 360ebf9b8f..7151dc4535 100644
--- a/docs/source/en/model_doc/dinov2_with_registers.md
+++ b/docs/source/en/model_doc/dinov2_with_registers.md
@@ -9,6 +9,11 @@ specific language governing permissions and limitations under the License.
# DINOv2 with Registers
+
+
+
+
+
## Overview
The DINOv2 with Registers model was proposed in [Vision Transformers Need Registers](https://arxiv.org/abs/2309.16588) by Timothée Darcet, Maxime Oquab, Julien Mairal, Piotr Bojanowski.
diff --git a/docs/source/en/model_doc/distilbert.md b/docs/source/en/model_doc/distilbert.md
index 10f7c2d757..66be95fa04 100644
--- a/docs/source/en/model_doc/distilbert.md
+++ b/docs/source/en/model_doc/distilbert.md
@@ -17,15 +17,12 @@ rendered properly in your Markdown viewer.
# DistilBERT
## Overview
diff --git a/docs/source/en/model_doc/dit.md b/docs/source/en/model_doc/dit.md
index 7f6691a15b..8848948375 100644
--- a/docs/source/en/model_doc/dit.md
+++ b/docs/source/en/model_doc/dit.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# DiT
+
+
+
+
+
## Overview
DiT was proposed in [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
diff --git a/docs/source/en/model_doc/dpr.md b/docs/source/en/model_doc/dpr.md
index 8b9f352b63..0f6b19c900 100644
--- a/docs/source/en/model_doc/dpr.md
+++ b/docs/source/en/model_doc/dpr.md
@@ -17,12 +17,9 @@ rendered properly in your Markdown viewer.
# DPR
## Overview
diff --git a/docs/source/en/model_doc/dpt.md b/docs/source/en/model_doc/dpt.md
index a02313a312..7010d03cdc 100644
--- a/docs/source/en/model_doc/dpt.md
+++ b/docs/source/en/model_doc/dpt.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# DPT
+
+
+
+
## Overview
The DPT model was proposed in [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
diff --git a/docs/source/en/model_doc/efficientformer.md b/docs/source/en/model_doc/efficientformer.md
index 24b20793b0..f05ccacc3d 100644
--- a/docs/source/en/model_doc/efficientformer.md
+++ b/docs/source/en/model_doc/efficientformer.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# EfficientFormer
+
+
+
+
+
+
+
+
## Overview
The EfficientNet model was proposed in [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946)
diff --git a/docs/source/en/model_doc/electra.md b/docs/source/en/model_doc/electra.md
index 700c49df79..bee883d641 100644
--- a/docs/source/en/model_doc/electra.md
+++ b/docs/source/en/model_doc/electra.md
@@ -17,12 +17,10 @@ rendered properly in your Markdown viewer.
# ELECTRA
## Overview
diff --git a/docs/source/en/model_doc/emu3.md b/docs/source/en/model_doc/emu3.md
index 619c9a3be5..4ac7d0b0c4 100644
--- a/docs/source/en/model_doc/emu3.md
+++ b/docs/source/en/model_doc/emu3.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# Emu3
+
+
+
+
+
+
## Overview
The Emu3 model was proposed in [Emu3: Next-Token Prediction is All You Need](https://arxiv.org/abs/2409.18869) by Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, Yingli Zhao, Yulong Ao, Xuebin Min, Tao Li, Boya Wu, Bo Zhao, Bowen Zhang, Liangdong Wang, Guang Liu, Zheqi He, Xi Yang, Jingjing Liu, Yonghua Lin, Tiejun Huang, Zhongyuan Wang.
diff --git a/docs/source/en/model_doc/encodec.md b/docs/source/en/model_doc/encodec.md
index 856f8be2b8..893954d5cf 100644
--- a/docs/source/en/model_doc/encodec.md
+++ b/docs/source/en/model_doc/encodec.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# EnCodec
+
+
+
+
## Overview
The EnCodec neural codec model was proposed in [High Fidelity Neural Audio Compression](https://arxiv.org/abs/2210.13438) by Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi.
diff --git a/docs/source/en/model_doc/encoder-decoder.md b/docs/source/en/model_doc/encoder-decoder.md
index 4bd0e6f188..d0a676fb33 100644
--- a/docs/source/en/model_doc/encoder-decoder.md
+++ b/docs/source/en/model_doc/encoder-decoder.md
@@ -16,6 +16,14 @@ rendered properly in your Markdown viewer.
# Encoder Decoder Models
+
+
+
+
+
+
+
## Overview
The [`EncoderDecoderModel`] can be used to initialize a sequence-to-sequence model with any
diff --git a/docs/source/en/model_doc/ernie.md b/docs/source/en/model_doc/ernie.md
index a5110b2d7b..82f2a0d5ba 100644
--- a/docs/source/en/model_doc/ernie.md
+++ b/docs/source/en/model_doc/ernie.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# ERNIE
+
+
+
+
## Overview
ERNIE is a series of powerful models proposed by baidu, especially in Chinese tasks,
including [ERNIE1.0](https://arxiv.org/abs/1904.09223), [ERNIE2.0](https://ojs.aaai.org/index.php/AAAI/article/view/6428),
diff --git a/docs/source/en/model_doc/ernie_m.md b/docs/source/en/model_doc/ernie_m.md
index 8525469350..3ce3b40c44 100644
--- a/docs/source/en/model_doc/ernie_m.md
+++ b/docs/source/en/model_doc/ernie_m.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# ErnieM
+
+
+
+
+
+
+
+
## Overview
This page provides code and pre-trained weights for Transformer protein language models from Meta AI's Fundamental
diff --git a/docs/source/en/model_doc/falcon.md b/docs/source/en/model_doc/falcon.md
index 9bf6c32a4e..1197d208a2 100644
--- a/docs/source/en/model_doc/falcon.md
+++ b/docs/source/en/model_doc/falcon.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# Falcon
+
+
+
+
+
+
## Overview
Falcon is a class of causal decoder-only models built by [TII](https://www.tii.ae/). The largest Falcon checkpoints
diff --git a/docs/source/en/model_doc/falcon3.md b/docs/source/en/model_doc/falcon3.md
index 813533dd7f..276548be77 100644
--- a/docs/source/en/model_doc/falcon3.md
+++ b/docs/source/en/model_doc/falcon3.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# Falcon3
+
+
+
+
+
## Overview
Falcon3 represents a natural evolution from previous releases, emphasizing expanding the models' science, math, and code capabilities. This iteration includes five base models: Falcon3-1B-Base, Falcon3-3B-Base, Falcon3-Mamba-7B-Base, Falcon3-7B-Base, and Falcon3-10B-Base. In developing these models, we incorporated several key innovations aimed at improving the models' performances while reducing training costs:
diff --git a/docs/source/en/model_doc/falcon_mamba.md b/docs/source/en/model_doc/falcon_mamba.md
index cbec6378cc..fb6debfef9 100644
--- a/docs/source/en/model_doc/falcon_mamba.md
+++ b/docs/source/en/model_doc/falcon_mamba.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# FalconMamba
+
+
+
+
## Overview
The FalconMamba model was proposed by TII UAE (Technology Innovation Institute) in their release.
diff --git a/docs/source/en/model_doc/fastspeech2_conformer.md b/docs/source/en/model_doc/fastspeech2_conformer.md
index 7d92502733..aeb055ceae 100644
--- a/docs/source/en/model_doc/fastspeech2_conformer.md
+++ b/docs/source/en/model_doc/fastspeech2_conformer.md
@@ -12,6 +12,10 @@ specific language governing permissions and limitations under the License.
# FastSpeech2Conformer
+
+
+
+
## Overview
The FastSpeech2Conformer model was proposed with the paper [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
diff --git a/docs/source/en/model_doc/flan-t5.md b/docs/source/en/model_doc/flan-t5.md
index c0fd6b0011..0e3b9ba073 100644
--- a/docs/source/en/model_doc/flan-t5.md
+++ b/docs/source/en/model_doc/flan-t5.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# FLAN-T5
+
+
+
+
+
+
## Overview
FLAN-T5 was released in the paper [Scaling Instruction-Finetuned Language Models](https://arxiv.org/pdf/2210.11416.pdf) - it is an enhanced version of T5 that has been finetuned in a mixture of tasks.
diff --git a/docs/source/en/model_doc/flan-ul2.md b/docs/source/en/model_doc/flan-ul2.md
index 5487bb7797..3b946b909b 100644
--- a/docs/source/en/model_doc/flan-ul2.md
+++ b/docs/source/en/model_doc/flan-ul2.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# FLAN-UL2
+
+
+
+
+
+
## Overview
Flan-UL2 is an encoder decoder model based on the T5 architecture. It uses the same configuration as the [UL2](ul2) model released earlier last year.
diff --git a/docs/source/en/model_doc/flaubert.md b/docs/source/en/model_doc/flaubert.md
index 04bcc2638a..59ab44ebff 100644
--- a/docs/source/en/model_doc/flaubert.md
+++ b/docs/source/en/model_doc/flaubert.md
@@ -17,12 +17,8 @@ rendered properly in your Markdown viewer.
# FlauBERT
## Overview
diff --git a/docs/source/en/model_doc/flava.md b/docs/source/en/model_doc/flava.md
index d9f9f1de51..b32f93fc8b 100644
--- a/docs/source/en/model_doc/flava.md
+++ b/docs/source/en/model_doc/flava.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# FLAVA
+
+
+
+
## Overview
The FLAVA model was proposed in [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela and is accepted at CVPR 2022.
diff --git a/docs/source/en/model_doc/fnet.md b/docs/source/en/model_doc/fnet.md
index 1bcae678e6..fcf75e21ca 100644
--- a/docs/source/en/model_doc/fnet.md
+++ b/docs/source/en/model_doc/fnet.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# FNet
+
+
+
+
## Overview
The FNet model was proposed in [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by
diff --git a/docs/source/en/model_doc/focalnet.md b/docs/source/en/model_doc/focalnet.md
index c4c97980f0..5312cae4ff 100644
--- a/docs/source/en/model_doc/focalnet.md
+++ b/docs/source/en/model_doc/focalnet.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# FocalNet
+
+
+
+
## Overview
The FocalNet model was proposed in [Focal Modulation Networks](https://arxiv.org/abs/2203.11926) by Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao.
diff --git a/docs/source/en/model_doc/funnel.md b/docs/source/en/model_doc/funnel.md
index d6929691f4..96050a153d 100644
--- a/docs/source/en/model_doc/funnel.md
+++ b/docs/source/en/model_doc/funnel.md
@@ -17,15 +17,10 @@ rendered properly in your Markdown viewer.
# Funnel Transformer
-
## Overview
The Funnel Transformer model was proposed in the paper [Funnel-Transformer: Filtering out Sequential Redundancy for
diff --git a/docs/source/en/model_doc/fuyu.md b/docs/source/en/model_doc/fuyu.md
index bd55737da5..c0ea89ad19 100644
--- a/docs/source/en/model_doc/fuyu.md
+++ b/docs/source/en/model_doc/fuyu.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Fuyu
+
+
+
+
## Overview
The Fuyu model was created by [ADEPT](https://www.adept.ai/blog/fuyu-8b), and authored by Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, Sağnak Taşırlar.
diff --git a/docs/source/en/model_doc/gemma.md b/docs/source/en/model_doc/gemma.md
index abd077af8d..144bcf3388 100644
--- a/docs/source/en/model_doc/gemma.md
+++ b/docs/source/en/model_doc/gemma.md
@@ -16,6 +16,14 @@ rendered properly in your Markdown viewer.
# Gemma
+
+
+
+
+
+
+
## Overview
The Gemma model was proposed in [Gemma: Open Models Based on Gemini Technology and Research](https://blog.google/technology/developers/gemma-open-models/) by Gemma Team, Google.
diff --git a/docs/source/en/model_doc/gemma2.md b/docs/source/en/model_doc/gemma2.md
index 431c4ecd25..9cf8ff7af1 100644
--- a/docs/source/en/model_doc/gemma2.md
+++ b/docs/source/en/model_doc/gemma2.md
@@ -17,6 +17,12 @@ rendered properly in your Markdown viewer.
# Gemma2
+
+
+
+
+
+
## Overview
The Gemma2 model was proposed in [Gemma2: Open Models Based on Gemini Technology and Research](https://blog.google/technology/developers/google-gemma-2/) by Gemma2 Team, Google.
diff --git a/docs/source/en/model_doc/git.md b/docs/source/en/model_doc/git.md
index bffa98b89e..825b73c5c5 100644
--- a/docs/source/en/model_doc/git.md
+++ b/docs/source/en/model_doc/git.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# GIT
+
+
+
+
## Overview
The GIT model was proposed in [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by
diff --git a/docs/source/en/model_doc/glm.md b/docs/source/en/model_doc/glm.md
index 1268b2e7cf..cfcd549d14 100644
--- a/docs/source/en/model_doc/glm.md
+++ b/docs/source/en/model_doc/glm.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# GLM
+
+
+
+
+
+
## Overview
The GLM Model was proposed
diff --git a/docs/source/en/model_doc/glpn.md b/docs/source/en/model_doc/glpn.md
index b57d1a7ccd..95ecc36bf5 100644
--- a/docs/source/en/model_doc/glpn.md
+++ b/docs/source/en/model_doc/glpn.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# GLPN
+
+
+
+
+
+
+
## Overview
The GOT-OCR2 model was proposed in [General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model](https://arxiv.org/abs/2409.01704) by Haoran Wei, Chenglong Liu, Jinyue Chen, Jia Wang, Lingyu Kong, Yanming Xu, Zheng Ge, Liang Zhao, Jianjian Sun, Yuang Peng, Chunrui Han, Xiangyu Zhang.
diff --git a/docs/source/en/model_doc/gpt-sw3.md b/docs/source/en/model_doc/gpt-sw3.md
index f69bd958e9..20daa3537a 100644
--- a/docs/source/en/model_doc/gpt-sw3.md
+++ b/docs/source/en/model_doc/gpt-sw3.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# GPT-Sw3
+
+
+
+
+
+
## Overview
The GPT-Sw3 model was first proposed in
diff --git a/docs/source/en/model_doc/gpt_bigcode.md b/docs/source/en/model_doc/gpt_bigcode.md
index 1635a9f50d..648fa6cb8d 100644
--- a/docs/source/en/model_doc/gpt_bigcode.md
+++ b/docs/source/en/model_doc/gpt_bigcode.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# GPTBigCode
+
+
+
+
+
+
## Overview
The GPTBigCode model was proposed in [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) by BigCode. The listed authors are: Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
diff --git a/docs/source/en/model_doc/gpt_neo.md b/docs/source/en/model_doc/gpt_neo.md
index 3c7858c998..f90e0d1849 100644
--- a/docs/source/en/model_doc/gpt_neo.md
+++ b/docs/source/en/model_doc/gpt_neo.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# GPT Neo
+
+
+
+
+
+
## Overview
The GPTNeo model was released in the [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) repository by Sid
diff --git a/docs/source/en/model_doc/gpt_neox.md b/docs/source/en/model_doc/gpt_neox.md
index 1319f2e93c..35f12bdb21 100644
--- a/docs/source/en/model_doc/gpt_neox.md
+++ b/docs/source/en/model_doc/gpt_neox.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# GPT-NeoX
+
+
+
+
+
## Overview
We introduce GPT-NeoX-20B, a 20 billion parameter autoregressive language model trained on the Pile, whose weights will
diff --git a/docs/source/en/model_doc/gpt_neox_japanese.md b/docs/source/en/model_doc/gpt_neox_japanese.md
index c69e643cae..cedfafa133 100644
--- a/docs/source/en/model_doc/gpt_neox_japanese.md
+++ b/docs/source/en/model_doc/gpt_neox_japanese.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# GPT-NeoX-Japanese
+
+
+
+
+
## Overview
We introduce GPT-NeoX-Japanese, which is an autoregressive language model for Japanese, trained on top of [https://github.com/EleutherAI/gpt-neox](https://github.com/EleutherAI/gpt-neox).
diff --git a/docs/source/en/model_doc/gptj.md b/docs/source/en/model_doc/gptj.md
index b515cf36dd..8e852d931a 100644
--- a/docs/source/en/model_doc/gptj.md
+++ b/docs/source/en/model_doc/gptj.md
@@ -16,6 +16,14 @@ rendered properly in your Markdown viewer.
# GPT-J
+
+
+
+
+
+
+
## Overview
The GPT-J model was released in the [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax) repository by Ben Wang and Aran Komatsuzaki. It is a GPT-2-like
diff --git a/docs/source/en/model_doc/gptsan-japanese.md b/docs/source/en/model_doc/gptsan-japanese.md
index 108e59048d..929e7330ce 100644
--- a/docs/source/en/model_doc/gptsan-japanese.md
+++ b/docs/source/en/model_doc/gptsan-japanese.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# GPTSAN-japanese
+
+
+
+
+
+
+
+
+
## Overview
The Granite model was proposed in [Power Scheduler: A Batch Size and Token Number Agnostic Learning Rate Scheduler](https://arxiv.org/abs/2408.13359) by Yikang Shen, Matthew Stallone, Mayank Mishra, Gaoyuan Zhang, Shawn Tan, Aditya Prasad, Adriana Meza Soria, David D. Cox and Rameswar Panda.
diff --git a/docs/source/en/model_doc/granitemoe.md b/docs/source/en/model_doc/granitemoe.md
index 176e833c24..56ba5d936c 100644
--- a/docs/source/en/model_doc/granitemoe.md
+++ b/docs/source/en/model_doc/granitemoe.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# GraniteMoe
+
+
+
+
+
+
## Overview
The GraniteMoe model was proposed in [Power Scheduler: A Batch Size and Token Number Agnostic Learning Rate Scheduler](https://arxiv.org/abs/2408.13359) by Yikang Shen, Matthew Stallone, Mayank Mishra, Gaoyuan Zhang, Shawn Tan, Aditya Prasad, Adriana Meza Soria, David D. Cox and Rameswar Panda.
diff --git a/docs/source/en/model_doc/graphormer.md b/docs/source/en/model_doc/graphormer.md
index d01bf04deb..0d88134d4b 100644
--- a/docs/source/en/model_doc/graphormer.md
+++ b/docs/source/en/model_doc/graphormer.md
@@ -14,6 +14,10 @@ rendered properly in your Markdown viewer.
# Graphormer
+
+
+
+
+
+
+
## Overview
The Grounding DINO model was proposed in [Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection](https://arxiv.org/abs/2303.05499) by Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang. Grounding DINO extends a closed-set object detection model with a text encoder, enabling open-set object detection. The model achieves remarkable results, such as 52.5 AP on COCO zero-shot.
diff --git a/docs/source/en/model_doc/groupvit.md b/docs/source/en/model_doc/groupvit.md
index 8728cf0da2..c77a51d8b1 100644
--- a/docs/source/en/model_doc/groupvit.md
+++ b/docs/source/en/model_doc/groupvit.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# GroupViT
+
+
+
+
+
## Overview
The GroupViT model was proposed in [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
diff --git a/docs/source/en/model_doc/helium.md b/docs/source/en/model_doc/helium.md
index b830c0a72b..a9296eb110 100644
--- a/docs/source/en/model_doc/helium.md
+++ b/docs/source/en/model_doc/helium.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# Helium
+
+
+
+
+
## Overview
diff --git a/docs/source/en/model_doc/herbert.md b/docs/source/en/model_doc/herbert.md
index 0049d6bfcf..aa4f535ed2 100644
--- a/docs/source/en/model_doc/herbert.md
+++ b/docs/source/en/model_doc/herbert.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# HerBERT
+
+
+
+
+
+
## Overview
The HerBERT model was proposed in [KLEJ: Comprehensive Benchmark for Polish Language Understanding](https://www.aclweb.org/anthology/2020.acl-main.111.pdf) by Piotr Rybak, Robert Mroczkowski, Janusz Tracz, and
diff --git a/docs/source/en/model_doc/hiera.md b/docs/source/en/model_doc/hiera.md
index c63c892c7c..a82eec950a 100644
--- a/docs/source/en/model_doc/hiera.md
+++ b/docs/source/en/model_doc/hiera.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Hiera
+
+
+
+
## Overview
Hiera was proposed in [Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles](https://arxiv.org/abs/2306.00989) by Chaitanya Ryali, Yuan-Ting Hu, Daniel Bolya, Chen Wei, Haoqi Fan, Po-Yao Huang, Vaibhav Aggarwal, Arkabandhu Chowdhury, Omid Poursaeed, Judy Hoffman, Jitendra Malik, Yanghao Li, Christoph Feichtenhofer
diff --git a/docs/source/en/model_doc/hubert.md b/docs/source/en/model_doc/hubert.md
index 93e40d4f4e..432e127c78 100644
--- a/docs/source/en/model_doc/hubert.md
+++ b/docs/source/en/model_doc/hubert.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# Hubert
+
+
+
+
+
+
+
## Overview
Hubert was proposed in [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan
diff --git a/docs/source/en/model_doc/ibert.md b/docs/source/en/model_doc/ibert.md
index 9ea623951a..8c43eeddaf 100644
--- a/docs/source/en/model_doc/ibert.md
+++ b/docs/source/en/model_doc/ibert.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# I-BERT
+
+
+
+
## Overview
The I-BERT model was proposed in [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by
diff --git a/docs/source/en/model_doc/idefics.md b/docs/source/en/model_doc/idefics.md
index ab66bd555a..2b8e471213 100644
--- a/docs/source/en/model_doc/idefics.md
+++ b/docs/source/en/model_doc/idefics.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# IDEFICS
+
+
+
+
+
+
## Overview
The IDEFICS model was proposed in [OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents
diff --git a/docs/source/en/model_doc/idefics2.md b/docs/source/en/model_doc/idefics2.md
index b9b51082f2..8de2c92d56 100644
--- a/docs/source/en/model_doc/idefics2.md
+++ b/docs/source/en/model_doc/idefics2.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# Idefics2
+
+
+
+
+
+
## Overview
The Idefics2 model was proposed in [What matters when building vision-language models?](https://arxiv.org/abs/2405.02246) by Léo Tronchon, Hugo Laurencon, Victor Sanh. The accompanying blog post can be found [here](https://huggingface.co/blog/idefics2).
diff --git a/docs/source/en/model_doc/idefics3.md b/docs/source/en/model_doc/idefics3.md
index cf7c043e92..deab4423f8 100644
--- a/docs/source/en/model_doc/idefics3.md
+++ b/docs/source/en/model_doc/idefics3.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# Idefics3
+
+
+
+
+
+
## Overview
The Idefics3 model was proposed in [Building and better understanding vision-language models: insights and future directions](https://huggingface.co/papers/2408.12637) by Hugo Laurençon, Andrés Marafioti, Victor Sanh, and Léo Tronchon.
diff --git a/docs/source/en/model_doc/ijepa.md b/docs/source/en/model_doc/ijepa.md
index cb2afd25e2..a92fdc83e8 100644
--- a/docs/source/en/model_doc/ijepa.md
+++ b/docs/source/en/model_doc/ijepa.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# I-JEPA
+
+
+
+
+
## Overview
The I-JEPA model was proposed in [Image-based Joint-Embedding Predictive Architecture](https://arxiv.org/abs/2301.08243) by Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, Nicolas Ballas.
diff --git a/docs/source/en/model_doc/imagegpt.md b/docs/source/en/model_doc/imagegpt.md
index 53a7ba3b34..7fbec62d30 100644
--- a/docs/source/en/model_doc/imagegpt.md
+++ b/docs/source/en/model_doc/imagegpt.md
@@ -15,6 +15,10 @@ specific language governing permissions and limitations under the License. -->
# ImageGPT
+
+
+
+
## Overview
The ImageGPT model was proposed in [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt) by Mark
diff --git a/docs/source/en/model_doc/informer.md b/docs/source/en/model_doc/informer.md
index f866afbfcb..1dfc397db7 100644
--- a/docs/source/en/model_doc/informer.md
+++ b/docs/source/en/model_doc/informer.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Informer
+
+
+
+
## Overview
The Informer model was proposed in [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
diff --git a/docs/source/en/model_doc/instructblip.md b/docs/source/en/model_doc/instructblip.md
index 904a96bc78..4f2feb015f 100644
--- a/docs/source/en/model_doc/instructblip.md
+++ b/docs/source/en/model_doc/instructblip.md
@@ -12,6 +12,10 @@ specific language governing permissions and limitations under the License.
# InstructBLIP
+
+
+
+
## Overview
The InstructBLIP model was proposed in [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
diff --git a/docs/source/en/model_doc/instructblipvideo.md b/docs/source/en/model_doc/instructblipvideo.md
index 8b2207ce17..c26562a853 100644
--- a/docs/source/en/model_doc/instructblipvideo.md
+++ b/docs/source/en/model_doc/instructblipvideo.md
@@ -12,7 +12,9 @@ specific language governing permissions and limitations under the License.
# InstructBlipVideo
-## Overview
+
+
+
## Overview
diff --git a/docs/source/en/model_doc/jamba.md b/docs/source/en/model_doc/jamba.md
index c3f66c1825..c8d66b163b 100644
--- a/docs/source/en/model_doc/jamba.md
+++ b/docs/source/en/model_doc/jamba.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# Jamba
+
+
+
+
+
+
## Overview
Jamba is a state-of-the-art, hybrid SSM-Transformer LLM. It is the first production-scale Mamba implementation, which opens up interesting research and application opportunities. While this initial experimentation shows encouraging gains, we expect these to be further enhanced with future optimizations and explorations.
diff --git a/docs/source/en/model_doc/jetmoe.md b/docs/source/en/model_doc/jetmoe.md
index 87f99c6f99..aba6577f70 100644
--- a/docs/source/en/model_doc/jetmoe.md
+++ b/docs/source/en/model_doc/jetmoe.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# JetMoe
+
+
+
+
+
+
## Overview
**JetMoe-8B** is an 8B Mixture-of-Experts (MoE) language model developed by [Yikang Shen](https://scholar.google.com.hk/citations?user=qff5rRYAAAAJ) and [MyShell](https://myshell.ai/).
diff --git a/docs/source/en/model_doc/jukebox.md b/docs/source/en/model_doc/jukebox.md
index 12f273b71e..144134d9b0 100644
--- a/docs/source/en/model_doc/jukebox.md
+++ b/docs/source/en/model_doc/jukebox.md
@@ -15,6 +15,10 @@ rendered properly in your Markdown viewer.
