From de24fb63ed3f151e1c962ffffbcc217982addd82 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Quentin=20Gallou=C3=A9dec?=
<45557362+qgallouedec@users.noreply.github.com>
Date: Fri, 13 Jun 2025 13:07:09 +0200
Subject: [PATCH] Use HF papers (#38184)
* Use hf papers
* Hugging Face papers
* doi to hf papers
* style
---
docs/source/ar/bertology.md | 12 +-
docs/source/ar/glossary.md | 4 +-
docs/source/ar/llm_tutorial_optimization.md | 40 +-
docs/source/ar/model_memory_anatomy.md | 2 +-
docs/source/ar/model_summary.md | 6 +-
docs/source/ar/peft.md | 2 +-
docs/source/ar/tasks_explained.md | 2 +-
docs/source/ar/tokenizer_summary.md | 6 +-
docs/source/ar/trainer.md | 2 +-
docs/source/de/index.md | 260 ++++++-------
docs/source/de/peft.md | 2 +-
docs/source/en/glossary.md | 4 +-
docs/source/en/llm_tutorial_optimization.md | 42 +-
docs/source/en/main_classes/processors.md | 6 +-
docs/source/en/model_doc/albert.md | 2 +-
docs/source/en/model_doc/altclip.md | 2 +-
.../audio-spectrogram-transformer.md | 6 +-
docs/source/en/model_doc/autoformer.md | 2 +-
docs/source/en/model_doc/barthez.md | 2 +-
docs/source/en/model_doc/bartpho.md | 2 +-
docs/source/en/model_doc/beit.md | 8 +-
docs/source/en/model_doc/bert-generation.md | 2 +-
docs/source/en/model_doc/big_bird.md | 1 -
docs/source/en/model_doc/bigbird_pegasus.md | 2 +-
docs/source/en/model_doc/bit.md | 6 +-
docs/source/en/model_doc/bitnet.md | 2 +-
docs/source/en/model_doc/blenderbot-small.md | 2 +-
docs/source/en/model_doc/blenderbot.md | 4 +-
docs/source/en/model_doc/blip-2.md | 6 +-
docs/source/en/model_doc/blip.md | 2 +-
docs/source/en/model_doc/bort.md | 2 +-
docs/source/en/model_doc/bridgetower.md | 6 +-
docs/source/en/model_doc/bros.md | 2 +-
docs/source/en/model_doc/camembert.md | 2 +-
docs/source/en/model_doc/chameleon.md | 4 +-
docs/source/en/model_doc/chinese_clip.md | 2 +-
docs/source/en/model_doc/clap.md | 2 +-
docs/source/en/model_doc/clipseg.md | 4 +-
docs/source/en/model_doc/clvp.md | 2 +-
docs/source/en/model_doc/codegen.md | 2 +-
docs/source/en/model_doc/colqwen2.md | 2 +-
docs/source/en/model_doc/conditional_detr.md | 4 +-
docs/source/en/model_doc/convbert.md | 2 +-
docs/source/en/model_doc/convnext.md | 4 +-
docs/source/en/model_doc/convnextv2.md | 4 +-
docs/source/en/model_doc/cpm.md | 2 +-
docs/source/en/model_doc/ctrl.md | 2 +-
docs/source/en/model_doc/cvt.md | 2 +-
docs/source/en/model_doc/d_fine.md | 2 +-
docs/source/en/model_doc/dab-detr.md | 2 +-
docs/source/en/model_doc/dac.md | 2 +-
docs/source/en/model_doc/data2vec.md | 2 +-
docs/source/en/model_doc/deberta-v2.md | 2 +-
docs/source/en/model_doc/deberta.md | 2 +-
.../en/model_doc/decision_transformer.md | 2 +-
docs/source/en/model_doc/deepseek_v3.md | 2 +-
docs/source/en/model_doc/deformable_detr.md | 4 +-
docs/source/en/model_doc/deit.md | 4 +-
docs/source/en/model_doc/deplot.md | 2 +-
docs/source/en/model_doc/depth_anything_v2.md | 4 +-
docs/source/en/model_doc/depth_pro.md | 6 +-
docs/source/en/model_doc/deta.md | 4 +-
docs/source/en/model_doc/detr.md | 2 +-
docs/source/en/model_doc/dialogpt.md | 2 +-
docs/source/en/model_doc/diffllama.md | 2 +-
docs/source/en/model_doc/dinat.md | 4 +-
.../en/model_doc/dinov2_with_registers.md | 4 +-
docs/source/en/model_doc/dpr.md | 2 +-
docs/source/en/model_doc/dpt.md | 4 +-
docs/source/en/model_doc/efficientformer.md | 2 +-
docs/source/en/model_doc/efficientnet.md | 2 +-
docs/source/en/model_doc/emu3.md | 2 +-
docs/source/en/model_doc/encodec.md | 2 +-
docs/source/en/model_doc/encoder-decoder.md | 4 +-
docs/source/en/model_doc/ernie.md | 4 +-
docs/source/en/model_doc/ernie_m.md | 2 +-
.../en/model_doc/fastspeech2_conformer.md | 2 +-
docs/source/en/model_doc/flan-t5.md | 2 +-
docs/source/en/model_doc/flaubert.md | 2 +-
docs/source/en/model_doc/flava.md | 2 +-
docs/source/en/model_doc/fnet.md | 2 +-
docs/source/en/model_doc/focalnet.md | 2 +-
docs/source/en/model_doc/fsmt.md | 2 +-
docs/source/en/model_doc/funnel.md | 2 +-
docs/source/en/model_doc/git.md | 4 +-
docs/source/en/model_doc/glm.md | 2 +-
docs/source/en/model_doc/glpn.md | 4 +-
docs/source/en/model_doc/got_ocr2.md | 4 +-
docs/source/en/model_doc/gpt_bigcode.md | 2 +-
docs/source/en/model_doc/granite_speech.md | 4 +-
docs/source/en/model_doc/granitemoe.md | 2 +-
docs/source/en/model_doc/granitemoeshared.md | 2 +-
docs/source/en/model_doc/graphormer.md | 2 +-
docs/source/en/model_doc/grounding-dino.md | 6 +-
docs/source/en/model_doc/groupvit.md | 2 +-
docs/source/en/model_doc/hgnet_v2.md | 2 +-
docs/source/en/model_doc/hiera.md | 4 +-
docs/source/en/model_doc/hubert.md | 2 +-
docs/source/en/model_doc/ibert.md | 2 +-
docs/source/en/model_doc/idefics2.md | 4 +-
docs/source/en/model_doc/ijepa.md | 4 +-
docs/source/en/model_doc/informer.md | 2 +-
docs/source/en/model_doc/instructblip.md | 4 +-
docs/source/en/model_doc/instructblipvideo.md | 4 +-
docs/source/en/model_doc/janus.md | 2 +-
docs/source/en/model_doc/jetmoe.md | 2 +-
docs/source/en/model_doc/jukebox.md | 4 +-
docs/source/en/model_doc/kosmos-2.md | 4 +-
docs/source/en/model_doc/layoutlm.md | 2 +-
docs/source/en/model_doc/layoutlmv2.md | 6 +-
docs/source/en/model_doc/layoutlmv3.md | 4 +-
docs/source/en/model_doc/layoutxlm.md | 4 +-
docs/source/en/model_doc/led.md | 2 +-
docs/source/en/model_doc/levit.md | 4 +-
docs/source/en/model_doc/lilt.md | 4 +-
docs/source/en/model_doc/llava.md | 4 +-
docs/source/en/model_doc/llava_next.md | 2 +-
docs/source/en/model_doc/llava_next_video.md | 2 +-
docs/source/en/model_doc/llava_onevision.md | 4 +-
docs/source/en/model_doc/longt5.md | 2 +-
docs/source/en/model_doc/luke.md | 2 +-
docs/source/en/model_doc/lxmert.md | 2 +-
docs/source/en/model_doc/m2m_100.md | 2 +-
docs/source/en/model_doc/markuplm.md | 4 +-
docs/source/en/model_doc/mask2former.md | 4 +-
docs/source/en/model_doc/maskformer.md | 4 +-
docs/source/en/model_doc/matcha.md | 2 +-
docs/source/en/model_doc/mctct.md | 2 +-
docs/source/en/model_doc/mega.md | 2 +-
docs/source/en/model_doc/megatron-bert.md | 2 +-
docs/source/en/model_doc/megatron_gpt2.md | 2 +-
docs/source/en/model_doc/mgp-str.md | 4 +-
docs/source/en/model_doc/minimax.md | 2 +-
docs/source/en/model_doc/mluke.md | 4 +-
docs/source/en/model_doc/mms.md | 2 +-
docs/source/en/model_doc/mobilevit.md | 4 +-
docs/source/en/model_doc/mobilevitv2.md | 4 +-
docs/source/en/model_doc/mpnet.md | 2 +-
docs/source/en/model_doc/mra.md | 2 +-
docs/source/en/model_doc/mt5.md | 2 +-
docs/source/en/model_doc/musicgen.md | 2 +-
docs/source/en/model_doc/musicgen_melody.md | 2 +-
docs/source/en/model_doc/mvp.md | 6 +-
docs/source/en/model_doc/myt5.md | 2 +-
docs/source/en/model_doc/nat.md | 4 +-
docs/source/en/model_doc/nemotron.md | 8 +-
docs/source/en/model_doc/nezha.md | 2 +-
docs/source/en/model_doc/nllb-moe.md | 2 +-
docs/source/en/model_doc/nllb.md | 2 +-
docs/source/en/model_doc/nougat.md | 4 +-
docs/source/en/model_doc/nystromformer.md | 2 +-
docs/source/en/model_doc/olmo.md | 2 +-
docs/source/en/model_doc/olmoe.md | 2 +-
docs/source/en/model_doc/omdet-turbo.md | 4 +-
docs/source/en/model_doc/oneformer.md | 4 +-
docs/source/en/model_doc/opt.md | 2 +-
docs/source/en/model_doc/owlv2.md | 4 +-
docs/source/en/model_doc/owlvit.md | 4 +-
docs/source/en/model_doc/patchtsmixer.md | 2 +-
docs/source/en/model_doc/patchtst.md | 2 +-
docs/source/en/model_doc/pegasus_x.md | 2 +-
docs/source/en/model_doc/perceiver.md | 6 +-
docs/source/en/model_doc/phi3.md | 2 +-
docs/source/en/model_doc/phimoe.md | 2 +-
docs/source/en/model_doc/pix2struct.md | 2 +-
docs/source/en/model_doc/plbart.md | 4 +-
docs/source/en/model_doc/poolformer.md | 4 +-
docs/source/en/model_doc/pop2piano.md | 4 +-
.../en/model_doc/prompt_depth_anything.md | 4 +-
docs/source/en/model_doc/prophetnet.md | 2 +-
docs/source/en/model_doc/pvt.md | 2 +-
docs/source/en/model_doc/pvt_v2.md | 10 +-
docs/source/en/model_doc/qdqbert.md | 2 +-
docs/source/en/model_doc/qwen2_audio.md | 2 +-
docs/source/en/model_doc/qwen2_vl.md | 2 +-
docs/source/en/model_doc/rag.md | 2 +-
docs/source/en/model_doc/realm.md | 2 +-
docs/source/en/model_doc/reformer.md | 6 +-
docs/source/en/model_doc/regnet.md | 4 +-
docs/source/en/model_doc/rembert.md | 2 +-
docs/source/en/model_doc/resnet.md | 4 +-
.../en/model_doc/roberta-prelayernorm.md | 4 +-
docs/source/en/model_doc/roberta.md | 2 +-
docs/source/en/model_doc/rt_detr.md | 4 +-
docs/source/en/model_doc/rt_detr_v2.md | 2 +-
docs/source/en/model_doc/sam.md | 6 +-
docs/source/en/model_doc/sam_hq.md | 2 +-
docs/source/en/model_doc/seamless_m4t.md | 2 +-
docs/source/en/model_doc/seamless_m4t_v2.md | 4 +-
docs/source/en/model_doc/segformer.md | 8 +-
docs/source/en/model_doc/seggpt.md | 2 +-
docs/source/en/model_doc/sew-d.md | 2 +-
docs/source/en/model_doc/sew.md | 2 +-
docs/source/en/model_doc/shieldgemma2.md | 2 +-
.../en/model_doc/speech-encoder-decoder.md | 2 +-
docs/source/en/model_doc/speech_to_text.md | 2 +-
docs/source/en/model_doc/speech_to_text_2.md | 2 +-
docs/source/en/model_doc/speecht5.md | 2 +-
docs/source/en/model_doc/splinter.md | 2 +-
docs/source/en/model_doc/squeezebert.md | 2 +-
docs/source/en/model_doc/starcoder2.md | 2 +-
docs/source/en/model_doc/superglue.md | 2 +-
docs/source/en/model_doc/superpoint.md | 4 +-
docs/source/en/model_doc/swiftformer.md | 2 +-
docs/source/en/model_doc/swin2sr.md | 4 +-
.../en/model_doc/switch_transformers.md | 2 +-
docs/source/en/model_doc/t5v1.1.md | 2 +-
docs/source/en/model_doc/table-transformer.md | 4 +-
docs/source/en/model_doc/tapex.md | 2 +-
docs/source/en/model_doc/textnet.md | 4 +-
docs/source/en/model_doc/timesformer.md | 2 +-
.../en/model_doc/trajectory_transformer.md | 2 +-
docs/source/en/model_doc/transfo-xl.md | 2 +-
docs/source/en/model_doc/trocr.md | 4 +-
docs/source/en/model_doc/tvlt.md | 4 +-
docs/source/en/model_doc/tvp.md | 6 +-
docs/source/en/model_doc/udop.md | 6 +-
docs/source/en/model_doc/ul2.md | 2 +-
docs/source/en/model_doc/unispeech-sat.md | 2 +-
docs/source/en/model_doc/unispeech.md | 2 +-
docs/source/en/model_doc/univnet.md | 2 +-
docs/source/en/model_doc/upernet.md | 4 +-
docs/source/en/model_doc/van.md | 4 +-
docs/source/en/model_doc/video_llava.md | 2 +-
docs/source/en/model_doc/videomae.md | 4 +-
docs/source/en/model_doc/vilt.md | 4 +-
docs/source/en/model_doc/vipllava.md | 2 +-
.../en/model_doc/vision-encoder-decoder.md | 2 +-
.../en/model_doc/vision-text-dual-encoder.md | 2 +-
docs/source/en/model_doc/visual_bert.md | 2 +-
docs/source/en/model_doc/vit_hybrid.md | 2 +-
docs/source/en/model_doc/vit_msn.md | 4 +-
docs/source/en/model_doc/vitdet.md | 2 +-
docs/source/en/model_doc/vitmatte.md | 4 +-
docs/source/en/model_doc/vitpose.md | 6 +-
docs/source/en/model_doc/vivit.md | 2 +-
.../source/en/model_doc/wav2vec2-conformer.md | 4 +-
docs/source/en/model_doc/wav2vec2.md | 2 +-
docs/source/en/model_doc/wav2vec2_phoneme.md | 2 +-
docs/source/en/model_doc/wavlm.md | 2 +-
docs/source/en/model_doc/xclip.md | 4 +-
docs/source/en/model_doc/xglm.md | 2 +-
docs/source/en/model_doc/xlm-prophetnet.md | 2 +-
docs/source/en/model_doc/xlm-v.md | 2 +-
docs/source/en/model_doc/xlnet.md | 2 +-
docs/source/en/model_doc/xls_r.md | 2 +-
docs/source/en/model_doc/xlsr_wav2vec2.md | 2 +-
docs/source/en/model_doc/yolos.md | 4 +-
docs/source/en/model_doc/yoso.md | 4 +-
docs/source/en/model_memory_anatomy.md | 2 +-
docs/source/en/model_summary.md | 6 +-
docs/source/en/quantization/aqlm.md | 2 +-
docs/source/en/quantization/bitnet.md | 4 +-
docs/source/en/quantization/higgs.md | 2 +-
docs/source/en/quantization/vptq.md | 2 +-
...e_distillation_for_image_classification.md | 2 +-
docs/source/en/tasks/video_classification.md | 2 +-
docs/source/en/tasks_explained.md | 2 +-
docs/source/en/tokenizer_summary.md | 6 +-
docs/source/es/bertology.md | 12 +-
docs/source/es/glossary.md | 4 +-
docs/source/es/index.md | 212 +++++-----
docs/source/es/model_memory_anatomy.md | 2 +-
docs/source/es/tasks_explained.md | 2 +-
docs/source/es/tokenizer_summary.md | 6 +-
docs/source/fr/index.md | 324 ++++++++--------
docs/source/fr/tasks_explained.md | 2 +-
docs/source/it/index.md | 226 +++++------
docs/source/it/perf_infer_gpu_one.md | 4 +-
docs/source/ja/bertology.md | 12 +-
docs/source/ja/generation_strategies.md | 4 +-
docs/source/ja/glossary.md | 4 +-
docs/source/ja/index.md | 312 +++++++--------
docs/source/ja/main_classes/deepspeed.md | 10 +-
docs/source/ja/main_classes/processors.md | 6 +-
docs/source/ja/main_classes/quantization.md | 6 +-
docs/source/ja/main_classes/trainer.md | 2 +-
docs/source/ja/model_doc/albert.md | 2 +-
docs/source/ja/model_doc/align.md | 2 +-
docs/source/ja/model_doc/altclip.md | 2 +-
.../audio-spectrogram-transformer.md | 6 +-
docs/source/ja/model_doc/autoformer.md | 2 +-
docs/source/ja/model_doc/bart.md | 6 +-
docs/source/ja/model_doc/barthez.md | 2 +-
docs/source/ja/model_doc/bartpho.md | 2 +-
docs/source/ja/model_doc/beit.md | 8 +-
docs/source/ja/model_doc/bert-generation.md | 2 +-
docs/source/ja/model_doc/bert.md | 2 +-
docs/source/ja/model_doc/big_bird.md | 2 +-
docs/source/ja/model_doc/bigbird_pegasus.md | 2 +-
docs/source/ja/model_doc/bit.md | 6 +-
docs/source/ja/model_doc/blenderbot-small.md | 2 +-
docs/source/ja/model_doc/blenderbot.md | 4 +-
docs/source/ja/model_doc/blip-2.md | 6 +-
docs/source/ja/model_doc/blip.md | 2 +-
docs/source/ja/model_doc/bort.md | 2 +-
docs/source/ja/model_doc/bridgetower.md | 6 +-
docs/source/ja/model_doc/bros.md | 2 +-
docs/source/ja/model_doc/byt5.md | 2 +-
docs/source/ja/model_doc/camembert.md | 2 +-
docs/source/ja/model_doc/canine.md | 2 +-
docs/source/ja/model_doc/chinese_clip.md | 2 +-
docs/source/ja/model_doc/clap.md | 2 +-
docs/source/ja/model_doc/clip.md | 2 +-
docs/source/ja/model_doc/clipseg.md | 4 +-
docs/source/ja/model_doc/clvp.md | 2 +-
docs/source/ja/model_doc/codegen.md | 2 +-
docs/source/ja/model_doc/conditional_detr.md | 4 +-
docs/source/ja/model_doc/convbert.md | 2 +-
docs/source/ja/model_doc/convnext.md | 4 +-
docs/source/ja/model_doc/convnextv2.md | 4 +-
docs/source/ja/model_doc/cpm.md | 2 +-
docs/source/ja/model_doc/ctrl.md | 2 +-
docs/source/ja/model_doc/cvt.md | 2 +-
docs/source/ja/model_doc/data2vec.md | 2 +-
docs/source/ja/model_doc/deberta-v2.md | 2 +-
docs/source/ja/model_doc/deberta.md | 2 +-
.../ja/model_doc/decision_transformer.md | 2 +-
docs/source/ja/model_doc/deformable_detr.md | 4 +-
docs/source/ja/model_doc/deit.md | 4 +-
docs/source/ja/model_doc/deplot.md | 2 +-
docs/source/ja/model_doc/deta.md | 4 +-
docs/source/ja/model_doc/detr.md | 2 +-
docs/source/ja/model_doc/dialogpt.md | 2 +-
docs/source/ja/model_doc/dinat.md | 4 +-
docs/source/ja/model_memory_anatomy.md | 2 +-
docs/source/ja/model_summary.md | 6 +-
docs/source/ja/peft.md | 2 +-
docs/source/ja/perf_infer_gpu_many.md | 2 +-
docs/source/ja/perf_infer_gpu_one.md | 8 +-
docs/source/ja/perf_train_gpu_many.md | 14 +-
docs/source/ja/perf_train_gpu_one.md | 8 +-
...e_distillation_for_image_classification.md | 2 +-
docs/source/ja/tasks/video_classification.md | 2 +-
docs/source/ja/tasks_explained.md | 2 +-
docs/source/ja/tokenizer_summary.md | 6 +-
docs/source/ko/bertology.md | 12 +-
docs/source/ko/generation_strategies.md | 6 +-
docs/source/ko/index.md | 280 +++++++-------
docs/source/ko/llm_tutorial_optimization.md | 40 +-
docs/source/ko/model_doc/altclip.md | 2 +-
docs/source/ko/model_doc/autoformer.md | 2 +-
docs/source/ko/model_doc/bart.md | 4 +-
docs/source/ko/model_doc/barthez.md | 2 +-
docs/source/ko/model_doc/bartpho.md | 2 +-
docs/source/ko/model_doc/bert.md | 2 +-
docs/source/ko/model_doc/blip-2.md | 4 +-
docs/source/ko/model_doc/blip.md | 2 +-
docs/source/ko/model_doc/chameleon.md | 4 +-
docs/source/ko/model_doc/clip.md | 2 +-
docs/source/ko/model_doc/codegen.md | 2 +-
docs/source/ko/model_doc/convbert.md | 2 +-
docs/source/ko/model_doc/deberta-v2.md | 2 +-
docs/source/ko/model_doc/deberta.md | 2 +-
docs/source/ko/model_doc/encoder-decoder.md | 4 +-
docs/source/ko/model_doc/graphormer.md | 2 +-
docs/source/ko/model_doc/informer.md | 2 +-
docs/source/ko/model_doc/llama.md | 2 +-
docs/source/ko/model_doc/llama2.md | 2 +-
docs/source/ko/model_doc/mamba.md | 2 +-
docs/source/ko/model_doc/mamba2.md | 2 +-
docs/source/ko/model_doc/patchtsmixer.md | 2 +-
docs/source/ko/model_doc/patchtst.md | 2 +-
docs/source/ko/model_doc/qwen2_vl.md | 2 +-
docs/source/ko/model_doc/rag.md | 2 +-
docs/source/ko/model_doc/roberta.md | 2 +-
docs/source/ko/model_doc/siglip.md | 4 +-
docs/source/ko/model_doc/swin.md | 4 +-
docs/source/ko/model_doc/swin2sr.md | 4 +-
docs/source/ko/model_doc/swinv2.md | 2 +-
docs/source/ko/model_doc/timesformer.md | 2 +-
.../ko/model_doc/trajectory_transformer.md | 2 +-
docs/source/ko/model_doc/vit.md | 6 +-
docs/source/ko/model_doc/vivit.md | 2 +-
docs/source/ko/model_memory_anatomy.md | 2 +-
docs/source/ko/model_summary.md | 6 +-
docs/source/ko/peft.md | 2 +-
docs/source/ko/perf_infer_gpu_one.md | 4 +-
docs/source/ko/perf_train_gpu_many.md | 14 +-
...e_distillation_for_image_classification.md | 2 +-
docs/source/ko/tasks/video_classification.md | 2 +-
docs/source/ko/tasks_explained.md | 2 +-
docs/source/ko/tokenizer_summary.md | 6 +-
docs/source/ko/trainer.md | 2 +-
docs/source/ms/index.md | 364 +++++++++---------
docs/source/pt/index.md | 210 +++++-----
docs/source/zh/bertology.md | 12 +-
docs/source/zh/main_classes/deepspeed.md | 10 +-
docs/source/zh/main_classes/processors.md | 4 +-
docs/source/zh/main_classes/quantization.md | 8 +-
docs/source/zh/main_classes/trainer.md | 2 +-
docs/source/zh/peft.md | 2 +-
docs/source/zh/tokenizer_summary.md | 6 +-
examples/flax/language-modeling/README.md | 6 +-
.../language-modeling/run_bart_dlm_flax.py | 2 +-
.../flax/language-modeling/run_t5_mlm_flax.py | 2 +-
examples/legacy/question-answering/README.md | 6 +-
.../configuration_my_new_model.py | 2 +-
.../configuration_new_model.py | 2 +-
.../modeling_add_function.py | 2 +-
.../modular-transformers/modeling_dummy.py | 2 +-
.../modeling_dummy_bert.py | 2 +-
.../modeling_multimodal1.py | 2 +-
.../modeling_my_new_model2.py | 2 +-
.../modular-transformers/modeling_roberta.py | 2 +-
.../modular-transformers/modeling_super.py | 2 +-
examples/pytorch/image-pretraining/README.md | 10 +-
examples/pytorch/image-pretraining/run_mae.py | 2 +-
examples/pytorch/language-modeling/README.md | 2 +-
examples/pytorch/speech-pretraining/README.md | 2 +-
.../run_wav2vec2_pretraining_no_trainer.py | 2 +-
examples/pytorch/speech-recognition/README.md | 2 +-
.../language-modeling-tpu/README.md | 2 +-
src/transformers/activations.py | 16 +-
src/transformers/activations_tf.py | 10 +-
src/transformers/cache_utils.py | 2 +-
src/transformers/generation/beam_search.py | 4 +-
.../generation/candidate_generator.py | 2 +-
.../generation/configuration_utils.py | 16 +-
src/transformers/generation/logits_process.py | 22 +-
.../generation/tf_logits_process.py | 2 +-
src/transformers/generation/utils.py | 8 +-
src/transformers/generation/watermarking.py | 2 +-
src/transformers/integrations/peft.py | 2 +-
.../integrations/tensor_parallel.py | 2 +-
.../loss/loss_for_object_detection.py | 2 +-
src/transformers/loss/loss_grounding_dino.py | 2 +-
src/transformers/modelcard.py | 4 +-
src/transformers/modeling_rope_utils.py | 2 +-
src/transformers/modeling_utils.py | 2 +-
.../models/albert/configuration_albert.py | 4 +-
.../models/align/configuration_align.py | 4 +-
.../models/altclip/configuration_altclip.py | 4 +-
.../models/altclip/modeling_altclip.py | 2 +-
.../models/aria/configuration_aria.py | 2 +-
src/transformers/models/aria/modular_aria.py | 2 +-
.../models/autoformer/modeling_autoformer.py | 4 +-
.../models/bamba/configuration_bamba.py | 2 +-
.../models/bart/configuration_bart.py | 4 +-
src/transformers/models/bart/modeling_bart.py | 12 +-
.../models/bart/modeling_flax_bart.py | 8 +-
.../models/bart/modeling_tf_bart.py | 4 +-
src/transformers/models/beit/modeling_beit.py | 6 +-
.../models/bert/configuration_bert.py | 4 +-
src/transformers/models/bert/modeling_bert.py | 2 +-
.../configuration_bert_generation.py | 4 +-
.../modeling_bert_generation.py | 4 +-
.../models/big_bird/modeling_big_bird.py | 2 +-
.../configuration_bigbird_pegasus.py | 4 +-
.../modeling_bigbird_pegasus.py | 12 +-
.../models/biogpt/configuration_biogpt.py | 2 +-
.../models/biogpt/modeling_biogpt.py | 2 +-
.../models/biogpt/modular_biogpt.py | 2 +-
src/transformers/models/bit/modeling_bit.py | 2 +-
.../models/bitnet/configuration_bitnet.py | 2 +-
.../blenderbot/configuration_blenderbot.py | 4 +-
.../models/blenderbot/modeling_blenderbot.py | 4 +-
.../blenderbot/modeling_flax_blenderbot.py | 8 +-
.../blenderbot/modeling_tf_blenderbot.py | 4 +-
.../configuration_blenderbot_small.py | 4 +-
.../modeling_blenderbot_small.py | 4 +-
.../modeling_flax_blenderbot_small.py | 8 +-
.../modeling_tf_blenderbot_small.py | 4 +-
.../models/blip/configuration_blip.py | 4 +-
.../models/blip/modeling_blip_text.py | 2 +-
.../models/blip/modeling_tf_blip_text.py | 2 +-
.../models/blip_2/configuration_blip_2.py | 4 +-
.../models/bloom/modeling_bloom.py | 2 +-
.../models/bloom/modeling_flax_bloom.py | 2 +-
.../bridgetower/configuration_bridgetower.py | 4 +-
.../bridgetower/modeling_bridgetower.py | 2 +-
.../camembert/configuration_camembert.py | 4 +-
.../models/camembert/modeling_camembert.py | 2 +-
.../chameleon/configuration_chameleon.py | 2 +-
.../models/chameleon/modeling_chameleon.py | 3 +-
.../configuration_chinese_clip.py | 4 +-
.../chinese_clip/modeling_chinese_clip.py | 2 +-
.../models/clap/configuration_clap.py | 4 +-
src/transformers/models/clap/modeling_clap.py | 2 +-
src/transformers/models/clvp/modeling_clvp.py | 2 +-
.../models/cohere/configuration_cohere.py | 2 +-
.../models/cohere2/configuration_cohere2.py | 2 +-
.../models/cohere2/modular_cohere2.py | 2 +-
.../models/colpali/modeling_colpali.py | 2 +-
.../models/colqwen2/modeling_colqwen2.py | 2 +-
.../models/colqwen2/modular_colqwen2.py | 2 +-
.../configuration_conditional_detr.py | 4 +-
.../modeling_conditional_detr.py | 4 +-
.../models/cpmant/modeling_cpmant.py | 2 +-
.../models/csm/configuration_csm.py | 4 +-
.../models/d_fine/modeling_d_fine.py | 2 +-
src/transformers/models/dac/modeling_dac.py | 4 +-
.../data2vec/configuration_data2vec_audio.py | 4 +-
.../data2vec/configuration_data2vec_text.py | 4 +-
.../data2vec/modeling_data2vec_audio.py | 6 +-
.../models/data2vec/modeling_data2vec_text.py | 2 +-
.../data2vec/modeling_data2vec_vision.py | 6 +-
.../data2vec/modeling_tf_data2vec_vision.py | 4 +-
src/transformers/models/dbrx/modeling_dbrx.py | 2 +-
.../models/deberta/modeling_tf_deberta.py | 2 +-
.../deberta_v2/modeling_tf_deberta_v2.py | 2 +-
.../modeling_decision_transformer.py | 2 +-
.../deepseek_v3/configuration_deepseek_v3.py | 2 +-
.../configuration_deformable_detr.py | 2 +-
src/transformers/models/deit/modeling_deit.py | 2 +-
.../models/deit/modeling_tf_deit.py | 2 +-
.../deprecated/deta/configuration_deta.py | 2 +-
.../models/deprecated/deta/modeling_deta.py | 2 +-
.../configuration_gptsan_japanese.py | 2 +-
.../modeling_gptsan_japanese.py | 10 +-
.../graphormer/configuration_graphormer.py | 2 +-
.../graphormer/modeling_graphormer.py | 2 +-
.../jukebox/configuration_jukebox.py | 2 +-
.../deprecated/jukebox/modeling_jukebox.py | 2 +-
.../models/deprecated/mctct/modeling_mctct.py | 4 +-
.../models/deprecated/mega/modeling_mega.py | 6 +-
.../models/deprecated/nezha/modeling_nezha.py | 2 +-
.../open_llama/modeling_open_llama.py | 2 +-
.../deprecated/qdqbert/modeling_qdqbert.py | 2 +-
.../configuration_speech_to_text_2.py | 4 +-
.../modeling_speech_to_text_2.py | 2 +-
.../models/deprecated/van/modeling_van.py | 4 +-
.../configuration_xlm_prophetnet.py | 4 +-
.../models/detr/configuration_detr.py | 4 +-
src/transformers/models/detr/modeling_detr.py | 4 +-
.../diffllama/configuration_diffllama.py | 2 +-
.../models/dpr/configuration_dpr.py | 4 +-
.../models/electra/configuration_electra.py | 4 +-
.../models/emu3/configuration_emu3.py | 2 +-
src/transformers/models/emu3/modeling_emu3.py | 3 +-
src/transformers/models/emu3/modular_emu3.py | 3 +-
.../modeling_flax_encoder_decoder.py | 2 +-
.../modeling_tf_encoder_decoder.py | 2 +-
.../models/ernie/configuration_ernie.py | 4 +-
.../models/ernie/modeling_ernie.py | 2 +-
.../models/esm/configuration_esm.py | 4 +-
src/transformers/models/esm/modeling_esm.py | 2 +-
.../models/esm/modeling_tf_esm.py | 2 +-
.../falcon_h1/configuration_falcon_h1.py | 2 +-
.../modeling_fastspeech2_conformer.py | 18 +-
.../models/flava/configuration_flava.py | 4 +-
src/transformers/models/fnet/modeling_fnet.py | 2 +-
.../models/focalnet/modeling_focalnet.py | 2 +-
src/transformers/models/fsmt/modeling_fsmt.py | 6 +-
.../models/funnel/modeling_funnel.py | 6 +-
.../models/funnel/modeling_tf_funnel.py | 8 +-
.../models/gemma/configuration_gemma.py | 2 +-
.../models/gemma/modeling_flax_gemma.py | 2 +-
.../models/gemma/modular_gemma.py | 2 +-
.../models/gemma2/configuration_gemma2.py | 2 +-
.../models/gemma2/modular_gemma2.py | 2 +-
.../models/gemma3/configuration_gemma3.py | 2 +-
.../models/gemma3/modular_gemma3.py | 2 +-
.../models/git/configuration_git.py | 4 +-
.../models/glm/configuration_glm.py | 2 +-
.../models/glm4/configuration_glm4.py | 2 +-
src/transformers/models/glpn/modeling_glpn.py | 6 +-
.../models/granite/configuration_granite.py | 2 +-
.../granite_speech/modeling_granite_speech.py | 2 +-
.../granitemoe/configuration_granitemoe.py | 2 +-
.../models/granitemoe/modeling_granitemoe.py | 2 +-
.../configuration_granitemoehybrid.py | 2 +-
.../modeling_granitemoehybrid.py | 2 +-
.../configuration_granitemoeshared.py | 2 +-
.../modeling_granitemoeshared.py | 2 +-
.../models/helium/configuration_helium.py | 2 +-
.../models/hubert/configuration_hubert.py | 6 +-
.../models/hubert/modeling_hubert.py | 8 +-
.../models/hubert/modeling_tf_hubert.py | 6 +-
.../models/ibert/configuration_ibert.py | 4 +-
.../models/ibert/modeling_ibert.py | 2 +-
.../models/idefics/modeling_tf_idefics.py | 2 +-
.../idefics2/image_processing_idefics2.py | 4 +-
.../models/idefics2/modeling_idefics2.py | 2 +-
.../models/idefics3/modeling_idefics3.py | 2 +-
.../models/informer/modeling_informer.py | 4 +-
.../models/informer/modular_informer.py | 2 +-
.../configuration_instructblip.py | 4 +-
.../configuration_instructblipvideo.py | 4 +-
.../models/jamba/configuration_jamba.py | 2 +-
.../models/jamba/modeling_jamba.py | 2 +-
.../models/janus/modeling_janus.py | 3 +-
.../models/jetmoe/modeling_jetmoe.py | 2 +-
.../models/kosmos2/configuration_kosmos2.py | 2 +-
.../models/kosmos2/modeling_kosmos2.py | 2 +-
.../models/layoutlm/configuration_layoutlm.py | 4 +-
.../models/layoutlmv3/modeling_layoutlmv3.py | 4 +-
.../layoutlmv3/modeling_tf_layoutlmv3.py | 2 +-
.../models/led/configuration_led.py | 4 +-
src/transformers/models/led/modeling_led.py | 24 +-
.../models/led/modeling_tf_led.py | 4 +-
.../models/lilt/configuration_lilt.py | 4 +-
.../models/llama/configuration_llama.py | 2 +-
.../models/llama/modeling_flax_llama.py | 2 +-
.../models/llama4/modeling_llama4.py | 2 +-
.../llava_next/image_processing_llava_next.py | 2 +-
.../models/longformer/modeling_longformer.py | 14 +-
.../longformer/modeling_tf_longformer.py | 4 +-
.../models/longt5/modeling_flax_longt5.py | 6 +-
.../models/longt5/modeling_longt5.py | 4 +-
.../models/luke/configuration_luke.py | 2 +-
.../models/lxmert/modeling_tf_lxmert.py | 2 +-
.../models/m2m_100/configuration_m2m_100.py | 4 +-
.../models/m2m_100/modeling_m2m_100.py | 4 +-
.../models/marian/configuration_marian.py | 4 +-
.../models/marian/modeling_flax_marian.py | 8 +-
.../models/marian/modeling_marian.py | 4 +-
.../models/marian/modeling_tf_marian.py | 4 +-
.../mask2former/modeling_mask2former.py | 2 +-
.../models/maskformer/modeling_maskformer.py | 8 +-
.../models/mbart/configuration_mbart.py | 4 +-
.../models/mbart/modeling_flax_mbart.py | 8 +-
.../models/mbart/modeling_mbart.py | 8 +-
.../models/mbart/modeling_tf_mbart.py | 4 +-
.../configuration_megatron_bert.py | 4 +-
.../megatron_bert/modeling_megatron_bert.py | 2 +-
.../models/mimi/configuration_mimi.py | 2 +-
src/transformers/models/mimi/modeling_mimi.py | 4 +-
.../models/minimax/configuration_minimax.py | 2 +-
.../models/minimax/modeling_minimax.py | 2 +-
.../models/minimax/modular_minimax.py | 2 +-
.../models/mistral/configuration_mistral.py | 2 +-
.../models/mistral/modeling_flax_mistral.py | 2 +-
.../models/mistral/modeling_tf_mistral.py | 2 +-
.../models/mixtral/configuration_mixtral.py | 2 +-
.../models/mixtral/modeling_mixtral.py | 2 +-
.../models/mixtral/modular_mixtral.py | 2 +-
src/transformers/models/mlcd/modeling_mlcd.py | 4 +-
src/transformers/models/mlcd/modular_mlcd.py | 4 +-
.../models/mobilebert/modeling_mobilebert.py | 4 +-
.../mobilebert/modeling_tf_mobilebert.py | 2 +-
.../mobilenet_v2/modeling_mobilenet_v2.py | 2 +-
.../models/mobilevit/modeling_mobilevit.py | 8 +-
.../models/mobilevit/modeling_tf_mobilevit.py | 8 +-
.../mobilevitv2/modeling_mobilevitv2.py | 10 +-
.../moonshine/configuration_moonshine.py | 4 +-
.../models/moonshine/modeling_moonshine.py | 8 +-
.../models/moonshine/modular_moonshine.py | 8 +-
.../models/moshi/configuration_moshi.py | 4 +-
.../models/moshi/modeling_moshi.py | 2 +-
src/transformers/models/mpt/modeling_mpt.py | 2 +-
src/transformers/models/mt5/modeling_mt5.py | 2 +-
.../models/musicgen/configuration_musicgen.py | 2 +-
.../models/musicgen/modeling_musicgen.py | 2 +-
.../configuration_musicgen_melody.py | 2 +-
.../modeling_musicgen_melody.py | 2 +-
.../models/mvp/configuration_mvp.py | 4 +-
src/transformers/models/mvp/modeling_mvp.py | 12 +-
.../models/nemotron/configuration_nemotron.py | 2 +-
.../models/nllb_moe/configuration_nllb_moe.py | 6 +-
.../models/nllb_moe/modeling_nllb_moe.py | 6 +-
.../models/olmo/configuration_olmo.py | 2 +-
.../models/olmo2/configuration_olmo2.py | 2 +-
.../models/olmo2/modular_olmo2.py | 2 +-
.../models/olmoe/configuration_olmoe.py | 2 +-
.../models/olmoe/modeling_olmoe.py | 2 +-
.../omdet_turbo/modeling_omdet_turbo.py | 2 +-
.../models/oneformer/modeling_oneformer.py | 2 +-
.../models/opt/configuration_opt.py | 2 +-
src/transformers/models/opt/modeling_opt.py | 2 +-
.../models/pegasus/configuration_pegasus.py | 4 +-
.../models/pegasus/modeling_flax_pegasus.py | 8 +-
.../models/pegasus/modeling_pegasus.py | 4 +-
.../models/pegasus/modeling_tf_pegasus.py | 4 +-
.../models/pegasus/tokenization_pegasus.py | 4 +-
.../pegasus/tokenization_pegasus_fast.py | 4 +-
.../pegasus_x/configuration_pegasus_x.py | 4 +-
.../models/pegasus_x/modeling_pegasus_x.py | 4 +-
.../models/phi/configuration_phi.py | 2 +-
.../models/phi3/configuration_phi3.py | 2 +-
.../configuration_phi4_multimodal.py | 2 +-
.../modular_phi4_multimodal.py | 2 +-
.../models/phimoe/configuration_phimoe.py | 2 +-
.../models/phimoe/modeling_phimoe.py | 4 +-
.../pix2struct/image_processing_pix2struct.py | 2 +-
.../models/pix2struct/modeling_pix2struct.py | 4 +-
.../models/plbart/configuration_plbart.py | 4 +-
.../models/plbart/modeling_plbart.py | 4 +-
.../models/pop2piano/modeling_pop2piano.py | 2 +-
.../prophetnet/configuration_prophetnet.py | 4 +-
src/transformers/models/pvt/modeling_pvt.py | 2 +-
.../models/qwen2/configuration_qwen2.py | 2 +-
.../configuration_qwen2_5_omni.py | 4 +-
.../qwen2_5_omni/modeling_qwen2_5_omni.py | 4 +-
.../qwen2_5_omni/modular_qwen2_5_omni.py | 8 +-
.../qwen2_5_vl/configuration_qwen2_5_vl.py | 2 +-
.../qwen2_audio/configuration_qwen2_audio.py | 2 +-
.../qwen2_audio/modeling_qwen2_audio.py | 2 +-
.../qwen2_moe/configuration_qwen2_moe.py | 2 +-
.../models/qwen2_moe/modeling_qwen2_moe.py | 2 +-
.../models/qwen2_vl/configuration_qwen2_vl.py | 2 +-
.../models/qwen3/configuration_qwen3.py | 2 +-
.../qwen3_moe/configuration_qwen3_moe.py | 3 +-
.../models/qwen3_moe/modeling_qwen3_moe.py | 2 +-
src/transformers/models/rag/modeling_rag.py | 4 +-
.../models/rag/modeling_tf_rag.py | 6 +-
.../models/reformer/modeling_reformer.py | 4 +-
.../regnet/convert_regnet_to_pytorch.py | 2 +-
.../models/regnet/modeling_flax_regnet.py | 2 +-
.../models/regnet/modeling_regnet.py | 2 +-
.../models/regnet/modeling_tf_regnet.py | 2 +-
.../models/rembert/modeling_rembert.py | 2 +-
.../models/roberta/configuration_roberta.py | 4 +-
.../models/roberta/modeling_roberta.py | 2 +-
.../configuration_roberta_prelayernorm.py | 4 +-
.../modeling_roberta_prelayernorm.py | 2 +-
.../models/roc_bert/configuration_roc_bert.py | 4 +-
.../models/roc_bert/modeling_roc_bert.py | 2 +-
.../models/roformer/modeling_roformer.py | 2 +-
.../models/rt_detr/modeling_rt_detr.py | 2 +-
.../models/rt_detr_v2/modeling_rt_detr_v2.py | 2 +-
src/transformers/models/sam/modeling_sam.py | 4 +-
.../models/sam_hq/modeling_sam_hq.py | 4 +-
.../models/sam_hq/modular_sam_hq.py | 4 +-
.../configuration_seamless_m4t.py | 6 +-
.../seamless_m4t/modeling_seamless_m4t.py | 24 +-
.../configuration_seamless_m4t_v2.py | 8 +-
.../modeling_seamless_m4t_v2.py | 19 +-
.../models/segformer/modeling_segformer.py | 2 +-
.../models/segformer/modeling_tf_segformer.py | 2 +-
.../models/seggpt/image_processing_seggpt.py | 2 +-
.../models/sew/configuration_sew.py | 6 +-
src/transformers/models/sew/modeling_sew.py | 6 +-
src/transformers/models/sew/modular_sew.py | 4 +-
.../models/sew_d/configuration_sew_d.py | 4 +-
.../models/sew_d/modeling_sew_d.py | 4 +-
.../models/smolvlm/modeling_smolvlm.py | 2 +-
.../modeling_flax_speech_encoder_decoder.py | 4 +-
.../configuration_speech_to_text.py | 4 +-
.../speech_to_text/modeling_speech_to_text.py | 10 +-
.../modeling_tf_speech_to_text.py | 6 +-
.../models/speecht5/configuration_speecht5.py | 8 +-
.../models/speecht5/modeling_speecht5.py | 22 +-
.../models/splinter/modeling_splinter.py | 2 +-
.../models/stablelm/configuration_stablelm.py | 2 +-
.../starcoder2/configuration_starcoder2.py | 2 +-
.../models/superglue/modeling_superglue.py | 2 +-
.../models/superpoint/modeling_superpoint.py | 2 +-
src/transformers/models/swin/modeling_swin.py | 2 +-
.../models/swin/modeling_tf_swin.py | 2 +-
.../models/swinv2/modeling_swinv2.py | 2 +-
.../configuration_switch_transformers.py | 2 +-
.../modeling_switch_transformers.py | 12 +-
.../models/t5/modeling_flax_t5.py | 4 +-
src/transformers/models/t5/modeling_t5.py | 2 +-
src/transformers/models/t5/modeling_tf_t5.py | 2 +-
.../configuration_table_transformer.py | 4 +-
.../modeling_table_transformer.py | 4 +-
.../models/tapas/modeling_tapas.py | 2 +-
.../modeling_time_series_transformer.py | 4 +-
.../models/trocr/configuration_trocr.py | 2 +-
.../models/trocr/modeling_trocr.py | 2 +-
src/transformers/models/udop/modeling_udop.py | 2 +-
src/transformers/models/umt5/modeling_umt5.py | 2 +-
.../unispeech/configuration_unispeech.py | 6 +-
.../models/unispeech/modeling_unispeech.py | 12 +-
.../models/unispeech/modular_unispeech.py | 2 +-
.../configuration_unispeech_sat.py | 6 +-
.../unispeech_sat/modeling_unispeech_sat.py | 12 +-
.../unispeech_sat/modular_unispeech_sat.py | 2 +-
.../models/univnet/modeling_univnet.py | 2 +-
.../models/upernet/modeling_upernet.py | 4 +-
.../modeling_flax_vision_encoder_decoder.py | 4 +-
.../modeling_tf_vision_encoder_decoder.py | 4 +-
.../modeling_flax_vision_text_dual_encoder.py | 2 +-
.../modeling_tf_vision_text_dual_encoder.py | 2 +-
.../visual_bert/modeling_visual_bert.py | 2 +-
src/transformers/models/vit/modeling_vit.py | 2 +-
.../models/vits/configuration_vits.py | 2 +-
src/transformers/models/vits/modeling_vits.py | 2 +-
.../models/wav2vec2/configuration_wav2vec2.py | 6 +-
.../models/wav2vec2/modeling_flax_wav2vec2.py | 8 +-
.../models/wav2vec2/modeling_tf_wav2vec2.py | 6 +-
.../models/wav2vec2/modeling_wav2vec2.py | 18 +-
.../configuration_wav2vec2_bert.py | 8 +-
.../wav2vec2_bert/modeling_wav2vec2_bert.py | 18 +-
.../wav2vec2_bert/modular_wav2vec2_bert.py | 8 +-
.../configuration_wav2vec2_conformer.py | 6 +-
.../modeling_wav2vec2_conformer.py | 28 +-
.../modular_wav2vec2_conformer.py | 20 +-
.../models/wavlm/configuration_wavlm.py | 6 +-
.../models/wavlm/modeling_wavlm.py | 10 +-
.../models/wavlm/modular_wavlm.py | 6 +-
.../models/whisper/configuration_whisper.py | 8 +-
.../models/whisper/generation_whisper.py | 2 +-
.../models/whisper/modeling_flax_whisper.py | 8 +-
.../models/whisper/modeling_tf_whisper.py | 6 +-
.../models/whisper/modeling_whisper.py | 12 +-
.../models/xglm/configuration_xglm.py | 2 +-
.../models/xglm/modeling_flax_xglm.py | 2 +-
.../models/xglm/modeling_tf_xglm.py | 2 +-
src/transformers/models/xglm/modeling_xglm.py | 2 +-
.../xlm_roberta/configuration_xlm_roberta.py | 4 +-
.../configuration_xlm_roberta_xl.py | 4 +-
.../models/xmod/configuration_xmod.py | 4 +-
src/transformers/models/xmod/modeling_xmod.py | 2 +-
.../models/zamba/configuration_zamba.py | 2 +-
.../models/zamba/modeling_zamba.py | 8 +-
.../models/zamba2/configuration_zamba2.py | 2 +-
.../models/zamba2/modeling_zamba2.py | 12 +-
.../models/zamba2/modular_zamba2.py | 6 +-
src/transformers/optimization.py | 4 +-
src/transformers/optimization_tf.py | 4 +-
.../quantizers/quantizer_auto_round.py | 2 +-
src/transformers/quantizers/quantizer_awq.py | 2 +-
.../quantizers/quantizer_bitnet.py | 2 +-
src/transformers/trainer.py | 2 +-
src/transformers/training_args.py | 6 +-
src/transformers/utils/quantization_config.py | 2 +-
tests/repo_utils/test_check_copies.py | 20 +-
tests/utils/test_model_card.py | 4 +-
811 files changed, 2622 insertions(+), 2617 deletions(-)
diff --git a/docs/source/ar/bertology.md b/docs/source/ar/bertology.md
index d12d783890..78f85b5c10 100644
--- a/docs/source/ar/bertology.md
+++ b/docs/source/ar/bertology.md
@@ -3,16 +3,16 @@
يُشهد في الآونة الأخيرة نمو مجال دراسي يُعنى باستكشاف آلية عمل نماذج المحولات الضخمة مثل BERT (والذي يُطلق عليها البعض اسم "BERTology"). ومن الأمثلة البارزة على هذا المجال ما يلي:
- BERT Rediscovers the Classical NLP Pipeline بواسطة Ian Tenney و Dipanjan Das و Ellie Pavlick:
- https://arxiv.org/abs/1905.05950
-- Are Sixteen Heads Really Better than One? بواسطة Paul Michel و Omer Levy و Graham Neubig: https://arxiv.org/abs/1905.10650
+ https://huggingface.co/papers/1905.05950
+- Are Sixteen Heads Really Better than One? بواسطة Paul Michel و Omer Levy و Graham Neubig: https://huggingface.co/papers/1905.10650
- What Does BERT Look At? An Analysis of BERT's Attention بواسطة Kevin Clark و Urvashi Khandelwal و Omer Levy و Christopher D.
- Manning: https://arxiv.org/abs/1906.04341
-- CAT-probing: A Metric-based Approach to Interpret How Pre-trained Models for Programming Language Attend Code Structure: https://arxiv.org/abs/2210.04633
+ Manning: https://huggingface.co/papers/1906.04341
+- CAT-probing: A Metric-based Approach to Interpret How Pre-trained Models for Programming Language Attend Code Structure: https://huggingface.co/papers/2210.04633
-لإثراء هذا المجال الناشئ، قمنا بتضمين بعض الميزات الإضافية في نماذج BERT/GPT/GPT-2 للسماح للناس بالوصول إلى التمثيلات الداخلية، والتي تم تكييفها بشكل أساسي من العمل الرائد لـ Paul Michel (https://arxiv.org/abs/1905.10650):
+لإثراء هذا المجال الناشئ، قمنا بتضمين بعض الميزات الإضافية في نماذج BERT/GPT/GPT-2 للسماح للناس بالوصول إلى التمثيلات الداخلية، والتي تم تكييفها بشكل أساسي من العمل الرائد لـ Paul Michel (https://huggingface.co/papers/1905.10650):
- الوصول إلى جميع الحالات المخفية في BERT/GPT/GPT-2،
- الوصول إلى جميع أوزان الانتباه لكل رأس في BERT/GPT/GPT-2،
-- استرجاع قيم ومشتقات مخرجات الرأس لحساب درجة أهمية الرأس وحذفه كما هو موضح في https://arxiv.org/abs/1905.10650.
+- استرجاع قيم ومشتقات مخرجات الرأس لحساب درجة أهمية الرأس وحذفه كما هو موضح في https://huggingface.co/papers/1905.10650.
ولمساعدتك على فهم واستخدام هذه الميزات بسهولة، أضفنا مثالًا برمجيًا محددًا: [bertology.py](https://github.com/huggingface/transformers-research-projects/tree/main/bertology/run_bertology.py) أثناء استخراج المعلومات وتقليص من نموذج تم تدريبه مسبقًا على GLUE.
\ No newline at end of file
diff --git a/docs/source/ar/glossary.md b/docs/source/ar/glossary.md
index 81753bad28..b1c59a68c3 100644
--- a/docs/source/ar/glossary.md
+++ b/docs/source/ar/glossary.md
@@ -135,7 +135,7 @@
في كل وحدة الانتباه الباقية في المحولات، تلي طبقة الاهتمام الانتباه عادة طبقتان للتغذية الأمامية.
حجم تضمين الطبقة الأمامية الوسيطة أكبر عادة من حجم المخفي للنموذج (على سبيل المثال، لـ
`google-bert/bert-base-uncased`).
-بالنسبة لإدخال بحجم `[batch_size, sequence_length]`، يمكن أن تمثل الذاكرة المطلوبة لتخزين التضمينات الأمامية الوسيطة `[batch_size، sequence_length, config.intermediate_size]` جزءًا كبيرًا من استخدام الذاكرة. لاحظ مؤلفو (https://arxiv.org/abs/2001.04451)[Reformer: The Efficient Transformer] أنه نظرًا لأن الحساب مستقل عن بعد `sequence_length`، فإنه من المكافئ رياضيًا حساب تضمينات الإخراج الأمامية `[batch_size، config.hidden_size]_0, ..., [batch_size، `config_size]_n
+بالنسبة لإدخال بحجم `[batch_size, sequence_length]`، يمكن أن تمثل الذاكرة المطلوبة لتخزين التضمينات الأمامية الوسيطة `[batch_size، sequence_length, config.intermediate_size]` جزءًا كبيرًا من استخدام الذاكرة. لاحظ مؤلفو (https://huggingface.co/papers/2001.04451)[Reformer: The Efficient Transformer] أنه نظرًا لأن الحساب مستقل عن بعد `sequence_length`، فإنه من المكافئ رياضيًا حساب تضمينات الإخراج الأمامية `[batch_size، config.hidden_size]_0, ..., [batch_size، `config_size]_n
فردياً والتوصيل بها لاحقًا إلى `[batch_size, sequence_length, config.hidden_size]` مع `n = sequence_length`، والذي يتداول زيادة وقت الحساب مقابل تقليل استخدام الذاكرة، ولكنه ينتج عنه نتيجة مكافئة رياضيا.
بالنسبة للنماذج التي تستخدم الدالة `[apply_chunking_to_forward]`، يحدد `chunk_size` عدد التضمينات يتم حساب الإخراج بالتوازي وبالتالي يحدد المقايضة بين حجم الذاكرة والتعقيد الوقت. إذا تم تعيين `chunk_size` إلى `0`، فلن يتم إجراء تجزئة التغذية الأمامية.
@@ -173,7 +173,7 @@
-يعمل كل محلل لغوي بشكل مختلف ولكن الآلية الأساسية تبقى كما هي. إليك مثال باستخدام محلل BERT اللغوي، والذي يعد محلل لغوي [WordPiece](https://arxiv.org/pdf/1609.08144.pdf):
+يعمل كل محلل لغوي بشكل مختلف ولكن الآلية الأساسية تبقى كما هي. إليك مثال باستخدام محلل BERT اللغوي، والذي يعد محلل لغوي [WordPiece](https://huggingface.co/papers/1609.08144):
```python
>>> from transformers import BertTokenizer
diff --git a/docs/source/ar/llm_tutorial_optimization.md b/docs/source/ar/llm_tutorial_optimization.md
index 887f718241..c4a45a609a 100644
--- a/docs/source/ar/llm_tutorial_optimization.md
+++ b/docs/source/ar/llm_tutorial_optimization.md
@@ -6,7 +6,7 @@
تحقق نماذج اللغة الكبيرة (LLMs) مثل GPT3/4، [Falcon](https://huggingface.co/tiiuae/falcon-40b)، و [Llama](https://huggingface.co/meta-llama/Llama-2-70b-hf) تقدمًا سريعًا في قدرتها على معالجة المهام التي تركز على الإنسان، مما يجعلها أدوات أساسية في الصناعات القائمة على المعرفة الحديثة.
لا يزال نشر هذه النماذج في المهام الواقعية يمثل تحديًا، ومع ذلك:
-- لكي تظهر نماذج اللغة الكبيرة قدرات فهم وتوليد النصوص قريبة من قدرات الإنسان، فإنها تتطلب حاليًا إلى تكوينها من مليارات المعلمات (انظر [كابلان وآخرون](https://arxiv.org/abs/2001.08361)، [وي وآخرون](https://arxiv.org/abs/2206.07682)). وهذا بدوره يزيد من متطلبات الذاكرة للاستدلال.
+- لكي تظهر نماذج اللغة الكبيرة قدرات فهم وتوليد النصوص قريبة من قدرات الإنسان، فإنها تتطلب حاليًا إلى تكوينها من مليارات المعلمات (انظر [كابلان وآخرون](https://huggingface.co/papers/2001.08361)، [وي وآخرون](https://huggingface.co/papers/2206.07682)). وهذا بدوره يزيد من متطلبات الذاكرة للاستدلال.
- في العديد من المهام الواقعية، تحتاج نماذج اللغة الكبيرة إلى معلومات سياقية شاملة. يتطلب ذلك قدرة النموذج على إدارة تسلسلات إدخال طويلة للغاية أثناء الاستدلال.
يكمن جوهر صعوبة هذه التحديات في تعزيز القدرات الحسابية والذاكرة لنماذج اللغة الكبيرة، خاصة عند التعامل مع تسلسلات الإدخال الضخمة.
@@ -17,7 +17,7 @@
2. **اFlash Attention:** إن Flash Attention وهي نسخة مُعدَّلة من خوارزمية الانتباه التي لا توفر فقط نهجًا أكثر كفاءة في استخدام الذاكرة، ولكنها تحقق أيضًا كفاءة متزايدة بسبب الاستخدام الأمثل لذاكرة GPU.
-3. **الابتكارات المعمارية:** حيث تم اقتراح هياكل متخصصة تسمح باستدلال أكثر فعالية نظرًا لأن نماذج اللغة الكبيرة يتم نشرها دائمًا بنفس الطريقة أثناء عملية الاستدلال، أي توليد النص التنبؤي التلقائي مع سياق الإدخال الطويل، فقد تم اقتراح بنيات نموذج متخصصة تسمح بالاستدلال الأكثر كفاءة. أهم تقدم في بنيات النماذج هنا هو [عذر](https://arxiv.org/abs/2108.12409)، [الترميز الدوار](https://arxiv.org/abs/2104.09864)، [الاهتمام متعدد الاستعلامات (MQA)](https://arxiv.org/abs/1911.02150) و [مجموعة الانتباه بالاستعلام (GQA)]((https://arxiv.org/abs/2305.13245)).
+3. **الابتكارات المعمارية:** حيث تم اقتراح هياكل متخصصة تسمح باستدلال أكثر فعالية نظرًا لأن نماذج اللغة الكبيرة يتم نشرها دائمًا بنفس الطريقة أثناء عملية الاستدلال، أي توليد النص التنبؤي التلقائي مع سياق الإدخال الطويل، فقد تم اقتراح بنيات نموذج متخصصة تسمح بالاستدلال الأكثر كفاءة. أهم تقدم في بنيات النماذج هنا هو [عذر](https://huggingface.co/papers/2108.12409)، [الترميز الدوار](https://huggingface.co/papers/2104.09864)، [الاهتمام متعدد الاستعلامات (MQA)](https://huggingface.co/papers/1911.02150) و [مجموعة الانتباه بالاستعلام (GQA)]((https://huggingface.co/papers/2305.13245)).
على مدار هذا الدليل، سنقدم تحليلًا للتوليد التنبؤي التلقائي من منظور المُوتِّرات. نتعمق في مزايا وعيوب استخدام دقة أقل، ونقدم استكشافًا شاملاً لخوارزميات الانتباه الأحدث، ونناقش بنيات نماذج نماذج اللغة الكبيرة المحسنة. سندعم الشرح بأمثلة عملية تُبرِز كل تحسين على حدة.
@@ -152,8 +152,8 @@ from accelerate.utils import release_memory
release_memory(model)
```
-والآن ماذا لو لم يكن لدى وحدة معالجة الرسومات (GPU) لديك 32 جيجا بايت من ذاكرة الفيديو العشوائية (VRAM)؟ لقد وجد أن أوزان النماذج يمكن تحويلها إلى 8 بتات أو 4 بتات دون خسارة كبيرة في الأداء (انظر [Dettmers et al.](https://arxiv.org/abs/2208.07339)).
-يمكن تحويل النموذج إلى 3 بتات أو 2 بتات مع فقدان مقبول في الأداء كما هو موضح في ورقة [GPTQ](https://arxiv.org/abs/2210.17323) 🤯.
+والآن ماذا لو لم يكن لدى وحدة معالجة الرسومات (GPU) لديك 32 جيجا بايت من ذاكرة الفيديو العشوائية (VRAM)؟ لقد وجد أن أوزان النماذج يمكن تحويلها إلى 8 بتات أو 4 بتات دون خسارة كبيرة في الأداء (انظر [Dettmers et al.](https://huggingface.co/papers/2208.07339)).
+يمكن تحويل النموذج إلى 3 بتات أو 2 بتات مع فقدان مقبول في الأداء كما هو موضح في ورقة [GPTQ](https://huggingface.co/papers/2210.17323) 🤯.
دون الدخول في الكثير من التفاصيل، تهدف مخططات التكميم إلى تخفيض دقة الأوزان مع محاولة الحفاظ على دقة نتائج النموذج كما هي (*أي* أقرب ما يمكن إلى bfloat16).
لاحظ أن التكميم يعمل بشكل خاص جيدًا لتوليد النص حيث كل ما نهتم به هو اختيار *مجموعة الرموز الأكثر احتمالًا التالية* ولا نهتم حقًا بالقيم الدقيقة لتوزيع الرمز التالي *logit*.
@@ -304,7 +304,7 @@ $$ \textbf{O} = \text{Attn}(\mathbf{X}) = \mathbf{V} \times \text{Softmax}(\math
مع تحسن LLMs في فهم النص وتوليد النص، يتم تطبيقها على مهام متزايدة التعقيد. في حين أن النماذج كانت تتعامل سابقًا مع ترجمة أو تلخيص بضع جمل، فإنها الآن تدير صفحات كاملة، مما يتطلب القدرة على معالجة أطوال إدخال واسعة.
-كيف يمكننا التخلص من متطلبات الذاكرة الباهظة للتطويلات المدخلة الكبيرة؟ نحن بحاجة إلى طريقة جديدة لحساب آلية الاهتمام الذاتي التي تتخلص من مصفوفة \\( QK^T \\). [طريقه داو وآخرون.](Https://arxiv.org/abs/2205.14135) طوروا بالضبط مثل هذا الخوارزمية الجديدة وأطلقوا عليها اسم **Flash Attention**.
+كيف يمكننا التخلص من متطلبات الذاكرة الباهظة للتطويلات المدخلة الكبيرة؟ نحن بحاجة إلى طريقة جديدة لحساب آلية الاهتمام الذاتي التي تتخلص من مصفوفة \\( QK^T \\). [طريقه داو وآخرون.](https://huggingface.co/papers/2205.14135) طوروا بالضبط مثل هذا الخوارزمية الجديدة وأطلقوا عليها اسم **Flash Attention**.
باختصار، يكسر الاهتمام الفلاشي حساب \\( \mathbf{V} \times \operatorname{Softmax}(\mathbf{QK}^T\\)) ويحسب بدلاً من ذلك قطعًا أصغر من الإخراج عن طريق التكرار عبر العديد من خطوات حساب Softmax:
@@ -318,7 +318,7 @@ $$ \textbf{O}_i \leftarrow s^a_{ij} * \textbf{O}_i + s^b_{ij} * \mathbf{V}_{j} \
> من خلال تتبع إحصائيات التطبيع softmax واستخدام بعض الرياضيات الذكية، يعطي Flash Attention **مخرجات متطابقة رقميًا** مقارنة بطبقة الاهتمام الذاتي الافتراضية بتكلفة ذاكرة لا تزيد خطيًا مع \\( N \\).
