diff --git a/docs/source/en/model_doc/conditional_detr.mdx b/docs/source/en/model_doc/conditional_detr.mdx
index 6aaa773f09..40cdbee345 100644
--- a/docs/source/en/model_doc/conditional_detr.mdx
+++ b/docs/source/en/model_doc/conditional_detr.mdx
@@ -21,7 +21,7 @@ The abstract from the paper is the following:
*The recently-developed DETR approach applies the transformer encoder and decoder architecture to object detection and achieves promising performance. In this paper, we handle the critical issue, slow training convergence, and present a conditional cross-attention mechanism for fast DETR training. Our approach is motivated by that the cross-attention in DETR relies highly on the content embeddings for localizing the four extremities and predicting the box, which increases the need for high-quality content embeddings and thus the training difficulty. Our approach, named conditional DETR, learns a conditional spatial query from the decoder embedding for decoder multi-head cross-attention. The benefit is that through the conditional spatial query, each cross-attention head is able to attend to a band containing a distinct region, e.g., one object extremity or a region inside the object box. This narrows down the spatial range for localizing the distinct regions for object classification and box regression, thus relaxing the dependence on the content embeddings and easing the training. Empirical results show that conditional DETR converges 6.7× faster for the backbones R50 and R101 and 10× faster for stronger backbones DC5-R50 and DC5-R101. Code is available at https://github.com/Atten4Vis/ConditionalDETR.*
 +alt="drawing" width="600"/>
Conditional DETR shows much faster convergence compared to the original DETR. Taken from the original paper.
@@ -32,6 +32,16 @@ This model was contributed by [DepuMeng](https://huggingface.co/DepuMeng). The o
[[autodoc]] ConditionalDetrConfig
+## ConditionalDetrImageProcessor
+
+[[autodoc]] ConditionalDetrImageProcessor
+ - preprocess
+ - pad_and_create_pixel_mask
+ - post_process_object_detection
+ - post_process_instance_segmentation
+ - post_process_semantic_segmentation
+ - post_process_panoptic_segmentation
+
## ConditionalDetrFeatureExtractor
[[autodoc]] ConditionalDetrFeatureExtractor
@@ -55,4 +65,4 @@ This model was contributed by [DepuMeng](https://huggingface.co/DepuMeng). The o
## ConditionalDetrForSegmentation
[[autodoc]] ConditionalDetrForSegmentation
- - forward
\ No newline at end of file
+ - forward
diff --git a/docs/source/en/model_doc/deformable_detr.mdx b/docs/source/en/model_doc/deformable_detr.mdx
index 974bc6691e..a0727bad1c 100644
--- a/docs/source/en/model_doc/deformable_detr.mdx
+++ b/docs/source/en/model_doc/deformable_detr.mdx
@@ -27,12 +27,19 @@ Tips:
- Training Deformable DETR is equivalent to training the original [DETR](detr) model. Demo notebooks can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR).
+alt="drawing" width="600"/>
Conditional DETR shows much faster convergence compared to the original DETR. Taken from the original paper.
@@ -32,6 +32,16 @@ This model was contributed by [DepuMeng](https://huggingface.co/DepuMeng). The o
[[autodoc]] ConditionalDetrConfig
+## ConditionalDetrImageProcessor
+
+[[autodoc]] ConditionalDetrImageProcessor
+ - preprocess
+ - pad_and_create_pixel_mask
+ - post_process_object_detection
+ - post_process_instance_segmentation
+ - post_process_semantic_segmentation
+ - post_process_panoptic_segmentation
+
## ConditionalDetrFeatureExtractor
[[autodoc]] ConditionalDetrFeatureExtractor
@@ -55,4 +65,4 @@ This model was contributed by [DepuMeng](https://huggingface.co/DepuMeng). The o
## ConditionalDetrForSegmentation
[[autodoc]] ConditionalDetrForSegmentation
- - forward
\ No newline at end of file
+ - forward
diff --git a/docs/source/en/model_doc/deformable_detr.mdx b/docs/source/en/model_doc/deformable_detr.mdx
index 974bc6691e..a0727bad1c 100644
--- a/docs/source/en/model_doc/deformable_detr.mdx
+++ b/docs/source/en/model_doc/deformable_detr.mdx
@@ -27,12 +27,19 @@ Tips:
- Training Deformable DETR is equivalent to training the original [DETR](detr) model. Demo notebooks can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR).
 +alt="drawing" width="600"/>
Deformable DETR architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/fundamentalvision/Deformable-DETR).
+## DeformableDetrImageProcessor
+
+[[autodoc]] DeformableDetrImageProcessor
+ - preprocess
+ - pad_and_create_pixel_mask
+ - post_process_object_detection
+
## DeformableDetrFeatureExtractor
[[autodoc]] DeformableDetrFeatureExtractor
@@ -55,4 +62,4 @@ This model was contributed by [nielsr](https://huggingface.co/nielsr). The origi
## DeformableDetrForObjectDetection
[[autodoc]] DeformableDetrForObjectDetection
- - forward
\ No newline at end of file
+ - forward
diff --git a/docs/source/en/model_doc/detr.mdx b/docs/source/en/model_doc/detr.mdx
index 4f9908772a..265d20255d 100644
--- a/docs/source/en/model_doc/detr.mdx
+++ b/docs/source/en/model_doc/detr.mdx
@@ -114,7 +114,7 @@ Tips:
It is advised to use a batch size of 2 per GPU. See [this Github thread](https://github.com/facebookresearch/detr/issues/150) for more info.
There are three ways to instantiate a DETR model (depending on what you prefer):
-
+
Option 1: Instantiate DETR with pre-trained weights for entire model
```py
>>> from transformers import DetrForObjectDetection
@@ -166,6 +166,15 @@ mean Average Precision (mAP) and Panoptic Quality (PQ). The latter objects are i
[[autodoc]] DetrConfig
+## DetrImageProcessor
+
+[[autodoc]] DetrImageProcessor
+ - preprocess
+ - post_process_object_detection
+ - post_process_semantic_segmentation
+ - post_process_instance_segmentation
+ - post_process_panoptic_segmentation
+
## DetrFeatureExtractor
[[autodoc]] DetrFeatureExtractor
diff --git a/docs/source/en/model_doc/maskformer.mdx b/docs/source/en/model_doc/maskformer.mdx
index bf4748686b..c52fb184ec 100644
--- a/docs/source/en/model_doc/maskformer.mdx
+++ b/docs/source/en/model_doc/maskformer.mdx
@@ -57,6 +57,15 @@ This model was contributed by [francesco](https://huggingface.co/francesco). The
[[autodoc]] MaskFormerConfig
+## MaskFormerImageProcessor
+
+[[autodoc]] MaskFormerImageProcessor
+ - preprocess
+ - encode_inputs
+ - post_process_semantic_segmentation
+ - post_process_instance_segmentation
+ - post_process_panoptic_segmentation
+
## MaskFormerFeatureExtractor
[[autodoc]] MaskFormerFeatureExtractor
diff --git a/docs/source/en/model_doc/owlvit.mdx b/docs/source/en/model_doc/owlvit.mdx
index 29a67aeb66..b95efd59b5 100644
--- a/docs/source/en/model_doc/owlvit.mdx
+++ b/docs/source/en/model_doc/owlvit.mdx
@@ -22,7 +22,7 @@ The abstract from the paper is the following:
## Usage
-OWL-ViT is a zero-shot text-conditioned object detection model. OWL-ViT uses [CLIP](clip) as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
+OWL-ViT is a zero-shot text-conditioned object detection model. OWL-ViT uses [CLIP](clip) as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
[`OwlViTFeatureExtractor`] can be used to resize (or rescale) and normalize images for the model and [`CLIPTokenizer`] is used to encode the text. [`OwlViTProcessor`] wraps [`OwlViTFeatureExtractor`] and [`CLIPTokenizer`] into a single instance to both encode the text and prepare the images. The following example shows how to perform object detection using [`OwlViTProcessor`] and [`OwlViTForObjectDetection`].
@@ -76,6 +76,13 @@ This model was contributed by [adirik](https://huggingface.co/adirik). The origi
[[autodoc]] OwlViTVisionConfig
+## OwlViTImageProcessor
+
+[[autodoc]] OwlViTImageProcessor
+ - preprocess
+ - post_process
+ - post_process_image_guided_detection
+
## OwlViTFeatureExtractor
[[autodoc]] OwlViTFeatureExtractor
diff --git a/docs/source/en/model_doc/yolos.mdx b/docs/source/en/model_doc/yolos.mdx
index 51c75252ac..185ee10c17 100644
--- a/docs/source/en/model_doc/yolos.mdx
+++ b/docs/source/en/model_doc/yolos.mdx
@@ -27,7 +27,7 @@ Tips:
- Demo notebooks (regarding inference and fine-tuning on custom data) can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/YOLOS).
+alt="drawing" width="600"/>
Deformable DETR architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/fundamentalvision/Deformable-DETR).
+## DeformableDetrImageProcessor
+
+[[autodoc]] DeformableDetrImageProcessor
+ - preprocess
+ - pad_and_create_pixel_mask
+ - post_process_object_detection
+
## DeformableDetrFeatureExtractor
[[autodoc]] DeformableDetrFeatureExtractor
@@ -55,4 +62,4 @@ This model was contributed by [nielsr](https://huggingface.co/nielsr). The origi
## DeformableDetrForObjectDetection
[[autodoc]] DeformableDetrForObjectDetection
- - forward
\ No newline at end of file
+ - forward
diff --git a/docs/source/en/model_doc/detr.mdx b/docs/source/en/model_doc/detr.mdx
index 4f9908772a..265d20255d 100644
--- a/docs/source/en/model_doc/detr.mdx
+++ b/docs/source/en/model_doc/detr.mdx
@@ -114,7 +114,7 @@ Tips:
It is advised to use a batch size of 2 per GPU. See [this Github thread](https://github.com/facebookresearch/detr/issues/150) for more info.
There are three ways to instantiate a DETR model (depending on what you prefer):
-
+
Option 1: Instantiate DETR with pre-trained weights for entire model
```py
>>> from transformers import DetrForObjectDetection
@@ -166,6 +166,15 @@ mean Average Precision (mAP) and Panoptic Quality (PQ). The latter objects are i
[[autodoc]] DetrConfig
+## DetrImageProcessor
+
+[[autodoc]] DetrImageProcessor
+ - preprocess
+ - post_process_object_detection
+ - post_process_semantic_segmentation
+ - post_process_instance_segmentation
+ - post_process_panoptic_segmentation
+
## DetrFeatureExtractor
[[autodoc]] DetrFeatureExtractor
diff --git a/docs/source/en/model_doc/maskformer.mdx b/docs/source/en/model_doc/maskformer.mdx
index bf4748686b..c52fb184ec 100644
--- a/docs/source/en/model_doc/maskformer.mdx
+++ b/docs/source/en/model_doc/maskformer.mdx
@@ -57,6 +57,15 @@ This model was contributed by [francesco](https://huggingface.co/francesco). The
[[autodoc]] MaskFormerConfig
+## MaskFormerImageProcessor
+
+[[autodoc]] MaskFormerImageProcessor
+ - preprocess
+ - encode_inputs
+ - post_process_semantic_segmentation
+ - post_process_instance_segmentation
+ - post_process_panoptic_segmentation
+
## MaskFormerFeatureExtractor
[[autodoc]] MaskFormerFeatureExtractor
diff --git a/docs/source/en/model_doc/owlvit.mdx b/docs/source/en/model_doc/owlvit.mdx
index 29a67aeb66..b95efd59b5 100644
--- a/docs/source/en/model_doc/owlvit.mdx
+++ b/docs/source/en/model_doc/owlvit.mdx
@@ -22,7 +22,7 @@ The abstract from the paper is the following:
## Usage
-OWL-ViT is a zero-shot text-conditioned object detection model. OWL-ViT uses [CLIP](clip) as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
+OWL-ViT is a zero-shot text-conditioned object detection model. OWL-ViT uses [CLIP](clip) as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
[`OwlViTFeatureExtractor`] can be used to resize (or rescale) and normalize images for the model and [`CLIPTokenizer`] is used to encode the text. [`OwlViTProcessor`] wraps [`OwlViTFeatureExtractor`] and [`CLIPTokenizer`] into a single instance to both encode the text and prepare the images. The following example shows how to perform object detection using [`OwlViTProcessor`] and [`OwlViTForObjectDetection`].
@@ -76,6 +76,13 @@ This model was contributed by [adirik](https://huggingface.co/adirik). The origi
[[autodoc]] OwlViTVisionConfig
+## OwlViTImageProcessor
+
+[[autodoc]] OwlViTImageProcessor
+ - preprocess
+ - post_process
+ - post_process_image_guided_detection
+
## OwlViTFeatureExtractor
[[autodoc]] OwlViTFeatureExtractor
diff --git a/docs/source/en/model_doc/yolos.mdx b/docs/source/en/model_doc/yolos.mdx
index 51c75252ac..185ee10c17 100644
--- a/docs/source/en/model_doc/yolos.mdx
+++ b/docs/source/en/model_doc/yolos.mdx
@@ -27,7 +27,7 @@ Tips:
- Demo notebooks (regarding inference and fine-tuning on custom data) can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/YOLOS).
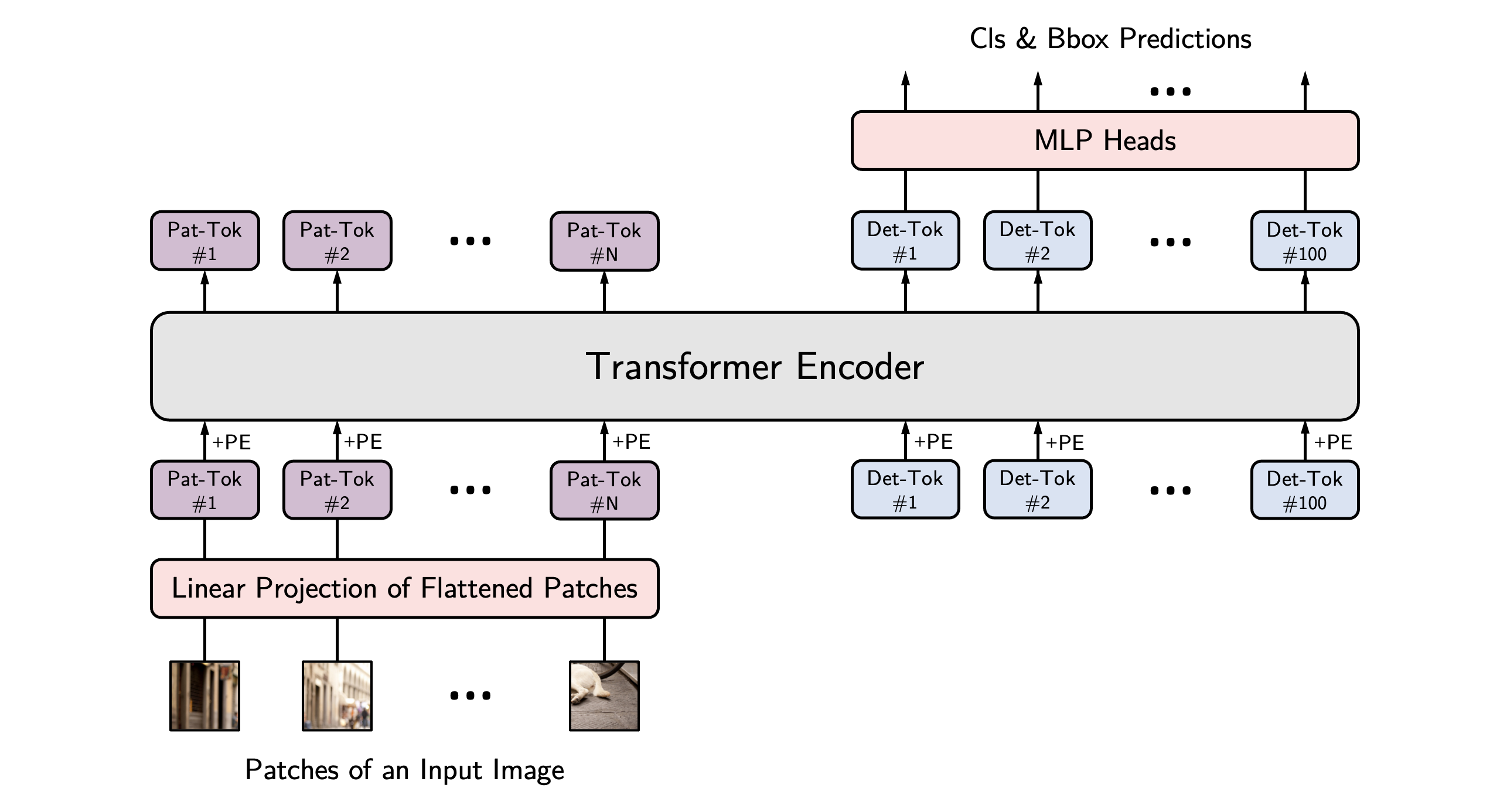 +alt="drawing" width="600"/>
YOLOS architecture. Taken from the original paper.
@@ -37,6 +37,12 @@ This model was contributed by [nielsr](https://huggingface.co/nielsr). The origi
[[autodoc]] YolosConfig
+## YolosImageProcessor
+
+[[autodoc]] YolosImageProcessor
+ - preprocess
+ - pad
+ - post_process_object_detection
## YolosFeatureExtractor
@@ -55,4 +61,4 @@ This model was contributed by [nielsr](https://huggingface.co/nielsr). The origi
## YolosForObjectDetection
[[autodoc]] YolosForObjectDetection
- - forward
\ No newline at end of file
+ - forward
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index 75c467fc93..59ec0912c9 100644
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -736,11 +736,15 @@ else:
_import_structure["image_utils"] = ["ImageFeatureExtractionMixin"]
_import_structure["models.beit"].extend(["BeitFeatureExtractor", "BeitImageProcessor"])
_import_structure["models.clip"].extend(["CLIPFeatureExtractor", "CLIPImageProcessor"])
- _import_structure["models.conditional_detr"].append("ConditionalDetrFeatureExtractor")
+ _import_structure["models.conditional_detr"].extend(
+ ["ConditionalDetrFeatureExtractor", "ConditionalDetrImageProcessor"]
+ )
_import_structure["models.convnext"].extend(["ConvNextFeatureExtractor", "ConvNextImageProcessor"])
- _import_structure["models.deformable_detr"].append("DeformableDetrFeatureExtractor")
+ _import_structure["models.deformable_detr"].extend(
+ ["DeformableDetrFeatureExtractor", "DeformableDetrImageProcessor"]
+ )
_import_structure["models.deit"].extend(["DeiTFeatureExtractor", "DeiTImageProcessor"])
- _import_structure["models.detr"].append("DetrFeatureExtractor")
+ _import_structure["models.detr"].extend(["DetrFeatureExtractor", "DetrImageProcessor"])
_import_structure["models.donut"].extend(["DonutFeatureExtractor", "DonutImageProcessor"])
_import_structure["models.dpt"].extend(["DPTFeatureExtractor", "DPTImageProcessor"])
_import_structure["models.flava"].extend(["FlavaFeatureExtractor", "FlavaImageProcessor", "FlavaProcessor"])
@@ -749,18 +753,18 @@ else:
_import_structure["models.layoutlmv2"].extend(["LayoutLMv2FeatureExtractor", "LayoutLMv2ImageProcessor"])
_import_structure["models.layoutlmv3"].extend(["LayoutLMv3FeatureExtractor", "LayoutLMv3ImageProcessor"])
_import_structure["models.levit"].extend(["LevitFeatureExtractor", "LevitImageProcessor"])
- _import_structure["models.maskformer"].append("MaskFormerFeatureExtractor")
+ _import_structure["models.maskformer"].extend(["MaskFormerFeatureExtractor", "MaskFormerImageProcessor"])
_import_structure["models.mobilenet_v1"].extend(["MobileNetV1FeatureExtractor", "MobileNetV1ImageProcessor"])
_import_structure["models.mobilenet_v2"].extend(["MobileNetV2FeatureExtractor", "MobileNetV2ImageProcessor"])
_import_structure["models.mobilevit"].extend(["MobileViTFeatureExtractor", "MobileViTImageProcessor"])
- _import_structure["models.owlvit"].append("OwlViTFeatureExtractor")
+ _import_structure["models.owlvit"].extend(["OwlViTFeatureExtractor", "OwlViTImageProcessor"])
_import_structure["models.perceiver"].extend(["PerceiverFeatureExtractor", "PerceiverImageProcessor"])
_import_structure["models.poolformer"].extend(["PoolFormerFeatureExtractor", "PoolFormerImageProcessor"])
_import_structure["models.segformer"].extend(["SegformerFeatureExtractor", "SegformerImageProcessor"])
_import_structure["models.videomae"].extend(["VideoMAEFeatureExtractor", "VideoMAEImageProcessor"])
_import_structure["models.vilt"].extend(["ViltFeatureExtractor", "ViltImageProcessor", "ViltProcessor"])
_import_structure["models.vit"].extend(["ViTFeatureExtractor", "ViTImageProcessor"])
- _import_structure["models.yolos"].extend(["YolosFeatureExtractor"])
+ _import_structure["models.yolos"].extend(["YolosFeatureExtractor", "YolosImageProcessor"])
# Timm-backed objects
try:
@@ -3869,11 +3873,11 @@ if TYPE_CHECKING:
from .image_utils import ImageFeatureExtractionMixin
from .models.beit import BeitFeatureExtractor, BeitImageProcessor
from .models.clip import CLIPFeatureExtractor, CLIPImageProcessor
- from .models.conditional_detr import ConditionalDetrFeatureExtractor
+ from .models.conditional_detr import ConditionalDetrFeatureExtractor, ConditionalDetrImageProcessor
from .models.convnext import ConvNextFeatureExtractor, ConvNextImageProcessor
- from .models.deformable_detr import DeformableDetrFeatureExtractor
+ from .models.deformable_detr import DeformableDetrFeatureExtractor, DeformableDetrImageProcessor
from .models.deit import DeiTFeatureExtractor, DeiTImageProcessor
- from .models.detr import DetrFeatureExtractor
+ from .models.detr import DetrFeatureExtractor, DetrImageProcessor
from .models.donut import DonutFeatureExtractor, DonutImageProcessor
from .models.dpt import DPTFeatureExtractor, DPTImageProcessor
from .models.flava import FlavaFeatureExtractor, FlavaImageProcessor, FlavaProcessor
@@ -3882,18 +3886,18 @@ if TYPE_CHECKING:
from .models.layoutlmv2 import LayoutLMv2FeatureExtractor, LayoutLMv2ImageProcessor
from .models.layoutlmv3 import LayoutLMv3FeatureExtractor, LayoutLMv3ImageProcessor
from .models.levit import LevitFeatureExtractor, LevitImageProcessor
- from .models.maskformer import MaskFormerFeatureExtractor
+ from .models.maskformer import MaskFormerFeatureExtractor, MaskFormerImageProcessor
from .models.mobilenet_v1 import MobileNetV1FeatureExtractor, MobileNetV1ImageProcessor
from .models.mobilenet_v2 import MobileNetV2FeatureExtractor, MobileNetV2ImageProcessor
from .models.mobilevit import MobileViTFeatureExtractor, MobileViTImageProcessor
- from .models.owlvit import OwlViTFeatureExtractor
+ from .models.owlvit import OwlViTFeatureExtractor, OwlViTImageProcessor
from .models.perceiver import PerceiverFeatureExtractor, PerceiverImageProcessor
from .models.poolformer import PoolFormerFeatureExtractor, PoolFormerImageProcessor
from .models.segformer import SegformerFeatureExtractor, SegformerImageProcessor
from .models.videomae import VideoMAEFeatureExtractor, VideoMAEImageProcessor
from .models.vilt import ViltFeatureExtractor, ViltImageProcessor, ViltProcessor
from .models.vit import ViTFeatureExtractor, ViTImageProcessor
- from .models.yolos import YolosFeatureExtractor
+ from .models.yolos import YolosFeatureExtractor, YolosImageProcessor
# Modeling
try:
diff --git a/src/transformers/image_utils.py b/src/transformers/image_utils.py
index 03aa15d722..789248fbca 100644
--- a/src/transformers/image_utils.py
+++ b/src/transformers/image_utils.py
@@ -14,7 +14,7 @@
# limitations under the License.
import os
-from typing import TYPE_CHECKING, List, Tuple, Union
+from typing import TYPE_CHECKING, Dict, Iterable, List, Tuple, Union
import numpy as np
from packaging import version
@@ -163,6 +163,47 @@ def get_image_size(image: np.ndarray, channel_dim: ChannelDimension = None) -> T
raise ValueError(f"Unsupported data format: {channel_dim}")
+def is_valid_annotation_coco_detection(annotation: Dict[str, Union[List, Tuple]]) -> bool:
+ if (
+ isinstance(annotation, dict)
+ and "image_id" in annotation
+ and "annotations" in annotation
+ and isinstance(annotation["annotations"], (list, tuple))
+ and (
+ # an image can have no annotations
+ len(annotation["annotations"]) == 0
+ or isinstance(annotation["annotations"][0], dict)
+ )
+ ):
+ return True
+ return False
+
+
+def is_valid_annotation_coco_panoptic(annotation: Dict[str, Union[List, Tuple]]) -> bool:
+ if (
+ isinstance(annotation, dict)
+ and "image_id" in annotation
+ and "segments_info" in annotation
+ and "file_name" in annotation
+ and isinstance(annotation["segments_info"], (list, tuple))
+ and (
+ # an image can have no segments
+ len(annotation["segments_info"]) == 0
+ or isinstance(annotation["segments_info"][0], dict)
+ )
+ ):
+ return True
+ return False
+
+
+def valid_coco_detection_annotations(annotations: Iterable[Dict[str, Union[List, Tuple]]]) -> bool:
+ return all(is_valid_annotation_coco_detection(ann) for ann in annotations)
+
+
+def valid_coco_panoptic_annotations(annotations: Iterable[Dict[str, Union[List, Tuple]]]) -> bool:
+ return all(is_valid_annotation_coco_panoptic(ann) for ann in annotations)
+
+
def load_image(image: Union[str, "PIL.Image.Image"]) -> "PIL.Image.Image":
"""
Loads `image` to a PIL Image.
diff --git a/src/transformers/models/auto/image_processing_auto.py b/src/transformers/models/auto/image_processing_auto.py
index df77c52314..fd540989f9 100644
--- a/src/transformers/models/auto/image_processing_auto.py
+++ b/src/transformers/models/auto/image_processing_auto.py
@@ -39,10 +39,14 @@ IMAGE_PROCESSOR_MAPPING_NAMES = OrderedDict(
[
("beit", "BeitImageProcessor"),
("clip", "CLIPImageProcessor"),
+ ("clipseg", "ViTImageProcessor"),
+ ("conditional_detr", "ConditionalDetrImageProcessor"),
("convnext", "ConvNextImageProcessor"),
("cvt", "ConvNextImageProcessor"),
("data2vec-vision", "BeitImageProcessor"),
+ ("deformable_detr", "DeformableDetrImageProcessor"),
("deit", "DeiTImageProcessor"),
+ ("detr", "DetrImageProcessor"),
("dinat", "ViTImageProcessor"),
("donut-swin", "DonutImageProcessor"),
("dpt", "DPTImageProcessor"),
@@ -53,10 +57,14 @@ IMAGE_PROCESSOR_MAPPING_NAMES = OrderedDict(
("layoutlmv2", "LayoutLMv2ImageProcessor"),
("layoutlmv3", "LayoutLMv3ImageProcessor"),
("levit", "LevitImageProcessor"),
+ ("maskformer", "MaskFormerImageProcessor"),
("mobilenet_v1", "MobileNetV1ImageProcessor"),
("mobilenet_v2", "MobileNetV2ImageProcessor"),
+ ("mobilenet_v2", "MobileNetV2ImageProcessor"),
+ ("mobilevit", "MobileViTImageProcessor"),
("mobilevit", "MobileViTImageProcessor"),
("nat", "ViTImageProcessor"),
+ ("owlvit", "OwlViTImageProcessor"),
("perceiver", "PerceiverImageProcessor"),
("poolformer", "PoolFormerImageProcessor"),
("regnet", "ConvNextImageProcessor"),
@@ -64,6 +72,7 @@ IMAGE_PROCESSOR_MAPPING_NAMES = OrderedDict(
("segformer", "SegformerImageProcessor"),
("swin", "ViTImageProcessor"),
("swinv2", "ViTImageProcessor"),
+ ("table-transformer", "DetrImageProcessor"),
("van", "ConvNextImageProcessor"),
("videomae", "VideoMAEImageProcessor"),
("vilt", "ViltImageProcessor"),
@@ -71,6 +80,7 @@ IMAGE_PROCESSOR_MAPPING_NAMES = OrderedDict(
("vit_mae", "ViTImageProcessor"),
("vit_msn", "ViTImageProcessor"),
("xclip", "CLIPImageProcessor"),
+ ("yolos", "YolosImageProcessor"),
]
)
@@ -113,7 +123,7 @@ def get_image_processor_config(
**kwargs,
):
"""
- Loads the image processor configuration from a pretrained model imag processor configuration. # FIXME
+ Loads the image processor configuration from a pretrained model image processor configuration.
Args:
pretrained_model_name_or_path (`str` or `os.PathLike`):
diff --git a/src/transformers/models/conditional_detr/__init__.py b/src/transformers/models/conditional_detr/__init__.py
index c2f1bdfdbb..fd69edfeb7 100644
--- a/src/transformers/models/conditional_detr/__init__.py
+++ b/src/transformers/models/conditional_detr/__init__.py
@@ -36,6 +36,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_conditional_detr"] = ["ConditionalDetrFeatureExtractor"]
+ _import_structure["image_processing_conditional_detr"] = ["ConditionalDetrImageProcessor"]
try:
if not is_timm_available():
@@ -66,6 +67,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_conditional_detr import ConditionalDetrFeatureExtractor
+ from .image_processing_conditional_detr import ConditionalDetrImageProcessor
try:
if not is_timm_available():
diff --git a/src/transformers/models/conditional_detr/feature_extraction_conditional_detr.py b/src/transformers/models/conditional_detr/feature_extraction_conditional_detr.py
index 01efb90542..ce04afba98 100644
--- a/src/transformers/models/conditional_detr/feature_extraction_conditional_detr.py
+++ b/src/transformers/models/conditional_detr/feature_extraction_conditional_detr.py
@@ -14,1108 +14,10 @@
# limitations under the License.
"""Feature extractor class for Conditional DETR."""
-import pathlib
-import warnings
-from typing import Dict, List, Optional, Set, Tuple, Union
+from ...utils import logging
+from .image_processing_conditional_detr import ConditionalDetrImageProcessor
-import numpy as np
-from PIL import Image
-
-from ...feature_extraction_utils import BatchFeature, FeatureExtractionMixin
-from ...image_transforms import center_to_corners_format, corners_to_center_format, rgb_to_id
-from ...image_utils import ImageFeatureExtractionMixin
-from ...utils import TensorType, is_torch_available, is_torch_tensor, logging
-
-
-if is_torch_available():
- import torch
- from torch import nn
logger = logging.get_logger(__name__)
-
-ImageInput = Union[Image.Image, np.ndarray, "torch.Tensor", List[Image.Image], List[np.ndarray], List["torch.Tensor"]]
-
-
-# Copied from transformers.models.detr.feature_extraction_detr.masks_to_boxes
-def masks_to_boxes(masks):
- """
- Compute the bounding boxes around the provided panoptic segmentation masks.
-
- The masks should be in format [N, H, W] where N is the number of masks, (H, W) are the spatial dimensions.
-
- Returns a [N, 4] tensor, with the boxes in corner (xyxy) format.
- """
- if masks.size == 0:
- return np.zeros((0, 4))
-
- h, w = masks.shape[-2:]
-
- y = np.arange(0, h, dtype=np.float32)
- x = np.arange(0, w, dtype=np.float32)
- # see https://github.com/pytorch/pytorch/issues/50276
- y, x = np.meshgrid(y, x, indexing="ij")
-
- x_mask = masks * np.expand_dims(x, axis=0)
- x_max = x_mask.reshape(x_mask.shape[0], -1).max(-1)
- x = np.ma.array(x_mask, mask=~(np.array(masks, dtype=bool)))
- x_min = x.filled(fill_value=1e8)
- x_min = x_min.reshape(x_min.shape[0], -1).min(-1)
-
- y_mask = masks * np.expand_dims(y, axis=0)
- y_max = y_mask.reshape(x_mask.shape[0], -1).max(-1)
- y = np.ma.array(y_mask, mask=~(np.array(masks, dtype=bool)))
- y_min = y.filled(fill_value=1e8)
- y_min = y_min.reshape(y_min.shape[0], -1).min(-1)
-
- return np.stack([x_min, y_min, x_max, y_max], 1)
-
-
-# Copied from transformers.models.detr.feature_extraction_detr.binary_mask_to_rle
-def binary_mask_to_rle(mask):
- """
- Args:
- Converts given binary mask of shape (height, width) to the run-length encoding (RLE) format.
- mask (`torch.Tensor` or `numpy.array`):
- A binary mask tensor of shape `(height, width)` where 0 denotes background and 1 denotes the target
- segment_id or class_id.
- Returns:
- `List`: Run-length encoded list of the binary mask. Refer to COCO API for more information about the RLE
- format.
- """
- if is_torch_tensor(mask):
- mask = mask.numpy()
-
- pixels = mask.flatten()
- pixels = np.concatenate([[0], pixels, [0]])
- runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
- runs[1::2] -= runs[::2]
- return [x for x in runs]
-
-
-# Copied from transformers.models.detr.feature_extraction_detr.convert_segmentation_to_rle
-def convert_segmentation_to_rle(segmentation):
- """
- Converts given segmentation map of shape (height, width) to the run-length encoding (RLE) format.
-
- Args:
- segmentation (`torch.Tensor` or `numpy.array`):
- A segmentation map of shape `(height, width)` where each value denotes a segment or class id.
- Returns:
- `List[List]`: A list of lists, where each list is the run-length encoding of a segment / class id.
- """
- segment_ids = torch.unique(segmentation)
-
- run_length_encodings = []
- for idx in segment_ids:
- mask = torch.where(segmentation == idx, 1, 0)
- rle = binary_mask_to_rle(mask)
- run_length_encodings.append(rle)
-
- return run_length_encodings
-
-
-# Copied from transformers.models.detr.feature_extraction_detr.remove_low_and_no_objects
-def remove_low_and_no_objects(masks, scores, labels, object_mask_threshold, num_labels):
- """
- Binarize the given masks using `object_mask_threshold`, it returns the associated values of `masks`, `scores` and
- `labels`.
-
- Args:
- masks (`torch.Tensor`):
- A tensor of shape `(num_queries, height, width)`.
- scores (`torch.Tensor`):
- A tensor of shape `(num_queries)`.
- labels (`torch.Tensor`):
- A tensor of shape `(num_queries)`.
- object_mask_threshold (`float`):
- A number between 0 and 1 used to binarize the masks.
- Raises:
- `ValueError`: Raised when the first dimension doesn't match in all input tensors.
- Returns:
- `Tuple[`torch.Tensor`, `torch.Tensor`, `torch.Tensor`]`: The `masks`, `scores` and `labels` without the region
- < `object_mask_threshold`.
- """
- if not (masks.shape[0] == scores.shape[0] == labels.shape[0]):
- raise ValueError("mask, scores and labels must have the same shape!")
-
- to_keep = labels.ne(num_labels) & (scores > object_mask_threshold)
-
- return masks[to_keep], scores[to_keep], labels[to_keep]
-
-
-# Copied from transformers.models.detr.feature_extraction_detr.check_segment_validity
-def check_segment_validity(mask_labels, mask_probs, k, mask_threshold=0.5, overlap_mask_area_threshold=0.8):
- # Get the mask associated with the k class
- mask_k = mask_labels == k
- mask_k_area = mask_k.sum()
-
- # Compute the area of all the stuff in query k
- original_area = (mask_probs[k] >= mask_threshold).sum()
- mask_exists = mask_k_area > 0 and original_area > 0
-
- # Eliminate disconnected tiny segments
- if mask_exists:
- area_ratio = mask_k_area / original_area
- if not area_ratio.item() > overlap_mask_area_threshold:
- mask_exists = False
-
- return mask_exists, mask_k
-
-
-# Copied from transformers.models.detr.feature_extraction_detr.compute_segments
-def compute_segments(
- mask_probs,
- pred_scores,
- pred_labels,
- mask_threshold: float = 0.5,
- overlap_mask_area_threshold: float = 0.8,
- label_ids_to_fuse: Optional[Set[int]] = None,
- target_size: Tuple[int, int] = None,
-):
- height = mask_probs.shape[1] if target_size is None else target_size[0]
- width = mask_probs.shape[2] if target_size is None else target_size[1]
-
- segmentation = torch.zeros((height, width), dtype=torch.int32, device=mask_probs.device)
- segments: List[Dict] = []
-
- if target_size is not None:
- mask_probs = nn.functional.interpolate(
- mask_probs.unsqueeze(0), size=target_size, mode="bilinear", align_corners=False
- )[0]
-
- current_segment_id = 0
-
- # Weigh each mask by its prediction score
- mask_probs *= pred_scores.view(-1, 1, 1)
- mask_labels = mask_probs.argmax(0) # [height, width]
-
- # Keep track of instances of each class
- stuff_memory_list: Dict[str, int] = {}
- for k in range(pred_labels.shape[0]):
- pred_class = pred_labels[k].item()
- should_fuse = pred_class in label_ids_to_fuse
-
- # Check if mask exists and large enough to be a segment
- mask_exists, mask_k = check_segment_validity(
- mask_labels, mask_probs, k, mask_threshold, overlap_mask_area_threshold
- )
-
- if mask_exists:
- if pred_class in stuff_memory_list:
- current_segment_id = stuff_memory_list[pred_class]
- else:
- current_segment_id += 1
-
- # Add current object segment to final segmentation map
- segmentation[mask_k] = current_segment_id
- segment_score = round(pred_scores[k].item(), 6)
- segments.append(
- {
- "id": current_segment_id,
- "label_id": pred_class,
- "was_fused": should_fuse,
- "score": segment_score,
- }
- )
- if should_fuse:
- stuff_memory_list[pred_class] = current_segment_id
-
- return segmentation, segments
-
-
-class ConditionalDetrFeatureExtractor(FeatureExtractionMixin, ImageFeatureExtractionMixin):
- r"""
- Constructs a Conditional DETR feature extractor.
-
- This feature extractor inherits from [`FeatureExtractionMixin`] which contains most of the main methods. Users
- should refer to this superclass for more information regarding those methods.
-
- Args:
- format (`str`, *optional*, defaults to `"coco_detection"`):
- Data format of the annotations. One of "coco_detection" or "coco_panoptic".
- do_resize (`bool`, *optional*, defaults to `True`):
- Whether to resize the input to a certain `size`.
- size (`int`, *optional*, defaults to 800):
- Resize the input to the given size. Only has an effect if `do_resize` is set to `True`. If size is a
- sequence like `(width, height)`, output size will be matched to this. If size is an int, smaller edge of
- the image will be matched to this number. i.e, if `height > width`, then image will be rescaled to `(size *
- height / width, size)`.
- max_size (`int`, *optional*, defaults to `1333`):
- The largest size an image dimension can have (otherwise it's capped). Only has an effect if `do_resize` is
- set to `True`.
- do_normalize (`bool`, *optional*, defaults to `True`):
- Whether or not to normalize the input with mean and standard deviation.
- image_mean (`int`, *optional*, defaults to `[0.485, 0.456, 0.406]`):
- The sequence of means for each channel, to be used when normalizing images. Defaults to the ImageNet mean.
- image_std (`int`, *optional*, defaults to `[0.229, 0.224, 0.225]`):
- The sequence of standard deviations for each channel, to be used when normalizing images. Defaults to the
- ImageNet std.
- """
-
- model_input_names = ["pixel_values", "pixel_mask"]
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.__init__
- def __init__(
- self,
- format="coco_detection",
- do_resize=True,
- size=800,
- max_size=1333,
- do_normalize=True,
- image_mean=None,
- image_std=None,
- **kwargs
- ):
- super().__init__(**kwargs)
- self.format = self._is_valid_format(format)
- self.do_resize = do_resize
- self.size = size
- self.max_size = max_size
- self.do_normalize = do_normalize
- self.image_mean = image_mean if image_mean is not None else [0.485, 0.456, 0.406] # ImageNet mean
- self.image_std = image_std if image_std is not None else [0.229, 0.224, 0.225] # ImageNet std
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._is_valid_format
- def _is_valid_format(self, format):
- if format not in ["coco_detection", "coco_panoptic"]:
- raise ValueError(f"Format {format} not supported")
- return format
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.prepare
- def prepare(self, image, target, return_segmentation_masks=False, masks_path=None):
- if self.format == "coco_detection":
- image, target = self.prepare_coco_detection(image, target, return_segmentation_masks)
- return image, target
- elif self.format == "coco_panoptic":
- image, target = self.prepare_coco_panoptic(image, target, masks_path)
- return image, target
- else:
- raise ValueError(f"Format {self.format} not supported")
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.convert_coco_poly_to_mask
- def convert_coco_poly_to_mask(self, segmentations, height, width):
-
- try:
- from pycocotools import mask as coco_mask
- except ImportError:
- raise ImportError("Pycocotools is not installed in your environment.")
-
- masks = []
- for polygons in segmentations:
- rles = coco_mask.frPyObjects(polygons, height, width)
- mask = coco_mask.decode(rles)
- if len(mask.shape) < 3:
- mask = mask[..., None]
- mask = np.asarray(mask, dtype=np.uint8)
- mask = np.any(mask, axis=2)
- masks.append(mask)
- if masks:
- masks = np.stack(masks, axis=0)
- else:
- masks = np.zeros((0, height, width), dtype=np.uint8)
-
- return masks
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.prepare_coco_detection with DETR->ConditionalDETR
- def prepare_coco_detection(self, image, target, return_segmentation_masks=False):
- """
- Convert the target in COCO format into the format expected by ConditionalDETR.
- """
- w, h = image.size
-
- image_id = target["image_id"]
- image_id = np.asarray([image_id], dtype=np.int64)
-
- # get all COCO annotations for the given image
- anno = target["annotations"]
-
- anno = [obj for obj in anno if "iscrowd" not in obj or obj["iscrowd"] == 0]
-
- boxes = [obj["bbox"] for obj in anno]
- # guard against no boxes via resizing
- boxes = np.asarray(boxes, dtype=np.float32).reshape(-1, 4)
- boxes[:, 2:] += boxes[:, :2]
- boxes[:, 0::2] = boxes[:, 0::2].clip(min=0, max=w)
- boxes[:, 1::2] = boxes[:, 1::2].clip(min=0, max=h)
-
- classes = [obj["category_id"] for obj in anno]
- classes = np.asarray(classes, dtype=np.int64)
-
- if return_segmentation_masks:
- segmentations = [obj["segmentation"] for obj in anno]
- masks = self.convert_coco_poly_to_mask(segmentations, h, w)
-
- keypoints = None
- if anno and "keypoints" in anno[0]:
- keypoints = [obj["keypoints"] for obj in anno]
- keypoints = np.asarray(keypoints, dtype=np.float32)
- num_keypoints = keypoints.shape[0]
- if num_keypoints:
- keypoints = keypoints.reshape((-1, 3))
-
- keep = (boxes[:, 3] > boxes[:, 1]) & (boxes[:, 2] > boxes[:, 0])
- boxes = boxes[keep]
- classes = classes[keep]
- if return_segmentation_masks:
- masks = masks[keep]
- if keypoints is not None:
- keypoints = keypoints[keep]
-
- target = {}
- target["boxes"] = boxes
- target["class_labels"] = classes
- if return_segmentation_masks:
- target["masks"] = masks
- target["image_id"] = image_id
- if keypoints is not None:
- target["keypoints"] = keypoints
-
- # for conversion to coco api
- area = np.asarray([obj["area"] for obj in anno], dtype=np.float32)
- iscrowd = np.asarray([obj["iscrowd"] if "iscrowd" in obj else 0 for obj in anno], dtype=np.int64)
- target["area"] = area[keep]
- target["iscrowd"] = iscrowd[keep]
-
- target["orig_size"] = np.asarray([int(h), int(w)], dtype=np.int64)
- target["size"] = np.asarray([int(h), int(w)], dtype=np.int64)
-
- return image, target
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.prepare_coco_panoptic
- def prepare_coco_panoptic(self, image, target, masks_path, return_masks=True):
- w, h = image.size
- ann_info = target.copy()
- ann_path = pathlib.Path(masks_path) / ann_info["file_name"]
-
- if "segments_info" in ann_info:
- masks = np.asarray(Image.open(ann_path), dtype=np.uint32)
- masks = rgb_to_id(masks)
-
- ids = np.array([ann["id"] for ann in ann_info["segments_info"]])
- masks = masks == ids[:, None, None]
- masks = np.asarray(masks, dtype=np.uint8)
-
- labels = np.asarray([ann["category_id"] for ann in ann_info["segments_info"]], dtype=np.int64)
-
- target = {}
- target["image_id"] = np.asarray(
- [ann_info["image_id"] if "image_id" in ann_info else ann_info["id"]], dtype=np.int64
- )
- if return_masks:
- target["masks"] = masks
- target["class_labels"] = labels
-
- target["boxes"] = masks_to_boxes(masks)
-
- target["size"] = np.asarray([int(h), int(w)], dtype=np.int64)
- target["orig_size"] = np.asarray([int(h), int(w)], dtype=np.int64)
- if "segments_info" in ann_info:
- target["iscrowd"] = np.asarray([ann["iscrowd"] for ann in ann_info["segments_info"]], dtype=np.int64)
- target["area"] = np.asarray([ann["area"] for ann in ann_info["segments_info"]], dtype=np.float32)
-
- return image, target
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._resize
- def _resize(self, image, size, target=None, max_size=None):
- """
- Resize the image to the given size. Size can be min_size (scalar) or (w, h) tuple. If size is an int, smaller
- edge of the image will be matched to this number.
-
- If given, also resize the target accordingly.
- """
- if not isinstance(image, Image.Image):
- image = self.to_pil_image(image)
-
- def get_size_with_aspect_ratio(image_size, size, max_size=None):
- w, h = image_size
- if max_size is not None:
- min_original_size = float(min((w, h)))
- max_original_size = float(max((w, h)))
- if max_original_size / min_original_size * size > max_size:
- size = int(round(max_size * min_original_size / max_original_size))
-
- if (w <= h and w == size) or (h <= w and h == size):
- return (h, w)
-
- if w < h:
- ow = size
- oh = int(size * h / w)
- else:
- oh = size
- ow = int(size * w / h)
-
- return (oh, ow)
-
- def get_size(image_size, size, max_size=None):
- if isinstance(size, (list, tuple)):
- return size
- else:
- # size returned must be (w, h) since we use PIL to resize images
- # so we revert the tuple
- return get_size_with_aspect_ratio(image_size, size, max_size)[::-1]
-
- size = get_size(image.size, size, max_size)
- rescaled_image = self.resize(image, size=size)
-
- if target is None:
- return rescaled_image, None
-
- ratios = tuple(float(s) / float(s_orig) for s, s_orig in zip(rescaled_image.size, image.size))
- ratio_width, ratio_height = ratios
-
- target = target.copy()
- if "boxes" in target:
- boxes = target["boxes"]
- scaled_boxes = boxes * np.asarray([ratio_width, ratio_height, ratio_width, ratio_height], dtype=np.float32)
- target["boxes"] = scaled_boxes
-
- if "area" in target:
- area = target["area"]
- scaled_area = area * (ratio_width * ratio_height)
- target["area"] = scaled_area
-
- w, h = size
- target["size"] = np.asarray([h, w], dtype=np.int64)
-
- if "masks" in target:
- # use PyTorch as current workaround
- # TODO replace by self.resize
- masks = torch.from_numpy(target["masks"][:, None]).float()
- interpolated_masks = nn.functional.interpolate(masks, size=(h, w), mode="nearest")[:, 0] > 0.5
- target["masks"] = interpolated_masks.numpy()
-
- return rescaled_image, target
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._normalize
- def _normalize(self, image, mean, std, target=None):
- """
- Normalize the image with a certain mean and std.
-
- If given, also normalize the target bounding boxes based on the size of the image.
- """
-
- image = self.normalize(image, mean=mean, std=std)
- if target is None:
- return image, None
-
- target = target.copy()
- h, w = image.shape[-2:]
-
- if "boxes" in target:
- boxes = target["boxes"]
- boxes = corners_to_center_format(boxes)
- boxes = boxes / np.asarray([w, h, w, h], dtype=np.float32)
- target["boxes"] = boxes
-
- return image, target
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.__call__ with Detr->ConditionalDetr,DETR->ConditionalDETR
- def __call__(
- self,
- images: ImageInput,
- annotations: Union[List[Dict], List[List[Dict]]] = None,
- return_segmentation_masks: Optional[bool] = False,
- masks_path: Optional[pathlib.Path] = None,
- pad_and_return_pixel_mask: Optional[bool] = True,
- return_tensors: Optional[Union[str, TensorType]] = None,
- **kwargs,
- ) -> BatchFeature:
- """
- Main method to prepare for the model one or several image(s) and optional annotations. Images are by default
- padded up to the largest image in a batch, and a pixel mask is created that indicates which pixels are
- real/which are padding.
-
-
-
- NumPy arrays and PyTorch tensors are converted to PIL images when resizing, so the most efficient is to pass
- PIL images.
-
-
-
- Args:
- images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
- The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
- tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a
- number of channels, H and W are image height and width.
-
- annotations (`Dict`, `List[Dict]`, *optional*):
- The corresponding annotations in COCO format.
-
- In case [`ConditionalDetrFeatureExtractor`] was initialized with `format = "coco_detection"`, the
- annotations for each image should have the following format: {'image_id': int, 'annotations':
- [annotation]}, with the annotations being a list of COCO object annotations.
-
- In case [`ConditionalDetrFeatureExtractor`] was initialized with `format = "coco_panoptic"`, the
- annotations for each image should have the following format: {'image_id': int, 'file_name': str,
- 'segments_info': [segment_info]} with segments_info being a list of COCO panoptic annotations.
-
- return_segmentation_masks (`Dict`, `List[Dict]`, *optional*, defaults to `False`):
- Whether to also include instance segmentation masks as part of the labels in case `format =
- "coco_detection"`.
-
- masks_path (`pathlib.Path`, *optional*):
- Path to the directory containing the PNG files that store the class-agnostic image segmentations. Only
- relevant in case [`ConditionalDetrFeatureExtractor`] was initialized with `format = "coco_panoptic"`.
-
- pad_and_return_pixel_mask (`bool`, *optional*, defaults to `True`):
- Whether or not to pad images up to the largest image in a batch and create a pixel mask.
-
- If left to the default, will return a pixel mask that is:
-
- - 1 for pixels that are real (i.e. **not masked**),
- - 0 for pixels that are padding (i.e. **masked**).
-
- return_tensors (`str` or [`~utils.TensorType`], *optional*):
- If set, will return tensors instead of NumPy arrays. If set to `'pt'`, return PyTorch `torch.Tensor`
- objects.
-
- Returns:
- [`BatchFeature`]: A [`BatchFeature`] with the following fields:
-
- - **pixel_values** -- Pixel values to be fed to a model.
- - **pixel_mask** -- Pixel mask to be fed to a model (when `pad_and_return_pixel_mask=True` or if
- *"pixel_mask"* is in `self.model_input_names`).
- - **labels** -- Optional labels to be fed to a model (when `annotations` are provided)
- """
- # Input type checking for clearer error
-
- valid_images = False
- valid_annotations = False
- valid_masks_path = False
-
- # Check that images has a valid type
- if isinstance(images, (Image.Image, np.ndarray)) or is_torch_tensor(images):
- valid_images = True
- elif isinstance(images, (list, tuple)):
- if len(images) == 0 or isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]):
- valid_images = True
-
- if not valid_images:
- raise ValueError(
- "Images must of type `PIL.Image.Image`, `np.ndarray` or `torch.Tensor` (single example), "
- "`List[PIL.Image.Image]`, `List[np.ndarray]` or `List[torch.Tensor]` (batch of examples)."
- )
-
- is_batched = bool(
- isinstance(images, (list, tuple))
- and (isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]))
- )
-
- # Check that annotations has a valid type
- if annotations is not None:
- if not is_batched:
- if self.format == "coco_detection":
- if isinstance(annotations, dict) and "image_id" in annotations and "annotations" in annotations:
- if isinstance(annotations["annotations"], (list, tuple)):
- # an image can have no annotations
- if len(annotations["annotations"]) == 0 or isinstance(annotations["annotations"][0], dict):
- valid_annotations = True
- elif self.format == "coco_panoptic":
- if isinstance(annotations, dict) and "image_id" in annotations and "segments_info" in annotations:
- if isinstance(annotations["segments_info"], (list, tuple)):
- # an image can have no segments (?)
- if len(annotations["segments_info"]) == 0 or isinstance(
- annotations["segments_info"][0], dict
- ):
- valid_annotations = True
- else:
- if isinstance(annotations, (list, tuple)):
- if len(images) != len(annotations):
- raise ValueError("There must be as many annotations as there are images")
- if isinstance(annotations[0], Dict):
- if self.format == "coco_detection":
- if isinstance(annotations[0]["annotations"], (list, tuple)):
- valid_annotations = True
- elif self.format == "coco_panoptic":
- if isinstance(annotations[0]["segments_info"], (list, tuple)):
- valid_annotations = True
-
- if not valid_annotations:
- raise ValueError(
- """
- Annotations must of type `Dict` (single image) or `List[Dict]` (batch of images). In case of object
- detection, each dictionary should contain the keys 'image_id' and 'annotations', with the latter
- being a list of annotations in COCO format. In case of panoptic segmentation, each dictionary
- should contain the keys 'file_name', 'image_id' and 'segments_info', with the latter being a list
- of annotations in COCO format.
- """
- )
-
- # Check that masks_path has a valid type
- if masks_path is not None:
- if self.format == "coco_panoptic":
- if isinstance(masks_path, pathlib.Path):
- valid_masks_path = True
- if not valid_masks_path:
- raise ValueError(
- "The path to the directory containing the mask PNG files should be provided as a"
- " `pathlib.Path` object."
- )
-
- if not is_batched:
- images = [images]
- if annotations is not None:
- annotations = [annotations]
-
- # Create a copy of the list to avoid editing it in place
- images = [image for image in images]
-
- if annotations is not None:
- annotations = [annotation for annotation in annotations]
-
- # prepare (COCO annotations as a list of Dict -> ConditionalDETR target as a single Dict per image)
- if annotations is not None:
- for idx, (image, target) in enumerate(zip(images, annotations)):
- if not isinstance(image, Image.Image):
- image = self.to_pil_image(image)
- image, target = self.prepare(image, target, return_segmentation_masks, masks_path)
- images[idx] = image
- annotations[idx] = target
-
- # transformations (resizing + normalization)
- if self.do_resize and self.size is not None:
- if annotations is not None:
- for idx, (image, target) in enumerate(zip(images, annotations)):
- image, target = self._resize(image=image, target=target, size=self.size, max_size=self.max_size)
- images[idx] = image
- annotations[idx] = target
- else:
- for idx, image in enumerate(images):
- images[idx] = self._resize(image=image, target=None, size=self.size, max_size=self.max_size)[0]
-
- if self.do_normalize:
- if annotations is not None:
- for idx, (image, target) in enumerate(zip(images, annotations)):
- image, target = self._normalize(
- image=image, mean=self.image_mean, std=self.image_std, target=target
- )
- images[idx] = image
- annotations[idx] = target
- else:
- images = [
- self._normalize(image=image, mean=self.image_mean, std=self.image_std)[0] for image in images
- ]
- else:
- images = [np.array(image) for image in images]
-
- if pad_and_return_pixel_mask:
- # pad images up to largest image in batch and create pixel_mask
- max_size = self._max_by_axis([list(image.shape) for image in images])
- c, h, w = max_size
- padded_images = []
- pixel_mask = []
- for image in images:
- # create padded image
- padded_image = np.zeros((c, h, w), dtype=np.float32)
- padded_image[: image.shape[0], : image.shape[1], : image.shape[2]] = np.copy(image)
- padded_images.append(padded_image)
- # create pixel mask
- mask = np.zeros((h, w), dtype=np.int64)
- mask[: image.shape[1], : image.shape[2]] = True
- pixel_mask.append(mask)
- images = padded_images
-
- # return as BatchFeature
- data = {}
- data["pixel_values"] = images
- if pad_and_return_pixel_mask:
- data["pixel_mask"] = pixel_mask
- encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
-
- if annotations is not None:
- # Convert to TensorType
- tensor_type = return_tensors
- if not isinstance(tensor_type, TensorType):
- tensor_type = TensorType(tensor_type)
-
- if not tensor_type == TensorType.PYTORCH:
- raise ValueError("Only PyTorch is supported for the moment.")
- else:
- if not is_torch_available():
- raise ImportError("Unable to convert output to PyTorch tensors format, PyTorch is not installed.")
-
- encoded_inputs["labels"] = [
- {k: torch.from_numpy(v) for k, v in target.items()} for target in annotations
- ]
-
- return encoded_inputs
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._max_by_axis
- def _max_by_axis(self, the_list):
- # type: (List[List[int]]) -> List[int]
- maxes = the_list[0]
- for sublist in the_list[1:]:
- for index, item in enumerate(sublist):
- maxes[index] = max(maxes[index], item)
- return maxes
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.pad_and_create_pixel_mask
- def pad_and_create_pixel_mask(
- self, pixel_values_list: List["torch.Tensor"], return_tensors: Optional[Union[str, TensorType]] = None
- ):
- """
- Pad images up to the largest image in a batch and create a corresponding `pixel_mask`.
-
- Args:
- pixel_values_list (`List[torch.Tensor]`):
- List of images (pixel values) to be padded. Each image should be a tensor of shape (C, H, W).
- return_tensors (`str` or [`~utils.TensorType`], *optional*):
- If set, will return tensors instead of NumPy arrays. If set to `'pt'`, return PyTorch `torch.Tensor`
- objects.
-
- Returns:
- [`BatchFeature`]: A [`BatchFeature`] with the following fields:
-
- - **pixel_values** -- Pixel values to be fed to a model.
- - **pixel_mask** -- Pixel mask to be fed to a model (when `pad_and_return_pixel_mask=True` or if
- *"pixel_mask"* is in `self.model_input_names`).
-
- """
-
- max_size = self._max_by_axis([list(image.shape) for image in pixel_values_list])
- c, h, w = max_size
- padded_images = []
- pixel_mask = []
- for image in pixel_values_list:
- # create padded image
- padded_image = np.zeros((c, h, w), dtype=np.float32)
- padded_image[: image.shape[0], : image.shape[1], : image.shape[2]] = np.copy(image)
- padded_images.append(padded_image)
- # create pixel mask
- mask = np.zeros((h, w), dtype=np.int64)
- mask[: image.shape[1], : image.shape[2]] = True
- pixel_mask.append(mask)
-
- # return as BatchFeature
- data = {"pixel_values": padded_images, "pixel_mask": pixel_mask}
- encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
-
- return encoded_inputs
-
- def post_process(self, outputs, target_sizes):
- """
- Args:
- Converts the output of [`ConditionalDetrForObjectDetection`] into the format expected by the COCO api. Only
- supports PyTorch.
- outputs ([`ConditionalDetrObjectDetectionOutput`]):
- Raw outputs of the model.
- target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
- Tensor containing the size (h, w) of each image of the batch. For evaluation, this must be the original
- image size (before any data augmentation). For visualization, this should be the image size after data
- augment, but before padding.
- Returns:
- `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
- in the batch as predicted by the model.
- """
- warnings.warn(
- "`post_process` is deprecated and will be removed in v5 of Transformers, please use"
- " `post_process_object_detection`",
- FutureWarning,
- )
-
- out_logits, out_bbox = outputs.logits, outputs.pred_boxes
-
- if len(out_logits) != len(target_sizes):
- raise ValueError("Make sure that you pass in as many target sizes as the batch dimension of the logits")
- if target_sizes.shape[1] != 2:
- raise ValueError("Each element of target_sizes must contain the size (h, w) of each image of the batch")
-
- prob = out_logits.sigmoid()
- topk_values, topk_indexes = torch.topk(prob.view(out_logits.shape[0], -1), 300, dim=1)
- scores = topk_values
- topk_boxes = topk_indexes // out_logits.shape[2]
- labels = topk_indexes % out_logits.shape[2]
- boxes = center_to_corners_format(out_bbox)
- boxes = torch.gather(boxes, 1, topk_boxes.unsqueeze(-1).repeat(1, 1, 4))
-
- # and from relative [0, 1] to absolute [0, height] coordinates
- img_h, img_w = target_sizes.unbind(1)
- scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
- boxes = boxes * scale_fct[:, None, :]
-
- results = [{"scores": s, "labels": l, "boxes": b} for s, l, b in zip(scores, labels, boxes)]
-
- return results
-
- # Copied from transformers.models.deformable_detr.feature_extraction_deformable_detr.DeformableDetrFeatureExtractor.post_process_object_detection with DeformableDetr->ConditionalDetr
- def post_process_object_detection(
- self, outputs, threshold: float = 0.5, target_sizes: Union[TensorType, List[Tuple]] = None
- ):
- """
- Converts the output of [`ConditionalDetrForObjectDetection`] into the format expected by the COCO api. Only
- supports PyTorch.
-
- Args:
- outputs ([`DetrObjectDetectionOutput`]):
- Raw outputs of the model.
- threshold (`float`, *optional*):
- Score threshold to keep object detection predictions.
- target_sizes (`torch.Tensor` or `List[Tuple[int, int]]`, *optional*, defaults to `None`):
- Tensor of shape `(batch_size, 2)` or list of tuples (`Tuple[int, int]`) containing the target size
- (height, width) of each image in the batch. If left to None, predictions will not be resized.
-
- Returns:
- `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
- in the batch as predicted by the model.
- """
- out_logits, out_bbox = outputs.logits, outputs.pred_boxes
-
- if target_sizes is not None:
- if len(out_logits) != len(target_sizes):
- raise ValueError(
- "Make sure that you pass in as many target sizes as the batch dimension of the logits"
- )
-
- prob = out_logits.sigmoid()
- topk_values, topk_indexes = torch.topk(prob.view(out_logits.shape[0], -1), 100, dim=1)
- scores = topk_values
- topk_boxes = topk_indexes // out_logits.shape[2]
- labels = topk_indexes % out_logits.shape[2]
- boxes = center_to_corners_format(out_bbox)
- boxes = torch.gather(boxes, 1, topk_boxes.unsqueeze(-1).repeat(1, 1, 4))
-
- # and from relative [0, 1] to absolute [0, height] coordinates
- if isinstance(target_sizes, List):
- img_h = torch.Tensor([i[0] for i in target_sizes])
- img_w = torch.Tensor([i[1] for i in target_sizes])
- else:
- img_h, img_w = target_sizes.unbind(1)
- scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1).to(boxes.device)
- boxes = boxes * scale_fct[:, None, :]
-
- results = []
- for s, l, b in zip(scores, labels, boxes):
- score = s[s > threshold]
- label = l[s > threshold]
- box = b[s > threshold]
- results.append({"scores": score, "labels": label, "boxes": box})
-
- return results
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.post_process_semantic_segmentation with Detr->ConditionalDetr
- def post_process_semantic_segmentation(self, outputs, target_sizes: List[Tuple[int, int]] = None):
- """
- Converts the output of [`ConditionalDetrForSegmentation`] into semantic segmentation maps. Only supports
- PyTorch.
-
- Args:
- outputs ([`ConditionalDetrForSegmentation`]):
- Raw outputs of the model.
- target_sizes (`List[Tuple[int, int]]`, *optional*, defaults to `None`):
- A list of tuples (`Tuple[int, int]`) containing the target size (height, width) of each image in the
- batch. If left to None, predictions will not be resized.
-
- Returns:
- `List[torch.Tensor]`:
- A list of length `batch_size`, where each item is a semantic segmentation map of shape (height, width)
- corresponding to the target_sizes entry (if `target_sizes` is specified). Each entry of each
- `torch.Tensor` correspond to a semantic class id.
- """
- class_queries_logits = outputs.logits # [batch_size, num_queries, num_classes+1]
- masks_queries_logits = outputs.pred_masks # [batch_size, num_queries, height, width]
-
- # Remove the null class `[..., :-1]`
- masks_classes = class_queries_logits.softmax(dim=-1)[..., :-1]
- masks_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
-
- # Semantic segmentation logits of shape (batch_size, num_classes, height, width)
- segmentation = torch.einsum("bqc, bqhw -> bchw", masks_classes, masks_probs)
- batch_size = class_queries_logits.shape[0]
-
- # Resize logits and compute semantic segmentation maps
- if target_sizes is not None:
- if batch_size != len(target_sizes):
- raise ValueError(
- "Make sure that you pass in as many target sizes as the batch dimension of the logits"
- )
-
- semantic_segmentation = []
- for idx in range(batch_size):
- resized_logits = nn.functional.interpolate(
- segmentation[idx].unsqueeze(dim=0), size=target_sizes[idx], mode="bilinear", align_corners=False
- )
- semantic_map = resized_logits[0].argmax(dim=0)
- semantic_segmentation.append(semantic_map)
- else:
- semantic_segmentation = segmentation.argmax(dim=1)
- semantic_segmentation = [semantic_segmentation[i] for i in range(semantic_segmentation.shape[0])]
-
- return semantic_segmentation
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.post_process_instance_segmentation with Detr->ConditionalDetr
- def post_process_instance_segmentation(
- self,
- outputs,
- threshold: float = 0.5,
- mask_threshold: float = 0.5,
- overlap_mask_area_threshold: float = 0.8,
- target_sizes: Optional[List[Tuple[int, int]]] = None,
- return_coco_annotation: Optional[bool] = False,
- ) -> List[Dict]:
- """
- Converts the output of [`ConditionalDetrForSegmentation`] into instance segmentation predictions. Only supports
- PyTorch.
-
- Args:
- outputs ([`ConditionalDetrForSegmentation`]):
- Raw outputs of the model.
- threshold (`float`, *optional*, defaults to 0.5):
- The probability score threshold to keep predicted instance masks.
- mask_threshold (`float`, *optional*, defaults to 0.5):
- Threshold to use when turning the predicted masks into binary values.
- overlap_mask_area_threshold (`float`, *optional*, defaults to 0.8):
- The overlap mask area threshold to merge or discard small disconnected parts within each binary
- instance mask.
- target_sizes (`List[Tuple]`, *optional*):
- List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
- final size (height, width) of each prediction. If left to None, predictions will not be resized.
- return_coco_annotation (`bool`, *optional*):
- Defaults to `False`. If set to `True`, segmentation maps are returned in COCO run-length encoding (RLE)
- format.
-
- Returns:
- `List[Dict]`: A list of dictionaries, one per image, each dictionary containing two keys:
- - **segmentation** -- A tensor of shape `(height, width)` where each pixel represents a `segment_id` or
- `List[List]` run-length encoding (RLE) of the segmentation map if return_coco_annotation is set to
- `True`. Set to `None` if no mask if found above `threshold`.
- - **segments_info** -- A dictionary that contains additional information on each segment.
- - **id** -- An integer representing the `segment_id`.
- - **label_id** -- An integer representing the label / semantic class id corresponding to `segment_id`.
- - **score** -- Prediction score of segment with `segment_id`.
- """
- class_queries_logits = outputs.logits # [batch_size, num_queries, num_classes+1]
- masks_queries_logits = outputs.pred_masks # [batch_size, num_queries, height, width]
-
- batch_size = class_queries_logits.shape[0]
- num_labels = class_queries_logits.shape[-1] - 1
-
- mask_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
-
- # Predicted label and score of each query (batch_size, num_queries)
- pred_scores, pred_labels = nn.functional.softmax(class_queries_logits, dim=-1).max(-1)
-
- # Loop over items in batch size
- results: List[Dict[str, TensorType]] = []
-
- for i in range(batch_size):
- mask_probs_item, pred_scores_item, pred_labels_item = remove_low_and_no_objects(
- mask_probs[i], pred_scores[i], pred_labels[i], threshold, num_labels
- )
-
- # No mask found
- if mask_probs_item.shape[0] <= 0:
- height, width = target_sizes[i] if target_sizes is not None else mask_probs_item.shape[1:]
- segmentation = torch.zeros((height, width)) - 1
- results.append({"segmentation": segmentation, "segments_info": []})
- continue
-
- # Get segmentation map and segment information of batch item
- target_size = target_sizes[i] if target_sizes is not None else None
- segmentation, segments = compute_segments(
- mask_probs=mask_probs_item,
- pred_scores=pred_scores_item,
- pred_labels=pred_labels_item,
- mask_threshold=mask_threshold,
- overlap_mask_area_threshold=overlap_mask_area_threshold,
- label_ids_to_fuse=[],
- target_size=target_size,
- )
-
- # Return segmentation map in run-length encoding (RLE) format
- if return_coco_annotation:
- segmentation = convert_segmentation_to_rle(segmentation)
-
- results.append({"segmentation": segmentation, "segments_info": segments})
- return results
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.post_process_panoptic_segmentation with Detr->ConditionalDetr
- def post_process_panoptic_segmentation(
- self,
- outputs,
- threshold: float = 0.5,
- mask_threshold: float = 0.5,
- overlap_mask_area_threshold: float = 0.8,
- label_ids_to_fuse: Optional[Set[int]] = None,
- target_sizes: Optional[List[Tuple[int, int]]] = None,
- ) -> List[Dict]:
- """
- Converts the output of [`ConditionalDetrForSegmentation`] into image panoptic segmentation predictions. Only
- supports PyTorch.
-
- Args:
- outputs ([`ConditionalDetrForSegmentation`]):
- The outputs from [`ConditionalDetrForSegmentation`].
- threshold (`float`, *optional*, defaults to 0.5):
- The probability score threshold to keep predicted instance masks.
- mask_threshold (`float`, *optional*, defaults to 0.5):
- Threshold to use when turning the predicted masks into binary values.
- overlap_mask_area_threshold (`float`, *optional*, defaults to 0.8):
- The overlap mask area threshold to merge or discard small disconnected parts within each binary
- instance mask.
- label_ids_to_fuse (`Set[int]`, *optional*):
- The labels in this state will have all their instances be fused together. For instance we could say
- there can only be one sky in an image, but several persons, so the label ID for sky would be in that
- set, but not the one for person.
- target_sizes (`List[Tuple]`, *optional*):
- List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
- final size (height, width) of each prediction in batch. If left to None, predictions will not be
- resized.
-
- Returns:
- `List[Dict]`: A list of dictionaries, one per image, each dictionary containing two keys:
- - **segmentation** -- a tensor of shape `(height, width)` where each pixel represents a `segment_id` or
- `None` if no mask if found above `threshold`. If `target_sizes` is specified, segmentation is resized to
- the corresponding `target_sizes` entry.
- - **segments_info** -- A dictionary that contains additional information on each segment.
- - **id** -- an integer representing the `segment_id`.
- - **label_id** -- An integer representing the label / semantic class id corresponding to `segment_id`.
- - **was_fused** -- a boolean, `True` if `label_id` was in `label_ids_to_fuse`, `False` otherwise.
- Multiple instances of the same class / label were fused and assigned a single `segment_id`.
- - **score** -- Prediction score of segment with `segment_id`.
- """
-
- if label_ids_to_fuse is None:
- warnings.warn("`label_ids_to_fuse` unset. No instance will be fused.")
- label_ids_to_fuse = set()
-
- class_queries_logits = outputs.logits # [batch_size, num_queries, num_classes+1]
- masks_queries_logits = outputs.pred_masks # [batch_size, num_queries, height, width]
-
- batch_size = class_queries_logits.shape[0]
- num_labels = class_queries_logits.shape[-1] - 1
-
- mask_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
-
- # Predicted label and score of each query (batch_size, num_queries)
- pred_scores, pred_labels = nn.functional.softmax(class_queries_logits, dim=-1).max(-1)
-
- # Loop over items in batch size
- results: List[Dict[str, TensorType]] = []
-
- for i in range(batch_size):
- mask_probs_item, pred_scores_item, pred_labels_item = remove_low_and_no_objects(
- mask_probs[i], pred_scores[i], pred_labels[i], threshold, num_labels
- )
-
- # No mask found
- if mask_probs_item.shape[0] <= 0:
- height, width = target_sizes[i] if target_sizes is not None else mask_probs_item.shape[1:]
- segmentation = torch.zeros((height, width)) - 1
- results.append({"segmentation": segmentation, "segments_info": []})
- continue
-
- # Get segmentation map and segment information of batch item
- target_size = target_sizes[i] if target_sizes is not None else None
- segmentation, segments = compute_segments(
- mask_probs=mask_probs_item,
- pred_scores=pred_scores_item,
- pred_labels=pred_labels_item,
- mask_threshold=mask_threshold,
- overlap_mask_area_threshold=overlap_mask_area_threshold,
- label_ids_to_fuse=label_ids_to_fuse,
- target_size=target_size,
- )
-
- results.append({"segmentation": segmentation, "segments_info": segments})
- return results
+ConditionalDetrFeatureExtractor = ConditionalDetrImageProcessor
diff --git a/src/transformers/models/conditional_detr/image_processing_conditional_detr.py b/src/transformers/models/conditional_detr/image_processing_conditional_detr.py
new file mode 100644
index 0000000000..c0a18c7d33
--- /dev/null
+++ b/src/transformers/models/conditional_detr/image_processing_conditional_detr.py
@@ -0,0 +1,1576 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Image processor class for Conditional DETR."""
+
+import io
+import pathlib
+import warnings
+from collections import defaultdict
+from typing import Any, Callable, Dict, Iterable, List, Optional, Set, Tuple, Union
+
+import numpy as np
+
+from transformers.feature_extraction_utils import BatchFeature
+from transformers.image_processing_utils import BaseImageProcessor, get_size_dict
+from transformers.image_transforms import (
+ PaddingMode,
+ center_to_corners_format,
+ corners_to_center_format,
+ id_to_rgb,
+ normalize,
+ pad,
+ rescale,
+ resize,
+ rgb_to_id,
+ to_channel_dimension_format,
+)
+from transformers.image_utils import (
+ IMAGENET_DEFAULT_MEAN,
+ IMAGENET_DEFAULT_STD,
+ ChannelDimension,
+ ImageInput,
+ PILImageResampling,
+ get_image_size,
+ infer_channel_dimension_format,
+ is_batched,
+ to_numpy_array,
+ valid_coco_detection_annotations,
+ valid_coco_panoptic_annotations,
+ valid_images,
+)
+from transformers.utils import (
+ is_flax_available,
+ is_jax_tensor,
+ is_scipy_available,
+ is_tf_available,
+ is_tf_tensor,
+ is_torch_available,
+ is_torch_tensor,
+ is_vision_available,
+)
+from transformers.utils.generic import ExplicitEnum, TensorType
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+
+if is_vision_available():
+ import PIL
+
+
+if is_scipy_available():
+ import scipy.special
+ import scipy.stats
+
+
+class AnnotionFormat(ExplicitEnum):
+ COCO_DETECTION = "coco_detection"
+ COCO_PANOPTIC = "coco_panoptic"
+
+
+SUPPORTED_ANNOTATION_FORMATS = (AnnotionFormat.COCO_DETECTION, AnnotionFormat.COCO_PANOPTIC)
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_size_with_aspect_ratio
+def get_size_with_aspect_ratio(image_size, size, max_size=None) -> Tuple[int, int]:
+ """
+ Computes the output image size given the input image size and the desired output size.
+
+ Args:
+ image_size (`Tuple[int, int]`):
+ The input image size.
+ size (`int`):
+ The desired output size.
+ max_size (`int`, *optional*):
+ The maximum allowed output size.
+ """
+ height, width = image_size
+ if max_size is not None:
+ min_original_size = float(min((height, width)))
+ max_original_size = float(max((height, width)))
+ if max_original_size / min_original_size * size > max_size:
+ size = int(round(max_size * min_original_size / max_original_size))
+
+ if (height <= width and height == size) or (width <= height and width == size):
+ return height, width
+
+ if width < height:
+ ow = size
+ oh = int(size * height / width)
+ else:
+ oh = size
+ ow = int(size * width / height)
+ return (oh, ow)
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_resize_output_image_size
+def get_resize_output_image_size(
+ input_image: np.ndarray, size: Union[int, Tuple[int, int], List[int]], max_size: Optional[int] = None
+) -> Tuple[int, int]:
+ """
+ Computes the output image size given the input image size and the desired output size. If the desired output size
+ is a tuple or list, the output image size is returned as is. If the desired output size is an integer, the output
+ image size is computed by keeping the aspect ratio of the input image size.
+
+ Args:
+ image_size (`Tuple[int, int]`):
+ The input image size.
+ size (`int`):
+ The desired output size.
+ max_size (`int`, *optional*):
+ The maximum allowed output size.
+ """
+ image_size = get_image_size(input_image)
+ if isinstance(size, (list, tuple)):
+ return size
+
+ return get_size_with_aspect_ratio(image_size, size, max_size)
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_numpy_to_framework_fn
+def get_numpy_to_framework_fn(arr) -> Callable:
+ """
+ Returns a function that converts a numpy array to the framework of the input array.
+
+ Args:
+ arr (`np.ndarray`): The array to convert.
+ """
+ if isinstance(arr, np.ndarray):
+ return np.array
+ if is_tf_available() and is_tf_tensor(arr):
+ import tensorflow as tf
+
+ return tf.convert_to_tensor
+ if is_torch_available() and is_torch_tensor(arr):
+ import torch
+
+ return torch.tensor
+ if is_flax_available() and is_jax_tensor(arr):
+ import jax.numpy as jnp
+
+ return jnp.array
+ raise ValueError(f"Cannot convert arrays of type {type(arr)}")
+
+
+# Copied from transformers.models.detr.image_processing_detr.safe_squeeze
+def safe_squeeze(arr: np.ndarray, axis: Optional[int] = None) -> np.ndarray:
+ """
+ Squeezes an array, but only if the axis specified has dim 1.
+ """
+ if axis is None:
+ return arr.squeeze()
+
+ try:
+ return arr.squeeze(axis=axis)
+ except ValueError:
+ return arr
+
+
+# Copied from transformers.models.detr.image_processing_detr.normalize_annotation
+def normalize_annotation(annotation: Dict, image_size: Tuple[int, int]) -> Dict:
+ image_height, image_width = image_size
+ norm_annotation = {}
+ for key, value in annotation.items():
+ if key == "boxes":
+ boxes = value
+ boxes = corners_to_center_format(boxes)
+ boxes /= np.asarray([image_width, image_height, image_width, image_height], dtype=np.float32)
+ norm_annotation[key] = boxes
+ else:
+ norm_annotation[key] = value
+ return norm_annotation
+
+
+# Copied from transformers.models.detr.image_processing_detr.max_across_indices
+def max_across_indices(values: Iterable[Any]) -> List[Any]:
+ """
+ Return the maximum value across all indices of an iterable of values.
+ """
+ return [max(values_i) for values_i in zip(*values)]
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_max_height_width
+def get_max_height_width(images: List[np.ndarray]) -> List[int]:
+ """
+ Get the maximum height and width across all images in a batch.
+ """
+ input_channel_dimension = infer_channel_dimension_format(images[0])
+
+ if input_channel_dimension == ChannelDimension.FIRST:
+ _, max_height, max_width = max_across_indices([img.shape for img in images])
+ elif input_channel_dimension == ChannelDimension.LAST:
+ max_height, max_width, _ = max_across_indices([img.shape for img in images])
+ else:
+ raise ValueError(f"Invalid channel dimension format: {input_channel_dimension}")
+ return (max_height, max_width)
+
+
+# Copied from transformers.models.detr.image_processing_detr.make_pixel_mask
+def make_pixel_mask(image: np.ndarray, output_size: Tuple[int, int]) -> np.ndarray:
+ """
+ Make a pixel mask for the image, where 1 indicates a valid pixel and 0 indicates padding.
+
+ Args:
+ image (`np.ndarray`):
+ Image to make the pixel mask for.
+ output_size (`Tuple[int, int]`):
+ Output size of the mask.
+ """
+ input_height, input_width = get_image_size(image)
+ mask = np.zeros(output_size, dtype=np.int64)
+ mask[:input_height, :input_width] = 1
+ return mask
+
+
+# Copied from transformers.models.detr.image_processing_detr.convert_coco_poly_to_mask
+def convert_coco_poly_to_mask(segmentations, height: int, width: int) -> np.ndarray:
+ """
+ Convert a COCO polygon annotation to a mask.
+
+ Args:
+ segmentations (`List[List[float]]`):
+ List of polygons, each polygon represented by a list of x-y coordinates.
+ height (`int`):
+ Height of the mask.
+ width (`int`):
+ Width of the mask.
+ """
+ try:
+ from pycocotools import mask as coco_mask
+ except ImportError:
+ raise ImportError("Pycocotools is not installed in your environment.")
+
+ masks = []
+ for polygons in segmentations:
+ rles = coco_mask.frPyObjects(polygons, height, width)
+ mask = coco_mask.decode(rles)
+ if len(mask.shape) < 3:
+ mask = mask[..., None]
+ mask = np.asarray(mask, dtype=np.uint8)
+ mask = np.any(mask, axis=2)
+ masks.append(mask)
+ if masks:
+ masks = np.stack(masks, axis=0)
+ else:
+ masks = np.zeros((0, height, width), dtype=np.uint8)
+
+ return masks
+
+
+# Copied from transformers.models.detr.image_processing_detr.prepare_coco_detection_annotation with DETR->ConditionalDetr
+def prepare_coco_detection_annotation(image, target, return_segmentation_masks: bool = False):
+ """
+ Convert the target in COCO format into the format expected by ConditionalDetr.
+ """
+ image_height, image_width = get_image_size(image)
+
+ image_id = target["image_id"]
+ image_id = np.asarray([image_id], dtype=np.int64)
+
+ # Get all COCO annotations for the given image.
+ annotations = target["annotations"]
+ annotations = [obj for obj in annotations if "iscrowd" not in obj or obj["iscrowd"] == 0]
+
+ classes = [obj["category_id"] for obj in annotations]
+ classes = np.asarray(classes, dtype=np.int64)
+
+ # for conversion to coco api
+ area = np.asarray([obj["area"] for obj in annotations], dtype=np.float32)
+ iscrowd = np.asarray([obj["iscrowd"] if "iscrowd" in obj else 0 for obj in annotations], dtype=np.int64)
+
+ boxes = [obj["bbox"] for obj in annotations]
+ # guard against no boxes via resizing
+ boxes = np.asarray(boxes, dtype=np.float32).reshape(-1, 4)
+ boxes[:, 2:] += boxes[:, :2]
+ boxes[:, 0::2] = boxes[:, 0::2].clip(min=0, max=image_width)
+ boxes[:, 1::2] = boxes[:, 1::2].clip(min=0, max=image_height)
+
+ keep = (boxes[:, 3] > boxes[:, 1]) & (boxes[:, 2] > boxes[:, 0])
+
+ new_target = {}
+ new_target["image_id"] = image_id
+ new_target["class_labels"] = classes[keep]
+ new_target["boxes"] = boxes[keep]
+ new_target["area"] = area[keep]
+ new_target["iscrowd"] = iscrowd[keep]
+ new_target["orig_size"] = np.asarray([int(image_height), int(image_width)], dtype=np.int64)
+
+ if annotations and "keypoints" in annotations[0]:
+ keypoints = [obj["keypoints"] for obj in annotations]
+ keypoints = np.asarray(keypoints, dtype=np.float32)
+ num_keypoints = keypoints.shape[0]
+ keypoints = keypoints.reshape((-1, 3)) if num_keypoints else keypoints
+ new_target["keypoints"] = keypoints[keep]
+
+ if return_segmentation_masks:
+ segmentation_masks = [obj["segmentation"] for obj in annotations]
+ masks = convert_coco_poly_to_mask(segmentation_masks, image_height, image_width)
+ new_target["masks"] = masks[keep]
+
+ return new_target
+
+
+# Copied from transformers.models.detr.image_processing_detr.masks_to_boxes
+def masks_to_boxes(masks: np.ndarray) -> np.ndarray:
+ """
+ Compute the bounding boxes around the provided panoptic segmentation masks.
+
+ Args:
+ masks: masks in format `[number_masks, height, width]` where N is the number of masks
+
+ Returns:
+ boxes: bounding boxes in format `[number_masks, 4]` in xyxy format
+ """
+ if masks.size == 0:
+ return np.zeros((0, 4))
+
+ h, w = masks.shape[-2:]
+ y = np.arange(0, h, dtype=np.float32)
+ x = np.arange(0, w, dtype=np.float32)
+ # see https://github.com/pytorch/pytorch/issues/50276
+ y, x = np.meshgrid(y, x, indexing="ij")
+
+ x_mask = masks * np.expand_dims(x, axis=0)
+ x_max = x_mask.reshape(x_mask.shape[0], -1).max(-1)
+ x = np.ma.array(x_mask, mask=~(np.array(masks, dtype=bool)))
+ x_min = x.filled(fill_value=1e8)
+ x_min = x_min.reshape(x_min.shape[0], -1).min(-1)
+
+ y_mask = masks * np.expand_dims(y, axis=0)
+ y_max = y_mask.reshape(x_mask.shape[0], -1).max(-1)
+ y = np.ma.array(y_mask, mask=~(np.array(masks, dtype=bool)))
+ y_min = y.filled(fill_value=1e8)
+ y_min = y_min.reshape(y_min.shape[0], -1).min(-1)
+
+ return np.stack([x_min, y_min, x_max, y_max], 1)
+
+
+# Copied from transformers.models.detr.image_processing_detr.prepare_coco_panoptic_annotation with DETR->ConditionalDetr
+def prepare_coco_panoptic_annotation(
+ image: np.ndarray, target: Dict, masks_path: Union[str, pathlib.Path], return_masks: bool = True
+) -> Dict:
+ """
+ Prepare a coco panoptic annotation for ConditionalDetr.
+ """
+ image_height, image_width = get_image_size(image)
+ annotation_path = pathlib.Path(masks_path) / target["file_name"]
+
+ new_target = {}
+ new_target["image_id"] = np.asarray([target["image_id"] if "image_id" in target else target["id"]], dtype=np.int64)
+ new_target["size"] = np.asarray([image_height, image_width], dtype=np.int64)
+ new_target["orig_size"] = np.asarray([image_height, image_width], dtype=np.int64)
+
+ if "segments_info" in target:
+ masks = np.asarray(PIL.Image.open(annotation_path), dtype=np.uint32)
+ masks = rgb_to_id(masks)
+
+ ids = np.array([segment_info["id"] for segment_info in target["segments_info"]])
+ masks = masks == ids[:, None, None]
+ masks = masks.astype(np.uint8)
+ if return_masks:
+ new_target["masks"] = masks
+ new_target["boxes"] = masks_to_boxes(masks)
+ new_target["class_labels"] = np.array(
+ [segment_info["category_id"] for segment_info in target["segments_info"]], dtype=np.int64
+ )
+ new_target["iscrowd"] = np.asarray(
+ [segment_info["iscrowd"] for segment_info in target["segments_info"]], dtype=np.int64
+ )
+ new_target["area"] = np.asarray(
+ [segment_info["area"] for segment_info in target["segments_info"]], dtype=np.float32
+ )
+
+ return new_target
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_segmentation_image
+def get_segmentation_image(
+ masks: np.ndarray, input_size: Tuple, target_size: Tuple, stuff_equiv_classes, deduplicate=False
+):
+ h, w = input_size
+ final_h, final_w = target_size
+
+ m_id = scipy.special.softmax(masks.transpose(0, 1), -1)
+
+ if m_id.shape[-1] == 0:
+ # We didn't detect any mask :(
+ m_id = np.zeros((h, w), dtype=np.int64)
+ else:
+ m_id = m_id.argmax(-1).reshape(h, w)
+
+ if deduplicate:
+ # Merge the masks corresponding to the same stuff class
+ for equiv in stuff_equiv_classes.values():
+ for eq_id in equiv:
+ m_id[m_id == eq_id] = equiv[0]
+
+ seg_img = id_to_rgb(m_id)
+ seg_img = resize(seg_img, (final_w, final_h), resample=PILImageResampling.NEAREST)
+ return seg_img
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_mask_area
+def get_mask_area(seg_img: np.ndarray, target_size: Tuple[int, int], n_classes: int) -> np.ndarray:
+ final_h, final_w = target_size
+ np_seg_img = seg_img.astype(np.uint8)
+ np_seg_img = np_seg_img.reshape(final_h, final_w, 3)
+ m_id = rgb_to_id(np_seg_img)
+ area = [(m_id == i).sum() for i in range(n_classes)]
+ return area
+
+
+# Copied from transformers.models.detr.image_processing_detr.score_labels_from_class_probabilities
+def score_labels_from_class_probabilities(logits: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
+ probs = scipy.special.softmax(logits, axis=-1)
+ labels = probs.argmax(-1, keepdims=True)
+ scores = np.take_along_axis(probs, labels, axis=-1)
+ scores, labels = scores.squeeze(-1), labels.squeeze(-1)
+ return scores, labels
+
+
+# Copied from transformers.models.detr.image_processing_detr.post_process_panoptic_sample with DetrForSegmentation->ConditionalDetrForSegmentation
+def post_process_panoptic_sample(
+ out_logits: np.ndarray,
+ masks: np.ndarray,
+ boxes: np.ndarray,
+ processed_size: Tuple[int, int],
+ target_size: Tuple[int, int],
+ is_thing_map: Dict,
+ threshold=0.85,
+) -> Dict:
+ """
+ Converts the output of [`ConditionalDetrForSegmentation`] into panoptic segmentation predictions for a single
+ sample.
+
+ Args:
+ out_logits (`torch.Tensor`):
+ The logits for this sample.
+ masks (`torch.Tensor`):
+ The predicted segmentation masks for this sample.
+ boxes (`torch.Tensor`):
+ The prediced bounding boxes for this sample. The boxes are in the normalized format `(center_x, center_y,
+ width, height)` and values between `[0, 1]`, relative to the size the image (disregarding padding).
+ processed_size (`Tuple[int, int]`):
+ The processed size of the image `(height, width)`, as returned by the preprocessing step i.e. the size
+ after data augmentation but before batching.
+ target_size (`Tuple[int, int]`):
+ The target size of the image, `(height, width)` corresponding to the requested final size of the
+ prediction.
+ is_thing_map (`Dict`):
+ A dictionary mapping class indices to a boolean value indicating whether the class is a thing or not.
+ threshold (`float`, *optional*, defaults to 0.85):
+ The threshold used to binarize the segmentation masks.
+ """
+ # we filter empty queries and detection below threshold
+ scores, labels = score_labels_from_class_probabilities(out_logits)
+ keep = (labels != out_logits.shape[-1] - 1) & (scores > threshold)
+
+ cur_scores = scores[keep]
+ cur_classes = labels[keep]
+ cur_boxes = center_to_corners_format(boxes[keep])
+
+ if len(cur_boxes) != len(cur_classes):
+ raise ValueError("Not as many boxes as there are classes")
+
+ cur_masks = masks[keep]
+ cur_masks = resize(cur_masks[:, None], processed_size, resample=PILImageResampling.BILINEAR)
+ cur_masks = safe_squeeze(cur_masks, 1)
+ b, h, w = cur_masks.shape
+
+ # It may be that we have several predicted masks for the same stuff class.
+ # In the following, we track the list of masks ids for each stuff class (they are merged later on)
+ cur_masks = cur_masks.reshape(b, -1)
+ stuff_equiv_classes = defaultdict(list)
+ for k, label in enumerate(cur_classes):
+ if not is_thing_map[label]:
+ stuff_equiv_classes[label].append(k)
+
+ seg_img = get_segmentation_image(cur_masks, processed_size, target_size, stuff_equiv_classes, deduplicate=True)
+ area = get_mask_area(cur_masks, processed_size, n_classes=len(cur_scores))
+
+ # We filter out any mask that is too small
+ if cur_classes.size() > 0:
+ # We know filter empty masks as long as we find some
+ filtered_small = np.array([a <= 4 for a in area], dtype=bool)
+ while filtered_small.any():
+ cur_masks = cur_masks[~filtered_small]
+ cur_scores = cur_scores[~filtered_small]
+ cur_classes = cur_classes[~filtered_small]
+ seg_img = get_segmentation_image(cur_masks, (h, w), target_size, stuff_equiv_classes, deduplicate=True)
+ area = get_mask_area(seg_img, target_size, n_classes=len(cur_scores))
+ filtered_small = np.array([a <= 4 for a in area], dtype=bool)
+ else:
+ cur_classes = np.ones((1, 1), dtype=np.int64)
+
+ segments_info = [
+ {"id": i, "isthing": is_thing_map[cat], "category_id": int(cat), "area": a}
+ for i, (cat, a) in enumerate(zip(cur_classes, area))
+ ]
+ del cur_classes
+
+ with io.BytesIO() as out:
+ PIL.Image.fromarray(seg_img).save(out, format="PNG")
+ predictions = {"png_string": out.getvalue(), "segments_info": segments_info}
+
+ return predictions
+
+
+# Copied from transformers.models.detr.image_processing_detr.resize_annotation
+def resize_annotation(
+ annotation: Dict[str, Any],
+ orig_size: Tuple[int, int],
+ target_size: Tuple[int, int],
+ threshold: float = 0.5,
+ resample: PILImageResampling = PILImageResampling.NEAREST,
+):
+ """
+ Resizes an annotation to a target size.
+
+ Args:
+ annotation (`Dict[str, Any]`):
+ The annotation dictionary.
+ orig_size (`Tuple[int, int]`):
+ The original size of the input image.
+ target_size (`Tuple[int, int]`):
+ The target size of the image, as returned by the preprocessing `resize` step.
+ threshold (`float`, *optional*, defaults to 0.5):
+ The threshold used to binarize the segmentation masks.
+ resample (`PILImageResampling`, defaults to `PILImageResampling.NEAREST`):
+ The resampling filter to use when resizing the masks.
+ """
+ ratios = tuple(float(s) / float(s_orig) for s, s_orig in zip(target_size, orig_size))
+ ratio_height, ratio_width = ratios
+
+ new_annotation = {}
+ new_annotation["size"] = target_size
+
+ for key, value in annotation.items():
+ if key == "boxes":
+ boxes = value
+ scaled_boxes = boxes * np.asarray([ratio_width, ratio_height, ratio_width, ratio_height], dtype=np.float32)
+ new_annotation["boxes"] = scaled_boxes
+ elif key == "area":
+ area = value
+ scaled_area = area * (ratio_width * ratio_height)
+ new_annotation["area"] = scaled_area
+ elif key == "masks":
+ masks = value[:, None]
+ masks = np.array([resize(mask, target_size, resample=resample) for mask in masks])
+ masks = masks.astype(np.float32)
+ masks = masks[:, 0] > threshold
+ new_annotation["masks"] = masks
+ elif key == "size":
+ new_annotation["size"] = target_size
+ else:
+ new_annotation[key] = value
+
+ return new_annotation
+
+
+# Copied from transformers.models.detr.image_processing_detr.binary_mask_to_rle
+def binary_mask_to_rle(mask):
+ """
+ Converts given binary mask of shape `(height, width)` to the run-length encoding (RLE) format.
+
+ Args:
+ mask (`torch.Tensor` or `numpy.array`):
+ A binary mask tensor of shape `(height, width)` where 0 denotes background and 1 denotes the target
+ segment_id or class_id.
+ Returns:
+ `List`: Run-length encoded list of the binary mask. Refer to COCO API for more information about the RLE
+ format.
+ """
+ if is_torch_tensor(mask):
+ mask = mask.numpy()
+
+ pixels = mask.flatten()
+ pixels = np.concatenate([[0], pixels, [0]])
+ runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
+ runs[1::2] -= runs[::2]
+ return [x for x in runs]
+
+
+# Copied from transformers.models.detr.image_processing_detr.convert_segmentation_to_rle
+def convert_segmentation_to_rle(segmentation):
+ """
+ Converts given segmentation map of shape `(height, width)` to the run-length encoding (RLE) format.
+
+ Args:
+ segmentation (`torch.Tensor` or `numpy.array`):
+ A segmentation map of shape `(height, width)` where each value denotes a segment or class id.
+ Returns:
+ `List[List]`: A list of lists, where each list is the run-length encoding of a segment / class id.
+ """
+ segment_ids = torch.unique(segmentation)
+
+ run_length_encodings = []
+ for idx in segment_ids:
+ mask = torch.where(segmentation == idx, 1, 0)
+ rle = binary_mask_to_rle(mask)
+ run_length_encodings.append(rle)
+
+ return run_length_encodings
+
+
+# Copied from transformers.models.detr.image_processing_detr.remove_low_and_no_objects
+def remove_low_and_no_objects(masks, scores, labels, object_mask_threshold, num_labels):
+ """
+ Binarize the given masks using `object_mask_threshold`, it returns the associated values of `masks`, `scores` and
+ `labels`.
+
+ Args:
+ masks (`torch.Tensor`):
+ A tensor of shape `(num_queries, height, width)`.
+ scores (`torch.Tensor`):
+ A tensor of shape `(num_queries)`.
+ labels (`torch.Tensor`):
+ A tensor of shape `(num_queries)`.
+ object_mask_threshold (`float`):
+ A number between 0 and 1 used to binarize the masks.
+ Raises:
+ `ValueError`: Raised when the first dimension doesn't match in all input tensors.
+ Returns:
+ `Tuple[`torch.Tensor`, `torch.Tensor`, `torch.Tensor`]`: The `masks`, `scores` and `labels` without the region
+ < `object_mask_threshold`.
+ """
+ if not (masks.shape[0] == scores.shape[0] == labels.shape[0]):
+ raise ValueError("mask, scores and labels must have the same shape!")
+
+ to_keep = labels.ne(num_labels) & (scores > object_mask_threshold)
+
+ return masks[to_keep], scores[to_keep], labels[to_keep]
+
+
+# Copied from transformers.models.detr.image_processing_detr.check_segment_validity
+def check_segment_validity(mask_labels, mask_probs, k, mask_threshold=0.5, overlap_mask_area_threshold=0.8):
+ # Get the mask associated with the k class
+ mask_k = mask_labels == k
+ mask_k_area = mask_k.sum()
+
+ # Compute the area of all the stuff in query k
+ original_area = (mask_probs[k] >= mask_threshold).sum()
+ mask_exists = mask_k_area > 0 and original_area > 0
+
+ # Eliminate disconnected tiny segments
+ if mask_exists:
+ area_ratio = mask_k_area / original_area
+ if not area_ratio.item() > overlap_mask_area_threshold:
+ mask_exists = False
+
+ return mask_exists, mask_k
+
+
+# Copied from transformers.models.detr.image_processing_detr.compute_segments
+def compute_segments(
+ mask_probs,
+ pred_scores,
+ pred_labels,
+ mask_threshold: float = 0.5,
+ overlap_mask_area_threshold: float = 0.8,
+ label_ids_to_fuse: Optional[Set[int]] = None,
+ target_size: Tuple[int, int] = None,
+):
+ height = mask_probs.shape[1] if target_size is None else target_size[0]
+ width = mask_probs.shape[2] if target_size is None else target_size[1]
+
+ segmentation = torch.zeros((height, width), dtype=torch.int32, device=mask_probs.device)
+ segments: List[Dict] = []
+
+ if target_size is not None:
+ mask_probs = nn.functional.interpolate(
+ mask_probs.unsqueeze(0), size=target_size, mode="bilinear", align_corners=False
+ )[0]
+
+ current_segment_id = 0
+
+ # Weigh each mask by its prediction score
+ mask_probs *= pred_scores.view(-1, 1, 1)
+ mask_labels = mask_probs.argmax(0) # [height, width]
+
+ # Keep track of instances of each class
+ stuff_memory_list: Dict[str, int] = {}
+ for k in range(pred_labels.shape[0]):
+ pred_class = pred_labels[k].item()
+ should_fuse = pred_class in label_ids_to_fuse
+
+ # Check if mask exists and large enough to be a segment
+ mask_exists, mask_k = check_segment_validity(
+ mask_labels, mask_probs, k, mask_threshold, overlap_mask_area_threshold
+ )
+
+ if mask_exists:
+ if pred_class in stuff_memory_list:
+ current_segment_id = stuff_memory_list[pred_class]
+ else:
+ current_segment_id += 1
+
+ # Add current object segment to final segmentation map
+ segmentation[mask_k] = current_segment_id
+ segment_score = round(pred_scores[k].item(), 6)
+ segments.append(
+ {
+ "id": current_segment_id,
+ "label_id": pred_class,
+ "was_fused": should_fuse,
+ "score": segment_score,
+ }
+ )
+ if should_fuse:
+ stuff_memory_list[pred_class] = current_segment_id
+
+ return segmentation, segments
+
+
+class ConditionalDetrImageProcessor(BaseImageProcessor):
+ r"""
+ Constructs a Conditional Detr image processor.
+
+ Args:
+ format (`str`, *optional*, defaults to `"coco_detection"`):
+ Data format of the annotations. One of "coco_detection" or "coco_panoptic".
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Controls whether to resize the image's (height, width) dimensions to the specified `size`. Can be
+ overridden by the `do_resize` parameter in the `preprocess` method.
+ size (`Dict[str, int]` *optional*, defaults to `{"shortest_edge": 800, "longest_edge": 1333}`):
+ Size of the image's (height, width) dimensions after resizing. Can be overridden by the `size` parameter in
+ the `preprocess` method.
+ resample (`PILImageResampling`, *optional*, defaults to `PILImageResampling.BILINEAR`):
+ Resampling filter to use if resizing the image.
+ do_rescale (`bool`, *optional*, defaults to `True`):
+ Controls whether to rescale the image by the specified scale `rescale_factor`. Can be overridden by the
+ `do_rescale` parameter in the `preprocess` method.
+ rescale_factor (`int` or `float`, *optional*, defaults to `1/255`):
+ Scale factor to use if rescaling the image. Can be overridden by the `rescale_factor` parameter in the
+ `preprocess` method.
+ do_normalize:
+ Controls whether to normalize the image. Can be overridden by the `do_normalize` parameter in the
+ `preprocess` method.
+ image_mean (`float` or `List[float]`, *optional*, defaults to `IMAGENET_DEFAULT_MEAN`):
+ Mean values to use when normalizing the image. Can be a single value or a list of values, one for each
+ channel. Can be overridden by the `image_mean` parameter in the `preprocess` method.
+ image_std (`float` or `List[float]`, *optional*, defaults to `IMAGENET_DEFAULT_STD`):
+ Standard deviation values to use when normalizing the image. Can be a single value or a list of values, one
+ for each channel. Can be overridden by the `image_std` parameter in the `preprocess` method.
+ do_pad (`bool`, *optional*, defaults to `True`):
+ Controls whether to pad the image to the largest image in a batch and create a pixel mask. Can be
+ overridden by the `do_pad` parameter in the `preprocess` method.
+ """
+
+ model_input_names = ["pixel_values", "pixel_mask"]
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.__init__
+ def __init__(
+ self,
+ format: Union[str, AnnotionFormat] = AnnotionFormat.COCO_DETECTION,
+ do_resize: bool = True,
+ size: Dict[str, int] = None,
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ do_rescale: bool = True,
+ rescale_factor: Union[int, float] = 1 / 255,
+ do_normalize: bool = True,
+ image_mean: Union[float, List[float]] = None,
+ image_std: Union[float, List[float]] = None,
+ do_pad: bool = True,
+ **kwargs
+ ) -> None:
+ if "pad_and_return_pixel_mask" in kwargs:
+ do_pad = kwargs.pop("pad_and_return_pixel_mask")
+
+ if "max_size" in kwargs:
+ warnings.warn(
+ "The `max_size` parameter is deprecated and will be removed in v4.26. "
+ "Please specify in `size['longest_edge'] instead`.",
+ FutureWarning,
+ )
+ max_size = kwargs.pop("max_size")
+ else:
+ max_size = None if size is None else 1333
+
+ size = size if size is not None else {"shortest_edge": 800, "longest_edge": 1333}
+ size = get_size_dict(size, max_size=max_size, default_to_square=False)
+
+ super().__init__(**kwargs)
+ self.format = format
+ self.do_resize = do_resize
+ self.size = size
+ self.resample = resample
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean if image_mean is not None else IMAGENET_DEFAULT_MEAN
+ self.image_std = image_std if image_std is not None else IMAGENET_DEFAULT_STD
+ self.do_pad = do_pad
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare_annotation with DETR->ConditionalDetr
+ def prepare_annotation(
+ self,
+ image: np.ndarray,
+ target: Dict,
+ format: Optional[AnnotionFormat] = None,
+ return_segmentation_masks: bool = None,
+ masks_path: Optional[Union[str, pathlib.Path]] = None,
+ ) -> Dict:
+ """
+ Prepare an annotation for feeding into ConditionalDetr model.
+ """
+ format = format if format is not None else self.format
+
+ if format == AnnotionFormat.COCO_DETECTION:
+ return_segmentation_masks = False if return_segmentation_masks is None else return_segmentation_masks
+ target = prepare_coco_detection_annotation(image, target, return_segmentation_masks)
+ elif format == AnnotionFormat.COCO_PANOPTIC:
+ return_segmentation_masks = True if return_segmentation_masks is None else return_segmentation_masks
+ target = prepare_coco_panoptic_annotation(
+ image, target, masks_path=masks_path, return_masks=return_segmentation_masks
+ )
+ else:
+ raise ValueError(f"Format {format} is not supported.")
+ return target
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare
+ def prepare(self, image, target, return_segmentation_masks=False, masks_path=None):
+ warnings.warn(
+ "The `prepare` method is deprecated and will be removed in a future version. "
+ "Please use `prepare_annotation` instead. Note: the `prepare_annotation` method "
+ "does not return the image anymore.",
+ )
+ target = self.prepare_annotation(image, target, return_segmentation_masks, masks_path, self.format)
+ return image, target
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.convert_coco_poly_to_mask
+ def convert_coco_poly_to_mask(self, *args, **kwargs):
+ warnings.warn("The `convert_coco_poly_to_mask` method is deprecated and will be removed in a future version. ")
+ return convert_coco_poly_to_mask(*args, **kwargs)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare_coco_detection with DETR->ConditionalDetr
+ def prepare_coco_detection(self, *args, **kwargs):
+ warnings.warn("The `prepare_coco_detection` method is deprecated and will be removed in a future version. ")
+ return prepare_coco_detection_annotation(*args, **kwargs)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare_coco_panoptic
+ def prepare_coco_panoptic(self, *args, **kwargs):
+ warnings.warn("The `prepare_coco_panoptic` method is deprecated and will be removed in a future version. ")
+ return prepare_coco_panoptic_annotation(*args, **kwargs)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.resize
+ def resize(
+ self,
+ image: np.ndarray,
+ size: Dict[str, int],
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ data_format: Optional[ChannelDimension] = None,
+ **kwargs
+ ) -> np.ndarray:
+ """
+ Resize the image to the given size. Size can be `min_size` (scalar) or `(height, width)` tuple. If size is an
+ int, smaller edge of the image will be matched to this number.
+ """
+ if "max_size" in kwargs:
+ warnings.warn(
+ "The `max_size` parameter is deprecated and will be removed in v4.26. "
+ "Please specify in `size['longest_edge'] instead`.",
+ FutureWarning,
+ )
+ max_size = kwargs.pop("max_size")
+ else:
+ max_size = None
+ size = get_size_dict(size, max_size=max_size, default_to_square=False)
+ if "shortest_edge" in size and "longest_edge" in size:
+ size = get_resize_output_image_size(image, size["shortest_edge"], size["longest_edge"])
+ elif "height" in size and "width" in size:
+ size = (size["height"], size["width"])
+ else:
+ raise ValueError(
+ "Size must contain 'height' and 'width' keys or 'shortest_edge' and 'longest_edge' keys. Got"
+ f" {size.keys()}."
+ )
+ image = resize(image, size=size, resample=resample, data_format=data_format)
+ return image
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.resize_annotation
+ def resize_annotation(
+ self,
+ annotation,
+ orig_size,
+ size,
+ resample: PILImageResampling = PILImageResampling.NEAREST,
+ ) -> Dict:
+ """
+ Resize the annotation to match the resized image. If size is an int, smaller edge of the mask will be matched
+ to this number.
+ """
+ return resize_annotation(annotation, orig_size=orig_size, target_size=size, resample=resample)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.rescale
+ def rescale(
+ self, image: np.ndarray, rescale_factor: Union[float, int], data_format: Optional[ChannelDimension] = None
+ ) -> np.ndarray:
+ """
+ Rescale the image by the given factor.
+ """
+ return rescale(image, rescale_factor, data_format=data_format)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.normalize
+ def normalize(
+ self,
+ image: np.ndarray,
+ mean: Union[float, Iterable[float]],
+ std: Union[float, Iterable[float]],
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Normalize the image with the given mean and standard deviation.
+ """
+ return normalize(image, mean=mean, std=std, data_format=data_format)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.normalize_annotation
+ def normalize_annotation(self, annotation: Dict, image_size: Tuple[int, int]) -> Dict:
+ """
+ Normalize the boxes in the annotation from `[top_left_x, top_left_y, bottom_right_x, bottom_right_y]` to
+ `[center_x, center_y, width, height]` format.
+ """
+ return normalize_annotation(annotation, image_size=image_size)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.pad_and_create_pixel_mask
+ def pad_and_create_pixel_mask(
+ self,
+ pixel_values_list: List[ImageInput],
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ data_format: Optional[ChannelDimension] = None,
+ ) -> BatchFeature:
+ """
+ Pads a batch of images with zeros to the size of largest height and width in the batch and returns their
+ corresponding pixel mask.
+
+ Args:
+ images (`List[np.ndarray]`):
+ Batch of images to pad.
+ return_tensors (`str` or `TensorType`, *optional*):
+ The type of tensors to return. Can be one of:
+ - Unset: Return a list of `np.ndarray`.
+ - `TensorType.TENSORFLOW` or `'tf'`: Return a batch of type `tf.Tensor`.
+ - `TensorType.PYTORCH` or `'pt'`: Return a batch of type `torch.Tensor`.
+ - `TensorType.NUMPY` or `'np'`: Return a batch of type `np.ndarray`.
+ - `TensorType.JAX` or `'jax'`: Return a batch of type `jax.numpy.ndarray`.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be the same as the input image.
+ """
+ warnings.warn(
+ "This method is deprecated and will be removed in v4.27.0. Please use pad instead.", FutureWarning
+ )
+ # pad expects a list of np.ndarray, but the previous feature extractors expected torch tensors
+ images = [to_numpy_array(image) for image in pixel_values_list]
+ return self.pad(
+ images=images,
+ return_pixel_mask=True,
+ return_tensors=return_tensors,
+ data_format=data_format,
+ )
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor._pad_image
+ def _pad_image(
+ self,
+ image: np.ndarray,
+ output_size: Tuple[int, int],
+ constant_values: Union[float, Iterable[float]] = 0,
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Pad an image with zeros to the given size.
+ """
+ input_height, input_width = get_image_size(image)
+ output_height, output_width = output_size
+
+ pad_bottom = output_height - input_height
+ pad_right = output_width - input_width
+ padding = ((0, pad_bottom), (0, pad_right))
+ padded_image = pad(
+ image, padding, mode=PaddingMode.CONSTANT, constant_values=constant_values, data_format=data_format
+ )
+ return padded_image
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.pad
+ def pad(
+ self,
+ images: List[np.ndarray],
+ constant_values: Union[float, Iterable[float]] = 0,
+ return_pixel_mask: bool = True,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Pads a batch of images to the bottom and right of the image with zeros to the size of largest height and width
+ in the batch and optionally returns their corresponding pixel mask.
+
+ Args:
+ image (`np.ndarray`):
+ Image to pad.
+ constant_values (`float` or `Iterable[float]`, *optional*):
+ The value to use for the padding if `mode` is `"constant"`.
+ return_pixel_mask (`bool`, *optional*, defaults to `True`):
+ Whether to return a pixel mask.
+ input_channel_dimension (`ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be inferred from the input image.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be the same as the input image.
+ """
+ pad_size = get_max_height_width(images)
+
+ padded_images = [
+ self._pad_image(image, pad_size, constant_values=constant_values, data_format=data_format)
+ for image in images
+ ]
+ data = {"pixel_values": padded_images}
+
+ if return_pixel_mask:
+ masks = [make_pixel_mask(image=image, output_size=pad_size) for image in images]
+ data["pixel_mask"] = masks
+
+ return BatchFeature(data=data, tensor_type=return_tensors)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.preprocess
+ def preprocess(
+ self,
+ images: ImageInput,
+ annotations: Optional[Union[List[Dict], List[List[Dict]]]] = None,
+ return_segmentation_masks: bool = None,
+ masks_path: Optional[Union[str, pathlib.Path]] = None,
+ do_resize: Optional[bool] = None,
+ size: Optional[Dict[str, int]] = None,
+ resample=None, # PILImageResampling
+ do_rescale: Optional[bool] = None,
+ rescale_factor: Optional[Union[int, float]] = None,
+ do_normalize: Optional[bool] = None,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ do_pad: Optional[bool] = None,
+ format: Optional[Union[str, AnnotionFormat]] = None,
+ return_tensors: Optional[Union[TensorType, str]] = None,
+ data_format: Union[str, ChannelDimension] = ChannelDimension.FIRST,
+ **kwargs
+ ) -> BatchFeature:
+ """
+ Preprocess an image or a batch of images so that it can be used by the model.
+
+ Args:
+ images (`ImageInput`):
+ Image or batch of images to preprocess.
+ annotations (`List[Dict]` or `List[List[Dict]]`, *optional*):
+ List of annotations associated with the image or batch of images. If annotionation is for object
+ detection, the annotations should be a dictionary with the following keys:
+ - "image_id" (`int`): The image id.
+ - "annotations" (`List[Dict]`): List of annotations for an image. Each annotation should be a
+ dictionary. An image can have no annotations, in which case the list should be empty.
+ If annotionation is for segmentation, the annotations should be a dictionary with the following keys:
+ - "image_id" (`int`): The image id.
+ - "segments_info" (`List[Dict]`): List of segments for an image. Each segment should be a dictionary.
+ An image can have no segments, in which case the list should be empty.
+ - "file_name" (`str`): The file name of the image.
+ return_segmentation_masks (`bool`, *optional*, defaults to self.return_segmentation_masks):
+ Whether to return segmentation masks.
+ masks_path (`str` or `pathlib.Path`, *optional*):
+ Path to the directory containing the segmentation masks.
+ do_resize (`bool`, *optional*, defaults to self.do_resize):
+ Whether to resize the image.
+ size (`Dict[str, int]`, *optional*, defaults to self.size):
+ Size of the image after resizing.
+ resample (`PILImageResampling`, *optional*, defaults to self.resample):
+ Resampling filter to use when resizing the image.
+ do_rescale (`bool`, *optional*, defaults to self.do_rescale):
+ Whether to rescale the image.
+ rescale_factor (`float`, *optional*, defaults to self.rescale_factor):
+ Rescale factor to use when rescaling the image.
+ do_normalize (`bool`, *optional*, defaults to self.do_normalize):
+ Whether to normalize the image.
+ image_mean (`float` or `List[float]`, *optional*, defaults to self.image_mean):
+ Mean to use when normalizing the image.
+ image_std (`float` or `List[float]`, *optional*, defaults to self.image_std):
+ Standard deviation to use when normalizing the image.
+ do_pad (`bool`, *optional*, defaults to self.do_pad):
+ Whether to pad the image.
+ format (`str` or `AnnotionFormat`, *optional*, defaults to self.format):
+ Format of the annotations.
+ return_tensors (`str` or `TensorType`, *optional*, defaults to self.return_tensors):
+ Type of tensors to return. If `None`, will return the list of images.
+ data_format (`str` or `ChannelDimension`, *optional*, defaults to self.data_format):
+ The channel dimension format of the image. If not provided, it will be the same as the input image.
+ """
+ if "pad_and_return_pixel_mask" in kwargs:
+ warnings.warn(
+ "The `pad_and_return_pixel_mask` argument is deprecated and will be removed in a future version, "
+ "use `do_pad` instead.",
+ FutureWarning,
+ )
+ do_pad = kwargs.pop("pad_and_return_pixel_mask")
+
+ max_size = None
+ if "max_size" in kwargs:
+ warnings.warn(
+ "The `max_size` argument is deprecated and will be removed in a future version, use"
+ " `size['longest_edge']` instead.",
+ FutureWarning,
+ )
+ size = kwargs.pop("max_size")
+
+ do_resize = self.do_resize if do_resize is None else do_resize
+ size = self.size if size is None else size
+ size = get_size_dict(size=size, max_size=max_size, default_to_square=False)
+ resample = self.resample if resample is None else resample
+ do_rescale = self.do_rescale if do_rescale is None else do_rescale
+ rescale_factor = self.rescale_factor if rescale_factor is None else rescale_factor
+ do_normalize = self.do_normalize if do_normalize is None else do_normalize
+ image_mean = self.image_mean if image_mean is None else image_mean
+ image_std = self.image_std if image_std is None else image_std
+ do_pad = self.do_pad if do_pad is None else do_pad
+ format = self.format if format is None else format
+
+ if do_resize is not None and size is None:
+ raise ValueError("Size and max_size must be specified if do_resize is True.")
+
+ if do_rescale is not None and rescale_factor is None:
+ raise ValueError("Rescale factor must be specified if do_rescale is True.")
+
+ if do_normalize is not None and (image_mean is None or image_std is None):
+ raise ValueError("Image mean and std must be specified if do_normalize is True.")
+
+ if not is_batched(images):
+ images = [images]
+ annotations = [annotations] if annotations is not None else None
+
+ if annotations is not None and len(images) != len(annotations):
+ raise ValueError(
+ f"The number of images ({len(images)}) and annotations ({len(annotations)}) do not match."
+ )
+
+ if not valid_images(images):
+ raise ValueError(
+ "Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
+ "torch.Tensor, tf.Tensor or jax.ndarray."
+ )
+
+ format = AnnotionFormat(format)
+ if annotations is not None:
+ if format == AnnotionFormat.COCO_DETECTION and not valid_coco_detection_annotations(annotations):
+ raise ValueError(
+ "Invalid COCO detection annotations. Annotations must a dict (single image) of list of dicts"
+ "(batch of images) with the following keys: `image_id` and `annotations`, with the latter "
+ "being a list of annotations in the COCO format."
+ )
+ elif format == AnnotionFormat.COCO_PANOPTIC and not valid_coco_panoptic_annotations(annotations):
+ raise ValueError(
+ "Invalid COCO panoptic annotations. Annotations must a dict (single image) of list of dicts "
+ "(batch of images) with the following keys: `image_id`, `file_name` and `segments_info`, with "
+ "the latter being a list of annotations in the COCO format."
+ )
+ elif format not in SUPPORTED_ANNOTATION_FORMATS:
+ raise ValueError(
+ f"Unsupported annotation format: {format} must be one of {SUPPORTED_ANNOTATION_FORMATS}"
+ )
+
+ if (
+ masks_path is not None
+ and format == AnnotionFormat.COCO_PANOPTIC
+ and not isinstance(masks_path, (pathlib.Path, str))
+ ):
+ raise ValueError(
+ "The path to the directory containing the mask PNG files should be provided as a"
+ f" `pathlib.Path` or string object, but is {type(masks_path)} instead."
+ )
+
+ # All transformations expect numpy arrays
+ images = [to_numpy_array(image) for image in images]
+
+ # prepare (COCO annotations as a list of Dict -> DETR target as a single Dict per image)
+ if annotations is not None:
+ prepared_images = []
+ prepared_annotations = []
+ for image, target in zip(images, annotations):
+ target = self.prepare_annotation(
+ image, target, format, return_segmentation_masks=return_segmentation_masks, masks_path=masks_path
+ )
+ prepared_images.append(image)
+ prepared_annotations.append(target)
+ images = prepared_images
+ annotations = prepared_annotations
+ del prepared_images, prepared_annotations
+
+ # transformations
+ if do_resize:
+ if annotations is not None:
+ resized_images, resized_annotations = [], []
+ for image, target in zip(images, annotations):
+ orig_size = get_image_size(image)
+ resized_image = self.resize(image, size=size, max_size=max_size, resample=resample)
+ resized_annotation = self.resize_annotation(target, orig_size, get_image_size(resized_image))
+ resized_images.append(resized_image)
+ resized_annotations.append(resized_annotation)
+ images = resized_images
+ annotations = resized_annotations
+ del resized_images, resized_annotations
+ else:
+ images = [self.resize(image, size=size, resample=resample) for image in images]
+
+ if do_rescale:
+ images = [self.rescale(image, rescale_factor) for image in images]
+
+ if do_normalize:
+ images = [self.normalize(image, image_mean, image_std) for image in images]
+ if annotations is not None:
+ annotations = [
+ self.normalize_annotation(annotation, get_image_size(image))
+ for annotation, image in zip(annotations, images)
+ ]
+
+ if do_pad:
+ # Pads images and returns their mask: {'pixel_values': ..., 'pixel_mask': ...}
+ data = self.pad(images, return_pixel_mask=True, data_format=data_format)
+ else:
+ images = [to_channel_dimension_format(image, data_format) for image in images]
+ data = {"pixel_values": images}
+
+ encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
+ if annotations is not None:
+ encoded_inputs["labels"] = [
+ BatchFeature(annotation, tensor_type=return_tensors) for annotation in annotations
+ ]
+
+ return encoded_inputs
+
+ # POSTPROCESSING METHODS - TODO: add support for other frameworks
+ def post_process(self, outputs, target_sizes):
+ """
+ Converts the output of [`ConditionalDetrForObjectDetection`] into the format expected by the COCO api. Only
+ supports PyTorch.
+
+ Args:
+ outputs ([`ConditionalDetrObjectDetectionOutput`]):
+ Raw outputs of the model.
+ target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
+ Tensor containing the size (h, w) of each image of the batch. For evaluation, this must be the original
+ image size (before any data augmentation). For visualization, this should be the image size after data
+ augment, but before padding.
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
+ in the batch as predicted by the model.
+ """
+ warnings.warn(
+ "`post_process` is deprecated and will be removed in v5 of Transformers, please use"
+ " `post_process_object_detection`",
+ FutureWarning,
+ )
+
+ out_logits, out_bbox = outputs.logits, outputs.pred_boxes
+
+ if len(out_logits) != len(target_sizes):
+ raise ValueError("Make sure that you pass in as many target sizes as the batch dimension of the logits")
+ if target_sizes.shape[1] != 2:
+ raise ValueError("Each element of target_sizes must contain the size (h, w) of each image of the batch")
+
+ prob = out_logits.sigmoid()
+ topk_values, topk_indexes = torch.topk(prob.view(out_logits.shape[0], -1), 300, dim=1)
+ scores = topk_values
+ topk_boxes = topk_indexes // out_logits.shape[2]
+ labels = topk_indexes % out_logits.shape[2]
+ boxes = center_to_corners_format(out_bbox)
+ boxes = torch.gather(boxes, 1, topk_boxes.unsqueeze(-1).repeat(1, 1, 4))
+
+ # and from relative [0, 1] to absolute [0, height] coordinates
+ img_h, img_w = target_sizes.unbind(1)
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1).to(boxes.device)
+ boxes = boxes * scale_fct[:, None, :]
+
+ results = [{"scores": s, "labels": l, "boxes": b} for s, l, b in zip(scores, labels, boxes)]
+
+ return results
+
+ # Copied from transformers.models.deformable_detr.image_processing_deformable_detr.DeformableDetrImageProcessor.post_process_object_detection with DeformableDetr->ConditionalDetr
+ def post_process_object_detection(
+ self, outputs, threshold: float = 0.5, target_sizes: Union[TensorType, List[Tuple]] = None
+ ):
+ """
+ Converts the output of [`ConditionalDetrForObjectDetection`] into the format expected by the COCO api. Only
+ supports PyTorch.
+
+ Args:
+ outputs ([`DetrObjectDetectionOutput`]):
+ Raw outputs of the model.
+ threshold (`float`, *optional*):
+ Score threshold to keep object detection predictions.
+ target_sizes (`torch.Tensor` or `List[Tuple[int, int]]`, *optional*):
+ Tensor of shape `(batch_size, 2)` or list of tuples (`Tuple[int, int]`) containing the target size
+ (height, width) of each image in the batch. If left to None, predictions will not be resized.
+
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
+ in the batch as predicted by the model.
+ """
+ out_logits, out_bbox = outputs.logits, outputs.pred_boxes
+
+ if target_sizes is not None:
+ if len(out_logits) != len(target_sizes):
+ raise ValueError(
+ "Make sure that you pass in as many target sizes as the batch dimension of the logits"
+ )
+
+ prob = out_logits.sigmoid()
+ topk_values, topk_indexes = torch.topk(prob.view(out_logits.shape[0], -1), 100, dim=1)
+ scores = topk_values
+ topk_boxes = topk_indexes // out_logits.shape[2]
+ labels = topk_indexes % out_logits.shape[2]
+ boxes = center_to_corners_format(out_bbox)
+ boxes = torch.gather(boxes, 1, topk_boxes.unsqueeze(-1).repeat(1, 1, 4))
+
+ # and from relative [0, 1] to absolute [0, height] coordinates
+ if isinstance(target_sizes, List):
+ img_h = torch.Tensor([i[0] for i in target_sizes])
+ img_w = torch.Tensor([i[1] for i in target_sizes])
+ else:
+ img_h, img_w = target_sizes.unbind(1)
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
+ boxes = boxes * scale_fct[:, None, :]
+
+ results = []
+ for s, l, b in zip(scores, labels, boxes):
+ score = s[s > threshold]
+ label = l[s > threshold]
+ box = b[s > threshold]
+ results.append({"scores": score, "labels": label, "boxes": box})
+
+ return results
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.post_process_semantic_segmentation with Detr->ConditionalDetr
+ def post_process_semantic_segmentation(self, outputs, target_sizes: List[Tuple[int, int]] = None):
+ """
+ Converts the output of [`ConditionalDetrForSegmentation`] into semantic segmentation maps. Only supports
+ PyTorch.
+
+ Args:
+ outputs ([`ConditionalDetrForSegmentation`]):
+ Raw outputs of the model.
+ target_sizes (`List[Tuple[int, int]]`, *optional*):
+ A list of tuples (`Tuple[int, int]`) containing the target size (height, width) of each image in the
+ batch. If unset, predictions will not be resized.
+ Returns:
+ `List[torch.Tensor]`:
+ A list of length `batch_size`, where each item is a semantic segmentation map of shape (height, width)
+ corresponding to the target_sizes entry (if `target_sizes` is specified). Each entry of each
+ `torch.Tensor` correspond to a semantic class id.
+ """
+ class_queries_logits = outputs.logits # [batch_size, num_queries, num_classes+1]
+ masks_queries_logits = outputs.pred_masks # [batch_size, num_queries, height, width]
+
+ # Remove the null class `[..., :-1]`
+ masks_classes = class_queries_logits.softmax(dim=-1)[..., :-1]
+ masks_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
+
+ # Semantic segmentation logits of shape (batch_size, num_classes, height, width)
+ segmentation = torch.einsum("bqc, bqhw -> bchw", masks_classes, masks_probs)
+ batch_size = class_queries_logits.shape[0]
+
+ # Resize logits and compute semantic segmentation maps
+ if target_sizes is not None:
+ if batch_size != len(target_sizes):
+ raise ValueError(
+ "Make sure that you pass in as many target sizes as the batch dimension of the logits"
+ )
+
+ semantic_segmentation = []
+ for idx in range(batch_size):
+ resized_logits = nn.functional.interpolate(
+ segmentation[idx].unsqueeze(dim=0), size=target_sizes[idx], mode="bilinear", align_corners=False
+ )
+ semantic_map = resized_logits[0].argmax(dim=0)
+ semantic_segmentation.append(semantic_map)
+ else:
+ semantic_segmentation = segmentation.argmax(dim=1)
+ semantic_segmentation = [semantic_segmentation[i] for i in range(semantic_segmentation.shape[0])]
+
+ return semantic_segmentation
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.post_process_instance_segmentation with Detr->ConditionalDetr
+ def post_process_instance_segmentation(
+ self,
+ outputs,
+ threshold: float = 0.5,
+ mask_threshold: float = 0.5,
+ overlap_mask_area_threshold: float = 0.8,
+ target_sizes: Optional[List[Tuple[int, int]]] = None,
+ return_coco_annotation: Optional[bool] = False,
+ ) -> List[Dict]:
+ """
+ Converts the output of [`ConditionalDetrForSegmentation`] into instance segmentation predictions. Only supports
+ PyTorch.
+
+ Args:
+ outputs ([`ConditionalDetrForSegmentation`]):
+ Raw outputs of the model.
+ threshold (`float`, *optional*, defaults to 0.5):
+ The probability score threshold to keep predicted instance masks.
+ mask_threshold (`float`, *optional*, defaults to 0.5):
+ Threshold to use when turning the predicted masks into binary values.
+ overlap_mask_area_threshold (`float`, *optional*, defaults to 0.8):
+ The overlap mask area threshold to merge or discard small disconnected parts within each binary
+ instance mask.
+ target_sizes (`List[Tuple]`, *optional*):
+ List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
+ final size (height, width) of each prediction. If unset, predictions will not be resized.
+ return_coco_annotation (`bool`, *optional*):
+ Defaults to `False`. If set to `True`, segmentation maps are returned in COCO run-length encoding (RLE)
+ format.
+ Returns:
+ `List[Dict]`: A list of dictionaries, one per image, each dictionary containing two keys:
+ - **segmentation** -- A tensor of shape `(height, width)` where each pixel represents a `segment_id` or
+ `List[List]` run-length encoding (RLE) of the segmentation map if return_coco_annotation is set to
+ `True`. Set to `None` if no mask if found above `threshold`.
+ - **segments_info** -- A dictionary that contains additional information on each segment.
+ - **id** -- An integer representing the `segment_id`.
+ - **label_id** -- An integer representing the label / semantic class id corresponding to `segment_id`.
+ - **score** -- Prediction score of segment with `segment_id`.
+ """
+ class_queries_logits = outputs.logits # [batch_size, num_queries, num_classes+1]
+ masks_queries_logits = outputs.pred_masks # [batch_size, num_queries, height, width]
+
+ batch_size = class_queries_logits.shape[0]
+ num_labels = class_queries_logits.shape[-1] - 1
+
+ mask_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
+
+ # Predicted label and score of each query (batch_size, num_queries)
+ pred_scores, pred_labels = nn.functional.softmax(class_queries_logits, dim=-1).max(-1)
+
+ # Loop over items in batch size
+ results: List[Dict[str, TensorType]] = []
+
+ for i in range(batch_size):
+ mask_probs_item, pred_scores_item, pred_labels_item = remove_low_and_no_objects(
+ mask_probs[i], pred_scores[i], pred_labels[i], threshold, num_labels
+ )
+
+ # No mask found
+ if mask_probs_item.shape[0] <= 0:
+ height, width = target_sizes[i] if target_sizes is not None else mask_probs_item.shape[1:]
+ segmentation = torch.zeros((height, width)) - 1
+ results.append({"segmentation": segmentation, "segments_info": []})
+ continue
+
+ # Get segmentation map and segment information of batch item
+ target_size = target_sizes[i] if target_sizes is not None else None
+ segmentation, segments = compute_segments(
+ mask_probs=mask_probs_item,
+ pred_scores=pred_scores_item,
+ pred_labels=pred_labels_item,
+ mask_threshold=mask_threshold,
+ overlap_mask_area_threshold=overlap_mask_area_threshold,
+ label_ids_to_fuse=[],
+ target_size=target_size,
+ )
+
+ # Return segmentation map in run-length encoding (RLE) format
+ if return_coco_annotation:
+ segmentation = convert_segmentation_to_rle(segmentation)
+
+ results.append({"segmentation": segmentation, "segments_info": segments})
+ return results
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.post_process_panoptic_segmentation with Detr->ConditionalDetr
+ def post_process_panoptic_segmentation(
+ self,
+ outputs,
+ threshold: float = 0.5,
+ mask_threshold: float = 0.5,
+ overlap_mask_area_threshold: float = 0.8,
+ label_ids_to_fuse: Optional[Set[int]] = None,
+ target_sizes: Optional[List[Tuple[int, int]]] = None,
+ ) -> List[Dict]:
+ """
+ Converts the output of [`ConditionalDetrForSegmentation`] into image panoptic segmentation predictions. Only
+ supports PyTorch.
+
+ Args:
+ outputs ([`ConditionalDetrForSegmentation`]):
+ The outputs from [`ConditionalDetrForSegmentation`].
+ threshold (`float`, *optional*, defaults to 0.5):
+ The probability score threshold to keep predicted instance masks.
+ mask_threshold (`float`, *optional*, defaults to 0.5):
+ Threshold to use when turning the predicted masks into binary values.
+ overlap_mask_area_threshold (`float`, *optional*, defaults to 0.8):
+ The overlap mask area threshold to merge or discard small disconnected parts within each binary
+ instance mask.
+ label_ids_to_fuse (`Set[int]`, *optional*):
+ The labels in this state will have all their instances be fused together. For instance we could say
+ there can only be one sky in an image, but several persons, so the label ID for sky would be in that
+ set, but not the one for person.
+ target_sizes (`List[Tuple]`, *optional*):
+ List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
+ final size (height, width) of each prediction in batch. If unset, predictions will not be resized.
+ Returns:
+ `List[Dict]`: A list of dictionaries, one per image, each dictionary containing two keys:
+ - **segmentation** -- a tensor of shape `(height, width)` where each pixel represents a `segment_id` or
+ `None` if no mask if found above `threshold`. If `target_sizes` is specified, segmentation is resized to
+ the corresponding `target_sizes` entry.
+ - **segments_info** -- A dictionary that contains additional information on each segment.
+ - **id** -- an integer representing the `segment_id`.
+ - **label_id** -- An integer representing the label / semantic class id corresponding to `segment_id`.
+ - **was_fused** -- a boolean, `True` if `label_id` was in `label_ids_to_fuse`, `False` otherwise.
+ Multiple instances of the same class / label were fused and assigned a single `segment_id`.
+ - **score** -- Prediction score of segment with `segment_id`.
+ """
+
+ if label_ids_to_fuse is None:
+ warnings.warn("`label_ids_to_fuse` unset. No instance will be fused.")
+ label_ids_to_fuse = set()
+
+ class_queries_logits = outputs.logits # [batch_size, num_queries, num_classes+1]
+ masks_queries_logits = outputs.pred_masks # [batch_size, num_queries, height, width]
+
+ batch_size = class_queries_logits.shape[0]
+ num_labels = class_queries_logits.shape[-1] - 1
+
+ mask_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
+
+ # Predicted label and score of each query (batch_size, num_queries)
+ pred_scores, pred_labels = nn.functional.softmax(class_queries_logits, dim=-1).max(-1)
+
+ # Loop over items in batch size
+ results: List[Dict[str, TensorType]] = []
+
+ for i in range(batch_size):
+ mask_probs_item, pred_scores_item, pred_labels_item = remove_low_and_no_objects(
+ mask_probs[i], pred_scores[i], pred_labels[i], threshold, num_labels
+ )
+
+ # No mask found
+ if mask_probs_item.shape[0] <= 0:
+ height, width = target_sizes[i] if target_sizes is not None else mask_probs_item.shape[1:]
+ segmentation = torch.zeros((height, width)) - 1
+ results.append({"segmentation": segmentation, "segments_info": []})
+ continue
+
+ # Get segmentation map and segment information of batch item
+ target_size = target_sizes[i] if target_sizes is not None else None
+ segmentation, segments = compute_segments(
+ mask_probs=mask_probs_item,
+ pred_scores=pred_scores_item,
+ pred_labels=pred_labels_item,
+ mask_threshold=mask_threshold,
+ overlap_mask_area_threshold=overlap_mask_area_threshold,
+ label_ids_to_fuse=label_ids_to_fuse,
+ target_size=target_size,
+ )
+
+ results.append({"segmentation": segmentation, "segments_info": segments})
+ return results
diff --git a/src/transformers/models/deformable_detr/__init__.py b/src/transformers/models/deformable_detr/__init__.py
index 36c1a83b0e..dd76e06c7b 100644
--- a/src/transformers/models/deformable_detr/__init__.py
+++ b/src/transformers/models/deformable_detr/__init__.py
@@ -32,6 +32,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_deformable_detr"] = ["DeformableDetrFeatureExtractor"]
+ _import_structure["image_processing_deformable_detr"] = ["DeformableDetrImageProcessor"]
try:
if not is_timm_available():
@@ -57,6 +58,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_deformable_detr import DeformableDetrFeatureExtractor
+ from .image_processing_deformable_detr import DeformableDetrImageProcessor
try:
if not is_timm_available():
diff --git a/src/transformers/models/deformable_detr/feature_extraction_deformable_detr.py b/src/transformers/models/deformable_detr/feature_extraction_deformable_detr.py
index a618106380..1473819f66 100644
--- a/src/transformers/models/deformable_detr/feature_extraction_deformable_detr.py
+++ b/src/transformers/models/deformable_detr/feature_extraction_deformable_detr.py
@@ -14,729 +14,10 @@
# limitations under the License.
"""Feature extractor class for Deformable DETR."""