-->
# Jukebox
+
+
+
+
+
+
+
## Overview
The KOSMOS-2 model was proposed in [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
diff --git a/docs/source/en/model_doc/layoutlm.md b/docs/source/en/model_doc/layoutlm.md
index 34b429fb73..51cc52b7f4 100644
--- a/docs/source/en/model_doc/layoutlm.md
+++ b/docs/source/en/model_doc/layoutlm.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# LayoutLM
+
+
+
+
+
## Overview
diff --git a/docs/source/en/model_doc/layoutlmv2.md b/docs/source/en/model_doc/layoutlmv2.md
index 0769322e9a..7fc5ae3619 100644
--- a/docs/source/en/model_doc/layoutlmv2.md
+++ b/docs/source/en/model_doc/layoutlmv2.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# LayoutLMV2
+
+
+
+
## Overview
The LayoutLMV2 model was proposed in [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu,
diff --git a/docs/source/en/model_doc/layoutxlm.md b/docs/source/en/model_doc/layoutxlm.md
index f6b2cbef9d..96e0a4d4bf 100644
--- a/docs/source/en/model_doc/layoutxlm.md
+++ b/docs/source/en/model_doc/layoutxlm.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# LayoutXLM
+
+
+
+
## Overview
LayoutXLM was proposed in [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha
diff --git a/docs/source/en/model_doc/led.md b/docs/source/en/model_doc/led.md
index 9a39b0b28e..729d5666d8 100644
--- a/docs/source/en/model_doc/led.md
+++ b/docs/source/en/model_doc/led.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# LED
+
+
+
+
+
## Overview
The LED model was proposed in [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz
diff --git a/docs/source/en/model_doc/levit.md b/docs/source/en/model_doc/levit.md
index 15dc2f4e13..af42c1533e 100644
--- a/docs/source/en/model_doc/levit.md
+++ b/docs/source/en/model_doc/levit.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# LeViT
+
+
+
+
## Overview
The LeViT model was proposed in [LeViT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze. LeViT improves the [Vision Transformer (ViT)](vit) in performance and efficiency by a few architectural differences such as activation maps with decreasing resolutions in Transformers and the introduction of an attention bias to integrate positional information.
diff --git a/docs/source/en/model_doc/lilt.md b/docs/source/en/model_doc/lilt.md
index 2514a6ebd8..2474d854e0 100644
--- a/docs/source/en/model_doc/lilt.md
+++ b/docs/source/en/model_doc/lilt.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# LiLT
+
+
+
+
## Overview
The LiLT model was proposed in [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
diff --git a/docs/source/en/model_doc/llama.md b/docs/source/en/model_doc/llama.md
index 2f0eb63da0..c127e0d73c 100644
--- a/docs/source/en/model_doc/llama.md
+++ b/docs/source/en/model_doc/llama.md
@@ -16,6 +16,14 @@ rendered properly in your Markdown viewer.
# LLaMA
+
+
+
+
+
+
+
## Overview
The LLaMA model was proposed in [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample. It is a collection of foundation language models ranging from 7B to 65B parameters.
diff --git a/docs/source/en/model_doc/llama2.md b/docs/source/en/model_doc/llama2.md
index b4cd6b9ca1..4e5f572c4b 100644
--- a/docs/source/en/model_doc/llama2.md
+++ b/docs/source/en/model_doc/llama2.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# Llama2
+
+
+
+
+
## Overview
The Llama2 model was proposed in [LLaMA: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/) by Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom. It is a collection of foundation language models ranging from 7B to 70B parameters, with checkpoints finetuned for chat application!
diff --git a/docs/source/en/model_doc/llama3.md b/docs/source/en/model_doc/llama3.md
index 9c77db44fc..0bb5e8160c 100644
--- a/docs/source/en/model_doc/llama3.md
+++ b/docs/source/en/model_doc/llama3.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# Llama3
+
+
+
+
+
```py3
import transformers
import torch
diff --git a/docs/source/en/model_doc/llava.md b/docs/source/en/model_doc/llava.md
index d89ec57be1..79033ec5a1 100644
--- a/docs/source/en/model_doc/llava.md
+++ b/docs/source/en/model_doc/llava.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# LLaVa
+
+
+
+
+
+
## Overview
LLaVa is an open-source chatbot trained by fine-tuning LlamA/Vicuna on GPT-generated multimodal instruction-following data. It is an auto-regressive language model, based on the transformer architecture. In other words, it is an multi-modal version of LLMs fine-tuned for chat / instructions.
diff --git a/docs/source/en/model_doc/llava_next.md b/docs/source/en/model_doc/llava_next.md
index e62b9ba68c..7d85ab8b69 100644
--- a/docs/source/en/model_doc/llava_next.md
+++ b/docs/source/en/model_doc/llava_next.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# LLaVA-NeXT
+
+
+
+
+
+
## Overview
The LLaVA-NeXT model was proposed in [LLaVA-NeXT: Improved reasoning, OCR, and world knowledge](https://llava-vl.github.io/blog/2024-01-30-llava-next/) by Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, Yong Jae Lee. LLaVa-NeXT (also called LLaVa-1.6) improves upon [LLaVa](llava) by increasing the input image resolution and training on an improved visual instruction tuning dataset to improve OCR and common sense reasoning.
diff --git a/docs/source/en/model_doc/llava_next_video.md b/docs/source/en/model_doc/llava_next_video.md
index ecd7b83a8b..b338bbfba1 100644
--- a/docs/source/en/model_doc/llava_next_video.md
+++ b/docs/source/en/model_doc/llava_next_video.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# LLaVa-NeXT-Video
+
+
+
+
+
+
## Overview
The LLaVa-NeXT-Video model was proposed in [LLaVA-NeXT: A Strong Zero-shot Video Understanding Model
diff --git a/docs/source/en/model_doc/llava_onevision.md b/docs/source/en/model_doc/llava_onevision.md
index 785e6af74a..77fe807d46 100644
--- a/docs/source/en/model_doc/llava_onevision.md
+++ b/docs/source/en/model_doc/llava_onevision.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# LLaVA-OneVision
+
+
+
+
+
+
## Overview
The LLaVA-OneVision model was proposed in [LLaVA-OneVision: Easy Visual Task Transfer](https://arxiv.org/abs/2408.03326) by
+
+
+
+
## Overview
The LongT5 model was proposed in [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916)
diff --git a/docs/source/en/model_doc/luke.md b/docs/source/en/model_doc/luke.md
index 4e070b1c4b..be4d5946df 100644
--- a/docs/source/en/model_doc/luke.md
+++ b/docs/source/en/model_doc/luke.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# LUKE
+
+
+
+
## Overview
The LUKE model was proposed in [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda and Yuji Matsumoto.
diff --git a/docs/source/en/model_doc/lxmert.md b/docs/source/en/model_doc/lxmert.md
index 435994196b..a0f686efc3 100644
--- a/docs/source/en/model_doc/lxmert.md
+++ b/docs/source/en/model_doc/lxmert.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# LXMERT
+
+
+
+
+
## Overview
The LXMERT model was proposed in [LXMERT: Learning Cross-Modality Encoder Representations from Transformers](https://arxiv.org/abs/1908.07490) by Hao Tan & Mohit Bansal. It is a series of bidirectional transformer encoders
diff --git a/docs/source/en/model_doc/m2m_100.md b/docs/source/en/model_doc/m2m_100.md
index d64545fafb..f4f2955bb0 100644
--- a/docs/source/en/model_doc/m2m_100.md
+++ b/docs/source/en/model_doc/m2m_100.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# M2M100
+
+
+
+
+
+
## Overview
The M2M100 model was proposed in [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky,
diff --git a/docs/source/en/model_doc/madlad-400.md b/docs/source/en/model_doc/madlad-400.md
index aeb4193849..db6abc38ea 100644
--- a/docs/source/en/model_doc/madlad-400.md
+++ b/docs/source/en/model_doc/madlad-400.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# MADLAD-400
+
+
+
+
+
+
## Overview
MADLAD-400 models were released in the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](MADLAD-400: A Multilingual And Document-Level Large Audited Dataset).
diff --git a/docs/source/en/model_doc/mamba.md b/docs/source/en/model_doc/mamba.md
index 317948331e..d5c0612b1e 100644
--- a/docs/source/en/model_doc/mamba.md
+++ b/docs/source/en/model_doc/mamba.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Mamba
+
+
+
+
## Overview
The Mamba model was proposed in [Mamba: Linear-Time Sequence Modeling with Selective State Spaces](https://arxiv.org/abs/2312.00752) by Albert Gu and Tri Dao.
diff --git a/docs/source/en/model_doc/mamba2.md b/docs/source/en/model_doc/mamba2.md
index 5ed27881cf..8d88d6c026 100644
--- a/docs/source/en/model_doc/mamba2.md
+++ b/docs/source/en/model_doc/mamba2.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Mamba 2
+
+
+
+
## Overview
The Mamba2 model was proposed in [Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality](https://arxiv.org/abs/2405.21060) by Tri Dao and Albert Gu. It is a State Space Model similar to Mamba 1, with better performances in a simplified architecture.
diff --git a/docs/source/en/model_doc/marian.md b/docs/source/en/model_doc/marian.md
index d8ebec8ffb..80bb73d26d 100644
--- a/docs/source/en/model_doc/marian.md
+++ b/docs/source/en/model_doc/marian.md
@@ -17,12 +17,10 @@ rendered properly in your Markdown viewer.
# MarianMT
## Overview
diff --git a/docs/source/en/model_doc/markuplm.md b/docs/source/en/model_doc/markuplm.md
index e52ff3157e..72948da2c5 100644
--- a/docs/source/en/model_doc/markuplm.md
+++ b/docs/source/en/model_doc/markuplm.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# MarkupLM
+
+
+
+
## Overview
The MarkupLM model was proposed in [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document
diff --git a/docs/source/en/model_doc/mask2former.md b/docs/source/en/model_doc/mask2former.md
index 4faeed5031..37a2603c68 100644
--- a/docs/source/en/model_doc/mask2former.md
+++ b/docs/source/en/model_doc/mask2former.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Mask2Former
+
+
+
+
## Overview
The Mask2Former model was proposed in [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar. Mask2Former is a unified framework for panoptic, instance and semantic segmentation and features significant performance and efficiency improvements over [MaskFormer](maskformer).
diff --git a/docs/source/en/model_doc/maskformer.md b/docs/source/en/model_doc/maskformer.md
index a0199f380c..0adbbf2285 100644
--- a/docs/source/en/model_doc/maskformer.md
+++ b/docs/source/en/model_doc/maskformer.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# MaskFormer
+
+
+
+
+
+
+
## Overview
MatCha has been proposed in the paper [MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering](https://arxiv.org/abs/2212.09662), from Fangyu Liu, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Yasemin Altun, Nigel Collier, Julian Martin Eisenschlos.
diff --git a/docs/source/en/model_doc/mbart.md b/docs/source/en/model_doc/mbart.md
index ca529e957e..62356ad264 100644
--- a/docs/source/en/model_doc/mbart.md
+++ b/docs/source/en/model_doc/mbart.md
@@ -17,12 +17,12 @@ rendered properly in your Markdown viewer.
# MBart and MBart-50
diff --git a/docs/source/en/model_doc/mctct.md b/docs/source/en/model_doc/mctct.md
index 7cf1a68f12..a755f5a027 100644
--- a/docs/source/en/model_doc/mctct.md
+++ b/docs/source/en/model_doc/mctct.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# M-CTC-T
+
+
+
+
+
+
+
+
+
+
## Overview
The MegatronBERT model was proposed in [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model
diff --git a/docs/source/en/model_doc/megatron_gpt2.md b/docs/source/en/model_doc/megatron_gpt2.md
index 284fd372c0..7e0ee3cb9e 100644
--- a/docs/source/en/model_doc/megatron_gpt2.md
+++ b/docs/source/en/model_doc/megatron_gpt2.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# MegatronGPT2
+
+
+
+
+
+
## Overview
The MegatronGPT2 model was proposed in [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model
diff --git a/docs/source/en/model_doc/mgp-str.md b/docs/source/en/model_doc/mgp-str.md
index d4152e92b2..168e5bd104 100644
--- a/docs/source/en/model_doc/mgp-str.md
+++ b/docs/source/en/model_doc/mgp-str.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# MGP-STR
+
+
+
+
## Overview
The MGP-STR model was proposed in [Multi-Granularity Prediction for Scene Text Recognition](https://arxiv.org/abs/2209.03592) by Peng Wang, Cheng Da, and Cong Yao. MGP-STR is a conceptually **simple** yet **powerful** vision Scene Text Recognition (STR) model, which is built upon the [Vision Transformer (ViT)](vit). To integrate linguistic knowledge, Multi-Granularity Prediction (MGP) strategy is proposed to inject information from the language modality into the model in an implicit way.
diff --git a/docs/source/en/model_doc/mimi.md b/docs/source/en/model_doc/mimi.md
index ad15a002da..6e68394fca 100644
--- a/docs/source/en/model_doc/mimi.md
+++ b/docs/source/en/model_doc/mimi.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# Mimi
+
+
+
+
+
+
## Overview
The Mimi model was proposed in [Moshi: a speech-text foundation model for real-time dialogue](https://kyutai.org/Moshi.pdf) by Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave and Neil Zeghidour. Mimi is a high-fidelity audio codec model developed by the Kyutai team, that combines semantic and acoustic information into audio tokens running at 12Hz and a bitrate of 1.1kbps. In other words, it can be used to map audio waveforms into “audio tokens”, known as “codebooks”.
diff --git a/docs/source/en/model_doc/mistral.md b/docs/source/en/model_doc/mistral.md
index cfa2af3678..097d8888f9 100644
--- a/docs/source/en/model_doc/mistral.md
+++ b/docs/source/en/model_doc/mistral.md
@@ -16,6 +16,15 @@ rendered properly in your Markdown viewer.
# Mistral
+
+
+
+
+
+
+
+
## Overview
Mistral was introduced in the [this blogpost](https://mistral.ai/news/announcing-mistral-7b/) by Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
diff --git a/docs/source/en/model_doc/mixtral.md b/docs/source/en/model_doc/mixtral.md
index b5451702e4..38c0c98ed0 100644
--- a/docs/source/en/model_doc/mixtral.md
+++ b/docs/source/en/model_doc/mixtral.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# Mixtral
+
+
+
+
+
+
## Overview
Mixtral-8x7B was introduced in the [Mixtral of Experts blogpost](https://mistral.ai/news/mixtral-of-experts/) by Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
diff --git a/docs/source/en/model_doc/mllama.md b/docs/source/en/model_doc/mllama.md
index 64da42b38b..77f5e211f1 100644
--- a/docs/source/en/model_doc/mllama.md
+++ b/docs/source/en/model_doc/mllama.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Mllama
+
+
+
+
## Overview
The Llama 3.2-Vision collection of multimodal large language models (LLMs) is a collection of pretrained and instruction-tuned image reasoning generative models in 11B and 90B sizes (text \+ images in / text out). The Llama 3.2-Vision instruction-tuned models are optimized for visual recognition, image reasoning, captioning, and answering general questions about an image.
diff --git a/docs/source/en/model_doc/mluke.md b/docs/source/en/model_doc/mluke.md
index 719af76ad4..aae607def6 100644
--- a/docs/source/en/model_doc/mluke.md
+++ b/docs/source/en/model_doc/mluke.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# mLUKE
+
+
+
+
## Overview
The mLUKE model was proposed in [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka. It's a multilingual extension
diff --git a/docs/source/en/model_doc/mms.md b/docs/source/en/model_doc/mms.md
index 7102b88966..480d5bc8dd 100644
--- a/docs/source/en/model_doc/mms.md
+++ b/docs/source/en/model_doc/mms.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# MMS
+
+
+
+
+
+
## Overview
The MMS model was proposed in [Scaling Speech Technology to 1,000+ Languages](https://arxiv.org/abs/2305.13516)
diff --git a/docs/source/en/model_doc/mobilebert.md b/docs/source/en/model_doc/mobilebert.md
index 5c9a230d0d..11a2b21b61 100644
--- a/docs/source/en/model_doc/mobilebert.md
+++ b/docs/source/en/model_doc/mobilebert.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# MobileBERT
+
+
+
+
+
## Overview
The MobileBERT model was proposed in [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny
diff --git a/docs/source/en/model_doc/mobilenet_v1.md b/docs/source/en/model_doc/mobilenet_v1.md
index 9f68035c63..7d94777d6f 100644
--- a/docs/source/en/model_doc/mobilenet_v1.md
+++ b/docs/source/en/model_doc/mobilenet_v1.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# MobileNet V1
+
+
+
+
## Overview
The MobileNet model was proposed in [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/abs/1704.04861) by Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam.
diff --git a/docs/source/en/model_doc/mobilenet_v2.md b/docs/source/en/model_doc/mobilenet_v2.md
index ff22231ae0..b78a8eb72f 100644
--- a/docs/source/en/model_doc/mobilenet_v2.md
+++ b/docs/source/en/model_doc/mobilenet_v2.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# MobileNet V2
+
+
+
+
## Overview
The MobileNet model was proposed in [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381) by Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen.
diff --git a/docs/source/en/model_doc/mobilevit.md b/docs/source/en/model_doc/mobilevit.md
index e724ffa380..c9054b59cb 100644
--- a/docs/source/en/model_doc/mobilevit.md
+++ b/docs/source/en/model_doc/mobilevit.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# MobileViT
+
+
+
+
+
## Overview
The MobileViT model was proposed in [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari. MobileViT introduces a new layer that replaces local processing in convolutions with global processing using transformers.
diff --git a/docs/source/en/model_doc/mobilevitv2.md b/docs/source/en/model_doc/mobilevitv2.md
index c3a650fc70..b654966685 100644
--- a/docs/source/en/model_doc/mobilevitv2.md
+++ b/docs/source/en/model_doc/mobilevitv2.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# MobileViTV2
+
+
+
+
## Overview
The MobileViTV2 model was proposed in [Separable Self-attention for Mobile Vision Transformers](https://arxiv.org/abs/2206.02680) by Sachin Mehta and Mohammad Rastegari.
diff --git a/docs/source/en/model_doc/modernbert.md b/docs/source/en/model_doc/modernbert.md
index e90f34a903..f7ceaae187 100644
--- a/docs/source/en/model_doc/modernbert.md
+++ b/docs/source/en/model_doc/modernbert.md
@@ -17,12 +17,9 @@ rendered properly in your Markdown viewer.
# ModernBERT
## Overview
diff --git a/docs/source/en/model_doc/moonshine.md b/docs/source/en/model_doc/moonshine.md
index 571e3febdb..2a4599e3d7 100644
--- a/docs/source/en/model_doc/moonshine.md
+++ b/docs/source/en/model_doc/moonshine.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# Moonshine
+
+
+
+
+
+
## Overview
The Moonshine model was proposed in [Moonshine: Speech Recognition for Live Transcription and Voice Commands
diff --git a/docs/source/en/model_doc/moshi.md b/docs/source/en/model_doc/moshi.md
index 2e2c5655de..9302a94619 100644
--- a/docs/source/en/model_doc/moshi.md
+++ b/docs/source/en/model_doc/moshi.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# Moshi
+
+
+
+
+
+
## Overview
The Moshi model was proposed in [Moshi: a speech-text foundation model for real-time dialogue](https://kyutai.org/Moshi.pdf) by Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave and Neil Zeghidour.
diff --git a/docs/source/en/model_doc/mpnet.md b/docs/source/en/model_doc/mpnet.md
index c571da47b0..cf84e2b410 100644
--- a/docs/source/en/model_doc/mpnet.md
+++ b/docs/source/en/model_doc/mpnet.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# MPNet
+
+
+
+
+
## Overview
The MPNet model was proposed in [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
diff --git a/docs/source/en/model_doc/mpt.md b/docs/source/en/model_doc/mpt.md
index 113b42573f..a4dbc5ea6a 100644
--- a/docs/source/en/model_doc/mpt.md
+++ b/docs/source/en/model_doc/mpt.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# MPT
+
+
+
+
## Overview
The MPT model was proposed by the [MosaicML](https://www.mosaicml.com/) team and released with multiple sizes and finetuned variants. The MPT models are a series of open source and commercially usable LLMs pre-trained on 1T tokens.
diff --git a/docs/source/en/model_doc/mra.md b/docs/source/en/model_doc/mra.md
index cc4c0d9cc9..a5490d5d37 100644
--- a/docs/source/en/model_doc/mra.md
+++ b/docs/source/en/model_doc/mra.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# MRA
+
+
+
+
## Overview
The MRA model was proposed in [Multi Resolution Analysis (MRA) for Approximate Self-Attention](https://arxiv.org/abs/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, and Vikas Singh.
diff --git a/docs/source/en/model_doc/mt5.md b/docs/source/en/model_doc/mt5.md
index 7f053bb724..d4af9f538c 100644
--- a/docs/source/en/model_doc/mt5.md
+++ b/docs/source/en/model_doc/mt5.md
@@ -17,12 +17,10 @@ rendered properly in your Markdown viewer.
# mT5
## Overview
diff --git a/docs/source/en/model_doc/musicgen.md b/docs/source/en/model_doc/musicgen.md
index 7c105e1f39..6d709a963c 100644
--- a/docs/source/en/model_doc/musicgen.md
+++ b/docs/source/en/model_doc/musicgen.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# MusicGen
+
+
+
+
+
+
## Overview
The MusicGen model was proposed in the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284)
diff --git a/docs/source/en/model_doc/musicgen_melody.md b/docs/source/en/model_doc/musicgen_melody.md
index 7b67713c42..b1f16c4574 100644
--- a/docs/source/en/model_doc/musicgen_melody.md
+++ b/docs/source/en/model_doc/musicgen_melody.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# MusicGen Melody
+
+
+
+
+
+
## Overview
The MusicGen Melody model was proposed in [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
diff --git a/docs/source/en/model_doc/mvp.md b/docs/source/en/model_doc/mvp.md
index 0d98e04cf0..d732977167 100644
--- a/docs/source/en/model_doc/mvp.md
+++ b/docs/source/en/model_doc/mvp.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# MVP
+
+
+
+
## Overview
The MVP model was proposed in [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
diff --git a/docs/source/en/model_doc/nat.md b/docs/source/en/model_doc/nat.md
index 02c2e466cc..c7725ed7a5 100644
--- a/docs/source/en/model_doc/nat.md
+++ b/docs/source/en/model_doc/nat.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Neighborhood Attention Transformer
+
+
+
+
+
+
+
+
### License
diff --git a/docs/source/en/model_doc/nezha.md b/docs/source/en/model_doc/nezha.md
index 976722592c..dc815e0ecc 100644
--- a/docs/source/en/model_doc/nezha.md
+++ b/docs/source/en/model_doc/nezha.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Nezha
+
+
+
+
+
+
## Overview
diff --git a/docs/source/en/model_doc/nllb.md b/docs/source/en/model_doc/nllb.md
index abdff7445a..4ba2737779 100644
--- a/docs/source/en/model_doc/nllb.md
+++ b/docs/source/en/model_doc/nllb.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# NLLB
+
+
+
+
+
+
## Updated tokenizer behavior
**DISCLAIMER:** The default behaviour for the tokenizer was fixed and thus changed in April 2023.
diff --git a/docs/source/en/model_doc/nougat.md b/docs/source/en/model_doc/nougat.md
index a39e74eb21..06b12b5ee8 100644
--- a/docs/source/en/model_doc/nougat.md
+++ b/docs/source/en/model_doc/nougat.md
@@ -15,6 +15,13 @@ specific language governing permissions and limitations under the License. -->
# Nougat
+
+
+
+
+
+
## Overview
The Nougat model was proposed in [Nougat: Neural Optical Understanding for Academic Documents](https://arxiv.org/abs/2308.13418) by
diff --git a/docs/source/en/model_doc/nystromformer.md b/docs/source/en/model_doc/nystromformer.md
index 185c4e1f01..b4c017b35f 100644
--- a/docs/source/en/model_doc/nystromformer.md
+++ b/docs/source/en/model_doc/nystromformer.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Nyströmformer
+
+
+
+
## Overview
The Nyströmformer model was proposed in [*Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention*](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn
diff --git a/docs/source/en/model_doc/olmo.md b/docs/source/en/model_doc/olmo.md
index 6db7d8ad5c..8d722185c3 100644
--- a/docs/source/en/model_doc/olmo.md
+++ b/docs/source/en/model_doc/olmo.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# OLMo
+
+
+
+
+
+
## Overview
The OLMo model was proposed in [OLMo: Accelerating the Science of Language Models](https://arxiv.org/abs/2402.00838) by Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Raghavi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E. Peters, Valentina Pyatkin, Abhilasha Ravichander, Dustin Schwenk, Saurabh Shah, Will Smith, Emma Strubell, Nishant Subramani, Mitchell Wortsman, Pradeep Dasigi, Nathan Lambert, Kyle Richardson, Luke Zettlemoyer, Jesse Dodge, Kyle Lo, Luca Soldaini, Noah A. Smith, Hannaneh Hajishirzi.