-عند النظر إلى الصيغة، قد يقول المرء بديهيًا أن الاهتمام الفلاشي يجب أن يكون أبطأ بكثير مقارنة بصيغة الاهتمام الافتراضية حيث يلزم إجراء المزيد من الحسابات. في الواقع، يتطلب Flash Attention المزيد من عمليات الفاصلة العائمة مقارنة بالاهتمام العادي حيث يجب إعادة حساب إحصائيات التطبيع softmax باستمرار (راجع [الورقة](https://arxiv.org/abs/2205.14135) لمزيد من التفاصيل إذا كنت مهتمًا)
+عند النظر إلى الصيغة، قد يقول المرء بديهيًا أن الاهتمام الفلاشي يجب أن يكون أبطأ بكثير مقارنة بصيغة الاهتمام الافتراضية حيث يلزم إجراء المزيد من الحسابات. في الواقع، يتطلب Flash Attention المزيد من عمليات الفاصلة العائمة مقارنة بالاهتمام العادي حيث يجب إعادة حساب إحصائيات التطبيع softmax باستمرار (راجع [الورقة](https://huggingface.co/papers/2205.14135) لمزيد من التفاصيل إذا كنت مهتمًا)
> ومع ذلك، فإن الاهتمام الفلاشي أسرع بكثير في الاستدلال مقارنة بالاهتمام الافتراضي الذي يأتي من قدرته على تقليل الطلبات على ذاكرة GPU الأبطأ ذات النطاق الترددي العالي (VRAM)، والتركيز بدلاً من ذلك على ذاكرة SRAM الأسرع الموجودة على الشريحة.
@@ -535,20 +535,20 @@ flush()
لكي يفهم LLM ترتيب الجملة، يلزم وجود *إشارة* إضافية ويتم تطبيقها عادةً في شكل *الترميزات الموضعية* (أو ما يُطلق عليه أيضًا *الترميزات الموضعية*).
لم يتم ترجمة النص الخاص والروابط وأكواد HTML وCSS بناءً على طلبك.
-قدم مؤلفو الورقة البحثية [*Attention Is All You Need*](https://arxiv.org/abs/1706.03762) تضمينات موضعية جيبية مثلثية \\( \mathbf{P} = \mathbf{p}_1, \ldots, \mathbf{p}_N \\) حيث يتم حساب كل متجه \\( \mathbf{p}_i \\) كدالة جيبية لموضعه \\( i \\) .
+قدم مؤلفو الورقة البحثية [*Attention Is All You Need*](https://huggingface.co/papers/1706.03762) تضمينات موضعية جيبية مثلثية \\( \mathbf{P} = \mathbf{p}_1, \ldots, \mathbf{p}_N \\) حيث يتم حساب كل متجه \\( \mathbf{p}_i \\) كدالة جيبية لموضعه \\( i \\) .
بعد ذلك يتم ببساطة إضافة التضمينات الموضعية إلى متجهات تسلسل الإدخال \\( \mathbf{\hat{X}} = \mathbf{\hat{x}}_1, \ldots, \mathbf{\hat{x}}_N \\) = \\( \mathbf{x}_1 + \mathbf{p}_1, \ldots, \mathbf{x}_N + \mathbf{p}_N \\) وبالتالي توجيه النموذج لتعلم ترتيب الجملة بشكل أفضل.
-بدلاً من استخدام التضمينات الموضعية الثابتة، استخدم آخرون (مثل [Devlin et al.](https://arxiv.org/abs/1810.04805)) تضمينات موضعية مكتسبة يتم من خلالها تعلم التضمينات الموضعية \\( \mathbf{P} \\) أثناء التدريب.
+بدلاً من استخدام التضمينات الموضعية الثابتة، استخدم آخرون (مثل [Devlin et al.](https://huggingface.co/papers/1810.04805)) تضمينات موضعية مكتسبة يتم من خلالها تعلم التضمينات الموضعية \\( \mathbf{P} \\) أثناء التدريب.
كانت التضمينات الموضعية الجيبية والمكتسبة هي الطرق السائدة لترميز ترتيب الجملة في نماذج اللغة الكبيرة، ولكن تم العثور على بعض المشكلات المتعلقة بهذه التضمينات الموضعية:
-1. التضمينات الموضعية الجيبية والمكتسبة هي تضمينات موضعية مطلقة، أي ترميز تضمين فريد لكل معرف موضعي: \\( 0, \ldots, N \\) . كما أظهر [Huang et al.](https://arxiv.org/abs/2009.13658) و [Su et al.](https://arxiv.org/abs/2104.09864)، تؤدي التضمينات الموضعية المطلقة إلى أداء ضعيف لنماذج اللغة الكبيرة للمدخلات النصية الطويلة. بالنسبة للمدخلات النصية الطويلة، يكون من المفيد إذا تعلم النموذج المسافة الموضعية النسبية التي تمتلكها رموز المدخلات إلى بعضها البعض بدلاً من موضعها المطلق.
+1. التضمينات الموضعية الجيبية والمكتسبة هي تضمينات موضعية مطلقة، أي ترميز تضمين فريد لكل معرف موضعي: \\( 0, \ldots, N \\) . كما أظهر [Huang et al.](https://huggingface.co/papers/2009.13658) و [Su et al.](https://huggingface.co/papers/2104.09864)، تؤدي التضمينات الموضعية المطلقة إلى أداء ضعيف لنماذج اللغة الكبيرة للمدخلات النصية الطويلة. بالنسبة للمدخلات النصية الطويلة، يكون من المفيد إذا تعلم النموذج المسافة الموضعية النسبية التي تمتلكها رموز المدخلات إلى بعضها البعض بدلاً من موضعها المطلق.
2. عند استخدام التضمينات الموضعية المكتسبة، يجب تدريب نموذج اللغة الكبيرة على طول إدخال ثابت \\( N \\)، مما يجعل من الصعب الاستقراء إلى طول إدخال أطول مما تم تدريبه عليه.
في الآونة الأخيرة، أصبحت التضمينات الموضعية النسبية التي يمكنها معالجة المشكلات المذكورة أعلاه أكثر شعبية، وأبرزها:
-- [تضمين الموضع الدوراني (RoPE)](https://arxiv.org/abs/2104.09864)
-- [ALiBi](https://arxiv.org/abs/2108.12409)
+- [تضمين الموضع الدوراني (RoPE)](https://huggingface.co/papers/2104.09864)
+- [ALiBi](https://huggingface.co/papers/2108.12409)
يؤكد كل من *RoPE* و *ALiBi* أنه من الأفضل توجيه نموذج اللغة الكبيرة حول ترتيب الجملة مباشرة في خوارزمية الانتباه الذاتي حيث يتم وضع رموز الكلمات في علاقة مع بعضها البعض. على وجه التحديد، يجب توجيه ترتيب الجملة عن طريق تعديل عملية \\( \mathbf{QK}^T \\) .
@@ -563,14 +563,14 @@ $$ \mathbf{\hat{q}}_i^T \mathbf{\hat{x}}_j = \mathbf{{q}}_i^T \mathbf{R}_{\theta
يستخدم *RoPE* في العديد من نماذج اللغة الكبيرة الأكثر أهمية اليوم، مثل:
- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
-- [**Llama**](https://arxiv.org/abs/2302.13971)
-- [**PaLM**](https://arxiv.org/abs/2204.02311)
+- [**Llama**](https://huggingface.co/papers/2302.13971)
+- [**PaLM**](https://huggingface.co/papers/2204.02311)
كبديل، يقترح *ALiBi* مخطط ترميز موضعي نسبي أبسط بكثير. يتم إضافة المسافة النسبية التي تمتلكها رموز المدخلات إلى بعضها البعض كعدد صحيح سلبي مقياس بقيمة محددة مسبقًا `m` إلى كل إدخال استعلام-مفتاح لمصفوفة \\( \mathbf{QK}^T \\) مباشرة قبل حساب softmax.

-كما هو موضح في ورقة [ALiBi](https://arxiv.org/abs/2108.12409)، يسمح هذا الترميز الموضعي النسبي البسيط للنموذج بالحفاظ على أداء عالٍ حتى في تسلسلات المدخلات النصية الطويلة جدًا.
+كما هو موضح في ورقة [ALiBi](https://huggingface.co/papers/2108.12409)، يسمح هذا الترميز الموضعي النسبي البسيط للنموذج بالحفاظ على أداء عالٍ حتى في تسلسلات المدخلات النصية الطويلة جدًا.
يُستخدم *ALiBi* في العديد من أهم نماذج اللغة الكبيرة المستخدمة اليوم، مثل:
@@ -579,7 +579,7 @@ $$ \mathbf{\hat{q}}_i^T \mathbf{\hat{x}}_j = \mathbf{{q}}_i^T \mathbf{R}_{\theta
يمكن لكل من ترميزات الموضع *RoPE* و *ALiBi* الاستقراء إلى أطوال إدخال لم يتم ملاحظتها أثناء التدريب، في حين ثبت أن الاستقراء يعمل بشكل أفضل بكثير خارج الصندوق لـ *ALiBi* مقارنة بـ *RoPE*.
بالنسبة لـ ALiBi، ما عليك سوى زيادة قيم مصفوفة الموضع المثلث السفلي لمطابقة طول تسلسل الإدخال.
-بالنسبة لـ *RoPE*، يؤدي الحفاظ على نفس \\( \theta \\) الذي تم استخدامه أثناء التدريب إلى نتائج سيئة عند تمرير إدخالات نصية أطول بكثير من تلك التي شوهدت أثناء التدريب، راجع [Press et al.](https://arxiv.org/abs/2108.12409). ومع ذلك، وجد المجتمع بعض الحيل الفعالة التي تقوم بتعديل \\( \theta \\)، مما يسمح لترميزات الموضع *RoPE* بالعمل بشكل جيد لتسلسلات إدخال النص المستقرئة (راجع [هنا](https://github.com/huggingface/transformers/pull/24653)).
+بالنسبة لـ *RoPE*، يؤدي الحفاظ على نفس \\( \theta \\) الذي تم استخدامه أثناء التدريب إلى نتائج سيئة عند تمرير إدخالات نصية أطول بكثير من تلك التي شوهدت أثناء التدريب، راجع [Press et al.](https://huggingface.co/papers/2108.12409). ومع ذلك، وجد المجتمع بعض الحيل الفعالة التي تقوم بتعديل \\( \theta \\)، مما يسمح لترميزات الموضع *RoPE* بالعمل بشكل جيد لتسلسلات إدخال النص المستقرئة (راجع [هنا](https://github.com/huggingface/transformers/pull/24653)).
> كل من RoPE و ALiBi عبارة عن ترميزات موضع نسبي *لا* يتم تعلمها أثناء التدريب، ولكن بدلاً من ذلك تستند إلى الحدس التالي:
- يجب إعطاء الإشارات الموضعية حول إدخالات النص مباشرة إلى مصفوفة \\( QK^T \\) لطبقة الاهتمام الذاتي
@@ -755,21 +755,21 @@ Roughly 8 مليار قيمة عائمة! يتطلب تخزين 8 مليارات
#### 3.2.2 Multi-Query-Attention (MQA)
-[Multi-Query-Attention](https://arxiv.org/abs/1911.02150) اقترحها Noam Shazeer في ورقته *Fast Transformer Decoding: One Write-Head is All You Need*. كما يقول العنوان، اكتشف Noam أنه بدلاً من استخدام `n_head` من أوزان إسقاط القيمة الرئيسية، يمكن استخدام زوج واحد من أوزان إسقاط رأس القيمة التي يتم مشاركتها عبر جميع رؤوس الاهتمام دون أن يتدهور أداء النموذج بشكل كبير.
+[Multi-Query-Attention](https://huggingface.co/papers/1911.02150) اقترحها Noam Shazeer في ورقته *Fast Transformer Decoding: One Write-Head is All You Need*. كما يقول العنوان، اكتشف Noam أنه بدلاً من استخدام `n_head` من أوزان إسقاط القيمة الرئيسية، يمكن استخدام زوج واحد من أوزان إسقاط رأس القيمة التي يتم مشاركتها عبر جميع رؤوس الاهتمام دون أن يتدهور أداء النموذج بشكل كبير.
> باستخدام زوج واحد من أوزان إسقاط رأس القيمة، يجب أن تكون متجهات القيمة الرئيسية \\( \mathbf{k}_i، \mathbf{v}_i \\) متطابقة عبر جميع رؤوس الاهتمام والتي بدورها تعني أننا بحاجة فقط إلى تخزين زوج إسقاط قيمة رئيسي واحد في ذاكرة التخزين المؤقت بدلاً من `n_head` منها.
نظرًا لأن معظم LLMs تستخدم ما بين 20 و100 رأس اهتمام، فإن MQA يقلل بشكل كبير من استهلاك الذاكرة لذاكرة التخزين المؤقت key-value. بالنسبة إلى LLM المستخدم في هذا الدفتر، يمكننا تقليل استهلاك الذاكرة المطلوبة من 15 جيجابايت إلى أقل من 400 ميجابايت عند طول تسلسل الإدخال 16000.
بالإضافة إلى توفير الذاكرة، يؤدي MQA أيضًا إلى تحسين الكفاءة الحسابية كما هو موضح في ما يلي.
-في فك التشفير التلقائي، يجب إعادة تحميل متجهات القيمة الرئيسية الكبيرة، ودمجها مع زوج متجه القيمة الحالي، ثم إدخالها في \\( \mathbf{q}_c\mathbf{K}^T \\) الحساب في كل خطوة. بالنسبة لفك التشفير التلقائي، يمكن أن تصبح عرض النطاق الترددي للذاكرة المطلوبة لإعادة التحميل المستمر عنق زجاجة زمنيًا خطيرًا. من خلال تقليل حجم متجهات القيمة الرئيسية، يجب الوصول إلى ذاكرة أقل، وبالتالي تقليل عنق الزجاجة في عرض النطاق الترددي للذاكرة. لمزيد من التفاصيل، يرجى إلقاء نظرة على [ورقة Noam](https://arxiv.org/abs/1911.02150).
+في فك التشفير التلقائي، يجب إعادة تحميل متجهات القيمة الرئيسية الكبيرة، ودمجها مع زوج متجه القيمة الحالي، ثم إدخالها في \\( \mathbf{q}_c\mathbf{K}^T \\) الحساب في كل خطوة. بالنسبة لفك التشفير التلقائي، يمكن أن تصبح عرض النطاق الترددي للذاكرة المطلوبة لإعادة التحميل المستمر عنق زجاجة زمنيًا خطيرًا. من خلال تقليل حجم متجهات القيمة الرئيسية، يجب الوصول إلى ذاكرة أقل، وبالتالي تقليل عنق الزجاجة في عرض النطاق الترددي للذاكرة. لمزيد من التفاصيل، يرجى إلقاء نظرة على [ورقة Noam](https://huggingface.co/papers/1911.02150).
الجزء المهم الذي يجب فهمه هنا هو أن تقليل عدد رؤوس الاهتمام بالقيمة الرئيسية إلى 1 لا معنى له إلا إذا تم استخدام ذاكرة التخزين المؤقت للقيمة الرئيسية. يظل الاستهلاك الذروي لذاكرة النموذج لمرور واحد للأمام بدون ذاكرة التخزين المؤقت للقيمة الرئيسية دون تغيير لأن كل رأس اهتمام لا يزال لديه متجه استعلام فريد بحيث يكون لكل رأس اهتمام مصفوفة \\( \mathbf{QK}^T \\) مختلفة.
شهدت MQA اعتمادًا واسع النطاق من قبل المجتمع ويتم استخدامها الآن بواسطة العديد من LLMs الأكثر شهرة:
- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
-- [**PaLM**](https://arxiv.org/abs/2204.02311)
+- [**PaLM**](https://huggingface.co/papers/2204.02311)
- [**MPT**](https://huggingface.co/mosaicml/mpt-30b)
- [**BLOOM**](https://huggingface.co/bigscience/bloom)
@@ -777,7 +777,7 @@ Roughly 8 مليار قيمة عائمة! يتطلب تخزين 8 مليارات
#### 3.2.3 مجموعة الاستعلام الاهتمام (GQA)
-[مجموعة الاستعلام الاهتمام](https://arxiv.org/abs/2305.13245)، كما اقترح Ainslie et al. من Google، وجد أن استخدام MQA يمكن أن يؤدي غالبًا إلى تدهور الجودة مقارنة باستخدام إسقاطات رأس القيمة الرئيسية المتعددة. تجادل الورقة بأنه يمكن الحفاظ على أداء النموذج بشكل أكبر عن طريق تقليل عدد أوزان إسقاط رأس الاستعلام بشكل أقل حدة. بدلاً من استخدام وزن إسقاط قيمة رئيسية واحدة فقط، يجب استخدام `n
-عملية التفاف أساسية بدون حشو أو خطو خطوة واسعة، مأخوذة من دليل لحساب الالتفاف للتعلم العميق.
+عملية التفاف أساسية بدون حشو أو خطو خطوة واسعة، مأخوذة من دليل لحساب الالتفاف للتعلم العميق.
يمكنك تغذية هذا الناتج إلى طبقة التفاف أخرى، ومع كل طبقة متتالية، تتعلم الشبكة أشياء أكثر تعقيدًا وتجريدية مثل النقانق أو الصواريخ. بين طبقات الالتفاف، من الشائع إضافة طبقة تجميع لتقليل الأبعاد وجعل النموذج أكثر قوة للتغيرات في موضع الميزة.
diff --git a/docs/source/ar/tokenizer_summary.md b/docs/source/ar/tokenizer_summary.md
index 109521d24b..5b0f24aba1 100644
--- a/docs/source/ar/tokenizer_summary.md
+++ b/docs/source/ar/tokenizer_summary.md
@@ -94,7 +94,7 @@
### ترميز الأزواج البايتية (BPE)
-تم تقديم رميز أزواج البايت (BPE) في ورقة بحثية بعنوان [الترجمة الآلية العصبية للكلمات النادرة باستخدام وحدات subword (Sennrich et al.، 2015)](https://arxiv.org/abs/1508.07909). يعتمد BPE على مُجزّئ أولي يقسم بيانات التدريب إلى
+تم تقديم رميز أزواج البايت (BPE) في ورقة بحثية بعنوان [الترجمة الآلية العصبية للكلمات النادرة باستخدام وحدات subword (Sennrich et al.، 2015)](https://huggingface.co/papers/1508.07909). يعتمد BPE على مُجزّئ أولي يقسم بيانات التدريب إلى
كلمات. يمكن أن يكون التحليل المسبق بسيطًا مثل التقسيم المكاني، على سبيل المثال [GPT-2](model_doc/gpt2)، [RoBERTa](model_doc/roberta). تشمل التقسيم الأكثر تقدمًا معتمد على التحليل القائم على القواعد، على سبيل المثال [XLM](model_doc/xlm)، [FlauBERT](model_doc/flaubert) الذي يستخدم Moses لمعظم اللغات، أو [GPT](model_doc/openai-gpt) الذي يستخدم spaCy و ftfy، لحساب تكرار كل كلمة في مجموعة بيانات التدريب.
بعد التحليل المسبق، يتم إنشاء مجموعة من الكلمات الفريدة وقد تم تحديد تكرار كل كلمة في تم تحديد بيانات التدريب. بعد ذلك، يقوم BPE بإنشاء مفردات أساسية تتكون من جميع الرموز التي تحدث في مجموعة الكلمات الفريدة ويتعلم قواعد الدمج لتشكيل رمز جديد من رمزين من المفردات الأساسية. إنه يفعل ذلك حتى تصل المفردات إلى حجم المفردات المطلوب. لاحظ أن حجم المفردات هو فرط معلمة لتحديد قبل تدريب مُجزّئ النصوص.
@@ -158,7 +158,7 @@ BPE. أولاً، يقوم WordPiece بتكوين المفردات لتضمين
### Unigram
Unigram هو خوارزمية توكنيز subword التي تم تقديمها في [تنظيم subword: تحسين نماذج الترجمة الشبكة العصبية
-نماذج مع مرشحين subword متعددة (Kudo، 2018)](https://arxiv.org/pdf/1804.10959.pdf). على عكس BPE أو
+نماذج مع مرشحين subword متعددة (Kudo، 2018)](https://huggingface.co/papers/1804.10959). على عكس BPE أو
WordPiece، يقوم Unigram بتكوين مفرداته الأساسية إلى عدد كبير من الرموز ويقللها تدريجياً للحصول على مفردات أصغر. يمكن أن تتوافق المفردات الأساسية على سبيل المثال مع جميع الكلمات المسبقة التوكنز والسلاسل الفرعية الأكثر شيوعًا. لا يتم استخدام Unigram مباشرة لأي من النماذج في المحولات، ولكنه يستخدم بالاقتران مع [SentencePiece](#sentencepiece).
في كل خطوة تدريب، يحدد خوارزمية Unigram خسارة (غالبًا ما يتم تعريفها على أنها اللوغاريتم) عبر بيانات التدريب بالنظر إلى المفردات الحالية ونموذج اللغة unigram. بعد ذلك، بالنسبة لكل رمز في المفردات، يحسب الخوارزمية مقدار زيادة الخسارة الإجمالية إذا تم إزالة الرمز من المفردات. ثم يقوم Unigram بإزالة p (مع p عادة ما تكون 10% أو 20%) في المائة من الرموز التي تكون زيادة الخسارة فيها هي الأدنى، *أي* تلك
@@ -188,7 +188,7 @@ $$\mathcal{L} = -\sum_{i=1}^{N} \log \left ( \sum_{x \in S(x_{i})} p(x) \right )
تحتوي جميع خوارزميات توكنز الموصوفة حتى الآن على نفس المشكلة: من المفترض أن النص المدخل يستخدم المسافات لفصل الكلمات. ومع ذلك، لا تستخدم جميع اللغات المسافات لفصل الكلمات. أحد الحلول الممكنة هو استخداممعالج مسبق للغة محدد، *مثال* [XLM](model_doc/xlm) يلذي يستخدم معالجات مسبقة محددة للصينية واليابانية والتايلاندية.
لحل هذه المشكلة بشكل أعم، [SentencePiece: A simple and language independent subword tokenizer and
-detokenizer for Neural Text Processing (Kudo et al.، 2018)](https://arxiv.org/pdf/1808.06226.pdf) يتعامل مع المدخلات
+detokenizer for Neural Text Processing (Kudo et al.، 2018)](https://huggingface.co/papers/1808.06226) يتعامل مع المدخلات
كتدفق بيانات خام، وبالتالي يشمل المسافة في مجموعة الأحرف التي سيتم استخدامها. ثم يستخدم خوارزمية BPE أو unigram
لبناء المفردات المناسبة.
diff --git a/docs/source/ar/trainer.md b/docs/source/ar/trainer.md
index 8b0d05c783..7bdebdca2a 100644
--- a/docs/source/ar/trainer.md
+++ b/docs/source/ar/trainer.md
@@ -377,7 +377,7 @@ trainer = trl.SFTTrainer(
trainer.train()
```
-يمكنك قراءة المزيد حول الطريقة في [المستودع الأصلي](https://github.com/jiaweizzhao/GaLore) أو [الورقة البحثية](https://arxiv.org/abs/2403.03507).
+يمكنك قراءة المزيد حول الطريقة في [المستودع الأصلي](https://github.com/jiaweizzhao/GaLore) أو [الورقة البحثية](https://huggingface.co/papers/2403.03507).
حاليًا، يمكنك فقط تدريب الطبقات الخطية التي تعتبر طبقات GaLore وستستخدم التحلل ذو الرتبة المنخفضة للتدريب بينما سيتم تحسين الطبقات المتبقية بالطريقة التقليدية.
diff --git a/docs/source/de/index.md b/docs/source/de/index.md
index 8aaaa5952c..1c4d4e7675 100644
--- a/docs/source/de/index.md
+++ b/docs/source/de/index.md
@@ -55,148 +55,148 @@ Die Bibliothek enthält derzeit JAX-, PyTorch- und TensorFlow-Implementierungen,
-1. **[ALBERT](model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
-1. **[ALIGN](model_doc/align)** (from Google Research) released with the paper [Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://arxiv.org/abs/2102.05918) by Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig.
-1. **[BART](model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
-1. **[BARThez](model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
-1. **[BARTpho](model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
-1. **[BEiT](model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
-1. **[BERT](model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
-1. **[BERT For Sequence Generation](model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[ALBERT](model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://huggingface.co/papers/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
+1. **[ALIGN](model_doc/align)** (from Google Research) released with the paper [Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://huggingface.co/papers/2102.05918) by Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig.
+1. **[BART](model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://huggingface.co/papers/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
+1. **[BARThez](model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://huggingface.co/papers/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
+1. **[BARTpho](model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://huggingface.co/papers/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
+1. **[BEiT](model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://huggingface.co/papers/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
+1. **[BERT](model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://huggingface.co/papers/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
+1. **[BERT For Sequence Generation](model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://huggingface.co/papers/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
1. **[BERTweet](model_doc/bertweet)** (from VinAI Research) released with the paper [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) by Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen.
-1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
-1. **[BigBird-RoBERTa](model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
-1. **[Blenderbot](model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
-1. **[BlenderbotSmall](model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://huggingface.co/papers/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[BigBird-RoBERTa](model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://huggingface.co/papers/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[Blenderbot](model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://huggingface.co/papers/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BlenderbotSmall](model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://huggingface.co/papers/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
1. **[BLOOM](model_doc/bloom)** (from BigScience workshop) released by the [BigScience Workshop](https://bigscience.huggingface.co/).
-1. **[BORT](model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
-1. **[ByT5](model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
-1. **[CamemBERT](model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
-1. **[CANINE](model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
-1. **[CLIP](model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
-1. **[CodeGen](model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
-1. **[ConvBERT](model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
-1. **[ConvNeXT](model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
-1. **[ConvNeXTV2](model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
-1. **[CPM](model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
-1. **[CTRL](model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
-1. **[CvT](model_doc/cvt)** (from Microsoft) released with the paper [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
-1. **[Data2Vec](model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
-1. **[DeBERTa](model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
-1. **[DeBERTa-v2](model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
-1. **[Decision Transformer](model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
-1. **[DeiT](model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
-1. **[DETR](model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
-1. **[DialoGPT](model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
-1. **[DistilBERT](model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers-research-projects/tree/main/distillation) and a German version of DistilBERT.
-1. **[DiT](model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
-1. **[DPR](model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
-1. **[DPT](master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
-1. **[EfficientNet](model_doc/efficientnet)** (from Google Research) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan and Quoc V. Le.
-1. **[ELECTRA](model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
-1. **[EncoderDecoder](model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
-1. **[FlauBERT](model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
-1. **[FLAVA](model_doc/flava)** (from Facebook AI) released with the paper [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela.
-1. **[FNet](model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
-1. **[Funnel Transformer](model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
-1. **[GLPN](model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
+1. **[BORT](model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://huggingface.co/papers/2010.10499) by Adrian de Wynter and Daniel J. Perry.
+1. **[ByT5](model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://huggingface.co/papers/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
+1. **[CamemBERT](model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://huggingface.co/papers/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
+1. **[CANINE](model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://huggingface.co/papers/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
+1. **[CLIP](model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://huggingface.co/papers/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
+1. **[CodeGen](model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://huggingface.co/papers/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
+1. **[ConvBERT](model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://huggingface.co/papers/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
+1. **[ConvNeXT](model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://huggingface.co/papers/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
+1. **[ConvNeXTV2](model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://huggingface.co/papers/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
+1. **[CPM](model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://huggingface.co/papers/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
+1. **[CTRL](model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://huggingface.co/papers/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
+1. **[CvT](model_doc/cvt)** (from Microsoft) released with the paper [CvT: Introducing Convolutions to Vision Transformers](https://huggingface.co/papers/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
+1. **[Data2Vec](model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://huggingface.co/papers/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
+1. **[DeBERTa](model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://huggingface.co/papers/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[DeBERTa-v2](model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://huggingface.co/papers/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[Decision Transformer](model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://huggingface.co/papers/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
+1. **[DeiT](model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://huggingface.co/papers/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
+1. **[DETR](model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://huggingface.co/papers/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
+1. **[DialoGPT](model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://huggingface.co/papers/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
+1. **[DistilBERT](model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://huggingface.co/papers/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers-research-projects/tree/main/distillation) and a German version of DistilBERT.
+1. **[DiT](model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://huggingface.co/papers/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
+1. **[DPR](model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://huggingface.co/papers/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
+1. **[DPT](master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://huggingface.co/papers/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
+1. **[EfficientNet](model_doc/efficientnet)** (from Google Research) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://huggingface.co/papers/1905.11946) by Mingxing Tan and Quoc V. Le.
+1. **[ELECTRA](model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://huggingface.co/papers/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
+1. **[EncoderDecoder](model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://huggingface.co/papers/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[FlauBERT](model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://huggingface.co/papers/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
+1. **[FLAVA](model_doc/flava)** (from Facebook AI) released with the paper [FLAVA: A Foundational Language And Vision Alignment Model](https://huggingface.co/papers/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela.
+1. **[FNet](model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://huggingface.co/papers/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
+1. **[Funnel Transformer](model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://huggingface.co/papers/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
+1. **[GLPN](model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://huggingface.co/papers/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
1. **[GPT](model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
1. **[GPT Neo](model_doc/gpt_neo)** (from EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
-1. **[GPT NeoX](model_doc/gpt_neox)** (from EleutherAI) released with the paper [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745) by Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
+1. **[GPT NeoX](model_doc/gpt_neox)** (from EleutherAI) released with the paper [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://huggingface.co/papers/2204.06745) by Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
1. **[GPT-2](model_doc/gpt2)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://openai.com/research/better-language-models/) by Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever.
1. **[GPT-J](model_doc/gptj)** (from EleutherAI) released in the repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
1. **[GPTSAN-japanese](model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
-1. **[GroupViT](model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
-1. **[Hubert](model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
-1. **[I-BERT](model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
+1. **[GroupViT](model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://huggingface.co/papers/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
+1. **[Hubert](model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://huggingface.co/papers/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
+1. **[I-BERT](model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://huggingface.co/papers/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
1. **[ImageGPT](model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
-1. **[LayoutLM](model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
-1. **[LayoutLMv2](model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
-1. **[LayoutLMv3](model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
-1. **[LayoutXLM](model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
-1. **[LED](model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
-1. **[LeViT](model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
-1. **[Longformer](model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
-1. **[LongT5](model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
-1. **[LUKE](model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
-1. **[LXMERT](model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
-1. **[M-CTC-T](model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
-1. **[M2M100](model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
+1. **[LayoutLM](model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://huggingface.co/papers/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
+1. **[LayoutLMv2](model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://huggingface.co/papers/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
+1. **[LayoutLMv3](model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://huggingface.co/papers/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
+1. **[LayoutXLM](model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://huggingface.co/papers/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
+1. **[LED](model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://huggingface.co/papers/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LeViT](model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://huggingface.co/papers/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
+1. **[Longformer](model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://huggingface.co/papers/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LongT5](model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://huggingface.co/papers/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
+1. **[LUKE](model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://huggingface.co/papers/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
+1. **[LXMERT](model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://huggingface.co/papers/1908.07490) by Hao Tan and Mohit Bansal.
+1. **[M-CTC-T](model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://huggingface.co/papers/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
+1. **[M2M100](model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://huggingface.co/papers/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
1. **[MarianMT](model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
-1. **[Mask2Former](model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
-1. **[MaskFormer](model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
-1. **[mBART](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
-1. **[mBART-50](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
-1. **[Megatron-BERT](model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
-1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
-1. **[mLUKE](model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
-1. **[MobileBERT](model_doc/mobilebert)** (from CMU/Google Brain) released with the paper [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou.
-1. **[MobileViT](model_doc/mobilevit)** (from Apple) released with the paper [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari.
-1. **[MPNet](model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
-1. **[MT5](model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
-1. **[MVP](model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
-1. **[Nezha](model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
-1. **[NLLB](model_doc/nllb)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
-1. **[Nyströmformer](model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
-1. **[OneFormer](model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
-1. **[OPT](master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
-1. **[OWL-ViT](model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
-1. **[Pegasus](model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
-1. **[Perceiver IO](model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
+1. **[Mask2Former](model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://huggingface.co/papers/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
+1. **[MaskFormer](model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://huggingface.co/papers/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
+1. **[mBART](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://huggingface.co/papers/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
+1. **[mBART-50](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://huggingface.co/papers/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
+1. **[Megatron-BERT](model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://huggingface.co/papers/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://huggingface.co/papers/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[mLUKE](model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://huggingface.co/papers/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
+1. **[MobileBERT](model_doc/mobilebert)** (from CMU/Google Brain) released with the paper [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://huggingface.co/papers/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou.
+1. **[MobileViT](model_doc/mobilevit)** (from Apple) released with the paper [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://huggingface.co/papers/2110.02178) by Sachin Mehta and Mohammad Rastegari.
+1. **[MPNet](model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://huggingface.co/papers/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
+1. **[MT5](model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://huggingface.co/papers/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
+1. **[MVP](model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://huggingface.co/papers/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
+1. **[Nezha](model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://huggingface.co/papers/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
+1. **[NLLB](model_doc/nllb)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://huggingface.co/papers/2207.04672) by the NLLB team.
+1. **[Nyströmformer](model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://huggingface.co/papers/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
+1. **[OneFormer](model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://huggingface.co/papers/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
+1. **[OPT](master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://huggingface.co/papers/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
+1. **[OWL-ViT](model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://huggingface.co/papers/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
+1. **[Pegasus](model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://huggingface.co/papers/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
+1. **[Perceiver IO](model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://huggingface.co/papers/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
1. **[PhoBERT](model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
-1. **[PLBart](model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
-1. **[PoolFormer](model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
-1. **[ProphetNet](model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
-1. **[QDQBert](model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
-1. **[RAG](model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
-1. **[REALM](model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
-1. **[Reformer](model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
-1. **[RegNet](model_doc/regnet)** (from META Platforms) released with the paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
-1. **[RemBERT](model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
-1. **[ResNet](model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
-1. **[RoBERTa](model_doc/roberta)** (from Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
-1. **[RoFormer](model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
-1. **[SegFormer](model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
-1. **[SEW](model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
-1. **[SEW-D](model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
-1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
-1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
-1. **[Splinter](model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
-1. **[SqueezeBERT](model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
-1. **[Swin Transformer](model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
-1. **[Swin Transformer V2](model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
-1. **[T5](model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
+1. **[PLBart](model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://huggingface.co/papers/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
+1. **[PoolFormer](model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://huggingface.co/papers/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
+1. **[ProphetNet](model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://huggingface.co/papers/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[QDQBert](model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://huggingface.co/papers/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
+1. **[RAG](model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://huggingface.co/papers/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
+1. **[REALM](model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://huggingface.co/papers/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
+1. **[Reformer](model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://huggingface.co/papers/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
+1. **[RegNet](model_doc/regnet)** (from META Platforms) released with the paper [Designing Network Design Space](https://huggingface.co/papers/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
+1. **[RemBERT](model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://huggingface.co/papers/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
+1. **[ResNet](model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://huggingface.co/papers/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
+1. **[RoBERTa](model_doc/roberta)** (from Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://huggingface.co/papers/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
+1. **[RoFormer](model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://huggingface.co/papers/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
+1. **[SegFormer](model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://huggingface.co/papers/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
+1. **[SEW](model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://huggingface.co/papers/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SEW-D](model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://huggingface.co/papers/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://huggingface.co/papers/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
+1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://huggingface.co/papers/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
+1. **[Splinter](model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://huggingface.co/papers/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
+1. **[SqueezeBERT](model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://huggingface.co/papers/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
+1. **[Swin Transformer](model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://huggingface.co/papers/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
+1. **[Swin Transformer V2](model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://huggingface.co/papers/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
+1. **[T5](model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://huggingface.co/papers/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[T5v1.1](model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
-1. **[TAPAS](model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
-1. **[TAPEX](model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
-1. **[Trajectory Transformer](model_doc/trajectory_transformers)** (from the University of California at Berkeley) released with the paper [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine
-1. **[Transformer-XL](model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
-1. **[TrOCR](model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
-1. **[UL2](model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
+1. **[TAPAS](model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://huggingface.co/papers/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
+1. **[TAPEX](model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://huggingface.co/papers/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
+1. **[Trajectory Transformer](model_doc/trajectory_transformers)** (from the University of California at Berkeley) released with the paper [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://huggingface.co/papers/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine
+1. **[Transformer-XL](model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://huggingface.co/papers/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
+1. **[TrOCR](model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://huggingface.co/papers/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
+1. **[UL2](model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://huggingface.co/papers/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
1. **[UMT5](model_doc/umt5)** (from Google Research) released with the paper [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
-1. **[UniSpeech](model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
-1. **[UniSpeechSat](model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
-1. **[VAN](model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
-1. **[VideoMAE](model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
-1. **[ViLT](model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
-1. **[Vision Transformer (ViT)](model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
-1. **[VisualBERT](model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
-1. **[ViTMAE](model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
-1. **[Wav2Vec2](model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
-1. **[Wav2Vec2-Conformer](model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
-1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
-1. **[WavLM](model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
-1. **[XGLM](model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
-1. **[XLM](model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau.
-1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
-1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
-1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (from Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
-1. **[XLM-V](model_doc/xlm-v)** (from Meta AI) released with the paper [XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models](https://arxiv.org/abs/2301.10472) by Davis Liang, Hila Gonen, Yuning Mao, Rui Hou, Naman Goyal, Marjan Ghazvininejad, Luke Zettlemoyer, Madian Khabsa.
-1. **[XLNet](model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
-1. **[XLS-R](model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
-1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
-1. **[YOLOS](model_doc/yolos)** (from Huazhong University of Science & Technology) released with the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
-1. **[YOSO](model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
+1. **[UniSpeech](model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://huggingface.co/papers/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
+1. **[UniSpeechSat](model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://huggingface.co/papers/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
+1. **[VAN](model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://huggingface.co/papers/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
+1. **[VideoMAE](model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://huggingface.co/papers/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
+1. **[ViLT](model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://huggingface.co/papers/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
+1. **[Vision Transformer (ViT)](model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://huggingface.co/papers/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
+1. **[VisualBERT](model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://huggingface.co/papers/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
+1. **[ViTMAE](model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://huggingface.co/papers/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
+1. **[Wav2Vec2](model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://huggingface.co/papers/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
+1. **[Wav2Vec2-Conformer](model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://huggingface.co/papers/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
+1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://huggingface.co/papers/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
+1. **[WavLM](model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://huggingface.co/papers/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
+1. **[XGLM](model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://huggingface.co/papers/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
+1. **[XLM](model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://huggingface.co/papers/1901.07291) by Guillaume Lample and Alexis Conneau.
+1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://huggingface.co/papers/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://huggingface.co/papers/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
+1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (from Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://huggingface.co/papers/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
+1. **[XLM-V](model_doc/xlm-v)** (from Meta AI) released with the paper [XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models](https://huggingface.co/papers/2301.10472) by Davis Liang, Hila Gonen, Yuning Mao, Rui Hou, Naman Goyal, Marjan Ghazvininejad, Luke Zettlemoyer, Madian Khabsa.
+1. **[XLNet](model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://huggingface.co/papers/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
+1. **[XLS-R](model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://huggingface.co/papers/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
+1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://huggingface.co/papers/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
+1. **[YOLOS](model_doc/yolos)** (from Huazhong University of Science & Technology) released with the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://huggingface.co/papers/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
+1. **[YOSO](model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://huggingface.co/papers/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
### Unterstützte Frameworks
diff --git a/docs/source/de/peft.md b/docs/source/de/peft.md
index eda8ce9435..f43d227a9a 100644
--- a/docs/source/de/peft.md
+++ b/docs/source/de/peft.md
@@ -44,7 +44,7 @@ Transformers unterstützt nativ einige PEFT-Methoden, d.h. Sie können lokal ode
- [Low Rank Adapters](https://huggingface.co/docs/peft/conceptual_guides/lora)
- [IA3](https://huggingface.co/docs/peft/conceptual_guides/ia3)
-- [AdaLoRA](https://arxiv.org/abs/2303.10512)
+- [AdaLoRA](https://huggingface.co/papers/2303.10512)
Wenn Sie andere PEFT-Methoden, wie z.B. Prompt Learning oder Prompt Tuning, verwenden möchten, oder über die 🤗 PEFT-Bibliothek im Allgemeinen, lesen Sie bitte die [Dokumentation](https://huggingface.co/docs/peft/index).
diff --git a/docs/source/en/glossary.md b/docs/source/en/glossary.md
index d9fdac2475..b65f45341e 100644
--- a/docs/source/en/glossary.md
+++ b/docs/source/en/glossary.md
@@ -163,7 +163,7 @@ The intermediate embedding size of the feed forward layers is often bigger than
For an input of size `[batch_size, sequence_length]`, the memory required to store the intermediate feed forward
embeddings `[batch_size, sequence_length, config.intermediate_size]` can account for a large fraction of the memory
-use. The authors of [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) noticed that since the
+use. The authors of [Reformer: The Efficient Transformer](https://huggingface.co/papers/2001.04451) noticed that since the
computation is independent of the `sequence_length` dimension, it is mathematically equivalent to compute the output
embeddings of both feed forward layers `[batch_size, config.hidden_size]_0, ..., [batch_size, config.hidden_size]_n`
individually and concat them afterward to `[batch_size, sequence_length, config.hidden_size]` with `n = sequence_length`, which trades increased computation time against reduced memory use, but yields a mathematically
@@ -207,7 +207,7 @@ numerical representations of tokens building the sequences that will be used as
Each tokenizer works differently but the underlying mechanism remains the same. Here's an example using the BERT
-tokenizer, which is a [WordPiece](https://arxiv.org/pdf/1609.08144.pdf) tokenizer:
+tokenizer, which is a [WordPiece](https://huggingface.co/papers/1609.08144) tokenizer:
```python
>>> from transformers import BertTokenizer
diff --git a/docs/source/en/llm_tutorial_optimization.md b/docs/source/en/llm_tutorial_optimization.md
index 038aa76689..f52bccdda8 100644
--- a/docs/source/en/llm_tutorial_optimization.md
+++ b/docs/source/en/llm_tutorial_optimization.md
@@ -16,7 +16,7 @@ rendered properly in your Markdown viewer.
Large Language Models (LLMs) such as GPT3/4, [Falcon](https://huggingface.co/tiiuae/falcon-40b), and [Llama](https://huggingface.co/meta-llama/Llama-2-70b-hf) are rapidly advancing in their ability to tackle human-centric tasks, establishing themselves as essential tools in modern knowledge-based industries.
Deploying these models in real-world tasks remains challenging, however:
-- To exhibit near-human text understanding and generation capabilities, LLMs currently require to be composed of billions of parameters (see [Kaplan et al](https://arxiv.org/abs/2001.08361), [Wei et. al](https://arxiv.org/abs/2206.07682)). This consequently amplifies the memory demands for inference.
+- To exhibit near-human text understanding and generation capabilities, LLMs currently require to be composed of billions of parameters (see [Kaplan et al](https://huggingface.co/papers/2001.08361), [Wei et. al](https://huggingface.co/papers/2206.07682)). This consequently amplifies the memory demands for inference.
- In many real-world tasks, LLMs need to be given extensive contextual information. This necessitates the model's capability to manage very long input sequences during inference.
The crux of these challenges lies in augmenting the computational and memory capabilities of LLMs, especially when handling expansive input sequences.
@@ -27,7 +27,7 @@ In this guide, we will go over the effective techniques for efficient LLM deploy
2. **Flash Attention:** Flash Attention is a variation of the attention algorithm that not only provides a more memory-efficient approach but also realizes increased efficiency due to optimized GPU memory utilization.
-3. **Architectural Innovations:** Considering that LLMs are always deployed in the same way during inference, namely autoregressive text generation with a long input context, specialized model architectures have been proposed that allow for more efficient inference. The most important advancement in model architectures hereby are [Alibi](https://arxiv.org/abs/2108.12409), [Rotary embeddings](https://arxiv.org/abs/2104.09864), [Multi-Query Attention (MQA)](https://arxiv.org/abs/1911.02150) and [Grouped-Query-Attention (GQA)]((https://arxiv.org/abs/2305.13245)).
+3. **Architectural Innovations:** Considering that LLMs are always deployed in the same way during inference, namely autoregressive text generation with a long input context, specialized model architectures have been proposed that allow for more efficient inference. The most important advancement in model architectures hereby are [Alibi](https://huggingface.co/papers/2108.12409), [Rotary embeddings](https://huggingface.co/papers/2104.09864), [Multi-Query Attention (MQA)](https://huggingface.co/papers/1911.02150) and [Grouped-Query-Attention (GQA)]((https://huggingface.co/papers/2305.13245)).
Throughout this guide, we will offer an analysis of auto-regressive generation from a tensor's perspective. We delve into the pros and cons of adopting lower precision, provide a comprehensive exploration of the latest attention algorithms, and discuss improved LLM architectures. While doing so, we run practical examples showcasing each of the feature improvements.
@@ -157,8 +157,8 @@ from accelerate.utils import release_memory
release_memory(model)
```
-Now what if your GPU does not have 32 GB of VRAM? It has been found that model weights can be quantized to 8-bit or 4-bits without a significant loss in performance (see [Dettmers et al.](https://arxiv.org/abs/2208.07339)).
-Model can be quantized to even 3 or 2 bits with an acceptable loss in performance as shown in the recent [GPTQ paper](https://arxiv.org/abs/2210.17323) 🤯.
+Now what if your GPU does not have 32 GB of VRAM? It has been found that model weights can be quantized to 8-bit or 4-bits without a significant loss in performance (see [Dettmers et al.](https://huggingface.co/papers/2208.07339)).
+Model can be quantized to even 3 or 2 bits with an acceptable loss in performance as shown in the recent [GPTQ paper](https://huggingface.co/papers/2210.17323) 🤯.
Without going into too many details, quantization schemes aim at reducing the precision of weights while trying to keep the model's inference results as accurate as possible (*a.k.a* as close as possible to bfloat16).
Note that quantization works especially well for text generation since all we care about is choosing the *set of most likely next tokens* and don't really care about the exact values of the next token *logit* distribution.
@@ -308,7 +308,7 @@ Long story short, the default self-attention algorithm quickly becomes prohibiti
As LLMs improve in text comprehension and generation, they are applied to increasingly complex tasks. While models once handled the translation or summarization of a few sentences, they now manage entire pages, demanding the capability to process extensive input lengths.
-How can we get rid of the exorbitant memory requirements for large input lengths? We need a new way to compute the self-attention mechanism that gets rid of the \\( QK^T \\) matrix. [Tri Dao et al.](https://arxiv.org/abs/2205.14135) developed exactly such a new algorithm and called it **Flash Attention**.
+How can we get rid of the exorbitant memory requirements for large input lengths? We need a new way to compute the self-attention mechanism that gets rid of the \\( QK^T \\) matrix. [Tri Dao et al.](https://huggingface.co/papers/2205.14135) developed exactly such a new algorithm and called it **Flash Attention**.
In a nutshell, Flash Attention breaks the \\(\mathbf{V} \times \text{Softmax}(\mathbf{QK}^T\\)) computation apart and instead computes smaller chunks of the output by iterating over multiple softmax computation steps:
@@ -316,13 +316,13 @@ $$ \textbf{O}_i \leftarrow s^a_{ij} * \textbf{O}_i + s^b_{ij} * \mathbf{V}_{j} \
with \\( s^a_{ij} \\) and \\( s^b_{ij} \\) being some softmax normalization statistics that need to be recomputed for every \\( i \\) and \\( j \\) .
-Please note that the whole Flash Attention is a bit more complex and is greatly simplified here as going in too much depth is out of scope for this guide. The reader is invited to take a look at the well-written [Flash Attention paper](https://arxiv.org/abs/2205.14135) for more details.
+Please note that the whole Flash Attention is a bit more complex and is greatly simplified here as going in too much depth is out of scope for this guide. The reader is invited to take a look at the well-written [Flash Attention paper](https://huggingface.co/papers/2205.14135) for more details.
The main takeaway here is:
> By keeping track of softmax normalization statistics and by using some smart mathematics, Flash Attention gives **numerical identical** outputs compared to the default self-attention layer at a memory cost that only increases linearly with \\( N \\) .
-Looking at the formula, one would intuitively say that Flash Attention must be much slower compared to the default self-attention formula as more computation needs to be done. Indeed Flash Attention requires more FLOPs compared to normal attention as the softmax normalization statistics have to constantly be recomputed (see [paper](https://arxiv.org/abs/2205.14135) for more details if interested)
+Looking at the formula, one would intuitively say that Flash Attention must be much slower compared to the default self-attention formula as more computation needs to be done. Indeed Flash Attention requires more FLOPs compared to normal attention as the softmax normalization statistics have to constantly be recomputed (see [paper](https://huggingface.co/papers/2205.14135) for more details if interested)
> However, Flash Attention is much faster in inference compared to default attention which comes from its ability to significantly reduce the demands on the slower, high-bandwidth memory of the GPU (VRAM), focusing instead on the faster on-chip memory (SRAM).
@@ -526,22 +526,22 @@ Therefore, for the LLM without position embeddings each token appears to have th
For the LLM to understand sentence order, an additional *cue* is needed and is usually applied in the form of *positional encodings* (or also called *positional embeddings*).
Positional encodings, encode the position of each token into a numerical presentation that the LLM can leverage to better understand sentence order.
-The authors of the [*Attention Is All You Need*](https://arxiv.org/abs/1706.03762) paper introduced sinusoidal positional embeddings \\( \mathbf{P} = \mathbf{p}_1, \ldots, \mathbf{p}_N \\) .
+The authors of the [*Attention Is All You Need*](https://huggingface.co/papers/1706.03762) paper introduced sinusoidal positional embeddings \\( \mathbf{P} = \mathbf{p}_1, \ldots, \mathbf{p}_N \\) .
where each vector \\( \mathbf{p}_i \\) is computed as a sinusoidal function of its position \\( i \\) .
The positional encodings are then simply added to the input sequence vectors \\( \mathbf{\hat{X}} = \mathbf{\hat{x}}_1, \ldots, \mathbf{\hat{x}}_N \\) = \\( \mathbf{x}_1 + \mathbf{p}_1, \ldots, \mathbf{x}_N + \mathbf{p}_N \\) thereby cueing the model to better learn sentence order.
-Instead of using fixed position embeddings, others (such as [Devlin et al.](https://arxiv.org/abs/1810.04805)) used learned positional encodings for which the positional embeddings
+Instead of using fixed position embeddings, others (such as [Devlin et al.](https://huggingface.co/papers/1810.04805)) used learned positional encodings for which the positional embeddings
\\( \mathbf{P} \\) are learned during training.
Sinusoidal and learned position embeddings used to be the predominant methods to encode sentence order into LLMs, but a couple of problems related to these positional encodings were found:
- 1. Sinusoidal and learned position embeddings are both absolute positional embeddings, *i.e.* encoding a unique embedding for each position id: \\( 0, \ldots, N \\) . As shown by [Huang et al.](https://arxiv.org/abs/2009.13658) and [Su et al.](https://arxiv.org/abs/2104.09864), absolute positional embeddings lead to poor LLM performance for long text inputs. For long text inputs, it is advantageous if the model learns the relative positional distance input tokens have to each other instead of their absolute position.
+ 1. Sinusoidal and learned position embeddings are both absolute positional embeddings, *i.e.* encoding a unique embedding for each position id: \\( 0, \ldots, N \\) . As shown by [Huang et al.](https://huggingface.co/papers/2009.13658) and [Su et al.](https://huggingface.co/papers/2104.09864), absolute positional embeddings lead to poor LLM performance for long text inputs. For long text inputs, it is advantageous if the model learns the relative positional distance input tokens have to each other instead of their absolute position.
2. When using learned position embeddings, the LLM has to be trained on a fixed input length \\( N \\), which makes it difficult to extrapolate to an input length longer than what it was trained on.
Recently, relative positional embeddings that can tackle the above mentioned problems have become more popular, most notably:
-- [Rotary Position Embedding (RoPE)](https://arxiv.org/abs/2104.09864)
-- [ALiBi](https://arxiv.org/abs/2108.12409)
+- [Rotary Position Embedding (RoPE)](https://huggingface.co/papers/2104.09864)
+- [ALiBi](https://huggingface.co/papers/2108.12409)
Both *RoPE* and *ALiBi* argue that it's best to cue the LLM about sentence order directly in the self-attention algorithm as it's there that word tokens are put into relation with each other. More specifically, sentence order should be cued by modifying the \\( \mathbf{QK}^T \\) computation.
@@ -556,14 +556,14 @@ $$ \mathbf{\hat{q}}_i^T \mathbf{\hat{x}}_j = \mathbf{{q}}_i^T \mathbf{R}_{\theta
*RoPE* is used in multiple of today's most important LLMs, such as:
- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
-- [**Llama**](https://arxiv.org/abs/2302.13971)
-- [**PaLM**](https://arxiv.org/abs/2204.02311)
+- [**Llama**](https://huggingface.co/papers/2302.13971)
+- [**PaLM**](https://huggingface.co/papers/2204.02311)
As an alternative, *ALiBi* proposes a much simpler relative position encoding scheme. The relative distance that input tokens have to each other is added as a negative integer scaled by a pre-defined value `m` to each query-key entry of the \\( \mathbf{QK}^T \\) matrix right before the softmax computation.

-As shown in the [ALiBi](https://arxiv.org/abs/2108.12409) paper, this simple relative positional encoding allows the model to retain a high performance even at very long text input sequences.
+As shown in the [ALiBi](https://huggingface.co/papers/2108.12409) paper, this simple relative positional encoding allows the model to retain a high performance even at very long text input sequences.
*ALiBi* is used in multiple of today's most important LLMs, such as:
@@ -572,7 +572,7 @@ As shown in the [ALiBi](https://arxiv.org/abs/2108.12409) paper, this simple rel
Both *RoPE* and *ALiBi* position encodings can extrapolate to input lengths not seen during training whereas it has been shown that extrapolation works much better out-of-the-box for *ALiBi* as compared to *RoPE*.
For ALiBi, one simply increases the values of the lower triangular position matrix to match the length of the input sequence.
-For *RoPE*, keeping the same \\( \theta \\) that was used during training leads to poor results when passing text inputs much longer than those seen during training, *c.f* [Press et al.](https://arxiv.org/abs/2108.12409). However, the community has found a couple of effective tricks that adapt \\( \theta \\), thereby allowing *RoPE* position embeddings to work well for extrapolated text input sequences (see [here](https://github.com/huggingface/transformers/pull/24653)).
+For *RoPE*, keeping the same \\( \theta \\) that was used during training leads to poor results when passing text inputs much longer than those seen during training, *c.f* [Press et al.](https://huggingface.co/papers/2108.12409). However, the community has found a couple of effective tricks that adapt \\( \theta \\), thereby allowing *RoPE* position embeddings to work well for extrapolated text input sequences (see [here](https://github.com/huggingface/transformers/pull/24653)).
> Both RoPE and ALiBi are relative positional embeddings that are *not* learned during training, but instead are based on the following intuitions:
- Positional cues about the text inputs should be given directly to the \\( QK^T \\) matrix of the self-attention layer
@@ -742,21 +742,21 @@ Researchers have proposed two methods that allow to significantly reduce the mem
#### 3.2.2 Multi-Query-Attention (MQA)
-[Multi-Query-Attention](https://arxiv.org/abs/1911.02150) was proposed in Noam Shazeer's *Fast Transformer Decoding: One Write-Head is All You Need* paper. As the title says, Noam found out that instead of using `n_head` key-value projections weights, one can use a single head-value projection weight pair that is shared across all attention heads without that the model's performance significantly degrades.
+[Multi-Query-Attention](https://huggingface.co/papers/1911.02150) was proposed in Noam Shazeer's *Fast Transformer Decoding: One Write-Head is All You Need* paper. As the title says, Noam found out that instead of using `n_head` key-value projections weights, one can use a single head-value projection weight pair that is shared across all attention heads without that the model's performance significantly degrades.
> By using a single head-value projection weight pair, the key value vectors \\( \mathbf{k}_i, \mathbf{v}_i \\) have to be identical across all attention heads which in turn means that we only need to store 1 key-value projection pair in the cache instead of `n_head` ones.
As most LLMs use between 20 and 100 attention heads, MQA significantly reduces the memory consumption of the key-value cache. For the LLM used in this notebook we could therefore reduce the required memory consumption from 15 GB to less than 400 MB at an input sequence length of 16000.
In addition to memory savings, MQA also leads to improved computational efficiency as explained in the following.
-In auto-regressive decoding, large key-value vectors need to be reloaded, concatenated with the current key-value vector pair to be then fed into the \\( \mathbf{q}_c\mathbf{K}^T \\) computation at every step. For auto-regressive decoding, the required memory bandwidth for the constant reloading can become a serious time bottleneck. By reducing the size of the key-value vectors less memory needs to be accessed, thus reducing the memory bandwidth bottleneck. For more detail, please have a look at [Noam's paper](https://arxiv.org/abs/1911.02150).
+In auto-regressive decoding, large key-value vectors need to be reloaded, concatenated with the current key-value vector pair to be then fed into the \\( \mathbf{q}_c\mathbf{K}^T \\) computation at every step. For auto-regressive decoding, the required memory bandwidth for the constant reloading can become a serious time bottleneck. By reducing the size of the key-value vectors less memory needs to be accessed, thus reducing the memory bandwidth bottleneck. For more detail, please have a look at [Noam's paper](https://huggingface.co/papers/1911.02150).
The important part to understand here is that reducing the number of key-value attention heads to 1 only makes sense if a key-value cache is used. The peak memory consumption of the model for a single forward pass without key-value cache stays unchanged as every attention head still has a unique query vector so that each attention head still has a different \\( \mathbf{QK}^T \\) matrix.
MQA has seen wide adoption by the community and is now used by many of the most popular LLMs:
- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
-- [**PaLM**](https://arxiv.org/abs/2204.02311)
+- [**PaLM**](https://huggingface.co/papers/2204.02311)
- [**MPT**](https://huggingface.co/mosaicml/mpt-30b)
- [**BLOOM**](https://huggingface.co/bigscience/bloom)
@@ -764,7 +764,7 @@ Also, the checkpoint used in this notebook - `bigcode/octocoder` - makes use of
#### 3.2.3 Grouped-Query-Attention (GQA)
-[Grouped-Query-Attention](https://arxiv.org/abs/2305.13245), as proposed by Ainslie et al. from Google, found that using MQA can often lead to quality degradation compared to using vanilla multi-key-value head projections. The paper argues that more model performance can be kept by less drastically reducing the number of query head projection weights. Instead of using just a single key-value projection weight, `n < n_head` key-value projection weights should be used. By choosing `n` to a significantly smaller value than `n_head`, such as 2,4 or 8 almost all of the memory and speed gains from MQA can be kept while sacrificing less model capacity and thus arguably less performance.
+[Grouped-Query-Attention](https://huggingface.co/papers/2305.13245), as proposed by Ainslie et al. from Google, found that using MQA can often lead to quality degradation compared to using vanilla multi-key-value head projections. The paper argues that more model performance can be kept by less drastically reducing the number of query head projection weights. Instead of using just a single key-value projection weight, `n < n_head` key-value projection weights should be used. By choosing `n` to a significantly smaller value than `n_head`, such as 2,4 or 8 almost all of the memory and speed gains from MQA can be kept while sacrificing less model capacity and thus arguably less performance.
Moreover, the authors of GQA found out that existing model checkpoints can be *uptrained* to have a GQA architecture with as little as 5% of the original pre-training compute. While 5% of the original pre-training compute can still be a massive amount, GQA *uptraining* allows existing checkpoints to be useful for longer input sequences.
@@ -776,7 +776,7 @@ The most notable application of GQA is [Llama-v2](https://huggingface.co/meta-ll
## Conclusion
-The research community is constantly coming up with new, nifty ways to speed up inference time for ever-larger LLMs. As an example, one such promising research direction is [speculative decoding](https://arxiv.org/abs/2211.17192) where "easy tokens" are generated by smaller, faster language models and only "hard tokens" are generated by the LLM itself. Going into more detail is out of the scope of this notebook, but can be read upon in this [nice blog post](https://huggingface.co/blog/assisted-generation).
+The research community is constantly coming up with new, nifty ways to speed up inference time for ever-larger LLMs. As an example, one such promising research direction is [speculative decoding](https://huggingface.co/papers/2211.17192) where "easy tokens" are generated by smaller, faster language models and only "hard tokens" are generated by the LLM itself. Going into more detail is out of the scope of this notebook, but can be read upon in this [nice blog post](https://huggingface.co/blog/assisted-generation).
The reason massive LLMs such as GPT3/4, Llama-2-70b, Claude, PaLM can run so quickly in chat-interfaces such as [Hugging Face Chat](https://huggingface.co/chat/) or ChatGPT is to a big part thanks to the above-mentioned improvements in precision, algorithms, and architecture.
Going forward, accelerators such as GPUs, TPUs, etc... will only get faster and allow for more memory, but one should nevertheless always make sure to use the best available algorithms and architectures to get the most bang for your buck 🤗
diff --git a/docs/source/en/main_classes/processors.md b/docs/source/en/main_classes/processors.md
index 5e943fc9fd..2c2e0cd31b 100644
--- a/docs/source/en/main_classes/processors.md
+++ b/docs/source/en/main_classes/processors.md
@@ -78,7 +78,7 @@ Additionally, the following method can be used to load values from a data file a
quality of cross-lingual text representations. XNLI is crowd-sourced dataset based on [*MultiNLI*](http://www.nyu.edu/projects/bowman/multinli/): pairs of text are labeled with textual entailment annotations for 15
different languages (including both high-resource language such as English and low-resource languages such as Swahili).
-It was released together with the paper [XNLI: Evaluating Cross-lingual Sentence Representations](https://arxiv.org/abs/1809.05053)
+It was released together with the paper [XNLI: Evaluating Cross-lingual Sentence Representations](https://huggingface.co/papers/1809.05053)
This library hosts the processor to load the XNLI data:
@@ -93,8 +93,8 @@ An example using these processors is given in the [run_xnli.py](https://github.c
[The Stanford Question Answering Dataset (SQuAD)](https://rajpurkar.github.io/SQuAD-explorer//) is a benchmark that
evaluates the performance of models on question answering. Two versions are available, v1.1 and v2.0. The first version
-(v1.1) was released together with the paper [SQuAD: 100,000+ Questions for Machine Comprehension of Text](https://arxiv.org/abs/1606.05250). The second version (v2.0) was released alongside the paper [Know What You Don't
-Know: Unanswerable Questions for SQuAD](https://arxiv.org/abs/1806.03822).
+(v1.1) was released together with the paper [SQuAD: 100,000+ Questions for Machine Comprehension of Text](https://huggingface.co/papers/1606.05250). The second version (v2.0) was released alongside the paper [Know What You Don't
+Know: Unanswerable Questions for SQuAD](https://huggingface.co/papers/1806.03822).
This library hosts a processor for each of the two versions:
diff --git a/docs/source/en/model_doc/albert.md b/docs/source/en/model_doc/albert.md
index 1e414735ed..d121e370da 100644
--- a/docs/source/en/model_doc/albert.md
+++ b/docs/source/en/model_doc/albert.md
@@ -26,7 +26,7 @@ rendered properly in your Markdown viewer.
## Overview
-The ALBERT model was proposed in [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942) by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma,
+The ALBERT model was proposed in [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://huggingface.co/papers/1909.11942) by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma,
Radu Soricut. It presents two parameter-reduction techniques to lower memory consumption and increase the training
speed of BERT:
diff --git a/docs/source/en/model_doc/altclip.md b/docs/source/en/model_doc/altclip.md
index 14d341764a..4d04173df7 100644
--- a/docs/source/en/model_doc/altclip.md
+++ b/docs/source/en/model_doc/altclip.md
@@ -21,7 +21,7 @@ rendered properly in your Markdown viewer.
# AltCLIP
-[AltCLIP](https://huggingface.co/papers/2211.06679v2) replaces the [CLIP](./clip) text encoder with a multilingual XLM-R encoder and aligns image and text representations with teacher learning and contrastive learning.
+[AltCLIP](https://huggingface.co/papers/2211.06679) replaces the [CLIP](./clip) text encoder with a multilingual XLM-R encoder and aligns image and text representations with teacher learning and contrastive learning.
You can find all the original AltCLIP checkpoints under the [AltClip](https://huggingface.co/collections/BAAI/alt-clip-diffusion-66987a97de8525205f1221bf) collection.
diff --git a/docs/source/en/model_doc/audio-spectrogram-transformer.md b/docs/source/en/model_doc/audio-spectrogram-transformer.md
index 14669ce0fb..46544de1f6 100644
--- a/docs/source/en/model_doc/audio-spectrogram-transformer.md
+++ b/docs/source/en/model_doc/audio-spectrogram-transformer.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Audio Spectrogram Transformer model was proposed in [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
+The Audio Spectrogram Transformer model was proposed in [AST: Audio Spectrogram Transformer](https://huggingface.co/papers/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
The Audio Spectrogram Transformer applies a [Vision Transformer](vit) to audio, by turning audio into an image (spectrogram). The model obtains state-of-the-art results
for audio classification.
@@ -35,7 +35,7 @@ The abstract from the paper is the following:
- Audio Spectrogram Transformer architecture. Taken from the original paper.
+ Audio Spectrogram Transformer architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/YuanGongND/ast).