-import pathlib
-import warnings
-from typing import Dict, List, Optional, Tuple, Union
+from ...utils import logging
+from .image_processing_deformable_detr import DeformableDetrImageProcessor
-import numpy as np
-from PIL import Image
-
-from ...feature_extraction_utils import BatchFeature, FeatureExtractionMixin
-from ...image_transforms import center_to_corners_format, corners_to_center_format, rgb_to_id
-from ...image_utils import ImageFeatureExtractionMixin
-from ...utils import TensorType, is_torch_available, is_torch_tensor, logging
-
-
-if is_torch_available():
- import torch
- from torch import nn
logger = logging.get_logger(__name__)
-
-ImageInput = Union[Image.Image, np.ndarray, "torch.Tensor", List[Image.Image], List[np.ndarray], List["torch.Tensor"]]
-
-
-# Copied from transformers.models.detr.feature_extraction_detr.masks_to_boxes
-def masks_to_boxes(masks):
- """
- Compute the bounding boxes around the provided panoptic segmentation masks.
-
- The masks should be in format [N, H, W] where N is the number of masks, (H, W) are the spatial dimensions.
-
- Returns a [N, 4] tensor, with the boxes in corner (xyxy) format.
- """
- if masks.size == 0:
- return np.zeros((0, 4))
-
- h, w = masks.shape[-2:]
-
- y = np.arange(0, h, dtype=np.float32)
- x = np.arange(0, w, dtype=np.float32)
- # see https://github.com/pytorch/pytorch/issues/50276
- y, x = np.meshgrid(y, x, indexing="ij")
-
- x_mask = masks * np.expand_dims(x, axis=0)
- x_max = x_mask.reshape(x_mask.shape[0], -1).max(-1)
- x = np.ma.array(x_mask, mask=~(np.array(masks, dtype=bool)))
- x_min = x.filled(fill_value=1e8)
- x_min = x_min.reshape(x_min.shape[0], -1).min(-1)
-
- y_mask = masks * np.expand_dims(y, axis=0)
- y_max = y_mask.reshape(x_mask.shape[0], -1).max(-1)
- y = np.ma.array(y_mask, mask=~(np.array(masks, dtype=bool)))
- y_min = y.filled(fill_value=1e8)
- y_min = y_min.reshape(y_min.shape[0], -1).min(-1)
-
- return np.stack([x_min, y_min, x_max, y_max], 1)
-
-
-class DeformableDetrFeatureExtractor(FeatureExtractionMixin, ImageFeatureExtractionMixin):
- r"""
- Constructs a Deformable DETR feature extractor. Differs only in the postprocessing of object detection compared to
- DETR.
-
- This feature extractor inherits from [`FeatureExtractionMixin`] which contains most of the main methods. Users
- should refer to this superclass for more information regarding those methods.
-
- Args:
- format (`str`, *optional*, defaults to `"coco_detection"`):
- Data format of the annotations. One of "coco_detection" or "coco_panoptic".
- do_resize (`bool`, *optional*, defaults to `True`):
- Whether to resize the input to a certain `size`.
- size (`int`, *optional*, defaults to 800):
- Resize the input to the given size. Only has an effect if `do_resize` is set to `True`. If size is a
- sequence like `(width, height)`, output size will be matched to this. If size is an int, smaller edge of
- the image will be matched to this number. i.e, if `height > width`, then image will be rescaled to `(size *
- height / width, size)`.
- max_size (`int`, *optional*, defaults to 1333):
- The largest size an image dimension can have (otherwise it's capped). Only has an effect if `do_resize` is
- set to `True`.
- do_normalize (`bool`, *optional*, defaults to `True`):
- Whether or not to normalize the input with mean and standard deviation.
- image_mean (`int`, *optional*, defaults to `[0.485, 0.456, 0.406]`):
- The sequence of means for each channel, to be used when normalizing images. Defaults to the ImageNet mean.
- image_std (`int`, *optional*, defaults to `[0.229, 0.224, 0.225]`):
- The sequence of standard deviations for each channel, to be used when normalizing images. Defaults to the
- ImageNet std.
- """
-
- model_input_names = ["pixel_values", "pixel_mask"]
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.__init__
- def __init__(
- self,
- format="coco_detection",
- do_resize=True,
- size=800,
- max_size=1333,
- do_normalize=True,
- image_mean=None,
- image_std=None,
- **kwargs
- ):
- super().__init__(**kwargs)
- self.format = self._is_valid_format(format)
- self.do_resize = do_resize
- self.size = size
- self.max_size = max_size
- self.do_normalize = do_normalize
- self.image_mean = image_mean if image_mean is not None else [0.485, 0.456, 0.406] # ImageNet mean
- self.image_std = image_std if image_std is not None else [0.229, 0.224, 0.225] # ImageNet std
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._is_valid_format
- def _is_valid_format(self, format):
- if format not in ["coco_detection", "coco_panoptic"]:
- raise ValueError(f"Format {format} not supported")
- return format
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.prepare
- def prepare(self, image, target, return_segmentation_masks=False, masks_path=None):
- if self.format == "coco_detection":
- image, target = self.prepare_coco_detection(image, target, return_segmentation_masks)
- return image, target
- elif self.format == "coco_panoptic":
- image, target = self.prepare_coco_panoptic(image, target, masks_path)
- return image, target
- else:
- raise ValueError(f"Format {self.format} not supported")
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.convert_coco_poly_to_mask
- def convert_coco_poly_to_mask(self, segmentations, height, width):
-
- try:
- from pycocotools import mask as coco_mask
- except ImportError:
- raise ImportError("Pycocotools is not installed in your environment.")
-
- masks = []
- for polygons in segmentations:
- rles = coco_mask.frPyObjects(polygons, height, width)
- mask = coco_mask.decode(rles)
- if len(mask.shape) < 3:
- mask = mask[..., None]
- mask = np.asarray(mask, dtype=np.uint8)
- mask = np.any(mask, axis=2)
- masks.append(mask)
- if masks:
- masks = np.stack(masks, axis=0)
- else:
- masks = np.zeros((0, height, width), dtype=np.uint8)
-
- return masks
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.prepare_coco_detection
- def prepare_coco_detection(self, image, target, return_segmentation_masks=False):
- """
- Convert the target in COCO format into the format expected by DETR.
- """
- w, h = image.size
-
- image_id = target["image_id"]
- image_id = np.asarray([image_id], dtype=np.int64)
-
- # get all COCO annotations for the given image
- anno = target["annotations"]
-
- anno = [obj for obj in anno if "iscrowd" not in obj or obj["iscrowd"] == 0]
-
- boxes = [obj["bbox"] for obj in anno]
- # guard against no boxes via resizing
- boxes = np.asarray(boxes, dtype=np.float32).reshape(-1, 4)
- boxes[:, 2:] += boxes[:, :2]
- boxes[:, 0::2] = boxes[:, 0::2].clip(min=0, max=w)
- boxes[:, 1::2] = boxes[:, 1::2].clip(min=0, max=h)
-
- classes = [obj["category_id"] for obj in anno]
- classes = np.asarray(classes, dtype=np.int64)
-
- if return_segmentation_masks:
- segmentations = [obj["segmentation"] for obj in anno]
- masks = self.convert_coco_poly_to_mask(segmentations, h, w)
-
- keypoints = None
- if anno and "keypoints" in anno[0]:
- keypoints = [obj["keypoints"] for obj in anno]
- keypoints = np.asarray(keypoints, dtype=np.float32)
- num_keypoints = keypoints.shape[0]
- if num_keypoints:
- keypoints = keypoints.reshape((-1, 3))
-
- keep = (boxes[:, 3] > boxes[:, 1]) & (boxes[:, 2] > boxes[:, 0])
- boxes = boxes[keep]
- classes = classes[keep]
- if return_segmentation_masks:
- masks = masks[keep]
- if keypoints is not None:
- keypoints = keypoints[keep]
-
- target = {}
- target["boxes"] = boxes
- target["class_labels"] = classes
- if return_segmentation_masks:
- target["masks"] = masks
- target["image_id"] = image_id
- if keypoints is not None:
- target["keypoints"] = keypoints
-
- # for conversion to coco api
- area = np.asarray([obj["area"] for obj in anno], dtype=np.float32)
- iscrowd = np.asarray([obj["iscrowd"] if "iscrowd" in obj else 0 for obj in anno], dtype=np.int64)
- target["area"] = area[keep]
- target["iscrowd"] = iscrowd[keep]
-
- target["orig_size"] = np.asarray([int(h), int(w)], dtype=np.int64)
- target["size"] = np.asarray([int(h), int(w)], dtype=np.int64)
-
- return image, target
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.prepare_coco_panoptic
- def prepare_coco_panoptic(self, image, target, masks_path, return_masks=True):
- w, h = image.size
- ann_info = target.copy()
- ann_path = pathlib.Path(masks_path) / ann_info["file_name"]
-
- if "segments_info" in ann_info:
- masks = np.asarray(Image.open(ann_path), dtype=np.uint32)
- masks = rgb_to_id(masks)
-
- ids = np.array([ann["id"] for ann in ann_info["segments_info"]])
- masks = masks == ids[:, None, None]
- masks = np.asarray(masks, dtype=np.uint8)
-
- labels = np.asarray([ann["category_id"] for ann in ann_info["segments_info"]], dtype=np.int64)
-
- target = {}
- target["image_id"] = np.asarray(
- [ann_info["image_id"] if "image_id" in ann_info else ann_info["id"]], dtype=np.int64
- )
- if return_masks:
- target["masks"] = masks
- target["class_labels"] = labels
-
- target["boxes"] = masks_to_boxes(masks)
-
- target["size"] = np.asarray([int(h), int(w)], dtype=np.int64)
- target["orig_size"] = np.asarray([int(h), int(w)], dtype=np.int64)
- if "segments_info" in ann_info:
- target["iscrowd"] = np.asarray([ann["iscrowd"] for ann in ann_info["segments_info"]], dtype=np.int64)
- target["area"] = np.asarray([ann["area"] for ann in ann_info["segments_info"]], dtype=np.float32)
-
- return image, target
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._resize
- def _resize(self, image, size, target=None, max_size=None):
- """
- Resize the image to the given size. Size can be min_size (scalar) or (w, h) tuple. If size is an int, smaller
- edge of the image will be matched to this number.
-
- If given, also resize the target accordingly.
- """
- if not isinstance(image, Image.Image):
- image = self.to_pil_image(image)
-
- def get_size_with_aspect_ratio(image_size, size, max_size=None):
- w, h = image_size
- if max_size is not None:
- min_original_size = float(min((w, h)))
- max_original_size = float(max((w, h)))
- if max_original_size / min_original_size * size > max_size:
- size = int(round(max_size * min_original_size / max_original_size))
-
- if (w <= h and w == size) or (h <= w and h == size):
- return (h, w)
-
- if w < h:
- ow = size
- oh = int(size * h / w)
- else:
- oh = size
- ow = int(size * w / h)
-
- return (oh, ow)
-
- def get_size(image_size, size, max_size=None):
- if isinstance(size, (list, tuple)):
- return size
- else:
- # size returned must be (w, h) since we use PIL to resize images
- # so we revert the tuple
- return get_size_with_aspect_ratio(image_size, size, max_size)[::-1]
-
- size = get_size(image.size, size, max_size)
- rescaled_image = self.resize(image, size=size)
-
- if target is None:
- return rescaled_image, None
-
- ratios = tuple(float(s) / float(s_orig) for s, s_orig in zip(rescaled_image.size, image.size))
- ratio_width, ratio_height = ratios
-
- target = target.copy()
- if "boxes" in target:
- boxes = target["boxes"]
- scaled_boxes = boxes * np.asarray([ratio_width, ratio_height, ratio_width, ratio_height], dtype=np.float32)
- target["boxes"] = scaled_boxes
-
- if "area" in target:
- area = target["area"]
- scaled_area = area * (ratio_width * ratio_height)
- target["area"] = scaled_area
-
- w, h = size
- target["size"] = np.asarray([h, w], dtype=np.int64)
-
- if "masks" in target:
- # use PyTorch as current workaround
- # TODO replace by self.resize
- masks = torch.from_numpy(target["masks"][:, None]).float()
- interpolated_masks = nn.functional.interpolate(masks, size=(h, w), mode="nearest")[:, 0] > 0.5
- target["masks"] = interpolated_masks.numpy()
-
- return rescaled_image, target
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._normalize
- def _normalize(self, image, mean, std, target=None):
- """
- Normalize the image with a certain mean and std.
-
- If given, also normalize the target bounding boxes based on the size of the image.
- """
-
- image = self.normalize(image, mean=mean, std=std)
- if target is None:
- return image, None
-
- target = target.copy()
- h, w = image.shape[-2:]
-
- if "boxes" in target:
- boxes = target["boxes"]
- boxes = corners_to_center_format(boxes)
- boxes = boxes / np.asarray([w, h, w, h], dtype=np.float32)
- target["boxes"] = boxes
-
- return image, target
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.__call__
- def __call__(
- self,
- images: ImageInput,
- annotations: Union[List[Dict], List[List[Dict]]] = None,
- return_segmentation_masks: Optional[bool] = False,
- masks_path: Optional[pathlib.Path] = None,
- pad_and_return_pixel_mask: Optional[bool] = True,
- return_tensors: Optional[Union[str, TensorType]] = None,
- **kwargs,
- ) -> BatchFeature:
- """
- Main method to prepare for the model one or several image(s) and optional annotations. Images are by default
- padded up to the largest image in a batch, and a pixel mask is created that indicates which pixels are
- real/which are padding.
-
-
-
- NumPy arrays and PyTorch tensors are converted to PIL images when resizing, so the most efficient is to pass
- PIL images.
-
-
-
- Args:
- images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
- The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
- tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a
- number of channels, H and W are image height and width.
-
- annotations (`Dict`, `List[Dict]`, *optional*):
- The corresponding annotations in COCO format.
-
- In case [`DetrFeatureExtractor`] was initialized with `format = "coco_detection"`, the annotations for
- each image should have the following format: {'image_id': int, 'annotations': [annotation]}, with the
- annotations being a list of COCO object annotations.
-
- In case [`DetrFeatureExtractor`] was initialized with `format = "coco_panoptic"`, the annotations for
- each image should have the following format: {'image_id': int, 'file_name': str, 'segments_info':
- [segment_info]} with segments_info being a list of COCO panoptic annotations.
-
- return_segmentation_masks (`Dict`, `List[Dict]`, *optional*, defaults to `False`):
- Whether to also include instance segmentation masks as part of the labels in case `format =
- "coco_detection"`.
-
- masks_path (`pathlib.Path`, *optional*):
- Path to the directory containing the PNG files that store the class-agnostic image segmentations. Only
- relevant in case [`DetrFeatureExtractor`] was initialized with `format = "coco_panoptic"`.
-
- pad_and_return_pixel_mask (`bool`, *optional*, defaults to `True`):
- Whether or not to pad images up to the largest image in a batch and create a pixel mask.
-
- If left to the default, will return a pixel mask that is:
-
- - 1 for pixels that are real (i.e. **not masked**),
- - 0 for pixels that are padding (i.e. **masked**).
-
- return_tensors (`str` or [`~utils.TensorType`], *optional*):
- If set, will return tensors instead of NumPy arrays. If set to `'pt'`, return PyTorch `torch.Tensor`
- objects.
-
- Returns:
- [`BatchFeature`]: A [`BatchFeature`] with the following fields:
-
- - **pixel_values** -- Pixel values to be fed to a model.
- - **pixel_mask** -- Pixel mask to be fed to a model (when `pad_and_return_pixel_mask=True` or if
- *"pixel_mask"* is in `self.model_input_names`).
- - **labels** -- Optional labels to be fed to a model (when `annotations` are provided)
- """
- # Input type checking for clearer error
-
- valid_images = False
- valid_annotations = False
- valid_masks_path = False
-
- # Check that images has a valid type
- if isinstance(images, (Image.Image, np.ndarray)) or is_torch_tensor(images):
- valid_images = True
- elif isinstance(images, (list, tuple)):
- if len(images) == 0 or isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]):
- valid_images = True
-
- if not valid_images:
- raise ValueError(
- "Images must of type `PIL.Image.Image`, `np.ndarray` or `torch.Tensor` (single example), "
- "`List[PIL.Image.Image]`, `List[np.ndarray]` or `List[torch.Tensor]` (batch of examples)."
- )
-
- is_batched = bool(
- isinstance(images, (list, tuple))
- and (isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]))
- )
-
- # Check that annotations has a valid type
- if annotations is not None:
- if not is_batched:
- if self.format == "coco_detection":
- if isinstance(annotations, dict) and "image_id" in annotations and "annotations" in annotations:
- if isinstance(annotations["annotations"], (list, tuple)):
- # an image can have no annotations
- if len(annotations["annotations"]) == 0 or isinstance(annotations["annotations"][0], dict):
- valid_annotations = True
- elif self.format == "coco_panoptic":
- if isinstance(annotations, dict) and "image_id" in annotations and "segments_info" in annotations:
- if isinstance(annotations["segments_info"], (list, tuple)):
- # an image can have no segments (?)
- if len(annotations["segments_info"]) == 0 or isinstance(
- annotations["segments_info"][0], dict
- ):
- valid_annotations = True
- else:
- if isinstance(annotations, (list, tuple)):
- if len(images) != len(annotations):
- raise ValueError("There must be as many annotations as there are images")
- if isinstance(annotations[0], Dict):
- if self.format == "coco_detection":
- if isinstance(annotations[0]["annotations"], (list, tuple)):
- valid_annotations = True
- elif self.format == "coco_panoptic":
- if isinstance(annotations[0]["segments_info"], (list, tuple)):
- valid_annotations = True
-
- if not valid_annotations:
- raise ValueError(
- """
- Annotations must of type `Dict` (single image) or `List[Dict]` (batch of images). In case of object
- detection, each dictionary should contain the keys 'image_id' and 'annotations', with the latter
- being a list of annotations in COCO format. In case of panoptic segmentation, each dictionary
- should contain the keys 'file_name', 'image_id' and 'segments_info', with the latter being a list
- of annotations in COCO format.
- """
- )
-
- # Check that masks_path has a valid type
- if masks_path is not None:
- if self.format == "coco_panoptic":
- if isinstance(masks_path, pathlib.Path):
- valid_masks_path = True
- if not valid_masks_path:
- raise ValueError(
- "The path to the directory containing the mask PNG files should be provided as a"
- " `pathlib.Path` object."
- )
-
- if not is_batched:
- images = [images]
- if annotations is not None:
- annotations = [annotations]
-
- # Create a copy of the list to avoid editing it in place
- images = [image for image in images]
-
- if annotations is not None:
- annotations = [annotation for annotation in annotations]
-
- # prepare (COCO annotations as a list of Dict -> DETR target as a single Dict per image)
- if annotations is not None:
- for idx, (image, target) in enumerate(zip(images, annotations)):
- if not isinstance(image, Image.Image):
- image = self.to_pil_image(image)
- image, target = self.prepare(image, target, return_segmentation_masks, masks_path)
- images[idx] = image
- annotations[idx] = target
-
- # transformations (resizing + normalization)
- if self.do_resize and self.size is not None:
- if annotations is not None:
- for idx, (image, target) in enumerate(zip(images, annotations)):
- image, target = self._resize(image=image, target=target, size=self.size, max_size=self.max_size)
- images[idx] = image
- annotations[idx] = target
- else:
- for idx, image in enumerate(images):
- images[idx] = self._resize(image=image, target=None, size=self.size, max_size=self.max_size)[0]
-
- if self.do_normalize:
- if annotations is not None:
- for idx, (image, target) in enumerate(zip(images, annotations)):
- image, target = self._normalize(
- image=image, mean=self.image_mean, std=self.image_std, target=target
- )
- images[idx] = image
- annotations[idx] = target
- else:
- images = [
- self._normalize(image=image, mean=self.image_mean, std=self.image_std)[0] for image in images
- ]
- else:
- images = [np.array(image) for image in images]
-
- if pad_and_return_pixel_mask:
- # pad images up to largest image in batch and create pixel_mask
- max_size = self._max_by_axis([list(image.shape) for image in images])
- c, h, w = max_size
- padded_images = []
- pixel_mask = []
- for image in images:
- # create padded image
- padded_image = np.zeros((c, h, w), dtype=np.float32)
- padded_image[: image.shape[0], : image.shape[1], : image.shape[2]] = np.copy(image)
- padded_images.append(padded_image)
- # create pixel mask
- mask = np.zeros((h, w), dtype=np.int64)
- mask[: image.shape[1], : image.shape[2]] = True
- pixel_mask.append(mask)
- images = padded_images
-
- # return as BatchFeature
- data = {}
- data["pixel_values"] = images
- if pad_and_return_pixel_mask:
- data["pixel_mask"] = pixel_mask
- encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
-
- if annotations is not None:
- # Convert to TensorType
- tensor_type = return_tensors
- if not isinstance(tensor_type, TensorType):
- tensor_type = TensorType(tensor_type)
-
- if not tensor_type == TensorType.PYTORCH:
- raise ValueError("Only PyTorch is supported for the moment.")
- else:
- if not is_torch_available():
- raise ImportError("Unable to convert output to PyTorch tensors format, PyTorch is not installed.")
-
- encoded_inputs["labels"] = [
- {k: torch.from_numpy(v) for k, v in target.items()} for target in annotations
- ]
-
- return encoded_inputs
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._max_by_axis
- def _max_by_axis(self, the_list):
- # type: (List[List[int]]) -> List[int]
- maxes = the_list[0]
- for sublist in the_list[1:]:
- for index, item in enumerate(sublist):
- maxes[index] = max(maxes[index], item)
- return maxes
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.pad_and_create_pixel_mask
- def pad_and_create_pixel_mask(
- self, pixel_values_list: List["torch.Tensor"], return_tensors: Optional[Union[str, TensorType]] = None
- ):
- """
- Pad images up to the largest image in a batch and create a corresponding `pixel_mask`.
-
- Args:
- pixel_values_list (`List[torch.Tensor]`):
- List of images (pixel values) to be padded. Each image should be a tensor of shape (C, H, W).
- return_tensors (`str` or [`~utils.TensorType`], *optional*):
- If set, will return tensors instead of NumPy arrays. If set to `'pt'`, return PyTorch `torch.Tensor`
- objects.
-
- Returns:
- [`BatchFeature`]: A [`BatchFeature`] with the following fields:
-
- - **pixel_values** -- Pixel values to be fed to a model.
- - **pixel_mask** -- Pixel mask to be fed to a model (when `pad_and_return_pixel_mask=True` or if
- *"pixel_mask"* is in `self.model_input_names`).
-
- """
-
- max_size = self._max_by_axis([list(image.shape) for image in pixel_values_list])
- c, h, w = max_size
- padded_images = []
- pixel_mask = []
- for image in pixel_values_list:
- # create padded image
- padded_image = np.zeros((c, h, w), dtype=np.float32)
- padded_image[: image.shape[0], : image.shape[1], : image.shape[2]] = np.copy(image)
- padded_images.append(padded_image)
- # create pixel mask
- mask = np.zeros((h, w), dtype=np.int64)
- mask[: image.shape[1], : image.shape[2]] = True
- pixel_mask.append(mask)
-
- # return as BatchFeature
- data = {"pixel_values": padded_images, "pixel_mask": pixel_mask}
- encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
-
- return encoded_inputs
-
- def post_process(self, outputs, target_sizes):
- """
- Converts the output of [`DeformableDetrForObjectDetection`] into the format expected by the COCO api. Only
- supports PyTorch.
-
- Args:
- outputs ([`DeformableDetrObjectDetectionOutput`]):
- Raw outputs of the model.
- target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
- Tensor containing the size (height, width) of each image of the batch. For evaluation, this must be the
- original image size (before any data augmentation). For visualization, this should be the image size
- after data augment, but before padding.
- Returns:
- `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
- in the batch as predicted by the model.
- """
- warnings.warn(
- "`post_process` is deprecated and will be removed in v5 of Transformers, please use"
- " `post_process_object_detection`.",
- FutureWarning,
- )
-
- out_logits, out_bbox = outputs.logits, outputs.pred_boxes
-
- if len(out_logits) != len(target_sizes):
- raise ValueError("Make sure that you pass in as many target sizes as the batch dimension of the logits")
- if target_sizes.shape[1] != 2:
- raise ValueError("Each element of target_sizes must contain the size (h, w) of each image of the batch")
-
- prob = out_logits.sigmoid()
- topk_values, topk_indexes = torch.topk(prob.view(out_logits.shape[0], -1), 100, dim=1)
- scores = topk_values
- topk_boxes = topk_indexes // out_logits.shape[2]
- labels = topk_indexes % out_logits.shape[2]
- boxes = center_to_corners_format(out_bbox)
- boxes = torch.gather(boxes, 1, topk_boxes.unsqueeze(-1).repeat(1, 1, 4))
-
- # and from relative [0, 1] to absolute [0, height] coordinates
- img_h, img_w = target_sizes.unbind(1)
- scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
- boxes = boxes * scale_fct[:, None, :]
-
- results = [{"scores": s, "labels": l, "boxes": b} for s, l, b in zip(scores, labels, boxes)]
-
- return results
-
- def post_process_object_detection(
- self, outputs, threshold: float = 0.5, target_sizes: Union[TensorType, List[Tuple]] = None
- ):
- """
- Converts the output of [`DeformableDetrForObjectDetection`] into the format expected by the COCO api. Only
- supports PyTorch.
-
- Args:
- outputs ([`DetrObjectDetectionOutput`]):
- Raw outputs of the model.
- threshold (`float`, *optional*):
- Score threshold to keep object detection predictions.
- target_sizes (`torch.Tensor` or `List[Tuple[int, int]]`, *optional*, defaults to `None`):
- Tensor of shape `(batch_size, 2)` or list of tuples (`Tuple[int, int]`) containing the target size
- (height, width) of each image in the batch. If left to None, predictions will not be resized.
-
- Returns:
- `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
- in the batch as predicted by the model.
- """
- out_logits, out_bbox = outputs.logits, outputs.pred_boxes
-
- if target_sizes is not None:
- if len(out_logits) != len(target_sizes):
- raise ValueError(
- "Make sure that you pass in as many target sizes as the batch dimension of the logits"
- )
-
- prob = out_logits.sigmoid()
- topk_values, topk_indexes = torch.topk(prob.view(out_logits.shape[0], -1), 100, dim=1)
- scores = topk_values
- topk_boxes = topk_indexes // out_logits.shape[2]
- labels = topk_indexes % out_logits.shape[2]
- boxes = center_to_corners_format(out_bbox)
- boxes = torch.gather(boxes, 1, topk_boxes.unsqueeze(-1).repeat(1, 1, 4))
-
- # and from relative [0, 1] to absolute [0, height] coordinates
- if isinstance(target_sizes, List):
- img_h = torch.Tensor([i[0] for i in target_sizes])
- img_w = torch.Tensor([i[1] for i in target_sizes])
- else:
- img_h, img_w = target_sizes.unbind(1)
- scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1).to(boxes.device)
- boxes = boxes * scale_fct[:, None, :]
-
- results = []
- for s, l, b in zip(scores, labels, boxes):
- score = s[s > threshold]
- label = l[s > threshold]
- box = b[s > threshold]
- results.append({"scores": score, "labels": label, "boxes": box})
-
- return results
+DeformableDetrFeatureExtractor = DeformableDetrImageProcessor
diff --git a/src/transformers/models/deformable_detr/image_processing_deformable_detr.py b/src/transformers/models/deformable_detr/image_processing_deformable_detr.py
new file mode 100644
index 0000000000..c1b71d629f
--- /dev/null
+++ b/src/transformers/models/deformable_detr/image_processing_deformable_detr.py
@@ -0,0 +1,1350 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Image processor class for Deformable DETR."""
+
+import io
+import pathlib
+import warnings
+from collections import defaultdict
+from typing import Any, Callable, Dict, Iterable, List, Optional, Set, Tuple, Union
+
+import numpy as np
+
+from transformers.feature_extraction_utils import BatchFeature
+from transformers.image_processing_utils import BaseImageProcessor, get_size_dict
+from transformers.image_transforms import (
+ PaddingMode,
+ center_to_corners_format,
+ corners_to_center_format,
+ id_to_rgb,
+ normalize,
+ pad,
+ rescale,
+ resize,
+ rgb_to_id,
+ to_channel_dimension_format,
+)
+from transformers.image_utils import (
+ IMAGENET_DEFAULT_MEAN,
+ IMAGENET_DEFAULT_STD,
+ ChannelDimension,
+ ImageInput,
+ PILImageResampling,
+ get_image_size,
+ infer_channel_dimension_format,
+ is_batched,
+ to_numpy_array,
+ valid_coco_detection_annotations,
+ valid_coco_panoptic_annotations,
+ valid_images,
+)
+from transformers.utils import (
+ is_flax_available,
+ is_jax_tensor,
+ is_scipy_available,
+ is_tf_available,
+ is_tf_tensor,
+ is_torch_available,
+ is_torch_tensor,
+ is_vision_available,
+)
+from transformers.utils.generic import ExplicitEnum, TensorType
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+
+if is_vision_available():
+ import PIL
+
+if is_scipy_available():
+ import scipy.special
+ import scipy.stats
+
+
+class AnnotionFormat(ExplicitEnum):
+ COCO_DETECTION = "coco_detection"
+ COCO_PANOPTIC = "coco_panoptic"
+
+
+SUPPORTED_ANNOTATION_FORMATS = (AnnotionFormat.COCO_DETECTION, AnnotionFormat.COCO_PANOPTIC)
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_size_with_aspect_ratio
+def get_size_with_aspect_ratio(image_size, size, max_size=None) -> Tuple[int, int]:
+ """
+ Computes the output image size given the input image size and the desired output size.
+
+ Args:
+ image_size (`Tuple[int, int]`):
+ The input image size.
+ size (`int`):
+ The desired output size.
+ max_size (`int`, *optional*):
+ The maximum allowed output size.
+ """
+ height, width = image_size
+ if max_size is not None:
+ min_original_size = float(min((height, width)))
+ max_original_size = float(max((height, width)))
+ if max_original_size / min_original_size * size > max_size:
+ size = int(round(max_size * min_original_size / max_original_size))
+
+ if (height <= width and height == size) or (width <= height and width == size):
+ return height, width
+
+ if width < height:
+ ow = size
+ oh = int(size * height / width)
+ else:
+ oh = size
+ ow = int(size * width / height)
+ return (oh, ow)
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_resize_output_image_size
+def get_resize_output_image_size(
+ input_image: np.ndarray, size: Union[int, Tuple[int, int], List[int]], max_size: Optional[int] = None
+) -> Tuple[int, int]:
+ """
+ Computes the output image size given the input image size and the desired output size. If the desired output size
+ is a tuple or list, the output image size is returned as is. If the desired output size is an integer, the output
+ image size is computed by keeping the aspect ratio of the input image size.
+
+ Args:
+ image_size (`Tuple[int, int]`):
+ The input image size.
+ size (`int`):
+ The desired output size.
+ max_size (`int`, *optional*):
+ The maximum allowed output size.
+ """
+ image_size = get_image_size(input_image)
+ if isinstance(size, (list, tuple)):
+ return size
+
+ return get_size_with_aspect_ratio(image_size, size, max_size)
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_numpy_to_framework_fn
+def get_numpy_to_framework_fn(arr) -> Callable:
+ """
+ Returns a function that converts a numpy array to the framework of the input array.
+
+ Args:
+ arr (`np.ndarray`): The array to convert.
+ """
+ if isinstance(arr, np.ndarray):
+ return np.array
+ if is_tf_available() and is_tf_tensor(arr):
+ import tensorflow as tf
+
+ return tf.convert_to_tensor
+ if is_torch_available() and is_torch_tensor(arr):
+ import torch
+
+ return torch.tensor
+ if is_flax_available() and is_jax_tensor(arr):
+ import jax.numpy as jnp
+
+ return jnp.array
+ raise ValueError(f"Cannot convert arrays of type {type(arr)}")
+
+
+# Copied from transformers.models.detr.image_processing_detr.safe_squeeze
+def safe_squeeze(arr: np.ndarray, axis: Optional[int] = None) -> np.ndarray:
+ """
+ Squeezes an array, but only if the axis specified has dim 1.
+ """
+ if axis is None:
+ return arr.squeeze()
+
+ try:
+ return arr.squeeze(axis=axis)
+ except ValueError:
+ return arr
+
+
+# Copied from transformers.models.detr.image_processing_detr.normalize_annotation
+def normalize_annotation(annotation: Dict, image_size: Tuple[int, int]) -> Dict:
+ image_height, image_width = image_size
+ norm_annotation = {}
+ for key, value in annotation.items():
+ if key == "boxes":
+ boxes = value
+ boxes = corners_to_center_format(boxes)
+ boxes /= np.asarray([image_width, image_height, image_width, image_height], dtype=np.float32)
+ norm_annotation[key] = boxes
+ else:
+ norm_annotation[key] = value
+ return norm_annotation
+
+
+# Copied from transformers.models.detr.image_processing_detr.max_across_indices
+def max_across_indices(values: Iterable[Any]) -> List[Any]:
+ """
+ Return the maximum value across all indices of an iterable of values.
+ """
+ return [max(values_i) for values_i in zip(*values)]
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_max_height_width
+def get_max_height_width(images: List[np.ndarray]) -> List[int]:
+ """
+ Get the maximum height and width across all images in a batch.
+ """
+ input_channel_dimension = infer_channel_dimension_format(images[0])
+
+ if input_channel_dimension == ChannelDimension.FIRST:
+ _, max_height, max_width = max_across_indices([img.shape for img in images])
+ elif input_channel_dimension == ChannelDimension.LAST:
+ max_height, max_width, _ = max_across_indices([img.shape for img in images])
+ else:
+ raise ValueError(f"Invalid channel dimension format: {input_channel_dimension}")
+ return (max_height, max_width)
+
+
+# Copied from transformers.models.detr.image_processing_detr.make_pixel_mask
+def make_pixel_mask(image: np.ndarray, output_size: Tuple[int, int]) -> np.ndarray:
+ """
+ Make a pixel mask for the image, where 1 indicates a valid pixel and 0 indicates padding.
+
+ Args:
+ image (`np.ndarray`):
+ Image to make the pixel mask for.
+ output_size (`Tuple[int, int]`):
+ Output size of the mask.
+ """
+ input_height, input_width = get_image_size(image)
+ mask = np.zeros(output_size, dtype=np.int64)
+ mask[:input_height, :input_width] = 1
+ return mask
+
+
+# Copied from transformers.models.detr.image_processing_detr.convert_coco_poly_to_mask
+def convert_coco_poly_to_mask(segmentations, height: int, width: int) -> np.ndarray:
+ """
+ Convert a COCO polygon annotation to a mask.
+
+ Args:
+ segmentations (`List[List[float]]`):
+ List of polygons, each polygon represented by a list of x-y coordinates.
+ height (`int`):
+ Height of the mask.
+ width (`int`):
+ Width of the mask.
+ """
+ try:
+ from pycocotools import mask as coco_mask
+ except ImportError:
+ raise ImportError("Pycocotools is not installed in your environment.")
+
+ masks = []
+ for polygons in segmentations:
+ rles = coco_mask.frPyObjects(polygons, height, width)
+ mask = coco_mask.decode(rles)
+ if len(mask.shape) < 3:
+ mask = mask[..., None]
+ mask = np.asarray(mask, dtype=np.uint8)
+ mask = np.any(mask, axis=2)
+ masks.append(mask)
+ if masks:
+ masks = np.stack(masks, axis=0)
+ else:
+ masks = np.zeros((0, height, width), dtype=np.uint8)
+
+ return masks
+
+
+# Copied from transformers.models.detr.image_processing_detr.prepare_coco_detection_annotation with DETR->DeformableDetr
+def prepare_coco_detection_annotation(image, target, return_segmentation_masks: bool = False):
+ """
+ Convert the target in COCO format into the format expected by DeformableDetr.
+ """
+ image_height, image_width = get_image_size(image)
+
+ image_id = target["image_id"]
+ image_id = np.asarray([image_id], dtype=np.int64)
+
+ # Get all COCO annotations for the given image.
+ annotations = target["annotations"]
+ annotations = [obj for obj in annotations if "iscrowd" not in obj or obj["iscrowd"] == 0]
+
+ classes = [obj["category_id"] for obj in annotations]
+ classes = np.asarray(classes, dtype=np.int64)
+
+ # for conversion to coco api
+ area = np.asarray([obj["area"] for obj in annotations], dtype=np.float32)
+ iscrowd = np.asarray([obj["iscrowd"] if "iscrowd" in obj else 0 for obj in annotations], dtype=np.int64)
+
+ boxes = [obj["bbox"] for obj in annotations]
+ # guard against no boxes via resizing
+ boxes = np.asarray(boxes, dtype=np.float32).reshape(-1, 4)
+ boxes[:, 2:] += boxes[:, :2]
+ boxes[:, 0::2] = boxes[:, 0::2].clip(min=0, max=image_width)
+ boxes[:, 1::2] = boxes[:, 1::2].clip(min=0, max=image_height)
+
+ keep = (boxes[:, 3] > boxes[:, 1]) & (boxes[:, 2] > boxes[:, 0])
+
+ new_target = {}
+ new_target["image_id"] = image_id
+ new_target["class_labels"] = classes[keep]
+ new_target["boxes"] = boxes[keep]
+ new_target["area"] = area[keep]
+ new_target["iscrowd"] = iscrowd[keep]
+ new_target["orig_size"] = np.asarray([int(image_height), int(image_width)], dtype=np.int64)
+
+ if annotations and "keypoints" in annotations[0]:
+ keypoints = [obj["keypoints"] for obj in annotations]
+ keypoints = np.asarray(keypoints, dtype=np.float32)
+ num_keypoints = keypoints.shape[0]
+ keypoints = keypoints.reshape((-1, 3)) if num_keypoints else keypoints
+ new_target["keypoints"] = keypoints[keep]
+
+ if return_segmentation_masks:
+ segmentation_masks = [obj["segmentation"] for obj in annotations]
+ masks = convert_coco_poly_to_mask(segmentation_masks, image_height, image_width)
+ new_target["masks"] = masks[keep]
+
+ return new_target
+
+
+# Copied from transformers.models.detr.image_processing_detr.masks_to_boxes
+def masks_to_boxes(masks: np.ndarray) -> np.ndarray:
+ """
+ Compute the bounding boxes around the provided panoptic segmentation masks.
+
+ Args:
+ masks: masks in format `[number_masks, height, width]` where N is the number of masks
+
+ Returns:
+ boxes: bounding boxes in format `[number_masks, 4]` in xyxy format
+ """
+ if masks.size == 0:
+ return np.zeros((0, 4))
+
+ h, w = masks.shape[-2:]
+ y = np.arange(0, h, dtype=np.float32)
+ x = np.arange(0, w, dtype=np.float32)
+ # see https://github.com/pytorch/pytorch/issues/50276
+ y, x = np.meshgrid(y, x, indexing="ij")
+
+ x_mask = masks * np.expand_dims(x, axis=0)
+ x_max = x_mask.reshape(x_mask.shape[0], -1).max(-1)
+ x = np.ma.array(x_mask, mask=~(np.array(masks, dtype=bool)))
+ x_min = x.filled(fill_value=1e8)
+ x_min = x_min.reshape(x_min.shape[0], -1).min(-1)
+
+ y_mask = masks * np.expand_dims(y, axis=0)
+ y_max = y_mask.reshape(x_mask.shape[0], -1).max(-1)
+ y = np.ma.array(y_mask, mask=~(np.array(masks, dtype=bool)))
+ y_min = y.filled(fill_value=1e8)
+ y_min = y_min.reshape(y_min.shape[0], -1).min(-1)
+
+ return np.stack([x_min, y_min, x_max, y_max], 1)
+
+
+# Copied from transformers.models.detr.image_processing_detr.prepare_coco_panoptic_annotation with DETR->DeformableDetr
+def prepare_coco_panoptic_annotation(
+ image: np.ndarray, target: Dict, masks_path: Union[str, pathlib.Path], return_masks: bool = True
+) -> Dict:
+ """
+ Prepare a coco panoptic annotation for DeformableDetr.
+ """
+ image_height, image_width = get_image_size(image)
+ annotation_path = pathlib.Path(masks_path) / target["file_name"]
+
+ new_target = {}
+ new_target["image_id"] = np.asarray([target["image_id"] if "image_id" in target else target["id"]], dtype=np.int64)
+ new_target["size"] = np.asarray([image_height, image_width], dtype=np.int64)
+ new_target["orig_size"] = np.asarray([image_height, image_width], dtype=np.int64)
+
+ if "segments_info" in target:
+ masks = np.asarray(PIL.Image.open(annotation_path), dtype=np.uint32)
+ masks = rgb_to_id(masks)
+
+ ids = np.array([segment_info["id"] for segment_info in target["segments_info"]])
+ masks = masks == ids[:, None, None]
+ masks = masks.astype(np.uint8)
+ if return_masks:
+ new_target["masks"] = masks
+ new_target["boxes"] = masks_to_boxes(masks)
+ new_target["class_labels"] = np.array(
+ [segment_info["category_id"] for segment_info in target["segments_info"]], dtype=np.int64
+ )
+ new_target["iscrowd"] = np.asarray(
+ [segment_info["iscrowd"] for segment_info in target["segments_info"]], dtype=np.int64
+ )
+ new_target["area"] = np.asarray(
+ [segment_info["area"] for segment_info in target["segments_info"]], dtype=np.float32
+ )
+
+ return new_target
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_segmentation_image
+def get_segmentation_image(
+ masks: np.ndarray, input_size: Tuple, target_size: Tuple, stuff_equiv_classes, deduplicate=False
+):
+ h, w = input_size
+ final_h, final_w = target_size
+
+ m_id = scipy.special.softmax(masks.transpose(0, 1), -1)
+
+ if m_id.shape[-1] == 0:
+ # We didn't detect any mask :(
+ m_id = np.zeros((h, w), dtype=np.int64)
+ else:
+ m_id = m_id.argmax(-1).reshape(h, w)
+
+ if deduplicate:
+ # Merge the masks corresponding to the same stuff class
+ for equiv in stuff_equiv_classes.values():
+ for eq_id in equiv:
+ m_id[m_id == eq_id] = equiv[0]
+
+ seg_img = id_to_rgb(m_id)
+ seg_img = resize(seg_img, (final_w, final_h), resample=PILImageResampling.NEAREST)
+ return seg_img
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_mask_area
+def get_mask_area(seg_img: np.ndarray, target_size: Tuple[int, int], n_classes: int) -> np.ndarray:
+ final_h, final_w = target_size
+ np_seg_img = seg_img.astype(np.uint8)
+ np_seg_img = np_seg_img.reshape(final_h, final_w, 3)
+ m_id = rgb_to_id(np_seg_img)
+ area = [(m_id == i).sum() for i in range(n_classes)]
+ return area
+
+
+# Copied from transformers.models.detr.image_processing_detr.score_labels_from_class_probabilities
+def score_labels_from_class_probabilities(logits: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
+ probs = scipy.special.softmax(logits, axis=-1)
+ labels = probs.argmax(-1, keepdims=True)
+ scores = np.take_along_axis(probs, labels, axis=-1)
+ scores, labels = scores.squeeze(-1), labels.squeeze(-1)
+ return scores, labels
+
+
+# Copied from transformers.models.detr.image_processing_detr.post_process_panoptic_sample
+def post_process_panoptic_sample(
+ out_logits: np.ndarray,
+ masks: np.ndarray,
+ boxes: np.ndarray,
+ processed_size: Tuple[int, int],
+ target_size: Tuple[int, int],
+ is_thing_map: Dict,
+ threshold=0.85,
+) -> Dict:
+ """
+ Converts the output of [`DetrForSegmentation`] into panoptic segmentation predictions for a single sample.
+
+ Args:
+ out_logits (`torch.Tensor`):
+ The logits for this sample.
+ masks (`torch.Tensor`):
+ The predicted segmentation masks for this sample.
+ boxes (`torch.Tensor`):
+ The prediced bounding boxes for this sample. The boxes are in the normalized format `(center_x, center_y,
+ width, height)` and values between `[0, 1]`, relative to the size the image (disregarding padding).
+ processed_size (`Tuple[int, int]`):
+ The processed size of the image `(height, width)`, as returned by the preprocessing step i.e. the size
+ after data augmentation but before batching.
+ target_size (`Tuple[int, int]`):
+ The target size of the image, `(height, width)` corresponding to the requested final size of the
+ prediction.
+ is_thing_map (`Dict`):
+ A dictionary mapping class indices to a boolean value indicating whether the class is a thing or not.
+ threshold (`float`, *optional*, defaults to 0.85):
+ The threshold used to binarize the segmentation masks.
+ """
+ # we filter empty queries and detection below threshold
+ scores, labels = score_labels_from_class_probabilities(out_logits)
+ keep = (labels != out_logits.shape[-1] - 1) & (scores > threshold)
+
+ cur_scores = scores[keep]
+ cur_classes = labels[keep]
+ cur_boxes = center_to_corners_format(boxes[keep])
+
+ if len(cur_boxes) != len(cur_classes):
+ raise ValueError("Not as many boxes as there are classes")
+
+ cur_masks = masks[keep]
+ cur_masks = resize(cur_masks[:, None], processed_size, resample=PILImageResampling.BILINEAR)
+ cur_masks = safe_squeeze(cur_masks, 1)
+ b, h, w = cur_masks.shape
+
+ # It may be that we have several predicted masks for the same stuff class.
+ # In the following, we track the list of masks ids for each stuff class (they are merged later on)
+ cur_masks = cur_masks.reshape(b, -1)
+ stuff_equiv_classes = defaultdict(list)
+ for k, label in enumerate(cur_classes):
+ if not is_thing_map[label]:
+ stuff_equiv_classes[label].append(k)
+
+ seg_img = get_segmentation_image(cur_masks, processed_size, target_size, stuff_equiv_classes, deduplicate=True)
+ area = get_mask_area(cur_masks, processed_size, n_classes=len(cur_scores))
+
+ # We filter out any mask that is too small
+ if cur_classes.size() > 0:
+ # We know filter empty masks as long as we find some
+ filtered_small = np.array([a <= 4 for a in area], dtype=bool)
+ while filtered_small.any():
+ cur_masks = cur_masks[~filtered_small]
+ cur_scores = cur_scores[~filtered_small]
+ cur_classes = cur_classes[~filtered_small]
+ seg_img = get_segmentation_image(cur_masks, (h, w), target_size, stuff_equiv_classes, deduplicate=True)
+ area = get_mask_area(seg_img, target_size, n_classes=len(cur_scores))
+ filtered_small = np.array([a <= 4 for a in area], dtype=bool)
+ else:
+ cur_classes = np.ones((1, 1), dtype=np.int64)
+
+ segments_info = [
+ {"id": i, "isthing": is_thing_map[cat], "category_id": int(cat), "area": a}
+ for i, (cat, a) in enumerate(zip(cur_classes, area))
+ ]
+ del cur_classes
+
+ with io.BytesIO() as out:
+ PIL.Image.fromarray(seg_img).save(out, format="PNG")
+ predictions = {"png_string": out.getvalue(), "segments_info": segments_info}
+
+ return predictions
+
+
+# Copied from transformers.models.detr.image_processing_detr.resize_annotation
+def resize_annotation(
+ annotation: Dict[str, Any],
+ orig_size: Tuple[int, int],
+ target_size: Tuple[int, int],
+ threshold: float = 0.5,
+ resample: PILImageResampling = PILImageResampling.NEAREST,
+):
+ """
+ Resizes an annotation to a target size.
+
+ Args:
+ annotation (`Dict[str, Any]`):
+ The annotation dictionary.
+ orig_size (`Tuple[int, int]`):
+ The original size of the input image.
+ target_size (`Tuple[int, int]`):
+ The target size of the image, as returned by the preprocessing `resize` step.
+ threshold (`float`, *optional*, defaults to 0.5):
+ The threshold used to binarize the segmentation masks.
+ resample (`PILImageResampling`, defaults to `PILImageResampling.NEAREST`):
+ The resampling filter to use when resizing the masks.
+ """
+ ratios = tuple(float(s) / float(s_orig) for s, s_orig in zip(target_size, orig_size))
+ ratio_height, ratio_width = ratios
+
+ new_annotation = {}
+ new_annotation["size"] = target_size
+
+ for key, value in annotation.items():
+ if key == "boxes":
+ boxes = value
+ scaled_boxes = boxes * np.asarray([ratio_width, ratio_height, ratio_width, ratio_height], dtype=np.float32)
+ new_annotation["boxes"] = scaled_boxes
+ elif key == "area":
+ area = value
+ scaled_area = area * (ratio_width * ratio_height)
+ new_annotation["area"] = scaled_area
+ elif key == "masks":
+ masks = value[:, None]
+ masks = np.array([resize(mask, target_size, resample=resample) for mask in masks])
+ masks = masks.astype(np.float32)
+ masks = masks[:, 0] > threshold
+ new_annotation["masks"] = masks
+ elif key == "size":
+ new_annotation["size"] = target_size
+ else:
+ new_annotation[key] = value
+
+ return new_annotation
+
+
+# Copied from transformers.models.detr.image_processing_detr.binary_mask_to_rle
+def binary_mask_to_rle(mask):
+ """
+ Converts given binary mask of shape `(height, width)` to the run-length encoding (RLE) format.
+
+ Args:
+ mask (`torch.Tensor` or `numpy.array`):
+ A binary mask tensor of shape `(height, width)` where 0 denotes background and 1 denotes the target
+ segment_id or class_id.
+ Returns:
+ `List`: Run-length encoded list of the binary mask. Refer to COCO API for more information about the RLE
+ format.
+ """
+ if is_torch_tensor(mask):
+ mask = mask.numpy()
+
+ pixels = mask.flatten()
+ pixels = np.concatenate([[0], pixels, [0]])
+ runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
+ runs[1::2] -= runs[::2]
+ return [x for x in runs]
+
+
+# Copied from transformers.models.detr.image_processing_detr.convert_segmentation_to_rle
+def convert_segmentation_to_rle(segmentation):
+ """
+ Converts given segmentation map of shape `(height, width)` to the run-length encoding (RLE) format.
+
+ Args:
+ segmentation (`torch.Tensor` or `numpy.array`):
+ A segmentation map of shape `(height, width)` where each value denotes a segment or class id.
+ Returns:
+ `List[List]`: A list of lists, where each list is the run-length encoding of a segment / class id.
+ """
+ segment_ids = torch.unique(segmentation)
+
+ run_length_encodings = []
+ for idx in segment_ids:
+ mask = torch.where(segmentation == idx, 1, 0)
+ rle = binary_mask_to_rle(mask)
+ run_length_encodings.append(rle)
+
+ return run_length_encodings
+
+
+# Copied from transformers.models.detr.image_processing_detr.remove_low_and_no_objects
+def remove_low_and_no_objects(masks, scores, labels, object_mask_threshold, num_labels):
+ """
+ Binarize the given masks using `object_mask_threshold`, it returns the associated values of `masks`, `scores` and
+ `labels`.
+
+ Args:
+ masks (`torch.Tensor`):
+ A tensor of shape `(num_queries, height, width)`.
+ scores (`torch.Tensor`):
+ A tensor of shape `(num_queries)`.
+ labels (`torch.Tensor`):
+ A tensor of shape `(num_queries)`.
+ object_mask_threshold (`float`):
+ A number between 0 and 1 used to binarize the masks.
+ Raises:
+ `ValueError`: Raised when the first dimension doesn't match in all input tensors.
+ Returns:
+ `Tuple[`torch.Tensor`, `torch.Tensor`, `torch.Tensor`]`: The `masks`, `scores` and `labels` without the region
+ < `object_mask_threshold`.
+ """
+ if not (masks.shape[0] == scores.shape[0] == labels.shape[0]):
+ raise ValueError("mask, scores and labels must have the same shape!")
+
+ to_keep = labels.ne(num_labels) & (scores > object_mask_threshold)
+
+ return masks[to_keep], scores[to_keep], labels[to_keep]
+
+
+# Copied from transformers.models.detr.image_processing_detr.check_segment_validity
+def check_segment_validity(mask_labels, mask_probs, k, mask_threshold=0.5, overlap_mask_area_threshold=0.8):
+ # Get the mask associated with the k class
+ mask_k = mask_labels == k
+ mask_k_area = mask_k.sum()
+
+ # Compute the area of all the stuff in query k
+ original_area = (mask_probs[k] >= mask_threshold).sum()
+ mask_exists = mask_k_area > 0 and original_area > 0
+
+ # Eliminate disconnected tiny segments
+ if mask_exists:
+ area_ratio = mask_k_area / original_area
+ if not area_ratio.item() > overlap_mask_area_threshold:
+ mask_exists = False
+
+ return mask_exists, mask_k
+
+
+# Copied from transformers.models.detr.image_processing_detr.compute_segments
+def compute_segments(
+ mask_probs,
+ pred_scores,
+ pred_labels,
+ mask_threshold: float = 0.5,
+ overlap_mask_area_threshold: float = 0.8,
+ label_ids_to_fuse: Optional[Set[int]] = None,
+ target_size: Tuple[int, int] = None,
+):
+ height = mask_probs.shape[1] if target_size is None else target_size[0]
+ width = mask_probs.shape[2] if target_size is None else target_size[1]
+
+ segmentation = torch.zeros((height, width), dtype=torch.int32, device=mask_probs.device)
+ segments: List[Dict] = []
+
+ if target_size is not None:
+ mask_probs = nn.functional.interpolate(
+ mask_probs.unsqueeze(0), size=target_size, mode="bilinear", align_corners=False
+ )[0]
+
+ current_segment_id = 0
+
+ # Weigh each mask by its prediction score
+ mask_probs *= pred_scores.view(-1, 1, 1)
+ mask_labels = mask_probs.argmax(0) # [height, width]
+
+ # Keep track of instances of each class
+ stuff_memory_list: Dict[str, int] = {}
+ for k in range(pred_labels.shape[0]):
+ pred_class = pred_labels[k].item()
+ should_fuse = pred_class in label_ids_to_fuse
+
+ # Check if mask exists and large enough to be a segment
+ mask_exists, mask_k = check_segment_validity(
+ mask_labels, mask_probs, k, mask_threshold, overlap_mask_area_threshold
+ )
+
+ if mask_exists:
+ if pred_class in stuff_memory_list:
+ current_segment_id = stuff_memory_list[pred_class]
+ else:
+ current_segment_id += 1
+
+ # Add current object segment to final segmentation map
+ segmentation[mask_k] = current_segment_id
+ segment_score = round(pred_scores[k].item(), 6)
+ segments.append(
+ {
+ "id": current_segment_id,
+ "label_id": pred_class,
+ "was_fused": should_fuse,
+ "score": segment_score,
+ }
+ )
+ if should_fuse:
+ stuff_memory_list[pred_class] = current_segment_id
+
+ return segmentation, segments
+
+
+class DeformableDetrImageProcessor(BaseImageProcessor):
+ r"""
+ Constructs a Deformable DETR image processor.
+
+ Args:
+ format (`str`, *optional*, defaults to `"coco_detection"`):
+ Data format of the annotations. One of "coco_detection" or "coco_panoptic".
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Controls whether to resize the image's (height, width) dimensions to the specified `size`. Can be
+ overridden by the `do_resize` parameter in the `preprocess` method.
+ size (`Dict[str, int]` *optional*, defaults to `{"shortest_edge": 800, "longest_edge": 1333}`):
+ Size of the image's (height, width) dimensions after resizing. Can be overridden by the `size` parameter in
+ the `preprocess` method.
+ resample (`PILImageResampling`, *optional*, defaults to `PILImageResampling.BILINEAR`):
+ Resampling filter to use if resizing the image.
+ do_rescale (`bool`, *optional*, defaults to `True`):
+ Controls whether to rescale the image by the specified scale `rescale_factor`. Can be overridden by the
+ `do_rescale` parameter in the `preprocess` method.
+ rescale_factor (`int` or `float`, *optional*, defaults to `1/255`):
+ Scale factor to use if rescaling the image. Can be overridden by the `rescale_factor` parameter in the
+ `preprocess` method.
+ do_normalize:
+ Controls whether to normalize the image. Can be overridden by the `do_normalize` parameter in the
+ `preprocess` method.
+ image_mean (`float` or `List[float]`, *optional*, defaults to `IMAGENET_DEFAULT_MEAN`):
+ Mean values to use when normalizing the image. Can be a single value or a list of values, one for each
+ channel. Can be overridden by the `image_mean` parameter in the `preprocess` method.
+ image_std (`float` or `List[float]`, *optional*, defaults to `IMAGENET_DEFAULT_STD`):
+ Standard deviation values to use when normalizing the image. Can be a single value or a list of values, one
+ for each channel. Can be overridden by the `image_std` parameter in the `preprocess` method.
+ do_pad (`bool`, *optional*, defaults to `True`):
+ Controls whether to pad the image to the largest image in a batch and create a pixel mask. Can be
+ overridden by the `do_pad` parameter in the `preprocess` method.
+ """
+
+ model_input_names = ["pixel_values", "pixel_mask"]
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.__init__
+ def __init__(
+ self,
+ format: Union[str, AnnotionFormat] = AnnotionFormat.COCO_DETECTION,
+ do_resize: bool = True,
+ size: Dict[str, int] = None,
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ do_rescale: bool = True,
+ rescale_factor: Union[int, float] = 1 / 255,
+ do_normalize: bool = True,
+ image_mean: Union[float, List[float]] = None,
+ image_std: Union[float, List[float]] = None,
+ do_pad: bool = True,
+ **kwargs
+ ) -> None:
+ if "pad_and_return_pixel_mask" in kwargs:
+ do_pad = kwargs.pop("pad_and_return_pixel_mask")
+
+ if "max_size" in kwargs:
+ warnings.warn(
+ "The `max_size` parameter is deprecated and will be removed in v4.26. "
+ "Please specify in `size['longest_edge'] instead`.",
+ FutureWarning,
+ )
+ max_size = kwargs.pop("max_size")
+ else:
+ max_size = None if size is None else 1333
+
+ size = size if size is not None else {"shortest_edge": 800, "longest_edge": 1333}
+ size = get_size_dict(size, max_size=max_size, default_to_square=False)
+
+ super().__init__(**kwargs)
+ self.format = format
+ self.do_resize = do_resize
+ self.size = size
+ self.resample = resample
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean if image_mean is not None else IMAGENET_DEFAULT_MEAN
+ self.image_std = image_std if image_std is not None else IMAGENET_DEFAULT_STD
+ self.do_pad = do_pad
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare_annotation with DETR->DeformableDetr
+ def prepare_annotation(
+ self,
+ image: np.ndarray,
+ target: Dict,
+ format: Optional[AnnotionFormat] = None,
+ return_segmentation_masks: bool = None,
+ masks_path: Optional[Union[str, pathlib.Path]] = None,
+ ) -> Dict:
+ """
+ Prepare an annotation for feeding into DeformableDetr model.
+ """
+ format = format if format is not None else self.format
+
+ if format == AnnotionFormat.COCO_DETECTION:
+ return_segmentation_masks = False if return_segmentation_masks is None else return_segmentation_masks
+ target = prepare_coco_detection_annotation(image, target, return_segmentation_masks)
+ elif format == AnnotionFormat.COCO_PANOPTIC:
+ return_segmentation_masks = True if return_segmentation_masks is None else return_segmentation_masks
+ target = prepare_coco_panoptic_annotation(
+ image, target, masks_path=masks_path, return_masks=return_segmentation_masks
+ )
+ else:
+ raise ValueError(f"Format {format} is not supported.")
+ return target
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare
+ def prepare(self, image, target, return_segmentation_masks=None, masks_path=None):
+ warnings.warn(
+ "The `prepare` method is deprecated and will be removed in a future version. "
+ "Please use `prepare_annotation` instead. Note: the `prepare_annotation` method "
+ "does not return the image anymore.",
+ )
+ target = self.prepare_annotation(image, target, return_segmentation_masks, masks_path, self.format)
+ return image, target
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.convert_coco_poly_to_mask
+ def convert_coco_poly_to_mask(self, *args, **kwargs):
+ warnings.warn("The `convert_coco_poly_to_mask` method is deprecated and will be removed in a future version. ")
+ return convert_coco_poly_to_mask(*args, **kwargs)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare_coco_detection
+ def prepare_coco_detection(self, *args, **kwargs):
+ warnings.warn("The `prepare_coco_detection` method is deprecated and will be removed in a future version. ")
+ return prepare_coco_detection_annotation(*args, **kwargs)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare_coco_panoptic
+ def prepare_coco_panoptic(self, *args, **kwargs):
+ warnings.warn("The `prepare_coco_panoptic` method is deprecated and will be removed in a future version. ")
+ return prepare_coco_panoptic_annotation(*args, **kwargs)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.resize
+ def resize(
+ self,
+ image: np.ndarray,
+ size: Dict[str, int],
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ data_format: Optional[ChannelDimension] = None,
+ **kwargs
+ ) -> np.ndarray:
+ """
+ Resize the image to the given size. Size can be `min_size` (scalar) or `(height, width)` tuple. If size is an
+ int, smaller edge of the image will be matched to this number.
+ """
+ if "max_size" in kwargs:
+ warnings.warn(
+ "The `max_size` parameter is deprecated and will be removed in v4.26. "
+ "Please specify in `size['longest_edge'] instead`.",
+ FutureWarning,
+ )
+ max_size = kwargs.pop("max_size")
+ else:
+ max_size = None
+ size = get_size_dict(size, max_size=max_size, default_to_square=False)
+ if "shortest_edge" in size and "longest_edge" in size:
+ size = get_resize_output_image_size(image, size["shortest_edge"], size["longest_edge"])
+ elif "height" in size and "width" in size:
+ size = (size["height"], size["width"])
+ else:
+ raise ValueError(
+ "Size must contain 'height' and 'width' keys or 'shortest_edge' and 'longest_edge' keys. Got"
+ f" {size.keys()}."
+ )
+ image = resize(image, size=size, resample=resample, data_format=data_format)
+ return image
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.resize_annotation
+ def resize_annotation(
+ self,
+ annotation,
+ orig_size,
+ size,
+ resample: PILImageResampling = PILImageResampling.NEAREST,
+ ) -> Dict:
+ """
+ Resize the annotation to match the resized image. If size is an int, smaller edge of the mask will be matched
+ to this number.
+ """
+ return resize_annotation(annotation, orig_size=orig_size, target_size=size, resample=resample)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.rescale
+ def rescale(
+ self, image: np.ndarray, rescale_factor: Union[float, int], data_format: Optional[ChannelDimension] = None
+ ) -> np.ndarray:
+ """
+ Rescale the image by the given factor.
+ """
+ return rescale(image, rescale_factor, data_format=data_format)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.normalize
+ def normalize(
+ self,
+ image: np.ndarray,
+ mean: Union[float, Iterable[float]],
+ std: Union[float, Iterable[float]],
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Normalize the image with the given mean and standard deviation.
+ """
+ return normalize(image, mean=mean, std=std, data_format=data_format)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.normalize_annotation
+ def normalize_annotation(self, annotation: Dict, image_size: Tuple[int, int]) -> Dict:
+ """
+ Normalize the boxes in the annotation from `[top_left_x, top_left_y, bottom_right_x, bottom_right_y]` to
+ `[center_x, center_y, width, height]` format.
+ """
+ return normalize_annotation(annotation, image_size=image_size)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.pad_and_create_pixel_mask
+ def pad_and_create_pixel_mask(
+ self,
+ pixel_values_list: List[ImageInput],
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ data_format: Optional[ChannelDimension] = None,
+ ) -> BatchFeature:
+ """
+ Pads a batch of images with zeros to the size of largest height and width in the batch and returns their
+ corresponding pixel mask.
+
+ Args:
+ images (`List[np.ndarray]`):
+ Batch of images to pad.
+ return_tensors (`str` or `TensorType`, *optional*):
+ The type of tensors to return. Can be one of:
+ - Unset: Return a list of `np.ndarray`.
+ - `TensorType.TENSORFLOW` or `'tf'`: Return a batch of type `tf.Tensor`.
+ - `TensorType.PYTORCH` or `'pt'`: Return a batch of type `torch.Tensor`.
+ - `TensorType.NUMPY` or `'np'`: Return a batch of type `np.ndarray`.
+ - `TensorType.JAX` or `'jax'`: Return a batch of type `jax.numpy.ndarray`.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be the same as the input image.
+ """
+ warnings.warn(
+ "This method is deprecated and will be removed in v4.27.0. Please use pad instead.", FutureWarning
+ )
+ # pad expects a list of np.ndarray, but the previous feature extractors expected torch tensors
+ images = [to_numpy_array(image) for image in pixel_values_list]
+ return self.pad(
+ images=images,
+ return_pixel_mask=True,
+ return_tensors=return_tensors,
+ data_format=data_format,
+ )
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor._pad_image
+ def _pad_image(
+ self,
+ image: np.ndarray,
+ output_size: Tuple[int, int],
+ constant_values: Union[float, Iterable[float]] = 0,
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Pad an image with zeros to the given size.
+ """
+ input_height, input_width = get_image_size(image)
+ output_height, output_width = output_size
+
+ pad_bottom = output_height - input_height
+ pad_right = output_width - input_width
+ padding = ((0, pad_bottom), (0, pad_right))
+ padded_image = pad(
+ image, padding, mode=PaddingMode.CONSTANT, constant_values=constant_values, data_format=data_format
+ )
+ return padded_image
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.pad
+ def pad(
+ self,
+ images: List[np.ndarray],
+ constant_values: Union[float, Iterable[float]] = 0,
+ return_pixel_mask: bool = True,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Pads a batch of images to the bottom and right of the image with zeros to the size of largest height and width
+ in the batch and optionally returns their corresponding pixel mask.
+
+ Args:
+ image (`np.ndarray`):
+ Image to pad.
+ constant_values (`float` or `Iterable[float]`, *optional*):
+ The value to use for the padding if `mode` is `"constant"`.
+ return_pixel_mask (`bool`, *optional*, defaults to `True`):
+ Whether to return a pixel mask.
+ input_channel_dimension (`ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be inferred from the input image.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be the same as the input image.
+ """
+ pad_size = get_max_height_width(images)
+
+ padded_images = [
+ self._pad_image(image, pad_size, constant_values=constant_values, data_format=data_format)
+ for image in images
+ ]
+ data = {"pixel_values": padded_images}
+
+ if return_pixel_mask:
+ masks = [make_pixel_mask(image=image, output_size=pad_size) for image in images]
+ data["pixel_mask"] = masks
+
+ return BatchFeature(data=data, tensor_type=return_tensors)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.preprocess
+ def preprocess(
+ self,
+ images: ImageInput,
+ annotations: Optional[Union[List[Dict], List[List[Dict]]]] = None,
+ return_segmentation_masks: bool = None,
+ masks_path: Optional[Union[str, pathlib.Path]] = None,
+ do_resize: Optional[bool] = None,
+ size: Optional[Dict[str, int]] = None,
+ resample=None, # PILImageResampling
+ do_rescale: Optional[bool] = None,
+ rescale_factor: Optional[Union[int, float]] = None,
+ do_normalize: Optional[bool] = None,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ do_pad: Optional[bool] = None,
+ format: Optional[Union[str, AnnotionFormat]] = None,
+ return_tensors: Optional[Union[TensorType, str]] = None,
+ data_format: Union[str, ChannelDimension] = ChannelDimension.FIRST,
+ **kwargs
+ ) -> BatchFeature:
+ """
+ Preprocess an image or a batch of images so that it can be used by the model.
+
+ Args:
+ images (`ImageInput`):
+ Image or batch of images to preprocess.
+ annotations (`List[Dict]` or `List[List[Dict]]`, *optional*):
+ List of annotations associated with the image or batch of images. If annotionation is for object
+ detection, the annotations should be a dictionary with the following keys:
+ - "image_id" (`int`): The image id.
+ - "annotations" (`List[Dict]`): List of annotations for an image. Each annotation should be a
+ dictionary. An image can have no annotations, in which case the list should be empty.
+ If annotionation is for segmentation, the annotations should be a dictionary with the following keys:
+ - "image_id" (`int`): The image id.
+ - "segments_info" (`List[Dict]`): List of segments for an image. Each segment should be a dictionary.
+ An image can have no segments, in which case the list should be empty.
+ - "file_name" (`str`): The file name of the image.
+ return_segmentation_masks (`bool`, *optional*, defaults to self.return_segmentation_masks):
+ Whether to return segmentation masks.
+ masks_path (`str` or `pathlib.Path`, *optional*):
+ Path to the directory containing the segmentation masks.
+ do_resize (`bool`, *optional*, defaults to self.do_resize):
+ Whether to resize the image.
+ size (`Dict[str, int]`, *optional*, defaults to self.size):
+ Size of the image after resizing.
+ resample (`PILImageResampling`, *optional*, defaults to self.resample):
+ Resampling filter to use when resizing the image.
+ do_rescale (`bool`, *optional*, defaults to self.do_rescale):
+ Whether to rescale the image.
+ rescale_factor (`float`, *optional*, defaults to self.rescale_factor):
+ Rescale factor to use when rescaling the image.
+ do_normalize (`bool`, *optional*, defaults to self.do_normalize):
+ Whether to normalize the image.
+ image_mean (`float` or `List[float]`, *optional*, defaults to self.image_mean):
+ Mean to use when normalizing the image.
+ image_std (`float` or `List[float]`, *optional*, defaults to self.image_std):
+ Standard deviation to use when normalizing the image.
+ do_pad (`bool`, *optional*, defaults to self.do_pad):
+ Whether to pad the image.
+ format (`str` or `AnnotionFormat`, *optional*, defaults to self.format):
+ Format of the annotations.
+ return_tensors (`str` or `TensorType`, *optional*, defaults to self.return_tensors):
+ Type of tensors to return. If `None`, will return the list of images.
+ data_format (`str` or `ChannelDimension`, *optional*, defaults to self.data_format):
+ The channel dimension format of the image. If not provided, it will be the same as the input image.
+ """
+ if "pad_and_return_pixel_mask" in kwargs:
+ warnings.warn(
+ "The `pad_and_return_pixel_mask` argument is deprecated and will be removed in a future version, "
+ "use `do_pad` instead.",
+ FutureWarning,
+ )
+ do_pad = kwargs.pop("pad_and_return_pixel_mask")
+
+ max_size = None
+ if "max_size" in kwargs:
+ warnings.warn(
+ "The `max_size` argument is deprecated and will be removed in a future version, use"
+ " `size['longest_edge']` instead.",
+ FutureWarning,
+ )
+ size = kwargs.pop("max_size")
+
+ do_resize = self.do_resize if do_resize is None else do_resize
+ size = self.size if size is None else size
+ size = get_size_dict(size=size, max_size=max_size, default_to_square=False)
+ resample = self.resample if resample is None else resample
+ do_rescale = self.do_rescale if do_rescale is None else do_rescale
+ rescale_factor = self.rescale_factor if rescale_factor is None else rescale_factor
+ do_normalize = self.do_normalize if do_normalize is None else do_normalize
+ image_mean = self.image_mean if image_mean is None else image_mean
+ image_std = self.image_std if image_std is None else image_std
+ do_pad = self.do_pad if do_pad is None else do_pad
+ format = self.format if format is None else format
+
+ if do_resize is not None and size is None:
+ raise ValueError("Size and max_size must be specified if do_resize is True.")
+
+ if do_rescale is not None and rescale_factor is None:
+ raise ValueError("Rescale factor must be specified if do_rescale is True.")
+
+ if do_normalize is not None and (image_mean is None or image_std is None):
+ raise ValueError("Image mean and std must be specified if do_normalize is True.")
+
+ if not is_batched(images):
+ images = [images]
+ annotations = [annotations] if annotations is not None else None
+
+ if annotations is not None and len(images) != len(annotations):
+ raise ValueError(
+ f"The number of images ({len(images)}) and annotations ({len(annotations)}) do not match."
+ )
+
+ if not valid_images(images):
+ raise ValueError(
+ "Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
+ "torch.Tensor, tf.Tensor or jax.ndarray."
+ )
+
+ format = AnnotionFormat(format)
+ if annotations is not None:
+ if format == AnnotionFormat.COCO_DETECTION and not valid_coco_detection_annotations(annotations):
+ raise ValueError(
+ "Invalid COCO detection annotations. Annotations must a dict (single image) of list of dicts"
+ "(batch of images) with the following keys: `image_id` and `annotations`, with the latter "
+ "being a list of annotations in the COCO format."
+ )
+ elif format == AnnotionFormat.COCO_PANOPTIC and not valid_coco_panoptic_annotations(annotations):
+ raise ValueError(
+ "Invalid COCO panoptic annotations. Annotations must a dict (single image) of list of dicts "
+ "(batch of images) with the following keys: `image_id`, `file_name` and `segments_info`, with "
+ "the latter being a list of annotations in the COCO format."
+ )
+ elif format not in SUPPORTED_ANNOTATION_FORMATS:
+ raise ValueError(
+ f"Unsupported annotation format: {format} must be one of {SUPPORTED_ANNOTATION_FORMATS}"
+ )
+
+ if (
+ masks_path is not None
+ and format == AnnotionFormat.COCO_PANOPTIC
+ and not isinstance(masks_path, (pathlib.Path, str))
+ ):
+ raise ValueError(
+ "The path to the directory containing the mask PNG files should be provided as a"
+ f" `pathlib.Path` or string object, but is {type(masks_path)} instead."
+ )
+
+ # All transformations expect numpy arrays
+ images = [to_numpy_array(image) for image in images]
+
+ # prepare (COCO annotations as a list of Dict -> DETR target as a single Dict per image)
+ if annotations is not None:
+ prepared_images = []
+ prepared_annotations = []
+ for image, target in zip(images, annotations):
+ target = self.prepare_annotation(
+ image, target, format, return_segmentation_masks=return_segmentation_masks, masks_path=masks_path
+ )
+ prepared_images.append(image)
+ prepared_annotations.append(target)
+ images = prepared_images
+ annotations = prepared_annotations
+ del prepared_images, prepared_annotations
+
+ # transformations
+ if do_resize:
+ if annotations is not None:
+ resized_images, resized_annotations = [], []
+ for image, target in zip(images, annotations):
+ orig_size = get_image_size(image)
+ resized_image = self.resize(image, size=size, max_size=max_size, resample=resample)
+ resized_annotation = self.resize_annotation(target, orig_size, get_image_size(resized_image))
+ resized_images.append(resized_image)
+ resized_annotations.append(resized_annotation)
+ images = resized_images
+ annotations = resized_annotations
+ del resized_images, resized_annotations
+ else:
+ images = [self.resize(image, size=size, resample=resample) for image in images]
+
+ if do_rescale:
+ images = [self.rescale(image, rescale_factor) for image in images]
+
+ if do_normalize:
+ images = [self.normalize(image, image_mean, image_std) for image in images]
+ if annotations is not None:
+ annotations = [
+ self.normalize_annotation(annotation, get_image_size(image))
+ for annotation, image in zip(annotations, images)
+ ]
+
+ if do_pad:
+ # Pads images and returns their mask: {'pixel_values': ..., 'pixel_mask': ...}
+ data = self.pad(images, return_pixel_mask=True, data_format=data_format)
+ else:
+ images = [to_channel_dimension_format(image, data_format) for image in images]
+ data = {"pixel_values": images}
+
+ encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
+ if annotations is not None:
+ encoded_inputs["labels"] = [
+ BatchFeature(annotation, tensor_type=return_tensors) for annotation in annotations
+ ]
+
+ return encoded_inputs
+
+ # POSTPROCESSING METHODS - TODO: add support for other frameworks
+ def post_process(self, outputs, target_sizes):
+ """
+ Converts the output of [`DeformableDetrForObjectDetection`] into the format expected by the COCO api. Only
+ supports PyTorch.
+
+ Args:
+ outputs ([`DeformableDetrObjectDetectionOutput`]):
+ Raw outputs of the model.
+ target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
+ Tensor containing the size (height, width) of each image of the batch. For evaluation, this must be the
+ original image size (before any data augmentation). For visualization, this should be the image size
+ after data augment, but before padding.
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
+ in the batch as predicted by the model.
+ """
+ warnings.warn(
+ "`post_process` is deprecated and will be removed in v5 of Transformers, please use"
+ " `post_process_object_detection`.",
+ FutureWarning,
+ )
+
+ out_logits, out_bbox = outputs.logits, outputs.pred_boxes
+
+ if len(out_logits) != len(target_sizes):
+ raise ValueError("Make sure that you pass in as many target sizes as the batch dimension of the logits")
+ if target_sizes.shape[1] != 2:
+ raise ValueError("Each element of target_sizes must contain the size (h, w) of each image of the batch")
+
+ prob = out_logits.sigmoid()
+ topk_values, topk_indexes = torch.topk(prob.view(out_logits.shape[0], -1), 100, dim=1)
+ scores = topk_values
+ topk_boxes = topk_indexes // out_logits.shape[2]
+ labels = topk_indexes % out_logits.shape[2]
+ boxes = center_to_corners_format(out_bbox)
+ boxes = torch.gather(boxes, 1, topk_boxes.unsqueeze(-1).repeat(1, 1, 4))
+
+ # and from relative [0, 1] to absolute [0, height] coordinates
+ img_h, img_w = target_sizes.unbind(1)
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1).to(boxes.device)
+ boxes = boxes * scale_fct[:, None, :]
+
+ results = [{"scores": s, "labels": l, "boxes": b} for s, l, b in zip(scores, labels, boxes)]
+
+ return results
+
+ def post_process_object_detection(
+ self, outputs, threshold: float = 0.5, target_sizes: Union[TensorType, List[Tuple]] = None
+ ):
+ """
+ Converts the output of [`DeformableDetrForObjectDetection`] into the format expected by the COCO api. Only
+ supports PyTorch.
+
+ Args:
+ outputs ([`DetrObjectDetectionOutput`]):
+ Raw outputs of the model.
+ threshold (`float`, *optional*):
+ Score threshold to keep object detection predictions.
+ target_sizes (`torch.Tensor` or `List[Tuple[int, int]]`, *optional*):
+ Tensor of shape `(batch_size, 2)` or list of tuples (`Tuple[int, int]`) containing the target size
+ (height, width) of each image in the batch. If left to None, predictions will not be resized.
+
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
+ in the batch as predicted by the model.
+ """
+ out_logits, out_bbox = outputs.logits, outputs.pred_boxes
+
+ if target_sizes is not None:
+ if len(out_logits) != len(target_sizes):
+ raise ValueError(
+ "Make sure that you pass in as many target sizes as the batch dimension of the logits"
+ )
+
+ prob = out_logits.sigmoid()
+ topk_values, topk_indexes = torch.topk(prob.view(out_logits.shape[0], -1), 100, dim=1)
+ scores = topk_values
+ topk_boxes = topk_indexes // out_logits.shape[2]
+ labels = topk_indexes % out_logits.shape[2]
+ boxes = center_to_corners_format(out_bbox)
+ boxes = torch.gather(boxes, 1, topk_boxes.unsqueeze(-1).repeat(1, 1, 4))
+
+ # and from relative [0, 1] to absolute [0, height] coordinates
+ if isinstance(target_sizes, List):
+ img_h = torch.Tensor([i[0] for i in target_sizes])
+ img_w = torch.Tensor([i[1] for i in target_sizes])
+ else:
+ img_h, img_w = target_sizes.unbind(1)
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
+ boxes = boxes * scale_fct[:, None, :]
+
+ results = []
+ for s, l, b in zip(scores, labels, boxes):
+ score = s[s > threshold]
+ label = l[s > threshold]
+ box = b[s > threshold]
+ results.append({"scores": score, "labels": label, "boxes": box})
+
+ return results
diff --git a/src/transformers/models/detr/__init__.py b/src/transformers/models/detr/__init__.py
index b9b6d30c32..9b0ca07cc3 100644
--- a/src/transformers/models/detr/__init__.py
+++ b/src/transformers/models/detr/__init__.py
@@ -30,6 +30,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_detr"] = ["DetrFeatureExtractor"]
+ _import_structure["image_processing_detr"] = ["DetrImageProcessor"]
try:
if not is_timm_available():
@@ -56,6 +57,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_detr import DetrFeatureExtractor
+ from .image_processing_detr import DetrImageProcessor
try:
if not is_timm_available():
diff --git a/src/transformers/models/detr/feature_extraction_detr.py b/src/transformers/models/detr/feature_extraction_detr.py
index 18c262fea4..c59a7e11ad 100644
--- a/src/transformers/models/detr/feature_extraction_detr.py
+++ b/src/transformers/models/detr/feature_extraction_detr.py
@@ -14,1325 +14,9 @@
# limitations under the License.
"""Feature extractor class for DETR."""
-import io
-import pathlib
-import warnings
-from collections import defaultdict
-from typing import Dict, List, Optional, Set, Tuple, Union
+from ...utils import logging
+from .image_processing_detr import DetrImageProcessor
-import numpy as np
-from PIL import Image
-
-from ...feature_extraction_utils import BatchFeature, FeatureExtractionMixin
-from ...image_transforms import center_to_corners_format, corners_to_center_format, id_to_rgb, rgb_to_id
-from ...image_utils import ImageFeatureExtractionMixin
-from ...utils import TensorType, is_torch_available, is_torch_tensor, logging
-
-
-if is_torch_available():
- import torch
- from torch import nn
logger = logging.get_logger(__name__)
-
-
-ImageInput = Union[Image.Image, np.ndarray, "torch.Tensor", List[Image.Image], List[np.ndarray], List["torch.Tensor"]]
-
-
-def masks_to_boxes(masks):
- """
- Compute the bounding boxes around the provided panoptic segmentation masks.
-
- The masks should be in format [N, H, W] where N is the number of masks, (H, W) are the spatial dimensions.
-
- Returns a [N, 4] tensor, with the boxes in corner (xyxy) format.
- """
- if masks.size == 0:
- return np.zeros((0, 4))
-
- h, w = masks.shape[-2:]
-
- y = np.arange(0, h, dtype=np.float32)
- x = np.arange(0, w, dtype=np.float32)
- # see https://github.com/pytorch/pytorch/issues/50276
- y, x = np.meshgrid(y, x, indexing="ij")
-
- x_mask = masks * np.expand_dims(x, axis=0)
- x_max = x_mask.reshape(x_mask.shape[0], -1).max(-1)
- x = np.ma.array(x_mask, mask=~(np.array(masks, dtype=bool)))
- x_min = x.filled(fill_value=1e8)
- x_min = x_min.reshape(x_min.shape[0], -1).min(-1)
-
- y_mask = masks * np.expand_dims(y, axis=0)
- y_max = y_mask.reshape(x_mask.shape[0], -1).max(-1)
- y = np.ma.array(y_mask, mask=~(np.array(masks, dtype=bool)))
- y_min = y.filled(fill_value=1e8)
- y_min = y_min.reshape(y_min.shape[0], -1).min(-1)
-
- return np.stack([x_min, y_min, x_max, y_max], 1)
-
-
-def binary_mask_to_rle(mask):
- """
- Args:
- Converts given binary mask of shape (height, width) to the run-length encoding (RLE) format.
- mask (`torch.Tensor` or `numpy.array`):
- A binary mask tensor of shape `(height, width)` where 0 denotes background and 1 denotes the target
- segment_id or class_id.
- Returns:
- `List`: Run-length encoded list of the binary mask. Refer to COCO API for more information about the RLE
- format.
- """
- if is_torch_tensor(mask):
- mask = mask.numpy()
-
- pixels = mask.flatten()
- pixels = np.concatenate([[0], pixels, [0]])
- runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
- runs[1::2] -= runs[::2]
- return [x for x in runs]
-
-
-def convert_segmentation_to_rle(segmentation):
- """
- Converts given segmentation map of shape (height, width) to the run-length encoding (RLE) format.
-
- Args:
- segmentation (`torch.Tensor` or `numpy.array`):
- A segmentation map of shape `(height, width)` where each value denotes a segment or class id.
- Returns:
- `List[List]`: A list of lists, where each list is the run-length encoding of a segment / class id.
- """
- segment_ids = torch.unique(segmentation)
-
- run_length_encodings = []
- for idx in segment_ids:
- mask = torch.where(segmentation == idx, 1, 0)
- rle = binary_mask_to_rle(mask)
- run_length_encodings.append(rle)
-
- return run_length_encodings
-
-
-def remove_low_and_no_objects(masks, scores, labels, object_mask_threshold, num_labels):
- """
- Binarize the given masks using `object_mask_threshold`, it returns the associated values of `masks`, `scores` and
- `labels`.
-
- Args:
- masks (`torch.Tensor`):
- A tensor of shape `(num_queries, height, width)`.
- scores (`torch.Tensor`):
- A tensor of shape `(num_queries)`.
- labels (`torch.Tensor`):
- A tensor of shape `(num_queries)`.
- object_mask_threshold (`float`):
- A number between 0 and 1 used to binarize the masks.
- Raises:
- `ValueError`: Raised when the first dimension doesn't match in all input tensors.
- Returns:
- `Tuple[`torch.Tensor`, `torch.Tensor`, `torch.Tensor`]`: The `masks`, `scores` and `labels` without the region
- < `object_mask_threshold`.
- """
- if not (masks.shape[0] == scores.shape[0] == labels.shape[0]):
- raise ValueError("mask, scores and labels must have the same shape!")
-
- to_keep = labels.ne(num_labels) & (scores > object_mask_threshold)
-
- return masks[to_keep], scores[to_keep], labels[to_keep]
-
-
-def check_segment_validity(mask_labels, mask_probs, k, mask_threshold=0.5, overlap_mask_area_threshold=0.8):
- # Get the mask associated with the k class
- mask_k = mask_labels == k
- mask_k_area = mask_k.sum()
-
- # Compute the area of all the stuff in query k
- original_area = (mask_probs[k] >= mask_threshold).sum()
- mask_exists = mask_k_area > 0 and original_area > 0
-
- # Eliminate disconnected tiny segments
- if mask_exists:
- area_ratio = mask_k_area / original_area
- if not area_ratio.item() > overlap_mask_area_threshold:
- mask_exists = False
-
- return mask_exists, mask_k
-
-
-def compute_segments(
- mask_probs,
- pred_scores,
- pred_labels,
- mask_threshold: float = 0.5,
- overlap_mask_area_threshold: float = 0.8,
- label_ids_to_fuse: Optional[Set[int]] = None,
- target_size: Tuple[int, int] = None,
-):
- height = mask_probs.shape[1] if target_size is None else target_size[0]
- width = mask_probs.shape[2] if target_size is None else target_size[1]
-
- segmentation = torch.zeros((height, width), dtype=torch.int32, device=mask_probs.device)
- segments: List[Dict] = []
-
- if target_size is not None:
- mask_probs = nn.functional.interpolate(
- mask_probs.unsqueeze(0), size=target_size, mode="bilinear", align_corners=False
- )[0]
-
- current_segment_id = 0
-
- # Weigh each mask by its prediction score
- mask_probs *= pred_scores.view(-1, 1, 1)
- mask_labels = mask_probs.argmax(0) # [height, width]
-
- # Keep track of instances of each class
- stuff_memory_list: Dict[str, int] = {}
- for k in range(pred_labels.shape[0]):
- pred_class = pred_labels[k].item()
- should_fuse = pred_class in label_ids_to_fuse
-
- # Check if mask exists and large enough to be a segment
- mask_exists, mask_k = check_segment_validity(
- mask_labels, mask_probs, k, mask_threshold, overlap_mask_area_threshold
- )
-
- if mask_exists:
- if pred_class in stuff_memory_list:
- current_segment_id = stuff_memory_list[pred_class]
- else:
- current_segment_id += 1
-
- # Add current object segment to final segmentation map
- segmentation[mask_k] = current_segment_id
- segment_score = round(pred_scores[k].item(), 6)
- segments.append(
- {
- "id": current_segment_id,
- "label_id": pred_class,
- "was_fused": should_fuse,
- "score": segment_score,
- }
- )
- if should_fuse:
- stuff_memory_list[pred_class] = current_segment_id
-
- return segmentation, segments
-
-
-class DetrFeatureExtractor(FeatureExtractionMixin, ImageFeatureExtractionMixin):
- r"""
- Constructs a DETR feature extractor.
-
- This feature extractor inherits from [`FeatureExtractionMixin`] which contains most of the main methods. Users
- should refer to this superclass for more information regarding those methods.
-
-
- Args:
- format (`str`, *optional*, defaults to `"coco_detection"`):
- Data format of the annotations. One of "coco_detection" or "coco_panoptic".
- do_resize (`bool`, *optional*, defaults to `True`):
- Whether to resize the input to a certain `size`.
- size (`int`, *optional*, defaults to 800):
- Resize the input to the given size. Only has an effect if `do_resize` is set to `True`. If size is a
- sequence like `(width, height)`, output size will be matched to this. If size is an int, smaller edge of
- the image will be matched to this number. i.e, if `height > width`, then image will be rescaled to `(size *
- height / width, size)`.
- max_size (`int`, *optional*, defaults to 1333):
- The largest size an image dimension can have (otherwise it's capped). Only has an effect if `do_resize` is
- set to `True`.
- do_normalize (`bool`, *optional*, defaults to `True`):
- Whether or not to normalize the input with mean and standard deviation.
- image_mean (`int`, *optional*, defaults to `[0.485, 0.456, 0.406]`):
- The sequence of means for each channel, to be used when normalizing images. Defaults to the ImageNet mean.
- image_std (`int`, *optional*, defaults to `[0.229, 0.224, 0.225]`):
- The sequence of standard deviations for each channel, to be used when normalizing images. Defaults to the
- ImageNet std.
- """
-
- model_input_names = ["pixel_values", "pixel_mask"]
-
- def __init__(
- self,
- format="coco_detection",
- do_resize=True,
- size=800,
- max_size=1333,
- do_normalize=True,
- image_mean=None,
- image_std=None,
- **kwargs
- ):
- super().__init__(**kwargs)
- self.format = self._is_valid_format(format)
- self.do_resize = do_resize
- self.size = size
- self.max_size = max_size
- self.do_normalize = do_normalize
- self.image_mean = image_mean if image_mean is not None else [0.485, 0.456, 0.406] # ImageNet mean
- self.image_std = image_std if image_std is not None else [0.229, 0.224, 0.225] # ImageNet std
-
- def _is_valid_format(self, format):
- if format not in ["coco_detection", "coco_panoptic"]:
- raise ValueError(f"Format {format} not supported")
- return format
-
- def prepare(self, image, target, return_segmentation_masks=False, masks_path=None):
- if self.format == "coco_detection":
- image, target = self.prepare_coco_detection(image, target, return_segmentation_masks)
- return image, target
- elif self.format == "coco_panoptic":
- image, target = self.prepare_coco_panoptic(image, target, masks_path)
- return image, target
- else:
- raise ValueError(f"Format {self.format} not supported")
-
- # inspired by https://github.com/facebookresearch/detr/blob/master/datasets/coco.py#L33
- def convert_coco_poly_to_mask(self, segmentations, height, width):
-
- try:
- from pycocotools import mask as coco_mask
- except ImportError:
- raise ImportError("Pycocotools is not installed in your environment.")
-
- masks = []
- for polygons in segmentations:
- rles = coco_mask.frPyObjects(polygons, height, width)
- mask = coco_mask.decode(rles)
- if len(mask.shape) < 3:
- mask = mask[..., None]
- mask = np.asarray(mask, dtype=np.uint8)
- mask = np.any(mask, axis=2)
- masks.append(mask)
- if masks:
- masks = np.stack(masks, axis=0)
- else:
- masks = np.zeros((0, height, width), dtype=np.uint8)
-
- return masks
-
- # inspired by https://github.com/facebookresearch/detr/blob/master/datasets/coco.py#L50
- def prepare_coco_detection(self, image, target, return_segmentation_masks=False):
- """
- Convert the target in COCO format into the format expected by DETR.
- """
- w, h = image.size
-
- image_id = target["image_id"]
- image_id = np.asarray([image_id], dtype=np.int64)
-
- # get all COCO annotations for the given image
- anno = target["annotations"]
-
- anno = [obj for obj in anno if "iscrowd" not in obj or obj["iscrowd"] == 0]
-
- boxes = [obj["bbox"] for obj in anno]
- # guard against no boxes via resizing
- boxes = np.asarray(boxes, dtype=np.float32).reshape(-1, 4)
- boxes[:, 2:] += boxes[:, :2]
- boxes[:, 0::2] = boxes[:, 0::2].clip(min=0, max=w)
- boxes[:, 1::2] = boxes[:, 1::2].clip(min=0, max=h)
-
- classes = [obj["category_id"] for obj in anno]
- classes = np.asarray(classes, dtype=np.int64)
-
- if return_segmentation_masks:
- segmentations = [obj["segmentation"] for obj in anno]
- masks = self.convert_coco_poly_to_mask(segmentations, h, w)
-
- keypoints = None
- if anno and "keypoints" in anno[0]:
- keypoints = [obj["keypoints"] for obj in anno]
- keypoints = np.asarray(keypoints, dtype=np.float32)
- num_keypoints = keypoints.shape[0]
- if num_keypoints:
- keypoints = keypoints.reshape((-1, 3))
-
- keep = (boxes[:, 3] > boxes[:, 1]) & (boxes[:, 2] > boxes[:, 0])
- boxes = boxes[keep]
- classes = classes[keep]
- if return_segmentation_masks:
- masks = masks[keep]
- if keypoints is not None:
- keypoints = keypoints[keep]
-
- target = {}
- target["boxes"] = boxes
- target["class_labels"] = classes
- if return_segmentation_masks:
- target["masks"] = masks
- target["image_id"] = image_id
- if keypoints is not None:
- target["keypoints"] = keypoints
-
- # for conversion to coco api
- area = np.asarray([obj["area"] for obj in anno], dtype=np.float32)
- iscrowd = np.asarray([obj["iscrowd"] if "iscrowd" in obj else 0 for obj in anno], dtype=np.int64)
- target["area"] = area[keep]
- target["iscrowd"] = iscrowd[keep]
-
- target["orig_size"] = np.asarray([int(h), int(w)], dtype=np.int64)
- target["size"] = np.asarray([int(h), int(w)], dtype=np.int64)
-
- return image, target
-
- def prepare_coco_panoptic(self, image, target, masks_path, return_masks=True):
- w, h = image.size
- ann_info = target.copy()
- ann_path = pathlib.Path(masks_path) / ann_info["file_name"]
-
- if "segments_info" in ann_info:
- masks = np.asarray(Image.open(ann_path), dtype=np.uint32)
- masks = rgb_to_id(masks)
-
- ids = np.array([ann["id"] for ann in ann_info["segments_info"]])
- masks = masks == ids[:, None, None]
- masks = np.asarray(masks, dtype=np.uint8)
-
- labels = np.asarray([ann["category_id"] for ann in ann_info["segments_info"]], dtype=np.int64)
-
- target = {}
- target["image_id"] = np.asarray(
- [ann_info["image_id"] if "image_id" in ann_info else ann_info["id"]], dtype=np.int64
- )
- if return_masks:
- target["masks"] = masks
- target["class_labels"] = labels
-
- target["boxes"] = masks_to_boxes(masks)
-
- target["size"] = np.asarray([int(h), int(w)], dtype=np.int64)
- target["orig_size"] = np.asarray([int(h), int(w)], dtype=np.int64)
- if "segments_info" in ann_info:
- target["iscrowd"] = np.asarray([ann["iscrowd"] for ann in ann_info["segments_info"]], dtype=np.int64)
- target["area"] = np.asarray([ann["area"] for ann in ann_info["segments_info"]], dtype=np.float32)
-
- return image, target
-
- def _resize(self, image, size, target=None, max_size=None):
- """
- Resize the image to the given size. Size can be min_size (scalar) or (w, h) tuple. If size is an int, smaller
- edge of the image will be matched to this number.
-
- If given, also resize the target accordingly.
- """
- if not isinstance(image, Image.Image):
- image = self.to_pil_image(image)
-
- def get_size_with_aspect_ratio(image_size, size, max_size=None):
- w, h = image_size
- if max_size is not None:
- min_original_size = float(min((w, h)))
- max_original_size = float(max((w, h)))
- if max_original_size / min_original_size * size > max_size:
- size = int(round(max_size * min_original_size / max_original_size))
-
- if (w <= h and w == size) or (h <= w and h == size):
- return (h, w)
-
- if w < h:
- ow = size
- oh = int(size * h / w)
- else:
- oh = size
- ow = int(size * w / h)
-
- return (oh, ow)
-
- def get_size(image_size, size, max_size=None):
- if isinstance(size, (list, tuple)):
- return size
- else:
- # size returned must be (w, h) since we use PIL to resize images
- # so we revert the tuple
- return get_size_with_aspect_ratio(image_size, size, max_size)[::-1]
-
- size = get_size(image.size, size, max_size)
- rescaled_image = self.resize(image, size=size)
-
- if target is None:
- return rescaled_image, None
-
- ratios = tuple(float(s) / float(s_orig) for s, s_orig in zip(rescaled_image.size, image.size))
- ratio_width, ratio_height = ratios
-
- target = target.copy()
- if "boxes" in target:
- boxes = target["boxes"]
- scaled_boxes = boxes * np.asarray([ratio_width, ratio_height, ratio_width, ratio_height], dtype=np.float32)
- target["boxes"] = scaled_boxes
-
- if "area" in target:
- area = target["area"]
- scaled_area = area * (ratio_width * ratio_height)
- target["area"] = scaled_area
-
- w, h = size
- target["size"] = np.asarray([h, w], dtype=np.int64)
-
- if "masks" in target:
- # use PyTorch as current workaround
- # TODO replace by self.resize
- masks = torch.from_numpy(target["masks"][:, None]).float()
- interpolated_masks = nn.functional.interpolate(masks, size=(h, w), mode="nearest")[:, 0] > 0.5
- target["masks"] = interpolated_masks.numpy()
-
- return rescaled_image, target
-
- def _normalize(self, image, mean, std, target=None):
- """
- Normalize the image with a certain mean and std.
-
- If given, also normalize the target bounding boxes based on the size of the image.
- """
-
- image = self.normalize(image, mean=mean, std=std)
- if target is None:
- return image, None
-
- target = target.copy()
- h, w = image.shape[-2:]
-
- if "boxes" in target:
- boxes = target["boxes"]
- boxes = corners_to_center_format(boxes)
- boxes = boxes / np.asarray([w, h, w, h], dtype=np.float32)
- target["boxes"] = boxes
-
- return image, target
-
- def __call__(
- self,
- images: ImageInput,
- annotations: Union[List[Dict], List[List[Dict]]] = None,
- return_segmentation_masks: Optional[bool] = False,
- masks_path: Optional[pathlib.Path] = None,
- pad_and_return_pixel_mask: Optional[bool] = True,
- return_tensors: Optional[Union[str, TensorType]] = None,
- **kwargs,
- ) -> BatchFeature:
- """
- Main method to prepare for the model one or several image(s) and optional annotations. Images are by default
- padded up to the largest image in a batch, and a pixel mask is created that indicates which pixels are
- real/which are padding.
-
-
-
- NumPy arrays and PyTorch tensors are converted to PIL images when resizing, so the most efficient is to pass
- PIL images.
-
-
-
- Args:
- images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
- The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
- tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a
- number of channels, H and W are image height and width.
-
- annotations (`Dict`, `List[Dict]`, *optional*):
- The corresponding annotations in COCO format.
-
- In case [`DetrFeatureExtractor`] was initialized with `format = "coco_detection"`, the annotations for
- each image should have the following format: {'image_id': int, 'annotations': [annotation]}, with the
- annotations being a list of COCO object annotations.
-
- In case [`DetrFeatureExtractor`] was initialized with `format = "coco_panoptic"`, the annotations for
- each image should have the following format: {'image_id': int, 'file_name': str, 'segments_info':
- [segment_info]} with segments_info being a list of COCO panoptic annotations.
-
- return_segmentation_masks (`Dict`, `List[Dict]`, *optional*, defaults to `False`):
- Whether to also include instance segmentation masks as part of the labels in case `format =
- "coco_detection"`.
-
- masks_path (`pathlib.Path`, *optional*):
- Path to the directory containing the PNG files that store the class-agnostic image segmentations. Only
- relevant in case [`DetrFeatureExtractor`] was initialized with `format = "coco_panoptic"`.
-
- pad_and_return_pixel_mask (`bool`, *optional*, defaults to `True`):
- Whether or not to pad images up to the largest image in a batch and create a pixel mask.
-
- If left to the default, will return a pixel mask that is:
-
- - 1 for pixels that are real (i.e. **not masked**),
- - 0 for pixels that are padding (i.e. **masked**).
-
- return_tensors (`str` or [`~utils.TensorType`], *optional*):
- If set, will return tensors instead of NumPy arrays. If set to `'pt'`, return PyTorch `torch.Tensor`
- objects.
-
- Returns:
- [`BatchFeature`]: A [`BatchFeature`] with the following fields:
-
- - **pixel_values** -- Pixel values to be fed to a model.
- - **pixel_mask** -- Pixel mask to be fed to a model (when `pad_and_return_pixel_mask=True` or if
- *"pixel_mask"* is in `self.model_input_names`).
- - **labels** -- Optional labels to be fed to a model (when `annotations` are provided)
- """
- # Input type checking for clearer error
-
- valid_images = False
- valid_annotations = False
- valid_masks_path = False
-
- # Check that images has a valid type
- if isinstance(images, (Image.Image, np.ndarray)) or is_torch_tensor(images):
- valid_images = True
- elif isinstance(images, (list, tuple)):
- if len(images) == 0 or isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]):
- valid_images = True
-
- if not valid_images:
- raise ValueError(
- "Images must of type `PIL.Image.Image`, `np.ndarray` or `torch.Tensor` (single example), "
- "`List[PIL.Image.Image]`, `List[np.ndarray]` or `List[torch.Tensor]` (batch of examples)."
- )
-
- is_batched = bool(
- isinstance(images, (list, tuple))
- and (isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]))
- )
-
- # Check that annotations has a valid type
- if annotations is not None:
- if not is_batched:
- if self.format == "coco_detection":
- if isinstance(annotations, dict) and "image_id" in annotations and "annotations" in annotations:
- if isinstance(annotations["annotations"], (list, tuple)):
- # an image can have no annotations
- if len(annotations["annotations"]) == 0 or isinstance(annotations["annotations"][0], dict):
- valid_annotations = True
- elif self.format == "coco_panoptic":
- if isinstance(annotations, dict) and "image_id" in annotations and "segments_info" in annotations:
- if isinstance(annotations["segments_info"], (list, tuple)):
- # an image can have no segments (?)
- if len(annotations["segments_info"]) == 0 or isinstance(
- annotations["segments_info"][0], dict
- ):
- valid_annotations = True
- else:
- if isinstance(annotations, (list, tuple)):
- if len(images) != len(annotations):
- raise ValueError("There must be as many annotations as there are images")
- if isinstance(annotations[0], Dict):
- if self.format == "coco_detection":
- if isinstance(annotations[0]["annotations"], (list, tuple)):
- valid_annotations = True
- elif self.format == "coco_panoptic":
- if isinstance(annotations[0]["segments_info"], (list, tuple)):
- valid_annotations = True
-
- if not valid_annotations:
- raise ValueError(
- """
- Annotations must of type `Dict` (single image) or `List[Dict]` (batch of images). In case of object
- detection, each dictionary should contain the keys 'image_id' and 'annotations', with the latter
- being a list of annotations in COCO format. In case of panoptic segmentation, each dictionary
- should contain the keys 'file_name', 'image_id' and 'segments_info', with the latter being a list
- of annotations in COCO format.
- """
- )
-
- # Check that masks_path has a valid type
- if masks_path is not None:
- if self.format == "coco_panoptic":
- if isinstance(masks_path, pathlib.Path):
- valid_masks_path = True
- if not valid_masks_path:
- raise ValueError(
- "The path to the directory containing the mask PNG files should be provided as a"
- " `pathlib.Path` object."
- )
-
- if not is_batched:
- images = [images]
- if annotations is not None:
- annotations = [annotations]
-
- # Create a copy of the list to avoid editing it in place
- images = [image for image in images]
-
- if annotations is not None:
- annotations = [annotation for annotation in annotations]
-
- # prepare (COCO annotations as a list of Dict -> DETR target as a single Dict per image)
- if annotations is not None:
- for idx, (image, target) in enumerate(zip(images, annotations)):
- if not isinstance(image, Image.Image):
- image = self.to_pil_image(image)
- image, target = self.prepare(image, target, return_segmentation_masks, masks_path)
- images[idx] = image
- annotations[idx] = target
-
- # transformations (resizing + normalization)
- if self.do_resize and self.size is not None:
- if annotations is not None:
- for idx, (image, target) in enumerate(zip(images, annotations)):
- image, target = self._resize(image=image, target=target, size=self.size, max_size=self.max_size)
- images[idx] = image
- annotations[idx] = target
- else:
- for idx, image in enumerate(images):
- images[idx] = self._resize(image=image, target=None, size=self.size, max_size=self.max_size)[0]
-
- if self.do_normalize:
- if annotations is not None:
- for idx, (image, target) in enumerate(zip(images, annotations)):
- image, target = self._normalize(
- image=image, mean=self.image_mean, std=self.image_std, target=target
- )
- images[idx] = image
- annotations[idx] = target
- else:
- images = [
- self._normalize(image=image, mean=self.image_mean, std=self.image_std)[0] for image in images
- ]
- else:
- images = [np.array(image) for image in images]
-
- if pad_and_return_pixel_mask:
- # pad images up to largest image in batch and create pixel_mask
- max_size = self._max_by_axis([list(image.shape) for image in images])
- c, h, w = max_size
- padded_images = []
- pixel_mask = []
- for image in images:
- # create padded image
- padded_image = np.zeros((c, h, w), dtype=np.float32)
- padded_image[: image.shape[0], : image.shape[1], : image.shape[2]] = np.copy(image)
- padded_images.append(padded_image)
- # create pixel mask
- mask = np.zeros((h, w), dtype=np.int64)
- mask[: image.shape[1], : image.shape[2]] = True
- pixel_mask.append(mask)
- images = padded_images
-
- # return as BatchFeature
- data = {}
- data["pixel_values"] = images
- if pad_and_return_pixel_mask:
- data["pixel_mask"] = pixel_mask
- encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
-
- if annotations is not None:
- # Convert to TensorType
- tensor_type = return_tensors
- if not isinstance(tensor_type, TensorType):
- tensor_type = TensorType(tensor_type)
-
- if not tensor_type == TensorType.PYTORCH:
- raise ValueError("Only PyTorch is supported for the moment.")
- else:
- if not is_torch_available():
- raise ImportError("Unable to convert output to PyTorch tensors format, PyTorch is not installed.")
-
- encoded_inputs["labels"] = [
- {k: torch.from_numpy(v) for k, v in target.items()} for target in annotations
- ]
-
- return encoded_inputs
-
- def _max_by_axis(self, the_list):
- # type: (List[List[int]]) -> List[int]
- maxes = the_list[0]
- for sublist in the_list[1:]:
- for index, item in enumerate(sublist):
- maxes[index] = max(maxes[index], item)
- return maxes
-
- def pad_and_create_pixel_mask(
- self, pixel_values_list: List["torch.Tensor"], return_tensors: Optional[Union[str, TensorType]] = None
- ):
- """
- Pad images up to the largest image in a batch and create a corresponding `pixel_mask`.
-
- Args:
- pixel_values_list (`List[torch.Tensor]`):
- List of images (pixel values) to be padded. Each image should be a tensor of shape (C, H, W).
- return_tensors (`str` or [`~utils.TensorType`], *optional*):
- If set, will return tensors instead of NumPy arrays. If set to `'pt'`, return PyTorch `torch.Tensor`
- objects.
-
- Returns:
- [`BatchFeature`]: A [`BatchFeature`] with the following fields:
-
- - **pixel_values** -- Pixel values to be fed to a model.
- - **pixel_mask** -- Pixel mask to be fed to a model (when `pad_and_return_pixel_mask=True` or if
- *"pixel_mask"* is in `self.model_input_names`).
-
- """
-
- max_size = self._max_by_axis([list(image.shape) for image in pixel_values_list])
- c, h, w = max_size
- padded_images = []
- pixel_mask = []
- for image in pixel_values_list:
- # create padded image
- padded_image = np.zeros((c, h, w), dtype=np.float32)
- padded_image[: image.shape[0], : image.shape[1], : image.shape[2]] = np.copy(image)
- padded_images.append(padded_image)
- # create pixel mask
- mask = np.zeros((h, w), dtype=np.int64)
- mask[: image.shape[1], : image.shape[2]] = True
- pixel_mask.append(mask)
-
- # return as BatchFeature
- data = {"pixel_values": padded_images, "pixel_mask": pixel_mask}
- encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
-
- return encoded_inputs
-
- # POSTPROCESSING METHODS
- # inspired by https://github.com/facebookresearch/detr/blob/master/models/detr.py#L258
- def post_process(self, outputs, target_sizes):
- """
- Converts the output of [`DetrForObjectDetection`] into the format expected by the COCO api. Only supports
- PyTorch.
-
- Args:
- outputs ([`DetrObjectDetectionOutput`]):
- Raw outputs of the model.
- target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
- Tensor containing the size (height, width) of each image of the batch. For evaluation, this must be the
- original image size (before any data augmentation). For visualization, this should be the image size
- after data augment, but before padding.
-
- Returns:
- `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
- in the batch as predicted by the model.
- """
- warnings.warn(
- "`post_process` is deprecated and will be removed in v5 of Transformers, please use"
- " `post_process_object_detection`",
- FutureWarning,
- )
-
- out_logits, out_bbox = outputs.logits, outputs.pred_boxes
-
- if len(out_logits) != len(target_sizes):
- raise ValueError("Make sure that you pass in as many target sizes as the batch dimension of the logits")
- if target_sizes.shape[1] != 2:
- raise ValueError("Each element of target_sizes must contain the size (h, w) of each image of the batch")
-
- prob = nn.functional.softmax(out_logits, -1)
- scores, labels = prob[..., :-1].max(-1)
-
- # convert to [x0, y0, x1, y1] format
- boxes = center_to_corners_format(out_bbox)
- # and from relative [0, 1] to absolute [0, height] coordinates
- img_h, img_w = target_sizes.unbind(1)
- scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
- boxes = boxes * scale_fct[:, None, :]
-
- results = [{"scores": s, "labels": l, "boxes": b} for s, l, b in zip(scores, labels, boxes)]
- return results
-
- def post_process_segmentation(self, outputs, target_sizes, threshold=0.9, mask_threshold=0.5):
- """
- Converts the output of [`DetrForSegmentation`] into image segmentation predictions. Only supports PyTorch.
-
- Args:
- outputs ([`DetrSegmentationOutput`]):
- Raw outputs of the model.
- target_sizes (`torch.Tensor` of shape `(batch_size, 2)` or `List[Tuple]` of length `batch_size`):
- Torch Tensor (or list) corresponding to the requested final size (h, w) of each prediction.
- threshold (`float`, *optional*, defaults to 0.9):
- Threshold to use to filter out queries.
- mask_threshold (`float`, *optional*, defaults to 0.5):
- Threshold to use when turning the predicted masks into binary values.
-
- Returns:
- `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels, and masks for an image
- in the batch as predicted by the model.
- """
- warnings.warn(
- "`post_process_segmentation` is deprecated and will be removed in v5 of Transformers, please use"
- " `post_process_semantic_segmentation`.",
- FutureWarning,
- )
- out_logits, raw_masks = outputs.logits, outputs.pred_masks
- preds = []
-
- def to_tuple(tup):
- if isinstance(tup, tuple):
- return tup
- return tuple(tup.cpu().tolist())
-
- for cur_logits, cur_masks, size in zip(out_logits, raw_masks, target_sizes):
- # we filter empty queries and detection below threshold
- scores, labels = cur_logits.softmax(-1).max(-1)
- keep = labels.ne(outputs.logits.shape[-1] - 1) & (scores > threshold)
- cur_scores, cur_classes = cur_logits.softmax(-1).max(-1)
- cur_scores = cur_scores[keep]
- cur_classes = cur_classes[keep]
- cur_masks = cur_masks[keep]
- cur_masks = nn.functional.interpolate(cur_masks[:, None], to_tuple(size), mode="bilinear").squeeze(1)
- cur_masks = (cur_masks.sigmoid() > mask_threshold) * 1
-
- predictions = {"scores": cur_scores, "labels": cur_classes, "masks": cur_masks}
- preds.append(predictions)
- return preds
-
- # inspired by https://github.com/facebookresearch/detr/blob/master/models/segmentation.py#L218
- def post_process_instance(self, results, outputs, orig_target_sizes, max_target_sizes, threshold=0.5):
- """
- Converts the output of [`DetrForSegmentation`] into actual instance segmentation predictions. Only supports
- PyTorch.
-
- Args:
- results (`List[Dict]`):
- Results list obtained by [`~DetrFeatureExtractor.post_process`], to which "masks" results will be
- added.
- outputs ([`DetrSegmentationOutput`]):
- Raw outputs of the model.
- orig_target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
- Tensor containing the size (h, w) of each image of the batch. For evaluation, this must be the original
- image size (before any data augmentation).
- max_target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
- Tensor containing the maximum size (h, w) of each image of the batch. For evaluation, this must be the
- original image size (before any data augmentation).
- threshold (`float`, *optional*, defaults to 0.5):
- Threshold to use when turning the predicted masks into binary values.
-
- Returns:
- `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels, boxes and masks for an
- image in the batch as predicted by the model.
- """
- warnings.warn(
- "`post_process_instance` is deprecated and will be removed in v5 of Transformers, please use"
- " `post_process_instance_segmentation`.",
- FutureWarning,
- )
-
- if len(orig_target_sizes) != len(max_target_sizes):
- raise ValueError("Make sure to pass in as many orig_target_sizes as max_target_sizes")
- max_h, max_w = max_target_sizes.max(0)[0].tolist()
- outputs_masks = outputs.pred_masks.squeeze(2)
- outputs_masks = nn.functional.interpolate(
- outputs_masks, size=(max_h, max_w), mode="bilinear", align_corners=False
- )
- outputs_masks = (outputs_masks.sigmoid() > threshold).cpu()
-
- for i, (cur_mask, t, tt) in enumerate(zip(outputs_masks, max_target_sizes, orig_target_sizes)):
- img_h, img_w = t[0], t[1]
- results[i]["masks"] = cur_mask[:, :img_h, :img_w].unsqueeze(1)
- results[i]["masks"] = nn.functional.interpolate(
- results[i]["masks"].float(), size=tuple(tt.tolist()), mode="nearest"
- ).byte()
-
- return results
-
- # inspired by https://github.com/facebookresearch/detr/blob/master/models/segmentation.py#L241
- def post_process_panoptic(self, outputs, processed_sizes, target_sizes=None, is_thing_map=None, threshold=0.85):
- """
- Converts the output of [`DetrForSegmentation`] into actual panoptic predictions. Only supports PyTorch.
-
- Args:
- outputs ([`DetrSegmentationOutput`]):
- Raw outputs of the model.
- processed_sizes (`torch.Tensor` of shape `(batch_size, 2)` or `List[Tuple]` of length `batch_size`):
- Torch Tensor (or list) containing the size (h, w) of each image of the batch, i.e. the size after data
- augmentation but before batching.
- target_sizes (`torch.Tensor` of shape `(batch_size, 2)` or `List[Tuple]` of length `batch_size`, *optional*):
- Torch Tensor (or list) corresponding to the requested final size (h, w) of each prediction. If left to
- None, it will default to the `processed_sizes`.
- is_thing_map (`torch.Tensor` of shape `(batch_size, 2)`, *optional*):
- Dictionary mapping class indices to either True or False, depending on whether or not they are a thing.
- If not set, defaults to the `is_thing_map` of COCO panoptic.
- threshold (`float`, *optional*, defaults to 0.85):
- Threshold to use to filter out queries.
-
- Returns:
- `List[Dict]`: A list of dictionaries, each dictionary containing a PNG string and segments_info values for
- an image in the batch as predicted by the model.
- """
- warnings.warn(
- "`post_process_panoptic is deprecated and will be removed in v5 of Transformers, please use"
- " `post_process_panoptic_segmentation`.",
- FutureWarning,
- )
- if target_sizes is None:
- target_sizes = processed_sizes
- if len(processed_sizes) != len(target_sizes):
- raise ValueError("Make sure to pass in as many processed_sizes as target_sizes")
-
- if is_thing_map is None:
- # default to is_thing_map of COCO panoptic
- is_thing_map = {i: i <= 90 for i in range(201)}
-
- out_logits, raw_masks, raw_boxes = outputs.logits, outputs.pred_masks, outputs.pred_boxes
- if not len(out_logits) == len(raw_masks) == len(target_sizes):
- raise ValueError(
- "Make sure that you pass in as many target sizes as the batch dimension of the logits and masks"
- )
- preds = []
-
- def to_tuple(tup):
- if isinstance(tup, tuple):
- return tup
- return tuple(tup.cpu().tolist())
-
- for cur_logits, cur_masks, cur_boxes, size, target_size in zip(
- out_logits, raw_masks, raw_boxes, processed_sizes, target_sizes
- ):
- # we filter empty queries and detection below threshold
- scores, labels = cur_logits.softmax(-1).max(-1)
- keep = labels.ne(outputs.logits.shape[-1] - 1) & (scores > threshold)
- cur_scores, cur_classes = cur_logits.softmax(-1).max(-1)
- cur_scores = cur_scores[keep]
- cur_classes = cur_classes[keep]
- cur_masks = cur_masks[keep]
- cur_masks = nn.functional.interpolate(cur_masks[:, None], to_tuple(size), mode="bilinear").squeeze(1)
- cur_boxes = center_to_corners_format(cur_boxes[keep])
-
- h, w = cur_masks.shape[-2:]
- if len(cur_boxes) != len(cur_classes):
- raise ValueError("Not as many boxes as there are classes")
-
- # It may be that we have several predicted masks for the same stuff class.
- # In the following, we track the list of masks ids for each stuff class (they are merged later on)
- cur_masks = cur_masks.flatten(1)
- stuff_equiv_classes = defaultdict(lambda: [])
- for k, label in enumerate(cur_classes):
- if not is_thing_map[label.item()]:
- stuff_equiv_classes[label.item()].append(k)
-
- def get_ids_area(masks, scores, dedup=False):
- # This helper function creates the final panoptic segmentation image
- # It also returns the area of the masks that appears on the image
-
- m_id = masks.transpose(0, 1).softmax(-1)
-
- if m_id.shape[-1] == 0:
- # We didn't detect any mask :(
- m_id = torch.zeros((h, w), dtype=torch.long, device=m_id.device)
- else:
- m_id = m_id.argmax(-1).view(h, w)
-
- if dedup:
- # Merge the masks corresponding to the same stuff class
- for equiv in stuff_equiv_classes.values():
- if len(equiv) > 1:
- for eq_id in equiv:
- m_id.masked_fill_(m_id.eq(eq_id), equiv[0])
-
- final_h, final_w = to_tuple(target_size)
-
- seg_img = Image.fromarray(id_to_rgb(m_id.view(h, w).cpu().numpy()))
- seg_img = seg_img.resize(size=(final_w, final_h), resample=Image.NEAREST)
-
- np_seg_img = torch.ByteTensor(torch.ByteStorage.from_buffer(seg_img.tobytes()))
- np_seg_img = np_seg_img.view(final_h, final_w, 3)
- np_seg_img = np_seg_img.numpy()
-
- m_id = torch.from_numpy(rgb_to_id(np_seg_img))
-
- area = []
- for i in range(len(scores)):
- area.append(m_id.eq(i).sum().item())
- return area, seg_img
-
- area, seg_img = get_ids_area(cur_masks, cur_scores, dedup=True)
- if cur_classes.numel() > 0:
- # We know filter empty masks as long as we find some
- while True:
- filtered_small = torch.as_tensor(
- [area[i] <= 4 for i, c in enumerate(cur_classes)], dtype=torch.bool, device=keep.device
- )
- if filtered_small.any().item():
- cur_scores = cur_scores[~filtered_small]
- cur_classes = cur_classes[~filtered_small]
- cur_masks = cur_masks[~filtered_small]
- area, seg_img = get_ids_area(cur_masks, cur_scores)
- else:
- break
-
- else:
- cur_classes = torch.ones(1, dtype=torch.long, device=cur_classes.device)
-
- segments_info = []
- for i, a in enumerate(area):
- cat = cur_classes[i].item()
- segments_info.append({"id": i, "isthing": is_thing_map[cat], "category_id": cat, "area": a})
- del cur_classes
-
- with io.BytesIO() as out:
- seg_img.save(out, format="PNG")
- predictions = {"png_string": out.getvalue(), "segments_info": segments_info}
- preds.append(predictions)
- return preds
-
- def post_process_object_detection(
- self, outputs, threshold: float = 0.5, target_sizes: Union[TensorType, List[Tuple]] = None
- ):
- """
- Converts the output of [`DetrForObjectDetection`] into the format expected by the COCO api. Only supports
- PyTorch.
-
- Args:
- outputs ([`DetrObjectDetectionOutput`]):
- Raw outputs of the model.
- threshold (`float`, *optional*):
- Score threshold to keep object detection predictions.
- target_sizes (`torch.Tensor` or `List[Tuple[int, int]]`, *optional*, defaults to `None`):
- Tensor of shape `(batch_size, 2)` or list of tuples (`Tuple[int, int]`) containing the target size
- (height, width) of each image in the batch. If left to None, predictions will not be resized.
-
- Returns:
- `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
- in the batch as predicted by the model.
- """
- out_logits, out_bbox = outputs.logits, outputs.pred_boxes
-
- if target_sizes is not None:
- if len(out_logits) != len(target_sizes):
- raise ValueError(
- "Make sure that you pass in as many target sizes as the batch dimension of the logits"
- )
-
- prob = nn.functional.softmax(out_logits, -1)
- scores, labels = prob[..., :-1].max(-1)
-
- # Convert to [x0, y0, x1, y1] format
- boxes = center_to_corners_format(out_bbox)
-
- # Convert from relative [0, 1] to absolute [0, height] coordinates
- if target_sizes is not None:
- if isinstance(target_sizes, List):
- img_h = torch.Tensor([i[0] for i in target_sizes])
- img_w = torch.Tensor([i[1] for i in target_sizes])
- else:
- img_h, img_w = target_sizes.unbind(1)
-
- scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1).to(boxes.device)
- boxes = boxes * scale_fct[:, None, :]
-
- results = []
- for s, l, b in zip(scores, labels, boxes):
- score = s[s > threshold]
- label = l[s > threshold]
- box = b[s > threshold]
- results.append({"scores": score, "labels": label, "boxes": box})
-
- return results
-
- def post_process_semantic_segmentation(self, outputs, target_sizes: List[Tuple[int, int]] = None):
- """
- Converts the output of [`DetrForSegmentation`] into semantic segmentation maps. Only supports PyTorch.
-
- Args:
- outputs ([`DetrForSegmentation`]):
- Raw outputs of the model.
- target_sizes (`List[Tuple[int, int]]`, *optional*, defaults to `None`):
- A list of tuples (`Tuple[int, int]`) containing the target size (height, width) of each image in the
- batch. If left to None, predictions will not be resized.
-
- Returns:
- `List[torch.Tensor]`:
- A list of length `batch_size`, where each item is a semantic segmentation map of shape (height, width)
- corresponding to the target_sizes entry (if `target_sizes` is specified). Each entry of each
- `torch.Tensor` correspond to a semantic class id.
- """
- class_queries_logits = outputs.logits # [batch_size, num_queries, num_classes+1]
- masks_queries_logits = outputs.pred_masks # [batch_size, num_queries, height, width]
-
- # Remove the null class `[..., :-1]`
- masks_classes = class_queries_logits.softmax(dim=-1)[..., :-1]
- masks_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
-
- # Semantic segmentation logits of shape (batch_size, num_classes, height, width)
- segmentation = torch.einsum("bqc, bqhw -> bchw", masks_classes, masks_probs)
- batch_size = class_queries_logits.shape[0]
-
- # Resize logits and compute semantic segmentation maps
- if target_sizes is not None:
- if batch_size != len(target_sizes):
- raise ValueError(
- "Make sure that you pass in as many target sizes as the batch dimension of the logits"
- )
-
- semantic_segmentation = []
- for idx in range(batch_size):
- resized_logits = nn.functional.interpolate(
- segmentation[idx].unsqueeze(dim=0), size=target_sizes[idx], mode="bilinear", align_corners=False
- )
- semantic_map = resized_logits[0].argmax(dim=0)
- semantic_segmentation.append(semantic_map)
- else:
- semantic_segmentation = segmentation.argmax(dim=1)
- semantic_segmentation = [semantic_segmentation[i] for i in range(semantic_segmentation.shape[0])]
-
- return semantic_segmentation
-
- def post_process_instance_segmentation(
- self,
- outputs,
- threshold: float = 0.5,
- mask_threshold: float = 0.5,
- overlap_mask_area_threshold: float = 0.8,
- target_sizes: Optional[List[Tuple[int, int]]] = None,
- return_coco_annotation: Optional[bool] = False,
- ) -> List[Dict]:
- """
- Converts the output of [`DetrForSegmentation`] into instance segmentation predictions. Only supports PyTorch.
-
- Args:
- outputs ([`DetrForSegmentation`]):
- Raw outputs of the model.
- threshold (`float`, *optional*, defaults to 0.5):
- The probability score threshold to keep predicted instance masks.
- mask_threshold (`float`, *optional*, defaults to 0.5):
- Threshold to use when turning the predicted masks into binary values.
- overlap_mask_area_threshold (`float`, *optional*, defaults to 0.8):
- The overlap mask area threshold to merge or discard small disconnected parts within each binary
- instance mask.
- target_sizes (`List[Tuple]`, *optional*):
- List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
- final size (height, width) of each prediction. If left to None, predictions will not be resized.
- return_coco_annotation (`bool`, *optional*):
- Defaults to `False`. If set to `True`, segmentation maps are returned in COCO run-length encoding (RLE)
- format.
-
- Returns:
- `List[Dict]`: A list of dictionaries, one per image, each dictionary containing two keys:
- - **segmentation** -- A tensor of shape `(height, width)` where each pixel represents a `segment_id` or
- `List[List]` run-length encoding (RLE) of the segmentation map if return_coco_annotation is set to
- `True`. Set to `None` if no mask if found above `threshold`.
- - **segments_info** -- A dictionary that contains additional information on each segment.
- - **id** -- An integer representing the `segment_id`.
- - **label_id** -- An integer representing the label / semantic class id corresponding to `segment_id`.
- - **score** -- Prediction score of segment with `segment_id`.
- """
- class_queries_logits = outputs.logits # [batch_size, num_queries, num_classes+1]
- masks_queries_logits = outputs.pred_masks # [batch_size, num_queries, height, width]
-
- batch_size = class_queries_logits.shape[0]
- num_labels = class_queries_logits.shape[-1] - 1
-
- mask_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
-
- # Predicted label and score of each query (batch_size, num_queries)
- pred_scores, pred_labels = nn.functional.softmax(class_queries_logits, dim=-1).max(-1)
-
- # Loop over items in batch size
- results: List[Dict[str, TensorType]] = []
-
- for i in range(batch_size):
- mask_probs_item, pred_scores_item, pred_labels_item = remove_low_and_no_objects(
- mask_probs[i], pred_scores[i], pred_labels[i], threshold, num_labels
- )
-
- # No mask found
- if mask_probs_item.shape[0] <= 0:
- height, width = target_sizes[i] if target_sizes is not None else mask_probs_item.shape[1:]
- segmentation = torch.zeros((height, width)) - 1
- results.append({"segmentation": segmentation, "segments_info": []})
- continue
-
- # Get segmentation map and segment information of batch item
- target_size = target_sizes[i] if target_sizes is not None else None
- segmentation, segments = compute_segments(
- mask_probs=mask_probs_item,
- pred_scores=pred_scores_item,
- pred_labels=pred_labels_item,
- mask_threshold=mask_threshold,
- overlap_mask_area_threshold=overlap_mask_area_threshold,
- label_ids_to_fuse=[],
- target_size=target_size,
- )
-
- # Return segmentation map in run-length encoding (RLE) format
- if return_coco_annotation:
- segmentation = convert_segmentation_to_rle(segmentation)
-
- results.append({"segmentation": segmentation, "segments_info": segments})
- return results
-
- def post_process_panoptic_segmentation(
- self,
- outputs,
- threshold: float = 0.5,
- mask_threshold: float = 0.5,
- overlap_mask_area_threshold: float = 0.8,
- label_ids_to_fuse: Optional[Set[int]] = None,
- target_sizes: Optional[List[Tuple[int, int]]] = None,
- ) -> List[Dict]:
- """
- Converts the output of [`DetrForSegmentation`] into image panoptic segmentation predictions. Only supports
- PyTorch.
-
- Args:
- outputs ([`DetrForSegmentation`]):
- The outputs from [`DetrForSegmentation`].
- threshold (`float`, *optional*, defaults to 0.5):
- The probability score threshold to keep predicted instance masks.
- mask_threshold (`float`, *optional*, defaults to 0.5):
- Threshold to use when turning the predicted masks into binary values.
- overlap_mask_area_threshold (`float`, *optional*, defaults to 0.8):
- The overlap mask area threshold to merge or discard small disconnected parts within each binary
- instance mask.
- label_ids_to_fuse (`Set[int]`, *optional*):
- The labels in this state will have all their instances be fused together. For instance we could say
- there can only be one sky in an image, but several persons, so the label ID for sky would be in that
- set, but not the one for person.
- target_sizes (`List[Tuple]`, *optional*):
- List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
- final size (height, width) of each prediction in batch. If left to None, predictions will not be
- resized.
-
- Returns:
- `List[Dict]`: A list of dictionaries, one per image, each dictionary containing two keys:
- - **segmentation** -- a tensor of shape `(height, width)` where each pixel represents a `segment_id` or
- `None` if no mask if found above `threshold`. If `target_sizes` is specified, segmentation is resized to
- the corresponding `target_sizes` entry.
- - **segments_info** -- A dictionary that contains additional information on each segment.
- - **id** -- an integer representing the `segment_id`.
- - **label_id** -- An integer representing the label / semantic class id corresponding to `segment_id`.
- - **was_fused** -- a boolean, `True` if `label_id` was in `label_ids_to_fuse`, `False` otherwise.
- Multiple instances of the same class / label were fused and assigned a single `segment_id`.
- - **score** -- Prediction score of segment with `segment_id`.
- """
-
- if label_ids_to_fuse is None:
- warnings.warn("`label_ids_to_fuse` unset. No instance will be fused.")
- label_ids_to_fuse = set()
-
- class_queries_logits = outputs.logits # [batch_size, num_queries, num_classes+1]
- masks_queries_logits = outputs.pred_masks # [batch_size, num_queries, height, width]
-
- batch_size = class_queries_logits.shape[0]
- num_labels = class_queries_logits.shape[-1] - 1
-
- mask_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
-
- # Predicted label and score of each query (batch_size, num_queries)
- pred_scores, pred_labels = nn.functional.softmax(class_queries_logits, dim=-1).max(-1)
-
- # Loop over items in batch size
- results: List[Dict[str, TensorType]] = []
-
- for i in range(batch_size):
- mask_probs_item, pred_scores_item, pred_labels_item = remove_low_and_no_objects(
- mask_probs[i], pred_scores[i], pred_labels[i], threshold, num_labels
- )
-
- # No mask found
- if mask_probs_item.shape[0] <= 0:
- height, width = target_sizes[i] if target_sizes is not None else mask_probs_item.shape[1:]
- segmentation = torch.zeros((height, width)) - 1
- results.append({"segmentation": segmentation, "segments_info": []})
- continue
-
- # Get segmentation map and segment information of batch item
- target_size = target_sizes[i] if target_sizes is not None else None
- segmentation, segments = compute_segments(
- mask_probs=mask_probs_item,
- pred_scores=pred_scores_item,
- pred_labels=pred_labels_item,
- mask_threshold=mask_threshold,
- overlap_mask_area_threshold=overlap_mask_area_threshold,
- label_ids_to_fuse=label_ids_to_fuse,
- target_size=target_size,
- )
-
- results.append({"segmentation": segmentation, "segments_info": segments})
- return results
+DetrFeatureExtractor = DetrImageProcessor
diff --git a/src/transformers/models/detr/image_processing_detr.py b/src/transformers/models/detr/image_processing_detr.py
new file mode 100644
index 0000000000..b72744db91
--- /dev/null
+++ b/src/transformers/models/detr/image_processing_detr.py
@@ -0,0 +1,1766 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Image processor class for DETR."""
+
+import io
+import pathlib
+import warnings
+from collections import defaultdict
+from typing import Any, Callable, Dict, Iterable, List, Optional, Set, Tuple, Union
+
+import numpy as np
+
+from transformers.image_processing_utils import BaseImageProcessor, BatchFeature, get_size_dict
+from transformers.image_transforms import (
+ PaddingMode,
+ center_to_corners_format,
+ corners_to_center_format,
+ id_to_rgb,
+ normalize,
+ pad,
+ rescale,
+ resize,
+ rgb_to_id,
+ to_channel_dimension_format,
+)
+from transformers.image_utils import (
+ IMAGENET_DEFAULT_MEAN,
+ IMAGENET_DEFAULT_STD,
+ ChannelDimension,
+ ImageInput,
+ PILImageResampling,
+ get_image_size,
+ infer_channel_dimension_format,
+ is_batched,
+ to_numpy_array,
+ valid_coco_detection_annotations,
+ valid_coco_panoptic_annotations,
+ valid_images,
+)
+from transformers.utils import (
+ is_flax_available,
+ is_jax_tensor,
+ is_scipy_available,
+ is_tf_available,
+ is_tf_tensor,
+ is_torch_available,
+ is_torch_tensor,
+ is_vision_available,
+)
+from transformers.utils.generic import ExplicitEnum, TensorType
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+
+if is_vision_available():
+ import PIL
+
+
+if is_scipy_available():
+ import scipy.special
+ import scipy.stats
+
+
+class AnnotionFormat(ExplicitEnum):
+ COCO_DETECTION = "coco_detection"
+ COCO_PANOPTIC = "coco_panoptic"
+
+
+SUPPORTED_ANNOTATION_FORMATS = (AnnotionFormat.COCO_DETECTION, AnnotionFormat.COCO_PANOPTIC)
+
+
+def get_size_with_aspect_ratio(image_size, size, max_size=None) -> Tuple[int, int]:
+ """
+ Computes the output image size given the input image size and the desired output size.
+
+ Args:
+ image_size (`Tuple[int, int]`):
+ The input image size.
+ size (`int`):
+ The desired output size.
+ max_size (`int`, *optional*):
+ The maximum allowed output size.
+ """
+ height, width = image_size
+ if max_size is not None:
+ min_original_size = float(min((height, width)))
+ max_original_size = float(max((height, width)))
+ if max_original_size / min_original_size * size > max_size:
+ size = int(round(max_size * min_original_size / max_original_size))
+
+ if (height <= width and height == size) or (width <= height and width == size):
+ return height, width
+
+ if width < height:
+ ow = size
+ oh = int(size * height / width)
+ else:
+ oh = size
+ ow = int(size * width / height)
+ return (oh, ow)
+
+
+def get_resize_output_image_size(
+ input_image: np.ndarray, size: Union[int, Tuple[int, int], List[int]], max_size: Optional[int] = None
+) -> Tuple[int, int]:
+ """
+ Computes the output image size given the input image size and the desired output size. If the desired output size
+ is a tuple or list, the output image size is returned as is. If the desired output size is an integer, the output
+ image size is computed by keeping the aspect ratio of the input image size.
+
+ Args:
+ image_size (`Tuple[int, int]`):
+ The input image size.
+ size (`int`):
+ The desired output size.
+ max_size (`int`, *optional*):
+ The maximum allowed output size.
+ """
+ image_size = get_image_size(input_image)
+ if isinstance(size, (list, tuple)):
+ return size
+
+ return get_size_with_aspect_ratio(image_size, size, max_size)
+
+
+def get_numpy_to_framework_fn(arr) -> Callable:
+ """
+ Returns a function that converts a numpy array to the framework of the input array.
+
+ Args:
+ arr (`np.ndarray`): The array to convert.
+ """
+ if isinstance(arr, np.ndarray):
+ return np.array
+ if is_tf_available() and is_tf_tensor(arr):
+ import tensorflow as tf
+
+ return tf.convert_to_tensor
+ if is_torch_available() and is_torch_tensor(arr):
+ import torch
+
+ return torch.tensor
+ if is_flax_available() and is_jax_tensor(arr):
+ import jax.numpy as jnp
+
+ return jnp.array
+ raise ValueError(f"Cannot convert arrays of type {type(arr)}")
+
+
+def safe_squeeze(arr: np.ndarray, axis: Optional[int] = None) -> np.ndarray:
+ """
+ Squeezes an array, but only if the axis specified has dim 1.
+ """
+ if axis is None:
+ return arr.squeeze()
+
+ try:
+ return arr.squeeze(axis=axis)
+ except ValueError:
+ return arr
+
+
+def normalize_annotation(annotation: Dict, image_size: Tuple[int, int]) -> Dict:
+ image_height, image_width = image_size
+ norm_annotation = {}
+ for key, value in annotation.items():
+ if key == "boxes":
+ boxes = value
+ boxes = corners_to_center_format(boxes)
+ boxes /= np.asarray([image_width, image_height, image_width, image_height], dtype=np.float32)
+ norm_annotation[key] = boxes
+ else:
+ norm_annotation[key] = value
+ return norm_annotation
+
+
+def max_across_indices(values: Iterable[Any]) -> List[Any]:
+ """
+ Return the maximum value across all indices of an iterable of values.