diff --git a/docs/source/en/model_doc/olmo2.md b/docs/source/en/model_doc/olmo2.md
index 8ca3326660..24030b8552 100644
--- a/docs/source/en/model_doc/olmo2.md
+++ b/docs/source/en/model_doc/olmo2.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# OLMo2
+
+
+
+
+
+
## Overview
The OLMo2 model is the successor of the OLMo model, which was proposed in
diff --git a/docs/source/en/model_doc/olmoe.md b/docs/source/en/model_doc/olmoe.md
index 5ebcf3f943..6496e44c1b 100644
--- a/docs/source/en/model_doc/olmoe.md
+++ b/docs/source/en/model_doc/olmoe.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# OLMoE
+
+
+
+
+
+
## Overview
The OLMoE model was proposed in [OLMoE: Open Mixture-of-Experts Language Models](https://arxiv.org/abs/2409.02060) by Niklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, Pete Walsh, Oyvind Tafjord, Nathan Lambert, Yuling Gu, Shane Arora, Akshita Bhagia, Dustin Schwenk, David Wadden, Alexander Wettig, Binyuan Hui, Tim Dettmers, Douwe Kiela, Ali Farhadi, Noah A. Smith, Pang Wei Koh, Amanpreet Singh, Hannaneh Hajishirzi.
diff --git a/docs/source/en/model_doc/omdet-turbo.md b/docs/source/en/model_doc/omdet-turbo.md
index 91419919b6..d73fef2d8b 100644
--- a/docs/source/en/model_doc/omdet-turbo.md
+++ b/docs/source/en/model_doc/omdet-turbo.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# OmDet-Turbo
+
+
+
+
## Overview
The OmDet-Turbo model was proposed in [Real-time Transformer-based Open-Vocabulary Detection with Efficient Fusion Head](https://arxiv.org/abs/2403.06892) by Tiancheng Zhao, Peng Liu, Xuan He, Lu Zhang, Kyusong Lee. OmDet-Turbo incorporates components from RT-DETR and introduces a swift multimodal fusion module to achieve real-time open-vocabulary object detection capabilities while maintaining high accuracy. The base model achieves performance of up to 100.2 FPS and 53.4 AP on COCO zero-shot.
diff --git a/docs/source/en/model_doc/oneformer.md b/docs/source/en/model_doc/oneformer.md
index 0132a600cc..f1c1de7912 100644
--- a/docs/source/en/model_doc/oneformer.md
+++ b/docs/source/en/model_doc/oneformer.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# OneFormer
+
+
+
+
## Overview
The OneFormer model was proposed in [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi. OneFormer is a universal image segmentation framework that can be trained on a single panoptic dataset to perform semantic, instance, and panoptic segmentation tasks. OneFormer uses a task token to condition the model on the task in focus, making the architecture task-guided for training, and task-dynamic for inference.
diff --git a/docs/source/en/model_doc/open-llama.md b/docs/source/en/model_doc/open-llama.md
index 01170e7e3b..3b4856cd4f 100644
--- a/docs/source/en/model_doc/open-llama.md
+++ b/docs/source/en/model_doc/open-llama.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Open-Llama
+
+
+
+
+
+
+
+
+
+
+
## Overview
The OPT model was proposed in [Open Pre-trained Transformer Language Models](https://arxiv.org/pdf/2205.01068) by Meta AI.
diff --git a/docs/source/en/model_doc/owlv2.md b/docs/source/en/model_doc/owlv2.md
index 696a1b0377..f01a5c5906 100644
--- a/docs/source/en/model_doc/owlv2.md
+++ b/docs/source/en/model_doc/owlv2.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# OWLv2
+
+
+
+
## Overview
OWLv2 was proposed in [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby. OWLv2 scales up [OWL-ViT](owlvit) using self-training, which uses an existing detector to generate pseudo-box annotations on image-text pairs. This results in large gains over the previous state-of-the-art for zero-shot object detection.
diff --git a/docs/source/en/model_doc/owlvit.md b/docs/source/en/model_doc/owlvit.md
index 519648bbd8..5be8ffc8f5 100644
--- a/docs/source/en/model_doc/owlvit.md
+++ b/docs/source/en/model_doc/owlvit.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# OWL-ViT
+
+
+
+
## Overview
The OWL-ViT (short for Vision Transformer for Open-World Localization) was proposed in [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby. OWL-ViT is an open-vocabulary object detection network trained on a variety of (image, text) pairs. It can be used to query an image with one or multiple text queries to search for and detect target objects described in text.
diff --git a/docs/source/en/model_doc/paligemma.md b/docs/source/en/model_doc/paligemma.md
index 8b88db39bd..3662f0fcf4 100644
--- a/docs/source/en/model_doc/paligemma.md
+++ b/docs/source/en/model_doc/paligemma.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# PaliGemma
+
+
+
+
+
+
## Overview
The PaliGemma model was proposed in [PaliGemma – Google's Cutting-Edge Open Vision Language Model](https://huggingface.co/blog/paligemma) by Google. It is a 3B vision-language model composed by a [SigLIP](siglip) vision encoder and a [Gemma](gemma) language decoder linked by a multimodal linear projection. It cuts an image into a fixed number of VIT tokens and prepends it to an optional prompt. One particularity is that the model uses full block attention on all the image tokens plus the input text tokens. It comes in 3 resolutions, 224x224, 448x448 and 896x896 with 3 base models, with 55 fine-tuned versions for different tasks, and 2 mix models.
diff --git a/docs/source/en/model_doc/patchtsmixer.md b/docs/source/en/model_doc/patchtsmixer.md
index a67138e533..dd678dd401 100644
--- a/docs/source/en/model_doc/patchtsmixer.md
+++ b/docs/source/en/model_doc/patchtsmixer.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# PatchTSMixer
+
+
+
+
## Overview
The PatchTSMixer model was proposed in [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf) by Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong and Jayant Kalagnanam.
diff --git a/docs/source/en/model_doc/patchtst.md b/docs/source/en/model_doc/patchtst.md
index 544e4cb378..c55ba33342 100644
--- a/docs/source/en/model_doc/patchtst.md
+++ b/docs/source/en/model_doc/patchtst.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# PatchTST
+
+
+
+
## Overview
The PatchTST model was proposed in [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/abs/2211.14730) by Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong and Jayant Kalagnanam.
diff --git a/docs/source/en/model_doc/pegasus.md b/docs/source/en/model_doc/pegasus.md
index 0622354e62..46fca71ac0 100644
--- a/docs/source/en/model_doc/pegasus.md
+++ b/docs/source/en/model_doc/pegasus.md
@@ -17,15 +17,12 @@ rendered properly in your Markdown viewer.
# Pegasus
-
## Overview
The Pegasus model was proposed in [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/pdf/1912.08777.pdf) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu on Dec 18, 2019.
diff --git a/docs/source/en/model_doc/pegasus_x.md b/docs/source/en/model_doc/pegasus_x.md
index d64d8ba954..3f982263cd 100644
--- a/docs/source/en/model_doc/pegasus_x.md
+++ b/docs/source/en/model_doc/pegasus_x.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# PEGASUS-X
+
+
+
+
## Overview
The PEGASUS-X model was proposed in [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao and Peter J. Liu.
diff --git a/docs/source/en/model_doc/perceiver.md b/docs/source/en/model_doc/perceiver.md
index ee678c22f6..700f49d42d 100644
--- a/docs/source/en/model_doc/perceiver.md
+++ b/docs/source/en/model_doc/perceiver.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Perceiver
+
+
+
+
## Overview
The Perceiver IO model was proposed in [Perceiver IO: A General Architecture for Structured Inputs &
diff --git a/docs/source/en/model_doc/persimmon.md b/docs/source/en/model_doc/persimmon.md
index 7a105ac554..bf721f19a1 100644
--- a/docs/source/en/model_doc/persimmon.md
+++ b/docs/source/en/model_doc/persimmon.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Persimmon
+
+
+
+
## Overview
The Persimmon model was created by [ADEPT](https://www.adept.ai/blog/persimmon-8b), and authored by Erich Elsen, Augustus Odena, Maxwell Nye, Sağnak Taşırlar, Tri Dao, Curtis Hawthorne, Deepak Moparthi, Arushi Somani.
diff --git a/docs/source/en/model_doc/phi.md b/docs/source/en/model_doc/phi.md
index ef163213bf..097d7fdd39 100644
--- a/docs/source/en/model_doc/phi.md
+++ b/docs/source/en/model_doc/phi.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# Phi
+
+
+
+
+
+
## Overview
The Phi-1 model was proposed in [Textbooks Are All You Need](https://arxiv.org/abs/2306.11644) by Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee and Yuanzhi Li.
diff --git a/docs/source/en/model_doc/phi3.md b/docs/source/en/model_doc/phi3.md
index fe68a6ae76..82973d39c0 100644
--- a/docs/source/en/model_doc/phi3.md
+++ b/docs/source/en/model_doc/phi3.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# Phi-3
+
+
+
+
+
+
## Overview
The Phi-3 model was proposed in [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/abs/2404.14219) by Microsoft.
diff --git a/docs/source/en/model_doc/phimoe.md b/docs/source/en/model_doc/phimoe.md
index d9c9ae4a18..6728248f2e 100644
--- a/docs/source/en/model_doc/phimoe.md
+++ b/docs/source/en/model_doc/phimoe.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# PhiMoE
+
+
+
+
+
+
## Overview
The PhiMoE model was proposed in [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/abs/2404.14219) by Microsoft.
diff --git a/docs/source/en/model_doc/phobert.md b/docs/source/en/model_doc/phobert.md
index adf5900ebe..c1c4b8742b 100644
--- a/docs/source/en/model_doc/phobert.md
+++ b/docs/source/en/model_doc/phobert.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# PhoBERT
+
+
+
+
+
+
## Overview
The PhoBERT model was proposed in [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92.pdf) by Dat Quoc Nguyen, Anh Tuan Nguyen.
diff --git a/docs/source/en/model_doc/pix2struct.md b/docs/source/en/model_doc/pix2struct.md
index 0c9baa18e0..e912cc96cd 100644
--- a/docs/source/en/model_doc/pix2struct.md
+++ b/docs/source/en/model_doc/pix2struct.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Pix2Struct
+
+
+
+
## Overview
The Pix2Struct model was proposed in [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
diff --git a/docs/source/en/model_doc/pixtral.md b/docs/source/en/model_doc/pixtral.md
index 348e0403b9..f287170a0e 100644
--- a/docs/source/en/model_doc/pixtral.md
+++ b/docs/source/en/model_doc/pixtral.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Pixtral
+
+
+
+
## Overview
The Pixtral model was released by the Mistral AI team in a [blog post](https://mistral.ai/news/pixtral-12b/). Pixtral is a multimodal version of [Mistral](mistral), incorporating a 400 million parameter vision encoder trained from scratch.
diff --git a/docs/source/en/model_doc/plbart.md b/docs/source/en/model_doc/plbart.md
index 61af52e54d..bac567615d 100644
--- a/docs/source/en/model_doc/plbart.md
+++ b/docs/source/en/model_doc/plbart.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# PLBart
+
+
+
+
## Overview
The PLBART model was proposed in [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
diff --git a/docs/source/en/model_doc/poolformer.md b/docs/source/en/model_doc/poolformer.md
index 823c441248..bce183706a 100644
--- a/docs/source/en/model_doc/poolformer.md
+++ b/docs/source/en/model_doc/poolformer.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# PoolFormer
+
+
+
+
## Overview
The PoolFormer model was proposed in [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Sea AI Labs. Instead of designing complicated token mixer to achieve SOTA performance, the target of this work is to demonstrate the competence of transformer models largely stem from the general architecture MetaFormer.
diff --git a/docs/source/en/model_doc/pop2piano.md b/docs/source/en/model_doc/pop2piano.md
index 8e7c1fbd34..a9554b4924 100644
--- a/docs/source/en/model_doc/pop2piano.md
+++ b/docs/source/en/model_doc/pop2piano.md
@@ -13,9 +13,7 @@ specific language governing permissions and limitations under the License.
# Pop2Piano
-
- -
+
-
+
## Overview
diff --git a/docs/source/en/model_doc/prophetnet.md b/docs/source/en/model_doc/prophetnet.md
index 764c3acb06..b768fef72a 100644
--- a/docs/source/en/model_doc/prophetnet.md
+++ b/docs/source/en/model_doc/prophetnet.md
@@ -17,12 +17,7 @@ rendered properly in your Markdown viewer.
# ProphetNet
## Overview
diff --git a/docs/source/en/model_doc/pvt.md b/docs/source/en/model_doc/pvt.md
index 3e88a24999..d4c80445bf 100644
--- a/docs/source/en/model_doc/pvt.md
+++ b/docs/source/en/model_doc/pvt.md
@@ -12,6 +12,10 @@ specific language governing permissions and limitations under the License.
# Pyramid Vision Transformer (PVT)
+
+
+
+
## Overview
The PVT model was proposed in
diff --git a/docs/source/en/model_doc/pvt_v2.md b/docs/source/en/model_doc/pvt_v2.md
index 4b580491ea..deac614d38 100644
--- a/docs/source/en/model_doc/pvt_v2.md
+++ b/docs/source/en/model_doc/pvt_v2.md
@@ -12,6 +12,10 @@ specific language governing permissions and limitations under the License.
# Pyramid Vision Transformer V2 (PVTv2)
+
+
+
+
## Overview
The PVTv2 model was proposed in
diff --git a/docs/source/en/model_doc/qdqbert.md b/docs/source/en/model_doc/qdqbert.md
index ca718f34af..76555909c7 100644
--- a/docs/source/en/model_doc/qdqbert.md
+++ b/docs/source/en/model_doc/qdqbert.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# QDQBERT
+
+
+
+
+
+
+
+
+
## Overview
Qwen2 is the new model series of large language models from the Qwen team. Previously, we released the Qwen series, including Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B, Qwen2-72B, Qwen2-Audio, etc.
diff --git a/docs/source/en/model_doc/qwen2_5_vl.md b/docs/source/en/model_doc/qwen2_5_vl.md
index f08343506b..b2c138999e 100644
--- a/docs/source/en/model_doc/qwen2_5_vl.md
+++ b/docs/source/en/model_doc/qwen2_5_vl.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# Qwen2.5-VL
+
+
+
+
+
+
## Overview
The [Qwen2.5-VL](https://qwenlm.github.io/blog/qwen2_5-vl/) model is an update to [Qwen2-VL](https://arxiv.org/abs/2409.12191) from Qwen team, Alibaba Group.
diff --git a/docs/source/en/model_doc/qwen2_audio.md b/docs/source/en/model_doc/qwen2_audio.md
index 2ef947ce43..8f7bd7c3b6 100644
--- a/docs/source/en/model_doc/qwen2_audio.md
+++ b/docs/source/en/model_doc/qwen2_audio.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# Qwen2Audio
+
+
+
+
+
+
## Overview
The Qwen2-Audio is the new model series of large audio-language models from the Qwen team. Qwen2-Audio is capable of accepting various audio signal inputs and performing audio analysis or direct textual responses with regard to speech instructions. We introduce two distinct audio interaction modes:
diff --git a/docs/source/en/model_doc/qwen2_moe.md b/docs/source/en/model_doc/qwen2_moe.md
index 3a7391ca19..eaaa66aedf 100644
--- a/docs/source/en/model_doc/qwen2_moe.md
+++ b/docs/source/en/model_doc/qwen2_moe.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# Qwen2MoE
+
+
+
+
+
+
## Overview
Qwen2MoE is the new model series of large language models from the Qwen team. Previously, we released the Qwen series, including Qwen-72B, Qwen-1.8B, Qwen-VL, Qwen-Audio, etc.
diff --git a/docs/source/en/model_doc/qwen2_vl.md b/docs/source/en/model_doc/qwen2_vl.md
index b0275ce94a..37c7ad31b3 100644
--- a/docs/source/en/model_doc/qwen2_vl.md
+++ b/docs/source/en/model_doc/qwen2_vl.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# Qwen2-VL
+
+
+
+
+
## Overview
The [Qwen2-VL](https://qwenlm.github.io/blog/qwen2-vl/) model is a major update to [Qwen-VL](https://arxiv.org/pdf/2308.12966) from the Qwen team at Alibaba Research.
diff --git a/docs/source/en/model_doc/rag.md b/docs/source/en/model_doc/rag.md
index 1891efe742..8b65da43a2 100644
--- a/docs/source/en/model_doc/rag.md
+++ b/docs/source/en/model_doc/rag.md
@@ -17,9 +17,9 @@ rendered properly in your Markdown viewer.
# RAG
## Overview
diff --git a/docs/source/en/model_doc/realm.md b/docs/source/en/model_doc/realm.md
index 558e83c08b..b5b9102c2c 100644
--- a/docs/source/en/model_doc/realm.md
+++ b/docs/source/en/model_doc/realm.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# REALM
+
+
+
+
+
+
+
## Overview
The Recurrent Gemma model was proposed in [RecurrentGemma: Moving Past Transformers for Efficient Open Language Models](https://storage.googleapis.com/deepmind-media/gemma/recurrentgemma-report.pdf) by the Griffin, RLHF and Gemma Teams of Google.
diff --git a/docs/source/en/model_doc/reformer.md b/docs/source/en/model_doc/reformer.md
index c78b1bbb83..7e403599fd 100644
--- a/docs/source/en/model_doc/reformer.md
+++ b/docs/source/en/model_doc/reformer.md
@@ -17,12 +17,7 @@ rendered properly in your Markdown viewer.
# Reformer
## Overview
diff --git a/docs/source/en/model_doc/regnet.md b/docs/source/en/model_doc/regnet.md
index acd833c77c..f292fe0df2 100644
--- a/docs/source/en/model_doc/regnet.md
+++ b/docs/source/en/model_doc/regnet.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# RegNet
+
+
+
+
+
+
## Overview
The RegNet model was proposed in [Designing Network Design Spaces](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
diff --git a/docs/source/en/model_doc/rembert.md b/docs/source/en/model_doc/rembert.md
index b755d34230..319e44cf09 100644
--- a/docs/source/en/model_doc/rembert.md
+++ b/docs/source/en/model_doc/rembert.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# RemBERT
+
+
+
+
+
## Overview
The RemBERT model was proposed in [Rethinking Embedding Coupling in Pre-trained Language Models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, Melvin Johnson, Sebastian Ruder.
diff --git a/docs/source/en/model_doc/resnet.md b/docs/source/en/model_doc/resnet.md
index b959266512..d7400b46c8 100644
--- a/docs/source/en/model_doc/resnet.md
+++ b/docs/source/en/model_doc/resnet.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# ResNet
+
+
+
+
+
+
## Overview
The ResNet model was proposed in [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren and Jian Sun. Our implementation follows the small changes made by [Nvidia](https://catalog.ngc.nvidia.com/orgs/nvidia/resources/resnet_50_v1_5_for_pytorch), we apply the `stride=2` for downsampling in bottleneck's `3x3` conv and not in the first `1x1`. This is generally known as "ResNet v1.5".
diff --git a/docs/source/en/model_doc/retribert.md b/docs/source/en/model_doc/retribert.md
index ab29ac966f..795f81caaa 100644
--- a/docs/source/en/model_doc/retribert.md
+++ b/docs/source/en/model_doc/retribert.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# RetriBERT
+
+
+
+
+
+
+
+
+
## Overview
The RoBERTa-PreLayerNorm model was proposed in [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://arxiv.org/abs/1904.01038) by Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli.
diff --git a/docs/source/en/model_doc/roberta.md b/docs/source/en/model_doc/roberta.md
index 2a1843d888..10a46d6f57 100644
--- a/docs/source/en/model_doc/roberta.md
+++ b/docs/source/en/model_doc/roberta.md
@@ -17,17 +17,12 @@ rendered properly in your Markdown viewer.
# RoBERTa
-
## Overview
The RoBERTa model was proposed in [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, [Myle Ott](https://huggingface.co/myleott), Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer
diff --git a/docs/source/en/model_doc/roc_bert.md b/docs/source/en/model_doc/roc_bert.md
index 30fadd5c2c..f3797663ff 100644
--- a/docs/source/en/model_doc/roc_bert.md
+++ b/docs/source/en/model_doc/roc_bert.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# RoCBert
+
+
+
+
## Overview
The RoCBert model was proposed in [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
diff --git a/docs/source/en/model_doc/roformer.md b/docs/source/en/model_doc/roformer.md
index 5d8f146c43..83d01c2fc9 100644
--- a/docs/source/en/model_doc/roformer.md
+++ b/docs/source/en/model_doc/roformer.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# RoFormer
+
+
+
+
+
+
## Overview
The RoFormer model was proposed in [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/pdf/2104.09864v1.pdf) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
diff --git a/docs/source/en/model_doc/rt_detr.md b/docs/source/en/model_doc/rt_detr.md
index 6a1545e123..c80e83e7b8 100644
--- a/docs/source/en/model_doc/rt_detr.md
+++ b/docs/source/en/model_doc/rt_detr.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# RT-DETR
+
+
+
+
## Overview
diff --git a/docs/source/en/model_doc/rt_detr_v2.md b/docs/source/en/model_doc/rt_detr_v2.md
index 0c125af3d2..e5212d945c 100644
--- a/docs/source/en/model_doc/rt_detr_v2.md
+++ b/docs/source/en/model_doc/rt_detr_v2.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# RT-DETRv2
+
+
+
+
## Overview
The RT-DETRv2 model was proposed in [RT-DETRv2: Improved Baseline with Bag-of-Freebies for Real-Time Detection Transformer](https://arxiv.org/abs/2407.17140) by Wenyu Lv, Yian Zhao, Qinyao Chang, Kui Huang, Guanzhong Wang, Yi Liu.
diff --git a/docs/source/en/model_doc/rwkv.md b/docs/source/en/model_doc/rwkv.md
index 1acb173060..8b54c25204 100644
--- a/docs/source/en/model_doc/rwkv.md
+++ b/docs/source/en/model_doc/rwkv.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# RWKV
+
+
+
+
## Overview
The RWKV model was proposed in [this repo](https://github.com/BlinkDL/RWKV-LM)
diff --git a/docs/source/en/model_doc/sam.md b/docs/source/en/model_doc/sam.md
index f45b08c2c2..cd9e3f5c3c 100644
--- a/docs/source/en/model_doc/sam.md
+++ b/docs/source/en/model_doc/sam.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# SAM
+
+
+
+
+
## Overview
SAM (Segment Anything Model) was proposed in [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
diff --git a/docs/source/en/model_doc/seamless_m4t.md b/docs/source/en/model_doc/seamless_m4t.md
index 486e58691f..100198e501 100644
--- a/docs/source/en/model_doc/seamless_m4t.md
+++ b/docs/source/en/model_doc/seamless_m4t.md
@@ -12,6 +12,10 @@ specific language governing permissions and limitations under the License.
# SeamlessM4T
+
+
+
+
## Overview
The SeamlessM4T model was proposed in [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team from Meta AI.
diff --git a/docs/source/en/model_doc/seamless_m4t_v2.md b/docs/source/en/model_doc/seamless_m4t_v2.md
index c6a2ec4b51..7b68d08b5f 100644
--- a/docs/source/en/model_doc/seamless_m4t_v2.md
+++ b/docs/source/en/model_doc/seamless_m4t_v2.md
@@ -12,6 +12,10 @@ specific language governing permissions and limitations under the License.
# SeamlessM4T-v2
+
+
+
+
## Overview
The SeamlessM4T-v2 model was proposed in [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team from Meta AI.
diff --git a/docs/source/en/model_doc/segformer.md b/docs/source/en/model_doc/segformer.md
index 1dc38ef45b..093a141eaf 100644
--- a/docs/source/en/model_doc/segformer.md
+++ b/docs/source/en/model_doc/segformer.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# SegFormer
+
+
+
+
+
## Overview
The SegFormer model was proposed in [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping
diff --git a/docs/source/en/model_doc/seggpt.md b/docs/source/en/model_doc/seggpt.md
index b53f5d6ca1..1eb82b8477 100644
--- a/docs/source/en/model_doc/seggpt.md
+++ b/docs/source/en/model_doc/seggpt.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# SegGPT
+
+
+
+
## Overview
The SegGPT model was proposed in [SegGPT: Segmenting Everything In Context](https://arxiv.org/abs/2304.03284) by Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang. SegGPT employs a decoder-only Transformer that can generate a segmentation mask given an input image, a prompt image and its corresponding prompt mask. The model achieves remarkable one-shot results with 56.1 mIoU on COCO-20 and 85.6 mIoU on FSS-1000.
diff --git a/docs/source/en/model_doc/sew-d.md b/docs/source/en/model_doc/sew-d.md
index 013e404bd0..3626d953d9 100644
--- a/docs/source/en/model_doc/sew-d.md
+++ b/docs/source/en/model_doc/sew-d.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# SEW-D
+
+
+
+
## Overview
SEW-D (Squeezed and Efficient Wav2Vec with Disentangled attention) was proposed in [Performance-Efficiency Trade-offs
diff --git a/docs/source/en/model_doc/sew.md b/docs/source/en/model_doc/sew.md
index ee8a36a4dc..cfc92db0ea 100644
--- a/docs/source/en/model_doc/sew.md
+++ b/docs/source/en/model_doc/sew.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# SEW
+
+
+
+
+
+
## Overview
SEW (Squeezed and Efficient Wav2Vec) was proposed in [Performance-Efficiency Trade-offs in Unsupervised Pre-training
diff --git a/docs/source/en/model_doc/siglip.md b/docs/source/en/model_doc/siglip.md
index 4beac361de..478e8a19a8 100644
--- a/docs/source/en/model_doc/siglip.md
+++ b/docs/source/en/model_doc/siglip.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# SigLIP
+
+
+
+
+
+
## Overview
The SigLIP model was proposed in [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) by Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer. SigLIP proposes to replace the loss function used in [CLIP](clip) by a simple pairwise sigmoid loss. This results in better performance in terms of zero-shot classification accuracy on ImageNet.
diff --git a/docs/source/en/model_doc/siglip2.md b/docs/source/en/model_doc/siglip2.md
index 054e09189a..0d49d93823 100644
--- a/docs/source/en/model_doc/siglip2.md
+++ b/docs/source/en/model_doc/siglip2.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# SigLIP2
+
+
+
+
+
+
## Overview
The SigLIP2 model was proposed in [SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features](https://huggingface.co/papers/2502.14786) by Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin,
diff --git a/docs/source/en/model_doc/smolvlm.md b/docs/source/en/model_doc/smolvlm.md
index b883fd162b..9512fb6aa2 100644
--- a/docs/source/en/model_doc/smolvlm.md
+++ b/docs/source/en/model_doc/smolvlm.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# SmolVLM
+
+
+
+
+
+
## Overview
SmolVLM2 is an adaptation of the Idefics3 model with two main differences:
diff --git a/docs/source/en/model_doc/speech-encoder-decoder.md b/docs/source/en/model_doc/speech-encoder-decoder.md
index 7e2bcef98a..8893adfdd4 100644
--- a/docs/source/en/model_doc/speech-encoder-decoder.md
+++ b/docs/source/en/model_doc/speech-encoder-decoder.md
@@ -16,6 +16,14 @@ rendered properly in your Markdown viewer.