@@ -47,7 +47,7 @@ sure the input has mean of 0 and std of 0.5). [`ASTFeatureExtractor`] takes care
mean and std by default. You can check [`ast/src/get_norm_stats.py`](https://github.com/YuanGongND/ast/blob/master/src/get_norm_stats.py) to see how
the authors compute the stats for a downstream dataset.
- Note that the AST needs a low learning rate (the authors use a 10 times smaller learning rate compared to their CNN model proposed in the
-[PSLA paper](https://arxiv.org/abs/2102.01243)) and converges quickly, so please search for a suitable learning rate and learning rate scheduler for your task.
+[PSLA paper](https://huggingface.co/papers/2102.01243)) and converges quickly, so please search for a suitable learning rate and learning rate scheduler for your task.
### Using Scaled Dot Product Attention (SDPA)
diff --git a/docs/source/en/model_doc/autoformer.md b/docs/source/en/model_doc/autoformer.md
index 2c5e27153e..0fd3890132 100644
--- a/docs/source/en/model_doc/autoformer.md
+++ b/docs/source/en/model_doc/autoformer.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Autoformer model was proposed in [Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008) by Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long.
+The Autoformer model was proposed in [Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://huggingface.co/papers/2106.13008) by Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long.
This model augments the Transformer as a deep decomposition architecture, which can progressively decompose the trend and seasonal components during the forecasting process.
diff --git a/docs/source/en/model_doc/barthez.md b/docs/source/en/model_doc/barthez.md
index 131b1dd8e1..0f8568cc05 100644
--- a/docs/source/en/model_doc/barthez.md
+++ b/docs/source/en/model_doc/barthez.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The BARThez model was proposed in [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis on 23 Oct,
+The BARThez model was proposed in [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://huggingface.co/papers/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis on 23 Oct,
2020.
The abstract of the paper:
diff --git a/docs/source/en/model_doc/bartpho.md b/docs/source/en/model_doc/bartpho.md
index b374951632..78c26c06a5 100644
--- a/docs/source/en/model_doc/bartpho.md
+++ b/docs/source/en/model_doc/bartpho.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The BARTpho model was proposed in [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
+The BARTpho model was proposed in [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://huggingface.co/papers/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/beit.md b/docs/source/en/model_doc/beit.md
index 7d29780260..32a0c160a1 100644
--- a/docs/source/en/model_doc/beit.md
+++ b/docs/source/en/model_doc/beit.md
@@ -25,11 +25,11 @@ rendered properly in your Markdown viewer.
## Overview
-The BEiT model was proposed in [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by
+The BEiT model was proposed in [BEiT: BERT Pre-Training of Image Transformers](https://huggingface.co/papers/2106.08254) by
Hangbo Bao, Li Dong and Furu Wei. Inspired by BERT, BEiT is the first paper that makes self-supervised pre-training of
Vision Transformers (ViTs) outperform supervised pre-training. Rather than pre-training the model to predict the class
-of an image (as done in the [original ViT paper](https://arxiv.org/abs/2010.11929)), BEiT models are pre-trained to
-predict visual tokens from the codebook of OpenAI's [DALL-E model](https://arxiv.org/abs/2102.12092) given masked
+of an image (as done in the [original ViT paper](https://huggingface.co/papers/2010.11929)), BEiT models are pre-trained to
+predict visual tokens from the codebook of OpenAI's [DALL-E model](https://huggingface.co/papers/2102.12092) given masked
patches.
The abstract from the paper is the following:
@@ -76,7 +76,7 @@ contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code
- BEiT pre-training. Taken from the original paper.
+ BEiT pre-training. Taken from the original paper.
### Using Scaled Dot Product Attention (SDPA)
diff --git a/docs/source/en/model_doc/bert-generation.md b/docs/source/en/model_doc/bert-generation.md
index 0c42adbeb5..a14966ce3a 100644
--- a/docs/source/en/model_doc/bert-generation.md
+++ b/docs/source/en/model_doc/bert-generation.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
The BertGeneration model is a BERT model that can be leveraged for sequence-to-sequence tasks using
[`EncoderDecoderModel`] as proposed in [Leveraging Pre-trained Checkpoints for Sequence Generation
-Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+Tasks](https://huggingface.co/papers/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/big_bird.md b/docs/source/en/model_doc/big_bird.md
index 16e1a3bff8..16f99043c6 100644
--- a/docs/source/en/model_doc/big_bird.md
+++ b/docs/source/en/model_doc/big_bird.md
@@ -26,7 +26,6 @@ rendered properly in your Markdown viewer.
[BigBird](https://huggingface.co/papers/2007.14062) is a transformer model built to handle sequence lengths up to 4096 compared to 512 for [BERT](./bert). Traditional transformers struggle with long inputs because attention gets really expensive as the sequence length grows. BigBird fixes this by using a sparse attention mechanism, which means it doesn’t try to look at everything at once. Instead, it mixes in local attention, random attention, and a few global tokens to process the whole input. This combination gives it the best of both worlds. It keeps the computation efficient while still capturing enough of the sequence to understand it well. Because of this, BigBird is great at tasks involving long documents, like question answering, summarization, and genomic applications.
-
You can find all the original BigBird checkpoints under the [Google](https://huggingface.co/google?search_models=bigbird) organization.
> [!TIP]
diff --git a/docs/source/en/model_doc/bigbird_pegasus.md b/docs/source/en/model_doc/bigbird_pegasus.md
index 499d40b314..5f7d37eef4 100644
--- a/docs/source/en/model_doc/bigbird_pegasus.md
+++ b/docs/source/en/model_doc/bigbird_pegasus.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The BigBird model was proposed in [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by
+The BigBird model was proposed in [Big Bird: Transformers for Longer Sequences](https://huggingface.co/papers/2007.14062) by
Zaheer, Manzil and Guruganesh, Guru and Dubey, Kumar Avinava and Ainslie, Joshua and Alberti, Chris and Ontanon,
Santiago and Pham, Philip and Ravula, Anirudh and Wang, Qifan and Yang, Li and others. BigBird, is a sparse-attention
based transformer which extends Transformer based models, such as BERT to much longer sequences. In addition to sparse
diff --git a/docs/source/en/model_doc/bit.md b/docs/source/en/model_doc/bit.md
index 0813b67af9..ea0c09b862 100644
--- a/docs/source/en/model_doc/bit.md
+++ b/docs/source/en/model_doc/bit.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The BiT model was proposed in [Big Transfer (BiT): General Visual Representation Learning](https://arxiv.org/abs/1912.11370) by Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby.
+The BiT model was proposed in [Big Transfer (BiT): General Visual Representation Learning](https://huggingface.co/papers/1912.11370) by Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby.
BiT is a simple recipe for scaling up pre-training of [ResNet](resnet)-like architectures (specifically, ResNetv2). The method results in significant improvements for transfer learning.
The abstract from the paper is the following:
@@ -34,8 +34,8 @@ The original code can be found [here](https://github.com/google-research/big_tra
## Usage tips
-- BiT models are equivalent to ResNetv2 in terms of architecture, except that: 1) all batch normalization layers are replaced by [group normalization](https://arxiv.org/abs/1803.08494),
-2) [weight standardization](https://arxiv.org/abs/1903.10520) is used for convolutional layers. The authors show that the combination of both is useful for training with large batch sizes, and has a significant
+- BiT models are equivalent to ResNetv2 in terms of architecture, except that: 1) all batch normalization layers are replaced by [group normalization](https://huggingface.co/papers/1803.08494),
+2) [weight standardization](https://huggingface.co/papers/1903.10520) is used for convolutional layers. The authors show that the combination of both is useful for training with large batch sizes, and has a significant
impact on transfer learning.
## Resources
diff --git a/docs/source/en/model_doc/bitnet.md b/docs/source/en/model_doc/bitnet.md
index b77ac6c700..2bf2b8e7b2 100644
--- a/docs/source/en/model_doc/bitnet.md
+++ b/docs/source/en/model_doc/bitnet.md
@@ -20,7 +20,7 @@ rendered properly in your Markdown viewer.
Trained on a corpus of 4 trillion tokens, this model demonstrates that native 1-bit LLMs can achieve performance comparable to leading open-weight, full-precision models of similar size, while offering substantial advantages in computational efficiency (memory, energy, latency).
-➡️ **Technical Report:** [BitNet b1.58 2B4T Technical Report](https://arxiv.org/abs/2504.12285)
+➡️ **Technical Report:** [BitNet b1.58 2B4T Technical Report](https://huggingface.co/papers/2504.12285)
➡️ **Official Inference Code:** [microsoft/BitNet (bitnet.cpp)](https://github.com/microsoft/BitNet)
diff --git a/docs/source/en/model_doc/blenderbot-small.md b/docs/source/en/model_doc/blenderbot-small.md
index 341e43c030..181fd01342 100644
--- a/docs/source/en/model_doc/blenderbot-small.md
+++ b/docs/source/en/model_doc/blenderbot-small.md
@@ -33,7 +33,7 @@ instead be used with [`BlenderbotModel`] and
## Overview
-The Blender chatbot model was proposed in [Recipes for building an open-domain chatbot](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu,
+The Blender chatbot model was proposed in [Recipes for building an open-domain chatbot](https://huggingface.co/papers/2004.13637) Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu,
Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston on 30 Apr 2020.
The abstract of the paper is the following:
diff --git a/docs/source/en/model_doc/blenderbot.md b/docs/source/en/model_doc/blenderbot.md
index adfa6841e1..cea6c49c36 100644
--- a/docs/source/en/model_doc/blenderbot.md
+++ b/docs/source/en/model_doc/blenderbot.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Blender chatbot model was proposed in [Recipes for building an open-domain chatbot](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu,
+The Blender chatbot model was proposed in [Recipes for building an open-domain chatbot](https://huggingface.co/papers/2004.13637) Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu,
Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston on 30 Apr 2020.
The abstract of the paper is the following:
@@ -67,7 +67,7 @@ An example:
## Implementation Notes
-- Blenderbot uses a standard [seq2seq model transformer](https://arxiv.org/pdf/1706.03762.pdf) based architecture.
+- Blenderbot uses a standard [seq2seq model transformer](https://huggingface.co/papers/1706.03762) based architecture.
- Available checkpoints can be found in the [model hub](https://huggingface.co/models?search=blenderbot).
- This is the *default* Blenderbot model class. However, some smaller checkpoints, such as
`facebook/blenderbot_small_90M`, have a different architecture and consequently should be used with
diff --git a/docs/source/en/model_doc/blip-2.md b/docs/source/en/model_doc/blip-2.md
index 94331d9a5f..fbfcda4613 100644
--- a/docs/source/en/model_doc/blip-2.md
+++ b/docs/source/en/model_doc/blip-2.md
@@ -22,9 +22,9 @@ rendered properly in your Markdown viewer.
## Overview
-The BLIP-2 model was proposed in [BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://arxiv.org/abs/2301.12597) by
+The BLIP-2 model was proposed in [BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://huggingface.co/papers/2301.12597) by
Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi. BLIP-2 leverages frozen pre-trained image encoders and large language models (LLMs) by training a lightweight, 12-layer Transformer
-encoder in between them, achieving state-of-the-art performance on various vision-language tasks. Most notably, BLIP-2 improves upon [Flamingo](https://arxiv.org/abs/2204.14198), an 80 billion parameter model, by 8.7%
+encoder in between them, achieving state-of-the-art performance on various vision-language tasks. Most notably, BLIP-2 improves upon [Flamingo](https://huggingface.co/papers/2204.14198), an 80 billion parameter model, by 8.7%
on zero-shot VQAv2 with 54x fewer trainable parameters.
The abstract from the paper is the following:
@@ -34,7 +34,7 @@ The abstract from the paper is the following:
- BLIP-2 architecture. Taken from the original paper.
+ BLIP-2 architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/salesforce/LAVIS/tree/5ee63d688ba4cebff63acee04adaef2dee9af207).
diff --git a/docs/source/en/model_doc/blip.md b/docs/source/en/model_doc/blip.md
index efb6b27082..e97f7374fd 100644
--- a/docs/source/en/model_doc/blip.md
+++ b/docs/source/en/model_doc/blip.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The BLIP model was proposed in [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) by Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
+The BLIP model was proposed in [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://huggingface.co/papers/2201.12086) by Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
BLIP is a model that is able to perform various multi-modal tasks including:
- Visual Question Answering
diff --git a/docs/source/en/model_doc/bort.md b/docs/source/en/model_doc/bort.md
index 04cc2feb06..5d5b923906 100644
--- a/docs/source/en/model_doc/bort.md
+++ b/docs/source/en/model_doc/bort.md
@@ -34,7 +34,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The BORT model was proposed in [Optimal Subarchitecture Extraction for BERT](https://arxiv.org/abs/2010.10499) by
+The BORT model was proposed in [Optimal Subarchitecture Extraction for BERT](https://huggingface.co/papers/2010.10499) by
Adrian de Wynter and Daniel J. Perry. It is an optimal subset of architectural parameters for the BERT, which the
authors refer to as "Bort".
diff --git a/docs/source/en/model_doc/bridgetower.md b/docs/source/en/model_doc/bridgetower.md
index 4b8601bf8a..fe63453523 100644
--- a/docs/source/en/model_doc/bridgetower.md
+++ b/docs/source/en/model_doc/bridgetower.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The BridgeTower model was proposed in [BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning](https://arxiv.org/abs/2206.08657) by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan. The goal of this model is to build a
+The BridgeTower model was proposed in [BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning](https://huggingface.co/papers/2206.08657) by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan. The goal of this model is to build a
bridge between each uni-modal encoder and the cross-modal encoder to enable comprehensive and detailed interaction at each layer of the cross-modal encoder thus achieving remarkable performance on various downstream tasks with almost negligible additional performance and computational costs.
This paper has been accepted to the [AAAI'23](https://aaai.org/Conferences/AAAI-23/) conference.
@@ -39,7 +39,7 @@ Notably, when further scaling the model, BRIDGETOWER achieves an accuracy of 81.
- BridgeTower architecture. Taken from the original paper.
+ BridgeTower architecture. Taken from the original paper.
This model was contributed by [Anahita Bhiwandiwalla](https://huggingface.co/anahita-b), [Tiep Le](https://huggingface.co/Tile) and [Shaoyen Tseng](https://huggingface.co/shaoyent). The original code can be found [here](https://github.com/microsoft/BridgeTower).
@@ -126,7 +126,7 @@ Tips:
- This implementation of BridgeTower uses [`RobertaTokenizer`] to generate text embeddings and OpenAI's CLIP/ViT model to compute visual embeddings.
- Checkpoints for pre-trained [bridgeTower-base](https://huggingface.co/BridgeTower/bridgetower-base) and [bridgetower masked language modeling and image text matching](https://huggingface.co/BridgeTower/bridgetower-base-itm-mlm) are released.
-- Please refer to [Table 5](https://arxiv.org/pdf/2206.08657.pdf) for BridgeTower's performance on Image Retrieval and other down stream tasks.
+- Please refer to [Table 5](https://huggingface.co/papers/2206.08657) for BridgeTower's performance on Image Retrieval and other down stream tasks.
- The PyTorch version of this model is only available in torch 1.10 and higher.
diff --git a/docs/source/en/model_doc/bros.md b/docs/source/en/model_doc/bros.md
index baa658e598..67b4bffd25 100644
--- a/docs/source/en/model_doc/bros.md
+++ b/docs/source/en/model_doc/bros.md
@@ -18,7 +18,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The BROS model was proposed in [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://arxiv.org/abs/2108.04539) by Teakgyu Hong, Donghyun Kim, Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park.
+The BROS model was proposed in [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://huggingface.co/papers/2108.04539) by Teakgyu Hong, Donghyun Kim, Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park.
BROS stands for *BERT Relying On Spatiality*. It is an encoder-only Transformer model that takes a sequence of tokens and their bounding boxes as inputs and outputs a sequence of hidden states. BROS encode relative spatial information instead of using absolute spatial information.
diff --git a/docs/source/en/model_doc/camembert.md b/docs/source/en/model_doc/camembert.md
index 9066ee360c..aad9662de9 100644
--- a/docs/source/en/model_doc/camembert.md
+++ b/docs/source/en/model_doc/camembert.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The CamemBERT model was proposed in [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by
+The CamemBERT model was proposed in [CamemBERT: a Tasty French Language Model](https://huggingface.co/papers/1911.03894) by
[Louis Martin](https://huggingface.co/louismartin), [Benjamin Muller](https://huggingface.co/benjamin-mlr), [Pedro Javier Ortiz Suárez](https://huggingface.co/pjox), Yoann Dupont, Laurent Romary, Éric Villemonte de la
Clergerie, [Djamé Seddah](https://huggingface.co/Djame), and [Benoît Sagot](https://huggingface.co/sagot). It is based on Facebook's RoBERTa model released in 2019. It is a model
trained on 138GB of French text.
diff --git a/docs/source/en/model_doc/chameleon.md b/docs/source/en/model_doc/chameleon.md
index e7edca9fd3..e7c04811de 100644
--- a/docs/source/en/model_doc/chameleon.md
+++ b/docs/source/en/model_doc/chameleon.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
The Chameleon model was proposed in [Chameleon: Mixed-Modal Early-Fusion Foundation Models
-](https://arxiv.org/abs/2405.09818v1) by META AI Chameleon Team. Chameleon is a Vision-Language Model that use vector quantization to tokenize images which enables the model to generate multimodal output. The model takes images and texts as input, including an interleaved format, and generates textual response. Image generation module is not released yet.
+](https://huggingface.co/papers/2405.09818) by META AI Chameleon Team. Chameleon is a Vision-Language Model that use vector quantization to tokenize images which enables the model to generate multimodal output. The model takes images and texts as input, including an interleaved format, and generates textual response. Image generation module is not released yet.
The abstract from the paper is the following:
@@ -46,7 +46,7 @@ text. Chameleon marks a significant step forward in unified modeling of full mul
- Chameleon incorporates a vector quantizer module to transform images into discrete tokens. That also enables image generation using an auto-regressive transformer. Taken from the original paper.
+ Chameleon incorporates a vector quantizer module to transform images into discrete tokens. That also enables image generation using an auto-regressive transformer. Taken from the original paper.
This model was contributed by [joaogante](https://huggingface.co/joaogante) and [RaushanTurganbay](https://huggingface.co/RaushanTurganbay).
The original code can be found [here](https://github.com/facebookresearch/chameleon).
diff --git a/docs/source/en/model_doc/chinese_clip.md b/docs/source/en/model_doc/chinese_clip.md
index f44cdbd145..2607c56e5e 100644
--- a/docs/source/en/model_doc/chinese_clip.md
+++ b/docs/source/en/model_doc/chinese_clip.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Chinese-CLIP model was proposed in [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://arxiv.org/abs/2211.01335) by An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou.
+The Chinese-CLIP model was proposed in [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://huggingface.co/papers/2211.01335) by An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou.
Chinese-CLIP is an implementation of CLIP (Radford et al., 2021) on a large-scale dataset of Chinese image-text pairs. It is capable of performing cross-modal retrieval and also playing as a vision backbone for vision tasks like zero-shot image classification, open-domain object detection, etc. The original Chinese-CLIP code is released [at this link](https://github.com/OFA-Sys/Chinese-CLIP).
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/clap.md b/docs/source/en/model_doc/clap.md
index e060662c01..c6684579d7 100644
--- a/docs/source/en/model_doc/clap.md
+++ b/docs/source/en/model_doc/clap.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
The CLAP model was proposed in [Large Scale Contrastive Language-Audio pretraining with
-feature fusion and keyword-to-caption augmentation](https://arxiv.org/pdf/2211.06687.pdf) by Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov.
+feature fusion and keyword-to-caption augmentation](https://huggingface.co/papers/2211.06687) by Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov.
CLAP (Contrastive Language-Audio Pretraining) is a neural network trained on a variety of (audio, text) pairs. It can be instructed in to predict the most relevant text snippet, given an audio, without directly optimizing for the task. The CLAP model uses a SWINTransformer to get audio features from a log-Mel spectrogram input, and a RoBERTa model to get text features. Both the text and audio features are then projected to a latent space with identical dimension. The dot product between the projected audio and text features is then used as a similar score.
diff --git a/docs/source/en/model_doc/clipseg.md b/docs/source/en/model_doc/clipseg.md
index f594dbc3e0..afc357b2ca 100644
--- a/docs/source/en/model_doc/clipseg.md
+++ b/docs/source/en/model_doc/clipseg.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The CLIPSeg model was proposed in [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke
+The CLIPSeg model was proposed in [Image Segmentation Using Text and Image Prompts](https://huggingface.co/papers/2112.10003) by Timo Lüddecke
and Alexander Ecker. CLIPSeg adds a minimal decoder on top of a frozen [CLIP](clip) model for zero-shot and one-shot image segmentation.
The abstract from the paper is the following:
@@ -48,7 +48,7 @@ to generalized queries involving affordances or properties*
- CLIPSeg overview. Taken from the original paper.
+ CLIPSeg overview. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/timojl/clipseg).
diff --git a/docs/source/en/model_doc/clvp.md b/docs/source/en/model_doc/clvp.md
index cfa4f97b82..7d3f18b34d 100644
--- a/docs/source/en/model_doc/clvp.md
+++ b/docs/source/en/model_doc/clvp.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The CLVP (Contrastive Language-Voice Pretrained Transformer) model was proposed in [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
+The CLVP (Contrastive Language-Voice Pretrained Transformer) model was proposed in [Better speech synthesis through scaling](https://huggingface.co/papers/2305.07243) by James Betker.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/codegen.md b/docs/source/en/model_doc/codegen.md
index 465c8e5445..73890f13d6 100644
--- a/docs/source/en/model_doc/codegen.md
+++ b/docs/source/en/model_doc/codegen.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The CodeGen model was proposed in [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong.
+The CodeGen model was proposed in [A Conversational Paradigm for Program Synthesis](https://huggingface.co/papers/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong.
CodeGen is an autoregressive language model for program synthesis trained sequentially on [The Pile](https://pile.eleuther.ai/), BigQuery, and BigPython.
diff --git a/docs/source/en/model_doc/colqwen2.md b/docs/source/en/model_doc/colqwen2.md
index e8c48f08a6..8a1a4de6ce 100644
--- a/docs/source/en/model_doc/colqwen2.md
+++ b/docs/source/en/model_doc/colqwen2.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
# ColQwen2
-[ColQwen2](https://doi.org/10.48550/arXiv.2407.01449) is a variant of the [ColPali](./colpali) model designed to retrieve documents by analyzing their visual features. Unlike traditional systems that rely heavily on text extraction and OCR, ColQwen2 treats each page as an image. It uses the [Qwen2-VL](./qwen2_vl) backbone to capture not only text, but also the layout, tables, charts, and other visual elements to create detailed multi-vector embeddings that can be used for retrieval by computing pairwise late interaction similarity scores. This offers a more comprehensive understanding of documents and enables more efficient and accurate retrieval.
+[ColQwen2](https://huggingface.co/papers/2407.01449) is a variant of the [ColPali](./colpali) model designed to retrieve documents by analyzing their visual features. Unlike traditional systems that rely heavily on text extraction and OCR, ColQwen2 treats each page as an image. It uses the [Qwen2-VL](./qwen2_vl) backbone to capture not only text, but also the layout, tables, charts, and other visual elements to create detailed multi-vector embeddings that can be used for retrieval by computing pairwise late interaction similarity scores. This offers a more comprehensive understanding of documents and enables more efficient and accurate retrieval.
This model was contributed by [@tonywu71](https://huggingface.co/tonywu71) (ILLUIN Technology) and [@yonigozlan](https://huggingface.co/yonigozlan) (HuggingFace).
diff --git a/docs/source/en/model_doc/conditional_detr.md b/docs/source/en/model_doc/conditional_detr.md
index 52de280ce8..68eda90e70 100644
--- a/docs/source/en/model_doc/conditional_detr.md
+++ b/docs/source/en/model_doc/conditional_detr.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Conditional DETR model was proposed in [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang. Conditional DETR presents a conditional cross-attention mechanism for fast DETR training. Conditional DETR converges 6.7× to 10× faster than DETR.
+The Conditional DETR model was proposed in [Conditional DETR for Fast Training Convergence](https://huggingface.co/papers/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang. Conditional DETR presents a conditional cross-attention mechanism for fast DETR training. Conditional DETR converges 6.7× to 10× faster than DETR.
The abstract from the paper is the following:
@@ -31,7 +31,7 @@ The abstract from the paper is the following:
- Conditional DETR shows much faster convergence compared to the original DETR. Taken from the original paper.
+ Conditional DETR shows much faster convergence compared to the original DETR. Taken from the original paper.
This model was contributed by [DepuMeng](https://huggingface.co/DepuMeng). The original code can be found [here](https://github.com/Atten4Vis/ConditionalDETR).
diff --git a/docs/source/en/model_doc/convbert.md b/docs/source/en/model_doc/convbert.md
index e52bbd5c47..62d9d11688 100644
--- a/docs/source/en/model_doc/convbert.md
+++ b/docs/source/en/model_doc/convbert.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The ConvBERT model was proposed in [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng
+The ConvBERT model was proposed in [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://huggingface.co/papers/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng
Yan.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/convnext.md b/docs/source/en/model_doc/convnext.md
index 576e95ee04..5a65c9f6cc 100644
--- a/docs/source/en/model_doc/convnext.md
+++ b/docs/source/en/model_doc/convnext.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The ConvNeXT model was proposed in [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
+The ConvNeXT model was proposed in [A ConvNet for the 2020s](https://huggingface.co/papers/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them.
The abstract from the paper is the following:
@@ -40,7 +40,7 @@ and outperforming Swin Transformers on COCO detection and ADE20K segmentation, w
- ConvNeXT architecture. Taken from the original paper.
+ ConvNeXT architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). TensorFlow version of the model was contributed by [ariG23498](https://github.com/ariG23498),
[gante](https://github.com/gante), and [sayakpaul](https://github.com/sayakpaul) (equal contribution). The original code can be found [here](https://github.com/facebookresearch/ConvNeXt).
diff --git a/docs/source/en/model_doc/convnextv2.md b/docs/source/en/model_doc/convnextv2.md
index 87a261b8de..4779c511fe 100644
--- a/docs/source/en/model_doc/convnextv2.md
+++ b/docs/source/en/model_doc/convnextv2.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The ConvNeXt V2 model was proposed in [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
+The ConvNeXt V2 model was proposed in [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://huggingface.co/papers/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
ConvNeXt V2 is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, and a successor of [ConvNeXT](convnext).
The abstract from the paper is the following:
@@ -33,7 +33,7 @@ The abstract from the paper is the following:
- ConvNeXt V2 architecture. Taken from the original paper.
+ ConvNeXt V2 architecture. Taken from the original paper.
This model was contributed by [adirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/facebookresearch/ConvNeXt-V2).
diff --git a/docs/source/en/model_doc/cpm.md b/docs/source/en/model_doc/cpm.md
index 8a1826a25c..e639622087 100644
--- a/docs/source/en/model_doc/cpm.md
+++ b/docs/source/en/model_doc/cpm.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The CPM model was proposed in [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin,
+The CPM model was proposed in [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://huggingface.co/papers/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin,
Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen,
Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
diff --git a/docs/source/en/model_doc/ctrl.md b/docs/source/en/model_doc/ctrl.md
index 0253d4e007..4b5fee2b0a 100644
--- a/docs/source/en/model_doc/ctrl.md
+++ b/docs/source/en/model_doc/ctrl.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-CTRL model was proposed in [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and
+CTRL model was proposed in [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://huggingface.co/papers/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and
Richard Socher. It's a causal (unidirectional) transformer pre-trained using language modeling on a very large corpus
of ~140 GB of text data with the first token reserved as a control code (such as Links, Books, Wikipedia etc.).
diff --git a/docs/source/en/model_doc/cvt.md b/docs/source/en/model_doc/cvt.md
index fec632ed84..d92dea065e 100644
--- a/docs/source/en/model_doc/cvt.md
+++ b/docs/source/en/model_doc/cvt.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The CvT model was proposed in [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan and Lei Zhang. The Convolutional vision Transformer (CvT) improves the [Vision Transformer (ViT)](vit) in performance and efficiency by introducing convolutions into ViT to yield the best of both designs.
+The CvT model was proposed in [CvT: Introducing Convolutions to Vision Transformers](https://huggingface.co/papers/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan and Lei Zhang. The Convolutional vision Transformer (CvT) improves the [Vision Transformer (ViT)](vit) in performance and efficiency by introducing convolutions into ViT to yield the best of both designs.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/d_fine.md b/docs/source/en/model_doc/d_fine.md
index 0d4689f049..b0ed576508 100644
--- a/docs/source/en/model_doc/d_fine.md
+++ b/docs/source/en/model_doc/d_fine.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-The D-FINE model was proposed in [D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement](https://arxiv.org/abs/2410.13842) by
+The D-FINE model was proposed in [D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement](https://huggingface.co/papers/2410.13842) by
Yansong Peng, Hebei Li, Peixi Wu, Yueyi Zhang, Xiaoyan Sun, Feng Wu
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/dab-detr.md b/docs/source/en/model_doc/dab-detr.md
index d19b45b486..0f9e8dc3f3 100644
--- a/docs/source/en/model_doc/dab-detr.md
+++ b/docs/source/en/model_doc/dab-detr.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The DAB-DETR model was proposed in [DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR](https://arxiv.org/abs/2201.12329) by Shilong Liu, Feng Li, Hao Zhang, Xiao Yang, Xianbiao Qi, Hang Su, Jun Zhu, Lei Zhang.
+The DAB-DETR model was proposed in [DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR](https://huggingface.co/papers/2201.12329) by Shilong Liu, Feng Li, Hao Zhang, Xiao Yang, Xianbiao Qi, Hang Su, Jun Zhu, Lei Zhang.
DAB-DETR is an enhanced variant of Conditional DETR. It utilizes dynamically updated anchor boxes to provide both a reference query point (x, y) and a reference anchor size (w, h), improving cross-attention computation. This new approach achieves 45.7% AP when trained for 50 epochs with a single ResNet-50 model as the backbone.
- Deformable DETR architecture. Taken from the original paper.
+ Deformable DETR architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/fundamentalvision/Deformable-DETR).
diff --git a/docs/source/en/model_doc/deit.md b/docs/source/en/model_doc/deit.md
index 57cfee1f11..c2f0f17c06 100644
--- a/docs/source/en/model_doc/deit.md
+++ b/docs/source/en/model_doc/deit.md
@@ -25,8 +25,8 @@ rendered properly in your Markdown viewer.
## Overview
-The DeiT model was proposed in [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre
-Sablayrolles, Hervé Jégou. The [Vision Transformer (ViT)](vit) introduced in [Dosovitskiy et al., 2020](https://arxiv.org/abs/2010.11929) has shown that one can match or even outperform existing convolutional neural
+The DeiT model was proposed in [Training data-efficient image transformers & distillation through attention](https://huggingface.co/papers/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre
+Sablayrolles, Hervé Jégou. The [Vision Transformer (ViT)](vit) introduced in [Dosovitskiy et al., 2020](https://huggingface.co/papers/2010.11929) has shown that one can match or even outperform existing convolutional neural
networks using a Transformer encoder (BERT-like). However, the ViT models introduced in that paper required training on
expensive infrastructure for multiple weeks, using external data. DeiT (data-efficient image transformers) are more
efficiently trained transformers for image classification, requiring far less data and far less computing resources
diff --git a/docs/source/en/model_doc/deplot.md b/docs/source/en/model_doc/deplot.md
index d3c0de7b7f..28a5c70940 100644
--- a/docs/source/en/model_doc/deplot.md
+++ b/docs/source/en/model_doc/deplot.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-DePlot was proposed in the paper [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) from Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.
+DePlot was proposed in the paper [DePlot: One-shot visual language reasoning by plot-to-table translation](https://huggingface.co/papers/2212.10505) from Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.
The abstract of the paper states the following:
diff --git a/docs/source/en/model_doc/depth_anything_v2.md b/docs/source/en/model_doc/depth_anything_v2.md
index c98017d2bb..413273b05d 100644
--- a/docs/source/en/model_doc/depth_anything_v2.md
+++ b/docs/source/en/model_doc/depth_anything_v2.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-Depth Anything V2 was introduced in [the paper of the same name](https://arxiv.org/abs/2406.09414) by Lihe Yang et al. It uses the same architecture as the original [Depth Anything model](depth_anything), but uses synthetic data and a larger capacity teacher model to achieve much finer and robust depth predictions.
+Depth Anything V2 was introduced in [the paper of the same name](https://huggingface.co/papers/2406.09414) by Lihe Yang et al. It uses the same architecture as the original [Depth Anything model](depth_anything), but uses synthetic data and a larger capacity teacher model to achieve much finer and robust depth predictions.
The abstract from the paper is the following:
@@ -27,7 +27,7 @@ The abstract from the paper is the following:
- Depth Anything overview. Taken from the original paper.
+ Depth Anything overview. Taken from the original paper.
The Depth Anything models were contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/DepthAnything/Depth-Anything-V2).
diff --git a/docs/source/en/model_doc/depth_pro.md b/docs/source/en/model_doc/depth_pro.md
index 42fd725a9a..84f350a2a0 100644
--- a/docs/source/en/model_doc/depth_pro.md
+++ b/docs/source/en/model_doc/depth_pro.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The DepthPro model was proposed in [Depth Pro: Sharp Monocular Metric Depth in Less Than a Second](https://arxiv.org/abs/2410.02073) by Aleksei Bochkovskii, Amaël Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan R. Richter, Vladlen Koltun.
+The DepthPro model was proposed in [Depth Pro: Sharp Monocular Metric Depth in Less Than a Second](https://huggingface.co/papers/2410.02073) by Aleksei Bochkovskii, Amaël Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan R. Richter, Vladlen Koltun.
DepthPro is a foundation model for zero-shot metric monocular depth estimation, designed to generate high-resolution depth maps with remarkable sharpness and fine-grained details. It employs a multi-scale Vision Transformer (ViT)-based architecture, where images are downsampled, divided into patches, and processed using a shared Dinov2 encoder. The extracted patch-level features are merged, upsampled, and refined using a DPT-like fusion stage, enabling precise depth estimation.
@@ -78,7 +78,7 @@ The DepthPro model processes an input image by first downsampling it at multiple
- DepthPro architecture. Taken from the original paper.
+ DepthPro architecture. Taken from the original paper.
The `DepthProForDepthEstimation` model uses a `DepthProEncoder`, for encoding the input image and a `FeatureFusionStage` for fusing the output features from encoder.
@@ -151,7 +151,7 @@ On a local benchmark (A100-40GB, PyTorch 2.3.0, OS Ubuntu 22.04) with `float32`
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DepthPro:
-- Research Paper: [Depth Pro: Sharp Monocular Metric Depth in Less Than a Second](https://arxiv.org/pdf/2410.02073)
+- Research Paper: [Depth Pro: Sharp Monocular Metric Depth in Less Than a Second](https://huggingface.co/papers/2410.02073)
- Official Implementation: [apple/ml-depth-pro](https://github.com/apple/ml-depth-pro)
- DepthPro Inference Notebook: [DepthPro Inference](https://github.com/qubvel/transformers-notebooks/blob/main/notebooks/DepthPro_inference.ipynb)
- DepthPro for Super Resolution and Image Segmentation
diff --git a/docs/source/en/model_doc/deta.md b/docs/source/en/model_doc/deta.md
index e3859341a7..c151734f92 100644
--- a/docs/source/en/model_doc/deta.md
+++ b/docs/source/en/model_doc/deta.md
@@ -30,7 +30,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The DETA model was proposed in [NMS Strikes Back](https://arxiv.org/abs/2212.06137) by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
+The DETA model was proposed in [NMS Strikes Back](https://huggingface.co/papers/2212.06137) by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
DETA (short for Detection Transformers with Assignment) improves [Deformable DETR](deformable_detr) by replacing the one-to-one bipartite Hungarian matching loss
with one-to-many label assignments used in traditional detectors with non-maximum suppression (NMS). This leads to significant gains of up to 2.5 mAP.
@@ -41,7 +41,7 @@ The abstract from the paper is the following:
- DETA overview. Taken from the original paper.
+ DETA overview. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/jozhang97/DETA).
diff --git a/docs/source/en/model_doc/detr.md b/docs/source/en/model_doc/detr.md
index 4614d549a1..54094f94df 100644
--- a/docs/source/en/model_doc/detr.md
+++ b/docs/source/en/model_doc/detr.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The DETR model was proposed in [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by
+The DETR model was proposed in [End-to-End Object Detection with Transformers](https://huggingface.co/papers/2005.12872) by
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov and Sergey Zagoruyko. DETR
consists of a convolutional backbone followed by an encoder-decoder Transformer which can be trained end-to-end for
object detection. It greatly simplifies a lot of the complexity of models like Faster-R-CNN and Mask-R-CNN, which use
diff --git a/docs/source/en/model_doc/dialogpt.md b/docs/source/en/model_doc/dialogpt.md
index 33d7e3b16d..946c61b305 100644
--- a/docs/source/en/model_doc/dialogpt.md
+++ b/docs/source/en/model_doc/dialogpt.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-DialoGPT was proposed in [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao,
+DialoGPT was proposed in [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://huggingface.co/papers/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao,
Jianfeng Gao, Jingjing Liu, Bill Dolan. It's a GPT2 Model trained on 147M conversation-like exchanges extracted from
Reddit.
diff --git a/docs/source/en/model_doc/diffllama.md b/docs/source/en/model_doc/diffllama.md
index c4a170c265..83ea51ac12 100644
--- a/docs/source/en/model_doc/diffllama.md
+++ b/docs/source/en/model_doc/diffllama.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The DiffLlama model was proposed in [Differential Transformer](https://arxiv.org/abs/2410.05258) by Kazuma Matsumoto and .
+The DiffLlama model was proposed in [Differential Transformer](https://huggingface.co/papers/2410.05258) by Kazuma Matsumoto and .
This model is combine Llama model and Differential Transformer's Attention.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/dinat.md b/docs/source/en/model_doc/dinat.md
index cd1d67073b..aab1c6388f 100644
--- a/docs/source/en/model_doc/dinat.md
+++ b/docs/source/en/model_doc/dinat.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-DiNAT was proposed in [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001)
+DiNAT was proposed in [Dilated Neighborhood Attention Transformer](https://huggingface.co/papers/2209.15001)
by Ali Hassani and Humphrey Shi.
It extends [NAT](nat) by adding a Dilated Neighborhood Attention pattern to capture global context,
@@ -53,7 +53,7 @@ src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/ma
alt="drawing" width="600"/>
Neighborhood Attention with different dilation values.
-Taken from the original paper.
+Taken from the original paper.
This model was contributed by [Ali Hassani](https://huggingface.co/alihassanijr).
The original code can be found [here](https://github.com/SHI-Labs/Neighborhood-Attention-Transformer).
diff --git a/docs/source/en/model_doc/dinov2_with_registers.md b/docs/source/en/model_doc/dinov2_with_registers.md
index 3b12d314a5..8bca569bc9 100644
--- a/docs/source/en/model_doc/dinov2_with_registers.md
+++ b/docs/source/en/model_doc/dinov2_with_registers.md
@@ -17,7 +17,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The DINOv2 with Registers model was proposed in [Vision Transformers Need Registers](https://arxiv.org/abs/2309.16588) by Timothée Darcet, Maxime Oquab, Julien Mairal, Piotr Bojanowski.
+The DINOv2 with Registers model was proposed in [Vision Transformers Need Registers](https://huggingface.co/papers/2309.16588) by Timothée Darcet, Maxime Oquab, Julien Mairal, Piotr Bojanowski.
The [Vision Transformer](vit) (ViT) is a transformer encoder model (BERT-like) originally introduced to do supervised image classification on ImageNet.
@@ -35,7 +35,7 @@ The abstract from the paper is the following:
- Visualization of attention maps of various models trained with vs. without registers. Taken from the original paper.
+ Visualization of attention maps of various models trained with vs. without registers. Taken from the original paper.
Tips:
diff --git a/docs/source/en/model_doc/dpr.md b/docs/source/en/model_doc/dpr.md
index 0f6b19c900..4b3d3f4a26 100644
--- a/docs/source/en/model_doc/dpr.md
+++ b/docs/source/en/model_doc/dpr.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
Dense Passage Retrieval (DPR) is a set of tools and models for state-of-the-art open-domain Q&A research. It was
-introduced in [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by
+introduced in [Dense Passage Retrieval for Open-Domain Question Answering](https://huggingface.co/papers/2004.04906) by
Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, Wen-tau Yih.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/dpt.md b/docs/source/en/model_doc/dpt.md
index 95e422dee8..1699207973 100644
--- a/docs/source/en/model_doc/dpt.md
+++ b/docs/source/en/model_doc/dpt.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The DPT model was proposed in [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
+The DPT model was proposed in [Vision Transformers for Dense Prediction](https://huggingface.co/papers/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
DPT is a model that leverages the [Vision Transformer (ViT)](vit) as backbone for dense prediction tasks like semantic segmentation and depth estimation.
The abstract from the paper is the following:
@@ -34,7 +34,7 @@ The abstract from the paper is the following:
- DPT architecture. Taken from the original paper.
+ DPT architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/isl-org/DPT).
diff --git a/docs/source/en/model_doc/efficientformer.md b/docs/source/en/model_doc/efficientformer.md
index f05ccacc3d..31b1d37f0f 100644
--- a/docs/source/en/model_doc/efficientformer.md
+++ b/docs/source/en/model_doc/efficientformer.md
@@ -31,7 +31,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The EfficientFormer model was proposed in [EfficientFormer: Vision Transformers at MobileNet Speed](https://arxiv.org/abs/2206.01191)
+The EfficientFormer model was proposed in [EfficientFormer: Vision Transformers at MobileNet Speed](https://huggingface.co/papers/2206.01191)
by Yanyu Li, Geng Yuan, Yang Wen, Eric Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren. EfficientFormer proposes a
dimension-consistent pure transformer that can be run on mobile devices for dense prediction tasks like image classification, object
detection and semantic segmentation.
diff --git a/docs/source/en/model_doc/efficientnet.md b/docs/source/en/model_doc/efficientnet.md
index 17a96aeb5a..e11eab612c 100644
--- a/docs/source/en/model_doc/efficientnet.md
+++ b/docs/source/en/model_doc/efficientnet.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The EfficientNet model was proposed in [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946)
+The EfficientNet model was proposed in [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://huggingface.co/papers/1905.11946)
by Mingxing Tan and Quoc V. Le. EfficientNets are a family of image classification models, which achieve state-of-the-art accuracy, yet being an order-of-magnitude smaller and faster than previous models.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/emu3.md b/docs/source/en/model_doc/emu3.md
index 20b8a5e1cd..5f51566084 100644
--- a/docs/source/en/model_doc/emu3.md
+++ b/docs/source/en/model_doc/emu3.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Emu3 model was proposed in [Emu3: Next-Token Prediction is All You Need](https://arxiv.org/abs/2409.18869) by Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, Yingli Zhao, Yulong Ao, Xuebin Min, Tao Li, Boya Wu, Bo Zhao, Bowen Zhang, Liangdong Wang, Guang Liu, Zheqi He, Xi Yang, Jingjing Liu, Yonghua Lin, Tiejun Huang, Zhongyuan Wang.
+The Emu3 model was proposed in [Emu3: Next-Token Prediction is All You Need](https://huggingface.co/papers/2409.18869) by Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, Yingli Zhao, Yulong Ao, Xuebin Min, Tao Li, Boya Wu, Bo Zhao, Bowen Zhang, Liangdong Wang, Guang Liu, Zheqi He, Xi Yang, Jingjing Liu, Yonghua Lin, Tiejun Huang, Zhongyuan Wang.
Emu3 is a multimodal LLM that uses vector quantization to tokenize images into discrete tokens. Discretized image tokens are later fused with text token ids for image and text generation. The model can additionally generate images by predicting image token ids.
diff --git a/docs/source/en/model_doc/encodec.md b/docs/source/en/model_doc/encodec.md
index 893954d5cf..06ce1e2faf 100644
--- a/docs/source/en/model_doc/encodec.md
+++ b/docs/source/en/model_doc/encodec.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The EnCodec neural codec model was proposed in [High Fidelity Neural Audio Compression](https://arxiv.org/abs/2210.13438) by Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi.
+The EnCodec neural codec model was proposed in [High Fidelity Neural Audio Compression](https://huggingface.co/papers/2210.13438) by Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/encoder-decoder.md b/docs/source/en/model_doc/encoder-decoder.md
index d0a676fb33..f697c213b7 100644
--- a/docs/source/en/model_doc/encoder-decoder.md
+++ b/docs/source/en/model_doc/encoder-decoder.md
@@ -30,14 +30,14 @@ The [`EncoderDecoderModel`] can be used to initialize a sequence-to-sequence mod
pretrained autoencoding model as the encoder and any pretrained autoregressive model as the decoder.
The effectiveness of initializing sequence-to-sequence models with pretrained checkpoints for sequence generation tasks
-was shown in [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by
+was shown in [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://huggingface.co/papers/1907.12461) by
Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
After such an [`EncoderDecoderModel`] has been trained/fine-tuned, it can be saved/loaded just like
any other models (see the examples for more information).
An application of this architecture could be to leverage two pretrained [`BertModel`] as the encoder
-and decoder for a summarization model as was shown in: [Text Summarization with Pretrained Encoders](https://arxiv.org/abs/1908.08345) by Yang Liu and Mirella Lapata.
+and decoder for a summarization model as was shown in: [Text Summarization with Pretrained Encoders](https://huggingface.co/papers/1908.08345) by Yang Liu and Mirella Lapata.
## Randomly initializing `EncoderDecoderModel` from model configurations.
diff --git a/docs/source/en/model_doc/ernie.md b/docs/source/en/model_doc/ernie.md
index 82f2a0d5ba..596a7b1f4b 100644
--- a/docs/source/en/model_doc/ernie.md
+++ b/docs/source/en/model_doc/ernie.md
@@ -22,8 +22,8 @@ rendered properly in your Markdown viewer.
## Overview
ERNIE is a series of powerful models proposed by baidu, especially in Chinese tasks,
-including [ERNIE1.0](https://arxiv.org/abs/1904.09223), [ERNIE2.0](https://ojs.aaai.org/index.php/AAAI/article/view/6428),
-[ERNIE3.0](https://arxiv.org/abs/2107.02137), [ERNIE-Gram](https://arxiv.org/abs/2010.12148), [ERNIE-health](https://arxiv.org/abs/2110.07244), etc.
+including [ERNIE1.0](https://huggingface.co/papers/1904.09223), [ERNIE2.0](https://ojs.aaai.org/index.php/AAAI/article/view/6428),
+[ERNIE3.0](https://huggingface.co/papers/2107.02137), [ERNIE-Gram](https://huggingface.co/papers/2010.12148), [ERNIE-health](https://huggingface.co/papers/2110.07244), etc.
These models are contributed by [nghuyong](https://huggingface.co/nghuyong) and the official code can be found in [PaddleNLP](https://github.com/PaddlePaddle/PaddleNLP) (in PaddlePaddle).
diff --git a/docs/source/en/model_doc/ernie_m.md b/docs/source/en/model_doc/ernie_m.md
index 3ce3b40c44..292fce2ac3 100644
--- a/docs/source/en/model_doc/ernie_m.md
+++ b/docs/source/en/model_doc/ernie_m.md
@@ -31,7 +31,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
The ErnieM model was proposed in [ERNIE-M: Enhanced Multilingual Representation by Aligning
-Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun,
+Cross-lingual Semantics with Monolingual Corpora](https://huggingface.co/papers/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun,
Hao Tian, Hua Wu, Haifeng Wang.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/fastspeech2_conformer.md b/docs/source/en/model_doc/fastspeech2_conformer.md
index aeb055ceae..f6abf6125f 100644
--- a/docs/source/en/model_doc/fastspeech2_conformer.md
+++ b/docs/source/en/model_doc/fastspeech2_conformer.md
@@ -18,7 +18,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The FastSpeech2Conformer model was proposed with the paper [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
+The FastSpeech2Conformer model was proposed with the paper [Recent Developments On Espnet Toolkit Boosted By Conformer](https://huggingface.co/papers/2010.13956) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
The abstract from the original FastSpeech2 paper is the following:
diff --git a/docs/source/en/model_doc/flan-t5.md b/docs/source/en/model_doc/flan-t5.md
index 0e3b9ba073..8f6f413894 100644
--- a/docs/source/en/model_doc/flan-t5.md
+++ b/docs/source/en/model_doc/flan-t5.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-FLAN-T5 was released in the paper [Scaling Instruction-Finetuned Language Models](https://arxiv.org/pdf/2210.11416.pdf) - it is an enhanced version of T5 that has been finetuned in a mixture of tasks.
+FLAN-T5 was released in the paper [Scaling Instruction-Finetuned Language Models](https://huggingface.co/papers/2210.11416) - it is an enhanced version of T5 that has been finetuned in a mixture of tasks.
One can directly use FLAN-T5 weights without finetuning the model:
diff --git a/docs/source/en/model_doc/flaubert.md b/docs/source/en/model_doc/flaubert.md
index 59ab44ebff..f921cfdce1 100644
--- a/docs/source/en/model_doc/flaubert.md
+++ b/docs/source/en/model_doc/flaubert.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The FlauBERT model was proposed in the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le et al. It's a transformer model pretrained using a masked language
+The FlauBERT model was proposed in the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://huggingface.co/papers/1912.05372) by Hang Le et al. It's a transformer model pretrained using a masked language
modeling (MLM) objective (like BERT).
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/flava.md b/docs/source/en/model_doc/flava.md
index c809be7358..9360bb7a97 100644
--- a/docs/source/en/model_doc/flava.md
+++ b/docs/source/en/model_doc/flava.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The FLAVA model was proposed in [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela and is accepted at CVPR 2022.
+The FLAVA model was proposed in [FLAVA: A Foundational Language And Vision Alignment Model](https://huggingface.co/papers/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela and is accepted at CVPR 2022.
The paper aims at creating a single unified foundation model which can work across vision, language
as well as vision-and-language multimodal tasks.
diff --git a/docs/source/en/model_doc/fnet.md b/docs/source/en/model_doc/fnet.md
index fcf75e21ca..5d1a7d498c 100644
--- a/docs/source/en/model_doc/fnet.md
+++ b/docs/source/en/model_doc/fnet.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The FNet model was proposed in [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by
+The FNet model was proposed in [FNet: Mixing Tokens with Fourier Transforms](https://huggingface.co/papers/2105.03824) by
James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon. The model replaces the self-attention layer in a BERT
model with a fourier transform which returns only the real parts of the transform. The model is significantly faster
than the BERT model because it has fewer parameters and is more memory efficient. The model achieves about 92-97%
diff --git a/docs/source/en/model_doc/focalnet.md b/docs/source/en/model_doc/focalnet.md
index 5312cae4ff..02cd9e173d 100644
--- a/docs/source/en/model_doc/focalnet.md
+++ b/docs/source/en/model_doc/focalnet.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The FocalNet model was proposed in [Focal Modulation Networks](https://arxiv.org/abs/2203.11926) by Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao.
+The FocalNet model was proposed in [Focal Modulation Networks](https://huggingface.co/papers/2203.11926) by Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao.
FocalNets completely replace self-attention (used in models like [ViT](vit) and [Swin](swin)) by a focal modulation mechanism for modeling token interactions in vision.
The authors claim that FocalNets outperform self-attention based models with similar computational costs on the tasks of image classification, object detection, and segmentation.
diff --git a/docs/source/en/model_doc/fsmt.md b/docs/source/en/model_doc/fsmt.md
index 9419dce71e..acce6979ba 100644
--- a/docs/source/en/model_doc/fsmt.md
+++ b/docs/source/en/model_doc/fsmt.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-FSMT (FairSeq MachineTranslation) models were introduced in [Facebook FAIR's WMT19 News Translation Task Submission](https://arxiv.org/abs/1907.06616) by Nathan Ng, Kyra Yee, Alexei Baevski, Myle Ott, Michael Auli, Sergey Edunov.
+FSMT (FairSeq MachineTranslation) models were introduced in [Facebook FAIR's WMT19 News Translation Task Submission](https://huggingface.co/papers/1907.06616) by Nathan Ng, Kyra Yee, Alexei Baevski, Myle Ott, Michael Auli, Sergey Edunov.
The abstract of the paper is the following:
diff --git a/docs/source/en/model_doc/funnel.md b/docs/source/en/model_doc/funnel.md
index 96050a153d..8eb35ea1d3 100644
--- a/docs/source/en/model_doc/funnel.md
+++ b/docs/source/en/model_doc/funnel.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
The Funnel Transformer model was proposed in the paper [Funnel-Transformer: Filtering out Sequential Redundancy for
-Efficient Language Processing](https://arxiv.org/abs/2006.03236). It is a bidirectional transformer model, like
+Efficient Language Processing](https://huggingface.co/papers/2006.03236). It is a bidirectional transformer model, like
BERT, but with a pooling operation after each block of layers, a bit like in traditional convolutional neural networks
(CNN) in computer vision.
diff --git a/docs/source/en/model_doc/git.md b/docs/source/en/model_doc/git.md
index 825b73c5c5..c1b7dba820 100644
--- a/docs/source/en/model_doc/git.md
+++ b/docs/source/en/model_doc/git.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The GIT model was proposed in [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by
+The GIT model was proposed in [GIT: A Generative Image-to-text Transformer for Vision and Language](https://huggingface.co/papers/2205.14100) by
Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang. GIT is a decoder-only Transformer
that leverages [CLIP](clip)'s vision encoder to condition the model on vision inputs besides text. The model obtains state-of-the-art results on
image captioning and visual question answering benchmarks.
@@ -34,7 +34,7 @@ The abstract from the paper is the following:
- GIT architecture. Taken from the original paper.
+ GIT architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/microsoft/GenerativeImage2Text).
diff --git a/docs/source/en/model_doc/glm.md b/docs/source/en/model_doc/glm.md
index cfcd549d14..bf5b95ac14 100644
--- a/docs/source/en/model_doc/glm.md
+++ b/docs/source/en/model_doc/glm.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
The GLM Model was proposed
-in [ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools](https://arxiv.org/html/2406.12793v1)
+in [ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools](https://huggingface.co/papers/2406.12793)
by GLM Team, THUDM & ZhipuAI.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/glpn.md b/docs/source/en/model_doc/glpn.md
index 95ecc36bf5..4a4433626f 100644
--- a/docs/source/en/model_doc/glpn.md
+++ b/docs/source/en/model_doc/glpn.md
@@ -29,7 +29,7 @@ breaking changes to fix it in the future. If you see something strange, file a [
## Overview
-The GLPN model was proposed in [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
+The GLPN model was proposed in [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://huggingface.co/papers/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
GLPN combines [SegFormer](segformer)'s hierarchical mix-Transformer with a lightweight decoder for monocular depth estimation. The proposed decoder shows better performance than the previously proposed decoders, with considerably
less computational complexity.
@@ -40,7 +40,7 @@ The abstract from the paper is the following:
- Summary of the approach. Taken from the original paper.
+ Summary of the approach. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/vinvino02/GLPDepth).
diff --git a/docs/source/en/model_doc/got_ocr2.md b/docs/source/en/model_doc/got_ocr2.md
index c7a73659e8..6f15f2526f 100644
--- a/docs/source/en/model_doc/got_ocr2.md
+++ b/docs/source/en/model_doc/got_ocr2.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The GOT-OCR2 model was proposed in [General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model](https://arxiv.org/abs/2409.01704) by Haoran Wei, Chenglong Liu, Jinyue Chen, Jia Wang, Lingyu Kong, Yanming Xu, Zheng Ge, Liang Zhao, Jianjian Sun, Yuang Peng, Chunrui Han, Xiangyu Zhang.
+The GOT-OCR2 model was proposed in [General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model](https://huggingface.co/papers/2409.01704) by Haoran Wei, Chenglong Liu, Jinyue Chen, Jia Wang, Lingyu Kong, Yanming Xu, Zheng Ge, Liang Zhao, Jianjian Sun, Yuang Peng, Chunrui Han, Xiangyu Zhang.
The abstract from the paper is the following:
@@ -31,7 +31,7 @@ The abstract from the paper is the following:
- GOT-OCR2 training stages. Taken from the original paper.
+ GOT-OCR2 training stages. Taken from the original paper.
Tips:
diff --git a/docs/source/en/model_doc/gpt_bigcode.md b/docs/source/en/model_doc/gpt_bigcode.md
index 3620281893..9e25f3c19e 100644
--- a/docs/source/en/model_doc/gpt_bigcode.md
+++ b/docs/source/en/model_doc/gpt_bigcode.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The GPTBigCode model was proposed in [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) by BigCode. The listed authors are: Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
+The GPTBigCode model was proposed in [SantaCoder: don't reach for the stars!](https://huggingface.co/papers/2301.03988) by BigCode. The listed authors are: Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/granite_speech.md b/docs/source/en/model_doc/granite_speech.md
index 212c3d1499..be5714a3ab 100644
--- a/docs/source/en/model_doc/granite_speech.md
+++ b/docs/source/en/model_doc/granite_speech.md
@@ -23,11 +23,11 @@ rendered properly in your Markdown viewer.
## Overview
The Granite Speech model is a multimodal language model, consisting of a speech encoder, speech projector, large language model, and LoRA adapter(s). More details regarding each component for the current (Granite 3.2 Speech) model architecture may be found below.
-1. Speech Encoder: A [Conformer](https://arxiv.org/abs/2005.08100) encoder trained with Connectionist Temporal Classification (CTC) on character-level targets on ASR corpora. The encoder uses block-attention and self-conditioned CTC from the middle layer.
+1. Speech Encoder: A [Conformer](https://huggingface.co/papers/2005.08100) encoder trained with Connectionist Temporal Classification (CTC) on character-level targets on ASR corpora. The encoder uses block-attention and self-conditioned CTC from the middle layer.
2. Speech Projector: A query transformer (q-former) operating on the outputs of the last encoder block. The encoder and projector temporally downsample the audio features to be merged into the multimodal embeddings to be processed by the llm.
-3. Large Language Model: The Granite Speech model leverages Granite LLMs, which were originally proposed in [this paper](https://arxiv.org/abs/2408.13359).
+3. Large Language Model: The Granite Speech model leverages Granite LLMs, which were originally proposed in [this paper](https://huggingface.co/papers/2408.13359).
4. LoRA adapter(s): The Granite Speech model contains a modality specific LoRA, which will be enabled when audio features are provided, and disabled otherwise.
diff --git a/docs/source/en/model_doc/granitemoe.md b/docs/source/en/model_doc/granitemoe.md
index 56ba5d936c..3334008f0c 100644
--- a/docs/source/en/model_doc/granitemoe.md
+++ b/docs/source/en/model_doc/granitemoe.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The GraniteMoe model was proposed in [Power Scheduler: A Batch Size and Token Number Agnostic Learning Rate Scheduler](https://arxiv.org/abs/2408.13359) by Yikang Shen, Matthew Stallone, Mayank Mishra, Gaoyuan Zhang, Shawn Tan, Aditya Prasad, Adriana Meza Soria, David D. Cox and Rameswar Panda.
+The GraniteMoe model was proposed in [Power Scheduler: A Batch Size and Token Number Agnostic Learning Rate Scheduler](https://huggingface.co/papers/2408.13359) by Yikang Shen, Matthew Stallone, Mayank Mishra, Gaoyuan Zhang, Shawn Tan, Aditya Prasad, Adriana Meza Soria, David D. Cox and Rameswar Panda.
PowerMoE-3B is a 3B sparse Mixture-of-Experts (sMoE) language model trained with the Power learning rate scheduler. It sparsely activates 800M parameters for each token. It is trained on a mix of open-source and proprietary datasets. PowerMoE-3B has shown promising results compared to other dense models with 2x activate parameters across various benchmarks, including natural language multi-choices, code generation, and math reasoning.
diff --git a/docs/source/en/model_doc/granitemoeshared.md b/docs/source/en/model_doc/granitemoeshared.md
index 38eb7daf8c..54a956c0f3 100644
--- a/docs/source/en/model_doc/granitemoeshared.md
+++ b/docs/source/en/model_doc/granitemoeshared.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## Overview
-The GraniteMoe model was proposed in [Power Scheduler: A Batch Size and Token Number Agnostic Learning Rate Scheduler](https://arxiv.org/abs/2408.13359) by Yikang Shen, Matthew Stallone, Mayank Mishra, Gaoyuan Zhang, Shawn Tan, Aditya Prasad, Adriana Meza Soria, David D. Cox and Rameswar Panda.
+The GraniteMoe model was proposed in [Power Scheduler: A Batch Size and Token Number Agnostic Learning Rate Scheduler](https://huggingface.co/papers/2408.13359) by Yikang Shen, Matthew Stallone, Mayank Mishra, Gaoyuan Zhang, Shawn Tan, Aditya Prasad, Adriana Meza Soria, David D. Cox and Rameswar Panda.
Additionally this class GraniteMoeSharedModel adds shared experts for Moe.
diff --git a/docs/source/en/model_doc/graphormer.md b/docs/source/en/model_doc/graphormer.md
index 0d88134d4b..b602bc9b0d 100644
--- a/docs/source/en/model_doc/graphormer.md
+++ b/docs/source/en/model_doc/graphormer.md
@@ -28,7 +28,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The Graphormer model was proposed in [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) by
+The Graphormer model was proposed in [Do Transformers Really Perform Bad for Graph Representation?](https://huggingface.co/papers/2106.05234) by
Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen and Tie-Yan Liu. It is a Graph Transformer model, modified to allow computations on graphs instead of text sequences by generating embeddings and features of interest during preprocessing and collation, then using a modified attention.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/grounding-dino.md b/docs/source/en/model_doc/grounding-dino.md
index 0222243519..145913da63 100644
--- a/docs/source/en/model_doc/grounding-dino.md
+++ b/docs/source/en/model_doc/grounding-dino.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Grounding DINO model was proposed in [Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection](https://arxiv.org/abs/2303.05499) by Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang. Grounding DINO extends a closed-set object detection model with a text encoder, enabling open-set object detection. The model achieves remarkable results, such as 52.5 AP on COCO zero-shot.
+The Grounding DINO model was proposed in [Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection](https://huggingface.co/papers/2303.05499) by Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang. Grounding DINO extends a closed-set object detection model with a text encoder, enabling open-set object detection. The model achieves remarkable results, such as 52.5 AP on COCO zero-shot.
The abstract from the paper is the following:
@@ -31,7 +31,7 @@ The abstract from the paper is the following:
- Grounding DINO overview. Taken from the original paper.
+ Grounding DINO overview. Taken from the original paper.
This model was contributed by [EduardoPacheco](https://huggingface.co/EduardoPacheco) and [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/IDEA-Research/GroundingDINO).
@@ -85,7 +85,7 @@ Detected a cat with confidence 0.426 at location [11.74, 51.55, 316.51, 473.22]
## Grounded SAM
-One can combine Grounding DINO with the [Segment Anything](sam) model for text-based mask generation as introduced in [Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks](https://arxiv.org/abs/2401.14159). You can refer to this [demo notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Grounding%20DINO/GroundingDINO_with_Segment_Anything.ipynb) 🌍 for details.
+One can combine Grounding DINO with the [Segment Anything](sam) model for text-based mask generation as introduced in [Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks](https://huggingface.co/papers/2401.14159). You can refer to this [demo notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Grounding%20DINO/GroundingDINO_with_Segment_Anything.ipynb) 🌍 for details.
diff --git a/docs/source/en/model_doc/groupvit.md b/docs/source/en/model_doc/groupvit.md
index c77a51d8b1..dbe83b64c8 100644
--- a/docs/source/en/model_doc/groupvit.md
+++ b/docs/source/en/model_doc/groupvit.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The GroupViT model was proposed in [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
+The GroupViT model was proposed in [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://huggingface.co/papers/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
Inspired by [CLIP](clip), GroupViT is a vision-language model that can perform zero-shot semantic segmentation on any given vocabulary categories.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/hgnet_v2.md b/docs/source/en/model_doc/hgnet_v2.md
index 7c868608f4..a2e594b5f9 100644
--- a/docs/source/en/model_doc/hgnet_v2.md
+++ b/docs/source/en/model_doc/hgnet_v2.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## Overview
A HGNet-V2 (High Performance GPU Net) image classification model.