+ """
+ return [max(values_i) for values_i in zip(*values)]
+
+
+def get_max_height_width(images: List[np.ndarray]) -> List[int]:
+ """
+ Get the maximum height and width across all images in a batch.
+ """
+ input_channel_dimension = infer_channel_dimension_format(images[0])
+
+ if input_channel_dimension == ChannelDimension.FIRST:
+ _, max_height, max_width = max_across_indices([img.shape for img in images])
+ elif input_channel_dimension == ChannelDimension.LAST:
+ max_height, max_width, _ = max_across_indices([img.shape for img in images])
+ else:
+ raise ValueError(f"Invalid channel dimension format: {input_channel_dimension}")
+ return (max_height, max_width)
+
+
+def make_pixel_mask(image: np.ndarray, output_size: Tuple[int, int]) -> np.ndarray:
+ """
+ Make a pixel mask for the image, where 1 indicates a valid pixel and 0 indicates padding.
+
+ Args:
+ image (`np.ndarray`):
+ Image to make the pixel mask for.
+ output_size (`Tuple[int, int]`):
+ Output size of the mask.
+ """
+ input_height, input_width = get_image_size(image)
+ mask = np.zeros(output_size, dtype=np.int64)
+ mask[:input_height, :input_width] = 1
+ return mask
+
+
+# inspired by https://github.com/facebookresearch/detr/blob/master/datasets/coco.py#L33
+def convert_coco_poly_to_mask(segmentations, height: int, width: int) -> np.ndarray:
+ """
+ Convert a COCO polygon annotation to a mask.
+
+ Args:
+ segmentations (`List[List[float]]`):
+ List of polygons, each polygon represented by a list of x-y coordinates.
+ height (`int`):
+ Height of the mask.
+ width (`int`):
+ Width of the mask.
+ """
+ try:
+ from pycocotools import mask as coco_mask
+ except ImportError:
+ raise ImportError("Pycocotools is not installed in your environment.")
+
+ masks = []
+ for polygons in segmentations:
+ rles = coco_mask.frPyObjects(polygons, height, width)
+ mask = coco_mask.decode(rles)
+ if len(mask.shape) < 3:
+ mask = mask[..., None]
+ mask = np.asarray(mask, dtype=np.uint8)
+ mask = np.any(mask, axis=2)
+ masks.append(mask)
+ if masks:
+ masks = np.stack(masks, axis=0)
+ else:
+ masks = np.zeros((0, height, width), dtype=np.uint8)
+
+ return masks
+
+
+# inspired by https://github.com/facebookresearch/detr/blob/master/datasets/coco.py#L50
+def prepare_coco_detection_annotation(image, target, return_segmentation_masks: bool = False):
+ """
+ Convert the target in COCO format into the format expected by DETR.
+ """
+ image_height, image_width = get_image_size(image)
+
+ image_id = target["image_id"]
+ image_id = np.asarray([image_id], dtype=np.int64)
+
+ # Get all COCO annotations for the given image.
+ annotations = target["annotations"]
+ annotations = [obj for obj in annotations if "iscrowd" not in obj or obj["iscrowd"] == 0]
+
+ classes = [obj["category_id"] for obj in annotations]
+ classes = np.asarray(classes, dtype=np.int64)
+
+ # for conversion to coco api
+ area = np.asarray([obj["area"] for obj in annotations], dtype=np.float32)
+ iscrowd = np.asarray([obj["iscrowd"] if "iscrowd" in obj else 0 for obj in annotations], dtype=np.int64)
+
+ boxes = [obj["bbox"] for obj in annotations]
+ # guard against no boxes via resizing
+ boxes = np.asarray(boxes, dtype=np.float32).reshape(-1, 4)
+ boxes[:, 2:] += boxes[:, :2]
+ boxes[:, 0::2] = boxes[:, 0::2].clip(min=0, max=image_width)
+ boxes[:, 1::2] = boxes[:, 1::2].clip(min=0, max=image_height)
+
+ keep = (boxes[:, 3] > boxes[:, 1]) & (boxes[:, 2] > boxes[:, 0])
+
+ new_target = {}
+ new_target["image_id"] = image_id
+ new_target["class_labels"] = classes[keep]
+ new_target["boxes"] = boxes[keep]
+ new_target["area"] = area[keep]
+ new_target["iscrowd"] = iscrowd[keep]
+ new_target["orig_size"] = np.asarray([int(image_height), int(image_width)], dtype=np.int64)
+
+ if annotations and "keypoints" in annotations[0]:
+ keypoints = [obj["keypoints"] for obj in annotations]
+ keypoints = np.asarray(keypoints, dtype=np.float32)
+ num_keypoints = keypoints.shape[0]
+ keypoints = keypoints.reshape((-1, 3)) if num_keypoints else keypoints
+ new_target["keypoints"] = keypoints[keep]
+
+ if return_segmentation_masks:
+ segmentation_masks = [obj["segmentation"] for obj in annotations]
+ masks = convert_coco_poly_to_mask(segmentation_masks, image_height, image_width)
+ new_target["masks"] = masks[keep]
+
+ return new_target
+
+
+def masks_to_boxes(masks: np.ndarray) -> np.ndarray:
+ """
+ Compute the bounding boxes around the provided panoptic segmentation masks.
+
+ Args:
+ masks: masks in format `[number_masks, height, width]` where N is the number of masks
+
+ Returns:
+ boxes: bounding boxes in format `[number_masks, 4]` in xyxy format
+ """
+ if masks.size == 0:
+ return np.zeros((0, 4))
+
+ h, w = masks.shape[-2:]
+ y = np.arange(0, h, dtype=np.float32)
+ x = np.arange(0, w, dtype=np.float32)
+ # see https://github.com/pytorch/pytorch/issues/50276
+ y, x = np.meshgrid(y, x, indexing="ij")
+
+ x_mask = masks * np.expand_dims(x, axis=0)
+ x_max = x_mask.reshape(x_mask.shape[0], -1).max(-1)
+ x = np.ma.array(x_mask, mask=~(np.array(masks, dtype=bool)))
+ x_min = x.filled(fill_value=1e8)
+ x_min = x_min.reshape(x_min.shape[0], -1).min(-1)
+
+ y_mask = masks * np.expand_dims(y, axis=0)
+ y_max = y_mask.reshape(x_mask.shape[0], -1).max(-1)
+ y = np.ma.array(y_mask, mask=~(np.array(masks, dtype=bool)))
+ y_min = y.filled(fill_value=1e8)
+ y_min = y_min.reshape(y_min.shape[0], -1).min(-1)
+
+ return np.stack([x_min, y_min, x_max, y_max], 1)
+
+
+def prepare_coco_panoptic_annotation(
+ image: np.ndarray, target: Dict, masks_path: Union[str, pathlib.Path], return_masks: bool = True
+) -> Dict:
+ """
+ Prepare a coco panoptic annotation for DETR.
+ """
+ image_height, image_width = get_image_size(image)
+ annotation_path = pathlib.Path(masks_path) / target["file_name"]
+
+ new_target = {}
+ new_target["image_id"] = np.asarray([target["image_id"] if "image_id" in target else target["id"]], dtype=np.int64)
+ new_target["size"] = np.asarray([image_height, image_width], dtype=np.int64)
+ new_target["orig_size"] = np.asarray([image_height, image_width], dtype=np.int64)
+
+ if "segments_info" in target:
+ masks = np.asarray(PIL.Image.open(annotation_path), dtype=np.uint32)
+ masks = rgb_to_id(masks)
+
+ ids = np.array([segment_info["id"] for segment_info in target["segments_info"]])
+ masks = masks == ids[:, None, None]
+ masks = masks.astype(np.uint8)
+ if return_masks:
+ new_target["masks"] = masks
+ new_target["boxes"] = masks_to_boxes(masks)
+ new_target["class_labels"] = np.array(
+ [segment_info["category_id"] for segment_info in target["segments_info"]], dtype=np.int64
+ )
+ new_target["iscrowd"] = np.asarray(
+ [segment_info["iscrowd"] for segment_info in target["segments_info"]], dtype=np.int64
+ )
+ new_target["area"] = np.asarray(
+ [segment_info["area"] for segment_info in target["segments_info"]], dtype=np.float32
+ )
+
+ return new_target
+
+
+def get_segmentation_image(
+ masks: np.ndarray, input_size: Tuple, target_size: Tuple, stuff_equiv_classes, deduplicate=False
+):
+ h, w = input_size
+ final_h, final_w = target_size
+
+ m_id = scipy.special.softmax(masks.transpose(0, 1), -1)
+
+ if m_id.shape[-1] == 0:
+ # We didn't detect any mask :(
+ m_id = np.zeros((h, w), dtype=np.int64)
+ else:
+ m_id = m_id.argmax(-1).reshape(h, w)
+
+ if deduplicate:
+ # Merge the masks corresponding to the same stuff class
+ for equiv in stuff_equiv_classes.values():
+ for eq_id in equiv:
+ m_id[m_id == eq_id] = equiv[0]
+
+ seg_img = id_to_rgb(m_id)
+ seg_img = resize(seg_img, (final_w, final_h), resample=PILImageResampling.NEAREST)
+ return seg_img
+
+
+def get_mask_area(seg_img: np.ndarray, target_size: Tuple[int, int], n_classes: int) -> np.ndarray:
+ final_h, final_w = target_size
+ np_seg_img = seg_img.astype(np.uint8)
+ np_seg_img = np_seg_img.reshape(final_h, final_w, 3)
+ m_id = rgb_to_id(np_seg_img)
+ area = [(m_id == i).sum() for i in range(n_classes)]
+ return area
+
+
+def score_labels_from_class_probabilities(logits: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
+ probs = scipy.special.softmax(logits, axis=-1)
+ labels = probs.argmax(-1, keepdims=True)
+ scores = np.take_along_axis(probs, labels, axis=-1)
+ scores, labels = scores.squeeze(-1), labels.squeeze(-1)
+ return scores, labels
+
+
+def post_process_panoptic_sample(
+ out_logits: np.ndarray,
+ masks: np.ndarray,
+ boxes: np.ndarray,
+ processed_size: Tuple[int, int],
+ target_size: Tuple[int, int],
+ is_thing_map: Dict,
+ threshold=0.85,
+) -> Dict:
+ """
+ Converts the output of [`DetrForSegmentation`] into panoptic segmentation predictions for a single sample.
+
+ Args:
+ out_logits (`torch.Tensor`):
+ The logits for this sample.
+ masks (`torch.Tensor`):
+ The predicted segmentation masks for this sample.
+ boxes (`torch.Tensor`):
+ The prediced bounding boxes for this sample. The boxes are in the normalized format `(center_x, center_y,
+ width, height)` and values between `[0, 1]`, relative to the size the image (disregarding padding).
+ processed_size (`Tuple[int, int]`):
+ The processed size of the image `(height, width)`, as returned by the preprocessing step i.e. the size
+ after data augmentation but before batching.
+ target_size (`Tuple[int, int]`):
+ The target size of the image, `(height, width)` corresponding to the requested final size of the
+ prediction.
+ is_thing_map (`Dict`):
+ A dictionary mapping class indices to a boolean value indicating whether the class is a thing or not.
+ threshold (`float`, *optional*, defaults to 0.85):
+ The threshold used to binarize the segmentation masks.
+ """
+ # we filter empty queries and detection below threshold
+ scores, labels = score_labels_from_class_probabilities(out_logits)
+ keep = (labels != out_logits.shape[-1] - 1) & (scores > threshold)
+
+ cur_scores = scores[keep]
+ cur_classes = labels[keep]
+ cur_boxes = center_to_corners_format(boxes[keep])
+
+ if len(cur_boxes) != len(cur_classes):
+ raise ValueError("Not as many boxes as there are classes")
+
+ cur_masks = masks[keep]
+ cur_masks = resize(cur_masks[:, None], processed_size, resample=PILImageResampling.BILINEAR)
+ cur_masks = safe_squeeze(cur_masks, 1)
+ b, h, w = cur_masks.shape
+
+ # It may be that we have several predicted masks for the same stuff class.
+ # In the following, we track the list of masks ids for each stuff class (they are merged later on)
+ cur_masks = cur_masks.reshape(b, -1)
+ stuff_equiv_classes = defaultdict(list)
+ for k, label in enumerate(cur_classes):
+ if not is_thing_map[label]:
+ stuff_equiv_classes[label].append(k)
+
+ seg_img = get_segmentation_image(cur_masks, processed_size, target_size, stuff_equiv_classes, deduplicate=True)
+ area = get_mask_area(cur_masks, processed_size, n_classes=len(cur_scores))
+
+ # We filter out any mask that is too small
+ if cur_classes.size() > 0:
+ # We know filter empty masks as long as we find some
+ filtered_small = np.array([a <= 4 for a in area], dtype=bool)
+ while filtered_small.any():
+ cur_masks = cur_masks[~filtered_small]
+ cur_scores = cur_scores[~filtered_small]
+ cur_classes = cur_classes[~filtered_small]
+ seg_img = get_segmentation_image(cur_masks, (h, w), target_size, stuff_equiv_classes, deduplicate=True)
+ area = get_mask_area(seg_img, target_size, n_classes=len(cur_scores))
+ filtered_small = np.array([a <= 4 for a in area], dtype=bool)
+ else:
+ cur_classes = np.ones((1, 1), dtype=np.int64)
+
+ segments_info = [
+ {"id": i, "isthing": is_thing_map[cat], "category_id": int(cat), "area": a}
+ for i, (cat, a) in enumerate(zip(cur_classes, area))
+ ]
+ del cur_classes
+
+ with io.BytesIO() as out:
+ PIL.Image.fromarray(seg_img).save(out, format="PNG")
+ predictions = {"png_string": out.getvalue(), "segments_info": segments_info}
+
+ return predictions
+
+
+def resize_annotation(
+ annotation: Dict[str, Any],
+ orig_size: Tuple[int, int],
+ target_size: Tuple[int, int],
+ threshold: float = 0.5,
+ resample: PILImageResampling = PILImageResampling.NEAREST,
+):
+ """
+ Resizes an annotation to a target size.
+
+ Args:
+ annotation (`Dict[str, Any]`):
+ The annotation dictionary.
+ orig_size (`Tuple[int, int]`):
+ The original size of the input image.
+ target_size (`Tuple[int, int]`):
+ The target size of the image, as returned by the preprocessing `resize` step.
+ threshold (`float`, *optional*, defaults to 0.5):
+ The threshold used to binarize the segmentation masks.
+ resample (`PILImageResampling`, defaults to `PILImageResampling.NEAREST`):
+ The resampling filter to use when resizing the masks.
+ """
+ ratios = tuple(float(s) / float(s_orig) for s, s_orig in zip(target_size, orig_size))
+ ratio_height, ratio_width = ratios
+
+ new_annotation = {}
+ new_annotation["size"] = target_size
+
+ for key, value in annotation.items():
+ if key == "boxes":
+ boxes = value
+ scaled_boxes = boxes * np.asarray([ratio_width, ratio_height, ratio_width, ratio_height], dtype=np.float32)
+ new_annotation["boxes"] = scaled_boxes
+ elif key == "area":
+ area = value
+ scaled_area = area * (ratio_width * ratio_height)
+ new_annotation["area"] = scaled_area
+ elif key == "masks":
+ masks = value[:, None]
+ masks = np.array([resize(mask, target_size, resample=resample) for mask in masks])
+ masks = masks.astype(np.float32)
+ masks = masks[:, 0] > threshold
+ new_annotation["masks"] = masks
+ elif key == "size":
+ new_annotation["size"] = target_size
+ else:
+ new_annotation[key] = value
+
+ return new_annotation
+
+
+# TODO - (Amy) make compatible with other frameworks
+def binary_mask_to_rle(mask):
+ """
+ Converts given binary mask of shape `(height, width)` to the run-length encoding (RLE) format.
+
+ Args:
+ mask (`torch.Tensor` or `numpy.array`):
+ A binary mask tensor of shape `(height, width)` where 0 denotes background and 1 denotes the target
+ segment_id or class_id.
+ Returns:
+ `List`: Run-length encoded list of the binary mask. Refer to COCO API for more information about the RLE
+ format.
+ """
+ if is_torch_tensor(mask):
+ mask = mask.numpy()
+
+ pixels = mask.flatten()
+ pixels = np.concatenate([[0], pixels, [0]])
+ runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
+ runs[1::2] -= runs[::2]
+ return [x for x in runs]
+
+
+# TODO - (Amy) make compatible with other frameworks
+def convert_segmentation_to_rle(segmentation):
+ """
+ Converts given segmentation map of shape `(height, width)` to the run-length encoding (RLE) format.
+
+ Args:
+ segmentation (`torch.Tensor` or `numpy.array`):
+ A segmentation map of shape `(height, width)` where each value denotes a segment or class id.
+ Returns:
+ `List[List]`: A list of lists, where each list is the run-length encoding of a segment / class id.
+ """
+ segment_ids = torch.unique(segmentation)
+
+ run_length_encodings = []
+ for idx in segment_ids:
+ mask = torch.where(segmentation == idx, 1, 0)
+ rle = binary_mask_to_rle(mask)
+ run_length_encodings.append(rle)
+
+ return run_length_encodings
+
+
+def remove_low_and_no_objects(masks, scores, labels, object_mask_threshold, num_labels):
+ """
+ Binarize the given masks using `object_mask_threshold`, it returns the associated values of `masks`, `scores` and
+ `labels`.
+
+ Args:
+ masks (`torch.Tensor`):
+ A tensor of shape `(num_queries, height, width)`.
+ scores (`torch.Tensor`):
+ A tensor of shape `(num_queries)`.
+ labels (`torch.Tensor`):
+ A tensor of shape `(num_queries)`.
+ object_mask_threshold (`float`):
+ A number between 0 and 1 used to binarize the masks.
+ Raises:
+ `ValueError`: Raised when the first dimension doesn't match in all input tensors.
+ Returns:
+ `Tuple[`torch.Tensor`, `torch.Tensor`, `torch.Tensor`]`: The `masks`, `scores` and `labels` without the region
+ < `object_mask_threshold`.
+ """
+ if not (masks.shape[0] == scores.shape[0] == labels.shape[0]):
+ raise ValueError("mask, scores and labels must have the same shape!")
+
+ to_keep = labels.ne(num_labels) & (scores > object_mask_threshold)
+
+ return masks[to_keep], scores[to_keep], labels[to_keep]
+
+
+def check_segment_validity(mask_labels, mask_probs, k, mask_threshold=0.5, overlap_mask_area_threshold=0.8):
+ # Get the mask associated with the k class
+ mask_k = mask_labels == k
+ mask_k_area = mask_k.sum()
+
+ # Compute the area of all the stuff in query k
+ original_area = (mask_probs[k] >= mask_threshold).sum()
+ mask_exists = mask_k_area > 0 and original_area > 0
+
+ # Eliminate disconnected tiny segments
+ if mask_exists:
+ area_ratio = mask_k_area / original_area
+ if not area_ratio.item() > overlap_mask_area_threshold:
+ mask_exists = False
+
+ return mask_exists, mask_k
+
+
+def compute_segments(
+ mask_probs,
+ pred_scores,
+ pred_labels,
+ mask_threshold: float = 0.5,
+ overlap_mask_area_threshold: float = 0.8,
+ label_ids_to_fuse: Optional[Set[int]] = None,
+ target_size: Tuple[int, int] = None,
+):
+ height = mask_probs.shape[1] if target_size is None else target_size[0]
+ width = mask_probs.shape[2] if target_size is None else target_size[1]
+
+ segmentation = torch.zeros((height, width), dtype=torch.int32, device=mask_probs.device)
+ segments: List[Dict] = []
+
+ if target_size is not None:
+ mask_probs = nn.functional.interpolate(
+ mask_probs.unsqueeze(0), size=target_size, mode="bilinear", align_corners=False
+ )[0]
+
+ current_segment_id = 0
+
+ # Weigh each mask by its prediction score
+ mask_probs *= pred_scores.view(-1, 1, 1)
+ mask_labels = mask_probs.argmax(0) # [height, width]
+
+ # Keep track of instances of each class
+ stuff_memory_list: Dict[str, int] = {}
+ for k in range(pred_labels.shape[0]):
+ pred_class = pred_labels[k].item()
+ should_fuse = pred_class in label_ids_to_fuse
+
+ # Check if mask exists and large enough to be a segment
+ mask_exists, mask_k = check_segment_validity(
+ mask_labels, mask_probs, k, mask_threshold, overlap_mask_area_threshold
+ )
+
+ if mask_exists:
+ if pred_class in stuff_memory_list:
+ current_segment_id = stuff_memory_list[pred_class]
+ else:
+ current_segment_id += 1
+
+ # Add current object segment to final segmentation map
+ segmentation[mask_k] = current_segment_id
+ segment_score = round(pred_scores[k].item(), 6)
+ segments.append(
+ {
+ "id": current_segment_id,
+ "label_id": pred_class,
+ "was_fused": should_fuse,
+ "score": segment_score,
+ }
+ )
+ if should_fuse:
+ stuff_memory_list[pred_class] = current_segment_id
+
+ return segmentation, segments
+
+
+class DetrImageProcessor(BaseImageProcessor):
+ r"""
+ Constructs a Detr image processor.
+
+ Args:
+ format (`str`, *optional*, defaults to `"coco_detection"`):
+ Data format of the annotations. One of "coco_detection" or "coco_panoptic".
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Controls whether to resize the image's `(height, width)` dimensions to the specified `size`. Can be
+ overridden by the `do_resize` parameter in the `preprocess` method.
+ size (`Dict[str, int]` *optional*, defaults to `{"shortest_edge": 800, "longest_edge": 1333}`):
+ Size of the image's `(height, width)` dimensions after resizing. Can be overridden by the `size` parameter
+ in the `preprocess` method.
+ resample (`PILImageResampling`, *optional*, defaults to `PILImageResampling.BILINEAR`):
+ Resampling filter to use if resizing the image.
+ do_rescale (`bool`, *optional*, defaults to `True`):
+ Controls whether to rescale the image by the specified scale `rescale_factor`. Can be overridden by the
+ `do_rescale` parameter in the `preprocess` method.
+ rescale_factor (`int` or `float`, *optional*, defaults to `1/255`):
+ Scale factor to use if rescaling the image. Can be overridden by the `rescale_factor` parameter in the
+ `preprocess` method.
+ do_normalize:
+ Controls whether to normalize the image. Can be overridden by the `do_normalize` parameter in the
+ `preprocess` method.
+ image_mean (`float` or `List[float]`, *optional*, defaults to `IMAGENET_DEFAULT_MEAN`):
+ Mean values to use when normalizing the image. Can be a single value or a list of values, one for each
+ channel. Can be overridden by the `image_mean` parameter in the `preprocess` method.
+ image_std (`float` or `List[float]`, *optional*, defaults to `IMAGENET_DEFAULT_STD`):
+ Standard deviation values to use when normalizing the image. Can be a single value or a list of values, one
+ for each channel. Can be overridden by the `image_std` parameter in the `preprocess` method.
+ do_pad (`bool`, *optional*, defaults to `True`):
+ Controls whether to pad the image to the largest image in a batch and create a pixel mask. Can be
+ overridden by the `do_pad` parameter in the `preprocess` method.
+ """
+
+ model_input_names = ["pixel_values", "pixel_mask"]
+
+ def __init__(
+ self,
+ format: Union[str, AnnotionFormat] = AnnotionFormat.COCO_DETECTION,
+ do_resize: bool = True,
+ size: Dict[str, int] = None,
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ do_rescale: bool = True,
+ rescale_factor: Union[int, float] = 1 / 255,
+ do_normalize: bool = True,
+ image_mean: Union[float, List[float]] = None,
+ image_std: Union[float, List[float]] = None,
+ do_pad: bool = True,
+ **kwargs
+ ) -> None:
+ if "pad_and_return_pixel_mask" in kwargs:
+ do_pad = kwargs.pop("pad_and_return_pixel_mask")
+
+ if "max_size" in kwargs:
+ warnings.warn(
+ "The `max_size` parameter is deprecated and will be removed in v4.26. "
+ "Please specify in `size['longest_edge'] instead`.",
+ FutureWarning,
+ )
+ max_size = kwargs.pop("max_size")
+ else:
+ max_size = None if size is None else 1333
+
+ size = size if size is not None else {"shortest_edge": 800, "longest_edge": 1333}
+ size = get_size_dict(size, max_size=max_size, default_to_square=False)
+
+ super().__init__(**kwargs)
+ self.format = format
+ self.do_resize = do_resize
+ self.size = size
+ self.resample = resample
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean if image_mean is not None else IMAGENET_DEFAULT_MEAN
+ self.image_std = image_std if image_std is not None else IMAGENET_DEFAULT_STD
+ self.do_pad = do_pad
+
+ def prepare_annotation(
+ self,
+ image: np.ndarray,
+ target: Dict,
+ format: Optional[AnnotionFormat] = None,
+ return_segmentation_masks: bool = None,
+ masks_path: Optional[Union[str, pathlib.Path]] = None,
+ ) -> Dict:
+ """
+ Prepare an annotation for feeding into DETR model.
+ """
+ format = format if format is not None else self.format
+
+ if format == AnnotionFormat.COCO_DETECTION:
+ return_segmentation_masks = False if return_segmentation_masks is None else return_segmentation_masks
+ target = prepare_coco_detection_annotation(image, target, return_segmentation_masks)
+ elif format == AnnotionFormat.COCO_PANOPTIC:
+ return_segmentation_masks = True if return_segmentation_masks is None else return_segmentation_masks
+ target = prepare_coco_panoptic_annotation(
+ image, target, masks_path=masks_path, return_masks=return_segmentation_masks
+ )
+ else:
+ raise ValueError(f"Format {format} is not supported.")
+ return target
+
+ def prepare(self, image, target, return_segmentation_masks=None, masks_path=None):
+ warnings.warn(
+ "The `prepare` method is deprecated and will be removed in a future version. "
+ "Please use `prepare_annotation` instead. Note: the `prepare_annotation` method "
+ "does not return the image anymore.",
+ )
+ target = self.prepare_annotation(image, target, return_segmentation_masks, masks_path, self.format)
+ return image, target
+
+ def convert_coco_poly_to_mask(self, *args, **kwargs):
+ warnings.warn("The `convert_coco_poly_to_mask` method is deprecated and will be removed in a future version. ")
+ return convert_coco_poly_to_mask(*args, **kwargs)
+
+ def prepare_coco_detection(self, *args, **kwargs):
+ warnings.warn("The `prepare_coco_detection` method is deprecated and will be removed in a future version. ")
+ return prepare_coco_detection_annotation(*args, **kwargs)
+
+ def prepare_coco_panoptic(self, *args, **kwargs):
+ warnings.warn("The `prepare_coco_panoptic` method is deprecated and will be removed in a future version. ")
+ return prepare_coco_panoptic_annotation(*args, **kwargs)
+
+ def resize(
+ self,
+ image: np.ndarray,
+ size: Dict[str, int],
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ data_format: Optional[ChannelDimension] = None,
+ **kwargs
+ ) -> np.ndarray:
+ """
+ Resize the image to the given size. Size can be `min_size` (scalar) or `(height, width)` tuple. If size is an
+ int, smaller edge of the image will be matched to this number.
+ """
+ if "max_size" in kwargs:
+ warnings.warn(
+ "The `max_size` parameter is deprecated and will be removed in v4.26. "
+ "Please specify in `size['longest_edge'] instead`.",
+ FutureWarning,
+ )
+ max_size = kwargs.pop("max_size")
+ else:
+ max_size = None
+ size = get_size_dict(size, max_size=max_size, default_to_square=False)
+ if "shortest_edge" in size and "longest_edge" in size:
+ size = get_resize_output_image_size(image, size["shortest_edge"], size["longest_edge"])
+ elif "height" in size and "width" in size:
+ size = (size["height"], size["width"])
+ else:
+ raise ValueError(
+ "Size must contain 'height' and 'width' keys or 'shortest_edge' and 'longest_edge' keys. Got"
+ f" {size.keys()}."
+ )
+ image = resize(image, size=size, resample=resample, data_format=data_format)
+ return image
+
+ def resize_annotation(
+ self,
+ annotation,
+ orig_size,
+ size,
+ resample: PILImageResampling = PILImageResampling.NEAREST,
+ ) -> Dict:
+ """
+ Resize the annotation to match the resized image. If size is an int, smaller edge of the mask will be matched
+ to this number.
+ """
+ return resize_annotation(annotation, orig_size=orig_size, target_size=size, resample=resample)
+
+ def rescale(
+ self, image: np.ndarray, rescale_factor: Union[float, int], data_format: Optional[ChannelDimension] = None
+ ) -> np.ndarray:
+ """
+ Rescale the image by the given factor.
+ """
+ return rescale(image, rescale_factor, data_format=data_format)
+
+ def normalize(
+ self,
+ image: np.ndarray,
+ mean: Union[float, Iterable[float]],
+ std: Union[float, Iterable[float]],
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Normalize the image with the given mean and standard deviation.
+ """
+ return normalize(image, mean=mean, std=std, data_format=data_format)
+
+ def normalize_annotation(self, annotation: Dict, image_size: Tuple[int, int]) -> Dict:
+ """
+ Normalize the boxes in the annotation from `[top_left_x, top_left_y, bottom_right_x, bottom_right_y]` to
+ `[center_x, center_y, width, height]` format.
+ """
+ return normalize_annotation(annotation, image_size=image_size)
+
+ def pad_and_create_pixel_mask(
+ self,
+ pixel_values_list: List[ImageInput],
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ data_format: Optional[ChannelDimension] = None,
+ ) -> BatchFeature:
+ """
+ Pads a batch of images with zeros to the size of largest height and width in the batch and returns their
+ corresponding pixel mask.
+
+ Args:
+ images (`List[np.ndarray]`):
+ Batch of images to pad.
+ return_tensors (`str` or `TensorType`, *optional*):
+ The type of tensors to return. Can be one of:
+ - Unset: Return a list of `np.ndarray`.
+ - `TensorType.TENSORFLOW` or `'tf'`: Return a batch of type `tf.Tensor`.
+ - `TensorType.PYTORCH` or `'pt'`: Return a batch of type `torch.Tensor`.
+ - `TensorType.NUMPY` or `'np'`: Return a batch of type `np.ndarray`.
+ - `TensorType.JAX` or `'jax'`: Return a batch of type `jax.numpy.ndarray`.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be the same as the input image.
+ """
+ warnings.warn(
+ "This method is deprecated and will be removed in v4.27.0. Please use pad instead.", FutureWarning
+ )
+ # pad expects a list of np.ndarray, but the previous feature extractors expected torch tensors
+ images = [to_numpy_array(image) for image in pixel_values_list]
+ return self.pad(
+ images=images,
+ return_pixel_mask=True,
+ return_tensors=return_tensors,
+ data_format=data_format,
+ )
+
+ def _pad_image(
+ self,
+ image: np.ndarray,
+ output_size: Tuple[int, int],
+ constant_values: Union[float, Iterable[float]] = 0,
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Pad an image with zeros to the given size.
+ """
+ input_height, input_width = get_image_size(image)
+ output_height, output_width = output_size
+
+ pad_bottom = output_height - input_height
+ pad_right = output_width - input_width
+ padding = ((0, pad_bottom), (0, pad_right))
+ padded_image = pad(
+ image, padding, mode=PaddingMode.CONSTANT, constant_values=constant_values, data_format=data_format
+ )
+ return padded_image
+
+ def pad(
+ self,
+ images: List[np.ndarray],
+ constant_values: Union[float, Iterable[float]] = 0,
+ return_pixel_mask: bool = True,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Pads a batch of images to the bottom and right of the image with zeros to the size of largest height and width
+ in the batch and optionally returns their corresponding pixel mask.
+
+ Args:
+ image (`np.ndarray`):
+ Image to pad.
+ constant_values (`float` or `Iterable[float]`, *optional*):
+ The value to use for the padding if `mode` is `"constant"`.
+ return_pixel_mask (`bool`, *optional*, defaults to `True`):
+ Whether to return a pixel mask.
+ input_channel_dimension (`ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be inferred from the input image.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be the same as the input image.
+ """
+ pad_size = get_max_height_width(images)
+
+ padded_images = [
+ self._pad_image(image, pad_size, constant_values=constant_values, data_format=data_format)
+ for image in images
+ ]
+ data = {"pixel_values": padded_images}
+
+ if return_pixel_mask:
+ masks = [make_pixel_mask(image=image, output_size=pad_size) for image in images]
+ data["pixel_mask"] = masks
+
+ return BatchFeature(data=data, tensor_type=return_tensors)
+
+ def preprocess(
+ self,
+ images: ImageInput,
+ annotations: Optional[Union[List[Dict], List[List[Dict]]]] = None,
+ return_segmentation_masks: bool = None,
+ masks_path: Optional[Union[str, pathlib.Path]] = None,
+ do_resize: Optional[bool] = None,
+ size: Optional[Dict[str, int]] = None,
+ resample=None, # PILImageResampling
+ do_rescale: Optional[bool] = None,
+ rescale_factor: Optional[Union[int, float]] = None,
+ do_normalize: Optional[bool] = None,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ do_pad: Optional[bool] = None,
+ format: Optional[Union[str, AnnotionFormat]] = None,
+ return_tensors: Optional[Union[TensorType, str]] = None,
+ data_format: Union[str, ChannelDimension] = ChannelDimension.FIRST,
+ **kwargs
+ ) -> BatchFeature:
+ """
+ Preprocess an image or a batch of images so that it can be used by the model.
+
+ Args:
+ images (`ImageInput`):
+ Image or batch of images to preprocess.
+ annotations (`List[Dict]` or `List[List[Dict]]`, *optional*):
+ List of annotations associated with the image or batch of images. If annotionation is for object
+ detection, the annotations should be a dictionary with the following keys:
+ - "image_id" (`int`): The image id.
+ - "annotations" (`List[Dict]`): List of annotations for an image. Each annotation should be a
+ dictionary. An image can have no annotations, in which case the list should be empty.
+ If annotionation is for segmentation, the annotations should be a dictionary with the following keys:
+ - "image_id" (`int`): The image id.
+ - "segments_info" (`List[Dict]`): List of segments for an image. Each segment should be a dictionary.
+ An image can have no segments, in which case the list should be empty.
+ - "file_name" (`str`): The file name of the image.
+ return_segmentation_masks (`bool`, *optional*, defaults to self.return_segmentation_masks):
+ Whether to return segmentation masks.
+ masks_path (`str` or `pathlib.Path`, *optional*):
+ Path to the directory containing the segmentation masks.
+ do_resize (`bool`, *optional*, defaults to self.do_resize):
+ Whether to resize the image.
+ size (`Dict[str, int]`, *optional*, defaults to self.size):
+ Size of the image after resizing.
+ resample (`PILImageResampling`, *optional*, defaults to self.resample):
+ Resampling filter to use when resizing the image.
+ do_rescale (`bool`, *optional*, defaults to self.do_rescale):
+ Whether to rescale the image.
+ rescale_factor (`float`, *optional*, defaults to self.rescale_factor):
+ Rescale factor to use when rescaling the image.
+ do_normalize (`bool`, *optional*, defaults to self.do_normalize):
+ Whether to normalize the image.
+ image_mean (`float` or `List[float]`, *optional*, defaults to self.image_mean):
+ Mean to use when normalizing the image.
+ image_std (`float` or `List[float]`, *optional*, defaults to self.image_std):
+ Standard deviation to use when normalizing the image.
+ do_pad (`bool`, *optional*, defaults to self.do_pad):
+ Whether to pad the image.
+ format (`str` or `AnnotionFormat`, *optional*, defaults to self.format):
+ Format of the annotations.
+ return_tensors (`str` or `TensorType`, *optional*, defaults to self.return_tensors):
+ Type of tensors to return. If `None`, will return the list of images.
+ data_format (`str` or `ChannelDimension`, *optional*, defaults to self.data_format):
+ The channel dimension format of the image. If not provided, it will be the same as the input image.
+ """
+ if "pad_and_return_pixel_mask" in kwargs:
+ warnings.warn(
+ "The `pad_and_return_pixel_mask` argument is deprecated and will be removed in a future version, "
+ "use `do_pad` instead.",
+ FutureWarning,
+ )
+ do_pad = kwargs.pop("pad_and_return_pixel_mask")
+
+ max_size = None
+ if "max_size" in kwargs:
+ warnings.warn(
+ "The `max_size` argument is deprecated and will be removed in a future version, use"
+ " `size['longest_edge']` instead.",
+ FutureWarning,
+ )
+ size = kwargs.pop("max_size")
+
+ do_resize = self.do_resize if do_resize is None else do_resize
+ size = self.size if size is None else size
+ size = get_size_dict(size=size, max_size=max_size, default_to_square=False)
+ resample = self.resample if resample is None else resample
+ do_rescale = self.do_rescale if do_rescale is None else do_rescale
+ rescale_factor = self.rescale_factor if rescale_factor is None else rescale_factor
+ do_normalize = self.do_normalize if do_normalize is None else do_normalize
+ image_mean = self.image_mean if image_mean is None else image_mean
+ image_std = self.image_std if image_std is None else image_std
+ do_pad = self.do_pad if do_pad is None else do_pad
+ format = self.format if format is None else format
+
+ if do_resize is not None and size is None:
+ raise ValueError("Size and max_size must be specified if do_resize is True.")
+
+ if do_rescale is not None and rescale_factor is None:
+ raise ValueError("Rescale factor must be specified if do_rescale is True.")
+
+ if do_normalize is not None and (image_mean is None or image_std is None):
+ raise ValueError("Image mean and std must be specified if do_normalize is True.")
+
+ if not is_batched(images):
+ images = [images]
+ annotations = [annotations] if annotations is not None else None
+
+ if annotations is not None and len(images) != len(annotations):
+ raise ValueError(
+ f"The number of images ({len(images)}) and annotations ({len(annotations)}) do not match."
+ )
+
+ if not valid_images(images):
+ raise ValueError(
+ "Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
+ "torch.Tensor, tf.Tensor or jax.ndarray."
+ )
+
+ format = AnnotionFormat(format)
+ if annotations is not None:
+ if format == AnnotionFormat.COCO_DETECTION and not valid_coco_detection_annotations(annotations):
+ raise ValueError(
+ "Invalid COCO detection annotations. Annotations must a dict (single image) of list of dicts"
+ "(batch of images) with the following keys: `image_id` and `annotations`, with the latter "
+ "being a list of annotations in the COCO format."
+ )
+ elif format == AnnotionFormat.COCO_PANOPTIC and not valid_coco_panoptic_annotations(annotations):
+ raise ValueError(
+ "Invalid COCO panoptic annotations. Annotations must a dict (single image) of list of dicts "
+ "(batch of images) with the following keys: `image_id`, `file_name` and `segments_info`, with "
+ "the latter being a list of annotations in the COCO format."
+ )
+ elif format not in SUPPORTED_ANNOTATION_FORMATS:
+ raise ValueError(
+ f"Unsupported annotation format: {format} must be one of {SUPPORTED_ANNOTATION_FORMATS}"
+ )
+
+ if (
+ masks_path is not None
+ and format == AnnotionFormat.COCO_PANOPTIC
+ and not isinstance(masks_path, (pathlib.Path, str))
+ ):
+ raise ValueError(
+ "The path to the directory containing the mask PNG files should be provided as a"
+ f" `pathlib.Path` or string object, but is {type(masks_path)} instead."
+ )
+
+ # All transformations expect numpy arrays
+ images = [to_numpy_array(image) for image in images]
+
+ # prepare (COCO annotations as a list of Dict -> DETR target as a single Dict per image)
+ if annotations is not None:
+ prepared_images = []
+ prepared_annotations = []
+ for image, target in zip(images, annotations):
+ target = self.prepare_annotation(
+ image, target, format, return_segmentation_masks=return_segmentation_masks, masks_path=masks_path
+ )
+ prepared_images.append(image)
+ prepared_annotations.append(target)
+ images = prepared_images
+ annotations = prepared_annotations
+ del prepared_images, prepared_annotations
+
+ # transformations
+ if do_resize:
+ if annotations is not None:
+ resized_images, resized_annotations = [], []
+ for image, target in zip(images, annotations):
+ orig_size = get_image_size(image)
+ resized_image = self.resize(image, size=size, max_size=max_size, resample=resample)
+ resized_annotation = self.resize_annotation(target, orig_size, get_image_size(resized_image))
+ resized_images.append(resized_image)
+ resized_annotations.append(resized_annotation)
+ images = resized_images
+ annotations = resized_annotations
+ del resized_images, resized_annotations
+ else:
+ images = [self.resize(image, size=size, resample=resample) for image in images]
+
+ if do_rescale:
+ images = [self.rescale(image, rescale_factor) for image in images]
+
+ if do_normalize:
+ images = [self.normalize(image, image_mean, image_std) for image in images]
+ if annotations is not None:
+ annotations = [
+ self.normalize_annotation(annotation, get_image_size(image))
+ for annotation, image in zip(annotations, images)
+ ]
+
+ if do_pad:
+ # Pads images and returns their mask: {'pixel_values': ..., 'pixel_mask': ...}
+ data = self.pad(images, return_pixel_mask=True, data_format=data_format)
+ else:
+ images = [to_channel_dimension_format(image, data_format) for image in images]
+ data = {"pixel_values": images}
+
+ encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
+ if annotations is not None:
+ encoded_inputs["labels"] = [
+ BatchFeature(annotation, tensor_type=return_tensors) for annotation in annotations
+ ]
+
+ return encoded_inputs
+
+ # POSTPROCESSING METHODS - TODO: add support for other frameworks
+ # inspired by https://github.com/facebookresearch/detr/blob/master/models/detr.py#L258
+ def post_process(self, outputs, target_sizes):
+ """
+ Converts the output of [`DetrForObjectDetection`] into the format expected by the COCO api. Only supports
+ PyTorch.
+
+ Args:
+ outputs ([`DetrObjectDetectionOutput`]):
+ Raw outputs of the model.
+ target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
+ Tensor containing the size (height, width) of each image of the batch. For evaluation, this must be the
+ original image size (before any data augmentation). For visualization, this should be the image size
+ after data augment, but before padding.
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
+ in the batch as predicted by the model.
+ """
+ warnings.warn(
+ "`post_process` is deprecated and will be removed in v5 of Transformers, please use"
+ " `post_process_object_detection`",
+ FutureWarning,
+ )
+
+ out_logits, out_bbox = outputs.logits, outputs.pred_boxes
+
+ if len(out_logits) != len(target_sizes):
+ raise ValueError("Make sure that you pass in as many target sizes as the batch dimension of the logits")
+ if target_sizes.shape[1] != 2:
+ raise ValueError("Each element of target_sizes must contain the size (h, w) of each image of the batch")
+
+ prob = nn.functional.softmax(out_logits, -1)
+ scores, labels = prob[..., :-1].max(-1)
+
+ # convert to [x0, y0, x1, y1] format
+ boxes = center_to_corners_format(out_bbox)
+ # and from relative [0, 1] to absolute [0, height] coordinates
+ img_h, img_w = target_sizes.unbind(1)
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1).to(boxes.device)
+ boxes = boxes * scale_fct[:, None, :]
+
+ results = [{"scores": s, "labels": l, "boxes": b} for s, l, b in zip(scores, labels, boxes)]
+ return results
+
+ def post_process_segmentation(self, outputs, target_sizes, threshold=0.9, mask_threshold=0.5):
+ """
+ Converts the output of [`DetrForSegmentation`] into image segmentation predictions. Only supports PyTorch.
+
+ Args:
+ outputs ([`DetrSegmentationOutput`]):
+ Raw outputs of the model.
+ target_sizes (`torch.Tensor` of shape `(batch_size, 2)` or `List[Tuple]` of length `batch_size`):
+ Torch Tensor (or list) corresponding to the requested final size (h, w) of each prediction.
+ threshold (`float`, *optional*, defaults to 0.9):
+ Threshold to use to filter out queries.
+ mask_threshold (`float`, *optional*, defaults to 0.5):
+ Threshold to use when turning the predicted masks into binary values.
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels, and masks for an image
+ in the batch as predicted by the model.
+ """
+ warnings.warn(
+ "`post_process_segmentation` is deprecated and will be removed in v5 of Transformers, please use"
+ " `post_process_semantic_segmentation`.",
+ FutureWarning,
+ )
+ out_logits, raw_masks = outputs.logits, outputs.pred_masks
+ preds = []
+
+ def to_tuple(tup):
+ if isinstance(tup, tuple):
+ return tup
+ return tuple(tup.cpu().tolist())
+
+ for cur_logits, cur_masks, size in zip(out_logits, raw_masks, target_sizes):
+ # we filter empty queries and detection below threshold
+ scores, labels = cur_logits.softmax(-1).max(-1)
+ keep = labels.ne(outputs.logits.shape[-1] - 1) & (scores > threshold)
+ cur_scores, cur_classes = cur_logits.softmax(-1).max(-1)
+ cur_scores = cur_scores[keep]
+ cur_classes = cur_classes[keep]
+ cur_masks = cur_masks[keep]
+ cur_masks = nn.functional.interpolate(cur_masks[:, None], to_tuple(size), mode="bilinear").squeeze(1)
+ cur_masks = (cur_masks.sigmoid() > mask_threshold) * 1
+
+ predictions = {"scores": cur_scores, "labels": cur_classes, "masks": cur_masks}
+ preds.append(predictions)
+ return preds
+
+ # inspired by https://github.com/facebookresearch/detr/blob/master/models/segmentation.py#L218
+ def post_process_instance(self, results, outputs, orig_target_sizes, max_target_sizes, threshold=0.5):
+ """
+ Converts the output of [`DetrForSegmentation`] into actual instance segmentation predictions. Only supports
+ PyTorch.
+
+ Args:
+ results (`List[Dict]`):
+ Results list obtained by [`~DetrFeatureExtractor.post_process`], to which "masks" results will be
+ added.
+ outputs ([`DetrSegmentationOutput`]):
+ Raw outputs of the model.
+ orig_target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
+ Tensor containing the size (h, w) of each image of the batch. For evaluation, this must be the original
+ image size (before any data augmentation).
+ max_target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
+ Tensor containing the maximum size (h, w) of each image of the batch. For evaluation, this must be the
+ original image size (before any data augmentation).
+ threshold (`float`, *optional*, defaults to 0.5):
+ Threshold to use when turning the predicted masks into binary values.
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels, boxes and masks for an
+ image in the batch as predicted by the model.
+ """
+ warnings.warn(
+ "`post_process_instance` is deprecated and will be removed in v5 of Transformers, please use"
+ " `post_process_instance_segmentation`.",
+ FutureWarning,
+ )
+
+ if len(orig_target_sizes) != len(max_target_sizes):
+ raise ValueError("Make sure to pass in as many orig_target_sizes as max_target_sizes")
+ max_h, max_w = max_target_sizes.max(0)[0].tolist()
+ outputs_masks = outputs.pred_masks.squeeze(2)
+ outputs_masks = nn.functional.interpolate(
+ outputs_masks, size=(max_h, max_w), mode="bilinear", align_corners=False
+ )
+ outputs_masks = (outputs_masks.sigmoid() > threshold).cpu()
+
+ for i, (cur_mask, t, tt) in enumerate(zip(outputs_masks, max_target_sizes, orig_target_sizes)):
+ img_h, img_w = t[0], t[1]
+ results[i]["masks"] = cur_mask[:, :img_h, :img_w].unsqueeze(1)
+ results[i]["masks"] = nn.functional.interpolate(
+ results[i]["masks"].float(), size=tuple(tt.tolist()), mode="nearest"
+ ).byte()
+
+ return results
+
+ # inspired by https://github.com/facebookresearch/detr/blob/master/models/segmentation.py#L241
+ def post_process_panoptic(self, outputs, processed_sizes, target_sizes=None, is_thing_map=None, threshold=0.85):
+ """
+ Converts the output of [`DetrForSegmentation`] into actual panoptic predictions. Only supports PyTorch.
+
+ Args:
+ outputs ([`DetrSegmentationOutput`]):
+ Raw outputs of the model.
+ processed_sizes (`torch.Tensor` of shape `(batch_size, 2)` or `List[Tuple]` of length `batch_size`):
+ Torch Tensor (or list) containing the size (h, w) of each image of the batch, i.e. the size after data
+ augmentation but before batching.
+ target_sizes (`torch.Tensor` of shape `(batch_size, 2)` or `List[Tuple]` of length `batch_size`, *optional*):
+ Torch Tensor (or list) corresponding to the requested final size `(height, width)` of each prediction.
+ If left to None, it will default to the `processed_sizes`.
+ is_thing_map (`torch.Tensor` of shape `(batch_size, 2)`, *optional*):
+ Dictionary mapping class indices to either True or False, depending on whether or not they are a thing.
+ If not set, defaults to the `is_thing_map` of COCO panoptic.
+ threshold (`float`, *optional*, defaults to 0.85):
+ Threshold to use to filter out queries.
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing a PNG string and segments_info values for
+ an image in the batch as predicted by the model.
+ """
+ warnings.warn(
+ "`post_process_panoptic is deprecated and will be removed in v5 of Transformers, please use"
+ " `post_process_panoptic_segmentation`.",
+ FutureWarning,
+ )
+ if target_sizes is None:
+ target_sizes = processed_sizes
+ if len(processed_sizes) != len(target_sizes):
+ raise ValueError("Make sure to pass in as many processed_sizes as target_sizes")
+
+ if is_thing_map is None:
+ # default to is_thing_map of COCO panoptic
+ is_thing_map = {i: i <= 90 for i in range(201)}
+
+ out_logits, raw_masks, raw_boxes = outputs.logits, outputs.pred_masks, outputs.pred_boxes
+ if not len(out_logits) == len(raw_masks) == len(target_sizes):
+ raise ValueError(
+ "Make sure that you pass in as many target sizes as the batch dimension of the logits and masks"
+ )
+ preds = []
+
+ def to_tuple(tup):
+ if isinstance(tup, tuple):
+ return tup
+ return tuple(tup.cpu().tolist())
+
+ for cur_logits, cur_masks, cur_boxes, size, target_size in zip(
+ out_logits, raw_masks, raw_boxes, processed_sizes, target_sizes
+ ):
+ # we filter empty queries and detection below threshold
+ scores, labels = cur_logits.softmax(-1).max(-1)
+ keep = labels.ne(outputs.logits.shape[-1] - 1) & (scores > threshold)
+ cur_scores, cur_classes = cur_logits.softmax(-1).max(-1)
+ cur_scores = cur_scores[keep]
+ cur_classes = cur_classes[keep]
+ cur_masks = cur_masks[keep]
+ cur_masks = nn.functional.interpolate(cur_masks[:, None], to_tuple(size), mode="bilinear").squeeze(1)
+ cur_boxes = center_to_corners_format(cur_boxes[keep])
+
+ h, w = cur_masks.shape[-2:]
+ if len(cur_boxes) != len(cur_classes):
+ raise ValueError("Not as many boxes as there are classes")
+
+ # It may be that we have several predicted masks for the same stuff class.
+ # In the following, we track the list of masks ids for each stuff class (they are merged later on)
+ cur_masks = cur_masks.flatten(1)
+ stuff_equiv_classes = defaultdict(lambda: [])
+ for k, label in enumerate(cur_classes):
+ if not is_thing_map[label.item()]:
+ stuff_equiv_classes[label.item()].append(k)
+
+ def get_ids_area(masks, scores, dedup=False):
+ # This helper function creates the final panoptic segmentation image
+ # It also returns the area of the masks that appears on the image
+
+ m_id = masks.transpose(0, 1).softmax(-1)
+
+ if m_id.shape[-1] == 0:
+ # We didn't detect any mask :(
+ m_id = torch.zeros((h, w), dtype=torch.long, device=m_id.device)
+ else:
+ m_id = m_id.argmax(-1).view(h, w)
+
+ if dedup:
+ # Merge the masks corresponding to the same stuff class
+ for equiv in stuff_equiv_classes.values():
+ if len(equiv) > 1:
+ for eq_id in equiv:
+ m_id.masked_fill_(m_id.eq(eq_id), equiv[0])
+
+ final_h, final_w = to_tuple(target_size)
+
+ seg_img = PIL.Image.fromarray(id_to_rgb(m_id.view(h, w).cpu().numpy()))
+ seg_img = seg_img.resize(size=(final_w, final_h), resample=PILImageResampling.NEAREST)
+
+ np_seg_img = torch.ByteTensor(torch.ByteStorage.from_buffer(seg_img.tobytes()))
+ np_seg_img = np_seg_img.view(final_h, final_w, 3)
+ np_seg_img = np_seg_img.numpy()
+
+ m_id = torch.from_numpy(rgb_to_id(np_seg_img))
+
+ area = []
+ for i in range(len(scores)):
+ area.append(m_id.eq(i).sum().item())
+ return area, seg_img
+
+ area, seg_img = get_ids_area(cur_masks, cur_scores, dedup=True)
+ if cur_classes.numel() > 0:
+ # We know filter empty masks as long as we find some
+ while True:
+ filtered_small = torch.as_tensor(
+ [area[i] <= 4 for i, c in enumerate(cur_classes)], dtype=torch.bool, device=keep.device
+ )
+ if filtered_small.any().item():
+ cur_scores = cur_scores[~filtered_small]
+ cur_classes = cur_classes[~filtered_small]
+ cur_masks = cur_masks[~filtered_small]
+ area, seg_img = get_ids_area(cur_masks, cur_scores)
+ else:
+ break
+
+ else:
+ cur_classes = torch.ones(1, dtype=torch.long, device=cur_classes.device)
+
+ segments_info = []
+ for i, a in enumerate(area):
+ cat = cur_classes[i].item()
+ segments_info.append({"id": i, "isthing": is_thing_map[cat], "category_id": cat, "area": a})
+ del cur_classes
+
+ with io.BytesIO() as out:
+ seg_img.save(out, format="PNG")
+ predictions = {"png_string": out.getvalue(), "segments_info": segments_info}
+ preds.append(predictions)
+ return preds
+
+ # inspired by https://github.com/facebookresearch/detr/blob/master/models/detr.py#L258
+ def post_process_object_detection(
+ self, outputs, threshold: float = 0.5, target_sizes: Union[TensorType, List[Tuple]] = None
+ ):
+ """
+ Converts the output of [`DetrForObjectDetection`] into the format expected by the COCO api. Only supports
+ PyTorch.
+
+ Args:
+ outputs ([`DetrObjectDetectionOutput`]):
+ Raw outputs of the model.
+ threshold (`float`, *optional*):
+ Score threshold to keep object detection predictions.
+ target_sizes (`torch.Tensor` or `List[Tuple[int, int]]`, *optional*):
+ Tensor of shape `(batch_size, 2)` or list of tuples (`Tuple[int, int]`) containing the target size
+ `(height, width)` of each image in the batch. If unset, predictions will not be resized.
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
+ in the batch as predicted by the model.
+ """
+ out_logits, out_bbox = outputs.logits, outputs.pred_boxes
+
+ if target_sizes is not None:
+ if len(out_logits) != len(target_sizes):
+ raise ValueError(
+ "Make sure that you pass in as many target sizes as the batch dimension of the logits"
+ )
+
+ prob = nn.functional.softmax(out_logits, -1)
+ scores, labels = prob[..., :-1].max(-1)
+
+ # Convert to [x0, y0, x1, y1] format
+ boxes = center_to_corners_format(out_bbox)
+
+ # Convert from relative [0, 1] to absolute [0, height] coordinates
+ if target_sizes is not None:
+ if isinstance(target_sizes, List):
+ img_h = torch.Tensor([i[0] for i in target_sizes])
+ img_w = torch.Tensor([i[1] for i in target_sizes])
+ else:
+ img_h, img_w = target_sizes.unbind(1)
+
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
+ boxes = boxes * scale_fct[:, None, :]
+
+ results = []
+ for s, l, b in zip(scores, labels, boxes):
+ score = s[s > threshold]
+ label = l[s > threshold]
+ box = b[s > threshold]
+ results.append({"scores": score, "labels": label, "boxes": box})
+
+ return results
+
+ def post_process_semantic_segmentation(self, outputs, target_sizes: List[Tuple[int, int]] = None):
+ """
+ Converts the output of [`DetrForSegmentation`] into semantic segmentation maps. Only supports PyTorch.
+
+ Args:
+ outputs ([`DetrForSegmentation`]):
+ Raw outputs of the model.
+ target_sizes (`List[Tuple[int, int]]`, *optional*):
+ A list of tuples (`Tuple[int, int]`) containing the target size (height, width) of each image in the
+ batch. If unset, predictions will not be resized.
+ Returns:
+ `List[torch.Tensor]`:
+ A list of length `batch_size`, where each item is a semantic segmentation map of shape (height, width)
+ corresponding to the target_sizes entry (if `target_sizes` is specified). Each entry of each
+ `torch.Tensor` correspond to a semantic class id.
+ """
+ class_queries_logits = outputs.logits # [batch_size, num_queries, num_classes+1]
+ masks_queries_logits = outputs.pred_masks # [batch_size, num_queries, height, width]
+
+ # Remove the null class `[..., :-1]`
+ masks_classes = class_queries_logits.softmax(dim=-1)[..., :-1]
+ masks_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
+
+ # Semantic segmentation logits of shape (batch_size, num_classes, height, width)
+ segmentation = torch.einsum("bqc, bqhw -> bchw", masks_classes, masks_probs)
+ batch_size = class_queries_logits.shape[0]
+
+ # Resize logits and compute semantic segmentation maps
+ if target_sizes is not None:
+ if batch_size != len(target_sizes):
+ raise ValueError(
+ "Make sure that you pass in as many target sizes as the batch dimension of the logits"
+ )
+
+ semantic_segmentation = []
+ for idx in range(batch_size):
+ resized_logits = nn.functional.interpolate(
+ segmentation[idx].unsqueeze(dim=0), size=target_sizes[idx], mode="bilinear", align_corners=False
+ )
+ semantic_map = resized_logits[0].argmax(dim=0)
+ semantic_segmentation.append(semantic_map)
+ else:
+ semantic_segmentation = segmentation.argmax(dim=1)
+ semantic_segmentation = [semantic_segmentation[i] for i in range(semantic_segmentation.shape[0])]
+
+ return semantic_segmentation
+
+ # inspired by https://github.com/facebookresearch/detr/blob/master/models/segmentation.py#L218
+ def post_process_instance_segmentation(
+ self,
+ outputs,
+ threshold: float = 0.5,
+ mask_threshold: float = 0.5,
+ overlap_mask_area_threshold: float = 0.8,
+ target_sizes: Optional[List[Tuple[int, int]]] = None,
+ return_coco_annotation: Optional[bool] = False,
+ ) -> List[Dict]:
+ """
+ Converts the output of [`DetrForSegmentation`] into instance segmentation predictions. Only supports PyTorch.
+
+ Args:
+ outputs ([`DetrForSegmentation`]):
+ Raw outputs of the model.
+ threshold (`float`, *optional*, defaults to 0.5):
+ The probability score threshold to keep predicted instance masks.
+ mask_threshold (`float`, *optional*, defaults to 0.5):
+ Threshold to use when turning the predicted masks into binary values.
+ overlap_mask_area_threshold (`float`, *optional*, defaults to 0.8):
+ The overlap mask area threshold to merge or discard small disconnected parts within each binary
+ instance mask.
+ target_sizes (`List[Tuple]`, *optional*):
+ List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
+ final size (height, width) of each prediction. If unset, predictions will not be resized.
+ return_coco_annotation (`bool`, *optional*):
+ Defaults to `False`. If set to `True`, segmentation maps are returned in COCO run-length encoding (RLE)
+ format.
+ Returns:
+ `List[Dict]`: A list of dictionaries, one per image, each dictionary containing two keys:
+ - **segmentation** -- A tensor of shape `(height, width)` where each pixel represents a `segment_id` or
+ `List[List]` run-length encoding (RLE) of the segmentation map if return_coco_annotation is set to
+ `True`. Set to `None` if no mask if found above `threshold`.
+ - **segments_info** -- A dictionary that contains additional information on each segment.
+ - **id** -- An integer representing the `segment_id`.
+ - **label_id** -- An integer representing the label / semantic class id corresponding to `segment_id`.
+ - **score** -- Prediction score of segment with `segment_id`.
+ """
+ class_queries_logits = outputs.logits # [batch_size, num_queries, num_classes+1]
+ masks_queries_logits = outputs.pred_masks # [batch_size, num_queries, height, width]
+
+ batch_size = class_queries_logits.shape[0]
+ num_labels = class_queries_logits.shape[-1] - 1
+
+ mask_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
+
+ # Predicted label and score of each query (batch_size, num_queries)
+ pred_scores, pred_labels = nn.functional.softmax(class_queries_logits, dim=-1).max(-1)
+
+ # Loop over items in batch size
+ results: List[Dict[str, TensorType]] = []
+
+ for i in range(batch_size):
+ mask_probs_item, pred_scores_item, pred_labels_item = remove_low_and_no_objects(
+ mask_probs[i], pred_scores[i], pred_labels[i], threshold, num_labels
+ )
+
+ # No mask found
+ if mask_probs_item.shape[0] <= 0:
+ height, width = target_sizes[i] if target_sizes is not None else mask_probs_item.shape[1:]
+ segmentation = torch.zeros((height, width)) - 1
+ results.append({"segmentation": segmentation, "segments_info": []})
+ continue
+
+ # Get segmentation map and segment information of batch item
+ target_size = target_sizes[i] if target_sizes is not None else None
+ segmentation, segments = compute_segments(
+ mask_probs=mask_probs_item,
+ pred_scores=pred_scores_item,
+ pred_labels=pred_labels_item,
+ mask_threshold=mask_threshold,
+ overlap_mask_area_threshold=overlap_mask_area_threshold,
+ label_ids_to_fuse=[],
+ target_size=target_size,
+ )
+
+ # Return segmentation map in run-length encoding (RLE) format
+ if return_coco_annotation:
+ segmentation = convert_segmentation_to_rle(segmentation)
+
+ results.append({"segmentation": segmentation, "segments_info": segments})
+ return results
+
+ # inspired by https://github.com/facebookresearch/detr/blob/master/models/segmentation.py#L241
+ def post_process_panoptic_segmentation(
+ self,
+ outputs,
+ threshold: float = 0.5,
+ mask_threshold: float = 0.5,
+ overlap_mask_area_threshold: float = 0.8,
+ label_ids_to_fuse: Optional[Set[int]] = None,
+ target_sizes: Optional[List[Tuple[int, int]]] = None,
+ ) -> List[Dict]:
+ """
+ Converts the output of [`DetrForSegmentation`] into image panoptic segmentation predictions. Only supports
+ PyTorch.
+
+ Args:
+ outputs ([`DetrForSegmentation`]):
+ The outputs from [`DetrForSegmentation`].
+ threshold (`float`, *optional*, defaults to 0.5):
+ The probability score threshold to keep predicted instance masks.
+ mask_threshold (`float`, *optional*, defaults to 0.5):
+ Threshold to use when turning the predicted masks into binary values.
+ overlap_mask_area_threshold (`float`, *optional*, defaults to 0.8):
+ The overlap mask area threshold to merge or discard small disconnected parts within each binary
+ instance mask.
+ label_ids_to_fuse (`Set[int]`, *optional*):
+ The labels in this state will have all their instances be fused together. For instance we could say
+ there can only be one sky in an image, but several persons, so the label ID for sky would be in that
+ set, but not the one for person.
+ target_sizes (`List[Tuple]`, *optional*):
+ List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
+ final size (height, width) of each prediction in batch. If unset, predictions will not be resized.
+ Returns:
+ `List[Dict]`: A list of dictionaries, one per image, each dictionary containing two keys:
+ - **segmentation** -- a tensor of shape `(height, width)` where each pixel represents a `segment_id` or
+ `None` if no mask if found above `threshold`. If `target_sizes` is specified, segmentation is resized to
+ the corresponding `target_sizes` entry.
+ - **segments_info** -- A dictionary that contains additional information on each segment.
+ - **id** -- an integer representing the `segment_id`.
+ - **label_id** -- An integer representing the label / semantic class id corresponding to `segment_id`.
+ - **was_fused** -- a boolean, `True` if `label_id` was in `label_ids_to_fuse`, `False` otherwise.
+ Multiple instances of the same class / label were fused and assigned a single `segment_id`.
+ - **score** -- Prediction score of segment with `segment_id`.
+ """
+
+ if label_ids_to_fuse is None:
+ warnings.warn("`label_ids_to_fuse` unset. No instance will be fused.")
+ label_ids_to_fuse = set()
+
+ class_queries_logits = outputs.logits # [batch_size, num_queries, num_classes+1]
+ masks_queries_logits = outputs.pred_masks # [batch_size, num_queries, height, width]
+
+ batch_size = class_queries_logits.shape[0]
+ num_labels = class_queries_logits.shape[-1] - 1
+
+ mask_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
+
+ # Predicted label and score of each query (batch_size, num_queries)
+ pred_scores, pred_labels = nn.functional.softmax(class_queries_logits, dim=-1).max(-1)
+
+ # Loop over items in batch size
+ results: List[Dict[str, TensorType]] = []
+
+ for i in range(batch_size):
+ mask_probs_item, pred_scores_item, pred_labels_item = remove_low_and_no_objects(
+ mask_probs[i], pred_scores[i], pred_labels[i], threshold, num_labels
+ )
+
+ # No mask found
+ if mask_probs_item.shape[0] <= 0:
+ height, width = target_sizes[i] if target_sizes is not None else mask_probs_item.shape[1:]
+ segmentation = torch.zeros((height, width)) - 1
+ results.append({"segmentation": segmentation, "segments_info": []})
+ continue
+
+ # Get segmentation map and segment information of batch item
+ target_size = target_sizes[i] if target_sizes is not None else None
+ segmentation, segments = compute_segments(
+ mask_probs=mask_probs_item,
+ pred_scores=pred_scores_item,
+ pred_labels=pred_labels_item,
+ mask_threshold=mask_threshold,
+ overlap_mask_area_threshold=overlap_mask_area_threshold,
+ label_ids_to_fuse=label_ids_to_fuse,
+ target_size=target_size,
+ )
+
+ results.append({"segmentation": segmentation, "segments_info": segments})
+ return results
diff --git a/src/transformers/models/detr/modeling_detr.py b/src/transformers/models/detr/modeling_detr.py
index 8fa47231c3..b06453479f 100644
--- a/src/transformers/models/detr/modeling_detr.py
+++ b/src/transformers/models/detr/modeling_detr.py
@@ -1589,7 +1589,7 @@ class DetrForSegmentation(DetrPreTrainedModel):
>>> import numpy
>>> from transformers import DetrFeatureExtractor, DetrForSegmentation
- >>> from transformers.models.detr.feature_extraction_detr import rgb_to_id
+ >>> from transformers.image_transforms import rgb_to_id
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
@@ -2289,8 +2289,6 @@ def generalized_box_iou(boxes1, boxes2):
# below: taken from https://github.com/facebookresearch/detr/blob/master/util/misc.py#L306
-
-
def _max_by_axis(the_list):
# type: (List[List[int]]) -> List[int]
maxes = the_list[0]
diff --git a/src/transformers/models/maskformer/__init__.py b/src/transformers/models/maskformer/__init__.py
index db2529ca24..ba6452c7c4 100644
--- a/src/transformers/models/maskformer/__init__.py
+++ b/src/transformers/models/maskformer/__init__.py
@@ -32,6 +32,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_maskformer"] = ["MaskFormerFeatureExtractor"]
+ _import_structure["image_processing_maskformer"] = ["MaskFormerImageProcessor"]
try:
@@ -63,6 +64,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_maskformer import MaskFormerFeatureExtractor
+ from .image_processing_maskformer import MaskFormerImageProcessor
try:
if not is_torch_available():
raise OptionalDependencyNotAvailable()
diff --git a/src/transformers/models/maskformer/feature_extraction_maskformer.py b/src/transformers/models/maskformer/feature_extraction_maskformer.py
index 21c252f265..068f3c8a11 100644
--- a/src/transformers/models/maskformer/feature_extraction_maskformer.py
+++ b/src/transformers/models/maskformer/feature_extraction_maskformer.py
@@ -14,923 +14,11 @@
# limitations under the License.
"""Feature extractor class for MaskFormer."""
-from typing import TYPE_CHECKING, Dict, List, Optional, Set, Tuple, Union
+from transformers.utils import logging
-import numpy as np
-from PIL import Image
+from .image_processing_maskformer import MaskFormerImageProcessor
-from transformers.image_utils import PILImageResampling
-
-from ...feature_extraction_utils import BatchFeature, FeatureExtractionMixin
-from ...image_utils import ImageFeatureExtractionMixin, ImageInput, is_torch_tensor
-from ...utils import TensorType, is_torch_available, logging
-
-
-if is_torch_available():
- import torch
- from torch import Tensor, nn
- from torch.nn.functional import interpolate
-
- if TYPE_CHECKING:
- from transformers.models.maskformer.modeling_maskformer import MaskFormerForInstanceSegmentationOutput
logger = logging.get_logger(__name__)
-
-# Copied from transformers.models.detr.feature_extraction_detr.binary_mask_to_rle
-def binary_mask_to_rle(mask):
- """
- Args:
- Converts given binary mask of shape (height, width) to the run-length encoding (RLE) format.
- mask (`torch.Tensor` or `numpy.array`):
- A binary mask tensor of shape `(height, width)` where 0 denotes background and 1 denotes the target
- segment_id or class_id.
- Returns:
- `List`: Run-length encoded list of the binary mask. Refer to COCO API for more information about the RLE
- format.
- """
- if is_torch_tensor(mask):
- mask = mask.numpy()
-
- pixels = mask.flatten()
- pixels = np.concatenate([[0], pixels, [0]])
- runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
- runs[1::2] -= runs[::2]
- return [x for x in runs]
-
-
-# Copied from transformers.models.detr.feature_extraction_detr.convert_segmentation_to_rle
-def convert_segmentation_to_rle(segmentation):
- """
- Converts given segmentation map of shape (height, width) to the run-length encoding (RLE) format.
-
- Args:
- segmentation (`torch.Tensor` or `numpy.array`):
- A segmentation map of shape `(height, width)` where each value denotes a segment or class id.
- Returns:
- `List[List]`: A list of lists, where each list is the run-length encoding of a segment / class id.
- """
- segment_ids = torch.unique(segmentation)
-
- run_length_encodings = []
- for idx in segment_ids:
- mask = torch.where(segmentation == idx, 1, 0)
- rle = binary_mask_to_rle(mask)
- run_length_encodings.append(rle)
-
- return run_length_encodings
-
-
-# Copied from transformers.models.detr.feature_extraction_detr.remove_low_and_no_objects
-def remove_low_and_no_objects(masks, scores, labels, object_mask_threshold, num_labels):
- """
- Binarize the given masks using `object_mask_threshold`, it returns the associated values of `masks`, `scores` and
- `labels`.
-
- Args:
- masks (`torch.Tensor`):
- A tensor of shape `(num_queries, height, width)`.
- scores (`torch.Tensor`):
- A tensor of shape `(num_queries)`.
- labels (`torch.Tensor`):
- A tensor of shape `(num_queries)`.
- object_mask_threshold (`float`):
- A number between 0 and 1 used to binarize the masks.
- Raises:
- `ValueError`: Raised when the first dimension doesn't match in all input tensors.
- Returns:
- `Tuple[`torch.Tensor`, `torch.Tensor`, `torch.Tensor`]`: The `masks`, `scores` and `labels` without the region
- < `object_mask_threshold`.
- """
- if not (masks.shape[0] == scores.shape[0] == labels.shape[0]):
- raise ValueError("mask, scores and labels must have the same shape!")
-
- to_keep = labels.ne(num_labels) & (scores > object_mask_threshold)
-
- return masks[to_keep], scores[to_keep], labels[to_keep]
-
-
-# Copied from transformers.models.detr.feature_extraction_detr.check_segment_validity
-def check_segment_validity(mask_labels, mask_probs, k, mask_threshold=0.5, overlap_mask_area_threshold=0.8):
- # Get the mask associated with the k class
- mask_k = mask_labels == k
- mask_k_area = mask_k.sum()
-
- # Compute the area of all the stuff in query k
- original_area = (mask_probs[k] >= mask_threshold).sum()
- mask_exists = mask_k_area > 0 and original_area > 0
-
- # Eliminate disconnected tiny segments
- if mask_exists:
- area_ratio = mask_k_area / original_area
- if not area_ratio.item() > overlap_mask_area_threshold:
- mask_exists = False
-
- return mask_exists, mask_k
-
-
-# Copied from transformers.models.detr.feature_extraction_detr.compute_segments
-def compute_segments(
- mask_probs,
- pred_scores,
- pred_labels,
- mask_threshold: float = 0.5,
- overlap_mask_area_threshold: float = 0.8,
- label_ids_to_fuse: Optional[Set[int]] = None,
- target_size: Tuple[int, int] = None,
-):
- height = mask_probs.shape[1] if target_size is None else target_size[0]
- width = mask_probs.shape[2] if target_size is None else target_size[1]
-
- segmentation = torch.zeros((height, width), dtype=torch.int32, device=mask_probs.device)
- segments: List[Dict] = []
-
- if target_size is not None:
- mask_probs = nn.functional.interpolate(
- mask_probs.unsqueeze(0), size=target_size, mode="bilinear", align_corners=False
- )[0]
-
- current_segment_id = 0
-
- # Weigh each mask by its prediction score
- mask_probs *= pred_scores.view(-1, 1, 1)
- mask_labels = mask_probs.argmax(0) # [height, width]
-
- # Keep track of instances of each class
- stuff_memory_list: Dict[str, int] = {}
- for k in range(pred_labels.shape[0]):
- pred_class = pred_labels[k].item()
- should_fuse = pred_class in label_ids_to_fuse
-
- # Check if mask exists and large enough to be a segment
- mask_exists, mask_k = check_segment_validity(
- mask_labels, mask_probs, k, mask_threshold, overlap_mask_area_threshold
- )
-
- if mask_exists:
- if pred_class in stuff_memory_list:
- current_segment_id = stuff_memory_list[pred_class]
- else:
- current_segment_id += 1
-
- # Add current object segment to final segmentation map
- segmentation[mask_k] = current_segment_id
- segment_score = round(pred_scores[k].item(), 6)
- segments.append(
- {
- "id": current_segment_id,
- "label_id": pred_class,
- "was_fused": should_fuse,
- "score": segment_score,
- }
- )
- if should_fuse:
- stuff_memory_list[pred_class] = current_segment_id
-
- return segmentation, segments
-
-
-class MaskFormerFeatureExtractor(FeatureExtractionMixin, ImageFeatureExtractionMixin):
- r"""
- Constructs a MaskFormer feature extractor. The feature extractor can be used to prepare image(s) and optional
- targets for the model.
-
- This feature extractor inherits from [`FeatureExtractionMixin`] which contains most of the main methods. Users
- should refer to this superclass for more information regarding those methods.
-
- Args:
- do_resize (`bool`, *optional*, defaults to `True`):
- Whether to resize the input to a certain `size`.
- size (`int`, *optional*, defaults to 800):
- Resize the input to the given size. Only has an effect if `do_resize` is set to `True`. If size is a
- sequence like `(width, height)`, output size will be matched to this. If size is an int, smaller edge of
- the image will be matched to this number. i.e, if `height > width`, then image will be rescaled to `(size *
- height / width, size)`.
- max_size (`int`, *optional*, defaults to 1333):
- The largest size an image dimension can have (otherwise it's capped). Only has an effect if `do_resize` is
- set to `True`.
- resample (`int`, *optional*, defaults to `PILImageResampling.BILINEAR`):
- An optional resampling filter. This can be one of `PILImageResampling.NEAREST`, `PILImageResampling.BOX`,
- `PILImageResampling.BILINEAR`, `PILImageResampling.HAMMING`, `PILImageResampling.BICUBIC` or
- `PILImageResampling.LANCZOS`. Only has an effect if `do_resize` is set to `True`.
- size_divisibility (`int`, *optional*, defaults to 32):
- Some backbones need images divisible by a certain number. If not passed, it defaults to the value used in
- Swin Transformer.
- do_normalize (`bool`, *optional*, defaults to `True`):
- Whether or not to normalize the input with mean and standard deviation.
- image_mean (`int`, *optional*, defaults to `[0.485, 0.456, 0.406]`):
- The sequence of means for each channel, to be used when normalizing images. Defaults to the ImageNet mean.
- image_std (`int`, *optional*, defaults to `[0.229, 0.224, 0.225]`):
- The sequence of standard deviations for each channel, to be used when normalizing images. Defaults to the
- ImageNet std.
- ignore_index (`int`, *optional*):
- Label to be assigned to background pixels in segmentation maps. If provided, segmentation map pixels
- denoted with 0 (background) will be replaced with `ignore_index`. The ignore index of the loss function of
- the model should then correspond to this ignore index.
- reduce_labels (`bool`, *optional*, defaults to `False`):
- Whether or not to decrement all label values of segmentation maps by 1. Usually used for datasets where 0
- is used for background, and background itself is not included in all classes of a dataset (e.g. ADE20k).
- The background label will be replaced by `ignore_index`.
-
- """
-
- model_input_names = ["pixel_values", "pixel_mask"]
-
- def __init__(
- self,
- do_resize=True,
- size=800,
- max_size=1333,
- resample=PILImageResampling.BILINEAR,
- size_divisibility=32,
- do_normalize=True,
- image_mean=None,
- image_std=None,
- ignore_index=None,
- reduce_labels=False,
- **kwargs
- ):
- super().__init__(**kwargs)
- self.do_resize = do_resize
- self.size = size
- self.max_size = max_size
- self.resample = resample
- self.size_divisibility = size_divisibility
- self.do_normalize = do_normalize
- self.image_mean = image_mean if image_mean is not None else [0.485, 0.456, 0.406] # ImageNet mean
- self.image_std = image_std if image_std is not None else [0.229, 0.224, 0.225] # ImageNet std
- self.ignore_index = ignore_index
- self.reduce_labels = reduce_labels
-
- def _resize_with_size_divisibility(self, image, size, target=None, max_size=None):
- """
- Resize the image to the given size. Size can be min_size (scalar) or (width, height) tuple. If size is an int,
- smaller edge of the image will be matched to this number.
-
- If given, also resize the target accordingly.
- """
- if not isinstance(image, Image.Image):
- image = self.to_pil_image(image)
-
- def get_size_with_aspect_ratio(image_size, size, max_size=None):
- width, height = image_size
- if max_size is not None:
- min_original_size = float(min((width, height)))
- max_original_size = float(max((width, height)))
- if max_original_size / min_original_size * size > max_size:
- size = int(round(max_size * min_original_size / max_original_size))
-
- if (width <= height and width == size) or (height <= width and height == size):
- return (height, width)
-
- if width < height:
- output_width = size
- output_height = int(size * height / width)
- else:
- output_height = size
- output_width = int(size * width / height)
-
- return (output_height, output_width)
-
- def get_size(image_size, size, max_size=None):
- if isinstance(size, (list, tuple)):
- return size
- else:
- # size returned must be (width, height) since we use PIL to resize images
- # so we revert the tuple
- return get_size_with_aspect_ratio(image_size, size, max_size)[::-1]
-
- width, height = get_size(image.size, size, max_size)
-
- if self.size_divisibility > 0:
- height = int(np.ceil(height / self.size_divisibility)) * self.size_divisibility
- width = int(np.ceil(width / self.size_divisibility)) * self.size_divisibility
-
- size = (width, height)
- image = self.resize(image, size=size, resample=self.resample)
-
- if target is not None:
- target = self.resize(target, size=size, resample=Image.NEAREST)
-
- return image, target
-
- def __call__(
- self,
- images: ImageInput,
- segmentation_maps: ImageInput = None,
- pad_and_return_pixel_mask: Optional[bool] = True,
- instance_id_to_semantic_id: Optional[Union[List[Dict[int, int]], Dict[int, int]]] = None,
- return_tensors: Optional[Union[str, TensorType]] = None,
- **kwargs,
- ) -> BatchFeature:
- """
- Main method to prepare for the model one or several image(s) and optional annotations. Images are by default
- padded up to the largest image in a batch, and a pixel mask is created that indicates which pixels are
- real/which are padding.
-
- Segmentation maps can be instance, semantic or panoptic segmentation maps. In case of instance and panoptic
- segmentation, one needs to provide `instance_id_to_semantic_id`, which is a mapping from instance/segment ids
- to semantic category ids.
-
- MaskFormer addresses all 3 forms of segmentation (instance, semantic and panoptic) in the same way, namely by
- converting the segmentation maps to a set of binary masks with corresponding classes.
-
- In case of instance segmentation, the segmentation maps contain the instance ids, and
- `instance_id_to_semantic_id` maps instance IDs to their corresponding semantic category.
-
- In case of semantic segmentation, the segmentation maps contain the semantic category ids. Let's see an
- example, assuming `segmentation_maps = [[2,6,7,9]]`, the output will contain `mask_labels =
- [[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1]]` (four binary masks) and `class_labels = [2,6,7,9]`, the labels for
- each mask.
-
- In case of panoptic segmentation, the segmentation maps contain the segment ids, and
- `instance_id_to_semantic_id` maps segment IDs to their corresponding semantic category.
-
-
-
- NumPy arrays and PyTorch tensors are converted to PIL images when resizing, so the most efficient is to pass
- PIL images.
-
-
-
- Args:
- images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
- The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
- tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a
- number of channels, H and W are image height and width.
-
- segmentation_maps (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`, *optional*):
- The corresponding segmentation maps with the pixel-wise instance id, semantic id or segment id
- annotations. Assumed to be semantic segmentation maps if no `instance_id_to_semantic_id map` is
- provided.
-
- pad_and_return_pixel_mask (`bool`, *optional*, defaults to `True`):
- Whether or not to pad images up to the largest image in a batch and create a pixel mask.
-
- If left to the default, will return a pixel mask that is:
-
- - 1 for pixels that are real (i.e. **not masked**),
- - 0 for pixels that are padding (i.e. **masked**).
-
- instance_id_to_semantic_id (`List[Dict[int, int]]` or `Dict[int, int]`, *optional*):
- A mapping between instance/segment ids and semantic category ids. If passed, `segmentation_maps` is
- treated as an instance or panoptic segmentation map where each pixel represents an instance or segment
- id. Can be provided as a single dictionary with a global / dataset-level mapping or as a list of
- dictionaries (one per image), to map instance ids in each image separately. Note that this assumes a
- mapping before reduction of labels.
-
- return_tensors (`str` or [`~file_utils.TensorType`], *optional*):
- If set, will return tensors instead of NumPy arrays. If set to `'pt'`, return PyTorch `torch.Tensor`
- objects.
-
- Returns:
- [`BatchFeature`]: A [`BatchFeature`] with the following fields:
-
- - **pixel_values** -- Pixel values to be fed to a model.
- - **pixel_mask** -- Pixel mask to be fed to a model (when `pad_and_return_pixel_mask=True` or if
- `pixel_mask` is in `self.model_input_names`).
- - **mask_labels** -- Optional list of mask labels of shape `(num_class_labels, height, width)` to be fed to
- a model (when `annotations` are provided).
- - **class_labels** -- Optional list of class labels of shape `(num_class_labels)` to be fed to a model
- (when `annotations` are provided). They identify the labels of `mask_labels`, e.g. the label of
- `mask_labels[i][j]` if `class_labels[i][j]`.
- """
- # Input type checking for clearer error
-
- valid_images = False
- valid_segmentation_maps = False
-
- # Check that images has a valid type
- if isinstance(images, (Image.Image, np.ndarray)) or is_torch_tensor(images):
- valid_images = True
- elif isinstance(images, (list, tuple)):
- if len(images) == 0 or isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]):
- valid_images = True
-
- if not valid_images:
- raise ValueError(
- "Images must of type `PIL.Image.Image`, `np.ndarray` or `torch.Tensor` (single example), "
- "`List[PIL.Image.Image]`, `List[np.ndarray]` or `List[torch.Tensor]` (batch of examples)."
- )
- # Check that segmentation maps has a valid type
- if segmentation_maps is not None:
- if isinstance(segmentation_maps, (Image.Image, np.ndarray)) or is_torch_tensor(segmentation_maps):
- valid_segmentation_maps = True
- elif isinstance(segmentation_maps, (list, tuple)):
- if (
- len(segmentation_maps) == 0
- or isinstance(segmentation_maps[0], (Image.Image, np.ndarray))
- or is_torch_tensor(segmentation_maps[0])
- ):
- valid_segmentation_maps = True
-
- if not valid_segmentation_maps:
- raise ValueError(
- "Segmentation maps must of type `PIL.Image.Image`, `np.ndarray` or `torch.Tensor` (single"
- " example),`List[PIL.Image.Image]`, `List[np.ndarray]` or `List[torch.Tensor]` (batch of"
- " examples)."
- )
-
- is_batched = bool(
- isinstance(images, (list, tuple))
- and (isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]))
- )
-
- if not is_batched:
- images = [images]
- if segmentation_maps is not None:
- segmentation_maps = [segmentation_maps]
-
- # transformations (resizing + normalization)
- if self.do_resize and self.size is not None:
- if segmentation_maps is not None:
- for idx, (image, target) in enumerate(zip(images, segmentation_maps)):
- image, target = self._resize_with_size_divisibility(
- image=image, target=target, size=self.size, max_size=self.max_size
- )
- images[idx] = image
- segmentation_maps[idx] = target
- else:
- for idx, image in enumerate(images):
- images[idx] = self._resize_with_size_divisibility(
- image=image, target=None, size=self.size, max_size=self.max_size
- )[0]
-
- if self.do_normalize:
- images = [self.normalize(image=image, mean=self.image_mean, std=self.image_std) for image in images]
- # NOTE I will be always forced to pad them them since they have to be stacked in the batch dim
- encoded_inputs = self.encode_inputs(
- images,
- segmentation_maps,
- pad_and_return_pixel_mask,
- instance_id_to_semantic_id=instance_id_to_semantic_id,
- return_tensors=return_tensors,
- )
-
- # Convert to TensorType
- tensor_type = return_tensors
- if not isinstance(tensor_type, TensorType):
- tensor_type = TensorType(tensor_type)
-
- if not tensor_type == TensorType.PYTORCH:
- raise ValueError("Only PyTorch is supported for the moment.")
- else:
- if not is_torch_available():
- raise ImportError("Unable to convert output to PyTorch tensors format, PyTorch is not installed.")
-
- return encoded_inputs
-
- def _max_by_axis(self, the_list: List[List[int]]) -> List[int]:
- maxes = the_list[0]
- for sublist in the_list[1:]:
- for index, item in enumerate(sublist):
- maxes[index] = max(maxes[index], item)
- return maxes
-
- def convert_segmentation_map_to_binary_masks(
- self,
- segmentation_map: "np.ndarray",
- instance_id_to_semantic_id: Optional[Dict[int, int]] = None,
- ):
- # Reduce labels, if requested
- if self.reduce_labels:
- if self.ignore_index is None:
- raise ValueError("`ignore_index` must be set when `reduce_labels` is `True`.")
- segmentation_map[segmentation_map == 0] = self.ignore_index
- segmentation_map -= 1
- segmentation_map[segmentation_map == self.ignore_index - 1] = self.ignore_index
-
- # Get unique ids (instance, class ids or segment ids based on input)
- all_labels = np.unique(segmentation_map)
-
- # Remove ignored label
- if self.ignore_index is not None:
- all_labels = all_labels[all_labels != self.ignore_index]
-
- # Generate a binary mask for each object instance
- binary_masks = [(segmentation_map == i) for i in all_labels]
- binary_masks = np.stack(binary_masks, axis=0) # (num_labels, height, width)
-
- # Convert instance/segment ids to class ids
- if instance_id_to_semantic_id is not None:
- labels = np.zeros(all_labels.shape[0])
-
- for label in all_labels:
- class_id = instance_id_to_semantic_id[label + 1 if self.reduce_labels else label]
- labels[all_labels == label] = class_id - 1 if self.reduce_labels else class_id
- else:
- labels = all_labels
-
- return binary_masks.astype(np.float32), labels.astype(np.int64)
-
- def encode_inputs(
- self,
- pixel_values_list: Union[List["np.ndarray"], List["torch.Tensor"]],
- segmentation_maps: ImageInput = None,
- pad_and_return_pixel_mask: bool = True,
- instance_id_to_semantic_id: Optional[Union[List[Dict[int, int]], Dict[int, int]]] = None,
- return_tensors: Optional[Union[str, TensorType]] = None,
- ):
- """
- Encode a list of pixel values and an optional list of corresponding segmentation maps.
-
- This method is useful if you have resized and normalized your images and segmentation maps yourself, using a
- library like [torchvision](https://pytorch.org/vision/stable/transforms.html) or
- [albumentations](https://albumentations.ai/).
-
- Images are padded up to the largest image in a batch, and a corresponding `pixel_mask` is created.
-
- Segmentation maps can be instance, semantic or panoptic segmentation maps. In case of instance and panoptic
- segmentation, one needs to provide `instance_id_to_semantic_id`, which is a mapping from instance/segment ids
- to semantic category ids.
-
- MaskFormer addresses all 3 forms of segmentation (instance, semantic and panoptic) in the same way, namely by
- converting the segmentation maps to a set of binary masks with corresponding classes.
-
- In case of instance segmentation, the segmentation maps contain the instance ids, and
- `instance_id_to_semantic_id` maps instance IDs to their corresponding semantic category.
-
- In case of semantic segmentation, the segmentation maps contain the semantic category ids. Let's see an
- example, assuming `segmentation_maps = [[2,6,7,9]]`, the output will contain `mask_labels =
- [[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1]]` (four binary masks) and `class_labels = [2,6,7,9]`, the labels for
- each mask.
-
- In case of panoptic segmentation, the segmentation maps contain the segment ids, and
- `instance_id_to_semantic_id` maps segment IDs to their corresponding semantic category.
-
- Args:
- pixel_values_list (`List[np.ndarray]` or `List[torch.Tensor]`):
- List of images (pixel values) to be padded. Each image should be a tensor of shape `(channels, height,
- width)`.
-
- segmentation_maps (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`, *optional*):
- The corresponding segmentation maps with the pixel-wise instance id, semantic id or segment id
- annotations. Assumed to be semantic segmentation maps if no `instance_id_to_semantic_id map` is
- provided.
-
- pad_and_return_pixel_mask (`bool`, *optional*, defaults to `True`):
- Whether or not to pad images up to the largest image in a batch and create a pixel mask.
-
- If left to the default, will return a pixel mask that is:
-
- - 1 for pixels that are real (i.e. **not masked**),
- - 0 for pixels that are padding (i.e. **masked**).
-
- instance_id_to_semantic_id (`List[Dict[int, int]]` or `Dict[int, int]`, *optional*):
- A mapping between instance/segment ids and semantic category ids. If passed, `segmentation_maps` is
- treated as an instance or panoptic segmentation map where each pixel represents an instance or segment
- id. Can be provided as a single dictionary with a global / dataset-level mapping or as a list of
- dictionaries (one per image), to map instance ids in each image separately. Note that this assumes a
- mapping before reduction of labels.
-
- return_tensors (`str` or [`~file_utils.TensorType`], *optional*):
- If set, will return tensors instead of NumPy arrays. If set to `'pt'`, return PyTorch `torch.Tensor`
- objects.
-
- Returns:
- [`BatchFeature`]: A [`BatchFeature`] with the following fields:
-
- - **pixel_values** -- Pixel values to be fed to a model.
- - **pixel_mask** -- Pixel mask to be fed to a model (when `pad_and_return_pixel_mask=True` or if
- `pixel_mask` is in `self.model_input_names`).
- - **mask_labels** -- Optional list of mask labels of shape `(labels, height, width)` to be fed to a model
- (when `annotations` are provided).
- - **class_labels** -- Optional list of class labels of shape `(labels)` to be fed to a model (when
- `annotations` are provided). They identify the labels of `mask_labels`, e.g. the label of
- `mask_labels[i][j]` if `class_labels[i][j]`.
- """
-
- max_size = self._max_by_axis([list(image.shape) for image in pixel_values_list])
-
- annotations = None
- if segmentation_maps is not None:
- segmentation_maps = map(np.array, segmentation_maps)
- converted_segmentation_maps = []
-
- for i, segmentation_map in enumerate(segmentation_maps):
- # Use instance2class_id mapping per image
- if isinstance(instance_id_to_semantic_id, List):
- converted_segmentation_map = self.convert_segmentation_map_to_binary_masks(
- segmentation_map, instance_id_to_semantic_id[i]
- )
- else:
- converted_segmentation_map = self.convert_segmentation_map_to_binary_masks(
- segmentation_map, instance_id_to_semantic_id
- )
- converted_segmentation_maps.append(converted_segmentation_map)
-
- annotations = []
- for mask, classes in converted_segmentation_maps:
- annotations.append({"masks": mask, "classes": classes})
-
- channels, height, width = max_size
- pixel_values = []
- pixel_mask = []
- mask_labels = []
- class_labels = []
- for idx, image in enumerate(pixel_values_list):
- # create padded image
- padded_image = np.zeros((channels, height, width), dtype=np.float32)
- padded_image[: image.shape[0], : image.shape[1], : image.shape[2]] = np.copy(image)
- image = padded_image
- pixel_values.append(image)
- # if we have a target, pad it
- if annotations:
- annotation = annotations[idx]
- masks = annotation["masks"]
- # pad mask with `ignore_index`
- masks = np.pad(
- masks,
- ((0, 0), (0, height - masks.shape[1]), (0, width - masks.shape[2])),
- constant_values=self.ignore_index,
- )
- annotation["masks"] = masks
- # create pixel mask
- mask = np.zeros((height, width), dtype=np.int64)
- mask[: image.shape[1], : image.shape[2]] = True
- pixel_mask.append(mask)
-
- # return as BatchFeature
- data = {"pixel_values": pixel_values, "pixel_mask": pixel_mask}
- encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
- # we cannot batch them since they don't share a common class size
- if annotations:
- for label in annotations:
- mask_labels.append(torch.from_numpy(label["masks"]))
- class_labels.append(torch.from_numpy(label["classes"]))
-
- encoded_inputs["mask_labels"] = mask_labels
- encoded_inputs["class_labels"] = class_labels
-
- return encoded_inputs
-
- def post_process_segmentation(
- self, outputs: "MaskFormerForInstanceSegmentationOutput", target_size: Tuple[int, int] = None
- ) -> "torch.Tensor":
- """
- Converts the output of [`MaskFormerForInstanceSegmentationOutput`] into image segmentation predictions. Only
- supports PyTorch.
-
- Args:
- outputs ([`MaskFormerForInstanceSegmentationOutput`]):
- The outputs from [`MaskFormerForInstanceSegmentation`].
-
- target_size (`Tuple[int, int]`, *optional*):
- If set, the `masks_queries_logits` will be resized to `target_size`.
-
- Returns:
- `torch.Tensor`:
- A tensor of shape (`batch_size, num_class_labels, height, width`).
- """
- logger.warning(
- "`post_process_segmentation` is deprecated and will be removed in v5 of Transformers, please use"
- " `post_process_instance_segmentation`",
- FutureWarning,
- )
-
- # class_queries_logits has shape [BATCH, QUERIES, CLASSES + 1]
- class_queries_logits = outputs.class_queries_logits
- # masks_queries_logits has shape [BATCH, QUERIES, HEIGHT, WIDTH]
- masks_queries_logits = outputs.masks_queries_logits
- if target_size is not None:
- masks_queries_logits = interpolate(
- masks_queries_logits,
- size=target_size,
- mode="bilinear",
- align_corners=False,
- )
- # remove the null class `[..., :-1]`
- masks_classes = class_queries_logits.softmax(dim=-1)[..., :-1]
- # mask probs has shape [BATCH, QUERIES, HEIGHT, WIDTH]
- masks_probs = masks_queries_logits.sigmoid()
- # now we want to sum over the queries,
- # $ out_{c,h,w} = \sum_q p_{q,c} * m_{q,h,w} $
- # where $ softmax(p) \in R^{q, c} $ is the mask classes
- # and $ sigmoid(m) \in R^{q, h, w}$ is the mask probabilities
- # b(atch)q(uery)c(lasses), b(atch)q(uery)h(eight)w(idth)
- segmentation = torch.einsum("bqc, bqhw -> bchw", masks_classes, masks_probs)
-
- return segmentation
-
- def post_process_semantic_segmentation(
- self, outputs, target_sizes: Optional[List[Tuple[int, int]]] = None
- ) -> "torch.Tensor":
- """
- Converts the output of [`MaskFormerForInstanceSegmentation`] into semantic segmentation maps. Only supports
- PyTorch.
-
- Args:
- outputs ([`MaskFormerForInstanceSegmentation`]):
- Raw outputs of the model.
- target_sizes (`List[Tuple[int, int]]`, *optional*, defaults to `None`):
- List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
- final size (height, width) of each prediction. If left to None, predictions will not be resized.
- Returns:
- `List[torch.Tensor]`:
- A list of length `batch_size`, where each item is a semantic segmentation map of shape (height, width)
- corresponding to the target_sizes entry (if `target_sizes` is specified). Each entry of each
- `torch.Tensor` correspond to a semantic class id.
- """
- class_queries_logits = outputs.class_queries_logits # [batch_size, num_queries, num_classes+1]
- masks_queries_logits = outputs.masks_queries_logits # [batch_size, num_queries, height, width]
-
- # Remove the null class `[..., :-1]`
- masks_classes = class_queries_logits.softmax(dim=-1)[..., :-1]
- masks_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
-
- # Semantic segmentation logits of shape (batch_size, num_classes, height, width)
- segmentation = torch.einsum("bqc, bqhw -> bchw", masks_classes, masks_probs)
- batch_size = class_queries_logits.shape[0]
-
- # Resize logits and compute semantic segmentation maps
- if target_sizes is not None:
- if batch_size != len(target_sizes):
- raise ValueError(
- "Make sure that you pass in as many target sizes as the batch dimension of the logits"
- )
-
- semantic_segmentation = []
- for idx in range(batch_size):
- resized_logits = torch.nn.functional.interpolate(
- segmentation[idx].unsqueeze(dim=0), size=target_sizes[idx], mode="bilinear", align_corners=False
- )
- semantic_map = resized_logits[0].argmax(dim=0)
- semantic_segmentation.append(semantic_map)
- else:
- semantic_segmentation = segmentation.argmax(dim=1)
- semantic_segmentation = [semantic_segmentation[i] for i in range(semantic_segmentation.shape[0])]
-
- return semantic_segmentation
-
- def post_process_instance_segmentation(
- self,
- outputs,
- threshold: float = 0.5,
- mask_threshold: float = 0.5,
- overlap_mask_area_threshold: float = 0.8,
- target_sizes: Optional[List[Tuple[int, int]]] = None,
- return_coco_annotation: Optional[bool] = False,
- ) -> List[Dict]:
- """
- Converts the output of [`MaskFormerForInstanceSegmentationOutput`] into instance segmentation predictions. Only
- supports PyTorch.
-
- Args:
- outputs ([`MaskFormerForInstanceSegmentation`]):
- Raw outputs of the model.
- threshold (`float`, *optional*, defaults to 0.5):
- The probability score threshold to keep predicted instance masks.
- mask_threshold (`float`, *optional*, defaults to 0.5):
- Threshold to use when turning the predicted masks into binary values.
- overlap_mask_area_threshold (`float`, *optional*, defaults to 0.8):
- The overlap mask area threshold to merge or discard small disconnected parts within each binary
- instance mask.
- target_sizes (`List[Tuple]`, *optional*):
- List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
- final size (height, width) of each prediction. If left to None, predictions will not be resized.
- return_coco_annotation (`bool`, *optional*):
- Defaults to `False`. If set to `True`, segmentation maps are returned in COCO run-length encoding (RLE)
- format.
- Returns:
- `List[Dict]`: A list of dictionaries, one per image, each dictionary containing two keys:
- - **segmentation** -- A tensor of shape `(height, width)` where each pixel represents a `segment_id` or
- `List[List]` run-length encoding (RLE) of the segmentation map if return_coco_annotation is set to
- `True`. Set to `None` if no mask if found above `threshold`.
- - **segments_info** -- A dictionary that contains additional information on each segment.
- - **id** -- An integer representing the `segment_id`.
- - **label_id** -- An integer representing the label / semantic class id corresponding to `segment_id`.
- - **score** -- Prediction score of segment with `segment_id`.
- """
- class_queries_logits = outputs.class_queries_logits # [batch_size, num_queries, num_classes+1]
- masks_queries_logits = outputs.masks_queries_logits # [batch_size, num_queries, height, width]
-
- batch_size = class_queries_logits.shape[0]
- num_labels = class_queries_logits.shape[-1] - 1
-
- mask_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
-
- # Predicted label and score of each query (batch_size, num_queries)
- pred_scores, pred_labels = nn.functional.softmax(class_queries_logits, dim=-1).max(-1)
-
- # Loop over items in batch size
- results: List[Dict[str, Tensor]] = []
-
- for i in range(batch_size):
- mask_probs_item, pred_scores_item, pred_labels_item = remove_low_and_no_objects(
- mask_probs[i], pred_scores[i], pred_labels[i], threshold, num_labels
- )
-
- # No mask found
- if mask_probs_item.shape[0] <= 0:
- height, width = target_sizes[i] if target_sizes is not None else mask_probs_item.shape[1:]
- segmentation = torch.zeros((height, width)) - 1
- results.append({"segmentation": segmentation, "segments_info": []})
- continue
-
- # Get segmentation map and segment information of batch item
- target_size = target_sizes[i] if target_sizes is not None else None
- segmentation, segments = compute_segments(
- mask_probs_item,
- pred_scores_item,
- pred_labels_item,
- mask_threshold,
- overlap_mask_area_threshold,
- target_size,
- )
-
- # Return segmentation map in run-length encoding (RLE) format
- if return_coco_annotation:
- segmentation = convert_segmentation_to_rle(segmentation)
-
- results.append({"segmentation": segmentation, "segments_info": segments})
- return results
-
- def post_process_panoptic_segmentation(
- self,
- outputs,
- threshold: float = 0.5,
- mask_threshold: float = 0.5,
- overlap_mask_area_threshold: float = 0.8,
- label_ids_to_fuse: Optional[Set[int]] = None,
- target_sizes: Optional[List[Tuple[int, int]]] = None,
- ) -> List[Dict]:
- """
- Converts the output of [`MaskFormerForInstanceSegmentationOutput`] into image panoptic segmentation
- predictions. Only supports PyTorch.
-
- Args:
- outputs ([`MaskFormerForInstanceSegmentationOutput`]):
- The outputs from [`MaskFormerForInstanceSegmentation`].
- threshold (`float`, *optional*, defaults to 0.5):
- The probability score threshold to keep predicted instance masks.
- mask_threshold (`float`, *optional*, defaults to 0.5):
- Threshold to use when turning the predicted masks into binary values.
- overlap_mask_area_threshold (`float`, *optional*, defaults to 0.8):
- The overlap mask area threshold to merge or discard small disconnected parts within each binary
- instance mask.
- label_ids_to_fuse (`Set[int]`, *optional*):
- The labels in this state will have all their instances be fused together. For instance we could say
- there can only be one sky in an image, but several persons, so the label ID for sky would be in that
- set, but not the one for person.
- target_sizes (`List[Tuple]`, *optional*):
- List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
- final size (height, width) of each prediction in batch. If left to None, predictions will not be
- resized.
-
- Returns:
- `List[Dict]`: A list of dictionaries, one per image, each dictionary containing two keys:
- - **segmentation** -- a tensor of shape `(height, width)` where each pixel represents a `segment_id`, set
- to `None` if no mask if found above `threshold`. If `target_sizes` is specified, segmentation is resized
- to the corresponding `target_sizes` entry.
- - **segments_info** -- A dictionary that contains additional information on each segment.
- - **id** -- an integer representing the `segment_id`.
- - **label_id** -- An integer representing the label / semantic class id corresponding to `segment_id`.
- - **was_fused** -- a boolean, `True` if `label_id` was in `label_ids_to_fuse`, `False` otherwise.
- Multiple instances of the same class / label were fused and assigned a single `segment_id`.
- - **score** -- Prediction score of segment with `segment_id`.
- """
-
- if label_ids_to_fuse is None:
- logger.warning("`label_ids_to_fuse` unset. No instance will be fused.")
- label_ids_to_fuse = set()
-
- class_queries_logits = outputs.class_queries_logits # [batch_size, num_queries, num_classes+1]
- masks_queries_logits = outputs.masks_queries_logits # [batch_size, num_queries, height, width]
-
- batch_size = class_queries_logits.shape[0]
- num_labels = class_queries_logits.shape[-1] - 1
-
- mask_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
-
- # Predicted label and score of each query (batch_size, num_queries)
- pred_scores, pred_labels = nn.functional.softmax(class_queries_logits, dim=-1).max(-1)
-
- # Loop over items in batch size
- results: List[Dict[str, Tensor]] = []
-
- for i in range(batch_size):
- mask_probs_item, pred_scores_item, pred_labels_item = remove_low_and_no_objects(
- mask_probs[i], pred_scores[i], pred_labels[i], threshold, num_labels
- )
-
- # No mask found
- if mask_probs_item.shape[0] <= 0:
- height, width = target_sizes[i] if target_sizes is not None else mask_probs_item.shape[1:]
- segmentation = torch.zeros((height, width)) - 1
- results.append({"segmentation": segmentation, "segments_info": []})
- continue
-
- # Get segmentation map and segment information of batch item
- target_size = target_sizes[i] if target_sizes is not None else None
- segmentation, segments = compute_segments(
- mask_probs_item,
- pred_scores_item,
- pred_labels_item,
- mask_threshold,
- overlap_mask_area_threshold,
- label_ids_to_fuse,
- target_size,
- )
-
- results.append({"segmentation": segmentation, "segments_info": segments})
- return results
+MaskFormerFeatureExtractor = MaskFormerImageProcessor
diff --git a/src/transformers/models/maskformer/image_processing_maskformer.py b/src/transformers/models/maskformer/image_processing_maskformer.py
new file mode 100644
index 0000000000..50cef60700
--- /dev/null
+++ b/src/transformers/models/maskformer/image_processing_maskformer.py
@@ -0,0 +1,1143 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Image processor class for MaskFormer."""
+
+import math
+import warnings
+from typing import TYPE_CHECKING, Any, Dict, Iterable, List, Optional, Set, Tuple, Union
+
+import numpy as np
+
+from transformers.image_processing_utils import BaseImageProcessor, BatchFeature, get_size_dict
+from transformers.image_transforms import (
+ PaddingMode,
+ get_resize_output_image_size,
+ normalize,
+ pad,
+ rescale,
+ resize,
+ to_channel_dimension_format,
+ to_numpy_array,
+)
+from transformers.image_utils import (
+ ChannelDimension,
+ ImageInput,
+ PILImageResampling,
+ get_image_size,
+ infer_channel_dimension_format,
+ is_batched,
+ valid_images,
+)
+from transformers.utils import (
+ IMAGENET_DEFAULT_MEAN,
+ IMAGENET_DEFAULT_STD,
+ TensorType,
+ is_torch_available,
+ is_torch_tensor,
+ logging,
+)
+
+
+logger = logging.get_logger(__name__)
+
+
+if TYPE_CHECKING:
+ from transformers import MaskFormerForInstanceSegmentationOutput
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+
+# Copied from transformers.models.detr.image_processing_detr.max_across_indices
+def max_across_indices(values: Iterable[Any]) -> List[Any]:
+ """
+ Return the maximum value across all indices of an iterable of values.
+ """
+ return [max(values_i) for values_i in zip(*values)]
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_max_height_width
+def get_max_height_width(images: List[np.ndarray]) -> List[int]:
+ """
+ Get the maximum height and width across all images in a batch.
+ """
+ input_channel_dimension = infer_channel_dimension_format(images[0])
+
+ if input_channel_dimension == ChannelDimension.FIRST:
+ _, max_height, max_width = max_across_indices([img.shape for img in images])
+ elif input_channel_dimension == ChannelDimension.LAST:
+ max_height, max_width, _ = max_across_indices([img.shape for img in images])
+ else:
+ raise ValueError(f"Invalid channel dimension format: {input_channel_dimension}")
+ return (max_height, max_width)
+
+
+# Copied from transformers.models.detr.image_processing_detr.make_pixel_mask
+def make_pixel_mask(image: np.ndarray, output_size: Tuple[int, int]) -> np.ndarray:
+ """
+ Make a pixel mask for the image, where 1 indicates a valid pixel and 0 indicates padding.
+
+ Args:
+ image (`np.ndarray`):
+ Image to make the pixel mask for.
+ output_size (`Tuple[int, int]`):
+ Output size of the mask.
+ """
+ input_height, input_width = get_image_size(image)
+ mask = np.zeros(output_size, dtype=np.int64)
+ mask[:input_height, :input_width] = 1
+ return mask
+
+
+# Copied from transformers.models.detr.image_processing_detr.binary_mask_to_rle
+def binary_mask_to_rle(mask):
+ """
+ Converts given binary mask of shape `(height, width)` to the run-length encoding (RLE) format.
+
+ Args:
+ mask (`torch.Tensor` or `numpy.array`):
+ A binary mask tensor of shape `(height, width)` where 0 denotes background and 1 denotes the target
+ segment_id or class_id.
+ Returns:
+ `List`: Run-length encoded list of the binary mask. Refer to COCO API for more information about the RLE
+ format.
+ """
+ if is_torch_tensor(mask):
+ mask = mask.numpy()
+
+ pixels = mask.flatten()
+ pixels = np.concatenate([[0], pixels, [0]])
+ runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
+ runs[1::2] -= runs[::2]
+ return [x for x in runs]
+
+
+# Copied from transformers.models.detr.image_processing_detr.convert_segmentation_to_rle
+def convert_segmentation_to_rle(segmentation):
+ """
+ Converts given segmentation map of shape `(height, width)` to the run-length encoding (RLE) format.
+
+ Args:
+ segmentation (`torch.Tensor` or `numpy.array`):
+ A segmentation map of shape `(height, width)` where each value denotes a segment or class id.
+ Returns:
+ `List[List]`: A list of lists, where each list is the run-length encoding of a segment / class id.
+ """
+ segment_ids = torch.unique(segmentation)
+
+ run_length_encodings = []
+ for idx in segment_ids:
+ mask = torch.where(segmentation == idx, 1, 0)
+ rle = binary_mask_to_rle(mask)
+ run_length_encodings.append(rle)
+
+ return run_length_encodings
+
+
+# Copied from transformers.models.detr.image_processing_detr.remove_low_and_no_objects
+def remove_low_and_no_objects(masks, scores, labels, object_mask_threshold, num_labels):
+ """
+ Binarize the given masks using `object_mask_threshold`, it returns the associated values of `masks`, `scores` and
+ `labels`.
+
+ Args:
+ masks (`torch.Tensor`):
+ A tensor of shape `(num_queries, height, width)`.
+ scores (`torch.Tensor`):
+ A tensor of shape `(num_queries)`.
+ labels (`torch.Tensor`):
+ A tensor of shape `(num_queries)`.
+ object_mask_threshold (`float`):
+ A number between 0 and 1 used to binarize the masks.
+ Raises:
+ `ValueError`: Raised when the first dimension doesn't match in all input tensors.
+ Returns:
+ `Tuple[`torch.Tensor`, `torch.Tensor`, `torch.Tensor`]`: The `masks`, `scores` and `labels` without the region
+ < `object_mask_threshold`.
+ """
+ if not (masks.shape[0] == scores.shape[0] == labels.shape[0]):
+ raise ValueError("mask, scores and labels must have the same shape!")
+
+ to_keep = labels.ne(num_labels) & (scores > object_mask_threshold)
+
+ return masks[to_keep], scores[to_keep], labels[to_keep]
+
+
+# Copied from transformers.models.detr.image_processing_detr.check_segment_validity
+def check_segment_validity(mask_labels, mask_probs, k, mask_threshold=0.5, overlap_mask_area_threshold=0.8):
+ # Get the mask associated with the k class
+ mask_k = mask_labels == k
+ mask_k_area = mask_k.sum()
+
+ # Compute the area of all the stuff in query k
+ original_area = (mask_probs[k] >= mask_threshold).sum()
+ mask_exists = mask_k_area > 0 and original_area > 0
+
+ # Eliminate disconnected tiny segments
+ if mask_exists:
+ area_ratio = mask_k_area / original_area
+ if not area_ratio.item() > overlap_mask_area_threshold:
+ mask_exists = False
+
+ return mask_exists, mask_k
+
+
+# Copied from transformers.models.detr.image_processing_detr.compute_segments
+def compute_segments(
+ mask_probs,
+ pred_scores,
+ pred_labels,
+ mask_threshold: float = 0.5,
+ overlap_mask_area_threshold: float = 0.8,
+ label_ids_to_fuse: Optional[Set[int]] = None,
+ target_size: Tuple[int, int] = None,
+):
+ height = mask_probs.shape[1] if target_size is None else target_size[0]
+ width = mask_probs.shape[2] if target_size is None else target_size[1]
+
+ segmentation = torch.zeros((height, width), dtype=torch.int32, device=mask_probs.device)
+ segments: List[Dict] = []
+
+ if target_size is not None:
+ mask_probs = nn.functional.interpolate(
+ mask_probs.unsqueeze(0), size=target_size, mode="bilinear", align_corners=False
+ )[0]
+
+ current_segment_id = 0
+
+ # Weigh each mask by its prediction score
+ mask_probs *= pred_scores.view(-1, 1, 1)
+ mask_labels = mask_probs.argmax(0) # [height, width]
+
+ # Keep track of instances of each class
+ stuff_memory_list: Dict[str, int] = {}
+ for k in range(pred_labels.shape[0]):
+ pred_class = pred_labels[k].item()
+ should_fuse = pred_class in label_ids_to_fuse
+
+ # Check if mask exists and large enough to be a segment
+ mask_exists, mask_k = check_segment_validity(
+ mask_labels, mask_probs, k, mask_threshold, overlap_mask_area_threshold
+ )
+
+ if mask_exists:
+ if pred_class in stuff_memory_list:
+ current_segment_id = stuff_memory_list[pred_class]
+ else:
+ current_segment_id += 1
+
+ # Add current object segment to final segmentation map
+ segmentation[mask_k] = current_segment_id
+ segment_score = round(pred_scores[k].item(), 6)
+ segments.append(
+ {
+ "id": current_segment_id,
+ "label_id": pred_class,
+ "was_fused": should_fuse,
+ "score": segment_score,
+ }
+ )
+ if should_fuse:
+ stuff_memory_list[pred_class] = current_segment_id
+
+ return segmentation, segments
+
+
+# TODO: (Amy) Move to image_transforms
+def convert_segmentation_map_to_binary_masks(
+ segmentation_map: "np.ndarray",
+ instance_id_to_semantic_id: Optional[Dict[int, int]] = None,
+ ignore_index: Optional[int] = None,
+ reduce_labels: bool = False,
+):
+ if reduce_labels and ignore_index is None:
+ raise ValueError("If `reduce_labels` is True, `ignore_index` must be provided.")
+
+ if reduce_labels:
+ segmentation_map = np.where(segmentation_map == 0, ignore_index, segmentation_map - 1)
+
+ # Get unique ids (class or instance ids based on input)
+ all_labels = np.unique(segmentation_map)
+
+ # Drop background label if applicable
+ if ignore_index is not None:
+ all_labels = all_labels[all_labels != ignore_index]
+
+ # Generate a binary mask for each object instance
+ binary_masks = [(segmentation_map == i) for i in all_labels]
+ binary_masks = np.stack(binary_masks, axis=0) # (num_labels, height, width)
+
+ # Convert instance ids to class ids
+ if instance_id_to_semantic_id is not None:
+ labels = np.zeros(all_labels.shape[0])
+
+ for label in all_labels:
+ class_id = instance_id_to_semantic_id[label + 1 if reduce_labels else label]
+ labels[all_labels == label] = class_id - 1 if reduce_labels else class_id
+ else:
+ labels = all_labels
+
+ return binary_masks.astype(np.float32), labels.astype(np.int64)
+
+
+def get_maskformer_resize_output_image_size(
+ image: np.ndarray,
+ size: Union[int, Tuple[int, int], List[int], Tuple[int]],
+ max_size: Optional[int] = None,
+ size_divisor: int = 0,
+ default_to_square: bool = True,
+) -> tuple:
+ """
+ Computes the output size given the desired size.
+
+ Args:
+ input_image (`np.ndarray`):
+ The input image.
+ size (`int`, `Tuple[int, int]`, `List[int]`, `Tuple[int]`):
+ The size of the output image.
+ default_to_square (`bool`, *optional*, defaults to `True`):
+ Whether to default to square if no size is provided.
+ max_size (`int`, *optional*):
+ The maximum size of the output image.
+ size_divisible (`int`, *optional*, defaults to `0`):
+ If size_divisible is given, the output image size will be divisible by the number.
+
+ Returns:
+ `Tuple[int, int]`: The output size.
+ """
+ output_size = get_resize_output_image_size(
+ input_image=image, size=size, default_to_square=default_to_square, max_size=max_size
+ )
+
+ if size_divisor > 0:
+ height, width = output_size
+ height = int(math.ceil(height / size_divisor) * size_divisor)
+ width = int(math.ceil(width / size_divisor) * size_divisor)
+ output_size = (height, width)
+
+ return output_size
+
+
+class MaskFormerImageProcessor(BaseImageProcessor):
+ r"""
+ Constructs a MaskFormer image processor. The image processor can be used to prepare image(s) and optional targets
+ for the model.
+
+ This image processor inherits from [`BaseImageProcessor`] which contains most of the main methods. Users should
+ refer to this superclass for more information regarding those methods.
+
+ Args:
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Whether to resize the input to a certain `size`.
+ size (`int`, *optional*, defaults to 800):
+ Resize the input to the given size. Only has an effect if `do_resize` is set to `True`. If size is a
+ sequence like `(width, height)`, output size will be matched to this. If size is an int, smaller edge of
+ the image will be matched to this number. i.e, if `height > width`, then image will be rescaled to `(size *
+ height / width, size)`.
+ max_size (`int`, *optional*, defaults to 1333):
+ The largest size an image dimension can have (otherwise it's capped). Only has an effect if `do_resize` is
+ set to `True`.
+ resample (`int`, *optional*, defaults to `PIL.Image.Resampling.BILINEAR`):
+ An optional resampling filter. This can be one of `PIL.Image.Resampling.NEAREST`,
+ `PIL.Image.Resampling.BOX`, `PIL.Image.Resampling.BILINEAR`, `PIL.Image.Resampling.HAMMING`,
+ `PIL.Image.Resampling.BICUBIC` or `PIL.Image.Resampling.LANCZOS`. Only has an effect if `do_resize` is set
+ to `True`.
+ size_divisor (`int`, *optional*, defaults to 32):
+ Some backbones need images divisible by a certain number. If not passed, it defaults to the value used in
+ Swin Transformer.
+ do_rescale (`bool`, *optional*, defaults to `True`):
+ Whether to rescale the input to a certain `scale`.
+ rescale_factor (`float`, *optional*, defaults to 1/ 255):
+ Rescale the input by the given factor. Only has an effect if `do_rescale` is set to `True`.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether or not to normalize the input with mean and standard deviation.
+ image_mean (`int`, *optional*, defaults to `[0.485, 0.456, 0.406]`):
+ The sequence of means for each channel, to be used when normalizing images. Defaults to the ImageNet mean.
+ image_std (`int`, *optional*, defaults to `[0.229, 0.224, 0.225]`):
+ The sequence of standard deviations for each channel, to be used when normalizing images. Defaults to the
+ ImageNet std.
+ ignore_index (`int`, *optional*):
+ Label to be assigned to background pixels in segmentation maps. If provided, segmentation map pixels
+ denoted with 0 (background) will be replaced with `ignore_index`.
+ reduce_labels (`bool`, *optional*, defaults to `False`):
+ Whether or not to decrement all label values of segmentation maps by 1. Usually used for datasets where 0
+ is used for background, and background itself is not included in all classes of a dataset (e.g. ADE20k).
+ The background label will be replaced by `ignore_index`.
+
+ """
+
+ model_input_names = ["pixel_values", "pixel_mask"]
+
+ def __init__(
+ self,
+ do_resize: bool = True,
+ size: Dict[str, int] = None,
+ size_divisor: int = 32,
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ do_rescale: bool = True,
+ rescale_factor: float = 1 / 255,
+ do_normalize: bool = True,
+ image_mean: Union[float, List[float]] = None,
+ image_std: Union[float, List[float]] = None,
+ ignore_index: Optional[int] = None,
+ reduce_labels: bool = False,
+ **kwargs
+ ):
+ if "size_divisibility" in kwargs:
+ warnings.warn(
+ "The `size_divisibility` argument is deprecated and will be removed in v4.27. Please use "
+ "`size_divisibility` instead.",
+ FutureWarning,
+ )
+ size_divisor = kwargs.pop("size_divisibility")
+ if "max_size" in kwargs:
+ warnings.warn(
+ "The `max_size` argument is deprecated and will be removed in v4.27. Please use size['longest_edge']"
+ " instead.",
+ FutureWarning,
+ )
+ # We make max_size a private attribute so we can pass it as a default value in the preprocess method whilst
+ # `size` can still be pass in as an int
+ self._max_size = kwargs.pop("max_size")
+ else:
+ self._max_size = 1333
+
+ size = size if size is not None else {"shortest_edge": 800, "longest_edge": self._max_size}
+ size = get_size_dict(size, max_size=self._max_size, default_to_square=False)
+
+ super().__init__(**kwargs)
+ self.do_resize = do_resize
+ self.size = size
+ self.resample = resample
+ self.size_divisor = size_divisor
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean if image_mean is not None else IMAGENET_DEFAULT_MEAN
+ self.image_std = image_std if image_std is not None else IMAGENET_DEFAULT_STD
+ self.ignore_index = ignore_index
+ self.reduce_labels = reduce_labels
+
+ @property
+ def size_divisibility(self):
+ warnings.warn(
+ "The `size_divisibility` property is deprecated and will be removed in v4.27. Please use "
+ "`size_divisor` instead.",
+ FutureWarning,
+ )
+ return self.size_divisor
+
+ @property
+ def max_size(self):
+ warnings.warn(
+ "The `max_size` property is deprecated and will be removed in v4.27. Please use size['longest_edge']"
+ " instead.",
+ FutureWarning,
+ )
+ return self.size["longest_edge"]
+
+ def resize(
+ self,
+ image: np.ndarray,
+ size: Dict[str, int],
+ size_divisor: int = 0,
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ data_format=None,
+ **kwargs
+ ) -> np.ndarray:
+ """
+ Resize the image to the given size. Size can be min_size (scalar) or `(height, width)` tuple. If size is an
+ int, smaller edge of the image will be matched to this number.
+ """
+ if "max_size" in kwargs:
+ warnings.warn(
+ "The `max_size` parameter is deprecated and will be removed in v4.27. "
+ "Please specify in `size['longest_edge'] instead`.",
+ FutureWarning,
+ )
+ max_size = kwargs.pop("max_size")
+ else:
+ max_size = None
+ size = get_size_dict(size, max_size=max_size, default_to_square=False)
+ if "shortest_edge" in size and "longest_edge" in size:
+ size, max_size = size["shortest_edge"], size["longest_edge"]
+ elif "height" in size and "width" in size:
+ size = (size["height"], size["width"])
+ max_size = None
+ else:
+ raise ValueError(
+ "Size must contain 'height' and 'width' keys or 'shortest_edge' and 'longest_edge' keys. Got"
+ f" {size.keys()}."
+ )
+ size = get_maskformer_resize_output_image_size(
+ image=image,
+ size=size,
+ max_size=max_size,
+ size_divisor=size_divisor,
+ default_to_square=False,
+ )
+ image = resize(image, size=size, resample=resample, data_format=data_format)
+ return image
+
+ def rescale(
+ self, image: np.ndarray, rescale_factor: float, data_format: Optional[ChannelDimension] = None
+ ) -> np.ndarray:
+ """
+ Rescale the image by the given factor.
+ """
+ return rescale(image, rescale_factor, data_format=data_format)
+
+ def normalize(
+ self,
+ image: np.ndarray,
+ mean: Union[float, Iterable[float]],
+ std: Union[float, Iterable[float]],
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Normalize the image with the given mean and standard deviation.
+ """
+ return normalize(image, mean=mean, std=std, data_format=data_format)
+
+ def convert_segmentation_map_to_binary_masks(
+ self,
+ segmentation_map: "np.ndarray",
+ instance_id_to_semantic_id: Optional[Dict[int, int]] = None,
+ ignore_index: Optional[int] = None,
+ reduce_labels: bool = False,
+ ):
+ reduce_labels = reduce_labels if reduce_labels is not None else self.reduce_labels
+ ignore_index = ignore_index if ignore_index is not None else self.ignore_index
+ return convert_segmentation_map_to_binary_masks(
+ segmentation_map=segmentation_map,
+ instance_id_to_semantic_id=instance_id_to_semantic_id,
+ ignore_index=ignore_index,
+ reduce_labels=reduce_labels,
+ )
+
+ def __call__(self, images, segmentation_maps=None, **kwargs) -> BatchFeature:
+ return self.preprocess(images, segmentation_maps=segmentation_maps, **kwargs)
+
+ def _preprocess(
+ self,
+ image: ImageInput,
+ do_resize: bool = None,
+ size: Dict[str, int] = None,
+ size_divisor: int = None,
+ resample: PILImageResampling = None,
+ do_rescale: bool = None,
+ rescale_factor: float = None,
+ do_normalize: bool = None,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ ):
+ if do_resize:
+ image = self.resize(image, size=size, size_divisor=size_divisor, resample=resample)
+ if do_rescale:
+ image = self.rescale(image, rescale_factor=rescale_factor)
+ if do_normalize:
+ image = self.normalize(image, mean=image_mean, std=image_std)
+ return image
+
+ def _preprocess_image(
+ self,
+ image: ImageInput,
+ do_resize: bool = None,
+ size: Dict[str, int] = None,
+ size_divisor: int = None,
+ resample: PILImageResampling = None,
+ do_rescale: bool = None,
+ rescale_factor: float = None,
+ do_normalize: bool = None,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ data_format: Optional[Union[str, ChannelDimension]] = None,
+ ) -> np.ndarray:
+ """Preprocesses a single image."""
+ # All transformations expect numpy arrays.
+ image = to_numpy_array(image)
+ image = self._preprocess(
+ image=image,
+ do_resize=do_resize,
+ size=size,
+ size_divisor=size_divisor,
+ resample=resample,
+ do_rescale=do_rescale,
+ rescale_factor=rescale_factor,
+ do_normalize=do_normalize,
+ image_mean=image_mean,
+ image_std=image_std,
+ )
+ if data_format is not None:
+ image = to_channel_dimension_format(image, data_format)
+ return image
+
+ def _preprocess_mask(
+ self,
+ segmentation_map: ImageInput,
+ do_resize: bool = None,
+ size: Dict[str, int] = None,
+ size_divisor: int = 0,
+ ) -> np.ndarray:
+ """Preprocesses a single mask."""
+ segmentation_map = to_numpy_array(segmentation_map)
+ # Add channel dimension if missing - needed for certain transformations
+ added_channel_dim = False
+ if segmentation_map.ndim == 2:
+ added_channel_dim = True
+ segmentation_map = segmentation_map[None, ...]
+ # TODO: (Amy)
+ # Remork segmentation map processing to include reducing labels and resizing which doesn't
+ # drop segment IDs > 255.
+ segmentation_map = self._preprocess(
+ image=segmentation_map,
+ do_resize=do_resize,
+ resample=PILImageResampling.NEAREST,
+ size=size,
+ size_divisor=size_divisor,
+ do_rescale=False,
+ do_normalize=False,
+ )
+ # Remove extra channel dimension if added for processing
+ if added_channel_dim:
+ segmentation_map = segmentation_map.squeeze(0)
+ return segmentation_map
+
+ def preprocess(
+ self,
+ images: ImageInput,
+ segmentation_maps: Optional[ImageInput] = None,
+ instance_id_to_semantic_id: Optional[Dict[int, int]] = None,
+ do_resize: Optional[bool] = None,
+ size: Optional[Dict[str, int]] = None,
+ size_divisor: Optional[int] = None,
+ resample: PILImageResampling = None,
+ do_rescale: Optional[bool] = None,
+ rescale_factor: Optional[float] = None,
+ do_normalize: Optional[bool] = None,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ ignore_index: Optional[int] = None,
+ reduce_labels: Optional[bool] = None,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ data_format: Union[str, ChannelDimension] = ChannelDimension.FIRST,
+ **kwargs
+ ) -> BatchFeature:
+ if "pad_and_return_pixel_mask" in kwargs:
+ warnings.warn(
+ "The `pad_and_return_pixel_mask` argument is deprecated and will be removed in a future version",
+ FutureWarning,
+ )
+
+ do_resize = do_resize if do_resize is not None else self.do_resize
+ size = size if size is not None else self.size
+ size = get_size_dict(size, default_to_square=False, max_size=self._max_size)
+ size_divisor = size_divisor if size_divisor is not None else self.size_divisor
+ resample = resample if resample is not None else self.resample
+ do_rescale = do_rescale if do_rescale is not None else self.do_rescale
+ rescale_factor = rescale_factor if rescale_factor is not None else self.rescale_factor
+ do_normalize = do_normalize if do_normalize is not None else self.do_normalize
+ image_mean = image_mean if image_mean is not None else self.image_mean
+ image_std = image_std if image_std is not None else self.image_std
+ ignore_index = ignore_index if ignore_index is not None else self.ignore_index
+ reduce_labels = reduce_labels if reduce_labels is not None else self.reduce_labels
+
+ if do_resize is not None and size is None or size_divisor is None:
+ raise ValueError("If `do_resize` is True, `size` and `size_divisor` must be provided.")
+
+ if do_rescale is not None and rescale_factor is None:
+ raise ValueError("If `do_rescale` is True, `rescale_factor` must be provided.")
+
+ if do_normalize is not None and (image_mean is None or image_std is None):
+ raise ValueError("If `do_normalize` is True, `image_mean` and `image_std` must be provided.")
+
+ if not valid_images(images):
+ raise ValueError(
+ "Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
+ "torch.Tensor, tf.Tensor or jax.ndarray."
+ )
+
+ if segmentation_maps is not None and not valid_images(segmentation_maps):
+ raise ValueError(
+ "Invalid segmentation map type. Must be of type PIL.Image.Image, numpy.ndarray, "
+ "torch.Tensor, tf.Tensor or jax.ndarray."
+ )
+
+ if not is_batched(images):
+ images = [images]
+ segmentation_maps = [segmentation_maps] if segmentation_maps is not None else None
+
+ if segmentation_maps is not None and len(images) != len(segmentation_maps):
+ raise ValueError("Images and segmentation maps must have the same length.")
+
+ images = [
+ self._preprocess_image(
+ image,
+ do_resize=do_resize,
+ size=size,
+ size_divisor=size_divisor,
+ resample=resample,
+ do_rescale=do_rescale,
+ rescale_factor=rescale_factor,
+ do_normalize=do_normalize,
+ image_mean=image_mean,
+ image_std=image_std,
+ data_format=data_format,
+ )
+ for image in images
+ ]
+
+ if segmentation_maps is not None:
+ segmentation_maps = [
+ self._preprocess_mask(segmentation_map, do_resize, size, size_divisor)
+ for segmentation_map in segmentation_maps
+ ]
+ encoded_inputs = self.encode_inputs(
+ images, segmentation_maps, instance_id_to_semantic_id, ignore_index, reduce_labels, return_tensors
+ )
+ return encoded_inputs
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor._pad_image
+ def _pad_image(
+ self,
+ image: np.ndarray,
+ output_size: Tuple[int, int],
+ constant_values: Union[float, Iterable[float]] = 0,
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Pad an image with zeros to the given size.
+ """
+ input_height, input_width = get_image_size(image)
+ output_height, output_width = output_size
+
+ pad_bottom = output_height - input_height
+ pad_right = output_width - input_width
+ padding = ((0, pad_bottom), (0, pad_right))
+ padded_image = pad(
+ image, padding, mode=PaddingMode.CONSTANT, constant_values=constant_values, data_format=data_format
+ )
+ return padded_image
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.pad
+ def pad(
+ self,
+ images: List[np.ndarray],
+ constant_values: Union[float, Iterable[float]] = 0,
+ return_pixel_mask: bool = True,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Pads a batch of images to the bottom and right of the image with zeros to the size of largest height and width
+ in the batch and optionally returns their corresponding pixel mask.
+
+ Args:
+ image (`np.ndarray`):
+ Image to pad.
+ constant_values (`float` or `Iterable[float]`, *optional*):
+ The value to use for the padding if `mode` is `"constant"`.
+ return_pixel_mask (`bool`, *optional*, defaults to `True`):
+ Whether to return a pixel mask.
+ input_channel_dimension (`ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be inferred from the input image.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be the same as the input image.
+ """
+ pad_size = get_max_height_width(images)
+
+ padded_images = [
+ self._pad_image(image, pad_size, constant_values=constant_values, data_format=data_format)
+ for image in images
+ ]
+ data = {"pixel_values": padded_images}
+
+ if return_pixel_mask:
+ masks = [make_pixel_mask(image=image, output_size=pad_size) for image in images]
+ data["pixel_mask"] = masks
+
+ return BatchFeature(data=data, tensor_type=return_tensors)
+
+ def encode_inputs(
+ self,
+ pixel_values_list: List[ImageInput],
+ segmentation_maps: ImageInput = None,
+ instance_id_to_semantic_id: Optional[Union[List[Dict[int, int]], Dict[int, int]]] = None,
+ ignore_index: Optional[int] = None,
+ reduce_labels: bool = False,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ **kwargs
+ ):
+ """
+ Pad images up to the largest image in a batch and create a corresponding `pixel_mask`.
+
+ MaskFormer addresses semantic segmentation with a mask classification paradigm, thus input segmentation maps
+ will be converted to lists of binary masks and their respective labels. Let's see an example, assuming
+ `segmentation_maps = [[2,6,7,9]]`, the output will contain `mask_labels =
+ [[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1]]` (four binary masks) and `class_labels = [2,6,7,9]`, the labels for
+ each mask.
+
+ Args:
+ pixel_values_list (`List[ImageInput]`):
+ List of images (pixel values) to be padded. Each image should be a tensor of shape `(channels, height,
+ width)`.
+
+ segmentation_maps (`ImageInput`, *optional*):
+ The corresponding semantic segmentation maps with the pixel-wise annotations.
+
+ (`bool`, *optional*, defaults to `True`):
+ Whether or not to pad images up to the largest image in a batch and create a pixel mask.
+
+ If left to the default, will return a pixel mask that is:
+
+ - 1 for pixels that are real (i.e. **not masked**),
+ - 0 for pixels that are padding (i.e. **masked**).
+
+ instance_id_to_semantic_id (`List[Dict[int, int]]` or `Dict[int, int]`, *optional*):
+ A mapping between object instance ids and class ids. If passed, `segmentation_maps` is treated as an
+ instance segmentation map where each pixel represents an instance id. Can be provided as a single
+ dictionary with a global/dataset-level mapping or as a list of dictionaries (one per image), to map
+ instance ids in each image separately.
+
+ return_tensors (`str` or [`~file_utils.TensorType`], *optional*):
+ If set, will return tensors instead of NumPy arrays. If set to `'pt'`, return PyTorch `torch.Tensor`
+ objects.
+
+ Returns:
+ [`BatchFeature`]: A [`BatchFeature`] with the following fields:
+
+ - **pixel_values** -- Pixel values to be fed to a model.
+ - **pixel_mask** -- Pixel mask to be fed to a model (when `=True` or if `pixel_mask` is in
+ `self.model_input_names`).
+ - **mask_labels** -- Optional list of mask labels of shape `(labels, height, width)` to be fed to a model
+ (when `annotations` are provided).
+ - **class_labels** -- Optional list of class labels of shape `(labels)` to be fed to a model (when
+ `annotations` are provided). They identify the labels of `mask_labels`, e.g. the label of
+ `mask_labels[i][j]` if `class_labels[i][j]`.
+ """
+ ignore_index = self.ignore_index if ignore_index is None else ignore_index
+ reduce_labels = self.reduce_labels if reduce_labels is None else reduce_labels
+
+ if "pad_and_return_pixel_mask" in kwargs:
+ warnings.warn(
+ "The `pad_and_return_pixel_mask` argument has no effect and will be removed in v4.27", FutureWarning
+ )
+
+ pixel_values_list = [to_numpy_array(pixel_values) for pixel_values in pixel_values_list]
+ encoded_inputs = self.pad(pixel_values_list, return_tensors=return_tensors)
+
+ if segmentation_maps is not None:
+ mask_labels = []
+ class_labels = []
+ pad_size = get_max_height_width(pixel_values_list)
+ # Convert to list of binary masks and labels
+ for idx, segmentation_map in enumerate(segmentation_maps):
+ segmentation_map = to_numpy_array(segmentation_map)
+ if isinstance(instance_id_to_semantic_id, list):
+ instance_id = instance_id_to_semantic_id[idx]
+ else:
+ instance_id = instance_id_to_semantic_id
+ # Use instance2class_id mapping per image
+ masks, classes = self.convert_segmentation_map_to_binary_masks(
+ segmentation_map, instance_id, ignore_index=ignore_index, reduce_labels=reduce_labels
+ )
+ # We add an axis to make them compatible with the transformations library
+ # this will be removed in the future
+ masks = [mask[None, ...] for mask in masks]
+ masks = [
+ self._pad_image(image=mask, output_size=pad_size, constant_values=ignore_index) for mask in masks
+ ]
+ masks = np.concatenate(masks, axis=0)
+ mask_labels.append(torch.from_numpy(masks))
+ class_labels.append(torch.from_numpy(classes))
+
+ # we cannot batch them since they don't share a common class size
+ encoded_inputs["mask_labels"] = mask_labels
+ encoded_inputs["class_labels"] = class_labels
+
+ return encoded_inputs
+
+ def post_process_segmentation(
+ self, outputs: "MaskFormerForInstanceSegmentationOutput", target_size: Tuple[int, int] = None
+ ) -> "torch.Tensor":
+ """
+ Converts the output of [`MaskFormerForInstanceSegmentationOutput`] into image segmentation predictions. Only
+ supports PyTorch.