# Speech Encoder Decoder Models
+
+
+
+
+
+
+
The [`SpeechEncoderDecoderModel`] can be used to initialize a speech-to-text model
with any pretrained speech autoencoding model as the encoder (*e.g.* [Wav2Vec2](wav2vec2), [Hubert](hubert)) and any pretrained autoregressive model as the decoder.
diff --git a/docs/source/en/model_doc/speech_to_text.md b/docs/source/en/model_doc/speech_to_text.md
index 23512b323a..8b375374ea 100644
--- a/docs/source/en/model_doc/speech_to_text.md
+++ b/docs/source/en/model_doc/speech_to_text.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# Speech2Text
+
+
+
+
+
## Overview
The Speech2Text model was proposed in [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino. It's a
diff --git a/docs/source/en/model_doc/speecht5.md b/docs/source/en/model_doc/speecht5.md
index 4d5e2098a5..acbadb137f 100644
--- a/docs/source/en/model_doc/speecht5.md
+++ b/docs/source/en/model_doc/speecht5.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# SpeechT5
+
+
+
+
## Overview
The SpeechT5 model was proposed in [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
diff --git a/docs/source/en/model_doc/splinter.md b/docs/source/en/model_doc/splinter.md
index a46c55966c..0d526beff9 100644
--- a/docs/source/en/model_doc/splinter.md
+++ b/docs/source/en/model_doc/splinter.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Splinter
+
+
+
+
## Overview
The Splinter model was proposed in [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy. Splinter
diff --git a/docs/source/en/model_doc/squeezebert.md b/docs/source/en/model_doc/squeezebert.md
index e2bb378fe5..56046e22b7 100644
--- a/docs/source/en/model_doc/squeezebert.md
+++ b/docs/source/en/model_doc/squeezebert.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# SqueezeBERT
+
+
+
+
## Overview
The SqueezeBERT model was proposed in [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, Kurt W. Keutzer. It's a
diff --git a/docs/source/en/model_doc/stablelm.md b/docs/source/en/model_doc/stablelm.md
index 09c0e5855c..b996b7fcf9 100644
--- a/docs/source/en/model_doc/stablelm.md
+++ b/docs/source/en/model_doc/stablelm.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# StableLM
+
+
+
+
+
+
## Overview
`StableLM 3B 4E1T` was proposed in [`StableLM 3B 4E1T`: Technical Report](https://stability.wandb.io/stability-llm/stable-lm/reports/StableLM-3B-4E1T--VmlldzoyMjU4?accessToken=u3zujipenkx5g7rtcj9qojjgxpconyjktjkli2po09nffrffdhhchq045vp0wyfo) by Stability AI and is the first model in a series of multi-epoch pre-trained language models.
diff --git a/docs/source/en/model_doc/starcoder2.md b/docs/source/en/model_doc/starcoder2.md
index 1d107b3855..c6b146bf30 100644
--- a/docs/source/en/model_doc/starcoder2.md
+++ b/docs/source/en/model_doc/starcoder2.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# Starcoder2
+
+
+
+
+
+
## Overview
StarCoder2 is a family of open LLMs for code and comes in 3 different sizes with 3B, 7B and 15B parameters. The flagship StarCoder2-15B model is trained on over 4 trillion tokens and 600+ programming languages from The Stack v2. All models use Grouped Query Attention, a context window of 16,384 tokens with a sliding window attention of 4,096 tokens, and were trained using the Fill-in-the-Middle objective. The models have been released with the paper [StarCoder 2 and The Stack v2: The Next Generation](https://arxiv.org/abs/2402.19173) by Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Zheltonozhskii, Nii Osae Osae Dade, Wenhao Yu, Lucas Krauß, Naman Jain, Yixuan Su, Xuanli He, Manan Dey, Edoardo Abati, Yekun Chai, Niklas Muennighoff, Xiangru Tang, Muhtasham Oblokulov, Christopher Akiki, Marc Marone, Chenghao Mou, Mayank Mishra, Alex Gu, Binyuan Hui, Tri Dao, Armel Zebaze, Olivier Dehaene, Nicolas Patry, Canwen Xu, Julian McAuley, Han Hu, Torsten Scholak, Sebastien Paquet, Jennifer Robinson, Carolyn Jane Anderson, Nicolas Chapados, Mostofa Patwary, Nima Tajbakhsh, Yacine Jernite, Carlos Muñoz Ferrandis, Lingming Zhang, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries.
diff --git a/docs/source/en/model_doc/superglue.md b/docs/source/en/model_doc/superglue.md
index 08a4575ddd..38ef55ab79 100644
--- a/docs/source/en/model_doc/superglue.md
+++ b/docs/source/en/model_doc/superglue.md
@@ -15,6 +15,10 @@ rendered properly in your Markdown viewer.
# SuperGlue
+
+
+
+
## Overview
The SuperGlue model was proposed in [SuperGlue: Learning Feature Matching with Graph Neural Networks](https://arxiv.org/abs/1911.11763) by Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
diff --git a/docs/source/en/model_doc/superpoint.md b/docs/source/en/model_doc/superpoint.md
index 59e451adce..06ae5cb081 100644
--- a/docs/source/en/model_doc/superpoint.md
+++ b/docs/source/en/model_doc/superpoint.md
@@ -15,6 +15,10 @@ rendered properly in your Markdown viewer.
# SuperPoint
+
+
+
+
## Overview
The SuperPoint model was proposed
diff --git a/docs/source/en/model_doc/swiftformer.md b/docs/source/en/model_doc/swiftformer.md
index 319c79fce4..48580a60f5 100644
--- a/docs/source/en/model_doc/swiftformer.md
+++ b/docs/source/en/model_doc/swiftformer.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# SwiftFormer
+
+
+
+
+
## Overview
The SwiftFormer model was proposed in [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://arxiv.org/abs/2303.15446) by Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan.
diff --git a/docs/source/en/model_doc/swin.md b/docs/source/en/model_doc/swin.md
index e23c882a3f..4e2adf5ca8 100644
--- a/docs/source/en/model_doc/swin.md
+++ b/docs/source/en/model_doc/swin.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# Swin Transformer
+
+
+
+
+
## Overview
The Swin Transformer was proposed in [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030)
diff --git a/docs/source/en/model_doc/swin2sr.md b/docs/source/en/model_doc/swin2sr.md
index 18d6635fef..136f1a1c1e 100644
--- a/docs/source/en/model_doc/swin2sr.md
+++ b/docs/source/en/model_doc/swin2sr.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Swin2SR
+
+
+
+
## Overview
The Swin2SR model was proposed in [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
diff --git a/docs/source/en/model_doc/swinv2.md b/docs/source/en/model_doc/swinv2.md
index 25233dca33..a709af9712 100644
--- a/docs/source/en/model_doc/swinv2.md
+++ b/docs/source/en/model_doc/swinv2.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Swin Transformer V2
+
+
+
+
## Overview
The Swin Transformer V2 model was proposed in [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
diff --git a/docs/source/en/model_doc/switch_transformers.md b/docs/source/en/model_doc/switch_transformers.md
index ca6748167f..433b84dd86 100644
--- a/docs/source/en/model_doc/switch_transformers.md
+++ b/docs/source/en/model_doc/switch_transformers.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# SwitchTransformers
+
+
+
+
## Overview
The SwitchTransformers model was proposed in [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
diff --git a/docs/source/en/model_doc/t5.md b/docs/source/en/model_doc/t5.md
index 86a645512c..87b9d2c6e8 100644
--- a/docs/source/en/model_doc/t5.md
+++ b/docs/source/en/model_doc/t5.md
@@ -17,15 +17,10 @@ rendered properly in your Markdown viewer.
# T5
## Overview
diff --git a/docs/source/en/model_doc/t5v1.1.md b/docs/source/en/model_doc/t5v1.1.md
index e18696f629..5ae908bacd 100644
--- a/docs/source/en/model_doc/t5v1.1.md
+++ b/docs/source/en/model_doc/t5v1.1.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# T5v1.1
+
+
+
+
+
+
## Overview
T5v1.1 was released in the [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511)
diff --git a/docs/source/en/model_doc/table-transformer.md b/docs/source/en/model_doc/table-transformer.md
index 850e7f50aa..fea4dabf3f 100644
--- a/docs/source/en/model_doc/table-transformer.md
+++ b/docs/source/en/model_doc/table-transformer.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Table Transformer
+
+
+
+
## Overview
The Table Transformer model was proposed in [PubTables-1M: Towards comprehensive table extraction from unstructured documents](https://arxiv.org/abs/2110.00061) by
diff --git a/docs/source/en/model_doc/tapas.md b/docs/source/en/model_doc/tapas.md
index 79bbe3e819..21eb697ee3 100644
--- a/docs/source/en/model_doc/tapas.md
+++ b/docs/source/en/model_doc/tapas.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# TAPAS
+
+
+
+
+
## Overview
The TAPAS model was proposed in [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://www.aclweb.org/anthology/2020.acl-main.398)
diff --git a/docs/source/en/model_doc/tapex.md b/docs/source/en/model_doc/tapex.md
index 15ac2463fd..d46d520c7d 100644
--- a/docs/source/en/model_doc/tapex.md
+++ b/docs/source/en/model_doc/tapex.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# TAPEX
+
+
+
+
+
+
+
+
+
## Overview
The TextNet model was proposed in [FAST: Faster Arbitrarily-Shaped Text Detector with Minimalist Kernel Representation](https://arxiv.org/abs/2111.02394) by Zhe Chen, Jiahao Wang, Wenhai Wang, Guo Chen, Enze Xie, Ping Luo, Tong Lu. TextNet is a vision backbone useful for text detection tasks. It is the result of neural architecture search (NAS) on backbones with reward function as text detection task (to provide powerful features for text detection).
diff --git a/docs/source/en/model_doc/time_series_transformer.md b/docs/source/en/model_doc/time_series_transformer.md
index c5bfcfc15e..a91633b6b0 100644
--- a/docs/source/en/model_doc/time_series_transformer.md
+++ b/docs/source/en/model_doc/time_series_transformer.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Time Series Transformer
+
+
+
+
## Overview
The Time Series Transformer model is a vanilla encoder-decoder Transformer for time series forecasting.
diff --git a/docs/source/en/model_doc/timesformer.md b/docs/source/en/model_doc/timesformer.md
index fe75bee5b2..c01f64efa7 100644
--- a/docs/source/en/model_doc/timesformer.md
+++ b/docs/source/en/model_doc/timesformer.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# TimeSformer
+
+
+
+
## Overview
The TimeSformer model was proposed in [TimeSformer: Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095) by Facebook Research.
diff --git a/docs/source/en/model_doc/timm_wrapper.md b/docs/source/en/model_doc/timm_wrapper.md
index 467f2addf9..8095a91054 100644
--- a/docs/source/en/model_doc/timm_wrapper.md
+++ b/docs/source/en/model_doc/timm_wrapper.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# TimmWrapper
+
+
+
+
## Overview
Helper class to enable loading timm models to be used with the transformers library and its autoclasses.
diff --git a/docs/source/en/model_doc/trajectory_transformer.md b/docs/source/en/model_doc/trajectory_transformer.md
index 4561625587..0c8fc29e01 100644
--- a/docs/source/en/model_doc/trajectory_transformer.md
+++ b/docs/source/en/model_doc/trajectory_transformer.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Trajectory Transformer
+
+
+
+
+
+
+
+
+
+
+
## Overview
The TrOCR model was proposed in [TrOCR: Transformer-based Optical Character Recognition with Pre-trained
diff --git a/docs/source/en/model_doc/tvlt.md b/docs/source/en/model_doc/tvlt.md
index 0a0f50e473..f1a97dfcd8 100644
--- a/docs/source/en/model_doc/tvlt.md
+++ b/docs/source/en/model_doc/tvlt.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# TVLT
+
+
+
+
+
+
+
## Overview
The text-visual prompting (TVP) framework was proposed in the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
diff --git a/docs/source/en/model_doc/udop.md b/docs/source/en/model_doc/udop.md
index 614bd2ff4f..b63bc11a53 100644
--- a/docs/source/en/model_doc/udop.md
+++ b/docs/source/en/model_doc/udop.md
@@ -12,6 +12,10 @@ specific language governing permissions and limitations under the License.
# UDOP
+
+
+
+
## Overview
The UDOP model was proposed in [Unifying Vision, Text, and Layout for Universal Document Processing](https://arxiv.org/abs/2212.02623) by Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal.
diff --git a/docs/source/en/model_doc/ul2.md b/docs/source/en/model_doc/ul2.md
index f4d01c40b0..18743a2842 100644
--- a/docs/source/en/model_doc/ul2.md
+++ b/docs/source/en/model_doc/ul2.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# UL2
+
+
+
+
+
+
## Overview
The T5 model was presented in [Unifying Language Learning Paradigms](https://arxiv.org/pdf/2205.05131v1.pdf) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler.
diff --git a/docs/source/en/model_doc/umt5.md b/docs/source/en/model_doc/umt5.md
index b9f86a0304..736574373c 100644
--- a/docs/source/en/model_doc/umt5.md
+++ b/docs/source/en/model_doc/umt5.md
@@ -17,12 +17,7 @@ rendered properly in your Markdown viewer.
# UMT5
## Overview
diff --git a/docs/source/en/model_doc/unispeech-sat.md b/docs/source/en/model_doc/unispeech-sat.md
index 3f0bbcc793..ae4eed7187 100644
--- a/docs/source/en/model_doc/unispeech-sat.md
+++ b/docs/source/en/model_doc/unispeech-sat.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# UniSpeech-SAT
+
+
+
+
+
+
## Overview
The UniSpeech-SAT model was proposed in [UniSpeech-SAT: Universal Speech Representation Learning with Speaker Aware
diff --git a/docs/source/en/model_doc/unispeech.md b/docs/source/en/model_doc/unispeech.md
index 2b2b13bed5..43b0c3bb11 100644
--- a/docs/source/en/model_doc/unispeech.md
+++ b/docs/source/en/model_doc/unispeech.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# UniSpeech
+
+
+
+
+
+
## Overview
The UniSpeech model was proposed in [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael
diff --git a/docs/source/en/model_doc/univnet.md b/docs/source/en/model_doc/univnet.md
index 45bd947327..3671471152 100644
--- a/docs/source/en/model_doc/univnet.md
+++ b/docs/source/en/model_doc/univnet.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# UnivNet
+
+
+
+
## Overview
The UnivNet model was proposed in [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kin, and Juntae Kim.
diff --git a/docs/source/en/model_doc/upernet.md b/docs/source/en/model_doc/upernet.md
index 418c3ef178..a2c96582f2 100644
--- a/docs/source/en/model_doc/upernet.md
+++ b/docs/source/en/model_doc/upernet.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# UPerNet
+
+
+
+
## Overview
The UPerNet model was proposed in [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221)
diff --git a/docs/source/en/model_doc/van.md b/docs/source/en/model_doc/van.md
index 2fb8475ce7..1df6a4640b 100644
--- a/docs/source/en/model_doc/van.md
+++ b/docs/source/en/model_doc/van.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# VAN
+
+
+
+
+
+
+
+
+
## Overview
Video-LLaVa is an open-source multimodal LLM trained by fine-tuning LlamA/Vicuna on multimodal instruction-following data generated by Llava1.5 and VideChat. It is an auto-regressive language model, based on the transformer architecture. Video-LLaVa unifies visual representations to the language feature space, and enables an LLM to perform visual reasoning capabilities on both images and videos simultaneously.
diff --git a/docs/source/en/model_doc/videomae.md b/docs/source/en/model_doc/videomae.md
index a785611185..f115d81694 100644
--- a/docs/source/en/model_doc/videomae.md
+++ b/docs/source/en/model_doc/videomae.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# VideoMAE
+
+
+
+
+
## Overview
The VideoMAE model was proposed in [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
diff --git a/docs/source/en/model_doc/vilt.md b/docs/source/en/model_doc/vilt.md
index 2b0ac022da..107271e2c9 100644
--- a/docs/source/en/model_doc/vilt.md
+++ b/docs/source/en/model_doc/vilt.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# ViLT
+
+
+
+
## Overview
The ViLT model was proposed in [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334)
diff --git a/docs/source/en/model_doc/vipllava.md b/docs/source/en/model_doc/vipllava.md
index cb625e3711..9438893dfb 100644
--- a/docs/source/en/model_doc/vipllava.md
+++ b/docs/source/en/model_doc/vipllava.md
@@ -16,6 +16,12 @@ rendered properly in your Markdown viewer.
# VipLlava
+
+
+
+
+
+
## Overview
The VipLlava model was proposed in [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://arxiv.org/abs/2312.00784) by Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee.
diff --git a/docs/source/en/model_doc/vision-encoder-decoder.md b/docs/source/en/model_doc/vision-encoder-decoder.md
index 41159b7fc5..0534085861 100644
--- a/docs/source/en/model_doc/vision-encoder-decoder.md
+++ b/docs/source/en/model_doc/vision-encoder-decoder.md
@@ -16,6 +16,15 @@ rendered properly in your Markdown viewer.
# Vision Encoder Decoder Models
+
+
+
+
+
+
+
+
## Overview
The [`VisionEncoderDecoderModel`] can be used to initialize an image-to-text model with any
diff --git a/docs/source/en/model_doc/vision-text-dual-encoder.md b/docs/source/en/model_doc/vision-text-dual-encoder.md
index 7cb68a2618..b9d6db38d5 100644
--- a/docs/source/en/model_doc/vision-text-dual-encoder.md
+++ b/docs/source/en/model_doc/vision-text-dual-encoder.md
@@ -16,6 +16,15 @@ rendered properly in your Markdown viewer.
# VisionTextDualEncoder
+
+
+
+
+
+
+
+
## Overview
The [`VisionTextDualEncoderModel`] can be used to initialize a vision-text dual encoder model with
diff --git a/docs/source/en/model_doc/visual_bert.md b/docs/source/en/model_doc/visual_bert.md
index 95e5ae4e84..55c526d067 100644
--- a/docs/source/en/model_doc/visual_bert.md
+++ b/docs/source/en/model_doc/visual_bert.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# VisualBERT
+
+
+
+
## Overview
The VisualBERT model was proposed in [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
diff --git a/docs/source/en/model_doc/vit.md b/docs/source/en/model_doc/vit.md
index 53a550895c..49c5c0e278 100644
--- a/docs/source/en/model_doc/vit.md
+++ b/docs/source/en/model_doc/vit.md
@@ -16,6 +16,14 @@ rendered properly in your Markdown viewer.
# Vision Transformer (ViT)
+
+
+
+
+
+
+
## Overview
The Vision Transformer (ViT) model was proposed in [An Image is Worth 16x16 Words: Transformers for Image Recognition
diff --git a/docs/source/en/model_doc/vit_hybrid.md b/docs/source/en/model_doc/vit_hybrid.md
index 5cde5e5298..a79fadd255 100644
--- a/docs/source/en/model_doc/vit_hybrid.md
+++ b/docs/source/en/model_doc/vit_hybrid.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# Hybrid Vision Transformer (ViT Hybrid)
+
+
+
+
+
+
+
+
+
+
## Overview
The ViTMAE model was proposed in [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377v2) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li,
diff --git a/docs/source/en/model_doc/vit_msn.md b/docs/source/en/model_doc/vit_msn.md
index e1210ce7f9..53cef45011 100644
--- a/docs/source/en/model_doc/vit_msn.md
+++ b/docs/source/en/model_doc/vit_msn.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# ViTMSN
+
+
+
+
+
## Overview
The ViTMSN model was proposed in [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes,
diff --git a/docs/source/en/model_doc/vitdet.md b/docs/source/en/model_doc/vitdet.md
index 81bf787d6c..d569e71d90 100644
--- a/docs/source/en/model_doc/vitdet.md
+++ b/docs/source/en/model_doc/vitdet.md
@@ -12,6 +12,10 @@ specific language governing permissions and limitations under the License.
# ViTDet
+
+
+
+
## Overview
The ViTDet model was proposed in [Exploring Plain Vision Transformer Backbones for Object Detection](https://arxiv.org/abs/2203.16527) by Yanghao Li, Hanzi Mao, Ross Girshick, Kaiming He.
diff --git a/docs/source/en/model_doc/vitmatte.md b/docs/source/en/model_doc/vitmatte.md
index 5a6d501030..105d529c2d 100644
--- a/docs/source/en/model_doc/vitmatte.md
+++ b/docs/source/en/model_doc/vitmatte.md
@@ -12,6 +12,10 @@ specific language governing permissions and limitations under the License.
# ViTMatte
+
+
+
+
## Overview
The ViTMatte model was proposed in [Boosting Image Matting with Pretrained Plain Vision Transformers](https://arxiv.org/abs/2305.15272) by Jingfeng Yao, Xinggang Wang, Shusheng Yang, Baoyuan Wang.
diff --git a/docs/source/en/model_doc/vitpose.md b/docs/source/en/model_doc/vitpose.md
index 4fbead04ea..02471ad39e 100644
--- a/docs/source/en/model_doc/vitpose.md
+++ b/docs/source/en/model_doc/vitpose.md
@@ -12,6 +12,10 @@ specific language governing permissions and limitations under the License.
# ViTPose
+
+
+
+
## Overview
The ViTPose model was proposed in [ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation](https://arxiv.org/abs/2204.12484) by Yufei Xu, Jing Zhang, Qiming Zhang, Dacheng Tao. ViTPose employs a standard, non-hierarchical [Vision Transformer](vit) as backbone for the task of keypoint estimation. A simple decoder head is added on top to predict the heatmaps from a given image. Despite its simplicity, the model gets state-of-the-art results on the challenging MS COCO Keypoint Detection benchmark. The model was further improved in [ViTPose++: Vision Transformer for Generic Body Pose Estimation](https://arxiv.org/abs/2212.04246) where the authors employ
diff --git a/docs/source/en/model_doc/vits.md b/docs/source/en/model_doc/vits.md
index 42997cae1e..225d0f6390 100644
--- a/docs/source/en/model_doc/vits.md
+++ b/docs/source/en/model_doc/vits.md
@@ -12,6 +12,10 @@ specific language governing permissions and limitations under the License.
# VITS
+
+
+
+
## Overview
The VITS model was proposed in [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103) by Jaehyeon Kim, Jungil Kong, Juhee Son.
diff --git a/docs/source/en/model_doc/vivit.md b/docs/source/en/model_doc/vivit.md
index c3e3df14ab..9c4b8f5f71 100644
--- a/docs/source/en/model_doc/vivit.md
+++ b/docs/source/en/model_doc/vivit.md
@@ -12,6 +12,11 @@ specific language governing permissions and limitations under the License.
# Video Vision Transformer (ViViT)
+
+
+
+
+
## Overview
The Vivit model was proposed in [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
diff --git a/docs/source/en/model_doc/wav2vec2-bert.md b/docs/source/en/model_doc/wav2vec2-bert.md
index 6514133330..c2cf464977 100644
--- a/docs/source/en/model_doc/wav2vec2-bert.md
+++ b/docs/source/en/model_doc/wav2vec2-bert.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Wav2Vec2-BERT
+
+
+
+
## Overview
The Wav2Vec2-BERT model was proposed in [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team from Meta AI.
diff --git a/docs/source/en/model_doc/wav2vec2-conformer.md b/docs/source/en/model_doc/wav2vec2-conformer.md
index 0b30cf5fa4..f84e6b3711 100644
--- a/docs/source/en/model_doc/wav2vec2-conformer.md
+++ b/docs/source/en/model_doc/wav2vec2-conformer.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# Wav2Vec2-Conformer
+
+
+
+
## Overview
The Wav2Vec2-Conformer was added to an updated version of [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
diff --git a/docs/source/en/model_doc/wav2vec2.md b/docs/source/en/model_doc/wav2vec2.md
index 5ef3fdbb1e..0dac623491 100644
--- a/docs/source/en/model_doc/wav2vec2.md
+++ b/docs/source/en/model_doc/wav2vec2.md
@@ -16,6 +16,15 @@ rendered properly in your Markdown viewer.