-HGNet arhtictecture was proposed in [HGNET: A Hierarchical Feature Guided Network for Occupancy Flow Field Prediction](https://arxiv.org/abs/2407.01097) by
+HGNet arhtictecture was proposed in [HGNET: A Hierarchical Feature Guided Network for Occupancy Flow Field Prediction](https://huggingface.co/papers/2407.01097) by
Zhan Chen, Chen Tang, Lu Xiong
The abstract from the HGNET paper is the following:
diff --git a/docs/source/en/model_doc/hiera.md b/docs/source/en/model_doc/hiera.md
index a82eec950a..9d20f34670 100644
--- a/docs/source/en/model_doc/hiera.md
+++ b/docs/source/en/model_doc/hiera.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-Hiera was proposed in [Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles](https://arxiv.org/abs/2306.00989) by Chaitanya Ryali, Yuan-Ting Hu, Daniel Bolya, Chen Wei, Haoqi Fan, Po-Yao Huang, Vaibhav Aggarwal, Arkabandhu Chowdhury, Omid Poursaeed, Judy Hoffman, Jitendra Malik, Yanghao Li, Christoph Feichtenhofer
+Hiera was proposed in [Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles](https://huggingface.co/papers/2306.00989) by Chaitanya Ryali, Yuan-Ting Hu, Daniel Bolya, Chen Wei, Haoqi Fan, Po-Yao Huang, Vaibhav Aggarwal, Arkabandhu Chowdhury, Omid Poursaeed, Judy Hoffman, Jitendra Malik, Yanghao Li, Christoph Feichtenhofer
The paper introduces "Hiera," a hierarchical Vision Transformer that simplifies the architecture of modern hierarchical vision transformers by removing unnecessary components without compromising on accuracy or efficiency. Unlike traditional transformers that add complex vision-specific components to improve supervised classification performance, Hiera demonstrates that such additions, often termed "bells-and-whistles," are not essential for high accuracy. By leveraging a strong visual pretext task (MAE) for pretraining, Hiera retains simplicity and achieves superior accuracy and speed both in inference and training across various image and video recognition tasks. The approach suggests that spatial biases required for vision tasks can be effectively learned through proper pretraining, eliminating the need for added architectural complexity.
@@ -33,7 +33,7 @@ The abstract from the paper is the following:
- Hiera architecture. Taken from the original paper.
+ Hiera architecture. Taken from the original paper.
This model was a joint contribution by [EduardoPacheco](https://huggingface.co/EduardoPacheco) and [namangarg110](https://huggingface.co/namangarg110). The original code can be found [here] (https://github.com/facebookresearch/hiera).
diff --git a/docs/source/en/model_doc/hubert.md b/docs/source/en/model_doc/hubert.md
index 98f00867bd..17255fa8d4 100644
--- a/docs/source/en/model_doc/hubert.md
+++ b/docs/source/en/model_doc/hubert.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-Hubert was proposed in [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan
+Hubert was proposed in [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://huggingface.co/papers/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan
Salakhutdinov, Abdelrahman Mohamed.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/ibert.md b/docs/source/en/model_doc/ibert.md
index 8c43eeddaf..34893c6c1d 100644
--- a/docs/source/en/model_doc/ibert.md
+++ b/docs/source/en/model_doc/ibert.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The I-BERT model was proposed in [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by
+The I-BERT model was proposed in [I-BERT: Integer-only BERT Quantization](https://huggingface.co/papers/2101.01321) by
Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney and Kurt Keutzer. It's a quantized version of RoBERTa running
inference up to four times faster.
diff --git a/docs/source/en/model_doc/idefics2.md b/docs/source/en/model_doc/idefics2.md
index 8de2c92d56..24d3fd23c7 100644
--- a/docs/source/en/model_doc/idefics2.md
+++ b/docs/source/en/model_doc/idefics2.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Idefics2 model was proposed in [What matters when building vision-language models?](https://arxiv.org/abs/2405.02246) by Léo Tronchon, Hugo Laurencon, Victor Sanh. The accompanying blog post can be found [here](https://huggingface.co/blog/idefics2).
+The Idefics2 model was proposed in [What matters when building vision-language models?](https://huggingface.co/papers/2405.02246) by Léo Tronchon, Hugo Laurencon, Victor Sanh. The accompanying blog post can be found [here](https://huggingface.co/blog/idefics2).
Idefics2 is an open multimodal model that accepts arbitrary sequences of image and text inputs and produces text
outputs. The model can answer questions about images, describe visual content, create stories grounded on multiple
@@ -39,7 +39,7 @@ The abstract from the paper is the following:
- Idefics2 architecture. Taken from the original paper.
+ Idefics2 architecture. Taken from the original paper.
This model was contributed by [amyeroberts](https://huggingface.co/amyeroberts).
The original code can be found [here](https://huggingface.co/HuggingFaceM4/idefics2).
diff --git a/docs/source/en/model_doc/ijepa.md b/docs/source/en/model_doc/ijepa.md
index d350114781..02c05b0bdd 100644
--- a/docs/source/en/model_doc/ijepa.md
+++ b/docs/source/en/model_doc/ijepa.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The I-JEPA model was proposed in [Image-based Joint-Embedding Predictive Architecture](https://arxiv.org/abs/2301.08243) by Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, Nicolas Ballas.
+The I-JEPA model was proposed in [Image-based Joint-Embedding Predictive Architecture](https://huggingface.co/papers/2301.08243) by Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, Nicolas Ballas.
I-JEPA is a self-supervised learning method that predicts the representations of one part of an image based on other parts of the same image. This approach focuses on learning semantic features without relying on pre-defined invariances from hand-crafted data transformations, which can bias specific tasks, or on filling in pixel-level details, which often leads to less meaningful representations.
The abstract from the paper is the following:
@@ -34,7 +34,7 @@ This paper demonstrates an approach for learning highly semantic image represent
- I-JEPA architecture. Taken from the original paper.
+ I-JEPA architecture. Taken from the original paper.
This model was contributed by [jmtzt](https://huggingface.co/jmtzt).
The original code can be found [here](https://github.com/facebookresearch/ijepa).
diff --git a/docs/source/en/model_doc/informer.md b/docs/source/en/model_doc/informer.md
index 1dfc397db7..d511d0f498 100644
--- a/docs/source/en/model_doc/informer.md
+++ b/docs/source/en/model_doc/informer.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Informer model was proposed in [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
+The Informer model was proposed in [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://huggingface.co/papers/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
This method introduces a Probabilistic Attention mechanism to select the "active" queries rather than the "lazy" queries and provides a sparse Transformer thus mitigating the quadratic compute and memory requirements of vanilla attention.
diff --git a/docs/source/en/model_doc/instructblip.md b/docs/source/en/model_doc/instructblip.md
index 944e8888fc..c297ca0ac4 100644
--- a/docs/source/en/model_doc/instructblip.md
+++ b/docs/source/en/model_doc/instructblip.md
@@ -18,7 +18,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The InstructBLIP model was proposed in [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
+The InstructBLIP model was proposed in [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://huggingface.co/papers/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
InstructBLIP leverages the [BLIP-2](blip2) architecture for visual instruction tuning.
The abstract from the paper is the following:
@@ -28,7 +28,7 @@ The abstract from the paper is the following:
- InstructBLIP architecture. Taken from the original paper.
+ InstructBLIP architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/salesforce/LAVIS/tree/main/projects/instructblip).
diff --git a/docs/source/en/model_doc/instructblipvideo.md b/docs/source/en/model_doc/instructblipvideo.md
index fd728c35bb..d0b4dc3cc0 100644
--- a/docs/source/en/model_doc/instructblipvideo.md
+++ b/docs/source/en/model_doc/instructblipvideo.md
@@ -18,7 +18,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The InstructBLIPVideo is an extension of the models proposed in [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
+The InstructBLIPVideo is an extension of the models proposed in [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://huggingface.co/papers/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
InstructBLIPVideo uses the same architecture as [InstructBLIP](instructblip) and works with the same checkpoints as [InstructBLIP](instructblip). The only difference is the ability to process videos.
The abstract from the paper is the following:
@@ -28,7 +28,7 @@ The abstract from the paper is the following:
- InstructBLIPVideo architecture. Taken from the original paper.
+ InstructBLIPVideo architecture. Taken from the original paper.
This model was contributed by [RaushanTurganbay](https://huggingface.co/RaushanTurganbay).
The original code can be found [here](https://github.com/salesforce/LAVIS/tree/main/projects/instructblip).
diff --git a/docs/source/en/model_doc/janus.md b/docs/source/en/model_doc/janus.md
index 015f2910df..d3973c45c1 100644
--- a/docs/source/en/model_doc/janus.md
+++ b/docs/source/en/model_doc/janus.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Janus Model was originally proposed in [Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation](https://arxiv.org/abs/2410.13848) by DeepSeek AI team and later refined in [Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling](https://arxiv.org/abs/2501.17811). Janus is a vision-language model that can generate both image and text output, it can also take both images and text as input.
+The Janus Model was originally proposed in [Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation](https://huggingface.co/papers/2410.13848) by DeepSeek AI team and later refined in [Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling](https://huggingface.co/papers/2501.17811). Janus is a vision-language model that can generate both image and text output, it can also take both images and text as input.
> [!NOTE]
> The model doesn't generate both images and text in an interleaved format. The user has to pass a parameter indicating whether to generate text or image.
diff --git a/docs/source/en/model_doc/jetmoe.md b/docs/source/en/model_doc/jetmoe.md
index aba6577f70..897270a383 100644
--- a/docs/source/en/model_doc/jetmoe.md
+++ b/docs/source/en/model_doc/jetmoe.md
@@ -26,7 +26,7 @@ rendered properly in your Markdown viewer.
**JetMoe-8B** is an 8B Mixture-of-Experts (MoE) language model developed by [Yikang Shen](https://scholar.google.com.hk/citations?user=qff5rRYAAAAJ) and [MyShell](https://myshell.ai/).
JetMoe project aims to provide a LLaMA2-level performance and efficient language model with a limited budget.
-To achieve this goal, JetMoe uses a sparsely activated architecture inspired by the [ModuleFormer](https://arxiv.org/abs/2306.04640).
+To achieve this goal, JetMoe uses a sparsely activated architecture inspired by the [ModuleFormer](https://huggingface.co/papers/2306.04640).
Each JetMoe block consists of two MoE layers: Mixture of Attention Heads and Mixture of MLP Experts.
Given the input tokens, it activates a subset of its experts to process them.
This sparse activation schema enables JetMoe to achieve much better training throughput than similar size dense models.
diff --git a/docs/source/en/model_doc/jukebox.md b/docs/source/en/model_doc/jukebox.md
index 144134d9b0..75351801b8 100644
--- a/docs/source/en/model_doc/jukebox.md
+++ b/docs/source/en/model_doc/jukebox.md
@@ -29,7 +29,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The Jukebox model was proposed in [Jukebox: A generative model for music](https://arxiv.org/pdf/2005.00341.pdf)
+The Jukebox model was proposed in [Jukebox: A generative model for music](https://huggingface.co/papers/2005.00341)
by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford,
Ilya Sutskever. It introduces a generative music model which can produce minute long samples that can be conditioned on
an artist, genres and lyrics.
@@ -38,7 +38,7 @@ The abstract from the paper is the following:
*We introduce Jukebox, a model that generates music with singing in the raw audio domain. We tackle the long context of raw audio using a multiscale VQ-VAE to compress it to discrete codes, and modeling those using autoregressive Transformers. We show that the combined model at scale can generate high-fidelity and diverse songs with coherence up to multiple minutes. We can condition on artist and genre to steer the musical and vocal style, and on unaligned lyrics to make the singing more controllable. We are releasing thousands of non cherry-picked samples, along with model weights and code.*
-As shown on the following figure, Jukebox is made of 3 `priors` which are decoder only models. They follow the architecture described in [Generating Long Sequences with Sparse Transformers](https://arxiv.org/abs/1904.10509), modified to support longer context length.
+As shown on the following figure, Jukebox is made of 3 `priors` which are decoder only models. They follow the architecture described in [Generating Long Sequences with Sparse Transformers](https://huggingface.co/papers/1904.10509), modified to support longer context length.
First, a autoencoder is used to encode the text lyrics. Next, the first (also called `top_prior`) prior attends to the last hidden states extracted from the lyrics encoder. The priors are linked to the previous priors respectively via an `AudioConditioner` module. The`AudioConditioner` upsamples the outputs of the previous prior to raw tokens at a certain audio frame per second resolution.
The metadata such as *artist, genre and timing* are passed to each prior, in the form of a start token and positional embedding for the timing data. The hidden states are mapped to the closest codebook vector from the VQVAE in order to convert them to raw audio.
diff --git a/docs/source/en/model_doc/kosmos-2.md b/docs/source/en/model_doc/kosmos-2.md
index 88a3b6bd99..d9105da5d1 100644
--- a/docs/source/en/model_doc/kosmos-2.md
+++ b/docs/source/en/model_doc/kosmos-2.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The KOSMOS-2 model was proposed in [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
+The KOSMOS-2 model was proposed in [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://huggingface.co/papers/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
KOSMOS-2 is a Transformer-based causal language model and is trained using the next-word prediction task on a web-scale
dataset of grounded image-text pairs [GRIT](https://huggingface.co/datasets/zzliang/GRIT). The spatial coordinates of
@@ -37,7 +37,7 @@ The abstract from the paper is the following:
- Overview of tasks that KOSMOS-2 can handle. Taken from the original paper.
+ Overview of tasks that KOSMOS-2 can handle. Taken from the original paper.
## Example
diff --git a/docs/source/en/model_doc/layoutlm.md b/docs/source/en/model_doc/layoutlm.md
index 51cc52b7f4..86c5c7c1fc 100644
--- a/docs/source/en/model_doc/layoutlm.md
+++ b/docs/source/en/model_doc/layoutlm.md
@@ -26,7 +26,7 @@ rendered properly in your Markdown viewer.
## Overview
The LayoutLM model was proposed in the paper [LayoutLM: Pre-training of Text and Layout for Document Image
-Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, and
+Understanding](https://huggingface.co/papers/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, and
Ming Zhou. It's a simple but effective pretraining method of text and layout for document image understanding and
information extraction tasks, such as form understanding and receipt understanding. It obtains state-of-the-art results
on several downstream tasks:
diff --git a/docs/source/en/model_doc/layoutlmv2.md b/docs/source/en/model_doc/layoutlmv2.md
index af20687571..b6c6242e45 100644
--- a/docs/source/en/model_doc/layoutlmv2.md
+++ b/docs/source/en/model_doc/layoutlmv2.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The LayoutLMV2 model was proposed in [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu,
+The LayoutLMV2 model was proposed in [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://huggingface.co/papers/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu,
Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou. LayoutLMV2 improves [LayoutLM](layoutlm) to obtain
state-of-the-art results across several document image understanding benchmarks:
@@ -34,7 +34,7 @@ state-of-the-art results across several document image understanding benchmarks:
documents for testing).
- document image classification: the [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/) dataset (a collection of
400,000 images belonging to one of 16 classes).
-- document visual question answering: the [DocVQA](https://arxiv.org/abs/2007.00398) dataset (a collection of 50,000
+- document visual question answering: the [DocVQA](https://huggingface.co/papers/2007.00398) dataset (a collection of 50,000
questions defined on 12,000+ document images).
The abstract from the paper is the following:
@@ -65,7 +65,7 @@ python -m pip install torchvision tesseract
- The main difference between LayoutLMv1 and LayoutLMv2 is that the latter incorporates visual embeddings during
pre-training (while LayoutLMv1 only adds visual embeddings during fine-tuning).
- LayoutLMv2 adds both a relative 1D attention bias as well as a spatial 2D attention bias to the attention scores in
- the self-attention layers. Details can be found on page 5 of the [paper](https://arxiv.org/abs/2012.14740).
+ the self-attention layers. Details can be found on page 5 of the [paper](https://huggingface.co/papers/2012.14740).
- Demo notebooks on how to use the LayoutLMv2 model on RVL-CDIP, FUNSD, DocVQA, CORD can be found [here](https://github.com/NielsRogge/Transformers-Tutorials).
- LayoutLMv2 uses Facebook AI's [Detectron2](https://github.com/facebookresearch/detectron2/) package for its visual
backbone. See [this link](https://detectron2.readthedocs.io/en/latest/tutorials/install.html) for installation
diff --git a/docs/source/en/model_doc/layoutlmv3.md b/docs/source/en/model_doc/layoutlmv3.md
index 07200be361..cbf6709727 100644
--- a/docs/source/en/model_doc/layoutlmv3.md
+++ b/docs/source/en/model_doc/layoutlmv3.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-The LayoutLMv3 model was proposed in [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
+The LayoutLMv3 model was proposed in [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://huggingface.co/papers/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
LayoutLMv3 simplifies [LayoutLMv2](layoutlmv2) by using patch embeddings (as in [ViT](vit)) instead of leveraging a CNN backbone, and pre-trains the model on 3 objectives: masked language modeling (MLM), masked image modeling (MIM)
and word-patch alignment (WPA).
@@ -29,7 +29,7 @@ The abstract from the paper is the following:
- LayoutLMv3 architecture. Taken from the original paper.
+ LayoutLMv3 architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version of this model was added by [chriskoo](https://huggingface.co/chriskoo), [tokec](https://huggingface.co/tokec), and [lre](https://huggingface.co/lre). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/layoutlmv3).
diff --git a/docs/source/en/model_doc/layoutxlm.md b/docs/source/en/model_doc/layoutxlm.md
index 96e0a4d4bf..32f453fb6f 100644
--- a/docs/source/en/model_doc/layoutxlm.md
+++ b/docs/source/en/model_doc/layoutxlm.md
@@ -22,8 +22,8 @@ rendered properly in your Markdown viewer.
## Overview
-LayoutXLM was proposed in [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha
-Zhang, Furu Wei. It's a multilingual extension of the [LayoutLMv2 model](https://arxiv.org/abs/2012.14740) trained
+LayoutXLM was proposed in [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://huggingface.co/papers/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha
+Zhang, Furu Wei. It's a multilingual extension of the [LayoutLMv2 model](https://huggingface.co/papers/2012.14740) trained
on 53 languages.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/led.md b/docs/source/en/model_doc/led.md
index 729d5666d8..e0d44107bc 100644
--- a/docs/source/en/model_doc/led.md
+++ b/docs/source/en/model_doc/led.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The LED model was proposed in [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz
+The LED model was proposed in [Longformer: The Long-Document Transformer](https://huggingface.co/papers/2004.05150) by Iz
Beltagy, Matthew E. Peters, Arman Cohan.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/levit.md b/docs/source/en/model_doc/levit.md
index f794f7902f..7596980ecd 100644
--- a/docs/source/en/model_doc/levit.md
+++ b/docs/source/en/model_doc/levit.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The LeViT model was proposed in [LeViT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze. LeViT improves the [Vision Transformer (ViT)](vit) in performance and efficiency by a few architectural differences such as activation maps with decreasing resolutions in Transformers and the introduction of an attention bias to integrate positional information.
+The LeViT model was proposed in [LeViT: Introducing Convolutions to Vision Transformers](https://huggingface.co/papers/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze. LeViT improves the [Vision Transformer (ViT)](vit) in performance and efficiency by a few architectural differences such as activation maps with decreasing resolutions in Transformers and the introduction of an attention bias to integrate positional information.
The abstract from the paper is the following:
@@ -40,7 +40,7 @@ to the speed/accuracy tradeoff. For example, at 80% ImageNet top-1 accuracy, LeV
- LeViT Architecture. Taken from the original paper.
+ LeViT Architecture. Taken from the original paper.
This model was contributed by [anugunj](https://huggingface.co/anugunj). The original code can be found [here](https://github.com/facebookresearch/LeViT).
diff --git a/docs/source/en/model_doc/lilt.md b/docs/source/en/model_doc/lilt.md
index 2474d854e0..57e8cac28f 100644
--- a/docs/source/en/model_doc/lilt.md
+++ b/docs/source/en/model_doc/lilt.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The LiLT model was proposed in [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
+The LiLT model was proposed in [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://huggingface.co/papers/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
LiLT allows to combine any pre-trained RoBERTa text encoder with a lightweight Layout Transformer, to enable [LayoutLM](layoutlm)-like document understanding for many
languages.
@@ -33,7 +33,7 @@ The abstract from the paper is the following:
- LiLT architecture. Taken from the original paper.
+ LiLT architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/jpwang/lilt).
diff --git a/docs/source/en/model_doc/llava.md b/docs/source/en/model_doc/llava.md
index d4cc90d2ec..ae1d3c92b1 100644
--- a/docs/source/en/model_doc/llava.md
+++ b/docs/source/en/model_doc/llava.md
@@ -26,7 +26,7 @@ rendered properly in your Markdown viewer.
LLaVa is an open-source chatbot trained by fine-tuning LlamA/Vicuna on GPT-generated multimodal instruction-following data. It is an auto-regressive language model, based on the transformer architecture. In other words, it is an multi-modal version of LLMs fine-tuned for chat / instructions.
-The LLaVa model was proposed in [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) and improved in [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/pdf/2310.03744) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
+The LLaVa model was proposed in [Visual Instruction Tuning](https://huggingface.co/papers/2304.08485) and improved in [Improved Baselines with Visual Instruction Tuning](https://huggingface.co/papers/2310.03744) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
The abstract from the paper is the following:
@@ -35,7 +35,7 @@ The abstract from the paper is the following:
- LLaVa architecture. Taken from the original paper.
+ LLaVa architecture. Taken from the original paper.
This model was contributed by [ArthurZ](https://huggingface.co/ArthurZ) and [ybelkada](https://huggingface.co/ybelkada).
The original code can be found [here](https://github.com/haotian-liu/LLaVA/tree/main/llava).
diff --git a/docs/source/en/model_doc/llava_next.md b/docs/source/en/model_doc/llava_next.md
index cfc60d074c..e4bb26f9c0 100644
--- a/docs/source/en/model_doc/llava_next.md
+++ b/docs/source/en/model_doc/llava_next.md
@@ -43,7 +43,7 @@ Along with performance improvements, LLaVA-NeXT maintains the minimalist design
- LLaVa-NeXT incorporates a higher input resolution by encoding various patches of the input image. Taken from the original paper.
+ LLaVa-NeXT incorporates a higher input resolution by encoding various patches of the input image. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/haotian-liu/LLaVA/tree/main).
diff --git a/docs/source/en/model_doc/llava_next_video.md b/docs/source/en/model_doc/llava_next_video.md
index aa61121162..b3e42698c6 100644
--- a/docs/source/en/model_doc/llava_next_video.md
+++ b/docs/source/en/model_doc/llava_next_video.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
The LLaVa-NeXT-Video model was proposed in [LLaVA-NeXT: A Strong Zero-shot Video Understanding Model
](https://llava-vl.github.io/blog/2024-04-30-llava-next-video/) by Yuanhan Zhang, Bo Li, Haotian Liu, Yong Jae Lee, Liangke Gui, Di Fu, Jiashi Feng, Ziwei Liu, Chunyuan Li. LLaVa-NeXT-Video improves upon [LLaVa-NeXT](llava_next) by fine-tuning on a mix if video and image dataset thus increasing the model's performance on videos.
-[LLaVA-NeXT](llava_next) surprisingly has strong performance in understanding video content in zero-shot fashion with the AnyRes technique that it uses. The AnyRes technique naturally represents a high-resolution image into multiple images. This technique is naturally generalizable to represent videos because videos can be considered as a set of frames (similar to a set of images in LLaVa-NeXT). The current version of LLaVA-NeXT makes use of AnyRes and trains with supervised fine-tuning (SFT) on top of LLaVA-Next on video data to achieves better video understanding capabilities.The model is a current SOTA among open-source models on [VideoMME bench](https://arxiv.org/abs/2405.21075).
+[LLaVA-NeXT](llava_next) surprisingly has strong performance in understanding video content in zero-shot fashion with the AnyRes technique that it uses. The AnyRes technique naturally represents a high-resolution image into multiple images. This technique is naturally generalizable to represent videos because videos can be considered as a set of frames (similar to a set of images in LLaVa-NeXT). The current version of LLaVA-NeXT makes use of AnyRes and trains with supervised fine-tuning (SFT) on top of LLaVA-Next on video data to achieves better video understanding capabilities.The model is a current SOTA among open-source models on [VideoMME bench](https://huggingface.co/papers/2405.21075).
The introduction from the blog is the following:
diff --git a/docs/source/en/model_doc/llava_onevision.md b/docs/source/en/model_doc/llava_onevision.md
index da3359f7e3..a8b63c9016 100644
--- a/docs/source/en/model_doc/llava_onevision.md
+++ b/docs/source/en/model_doc/llava_onevision.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The LLaVA-OneVision model was proposed in [LLaVA-OneVision: Easy Visual Task Transfer](https://arxiv.org/abs/2408.03326) by
- LLaVA-OneVision architecture. Taken from the original paper.
+ LLaVA-OneVision architecture. Taken from the original paper.
Tips:
diff --git a/docs/source/en/model_doc/longt5.md b/docs/source/en/model_doc/longt5.md
index 85a869f3c5..b73f408c46 100644
--- a/docs/source/en/model_doc/longt5.md
+++ b/docs/source/en/model_doc/longt5.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The LongT5 model was proposed in [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916)
+The LongT5 model was proposed in [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://huggingface.co/papers/2112.07916)
by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung and Yinfei Yang. It's an
encoder-decoder transformer pre-trained in a text-to-text denoising generative setting. LongT5 model is an extension of
T5 model, and it enables using one of the two different efficient attention mechanisms - (1) Local attention, or (2)
diff --git a/docs/source/en/model_doc/luke.md b/docs/source/en/model_doc/luke.md
index be4d5946df..6880d2f98a 100644
--- a/docs/source/en/model_doc/luke.md
+++ b/docs/source/en/model_doc/luke.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The LUKE model was proposed in [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda and Yuji Matsumoto.
+The LUKE model was proposed in [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://huggingface.co/papers/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda and Yuji Matsumoto.
It is based on RoBERTa and adds entity embeddings as well as an entity-aware self-attention mechanism, which helps
improve performance on various downstream tasks involving reasoning about entities such as named entity recognition,
extractive and cloze-style question answering, entity typing, and relation classification.
diff --git a/docs/source/en/model_doc/lxmert.md b/docs/source/en/model_doc/lxmert.md
index a0f686efc3..77edd6bf78 100644
--- a/docs/source/en/model_doc/lxmert.md
+++ b/docs/source/en/model_doc/lxmert.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The LXMERT model was proposed in [LXMERT: Learning Cross-Modality Encoder Representations from Transformers](https://arxiv.org/abs/1908.07490) by Hao Tan & Mohit Bansal. It is a series of bidirectional transformer encoders
+The LXMERT model was proposed in [LXMERT: Learning Cross-Modality Encoder Representations from Transformers](https://huggingface.co/papers/1908.07490) by Hao Tan & Mohit Bansal. It is a series of bidirectional transformer encoders
(one for the vision modality, one for the language modality, and then one to fuse both modalities) pretrained using a
combination of masked language modeling, visual-language text alignment, ROI-feature regression, masked
visual-attribute modeling, masked visual-object modeling, and visual-question answering objectives. The pretraining
diff --git a/docs/source/en/model_doc/m2m_100.md b/docs/source/en/model_doc/m2m_100.md
index 550916b558..6e7b216d7c 100644
--- a/docs/source/en/model_doc/m2m_100.md
+++ b/docs/source/en/model_doc/m2m_100.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The M2M100 model was proposed in [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky,
+The M2M100 model was proposed in [Beyond English-Centric Multilingual Machine Translation](https://huggingface.co/papers/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky,
Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy
Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
diff --git a/docs/source/en/model_doc/markuplm.md b/docs/source/en/model_doc/markuplm.md
index 72948da2c5..07a7342781 100644
--- a/docs/source/en/model_doc/markuplm.md
+++ b/docs/source/en/model_doc/markuplm.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
The MarkupLM model was proposed in [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document
-Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei. MarkupLM is BERT, but
+Understanding](https://huggingface.co/papers/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei. MarkupLM is BERT, but
applied to HTML pages instead of raw text documents. The model incorporates additional embedding layers to improve
performance, similar to [LayoutLM](layoutlm).
@@ -55,7 +55,7 @@ These are the XPATH tags and subscripts respectively for each token in the input
- MarkupLM architecture. Taken from the original paper.
+ MarkupLM architecture. Taken from the original paper.
## Usage: MarkupLMProcessor
diff --git a/docs/source/en/model_doc/mask2former.md b/docs/source/en/model_doc/mask2former.md
index 37a2603c68..f27fd5948f 100644
--- a/docs/source/en/model_doc/mask2former.md
+++ b/docs/source/en/model_doc/mask2former.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Mask2Former model was proposed in [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar. Mask2Former is a unified framework for panoptic, instance and semantic segmentation and features significant performance and efficiency improvements over [MaskFormer](maskformer).
+The Mask2Former model was proposed in [Masked-attention Mask Transformer for Universal Image Segmentation](https://huggingface.co/papers/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar. Mask2Former is a unified framework for panoptic, instance and semantic segmentation and features significant performance and efficiency improvements over [MaskFormer](maskformer).
The abstract from the paper is the following:
@@ -31,7 +31,7 @@ of semantics defines a task. While only the semantics of each task differ, curre
- Mask2Former architecture. Taken from the original paper.
+ Mask2Former architecture. Taken from the original paper.
This model was contributed by [Shivalika Singh](https://huggingface.co/shivi) and [Alara Dirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/facebookresearch/Mask2Former).
diff --git a/docs/source/en/model_doc/maskformer.md b/docs/source/en/model_doc/maskformer.md
index 0adbbf2285..fcfe11ec55 100644
--- a/docs/source/en/model_doc/maskformer.md
+++ b/docs/source/en/model_doc/maskformer.md
@@ -29,13 +29,13 @@ breaking changes to fix it in the future. If you see something strange, file a [
## Overview
-The MaskFormer model was proposed in [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov. MaskFormer addresses semantic segmentation with a mask classification paradigm instead of performing classic pixel-level classification.
+The MaskFormer model was proposed in [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://huggingface.co/papers/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov. MaskFormer addresses semantic segmentation with a mask classification paradigm instead of performing classic pixel-level classification.
The abstract from the paper is the following:
*Modern approaches typically formulate semantic segmentation as a per-pixel classification task, while instance-level segmentation is handled with an alternative mask classification. Our key insight: mask classification is sufficiently general to solve both semantic- and instance-level segmentation tasks in a unified manner using the exact same model, loss, and training procedure. Following this observation, we propose MaskFormer, a simple mask classification model which predicts a set of binary masks, each associated with a single global class label prediction. Overall, the proposed mask classification-based method simplifies the landscape of effective approaches to semantic and panoptic segmentation tasks and shows excellent empirical results. In particular, we observe that MaskFormer outperforms per-pixel classification baselines when the number of classes is large. Our mask classification-based method outperforms both current state-of-the-art semantic (55.6 mIoU on ADE20K) and panoptic segmentation (52.7 PQ on COCO) models.*
-The figure below illustrates the architecture of MaskFormer. Taken from the [original paper](https://arxiv.org/abs/2107.06278).
+The figure below illustrates the architecture of MaskFormer. Taken from the [original paper](https://huggingface.co/papers/2107.06278).
diff --git a/docs/source/en/model_doc/matcha.md b/docs/source/en/model_doc/matcha.md
index f3c618953b..7dc5660db6 100644
--- a/docs/source/en/model_doc/matcha.md
+++ b/docs/source/en/model_doc/matcha.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-MatCha has been proposed in the paper [MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering](https://arxiv.org/abs/2212.09662), from Fangyu Liu, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Yasemin Altun, Nigel Collier, Julian Martin Eisenschlos.
+MatCha has been proposed in the paper [MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering](https://huggingface.co/papers/2212.09662), from Fangyu Liu, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Yasemin Altun, Nigel Collier, Julian Martin Eisenschlos.
The abstract of the paper states the following:
diff --git a/docs/source/en/model_doc/mctct.md b/docs/source/en/model_doc/mctct.md
index a755f5a027..beb381f6a0 100644
--- a/docs/source/en/model_doc/mctct.md
+++ b/docs/source/en/model_doc/mctct.md
@@ -31,7 +31,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The M-CTC-T model was proposed in [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert. The model is a 1B-param transformer encoder, with a CTC head over 8065 character labels and a language identification head over 60 language ID labels. It is trained on Common Voice (version 6.1, December 2020 release) and VoxPopuli. After training on Common Voice and VoxPopuli, the model is trained on Common Voice only. The labels are unnormalized character-level transcripts (punctuation and capitalization are not removed). The model takes as input Mel filterbank features from a 16Khz audio signal.
+The M-CTC-T model was proposed in [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://huggingface.co/papers/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert. The model is a 1B-param transformer encoder, with a CTC head over 8065 character labels and a language identification head over 60 language ID labels. It is trained on Common Voice (version 6.1, December 2020 release) and VoxPopuli. After training on Common Voice and VoxPopuli, the model is trained on Common Voice only. The labels are unnormalized character-level transcripts (punctuation and capitalization are not removed). The model takes as input Mel filterbank features from a 16Khz audio signal.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/mega.md b/docs/source/en/model_doc/mega.md
index 4e8ccd4b29..080d8de529 100644
--- a/docs/source/en/model_doc/mega.md
+++ b/docs/source/en/model_doc/mega.md
@@ -30,7 +30,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The MEGA model was proposed in [Mega: Moving Average Equipped Gated Attention](https://arxiv.org/abs/2209.10655) by Xuezhe Ma, Chunting Zhou, Xiang Kong, Junxian He, Liangke Gui, Graham Neubig, Jonathan May, and Luke Zettlemoyer.
+The MEGA model was proposed in [Mega: Moving Average Equipped Gated Attention](https://huggingface.co/papers/2209.10655) by Xuezhe Ma, Chunting Zhou, Xiang Kong, Junxian He, Liangke Gui, Graham Neubig, Jonathan May, and Luke Zettlemoyer.
MEGA proposes a new approach to self-attention with each encoder layer having a multi-headed exponential moving average in addition to a single head of standard dot-product attention, giving the attention mechanism
stronger positional biases. This allows MEGA to perform competitively to Transformers on standard benchmarks including LRA
while also having significantly fewer parameters. MEGA's compute efficiency allows it to scale to very long sequences, making it an
diff --git a/docs/source/en/model_doc/megatron-bert.md b/docs/source/en/model_doc/megatron-bert.md
index b032655f75..8d3ba12295 100644
--- a/docs/source/en/model_doc/megatron-bert.md
+++ b/docs/source/en/model_doc/megatron-bert.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
The MegatronBERT model was proposed in [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model
-Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley,
+Parallelism](https://huggingface.co/papers/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley,
Jared Casper and Bryan Catanzaro.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/megatron_gpt2.md b/docs/source/en/model_doc/megatron_gpt2.md
index 7e0ee3cb9e..fc90474663 100644
--- a/docs/source/en/model_doc/megatron_gpt2.md
+++ b/docs/source/en/model_doc/megatron_gpt2.md
@@ -26,7 +26,7 @@ rendered properly in your Markdown viewer.
## Overview
The MegatronGPT2 model was proposed in [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model
-Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley,
+Parallelism](https://huggingface.co/papers/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley,
Jared Casper and Bryan Catanzaro.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/mgp-str.md b/docs/source/en/model_doc/mgp-str.md
index 168e5bd104..b98a34874e 100644
--- a/docs/source/en/model_doc/mgp-str.md
+++ b/docs/source/en/model_doc/mgp-str.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MGP-STR model was proposed in [Multi-Granularity Prediction for Scene Text Recognition](https://arxiv.org/abs/2209.03592) by Peng Wang, Cheng Da, and Cong Yao. MGP-STR is a conceptually **simple** yet **powerful** vision Scene Text Recognition (STR) model, which is built upon the [Vision Transformer (ViT)](vit). To integrate linguistic knowledge, Multi-Granularity Prediction (MGP) strategy is proposed to inject information from the language modality into the model in an implicit way.
+The MGP-STR model was proposed in [Multi-Granularity Prediction for Scene Text Recognition](https://huggingface.co/papers/2209.03592) by Peng Wang, Cheng Da, and Cong Yao. MGP-STR is a conceptually **simple** yet **powerful** vision Scene Text Recognition (STR) model, which is built upon the [Vision Transformer (ViT)](vit). To integrate linguistic knowledge, Multi-Granularity Prediction (MGP) strategy is proposed to inject information from the language modality into the model in an implicit way.
The abstract from the paper is the following:
@@ -31,7 +31,7 @@ The abstract from the paper is the following:
- MGP-STR architecture. Taken from the original paper.
+ MGP-STR architecture. Taken from the original paper.
MGP-STR is trained on two synthetic datasets [MJSynth]((http://www.robots.ox.ac.uk/~vgg/data/text/)) (MJ) and [SynthText](http://www.robots.ox.ac.uk/~vgg/data/scenetext/) (ST) without fine-tuning on other datasets. It achieves state-of-the-art results on six standard Latin scene text benchmarks, including 3 regular text datasets (IC13, SVT, IIIT) and 3 irregular ones (IC15, SVTP, CUTE).
This model was contributed by [yuekun](https://huggingface.co/yuekun). The original code can be found [here](https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/OCR/MGP-STR).
diff --git a/docs/source/en/model_doc/minimax.md b/docs/source/en/model_doc/minimax.md
index 7ae1ca6700..d4b9e56f0b 100644
--- a/docs/source/en/model_doc/minimax.md
+++ b/docs/source/en/model_doc/minimax.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MiniMax-Text-01 model was proposed in [MiniMax-01: Scaling Foundation Models with Lightning Attention](https://arxiv.org/abs/2501.08313) by MiniMax, Aonian Li, Bangwei Gong, Bo Yang, Boji Shan, Chang Liu, Cheng Zhu, Chunhao Zhang, Congchao Guo, Da Chen, Dong Li, Enwei Jiao, Gengxin Li, Guojun Zhang, Haohai Sun, Houze Dong, Jiadai Zhu, Jiaqi Zhuang, Jiayuan Song, Jin Zhu, Jingtao Han, Jingyang Li, Junbin Xie, Junhao Xu, Junjie Yan, Kaishun Zhang, Kecheng Xiao, Kexi Kang, Le Han, Leyang Wang, Lianfei Yu, Liheng Feng, Lin Zheng, Linbo Chai, Long Xing, Meizhi Ju, Mingyuan Chi, Mozhi Zhang, Peikai Huang, Pengcheng Niu, Pengfei Li, Pengyu Zhao, Qi Yang, Qidi Xu, Qiexiang Wang, Qin Wang, Qiuhui Li, Ruitao Leng, Shengmin Shi, Shuqi Yu, Sichen Li, Songquan Zhu, Tao Huang, Tianrun Liang, Weigao Sun, Weixuan Sun, Weiyu Cheng, Wenkai Li, Xiangjun Song, Xiao Su, Xiaodong Han, Xinjie Zhang, Xinzhu Hou, Xu Min, Xun Zou, Xuyang Shen, Yan Gong, Yingjie Zhu, Yipeng Zhou, Yiran Zhong, Yongyi Hu, Yuanxiang Fan, Yue Yu, Yufeng Yang, Yuhao Li, Yunan Huang, Yunji Li, Yunpeng Huang, Yunzhi Xu, Yuxin Mao, Zehan Li, Zekang Li, Zewei Tao, Zewen Ying, Zhaoyang Cong, Zhen Qin, Zhenhua Fan, Zhihang Yu, Zhuo Jiang, Zijia Wu.
+The MiniMax-Text-01 model was proposed in [MiniMax-01: Scaling Foundation Models with Lightning Attention](https://huggingface.co/papers/2501.08313) by MiniMax, Aonian Li, Bangwei Gong, Bo Yang, Boji Shan, Chang Liu, Cheng Zhu, Chunhao Zhang, Congchao Guo, Da Chen, Dong Li, Enwei Jiao, Gengxin Li, Guojun Zhang, Haohai Sun, Houze Dong, Jiadai Zhu, Jiaqi Zhuang, Jiayuan Song, Jin Zhu, Jingtao Han, Jingyang Li, Junbin Xie, Junhao Xu, Junjie Yan, Kaishun Zhang, Kecheng Xiao, Kexi Kang, Le Han, Leyang Wang, Lianfei Yu, Liheng Feng, Lin Zheng, Linbo Chai, Long Xing, Meizhi Ju, Mingyuan Chi, Mozhi Zhang, Peikai Huang, Pengcheng Niu, Pengfei Li, Pengyu Zhao, Qi Yang, Qidi Xu, Qiexiang Wang, Qin Wang, Qiuhui Li, Ruitao Leng, Shengmin Shi, Shuqi Yu, Sichen Li, Songquan Zhu, Tao Huang, Tianrun Liang, Weigao Sun, Weixuan Sun, Weiyu Cheng, Wenkai Li, Xiangjun Song, Xiao Su, Xiaodong Han, Xinjie Zhang, Xinzhu Hou, Xu Min, Xun Zou, Xuyang Shen, Yan Gong, Yingjie Zhu, Yipeng Zhou, Yiran Zhong, Yongyi Hu, Yuanxiang Fan, Yue Yu, Yufeng Yang, Yuhao Li, Yunan Huang, Yunji Li, Yunpeng Huang, Yunzhi Xu, Yuxin Mao, Zehan Li, Zekang Li, Zewei Tao, Zewen Ying, Zhaoyang Cong, Zhen Qin, Zhenhua Fan, Zhihang Yu, Zhuo Jiang, Zijia Wu.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/mluke.md b/docs/source/en/model_doc/mluke.md
index aae607def6..3472ebc220 100644
--- a/docs/source/en/model_doc/mluke.md
+++ b/docs/source/en/model_doc/mluke.md
@@ -22,8 +22,8 @@ rendered properly in your Markdown viewer.
## Overview
-The mLUKE model was proposed in [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka. It's a multilingual extension
-of the [LUKE model](https://arxiv.org/abs/2010.01057) trained on the basis of XLM-RoBERTa.
+The mLUKE model was proposed in [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://huggingface.co/papers/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka. It's a multilingual extension
+of the [LUKE model](https://huggingface.co/papers/2010.01057) trained on the basis of XLM-RoBERTa.
It is based on XLM-RoBERTa and adds entity embeddings, which helps improve performance on various downstream tasks
involving reasoning about entities such as named entity recognition, extractive question answering, relation
diff --git a/docs/source/en/model_doc/mms.md b/docs/source/en/model_doc/mms.md
index 480d5bc8dd..53b73f8295 100644
--- a/docs/source/en/model_doc/mms.md
+++ b/docs/source/en/model_doc/mms.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MMS model was proposed in [Scaling Speech Technology to 1,000+ Languages](https://arxiv.org/abs/2305.13516)
+The MMS model was proposed in [Scaling Speech Technology to 1,000+ Languages](https://huggingface.co/papers/2305.13516)
by Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, Alexei Baevski, Yossi Adi, Xiaohui Zhang, Wei-Ning Hsu, Alexis Conneau, Michael Auli
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/mobilevit.md b/docs/source/en/model_doc/mobilevit.md
index c9054b59cb..6fb69649ee 100644
--- a/docs/source/en/model_doc/mobilevit.md
+++ b/docs/source/en/model_doc/mobilevit.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MobileViT model was proposed in [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari. MobileViT introduces a new layer that replaces local processing in convolutions with global processing using transformers.
+The MobileViT model was proposed in [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://huggingface.co/papers/2110.02178) by Sachin Mehta and Mohammad Rastegari. MobileViT introduces a new layer that replaces local processing in convolutions with global processing using transformers.
The abstract from the paper is the following:
@@ -36,7 +36,7 @@ This model was contributed by [matthijs](https://huggingface.co/Matthijs). The T
- MobileViT is more like a CNN than a Transformer model. It does not work on sequence data but on batches of images. Unlike ViT, there are no embeddings. The backbone model outputs a feature map. You can follow [this tutorial](https://keras.io/examples/vision/mobilevit) for a lightweight introduction.
- One can use [`MobileViTImageProcessor`] to prepare images for the model. Note that if you do your own preprocessing, the pretrained checkpoints expect images to be in BGR pixel order (not RGB).
- The available image classification checkpoints are pre-trained on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k) (also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes).
-- The segmentation model uses a [DeepLabV3](https://arxiv.org/abs/1706.05587) head. The available semantic segmentation checkpoints are pre-trained on [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/).
+- The segmentation model uses a [DeepLabV3](https://huggingface.co/papers/1706.05587) head. The available semantic segmentation checkpoints are pre-trained on [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/).
- As the name suggests MobileViT was designed to be performant and efficient on mobile phones. The TensorFlow versions of the MobileViT models are fully compatible with [TensorFlow Lite](https://www.tensorflow.org/lite).
You can use the following code to convert a MobileViT checkpoint (be it image classification or semantic segmentation) to generate a
diff --git a/docs/source/en/model_doc/mobilevitv2.md b/docs/source/en/model_doc/mobilevitv2.md
index b654966685..9c20fb6e96 100644
--- a/docs/source/en/model_doc/mobilevitv2.md
+++ b/docs/source/en/model_doc/mobilevitv2.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MobileViTV2 model was proposed in [Separable Self-attention for Mobile Vision Transformers](https://arxiv.org/abs/2206.02680) by Sachin Mehta and Mohammad Rastegari.
+The MobileViTV2 model was proposed in [Separable Self-attention for Mobile Vision Transformers](https://huggingface.co/papers/2206.02680) by Sachin Mehta and Mohammad Rastegari.
MobileViTV2 is the second version of MobileViT, constructed by replacing the multi-headed self-attention in MobileViT with separable self-attention.
@@ -38,7 +38,7 @@ The original code can be found [here](https://github.com/apple/ml-cvnets).
- MobileViTV2 is more like a CNN than a Transformer model. It does not work on sequence data but on batches of images. Unlike ViT, there are no embeddings. The backbone model outputs a feature map.
- One can use [`MobileViTImageProcessor`] to prepare images for the model. Note that if you do your own preprocessing, the pretrained checkpoints expect images to be in BGR pixel order (not RGB).
- The available image classification checkpoints are pre-trained on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k) (also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes).
-- The segmentation model uses a [DeepLabV3](https://arxiv.org/abs/1706.05587) head. The available semantic segmentation checkpoints are pre-trained on [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/).
+- The segmentation model uses a [DeepLabV3](https://huggingface.co/papers/1706.05587) head. The available semantic segmentation checkpoints are pre-trained on [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/).
## MobileViTV2Config
diff --git a/docs/source/en/model_doc/mpnet.md b/docs/source/en/model_doc/mpnet.md
index cf84e2b410..caddc635cb 100644
--- a/docs/source/en/model_doc/mpnet.md
+++ b/docs/source/en/model_doc/mpnet.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MPNet model was proposed in [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
+The MPNet model was proposed in [MPNet: Masked and Permuted Pre-training for Language Understanding](https://huggingface.co/papers/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
MPNet adopts a novel pre-training method, named masked and permuted language modeling, to inherit the advantages of
masked language modeling and permuted language modeling for natural language understanding.
diff --git a/docs/source/en/model_doc/mra.md b/docs/source/en/model_doc/mra.md
index a5490d5d37..9faa9a2616 100644
--- a/docs/source/en/model_doc/mra.md
+++ b/docs/source/en/model_doc/mra.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MRA model was proposed in [Multi Resolution Analysis (MRA) for Approximate Self-Attention](https://arxiv.org/abs/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, and Vikas Singh.
+The MRA model was proposed in [Multi Resolution Analysis (MRA) for Approximate Self-Attention](https://huggingface.co/papers/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, and Vikas Singh.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/mt5.md b/docs/source/en/model_doc/mt5.md
index d4af9f538c..d6b9ef99cb 100644
--- a/docs/source/en/model_doc/mt5.md
+++ b/docs/source/en/model_doc/mt5.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The mT5 model was presented in [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya
+The mT5 model was presented in [mT5: A massively multilingual pre-trained text-to-text transformer](https://huggingface.co/papers/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya
Siddhant, Aditya Barua, Colin Raffel.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/musicgen.md b/docs/source/en/model_doc/musicgen.md
index 917347af10..ff7645bcea 100644
--- a/docs/source/en/model_doc/musicgen.md
+++ b/docs/source/en/model_doc/musicgen.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MusicGen model was proposed in the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284)
+The MusicGen model was proposed in the paper [Simple and Controllable Music Generation](https://huggingface.co/papers/2306.05284)
by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
MusicGen is a single stage auto-regressive Transformer model capable of generating high-quality music samples conditioned
diff --git a/docs/source/en/model_doc/musicgen_melody.md b/docs/source/en/model_doc/musicgen_melody.md
index eea1a184e8..3e4bbabc6c 100644
--- a/docs/source/en/model_doc/musicgen_melody.md
+++ b/docs/source/en/model_doc/musicgen_melody.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MusicGen Melody model was proposed in [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
+The MusicGen Melody model was proposed in [Simple and Controllable Music Generation](https://huggingface.co/papers/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
MusicGen Melody is a single stage auto-regressive Transformer model capable of generating high-quality music samples conditioned on text descriptions or audio prompts. The text descriptions are passed through a frozen text encoder model to obtain a sequence of hidden-state representations. MusicGen is then trained to predict discrete audio tokens, or *audio codes*, conditioned on these hidden-states. These audio tokens are then decoded using an audio compression model, such as EnCodec, to recover the audio waveform.
diff --git a/docs/source/en/model_doc/mvp.md b/docs/source/en/model_doc/mvp.md
index d732977167..d2dcdeb301 100644
--- a/docs/source/en/model_doc/mvp.md
+++ b/docs/source/en/model_doc/mvp.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MVP model was proposed in [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
+The MVP model was proposed in [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://huggingface.co/papers/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
According to the abstract,
@@ -39,7 +39,7 @@ This model was contributed by [Tianyi Tang](https://huggingface.co/StevenTang).
- We have released a series of models [here](https://huggingface.co/models?filter=mvp), including MVP, MVP with task-specific prompts, and multi-task pre-trained variants.
- If you want to use a model without prompts (standard Transformer), you can load it through `MvpForConditionalGeneration.from_pretrained('RUCAIBox/mvp')`.
- If you want to use a model with task-specific prompts, such as summarization, you can load it through `MvpForConditionalGeneration.from_pretrained('RUCAIBox/mvp-summarization')`.
-- Our model supports lightweight prompt tuning following [Prefix-tuning](https://arxiv.org/abs/2101.00190) with method `set_lightweight_tuning()`.
+- Our model supports lightweight prompt tuning following [Prefix-tuning](https://huggingface.co/papers/2101.00190) with method `set_lightweight_tuning()`.
## Usage examples
@@ -86,7 +86,7 @@ For data-to-text generation, it is an example to use MVP and multi-task pre-trai
['Iron Man is a fictional superhero appearing in American comic books published by Marvel Comics.']
```
-For lightweight tuning, *i.e.*, fixing the model and only tuning prompts, you can load MVP with randomly initialized prompts or with task-specific prompts. Our code also supports Prefix-tuning with BART following the [original paper](https://arxiv.org/abs/2101.00190).
+For lightweight tuning, *i.e.*, fixing the model and only tuning prompts, you can load MVP with randomly initialized prompts or with task-specific prompts. Our code also supports Prefix-tuning with BART following the [original paper](https://huggingface.co/papers/2101.00190).
```python
>>> from transformers import MvpForConditionalGeneration
diff --git a/docs/source/en/model_doc/myt5.md b/docs/source/en/model_doc/myt5.md
index c8b46f4351..cb406e9d7d 100644
--- a/docs/source/en/model_doc/myt5.md
+++ b/docs/source/en/model_doc/myt5.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-The myt5 model was proposed in [MYTE: Morphology-Driven Byte Encoding for Better and Fairer Multilingual Language Modeling](https://arxiv.org/pdf/2403.10691.pdf) by Tomasz Limisiewicz, Terra Blevins, Hila Gonen, Orevaoghene Ahia, and Luke Zettlemoyer.
+The myt5 model was proposed in [MYTE: Morphology-Driven Byte Encoding for Better and Fairer Multilingual Language Modeling](https://huggingface.co/papers/2403.10691) by Tomasz Limisiewicz, Terra Blevins, Hila Gonen, Orevaoghene Ahia, and Luke Zettlemoyer.
MyT5 (**My**te **T5**) is a multilingual language model based on T5 architecture.
The model uses a **m**orphologically-driven **byte** (**MYTE**) representation described in our paper.
**MYTE** uses codepoints corresponding to morphemes in contrast to characters used in UTF-8 encoding.
diff --git a/docs/source/en/model_doc/nat.md b/docs/source/en/model_doc/nat.md
index c7725ed7a5..86a935f9f6 100644
--- a/docs/source/en/model_doc/nat.md
+++ b/docs/source/en/model_doc/nat.md
@@ -30,7 +30,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-NAT was proposed in [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143)
+NAT was proposed in [Neighborhood Attention Transformer](https://huggingface.co/papers/2204.07143)
by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
It is a hierarchical vision transformer based on Neighborhood Attention, a sliding-window self attention pattern.
@@ -53,7 +53,7 @@ src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/ma
alt="drawing" width="600"/>
Neighborhood Attention compared to other attention patterns.
-Taken from the original paper.
+Taken from the original paper.
This model was contributed by [Ali Hassani](https://huggingface.co/alihassanijr).
The original code can be found [here](https://github.com/SHI-Labs/Neighborhood-Attention-Transformer).
diff --git a/docs/source/en/model_doc/nemotron.md b/docs/source/en/model_doc/nemotron.md
index 13b1b9be2f..761ad33fde 100644
--- a/docs/source/en/model_doc/nemotron.md
+++ b/docs/source/en/model_doc/nemotron.md
@@ -44,9 +44,9 @@ NVIDIA NeMo is an end-to-end, cloud-native platform to build, customize, and dep
### Minitron 4B Base
-Minitron is a family of small language models (SLMs) obtained by pruning NVIDIA's [Nemotron-4 15B](https://arxiv.org/abs/2402.16819) model. We prune model embedding size, attention heads, and MLP intermediate dimension, following which, we perform continued training with distillation to arrive at the final models.
+Minitron is a family of small language models (SLMs) obtained by pruning NVIDIA's [Nemotron-4 15B](https://huggingface.co/papers/2402.16819) model. We prune model embedding size, attention heads, and MLP intermediate dimension, following which, we perform continued training with distillation to arrive at the final models.
-Deriving the Minitron 8B and 4B models from the base 15B model using our approach requires up to **40x fewer training tokens** per model compared to training from scratch; this results in **compute cost savings of 1.8x** for training the full model family (15B, 8B, and 4B). Minitron models exhibit up to a 16% improvement in MMLU scores compared to training from scratch, perform comparably to other community models such as Mistral 7B, Gemma 7B and Llama-3 8B, and outperform state-of-the-art compression techniques from the literature. Please refer to our [arXiv paper](https://arxiv.org/abs/2407.14679) for more details.
+Deriving the Minitron 8B and 4B models from the base 15B model using our approach requires up to **40x fewer training tokens** per model compared to training from scratch; this results in **compute cost savings of 1.8x** for training the full model family (15B, 8B, and 4B). Minitron models exhibit up to a 16% improvement in MMLU scores compared to training from scratch, perform comparably to other community models such as Mistral 7B, Gemma 7B and Llama-3 8B, and outperform state-of-the-art compression techniques from the literature. Please refer to our [arXiv paper](https://huggingface.co/papers/2407.14679) for more details.
Minitron models are for research and development only.
@@ -84,7 +84,7 @@ Minitron is released under the [NVIDIA Open Model License Agreement](https://dev
### Evaluation Results
-*5-shot performance.* Language Understanding evaluated using [Massive Multitask Language Understanding](https://arxiv.org/abs/2009.03300):
+*5-shot performance.* Language Understanding evaluated using [Massive Multitask Language Understanding](https://huggingface.co/papers/2009.03300):
| Average |
| :---- |
@@ -103,7 +103,7 @@ Minitron is released under the [NVIDIA Open Model License Agreement](https://dev
| :------------- |
| 23.3 |
-Please refer to our [paper](https://arxiv.org/abs/2407.14679) for the full set of results.
+Please refer to our [paper](https://huggingface.co/papers/2407.14679) for the full set of results.
### Citation
diff --git a/docs/source/en/model_doc/nezha.md b/docs/source/en/model_doc/nezha.md
index dc815e0ecc..edbadcb220 100644
--- a/docs/source/en/model_doc/nezha.md
+++ b/docs/source/en/model_doc/nezha.md
@@ -30,7 +30,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The Nezha model was proposed in [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei et al.
+The Nezha model was proposed in [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://huggingface.co/papers/1909.00204) by Junqiu Wei et al.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/nllb-moe.md b/docs/source/en/model_doc/nllb-moe.md
index fc8c8c9211..4e5af4fb18 100644
--- a/docs/source/en/model_doc/nllb-moe.md
+++ b/docs/source/en/model_doc/nllb-moe.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The NLLB model was presented in [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by Marta R. Costa-jussà, James Cross, Onur Çelebi,
+The NLLB model was presented in [No Language Left Behind: Scaling Human-Centered Machine Translation](https://huggingface.co/papers/2207.04672) by Marta R. Costa-jussà, James Cross, Onur Çelebi,
Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula,
Loic Barrault, Gabriel Mejia Gonzalez, Prangthip Hansanti, John Hoffman, Semarley Jarrett, Kaushik Ram Sadagopan, Dirk Rowe, Shannon Spruit, Chau Tran, Pierre Andrews,
Necip Fazil Ayan, Shruti Bhosale, Sergey Edunov, Angela Fan, Cynthia Gao, Vedanuj Goswami, Francisco Guzmán, Philipp Koehn, Alexandre Mourachko, Christophe Ropers,
diff --git a/docs/source/en/model_doc/nllb.md b/docs/source/en/model_doc/nllb.md
index 4ba2737779..483d590016 100644
--- a/docs/source/en/model_doc/nllb.md
+++ b/docs/source/en/model_doc/nllb.md
@@ -65,7 +65,7 @@ For more details, feel free to check the linked [PR](https://github.com/huggingf
## Overview
-The NLLB model was presented in [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by Marta R. Costa-jussà, James Cross, Onur Çelebi,
+The NLLB model was presented in [No Language Left Behind: Scaling Human-Centered Machine Translation](https://huggingface.co/papers/2207.04672) by Marta R. Costa-jussà, James Cross, Onur Çelebi,
Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula,
Loic Barrault, Gabriel Mejia Gonzalez, Prangthip Hansanti, John Hoffman, Semarley Jarrett, Kaushik Ram Sadagopan, Dirk Rowe, Shannon Spruit, Chau Tran, Pierre Andrews,
Necip Fazil Ayan, Shruti Bhosale, Sergey Edunov, Angela Fan, Cynthia Gao, Vedanuj Goswami, Francisco Guzmán, Philipp Koehn, Alexandre Mourachko, Christophe Ropers,
diff --git a/docs/source/en/model_doc/nougat.md b/docs/source/en/model_doc/nougat.md
index 06b12b5ee8..c3d6ef54f4 100644
--- a/docs/source/en/model_doc/nougat.md
+++ b/docs/source/en/model_doc/nougat.md
@@ -24,7 +24,7 @@ specific language governing permissions and limitations under the License. -->
## Overview
-The Nougat model was proposed in [Nougat: Neural Optical Understanding for Academic Documents](https://arxiv.org/abs/2308.13418) by
+The Nougat model was proposed in [Nougat: Neural Optical Understanding for Academic Documents](https://huggingface.co/papers/2308.13418) by
Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic. Nougat uses the same architecture as [Donut](donut), meaning an image Transformer
encoder and an autoregressive text Transformer decoder to translate scientific PDFs to markdown, enabling easier access to them.
@@ -35,7 +35,7 @@ The abstract from the paper is the following:
- Nougat high-level overview. Taken from the original paper.
+ Nougat high-level overview. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
[here](https://github.com/facebookresearch/nougat).
diff --git a/docs/source/en/model_doc/nystromformer.md b/docs/source/en/model_doc/nystromformer.md
index b4c017b35f..f368a77a3c 100644
--- a/docs/source/en/model_doc/nystromformer.md
+++ b/docs/source/en/model_doc/nystromformer.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Nyströmformer model was proposed in [*Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention*](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn
+The Nyströmformer model was proposed in [*Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention*](https://huggingface.co/papers/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn
Fung, Yin Li, and Vikas Singh.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/olmo.md b/docs/source/en/model_doc/olmo.md
index 8d722185c3..c0d227cb54 100644
--- a/docs/source/en/model_doc/olmo.md
+++ b/docs/source/en/model_doc/olmo.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The OLMo model was proposed in [OLMo: Accelerating the Science of Language Models](https://arxiv.org/abs/2402.00838) by Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Raghavi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E. Peters, Valentina Pyatkin, Abhilasha Ravichander, Dustin Schwenk, Saurabh Shah, Will Smith, Emma Strubell, Nishant Subramani, Mitchell Wortsman, Pradeep Dasigi, Nathan Lambert, Kyle Richardson, Luke Zettlemoyer, Jesse Dodge, Kyle Lo, Luca Soldaini, Noah A. Smith, Hannaneh Hajishirzi.
+The OLMo model was proposed in [OLMo: Accelerating the Science of Language Models](https://huggingface.co/papers/2402.00838) by Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Raghavi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E. Peters, Valentina Pyatkin, Abhilasha Ravichander, Dustin Schwenk, Saurabh Shah, Will Smith, Emma Strubell, Nishant Subramani, Mitchell Wortsman, Pradeep Dasigi, Nathan Lambert, Kyle Richardson, Luke Zettlemoyer, Jesse Dodge, Kyle Lo, Luca Soldaini, Noah A. Smith, Hannaneh Hajishirzi.
OLMo is a series of **O**pen **L**anguage **Mo**dels designed to enable the science of language models. The OLMo models are trained on the Dolma dataset. We release all code, checkpoints, logs (coming soon), and details involved in training these models.
diff --git a/docs/source/en/model_doc/olmoe.md b/docs/source/en/model_doc/olmoe.md
index 6496e44c1b..701d1b7c2f 100644
--- a/docs/source/en/model_doc/olmoe.md
+++ b/docs/source/en/model_doc/olmoe.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The OLMoE model was proposed in [OLMoE: Open Mixture-of-Experts Language Models](https://arxiv.org/abs/2409.02060) by Niklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, Pete Walsh, Oyvind Tafjord, Nathan Lambert, Yuling Gu, Shane Arora, Akshita Bhagia, Dustin Schwenk, David Wadden, Alexander Wettig, Binyuan Hui, Tim Dettmers, Douwe Kiela, Ali Farhadi, Noah A. Smith, Pang Wei Koh, Amanpreet Singh, Hannaneh Hajishirzi.
+The OLMoE model was proposed in [OLMoE: Open Mixture-of-Experts Language Models](https://huggingface.co/papers/2409.02060) by Niklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, Pete Walsh, Oyvind Tafjord, Nathan Lambert, Yuling Gu, Shane Arora, Akshita Bhagia, Dustin Schwenk, David Wadden, Alexander Wettig, Binyuan Hui, Tim Dettmers, Douwe Kiela, Ali Farhadi, Noah A. Smith, Pang Wei Koh, Amanpreet Singh, Hannaneh Hajishirzi.
OLMoE is a series of **O**pen **L**anguage **Mo**dels using sparse **M**ixture-**o**f-**E**xperts designed to enable the science of language models. We release all code, checkpoints, logs, and details involved in training these models.
diff --git a/docs/source/en/model_doc/omdet-turbo.md b/docs/source/en/model_doc/omdet-turbo.md
index d73fef2d8b..b4fc6adef3 100644
--- a/docs/source/en/model_doc/omdet-turbo.md
+++ b/docs/source/en/model_doc/omdet-turbo.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The OmDet-Turbo model was proposed in [Real-time Transformer-based Open-Vocabulary Detection with Efficient Fusion Head](https://arxiv.org/abs/2403.06892) by Tiancheng Zhao, Peng Liu, Xuan He, Lu Zhang, Kyusong Lee. OmDet-Turbo incorporates components from RT-DETR and introduces a swift multimodal fusion module to achieve real-time open-vocabulary object detection capabilities while maintaining high accuracy. The base model achieves performance of up to 100.2 FPS and 53.4 AP on COCO zero-shot.
+The OmDet-Turbo model was proposed in [Real-time Transformer-based Open-Vocabulary Detection with Efficient Fusion Head](https://huggingface.co/papers/2403.06892) by Tiancheng Zhao, Peng Liu, Xuan He, Lu Zhang, Kyusong Lee. OmDet-Turbo incorporates components from RT-DETR and introduces a swift multimodal fusion module to achieve real-time open-vocabulary object detection capabilities while maintaining high accuracy. The base model achieves performance of up to 100.2 FPS and 53.4 AP on COCO zero-shot.
The abstract from the paper is the following:
@@ -30,7 +30,7 @@ The abstract from the paper is the following:
- OmDet-Turbo architecture overview. Taken from the original paper.
+ OmDet-Turbo architecture overview. Taken from the original paper.
This model was contributed by [yonigozlan](https://huggingface.co/yonigozlan).
The original code can be found [here](https://github.com/om-ai-lab/OmDet).
diff --git a/docs/source/en/model_doc/oneformer.md b/docs/source/en/model_doc/oneformer.md
index f1c1de7912..c0dcfd8800 100644
--- a/docs/source/en/model_doc/oneformer.md
+++ b/docs/source/en/model_doc/oneformer.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The OneFormer model was proposed in [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi. OneFormer is a universal image segmentation framework that can be trained on a single panoptic dataset to perform semantic, instance, and panoptic segmentation tasks. OneFormer uses a task token to condition the model on the task in focus, making the architecture task-guided for training, and task-dynamic for inference.
+The OneFormer model was proposed in [OneFormer: One Transformer to Rule Universal Image Segmentation](https://huggingface.co/papers/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi. OneFormer is a universal image segmentation framework that can be trained on a single panoptic dataset to perform semantic, instance, and panoptic segmentation tasks. OneFormer uses a task token to condition the model on the task in focus, making the architecture task-guided for training, and task-dynamic for inference.