+
+ Args:
+ outputs ([`MaskFormerForInstanceSegmentationOutput`]):
+ The outputs from [`MaskFormerForInstanceSegmentation`].
+
+ target_size (`Tuple[int, int]`, *optional*):
+ If set, the `masks_queries_logits` will be resized to `target_size`.
+
+ Returns:
+ `torch.Tensor`:
+ A tensor of shape (`batch_size, num_class_labels, height, width`).
+ """
+ logger.warning(
+ "`post_process_segmentation` is deprecated and will be removed in v5 of Transformers, please use"
+ " `post_process_instance_segmentation`",
+ FutureWarning,
+ )
+
+ # class_queries_logits has shape [BATCH, QUERIES, CLASSES + 1]
+ class_queries_logits = outputs.class_queries_logits
+ # masks_queries_logits has shape [BATCH, QUERIES, HEIGHT, WIDTH]
+ masks_queries_logits = outputs.masks_queries_logits
+ if target_size is not None:
+ masks_queries_logits = torch.nn.functional.interpolate(
+ masks_queries_logits,
+ size=target_size,
+ mode="bilinear",
+ align_corners=False,
+ )
+ # remove the null class `[..., :-1]`
+ masks_classes = class_queries_logits.softmax(dim=-1)[..., :-1]
+ # mask probs has shape [BATCH, QUERIES, HEIGHT, WIDTH]
+ masks_probs = masks_queries_logits.sigmoid()
+ # now we want to sum over the queries,
+ # $ out_{c,h,w} = \sum_q p_{q,c} * m_{q,h,w} $
+ # where $ softmax(p) \in R^{q, c} $ is the mask classes
+ # and $ sigmoid(m) \in R^{q, h, w}$ is the mask probabilities
+ # b(atch)q(uery)c(lasses), b(atch)q(uery)h(eight)w(idth)
+ segmentation = torch.einsum("bqc, bqhw -> bchw", masks_classes, masks_probs)
+
+ return segmentation
+
+ def post_process_semantic_segmentation(
+ self, outputs, target_sizes: Optional[List[Tuple[int, int]]] = None
+ ) -> "torch.Tensor":
+ """
+ Converts the output of [`MaskFormerForInstanceSegmentation`] into semantic segmentation maps. Only supports
+ PyTorch.
+
+ Args:
+ outputs ([`MaskFormerForInstanceSegmentation`]):
+ Raw outputs of the model.
+ target_sizes (`List[Tuple[int, int]]`, *optional*):
+ List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
+ final size (height, width) of each prediction. If left to None, predictions will not be resized.
+ Returns:
+ `List[torch.Tensor]`:
+ A list of length `batch_size`, where each item is a semantic segmentation map of shape (height, width)
+ corresponding to the target_sizes entry (if `target_sizes` is specified). Each entry of each
+ `torch.Tensor` correspond to a semantic class id.
+ """
+ class_queries_logits = outputs.class_queries_logits # [batch_size, num_queries, num_classes+1]
+ masks_queries_logits = outputs.masks_queries_logits # [batch_size, num_queries, height, width]
+
+ # Remove the null class `[..., :-1]`
+ masks_classes = class_queries_logits.softmax(dim=-1)[..., :-1]
+ masks_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
+
+ # Semantic segmentation logits of shape (batch_size, num_classes, height, width)
+ segmentation = torch.einsum("bqc, bqhw -> bchw", masks_classes, masks_probs)
+ batch_size = class_queries_logits.shape[0]
+
+ # Resize logits and compute semantic segmentation maps
+ if target_sizes is not None:
+ if batch_size != len(target_sizes):
+ raise ValueError(
+ "Make sure that you pass in as many target sizes as the batch dimension of the logits"
+ )
+
+ semantic_segmentation = []
+ for idx in range(batch_size):
+ resized_logits = torch.nn.functional.interpolate(
+ segmentation[idx].unsqueeze(dim=0), size=target_sizes[idx], mode="bilinear", align_corners=False
+ )
+ semantic_map = resized_logits[0].argmax(dim=0)
+ semantic_segmentation.append(semantic_map)
+ else:
+ semantic_segmentation = segmentation.argmax(dim=1)
+ semantic_segmentation = [semantic_segmentation[i] for i in range(semantic_segmentation.shape[0])]
+
+ return semantic_segmentation
+
+ def post_process_instance_segmentation(
+ self,
+ outputs,
+ threshold: float = 0.5,
+ mask_threshold: float = 0.5,
+ overlap_mask_area_threshold: float = 0.8,
+ target_sizes: Optional[List[Tuple[int, int]]] = None,
+ return_coco_annotation: Optional[bool] = False,
+ ) -> List[Dict]:
+ """
+ Converts the output of [`MaskFormerForInstanceSegmentationOutput`] into instance segmentation predictions. Only
+ supports PyTorch.
+
+ Args:
+ outputs ([`MaskFormerForInstanceSegmentation`]):
+ Raw outputs of the model.
+ threshold (`float`, *optional*, defaults to 0.5):
+ The probability score threshold to keep predicted instance masks.
+ mask_threshold (`float`, *optional*, defaults to 0.5):
+ Threshold to use when turning the predicted masks into binary values.
+ overlap_mask_area_threshold (`float`, *optional*, defaults to 0.8):
+ The overlap mask area threshold to merge or discard small disconnected parts within each binary
+ instance mask.
+ target_sizes (`List[Tuple]`, *optional*):
+ List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
+ final size (height, width) of each prediction. If left to None, predictions will not be resized.
+ return_coco_annotation (`bool`, *optional*):
+ Defaults to `False`. If set to `True`, segmentation maps are returned in COCO run-length encoding (RLE)
+ format.
+ Returns:
+ `List[Dict]`: A list of dictionaries, one per image, each dictionary containing two keys:
+ - **segmentation** -- A tensor of shape `(height, width)` where each pixel represents a `segment_id` or
+ `List[List]` run-length encoding (RLE) of the segmentation map if return_coco_annotation is set to
+ `True`. Set to `None` if no mask if found above `threshold`.
+ - **segments_info** -- A dictionary that contains additional information on each segment.
+ - **id** -- An integer representing the `segment_id`.
+ - **label_id** -- An integer representing the label / semantic class id corresponding to `segment_id`.
+ - **score** -- Prediction score of segment with `segment_id`.
+ """
+ class_queries_logits = outputs.class_queries_logits # [batch_size, num_queries, num_classes+1]
+ masks_queries_logits = outputs.masks_queries_logits # [batch_size, num_queries, height, width]
+
+ batch_size = class_queries_logits.shape[0]
+ num_labels = class_queries_logits.shape[-1] - 1
+
+ mask_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
+
+ # Predicted label and score of each query (batch_size, num_queries)
+ pred_scores, pred_labels = nn.functional.softmax(class_queries_logits, dim=-1).max(-1)
+
+ # Loop over items in batch size
+ results: List[Dict[str, TensorType]] = []
+
+ for i in range(batch_size):
+ mask_probs_item, pred_scores_item, pred_labels_item = remove_low_and_no_objects(
+ mask_probs[i], pred_scores[i], pred_labels[i], threshold, num_labels
+ )
+
+ # No mask found
+ if mask_probs_item.shape[0] <= 0:
+ height, width = target_sizes[i] if target_sizes is not None else mask_probs_item.shape[1:]
+ segmentation = torch.zeros((height, width)) - 1
+ results.append({"segmentation": segmentation, "segments_info": []})
+ continue
+
+ # Get segmentation map and segment information of batch item
+ target_size = target_sizes[i] if target_sizes is not None else None
+ segmentation, segments = compute_segments(
+ mask_probs_item,
+ pred_scores_item,
+ pred_labels_item,
+ mask_threshold,
+ overlap_mask_area_threshold,
+ target_size,
+ )
+
+ # Return segmentation map in run-length encoding (RLE) format
+ if return_coco_annotation:
+ segmentation = convert_segmentation_to_rle(segmentation)
+
+ results.append({"segmentation": segmentation, "segments_info": segments})
+ return results
+
+ def post_process_panoptic_segmentation(
+ self,
+ outputs,
+ threshold: float = 0.5,
+ mask_threshold: float = 0.5,
+ overlap_mask_area_threshold: float = 0.8,
+ label_ids_to_fuse: Optional[Set[int]] = None,
+ target_sizes: Optional[List[Tuple[int, int]]] = None,
+ ) -> List[Dict]:
+ """
+ Converts the output of [`MaskFormerForInstanceSegmentationOutput`] into image panoptic segmentation
+ predictions. Only supports PyTorch.
+
+ Args:
+ outputs ([`MaskFormerForInstanceSegmentationOutput`]):
+ The outputs from [`MaskFormerForInstanceSegmentation`].
+ threshold (`float`, *optional*, defaults to 0.5):
+ The probability score threshold to keep predicted instance masks.
+ mask_threshold (`float`, *optional*, defaults to 0.5):
+ Threshold to use when turning the predicted masks into binary values.
+ overlap_mask_area_threshold (`float`, *optional*, defaults to 0.8):
+ The overlap mask area threshold to merge or discard small disconnected parts within each binary
+ instance mask.
+ label_ids_to_fuse (`Set[int]`, *optional*):
+ The labels in this state will have all their instances be fused together. For instance we could say
+ there can only be one sky in an image, but several persons, so the label ID for sky would be in that
+ set, but not the one for person.
+ target_sizes (`List[Tuple]`, *optional*):
+ List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
+ final size (height, width) of each prediction in batch. If left to None, predictions will not be
+ resized.
+
+ Returns:
+ `List[Dict]`: A list of dictionaries, one per image, each dictionary containing two keys:
+ - **segmentation** -- a tensor of shape `(height, width)` where each pixel represents a `segment_id`, set
+ to `None` if no mask if found above `threshold`. If `target_sizes` is specified, segmentation is resized
+ to the corresponding `target_sizes` entry.
+ - **segments_info** -- A dictionary that contains additional information on each segment.
+ - **id** -- an integer representing the `segment_id`.
+ - **label_id** -- An integer representing the label / semantic class id corresponding to `segment_id`.
+ - **was_fused** -- a boolean, `True` if `label_id` was in `label_ids_to_fuse`, `False` otherwise.
+ Multiple instances of the same class / label were fused and assigned a single `segment_id`.
+ - **score** -- Prediction score of segment with `segment_id`.
+ """
+
+ if label_ids_to_fuse is None:
+ logger.warning("`label_ids_to_fuse` unset. No instance will be fused.")
+ label_ids_to_fuse = set()
+
+ class_queries_logits = outputs.class_queries_logits # [batch_size, num_queries, num_classes+1]
+ masks_queries_logits = outputs.masks_queries_logits # [batch_size, num_queries, height, width]
+
+ batch_size = class_queries_logits.shape[0]
+ num_labels = class_queries_logits.shape[-1] - 1
+
+ mask_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
+
+ # Predicted label and score of each query (batch_size, num_queries)
+ pred_scores, pred_labels = nn.functional.softmax(class_queries_logits, dim=-1).max(-1)
+
+ # Loop over items in batch size
+ results: List[Dict[str, TensorType]] = []
+
+ for i in range(batch_size):
+ mask_probs_item, pred_scores_item, pred_labels_item = remove_low_and_no_objects(
+ mask_probs[i], pred_scores[i], pred_labels[i], threshold, num_labels
+ )
+
+ # No mask found
+ if mask_probs_item.shape[0] <= 0:
+ height, width = target_sizes[i] if target_sizes is not None else mask_probs_item.shape[1:]
+ segmentation = torch.zeros((height, width)) - 1
+ results.append({"segmentation": segmentation, "segments_info": []})
+ continue
+
+ # Get segmentation map and segment information of batch item
+ target_size = target_sizes[i] if target_sizes is not None else None
+ segmentation, segments = compute_segments(
+ mask_probs_item,
+ pred_scores_item,
+ pred_labels_item,
+ mask_threshold,
+ overlap_mask_area_threshold,
+ label_ids_to_fuse,
+ target_size,
+ )
+
+ results.append({"segmentation": segmentation, "segments_info": segments})
+ return results
diff --git a/src/transformers/models/owlvit/__init__.py b/src/transformers/models/owlvit/__init__.py
index cc528d315e..f29db2f06c 100644
--- a/src/transformers/models/owlvit/__init__.py
+++ b/src/transformers/models/owlvit/__init__.py
@@ -47,6 +47,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_owlvit"] = ["OwlViTFeatureExtractor"]
+ _import_structure["image_processing_owlvit"] = ["OwlViTImageProcessor"]
try:
if not is_torch_available():
@@ -80,6 +81,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_owlvit import OwlViTFeatureExtractor
+ from .image_processing_owlvit import OwlViTImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/models/owlvit/feature_extraction_owlvit.py b/src/transformers/models/owlvit/feature_extraction_owlvit.py
index 0bbb8c3105..424111ada0 100644
--- a/src/transformers/models/owlvit/feature_extraction_owlvit.py
+++ b/src/transformers/models/owlvit/feature_extraction_owlvit.py
@@ -14,317 +14,11 @@
# limitations under the License.
"""Feature extractor class for OwlViT."""
-from typing import List, Optional, Union
+from ...utils import logging
+from .image_processing_owlvit import OwlViTImageProcessor
-import numpy as np
-from PIL import Image
-
-from transformers.image_utils import PILImageResampling
-
-from ...feature_extraction_utils import BatchFeature, FeatureExtractionMixin
-from ...image_transforms import center_to_corners_format
-from ...image_utils import ImageFeatureExtractionMixin
-from ...utils import TensorType, is_torch_available, is_torch_tensor, logging
-
-
-if is_torch_available():
- import torch
logger = logging.get_logger(__name__)
-# Copied from transformers.models.detr.modeling_detr._upcast
-def _upcast(t):
- # Protects from numerical overflows in multiplications by upcasting to the equivalent higher type
- if t.is_floating_point():
- return t if t.dtype in (torch.float32, torch.float64) else t.float()
- else:
- return t if t.dtype in (torch.int32, torch.int64) else t.int()
-
-
-def box_area(boxes):
- """
- Computes the area of a set of bounding boxes, which are specified by its (x1, y1, x2, y2) coordinates.
-
- Args:
- boxes (`torch.FloatTensor` of shape `(number_of_boxes, 4)`):
- Boxes for which the area will be computed. They are expected to be in (x1, y1, x2, y2) format with `0 <= x1
- < x2` and `0 <= y1 < y2`.
-
- Returns:
- `torch.FloatTensor`: a tensor containing the area for each box.
- """
- boxes = _upcast(boxes)
- return (boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1])
-
-
-def box_iou(boxes1, boxes2):
- area1 = box_area(boxes1)
- area2 = box_area(boxes2)
-
- left_top = torch.max(boxes1[:, None, :2], boxes2[:, :2]) # [N,M,2]
- right_bottom = torch.min(boxes1[:, None, 2:], boxes2[:, 2:]) # [N,M,2]
-
- width_height = (right_bottom - left_top).clamp(min=0) # [N,M,2]
- inter = width_height[:, :, 0] * width_height[:, :, 1] # [N,M]
-
- union = area1[:, None] + area2 - inter
-
- iou = inter / union
- return iou, union
-
-
-class OwlViTFeatureExtractor(FeatureExtractionMixin, ImageFeatureExtractionMixin):
- r"""
- Constructs an OWL-ViT feature extractor.
-
- This feature extractor inherits from [`FeatureExtractionMixin`] which contains most of the main methods. Users
- should refer to this superclass for more information regarding those methods.
-
- Args:
- do_resize (`bool`, *optional*, defaults to `True`):
- Whether to resize the shorter edge of the input to a certain `size`.
- size (`int` or `Tuple[int, int]`, *optional*, defaults to (768, 768)):
- The size to use for resizing the image. Only has an effect if `do_resize` is set to `True`. If `size` is a
- sequence like (h, w), output size will be matched to this. If `size` is an int, then image will be resized
- to (size, size).
- resample (`int`, *optional*, defaults to `PIL.Image.Resampling.BICUBIC`):
- An optional resampling filter. This can be one of `PIL.Image.Resampling.NEAREST`,
- `PIL.Image.Resampling.BOX`, `PIL.Image.Resampling.BILINEAR`, `PIL.Image.Resampling.HAMMING`,
- `PIL.Image.Resampling.BICUBIC` or `PIL.Image.Resampling.LANCZOS`. Only has an effect if `do_resize` is set
- to `True`.
- do_center_crop (`bool`, *optional*, defaults to `False`):
- Whether to crop the input at the center. If the input size is smaller than `crop_size` along any edge, the
- image is padded with 0's and then center cropped.
- crop_size (`int`, *optional*, defaults to 768):
- do_normalize (`bool`, *optional*, defaults to `True`):
- Whether or not to normalize the input with `image_mean` and `image_std`. Desired output size when applying
- center-cropping. Only has an effect if `do_center_crop` is set to `True`.
- image_mean (`List[int]`, *optional*, defaults to `[0.48145466, 0.4578275, 0.40821073]`):
- The sequence of means for each channel, to be used when normalizing images.
- image_std (`List[int]`, *optional*, defaults to `[0.26862954, 0.26130258, 0.27577711]`):
- The sequence of standard deviations for each channel, to be used when normalizing images.
- """
-
- model_input_names = ["pixel_values"]
-
- def __init__(
- self,
- do_resize=True,
- size=(768, 768),
- resample=PILImageResampling.BICUBIC,
- crop_size=768,
- do_center_crop=False,
- do_normalize=True,
- image_mean=None,
- image_std=None,
- **kwargs
- ):
- # Early versions of the OWL-ViT config on the hub had "rescale" as a flag. This clashes with the
- # vision feature extractor method `rescale` as it would be set as an attribute during the super().__init__
- # call. This is for backwards compatibility.
- if "rescale" in kwargs:
- rescale_val = kwargs.pop("rescale")
- kwargs["do_rescale"] = rescale_val
-
- super().__init__(**kwargs)
- self.size = size
- self.resample = resample
- self.crop_size = crop_size
- self.do_resize = do_resize
- self.do_center_crop = do_center_crop
- self.do_normalize = do_normalize
- self.image_mean = image_mean if image_mean is not None else [0.48145466, 0.4578275, 0.40821073]
- self.image_std = image_std if image_std is not None else [0.26862954, 0.26130258, 0.27577711]
-
- def post_process(self, outputs, target_sizes):
- """
- Converts the output of [`OwlViTForObjectDetection`] into the format expected by the COCO api.
-
- Args:
- outputs ([`OwlViTObjectDetectionOutput`]):
- Raw outputs of the model.
- target_sizes (`torch.Tensor`, *optional*):
- Tensor of shape (batch_size, 2) where each entry is the (height, width) of the corresponding image in
- the batch. If set, predicted normalized bounding boxes are rescaled to the target sizes. If left to
- None, predictions will not be unnormalized.
-
- Returns:
- `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
- in the batch as predicted by the model.
- """
- logits, boxes = outputs.logits, outputs.pred_boxes
-
- if len(logits) != len(target_sizes):
- raise ValueError("Make sure that you pass in as many target sizes as the batch dimension of the logits")
- if target_sizes.shape[1] != 2:
- raise ValueError("Each element of target_sizes must contain the size (h, w) of each image of the batch")
-
- probs = torch.max(logits, dim=-1)
- scores = torch.sigmoid(probs.values)
- labels = probs.indices
-
- # Convert to [x0, y0, x1, y1] format
- boxes = center_to_corners_format(boxes)
-
- # Convert from relative [0, 1] to absolute [0, height] coordinates
- img_h, img_w = target_sizes.unbind(1)
- scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
- boxes = boxes * scale_fct[:, None, :]
-
- results = [{"scores": s, "labels": l, "boxes": b} for s, l, b in zip(scores, labels, boxes)]
-
- return results
-
- def post_process_image_guided_detection(self, outputs, threshold=0.6, nms_threshold=0.3, target_sizes=None):
- """
- Converts the output of [`OwlViTForObjectDetection.image_guided_detection`] into the format expected by the COCO
- api.
-
- Args:
- outputs ([`OwlViTImageGuidedObjectDetectionOutput`]):
- Raw outputs of the model.
- threshold (`float`, *optional*, defaults to 0.6):
- Minimum confidence threshold to use to filter out predicted boxes.
- nms_threshold (`float`, *optional*, defaults to 0.3):
- IoU threshold for non-maximum suppression of overlapping boxes.
- target_sizes (`torch.Tensor`, *optional*):
- Tensor of shape (batch_size, 2) where each entry is the (height, width) of the corresponding image in
- the batch. If set, predicted normalized bounding boxes are rescaled to the target sizes. If left to
- None, predictions will not be unnormalized.
-
- Returns:
- `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
- in the batch as predicted by the model. All labels are set to None as
- `OwlViTForObjectDetection.image_guided_detection` perform one-shot object detection.
- """
- logits, target_boxes = outputs.logits, outputs.target_pred_boxes
-
- if len(logits) != len(target_sizes):
- raise ValueError("Make sure that you pass in as many target sizes as the batch dimension of the logits")
- if target_sizes.shape[1] != 2:
- raise ValueError("Each element of target_sizes must contain the size (h, w) of each image of the batch")
-
- probs = torch.max(logits, dim=-1)
- scores = torch.sigmoid(probs.values)
-
- # Convert to [x0, y0, x1, y1] format
- target_boxes = center_to_corners_format(target_boxes)
-
- # Apply non-maximum suppression (NMS)
- if nms_threshold < 1.0:
- for idx in range(target_boxes.shape[0]):
- for i in torch.argsort(-scores[idx]):
- if not scores[idx][i]:
- continue
-
- ious = box_iou(target_boxes[idx][i, :].unsqueeze(0), target_boxes[idx])[0][0]
- ious[i] = -1.0 # Mask self-IoU.
- scores[idx][ious > nms_threshold] = 0.0
-
- # Convert from relative [0, 1] to absolute [0, height] coordinates
- img_h, img_w = target_sizes.unbind(1)
- scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
- target_boxes = target_boxes * scale_fct[:, None, :]
-
- # Compute box display alphas based on prediction scores
- results = []
- alphas = torch.zeros_like(scores)
-
- for idx in range(target_boxes.shape[0]):
- # Select scores for boxes matching the current query:
- query_scores = scores[idx]
- if not query_scores.nonzero().numel():
- continue
-
- # Scale box alpha such that the best box for each query has alpha 1.0 and the worst box has alpha 0.1.
- # All other boxes will either belong to a different query, or will not be shown.
- max_score = torch.max(query_scores) + 1e-6
- query_alphas = (query_scores - (max_score * 0.1)) / (max_score * 0.9)
- query_alphas[query_alphas < threshold] = 0.0
- query_alphas = torch.clip(query_alphas, 0.0, 1.0)
- alphas[idx] = query_alphas
-
- mask = alphas[idx] > 0
- box_scores = alphas[idx][mask]
- boxes = target_boxes[idx][mask]
- results.append({"scores": box_scores, "labels": None, "boxes": boxes})
-
- return results
-
- def __call__(
- self,
- images: Union[
- Image.Image, np.ndarray, "torch.Tensor", List[Image.Image], List[np.ndarray], List["torch.Tensor"] # noqa
- ],
- return_tensors: Optional[Union[str, TensorType]] = None,
- **kwargs
- ) -> BatchFeature:
- """
- Main method to prepare for the model one or several image(s).
-
-
-
- NumPy arrays and PyTorch tensors are converted to PIL images when resizing, so the most efficient is to pass
- PIL images.
-
-
-
- Args:
- images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
- The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
- tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W) or (H, W, C),
- where C is a number of channels, H and W are image height and width.
-
- return_tensors (`str` or [`~utils.TensorType`], *optional*, defaults to `'np'`):
- If set, will return tensors of a particular framework. Acceptable values are:
- - `'tf'`: Return TensorFlow `tf.constant` objects.
- - `'pt'`: Return PyTorch `torch.Tensor` objects.
- - `'np'`: Return NumPy `np.ndarray` objects.
- - `'jax'`: Return JAX `jnp.ndarray` objects.
-
- Returns:
- [`BatchFeature`]: A [`BatchFeature`] with the following fields:
-
- - **pixel_values** -- Pixel values to be fed to a model.
- """
- # Input type checking for clearer error
- valid_images = False
-
- # Check that images has a valid type
- if isinstance(images, (Image.Image, np.ndarray)) or is_torch_tensor(images):
- valid_images = True
- elif isinstance(images, (list, tuple)):
- if isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]):
- valid_images = True
-
- if not valid_images:
- raise ValueError(
- "Images must of type `PIL.Image.Image`, `np.ndarray` or `torch.Tensor` (single example), "
- "`List[PIL.Image.Image]`, `List[np.ndarray]` or `List[torch.Tensor]` (batch of examples)."
- )
-
- is_batched = bool(
- isinstance(images, (list, tuple))
- and (isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]))
- )
-
- if not is_batched:
- images = [images]
-
- # transformations (resizing + center cropping + normalization)
- if self.do_resize and self.size is not None and self.resample is not None:
- images = [
- self.resize(image=image, size=self.size, resample=self.resample, default_to_square=True)
- for image in images
- ]
- if self.do_center_crop and self.crop_size is not None:
- images = [self.center_crop(image, self.crop_size) for image in images]
- if self.do_normalize:
- images = [self.normalize(image=image, mean=self.image_mean, std=self.image_std) for image in images]
-
- # return as BatchFeature
- data = {"pixel_values": images}
- encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
-
- return encoded_inputs
+OwlViTFeatureExtractor = OwlViTImageProcessor
diff --git a/src/transformers/models/owlvit/image_processing_owlvit.py b/src/transformers/models/owlvit/image_processing_owlvit.py
new file mode 100644
index 0000000000..0ccb11a122
--- /dev/null
+++ b/src/transformers/models/owlvit/image_processing_owlvit.py
@@ -0,0 +1,445 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Image processor class for OwlViT"""
+
+from typing import Dict, List, Optional, Union
+
+import numpy as np
+
+from transformers.image_processing_utils import BaseImageProcessor, BatchFeature, get_size_dict
+from transformers.image_transforms import (
+ center_crop,
+ center_to_corners_format,
+ normalize,
+ rescale,
+ resize,
+ to_channel_dimension_format,
+ to_numpy_array,
+)
+from transformers.image_utils import ChannelDimension, ImageInput, PILImageResampling, is_batched, valid_images
+from transformers.utils import TensorType, is_torch_available, logging
+
+
+if is_torch_available():
+ import torch
+
+
+logger = logging.get_logger(__name__)
+
+
+# Copied from transformers.models.detr.modeling_detr._upcast
+def _upcast(t):
+ # Protects from numerical overflows in multiplications by upcasting to the equivalent higher type
+ if t.is_floating_point():
+ return t if t.dtype in (torch.float32, torch.float64) else t.float()
+ else:
+ return t if t.dtype in (torch.int32, torch.int64) else t.int()
+
+
+def box_area(boxes):
+ """
+ Computes the area of a set of bounding boxes, which are specified by its (x1, y1, x2, y2) coordinates.
+
+ Args:
+ boxes (`torch.FloatTensor` of shape `(number_of_boxes, 4)`):
+ Boxes for which the area will be computed. They are expected to be in (x1, y1, x2, y2) format with `0 <= x1
+ < x2` and `0 <= y1 < y2`.
+ Returns:
+ `torch.FloatTensor`: a tensor containing the area for each box.
+ """
+ boxes = _upcast(boxes)
+ return (boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1])
+
+
+def box_iou(boxes1, boxes2):
+ area1 = box_area(boxes1)
+ area2 = box_area(boxes2)
+
+ left_top = torch.max(boxes1[:, None, :2], boxes2[:, :2]) # [N,M,2]
+ right_bottom = torch.min(boxes1[:, None, 2:], boxes2[:, 2:]) # [N,M,2]
+
+ width_height = (right_bottom - left_top).clamp(min=0) # [N,M,2]
+ inter = width_height[:, :, 0] * width_height[:, :, 1] # [N,M]
+
+ union = area1[:, None] + area2 - inter
+
+ iou = inter / union
+ return iou, union
+
+
+class OwlViTImageProcessor(BaseImageProcessor):
+ r"""
+ Constructs an OWL-ViT feature extractor.
+
+ This feature extractor inherits from [`FeatureExtractionMixin`] which contains most of the main methods. Users
+ should refer to this superclass for more information regarding those methods.
+
+ Args:
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Whether to resize the shorter edge of the input to a certain `size`.
+ size (`Dict[str, int]`, *optional*, defaults to {"height": 768, "width": 768}):
+ The size to use for resizing the image. Only has an effect if `do_resize` is set to `True`. If `size` is a
+ sequence like (h, w), output size will be matched to this. If `size` is an int, then image will be resized
+ to (size, size).
+ resample (`int`, *optional*, defaults to `PIL.Image.Resampling.BICUBIC`):
+ An optional resampling filter. This can be one of `PIL.Image.Resampling.NEAREST`,
+ `PIL.Image.Resampling.BOX`, `PIL.Image.Resampling.BILINEAR`, `PIL.Image.Resampling.HAMMING`,
+ `PIL.Image.Resampling.BICUBIC` or `PIL.Image.Resampling.LANCZOS`. Only has an effect if `do_resize` is set
+ to `True`.
+ do_center_crop (`bool`, *optional*, defaults to `False`):
+ Whether to crop the input at the center. If the input size is smaller than `crop_size` along any edge, the
+ image is padded with 0's and then center cropped.
+ crop_size (`int`, *optional*, defaults to {"height": 768, "width": 768}):
+ The size to use for center cropping the image. Only has an effect if `do_center_crop` is set to `True`.
+ do_rescale (`bool`, *optional*, defaults to `True`):
+ Whether to rescale the input by a certain factor.
+ rescale_factor (`float`, *optional*, defaults to `1/255`):
+ The factor to use for rescaling the image. Only has an effect if `do_rescale` is set to `True`.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether or not to normalize the input with `image_mean` and `image_std`. Desired output size when applying
+ center-cropping. Only has an effect if `do_center_crop` is set to `True`.
+ image_mean (`List[int]`, *optional*, defaults to `[0.48145466, 0.4578275, 0.40821073]`):
+ The sequence of means for each channel, to be used when normalizing images.
+ image_std (`List[int]`, *optional*, defaults to `[0.26862954, 0.26130258, 0.27577711]`):
+ The sequence of standard deviations for each channel, to be used when normalizing images.
+ """
+
+ model_input_names = ["pixel_values"]
+
+ def __init__(
+ self,
+ do_resize=True,
+ size=None,
+ resample=PILImageResampling.BICUBIC,
+ do_center_crop=False,
+ crop_size=None,
+ do_rescale=True,
+ rescale_factor=1 / 255,
+ do_normalize=True,
+ image_mean=None,
+ image_std=None,
+ **kwargs
+ ):
+ size = size if size is not None else {"height": 768, "width": 768}
+ size = get_size_dict(size, default_to_square=True)
+
+ crop_size = crop_size if crop_size is not None else {"height": 768, "width": 768}
+ crop_size = get_size_dict(crop_size, default_to_square=True)
+
+ # Early versions of the OWL-ViT config on the hub had "rescale" as a flag. This clashes with the
+ # vision feature extractor method `rescale` as it would be set as an attribute during the super().__init__
+ # call. This is for backwards compatibility.
+ if "rescale" in kwargs:
+ rescale_val = kwargs.pop("rescale")
+ kwargs["do_rescale"] = rescale_val
+
+ super().__init__(**kwargs)
+ self.do_resize = do_resize
+ self.size = size
+ self.resample = resample
+ self.do_center_crop = do_center_crop
+ self.crop_size = crop_size
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean if image_mean is not None else [0.48145466, 0.4578275, 0.40821073]
+ self.image_std = image_std if image_std is not None else [0.26862954, 0.26130258, 0.27577711]
+
+ def resize(
+ self,
+ image: np.ndarray,
+ size: Dict[str, int],
+ resample: PILImageResampling.BICUBIC,
+ data_format: Optional[Union[str, ChannelDimension]] = None,
+ **kwargs
+ ) -> np.ndarray:
+ """
+ Resize an image to a certain size.
+ """
+ size = get_size_dict(size, default_to_square=True)
+ if "height" not in size or "width" not in size:
+ raise ValueError("size dictionary must contain height and width keys")
+
+ return resize(image, (size["height"], size["width"]), resample=resample, data_format=data_format, **kwargs)
+
+ def center_crop(
+ self,
+ image: np.ndarray,
+ crop_size: Dict[str, int],
+ data_format: Optional[Union[str, ChannelDimension]] = None,
+ **kwargs
+ ) -> np.ndarray:
+ """
+ Center crop an image to a certain size.
+ """
+ crop_size = get_size_dict(crop_size, default_to_square=True)
+ if "height" not in crop_size or "width" not in crop_size:
+ raise ValueError("crop_size dictionary must contain height and width keys")
+
+ return center_crop(image, (crop_size["height"], crop_size["width"]), data_format=data_format, **kwargs)
+
+ def rescale(
+ self,
+ image: np.ndarray,
+ rescale_factor: float,
+ data_format: Optional[Union[str, ChannelDimension]] = None,
+ **kwargs
+ ) -> np.ndarray:
+ """
+ Rescale an image by a certain factor.
+ """
+ return rescale(image, rescale_factor, data_format=data_format, **kwargs)
+
+ def normalize(
+ self,
+ image: np.ndarray,
+ mean: List[float],
+ std: List[float],
+ data_format: Optional[Union[str, ChannelDimension]] = None,
+ **kwargs
+ ) -> np.ndarray:
+ """
+ Normalize an image with a certain mean and standard deviation.
+ """
+ return normalize(image, mean, std, data_format=data_format, **kwargs)
+
+ def preprocess(
+ self,
+ images: ImageInput,
+ do_resize: Optional[bool] = None,
+ size: Optional[Dict[str, int]] = None,
+ resample: PILImageResampling = None,
+ do_center_crop: Optional[bool] = None,
+ crop_size: Optional[Dict[str, int]] = None,
+ do_rescale: Optional[bool] = None,
+ rescale_factor: Optional[float] = None,
+ do_normalize: Optional[bool] = None,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ return_tensors: Optional[Union[TensorType, str]] = None,
+ data_format: Union[str, ChannelDimension] = ChannelDimension.FIRST,
+ **kwargs
+ ) -> BatchFeature:
+ """
+ Prepares an image or batch of images for the model.
+
+ Args:
+ images (`ImageInput`):
+ The image or batch of images to be prepared.
+ do_resize (`bool`, *optional*, defaults to `self.do_resize`):
+ Whether or not to resize the input. If `True`, will resize the input to the size specified by `size`.
+ size (`Dict[str, int]`, *optional*, defaults to `self.size`):
+ The size to resize the input to. Only has an effect if `do_resize` is set to `True`.
+ resample (`PILImageResampling`, *optional*, defaults to `self.resample`):
+ The resampling filter to use when resizing the input. Only has an effect if `do_resize` is set to
+ `True`.
+ do_center_crop (`bool`, *optional*, defaults to `self.do_center_crop`):
+ Whether or not to center crop the input. If `True`, will center crop the input to the size specified by
+ `crop_size`.
+ crop_size (`Dict[str, int]`, *optional*, defaults to `self.crop_size`):
+ The size to center crop the input to. Only has an effect if `do_center_crop` is set to `True`.
+ do_rescale (`bool`, *optional*, defaults to `self.do_rescale`):
+ Whether or not to rescale the input. If `True`, will rescale the input by dividing it by
+ `rescale_factor`.
+ rescale_factor (`float`, *optional*, defaults to `self.rescale_factor`):
+ The factor to rescale the input by. Only has an effect if `do_rescale` is set to `True`.
+ do_normalize (`bool`, *optional*, defaults to `self.do_normalize`):
+ Whether or not to normalize the input. If `True`, will normalize the input by subtracting `image_mean`
+ and dividing by `image_std`.
+ image_mean (`Union[float, List[float]]`, *optional*, defaults to `self.image_mean`):
+ The mean to subtract from the input when normalizing. Only has an effect if `do_normalize` is set to
+ `True`.
+ image_std (`Union[float, List[float]]`, *optional*, defaults to `self.image_std`):
+ The standard deviation to divide the input by when normalizing. Only has an effect if `do_normalize` is
+ set to `True`.
+ return_tensors (`str` or `TensorType`, *optional*):
+ The type of tensors to return. Can be one of:
+ - Unset: Return a list of `np.ndarray`.
+ - `TensorType.TENSORFLOW` or `'tf'`: Return a batch of type `tf.Tensor`.
+ - `TensorType.PYTORCH` or `'pt'`: Return a batch of type `torch.Tensor`.
+ - `TensorType.NUMPY` or `'np'`: Return a batch of type `np.ndarray`.
+ - `TensorType.JAX` or `'jax'`: Return a batch of type `jax.numpy.ndarray`.
+ data_format (`ChannelDimension` or `str`, *optional*, defaults to `ChannelDimension.FIRST`):
+ The channel dimension format for the output image. Can be one of:
+ - `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - Unset: defaults to the channel dimension format of the input image.
+ """
+ do_resize = do_resize if do_resize is not None else self.do_resize
+ size = size if size is not None else self.size
+ resample = resample if resample is not None else self.resample
+ do_center_crop = do_center_crop if do_center_crop is not None else self.do_center_crop
+ crop_size = crop_size if crop_size is not None else self.crop_size
+ do_rescale = do_rescale if do_rescale is not None else self.do_rescale
+ rescale_factor = rescale_factor if rescale_factor is not None else self.rescale_factor
+ do_normalize = do_normalize if do_normalize is not None else self.do_normalize
+ image_mean = image_mean if image_mean is not None else self.image_mean
+ image_std = image_std if image_std is not None else self.image_std
+
+ if do_resize is not None and size is None:
+ raise ValueError("Size and max_size must be specified if do_resize is True.")
+
+ if do_center_crop is not None and crop_size is None:
+ raise ValueError("Crop size must be specified if do_center_crop is True.")
+
+ if do_rescale is not None and rescale_factor is None:
+ raise ValueError("Rescale factor must be specified if do_rescale is True.")
+
+ if do_normalize is not None and (image_mean is None or image_std is None):
+ raise ValueError("Image mean and std must be specified if do_normalize is True.")
+
+ if not is_batched(images):
+ images = [images]
+
+ if not valid_images(images):
+ raise ValueError(
+ "Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
+ "torch.Tensor, tf.Tensor or jax.ndarray."
+ )
+
+ # All transformations expect numpy arrays
+ images = [to_numpy_array(image) for image in images]
+
+ if do_resize:
+ images = [self.resize(image, size=size, resample=resample) for image in images]
+
+ if do_center_crop:
+ images = [self.center_crop(image, crop_size=crop_size) for image in images]
+
+ if do_rescale:
+ images = [self.rescale(image, rescale_factor=rescale_factor) for image in images]
+
+ if do_normalize:
+ images = [self.normalize(image, mean=image_mean, std=image_std) for image in images]
+
+ images = [to_channel_dimension_format(image, data_format) for image in images]
+ encoded_inputs = BatchFeature(data={"pixel_values": images}, tensor_type=return_tensors)
+ return encoded_inputs
+
+ def post_process(self, outputs, target_sizes):
+ """
+ Converts the output of [`OwlViTForObjectDetection`] into the format expected by the COCO api.
+
+ Args:
+ outputs ([`OwlViTObjectDetectionOutput`]):
+ Raw outputs of the model.
+ target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
+ Tensor containing the size (h, w) of each image of the batch. For evaluation, this must be the original
+ image size (before any data augmentation). For visualization, this should be the image size after data
+ augment, but before padding.
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
+ in the batch as predicted by the model.
+ """
+ # TODO: (amy) add support for other frameworks
+ logits, boxes = outputs.logits, outputs.pred_boxes
+
+ if len(logits) != len(target_sizes):
+ raise ValueError("Make sure that you pass in as many target sizes as the batch dimension of the logits")
+ if target_sizes.shape[1] != 2:
+ raise ValueError("Each element of target_sizes must contain the size (h, w) of each image of the batch")
+
+ probs = torch.max(logits, dim=-1)
+ scores = torch.sigmoid(probs.values)
+ labels = probs.indices
+
+ # Convert to [x0, y0, x1, y1] format
+ boxes = center_to_corners_format(boxes)
+
+ # Convert from relative [0, 1] to absolute [0, height] coordinates
+ img_h, img_w = target_sizes.unbind(1)
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
+ boxes = boxes * scale_fct[:, None, :]
+
+ results = [{"scores": s, "labels": l, "boxes": b} for s, l, b in zip(scores, labels, boxes)]
+
+ return results
+
+ # TODO: (Amy) Make compatible with other frameworks
+ def post_process_image_guided_detection(self, outputs, threshold=0.6, nms_threshold=0.3, target_sizes=None):
+ """
+ Converts the output of [`OwlViTForObjectDetection.image_guided_detection`] into the format expected by the COCO
+ api.
+
+ Args:
+ outputs ([`OwlViTImageGuidedObjectDetectionOutput`]):
+ Raw outputs of the model.
+ threshold (`float`, *optional*, defaults to 0.6):
+ Minimum confidence threshold to use to filter out predicted boxes.
+ nms_threshold (`float`, *optional*, defaults to 0.3):
+ IoU threshold for non-maximum suppression of overlapping boxes.
+ target_sizes (`torch.Tensor`, *optional*):
+ Tensor of shape (batch_size, 2) where each entry is the (height, width) of the corresponding image in
+ the batch. If set, predicted normalized bounding boxes are rescaled to the target sizes. If left to
+ None, predictions will not be unnormalized.
+
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
+ in the batch as predicted by the model. All labels are set to None as
+ `OwlViTForObjectDetection.image_guided_detection` perform one-shot object detection.
+ """
+ logits, target_boxes = outputs.logits, outputs.target_pred_boxes
+
+ if len(logits) != len(target_sizes):
+ raise ValueError("Make sure that you pass in as many target sizes as the batch dimension of the logits")
+ if target_sizes.shape[1] != 2:
+ raise ValueError("Each element of target_sizes must contain the size (h, w) of each image of the batch")
+
+ probs = torch.max(logits, dim=-1)
+ scores = torch.sigmoid(probs.values)
+
+ # Convert to [x0, y0, x1, y1] format
+ target_boxes = center_to_corners_format(target_boxes)
+
+ # Apply non-maximum suppression (NMS)
+ if nms_threshold < 1.0:
+ for idx in range(target_boxes.shape[0]):
+ for i in torch.argsort(-scores[idx]):
+ if not scores[idx][i]:
+ continue
+
+ ious = box_iou(target_boxes[idx][i, :].unsqueeze(0), target_boxes[idx])[0][0]
+ ious[i] = -1.0 # Mask self-IoU.
+ scores[idx][ious > nms_threshold] = 0.0
+
+ # Convert from relative [0, 1] to absolute [0, height] coordinates
+ img_h, img_w = target_sizes.unbind(1)
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
+ target_boxes = target_boxes * scale_fct[:, None, :]
+
+ # Compute box display alphas based on prediction scores
+ results = []
+ alphas = torch.zeros_like(scores)
+
+ for idx in range(target_boxes.shape[0]):
+ # Select scores for boxes matching the current query:
+ query_scores = scores[idx]
+ if not query_scores.nonzero().numel():
+ continue
+
+ # Scale box alpha such that the best box for each query has alpha 1.0 and the worst box has alpha 0.1.
+ # All other boxes will either belong to a different query, or will not be shown.
+ max_score = torch.max(query_scores) + 1e-6
+ query_alphas = (query_scores - (max_score * 0.1)) / (max_score * 0.9)
+ query_alphas[query_alphas < threshold] = 0.0
+ query_alphas = torch.clip(query_alphas, 0.0, 1.0)
+ alphas[idx] = query_alphas
+
+ mask = alphas[idx] > 0
+ box_scores = alphas[idx][mask]
+ boxes = target_boxes[idx][mask]
+ results.append({"scores": box_scores, "labels": None, "boxes": boxes})
+
+ return results
diff --git a/src/transformers/models/owlvit/processing_owlvit.py b/src/transformers/models/owlvit/processing_owlvit.py
index b88593158f..1cc29cd511 100644
--- a/src/transformers/models/owlvit/processing_owlvit.py
+++ b/src/transformers/models/owlvit/processing_owlvit.py
@@ -15,6 +15,7 @@
"""
Image/Text processor class for OWL-ViT
"""
+
from typing import List
import numpy as np
@@ -33,15 +34,15 @@ class OwlViTProcessor(ProcessorMixin):
Args:
feature_extractor ([`OwlViTFeatureExtractor`]):
- The feature extractor is a required input.
+ The image processor is a required input.
tokenizer ([`CLIPTokenizer`, `CLIPTokenizerFast`]):
The tokenizer is a required input.
"""
feature_extractor_class = "OwlViTFeatureExtractor"
tokenizer_class = ("CLIPTokenizer", "CLIPTokenizerFast")
- def __init__(self, feature_extractor, tokenizer):
- super().__init__(feature_extractor, tokenizer)
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
def __call__(self, text=None, images=None, query_images=None, padding="max_length", return_tensors="np", **kwargs):
"""
diff --git a/src/transformers/models/segformer/image_processing_segformer.py b/src/transformers/models/segformer/image_processing_segformer.py
index 289eac22b0..4f6498b527 100644
--- a/src/transformers/models/segformer/image_processing_segformer.py
+++ b/src/transformers/models/segformer/image_processing_segformer.py
@@ -287,7 +287,6 @@ class SegformerImageProcessor(BaseImageProcessor):
do_reduce_labels: bool = None,
do_resize: bool = None,
size: Dict[str, int] = None,
- resample: PILImageResampling = None,
) -> np.ndarray:
"""Preprocesses a single mask."""
segmentation_map = to_numpy_array(segmentation_map)
@@ -301,7 +300,7 @@ class SegformerImageProcessor(BaseImageProcessor):
image=segmentation_map,
do_reduce_labels=do_reduce_labels,
do_resize=do_resize,
- resample=PIL.Image.NEAREST,
+ resample=PILImageResampling.NEAREST,
size=size,
do_rescale=False,
do_normalize=False,
@@ -438,7 +437,6 @@ class SegformerImageProcessor(BaseImageProcessor):
segmentation_map=segmentation_map,
do_reduce_labels=do_reduce_labels,
do_resize=do_resize,
- resample=PIL.Image.NEAREST,
size=size,
)
for segmentation_map in segmentation_maps
diff --git a/src/transformers/models/yolos/__init__.py b/src/transformers/models/yolos/__init__.py
index 6ae73421a8..f16fc90da4 100644
--- a/src/transformers/models/yolos/__init__.py
+++ b/src/transformers/models/yolos/__init__.py
@@ -29,6 +29,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_yolos"] = ["YolosFeatureExtractor"]
+ _import_structure["image_processing_yolos"] = ["YolosImageProcessor"]
try:
if not is_torch_available():
@@ -54,6 +55,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_yolos import YolosFeatureExtractor
+ from .image_processing_yolos import YolosImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/models/yolos/feature_extraction_yolos.py b/src/transformers/models/yolos/feature_extraction_yolos.py
index de6db49434..6133a9808b 100644
--- a/src/transformers/models/yolos/feature_extraction_yolos.py
+++ b/src/transformers/models/yolos/feature_extraction_yolos.py
@@ -14,694 +14,11 @@
# limitations under the License.
"""Feature extractor class for YOLOS."""
-import pathlib
-import warnings
-from typing import Dict, List, Optional, Tuple, Union
+from ...utils import logging
+from .image_processing_yolos import YolosImageProcessor
-import numpy as np
-from PIL import Image
-
-from ...feature_extraction_utils import BatchFeature, FeatureExtractionMixin
-from ...image_transforms import center_to_corners_format, corners_to_center_format, rgb_to_id
-from ...image_utils import ImageFeatureExtractionMixin, is_torch_tensor
-from ...utils import TensorType, is_torch_available, logging
-
-
-if is_torch_available():
- import torch
- from torch import nn
logger = logging.get_logger(__name__)
-ImageInput = Union[Image.Image, np.ndarray, "torch.Tensor", List[Image.Image], List[np.ndarray], List["torch.Tensor"]]
-
-
-# Copied from transformers.models.detr.feature_extraction_detr.masks_to_boxes
-def masks_to_boxes(masks):
- """
- Compute the bounding boxes around the provided panoptic segmentation masks.
-
- The masks should be in format [N, H, W] where N is the number of masks, (H, W) are the spatial dimensions.
-
- Returns a [N, 4] tensor, with the boxes in corner (xyxy) format.
- """
- if masks.size == 0:
- return np.zeros((0, 4))
-
- h, w = masks.shape[-2:]
-
- y = np.arange(0, h, dtype=np.float32)
- x = np.arange(0, w, dtype=np.float32)
- # see https://github.com/pytorch/pytorch/issues/50276
- y, x = np.meshgrid(y, x, indexing="ij")
-
- x_mask = masks * np.expand_dims(x, axis=0)
- x_max = x_mask.reshape(x_mask.shape[0], -1).max(-1)
- x = np.ma.array(x_mask, mask=~(np.array(masks, dtype=bool)))
- x_min = x.filled(fill_value=1e8)
- x_min = x_min.reshape(x_min.shape[0], -1).min(-1)
-
- y_mask = masks * np.expand_dims(y, axis=0)
- y_max = y_mask.reshape(x_mask.shape[0], -1).max(-1)
- y = np.ma.array(y_mask, mask=~(np.array(masks, dtype=bool)))
- y_min = y.filled(fill_value=1e8)
- y_min = y_min.reshape(y_min.shape[0], -1).min(-1)
-
- return np.stack([x_min, y_min, x_max, y_max], 1)
-
-
-class YolosFeatureExtractor(FeatureExtractionMixin, ImageFeatureExtractionMixin):
- r"""
- Constructs a YOLOS feature extractor.
-
- This feature extractor inherits from [`FeatureExtractionMixin`] which contains most of the main methods. Users
- should refer to this superclass for more information regarding those methods.
-
-
- Args:
- format (`str`, *optional*, defaults to `"coco_detection"`):
- Data format of the annotations. One of "coco_detection" or "coco_panoptic".
- do_resize (`bool`, *optional*, defaults to `True`):
- Whether to resize the input to a certain `size`.
- size (`int`, *optional*, defaults to 800):
- Resize the input to the given size. Only has an effect if `do_resize` is set to `True`. If size is a
- sequence like `(width, height)`, output size will be matched to this. If size is an int, smaller edge of
- the image will be matched to this number. i.e, if `height > width`, then image will be rescaled to `(size *
- height / width, size)`.
- max_size (`int`, *optional*, defaults to `1333`):
- The largest size an image dimension can have (otherwise it's capped). Only has an effect if `do_resize` is
- set to `True`.
- do_normalize (`bool`, *optional*, defaults to `True`):
- Whether or not to normalize the input with mean and standard deviation.
- image_mean (`int`, *optional*, defaults to `[0.485, 0.456, 0.406]`):
- The sequence of means for each channel, to be used when normalizing images. Defaults to the ImageNet mean.
- image_std (`int`, *optional*, defaults to `[0.229, 0.224, 0.225]`):
- The sequence of standard deviations for each channel, to be used when normalizing images. Defaults to the
- ImageNet std.
- """
-
- model_input_names = ["pixel_values"]
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.__init__
- def __init__(
- self,
- format="coco_detection",
- do_resize=True,
- size=800,
- max_size=1333,
- do_normalize=True,
- image_mean=None,
- image_std=None,
- **kwargs
- ):
- super().__init__(**kwargs)
- self.format = self._is_valid_format(format)
- self.do_resize = do_resize
- self.size = size
- self.max_size = max_size
- self.do_normalize = do_normalize
- self.image_mean = image_mean if image_mean is not None else [0.485, 0.456, 0.406] # ImageNet mean
- self.image_std = image_std if image_std is not None else [0.229, 0.224, 0.225] # ImageNet std
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._is_valid_format
- def _is_valid_format(self, format):
- if format not in ["coco_detection", "coco_panoptic"]:
- raise ValueError(f"Format {format} not supported")
- return format
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.prepare
- def prepare(self, image, target, return_segmentation_masks=False, masks_path=None):
- if self.format == "coco_detection":
- image, target = self.prepare_coco_detection(image, target, return_segmentation_masks)
- return image, target
- elif self.format == "coco_panoptic":
- image, target = self.prepare_coco_panoptic(image, target, masks_path)
- return image, target
- else:
- raise ValueError(f"Format {self.format} not supported")
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.convert_coco_poly_to_mask
- def convert_coco_poly_to_mask(self, segmentations, height, width):
-
- try:
- from pycocotools import mask as coco_mask
- except ImportError:
- raise ImportError("Pycocotools is not installed in your environment.")
-
- masks = []
- for polygons in segmentations:
- rles = coco_mask.frPyObjects(polygons, height, width)
- mask = coco_mask.decode(rles)
- if len(mask.shape) < 3:
- mask = mask[..., None]
- mask = np.asarray(mask, dtype=np.uint8)
- mask = np.any(mask, axis=2)
- masks.append(mask)
- if masks:
- masks = np.stack(masks, axis=0)
- else:
- masks = np.zeros((0, height, width), dtype=np.uint8)
-
- return masks
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.prepare_coco_detection
- def prepare_coco_detection(self, image, target, return_segmentation_masks=False):
- """
- Convert the target in COCO format into the format expected by DETR.
- """
- w, h = image.size
-
- image_id = target["image_id"]
- image_id = np.asarray([image_id], dtype=np.int64)
-
- # get all COCO annotations for the given image
- anno = target["annotations"]
-
- anno = [obj for obj in anno if "iscrowd" not in obj or obj["iscrowd"] == 0]
-
- boxes = [obj["bbox"] for obj in anno]
- # guard against no boxes via resizing
- boxes = np.asarray(boxes, dtype=np.float32).reshape(-1, 4)
- boxes[:, 2:] += boxes[:, :2]
- boxes[:, 0::2] = boxes[:, 0::2].clip(min=0, max=w)
- boxes[:, 1::2] = boxes[:, 1::2].clip(min=0, max=h)
-
- classes = [obj["category_id"] for obj in anno]
- classes = np.asarray(classes, dtype=np.int64)
-
- if return_segmentation_masks:
- segmentations = [obj["segmentation"] for obj in anno]
- masks = self.convert_coco_poly_to_mask(segmentations, h, w)
-
- keypoints = None
- if anno and "keypoints" in anno[0]:
- keypoints = [obj["keypoints"] for obj in anno]
- keypoints = np.asarray(keypoints, dtype=np.float32)
- num_keypoints = keypoints.shape[0]
- if num_keypoints:
- keypoints = keypoints.reshape((-1, 3))
-
- keep = (boxes[:, 3] > boxes[:, 1]) & (boxes[:, 2] > boxes[:, 0])
- boxes = boxes[keep]
- classes = classes[keep]
- if return_segmentation_masks:
- masks = masks[keep]
- if keypoints is not None:
- keypoints = keypoints[keep]
-
- target = {}
- target["boxes"] = boxes
- target["class_labels"] = classes
- if return_segmentation_masks:
- target["masks"] = masks
- target["image_id"] = image_id
- if keypoints is not None:
- target["keypoints"] = keypoints
-
- # for conversion to coco api
- area = np.asarray([obj["area"] for obj in anno], dtype=np.float32)
- iscrowd = np.asarray([obj["iscrowd"] if "iscrowd" in obj else 0 for obj in anno], dtype=np.int64)
- target["area"] = area[keep]
- target["iscrowd"] = iscrowd[keep]
-
- target["orig_size"] = np.asarray([int(h), int(w)], dtype=np.int64)
- target["size"] = np.asarray([int(h), int(w)], dtype=np.int64)
-
- return image, target
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.prepare_coco_panoptic
- def prepare_coco_panoptic(self, image, target, masks_path, return_masks=True):
- w, h = image.size
- ann_info = target.copy()
- ann_path = pathlib.Path(masks_path) / ann_info["file_name"]
-
- if "segments_info" in ann_info:
- masks = np.asarray(Image.open(ann_path), dtype=np.uint32)
- masks = rgb_to_id(masks)
-
- ids = np.array([ann["id"] for ann in ann_info["segments_info"]])
- masks = masks == ids[:, None, None]
- masks = np.asarray(masks, dtype=np.uint8)
-
- labels = np.asarray([ann["category_id"] for ann in ann_info["segments_info"]], dtype=np.int64)
-
- target = {}
- target["image_id"] = np.asarray(
- [ann_info["image_id"] if "image_id" in ann_info else ann_info["id"]], dtype=np.int64
- )
- if return_masks:
- target["masks"] = masks
- target["class_labels"] = labels
-
- target["boxes"] = masks_to_boxes(masks)
-
- target["size"] = np.asarray([int(h), int(w)], dtype=np.int64)
- target["orig_size"] = np.asarray([int(h), int(w)], dtype=np.int64)
- if "segments_info" in ann_info:
- target["iscrowd"] = np.asarray([ann["iscrowd"] for ann in ann_info["segments_info"]], dtype=np.int64)
- target["area"] = np.asarray([ann["area"] for ann in ann_info["segments_info"]], dtype=np.float32)
-
- return image, target
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._resize
- def _resize(self, image, size, target=None, max_size=None):
- """
- Resize the image to the given size. Size can be min_size (scalar) or (w, h) tuple. If size is an int, smaller
- edge of the image will be matched to this number.
-
- If given, also resize the target accordingly.
- """
- if not isinstance(image, Image.Image):
- image = self.to_pil_image(image)
-
- def get_size_with_aspect_ratio(image_size, size, max_size=None):
- w, h = image_size
- if max_size is not None:
- min_original_size = float(min((w, h)))
- max_original_size = float(max((w, h)))
- if max_original_size / min_original_size * size > max_size:
- size = int(round(max_size * min_original_size / max_original_size))
-
- if (w <= h and w == size) or (h <= w and h == size):
- return (h, w)
-
- if w < h:
- ow = size
- oh = int(size * h / w)
- else:
- oh = size
- ow = int(size * w / h)
-
- return (oh, ow)
-
- def get_size(image_size, size, max_size=None):
- if isinstance(size, (list, tuple)):
- return size
- else:
- # size returned must be (w, h) since we use PIL to resize images
- # so we revert the tuple
- return get_size_with_aspect_ratio(image_size, size, max_size)[::-1]
-
- size = get_size(image.size, size, max_size)
- rescaled_image = self.resize(image, size=size)
-
- if target is None:
- return rescaled_image, None
-
- ratios = tuple(float(s) / float(s_orig) for s, s_orig in zip(rescaled_image.size, image.size))
- ratio_width, ratio_height = ratios
-
- target = target.copy()
- if "boxes" in target:
- boxes = target["boxes"]
- scaled_boxes = boxes * np.asarray([ratio_width, ratio_height, ratio_width, ratio_height], dtype=np.float32)
- target["boxes"] = scaled_boxes
-
- if "area" in target:
- area = target["area"]
- scaled_area = area * (ratio_width * ratio_height)
- target["area"] = scaled_area
-
- w, h = size
- target["size"] = np.asarray([h, w], dtype=np.int64)
-
- if "masks" in target:
- # use PyTorch as current workaround
- # TODO replace by self.resize
- masks = torch.from_numpy(target["masks"][:, None]).float()
- interpolated_masks = nn.functional.interpolate(masks, size=(h, w), mode="nearest")[:, 0] > 0.5
- target["masks"] = interpolated_masks.numpy()
-
- return rescaled_image, target
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._normalize
- def _normalize(self, image, mean, std, target=None):
- """
- Normalize the image with a certain mean and std.
-
- If given, also normalize the target bounding boxes based on the size of the image.
- """
-
- image = self.normalize(image, mean=mean, std=std)
- if target is None:
- return image, None
-
- target = target.copy()
- h, w = image.shape[-2:]
-
- if "boxes" in target:
- boxes = target["boxes"]
- boxes = corners_to_center_format(boxes)
- boxes = boxes / np.asarray([w, h, w, h], dtype=np.float32)
- target["boxes"] = boxes
-
- return image, target
-
- def __call__(
- self,
- images: ImageInput,
- annotations: Union[List[Dict], List[List[Dict]]] = None,
- return_segmentation_masks: Optional[bool] = False,
- masks_path: Optional[pathlib.Path] = None,
- padding: Optional[bool] = True,
- return_tensors: Optional[Union[str, TensorType]] = None,
- **kwargs,
- ) -> BatchFeature:
- """
- Main method to prepare for the model one or several image(s) and optional annotations. Images are by default
- padded up to the largest image in a batch.
-
-
-
- NumPy arrays and PyTorch tensors are converted to PIL images when resizing, so the most efficient is to pass
- PIL images.
-
-
-
- Args:
- images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
- The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
- tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a
- number of channels, H and W are image height and width.
-
- annotations (`Dict`, `List[Dict]`, *optional*):
- The corresponding annotations in COCO format.
-
- In case [`DetrFeatureExtractor`] was initialized with `format = "coco_detection"`, the annotations for
- each image should have the following format: {'image_id': int, 'annotations': [annotation]}, with the
- annotations being a list of COCO object annotations.
-
- In case [`DetrFeatureExtractor`] was initialized with `format = "coco_panoptic"`, the annotations for
- each image should have the following format: {'image_id': int, 'file_name': str, 'segments_info':
- [segment_info]} with segments_info being a list of COCO panoptic annotations.
-
- return_segmentation_masks (`Dict`, `List[Dict]`, *optional*, defaults to `False`):
- Whether to also include instance segmentation masks as part of the labels in case `format =
- "coco_detection"`.
-
- masks_path (`pathlib.Path`, *optional*):
- Path to the directory containing the PNG files that store the class-agnostic image segmentations. Only
- relevant in case [`DetrFeatureExtractor`] was initialized with `format = "coco_panoptic"`.
-
- padding (`bool`, *optional*, defaults to `True`):
- Whether or not to pad images up to the largest image in a batch.
-
- return_tensors (`str` or [`~utils.TensorType`], *optional*):
- If set, will return tensors instead of NumPy arrays. If set to `'pt'`, return PyTorch `torch.Tensor`
- objects.
-
- Returns:
- [`BatchFeature`]: A [`BatchFeature`] with the following fields:
-
- - **pixel_values** -- Pixel values to be fed to a model.
- - **labels** -- Optional labels to be fed to a model (when `annotations` are provided)
- """
- # Input type checking for clearer error
-
- valid_images = False
- valid_annotations = False
- valid_masks_path = False
-
- # Check that images has a valid type
- if isinstance(images, (Image.Image, np.ndarray)) or is_torch_tensor(images):
- valid_images = True
- elif isinstance(images, (list, tuple)):
- if len(images) == 0 or isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]):
- valid_images = True
-
- if not valid_images:
- raise ValueError(
- "Images must of type `PIL.Image.Image`, `np.ndarray` or `torch.Tensor` (single example), "
- "`List[PIL.Image.Image]`, `List[np.ndarray]` or `List[torch.Tensor]` (batch of examples)."
- )
-
- is_batched = bool(
- isinstance(images, (list, tuple))
- and (isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]))
- )
-
- # Check that annotations has a valid type
- if annotations is not None:
- if not is_batched:
- if self.format == "coco_detection":
- if isinstance(annotations, dict) and "image_id" in annotations and "annotations" in annotations:
- if isinstance(annotations["annotations"], (list, tuple)):
- # an image can have no annotations
- if len(annotations["annotations"]) == 0 or isinstance(annotations["annotations"][0], dict):
- valid_annotations = True
- elif self.format == "coco_panoptic":
- if isinstance(annotations, dict) and "image_id" in annotations and "segments_info" in annotations:
- if isinstance(annotations["segments_info"], (list, tuple)):
- # an image can have no segments (?)
- if len(annotations["segments_info"]) == 0 or isinstance(
- annotations["segments_info"][0], dict
- ):
- valid_annotations = True
- else:
- if isinstance(annotations, (list, tuple)):
- if len(images) != len(annotations):
- raise ValueError("There must be as many annotations as there are images")
- if isinstance(annotations[0], Dict):
- if self.format == "coco_detection":
- if isinstance(annotations[0]["annotations"], (list, tuple)):
- valid_annotations = True
- elif self.format == "coco_panoptic":
- if isinstance(annotations[0]["segments_info"], (list, tuple)):
- valid_annotations = True
-
- if not valid_annotations:
- raise ValueError(
- """
- Annotations must of type `Dict` (single image) or `List[Dict]` (batch of images). In case of object
- detection, each dictionary should contain the keys 'image_id' and 'annotations', with the latter
- being a list of annotations in COCO format. In case of panoptic segmentation, each dictionary
- should contain the keys 'file_name', 'image_id' and 'segments_info', with the latter being a list
- of annotations in COCO format.
- """
- )
-
- # Check that masks_path has a valid type
- if masks_path is not None:
- if self.format == "coco_panoptic":
- if isinstance(masks_path, pathlib.Path):
- valid_masks_path = True
- if not valid_masks_path:
- raise ValueError(
- "The path to the directory containing the mask PNG files should be provided as a"
- " `pathlib.Path` object."
- )
-
- if not is_batched:
- images = [images]
- if annotations is not None:
- annotations = [annotations]
-
- # prepare (COCO annotations as a list of Dict -> DETR target as a single Dict per image)
- if annotations is not None:
- for idx, (image, target) in enumerate(zip(images, annotations)):
- if not isinstance(image, Image.Image):
- image = self.to_pil_image(image)
- image, target = self.prepare(image, target, return_segmentation_masks, masks_path)
- images[idx] = image
- annotations[idx] = target
-
- # transformations (resizing + normalization)
- if self.do_resize and self.size is not None:
- if annotations is not None:
- for idx, (image, target) in enumerate(zip(images, annotations)):
- image, target = self._resize(image=image, target=target, size=self.size, max_size=self.max_size)
- images[idx] = image
- annotations[idx] = target
- else:
- for idx, image in enumerate(images):
- images[idx] = self._resize(image=image, target=None, size=self.size, max_size=self.max_size)[0]
-
- if self.do_normalize:
- if annotations is not None:
- for idx, (image, target) in enumerate(zip(images, annotations)):
- image, target = self._normalize(
- image=image, mean=self.image_mean, std=self.image_std, target=target
- )
- images[idx] = image
- annotations[idx] = target
- else:
- images = [
- self._normalize(image=image, mean=self.image_mean, std=self.image_std)[0] for image in images
- ]
-
- if padding:
- # pad images up to largest image in batch
- max_size = self._max_by_axis([list(image.shape) for image in images])
- c, h, w = max_size
- padded_images = []
- for image in images:
- # create padded image
- padded_image = np.zeros((c, h, w), dtype=np.float32)
- padded_image[: image.shape[0], : image.shape[1], : image.shape[2]] = np.copy(image)
- padded_images.append(padded_image)
- images = padded_images
-
- # return as BatchFeature
- data = {}
- data["pixel_values"] = images
- encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
-
- if annotations is not None:
- # Convert to TensorType
- tensor_type = return_tensors
- if not isinstance(tensor_type, TensorType):
- tensor_type = TensorType(tensor_type)
-
- if not tensor_type == TensorType.PYTORCH:
- raise ValueError("Only PyTorch is supported for the moment.")
- else:
- if not is_torch_available():
- raise ImportError("Unable to convert output to PyTorch tensors format, PyTorch is not installed.")
-
- encoded_inputs["labels"] = [
- {k: torch.from_numpy(v) for k, v in target.items()} for target in annotations
- ]
-
- return encoded_inputs
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._max_by_axis
- def _max_by_axis(self, the_list):
- # type: (List[List[int]]) -> List[int]
- maxes = the_list[0]
- for sublist in the_list[1:]:
- for index, item in enumerate(sublist):
- maxes[index] = max(maxes[index], item)
- return maxes
-
- def pad(self, pixel_values_list: List["torch.Tensor"], return_tensors: Optional[Union[str, TensorType]] = None):
- """
- Pad images up to the largest image in a batch.
-
- Args:
- pixel_values_list (`List[torch.Tensor]`):
- List of images (pixel values) to be padded. Each image should be a tensor of shape (C, H, W).
- return_tensors (`str` or [`~utils.TensorType`], *optional*):
- If set, will return tensors instead of NumPy arrays. If set to `'pt'`, return PyTorch `torch.Tensor`
- objects.
-
- Returns:
- [`BatchFeature`]: A [`BatchFeature`] with the following field:
-
- - **pixel_values** -- Pixel values to be fed to a model.
-
- """
-
- max_size = self._max_by_axis([list(image.shape) for image in pixel_values_list])
- c, h, w = max_size
- padded_images = []
- for image in pixel_values_list:
- # create padded image
- padded_image = np.zeros((c, h, w), dtype=np.float32)
- padded_image[: image.shape[0], : image.shape[1], : image.shape[2]] = np.copy(image)
- padded_images.append(padded_image)
-
- # return as BatchFeature
- data = {"pixel_values": padded_images}
- encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
-
- return encoded_inputs
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.post_process
- def post_process(self, outputs, target_sizes):
- """
- Converts the output of [`DetrForObjectDetection`] into the format expected by the COCO api. Only supports
- PyTorch.
-
- Args:
- outputs ([`DetrObjectDetectionOutput`]):
- Raw outputs of the model.
- target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
- Tensor containing the size (height, width) of each image of the batch. For evaluation, this must be the
- original image size (before any data augmentation). For visualization, this should be the image size
- after data augment, but before padding.
-
- Returns:
- `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
- in the batch as predicted by the model.
- """
- warnings.warn(
- "`post_process` is deprecated and will be removed in v5 of Transformers, please use"
- " `post_process_object_detection`",
- FutureWarning,
- )
-
- out_logits, out_bbox = outputs.logits, outputs.pred_boxes
-
- if len(out_logits) != len(target_sizes):
- raise ValueError("Make sure that you pass in as many target sizes as the batch dimension of the logits")
- if target_sizes.shape[1] != 2:
- raise ValueError("Each element of target_sizes must contain the size (h, w) of each image of the batch")
-
- prob = nn.functional.softmax(out_logits, -1)
- scores, labels = prob[..., :-1].max(-1)
-
- # convert to [x0, y0, x1, y1] format
- boxes = center_to_corners_format(out_bbox)
- # and from relative [0, 1] to absolute [0, height] coordinates
- img_h, img_w = target_sizes.unbind(1)
- scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
- boxes = boxes * scale_fct[:, None, :]
-
- results = [{"scores": s, "labels": l, "boxes": b} for s, l, b in zip(scores, labels, boxes)]
- return results
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.post_process_object_detection with Detr->Yolos
- def post_process_object_detection(
- self, outputs, threshold: float = 0.5, target_sizes: Union[TensorType, List[Tuple]] = None
- ):
- """
- Converts the output of [`YolosForObjectDetection`] into the format expected by the COCO api. Only supports
- PyTorch.
-
- Args:
- outputs ([`YolosObjectDetectionOutput`]):
- Raw outputs of the model.
- threshold (`float`, *optional*):
- Score threshold to keep object detection predictions.
- target_sizes (`torch.Tensor` or `List[Tuple[int, int]]`, *optional*, defaults to `None`):
- Tensor of shape `(batch_size, 2)` or list of tuples (`Tuple[int, int]`) containing the target size
- (height, width) of each image in the batch. If left to None, predictions will not be resized.
-
- Returns:
- `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
- in the batch as predicted by the model.
- """
- out_logits, out_bbox = outputs.logits, outputs.pred_boxes
-
- if target_sizes is not None:
- if len(out_logits) != len(target_sizes):
- raise ValueError(
- "Make sure that you pass in as many target sizes as the batch dimension of the logits"
- )
-
- prob = nn.functional.softmax(out_logits, -1)
- scores, labels = prob[..., :-1].max(-1)
-
- # Convert to [x0, y0, x1, y1] format
- boxes = center_to_corners_format(out_bbox)
-
- # Convert from relative [0, 1] to absolute [0, height] coordinates
- if target_sizes is not None:
- if isinstance(target_sizes, List):
- img_h = torch.Tensor([i[0] for i in target_sizes])
- img_w = torch.Tensor([i[1] for i in target_sizes])
- else:
- img_h, img_w = target_sizes.unbind(1)
-
- scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1).to(boxes.device)
- boxes = boxes * scale_fct[:, None, :]
-
- results = []
- for s, l, b in zip(scores, labels, boxes):
- score = s[s > threshold]
- label = l[s > threshold]
- box = b[s > threshold]
- results.append({"scores": score, "labels": label, "boxes": box})
-
- return results
+YolosFeatureExtractor = YolosImageProcessor
diff --git a/src/transformers/models/yolos/image_processing_yolos.py b/src/transformers/models/yolos/image_processing_yolos.py
new file mode 100644
index 0000000000..02e14cc2cd
--- /dev/null
+++ b/src/transformers/models/yolos/image_processing_yolos.py
@@ -0,0 +1,1214 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Image processor class for YOLOS."""
+
+import pathlib
+import warnings
+from typing import Any, Callable, Dict, Iterable, List, Optional, Set, Tuple, Union
+
+import numpy as np
+
+from transformers.feature_extraction_utils import BatchFeature
+from transformers.image_processing_utils import BaseImageProcessor, get_size_dict
+from transformers.image_transforms import (
+ PaddingMode,
+ center_to_corners_format,
+ corners_to_center_format,
+ id_to_rgb,
+ normalize,
+ pad,
+ rescale,
+ resize,
+ rgb_to_id,
+ to_channel_dimension_format,
+)
+from transformers.image_utils import (
+ IMAGENET_DEFAULT_MEAN,
+ IMAGENET_DEFAULT_STD,
+ ChannelDimension,
+ ImageInput,
+ PILImageResampling,
+ get_image_size,
+ infer_channel_dimension_format,
+ is_batched,
+ to_numpy_array,
+ valid_coco_detection_annotations,
+ valid_coco_panoptic_annotations,
+ valid_images,
+)
+from transformers.utils import (
+ is_flax_available,
+ is_jax_tensor,
+ is_scipy_available,
+ is_tf_available,
+ is_tf_tensor,
+ is_torch_available,
+ is_torch_tensor,
+ is_vision_available,
+)
+from transformers.utils.generic import ExplicitEnum, TensorType
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+
+if is_vision_available():
+ import PIL
+
+
+if is_scipy_available():
+ import scipy.special
+ import scipy.stats
+
+
+class AnnotionFormat(ExplicitEnum):
+ COCO_DETECTION = "coco_detection"
+ COCO_PANOPTIC = "coco_panoptic"
+
+
+SUPPORTED_ANNOTATION_FORMATS = (AnnotionFormat.COCO_DETECTION, AnnotionFormat.COCO_PANOPTIC)
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_max_height_width
+def get_max_height_width(images: List[np.ndarray]) -> List[int]:
+ """
+ Get the maximum height and width across all images in a batch.
+ """
+ input_channel_dimension = infer_channel_dimension_format(images[0])
+
+ if input_channel_dimension == ChannelDimension.FIRST:
+ _, max_height, max_width = max_across_indices([img.shape for img in images])
+ elif input_channel_dimension == ChannelDimension.LAST:
+ max_height, max_width, _ = max_across_indices([img.shape for img in images])
+ else:
+ raise ValueError(f"Invalid channel dimension format: {input_channel_dimension}")
+ return (max_height, max_width)
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_size_with_aspect_ratio
+def get_size_with_aspect_ratio(image_size, size, max_size=None) -> Tuple[int, int]:
+ """
+ Computes the output image size given the input image size and the desired output size.
+
+ Args:
+ image_size (`Tuple[int, int]`):
+ The input image size.
+ size (`int`):
+ The desired output size.
+ max_size (`int`, *optional*):
+ The maximum allowed output size.
+ """
+ height, width = image_size
+ if max_size is not None:
+ min_original_size = float(min((height, width)))
+ max_original_size = float(max((height, width)))
+ if max_original_size / min_original_size * size > max_size:
+ size = int(round(max_size * min_original_size / max_original_size))
+
+ if (height <= width and height == size) or (width <= height and width == size):
+ return height, width
+
+ if width < height:
+ ow = size
+ oh = int(size * height / width)
+ else:
+ oh = size
+ ow = int(size * width / height)
+ return (oh, ow)
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_resize_output_image_size
+def get_resize_output_image_size(
+ input_image: np.ndarray, size: Union[int, Tuple[int, int], List[int]], max_size: Optional[int] = None
+) -> Tuple[int, int]:
+ """
+ Computes the output image size given the input image size and the desired output size. If the desired output size
+ is a tuple or list, the output image size is returned as is. If the desired output size is an integer, the output
+ image size is computed by keeping the aspect ratio of the input image size.
+
+ Args:
+ image_size (`Tuple[int, int]`):
+ The input image size.
+ size (`int`):
+ The desired output size.
+ max_size (`int`, *optional*):
+ The maximum allowed output size.
+ """
+ image_size = get_image_size(input_image)
+ if isinstance(size, (list, tuple)):
+ return size
+
+ return get_size_with_aspect_ratio(image_size, size, max_size)
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_numpy_to_framework_fn
+def get_numpy_to_framework_fn(arr) -> Callable:
+ """
+ Returns a function that converts a numpy array to the framework of the input array.
+
+ Args:
+ arr (`np.ndarray`): The array to convert.
+ """
+ if isinstance(arr, np.ndarray):
+ return np.array
+ if is_tf_available() and is_tf_tensor(arr):
+ import tensorflow as tf
+
+ return tf.convert_to_tensor
+ if is_torch_available() and is_torch_tensor(arr):
+ import torch
+
+ return torch.tensor
+ if is_flax_available() and is_jax_tensor(arr):
+ import jax.numpy as jnp
+
+ return jnp.array
+ raise ValueError(f"Cannot convert arrays of type {type(arr)}")
+
+
+# Copied from transformers.models.detr.image_processing_detr.safe_squeeze
+def safe_squeeze(arr: np.ndarray, axis: Optional[int] = None) -> np.ndarray:
+ """
+ Squeezes an array, but only if the axis specified has dim 1.
+ """
+ if axis is None:
+ return arr.squeeze()
+
+ try:
+ return arr.squeeze(axis=axis)
+ except ValueError:
+ return arr
+
+
+# Copied from transformers.models.detr.image_processing_detr.normalize_annotation
+def normalize_annotation(annotation: Dict, image_size: Tuple[int, int]) -> Dict:
+ image_height, image_width = image_size
+ norm_annotation = {}
+ for key, value in annotation.items():
+ if key == "boxes":
+ boxes = value
+ boxes = corners_to_center_format(boxes)
+ boxes /= np.asarray([image_width, image_height, image_width, image_height], dtype=np.float32)
+ norm_annotation[key] = boxes
+ else:
+ norm_annotation[key] = value
+ return norm_annotation
+
+
+# Copied from transformers.models.detr.image_processing_detr.max_across_indices
+def max_across_indices(values: Iterable[Any]) -> List[Any]:
+ """
+ Return the maximum value across all indices of an iterable of values.
+ """
+ return [max(values_i) for values_i in zip(*values)]
+
+
+# Copied from transformers.models.detr.image_processing_detr.make_pixel_mask
+def make_pixel_mask(image: np.ndarray, output_size: Tuple[int, int]) -> np.ndarray:
+ """
+ Make a pixel mask for the image, where 1 indicates a valid pixel and 0 indicates padding.
+
+ Args:
+ image (`np.ndarray`):
+ Image to make the pixel mask for.
+ output_size (`Tuple[int, int]`):
+ Output size of the mask.
+ """
+ input_height, input_width = get_image_size(image)
+ mask = np.zeros(output_size, dtype=np.int64)
+ mask[:input_height, :input_width] = 1
+ return mask
+
+
+# Copied from transformers.models.detr.image_processing_detr.convert_coco_poly_to_mask
+def convert_coco_poly_to_mask(segmentations, height: int, width: int) -> np.ndarray:
+ """
+ Convert a COCO polygon annotation to a mask.
+
+ Args:
+ segmentations (`List[List[float]]`):
+ List of polygons, each polygon represented by a list of x-y coordinates.
+ height (`int`):
+ Height of the mask.
+ width (`int`):
+ Width of the mask.
+ """
+ try:
+ from pycocotools import mask as coco_mask
+ except ImportError:
+ raise ImportError("Pycocotools is not installed in your environment.")
+
+ masks = []
+ for polygons in segmentations:
+ rles = coco_mask.frPyObjects(polygons, height, width)
+ mask = coco_mask.decode(rles)
+ if len(mask.shape) < 3:
+ mask = mask[..., None]
+ mask = np.asarray(mask, dtype=np.uint8)
+ mask = np.any(mask, axis=2)
+ masks.append(mask)
+ if masks:
+ masks = np.stack(masks, axis=0)
+ else:
+ masks = np.zeros((0, height, width), dtype=np.uint8)
+
+ return masks
+
+
+# Copied from transformers.models.detr.image_processing_detr.prepare_coco_detection_annotation
+def prepare_coco_detection_annotation(image, target, return_segmentation_masks: bool = False):
+ """
+ Convert the target in COCO format into the format expected by DETR.
+ """
+ image_height, image_width = get_image_size(image)
+
+ image_id = target["image_id"]
+ image_id = np.asarray([image_id], dtype=np.int64)
+
+ # Get all COCO annotations for the given image.
+ annotations = target["annotations"]
+ annotations = [obj for obj in annotations if "iscrowd" not in obj or obj["iscrowd"] == 0]
+
+ classes = [obj["category_id"] for obj in annotations]
+ classes = np.asarray(classes, dtype=np.int64)
+
+ # for conversion to coco api
+ area = np.asarray([obj["area"] for obj in annotations], dtype=np.float32)
+ iscrowd = np.asarray([obj["iscrowd"] if "iscrowd" in obj else 0 for obj in annotations], dtype=np.int64)
+
+ boxes = [obj["bbox"] for obj in annotations]
+ # guard against no boxes via resizing
+ boxes = np.asarray(boxes, dtype=np.float32).reshape(-1, 4)
+ boxes[:, 2:] += boxes[:, :2]
+ boxes[:, 0::2] = boxes[:, 0::2].clip(min=0, max=image_width)
+ boxes[:, 1::2] = boxes[:, 1::2].clip(min=0, max=image_height)
+
+ keep = (boxes[:, 3] > boxes[:, 1]) & (boxes[:, 2] > boxes[:, 0])
+
+ new_target = {}
+ new_target["image_id"] = image_id
+ new_target["class_labels"] = classes[keep]
+ new_target["boxes"] = boxes[keep]
+ new_target["area"] = area[keep]
+ new_target["iscrowd"] = iscrowd[keep]
+ new_target["orig_size"] = np.asarray([int(image_height), int(image_width)], dtype=np.int64)
+
+ if annotations and "keypoints" in annotations[0]:
+ keypoints = [obj["keypoints"] for obj in annotations]
+ keypoints = np.asarray(keypoints, dtype=np.float32)
+ num_keypoints = keypoints.shape[0]
+ keypoints = keypoints.reshape((-1, 3)) if num_keypoints else keypoints
+ new_target["keypoints"] = keypoints[keep]
+
+ if return_segmentation_masks:
+ segmentation_masks = [obj["segmentation"] for obj in annotations]
+ masks = convert_coco_poly_to_mask(segmentation_masks, image_height, image_width)
+ new_target["masks"] = masks[keep]
+
+ return new_target
+
+
+# Copied from transformers.models.detr.image_processing_detr.masks_to_boxes
+def masks_to_boxes(masks: np.ndarray) -> np.ndarray:
+ """
+ Compute the bounding boxes around the provided panoptic segmentation masks.
+
+ Args:
+ masks: masks in format `[number_masks, height, width]` where N is the number of masks
+
+ Returns:
+ boxes: bounding boxes in format `[number_masks, 4]` in xyxy format
+ """
+ if masks.size == 0:
+ return np.zeros((0, 4))
+
+ h, w = masks.shape[-2:]
+ y = np.arange(0, h, dtype=np.float32)
+ x = np.arange(0, w, dtype=np.float32)
+ # see https://github.com/pytorch/pytorch/issues/50276
+ y, x = np.meshgrid(y, x, indexing="ij")
+
+ x_mask = masks * np.expand_dims(x, axis=0)
+ x_max = x_mask.reshape(x_mask.shape[0], -1).max(-1)
+ x = np.ma.array(x_mask, mask=~(np.array(masks, dtype=bool)))
+ x_min = x.filled(fill_value=1e8)
+ x_min = x_min.reshape(x_min.shape[0], -1).min(-1)
+
+ y_mask = masks * np.expand_dims(y, axis=0)
+ y_max = y_mask.reshape(x_mask.shape[0], -1).max(-1)
+ y = np.ma.array(y_mask, mask=~(np.array(masks, dtype=bool)))
+ y_min = y.filled(fill_value=1e8)
+ y_min = y_min.reshape(y_min.shape[0], -1).min(-1)
+
+ return np.stack([x_min, y_min, x_max, y_max], 1)
+
+
+# Copied from transformers.models.detr.image_processing_detr.prepare_coco_panoptic_annotation with DETR->YOLOS
+def prepare_coco_panoptic_annotation(
+ image: np.ndarray, target: Dict, masks_path: Union[str, pathlib.Path], return_masks: bool = True
+) -> Dict:
+ """
+ Prepare a coco panoptic annotation for YOLOS.
+ """
+ image_height, image_width = get_image_size(image)
+ annotation_path = pathlib.Path(masks_path) / target["file_name"]
+
+ new_target = {}
+ new_target["image_id"] = np.asarray([target["image_id"] if "image_id" in target else target["id"]], dtype=np.int64)
+ new_target["size"] = np.asarray([image_height, image_width], dtype=np.int64)
+ new_target["orig_size"] = np.asarray([image_height, image_width], dtype=np.int64)
+
+ if "segments_info" in target:
+ masks = np.asarray(PIL.Image.open(annotation_path), dtype=np.uint32)
+ masks = rgb_to_id(masks)
+
+ ids = np.array([segment_info["id"] for segment_info in target["segments_info"]])
+ masks = masks == ids[:, None, None]
+ masks = masks.astype(np.uint8)
+ if return_masks:
+ new_target["masks"] = masks
+ new_target["boxes"] = masks_to_boxes(masks)
+ new_target["class_labels"] = np.array(
+ [segment_info["category_id"] for segment_info in target["segments_info"]], dtype=np.int64
+ )
+ new_target["iscrowd"] = np.asarray(
+ [segment_info["iscrowd"] for segment_info in target["segments_info"]], dtype=np.int64
+ )
+ new_target["area"] = np.asarray(
+ [segment_info["area"] for segment_info in target["segments_info"]], dtype=np.float32
+ )
+
+ return new_target
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_segmentation_image
+def get_segmentation_image(
+ masks: np.ndarray, input_size: Tuple, target_size: Tuple, stuff_equiv_classes, deduplicate=False
+):
+ h, w = input_size
+ final_h, final_w = target_size
+
+ m_id = scipy.special.softmax(masks.transpose(0, 1), -1)
+
+ if m_id.shape[-1] == 0:
+ # We didn't detect any mask :(
+ m_id = np.zeros((h, w), dtype=np.int64)
+ else:
+ m_id = m_id.argmax(-1).reshape(h, w)
+
+ if deduplicate:
+ # Merge the masks corresponding to the same stuff class
+ for equiv in stuff_equiv_classes.values():
+ for eq_id in equiv:
+ m_id[m_id == eq_id] = equiv[0]
+
+ seg_img = id_to_rgb(m_id)
+ seg_img = resize(seg_img, (final_w, final_h), resample=PILImageResampling.NEAREST)
+ return seg_img
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_mask_area
+def get_mask_area(seg_img: np.ndarray, target_size: Tuple[int, int], n_classes: int) -> np.ndarray:
+ final_h, final_w = target_size
+ np_seg_img = seg_img.astype(np.uint8)
+ np_seg_img = np_seg_img.reshape(final_h, final_w, 3)
+ m_id = rgb_to_id(np_seg_img)
+ area = [(m_id == i).sum() for i in range(n_classes)]
+ return area
+
+
+# Copied from transformers.models.detr.image_processing_detr.score_labels_from_class_probabilities
+def score_labels_from_class_probabilities(logits: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
+ probs = scipy.special.softmax(logits, axis=-1)
+ labels = probs.argmax(-1, keepdims=True)
+ scores = np.take_along_axis(probs, labels, axis=-1)
+ scores, labels = scores.squeeze(-1), labels.squeeze(-1)
+ return scores, labels
+
+
+# Copied from transformers.models.detr.image_processing_detr.resize_annotation
+def resize_annotation(
+ annotation: Dict[str, Any],
+ orig_size: Tuple[int, int],
+ target_size: Tuple[int, int],
+ threshold: float = 0.5,
+ resample: PILImageResampling = PILImageResampling.NEAREST,
+):
+ """
+ Resizes an annotation to a target size.
+
+ Args:
+ annotation (`Dict[str, Any]`):
+ The annotation dictionary.
+ orig_size (`Tuple[int, int]`):
+ The original size of the input image.
+ target_size (`Tuple[int, int]`):
+ The target size of the image, as returned by the preprocessing `resize` step.
+ threshold (`float`, *optional*, defaults to 0.5):
+ The threshold used to binarize the segmentation masks.
+ resample (`PILImageResampling`, defaults to `PILImageResampling.NEAREST`):
+ The resampling filter to use when resizing the masks.
+ """
+ ratios = tuple(float(s) / float(s_orig) for s, s_orig in zip(target_size, orig_size))
+ ratio_height, ratio_width = ratios
+
+ new_annotation = {}
+ new_annotation["size"] = target_size
+
+ for key, value in annotation.items():
+ if key == "boxes":
+ boxes = value
+ scaled_boxes = boxes * np.asarray([ratio_width, ratio_height, ratio_width, ratio_height], dtype=np.float32)
+ new_annotation["boxes"] = scaled_boxes
+ elif key == "area":
+ area = value
+ scaled_area = area * (ratio_width * ratio_height)
+ new_annotation["area"] = scaled_area
+ elif key == "masks":
+ masks = value[:, None]
+ masks = np.array([resize(mask, target_size, resample=resample) for mask in masks])
+ masks = masks.astype(np.float32)
+ masks = masks[:, 0] > threshold
+ new_annotation["masks"] = masks
+ elif key == "size":
+ new_annotation["size"] = target_size
+ else:
+ new_annotation[key] = value
+
+ return new_annotation
+
+
+# Copied from transformers.models.detr.image_processing_detr.binary_mask_to_rle
+def binary_mask_to_rle(mask):
+ """
+ Converts given binary mask of shape `(height, width)` to the run-length encoding (RLE) format.
+
+ Args:
+ mask (`torch.Tensor` or `numpy.array`):
+ A binary mask tensor of shape `(height, width)` where 0 denotes background and 1 denotes the target
+ segment_id or class_id.
+ Returns:
+ `List`: Run-length encoded list of the binary mask. Refer to COCO API for more information about the RLE
+ format.
+ """
+ if is_torch_tensor(mask):
+ mask = mask.numpy()
+
+ pixels = mask.flatten()
+ pixels = np.concatenate([[0], pixels, [0]])
+ runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
+ runs[1::2] -= runs[::2]
+ return [x for x in runs]
+
+
+# Copied from transformers.models.detr.image_processing_detr.convert_segmentation_to_rle
+def convert_segmentation_to_rle(segmentation):
+ """
+ Converts given segmentation map of shape `(height, width)` to the run-length encoding (RLE) format.
+
+ Args:
+ segmentation (`torch.Tensor` or `numpy.array`):
+ A segmentation map of shape `(height, width)` where each value denotes a segment or class id.
+ Returns:
+ `List[List]`: A list of lists, where each list is the run-length encoding of a segment / class id.
+ """
+ segment_ids = torch.unique(segmentation)
+
+ run_length_encodings = []
+ for idx in segment_ids:
+ mask = torch.where(segmentation == idx, 1, 0)
+ rle = binary_mask_to_rle(mask)
+ run_length_encodings.append(rle)
+
+ return run_length_encodings
+
+
+# Copied from transformers.models.detr.image_processing_detr.remove_low_and_no_objects
+def remove_low_and_no_objects(masks, scores, labels, object_mask_threshold, num_labels):
+ """
+ Binarize the given masks using `object_mask_threshold`, it returns the associated values of `masks`, `scores` and
+ `labels`.
+
+ Args:
+ masks (`torch.Tensor`):
+ A tensor of shape `(num_queries, height, width)`.
+ scores (`torch.Tensor`):
+ A tensor of shape `(num_queries)`.
+ labels (`torch.Tensor`):
+ A tensor of shape `(num_queries)`.
+ object_mask_threshold (`float`):
+ A number between 0 and 1 used to binarize the masks.
+ Raises:
+ `ValueError`: Raised when the first dimension doesn't match in all input tensors.
+ Returns:
+ `Tuple[`torch.Tensor`, `torch.Tensor`, `torch.Tensor`]`: The `masks`, `scores` and `labels` without the region
+ < `object_mask_threshold`.
+ """
+ if not (masks.shape[0] == scores.shape[0] == labels.shape[0]):
+ raise ValueError("mask, scores and labels must have the same shape!")
+
+ to_keep = labels.ne(num_labels) & (scores > object_mask_threshold)
+
+ return masks[to_keep], scores[to_keep], labels[to_keep]
+
+
+# Copied from transformers.models.detr.image_processing_detr.check_segment_validity
+def check_segment_validity(mask_labels, mask_probs, k, mask_threshold=0.5, overlap_mask_area_threshold=0.8):
+ # Get the mask associated with the k class
+ mask_k = mask_labels == k
+ mask_k_area = mask_k.sum()
+
+ # Compute the area of all the stuff in query k
+ original_area = (mask_probs[k] >= mask_threshold).sum()
+ mask_exists = mask_k_area > 0 and original_area > 0
+
+ # Eliminate disconnected tiny segments
+ if mask_exists:
+ area_ratio = mask_k_area / original_area
+ if not area_ratio.item() > overlap_mask_area_threshold:
+ mask_exists = False
+
+ return mask_exists, mask_k
+
+
+# Copied from transformers.models.detr.image_processing_detr.compute_segments
+def compute_segments(
+ mask_probs,
+ pred_scores,
+ pred_labels,
+ mask_threshold: float = 0.5,
+ overlap_mask_area_threshold: float = 0.8,
+ label_ids_to_fuse: Optional[Set[int]] = None,
+ target_size: Tuple[int, int] = None,
+):
+ height = mask_probs.shape[1] if target_size is None else target_size[0]
+ width = mask_probs.shape[2] if target_size is None else target_size[1]
+
+ segmentation = torch.zeros((height, width), dtype=torch.int32, device=mask_probs.device)
+ segments: List[Dict] = []
+
+ if target_size is not None:
+ mask_probs = nn.functional.interpolate(
+ mask_probs.unsqueeze(0), size=target_size, mode="bilinear", align_corners=False
+ )[0]
+
+ current_segment_id = 0
+
+ # Weigh each mask by its prediction score
+ mask_probs *= pred_scores.view(-1, 1, 1)
+ mask_labels = mask_probs.argmax(0) # [height, width]
+
+ # Keep track of instances of each class
+ stuff_memory_list: Dict[str, int] = {}
+ for k in range(pred_labels.shape[0]):
+ pred_class = pred_labels[k].item()
+ should_fuse = pred_class in label_ids_to_fuse
+
+ # Check if mask exists and large enough to be a segment
+ mask_exists, mask_k = check_segment_validity(
+ mask_labels, mask_probs, k, mask_threshold, overlap_mask_area_threshold
+ )
+
+ if mask_exists:
+ if pred_class in stuff_memory_list:
+ current_segment_id = stuff_memory_list[pred_class]
+ else:
+ current_segment_id += 1
+
+ # Add current object segment to final segmentation map
+ segmentation[mask_k] = current_segment_id
+ segment_score = round(pred_scores[k].item(), 6)
+ segments.append(
+ {
+ "id": current_segment_id,
+ "label_id": pred_class,
+ "was_fused": should_fuse,
+ "score": segment_score,
+ }
+ )
+ if should_fuse:
+ stuff_memory_list[pred_class] = current_segment_id
+
+ return segmentation, segments
+
+
+class YolosImageProcessor(BaseImageProcessor):
+ r"""
+ Constructs a Detr image processor.
+
+ Args:
+ format (`str`, *optional*, defaults to `"coco_detection"`):
+ Data format of the annotations. One of "coco_detection" or "coco_panoptic".
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Controls whether to resize the image's (height, width) dimensions to the specified `size`. Can be
+ overridden by the `do_resize` parameter in the `preprocess` method.
+ size (`Dict[str, int]` *optional*, defaults to `{"shortest_edge": 800, "longest_edge": 1333}`):
+ Size of the image's (height, width) dimensions after resizing. Can be overridden by the `size` parameter in
+ the `preprocess` method.
+ resample (`PILImageResampling`, *optional*, defaults to `PILImageResampling.BILINEAR`):
+ Resampling filter to use if resizing the image.
+ do_rescale (`bool`, *optional*, defaults to `True`):
+ Controls whether to rescale the image by the specified scale `rescale_factor`. Can be overridden by the
+ `do_rescale` parameter in the `preprocess` method.
+ rescale_factor (`int` or `float`, *optional*, defaults to `1/255`):
+ Scale factor to use if rescaling the image. Can be overridden by the `rescale_factor` parameter in the
+ `preprocess` method.
+ do_normalize:
+ Controls whether to normalize the image. Can be overridden by the `do_normalize` parameter in the
+ `preprocess` method.
+ image_mean (`float` or `List[float]`, *optional*, defaults to `IMAGENET_DEFAULT_MEAN`):
+ Mean values to use when normalizing the image. Can be a single value or a list of values, one for each
+ channel. Can be overridden by the `image_mean` parameter in the `preprocess` method.
+ image_std (`float` or `List[float]`, *optional*, defaults to `IMAGENET_DEFAULT_STD`):
+ Standard deviation values to use when normalizing the image. Can be a single value or a list of values, one
+ for each channel. Can be overridden by the `image_std` parameter in the `preprocess` method.
+ do_pad (`bool`, *optional*, defaults to `True`):
+ Controls whether to pad the image to the largest image in a batch and create a pixel mask. Can be
+ overridden by the `do_pad` parameter in the `preprocess` method.
+ """
+
+ model_input_names = ["pixel_values", "pixel_mask"]
+
+ def __init__(
+ self,
+ format: Union[str, AnnotionFormat] = AnnotionFormat.COCO_DETECTION,
+ do_resize: bool = True,
+ size: Dict[str, int] = None,
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ do_rescale: bool = True,
+ rescale_factor: Union[int, float] = 1 / 255,
+ do_normalize: bool = True,
+ image_mean: Union[float, List[float]] = None,
+ image_std: Union[float, List[float]] = None,
+ do_pad: bool = True,
+ **kwargs
+ ) -> None:
+ if "pad_and_return_pixel_mask" in kwargs:
+ do_pad = kwargs.pop("pad_and_return_pixel_mask")
+
+ if "max_size" in kwargs:
+ warnings.warn(
+ "The `max_size` parameter is deprecated and will be removed in v4.26. "
+ "Please specify in `size['longest_edge'] instead`.",
+ FutureWarning,
+ )
+ max_size = kwargs.pop("max_size")
+ else:
+ max_size = None if size is None else 1333
+
+ size = size if size is not None else {"shortest_edge": 800, "longest_edge": 1333}
+ size = get_size_dict(size, max_size=max_size, default_to_square=False)
+
+ super().__init__(**kwargs)
+ self.format = format
+ self.do_resize = do_resize
+ self.size = size
+ self.resample = resample
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean if image_mean is not None else IMAGENET_DEFAULT_MEAN
+ self.image_std = image_std if image_std is not None else IMAGENET_DEFAULT_STD
+ self.do_pad = do_pad
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare_annotation
+ def prepare_annotation(
+ self,
+ image: np.ndarray,
+ target: Dict,
+ format: Optional[AnnotionFormat] = None,
+ return_segmentation_masks: bool = None,
+ masks_path: Optional[Union[str, pathlib.Path]] = None,
+ ) -> Dict:
+ """
+ Prepare an annotation for feeding into DETR model.
+ """
+ format = format if format is not None else self.format
+
+ if format == AnnotionFormat.COCO_DETECTION:
+ return_segmentation_masks = False if return_segmentation_masks is None else return_segmentation_masks
+ target = prepare_coco_detection_annotation(image, target, return_segmentation_masks)
+ elif format == AnnotionFormat.COCO_PANOPTIC:
+ return_segmentation_masks = True if return_segmentation_masks is None else return_segmentation_masks
+ target = prepare_coco_panoptic_annotation(
+ image, target, masks_path=masks_path, return_masks=return_segmentation_masks
+ )
+ else:
+ raise ValueError(f"Format {format} is not supported.")
+ return target
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare
+ def prepare(self, image, target, return_segmentation_masks=False, masks_path=None):
+ warnings.warn(
+ "The `prepare` method is deprecated and will be removed in a future version. "
+ "Please use `prepare_annotation` instead. Note: the `prepare_annotation` method "
+ "does not return the image anymore.",
+ )
+ target = self.prepare_annotation(image, target, return_segmentation_masks, masks_path, self.format)
+ return image, target
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.convert_coco_poly_to_mask
+ def convert_coco_poly_to_mask(self, *args, **kwargs):
+ warnings.warn("The `convert_coco_poly_to_mask` method is deprecated and will be removed in a future version. ")
+ return convert_coco_poly_to_mask(*args, **kwargs)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare_coco_detection with DETR->Yolos
+ def prepare_coco_detection(self, *args, **kwargs):
+ warnings.warn("The `prepare_coco_detection` method is deprecated and will be removed in a future version. ")
+ return prepare_coco_detection_annotation(*args, **kwargs)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare_coco_panoptic
+ def prepare_coco_panoptic(self, *args, **kwargs):
+ warnings.warn("The `prepare_coco_panoptic` method is deprecated and will be removed in a future version. ")
+ return prepare_coco_panoptic_annotation(*args, **kwargs)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.resize
+ def resize(
+ self,
+ image: np.ndarray,
+ size: Dict[str, int],
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ data_format: Optional[ChannelDimension] = None,
+ **kwargs
+ ) -> np.ndarray:
+ """
+ Resize the image to the given size. Size can be `min_size` (scalar) or `(height, width)` tuple. If size is an
+ int, smaller edge of the image will be matched to this number.
+ """
+ if "max_size" in kwargs:
+ warnings.warn(
+ "The `max_size` parameter is deprecated and will be removed in v4.26. "
+ "Please specify in `size['longest_edge'] instead`.",
+ FutureWarning,
+ )
+ max_size = kwargs.pop("max_size")
+ else:
+ max_size = None
+ size = get_size_dict(size, max_size=max_size, default_to_square=False)
+ if "shortest_edge" in size and "longest_edge" in size:
+ size = get_resize_output_image_size(image, size["shortest_edge"], size["longest_edge"])
+ elif "height" in size and "width" in size:
+ size = (size["height"], size["width"])
+ else:
+ raise ValueError(
+ "Size must contain 'height' and 'width' keys or 'shortest_edge' and 'longest_edge' keys. Got"
+ f" {size.keys()}."
+ )
+ image = resize(image, size=size, resample=resample, data_format=data_format)
+ return image
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.resize_annotation
+ def resize_annotation(
+ self,
+ annotation,
+ orig_size,
+ size,
+ resample: PILImageResampling = PILImageResampling.NEAREST,
+ ) -> Dict:
+ """
+ Resize the annotation to match the resized image. If size is an int, smaller edge of the mask will be matched
+ to this number.
+ """
+ return resize_annotation(annotation, orig_size=orig_size, target_size=size, resample=resample)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.rescale
+ def rescale(
+ self, image: np.ndarray, rescale_factor: Union[float, int], data_format: Optional[ChannelDimension] = None
+ ) -> np.ndarray:
+ """
+ Rescale the image by the given factor.
+ """
+ return rescale(image, rescale_factor, data_format=data_format)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.normalize
+ def normalize(
+ self,
+ image: np.ndarray,
+ mean: Union[float, Iterable[float]],
+ std: Union[float, Iterable[float]],
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Normalize the image with the given mean and standard deviation.
+ """
+ return normalize(image, mean=mean, std=std, data_format=data_format)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.normalize_annotation
+ def normalize_annotation(self, annotation: Dict, image_size: Tuple[int, int]) -> Dict:
+ """
+ Normalize the boxes in the annotation from `[top_left_x, top_left_y, bottom_right_x, bottom_right_y]` to
+ `[center_x, center_y, width, height]` format.
+ """
+ return normalize_annotation(annotation, image_size=image_size)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor._pad_image
+ def _pad_image(
+ self,
+ image: np.ndarray,
+ output_size: Tuple[int, int],
+ constant_values: Union[float, Iterable[float]] = 0,
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Pad an image with zeros to the given size.
+ """
+ input_height, input_width = get_image_size(image)
+ output_height, output_width = output_size
+
+ pad_bottom = output_height - input_height
+ pad_right = output_width - input_width
+ padding = ((0, pad_bottom), (0, pad_right))
+ padded_image = pad(
+ image, padding, mode=PaddingMode.CONSTANT, constant_values=constant_values, data_format=data_format
+ )
+ return padded_image
+
+ def pad(
+ self,
+ images: List[np.ndarray],
+ return_pixel_mask: bool = False,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Pads a batch of images to the bottom and right of the image with zeros to the size of largest height and width
+ in the batch and optionally returns their corresponding pixel mask.
+
+ Args:
+ image (`np.ndarray`):
+ Image to pad.
+ return_pixel_mask (`bool`, *optional*, defaults to `True`):
+ Whether to return a pixel mask.
+ input_channel_dimension (`ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be inferred from the input image.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be the same as the input image.
+ """
+ pad_size = get_max_height_width(images)
+
+ padded_images = [self._pad_image(image, pad_size, data_format=data_format) for image in images]
+ data = {"pixel_values": padded_images}
+
+ if return_pixel_mask:
+ masks = [make_pixel_mask(image=image, output_size=pad_size) for image in images]
+ data["pixel_mask"] = masks
+
+ return BatchFeature(data=data, tensor_type=return_tensors)
+
+ def preprocess(
+ self,
+ images: ImageInput,
+ annotations: Optional[Union[List[Dict], List[List[Dict]]]] = None,
+ return_segmentation_masks: bool = None,
+ masks_path: Optional[Union[str, pathlib.Path]] = None,
+ do_resize: Optional[bool] = None,
+ size: Optional[Dict[str, int]] = None,
+ resample=None, # PILImageResampling
+ do_rescale: Optional[bool] = None,
+ rescale_factor: Optional[Union[int, float]] = None,
+ do_normalize: Optional[bool] = None,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ do_pad: Optional[bool] = None,
+ format: Optional[Union[str, AnnotionFormat]] = None,
+ return_tensors: Optional[Union[TensorType, str]] = None,
+ data_format: Union[str, ChannelDimension] = ChannelDimension.FIRST,
+ **kwargs
+ ) -> BatchFeature:
+ """
+ Preprocess an image or a batch of images so that it can be used by the model.
+
+ Args:
+ images (`ImageInput`):
+ Image or batch of images to preprocess.
+ annotations (`List[Dict]` or `List[List[Dict]]`, *optional*):
+ List of annotations associated with the image or batch of images. If annotionation is for object
+ detection, the annotations should be a dictionary with the following keys:
+ - "image_id" (`int`): The image id.
+ - "annotations" (`List[Dict]`): List of annotations for an image. Each annotation should be a
+ dictionary. An image can have no annotations, in which case the list should be empty.
+ If annotionation is for segmentation, the annotations should be a dictionary with the following keys:
+ - "image_id" (`int`): The image id.
+ - "segments_info" (`List[Dict]`): List of segments for an image. Each segment should be a dictionary.
+ An image can have no segments, in which case the list should be empty.
+ - "file_name" (`str`): The file name of the image.
+ return_segmentation_masks (`bool`, *optional*, defaults to self.return_segmentation_masks):
+ Whether to return segmentation masks.
+ masks_path (`str` or `pathlib.Path`, *optional*):
+ Path to the directory containing the segmentation masks.
+ do_resize (`bool`, *optional*, defaults to self.do_resize):
+ Whether to resize the image.
+ size (`Dict[str, int]`, *optional*, defaults to self.size):
+ Size of the image after resizing.
+ resample (`PILImageResampling`, *optional*, defaults to self.resample):
+ Resampling filter to use when resizing the image.
+ do_rescale (`bool`, *optional*, defaults to self.do_rescale):
+ Whether to rescale the image.
+ rescale_factor (`float`, *optional*, defaults to self.rescale_factor):
+ Rescale factor to use when rescaling the image.
+ do_normalize (`bool`, *optional*, defaults to self.do_normalize):
+ Whether to normalize the image.
+ image_mean (`float` or `List[float]`, *optional*, defaults to self.image_mean):
+ Mean to use when normalizing the image.
+ image_std (`float` or `List[float]`, *optional*, defaults to self.image_std):
+ Standard deviation to use when normalizing the image.
+ do_pad (`bool`, *optional*, defaults to self.do_pad):
+ Whether to pad the image.
+ format (`str` or `AnnotionFormat`, *optional*, defaults to self.format):
+ Format of the annotations.
+ return_tensors (`str` or `TensorType`, *optional*, defaults to self.return_tensors):
+ Type of tensors to return. If `None`, will return the list of images.
+ data_format (`str` or `ChannelDimension`, *optional*, defaults to self.data_format):
+ The channel dimension format of the image. If not provided, it will be the same as the input image.
+ """
+ if "pad_and_return_pixel_mask" in kwargs:
+ warnings.warn(
+ "The `pad_and_return_pixel_mask` argument is deprecated and will be removed in a future version, "
+ "use `do_pad` instead.",
+ FutureWarning,
+ )
+ do_pad = kwargs.pop("pad_and_return_pixel_mask")
+
+ max_size = None
+ if "max_size" in kwargs:
+ warnings.warn(
+ "The `max_size` argument is deprecated and will be removed in a future version, use"
+ " `size['longest_edge']` instead.",
+ FutureWarning,
+ )
+ size = kwargs.pop("max_size")
+
+ do_resize = self.do_resize if do_resize is None else do_resize
+ size = self.size if size is None else size
+ size = get_size_dict(size=size, max_size=max_size, default_to_square=False)
+ resample = self.resample if resample is None else resample
+ do_rescale = self.do_rescale if do_rescale is None else do_rescale
+ rescale_factor = self.rescale_factor if rescale_factor is None else rescale_factor
+ do_normalize = self.do_normalize if do_normalize is None else do_normalize
+ image_mean = self.image_mean if image_mean is None else image_mean
+ image_std = self.image_std if image_std is None else image_std
+ do_pad = self.do_pad if do_pad is None else do_pad
+ format = self.format if format is None else format
+
+ if do_resize is not None and size is None:
+ raise ValueError("Size and max_size must be specified if do_resize is True.")
+
+ if do_rescale is not None and rescale_factor is None:
+ raise ValueError("Rescale factor must be specified if do_rescale is True.")
+
+ if do_normalize is not None and (image_mean is None or image_std is None):
+ raise ValueError("Image mean and std must be specified if do_normalize is True.")
+
+ if not is_batched(images):
+ images = [images]
+ annotations = [annotations] if annotations is not None else None
+
+ if annotations is not None and len(images) != len(annotations):
+ raise ValueError(
+ f"The number of images ({len(images)}) and annotations ({len(annotations)}) do not match."
+ )
+
+ if not valid_images(images):
+ raise ValueError(
+ "Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
+ "torch.Tensor, tf.Tensor or jax.ndarray."
+ )
+
+ format = AnnotionFormat(format)
+ if annotations is not None:
+ if format == AnnotionFormat.COCO_DETECTION and not valid_coco_detection_annotations(annotations):
+ raise ValueError(
+ "Invalid COCO detection annotations. Annotations must a dict (single image) of list of dicts"
+ "(batch of images) with the following keys: `image_id` and `annotations`, with the latter "
+ "being a list of annotations in the COCO format."
+ )
+ elif format == AnnotionFormat.COCO_PANOPTIC and not valid_coco_panoptic_annotations(annotations):
+ raise ValueError(
+ "Invalid COCO panoptic annotations. Annotations must a dict (single image) of list of dicts "
+ "(batch of images) with the following keys: `image_id`, `file_name` and `segments_info`, with "
+ "the latter being a list of annotations in the COCO format."
+ )
+ elif format not in SUPPORTED_ANNOTATION_FORMATS:
+ raise ValueError(
+ f"Unsupported annotation format: {format} must be one of {SUPPORTED_ANNOTATION_FORMATS}"
+ )
+
+ if (
+ masks_path is not None
+ and format == AnnotionFormat.COCO_PANOPTIC
+ and not isinstance(masks_path, (pathlib.Path, str))
+ ):
+ raise ValueError(
+ "The path to the directory containing the mask PNG files should be provided as a"
+ f" `pathlib.Path` or string object, but is {type(masks_path)} instead."
+ )
+
+ # All transformations expect numpy arrays
+ images = [to_numpy_array(image) for image in images]
+
+ # prepare (COCO annotations as a list of Dict -> DETR target as a single Dict per image)
+ if annotations is not None:
+ prepared_images = []
+ prepared_annotations = []
+ for image, target in zip(images, annotations):
+ target = self.prepare_annotation(
+ image, target, format, return_segmentation_masks=return_segmentation_masks, masks_path=masks_path
+ )
+ prepared_images.append(image)
+ prepared_annotations.append(target)
+ images = prepared_images
+ annotations = prepared_annotations
+ del prepared_images, prepared_annotations
+
+ # transformations
+ if do_resize:
+ if annotations is not None:
+ resized_images, resized_annotations = [], []
+ for image, target in zip(images, annotations):
+ orig_size = get_image_size(image)
+ resized_image = self.resize(image, size=size, max_size=max_size, resample=resample)
+ resized_annotation = self.resize_annotation(target, orig_size, get_image_size(resized_image))
+ resized_images.append(resized_image)
+ resized_annotations.append(resized_annotation)
+ images = resized_images
+ annotations = resized_annotations
+ del resized_images, resized_annotations
+ else:
+ images = [self.resize(image, size=size, resample=resample) for image in images]
+
+ if do_rescale:
+ images = [self.rescale(image, rescale_factor) for image in images]
+
+ if do_normalize:
+ images = [self.normalize(image, image_mean, image_std) for image in images]
+ if annotations is not None:
+ annotations = [
+ self.normalize_annotation(annotation, get_image_size(image))
+ for annotation, image in zip(annotations, images)
+ ]
+
+ if do_pad:
+ data = self.pad(images, data_format=data_format)
+ else:
+ images = [to_channel_dimension_format(image, data_format) for image in images]
+ data = {"pixel_values": images}
+
+ encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
+ if annotations is not None:
+ encoded_inputs["labels"] = [
+ BatchFeature(annotation, tensor_type=return_tensors) for annotation in annotations
+ ]
+
+ return encoded_inputs
+
+ # POSTPROCESSING METHODS - TODO: add support for other frameworks
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.post_process
+ def post_process(self, outputs, target_sizes):
+ """
+ Converts the output of [`DetrForObjectDetection`] into the format expected by the COCO api. Only supports
+ PyTorch.
+
+ Args:
+ outputs ([`DetrObjectDetectionOutput`]):
+ Raw outputs of the model.
+ target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
+ Tensor containing the size (height, width) of each image of the batch. For evaluation, this must be the
+ original image size (before any data augmentation). For visualization, this should be the image size
+ after data augment, but before padding.
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
+ in the batch as predicted by the model.
+ """
+ warnings.warn(
+ "`post_process` is deprecated and will be removed in v5 of Transformers, please use"
+ " `post_process_object_detection`",
+ FutureWarning,
+ )
+
+ out_logits, out_bbox = outputs.logits, outputs.pred_boxes
+
+ if len(out_logits) != len(target_sizes):
+ raise ValueError("Make sure that you pass in as many target sizes as the batch dimension of the logits")
+ if target_sizes.shape[1] != 2:
+ raise ValueError("Each element of target_sizes must contain the size (h, w) of each image of the batch")
+
+ prob = nn.functional.softmax(out_logits, -1)
+ scores, labels = prob[..., :-1].max(-1)
+
+ # convert to [x0, y0, x1, y1] format
+ boxes = center_to_corners_format(out_bbox)
+ # and from relative [0, 1] to absolute [0, height] coordinates
+ img_h, img_w = target_sizes.unbind(1)
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1).to(boxes.device)
+ boxes = boxes * scale_fct[:, None, :]
+
+ results = [{"scores": s, "labels": l, "boxes": b} for s, l, b in zip(scores, labels, boxes)]
+ return results
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.post_process_object_detection with Detr->Yolos
+ def post_process_object_detection(
+ self, outputs, threshold: float = 0.5, target_sizes: Union[TensorType, List[Tuple]] = None
+ ):
+ """
+ Converts the output of [`YolosForObjectDetection`] into the format expected by the COCO api. Only supports
+ PyTorch.
+
+ Args:
+ outputs ([`YolosObjectDetectionOutput`]):
+ Raw outputs of the model.
+ threshold (`float`, *optional*):
+ Score threshold to keep object detection predictions.
+ target_sizes (`torch.Tensor` or `List[Tuple[int, int]]`, *optional*):
+ Tensor of shape `(batch_size, 2)` or list of tuples (`Tuple[int, int]`) containing the target size
+ `(height, width)` of each image in the batch. If unset, predictions will not be resized.
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
+ in the batch as predicted by the model.
+ """
+ out_logits, out_bbox = outputs.logits, outputs.pred_boxes
+
+ if target_sizes is not None:
+ if len(out_logits) != len(target_sizes):
+ raise ValueError(
+ "Make sure that you pass in as many target sizes as the batch dimension of the logits"
+ )
+
+ prob = nn.functional.softmax(out_logits, -1)
+ scores, labels = prob[..., :-1].max(-1)
+
+ # Convert to [x0, y0, x1, y1] format
+ boxes = center_to_corners_format(out_bbox)
+
+ # Convert from relative [0, 1] to absolute [0, height] coordinates
+ if target_sizes is not None:
+ if isinstance(target_sizes, List):
+ img_h = torch.Tensor([i[0] for i in target_sizes])
+ img_w = torch.Tensor([i[1] for i in target_sizes])
+ else:
+ img_h, img_w = target_sizes.unbind(1)
+
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
+ boxes = boxes * scale_fct[:, None, :]
+
+ results = []
+ for s, l, b in zip(scores, labels, boxes):
+ score = s[s > threshold]
+ label = l[s > threshold]
+ box = b[s > threshold]
+ results.append({"scores": score, "labels": label, "boxes": box})
+
+ return results
diff --git a/src/transformers/utils/dummy_vision_objects.py b/src/transformers/utils/dummy_vision_objects.py
index fb35aad69a..0db4d433a9 100644
--- a/src/transformers/utils/dummy_vision_objects.py
+++ b/src/transformers/utils/dummy_vision_objects.py
@@ -64,6 +64,13 @@ class ConditionalDetrFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class ConditionalDetrImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class ConvNextFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -85,6 +92,13 @@ class DeformableDetrFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class DeformableDetrImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class DeiTFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -106,6 +120,13 @@ class DetrFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class DetrImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class DonutFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -232,6 +253,13 @@ class MaskFormerFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class MaskFormerImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class MobileNetV1FeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -281,6 +309,13 @@ class OwlViTFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class OwlViTImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class PerceiverFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -377,3 +412,10 @@ class YolosFeatureExtractor(metaclass=DummyObject):
def __init__(self, *args, **kwargs):
requires_backends(self, ["vision"])
+
+
+class YolosImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
diff --git a/tests/models/conditional_detr/test_feature_extraction_conditional_detr.py b/tests/models/conditional_detr/test_feature_extraction_conditional_detr.py
index ef7d0109ac..92ff4fe08f 100644
--- a/tests/models/conditional_detr/test_feature_extraction_conditional_detr.py
+++ b/tests/models/conditional_detr/test_feature_extraction_conditional_detr.py
@@ -44,12 +44,16 @@ class ConditionalDetrFeatureExtractionTester(unittest.TestCase):
min_resolution=30,
max_resolution=400,
do_resize=True,
- size=18,
- max_size=1333, # by setting max_size > max_resolution we're effectively not testing this :p
+ size=None,
do_normalize=True,
image_mean=[0.5, 0.5, 0.5],
image_std=[0.5, 0.5, 0.5],
+ do_rescale=True,
+ rescale_factor=1 / 255,
+ do_pad=True,
):
+ # by setting size["longest_edge"] > max_resolution we're effectively not testing this :p
+ size = size if size is not None else {"shortest_edge": 18, "longest_edge": 1333}
self.parent = parent
self.batch_size = batch_size
self.num_channels = num_channels
@@ -57,19 +61,23 @@ class ConditionalDetrFeatureExtractionTester(unittest.TestCase):
self.max_resolution = max_resolution
self.do_resize = do_resize
self.size = size
- self.max_size = max_size
self.do_normalize = do_normalize
self.image_mean = image_mean
self.image_std = image_std
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_pad = do_pad
def prepare_feat_extract_dict(self):
return {
"do_resize": self.do_resize,
"size": self.size,
- "max_size": self.max_size,
"do_normalize": self.do_normalize,
"image_mean": self.image_mean,
"image_std": self.image_std,
+ "do_rescale": self.do_rescale,
+ "rescale_factor": self.rescale_factor,
+ "do_pad": self.do_pad,
}
def get_expected_values(self, image_inputs, batched=False):
@@ -84,14 +92,14 @@ class ConditionalDetrFeatureExtractionTester(unittest.TestCase):
else:
h, w = image.shape[1], image.shape[2]
if w < h:
- expected_height = int(self.size * h / w)
- expected_width = self.size
+ expected_height = int(self.size["shortest_edge"] * h / w)
+ expected_width = self.size["shortest_edge"]
elif w > h:
- expected_height = self.size
- expected_width = int(self.size * w / h)
+ expected_height = self.size["shortest_edge"]
+ expected_width = int(self.size["shortest_edge"] * w / h)
else:
- expected_height = self.size
- expected_width = self.size
+ expected_height = self.size["shortest_edge"]
+ expected_width = self.size["shortest_edge"]
else:
expected_values = []
@@ -124,7 +132,6 @@ class ConditionalDetrFeatureExtractionTest(FeatureExtractionSavingTestMixin, uni
self.assertTrue(hasattr(feature_extractor, "do_normalize"))
self.assertTrue(hasattr(feature_extractor, "do_resize"))
self.assertTrue(hasattr(feature_extractor, "size"))
- self.assertTrue(hasattr(feature_extractor, "max_size"))
def test_batch_feature(self):
pass
@@ -230,7 +237,7 @@ class ConditionalDetrFeatureExtractionTest(FeatureExtractionSavingTestMixin, uni
def test_equivalence_pad_and_create_pixel_mask(self):
# Initialize feature_extractors
feature_extractor_1 = self.feature_extraction_class(**self.feat_extract_dict)
- feature_extractor_2 = self.feature_extraction_class(do_resize=False, do_normalize=False)
+ feature_extractor_2 = self.feature_extraction_class(do_resize=False, do_normalize=False, do_rescale=False)
# create random PyTorch tensors
image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False, torchify=True)
for image in image_inputs:
@@ -331,7 +338,7 @@ class ConditionalDetrFeatureExtractionTest(FeatureExtractionSavingTestMixin, uni
expected_class_labels = torch.tensor([17, 17, 63, 75, 75, 93])
self.assertTrue(torch.allclose(encoding["labels"][0]["class_labels"], expected_class_labels))
# verify masks
- expected_masks_sum = 822338
+ expected_masks_sum = 822873
self.assertEqual(encoding["labels"][0]["masks"].sum().item(), expected_masks_sum)
# verify orig_size
expected_orig_size = torch.tensor([480, 640])
diff --git a/tests/models/deformable_detr/test_feature_extraction_deformable_detr.py b/tests/models/deformable_detr/test_feature_extraction_deformable_detr.py
index 6a7cfefee5..e205f47a8d 100644
--- a/tests/models/deformable_detr/test_feature_extraction_deformable_detr.py
+++ b/tests/models/deformable_detr/test_feature_extraction_deformable_detr.py
@@ -44,12 +44,16 @@ class DeformableDetrFeatureExtractionTester(unittest.TestCase):
min_resolution=30,
max_resolution=400,
do_resize=True,
- size=18,
- max_size=1333, # by setting max_size > max_resolution we're effectively not testing this :p
+ size=None,
do_normalize=True,
image_mean=[0.5, 0.5, 0.5],
image_std=[0.5, 0.5, 0.5],
+ do_rescale=True,
+ rescale_factor=1 / 255,
+ do_pad=True,
):
+ # by setting size["longest_edge"] > max_resolution we're effectively not testing this :p
+ size = size if size is not None else {"shortest_edge": 18, "longest_edge": 1333}
self.parent = parent
self.batch_size = batch_size
self.num_channels = num_channels
@@ -57,19 +61,23 @@ class DeformableDetrFeatureExtractionTester(unittest.TestCase):
self.max_resolution = max_resolution
self.do_resize = do_resize
self.size = size
- self.max_size = max_size
self.do_normalize = do_normalize
self.image_mean = image_mean
self.image_std = image_std
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_pad = do_pad
def prepare_feat_extract_dict(self):
return {
"do_resize": self.do_resize,
"size": self.size,
- "max_size": self.max_size,
"do_normalize": self.do_normalize,
"image_mean": self.image_mean,
"image_std": self.image_std,
+ "do_rescale": self.do_rescale,
+ "rescale_factor": self.rescale_factor,
+ "do_pad": self.do_pad,
}
def get_expected_values(self, image_inputs, batched=False):
@@ -84,14 +92,14 @@ class DeformableDetrFeatureExtractionTester(unittest.TestCase):
else:
h, w = image.shape[1], image.shape[2]
if w < h:
- expected_height = int(self.size * h / w)
- expected_width = self.size
+ expected_height = int(self.size["shortest_edge"] * h / w)
+ expected_width = self.size["shortest_edge"]
elif w > h:
- expected_height = self.size
- expected_width = int(self.size * w / h)
+ expected_height = self.size["shortest_edge"]
+ expected_width = int(self.size["shortest_edge"] * w / h)
else:
- expected_height = self.size
- expected_width = self.size
+ expected_height = self.size["shortest_edge"]
+ expected_width = self.size["shortest_edge"]
else:
expected_values = []
@@ -123,8 +131,9 @@ class DeformableDetrFeatureExtractionTest(FeatureExtractionSavingTestMixin, unit
self.assertTrue(hasattr(feature_extractor, "image_std"))
self.assertTrue(hasattr(feature_extractor, "do_normalize"))
self.assertTrue(hasattr(feature_extractor, "do_resize"))
+ self.assertTrue(hasattr(feature_extractor, "do_rescale"))
+ self.assertTrue(hasattr(feature_extractor, "do_pad"))
self.assertTrue(hasattr(feature_extractor, "size"))
- self.assertTrue(hasattr(feature_extractor, "max_size"))
def test_batch_feature(self):
pass
@@ -230,7 +239,8 @@ class DeformableDetrFeatureExtractionTest(FeatureExtractionSavingTestMixin, unit
def test_equivalence_pad_and_create_pixel_mask(self):
# Initialize feature_extractors
feature_extractor_1 = self.feature_extraction_class(**self.feat_extract_dict)
- feature_extractor_2 = self.feature_extraction_class(do_resize=False, do_normalize=False)
+ feature_extractor_2 = self.feature_extraction_class(do_resize=False, do_normalize=False, do_rescale=False)
+
# create random PyTorch tensors
image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False, torchify=True)
for image in image_inputs:
@@ -331,7 +341,7 @@ class DeformableDetrFeatureExtractionTest(FeatureExtractionSavingTestMixin, unit
expected_class_labels = torch.tensor([17, 17, 63, 75, 75, 93])
self.assertTrue(torch.allclose(encoding["labels"][0]["class_labels"], expected_class_labels))
# verify masks
- expected_masks_sum = 822338
+ expected_masks_sum = 822873
self.assertEqual(encoding["labels"][0]["masks"].sum().item(), expected_masks_sum)
# verify orig_size
expected_orig_size = torch.tensor([480, 640])
diff --git a/tests/models/detr/test_feature_extraction_detr.py b/tests/models/detr/test_feature_extraction_detr.py
index 30fae36ed8..12e74c1203 100644
--- a/tests/models/detr/test_feature_extraction_detr.py
+++ b/tests/models/detr/test_feature_extraction_detr.py
@@ -44,12 +44,16 @@ class DetrFeatureExtractionTester(unittest.TestCase):
min_resolution=30,
max_resolution=400,
do_resize=True,
- size=18,
- max_size=1333, # by setting max_size > max_resolution we're effectively not testing this :p
+ size=None,
+ do_rescale=True,
+ rescale_factor=1 / 255,
do_normalize=True,
image_mean=[0.5, 0.5, 0.5],
image_std=[0.5, 0.5, 0.5],
+ do_pad=True,
):
+ # by setting size["longest_edge"] > max_resolution we're effectively not testing this :p
+ size = size if size is not None else {"shortest_edge": 18, "longest_edge": 1333}
self.parent = parent
self.batch_size = batch_size
self.num_channels = num_channels
@@ -57,19 +61,23 @@ class DetrFeatureExtractionTester(unittest.TestCase):
self.max_resolution = max_resolution
self.do_resize = do_resize
self.size = size
- self.max_size = max_size
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
self.do_normalize = do_normalize
self.image_mean = image_mean
self.image_std = image_std
+ self.do_pad = do_pad
def prepare_feat_extract_dict(self):
return {
"do_resize": self.do_resize,
"size": self.size,
- "max_size": self.max_size,
+ "do_rescale": self.do_rescale,
+ "rescale_factor": self.rescale_factor,
"do_normalize": self.do_normalize,
"image_mean": self.image_mean,
"image_std": self.image_std,
+ "do_pad": self.do_pad,
}
def get_expected_values(self, image_inputs, batched=False):
@@ -84,14 +92,14 @@ class DetrFeatureExtractionTester(unittest.TestCase):
else:
h, w = image.shape[1], image.shape[2]
if w < h:
- expected_height = int(self.size * h / w)
- expected_width = self.size
+ expected_height = int(self.size["shortest_edge"] * h / w)
+ expected_width = self.size["shortest_edge"]
elif w > h:
- expected_height = self.size
- expected_width = int(self.size * w / h)
+ expected_height = self.size["shortest_edge"]
+ expected_width = int(self.size["shortest_edge"] * w / h)
else:
- expected_height = self.size
- expected_width = self.size
+ expected_height = self.size["shortest_edge"]
+ expected_width = self.size["shortest_edge"]
else:
expected_values = []
@@ -122,9 +130,11 @@ class DetrFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.TestC
self.assertTrue(hasattr(feature_extractor, "image_mean"))
self.assertTrue(hasattr(feature_extractor, "image_std"))
self.assertTrue(hasattr(feature_extractor, "do_normalize"))
+ self.assertTrue(hasattr(feature_extractor, "do_rescale"))
+ self.assertTrue(hasattr(feature_extractor, "rescale_factor"))
self.assertTrue(hasattr(feature_extractor, "do_resize"))
self.assertTrue(hasattr(feature_extractor, "size"))
- self.assertTrue(hasattr(feature_extractor, "max_size"))
+ self.assertTrue(hasattr(feature_extractor, "do_pad"))
def test_batch_feature(self):
pass
@@ -230,7 +240,7 @@ class DetrFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.TestC
def test_equivalence_pad_and_create_pixel_mask(self):
# Initialize feature_extractors
feature_extractor_1 = self.feature_extraction_class(**self.feat_extract_dict)
- feature_extractor_2 = self.feature_extraction_class(do_resize=False, do_normalize=False)
+ feature_extractor_2 = self.feature_extraction_class(do_resize=False, do_normalize=False, do_rescale=False)
# create random PyTorch tensors
image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False, torchify=True)
for image in image_inputs:
@@ -331,7 +341,7 @@ class DetrFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.TestC
expected_class_labels = torch.tensor([17, 17, 63, 75, 75, 93])
self.assertTrue(torch.allclose(encoding["labels"][0]["class_labels"], expected_class_labels))
# verify masks
- expected_masks_sum = 822338
+ expected_masks_sum = 822873
self.assertEqual(encoding["labels"][0]["masks"].sum().item(), expected_masks_sum)
# verify orig_size
expected_orig_size = torch.tensor([480, 640])
diff --git a/tests/models/maskformer/test_feature_extraction_maskformer.py b/tests/models/maskformer/test_feature_extraction_maskformer.py
index e4384a5134..ca2f504c06 100644
--- a/tests/models/maskformer/test_feature_extraction_maskformer.py
+++ b/tests/models/maskformer/test_feature_extraction_maskformer.py
@@ -31,7 +31,7 @@ if is_torch_available():
if is_vision_available():
from transformers import MaskFormerFeatureExtractor
- from transformers.models.maskformer.feature_extraction_maskformer import binary_mask_to_rle
+ from transformers.models.maskformer.image_processing_maskformer import binary_mask_to_rle
from transformers.models.maskformer.modeling_maskformer import MaskFormerForInstanceSegmentationOutput
if is_vision_available():
@@ -46,9 +46,8 @@ class MaskFormerFeatureExtractionTester(unittest.TestCase):
num_channels=3,
min_resolution=30,
max_resolution=400,
+ size=None,
do_resize=True,
- size=32,
- max_size=1333, # by setting max_size > max_resolution we're effectively not testing this :p
do_normalize=True,
image_mean=[0.5, 0.5, 0.5],
image_std=[0.5, 0.5, 0.5],
@@ -62,12 +61,11 @@ class MaskFormerFeatureExtractionTester(unittest.TestCase):
self.min_resolution = min_resolution
self.max_resolution = max_resolution
self.do_resize = do_resize
- self.size = size
- self.max_size = max_size
+ self.size = {"shortest_edge": 32, "longest_edge": 1333} if size is None else size
self.do_normalize = do_normalize
self.image_mean = image_mean
self.image_std = image_std
- self.size_divisibility = 0
+ self.size_divisor = 0
# for the post_process_functions
self.batch_size = 2
self.num_queries = 3
@@ -82,11 +80,10 @@ class MaskFormerFeatureExtractionTester(unittest.TestCase):
return {
"do_resize": self.do_resize,
"size": self.size,
- "max_size": self.max_size,
"do_normalize": self.do_normalize,
"image_mean": self.image_mean,
"image_std": self.image_std,
- "size_divisibility": self.size_divisibility,
+ "size_divisor": self.size_divisor,
"num_labels": self.num_labels,
"reduce_labels": self.reduce_labels,
"ignore_index": self.ignore_index,
@@ -104,14 +101,14 @@ class MaskFormerFeatureExtractionTester(unittest.TestCase):
else:
h, w = image.shape[1], image.shape[2]
if w < h:
- expected_height = int(self.size * h / w)
- expected_width = self.size
+ expected_height = int(self.size["shortest_edge"] * h / w)
+ expected_width = self.size["shortest_edge"]
elif w > h:
- expected_height = self.size
- expected_width = int(self.size * w / h)
+ expected_height = self.size["shortest_edge"]
+ expected_width = int(self.size["shortest_edge"] * w / h)
else:
- expected_height = self.size
- expected_width = self.size
+ expected_height = self.size["shortest_edge"]
+ expected_width = self.size["shortest_edge"]
else:
expected_values = []
@@ -260,7 +257,7 @@ class MaskFormerFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest
# Initialize feature_extractors
feature_extractor_1 = self.feature_extraction_class(**self.feat_extract_dict)
feature_extractor_2 = self.feature_extraction_class(
- do_resize=False, do_normalize=False, num_labels=self.feature_extract_tester.num_classes
+ do_resize=False, do_normalize=False, do_rescale=False, num_labels=self.feature_extract_tester.num_classes
)
# create random PyTorch tensors
image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False, torchify=True)
@@ -283,23 +280,23 @@ class MaskFormerFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest
):
feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
# prepare image and target
- batch_size = self.feature_extract_tester.batch_size
num_labels = self.feature_extract_tester.num_labels
annotations = None
instance_id_to_semantic_id = None
+ image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False)
if with_segmentation_maps:
high = num_labels
if is_instance_map:
- high * 2
labels_expanded = list(range(num_labels)) * 2
instance_id_to_semantic_id = {
instance_id: label_id for instance_id, label_id in enumerate(labels_expanded)
}
- annotations = [np.random.randint(0, high, (384, 384)).astype(np.uint8) for _ in range(batch_size)]
+ annotations = [
+ np.random.randint(0, high * 2, (img.size[1], img.size[0])).astype(np.uint8) for img in image_inputs
+ ]
if segmentation_type == "pil":
annotations = [Image.fromarray(annotation) for annotation in annotations]
- image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False)
inputs = feature_extractor(
image_inputs,
annotations,
@@ -313,18 +310,18 @@ class MaskFormerFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest
def test_init_without_params(self):
pass
- def test_with_size_divisibility(self):
- size_divisibilities = [8, 16, 32]
+ def test_with_size_divisor(self):
+ size_divisors = [8, 16, 32]
weird_input_sizes = [(407, 802), (582, 1094)]
- for size_divisibility in size_divisibilities:
- feat_extract_dict = {**self.feat_extract_dict, **{"size_divisibility": size_divisibility}}
+ for size_divisor in size_divisors:
+ feat_extract_dict = {**self.feat_extract_dict, **{"size_divisor": size_divisor}}
feature_extractor = self.feature_extraction_class(**feat_extract_dict)
for weird_input_size in weird_input_sizes:
inputs = feature_extractor([np.ones((3, *weird_input_size))], return_tensors="pt")
pixel_values = inputs["pixel_values"]
# check if divisible
- self.assertTrue((pixel_values.shape[-1] % size_divisibility) == 0)
- self.assertTrue((pixel_values.shape[-2] % size_divisibility) == 0)
+ self.assertTrue((pixel_values.shape[-1] % size_divisor) == 0)
+ self.assertTrue((pixel_values.shape[-2] % size_divisor) == 0)
def test_call_with_segmentation_maps(self):
def common(is_instance_map=False, segmentation_type=None):
diff --git a/tests/models/owlvit/test_feature_extraction_owlvit.py b/tests/models/owlvit/test_feature_extraction_owlvit.py
index c9198280d7..0435ea91b9 100644
--- a/tests/models/owlvit/test_feature_extraction_owlvit.py
+++ b/tests/models/owlvit/test_feature_extraction_owlvit.py
@@ -43,9 +43,9 @@ class OwlViTFeatureExtractionTester(unittest.TestCase):
min_resolution=30,
max_resolution=400,
do_resize=True,
- size=20,
+ size=None,
do_center_crop=True,
- crop_size=18,
+ crop_size=None,
do_normalize=True,
image_mean=[0.48145466, 0.4578275, 0.40821073],
image_std=[0.26862954, 0.26130258, 0.27577711],
@@ -58,9 +58,9 @@ class OwlViTFeatureExtractionTester(unittest.TestCase):
self.min_resolution = min_resolution
self.max_resolution = max_resolution
self.do_resize = do_resize
- self.size = size
+ self.size = size if size is not None else {"height": 18, "width": 18}
self.do_center_crop = do_center_crop
- self.crop_size = crop_size
+ self.crop_size = crop_size if crop_size is not None else {"height": 18, "width": 18}
self.do_normalize = do_normalize
self.image_mean = image_mean
self.image_std = image_std
@@ -119,8 +119,8 @@ class OwlViTFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.Tes
(
1,
self.feature_extract_tester.num_channels,
- self.feature_extract_tester.crop_size,
- self.feature_extract_tester.crop_size,
+ self.feature_extract_tester.crop_size["height"],
+ self.feature_extract_tester.crop_size["width"],
),
)
@@ -131,8 +131,8 @@ class OwlViTFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.Tes
(
self.feature_extract_tester.batch_size,
self.feature_extract_tester.num_channels,
- self.feature_extract_tester.crop_size,
- self.feature_extract_tester.crop_size,
+ self.feature_extract_tester.crop_size["height"],
+ self.feature_extract_tester.crop_size["width"],
),
)
@@ -151,8 +151,8 @@ class OwlViTFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.Tes
(
1,
self.feature_extract_tester.num_channels,
- self.feature_extract_tester.crop_size,
- self.feature_extract_tester.crop_size,
+ self.feature_extract_tester.crop_size["height"],
+ self.feature_extract_tester.crop_size["width"],
),
)
@@ -163,8 +163,8 @@ class OwlViTFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.Tes
(
self.feature_extract_tester.batch_size,
self.feature_extract_tester.num_channels,
- self.feature_extract_tester.crop_size,
- self.feature_extract_tester.crop_size,
+ self.feature_extract_tester.crop_size["height"],
+ self.feature_extract_tester.crop_size["width"],
),
)
@@ -183,8 +183,8 @@ class OwlViTFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.Tes
(
1,
self.feature_extract_tester.num_channels,
- self.feature_extract_tester.crop_size,
- self.feature_extract_tester.crop_size,
+ self.feature_extract_tester.crop_size["height"],
+ self.feature_extract_tester.crop_size["width"],
),
)
@@ -195,7 +195,7 @@ class OwlViTFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.Tes
(
self.feature_extract_tester.batch_size,
self.feature_extract_tester.num_channels,
- self.feature_extract_tester.crop_size,
- self.feature_extract_tester.crop_size,
+ self.feature_extract_tester.crop_size["height"],
+ self.feature_extract_tester.crop_size["width"],
),
)
diff --git a/tests/models/yolos/test_feature_extraction_yolos.py b/tests/models/yolos/test_feature_extraction_yolos.py
index 1c3805e8cd..162146e6b6 100644
--- a/tests/models/yolos/test_feature_extraction_yolos.py
+++ b/tests/models/yolos/test_feature_extraction_yolos.py
@@ -44,12 +44,16 @@ class YolosFeatureExtractionTester(unittest.TestCase):
min_resolution=30,
max_resolution=400,
do_resize=True,
- size=18,
- max_size=1333, # by setting max_size > max_resolution we're effectively not testing this :p
+ size=None,
do_normalize=True,
image_mean=[0.5, 0.5, 0.5],
image_std=[0.5, 0.5, 0.5],
+ do_rescale=True,
+ rescale_factor=1 / 255,
+ do_pad=True,
):
+ # by setting size["longest_edge"] > max_resolution we're effectively not testing this :p
+ size = size if size is not None else {"shortest_edge": 18, "longest_edge": 1333}
self.parent = parent
self.batch_size = batch_size
self.num_channels = num_channels
@@ -57,19 +61,23 @@ class YolosFeatureExtractionTester(unittest.TestCase):
self.max_resolution = max_resolution
self.do_resize = do_resize
self.size = size
- self.max_size = max_size
self.do_normalize = do_normalize
self.image_mean = image_mean
self.image_std = image_std
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_pad = do_pad
def prepare_feat_extract_dict(self):
return {
"do_resize": self.do_resize,
"size": self.size,
- "max_size": self.max_size,
"do_normalize": self.do_normalize,
"image_mean": self.image_mean,
"image_std": self.image_std,
+ "do_rescale": self.do_rescale,
+ "rescale_factor": self.rescale_factor,
+ "do_pad": self.do_pad,
}
def get_expected_values(self, image_inputs, batched=False):
@@ -84,14 +92,14 @@ class YolosFeatureExtractionTester(unittest.TestCase):
else:
h, w = image.shape[1], image.shape[2]
if w < h:
- expected_height = int(self.size * h / w)
- expected_width = self.size
+ expected_height = int(self.size["shortest_edge"] * h / w)
+ expected_width = self.size["shortest_edge"]
elif w > h:
- expected_height = self.size
- expected_width = int(self.size * w / h)
+ expected_height = self.size["shortest_edge"]
+ expected_width = int(self.size["shortest_edge"] * w / h)
else:
- expected_height = self.size
- expected_width = self.size
+ expected_height = self.size["shortest_edge"]
+ expected_width = self.size["shortest_edge"]
else:
expected_values = []
@@ -124,7 +132,6 @@ class YolosFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.Test
self.assertTrue(hasattr(feature_extractor, "do_normalize"))
self.assertTrue(hasattr(feature_extractor, "do_resize"))
self.assertTrue(hasattr(feature_extractor, "size"))
- self.assertTrue(hasattr(feature_extractor, "max_size"))
def test_batch_feature(self):
pass
@@ -230,7 +237,7 @@ class YolosFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.Test
def test_equivalence_padding(self):
# Initialize feature_extractors
feature_extractor_1 = self.feature_extraction_class(**self.feat_extract_dict)
- feature_extractor_2 = self.feature_extraction_class(do_resize=False, do_normalize=False)
+ feature_extractor_2 = self.feature_extraction_class(do_resize=False, do_normalize=False, do_rescale=False)
# create random PyTorch tensors
image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False, torchify=True)
for image in image_inputs:
@@ -328,7 +335,7 @@ class YolosFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.Test
expected_class_labels = torch.tensor([17, 17, 63, 75, 75, 93])
self.assertTrue(torch.allclose(encoding["labels"][0]["class_labels"], expected_class_labels))
# verify masks
- expected_masks_sum = 822338
+ expected_masks_sum = 822873
self.assertEqual(encoding["labels"][0]["masks"].sum().item(), expected_masks_sum)
# verify orig_size
expected_orig_size = torch.tensor([480, 640])
+alt="drawing" width="600"/>
YOLOS architecture. Taken from the original paper.