# Wav2Vec2
+
+
+
+
+
+
+
+
## Overview
The Wav2Vec2 model was proposed in [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
diff --git a/docs/source/en/model_doc/wav2vec2_phoneme.md b/docs/source/en/model_doc/wav2vec2_phoneme.md
index 93e0656f49..c5c1edd6ac 100644
--- a/docs/source/en/model_doc/wav2vec2_phoneme.md
+++ b/docs/source/en/model_doc/wav2vec2_phoneme.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# Wav2Vec2Phoneme
+
+
+
+
+
+
## Overview
The Wav2Vec2Phoneme model was proposed in [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition (Xu et al.,
diff --git a/docs/source/en/model_doc/wavlm.md b/docs/source/en/model_doc/wavlm.md
index a42fbff139..54947e2f15 100644
--- a/docs/source/en/model_doc/wavlm.md
+++ b/docs/source/en/model_doc/wavlm.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# WavLM
+
+
+
+
## Overview
The WavLM model was proposed in [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen,
diff --git a/docs/source/en/model_doc/whisper.md b/docs/source/en/model_doc/whisper.md
index 58e641a5d0..aa9007a860 100644
--- a/docs/source/en/model_doc/whisper.md
+++ b/docs/source/en/model_doc/whisper.md
@@ -16,6 +16,15 @@ rendered properly in your Markdown viewer.
# Whisper
+
+
+
+
+
+
+
+
## Overview
The Whisper model was proposed in [Robust Speech Recognition via Large-Scale Weak Supervision](https://cdn.openai.com/papers/whisper.pdf) by Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever.
diff --git a/docs/source/en/model_doc/xclip.md b/docs/source/en/model_doc/xclip.md
index 8c22747387..62f0c3aa2e 100644
--- a/docs/source/en/model_doc/xclip.md
+++ b/docs/source/en/model_doc/xclip.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# X-CLIP
+
+
+
+
## Overview
The X-CLIP model was proposed in [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816) by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
diff --git a/docs/source/en/model_doc/xglm.md b/docs/source/en/model_doc/xglm.md
index 470e42c747..4032de2cd7 100644
--- a/docs/source/en/model_doc/xglm.md
+++ b/docs/source/en/model_doc/xglm.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# XGLM
+
+
+
+
+
+
## Overview
The XGLM model was proposed in [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668)
diff --git a/docs/source/en/model_doc/xlm-prophetnet.md b/docs/source/en/model_doc/xlm-prophetnet.md
index b350cb554b..046904d885 100644
--- a/docs/source/en/model_doc/xlm-prophetnet.md
+++ b/docs/source/en/model_doc/xlm-prophetnet.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# XLM-ProphetNet
+
+
+
+
+
+
+
+
## Overview
The XLM-RoBERTa-XL model was proposed in [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
diff --git a/docs/source/en/model_doc/xlm-roberta.md b/docs/source/en/model_doc/xlm-roberta.md
index 414afba116..2bc890257a 100644
--- a/docs/source/en/model_doc/xlm-roberta.md
+++ b/docs/source/en/model_doc/xlm-roberta.md
@@ -17,12 +17,11 @@ rendered properly in your Markdown viewer.
# XLM-RoBERTa
## Overview
diff --git a/docs/source/en/model_doc/xlm-v.md b/docs/source/en/model_doc/xlm-v.md
index 049a1f35ad..69badfe2e6 100644
--- a/docs/source/en/model_doc/xlm-v.md
+++ b/docs/source/en/model_doc/xlm-v.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# XLM-V
+
+
+
+
+
+
## Overview
XLM-V is multilingual language model with a one million token vocabulary trained on 2.5TB of data from Common Crawl (same as XLM-R).
diff --git a/docs/source/en/model_doc/xlm.md b/docs/source/en/model_doc/xlm.md
index 0ee11c6add..61effea7cc 100644
--- a/docs/source/en/model_doc/xlm.md
+++ b/docs/source/en/model_doc/xlm.md
@@ -17,12 +17,8 @@ rendered properly in your Markdown viewer.
# XLM
## Overview
diff --git a/docs/source/en/model_doc/xlnet.md b/docs/source/en/model_doc/xlnet.md
index 90b454e8af..0b90de75cc 100644
--- a/docs/source/en/model_doc/xlnet.md
+++ b/docs/source/en/model_doc/xlnet.md
@@ -17,12 +17,8 @@ rendered properly in your Markdown viewer.
# XLNet
## Overview
diff --git a/docs/source/en/model_doc/xls_r.md b/docs/source/en/model_doc/xls_r.md
index 2226c813e7..d24d88907e 100644
--- a/docs/source/en/model_doc/xls_r.md
+++ b/docs/source/en/model_doc/xls_r.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# XLS-R
+
+
+
+
+
+
## Overview
The XLS-R model was proposed in [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman
diff --git a/docs/source/en/model_doc/xlsr_wav2vec2.md b/docs/source/en/model_doc/xlsr_wav2vec2.md
index 6369d06885..f88b0dc9e1 100644
--- a/docs/source/en/model_doc/xlsr_wav2vec2.md
+++ b/docs/source/en/model_doc/xlsr_wav2vec2.md
@@ -16,6 +16,13 @@ rendered properly in your Markdown viewer.
# XLSR-Wav2Vec2
+
+
+
+
+
+
## Overview
The XLSR-Wav2Vec2 model was proposed in [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael
diff --git a/docs/source/en/model_doc/xmod.md b/docs/source/en/model_doc/xmod.md
index 47797fa649..e07601074c 100644
--- a/docs/source/en/model_doc/xmod.md
+++ b/docs/source/en/model_doc/xmod.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# X-MOD
+
+
+
+
## Overview
The X-MOD model was proposed in [Lifting the Curse of Multilinguality by Pre-training Modular Transformers](http://dx.doi.org/10.18653/v1/2022.naacl-main.255) by Jonas Pfeiffer, Naman Goyal, Xi Lin, Xian Li, James Cross, Sebastian Riedel, and Mikel Artetxe.
diff --git a/docs/source/en/model_doc/yolos.md b/docs/source/en/model_doc/yolos.md
index ebe249517f..a988d0d507 100644
--- a/docs/source/en/model_doc/yolos.md
+++ b/docs/source/en/model_doc/yolos.md
@@ -16,6 +16,11 @@ rendered properly in your Markdown viewer.
# YOLOS
+
+
+
+
+
## Overview
The YOLOS model was proposed in [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
diff --git a/docs/source/en/model_doc/yoso.md b/docs/source/en/model_doc/yoso.md
index a3dfa3fed8..c9fbb11b1e 100644
--- a/docs/source/en/model_doc/yoso.md
+++ b/docs/source/en/model_doc/yoso.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# YOSO
+
+
+
+
## Overview
The YOSO model was proposed in [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714)
diff --git a/docs/source/en/model_doc/zamba.md b/docs/source/en/model_doc/zamba.md
index 450b68c77d..a6a7ee38cf 100644
--- a/docs/source/en/model_doc/zamba.md
+++ b/docs/source/en/model_doc/zamba.md
@@ -15,6 +15,10 @@ rendered properly in your Markdown viewer.
-->
# Zamba
+
+
+
+
Zamba is a large language model (LLM) trained by Zyphra, and made available under an Apache 2.0 license. Please see the [Zyphra Hugging Face](https://huggingface.co/collections/zyphra/) repository for model weights.
This model was contributed by [pglo](https://huggingface.co/pglo).
diff --git a/docs/source/en/model_doc/zamba2.md b/docs/source/en/model_doc/zamba2.md
index c3e6729103..447fa27b69 100644
--- a/docs/source/en/model_doc/zamba2.md
+++ b/docs/source/en/model_doc/zamba2.md
@@ -15,6 +15,12 @@ rendered properly in your Markdown viewer.
-->
# Zamba2
+
+
+
+
+
+
Zamba2 is a large language model (LLM) trained by Zyphra, and made available under an Apache 2.0 license. Please see the [Zyphra Hugging Face](https://huggingface.co/collections/zyphra/) repository for model weights.
This model was contributed by [pglo](https://huggingface.co/pglo).
diff --git a/docs/source/en/model_doc/zoedepth.md b/docs/source/en/model_doc/zoedepth.md
index ecd068511e..fefadfba6a 100644
--- a/docs/source/en/model_doc/zoedepth.md
+++ b/docs/source/en/model_doc/zoedepth.md
@@ -16,6 +16,10 @@ rendered properly in your Markdown viewer.
# ZoeDepth
+
+
+
+
## Overview
The ZoeDepth model was proposed in [ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth](https://arxiv.org/abs/2302.12288) by Shariq Farooq Bhat, Reiner Birkl, Diana Wofk, Peter Wonka, Matthias Müller. ZoeDepth extends the [DPT](dpt) framework for metric (also called absolute) depth estimation. ZoeDepth is pre-trained on 12 datasets using relative depth and fine-tuned on two domains (NYU and KITTI) using metric depth. A lightweight head is used with a novel bin adjustment design called metric bins module for each domain. During inference, each input image is automatically routed to the appropriate head using a latent classifier.
diff --git a/docs/source/en/model_sharing.md b/docs/source/en/model_sharing.md
index 076fc2ccdd..a6ebdfb396 100644
--- a/docs/source/en/model_sharing.md
+++ b/docs/source/en/model_sharing.md
@@ -1,4 +1,4 @@
-
-# Share a model
+# Sharing
-The last two tutorials showed how you can fine-tune a model with PyTorch, Keras, and 🤗 Accelerate for distributed setups. The next step is to share your model with the community! At Hugging Face, we believe in openly sharing knowledge and resources to democratize artificial intelligence for everyone. We encourage you to consider sharing your model with the community to help others save time and resources.
+The Hugging Face [Hub](https://hf.co/models) is a platform for sharing, discovering, and consuming models of all different types and sizes. We highly recommend sharing your model on the Hub to push open-source machine learning forward for everyone!
-In this tutorial, you will learn two methods for sharing a trained or fine-tuned model on the [Model Hub](https://huggingface.co/models):
+This guide will show you how to share a model to the Hub from Transformers.
-- Programmatically push your files to the Hub.
-- Drag-and-drop your files to the Hub with the web interface.
+## Set up
-
+To share a model to the Hub, you need a Hugging Face [account](https://hf.co/join). Create a [User Access Token](https://hf.co/docs/hub/security-tokens#user-access-tokens) (stored in the [cache](./installation#cache-directory) by default) and login to your account from either the command line or notebook.
-
+  +
+
+
+Versioning is based on [Git](https://git-scm.com/) and [Git Large File Storage (LFS)](https://git-lfs.github.com/), and it enables revisions, a way to specify a model version with a commit hash, tag or branch.
+
+For example, use the `revision` parameter in [`~PreTrainedModel.from_pretrained`] to load a specific model version from a commit hash.
```py
->>> pt_model = DistilBertForSequenceClassification.from_pretrained("path/to/awesome-name-you-picked", from_tf=True)
->>> pt_model.save_pretrained("path/to/awesome-name-you-picked")
+model = AutoModel.from_pretrained(
+ "julien-c/EsperBERTo-small", revision="4c77982"
+)
```
-
+
+  +
+
+
+A model repository also includes an inference [widget](https://hf.co/docs/hub/models-widgets) for users to directly interact with a model on the Hub.
+
+Check out the Hub [Models](https://hf.co/docs/hub/models) documentation to for more information.
+
+## Model framework conversion
+
+Reach a wider audience by making a model available in PyTorch, TensorFlow, and Flax. While users can still load a model if they're using a different framework, it is slower because Transformers needs to convert the checkpoint on the fly. It is faster to convert the checkpoint first.
+
+
+
+  +
+
-This creates a repository under your username with the model name `my-awesome-model`. Users can now load your model with the `from_pretrained` function:
-
-```py
->>> from transformers import AutoModel
-
->>> model = AutoModel.from_pretrained("your_username/my-awesome-model")
-```
-
-If you belong to an organization and want to push your model under the organization name instead, just add it to the `repo_id`:
-
-```py
->>> pt_model.push_to_hub("my-awesome-org/my-awesome-model")
-```
-
-The `push_to_hub` function can also be used to add other files to a model repository. For example, add a tokenizer to a model repository:
-
-```py
->>> tokenizer.push_to_hub("my-awesome-model")
-```
-
-Or perhaps you'd like to add the TensorFlow version of your fine-tuned PyTorch model:
-
-```py
->>> tf_model.push_to_hub("my-awesome-model")
-```
-
-Now when you navigate to your Hugging Face profile, you should see your newly created model repository. Clicking on the **Files** tab will display all the files you've uploaded to the repository.
-
-For more details on how to create and upload files to a repository, refer to the Hub documentation [here](https://huggingface.co/docs/hub/how-to-upstream).
-
-## Upload with the web interface
-
-Users who prefer a no-code approach are able to upload a model through the Hub's web interface. Visit [huggingface.co/new](https://huggingface.co/new) to create a new repository:
-
-
-
-From here, add some information about your model:
+Add some information about your model:
- Select the **owner** of the repository. This can be yourself or any of the organizations you belong to.
- Pick a name for your model, which will also be the repository name.
- Choose whether your model is public or private.
-- Specify the license usage for your model.
+- Set the license usage.
-Now click on the **Files** tab and click on the **Add file** button to upload a new file to your repository. Then drag-and-drop a file to upload and add a commit message.
+2. Click on **Create model** to create the model repository.
-
+3. Select the **Files** tab and click on the **Add file** button to drag-and-drop a file to your repository. Add a commit message and click on **Commit changes to main** to commit the file.
-## Add a model card
+
+
+  +
+
-To make sure users understand your model's capabilities, limitations, potential biases and ethical considerations, please add a model card to your repository. The model card is defined in the `README.md` file. You can add a model card by:
+## Model card
-* Manually creating and uploading a `README.md` file.
-* Clicking on the **Edit model card** button in your model repository.
+[Model cards](https://hf.co/docs/hub/model-cards#model-cards) inform users about a models performance, limitations, potential biases, and ethical considerations. It is highly recommended to add a model card to your repository!
-Take a look at the DistilBert [model card](https://huggingface.co/distilbert/distilbert-base-uncased) for a good example of the type of information a model card should include. For more details about other options you can control in the `README.md` file such as a model's carbon footprint or widget examples, refer to the documentation [here](https://huggingface.co/docs/hub/models-cards).
+A model card is a `README.md` file in your repository. Add this file by:
+
+- manually creating and uploading a `README.md` file
+- clicking on the **Edit model card** button in the repository
+
+Take a look at the Llama 3.1 [model card](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct) for an example of what to include on a model card.
+
+Learn more about other model card metadata (carbon emissions, license, link to paper, etc.) available in the [Model Cards](https://hf.co/docs/hub/model-cards#model-cards) guide.
diff --git a/docs/source/en/models.md b/docs/source/en/models.md
new file mode 100644
index 0000000000..cc897dcc95
--- /dev/null
+++ b/docs/source/en/models.md
@@ -0,0 +1,325 @@
+
+
+# Loading models
+
+Transformers provides many pretrained models that are ready to use with a single line of code. It requires a model class and the [`~PreTrainedModel.from_pretrained`] method.
+
+Call [`~PreTrainedModel.from_pretrained`] to download and load a models weights and configuration stored on the Hugging Face [Hub](https://hf.co/models).
+
+> [!TIP]
+> The [`~PreTrainedModel.from_pretrained`] method loads weights stored in the [safetensors](https://hf.co/docs/safetensors/index) file format if they're available. Traditionally, PyTorch model weights are serialized with the [pickle](https://docs.python.org/3/library/pickle.html) utility which is known to be unsecure. Safetensor files are more secure and faster to load.
+
+```py
+from transformers import AutoModelForCausalLM
+
+model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf", torch_dtype="auto", device_map="auto")
+```
+
+This guide explains how models are loaded, the different ways you can load a model, how to overcome memory issues for really big models, and how to load custom models.
+
+## Models and configurations
+
+All models have a `configuration.py` file with specific attributes like the number of hidden layers, vocabulary size, activation function, and more. You'll also find a `modeling.py` file that defines the layers and mathematical operations taking place inside each layer. The `modeling.py` file takes the model attributes in `configuration.py` and builds the model accordingly. At this point, you have a model with random weights that needs to be trained to output meaningful results.
+
+
+
+> [!TIP]
+> An *architecture* refers to the model's skeleton and a *checkpoint* refers to the model's weights for a given architecture. For example, [BERT](./model_doc/bert) is an architecture while [google-bert/bert-base-uncased](https://huggingface.co/google-bert/bert-base-uncased) is a checkpoint. You'll see the term *model* used interchangeably with architecture and checkpoint.
+
+There are two general types of models you can load:
+
+1. A barebones model, like [`AutoModel`] or [`LlamaModel`], that outputs hidden states.
+2. A model with a specific *head* attached, like [`AutoModelForCausalLM`] or [`LlamaForCausalLM`], for performing specific tasks.
+
+For each model type, there is a separate class for each machine learning framework (PyTorch, TensorFlow, Flax). Pick the corresponding prefix for the framework you're using.
+
+
+
-  -
- The adapter weights for a OPTForCausalLM model stored on the Hub are only ~6MB compared to the full size of the model weights, which can be ~700MB.
-
+Install PEFT with the command below.
-If you're interested in learning more about the 🤗 PEFT library, check out the [documentation](https://huggingface.co/docs/peft/index).
-
-## Setup
-
-Get started by installing 🤗 PEFT:
+
-
+
+
+Set `tp_plan="auto"` in [`~AutoModel.from_pretrained`] to enable tensor parallelism for inference.
+
+```py
import os
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
-model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
-
-# Initialize distributed
+# initialize distributed environment
rank = int(os.environ["RANK"])
device = torch.device(f"cuda:{rank}")
torch.cuda.set_device(device)
torch.distributed.init_process_group("nccl", device_id=device)
-# Retrieve tensor parallel model
+# enable tensor parallelism
model = AutoModelForCausalLM.from_pretrained(
- model_id,
+ "meta-llama/Meta-Llama-3-8B-Instruct",
tp_plan="auto",
)
-# Prepare input tokens
-tokenizer = AutoTokenizer.from_pretrained(model_id)
+# prepare input tokens
+tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct")
prompt = "Can I help"
inputs = tokenizer(prompt, return_tensors="pt").input_ids.to(device)
-# Distributed run
+# distributed run
outputs = model(inputs)
```
-You can use `torchrun` to launch the above script with multiple processes, each mapping to a GPU:
+Launch the inference script above on [torchrun](https://pytorch.org/docs/stable/elastic/run.html) with 4 processes per GPU.
-```
+```bash
torchrun --nproc-per-node 4 demo.py
```
-PyTorch tensor parallel is currently supported for the following models:
-* [Llama](https://huggingface.co/docs/transformers/model_doc/llama#transformers.LlamaModel)
-* [Gemma](https://huggingface.co/docs/transformers/en/model_doc/gemma), [Gemma2](https://huggingface.co/docs/transformers/en/model_doc/gemma2)
-* [Granite](https://huggingface.co/docs/transformers/en/model_doc/granite)
-* [Mistral](https://huggingface.co/docs/transformers/en/model_doc/mistral)
-* [Qwen2](https://huggingface.co/docs/transformers/en/model_doc/qwen2), [Qwen2MoE](https://huggingface.co/docs/transformers/en/model_doc/qwen2_moe), [Qwen2-VL](https://huggingface.co/docs/transformers/v4.48.0/en/model_doc/qwen2_vl)
-* [Starcoder2](https://huggingface.co/docs/transformers/en/model_doc/starcoder2)
-* [Cohere](https://huggingface.co/docs/transformers/en/model_doc/cohere), [Cohere2](https://huggingface.co/docs/transformers/en/model_doc/cohere2)
-* [GLM](https://huggingface.co/docs/transformers/en/model_doc/glm)
-* [Mixtral](https://huggingface.co/docs/transformers/en/model_doc/mixtral)
-* [OLMo](https://huggingface.co/docs/transformers/en/model_doc/olmo), [OLMo2](https://huggingface.co/docs/transformers/en/model_doc/olmo2)
-* [Phi](https://huggingface.co/docs/transformers/en/model_doc/phi), [Phi-3](https://huggingface.co/docs/transformers/en/model_doc/phi3)
+You can benefit from considerable speed ups for inference, especially for inputs with large batch size or long sequences.
-You can request to add tensor parallel support for another model by opening a GitHub Issue or Pull Request.
-
-### Expected speedups
-
-You can benefit from considerable speedups for inference, especially for inputs with large batch size or long sequences.
-
-For a single forward pass on [Llama](https://huggingface.co/docs/transformers/model_doc/llama#transformers.LlamaModel) with a sequence length of 512 and various batch sizes, the expected speedup is as follows:
+For a single forward pass on [Llama](./model_doc/llama) with a sequence length of 512 and various batch sizes, you can expect the following speed ups.
Supported models
+ +* [Cohere](./model_doc/cohere) and [Cohere 2](./model_doc/cohere2) +* [Gemma](./model_doc/gemma) and [Gemma 2](./model_doc/gemma2) +* [GLM](./model_doc/glm) +* [Granite](./model_doc/granite) +* [Llama](./model_doc/llama) +* [Mistral](./model_doc/mistral) +* [Mixtral](./model_doc/mixtral) +* [OLMo](./model_doc/olmo) and [OLMo2](./model_doc/olmo2) +* [Phi](./model_doc/phi) and [Phi-3](./model_doc/phi3) +* [Qwen2](./model_doc/qwen2), [Qwen2Moe](./model_doc/qwen2_moe), and [Qwen2-VL](./model_doc/qwen2_5_vl) +* [Starcoder2](./model_doc/starcoder2) + + diff --git a/docs/source/en/perf_infer_gpu_one.md b/docs/source/en/perf_infer_gpu_one.md
index 7f57a99c7d..4bb34acf6c 100644
--- a/docs/source/en/perf_infer_gpu_one.md
+++ b/docs/source/en/perf_infer_gpu_one.md
@@ -1,4 +1,4 @@
-
-# GPU inference
+# GPU
-GPUs are the standard choice of hardware for machine learning, unlike CPUs, because they are optimized for memory bandwidth and parallelism. To keep up with the larger sizes of modern models or to run these large models on existing and older hardware, there are several optimizations you can use to speed up GPU inference. In this guide, you'll learn how to use FlashAttention-2 (a more memory-efficient attention mechanism), BetterTransformer (a PyTorch native fastpath execution), and bitsandbytes to quantize your model to a lower precision. Finally, learn how to use 🤗 Optimum to accelerate inference with ONNX Runtime on Nvidia and AMD GPUs.
+GPUs are the standard hardware for machine learning because they're optimized for memory bandwidth and parallelism. With the increasing sizes of modern models, it's more important than ever to make sure GPUs are capable of efficiently handling and delivering the best possible performance.
-
diff --git a/docs/source/en/perf_infer_gpu_one.md b/docs/source/en/perf_infer_gpu_one.md
index 7f57a99c7d..4bb34acf6c 100644
--- a/docs/source/en/perf_infer_gpu_one.md
+++ b/docs/source/en/perf_infer_gpu_one.md
@@ -1,4 +1,4 @@
-
-# GPU inference
+# GPU
-GPUs are the standard choice of hardware for machine learning, unlike CPUs, because they are optimized for memory bandwidth and parallelism. To keep up with the larger sizes of modern models or to run these large models on existing and older hardware, there are several optimizations you can use to speed up GPU inference. In this guide, you'll learn how to use FlashAttention-2 (a more memory-efficient attention mechanism), BetterTransformer (a PyTorch native fastpath execution), and bitsandbytes to quantize your model to a lower precision. Finally, learn how to use 🤗 Optimum to accelerate inference with ONNX Runtime on Nvidia and AMD GPUs.
+GPUs are the standard hardware for machine learning because they're optimized for memory bandwidth and parallelism. With the increasing sizes of modern models, it's more important than ever to make sure GPUs are capable of efficiently handling and delivering the best possible performance.