@@ -30,7 +30,7 @@ The abstract from the paper is the following:
*Universal Image Segmentation is not a new concept. Past attempts to unify image segmentation in the last decades include scene parsing, panoptic segmentation, and, more recently, new panoptic architectures. However, such panoptic architectures do not truly unify image segmentation because they need to be trained individually on the semantic, instance, or panoptic segmentation to achieve the best performance. Ideally, a truly universal framework should be trained only once and achieve SOTA performance across all three image segmentation tasks. To that end, we propose OneFormer, a universal image segmentation framework that unifies segmentation with a multi-task train-once design. We first propose a task-conditioned joint training strategy that enables training on ground truths of each domain (semantic, instance, and panoptic segmentation) within a single multi-task training process. Secondly, we introduce a task token to condition our model on the task at hand, making our model task-dynamic to support multi-task training and inference. Thirdly, we propose using a query-text contrastive loss during training to establish better inter-task and inter-class distinctions. Notably, our single OneFormer model outperforms specialized Mask2Former models across all three segmentation tasks on ADE20k, CityScapes, and COCO, despite the latter being trained on each of the three tasks individually with three times the resources. With new ConvNeXt and DiNAT backbones, we observe even more performance improvement. We believe OneFormer is a significant step towards making image segmentation more universal and accessible.*
-The figure below illustrates the architecture of OneFormer. Taken from the [original paper](https://arxiv.org/abs/2211.06220).
+The figure below illustrates the architecture of OneFormer. Taken from the [original paper](https://huggingface.co/papers/2211.06220).
diff --git a/docs/source/en/model_doc/opt.md b/docs/source/en/model_doc/opt.md
index 8d72403aba..93db673065 100644
--- a/docs/source/en/model_doc/opt.md
+++ b/docs/source/en/model_doc/opt.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
## Overview
-The OPT model was proposed in [Open Pre-trained Transformer Language Models](https://arxiv.org/pdf/2205.01068) by Meta AI.
+The OPT model was proposed in [Open Pre-trained Transformer Language Models](https://huggingface.co/papers/2205.01068) by Meta AI.
OPT is a series of open-sourced large causal language models which perform similar in performance to GPT3.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/owlv2.md b/docs/source/en/model_doc/owlv2.md
index f01a5c5906..b7ab61cc98 100644
--- a/docs/source/en/model_doc/owlv2.md
+++ b/docs/source/en/model_doc/owlv2.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-OWLv2 was proposed in [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby. OWLv2 scales up [OWL-ViT](owlvit) using self-training, which uses an existing detector to generate pseudo-box annotations on image-text pairs. This results in large gains over the previous state-of-the-art for zero-shot object detection.
+OWLv2 was proposed in [Scaling Open-Vocabulary Object Detection](https://huggingface.co/papers/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby. OWLv2 scales up [OWL-ViT](owlvit) using self-training, which uses an existing detector to generate pseudo-box annotations on image-text pairs. This results in large gains over the previous state-of-the-art for zero-shot object detection.
The abstract from the paper is the following:
@@ -31,7 +31,7 @@ The abstract from the paper is the following:
- OWLv2 high-level overview. Taken from the original paper.
+ OWLv2 high-level overview. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
diff --git a/docs/source/en/model_doc/owlvit.md b/docs/source/en/model_doc/owlvit.md
index bbcfe0de9f..a69eee88c1 100644
--- a/docs/source/en/model_doc/owlvit.md
+++ b/docs/source/en/model_doc/owlvit.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The OWL-ViT (short for Vision Transformer for Open-World Localization) was proposed in [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby. OWL-ViT is an open-vocabulary object detection network trained on a variety of (image, text) pairs. It can be used to query an image with one or multiple text queries to search for and detect target objects described in text.
+The OWL-ViT (short for Vision Transformer for Open-World Localization) was proposed in [Simple Open-Vocabulary Object Detection with Vision Transformers](https://huggingface.co/papers/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby. OWL-ViT is an open-vocabulary object detection network trained on a variety of (image, text) pairs. It can be used to query an image with one or multiple text queries to search for and detect target objects described in text.
The abstract from the paper is the following:
@@ -31,7 +31,7 @@ The abstract from the paper is the following:
- OWL-ViT architecture. Taken from the original paper.
+ OWL-ViT architecture. Taken from the original paper.
This model was contributed by [adirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
diff --git a/docs/source/en/model_doc/patchtsmixer.md b/docs/source/en/model_doc/patchtsmixer.md
index dd678dd401..3093206793 100644
--- a/docs/source/en/model_doc/patchtsmixer.md
+++ b/docs/source/en/model_doc/patchtsmixer.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The PatchTSMixer model was proposed in [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf) by Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong and Jayant Kalagnanam.
+The PatchTSMixer model was proposed in [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://huggingface.co/papers/2306.09364) by Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong and Jayant Kalagnanam.
PatchTSMixer is a lightweight time-series modeling approach based on the MLP-Mixer architecture. In this HuggingFace implementation, we provide PatchTSMixer's capabilities to effortlessly facilitate lightweight mixing across patches, channels, and hidden features for effective multivariate time-series modeling. It also supports various attention mechanisms starting from simple gated attention to more complex self-attention blocks that can be customized accordingly. The model can be pretrained and subsequently used for various downstream tasks such as forecasting, classification and regression.
diff --git a/docs/source/en/model_doc/patchtst.md b/docs/source/en/model_doc/patchtst.md
index c55ba33342..5d9a2f402e 100644
--- a/docs/source/en/model_doc/patchtst.md
+++ b/docs/source/en/model_doc/patchtst.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The PatchTST model was proposed in [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/abs/2211.14730) by Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong and Jayant Kalagnanam.
+The PatchTST model was proposed in [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://huggingface.co/papers/2211.14730) by Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong and Jayant Kalagnanam.
At a high level the model vectorizes time series into patches of a given size and encodes the resulting sequence of vectors via a Transformer that then outputs the prediction length forecast via an appropriate head. The model is illustrated in the following figure:
diff --git a/docs/source/en/model_doc/pegasus_x.md b/docs/source/en/model_doc/pegasus_x.md
index 97e50601b7..379e0362bb 100644
--- a/docs/source/en/model_doc/pegasus_x.md
+++ b/docs/source/en/model_doc/pegasus_x.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The PEGASUS-X model was proposed in [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao and Peter J. Liu.
+The PEGASUS-X model was proposed in [Investigating Efficiently Extending Transformers for Long Input Summarization](https://huggingface.co/papers/2208.04347) by Jason Phang, Yao Zhao and Peter J. Liu.
PEGASUS-X (PEGASUS eXtended) extends the PEGASUS models for long input summarization through additional long input pretraining and using staggered block-local attention with global tokens in the encoder.
diff --git a/docs/source/en/model_doc/perceiver.md b/docs/source/en/model_doc/perceiver.md
index 629f185953..eb930bd4bd 100644
--- a/docs/source/en/model_doc/perceiver.md
+++ b/docs/source/en/model_doc/perceiver.md
@@ -23,11 +23,11 @@ rendered properly in your Markdown viewer.
## Overview
The Perceiver IO model was proposed in [Perceiver IO: A General Architecture for Structured Inputs &
-Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch,
+Outputs](https://huggingface.co/papers/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch,
Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M.
Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
-Perceiver IO is a generalization of [Perceiver](https://arxiv.org/abs/2103.03206) to handle arbitrary outputs in
+Perceiver IO is a generalization of [Perceiver](https://huggingface.co/papers/2103.03206) to handle arbitrary outputs in
addition to arbitrary inputs. The original Perceiver only produced a single classification label. In addition to
classification labels, Perceiver IO can produce (for example) language, optical flow, and multimodal videos with audio.
This is done using the same building blocks as the original Perceiver. The computational complexity of Perceiver IO is
@@ -80,7 +80,7 @@ size of 262 byte IDs).
- Perceiver IO architecture. Taken from the original paper
+ Perceiver IO architecture. Taken from the original paper
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
[here](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
diff --git a/docs/source/en/model_doc/phi3.md b/docs/source/en/model_doc/phi3.md
index 82973d39c0..41753bff5b 100644
--- a/docs/source/en/model_doc/phi3.md
+++ b/docs/source/en/model_doc/phi3.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Phi-3 model was proposed in [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/abs/2404.14219) by Microsoft.
+The Phi-3 model was proposed in [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://huggingface.co/papers/2404.14219) by Microsoft.
### Summary
diff --git a/docs/source/en/model_doc/phimoe.md b/docs/source/en/model_doc/phimoe.md
index 6728248f2e..8395021411 100644
--- a/docs/source/en/model_doc/phimoe.md
+++ b/docs/source/en/model_doc/phimoe.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The PhiMoE model was proposed in [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/abs/2404.14219) by Microsoft.
+The PhiMoE model was proposed in [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://huggingface.co/papers/2404.14219) by Microsoft.
### Summary
diff --git a/docs/source/en/model_doc/pix2struct.md b/docs/source/en/model_doc/pix2struct.md
index e912cc96cd..b03e73d246 100644
--- a/docs/source/en/model_doc/pix2struct.md
+++ b/docs/source/en/model_doc/pix2struct.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Pix2Struct model was proposed in [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
+The Pix2Struct model was proposed in [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://huggingface.co/papers/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/plbart.md b/docs/source/en/model_doc/plbart.md
index d57ee8ed99..a885924530 100644
--- a/docs/source/en/model_doc/plbart.md
+++ b/docs/source/en/model_doc/plbart.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The PLBART model was proposed in [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
+The PLBART model was proposed in [Unified Pre-training for Program Understanding and Generation](https://huggingface.co/papers/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
This is a BART-like model which can be used to perform code-summarization, code-generation, and code-translation tasks. The pre-trained model `plbart-base` has been trained using multilingual denoising task
on Java, Python and English.
@@ -50,7 +50,7 @@ model is multilingual it expects the sequences in a different format. A special
source and target text. The source text format is `X [eos, src_lang_code]` where `X` is the source text. The
target text format is `[tgt_lang_code] X [eos]`. `bos` is never used.
-However, for fine-tuning, in some cases no language token is provided in cases where a single language is used. Please refer to [the paper](https://arxiv.org/abs/2103.06333) to learn more about this.
+However, for fine-tuning, in some cases no language token is provided in cases where a single language is used. Please refer to [the paper](https://huggingface.co/papers/2103.06333) to learn more about this.
In cases where the language code is needed, the regular [`~PLBartTokenizer.__call__`] will encode source text format
when you pass texts as the first argument or with the keyword argument `text`, and will encode target text format if
diff --git a/docs/source/en/model_doc/poolformer.md b/docs/source/en/model_doc/poolformer.md
index 60573162d6..46c84d04fa 100644
--- a/docs/source/en/model_doc/poolformer.md
+++ b/docs/source/en/model_doc/poolformer.md
@@ -22,13 +22,13 @@ rendered properly in your Markdown viewer.
## Overview
-The PoolFormer model was proposed in [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Sea AI Labs. Instead of designing complicated token mixer to achieve SOTA performance, the target of this work is to demonstrate the competence of transformer models largely stem from the general architecture MetaFormer.
+The PoolFormer model was proposed in [MetaFormer is Actually What You Need for Vision](https://huggingface.co/papers/2111.11418) by Sea AI Labs. Instead of designing complicated token mixer to achieve SOTA performance, the target of this work is to demonstrate the competence of transformer models largely stem from the general architecture MetaFormer.
The abstract from the paper is the following:
*Transformers have shown great potential in computer vision tasks. A common belief is their attention-based token mixer module contributes most to their competence. However, recent works show the attention-based module in transformers can be replaced by spatial MLPs and the resulted models still perform quite well. Based on this observation, we hypothesize that the general architecture of the transformers, instead of the specific token mixer module, is more essential to the model's performance. To verify this, we deliberately replace the attention module in transformers with an embarrassingly simple spatial pooling operator to conduct only the most basic token mixing. Surprisingly, we observe that the derived model, termed as PoolFormer, achieves competitive performance on multiple computer vision tasks. For example, on ImageNet-1K, PoolFormer achieves 82.1% top-1 accuracy, surpassing well-tuned vision transformer/MLP-like baselines DeiT-B/ResMLP-B24 by 0.3%/1.1% accuracy with 35%/52% fewer parameters and 48%/60% fewer MACs. The effectiveness of PoolFormer verifies our hypothesis and urges us to initiate the concept of "MetaFormer", a general architecture abstracted from transformers without specifying the token mixer. Based on the extensive experiments, we argue that MetaFormer is the key player in achieving superior results for recent transformer and MLP-like models on vision tasks. This work calls for more future research dedicated to improving MetaFormer instead of focusing on the token mixer modules. Additionally, our proposed PoolFormer could serve as a starting baseline for future MetaFormer architecture design.*
-The figure below illustrates the architecture of PoolFormer. Taken from the [original paper](https://arxiv.org/abs/2111.11418).
+The figure below illustrates the architecture of PoolFormer. Taken from the [original paper](https://huggingface.co/papers/2111.11418).
diff --git a/docs/source/en/model_doc/pop2piano.md b/docs/source/en/model_doc/pop2piano.md
index a9554b4924..6f78233d2c 100644
--- a/docs/source/en/model_doc/pop2piano.md
+++ b/docs/source/en/model_doc/pop2piano.md
@@ -18,14 +18,14 @@ specific language governing permissions and limitations under the License.
## Overview
-The Pop2Piano model was proposed in [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi and Kyogu Lee.
+The Pop2Piano model was proposed in [Pop2Piano : Pop Audio-based Piano Cover Generation](https://huggingface.co/papers/2211.00895) by Jongho Choi and Kyogu Lee.
Piano covers of pop music are widely enjoyed, but generating them from music is not a trivial task. It requires great
expertise with playing piano as well as knowing different characteristics and melodies of a song. With Pop2Piano you
can directly generate a cover from a song's audio waveform. It is the first model to directly generate a piano cover
from pop audio without melody and chord extraction modules.
-Pop2Piano is an encoder-decoder Transformer model based on [T5](https://arxiv.org/pdf/1910.10683.pdf). The input audio
+Pop2Piano is an encoder-decoder Transformer model based on [T5](https://huggingface.co/papers/1910.10683). The input audio
is transformed to its waveform and passed to the encoder, which transforms it to a latent representation. The decoder
uses these latent representations to generate token ids in an autoregressive way. Each token id corresponds to one of four
different token types: time, velocity, note and 'special'. The token ids are then decoded to their equivalent MIDI file.
diff --git a/docs/source/en/model_doc/prompt_depth_anything.md b/docs/source/en/model_doc/prompt_depth_anything.md
index 910298fa8c..271fc4e2c0 100644
--- a/docs/source/en/model_doc/prompt_depth_anything.md
+++ b/docs/source/en/model_doc/prompt_depth_anything.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Prompt Depth Anything model was introduced in [Prompting Depth Anything for 4K Resolution Accurate Metric Depth Estimation](https://arxiv.org/abs/2412.14015) by Haotong Lin, Sida Peng, Jingxiao Chen, Songyou Peng, Jiaming Sun, Minghuan Liu, Hujun Bao, Jiashi Feng, Xiaowei Zhou, Bingyi Kang.
+The Prompt Depth Anything model was introduced in [Prompting Depth Anything for 4K Resolution Accurate Metric Depth Estimation](https://huggingface.co/papers/2412.14015) by Haotong Lin, Sida Peng, Jingxiao Chen, Songyou Peng, Jiaming Sun, Minghuan Liu, Hujun Bao, Jiashi Feng, Xiaowei Zhou, Bingyi Kang.
The abstract from the paper is as follows:
@@ -28,7 +28,7 @@ The abstract from the paper is as follows:
- Prompt Depth Anything overview. Taken from the original paper.
+ Prompt Depth Anything overview. Taken from the original paper.
## Usage example
diff --git a/docs/source/en/model_doc/prophetnet.md b/docs/source/en/model_doc/prophetnet.md
index b768fef72a..9085886cde 100644
--- a/docs/source/en/model_doc/prophetnet.md
+++ b/docs/source/en/model_doc/prophetnet.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The ProphetNet model was proposed in [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei
+The ProphetNet model was proposed in [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://huggingface.co/papers/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei
Zhang, Ming Zhou on 13 Jan, 2020.
ProphetNet is an encoder-decoder model and can predict n-future tokens for "ngram" language modeling instead of just
diff --git a/docs/source/en/model_doc/pvt.md b/docs/source/en/model_doc/pvt.md
index daa4806bc3..4b221c9791 100644
--- a/docs/source/en/model_doc/pvt.md
+++ b/docs/source/en/model_doc/pvt.md
@@ -19,7 +19,7 @@ specific language governing permissions and limitations under the License.
## Overview
The PVT model was proposed in
-[Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/abs/2102.12122)
+[Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://huggingface.co/papers/2102.12122)
by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao. The PVT is a type of
vision transformer that utilizes a pyramid structure to make it an effective backbone for dense prediction tasks. Specifically
it allows for more fine-grained inputs (4 x 4 pixels per patch) to be used, while simultaneously shrinking the sequence length
diff --git a/docs/source/en/model_doc/pvt_v2.md b/docs/source/en/model_doc/pvt_v2.md
index deac614d38..b8ebe9198a 100644
--- a/docs/source/en/model_doc/pvt_v2.md
+++ b/docs/source/en/model_doc/pvt_v2.md
@@ -19,11 +19,11 @@ specific language governing permissions and limitations under the License.
## Overview
The PVTv2 model was proposed in
-[PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. As an improved variant of PVT, it eschews position embeddings, relying instead on positional information encoded through zero-padding and overlapping patch embeddings. This lack of reliance on position embeddings simplifies the architecture, and enables running inference at any resolution without needing to interpolate them.
+[PVT v2: Improved Baselines with Pyramid Vision Transformer](https://huggingface.co/papers/2106.13797) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. As an improved variant of PVT, it eschews position embeddings, relying instead on positional information encoded through zero-padding and overlapping patch embeddings. This lack of reliance on position embeddings simplifies the architecture, and enables running inference at any resolution without needing to interpolate them.
-The PVTv2 encoder structure has been successfully deployed to achieve state-of-the-art scores in [Segformer](https://arxiv.org/abs/2105.15203) for semantic segmentation, [GLPN](https://arxiv.org/abs/2201.07436) for monocular depth, and [Panoptic Segformer](https://arxiv.org/abs/2109.03814) for panoptic segmentation.
+The PVTv2 encoder structure has been successfully deployed to achieve state-of-the-art scores in [Segformer](https://huggingface.co/papers/2105.15203) for semantic segmentation, [GLPN](https://huggingface.co/papers/2201.07436) for monocular depth, and [Panoptic Segformer](https://huggingface.co/papers/2109.03814) for panoptic segmentation.
-PVTv2 belongs to a family of models called [hierarchical transformers](https://natecibik.medium.com/the-rise-of-vision-transformers-f623c980419f) , which make adaptations to transformer layers in order to generate multi-scale feature maps. Unlike the columnal structure of Vision Transformer ([ViT](https://arxiv.org/abs/2010.11929)) which loses fine-grained detail, multi-scale feature maps are known preserve this detail and aid performance in dense prediction tasks. In the case of PVTv2, this is achieved by generating image patch tokens using 2D convolution with overlapping kernels in each encoder layer.
+PVTv2 belongs to a family of models called [hierarchical transformers](https://natecibik.medium.com/the-rise-of-vision-transformers-f623c980419f) , which make adaptations to transformer layers in order to generate multi-scale feature maps. Unlike the columnal structure of Vision Transformer ([ViT](https://huggingface.co/papers/2010.11929)) which loses fine-grained detail, multi-scale feature maps are known preserve this detail and aid performance in dense prediction tasks. In the case of PVTv2, this is achieved by generating image patch tokens using 2D convolution with overlapping kernels in each encoder layer.
The multi-scale features of hierarchical transformers allow them to be easily swapped in for traditional workhorse computer vision backbone models like ResNet in larger architectures. Both Segformer and Panoptic Segformer demonstrated that configurations using PVTv2 for a backbone consistently outperformed those with similarly sized ResNet backbones.
@@ -39,8 +39,8 @@ This model was contributed by [FoamoftheSea](https://huggingface.co/FoamoftheSea
## Usage tips
-- [PVTv2](https://arxiv.org/abs/2106.13797) is a hierarchical transformer model which has demonstrated powerful performance in image classification and multiple other tasks, used as a backbone for semantic segmentation in [Segformer](https://arxiv.org/abs/2105.15203), monocular depth estimation in [GLPN](https://arxiv.org/abs/2201.07436), and panoptic segmentation in [Panoptic Segformer](https://arxiv.org/abs/2109.03814), consistently showing higher performance than similar ResNet configurations.
-- Hierarchical transformers like PVTv2 achieve superior data and parameter efficiency on image data compared with pure transformer architectures by incorporating design elements of convolutional neural networks (CNNs) into their encoders. This creates a best-of-both-worlds architecture that infuses the useful inductive biases of CNNs like translation equivariance and locality into the network while still enjoying the benefits of dynamic data response and global relationship modeling provided by the self-attention mechanism of [transformers](https://arxiv.org/abs/1706.03762).
+- [PVTv2](https://huggingface.co/papers/2106.13797) is a hierarchical transformer model which has demonstrated powerful performance in image classification and multiple other tasks, used as a backbone for semantic segmentation in [Segformer](https://huggingface.co/papers/2105.15203), monocular depth estimation in [GLPN](https://huggingface.co/papers/2201.07436), and panoptic segmentation in [Panoptic Segformer](https://huggingface.co/papers/2109.03814), consistently showing higher performance than similar ResNet configurations.
+- Hierarchical transformers like PVTv2 achieve superior data and parameter efficiency on image data compared with pure transformer architectures by incorporating design elements of convolutional neural networks (CNNs) into their encoders. This creates a best-of-both-worlds architecture that infuses the useful inductive biases of CNNs like translation equivariance and locality into the network while still enjoying the benefits of dynamic data response and global relationship modeling provided by the self-attention mechanism of [transformers](https://huggingface.co/papers/1706.03762).
- PVTv2 uses overlapping patch embeddings to create multi-scale feature maps, which are infused with location information using zero-padding and depth-wise convolutions.
- To reduce the complexity in the attention layers, PVTv2 performs a spatial reduction on the hidden states using either strided 2D convolution (SRA) or fixed-size average pooling (Linear SRA). Although inherently more lossy, Linear SRA provides impressive performance with a linear complexity with respect to image size. To use Linear SRA in the self-attention layers, set `linear_attention=True` in the `PvtV2Config`.
- [`PvtV2Model`] is the hierarchical transformer encoder (which is also often referred to as Mix Transformer or MiT in the literature). [`PvtV2ForImageClassification`] adds a simple classifier head on top to perform Image Classification. [`PvtV2Backbone`] can be used with the [`AutoBackbone`] system in larger architectures like Deformable DETR.
diff --git a/docs/source/en/model_doc/qdqbert.md b/docs/source/en/model_doc/qdqbert.md
index 4c1a485b11..64e00d6a43 100644
--- a/docs/source/en/model_doc/qdqbert.md
+++ b/docs/source/en/model_doc/qdqbert.md
@@ -31,7 +31,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
The QDQBERT model can be referenced in [Integer Quantization for Deep Learning Inference: Principles and Empirical
-Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius
+Evaluation](https://huggingface.co/papers/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius
Micikevicius.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/qwen2_audio.md b/docs/source/en/model_doc/qwen2_audio.md
index 03a54f3893..22e1effd27 100644
--- a/docs/source/en/model_doc/qwen2_audio.md
+++ b/docs/source/en/model_doc/qwen2_audio.md
@@ -29,7 +29,7 @@ The Qwen2-Audio is the new model series of large audio-language models from the
* voice chat: users can freely engage in voice interactions with Qwen2-Audio without text input
* audio analysis: users could provide audio and text instructions for analysis during the interaction
-It was proposed in [Qwen2-Audio Technical Report](https://arxiv.org/abs/2407.10759) by Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, Chang Zhou, Jingren Zhou.
+It was proposed in [Qwen2-Audio Technical Report](https://huggingface.co/papers/2407.10759) by Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, Chang Zhou, Jingren Zhou.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/qwen2_vl.md b/docs/source/en/model_doc/qwen2_vl.md
index c6bf692f9d..39ddbdc006 100644
--- a/docs/source/en/model_doc/qwen2_vl.md
+++ b/docs/source/en/model_doc/qwen2_vl.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The [Qwen2-VL](https://qwenlm.github.io/blog/qwen2-vl/) model is a major update to [Qwen-VL](https://arxiv.org/pdf/2308.12966) from the Qwen team at Alibaba Research.
+The [Qwen2-VL](https://qwenlm.github.io/blog/qwen2-vl/) model is a major update to [Qwen-VL](https://huggingface.co/papers/2308.12966) from the Qwen team at Alibaba Research.
The abstract from the blog is the following:
diff --git a/docs/source/en/model_doc/rag.md b/docs/source/en/model_doc/rag.md
index 8b65da43a2..425d5c70d1 100644
--- a/docs/source/en/model_doc/rag.md
+++ b/docs/source/en/model_doc/rag.md
@@ -29,7 +29,7 @@ sequence-to-sequence models. RAG models retrieve documents, pass them to a seq2s
outputs. The retriever and seq2seq modules are initialized from pretrained models, and fine-tuned jointly, allowing
both retrieval and generation to adapt to downstream tasks.
-It is based on the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir
+It is based on the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://huggingface.co/papers/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir
Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/realm.md b/docs/source/en/model_doc/realm.md
index b5b9102c2c..efff6717d8 100644
--- a/docs/source/en/model_doc/realm.md
+++ b/docs/source/en/model_doc/realm.md
@@ -30,7 +30,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The REALM model was proposed in [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang. It's a
+The REALM model was proposed in [REALM: Retrieval-Augmented Language Model Pre-Training](https://huggingface.co/papers/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang. It's a
retrieval-augmented language model that firstly retrieves documents from a textual knowledge corpus and then
utilizes retrieved documents to process question answering tasks.
diff --git a/docs/source/en/model_doc/reformer.md b/docs/source/en/model_doc/reformer.md
index 7e403599fd..e65c725d90 100644
--- a/docs/source/en/model_doc/reformer.md
+++ b/docs/source/en/model_doc/reformer.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Reformer model was proposed in the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451.pdf) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
+The Reformer model was proposed in the paper [Reformer: The Efficient Transformer](https://huggingface.co/papers/2001.04451.pdf) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
The abstract from the paper is the following:
@@ -93,7 +93,7 @@ length* of the `input_ids`.
In Locality sensitive hashing (LSH) self attention the key and query projection weights are tied. Therefore, the key
query embedding vectors are also tied. LSH self attention uses the locality sensitive hashing mechanism proposed in
-[Practical and Optimal LSH for Angular Distance](https://arxiv.org/abs/1509.02897) to assign each of the tied key
+[Practical and Optimal LSH for Angular Distance](https://huggingface.co/papers/1509.02897) to assign each of the tied key
query embedding vectors to one of `config.num_buckets` possible buckets. The premise is that the more "similar"
key query embedding vectors (in terms of *cosine similarity*) are to each other, the more likely they are assigned to
the same bucket.
@@ -105,7 +105,7 @@ each of length `config.lsh_chunk_length`. For each chunk, the query embedding ve
(which are tied to themselves) and to the key embedding vectors of `config.lsh_num_chunks_before` previous
neighboring chunks and `config.lsh_num_chunks_after` following neighboring chunks.
-For more information, see the [original Paper](https://arxiv.org/abs/2001.04451) or this great [blog post](https://www.pragmatic.ml/reformer-deep-dive/).
+For more information, see the [original Paper](https://huggingface.co/papers/2001.04451) or this great [blog post](https://www.pragmatic.ml/reformer-deep-dive/).
Note that `config.num_buckets` can also be factorized into a list \\((n_{\text{buckets}}^1,
n_{\text{buckets}}^2)\\). This way instead of assigning the query key embedding vectors to one of \\((1,\ldots,
diff --git a/docs/source/en/model_doc/regnet.md b/docs/source/en/model_doc/regnet.md
index f292fe0df2..a86176bcf2 100644
--- a/docs/source/en/model_doc/regnet.md
+++ b/docs/source/en/model_doc/regnet.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The RegNet model was proposed in [Designing Network Design Spaces](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
+The RegNet model was proposed in [Designing Network Design Spaces](https://huggingface.co/papers/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
The authors design search spaces to perform Neural Architecture Search (NAS). They first start from a high dimensional search space and iteratively reduce the search space by empirically applying constraints based on the best-performing models sampled by the current search space.
@@ -37,7 +37,7 @@ This model was contributed by [Francesco](https://huggingface.co/Francesco). The
was contributed by [sayakpaul](https://huggingface.co/sayakpaul) and [ariG23498](https://huggingface.co/ariG23498).
The original code can be found [here](https://github.com/facebookresearch/pycls).
-The huge 10B model from [Self-supervised Pretraining of Visual Features in the Wild](https://arxiv.org/abs/2103.01988),
+The huge 10B model from [Self-supervised Pretraining of Visual Features in the Wild](https://huggingface.co/papers/2103.01988),
trained on one billion Instagram images, is available on the [hub](https://huggingface.co/facebook/regnet-y-10b-seer)
## Resources
diff --git a/docs/source/en/model_doc/rembert.md b/docs/source/en/model_doc/rembert.md
index 319e44cf09..6cf0e35c2a 100644
--- a/docs/source/en/model_doc/rembert.md
+++ b/docs/source/en/model_doc/rembert.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The RemBERT model was proposed in [Rethinking Embedding Coupling in Pre-trained Language Models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, Melvin Johnson, Sebastian Ruder.
+The RemBERT model was proposed in [Rethinking Embedding Coupling in Pre-trained Language Models](https://huggingface.co/papers/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, Melvin Johnson, Sebastian Ruder.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/resnet.md b/docs/source/en/model_doc/resnet.md
index d7400b46c8..03ad0b0c32 100644
--- a/docs/source/en/model_doc/resnet.md
+++ b/docs/source/en/model_doc/resnet.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The ResNet model was proposed in [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren and Jian Sun. Our implementation follows the small changes made by [Nvidia](https://catalog.ngc.nvidia.com/orgs/nvidia/resources/resnet_50_v1_5_for_pytorch), we apply the `stride=2` for downsampling in bottleneck's `3x3` conv and not in the first `1x1`. This is generally known as "ResNet v1.5".
+The ResNet model was proposed in [Deep Residual Learning for Image Recognition](https://huggingface.co/papers/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren and Jian Sun. Our implementation follows the small changes made by [Nvidia](https://catalog.ngc.nvidia.com/orgs/nvidia/resources/resnet_50_v1_5_for_pytorch), we apply the `stride=2` for downsampling in bottleneck's `3x3` conv and not in the first `1x1`. This is generally known as "ResNet v1.5".
ResNet introduced residual connections, they allow to train networks with an unseen number of layers (up to 1000). ResNet won the 2015 ILSVRC & COCO competition, one important milestone in deep computer vision.
@@ -34,7 +34,7 @@ The abstract from the paper is the following:
*Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers---8x deeper than VGG nets but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers.
The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions, where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.*
-The figure below illustrates the architecture of ResNet. Taken from the [original paper](https://arxiv.org/abs/1512.03385).
+The figure below illustrates the architecture of ResNet. Taken from the [original paper](https://huggingface.co/papers/1512.03385).
diff --git a/docs/source/en/model_doc/roberta-prelayernorm.md b/docs/source/en/model_doc/roberta-prelayernorm.md
index 7cef8526c2..81b52fec02 100644
--- a/docs/source/en/model_doc/roberta-prelayernorm.md
+++ b/docs/source/en/model_doc/roberta-prelayernorm.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The RoBERTa-PreLayerNorm model was proposed in [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://arxiv.org/abs/1904.01038) by Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli.
+The RoBERTa-PreLayerNorm model was proposed in [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://huggingface.co/papers/1904.01038) by Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli.
It is identical to using the `--encoder-normalize-before` flag in [fairseq](https://fairseq.readthedocs.io/).
The abstract from the paper is the following:
@@ -37,7 +37,7 @@ The original code can be found [here](https://github.com/princeton-nlp/DinkyTrai
## Usage tips
-- The implementation is the same as [Roberta](roberta) except instead of using _Add and Norm_ it does _Norm and Add_. _Add_ and _Norm_ refers to the Addition and LayerNormalization as described in [Attention Is All You Need](https://arxiv.org/abs/1706.03762).
+- The implementation is the same as [Roberta](roberta) except instead of using _Add and Norm_ it does _Norm and Add_. _Add_ and _Norm_ refers to the Addition and LayerNormalization as described in [Attention Is All You Need](https://huggingface.co/papers/1706.03762).
- This is identical to using the `--encoder-normalize-before` flag in [fairseq](https://fairseq.readthedocs.io/).
## Resources
diff --git a/docs/source/en/model_doc/roberta.md b/docs/source/en/model_doc/roberta.md
index 7268888d77..cfbf31fcee 100644
--- a/docs/source/en/model_doc/roberta.md
+++ b/docs/source/en/model_doc/roberta.md
@@ -26,7 +26,7 @@ rendered properly in your Markdown viewer.
## Overview
-The RoBERTa model was proposed in [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, [Myle Ott](https://huggingface.co/myleott), Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer
+The RoBERTa model was proposed in [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://huggingface.co/papers/1907.11692) by Yinhan Liu, [Myle Ott](https://huggingface.co/myleott), Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer
Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov. It is based on Google's BERT model released in 2018.
It builds on BERT and modifies key hyperparameters, removing the next-sentence pretraining objective and training with
diff --git a/docs/source/en/model_doc/rt_detr.md b/docs/source/en/model_doc/rt_detr.md
index c80e83e7b8..aeee1f4c03 100644
--- a/docs/source/en/model_doc/rt_detr.md
+++ b/docs/source/en/model_doc/rt_detr.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The RT-DETR model was proposed in [DETRs Beat YOLOs on Real-time Object Detection](https://arxiv.org/abs/2304.08069) by Wenyu Lv, Yian Zhao, Shangliang Xu, Jinman Wei, Guanzhong Wang, Cheng Cui, Yuning Du, Qingqing Dang, Yi Liu.
+The RT-DETR model was proposed in [DETRs Beat YOLOs on Real-time Object Detection](https://huggingface.co/papers/2304.08069) by Wenyu Lv, Yian Zhao, Shangliang Xu, Jinman Wei, Guanzhong Wang, Cheng Cui, Yuning Du, Qingqing Dang, Yi Liu.
RT-DETR is an object detection model that stands for "Real-Time DEtection Transformer." This model is designed to perform object detection tasks with a focus on achieving real-time performance while maintaining high accuracy. Leveraging the transformer architecture, which has gained significant popularity in various fields of deep learning, RT-DETR processes images to identify and locate multiple objects within them.
@@ -34,7 +34,7 @@ The abstract from the paper is the following:
- RT-DETR performance relative to YOLO models. Taken from the original paper.
+ RT-DETR performance relative to YOLO models. Taken from the original paper.
The model version was contributed by [rafaelpadilla](https://huggingface.co/rafaelpadilla) and [sangbumchoi](https://github.com/SangbumChoi). The original code can be found [here](https://github.com/lyuwenyu/RT-DETR/).
diff --git a/docs/source/en/model_doc/rt_detr_v2.md b/docs/source/en/model_doc/rt_detr_v2.md
index e5212d945c..6390d36b07 100644
--- a/docs/source/en/model_doc/rt_detr_v2.md
+++ b/docs/source/en/model_doc/rt_detr_v2.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The RT-DETRv2 model was proposed in [RT-DETRv2: Improved Baseline with Bag-of-Freebies for Real-Time Detection Transformer](https://arxiv.org/abs/2407.17140) by Wenyu Lv, Yian Zhao, Qinyao Chang, Kui Huang, Guanzhong Wang, Yi Liu.
+The RT-DETRv2 model was proposed in [RT-DETRv2: Improved Baseline with Bag-of-Freebies for Real-Time Detection Transformer](https://huggingface.co/papers/2407.17140) by Wenyu Lv, Yian Zhao, Qinyao Chang, Kui Huang, Guanzhong Wang, Yi Liu.
RT-DETRv2 refines RT-DETR by introducing selective multi-scale feature extraction, a discrete sampling operator for broader deployment compatibility, and improved training strategies like dynamic data augmentation and scale-adaptive hyperparameters. These changes enhance flexibility and practicality while maintaining real-time performance.
diff --git a/docs/source/en/model_doc/sam.md b/docs/source/en/model_doc/sam.md
index 58cbfbfb21..cf5273e089 100644
--- a/docs/source/en/model_doc/sam.md
+++ b/docs/source/en/model_doc/sam.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-SAM (Segment Anything Model) was proposed in [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
+SAM (Segment Anything Model) was proposed in [Segment Anything](https://huggingface.co/papers/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
The model can be used to predict segmentation masks of any object of interest given an input image.
@@ -109,13 +109,13 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
## SlimSAM
-SlimSAM, a pruned version of SAM, was proposed in [0.1% Data Makes Segment Anything Slim](https://arxiv.org/abs/2312.05284) by Zigeng Chen et al. SlimSAM reduces the size of the SAM models considerably while maintaining the same performance.
+SlimSAM, a pruned version of SAM, was proposed in [0.1% Data Makes Segment Anything Slim](https://huggingface.co/papers/2312.05284) by Zigeng Chen et al. SlimSAM reduces the size of the SAM models considerably while maintaining the same performance.
Checkpoints can be found on the [hub](https://huggingface.co/models?other=slimsam), and they can be used as a drop-in replacement of SAM.
## Grounded SAM
-One can combine [Grounding DINO](grounding-dino) with SAM for text-based mask generation as introduced in [Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks](https://arxiv.org/abs/2401.14159). You can refer to this [demo notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Grounding%20DINO/GroundingDINO_with_Segment_Anything.ipynb) 🌍 for details.
+One can combine [Grounding DINO](grounding-dino) with SAM for text-based mask generation as introduced in [Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks](https://huggingface.co/papers/2401.14159). You can refer to this [demo notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Grounding%20DINO/GroundingDINO_with_Segment_Anything.ipynb) 🌍 for details.
diff --git a/docs/source/en/model_doc/sam_hq.md b/docs/source/en/model_doc/sam_hq.md
index 32181c4b87..8e8e4e559f 100644
--- a/docs/source/en/model_doc/sam_hq.md
+++ b/docs/source/en/model_doc/sam_hq.md
@@ -2,7 +2,7 @@
## Overview
-SAM-HQ (High-Quality Segment Anything Model) was proposed in [Segment Anything in High Quality](https://arxiv.org/pdf/2306.01567.pdf) by Lei Ke, Mingqiao Ye, Martin Danelljan, Yifan Liu, Yu-Wing Tai, Chi-Keung Tang, Fisher Yu.
+SAM-HQ (High-Quality Segment Anything Model) was proposed in [Segment Anything in High Quality](https://huggingface.co/papers/2306.01567) by Lei Ke, Mingqiao Ye, Martin Danelljan, Yifan Liu, Yu-Wing Tai, Chi-Keung Tang, Fisher Yu.
The model is an enhancement to the original SAM model that produces significantly higher quality segmentation masks while maintaining SAM's original promptable design, efficiency, and zero-shot generalizability.
diff --git a/docs/source/en/model_doc/seamless_m4t.md b/docs/source/en/model_doc/seamless_m4t.md
index 100198e501..1d42de0a54 100644
--- a/docs/source/en/model_doc/seamless_m4t.md
+++ b/docs/source/en/model_doc/seamless_m4t.md
@@ -132,7 +132,7 @@ Use `return_intermediate_token_ids=True` with [`SeamlessM4TModel`] to return bot
SeamlessM4T features a versatile architecture that smoothly handles the sequential generation of text and speech. This setup comprises two sequence-to-sequence (seq2seq) models. The first model translates the input modality into translated text, while the second model generates speech tokens, known as "unit tokens," from the translated text.
-Each modality has its own dedicated encoder with a unique architecture. Additionally, for speech output, a vocoder inspired by the [HiFi-GAN](https://arxiv.org/abs/2010.05646) architecture is placed on top of the second seq2seq model.
+Each modality has its own dedicated encoder with a unique architecture. Additionally, for speech output, a vocoder inspired by the [HiFi-GAN](https://huggingface.co/papers/2010.05646) architecture is placed on top of the second seq2seq model.
Here's how the generation process works:
diff --git a/docs/source/en/model_doc/seamless_m4t_v2.md b/docs/source/en/model_doc/seamless_m4t_v2.md
index 7b68d08b5f..7898799ee4 100644
--- a/docs/source/en/model_doc/seamless_m4t_v2.md
+++ b/docs/source/en/model_doc/seamless_m4t_v2.md
@@ -131,7 +131,7 @@ Use `return_intermediate_token_ids=True` with [`SeamlessM4Tv2Model`] to return b
SeamlessM4T-v2 features a versatile architecture that smoothly handles the sequential generation of text and speech. This setup comprises two sequence-to-sequence (seq2seq) models. The first model translates the input modality into translated text, while the second model generates speech tokens, known as "unit tokens," from the translated text.
-Each modality has its own dedicated encoder with a unique architecture. Additionally, for speech output, a vocoder inspired by the [HiFi-GAN](https://arxiv.org/abs/2010.05646) architecture is placed on top of the second seq2seq model.
+Each modality has its own dedicated encoder with a unique architecture. Additionally, for speech output, a vocoder inspired by the [HiFi-GAN](https://huggingface.co/papers/2010.05646) architecture is placed on top of the second seq2seq model.
### Difference with SeamlessM4T-v1
@@ -148,7 +148,7 @@ The second seq2seq model, named text-to-unit model, is now non-auto regressive,
The speech encoder, which is used during the first-pass generation process to predict the translated text, differs mainly from the previous speech encoder through these mechanisms:
- the use of chunked attention mask to prevent attention across chunks, ensuring that each position attends only to positions within its own chunk and a fixed number of previous chunks.
-- the use of relative position embeddings which only considers distance between sequence elements rather than absolute positions. Please refer to [Self-Attentionwith Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155) for more details.
+- the use of relative position embeddings which only considers distance between sequence elements rather than absolute positions. Please refer to [Self-Attentionwith Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155) for more details.
- the use of a causal depth-wise convolution instead of a non-causal one.
### Generation process
diff --git a/docs/source/en/model_doc/segformer.md b/docs/source/en/model_doc/segformer.md
index 093a141eaf..5bcb8ca2fc 100644
--- a/docs/source/en/model_doc/segformer.md
+++ b/docs/source/en/model_doc/segformer.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The SegFormer model was proposed in [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping
+The SegFormer model was proposed in [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://huggingface.co/papers/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping
Luo. The model consists of a hierarchical Transformer encoder and a lightweight all-MLP decode head to achieve great
results on image segmentation benchmarks such as ADE20K and Cityscapes.
@@ -41,7 +41,7 @@ and efficiency than previous counterparts. For example, SegFormer-B4 achieves 50
being 5x smaller and 2.2% better than the previous best method. Our best model, SegFormer-B5, achieves 84.0% mIoU on
Cityscapes validation set and shows excellent zero-shot robustness on Cityscapes-C.*
-The figure below illustrates the architecture of SegFormer. Taken from the [original paper](https://arxiv.org/abs/2105.15203).
+The figure below illustrates the architecture of SegFormer. Taken from the [original paper](https://huggingface.co/papers/2105.15203).
@@ -79,7 +79,7 @@ of the model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). T
background class and include this class as part of all labels. In that case, `do_reduce_labels` should be set to
`False`, as loss should also be computed for the background class.
- As most models, SegFormer comes in different sizes, the details of which can be found in the table below
- (taken from Table 7 of the [original paper](https://arxiv.org/abs/2105.15203)).
+ (taken from Table 7 of the [original paper](https://huggingface.co/papers/2105.15203)).
| **Model variant** | **Depths** | **Hidden sizes** | **Decoder hidden size** | **Params (M)** | **ImageNet-1k Top 1** |
| :---------------: | ------------- | ------------------- | :---------------------: | :------------: | :-------------------: |
@@ -91,7 +91,7 @@ of the model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). T
| MiT-b5 | [3, 6, 40, 3] | [64, 128, 320, 512] | 768 | 82.0 | 83.8 |
Note that MiT in the above table refers to the Mix Transformer encoder backbone introduced in SegFormer. For
-SegFormer's results on the segmentation datasets like ADE20k, refer to the [paper](https://arxiv.org/abs/2105.15203).
+SegFormer's results on the segmentation datasets like ADE20k, refer to the [paper](https://huggingface.co/papers/2105.15203).
## Resources
diff --git a/docs/source/en/model_doc/seggpt.md b/docs/source/en/model_doc/seggpt.md
index 1eb82b8477..89f80871ac 100644
--- a/docs/source/en/model_doc/seggpt.md
+++ b/docs/source/en/model_doc/seggpt.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The SegGPT model was proposed in [SegGPT: Segmenting Everything In Context](https://arxiv.org/abs/2304.03284) by Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang. SegGPT employs a decoder-only Transformer that can generate a segmentation mask given an input image, a prompt image and its corresponding prompt mask. The model achieves remarkable one-shot results with 56.1 mIoU on COCO-20 and 85.6 mIoU on FSS-1000.
+The SegGPT model was proposed in [SegGPT: Segmenting Everything In Context](https://huggingface.co/papers/2304.03284) by Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang. SegGPT employs a decoder-only Transformer that can generate a segmentation mask given an input image, a prompt image and its corresponding prompt mask. The model achieves remarkable one-shot results with 56.1 mIoU on COCO-20 and 85.6 mIoU on FSS-1000.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/sew-d.md b/docs/source/en/model_doc/sew-d.md
index 3626d953d9..a6648d2980 100644
--- a/docs/source/en/model_doc/sew-d.md
+++ b/docs/source/en/model_doc/sew-d.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
SEW-D (Squeezed and Efficient Wav2Vec with Disentangled attention) was proposed in [Performance-Efficiency Trade-offs
-in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim,
+in Unsupervised Pre-training for Speech Recognition](https://huggingface.co/papers/2109.06870) by Felix Wu, Kwangyoun Kim,
Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/sew.md b/docs/source/en/model_doc/sew.md
index 660d8176c2..865b4943c3 100644
--- a/docs/source/en/model_doc/sew.md
+++ b/docs/source/en/model_doc/sew.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
SEW (Squeezed and Efficient Wav2Vec) was proposed in [Performance-Efficiency Trade-offs in Unsupervised Pre-training
-for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q.
+for Speech Recognition](https://huggingface.co/papers/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q.
Weinberger, Yoav Artzi.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/shieldgemma2.md b/docs/source/en/model_doc/shieldgemma2.md
index ed25f57eb7..0e53418a73 100644
--- a/docs/source/en/model_doc/shieldgemma2.md
+++ b/docs/source/en/model_doc/shieldgemma2.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## Overview
-The ShieldGemma 2 model was proposed in a [technical report](https://arxiv.org/abs/2504.01081) by Google. ShieldGemma 2, built on [Gemma 3](https://ai.google.dev/gemma/docs/core/model_card_3), is a 4 billion (4B) parameter model that checks the safety of both synthetic and natural images against key categories to help you build robust datasets and models. With this addition to the Gemma family of models, researchers and developers can now easily minimize the risk of harmful content in their models across key areas of harm as defined below:
+The ShieldGemma 2 model was proposed in a [technical report](https://huggingface.co/papers/2504.01081) by Google. ShieldGemma 2, built on [Gemma 3](https://ai.google.dev/gemma/docs/core/model_card_3), is a 4 billion (4B) parameter model that checks the safety of both synthetic and natural images against key categories to help you build robust datasets and models. With this addition to the Gemma family of models, researchers and developers can now easily minimize the risk of harmful content in their models across key areas of harm as defined below:
- No Sexually Explicit content: The image shall not contain content that depicts explicit or graphic sexual acts (e.g., pornography, erotic nudity, depictions of rape or sexual assault).
- No Dangerous Content: The image shall not contain content that facilitates or encourages activities that could cause real-world harm (e.g., building firearms and explosive devices, promotion of terrorism, instructions for suicide).
diff --git a/docs/source/en/model_doc/speech-encoder-decoder.md b/docs/source/en/model_doc/speech-encoder-decoder.md
index 8893adfdd4..52f6634f9f 100644
--- a/docs/source/en/model_doc/speech-encoder-decoder.md
+++ b/docs/source/en/model_doc/speech-encoder-decoder.md
@@ -29,7 +29,7 @@ with any pretrained speech autoencoding model as the encoder (*e.g.* [Wav2Vec2](
The effectiveness of initializing speech-sequence-to-text-sequence models with pretrained checkpoints for speech
recognition and speech translation has *e.g.* been shown in [Large-Scale Self- and Semi-Supervised Learning for Speech
-Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli,
+Translation](https://huggingface.co/papers/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli,
Alexis Conneau.
An example of how to use a [`SpeechEncoderDecoderModel`] for inference can be seen in [Speech2Text2](speech_to_text_2).
diff --git a/docs/source/en/model_doc/speech_to_text.md b/docs/source/en/model_doc/speech_to_text.md
index bc65ea7965..1b6c74892f 100644
--- a/docs/source/en/model_doc/speech_to_text.md
+++ b/docs/source/en/model_doc/speech_to_text.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Speech2Text model was proposed in [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino. It's a
+The Speech2Text model was proposed in [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://huggingface.co/papers/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino. It's a
transformer-based seq2seq (encoder-decoder) model designed for end-to-end Automatic Speech Recognition (ASR) and Speech
Translation (ST). It uses a convolutional downsampler to reduce the length of speech inputs by 3/4th before they are
fed into the encoder. The model is trained with standard autoregressive cross-entropy loss and generates the
diff --git a/docs/source/en/model_doc/speech_to_text_2.md b/docs/source/en/model_doc/speech_to_text_2.md
index fc2d0357c5..8caf774e73 100644
--- a/docs/source/en/model_doc/speech_to_text_2.md
+++ b/docs/source/en/model_doc/speech_to_text_2.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
## Overview
The Speech2Text2 model is used together with [Wav2Vec2](wav2vec2) for Speech Translation models proposed in
-[Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by
+[Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://huggingface.co/papers/2104.06678) by
Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
Speech2Text2 is a *decoder-only* transformer model that can be used with any speech *encoder-only*, such as
diff --git a/docs/source/en/model_doc/speecht5.md b/docs/source/en/model_doc/speecht5.md
index acbadb137f..d41a583d7a 100644
--- a/docs/source/en/model_doc/speecht5.md
+++ b/docs/source/en/model_doc/speecht5.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The SpeechT5 model was proposed in [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
+The SpeechT5 model was proposed in [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://huggingface.co/papers/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/splinter.md b/docs/source/en/model_doc/splinter.md
index 0d526beff9..74e9ffc250 100644
--- a/docs/source/en/model_doc/splinter.md
+++ b/docs/source/en/model_doc/splinter.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Splinter model was proposed in [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy. Splinter
+The Splinter model was proposed in [Few-Shot Question Answering by Pretraining Span Selection](https://huggingface.co/papers/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy. Splinter
is an encoder-only transformer (similar to BERT) pretrained using the recurring span selection task on a large corpus
comprising Wikipedia and the Toronto Book Corpus.
diff --git a/docs/source/en/model_doc/squeezebert.md b/docs/source/en/model_doc/squeezebert.md
index 56046e22b7..2b91878296 100644
--- a/docs/source/en/model_doc/squeezebert.md
+++ b/docs/source/en/model_doc/squeezebert.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The SqueezeBERT model was proposed in [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, Kurt W. Keutzer. It's a
+The SqueezeBERT model was proposed in [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://huggingface.co/papers/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, Kurt W. Keutzer. It's a
bidirectional transformer similar to the BERT model. The key difference between the BERT architecture and the
SqueezeBERT architecture is that SqueezeBERT uses [grouped convolutions](https://blog.yani.io/filter-group-tutorial)
instead of fully-connected layers for the Q, K, V and FFN layers.
diff --git a/docs/source/en/model_doc/starcoder2.md b/docs/source/en/model_doc/starcoder2.md
index c6b146bf30..61e70b18fd 100644
--- a/docs/source/en/model_doc/starcoder2.md
+++ b/docs/source/en/model_doc/starcoder2.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-StarCoder2 is a family of open LLMs for code and comes in 3 different sizes with 3B, 7B and 15B parameters. The flagship StarCoder2-15B model is trained on over 4 trillion tokens and 600+ programming languages from The Stack v2. All models use Grouped Query Attention, a context window of 16,384 tokens with a sliding window attention of 4,096 tokens, and were trained using the Fill-in-the-Middle objective. The models have been released with the paper [StarCoder 2 and The Stack v2: The Next Generation](https://arxiv.org/abs/2402.19173) by Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Zheltonozhskii, Nii Osae Osae Dade, Wenhao Yu, Lucas Krauß, Naman Jain, Yixuan Su, Xuanli He, Manan Dey, Edoardo Abati, Yekun Chai, Niklas Muennighoff, Xiangru Tang, Muhtasham Oblokulov, Christopher Akiki, Marc Marone, Chenghao Mou, Mayank Mishra, Alex Gu, Binyuan Hui, Tri Dao, Armel Zebaze, Olivier Dehaene, Nicolas Patry, Canwen Xu, Julian McAuley, Han Hu, Torsten Scholak, Sebastien Paquet, Jennifer Robinson, Carolyn Jane Anderson, Nicolas Chapados, Mostofa Patwary, Nima Tajbakhsh, Yacine Jernite, Carlos Muñoz Ferrandis, Lingming Zhang, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries.
+StarCoder2 is a family of open LLMs for code and comes in 3 different sizes with 3B, 7B and 15B parameters. The flagship StarCoder2-15B model is trained on over 4 trillion tokens and 600+ programming languages from The Stack v2. All models use Grouped Query Attention, a context window of 16,384 tokens with a sliding window attention of 4,096 tokens, and were trained using the Fill-in-the-Middle objective. The models have been released with the paper [StarCoder 2 and The Stack v2: The Next Generation](https://huggingface.co/papers/2402.19173) by Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Zheltonozhskii, Nii Osae Osae Dade, Wenhao Yu, Lucas Krauß, Naman Jain, Yixuan Su, Xuanli He, Manan Dey, Edoardo Abati, Yekun Chai, Niklas Muennighoff, Xiangru Tang, Muhtasham Oblokulov, Christopher Akiki, Marc Marone, Chenghao Mou, Mayank Mishra, Alex Gu, Binyuan Hui, Tri Dao, Armel Zebaze, Olivier Dehaene, Nicolas Patry, Canwen Xu, Julian McAuley, Han Hu, Torsten Scholak, Sebastien Paquet, Jennifer Robinson, Carolyn Jane Anderson, Nicolas Chapados, Mostofa Patwary, Nima Tajbakhsh, Yacine Jernite, Carlos Muñoz Ferrandis, Lingming Zhang, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries.
The abstract of the paper is the following:
diff --git a/docs/source/en/model_doc/superglue.md b/docs/source/en/model_doc/superglue.md
index 38ef55ab79..38a5d2d888 100644
--- a/docs/source/en/model_doc/superglue.md
+++ b/docs/source/en/model_doc/superglue.md
@@ -21,7 +21,7 @@ rendered properly in your Markdown viewer.
## Overview
-The SuperGlue model was proposed in [SuperGlue: Learning Feature Matching with Graph Neural Networks](https://arxiv.org/abs/1911.11763) by Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
+The SuperGlue model was proposed in [SuperGlue: Learning Feature Matching with Graph Neural Networks](https://huggingface.co/papers/1911.11763) by Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
This model consists of matching two sets of interest points detected in an image. Paired with the
[SuperPoint model](https://huggingface.co/magic-leap-community/superpoint), it can be used to match two images and
diff --git a/docs/source/en/model_doc/superpoint.md b/docs/source/en/model_doc/superpoint.md
index 06ae5cb081..aa22d30961 100644
--- a/docs/source/en/model_doc/superpoint.md
+++ b/docs/source/en/model_doc/superpoint.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
The SuperPoint model was proposed
-in [SuperPoint: Self-Supervised Interest Point Detection and Description](https://arxiv.org/abs/1712.07629) by Daniel
+in [SuperPoint: Self-Supervised Interest Point Detection and Description](https://huggingface.co/papers/1712.07629) by Daniel
DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
This model is the result of a self-supervised training of a fully-convolutional network for interest point detection and
@@ -45,7 +45,7 @@ when compared to LIFT, SIFT and ORB.*
- SuperPoint overview. Taken from the original paper.
+ SuperPoint overview. Taken from the original paper.
## Usage tips
diff --git a/docs/source/en/model_doc/swiftformer.md b/docs/source/en/model_doc/swiftformer.md
index 48580a60f5..5f9c38d614 100644
--- a/docs/source/en/model_doc/swiftformer.md
+++ b/docs/source/en/model_doc/swiftformer.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The SwiftFormer model was proposed in [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://arxiv.org/abs/2303.15446) by Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan.
+The SwiftFormer model was proposed in [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://huggingface.co/papers/2303.15446) by Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan.
The SwiftFormer paper introduces a novel efficient additive attention mechanism that effectively replaces the quadratic matrix multiplication operations in the self-attention computation with linear element-wise multiplications. A series of models called 'SwiftFormer' is built based on this, which achieves state-of-the-art performance in terms of both accuracy and mobile inference speed. Even their small variant achieves 78.5% top-1 ImageNet1K accuracy with only 0.8 ms latency on iPhone 14, which is more accurate and 2× faster compared to MobileViT-v2.
diff --git a/docs/source/en/model_doc/swin2sr.md b/docs/source/en/model_doc/swin2sr.md
index 3ea713fdc7..340594b80e 100644
--- a/docs/source/en/model_doc/swin2sr.md
+++ b/docs/source/en/model_doc/swin2sr.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Swin2SR model was proposed in [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
+The Swin2SR model was proposed in [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://huggingface.co/papers/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
Swin2SR improves the [SwinIR](https://github.com/JingyunLiang/SwinIR/) model by incorporating [Swin Transformer v2](swinv2) layers which mitigates issues such as training instability, resolution gaps between pre-training
and fine-tuning, and hunger on data.
@@ -34,7 +34,7 @@ In this paper, we explore the novel Swin Transformer V2, to improve SwinIR for i
- Swin2SR architecture. Taken from the original paper.
+ Swin2SR architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/mv-lab/swin2sr).
diff --git a/docs/source/en/model_doc/switch_transformers.md b/docs/source/en/model_doc/switch_transformers.md
index 433b84dd86..8854bcc941 100644
--- a/docs/source/en/model_doc/switch_transformers.md
+++ b/docs/source/en/model_doc/switch_transformers.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The SwitchTransformers model was proposed in [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
+The SwitchTransformers model was proposed in [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://huggingface.co/papers/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
The Switch Transformer model uses a sparse T5 encoder-decoder architecture, where the MLP are replaced by a Mixture of Experts (MoE). A routing mechanism (top 1 in this case) associates each token to one of the expert, where each expert is a dense MLP. While switch transformers have a lot more weights than their equivalent dense models, the sparsity allows better scaling and better finetuning performance at scale.
During a forward pass, only a fraction of the weights are used. The routing mechanism allows the model to select relevant weights on the fly which increases the model capacity without increasing the number of operations.
diff --git a/docs/source/en/model_doc/t5v1.1.md b/docs/source/en/model_doc/t5v1.1.md
index 5ae908bacd..7f10f30243 100644
--- a/docs/source/en/model_doc/t5v1.1.md
+++ b/docs/source/en/model_doc/t5v1.1.md
@@ -42,7 +42,7 @@ One can directly plug in the weights of T5v1.1 into a T5 model, like so:
T5 Version 1.1 includes the following improvements compared to the original T5 model:
-- GEGLU activation in the feed-forward hidden layer, rather than ReLU. See [this paper](https://arxiv.org/abs/2002.05202).
+- GEGLU activation in the feed-forward hidden layer, rather than ReLU. See [this paper](https://huggingface.co/papers/2002.05202).
- Dropout was turned off in pre-training (quality win). Dropout should be re-enabled during fine-tuning.
diff --git a/docs/source/en/model_doc/table-transformer.md b/docs/source/en/model_doc/table-transformer.md
index fea4dabf3f..534ab49c64 100644
--- a/docs/source/en/model_doc/table-transformer.md
+++ b/docs/source/en/model_doc/table-transformer.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Table Transformer model was proposed in [PubTables-1M: Towards comprehensive table extraction from unstructured documents](https://arxiv.org/abs/2110.00061) by
+The Table Transformer model was proposed in [PubTables-1M: Towards comprehensive table extraction from unstructured documents](https://huggingface.co/papers/2110.00061) by
Brandon Smock, Rohith Pesala, Robin Abraham. The authors introduce a new dataset, PubTables-1M, to benchmark progress in table extraction from unstructured documents,
as well as table structure recognition and functional analysis. The authors train 2 [DETR](detr) models, one for table detection and one for table structure recognition, dubbed Table Transformers.
@@ -40,7 +40,7 @@ special customization for these tasks.*
- Table detection and table structure recognition clarified. Taken from the original paper.
+ Table detection and table structure recognition clarified. Taken from the original paper.
The authors released 2 models, one for [table detection](https://huggingface.co/microsoft/table-transformer-detection) in
documents, one for [table structure recognition](https://huggingface.co/microsoft/table-transformer-structure-recognition)
diff --git a/docs/source/en/model_doc/tapex.md b/docs/source/en/model_doc/tapex.md
index d46d520c7d..9694b098ea 100644
--- a/docs/source/en/model_doc/tapex.md
+++ b/docs/source/en/model_doc/tapex.md
@@ -34,7 +34,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The TAPEX model was proposed in [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu,
+The TAPEX model was proposed in [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://huggingface.co/papers/2107.07653) by Qian Liu,
Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou. TAPEX pre-trains a BART model to solve synthetic SQL queries, after
which it can be fine-tuned to answer natural language questions related to tabular data, as well as performing table fact checking.
diff --git a/docs/source/en/model_doc/textnet.md b/docs/source/en/model_doc/textnet.md
index 72f29b4463..f14cd2e941 100644
--- a/docs/source/en/model_doc/textnet.md
+++ b/docs/source/en/model_doc/textnet.md
@@ -22,12 +22,12 @@ rendered properly in your Markdown viewer.
## Overview
-The TextNet model was proposed in [FAST: Faster Arbitrarily-Shaped Text Detector with Minimalist Kernel Representation](https://arxiv.org/abs/2111.02394) by Zhe Chen, Jiahao Wang, Wenhai Wang, Guo Chen, Enze Xie, Ping Luo, Tong Lu. TextNet is a vision backbone useful for text detection tasks. It is the result of neural architecture search (NAS) on backbones with reward function as text detection task (to provide powerful features for text detection).
+The TextNet model was proposed in [FAST: Faster Arbitrarily-Shaped Text Detector with Minimalist Kernel Representation](https://huggingface.co/papers/2111.02394) by Zhe Chen, Jiahao Wang, Wenhai Wang, Guo Chen, Enze Xie, Ping Luo, Tong Lu. TextNet is a vision backbone useful for text detection tasks. It is the result of neural architecture search (NAS) on backbones with reward function as text detection task (to provide powerful features for text detection).
- TextNet backbone as part of FAST. Taken from the original paper.
+ TextNet backbone as part of FAST. Taken from the original paper.
This model was contributed by [Raghavan](https://huggingface.co/Raghavan), [jadechoghari](https://huggingface.co/jadechoghari) and [nielsr](https://huggingface.co/nielsr).
diff --git a/docs/source/en/model_doc/timesformer.md b/docs/source/en/model_doc/timesformer.md
index c01f64efa7..c39a63a668 100644
--- a/docs/source/en/model_doc/timesformer.md
+++ b/docs/source/en/model_doc/timesformer.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The TimeSformer model was proposed in [TimeSformer: Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095) by Facebook Research.
+The TimeSformer model was proposed in [TimeSformer: Is Space-Time Attention All You Need for Video Understanding?](https://huggingface.co/papers/2102.05095) by Facebook Research.
This work is a milestone in action-recognition field being the first video transformer. It inspired many transformer based video understanding and classification papers.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/trajectory_transformer.md b/docs/source/en/model_doc/trajectory_transformer.md
index 0c8fc29e01..a2353c9414 100644
--- a/docs/source/en/model_doc/trajectory_transformer.md
+++ b/docs/source/en/model_doc/trajectory_transformer.md
@@ -31,7 +31,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The Trajectory Transformer model was proposed in [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine.
+The Trajectory Transformer model was proposed in [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://huggingface.co/papers/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/transfo-xl.md b/docs/source/en/model_doc/transfo-xl.md
index 4d4f68ab07..66f249f24e 100644
--- a/docs/source/en/model_doc/transfo-xl.md
+++ b/docs/source/en/model_doc/transfo-xl.md
@@ -61,7 +61,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The Transformer-XL model was proposed in [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan
+The Transformer-XL model was proposed in [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://huggingface.co/papers/1901.02860) by Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan
Salakhutdinov. It's a causal (uni-directional) transformer with relative positioning (sinusoïdal) embeddings which can
reuse previously computed hidden-states to attend to longer context (memory). This model also uses adaptive softmax
inputs and outputs (tied).
diff --git a/docs/source/en/model_doc/trocr.md b/docs/source/en/model_doc/trocr.md
index 0d0fb6ca24..420398376a 100644
--- a/docs/source/en/model_doc/trocr.md
+++ b/docs/source/en/model_doc/trocr.md
@@ -22,7 +22,7 @@ specific language governing permissions and limitations under the License. -->
## Overview
The TrOCR model was proposed in [TrOCR: Transformer-based Optical Character Recognition with Pre-trained
-Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang,
+Models](https://huggingface.co/papers/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang,
Zhoujun Li, Furu Wei. TrOCR consists of an image Transformer encoder and an autoregressive text Transformer decoder to
perform [optical character recognition (OCR)](https://en.wikipedia.org/wiki/Optical_character_recognition).