@@ -37,6 +37,12 @@ This model was contributed by [nielsr](https://huggingface.co/nielsr). The origi
[[autodoc]] YolosConfig
+## YolosImageProcessor
+
+[[autodoc]] YolosImageProcessor
+ - preprocess
+ - pad
+ - post_process_object_detection
## YolosFeatureExtractor
@@ -55,4 +61,4 @@ This model was contributed by [nielsr](https://huggingface.co/nielsr). The origi
## YolosForObjectDetection
[[autodoc]] YolosForObjectDetection
- - forward
\ No newline at end of file
+ - forward
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index 75c467fc93..59ec0912c9 100644
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -736,11 +736,15 @@ else:
_import_structure["image_utils"] = ["ImageFeatureExtractionMixin"]
_import_structure["models.beit"].extend(["BeitFeatureExtractor", "BeitImageProcessor"])
_import_structure["models.clip"].extend(["CLIPFeatureExtractor", "CLIPImageProcessor"])
- _import_structure["models.conditional_detr"].append("ConditionalDetrFeatureExtractor")
+ _import_structure["models.conditional_detr"].extend(
+ ["ConditionalDetrFeatureExtractor", "ConditionalDetrImageProcessor"]
+ )
_import_structure["models.convnext"].extend(["ConvNextFeatureExtractor", "ConvNextImageProcessor"])
- _import_structure["models.deformable_detr"].append("DeformableDetrFeatureExtractor")
+ _import_structure["models.deformable_detr"].extend(
+ ["DeformableDetrFeatureExtractor", "DeformableDetrImageProcessor"]
+ )
_import_structure["models.deit"].extend(["DeiTFeatureExtractor", "DeiTImageProcessor"])
- _import_structure["models.detr"].append("DetrFeatureExtractor")
+ _import_structure["models.detr"].extend(["DetrFeatureExtractor", "DetrImageProcessor"])
_import_structure["models.donut"].extend(["DonutFeatureExtractor", "DonutImageProcessor"])
_import_structure["models.dpt"].extend(["DPTFeatureExtractor", "DPTImageProcessor"])
_import_structure["models.flava"].extend(["FlavaFeatureExtractor", "FlavaImageProcessor", "FlavaProcessor"])
@@ -749,18 +753,18 @@ else:
_import_structure["models.layoutlmv2"].extend(["LayoutLMv2FeatureExtractor", "LayoutLMv2ImageProcessor"])
_import_structure["models.layoutlmv3"].extend(["LayoutLMv3FeatureExtractor", "LayoutLMv3ImageProcessor"])
_import_structure["models.levit"].extend(["LevitFeatureExtractor", "LevitImageProcessor"])
- _import_structure["models.maskformer"].append("MaskFormerFeatureExtractor")
+ _import_structure["models.maskformer"].extend(["MaskFormerFeatureExtractor", "MaskFormerImageProcessor"])
_import_structure["models.mobilenet_v1"].extend(["MobileNetV1FeatureExtractor", "MobileNetV1ImageProcessor"])
_import_structure["models.mobilenet_v2"].extend(["MobileNetV2FeatureExtractor", "MobileNetV2ImageProcessor"])
_import_structure["models.mobilevit"].extend(["MobileViTFeatureExtractor", "MobileViTImageProcessor"])
- _import_structure["models.owlvit"].append("OwlViTFeatureExtractor")
+ _import_structure["models.owlvit"].extend(["OwlViTFeatureExtractor", "OwlViTImageProcessor"])
_import_structure["models.perceiver"].extend(["PerceiverFeatureExtractor", "PerceiverImageProcessor"])
_import_structure["models.poolformer"].extend(["PoolFormerFeatureExtractor", "PoolFormerImageProcessor"])
_import_structure["models.segformer"].extend(["SegformerFeatureExtractor", "SegformerImageProcessor"])
_import_structure["models.videomae"].extend(["VideoMAEFeatureExtractor", "VideoMAEImageProcessor"])
_import_structure["models.vilt"].extend(["ViltFeatureExtractor", "ViltImageProcessor", "ViltProcessor"])
_import_structure["models.vit"].extend(["ViTFeatureExtractor", "ViTImageProcessor"])
- _import_structure["models.yolos"].extend(["YolosFeatureExtractor"])
+ _import_structure["models.yolos"].extend(["YolosFeatureExtractor", "YolosImageProcessor"])
# Timm-backed objects
try:
@@ -3869,11 +3873,11 @@ if TYPE_CHECKING:
from .image_utils import ImageFeatureExtractionMixin
from .models.beit import BeitFeatureExtractor, BeitImageProcessor
from .models.clip import CLIPFeatureExtractor, CLIPImageProcessor
- from .models.conditional_detr import ConditionalDetrFeatureExtractor
+ from .models.conditional_detr import ConditionalDetrFeatureExtractor, ConditionalDetrImageProcessor
from .models.convnext import ConvNextFeatureExtractor, ConvNextImageProcessor
- from .models.deformable_detr import DeformableDetrFeatureExtractor
+ from .models.deformable_detr import DeformableDetrFeatureExtractor, DeformableDetrImageProcessor
from .models.deit import DeiTFeatureExtractor, DeiTImageProcessor
- from .models.detr import DetrFeatureExtractor
+ from .models.detr import DetrFeatureExtractor, DetrImageProcessor
from .models.donut import DonutFeatureExtractor, DonutImageProcessor
from .models.dpt import DPTFeatureExtractor, DPTImageProcessor
from .models.flava import FlavaFeatureExtractor, FlavaImageProcessor, FlavaProcessor
@@ -3882,18 +3886,18 @@ if TYPE_CHECKING:
from .models.layoutlmv2 import LayoutLMv2FeatureExtractor, LayoutLMv2ImageProcessor
from .models.layoutlmv3 import LayoutLMv3FeatureExtractor, LayoutLMv3ImageProcessor
from .models.levit import LevitFeatureExtractor, LevitImageProcessor
- from .models.maskformer import MaskFormerFeatureExtractor
+ from .models.maskformer import MaskFormerFeatureExtractor, MaskFormerImageProcessor
from .models.mobilenet_v1 import MobileNetV1FeatureExtractor, MobileNetV1ImageProcessor
from .models.mobilenet_v2 import MobileNetV2FeatureExtractor, MobileNetV2ImageProcessor
from .models.mobilevit import MobileViTFeatureExtractor, MobileViTImageProcessor
- from .models.owlvit import OwlViTFeatureExtractor
+ from .models.owlvit import OwlViTFeatureExtractor, OwlViTImageProcessor
from .models.perceiver import PerceiverFeatureExtractor, PerceiverImageProcessor
from .models.poolformer import PoolFormerFeatureExtractor, PoolFormerImageProcessor
from .models.segformer import SegformerFeatureExtractor, SegformerImageProcessor
from .models.videomae import VideoMAEFeatureExtractor, VideoMAEImageProcessor
from .models.vilt import ViltFeatureExtractor, ViltImageProcessor, ViltProcessor
from .models.vit import ViTFeatureExtractor, ViTImageProcessor
- from .models.yolos import YolosFeatureExtractor
+ from .models.yolos import YolosFeatureExtractor, YolosImageProcessor
# Modeling
try:
diff --git a/src/transformers/image_utils.py b/src/transformers/image_utils.py
index 03aa15d722..789248fbca 100644
--- a/src/transformers/image_utils.py
+++ b/src/transformers/image_utils.py
@@ -14,7 +14,7 @@
# limitations under the License.
import os
-from typing import TYPE_CHECKING, List, Tuple, Union
+from typing import TYPE_CHECKING, Dict, Iterable, List, Tuple, Union
import numpy as np
from packaging import version
@@ -163,6 +163,47 @@ def get_image_size(image: np.ndarray, channel_dim: ChannelDimension = None) -> T
raise ValueError(f"Unsupported data format: {channel_dim}")
+def is_valid_annotation_coco_detection(annotation: Dict[str, Union[List, Tuple]]) -> bool:
+ if (
+ isinstance(annotation, dict)
+ and "image_id" in annotation
+ and "annotations" in annotation
+ and isinstance(annotation["annotations"], (list, tuple))
+ and (
+ # an image can have no annotations
+ len(annotation["annotations"]) == 0
+ or isinstance(annotation["annotations"][0], dict)
+ )
+ ):
+ return True
+ return False
+
+
+def is_valid_annotation_coco_panoptic(annotation: Dict[str, Union[List, Tuple]]) -> bool:
+ if (
+ isinstance(annotation, dict)
+ and "image_id" in annotation
+ and "segments_info" in annotation
+ and "file_name" in annotation
+ and isinstance(annotation["segments_info"], (list, tuple))
+ and (
+ # an image can have no segments
+ len(annotation["segments_info"]) == 0
+ or isinstance(annotation["segments_info"][0], dict)
+ )
+ ):
+ return True
+ return False
+
+
+def valid_coco_detection_annotations(annotations: Iterable[Dict[str, Union[List, Tuple]]]) -> bool:
+ return all(is_valid_annotation_coco_detection(ann) for ann in annotations)
+
+
+def valid_coco_panoptic_annotations(annotations: Iterable[Dict[str, Union[List, Tuple]]]) -> bool:
+ return all(is_valid_annotation_coco_panoptic(ann) for ann in annotations)
+
+
def load_image(image: Union[str, "PIL.Image.Image"]) -> "PIL.Image.Image":
"""
Loads `image` to a PIL Image.
diff --git a/src/transformers/models/auto/image_processing_auto.py b/src/transformers/models/auto/image_processing_auto.py
index df77c52314..fd540989f9 100644
--- a/src/transformers/models/auto/image_processing_auto.py
+++ b/src/transformers/models/auto/image_processing_auto.py
@@ -39,10 +39,14 @@ IMAGE_PROCESSOR_MAPPING_NAMES = OrderedDict(
[
("beit", "BeitImageProcessor"),
("clip", "CLIPImageProcessor"),
+ ("clipseg", "ViTImageProcessor"),
+ ("conditional_detr", "ConditionalDetrImageProcessor"),
("convnext", "ConvNextImageProcessor"),
("cvt", "ConvNextImageProcessor"),
("data2vec-vision", "BeitImageProcessor"),
+ ("deformable_detr", "DeformableDetrImageProcessor"),
("deit", "DeiTImageProcessor"),
+ ("detr", "DetrImageProcessor"),
("dinat", "ViTImageProcessor"),
("donut-swin", "DonutImageProcessor"),
("dpt", "DPTImageProcessor"),
@@ -53,10 +57,14 @@ IMAGE_PROCESSOR_MAPPING_NAMES = OrderedDict(
("layoutlmv2", "LayoutLMv2ImageProcessor"),
("layoutlmv3", "LayoutLMv3ImageProcessor"),
("levit", "LevitImageProcessor"),
+ ("maskformer", "MaskFormerImageProcessor"),
("mobilenet_v1", "MobileNetV1ImageProcessor"),
("mobilenet_v2", "MobileNetV2ImageProcessor"),
+ ("mobilenet_v2", "MobileNetV2ImageProcessor"),
+ ("mobilevit", "MobileViTImageProcessor"),
("mobilevit", "MobileViTImageProcessor"),
("nat", "ViTImageProcessor"),
+ ("owlvit", "OwlViTImageProcessor"),
("perceiver", "PerceiverImageProcessor"),
("poolformer", "PoolFormerImageProcessor"),
("regnet", "ConvNextImageProcessor"),
@@ -64,6 +72,7 @@ IMAGE_PROCESSOR_MAPPING_NAMES = OrderedDict(
("segformer", "SegformerImageProcessor"),
("swin", "ViTImageProcessor"),
("swinv2", "ViTImageProcessor"),
+ ("table-transformer", "DetrImageProcessor"),
("van", "ConvNextImageProcessor"),
("videomae", "VideoMAEImageProcessor"),
("vilt", "ViltImageProcessor"),
@@ -71,6 +80,7 @@ IMAGE_PROCESSOR_MAPPING_NAMES = OrderedDict(
("vit_mae", "ViTImageProcessor"),
("vit_msn", "ViTImageProcessor"),
("xclip", "CLIPImageProcessor"),
+ ("yolos", "YolosImageProcessor"),
]
)
@@ -113,7 +123,7 @@ def get_image_processor_config(
**kwargs,
):
"""
- Loads the image processor configuration from a pretrained model imag processor configuration. # FIXME
+ Loads the image processor configuration from a pretrained model image processor configuration.
Args:
pretrained_model_name_or_path (`str` or `os.PathLike`):
diff --git a/src/transformers/models/conditional_detr/__init__.py b/src/transformers/models/conditional_detr/__init__.py
index c2f1bdfdbb..fd69edfeb7 100644
--- a/src/transformers/models/conditional_detr/__init__.py
+++ b/src/transformers/models/conditional_detr/__init__.py
@@ -36,6 +36,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_conditional_detr"] = ["ConditionalDetrFeatureExtractor"]
+ _import_structure["image_processing_conditional_detr"] = ["ConditionalDetrImageProcessor"]
try:
if not is_timm_available():
@@ -66,6 +67,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_conditional_detr import ConditionalDetrFeatureExtractor
+ from .image_processing_conditional_detr import ConditionalDetrImageProcessor
try:
if not is_timm_available():
diff --git a/src/transformers/models/conditional_detr/feature_extraction_conditional_detr.py b/src/transformers/models/conditional_detr/feature_extraction_conditional_detr.py
index 01efb90542..ce04afba98 100644
--- a/src/transformers/models/conditional_detr/feature_extraction_conditional_detr.py
+++ b/src/transformers/models/conditional_detr/feature_extraction_conditional_detr.py
@@ -14,1108 +14,10 @@
# limitations under the License.
"""Feature extractor class for Conditional DETR."""
-import pathlib
-import warnings
-from typing import Dict, List, Optional, Set, Tuple, Union
+from ...utils import logging
+from .image_processing_conditional_detr import ConditionalDetrImageProcessor
-import numpy as np
-from PIL import Image
-
-from ...feature_extraction_utils import BatchFeature, FeatureExtractionMixin
-from ...image_transforms import center_to_corners_format, corners_to_center_format, rgb_to_id
-from ...image_utils import ImageFeatureExtractionMixin
-from ...utils import TensorType, is_torch_available, is_torch_tensor, logging
-
-
-if is_torch_available():
- import torch
- from torch import nn
logger = logging.get_logger(__name__)
-
-ImageInput = Union[Image.Image, np.ndarray, "torch.Tensor", List[Image.Image], List[np.ndarray], List["torch.Tensor"]]
-
-
-# Copied from transformers.models.detr.feature_extraction_detr.masks_to_boxes
-def masks_to_boxes(masks):
- """
- Compute the bounding boxes around the provided panoptic segmentation masks.
-
- The masks should be in format [N, H, W] where N is the number of masks, (H, W) are the spatial dimensions.
-
- Returns a [N, 4] tensor, with the boxes in corner (xyxy) format.
- """
- if masks.size == 0:
- return np.zeros((0, 4))
-
- h, w = masks.shape[-2:]
-
- y = np.arange(0, h, dtype=np.float32)
- x = np.arange(0, w, dtype=np.float32)
- # see https://github.com/pytorch/pytorch/issues/50276
- y, x = np.meshgrid(y, x, indexing="ij")
-
- x_mask = masks * np.expand_dims(x, axis=0)
- x_max = x_mask.reshape(x_mask.shape[0], -1).max(-1)
- x = np.ma.array(x_mask, mask=~(np.array(masks, dtype=bool)))
- x_min = x.filled(fill_value=1e8)
- x_min = x_min.reshape(x_min.shape[0], -1).min(-1)
-
- y_mask = masks * np.expand_dims(y, axis=0)
- y_max = y_mask.reshape(x_mask.shape[0], -1).max(-1)
- y = np.ma.array(y_mask, mask=~(np.array(masks, dtype=bool)))
- y_min = y.filled(fill_value=1e8)
- y_min = y_min.reshape(y_min.shape[0], -1).min(-1)
-
- return np.stack([x_min, y_min, x_max, y_max], 1)
-
-
-# Copied from transformers.models.detr.feature_extraction_detr.binary_mask_to_rle
-def binary_mask_to_rle(mask):
- """
- Args:
- Converts given binary mask of shape (height, width) to the run-length encoding (RLE) format.
- mask (`torch.Tensor` or `numpy.array`):
- A binary mask tensor of shape `(height, width)` where 0 denotes background and 1 denotes the target
- segment_id or class_id.
- Returns:
- `List`: Run-length encoded list of the binary mask. Refer to COCO API for more information about the RLE
- format.
- """
- if is_torch_tensor(mask):
- mask = mask.numpy()
-
- pixels = mask.flatten()
- pixels = np.concatenate([[0], pixels, [0]])
- runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
- runs[1::2] -= runs[::2]
- return [x for x in runs]
-
-
-# Copied from transformers.models.detr.feature_extraction_detr.convert_segmentation_to_rle
-def convert_segmentation_to_rle(segmentation):
- """
- Converts given segmentation map of shape (height, width) to the run-length encoding (RLE) format.
-
- Args:
- segmentation (`torch.Tensor` or `numpy.array`):
- A segmentation map of shape `(height, width)` where each value denotes a segment or class id.
- Returns:
- `List[List]`: A list of lists, where each list is the run-length encoding of a segment / class id.
- """
- segment_ids = torch.unique(segmentation)
-
- run_length_encodings = []
- for idx in segment_ids:
- mask = torch.where(segmentation == idx, 1, 0)
- rle = binary_mask_to_rle(mask)
- run_length_encodings.append(rle)
-
- return run_length_encodings
-
-
-# Copied from transformers.models.detr.feature_extraction_detr.remove_low_and_no_objects
-def remove_low_and_no_objects(masks, scores, labels, object_mask_threshold, num_labels):
- """
- Binarize the given masks using `object_mask_threshold`, it returns the associated values of `masks`, `scores` and
- `labels`.
-
- Args:
- masks (`torch.Tensor`):
- A tensor of shape `(num_queries, height, width)`.
- scores (`torch.Tensor`):
- A tensor of shape `(num_queries)`.
- labels (`torch.Tensor`):
- A tensor of shape `(num_queries)`.
- object_mask_threshold (`float`):
- A number between 0 and 1 used to binarize the masks.
- Raises:
- `ValueError`: Raised when the first dimension doesn't match in all input tensors.
- Returns:
- `Tuple[`torch.Tensor`, `torch.Tensor`, `torch.Tensor`]`: The `masks`, `scores` and `labels` without the region
- < `object_mask_threshold`.
- """
- if not (masks.shape[0] == scores.shape[0] == labels.shape[0]):
- raise ValueError("mask, scores and labels must have the same shape!")
-
- to_keep = labels.ne(num_labels) & (scores > object_mask_threshold)
-
- return masks[to_keep], scores[to_keep], labels[to_keep]
-
-
-# Copied from transformers.models.detr.feature_extraction_detr.check_segment_validity
-def check_segment_validity(mask_labels, mask_probs, k, mask_threshold=0.5, overlap_mask_area_threshold=0.8):
- # Get the mask associated with the k class
- mask_k = mask_labels == k
- mask_k_area = mask_k.sum()
-
- # Compute the area of all the stuff in query k
- original_area = (mask_probs[k] >= mask_threshold).sum()
- mask_exists = mask_k_area > 0 and original_area > 0
-
- # Eliminate disconnected tiny segments
- if mask_exists:
- area_ratio = mask_k_area / original_area
- if not area_ratio.item() > overlap_mask_area_threshold:
- mask_exists = False
-
- return mask_exists, mask_k
-
-
-# Copied from transformers.models.detr.feature_extraction_detr.compute_segments
-def compute_segments(
- mask_probs,
- pred_scores,
- pred_labels,
- mask_threshold: float = 0.5,
- overlap_mask_area_threshold: float = 0.8,
- label_ids_to_fuse: Optional[Set[int]] = None,
- target_size: Tuple[int, int] = None,
-):
- height = mask_probs.shape[1] if target_size is None else target_size[0]
- width = mask_probs.shape[2] if target_size is None else target_size[1]
-
- segmentation = torch.zeros((height, width), dtype=torch.int32, device=mask_probs.device)
- segments: List[Dict] = []
-
- if target_size is not None:
- mask_probs = nn.functional.interpolate(
- mask_probs.unsqueeze(0), size=target_size, mode="bilinear", align_corners=False
- )[0]
-
- current_segment_id = 0
-
- # Weigh each mask by its prediction score
- mask_probs *= pred_scores.view(-1, 1, 1)
- mask_labels = mask_probs.argmax(0) # [height, width]
-
- # Keep track of instances of each class
- stuff_memory_list: Dict[str, int] = {}
- for k in range(pred_labels.shape[0]):
- pred_class = pred_labels[k].item()
- should_fuse = pred_class in label_ids_to_fuse
-
- # Check if mask exists and large enough to be a segment
- mask_exists, mask_k = check_segment_validity(
- mask_labels, mask_probs, k, mask_threshold, overlap_mask_area_threshold
- )
-
- if mask_exists:
- if pred_class in stuff_memory_list:
- current_segment_id = stuff_memory_list[pred_class]
- else:
- current_segment_id += 1
-
- # Add current object segment to final segmentation map
- segmentation[mask_k] = current_segment_id
- segment_score = round(pred_scores[k].item(), 6)
- segments.append(
- {
- "id": current_segment_id,
- "label_id": pred_class,
- "was_fused": should_fuse,
- "score": segment_score,
- }
- )
- if should_fuse:
- stuff_memory_list[pred_class] = current_segment_id
-
- return segmentation, segments
-
-
-class ConditionalDetrFeatureExtractor(FeatureExtractionMixin, ImageFeatureExtractionMixin):
- r"""
- Constructs a Conditional DETR feature extractor.
-
- This feature extractor inherits from [`FeatureExtractionMixin`] which contains most of the main methods. Users
- should refer to this superclass for more information regarding those methods.
-
- Args:
- format (`str`, *optional*, defaults to `"coco_detection"`):
- Data format of the annotations. One of "coco_detection" or "coco_panoptic".
- do_resize (`bool`, *optional*, defaults to `True`):
- Whether to resize the input to a certain `size`.
- size (`int`, *optional*, defaults to 800):
- Resize the input to the given size. Only has an effect if `do_resize` is set to `True`. If size is a
- sequence like `(width, height)`, output size will be matched to this. If size is an int, smaller edge of
- the image will be matched to this number. i.e, if `height > width`, then image will be rescaled to `(size *
- height / width, size)`.
- max_size (`int`, *optional*, defaults to `1333`):
- The largest size an image dimension can have (otherwise it's capped). Only has an effect if `do_resize` is
- set to `True`.
- do_normalize (`bool`, *optional*, defaults to `True`):
- Whether or not to normalize the input with mean and standard deviation.
- image_mean (`int`, *optional*, defaults to `[0.485, 0.456, 0.406]`):
- The sequence of means for each channel, to be used when normalizing images. Defaults to the ImageNet mean.
- image_std (`int`, *optional*, defaults to `[0.229, 0.224, 0.225]`):
- The sequence of standard deviations for each channel, to be used when normalizing images. Defaults to the
- ImageNet std.
- """
-
- model_input_names = ["pixel_values", "pixel_mask"]
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.__init__
- def __init__(
- self,
- format="coco_detection",
- do_resize=True,
- size=800,
- max_size=1333,
- do_normalize=True,
- image_mean=None,
- image_std=None,
- **kwargs
- ):
- super().__init__(**kwargs)
- self.format = self._is_valid_format(format)
- self.do_resize = do_resize
- self.size = size
- self.max_size = max_size
- self.do_normalize = do_normalize
- self.image_mean = image_mean if image_mean is not None else [0.485, 0.456, 0.406] # ImageNet mean
- self.image_std = image_std if image_std is not None else [0.229, 0.224, 0.225] # ImageNet std
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._is_valid_format
- def _is_valid_format(self, format):
- if format not in ["coco_detection", "coco_panoptic"]:
- raise ValueError(f"Format {format} not supported")
- return format
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.prepare
- def prepare(self, image, target, return_segmentation_masks=False, masks_path=None):
- if self.format == "coco_detection":
- image, target = self.prepare_coco_detection(image, target, return_segmentation_masks)
- return image, target
- elif self.format == "coco_panoptic":
- image, target = self.prepare_coco_panoptic(image, target, masks_path)
- return image, target
- else:
- raise ValueError(f"Format {self.format} not supported")
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.convert_coco_poly_to_mask
- def convert_coco_poly_to_mask(self, segmentations, height, width):
-
- try:
- from pycocotools import mask as coco_mask
- except ImportError:
- raise ImportError("Pycocotools is not installed in your environment.")
-
- masks = []
- for polygons in segmentations:
- rles = coco_mask.frPyObjects(polygons, height, width)
- mask = coco_mask.decode(rles)
- if len(mask.shape) < 3:
- mask = mask[..., None]
- mask = np.asarray(mask, dtype=np.uint8)
- mask = np.any(mask, axis=2)
- masks.append(mask)
- if masks:
- masks = np.stack(masks, axis=0)
- else:
- masks = np.zeros((0, height, width), dtype=np.uint8)
-
- return masks
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.prepare_coco_detection with DETR->ConditionalDETR
- def prepare_coco_detection(self, image, target, return_segmentation_masks=False):
- """
- Convert the target in COCO format into the format expected by ConditionalDETR.
- """
- w, h = image.size
-
- image_id = target["image_id"]
- image_id = np.asarray([image_id], dtype=np.int64)
-
- # get all COCO annotations for the given image
- anno = target["annotations"]
-
- anno = [obj for obj in anno if "iscrowd" not in obj or obj["iscrowd"] == 0]
-
- boxes = [obj["bbox"] for obj in anno]
- # guard against no boxes via resizing
- boxes = np.asarray(boxes, dtype=np.float32).reshape(-1, 4)
- boxes[:, 2:] += boxes[:, :2]
- boxes[:, 0::2] = boxes[:, 0::2].clip(min=0, max=w)
- boxes[:, 1::2] = boxes[:, 1::2].clip(min=0, max=h)
-
- classes = [obj["category_id"] for obj in anno]
- classes = np.asarray(classes, dtype=np.int64)
-
- if return_segmentation_masks:
- segmentations = [obj["segmentation"] for obj in anno]
- masks = self.convert_coco_poly_to_mask(segmentations, h, w)
-
- keypoints = None
- if anno and "keypoints" in anno[0]:
- keypoints = [obj["keypoints"] for obj in anno]
- keypoints = np.asarray(keypoints, dtype=np.float32)
- num_keypoints = keypoints.shape[0]
- if num_keypoints:
- keypoints = keypoints.reshape((-1, 3))
-
- keep = (boxes[:, 3] > boxes[:, 1]) & (boxes[:, 2] > boxes[:, 0])
- boxes = boxes[keep]
- classes = classes[keep]
- if return_segmentation_masks:
- masks = masks[keep]
- if keypoints is not None:
- keypoints = keypoints[keep]
-
- target = {}
- target["boxes"] = boxes
- target["class_labels"] = classes
- if return_segmentation_masks:
- target["masks"] = masks
- target["image_id"] = image_id
- if keypoints is not None:
- target["keypoints"] = keypoints
-
- # for conversion to coco api
- area = np.asarray([obj["area"] for obj in anno], dtype=np.float32)
- iscrowd = np.asarray([obj["iscrowd"] if "iscrowd" in obj else 0 for obj in anno], dtype=np.int64)
- target["area"] = area[keep]
- target["iscrowd"] = iscrowd[keep]
-
- target["orig_size"] = np.asarray([int(h), int(w)], dtype=np.int64)
- target["size"] = np.asarray([int(h), int(w)], dtype=np.int64)
-
- return image, target
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.prepare_coco_panoptic
- def prepare_coco_panoptic(self, image, target, masks_path, return_masks=True):
- w, h = image.size
- ann_info = target.copy()
- ann_path = pathlib.Path(masks_path) / ann_info["file_name"]
-
- if "segments_info" in ann_info:
- masks = np.asarray(Image.open(ann_path), dtype=np.uint32)
- masks = rgb_to_id(masks)
-
- ids = np.array([ann["id"] for ann in ann_info["segments_info"]])
- masks = masks == ids[:, None, None]
- masks = np.asarray(masks, dtype=np.uint8)
-
- labels = np.asarray([ann["category_id"] for ann in ann_info["segments_info"]], dtype=np.int64)
-
- target = {}
- target["image_id"] = np.asarray(
- [ann_info["image_id"] if "image_id" in ann_info else ann_info["id"]], dtype=np.int64
- )
- if return_masks:
- target["masks"] = masks
- target["class_labels"] = labels
-
- target["boxes"] = masks_to_boxes(masks)
-
- target["size"] = np.asarray([int(h), int(w)], dtype=np.int64)
- target["orig_size"] = np.asarray([int(h), int(w)], dtype=np.int64)
- if "segments_info" in ann_info:
- target["iscrowd"] = np.asarray([ann["iscrowd"] for ann in ann_info["segments_info"]], dtype=np.int64)
- target["area"] = np.asarray([ann["area"] for ann in ann_info["segments_info"]], dtype=np.float32)
-
- return image, target
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._resize
- def _resize(self, image, size, target=None, max_size=None):
- """
- Resize the image to the given size. Size can be min_size (scalar) or (w, h) tuple. If size is an int, smaller
- edge of the image will be matched to this number.
-
- If given, also resize the target accordingly.
- """
- if not isinstance(image, Image.Image):
- image = self.to_pil_image(image)
-
- def get_size_with_aspect_ratio(image_size, size, max_size=None):
- w, h = image_size
- if max_size is not None:
- min_original_size = float(min((w, h)))
- max_original_size = float(max((w, h)))
- if max_original_size / min_original_size * size > max_size:
- size = int(round(max_size * min_original_size / max_original_size))
-
- if (w <= h and w == size) or (h <= w and h == size):
- return (h, w)
-
- if w < h:
- ow = size
- oh = int(size * h / w)
- else:
- oh = size
- ow = int(size * w / h)
-
- return (oh, ow)
-
- def get_size(image_size, size, max_size=None):
- if isinstance(size, (list, tuple)):
- return size
- else:
- # size returned must be (w, h) since we use PIL to resize images
- # so we revert the tuple
- return get_size_with_aspect_ratio(image_size, size, max_size)[::-1]
-
- size = get_size(image.size, size, max_size)
- rescaled_image = self.resize(image, size=size)
-
- if target is None:
- return rescaled_image, None
-
- ratios = tuple(float(s) / float(s_orig) for s, s_orig in zip(rescaled_image.size, image.size))
- ratio_width, ratio_height = ratios
-
- target = target.copy()
- if "boxes" in target:
- boxes = target["boxes"]
- scaled_boxes = boxes * np.asarray([ratio_width, ratio_height, ratio_width, ratio_height], dtype=np.float32)
- target["boxes"] = scaled_boxes
-
- if "area" in target:
- area = target["area"]
- scaled_area = area * (ratio_width * ratio_height)
- target["area"] = scaled_area
-
- w, h = size
- target["size"] = np.asarray([h, w], dtype=np.int64)
-
- if "masks" in target:
- # use PyTorch as current workaround
- # TODO replace by self.resize
- masks = torch.from_numpy(target["masks"][:, None]).float()
- interpolated_masks = nn.functional.interpolate(masks, size=(h, w), mode="nearest")[:, 0] > 0.5
- target["masks"] = interpolated_masks.numpy()
-
- return rescaled_image, target
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._normalize
- def _normalize(self, image, mean, std, target=None):
- """
- Normalize the image with a certain mean and std.
-
- If given, also normalize the target bounding boxes based on the size of the image.
- """
-
- image = self.normalize(image, mean=mean, std=std)
- if target is None:
- return image, None
-
- target = target.copy()
- h, w = image.shape[-2:]
-
- if "boxes" in target:
- boxes = target["boxes"]
- boxes = corners_to_center_format(boxes)
- boxes = boxes / np.asarray([w, h, w, h], dtype=np.float32)
- target["boxes"] = boxes
-
- return image, target
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.__call__ with Detr->ConditionalDetr,DETR->ConditionalDETR
- def __call__(
- self,
- images: ImageInput,
- annotations: Union[List[Dict], List[List[Dict]]] = None,
- return_segmentation_masks: Optional[bool] = False,
- masks_path: Optional[pathlib.Path] = None,
- pad_and_return_pixel_mask: Optional[bool] = True,
- return_tensors: Optional[Union[str, TensorType]] = None,
- **kwargs,
- ) -> BatchFeature:
- """
- Main method to prepare for the model one or several image(s) and optional annotations. Images are by default
- padded up to the largest image in a batch, and a pixel mask is created that indicates which pixels are
- real/which are padding.
-
-
-
- NumPy arrays and PyTorch tensors are converted to PIL images when resizing, so the most efficient is to pass
- PIL images.
-
-
-
- Args:
- images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
- The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
- tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a
- number of channels, H and W are image height and width.
-
- annotations (`Dict`, `List[Dict]`, *optional*):
- The corresponding annotations in COCO format.
-
- In case [`ConditionalDetrFeatureExtractor`] was initialized with `format = "coco_detection"`, the
- annotations for each image should have the following format: {'image_id': int, 'annotations':
- [annotation]}, with the annotations being a list of COCO object annotations.
-
- In case [`ConditionalDetrFeatureExtractor`] was initialized with `format = "coco_panoptic"`, the
- annotations for each image should have the following format: {'image_id': int, 'file_name': str,
- 'segments_info': [segment_info]} with segments_info being a list of COCO panoptic annotations.
-
- return_segmentation_masks (`Dict`, `List[Dict]`, *optional*, defaults to `False`):
- Whether to also include instance segmentation masks as part of the labels in case `format =
- "coco_detection"`.
-
- masks_path (`pathlib.Path`, *optional*):
- Path to the directory containing the PNG files that store the class-agnostic image segmentations. Only
- relevant in case [`ConditionalDetrFeatureExtractor`] was initialized with `format = "coco_panoptic"`.
-
- pad_and_return_pixel_mask (`bool`, *optional*, defaults to `True`):
- Whether or not to pad images up to the largest image in a batch and create a pixel mask.
-
- If left to the default, will return a pixel mask that is:
-
- - 1 for pixels that are real (i.e. **not masked**),
- - 0 for pixels that are padding (i.e. **masked**).
-
- return_tensors (`str` or [`~utils.TensorType`], *optional*):
- If set, will return tensors instead of NumPy arrays. If set to `'pt'`, return PyTorch `torch.Tensor`
- objects.
-
- Returns:
- [`BatchFeature`]: A [`BatchFeature`] with the following fields:
-
- - **pixel_values** -- Pixel values to be fed to a model.
- - **pixel_mask** -- Pixel mask to be fed to a model (when `pad_and_return_pixel_mask=True` or if
- *"pixel_mask"* is in `self.model_input_names`).
- - **labels** -- Optional labels to be fed to a model (when `annotations` are provided)
- """
- # Input type checking for clearer error
-
- valid_images = False
- valid_annotations = False
- valid_masks_path = False
-
- # Check that images has a valid type
- if isinstance(images, (Image.Image, np.ndarray)) or is_torch_tensor(images):
- valid_images = True
- elif isinstance(images, (list, tuple)):
- if len(images) == 0 or isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]):
- valid_images = True
-
- if not valid_images:
- raise ValueError(
- "Images must of type `PIL.Image.Image`, `np.ndarray` or `torch.Tensor` (single example), "
- "`List[PIL.Image.Image]`, `List[np.ndarray]` or `List[torch.Tensor]` (batch of examples)."
- )
-
- is_batched = bool(
- isinstance(images, (list, tuple))
- and (isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]))
- )
-
- # Check that annotations has a valid type
- if annotations is not None:
- if not is_batched:
- if self.format == "coco_detection":
- if isinstance(annotations, dict) and "image_id" in annotations and "annotations" in annotations:
- if isinstance(annotations["annotations"], (list, tuple)):
- # an image can have no annotations
- if len(annotations["annotations"]) == 0 or isinstance(annotations["annotations"][0], dict):
- valid_annotations = True
- elif self.format == "coco_panoptic":
- if isinstance(annotations, dict) and "image_id" in annotations and "segments_info" in annotations:
- if isinstance(annotations["segments_info"], (list, tuple)):
- # an image can have no segments (?)
- if len(annotations["segments_info"]) == 0 or isinstance(
- annotations["segments_info"][0], dict
- ):
- valid_annotations = True
- else:
- if isinstance(annotations, (list, tuple)):
- if len(images) != len(annotations):
- raise ValueError("There must be as many annotations as there are images")
- if isinstance(annotations[0], Dict):
- if self.format == "coco_detection":
- if isinstance(annotations[0]["annotations"], (list, tuple)):
- valid_annotations = True
- elif self.format == "coco_panoptic":
- if isinstance(annotations[0]["segments_info"], (list, tuple)):
- valid_annotations = True
-
- if not valid_annotations:
- raise ValueError(
- """
- Annotations must of type `Dict` (single image) or `List[Dict]` (batch of images). In case of object
- detection, each dictionary should contain the keys 'image_id' and 'annotations', with the latter
- being a list of annotations in COCO format. In case of panoptic segmentation, each dictionary
- should contain the keys 'file_name', 'image_id' and 'segments_info', with the latter being a list
- of annotations in COCO format.
- """
- )
-
- # Check that masks_path has a valid type
- if masks_path is not None:
- if self.format == "coco_panoptic":
- if isinstance(masks_path, pathlib.Path):
- valid_masks_path = True
- if not valid_masks_path:
- raise ValueError(
- "The path to the directory containing the mask PNG files should be provided as a"
- " `pathlib.Path` object."
- )
-
- if not is_batched:
- images = [images]
- if annotations is not None:
- annotations = [annotations]
-
- # Create a copy of the list to avoid editing it in place
- images = [image for image in images]
-
- if annotations is not None:
- annotations = [annotation for annotation in annotations]
-
- # prepare (COCO annotations as a list of Dict -> ConditionalDETR target as a single Dict per image)
- if annotations is not None:
- for idx, (image, target) in enumerate(zip(images, annotations)):
- if not isinstance(image, Image.Image):
- image = self.to_pil_image(image)
- image, target = self.prepare(image, target, return_segmentation_masks, masks_path)
- images[idx] = image
- annotations[idx] = target
-
- # transformations (resizing + normalization)
- if self.do_resize and self.size is not None:
- if annotations is not None:
- for idx, (image, target) in enumerate(zip(images, annotations)):
- image, target = self._resize(image=image, target=target, size=self.size, max_size=self.max_size)
- images[idx] = image
- annotations[idx] = target
- else:
- for idx, image in enumerate(images):
- images[idx] = self._resize(image=image, target=None, size=self.size, max_size=self.max_size)[0]
-
- if self.do_normalize:
- if annotations is not None:
- for idx, (image, target) in enumerate(zip(images, annotations)):
- image, target = self._normalize(
- image=image, mean=self.image_mean, std=self.image_std, target=target
- )
- images[idx] = image
- annotations[idx] = target
- else:
- images = [
- self._normalize(image=image, mean=self.image_mean, std=self.image_std)[0] for image in images
- ]
- else:
- images = [np.array(image) for image in images]
-
- if pad_and_return_pixel_mask:
- # pad images up to largest image in batch and create pixel_mask
- max_size = self._max_by_axis([list(image.shape) for image in images])
- c, h, w = max_size
- padded_images = []
- pixel_mask = []
- for image in images:
- # create padded image
- padded_image = np.zeros((c, h, w), dtype=np.float32)
- padded_image[: image.shape[0], : image.shape[1], : image.shape[2]] = np.copy(image)
- padded_images.append(padded_image)
- # create pixel mask
- mask = np.zeros((h, w), dtype=np.int64)
- mask[: image.shape[1], : image.shape[2]] = True
- pixel_mask.append(mask)
- images = padded_images
-
- # return as BatchFeature
- data = {}
- data["pixel_values"] = images
- if pad_and_return_pixel_mask:
- data["pixel_mask"] = pixel_mask
- encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
-
- if annotations is not None:
- # Convert to TensorType
- tensor_type = return_tensors
- if not isinstance(tensor_type, TensorType):
- tensor_type = TensorType(tensor_type)
-
- if not tensor_type == TensorType.PYTORCH:
- raise ValueError("Only PyTorch is supported for the moment.")
- else:
- if not is_torch_available():
- raise ImportError("Unable to convert output to PyTorch tensors format, PyTorch is not installed.")
-
- encoded_inputs["labels"] = [
- {k: torch.from_numpy(v) for k, v in target.items()} for target in annotations
- ]
-
- return encoded_inputs
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._max_by_axis
- def _max_by_axis(self, the_list):
- # type: (List[List[int]]) -> List[int]
- maxes = the_list[0]
- for sublist in the_list[1:]:
- for index, item in enumerate(sublist):
- maxes[index] = max(maxes[index], item)
- return maxes
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.pad_and_create_pixel_mask
- def pad_and_create_pixel_mask(
- self, pixel_values_list: List["torch.Tensor"], return_tensors: Optional[Union[str, TensorType]] = None
- ):
- """
- Pad images up to the largest image in a batch and create a corresponding `pixel_mask`.
-
- Args:
- pixel_values_list (`List[torch.Tensor]`):
- List of images (pixel values) to be padded. Each image should be a tensor of shape (C, H, W).
- return_tensors (`str` or [`~utils.TensorType`], *optional*):
- If set, will return tensors instead of NumPy arrays. If set to `'pt'`, return PyTorch `torch.Tensor`
- objects.
-
- Returns:
- [`BatchFeature`]: A [`BatchFeature`] with the following fields:
-
- - **pixel_values** -- Pixel values to be fed to a model.
- - **pixel_mask** -- Pixel mask to be fed to a model (when `pad_and_return_pixel_mask=True` or if
- *"pixel_mask"* is in `self.model_input_names`).
-
- """
-
- max_size = self._max_by_axis([list(image.shape) for image in pixel_values_list])
- c, h, w = max_size
- padded_images = []
- pixel_mask = []
- for image in pixel_values_list:
- # create padded image
- padded_image = np.zeros((c, h, w), dtype=np.float32)
- padded_image[: image.shape[0], : image.shape[1], : image.shape[2]] = np.copy(image)
- padded_images.append(padded_image)
- # create pixel mask
- mask = np.zeros((h, w), dtype=np.int64)
- mask[: image.shape[1], : image.shape[2]] = True
- pixel_mask.append(mask)
-
- # return as BatchFeature
- data = {"pixel_values": padded_images, "pixel_mask": pixel_mask}
- encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
-
- return encoded_inputs
-
- def post_process(self, outputs, target_sizes):
- """
- Args:
- Converts the output of [`ConditionalDetrForObjectDetection`] into the format expected by the COCO api. Only
- supports PyTorch.
- outputs ([`ConditionalDetrObjectDetectionOutput`]):
- Raw outputs of the model.
- target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
- Tensor containing the size (h, w) of each image of the batch. For evaluation, this must be the original
- image size (before any data augmentation). For visualization, this should be the image size after data
- augment, but before padding.
- Returns:
- `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
- in the batch as predicted by the model.
- """
- warnings.warn(
- "`post_process` is deprecated and will be removed in v5 of Transformers, please use"
- " `post_process_object_detection`",
- FutureWarning,
- )
-
- out_logits, out_bbox = outputs.logits, outputs.pred_boxes
-
- if len(out_logits) != len(target_sizes):
- raise ValueError("Make sure that you pass in as many target sizes as the batch dimension of the logits")
- if target_sizes.shape[1] != 2:
- raise ValueError("Each element of target_sizes must contain the size (h, w) of each image of the batch")
-
- prob = out_logits.sigmoid()
- topk_values, topk_indexes = torch.topk(prob.view(out_logits.shape[0], -1), 300, dim=1)
- scores = topk_values
- topk_boxes = topk_indexes // out_logits.shape[2]
- labels = topk_indexes % out_logits.shape[2]
- boxes = center_to_corners_format(out_bbox)
- boxes = torch.gather(boxes, 1, topk_boxes.unsqueeze(-1).repeat(1, 1, 4))
-
- # and from relative [0, 1] to absolute [0, height] coordinates
- img_h, img_w = target_sizes.unbind(1)
- scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
- boxes = boxes * scale_fct[:, None, :]
-
- results = [{"scores": s, "labels": l, "boxes": b} for s, l, b in zip(scores, labels, boxes)]
-
- return results
-
- # Copied from transformers.models.deformable_detr.feature_extraction_deformable_detr.DeformableDetrFeatureExtractor.post_process_object_detection with DeformableDetr->ConditionalDetr
- def post_process_object_detection(
- self, outputs, threshold: float = 0.5, target_sizes: Union[TensorType, List[Tuple]] = None
- ):
- """
- Converts the output of [`ConditionalDetrForObjectDetection`] into the format expected by the COCO api. Only
- supports PyTorch.
-
- Args:
- outputs ([`DetrObjectDetectionOutput`]):
- Raw outputs of the model.
- threshold (`float`, *optional*):
- Score threshold to keep object detection predictions.
- target_sizes (`torch.Tensor` or `List[Tuple[int, int]]`, *optional*, defaults to `None`):
- Tensor of shape `(batch_size, 2)` or list of tuples (`Tuple[int, int]`) containing the target size
- (height, width) of each image in the batch. If left to None, predictions will not be resized.
-
- Returns:
- `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
- in the batch as predicted by the model.
- """
- out_logits, out_bbox = outputs.logits, outputs.pred_boxes
-
- if target_sizes is not None:
- if len(out_logits) != len(target_sizes):
- raise ValueError(
- "Make sure that you pass in as many target sizes as the batch dimension of the logits"
- )
-
- prob = out_logits.sigmoid()
- topk_values, topk_indexes = torch.topk(prob.view(out_logits.shape[0], -1), 100, dim=1)
- scores = topk_values
- topk_boxes = topk_indexes // out_logits.shape[2]
- labels = topk_indexes % out_logits.shape[2]
- boxes = center_to_corners_format(out_bbox)
- boxes = torch.gather(boxes, 1, topk_boxes.unsqueeze(-1).repeat(1, 1, 4))
-
- # and from relative [0, 1] to absolute [0, height] coordinates
- if isinstance(target_sizes, List):
- img_h = torch.Tensor([i[0] for i in target_sizes])
- img_w = torch.Tensor([i[1] for i in target_sizes])
- else:
- img_h, img_w = target_sizes.unbind(1)
- scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1).to(boxes.device)
- boxes = boxes * scale_fct[:, None, :]
-
- results = []
- for s, l, b in zip(scores, labels, boxes):
- score = s[s > threshold]
- label = l[s > threshold]
- box = b[s > threshold]
- results.append({"scores": score, "labels": label, "boxes": box})
-
- return results
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.post_process_semantic_segmentation with Detr->ConditionalDetr
- def post_process_semantic_segmentation(self, outputs, target_sizes: List[Tuple[int, int]] = None):
- """
- Converts the output of [`ConditionalDetrForSegmentation`] into semantic segmentation maps. Only supports
- PyTorch.
-
- Args:
- outputs ([`ConditionalDetrForSegmentation`]):
- Raw outputs of the model.
- target_sizes (`List[Tuple[int, int]]`, *optional*, defaults to `None`):
- A list of tuples (`Tuple[int, int]`) containing the target size (height, width) of each image in the
- batch. If left to None, predictions will not be resized.
-
- Returns:
- `List[torch.Tensor]`:
- A list of length `batch_size`, where each item is a semantic segmentation map of shape (height, width)
- corresponding to the target_sizes entry (if `target_sizes` is specified). Each entry of each
- `torch.Tensor` correspond to a semantic class id.
- """
- class_queries_logits = outputs.logits # [batch_size, num_queries, num_classes+1]
- masks_queries_logits = outputs.pred_masks # [batch_size, num_queries, height, width]
-
- # Remove the null class `[..., :-1]`
- masks_classes = class_queries_logits.softmax(dim=-1)[..., :-1]
- masks_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
-
- # Semantic segmentation logits of shape (batch_size, num_classes, height, width)
- segmentation = torch.einsum("bqc, bqhw -> bchw", masks_classes, masks_probs)
- batch_size = class_queries_logits.shape[0]
-
- # Resize logits and compute semantic segmentation maps
- if target_sizes is not None:
- if batch_size != len(target_sizes):
- raise ValueError(
- "Make sure that you pass in as many target sizes as the batch dimension of the logits"
- )
-
- semantic_segmentation = []
- for idx in range(batch_size):
- resized_logits = nn.functional.interpolate(
- segmentation[idx].unsqueeze(dim=0), size=target_sizes[idx], mode="bilinear", align_corners=False
- )
- semantic_map = resized_logits[0].argmax(dim=0)
- semantic_segmentation.append(semantic_map)
- else:
- semantic_segmentation = segmentation.argmax(dim=1)
- semantic_segmentation = [semantic_segmentation[i] for i in range(semantic_segmentation.shape[0])]
-
- return semantic_segmentation
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.post_process_instance_segmentation with Detr->ConditionalDetr
- def post_process_instance_segmentation(
- self,
- outputs,
- threshold: float = 0.5,
- mask_threshold: float = 0.5,
- overlap_mask_area_threshold: float = 0.8,
- target_sizes: Optional[List[Tuple[int, int]]] = None,
- return_coco_annotation: Optional[bool] = False,
- ) -> List[Dict]:
- """
- Converts the output of [`ConditionalDetrForSegmentation`] into instance segmentation predictions. Only supports
- PyTorch.
-
- Args:
- outputs ([`ConditionalDetrForSegmentation`]):
- Raw outputs of the model.
- threshold (`float`, *optional*, defaults to 0.5):
- The probability score threshold to keep predicted instance masks.
- mask_threshold (`float`, *optional*, defaults to 0.5):
- Threshold to use when turning the predicted masks into binary values.
- overlap_mask_area_threshold (`float`, *optional*, defaults to 0.8):
- The overlap mask area threshold to merge or discard small disconnected parts within each binary
- instance mask.
- target_sizes (`List[Tuple]`, *optional*):
- List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
- final size (height, width) of each prediction. If left to None, predictions will not be resized.
- return_coco_annotation (`bool`, *optional*):
- Defaults to `False`. If set to `True`, segmentation maps are returned in COCO run-length encoding (RLE)
- format.
-
- Returns:
- `List[Dict]`: A list of dictionaries, one per image, each dictionary containing two keys:
- - **segmentation** -- A tensor of shape `(height, width)` where each pixel represents a `segment_id` or
- `List[List]` run-length encoding (RLE) of the segmentation map if return_coco_annotation is set to
- `True`. Set to `None` if no mask if found above `threshold`.
- - **segments_info** -- A dictionary that contains additional information on each segment.
- - **id** -- An integer representing the `segment_id`.
- - **label_id** -- An integer representing the label / semantic class id corresponding to `segment_id`.
- - **score** -- Prediction score of segment with `segment_id`.
- """
- class_queries_logits = outputs.logits # [batch_size, num_queries, num_classes+1]
- masks_queries_logits = outputs.pred_masks # [batch_size, num_queries, height, width]
-
- batch_size = class_queries_logits.shape[0]
- num_labels = class_queries_logits.shape[-1] - 1
-
- mask_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
-
- # Predicted label and score of each query (batch_size, num_queries)
- pred_scores, pred_labels = nn.functional.softmax(class_queries_logits, dim=-1).max(-1)
-
- # Loop over items in batch size
- results: List[Dict[str, TensorType]] = []
-
- for i in range(batch_size):
- mask_probs_item, pred_scores_item, pred_labels_item = remove_low_and_no_objects(
- mask_probs[i], pred_scores[i], pred_labels[i], threshold, num_labels
- )
-
- # No mask found
- if mask_probs_item.shape[0] <= 0:
- height, width = target_sizes[i] if target_sizes is not None else mask_probs_item.shape[1:]
- segmentation = torch.zeros((height, width)) - 1
- results.append({"segmentation": segmentation, "segments_info": []})
- continue
-
- # Get segmentation map and segment information of batch item
- target_size = target_sizes[i] if target_sizes is not None else None
- segmentation, segments = compute_segments(
- mask_probs=mask_probs_item,
- pred_scores=pred_scores_item,
- pred_labels=pred_labels_item,
- mask_threshold=mask_threshold,
- overlap_mask_area_threshold=overlap_mask_area_threshold,
- label_ids_to_fuse=[],
- target_size=target_size,
- )
-
- # Return segmentation map in run-length encoding (RLE) format
- if return_coco_annotation:
- segmentation = convert_segmentation_to_rle(segmentation)
-
- results.append({"segmentation": segmentation, "segments_info": segments})
- return results
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.post_process_panoptic_segmentation with Detr->ConditionalDetr
- def post_process_panoptic_segmentation(
- self,
- outputs,
- threshold: float = 0.5,
- mask_threshold: float = 0.5,
- overlap_mask_area_threshold: float = 0.8,
- label_ids_to_fuse: Optional[Set[int]] = None,
- target_sizes: Optional[List[Tuple[int, int]]] = None,
- ) -> List[Dict]:
- """
- Converts the output of [`ConditionalDetrForSegmentation`] into image panoptic segmentation predictions. Only
- supports PyTorch.
-
- Args:
- outputs ([`ConditionalDetrForSegmentation`]):
- The outputs from [`ConditionalDetrForSegmentation`].
- threshold (`float`, *optional*, defaults to 0.5):
- The probability score threshold to keep predicted instance masks.
- mask_threshold (`float`, *optional*, defaults to 0.5):
- Threshold to use when turning the predicted masks into binary values.
- overlap_mask_area_threshold (`float`, *optional*, defaults to 0.8):
- The overlap mask area threshold to merge or discard small disconnected parts within each binary
- instance mask.
- label_ids_to_fuse (`Set[int]`, *optional*):
- The labels in this state will have all their instances be fused together. For instance we could say
- there can only be one sky in an image, but several persons, so the label ID for sky would be in that
- set, but not the one for person.
- target_sizes (`List[Tuple]`, *optional*):
- List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
- final size (height, width) of each prediction in batch. If left to None, predictions will not be
- resized.
-
- Returns:
- `List[Dict]`: A list of dictionaries, one per image, each dictionary containing two keys:
- - **segmentation** -- a tensor of shape `(height, width)` where each pixel represents a `segment_id` or
- `None` if no mask if found above `threshold`. If `target_sizes` is specified, segmentation is resized to
- the corresponding `target_sizes` entry.
- - **segments_info** -- A dictionary that contains additional information on each segment.
- - **id** -- an integer representing the `segment_id`.
- - **label_id** -- An integer representing the label / semantic class id corresponding to `segment_id`.
- - **was_fused** -- a boolean, `True` if `label_id` was in `label_ids_to_fuse`, `False` otherwise.
- Multiple instances of the same class / label were fused and assigned a single `segment_id`.
- - **score** -- Prediction score of segment with `segment_id`.
- """
-
- if label_ids_to_fuse is None:
- warnings.warn("`label_ids_to_fuse` unset. No instance will be fused.")
- label_ids_to_fuse = set()
-
- class_queries_logits = outputs.logits # [batch_size, num_queries, num_classes+1]
- masks_queries_logits = outputs.pred_masks # [batch_size, num_queries, height, width]
-
- batch_size = class_queries_logits.shape[0]
- num_labels = class_queries_logits.shape[-1] - 1
-
- mask_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
-
- # Predicted label and score of each query (batch_size, num_queries)
- pred_scores, pred_labels = nn.functional.softmax(class_queries_logits, dim=-1).max(-1)
-
- # Loop over items in batch size
- results: List[Dict[str, TensorType]] = []
-
- for i in range(batch_size):
- mask_probs_item, pred_scores_item, pred_labels_item = remove_low_and_no_objects(
- mask_probs[i], pred_scores[i], pred_labels[i], threshold, num_labels
- )
-
- # No mask found
- if mask_probs_item.shape[0] <= 0:
- height, width = target_sizes[i] if target_sizes is not None else mask_probs_item.shape[1:]
- segmentation = torch.zeros((height, width)) - 1
- results.append({"segmentation": segmentation, "segments_info": []})
- continue
-
- # Get segmentation map and segment information of batch item
- target_size = target_sizes[i] if target_sizes is not None else None
- segmentation, segments = compute_segments(
- mask_probs=mask_probs_item,
- pred_scores=pred_scores_item,
- pred_labels=pred_labels_item,
- mask_threshold=mask_threshold,
- overlap_mask_area_threshold=overlap_mask_area_threshold,
- label_ids_to_fuse=label_ids_to_fuse,
- target_size=target_size,
- )
-
- results.append({"segmentation": segmentation, "segments_info": segments})
- return results
+ConditionalDetrFeatureExtractor = ConditionalDetrImageProcessor
diff --git a/src/transformers/models/conditional_detr/image_processing_conditional_detr.py b/src/transformers/models/conditional_detr/image_processing_conditional_detr.py
new file mode 100644
index 0000000000..c0a18c7d33
--- /dev/null
+++ b/src/transformers/models/conditional_detr/image_processing_conditional_detr.py
@@ -0,0 +1,1576 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Image processor class for Conditional DETR."""
+
+import io
+import pathlib
+import warnings
+from collections import defaultdict
+from typing import Any, Callable, Dict, Iterable, List, Optional, Set, Tuple, Union
+
+import numpy as np
+
+from transformers.feature_extraction_utils import BatchFeature
+from transformers.image_processing_utils import BaseImageProcessor, get_size_dict
+from transformers.image_transforms import (
+ PaddingMode,
+ center_to_corners_format,
+ corners_to_center_format,
+ id_to_rgb,
+ normalize,
+ pad,
+ rescale,
+ resize,
+ rgb_to_id,
+ to_channel_dimension_format,
+)
+from transformers.image_utils import (
+ IMAGENET_DEFAULT_MEAN,
+ IMAGENET_DEFAULT_STD,
+ ChannelDimension,
+ ImageInput,
+ PILImageResampling,
+ get_image_size,
+ infer_channel_dimension_format,
+ is_batched,
+ to_numpy_array,
+ valid_coco_detection_annotations,
+ valid_coco_panoptic_annotations,
+ valid_images,
+)
+from transformers.utils import (
+ is_flax_available,
+ is_jax_tensor,
+ is_scipy_available,
+ is_tf_available,
+ is_tf_tensor,
+ is_torch_available,
+ is_torch_tensor,
+ is_vision_available,
+)
+from transformers.utils.generic import ExplicitEnum, TensorType
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+
+if is_vision_available():
+ import PIL
+
+
+if is_scipy_available():
+ import scipy.special
+ import scipy.stats
+
+
+class AnnotionFormat(ExplicitEnum):
+ COCO_DETECTION = "coco_detection"
+ COCO_PANOPTIC = "coco_panoptic"
+
+
+SUPPORTED_ANNOTATION_FORMATS = (AnnotionFormat.COCO_DETECTION, AnnotionFormat.COCO_PANOPTIC)
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_size_with_aspect_ratio
+def get_size_with_aspect_ratio(image_size, size, max_size=None) -> Tuple[int, int]:
+ """
+ Computes the output image size given the input image size and the desired output size.
+
+ Args:
+ image_size (`Tuple[int, int]`):
+ The input image size.
+ size (`int`):
+ The desired output size.
+ max_size (`int`, *optional*):
+ The maximum allowed output size.
+ """
+ height, width = image_size
+ if max_size is not None:
+ min_original_size = float(min((height, width)))
+ max_original_size = float(max((height, width)))
+ if max_original_size / min_original_size * size > max_size:
+ size = int(round(max_size * min_original_size / max_original_size))
+
+ if (height <= width and height == size) or (width <= height and width == size):
+ return height, width
+
+ if width < height:
+ ow = size
+ oh = int(size * height / width)
+ else:
+ oh = size
+ ow = int(size * width / height)
+ return (oh, ow)
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_resize_output_image_size
+def get_resize_output_image_size(
+ input_image: np.ndarray, size: Union[int, Tuple[int, int], List[int]], max_size: Optional[int] = None
+) -> Tuple[int, int]:
+ """
+ Computes the output image size given the input image size and the desired output size. If the desired output size
+ is a tuple or list, the output image size is returned as is. If the desired output size is an integer, the output
+ image size is computed by keeping the aspect ratio of the input image size.
+
+ Args:
+ image_size (`Tuple[int, int]`):
+ The input image size.
+ size (`int`):
+ The desired output size.
+ max_size (`int`, *optional*):
+ The maximum allowed output size.
+ """
+ image_size = get_image_size(input_image)
+ if isinstance(size, (list, tuple)):
+ return size
+
+ return get_size_with_aspect_ratio(image_size, size, max_size)
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_numpy_to_framework_fn
+def get_numpy_to_framework_fn(arr) -> Callable:
+ """
+ Returns a function that converts a numpy array to the framework of the input array.
+
+ Args:
+ arr (`np.ndarray`): The array to convert.
+ """
+ if isinstance(arr, np.ndarray):
+ return np.array
+ if is_tf_available() and is_tf_tensor(arr):
+ import tensorflow as tf
+
+ return tf.convert_to_tensor
+ if is_torch_available() and is_torch_tensor(arr):
+ import torch
+
+ return torch.tensor
+ if is_flax_available() and is_jax_tensor(arr):
+ import jax.numpy as jnp
+
+ return jnp.array
+ raise ValueError(f"Cannot convert arrays of type {type(arr)}")
+
+
+# Copied from transformers.models.detr.image_processing_detr.safe_squeeze
+def safe_squeeze(arr: np.ndarray, axis: Optional[int] = None) -> np.ndarray:
+ """
+ Squeezes an array, but only if the axis specified has dim 1.
+ """
+ if axis is None:
+ return arr.squeeze()
+
+ try:
+ return arr.squeeze(axis=axis)
+ except ValueError:
+ return arr
+
+
+# Copied from transformers.models.detr.image_processing_detr.normalize_annotation
+def normalize_annotation(annotation: Dict, image_size: Tuple[int, int]) -> Dict:
+ image_height, image_width = image_size
+ norm_annotation = {}
+ for key, value in annotation.items():
+ if key == "boxes":
+ boxes = value
+ boxes = corners_to_center_format(boxes)
+ boxes /= np.asarray([image_width, image_height, image_width, image_height], dtype=np.float32)
+ norm_annotation[key] = boxes
+ else:
+ norm_annotation[key] = value
+ return norm_annotation
+
+
+# Copied from transformers.models.detr.image_processing_detr.max_across_indices
+def max_across_indices(values: Iterable[Any]) -> List[Any]:
+ """
+ Return the maximum value across all indices of an iterable of values.
+ """
+ return [max(values_i) for values_i in zip(*values)]
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_max_height_width
+def get_max_height_width(images: List[np.ndarray]) -> List[int]:
+ """
+ Get the maximum height and width across all images in a batch.
+ """
+ input_channel_dimension = infer_channel_dimension_format(images[0])
+
+ if input_channel_dimension == ChannelDimension.FIRST:
+ _, max_height, max_width = max_across_indices([img.shape for img in images])
+ elif input_channel_dimension == ChannelDimension.LAST:
+ max_height, max_width, _ = max_across_indices([img.shape for img in images])
+ else:
+ raise ValueError(f"Invalid channel dimension format: {input_channel_dimension}")
+ return (max_height, max_width)
+
+
+# Copied from transformers.models.detr.image_processing_detr.make_pixel_mask
+def make_pixel_mask(image: np.ndarray, output_size: Tuple[int, int]) -> np.ndarray:
+ """
+ Make a pixel mask for the image, where 1 indicates a valid pixel and 0 indicates padding.
+
+ Args:
+ image (`np.ndarray`):
+ Image to make the pixel mask for.
+ output_size (`Tuple[int, int]`):
+ Output size of the mask.
+ """
+ input_height, input_width = get_image_size(image)
+ mask = np.zeros(output_size, dtype=np.int64)
+ mask[:input_height, :input_width] = 1
+ return mask
+
+
+# Copied from transformers.models.detr.image_processing_detr.convert_coco_poly_to_mask
+def convert_coco_poly_to_mask(segmentations, height: int, width: int) -> np.ndarray:
+ """
+ Convert a COCO polygon annotation to a mask.
+
+ Args:
+ segmentations (`List[List[float]]`):
+ List of polygons, each polygon represented by a list of x-y coordinates.
+ height (`int`):
+ Height of the mask.
+ width (`int`):
+ Width of the mask.
+ """
+ try:
+ from pycocotools import mask as coco_mask
+ except ImportError:
+ raise ImportError("Pycocotools is not installed in your environment.")
+
+ masks = []
+ for polygons in segmentations:
+ rles = coco_mask.frPyObjects(polygons, height, width)
+ mask = coco_mask.decode(rles)
+ if len(mask.shape) < 3:
+ mask = mask[..., None]
+ mask = np.asarray(mask, dtype=np.uint8)
+ mask = np.any(mask, axis=2)
+ masks.append(mask)
+ if masks:
+ masks = np.stack(masks, axis=0)
+ else:
+ masks = np.zeros((0, height, width), dtype=np.uint8)
+
+ return masks
+
+
+# Copied from transformers.models.detr.image_processing_detr.prepare_coco_detection_annotation with DETR->ConditionalDetr
+def prepare_coco_detection_annotation(image, target, return_segmentation_masks: bool = False):
+ """
+ Convert the target in COCO format into the format expected by ConditionalDetr.
+ """
+ image_height, image_width = get_image_size(image)
+
+ image_id = target["image_id"]
+ image_id = np.asarray([image_id], dtype=np.int64)
+
+ # Get all COCO annotations for the given image.
+ annotations = target["annotations"]
+ annotations = [obj for obj in annotations if "iscrowd" not in obj or obj["iscrowd"] == 0]
+
+ classes = [obj["category_id"] for obj in annotations]
+ classes = np.asarray(classes, dtype=np.int64)
+
+ # for conversion to coco api
+ area = np.asarray([obj["area"] for obj in annotations], dtype=np.float32)
+ iscrowd = np.asarray([obj["iscrowd"] if "iscrowd" in obj else 0 for obj in annotations], dtype=np.int64)
+
+ boxes = [obj["bbox"] for obj in annotations]
+ # guard against no boxes via resizing
+ boxes = np.asarray(boxes, dtype=np.float32).reshape(-1, 4)
+ boxes[:, 2:] += boxes[:, :2]
+ boxes[:, 0::2] = boxes[:, 0::2].clip(min=0, max=image_width)
+ boxes[:, 1::2] = boxes[:, 1::2].clip(min=0, max=image_height)
+
+ keep = (boxes[:, 3] > boxes[:, 1]) & (boxes[:, 2] > boxes[:, 0])
+
+ new_target = {}
+ new_target["image_id"] = image_id
+ new_target["class_labels"] = classes[keep]
+ new_target["boxes"] = boxes[keep]
+ new_target["area"] = area[keep]
+ new_target["iscrowd"] = iscrowd[keep]
+ new_target["orig_size"] = np.asarray([int(image_height), int(image_width)], dtype=np.int64)
+
+ if annotations and "keypoints" in annotations[0]:
+ keypoints = [obj["keypoints"] for obj in annotations]
+ keypoints = np.asarray(keypoints, dtype=np.float32)
+ num_keypoints = keypoints.shape[0]
+ keypoints = keypoints.reshape((-1, 3)) if num_keypoints else keypoints
+ new_target["keypoints"] = keypoints[keep]
+
+ if return_segmentation_masks:
+ segmentation_masks = [obj["segmentation"] for obj in annotations]
+ masks = convert_coco_poly_to_mask(segmentation_masks, image_height, image_width)
+ new_target["masks"] = masks[keep]
+
+ return new_target
+
+
+# Copied from transformers.models.detr.image_processing_detr.masks_to_boxes
+def masks_to_boxes(masks: np.ndarray) -> np.ndarray:
+ """
+ Compute the bounding boxes around the provided panoptic segmentation masks.
+
+ Args:
+ masks: masks in format `[number_masks, height, width]` where N is the number of masks
+
+ Returns:
+ boxes: bounding boxes in format `[number_masks, 4]` in xyxy format
+ """
+ if masks.size == 0:
+ return np.zeros((0, 4))
+
+ h, w = masks.shape[-2:]
+ y = np.arange(0, h, dtype=np.float32)
+ x = np.arange(0, w, dtype=np.float32)
+ # see https://github.com/pytorch/pytorch/issues/50276
+ y, x = np.meshgrid(y, x, indexing="ij")
+
+ x_mask = masks * np.expand_dims(x, axis=0)
+ x_max = x_mask.reshape(x_mask.shape[0], -1).max(-1)
+ x = np.ma.array(x_mask, mask=~(np.array(masks, dtype=bool)))
+ x_min = x.filled(fill_value=1e8)
+ x_min = x_min.reshape(x_min.shape[0], -1).min(-1)
+
+ y_mask = masks * np.expand_dims(y, axis=0)
+ y_max = y_mask.reshape(x_mask.shape[0], -1).max(-1)
+ y = np.ma.array(y_mask, mask=~(np.array(masks, dtype=bool)))
+ y_min = y.filled(fill_value=1e8)
+ y_min = y_min.reshape(y_min.shape[0], -1).min(-1)
+
+ return np.stack([x_min, y_min, x_max, y_max], 1)
+
+
+# Copied from transformers.models.detr.image_processing_detr.prepare_coco_panoptic_annotation with DETR->ConditionalDetr
+def prepare_coco_panoptic_annotation(
+ image: np.ndarray, target: Dict, masks_path: Union[str, pathlib.Path], return_masks: bool = True
+) -> Dict:
+ """
+ Prepare a coco panoptic annotation for ConditionalDetr.
+ """
+ image_height, image_width = get_image_size(image)
+ annotation_path = pathlib.Path(masks_path) / target["file_name"]
+
+ new_target = {}
+ new_target["image_id"] = np.asarray([target["image_id"] if "image_id" in target else target["id"]], dtype=np.int64)
+ new_target["size"] = np.asarray([image_height, image_width], dtype=np.int64)
+ new_target["orig_size"] = np.asarray([image_height, image_width], dtype=np.int64)
+
+ if "segments_info" in target:
+ masks = np.asarray(PIL.Image.open(annotation_path), dtype=np.uint32)
+ masks = rgb_to_id(masks)
+
+ ids = np.array([segment_info["id"] for segment_info in target["segments_info"]])
+ masks = masks == ids[:, None, None]
+ masks = masks.astype(np.uint8)
+ if return_masks:
+ new_target["masks"] = masks
+ new_target["boxes"] = masks_to_boxes(masks)
+ new_target["class_labels"] = np.array(
+ [segment_info["category_id"] for segment_info in target["segments_info"]], dtype=np.int64
+ )
+ new_target["iscrowd"] = np.asarray(
+ [segment_info["iscrowd"] for segment_info in target["segments_info"]], dtype=np.int64
+ )
+ new_target["area"] = np.asarray(
+ [segment_info["area"] for segment_info in target["segments_info"]], dtype=np.float32
+ )
+
+ return new_target
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_segmentation_image
+def get_segmentation_image(
+ masks: np.ndarray, input_size: Tuple, target_size: Tuple, stuff_equiv_classes, deduplicate=False
+):
+ h, w = input_size
+ final_h, final_w = target_size
+
+ m_id = scipy.special.softmax(masks.transpose(0, 1), -1)
+
+ if m_id.shape[-1] == 0:
+ # We didn't detect any mask :(
+ m_id = np.zeros((h, w), dtype=np.int64)
+ else:
+ m_id = m_id.argmax(-1).reshape(h, w)
+
+ if deduplicate:
+ # Merge the masks corresponding to the same stuff class
+ for equiv in stuff_equiv_classes.values():
+ for eq_id in equiv:
+ m_id[m_id == eq_id] = equiv[0]
+
+ seg_img = id_to_rgb(m_id)
+ seg_img = resize(seg_img, (final_w, final_h), resample=PILImageResampling.NEAREST)
+ return seg_img
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_mask_area
+def get_mask_area(seg_img: np.ndarray, target_size: Tuple[int, int], n_classes: int) -> np.ndarray:
+ final_h, final_w = target_size
+ np_seg_img = seg_img.astype(np.uint8)
+ np_seg_img = np_seg_img.reshape(final_h, final_w, 3)
+ m_id = rgb_to_id(np_seg_img)
+ area = [(m_id == i).sum() for i in range(n_classes)]
+ return area
+
+
+# Copied from transformers.models.detr.image_processing_detr.score_labels_from_class_probabilities
+def score_labels_from_class_probabilities(logits: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
+ probs = scipy.special.softmax(logits, axis=-1)
+ labels = probs.argmax(-1, keepdims=True)
+ scores = np.take_along_axis(probs, labels, axis=-1)
+ scores, labels = scores.squeeze(-1), labels.squeeze(-1)
+ return scores, labels
+
+
+# Copied from transformers.models.detr.image_processing_detr.post_process_panoptic_sample with DetrForSegmentation->ConditionalDetrForSegmentation
+def post_process_panoptic_sample(
+ out_logits: np.ndarray,
+ masks: np.ndarray,
+ boxes: np.ndarray,
+ processed_size: Tuple[int, int],
+ target_size: Tuple[int, int],
+ is_thing_map: Dict,
+ threshold=0.85,
+) -> Dict:
+ """
+ Converts the output of [`ConditionalDetrForSegmentation`] into panoptic segmentation predictions for a single
+ sample.
+
+ Args:
+ out_logits (`torch.Tensor`):
+ The logits for this sample.
+ masks (`torch.Tensor`):
+ The predicted segmentation masks for this sample.
+ boxes (`torch.Tensor`):
+ The prediced bounding boxes for this sample. The boxes are in the normalized format `(center_x, center_y,
+ width, height)` and values between `[0, 1]`, relative to the size the image (disregarding padding).
+ processed_size (`Tuple[int, int]`):
+ The processed size of the image `(height, width)`, as returned by the preprocessing step i.e. the size
+ after data augmentation but before batching.
+ target_size (`Tuple[int, int]`):
+ The target size of the image, `(height, width)` corresponding to the requested final size of the
+ prediction.
+ is_thing_map (`Dict`):
+ A dictionary mapping class indices to a boolean value indicating whether the class is a thing or not.
+ threshold (`float`, *optional*, defaults to 0.85):
+ The threshold used to binarize the segmentation masks.
+ """
+ # we filter empty queries and detection below threshold
+ scores, labels = score_labels_from_class_probabilities(out_logits)
+ keep = (labels != out_logits.shape[-1] - 1) & (scores > threshold)
+
+ cur_scores = scores[keep]
+ cur_classes = labels[keep]
+ cur_boxes = center_to_corners_format(boxes[keep])
+
+ if len(cur_boxes) != len(cur_classes):
+ raise ValueError("Not as many boxes as there are classes")
+
+ cur_masks = masks[keep]
+ cur_masks = resize(cur_masks[:, None], processed_size, resample=PILImageResampling.BILINEAR)
+ cur_masks = safe_squeeze(cur_masks, 1)
+ b, h, w = cur_masks.shape
+
+ # It may be that we have several predicted masks for the same stuff class.
+ # In the following, we track the list of masks ids for each stuff class (they are merged later on)
+ cur_masks = cur_masks.reshape(b, -1)
+ stuff_equiv_classes = defaultdict(list)
+ for k, label in enumerate(cur_classes):
+ if not is_thing_map[label]:
+ stuff_equiv_classes[label].append(k)
+
+ seg_img = get_segmentation_image(cur_masks, processed_size, target_size, stuff_equiv_classes, deduplicate=True)
+ area = get_mask_area(cur_masks, processed_size, n_classes=len(cur_scores))
+
+ # We filter out any mask that is too small
+ if cur_classes.size() > 0:
+ # We know filter empty masks as long as we find some
+ filtered_small = np.array([a <= 4 for a in area], dtype=bool)
+ while filtered_small.any():
+ cur_masks = cur_masks[~filtered_small]
+ cur_scores = cur_scores[~filtered_small]
+ cur_classes = cur_classes[~filtered_small]
+ seg_img = get_segmentation_image(cur_masks, (h, w), target_size, stuff_equiv_classes, deduplicate=True)
+ area = get_mask_area(seg_img, target_size, n_classes=len(cur_scores))
+ filtered_small = np.array([a <= 4 for a in area], dtype=bool)
+ else:
+ cur_classes = np.ones((1, 1), dtype=np.int64)
+
+ segments_info = [
+ {"id": i, "isthing": is_thing_map[cat], "category_id": int(cat), "area": a}
+ for i, (cat, a) in enumerate(zip(cur_classes, area))
+ ]
+ del cur_classes
+
+ with io.BytesIO() as out:
+ PIL.Image.fromarray(seg_img).save(out, format="PNG")
+ predictions = {"png_string": out.getvalue(), "segments_info": segments_info}
+
+ return predictions
+
+
+# Copied from transformers.models.detr.image_processing_detr.resize_annotation
+def resize_annotation(
+ annotation: Dict[str, Any],
+ orig_size: Tuple[int, int],
+ target_size: Tuple[int, int],
+ threshold: float = 0.5,
+ resample: PILImageResampling = PILImageResampling.NEAREST,
+):
+ """
+ Resizes an annotation to a target size.
+
+ Args:
+ annotation (`Dict[str, Any]`):
+ The annotation dictionary.
+ orig_size (`Tuple[int, int]`):
+ The original size of the input image.
+ target_size (`Tuple[int, int]`):
+ The target size of the image, as returned by the preprocessing `resize` step.
+ threshold (`float`, *optional*, defaults to 0.5):
+ The threshold used to binarize the segmentation masks.
+ resample (`PILImageResampling`, defaults to `PILImageResampling.NEAREST`):
+ The resampling filter to use when resizing the masks.
+ """
+ ratios = tuple(float(s) / float(s_orig) for s, s_orig in zip(target_size, orig_size))
+ ratio_height, ratio_width = ratios
+
+ new_annotation = {}
+ new_annotation["size"] = target_size
+
+ for key, value in annotation.items():
+ if key == "boxes":
+ boxes = value
+ scaled_boxes = boxes * np.asarray([ratio_width, ratio_height, ratio_width, ratio_height], dtype=np.float32)
+ new_annotation["boxes"] = scaled_boxes
+ elif key == "area":
+ area = value
+ scaled_area = area * (ratio_width * ratio_height)
+ new_annotation["area"] = scaled_area
+ elif key == "masks":
+ masks = value[:, None]
+ masks = np.array([resize(mask, target_size, resample=resample) for mask in masks])
+ masks = masks.astype(np.float32)
+ masks = masks[:, 0] > threshold
+ new_annotation["masks"] = masks
+ elif key == "size":
+ new_annotation["size"] = target_size
+ else:
+ new_annotation[key] = value
+
+ return new_annotation
+
+
+# Copied from transformers.models.detr.image_processing_detr.binary_mask_to_rle
+def binary_mask_to_rle(mask):
+ """
+ Converts given binary mask of shape `(height, width)` to the run-length encoding (RLE) format.
+
+ Args:
+ mask (`torch.Tensor` or `numpy.array`):
+ A binary mask tensor of shape `(height, width)` where 0 denotes background and 1 denotes the target
+ segment_id or class_id.
+ Returns:
+ `List`: Run-length encoded list of the binary mask. Refer to COCO API for more information about the RLE
+ format.
+ """
+ if is_torch_tensor(mask):
+ mask = mask.numpy()
+
+ pixels = mask.flatten()
+ pixels = np.concatenate([[0], pixels, [0]])
+ runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
+ runs[1::2] -= runs[::2]
+ return [x for x in runs]
+
+
+# Copied from transformers.models.detr.image_processing_detr.convert_segmentation_to_rle
+def convert_segmentation_to_rle(segmentation):
+ """
+ Converts given segmentation map of shape `(height, width)` to the run-length encoding (RLE) format.
+
+ Args:
+ segmentation (`torch.Tensor` or `numpy.array`):
+ A segmentation map of shape `(height, width)` where each value denotes a segment or class id.
+ Returns:
+ `List[List]`: A list of lists, where each list is the run-length encoding of a segment / class id.
+ """
+ segment_ids = torch.unique(segmentation)
+
+ run_length_encodings = []
+ for idx in segment_ids:
+ mask = torch.where(segmentation == idx, 1, 0)
+ rle = binary_mask_to_rle(mask)
+ run_length_encodings.append(rle)
+
+ return run_length_encodings
+
+
+# Copied from transformers.models.detr.image_processing_detr.remove_low_and_no_objects
+def remove_low_and_no_objects(masks, scores, labels, object_mask_threshold, num_labels):
+ """
+ Binarize the given masks using `object_mask_threshold`, it returns the associated values of `masks`, `scores` and
+ `labels`.
+
+ Args:
+ masks (`torch.Tensor`):
+ A tensor of shape `(num_queries, height, width)`.
+ scores (`torch.Tensor`):
+ A tensor of shape `(num_queries)`.
+ labels (`torch.Tensor`):
+ A tensor of shape `(num_queries)`.
+ object_mask_threshold (`float`):
+ A number between 0 and 1 used to binarize the masks.
+ Raises:
+ `ValueError`: Raised when the first dimension doesn't match in all input tensors.
+ Returns:
+ `Tuple[`torch.Tensor`, `torch.Tensor`, `torch.Tensor`]`: The `masks`, `scores` and `labels` without the region
+ < `object_mask_threshold`.
+ """
+ if not (masks.shape[0] == scores.shape[0] == labels.shape[0]):
+ raise ValueError("mask, scores and labels must have the same shape!")
+
+ to_keep = labels.ne(num_labels) & (scores > object_mask_threshold)
+
+ return masks[to_keep], scores[to_keep], labels[to_keep]
+
+
+# Copied from transformers.models.detr.image_processing_detr.check_segment_validity
+def check_segment_validity(mask_labels, mask_probs, k, mask_threshold=0.5, overlap_mask_area_threshold=0.8):
+ # Get the mask associated with the k class
+ mask_k = mask_labels == k
+ mask_k_area = mask_k.sum()
+
+ # Compute the area of all the stuff in query k
+ original_area = (mask_probs[k] >= mask_threshold).sum()
+ mask_exists = mask_k_area > 0 and original_area > 0
+
+ # Eliminate disconnected tiny segments
+ if mask_exists:
+ area_ratio = mask_k_area / original_area
+ if not area_ratio.item() > overlap_mask_area_threshold:
+ mask_exists = False
+
+ return mask_exists, mask_k
+
+
+# Copied from transformers.models.detr.image_processing_detr.compute_segments
+def compute_segments(
+ mask_probs,
+ pred_scores,
+ pred_labels,
+ mask_threshold: float = 0.5,
+ overlap_mask_area_threshold: float = 0.8,
+ label_ids_to_fuse: Optional[Set[int]] = None,
+ target_size: Tuple[int, int] = None,
+):
+ height = mask_probs.shape[1] if target_size is None else target_size[0]
+ width = mask_probs.shape[2] if target_size is None else target_size[1]
+
+ segmentation = torch.zeros((height, width), dtype=torch.int32, device=mask_probs.device)
+ segments: List[Dict] = []
+
+ if target_size is not None:
+ mask_probs = nn.functional.interpolate(
+ mask_probs.unsqueeze(0), size=target_size, mode="bilinear", align_corners=False
+ )[0]
+
+ current_segment_id = 0
+
+ # Weigh each mask by its prediction score
+ mask_probs *= pred_scores.view(-1, 1, 1)
+ mask_labels = mask_probs.argmax(0) # [height, width]
+
+ # Keep track of instances of each class
+ stuff_memory_list: Dict[str, int] = {}
+ for k in range(pred_labels.shape[0]):
+ pred_class = pred_labels[k].item()
+ should_fuse = pred_class in label_ids_to_fuse
+
+ # Check if mask exists and large enough to be a segment
+ mask_exists, mask_k = check_segment_validity(
+ mask_labels, mask_probs, k, mask_threshold, overlap_mask_area_threshold
+ )
+
+ if mask_exists:
+ if pred_class in stuff_memory_list:
+ current_segment_id = stuff_memory_list[pred_class]
+ else:
+ current_segment_id += 1
+
+ # Add current object segment to final segmentation map
+ segmentation[mask_k] = current_segment_id
+ segment_score = round(pred_scores[k].item(), 6)
+ segments.append(
+ {
+ "id": current_segment_id,
+ "label_id": pred_class,
+ "was_fused": should_fuse,
+ "score": segment_score,
+ }
+ )
+ if should_fuse:
+ stuff_memory_list[pred_class] = current_segment_id
+
+ return segmentation, segments
+
+
+class ConditionalDetrImageProcessor(BaseImageProcessor):
+ r"""
+ Constructs a Conditional Detr image processor.
+
+ Args:
+ format (`str`, *optional*, defaults to `"coco_detection"`):
+ Data format of the annotations. One of "coco_detection" or "coco_panoptic".
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Controls whether to resize the image's (height, width) dimensions to the specified `size`. Can be
+ overridden by the `do_resize` parameter in the `preprocess` method.
+ size (`Dict[str, int]` *optional*, defaults to `{"shortest_edge": 800, "longest_edge": 1333}`):
+ Size of the image's (height, width) dimensions after resizing. Can be overridden by the `size` parameter in
+ the `preprocess` method.
+ resample (`PILImageResampling`, *optional*, defaults to `PILImageResampling.BILINEAR`):
+ Resampling filter to use if resizing the image.
+ do_rescale (`bool`, *optional*, defaults to `True`):
+ Controls whether to rescale the image by the specified scale `rescale_factor`. Can be overridden by the
+ `do_rescale` parameter in the `preprocess` method.
+ rescale_factor (`int` or `float`, *optional*, defaults to `1/255`):
+ Scale factor to use if rescaling the image. Can be overridden by the `rescale_factor` parameter in the
+ `preprocess` method.
+ do_normalize:
+ Controls whether to normalize the image. Can be overridden by the `do_normalize` parameter in the
+ `preprocess` method.
+ image_mean (`float` or `List[float]`, *optional*, defaults to `IMAGENET_DEFAULT_MEAN`):
+ Mean values to use when normalizing the image. Can be a single value or a list of values, one for each
+ channel. Can be overridden by the `image_mean` parameter in the `preprocess` method.
+ image_std (`float` or `List[float]`, *optional*, defaults to `IMAGENET_DEFAULT_STD`):
+ Standard deviation values to use when normalizing the image. Can be a single value or a list of values, one
+ for each channel. Can be overridden by the `image_std` parameter in the `preprocess` method.
+ do_pad (`bool`, *optional*, defaults to `True`):
+ Controls whether to pad the image to the largest image in a batch and create a pixel mask. Can be
+ overridden by the `do_pad` parameter in the `preprocess` method.
+ """
+
+ model_input_names = ["pixel_values", "pixel_mask"]
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.__init__
+ def __init__(
+ self,
+ format: Union[str, AnnotionFormat] = AnnotionFormat.COCO_DETECTION,
+ do_resize: bool = True,
+ size: Dict[str, int] = None,
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ do_rescale: bool = True,
+ rescale_factor: Union[int, float] = 1 / 255,
+ do_normalize: bool = True,
+ image_mean: Union[float, List[float]] = None,
+ image_std: Union[float, List[float]] = None,
+ do_pad: bool = True,
+ **kwargs
+ ) -> None:
+ if "pad_and_return_pixel_mask" in kwargs:
+ do_pad = kwargs.pop("pad_and_return_pixel_mask")
+
+ if "max_size" in kwargs:
+ warnings.warn(
+ "The `max_size` parameter is deprecated and will be removed in v4.26. "
+ "Please specify in `size['longest_edge'] instead`.",
+ FutureWarning,
+ )
+ max_size = kwargs.pop("max_size")
+ else:
+ max_size = None if size is None else 1333
+
+ size = size if size is not None else {"shortest_edge": 800, "longest_edge": 1333}
+ size = get_size_dict(size, max_size=max_size, default_to_square=False)
+
+ super().__init__(**kwargs)
+ self.format = format
+ self.do_resize = do_resize
+ self.size = size
+ self.resample = resample
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean if image_mean is not None else IMAGENET_DEFAULT_MEAN
+ self.image_std = image_std if image_std is not None else IMAGENET_DEFAULT_STD
+ self.do_pad = do_pad
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare_annotation with DETR->ConditionalDetr
+ def prepare_annotation(
+ self,
+ image: np.ndarray,
+ target: Dict,
+ format: Optional[AnnotionFormat] = None,
+ return_segmentation_masks: bool = None,
+ masks_path: Optional[Union[str, pathlib.Path]] = None,
+ ) -> Dict:
+ """
+ Prepare an annotation for feeding into ConditionalDetr model.
+ """
+ format = format if format is not None else self.format
+
+ if format == AnnotionFormat.COCO_DETECTION:
+ return_segmentation_masks = False if return_segmentation_masks is None else return_segmentation_masks
+ target = prepare_coco_detection_annotation(image, target, return_segmentation_masks)
+ elif format == AnnotionFormat.COCO_PANOPTIC:
+ return_segmentation_masks = True if return_segmentation_masks is None else return_segmentation_masks
+ target = prepare_coco_panoptic_annotation(
+ image, target, masks_path=masks_path, return_masks=return_segmentation_masks
+ )
+ else:
+ raise ValueError(f"Format {format} is not supported.")
+ return target
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare
+ def prepare(self, image, target, return_segmentation_masks=False, masks_path=None):
+ warnings.warn(
+ "The `prepare` method is deprecated and will be removed in a future version. "
+ "Please use `prepare_annotation` instead. Note: the `prepare_annotation` method "
+ "does not return the image anymore.",
+ )
+ target = self.prepare_annotation(image, target, return_segmentation_masks, masks_path, self.format)
+ return image, target
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.convert_coco_poly_to_mask
+ def convert_coco_poly_to_mask(self, *args, **kwargs):
+ warnings.warn("The `convert_coco_poly_to_mask` method is deprecated and will be removed in a future version. ")
+ return convert_coco_poly_to_mask(*args, **kwargs)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare_coco_detection with DETR->ConditionalDetr
+ def prepare_coco_detection(self, *args, **kwargs):
+ warnings.warn("The `prepare_coco_detection` method is deprecated and will be removed in a future version. ")
+ return prepare_coco_detection_annotation(*args, **kwargs)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare_coco_panoptic
+ def prepare_coco_panoptic(self, *args, **kwargs):
+ warnings.warn("The `prepare_coco_panoptic` method is deprecated and will be removed in a future version. ")
+ return prepare_coco_panoptic_annotation(*args, **kwargs)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.resize
+ def resize(
+ self,
+ image: np.ndarray,
+ size: Dict[str, int],
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ data_format: Optional[ChannelDimension] = None,
+ **kwargs
+ ) -> np.ndarray:
+ """
+ Resize the image to the given size. Size can be `min_size` (scalar) or `(height, width)` tuple. If size is an
+ int, smaller edge of the image will be matched to this number.
+ """
+ if "max_size" in kwargs:
+ warnings.warn(
+ "The `max_size` parameter is deprecated and will be removed in v4.26. "
+ "Please specify in `size['longest_edge'] instead`.",
+ FutureWarning,
+ )
+ max_size = kwargs.pop("max_size")
+ else:
+ max_size = None
+ size = get_size_dict(size, max_size=max_size, default_to_square=False)
+ if "shortest_edge" in size and "longest_edge" in size:
+ size = get_resize_output_image_size(image, size["shortest_edge"], size["longest_edge"])
+ elif "height" in size and "width" in size:
+ size = (size["height"], size["width"])
+ else:
+ raise ValueError(
+ "Size must contain 'height' and 'width' keys or 'shortest_edge' and 'longest_edge' keys. Got"
+ f" {size.keys()}."
+ )
+ image = resize(image, size=size, resample=resample, data_format=data_format)
+ return image
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.resize_annotation
+ def resize_annotation(
+ self,
+ annotation,
+ orig_size,
+ size,
+ resample: PILImageResampling = PILImageResampling.NEAREST,
+ ) -> Dict:
+ """
+ Resize the annotation to match the resized image. If size is an int, smaller edge of the mask will be matched
+ to this number.
+ """
+ return resize_annotation(annotation, orig_size=orig_size, target_size=size, resample=resample)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.rescale
+ def rescale(
+ self, image: np.ndarray, rescale_factor: Union[float, int], data_format: Optional[ChannelDimension] = None
+ ) -> np.ndarray:
+ """
+ Rescale the image by the given factor.
+ """
+ return rescale(image, rescale_factor, data_format=data_format)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.normalize
+ def normalize(
+ self,
+ image: np.ndarray,
+ mean: Union[float, Iterable[float]],
+ std: Union[float, Iterable[float]],
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Normalize the image with the given mean and standard deviation.
+ """
+ return normalize(image, mean=mean, std=std, data_format=data_format)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.normalize_annotation
+ def normalize_annotation(self, annotation: Dict, image_size: Tuple[int, int]) -> Dict:
+ """
+ Normalize the boxes in the annotation from `[top_left_x, top_left_y, bottom_right_x, bottom_right_y]` to
+ `[center_x, center_y, width, height]` format.
+ """
+ return normalize_annotation(annotation, image_size=image_size)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.pad_and_create_pixel_mask
+ def pad_and_create_pixel_mask(
+ self,
+ pixel_values_list: List[ImageInput],
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ data_format: Optional[ChannelDimension] = None,
+ ) -> BatchFeature:
+ """
+ Pads a batch of images with zeros to the size of largest height and width in the batch and returns their
+ corresponding pixel mask.
+
+ Args:
+ images (`List[np.ndarray]`):
+ Batch of images to pad.
+ return_tensors (`str` or `TensorType`, *optional*):
+ The type of tensors to return. Can be one of:
+ - Unset: Return a list of `np.ndarray`.
+ - `TensorType.TENSORFLOW` or `'tf'`: Return a batch of type `tf.Tensor`.
+ - `TensorType.PYTORCH` or `'pt'`: Return a batch of type `torch.Tensor`.
+ - `TensorType.NUMPY` or `'np'`: Return a batch of type `np.ndarray`.
+ - `TensorType.JAX` or `'jax'`: Return a batch of type `jax.numpy.ndarray`.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be the same as the input image.
+ """
+ warnings.warn(
+ "This method is deprecated and will be removed in v4.27.0. Please use pad instead.", FutureWarning
+ )
+ # pad expects a list of np.ndarray, but the previous feature extractors expected torch tensors
+ images = [to_numpy_array(image) for image in pixel_values_list]
+ return self.pad(
+ images=images,
+ return_pixel_mask=True,
+ return_tensors=return_tensors,
+ data_format=data_format,
+ )
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor._pad_image
+ def _pad_image(
+ self,
+ image: np.ndarray,
+ output_size: Tuple[int, int],
+ constant_values: Union[float, Iterable[float]] = 0,
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Pad an image with zeros to the given size.
+ """
+ input_height, input_width = get_image_size(image)
+ output_height, output_width = output_size
+
+ pad_bottom = output_height - input_height
+ pad_right = output_width - input_width
+ padding = ((0, pad_bottom), (0, pad_right))
+ padded_image = pad(
+ image, padding, mode=PaddingMode.CONSTANT, constant_values=constant_values, data_format=data_format
+ )
+ return padded_image
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.pad
+ def pad(
+ self,
+ images: List[np.ndarray],
+ constant_values: Union[float, Iterable[float]] = 0,
+ return_pixel_mask: bool = True,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Pads a batch of images to the bottom and right of the image with zeros to the size of largest height and width
+ in the batch and optionally returns their corresponding pixel mask.
+
+ Args:
+ image (`np.ndarray`):
+ Image to pad.
+ constant_values (`float` or `Iterable[float]`, *optional*):
+ The value to use for the padding if `mode` is `"constant"`.
+ return_pixel_mask (`bool`, *optional*, defaults to `True`):
+ Whether to return a pixel mask.
+ input_channel_dimension (`ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be inferred from the input image.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be the same as the input image.
+ """
+ pad_size = get_max_height_width(images)
+
+ padded_images = [
+ self._pad_image(image, pad_size, constant_values=constant_values, data_format=data_format)
+ for image in images
+ ]
+ data = {"pixel_values": padded_images}
+
+ if return_pixel_mask:
+ masks = [make_pixel_mask(image=image, output_size=pad_size) for image in images]
+ data["pixel_mask"] = masks
+
+ return BatchFeature(data=data, tensor_type=return_tensors)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.preprocess
+ def preprocess(
+ self,
+ images: ImageInput,
+ annotations: Optional[Union[List[Dict], List[List[Dict]]]] = None,
+ return_segmentation_masks: bool = None,
+ masks_path: Optional[Union[str, pathlib.Path]] = None,
+ do_resize: Optional[bool] = None,
+ size: Optional[Dict[str, int]] = None,
+ resample=None, # PILImageResampling
+ do_rescale: Optional[bool] = None,
+ rescale_factor: Optional[Union[int, float]] = None,
+ do_normalize: Optional[bool] = None,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ do_pad: Optional[bool] = None,
+ format: Optional[Union[str, AnnotionFormat]] = None,
+ return_tensors: Optional[Union[TensorType, str]] = None,
+ data_format: Union[str, ChannelDimension] = ChannelDimension.FIRST,
+ **kwargs
+ ) -> BatchFeature:
+ """
+ Preprocess an image or a batch of images so that it can be used by the model.
+
+ Args:
+ images (`ImageInput`):
+ Image or batch of images to preprocess.
+ annotations (`List[Dict]` or `List[List[Dict]]`, *optional*):
+ List of annotations associated with the image or batch of images. If annotionation is for object
+ detection, the annotations should be a dictionary with the following keys:
+ - "image_id" (`int`): The image id.
+ - "annotations" (`List[Dict]`): List of annotations for an image. Each annotation should be a
+ dictionary. An image can have no annotations, in which case the list should be empty.
+ If annotionation is for segmentation, the annotations should be a dictionary with the following keys:
+ - "image_id" (`int`): The image id.
+ - "segments_info" (`List[Dict]`): List of segments for an image. Each segment should be a dictionary.
+ An image can have no segments, in which case the list should be empty.
+ - "file_name" (`str`): The file name of the image.
+ return_segmentation_masks (`bool`, *optional*, defaults to self.return_segmentation_masks):
+ Whether to return segmentation masks.
+ masks_path (`str` or `pathlib.Path`, *optional*):
+ Path to the directory containing the segmentation masks.
+ do_resize (`bool`, *optional*, defaults to self.do_resize):
+ Whether to resize the image.
+ size (`Dict[str, int]`, *optional*, defaults to self.size):
+ Size of the image after resizing.
+ resample (`PILImageResampling`, *optional*, defaults to self.resample):
+ Resampling filter to use when resizing the image.
+ do_rescale (`bool`, *optional*, defaults to self.do_rescale):
+ Whether to rescale the image.
+ rescale_factor (`float`, *optional*, defaults to self.rescale_factor):
+ Rescale factor to use when rescaling the image.
+ do_normalize (`bool`, *optional*, defaults to self.do_normalize):
+ Whether to normalize the image.
+ image_mean (`float` or `List[float]`, *optional*, defaults to self.image_mean):
+ Mean to use when normalizing the image.
+ image_std (`float` or `List[float]`, *optional*, defaults to self.image_std):
+ Standard deviation to use when normalizing the image.
+ do_pad (`bool`, *optional*, defaults to self.do_pad):
+ Whether to pad the image.
+ format (`str` or `AnnotionFormat`, *optional*, defaults to self.format):
+ Format of the annotations.
+ return_tensors (`str` or `TensorType`, *optional*, defaults to self.return_tensors):
+ Type of tensors to return. If `None`, will return the list of images.
+ data_format (`str` or `ChannelDimension`, *optional*, defaults to self.data_format):
+ The channel dimension format of the image. If not provided, it will be the same as the input image.
+ """
+ if "pad_and_return_pixel_mask" in kwargs:
+ warnings.warn(
+ "The `pad_and_return_pixel_mask` argument is deprecated and will be removed in a future version, "
+ "use `do_pad` instead.",
+ FutureWarning,
+ )
+ do_pad = kwargs.pop("pad_and_return_pixel_mask")
+
+ max_size = None
+ if "max_size" in kwargs:
+ warnings.warn(
+ "The `max_size` argument is deprecated and will be removed in a future version, use"
+ " `size['longest_edge']` instead.",
+ FutureWarning,
+ )
+ size = kwargs.pop("max_size")
+
+ do_resize = self.do_resize if do_resize is None else do_resize
+ size = self.size if size is None else size
+ size = get_size_dict(size=size, max_size=max_size, default_to_square=False)
+ resample = self.resample if resample is None else resample
+ do_rescale = self.do_rescale if do_rescale is None else do_rescale
+ rescale_factor = self.rescale_factor if rescale_factor is None else rescale_factor
+ do_normalize = self.do_normalize if do_normalize is None else do_normalize
+ image_mean = self.image_mean if image_mean is None else image_mean
+ image_std = self.image_std if image_std is None else image_std
+ do_pad = self.do_pad if do_pad is None else do_pad
+ format = self.format if format is None else format
+
+ if do_resize is not None and size is None:
+ raise ValueError("Size and max_size must be specified if do_resize is True.")
+
+ if do_rescale is not None and rescale_factor is None:
+ raise ValueError("Rescale factor must be specified if do_rescale is True.")
+
+ if do_normalize is not None and (image_mean is None or image_std is None):
+ raise ValueError("Image mean and std must be specified if do_normalize is True.")
+
+ if not is_batched(images):
+ images = [images]
+ annotations = [annotations] if annotations is not None else None
+
+ if annotations is not None and len(images) != len(annotations):
+ raise ValueError(
+ f"The number of images ({len(images)}) and annotations ({len(annotations)}) do not match."
+ )
+
+ if not valid_images(images):
+ raise ValueError(
+ "Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
+ "torch.Tensor, tf.Tensor or jax.ndarray."
+ )
+
+ format = AnnotionFormat(format)
+ if annotations is not None:
+ if format == AnnotionFormat.COCO_DETECTION and not valid_coco_detection_annotations(annotations):
+ raise ValueError(
+ "Invalid COCO detection annotations. Annotations must a dict (single image) of list of dicts"
+ "(batch of images) with the following keys: `image_id` and `annotations`, with the latter "
+ "being a list of annotations in the COCO format."
+ )
+ elif format == AnnotionFormat.COCO_PANOPTIC and not valid_coco_panoptic_annotations(annotations):
+ raise ValueError(
+ "Invalid COCO panoptic annotations. Annotations must a dict (single image) of list of dicts "
+ "(batch of images) with the following keys: `image_id`, `file_name` and `segments_info`, with "
+ "the latter being a list of annotations in the COCO format."
+ )
+ elif format not in SUPPORTED_ANNOTATION_FORMATS:
+ raise ValueError(
+ f"Unsupported annotation format: {format} must be one of {SUPPORTED_ANNOTATION_FORMATS}"
+ )
+
+ if (
+ masks_path is not None
+ and format == AnnotionFormat.COCO_PANOPTIC
+ and not isinstance(masks_path, (pathlib.Path, str))
+ ):
+ raise ValueError(
+ "The path to the directory containing the mask PNG files should be provided as a"
+ f" `pathlib.Path` or string object, but is {type(masks_path)} instead."
+ )
+
+ # All transformations expect numpy arrays
+ images = [to_numpy_array(image) for image in images]
+
+ # prepare (COCO annotations as a list of Dict -> DETR target as a single Dict per image)
+ if annotations is not None:
+ prepared_images = []
+ prepared_annotations = []
+ for image, target in zip(images, annotations):
+ target = self.prepare_annotation(
+ image, target, format, return_segmentation_masks=return_segmentation_masks, masks_path=masks_path
+ )
+ prepared_images.append(image)
+ prepared_annotations.append(target)
+ images = prepared_images
+ annotations = prepared_annotations
+ del prepared_images, prepared_annotations
+
+ # transformations
+ if do_resize:
+ if annotations is not None:
+ resized_images, resized_annotations = [], []
+ for image, target in zip(images, annotations):
+ orig_size = get_image_size(image)
+ resized_image = self.resize(image, size=size, max_size=max_size, resample=resample)
+ resized_annotation = self.resize_annotation(target, orig_size, get_image_size(resized_image))
+ resized_images.append(resized_image)
+ resized_annotations.append(resized_annotation)
+ images = resized_images
+ annotations = resized_annotations
+ del resized_images, resized_annotations
+ else:
+ images = [self.resize(image, size=size, resample=resample) for image in images]
+
+ if do_rescale:
+ images = [self.rescale(image, rescale_factor) for image in images]
+
+ if do_normalize:
+ images = [self.normalize(image, image_mean, image_std) for image in images]
+ if annotations is not None:
+ annotations = [
+ self.normalize_annotation(annotation, get_image_size(image))
+ for annotation, image in zip(annotations, images)
+ ]
+
+ if do_pad:
+ # Pads images and returns their mask: {'pixel_values': ..., 'pixel_mask': ...}
+ data = self.pad(images, return_pixel_mask=True, data_format=data_format)
+ else:
+ images = [to_channel_dimension_format(image, data_format) for image in images]
+ data = {"pixel_values": images}
+
+ encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
+ if annotations is not None:
+ encoded_inputs["labels"] = [
+ BatchFeature(annotation, tensor_type=return_tensors) for annotation in annotations
+ ]
+
+ return encoded_inputs
+
+ # POSTPROCESSING METHODS - TODO: add support for other frameworks
+ def post_process(self, outputs, target_sizes):
+ """
+ Converts the output of [`ConditionalDetrForObjectDetection`] into the format expected by the COCO api. Only
+ supports PyTorch.
+
+ Args:
+ outputs ([`ConditionalDetrObjectDetectionOutput`]):
+ Raw outputs of the model.
+ target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
+ Tensor containing the size (h, w) of each image of the batch. For evaluation, this must be the original
+ image size (before any data augmentation). For visualization, this should be the image size after data
+ augment, but before padding.
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
+ in the batch as predicted by the model.
+ """
+ warnings.warn(
+ "`post_process` is deprecated and will be removed in v5 of Transformers, please use"
+ " `post_process_object_detection`",
+ FutureWarning,
+ )
+
+ out_logits, out_bbox = outputs.logits, outputs.pred_boxes
+
+ if len(out_logits) != len(target_sizes):
+ raise ValueError("Make sure that you pass in as many target sizes as the batch dimension of the logits")
+ if target_sizes.shape[1] != 2:
+ raise ValueError("Each element of target_sizes must contain the size (h, w) of each image of the batch")
+
+ prob = out_logits.sigmoid()
+ topk_values, topk_indexes = torch.topk(prob.view(out_logits.shape[0], -1), 300, dim=1)
+ scores = topk_values
+ topk_boxes = topk_indexes // out_logits.shape[2]
+ labels = topk_indexes % out_logits.shape[2]
+ boxes = center_to_corners_format(out_bbox)
+ boxes = torch.gather(boxes, 1, topk_boxes.unsqueeze(-1).repeat(1, 1, 4))
+
+ # and from relative [0, 1] to absolute [0, height] coordinates
+ img_h, img_w = target_sizes.unbind(1)
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1).to(boxes.device)
+ boxes = boxes * scale_fct[:, None, :]
+
+ results = [{"scores": s, "labels": l, "boxes": b} for s, l, b in zip(scores, labels, boxes)]
+
+ return results
+
+ # Copied from transformers.models.deformable_detr.image_processing_deformable_detr.DeformableDetrImageProcessor.post_process_object_detection with DeformableDetr->ConditionalDetr
+ def post_process_object_detection(
+ self, outputs, threshold: float = 0.5, target_sizes: Union[TensorType, List[Tuple]] = None
+ ):
+ """
+ Converts the output of [`ConditionalDetrForObjectDetection`] into the format expected by the COCO api. Only
+ supports PyTorch.
+
+ Args:
+ outputs ([`DetrObjectDetectionOutput`]):
+ Raw outputs of the model.
+ threshold (`float`, *optional*):
+ Score threshold to keep object detection predictions.
+ target_sizes (`torch.Tensor` or `List[Tuple[int, int]]`, *optional*):
+ Tensor of shape `(batch_size, 2)` or list of tuples (`Tuple[int, int]`) containing the target size
+ (height, width) of each image in the batch. If left to None, predictions will not be resized.
+
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
+ in the batch as predicted by the model.
+ """
+ out_logits, out_bbox = outputs.logits, outputs.pred_boxes
+
+ if target_sizes is not None:
+ if len(out_logits) != len(target_sizes):
+ raise ValueError(
+ "Make sure that you pass in as many target sizes as the batch dimension of the logits"
+ )
+
+ prob = out_logits.sigmoid()
+ topk_values, topk_indexes = torch.topk(prob.view(out_logits.shape[0], -1), 100, dim=1)
+ scores = topk_values
+ topk_boxes = topk_indexes // out_logits.shape[2]
+ labels = topk_indexes % out_logits.shape[2]
+ boxes = center_to_corners_format(out_bbox)
+ boxes = torch.gather(boxes, 1, topk_boxes.unsqueeze(-1).repeat(1, 1, 4))
+
+ # and from relative [0, 1] to absolute [0, height] coordinates
+ if isinstance(target_sizes, List):
+ img_h = torch.Tensor([i[0] for i in target_sizes])
+ img_w = torch.Tensor([i[1] for i in target_sizes])
+ else:
+ img_h, img_w = target_sizes.unbind(1)
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
+ boxes = boxes * scale_fct[:, None, :]
+
+ results = []
+ for s, l, b in zip(scores, labels, boxes):
+ score = s[s > threshold]
+ label = l[s > threshold]
+ box = b[s > threshold]
+ results.append({"scores": score, "labels": label, "boxes": box})
+
+ return results
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.post_process_semantic_segmentation with Detr->ConditionalDetr
+ def post_process_semantic_segmentation(self, outputs, target_sizes: List[Tuple[int, int]] = None):
+ """
+ Converts the output of [`ConditionalDetrForSegmentation`] into semantic segmentation maps. Only supports
+ PyTorch.
+
+ Args:
+ outputs ([`ConditionalDetrForSegmentation`]):
+ Raw outputs of the model.
+ target_sizes (`List[Tuple[int, int]]`, *optional*):
+ A list of tuples (`Tuple[int, int]`) containing the target size (height, width) of each image in the
+ batch. If unset, predictions will not be resized.
+ Returns:
+ `List[torch.Tensor]`:
+ A list of length `batch_size`, where each item is a semantic segmentation map of shape (height, width)
+ corresponding to the target_sizes entry (if `target_sizes` is specified). Each entry of each
+ `torch.Tensor` correspond to a semantic class id.
+ """
+ class_queries_logits = outputs.logits # [batch_size, num_queries, num_classes+1]
+ masks_queries_logits = outputs.pred_masks # [batch_size, num_queries, height, width]
+
+ # Remove the null class `[..., :-1]`
+ masks_classes = class_queries_logits.softmax(dim=-1)[..., :-1]
+ masks_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
+
+ # Semantic segmentation logits of shape (batch_size, num_classes, height, width)
+ segmentation = torch.einsum("bqc, bqhw -> bchw", masks_classes, masks_probs)
+ batch_size = class_queries_logits.shape[0]
+
+ # Resize logits and compute semantic segmentation maps
+ if target_sizes is not None:
+ if batch_size != len(target_sizes):
+ raise ValueError(
+ "Make sure that you pass in as many target sizes as the batch dimension of the logits"
+ )
+
+ semantic_segmentation = []
+ for idx in range(batch_size):
+ resized_logits = nn.functional.interpolate(
+ segmentation[idx].unsqueeze(dim=0), size=target_sizes[idx], mode="bilinear", align_corners=False
+ )
+ semantic_map = resized_logits[0].argmax(dim=0)
+ semantic_segmentation.append(semantic_map)
+ else:
+ semantic_segmentation = segmentation.argmax(dim=1)
+ semantic_segmentation = [semantic_segmentation[i] for i in range(semantic_segmentation.shape[0])]
+
+ return semantic_segmentation
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.post_process_instance_segmentation with Detr->ConditionalDetr
+ def post_process_instance_segmentation(
+ self,
+ outputs,
+ threshold: float = 0.5,
+ mask_threshold: float = 0.5,
+ overlap_mask_area_threshold: float = 0.8,
+ target_sizes: Optional[List[Tuple[int, int]]] = None,
+ return_coco_annotation: Optional[bool] = False,
+ ) -> List[Dict]:
+ """
+ Converts the output of [`ConditionalDetrForSegmentation`] into instance segmentation predictions. Only supports
+ PyTorch.
+
+ Args:
+ outputs ([`ConditionalDetrForSegmentation`]):
+ Raw outputs of the model.
+ threshold (`float`, *optional*, defaults to 0.5):
+ The probability score threshold to keep predicted instance masks.
+ mask_threshold (`float`, *optional*, defaults to 0.5):
+ Threshold to use when turning the predicted masks into binary values.
+ overlap_mask_area_threshold (`float`, *optional*, defaults to 0.8):
+ The overlap mask area threshold to merge or discard small disconnected parts within each binary
+ instance mask.
+ target_sizes (`List[Tuple]`, *optional*):
+ List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
+ final size (height, width) of each prediction. If unset, predictions will not be resized.
+ return_coco_annotation (`bool`, *optional*):
+ Defaults to `False`. If set to `True`, segmentation maps are returned in COCO run-length encoding (RLE)
+ format.
+ Returns:
+ `List[Dict]`: A list of dictionaries, one per image, each dictionary containing two keys:
+ - **segmentation** -- A tensor of shape `(height, width)` where each pixel represents a `segment_id` or
+ `List[List]` run-length encoding (RLE) of the segmentation map if return_coco_annotation is set to
+ `True`. Set to `None` if no mask if found above `threshold`.
+ - **segments_info** -- A dictionary that contains additional information on each segment.
+ - **id** -- An integer representing the `segment_id`.
+ - **label_id** -- An integer representing the label / semantic class id corresponding to `segment_id`.
+ - **score** -- Prediction score of segment with `segment_id`.
+ """
+ class_queries_logits = outputs.logits # [batch_size, num_queries, num_classes+1]
+ masks_queries_logits = outputs.pred_masks # [batch_size, num_queries, height, width]
+
+ batch_size = class_queries_logits.shape[0]
+ num_labels = class_queries_logits.shape[-1] - 1
+
+ mask_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
+
+ # Predicted label and score of each query (batch_size, num_queries)
+ pred_scores, pred_labels = nn.functional.softmax(class_queries_logits, dim=-1).max(-1)
+
+ # Loop over items in batch size
+ results: List[Dict[str, TensorType]] = []
+
+ for i in range(batch_size):
+ mask_probs_item, pred_scores_item, pred_labels_item = remove_low_and_no_objects(
+ mask_probs[i], pred_scores[i], pred_labels[i], threshold, num_labels
+ )
+
+ # No mask found
+ if mask_probs_item.shape[0] <= 0:
+ height, width = target_sizes[i] if target_sizes is not None else mask_probs_item.shape[1:]
+ segmentation = torch.zeros((height, width)) - 1
+ results.append({"segmentation": segmentation, "segments_info": []})
+ continue
+
+ # Get segmentation map and segment information of batch item
+ target_size = target_sizes[i] if target_sizes is not None else None
+ segmentation, segments = compute_segments(
+ mask_probs=mask_probs_item,
+ pred_scores=pred_scores_item,
+ pred_labels=pred_labels_item,
+ mask_threshold=mask_threshold,
+ overlap_mask_area_threshold=overlap_mask_area_threshold,
+ label_ids_to_fuse=[],
+ target_size=target_size,
+ )
+
+ # Return segmentation map in run-length encoding (RLE) format
+ if return_coco_annotation:
+ segmentation = convert_segmentation_to_rle(segmentation)
+
+ results.append({"segmentation": segmentation, "segments_info": segments})
+ return results
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.post_process_panoptic_segmentation with Detr->ConditionalDetr
+ def post_process_panoptic_segmentation(
+ self,
+ outputs,
+ threshold: float = 0.5,
+ mask_threshold: float = 0.5,
+ overlap_mask_area_threshold: float = 0.8,
+ label_ids_to_fuse: Optional[Set[int]] = None,
+ target_sizes: Optional[List[Tuple[int, int]]] = None,
+ ) -> List[Dict]:
+ """
+ Converts the output of [`ConditionalDetrForSegmentation`] into image panoptic segmentation predictions. Only
+ supports PyTorch.
+
+ Args:
+ outputs ([`ConditionalDetrForSegmentation`]):
+ The outputs from [`ConditionalDetrForSegmentation`].
+ threshold (`float`, *optional*, defaults to 0.5):
+ The probability score threshold to keep predicted instance masks.
+ mask_threshold (`float`, *optional*, defaults to 0.5):
+ Threshold to use when turning the predicted masks into binary values.
+ overlap_mask_area_threshold (`float`, *optional*, defaults to 0.8):
+ The overlap mask area threshold to merge or discard small disconnected parts within each binary
+ instance mask.
+ label_ids_to_fuse (`Set[int]`, *optional*):
+ The labels in this state will have all their instances be fused together. For instance we could say
+ there can only be one sky in an image, but several persons, so the label ID for sky would be in that
+ set, but not the one for person.
+ target_sizes (`List[Tuple]`, *optional*):
+ List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
+ final size (height, width) of each prediction in batch. If unset, predictions will not be resized.
+ Returns:
+ `List[Dict]`: A list of dictionaries, one per image, each dictionary containing two keys:
+ - **segmentation** -- a tensor of shape `(height, width)` where each pixel represents a `segment_id` or
+ `None` if no mask if found above `threshold`. If `target_sizes` is specified, segmentation is resized to
+ the corresponding `target_sizes` entry.
+ - **segments_info** -- A dictionary that contains additional information on each segment.
+ - **id** -- an integer representing the `segment_id`.
+ - **label_id** -- An integer representing the label / semantic class id corresponding to `segment_id`.
+ - **was_fused** -- a boolean, `True` if `label_id` was in `label_ids_to_fuse`, `False` otherwise.
+ Multiple instances of the same class / label were fused and assigned a single `segment_id`.
+ - **score** -- Prediction score of segment with `segment_id`.
+ """
+
+ if label_ids_to_fuse is None:
+ warnings.warn("`label_ids_to_fuse` unset. No instance will be fused.")
+ label_ids_to_fuse = set()
+
+ class_queries_logits = outputs.logits # [batch_size, num_queries, num_classes+1]
+ masks_queries_logits = outputs.pred_masks # [batch_size, num_queries, height, width]
+
+ batch_size = class_queries_logits.shape[0]
+ num_labels = class_queries_logits.shape[-1] - 1
+
+ mask_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
+
+ # Predicted label and score of each query (batch_size, num_queries)
+ pred_scores, pred_labels = nn.functional.softmax(class_queries_logits, dim=-1).max(-1)
+
+ # Loop over items in batch size
+ results: List[Dict[str, TensorType]] = []
+
+ for i in range(batch_size):
+ mask_probs_item, pred_scores_item, pred_labels_item = remove_low_and_no_objects(
+ mask_probs[i], pred_scores[i], pred_labels[i], threshold, num_labels
+ )
+
+ # No mask found
+ if mask_probs_item.shape[0] <= 0:
+ height, width = target_sizes[i] if target_sizes is not None else mask_probs_item.shape[1:]
+ segmentation = torch.zeros((height, width)) - 1
+ results.append({"segmentation": segmentation, "segments_info": []})
+ continue
+
+ # Get segmentation map and segment information of batch item
+ target_size = target_sizes[i] if target_sizes is not None else None
+ segmentation, segments = compute_segments(
+ mask_probs=mask_probs_item,
+ pred_scores=pred_scores_item,
+ pred_labels=pred_labels_item,
+ mask_threshold=mask_threshold,
+ overlap_mask_area_threshold=overlap_mask_area_threshold,
+ label_ids_to_fuse=label_ids_to_fuse,
+ target_size=target_size,
+ )
+
+ results.append({"segmentation": segmentation, "segments_info": segments})
+ return results
diff --git a/src/transformers/models/deformable_detr/__init__.py b/src/transformers/models/deformable_detr/__init__.py
index 36c1a83b0e..dd76e06c7b 100644
--- a/src/transformers/models/deformable_detr/__init__.py
+++ b/src/transformers/models/deformable_detr/__init__.py
@@ -32,6 +32,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_deformable_detr"] = ["DeformableDetrFeatureExtractor"]
+ _import_structure["image_processing_deformable_detr"] = ["DeformableDetrImageProcessor"]
try:
if not is_timm_available():
@@ -57,6 +58,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_deformable_detr import DeformableDetrFeatureExtractor
+ from .image_processing_deformable_detr import DeformableDetrImageProcessor
try:
if not is_timm_available():
diff --git a/src/transformers/models/deformable_detr/feature_extraction_deformable_detr.py b/src/transformers/models/deformable_detr/feature_extraction_deformable_detr.py
index a618106380..1473819f66 100644
--- a/src/transformers/models/deformable_detr/feature_extraction_deformable_detr.py
+++ b/src/transformers/models/deformable_detr/feature_extraction_deformable_detr.py
@@ -14,729 +14,10 @@
# limitations under the License.
"""Feature extractor class for Deformable DETR."""
-import pathlib
-import warnings
-from typing import Dict, List, Optional, Tuple, Union
+from ...utils import logging
+from .image_processing_deformable_detr import DeformableDetrImageProcessor
-import numpy as np
-from PIL import Image
-
-from ...feature_extraction_utils import BatchFeature, FeatureExtractionMixin
-from ...image_transforms import center_to_corners_format, corners_to_center_format, rgb_to_id
-from ...image_utils import ImageFeatureExtractionMixin
-from ...utils import TensorType, is_torch_available, is_torch_tensor, logging
-
-
-if is_torch_available():
- import torch
- from torch import nn
logger = logging.get_logger(__name__)
-
-ImageInput = Union[Image.Image, np.ndarray, "torch.Tensor", List[Image.Image], List[np.ndarray], List["torch.Tensor"]]
-
-
-# Copied from transformers.models.detr.feature_extraction_detr.masks_to_boxes
-def masks_to_boxes(masks):
- """
- Compute the bounding boxes around the provided panoptic segmentation masks.
-
- The masks should be in format [N, H, W] where N is the number of masks, (H, W) are the spatial dimensions.
-
- Returns a [N, 4] tensor, with the boxes in corner (xyxy) format.
- """
- if masks.size == 0:
- return np.zeros((0, 4))
-
- h, w = masks.shape[-2:]
-
- y = np.arange(0, h, dtype=np.float32)
- x = np.arange(0, w, dtype=np.float32)
- # see https://github.com/pytorch/pytorch/issues/50276
- y, x = np.meshgrid(y, x, indexing="ij")
-
- x_mask = masks * np.expand_dims(x, axis=0)
- x_max = x_mask.reshape(x_mask.shape[0], -1).max(-1)
- x = np.ma.array(x_mask, mask=~(np.array(masks, dtype=bool)))
- x_min = x.filled(fill_value=1e8)
- x_min = x_min.reshape(x_min.shape[0], -1).min(-1)
-
- y_mask = masks * np.expand_dims(y, axis=0)
- y_max = y_mask.reshape(x_mask.shape[0], -1).max(-1)
- y = np.ma.array(y_mask, mask=~(np.array(masks, dtype=bool)))
- y_min = y.filled(fill_value=1e8)
- y_min = y_min.reshape(y_min.shape[0], -1).min(-1)
-
- return np.stack([x_min, y_min, x_max, y_max], 1)
-
-
-class DeformableDetrFeatureExtractor(FeatureExtractionMixin, ImageFeatureExtractionMixin):
- r"""
- Constructs a Deformable DETR feature extractor. Differs only in the postprocessing of object detection compared to
- DETR.
-
- This feature extractor inherits from [`FeatureExtractionMixin`] which contains most of the main methods. Users
- should refer to this superclass for more information regarding those methods.
-
- Args:
- format (`str`, *optional*, defaults to `"coco_detection"`):
- Data format of the annotations. One of "coco_detection" or "coco_panoptic".
- do_resize (`bool`, *optional*, defaults to `True`):
- Whether to resize the input to a certain `size`.
- size (`int`, *optional*, defaults to 800):
- Resize the input to the given size. Only has an effect if `do_resize` is set to `True`. If size is a
- sequence like `(width, height)`, output size will be matched to this. If size is an int, smaller edge of
- the image will be matched to this number. i.e, if `height > width`, then image will be rescaled to `(size *
- height / width, size)`.
- max_size (`int`, *optional*, defaults to 1333):
- The largest size an image dimension can have (otherwise it's capped). Only has an effect if `do_resize` is
- set to `True`.
- do_normalize (`bool`, *optional*, defaults to `True`):
- Whether or not to normalize the input with mean and standard deviation.
- image_mean (`int`, *optional*, defaults to `[0.485, 0.456, 0.406]`):
- The sequence of means for each channel, to be used when normalizing images. Defaults to the ImageNet mean.
- image_std (`int`, *optional*, defaults to `[0.229, 0.224, 0.225]`):
- The sequence of standard deviations for each channel, to be used when normalizing images. Defaults to the
- ImageNet std.
- """
-
- model_input_names = ["pixel_values", "pixel_mask"]
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.__init__
- def __init__(
- self,
- format="coco_detection",
- do_resize=True,
- size=800,
- max_size=1333,
- do_normalize=True,
- image_mean=None,
- image_std=None,
- **kwargs
- ):
- super().__init__(**kwargs)
- self.format = self._is_valid_format(format)
- self.do_resize = do_resize
- self.size = size
- self.max_size = max_size
- self.do_normalize = do_normalize
- self.image_mean = image_mean if image_mean is not None else [0.485, 0.456, 0.406] # ImageNet mean
- self.image_std = image_std if image_std is not None else [0.229, 0.224, 0.225] # ImageNet std
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._is_valid_format
- def _is_valid_format(self, format):
- if format not in ["coco_detection", "coco_panoptic"]:
- raise ValueError(f"Format {format} not supported")
- return format
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.prepare
- def prepare(self, image, target, return_segmentation_masks=False, masks_path=None):
- if self.format == "coco_detection":
- image, target = self.prepare_coco_detection(image, target, return_segmentation_masks)
- return image, target
- elif self.format == "coco_panoptic":
- image, target = self.prepare_coco_panoptic(image, target, masks_path)
- return image, target
- else:
- raise ValueError(f"Format {self.format} not supported")
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.convert_coco_poly_to_mask
- def convert_coco_poly_to_mask(self, segmentations, height, width):
-
- try:
- from pycocotools import mask as coco_mask
- except ImportError:
- raise ImportError("Pycocotools is not installed in your environment.")
-
- masks = []
- for polygons in segmentations:
- rles = coco_mask.frPyObjects(polygons, height, width)
- mask = coco_mask.decode(rles)
- if len(mask.shape) < 3:
- mask = mask[..., None]
- mask = np.asarray(mask, dtype=np.uint8)
- mask = np.any(mask, axis=2)
- masks.append(mask)
- if masks:
- masks = np.stack(masks, axis=0)
- else:
- masks = np.zeros((0, height, width), dtype=np.uint8)
-
- return masks
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.prepare_coco_detection
- def prepare_coco_detection(self, image, target, return_segmentation_masks=False):
- """
- Convert the target in COCO format into the format expected by DETR.
- """
- w, h = image.size
-
- image_id = target["image_id"]
- image_id = np.asarray([image_id], dtype=np.int64)
-
- # get all COCO annotations for the given image
- anno = target["annotations"]
-
- anno = [obj for obj in anno if "iscrowd" not in obj or obj["iscrowd"] == 0]
-
- boxes = [obj["bbox"] for obj in anno]
- # guard against no boxes via resizing
- boxes = np.asarray(boxes, dtype=np.float32).reshape(-1, 4)
- boxes[:, 2:] += boxes[:, :2]
- boxes[:, 0::2] = boxes[:, 0::2].clip(min=0, max=w)
- boxes[:, 1::2] = boxes[:, 1::2].clip(min=0, max=h)
-
- classes = [obj["category_id"] for obj in anno]
- classes = np.asarray(classes, dtype=np.int64)
-
- if return_segmentation_masks:
- segmentations = [obj["segmentation"] for obj in anno]
- masks = self.convert_coco_poly_to_mask(segmentations, h, w)
-
- keypoints = None
- if anno and "keypoints" in anno[0]:
- keypoints = [obj["keypoints"] for obj in anno]
- keypoints = np.asarray(keypoints, dtype=np.float32)
- num_keypoints = keypoints.shape[0]
- if num_keypoints:
- keypoints = keypoints.reshape((-1, 3))
-
- keep = (boxes[:, 3] > boxes[:, 1]) & (boxes[:, 2] > boxes[:, 0])
- boxes = boxes[keep]
- classes = classes[keep]
- if return_segmentation_masks:
- masks = masks[keep]
- if keypoints is not None:
- keypoints = keypoints[keep]
-
- target = {}
- target["boxes"] = boxes
- target["class_labels"] = classes
- if return_segmentation_masks:
- target["masks"] = masks
- target["image_id"] = image_id
- if keypoints is not None:
- target["keypoints"] = keypoints
-
- # for conversion to coco api
- area = np.asarray([obj["area"] for obj in anno], dtype=np.float32)
- iscrowd = np.asarray([obj["iscrowd"] if "iscrowd" in obj else 0 for obj in anno], dtype=np.int64)
- target["area"] = area[keep]
- target["iscrowd"] = iscrowd[keep]
-
- target["orig_size"] = np.asarray([int(h), int(w)], dtype=np.int64)
- target["size"] = np.asarray([int(h), int(w)], dtype=np.int64)
-
- return image, target
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.prepare_coco_panoptic
- def prepare_coco_panoptic(self, image, target, masks_path, return_masks=True):
- w, h = image.size
- ann_info = target.copy()
- ann_path = pathlib.Path(masks_path) / ann_info["file_name"]
-
- if "segments_info" in ann_info:
- masks = np.asarray(Image.open(ann_path), dtype=np.uint32)
- masks = rgb_to_id(masks)
-
- ids = np.array([ann["id"] for ann in ann_info["segments_info"]])
- masks = masks == ids[:, None, None]
- masks = np.asarray(masks, dtype=np.uint8)
-
- labels = np.asarray([ann["category_id"] for ann in ann_info["segments_info"]], dtype=np.int64)
-
- target = {}
- target["image_id"] = np.asarray(
- [ann_info["image_id"] if "image_id" in ann_info else ann_info["id"]], dtype=np.int64
- )
- if return_masks:
- target["masks"] = masks
- target["class_labels"] = labels
-
- target["boxes"] = masks_to_boxes(masks)
-
- target["size"] = np.asarray([int(h), int(w)], dtype=np.int64)
- target["orig_size"] = np.asarray([int(h), int(w)], dtype=np.int64)
- if "segments_info" in ann_info:
- target["iscrowd"] = np.asarray([ann["iscrowd"] for ann in ann_info["segments_info"]], dtype=np.int64)
- target["area"] = np.asarray([ann["area"] for ann in ann_info["segments_info"]], dtype=np.float32)
-
- return image, target
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._resize
- def _resize(self, image, size, target=None, max_size=None):
- """
- Resize the image to the given size. Size can be min_size (scalar) or (w, h) tuple. If size is an int, smaller
- edge of the image will be matched to this number.