-- -You can also set `use_flash_attention_2=True` to enable FlashAttention-2 but it is deprecated in favor of `attn_implementation="flash_attention_2"`. - -
-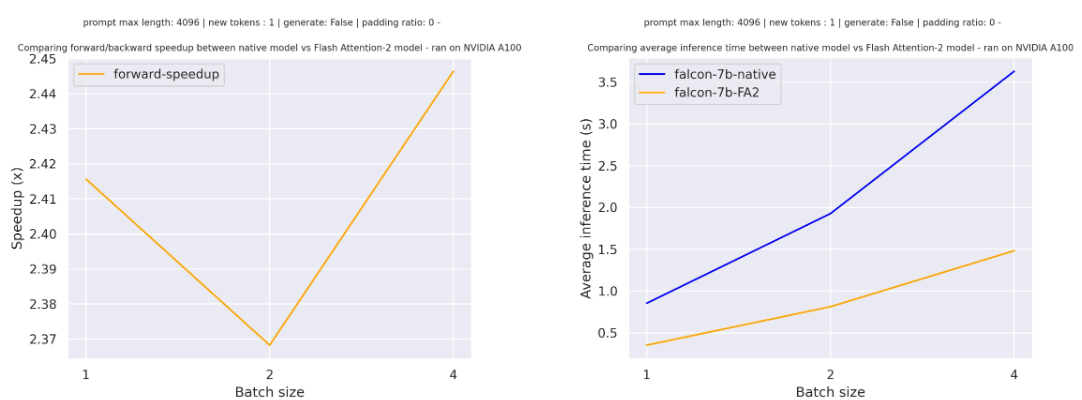 -
-
-
-For a single forward pass on [meta-llama/Llama-7b-hf](https://hf.co/meta-llama/Llama-7b-hf) with a sequence length of 4096 and various batch sizes without padding tokens, the expected speedup is:
-
-
-
-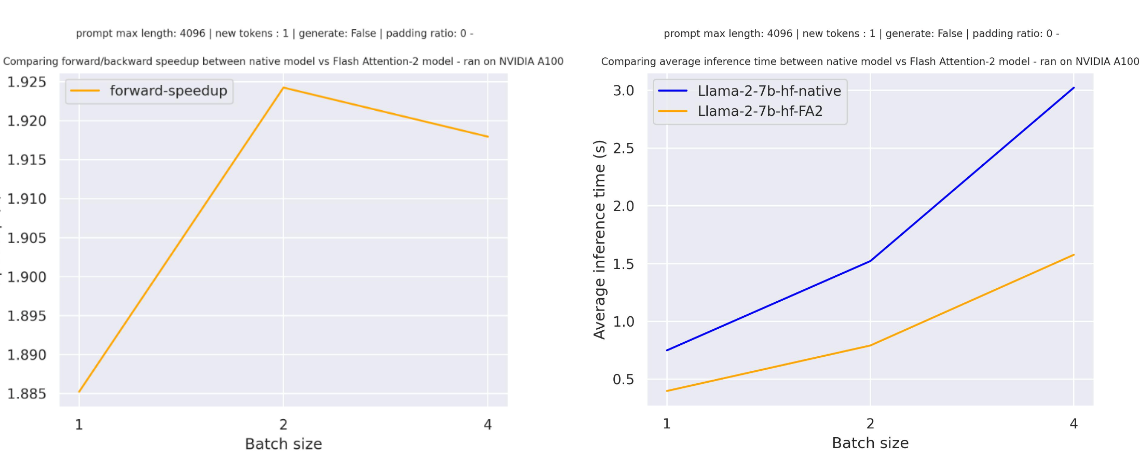 -
-
-
-For sequences with padding tokens (generating with padding tokens), you need to unpad/pad the input sequences to correctly compute the attention scores. With a relatively small sequence length, a single forward pass creates overhead leading to a small speedup (in the example below, 30% of the input is filled with padding tokens):
-
-
-
-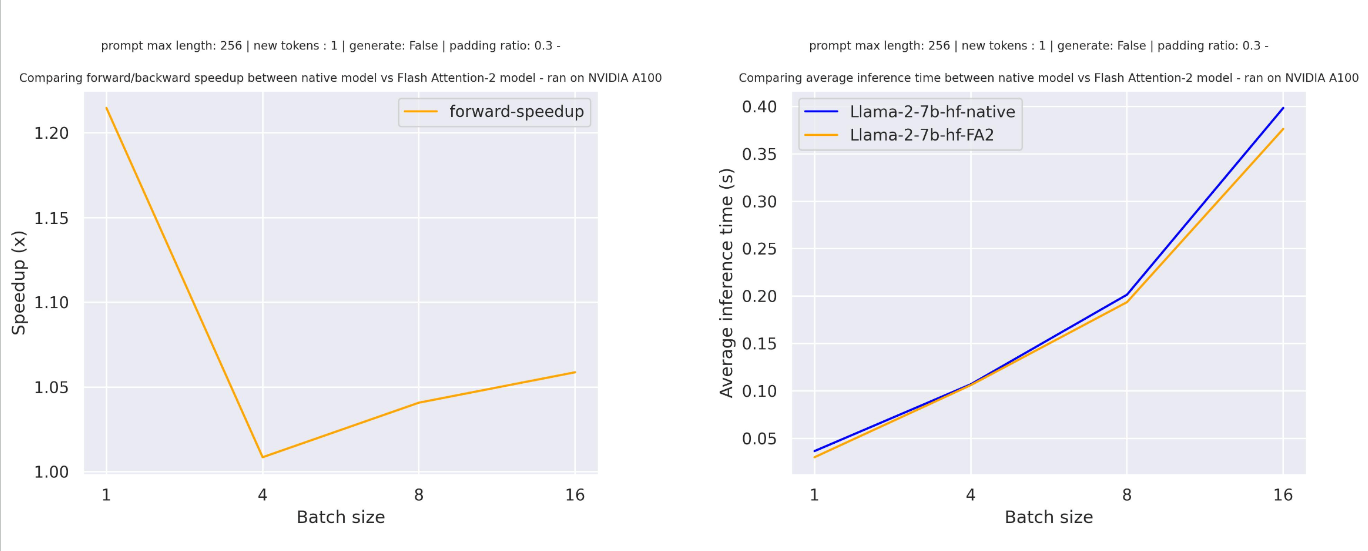 -
-
-
-But for larger sequence lengths, you can expect even more speedup benefits:
-
-
-
- -
-
-
-## PyTorch scaled dot product attention
-
-PyTorch's [`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html) (SDPA) can also call FlashAttention and memory-efficient attention kernels under the hood. SDPA support is currently being added natively in Transformers and is used by default for `torch>=2.1.1` when an implementation is available. You may also set `attn_implementation="sdpa"` in `from_pretrained()` to explicitly request SDPA to be used.
-
-For now, Transformers supports SDPA inference and training for the following architectures:
-* [Albert](https://huggingface.co/docs/transformers/model_doc/albert#transformers.AlbertModel)
-* [Aria](https://huggingface.co/docs/transformers/model_doc/aria#transformers.AriaForConditionalGeneration)
-* [Audio Spectrogram Transformer](https://huggingface.co/docs/transformers/model_doc/audio-spectrogram-transformer#transformers.ASTModel)
-* [Bamba](https://huggingface.co/docs/transformers/model_doc/bamba#transformers.BambaModel)
-* [Bart](https://huggingface.co/docs/transformers/model_doc/bart#transformers.BartModel)
-* [Beit](https://huggingface.co/docs/transformers/model_doc/beit#transformers.BeitModel)
-* [Bert](https://huggingface.co/docs/transformers/model_doc/bert#transformers.BertModel)
-* [BioGpt](https://huggingface.co/docs/transformers/model_doc/biogpt#transformers.BioGptModel)
-* [CamemBERT](https://huggingface.co/docs/transformers/model_doc/camembert#transformers.CamembertModel)
-* [Chameleon](https://huggingface.co/docs/transformers/model_doc/chameleon#transformers.Chameleon)
-* [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPModel)
-* [GLM](https://huggingface.co/docs/transformers/model_doc/glm#transformers.GLMModel)
-* [Cohere](https://huggingface.co/docs/transformers/model_doc/cohere#transformers.CohereModel)
-* [Cohere2](https://huggingface.co/docs/transformers/model_doc/cohere2#transformers.Cohere2Model)
-* [data2vec_audio](https://huggingface.co/docs/transformers/main/en/model_doc/data2vec#transformers.Data2VecAudioModel)
-* [data2vec_vision](https://huggingface.co/docs/transformers/main/en/model_doc/data2vec#transformers.Data2VecVisionModel)
-* [Dbrx](https://huggingface.co/docs/transformers/model_doc/dbrx#transformers.DbrxModel)
-* [DeiT](https://huggingface.co/docs/transformers/model_doc/deit#transformers.DeiTModel)
-* [DepthPro](https://huggingface.co/docs/transformers/model_doc/depth_pro#transformers.DepthProModel)
-* [DiffLlama](https://huggingface.co/docs/transformers/model_doc/diffllama#transformers.DiffLlamaModel)
-* [Dinov2](https://huggingface.co/docs/transformers/en/model_doc/dinov2)
-* [Dinov2_with_registers](https://huggingface.co/docs/transformers/en/model_doc/dinov2)
-* [DistilBert](https://huggingface.co/docs/transformers/model_doc/distilbert#transformers.DistilBertModel)
-* [Dpr](https://huggingface.co/docs/transformers/model_doc/dpr#transformers.DprReader)
-* [EncoderDecoder](https://huggingface.co/docs/transformers/model_doc/encoder_decoder#transformers.EncoderDecoderModel)
-* [Emu3](https://huggingface.co/docs/transformers/model_doc/emu3)
-* [Falcon](https://huggingface.co/docs/transformers/model_doc/falcon#transformers.FalconModel)
-* [Gemma](https://huggingface.co/docs/transformers/model_doc/gemma#transformers.GemmaModel)
-* [Gemma2](https://huggingface.co/docs/transformers/model_doc/gemma2#transformers.Gemma2Model)
-* [GotOcr2](https://huggingface.co/docs/transformers/model_doc/got_ocr2#transformers.GotOcr2ForConditionalGeneration)
-* [Granite](https://huggingface.co/docs/transformers/model_doc/granite#transformers.GraniteModel)
-* [GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2)
-* [GPTBigCode](https://huggingface.co/docs/transformers/model_doc/gpt_bigcode#transformers.GPTBigCodeModel)
-* [GPTNeoX](https://huggingface.co/docs/transformers/model_doc/gpt_neox#transformers.GPTNeoXModel)
-* [Hubert](https://huggingface.co/docs/transformers/model_doc/hubert#transformers.HubertModel)
-* [Idefics](https://huggingface.co/docs/transformers/model_doc/idefics#transformers.IdeficsModel)
-* [Idefics2](https://huggingface.co/docs/transformers/model_doc/idefics2#transformers.Idefics2Model)
-* [Idefics3](https://huggingface.co/docs/transformers/model_doc/idefics3#transformers.Idefics3Model)
-* [I-JEPA](https://huggingface.co/docs/transformers/model_doc/ijepa#transformers.IJepaModel)
-* [GraniteMoe](https://huggingface.co/docs/transformers/model_doc/granitemoe#transformers.GraniteMoeModel)
-* [GraniteMoeShared](https://huggingface.co/docs/transformers/model_doc/granitemoeshared#transformers.GraniteMoeSharedModel)
-* [JetMoe](https://huggingface.co/docs/transformers/model_doc/jetmoe#transformers.JetMoeModel)
-* [Jamba](https://huggingface.co/docs/transformers/model_doc/jamba#transformers.JambaModel)
-* [Llama](https://huggingface.co/docs/transformers/model_doc/llama#transformers.LlamaModel)
-* [Llava](https://huggingface.co/docs/transformers/model_doc/llava)
-* [Llava-NeXT](https://huggingface.co/docs/transformers/model_doc/llava_next)
-* [Llava-NeXT-Video](https://huggingface.co/docs/transformers/model_doc/llava_next_video)
-* [LLaVA-Onevision](https://huggingface.co/docs/transformers/model_doc/llava_onevision)
-* [M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100#transformers.M2M100Model)
-* [Moonshine](https://huggingface.co/docs/transformers/model_doc/moonshine#transformers.MoonshineModel)
-* [Mimi](https://huggingface.co/docs/transformers/model_doc/mimi)
-* [Mistral](https://huggingface.co/docs/transformers/model_doc/mistral#transformers.MistralModel)
-* [Mllama](https://huggingface.co/docs/transformers/model_doc/mllama#transformers.MllamaForConditionalGeneration)
-* [Mixtral](https://huggingface.co/docs/transformers/model_doc/mixtral#transformers.MixtralModel)
-* [ModernBert](https://huggingface.co/docs/transformers/model_doc/modernbert#transformers.ModernBert)
-* [Moshi](https://huggingface.co/docs/transformers/model_doc/moshi#transformers.MoshiModel)
-* [Musicgen](https://huggingface.co/docs/transformers/model_doc/musicgen#transformers.MusicgenModel)
-* [MusicGen Melody](https://huggingface.co/docs/transformers/model_doc/musicgen_melody#transformers.MusicgenMelodyModel)
-* [NLLB](https://huggingface.co/docs/transformers/model_doc/nllb)
-* [OLMo](https://huggingface.co/docs/transformers/model_doc/olmo#transformers.OlmoModel)
-* [OLMo2](https://huggingface.co/docs/transformers/model_doc/olmo2#transformers.Olmo2Model)
-* [OLMoE](https://huggingface.co/docs/transformers/model_doc/olmoe#transformers.OlmoeModel)
-* [OPT](https://huggingface.co/docs/transformers/en/model_doc/opt)
-* [PaliGemma](https://huggingface.co/docs/transformers/model_doc/paligemma#transformers.PaliGemmaForConditionalGeneration)
-* [Phi](https://huggingface.co/docs/transformers/model_doc/phi#transformers.PhiModel)
-* [Phi3](https://huggingface.co/docs/transformers/model_doc/phi3#transformers.Phi3Model)
-* [PhiMoE](https://huggingface.co/docs/transformers/model_doc/phimoe#transformers.PhimoeModel)
-* [Idefics](https://huggingface.co/docs/transformers/model_doc/idefics#transformers.IdeficsModel)
-* [mBart](https://huggingface.co/docs/transformers/model_doc/mbart#transformers.MBartModel)
-* [Moonshine](https://huggingface.co/docs/transformers/model_doc/moonshine#transformers.MoonshineModel)
-* [Mistral](https://huggingface.co/docs/transformers/model_doc/mistral#transformers.MistralModel)
-* [Mixtral](https://huggingface.co/docs/transformers/model_doc/mixtral#transformers.MixtralModel)
-* [StableLm](https://huggingface.co/docs/transformers/model_doc/stablelm#transformers.StableLmModel)
-* [Starcoder2](https://huggingface.co/docs/transformers/model_doc/starcoder2#transformers.Starcoder2Model)
-* [SmolVLM](https://huggingface.co/docs/transformers/model_doc/smolvlm#transformers.SmolVLMModel)
-* [Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2#transformers.Qwen2Model)
-* [Qwen2Audio](https://huggingface.co/docs/transformers/model_doc/qwen2_audio#transformers.Qwen2AudioEncoder)
-* [Qwen2MoE](https://huggingface.co/docs/transformers/model_doc/qwen2_moe#transformers.Qwen2MoeModel)
-* [Qwen2.5VL](https://huggingface.co/docs/transformers/model_doc/qwen2_5_vl#transformers.Qwen2_5_VLModel)
-* [RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta#transformers.RobertaModel)
-* [Sew](https://huggingface.co/docs/transformers/main/en/model_doc/sew#transformers.SEWModel)
-* [SigLIP](https://huggingface.co/docs/transformers/model_doc/siglip)
-* [SigLIP2](https://huggingface.co/docs/transformers/model_doc/siglip2)
-* [StableLm](https://huggingface.co/docs/transformers/model_doc/stablelm#transformers.StableLmModel)
-* [Starcoder2](https://huggingface.co/docs/transformers/model_doc/starcoder2#transformers.Starcoder2Model)
-* [UniSpeech](https://huggingface.co/docs/transformers/v4.39.3/en/model_doc/unispeech#transformers.UniSpeechModel)
-* [unispeech_sat](https://huggingface.co/docs/transformers/v4.39.3/en/model_doc/unispeech-sat#transformers.UniSpeechSatModel)
-* [RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta#transformers.RobertaModel)
-* [Qwen2VL](https://huggingface.co/docs/transformers/model_doc/qwen2_vl#transformers.Qwen2VLModel)
-* [Musicgen](https://huggingface.co/docs/transformers/model_doc/musicgen#transformers.MusicgenModel)
-* [MusicGen Melody](https://huggingface.co/docs/transformers/model_doc/musicgen_melody#transformers.MusicgenMelodyModel)
-* [Nemotron](https://huggingface.co/docs/transformers/model_doc/nemotron)
-* [SpeechEncoderDecoder](https://huggingface.co/docs/transformers/model_doc/speech_encoder_decoder#transformers.SpeechEncoderDecoderModel)
-* [VideoLlava](https://huggingface.co/docs/transformers/model_doc/video_llava)
-* [VipLlava](https://huggingface.co/docs/transformers/model_doc/vipllava)
-* [VisionEncoderDecoder](https://huggingface.co/docs/transformers/model_doc/vision_encoder_decoder#transformers.VisionEncoderDecoderModel)
-* [ViT](https://huggingface.co/docs/transformers/model_doc/vit#transformers.ViTModel)
-* [ViTHybrid](https://huggingface.co/docs/transformers/model_doc/vit_hybrid#transformers.ViTHybridModel)
-* [ViTMAE](https://huggingface.co/docs/transformers/model_doc/vit_mae#transformers.ViTMAEModel)
-* [ViTMSN](https://huggingface.co/docs/transformers/model_doc/vit_msn#transformers.ViTMSNModel)
-* [VisionTextDualEncoder](https://huggingface.co/docs/transformers/model_doc/vision_text_dual_encoder#transformers.VisionTextDualEncoderModel)
-* [VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae#transformers.VideoMAEModell)
-* [ViViT](https://huggingface.co/docs/transformers/model_doc/vivit#transformers.VivitModel)
-* [wav2vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2#transformers.Wav2Vec2Model)
-* [Whisper](https://huggingface.co/docs/transformers/model_doc/whisper#transformers.WhisperModel)
-* [XLM-RoBERTa](https://huggingface.co/docs/transformers/model_doc/xlm-roberta#transformers.XLMRobertaModel)
-* [XLM-RoBERTa-XL](https://huggingface.co/docs/transformers/model_doc/xlm-roberta-xl#transformers.XLMRobertaXLModel)
-* [YOLOS](https://huggingface.co/docs/transformers/model_doc/yolos#transformers.YolosModel)
-* [helium](https://huggingface.co/docs/transformers/main/en/model_doc/heliumtransformers.HeliumModel)
-* [Zamba2](https://huggingface.co/docs/transformers/model_doc/zamba2)
-
-
-
+
+
-
+
+
+
-model_name = "bigscience/bloom-1b7"
-model_8bit = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", quantization_config=BitsAndBytesConfig(load_in_8bit=True))
-```
+
+
+
+
-To load a model in 8-bit for inference with multiple GPUs, you can control how much GPU RAM you want to allocate to each GPU. For example, to distribute 2GB of memory to the first GPU and 5GB of memory to the second GPU:
+
+
+
+
-Feel free to try running a 11 billion parameter [T5 model](https://colab.research.google.com/drive/1YORPWx4okIHXnjW7MSAidXN29mPVNT7F?usp=sharing) or the 3 billion parameter [BLOOM model](https://colab.research.google.com/drive/1qOjXfQIAULfKvZqwCen8-MoWKGdSatZ4?usp=sharing) for inference on Google Colab's free tier GPUs!
-
-
+
-
-
-
- 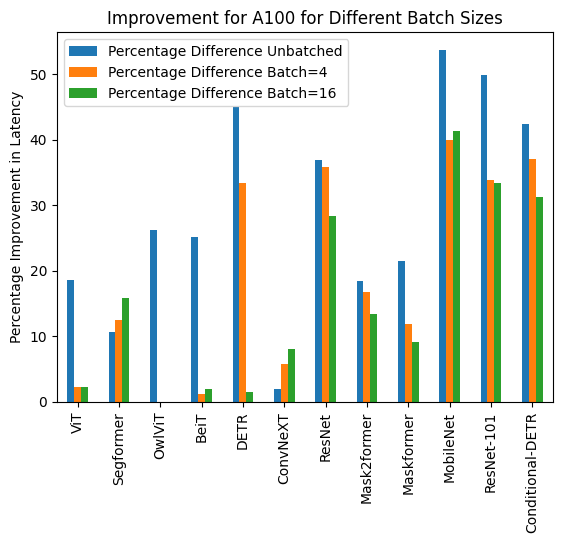 -
-
-
-
- 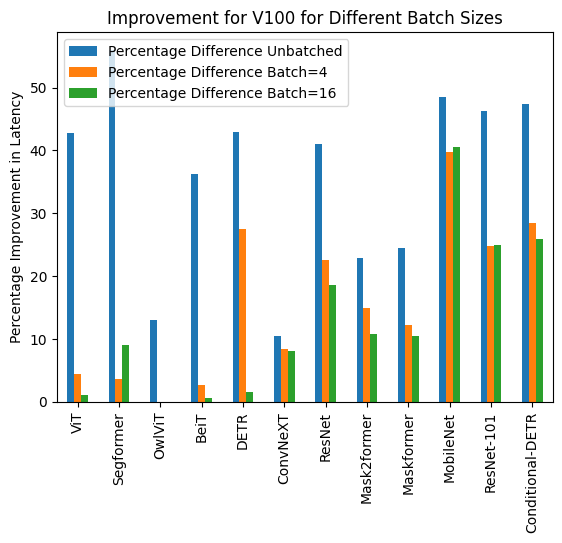 -
-
-
-
- 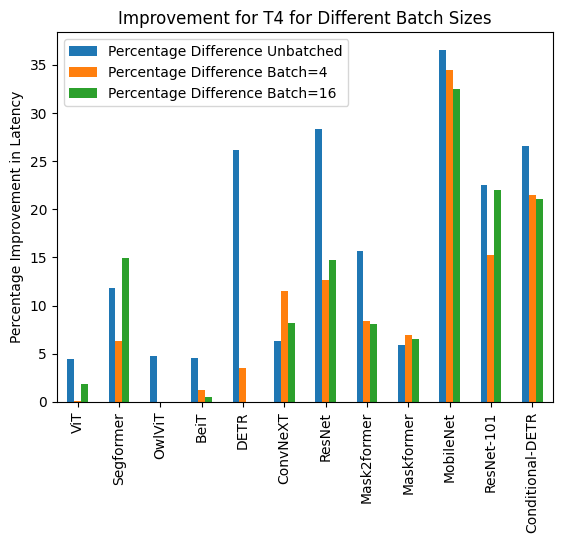 -
-
-
-
-
-
-
-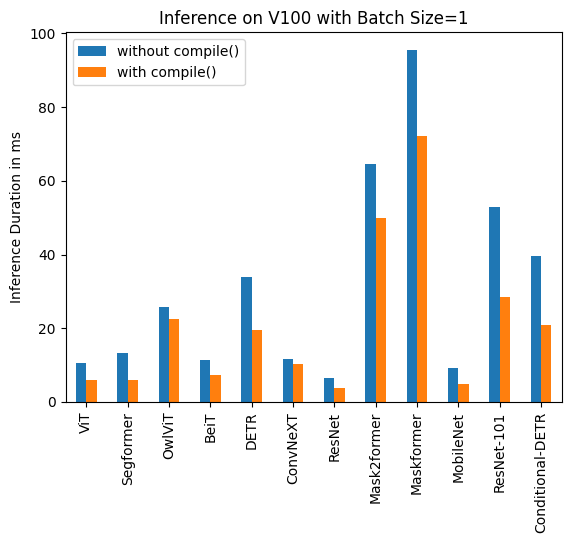
-
-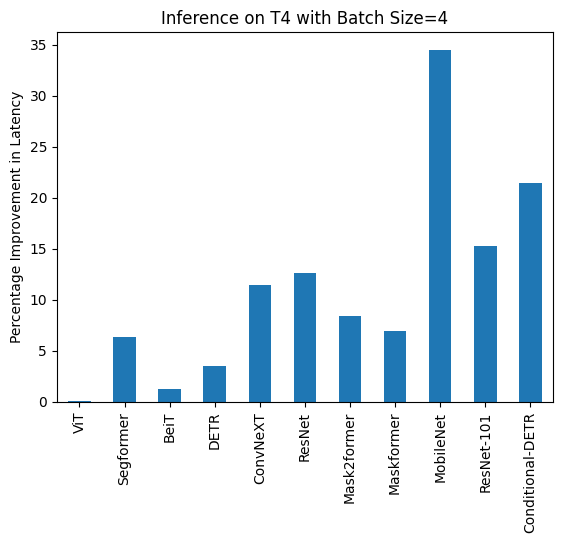
-
-Below you can find inference durations in milliseconds for each model with and without `compile()`. Note that OwlViT results in OOM in larger batch sizes.