@@ -40,7 +40,7 @@ tasks.*
- TrOCR architecture. Taken from the original paper.
+ TrOCR architecture. Taken from the original paper.
Please refer to the [`VisionEncoderDecoder`] class on how to use this model.
diff --git a/docs/source/en/model_doc/tvlt.md b/docs/source/en/model_doc/tvlt.md
index f1a97dfcd8..949c8549f5 100644
--- a/docs/source/en/model_doc/tvlt.md
+++ b/docs/source/en/model_doc/tvlt.md
@@ -30,7 +30,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The TVLT model was proposed in [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156)
+The TVLT model was proposed in [TVLT: Textless Vision-Language Transformer](https://huggingface.co/papers/2209.14156)
by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal (the first three authors contributed equally). The Textless Vision-Language Transformer (TVLT) is a model that uses raw visual and audio inputs for vision-and-language representation learning, without using text-specific modules such as tokenization or automatic speech recognition (ASR). It can perform various audiovisual and vision-language tasks like retrieval, question answering, etc.
The abstract from the paper is the following:
@@ -42,7 +42,7 @@ The abstract from the paper is the following:
alt="drawing" width="600"/>
- TVLT architecture. Taken from the original paper.
+ TVLT architecture. Taken from the original paper.
The original code can be found [here](https://github.com/zinengtang/TVLT). This model was contributed by [Zineng Tang](https://huggingface.co/ZinengTang).
diff --git a/docs/source/en/model_doc/tvp.md b/docs/source/en/model_doc/tvp.md
index cadb6e71f0..1b83ebfa6d 100644
--- a/docs/source/en/model_doc/tvp.md
+++ b/docs/source/en/model_doc/tvp.md
@@ -18,7 +18,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The text-visual prompting (TVP) framework was proposed in the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
+The text-visual prompting (TVP) framework was proposed in the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://huggingface.co/papers/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
The abstract from the paper is the following:
@@ -29,7 +29,7 @@ This research addresses temporal video grounding (TVG), which is the process of
- TVP architecture. Taken from the original paper.
+ TVP architecture. Taken from the original paper.
This model was contributed by [Jiqing Feng](https://huggingface.co/Jiqing). The original code can be found [here](https://github.com/intel/TVP).
@@ -162,7 +162,7 @@ Tips:
- This implementation of TVP uses [`BertTokenizer`] to generate text embeddings and Resnet-50 model to compute visual embeddings.
- Checkpoints for pre-trained [tvp-base](https://huggingface.co/Intel/tvp-base) is released.
-- Please refer to [Table 2](https://arxiv.org/pdf/2303.04995.pdf) for TVP's performance on Temporal Video Grounding task.
+- Please refer to [Table 2](https://huggingface.co/papers/2303.04995) for TVP's performance on Temporal Video Grounding task.
## TvpConfig
diff --git a/docs/source/en/model_doc/udop.md b/docs/source/en/model_doc/udop.md
index b63bc11a53..fd2a70d7ec 100644
--- a/docs/source/en/model_doc/udop.md
+++ b/docs/source/en/model_doc/udop.md
@@ -18,7 +18,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The UDOP model was proposed in [Unifying Vision, Text, and Layout for Universal Document Processing](https://arxiv.org/abs/2212.02623) by Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal.
+The UDOP model was proposed in [Unifying Vision, Text, and Layout for Universal Document Processing](https://huggingface.co/papers/2212.02623) by Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal.
UDOP adopts an encoder-decoder Transformer architecture based on [T5](t5) for document AI tasks like document image classification, document parsing and document visual question answering.
The abstract from the paper is the following:
@@ -28,7 +28,7 @@ We propose Universal Document Processing (UDOP), a foundation Document AI model
- UDOP architecture. Taken from the original paper.
+ UDOP architecture. Taken from the original paper.
## Usage tips
@@ -64,7 +64,7 @@ One can use [`UdopProcessor`] to prepare images and text for the model, which ta
- If using an own OCR engine of choice, one recommendation is Azure's [Read API](https://learn.microsoft.com/en-us/azure/ai-services/computer-vision/how-to/call-read-api), which supports so-called line segments. Use of segment position embeddings typically results in better performance.
- At inference time, it's recommended to use the `generate` method to autoregressively generate text given a document image.
-- The model has been pre-trained on both self-supervised and supervised objectives. One can use the various task prefixes (prompts) used during pre-training to test out the out-of-the-box capabilities. For instance, the model can be prompted with "Question answering. What is the date?", as "Question answering." is the task prefix used during pre-training for DocVQA. Refer to the [paper](https://arxiv.org/abs/2212.02623) (table 1) for all task prefixes.
+- The model has been pre-trained on both self-supervised and supervised objectives. One can use the various task prefixes (prompts) used during pre-training to test out the out-of-the-box capabilities. For instance, the model can be prompted with "Question answering. What is the date?", as "Question answering." is the task prefix used during pre-training for DocVQA. Refer to the [paper](https://huggingface.co/papers/2212.02623) (table 1) for all task prefixes.
- One can also fine-tune [`UdopEncoderModel`], which is the encoder-only part of UDOP, which can be seen as a LayoutLMv3-like Transformer encoder. For discriminative tasks, one can just add a linear classifier on top of it and fine-tune it on a labeled dataset.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
diff --git a/docs/source/en/model_doc/ul2.md b/docs/source/en/model_doc/ul2.md
index 18743a2842..b3c1a22260 100644
--- a/docs/source/en/model_doc/ul2.md
+++ b/docs/source/en/model_doc/ul2.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The T5 model was presented in [Unifying Language Learning Paradigms](https://arxiv.org/pdf/2205.05131v1.pdf) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler.
+The T5 model was presented in [Unifying Language Learning Paradigms](https://huggingface.co/papers/2205.05131) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/unispeech-sat.md b/docs/source/en/model_doc/unispeech-sat.md
index c526bb434d..8d0adb8e78 100644
--- a/docs/source/en/model_doc/unispeech-sat.md
+++ b/docs/source/en/model_doc/unispeech-sat.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
The UniSpeech-SAT model was proposed in [UniSpeech-SAT: Universal Speech Representation Learning with Speaker Aware
-Pre-Training](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen,
+Pre-Training](https://huggingface.co/papers/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen,
Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu .
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/unispeech.md b/docs/source/en/model_doc/unispeech.md
index 9f23656b22..a83f7600d5 100644
--- a/docs/source/en/model_doc/unispeech.md
+++ b/docs/source/en/model_doc/unispeech.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The UniSpeech model was proposed in [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael
+The UniSpeech model was proposed in [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://huggingface.co/papers/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael
Zeng, Xuedong Huang .
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/univnet.md b/docs/source/en/model_doc/univnet.md
index 3671471152..57492dcd68 100644
--- a/docs/source/en/model_doc/univnet.md
+++ b/docs/source/en/model_doc/univnet.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The UnivNet model was proposed in [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kin, and Juntae Kim.
+The UnivNet model was proposed in [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://huggingface.co/papers/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kin, and Juntae Kim.
The UnivNet model is a generative adversarial network (GAN) trained to synthesize high fidelity speech waveforms. The UnivNet model shared in `transformers` is the *generator*, which maps a conditioning log-mel spectrogram and optional noise sequence to a speech waveform (e.g. a vocoder). Only the generator is required for inference. The *discriminator* used to train the `generator` is not implemented.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/upernet.md b/docs/source/en/model_doc/upernet.md
index a2c96582f2..e215ec8621 100644
--- a/docs/source/en/model_doc/upernet.md
+++ b/docs/source/en/model_doc/upernet.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The UPerNet model was proposed in [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221)
+The UPerNet model was proposed in [Unified Perceptual Parsing for Scene Understanding](https://huggingface.co/papers/1807.10221)
by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun. UPerNet is a general framework to effectively segment
a wide range of concepts from images, leveraging any vision backbone like [ConvNeXt](convnext) or [Swin](swin).
@@ -33,7 +33,7 @@ The abstract from the paper is the following:
- UPerNet framework. Taken from the original paper.
+ UPerNet framework. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code is based on OpenMMLab's mmsegmentation [here](https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/uper_head.py).
diff --git a/docs/source/en/model_doc/van.md b/docs/source/en/model_doc/van.md
index 1df6a4640b..0a25691823 100644
--- a/docs/source/en/model_doc/van.md
+++ b/docs/source/en/model_doc/van.md
@@ -31,7 +31,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The VAN model was proposed in [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
+The VAN model was proposed in [Visual Attention Network](https://huggingface.co/papers/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
This paper introduces a new attention layer based on convolution operations able to capture both local and distant relationships. This is done by combining normal and large kernel convolution layers. The latter uses a dilated convolution to capture distant correlations.
@@ -43,7 +43,7 @@ Tips:
- VAN does not have an embedding layer, thus the `hidden_states` will have a length equal to the number of stages.
-The figure below illustrates the architecture of a Visual Attention Layer. Taken from the [original paper](https://arxiv.org/abs/2202.09741).
+The figure below illustrates the architecture of a Visual Attention Layer. Taken from the [original paper](https://huggingface.co/papers/2202.09741).
diff --git a/docs/source/en/model_doc/video_llava.md b/docs/source/en/model_doc/video_llava.md
index 9eaed2e7d5..a9282bdad0 100644
--- a/docs/source/en/model_doc/video_llava.md
+++ b/docs/source/en/model_doc/video_llava.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
Video-LLaVa is an open-source multimodal LLM trained by fine-tuning LlamA/Vicuna on multimodal instruction-following data generated by Llava1.5 and VideChat. It is an auto-regressive language model, based on the transformer architecture. Video-LLaVa unifies visual representations to the language feature space, and enables an LLM to perform visual reasoning capabilities on both images and videos simultaneously.
-The Video-LLaVA model was proposed in [Video-LLaVA: Learning United Visual Representation by Alignment Before Projection](https://arxiv.org/abs/2311.10122) by Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munang Ning, Peng Jin, Li Yuan.
+The Video-LLaVA model was proposed in [Video-LLaVA: Learning United Visual Representation by Alignment Before Projection](https://huggingface.co/papers/2311.10122) by Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munang Ning, Peng Jin, Li Yuan.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/videomae.md b/docs/source/en/model_doc/videomae.md
index be048d5b73..ac3d6c044e 100644
--- a/docs/source/en/model_doc/videomae.md
+++ b/docs/source/en/model_doc/videomae.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The VideoMAE model was proposed in [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
+The VideoMAE model was proposed in [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://huggingface.co/papers/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
VideoMAE extends masked auto encoders ([MAE](vit_mae)) to video, claiming state-of-the-art performance on several video classification benchmarks.
The abstract from the paper is the following:
@@ -34,7 +34,7 @@ The abstract from the paper is the following:
- VideoMAE pre-training. Taken from the original paper.
+ VideoMAE pre-training. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/MCG-NJU/VideoMAE).
diff --git a/docs/source/en/model_doc/vilt.md b/docs/source/en/model_doc/vilt.md
index ea598cbbe2..19146e3846 100644
--- a/docs/source/en/model_doc/vilt.md
+++ b/docs/source/en/model_doc/vilt.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The ViLT model was proposed in [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334)
+The ViLT model was proposed in [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://huggingface.co/papers/2102.03334)
by Wonjae Kim, Bokyung Son, Ildoo Kim. ViLT incorporates text embeddings into a Vision Transformer (ViT), allowing it to have a minimal design
for Vision-and-Language Pre-training (VLP).
@@ -41,7 +41,7 @@ times faster than previous VLP models, yet with competitive or better downstream
- ViLT architecture. Taken from the original paper.
+ ViLT architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/dandelin/ViLT).
diff --git a/docs/source/en/model_doc/vipllava.md b/docs/source/en/model_doc/vipllava.md
index 8edf154026..c60b172045 100644
--- a/docs/source/en/model_doc/vipllava.md
+++ b/docs/source/en/model_doc/vipllava.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The VipLlava model was proposed in [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://arxiv.org/abs/2312.00784) by Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee.
+The VipLlava model was proposed in [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://huggingface.co/papers/2312.00784) by Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee.
VipLlava enhances the training protocol of Llava by marking images and interact with the model using natural cues like a "red bounding box" or "pointed arrow" during training.
diff --git a/docs/source/en/model_doc/vision-encoder-decoder.md b/docs/source/en/model_doc/vision-encoder-decoder.md
index 0534085861..53c573be47 100644
--- a/docs/source/en/model_doc/vision-encoder-decoder.md
+++ b/docs/source/en/model_doc/vision-encoder-decoder.md
@@ -32,7 +32,7 @@ pretrained Transformer-based vision model as the encoder (*e.g.* [ViT](vit), [BE
and any pretrained language model as the decoder (*e.g.* [RoBERTa](roberta), [GPT2](gpt2), [BERT](bert), [DistilBERT](distilbert)).
The effectiveness of initializing image-to-text-sequence models with pretrained checkpoints has been shown in (for
-example) [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang,
+example) [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://huggingface.co/papers/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang,
Zhoujun Li, Furu Wei.
After such a [`VisionEncoderDecoderModel`] has been trained/fine-tuned, it can be saved/loaded just like any other models (see the examples below
diff --git a/docs/source/en/model_doc/vision-text-dual-encoder.md b/docs/source/en/model_doc/vision-text-dual-encoder.md
index b9d6db38d5..3106cb0ac3 100644
--- a/docs/source/en/model_doc/vision-text-dual-encoder.md
+++ b/docs/source/en/model_doc/vision-text-dual-encoder.md
@@ -33,7 +33,7 @@ to a shared latent space. The projection layers are randomly initialized so the
downstream task. This model can be used to align the vision-text embeddings using CLIP like contrastive image-text
training and then can be used for zero-shot vision tasks such image-classification or retrieval.
-In [LiT: Zero-Shot Transfer with Locked-image Text Tuning](https://arxiv.org/abs/2111.07991) it is shown how
+In [LiT: Zero-Shot Transfer with Locked-image Text Tuning](https://huggingface.co/papers/2111.07991) it is shown how
leveraging pre-trained (locked/frozen) image and text model for contrastive learning yields significant improvement on
new zero-shot vision tasks such as image classification or retrieval.
diff --git a/docs/source/en/model_doc/visual_bert.md b/docs/source/en/model_doc/visual_bert.md
index 265d482c19..02c98ba3d9 100644
--- a/docs/source/en/model_doc/visual_bert.md
+++ b/docs/source/en/model_doc/visual_bert.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The VisualBERT model was proposed in [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
+The VisualBERT model was proposed in [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://huggingface.co/papers/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
VisualBERT is a neural network trained on a variety of (image, text) pairs.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/vit_hybrid.md b/docs/source/en/model_doc/vit_hybrid.md
index a79fadd255..c268c2fad3 100644
--- a/docs/source/en/model_doc/vit_hybrid.md
+++ b/docs/source/en/model_doc/vit_hybrid.md
@@ -32,7 +32,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
The hybrid Vision Transformer (ViT) model was proposed in [An Image is Worth 16x16 Words: Transformers for Image Recognition
-at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk
+at Scale](https://huggingface.co/papers/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk
Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob
Uszkoreit, Neil Houlsby. It's the first paper that successfully trains a Transformer encoder on ImageNet, attaining
very good results compared to familiar convolutional architectures. ViT hybrid is a slight variant of the [plain Vision Transformer](vit),
diff --git a/docs/source/en/model_doc/vit_msn.md b/docs/source/en/model_doc/vit_msn.md
index a3aadef0e9..8835f01cd8 100644
--- a/docs/source/en/model_doc/vit_msn.md
+++ b/docs/source/en/model_doc/vit_msn.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The ViTMSN model was proposed in [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes,
+The ViTMSN model was proposed in [Masked Siamese Networks for Label-Efficient Learning](https://huggingface.co/papers/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes,
Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas. The paper presents a joint-embedding architecture to match the prototypes
of masked patches with that of the unmasked patches. With this setup, their method yields excellent performance in the low-shot and extreme low-shot
regimes.
@@ -41,7 +41,7 @@ and with 1% of ImageNet-1K labels, we achieve 75.7% top-1 accuracy, setting a ne
- MSN architecture. Taken from the original paper.
+ MSN architecture. Taken from the original paper.
This model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/facebookresearch/msn).
diff --git a/docs/source/en/model_doc/vitdet.md b/docs/source/en/model_doc/vitdet.md
index d569e71d90..738d83461b 100644
--- a/docs/source/en/model_doc/vitdet.md
+++ b/docs/source/en/model_doc/vitdet.md
@@ -18,7 +18,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The ViTDet model was proposed in [Exploring Plain Vision Transformer Backbones for Object Detection](https://arxiv.org/abs/2203.16527) by Yanghao Li, Hanzi Mao, Ross Girshick, Kaiming He.
+The ViTDet model was proposed in [Exploring Plain Vision Transformer Backbones for Object Detection](https://huggingface.co/papers/2203.16527) by Yanghao Li, Hanzi Mao, Ross Girshick, Kaiming He.
VitDet leverages the plain [Vision Transformer](vit) for the task of object detection.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/vitmatte.md b/docs/source/en/model_doc/vitmatte.md
index 566c296229..f661de1622 100644
--- a/docs/source/en/model_doc/vitmatte.md
+++ b/docs/source/en/model_doc/vitmatte.md
@@ -18,7 +18,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The ViTMatte model was proposed in [Boosting Image Matting with Pretrained Plain Vision Transformers](https://arxiv.org/abs/2305.15272) by Jingfeng Yao, Xinggang Wang, Shusheng Yang, Baoyuan Wang.
+The ViTMatte model was proposed in [Boosting Image Matting with Pretrained Plain Vision Transformers](https://huggingface.co/papers/2305.15272) by Jingfeng Yao, Xinggang Wang, Shusheng Yang, Baoyuan Wang.
ViTMatte leverages plain [Vision Transformers](vit) for the task of image matting, which is the process of accurately estimating the foreground object in images and videos.
The abstract from the paper is the following:
@@ -31,7 +31,7 @@ The original code can be found [here](https://github.com/hustvl/ViTMatte).
- ViTMatte high-level overview. Taken from the original paper.
+ ViTMatte high-level overview. Taken from the original paper.
## Resources
diff --git a/docs/source/en/model_doc/vitpose.md b/docs/source/en/model_doc/vitpose.md
index 02471ad39e..7a417cc213 100644
--- a/docs/source/en/model_doc/vitpose.md
+++ b/docs/source/en/model_doc/vitpose.md
@@ -18,7 +18,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The ViTPose model was proposed in [ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation](https://arxiv.org/abs/2204.12484) by Yufei Xu, Jing Zhang, Qiming Zhang, Dacheng Tao. ViTPose employs a standard, non-hierarchical [Vision Transformer](vit) as backbone for the task of keypoint estimation. A simple decoder head is added on top to predict the heatmaps from a given image. Despite its simplicity, the model gets state-of-the-art results on the challenging MS COCO Keypoint Detection benchmark. The model was further improved in [ViTPose++: Vision Transformer for Generic Body Pose Estimation](https://arxiv.org/abs/2212.04246) where the authors employ
+The ViTPose model was proposed in [ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation](https://huggingface.co/papers/2204.12484) by Yufei Xu, Jing Zhang, Qiming Zhang, Dacheng Tao. ViTPose employs a standard, non-hierarchical [Vision Transformer](vit) as backbone for the task of keypoint estimation. A simple decoder head is added on top to predict the heatmaps from a given image. Despite its simplicity, the model gets state-of-the-art results on the challenging MS COCO Keypoint Detection benchmark. The model was further improved in [ViTPose++: Vision Transformer for Generic Body Pose Estimation](https://huggingface.co/papers/2212.04246) where the authors employ
a mixture-of-experts (MoE) module in the ViT backbone along with pre-training on more data, which further enhances the performance.
The abstract from the paper is the following:
@@ -28,7 +28,7 @@ The abstract from the paper is the following:
- ViTPose architecture. Taken from the original paper.
+ ViTPose architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr) and [sangbumchoi](https://github.com/SangbumChoi).
The original code can be found [here](https://github.com/ViTAE-Transformer/ViTPose).
@@ -95,7 +95,7 @@ image_pose_result = pose_results[0] # results for first image
### ViTPose++ models
-The best [checkpoints](https://huggingface.co/collections/usyd-community/vitpose-677fcfd0a0b2b5c8f79c4335) are those of the [ViTPose++ paper](https://arxiv.org/abs/2212.04246). ViTPose++ models employ a so-called [Mixture-of-Experts (MoE)](https://huggingface.co/blog/moe) architecture for the ViT backbone, resulting in better performance.
+The best [checkpoints](https://huggingface.co/collections/usyd-community/vitpose-677fcfd0a0b2b5c8f79c4335) are those of the [ViTPose++ paper](https://huggingface.co/papers/2212.04246). ViTPose++ models employ a so-called [Mixture-of-Experts (MoE)](https://huggingface.co/blog/moe) architecture for the ViT backbone, resulting in better performance.
The ViTPose+ checkpoints use 6 experts, hence 6 different dataset indices can be passed.
An overview of the various dataset indices is provided below:
diff --git a/docs/source/en/model_doc/vivit.md b/docs/source/en/model_doc/vivit.md
index a2cba9793e..cf32c749e2 100644
--- a/docs/source/en/model_doc/vivit.md
+++ b/docs/source/en/model_doc/vivit.md
@@ -20,7 +20,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The Vivit model was proposed in [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
+The Vivit model was proposed in [ViViT: A Video Vision Transformer](https://huggingface.co/papers/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
The paper proposes one of the first successful pure-transformer based set of models for video understanding.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/wav2vec2-conformer.md b/docs/source/en/model_doc/wav2vec2-conformer.md
index f84e6b3711..fa304b3a86 100644
--- a/docs/source/en/model_doc/wav2vec2-conformer.md
+++ b/docs/source/en/model_doc/wav2vec2-conformer.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Wav2Vec2-Conformer was added to an updated version of [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
+The Wav2Vec2-Conformer was added to an updated version of [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://huggingface.co/papers/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
The official results of the model can be found in Table 3 and Table 4 of the paper.
@@ -36,7 +36,7 @@ Note: Meta (FAIR) released a new version of [Wav2Vec2-BERT 2.0](https://huggingf
## Usage tips
- Wav2Vec2-Conformer follows the same architecture as Wav2Vec2, but replaces the *Attention*-block with a *Conformer*-block
- as introduced in [Conformer: Convolution-augmented Transformer for Speech Recognition](https://arxiv.org/abs/2005.08100).
+ as introduced in [Conformer: Convolution-augmented Transformer for Speech Recognition](https://huggingface.co/papers/2005.08100).
- For the same number of layers, Wav2Vec2-Conformer requires more parameters than Wav2Vec2, but also yields
an improved word error rate.
- Wav2Vec2-Conformer uses the same tokenizer and feature extractor as Wav2Vec2.
diff --git a/docs/source/en/model_doc/wav2vec2.md b/docs/source/en/model_doc/wav2vec2.md
index a5fedef0f7..d884f44b1e 100644
--- a/docs/source/en/model_doc/wav2vec2.md
+++ b/docs/source/en/model_doc/wav2vec2.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Wav2Vec2 model was proposed in [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
+The Wav2Vec2 model was proposed in [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://huggingface.co/papers/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/wav2vec2_phoneme.md b/docs/source/en/model_doc/wav2vec2_phoneme.md
index c5c1edd6ac..863bdafca3 100644
--- a/docs/source/en/model_doc/wav2vec2_phoneme.md
+++ b/docs/source/en/model_doc/wav2vec2_phoneme.md
@@ -26,7 +26,7 @@ rendered properly in your Markdown viewer.
## Overview
The Wav2Vec2Phoneme model was proposed in [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition (Xu et al.,
-2021](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
+2021)](https://huggingface.co/papers/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/wavlm.md b/docs/source/en/model_doc/wavlm.md
index 54947e2f15..7dfe6f26bb 100644
--- a/docs/source/en/model_doc/wavlm.md
+++ b/docs/source/en/model_doc/wavlm.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The WavLM model was proposed in [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen,
+The WavLM model was proposed in [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://huggingface.co/papers/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen,
Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu,
Michael Zeng, Furu Wei.
diff --git a/docs/source/en/model_doc/xclip.md b/docs/source/en/model_doc/xclip.md
index 62f0c3aa2e..ca78a68ae2 100644
--- a/docs/source/en/model_doc/xclip.md
+++ b/docs/source/en/model_doc/xclip.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The X-CLIP model was proposed in [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816) by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
+The X-CLIP model was proposed in [Expanding Language-Image Pretrained Models for General Video Recognition](https://huggingface.co/papers/2208.02816) by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
X-CLIP is a minimal extension of [CLIP](clip) for video. The model consists of a text encoder, a cross-frame vision encoder, a multi-frame integration Transformer, and a video-specific prompt generator.
The abstract from the paper is the following:
@@ -36,7 +36,7 @@ Tips:
- X-CLIP architecture. Taken from the original paper.
+ X-CLIP architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/microsoft/VideoX/tree/master/X-CLIP).
diff --git a/docs/source/en/model_doc/xglm.md b/docs/source/en/model_doc/xglm.md
index 4032de2cd7..6c0c180727 100644
--- a/docs/source/en/model_doc/xglm.md
+++ b/docs/source/en/model_doc/xglm.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The XGLM model was proposed in [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668)
+The XGLM model was proposed in [Few-shot Learning with Multilingual Language Models](https://huggingface.co/papers/2112.10668)
by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal,
Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo,
Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
diff --git a/docs/source/en/model_doc/xlm-prophetnet.md b/docs/source/en/model_doc/xlm-prophetnet.md
index 046904d885..5d11a532f2 100644
--- a/docs/source/en/model_doc/xlm-prophetnet.md
+++ b/docs/source/en/model_doc/xlm-prophetnet.md
@@ -43,7 +43,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The XLM-ProphetNet model was proposed in [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei
+The XLM-ProphetNet model was proposed in [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://huggingface.co/papers/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei
Zhang, Ming Zhou on 13 Jan, 2020.
XLM-ProphetNet is an encoder-decoder model and can predict n-future tokens for "ngram" language modeling instead of
diff --git a/docs/source/en/model_doc/xlm-v.md b/docs/source/en/model_doc/xlm-v.md
index 69badfe2e6..05b4a42593 100644
--- a/docs/source/en/model_doc/xlm-v.md
+++ b/docs/source/en/model_doc/xlm-v.md
@@ -26,7 +26,7 @@ rendered properly in your Markdown viewer.
## Overview
XLM-V is multilingual language model with a one million token vocabulary trained on 2.5TB of data from Common Crawl (same as XLM-R).
-It was introduced in the [XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models](https://arxiv.org/abs/2301.10472)
+It was introduced in the [XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models](https://huggingface.co/papers/2301.10472)
paper by Davis Liang, Hila Gonen, Yuning Mao, Rui Hou, Naman Goyal, Marjan Ghazvininejad, Luke Zettlemoyer and Madian Khabsa.
From the abstract of the XLM-V paper:
diff --git a/docs/source/en/model_doc/xlnet.md b/docs/source/en/model_doc/xlnet.md
index 0b90de75cc..e35851d5d2 100644
--- a/docs/source/en/model_doc/xlnet.md
+++ b/docs/source/en/model_doc/xlnet.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The XLNet model was proposed in [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov,
+The XLNet model was proposed in [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://huggingface.co/papers/1906.08237) by Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov,
Quoc V. Le. XLnet is an extension of the Transformer-XL model pre-trained using an autoregressive method to learn
bidirectional contexts by maximizing the expected likelihood over all permutations of the input sequence factorization
order.
diff --git a/docs/source/en/model_doc/xls_r.md b/docs/source/en/model_doc/xls_r.md
index d24d88907e..238c703f3e 100644
--- a/docs/source/en/model_doc/xls_r.md
+++ b/docs/source/en/model_doc/xls_r.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The XLS-R model was proposed in [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman
+The XLS-R model was proposed in [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://huggingface.co/papers/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman
Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/xlsr_wav2vec2.md b/docs/source/en/model_doc/xlsr_wav2vec2.md
index f88b0dc9e1..eceea3be20 100644
--- a/docs/source/en/model_doc/xlsr_wav2vec2.md
+++ b/docs/source/en/model_doc/xlsr_wav2vec2.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The XLSR-Wav2Vec2 model was proposed in [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael
+The XLSR-Wav2Vec2 model was proposed in [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://huggingface.co/papers/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael
Auli.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/yolos.md b/docs/source/en/model_doc/yolos.md
index c4a9e21228..9eaf56d2be 100644
--- a/docs/source/en/model_doc/yolos.md
+++ b/docs/source/en/model_doc/yolos.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The YOLOS model was proposed in [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
+The YOLOS model was proposed in [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://huggingface.co/papers/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
YOLOS proposes to just leverage the plain [Vision Transformer (ViT)](vit) for object detection, inspired by DETR. It turns out that a base-sized encoder-only Transformer can also achieve 42 AP on COCO, similar to DETR and much more complex frameworks such as Faster R-CNN.
The abstract from the paper is the following:
@@ -34,7 +34,7 @@ The abstract from the paper is the following:
- YOLOS architecture. Taken from the original paper.
+ YOLOS architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/hustvl/YOLOS).
diff --git a/docs/source/en/model_doc/yoso.md b/docs/source/en/model_doc/yoso.md
index c9fbb11b1e..344fad9e12 100644
--- a/docs/source/en/model_doc/yoso.md
+++ b/docs/source/en/model_doc/yoso.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The YOSO model was proposed in [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714)
+The YOSO model was proposed in [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://huggingface.co/papers/2111.09714)
by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh. YOSO approximates standard softmax self-attention
via a Bernoulli sampling scheme based on Locality Sensitive Hashing (LSH). In principle, all the Bernoulli random variables can be sampled with
a single hash.
@@ -56,7 +56,7 @@ does not require compiling CUDA kernels.
- YOSO Attention Algorithm. Taken from the original paper.
+ YOSO Attention Algorithm. Taken from the original paper.
## Resources
diff --git a/docs/source/en/model_memory_anatomy.md b/docs/source/en/model_memory_anatomy.md
index 44c197aae5..7ef53f4056 100644
--- a/docs/source/en/model_memory_anatomy.md
+++ b/docs/source/en/model_memory_anatomy.md
@@ -204,7 +204,7 @@ Transformers architecture includes 3 main groups of operations grouped below by
This knowledge can be helpful to know when analyzing performance bottlenecks.
-This summary is derived from [Data Movement Is All You Need: A Case Study on Optimizing Transformers 2020](https://arxiv.org/abs/2007.00072)
+This summary is derived from [Data Movement Is All You Need: A Case Study on Optimizing Transformers 2020](https://huggingface.co/papers/2007.00072)
## Anatomy of Model's Memory
diff --git a/docs/source/en/model_summary.md b/docs/source/en/model_summary.md
index c7efc4c00d..0836f27283 100644
--- a/docs/source/en/model_summary.md
+++ b/docs/source/en/model_summary.md
@@ -16,7 +16,7 @@ rendered properly in your Markdown viewer.
# The Transformer model family
-Since its introduction in 2017, the [original Transformer](https://arxiv.org/abs/1706.03762) model (see the [Annotated Transformer](http://nlp.seas.harvard.edu/2018/04/03/attention.html) blog post for a gentle technical introduction) has inspired many new and exciting models that extend beyond natural language processing (NLP) tasks. There are models for [predicting the folded structure of proteins](https://huggingface.co/blog/deep-learning-with-proteins), [training a cheetah to run](https://huggingface.co/blog/train-decision-transformers), and [time series forecasting](https://huggingface.co/blog/time-series-transformers). With so many Transformer variants available, it can be easy to miss the bigger picture. What all these models have in common is they're based on the original Transformer architecture. Some models only use the encoder or decoder, while others use both. This provides a useful taxonomy to categorize and examine the high-level differences within models in the Transformer family, and it'll help you understand Transformers you haven't encountered before.
+Since its introduction in 2017, the [original Transformer](https://huggingface.co/papers/1706.03762) model (see the [Annotated Transformer](http://nlp.seas.harvard.edu/2018/04/03/attention.html) blog post for a gentle technical introduction) has inspired many new and exciting models that extend beyond natural language processing (NLP) tasks. There are models for [predicting the folded structure of proteins](https://huggingface.co/blog/deep-learning-with-proteins), [training a cheetah to run](https://huggingface.co/blog/train-decision-transformers), and [time series forecasting](https://huggingface.co/blog/time-series-transformers). With so many Transformer variants available, it can be easy to miss the bigger picture. What all these models have in common is they're based on the original Transformer architecture. Some models only use the encoder or decoder, while others use both. This provides a useful taxonomy to categorize and examine the high-level differences within models in the Transformer family, and it'll help you understand Transformers you haven't encountered before.
If you aren't familiar with the original Transformer model or need a refresher, check out the [How do Transformers work](https://huggingface.co/course/chapter1/4?fw=pt) chapter from the Hugging Face course.
@@ -32,7 +32,7 @@ If you aren't familiar with the original Transformer model or need a refresher,
### Convolutional network
-For a long time, convolutional networks (CNNs) were the dominant paradigm for computer vision tasks until the [Vision Transformer](https://arxiv.org/abs/2010.11929) demonstrated its scalability and efficiency. Even then, some of a CNN's best qualities, like translation invariance, are so powerful (especially for certain tasks) that some Transformers incorporate convolutions in their architecture. [ConvNeXt](model_doc/convnext) flipped this exchange around and incorporated design choices from Transformers to modernize a CNN. For example, ConvNeXt uses non-overlapping sliding windows to patchify an image and a larger kernel to increase its global receptive field. ConvNeXt also makes several layer design choices to be more memory-efficient and improve performance, so it competes favorably with Transformers!
+For a long time, convolutional networks (CNNs) were the dominant paradigm for computer vision tasks until the [Vision Transformer](https://huggingface.co/papers/2010.11929) demonstrated its scalability and efficiency. Even then, some of a CNN's best qualities, like translation invariance, are so powerful (especially for certain tasks) that some Transformers incorporate convolutions in their architecture. [ConvNeXt](model_doc/convnext) flipped this exchange around and incorporated design choices from Transformers to modernize a CNN. For example, ConvNeXt uses non-overlapping sliding windows to patchify an image and a larger kernel to increase its global receptive field. ConvNeXt also makes several layer design choices to be more memory-efficient and improve performance, so it competes favorably with Transformers!
### Encoder[[cv-encoder]]
@@ -58,7 +58,7 @@ Vision models commonly use an encoder (also known as a backbone) to extract impo
[BERT](model_doc/bert) is an encoder-only Transformer that randomly masks certain tokens in the input to avoid seeing other tokens, which would allow it to "cheat". The pretraining objective is to predict the masked token based on the context. This allows BERT to fully use the left and right contexts to help it learn a deeper and richer representation of the inputs. However, there was still room for improvement in BERT's pretraining strategy. [RoBERTa](model_doc/roberta) improved upon this by introducing a new pretraining recipe that includes training for longer and on larger batches, randomly masking tokens at each epoch instead of just once during preprocessing, and removing the next-sentence prediction objective.
-The dominant strategy to improve performance is to increase the model size. But training large models is computationally expensive. One way to reduce computational costs is using a smaller model like [DistilBERT](model_doc/distilbert). DistilBERT uses [knowledge distillation](https://arxiv.org/abs/1503.02531) - a compression technique - to create a smaller version of BERT while keeping nearly all of its language understanding capabilities.
+The dominant strategy to improve performance is to increase the model size. But training large models is computationally expensive. One way to reduce computational costs is using a smaller model like [DistilBERT](model_doc/distilbert). DistilBERT uses [knowledge distillation](https://huggingface.co/papers/1503.02531) - a compression technique - to create a smaller version of BERT while keeping nearly all of its language understanding capabilities.
However, most Transformer models continued to trend towards more parameters, leading to new models focused on improving training efficiency. [ALBERT](model_doc/albert) reduces memory consumption by lowering the number of parameters in two ways: separating the larger vocabulary embedding into two smaller matrices and allowing layers to share parameters. [DeBERTa](model_doc/deberta) added a disentangled attention mechanism where the word and its position are separately encoded in two vectors. The attention is computed from these separate vectors instead of a single vector containing the word and position embeddings. [Longformer](model_doc/longformer) also focused on making attention more efficient, especially for processing documents with longer sequence lengths. It uses a combination of local windowed attention (attention only calculated from fixed window size around each token) and global attention (only for specific task tokens like `[CLS]` for classification) to create a sparse attention matrix instead of a full attention matrix.
diff --git a/docs/source/en/quantization/aqlm.md b/docs/source/en/quantization/aqlm.md
index 9c9b6ac071..49bd7f89bc 100644
--- a/docs/source/en/quantization/aqlm.md
+++ b/docs/source/en/quantization/aqlm.md
@@ -16,7 +16,7 @@ rendered properly in your Markdown viewer.
# AQLM
-Additive Quantization of Language Models ([AQLM](https://arxiv.org/abs/2401.06118)) quantizes multiple weights together and takes advantage of interdependencies between them. AQLM represents groups of 8-16 weights as a sum of multiple vector codes.
+Additive Quantization of Language Models ([AQLM](https://huggingface.co/papers/2401.06118)) quantizes multiple weights together and takes advantage of interdependencies between them. AQLM represents groups of 8-16 weights as a sum of multiple vector codes.
AQLM also supports fine-tuning with [LoRA](https://huggingface.co/docs/peft/package_reference/lora) with the [PEFT](https://huggingface.co/docs/peft) library, and is fully compatible with [torch.compile](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) for even faster inference and training.
diff --git a/docs/source/en/quantization/bitnet.md b/docs/source/en/quantization/bitnet.md
index 5f713a20d3..922210b213 100644
--- a/docs/source/en/quantization/bitnet.md
+++ b/docs/source/en/quantization/bitnet.md
@@ -16,7 +16,7 @@ rendered properly in your Markdown viewer.
# BitNet
-[BitNet](https://arxiv.org/abs/2402.17764) replaces traditional linear layers in Multi-Head Attention and feed-forward networks with specialized BitLinear layers. The BitLinear layers quantize the weights using ternary precision (with values of -1, 0, and 1) and quantize the activations to 8-bit precision.
+[BitNet](https://huggingface.co/papers/2402.17764) replaces traditional linear layers in Multi-Head Attention and feed-forward networks with specialized BitLinear layers. The BitLinear layers quantize the weights using ternary precision (with values of -1, 0, and 1) and quantize the activations to 8-bit precision.
@@ -27,7 +27,7 @@ BitNet models can't be quantized on the fly. They need to be quantized during pr
1. Compute the average of the absolute values of the weight matrix and use as a scale.
2. Divide the weights by the scale, round the values, constrain them between -1 and 1, and rescale them to continue in full precision.
-3. Activations are quantized to a specified bit-width (8-bit) using [absmax](https://arxiv.org/pdf/2208.07339) quantization (symmetric per channel quantization). This involves scaling the activations into a range of [−128,127].
+3. Activations are quantized to a specified bit-width (8-bit) using [absmax](https://huggingface.co/papers/2208.07339) quantization (symmetric per channel quantization). This involves scaling the activations into a range of [−128,127].
Refer to this [PR](https://github.com/huggingface/nanotron/pull/180) to pretrain or fine-tune a 1.58-bit model with [Nanotron](https://github.com/huggingface/nanotron). For fine-tuning, convert a model from the Hugging Face to Nanotron format. Find the conversion steps in this [PR](https://github.com/huggingface/nanotron/pull/174).
diff --git a/docs/source/en/quantization/higgs.md b/docs/source/en/quantization/higgs.md
index 11c42b208c..07f6e2b31f 100644
--- a/docs/source/en/quantization/higgs.md
+++ b/docs/source/en/quantization/higgs.md
@@ -16,7 +16,7 @@ rendered properly in your Markdown viewer.
# HIGGS
-[HIGGS](https://arxiv.org/abs/2411.17525) is a zero-shot quantization algorithm that combines Hadamard preprocessing with MSE-Optimal quantization grids to achieve lower quantization error and state-of-the-art performance.
+[HIGGS](https://huggingface.co/papers/2411.17525) is a zero-shot quantization algorithm that combines Hadamard preprocessing with MSE-Optimal quantization grids to achieve lower quantization error and state-of-the-art performance.
Runtime support for HIGGS is implemented through the [FLUTE](https://github.com/HanGuo97/flute) library. Only the 70B and 405B variants of Llama 3 and Llama 3.0, and the 8B and 27B variants of Gemma 2 are currently supported. HIGGS also doesn't support quantized training and backward passes in general at the moment.
diff --git a/docs/source/en/quantization/vptq.md b/docs/source/en/quantization/vptq.md
index af082c5f2f..392895e0ea 100644
--- a/docs/source/en/quantization/vptq.md
+++ b/docs/source/en/quantization/vptq.md
@@ -69,4 +69,4 @@ VPTQ achieves better accuracy and higher throughput with lower quantization over
See an example demo of VPTQ on the VPTQ Online Demo [Space](https://huggingface.co/spaces/microsoft/VPTQ) or try running the VPTQ inference [notebook](https://colab.research.google.com/github/microsoft/VPTQ/blob/main/notebooks/vptq_example.ipynb).
-For more information, read the VPTQ [paper](https://arxiv.org/pdf/2409.17066).
+For more information, read the VPTQ [paper](https://huggingface.co/papers/2409.17066).
diff --git a/docs/source/en/tasks/knowledge_distillation_for_image_classification.md b/docs/source/en/tasks/knowledge_distillation_for_image_classification.md
index c1ccafb6fc..4d1e735bd7 100644
--- a/docs/source/en/tasks/knowledge_distillation_for_image_classification.md
+++ b/docs/source/en/tasks/knowledge_distillation_for_image_classification.md
@@ -17,7 +17,7 @@ rendered properly in your Markdown viewer.
[[open-in-colab]]
-Knowledge distillation is a technique used to transfer knowledge from a larger, more complex model (teacher) to a smaller, simpler model (student). To distill knowledge from one model to another, we take a pre-trained teacher model trained on a certain task (image classification for this case) and randomly initialize a student model to be trained on image classification. Next, we train the student model to minimize the difference between its outputs and the teacher's outputs, thus making it mimic the behavior. It was first introduced in [Distilling the Knowledge in a Neural Network by Hinton et al](https://arxiv.org/abs/1503.02531). In this guide, we will do task-specific knowledge distillation. We will use the [beans dataset](https://huggingface.co/datasets/beans) for this.
+Knowledge distillation is a technique used to transfer knowledge from a larger, more complex model (teacher) to a smaller, simpler model (student). To distill knowledge from one model to another, we take a pre-trained teacher model trained on a certain task (image classification for this case) and randomly initialize a student model to be trained on image classification. Next, we train the student model to minimize the difference between its outputs and the teacher's outputs, thus making it mimic the behavior. It was first introduced in [Distilling the Knowledge in a Neural Network by Hinton et al](https://huggingface.co/papers/1503.02531). In this guide, we will do task-specific knowledge distillation. We will use the [beans dataset](https://huggingface.co/datasets/beans) for this.
This guide demonstrates how you can distill a [fine-tuned ViT model](https://huggingface.co/merve/vit-mobilenet-beans-224) (teacher model) to a [MobileNet](https://huggingface.co/google/mobilenet_v2_1.4_224) (student model) using the [Trainer API](https://huggingface.co/docs/transformers/en/main_classes/trainer#trainer) of 🤗 Transformers.
diff --git a/docs/source/en/tasks/video_classification.md b/docs/source/en/tasks/video_classification.md
index c268de1786..7a8c6ba45d 100644
--- a/docs/source/en/tasks/video_classification.md
+++ b/docs/source/en/tasks/video_classification.md
@@ -405,7 +405,7 @@ def compute_metrics(eval_pred):
**A note on evaluation**:
-In the [VideoMAE paper](https://arxiv.org/abs/2203.12602), the authors use the following evaluation strategy. They evaluate the model on several clips from test videos and apply different crops to those clips and report the aggregate score. However, in the interest of simplicity and brevity, we don't consider that in this tutorial.
+In the [VideoMAE paper](https://huggingface.co/papers/2203.12602), the authors use the following evaluation strategy. They evaluate the model on several clips from test videos and apply different crops to those clips and report the aggregate score. However, in the interest of simplicity and brevity, we don't consider that in this tutorial.
Also, define a `collate_fn`, which will be used to batch examples together. Each batch consists of 2 keys, namely `pixel_values` and `labels`.
diff --git a/docs/source/en/tasks_explained.md b/docs/source/en/tasks_explained.md
index 1cc60ba096..afdfb86989 100644
--- a/docs/source/en/tasks_explained.md
+++ b/docs/source/en/tasks_explained.md
@@ -120,7 +120,7 @@ This section briefly explains convolutions, but it'd be helpful to have a prior
-A basic convolution without padding or stride, taken from A guide to convolution arithmetic for deep learning.
+A basic convolution without padding or stride, taken from A guide to convolution arithmetic for deep learning.
You can feed this output to another convolutional layer, and with each successive layer, the network learns more complex and abstract things like hotdogs or rockets. Between convolutional layers, it is common to add a pooling layer to reduce dimensionality and make the model more robust to variations of a feature's position.
diff --git a/docs/source/en/tokenizer_summary.md b/docs/source/en/tokenizer_summary.md
index c5f12dd20d..801948f35d 100644
--- a/docs/source/en/tokenizer_summary.md
+++ b/docs/source/en/tokenizer_summary.md
@@ -140,7 +140,7 @@ on.
### Byte-Pair Encoding (BPE)
Byte-Pair Encoding (BPE) was introduced in [Neural Machine Translation of Rare Words with Subword Units (Sennrich et
-al., 2015)](https://arxiv.org/abs/1508.07909). BPE relies on a pre-tokenizer that splits the training data into
+al., 2015)](https://huggingface.co/papers/1508.07909). BPE relies on a pre-tokenizer that splits the training data into
words. Pretokenization can be as simple as space tokenization, e.g. [GPT-2](model_doc/gpt2), [RoBERTa](model_doc/roberta). More advanced pre-tokenization include rule-based tokenization, e.g. [XLM](model_doc/xlm),
[FlauBERT](model_doc/flaubert) which uses Moses for most languages, or [GPT](model_doc/openai-gpt) which uses
spaCy and ftfy, to count the frequency of each word in the training corpus.
@@ -230,7 +230,7 @@ to ensure it's _worth it_.
### Unigram
Unigram is a subword tokenization algorithm introduced in [Subword Regularization: Improving Neural Network Translation
-Models with Multiple Subword Candidates (Kudo, 2018)](https://arxiv.org/pdf/1804.10959.pdf). In contrast to BPE or
+Models with Multiple Subword Candidates (Kudo, 2018)](https://huggingface.co/papers/1804.10959). In contrast to BPE or
WordPiece, Unigram initializes its base vocabulary to a large number of symbols and progressively trims down each
symbol to obtain a smaller vocabulary. The base vocabulary could for instance correspond to all pre-tokenized words and
the most common substrings. Unigram is not used directly for any of the models in the transformers, but it's used in
@@ -270,7 +270,7 @@ All tokenization algorithms described so far have the same problem: It is assume
separate words. However, not all languages use spaces to separate words. One possible solution is to use language
specific pre-tokenizers, *e.g.* [XLM](model_doc/xlm) uses a specific Chinese, Japanese, and Thai pre-tokenizer.
To solve this problem more generally, [SentencePiece: A simple and language independent subword tokenizer and
-detokenizer for Neural Text Processing (Kudo et al., 2018)](https://arxiv.org/pdf/1808.06226.pdf) treats the input
+detokenizer for Neural Text Processing (Kudo et al., 2018)](https://huggingface.co/papers/1808.06226) treats the input
as a raw input stream, thus including the space in the set of characters to use. It then uses the BPE or unigram
algorithm to construct the appropriate vocabulary.
diff --git a/docs/source/es/bertology.md b/docs/source/es/bertology.md
index c62e5aaf97..19ae1444ae 100644
--- a/docs/source/es/bertology.md
+++ b/docs/source/es/bertology.md
@@ -21,21 +21,21 @@ Hay un creciente campo de estudio empeñado en la investigación del funcionamie
- BERT Rediscovers the Classical NLP Pipeline por Ian Tenney, Dipanjan Das, Ellie Pavlick:
- https://arxiv.org/abs/1905.05950
-- Are Sixteen Heads Really Better than One? por Paul Michel, Omer Levy, Graham Neubig: https://arxiv.org/abs/1905.10650
+ https://huggingface.co/papers/1905.05950
+- Are Sixteen Heads Really Better than One? por Paul Michel, Omer Levy, Graham Neubig: https://huggingface.co/papers/1905.10650
- What Does BERT Look At? An Analysis of BERT's Attention por Kevin Clark, Urvashi Khandelwal, Omer Levy, Christopher D.
- Manning: https://arxiv.org/abs/1906.04341
-- CAT-probing: A Metric-based Approach to Interpret How Pre-trained Models for Programming Language Attend Code Structure: https://arxiv.org/abs/2210.04633
+ Manning: https://huggingface.co/papers/1906.04341
+- CAT-probing: A Metric-based Approach to Interpret How Pre-trained Models for Programming Language Attend Code Structure: https://huggingface.co/papers/2210.04633
Para asistir al desarrollo de este nuevo campo, hemos incluido algunas features adicionales en los modelos BERT/GPT/GPT-2 para
ayudar a acceder a las representaciones internas, principalmente adaptado de la gran obra de Paul Michel
-(https://arxiv.org/abs/1905.10650):
+(https://huggingface.co/papers/1905.10650):
- accediendo a todos los hidden-states de BERT/GPT/GPT-2,
- accediendo a todos los pesos de atención para cada head de BERT/GPT/GPT-2,
- adquiriendo los valores de salida y gradientes de las heads para poder computar la métrica de importancia de las heads y realizar la poda de heads como se explica
- en https://arxiv.org/abs/1905.10650.
+ en https://huggingface.co/papers/1905.10650.
Para ayudarte a entender y usar estas features, hemos añadido un script específico de ejemplo: [bertology.py](https://github.com/huggingface/transformers-research-projects/tree/main/bertology/run_bertology.py) mientras extraes información y cortas un modelo pre-entrenado en
GLUE.
diff --git a/docs/source/es/glossary.md b/docs/source/es/glossary.md
index 790fa1fecb..3debcdbd35 100644
--- a/docs/source/es/glossary.md
+++ b/docs/source/es/glossary.md
@@ -147,7 +147,7 @@ El proceso de seleccionar y transformar datos crudos en un conjunto de caracter
En cada bloque de atención residual en los transformadores, la capa de autoatención suele ir seguida de 2 capas de avance. El tamaño de embedding intermedio de las capas de avance suele ser mayor que el tamaño oculto del modelo (por ejemplo, para `google-bert/bert-base-uncased`).
-Para una entrada de tamaño `[batch_size, sequence_length]`, la memoria requerida para almacenar los embeddings intermedios de avance `[batch_size, sequence_length, config.intermediate_size]` puede representar una gran fracción del uso de memoria. Los autores de [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) observaron que, dado que el cálculo es independiente de la dimensión `sequence_length`, es matemáticamente equivalente calcular los embeddings de salida de ambas capas de avance `[batch_size, config.hidden_size]_0, ..., [batch_size, config.hidden_size]_n` individualmente y concatenarlos después a `[batch_size, sequence_length, config.hidden_size]` con `n = sequence_length`, lo que intercambia el aumento del tiempo de cálculo por una reducción en el uso de memoria, pero produce un resultado matemáticamente **equivalente**.
+Para una entrada de tamaño `[batch_size, sequence_length]`, la memoria requerida para almacenar los embeddings intermedios de avance `[batch_size, sequence_length, config.intermediate_size]` puede representar una gran fracción del uso de memoria. Los autores de [Reformer: The Efficient Transformer](https://huggingface.co/papers/2001.04451) observaron que, dado que el cálculo es independiente de la dimensión `sequence_length`, es matemáticamente equivalente calcular los embeddings de salida de ambas capas de avance `[batch_size, config.hidden_size]_0, ..., [batch_size, config.hidden_size]_n` individualmente y concatenarlos después a `[batch_size, sequence_length, config.hidden_size]` con `n = sequence_length`, lo que intercambia el aumento del tiempo de cálculo por una reducción en el uso de memoria, pero produce un resultado matemáticamente **equivalente**.
Para modelos que utilizan la función [`apply_chunking_to_forward`], el `chunk_size` define el número de embeddings de salida que se calculan en paralelo y, por lo tanto, define el equilibrio entre la complejidad de memoria y tiempo. Si `chunk_size` se establece en 0, no se realiza ninguna fragmentación de avance.
@@ -183,7 +183,7 @@ Los IDs de entrada a menudo son los únicos parámetros necesarios que se deben
-Cada tokenizador funciona de manera diferente, pero el mecanismo subyacente sigue siendo el mismo. Aquí tienes un ejemplo utilizando el tokenizador BERT, que es un tokenizador [WordPiece](https://arxiv.org/pdf/1609.08144.pdf):
+Cada tokenizador funciona de manera diferente, pero el mecanismo subyacente sigue siendo el mismo. Aquí tienes un ejemplo utilizando el tokenizador BERT, que es un tokenizador [WordPiece](https://huggingface.co/papers/1609.08144):
```python
>>> from transformers import BertTokenizer
diff --git a/docs/source/es/index.md b/docs/source/es/index.md
index 3c10e71ebf..428a729447 100644
--- a/docs/source/es/index.md
+++ b/docs/source/es/index.md
@@ -49,122 +49,122 @@ La biblioteca actualmente contiene implementaciones de JAX, PyTorch y TensorFlow
-1. **[ALBERT](model_doc/albert)** (de Google Research y el Instituto Tecnológico de Toyota en Chicago) publicado con el paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), por Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
-1. **[ALIGN](model_doc/align)** (de Google Research) publicado con el paper [Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://arxiv.org/abs/2102.05918) por Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig.
-1. **[BART](model_doc/bart)** (de Facebook) publicado con el paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) por Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov y Luke Zettlemoyer.
-1. **[BARThez](model_doc/barthez)** (de École polytechnique) publicado con el paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) por Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
-1. **[BARTpho](model_doc/bartpho)** (de VinAI Research) publicado con el paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) por Nguyen Luong Tran, Duong Minh Le y Dat Quoc Nguyen.
-1. **[BEiT](model_doc/beit)** (de Microsoft) publicado con el paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) por Hangbo Bao, Li Dong, Furu Wei.
-1. **[BERT](model_doc/bert)** (de Google) publicado con el paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) por Jacob Devlin, Ming-Wei Chang, Kenton Lee y Kristina Toutanova.
+1. **[ALBERT](model_doc/albert)** (de Google Research y el Instituto Tecnológico de Toyota en Chicago) publicado con el paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://huggingface.co/papers/1909.11942), por Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
+1. **[ALIGN](model_doc/align)** (de Google Research) publicado con el paper [Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://huggingface.co/papers/2102.05918) por Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig.
+1. **[BART](model_doc/bart)** (de Facebook) publicado con el paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://huggingface.co/papers/1910.13461) por Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov y Luke Zettlemoyer.
+1. **[BARThez](model_doc/barthez)** (de École polytechnique) publicado con el paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://huggingface.co/papers/2010.12321) por Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
+1. **[BARTpho](model_doc/bartpho)** (de VinAI Research) publicado con el paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://huggingface.co/papers/2109.09701) por Nguyen Luong Tran, Duong Minh Le y Dat Quoc Nguyen.
+1. **[BEiT](model_doc/beit)** (de Microsoft) publicado con el paper [BEiT: BERT Pre-Training of Image Transformers](https://huggingface.co/papers/2106.08254) por Hangbo Bao, Li Dong, Furu Wei.
+1. **[BERT](model_doc/bert)** (de Google) publicado con el paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://huggingface.co/papers/1810.04805) por Jacob Devlin, Ming-Wei Chang, Kenton Lee y Kristina Toutanova.
1. **[BERTweet](model_doc/bertweet)** (de VinAI Research) publicado con el paper [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) por Dat Quoc Nguyen, Thanh Vu y Anh Tuan Nguyen.
-1. **[BERT For Sequence Generation](model_doc/bert-generation)** (de Google) publicado con el paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) por Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
-1. **[BigBird-RoBERTa](model_doc/big_bird)** (de Google Research) publicado con el paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) por Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
-1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (de Google Research) publicado con el paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) por Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
-1. **[Blenderbot](model_doc/blenderbot)** (de Facebook) publicado con el paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) por Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
-1. **[BlenderbotSmall](model_doc/blenderbot-small)** (de Facebook) publicado con el paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) por Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
-1. **[BORT](model_doc/bort)** (de Alexa) publicado con el paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) por Adrian de Wynter y Daniel J. Perry.
-1. **[ByT5](model_doc/byt5)** (de Google Research) publicado con el paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) por Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
-1. **[CamemBERT](model_doc/camembert)** (de Inria/Facebook/Sorbonne) publicado con el paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) por Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah y Benoît Sagot.
-1. **[CANINE](model_doc/canine)** (de Google Research) publicado con el paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) por Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
-1. **[ConvNeXT](model_doc/convnext)** (de Facebook AI) publicado con el paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) por Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
-1. **[ConvNeXTV2](model_doc/convnextv2)** (de Facebook AI) publicado con el paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) por Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
-1. **[CLIP](model_doc/clip)** (de OpenAI) publicado con el paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) por Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
-1. **[ConvBERT](model_doc/convbert)** (de YituTech) publicado con el paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) por Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
-1. **[CPM](model_doc/cpm)** (de Universidad de Tsinghua) publicado con el paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) por Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
-1. **[CTRL](model_doc/ctrl)** (de Salesforce) publicado con el paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) por Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong y Richard Socher.
-1. **[Data2Vec](model_doc/data2vec)** (de Facebook) publicado con el paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) por Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
-1. **[DeBERTa](model_doc/deberta)** (de Microsoft) publicado con el paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) por Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
-1. **[DeBERTa-v2](model_doc/deberta-v2)** (de Microsoft) publicado con el paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) por Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
-1. **[Decision Transformer](model_doc/decision_transformer)** (de Berkeley/Facebook/Google) publicado con el paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) por Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
-1. **[DiT](model_doc/dit)** (de Microsoft Research) publicado con el paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) por Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
-1. **[DeiT](model_doc/deit)** (de Facebook) publicado con el paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) por Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
-1. **[DETR](model_doc/detr)** (de Facebook) publicado con el paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) por Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
-1. **[DialoGPT](model_doc/dialogpt)** (de Microsoft Research) publicado con el paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) por Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
-1. **[DistilBERT](model_doc/distilbert)** (de HuggingFace), publicado junto con el paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) por Victor Sanh, Lysandre Debut y Thomas Wolf. Se ha aplicado el mismo método para comprimir GPT2 en [DistilGPT2](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), RoBERTa en [DistilRoBERTa](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), BERT multilingüe en [DistilmBERT](https://github.com/huggingface/transformers-research-projects/tree/main/distillation) y una versión alemana de DistilBERT.
-1. **[DPR](model_doc/dpr)** (de Facebook) publicado con el paper [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) por Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, y Wen-tau Yih.
-1. **[DPT](master/model_doc/dpt)** (de Intel Labs) publicado con el paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) por René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
-1. **[EfficientNet](model_doc/efficientnet)** (from Google Research) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan and Quoc V. Le.
-1. **[EncoderDecoder](model_doc/encoder-decoder)** (de Google Research) publicado con el paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) por Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
-1. **[ELECTRA](model_doc/electra)** (de Google Research/Universidad de Stanford) publicado con el paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) por Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
-1. **[FlauBERT](model_doc/flaubert)** (de CNRS) publicado con el paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) por Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
-1. **[FNet](model_doc/fnet)** (de Google Research) publicado con el paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) por James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
-1. **[Funnel Transformer](model_doc/funnel)** (de CMU/Google Brain) publicado con el paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) por Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
-1. **[GLPN](model_doc/glpn)** (de KAIST) publicado con el paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) por Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
+1. **[BERT For Sequence Generation](model_doc/bert-generation)** (de Google) publicado con el paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://huggingface.co/papers/1907.12461) por Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[BigBird-RoBERTa](model_doc/big_bird)** (de Google Research) publicado con el paper [Big Bird: Transformers for Longer Sequences](https://huggingface.co/papers/2007.14062) por Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (de Google Research) publicado con el paper [Big Bird: Transformers for Longer Sequences](https://huggingface.co/papers/2007.14062) por Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[Blenderbot](model_doc/blenderbot)** (de Facebook) publicado con el paper [Recipes for building an open-domain chatbot](https://huggingface.co/papers/2004.13637) por Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BlenderbotSmall](model_doc/blenderbot-small)** (de Facebook) publicado con el paper [Recipes for building an open-domain chatbot](https://huggingface.co/papers/2004.13637) por Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BORT](model_doc/bort)** (de Alexa) publicado con el paper [Optimal Subarchitecture Extraction For BERT](https://huggingface.co/papers/2010.10499) por Adrian de Wynter y Daniel J. Perry.
+1. **[ByT5](model_doc/byt5)** (de Google Research) publicado con el paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://huggingface.co/papers/2105.13626) por Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
+1. **[CamemBERT](model_doc/camembert)** (de Inria/Facebook/Sorbonne) publicado con el paper [CamemBERT: a Tasty French Language Model](https://huggingface.co/papers/1911.03894) por Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah y Benoît Sagot.
+1. **[CANINE](model_doc/canine)** (de Google Research) publicado con el paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://huggingface.co/papers/2103.06874) por Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
+1. **[ConvNeXT](model_doc/convnext)** (de Facebook AI) publicado con el paper [A ConvNet for the 2020s](https://huggingface.co/papers/2201.03545) por Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
+1. **[ConvNeXTV2](model_doc/convnextv2)** (de Facebook AI) publicado con el paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://huggingface.co/papers/2301.00808) por Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
+1. **[CLIP](model_doc/clip)** (de OpenAI) publicado con el paper [Learning Transferable Visual Models From Natural Language Supervision](https://huggingface.co/papers/2103.00020) por Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
+1. **[ConvBERT](model_doc/convbert)** (de YituTech) publicado con el paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://huggingface.co/papers/2008.02496) por Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
+1. **[CPM](model_doc/cpm)** (de Universidad de Tsinghua) publicado con el paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://huggingface.co/papers/2012.00413) por Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
+1. **[CTRL](model_doc/ctrl)** (de Salesforce) publicado con el paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://huggingface.co/papers/1909.05858) por Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong y Richard Socher.
+1. **[Data2Vec](model_doc/data2vec)** (de Facebook) publicado con el paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://huggingface.co/papers/2202.03555) por Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
+1. **[DeBERTa](model_doc/deberta)** (de Microsoft) publicado con el paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://huggingface.co/papers/2006.03654) por Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[DeBERTa-v2](model_doc/deberta-v2)** (de Microsoft) publicado con el paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://huggingface.co/papers/2006.03654) por Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[Decision Transformer](model_doc/decision_transformer)** (de Berkeley/Facebook/Google) publicado con el paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://huggingface.co/papers/2106.01345) por Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
+1. **[DiT](model_doc/dit)** (de Microsoft Research) publicado con el paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://huggingface.co/papers/2203.02378) por Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
+1. **[DeiT](model_doc/deit)** (de Facebook) publicado con el paper [Training data-efficient image transformers & distillation through attention](https://huggingface.co/papers/2012.12877) por Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
+1. **[DETR](model_doc/detr)** (de Facebook) publicado con el paper [End-to-End Object Detection with Transformers](https://huggingface.co/papers/2005.12872) por Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
+1. **[DialoGPT](model_doc/dialogpt)** (de Microsoft Research) publicado con el paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://huggingface.co/papers/1911.00536) por Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
+1. **[DistilBERT](model_doc/distilbert)** (de HuggingFace), publicado junto con el paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://huggingface.co/papers/1910.01108) por Victor Sanh, Lysandre Debut y Thomas Wolf. Se ha aplicado el mismo método para comprimir GPT2 en [DistilGPT2](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), RoBERTa en [DistilRoBERTa](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), BERT multilingüe en [DistilmBERT](https://github.com/huggingface/transformers-research-projects/tree/main/distillation) y una versión alemana de DistilBERT.
+1. **[DPR](model_doc/dpr)** (de Facebook) publicado con el paper [Dense Passage Retrieval for Open-Domain Question Answering](https://huggingface.co/papers/2004.04906) por Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, y Wen-tau Yih.
+1. **[DPT](master/model_doc/dpt)** (de Intel Labs) publicado con el paper [Vision Transformers for Dense Prediction](https://huggingface.co/papers/2103.13413) por René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
+1. **[EfficientNet](model_doc/efficientnet)** (from Google Research) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://huggingface.co/papers/1905.11946) by Mingxing Tan and Quoc V. Le.