-
- If given, also resize the target accordingly.
- """
- if not isinstance(image, Image.Image):
- image = self.to_pil_image(image)
-
- def get_size_with_aspect_ratio(image_size, size, max_size=None):
- w, h = image_size
- if max_size is not None:
- min_original_size = float(min((w, h)))
- max_original_size = float(max((w, h)))
- if max_original_size / min_original_size * size > max_size:
- size = int(round(max_size * min_original_size / max_original_size))
-
- if (w <= h and w == size) or (h <= w and h == size):
- return (h, w)
-
- if w < h:
- ow = size
- oh = int(size * h / w)
- else:
- oh = size
- ow = int(size * w / h)
-
- return (oh, ow)
-
- def get_size(image_size, size, max_size=None):
- if isinstance(size, (list, tuple)):
- return size
- else:
- # size returned must be (w, h) since we use PIL to resize images
- # so we revert the tuple
- return get_size_with_aspect_ratio(image_size, size, max_size)[::-1]
-
- size = get_size(image.size, size, max_size)
- rescaled_image = self.resize(image, size=size)
-
- if target is None:
- return rescaled_image, None
-
- ratios = tuple(float(s) / float(s_orig) for s, s_orig in zip(rescaled_image.size, image.size))
- ratio_width, ratio_height = ratios
-
- target = target.copy()
- if "boxes" in target:
- boxes = target["boxes"]
- scaled_boxes = boxes * np.asarray([ratio_width, ratio_height, ratio_width, ratio_height], dtype=np.float32)
- target["boxes"] = scaled_boxes
-
- if "area" in target:
- area = target["area"]
- scaled_area = area * (ratio_width * ratio_height)
- target["area"] = scaled_area
-
- w, h = size
- target["size"] = np.asarray([h, w], dtype=np.int64)
-
- if "masks" in target:
- # use PyTorch as current workaround
- # TODO replace by self.resize
- masks = torch.from_numpy(target["masks"][:, None]).float()
- interpolated_masks = nn.functional.interpolate(masks, size=(h, w), mode="nearest")[:, 0] > 0.5
- target["masks"] = interpolated_masks.numpy()
-
- return rescaled_image, target
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._normalize
- def _normalize(self, image, mean, std, target=None):
- """
- Normalize the image with a certain mean and std.
-
- If given, also normalize the target bounding boxes based on the size of the image.
- """
-
- image = self.normalize(image, mean=mean, std=std)
- if target is None:
- return image, None
-
- target = target.copy()
- h, w = image.shape[-2:]
-
- if "boxes" in target:
- boxes = target["boxes"]
- boxes = corners_to_center_format(boxes)
- boxes = boxes / np.asarray([w, h, w, h], dtype=np.float32)
- target["boxes"] = boxes
-
- return image, target
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.__call__
- def __call__(
- self,
- images: ImageInput,
- annotations: Union[List[Dict], List[List[Dict]]] = None,
- return_segmentation_masks: Optional[bool] = False,
- masks_path: Optional[pathlib.Path] = None,
- pad_and_return_pixel_mask: Optional[bool] = True,
- return_tensors: Optional[Union[str, TensorType]] = None,
- **kwargs,
- ) -> BatchFeature:
- """
- Main method to prepare for the model one or several image(s) and optional annotations. Images are by default
- padded up to the largest image in a batch, and a pixel mask is created that indicates which pixels are
- real/which are padding.
-
-
-
- NumPy arrays and PyTorch tensors are converted to PIL images when resizing, so the most efficient is to pass
- PIL images.
-
-
-
- Args:
- images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
- The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
- tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a
- number of channels, H and W are image height and width.
-
- annotations (`Dict`, `List[Dict]`, *optional*):
- The corresponding annotations in COCO format.
-
- In case [`DetrFeatureExtractor`] was initialized with `format = "coco_detection"`, the annotations for
- each image should have the following format: {'image_id': int, 'annotations': [annotation]}, with the
- annotations being a list of COCO object annotations.
-
- In case [`DetrFeatureExtractor`] was initialized with `format = "coco_panoptic"`, the annotations for
- each image should have the following format: {'image_id': int, 'file_name': str, 'segments_info':
- [segment_info]} with segments_info being a list of COCO panoptic annotations.
-
- return_segmentation_masks (`Dict`, `List[Dict]`, *optional*, defaults to `False`):
- Whether to also include instance segmentation masks as part of the labels in case `format =
- "coco_detection"`.
-
- masks_path (`pathlib.Path`, *optional*):
- Path to the directory containing the PNG files that store the class-agnostic image segmentations. Only
- relevant in case [`DetrFeatureExtractor`] was initialized with `format = "coco_panoptic"`.
-
- pad_and_return_pixel_mask (`bool`, *optional*, defaults to `True`):
- Whether or not to pad images up to the largest image in a batch and create a pixel mask.
-
- If left to the default, will return a pixel mask that is:
-
- - 1 for pixels that are real (i.e. **not masked**),
- - 0 for pixels that are padding (i.e. **masked**).
-
- return_tensors (`str` or [`~utils.TensorType`], *optional*):
- If set, will return tensors instead of NumPy arrays. If set to `'pt'`, return PyTorch `torch.Tensor`
- objects.
-
- Returns:
- [`BatchFeature`]: A [`BatchFeature`] with the following fields:
-
- - **pixel_values** -- Pixel values to be fed to a model.
- - **pixel_mask** -- Pixel mask to be fed to a model (when `pad_and_return_pixel_mask=True` or if
- *"pixel_mask"* is in `self.model_input_names`).
- - **labels** -- Optional labels to be fed to a model (when `annotations` are provided)
- """
- # Input type checking for clearer error
-
- valid_images = False
- valid_annotations = False
- valid_masks_path = False
-
- # Check that images has a valid type
- if isinstance(images, (Image.Image, np.ndarray)) or is_torch_tensor(images):
- valid_images = True
- elif isinstance(images, (list, tuple)):
- if len(images) == 0 or isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]):
- valid_images = True
-
- if not valid_images:
- raise ValueError(
- "Images must of type `PIL.Image.Image`, `np.ndarray` or `torch.Tensor` (single example), "
- "`List[PIL.Image.Image]`, `List[np.ndarray]` or `List[torch.Tensor]` (batch of examples)."
- )
-
- is_batched = bool(
- isinstance(images, (list, tuple))
- and (isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]))
- )
-
- # Check that annotations has a valid type
- if annotations is not None:
- if not is_batched:
- if self.format == "coco_detection":
- if isinstance(annotations, dict) and "image_id" in annotations and "annotations" in annotations:
- if isinstance(annotations["annotations"], (list, tuple)):
- # an image can have no annotations
- if len(annotations["annotations"]) == 0 or isinstance(annotations["annotations"][0], dict):
- valid_annotations = True
- elif self.format == "coco_panoptic":
- if isinstance(annotations, dict) and "image_id" in annotations and "segments_info" in annotations:
- if isinstance(annotations["segments_info"], (list, tuple)):
- # an image can have no segments (?)
- if len(annotations["segments_info"]) == 0 or isinstance(
- annotations["segments_info"][0], dict
- ):
- valid_annotations = True
- else:
- if isinstance(annotations, (list, tuple)):
- if len(images) != len(annotations):
- raise ValueError("There must be as many annotations as there are images")
- if isinstance(annotations[0], Dict):
- if self.format == "coco_detection":
- if isinstance(annotations[0]["annotations"], (list, tuple)):
- valid_annotations = True
- elif self.format == "coco_panoptic":
- if isinstance(annotations[0]["segments_info"], (list, tuple)):
- valid_annotations = True
-
- if not valid_annotations:
- raise ValueError(
- """
- Annotations must of type `Dict` (single image) or `List[Dict]` (batch of images). In case of object
- detection, each dictionary should contain the keys 'image_id' and 'annotations', with the latter
- being a list of annotations in COCO format. In case of panoptic segmentation, each dictionary
- should contain the keys 'file_name', 'image_id' and 'segments_info', with the latter being a list
- of annotations in COCO format.
- """
- )
-
- # Check that masks_path has a valid type
- if masks_path is not None:
- if self.format == "coco_panoptic":
- if isinstance(masks_path, pathlib.Path):
- valid_masks_path = True
- if not valid_masks_path:
- raise ValueError(
- "The path to the directory containing the mask PNG files should be provided as a"
- " `pathlib.Path` object."
- )
-
- if not is_batched:
- images = [images]
- if annotations is not None:
- annotations = [annotations]
-
- # Create a copy of the list to avoid editing it in place
- images = [image for image in images]
-
- if annotations is not None:
- annotations = [annotation for annotation in annotations]
-
- # prepare (COCO annotations as a list of Dict -> DETR target as a single Dict per image)
- if annotations is not None:
- for idx, (image, target) in enumerate(zip(images, annotations)):
- if not isinstance(image, Image.Image):
- image = self.to_pil_image(image)
- image, target = self.prepare(image, target, return_segmentation_masks, masks_path)
- images[idx] = image
- annotations[idx] = target
-
- # transformations (resizing + normalization)
- if self.do_resize and self.size is not None:
- if annotations is not None:
- for idx, (image, target) in enumerate(zip(images, annotations)):
- image, target = self._resize(image=image, target=target, size=self.size, max_size=self.max_size)
- images[idx] = image
- annotations[idx] = target
- else:
- for idx, image in enumerate(images):
- images[idx] = self._resize(image=image, target=None, size=self.size, max_size=self.max_size)[0]
-
- if self.do_normalize:
- if annotations is not None:
- for idx, (image, target) in enumerate(zip(images, annotations)):
- image, target = self._normalize(
- image=image, mean=self.image_mean, std=self.image_std, target=target
- )
- images[idx] = image
- annotations[idx] = target
- else:
- images = [
- self._normalize(image=image, mean=self.image_mean, std=self.image_std)[0] for image in images
- ]
- else:
- images = [np.array(image) for image in images]
-
- if pad_and_return_pixel_mask:
- # pad images up to largest image in batch and create pixel_mask
- max_size = self._max_by_axis([list(image.shape) for image in images])
- c, h, w = max_size
- padded_images = []
- pixel_mask = []
- for image in images:
- # create padded image
- padded_image = np.zeros((c, h, w), dtype=np.float32)
- padded_image[: image.shape[0], : image.shape[1], : image.shape[2]] = np.copy(image)
- padded_images.append(padded_image)
- # create pixel mask
- mask = np.zeros((h, w), dtype=np.int64)
- mask[: image.shape[1], : image.shape[2]] = True
- pixel_mask.append(mask)
- images = padded_images
-
- # return as BatchFeature
- data = {}
- data["pixel_values"] = images
- if pad_and_return_pixel_mask:
- data["pixel_mask"] = pixel_mask
- encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
-
- if annotations is not None:
- # Convert to TensorType
- tensor_type = return_tensors
- if not isinstance(tensor_type, TensorType):
- tensor_type = TensorType(tensor_type)
-
- if not tensor_type == TensorType.PYTORCH:
- raise ValueError("Only PyTorch is supported for the moment.")
- else:
- if not is_torch_available():
- raise ImportError("Unable to convert output to PyTorch tensors format, PyTorch is not installed.")
-
- encoded_inputs["labels"] = [
- {k: torch.from_numpy(v) for k, v in target.items()} for target in annotations
- ]
-
- return encoded_inputs
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._max_by_axis
- def _max_by_axis(self, the_list):
- # type: (List[List[int]]) -> List[int]
- maxes = the_list[0]
- for sublist in the_list[1:]:
- for index, item in enumerate(sublist):
- maxes[index] = max(maxes[index], item)
- return maxes
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.pad_and_create_pixel_mask
- def pad_and_create_pixel_mask(
- self, pixel_values_list: List["torch.Tensor"], return_tensors: Optional[Union[str, TensorType]] = None
- ):
- """
- Pad images up to the largest image in a batch and create a corresponding `pixel_mask`.
-
- Args:
- pixel_values_list (`List[torch.Tensor]`):
- List of images (pixel values) to be padded. Each image should be a tensor of shape (C, H, W).
- return_tensors (`str` or [`~utils.TensorType`], *optional*):
- If set, will return tensors instead of NumPy arrays. If set to `'pt'`, return PyTorch `torch.Tensor`
- objects.
-
- Returns:
- [`BatchFeature`]: A [`BatchFeature`] with the following fields:
-
- - **pixel_values** -- Pixel values to be fed to a model.
- - **pixel_mask** -- Pixel mask to be fed to a model (when `pad_and_return_pixel_mask=True` or if
- *"pixel_mask"* is in `self.model_input_names`).
-
- """
-
- max_size = self._max_by_axis([list(image.shape) for image in pixel_values_list])
- c, h, w = max_size
- padded_images = []
- pixel_mask = []
- for image in pixel_values_list:
- # create padded image
- padded_image = np.zeros((c, h, w), dtype=np.float32)
- padded_image[: image.shape[0], : image.shape[1], : image.shape[2]] = np.copy(image)
- padded_images.append(padded_image)
- # create pixel mask
- mask = np.zeros((h, w), dtype=np.int64)
- mask[: image.shape[1], : image.shape[2]] = True
- pixel_mask.append(mask)
-
- # return as BatchFeature
- data = {"pixel_values": padded_images, "pixel_mask": pixel_mask}
- encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
-
- return encoded_inputs
-
- def post_process(self, outputs, target_sizes):
- """
- Converts the output of [`DeformableDetrForObjectDetection`] into the format expected by the COCO api. Only
- supports PyTorch.
-
- Args:
- outputs ([`DeformableDetrObjectDetectionOutput`]):
- Raw outputs of the model.
- target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
- Tensor containing the size (height, width) of each image of the batch. For evaluation, this must be the
- original image size (before any data augmentation). For visualization, this should be the image size
- after data augment, but before padding.
- Returns:
- `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
- in the batch as predicted by the model.
- """
- warnings.warn(
- "`post_process` is deprecated and will be removed in v5 of Transformers, please use"
- " `post_process_object_detection`.",
- FutureWarning,
- )
-
- out_logits, out_bbox = outputs.logits, outputs.pred_boxes
-
- if len(out_logits) != len(target_sizes):
- raise ValueError("Make sure that you pass in as many target sizes as the batch dimension of the logits")
- if target_sizes.shape[1] != 2:
- raise ValueError("Each element of target_sizes must contain the size (h, w) of each image of the batch")
-
- prob = out_logits.sigmoid()
- topk_values, topk_indexes = torch.topk(prob.view(out_logits.shape[0], -1), 100, dim=1)
- scores = topk_values
- topk_boxes = topk_indexes // out_logits.shape[2]
- labels = topk_indexes % out_logits.shape[2]
- boxes = center_to_corners_format(out_bbox)
- boxes = torch.gather(boxes, 1, topk_boxes.unsqueeze(-1).repeat(1, 1, 4))
-
- # and from relative [0, 1] to absolute [0, height] coordinates
- img_h, img_w = target_sizes.unbind(1)
- scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
- boxes = boxes * scale_fct[:, None, :]
-
- results = [{"scores": s, "labels": l, "boxes": b} for s, l, b in zip(scores, labels, boxes)]
-
- return results
-
- def post_process_object_detection(
- self, outputs, threshold: float = 0.5, target_sizes: Union[TensorType, List[Tuple]] = None
- ):
- """
- Converts the output of [`DeformableDetrForObjectDetection`] into the format expected by the COCO api. Only
- supports PyTorch.
-
- Args:
- outputs ([`DetrObjectDetectionOutput`]):
- Raw outputs of the model.
- threshold (`float`, *optional*):
- Score threshold to keep object detection predictions.
- target_sizes (`torch.Tensor` or `List[Tuple[int, int]]`, *optional*, defaults to `None`):
- Tensor of shape `(batch_size, 2)` or list of tuples (`Tuple[int, int]`) containing the target size
- (height, width) of each image in the batch. If left to None, predictions will not be resized.
-
- Returns:
- `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
- in the batch as predicted by the model.
- """
- out_logits, out_bbox = outputs.logits, outputs.pred_boxes
-
- if target_sizes is not None:
- if len(out_logits) != len(target_sizes):
- raise ValueError(
- "Make sure that you pass in as many target sizes as the batch dimension of the logits"
- )
-
- prob = out_logits.sigmoid()
- topk_values, topk_indexes = torch.topk(prob.view(out_logits.shape[0], -1), 100, dim=1)
- scores = topk_values
- topk_boxes = topk_indexes // out_logits.shape[2]
- labels = topk_indexes % out_logits.shape[2]
- boxes = center_to_corners_format(out_bbox)
- boxes = torch.gather(boxes, 1, topk_boxes.unsqueeze(-1).repeat(1, 1, 4))
-
- # and from relative [0, 1] to absolute [0, height] coordinates
- if isinstance(target_sizes, List):
- img_h = torch.Tensor([i[0] for i in target_sizes])
- img_w = torch.Tensor([i[1] for i in target_sizes])
- else:
- img_h, img_w = target_sizes.unbind(1)
- scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1).to(boxes.device)
- boxes = boxes * scale_fct[:, None, :]
-
- results = []
- for s, l, b in zip(scores, labels, boxes):
- score = s[s > threshold]
- label = l[s > threshold]
- box = b[s > threshold]
- results.append({"scores": score, "labels": label, "boxes": box})
-
- return results
+DeformableDetrFeatureExtractor = DeformableDetrImageProcessor
diff --git a/src/transformers/models/deformable_detr/image_processing_deformable_detr.py b/src/transformers/models/deformable_detr/image_processing_deformable_detr.py
new file mode 100644
index 0000000000..c1b71d629f
--- /dev/null
+++ b/src/transformers/models/deformable_detr/image_processing_deformable_detr.py
@@ -0,0 +1,1350 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Image processor class for Deformable DETR."""
+
+import io
+import pathlib
+import warnings
+from collections import defaultdict
+from typing import Any, Callable, Dict, Iterable, List, Optional, Set, Tuple, Union
+
+import numpy as np
+
+from transformers.feature_extraction_utils import BatchFeature
+from transformers.image_processing_utils import BaseImageProcessor, get_size_dict
+from transformers.image_transforms import (
+ PaddingMode,
+ center_to_corners_format,
+ corners_to_center_format,
+ id_to_rgb,
+ normalize,
+ pad,
+ rescale,
+ resize,
+ rgb_to_id,
+ to_channel_dimension_format,
+)
+from transformers.image_utils import (
+ IMAGENET_DEFAULT_MEAN,
+ IMAGENET_DEFAULT_STD,
+ ChannelDimension,
+ ImageInput,
+ PILImageResampling,
+ get_image_size,
+ infer_channel_dimension_format,
+ is_batched,
+ to_numpy_array,
+ valid_coco_detection_annotations,
+ valid_coco_panoptic_annotations,
+ valid_images,
+)
+from transformers.utils import (
+ is_flax_available,
+ is_jax_tensor,
+ is_scipy_available,
+ is_tf_available,
+ is_tf_tensor,
+ is_torch_available,
+ is_torch_tensor,
+ is_vision_available,
+)
+from transformers.utils.generic import ExplicitEnum, TensorType
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+
+if is_vision_available():
+ import PIL
+
+if is_scipy_available():
+ import scipy.special
+ import scipy.stats
+
+
+class AnnotionFormat(ExplicitEnum):
+ COCO_DETECTION = "coco_detection"
+ COCO_PANOPTIC = "coco_panoptic"
+
+
+SUPPORTED_ANNOTATION_FORMATS = (AnnotionFormat.COCO_DETECTION, AnnotionFormat.COCO_PANOPTIC)
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_size_with_aspect_ratio
+def get_size_with_aspect_ratio(image_size, size, max_size=None) -> Tuple[int, int]:
+ """
+ Computes the output image size given the input image size and the desired output size.
+
+ Args:
+ image_size (`Tuple[int, int]`):
+ The input image size.
+ size (`int`):
+ The desired output size.
+ max_size (`int`, *optional*):
+ The maximum allowed output size.
+ """
+ height, width = image_size
+ if max_size is not None:
+ min_original_size = float(min((height, width)))
+ max_original_size = float(max((height, width)))
+ if max_original_size / min_original_size * size > max_size:
+ size = int(round(max_size * min_original_size / max_original_size))
+
+ if (height <= width and height == size) or (width <= height and width == size):
+ return height, width
+
+ if width < height:
+ ow = size
+ oh = int(size * height / width)
+ else:
+ oh = size
+ ow = int(size * width / height)
+ return (oh, ow)
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_resize_output_image_size
+def get_resize_output_image_size(
+ input_image: np.ndarray, size: Union[int, Tuple[int, int], List[int]], max_size: Optional[int] = None
+) -> Tuple[int, int]:
+ """
+ Computes the output image size given the input image size and the desired output size. If the desired output size
+ is a tuple or list, the output image size is returned as is. If the desired output size is an integer, the output
+ image size is computed by keeping the aspect ratio of the input image size.
+
+ Args:
+ image_size (`Tuple[int, int]`):
+ The input image size.
+ size (`int`):
+ The desired output size.
+ max_size (`int`, *optional*):
+ The maximum allowed output size.
+ """
+ image_size = get_image_size(input_image)
+ if isinstance(size, (list, tuple)):
+ return size
+
+ return get_size_with_aspect_ratio(image_size, size, max_size)
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_numpy_to_framework_fn
+def get_numpy_to_framework_fn(arr) -> Callable:
+ """
+ Returns a function that converts a numpy array to the framework of the input array.
+
+ Args:
+ arr (`np.ndarray`): The array to convert.
+ """
+ if isinstance(arr, np.ndarray):
+ return np.array
+ if is_tf_available() and is_tf_tensor(arr):
+ import tensorflow as tf
+
+ return tf.convert_to_tensor
+ if is_torch_available() and is_torch_tensor(arr):
+ import torch
+
+ return torch.tensor
+ if is_flax_available() and is_jax_tensor(arr):
+ import jax.numpy as jnp
+
+ return jnp.array
+ raise ValueError(f"Cannot convert arrays of type {type(arr)}")
+
+
+# Copied from transformers.models.detr.image_processing_detr.safe_squeeze
+def safe_squeeze(arr: np.ndarray, axis: Optional[int] = None) -> np.ndarray:
+ """
+ Squeezes an array, but only if the axis specified has dim 1.
+ """
+ if axis is None:
+ return arr.squeeze()
+
+ try:
+ return arr.squeeze(axis=axis)
+ except ValueError:
+ return arr
+
+
+# Copied from transformers.models.detr.image_processing_detr.normalize_annotation
+def normalize_annotation(annotation: Dict, image_size: Tuple[int, int]) -> Dict:
+ image_height, image_width = image_size
+ norm_annotation = {}
+ for key, value in annotation.items():
+ if key == "boxes":
+ boxes = value
+ boxes = corners_to_center_format(boxes)
+ boxes /= np.asarray([image_width, image_height, image_width, image_height], dtype=np.float32)
+ norm_annotation[key] = boxes
+ else:
+ norm_annotation[key] = value
+ return norm_annotation
+
+
+# Copied from transformers.models.detr.image_processing_detr.max_across_indices
+def max_across_indices(values: Iterable[Any]) -> List[Any]:
+ """
+ Return the maximum value across all indices of an iterable of values.
+ """
+ return [max(values_i) for values_i in zip(*values)]
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_max_height_width
+def get_max_height_width(images: List[np.ndarray]) -> List[int]:
+ """
+ Get the maximum height and width across all images in a batch.
+ """
+ input_channel_dimension = infer_channel_dimension_format(images[0])
+
+ if input_channel_dimension == ChannelDimension.FIRST:
+ _, max_height, max_width = max_across_indices([img.shape for img in images])
+ elif input_channel_dimension == ChannelDimension.LAST:
+ max_height, max_width, _ = max_across_indices([img.shape for img in images])
+ else:
+ raise ValueError(f"Invalid channel dimension format: {input_channel_dimension}")
+ return (max_height, max_width)
+
+
+# Copied from transformers.models.detr.image_processing_detr.make_pixel_mask
+def make_pixel_mask(image: np.ndarray, output_size: Tuple[int, int]) -> np.ndarray:
+ """
+ Make a pixel mask for the image, where 1 indicates a valid pixel and 0 indicates padding.
+
+ Args:
+ image (`np.ndarray`):
+ Image to make the pixel mask for.
+ output_size (`Tuple[int, int]`):
+ Output size of the mask.
+ """
+ input_height, input_width = get_image_size(image)
+ mask = np.zeros(output_size, dtype=np.int64)
+ mask[:input_height, :input_width] = 1
+ return mask
+
+
+# Copied from transformers.models.detr.image_processing_detr.convert_coco_poly_to_mask
+def convert_coco_poly_to_mask(segmentations, height: int, width: int) -> np.ndarray:
+ """
+ Convert a COCO polygon annotation to a mask.
+
+ Args:
+ segmentations (`List[List[float]]`):
+ List of polygons, each polygon represented by a list of x-y coordinates.
+ height (`int`):
+ Height of the mask.
+ width (`int`):
+ Width of the mask.
+ """
+ try:
+ from pycocotools import mask as coco_mask
+ except ImportError:
+ raise ImportError("Pycocotools is not installed in your environment.")
+
+ masks = []
+ for polygons in segmentations:
+ rles = coco_mask.frPyObjects(polygons, height, width)
+ mask = coco_mask.decode(rles)
+ if len(mask.shape) < 3:
+ mask = mask[..., None]
+ mask = np.asarray(mask, dtype=np.uint8)
+ mask = np.any(mask, axis=2)
+ masks.append(mask)
+ if masks:
+ masks = np.stack(masks, axis=0)
+ else:
+ masks = np.zeros((0, height, width), dtype=np.uint8)
+
+ return masks
+
+
+# Copied from transformers.models.detr.image_processing_detr.prepare_coco_detection_annotation with DETR->DeformableDetr
+def prepare_coco_detection_annotation(image, target, return_segmentation_masks: bool = False):
+ """
+ Convert the target in COCO format into the format expected by DeformableDetr.
+ """
+ image_height, image_width = get_image_size(image)
+
+ image_id = target["image_id"]
+ image_id = np.asarray([image_id], dtype=np.int64)
+
+ # Get all COCO annotations for the given image.
+ annotations = target["annotations"]
+ annotations = [obj for obj in annotations if "iscrowd" not in obj or obj["iscrowd"] == 0]
+
+ classes = [obj["category_id"] for obj in annotations]
+ classes = np.asarray(classes, dtype=np.int64)
+
+ # for conversion to coco api
+ area = np.asarray([obj["area"] for obj in annotations], dtype=np.float32)
+ iscrowd = np.asarray([obj["iscrowd"] if "iscrowd" in obj else 0 for obj in annotations], dtype=np.int64)
+
+ boxes = [obj["bbox"] for obj in annotations]
+ # guard against no boxes via resizing
+ boxes = np.asarray(boxes, dtype=np.float32).reshape(-1, 4)
+ boxes[:, 2:] += boxes[:, :2]
+ boxes[:, 0::2] = boxes[:, 0::2].clip(min=0, max=image_width)
+ boxes[:, 1::2] = boxes[:, 1::2].clip(min=0, max=image_height)
+
+ keep = (boxes[:, 3] > boxes[:, 1]) & (boxes[:, 2] > boxes[:, 0])
+
+ new_target = {}
+ new_target["image_id"] = image_id
+ new_target["class_labels"] = classes[keep]
+ new_target["boxes"] = boxes[keep]
+ new_target["area"] = area[keep]
+ new_target["iscrowd"] = iscrowd[keep]
+ new_target["orig_size"] = np.asarray([int(image_height), int(image_width)], dtype=np.int64)
+
+ if annotations and "keypoints" in annotations[0]:
+ keypoints = [obj["keypoints"] for obj in annotations]
+ keypoints = np.asarray(keypoints, dtype=np.float32)
+ num_keypoints = keypoints.shape[0]
+ keypoints = keypoints.reshape((-1, 3)) if num_keypoints else keypoints
+ new_target["keypoints"] = keypoints[keep]
+
+ if return_segmentation_masks:
+ segmentation_masks = [obj["segmentation"] for obj in annotations]
+ masks = convert_coco_poly_to_mask(segmentation_masks, image_height, image_width)
+ new_target["masks"] = masks[keep]
+
+ return new_target
+
+
+# Copied from transformers.models.detr.image_processing_detr.masks_to_boxes
+def masks_to_boxes(masks: np.ndarray) -> np.ndarray:
+ """
+ Compute the bounding boxes around the provided panoptic segmentation masks.
+
+ Args:
+ masks: masks in format `[number_masks, height, width]` where N is the number of masks
+
+ Returns:
+ boxes: bounding boxes in format `[number_masks, 4]` in xyxy format
+ """
+ if masks.size == 0:
+ return np.zeros((0, 4))
+
+ h, w = masks.shape[-2:]
+ y = np.arange(0, h, dtype=np.float32)
+ x = np.arange(0, w, dtype=np.float32)
+ # see https://github.com/pytorch/pytorch/issues/50276
+ y, x = np.meshgrid(y, x, indexing="ij")
+
+ x_mask = masks * np.expand_dims(x, axis=0)
+ x_max = x_mask.reshape(x_mask.shape[0], -1).max(-1)
+ x = np.ma.array(x_mask, mask=~(np.array(masks, dtype=bool)))
+ x_min = x.filled(fill_value=1e8)
+ x_min = x_min.reshape(x_min.shape[0], -1).min(-1)
+
+ y_mask = masks * np.expand_dims(y, axis=0)
+ y_max = y_mask.reshape(x_mask.shape[0], -1).max(-1)
+ y = np.ma.array(y_mask, mask=~(np.array(masks, dtype=bool)))
+ y_min = y.filled(fill_value=1e8)
+ y_min = y_min.reshape(y_min.shape[0], -1).min(-1)
+
+ return np.stack([x_min, y_min, x_max, y_max], 1)
+
+
+# Copied from transformers.models.detr.image_processing_detr.prepare_coco_panoptic_annotation with DETR->DeformableDetr
+def prepare_coco_panoptic_annotation(
+ image: np.ndarray, target: Dict, masks_path: Union[str, pathlib.Path], return_masks: bool = True
+) -> Dict:
+ """
+ Prepare a coco panoptic annotation for DeformableDetr.
+ """
+ image_height, image_width = get_image_size(image)
+ annotation_path = pathlib.Path(masks_path) / target["file_name"]
+
+ new_target = {}
+ new_target["image_id"] = np.asarray([target["image_id"] if "image_id" in target else target["id"]], dtype=np.int64)
+ new_target["size"] = np.asarray([image_height, image_width], dtype=np.int64)
+ new_target["orig_size"] = np.asarray([image_height, image_width], dtype=np.int64)
+
+ if "segments_info" in target:
+ masks = np.asarray(PIL.Image.open(annotation_path), dtype=np.uint32)
+ masks = rgb_to_id(masks)
+
+ ids = np.array([segment_info["id"] for segment_info in target["segments_info"]])
+ masks = masks == ids[:, None, None]
+ masks = masks.astype(np.uint8)
+ if return_masks:
+ new_target["masks"] = masks
+ new_target["boxes"] = masks_to_boxes(masks)
+ new_target["class_labels"] = np.array(
+ [segment_info["category_id"] for segment_info in target["segments_info"]], dtype=np.int64
+ )
+ new_target["iscrowd"] = np.asarray(
+ [segment_info["iscrowd"] for segment_info in target["segments_info"]], dtype=np.int64
+ )
+ new_target["area"] = np.asarray(
+ [segment_info["area"] for segment_info in target["segments_info"]], dtype=np.float32
+ )
+
+ return new_target
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_segmentation_image
+def get_segmentation_image(
+ masks: np.ndarray, input_size: Tuple, target_size: Tuple, stuff_equiv_classes, deduplicate=False
+):
+ h, w = input_size
+ final_h, final_w = target_size
+
+ m_id = scipy.special.softmax(masks.transpose(0, 1), -1)
+
+ if m_id.shape[-1] == 0:
+ # We didn't detect any mask :(
+ m_id = np.zeros((h, w), dtype=np.int64)
+ else:
+ m_id = m_id.argmax(-1).reshape(h, w)
+
+ if deduplicate:
+ # Merge the masks corresponding to the same stuff class
+ for equiv in stuff_equiv_classes.values():
+ for eq_id in equiv:
+ m_id[m_id == eq_id] = equiv[0]
+
+ seg_img = id_to_rgb(m_id)
+ seg_img = resize(seg_img, (final_w, final_h), resample=PILImageResampling.NEAREST)
+ return seg_img
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_mask_area
+def get_mask_area(seg_img: np.ndarray, target_size: Tuple[int, int], n_classes: int) -> np.ndarray:
+ final_h, final_w = target_size
+ np_seg_img = seg_img.astype(np.uint8)
+ np_seg_img = np_seg_img.reshape(final_h, final_w, 3)
+ m_id = rgb_to_id(np_seg_img)
+ area = [(m_id == i).sum() for i in range(n_classes)]
+ return area
+
+
+# Copied from transformers.models.detr.image_processing_detr.score_labels_from_class_probabilities
+def score_labels_from_class_probabilities(logits: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
+ probs = scipy.special.softmax(logits, axis=-1)
+ labels = probs.argmax(-1, keepdims=True)
+ scores = np.take_along_axis(probs, labels, axis=-1)
+ scores, labels = scores.squeeze(-1), labels.squeeze(-1)
+ return scores, labels
+
+
+# Copied from transformers.models.detr.image_processing_detr.post_process_panoptic_sample
+def post_process_panoptic_sample(
+ out_logits: np.ndarray,
+ masks: np.ndarray,
+ boxes: np.ndarray,
+ processed_size: Tuple[int, int],
+ target_size: Tuple[int, int],
+ is_thing_map: Dict,
+ threshold=0.85,
+) -> Dict:
+ """
+ Converts the output of [`DetrForSegmentation`] into panoptic segmentation predictions for a single sample.
+
+ Args:
+ out_logits (`torch.Tensor`):
+ The logits for this sample.
+ masks (`torch.Tensor`):
+ The predicted segmentation masks for this sample.
+ boxes (`torch.Tensor`):
+ The prediced bounding boxes for this sample. The boxes are in the normalized format `(center_x, center_y,
+ width, height)` and values between `[0, 1]`, relative to the size the image (disregarding padding).
+ processed_size (`Tuple[int, int]`):
+ The processed size of the image `(height, width)`, as returned by the preprocessing step i.e. the size
+ after data augmentation but before batching.
+ target_size (`Tuple[int, int]`):
+ The target size of the image, `(height, width)` corresponding to the requested final size of the
+ prediction.
+ is_thing_map (`Dict`):
+ A dictionary mapping class indices to a boolean value indicating whether the class is a thing or not.
+ threshold (`float`, *optional*, defaults to 0.85):
+ The threshold used to binarize the segmentation masks.
+ """
+ # we filter empty queries and detection below threshold
+ scores, labels = score_labels_from_class_probabilities(out_logits)
+ keep = (labels != out_logits.shape[-1] - 1) & (scores > threshold)
+
+ cur_scores = scores[keep]
+ cur_classes = labels[keep]
+ cur_boxes = center_to_corners_format(boxes[keep])
+
+ if len(cur_boxes) != len(cur_classes):
+ raise ValueError("Not as many boxes as there are classes")
+
+ cur_masks = masks[keep]
+ cur_masks = resize(cur_masks[:, None], processed_size, resample=PILImageResampling.BILINEAR)
+ cur_masks = safe_squeeze(cur_masks, 1)
+ b, h, w = cur_masks.shape
+
+ # It may be that we have several predicted masks for the same stuff class.
+ # In the following, we track the list of masks ids for each stuff class (they are merged later on)
+ cur_masks = cur_masks.reshape(b, -1)
+ stuff_equiv_classes = defaultdict(list)
+ for k, label in enumerate(cur_classes):
+ if not is_thing_map[label]:
+ stuff_equiv_classes[label].append(k)
+
+ seg_img = get_segmentation_image(cur_masks, processed_size, target_size, stuff_equiv_classes, deduplicate=True)
+ area = get_mask_area(cur_masks, processed_size, n_classes=len(cur_scores))
+
+ # We filter out any mask that is too small
+ if cur_classes.size() > 0:
+ # We know filter empty masks as long as we find some
+ filtered_small = np.array([a <= 4 for a in area], dtype=bool)
+ while filtered_small.any():
+ cur_masks = cur_masks[~filtered_small]
+ cur_scores = cur_scores[~filtered_small]
+ cur_classes = cur_classes[~filtered_small]
+ seg_img = get_segmentation_image(cur_masks, (h, w), target_size, stuff_equiv_classes, deduplicate=True)
+ area = get_mask_area(seg_img, target_size, n_classes=len(cur_scores))
+ filtered_small = np.array([a <= 4 for a in area], dtype=bool)
+ else:
+ cur_classes = np.ones((1, 1), dtype=np.int64)
+
+ segments_info = [
+ {"id": i, "isthing": is_thing_map[cat], "category_id": int(cat), "area": a}
+ for i, (cat, a) in enumerate(zip(cur_classes, area))
+ ]
+ del cur_classes
+
+ with io.BytesIO() as out:
+ PIL.Image.fromarray(seg_img).save(out, format="PNG")
+ predictions = {"png_string": out.getvalue(), "segments_info": segments_info}
+
+ return predictions
+
+
+# Copied from transformers.models.detr.image_processing_detr.resize_annotation
+def resize_annotation(
+ annotation: Dict[str, Any],
+ orig_size: Tuple[int, int],
+ target_size: Tuple[int, int],
+ threshold: float = 0.5,
+ resample: PILImageResampling = PILImageResampling.NEAREST,
+):
+ """
+ Resizes an annotation to a target size.
+
+ Args:
+ annotation (`Dict[str, Any]`):
+ The annotation dictionary.
+ orig_size (`Tuple[int, int]`):
+ The original size of the input image.
+ target_size (`Tuple[int, int]`):
+ The target size of the image, as returned by the preprocessing `resize` step.
+ threshold (`float`, *optional*, defaults to 0.5):
+ The threshold used to binarize the segmentation masks.
+ resample (`PILImageResampling`, defaults to `PILImageResampling.NEAREST`):
+ The resampling filter to use when resizing the masks.
+ """
+ ratios = tuple(float(s) / float(s_orig) for s, s_orig in zip(target_size, orig_size))
+ ratio_height, ratio_width = ratios
+
+ new_annotation = {}
+ new_annotation["size"] = target_size
+
+ for key, value in annotation.items():
+ if key == "boxes":
+ boxes = value
+ scaled_boxes = boxes * np.asarray([ratio_width, ratio_height, ratio_width, ratio_height], dtype=np.float32)
+ new_annotation["boxes"] = scaled_boxes
+ elif key == "area":
+ area = value
+ scaled_area = area * (ratio_width * ratio_height)
+ new_annotation["area"] = scaled_area
+ elif key == "masks":
+ masks = value[:, None]
+ masks = np.array([resize(mask, target_size, resample=resample) for mask in masks])
+ masks = masks.astype(np.float32)
+ masks = masks[:, 0] > threshold
+ new_annotation["masks"] = masks
+ elif key == "size":
+ new_annotation["size"] = target_size
+ else:
+ new_annotation[key] = value
+
+ return new_annotation
+
+
+# Copied from transformers.models.detr.image_processing_detr.binary_mask_to_rle
+def binary_mask_to_rle(mask):
+ """
+ Converts given binary mask of shape `(height, width)` to the run-length encoding (RLE) format.
+
+ Args:
+ mask (`torch.Tensor` or `numpy.array`):
+ A binary mask tensor of shape `(height, width)` where 0 denotes background and 1 denotes the target
+ segment_id or class_id.
+ Returns:
+ `List`: Run-length encoded list of the binary mask. Refer to COCO API for more information about the RLE
+ format.
+ """
+ if is_torch_tensor(mask):
+ mask = mask.numpy()
+
+ pixels = mask.flatten()
+ pixels = np.concatenate([[0], pixels, [0]])
+ runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
+ runs[1::2] -= runs[::2]
+ return [x for x in runs]
+
+
+# Copied from transformers.models.detr.image_processing_detr.convert_segmentation_to_rle
+def convert_segmentation_to_rle(segmentation):
+ """
+ Converts given segmentation map of shape `(height, width)` to the run-length encoding (RLE) format.
+
+ Args:
+ segmentation (`torch.Tensor` or `numpy.array`):
+ A segmentation map of shape `(height, width)` where each value denotes a segment or class id.
+ Returns:
+ `List[List]`: A list of lists, where each list is the run-length encoding of a segment / class id.
+ """
+ segment_ids = torch.unique(segmentation)
+
+ run_length_encodings = []
+ for idx in segment_ids:
+ mask = torch.where(segmentation == idx, 1, 0)
+ rle = binary_mask_to_rle(mask)
+ run_length_encodings.append(rle)
+
+ return run_length_encodings
+
+
+# Copied from transformers.models.detr.image_processing_detr.remove_low_and_no_objects
+def remove_low_and_no_objects(masks, scores, labels, object_mask_threshold, num_labels):
+ """
+ Binarize the given masks using `object_mask_threshold`, it returns the associated values of `masks`, `scores` and
+ `labels`.
+
+ Args:
+ masks (`torch.Tensor`):
+ A tensor of shape `(num_queries, height, width)`.
+ scores (`torch.Tensor`):
+ A tensor of shape `(num_queries)`.
+ labels (`torch.Tensor`):
+ A tensor of shape `(num_queries)`.
+ object_mask_threshold (`float`):
+ A number between 0 and 1 used to binarize the masks.
+ Raises:
+ `ValueError`: Raised when the first dimension doesn't match in all input tensors.
+ Returns:
+ `Tuple[`torch.Tensor`, `torch.Tensor`, `torch.Tensor`]`: The `masks`, `scores` and `labels` without the region
+ < `object_mask_threshold`.
+ """
+ if not (masks.shape[0] == scores.shape[0] == labels.shape[0]):
+ raise ValueError("mask, scores and labels must have the same shape!")
+
+ to_keep = labels.ne(num_labels) & (scores > object_mask_threshold)
+
+ return masks[to_keep], scores[to_keep], labels[to_keep]
+
+
+# Copied from transformers.models.detr.image_processing_detr.check_segment_validity
+def check_segment_validity(mask_labels, mask_probs, k, mask_threshold=0.5, overlap_mask_area_threshold=0.8):
+ # Get the mask associated with the k class
+ mask_k = mask_labels == k
+ mask_k_area = mask_k.sum()
+
+ # Compute the area of all the stuff in query k
+ original_area = (mask_probs[k] >= mask_threshold).sum()
+ mask_exists = mask_k_area > 0 and original_area > 0
+
+ # Eliminate disconnected tiny segments
+ if mask_exists:
+ area_ratio = mask_k_area / original_area
+ if not area_ratio.item() > overlap_mask_area_threshold:
+ mask_exists = False
+
+ return mask_exists, mask_k
+
+
+# Copied from transformers.models.detr.image_processing_detr.compute_segments
+def compute_segments(
+ mask_probs,
+ pred_scores,
+ pred_labels,
+ mask_threshold: float = 0.5,
+ overlap_mask_area_threshold: float = 0.8,
+ label_ids_to_fuse: Optional[Set[int]] = None,
+ target_size: Tuple[int, int] = None,
+):
+ height = mask_probs.shape[1] if target_size is None else target_size[0]
+ width = mask_probs.shape[2] if target_size is None else target_size[1]
+
+ segmentation = torch.zeros((height, width), dtype=torch.int32, device=mask_probs.device)
+ segments: List[Dict] = []
+
+ if target_size is not None:
+ mask_probs = nn.functional.interpolate(
+ mask_probs.unsqueeze(0), size=target_size, mode="bilinear", align_corners=False
+ )[0]
+
+ current_segment_id = 0
+
+ # Weigh each mask by its prediction score
+ mask_probs *= pred_scores.view(-1, 1, 1)
+ mask_labels = mask_probs.argmax(0) # [height, width]
+
+ # Keep track of instances of each class
+ stuff_memory_list: Dict[str, int] = {}
+ for k in range(pred_labels.shape[0]):
+ pred_class = pred_labels[k].item()
+ should_fuse = pred_class in label_ids_to_fuse
+
+ # Check if mask exists and large enough to be a segment
+ mask_exists, mask_k = check_segment_validity(
+ mask_labels, mask_probs, k, mask_threshold, overlap_mask_area_threshold
+ )
+
+ if mask_exists:
+ if pred_class in stuff_memory_list:
+ current_segment_id = stuff_memory_list[pred_class]
+ else:
+ current_segment_id += 1
+
+ # Add current object segment to final segmentation map
+ segmentation[mask_k] = current_segment_id
+ segment_score = round(pred_scores[k].item(), 6)
+ segments.append(
+ {
+ "id": current_segment_id,
+ "label_id": pred_class,
+ "was_fused": should_fuse,
+ "score": segment_score,
+ }
+ )
+ if should_fuse:
+ stuff_memory_list[pred_class] = current_segment_id
+
+ return segmentation, segments
+
+
+class DeformableDetrImageProcessor(BaseImageProcessor):
+ r"""
+ Constructs a Deformable DETR image processor.
+
+ Args:
+ format (`str`, *optional*, defaults to `"coco_detection"`):
+ Data format of the annotations. One of "coco_detection" or "coco_panoptic".
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Controls whether to resize the image's (height, width) dimensions to the specified `size`. Can be
+ overridden by the `do_resize` parameter in the `preprocess` method.
+ size (`Dict[str, int]` *optional*, defaults to `{"shortest_edge": 800, "longest_edge": 1333}`):
+ Size of the image's (height, width) dimensions after resizing. Can be overridden by the `size` parameter in
+ the `preprocess` method.
+ resample (`PILImageResampling`, *optional*, defaults to `PILImageResampling.BILINEAR`):
+ Resampling filter to use if resizing the image.
+ do_rescale (`bool`, *optional*, defaults to `True`):
+ Controls whether to rescale the image by the specified scale `rescale_factor`. Can be overridden by the
+ `do_rescale` parameter in the `preprocess` method.
+ rescale_factor (`int` or `float`, *optional*, defaults to `1/255`):
+ Scale factor to use if rescaling the image. Can be overridden by the `rescale_factor` parameter in the
+ `preprocess` method.
+ do_normalize:
+ Controls whether to normalize the image. Can be overridden by the `do_normalize` parameter in the
+ `preprocess` method.
+ image_mean (`float` or `List[float]`, *optional*, defaults to `IMAGENET_DEFAULT_MEAN`):
+ Mean values to use when normalizing the image. Can be a single value or a list of values, one for each
+ channel. Can be overridden by the `image_mean` parameter in the `preprocess` method.
+ image_std (`float` or `List[float]`, *optional*, defaults to `IMAGENET_DEFAULT_STD`):
+ Standard deviation values to use when normalizing the image. Can be a single value or a list of values, one
+ for each channel. Can be overridden by the `image_std` parameter in the `preprocess` method.
+ do_pad (`bool`, *optional*, defaults to `True`):
+ Controls whether to pad the image to the largest image in a batch and create a pixel mask. Can be
+ overridden by the `do_pad` parameter in the `preprocess` method.
+ """
+
+ model_input_names = ["pixel_values", "pixel_mask"]
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.__init__
+ def __init__(
+ self,
+ format: Union[str, AnnotionFormat] = AnnotionFormat.COCO_DETECTION,
+ do_resize: bool = True,
+ size: Dict[str, int] = None,
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ do_rescale: bool = True,
+ rescale_factor: Union[int, float] = 1 / 255,
+ do_normalize: bool = True,
+ image_mean: Union[float, List[float]] = None,
+ image_std: Union[float, List[float]] = None,
+ do_pad: bool = True,
+ **kwargs
+ ) -> None:
+ if "pad_and_return_pixel_mask" in kwargs:
+ do_pad = kwargs.pop("pad_and_return_pixel_mask")
+
+ if "max_size" in kwargs:
+ warnings.warn(
+ "The `max_size` parameter is deprecated and will be removed in v4.26. "
+ "Please specify in `size['longest_edge'] instead`.",
+ FutureWarning,
+ )
+ max_size = kwargs.pop("max_size")
+ else:
+ max_size = None if size is None else 1333
+
+ size = size if size is not None else {"shortest_edge": 800, "longest_edge": 1333}
+ size = get_size_dict(size, max_size=max_size, default_to_square=False)
+
+ super().__init__(**kwargs)
+ self.format = format
+ self.do_resize = do_resize
+ self.size = size
+ self.resample = resample
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean if image_mean is not None else IMAGENET_DEFAULT_MEAN
+ self.image_std = image_std if image_std is not None else IMAGENET_DEFAULT_STD
+ self.do_pad = do_pad
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare_annotation with DETR->DeformableDetr
+ def prepare_annotation(
+ self,
+ image: np.ndarray,
+ target: Dict,
+ format: Optional[AnnotionFormat] = None,
+ return_segmentation_masks: bool = None,
+ masks_path: Optional[Union[str, pathlib.Path]] = None,
+ ) -> Dict:
+ """
+ Prepare an annotation for feeding into DeformableDetr model.
+ """
+ format = format if format is not None else self.format
+
+ if format == AnnotionFormat.COCO_DETECTION:
+ return_segmentation_masks = False if return_segmentation_masks is None else return_segmentation_masks
+ target = prepare_coco_detection_annotation(image, target, return_segmentation_masks)
+ elif format == AnnotionFormat.COCO_PANOPTIC:
+ return_segmentation_masks = True if return_segmentation_masks is None else return_segmentation_masks
+ target = prepare_coco_panoptic_annotation(
+ image, target, masks_path=masks_path, return_masks=return_segmentation_masks
+ )
+ else:
+ raise ValueError(f"Format {format} is not supported.")
+ return target
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare
+ def prepare(self, image, target, return_segmentation_masks=None, masks_path=None):
+ warnings.warn(
+ "The `prepare` method is deprecated and will be removed in a future version. "
+ "Please use `prepare_annotation` instead. Note: the `prepare_annotation` method "
+ "does not return the image anymore.",
+ )
+ target = self.prepare_annotation(image, target, return_segmentation_masks, masks_path, self.format)
+ return image, target
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.convert_coco_poly_to_mask
+ def convert_coco_poly_to_mask(self, *args, **kwargs):
+ warnings.warn("The `convert_coco_poly_to_mask` method is deprecated and will be removed in a future version. ")
+ return convert_coco_poly_to_mask(*args, **kwargs)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare_coco_detection
+ def prepare_coco_detection(self, *args, **kwargs):
+ warnings.warn("The `prepare_coco_detection` method is deprecated and will be removed in a future version. ")
+ return prepare_coco_detection_annotation(*args, **kwargs)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare_coco_panoptic
+ def prepare_coco_panoptic(self, *args, **kwargs):
+ warnings.warn("The `prepare_coco_panoptic` method is deprecated and will be removed in a future version. ")
+ return prepare_coco_panoptic_annotation(*args, **kwargs)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.resize
+ def resize(
+ self,
+ image: np.ndarray,
+ size: Dict[str, int],
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ data_format: Optional[ChannelDimension] = None,
+ **kwargs
+ ) -> np.ndarray:
+ """
+ Resize the image to the given size. Size can be `min_size` (scalar) or `(height, width)` tuple. If size is an
+ int, smaller edge of the image will be matched to this number.
+ """
+ if "max_size" in kwargs:
+ warnings.warn(
+ "The `max_size` parameter is deprecated and will be removed in v4.26. "
+ "Please specify in `size['longest_edge'] instead`.",
+ FutureWarning,
+ )
+ max_size = kwargs.pop("max_size")
+ else:
+ max_size = None
+ size = get_size_dict(size, max_size=max_size, default_to_square=False)
+ if "shortest_edge" in size and "longest_edge" in size:
+ size = get_resize_output_image_size(image, size["shortest_edge"], size["longest_edge"])
+ elif "height" in size and "width" in size:
+ size = (size["height"], size["width"])
+ else:
+ raise ValueError(
+ "Size must contain 'height' and 'width' keys or 'shortest_edge' and 'longest_edge' keys. Got"
+ f" {size.keys()}."
+ )
+ image = resize(image, size=size, resample=resample, data_format=data_format)
+ return image
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.resize_annotation
+ def resize_annotation(
+ self,
+ annotation,
+ orig_size,
+ size,
+ resample: PILImageResampling = PILImageResampling.NEAREST,
+ ) -> Dict:
+ """
+ Resize the annotation to match the resized image. If size is an int, smaller edge of the mask will be matched
+ to this number.
+ """
+ return resize_annotation(annotation, orig_size=orig_size, target_size=size, resample=resample)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.rescale
+ def rescale(
+ self, image: np.ndarray, rescale_factor: Union[float, int], data_format: Optional[ChannelDimension] = None
+ ) -> np.ndarray:
+ """
+ Rescale the image by the given factor.
+ """
+ return rescale(image, rescale_factor, data_format=data_format)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.normalize
+ def normalize(
+ self,
+ image: np.ndarray,
+ mean: Union[float, Iterable[float]],
+ std: Union[float, Iterable[float]],
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Normalize the image with the given mean and standard deviation.
+ """
+ return normalize(image, mean=mean, std=std, data_format=data_format)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.normalize_annotation
+ def normalize_annotation(self, annotation: Dict, image_size: Tuple[int, int]) -> Dict:
+ """
+ Normalize the boxes in the annotation from `[top_left_x, top_left_y, bottom_right_x, bottom_right_y]` to
+ `[center_x, center_y, width, height]` format.
+ """
+ return normalize_annotation(annotation, image_size=image_size)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.pad_and_create_pixel_mask
+ def pad_and_create_pixel_mask(
+ self,
+ pixel_values_list: List[ImageInput],
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ data_format: Optional[ChannelDimension] = None,
+ ) -> BatchFeature:
+ """
+ Pads a batch of images with zeros to the size of largest height and width in the batch and returns their
+ corresponding pixel mask.
+
+ Args:
+ images (`List[np.ndarray]`):
+ Batch of images to pad.
+ return_tensors (`str` or `TensorType`, *optional*):
+ The type of tensors to return. Can be one of:
+ - Unset: Return a list of `np.ndarray`.
+ - `TensorType.TENSORFLOW` or `'tf'`: Return a batch of type `tf.Tensor`.
+ - `TensorType.PYTORCH` or `'pt'`: Return a batch of type `torch.Tensor`.
+ - `TensorType.NUMPY` or `'np'`: Return a batch of type `np.ndarray`.
+ - `TensorType.JAX` or `'jax'`: Return a batch of type `jax.numpy.ndarray`.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be the same as the input image.
+ """
+ warnings.warn(
+ "This method is deprecated and will be removed in v4.27.0. Please use pad instead.", FutureWarning
+ )
+ # pad expects a list of np.ndarray, but the previous feature extractors expected torch tensors
+ images = [to_numpy_array(image) for image in pixel_values_list]
+ return self.pad(
+ images=images,
+ return_pixel_mask=True,
+ return_tensors=return_tensors,
+ data_format=data_format,
+ )
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor._pad_image
+ def _pad_image(
+ self,
+ image: np.ndarray,
+ output_size: Tuple[int, int],
+ constant_values: Union[float, Iterable[float]] = 0,
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Pad an image with zeros to the given size.
+ """
+ input_height, input_width = get_image_size(image)
+ output_height, output_width = output_size
+
+ pad_bottom = output_height - input_height
+ pad_right = output_width - input_width
+ padding = ((0, pad_bottom), (0, pad_right))
+ padded_image = pad(
+ image, padding, mode=PaddingMode.CONSTANT, constant_values=constant_values, data_format=data_format
+ )
+ return padded_image
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.pad
+ def pad(
+ self,
+ images: List[np.ndarray],
+ constant_values: Union[float, Iterable[float]] = 0,
+ return_pixel_mask: bool = True,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Pads a batch of images to the bottom and right of the image with zeros to the size of largest height and width
+ in the batch and optionally returns their corresponding pixel mask.
+
+ Args:
+ image (`np.ndarray`):
+ Image to pad.
+ constant_values (`float` or `Iterable[float]`, *optional*):
+ The value to use for the padding if `mode` is `"constant"`.
+ return_pixel_mask (`bool`, *optional*, defaults to `True`):
+ Whether to return a pixel mask.
+ input_channel_dimension (`ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be inferred from the input image.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be the same as the input image.
+ """
+ pad_size = get_max_height_width(images)
+
+ padded_images = [
+ self._pad_image(image, pad_size, constant_values=constant_values, data_format=data_format)
+ for image in images
+ ]
+ data = {"pixel_values": padded_images}
+
+ if return_pixel_mask:
+ masks = [make_pixel_mask(image=image, output_size=pad_size) for image in images]
+ data["pixel_mask"] = masks
+
+ return BatchFeature(data=data, tensor_type=return_tensors)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.preprocess
+ def preprocess(
+ self,
+ images: ImageInput,
+ annotations: Optional[Union[List[Dict], List[List[Dict]]]] = None,
+ return_segmentation_masks: bool = None,
+ masks_path: Optional[Union[str, pathlib.Path]] = None,
+ do_resize: Optional[bool] = None,
+ size: Optional[Dict[str, int]] = None,
+ resample=None, # PILImageResampling
+ do_rescale: Optional[bool] = None,
+ rescale_factor: Optional[Union[int, float]] = None,
+ do_normalize: Optional[bool] = None,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ do_pad: Optional[bool] = None,
+ format: Optional[Union[str, AnnotionFormat]] = None,
+ return_tensors: Optional[Union[TensorType, str]] = None,
+ data_format: Union[str, ChannelDimension] = ChannelDimension.FIRST,
+ **kwargs
+ ) -> BatchFeature:
+ """
+ Preprocess an image or a batch of images so that it can be used by the model.
+
+ Args:
+ images (`ImageInput`):
+ Image or batch of images to preprocess.
+ annotations (`List[Dict]` or `List[List[Dict]]`, *optional*):
+ List of annotations associated with the image or batch of images. If annotionation is for object
+ detection, the annotations should be a dictionary with the following keys:
+ - "image_id" (`int`): The image id.
+ - "annotations" (`List[Dict]`): List of annotations for an image. Each annotation should be a
+ dictionary. An image can have no annotations, in which case the list should be empty.
+ If annotionation is for segmentation, the annotations should be a dictionary with the following keys:
+ - "image_id" (`int`): The image id.
+ - "segments_info" (`List[Dict]`): List of segments for an image. Each segment should be a dictionary.
+ An image can have no segments, in which case the list should be empty.
+ - "file_name" (`str`): The file name of the image.
+ return_segmentation_masks (`bool`, *optional*, defaults to self.return_segmentation_masks):
+ Whether to return segmentation masks.
+ masks_path (`str` or `pathlib.Path`, *optional*):
+ Path to the directory containing the segmentation masks.
+ do_resize (`bool`, *optional*, defaults to self.do_resize):
+ Whether to resize the image.
+ size (`Dict[str, int]`, *optional*, defaults to self.size):
+ Size of the image after resizing.
+ resample (`PILImageResampling`, *optional*, defaults to self.resample):
+ Resampling filter to use when resizing the image.
+ do_rescale (`bool`, *optional*, defaults to self.do_rescale):
+ Whether to rescale the image.
+ rescale_factor (`float`, *optional*, defaults to self.rescale_factor):
+ Rescale factor to use when rescaling the image.
+ do_normalize (`bool`, *optional*, defaults to self.do_normalize):
+ Whether to normalize the image.
+ image_mean (`float` or `List[float]`, *optional*, defaults to self.image_mean):
+ Mean to use when normalizing the image.
+ image_std (`float` or `List[float]`, *optional*, defaults to self.image_std):
+ Standard deviation to use when normalizing the image.
+ do_pad (`bool`, *optional*, defaults to self.do_pad):
+ Whether to pad the image.
+ format (`str` or `AnnotionFormat`, *optional*, defaults to self.format):
+ Format of the annotations.
+ return_tensors (`str` or `TensorType`, *optional*, defaults to self.return_tensors):
+ Type of tensors to return. If `None`, will return the list of images.
+ data_format (`str` or `ChannelDimension`, *optional*, defaults to self.data_format):
+ The channel dimension format of the image. If not provided, it will be the same as the input image.
+ """
+ if "pad_and_return_pixel_mask" in kwargs:
+ warnings.warn(
+ "The `pad_and_return_pixel_mask` argument is deprecated and will be removed in a future version, "
+ "use `do_pad` instead.",
+ FutureWarning,
+ )
+ do_pad = kwargs.pop("pad_and_return_pixel_mask")
+
+ max_size = None
+ if "max_size" in kwargs:
+ warnings.warn(
+ "The `max_size` argument is deprecated and will be removed in a future version, use"
+ " `size['longest_edge']` instead.",
+ FutureWarning,
+ )
+ size = kwargs.pop("max_size")
+
+ do_resize = self.do_resize if do_resize is None else do_resize
+ size = self.size if size is None else size
+ size = get_size_dict(size=size, max_size=max_size, default_to_square=False)
+ resample = self.resample if resample is None else resample
+ do_rescale = self.do_rescale if do_rescale is None else do_rescale
+ rescale_factor = self.rescale_factor if rescale_factor is None else rescale_factor
+ do_normalize = self.do_normalize if do_normalize is None else do_normalize
+ image_mean = self.image_mean if image_mean is None else image_mean
+ image_std = self.image_std if image_std is None else image_std
+ do_pad = self.do_pad if do_pad is None else do_pad
+ format = self.format if format is None else format
+
+ if do_resize is not None and size is None:
+ raise ValueError("Size and max_size must be specified if do_resize is True.")
+
+ if do_rescale is not None and rescale_factor is None:
+ raise ValueError("Rescale factor must be specified if do_rescale is True.")
+
+ if do_normalize is not None and (image_mean is None or image_std is None):
+ raise ValueError("Image mean and std must be specified if do_normalize is True.")
+
+ if not is_batched(images):
+ images = [images]
+ annotations = [annotations] if annotations is not None else None
+
+ if annotations is not None and len(images) != len(annotations):
+ raise ValueError(
+ f"The number of images ({len(images)}) and annotations ({len(annotations)}) do not match."
+ )
+
+ if not valid_images(images):
+ raise ValueError(
+ "Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
+ "torch.Tensor, tf.Tensor or jax.ndarray."
+ )
+
+ format = AnnotionFormat(format)
+ if annotations is not None:
+ if format == AnnotionFormat.COCO_DETECTION and not valid_coco_detection_annotations(annotations):
+ raise ValueError(
+ "Invalid COCO detection annotations. Annotations must a dict (single image) of list of dicts"
+ "(batch of images) with the following keys: `image_id` and `annotations`, with the latter "
+ "being a list of annotations in the COCO format."
+ )
+ elif format == AnnotionFormat.COCO_PANOPTIC and not valid_coco_panoptic_annotations(annotations):
+ raise ValueError(
+ "Invalid COCO panoptic annotations. Annotations must a dict (single image) of list of dicts "
+ "(batch of images) with the following keys: `image_id`, `file_name` and `segments_info`, with "
+ "the latter being a list of annotations in the COCO format."
+ )
+ elif format not in SUPPORTED_ANNOTATION_FORMATS:
+ raise ValueError(
+ f"Unsupported annotation format: {format} must be one of {SUPPORTED_ANNOTATION_FORMATS}"
+ )
+
+ if (
+ masks_path is not None
+ and format == AnnotionFormat.COCO_PANOPTIC
+ and not isinstance(masks_path, (pathlib.Path, str))
+ ):
+ raise ValueError(
+ "The path to the directory containing the mask PNG files should be provided as a"
+ f" `pathlib.Path` or string object, but is {type(masks_path)} instead."
+ )
+
+ # All transformations expect numpy arrays
+ images = [to_numpy_array(image) for image in images]
+
+ # prepare (COCO annotations as a list of Dict -> DETR target as a single Dict per image)
+ if annotations is not None:
+ prepared_images = []
+ prepared_annotations = []
+ for image, target in zip(images, annotations):
+ target = self.prepare_annotation(
+ image, target, format, return_segmentation_masks=return_segmentation_masks, masks_path=masks_path
+ )
+ prepared_images.append(image)
+ prepared_annotations.append(target)
+ images = prepared_images
+ annotations = prepared_annotations
+ del prepared_images, prepared_annotations
+
+ # transformations
+ if do_resize:
+ if annotations is not None:
+ resized_images, resized_annotations = [], []
+ for image, target in zip(images, annotations):
+ orig_size = get_image_size(image)
+ resized_image = self.resize(image, size=size, max_size=max_size, resample=resample)
+ resized_annotation = self.resize_annotation(target, orig_size, get_image_size(resized_image))
+ resized_images.append(resized_image)
+ resized_annotations.append(resized_annotation)
+ images = resized_images
+ annotations = resized_annotations
+ del resized_images, resized_annotations
+ else:
+ images = [self.resize(image, size=size, resample=resample) for image in images]
+
+ if do_rescale:
+ images = [self.rescale(image, rescale_factor) for image in images]
+
+ if do_normalize:
+ images = [self.normalize(image, image_mean, image_std) for image in images]
+ if annotations is not None:
+ annotations = [
+ self.normalize_annotation(annotation, get_image_size(image))
+ for annotation, image in zip(annotations, images)
+ ]
+
+ if do_pad:
+ # Pads images and returns their mask: {'pixel_values': ..., 'pixel_mask': ...}
+ data = self.pad(images, return_pixel_mask=True, data_format=data_format)
+ else:
+ images = [to_channel_dimension_format(image, data_format) for image in images]
+ data = {"pixel_values": images}
+
+ encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
+ if annotations is not None:
+ encoded_inputs["labels"] = [
+ BatchFeature(annotation, tensor_type=return_tensors) for annotation in annotations
+ ]
+
+ return encoded_inputs
+
+ # POSTPROCESSING METHODS - TODO: add support for other frameworks
+ def post_process(self, outputs, target_sizes):
+ """
+ Converts the output of [`DeformableDetrForObjectDetection`] into the format expected by the COCO api. Only
+ supports PyTorch.
+
+ Args:
+ outputs ([`DeformableDetrObjectDetectionOutput`]):
+ Raw outputs of the model.
+ target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
+ Tensor containing the size (height, width) of each image of the batch. For evaluation, this must be the
+ original image size (before any data augmentation). For visualization, this should be the image size
+ after data augment, but before padding.
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
+ in the batch as predicted by the model.
+ """
+ warnings.warn(
+ "`post_process` is deprecated and will be removed in v5 of Transformers, please use"
+ " `post_process_object_detection`.",
+ FutureWarning,
+ )
+
+ out_logits, out_bbox = outputs.logits, outputs.pred_boxes
+
+ if len(out_logits) != len(target_sizes):
+ raise ValueError("Make sure that you pass in as many target sizes as the batch dimension of the logits")
+ if target_sizes.shape[1] != 2:
+ raise ValueError("Each element of target_sizes must contain the size (h, w) of each image of the batch")
+
+ prob = out_logits.sigmoid()
+ topk_values, topk_indexes = torch.topk(prob.view(out_logits.shape[0], -1), 100, dim=1)
+ scores = topk_values
+ topk_boxes = topk_indexes // out_logits.shape[2]
+ labels = topk_indexes % out_logits.shape[2]
+ boxes = center_to_corners_format(out_bbox)
+ boxes = torch.gather(boxes, 1, topk_boxes.unsqueeze(-1).repeat(1, 1, 4))
+
+ # and from relative [0, 1] to absolute [0, height] coordinates
+ img_h, img_w = target_sizes.unbind(1)
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1).to(boxes.device)
+ boxes = boxes * scale_fct[:, None, :]
+
+ results = [{"scores": s, "labels": l, "boxes": b} for s, l, b in zip(scores, labels, boxes)]
+
+ return results
+
+ def post_process_object_detection(
+ self, outputs, threshold: float = 0.5, target_sizes: Union[TensorType, List[Tuple]] = None
+ ):
+ """
+ Converts the output of [`DeformableDetrForObjectDetection`] into the format expected by the COCO api. Only
+ supports PyTorch.
+
+ Args:
+ outputs ([`DetrObjectDetectionOutput`]):
+ Raw outputs of the model.
+ threshold (`float`, *optional*):
+ Score threshold to keep object detection predictions.
+ target_sizes (`torch.Tensor` or `List[Tuple[int, int]]`, *optional*):
+ Tensor of shape `(batch_size, 2)` or list of tuples (`Tuple[int, int]`) containing the target size
+ (height, width) of each image in the batch. If left to None, predictions will not be resized.
+
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
+ in the batch as predicted by the model.
+ """
+ out_logits, out_bbox = outputs.logits, outputs.pred_boxes
+
+ if target_sizes is not None:
+ if len(out_logits) != len(target_sizes):
+ raise ValueError(
+ "Make sure that you pass in as many target sizes as the batch dimension of the logits"
+ )
+
+ prob = out_logits.sigmoid()
+ topk_values, topk_indexes = torch.topk(prob.view(out_logits.shape[0], -1), 100, dim=1)
+ scores = topk_values
+ topk_boxes = topk_indexes // out_logits.shape[2]
+ labels = topk_indexes % out_logits.shape[2]
+ boxes = center_to_corners_format(out_bbox)
+ boxes = torch.gather(boxes, 1, topk_boxes.unsqueeze(-1).repeat(1, 1, 4))
+
+ # and from relative [0, 1] to absolute [0, height] coordinates
+ if isinstance(target_sizes, List):
+ img_h = torch.Tensor([i[0] for i in target_sizes])
+ img_w = torch.Tensor([i[1] for i in target_sizes])
+ else:
+ img_h, img_w = target_sizes.unbind(1)
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
+ boxes = boxes * scale_fct[:, None, :]
+
+ results = []
+ for s, l, b in zip(scores, labels, boxes):
+ score = s[s > threshold]
+ label = l[s > threshold]
+ box = b[s > threshold]
+ results.append({"scores": score, "labels": label, "boxes": box})
+
+ return results
diff --git a/src/transformers/models/detr/__init__.py b/src/transformers/models/detr/__init__.py
index b9b6d30c32..9b0ca07cc3 100644
--- a/src/transformers/models/detr/__init__.py
+++ b/src/transformers/models/detr/__init__.py
@@ -30,6 +30,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_detr"] = ["DetrFeatureExtractor"]
+ _import_structure["image_processing_detr"] = ["DetrImageProcessor"]
try:
if not is_timm_available():
@@ -56,6 +57,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_detr import DetrFeatureExtractor
+ from .image_processing_detr import DetrImageProcessor
try:
if not is_timm_available():
diff --git a/src/transformers/models/detr/feature_extraction_detr.py b/src/transformers/models/detr/feature_extraction_detr.py
index 18c262fea4..c59a7e11ad 100644
--- a/src/transformers/models/detr/feature_extraction_detr.py
+++ b/src/transformers/models/detr/feature_extraction_detr.py
@@ -14,1325 +14,9 @@
# limitations under the License.
"""Feature extractor class for DETR."""
-import io
-import pathlib
-import warnings
-from collections import defaultdict
-from typing import Dict, List, Optional, Set, Tuple, Union
+from ...utils import logging
+from .image_processing_detr import DetrImageProcessor
-import numpy as np
-from PIL import Image
-
-from ...feature_extraction_utils import BatchFeature, FeatureExtractionMixin
-from ...image_transforms import center_to_corners_format, corners_to_center_format, id_to_rgb, rgb_to_id
-from ...image_utils import ImageFeatureExtractionMixin
-from ...utils import TensorType, is_torch_available, is_torch_tensor, logging
-
-
-if is_torch_available():
- import torch
- from torch import nn
logger = logging.get_logger(__name__)
-
-
-ImageInput = Union[Image.Image, np.ndarray, "torch.Tensor", List[Image.Image], List[np.ndarray], List["torch.Tensor"]]
-
-
-def masks_to_boxes(masks):
- """
- Compute the bounding boxes around the provided panoptic segmentation masks.
-
- The masks should be in format [N, H, W] where N is the number of masks, (H, W) are the spatial dimensions.
-
- Returns a [N, 4] tensor, with the boxes in corner (xyxy) format.
- """
- if masks.size == 0:
- return np.zeros((0, 4))
-
- h, w = masks.shape[-2:]
-
- y = np.arange(0, h, dtype=np.float32)
- x = np.arange(0, w, dtype=np.float32)
- # see https://github.com/pytorch/pytorch/issues/50276
- y, x = np.meshgrid(y, x, indexing="ij")
-
- x_mask = masks * np.expand_dims(x, axis=0)
- x_max = x_mask.reshape(x_mask.shape[0], -1).max(-1)
- x = np.ma.array(x_mask, mask=~(np.array(masks, dtype=bool)))
- x_min = x.filled(fill_value=1e8)
- x_min = x_min.reshape(x_min.shape[0], -1).min(-1)
-
- y_mask = masks * np.expand_dims(y, axis=0)
- y_max = y_mask.reshape(x_mask.shape[0], -1).max(-1)
- y = np.ma.array(y_mask, mask=~(np.array(masks, dtype=bool)))
- y_min = y.filled(fill_value=1e8)
- y_min = y_min.reshape(y_min.shape[0], -1).min(-1)
-
- return np.stack([x_min, y_min, x_max, y_max], 1)
-
-
-def binary_mask_to_rle(mask):
- """
- Args:
- Converts given binary mask of shape (height, width) to the run-length encoding (RLE) format.
- mask (`torch.Tensor` or `numpy.array`):
- A binary mask tensor of shape `(height, width)` where 0 denotes background and 1 denotes the target
- segment_id or class_id.
- Returns:
- `List`: Run-length encoded list of the binary mask. Refer to COCO API for more information about the RLE
- format.
- """
- if is_torch_tensor(mask):
- mask = mask.numpy()
-
- pixels = mask.flatten()
- pixels = np.concatenate([[0], pixels, [0]])
- runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
- runs[1::2] -= runs[::2]
- return [x for x in runs]
-
-
-def convert_segmentation_to_rle(segmentation):
- """
- Converts given segmentation map of shape (height, width) to the run-length encoding (RLE) format.
-
- Args:
- segmentation (`torch.Tensor` or `numpy.array`):
- A segmentation map of shape `(height, width)` where each value denotes a segment or class id.
- Returns:
- `List[List]`: A list of lists, where each list is the run-length encoding of a segment / class id.
- """
- segment_ids = torch.unique(segmentation)
-
- run_length_encodings = []
- for idx in segment_ids:
- mask = torch.where(segmentation == idx, 1, 0)
- rle = binary_mask_to_rle(mask)
- run_length_encodings.append(rle)
-
- return run_length_encodings
-
-
-def remove_low_and_no_objects(masks, scores, labels, object_mask_threshold, num_labels):
- """
- Binarize the given masks using `object_mask_threshold`, it returns the associated values of `masks`, `scores` and
- `labels`.
-
- Args:
- masks (`torch.Tensor`):
- A tensor of shape `(num_queries, height, width)`.
- scores (`torch.Tensor`):
- A tensor of shape `(num_queries)`.
- labels (`torch.Tensor`):
- A tensor of shape `(num_queries)`.
- object_mask_threshold (`float`):
- A number between 0 and 1 used to binarize the masks.
- Raises:
- `ValueError`: Raised when the first dimension doesn't match in all input tensors.
- Returns:
- `Tuple[`torch.Tensor`, `torch.Tensor`, `torch.Tensor`]`: The `masks`, `scores` and `labels` without the region
- < `object_mask_threshold`.
- """
- if not (masks.shape[0] == scores.shape[0] == labels.shape[0]):
- raise ValueError("mask, scores and labels must have the same shape!")
-
- to_keep = labels.ne(num_labels) & (scores > object_mask_threshold)
-
- return masks[to_keep], scores[to_keep], labels[to_keep]
-
-
-def check_segment_validity(mask_labels, mask_probs, k, mask_threshold=0.5, overlap_mask_area_threshold=0.8):
- # Get the mask associated with the k class
- mask_k = mask_labels == k
- mask_k_area = mask_k.sum()
-
- # Compute the area of all the stuff in query k
- original_area = (mask_probs[k] >= mask_threshold).sum()
- mask_exists = mask_k_area > 0 and original_area > 0
-
- # Eliminate disconnected tiny segments
- if mask_exists:
- area_ratio = mask_k_area / original_area
- if not area_ratio.item() > overlap_mask_area_threshold:
- mask_exists = False
-
- return mask_exists, mask_k
-
-
-def compute_segments(
- mask_probs,
- pred_scores,
- pred_labels,
- mask_threshold: float = 0.5,
- overlap_mask_area_threshold: float = 0.8,
- label_ids_to_fuse: Optional[Set[int]] = None,
- target_size: Tuple[int, int] = None,
-):
- height = mask_probs.shape[1] if target_size is None else target_size[0]
- width = mask_probs.shape[2] if target_size is None else target_size[1]
-
- segmentation = torch.zeros((height, width), dtype=torch.int32, device=mask_probs.device)
- segments: List[Dict] = []
-
- if target_size is not None:
- mask_probs = nn.functional.interpolate(
- mask_probs.unsqueeze(0), size=target_size, mode="bilinear", align_corners=False
- )[0]
-
- current_segment_id = 0
-
- # Weigh each mask by its prediction score
- mask_probs *= pred_scores.view(-1, 1, 1)
- mask_labels = mask_probs.argmax(0) # [height, width]
-
- # Keep track of instances of each class
- stuff_memory_list: Dict[str, int] = {}
- for k in range(pred_labels.shape[0]):
- pred_class = pred_labels[k].item()
- should_fuse = pred_class in label_ids_to_fuse
-
- # Check if mask exists and large enough to be a segment
- mask_exists, mask_k = check_segment_validity(
- mask_labels, mask_probs, k, mask_threshold, overlap_mask_area_threshold
- )
-
- if mask_exists:
- if pred_class in stuff_memory_list:
- current_segment_id = stuff_memory_list[pred_class]
- else:
- current_segment_id += 1
-
- # Add current object segment to final segmentation map
- segmentation[mask_k] = current_segment_id
- segment_score = round(pred_scores[k].item(), 6)
- segments.append(
- {
- "id": current_segment_id,
- "label_id": pred_class,
- "was_fused": should_fuse,
- "score": segment_score,
- }
- )
- if should_fuse:
- stuff_memory_list[pred_class] = current_segment_id
-
- return segmentation, segments
-
-
-class DetrFeatureExtractor(FeatureExtractionMixin, ImageFeatureExtractionMixin):
- r"""
- Constructs a DETR feature extractor.
-
- This feature extractor inherits from [`FeatureExtractionMixin`] which contains most of the main methods. Users
- should refer to this superclass for more information regarding those methods.
-
-
- Args:
- format (`str`, *optional*, defaults to `"coco_detection"`):
- Data format of the annotations. One of "coco_detection" or "coco_panoptic".
- do_resize (`bool`, *optional*, defaults to `True`):
- Whether to resize the input to a certain `size`.
- size (`int`, *optional*, defaults to 800):
- Resize the input to the given size. Only has an effect if `do_resize` is set to `True`. If size is a
- sequence like `(width, height)`, output size will be matched to this. If size is an int, smaller edge of
- the image will be matched to this number. i.e, if `height > width`, then image will be rescaled to `(size *
- height / width, size)`.
- max_size (`int`, *optional*, defaults to 1333):
- The largest size an image dimension can have (otherwise it's capped). Only has an effect if `do_resize` is
- set to `True`.
- do_normalize (`bool`, *optional*, defaults to `True`):
- Whether or not to normalize the input with mean and standard deviation.
- image_mean (`int`, *optional*, defaults to `[0.485, 0.456, 0.406]`):
- The sequence of means for each channel, to be used when normalizing images. Defaults to the ImageNet mean.
- image_std (`int`, *optional*, defaults to `[0.229, 0.224, 0.225]`):
- The sequence of standard deviations for each channel, to be used when normalizing images. Defaults to the
- ImageNet std.
- """
-
- model_input_names = ["pixel_values", "pixel_mask"]
-
- def __init__(
- self,
- format="coco_detection",
- do_resize=True,
- size=800,
- max_size=1333,
- do_normalize=True,
- image_mean=None,
- image_std=None,
- **kwargs
- ):
- super().__init__(**kwargs)
- self.format = self._is_valid_format(format)
- self.do_resize = do_resize
- self.size = size
- self.max_size = max_size
- self.do_normalize = do_normalize
- self.image_mean = image_mean if image_mean is not None else [0.485, 0.456, 0.406] # ImageNet mean
- self.image_std = image_std if image_std is not None else [0.229, 0.224, 0.225] # ImageNet std
-
- def _is_valid_format(self, format):
- if format not in ["coco_detection", "coco_panoptic"]:
- raise ValueError(f"Format {format} not supported")
- return format
-
- def prepare(self, image, target, return_segmentation_masks=False, masks_path=None):
- if self.format == "coco_detection":
- image, target = self.prepare_coco_detection(image, target, return_segmentation_masks)
- return image, target
- elif self.format == "coco_panoptic":
- image, target = self.prepare_coco_panoptic(image, target, masks_path)
- return image, target
- else:
- raise ValueError(f"Format {self.format} not supported")
-
- # inspired by https://github.com/facebookresearch/detr/blob/master/datasets/coco.py#L33
- def convert_coco_poly_to_mask(self, segmentations, height, width):
-
- try:
- from pycocotools import mask as coco_mask
- except ImportError:
- raise ImportError("Pycocotools is not installed in your environment.")
-
- masks = []
- for polygons in segmentations:
- rles = coco_mask.frPyObjects(polygons, height, width)
- mask = coco_mask.decode(rles)
- if len(mask.shape) < 3:
- mask = mask[..., None]
- mask = np.asarray(mask, dtype=np.uint8)
- mask = np.any(mask, axis=2)
- masks.append(mask)
- if masks:
- masks = np.stack(masks, axis=0)
- else:
- masks = np.zeros((0, height, width), dtype=np.uint8)
-
- return masks
-
- # inspired by https://github.com/facebookresearch/detr/blob/master/datasets/coco.py#L50
- def prepare_coco_detection(self, image, target, return_segmentation_masks=False):
- """
- Convert the target in COCO format into the format expected by DETR.
- """
- w, h = image.size
-
- image_id = target["image_id"]
- image_id = np.asarray([image_id], dtype=np.int64)
-
- # get all COCO annotations for the given image
- anno = target["annotations"]
-
- anno = [obj for obj in anno if "iscrowd" not in obj or obj["iscrowd"] == 0]
-
- boxes = [obj["bbox"] for obj in anno]
- # guard against no boxes via resizing
- boxes = np.asarray(boxes, dtype=np.float32).reshape(-1, 4)
- boxes[:, 2:] += boxes[:, :2]
- boxes[:, 0::2] = boxes[:, 0::2].clip(min=0, max=w)
- boxes[:, 1::2] = boxes[:, 1::2].clip(min=0, max=h)
-
- classes = [obj["category_id"] for obj in anno]
- classes = np.asarray(classes, dtype=np.int64)
-
- if return_segmentation_masks:
- segmentations = [obj["segmentation"] for obj in anno]
- masks = self.convert_coco_poly_to_mask(segmentations, h, w)
-
- keypoints = None
- if anno and "keypoints" in anno[0]:
- keypoints = [obj["keypoints"] for obj in anno]
- keypoints = np.asarray(keypoints, dtype=np.float32)
- num_keypoints = keypoints.shape[0]
- if num_keypoints:
- keypoints = keypoints.reshape((-1, 3))
-
- keep = (boxes[:, 3] > boxes[:, 1]) & (boxes[:, 2] > boxes[:, 0])
- boxes = boxes[keep]
- classes = classes[keep]
- if return_segmentation_masks:
- masks = masks[keep]
- if keypoints is not None:
- keypoints = keypoints[keep]
-
- target = {}
- target["boxes"] = boxes
- target["class_labels"] = classes
- if return_segmentation_masks:
- target["masks"] = masks
- target["image_id"] = image_id
- if keypoints is not None:
- target["keypoints"] = keypoints
-
- # for conversion to coco api
- area = np.asarray([obj["area"] for obj in anno], dtype=np.float32)
- iscrowd = np.asarray([obj["iscrowd"] if "iscrowd" in obj else 0 for obj in anno], dtype=np.int64)
- target["area"] = area[keep]
- target["iscrowd"] = iscrowd[keep]
-
- target["orig_size"] = np.asarray([int(h), int(w)], dtype=np.int64)
- target["size"] = np.asarray([int(h), int(w)], dtype=np.int64)
-
- return image, target
-
- def prepare_coco_panoptic(self, image, target, masks_path, return_masks=True):
- w, h = image.size
- ann_info = target.copy()
- ann_path = pathlib.Path(masks_path) / ann_info["file_name"]
-
- if "segments_info" in ann_info:
- masks = np.asarray(Image.open(ann_path), dtype=np.uint32)
- masks = rgb_to_id(masks)
-
- ids = np.array([ann["id"] for ann in ann_info["segments_info"]])
- masks = masks == ids[:, None, None]
- masks = np.asarray(masks, dtype=np.uint8)
-
- labels = np.asarray([ann["category_id"] for ann in ann_info["segments_info"]], dtype=np.int64)
-
- target = {}
- target["image_id"] = np.asarray(
- [ann_info["image_id"] if "image_id" in ann_info else ann_info["id"]], dtype=np.int64
- )
- if return_masks:
- target["masks"] = masks
- target["class_labels"] = labels
-
- target["boxes"] = masks_to_boxes(masks)
-
- target["size"] = np.asarray([int(h), int(w)], dtype=np.int64)
- target["orig_size"] = np.asarray([int(h), int(w)], dtype=np.int64)
- if "segments_info" in ann_info:
- target["iscrowd"] = np.asarray([ann["iscrowd"] for ann in ann_info["segments_info"]], dtype=np.int64)
- target["area"] = np.asarray([ann["area"] for ann in ann_info["segments_info"]], dtype=np.float32)
-
- return image, target
-
- def _resize(self, image, size, target=None, max_size=None):
- """
- Resize the image to the given size. Size can be min_size (scalar) or (w, h) tuple. If size is an int, smaller
- edge of the image will be matched to this number.
-
- If given, also resize the target accordingly.
- """
- if not isinstance(image, Image.Image):
- image = self.to_pil_image(image)
-
- def get_size_with_aspect_ratio(image_size, size, max_size=None):
- w, h = image_size
- if max_size is not None:
- min_original_size = float(min((w, h)))
- max_original_size = float(max((w, h)))
- if max_original_size / min_original_size * size > max_size:
- size = int(round(max_size * min_original_size / max_original_size))
-
- if (w <= h and w == size) or (h <= w and h == size):
- return (h, w)
-
- if w < h:
- ow = size
- oh = int(size * h / w)
- else:
- oh = size
- ow = int(size * w / h)
-
- return (oh, ow)
-
- def get_size(image_size, size, max_size=None):
- if isinstance(size, (list, tuple)):
- return size
- else:
- # size returned must be (w, h) since we use PIL to resize images
- # so we revert the tuple
- return get_size_with_aspect_ratio(image_size, size, max_size)[::-1]
-
- size = get_size(image.size, size, max_size)
- rescaled_image = self.resize(image, size=size)
-
- if target is None:
- return rescaled_image, None
-
- ratios = tuple(float(s) / float(s_orig) for s, s_orig in zip(rescaled_image.size, image.size))
- ratio_width, ratio_height = ratios
-
- target = target.copy()
- if "boxes" in target:
- boxes = target["boxes"]
- scaled_boxes = boxes * np.asarray([ratio_width, ratio_height, ratio_width, ratio_height], dtype=np.float32)
- target["boxes"] = scaled_boxes
-
- if "area" in target:
- area = target["area"]
- scaled_area = area * (ratio_width * ratio_height)
- target["area"] = scaled_area
-
- w, h = size
- target["size"] = np.asarray([h, w], dtype=np.int64)
-
- if "masks" in target:
- # use PyTorch as current workaround
- # TODO replace by self.resize
- masks = torch.from_numpy(target["masks"][:, None]).float()
- interpolated_masks = nn.functional.interpolate(masks, size=(h, w), mode="nearest")[:, 0] > 0.5
- target["masks"] = interpolated_masks.numpy()
-
- return rescaled_image, target
-
- def _normalize(self, image, mean, std, target=None):
- """
- Normalize the image with a certain mean and std.
-
- If given, also normalize the target bounding boxes based on the size of the image.
- """
-
- image = self.normalize(image, mean=mean, std=std)
- if target is None:
- return image, None
-
- target = target.copy()
- h, w = image.shape[-2:]
-
- if "boxes" in target:
- boxes = target["boxes"]
- boxes = corners_to_center_format(boxes)
- boxes = boxes / np.asarray([w, h, w, h], dtype=np.float32)
- target["boxes"] = boxes
-
- return image, target
-
- def __call__(
- self,
- images: ImageInput,
- annotations: Union[List[Dict], List[List[Dict]]] = None,
- return_segmentation_masks: Optional[bool] = False,
- masks_path: Optional[pathlib.Path] = None,
- pad_and_return_pixel_mask: Optional[bool] = True,
- return_tensors: Optional[Union[str, TensorType]] = None,
- **kwargs,
- ) -> BatchFeature:
- """
- Main method to prepare for the model one or several image(s) and optional annotations. Images are by default
- padded up to the largest image in a batch, and a pixel mask is created that indicates which pixels are
- real/which are padding.
-
-
-
- NumPy arrays and PyTorch tensors are converted to PIL images when resizing, so the most efficient is to pass
- PIL images.
-
-
-
- Args:
- images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
- The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
- tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a
- number of channels, H and W are image height and width.
-
- annotations (`Dict`, `List[Dict]`, *optional*):
- The corresponding annotations in COCO format.
-
- In case [`DetrFeatureExtractor`] was initialized with `format = "coco_detection"`, the annotations for
- each image should have the following format: {'image_id': int, 'annotations': [annotation]}, with the
- annotations being a list of COCO object annotations.
-
- In case [`DetrFeatureExtractor`] was initialized with `format = "coco_panoptic"`, the annotations for
- each image should have the following format: {'image_id': int, 'file_name': str, 'segments_info':
- [segment_info]} with segments_info being a list of COCO panoptic annotations.
-
- return_segmentation_masks (`Dict`, `List[Dict]`, *optional*, defaults to `False`):
- Whether to also include instance segmentation masks as part of the labels in case `format =
- "coco_detection"`.
-
- masks_path (`pathlib.Path`, *optional*):
- Path to the directory containing the PNG files that store the class-agnostic image segmentations. Only
- relevant in case [`DetrFeatureExtractor`] was initialized with `format = "coco_panoptic"`.
-
- pad_and_return_pixel_mask (`bool`, *optional*, defaults to `True`):
- Whether or not to pad images up to the largest image in a batch and create a pixel mask.
-
- If left to the default, will return a pixel mask that is:
-
- - 1 for pixels that are real (i.e. **not masked**),
- - 0 for pixels that are padding (i.e. **masked**).
-
- return_tensors (`str` or [`~utils.TensorType`], *optional*):
- If set, will return tensors instead of NumPy arrays. If set to `'pt'`, return PyTorch `torch.Tensor`
- objects.
-
- Returns:
- [`BatchFeature`]: A [`BatchFeature`] with the following fields:
-
- - **pixel_values** -- Pixel values to be fed to a model.
- - **pixel_mask** -- Pixel mask to be fed to a model (when `pad_and_return_pixel_mask=True` or if
- *"pixel_mask"* is in `self.model_input_names`).
- - **labels** -- Optional labels to be fed to a model (when `annotations` are provided)
- """
- # Input type checking for clearer error
-
- valid_images = False
- valid_annotations = False
- valid_masks_path = False
-
- # Check that images has a valid type
- if isinstance(images, (Image.Image, np.ndarray)) or is_torch_tensor(images):
- valid_images = True
- elif isinstance(images, (list, tuple)):
- if len(images) == 0 or isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]):
- valid_images = True
-
- if not valid_images:
- raise ValueError(
- "Images must of type `PIL.Image.Image`, `np.ndarray` or `torch.Tensor` (single example), "
- "`List[PIL.Image.Image]`, `List[np.ndarray]` or `List[torch.Tensor]` (batch of examples)."
- )
-
- is_batched = bool(
- isinstance(images, (list, tuple))
- and (isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]))
- )
-
- # Check that annotations has a valid type
- if annotations is not None:
- if not is_batched:
- if self.format == "coco_detection":
- if isinstance(annotations, dict) and "image_id" in annotations and "annotations" in annotations:
- if isinstance(annotations["annotations"], (list, tuple)):
- # an image can have no annotations
- if len(annotations["annotations"]) == 0 or isinstance(annotations["annotations"][0], dict):
- valid_annotations = True
- elif self.format == "coco_panoptic":
- if isinstance(annotations, dict) and "image_id" in annotations and "segments_info" in annotations:
- if isinstance(annotations["segments_info"], (list, tuple)):
- # an image can have no segments (?)
- if len(annotations["segments_info"]) == 0 or isinstance(
- annotations["segments_info"][0], dict
- ):
- valid_annotations = True
- else:
- if isinstance(annotations, (list, tuple)):
- if len(images) != len(annotations):
- raise ValueError("There must be as many annotations as there are images")
- if isinstance(annotations[0], Dict):
- if self.format == "coco_detection":
- if isinstance(annotations[0]["annotations"], (list, tuple)):
- valid_annotations = True
- elif self.format == "coco_panoptic":
- if isinstance(annotations[0]["segments_info"], (list, tuple)):
- valid_annotations = True
-
- if not valid_annotations:
- raise ValueError(
- """
- Annotations must of type `Dict` (single image) or `List[Dict]` (batch of images). In case of object
- detection, each dictionary should contain the keys 'image_id' and 'annotations', with the latter
- being a list of annotations in COCO format. In case of panoptic segmentation, each dictionary
- should contain the keys 'file_name', 'image_id' and 'segments_info', with the latter being a list
- of annotations in COCO format.
- """
- )
-
- # Check that masks_path has a valid type
- if masks_path is not None:
- if self.format == "coco_panoptic":
- if isinstance(masks_path, pathlib.Path):
- valid_masks_path = True
- if not valid_masks_path:
- raise ValueError(
- "The path to the directory containing the mask PNG files should be provided as a"
- " `pathlib.Path` object."
- )
-
- if not is_batched:
- images = [images]
- if annotations is not None:
- annotations = [annotations]
-
- # Create a copy of the list to avoid editing it in place
- images = [image for image in images]
-
- if annotations is not None:
- annotations = [annotation for annotation in annotations]
-
- # prepare (COCO annotations as a list of Dict -> DETR target as a single Dict per image)
- if annotations is not None:
- for idx, (image, target) in enumerate(zip(images, annotations)):
- if not isinstance(image, Image.Image):
- image = self.to_pil_image(image)
- image, target = self.prepare(image, target, return_segmentation_masks, masks_path)
- images[idx] = image
- annotations[idx] = target
-
- # transformations (resizing + normalization)
- if self.do_resize and self.size is not None:
- if annotations is not None:
- for idx, (image, target) in enumerate(zip(images, annotations)):
- image, target = self._resize(image=image, target=target, size=self.size, max_size=self.max_size)
- images[idx] = image
- annotations[idx] = target
- else:
- for idx, image in enumerate(images):
- images[idx] = self._resize(image=image, target=None, size=self.size, max_size=self.max_size)[0]
-
- if self.do_normalize:
- if annotations is not None:
- for idx, (image, target) in enumerate(zip(images, annotations)):
- image, target = self._normalize(
- image=image, mean=self.image_mean, std=self.image_std, target=target
- )
- images[idx] = image
- annotations[idx] = target
- else:
- images = [
- self._normalize(image=image, mean=self.image_mean, std=self.image_std)[0] for image in images
- ]
- else:
- images = [np.array(image) for image in images]
-
- if pad_and_return_pixel_mask:
- # pad images up to largest image in batch and create pixel_mask
- max_size = self._max_by_axis([list(image.shape) for image in images])
- c, h, w = max_size
- padded_images = []
- pixel_mask = []
- for image in images:
- # create padded image
- padded_image = np.zeros((c, h, w), dtype=np.float32)
- padded_image[: image.shape[0], : image.shape[1], : image.shape[2]] = np.copy(image)
- padded_images.append(padded_image)
- # create pixel mask
- mask = np.zeros((h, w), dtype=np.int64)
- mask[: image.shape[1], : image.shape[2]] = True
- pixel_mask.append(mask)
- images = padded_images
-
- # return as BatchFeature
- data = {}
- data["pixel_values"] = images
- if pad_and_return_pixel_mask:
- data["pixel_mask"] = pixel_mask
- encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
-
- if annotations is not None:
- # Convert to TensorType
- tensor_type = return_tensors
- if not isinstance(tensor_type, TensorType):
- tensor_type = TensorType(tensor_type)
-
- if not tensor_type == TensorType.PYTORCH:
- raise ValueError("Only PyTorch is supported for the moment.")
- else:
- if not is_torch_available():
- raise ImportError("Unable to convert output to PyTorch tensors format, PyTorch is not installed.")
-
- encoded_inputs["labels"] = [
- {k: torch.from_numpy(v) for k, v in target.items()} for target in annotations
- ]
-
- return encoded_inputs
-
- def _max_by_axis(self, the_list):
- # type: (List[List[int]]) -> List[int]
- maxes = the_list[0]
- for sublist in the_list[1:]:
- for index, item in enumerate(sublist):
- maxes[index] = max(maxes[index], item)
- return maxes
-
- def pad_and_create_pixel_mask(
- self, pixel_values_list: List["torch.Tensor"], return_tensors: Optional[Union[str, TensorType]] = None
- ):
- """
- Pad images up to the largest image in a batch and create a corresponding `pixel_mask`.
-
- Args:
- pixel_values_list (`List[torch.Tensor]`):
- List of images (pixel values) to be padded. Each image should be a tensor of shape (C, H, W).
- return_tensors (`str` or [`~utils.TensorType`], *optional*):
- If set, will return tensors instead of NumPy arrays. If set to `'pt'`, return PyTorch `torch.Tensor`
- objects.
-
- Returns:
- [`BatchFeature`]: A [`BatchFeature`] with the following fields:
-
- - **pixel_values** -- Pixel values to be fed to a model.
- - **pixel_mask** -- Pixel mask to be fed to a model (when `pad_and_return_pixel_mask=True` or if
- *"pixel_mask"* is in `self.model_input_names`).
-
- """
-
- max_size = self._max_by_axis([list(image.shape) for image in pixel_values_list])
- c, h, w = max_size
- padded_images = []
- pixel_mask = []
- for image in pixel_values_list:
- # create padded image
- padded_image = np.zeros((c, h, w), dtype=np.float32)
- padded_image[: image.shape[0], : image.shape[1], : image.shape[2]] = np.copy(image)
- padded_images.append(padded_image)
- # create pixel mask
- mask = np.zeros((h, w), dtype=np.int64)
- mask[: image.shape[1], : image.shape[2]] = True
- pixel_mask.append(mask)
-
- # return as BatchFeature
- data = {"pixel_values": padded_images, "pixel_mask": pixel_mask}
- encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
-
- return encoded_inputs
-
- # POSTPROCESSING METHODS
- # inspired by https://github.com/facebookresearch/detr/blob/master/models/detr.py#L258
- def post_process(self, outputs, target_sizes):
- """
- Converts the output of [`DetrForObjectDetection`] into the format expected by the COCO api. Only supports
- PyTorch.
-
- Args:
- outputs ([`DetrObjectDetectionOutput`]):
- Raw outputs of the model.
- target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
- Tensor containing the size (height, width) of each image of the batch. For evaluation, this must be the
- original image size (before any data augmentation). For visualization, this should be the image size
- after data augment, but before padding.
-
- Returns:
- `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
- in the batch as predicted by the model.
- """
- warnings.warn(
- "`post_process` is deprecated and will be removed in v5 of Transformers, please use"
- " `post_process_object_detection`",
- FutureWarning,
- )
-
- out_logits, out_bbox = outputs.logits, outputs.pred_boxes
-
- if len(out_logits) != len(target_sizes):
- raise ValueError("Make sure that you pass in as many target sizes as the batch dimension of the logits")
- if target_sizes.shape[1] != 2:
- raise ValueError("Each element of target_sizes must contain the size (h, w) of each image of the batch")
-
- prob = nn.functional.softmax(out_logits, -1)
- scores, labels = prob[..., :-1].max(-1)
-
- # convert to [x0, y0, x1, y1] format
- boxes = center_to_corners_format(out_bbox)
- # and from relative [0, 1] to absolute [0, height] coordinates
- img_h, img_w = target_sizes.unbind(1)
- scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
- boxes = boxes * scale_fct[:, None, :]
-
- results = [{"scores": s, "labels": l, "boxes": b} for s, l, b in zip(scores, labels, boxes)]
- return results
-
- def post_process_segmentation(self, outputs, target_sizes, threshold=0.9, mask_threshold=0.5):
- """
- Converts the output of [`DetrForSegmentation`] into image segmentation predictions. Only supports PyTorch.
-
- Args:
- outputs ([`DetrSegmentationOutput`]):
- Raw outputs of the model.
- target_sizes (`torch.Tensor` of shape `(batch_size, 2)` or `List[Tuple]` of length `batch_size`):
- Torch Tensor (or list) corresponding to the requested final size (h, w) of each prediction.
- threshold (`float`, *optional*, defaults to 0.9):
- Threshold to use to filter out queries.
- mask_threshold (`float`, *optional*, defaults to 0.5):
- Threshold to use when turning the predicted masks into binary values.
-
- Returns:
- `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels, and masks for an image
- in the batch as predicted by the model.
- """
- warnings.warn(
- "`post_process_segmentation` is deprecated and will be removed in v5 of Transformers, please use"
- " `post_process_semantic_segmentation`.",
- FutureWarning,
- )
- out_logits, raw_masks = outputs.logits, outputs.pred_masks
- preds = []
-
- def to_tuple(tup):
- if isinstance(tup, tuple):
- return tup
- return tuple(tup.cpu().tolist())
-
- for cur_logits, cur_masks, size in zip(out_logits, raw_masks, target_sizes):
- # we filter empty queries and detection below threshold
- scores, labels = cur_logits.softmax(-1).max(-1)
- keep = labels.ne(outputs.logits.shape[-1] - 1) & (scores > threshold)
- cur_scores, cur_classes = cur_logits.softmax(-1).max(-1)
- cur_scores = cur_scores[keep]
- cur_classes = cur_classes[keep]
- cur_masks = cur_masks[keep]
- cur_masks = nn.functional.interpolate(cur_masks[:, None], to_tuple(size), mode="bilinear").squeeze(1)
- cur_masks = (cur_masks.sigmoid() > mask_threshold) * 1
-
- predictions = {"scores": cur_scores, "labels": cur_classes, "masks": cur_masks}
- preds.append(predictions)
- return preds
-
- # inspired by https://github.com/facebookresearch/detr/blob/master/models/segmentation.py#L218
- def post_process_instance(self, results, outputs, orig_target_sizes, max_target_sizes, threshold=0.5):
- """
- Converts the output of [`DetrForSegmentation`] into actual instance segmentation predictions. Only supports
- PyTorch.
-
- Args:
- results (`List[Dict]`):
- Results list obtained by [`~DetrFeatureExtractor.post_process`], to which "masks" results will be
- added.
- outputs ([`DetrSegmentationOutput`]):
- Raw outputs of the model.
- orig_target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
- Tensor containing the size (h, w) of each image of the batch. For evaluation, this must be the original
- image size (before any data augmentation).
- max_target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
- Tensor containing the maximum size (h, w) of each image of the batch. For evaluation, this must be the
- original image size (before any data augmentation).
- threshold (`float`, *optional*, defaults to 0.5):
- Threshold to use when turning the predicted masks into binary values.
-
- Returns:
- `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels, boxes and masks for an
- image in the batch as predicted by the model.
- """
- warnings.warn(
- "`post_process_instance` is deprecated and will be removed in v5 of Transformers, please use"
- " `post_process_instance_segmentation`.",
- FutureWarning,
- )
-
- if len(orig_target_sizes) != len(max_target_sizes):
- raise ValueError("Make sure to pass in as many orig_target_sizes as max_target_sizes")
- max_h, max_w = max_target_sizes.max(0)[0].tolist()
- outputs_masks = outputs.pred_masks.squeeze(2)
- outputs_masks = nn.functional.interpolate(
- outputs_masks, size=(max_h, max_w), mode="bilinear", align_corners=False
- )
- outputs_masks = (outputs_masks.sigmoid() > threshold).cpu()
-
- for i, (cur_mask, t, tt) in enumerate(zip(outputs_masks, max_target_sizes, orig_target_sizes)):
- img_h, img_w = t[0], t[1]
- results[i]["masks"] = cur_mask[:, :img_h, :img_w].unsqueeze(1)
- results[i]["masks"] = nn.functional.interpolate(
- results[i]["masks"].float(), size=tuple(tt.tolist()), mode="nearest"
- ).byte()
-
- return results
-
- # inspired by https://github.com/facebookresearch/detr/blob/master/models/segmentation.py#L241
- def post_process_panoptic(self, outputs, processed_sizes, target_sizes=None, is_thing_map=None, threshold=0.85):
- """
- Converts the output of [`DetrForSegmentation`] into actual panoptic predictions. Only supports PyTorch.
-
- Args:
- outputs ([`DetrSegmentationOutput`]):
- Raw outputs of the model.
- processed_sizes (`torch.Tensor` of shape `(batch_size, 2)` or `List[Tuple]` of length `batch_size`):
- Torch Tensor (or list) containing the size (h, w) of each image of the batch, i.e. the size after data
- augmentation but before batching.
- target_sizes (`torch.Tensor` of shape `(batch_size, 2)` or `List[Tuple]` of length `batch_size`, *optional*):
- Torch Tensor (or list) corresponding to the requested final size (h, w) of each prediction. If left to
- None, it will default to the `processed_sizes`.
- is_thing_map (`torch.Tensor` of shape `(batch_size, 2)`, *optional*):
- Dictionary mapping class indices to either True or False, depending on whether or not they are a thing.
- If not set, defaults to the `is_thing_map` of COCO panoptic.
- threshold (`float`, *optional*, defaults to 0.85):
- Threshold to use to filter out queries.
-
- Returns:
- `List[Dict]`: A list of dictionaries, each dictionary containing a PNG string and segments_info values for
- an image in the batch as predicted by the model.
- """
- warnings.warn(
- "`post_process_panoptic is deprecated and will be removed in v5 of Transformers, please use"
- " `post_process_panoptic_segmentation`.",
- FutureWarning,
- )
- if target_sizes is None:
- target_sizes = processed_sizes
- if len(processed_sizes) != len(target_sizes):
- raise ValueError("Make sure to pass in as many processed_sizes as target_sizes")
-
- if is_thing_map is None:
- # default to is_thing_map of COCO panoptic
- is_thing_map = {i: i <= 90 for i in range(201)}
-
- out_logits, raw_masks, raw_boxes = outputs.logits, outputs.pred_masks, outputs.pred_boxes
- if not len(out_logits) == len(raw_masks) == len(target_sizes):
- raise ValueError(
- "Make sure that you pass in as many target sizes as the batch dimension of the logits and masks"
- )
- preds = []
-
- def to_tuple(tup):
- if isinstance(tup, tuple):
- return tup
- return tuple(tup.cpu().tolist())
-
- for cur_logits, cur_masks, cur_boxes, size, target_size in zip(
- out_logits, raw_masks, raw_boxes, processed_sizes, target_sizes
- ):
- # we filter empty queries and detection below threshold
- scores, labels = cur_logits.softmax(-1).max(-1)
- keep = labels.ne(outputs.logits.shape[-1] - 1) & (scores > threshold)
- cur_scores, cur_classes = cur_logits.softmax(-1).max(-1)
- cur_scores = cur_scores[keep]
- cur_classes = cur_classes[keep]
- cur_masks = cur_masks[keep]
- cur_masks = nn.functional.interpolate(cur_masks[:, None], to_tuple(size), mode="bilinear").squeeze(1)
- cur_boxes = center_to_corners_format(cur_boxes[keep])
-
- h, w = cur_masks.shape[-2:]
- if len(cur_boxes) != len(cur_classes):
- raise ValueError("Not as many boxes as there are classes")
-
- # It may be that we have several predicted masks for the same stuff class.
- # In the following, we track the list of masks ids for each stuff class (they are merged later on)
- cur_masks = cur_masks.flatten(1)
- stuff_equiv_classes = defaultdict(lambda: [])
- for k, label in enumerate(cur_classes):
- if not is_thing_map[label.item()]:
- stuff_equiv_classes[label.item()].append(k)
-
- def get_ids_area(masks, scores, dedup=False):
- # This helper function creates the final panoptic segmentation image
- # It also returns the area of the masks that appears on the image
-
- m_id = masks.transpose(0, 1).softmax(-1)
-
- if m_id.shape[-1] == 0:
- # We didn't detect any mask :(
- m_id = torch.zeros((h, w), dtype=torch.long, device=m_id.device)
- else:
- m_id = m_id.argmax(-1).view(h, w)
-
- if dedup:
- # Merge the masks corresponding to the same stuff class
- for equiv in stuff_equiv_classes.values():
- if len(equiv) > 1:
- for eq_id in equiv:
- m_id.masked_fill_(m_id.eq(eq_id), equiv[0])
-
- final_h, final_w = to_tuple(target_size)
-
- seg_img = Image.fromarray(id_to_rgb(m_id.view(h, w).cpu().numpy()))
- seg_img = seg_img.resize(size=(final_w, final_h), resample=Image.NEAREST)
-
- np_seg_img = torch.ByteTensor(torch.ByteStorage.from_buffer(seg_img.tobytes()))
- np_seg_img = np_seg_img.view(final_h, final_w, 3)
- np_seg_img = np_seg_img.numpy()
-
- m_id = torch.from_numpy(rgb_to_id(np_seg_img))
-
- area = []
- for i in range(len(scores)):
- area.append(m_id.eq(i).sum().item())
- return area, seg_img
-
- area, seg_img = get_ids_area(cur_masks, cur_scores, dedup=True)
- if cur_classes.numel() > 0:
- # We know filter empty masks as long as we find some
- while True:
- filtered_small = torch.as_tensor(
- [area[i] <= 4 for i, c in enumerate(cur_classes)], dtype=torch.bool, device=keep.device
- )
- if filtered_small.any().item():
- cur_scores = cur_scores[~filtered_small]
- cur_classes = cur_classes[~filtered_small]
- cur_masks = cur_masks[~filtered_small]
- area, seg_img = get_ids_area(cur_masks, cur_scores)
- else:
- break
-
- else:
- cur_classes = torch.ones(1, dtype=torch.long, device=cur_classes.device)
-
- segments_info = []
- for i, a in enumerate(area):
- cat = cur_classes[i].item()
- segments_info.append({"id": i, "isthing": is_thing_map[cat], "category_id": cat, "area": a})
- del cur_classes
-
- with io.BytesIO() as out:
- seg_img.save(out, format="PNG")
- predictions = {"png_string": out.getvalue(), "segments_info": segments_info}
- preds.append(predictions)
- return preds
-
- def post_process_object_detection(
- self, outputs, threshold: float = 0.5, target_sizes: Union[TensorType, List[Tuple]] = None
- ):
- """
- Converts the output of [`DetrForObjectDetection`] into the format expected by the COCO api. Only supports
- PyTorch.
-
- Args:
- outputs ([`DetrObjectDetectionOutput`]):
- Raw outputs of the model.
- threshold (`float`, *optional*):
- Score threshold to keep object detection predictions.
- target_sizes (`torch.Tensor` or `List[Tuple[int, int]]`, *optional*, defaults to `None`):
- Tensor of shape `(batch_size, 2)` or list of tuples (`Tuple[int, int]`) containing the target size
- (height, width) of each image in the batch. If left to None, predictions will not be resized.
-
- Returns:
- `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
- in the batch as predicted by the model.
- """
- out_logits, out_bbox = outputs.logits, outputs.pred_boxes
-
- if target_sizes is not None:
- if len(out_logits) != len(target_sizes):
- raise ValueError(
- "Make sure that you pass in as many target sizes as the batch dimension of the logits"
- )
-
- prob = nn.functional.softmax(out_logits, -1)
- scores, labels = prob[..., :-1].max(-1)
-
- # Convert to [x0, y0, x1, y1] format
- boxes = center_to_corners_format(out_bbox)
-
- # Convert from relative [0, 1] to absolute [0, height] coordinates
- if target_sizes is not None:
- if isinstance(target_sizes, List):
- img_h = torch.Tensor([i[0] for i in target_sizes])
- img_w = torch.Tensor([i[1] for i in target_sizes])
- else:
- img_h, img_w = target_sizes.unbind(1)
-
- scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1).to(boxes.device)
- boxes = boxes * scale_fct[:, None, :]
-
- results = []
- for s, l, b in zip(scores, labels, boxes):
- score = s[s > threshold]
- label = l[s > threshold]
- box = b[s > threshold]
- results.append({"scores": score, "labels": label, "boxes": box})
-
- return results
-
- def post_process_semantic_segmentation(self, outputs, target_sizes: List[Tuple[int, int]] = None):
- """
- Converts the output of [`DetrForSegmentation`] into semantic segmentation maps. Only supports PyTorch.
-
- Args:
- outputs ([`DetrForSegmentation`]):
- Raw outputs of the model.
- target_sizes (`List[Tuple[int, int]]`, *optional*, defaults to `None`):
- A list of tuples (`Tuple[int, int]`) containing the target size (height, width) of each image in the
- batch. If left to None, predictions will not be resized.
-
- Returns:
- `List[torch.Tensor]`:
- A list of length `batch_size`, where each item is a semantic segmentation map of shape (height, width)
- corresponding to the target_sizes entry (if `target_sizes` is specified). Each entry of each
- `torch.Tensor` correspond to a semantic class id.
- """
- class_queries_logits = outputs.logits # [batch_size, num_queries, num_classes+1]
- masks_queries_logits = outputs.pred_masks # [batch_size, num_queries, height, width]
-
- # Remove the null class `[..., :-1]`
- masks_classes = class_queries_logits.softmax(dim=-1)[..., :-1]
- masks_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
-
- # Semantic segmentation logits of shape (batch_size, num_classes, height, width)
- segmentation = torch.einsum("bqc, bqhw -> bchw", masks_classes, masks_probs)
- batch_size = class_queries_logits.shape[0]
-
- # Resize logits and compute semantic segmentation maps
- if target_sizes is not None:
- if batch_size != len(target_sizes):
- raise ValueError(
- "Make sure that you pass in as many target sizes as the batch dimension of the logits"
- )
-
- semantic_segmentation = []
- for idx in range(batch_size):
- resized_logits = nn.functional.interpolate(
- segmentation[idx].unsqueeze(dim=0), size=target_sizes[idx], mode="bilinear", align_corners=False
- )
- semantic_map = resized_logits[0].argmax(dim=0)
- semantic_segmentation.append(semantic_map)
- else:
- semantic_segmentation = segmentation.argmax(dim=1)
- semantic_segmentation = [semantic_segmentation[i] for i in range(semantic_segmentation.shape[0])]
-
- return semantic_segmentation
-
- def post_process_instance_segmentation(
- self,
- outputs,
- threshold: float = 0.5,
- mask_threshold: float = 0.5,
- overlap_mask_area_threshold: float = 0.8,
- target_sizes: Optional[List[Tuple[int, int]]] = None,
- return_coco_annotation: Optional[bool] = False,
- ) -> List[Dict]:
- """
- Converts the output of [`DetrForSegmentation`] into instance segmentation predictions. Only supports PyTorch.
-
- Args:
- outputs ([`DetrForSegmentation`]):
- Raw outputs of the model.
- threshold (`float`, *optional*, defaults to 0.5):
- The probability score threshold to keep predicted instance masks.
- mask_threshold (`float`, *optional*, defaults to 0.5):
- Threshold to use when turning the predicted masks into binary values.
- overlap_mask_area_threshold (`float`, *optional*, defaults to 0.8):
- The overlap mask area threshold to merge or discard small disconnected parts within each binary
- instance mask.
- target_sizes (`List[Tuple]`, *optional*):
- List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
- final size (height, width) of each prediction. If left to None, predictions will not be resized.
- return_coco_annotation (`bool`, *optional*):
- Defaults to `False`. If set to `True`, segmentation maps are returned in COCO run-length encoding (RLE)
- format.
-
- Returns:
- `List[Dict]`: A list of dictionaries, one per image, each dictionary containing two keys:
- - **segmentation** -- A tensor of shape `(height, width)` where each pixel represents a `segment_id` or
- `List[List]` run-length encoding (RLE) of the segmentation map if return_coco_annotation is set to
- `True`. Set to `None` if no mask if found above `threshold`.
- - **segments_info** -- A dictionary that contains additional information on each segment.
- - **id** -- An integer representing the `segment_id`.
- - **label_id** -- An integer representing the label / semantic class id corresponding to `segment_id`.
- - **score** -- Prediction score of segment with `segment_id`.
- """
- class_queries_logits = outputs.logits # [batch_size, num_queries, num_classes+1]
- masks_queries_logits = outputs.pred_masks # [batch_size, num_queries, height, width]
-
- batch_size = class_queries_logits.shape[0]
- num_labels = class_queries_logits.shape[-1] - 1
-
- mask_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
-
- # Predicted label and score of each query (batch_size, num_queries)
- pred_scores, pred_labels = nn.functional.softmax(class_queries_logits, dim=-1).max(-1)
-
- # Loop over items in batch size
- results: List[Dict[str, TensorType]] = []
-
- for i in range(batch_size):
- mask_probs_item, pred_scores_item, pred_labels_item = remove_low_and_no_objects(
- mask_probs[i], pred_scores[i], pred_labels[i], threshold, num_labels
- )
-
- # No mask found
- if mask_probs_item.shape[0] <= 0:
- height, width = target_sizes[i] if target_sizes is not None else mask_probs_item.shape[1:]
- segmentation = torch.zeros((height, width)) - 1
- results.append({"segmentation": segmentation, "segments_info": []})
- continue
-
- # Get segmentation map and segment information of batch item
- target_size = target_sizes[i] if target_sizes is not None else None
- segmentation, segments = compute_segments(
- mask_probs=mask_probs_item,
- pred_scores=pred_scores_item,
- pred_labels=pred_labels_item,
- mask_threshold=mask_threshold,
- overlap_mask_area_threshold=overlap_mask_area_threshold,
- label_ids_to_fuse=[],
- target_size=target_size,
- )
-
- # Return segmentation map in run-length encoding (RLE) format
- if return_coco_annotation:
- segmentation = convert_segmentation_to_rle(segmentation)
-
- results.append({"segmentation": segmentation, "segments_info": segments})
- return results
-
- def post_process_panoptic_segmentation(
- self,
- outputs,
- threshold: float = 0.5,
- mask_threshold: float = 0.5,
- overlap_mask_area_threshold: float = 0.8,
- label_ids_to_fuse: Optional[Set[int]] = None,
- target_sizes: Optional[List[Tuple[int, int]]] = None,
- ) -> List[Dict]:
- """
- Converts the output of [`DetrForSegmentation`] into image panoptic segmentation predictions. Only supports
- PyTorch.
-
- Args:
- outputs ([`DetrForSegmentation`]):
- The outputs from [`DetrForSegmentation`].
- threshold (`float`, *optional*, defaults to 0.5):
- The probability score threshold to keep predicted instance masks.
- mask_threshold (`float`, *optional*, defaults to 0.5):
- Threshold to use when turning the predicted masks into binary values.
- overlap_mask_area_threshold (`float`, *optional*, defaults to 0.8):
- The overlap mask area threshold to merge or discard small disconnected parts within each binary
- instance mask.
- label_ids_to_fuse (`Set[int]`, *optional*):
- The labels in this state will have all their instances be fused together. For instance we could say
- there can only be one sky in an image, but several persons, so the label ID for sky would be in that
- set, but not the one for person.
- target_sizes (`List[Tuple]`, *optional*):
- List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
- final size (height, width) of each prediction in batch. If left to None, predictions will not be
- resized.
-
- Returns:
- `List[Dict]`: A list of dictionaries, one per image, each dictionary containing two keys:
- - **segmentation** -- a tensor of shape `(height, width)` where each pixel represents a `segment_id` or
- `None` if no mask if found above `threshold`. If `target_sizes` is specified, segmentation is resized to
- the corresponding `target_sizes` entry.
- - **segments_info** -- A dictionary that contains additional information on each segment.
- - **id** -- an integer representing the `segment_id`.
- - **label_id** -- An integer representing the label / semantic class id corresponding to `segment_id`.
- - **was_fused** -- a boolean, `True` if `label_id` was in `label_ids_to_fuse`, `False` otherwise.
- Multiple instances of the same class / label were fused and assigned a single `segment_id`.
- - **score** -- Prediction score of segment with `segment_id`.
- """
-
- if label_ids_to_fuse is None:
- warnings.warn("`label_ids_to_fuse` unset. No instance will be fused.")
- label_ids_to_fuse = set()
-
- class_queries_logits = outputs.logits # [batch_size, num_queries, num_classes+1]
- masks_queries_logits = outputs.pred_masks # [batch_size, num_queries, height, width]
-
- batch_size = class_queries_logits.shape[0]
- num_labels = class_queries_logits.shape[-1] - 1
-
- mask_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
-
- # Predicted label and score of each query (batch_size, num_queries)
- pred_scores, pred_labels = nn.functional.softmax(class_queries_logits, dim=-1).max(-1)
-
- # Loop over items in batch size
- results: List[Dict[str, TensorType]] = []
-
- for i in range(batch_size):
- mask_probs_item, pred_scores_item, pred_labels_item = remove_low_and_no_objects(
- mask_probs[i], pred_scores[i], pred_labels[i], threshold, num_labels
- )
-
- # No mask found
- if mask_probs_item.shape[0] <= 0:
- height, width = target_sizes[i] if target_sizes is not None else mask_probs_item.shape[1:]
- segmentation = torch.zeros((height, width)) - 1
- results.append({"segmentation": segmentation, "segments_info": []})
- continue
-
- # Get segmentation map and segment information of batch item
- target_size = target_sizes[i] if target_sizes is not None else None
- segmentation, segments = compute_segments(
- mask_probs=mask_probs_item,
- pred_scores=pred_scores_item,
- pred_labels=pred_labels_item,
- mask_threshold=mask_threshold,
- overlap_mask_area_threshold=overlap_mask_area_threshold,
- label_ids_to_fuse=label_ids_to_fuse,
- target_size=target_size,
- )
-
- results.append({"segmentation": segmentation, "segments_info": segments})
- return results
+DetrFeatureExtractor = DetrImageProcessor
diff --git a/src/transformers/models/detr/image_processing_detr.py b/src/transformers/models/detr/image_processing_detr.py
new file mode 100644
index 0000000000..b72744db91
--- /dev/null
+++ b/src/transformers/models/detr/image_processing_detr.py
@@ -0,0 +1,1766 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Image processor class for DETR."""
+
+import io
+import pathlib
+import warnings
+from collections import defaultdict
+from typing import Any, Callable, Dict, Iterable, List, Optional, Set, Tuple, Union
+
+import numpy as np
+
+from transformers.image_processing_utils import BaseImageProcessor, BatchFeature, get_size_dict
+from transformers.image_transforms import (
+ PaddingMode,
+ center_to_corners_format,
+ corners_to_center_format,
+ id_to_rgb,
+ normalize,
+ pad,
+ rescale,
+ resize,
+ rgb_to_id,
+ to_channel_dimension_format,
+)
+from transformers.image_utils import (
+ IMAGENET_DEFAULT_MEAN,
+ IMAGENET_DEFAULT_STD,
+ ChannelDimension,
+ ImageInput,
+ PILImageResampling,
+ get_image_size,
+ infer_channel_dimension_format,
+ is_batched,
+ to_numpy_array,
+ valid_coco_detection_annotations,
+ valid_coco_panoptic_annotations,
+ valid_images,
+)
+from transformers.utils import (
+ is_flax_available,
+ is_jax_tensor,
+ is_scipy_available,
+ is_tf_available,
+ is_tf_tensor,
+ is_torch_available,
+ is_torch_tensor,
+ is_vision_available,
+)
+from transformers.utils.generic import ExplicitEnum, TensorType
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+
+if is_vision_available():
+ import PIL
+
+
+if is_scipy_available():
+ import scipy.special
+ import scipy.stats
+
+
+class AnnotionFormat(ExplicitEnum):
+ COCO_DETECTION = "coco_detection"
+ COCO_PANOPTIC = "coco_panoptic"
+
+
+SUPPORTED_ANNOTATION_FORMATS = (AnnotionFormat.COCO_DETECTION, AnnotionFormat.COCO_PANOPTIC)
+
+
+def get_size_with_aspect_ratio(image_size, size, max_size=None) -> Tuple[int, int]:
+ """
+ Computes the output image size given the input image size and the desired output size.
+
+ Args:
+ image_size (`Tuple[int, int]`):
+ The input image size.
+ size (`int`):
+ The desired output size.
+ max_size (`int`, *optional*):
+ The maximum allowed output size.
+ """
+ height, width = image_size
+ if max_size is not None:
+ min_original_size = float(min((height, width)))
+ max_original_size = float(max((height, width)))
+ if max_original_size / min_original_size * size > max_size:
+ size = int(round(max_size * min_original_size / max_original_size))
+
+ if (height <= width and height == size) or (width <= height and width == size):
+ return height, width
+
+ if width < height:
+ ow = size
+ oh = int(size * height / width)
+ else:
+ oh = size
+ ow = int(size * width / height)
+ return (oh, ow)
+
+
+def get_resize_output_image_size(
+ input_image: np.ndarray, size: Union[int, Tuple[int, int], List[int]], max_size: Optional[int] = None
+) -> Tuple[int, int]:
+ """
+ Computes the output image size given the input image size and the desired output size. If the desired output size
+ is a tuple or list, the output image size is returned as is. If the desired output size is an integer, the output
+ image size is computed by keeping the aspect ratio of the input image size.
+
+ Args:
+ image_size (`Tuple[int, int]`):
+ The input image size.
+ size (`int`):
+ The desired output size.
+ max_size (`int`, *optional*):
+ The maximum allowed output size.
+ """
+ image_size = get_image_size(input_image)
+ if isinstance(size, (list, tuple)):
+ return size
+
+ return get_size_with_aspect_ratio(image_size, size, max_size)
+
+
+def get_numpy_to_framework_fn(arr) -> Callable:
+ """
+ Returns a function that converts a numpy array to the framework of the input array.
+
+ Args:
+ arr (`np.ndarray`): The array to convert.
+ """
+ if isinstance(arr, np.ndarray):
+ return np.array
+ if is_tf_available() and is_tf_tensor(arr):
+ import tensorflow as tf
+
+ return tf.convert_to_tensor
+ if is_torch_available() and is_torch_tensor(arr):
+ import torch
+
+ return torch.tensor
+ if is_flax_available() and is_jax_tensor(arr):
+ import jax.numpy as jnp
+
+ return jnp.array
+ raise ValueError(f"Cannot convert arrays of type {type(arr)}")
+
+
+def safe_squeeze(arr: np.ndarray, axis: Optional[int] = None) -> np.ndarray:
+ """
+ Squeezes an array, but only if the axis specified has dim 1.
+ """
+ if axis is None:
+ return arr.squeeze()
+
+ try:
+ return arr.squeeze(axis=axis)
+ except ValueError:
+ return arr
+
+
+def normalize_annotation(annotation: Dict, image_size: Tuple[int, int]) -> Dict:
+ image_height, image_width = image_size
+ norm_annotation = {}
+ for key, value in annotation.items():
+ if key == "boxes":
+ boxes = value
+ boxes = corners_to_center_format(boxes)
+ boxes /= np.asarray([image_width, image_height, image_width, image_height], dtype=np.float32)
+ norm_annotation[key] = boxes
+ else:
+ norm_annotation[key] = value
+ return norm_annotation
+
+
+def max_across_indices(values: Iterable[Any]) -> List[Any]:
+ """
+ Return the maximum value across all indices of an iterable of values.
+ """
+ return [max(values_i) for values_i in zip(*values)]
+
+
+def get_max_height_width(images: List[np.ndarray]) -> List[int]:
+ """
+ Get the maximum height and width across all images in a batch.
+ """
+ input_channel_dimension = infer_channel_dimension_format(images[0])
+
+ if input_channel_dimension == ChannelDimension.FIRST:
+ _, max_height, max_width = max_across_indices([img.shape for img in images])
+ elif input_channel_dimension == ChannelDimension.LAST:
+ max_height, max_width, _ = max_across_indices([img.shape for img in images])
+ else:
+ raise ValueError(f"Invalid channel dimension format: {input_channel_dimension}")
+ return (max_height, max_width)
+
+
+def make_pixel_mask(image: np.ndarray, output_size: Tuple[int, int]) -> np.ndarray:
+ """
+ Make a pixel mask for the image, where 1 indicates a valid pixel and 0 indicates padding.
+
+ Args:
+ image (`np.ndarray`):
+ Image to make the pixel mask for.
+ output_size (`Tuple[int, int]`):
+ Output size of the mask.
+ """
+ input_height, input_width = get_image_size(image)
+ mask = np.zeros(output_size, dtype=np.int64)
+ mask[:input_height, :input_width] = 1
+ return mask
+
+
+# inspired by https://github.com/facebookresearch/detr/blob/master/datasets/coco.py#L33
+def convert_coco_poly_to_mask(segmentations, height: int, width: int) -> np.ndarray:
+ """
+ Convert a COCO polygon annotation to a mask.
+
+ Args:
+ segmentations (`List[List[float]]`):
+ List of polygons, each polygon represented by a list of x-y coordinates.
+ height (`int`):
+ Height of the mask.
+ width (`int`):
+ Width of the mask.
+ """
+ try:
+ from pycocotools import mask as coco_mask
+ except ImportError:
+ raise ImportError("Pycocotools is not installed in your environment.")
+
+ masks = []
+ for polygons in segmentations:
+ rles = coco_mask.frPyObjects(polygons, height, width)
+ mask = coco_mask.decode(rles)
+ if len(mask.shape) < 3:
+ mask = mask[..., None]
+ mask = np.asarray(mask, dtype=np.uint8)
+ mask = np.any(mask, axis=2)
+ masks.append(mask)
+ if masks:
+ masks = np.stack(masks, axis=0)
+ else:
+ masks = np.zeros((0, height, width), dtype=np.uint8)
+
+ return masks
+
+
+# inspired by https://github.com/facebookresearch/detr/blob/master/datasets/coco.py#L50
+def prepare_coco_detection_annotation(image, target, return_segmentation_masks: bool = False):
+ """
+ Convert the target in COCO format into the format expected by DETR.
+ """
+ image_height, image_width = get_image_size(image)
+
+ image_id = target["image_id"]
+ image_id = np.asarray([image_id], dtype=np.int64)
+
+ # Get all COCO annotations for the given image.
+ annotations = target["annotations"]
+ annotations = [obj for obj in annotations if "iscrowd" not in obj or obj["iscrowd"] == 0]
+
+ classes = [obj["category_id"] for obj in annotations]
+ classes = np.asarray(classes, dtype=np.int64)
+
+ # for conversion to coco api
+ area = np.asarray([obj["area"] for obj in annotations], dtype=np.float32)
+ iscrowd = np.asarray([obj["iscrowd"] if "iscrowd" in obj else 0 for obj in annotations], dtype=np.int64)
+
+ boxes = [obj["bbox"] for obj in annotations]
+ # guard against no boxes via resizing
+ boxes = np.asarray(boxes, dtype=np.float32).reshape(-1, 4)
+ boxes[:, 2:] += boxes[:, :2]
+ boxes[:, 0::2] = boxes[:, 0::2].clip(min=0, max=image_width)
+ boxes[:, 1::2] = boxes[:, 1::2].clip(min=0, max=image_height)
+
+ keep = (boxes[:, 3] > boxes[:, 1]) & (boxes[:, 2] > boxes[:, 0])
+
+ new_target = {}
+ new_target["image_id"] = image_id
+ new_target["class_labels"] = classes[keep]
+ new_target["boxes"] = boxes[keep]
+ new_target["area"] = area[keep]
+ new_target["iscrowd"] = iscrowd[keep]
+ new_target["orig_size"] = np.asarray([int(image_height), int(image_width)], dtype=np.int64)
+
+ if annotations and "keypoints" in annotations[0]:
+ keypoints = [obj["keypoints"] for obj in annotations]
+ keypoints = np.asarray(keypoints, dtype=np.float32)
+ num_keypoints = keypoints.shape[0]
+ keypoints = keypoints.reshape((-1, 3)) if num_keypoints else keypoints
+ new_target["keypoints"] = keypoints[keep]
+
+ if return_segmentation_masks:
+ segmentation_masks = [obj["segmentation"] for obj in annotations]
+ masks = convert_coco_poly_to_mask(segmentation_masks, image_height, image_width)
+ new_target["masks"] = masks[keep]
+
+ return new_target
+
+
+def masks_to_boxes(masks: np.ndarray) -> np.ndarray:
+ """
+ Compute the bounding boxes around the provided panoptic segmentation masks.
+
+ Args:
+ masks: masks in format `[number_masks, height, width]` where N is the number of masks
+
+ Returns:
+ boxes: bounding boxes in format `[number_masks, 4]` in xyxy format
+ """
+ if masks.size == 0:
+ return np.zeros((0, 4))
+
+ h, w = masks.shape[-2:]
+ y = np.arange(0, h, dtype=np.float32)
+ x = np.arange(0, w, dtype=np.float32)
+ # see https://github.com/pytorch/pytorch/issues/50276
+ y, x = np.meshgrid(y, x, indexing="ij")
+
+ x_mask = masks * np.expand_dims(x, axis=0)
+ x_max = x_mask.reshape(x_mask.shape[0], -1).max(-1)
+ x = np.ma.array(x_mask, mask=~(np.array(masks, dtype=bool)))
+ x_min = x.filled(fill_value=1e8)
+ x_min = x_min.reshape(x_min.shape[0], -1).min(-1)
+
+ y_mask = masks * np.expand_dims(y, axis=0)
+ y_max = y_mask.reshape(x_mask.shape[0], -1).max(-1)
+ y = np.ma.array(y_mask, mask=~(np.array(masks, dtype=bool)))
+ y_min = y.filled(fill_value=1e8)
+ y_min = y_min.reshape(y_min.shape[0], -1).min(-1)
+
+ return np.stack([x_min, y_min, x_max, y_max], 1)
+
+
+def prepare_coco_panoptic_annotation(
+ image: np.ndarray, target: Dict, masks_path: Union[str, pathlib.Path], return_masks: bool = True
+) -> Dict:
+ """
+ Prepare a coco panoptic annotation for DETR.
+ """
+ image_height, image_width = get_image_size(image)
+ annotation_path = pathlib.Path(masks_path) / target["file_name"]
+
+ new_target = {}
+ new_target["image_id"] = np.asarray([target["image_id"] if "image_id" in target else target["id"]], dtype=np.int64)
+ new_target["size"] = np.asarray([image_height, image_width], dtype=np.int64)
+ new_target["orig_size"] = np.asarray([image_height, image_width], dtype=np.int64)
+
+ if "segments_info" in target:
+ masks = np.asarray(PIL.Image.open(annotation_path), dtype=np.uint32)
+ masks = rgb_to_id(masks)
+
+ ids = np.array([segment_info["id"] for segment_info in target["segments_info"]])
+ masks = masks == ids[:, None, None]
+ masks = masks.astype(np.uint8)
+ if return_masks:
+ new_target["masks"] = masks
+ new_target["boxes"] = masks_to_boxes(masks)
+ new_target["class_labels"] = np.array(
+ [segment_info["category_id"] for segment_info in target["segments_info"]], dtype=np.int64
+ )
+ new_target["iscrowd"] = np.asarray(
+ [segment_info["iscrowd"] for segment_info in target["segments_info"]], dtype=np.int64
+ )
+ new_target["area"] = np.asarray(
+ [segment_info["area"] for segment_info in target["segments_info"]], dtype=np.float32
+ )
+
+ return new_target
+
+
+def get_segmentation_image(
+ masks: np.ndarray, input_size: Tuple, target_size: Tuple, stuff_equiv_classes, deduplicate=False
+):
+ h, w = input_size
+ final_h, final_w = target_size
+
+ m_id = scipy.special.softmax(masks.transpose(0, 1), -1)
+
+ if m_id.shape[-1] == 0:
+ # We didn't detect any mask :(
+ m_id = np.zeros((h, w), dtype=np.int64)
+ else:
+ m_id = m_id.argmax(-1).reshape(h, w)
+
+ if deduplicate:
+ # Merge the masks corresponding to the same stuff class
+ for equiv in stuff_equiv_classes.values():
+ for eq_id in equiv:
+ m_id[m_id == eq_id] = equiv[0]
+
+ seg_img = id_to_rgb(m_id)
+ seg_img = resize(seg_img, (final_w, final_h), resample=PILImageResampling.NEAREST)
+ return seg_img
+
+
+def get_mask_area(seg_img: np.ndarray, target_size: Tuple[int, int], n_classes: int) -> np.ndarray:
+ final_h, final_w = target_size
+ np_seg_img = seg_img.astype(np.uint8)
+ np_seg_img = np_seg_img.reshape(final_h, final_w, 3)
+ m_id = rgb_to_id(np_seg_img)
+ area = [(m_id == i).sum() for i in range(n_classes)]
+ return area
+
+
+def score_labels_from_class_probabilities(logits: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
+ probs = scipy.special.softmax(logits, axis=-1)
+ labels = probs.argmax(-1, keepdims=True)
+ scores = np.take_along_axis(probs, labels, axis=-1)
+ scores, labels = scores.squeeze(-1), labels.squeeze(-1)
+ return scores, labels
+
+
+def post_process_panoptic_sample(
+ out_logits: np.ndarray,
+ masks: np.ndarray,
+ boxes: np.ndarray,
+ processed_size: Tuple[int, int],
+ target_size: Tuple[int, int],
+ is_thing_map: Dict,
+ threshold=0.85,
+) -> Dict:
+ """
+ Converts the output of [`DetrForSegmentation`] into panoptic segmentation predictions for a single sample.