-
-### A100 (batch size: 1)
-
-| **Task/Model** | **torch 2.0 -
- 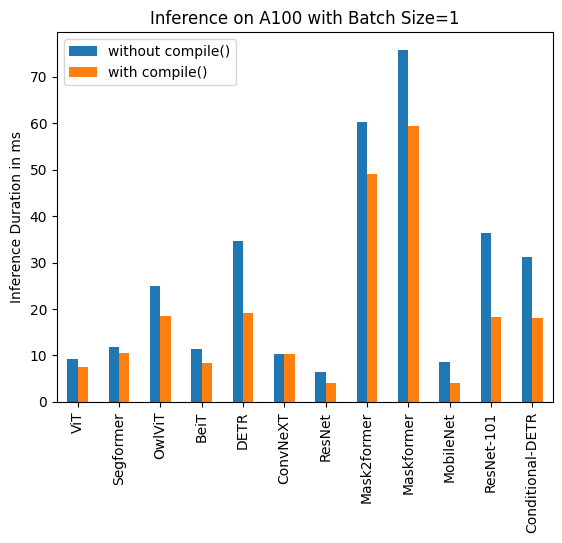 -
-
-
-
- 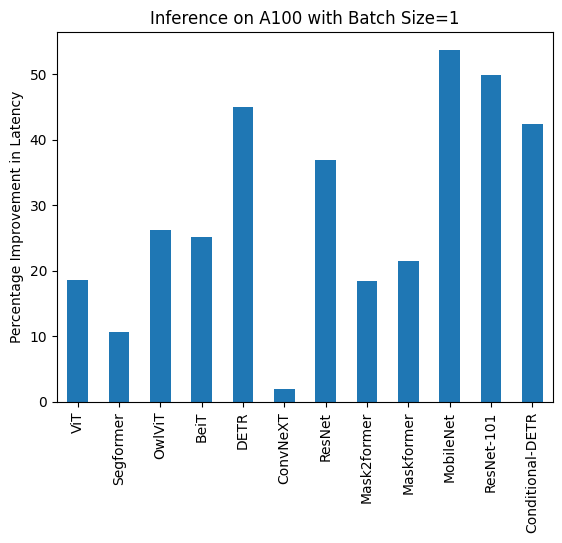 -
-
-
- no compile** | **torch 2.0 -
compile** | -|:---:|:---:|:---:| -| Image Classification/ViT | 9.325 | 7.584 | -| Image Segmentation/Segformer | 11.759 | 10.500 | -| Object Detection/OwlViT | 24.978 | 18.420 | -| Image Classification/BeiT | 11.282 | 8.448 | -| Object Detection/DETR | 34.619 | 19.040 | -| Image Classification/ConvNeXT | 10.410 | 10.208 | -| Image Classification/ResNet | 6.531 | 4.124 | -| Image Segmentation/Mask2former | 60.188 | 49.117 | -| Image Segmentation/Maskformer | 75.764 | 59.487 | -| Image Segmentation/MobileNet | 8.583 | 3.974 | -| Object Detection/Resnet-101 | 36.276 | 18.197 | -| Object Detection/Conditional-DETR | 31.219 | 17.993 | - - -### A100 (batch size: 4) - -| **Task/Model** | **torch 2.0 -
no compile** | **torch 2.0 -
compile** | -|:---:|:---:|:---:| -| Image Classification/ViT | 14.832 | 14.499 | -| Image Segmentation/Segformer | 18.838 | 16.476 | -| Image Classification/BeiT | 13.205 | 13.048 | -| Object Detection/DETR | 48.657 | 32.418| -| Image Classification/ConvNeXT | 22.940 | 21.631 | -| Image Classification/ResNet | 6.657 | 4.268 | -| Image Segmentation/Mask2former | 74.277 | 61.781 | -| Image Segmentation/Maskformer | 180.700 | 159.116 | -| Image Segmentation/MobileNet | 14.174 | 8.515 | -| Object Detection/Resnet-101 | 68.101 | 44.998 | -| Object Detection/Conditional-DETR | 56.470 | 35.552 | - -### A100 (batch size: 16) - -| **Task/Model** | **torch 2.0 -
no compile** | **torch 2.0 -
compile** | -|:---:|:---:|:---:| -| Image Classification/ViT | 40.944 | 40.010 | -| Image Segmentation/Segformer | 37.005 | 31.144 | -| Image Classification/BeiT | 41.854 | 41.048 | -| Object Detection/DETR | 164.382 | 161.902 | -| Image Classification/ConvNeXT | 82.258 | 75.561 | -| Image Classification/ResNet | 7.018 | 5.024 | -| Image Segmentation/Mask2former | 178.945 | 154.814 | -| Image Segmentation/Maskformer | 638.570 | 579.826 | -| Image Segmentation/MobileNet | 51.693 | 30.310 | -| Object Detection/Resnet-101 | 232.887 | 155.021 | -| Object Detection/Conditional-DETR | 180.491 | 124.032 | - -### V100 (batch size: 1) - -| **Task/Model** | **torch 2.0 -
no compile** | **torch 2.0 -
compile** | -|:---:|:---:|:---:| -| Image Classification/ViT | 10.495 | 6.00 | -| Image Segmentation/Segformer | 13.321 | 5.862 | -| Object Detection/OwlViT | 25.769 | 22.395 | -| Image Classification/BeiT | 11.347 | 7.234 | -| Object Detection/DETR | 33.951 | 19.388 | -| Image Classification/ConvNeXT | 11.623 | 10.412 | -| Image Classification/ResNet | 6.484 | 3.820 | -| Image Segmentation/Mask2former | 64.640 | 49.873 | -| Image Segmentation/Maskformer | 95.532 | 72.207 | -| Image Segmentation/MobileNet | 9.217 | 4.753 | -| Object Detection/Resnet-101 | 52.818 | 28.367 | -| Object Detection/Conditional-DETR | 39.512 | 20.816 | - -### V100 (batch size: 4) - -| **Task/Model** | **torch 2.0 -
no compile** | **torch 2.0 -
compile** | -|:---:|:---:|:---:| -| Image Classification/ViT | 15.181 | 14.501 | -| Image Segmentation/Segformer | 16.787 | 16.188 | -| Image Classification/BeiT | 15.171 | 14.753 | -| Object Detection/DETR | 88.529 | 64.195 | -| Image Classification/ConvNeXT | 29.574 | 27.085 | -| Image Classification/ResNet | 6.109 | 4.731 | -| Image Segmentation/Mask2former | 90.402 | 76.926 | -| Image Segmentation/Maskformer | 234.261 | 205.456 | -| Image Segmentation/MobileNet | 24.623 | 14.816 | -| Object Detection/Resnet-101 | 134.672 | 101.304 | -| Object Detection/Conditional-DETR | 97.464 | 69.739 | - -### V100 (batch size: 16) - -| **Task/Model** | **torch 2.0 -
no compile** | **torch 2.0 -
compile** | -|:---:|:---:|:---:| -| Image Classification/ViT | 52.209 | 51.633 | -| Image Segmentation/Segformer | 61.013 | 55.499 | -| Image Classification/BeiT | 53.938 | 53.581 | -| Object Detection/DETR | OOM | OOM | -| Image Classification/ConvNeXT | 109.682 | 100.771 | -| Image Classification/ResNet | 14.857 | 12.089 | -| Image Segmentation/Mask2former | 249.605 | 222.801 | -| Image Segmentation/Maskformer | 831.142 | 743.645 | -| Image Segmentation/MobileNet | 93.129 | 55.365 | -| Object Detection/Resnet-101 | 482.425 | 361.843 | -| Object Detection/Conditional-DETR | 344.661 | 255.298 | - -### T4 (batch size: 1) - -| **Task/Model** | **torch 2.0 -
no compile** | **torch 2.0 -
compile** | -|:---:|:---:|:---:| -| Image Classification/ViT | 16.520 | 15.786 | -| Image Segmentation/Segformer | 16.116 | 14.205 | -| Object Detection/OwlViT | 53.634 | 51.105 | -| Image Classification/BeiT | 16.464 | 15.710 | -| Object Detection/DETR | 73.100 | 53.99 | -| Image Classification/ConvNeXT | 32.932 | 30.845 | -| Image Classification/ResNet | 6.031 | 4.321 | -| Image Segmentation/Mask2former | 79.192 | 66.815 | -| Image Segmentation/Maskformer | 200.026 | 188.268 | -| Image Segmentation/MobileNet | 18.908 | 11.997 | -| Object Detection/Resnet-101 | 106.622 | 82.566 | -| Object Detection/Conditional-DETR | 77.594 | 56.984 | - -### T4 (batch size: 4) - -| **Task/Model** | **torch 2.0 -
no compile** | **torch 2.0 -
compile** | -|:---:|:---:|:---:| -| Image Classification/ViT | 43.653 | 43.626 | -| Image Segmentation/Segformer | 45.327 | 42.445 | -| Image Classification/BeiT | 52.007 | 51.354 | -| Object Detection/DETR | 277.850 | 268.003 | -| Image Classification/ConvNeXT | 119.259 | 105.580 | -| Image Classification/ResNet | 13.039 | 11.388 | -| Image Segmentation/Mask2former | 201.540 | 184.670 | -| Image Segmentation/Maskformer | 764.052 | 711.280 | -| Image Segmentation/MobileNet | 74.289 | 48.677 | -| Object Detection/Resnet-101 | 421.859 | 357.614 | -| Object Detection/Conditional-DETR | 289.002 | 226.945 | - -### T4 (batch size: 16) - -| **Task/Model** | **torch 2.0 -
no compile** | **torch 2.0 -
compile** | -|:---:|:---:|:---:| -| Image Classification/ViT | 163.914 | 160.907 | -| Image Segmentation/Segformer | 192.412 | 163.620 | -| Image Classification/BeiT | 188.978 | 187.976 | -| Object Detection/DETR | OOM | OOM | -| Image Classification/ConvNeXT | 422.886 | 388.078 | -| Image Classification/ResNet | 44.114 | 37.604 | -| Image Segmentation/Mask2former | 756.337 | 695.291 | -| Image Segmentation/Maskformer | 2842.940 | 2656.88 | -| Image Segmentation/MobileNet | 299.003 | 201.942 | -| Object Detection/Resnet-101 | 1619.505 | 1262.758 | -| Object Detection/Conditional-DETR | 1137.513 | 897.390| - -## PyTorch Nightly -We also benchmarked on PyTorch nightly (2.1.0dev, find the wheel [here](https://download.pytorch.org/whl/nightly/cu118)) and observed improvement in latency both for uncompiled and compiled models. - -### A100 - -| **Task/Model** | **Batch Size** | **torch 2.0 - no compile** | **torch 2.0 -
compile** | -|:---:|:---:|:---:|:---:| -| Image Classification/BeiT | Unbatched | 12.462 | 6.954 | -| Image Classification/BeiT | 4 | 14.109 | 12.851 | -| Image Classification/BeiT | 16 | 42.179 | 42.147 | -| Object Detection/DETR | Unbatched | 30.484 | 15.221 | -| Object Detection/DETR | 4 | 46.816 | 30.942 | -| Object Detection/DETR | 16 | 163.749 | 163.706 | - -### T4 - -| **Task/Model** | **Batch Size** | **torch 2.0 -
no compile** | **torch 2.0 -
compile** | -|:---:|:---:|:---:|:---:| -| Image Classification/BeiT | Unbatched | 14.408 | 14.052 | -| Image Classification/BeiT | 4 | 47.381 | 46.604 | -| Image Classification/BeiT | 16 | 42.179 | 42.147 | -| Object Detection/DETR | Unbatched | 68.382 | 53.481 | -| Object Detection/DETR | 4 | 269.615 | 204.785 | -| Object Detection/DETR | 16 | OOM | OOM | - -### V100 - -| **Task/Model** | **Batch Size** | **torch 2.0 -
no compile** | **torch 2.0 -
compile** | -|:---:|:---:|:---:|:---:| -| Image Classification/BeiT | Unbatched | 13.477 | 7.926 | -| Image Classification/BeiT | 4 | 15.103 | 14.378 | -| Image Classification/BeiT | 16 | 52.517 | 51.691 | -| Object Detection/DETR | Unbatched | 28.706 | 19.077 | -| Object Detection/DETR | 4 | 88.402 | 62.949| -| Object Detection/DETR | 16 | OOM | OOM | - - -## Reduce Overhead -We benchmarked `reduce-overhead` compilation mode for A100 and T4 in Nightly. - -### A100 - -| **Task/Model** | **Batch Size** | **torch 2.0 -
no compile** | **torch 2.0 -
compile** | -|:---:|:---:|:---:|:---:| -| Image Classification/ConvNeXT | Unbatched | 11.758 | 7.335 | -| Image Classification/ConvNeXT | 4 | 23.171 | 21.490 | -| Image Classification/ResNet | Unbatched | 7.435 | 3.801 | -| Image Classification/ResNet | 4 | 7.261 | 2.187 | -| Object Detection/Conditional-DETR | Unbatched | 32.823 | 11.627 | -| Object Detection/Conditional-DETR | 4 | 50.622 | 33.831 | -| Image Segmentation/MobileNet | Unbatched | 9.869 | 4.244 | -| Image Segmentation/MobileNet | 4 | 14.385 | 7.946 | - - -### T4 - -| **Task/Model** | **Batch Size** | **torch 2.0 -
no compile** | **torch 2.0 -
compile** | -|:---:|:---:|:---:|:---:| -| Image Classification/ConvNeXT | Unbatched | 32.137 | 31.84 | -| Image Classification/ConvNeXT | 4 | 120.944 | 110.209 | -| Image Classification/ResNet | Unbatched | 9.761 | 7.698 | -| Image Classification/ResNet | 4 | 15.215 | 13.871 | -| Object Detection/Conditional-DETR | Unbatched | 72.150 | 57.660 | -| Object Detection/Conditional-DETR | 4 | 301.494 | 247.543 | -| Image Segmentation/MobileNet | Unbatched | 22.266 | 19.339 | -| Image Segmentation/MobileNet | 4 | 78.311 | 50.983 | +Refer to the table below for performance benchmarks comparing the mean inference time in milliseconds with torch.compile enabled and disabled across various GPUs and batch sizes on the same image for different vision tasks. +Select **Subset** in the table below to switch between different GPUs, as well as benchmarks on [PyTorch nightly](https://download.pytorch.org/whl/nightly/cu118) 2.1.0dev and torch.compile with `reduce-overhead` mode enabled. + diff --git a/docs/source/en/perf_train_cpu.md b/docs/source/en/perf_train_cpu.md index ab2f735ecb..1eab6afbde 100644 --- a/docs/source/en/perf_train_cpu.md +++ b/docs/source/en/perf_train_cpu.md @@ -1,4 +1,4 @@ - -# Efficient Training on CPU +# CPU -This guide focuses on training large models efficiently on CPU. +A modern CPU is capable of efficiently training large models by leveraging the underlying optimizations built into the hardware and training on fp16 or bf16 data types. -## Mixed precision with IPEX -Mixed precision uses single (fp32) and half-precision (bf16/fp16) data types in a model to accelerate training or inference while still preserving much of the single-precision accuracy. Modern CPUs such as 3rd, 4th, and 5th Gen Intel® Xeon® Scalable processors natively support bf16. 6th Gen Intel® Xeon® Scalable processors natively support bf16 and fp16. You should get more performance out of the box by enabling mixed precision training with bf16 or fp16. +This guide focuses on how to train large models on an Intel CPU using mixed precision and the [Intel Extension for PyTorch (IPEX)](https://intel.github.io/intel-extension-for-pytorch/index.html) library. -To further maximize training performance, you can use Intel® Extension for PyTorch (IPEX), which is a library built on PyTorch and adds additional CPU instruction level architecture (ISA) level support such as Intel® Advanced Vector Extensions 512 Vector Neural Network Instructions (Intel® AVX512-VNNI), and Intel® Advanced Matrix Extensions (Intel® AMX) for an extra performance boost on Intel CPUs. However, CPUs with only AVX2 (e.g., AMD or older Intel CPUs) are not guaranteed to have better performance under IPEX. +You can Find your PyTorch version by running the command below. -Auto Mixed Precision (AMP) for CPU backends has been enabled since PyTorch 1.10. AMP support for bf16/fp16 on CPUs and bf16/fp16 operator optimization is also supported in IPEX and partially upstreamed to the main PyTorch branch. You can get better performance and user experience with IPEX AMP. +```bash +pip list | grep torch +``` -Check more detailed information for [Auto Mixed Precision](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/features/amp.html). +Install IPEX with the PyTorch version from above. -### IPEX installation: - -IPEX release is following PyTorch, to install via pip: - -| PyTorch Version | IPEX version | -| :---------------: | :----------: | -| 2.5.0 | 2.5.0+cpu | -| 2.4.0 | 2.4.0+cpu | -| 2.3.0 | 2.3.0+cpu | -| 2.2.0 | 2.2.0+cpu | - -Please run `pip list | grep torch` to get your `pytorch_version`, so you can get the `IPEX version_name`. ```bash pip install intel_extension_for_pytorch==
python examples/pytorch/question-answering/run_qa.py \ ---model_name_or_path google-bert/bert-base-uncased \ ---dataset_name squad \ ---do_train \ ---do_eval \ ---per_device_train_batch_size 12 \ ---learning_rate 3e-5 \ ---num_train_epochs 2 \ ---max_seq_length 384 \ ---doc_stride 128 \ ---output_dir /tmp/debug_squad/ \ ---use_ipex \ ---bf16 \ ---use_cpu+AMP is enabled for CPU backends training with PyTorch. -If you want to enable `use_ipex` and `bf16` in your script, add these parameters to `TrainingArguments` like this: -```diff +[`Trainer`] supports AMP training with a CPU by adding the `--use_cpu`, `--use_ipex`, and `--bf16` parameters. The example below demonstrates the [run_qa.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering) script. + +```bash +python run_qa.py \ + --model_name_or_path google-bert/bert-base-uncased \ + --dataset_name squad \ + --do_train \ + --do_eval \ + --per_device_train_batch_size 12 \ + --learning_rate 3e-5 \ + --num_train_epochs 2 \ + --max_seq_length 384 \ + --doc_stride 128 \ + --output_dir /tmp/debug_squad/ \ + --use_ipex \ + --bf16 \ + --use_cpu +``` + +These parameters can also be added to [`TrainingArguments`] as shown below. + +```py training_args = TrainingArguments( - output_dir=args.output_path, -+ bf16=True, -+ use_ipex=True, -+ use_cpu=True, - **kwargs + output_dir="./outputs", + bf16=True, + use_ipex=True, + use_cpu=True, ) ``` -### Practice example +## Resources -Blog: [Accelerating PyTorch Transformers with Intel Sapphire Rapids](https://huggingface.co/blog/intel-sapphire-rapids) +Learn more about training on Intel CPUs in the [Accelerating PyTorch Transformers with Intel Sapphire Rapids](https://huggingface.co/blog/intel-sapphire-rapids) blog post. diff --git a/docs/source/en/perf_train_cpu_many.md b/docs/source/en/perf_train_cpu_many.md index d6a029c471..bd332d15e1 100644 --- a/docs/source/en/perf_train_cpu_many.md +++ b/docs/source/en/perf_train_cpu_many.md @@ -1,4 +1,4 @@ - -# Efficient Training on Multiple CPUs +# Distributed CPUs -When training on a single CPU is too slow, we can use multiple CPUs. This guide focuses on PyTorch-based DDP enabling -distributed CPU training efficiently on [bare metal](#usage-in-trainer) and [Kubernetes](#usage-with-kubernetes). +CPUs are commonly available and can be a cost-effective training option when GPUs are unavailable. When training large models or if a single CPU is too slow, distributed training with CPUs can help speed up training. -## Intel® oneCCL Bindings for PyTorch +This guide demonstrates how to perform distributed training with multiple CPUs using a [DistributedDataParallel (DDP)](./perf_train_gpu_many#distributeddataparallel) strategy on bare metal with [`Trainer`] and a Kubernetes cluster. All examples shown in this guide depend on the [Intel oneAPI HPC Toolkit](https://www.intel.com/content/www/us/en/developer/tools/oneapi/hpc-toolkit.html). -[Intel® oneCCL](https://github.com/oneapi-src/oneCCL) (collective communications library) is a library for efficient distributed deep learning training implementing such collectives like allreduce, allgather, alltoall. For more information on oneCCL, please refer to the [oneCCL documentation](https://spec.oneapi.com/versions/latest/elements/oneCCL/source/index.html) and [oneCCL specification](https://spec.oneapi.com/versions/latest/elements/oneCCL/source/index.html). +There are two toolkits you'll need from Intel oneAPI. -Module `oneccl_bindings_for_pytorch` (`torch_ccl` before version 1.12) implements PyTorch C10D ProcessGroup API and can be dynamically loaded as external ProcessGroup and only works on Linux platform now +1. [oneCCL](https://www.intel.com/content/www/us/en/developer/tools/oneapi/oneccl.html) includes efficient implementations of collectives commonly used in deep learning such as all-gather, all-reduce, and reduce-scatter. To install from a prebuilt wheel, make sure you always use the latest release. Refer to the table [here](https://github.com/intel/torch-ccl#install-prebuilt-wheel) to check if a version of oneCCL is supported for a Python and PyTorch version. -Check more detailed information for [oneccl_bind_pt](https://github.com/intel/torch-ccl). - -### Intel® oneCCL Bindings for PyTorch installation - -Wheel files are available for the following Python versions: - -| Extension Version | Python 3.7 | Python 3.8 | Python 3.9 | Python 3.10 | Python 3.11 | -| :---------------: | :--------: | :--------: | :--------: | :---------: | :---------: | -| 2.5.0 | | √ | √ | √ | √ | -| 2.4.0 | | √ | √ | √ | √ | -| 2.3.0 | | √ | √ | √ | √ | -| 2.2.0 | | √ | √ | √ | √ | - -Please run `pip list | grep torch` to get your `pytorch_version`. ```bash -pip install oneccl_bind_pt=={pytorch_version} -f https://developer.intel.com/ipex-whl-stable-cpu +# installs oneCCL for PyTorch 2.4.0 +pip install oneccl_bind_pt==2.4.0 -f https://developer.intel.com/ipex-whl-stable-cpu ``` -where `{pytorch_version}` should be your PyTorch version, for instance 2.4.0. -Check more approaches for [oneccl_bind_pt installation](https://github.com/intel/torch-ccl). -Versions of oneCCL and PyTorch must match. +> [!TIP] +> Refer to the oneCCL [installation](https://github.com/intel/torch-ccl#installation) for more details. -## Intel® MPI library -Use this standards-based MPI implementation to deliver flexible, efficient, scalable cluster messaging on Intel® architecture. This component is part of the Intel® oneAPI HPC Toolkit. - -oneccl_bindings_for_pytorch is installed along with the MPI tool set. Need to source the environment before using it. +1. [MPI](https://www.intel.com/content/www/us/en/developer/tools/oneapi/mpi-library.html) is a message-passing interface for communications between hardware and networks. The oneCCL toolkit is installed along with MPI, but you need to source the environment as shown below before using it. ```bash oneccl_bindings_for_pytorch_path=$(python -c "from oneccl_bindings_for_pytorch import cwd; print(cwd)") source $oneccl_bindings_for_pytorch_path/env/setvars.sh ``` -#### Intel® Extension for PyTorch installation +Lastly, install the [Intex Extension for PyTorch (IPEX)](https://intel.github.io/intel-extension-for-pytorch/index.html) which enables additional performance optimizations for Intel hardware such as weight sharing and better thread runtime control. -Intel Extension for PyTorch (IPEX) provides performance optimizations for CPU training with both Float32 and BFloat16 (refer to the [single CPU section](./perf_train_cpu) to learn more). +```bash +pip install intel_extension_for_pytorch==
-  -
-
-
-While it may appear complex, it is a very similar concept to `DataParallel` (DP). The difference is that instead of
-replicating the full model parameters, gradients and optimizer states, each GPU stores only a slice of it. Then, at
-run-time when the full layer parameters are needed just for the given layer, all GPUs synchronize to give each other
-parts that they miss.
-
-To illustrate this idea, consider a simple model with 3 layers (La, Lb, and Lc), where each layer has 3 parameters.
-Layer La, for example, has weights a0, a1 and a2:
-
-```
-La | Lb | Lc
----|----|---
-a0 | b0 | c0
-a1 | b1 | c1
-a2 | b2 | c2
-```
-
-If we have 3 GPUs, ZeRO-DP splits the model onto 3 GPUs like so:
-
-```
-GPU0:
-La | Lb | Lc
----|----|---
-a0 | b0 | c0
-
-GPU1:
-La | Lb | Lc
----|----|---
-a1 | b1 | c1
-
-GPU2:
-La | Lb | Lc
----|----|---
-a2 | b2 | c2
-```
-
-In a way, this is the same horizontal slicing as tensor parallelism, as opposed to Vertical
-slicing, where one puts whole layer-groups on different GPUs. Now let's see how this works:
-
-Each of these GPUs will get the usual mini-batch as it works in DP:
-
-```
-x0 => GPU0
-x1 => GPU1
-x2 => GPU2
-```
-
-The inputs are passed without modifications as if they would be processed by the original model.
-
-First, the inputs get to the layer `La`. What happens at this point?
-
-On GPU0: the x0 mini-batch requires the a0, a1, a2 parameters to do its forward path through the layer, but the GPU0 has only a0.
-It will get a1 from GPU1 and a2 from GPU2, bringing all the pieces of the model together.
-
-In parallel, GPU1 gets another mini-batch - x1. GPU1 has the a1 parameter, but needs a0 and a2, so it gets those from GPU0 and GPU2.
-Same happens to GPU2 that gets the mini-batch x2. It gets a0 and a1 from GPU0 and GPU1.
-
-This way each of the 3 GPUs gets the full tensors reconstructed and makes a forward pass with its own mini-batch.
-As soon as the calculation is done, the data that is no longer needed gets dropped - it's only used during the calculation.
-The reconstruction is done efficiently via a pre-fetch.
-
-Then the whole process is repeated for layer Lb, then Lc forward-wise, and then backward Lc -> Lb -> La.
-
-
-
-  +
+
-At the bottom of the diagram, you can observe that the Pipeline Parallelism (PP) approach minimizes the number of idle
-GPU zones, referred to as 'bubbles'. Both parts of the diagram show a parallelism level of degree 4, meaning that 4 GPUs
-are involved in the pipeline. You can see that there's a forward path of 4 pipe stages (F0, F1, F2 and F3) followed by
-a backward path in reverse order (B3, B2, B1, and B0).
+## Model parallelism
-PP introduces a new hyperparameter to tune - `chunks`, which determines how many data chunks are sent in a sequence
-through the same pipe stage. For example, in the bottom diagram you can see `chunks=4`. GPU0 performs the same
-forward path on chunk 0, 1, 2 and 3 (F0,0, F0,1, F0,2, F0,3) and then it waits for other GPUs to do complete their work.
-Only when the other GPUs begin to complete their work, GPU0 starts to work again doing the backward path for chunks
-3, 2, 1 and 0 (B0,3, B0,2, B0,1, B0,0).
+Model parallelism distributes a model across multiple GPUs. There are several ways to split a model, but the typical method distributes the model layers across GPUs. On the `forward` pass, the first GPU processes a batch of data and passes it to the next group of layers on the next GPU. For the `backward` pass, the data is sent backward from the final layer to the first layer.
-Note that this is the same concept as gradient accumulation steps. PyTorch uses `chunks`, while DeepSpeed refers
-to the same hyperparameter as gradient accumulation steps.
+Model parallelism is a useful strategy for training models that are too large to fit into the memory of a single GPU. However, GPU utilization is unbalanced because only one GPU is active at a time. Passing results between GPUs also adds communication overhead and it can be a bottleneck.