+1. **[EncoderDecoder](model_doc/encoder-decoder)** (de Google Research) publicado con el paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://huggingface.co/papers/1907.12461) por Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[ELECTRA](model_doc/electra)** (de Google Research/Universidad de Stanford) publicado con el paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://huggingface.co/papers/2003.10555) por Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
+1. **[FlauBERT](model_doc/flaubert)** (de CNRS) publicado con el paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://huggingface.co/papers/1912.05372) por Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
+1. **[FNet](model_doc/fnet)** (de Google Research) publicado con el paper [FNet: Mixing Tokens with Fourier Transforms](https://huggingface.co/papers/2105.03824) por James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
+1. **[Funnel Transformer](model_doc/funnel)** (de CMU/Google Brain) publicado con el paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://huggingface.co/papers/2006.03236) por Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
+1. **[GLPN](model_doc/glpn)** (de KAIST) publicado con el paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://huggingface.co/papers/2201.07436) por Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
1. **[GPT](model_doc/openai-gpt)** (de OpenAI) publicado con el paper [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/) por Alec Radford, Karthik Narasimhan, Tim Salimans y Ilya Sutskever.
1. **[GPT-2](model_doc/gpt2)** (de OpenAI) publicado con el paper [Language Models are Unsupervised Multitask Learners](https://openai.com/research/better-language-models/) por Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei y Ilya Sutskever.
1. **[GPT-J](model_doc/gptj)** (de EleutherAI) publicado con el repositorio [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) por Ben Wang y Aran Komatsuzaki.
1. **[GPT Neo](model_doc/gpt_neo)** (de EleutherAI) publicado en el paper [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) por Sid Black, Stella Biderman, Leo Gao, Phil Wang y Connor Leahy.
1. **[GPTSAN-japanese](model_doc/gptsan-japanese)** released with [GPTSAN](https://github.com/tanreinama/GPTSAN) by Toshiyuki Sakamoto (tanreinama).
-1. **[Hubert](model_doc/hubert)** (de Facebook) publicado con el paper [HuBERT: Self-Supervised Speech Representation Learning por Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) por Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
-1. **[I-BERT](model_doc/ibert)** (de Berkeley) publicado con el paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) por Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
+1. **[Hubert](model_doc/hubert)** (de Facebook) publicado con el paper [HuBERT: Self-Supervised Speech Representation Learning por Masked Prediction of Hidden Units](https://huggingface.co/papers/2106.07447) por Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
+1. **[I-BERT](model_doc/ibert)** (de Berkeley) publicado con el paper [I-BERT: Integer-only BERT Quantization](https://huggingface.co/papers/2101.01321) por Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
1. **[ImageGPT](model_doc/imagegpt)** (de OpenAI) publicado con el paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) por Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
-1. **[LayoutLM](model_doc/layoutlm)** (de Microsoft Research Asia) publicado con el paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) por Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
-1. **[LayoutLMv2](model_doc/layoutlmv2)** (de Microsoft Research Asia) publicado con el paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) por Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
-1. **[LayoutXLM](model_doc/layoutxlm)** (de Microsoft Research Asia) publicado con el paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) por Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
-1. **[LED](model_doc/led)** (de AllenAI) publicado con el paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) por Iz Beltagy, Matthew E. Peters, Arman Cohan.
-1. **[Longformer](model_doc/longformer)** (de AllenAI) publicado con el paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) por Iz Beltagy, Matthew E. Peters, Arman Cohan.
-1. **[LUKE](model_doc/luke)** (de Studio Ousia) publicado con el paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) por Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
-1. **[mLUKE](model_doc/mluke)** (de Studio Ousia) publicado con el paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) por Ryokan Ri, Ikuya Yamada, y Yoshimasa Tsuruoka.
-1. **[LXMERT](model_doc/lxmert)** (de UNC Chapel Hill) publicado con el paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) por Hao Tan y Mohit Bansal.
-1. **[M2M100](model_doc/m2m_100)** (de Facebook) publicado con el paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) por Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
+1. **[LayoutLM](model_doc/layoutlm)** (de Microsoft Research Asia) publicado con el paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://huggingface.co/papers/1912.13318) por Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
+1. **[LayoutLMv2](model_doc/layoutlmv2)** (de Microsoft Research Asia) publicado con el paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://huggingface.co/papers/2012.14740) por Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
+1. **[LayoutXLM](model_doc/layoutxlm)** (de Microsoft Research Asia) publicado con el paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://huggingface.co/papers/2104.08836) por Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
+1. **[LED](model_doc/led)** (de AllenAI) publicado con el paper [Longformer: The Long-Document Transformer](https://huggingface.co/papers/2004.05150) por Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[Longformer](model_doc/longformer)** (de AllenAI) publicado con el paper [Longformer: The Long-Document Transformer](https://huggingface.co/papers/2004.05150) por Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LUKE](model_doc/luke)** (de Studio Ousia) publicado con el paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://huggingface.co/papers/2010.01057) por Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
+1. **[mLUKE](model_doc/mluke)** (de Studio Ousia) publicado con el paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://huggingface.co/papers/2110.08151) por Ryokan Ri, Ikuya Yamada, y Yoshimasa Tsuruoka.
+1. **[LXMERT](model_doc/lxmert)** (de UNC Chapel Hill) publicado con el paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://huggingface.co/papers/1908.07490) por Hao Tan y Mohit Bansal.
+1. **[M2M100](model_doc/m2m_100)** (de Facebook) publicado con el paper [Beyond English-Centric Multilingual Machine Translation](https://huggingface.co/papers/2010.11125) por Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
1. **[MarianMT](model_doc/marian)** Modelos de traducción automática entrenados usando [OPUS](http://opus.nlpl.eu/) data por Jörg Tiedemann. El [Marian Framework](https://marian-nmt.github.io/) está siendo desarrollado por el equipo de traductores de Microsoft.
-1. **[Mask2Former](model_doc/mask2former)** (de FAIR y UIUC) publicado con el paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) por Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
-1. **[MaskFormer](model_doc/maskformer)** (de Meta y UIUC) publicado con el paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) por Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
-1. **[MBart](model_doc/mbart)** (de Facebook) publicado con el paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) por Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
-1. **[MBart-50](model_doc/mbart)** (de Facebook) publicado con el paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) por Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
-1. **[Megatron-BERT](model_doc/megatron-bert)** (de NVIDIA) publicado con el paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) por Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper y Bryan Catanzaro.
-1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (de NVIDIA) publicado con el paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) por Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper y Bryan Catanzaro.
-1. **[MPNet](model_doc/mpnet)** (de Microsoft Research) publicado con el paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) por Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
-1. **[MT5](model_doc/mt5)** (de Google AI) publicado con el paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) por Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
-1. **[Nyströmformer](model_doc/nystromformer)** (de la Universidad de Wisconsin - Madison) publicado con el paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) por Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
-1. **[OneFormer](model_doc/oneformer)** (de la SHI Labs) publicado con el paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) por Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
-1. **[Pegasus](model_doc/pegasus)** (de Google) publicado con el paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) por Jingqing Zhang, Yao Zhao, Mohammad Saleh y Peter J. Liu.
-1. **[Perceiver IO](model_doc/perceiver)** (de Deepmind) publicado con el paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) por Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
+1. **[Mask2Former](model_doc/mask2former)** (de FAIR y UIUC) publicado con el paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://huggingface.co/papers/2112.01527) por Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
+1. **[MaskFormer](model_doc/maskformer)** (de Meta y UIUC) publicado con el paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://huggingface.co/papers/2107.06278) por Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
+1. **[MBart](model_doc/mbart)** (de Facebook) publicado con el paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://huggingface.co/papers/2001.08210) por Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
+1. **[MBart-50](model_doc/mbart)** (de Facebook) publicado con el paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://huggingface.co/papers/2008.00401) por Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
+1. **[Megatron-BERT](model_doc/megatron-bert)** (de NVIDIA) publicado con el paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://huggingface.co/papers/1909.08053) por Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper y Bryan Catanzaro.
+1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (de NVIDIA) publicado con el paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://huggingface.co/papers/1909.08053) por Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper y Bryan Catanzaro.
+1. **[MPNet](model_doc/mpnet)** (de Microsoft Research) publicado con el paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://huggingface.co/papers/2004.09297) por Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
+1. **[MT5](model_doc/mt5)** (de Google AI) publicado con el paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://huggingface.co/papers/2010.11934) por Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
+1. **[Nyströmformer](model_doc/nystromformer)** (de la Universidad de Wisconsin - Madison) publicado con el paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://huggingface.co/papers/2102.03902) por Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
+1. **[OneFormer](model_doc/oneformer)** (de la SHI Labs) publicado con el paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://huggingface.co/papers/2211.06220) por Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
+1. **[Pegasus](model_doc/pegasus)** (de Google) publicado con el paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://huggingface.co/papers/1912.08777) por Jingqing Zhang, Yao Zhao, Mohammad Saleh y Peter J. Liu.
+1. **[Perceiver IO](model_doc/perceiver)** (de Deepmind) publicado con el paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://huggingface.co/papers/2107.14795) por Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
1. **[PhoBERT](model_doc/phobert)** (de VinAI Research) publicado con el paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) por Dat Quoc Nguyen y Anh Tuan Nguyen.
-1. **[PLBart](model_doc/plbart)** (de UCLA NLP) publicado con el paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) por Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
-1. **[PoolFormer](model_doc/poolformer)** (de Sea AI Labs) publicado con el paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) por Yu, Weihao y Luo, Mi y Zhou, Pan y Si, Chenyang y Zhou, Yichen y Wang, Xinchao y Feng, Jiashi y Yan, Shuicheng.
-1. **[ProphetNet](model_doc/prophetnet)** (de Microsoft Research) publicado con el paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) por Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang y Ming Zhou.
-1. **[QDQBert](model_doc/qdqbert)** (de NVIDIA) publicado con el paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) por Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev y Paulius Micikevicius.
-1. **[REALM](model_doc/realm.html)** (de Google Research) publicado con el paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) por Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat y Ming-Wei Chang.
-1. **[Reformer](model_doc/reformer)** (de Google Research) publicado con el paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) por Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
-1. **[RemBERT](model_doc/rembert)** (de Google Research) publicado con el paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) por Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
-1. **[RegNet](model_doc/regnet)** (de META Platforms) publicado con el paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) por Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
-1. **[ResNet](model_doc/resnet)** (de Microsoft Research) publicado con el paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) por Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
-1. **[RoBERTa](model_doc/roberta)** (de Facebook), publicado junto con el paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) por Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
-1. **[RoFormer](model_doc/roformer)** (de ZhuiyiTechnology), publicado junto con el paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) por Jianlin Su y Yu Lu y Shengfeng Pan y Bo Wen y Yunfeng Liu.
-1. **[SegFormer](model_doc/segformer)** (de NVIDIA) publicado con el paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) por Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
-1. **[SEW](model_doc/sew)** (de ASAPP) publicado con el paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) por Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
-1. **[SEW-D](model_doc/sew_d)** (de ASAPP) publicado con el paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) por Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
-1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (de Facebook), publicado junto con el paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) por Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
-1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (de Facebook), publicado junto con el paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) por Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
-1. **[Splinter](model_doc/splinter)** (de Universidad de Tel Aviv), publicado junto con el paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) pory Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
-1. **[SqueezeBert](model_doc/squeezebert)** (de Berkeley) publicado con el paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) por Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, y Kurt W. Keutzer.
-1. **[Swin Transformer](model_doc/swin)** (de Microsoft) publicado con el paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) por Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
-1. **[T5](model_doc/t5)** (de Google AI) publicado con el paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) por Colin Raffel y Noam Shazeer y Adam Roberts y Katherine Lee y Sharan Narang y Michael Matena y Yanqi Zhou y Wei Li y Peter J. Liu.
+1. **[PLBart](model_doc/plbart)** (de UCLA NLP) publicado con el paper [Unified Pre-training for Program Understanding and Generation](https://huggingface.co/papers/2103.06333) por Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
+1. **[PoolFormer](model_doc/poolformer)** (de Sea AI Labs) publicado con el paper [MetaFormer is Actually What You Need for Vision](https://huggingface.co/papers/2111.11418) por Yu, Weihao y Luo, Mi y Zhou, Pan y Si, Chenyang y Zhou, Yichen y Wang, Xinchao y Feng, Jiashi y Yan, Shuicheng.
+1. **[ProphetNet](model_doc/prophetnet)** (de Microsoft Research) publicado con el paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://huggingface.co/papers/2001.04063) por Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang y Ming Zhou.
+1. **[QDQBert](model_doc/qdqbert)** (de NVIDIA) publicado con el paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://huggingface.co/papers/2004.09602) por Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev y Paulius Micikevicius.
+1. **[REALM](model_doc/realm.html)** (de Google Research) publicado con el paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://huggingface.co/papers/2002.08909) por Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat y Ming-Wei Chang.
+1. **[Reformer](model_doc/reformer)** (de Google Research) publicado con el paper [Reformer: The Efficient Transformer](https://huggingface.co/papers/2001.04451) por Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
+1. **[RemBERT](model_doc/rembert)** (de Google Research) publicado con el paper [Rethinking embedding coupling in pre-trained language models](https://huggingface.co/papers/2010.12821) por Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
+1. **[RegNet](model_doc/regnet)** (de META Platforms) publicado con el paper [Designing Network Design Space](https://huggingface.co/papers/2003.13678) por Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
+1. **[ResNet](model_doc/resnet)** (de Microsoft Research) publicado con el paper [Deep Residual Learning for Image Recognition](https://huggingface.co/papers/1512.03385) por Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
+1. **[RoBERTa](model_doc/roberta)** (de Facebook), publicado junto con el paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://huggingface.co/papers/1907.11692) por Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
+1. **[RoFormer](model_doc/roformer)** (de ZhuiyiTechnology), publicado junto con el paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://huggingface.co/papers/2104.09864) por Jianlin Su y Yu Lu y Shengfeng Pan y Bo Wen y Yunfeng Liu.
+1. **[SegFormer](model_doc/segformer)** (de NVIDIA) publicado con el paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://huggingface.co/papers/2105.15203) por Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
+1. **[SEW](model_doc/sew)** (de ASAPP) publicado con el paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://huggingface.co/papers/2109.06870) por Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SEW-D](model_doc/sew_d)** (de ASAPP) publicado con el paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://huggingface.co/papers/2109.06870) por Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (de Facebook), publicado junto con el paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://huggingface.co/papers/2010.05171) por Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
+1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (de Facebook), publicado junto con el paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://huggingface.co/papers/2104.06678) por Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
+1. **[Splinter](model_doc/splinter)** (de Universidad de Tel Aviv), publicado junto con el paper [Few-Shot Question Answering by Pretraining Span Selection](https://huggingface.co/papers/2101.00438) pory Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
+1. **[SqueezeBert](model_doc/squeezebert)** (de Berkeley) publicado con el paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://huggingface.co/papers/2006.11316) por Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, y Kurt W. Keutzer.
+1. **[Swin Transformer](model_doc/swin)** (de Microsoft) publicado con el paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://huggingface.co/papers/2103.14030) por Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
+1. **[T5](model_doc/t5)** (de Google AI) publicado con el paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://huggingface.co/papers/1910.10683) por Colin Raffel y Noam Shazeer y Adam Roberts y Katherine Lee y Sharan Narang y Michael Matena y Yanqi Zhou y Wei Li y Peter J. Liu.
1. **[T5v1.1](model_doc/t5v1.1)** (de Google AI) publicado en el repositorio [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) por Colin Raffel y Noam Shazeer y Adam Roberts y Katherine Lee y Sharan Narang y Michael Matena y Yanqi Zhou y Wei Li y Peter J. Liu.
-1. **[TAPAS](model_doc/tapas)** (de Google AI) publicado con el paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) por Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno y Julian Martin Eisenschlos.
-1. **[TAPEX](model_doc/tapex)** (de Microsoft Research) publicado con el paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) por Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
-1. **[Transformer-XL](model_doc/transfo-xl)** (de Google/CMU) publicado con el paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) por Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
-1. **[TrOCR](model_doc/trocr)** (de Microsoft), publicado junto con el paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) por Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
-1. **[UniSpeech](model_doc/unispeech)** (de Microsoft Research) publicado con el paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) por Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
-1. **[UniSpeechSat](model_doc/unispeech-sat)** (de Microsoft Research) publicado con el paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) por Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
-1. **[VAN](model_doc/van)** (de la Universidad de Tsinghua y la Universidad de Nankai) publicado con el paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) por Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
-1. **[ViLT](model_doc/vilt)** (de NAVER AI Lab/Kakao Enterprise/Kakao Brain) publicado con el paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) por Wonjae Kim, Bokyung Son, Ildoo Kim.
-1. **[Vision Transformer (ViT)](model_doc/vit)** (de Google AI) publicado con el paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) por Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
-1. **[ViTMAE](model_doc/vit_mae)** (de Meta AI) publicado con el paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) por Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
-1. **[VisualBERT](model_doc/visual_bert)** (de UCLA NLP) publicado con el paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) por Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
-1. **[WavLM](model_doc/wavlm)** (de Microsoft Research) publicado con el paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) por Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
-1. **[Wav2Vec2](model_doc/wav2vec2)** (de Facebook AI) publicado con el paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) por Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
-1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (de Facebook AI) publicado con el paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) por Qiantong Xu, Alexei Baevski, Michael Auli.
-1. **[XGLM](model_doc/xglm)** (de Facebook AI) publicado con el paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) por Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
-1. **[XLM](model_doc/xlm)** (de Facebook) publicado junto con el paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) por Guillaume Lample y Alexis Conneau.
-1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (de Microsoft Research) publicado con el paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) por Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang y Ming Zhou.
-1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (de Facebook AI), publicado junto con el paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) por Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer y Veselin Stoyanov.
-1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (de Facebook AI), publicado junto con el paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) por Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
-1. **[XLNet](model_doc/xlnet)** (de Google/CMU) publicado con el paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) por Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
-1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (de Facebook AI) publicado con el paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) por Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
-1. **[XLS-R](model_doc/xls_r)** (de Facebook AI) publicado con el paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) por Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
-1. **[YOSO](model_doc/yoso)** (de la Universidad de Wisconsin-Madison) publicado con el paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) por Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
+1. **[TAPAS](model_doc/tapas)** (de Google AI) publicado con el paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://huggingface.co/papers/2004.02349) por Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno y Julian Martin Eisenschlos.
+1. **[TAPEX](model_doc/tapex)** (de Microsoft Research) publicado con el paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://huggingface.co/papers/2107.07653) por Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
+1. **[Transformer-XL](model_doc/transfo-xl)** (de Google/CMU) publicado con el paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://huggingface.co/papers/1901.02860) por Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
+1. **[TrOCR](model_doc/trocr)** (de Microsoft), publicado junto con el paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://huggingface.co/papers/2109.10282) por Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
+1. **[UniSpeech](model_doc/unispeech)** (de Microsoft Research) publicado con el paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://huggingface.co/papers/2101.07597) por Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
+1. **[UniSpeechSat](model_doc/unispeech-sat)** (de Microsoft Research) publicado con el paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://huggingface.co/papers/2110.05752) por Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
+1. **[VAN](model_doc/van)** (de la Universidad de Tsinghua y la Universidad de Nankai) publicado con el paper [Visual Attention Network](https://huggingface.co/papers/2202.09741) por Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
+1. **[ViLT](model_doc/vilt)** (de NAVER AI Lab/Kakao Enterprise/Kakao Brain) publicado con el paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://huggingface.co/papers/2102.03334) por Wonjae Kim, Bokyung Son, Ildoo Kim.
+1. **[Vision Transformer (ViT)](model_doc/vit)** (de Google AI) publicado con el paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://huggingface.co/papers/2010.11929) por Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
+1. **[ViTMAE](model_doc/vit_mae)** (de Meta AI) publicado con el paper [Masked Autoencoders Are Scalable Vision Learners](https://huggingface.co/papers/2111.06377) por Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
+1. **[VisualBERT](model_doc/visual_bert)** (de UCLA NLP) publicado con el paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://huggingface.co/papers/1908.03557) por Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
+1. **[WavLM](model_doc/wavlm)** (de Microsoft Research) publicado con el paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://huggingface.co/papers/2110.13900) por Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
+1. **[Wav2Vec2](model_doc/wav2vec2)** (de Facebook AI) publicado con el paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://huggingface.co/papers/2006.11477) por Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
+1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (de Facebook AI) publicado con el paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://huggingface.co/papers/2109.11680) por Qiantong Xu, Alexei Baevski, Michael Auli.
+1. **[XGLM](model_doc/xglm)** (de Facebook AI) publicado con el paper [Few-shot Learning with Multilingual Language Models](https://huggingface.co/papers/2112.10668) por Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
+1. **[XLM](model_doc/xlm)** (de Facebook) publicado junto con el paper [Cross-lingual Language Model Pretraining](https://huggingface.co/papers/1901.07291) por Guillaume Lample y Alexis Conneau.
+1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (de Microsoft Research) publicado con el paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://huggingface.co/papers/2001.04063) por Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang y Ming Zhou.
+1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (de Facebook AI), publicado junto con el paper [Unsupervised Cross-lingual Representation Learning at Scale](https://huggingface.co/papers/1911.02116) por Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer y Veselin Stoyanov.
+1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (de Facebook AI), publicado junto con el paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://huggingface.co/papers/2105.00572) por Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
+1. **[XLNet](model_doc/xlnet)** (de Google/CMU) publicado con el paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://huggingface.co/papers/1906.08237) por Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
+1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (de Facebook AI) publicado con el paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://huggingface.co/papers/2006.13979) por Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
+1. **[XLS-R](model_doc/xls_r)** (de Facebook AI) publicado con el paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://huggingface.co/papers/2111.09296) por Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
+1. **[YOSO](model_doc/yoso)** (de la Universidad de Wisconsin-Madison) publicado con el paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://huggingface.co/papers/2111.09714) por Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
### Frameworks compatibles
diff --git a/docs/source/es/model_memory_anatomy.md b/docs/source/es/model_memory_anatomy.md
index 6a220da993..54609a1c1e 100644
--- a/docs/source/es/model_memory_anatomy.md
+++ b/docs/source/es/model_memory_anatomy.md
@@ -185,7 +185,7 @@ La arquitectura de los transformers incluye 3 grupos principales de operaciones
Este conocimiento puede ser útil al analizar cuellos de botella de rendimiento.
-Este resumen se deriva de [Data Movement Is All You Need: A Case Study on Optimizing Transformers 2020](https://arxiv.org/abs/2007.00072)
+Este resumen se deriva de [Data Movement Is All You Need: A Case Study on Optimizing Transformers 2020](https://huggingface.co/papers/2007.00072)
## Anatomía de la Memoria del Modelo
diff --git a/docs/source/es/tasks_explained.md b/docs/source/es/tasks_explained.md
index 9b13f52141..69d822e82a 100644
--- a/docs/source/es/tasks_explained.md
+++ b/docs/source/es/tasks_explained.md
@@ -120,7 +120,7 @@ Esta sección explica brevemente las convoluciones, pero sería útil tener un e
-Una convolución básica sin relleno ni paso, tomada de Una guía para la aritmética de convoluciones para el aprendizaje profundo.
+Una convolución básica sin relleno ni paso, tomada de Una guía para la aritmética de convoluciones para el aprendizaje profundo.
Puedes alimentar esta salida a otra capa convolucional, y con cada capa sucesiva, la red aprende cosas más complejas y abstractas como perros calientes o cohetes. Entre capas convolucionales, es común añadir una capa de agrupación para reducir la dimensionalidad y hacer que el modelo sea más robusto a las variaciones de la posición de una característica.
diff --git a/docs/source/es/tokenizer_summary.md b/docs/source/es/tokenizer_summary.md
index c4c8ee1783..731f16b3fe 100644
--- a/docs/source/es/tokenizer_summary.md
+++ b/docs/source/es/tokenizer_summary.md
@@ -98,7 +98,7 @@ Ahora, veamos cómo funcionan los diferentes algoritmos de tokenización de subp
### Byte-Pair Encoding (BPE)
-La Codificación por Pares de Bytes (BPE por sus siglas en inglés) fue introducida en [Neural Machine Translation of Rare Words with Subword Units (Sennrich et al., 2015)](https://arxiv.org/abs/1508.07909). BPE se basa en un pre-tokenizador que divide los datos de entrenamiento en palabras. La pre-tokenización puede ser tan simple como la tokenización por espacio, por ejemplo, [GPT-2](https://huggingface.co/docs/transformers/en/model_doc/gpt2), [RoBERTa](https://huggingface.co/docs/transformers/en/model_doc/roberta). La pre-tokenización más avanzada incluye la tokenización basada en reglas, por ejemplo, [XLM](https://huggingface.co/docs/transformers/en/model_doc/xlm), [FlauBERT](https://huggingface.co/docs/transformers/en/model_doc/flaubert) que utiliza Moses para la mayoría de los idiomas, o [GPT](https://huggingface.co/docs/transformers/en/model_doc/openai-gpt) que utiliza spaCy y ftfy, para contar la frecuencia de cada palabra en el corpus de entrenamiento.
+La Codificación por Pares de Bytes (BPE por sus siglas en inglés) fue introducida en [Neural Machine Translation of Rare Words with Subword Units (Sennrich et al., 2015)](https://huggingface.co/papers/1508.07909). BPE se basa en un pre-tokenizador que divide los datos de entrenamiento en palabras. La pre-tokenización puede ser tan simple como la tokenización por espacio, por ejemplo, [GPT-2](https://huggingface.co/docs/transformers/en/model_doc/gpt2), [RoBERTa](https://huggingface.co/docs/transformers/en/model_doc/roberta). La pre-tokenización más avanzada incluye la tokenización basada en reglas, por ejemplo, [XLM](https://huggingface.co/docs/transformers/en/model_doc/xlm), [FlauBERT](https://huggingface.co/docs/transformers/en/model_doc/flaubert) que utiliza Moses para la mayoría de los idiomas, o [GPT](https://huggingface.co/docs/transformers/en/model_doc/openai-gpt) que utiliza spaCy y ftfy, para contar la frecuencia de cada palabra en el corpus de entrenamiento.
Después de la pre-tokenización, se ha creado un conjunto de palabras únicas y ha determinado la frecuencia con la que cada palabra apareció en los datos de entrenamiento. A continuación, BPE crea un vocabulario base que consiste en todos los símbolos que aparecen en el conjunto de palabras únicas y aprende reglas de fusión para formar un nuevo símbolo a partir de dos símbolos del vocabulario base. Lo hace hasta que el vocabulario ha alcanzado el tamaño de vocabulario deseado. Tenga en cuenta que el tamaño de vocabulario deseado es un hiperparámetro que se debe definir antes de entrenar el tokenizador.
@@ -148,7 +148,7 @@ WordPiece es el algoritmo de tokenización de subpalabras utilizado por [BERT](h
### Unigram
-Unigram es un algoritmo de tokenización de subpalabras introducido en [Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates (Kudo, 2018)](https://arxiv.org/pdf/1804.10959.pdf). A diferencia de BPE o WordPiece, Unigram inicializa su vocabulario base con un gran número de símbolos y progresivamente recorta cada símbolo para obtener un vocabulario más pequeño. El vocabulario base podría corresponder, por ejemplo, a todas las palabras pre-tokenizadas y las subcadenas más comunes. Unigram no se utiliza directamente para ninguno de los modelos transformers, pero se utiliza en conjunto con [SentencePiece](#sentencepiece).
+Unigram es un algoritmo de tokenización de subpalabras introducido en [Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates (Kudo, 2018)](https://huggingface.co/papers/1804.10959). A diferencia de BPE o WordPiece, Unigram inicializa su vocabulario base con un gran número de símbolos y progresivamente recorta cada símbolo para obtener un vocabulario más pequeño. El vocabulario base podría corresponder, por ejemplo, a todas las palabras pre-tokenizadas y las subcadenas más comunes. Unigram no se utiliza directamente para ninguno de los modelos transformers, pero se utiliza en conjunto con [SentencePiece](#sentencepiece).
En cada paso de entrenamiento, el algoritmo Unigram define una pérdida (a menudo definida como la probabilidad logarítmica) sobre los datos de entrenamiento dados el vocabulario actual y un modelo de lenguaje unigram. Luego, para cada símbolo en el vocabulario, el algoritmo calcula cuánto aumentaría la pérdida general si el símbolo se eliminara del vocabulario. Luego, Unigram elimina un porcentaje `p` de los símbolos cuyo aumento de pérdida es el más bajo (siendo `p` generalmente 10% o 20%), es decir, aquellos símbolos que menos afectan la pérdida general sobre los datos de entrenamiento. Este proceso se repite hasta que el vocabulario haya alcanzado el tamaño deseado. El algoritmo Unigram siempre mantiene los caracteres base para que cualquier palabra pueda ser tokenizada.
@@ -168,7 +168,7 @@ $$\mathcal{L} = -\sum_{i=1}^{N} \log \left ( \sum_{x \in S(x_{i})} p(x) \right )
### SentencePiece
-Todos los algoritmos de tokenización descritos hasta ahora tienen el mismo problema: se asume que el texto de entrada utiliza espacios para separar palabras. Sin embargo, no todos los idiomas utilizan espacios para separar palabras. Una posible solución es utilizar pre-tokenizadores específicos del idioma, *ej.* [XLM](https://huggingface.co/docs/transformers/en/model_doc/xlm) utiliza un pre-tokenizador específico para chino, japonés y tailandés. Para resolver este problema de manera más general, [SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing (Kudo et al., 2018)](https://arxiv.org/pdf/1808.06226.pdf) trata el texto de entrada como una corriente de entrada bruta, por lo que incluye el espacio en el conjunto de caracteres para utilizar. Luego utiliza el algoritmo BPE o unigram para construir el vocabulario apropiado.
+Todos los algoritmos de tokenización descritos hasta ahora tienen el mismo problema: se asume que el texto de entrada utiliza espacios para separar palabras. Sin embargo, no todos los idiomas utilizan espacios para separar palabras. Una posible solución es utilizar pre-tokenizadores específicos del idioma, *ej.* [XLM](https://huggingface.co/docs/transformers/en/model_doc/xlm) utiliza un pre-tokenizador específico para chino, japonés y tailandés. Para resolver este problema de manera más general, [SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing (Kudo et al., 2018)](https://huggingface.co/papers/1808.06226) trata el texto de entrada como una corriente de entrada bruta, por lo que incluye el espacio en el conjunto de caracteres para utilizar. Luego utiliza el algoritmo BPE o unigram para construir el vocabulario apropiado.
Por ejemplo, [`XLNetTokenizer`](https://huggingface.co/docs/transformers/en/model_doc/xlnet#transformers.XLNetTokenizer) utiliza SentencePiece, razón por la cual en el ejemplo anterior se incluyó el carácter `"▁"` en el vocabulario. Decodificar con SentencePiece es muy fácil, ya que todos los tokens pueden simplemente concatenarse y `"▁"` se reemplaza por un espacio.
diff --git a/docs/source/fr/index.md b/docs/source/fr/index.md
index 963afe48ce..61ca795cf9 100644
--- a/docs/source/fr/index.md
+++ b/docs/source/fr/index.md
@@ -53,186 +53,186 @@ La documentation est organisée en 5 parties:
-1. **[ALBERT](model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
-1. **[ALIGN](model_doc/align)** (from Google Research) released with the paper [Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://arxiv.org/abs/2102.05918) by Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig.
-1. **[AltCLIP](model_doc/altclip)** (from BAAI) released with the paper [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) by Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell.
-1. **[Audio Spectrogram Transformer](model_doc/audio-spectrogram-transformer)** (from MIT) released with the paper [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
-1. **[BART](model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
-1. **[BARThez](model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
-1. **[BARTpho](model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
-1. **[BEiT](model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
-1. **[BERT](model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
-1. **[BERT For Sequence Generation](model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[ALBERT](model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://huggingface.co/papers/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
+1. **[ALIGN](model_doc/align)** (from Google Research) released with the paper [Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://huggingface.co/papers/2102.05918) by Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig.
+1. **[AltCLIP](model_doc/altclip)** (from BAAI) released with the paper [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://huggingface.co/papers/2211.06679) by Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell.
+1. **[Audio Spectrogram Transformer](model_doc/audio-spectrogram-transformer)** (from MIT) released with the paper [AST: Audio Spectrogram Transformer](https://huggingface.co/papers/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
+1. **[BART](model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://huggingface.co/papers/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
+1. **[BARThez](model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://huggingface.co/papers/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
+1. **[BARTpho](model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://huggingface.co/papers/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
+1. **[BEiT](model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://huggingface.co/papers/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
+1. **[BERT](model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://huggingface.co/papers/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
+1. **[BERT For Sequence Generation](model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://huggingface.co/papers/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
1. **[BERTweet](model_doc/bertweet)** (from VinAI Research) released with the paper [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) by Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen.
-1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
-1. **[BigBird-RoBERTa](model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://huggingface.co/papers/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[BigBird-RoBERTa](model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://huggingface.co/papers/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
1. **[BioGpt](model_doc/biogpt)** (from Microsoft Research AI4Science) released with the paper [BioGPT: generative pre-trained transformer for biomedical text generation and mining](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9) by Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon and Tie-Yan Liu.
-1. **[BiT](model_doc/bit)** (from Google AI) released with the paper [Big Transfer (BiT): General Visual Representation Learning](https://arxiv.org/abs/1912.11370) by Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby.
-1. **[Blenderbot](model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
-1. **[BlenderbotSmall](model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
-1. **[BLIP](model_doc/blip)** (from Salesforce) released with the paper [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) by Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
+1. **[BiT](model_doc/bit)** (from Google AI) released with the paper [Big Transfer (BiT): General Visual Representation Learning](https://huggingface.co/papers/1912.11370) by Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby.
+1. **[Blenderbot](model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://huggingface.co/papers/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BlenderbotSmall](model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://huggingface.co/papers/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BLIP](model_doc/blip)** (from Salesforce) released with the paper [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://huggingface.co/papers/2201.12086) by Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
1. **[BLOOM](model_doc/bloom)** (from BigScience workshop) released by the [BigScience Workshop](https://bigscience.huggingface.co/).
-1. **[BORT](model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
-1. **[BridgeTower](model_doc/bridgetower)** (from Harbin Institute of Technology/Microsoft Research Asia/Intel Labs) released with the paper [BridgeTower: Building Bridges Between Encoders in Vision-Language Representation Learning](https://arxiv.org/abs/2206.08657) by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan.
-1. **[ByT5](model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
-1. **[CamemBERT](model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
-1. **[CANINE](model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
-1. **[Chinese-CLIP](model_doc/chinese_clip)** (from OFA-Sys) released with the paper [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://arxiv.org/abs/2211.01335) by An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou.
-1. **[CLIP](model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
-1. **[CLIPSeg](model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
-1. **[CodeGen](model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
-1. **[Conditional DETR](model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
-1. **[ConvBERT](model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
-1. **[ConvNeXT](model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
-1. **[ConvNeXTV2](model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
-1. **[CPM](model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
-1. **[CTRL](model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
-1. **[CvT](model_doc/cvt)** (from Microsoft) released with the paper [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
-1. **[Data2Vec](model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
-1. **[DeBERTa](model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
-1. **[DeBERTa-v2](model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
-1. **[Decision Transformer](model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
-1. **[Deformable DETR](model_doc/deformable_detr)** (from SenseTime Research) released with the paper [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
-1. **[DeiT](model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
-1. **[DETA](model_doc/deta)** (from The University of Texas at Austin) released with the paper [NMS Strikes Back](https://arxiv.org/abs/2212.06137) by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
-1. **[DETR](model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
-1. **[DialoGPT](model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
-1. **[DiNAT](model_doc/dinat)** (from SHI Labs) released with the paper [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) by Ali Hassani and Humphrey Shi.
-1. **[DistilBERT](model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers-research-projects/tree/main/distillation) and a German version of DistilBERT.
-1. **[DiT](model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
-1. **[Donut](model_doc/donut)** (from NAVER), released together with the paper [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) by Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park.
-1. **[DPR](model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
-1. **[DPT](master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
-1. **[EfficientFormer](model_doc/efficientformer)** (from Snap Research) released with the paper [EfficientFormer: Vision Transformers at MobileNetSpeed](https://arxiv.org/abs/2206.01191) by Yanyu Li, Geng Yuan, Yang Wen, Ju Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren.
-1. **[ELECTRA](model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
-1. **[EncoderDecoder](model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
-1. **[ERNIE](model_doc/ernie)** (from Baidu) released with the paper [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223) by Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu.
+1. **[BORT](model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://huggingface.co/papers/2010.10499) by Adrian de Wynter and Daniel J. Perry.
+1. **[BridgeTower](model_doc/bridgetower)** (from Harbin Institute of Technology/Microsoft Research Asia/Intel Labs) released with the paper [BridgeTower: Building Bridges Between Encoders in Vision-Language Representation Learning](https://huggingface.co/papers/2206.08657) by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan.
+1. **[ByT5](model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://huggingface.co/papers/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
+1. **[CamemBERT](model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://huggingface.co/papers/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
+1. **[CANINE](model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://huggingface.co/papers/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
+1. **[Chinese-CLIP](model_doc/chinese_clip)** (from OFA-Sys) released with the paper [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://huggingface.co/papers/2211.01335) by An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou.
+1. **[CLIP](model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://huggingface.co/papers/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
+1. **[CLIPSeg](model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://huggingface.co/papers/2112.10003) by Timo Lüddecke and Alexander Ecker.
+1. **[CodeGen](model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://huggingface.co/papers/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
+1. **[Conditional DETR](model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://huggingface.co/papers/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
+1. **[ConvBERT](model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://huggingface.co/papers/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
+1. **[ConvNeXT](model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://huggingface.co/papers/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
+1. **[ConvNeXTV2](model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://huggingface.co/papers/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
+1. **[CPM](model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://huggingface.co/papers/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
+1. **[CTRL](model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://huggingface.co/papers/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
+1. **[CvT](model_doc/cvt)** (from Microsoft) released with the paper [CvT: Introducing Convolutions to Vision Transformers](https://huggingface.co/papers/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
+1. **[Data2Vec](model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://huggingface.co/papers/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
+1. **[DeBERTa](model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://huggingface.co/papers/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[DeBERTa-v2](model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://huggingface.co/papers/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[Decision Transformer](model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://huggingface.co/papers/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
+1. **[Deformable DETR](model_doc/deformable_detr)** (from SenseTime Research) released with the paper [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://huggingface.co/papers/2010.04159) by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
+1. **[DeiT](model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://huggingface.co/papers/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
+1. **[DETA](model_doc/deta)** (from The University of Texas at Austin) released with the paper [NMS Strikes Back](https://huggingface.co/papers/2212.06137) by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
+1. **[DETR](model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://huggingface.co/papers/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
+1. **[DialoGPT](model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://huggingface.co/papers/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
+1. **[DiNAT](model_doc/dinat)** (from SHI Labs) released with the paper [Dilated Neighborhood Attention Transformer](https://huggingface.co/papers/2209.15001) by Ali Hassani and Humphrey Shi.
+1. **[DistilBERT](model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://huggingface.co/papers/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers-research-projects/tree/main/distillation) and a German version of DistilBERT.
+1. **[DiT](model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://huggingface.co/papers/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
+1. **[Donut](model_doc/donut)** (from NAVER), released together with the paper [OCR-free Document Understanding Transformer](https://huggingface.co/papers/2111.15664) by Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park.
+1. **[DPR](model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://huggingface.co/papers/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
+1. **[DPT](master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://huggingface.co/papers/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
+1. **[EfficientFormer](model_doc/efficientformer)** (from Snap Research) released with the paper [EfficientFormer: Vision Transformers at MobileNetSpeed](https://huggingface.co/papers/2206.01191) by Yanyu Li, Geng Yuan, Yang Wen, Ju Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren.
+1. **[ELECTRA](model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://huggingface.co/papers/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
+1. **[EncoderDecoder](model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://huggingface.co/papers/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[ERNIE](model_doc/ernie)** (from Baidu) released with the paper [ERNIE: Enhanced Representation through Knowledge Integration](https://huggingface.co/papers/1904.09223) by Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu.
1. **[ESM](model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2 and ESMFold** were released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
-1. **[FastSpeech2Conformer](model_doc/fastspeech2_conformer)** (from ESPnet) released with the paper [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
+1. **[FastSpeech2Conformer](model_doc/fastspeech2_conformer)** (from ESPnet) released with the paper [Recent Developments On Espnet Toolkit Boosted By Conformer](https://huggingface.co/papers/2010.13956) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
1. **[FLAN-T5](model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
-1. **[FlauBERT](model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
-1. **[FLAVA](model_doc/flava)** (from Facebook AI) released with the paper [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela.
-1. **[FNet](model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
-1. **[Funnel Transformer](model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
-1. **[GIT](model_doc/git)** (from Microsoft Research) released with the paper [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang.
-1. **[GLPN](model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
+1. **[FlauBERT](model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://huggingface.co/papers/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
+1. **[FLAVA](model_doc/flava)** (from Facebook AI) released with the paper [FLAVA: A Foundational Language And Vision Alignment Model](https://huggingface.co/papers/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela.
+1. **[FNet](model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://huggingface.co/papers/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
+1. **[Funnel Transformer](model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://huggingface.co/papers/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
+1. **[GIT](model_doc/git)** (from Microsoft Research) released with the paper [GIT: A Generative Image-to-text Transformer for Vision and Language](https://huggingface.co/papers/2205.14100) by Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang.
+1. **[GLPN](model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://huggingface.co/papers/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
1. **[GPT](model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
1. **[GPT Neo](model_doc/gpt_neo)** (from EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
-1. **[GPT NeoX](model_doc/gpt_neox)** (from EleutherAI) released with the paper [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745) by Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
+1. **[GPT NeoX](model_doc/gpt_neox)** (from EleutherAI) released with the paper [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://huggingface.co/papers/2204.06745) by Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
1. **[GPT NeoX Japanese](model_doc/gpt_neox_japanese)** (from ABEJA) released by Shinya Otani, Takayoshi Makabe, Anuj Arora, and Kyo Hattori.
1. **[GPT-2](model_doc/gpt2)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://openai.com/research/better-language-models/) by Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever.
1. **[GPT-J](model_doc/gptj)** (from EleutherAI) released in the repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
1. **[GPT-Sw3](model_doc/gpt-sw3)** (from AI-Sweden) released with the paper [Lessons Learned from GPT-SW3: Building the First Large-Scale Generative Language Model for Swedish](http://www.lrec-conf.org/proceedings/lrec2022/pdf/2022.lrec-1.376.pdf) by Ariel Ekgren, Amaru Cuba Gyllensten, Evangelia Gogoulou, Alice Heiman, Severine Verlinden, Joey Öhman, Fredrik Carlsson, Magnus Sahlgren.
-1. **[Graphormer](model_doc/graphormer)** (from Microsoft) released with the paper [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) by Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu.
-1. **[GroupViT](model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
-1. **[Hubert](model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
-1. **[I-BERT](model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
+1. **[Graphormer](model_doc/graphormer)** (from Microsoft) released with the paper [Do Transformers Really Perform Bad for Graph Representation?](https://huggingface.co/papers/2106.05234) by Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu.
+1. **[GroupViT](model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://huggingface.co/papers/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
+1. **[Hubert](model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://huggingface.co/papers/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
+1. **[I-BERT](model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://huggingface.co/papers/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
1. **[ImageGPT](model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
-1. **[Jukebox](model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
-1. **[LayoutLM](model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
-1. **[LayoutLMv2](model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
-1. **[LayoutLMv3](model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
-1. **[LayoutXLM](model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
-1. **[LED](model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
-1. **[LeViT](model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
-1. **[LiLT](model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
-1. **[Longformer](model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
-1. **[LongT5](model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
-1. **[LUKE](model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
-1. **[LXMERT](model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
-1. **[M-CTC-T](model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
-1. **[M2M100](model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
+1. **[Jukebox](model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://huggingface.co/papers/2005.00341) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
+1. **[LayoutLM](model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://huggingface.co/papers/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
+1. **[LayoutLMv2](model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://huggingface.co/papers/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
+1. **[LayoutLMv3](model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://huggingface.co/papers/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
+1. **[LayoutXLM](model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://huggingface.co/papers/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
+1. **[LED](model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://huggingface.co/papers/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LeViT](model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://huggingface.co/papers/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
+1. **[LiLT](model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://huggingface.co/papers/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
+1. **[Longformer](model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://huggingface.co/papers/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LongT5](model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://huggingface.co/papers/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
+1. **[LUKE](model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://huggingface.co/papers/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
+1. **[LXMERT](model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://huggingface.co/papers/1908.07490) by Hao Tan and Mohit Bansal.
+1. **[M-CTC-T](model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://huggingface.co/papers/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
+1. **[M2M100](model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://huggingface.co/papers/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
1. **[MarianMT](model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
-1. **[MarkupLM](model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
-1. **[Mask2Former](model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
-1. **[MaskFormer](model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
-1. **[mBART](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
-1. **[mBART-50](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
-1. **[Megatron-BERT](model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
-1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
-1. **[mLUKE](model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
-1. **[MobileBERT](model_doc/mobilebert)** (from CMU/Google Brain) released with the paper [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou.
-1. **[MobileNetV1](model_doc/mobilenet_v1)** (from Google Inc.) released with the paper [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/abs/1704.04861) by Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam.
-1. **[MobileNetV2](model_doc/mobilenet_v2)** (from Google Inc.) released with the paper [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381) by Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen.
-1. **[MobileViT](model_doc/mobilevit)** (from Apple) released with the paper [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari.
-1. **[MPNet](model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
-1. **[MT5](model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
-1. **[MVP](model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
-1. **[NAT](model_doc/nat)** (from SHI Labs) released with the paper [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
-1. **[Nezha](model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
-1. **[NLLB](model_doc/nllb)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
-1. **[Nyströmformer](model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
-1. **[OneFormer](model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
-1. **[OPT](master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
-1. **[OWL-ViT](model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
-1. **[Pegasus](model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
-1. **[PEGASUS-X](model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao, and Peter J. Liu.
-1. **[Perceiver IO](model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
+1. **[MarkupLM](model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://huggingface.co/papers/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
+1. **[Mask2Former](model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://huggingface.co/papers/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
+1. **[MaskFormer](model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://huggingface.co/papers/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
+1. **[mBART](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://huggingface.co/papers/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
+1. **[mBART-50](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://huggingface.co/papers/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
+1. **[Megatron-BERT](model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://huggingface.co/papers/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://huggingface.co/papers/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[mLUKE](model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://huggingface.co/papers/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
+1. **[MobileBERT](model_doc/mobilebert)** (from CMU/Google Brain) released with the paper [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://huggingface.co/papers/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou.
+1. **[MobileNetV1](model_doc/mobilenet_v1)** (from Google Inc.) released with the paper [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://huggingface.co/papers/1704.04861) by Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam.
+1. **[MobileNetV2](model_doc/mobilenet_v2)** (from Google Inc.) released with the paper [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://huggingface.co/papers/1801.04381) by Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen.
+1. **[MobileViT](model_doc/mobilevit)** (from Apple) released with the paper [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://huggingface.co/papers/2110.02178) by Sachin Mehta and Mohammad Rastegari.
+1. **[MPNet](model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://huggingface.co/papers/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
+1. **[MT5](model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://huggingface.co/papers/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
+1. **[MVP](model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://huggingface.co/papers/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
+1. **[NAT](model_doc/nat)** (from SHI Labs) released with the paper [Neighborhood Attention Transformer](https://huggingface.co/papers/2204.07143) by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
+1. **[Nezha](model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://huggingface.co/papers/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
+1. **[NLLB](model_doc/nllb)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://huggingface.co/papers/2207.04672) by the NLLB team.
+1. **[Nyströmformer](model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://huggingface.co/papers/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
+1. **[OneFormer](model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://huggingface.co/papers/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
+1. **[OPT](master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://huggingface.co/papers/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
+1. **[OWL-ViT](model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://huggingface.co/papers/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
+1. **[Pegasus](model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://huggingface.co/papers/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
+1. **[PEGASUS-X](model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://huggingface.co/papers/2208.04347) by Jason Phang, Yao Zhao, and Peter J. Liu.
+1. **[Perceiver IO](model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://huggingface.co/papers/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
1. **[PhoBERT](model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
-1. **[PLBart](model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
-1. **[PoolFormer](model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
-1. **[ProphetNet](model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
-1. **[QDQBert](model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
-1. **[RAG](model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
-1. **[REALM](model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
-1. **[Reformer](model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
-1. **[RegNet](model_doc/regnet)** (from META Platforms) released with the paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
-1. **[RemBERT](model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
-1. **[ResNet](model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
-1. **[RoBERTa](model_doc/roberta)** (from Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
-1. **[RoBERTa-PreLayerNorm](model_doc/roberta-prelayernorm)** (from Facebook) released with the paper [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://arxiv.org/abs/1904.01038) by Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli.
+1. **[PLBart](model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://huggingface.co/papers/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
+1. **[PoolFormer](model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://huggingface.co/papers/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
+1. **[ProphetNet](model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://huggingface.co/papers/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[QDQBert](model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://huggingface.co/papers/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
+1. **[RAG](model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://huggingface.co/papers/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
+1. **[REALM](model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://huggingface.co/papers/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
+1. **[Reformer](model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://huggingface.co/papers/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
+1. **[RegNet](model_doc/regnet)** (from META Platforms) released with the paper [Designing Network Design Space](https://huggingface.co/papers/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
+1. **[RemBERT](model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://huggingface.co/papers/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
+1. **[ResNet](model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://huggingface.co/papers/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
+1. **[RoBERTa](model_doc/roberta)** (from Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://huggingface.co/papers/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
+1. **[RoBERTa-PreLayerNorm](model_doc/roberta-prelayernorm)** (from Facebook) released with the paper [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://huggingface.co/papers/1904.01038) by Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli.
1. **[RoCBert](model_doc/roc_bert)** (from WeChatAI) released with the paper [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
-1. **[RoFormer](model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
-1. **[SegFormer](model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
-1. **[SEW](model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
-1. **[SEW-D](model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
-1. **[SpeechT5](model_doc/speecht5)** (from Microsoft Research) released with the paper [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
-1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
-1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
-1. **[Splinter](model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
-1. **[SqueezeBERT](model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
-1. **[Swin Transformer](model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
-1. **[Swin Transformer V2](model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
-1. **[Swin2SR](model_doc/swin2sr)** (from University of Würzburg) released with the paper [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
-1. **[SwitchTransformers](model_doc/switch_transformers)** (from Google) released with the paper [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
-1. **[T5](model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
+1. **[RoFormer](model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://huggingface.co/papers/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
+1. **[SegFormer](model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://huggingface.co/papers/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
+1. **[SEW](model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://huggingface.co/papers/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SEW-D](model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://huggingface.co/papers/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SpeechT5](model_doc/speecht5)** (from Microsoft Research) released with the paper [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://huggingface.co/papers/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
+1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://huggingface.co/papers/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
+1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://huggingface.co/papers/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
+1. **[Splinter](model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://huggingface.co/papers/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
+1. **[SqueezeBERT](model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://huggingface.co/papers/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
+1. **[Swin Transformer](model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://huggingface.co/papers/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
+1. **[Swin Transformer V2](model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://huggingface.co/papers/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
+1. **[Swin2SR](model_doc/swin2sr)** (from University of Würzburg) released with the paper [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://huggingface.co/papers/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
+1. **[SwitchTransformers](model_doc/switch_transformers)** (from Google) released with the paper [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://huggingface.co/papers/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
+1. **[T5](model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://huggingface.co/papers/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[T5v1.1](model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
-1. **[Table Transformer](model_doc/table-transformer)** (from Microsoft Research) released with the paper [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061) by Brandon Smock, Rohith Pesala, Robin Abraham.
-1. **[TAPAS](model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
-1. **[TAPEX](model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
+1. **[Table Transformer](model_doc/table-transformer)** (from Microsoft Research) released with the paper [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://huggingface.co/papers/2110.00061) by Brandon Smock, Rohith Pesala, Robin Abraham.
+1. **[TAPAS](model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://huggingface.co/papers/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
+1. **[TAPEX](model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://huggingface.co/papers/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
1. **[Time Series Transformer](model_doc/time_series_transformer)** (from HuggingFace).
-1. **[TimeSformer](model_doc/timesformer)** (from Facebook) released with the paper [Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095) by Gedas Bertasius, Heng Wang, Lorenzo Torresani.
-1. **[Trajectory Transformer](model_doc/trajectory_transformers)** (from the University of California at Berkeley) released with the paper [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine
-1. **[Transformer-XL](model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
-1. **[TrOCR](model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
-1. **[UL2](model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
-1. **[UniSpeech](model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
-1. **[UniSpeechSat](model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
-1. **[UPerNet](model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
-1. **[VAN](model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
-1. **[VideoMAE](model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
-1. **[ViLT](model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
-1. **[Vision Transformer (ViT)](model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
-1. **[VisualBERT](model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
-1. **[ViT Hybrid](model_doc/vit_hybrid)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
-1. **[ViTMAE](model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
-1. **[ViTMSN](model_doc/vit_msn)** (from Meta AI) released with the paper [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas.
-1. **[Wav2Vec2](model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
-1. **[Wav2Vec2-Conformer](model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
-1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
-1. **[WavLM](model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
+1. **[TimeSformer](model_doc/timesformer)** (from Facebook) released with the paper [Is Space-Time Attention All You Need for Video Understanding?](https://huggingface.co/papers/2102.05095) by Gedas Bertasius, Heng Wang, Lorenzo Torresani.
+1. **[Trajectory Transformer](model_doc/trajectory_transformers)** (from the University of California at Berkeley) released with the paper [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://huggingface.co/papers/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine
+1. **[Transformer-XL](model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://huggingface.co/papers/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
+1. **[TrOCR](model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://huggingface.co/papers/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
+1. **[UL2](model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://huggingface.co/papers/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
+1. **[UniSpeech](model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://huggingface.co/papers/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
+1. **[UniSpeechSat](model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://huggingface.co/papers/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
+1. **[UPerNet](model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://huggingface.co/papers/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
+1. **[VAN](model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://huggingface.co/papers/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
+1. **[VideoMAE](model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://huggingface.co/papers/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
+1. **[ViLT](model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://huggingface.co/papers/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
+1. **[Vision Transformer (ViT)](model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://huggingface.co/papers/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
+1. **[VisualBERT](model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://huggingface.co/papers/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
+1. **[ViT Hybrid](model_doc/vit_hybrid)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://huggingface.co/papers/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
+1. **[ViTMAE](model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://huggingface.co/papers/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
+1. **[ViTMSN](model_doc/vit_msn)** (from Meta AI) released with the paper [Masked Siamese Networks for Label-Efficient Learning](https://huggingface.co/papers/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas.
+1. **[Wav2Vec2](model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://huggingface.co/papers/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
+1. **[Wav2Vec2-Conformer](model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://huggingface.co/papers/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
+1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://huggingface.co/papers/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
+1. **[WavLM](model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://huggingface.co/papers/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
1. **[Whisper](model_doc/whisper)** (from OpenAI) released with the paper [Robust Speech Recognition via Large-Scale Weak Supervision](https://cdn.openai.com/papers/whisper.pdf) by Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever.
-1. **[X-CLIP](model_doc/xclip)** (from Microsoft Research) released with the paper [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816) by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
-1. **[XGLM](model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
-1. **[XLM](model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau.
-1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
-1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
-1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (from Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
-1. **[XLNet](model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
-1. **[XLS-R](model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
-1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
-1. **[YOLOS](model_doc/yolos)** (from Huazhong University of Science & Technology) released with the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
-1. **[YOSO](model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
+1. **[X-CLIP](model_doc/xclip)** (from Microsoft Research) released with the paper [Expanding Language-Image Pretrained Models for General Video Recognition](https://huggingface.co/papers/2208.02816) by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
+1. **[XGLM](model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://huggingface.co/papers/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
+1. **[XLM](model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://huggingface.co/papers/1901.07291) by Guillaume Lample and Alexis Conneau.
+1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://huggingface.co/papers/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://huggingface.co/papers/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
+1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (from Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://huggingface.co/papers/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
+1. **[XLNet](model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://huggingface.co/papers/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
+1. **[XLS-R](model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://huggingface.co/papers/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
+1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://huggingface.co/papers/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
+1. **[YOLOS](model_doc/yolos)** (from Huazhong University of Science & Technology) released with the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://huggingface.co/papers/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
+1. **[YOSO](model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://huggingface.co/papers/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
### Frameworks compatibles
diff --git a/docs/source/fr/tasks_explained.md b/docs/source/fr/tasks_explained.md
index a39096b2b8..775f8f4ff7 100644
--- a/docs/source/fr/tasks_explained.md
+++ b/docs/source/fr/tasks_explained.md
@@ -120,7 +120,7 @@ Cette section explique brièvement les convolutions, mais il serait utile d'avoi
-Une convolution de base sans padding ni stride, tirée de Un guide des calculs de convolution pour l'apprentissage profond.
+Une convolution de base sans padding ni stride, tirée de Un guide des calculs de convolution pour l'apprentissage profond.
Vous pouvez alimenter la sortie d'une couche convolutionnelle à une autre couche convolutionnelle. À chaque couche successive, le réseau apprend des caractéristiques de plus en plus complexes et abstraites, telles que des objets spécifiques comme des hot-dogs ou des fusées. Entre les couches convolutionnelles, il est courant d'ajouter des couches de pooling pour réduire la dimensionnalité et rendre le modèle plus robuste aux variations de position des caractéristiques.
diff --git a/docs/source/it/index.md b/docs/source/it/index.md
index bbab23eed6..a0c2523966 100644
--- a/docs/source/it/index.md
+++ b/docs/source/it/index.md
@@ -54,128 +54,128 @@ La libreria attualmente contiene implementazioni in JAX, PyTorch e TensorFlow, p
-1. **[ALBERT](model_doc/albert)** (da Google Research e l'Istituto Tecnologico di Chicago) rilasciato con il paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), da Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
-1. **[ALIGN](model_doc/align)** (from Google Research) rilasciato con il paper [Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://arxiv.org/abs/2102.05918) da Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig.
-1. **[BART](model_doc/bart)** (da Facebook) rilasciato con il paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) da Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov e Luke Zettlemoyer.
-1. **[BARThez](model_doc/barthez)** (da politecnico di École) rilasciato con il paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) da Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
-1. **[BARTpho](model_doc/bartpho)** (da VinAI Research) rilasciato con il paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) da Nguyen Luong Tran, Duong Minh Le e Dat Quoc Nguyen.
-1. **[BEiT](model_doc/beit)** (da Microsoft) rilasciato con il paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) da Hangbo Bao, Li Dong, Furu Wei.
-1. **[BERT](model_doc/bert)** (da Google) rilasciato con il paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) da Jacob Devlin, Ming-Wei Chang, Kenton Lee e Kristina Toutanova.
+1. **[ALBERT](model_doc/albert)** (da Google Research e l'Istituto Tecnologico di Chicago) rilasciato con il paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://huggingface.co/papers/1909.11942), da Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
+1. **[ALIGN](model_doc/align)** (from Google Research) rilasciato con il paper [Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://huggingface.co/papers/2102.05918) da Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig.
+1. **[BART](model_doc/bart)** (da Facebook) rilasciato con il paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://huggingface.co/papers/1910.13461) da Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov e Luke Zettlemoyer.
+1. **[BARThez](model_doc/barthez)** (da politecnico di École) rilasciato con il paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://huggingface.co/papers/2010.12321) da Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
+1. **[BARTpho](model_doc/bartpho)** (da VinAI Research) rilasciato con il paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://huggingface.co/papers/2109.09701) da Nguyen Luong Tran, Duong Minh Le e Dat Quoc Nguyen.
+1. **[BEiT](model_doc/beit)** (da Microsoft) rilasciato con il paper [BEiT: BERT Pre-Training of Image Transformers](https://huggingface.co/papers/2106.08254) da Hangbo Bao, Li Dong, Furu Wei.
+1. **[BERT](model_doc/bert)** (da Google) rilasciato con il paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://huggingface.co/papers/1810.04805) da Jacob Devlin, Ming-Wei Chang, Kenton Lee e Kristina Toutanova.
1. **[BERTweet](model_doc/bertweet)** (da VinAI Research) rilasciato con il paper [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) da Dat Quoc Nguyen, Thanh Vu e Anh Tuan Nguyen.
-1. **[BERT For Sequence Generation](model_doc/bert-generation)** (da Google) rilasciato con il paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) da Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
-1. **[BigBird-RoBERTa](model_doc/big_bird)** (da Google Research) rilasciato con il paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) da Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
-1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (v Google Research) rilasciato con il paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) da Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
-1. **[Blenderbot](model_doc/blenderbot)** (da Facebook) rilasciato con il paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) da Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
-1. **[BlenderbotSmall](model_doc/blenderbot-small)** (da Facebook) rilasciato con il paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) da Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
-1. **[BORT](model_doc/bort)** (da Alexa) rilasciato con il paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) da Adrian de Wynter e Daniel J. Perry.
-1. **[ByT5](model_doc/byt5)** (da Google Research) rilasciato con il paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) da Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
-1. **[CamemBERT](model_doc/camembert)** (da Inria/Facebook/Sorbonne) rilasciato con il paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) da Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah e Benoît Sagot.
-1. **[CANINE](model_doc/canine)** (da Google Research) rilasciato con il paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) da Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
-1. **[ConvNeXT](model_doc/convnext)** (da Facebook AI) rilasciato con il paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) da Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
-1. **[ConvNeXTV2](model_doc/convnextv2)** (da Facebook AI) rilasciato con il paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) da Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
-1. **[CLIP](model_doc/clip)** (da OpenAI) rilasciato con il paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) da Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
-1. **[ConvBERT](model_doc/convbert)** (da YituTech) rilasciato con il paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) da Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
-1. **[CPM](model_doc/cpm)** (dalla Università di Tsinghua) rilasciato con il paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) da Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
-1. **[CTRL](model_doc/ctrl)** (da Salesforce) rilasciato con il paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) da Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong e Richard Socher.
-1. **[CvT](model_doc/cvt)** (da Microsoft) rilasciato con il paper [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) da Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
-1. **[Data2Vec](model_doc/data2vec)** (da Facebook) rilasciato con il paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) da Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
-1. **[DeBERTa](model_doc/deberta)** (da Microsoft) rilasciato con il paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) da Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
-1. **[DeBERTa-v2](model_doc/deberta-v2)** (da Microsoft) rilasciato con il paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) da Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
-1. **[Decision Transformer](model_doc/decision_transformer)** (da Berkeley/Facebook/Google) rilasciato con il paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) da Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
-1. **[DiT](model_doc/dit)** (da Microsoft Research) rilasciato con il paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) da Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
-1. **[DeiT](model_doc/deit)** (da Facebook) rilasciato con il paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) da Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
-1. **[DETR](model_doc/detr)** (da Facebook) rilasciato con il paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) da Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
-1. **[DialoGPT](model_doc/dialogpt)** (da Microsoft Research) rilasciato con il paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) da Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
-1. **[DistilBERT](model_doc/distilbert)** (da HuggingFace), rilasciato assieme al paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) da Victor Sanh, Lysandre Debut e Thomas Wolf. La stessa tecnica è stata applicata per comprimere GPT2 in [DistilGPT2](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), RoBERTa in [DistilRoBERTa](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), Multilingual BERT in [DistilmBERT](https://github.com/huggingface/transformers-research-projects/tree/main/distillation) and a German version of DistilBERT.
-1. **[DPR](model_doc/dpr)** (da Facebook) rilasciato con il paper [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) da Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, e Wen-tau Yih.
-1. **[DPT](master/model_doc/dpt)** (da Intel Labs) rilasciato con il paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) da René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
-1. **[EfficientNet](model_doc/efficientnet)** (from Google Research) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan and Quoc V. Le.
-1. **[EncoderDecoder](model_doc/encoder-decoder)** (da Google Research) rilasciato con il paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) da Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
-1. **[ELECTRA](model_doc/electra)** (da Google Research/Stanford University) rilasciato con il paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) da Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
-1. **[FlauBERT](model_doc/flaubert)** (da CNRS) rilasciato con il paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) da Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
-1. **[FLAVA](model_doc/flava)** (da Facebook AI) rilasciato con il paper [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) da Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, e Douwe Kiela.
-1. **[FNet](model_doc/fnet)** (da Google Research) rilasciato con il paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) da James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
-1. **[Funnel Transformer](model_doc/funnel)** (da CMU/Google Brain) rilasciato con il paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) da Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
-1. **[GLPN](model_doc/glpn)** (da KAIST) rilasciato con il paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) da Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
+1. **[BERT For Sequence Generation](model_doc/bert-generation)** (da Google) rilasciato con il paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://huggingface.co/papers/1907.12461) da Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[BigBird-RoBERTa](model_doc/big_bird)** (da Google Research) rilasciato con il paper [Big Bird: Transformers for Longer Sequences](https://huggingface.co/papers/2007.14062) da Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (v Google Research) rilasciato con il paper [Big Bird: Transformers for Longer Sequences](https://huggingface.co/papers/2007.14062) da Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[Blenderbot](model_doc/blenderbot)** (da Facebook) rilasciato con il paper [Recipes for building an open-domain chatbot](https://huggingface.co/papers/2004.13637) da Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BlenderbotSmall](model_doc/blenderbot-small)** (da Facebook) rilasciato con il paper [Recipes for building an open-domain chatbot](https://huggingface.co/papers/2004.13637) da Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BORT](model_doc/bort)** (da Alexa) rilasciato con il paper [Optimal Subarchitecture Extraction For BERT](https://huggingface.co/papers/2010.10499) da Adrian de Wynter e Daniel J. Perry.