+
+ Args:
+ out_logits (`torch.Tensor`):
+ The logits for this sample.
+ masks (`torch.Tensor`):
+ The predicted segmentation masks for this sample.
+ boxes (`torch.Tensor`):
+ The prediced bounding boxes for this sample. The boxes are in the normalized format `(center_x, center_y,
+ width, height)` and values between `[0, 1]`, relative to the size the image (disregarding padding).
+ processed_size (`Tuple[int, int]`):
+ The processed size of the image `(height, width)`, as returned by the preprocessing step i.e. the size
+ after data augmentation but before batching.
+ target_size (`Tuple[int, int]`):
+ The target size of the image, `(height, width)` corresponding to the requested final size of the
+ prediction.
+ is_thing_map (`Dict`):
+ A dictionary mapping class indices to a boolean value indicating whether the class is a thing or not.
+ threshold (`float`, *optional*, defaults to 0.85):
+ The threshold used to binarize the segmentation masks.
+ """
+ # we filter empty queries and detection below threshold
+ scores, labels = score_labels_from_class_probabilities(out_logits)
+ keep = (labels != out_logits.shape[-1] - 1) & (scores > threshold)
+
+ cur_scores = scores[keep]
+ cur_classes = labels[keep]
+ cur_boxes = center_to_corners_format(boxes[keep])
+
+ if len(cur_boxes) != len(cur_classes):
+ raise ValueError("Not as many boxes as there are classes")
+
+ cur_masks = masks[keep]
+ cur_masks = resize(cur_masks[:, None], processed_size, resample=PILImageResampling.BILINEAR)
+ cur_masks = safe_squeeze(cur_masks, 1)
+ b, h, w = cur_masks.shape
+
+ # It may be that we have several predicted masks for the same stuff class.
+ # In the following, we track the list of masks ids for each stuff class (they are merged later on)
+ cur_masks = cur_masks.reshape(b, -1)
+ stuff_equiv_classes = defaultdict(list)
+ for k, label in enumerate(cur_classes):
+ if not is_thing_map[label]:
+ stuff_equiv_classes[label].append(k)
+
+ seg_img = get_segmentation_image(cur_masks, processed_size, target_size, stuff_equiv_classes, deduplicate=True)
+ area = get_mask_area(cur_masks, processed_size, n_classes=len(cur_scores))
+
+ # We filter out any mask that is too small
+ if cur_classes.size() > 0:
+ # We know filter empty masks as long as we find some
+ filtered_small = np.array([a <= 4 for a in area], dtype=bool)
+ while filtered_small.any():
+ cur_masks = cur_masks[~filtered_small]
+ cur_scores = cur_scores[~filtered_small]
+ cur_classes = cur_classes[~filtered_small]
+ seg_img = get_segmentation_image(cur_masks, (h, w), target_size, stuff_equiv_classes, deduplicate=True)
+ area = get_mask_area(seg_img, target_size, n_classes=len(cur_scores))
+ filtered_small = np.array([a <= 4 for a in area], dtype=bool)
+ else:
+ cur_classes = np.ones((1, 1), dtype=np.int64)
+
+ segments_info = [
+ {"id": i, "isthing": is_thing_map[cat], "category_id": int(cat), "area": a}
+ for i, (cat, a) in enumerate(zip(cur_classes, area))
+ ]
+ del cur_classes
+
+ with io.BytesIO() as out:
+ PIL.Image.fromarray(seg_img).save(out, format="PNG")
+ predictions = {"png_string": out.getvalue(), "segments_info": segments_info}
+
+ return predictions
+
+
+def resize_annotation(
+ annotation: Dict[str, Any],
+ orig_size: Tuple[int, int],
+ target_size: Tuple[int, int],
+ threshold: float = 0.5,
+ resample: PILImageResampling = PILImageResampling.NEAREST,
+):
+ """
+ Resizes an annotation to a target size.
+
+ Args:
+ annotation (`Dict[str, Any]`):
+ The annotation dictionary.
+ orig_size (`Tuple[int, int]`):
+ The original size of the input image.
+ target_size (`Tuple[int, int]`):
+ The target size of the image, as returned by the preprocessing `resize` step.
+ threshold (`float`, *optional*, defaults to 0.5):
+ The threshold used to binarize the segmentation masks.
+ resample (`PILImageResampling`, defaults to `PILImageResampling.NEAREST`):
+ The resampling filter to use when resizing the masks.
+ """
+ ratios = tuple(float(s) / float(s_orig) for s, s_orig in zip(target_size, orig_size))
+ ratio_height, ratio_width = ratios
+
+ new_annotation = {}
+ new_annotation["size"] = target_size
+
+ for key, value in annotation.items():
+ if key == "boxes":
+ boxes = value
+ scaled_boxes = boxes * np.asarray([ratio_width, ratio_height, ratio_width, ratio_height], dtype=np.float32)
+ new_annotation["boxes"] = scaled_boxes
+ elif key == "area":
+ area = value
+ scaled_area = area * (ratio_width * ratio_height)
+ new_annotation["area"] = scaled_area
+ elif key == "masks":
+ masks = value[:, None]
+ masks = np.array([resize(mask, target_size, resample=resample) for mask in masks])
+ masks = masks.astype(np.float32)
+ masks = masks[:, 0] > threshold
+ new_annotation["masks"] = masks
+ elif key == "size":
+ new_annotation["size"] = target_size
+ else:
+ new_annotation[key] = value
+
+ return new_annotation
+
+
+# TODO - (Amy) make compatible with other frameworks
+def binary_mask_to_rle(mask):
+ """
+ Converts given binary mask of shape `(height, width)` to the run-length encoding (RLE) format.
+
+ Args:
+ mask (`torch.Tensor` or `numpy.array`):
+ A binary mask tensor of shape `(height, width)` where 0 denotes background and 1 denotes the target
+ segment_id or class_id.
+ Returns:
+ `List`: Run-length encoded list of the binary mask. Refer to COCO API for more information about the RLE
+ format.
+ """
+ if is_torch_tensor(mask):
+ mask = mask.numpy()
+
+ pixels = mask.flatten()
+ pixels = np.concatenate([[0], pixels, [0]])
+ runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
+ runs[1::2] -= runs[::2]
+ return [x for x in runs]
+
+
+# TODO - (Amy) make compatible with other frameworks
+def convert_segmentation_to_rle(segmentation):
+ """
+ Converts given segmentation map of shape `(height, width)` to the run-length encoding (RLE) format.
+
+ Args:
+ segmentation (`torch.Tensor` or `numpy.array`):
+ A segmentation map of shape `(height, width)` where each value denotes a segment or class id.
+ Returns:
+ `List[List]`: A list of lists, where each list is the run-length encoding of a segment / class id.
+ """
+ segment_ids = torch.unique(segmentation)
+
+ run_length_encodings = []
+ for idx in segment_ids:
+ mask = torch.where(segmentation == idx, 1, 0)
+ rle = binary_mask_to_rle(mask)
+ run_length_encodings.append(rle)
+
+ return run_length_encodings
+
+
+def remove_low_and_no_objects(masks, scores, labels, object_mask_threshold, num_labels):
+ """
+ Binarize the given masks using `object_mask_threshold`, it returns the associated values of `masks`, `scores` and
+ `labels`.
+
+ Args:
+ masks (`torch.Tensor`):
+ A tensor of shape `(num_queries, height, width)`.
+ scores (`torch.Tensor`):
+ A tensor of shape `(num_queries)`.
+ labels (`torch.Tensor`):
+ A tensor of shape `(num_queries)`.
+ object_mask_threshold (`float`):
+ A number between 0 and 1 used to binarize the masks.
+ Raises:
+ `ValueError`: Raised when the first dimension doesn't match in all input tensors.
+ Returns:
+ `Tuple[`torch.Tensor`, `torch.Tensor`, `torch.Tensor`]`: The `masks`, `scores` and `labels` without the region
+ < `object_mask_threshold`.
+ """
+ if not (masks.shape[0] == scores.shape[0] == labels.shape[0]):
+ raise ValueError("mask, scores and labels must have the same shape!")
+
+ to_keep = labels.ne(num_labels) & (scores > object_mask_threshold)
+
+ return masks[to_keep], scores[to_keep], labels[to_keep]
+
+
+def check_segment_validity(mask_labels, mask_probs, k, mask_threshold=0.5, overlap_mask_area_threshold=0.8):
+ # Get the mask associated with the k class
+ mask_k = mask_labels == k
+ mask_k_area = mask_k.sum()
+
+ # Compute the area of all the stuff in query k
+ original_area = (mask_probs[k] >= mask_threshold).sum()
+ mask_exists = mask_k_area > 0 and original_area > 0
+
+ # Eliminate disconnected tiny segments
+ if mask_exists:
+ area_ratio = mask_k_area / original_area
+ if not area_ratio.item() > overlap_mask_area_threshold:
+ mask_exists = False
+
+ return mask_exists, mask_k
+
+
+def compute_segments(
+ mask_probs,
+ pred_scores,
+ pred_labels,
+ mask_threshold: float = 0.5,
+ overlap_mask_area_threshold: float = 0.8,
+ label_ids_to_fuse: Optional[Set[int]] = None,
+ target_size: Tuple[int, int] = None,
+):
+ height = mask_probs.shape[1] if target_size is None else target_size[0]
+ width = mask_probs.shape[2] if target_size is None else target_size[1]
+
+ segmentation = torch.zeros((height, width), dtype=torch.int32, device=mask_probs.device)
+ segments: List[Dict] = []
+
+ if target_size is not None:
+ mask_probs = nn.functional.interpolate(
+ mask_probs.unsqueeze(0), size=target_size, mode="bilinear", align_corners=False
+ )[0]
+
+ current_segment_id = 0
+
+ # Weigh each mask by its prediction score
+ mask_probs *= pred_scores.view(-1, 1, 1)
+ mask_labels = mask_probs.argmax(0) # [height, width]
+
+ # Keep track of instances of each class
+ stuff_memory_list: Dict[str, int] = {}
+ for k in range(pred_labels.shape[0]):
+ pred_class = pred_labels[k].item()
+ should_fuse = pred_class in label_ids_to_fuse
+
+ # Check if mask exists and large enough to be a segment
+ mask_exists, mask_k = check_segment_validity(
+ mask_labels, mask_probs, k, mask_threshold, overlap_mask_area_threshold
+ )
+
+ if mask_exists:
+ if pred_class in stuff_memory_list:
+ current_segment_id = stuff_memory_list[pred_class]
+ else:
+ current_segment_id += 1
+
+ # Add current object segment to final segmentation map
+ segmentation[mask_k] = current_segment_id
+ segment_score = round(pred_scores[k].item(), 6)
+ segments.append(
+ {
+ "id": current_segment_id,
+ "label_id": pred_class,
+ "was_fused": should_fuse,
+ "score": segment_score,
+ }
+ )
+ if should_fuse:
+ stuff_memory_list[pred_class] = current_segment_id
+
+ return segmentation, segments
+
+
+class DetrImageProcessor(BaseImageProcessor):
+ r"""
+ Constructs a Detr image processor.
+
+ Args:
+ format (`str`, *optional*, defaults to `"coco_detection"`):
+ Data format of the annotations. One of "coco_detection" or "coco_panoptic".
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Controls whether to resize the image's `(height, width)` dimensions to the specified `size`. Can be
+ overridden by the `do_resize` parameter in the `preprocess` method.
+ size (`Dict[str, int]` *optional*, defaults to `{"shortest_edge": 800, "longest_edge": 1333}`):
+ Size of the image's `(height, width)` dimensions after resizing. Can be overridden by the `size` parameter
+ in the `preprocess` method.
+ resample (`PILImageResampling`, *optional*, defaults to `PILImageResampling.BILINEAR`):
+ Resampling filter to use if resizing the image.
+ do_rescale (`bool`, *optional*, defaults to `True`):
+ Controls whether to rescale the image by the specified scale `rescale_factor`. Can be overridden by the
+ `do_rescale` parameter in the `preprocess` method.
+ rescale_factor (`int` or `float`, *optional*, defaults to `1/255`):
+ Scale factor to use if rescaling the image. Can be overridden by the `rescale_factor` parameter in the
+ `preprocess` method.
+ do_normalize:
+ Controls whether to normalize the image. Can be overridden by the `do_normalize` parameter in the
+ `preprocess` method.
+ image_mean (`float` or `List[float]`, *optional*, defaults to `IMAGENET_DEFAULT_MEAN`):
+ Mean values to use when normalizing the image. Can be a single value or a list of values, one for each
+ channel. Can be overridden by the `image_mean` parameter in the `preprocess` method.
+ image_std (`float` or `List[float]`, *optional*, defaults to `IMAGENET_DEFAULT_STD`):
+ Standard deviation values to use when normalizing the image. Can be a single value or a list of values, one
+ for each channel. Can be overridden by the `image_std` parameter in the `preprocess` method.
+ do_pad (`bool`, *optional*, defaults to `True`):
+ Controls whether to pad the image to the largest image in a batch and create a pixel mask. Can be
+ overridden by the `do_pad` parameter in the `preprocess` method.
+ """
+
+ model_input_names = ["pixel_values", "pixel_mask"]
+
+ def __init__(
+ self,
+ format: Union[str, AnnotionFormat] = AnnotionFormat.COCO_DETECTION,
+ do_resize: bool = True,
+ size: Dict[str, int] = None,
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ do_rescale: bool = True,
+ rescale_factor: Union[int, float] = 1 / 255,
+ do_normalize: bool = True,
+ image_mean: Union[float, List[float]] = None,
+ image_std: Union[float, List[float]] = None,
+ do_pad: bool = True,
+ **kwargs
+ ) -> None:
+ if "pad_and_return_pixel_mask" in kwargs:
+ do_pad = kwargs.pop("pad_and_return_pixel_mask")
+
+ if "max_size" in kwargs:
+ warnings.warn(
+ "The `max_size` parameter is deprecated and will be removed in v4.26. "
+ "Please specify in `size['longest_edge'] instead`.",
+ FutureWarning,
+ )
+ max_size = kwargs.pop("max_size")
+ else:
+ max_size = None if size is None else 1333
+
+ size = size if size is not None else {"shortest_edge": 800, "longest_edge": 1333}
+ size = get_size_dict(size, max_size=max_size, default_to_square=False)
+
+ super().__init__(**kwargs)
+ self.format = format
+ self.do_resize = do_resize
+ self.size = size
+ self.resample = resample
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean if image_mean is not None else IMAGENET_DEFAULT_MEAN
+ self.image_std = image_std if image_std is not None else IMAGENET_DEFAULT_STD
+ self.do_pad = do_pad
+
+ def prepare_annotation(
+ self,
+ image: np.ndarray,
+ target: Dict,
+ format: Optional[AnnotionFormat] = None,
+ return_segmentation_masks: bool = None,
+ masks_path: Optional[Union[str, pathlib.Path]] = None,
+ ) -> Dict:
+ """
+ Prepare an annotation for feeding into DETR model.
+ """
+ format = format if format is not None else self.format
+
+ if format == AnnotionFormat.COCO_DETECTION:
+ return_segmentation_masks = False if return_segmentation_masks is None else return_segmentation_masks
+ target = prepare_coco_detection_annotation(image, target, return_segmentation_masks)
+ elif format == AnnotionFormat.COCO_PANOPTIC:
+ return_segmentation_masks = True if return_segmentation_masks is None else return_segmentation_masks
+ target = prepare_coco_panoptic_annotation(
+ image, target, masks_path=masks_path, return_masks=return_segmentation_masks
+ )
+ else:
+ raise ValueError(f"Format {format} is not supported.")
+ return target
+
+ def prepare(self, image, target, return_segmentation_masks=None, masks_path=None):
+ warnings.warn(
+ "The `prepare` method is deprecated and will be removed in a future version. "
+ "Please use `prepare_annotation` instead. Note: the `prepare_annotation` method "
+ "does not return the image anymore.",
+ )
+ target = self.prepare_annotation(image, target, return_segmentation_masks, masks_path, self.format)
+ return image, target
+
+ def convert_coco_poly_to_mask(self, *args, **kwargs):
+ warnings.warn("The `convert_coco_poly_to_mask` method is deprecated and will be removed in a future version. ")
+ return convert_coco_poly_to_mask(*args, **kwargs)
+
+ def prepare_coco_detection(self, *args, **kwargs):
+ warnings.warn("The `prepare_coco_detection` method is deprecated and will be removed in a future version. ")
+ return prepare_coco_detection_annotation(*args, **kwargs)
+
+ def prepare_coco_panoptic(self, *args, **kwargs):
+ warnings.warn("The `prepare_coco_panoptic` method is deprecated and will be removed in a future version. ")
+ return prepare_coco_panoptic_annotation(*args, **kwargs)
+
+ def resize(
+ self,
+ image: np.ndarray,
+ size: Dict[str, int],
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ data_format: Optional[ChannelDimension] = None,
+ **kwargs
+ ) -> np.ndarray:
+ """
+ Resize the image to the given size. Size can be `min_size` (scalar) or `(height, width)` tuple. If size is an
+ int, smaller edge of the image will be matched to this number.
+ """
+ if "max_size" in kwargs:
+ warnings.warn(
+ "The `max_size` parameter is deprecated and will be removed in v4.26. "
+ "Please specify in `size['longest_edge'] instead`.",
+ FutureWarning,
+ )
+ max_size = kwargs.pop("max_size")
+ else:
+ max_size = None
+ size = get_size_dict(size, max_size=max_size, default_to_square=False)
+ if "shortest_edge" in size and "longest_edge" in size:
+ size = get_resize_output_image_size(image, size["shortest_edge"], size["longest_edge"])
+ elif "height" in size and "width" in size:
+ size = (size["height"], size["width"])
+ else:
+ raise ValueError(
+ "Size must contain 'height' and 'width' keys or 'shortest_edge' and 'longest_edge' keys. Got"
+ f" {size.keys()}."
+ )
+ image = resize(image, size=size, resample=resample, data_format=data_format)
+ return image
+
+ def resize_annotation(
+ self,
+ annotation,
+ orig_size,
+ size,
+ resample: PILImageResampling = PILImageResampling.NEAREST,
+ ) -> Dict:
+ """
+ Resize the annotation to match the resized image. If size is an int, smaller edge of the mask will be matched
+ to this number.
+ """
+ return resize_annotation(annotation, orig_size=orig_size, target_size=size, resample=resample)
+
+ def rescale(
+ self, image: np.ndarray, rescale_factor: Union[float, int], data_format: Optional[ChannelDimension] = None
+ ) -> np.ndarray:
+ """
+ Rescale the image by the given factor.
+ """
+ return rescale(image, rescale_factor, data_format=data_format)
+
+ def normalize(
+ self,
+ image: np.ndarray,
+ mean: Union[float, Iterable[float]],
+ std: Union[float, Iterable[float]],
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Normalize the image with the given mean and standard deviation.
+ """
+ return normalize(image, mean=mean, std=std, data_format=data_format)
+
+ def normalize_annotation(self, annotation: Dict, image_size: Tuple[int, int]) -> Dict:
+ """
+ Normalize the boxes in the annotation from `[top_left_x, top_left_y, bottom_right_x, bottom_right_y]` to
+ `[center_x, center_y, width, height]` format.
+ """
+ return normalize_annotation(annotation, image_size=image_size)
+
+ def pad_and_create_pixel_mask(
+ self,
+ pixel_values_list: List[ImageInput],
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ data_format: Optional[ChannelDimension] = None,
+ ) -> BatchFeature:
+ """
+ Pads a batch of images with zeros to the size of largest height and width in the batch and returns their
+ corresponding pixel mask.
+
+ Args:
+ images (`List[np.ndarray]`):
+ Batch of images to pad.
+ return_tensors (`str` or `TensorType`, *optional*):
+ The type of tensors to return. Can be one of:
+ - Unset: Return a list of `np.ndarray`.
+ - `TensorType.TENSORFLOW` or `'tf'`: Return a batch of type `tf.Tensor`.
+ - `TensorType.PYTORCH` or `'pt'`: Return a batch of type `torch.Tensor`.
+ - `TensorType.NUMPY` or `'np'`: Return a batch of type `np.ndarray`.
+ - `TensorType.JAX` or `'jax'`: Return a batch of type `jax.numpy.ndarray`.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be the same as the input image.
+ """
+ warnings.warn(
+ "This method is deprecated and will be removed in v4.27.0. Please use pad instead.", FutureWarning
+ )
+ # pad expects a list of np.ndarray, but the previous feature extractors expected torch tensors
+ images = [to_numpy_array(image) for image in pixel_values_list]
+ return self.pad(
+ images=images,
+ return_pixel_mask=True,
+ return_tensors=return_tensors,
+ data_format=data_format,
+ )
+
+ def _pad_image(
+ self,
+ image: np.ndarray,
+ output_size: Tuple[int, int],
+ constant_values: Union[float, Iterable[float]] = 0,
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Pad an image with zeros to the given size.
+ """
+ input_height, input_width = get_image_size(image)
+ output_height, output_width = output_size
+
+ pad_bottom = output_height - input_height
+ pad_right = output_width - input_width
+ padding = ((0, pad_bottom), (0, pad_right))
+ padded_image = pad(
+ image, padding, mode=PaddingMode.CONSTANT, constant_values=constant_values, data_format=data_format
+ )
+ return padded_image
+
+ def pad(
+ self,
+ images: List[np.ndarray],
+ constant_values: Union[float, Iterable[float]] = 0,
+ return_pixel_mask: bool = True,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Pads a batch of images to the bottom and right of the image with zeros to the size of largest height and width
+ in the batch and optionally returns their corresponding pixel mask.
+
+ Args:
+ image (`np.ndarray`):
+ Image to pad.
+ constant_values (`float` or `Iterable[float]`, *optional*):
+ The value to use for the padding if `mode` is `"constant"`.
+ return_pixel_mask (`bool`, *optional*, defaults to `True`):
+ Whether to return a pixel mask.
+ input_channel_dimension (`ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be inferred from the input image.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be the same as the input image.
+ """
+ pad_size = get_max_height_width(images)
+
+ padded_images = [
+ self._pad_image(image, pad_size, constant_values=constant_values, data_format=data_format)
+ for image in images
+ ]
+ data = {"pixel_values": padded_images}
+
+ if return_pixel_mask:
+ masks = [make_pixel_mask(image=image, output_size=pad_size) for image in images]
+ data["pixel_mask"] = masks
+
+ return BatchFeature(data=data, tensor_type=return_tensors)
+
+ def preprocess(
+ self,
+ images: ImageInput,
+ annotations: Optional[Union[List[Dict], List[List[Dict]]]] = None,
+ return_segmentation_masks: bool = None,
+ masks_path: Optional[Union[str, pathlib.Path]] = None,
+ do_resize: Optional[bool] = None,
+ size: Optional[Dict[str, int]] = None,
+ resample=None, # PILImageResampling
+ do_rescale: Optional[bool] = None,
+ rescale_factor: Optional[Union[int, float]] = None,
+ do_normalize: Optional[bool] = None,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ do_pad: Optional[bool] = None,
+ format: Optional[Union[str, AnnotionFormat]] = None,
+ return_tensors: Optional[Union[TensorType, str]] = None,
+ data_format: Union[str, ChannelDimension] = ChannelDimension.FIRST,
+ **kwargs
+ ) -> BatchFeature:
+ """
+ Preprocess an image or a batch of images so that it can be used by the model.
+
+ Args:
+ images (`ImageInput`):
+ Image or batch of images to preprocess.
+ annotations (`List[Dict]` or `List[List[Dict]]`, *optional*):
+ List of annotations associated with the image or batch of images. If annotionation is for object
+ detection, the annotations should be a dictionary with the following keys:
+ - "image_id" (`int`): The image id.
+ - "annotations" (`List[Dict]`): List of annotations for an image. Each annotation should be a
+ dictionary. An image can have no annotations, in which case the list should be empty.
+ If annotionation is for segmentation, the annotations should be a dictionary with the following keys:
+ - "image_id" (`int`): The image id.
+ - "segments_info" (`List[Dict]`): List of segments for an image. Each segment should be a dictionary.
+ An image can have no segments, in which case the list should be empty.
+ - "file_name" (`str`): The file name of the image.
+ return_segmentation_masks (`bool`, *optional*, defaults to self.return_segmentation_masks):
+ Whether to return segmentation masks.
+ masks_path (`str` or `pathlib.Path`, *optional*):
+ Path to the directory containing the segmentation masks.
+ do_resize (`bool`, *optional*, defaults to self.do_resize):
+ Whether to resize the image.
+ size (`Dict[str, int]`, *optional*, defaults to self.size):
+ Size of the image after resizing.
+ resample (`PILImageResampling`, *optional*, defaults to self.resample):
+ Resampling filter to use when resizing the image.
+ do_rescale (`bool`, *optional*, defaults to self.do_rescale):
+ Whether to rescale the image.
+ rescale_factor (`float`, *optional*, defaults to self.rescale_factor):
+ Rescale factor to use when rescaling the image.
+ do_normalize (`bool`, *optional*, defaults to self.do_normalize):
+ Whether to normalize the image.
+ image_mean (`float` or `List[float]`, *optional*, defaults to self.image_mean):
+ Mean to use when normalizing the image.
+ image_std (`float` or `List[float]`, *optional*, defaults to self.image_std):
+ Standard deviation to use when normalizing the image.
+ do_pad (`bool`, *optional*, defaults to self.do_pad):
+ Whether to pad the image.
+ format (`str` or `AnnotionFormat`, *optional*, defaults to self.format):
+ Format of the annotations.
+ return_tensors (`str` or `TensorType`, *optional*, defaults to self.return_tensors):
+ Type of tensors to return. If `None`, will return the list of images.
+ data_format (`str` or `ChannelDimension`, *optional*, defaults to self.data_format):
+ The channel dimension format of the image. If not provided, it will be the same as the input image.
+ """
+ if "pad_and_return_pixel_mask" in kwargs:
+ warnings.warn(
+ "The `pad_and_return_pixel_mask` argument is deprecated and will be removed in a future version, "
+ "use `do_pad` instead.",
+ FutureWarning,
+ )
+ do_pad = kwargs.pop("pad_and_return_pixel_mask")
+
+ max_size = None
+ if "max_size" in kwargs:
+ warnings.warn(
+ "The `max_size` argument is deprecated and will be removed in a future version, use"
+ " `size['longest_edge']` instead.",
+ FutureWarning,
+ )
+ size = kwargs.pop("max_size")
+
+ do_resize = self.do_resize if do_resize is None else do_resize
+ size = self.size if size is None else size
+ size = get_size_dict(size=size, max_size=max_size, default_to_square=False)
+ resample = self.resample if resample is None else resample
+ do_rescale = self.do_rescale if do_rescale is None else do_rescale
+ rescale_factor = self.rescale_factor if rescale_factor is None else rescale_factor
+ do_normalize = self.do_normalize if do_normalize is None else do_normalize
+ image_mean = self.image_mean if image_mean is None else image_mean
+ image_std = self.image_std if image_std is None else image_std
+ do_pad = self.do_pad if do_pad is None else do_pad
+ format = self.format if format is None else format
+
+ if do_resize is not None and size is None:
+ raise ValueError("Size and max_size must be specified if do_resize is True.")
+
+ if do_rescale is not None and rescale_factor is None:
+ raise ValueError("Rescale factor must be specified if do_rescale is True.")
+
+ if do_normalize is not None and (image_mean is None or image_std is None):
+ raise ValueError("Image mean and std must be specified if do_normalize is True.")
+
+ if not is_batched(images):
+ images = [images]
+ annotations = [annotations] if annotations is not None else None
+
+ if annotations is not None and len(images) != len(annotations):
+ raise ValueError(
+ f"The number of images ({len(images)}) and annotations ({len(annotations)}) do not match."
+ )
+
+ if not valid_images(images):
+ raise ValueError(
+ "Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
+ "torch.Tensor, tf.Tensor or jax.ndarray."
+ )
+
+ format = AnnotionFormat(format)
+ if annotations is not None:
+ if format == AnnotionFormat.COCO_DETECTION and not valid_coco_detection_annotations(annotations):
+ raise ValueError(
+ "Invalid COCO detection annotations. Annotations must a dict (single image) of list of dicts"
+ "(batch of images) with the following keys: `image_id` and `annotations`, with the latter "
+ "being a list of annotations in the COCO format."
+ )
+ elif format == AnnotionFormat.COCO_PANOPTIC and not valid_coco_panoptic_annotations(annotations):
+ raise ValueError(
+ "Invalid COCO panoptic annotations. Annotations must a dict (single image) of list of dicts "
+ "(batch of images) with the following keys: `image_id`, `file_name` and `segments_info`, with "
+ "the latter being a list of annotations in the COCO format."
+ )
+ elif format not in SUPPORTED_ANNOTATION_FORMATS:
+ raise ValueError(
+ f"Unsupported annotation format: {format} must be one of {SUPPORTED_ANNOTATION_FORMATS}"
+ )
+
+ if (
+ masks_path is not None
+ and format == AnnotionFormat.COCO_PANOPTIC
+ and not isinstance(masks_path, (pathlib.Path, str))
+ ):
+ raise ValueError(
+ "The path to the directory containing the mask PNG files should be provided as a"
+ f" `pathlib.Path` or string object, but is {type(masks_path)} instead."
+ )
+
+ # All transformations expect numpy arrays
+ images = [to_numpy_array(image) for image in images]
+
+ # prepare (COCO annotations as a list of Dict -> DETR target as a single Dict per image)
+ if annotations is not None:
+ prepared_images = []
+ prepared_annotations = []
+ for image, target in zip(images, annotations):
+ target = self.prepare_annotation(
+ image, target, format, return_segmentation_masks=return_segmentation_masks, masks_path=masks_path
+ )
+ prepared_images.append(image)
+ prepared_annotations.append(target)
+ images = prepared_images
+ annotations = prepared_annotations
+ del prepared_images, prepared_annotations
+
+ # transformations
+ if do_resize:
+ if annotations is not None:
+ resized_images, resized_annotations = [], []
+ for image, target in zip(images, annotations):
+ orig_size = get_image_size(image)
+ resized_image = self.resize(image, size=size, max_size=max_size, resample=resample)
+ resized_annotation = self.resize_annotation(target, orig_size, get_image_size(resized_image))
+ resized_images.append(resized_image)
+ resized_annotations.append(resized_annotation)
+ images = resized_images
+ annotations = resized_annotations
+ del resized_images, resized_annotations
+ else:
+ images = [self.resize(image, size=size, resample=resample) for image in images]
+
+ if do_rescale:
+ images = [self.rescale(image, rescale_factor) for image in images]
+
+ if do_normalize:
+ images = [self.normalize(image, image_mean, image_std) for image in images]
+ if annotations is not None:
+ annotations = [
+ self.normalize_annotation(annotation, get_image_size(image))
+ for annotation, image in zip(annotations, images)
+ ]
+
+ if do_pad:
+ # Pads images and returns their mask: {'pixel_values': ..., 'pixel_mask': ...}
+ data = self.pad(images, return_pixel_mask=True, data_format=data_format)
+ else:
+ images = [to_channel_dimension_format(image, data_format) for image in images]
+ data = {"pixel_values": images}
+
+ encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
+ if annotations is not None:
+ encoded_inputs["labels"] = [
+ BatchFeature(annotation, tensor_type=return_tensors) for annotation in annotations
+ ]
+
+ return encoded_inputs
+
+ # POSTPROCESSING METHODS - TODO: add support for other frameworks
+ # inspired by https://github.com/facebookresearch/detr/blob/master/models/detr.py#L258
+ def post_process(self, outputs, target_sizes):
+ """
+ Converts the output of [`DetrForObjectDetection`] into the format expected by the COCO api. Only supports
+ PyTorch.
+
+ Args:
+ outputs ([`DetrObjectDetectionOutput`]):
+ Raw outputs of the model.
+ target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
+ Tensor containing the size (height, width) of each image of the batch. For evaluation, this must be the
+ original image size (before any data augmentation). For visualization, this should be the image size
+ after data augment, but before padding.
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
+ in the batch as predicted by the model.
+ """
+ warnings.warn(
+ "`post_process` is deprecated and will be removed in v5 of Transformers, please use"
+ " `post_process_object_detection`",
+ FutureWarning,
+ )
+
+ out_logits, out_bbox = outputs.logits, outputs.pred_boxes
+
+ if len(out_logits) != len(target_sizes):
+ raise ValueError("Make sure that you pass in as many target sizes as the batch dimension of the logits")
+ if target_sizes.shape[1] != 2:
+ raise ValueError("Each element of target_sizes must contain the size (h, w) of each image of the batch")
+
+ prob = nn.functional.softmax(out_logits, -1)
+ scores, labels = prob[..., :-1].max(-1)
+
+ # convert to [x0, y0, x1, y1] format
+ boxes = center_to_corners_format(out_bbox)
+ # and from relative [0, 1] to absolute [0, height] coordinates
+ img_h, img_w = target_sizes.unbind(1)
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1).to(boxes.device)
+ boxes = boxes * scale_fct[:, None, :]
+
+ results = [{"scores": s, "labels": l, "boxes": b} for s, l, b in zip(scores, labels, boxes)]
+ return results
+
+ def post_process_segmentation(self, outputs, target_sizes, threshold=0.9, mask_threshold=0.5):
+ """
+ Converts the output of [`DetrForSegmentation`] into image segmentation predictions. Only supports PyTorch.
+
+ Args:
+ outputs ([`DetrSegmentationOutput`]):
+ Raw outputs of the model.
+ target_sizes (`torch.Tensor` of shape `(batch_size, 2)` or `List[Tuple]` of length `batch_size`):
+ Torch Tensor (or list) corresponding to the requested final size (h, w) of each prediction.
+ threshold (`float`, *optional*, defaults to 0.9):
+ Threshold to use to filter out queries.
+ mask_threshold (`float`, *optional*, defaults to 0.5):
+ Threshold to use when turning the predicted masks into binary values.
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels, and masks for an image
+ in the batch as predicted by the model.
+ """
+ warnings.warn(
+ "`post_process_segmentation` is deprecated and will be removed in v5 of Transformers, please use"
+ " `post_process_semantic_segmentation`.",
+ FutureWarning,
+ )
+ out_logits, raw_masks = outputs.logits, outputs.pred_masks
+ preds = []
+
+ def to_tuple(tup):
+ if isinstance(tup, tuple):
+ return tup
+ return tuple(tup.cpu().tolist())
+
+ for cur_logits, cur_masks, size in zip(out_logits, raw_masks, target_sizes):
+ # we filter empty queries and detection below threshold
+ scores, labels = cur_logits.softmax(-1).max(-1)
+ keep = labels.ne(outputs.logits.shape[-1] - 1) & (scores > threshold)
+ cur_scores, cur_classes = cur_logits.softmax(-1).max(-1)
+ cur_scores = cur_scores[keep]
+ cur_classes = cur_classes[keep]
+ cur_masks = cur_masks[keep]
+ cur_masks = nn.functional.interpolate(cur_masks[:, None], to_tuple(size), mode="bilinear").squeeze(1)
+ cur_masks = (cur_masks.sigmoid() > mask_threshold) * 1
+
+ predictions = {"scores": cur_scores, "labels": cur_classes, "masks": cur_masks}
+ preds.append(predictions)
+ return preds
+
+ # inspired by https://github.com/facebookresearch/detr/blob/master/models/segmentation.py#L218
+ def post_process_instance(self, results, outputs, orig_target_sizes, max_target_sizes, threshold=0.5):
+ """
+ Converts the output of [`DetrForSegmentation`] into actual instance segmentation predictions. Only supports
+ PyTorch.
+
+ Args:
+ results (`List[Dict]`):
+ Results list obtained by [`~DetrFeatureExtractor.post_process`], to which "masks" results will be
+ added.
+ outputs ([`DetrSegmentationOutput`]):
+ Raw outputs of the model.
+ orig_target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
+ Tensor containing the size (h, w) of each image of the batch. For evaluation, this must be the original
+ image size (before any data augmentation).
+ max_target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
+ Tensor containing the maximum size (h, w) of each image of the batch. For evaluation, this must be the
+ original image size (before any data augmentation).
+ threshold (`float`, *optional*, defaults to 0.5):
+ Threshold to use when turning the predicted masks into binary values.
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels, boxes and masks for an
+ image in the batch as predicted by the model.
+ """
+ warnings.warn(
+ "`post_process_instance` is deprecated and will be removed in v5 of Transformers, please use"
+ " `post_process_instance_segmentation`.",
+ FutureWarning,
+ )
+
+ if len(orig_target_sizes) != len(max_target_sizes):
+ raise ValueError("Make sure to pass in as many orig_target_sizes as max_target_sizes")
+ max_h, max_w = max_target_sizes.max(0)[0].tolist()
+ outputs_masks = outputs.pred_masks.squeeze(2)
+ outputs_masks = nn.functional.interpolate(
+ outputs_masks, size=(max_h, max_w), mode="bilinear", align_corners=False
+ )
+ outputs_masks = (outputs_masks.sigmoid() > threshold).cpu()
+
+ for i, (cur_mask, t, tt) in enumerate(zip(outputs_masks, max_target_sizes, orig_target_sizes)):
+ img_h, img_w = t[0], t[1]
+ results[i]["masks"] = cur_mask[:, :img_h, :img_w].unsqueeze(1)
+ results[i]["masks"] = nn.functional.interpolate(
+ results[i]["masks"].float(), size=tuple(tt.tolist()), mode="nearest"
+ ).byte()
+
+ return results
+
+ # inspired by https://github.com/facebookresearch/detr/blob/master/models/segmentation.py#L241
+ def post_process_panoptic(self, outputs, processed_sizes, target_sizes=None, is_thing_map=None, threshold=0.85):
+ """
+ Converts the output of [`DetrForSegmentation`] into actual panoptic predictions. Only supports PyTorch.
+
+ Args:
+ outputs ([`DetrSegmentationOutput`]):
+ Raw outputs of the model.
+ processed_sizes (`torch.Tensor` of shape `(batch_size, 2)` or `List[Tuple]` of length `batch_size`):
+ Torch Tensor (or list) containing the size (h, w) of each image of the batch, i.e. the size after data
+ augmentation but before batching.
+ target_sizes (`torch.Tensor` of shape `(batch_size, 2)` or `List[Tuple]` of length `batch_size`, *optional*):
+ Torch Tensor (or list) corresponding to the requested final size `(height, width)` of each prediction.
+ If left to None, it will default to the `processed_sizes`.
+ is_thing_map (`torch.Tensor` of shape `(batch_size, 2)`, *optional*):
+ Dictionary mapping class indices to either True or False, depending on whether or not they are a thing.
+ If not set, defaults to the `is_thing_map` of COCO panoptic.
+ threshold (`float`, *optional*, defaults to 0.85):
+ Threshold to use to filter out queries.
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing a PNG string and segments_info values for
+ an image in the batch as predicted by the model.
+ """
+ warnings.warn(
+ "`post_process_panoptic is deprecated and will be removed in v5 of Transformers, please use"
+ " `post_process_panoptic_segmentation`.",
+ FutureWarning,
+ )
+ if target_sizes is None:
+ target_sizes = processed_sizes
+ if len(processed_sizes) != len(target_sizes):
+ raise ValueError("Make sure to pass in as many processed_sizes as target_sizes")
+
+ if is_thing_map is None:
+ # default to is_thing_map of COCO panoptic
+ is_thing_map = {i: i <= 90 for i in range(201)}
+
+ out_logits, raw_masks, raw_boxes = outputs.logits, outputs.pred_masks, outputs.pred_boxes
+ if not len(out_logits) == len(raw_masks) == len(target_sizes):
+ raise ValueError(
+ "Make sure that you pass in as many target sizes as the batch dimension of the logits and masks"
+ )
+ preds = []
+
+ def to_tuple(tup):
+ if isinstance(tup, tuple):
+ return tup
+ return tuple(tup.cpu().tolist())
+
+ for cur_logits, cur_masks, cur_boxes, size, target_size in zip(
+ out_logits, raw_masks, raw_boxes, processed_sizes, target_sizes
+ ):
+ # we filter empty queries and detection below threshold
+ scores, labels = cur_logits.softmax(-1).max(-1)
+ keep = labels.ne(outputs.logits.shape[-1] - 1) & (scores > threshold)
+ cur_scores, cur_classes = cur_logits.softmax(-1).max(-1)
+ cur_scores = cur_scores[keep]
+ cur_classes = cur_classes[keep]
+ cur_masks = cur_masks[keep]
+ cur_masks = nn.functional.interpolate(cur_masks[:, None], to_tuple(size), mode="bilinear").squeeze(1)
+ cur_boxes = center_to_corners_format(cur_boxes[keep])
+
+ h, w = cur_masks.shape[-2:]
+ if len(cur_boxes) != len(cur_classes):
+ raise ValueError("Not as many boxes as there are classes")
+
+ # It may be that we have several predicted masks for the same stuff class.
+ # In the following, we track the list of masks ids for each stuff class (they are merged later on)
+ cur_masks = cur_masks.flatten(1)
+ stuff_equiv_classes = defaultdict(lambda: [])
+ for k, label in enumerate(cur_classes):
+ if not is_thing_map[label.item()]:
+ stuff_equiv_classes[label.item()].append(k)
+
+ def get_ids_area(masks, scores, dedup=False):
+ # This helper function creates the final panoptic segmentation image
+ # It also returns the area of the masks that appears on the image
+
+ m_id = masks.transpose(0, 1).softmax(-1)
+
+ if m_id.shape[-1] == 0:
+ # We didn't detect any mask :(
+ m_id = torch.zeros((h, w), dtype=torch.long, device=m_id.device)
+ else:
+ m_id = m_id.argmax(-1).view(h, w)
+
+ if dedup:
+ # Merge the masks corresponding to the same stuff class
+ for equiv in stuff_equiv_classes.values():
+ if len(equiv) > 1:
+ for eq_id in equiv:
+ m_id.masked_fill_(m_id.eq(eq_id), equiv[0])
+
+ final_h, final_w = to_tuple(target_size)
+
+ seg_img = PIL.Image.fromarray(id_to_rgb(m_id.view(h, w).cpu().numpy()))
+ seg_img = seg_img.resize(size=(final_w, final_h), resample=PILImageResampling.NEAREST)
+
+ np_seg_img = torch.ByteTensor(torch.ByteStorage.from_buffer(seg_img.tobytes()))
+ np_seg_img = np_seg_img.view(final_h, final_w, 3)
+ np_seg_img = np_seg_img.numpy()
+
+ m_id = torch.from_numpy(rgb_to_id(np_seg_img))
+
+ area = []
+ for i in range(len(scores)):
+ area.append(m_id.eq(i).sum().item())
+ return area, seg_img
+
+ area, seg_img = get_ids_area(cur_masks, cur_scores, dedup=True)
+ if cur_classes.numel() > 0:
+ # We know filter empty masks as long as we find some
+ while True:
+ filtered_small = torch.as_tensor(
+ [area[i] <= 4 for i, c in enumerate(cur_classes)], dtype=torch.bool, device=keep.device
+ )
+ if filtered_small.any().item():
+ cur_scores = cur_scores[~filtered_small]
+ cur_classes = cur_classes[~filtered_small]
+ cur_masks = cur_masks[~filtered_small]
+ area, seg_img = get_ids_area(cur_masks, cur_scores)
+ else:
+ break
+
+ else:
+ cur_classes = torch.ones(1, dtype=torch.long, device=cur_classes.device)
+
+ segments_info = []
+ for i, a in enumerate(area):
+ cat = cur_classes[i].item()
+ segments_info.append({"id": i, "isthing": is_thing_map[cat], "category_id": cat, "area": a})
+ del cur_classes
+
+ with io.BytesIO() as out:
+ seg_img.save(out, format="PNG")
+ predictions = {"png_string": out.getvalue(), "segments_info": segments_info}
+ preds.append(predictions)
+ return preds
+
+ # inspired by https://github.com/facebookresearch/detr/blob/master/models/detr.py#L258
+ def post_process_object_detection(
+ self, outputs, threshold: float = 0.5, target_sizes: Union[TensorType, List[Tuple]] = None
+ ):
+ """
+ Converts the output of [`DetrForObjectDetection`] into the format expected by the COCO api. Only supports
+ PyTorch.
+
+ Args:
+ outputs ([`DetrObjectDetectionOutput`]):
+ Raw outputs of the model.
+ threshold (`float`, *optional*):
+ Score threshold to keep object detection predictions.
+ target_sizes (`torch.Tensor` or `List[Tuple[int, int]]`, *optional*):
+ Tensor of shape `(batch_size, 2)` or list of tuples (`Tuple[int, int]`) containing the target size
+ `(height, width)` of each image in the batch. If unset, predictions will not be resized.
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
+ in the batch as predicted by the model.
+ """
+ out_logits, out_bbox = outputs.logits, outputs.pred_boxes
+
+ if target_sizes is not None:
+ if len(out_logits) != len(target_sizes):
+ raise ValueError(
+ "Make sure that you pass in as many target sizes as the batch dimension of the logits"
+ )
+
+ prob = nn.functional.softmax(out_logits, -1)
+ scores, labels = prob[..., :-1].max(-1)
+
+ # Convert to [x0, y0, x1, y1] format
+ boxes = center_to_corners_format(out_bbox)
+
+ # Convert from relative [0, 1] to absolute [0, height] coordinates
+ if target_sizes is not None:
+ if isinstance(target_sizes, List):
+ img_h = torch.Tensor([i[0] for i in target_sizes])
+ img_w = torch.Tensor([i[1] for i in target_sizes])
+ else:
+ img_h, img_w = target_sizes.unbind(1)
+
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
+ boxes = boxes * scale_fct[:, None, :]
+
+ results = []
+ for s, l, b in zip(scores, labels, boxes):
+ score = s[s > threshold]
+ label = l[s > threshold]
+ box = b[s > threshold]
+ results.append({"scores": score, "labels": label, "boxes": box})
+
+ return results
+
+ def post_process_semantic_segmentation(self, outputs, target_sizes: List[Tuple[int, int]] = None):
+ """
+ Converts the output of [`DetrForSegmentation`] into semantic segmentation maps. Only supports PyTorch.
+
+ Args:
+ outputs ([`DetrForSegmentation`]):
+ Raw outputs of the model.
+ target_sizes (`List[Tuple[int, int]]`, *optional*):
+ A list of tuples (`Tuple[int, int]`) containing the target size (height, width) of each image in the
+ batch. If unset, predictions will not be resized.
+ Returns:
+ `List[torch.Tensor]`:
+ A list of length `batch_size`, where each item is a semantic segmentation map of shape (height, width)
+ corresponding to the target_sizes entry (if `target_sizes` is specified). Each entry of each
+ `torch.Tensor` correspond to a semantic class id.
+ """
+ class_queries_logits = outputs.logits # [batch_size, num_queries, num_classes+1]
+ masks_queries_logits = outputs.pred_masks # [batch_size, num_queries, height, width]
+
+ # Remove the null class `[..., :-1]`
+ masks_classes = class_queries_logits.softmax(dim=-1)[..., :-1]
+ masks_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
+
+ # Semantic segmentation logits of shape (batch_size, num_classes, height, width)
+ segmentation = torch.einsum("bqc, bqhw -> bchw", masks_classes, masks_probs)
+ batch_size = class_queries_logits.shape[0]
+
+ # Resize logits and compute semantic segmentation maps
+ if target_sizes is not None:
+ if batch_size != len(target_sizes):
+ raise ValueError(
+ "Make sure that you pass in as many target sizes as the batch dimension of the logits"
+ )
+
+ semantic_segmentation = []
+ for idx in range(batch_size):
+ resized_logits = nn.functional.interpolate(
+ segmentation[idx].unsqueeze(dim=0), size=target_sizes[idx], mode="bilinear", align_corners=False
+ )
+ semantic_map = resized_logits[0].argmax(dim=0)
+ semantic_segmentation.append(semantic_map)
+ else:
+ semantic_segmentation = segmentation.argmax(dim=1)
+ semantic_segmentation = [semantic_segmentation[i] for i in range(semantic_segmentation.shape[0])]
+
+ return semantic_segmentation
+
+ # inspired by https://github.com/facebookresearch/detr/blob/master/models/segmentation.py#L218
+ def post_process_instance_segmentation(
+ self,
+ outputs,
+ threshold: float = 0.5,
+ mask_threshold: float = 0.5,
+ overlap_mask_area_threshold: float = 0.8,
+ target_sizes: Optional[List[Tuple[int, int]]] = None,
+ return_coco_annotation: Optional[bool] = False,
+ ) -> List[Dict]:
+ """
+ Converts the output of [`DetrForSegmentation`] into instance segmentation predictions. Only supports PyTorch.
+
+ Args:
+ outputs ([`DetrForSegmentation`]):
+ Raw outputs of the model.
+ threshold (`float`, *optional*, defaults to 0.5):
+ The probability score threshold to keep predicted instance masks.
+ mask_threshold (`float`, *optional*, defaults to 0.5):
+ Threshold to use when turning the predicted masks into binary values.
+ overlap_mask_area_threshold (`float`, *optional*, defaults to 0.8):
+ The overlap mask area threshold to merge or discard small disconnected parts within each binary
+ instance mask.
+ target_sizes (`List[Tuple]`, *optional*):
+ List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
+ final size (height, width) of each prediction. If unset, predictions will not be resized.
+ return_coco_annotation (`bool`, *optional*):
+ Defaults to `False`. If set to `True`, segmentation maps are returned in COCO run-length encoding (RLE)
+ format.
+ Returns:
+ `List[Dict]`: A list of dictionaries, one per image, each dictionary containing two keys:
+ - **segmentation** -- A tensor of shape `(height, width)` where each pixel represents a `segment_id` or
+ `List[List]` run-length encoding (RLE) of the segmentation map if return_coco_annotation is set to
+ `True`. Set to `None` if no mask if found above `threshold`.
+ - **segments_info** -- A dictionary that contains additional information on each segment.
+ - **id** -- An integer representing the `segment_id`.
+ - **label_id** -- An integer representing the label / semantic class id corresponding to `segment_id`.
+ - **score** -- Prediction score of segment with `segment_id`.
+ """
+ class_queries_logits = outputs.logits # [batch_size, num_queries, num_classes+1]
+ masks_queries_logits = outputs.pred_masks # [batch_size, num_queries, height, width]
+
+ batch_size = class_queries_logits.shape[0]
+ num_labels = class_queries_logits.shape[-1] - 1
+
+ mask_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
+
+ # Predicted label and score of each query (batch_size, num_queries)
+ pred_scores, pred_labels = nn.functional.softmax(class_queries_logits, dim=-1).max(-1)
+
+ # Loop over items in batch size
+ results: List[Dict[str, TensorType]] = []
+
+ for i in range(batch_size):
+ mask_probs_item, pred_scores_item, pred_labels_item = remove_low_and_no_objects(
+ mask_probs[i], pred_scores[i], pred_labels[i], threshold, num_labels
+ )
+
+ # No mask found
+ if mask_probs_item.shape[0] <= 0:
+ height, width = target_sizes[i] if target_sizes is not None else mask_probs_item.shape[1:]
+ segmentation = torch.zeros((height, width)) - 1
+ results.append({"segmentation": segmentation, "segments_info": []})
+ continue
+
+ # Get segmentation map and segment information of batch item
+ target_size = target_sizes[i] if target_sizes is not None else None
+ segmentation, segments = compute_segments(
+ mask_probs=mask_probs_item,
+ pred_scores=pred_scores_item,
+ pred_labels=pred_labels_item,
+ mask_threshold=mask_threshold,
+ overlap_mask_area_threshold=overlap_mask_area_threshold,
+ label_ids_to_fuse=[],
+ target_size=target_size,
+ )
+
+ # Return segmentation map in run-length encoding (RLE) format
+ if return_coco_annotation:
+ segmentation = convert_segmentation_to_rle(segmentation)
+
+ results.append({"segmentation": segmentation, "segments_info": segments})
+ return results
+
+ # inspired by https://github.com/facebookresearch/detr/blob/master/models/segmentation.py#L241
+ def post_process_panoptic_segmentation(
+ self,
+ outputs,
+ threshold: float = 0.5,
+ mask_threshold: float = 0.5,
+ overlap_mask_area_threshold: float = 0.8,
+ label_ids_to_fuse: Optional[Set[int]] = None,
+ target_sizes: Optional[List[Tuple[int, int]]] = None,
+ ) -> List[Dict]:
+ """
+ Converts the output of [`DetrForSegmentation`] into image panoptic segmentation predictions. Only supports
+ PyTorch.
+
+ Args:
+ outputs ([`DetrForSegmentation`]):
+ The outputs from [`DetrForSegmentation`].
+ threshold (`float`, *optional*, defaults to 0.5):
+ The probability score threshold to keep predicted instance masks.
+ mask_threshold (`float`, *optional*, defaults to 0.5):
+ Threshold to use when turning the predicted masks into binary values.
+ overlap_mask_area_threshold (`float`, *optional*, defaults to 0.8):
+ The overlap mask area threshold to merge or discard small disconnected parts within each binary
+ instance mask.
+ label_ids_to_fuse (`Set[int]`, *optional*):
+ The labels in this state will have all their instances be fused together. For instance we could say
+ there can only be one sky in an image, but several persons, so the label ID for sky would be in that
+ set, but not the one for person.
+ target_sizes (`List[Tuple]`, *optional*):
+ List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
+ final size (height, width) of each prediction in batch. If unset, predictions will not be resized.
+ Returns:
+ `List[Dict]`: A list of dictionaries, one per image, each dictionary containing two keys:
+ - **segmentation** -- a tensor of shape `(height, width)` where each pixel represents a `segment_id` or
+ `None` if no mask if found above `threshold`. If `target_sizes` is specified, segmentation is resized to
+ the corresponding `target_sizes` entry.
+ - **segments_info** -- A dictionary that contains additional information on each segment.
+ - **id** -- an integer representing the `segment_id`.
+ - **label_id** -- An integer representing the label / semantic class id corresponding to `segment_id`.
+ - **was_fused** -- a boolean, `True` if `label_id` was in `label_ids_to_fuse`, `False` otherwise.
+ Multiple instances of the same class / label were fused and assigned a single `segment_id`.
+ - **score** -- Prediction score of segment with `segment_id`.
+ """
+
+ if label_ids_to_fuse is None:
+ warnings.warn("`label_ids_to_fuse` unset. No instance will be fused.")
+ label_ids_to_fuse = set()
+
+ class_queries_logits = outputs.logits # [batch_size, num_queries, num_classes+1]
+ masks_queries_logits = outputs.pred_masks # [batch_size, num_queries, height, width]
+
+ batch_size = class_queries_logits.shape[0]
+ num_labels = class_queries_logits.shape[-1] - 1
+
+ mask_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
+
+ # Predicted label and score of each query (batch_size, num_queries)
+ pred_scores, pred_labels = nn.functional.softmax(class_queries_logits, dim=-1).max(-1)
+
+ # Loop over items in batch size
+ results: List[Dict[str, TensorType]] = []
+
+ for i in range(batch_size):
+ mask_probs_item, pred_scores_item, pred_labels_item = remove_low_and_no_objects(
+ mask_probs[i], pred_scores[i], pred_labels[i], threshold, num_labels
+ )
+
+ # No mask found
+ if mask_probs_item.shape[0] <= 0:
+ height, width = target_sizes[i] if target_sizes is not None else mask_probs_item.shape[1:]
+ segmentation = torch.zeros((height, width)) - 1
+ results.append({"segmentation": segmentation, "segments_info": []})
+ continue
+
+ # Get segmentation map and segment information of batch item
+ target_size = target_sizes[i] if target_sizes is not None else None
+ segmentation, segments = compute_segments(
+ mask_probs=mask_probs_item,
+ pred_scores=pred_scores_item,
+ pred_labels=pred_labels_item,
+ mask_threshold=mask_threshold,
+ overlap_mask_area_threshold=overlap_mask_area_threshold,
+ label_ids_to_fuse=label_ids_to_fuse,
+ target_size=target_size,
+ )
+
+ results.append({"segmentation": segmentation, "segments_info": segments})
+ return results
diff --git a/src/transformers/models/detr/modeling_detr.py b/src/transformers/models/detr/modeling_detr.py
index 8fa47231c3..b06453479f 100644
--- a/src/transformers/models/detr/modeling_detr.py
+++ b/src/transformers/models/detr/modeling_detr.py
@@ -1589,7 +1589,7 @@ class DetrForSegmentation(DetrPreTrainedModel):
>>> import numpy
>>> from transformers import DetrFeatureExtractor, DetrForSegmentation
- >>> from transformers.models.detr.feature_extraction_detr import rgb_to_id
+ >>> from transformers.image_transforms import rgb_to_id
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
@@ -2289,8 +2289,6 @@ def generalized_box_iou(boxes1, boxes2):
# below: taken from https://github.com/facebookresearch/detr/blob/master/util/misc.py#L306
-
-
def _max_by_axis(the_list):
# type: (List[List[int]]) -> List[int]
maxes = the_list[0]
diff --git a/src/transformers/models/maskformer/__init__.py b/src/transformers/models/maskformer/__init__.py
index db2529ca24..ba6452c7c4 100644
--- a/src/transformers/models/maskformer/__init__.py
+++ b/src/transformers/models/maskformer/__init__.py
@@ -32,6 +32,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_maskformer"] = ["MaskFormerFeatureExtractor"]
+ _import_structure["image_processing_maskformer"] = ["MaskFormerImageProcessor"]
try:
@@ -63,6 +64,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_maskformer import MaskFormerFeatureExtractor
+ from .image_processing_maskformer import MaskFormerImageProcessor
try:
if not is_torch_available():
raise OptionalDependencyNotAvailable()
diff --git a/src/transformers/models/maskformer/feature_extraction_maskformer.py b/src/transformers/models/maskformer/feature_extraction_maskformer.py
index 21c252f265..068f3c8a11 100644
--- a/src/transformers/models/maskformer/feature_extraction_maskformer.py
+++ b/src/transformers/models/maskformer/feature_extraction_maskformer.py
@@ -14,923 +14,11 @@
# limitations under the License.
"""Feature extractor class for MaskFormer."""
-from typing import TYPE_CHECKING, Dict, List, Optional, Set, Tuple, Union
+from transformers.utils import logging
-import numpy as np
-from PIL import Image
+from .image_processing_maskformer import MaskFormerImageProcessor
-from transformers.image_utils import PILImageResampling
-
-from ...feature_extraction_utils import BatchFeature, FeatureExtractionMixin
-from ...image_utils import ImageFeatureExtractionMixin, ImageInput, is_torch_tensor
-from ...utils import TensorType, is_torch_available, logging
-
-
-if is_torch_available():
- import torch
- from torch import Tensor, nn
- from torch.nn.functional import interpolate
-
- if TYPE_CHECKING:
- from transformers.models.maskformer.modeling_maskformer import MaskFormerForInstanceSegmentationOutput
logger = logging.get_logger(__name__)
-
-# Copied from transformers.models.detr.feature_extraction_detr.binary_mask_to_rle
-def binary_mask_to_rle(mask):
- """
- Args:
- Converts given binary mask of shape (height, width) to the run-length encoding (RLE) format.
- mask (`torch.Tensor` or `numpy.array`):
- A binary mask tensor of shape `(height, width)` where 0 denotes background and 1 denotes the target
- segment_id or class_id.
- Returns:
- `List`: Run-length encoded list of the binary mask. Refer to COCO API for more information about the RLE
- format.
- """
- if is_torch_tensor(mask):
- mask = mask.numpy()
-
- pixels = mask.flatten()
- pixels = np.concatenate([[0], pixels, [0]])
- runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
- runs[1::2] -= runs[::2]
- return [x for x in runs]
-
-
-# Copied from transformers.models.detr.feature_extraction_detr.convert_segmentation_to_rle
-def convert_segmentation_to_rle(segmentation):
- """
- Converts given segmentation map of shape (height, width) to the run-length encoding (RLE) format.
-
- Args:
- segmentation (`torch.Tensor` or `numpy.array`):
- A segmentation map of shape `(height, width)` where each value denotes a segment or class id.
- Returns:
- `List[List]`: A list of lists, where each list is the run-length encoding of a segment / class id.
- """
- segment_ids = torch.unique(segmentation)
-
- run_length_encodings = []
- for idx in segment_ids:
- mask = torch.where(segmentation == idx, 1, 0)
- rle = binary_mask_to_rle(mask)
- run_length_encodings.append(rle)
-
- return run_length_encodings
-
-
-# Copied from transformers.models.detr.feature_extraction_detr.remove_low_and_no_objects
-def remove_low_and_no_objects(masks, scores, labels, object_mask_threshold, num_labels):
- """
- Binarize the given masks using `object_mask_threshold`, it returns the associated values of `masks`, `scores` and
- `labels`.
-
- Args:
- masks (`torch.Tensor`):
- A tensor of shape `(num_queries, height, width)`.
- scores (`torch.Tensor`):
- A tensor of shape `(num_queries)`.
- labels (`torch.Tensor`):
- A tensor of shape `(num_queries)`.
- object_mask_threshold (`float`):
- A number between 0 and 1 used to binarize the masks.
- Raises:
- `ValueError`: Raised when the first dimension doesn't match in all input tensors.
- Returns:
- `Tuple[`torch.Tensor`, `torch.Tensor`, `torch.Tensor`]`: The `masks`, `scores` and `labels` without the region
- < `object_mask_threshold`.
- """
- if not (masks.shape[0] == scores.shape[0] == labels.shape[0]):
- raise ValueError("mask, scores and labels must have the same shape!")
-
- to_keep = labels.ne(num_labels) & (scores > object_mask_threshold)
-
- return masks[to_keep], scores[to_keep], labels[to_keep]
-
-
-# Copied from transformers.models.detr.feature_extraction_detr.check_segment_validity
-def check_segment_validity(mask_labels, mask_probs, k, mask_threshold=0.5, overlap_mask_area_threshold=0.8):
- # Get the mask associated with the k class
- mask_k = mask_labels == k
- mask_k_area = mask_k.sum()
-
- # Compute the area of all the stuff in query k
- original_area = (mask_probs[k] >= mask_threshold).sum()
- mask_exists = mask_k_area > 0 and original_area > 0
-
- # Eliminate disconnected tiny segments
- if mask_exists:
- area_ratio = mask_k_area / original_area
- if not area_ratio.item() > overlap_mask_area_threshold:
- mask_exists = False
-
- return mask_exists, mask_k
-
-
-# Copied from transformers.models.detr.feature_extraction_detr.compute_segments
-def compute_segments(
- mask_probs,
- pred_scores,
- pred_labels,
- mask_threshold: float = 0.5,
- overlap_mask_area_threshold: float = 0.8,
- label_ids_to_fuse: Optional[Set[int]] = None,
- target_size: Tuple[int, int] = None,
-):
- height = mask_probs.shape[1] if target_size is None else target_size[0]
- width = mask_probs.shape[2] if target_size is None else target_size[1]
-
- segmentation = torch.zeros((height, width), dtype=torch.int32, device=mask_probs.device)
- segments: List[Dict] = []
-
- if target_size is not None:
- mask_probs = nn.functional.interpolate(
- mask_probs.unsqueeze(0), size=target_size, mode="bilinear", align_corners=False
- )[0]
-
- current_segment_id = 0
-
- # Weigh each mask by its prediction score
- mask_probs *= pred_scores.view(-1, 1, 1)
- mask_labels = mask_probs.argmax(0) # [height, width]
-
- # Keep track of instances of each class
- stuff_memory_list: Dict[str, int] = {}
- for k in range(pred_labels.shape[0]):
- pred_class = pred_labels[k].item()
- should_fuse = pred_class in label_ids_to_fuse
-
- # Check if mask exists and large enough to be a segment
- mask_exists, mask_k = check_segment_validity(
- mask_labels, mask_probs, k, mask_threshold, overlap_mask_area_threshold
- )
-
- if mask_exists:
- if pred_class in stuff_memory_list:
- current_segment_id = stuff_memory_list[pred_class]
- else:
- current_segment_id += 1
-
- # Add current object segment to final segmentation map
- segmentation[mask_k] = current_segment_id
- segment_score = round(pred_scores[k].item(), 6)
- segments.append(
- {
- "id": current_segment_id,
- "label_id": pred_class,
- "was_fused": should_fuse,
- "score": segment_score,
- }
- )
- if should_fuse:
- stuff_memory_list[pred_class] = current_segment_id
-
- return segmentation, segments
-
-
-class MaskFormerFeatureExtractor(FeatureExtractionMixin, ImageFeatureExtractionMixin):
- r"""
- Constructs a MaskFormer feature extractor. The feature extractor can be used to prepare image(s) and optional
- targets for the model.
-
- This feature extractor inherits from [`FeatureExtractionMixin`] which contains most of the main methods. Users
- should refer to this superclass for more information regarding those methods.
-
- Args:
- do_resize (`bool`, *optional*, defaults to `True`):
- Whether to resize the input to a certain `size`.
- size (`int`, *optional*, defaults to 800):
- Resize the input to the given size. Only has an effect if `do_resize` is set to `True`. If size is a
- sequence like `(width, height)`, output size will be matched to this. If size is an int, smaller edge of
- the image will be matched to this number. i.e, if `height > width`, then image will be rescaled to `(size *
- height / width, size)`.
- max_size (`int`, *optional*, defaults to 1333):
- The largest size an image dimension can have (otherwise it's capped). Only has an effect if `do_resize` is
- set to `True`.
- resample (`int`, *optional*, defaults to `PILImageResampling.BILINEAR`):
- An optional resampling filter. This can be one of `PILImageResampling.NEAREST`, `PILImageResampling.BOX`,
- `PILImageResampling.BILINEAR`, `PILImageResampling.HAMMING`, `PILImageResampling.BICUBIC` or
- `PILImageResampling.LANCZOS`. Only has an effect if `do_resize` is set to `True`.
- size_divisibility (`int`, *optional*, defaults to 32):
- Some backbones need images divisible by a certain number. If not passed, it defaults to the value used in
- Swin Transformer.
- do_normalize (`bool`, *optional*, defaults to `True`):
- Whether or not to normalize the input with mean and standard deviation.
- image_mean (`int`, *optional*, defaults to `[0.485, 0.456, 0.406]`):
- The sequence of means for each channel, to be used when normalizing images. Defaults to the ImageNet mean.
- image_std (`int`, *optional*, defaults to `[0.229, 0.224, 0.225]`):
- The sequence of standard deviations for each channel, to be used when normalizing images. Defaults to the
- ImageNet std.
- ignore_index (`int`, *optional*):
- Label to be assigned to background pixels in segmentation maps. If provided, segmentation map pixels
- denoted with 0 (background) will be replaced with `ignore_index`. The ignore index of the loss function of
- the model should then correspond to this ignore index.
- reduce_labels (`bool`, *optional*, defaults to `False`):
- Whether or not to decrement all label values of segmentation maps by 1. Usually used for datasets where 0
- is used for background, and background itself is not included in all classes of a dataset (e.g. ADE20k).
- The background label will be replaced by `ignore_index`.
-
- """
-
- model_input_names = ["pixel_values", "pixel_mask"]
-
- def __init__(
- self,
- do_resize=True,
- size=800,
- max_size=1333,
- resample=PILImageResampling.BILINEAR,
- size_divisibility=32,
- do_normalize=True,
- image_mean=None,
- image_std=None,
- ignore_index=None,
- reduce_labels=False,
- **kwargs
- ):
- super().__init__(**kwargs)
- self.do_resize = do_resize
- self.size = size
- self.max_size = max_size
- self.resample = resample
- self.size_divisibility = size_divisibility
- self.do_normalize = do_normalize
- self.image_mean = image_mean if image_mean is not None else [0.485, 0.456, 0.406] # ImageNet mean
- self.image_std = image_std if image_std is not None else [0.229, 0.224, 0.225] # ImageNet std
- self.ignore_index = ignore_index
- self.reduce_labels = reduce_labels
-
- def _resize_with_size_divisibility(self, image, size, target=None, max_size=None):
- """
- Resize the image to the given size. Size can be min_size (scalar) or (width, height) tuple. If size is an int,
- smaller edge of the image will be matched to this number.
-
- If given, also resize the target accordingly.
- """
- if not isinstance(image, Image.Image):
- image = self.to_pil_image(image)
-
- def get_size_with_aspect_ratio(image_size, size, max_size=None):
- width, height = image_size
- if max_size is not None:
- min_original_size = float(min((width, height)))
- max_original_size = float(max((width, height)))
- if max_original_size / min_original_size * size > max_size:
- size = int(round(max_size * min_original_size / max_original_size))
-
- if (width <= height and width == size) or (height <= width and height == size):
- return (height, width)
-
- if width < height:
- output_width = size
- output_height = int(size * height / width)
- else:
- output_height = size
- output_width = int(size * width / height)
-
- return (output_height, output_width)
-
- def get_size(image_size, size, max_size=None):
- if isinstance(size, (list, tuple)):
- return size
- else:
- # size returned must be (width, height) since we use PIL to resize images
- # so we revert the tuple
- return get_size_with_aspect_ratio(image_size, size, max_size)[::-1]
-
- width, height = get_size(image.size, size, max_size)
-
- if self.size_divisibility > 0:
- height = int(np.ceil(height / self.size_divisibility)) * self.size_divisibility
- width = int(np.ceil(width / self.size_divisibility)) * self.size_divisibility
-
- size = (width, height)
- image = self.resize(image, size=size, resample=self.resample)
-
- if target is not None:
- target = self.resize(target, size=size, resample=Image.NEAREST)
-
- return image, target
-
- def __call__(
- self,
- images: ImageInput,
- segmentation_maps: ImageInput = None,
- pad_and_return_pixel_mask: Optional[bool] = True,
- instance_id_to_semantic_id: Optional[Union[List[Dict[int, int]], Dict[int, int]]] = None,
- return_tensors: Optional[Union[str, TensorType]] = None,
- **kwargs,
- ) -> BatchFeature:
- """
- Main method to prepare for the model one or several image(s) and optional annotations. Images are by default
- padded up to the largest image in a batch, and a pixel mask is created that indicates which pixels are
- real/which are padding.
-
- Segmentation maps can be instance, semantic or panoptic segmentation maps. In case of instance and panoptic
- segmentation, one needs to provide `instance_id_to_semantic_id`, which is a mapping from instance/segment ids
- to semantic category ids.
-
- MaskFormer addresses all 3 forms of segmentation (instance, semantic and panoptic) in the same way, namely by
- converting the segmentation maps to a set of binary masks with corresponding classes.
-
- In case of instance segmentation, the segmentation maps contain the instance ids, and
- `instance_id_to_semantic_id` maps instance IDs to their corresponding semantic category.
-
- In case of semantic segmentation, the segmentation maps contain the semantic category ids. Let's see an
- example, assuming `segmentation_maps = [[2,6,7,9]]`, the output will contain `mask_labels =
- [[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1]]` (four binary masks) and `class_labels = [2,6,7,9]`, the labels for
- each mask.
-
- In case of panoptic segmentation, the segmentation maps contain the segment ids, and
- `instance_id_to_semantic_id` maps segment IDs to their corresponding semantic category.
-
-
-
- NumPy arrays and PyTorch tensors are converted to PIL images when resizing, so the most efficient is to pass
- PIL images.
-
-
-
- Args:
- images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
- The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
- tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a
- number of channels, H and W are image height and width.
-
- segmentation_maps (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`, *optional*):
- The corresponding segmentation maps with the pixel-wise instance id, semantic id or segment id
- annotations. Assumed to be semantic segmentation maps if no `instance_id_to_semantic_id map` is
- provided.
-
- pad_and_return_pixel_mask (`bool`, *optional*, defaults to `True`):
- Whether or not to pad images up to the largest image in a batch and create a pixel mask.
-
- If left to the default, will return a pixel mask that is:
-
- - 1 for pixels that are real (i.e. **not masked**),
- - 0 for pixels that are padding (i.e. **masked**).
-
- instance_id_to_semantic_id (`List[Dict[int, int]]` or `Dict[int, int]`, *optional*):
- A mapping between instance/segment ids and semantic category ids. If passed, `segmentation_maps` is
- treated as an instance or panoptic segmentation map where each pixel represents an instance or segment
- id. Can be provided as a single dictionary with a global / dataset-level mapping or as a list of
- dictionaries (one per image), to map instance ids in each image separately. Note that this assumes a
- mapping before reduction of labels.
-
- return_tensors (`str` or [`~file_utils.TensorType`], *optional*):
- If set, will return tensors instead of NumPy arrays. If set to `'pt'`, return PyTorch `torch.Tensor`
- objects.
-
- Returns:
- [`BatchFeature`]: A [`BatchFeature`] with the following fields:
-
- - **pixel_values** -- Pixel values to be fed to a model.
- - **pixel_mask** -- Pixel mask to be fed to a model (when `pad_and_return_pixel_mask=True` or if
- `pixel_mask` is in `self.model_input_names`).
- - **mask_labels** -- Optional list of mask labels of shape `(num_class_labels, height, width)` to be fed to
- a model (when `annotations` are provided).
- - **class_labels** -- Optional list of class labels of shape `(num_class_labels)` to be fed to a model
- (when `annotations` are provided). They identify the labels of `mask_labels`, e.g. the label of
- `mask_labels[i][j]` if `class_labels[i][j]`.
- """
- # Input type checking for clearer error
-
- valid_images = False
- valid_segmentation_maps = False
-
- # Check that images has a valid type
- if isinstance(images, (Image.Image, np.ndarray)) or is_torch_tensor(images):
- valid_images = True
- elif isinstance(images, (list, tuple)):
- if len(images) == 0 or isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]):
- valid_images = True
-
- if not valid_images:
- raise ValueError(
- "Images must of type `PIL.Image.Image`, `np.ndarray` or `torch.Tensor` (single example), "
- "`List[PIL.Image.Image]`, `List[np.ndarray]` or `List[torch.Tensor]` (batch of examples)."
- )
- # Check that segmentation maps has a valid type
- if segmentation_maps is not None:
- if isinstance(segmentation_maps, (Image.Image, np.ndarray)) or is_torch_tensor(segmentation_maps):
- valid_segmentation_maps = True
- elif isinstance(segmentation_maps, (list, tuple)):
- if (
- len(segmentation_maps) == 0
- or isinstance(segmentation_maps[0], (Image.Image, np.ndarray))
- or is_torch_tensor(segmentation_maps[0])
- ):
- valid_segmentation_maps = True
-
- if not valid_segmentation_maps:
- raise ValueError(
- "Segmentation maps must of type `PIL.Image.Image`, `np.ndarray` or `torch.Tensor` (single"
- " example),`List[PIL.Image.Image]`, `List[np.ndarray]` or `List[torch.Tensor]` (batch of"
- " examples)."
- )
-
- is_batched = bool(
- isinstance(images, (list, tuple))
- and (isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]))
- )
-
- if not is_batched:
- images = [images]
- if segmentation_maps is not None:
- segmentation_maps = [segmentation_maps]
-
- # transformations (resizing + normalization)
- if self.do_resize and self.size is not None:
- if segmentation_maps is not None:
- for idx, (image, target) in enumerate(zip(images, segmentation_maps)):
- image, target = self._resize_with_size_divisibility(
- image=image, target=target, size=self.size, max_size=self.max_size
- )
- images[idx] = image
- segmentation_maps[idx] = target
- else:
- for idx, image in enumerate(images):
- images[idx] = self._resize_with_size_divisibility(
- image=image, target=None, size=self.size, max_size=self.max_size
- )[0]
-
- if self.do_normalize:
- images = [self.normalize(image=image, mean=self.image_mean, std=self.image_std) for image in images]
- # NOTE I will be always forced to pad them them since they have to be stacked in the batch dim
- encoded_inputs = self.encode_inputs(
- images,
- segmentation_maps,
- pad_and_return_pixel_mask,
- instance_id_to_semantic_id=instance_id_to_semantic_id,
- return_tensors=return_tensors,
- )
-
- # Convert to TensorType
- tensor_type = return_tensors
- if not isinstance(tensor_type, TensorType):
- tensor_type = TensorType(tensor_type)
-
- if not tensor_type == TensorType.PYTORCH:
- raise ValueError("Only PyTorch is supported for the moment.")
- else:
- if not is_torch_available():
- raise ImportError("Unable to convert output to PyTorch tensors format, PyTorch is not installed.")
-
- return encoded_inputs
-
- def _max_by_axis(self, the_list: List[List[int]]) -> List[int]:
- maxes = the_list[0]
- for sublist in the_list[1:]:
- for index, item in enumerate(sublist):
- maxes[index] = max(maxes[index], item)
- return maxes
-
- def convert_segmentation_map_to_binary_masks(
- self,
- segmentation_map: "np.ndarray",
- instance_id_to_semantic_id: Optional[Dict[int, int]] = None,
- ):
- # Reduce labels, if requested
- if self.reduce_labels:
- if self.ignore_index is None:
- raise ValueError("`ignore_index` must be set when `reduce_labels` is `True`.")
- segmentation_map[segmentation_map == 0] = self.ignore_index
- segmentation_map -= 1
- segmentation_map[segmentation_map == self.ignore_index - 1] = self.ignore_index
-
- # Get unique ids (instance, class ids or segment ids based on input)
- all_labels = np.unique(segmentation_map)
-
- # Remove ignored label
- if self.ignore_index is not None:
- all_labels = all_labels[all_labels != self.ignore_index]
-
- # Generate a binary mask for each object instance
- binary_masks = [(segmentation_map == i) for i in all_labels]
- binary_masks = np.stack(binary_masks, axis=0) # (num_labels, height, width)
-
- # Convert instance/segment ids to class ids
- if instance_id_to_semantic_id is not None:
- labels = np.zeros(all_labels.shape[0])
-
- for label in all_labels:
- class_id = instance_id_to_semantic_id[label + 1 if self.reduce_labels else label]
- labels[all_labels == label] = class_id - 1 if self.reduce_labels else class_id
- else:
- labels = all_labels
-
- return binary_masks.astype(np.float32), labels.astype(np.int64)
-
- def encode_inputs(
- self,
- pixel_values_list: Union[List["np.ndarray"], List["torch.Tensor"]],
- segmentation_maps: ImageInput = None,
- pad_and_return_pixel_mask: bool = True,
- instance_id_to_semantic_id: Optional[Union[List[Dict[int, int]], Dict[int, int]]] = None,
- return_tensors: Optional[Union[str, TensorType]] = None,
- ):
- """
- Encode a list of pixel values and an optional list of corresponding segmentation maps.
-
- This method is useful if you have resized and normalized your images and segmentation maps yourself, using a
- library like [torchvision](https://pytorch.org/vision/stable/transforms.html) or
- [albumentations](https://albumentations.ai/).
-
- Images are padded up to the largest image in a batch, and a corresponding `pixel_mask` is created.
-
- Segmentation maps can be instance, semantic or panoptic segmentation maps. In case of instance and panoptic
- segmentation, one needs to provide `instance_id_to_semantic_id`, which is a mapping from instance/segment ids
- to semantic category ids.
-
- MaskFormer addresses all 3 forms of segmentation (instance, semantic and panoptic) in the same way, namely by
- converting the segmentation maps to a set of binary masks with corresponding classes.
-
- In case of instance segmentation, the segmentation maps contain the instance ids, and
- `instance_id_to_semantic_id` maps instance IDs to their corresponding semantic category.
-
- In case of semantic segmentation, the segmentation maps contain the semantic category ids. Let's see an
- example, assuming `segmentation_maps = [[2,6,7,9]]`, the output will contain `mask_labels =
- [[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1]]` (four binary masks) and `class_labels = [2,6,7,9]`, the labels for
- each mask.
-
- In case of panoptic segmentation, the segmentation maps contain the segment ids, and
- `instance_id_to_semantic_id` maps segment IDs to their corresponding semantic category.
-
- Args:
- pixel_values_list (`List[np.ndarray]` or `List[torch.Tensor]`):
- List of images (pixel values) to be padded. Each image should be a tensor of shape `(channels, height,
- width)`.
-
- segmentation_maps (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`, *optional*):
- The corresponding segmentation maps with the pixel-wise instance id, semantic id or segment id
- annotations. Assumed to be semantic segmentation maps if no `instance_id_to_semantic_id map` is
- provided.
-
- pad_and_return_pixel_mask (`bool`, *optional*, defaults to `True`):
- Whether or not to pad images up to the largest image in a batch and create a pixel mask.
-
- If left to the default, will return a pixel mask that is:
-
- - 1 for pixels that are real (i.e. **not masked**),
- - 0 for pixels that are padding (i.e. **masked**).
-
- instance_id_to_semantic_id (`List[Dict[int, int]]` or `Dict[int, int]`, *optional*):
- A mapping between instance/segment ids and semantic category ids. If passed, `segmentation_maps` is
- treated as an instance or panoptic segmentation map where each pixel represents an instance or segment
- id. Can be provided as a single dictionary with a global / dataset-level mapping or as a list of
- dictionaries (one per image), to map instance ids in each image separately. Note that this assumes a
- mapping before reduction of labels.
-
- return_tensors (`str` or [`~file_utils.TensorType`], *optional*):
- If set, will return tensors instead of NumPy arrays. If set to `'pt'`, return PyTorch `torch.Tensor`
- objects.
-
- Returns:
- [`BatchFeature`]: A [`BatchFeature`] with the following fields:
-
- - **pixel_values** -- Pixel values to be fed to a model.
- - **pixel_mask** -- Pixel mask to be fed to a model (when `pad_and_return_pixel_mask=True` or if
- `pixel_mask` is in `self.model_input_names`).
- - **mask_labels** -- Optional list of mask labels of shape `(labels, height, width)` to be fed to a model
- (when `annotations` are provided).
- - **class_labels** -- Optional list of class labels of shape `(labels)` to be fed to a model (when
- `annotations` are provided). They identify the labels of `mask_labels`, e.g. the label of
- `mask_labels[i][j]` if `class_labels[i][j]`.
- """
-
- max_size = self._max_by_axis([list(image.shape) for image in pixel_values_list])
-
- annotations = None
- if segmentation_maps is not None:
- segmentation_maps = map(np.array, segmentation_maps)
- converted_segmentation_maps = []
-
- for i, segmentation_map in enumerate(segmentation_maps):
- # Use instance2class_id mapping per image
- if isinstance(instance_id_to_semantic_id, List):
- converted_segmentation_map = self.convert_segmentation_map_to_binary_masks(
- segmentation_map, instance_id_to_semantic_id[i]
- )
- else:
- converted_segmentation_map = self.convert_segmentation_map_to_binary_masks(
- segmentation_map, instance_id_to_semantic_id
- )
- converted_segmentation_maps.append(converted_segmentation_map)
-
- annotations = []
- for mask, classes in converted_segmentation_maps:
- annotations.append({"masks": mask, "classes": classes})
-
- channels, height, width = max_size
- pixel_values = []
- pixel_mask = []
- mask_labels = []
- class_labels = []
- for idx, image in enumerate(pixel_values_list):
- # create padded image
- padded_image = np.zeros((channels, height, width), dtype=np.float32)
- padded_image[: image.shape[0], : image.shape[1], : image.shape[2]] = np.copy(image)
- image = padded_image
- pixel_values.append(image)
- # if we have a target, pad it
- if annotations:
- annotation = annotations[idx]
- masks = annotation["masks"]
- # pad mask with `ignore_index`
- masks = np.pad(
- masks,
- ((0, 0), (0, height - masks.shape[1]), (0, width - masks.shape[2])),
- constant_values=self.ignore_index,
- )
- annotation["masks"] = masks
- # create pixel mask
- mask = np.zeros((height, width), dtype=np.int64)
- mask[: image.shape[1], : image.shape[2]] = True
- pixel_mask.append(mask)
-
- # return as BatchFeature
- data = {"pixel_values": pixel_values, "pixel_mask": pixel_mask}
- encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
- # we cannot batch them since they don't share a common class size
- if annotations:
- for label in annotations:
- mask_labels.append(torch.from_numpy(label["masks"]))
- class_labels.append(torch.from_numpy(label["classes"]))
-
- encoded_inputs["mask_labels"] = mask_labels
- encoded_inputs["class_labels"] = class_labels
-
- return encoded_inputs
-
- def post_process_segmentation(
- self, outputs: "MaskFormerForInstanceSegmentationOutput", target_size: Tuple[int, int] = None
- ) -> "torch.Tensor":
- """
- Converts the output of [`MaskFormerForInstanceSegmentationOutput`] into image segmentation predictions. Only
- supports PyTorch.
-
- Args:
- outputs ([`MaskFormerForInstanceSegmentationOutput`]):
- The outputs from [`MaskFormerForInstanceSegmentation`].
-
- target_size (`Tuple[int, int]`, *optional*):
- If set, the `masks_queries_logits` will be resized to `target_size`.
-
- Returns:
- `torch.Tensor`:
- A tensor of shape (`batch_size, num_class_labels, height, width`).
- """
- logger.warning(
- "`post_process_segmentation` is deprecated and will be removed in v5 of Transformers, please use"
- " `post_process_instance_segmentation`",
- FutureWarning,
- )
-
- # class_queries_logits has shape [BATCH, QUERIES, CLASSES + 1]
- class_queries_logits = outputs.class_queries_logits
- # masks_queries_logits has shape [BATCH, QUERIES, HEIGHT, WIDTH]
- masks_queries_logits = outputs.masks_queries_logits
- if target_size is not None:
- masks_queries_logits = interpolate(
- masks_queries_logits,
- size=target_size,
- mode="bilinear",
- align_corners=False,
- )
- # remove the null class `[..., :-1]`
- masks_classes = class_queries_logits.softmax(dim=-1)[..., :-1]
- # mask probs has shape [BATCH, QUERIES, HEIGHT, WIDTH]
- masks_probs = masks_queries_logits.sigmoid()
- # now we want to sum over the queries,
- # $ out_{c,h,w} = \sum_q p_{q,c} * m_{q,h,w} $
- # where $ softmax(p) \in R^{q, c} $ is the mask classes
- # and $ sigmoid(m) \in R^{q, h, w}$ is the mask probabilities
- # b(atch)q(uery)c(lasses), b(atch)q(uery)h(eight)w(idth)
- segmentation = torch.einsum("bqc, bqhw -> bchw", masks_classes, masks_probs)
-
- return segmentation
-
- def post_process_semantic_segmentation(
- self, outputs, target_sizes: Optional[List[Tuple[int, int]]] = None
- ) -> "torch.Tensor":
- """
- Converts the output of [`MaskFormerForInstanceSegmentation`] into semantic segmentation maps. Only supports
- PyTorch.
-
- Args:
- outputs ([`MaskFormerForInstanceSegmentation`]):
- Raw outputs of the model.
- target_sizes (`List[Tuple[int, int]]`, *optional*, defaults to `None`):
- List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
- final size (height, width) of each prediction. If left to None, predictions will not be resized.
- Returns:
- `List[torch.Tensor]`:
- A list of length `batch_size`, where each item is a semantic segmentation map of shape (height, width)
- corresponding to the target_sizes entry (if `target_sizes` is specified). Each entry of each
- `torch.Tensor` correspond to a semantic class id.
- """
- class_queries_logits = outputs.class_queries_logits # [batch_size, num_queries, num_classes+1]
- masks_queries_logits = outputs.masks_queries_logits # [batch_size, num_queries, height, width]
-
- # Remove the null class `[..., :-1]`
- masks_classes = class_queries_logits.softmax(dim=-1)[..., :-1]
- masks_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
-
- # Semantic segmentation logits of shape (batch_size, num_classes, height, width)
- segmentation = torch.einsum("bqc, bqhw -> bchw", masks_classes, masks_probs)
- batch_size = class_queries_logits.shape[0]
-
- # Resize logits and compute semantic segmentation maps
- if target_sizes is not None:
- if batch_size != len(target_sizes):
- raise ValueError(
- "Make sure that you pass in as many target sizes as the batch dimension of the logits"
- )
-
- semantic_segmentation = []
- for idx in range(batch_size):
- resized_logits = torch.nn.functional.interpolate(
- segmentation[idx].unsqueeze(dim=0), size=target_sizes[idx], mode="bilinear", align_corners=False
- )
- semantic_map = resized_logits[0].argmax(dim=0)
- semantic_segmentation.append(semantic_map)
- else:
- semantic_segmentation = segmentation.argmax(dim=1)
- semantic_segmentation = [semantic_segmentation[i] for i in range(semantic_segmentation.shape[0])]
-
- return semantic_segmentation
-
- def post_process_instance_segmentation(
- self,
- outputs,
- threshold: float = 0.5,
- mask_threshold: float = 0.5,
- overlap_mask_area_threshold: float = 0.8,
- target_sizes: Optional[List[Tuple[int, int]]] = None,
- return_coco_annotation: Optional[bool] = False,
- ) -> List[Dict]:
- """
- Converts the output of [`MaskFormerForInstanceSegmentationOutput`] into instance segmentation predictions. Only
- supports PyTorch.
-
- Args:
- outputs ([`MaskFormerForInstanceSegmentation`]):
- Raw outputs of the model.
- threshold (`float`, *optional*, defaults to 0.5):
- The probability score threshold to keep predicted instance masks.
- mask_threshold (`float`, *optional*, defaults to 0.5):
- Threshold to use when turning the predicted masks into binary values.
- overlap_mask_area_threshold (`float`, *optional*, defaults to 0.8):
- The overlap mask area threshold to merge or discard small disconnected parts within each binary
- instance mask.
- target_sizes (`List[Tuple]`, *optional*):
- List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
- final size (height, width) of each prediction. If left to None, predictions will not be resized.
- return_coco_annotation (`bool`, *optional*):
- Defaults to `False`. If set to `True`, segmentation maps are returned in COCO run-length encoding (RLE)
- format.
- Returns:
- `List[Dict]`: A list of dictionaries, one per image, each dictionary containing two keys:
- - **segmentation** -- A tensor of shape `(height, width)` where each pixel represents a `segment_id` or
- `List[List]` run-length encoding (RLE) of the segmentation map if return_coco_annotation is set to
- `True`. Set to `None` if no mask if found above `threshold`.
- - **segments_info** -- A dictionary that contains additional information on each segment.
- - **id** -- An integer representing the `segment_id`.
- - **label_id** -- An integer representing the label / semantic class id corresponding to `segment_id`.
- - **score** -- Prediction score of segment with `segment_id`.
- """
- class_queries_logits = outputs.class_queries_logits # [batch_size, num_queries, num_classes+1]
- masks_queries_logits = outputs.masks_queries_logits # [batch_size, num_queries, height, width]
-
- batch_size = class_queries_logits.shape[0]
- num_labels = class_queries_logits.shape[-1] - 1
-
- mask_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
-
- # Predicted label and score of each query (batch_size, num_queries)
- pred_scores, pred_labels = nn.functional.softmax(class_queries_logits, dim=-1).max(-1)
-
- # Loop over items in batch size
- results: List[Dict[str, Tensor]] = []
-
- for i in range(batch_size):
- mask_probs_item, pred_scores_item, pred_labels_item = remove_low_and_no_objects(
- mask_probs[i], pred_scores[i], pred_labels[i], threshold, num_labels
- )
-
- # No mask found
- if mask_probs_item.shape[0] <= 0:
- height, width = target_sizes[i] if target_sizes is not None else mask_probs_item.shape[1:]
- segmentation = torch.zeros((height, width)) - 1
- results.append({"segmentation": segmentation, "segments_info": []})
- continue
-
- # Get segmentation map and segment information of batch item
- target_size = target_sizes[i] if target_sizes is not None else None
- segmentation, segments = compute_segments(
- mask_probs_item,
- pred_scores_item,
- pred_labels_item,
- mask_threshold,
- overlap_mask_area_threshold,
- target_size,
- )
-
- # Return segmentation map in run-length encoding (RLE) format
- if return_coco_annotation:
- segmentation = convert_segmentation_to_rle(segmentation)
-
- results.append({"segmentation": segmentation, "segments_info": segments})
- return results
-
- def post_process_panoptic_segmentation(
- self,
- outputs,
- threshold: float = 0.5,
- mask_threshold: float = 0.5,
- overlap_mask_area_threshold: float = 0.8,
- label_ids_to_fuse: Optional[Set[int]] = None,
- target_sizes: Optional[List[Tuple[int, int]]] = None,
- ) -> List[Dict]:
- """
- Converts the output of [`MaskFormerForInstanceSegmentationOutput`] into image panoptic segmentation
- predictions. Only supports PyTorch.
-
- Args:
- outputs ([`MaskFormerForInstanceSegmentationOutput`]):
- The outputs from [`MaskFormerForInstanceSegmentation`].
- threshold (`float`, *optional*, defaults to 0.5):
- The probability score threshold to keep predicted instance masks.
- mask_threshold (`float`, *optional*, defaults to 0.5):
- Threshold to use when turning the predicted masks into binary values.
- overlap_mask_area_threshold (`float`, *optional*, defaults to 0.8):
- The overlap mask area threshold to merge or discard small disconnected parts within each binary
- instance mask.
- label_ids_to_fuse (`Set[int]`, *optional*):
- The labels in this state will have all their instances be fused together. For instance we could say
- there can only be one sky in an image, but several persons, so the label ID for sky would be in that
- set, but not the one for person.
- target_sizes (`List[Tuple]`, *optional*):
- List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
- final size (height, width) of each prediction in batch. If left to None, predictions will not be
- resized.
-
- Returns:
- `List[Dict]`: A list of dictionaries, one per image, each dictionary containing two keys:
- - **segmentation** -- a tensor of shape `(height, width)` where each pixel represents a `segment_id`, set
- to `None` if no mask if found above `threshold`. If `target_sizes` is specified, segmentation is resized
- to the corresponding `target_sizes` entry.
- - **segments_info** -- A dictionary that contains additional information on each segment.
- - **id** -- an integer representing the `segment_id`.
- - **label_id** -- An integer representing the label / semantic class id corresponding to `segment_id`.
- - **was_fused** -- a boolean, `True` if `label_id` was in `label_ids_to_fuse`, `False` otherwise.
- Multiple instances of the same class / label were fused and assigned a single `segment_id`.
- - **score** -- Prediction score of segment with `segment_id`.
- """
-
- if label_ids_to_fuse is None:
- logger.warning("`label_ids_to_fuse` unset. No instance will be fused.")
- label_ids_to_fuse = set()
-
- class_queries_logits = outputs.class_queries_logits # [batch_size, num_queries, num_classes+1]
- masks_queries_logits = outputs.masks_queries_logits # [batch_size, num_queries, height, width]
-
- batch_size = class_queries_logits.shape[0]
- num_labels = class_queries_logits.shape[-1] - 1
-
- mask_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
-
- # Predicted label and score of each query (batch_size, num_queries)
- pred_scores, pred_labels = nn.functional.softmax(class_queries_logits, dim=-1).max(-1)
-
- # Loop over items in batch size
- results: List[Dict[str, Tensor]] = []
-
- for i in range(batch_size):
- mask_probs_item, pred_scores_item, pred_labels_item = remove_low_and_no_objects(
- mask_probs[i], pred_scores[i], pred_labels[i], threshold, num_labels
- )
-
- # No mask found
- if mask_probs_item.shape[0] <= 0:
- height, width = target_sizes[i] if target_sizes is not None else mask_probs_item.shape[1:]
- segmentation = torch.zeros((height, width)) - 1
- results.append({"segmentation": segmentation, "segments_info": []})
- continue
-
- # Get segmentation map and segment information of batch item
- target_size = target_sizes[i] if target_sizes is not None else None
- segmentation, segments = compute_segments(
- mask_probs_item,
- pred_scores_item,
- pred_labels_item,
- mask_threshold,
- overlap_mask_area_threshold,
- label_ids_to_fuse,
- target_size,
- )
-
- results.append({"segmentation": segmentation, "segments_info": segments})
- return results
+MaskFormerFeatureExtractor = MaskFormerImageProcessor
diff --git a/src/transformers/models/maskformer/image_processing_maskformer.py b/src/transformers/models/maskformer/image_processing_maskformer.py
new file mode 100644
index 0000000000..50cef60700
--- /dev/null
+++ b/src/transformers/models/maskformer/image_processing_maskformer.py
@@ -0,0 +1,1143 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Image processor class for MaskFormer."""
+
+import math
+import warnings
+from typing import TYPE_CHECKING, Any, Dict, Iterable, List, Optional, Set, Tuple, Union
+
+import numpy as np
+
+from transformers.image_processing_utils import BaseImageProcessor, BatchFeature, get_size_dict
+from transformers.image_transforms import (
+ PaddingMode,
+ get_resize_output_image_size,
+ normalize,
+ pad,
+ rescale,
+ resize,
+ to_channel_dimension_format,
+ to_numpy_array,
+)
+from transformers.image_utils import (
+ ChannelDimension,
+ ImageInput,
+ PILImageResampling,
+ get_image_size,
+ infer_channel_dimension_format,
+ is_batched,
+ valid_images,
+)
+from transformers.utils import (
+ IMAGENET_DEFAULT_MEAN,
+ IMAGENET_DEFAULT_STD,
+ TensorType,
+ is_torch_available,
+ is_torch_tensor,
+ logging,
+)
+
+
+logger = logging.get_logger(__name__)
+
+
+if TYPE_CHECKING:
+ from transformers import MaskFormerForInstanceSegmentationOutput
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+
+# Copied from transformers.models.detr.image_processing_detr.max_across_indices
+def max_across_indices(values: Iterable[Any]) -> List[Any]:
+ """
+ Return the maximum value across all indices of an iterable of values.
+ """
+ return [max(values_i) for values_i in zip(*values)]
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_max_height_width
+def get_max_height_width(images: List[np.ndarray]) -> List[int]:
+ """
+ Get the maximum height and width across all images in a batch.
+ """
+ input_channel_dimension = infer_channel_dimension_format(images[0])
+
+ if input_channel_dimension == ChannelDimension.FIRST:
+ _, max_height, max_width = max_across_indices([img.shape for img in images])
+ elif input_channel_dimension == ChannelDimension.LAST:
+ max_height, max_width, _ = max_across_indices([img.shape for img in images])
+ else:
+ raise ValueError(f"Invalid channel dimension format: {input_channel_dimension}")
+ return (max_height, max_width)
+
+
+# Copied from transformers.models.detr.image_processing_detr.make_pixel_mask
+def make_pixel_mask(image: np.ndarray, output_size: Tuple[int, int]) -> np.ndarray:
+ """
+ Make a pixel mask for the image, where 1 indicates a valid pixel and 0 indicates padding.
+
+ Args:
+ image (`np.ndarray`):
+ Image to make the pixel mask for.
+ output_size (`Tuple[int, int]`):
+ Output size of the mask.
+ """
+ input_height, input_width = get_image_size(image)
+ mask = np.zeros(output_size, dtype=np.int64)
+ mask[:input_height, :input_width] = 1
+ return mask
+
+
+# Copied from transformers.models.detr.image_processing_detr.binary_mask_to_rle
+def binary_mask_to_rle(mask):
+ """
+ Converts given binary mask of shape `(height, width)` to the run-length encoding (RLE) format.
+
+ Args:
+ mask (`torch.Tensor` or `numpy.array`):
+ A binary mask tensor of shape `(height, width)` where 0 denotes background and 1 denotes the target
+ segment_id or class_id.
+ Returns:
+ `List`: Run-length encoded list of the binary mask. Refer to COCO API for more information about the RLE
+ format.
+ """
+ if is_torch_tensor(mask):
+ mask = mask.numpy()
+
+ pixels = mask.flatten()
+ pixels = np.concatenate([[0], pixels, [0]])
+ runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
+ runs[1::2] -= runs[::2]
+ return [x for x in runs]
+
+
+# Copied from transformers.models.detr.image_processing_detr.convert_segmentation_to_rle
+def convert_segmentation_to_rle(segmentation):
+ """
+ Converts given segmentation map of shape `(height, width)` to the run-length encoding (RLE) format.
+
+ Args:
+ segmentation (`torch.Tensor` or `numpy.array`):
+ A segmentation map of shape `(height, width)` where each value denotes a segment or class id.
+ Returns:
+ `List[List]`: A list of lists, where each list is the run-length encoding of a segment / class id.
+ """
+ segment_ids = torch.unique(segmentation)
+
+ run_length_encodings = []
+ for idx in segment_ids:
+ mask = torch.where(segmentation == idx, 1, 0)
+ rle = binary_mask_to_rle(mask)
+ run_length_encodings.append(rle)
+
+ return run_length_encodings
+
+
+# Copied from transformers.models.detr.image_processing_detr.remove_low_and_no_objects
+def remove_low_and_no_objects(masks, scores, labels, object_mask_threshold, num_labels):
+ """
+ Binarize the given masks using `object_mask_threshold`, it returns the associated values of `masks`, `scores` and
+ `labels`.
+
+ Args:
+ masks (`torch.Tensor`):
+ A tensor of shape `(num_queries, height, width)`.
+ scores (`torch.Tensor`):
+ A tensor of shape `(num_queries)`.
+ labels (`torch.Tensor`):
+ A tensor of shape `(num_queries)`.
+ object_mask_threshold (`float`):
+ A number between 0 and 1 used to binarize the masks.
+ Raises:
+ `ValueError`: Raised when the first dimension doesn't match in all input tensors.
+ Returns:
+ `Tuple[`torch.Tensor`, `torch.Tensor`, `torch.Tensor`]`: The `masks`, `scores` and `labels` without the region
+ < `object_mask_threshold`.
+ """
+ if not (masks.shape[0] == scores.shape[0] == labels.shape[0]):
+ raise ValueError("mask, scores and labels must have the same shape!")
+
+ to_keep = labels.ne(num_labels) & (scores > object_mask_threshold)
+
+ return masks[to_keep], scores[to_keep], labels[to_keep]
+
+
+# Copied from transformers.models.detr.image_processing_detr.check_segment_validity
+def check_segment_validity(mask_labels, mask_probs, k, mask_threshold=0.5, overlap_mask_area_threshold=0.8):
+ # Get the mask associated with the k class
+ mask_k = mask_labels == k
+ mask_k_area = mask_k.sum()
+
+ # Compute the area of all the stuff in query k
+ original_area = (mask_probs[k] >= mask_threshold).sum()
+ mask_exists = mask_k_area > 0 and original_area > 0
+
+ # Eliminate disconnected tiny segments
+ if mask_exists:
+ area_ratio = mask_k_area / original_area
+ if not area_ratio.item() > overlap_mask_area_threshold:
+ mask_exists = False
+
+ return mask_exists, mask_k
+
+
+# Copied from transformers.models.detr.image_processing_detr.compute_segments
+def compute_segments(
+ mask_probs,
+ pred_scores,
+ pred_labels,
+ mask_threshold: float = 0.5,
+ overlap_mask_area_threshold: float = 0.8,
+ label_ids_to_fuse: Optional[Set[int]] = None,
+ target_size: Tuple[int, int] = None,
+):
+ height = mask_probs.shape[1] if target_size is None else target_size[0]
+ width = mask_probs.shape[2] if target_size is None else target_size[1]
+
+ segmentation = torch.zeros((height, width), dtype=torch.int32, device=mask_probs.device)
+ segments: List[Dict] = []
+
+ if target_size is not None:
+ mask_probs = nn.functional.interpolate(
+ mask_probs.unsqueeze(0), size=target_size, mode="bilinear", align_corners=False
+ )[0]
+
+ current_segment_id = 0
+
+ # Weigh each mask by its prediction score
+ mask_probs *= pred_scores.view(-1, 1, 1)
+ mask_labels = mask_probs.argmax(0) # [height, width]
+
+ # Keep track of instances of each class
+ stuff_memory_list: Dict[str, int] = {}
+ for k in range(pred_labels.shape[0]):
+ pred_class = pred_labels[k].item()
+ should_fuse = pred_class in label_ids_to_fuse
+
+ # Check if mask exists and large enough to be a segment
+ mask_exists, mask_k = check_segment_validity(
+ mask_labels, mask_probs, k, mask_threshold, overlap_mask_area_threshold
+ )
+
+ if mask_exists:
+ if pred_class in stuff_memory_list:
+ current_segment_id = stuff_memory_list[pred_class]
+ else:
+ current_segment_id += 1
+
+ # Add current object segment to final segmentation map
+ segmentation[mask_k] = current_segment_id
+ segment_score = round(pred_scores[k].item(), 6)
+ segments.append(
+ {
+ "id": current_segment_id,
+ "label_id": pred_class,
+ "was_fused": should_fuse,
+ "score": segment_score,
+ }
+ )
+ if should_fuse:
+ stuff_memory_list[pred_class] = current_segment_id
+
+ return segmentation, segments
+
+
+# TODO: (Amy) Move to image_transforms
+def convert_segmentation_map_to_binary_masks(
+ segmentation_map: "np.ndarray",
+ instance_id_to_semantic_id: Optional[Dict[int, int]] = None,
+ ignore_index: Optional[int] = None,
+ reduce_labels: bool = False,
+):
+ if reduce_labels and ignore_index is None:
+ raise ValueError("If `reduce_labels` is True, `ignore_index` must be provided.")
+
+ if reduce_labels:
+ segmentation_map = np.where(segmentation_map == 0, ignore_index, segmentation_map - 1)
+
+ # Get unique ids (class or instance ids based on input)
+ all_labels = np.unique(segmentation_map)
+
+ # Drop background label if applicable
+ if ignore_index is not None:
+ all_labels = all_labels[all_labels != ignore_index]
+
+ # Generate a binary mask for each object instance
+ binary_masks = [(segmentation_map == i) for i in all_labels]
+ binary_masks = np.stack(binary_masks, axis=0) # (num_labels, height, width)
+
+ # Convert instance ids to class ids
+ if instance_id_to_semantic_id is not None:
+ labels = np.zeros(all_labels.shape[0])
+
+ for label in all_labels:
+ class_id = instance_id_to_semantic_id[label + 1 if reduce_labels else label]
+ labels[all_labels == label] = class_id - 1 if reduce_labels else class_id
+ else:
+ labels = all_labels
+
+ return binary_masks.astype(np.float32), labels.astype(np.int64)
+
+
+def get_maskformer_resize_output_image_size(
+ image: np.ndarray,
+ size: Union[int, Tuple[int, int], List[int], Tuple[int]],
+ max_size: Optional[int] = None,
+ size_divisor: int = 0,
+ default_to_square: bool = True,
+) -> tuple:
+ """
+ Computes the output size given the desired size.
+
+ Args:
+ input_image (`np.ndarray`):
+ The input image.
+ size (`int`, `Tuple[int, int]`, `List[int]`, `Tuple[int]`):
+ The size of the output image.
+ default_to_square (`bool`, *optional*, defaults to `True`):
+ Whether to default to square if no size is provided.
+ max_size (`int`, *optional*):
+ The maximum size of the output image.
+ size_divisible (`int`, *optional*, defaults to `0`):
+ If size_divisible is given, the output image size will be divisible by the number.
+
+ Returns:
+ `Tuple[int, int]`: The output size.
+ """
+ output_size = get_resize_output_image_size(
+ input_image=image, size=size, default_to_square=default_to_square, max_size=max_size
+ )
+
+ if size_divisor > 0:
+ height, width = output_size
+ height = int(math.ceil(height / size_divisor) * size_divisor)
+ width = int(math.ceil(width / size_divisor) * size_divisor)
+ output_size = (height, width)
+
+ return output_size
+
+
+class MaskFormerImageProcessor(BaseImageProcessor):
+ r"""
+ Constructs a MaskFormer image processor. The image processor can be used to prepare image(s) and optional targets
+ for the model.
+
+ This image processor inherits from [`BaseImageProcessor`] which contains most of the main methods. Users should
+ refer to this superclass for more information regarding those methods.
+
+ Args:
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Whether to resize the input to a certain `size`.
+ size (`int`, *optional*, defaults to 800):
+ Resize the input to the given size. Only has an effect if `do_resize` is set to `True`. If size is a
+ sequence like `(width, height)`, output size will be matched to this. If size is an int, smaller edge of
+ the image will be matched to this number. i.e, if `height > width`, then image will be rescaled to `(size *
+ height / width, size)`.
+ max_size (`int`, *optional*, defaults to 1333):
+ The largest size an image dimension can have (otherwise it's capped). Only has an effect if `do_resize` is
+ set to `True`.
+ resample (`int`, *optional*, defaults to `PIL.Image.Resampling.BILINEAR`):
+ An optional resampling filter. This can be one of `PIL.Image.Resampling.NEAREST`,
+ `PIL.Image.Resampling.BOX`, `PIL.Image.Resampling.BILINEAR`, `PIL.Image.Resampling.HAMMING`,
+ `PIL.Image.Resampling.BICUBIC` or `PIL.Image.Resampling.LANCZOS`. Only has an effect if `do_resize` is set
+ to `True`.
+ size_divisor (`int`, *optional*, defaults to 32):
+ Some backbones need images divisible by a certain number. If not passed, it defaults to the value used in
+ Swin Transformer.
+ do_rescale (`bool`, *optional*, defaults to `True`):
+ Whether to rescale the input to a certain `scale`.
+ rescale_factor (`float`, *optional*, defaults to 1/ 255):
+ Rescale the input by the given factor. Only has an effect if `do_rescale` is set to `True`.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether or not to normalize the input with mean and standard deviation.
+ image_mean (`int`, *optional*, defaults to `[0.485, 0.456, 0.406]`):
+ The sequence of means for each channel, to be used when normalizing images. Defaults to the ImageNet mean.
+ image_std (`int`, *optional*, defaults to `[0.229, 0.224, 0.225]`):
+ The sequence of standard deviations for each channel, to be used when normalizing images. Defaults to the
+ ImageNet std.
+ ignore_index (`int`, *optional*):
+ Label to be assigned to background pixels in segmentation maps. If provided, segmentation map pixels
+ denoted with 0 (background) will be replaced with `ignore_index`.
+ reduce_labels (`bool`, *optional*, defaults to `False`):
+ Whether or not to decrement all label values of segmentation maps by 1. Usually used for datasets where 0
+ is used for background, and background itself is not included in all classes of a dataset (e.g. ADE20k).
+ The background label will be replaced by `ignore_index`.
+
+ """
+
+ model_input_names = ["pixel_values", "pixel_mask"]
+
+ def __init__(
+ self,
+ do_resize: bool = True,
+ size: Dict[str, int] = None,
+ size_divisor: int = 32,
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ do_rescale: bool = True,
+ rescale_factor: float = 1 / 255,
+ do_normalize: bool = True,
+ image_mean: Union[float, List[float]] = None,
+ image_std: Union[float, List[float]] = None,
+ ignore_index: Optional[int] = None,
+ reduce_labels: bool = False,
+ **kwargs
+ ):
+ if "size_divisibility" in kwargs:
+ warnings.warn(
+ "The `size_divisibility` argument is deprecated and will be removed in v4.27. Please use "
+ "`size_divisibility` instead.",
+ FutureWarning,
+ )
+ size_divisor = kwargs.pop("size_divisibility")
+ if "max_size" in kwargs:
+ warnings.warn(
+ "The `max_size` argument is deprecated and will be removed in v4.27. Please use size['longest_edge']"
+ " instead.",
+ FutureWarning,
+ )
+ # We make max_size a private attribute so we can pass it as a default value in the preprocess method whilst
+ # `size` can still be pass in as an int
+ self._max_size = kwargs.pop("max_size")
+ else:
+ self._max_size = 1333
+
+ size = size if size is not None else {"shortest_edge": 800, "longest_edge": self._max_size}
+ size = get_size_dict(size, max_size=self._max_size, default_to_square=False)
+
+ super().__init__(**kwargs)
+ self.do_resize = do_resize
+ self.size = size
+ self.resample = resample
+ self.size_divisor = size_divisor
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean if image_mean is not None else IMAGENET_DEFAULT_MEAN
+ self.image_std = image_std if image_std is not None else IMAGENET_DEFAULT_STD
+ self.ignore_index = ignore_index
+ self.reduce_labels = reduce_labels
+
+ @property
+ def size_divisibility(self):
+ warnings.warn(
+ "The `size_divisibility` property is deprecated and will be removed in v4.27. Please use "
+ "`size_divisor` instead.",
+ FutureWarning,
+ )
+ return self.size_divisor
+
+ @property
+ def max_size(self):
+ warnings.warn(
+ "The `max_size` property is deprecated and will be removed in v4.27. Please use size['longest_edge']"
+ " instead.",
+ FutureWarning,
+ )
+ return self.size["longest_edge"]
+
+ def resize(
+ self,
+ image: np.ndarray,
+ size: Dict[str, int],
+ size_divisor: int = 0,
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ data_format=None,
+ **kwargs
+ ) -> np.ndarray:
+ """
+ Resize the image to the given size. Size can be min_size (scalar) or `(height, width)` tuple. If size is an
+ int, smaller edge of the image will be matched to this number.
+ """
+ if "max_size" in kwargs:
+ warnings.warn(
+ "The `max_size` parameter is deprecated and will be removed in v4.27. "
+ "Please specify in `size['longest_edge'] instead`.",
+ FutureWarning,
+ )
+ max_size = kwargs.pop("max_size")
+ else:
+ max_size = None
+ size = get_size_dict(size, max_size=max_size, default_to_square=False)
+ if "shortest_edge" in size and "longest_edge" in size:
+ size, max_size = size["shortest_edge"], size["longest_edge"]
+ elif "height" in size and "width" in size:
+ size = (size["height"], size["width"])
+ max_size = None
+ else:
+ raise ValueError(
+ "Size must contain 'height' and 'width' keys or 'shortest_edge' and 'longest_edge' keys. Got"
+ f" {size.keys()}."
+ )
+ size = get_maskformer_resize_output_image_size(
+ image=image,
+ size=size,
+ max_size=max_size,
+ size_divisor=size_divisor,
+ default_to_square=False,
+ )
+ image = resize(image, size=size, resample=resample, data_format=data_format)
+ return image
+
+ def rescale(
+ self, image: np.ndarray, rescale_factor: float, data_format: Optional[ChannelDimension] = None
+ ) -> np.ndarray:
+ """
+ Rescale the image by the given factor.
+ """
+ return rescale(image, rescale_factor, data_format=data_format)
+
+ def normalize(
+ self,
+ image: np.ndarray,
+ mean: Union[float, Iterable[float]],
+ std: Union[float, Iterable[float]],
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Normalize the image with the given mean and standard deviation.
+ """
+ return normalize(image, mean=mean, std=std, data_format=data_format)
+
+ def convert_segmentation_map_to_binary_masks(
+ self,
+ segmentation_map: "np.ndarray",
+ instance_id_to_semantic_id: Optional[Dict[int, int]] = None,
+ ignore_index: Optional[int] = None,
+ reduce_labels: bool = False,
+ ):
+ reduce_labels = reduce_labels if reduce_labels is not None else self.reduce_labels
+ ignore_index = ignore_index if ignore_index is not None else self.ignore_index
+ return convert_segmentation_map_to_binary_masks(
+ segmentation_map=segmentation_map,
+ instance_id_to_semantic_id=instance_id_to_semantic_id,
+ ignore_index=ignore_index,
+ reduce_labels=reduce_labels,
+ )
+
+ def __call__(self, images, segmentation_maps=None, **kwargs) -> BatchFeature:
+ return self.preprocess(images, segmentation_maps=segmentation_maps, **kwargs)
+
+ def _preprocess(
+ self,
+ image: ImageInput,
+ do_resize: bool = None,
+ size: Dict[str, int] = None,
+ size_divisor: int = None,
+ resample: PILImageResampling = None,
+ do_rescale: bool = None,
+ rescale_factor: float = None,
+ do_normalize: bool = None,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ ):
+ if do_resize:
+ image = self.resize(image, size=size, size_divisor=size_divisor, resample=resample)
+ if do_rescale:
+ image = self.rescale(image, rescale_factor=rescale_factor)
+ if do_normalize:
+ image = self.normalize(image, mean=image_mean, std=image_std)
+ return image
+
+ def _preprocess_image(
+ self,
+ image: ImageInput,
+ do_resize: bool = None,
+ size: Dict[str, int] = None,
+ size_divisor: int = None,
+ resample: PILImageResampling = None,
+ do_rescale: bool = None,
+ rescale_factor: float = None,
+ do_normalize: bool = None,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ data_format: Optional[Union[str, ChannelDimension]] = None,
+ ) -> np.ndarray:
+ """Preprocesses a single image."""
+ # All transformations expect numpy arrays.
+ image = to_numpy_array(image)
+ image = self._preprocess(
+ image=image,
+ do_resize=do_resize,
+ size=size,
+ size_divisor=size_divisor,
+ resample=resample,
+ do_rescale=do_rescale,
+ rescale_factor=rescale_factor,
+ do_normalize=do_normalize,
+ image_mean=image_mean,
+ image_std=image_std,
+ )
+ if data_format is not None:
+ image = to_channel_dimension_format(image, data_format)
+ return image
+
+ def _preprocess_mask(
+ self,
+ segmentation_map: ImageInput,
+ do_resize: bool = None,
+ size: Dict[str, int] = None,
+ size_divisor: int = 0,
+ ) -> np.ndarray:
+ """Preprocesses a single mask."""
+ segmentation_map = to_numpy_array(segmentation_map)
+ # Add channel dimension if missing - needed for certain transformations
+ added_channel_dim = False
+ if segmentation_map.ndim == 2:
+ added_channel_dim = True
+ segmentation_map = segmentation_map[None, ...]
+ # TODO: (Amy)
+ # Remork segmentation map processing to include reducing labels and resizing which doesn't
+ # drop segment IDs > 255.
+ segmentation_map = self._preprocess(
+ image=segmentation_map,
+ do_resize=do_resize,
+ resample=PILImageResampling.NEAREST,
+ size=size,
+ size_divisor=size_divisor,
+ do_rescale=False,
+ do_normalize=False,
+ )
+ # Remove extra channel dimension if added for processing
+ if added_channel_dim:
+ segmentation_map = segmentation_map.squeeze(0)
+ return segmentation_map
+
+ def preprocess(
+ self,
+ images: ImageInput,
+ segmentation_maps: Optional[ImageInput] = None,
+ instance_id_to_semantic_id: Optional[Dict[int, int]] = None,
+ do_resize: Optional[bool] = None,
+ size: Optional[Dict[str, int]] = None,
+ size_divisor: Optional[int] = None,
+ resample: PILImageResampling = None,
+ do_rescale: Optional[bool] = None,
+ rescale_factor: Optional[float] = None,
+ do_normalize: Optional[bool] = None,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ ignore_index: Optional[int] = None,
+ reduce_labels: Optional[bool] = None,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ data_format: Union[str, ChannelDimension] = ChannelDimension.FIRST,
+ **kwargs
+ ) -> BatchFeature:
+ if "pad_and_return_pixel_mask" in kwargs:
+ warnings.warn(
+ "The `pad_and_return_pixel_mask` argument is deprecated and will be removed in a future version",
+ FutureWarning,
+ )
+
+ do_resize = do_resize if do_resize is not None else self.do_resize
+ size = size if size is not None else self.size
+ size = get_size_dict(size, default_to_square=False, max_size=self._max_size)
+ size_divisor = size_divisor if size_divisor is not None else self.size_divisor
+ resample = resample if resample is not None else self.resample
+ do_rescale = do_rescale if do_rescale is not None else self.do_rescale
+ rescale_factor = rescale_factor if rescale_factor is not None else self.rescale_factor
+ do_normalize = do_normalize if do_normalize is not None else self.do_normalize
+ image_mean = image_mean if image_mean is not None else self.image_mean
+ image_std = image_std if image_std is not None else self.image_std
+ ignore_index = ignore_index if ignore_index is not None else self.ignore_index
+ reduce_labels = reduce_labels if reduce_labels is not None else self.reduce_labels
+
+ if do_resize is not None and size is None or size_divisor is None:
+ raise ValueError("If `do_resize` is True, `size` and `size_divisor` must be provided.")
+
+ if do_rescale is not None and rescale_factor is None:
+ raise ValueError("If `do_rescale` is True, `rescale_factor` must be provided.")
+
+ if do_normalize is not None and (image_mean is None or image_std is None):
+ raise ValueError("If `do_normalize` is True, `image_mean` and `image_std` must be provided.")
+
+ if not valid_images(images):
+ raise ValueError(
+ "Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
+ "torch.Tensor, tf.Tensor or jax.ndarray."
+ )
+
+ if segmentation_maps is not None and not valid_images(segmentation_maps):
+ raise ValueError(
+ "Invalid segmentation map type. Must be of type PIL.Image.Image, numpy.ndarray, "
+ "torch.Tensor, tf.Tensor or jax.ndarray."
+ )
+
+ if not is_batched(images):
+ images = [images]
+ segmentation_maps = [segmentation_maps] if segmentation_maps is not None else None
+
+ if segmentation_maps is not None and len(images) != len(segmentation_maps):
+ raise ValueError("Images and segmentation maps must have the same length.")
+
+ images = [
+ self._preprocess_image(
+ image,
+ do_resize=do_resize,
+ size=size,
+ size_divisor=size_divisor,
+ resample=resample,
+ do_rescale=do_rescale,
+ rescale_factor=rescale_factor,
+ do_normalize=do_normalize,
+ image_mean=image_mean,
+ image_std=image_std,
+ data_format=data_format,
+ )
+ for image in images
+ ]
+
+ if segmentation_maps is not None:
+ segmentation_maps = [
+ self._preprocess_mask(segmentation_map, do_resize, size, size_divisor)
+ for segmentation_map in segmentation_maps
+ ]
+ encoded_inputs = self.encode_inputs(
+ images, segmentation_maps, instance_id_to_semantic_id, ignore_index, reduce_labels, return_tensors
+ )
+ return encoded_inputs
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor._pad_image
+ def _pad_image(
+ self,
+ image: np.ndarray,
+ output_size: Tuple[int, int],
+ constant_values: Union[float, Iterable[float]] = 0,
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Pad an image with zeros to the given size.
+ """
+ input_height, input_width = get_image_size(image)
+ output_height, output_width = output_size
+
+ pad_bottom = output_height - input_height
+ pad_right = output_width - input_width
+ padding = ((0, pad_bottom), (0, pad_right))
+ padded_image = pad(
+ image, padding, mode=PaddingMode.CONSTANT, constant_values=constant_values, data_format=data_format
+ )
+ return padded_image
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.pad
+ def pad(
+ self,
+ images: List[np.ndarray],
+ constant_values: Union[float, Iterable[float]] = 0,
+ return_pixel_mask: bool = True,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Pads a batch of images to the bottom and right of the image with zeros to the size of largest height and width
+ in the batch and optionally returns their corresponding pixel mask.
+
+ Args:
+ image (`np.ndarray`):
+ Image to pad.
+ constant_values (`float` or `Iterable[float]`, *optional*):
+ The value to use for the padding if `mode` is `"constant"`.
+ return_pixel_mask (`bool`, *optional*, defaults to `True`):
+ Whether to return a pixel mask.
+ input_channel_dimension (`ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be inferred from the input image.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be the same as the input image.
+ """
+ pad_size = get_max_height_width(images)
+
+ padded_images = [
+ self._pad_image(image, pad_size, constant_values=constant_values, data_format=data_format)
+ for image in images
+ ]
+ data = {"pixel_values": padded_images}
+
+ if return_pixel_mask:
+ masks = [make_pixel_mask(image=image, output_size=pad_size) for image in images]
+ data["pixel_mask"] = masks
+
+ return BatchFeature(data=data, tensor_type=return_tensors)
+
+ def encode_inputs(
+ self,
+ pixel_values_list: List[ImageInput],
+ segmentation_maps: ImageInput = None,
+ instance_id_to_semantic_id: Optional[Union[List[Dict[int, int]], Dict[int, int]]] = None,
+ ignore_index: Optional[int] = None,
+ reduce_labels: bool = False,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ **kwargs
+ ):
+ """
+ Pad images up to the largest image in a batch and create a corresponding `pixel_mask`.
+
+ MaskFormer addresses semantic segmentation with a mask classification paradigm, thus input segmentation maps
+ will be converted to lists of binary masks and their respective labels. Let's see an example, assuming
+ `segmentation_maps = [[2,6,7,9]]`, the output will contain `mask_labels =
+ [[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1]]` (four binary masks) and `class_labels = [2,6,7,9]`, the labels for
+ each mask.
+
+ Args:
+ pixel_values_list (`List[ImageInput]`):
+ List of images (pixel values) to be padded. Each image should be a tensor of shape `(channels, height,
+ width)`.
+
+ segmentation_maps (`ImageInput`, *optional*):
+ The corresponding semantic segmentation maps with the pixel-wise annotations.
+
+ (`bool`, *optional*, defaults to `True`):
+ Whether or not to pad images up to the largest image in a batch and create a pixel mask.
+
+ If left to the default, will return a pixel mask that is:
+
+ - 1 for pixels that are real (i.e. **not masked**),
+ - 0 for pixels that are padding (i.e. **masked**).
+
+ instance_id_to_semantic_id (`List[Dict[int, int]]` or `Dict[int, int]`, *optional*):
+ A mapping between object instance ids and class ids. If passed, `segmentation_maps` is treated as an
+ instance segmentation map where each pixel represents an instance id. Can be provided as a single
+ dictionary with a global/dataset-level mapping or as a list of dictionaries (one per image), to map
+ instance ids in each image separately.
+
+ return_tensors (`str` or [`~file_utils.TensorType`], *optional*):
+ If set, will return tensors instead of NumPy arrays. If set to `'pt'`, return PyTorch `torch.Tensor`
+ objects.
+
+ Returns:
+ [`BatchFeature`]: A [`BatchFeature`] with the following fields:
+
+ - **pixel_values** -- Pixel values to be fed to a model.
+ - **pixel_mask** -- Pixel mask to be fed to a model (when `=True` or if `pixel_mask` is in
+ `self.model_input_names`).
+ - **mask_labels** -- Optional list of mask labels of shape `(labels, height, width)` to be fed to a model
+ (when `annotations` are provided).
+ - **class_labels** -- Optional list of class labels of shape `(labels)` to be fed to a model (when
+ `annotations` are provided). They identify the labels of `mask_labels`, e.g. the label of
+ `mask_labels[i][j]` if `class_labels[i][j]`.
+ """
+ ignore_index = self.ignore_index if ignore_index is None else ignore_index
+ reduce_labels = self.reduce_labels if reduce_labels is None else reduce_labels
+
+ if "pad_and_return_pixel_mask" in kwargs:
+ warnings.warn(
+ "The `pad_and_return_pixel_mask` argument has no effect and will be removed in v4.27", FutureWarning
+ )
+
+ pixel_values_list = [to_numpy_array(pixel_values) for pixel_values in pixel_values_list]
+ encoded_inputs = self.pad(pixel_values_list, return_tensors=return_tensors)
+
+ if segmentation_maps is not None:
+ mask_labels = []
+ class_labels = []
+ pad_size = get_max_height_width(pixel_values_list)
+ # Convert to list of binary masks and labels
+ for idx, segmentation_map in enumerate(segmentation_maps):
+ segmentation_map = to_numpy_array(segmentation_map)
+ if isinstance(instance_id_to_semantic_id, list):
+ instance_id = instance_id_to_semantic_id[idx]
+ else:
+ instance_id = instance_id_to_semantic_id
+ # Use instance2class_id mapping per image
+ masks, classes = self.convert_segmentation_map_to_binary_masks(
+ segmentation_map, instance_id, ignore_index=ignore_index, reduce_labels=reduce_labels
+ )
+ # We add an axis to make them compatible with the transformations library
+ # this will be removed in the future
+ masks = [mask[None, ...] for mask in masks]
+ masks = [
+ self._pad_image(image=mask, output_size=pad_size, constant_values=ignore_index) for mask in masks
+ ]
+ masks = np.concatenate(masks, axis=0)
+ mask_labels.append(torch.from_numpy(masks))
+ class_labels.append(torch.from_numpy(classes))
+
+ # we cannot batch them since they don't share a common class size
+ encoded_inputs["mask_labels"] = mask_labels
+ encoded_inputs["class_labels"] = class_labels
+
+ return encoded_inputs
+
+ def post_process_segmentation(
+ self, outputs: "MaskFormerForInstanceSegmentationOutput", target_size: Tuple[int, int] = None
+ ) -> "torch.Tensor":
+ """
+ Converts the output of [`MaskFormerForInstanceSegmentationOutput`] into image segmentation predictions. Only
+ supports PyTorch.
+
+ Args:
+ outputs ([`MaskFormerForInstanceSegmentationOutput`]):
+ The outputs from [`MaskFormerForInstanceSegmentation`].
+
+ target_size (`Tuple[int, int]`, *optional*):
+ If set, the `masks_queries_logits` will be resized to `target_size`.
+
+ Returns:
+ `torch.Tensor`:
+ A tensor of shape (`batch_size, num_class_labels, height, width`).
+ """
+ logger.warning(
+ "`post_process_segmentation` is deprecated and will be removed in v5 of Transformers, please use"
+ " `post_process_instance_segmentation`",
+ FutureWarning,
+ )
+
+ # class_queries_logits has shape [BATCH, QUERIES, CLASSES + 1]
+ class_queries_logits = outputs.class_queries_logits
+ # masks_queries_logits has shape [BATCH, QUERIES, HEIGHT, WIDTH]
+ masks_queries_logits = outputs.masks_queries_logits
+ if target_size is not None:
+ masks_queries_logits = torch.nn.functional.interpolate(
+ masks_queries_logits,
+ size=target_size,
+ mode="bilinear",
+ align_corners=False,
+ )
+ # remove the null class `[..., :-1]`
+ masks_classes = class_queries_logits.softmax(dim=-1)[..., :-1]
+ # mask probs has shape [BATCH, QUERIES, HEIGHT, WIDTH]
+ masks_probs = masks_queries_logits.sigmoid()
+ # now we want to sum over the queries,
+ # $ out_{c,h,w} = \sum_q p_{q,c} * m_{q,h,w} $
+ # where $ softmax(p) \in R^{q, c} $ is the mask classes
+ # and $ sigmoid(m) \in R^{q, h, w}$ is the mask probabilities
+ # b(atch)q(uery)c(lasses), b(atch)q(uery)h(eight)w(idth)
+ segmentation = torch.einsum("bqc, bqhw -> bchw", masks_classes, masks_probs)
+
+ return segmentation
+
+ def post_process_semantic_segmentation(
+ self, outputs, target_sizes: Optional[List[Tuple[int, int]]] = None
+ ) -> "torch.Tensor":
+ """
+ Converts the output of [`MaskFormerForInstanceSegmentation`] into semantic segmentation maps. Only supports
+ PyTorch.
+
+ Args:
+ outputs ([`MaskFormerForInstanceSegmentation`]):
+ Raw outputs of the model.
+ target_sizes (`List[Tuple[int, int]]`, *optional*):
+ List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
+ final size (height, width) of each prediction. If left to None, predictions will not be resized.
+ Returns:
+ `List[torch.Tensor]`:
+ A list of length `batch_size`, where each item is a semantic segmentation map of shape (height, width)
+ corresponding to the target_sizes entry (if `target_sizes` is specified). Each entry of each
+ `torch.Tensor` correspond to a semantic class id.
+ """
+ class_queries_logits = outputs.class_queries_logits # [batch_size, num_queries, num_classes+1]
+ masks_queries_logits = outputs.masks_queries_logits # [batch_size, num_queries, height, width]
+
+ # Remove the null class `[..., :-1]`
+ masks_classes = class_queries_logits.softmax(dim=-1)[..., :-1]
+ masks_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
+
+ # Semantic segmentation logits of shape (batch_size, num_classes, height, width)
+ segmentation = torch.einsum("bqc, bqhw -> bchw", masks_classes, masks_probs)
+ batch_size = class_queries_logits.shape[0]
+
+ # Resize logits and compute semantic segmentation maps
+ if target_sizes is not None:
+ if batch_size != len(target_sizes):
+ raise ValueError(
+ "Make sure that you pass in as many target sizes as the batch dimension of the logits"
+ )
+
+ semantic_segmentation = []
+ for idx in range(batch_size):
+ resized_logits = torch.nn.functional.interpolate(
+ segmentation[idx].unsqueeze(dim=0), size=target_sizes[idx], mode="bilinear", align_corners=False
+ )
+ semantic_map = resized_logits[0].argmax(dim=0)
+ semantic_segmentation.append(semantic_map)
+ else:
+ semantic_segmentation = segmentation.argmax(dim=1)
+ semantic_segmentation = [semantic_segmentation[i] for i in range(semantic_segmentation.shape[0])]
+
+ return semantic_segmentation
+
+ def post_process_instance_segmentation(
+ self,
+ outputs,
+ threshold: float = 0.5,
+ mask_threshold: float = 0.5,
+ overlap_mask_area_threshold: float = 0.8,
+ target_sizes: Optional[List[Tuple[int, int]]] = None,
+ return_coco_annotation: Optional[bool] = False,
+ ) -> List[Dict]:
+ """
+ Converts the output of [`MaskFormerForInstanceSegmentationOutput`] into instance segmentation predictions. Only
+ supports PyTorch.
+
+ Args:
+ outputs ([`MaskFormerForInstanceSegmentation`]):
+ Raw outputs of the model.
+ threshold (`float`, *optional*, defaults to 0.5):
+ The probability score threshold to keep predicted instance masks.
+ mask_threshold (`float`, *optional*, defaults to 0.5):
+ Threshold to use when turning the predicted masks into binary values.
+ overlap_mask_area_threshold (`float`, *optional*, defaults to 0.8):
+ The overlap mask area threshold to merge or discard small disconnected parts within each binary
+ instance mask.
+ target_sizes (`List[Tuple]`, *optional*):
+ List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
+ final size (height, width) of each prediction. If left to None, predictions will not be resized.
+ return_coco_annotation (`bool`, *optional*):
+ Defaults to `False`. If set to `True`, segmentation maps are returned in COCO run-length encoding (RLE)
+ format.
+ Returns:
+ `List[Dict]`: A list of dictionaries, one per image, each dictionary containing two keys:
+ - **segmentation** -- A tensor of shape `(height, width)` where each pixel represents a `segment_id` or
+ `List[List]` run-length encoding (RLE) of the segmentation map if return_coco_annotation is set to
+ `True`. Set to `None` if no mask if found above `threshold`.
+ - **segments_info** -- A dictionary that contains additional information on each segment.
+ - **id** -- An integer representing the `segment_id`.
+ - **label_id** -- An integer representing the label / semantic class id corresponding to `segment_id`.
+ - **score** -- Prediction score of segment with `segment_id`.
+ """
+ class_queries_logits = outputs.class_queries_logits # [batch_size, num_queries, num_classes+1]
+ masks_queries_logits = outputs.masks_queries_logits # [batch_size, num_queries, height, width]
+
+ batch_size = class_queries_logits.shape[0]
+ num_labels = class_queries_logits.shape[-1] - 1
+
+ mask_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
+
+ # Predicted label and score of each query (batch_size, num_queries)
+ pred_scores, pred_labels = nn.functional.softmax(class_queries_logits, dim=-1).max(-1)
+
+ # Loop over items in batch size
+ results: List[Dict[str, TensorType]] = []
+
+ for i in range(batch_size):
+ mask_probs_item, pred_scores_item, pred_labels_item = remove_low_and_no_objects(
+ mask_probs[i], pred_scores[i], pred_labels[i], threshold, num_labels
+ )
+
+ # No mask found
+ if mask_probs_item.shape[0] <= 0:
+ height, width = target_sizes[i] if target_sizes is not None else mask_probs_item.shape[1:]
+ segmentation = torch.zeros((height, width)) - 1
+ results.append({"segmentation": segmentation, "segments_info": []})
+ continue
+
+ # Get segmentation map and segment information of batch item
+ target_size = target_sizes[i] if target_sizes is not None else None
+ segmentation, segments = compute_segments(
+ mask_probs_item,
+ pred_scores_item,
+ pred_labels_item,
+ mask_threshold,
+ overlap_mask_area_threshold,
+ target_size,
+ )
+
+ # Return segmentation map in run-length encoding (RLE) format
+ if return_coco_annotation:
+ segmentation = convert_segmentation_to_rle(segmentation)
+
+ results.append({"segmentation": segmentation, "segments_info": segments})
+ return results
+
+ def post_process_panoptic_segmentation(
+ self,
+ outputs,
+ threshold: float = 0.5,
+ mask_threshold: float = 0.5,
+ overlap_mask_area_threshold: float = 0.8,
+ label_ids_to_fuse: Optional[Set[int]] = None,
+ target_sizes: Optional[List[Tuple[int, int]]] = None,
+ ) -> List[Dict]:
+ """
+ Converts the output of [`MaskFormerForInstanceSegmentationOutput`] into image panoptic segmentation
+ predictions. Only supports PyTorch.