-Because of the chunks, PP introduces the notion of micro-batches (MBS). DP splits the global data batch size into
-mini-batches, so if you have a DP degree of 4, a global batch size of 1024 gets split up into 4 mini-batches of
-256 each (1024/4). And if the number of `chunks` (or GAS) is 32 we end up with a micro-batch size of 8 (256/32). Each
-Pipeline stage works with a single micro-batch at a time. To calculate the global batch size of the DP + PP setup,
-use the formula: `mbs * chunks * dp_degree` (`8 * 32 * 4 = 1024`).
-With `chunks=1` you end up with the naive MP, which is inefficient. With a large `chunks` value you end up with
-tiny micro-batch sizes which is also inefficient. For this reason, we encourage to experiment with the `chunks` value to
-find the one that leads to the most efficient GPUs utilization.
+## Pipeline parallelism
-You may notice a bubble of "dead" time on the diagram that can't be parallelized because the last `forward` stage
-has to wait for `backward` to complete the pipeline. The purpose of finding the best value for `chunks` is to enable a high
-concurrent GPU utilization across all participating GPUs which translates to minimizing the size of the bubble.
+Pipeline parallelism is conceptually very similar to model parallelism, but it's more efficient because it reduces the amount of idle GPU time. Instead of waiting for each GPU to finish processing a batch of data, pipeline parallelism creates *micro-batches* of data. As soon as one micro-batch is finished, it is passed to the next GPU. This way, each GPU can concurrently process part of the data without waiting for the other GPU to completely finish processing a mini batch of data.
-Pipeline API solutions have been implemented in:
-- PyTorch
-- DeepSpeed
-- Megatron-LM
+Pipeline parallelism shares the same advantages as model parallelism, but it optimizes GPU utilization and reduces idle time. But pipeline parallelism can be more complex because models may need to be rewritten as a sequence of [nn.Sequential](https://pytorch.org/docs/stable/generated/torch.nn.Sequential.html) modules and it also isn't possible to completely reduce idle time because the last `forward` pass must also wait for the `backward` pass to finish.
-These come with some shortcomings:
-- They have to modify the model quite heavily, because Pipeline requires one to rewrite the normal flow of modules into a `nn.Sequential` sequence of the same, which may require changes to the design of the model.
-- Currently the Pipeline API is very restricted. If you had a bunch of Python variables being passed in the very first stage of the Pipeline, you will have to find a way around it. Currently, the pipeline interface requires either a single Tensor or a tuple of Tensors as the only input and output. These tensors must have a batch size as the very first dimension, since pipeline is going to chunk the mini batch into micro-batches. Possible improvements are being discussed here https://github.com/pytorch/pytorch/pull/50693
-- Conditional control flow at the level of pipe stages is not possible - e.g., Encoder-Decoder models like T5 require special workarounds to handle a conditional encoder stage.
-- They have to arrange each layer so that the output of one layer becomes an input to the other layer.
+## Tensor parallelism
-More recent solutions include:
-- Varuna
-- Sagemaker
+Tensor parallelism distributes large tensor computations across multiple GPUs. The tensors are sliced horizontally or vertically and each slice is processed by a separate GPU. Each GPU performs its calculations on its tensor slice and the results are synchronized at the end to reconstruct the final result.
-We have not experimented with Varuna and SageMaker but their papers report that they have overcome the list of problems
-mentioned above and that they require smaller changes to the user's model.
+Tensor parallelism is effective for training large models that don't fit into the memory of a single GPU. It is also faster and more efficient because each GPU can process its tensor slice in parallel, and it can be combined with other parallelism methods. Like other parallelism methods though, tensor parallelism adds communication overhead between GPUs.
-Implementations:
-- [PyTorch](https://pytorch.org/docs/stable/pipeline.html) (initial support in pytorch-1.8, and progressively getting improved in 1.9 and more so in 1.10). Some [examples](https://github.com/pytorch/pytorch/blob/master/benchmarks/distributed/pipeline/pipe.py)
-- [DeepSpeed](https://www.deepspeed.ai/tutorials/pipeline/)
-- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) has an internal implementation - no API.
-- [Varuna](https://github.com/microsoft/varuna)
-- [SageMaker](https://arxiv.org/abs/2111.05972) - this is a proprietary solution that can only be used on AWS.
-- [OSLO](https://github.com/tunib-ai/oslo) - this is implemented based on the Hugging Face Transformers.
+## Hybrid parallelism
-🤗 Transformers status: as of this writing none of the models supports full-PP. GPT2 and T5 models have naive MP support.
-The main obstacle is being unable to convert the models to `nn.Sequential` and have all the inputs to be Tensors. This
-is because currently the models include many features that make the conversion very complicated, and will need to be removed to accomplish that.
+Parallelism methods can be combined to achieve even greater memory savings and more efficiently train models with billions of parameters.
-DeepSpeed and Megatron-LM integrations are available in [🤗 Accelerate](https://huggingface.co/docs/accelerate/main/en/usage_guides/deepspeed)
+### Data parallelism and pipeline parallelism
-Other approaches:
+Data and pipeline parallelism distributes the data across GPUs and divides each mini batch of data into micro-batches to achieve pipeline parallelism.
-DeepSpeed, Varuna and SageMaker use the concept of an [Interleaved Pipeline](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-core-features.html)
+Each data parallel rank treats the process as if there were only one GPU instead of two, but GPUs 0 and 1 can offload micro-batches of data to GPUs 2 and 3 and reduce idle time.
+
+This approach optimizes parallel data processing by reducing idle GPU utilization.
+
-  +
+ 
-Here the bubble (idle time) is further minimized by prioritizing backward passes. Varuna further attempts to improve the
-schedule by using simulations to discover the most efficient scheduling.
+### ZeRO data parallelism, pipeline parallelism, and model parallelism (3D parallelism)
-OSLO has pipeline parallelism implementation based on the Transformers without `nn.Sequential` conversion.
+Data, pipeline and model parallelism combine to form [3D parallelism](https://www.microsoft.com/en-us/research/blog/deepspeed-extreme-scale-model-training-for-everyone/) to optimize memory and compute efficiency.
-## Tensor Parallelism
+Memory effiiciency is achieved by splitting the model across GPUs and also dividing it into stages to create a pipeline. This allows GPUs to work in parallel on micro-batches of data, reducing the memory usage of the model, optimizer, and activations.
-In Tensor Parallelism, each GPU processes a slice of a tensor and only aggregates the full tensor for operations requiring it.
-To describe this method, this section of the guide relies on the concepts and diagrams from the [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
-paper: [Efficient Large-Scale Language Model Training on GPU Clusters](https://arxiv.org/abs/2104.04473).
+Compute efficiency is enabled by ZeRO data parallelism where each GPU only stores a slice of the model, optimizer, and activations. This allows higher communication bandwidth between data parallel nodes because communication can occur independently or in parallel with the other pipeline stages.
-The main building block of any transformer is a fully connected `nn.Linear` followed by a nonlinear activation `GeLU`.
-The dot dot-product part of it, following the Megatron's paper notation, can be written as `Y = GeLU(XA)`, where `X` is
-an input vector, `Y` is the output vector, and `A` is the weight matrix.
-
-If we look at the computation in matrix form, you can see how the matrix multiplication can be split between multiple GPUs:
+This approach is scalable to extremely large models with trillions of parameters.
+
-  +
+ 
-
-If we split the weight matrix `A` column-wise across `N` GPUs and perform matrix multiplications `XA_1` through `XA_n` in parallel,
-then we will end up with `N` output vectors `Y_1, Y_2, ..., Y_n` which can be fed into `GeLU` independently:
-
-
+
-  -
-
-
-Using this principle, we can update a multi-layer perceptron of arbitrary depth, without the need for any synchronization
-between GPUs until the very end, where we need to reconstruct the output vector from shards. The Megatron-LM paper authors
-provide a helpful illustration for that:
-
-
-
-  -
-
-
-Parallelizing the multi-headed attention layers is even simpler, since they are already inherently parallel, due to having
-multiple independent heads!
-
-
-
-  -
-
-
-Special considerations: TP requires very fast network, and therefore it's not advisable to do TP across more than one node.
-Practically, if a node has 4 GPUs, the highest TP degree is therefore 4. If you need a TP degree of 8, you need to use
-nodes that have at least 8 GPUs.
-
-This section is based on the original much more [detailed TP overview](https://github.com/huggingface/transformers/issues/10321#issuecomment-783543530).
-by [@anton-l](https://github.com/anton-l).
-
-Alternative names:
-- DeepSpeed calls it [tensor slicing](https://www.deepspeed.ai/training/#model-parallelism)
-
-Implementations:
-- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) has an internal implementation, as it's very model-specific
-- [parallelformers](https://github.com/tunib-ai/parallelformers) (only inference at the moment)
-- [SageMaker](https://arxiv.org/abs/2111.05972) - this is a proprietary solution that can only be used on AWS.
-- [OSLO](https://github.com/tunib-ai/oslo) has the tensor parallelism implementation based on the Transformers.
-- [`transformers` integration](main_classes/trainer) tensor parallelism is available through tp_size attribute for models having `base_tp_plan`. Further you can look at [example usage](perf_infer_gpu_multi)
-
-SageMaker combines TP with DP for a more efficient processing.
-
-🤗 Transformers status:
-- core: uses PyTorch 2 APIs to support tensor parallelism to models having base_tp_plan in their respective config classes.
-- Alternatively, you can as well try [parallelformers](https://github.com/tunib-ai/parallelformers) that provides this support for most of our models. Training mode with TP is as well supported natively in transformers.
-- Deepspeed-Inference also supports our BERT, GPT-2, and GPT-Neo models in their super-fast CUDA-kernel-based inference mode, see more [here](https://www.deepspeed.ai/tutorials/inference-tutorial/)
-
-🤗 Accelerate integrates with [TP from Megatron-LM](https://huggingface.co/docs/accelerate/v0.23.0/en/usage_guides/megatron_lm).
-
-## Data Parallelism + Pipeline Parallelism
-
-The following diagram from the DeepSpeed [pipeline tutorial](https://www.deepspeed.ai/tutorials/pipeline/) demonstrates
-how one can combine DP with PP.
-
-
-
-
-
-
-Here it's important to see how DP rank 0 doesn't see GPU2 and DP rank 1 doesn't see GPU3. To DP there is just GPUs 0
-and 1 where it feeds data as if there were just 2 GPUs. GPU0 "secretly" offloads some of its load to GPU2 using PP.
-And GPU1 does the same by enlisting GPU3 to its aid.
-
-Since each dimension requires at least 2 GPUs, here you'd need at least 4 GPUs.
-
-Implementations:
-- [DeepSpeed](https://github.com/deepspeedai/DeepSpeed)
-- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
-- [Varuna](https://github.com/microsoft/varuna)
-- [SageMaker](https://arxiv.org/abs/2111.05972)
-- [OSLO](https://github.com/tunib-ai/oslo)
-
-🤗 Transformers status: not yet implemented
-
-## Data Parallelism + Pipeline Parallelism + Tensor Parallelism
-
-To get an even more efficient training a 3D parallelism is used where PP is combined with TP and DP. This can be seen in the following diagram.
-
-
-
-
-
-
-This diagram is from a blog post [3D parallelism: Scaling to trillion-parameter models](https://www.microsoft.com/en-us/research/blog/deepspeed-extreme-scale-model-training-for-everyone/), which is a good read as well.
-
-Since each dimension requires at least 2 GPUs, here you'd need at least 8 GPUs.
-
-Implementations:
-- [DeepSpeed](https://github.com/deepspeedai/DeepSpeed) - DeepSpeed also includes an even more efficient DP, which they call ZeRO-DP.
-- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
-- [Varuna](https://github.com/microsoft/varuna)
-- [SageMaker](https://arxiv.org/abs/2111.05972)
-- [OSLO](https://github.com/tunib-ai/oslo)
-
-🤗 Transformers status: not yet implemented, since we have no PP and TP.
-
-## ZeRO Data Parallelism + Pipeline Parallelism + Tensor Parallelism
-
-One of the main features of DeepSpeed is ZeRO, which is a super-scalable extension of DP. It has already been
-discussed in [ZeRO Data Parallelism](#zero-data-parallelism). Normally it's a standalone feature that doesn't require PP or TP.
-But it can be combined with PP and TP.
-
-When ZeRO-DP is combined with PP (and optionally TP) it typically enables only ZeRO stage 1 (optimizer sharding).
-
-While it's theoretically possible to use ZeRO stage 2 (gradient sharding) with Pipeline Parallelism, it will have negative
-performance impacts. There would need to be an additional reduce-scatter collective for every micro-batch to aggregate
-the gradients before sharding, which adds a potentially significant communication overhead. By nature of Pipeline Parallelism,
-small micro-batches are used and instead the focus is on trying to balance arithmetic intensity (micro-batch size) with
-minimizing the Pipeline bubble (number of micro-batches). Therefore those communication costs are going to impact the performance.
-
-In addition, there are already fewer layers than normal due to PP and so the memory savings won't be huge. PP already
-reduces gradient size by ``1/PP``, and so gradient sharding savings on top of that are less significant than pure DP.
-
-ZeRO stage 3 is not a good choice either for the same reason - more inter-node communications required.
-
-And since we have ZeRO, the other benefit is ZeRO-Offload. Since this is stage 1 optimizer states can be offloaded to CPU.
-
-Implementations:
-- [Megatron-DeepSpeed](https://github.com/microsoft/Megatron-DeepSpeed) and [Megatron-Deepspeed from BigScience](https://github.com/bigscience-workshop/Megatron-DeepSpeed), which is the fork of the former repo.
-- [OSLO](https://github.com/tunib-ai/oslo)
-
-Important papers:
-
-- [Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model](
-https://arxiv.org/abs/2201.11990)
-
-🤗 Transformers status: not yet implemented, since we have no PP.
-
-## FlexFlow
-
-[FlexFlow](https://github.com/flexflow/FlexFlow) also solves the parallelization problem in a slightly different approach.
-
-Paper: ["Beyond Data and Model Parallelism for Deep Neural Networks" by Zhihao Jia, Matei Zaharia, Alex Aiken](https://arxiv.org/abs/1807.05358)
-
-It performs a sort of 4D Parallelism over Sample-Operator-Attribute-Parameter.
-
-1. Sample = Data Parallelism (sample-wise parallel)
-2. Operator = Parallelize a single operation into several sub-operations
-3. Attribute = Data Parallelism (length-wise parallel)
-4. Parameter = Model Parallelism (regardless of dimension - horizontal or vertical)
-
-Examples:
-* Sample
-
-Let's take 10 batches of sequence length 512. If we parallelize them by sample dimension into 2 devices, we get 10 x 512 which becomes 5 x 2 x 512.
-
-* Operator
-
-If we perform layer normalization, we compute std first and mean second, and then we can normalize data.
-Operator parallelism allows computing std and mean in parallel. So if we parallelize them by operator dimension into 2
-devices (cuda:0, cuda:1), first we copy input data into both devices, and cuda:0 computes std, cuda:1 computes mean at the same time.
-
-* Attribute
-
-We have 10 batches of 512 length. If we parallelize them by attribute dimension into 2 devices, 10 x 512 will be 10 x 2 x 256.
-
-* Parameter
-
-It is similar with tensor model parallelism or naive layer-wise model parallelism.
-
-
-
-  -
-
-
-The significance of this framework is that it takes resources like (1) GPU/TPU/CPU vs. (2) RAM/DRAM vs. (3)
-fast-intra-connect/slow-inter-connect and it automatically optimizes all these algorithmically deciding which
-parallelisation to use where.
-
-One very important aspect is that FlexFlow is designed for optimizing DNN parallelizations for models with static and
-fixed workloads, since models with dynamic behavior may prefer different parallelization strategies across iterations.
-
-So the promise is very attractive - it runs a 30min simulation on the cluster of choice and it comes up with the best
-strategy to utilise this specific environment. If you add/remove/replace any parts it'll run and re-optimize the plan
-for that. And then you can train. A different setup will have its own custom optimization.
-
-🤗 Transformers status: Transformers models are FX-trace-able via [transformers.utils.fx](https://github.com/huggingface/transformers/blob/master/src/transformers/utils/fx.py),
-which is a prerequisite for FlexFlow, however, changes are required on the FlexFlow side to make it work with Transformers models.
-
-## GPU selection
-
-When training on multiple GPUs, you can specify the number of GPUs to use and in what order. This can be useful for instance when you have GPUs with different computing power and want to use the faster GPU first. The selection process works for both [DistributedDataParallel](https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html) and [DataParallel](https://pytorch.org/docs/stable/generated/torch.nn.DataParallel.html) to use only a subset of the available GPUs, and you don't need Accelerate or the [DeepSpeed integration](./main_classes/deepspeed).
-
-### Number of GPUs
-
-For example, if you have 4 GPUs and you only want to use the first 2:
-
-
-+[`TrainingArguments`] and [`Trainer`] detects and sets the backend device to `mps` if an Apple Silicon device is available. No additional changes are required to enable training on your device. -If you run into any other errors, please open an issue in the [PyTorch](https://github.com/pytorch/pytorch/issues) repository because the [`Trainer`] only integrates the MPS backend. +The `mps` backend doesn't support [distributed training](https://pytorch.org/docs/stable/distributed.html#backends). -
-
-
-
-Load the image processor with [`AutoImageProcessor.from_pretrained`]:
-
-```py
->>> from transformers import AutoImageProcessor
-
->>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
-```
-
-First, let's add some image augmentation. You can use any library you prefer, but in this tutorial, we'll use torchvision's [`transforms`](https://pytorch.org/vision/stable/transforms.html) module. If you're interested in using another data augmentation library, learn how in the [Albumentations](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_albumentations.ipynb) or [Kornia notebooks](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_kornia.ipynb).
-
-1. Here we use [`Compose`](https://pytorch.org/vision/master/generated/torchvision.transforms.Compose.html) to chain together a couple of
-transforms - [`RandomResizedCrop`](https://pytorch.org/vision/main/generated/torchvision.transforms.RandomResizedCrop.html) and [`ColorJitter`](https://pytorch.org/vision/main/generated/torchvision.transforms.ColorJitter.html).
-Note that for resizing, we can get the image size requirements from the `image_processor`. For some models, an exact height and
-width are expected, for others only the `shortest_edge` is defined.
-
-```py
->>> from torchvision.transforms import RandomResizedCrop, ColorJitter, Compose
-
->>> size = (
-... image_processor.size["shortest_edge"]
-... if "shortest_edge" in image_processor.size
-... else (image_processor.size["height"], image_processor.size["width"])
-... )
-
->>> _transforms = Compose([RandomResizedCrop(size), ColorJitter(brightness=0.5, hue=0.5)])
-```
-
-2. The model accepts [`pixel_values`](model_doc/vision-encoder-decoder#transformers.VisionEncoderDecoderModel.forward.pixel_values)
-as its input. `ImageProcessor` can take care of normalizing the images, and generating appropriate tensors.
-Create a function that combines image augmentation and image preprocessing for a batch of images and generates `pixel_values`:
-
-```py
->>> def transforms(examples):
-... images = [_transforms(img.convert("RGB")) for img in examples["image"]]
-... examples["pixel_values"] = image_processor(images, do_resize=False, return_tensors="pt")["pixel_values"]
-... return examples
-```
-
-
-
-
-
-
-
- -
-
-
+```py
+import torch
+from transformers import AutoModelForSpeechSeq2Seq, QuantoConfig
-The library is versatile enough to be compatible with most PTQ optimization algorithms. The plan in the future is to integrate the most popular algorithms in the most seamless possible way (AWQ, Smoothquant).
\ No newline at end of file
+quant_config = QuantoConfig(weights="int8")
+model = AutoModelForSpeechSeq2Seq.from_pretrained(
+ "openai/whisper-large-v2",
+ torch_dtype="auto",
+ device_map="auto",
+ quantization_config=quant_config
+)
+
+model = torch.compile(model)
+```
+
+## Resources
+
+Read the [Quanto: a PyTorch quantization backend for Optimum](https://huggingface.co/blog/quanto-introduction) blog post to learn more about the library design and benchmarks.
+
+For more hands-on examples, take a look at the Quanto [notebook](https://colab.research.google.com/drive/16CXfVmtdQvciSh9BopZUDYcmXCDpvgrT?usp=sharing).
\ No newline at end of file
diff --git a/docs/source/en/quantization/spqr.md b/docs/source/en/quantization/spqr.md
index b9ebb99b69..cff6821b0b 100644
--- a/docs/source/en/quantization/spqr.md
+++ b/docs/source/en/quantization/spqr.md
@@ -16,11 +16,16 @@ rendered properly in your Markdown viewer.
# SpQR
-[SpQR](https://github.com/Vahe1994/SpQR) quantization algorithm involves a 16x16 tiled bi-level group 3-bit quantization structure, with sparse outliers as detailed in [SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression](https://arxiv.org/abs/2306.03078).
+The [SpQR]((https://hf.co/papers/2306.03078)) quantization algorithm involves a 16x16 tiled bi-level group 3-bit quantization structure with sparse outliers.
-To SpQR-quantize a model, refer to the [Vahe1994/SpQR](https://github.com/Vahe1994/SpQR) repository.
+
- 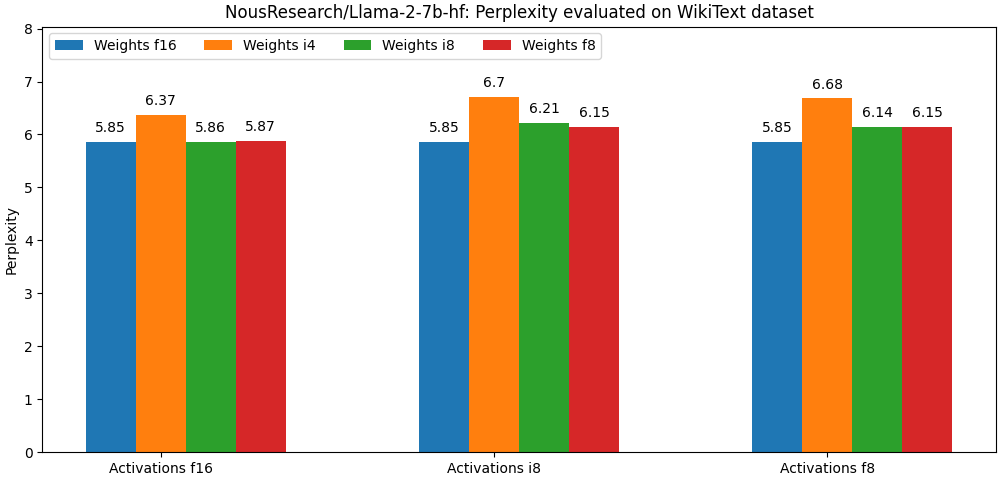 -
-
-
-
+  +
+
-Load a pre-SpQR-quantized model in [`~PreTrainedModel.from_pretrained`].
+> [!TIP]
+> To quantize a model with SpQR, refer to the [Vahe1994/SpQR](https://github.com/Vahe1994/SpQR) repository.
+
+Load a SpQR-quantized model with [`~PreTrainedModel.from_pretrained`].
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
diff --git a/docs/source/en/quantization/torchao.md b/docs/source/en/quantization/torchao.md
index c8116bf8ea..b2da1aba88 100644
--- a/docs/source/en/quantization/torchao.md
+++ b/docs/source/en/quantization/torchao.md
@@ -9,46 +9,53 @@ specific language governing permissions and limitations under the License.
rendered properly in your Markdown viewer.
-->
-# TorchAO
+# torchao
-[TorchAO](https://github.com/pytorch/ao) is an architecture optimization library for PyTorch, it provides high performance dtypes, optimization techniques and kernels for inference and training, featuring composability with native PyTorch features like `torch.compile`, FSDP etc.. Some benchmark numbers can be found [here](https://github.com/pytorch/ao/tree/main/torchao/quantization#benchmarks).
+[torchao](https://github.com/pytorch/ao) is a PyTorch architecture optimization library with support for custom high performance data types, quantization, and sparsity. It is composable with native PyTorch features such as [torch.compile](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) for even faster inference and training.
-Before you begin, make sure the following libraries are installed with their latest version:
+Install torchao with the following command.
```bash
# Updating 🤗 Transformers to the latest version, as the example script below uses the new auto compilation
pip install --upgrade torch torchao transformers
```
-By default, the weights are loaded in full precision (torch.float32) regardless of the actual data type the weights are stored in such as torch.float16. Set `torch_dtype="auto"` to load the weights in the data type defined in a model's `config.json` file to automatically load the most memory-optimal data type.
+torchao supports many quantization types for different data types (int4, float8, weight only, etc.), but the Transformers integration only currently supports int8 weight quantization and int8 dynamic quantization of weights.
+You can manually choose the quantization types and settings or automatically select the quantization types.
-## Manually Choose Quantization Types and Settings
+
+
+  +
+
```py
->>> import torch
->>> from transformers import pipeline
-
->>> speech_recognizer = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h")
+segments = pipeline("https://huggingface.co/datasets/Narsil/image_dummy/raw/main/parrots.png")
+segments[0]["label"]
+'bird'
+segments[1]["label"]
+'bird'
```
-Load an audio dataset (see the 🤗 Datasets [Quick Start](https://huggingface.co/docs/datasets/quickstart#audio) for more details) you'd like to iterate over. For example, load the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset:
+
+
-
-
-Then switch your current clone of 🤗 Transformers to a specific version, like v3.5.1 for example:
+Run the command below to checkout a script from a specific or older version of Transformers.
```bash
git checkout tags/v3.5.1
```
-After you've setup the correct library version, navigate to the example folder of your choice and install the example specific requirements:
+After you've setup the correct version, navigate to the example folder of your choice and install the example specific requirements.
```bash
pip install -r requirements.txt
@@ -85,13 +48,35 @@ pip install -r requirements.txt
## Run a script
-