+
+ Args:
+ outputs ([`MaskFormerForInstanceSegmentationOutput`]):
+ The outputs from [`MaskFormerForInstanceSegmentation`].
+ threshold (`float`, *optional*, defaults to 0.5):
+ The probability score threshold to keep predicted instance masks.
+ mask_threshold (`float`, *optional*, defaults to 0.5):
+ Threshold to use when turning the predicted masks into binary values.
+ overlap_mask_area_threshold (`float`, *optional*, defaults to 0.8):
+ The overlap mask area threshold to merge or discard small disconnected parts within each binary
+ instance mask.
+ label_ids_to_fuse (`Set[int]`, *optional*):
+ The labels in this state will have all their instances be fused together. For instance we could say
+ there can only be one sky in an image, but several persons, so the label ID for sky would be in that
+ set, but not the one for person.
+ target_sizes (`List[Tuple]`, *optional*):
+ List of length (batch_size), where each list item (`Tuple[int, int]]`) corresponds to the requested
+ final size (height, width) of each prediction in batch. If left to None, predictions will not be
+ resized.
+
+ Returns:
+ `List[Dict]`: A list of dictionaries, one per image, each dictionary containing two keys:
+ - **segmentation** -- a tensor of shape `(height, width)` where each pixel represents a `segment_id`, set
+ to `None` if no mask if found above `threshold`. If `target_sizes` is specified, segmentation is resized
+ to the corresponding `target_sizes` entry.
+ - **segments_info** -- A dictionary that contains additional information on each segment.
+ - **id** -- an integer representing the `segment_id`.
+ - **label_id** -- An integer representing the label / semantic class id corresponding to `segment_id`.
+ - **was_fused** -- a boolean, `True` if `label_id` was in `label_ids_to_fuse`, `False` otherwise.
+ Multiple instances of the same class / label were fused and assigned a single `segment_id`.
+ - **score** -- Prediction score of segment with `segment_id`.
+ """
+
+ if label_ids_to_fuse is None:
+ logger.warning("`label_ids_to_fuse` unset. No instance will be fused.")
+ label_ids_to_fuse = set()
+
+ class_queries_logits = outputs.class_queries_logits # [batch_size, num_queries, num_classes+1]
+ masks_queries_logits = outputs.masks_queries_logits # [batch_size, num_queries, height, width]
+
+ batch_size = class_queries_logits.shape[0]
+ num_labels = class_queries_logits.shape[-1] - 1
+
+ mask_probs = masks_queries_logits.sigmoid() # [batch_size, num_queries, height, width]
+
+ # Predicted label and score of each query (batch_size, num_queries)
+ pred_scores, pred_labels = nn.functional.softmax(class_queries_logits, dim=-1).max(-1)
+
+ # Loop over items in batch size
+ results: List[Dict[str, TensorType]] = []
+
+ for i in range(batch_size):
+ mask_probs_item, pred_scores_item, pred_labels_item = remove_low_and_no_objects(
+ mask_probs[i], pred_scores[i], pred_labels[i], threshold, num_labels
+ )
+
+ # No mask found
+ if mask_probs_item.shape[0] <= 0:
+ height, width = target_sizes[i] if target_sizes is not None else mask_probs_item.shape[1:]
+ segmentation = torch.zeros((height, width)) - 1
+ results.append({"segmentation": segmentation, "segments_info": []})
+ continue
+
+ # Get segmentation map and segment information of batch item
+ target_size = target_sizes[i] if target_sizes is not None else None
+ segmentation, segments = compute_segments(
+ mask_probs_item,
+ pred_scores_item,
+ pred_labels_item,
+ mask_threshold,
+ overlap_mask_area_threshold,
+ label_ids_to_fuse,
+ target_size,
+ )
+
+ results.append({"segmentation": segmentation, "segments_info": segments})
+ return results
diff --git a/src/transformers/models/owlvit/__init__.py b/src/transformers/models/owlvit/__init__.py
index cc528d315e..f29db2f06c 100644
--- a/src/transformers/models/owlvit/__init__.py
+++ b/src/transformers/models/owlvit/__init__.py
@@ -47,6 +47,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_owlvit"] = ["OwlViTFeatureExtractor"]
+ _import_structure["image_processing_owlvit"] = ["OwlViTImageProcessor"]
try:
if not is_torch_available():
@@ -80,6 +81,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_owlvit import OwlViTFeatureExtractor
+ from .image_processing_owlvit import OwlViTImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/models/owlvit/feature_extraction_owlvit.py b/src/transformers/models/owlvit/feature_extraction_owlvit.py
index 0bbb8c3105..424111ada0 100644
--- a/src/transformers/models/owlvit/feature_extraction_owlvit.py
+++ b/src/transformers/models/owlvit/feature_extraction_owlvit.py
@@ -14,317 +14,11 @@
# limitations under the License.
"""Feature extractor class for OwlViT."""
-from typing import List, Optional, Union
+from ...utils import logging
+from .image_processing_owlvit import OwlViTImageProcessor
-import numpy as np
-from PIL import Image
-
-from transformers.image_utils import PILImageResampling
-
-from ...feature_extraction_utils import BatchFeature, FeatureExtractionMixin
-from ...image_transforms import center_to_corners_format
-from ...image_utils import ImageFeatureExtractionMixin
-from ...utils import TensorType, is_torch_available, is_torch_tensor, logging
-
-
-if is_torch_available():
- import torch
logger = logging.get_logger(__name__)
-# Copied from transformers.models.detr.modeling_detr._upcast
-def _upcast(t):
- # Protects from numerical overflows in multiplications by upcasting to the equivalent higher type
- if t.is_floating_point():
- return t if t.dtype in (torch.float32, torch.float64) else t.float()
- else:
- return t if t.dtype in (torch.int32, torch.int64) else t.int()
-
-
-def box_area(boxes):
- """
- Computes the area of a set of bounding boxes, which are specified by its (x1, y1, x2, y2) coordinates.
-
- Args:
- boxes (`torch.FloatTensor` of shape `(number_of_boxes, 4)`):
- Boxes for which the area will be computed. They are expected to be in (x1, y1, x2, y2) format with `0 <= x1
- < x2` and `0 <= y1 < y2`.
-
- Returns:
- `torch.FloatTensor`: a tensor containing the area for each box.
- """
- boxes = _upcast(boxes)
- return (boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1])
-
-
-def box_iou(boxes1, boxes2):
- area1 = box_area(boxes1)
- area2 = box_area(boxes2)
-
- left_top = torch.max(boxes1[:, None, :2], boxes2[:, :2]) # [N,M,2]
- right_bottom = torch.min(boxes1[:, None, 2:], boxes2[:, 2:]) # [N,M,2]
-
- width_height = (right_bottom - left_top).clamp(min=0) # [N,M,2]
- inter = width_height[:, :, 0] * width_height[:, :, 1] # [N,M]
-
- union = area1[:, None] + area2 - inter
-
- iou = inter / union
- return iou, union
-
-
-class OwlViTFeatureExtractor(FeatureExtractionMixin, ImageFeatureExtractionMixin):
- r"""
- Constructs an OWL-ViT feature extractor.
-
- This feature extractor inherits from [`FeatureExtractionMixin`] which contains most of the main methods. Users
- should refer to this superclass for more information regarding those methods.
-
- Args:
- do_resize (`bool`, *optional*, defaults to `True`):
- Whether to resize the shorter edge of the input to a certain `size`.
- size (`int` or `Tuple[int, int]`, *optional*, defaults to (768, 768)):
- The size to use for resizing the image. Only has an effect if `do_resize` is set to `True`. If `size` is a
- sequence like (h, w), output size will be matched to this. If `size` is an int, then image will be resized
- to (size, size).
- resample (`int`, *optional*, defaults to `PIL.Image.Resampling.BICUBIC`):
- An optional resampling filter. This can be one of `PIL.Image.Resampling.NEAREST`,
- `PIL.Image.Resampling.BOX`, `PIL.Image.Resampling.BILINEAR`, `PIL.Image.Resampling.HAMMING`,
- `PIL.Image.Resampling.BICUBIC` or `PIL.Image.Resampling.LANCZOS`. Only has an effect if `do_resize` is set
- to `True`.
- do_center_crop (`bool`, *optional*, defaults to `False`):
- Whether to crop the input at the center. If the input size is smaller than `crop_size` along any edge, the
- image is padded with 0's and then center cropped.
- crop_size (`int`, *optional*, defaults to 768):
- do_normalize (`bool`, *optional*, defaults to `True`):
- Whether or not to normalize the input with `image_mean` and `image_std`. Desired output size when applying
- center-cropping. Only has an effect if `do_center_crop` is set to `True`.
- image_mean (`List[int]`, *optional*, defaults to `[0.48145466, 0.4578275, 0.40821073]`):
- The sequence of means for each channel, to be used when normalizing images.
- image_std (`List[int]`, *optional*, defaults to `[0.26862954, 0.26130258, 0.27577711]`):
- The sequence of standard deviations for each channel, to be used when normalizing images.
- """
-
- model_input_names = ["pixel_values"]
-
- def __init__(
- self,
- do_resize=True,
- size=(768, 768),
- resample=PILImageResampling.BICUBIC,
- crop_size=768,
- do_center_crop=False,
- do_normalize=True,
- image_mean=None,
- image_std=None,
- **kwargs
- ):
- # Early versions of the OWL-ViT config on the hub had "rescale" as a flag. This clashes with the
- # vision feature extractor method `rescale` as it would be set as an attribute during the super().__init__
- # call. This is for backwards compatibility.
- if "rescale" in kwargs:
- rescale_val = kwargs.pop("rescale")
- kwargs["do_rescale"] = rescale_val
-
- super().__init__(**kwargs)
- self.size = size
- self.resample = resample
- self.crop_size = crop_size
- self.do_resize = do_resize
- self.do_center_crop = do_center_crop
- self.do_normalize = do_normalize
- self.image_mean = image_mean if image_mean is not None else [0.48145466, 0.4578275, 0.40821073]
- self.image_std = image_std if image_std is not None else [0.26862954, 0.26130258, 0.27577711]
-
- def post_process(self, outputs, target_sizes):
- """
- Converts the output of [`OwlViTForObjectDetection`] into the format expected by the COCO api.
-
- Args:
- outputs ([`OwlViTObjectDetectionOutput`]):
- Raw outputs of the model.
- target_sizes (`torch.Tensor`, *optional*):
- Tensor of shape (batch_size, 2) where each entry is the (height, width) of the corresponding image in
- the batch. If set, predicted normalized bounding boxes are rescaled to the target sizes. If left to
- None, predictions will not be unnormalized.
-
- Returns:
- `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
- in the batch as predicted by the model.
- """
- logits, boxes = outputs.logits, outputs.pred_boxes
-
- if len(logits) != len(target_sizes):
- raise ValueError("Make sure that you pass in as many target sizes as the batch dimension of the logits")
- if target_sizes.shape[1] != 2:
- raise ValueError("Each element of target_sizes must contain the size (h, w) of each image of the batch")
-
- probs = torch.max(logits, dim=-1)
- scores = torch.sigmoid(probs.values)
- labels = probs.indices
-
- # Convert to [x0, y0, x1, y1] format
- boxes = center_to_corners_format(boxes)
-
- # Convert from relative [0, 1] to absolute [0, height] coordinates
- img_h, img_w = target_sizes.unbind(1)
- scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
- boxes = boxes * scale_fct[:, None, :]
-
- results = [{"scores": s, "labels": l, "boxes": b} for s, l, b in zip(scores, labels, boxes)]
-
- return results
-
- def post_process_image_guided_detection(self, outputs, threshold=0.6, nms_threshold=0.3, target_sizes=None):
- """
- Converts the output of [`OwlViTForObjectDetection.image_guided_detection`] into the format expected by the COCO
- api.
-
- Args:
- outputs ([`OwlViTImageGuidedObjectDetectionOutput`]):
- Raw outputs of the model.
- threshold (`float`, *optional*, defaults to 0.6):
- Minimum confidence threshold to use to filter out predicted boxes.
- nms_threshold (`float`, *optional*, defaults to 0.3):
- IoU threshold for non-maximum suppression of overlapping boxes.
- target_sizes (`torch.Tensor`, *optional*):
- Tensor of shape (batch_size, 2) where each entry is the (height, width) of the corresponding image in
- the batch. If set, predicted normalized bounding boxes are rescaled to the target sizes. If left to
- None, predictions will not be unnormalized.
-
- Returns:
- `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
- in the batch as predicted by the model. All labels are set to None as
- `OwlViTForObjectDetection.image_guided_detection` perform one-shot object detection.
- """
- logits, target_boxes = outputs.logits, outputs.target_pred_boxes
-
- if len(logits) != len(target_sizes):
- raise ValueError("Make sure that you pass in as many target sizes as the batch dimension of the logits")
- if target_sizes.shape[1] != 2:
- raise ValueError("Each element of target_sizes must contain the size (h, w) of each image of the batch")
-
- probs = torch.max(logits, dim=-1)
- scores = torch.sigmoid(probs.values)
-
- # Convert to [x0, y0, x1, y1] format
- target_boxes = center_to_corners_format(target_boxes)
-
- # Apply non-maximum suppression (NMS)
- if nms_threshold < 1.0:
- for idx in range(target_boxes.shape[0]):
- for i in torch.argsort(-scores[idx]):
- if not scores[idx][i]:
- continue
-
- ious = box_iou(target_boxes[idx][i, :].unsqueeze(0), target_boxes[idx])[0][0]
- ious[i] = -1.0 # Mask self-IoU.
- scores[idx][ious > nms_threshold] = 0.0
-
- # Convert from relative [0, 1] to absolute [0, height] coordinates
- img_h, img_w = target_sizes.unbind(1)
- scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
- target_boxes = target_boxes * scale_fct[:, None, :]
-
- # Compute box display alphas based on prediction scores
- results = []
- alphas = torch.zeros_like(scores)
-
- for idx in range(target_boxes.shape[0]):
- # Select scores for boxes matching the current query:
- query_scores = scores[idx]
- if not query_scores.nonzero().numel():
- continue
-
- # Scale box alpha such that the best box for each query has alpha 1.0 and the worst box has alpha 0.1.
- # All other boxes will either belong to a different query, or will not be shown.
- max_score = torch.max(query_scores) + 1e-6
- query_alphas = (query_scores - (max_score * 0.1)) / (max_score * 0.9)
- query_alphas[query_alphas < threshold] = 0.0
- query_alphas = torch.clip(query_alphas, 0.0, 1.0)
- alphas[idx] = query_alphas
-
- mask = alphas[idx] > 0
- box_scores = alphas[idx][mask]
- boxes = target_boxes[idx][mask]
- results.append({"scores": box_scores, "labels": None, "boxes": boxes})
-
- return results
-
- def __call__(
- self,
- images: Union[
- Image.Image, np.ndarray, "torch.Tensor", List[Image.Image], List[np.ndarray], List["torch.Tensor"] # noqa
- ],
- return_tensors: Optional[Union[str, TensorType]] = None,
- **kwargs
- ) -> BatchFeature:
- """
- Main method to prepare for the model one or several image(s).
-
-
-
- NumPy arrays and PyTorch tensors are converted to PIL images when resizing, so the most efficient is to pass
- PIL images.
-
-
-
- Args:
- images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
- The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
- tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W) or (H, W, C),
- where C is a number of channels, H and W are image height and width.
-
- return_tensors (`str` or [`~utils.TensorType`], *optional*, defaults to `'np'`):
- If set, will return tensors of a particular framework. Acceptable values are:
- - `'tf'`: Return TensorFlow `tf.constant` objects.
- - `'pt'`: Return PyTorch `torch.Tensor` objects.
- - `'np'`: Return NumPy `np.ndarray` objects.
- - `'jax'`: Return JAX `jnp.ndarray` objects.
-
- Returns:
- [`BatchFeature`]: A [`BatchFeature`] with the following fields:
-
- - **pixel_values** -- Pixel values to be fed to a model.
- """
- # Input type checking for clearer error
- valid_images = False
-
- # Check that images has a valid type
- if isinstance(images, (Image.Image, np.ndarray)) or is_torch_tensor(images):
- valid_images = True
- elif isinstance(images, (list, tuple)):
- if isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]):
- valid_images = True
-
- if not valid_images:
- raise ValueError(
- "Images must of type `PIL.Image.Image`, `np.ndarray` or `torch.Tensor` (single example), "
- "`List[PIL.Image.Image]`, `List[np.ndarray]` or `List[torch.Tensor]` (batch of examples)."
- )
-
- is_batched = bool(
- isinstance(images, (list, tuple))
- and (isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]))
- )
-
- if not is_batched:
- images = [images]
-
- # transformations (resizing + center cropping + normalization)
- if self.do_resize and self.size is not None and self.resample is not None:
- images = [
- self.resize(image=image, size=self.size, resample=self.resample, default_to_square=True)
- for image in images
- ]
- if self.do_center_crop and self.crop_size is not None:
- images = [self.center_crop(image, self.crop_size) for image in images]
- if self.do_normalize:
- images = [self.normalize(image=image, mean=self.image_mean, std=self.image_std) for image in images]
-
- # return as BatchFeature
- data = {"pixel_values": images}
- encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
-
- return encoded_inputs
+OwlViTFeatureExtractor = OwlViTImageProcessor
diff --git a/src/transformers/models/owlvit/image_processing_owlvit.py b/src/transformers/models/owlvit/image_processing_owlvit.py
new file mode 100644
index 0000000000..0ccb11a122
--- /dev/null
+++ b/src/transformers/models/owlvit/image_processing_owlvit.py
@@ -0,0 +1,445 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Image processor class for OwlViT"""
+
+from typing import Dict, List, Optional, Union
+
+import numpy as np
+
+from transformers.image_processing_utils import BaseImageProcessor, BatchFeature, get_size_dict
+from transformers.image_transforms import (
+ center_crop,
+ center_to_corners_format,
+ normalize,
+ rescale,
+ resize,
+ to_channel_dimension_format,
+ to_numpy_array,
+)
+from transformers.image_utils import ChannelDimension, ImageInput, PILImageResampling, is_batched, valid_images
+from transformers.utils import TensorType, is_torch_available, logging
+
+
+if is_torch_available():
+ import torch
+
+
+logger = logging.get_logger(__name__)
+
+
+# Copied from transformers.models.detr.modeling_detr._upcast
+def _upcast(t):
+ # Protects from numerical overflows in multiplications by upcasting to the equivalent higher type
+ if t.is_floating_point():
+ return t if t.dtype in (torch.float32, torch.float64) else t.float()
+ else:
+ return t if t.dtype in (torch.int32, torch.int64) else t.int()
+
+
+def box_area(boxes):
+ """
+ Computes the area of a set of bounding boxes, which are specified by its (x1, y1, x2, y2) coordinates.
+
+ Args:
+ boxes (`torch.FloatTensor` of shape `(number_of_boxes, 4)`):
+ Boxes for which the area will be computed. They are expected to be in (x1, y1, x2, y2) format with `0 <= x1
+ < x2` and `0 <= y1 < y2`.
+ Returns:
+ `torch.FloatTensor`: a tensor containing the area for each box.
+ """
+ boxes = _upcast(boxes)
+ return (boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1])
+
+
+def box_iou(boxes1, boxes2):
+ area1 = box_area(boxes1)
+ area2 = box_area(boxes2)
+
+ left_top = torch.max(boxes1[:, None, :2], boxes2[:, :2]) # [N,M,2]
+ right_bottom = torch.min(boxes1[:, None, 2:], boxes2[:, 2:]) # [N,M,2]
+
+ width_height = (right_bottom - left_top).clamp(min=0) # [N,M,2]
+ inter = width_height[:, :, 0] * width_height[:, :, 1] # [N,M]
+
+ union = area1[:, None] + area2 - inter
+
+ iou = inter / union
+ return iou, union
+
+
+class OwlViTImageProcessor(BaseImageProcessor):
+ r"""
+ Constructs an OWL-ViT feature extractor.
+
+ This feature extractor inherits from [`FeatureExtractionMixin`] which contains most of the main methods. Users
+ should refer to this superclass for more information regarding those methods.
+
+ Args:
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Whether to resize the shorter edge of the input to a certain `size`.
+ size (`Dict[str, int]`, *optional*, defaults to {"height": 768, "width": 768}):
+ The size to use for resizing the image. Only has an effect if `do_resize` is set to `True`. If `size` is a
+ sequence like (h, w), output size will be matched to this. If `size` is an int, then image will be resized
+ to (size, size).
+ resample (`int`, *optional*, defaults to `PIL.Image.Resampling.BICUBIC`):
+ An optional resampling filter. This can be one of `PIL.Image.Resampling.NEAREST`,
+ `PIL.Image.Resampling.BOX`, `PIL.Image.Resampling.BILINEAR`, `PIL.Image.Resampling.HAMMING`,
+ `PIL.Image.Resampling.BICUBIC` or `PIL.Image.Resampling.LANCZOS`. Only has an effect if `do_resize` is set
+ to `True`.
+ do_center_crop (`bool`, *optional*, defaults to `False`):
+ Whether to crop the input at the center. If the input size is smaller than `crop_size` along any edge, the
+ image is padded with 0's and then center cropped.
+ crop_size (`int`, *optional*, defaults to {"height": 768, "width": 768}):
+ The size to use for center cropping the image. Only has an effect if `do_center_crop` is set to `True`.
+ do_rescale (`bool`, *optional*, defaults to `True`):
+ Whether to rescale the input by a certain factor.
+ rescale_factor (`float`, *optional*, defaults to `1/255`):
+ The factor to use for rescaling the image. Only has an effect if `do_rescale` is set to `True`.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether or not to normalize the input with `image_mean` and `image_std`. Desired output size when applying
+ center-cropping. Only has an effect if `do_center_crop` is set to `True`.
+ image_mean (`List[int]`, *optional*, defaults to `[0.48145466, 0.4578275, 0.40821073]`):
+ The sequence of means for each channel, to be used when normalizing images.
+ image_std (`List[int]`, *optional*, defaults to `[0.26862954, 0.26130258, 0.27577711]`):
+ The sequence of standard deviations for each channel, to be used when normalizing images.
+ """
+
+ model_input_names = ["pixel_values"]
+
+ def __init__(
+ self,
+ do_resize=True,
+ size=None,
+ resample=PILImageResampling.BICUBIC,
+ do_center_crop=False,
+ crop_size=None,
+ do_rescale=True,
+ rescale_factor=1 / 255,
+ do_normalize=True,
+ image_mean=None,
+ image_std=None,
+ **kwargs
+ ):
+ size = size if size is not None else {"height": 768, "width": 768}
+ size = get_size_dict(size, default_to_square=True)
+
+ crop_size = crop_size if crop_size is not None else {"height": 768, "width": 768}
+ crop_size = get_size_dict(crop_size, default_to_square=True)
+
+ # Early versions of the OWL-ViT config on the hub had "rescale" as a flag. This clashes with the
+ # vision feature extractor method `rescale` as it would be set as an attribute during the super().__init__
+ # call. This is for backwards compatibility.
+ if "rescale" in kwargs:
+ rescale_val = kwargs.pop("rescale")
+ kwargs["do_rescale"] = rescale_val
+
+ super().__init__(**kwargs)
+ self.do_resize = do_resize
+ self.size = size
+ self.resample = resample
+ self.do_center_crop = do_center_crop
+ self.crop_size = crop_size
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean if image_mean is not None else [0.48145466, 0.4578275, 0.40821073]
+ self.image_std = image_std if image_std is not None else [0.26862954, 0.26130258, 0.27577711]
+
+ def resize(
+ self,
+ image: np.ndarray,
+ size: Dict[str, int],
+ resample: PILImageResampling.BICUBIC,
+ data_format: Optional[Union[str, ChannelDimension]] = None,
+ **kwargs
+ ) -> np.ndarray:
+ """
+ Resize an image to a certain size.
+ """
+ size = get_size_dict(size, default_to_square=True)
+ if "height" not in size or "width" not in size:
+ raise ValueError("size dictionary must contain height and width keys")
+
+ return resize(image, (size["height"], size["width"]), resample=resample, data_format=data_format, **kwargs)
+
+ def center_crop(
+ self,
+ image: np.ndarray,
+ crop_size: Dict[str, int],
+ data_format: Optional[Union[str, ChannelDimension]] = None,
+ **kwargs
+ ) -> np.ndarray:
+ """
+ Center crop an image to a certain size.
+ """
+ crop_size = get_size_dict(crop_size, default_to_square=True)
+ if "height" not in crop_size or "width" not in crop_size:
+ raise ValueError("crop_size dictionary must contain height and width keys")
+
+ return center_crop(image, (crop_size["height"], crop_size["width"]), data_format=data_format, **kwargs)
+
+ def rescale(
+ self,
+ image: np.ndarray,
+ rescale_factor: float,
+ data_format: Optional[Union[str, ChannelDimension]] = None,
+ **kwargs
+ ) -> np.ndarray:
+ """
+ Rescale an image by a certain factor.
+ """
+ return rescale(image, rescale_factor, data_format=data_format, **kwargs)
+
+ def normalize(
+ self,
+ image: np.ndarray,
+ mean: List[float],
+ std: List[float],
+ data_format: Optional[Union[str, ChannelDimension]] = None,
+ **kwargs
+ ) -> np.ndarray:
+ """
+ Normalize an image with a certain mean and standard deviation.
+ """
+ return normalize(image, mean, std, data_format=data_format, **kwargs)
+
+ def preprocess(
+ self,
+ images: ImageInput,
+ do_resize: Optional[bool] = None,
+ size: Optional[Dict[str, int]] = None,
+ resample: PILImageResampling = None,
+ do_center_crop: Optional[bool] = None,
+ crop_size: Optional[Dict[str, int]] = None,
+ do_rescale: Optional[bool] = None,
+ rescale_factor: Optional[float] = None,
+ do_normalize: Optional[bool] = None,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ return_tensors: Optional[Union[TensorType, str]] = None,
+ data_format: Union[str, ChannelDimension] = ChannelDimension.FIRST,
+ **kwargs
+ ) -> BatchFeature:
+ """
+ Prepares an image or batch of images for the model.
+
+ Args:
+ images (`ImageInput`):
+ The image or batch of images to be prepared.
+ do_resize (`bool`, *optional*, defaults to `self.do_resize`):
+ Whether or not to resize the input. If `True`, will resize the input to the size specified by `size`.
+ size (`Dict[str, int]`, *optional*, defaults to `self.size`):
+ The size to resize the input to. Only has an effect if `do_resize` is set to `True`.
+ resample (`PILImageResampling`, *optional*, defaults to `self.resample`):
+ The resampling filter to use when resizing the input. Only has an effect if `do_resize` is set to
+ `True`.
+ do_center_crop (`bool`, *optional*, defaults to `self.do_center_crop`):
+ Whether or not to center crop the input. If `True`, will center crop the input to the size specified by
+ `crop_size`.
+ crop_size (`Dict[str, int]`, *optional*, defaults to `self.crop_size`):
+ The size to center crop the input to. Only has an effect if `do_center_crop` is set to `True`.
+ do_rescale (`bool`, *optional*, defaults to `self.do_rescale`):
+ Whether or not to rescale the input. If `True`, will rescale the input by dividing it by
+ `rescale_factor`.
+ rescale_factor (`float`, *optional*, defaults to `self.rescale_factor`):
+ The factor to rescale the input by. Only has an effect if `do_rescale` is set to `True`.
+ do_normalize (`bool`, *optional*, defaults to `self.do_normalize`):
+ Whether or not to normalize the input. If `True`, will normalize the input by subtracting `image_mean`
+ and dividing by `image_std`.
+ image_mean (`Union[float, List[float]]`, *optional*, defaults to `self.image_mean`):
+ The mean to subtract from the input when normalizing. Only has an effect if `do_normalize` is set to
+ `True`.
+ image_std (`Union[float, List[float]]`, *optional*, defaults to `self.image_std`):
+ The standard deviation to divide the input by when normalizing. Only has an effect if `do_normalize` is
+ set to `True`.
+ return_tensors (`str` or `TensorType`, *optional*):
+ The type of tensors to return. Can be one of:
+ - Unset: Return a list of `np.ndarray`.
+ - `TensorType.TENSORFLOW` or `'tf'`: Return a batch of type `tf.Tensor`.
+ - `TensorType.PYTORCH` or `'pt'`: Return a batch of type `torch.Tensor`.
+ - `TensorType.NUMPY` or `'np'`: Return a batch of type `np.ndarray`.
+ - `TensorType.JAX` or `'jax'`: Return a batch of type `jax.numpy.ndarray`.
+ data_format (`ChannelDimension` or `str`, *optional*, defaults to `ChannelDimension.FIRST`):
+ The channel dimension format for the output image. Can be one of:
+ - `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - Unset: defaults to the channel dimension format of the input image.
+ """
+ do_resize = do_resize if do_resize is not None else self.do_resize
+ size = size if size is not None else self.size
+ resample = resample if resample is not None else self.resample
+ do_center_crop = do_center_crop if do_center_crop is not None else self.do_center_crop
+ crop_size = crop_size if crop_size is not None else self.crop_size
+ do_rescale = do_rescale if do_rescale is not None else self.do_rescale
+ rescale_factor = rescale_factor if rescale_factor is not None else self.rescale_factor
+ do_normalize = do_normalize if do_normalize is not None else self.do_normalize
+ image_mean = image_mean if image_mean is not None else self.image_mean
+ image_std = image_std if image_std is not None else self.image_std
+
+ if do_resize is not None and size is None:
+ raise ValueError("Size and max_size must be specified if do_resize is True.")
+
+ if do_center_crop is not None and crop_size is None:
+ raise ValueError("Crop size must be specified if do_center_crop is True.")
+
+ if do_rescale is not None and rescale_factor is None:
+ raise ValueError("Rescale factor must be specified if do_rescale is True.")
+
+ if do_normalize is not None and (image_mean is None or image_std is None):
+ raise ValueError("Image mean and std must be specified if do_normalize is True.")
+
+ if not is_batched(images):
+ images = [images]
+
+ if not valid_images(images):
+ raise ValueError(
+ "Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
+ "torch.Tensor, tf.Tensor or jax.ndarray."
+ )
+
+ # All transformations expect numpy arrays
+ images = [to_numpy_array(image) for image in images]
+
+ if do_resize:
+ images = [self.resize(image, size=size, resample=resample) for image in images]
+
+ if do_center_crop:
+ images = [self.center_crop(image, crop_size=crop_size) for image in images]
+
+ if do_rescale:
+ images = [self.rescale(image, rescale_factor=rescale_factor) for image in images]
+
+ if do_normalize:
+ images = [self.normalize(image, mean=image_mean, std=image_std) for image in images]
+
+ images = [to_channel_dimension_format(image, data_format) for image in images]
+ encoded_inputs = BatchFeature(data={"pixel_values": images}, tensor_type=return_tensors)
+ return encoded_inputs
+
+ def post_process(self, outputs, target_sizes):
+ """
+ Converts the output of [`OwlViTForObjectDetection`] into the format expected by the COCO api.
+
+ Args:
+ outputs ([`OwlViTObjectDetectionOutput`]):
+ Raw outputs of the model.
+ target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
+ Tensor containing the size (h, w) of each image of the batch. For evaluation, this must be the original
+ image size (before any data augmentation). For visualization, this should be the image size after data
+ augment, but before padding.
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
+ in the batch as predicted by the model.
+ """
+ # TODO: (amy) add support for other frameworks
+ logits, boxes = outputs.logits, outputs.pred_boxes
+
+ if len(logits) != len(target_sizes):
+ raise ValueError("Make sure that you pass in as many target sizes as the batch dimension of the logits")
+ if target_sizes.shape[1] != 2:
+ raise ValueError("Each element of target_sizes must contain the size (h, w) of each image of the batch")
+
+ probs = torch.max(logits, dim=-1)
+ scores = torch.sigmoid(probs.values)
+ labels = probs.indices
+
+ # Convert to [x0, y0, x1, y1] format
+ boxes = center_to_corners_format(boxes)
+
+ # Convert from relative [0, 1] to absolute [0, height] coordinates
+ img_h, img_w = target_sizes.unbind(1)
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
+ boxes = boxes * scale_fct[:, None, :]
+
+ results = [{"scores": s, "labels": l, "boxes": b} for s, l, b in zip(scores, labels, boxes)]
+
+ return results
+
+ # TODO: (Amy) Make compatible with other frameworks
+ def post_process_image_guided_detection(self, outputs, threshold=0.6, nms_threshold=0.3, target_sizes=None):
+ """
+ Converts the output of [`OwlViTForObjectDetection.image_guided_detection`] into the format expected by the COCO
+ api.
+
+ Args:
+ outputs ([`OwlViTImageGuidedObjectDetectionOutput`]):
+ Raw outputs of the model.
+ threshold (`float`, *optional*, defaults to 0.6):
+ Minimum confidence threshold to use to filter out predicted boxes.
+ nms_threshold (`float`, *optional*, defaults to 0.3):
+ IoU threshold for non-maximum suppression of overlapping boxes.
+ target_sizes (`torch.Tensor`, *optional*):
+ Tensor of shape (batch_size, 2) where each entry is the (height, width) of the corresponding image in
+ the batch. If set, predicted normalized bounding boxes are rescaled to the target sizes. If left to
+ None, predictions will not be unnormalized.
+
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
+ in the batch as predicted by the model. All labels are set to None as
+ `OwlViTForObjectDetection.image_guided_detection` perform one-shot object detection.
+ """
+ logits, target_boxes = outputs.logits, outputs.target_pred_boxes
+
+ if len(logits) != len(target_sizes):
+ raise ValueError("Make sure that you pass in as many target sizes as the batch dimension of the logits")
+ if target_sizes.shape[1] != 2:
+ raise ValueError("Each element of target_sizes must contain the size (h, w) of each image of the batch")
+
+ probs = torch.max(logits, dim=-1)
+ scores = torch.sigmoid(probs.values)
+
+ # Convert to [x0, y0, x1, y1] format
+ target_boxes = center_to_corners_format(target_boxes)
+
+ # Apply non-maximum suppression (NMS)
+ if nms_threshold < 1.0:
+ for idx in range(target_boxes.shape[0]):
+ for i in torch.argsort(-scores[idx]):
+ if not scores[idx][i]:
+ continue
+
+ ious = box_iou(target_boxes[idx][i, :].unsqueeze(0), target_boxes[idx])[0][0]
+ ious[i] = -1.0 # Mask self-IoU.
+ scores[idx][ious > nms_threshold] = 0.0
+
+ # Convert from relative [0, 1] to absolute [0, height] coordinates
+ img_h, img_w = target_sizes.unbind(1)
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
+ target_boxes = target_boxes * scale_fct[:, None, :]
+
+ # Compute box display alphas based on prediction scores
+ results = []
+ alphas = torch.zeros_like(scores)
+
+ for idx in range(target_boxes.shape[0]):
+ # Select scores for boxes matching the current query:
+ query_scores = scores[idx]
+ if not query_scores.nonzero().numel():
+ continue
+
+ # Scale box alpha such that the best box for each query has alpha 1.0 and the worst box has alpha 0.1.
+ # All other boxes will either belong to a different query, or will not be shown.
+ max_score = torch.max(query_scores) + 1e-6
+ query_alphas = (query_scores - (max_score * 0.1)) / (max_score * 0.9)
+ query_alphas[query_alphas < threshold] = 0.0
+ query_alphas = torch.clip(query_alphas, 0.0, 1.0)
+ alphas[idx] = query_alphas
+
+ mask = alphas[idx] > 0
+ box_scores = alphas[idx][mask]
+ boxes = target_boxes[idx][mask]
+ results.append({"scores": box_scores, "labels": None, "boxes": boxes})
+
+ return results
diff --git a/src/transformers/models/owlvit/processing_owlvit.py b/src/transformers/models/owlvit/processing_owlvit.py
index b88593158f..1cc29cd511 100644
--- a/src/transformers/models/owlvit/processing_owlvit.py
+++ b/src/transformers/models/owlvit/processing_owlvit.py
@@ -15,6 +15,7 @@
"""
Image/Text processor class for OWL-ViT
"""
+
from typing import List
import numpy as np
@@ -33,15 +34,15 @@ class OwlViTProcessor(ProcessorMixin):
Args:
feature_extractor ([`OwlViTFeatureExtractor`]):
- The feature extractor is a required input.
+ The image processor is a required input.
tokenizer ([`CLIPTokenizer`, `CLIPTokenizerFast`]):
The tokenizer is a required input.
"""
feature_extractor_class = "OwlViTFeatureExtractor"
tokenizer_class = ("CLIPTokenizer", "CLIPTokenizerFast")
- def __init__(self, feature_extractor, tokenizer):
- super().__init__(feature_extractor, tokenizer)
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
def __call__(self, text=None, images=None, query_images=None, padding="max_length", return_tensors="np", **kwargs):
"""
diff --git a/src/transformers/models/segformer/image_processing_segformer.py b/src/transformers/models/segformer/image_processing_segformer.py
index 289eac22b0..4f6498b527 100644
--- a/src/transformers/models/segformer/image_processing_segformer.py
+++ b/src/transformers/models/segformer/image_processing_segformer.py
@@ -287,7 +287,6 @@ class SegformerImageProcessor(BaseImageProcessor):
do_reduce_labels: bool = None,
do_resize: bool = None,
size: Dict[str, int] = None,
- resample: PILImageResampling = None,
) -> np.ndarray:
"""Preprocesses a single mask."""
segmentation_map = to_numpy_array(segmentation_map)
@@ -301,7 +300,7 @@ class SegformerImageProcessor(BaseImageProcessor):
image=segmentation_map,
do_reduce_labels=do_reduce_labels,
do_resize=do_resize,
- resample=PIL.Image.NEAREST,
+ resample=PILImageResampling.NEAREST,
size=size,
do_rescale=False,
do_normalize=False,
@@ -438,7 +437,6 @@ class SegformerImageProcessor(BaseImageProcessor):
segmentation_map=segmentation_map,
do_reduce_labels=do_reduce_labels,
do_resize=do_resize,
- resample=PIL.Image.NEAREST,
size=size,
)
for segmentation_map in segmentation_maps
diff --git a/src/transformers/models/yolos/__init__.py b/src/transformers/models/yolos/__init__.py
index 6ae73421a8..f16fc90da4 100644
--- a/src/transformers/models/yolos/__init__.py
+++ b/src/transformers/models/yolos/__init__.py
@@ -29,6 +29,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_yolos"] = ["YolosFeatureExtractor"]
+ _import_structure["image_processing_yolos"] = ["YolosImageProcessor"]
try:
if not is_torch_available():
@@ -54,6 +55,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_yolos import YolosFeatureExtractor
+ from .image_processing_yolos import YolosImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/models/yolos/feature_extraction_yolos.py b/src/transformers/models/yolos/feature_extraction_yolos.py
index de6db49434..6133a9808b 100644
--- a/src/transformers/models/yolos/feature_extraction_yolos.py
+++ b/src/transformers/models/yolos/feature_extraction_yolos.py
@@ -14,694 +14,11 @@
# limitations under the License.
"""Feature extractor class for YOLOS."""
-import pathlib
-import warnings
-from typing import Dict, List, Optional, Tuple, Union
+from ...utils import logging
+from .image_processing_yolos import YolosImageProcessor
-import numpy as np
-from PIL import Image
-
-from ...feature_extraction_utils import BatchFeature, FeatureExtractionMixin
-from ...image_transforms import center_to_corners_format, corners_to_center_format, rgb_to_id
-from ...image_utils import ImageFeatureExtractionMixin, is_torch_tensor
-from ...utils import TensorType, is_torch_available, logging
-
-
-if is_torch_available():
- import torch
- from torch import nn
logger = logging.get_logger(__name__)
-ImageInput = Union[Image.Image, np.ndarray, "torch.Tensor", List[Image.Image], List[np.ndarray], List["torch.Tensor"]]
-
-
-# Copied from transformers.models.detr.feature_extraction_detr.masks_to_boxes
-def masks_to_boxes(masks):
- """
- Compute the bounding boxes around the provided panoptic segmentation masks.
-
- The masks should be in format [N, H, W] where N is the number of masks, (H, W) are the spatial dimensions.
-
- Returns a [N, 4] tensor, with the boxes in corner (xyxy) format.
- """
- if masks.size == 0:
- return np.zeros((0, 4))
-
- h, w = masks.shape[-2:]
-
- y = np.arange(0, h, dtype=np.float32)
- x = np.arange(0, w, dtype=np.float32)
- # see https://github.com/pytorch/pytorch/issues/50276
- y, x = np.meshgrid(y, x, indexing="ij")
-
- x_mask = masks * np.expand_dims(x, axis=0)
- x_max = x_mask.reshape(x_mask.shape[0], -1).max(-1)
- x = np.ma.array(x_mask, mask=~(np.array(masks, dtype=bool)))
- x_min = x.filled(fill_value=1e8)
- x_min = x_min.reshape(x_min.shape[0], -1).min(-1)
-
- y_mask = masks * np.expand_dims(y, axis=0)
- y_max = y_mask.reshape(x_mask.shape[0], -1).max(-1)
- y = np.ma.array(y_mask, mask=~(np.array(masks, dtype=bool)))
- y_min = y.filled(fill_value=1e8)
- y_min = y_min.reshape(y_min.shape[0], -1).min(-1)
-
- return np.stack([x_min, y_min, x_max, y_max], 1)
-
-
-class YolosFeatureExtractor(FeatureExtractionMixin, ImageFeatureExtractionMixin):
- r"""
- Constructs a YOLOS feature extractor.
-
- This feature extractor inherits from [`FeatureExtractionMixin`] which contains most of the main methods. Users
- should refer to this superclass for more information regarding those methods.
-
-
- Args:
- format (`str`, *optional*, defaults to `"coco_detection"`):
- Data format of the annotations. One of "coco_detection" or "coco_panoptic".
- do_resize (`bool`, *optional*, defaults to `True`):
- Whether to resize the input to a certain `size`.
- size (`int`, *optional*, defaults to 800):
- Resize the input to the given size. Only has an effect if `do_resize` is set to `True`. If size is a
- sequence like `(width, height)`, output size will be matched to this. If size is an int, smaller edge of
- the image will be matched to this number. i.e, if `height > width`, then image will be rescaled to `(size *
- height / width, size)`.
- max_size (`int`, *optional*, defaults to `1333`):
- The largest size an image dimension can have (otherwise it's capped). Only has an effect if `do_resize` is
- set to `True`.
- do_normalize (`bool`, *optional*, defaults to `True`):
- Whether or not to normalize the input with mean and standard deviation.
- image_mean (`int`, *optional*, defaults to `[0.485, 0.456, 0.406]`):
- The sequence of means for each channel, to be used when normalizing images. Defaults to the ImageNet mean.
- image_std (`int`, *optional*, defaults to `[0.229, 0.224, 0.225]`):
- The sequence of standard deviations for each channel, to be used when normalizing images. Defaults to the
- ImageNet std.
- """
-
- model_input_names = ["pixel_values"]
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.__init__
- def __init__(
- self,
- format="coco_detection",
- do_resize=True,
- size=800,
- max_size=1333,
- do_normalize=True,
- image_mean=None,
- image_std=None,
- **kwargs
- ):
- super().__init__(**kwargs)
- self.format = self._is_valid_format(format)
- self.do_resize = do_resize
- self.size = size
- self.max_size = max_size
- self.do_normalize = do_normalize
- self.image_mean = image_mean if image_mean is not None else [0.485, 0.456, 0.406] # ImageNet mean
- self.image_std = image_std if image_std is not None else [0.229, 0.224, 0.225] # ImageNet std
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._is_valid_format
- def _is_valid_format(self, format):
- if format not in ["coco_detection", "coco_panoptic"]:
- raise ValueError(f"Format {format} not supported")
- return format
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.prepare
- def prepare(self, image, target, return_segmentation_masks=False, masks_path=None):
- if self.format == "coco_detection":
- image, target = self.prepare_coco_detection(image, target, return_segmentation_masks)
- return image, target
- elif self.format == "coco_panoptic":
- image, target = self.prepare_coco_panoptic(image, target, masks_path)
- return image, target
- else:
- raise ValueError(f"Format {self.format} not supported")
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.convert_coco_poly_to_mask
- def convert_coco_poly_to_mask(self, segmentations, height, width):
-
- try:
- from pycocotools import mask as coco_mask
- except ImportError:
- raise ImportError("Pycocotools is not installed in your environment.")
-
- masks = []
- for polygons in segmentations:
- rles = coco_mask.frPyObjects(polygons, height, width)
- mask = coco_mask.decode(rles)
- if len(mask.shape) < 3:
- mask = mask[..., None]
- mask = np.asarray(mask, dtype=np.uint8)
- mask = np.any(mask, axis=2)
- masks.append(mask)
- if masks:
- masks = np.stack(masks, axis=0)
- else:
- masks = np.zeros((0, height, width), dtype=np.uint8)
-
- return masks
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.prepare_coco_detection
- def prepare_coco_detection(self, image, target, return_segmentation_masks=False):
- """
- Convert the target in COCO format into the format expected by DETR.
- """
- w, h = image.size
-
- image_id = target["image_id"]
- image_id = np.asarray([image_id], dtype=np.int64)
-
- # get all COCO annotations for the given image
- anno = target["annotations"]
-
- anno = [obj for obj in anno if "iscrowd" not in obj or obj["iscrowd"] == 0]
-
- boxes = [obj["bbox"] for obj in anno]
- # guard against no boxes via resizing
- boxes = np.asarray(boxes, dtype=np.float32).reshape(-1, 4)
- boxes[:, 2:] += boxes[:, :2]
- boxes[:, 0::2] = boxes[:, 0::2].clip(min=0, max=w)
- boxes[:, 1::2] = boxes[:, 1::2].clip(min=0, max=h)
-
- classes = [obj["category_id"] for obj in anno]
- classes = np.asarray(classes, dtype=np.int64)
-
- if return_segmentation_masks:
- segmentations = [obj["segmentation"] for obj in anno]
- masks = self.convert_coco_poly_to_mask(segmentations, h, w)
-
- keypoints = None
- if anno and "keypoints" in anno[0]:
- keypoints = [obj["keypoints"] for obj in anno]
- keypoints = np.asarray(keypoints, dtype=np.float32)
- num_keypoints = keypoints.shape[0]
- if num_keypoints:
- keypoints = keypoints.reshape((-1, 3))
-
- keep = (boxes[:, 3] > boxes[:, 1]) & (boxes[:, 2] > boxes[:, 0])
- boxes = boxes[keep]
- classes = classes[keep]
- if return_segmentation_masks:
- masks = masks[keep]
- if keypoints is not None:
- keypoints = keypoints[keep]
-
- target = {}
- target["boxes"] = boxes
- target["class_labels"] = classes
- if return_segmentation_masks:
- target["masks"] = masks
- target["image_id"] = image_id
- if keypoints is not None:
- target["keypoints"] = keypoints
-
- # for conversion to coco api
- area = np.asarray([obj["area"] for obj in anno], dtype=np.float32)
- iscrowd = np.asarray([obj["iscrowd"] if "iscrowd" in obj else 0 for obj in anno], dtype=np.int64)
- target["area"] = area[keep]
- target["iscrowd"] = iscrowd[keep]
-
- target["orig_size"] = np.asarray([int(h), int(w)], dtype=np.int64)
- target["size"] = np.asarray([int(h), int(w)], dtype=np.int64)
-
- return image, target
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.prepare_coco_panoptic
- def prepare_coco_panoptic(self, image, target, masks_path, return_masks=True):
- w, h = image.size
- ann_info = target.copy()
- ann_path = pathlib.Path(masks_path) / ann_info["file_name"]
-
- if "segments_info" in ann_info:
- masks = np.asarray(Image.open(ann_path), dtype=np.uint32)
- masks = rgb_to_id(masks)
-
- ids = np.array([ann["id"] for ann in ann_info["segments_info"]])
- masks = masks == ids[:, None, None]
- masks = np.asarray(masks, dtype=np.uint8)
-
- labels = np.asarray([ann["category_id"] for ann in ann_info["segments_info"]], dtype=np.int64)
-
- target = {}
- target["image_id"] = np.asarray(
- [ann_info["image_id"] if "image_id" in ann_info else ann_info["id"]], dtype=np.int64
- )
- if return_masks:
- target["masks"] = masks
- target["class_labels"] = labels
-
- target["boxes"] = masks_to_boxes(masks)
-
- target["size"] = np.asarray([int(h), int(w)], dtype=np.int64)
- target["orig_size"] = np.asarray([int(h), int(w)], dtype=np.int64)
- if "segments_info" in ann_info:
- target["iscrowd"] = np.asarray([ann["iscrowd"] for ann in ann_info["segments_info"]], dtype=np.int64)
- target["area"] = np.asarray([ann["area"] for ann in ann_info["segments_info"]], dtype=np.float32)
-
- return image, target
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._resize
- def _resize(self, image, size, target=None, max_size=None):
- """
- Resize the image to the given size. Size can be min_size (scalar) or (w, h) tuple. If size is an int, smaller
- edge of the image will be matched to this number.
-
- If given, also resize the target accordingly.
- """
- if not isinstance(image, Image.Image):
- image = self.to_pil_image(image)
-
- def get_size_with_aspect_ratio(image_size, size, max_size=None):
- w, h = image_size
- if max_size is not None:
- min_original_size = float(min((w, h)))
- max_original_size = float(max((w, h)))
- if max_original_size / min_original_size * size > max_size:
- size = int(round(max_size * min_original_size / max_original_size))
-
- if (w <= h and w == size) or (h <= w and h == size):
- return (h, w)
-
- if w < h:
- ow = size
- oh = int(size * h / w)
- else:
- oh = size
- ow = int(size * w / h)
-
- return (oh, ow)
-
- def get_size(image_size, size, max_size=None):
- if isinstance(size, (list, tuple)):
- return size
- else:
- # size returned must be (w, h) since we use PIL to resize images
- # so we revert the tuple
- return get_size_with_aspect_ratio(image_size, size, max_size)[::-1]
-
- size = get_size(image.size, size, max_size)
- rescaled_image = self.resize(image, size=size)
-
- if target is None:
- return rescaled_image, None
-
- ratios = tuple(float(s) / float(s_orig) for s, s_orig in zip(rescaled_image.size, image.size))
- ratio_width, ratio_height = ratios
-
- target = target.copy()
- if "boxes" in target:
- boxes = target["boxes"]
- scaled_boxes = boxes * np.asarray([ratio_width, ratio_height, ratio_width, ratio_height], dtype=np.float32)
- target["boxes"] = scaled_boxes
-
- if "area" in target:
- area = target["area"]
- scaled_area = area * (ratio_width * ratio_height)
- target["area"] = scaled_area
-
- w, h = size
- target["size"] = np.asarray([h, w], dtype=np.int64)
-
- if "masks" in target:
- # use PyTorch as current workaround
- # TODO replace by self.resize
- masks = torch.from_numpy(target["masks"][:, None]).float()
- interpolated_masks = nn.functional.interpolate(masks, size=(h, w), mode="nearest")[:, 0] > 0.5
- target["masks"] = interpolated_masks.numpy()
-
- return rescaled_image, target
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._normalize
- def _normalize(self, image, mean, std, target=None):
- """
- Normalize the image with a certain mean and std.
-
- If given, also normalize the target bounding boxes based on the size of the image.
- """
-
- image = self.normalize(image, mean=mean, std=std)
- if target is None:
- return image, None
-
- target = target.copy()
- h, w = image.shape[-2:]
-
- if "boxes" in target:
- boxes = target["boxes"]
- boxes = corners_to_center_format(boxes)
- boxes = boxes / np.asarray([w, h, w, h], dtype=np.float32)
- target["boxes"] = boxes
-
- return image, target
-
- def __call__(
- self,
- images: ImageInput,
- annotations: Union[List[Dict], List[List[Dict]]] = None,
- return_segmentation_masks: Optional[bool] = False,
- masks_path: Optional[pathlib.Path] = None,
- padding: Optional[bool] = True,
- return_tensors: Optional[Union[str, TensorType]] = None,
- **kwargs,
- ) -> BatchFeature:
- """
- Main method to prepare for the model one or several image(s) and optional annotations. Images are by default
- padded up to the largest image in a batch.
-
-
-
- NumPy arrays and PyTorch tensors are converted to PIL images when resizing, so the most efficient is to pass
- PIL images.
-
-
-
- Args:
- images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
- The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
- tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a
- number of channels, H and W are image height and width.
-
- annotations (`Dict`, `List[Dict]`, *optional*):
- The corresponding annotations in COCO format.
-
- In case [`DetrFeatureExtractor`] was initialized with `format = "coco_detection"`, the annotations for
- each image should have the following format: {'image_id': int, 'annotations': [annotation]}, with the
- annotations being a list of COCO object annotations.
-
- In case [`DetrFeatureExtractor`] was initialized with `format = "coco_panoptic"`, the annotations for
- each image should have the following format: {'image_id': int, 'file_name': str, 'segments_info':
- [segment_info]} with segments_info being a list of COCO panoptic annotations.
-
- return_segmentation_masks (`Dict`, `List[Dict]`, *optional*, defaults to `False`):
- Whether to also include instance segmentation masks as part of the labels in case `format =
- "coco_detection"`.
-
- masks_path (`pathlib.Path`, *optional*):
- Path to the directory containing the PNG files that store the class-agnostic image segmentations. Only
- relevant in case [`DetrFeatureExtractor`] was initialized with `format = "coco_panoptic"`.
-
- padding (`bool`, *optional*, defaults to `True`):
- Whether or not to pad images up to the largest image in a batch.
-
- return_tensors (`str` or [`~utils.TensorType`], *optional*):
- If set, will return tensors instead of NumPy arrays. If set to `'pt'`, return PyTorch `torch.Tensor`
- objects.
-
- Returns:
- [`BatchFeature`]: A [`BatchFeature`] with the following fields:
-
- - **pixel_values** -- Pixel values to be fed to a model.
- - **labels** -- Optional labels to be fed to a model (when `annotations` are provided)
- """
- # Input type checking for clearer error
-
- valid_images = False
- valid_annotations = False
- valid_masks_path = False
-
- # Check that images has a valid type
- if isinstance(images, (Image.Image, np.ndarray)) or is_torch_tensor(images):
- valid_images = True
- elif isinstance(images, (list, tuple)):
- if len(images) == 0 or isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]):
- valid_images = True
-
- if not valid_images:
- raise ValueError(
- "Images must of type `PIL.Image.Image`, `np.ndarray` or `torch.Tensor` (single example), "
- "`List[PIL.Image.Image]`, `List[np.ndarray]` or `List[torch.Tensor]` (batch of examples)."
- )
-
- is_batched = bool(
- isinstance(images, (list, tuple))
- and (isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]))
- )
-
- # Check that annotations has a valid type
- if annotations is not None:
- if not is_batched:
- if self.format == "coco_detection":
- if isinstance(annotations, dict) and "image_id" in annotations and "annotations" in annotations:
- if isinstance(annotations["annotations"], (list, tuple)):
- # an image can have no annotations
- if len(annotations["annotations"]) == 0 or isinstance(annotations["annotations"][0], dict):
- valid_annotations = True
- elif self.format == "coco_panoptic":
- if isinstance(annotations, dict) and "image_id" in annotations and "segments_info" in annotations:
- if isinstance(annotations["segments_info"], (list, tuple)):
- # an image can have no segments (?)
- if len(annotations["segments_info"]) == 0 or isinstance(
- annotations["segments_info"][0], dict
- ):
- valid_annotations = True
- else:
- if isinstance(annotations, (list, tuple)):
- if len(images) != len(annotations):
- raise ValueError("There must be as many annotations as there are images")
- if isinstance(annotations[0], Dict):
- if self.format == "coco_detection":
- if isinstance(annotations[0]["annotations"], (list, tuple)):
- valid_annotations = True
- elif self.format == "coco_panoptic":
- if isinstance(annotations[0]["segments_info"], (list, tuple)):
- valid_annotations = True
-
- if not valid_annotations:
- raise ValueError(
- """
- Annotations must of type `Dict` (single image) or `List[Dict]` (batch of images). In case of object
- detection, each dictionary should contain the keys 'image_id' and 'annotations', with the latter
- being a list of annotations in COCO format. In case of panoptic segmentation, each dictionary
- should contain the keys 'file_name', 'image_id' and 'segments_info', with the latter being a list
- of annotations in COCO format.
- """
- )
-
- # Check that masks_path has a valid type
- if masks_path is not None:
- if self.format == "coco_panoptic":
- if isinstance(masks_path, pathlib.Path):
- valid_masks_path = True
- if not valid_masks_path:
- raise ValueError(
- "The path to the directory containing the mask PNG files should be provided as a"
- " `pathlib.Path` object."
- )
-
- if not is_batched:
- images = [images]
- if annotations is not None:
- annotations = [annotations]
-
- # prepare (COCO annotations as a list of Dict -> DETR target as a single Dict per image)
- if annotations is not None:
- for idx, (image, target) in enumerate(zip(images, annotations)):
- if not isinstance(image, Image.Image):
- image = self.to_pil_image(image)
- image, target = self.prepare(image, target, return_segmentation_masks, masks_path)
- images[idx] = image
- annotations[idx] = target
-
- # transformations (resizing + normalization)
- if self.do_resize and self.size is not None:
- if annotations is not None:
- for idx, (image, target) in enumerate(zip(images, annotations)):
- image, target = self._resize(image=image, target=target, size=self.size, max_size=self.max_size)
- images[idx] = image
- annotations[idx] = target
- else:
- for idx, image in enumerate(images):
- images[idx] = self._resize(image=image, target=None, size=self.size, max_size=self.max_size)[0]
-
- if self.do_normalize:
- if annotations is not None:
- for idx, (image, target) in enumerate(zip(images, annotations)):
- image, target = self._normalize(
- image=image, mean=self.image_mean, std=self.image_std, target=target
- )
- images[idx] = image
- annotations[idx] = target
- else:
- images = [
- self._normalize(image=image, mean=self.image_mean, std=self.image_std)[0] for image in images
- ]
-
- if padding:
- # pad images up to largest image in batch
- max_size = self._max_by_axis([list(image.shape) for image in images])
- c, h, w = max_size
- padded_images = []
- for image in images:
- # create padded image
- padded_image = np.zeros((c, h, w), dtype=np.float32)
- padded_image[: image.shape[0], : image.shape[1], : image.shape[2]] = np.copy(image)
- padded_images.append(padded_image)
- images = padded_images
-
- # return as BatchFeature
- data = {}
- data["pixel_values"] = images
- encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
-
- if annotations is not None:
- # Convert to TensorType
- tensor_type = return_tensors
- if not isinstance(tensor_type, TensorType):
- tensor_type = TensorType(tensor_type)
-
- if not tensor_type == TensorType.PYTORCH:
- raise ValueError("Only PyTorch is supported for the moment.")
- else:
- if not is_torch_available():
- raise ImportError("Unable to convert output to PyTorch tensors format, PyTorch is not installed.")
-
- encoded_inputs["labels"] = [
- {k: torch.from_numpy(v) for k, v in target.items()} for target in annotations
- ]
-
- return encoded_inputs
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._max_by_axis
- def _max_by_axis(self, the_list):
- # type: (List[List[int]]) -> List[int]
- maxes = the_list[0]
- for sublist in the_list[1:]:
- for index, item in enumerate(sublist):
- maxes[index] = max(maxes[index], item)
- return maxes
-
- def pad(self, pixel_values_list: List["torch.Tensor"], return_tensors: Optional[Union[str, TensorType]] = None):
- """
- Pad images up to the largest image in a batch.
-
- Args:
- pixel_values_list (`List[torch.Tensor]`):
- List of images (pixel values) to be padded. Each image should be a tensor of shape (C, H, W).
- return_tensors (`str` or [`~utils.TensorType`], *optional*):
- If set, will return tensors instead of NumPy arrays. If set to `'pt'`, return PyTorch `torch.Tensor`
- objects.
-
- Returns:
- [`BatchFeature`]: A [`BatchFeature`] with the following field:
-
- - **pixel_values** -- Pixel values to be fed to a model.
-
- """
-
- max_size = self._max_by_axis([list(image.shape) for image in pixel_values_list])
- c, h, w = max_size
- padded_images = []
- for image in pixel_values_list:
- # create padded image
- padded_image = np.zeros((c, h, w), dtype=np.float32)
- padded_image[: image.shape[0], : image.shape[1], : image.shape[2]] = np.copy(image)
- padded_images.append(padded_image)
-
- # return as BatchFeature
- data = {"pixel_values": padded_images}
- encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
-
- return encoded_inputs
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.post_process
- def post_process(self, outputs, target_sizes):
- """
- Converts the output of [`DetrForObjectDetection`] into the format expected by the COCO api. Only supports
- PyTorch.
-
- Args:
- outputs ([`DetrObjectDetectionOutput`]):
- Raw outputs of the model.
- target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
- Tensor containing the size (height, width) of each image of the batch. For evaluation, this must be the
- original image size (before any data augmentation). For visualization, this should be the image size
- after data augment, but before padding.
-
- Returns:
- `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
- in the batch as predicted by the model.
- """
- warnings.warn(
- "`post_process` is deprecated and will be removed in v5 of Transformers, please use"
- " `post_process_object_detection`",
- FutureWarning,
- )
-
- out_logits, out_bbox = outputs.logits, outputs.pred_boxes
-
- if len(out_logits) != len(target_sizes):
- raise ValueError("Make sure that you pass in as many target sizes as the batch dimension of the logits")
- if target_sizes.shape[1] != 2:
- raise ValueError("Each element of target_sizes must contain the size (h, w) of each image of the batch")
-
- prob = nn.functional.softmax(out_logits, -1)
- scores, labels = prob[..., :-1].max(-1)
-
- # convert to [x0, y0, x1, y1] format
- boxes = center_to_corners_format(out_bbox)
- # and from relative [0, 1] to absolute [0, height] coordinates
- img_h, img_w = target_sizes.unbind(1)
- scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
- boxes = boxes * scale_fct[:, None, :]
-
- results = [{"scores": s, "labels": l, "boxes": b} for s, l, b in zip(scores, labels, boxes)]
- return results
-
- # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.post_process_object_detection with Detr->Yolos
- def post_process_object_detection(
- self, outputs, threshold: float = 0.5, target_sizes: Union[TensorType, List[Tuple]] = None
- ):
- """
- Converts the output of [`YolosForObjectDetection`] into the format expected by the COCO api. Only supports
- PyTorch.
-
- Args:
- outputs ([`YolosObjectDetectionOutput`]):
- Raw outputs of the model.
- threshold (`float`, *optional*):
- Score threshold to keep object detection predictions.
- target_sizes (`torch.Tensor` or `List[Tuple[int, int]]`, *optional*, defaults to `None`):
- Tensor of shape `(batch_size, 2)` or list of tuples (`Tuple[int, int]`) containing the target size
- (height, width) of each image in the batch. If left to None, predictions will not be resized.
-
- Returns:
- `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
- in the batch as predicted by the model.
- """
- out_logits, out_bbox = outputs.logits, outputs.pred_boxes
-
- if target_sizes is not None:
- if len(out_logits) != len(target_sizes):
- raise ValueError(
- "Make sure that you pass in as many target sizes as the batch dimension of the logits"
- )
-
- prob = nn.functional.softmax(out_logits, -1)
- scores, labels = prob[..., :-1].max(-1)
-
- # Convert to [x0, y0, x1, y1] format
- boxes = center_to_corners_format(out_bbox)
-
- # Convert from relative [0, 1] to absolute [0, height] coordinates
- if target_sizes is not None:
- if isinstance(target_sizes, List):
- img_h = torch.Tensor([i[0] for i in target_sizes])
- img_w = torch.Tensor([i[1] for i in target_sizes])
- else:
- img_h, img_w = target_sizes.unbind(1)
-
- scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1).to(boxes.device)
- boxes = boxes * scale_fct[:, None, :]
-
- results = []
- for s, l, b in zip(scores, labels, boxes):
- score = s[s > threshold]
- label = l[s > threshold]
- box = b[s > threshold]
- results.append({"scores": score, "labels": label, "boxes": box})
-
- return results
+YolosFeatureExtractor = YolosImageProcessor
diff --git a/src/transformers/models/yolos/image_processing_yolos.py b/src/transformers/models/yolos/image_processing_yolos.py
new file mode 100644
index 0000000000..02e14cc2cd
--- /dev/null
+++ b/src/transformers/models/yolos/image_processing_yolos.py
@@ -0,0 +1,1214 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Image processor class for YOLOS."""
+
+import pathlib
+import warnings
+from typing import Any, Callable, Dict, Iterable, List, Optional, Set, Tuple, Union
+
+import numpy as np
+
+from transformers.feature_extraction_utils import BatchFeature
+from transformers.image_processing_utils import BaseImageProcessor, get_size_dict
+from transformers.image_transforms import (
+ PaddingMode,
+ center_to_corners_format,
+ corners_to_center_format,
+ id_to_rgb,
+ normalize,
+ pad,
+ rescale,
+ resize,
+ rgb_to_id,
+ to_channel_dimension_format,
+)
+from transformers.image_utils import (
+ IMAGENET_DEFAULT_MEAN,
+ IMAGENET_DEFAULT_STD,
+ ChannelDimension,
+ ImageInput,
+ PILImageResampling,
+ get_image_size,
+ infer_channel_dimension_format,
+ is_batched,
+ to_numpy_array,
+ valid_coco_detection_annotations,
+ valid_coco_panoptic_annotations,
+ valid_images,
+)
+from transformers.utils import (
+ is_flax_available,
+ is_jax_tensor,
+ is_scipy_available,
+ is_tf_available,
+ is_tf_tensor,
+ is_torch_available,
+ is_torch_tensor,
+ is_vision_available,
+)
+from transformers.utils.generic import ExplicitEnum, TensorType
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+
+if is_vision_available():
+ import PIL
+
+
+if is_scipy_available():
+ import scipy.special
+ import scipy.stats
+
+
+class AnnotionFormat(ExplicitEnum):
+ COCO_DETECTION = "coco_detection"
+ COCO_PANOPTIC = "coco_panoptic"
+
+
+SUPPORTED_ANNOTATION_FORMATS = (AnnotionFormat.COCO_DETECTION, AnnotionFormat.COCO_PANOPTIC)
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_max_height_width
+def get_max_height_width(images: List[np.ndarray]) -> List[int]:
+ """
+ Get the maximum height and width across all images in a batch.
+ """
+ input_channel_dimension = infer_channel_dimension_format(images[0])
+
+ if input_channel_dimension == ChannelDimension.FIRST:
+ _, max_height, max_width = max_across_indices([img.shape for img in images])
+ elif input_channel_dimension == ChannelDimension.LAST:
+ max_height, max_width, _ = max_across_indices([img.shape for img in images])
+ else:
+ raise ValueError(f"Invalid channel dimension format: {input_channel_dimension}")
+ return (max_height, max_width)
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_size_with_aspect_ratio
+def get_size_with_aspect_ratio(image_size, size, max_size=None) -> Tuple[int, int]:
+ """
+ Computes the output image size given the input image size and the desired output size.
+
+ Args:
+ image_size (`Tuple[int, int]`):
+ The input image size.
+ size (`int`):
+ The desired output size.
+ max_size (`int`, *optional*):
+ The maximum allowed output size.
+ """
+ height, width = image_size
+ if max_size is not None:
+ min_original_size = float(min((height, width)))
+ max_original_size = float(max((height, width)))
+ if max_original_size / min_original_size * size > max_size:
+ size = int(round(max_size * min_original_size / max_original_size))
+
+ if (height <= width and height == size) or (width <= height and width == size):
+ return height, width
+
+ if width < height:
+ ow = size
+ oh = int(size * height / width)
+ else:
+ oh = size
+ ow = int(size * width / height)
+ return (oh, ow)
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_resize_output_image_size
+def get_resize_output_image_size(
+ input_image: np.ndarray, size: Union[int, Tuple[int, int], List[int]], max_size: Optional[int] = None
+) -> Tuple[int, int]:
+ """
+ Computes the output image size given the input image size and the desired output size. If the desired output size
+ is a tuple or list, the output image size is returned as is. If the desired output size is an integer, the output
+ image size is computed by keeping the aspect ratio of the input image size.
+
+ Args:
+ image_size (`Tuple[int, int]`):
+ The input image size.
+ size (`int`):
+ The desired output size.
+ max_size (`int`, *optional*):
+ The maximum allowed output size.
+ """
+ image_size = get_image_size(input_image)
+ if isinstance(size, (list, tuple)):
+ return size
+
+ return get_size_with_aspect_ratio(image_size, size, max_size)
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_numpy_to_framework_fn
+def get_numpy_to_framework_fn(arr) -> Callable:
+ """
+ Returns a function that converts a numpy array to the framework of the input array.
+
+ Args:
+ arr (`np.ndarray`): The array to convert.
+ """
+ if isinstance(arr, np.ndarray):
+ return np.array
+ if is_tf_available() and is_tf_tensor(arr):
+ import tensorflow as tf
+
+ return tf.convert_to_tensor
+ if is_torch_available() and is_torch_tensor(arr):
+ import torch
+
+ return torch.tensor
+ if is_flax_available() and is_jax_tensor(arr):
+ import jax.numpy as jnp
+
+ return jnp.array
+ raise ValueError(f"Cannot convert arrays of type {type(arr)}")
+
+
+# Copied from transformers.models.detr.image_processing_detr.safe_squeeze
+def safe_squeeze(arr: np.ndarray, axis: Optional[int] = None) -> np.ndarray:
+ """
+ Squeezes an array, but only if the axis specified has dim 1.
+ """
+ if axis is None:
+ return arr.squeeze()
+
+ try:
+ return arr.squeeze(axis=axis)
+ except ValueError:
+ return arr
+
+
+# Copied from transformers.models.detr.image_processing_detr.normalize_annotation
+def normalize_annotation(annotation: Dict, image_size: Tuple[int, int]) -> Dict:
+ image_height, image_width = image_size
+ norm_annotation = {}
+ for key, value in annotation.items():
+ if key == "boxes":
+ boxes = value
+ boxes = corners_to_center_format(boxes)
+ boxes /= np.asarray([image_width, image_height, image_width, image_height], dtype=np.float32)
+ norm_annotation[key] = boxes
+ else:
+ norm_annotation[key] = value
+ return norm_annotation
+
+
+# Copied from transformers.models.detr.image_processing_detr.max_across_indices
+def max_across_indices(values: Iterable[Any]) -> List[Any]:
+ """
+ Return the maximum value across all indices of an iterable of values.
+ """
+ return [max(values_i) for values_i in zip(*values)]
+
+
+# Copied from transformers.models.detr.image_processing_detr.make_pixel_mask
+def make_pixel_mask(image: np.ndarray, output_size: Tuple[int, int]) -> np.ndarray:
+ """
+ Make a pixel mask for the image, where 1 indicates a valid pixel and 0 indicates padding.
+
+ Args:
+ image (`np.ndarray`):
+ Image to make the pixel mask for.
+ output_size (`Tuple[int, int]`):
+ Output size of the mask.
+ """
+ input_height, input_width = get_image_size(image)
+ mask = np.zeros(output_size, dtype=np.int64)
+ mask[:input_height, :input_width] = 1
+ return mask
+
+
+# Copied from transformers.models.detr.image_processing_detr.convert_coco_poly_to_mask
+def convert_coco_poly_to_mask(segmentations, height: int, width: int) -> np.ndarray:
+ """
+ Convert a COCO polygon annotation to a mask.
+
+ Args:
+ segmentations (`List[List[float]]`):
+ List of polygons, each polygon represented by a list of x-y coordinates.
+ height (`int`):
+ Height of the mask.
+ width (`int`):
+ Width of the mask.
+ """
+ try:
+ from pycocotools import mask as coco_mask
+ except ImportError:
+ raise ImportError("Pycocotools is not installed in your environment.")
+
+ masks = []
+ for polygons in segmentations:
+ rles = coco_mask.frPyObjects(polygons, height, width)
+ mask = coco_mask.decode(rles)
+ if len(mask.shape) < 3:
+ mask = mask[..., None]
+ mask = np.asarray(mask, dtype=np.uint8)
+ mask = np.any(mask, axis=2)
+ masks.append(mask)
+ if masks:
+ masks = np.stack(masks, axis=0)
+ else:
+ masks = np.zeros((0, height, width), dtype=np.uint8)
+
+ return masks
+
+
+# Copied from transformers.models.detr.image_processing_detr.prepare_coco_detection_annotation
+def prepare_coco_detection_annotation(image, target, return_segmentation_masks: bool = False):
+ """
+ Convert the target in COCO format into the format expected by DETR.
+ """
+ image_height, image_width = get_image_size(image)
+
+ image_id = target["image_id"]
+ image_id = np.asarray([image_id], dtype=np.int64)
+
+ # Get all COCO annotations for the given image.
+ annotations = target["annotations"]
+ annotations = [obj for obj in annotations if "iscrowd" not in obj or obj["iscrowd"] == 0]
+
+ classes = [obj["category_id"] for obj in annotations]
+ classes = np.asarray(classes, dtype=np.int64)
+
+ # for conversion to coco api
+ area = np.asarray([obj["area"] for obj in annotations], dtype=np.float32)
+ iscrowd = np.asarray([obj["iscrowd"] if "iscrowd" in obj else 0 for obj in annotations], dtype=np.int64)
+
+ boxes = [obj["bbox"] for obj in annotations]
+ # guard against no boxes via resizing
+ boxes = np.asarray(boxes, dtype=np.float32).reshape(-1, 4)
+ boxes[:, 2:] += boxes[:, :2]
+ boxes[:, 0::2] = boxes[:, 0::2].clip(min=0, max=image_width)
+ boxes[:, 1::2] = boxes[:, 1::2].clip(min=0, max=image_height)
+
+ keep = (boxes[:, 3] > boxes[:, 1]) & (boxes[:, 2] > boxes[:, 0])
+
+ new_target = {}
+ new_target["image_id"] = image_id
+ new_target["class_labels"] = classes[keep]
+ new_target["boxes"] = boxes[keep]
+ new_target["area"] = area[keep]
+ new_target["iscrowd"] = iscrowd[keep]
+ new_target["orig_size"] = np.asarray([int(image_height), int(image_width)], dtype=np.int64)
+
+ if annotations and "keypoints" in annotations[0]:
+ keypoints = [obj["keypoints"] for obj in annotations]
+ keypoints = np.asarray(keypoints, dtype=np.float32)
+ num_keypoints = keypoints.shape[0]
+ keypoints = keypoints.reshape((-1, 3)) if num_keypoints else keypoints
+ new_target["keypoints"] = keypoints[keep]
+
+ if return_segmentation_masks:
+ segmentation_masks = [obj["segmentation"] for obj in annotations]
+ masks = convert_coco_poly_to_mask(segmentation_masks, image_height, image_width)
+ new_target["masks"] = masks[keep]
+
+ return new_target
+
+
+# Copied from transformers.models.detr.image_processing_detr.masks_to_boxes
+def masks_to_boxes(masks: np.ndarray) -> np.ndarray:
+ """
+ Compute the bounding boxes around the provided panoptic segmentation masks.
+
+ Args:
+ masks: masks in format `[number_masks, height, width]` where N is the number of masks
+
+ Returns:
+ boxes: bounding boxes in format `[number_masks, 4]` in xyxy format
+ """
+ if masks.size == 0:
+ return np.zeros((0, 4))
+
+ h, w = masks.shape[-2:]
+ y = np.arange(0, h, dtype=np.float32)
+ x = np.arange(0, w, dtype=np.float32)
+ # see https://github.com/pytorch/pytorch/issues/50276
+ y, x = np.meshgrid(y, x, indexing="ij")
+
+ x_mask = masks * np.expand_dims(x, axis=0)
+ x_max = x_mask.reshape(x_mask.shape[0], -1).max(-1)
+ x = np.ma.array(x_mask, mask=~(np.array(masks, dtype=bool)))
+ x_min = x.filled(fill_value=1e8)
+ x_min = x_min.reshape(x_min.shape[0], -1).min(-1)
+
+ y_mask = masks * np.expand_dims(y, axis=0)
+ y_max = y_mask.reshape(x_mask.shape[0], -1).max(-1)
+ y = np.ma.array(y_mask, mask=~(np.array(masks, dtype=bool)))
+ y_min = y.filled(fill_value=1e8)
+ y_min = y_min.reshape(y_min.shape[0], -1).min(-1)
+
+ return np.stack([x_min, y_min, x_max, y_max], 1)
+
+
+# Copied from transformers.models.detr.image_processing_detr.prepare_coco_panoptic_annotation with DETR->YOLOS
+def prepare_coco_panoptic_annotation(
+ image: np.ndarray, target: Dict, masks_path: Union[str, pathlib.Path], return_masks: bool = True
+) -> Dict:
+ """
+ Prepare a coco panoptic annotation for YOLOS.
+ """
+ image_height, image_width = get_image_size(image)
+ annotation_path = pathlib.Path(masks_path) / target["file_name"]
+
+ new_target = {}
+ new_target["image_id"] = np.asarray([target["image_id"] if "image_id" in target else target["id"]], dtype=np.int64)
+ new_target["size"] = np.asarray([image_height, image_width], dtype=np.int64)
+ new_target["orig_size"] = np.asarray([image_height, image_width], dtype=np.int64)
+
+ if "segments_info" in target:
+ masks = np.asarray(PIL.Image.open(annotation_path), dtype=np.uint32)
+ masks = rgb_to_id(masks)
+
+ ids = np.array([segment_info["id"] for segment_info in target["segments_info"]])
+ masks = masks == ids[:, None, None]
+ masks = masks.astype(np.uint8)
+ if return_masks:
+ new_target["masks"] = masks
+ new_target["boxes"] = masks_to_boxes(masks)
+ new_target["class_labels"] = np.array(
+ [segment_info["category_id"] for segment_info in target["segments_info"]], dtype=np.int64
+ )
+ new_target["iscrowd"] = np.asarray(
+ [segment_info["iscrowd"] for segment_info in target["segments_info"]], dtype=np.int64
+ )
+ new_target["area"] = np.asarray(
+ [segment_info["area"] for segment_info in target["segments_info"]], dtype=np.float32
+ )
+
+ return new_target
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_segmentation_image
+def get_segmentation_image(
+ masks: np.ndarray, input_size: Tuple, target_size: Tuple, stuff_equiv_classes, deduplicate=False
+):
+ h, w = input_size
+ final_h, final_w = target_size
+
+ m_id = scipy.special.softmax(masks.transpose(0, 1), -1)
+
+ if m_id.shape[-1] == 0:
+ # We didn't detect any mask :(
+ m_id = np.zeros((h, w), dtype=np.int64)
+ else:
+ m_id = m_id.argmax(-1).reshape(h, w)
+
+ if deduplicate:
+ # Merge the masks corresponding to the same stuff class
+ for equiv in stuff_equiv_classes.values():
+ for eq_id in equiv:
+ m_id[m_id == eq_id] = equiv[0]
+
+ seg_img = id_to_rgb(m_id)
+ seg_img = resize(seg_img, (final_w, final_h), resample=PILImageResampling.NEAREST)
+ return seg_img
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_mask_area
+def get_mask_area(seg_img: np.ndarray, target_size: Tuple[int, int], n_classes: int) -> np.ndarray:
+ final_h, final_w = target_size
+ np_seg_img = seg_img.astype(np.uint8)
+ np_seg_img = np_seg_img.reshape(final_h, final_w, 3)
+ m_id = rgb_to_id(np_seg_img)
+ area = [(m_id == i).sum() for i in range(n_classes)]
+ return area
+
+
+# Copied from transformers.models.detr.image_processing_detr.score_labels_from_class_probabilities
+def score_labels_from_class_probabilities(logits: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
+ probs = scipy.special.softmax(logits, axis=-1)
+ labels = probs.argmax(-1, keepdims=True)
+ scores = np.take_along_axis(probs, labels, axis=-1)
+ scores, labels = scores.squeeze(-1), labels.squeeze(-1)
+ return scores, labels
+
+
+# Copied from transformers.models.detr.image_processing_detr.resize_annotation
+def resize_annotation(
+ annotation: Dict[str, Any],
+ orig_size: Tuple[int, int],
+ target_size: Tuple[int, int],
+ threshold: float = 0.5,
+ resample: PILImageResampling = PILImageResampling.NEAREST,
+):
+ """
+ Resizes an annotation to a target size.
+
+ Args:
+ annotation (`Dict[str, Any]`):
+ The annotation dictionary.
+ orig_size (`Tuple[int, int]`):
+ The original size of the input image.
+ target_size (`Tuple[int, int]`):
+ The target size of the image, as returned by the preprocessing `resize` step.
+ threshold (`float`, *optional*, defaults to 0.5):
+ The threshold used to binarize the segmentation masks.
+ resample (`PILImageResampling`, defaults to `PILImageResampling.NEAREST`):
+ The resampling filter to use when resizing the masks.
+ """
+ ratios = tuple(float(s) / float(s_orig) for s, s_orig in zip(target_size, orig_size))
+ ratio_height, ratio_width = ratios
+
+ new_annotation = {}
+ new_annotation["size"] = target_size
+
+ for key, value in annotation.items():
+ if key == "boxes":
+ boxes = value
+ scaled_boxes = boxes * np.asarray([ratio_width, ratio_height, ratio_width, ratio_height], dtype=np.float32)
+ new_annotation["boxes"] = scaled_boxes
+ elif key == "area":
+ area = value
+ scaled_area = area * (ratio_width * ratio_height)
+ new_annotation["area"] = scaled_area
+ elif key == "masks":
+ masks = value[:, None]
+ masks = np.array([resize(mask, target_size, resample=resample) for mask in masks])
+ masks = masks.astype(np.float32)
+ masks = masks[:, 0] > threshold
+ new_annotation["masks"] = masks
+ elif key == "size":
+ new_annotation["size"] = target_size
+ else:
+ new_annotation[key] = value
+
+ return new_annotation
+
+
+# Copied from transformers.models.detr.image_processing_detr.binary_mask_to_rle
+def binary_mask_to_rle(mask):
+ """
+ Converts given binary mask of shape `(height, width)` to the run-length encoding (RLE) format.
+
+ Args:
+ mask (`torch.Tensor` or `numpy.array`):
+ A binary mask tensor of shape `(height, width)` where 0 denotes background and 1 denotes the target
+ segment_id or class_id.
+ Returns:
+ `List`: Run-length encoded list of the binary mask. Refer to COCO API for more information about the RLE
+ format.
+ """
+ if is_torch_tensor(mask):
+ mask = mask.numpy()
+
+ pixels = mask.flatten()
+ pixels = np.concatenate([[0], pixels, [0]])
+ runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
+ runs[1::2] -= runs[::2]
+ return [x for x in runs]
+
+
+# Copied from transformers.models.detr.image_processing_detr.convert_segmentation_to_rle
+def convert_segmentation_to_rle(segmentation):
+ """
+ Converts given segmentation map of shape `(height, width)` to the run-length encoding (RLE) format.
+
+ Args:
+ segmentation (`torch.Tensor` or `numpy.array`):
+ A segmentation map of shape `(height, width)` where each value denotes a segment or class id.
+ Returns:
+ `List[List]`: A list of lists, where each list is the run-length encoding of a segment / class id.
+ """
+ segment_ids = torch.unique(segmentation)
+
+ run_length_encodings = []
+ for idx in segment_ids:
+ mask = torch.where(segmentation == idx, 1, 0)
+ rle = binary_mask_to_rle(mask)
+ run_length_encodings.append(rle)
+
+ return run_length_encodings
+
+
+# Copied from transformers.models.detr.image_processing_detr.remove_low_and_no_objects
+def remove_low_and_no_objects(masks, scores, labels, object_mask_threshold, num_labels):
+ """
+ Binarize the given masks using `object_mask_threshold`, it returns the associated values of `masks`, `scores` and
+ `labels`.
+
+ Args:
+ masks (`torch.Tensor`):
+ A tensor of shape `(num_queries, height, width)`.
+ scores (`torch.Tensor`):
+ A tensor of shape `(num_queries)`.
+ labels (`torch.Tensor`):
+ A tensor of shape `(num_queries)`.
+ object_mask_threshold (`float`):
+ A number between 0 and 1 used to binarize the masks.
+ Raises:
+ `ValueError`: Raised when the first dimension doesn't match in all input tensors.
+ Returns:
+ `Tuple[`torch.Tensor`, `torch.Tensor`, `torch.Tensor`]`: The `masks`, `scores` and `labels` without the region
+ < `object_mask_threshold`.
+ """
+ if not (masks.shape[0] == scores.shape[0] == labels.shape[0]):
+ raise ValueError("mask, scores and labels must have the same shape!")
+
+ to_keep = labels.ne(num_labels) & (scores > object_mask_threshold)
+
+ return masks[to_keep], scores[to_keep], labels[to_keep]
+
+
+# Copied from transformers.models.detr.image_processing_detr.check_segment_validity
+def check_segment_validity(mask_labels, mask_probs, k, mask_threshold=0.5, overlap_mask_area_threshold=0.8):
+ # Get the mask associated with the k class
+ mask_k = mask_labels == k
+ mask_k_area = mask_k.sum()
+
+ # Compute the area of all the stuff in query k
+ original_area = (mask_probs[k] >= mask_threshold).sum()
+ mask_exists = mask_k_area > 0 and original_area > 0
+
+ # Eliminate disconnected tiny segments
+ if mask_exists:
+ area_ratio = mask_k_area / original_area
+ if not area_ratio.item() > overlap_mask_area_threshold:
+ mask_exists = False
+
+ return mask_exists, mask_k
+
+
+# Copied from transformers.models.detr.image_processing_detr.compute_segments
+def compute_segments(
+ mask_probs,
+ pred_scores,
+ pred_labels,
+ mask_threshold: float = 0.5,
+ overlap_mask_area_threshold: float = 0.8,
+ label_ids_to_fuse: Optional[Set[int]] = None,
+ target_size: Tuple[int, int] = None,
+):
+ height = mask_probs.shape[1] if target_size is None else target_size[0]
+ width = mask_probs.shape[2] if target_size is None else target_size[1]
+
+ segmentation = torch.zeros((height, width), dtype=torch.int32, device=mask_probs.device)
+ segments: List[Dict] = []
+
+ if target_size is not None:
+ mask_probs = nn.functional.interpolate(
+ mask_probs.unsqueeze(0), size=target_size, mode="bilinear", align_corners=False
+ )[0]
+
+ current_segment_id = 0
+
+ # Weigh each mask by its prediction score
+ mask_probs *= pred_scores.view(-1, 1, 1)
+ mask_labels = mask_probs.argmax(0) # [height, width]
+
+ # Keep track of instances of each class
+ stuff_memory_list: Dict[str, int] = {}
+ for k in range(pred_labels.shape[0]):
+ pred_class = pred_labels[k].item()
+ should_fuse = pred_class in label_ids_to_fuse
+
+ # Check if mask exists and large enough to be a segment
+ mask_exists, mask_k = check_segment_validity(
+ mask_labels, mask_probs, k, mask_threshold, overlap_mask_area_threshold
+ )
+
+ if mask_exists:
+ if pred_class in stuff_memory_list:
+ current_segment_id = stuff_memory_list[pred_class]
+ else:
+ current_segment_id += 1
+
+ # Add current object segment to final segmentation map
+ segmentation[mask_k] = current_segment_id
+ segment_score = round(pred_scores[k].item(), 6)
+ segments.append(
+ {
+ "id": current_segment_id,
+ "label_id": pred_class,
+ "was_fused": should_fuse,
+ "score": segment_score,
+ }
+ )
+ if should_fuse:
+ stuff_memory_list[pred_class] = current_segment_id
+
+ return segmentation, segments
+
+
+class YolosImageProcessor(BaseImageProcessor):
+ r"""
+ Constructs a Detr image processor.
+
+ Args:
+ format (`str`, *optional*, defaults to `"coco_detection"`):
+ Data format of the annotations. One of "coco_detection" or "coco_panoptic".
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Controls whether to resize the image's (height, width) dimensions to the specified `size`. Can be
+ overridden by the `do_resize` parameter in the `preprocess` method.
+ size (`Dict[str, int]` *optional*, defaults to `{"shortest_edge": 800, "longest_edge": 1333}`):
+ Size of the image's (height, width) dimensions after resizing. Can be overridden by the `size` parameter in
+ the `preprocess` method.
+ resample (`PILImageResampling`, *optional*, defaults to `PILImageResampling.BILINEAR`):
+ Resampling filter to use if resizing the image.
+ do_rescale (`bool`, *optional*, defaults to `True`):
+ Controls whether to rescale the image by the specified scale `rescale_factor`. Can be overridden by the
+ `do_rescale` parameter in the `preprocess` method.
+ rescale_factor (`int` or `float`, *optional*, defaults to `1/255`):
+ Scale factor to use if rescaling the image. Can be overridden by the `rescale_factor` parameter in the
+ `preprocess` method.
+ do_normalize:
+ Controls whether to normalize the image. Can be overridden by the `do_normalize` parameter in the
+ `preprocess` method.
+ image_mean (`float` or `List[float]`, *optional*, defaults to `IMAGENET_DEFAULT_MEAN`):
+ Mean values to use when normalizing the image. Can be a single value or a list of values, one for each
+ channel. Can be overridden by the `image_mean` parameter in the `preprocess` method.
+ image_std (`float` or `List[float]`, *optional*, defaults to `IMAGENET_DEFAULT_STD`):
+ Standard deviation values to use when normalizing the image. Can be a single value or a list of values, one
+ for each channel. Can be overridden by the `image_std` parameter in the `preprocess` method.
+ do_pad (`bool`, *optional*, defaults to `True`):
+ Controls whether to pad the image to the largest image in a batch and create a pixel mask. Can be
+ overridden by the `do_pad` parameter in the `preprocess` method.
+ """
+
+ model_input_names = ["pixel_values", "pixel_mask"]
+
+ def __init__(
+ self,
+ format: Union[str, AnnotionFormat] = AnnotionFormat.COCO_DETECTION,
+ do_resize: bool = True,
+ size: Dict[str, int] = None,
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ do_rescale: bool = True,
+ rescale_factor: Union[int, float] = 1 / 255,
+ do_normalize: bool = True,
+ image_mean: Union[float, List[float]] = None,
+ image_std: Union[float, List[float]] = None,
+ do_pad: bool = True,
+ **kwargs
+ ) -> None:
+ if "pad_and_return_pixel_mask" in kwargs:
+ do_pad = kwargs.pop("pad_and_return_pixel_mask")
+
+ if "max_size" in kwargs:
+ warnings.warn(
+ "The `max_size` parameter is deprecated and will be removed in v4.26. "
+ "Please specify in `size['longest_edge'] instead`.",
+ FutureWarning,
+ )
+ max_size = kwargs.pop("max_size")
+ else:
+ max_size = None if size is None else 1333
+
+ size = size if size is not None else {"shortest_edge": 800, "longest_edge": 1333}
+ size = get_size_dict(size, max_size=max_size, default_to_square=False)
+
+ super().__init__(**kwargs)
+ self.format = format
+ self.do_resize = do_resize
+ self.size = size
+ self.resample = resample
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean if image_mean is not None else IMAGENET_DEFAULT_MEAN
+ self.image_std = image_std if image_std is not None else IMAGENET_DEFAULT_STD
+ self.do_pad = do_pad
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare_annotation
+ def prepare_annotation(
+ self,
+ image: np.ndarray,
+ target: Dict,
+ format: Optional[AnnotionFormat] = None,
+ return_segmentation_masks: bool = None,
+ masks_path: Optional[Union[str, pathlib.Path]] = None,
+ ) -> Dict:
+ """
+ Prepare an annotation for feeding into DETR model.
+ """
+ format = format if format is not None else self.format
+
+ if format == AnnotionFormat.COCO_DETECTION:
+ return_segmentation_masks = False if return_segmentation_masks is None else return_segmentation_masks
+ target = prepare_coco_detection_annotation(image, target, return_segmentation_masks)
+ elif format == AnnotionFormat.COCO_PANOPTIC:
+ return_segmentation_masks = True if return_segmentation_masks is None else return_segmentation_masks
+ target = prepare_coco_panoptic_annotation(
+ image, target, masks_path=masks_path, return_masks=return_segmentation_masks
+ )
+ else:
+ raise ValueError(f"Format {format} is not supported.")
+ return target
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare
+ def prepare(self, image, target, return_segmentation_masks=False, masks_path=None):
+ warnings.warn(
+ "The `prepare` method is deprecated and will be removed in a future version. "
+ "Please use `prepare_annotation` instead. Note: the `prepare_annotation` method "
+ "does not return the image anymore.",
+ )
+ target = self.prepare_annotation(image, target, return_segmentation_masks, masks_path, self.format)
+ return image, target
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.convert_coco_poly_to_mask
+ def convert_coco_poly_to_mask(self, *args, **kwargs):
+ warnings.warn("The `convert_coco_poly_to_mask` method is deprecated and will be removed in a future version. ")
+ return convert_coco_poly_to_mask(*args, **kwargs)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare_coco_detection with DETR->Yolos
+ def prepare_coco_detection(self, *args, **kwargs):
+ warnings.warn("The `prepare_coco_detection` method is deprecated and will be removed in a future version. ")
+ return prepare_coco_detection_annotation(*args, **kwargs)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare_coco_panoptic
+ def prepare_coco_panoptic(self, *args, **kwargs):
+ warnings.warn("The `prepare_coco_panoptic` method is deprecated and will be removed in a future version. ")
+ return prepare_coco_panoptic_annotation(*args, **kwargs)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.resize
+ def resize(
+ self,
+ image: np.ndarray,
+ size: Dict[str, int],
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ data_format: Optional[ChannelDimension] = None,
+ **kwargs
+ ) -> np.ndarray:
+ """
+ Resize the image to the given size. Size can be `min_size` (scalar) or `(height, width)` tuple. If size is an
+ int, smaller edge of the image will be matched to this number.
+ """
+ if "max_size" in kwargs:
+ warnings.warn(
+ "The `max_size` parameter is deprecated and will be removed in v4.26. "
+ "Please specify in `size['longest_edge'] instead`.",
+ FutureWarning,
+ )
+ max_size = kwargs.pop("max_size")
+ else:
+ max_size = None
+ size = get_size_dict(size, max_size=max_size, default_to_square=False)
+ if "shortest_edge" in size and "longest_edge" in size:
+ size = get_resize_output_image_size(image, size["shortest_edge"], size["longest_edge"])
+ elif "height" in size and "width" in size:
+ size = (size["height"], size["width"])
+ else:
+ raise ValueError(
+ "Size must contain 'height' and 'width' keys or 'shortest_edge' and 'longest_edge' keys. Got"
+ f" {size.keys()}."
+ )
+ image = resize(image, size=size, resample=resample, data_format=data_format)
+ return image
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.resize_annotation
+ def resize_annotation(
+ self,
+ annotation,
+ orig_size,
+ size,
+ resample: PILImageResampling = PILImageResampling.NEAREST,
+ ) -> Dict:
+ """
+ Resize the annotation to match the resized image. If size is an int, smaller edge of the mask will be matched
+ to this number.
+ """
+ return resize_annotation(annotation, orig_size=orig_size, target_size=size, resample=resample)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.rescale
+ def rescale(
+ self, image: np.ndarray, rescale_factor: Union[float, int], data_format: Optional[ChannelDimension] = None
+ ) -> np.ndarray:
+ """
+ Rescale the image by the given factor.
+ """
+ return rescale(image, rescale_factor, data_format=data_format)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.normalize
+ def normalize(
+ self,
+ image: np.ndarray,
+ mean: Union[float, Iterable[float]],
+ std: Union[float, Iterable[float]],
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Normalize the image with the given mean and standard deviation.
+ """
+ return normalize(image, mean=mean, std=std, data_format=data_format)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.normalize_annotation
+ def normalize_annotation(self, annotation: Dict, image_size: Tuple[int, int]) -> Dict:
+ """
+ Normalize the boxes in the annotation from `[top_left_x, top_left_y, bottom_right_x, bottom_right_y]` to
+ `[center_x, center_y, width, height]` format.
+ """
+ return normalize_annotation(annotation, image_size=image_size)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor._pad_image
+ def _pad_image(
+ self,
+ image: np.ndarray,
+ output_size: Tuple[int, int],
+ constant_values: Union[float, Iterable[float]] = 0,
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Pad an image with zeros to the given size.
+ """
+ input_height, input_width = get_image_size(image)
+ output_height, output_width = output_size
+
+ pad_bottom = output_height - input_height
+ pad_right = output_width - input_width
+ padding = ((0, pad_bottom), (0, pad_right))
+ padded_image = pad(
+ image, padding, mode=PaddingMode.CONSTANT, constant_values=constant_values, data_format=data_format
+ )
+ return padded_image
+
+ def pad(
+ self,
+ images: List[np.ndarray],
+ return_pixel_mask: bool = False,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ data_format: Optional[ChannelDimension] = None,
+ ) -> np.ndarray:
+ """
+ Pads a batch of images to the bottom and right of the image with zeros to the size of largest height and width
+ in the batch and optionally returns their corresponding pixel mask.
+
+ Args:
+ image (`np.ndarray`):
+ Image to pad.
+ return_pixel_mask (`bool`, *optional*, defaults to `True`):
+ Whether to return a pixel mask.
+ input_channel_dimension (`ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be inferred from the input image.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be the same as the input image.
+ """
+ pad_size = get_max_height_width(images)
+
+ padded_images = [self._pad_image(image, pad_size, data_format=data_format) for image in images]
+ data = {"pixel_values": padded_images}
+
+ if return_pixel_mask:
+ masks = [make_pixel_mask(image=image, output_size=pad_size) for image in images]
+ data["pixel_mask"] = masks
+
+ return BatchFeature(data=data, tensor_type=return_tensors)
+
+ def preprocess(
+ self,
+ images: ImageInput,
+ annotations: Optional[Union[List[Dict], List[List[Dict]]]] = None,
+ return_segmentation_masks: bool = None,
+ masks_path: Optional[Union[str, pathlib.Path]] = None,
+ do_resize: Optional[bool] = None,
+ size: Optional[Dict[str, int]] = None,
+ resample=None, # PILImageResampling
+ do_rescale: Optional[bool] = None,
+ rescale_factor: Optional[Union[int, float]] = None,
+ do_normalize: Optional[bool] = None,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ do_pad: Optional[bool] = None,
+ format: Optional[Union[str, AnnotionFormat]] = None,
+ return_tensors: Optional[Union[TensorType, str]] = None,
+ data_format: Union[str, ChannelDimension] = ChannelDimension.FIRST,
+ **kwargs
+ ) -> BatchFeature:
+ """
+ Preprocess an image or a batch of images so that it can be used by the model.
+
+ Args:
+ images (`ImageInput`):
+ Image or batch of images to preprocess.
+ annotations (`List[Dict]` or `List[List[Dict]]`, *optional*):
+ List of annotations associated with the image or batch of images. If annotionation is for object
+ detection, the annotations should be a dictionary with the following keys:
+ - "image_id" (`int`): The image id.
+ - "annotations" (`List[Dict]`): List of annotations for an image. Each annotation should be a
+ dictionary. An image can have no annotations, in which case the list should be empty.
+ If annotionation is for segmentation, the annotations should be a dictionary with the following keys:
+ - "image_id" (`int`): The image id.
+ - "segments_info" (`List[Dict]`): List of segments for an image. Each segment should be a dictionary.
+ An image can have no segments, in which case the list should be empty.
+ - "file_name" (`str`): The file name of the image.
+ return_segmentation_masks (`bool`, *optional*, defaults to self.return_segmentation_masks):
+ Whether to return segmentation masks.
+ masks_path (`str` or `pathlib.Path`, *optional*):
+ Path to the directory containing the segmentation masks.
+ do_resize (`bool`, *optional*, defaults to self.do_resize):
+ Whether to resize the image.
+ size (`Dict[str, int]`, *optional*, defaults to self.size):
+ Size of the image after resizing.
+ resample (`PILImageResampling`, *optional*, defaults to self.resample):
+ Resampling filter to use when resizing the image.
+ do_rescale (`bool`, *optional*, defaults to self.do_rescale):
+ Whether to rescale the image.
+ rescale_factor (`float`, *optional*, defaults to self.rescale_factor):
+ Rescale factor to use when rescaling the image.
+ do_normalize (`bool`, *optional*, defaults to self.do_normalize):
+ Whether to normalize the image.
+ image_mean (`float` or `List[float]`, *optional*, defaults to self.image_mean):
+ Mean to use when normalizing the image.
+ image_std (`float` or `List[float]`, *optional*, defaults to self.image_std):
+ Standard deviation to use when normalizing the image.
+ do_pad (`bool`, *optional*, defaults to self.do_pad):
+ Whether to pad the image.
+ format (`str` or `AnnotionFormat`, *optional*, defaults to self.format):
+ Format of the annotations.
+ return_tensors (`str` or `TensorType`, *optional*, defaults to self.return_tensors):
+ Type of tensors to return. If `None`, will return the list of images.
+ data_format (`str` or `ChannelDimension`, *optional*, defaults to self.data_format):
+ The channel dimension format of the image. If not provided, it will be the same as the input image.
+ """
+ if "pad_and_return_pixel_mask" in kwargs:
+ warnings.warn(
+ "The `pad_and_return_pixel_mask` argument is deprecated and will be removed in a future version, "
+ "use `do_pad` instead.",
+ FutureWarning,
+ )
+ do_pad = kwargs.pop("pad_and_return_pixel_mask")
+
+ max_size = None
+ if "max_size" in kwargs:
+ warnings.warn(
+ "The `max_size` argument is deprecated and will be removed in a future version, use"
+ " `size['longest_edge']` instead.",
+ FutureWarning,
+ )
+ size = kwargs.pop("max_size")
+
+ do_resize = self.do_resize if do_resize is None else do_resize
+ size = self.size if size is None else size
+ size = get_size_dict(size=size, max_size=max_size, default_to_square=False)
+ resample = self.resample if resample is None else resample
+ do_rescale = self.do_rescale if do_rescale is None else do_rescale
+ rescale_factor = self.rescale_factor if rescale_factor is None else rescale_factor
+ do_normalize = self.do_normalize if do_normalize is None else do_normalize
+ image_mean = self.image_mean if image_mean is None else image_mean
+ image_std = self.image_std if image_std is None else image_std
+ do_pad = self.do_pad if do_pad is None else do_pad
+ format = self.format if format is None else format
+
+ if do_resize is not None and size is None:
+ raise ValueError("Size and max_size must be specified if do_resize is True.")
+
+ if do_rescale is not None and rescale_factor is None:
+ raise ValueError("Rescale factor must be specified if do_rescale is True.")
+
+ if do_normalize is not None and (image_mean is None or image_std is None):
+ raise ValueError("Image mean and std must be specified if do_normalize is True.")
+
+ if not is_batched(images):
+ images = [images]
+ annotations = [annotations] if annotations is not None else None
+
+ if annotations is not None and len(images) != len(annotations):
+ raise ValueError(
+ f"The number of images ({len(images)}) and annotations ({len(annotations)}) do not match."
+ )
+
+ if not valid_images(images):
+ raise ValueError(
+ "Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
+ "torch.Tensor, tf.Tensor or jax.ndarray."
+ )
+
+ format = AnnotionFormat(format)
+ if annotations is not None:
+ if format == AnnotionFormat.COCO_DETECTION and not valid_coco_detection_annotations(annotations):
+ raise ValueError(
+ "Invalid COCO detection annotations. Annotations must a dict (single image) of list of dicts"
+ "(batch of images) with the following keys: `image_id` and `annotations`, with the latter "
+ "being a list of annotations in the COCO format."
+ )
+ elif format == AnnotionFormat.COCO_PANOPTIC and not valid_coco_panoptic_annotations(annotations):
+ raise ValueError(
+ "Invalid COCO panoptic annotations. Annotations must a dict (single image) of list of dicts "
+ "(batch of images) with the following keys: `image_id`, `file_name` and `segments_info`, with "
+ "the latter being a list of annotations in the COCO format."
+ )
+ elif format not in SUPPORTED_ANNOTATION_FORMATS:
+ raise ValueError(
+ f"Unsupported annotation format: {format} must be one of {SUPPORTED_ANNOTATION_FORMATS}"
+ )
+
+ if (
+ masks_path is not None
+ and format == AnnotionFormat.COCO_PANOPTIC
+ and not isinstance(masks_path, (pathlib.Path, str))
+ ):
+ raise ValueError(
+ "The path to the directory containing the mask PNG files should be provided as a"
+ f" `pathlib.Path` or string object, but is {type(masks_path)} instead."
+ )
+
+ # All transformations expect numpy arrays
+ images = [to_numpy_array(image) for image in images]
+
+ # prepare (COCO annotations as a list of Dict -> DETR target as a single Dict per image)
+ if annotations is not None:
+ prepared_images = []
+ prepared_annotations = []
+ for image, target in zip(images, annotations):
+ target = self.prepare_annotation(
+ image, target, format, return_segmentation_masks=return_segmentation_masks, masks_path=masks_path
+ )
+ prepared_images.append(image)
+ prepared_annotations.append(target)
+ images = prepared_images
+ annotations = prepared_annotations
+ del prepared_images, prepared_annotations
+
+ # transformations
+ if do_resize:
+ if annotations is not None:
+ resized_images, resized_annotations = [], []
+ for image, target in zip(images, annotations):
+ orig_size = get_image_size(image)
+ resized_image = self.resize(image, size=size, max_size=max_size, resample=resample)
+ resized_annotation = self.resize_annotation(target, orig_size, get_image_size(resized_image))
+ resized_images.append(resized_image)
+ resized_annotations.append(resized_annotation)
+ images = resized_images
+ annotations = resized_annotations
+ del resized_images, resized_annotations
+ else:
+ images = [self.resize(image, size=size, resample=resample) for image in images]
+
+ if do_rescale:
+ images = [self.rescale(image, rescale_factor) for image in images]
+
+ if do_normalize:
+ images = [self.normalize(image, image_mean, image_std) for image in images]
+ if annotations is not None:
+ annotations = [
+ self.normalize_annotation(annotation, get_image_size(image))
+ for annotation, image in zip(annotations, images)
+ ]
+
+ if do_pad:
+ data = self.pad(images, data_format=data_format)
+ else:
+ images = [to_channel_dimension_format(image, data_format) for image in images]
+ data = {"pixel_values": images}
+
+ encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
+ if annotations is not None:
+ encoded_inputs["labels"] = [
+ BatchFeature(annotation, tensor_type=return_tensors) for annotation in annotations
+ ]
+
+ return encoded_inputs
+
+ # POSTPROCESSING METHODS - TODO: add support for other frameworks
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.post_process
+ def post_process(self, outputs, target_sizes):
+ """
+ Converts the output of [`DetrForObjectDetection`] into the format expected by the COCO api. Only supports
+ PyTorch.
+
+ Args:
+ outputs ([`DetrObjectDetectionOutput`]):
+ Raw outputs of the model.
+ target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
+ Tensor containing the size (height, width) of each image of the batch. For evaluation, this must be the
+ original image size (before any data augmentation). For visualization, this should be the image size
+ after data augment, but before padding.
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
+ in the batch as predicted by the model.
+ """
+ warnings.warn(
+ "`post_process` is deprecated and will be removed in v5 of Transformers, please use"
+ " `post_process_object_detection`",
+ FutureWarning,
+ )
+
+ out_logits, out_bbox = outputs.logits, outputs.pred_boxes
+
+ if len(out_logits) != len(target_sizes):
+ raise ValueError("Make sure that you pass in as many target sizes as the batch dimension of the logits")
+ if target_sizes.shape[1] != 2:
+ raise ValueError("Each element of target_sizes must contain the size (h, w) of each image of the batch")
+
+ prob = nn.functional.softmax(out_logits, -1)
+ scores, labels = prob[..., :-1].max(-1)
+
+ # convert to [x0, y0, x1, y1] format
+ boxes = center_to_corners_format(out_bbox)
+ # and from relative [0, 1] to absolute [0, height] coordinates
+ img_h, img_w = target_sizes.unbind(1)
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1).to(boxes.device)
+ boxes = boxes * scale_fct[:, None, :]
+
+ results = [{"scores": s, "labels": l, "boxes": b} for s, l, b in zip(scores, labels, boxes)]
+ return results
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.post_process_object_detection with Detr->Yolos
+ def post_process_object_detection(
+ self, outputs, threshold: float = 0.5, target_sizes: Union[TensorType, List[Tuple]] = None
+ ):
+ """
+ Converts the output of [`YolosForObjectDetection`] into the format expected by the COCO api. Only supports
+ PyTorch.
+
+ Args:
+ outputs ([`YolosObjectDetectionOutput`]):
+ Raw outputs of the model.
+ threshold (`float`, *optional*):
+ Score threshold to keep object detection predictions.
+ target_sizes (`torch.Tensor` or `List[Tuple[int, int]]`, *optional*):
+ Tensor of shape `(batch_size, 2)` or list of tuples (`Tuple[int, int]`) containing the target size
+ `(height, width)` of each image in the batch. If unset, predictions will not be resized.
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
+ in the batch as predicted by the model.
+ """
+ out_logits, out_bbox = outputs.logits, outputs.pred_boxes
+
+ if target_sizes is not None:
+ if len(out_logits) != len(target_sizes):
+ raise ValueError(
+ "Make sure that you pass in as many target sizes as the batch dimension of the logits"
+ )
+
+ prob = nn.functional.softmax(out_logits, -1)
+ scores, labels = prob[..., :-1].max(-1)
+
+ # Convert to [x0, y0, x1, y1] format
+ boxes = center_to_corners_format(out_bbox)
+
+ # Convert from relative [0, 1] to absolute [0, height] coordinates
+ if target_sizes is not None:
+ if isinstance(target_sizes, List):
+ img_h = torch.Tensor([i[0] for i in target_sizes])
+ img_w = torch.Tensor([i[1] for i in target_sizes])
+ else:
+ img_h, img_w = target_sizes.unbind(1)
+
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
+ boxes = boxes * scale_fct[:, None, :]
+
+ results = []
+ for s, l, b in zip(scores, labels, boxes):
+ score = s[s > threshold]
+ label = l[s > threshold]
+ box = b[s > threshold]
+ results.append({"scores": score, "labels": label, "boxes": box})
+
+ return results
diff --git a/src/transformers/utils/dummy_vision_objects.py b/src/transformers/utils/dummy_vision_objects.py
index fb35aad69a..0db4d433a9 100644
--- a/src/transformers/utils/dummy_vision_objects.py
+++ b/src/transformers/utils/dummy_vision_objects.py
@@ -64,6 +64,13 @@ class ConditionalDetrFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class ConditionalDetrImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class ConvNextFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -85,6 +92,13 @@ class DeformableDetrFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class DeformableDetrImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class DeiTFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -106,6 +120,13 @@ class DetrFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class DetrImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class DonutFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -232,6 +253,13 @@ class MaskFormerFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class MaskFormerImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class MobileNetV1FeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -281,6 +309,13 @@ class OwlViTFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class OwlViTImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class PerceiverFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -377,3 +412,10 @@ class YolosFeatureExtractor(metaclass=DummyObject):
def __init__(self, *args, **kwargs):
requires_backends(self, ["vision"])
+
+
+class YolosImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
diff --git a/tests/models/conditional_detr/test_feature_extraction_conditional_detr.py b/tests/models/conditional_detr/test_feature_extraction_conditional_detr.py
index ef7d0109ac..92ff4fe08f 100644
--- a/tests/models/conditional_detr/test_feature_extraction_conditional_detr.py
+++ b/tests/models/conditional_detr/test_feature_extraction_conditional_detr.py
@@ -44,12 +44,16 @@ class ConditionalDetrFeatureExtractionTester(unittest.TestCase):
min_resolution=30,
max_resolution=400,
do_resize=True,
- size=18,
- max_size=1333, # by setting max_size > max_resolution we're effectively not testing this :p
+ size=None,
do_normalize=True,
image_mean=[0.5, 0.5, 0.5],
image_std=[0.5, 0.5, 0.5],
+ do_rescale=True,
+ rescale_factor=1 / 255,
+ do_pad=True,
):
+ # by setting size["longest_edge"] > max_resolution we're effectively not testing this :p
+ size = size if size is not None else {"shortest_edge": 18, "longest_edge": 1333}
self.parent = parent
self.batch_size = batch_size
self.num_channels = num_channels
@@ -57,19 +61,23 @@ class ConditionalDetrFeatureExtractionTester(unittest.TestCase):
self.max_resolution = max_resolution
self.do_resize = do_resize
self.size = size
- self.max_size = max_size
self.do_normalize = do_normalize
self.image_mean = image_mean
self.image_std = image_std
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_pad = do_pad
def prepare_feat_extract_dict(self):
return {
"do_resize": self.do_resize,
"size": self.size,
- "max_size": self.max_size,
"do_normalize": self.do_normalize,
"image_mean": self.image_mean,
"image_std": self.image_std,
+ "do_rescale": self.do_rescale,
+ "rescale_factor": self.rescale_factor,
+ "do_pad": self.do_pad,
}
def get_expected_values(self, image_inputs, batched=False):
@@ -84,14 +92,14 @@ class ConditionalDetrFeatureExtractionTester(unittest.TestCase):
else:
h, w = image.shape[1], image.shape[2]
if w < h:
- expected_height = int(self.size * h / w)
- expected_width = self.size
+ expected_height = int(self.size["shortest_edge"] * h / w)
+ expected_width = self.size["shortest_edge"]
elif w > h:
- expected_height = self.size
- expected_width = int(self.size * w / h)
+ expected_height = self.size["shortest_edge"]
+ expected_width = int(self.size["shortest_edge"] * w / h)
else:
- expected_height = self.size
- expected_width = self.size
+ expected_height = self.size["shortest_edge"]
+ expected_width = self.size["shortest_edge"]
else:
expected_values = []
@@ -124,7 +132,6 @@ class ConditionalDetrFeatureExtractionTest(FeatureExtractionSavingTestMixin, uni
self.assertTrue(hasattr(feature_extractor, "do_normalize"))
self.assertTrue(hasattr(feature_extractor, "do_resize"))
self.assertTrue(hasattr(feature_extractor, "size"))
- self.assertTrue(hasattr(feature_extractor, "max_size"))
def test_batch_feature(self):
pass
@@ -230,7 +237,7 @@ class ConditionalDetrFeatureExtractionTest(FeatureExtractionSavingTestMixin, uni
def test_equivalence_pad_and_create_pixel_mask(self):
# Initialize feature_extractors
feature_extractor_1 = self.feature_extraction_class(**self.feat_extract_dict)
- feature_extractor_2 = self.feature_extraction_class(do_resize=False, do_normalize=False)
+ feature_extractor_2 = self.feature_extraction_class(do_resize=False, do_normalize=False, do_rescale=False)
# create random PyTorch tensors
image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False, torchify=True)
for image in image_inputs:
@@ -331,7 +338,7 @@ class ConditionalDetrFeatureExtractionTest(FeatureExtractionSavingTestMixin, uni
expected_class_labels = torch.tensor([17, 17, 63, 75, 75, 93])
self.assertTrue(torch.allclose(encoding["labels"][0]["class_labels"], expected_class_labels))
# verify masks
- expected_masks_sum = 822338
+ expected_masks_sum = 822873
self.assertEqual(encoding["labels"][0]["masks"].sum().item(), expected_masks_sum)
# verify orig_size
expected_orig_size = torch.tensor([480, 640])
diff --git a/tests/models/deformable_detr/test_feature_extraction_deformable_detr.py b/tests/models/deformable_detr/test_feature_extraction_deformable_detr.py
index 6a7cfefee5..e205f47a8d 100644
--- a/tests/models/deformable_detr/test_feature_extraction_deformable_detr.py
+++ b/tests/models/deformable_detr/test_feature_extraction_deformable_detr.py
@@ -44,12 +44,16 @@ class DeformableDetrFeatureExtractionTester(unittest.TestCase):
min_resolution=30,
max_resolution=400,
do_resize=True,
- size=18,
- max_size=1333, # by setting max_size > max_resolution we're effectively not testing this :p
+ size=None,
do_normalize=True,
image_mean=[0.5, 0.5, 0.5],
image_std=[0.5, 0.5, 0.5],
+ do_rescale=True,
+ rescale_factor=1 / 255,
+ do_pad=True,
):
+ # by setting size["longest_edge"] > max_resolution we're effectively not testing this :p
+ size = size if size is not None else {"shortest_edge": 18, "longest_edge": 1333}
self.parent = parent
self.batch_size = batch_size
self.num_channels = num_channels
@@ -57,19 +61,23 @@ class DeformableDetrFeatureExtractionTester(unittest.TestCase):
self.max_resolution = max_resolution
self.do_resize = do_resize
self.size = size
- self.max_size = max_size
self.do_normalize = do_normalize
self.image_mean = image_mean
self.image_std = image_std
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_pad = do_pad
def prepare_feat_extract_dict(self):
return {
"do_resize": self.do_resize,
"size": self.size,
- "max_size": self.max_size,
"do_normalize": self.do_normalize,
"image_mean": self.image_mean,
"image_std": self.image_std,
+ "do_rescale": self.do_rescale,
+ "rescale_factor": self.rescale_factor,
+ "do_pad": self.do_pad,
}
def get_expected_values(self, image_inputs, batched=False):
@@ -84,14 +92,14 @@ class DeformableDetrFeatureExtractionTester(unittest.TestCase):
else:
h, w = image.shape[1], image.shape[2]
if w < h:
- expected_height = int(self.size * h / w)
- expected_width = self.size
+ expected_height = int(self.size["shortest_edge"] * h / w)
+ expected_width = self.size["shortest_edge"]
elif w > h:
- expected_height = self.size
- expected_width = int(self.size * w / h)
+ expected_height = self.size["shortest_edge"]
+ expected_width = int(self.size["shortest_edge"] * w / h)
else:
- expected_height = self.size
- expected_width = self.size
+ expected_height = self.size["shortest_edge"]
+ expected_width = self.size["shortest_edge"]
else:
expected_values = []
@@ -123,8 +131,9 @@ class DeformableDetrFeatureExtractionTest(FeatureExtractionSavingTestMixin, unit
self.assertTrue(hasattr(feature_extractor, "image_std"))
self.assertTrue(hasattr(feature_extractor, "do_normalize"))
self.assertTrue(hasattr(feature_extractor, "do_resize"))
+ self.assertTrue(hasattr(feature_extractor, "do_rescale"))
+ self.assertTrue(hasattr(feature_extractor, "do_pad"))
self.assertTrue(hasattr(feature_extractor, "size"))
- self.assertTrue(hasattr(feature_extractor, "max_size"))
def test_batch_feature(self):
pass
@@ -230,7 +239,8 @@ class DeformableDetrFeatureExtractionTest(FeatureExtractionSavingTestMixin, unit
def test_equivalence_pad_and_create_pixel_mask(self):
# Initialize feature_extractors
feature_extractor_1 = self.feature_extraction_class(**self.feat_extract_dict)
- feature_extractor_2 = self.feature_extraction_class(do_resize=False, do_normalize=False)
+ feature_extractor_2 = self.feature_extraction_class(do_resize=False, do_normalize=False, do_rescale=False)
+
# create random PyTorch tensors
image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False, torchify=True)
for image in image_inputs:
@@ -331,7 +341,7 @@ class DeformableDetrFeatureExtractionTest(FeatureExtractionSavingTestMixin, unit
expected_class_labels = torch.tensor([17, 17, 63, 75, 75, 93])
self.assertTrue(torch.allclose(encoding["labels"][0]["class_labels"], expected_class_labels))
# verify masks
- expected_masks_sum = 822338
+ expected_masks_sum = 822873
self.assertEqual(encoding["labels"][0]["masks"].sum().item(), expected_masks_sum)
# verify orig_size
expected_orig_size = torch.tensor([480, 640])
diff --git a/tests/models/detr/test_feature_extraction_detr.py b/tests/models/detr/test_feature_extraction_detr.py
index 30fae36ed8..12e74c1203 100644
--- a/tests/models/detr/test_feature_extraction_detr.py
+++ b/tests/models/detr/test_feature_extraction_detr.py
@@ -44,12 +44,16 @@ class DetrFeatureExtractionTester(unittest.TestCase):
min_resolution=30,
max_resolution=400,
do_resize=True,
- size=18,
- max_size=1333, # by setting max_size > max_resolution we're effectively not testing this :p
+ size=None,
+ do_rescale=True,
+ rescale_factor=1 / 255,
do_normalize=True,
image_mean=[0.5, 0.5, 0.5],
image_std=[0.5, 0.5, 0.5],
+ do_pad=True,
):
+ # by setting size["longest_edge"] > max_resolution we're effectively not testing this :p
+ size = size if size is not None else {"shortest_edge": 18, "longest_edge": 1333}
self.parent = parent
self.batch_size = batch_size
self.num_channels = num_channels
@@ -57,19 +61,23 @@ class DetrFeatureExtractionTester(unittest.TestCase):
self.max_resolution = max_resolution
self.do_resize = do_resize
self.size = size
- self.max_size = max_size
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
self.do_normalize = do_normalize
self.image_mean = image_mean
self.image_std = image_std
+ self.do_pad = do_pad
def prepare_feat_extract_dict(self):
return {
"do_resize": self.do_resize,
"size": self.size,
- "max_size": self.max_size,
+ "do_rescale": self.do_rescale,
+ "rescale_factor": self.rescale_factor,
"do_normalize": self.do_normalize,
"image_mean": self.image_mean,
"image_std": self.image_std,
+ "do_pad": self.do_pad,
}
def get_expected_values(self, image_inputs, batched=False):
@@ -84,14 +92,14 @@ class DetrFeatureExtractionTester(unittest.TestCase):
else:
h, w = image.shape[1], image.shape[2]
if w < h:
- expected_height = int(self.size * h / w)
- expected_width = self.size
+ expected_height = int(self.size["shortest_edge"] * h / w)
+ expected_width = self.size["shortest_edge"]
elif w > h:
- expected_height = self.size
- expected_width = int(self.size * w / h)
+ expected_height = self.size["shortest_edge"]
+ expected_width = int(self.size["shortest_edge"] * w / h)
else:
- expected_height = self.size
- expected_width = self.size
+ expected_height = self.size["shortest_edge"]
+ expected_width = self.size["shortest_edge"]
else:
expected_values = []
@@ -122,9 +130,11 @@ class DetrFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.TestC
self.assertTrue(hasattr(feature_extractor, "image_mean"))
self.assertTrue(hasattr(feature_extractor, "image_std"))
self.assertTrue(hasattr(feature_extractor, "do_normalize"))
+ self.assertTrue(hasattr(feature_extractor, "do_rescale"))
+ self.assertTrue(hasattr(feature_extractor, "rescale_factor"))
self.assertTrue(hasattr(feature_extractor, "do_resize"))
self.assertTrue(hasattr(feature_extractor, "size"))
- self.assertTrue(hasattr(feature_extractor, "max_size"))
+ self.assertTrue(hasattr(feature_extractor, "do_pad"))
def test_batch_feature(self):
pass
@@ -230,7 +240,7 @@ class DetrFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.TestC
def test_equivalence_pad_and_create_pixel_mask(self):
# Initialize feature_extractors
feature_extractor_1 = self.feature_extraction_class(**self.feat_extract_dict)
- feature_extractor_2 = self.feature_extraction_class(do_resize=False, do_normalize=False)
+ feature_extractor_2 = self.feature_extraction_class(do_resize=False, do_normalize=False, do_rescale=False)
# create random PyTorch tensors
image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False, torchify=True)
for image in image_inputs:
@@ -331,7 +341,7 @@ class DetrFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.TestC
expected_class_labels = torch.tensor([17, 17, 63, 75, 75, 93])
self.assertTrue(torch.allclose(encoding["labels"][0]["class_labels"], expected_class_labels))
# verify masks
- expected_masks_sum = 822338
+ expected_masks_sum = 822873
self.assertEqual(encoding["labels"][0]["masks"].sum().item(), expected_masks_sum)
# verify orig_size
expected_orig_size = torch.tensor([480, 640])
diff --git a/tests/models/maskformer/test_feature_extraction_maskformer.py b/tests/models/maskformer/test_feature_extraction_maskformer.py
index e4384a5134..ca2f504c06 100644
--- a/tests/models/maskformer/test_feature_extraction_maskformer.py
+++ b/tests/models/maskformer/test_feature_extraction_maskformer.py
@@ -31,7 +31,7 @@ if is_torch_available():
if is_vision_available():
from transformers import MaskFormerFeatureExtractor
- from transformers.models.maskformer.feature_extraction_maskformer import binary_mask_to_rle
+ from transformers.models.maskformer.image_processing_maskformer import binary_mask_to_rle
from transformers.models.maskformer.modeling_maskformer import MaskFormerForInstanceSegmentationOutput
if is_vision_available():
@@ -46,9 +46,8 @@ class MaskFormerFeatureExtractionTester(unittest.TestCase):
num_channels=3,
min_resolution=30,
max_resolution=400,
+ size=None,
do_resize=True,
- size=32,
- max_size=1333, # by setting max_size > max_resolution we're effectively not testing this :p
do_normalize=True,
image_mean=[0.5, 0.5, 0.5],
image_std=[0.5, 0.5, 0.5],
@@ -62,12 +61,11 @@ class MaskFormerFeatureExtractionTester(unittest.TestCase):
self.min_resolution = min_resolution
self.max_resolution = max_resolution
self.do_resize = do_resize
- self.size = size
- self.max_size = max_size
+ self.size = {"shortest_edge": 32, "longest_edge": 1333} if size is None else size
self.do_normalize = do_normalize
self.image_mean = image_mean
self.image_std = image_std
- self.size_divisibility = 0
+ self.size_divisor = 0
# for the post_process_functions
self.batch_size = 2
self.num_queries = 3
@@ -82,11 +80,10 @@ class MaskFormerFeatureExtractionTester(unittest.TestCase):
return {
"do_resize": self.do_resize,
"size": self.size,
- "max_size": self.max_size,
"do_normalize": self.do_normalize,
"image_mean": self.image_mean,
"image_std": self.image_std,
- "size_divisibility": self.size_divisibility,
+ "size_divisor": self.size_divisor,
"num_labels": self.num_labels,
"reduce_labels": self.reduce_labels,
"ignore_index": self.ignore_index,
@@ -104,14 +101,14 @@ class MaskFormerFeatureExtractionTester(unittest.TestCase):
else:
h, w = image.shape[1], image.shape[2]
if w < h:
- expected_height = int(self.size * h / w)
- expected_width = self.size
+ expected_height = int(self.size["shortest_edge"] * h / w)
+ expected_width = self.size["shortest_edge"]
elif w > h:
- expected_height = self.size
- expected_width = int(self.size * w / h)
+ expected_height = self.size["shortest_edge"]
+ expected_width = int(self.size["shortest_edge"] * w / h)
else:
- expected_height = self.size
- expected_width = self.size
+ expected_height = self.size["shortest_edge"]
+ expected_width = self.size["shortest_edge"]
else:
expected_values = []
@@ -260,7 +257,7 @@ class MaskFormerFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest
# Initialize feature_extractors
feature_extractor_1 = self.feature_extraction_class(**self.feat_extract_dict)
feature_extractor_2 = self.feature_extraction_class(
- do_resize=False, do_normalize=False, num_labels=self.feature_extract_tester.num_classes
+ do_resize=False, do_normalize=False, do_rescale=False, num_labels=self.feature_extract_tester.num_classes
)
# create random PyTorch tensors
image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False, torchify=True)
@@ -283,23 +280,23 @@ class MaskFormerFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest
):
feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
# prepare image and target
- batch_size = self.feature_extract_tester.batch_size
num_labels = self.feature_extract_tester.num_labels
annotations = None
instance_id_to_semantic_id = None
+ image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False)
if with_segmentation_maps:
high = num_labels
if is_instance_map:
- high * 2
labels_expanded = list(range(num_labels)) * 2
instance_id_to_semantic_id = {
instance_id: label_id for instance_id, label_id in enumerate(labels_expanded)
}
- annotations = [np.random.randint(0, high, (384, 384)).astype(np.uint8) for _ in range(batch_size)]
+ annotations = [
+ np.random.randint(0, high * 2, (img.size[1], img.size[0])).astype(np.uint8) for img in image_inputs
+ ]
if segmentation_type == "pil":
annotations = [Image.fromarray(annotation) for annotation in annotations]
- image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False)
inputs = feature_extractor(
image_inputs,
annotations,
@@ -313,18 +310,18 @@ class MaskFormerFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest
def test_init_without_params(self):
pass
- def test_with_size_divisibility(self):
- size_divisibilities = [8, 16, 32]
+ def test_with_size_divisor(self):
+ size_divisors = [8, 16, 32]
weird_input_sizes = [(407, 802), (582, 1094)]
- for size_divisibility in size_divisibilities:
- feat_extract_dict = {**self.feat_extract_dict, **{"size_divisibility": size_divisibility}}
+ for size_divisor in size_divisors:
+ feat_extract_dict = {**self.feat_extract_dict, **{"size_divisor": size_divisor}}
feature_extractor = self.feature_extraction_class(**feat_extract_dict)
for weird_input_size in weird_input_sizes:
inputs = feature_extractor([np.ones((3, *weird_input_size))], return_tensors="pt")
pixel_values = inputs["pixel_values"]
# check if divisible
- self.assertTrue((pixel_values.shape[-1] % size_divisibility) == 0)
- self.assertTrue((pixel_values.shape[-2] % size_divisibility) == 0)
+ self.assertTrue((pixel_values.shape[-1] % size_divisor) == 0)
+ self.assertTrue((pixel_values.shape[-2] % size_divisor) == 0)
def test_call_with_segmentation_maps(self):
def common(is_instance_map=False, segmentation_type=None):
diff --git a/tests/models/owlvit/test_feature_extraction_owlvit.py b/tests/models/owlvit/test_feature_extraction_owlvit.py
index c9198280d7..0435ea91b9 100644
--- a/tests/models/owlvit/test_feature_extraction_owlvit.py
+++ b/tests/models/owlvit/test_feature_extraction_owlvit.py
@@ -43,9 +43,9 @@ class OwlViTFeatureExtractionTester(unittest.TestCase):
min_resolution=30,
max_resolution=400,
do_resize=True,
- size=20,
+ size=None,
do_center_crop=True,
- crop_size=18,
+ crop_size=None,
do_normalize=True,
image_mean=[0.48145466, 0.4578275, 0.40821073],
image_std=[0.26862954, 0.26130258, 0.27577711],
@@ -58,9 +58,9 @@ class OwlViTFeatureExtractionTester(unittest.TestCase):
self.min_resolution = min_resolution
self.max_resolution = max_resolution
self.do_resize = do_resize
- self.size = size
+ self.size = size if size is not None else {"height": 18, "width": 18}
self.do_center_crop = do_center_crop
- self.crop_size = crop_size
+ self.crop_size = crop_size if crop_size is not None else {"height": 18, "width": 18}
self.do_normalize = do_normalize
self.image_mean = image_mean
self.image_std = image_std
@@ -119,8 +119,8 @@ class OwlViTFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.Tes
(
1,
self.feature_extract_tester.num_channels,
- self.feature_extract_tester.crop_size,
- self.feature_extract_tester.crop_size,
+ self.feature_extract_tester.crop_size["height"],
+ self.feature_extract_tester.crop_size["width"],
),
)
@@ -131,8 +131,8 @@ class OwlViTFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.Tes
(
self.feature_extract_tester.batch_size,
self.feature_extract_tester.num_channels,
- self.feature_extract_tester.crop_size,
- self.feature_extract_tester.crop_size,
+ self.feature_extract_tester.crop_size["height"],
+ self.feature_extract_tester.crop_size["width"],
),
)
@@ -151,8 +151,8 @@ class OwlViTFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.Tes
(
1,
self.feature_extract_tester.num_channels,
- self.feature_extract_tester.crop_size,
- self.feature_extract_tester.crop_size,
+ self.feature_extract_tester.crop_size["height"],
+ self.feature_extract_tester.crop_size["width"],
),
)
@@ -163,8 +163,8 @@ class OwlViTFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.Tes
(
self.feature_extract_tester.batch_size,
self.feature_extract_tester.num_channels,
- self.feature_extract_tester.crop_size,
- self.feature_extract_tester.crop_size,
+ self.feature_extract_tester.crop_size["height"],
+ self.feature_extract_tester.crop_size["width"],
),
)
@@ -183,8 +183,8 @@ class OwlViTFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.Tes
(
1,
self.feature_extract_tester.num_channels,
- self.feature_extract_tester.crop_size,
- self.feature_extract_tester.crop_size,
+ self.feature_extract_tester.crop_size["height"],
+ self.feature_extract_tester.crop_size["width"],
),
)
@@ -195,7 +195,7 @@ class OwlViTFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.Tes
(
self.feature_extract_tester.batch_size,
self.feature_extract_tester.num_channels,
- self.feature_extract_tester.crop_size,
- self.feature_extract_tester.crop_size,
+ self.feature_extract_tester.crop_size["height"],
+ self.feature_extract_tester.crop_size["width"],
),
)
diff --git a/tests/models/yolos/test_feature_extraction_yolos.py b/tests/models/yolos/test_feature_extraction_yolos.py
index 1c3805e8cd..162146e6b6 100644
--- a/tests/models/yolos/test_feature_extraction_yolos.py
+++ b/tests/models/yolos/test_feature_extraction_yolos.py
@@ -44,12 +44,16 @@ class YolosFeatureExtractionTester(unittest.TestCase):
min_resolution=30,
max_resolution=400,
do_resize=True,
- size=18,
- max_size=1333, # by setting max_size > max_resolution we're effectively not testing this :p
+ size=None,
do_normalize=True,
image_mean=[0.5, 0.5, 0.5],
image_std=[0.5, 0.5, 0.5],
+ do_rescale=True,
+ rescale_factor=1 / 255,
+ do_pad=True,
):
+ # by setting size["longest_edge"] > max_resolution we're effectively not testing this :p
+ size = size if size is not None else {"shortest_edge": 18, "longest_edge": 1333}
self.parent = parent
self.batch_size = batch_size
self.num_channels = num_channels
@@ -57,19 +61,23 @@ class YolosFeatureExtractionTester(unittest.TestCase):
self.max_resolution = max_resolution
self.do_resize = do_resize
self.size = size
- self.max_size = max_size
self.do_normalize = do_normalize
self.image_mean = image_mean
self.image_std = image_std
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_pad = do_pad
def prepare_feat_extract_dict(self):
return {
"do_resize": self.do_resize,
"size": self.size,
- "max_size": self.max_size,
"do_normalize": self.do_normalize,
"image_mean": self.image_mean,
"image_std": self.image_std,
+ "do_rescale": self.do_rescale,
+ "rescale_factor": self.rescale_factor,
+ "do_pad": self.do_pad,
}
def get_expected_values(self, image_inputs, batched=False):
@@ -84,14 +92,14 @@ class YolosFeatureExtractionTester(unittest.TestCase):
else:
h, w = image.shape[1], image.shape[2]
if w < h:
- expected_height = int(self.size * h / w)
- expected_width = self.size
+ expected_height = int(self.size["shortest_edge"] * h / w)
+ expected_width = self.size["shortest_edge"]
elif w > h:
- expected_height = self.size
- expected_width = int(self.size * w / h)
+ expected_height = self.size["shortest_edge"]
+ expected_width = int(self.size["shortest_edge"] * w / h)
else:
- expected_height = self.size
- expected_width = self.size
+ expected_height = self.size["shortest_edge"]
+ expected_width = self.size["shortest_edge"]
else:
expected_values = []
@@ -124,7 +132,6 @@ class YolosFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.Test
self.assertTrue(hasattr(feature_extractor, "do_normalize"))
self.assertTrue(hasattr(feature_extractor, "do_resize"))
self.assertTrue(hasattr(feature_extractor, "size"))
- self.assertTrue(hasattr(feature_extractor, "max_size"))
def test_batch_feature(self):
pass
@@ -230,7 +237,7 @@ class YolosFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.Test
def test_equivalence_padding(self):
# Initialize feature_extractors
feature_extractor_1 = self.feature_extraction_class(**self.feat_extract_dict)
- feature_extractor_2 = self.feature_extraction_class(do_resize=False, do_normalize=False)
+ feature_extractor_2 = self.feature_extraction_class(do_resize=False, do_normalize=False, do_rescale=False)
# create random PyTorch tensors
image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False, torchify=True)
for image in image_inputs:
@@ -328,7 +335,7 @@ class YolosFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.Test
expected_class_labels = torch.tensor([17, 17, 63, 75, 75, 93])
self.assertTrue(torch.allclose(encoding["labels"][0]["class_labels"], expected_class_labels))
# verify masks
- expected_masks_sum = 822338
+ expected_masks_sum = 822873
self.assertEqual(encoding["labels"][0]["masks"].sum().item(), expected_masks_sum)
# verify orig_size
expected_orig_size = torch.tensor([480, 640])