+1. **[ByT5](model_doc/byt5)** (da Google Research) rilasciato con il paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://huggingface.co/papers/2105.13626) da Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
+1. **[CamemBERT](model_doc/camembert)** (da Inria/Facebook/Sorbonne) rilasciato con il paper [CamemBERT: a Tasty French Language Model](https://huggingface.co/papers/1911.03894) da Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah e Benoît Sagot.
+1. **[CANINE](model_doc/canine)** (da Google Research) rilasciato con il paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://huggingface.co/papers/2103.06874) da Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
+1. **[ConvNeXT](model_doc/convnext)** (da Facebook AI) rilasciato con il paper [A ConvNet for the 2020s](https://huggingface.co/papers/2201.03545) da Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
+1. **[ConvNeXTV2](model_doc/convnextv2)** (da Facebook AI) rilasciato con il paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://huggingface.co/papers/2301.00808) da Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
+1. **[CLIP](model_doc/clip)** (da OpenAI) rilasciato con il paper [Learning Transferable Visual Models From Natural Language Supervision](https://huggingface.co/papers/2103.00020) da Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
+1. **[ConvBERT](model_doc/convbert)** (da YituTech) rilasciato con il paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://huggingface.co/papers/2008.02496) da Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
+1. **[CPM](model_doc/cpm)** (dalla Università di Tsinghua) rilasciato con il paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://huggingface.co/papers/2012.00413) da Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
+1. **[CTRL](model_doc/ctrl)** (da Salesforce) rilasciato con il paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://huggingface.co/papers/1909.05858) da Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong e Richard Socher.
+1. **[CvT](model_doc/cvt)** (da Microsoft) rilasciato con il paper [CvT: Introducing Convolutions to Vision Transformers](https://huggingface.co/papers/2103.15808) da Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
+1. **[Data2Vec](model_doc/data2vec)** (da Facebook) rilasciato con il paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://huggingface.co/papers/2202.03555) da Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
+1. **[DeBERTa](model_doc/deberta)** (da Microsoft) rilasciato con il paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://huggingface.co/papers/2006.03654) da Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[DeBERTa-v2](model_doc/deberta-v2)** (da Microsoft) rilasciato con il paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://huggingface.co/papers/2006.03654) da Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[Decision Transformer](model_doc/decision_transformer)** (da Berkeley/Facebook/Google) rilasciato con il paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://huggingface.co/papers/2106.01345) da Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
+1. **[DiT](model_doc/dit)** (da Microsoft Research) rilasciato con il paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://huggingface.co/papers/2203.02378) da Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
+1. **[DeiT](model_doc/deit)** (da Facebook) rilasciato con il paper [Training data-efficient image transformers & distillation through attention](https://huggingface.co/papers/2012.12877) da Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
+1. **[DETR](model_doc/detr)** (da Facebook) rilasciato con il paper [End-to-End Object Detection with Transformers](https://huggingface.co/papers/2005.12872) da Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
+1. **[DialoGPT](model_doc/dialogpt)** (da Microsoft Research) rilasciato con il paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://huggingface.co/papers/1911.00536) da Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
+1. **[DistilBERT](model_doc/distilbert)** (da HuggingFace), rilasciato assieme al paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://huggingface.co/papers/1910.01108) da Victor Sanh, Lysandre Debut e Thomas Wolf. La stessa tecnica è stata applicata per comprimere GPT2 in [DistilGPT2](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), RoBERTa in [DistilRoBERTa](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), Multilingual BERT in [DistilmBERT](https://github.com/huggingface/transformers-research-projects/tree/main/distillation) and a German version of DistilBERT.
+1. **[DPR](model_doc/dpr)** (da Facebook) rilasciato con il paper [Dense Passage Retrieval for Open-Domain Question Answering](https://huggingface.co/papers/2004.04906) da Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, e Wen-tau Yih.
+1. **[DPT](master/model_doc/dpt)** (da Intel Labs) rilasciato con il paper [Vision Transformers for Dense Prediction](https://huggingface.co/papers/2103.13413) da René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
+1. **[EfficientNet](model_doc/efficientnet)** (from Google Research) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://huggingface.co/papers/1905.11946) by Mingxing Tan and Quoc V. Le.
+1. **[EncoderDecoder](model_doc/encoder-decoder)** (da Google Research) rilasciato con il paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://huggingface.co/papers/1907.12461) da Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[ELECTRA](model_doc/electra)** (da Google Research/Stanford University) rilasciato con il paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://huggingface.co/papers/2003.10555) da Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
+1. **[FlauBERT](model_doc/flaubert)** (da CNRS) rilasciato con il paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://huggingface.co/papers/1912.05372) da Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
+1. **[FLAVA](model_doc/flava)** (da Facebook AI) rilasciato con il paper [FLAVA: A Foundational Language And Vision Alignment Model](https://huggingface.co/papers/2112.04482) da Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, e Douwe Kiela.
+1. **[FNet](model_doc/fnet)** (da Google Research) rilasciato con il paper [FNet: Mixing Tokens with Fourier Transforms](https://huggingface.co/papers/2105.03824) da James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
+1. **[Funnel Transformer](model_doc/funnel)** (da CMU/Google Brain) rilasciato con il paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://huggingface.co/papers/2006.03236) da Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
+1. **[GLPN](model_doc/glpn)** (da KAIST) rilasciato con il paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://huggingface.co/papers/2201.07436) da Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
1. **[GPT](model_doc/openai-gpt)** (da OpenAI) rilasciato con il paper [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/) da Alec Radford, Karthik Narasimhan, Tim Salimans e Ilya Sutskever.
1. **[GPT-2](model_doc/gpt2)** (da OpenAI) rilasciato con il paper [Language Models are Unsupervised Multitask Learners](https://openai.com/research/better-language-models/) da Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei e Ilya Sutskever.
1. **[GPT-J](model_doc/gptj)** (da EleutherAI) rilasciato nel repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) da Ben Wang e Aran Komatsuzaki.
1. **[GPT Neo](model_doc/gpt_neo)** (da EleutherAI) rilasciato nel repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) da Sid Black, Stella Biderman, Leo Gao, Phil Wang e Connor Leahy.
-1. **[GPT NeoX](model_doc/gpt_neox)** (da EleutherAI) rilasciato con il paper [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745) da Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
-1. **[Hubert](model_doc/hubert)** (da Facebook) rilasciato con il paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) da Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
-1. **[I-BERT](model_doc/ibert)** (da Berkeley) rilasciato con il paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) da Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
+1. **[GPT NeoX](model_doc/gpt_neox)** (da EleutherAI) rilasciato con il paper [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://huggingface.co/papers/2204.06745) da Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
+1. **[Hubert](model_doc/hubert)** (da Facebook) rilasciato con il paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://huggingface.co/papers/2106.07447) da Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
+1. **[I-BERT](model_doc/ibert)** (da Berkeley) rilasciato con il paper [I-BERT: Integer-only BERT Quantization](https://huggingface.co/papers/2101.01321) da Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
1. **[ImageGPT](model_doc/imagegpt)** (da OpenAI) rilasciato con il paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) da Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
-1. **[LayoutLM](model_doc/layoutlm)** (da Microsoft Research Asia) rilasciato con il paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) da Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
-1. **[LayoutLMv2](model_doc/layoutlmv2)** (da Microsoft Research Asia) rilasciato con il paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) da Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
-1. **[LayoutLMv3](model_doc/layoutlmv3)** (da Microsoft Research Asia) rilasciato con il paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) da Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
-1. **[LayoutXLM](model_doc/layoutlxlm)** (da Microsoft Research Asia) rilasciato con il paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) da Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
-1. **[LED](model_doc/led)** (da AllenAI) rilasciato con il paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) da Iz Beltagy, Matthew E. Peters, Arman Cohan.
-1. **[Longformer](model_doc/longformer)** (da AllenAI) rilasciato con il paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) da Iz Beltagy, Matthew E. Peters, Arman Cohan.
-1. **[LUKE](model_doc/luke)** (da Studio Ousia) rilasciato con il paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) da Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
-1. **[mLUKE](model_doc/mluke)** (da Studio Ousia) rilasciato con il paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) da Ryokan Ri, Ikuya Yamada, e Yoshimasa Tsuruoka.
-1. **[LXMERT](model_doc/lxmert)** (da UNC Chapel Hill) rilasciato con il paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) da Hao Tan e Mohit Bansal.
-1. **[M2M100](model_doc/m2m_100)** (da Facebook) rilasciato con il paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) da Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
+1. **[LayoutLM](model_doc/layoutlm)** (da Microsoft Research Asia) rilasciato con il paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://huggingface.co/papers/1912.13318) da Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
+1. **[LayoutLMv2](model_doc/layoutlmv2)** (da Microsoft Research Asia) rilasciato con il paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://huggingface.co/papers/2012.14740) da Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
+1. **[LayoutLMv3](model_doc/layoutlmv3)** (da Microsoft Research Asia) rilasciato con il paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://huggingface.co/papers/2204.08387) da Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
+1. **[LayoutXLM](model_doc/layoutlxlm)** (da Microsoft Research Asia) rilasciato con il paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://huggingface.co/papers/2104.08836) da Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
+1. **[LED](model_doc/led)** (da AllenAI) rilasciato con il paper [Longformer: The Long-Document Transformer](https://huggingface.co/papers/2004.05150) da Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[Longformer](model_doc/longformer)** (da AllenAI) rilasciato con il paper [Longformer: The Long-Document Transformer](https://huggingface.co/papers/2004.05150) da Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LUKE](model_doc/luke)** (da Studio Ousia) rilasciato con il paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://huggingface.co/papers/2010.01057) da Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
+1. **[mLUKE](model_doc/mluke)** (da Studio Ousia) rilasciato con il paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://huggingface.co/papers/2110.08151) da Ryokan Ri, Ikuya Yamada, e Yoshimasa Tsuruoka.
+1. **[LXMERT](model_doc/lxmert)** (da UNC Chapel Hill) rilasciato con il paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://huggingface.co/papers/1908.07490) da Hao Tan e Mohit Bansal.
+1. **[M2M100](model_doc/m2m_100)** (da Facebook) rilasciato con il paper [Beyond English-Centric Multilingual Machine Translation](https://huggingface.co/papers/2010.11125) da Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
1. **[MarianMT](model_doc/marian)** Modello di machine learning per le traduzioni allenato utilizzando i dati [OPUS](http://opus.nlpl.eu/) di Jörg Tiedemann. Il [Framework Marian](https://marian-nmt.github.io/) è stato sviluppato dal Microsoft Translator Team.
-1. **[Mask2Former](model_doc/mask2former)** (da FAIR e UIUC) rilasciato con il paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) da Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
-1. **[MaskFormer](model_doc/maskformer)** (da Meta e UIUC) rilasciato con il paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) da Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
-1. **[MBart](model_doc/mbart)** (da Facebook) rilasciato con il paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) da Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
-1. **[MBart-50](model_doc/mbart)** (da Facebook) rilasciato con il paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) da Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
-1. **[Megatron-BERT](model_doc/megatron-bert)** (da NVIDIA) rilasciato con il paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) da Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper e Bryan Catanzaro.
-1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (da NVIDIA) rilasciato con il paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) da Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper e Bryan Catanzaro.
-1. **[MPNet](model_doc/mpnet)** (da Microsoft Research) rilasciato con il paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) da Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
-1. **[MT5](model_doc/mt5)** (da Google AI) rilasciato con il paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) da Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
-1. **[Nyströmformer](model_doc/nystromformer)** (dalla Università del Wisconsin - Madison) rilasciato con il paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) da Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
-1. **[OneFormer](model_doc/oneformer)** (da SHI Labs) rilasciato con il paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) da Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
-1. **[OPT](master/model_doc/opt)** (da Meta AI) rilasciato con il paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) da Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
-1. **[Pegasus](model_doc/pegasus)** (da Google) rilasciato con il paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) da Jingqing Zhang, Yao Zhao, Mohammad Saleh e Peter J. Liu.
-1. **[Perceiver IO](model_doc/perceiver)** (da Deepmind) rilasciato con il paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) da Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
+1. **[Mask2Former](model_doc/mask2former)** (da FAIR e UIUC) rilasciato con il paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://huggingface.co/papers/2112.01527) da Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
+1. **[MaskFormer](model_doc/maskformer)** (da Meta e UIUC) rilasciato con il paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://huggingface.co/papers/2107.06278) da Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
+1. **[MBart](model_doc/mbart)** (da Facebook) rilasciato con il paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://huggingface.co/papers/2001.08210) da Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
+1. **[MBart-50](model_doc/mbart)** (da Facebook) rilasciato con il paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://huggingface.co/papers/2008.00401) da Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
+1. **[Megatron-BERT](model_doc/megatron-bert)** (da NVIDIA) rilasciato con il paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://huggingface.co/papers/1909.08053) da Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper e Bryan Catanzaro.
+1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (da NVIDIA) rilasciato con il paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://huggingface.co/papers/1909.08053) da Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper e Bryan Catanzaro.
+1. **[MPNet](model_doc/mpnet)** (da Microsoft Research) rilasciato con il paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://huggingface.co/papers/2004.09297) da Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
+1. **[MT5](model_doc/mt5)** (da Google AI) rilasciato con il paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://huggingface.co/papers/2010.11934) da Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
+1. **[Nyströmformer](model_doc/nystromformer)** (dalla Università del Wisconsin - Madison) rilasciato con il paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://huggingface.co/papers/2102.03902) da Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
+1. **[OneFormer](model_doc/oneformer)** (da SHI Labs) rilasciato con il paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://huggingface.co/papers/2211.06220) da Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
+1. **[OPT](master/model_doc/opt)** (da Meta AI) rilasciato con il paper [OPT: Open Pre-trained Transformer Language Models](https://huggingface.co/papers/2205.01068) da Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
+1. **[Pegasus](model_doc/pegasus)** (da Google) rilasciato con il paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://huggingface.co/papers/1912.08777) da Jingqing Zhang, Yao Zhao, Mohammad Saleh e Peter J. Liu.
+1. **[Perceiver IO](model_doc/perceiver)** (da Deepmind) rilasciato con il paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://huggingface.co/papers/2107.14795) da Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
1. **[PhoBERT](model_doc/phobert)** (da VinAI Research) rilasciato con il paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) da Dat Quoc Nguyen e Anh Tuan Nguyen.
-1. **[PLBart](model_doc/plbart)** (da UCLA NLP) rilasciato con il paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) da Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
-1. **[PoolFormer](model_doc/poolformer)** (da Sea AI Labs) rilasciato con il paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) da Yu, Weihao e Luo, Mi e Zhou, Pan e Si, Chenyang e Zhou, Yichen e Wang, Xinchao e Feng, Jiashi e Yan, Shuicheng.
-1. **[ProphetNet](model_doc/prophetnet)** (da Microsoft Research) rilasciato con il paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) da Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang e Ming Zhou.
-1. **[QDQBert](model_doc/qdqbert)** (da NVIDIA) rilasciato con il paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) da Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev e Paulius Micikevicius.
-1. **[REALM](model_doc/realm.html)** (da Google Research) rilasciato con il paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) da Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat e Ming-Wei Chang.
-1. **[Reformer](model_doc/reformer)** (da Google Research) rilasciato con il paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) da Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
-1. **[RemBERT](model_doc/rembert)** (da Google Research) rilasciato con il paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) da Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
-1. **[RegNet](model_doc/regnet)** (da META Platforms) rilasciato con il paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) da Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
-1. **[ResNet](model_doc/resnet)** (da Microsoft Research) rilasciato con il paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) da Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
-1. **[RoBERTa](model_doc/roberta)** (da Facebook), rilasciato assieme al paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) da Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
-1. **[RoFormer](model_doc/roformer)** (da ZhuiyiTechnology), rilasciato assieme al paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) da Jianlin Su e Yu Lu e Shengfeng Pan e Bo Wen e Yunfeng Liu.
-1. **[SegFormer](model_doc/segformer)** (da NVIDIA) rilasciato con il paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) da Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
-1. **[SEW](model_doc/sew)** (da ASAPP) rilasciato con il paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) da Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
-1. **[SEW-D](model_doc/sew_d)** (da ASAPP) rilasciato con il paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) da Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
-1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (da Facebook), rilasciato assieme al paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) da Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
-1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (da Facebook), rilasciato assieme al paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) da Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
-1. **[Splinter](model_doc/splinter)** (dalla Università di Tel Aviv), rilasciato assieme al paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) da Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
-1. **[SqueezeBert](model_doc/squeezebert)** (da Berkeley) rilasciato con il paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) da Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, e Kurt W. Keutzer.
-1. **[Swin Transformer](model_doc/swin)** (da Microsoft) rilasciato con il paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) da Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
-1. **[T5](model_doc/t5)** (da Google AI) rilasciato con il paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) da Colin Raffel e Noam Shazeer e Adam Roberts e Katherine Lee e Sharan Narang e Michael Matena e Yanqi Zhou e Wei Li e Peter J. Liu.
+1. **[PLBart](model_doc/plbart)** (da UCLA NLP) rilasciato con il paper [Unified Pre-training for Program Understanding and Generation](https://huggingface.co/papers/2103.06333) da Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
+1. **[PoolFormer](model_doc/poolformer)** (da Sea AI Labs) rilasciato con il paper [MetaFormer is Actually What You Need for Vision](https://huggingface.co/papers/2111.11418) da Yu, Weihao e Luo, Mi e Zhou, Pan e Si, Chenyang e Zhou, Yichen e Wang, Xinchao e Feng, Jiashi e Yan, Shuicheng.
+1. **[ProphetNet](model_doc/prophetnet)** (da Microsoft Research) rilasciato con il paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://huggingface.co/papers/2001.04063) da Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang e Ming Zhou.
+1. **[QDQBert](model_doc/qdqbert)** (da NVIDIA) rilasciato con il paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://huggingface.co/papers/2004.09602) da Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev e Paulius Micikevicius.
+1. **[REALM](model_doc/realm.html)** (da Google Research) rilasciato con il paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://huggingface.co/papers/2002.08909) da Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat e Ming-Wei Chang.
+1. **[Reformer](model_doc/reformer)** (da Google Research) rilasciato con il paper [Reformer: The Efficient Transformer](https://huggingface.co/papers/2001.04451) da Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
+1. **[RemBERT](model_doc/rembert)** (da Google Research) rilasciato con il paper [Rethinking embedding coupling in pre-trained language models](https://huggingface.co/papers/2010.12821) da Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
+1. **[RegNet](model_doc/regnet)** (da META Platforms) rilasciato con il paper [Designing Network Design Space](https://huggingface.co/papers/2003.13678) da Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
+1. **[ResNet](model_doc/resnet)** (da Microsoft Research) rilasciato con il paper [Deep Residual Learning for Image Recognition](https://huggingface.co/papers/1512.03385) da Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
+1. **[RoBERTa](model_doc/roberta)** (da Facebook), rilasciato assieme al paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://huggingface.co/papers/1907.11692) da Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
+1. **[RoFormer](model_doc/roformer)** (da ZhuiyiTechnology), rilasciato assieme al paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://huggingface.co/papers/2104.09864) da Jianlin Su e Yu Lu e Shengfeng Pan e Bo Wen e Yunfeng Liu.
+1. **[SegFormer](model_doc/segformer)** (da NVIDIA) rilasciato con il paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://huggingface.co/papers/2105.15203) da Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
+1. **[SEW](model_doc/sew)** (da ASAPP) rilasciato con il paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://huggingface.co/papers/2109.06870) da Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SEW-D](model_doc/sew_d)** (da ASAPP) rilasciato con il paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://huggingface.co/papers/2109.06870) da Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (da Facebook), rilasciato assieme al paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://huggingface.co/papers/2010.05171) da Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
+1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (da Facebook), rilasciato assieme al paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://huggingface.co/papers/2104.06678) da Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
+1. **[Splinter](model_doc/splinter)** (dalla Università di Tel Aviv), rilasciato assieme al paper [Few-Shot Question Answering by Pretraining Span Selection](https://huggingface.co/papers/2101.00438) da Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
+1. **[SqueezeBert](model_doc/squeezebert)** (da Berkeley) rilasciato con il paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://huggingface.co/papers/2006.11316) da Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, e Kurt W. Keutzer.
+1. **[Swin Transformer](model_doc/swin)** (da Microsoft) rilasciato con il paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://huggingface.co/papers/2103.14030) da Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
+1. **[T5](model_doc/t5)** (da Google AI) rilasciato con il paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://huggingface.co/papers/1910.10683) da Colin Raffel e Noam Shazeer e Adam Roberts e Katherine Lee e Sharan Narang e Michael Matena e Yanqi Zhou e Wei Li e Peter J. Liu.
1. **[T5v1.1](model_doc/t5v1.1)** (da Google AI) rilasciato nel repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) da Colin Raffel e Noam Shazeer e Adam Roberts e Katherine Lee e Sharan Narang e Michael Matena e Yanqi Zhou e Wei Li e Peter J. Liu.
-1. **[TAPAS](model_doc/tapas)** (da Google AI) rilasciato con il paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) da Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno e Julian Martin Eisenschlos.
-1. **[TAPEX](model_doc/tapex)** (da Microsoft Research) rilasciato con il paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) da Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
-1. **[Trajectory Transformer](model_doc/trajectory_transformers)** (dall'Università della California a Berkeley) rilasciato con il paper [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) da Michael Janner, Qiyang Li, Sergey Levine
-1. **[Transformer-XL](model_doc/transfo-xl)** (da Google/CMU) rilasciato con il paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) da Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
-1. **[TrOCR](model_doc/trocr)** (da Microsoft), rilasciato assieme al paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) da Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
-1. **[UniSpeech](model_doc/unispeech)** (da Microsoft Research) rilasciato con il paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) da Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
-1. **[UniSpeechSat](model_doc/unispeech-sat)** (da Microsoft Research) rilasciato con il paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) da Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
-1. **[VAN](model_doc/van)** (dalle Università di Tsinghua e Nankai) rilasciato con il paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) da Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
-1. **[ViLT](model_doc/vilt)** (da NAVER AI Lab/Kakao Enterprise/Kakao Brain) rilasciato con il paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) da Wonjae Kim, Bokyung Son, Ildoo Kim.
-1. **[Vision Transformer (ViT)](model_doc/vit)** (da Google AI) rilasciato con il paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) da Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
-1. **[ViTMAE](model_doc/vit_mae)** (da Meta AI) rilasciato con il paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) da Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
-1. **[VisualBERT](model_doc/visual_bert)** (da UCLA NLP) rilasciato con il paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) da Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
-1. **[WavLM](model_doc/wavlm)** (da Microsoft Research) rilasciato con il paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) da Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
-1. **[Wav2Vec2](model_doc/wav2vec2)** (da Facebook AI) rilasciato con il paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) da Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
-1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (da Facebook AI) rilasciato con il paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) da Qiantong Xu, Alexei Baevski, Michael Auli.
-1. **[XGLM](model_doc/xglm)** (da Facebook AI) rilasciato con il paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) da Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
-1. **[XLM](model_doc/xlm)** (v Facebook) rilasciato assieme al paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) da Guillaume Lample e Alexis Conneau.
-1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (da Microsoft Research) rilasciato con il paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) da Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang e Ming Zhou.
-1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (da Facebook AI), rilasciato assieme al paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) da Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer e Veselin Stoyanov.
-1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (da Facebook AI), rilasciato assieme al paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) da Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
-1. **[XLNet](model_doc/xlnet)** (da Google/CMU) rilasciato con il paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) da Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
-1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (da Facebook AI) rilasciato con il paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) da Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
-1. **[XLS-R](model_doc/xls_r)** (da Facebook AI) rilasciato con il paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) da Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
-1. **[YOLOS](model_doc/yolos)** (dalla Università della scienza e tecnologia di Huazhong) rilasciato con il paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) da Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
-1. **[YOSO](model_doc/yoso)** (dall'Università del Wisconsin - Madison) rilasciato con il paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) da Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
+1. **[TAPAS](model_doc/tapas)** (da Google AI) rilasciato con il paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://huggingface.co/papers/2004.02349) da Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno e Julian Martin Eisenschlos.
+1. **[TAPEX](model_doc/tapex)** (da Microsoft Research) rilasciato con il paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://huggingface.co/papers/2107.07653) da Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
+1. **[Trajectory Transformer](model_doc/trajectory_transformers)** (dall'Università della California a Berkeley) rilasciato con il paper [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://huggingface.co/papers/2106.02039) da Michael Janner, Qiyang Li, Sergey Levine
+1. **[Transformer-XL](model_doc/transfo-xl)** (da Google/CMU) rilasciato con il paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://huggingface.co/papers/1901.02860) da Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
+1. **[TrOCR](model_doc/trocr)** (da Microsoft), rilasciato assieme al paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://huggingface.co/papers/2109.10282) da Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
+1. **[UniSpeech](model_doc/unispeech)** (da Microsoft Research) rilasciato con il paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://huggingface.co/papers/2101.07597) da Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
+1. **[UniSpeechSat](model_doc/unispeech-sat)** (da Microsoft Research) rilasciato con il paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://huggingface.co/papers/2110.05752) da Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
+1. **[VAN](model_doc/van)** (dalle Università di Tsinghua e Nankai) rilasciato con il paper [Visual Attention Network](https://huggingface.co/papers/2202.09741) da Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
+1. **[ViLT](model_doc/vilt)** (da NAVER AI Lab/Kakao Enterprise/Kakao Brain) rilasciato con il paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://huggingface.co/papers/2102.03334) da Wonjae Kim, Bokyung Son, Ildoo Kim.
+1. **[Vision Transformer (ViT)](model_doc/vit)** (da Google AI) rilasciato con il paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://huggingface.co/papers/2010.11929) da Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
+1. **[ViTMAE](model_doc/vit_mae)** (da Meta AI) rilasciato con il paper [Masked Autoencoders Are Scalable Vision Learners](https://huggingface.co/papers/2111.06377) da Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
+1. **[VisualBERT](model_doc/visual_bert)** (da UCLA NLP) rilasciato con il paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://huggingface.co/papers/1908.03557) da Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
+1. **[WavLM](model_doc/wavlm)** (da Microsoft Research) rilasciato con il paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://huggingface.co/papers/2110.13900) da Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
+1. **[Wav2Vec2](model_doc/wav2vec2)** (da Facebook AI) rilasciato con il paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://huggingface.co/papers/2006.11477) da Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
+1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (da Facebook AI) rilasciato con il paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://huggingface.co/papers/2109.11680) da Qiantong Xu, Alexei Baevski, Michael Auli.
+1. **[XGLM](model_doc/xglm)** (da Facebook AI) rilasciato con il paper [Few-shot Learning with Multilingual Language Models](https://huggingface.co/papers/2112.10668) da Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
+1. **[XLM](model_doc/xlm)** (v Facebook) rilasciato assieme al paper [Cross-lingual Language Model Pretraining](https://huggingface.co/papers/1901.07291) da Guillaume Lample e Alexis Conneau.
+1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (da Microsoft Research) rilasciato con il paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://huggingface.co/papers/2001.04063) da Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang e Ming Zhou.
+1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (da Facebook AI), rilasciato assieme al paper [Unsupervised Cross-lingual Representation Learning at Scale](https://huggingface.co/papers/1911.02116) da Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer e Veselin Stoyanov.
+1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (da Facebook AI), rilasciato assieme al paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://huggingface.co/papers/2105.00572) da Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
+1. **[XLNet](model_doc/xlnet)** (da Google/CMU) rilasciato con il paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://huggingface.co/papers/1906.08237) da Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
+1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (da Facebook AI) rilasciato con il paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://huggingface.co/papers/2006.13979) da Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
+1. **[XLS-R](model_doc/xls_r)** (da Facebook AI) rilasciato con il paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://huggingface.co/papers/2111.09296) da Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
+1. **[YOLOS](model_doc/yolos)** (dalla Università della scienza e tecnologia di Huazhong) rilasciato con il paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://huggingface.co/papers/2106.00666) da Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
+1. **[YOSO](model_doc/yoso)** (dall'Università del Wisconsin - Madison) rilasciato con il paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://huggingface.co/papers/2111.09714) da Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
### Framework supportati
diff --git a/docs/source/it/perf_infer_gpu_one.md b/docs/source/it/perf_infer_gpu_one.md
index e618ec34a1..5339d72d4c 100644
--- a/docs/source/it/perf_infer_gpu_one.md
+++ b/docs/source/it/perf_infer_gpu_one.md
@@ -29,13 +29,13 @@ Nota che questa funzione può essere utilizzata anche nelle configurazioni multi
-Dal paper [`LLM.int8() : 8-bit Matrix Multiplication for Transformers at Scale`](https://arxiv.org/abs/2208.07339), noi supportiamo l'integrazione di Hugging Face per tutti i modelli dell'Hub con poche righe di codice.
+Dal paper [`LLM.int8() : 8-bit Matrix Multiplication for Transformers at Scale`](https://huggingface.co/papers/2208.07339), noi supportiamo l'integrazione di Hugging Face per tutti i modelli dell'Hub con poche righe di codice.
Il metodo `nn.Linear` riduce la dimensione di 2 per i pesi `float16` e `bfloat16` e di 4 per i pesi `float32`, con un impatto quasi nullo sulla qualità, operando sugli outlier in half-precision.

Il metodo Int8 mixed-precision matrix decomposition funziona separando la moltiplicazione tra matrici in due flussi: (1) una matrice di flusso di outlier di caratteristiche sistematiche moltiplicata in fp16, (2) in flusso regolare di moltiplicazione di matrici int8 (99,9%). Con questo metodo, è possibile effettutare inferenza int8 per modelli molto grandi senza degrado predittivo.
-Per maggiori dettagli sul metodo, consultare il [paper](https://arxiv.org/abs/2208.07339) o il nostro [blogpost sull'integrazione](https://huggingface.co/blog/hf-bitsandbytes-integration).
+Per maggiori dettagli sul metodo, consultare il [paper](https://huggingface.co/papers/2208.07339) o il nostro [blogpost sull'integrazione](https://huggingface.co/blog/hf-bitsandbytes-integration).

diff --git a/docs/source/ja/bertology.md b/docs/source/ja/bertology.md
index 2525d5edef..5287354cb2 100644
--- a/docs/source/ja/bertology.md
+++ b/docs/source/ja/bertology.md
@@ -20,15 +20,15 @@ rendered properly in your Markdown viewer.
大規模なトランスフォーマー、例えばBERTの内部動作を調査する研究領域が急成長しています(これを「BERTology」とも呼びます)。この分野の良い例は以下です:
- BERT Rediscovers the Classical NLP Pipeline by Ian Tenney, Dipanjan Das, Ellie Pavlick:
- [論文リンク](https://arxiv.org/abs/1905.05950)
-- Are Sixteen Heads Really Better than One? by Paul Michel, Omer Levy, Graham Neubig: [論文リンク](https://arxiv.org/abs/1905.10650)
-- What Does BERT Look At? An Analysis of BERT's Attention by Kevin Clark, Urvashi Khandelwal, Omer Levy, Christopher D. Manning: [論文リンク](https://arxiv.org/abs/1906.04341)
-- CAT-probing: A Metric-based Approach to Interpret How Pre-trained Models for Programming Language Attend Code Structure: [論文リンク](https://arxiv.org/abs/2210.04633)
+ [論文リンク](https://huggingface.co/papers/1905.05950)
+- Are Sixteen Heads Really Better than One? by Paul Michel, Omer Levy, Graham Neubig: [論文リンク](https://huggingface.co/papers/1905.10650)
+- What Does BERT Look At? An Analysis of BERT's Attention by Kevin Clark, Urvashi Khandelwal, Omer Levy, Christopher D. Manning: [論文リンク](https://huggingface.co/papers/1906.04341)
+- CAT-probing: A Metric-based Approach to Interpret How Pre-trained Models for Programming Language Attend Code Structure: [論文リンク](https://huggingface.co/papers/2210.04633)
-この新しい分野の発展を支援するために、BERT/GPT/GPT-2モデルにいくつかの追加機能を組み込み、人々が内部表現にアクセスできるようにしました。これらの機能は、主にPaul Michel氏の優れた研究([論文リンク](https://arxiv.org/abs/1905.10650))に基づいています。具体的には、以下の機能が含まれています:
+この新しい分野の発展を支援するために、BERT/GPT/GPT-2モデルにいくつかの追加機能を組み込み、人々が内部表現にアクセスできるようにしました。これらの機能は、主にPaul Michel氏の優れた研究([論文リンク](https://huggingface.co/papers/1905.10650))に基づいています。具体的には、以下の機能が含まれています:
- BERT/GPT/GPT-2のすべての隠れ状態にアクセスすることができます。
- BERT/GPT/GPT-2の各ヘッドの注意重みにアクセスできます。
-- ヘッドの出力値と勾配を取得し、ヘッドの重要性スコアを計算し、[論文リンク](https://arxiv.org/abs/1905.10650)で説明されているようにヘッドを削減できます。
+- ヘッドの出力値と勾配を取得し、ヘッドの重要性スコアを計算し、[論文リンク](https://huggingface.co/papers/1905.10650)で説明されているようにヘッドを削減できます。
これらの機能を理解し、使用するのを支援するために、特定のサンプルスクリプト「[bertology.py](https://github.com/huggingface/transformers-research-projects/tree/main/bertology/run_bertology.py)」を追加しました。このスクリプトは、GLUEで事前トレーニングされたモデルから情報を抽出し、ヘッドを削減する役割を果たします。
diff --git a/docs/source/ja/generation_strategies.md b/docs/source/ja/generation_strategies.md
index 870a489d6f..9fca784d00 100644
--- a/docs/source/ja/generation_strategies.md
+++ b/docs/source/ja/generation_strategies.md
@@ -170,7 +170,7 @@ An increasing sequence: one, two, three, four, five, six, seven, eight, nine, te
### Contrastive search
-コントラスティブ検索デコーディング戦略は、2022年の論文[A Contrastive Framework for Neural Text Generation](https://arxiv.org/abs/2202.06417)で提案されました。
+コントラスティブ検索デコーディング戦略は、2022年の論文[A Contrastive Framework for Neural Text Generation](https://huggingface.co/papers/2202.06417)で提案されました。
これは、非反復的でありながら一貫性のある長い出力を生成するために優れた結果を示しています。コントラスティブ検索の動作原理を学ぶには、[このブログポスト](https://huggingface.co/blog/introducing-csearch)をご覧ください。
コントラスティブ検索の動作を有効にし、制御する2つの主要なパラメータは「penalty_alpha」と「top_k」です:
@@ -266,7 +266,7 @@ time."\n\nHe added: "I am very proud of the work I have been able to do in the l
### Diverse beam search decoding
-多様なビームサーチデコーディング戦略は、ビームサーチ戦略の拡張であり、選択肢からより多様なビームシーケンスを生成できるようにします。この仕組みの詳細については、[Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models](https://arxiv.org/pdf/1610.02424.pdf) をご参照ください。このアプローチには、`num_beams`、`num_beam_groups`、および `diversity_penalty` という3つの主要なパラメータがあります。多様性ペナルティは、出力がグループごとに異なることを保証し、ビームサーチは各グループ内で使用されます。
+多様なビームサーチデコーディング戦略は、ビームサーチ戦略の拡張であり、選択肢からより多様なビームシーケンスを生成できるようにします。この仕組みの詳細については、[Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models](https://huggingface.co/papers/1610.02424) をご参照ください。このアプローチには、`num_beams`、`num_beam_groups`、および `diversity_penalty` という3つの主要なパラメータがあります。多様性ペナルティは、出力がグループごとに異なることを保証し、ビームサーチは各グループ内で使用されます。
```python
diff --git a/docs/source/ja/glossary.md b/docs/source/ja/glossary.md
index 39148f5d0f..775bffdd0c 100644
--- a/docs/source/ja/glossary.md
+++ b/docs/source/ja/glossary.md
@@ -149,7 +149,7 @@ The encoded versions have different lengths:
トランスフォーマー内の各残差注意ブロックでは、通常、自己注意層の後に2つのフィードフォワード層が続きます。
フィードフォワード層の中間埋め込みサイズは、モデルの隠れたサイズよりも大きいことがよくあります(たとえば、`google-bert/bert-base-uncased`の場合)。
-入力サイズが `[batch_size、sequence_length]` の場合、中間フィードフォワード埋め込み `[batch_size、sequence_length、config.intermediate_size]` を保存するために必要なメモリは、メモリの大部分を占めることがあります。[Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451)の著者は、計算が `sequence_length` 次元に依存しないため、両方のフィードフォワード層の出力埋め込み `[batch_size、config.hidden_size]_0、...、[batch_size、config.hidden_size]_n` を個別に計算し、後で `[batch_size、sequence_length、config.hidden_size]` に連結することは数学的に等価であると気付きました。これにより、増加した計算時間とメモリ使用量のトレードオフが生じますが、数学的に等価な結果が得られます。
+入力サイズが `[batch_size、sequence_length]` の場合、中間フィードフォワード埋め込み `[batch_size、sequence_length、config.intermediate_size]` を保存するために必要なメモリは、メモリの大部分を占めることがあります。[Reformer: The Efficient Transformer](https://huggingface.co/papers/2001.04451)の著者は、計算が `sequence_length` 次元に依存しないため、両方のフィードフォワード層の出力埋め込み `[batch_size、config.hidden_size]_0、...、[batch_size、config.hidden_size]_n` を個別に計算し、後で `[batch_size、sequence_length、config.hidden_size]` に連結することは数学的に等価であると気付きました。これにより、増加した計算時間とメモリ使用量のトレードオフが生じますが、数学的に等価な結果が得られます。
[`apply_chunking_to_forward`] 関数を使用するモデルの場合、`chunk_size` は並列に計算される出力埋め込みの数を定義し、メモリと時間の複雑さのトレードオフを定義します。`chunk_size` が 0 に設定されている場合、フィードフォワードのチャンキングは行われません。
@@ -185,7 +185,7 @@ The encoded versions have different lengths:
-各トークナイザーは異なる方法で動作しますが、基本的なメカニズムは同じです。以下はBERTトークナイザーを使用した例です。BERTトークナイザーは[WordPiece](https://arxiv.org/pdf/1609.08144.pdf)トークナイザーです。
+各トークナイザーは異なる方法で動作しますが、基本的なメカニズムは同じです。以下はBERTトークナイザーを使用した例です。BERTトークナイザーは[WordPiece](https://huggingface.co/papers/1609.08144)トークナイザーです。
```python
diff --git a/docs/source/ja/index.md b/docs/source/ja/index.md
index d606662ed8..1fdd300b76 100644
--- a/docs/source/ja/index.md
+++ b/docs/source/ja/index.md
@@ -53,180 +53,180 @@ rendered properly in your Markdown viewer.
-1. **[ALBERT](https://huggingface.co/docs/transformers/model_doc/albert)** (Google Research and the Toyota Technological Institute at Chicago から) Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut から公開された研究論文: [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942)
-1. **[AltCLIP](https://huggingface.co/docs/transformers/main/model_doc/altclip)** (BAAI から) Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell から公開された研究論文: [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679)
-1. **[Audio Spectrogram Transformer](https://huggingface.co/docs/transformers/model_doc/audio-spectrogram-transformer)** (MIT から) Yuan Gong, Yu-An Chung, James Glass から公開された研究論文: [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778)
-1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (Facebook から) Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer から公開された研究論文: [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461)
-1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (École polytechnique から) Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis から公開された研究論文: [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321)
-1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (VinAI Research から) Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen から公開された研究論文: [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701)
-1. **[BEiT](https://huggingface.co/docs/transformers/model_doc/beit)** (Microsoft から) Hangbo Bao, Li Dong, Furu Wei から公開された研究論文: [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254)
-1. **[BERT](https://huggingface.co/docs/transformers/model_doc/bert)** (Google から) Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova から公開された研究論文: [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805)
-1. **[BERT For Sequence Generation](https://huggingface.co/docs/transformers/model_doc/bert-generation)** (Google から) Sascha Rothe, Shashi Narayan, Aliaksei Severyn から公開された研究論文: [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461)
+1. **[ALBERT](https://huggingface.co/docs/transformers/model_doc/albert)** (Google Research and the Toyota Technological Institute at Chicago から) Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut から公開された研究論文: [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://huggingface.co/papers/1909.11942)
+1. **[AltCLIP](https://huggingface.co/docs/transformers/main/model_doc/altclip)** (BAAI から) Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell から公開された研究論文: [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://huggingface.co/papers/2211.06679)
+1. **[Audio Spectrogram Transformer](https://huggingface.co/docs/transformers/model_doc/audio-spectrogram-transformer)** (MIT から) Yuan Gong, Yu-An Chung, James Glass から公開された研究論文: [AST: Audio Spectrogram Transformer](https://huggingface.co/papers/2104.01778)
+1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (Facebook から) Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer から公開された研究論文: [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://huggingface.co/papers/1910.13461)
+1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (École polytechnique から) Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis から公開された研究論文: [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://huggingface.co/papers/2010.12321)
+1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (VinAI Research から) Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen から公開された研究論文: [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://huggingface.co/papers/2109.09701)
+1. **[BEiT](https://huggingface.co/docs/transformers/model_doc/beit)** (Microsoft から) Hangbo Bao, Li Dong, Furu Wei から公開された研究論文: [BEiT: BERT Pre-Training of Image Transformers](https://huggingface.co/papers/2106.08254)
+1. **[BERT](https://huggingface.co/docs/transformers/model_doc/bert)** (Google から) Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova から公開された研究論文: [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://huggingface.co/papers/1810.04805)
+1. **[BERT For Sequence Generation](https://huggingface.co/docs/transformers/model_doc/bert-generation)** (Google から) Sascha Rothe, Shashi Narayan, Aliaksei Severyn から公開された研究論文: [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://huggingface.co/papers/1907.12461)
1. **[BERTweet](https://huggingface.co/docs/transformers/model_doc/bertweet)** (VinAI Research から) Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen から公開された研究論文: [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/)
-1. **[BigBird-Pegasus](https://huggingface.co/docs/transformers/model_doc/bigbird_pegasus)** (Google Research から) Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed から公開された研究論文: [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062)
-1. **[BigBird-RoBERTa](https://huggingface.co/docs/transformers/model_doc/big_bird)** (Google Research から) Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed から公開された研究論文: [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062)
+1. **[BigBird-Pegasus](https://huggingface.co/docs/transformers/model_doc/bigbird_pegasus)** (Google Research から) Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed から公開された研究論文: [Big Bird: Transformers for Longer Sequences](https://huggingface.co/papers/2007.14062)
+1. **[BigBird-RoBERTa](https://huggingface.co/docs/transformers/model_doc/big_bird)** (Google Research から) Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed から公開された研究論文: [Big Bird: Transformers for Longer Sequences](https://huggingface.co/papers/2007.14062)
1. **[BioGpt](https://huggingface.co/docs/transformers/main/model_doc/biogpt)** (Microsoft Research AI4Science から) Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon and Tie-Yan Liu から公開された研究論文: [BioGPT: generative pre-trained transformer for biomedical text generation and mining](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9)
-1. **[BiT](https://huggingface.co/docs/transformers/main/model_doc/bit)** (Google AI から) Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil から公開された研究論文: [Big Transfer (BiT)](https://arxiv.org/abs/1912.11370)Houlsby.
-1. **[Blenderbot](https://huggingface.co/docs/transformers/model_doc/blenderbot)** (Facebook から) Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston から公開された研究論文: [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637)
-1. **[BlenderbotSmall](https://huggingface.co/docs/transformers/model_doc/blenderbot-small)** (Facebook から) Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston から公開された研究論文: [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637)
-1. **[BLIP](https://huggingface.co/docs/transformers/main/model_doc/blip)** (Salesforce から) Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi から公開された研究論文: [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086)
+1. **[BiT](https://huggingface.co/docs/transformers/main/model_doc/bit)** (Google AI から) Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil から公開された研究論文: [Big Transfer (BiT)](https://huggingface.co/papers/1912.11370)Houlsby.
+1. **[Blenderbot](https://huggingface.co/docs/transformers/model_doc/blenderbot)** (Facebook から) Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston から公開された研究論文: [Recipes for building an open-domain chatbot](https://huggingface.co/papers/2004.13637)
+1. **[BlenderbotSmall](https://huggingface.co/docs/transformers/model_doc/blenderbot-small)** (Facebook から) Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston から公開された研究論文: [Recipes for building an open-domain chatbot](https://huggingface.co/papers/2004.13637)
+1. **[BLIP](https://huggingface.co/docs/transformers/main/model_doc/blip)** (Salesforce から) Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi から公開された研究論文: [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://huggingface.co/papers/2201.12086)
1. **[BLOOM](https://huggingface.co/docs/transformers/model_doc/bloom)** (BigScience workshop から) [BigScience Workshop](https://bigscience.huggingface.co/) から公開されました.
-1. **[BORT](https://huggingface.co/docs/transformers/model_doc/bort)** (Alexa から) Adrian de Wynter and Daniel J. Perry から公開された研究論文: [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499)
-1. **[ByT5](https://huggingface.co/docs/transformers/model_doc/byt5)** (Google Research から) Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel から公開された研究論文: [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626)
-1. **[CamemBERT](https://huggingface.co/docs/transformers/model_doc/camembert)** (Inria/Facebook/Sorbonne から) Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot から公開された研究論文: [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894)
-1. **[CANINE](https://huggingface.co/docs/transformers/model_doc/canine)** (Google Research から) Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting から公開された研究論文: [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874)
-1. **[Chinese-CLIP](https://huggingface.co/docs/transformers/model_doc/chinese_clip)** (OFA-Sys から) An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou から公開された研究論文: [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://arxiv.org/abs/2211.01335)
-1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (OpenAI から) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever から公開された研究論文: [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020)
-1. **[CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)** (University of Göttingen から) Timo Lüddecke and Alexander Ecker から公開された研究論文: [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003)
-1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (Salesforce から) Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong から公開された研究論文: [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474)
-1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (Microsoft Research Asia から) Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang から公開された研究論文: [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152)
-1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (YituTech から) Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan から公開された研究論文: [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496)
-1. **[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)** (Facebook AI から) Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie から公開された研究論文: [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545)
-1. **[ConvNeXTV2](model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
-1. **[CPM](https://huggingface.co/docs/transformers/model_doc/cpm)** (Tsinghua University から) Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun から公開された研究論文: [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413)
-1. **[CTRL](https://huggingface.co/docs/transformers/model_doc/ctrl)** (Salesforce から) Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher から公開された研究論文: [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858)
-1. **[CvT](https://huggingface.co/docs/transformers/model_doc/cvt)** (Microsoft から) Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang から公開された研究論文: [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808)
-1. **[Data2Vec](https://huggingface.co/docs/transformers/model_doc/data2vec)** (Facebook から) Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli から公開された研究論文: [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555)
-1. **[DeBERTa](https://huggingface.co/docs/transformers/model_doc/deberta)** (Microsoft から) Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen から公開された研究論文: [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654)
-1. **[DeBERTa-v2](https://huggingface.co/docs/transformers/model_doc/deberta-v2)** (Microsoft から) Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen から公開された研究論文: [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654)
-1. **[Decision Transformer](https://huggingface.co/docs/transformers/model_doc/decision_transformer)** (Berkeley/Facebook/Google から) Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch から公開された研究論文: [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345)
-1. **[Deformable DETR](https://huggingface.co/docs/transformers/model_doc/deformable_detr)** (SenseTime Research から) Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai から公開された研究論文: [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159)
-1. **[DeiT](https://huggingface.co/docs/transformers/model_doc/deit)** (Facebook から) Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou から公開された研究論文: [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877)
-1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (Facebook から) Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko から公開された研究論文: [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872)
-1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (Microsoft Research から) Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan から公開された研究論文: [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536)
-1. **[DiNAT](https://huggingface.co/docs/transformers/model_doc/dinat)** (SHI Labs から) Ali Hassani and Humphrey Shi から公開された研究論文: [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001)
-1. **[DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)** (HuggingFace から), Victor Sanh, Lysandre Debut and Thomas Wolf. 同じ手法で GPT2, RoBERTa と Multilingual BERT の圧縮を行いました.圧縮されたモデルはそれぞれ [DistilGPT2](https://github.com/huggingface/transformers-research-projects/tree/main/distillation)、[DistilRoBERTa](https://github.com/huggingface/transformers-research-projects/tree/main/distillation)、[DistilmBERT](https://github.com/huggingface/transformers-research-projects/tree/main/distillation) と名付けられました. 公開された研究論文: [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108)
-1. **[DiT](https://huggingface.co/docs/transformers/model_doc/dit)** (Microsoft Research から) Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei から公開された研究論文: [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378)
-1. **[Donut](https://huggingface.co/docs/transformers/model_doc/donut)** (NAVER から), Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park から公開された研究論文: [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664)
-1. **[DPR](https://huggingface.co/docs/transformers/model_doc/dpr)** (Facebook から) Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih から公開された研究論文: [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906)
-1. **[DPT](https://huggingface.co/docs/transformers/master/model_doc/dpt)** (Intel Labs から) René Ranftl, Alexey Bochkovskiy, Vladlen Koltun から公開された研究論文: [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413)
-1. **[EfficientNet](https://huggingface.co/docs/transformers/model_doc/efficientnet)** (from Google Research) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan and Quoc V. Le.
-1. **[ELECTRA](https://huggingface.co/docs/transformers/model_doc/electra)** (Google Research/Stanford University から) Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning から公開された研究論文: [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555)
-1. **[EncoderDecoder](https://huggingface.co/docs/transformers/model_doc/encoder-decoder)** (Google Research から) Sascha Rothe, Shashi Narayan, Aliaksei Severyn から公開された研究論文: [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461)
-1. **[ERNIE](https://huggingface.co/docs/transformers/model_doc/ernie)** (Baidu から) Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu から公開された研究論文: [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223)
+1. **[BORT](https://huggingface.co/docs/transformers/model_doc/bort)** (Alexa から) Adrian de Wynter and Daniel J. Perry から公開された研究論文: [Optimal Subarchitecture Extraction For BERT](https://huggingface.co/papers/2010.10499)
+1. **[ByT5](https://huggingface.co/docs/transformers/model_doc/byt5)** (Google Research から) Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel から公開された研究論文: [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://huggingface.co/papers/2105.13626)
+1. **[CamemBERT](https://huggingface.co/docs/transformers/model_doc/camembert)** (Inria/Facebook/Sorbonne から) Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot から公開された研究論文: [CamemBERT: a Tasty French Language Model](https://huggingface.co/papers/1911.03894)
+1. **[CANINE](https://huggingface.co/docs/transformers/model_doc/canine)** (Google Research から) Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting から公開された研究論文: [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://huggingface.co/papers/2103.06874)
+1. **[Chinese-CLIP](https://huggingface.co/docs/transformers/model_doc/chinese_clip)** (OFA-Sys から) An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou から公開された研究論文: [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://huggingface.co/papers/2211.01335)
+1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (OpenAI から) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever から公開された研究論文: [Learning Transferable Visual Models From Natural Language Supervision](https://huggingface.co/papers/2103.00020)
+1. **[CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)** (University of Göttingen から) Timo Lüddecke and Alexander Ecker から公開された研究論文: [Image Segmentation Using Text and Image Prompts](https://huggingface.co/papers/2112.10003)
+1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (Salesforce から) Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong から公開された研究論文: [A Conversational Paradigm for Program Synthesis](https://huggingface.co/papers/2203.13474)
+1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (Microsoft Research Asia から) Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang から公開された研究論文: [Conditional DETR for Fast Training Convergence](https://huggingface.co/papers/2108.06152)
+1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (YituTech から) Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan から公開された研究論文: [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://huggingface.co/papers/2008.02496)
+1. **[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)** (Facebook AI から) Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie から公開された研究論文: [A ConvNet for the 2020s](https://huggingface.co/papers/2201.03545)
+1. **[ConvNeXTV2](model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://huggingface.co/papers/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
+1. **[CPM](https://huggingface.co/docs/transformers/model_doc/cpm)** (Tsinghua University から) Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun から公開された研究論文: [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://huggingface.co/papers/2012.00413)
+1. **[CTRL](https://huggingface.co/docs/transformers/model_doc/ctrl)** (Salesforce から) Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher から公開された研究論文: [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://huggingface.co/papers/1909.05858)
+1. **[CvT](https://huggingface.co/docs/transformers/model_doc/cvt)** (Microsoft から) Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang から公開された研究論文: [CvT: Introducing Convolutions to Vision Transformers](https://huggingface.co/papers/2103.15808)
+1. **[Data2Vec](https://huggingface.co/docs/transformers/model_doc/data2vec)** (Facebook から) Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli から公開された研究論文: [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://huggingface.co/papers/2202.03555)
+1. **[DeBERTa](https://huggingface.co/docs/transformers/model_doc/deberta)** (Microsoft から) Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen から公開された研究論文: [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://huggingface.co/papers/2006.03654)
+1. **[DeBERTa-v2](https://huggingface.co/docs/transformers/model_doc/deberta-v2)** (Microsoft から) Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen から公開された研究論文: [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://huggingface.co/papers/2006.03654)
+1. **[Decision Transformer](https://huggingface.co/docs/transformers/model_doc/decision_transformer)** (Berkeley/Facebook/Google から) Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch から公開された研究論文: [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://huggingface.co/papers/2106.01345)
+1. **[Deformable DETR](https://huggingface.co/docs/transformers/model_doc/deformable_detr)** (SenseTime Research から) Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai から公開された研究論文: [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://huggingface.co/papers/2010.04159)
+1. **[DeiT](https://huggingface.co/docs/transformers/model_doc/deit)** (Facebook から) Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou から公開された研究論文: [Training data-efficient image transformers & distillation through attention](https://huggingface.co/papers/2012.12877)
+1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (Facebook から) Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko から公開された研究論文: [End-to-End Object Detection with Transformers](https://huggingface.co/papers/2005.12872)
+1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (Microsoft Research から) Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan から公開された研究論文: [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://huggingface.co/papers/1911.00536)
+1. **[DiNAT](https://huggingface.co/docs/transformers/model_doc/dinat)** (SHI Labs から) Ali Hassani and Humphrey Shi から公開された研究論文: [Dilated Neighborhood Attention Transformer](https://huggingface.co/papers/2209.15001)
+1. **[DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)** (HuggingFace から), Victor Sanh, Lysandre Debut and Thomas Wolf. 同じ手法で GPT2, RoBERTa と Multilingual BERT の圧縮を行いました.圧縮されたモデルはそれぞれ [DistilGPT2](https://github.com/huggingface/transformers-research-projects/tree/main/distillation)、[DistilRoBERTa](https://github.com/huggingface/transformers-research-projects/tree/main/distillation)、[DistilmBERT](https://github.com/huggingface/transformers-research-projects/tree/main/distillation) と名付けられました. 公開された研究論文: [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://huggingface.co/papers/1910.01108)
+1. **[DiT](https://huggingface.co/docs/transformers/model_doc/dit)** (Microsoft Research から) Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei から公開された研究論文: [DiT: Self-supervised Pre-training for Document Image Transformer](https://huggingface.co/papers/2203.02378)
+1. **[Donut](https://huggingface.co/docs/transformers/model_doc/donut)** (NAVER から), Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park から公開された研究論文: [OCR-free Document Understanding Transformer](https://huggingface.co/papers/2111.15664)
+1. **[DPR](https://huggingface.co/docs/transformers/model_doc/dpr)** (Facebook から) Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih から公開された研究論文: [Dense Passage Retrieval for Open-Domain Question Answering](https://huggingface.co/papers/2004.04906)
+1. **[DPT](https://huggingface.co/docs/transformers/master/model_doc/dpt)** (Intel Labs から) René Ranftl, Alexey Bochkovskiy, Vladlen Koltun から公開された研究論文: [Vision Transformers for Dense Prediction](https://huggingface.co/papers/2103.13413)
+1. **[EfficientNet](https://huggingface.co/docs/transformers/model_doc/efficientnet)** (from Google Research) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://huggingface.co/papers/1905.11946) by Mingxing Tan and Quoc V. Le.
+1. **[ELECTRA](https://huggingface.co/docs/transformers/model_doc/electra)** (Google Research/Stanford University から) Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning から公開された研究論文: [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://huggingface.co/papers/2003.10555)
+1. **[EncoderDecoder](https://huggingface.co/docs/transformers/model_doc/encoder-decoder)** (Google Research から) Sascha Rothe, Shashi Narayan, Aliaksei Severyn から公開された研究論文: [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://huggingface.co/papers/1907.12461)
+1. **[ERNIE](https://huggingface.co/docs/transformers/model_doc/ernie)** (Baidu から) Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu から公開された研究論文: [ERNIE: Enhanced Representation through Knowledge Integration](https://huggingface.co/papers/1904.09223)
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (Meta AI から) はトランスフォーマープロテイン言語モデルです. **ESM-1b** は Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus から公開された研究論文: [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118). **ESM-1v** は Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives から公開された研究論文: [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648). **ESM-2** と **ESMFold** は Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives から公開された研究論文: [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902)
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (Google AI から) Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V から公開されたレポジトリー [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) Le, and Jason Wei
-1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (CNRS から) Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab から公開された研究論文: [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372)
-1. **[FLAVA](https://huggingface.co/docs/transformers/model_doc/flava)** (Facebook AI から) Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela から公開された研究論文: [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482)
-1. **[FNet](https://huggingface.co/docs/transformers/model_doc/fnet)** (Google Research から) James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon から公開された研究論文: [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824)
-1. **[Funnel Transformer](https://huggingface.co/docs/transformers/model_doc/funnel)** (CMU/Google Brain から) Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le から公開された研究論文: [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236)
-1. **[GIT](https://huggingface.co/docs/transformers/main/model_doc/git)** (Microsoft Research から) Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang. から公開された研究論文 [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100)
-1. **[GLPN](https://huggingface.co/docs/transformers/model_doc/glpn)** (KAIST から) Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim から公開された研究論文: [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436)
+1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (CNRS から) Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab から公開された研究論文: [FlauBERT: Unsupervised Language Model Pre-training for French](https://huggingface.co/papers/1912.05372)
+1. **[FLAVA](https://huggingface.co/docs/transformers/model_doc/flava)** (Facebook AI から) Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela から公開された研究論文: [FLAVA: A Foundational Language And Vision Alignment Model](https://huggingface.co/papers/2112.04482)
+1. **[FNet](https://huggingface.co/docs/transformers/model_doc/fnet)** (Google Research から) James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon から公開された研究論文: [FNet: Mixing Tokens with Fourier Transforms](https://huggingface.co/papers/2105.03824)
+1. **[Funnel Transformer](https://huggingface.co/docs/transformers/model_doc/funnel)** (CMU/Google Brain から) Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le から公開された研究論文: [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://huggingface.co/papers/2006.03236)
+1. **[GIT](https://huggingface.co/docs/transformers/main/model_doc/git)** (Microsoft Research から) Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang. から公開された研究論文 [GIT: A Generative Image-to-text Transformer for Vision and Language](https://huggingface.co/papers/2205.14100)
+1. **[GLPN](https://huggingface.co/docs/transformers/model_doc/glpn)** (KAIST から) Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim から公開された研究論文: [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://huggingface.co/papers/2201.07436)
1. **[GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)** (OpenAI から) Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever から公開された研究論文: [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/)
1. **[GPT Neo](https://huggingface.co/docs/transformers/model_doc/gpt_neo)** (EleutherAI から) Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy から公開されたレポジトリー : [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo)
-1. **[GPT NeoX](https://huggingface.co/docs/transformers/model_doc/gpt_neox)** (EleutherAI から) Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach から公開された研究論文: [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745)
+1. **[GPT NeoX](https://huggingface.co/docs/transformers/model_doc/gpt_neox)** (EleutherAI から) Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach から公開された研究論文: [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://huggingface.co/papers/2204.06745)
1. **[GPT NeoX Japanese](https://huggingface.co/docs/transformers/model_doc/gpt_neox_japanese)** (ABEJA から) Shinya Otani, Takayoshi Makabe, Anuj Arora, and Kyo Hattori からリリース.
1. **[GPT-2](https://huggingface.co/docs/transformers/model_doc/gpt2)** (OpenAI から) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever から公開された研究論文: [Language Models are Unsupervised Multitask Learners](https://openai.com/research/better-language-models/)
1. **[GPT-J](https://huggingface.co/docs/transformers/model_doc/gptj)** (EleutherAI から) Ben Wang and Aran Komatsuzaki から公開されたレポジトリー [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/)
1. **[GPT-Sw3](https://huggingface.co/docs/transformers/main/model_doc/gpt-sw3)** (AI-Sweden から) Ariel Ekgren, Amaru Cuba Gyllensten, Evangelia Gogoulou, Alice Heiman, Severine Verlinden, Joey Öhman, Fredrik Carlsson, Magnus Sahlgren から公開された研究論文: [Lessons Learned from GPT-SW3: Building the First Large-Scale Generative Language Model for Swedish](http://www.lrec-conf.org/proceedings/lrec2022/pdf/2022.lrec-1.376.pdf)
-1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (UCSD, NVIDIA から) Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang から公開された研究論文: [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094)
-1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (Facebook から) Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed から公開された研究論文: [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447)
-1. **[I-BERT](https://huggingface.co/docs/transformers/model_doc/ibert)** (Berkeley から) Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer から公開された研究論文: [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321)
+1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (UCSD, NVIDIA から) Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang から公開された研究論文: [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://huggingface.co/papers/2202.11094)
+1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (Facebook から) Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed から公開された研究論文: [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://huggingface.co/papers/2106.07447)
+1. **[I-BERT](https://huggingface.co/docs/transformers/model_doc/ibert)** (Berkeley から) Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer から公開された研究論文: [I-BERT: Integer-only BERT Quantization](https://huggingface.co/papers/2101.01321)
1. **[ImageGPT](https://huggingface.co/docs/transformers/model_doc/imagegpt)** (OpenAI から) Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever から公開された研究論文: [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/)
-1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (OpenAI から) Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever から公開された研究論文: [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf)
-1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (Microsoft Research Asia から) Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou から公開された研究論文: [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318)
-1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (Microsoft Research Asia から) Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou から公開された研究論文: [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740)
-1. **[LayoutLMv3](https://huggingface.co/docs/transformers/model_doc/layoutlmv3)** (Microsoft Research Asia から) Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei から公開された研究論文: [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387)
-1. **[LayoutXLM](https://huggingface.co/docs/transformers/model_doc/layoutxlm)** (Microsoft Research Asia から) Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei から公開された研究論文: [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836)
-1. **[LED](https://huggingface.co/docs/transformers/model_doc/led)** (AllenAI から) Iz Beltagy, Matthew E. Peters, Arman Cohan から公開された研究論文: [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150)
-1. **[LeViT](https://huggingface.co/docs/transformers/model_doc/levit)** (Meta AI から) Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze から公開された研究論文: [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136)
-1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (South China University of Technology から) Jiapeng Wang, Lianwen Jin, Kai Ding から公開された研究論文: [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669)
-1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (AllenAI から) Iz Beltagy, Matthew E. Peters, Arman Cohan から公開された研究論文: [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150)
-1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (Google AI から) Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang から公開された研究論文: [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916)
-1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (Studio Ousia から) Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto から公開された研究論文: [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057)
-1. **[LXMERT](https://huggingface.co/docs/transformers/model_doc/lxmert)** (UNC Chapel Hill から) Hao Tan and Mohit Bansal から公開された研究論文: [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490)
-1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (Facebook から) Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert から公開された研究論文: [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161)
-1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (Facebook から) Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin から公開された研究論文: [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125)
+1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (OpenAI から) Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever から公開された研究論文: [Jukebox: A Generative Model for Music](https://huggingface.co/papers/2005.00341)
+1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (Microsoft Research Asia から) Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou から公開された研究論文: [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://huggingface.co/papers/1912.13318)
+1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (Microsoft Research Asia から) Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou から公開された研究論文: [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://huggingface.co/papers/2012.14740)
+1. **[LayoutLMv3](https://huggingface.co/docs/transformers/model_doc/layoutlmv3)** (Microsoft Research Asia から) Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei から公開された研究論文: [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://huggingface.co/papers/2204.08387)
+1. **[LayoutXLM](https://huggingface.co/docs/transformers/model_doc/layoutxlm)** (Microsoft Research Asia から) Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei から公開された研究論文: [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://huggingface.co/papers/2104.08836)
+1. **[LED](https://huggingface.co/docs/transformers/model_doc/led)** (AllenAI から) Iz Beltagy, Matthew E. Peters, Arman Cohan から公開された研究論文: [Longformer: The Long-Document Transformer](https://huggingface.co/papers/2004.05150)
+1. **[LeViT](https://huggingface.co/docs/transformers/model_doc/levit)** (Meta AI から) Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze から公開された研究論文: [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://huggingface.co/papers/2104.01136)
+1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (South China University of Technology から) Jiapeng Wang, Lianwen Jin, Kai Ding から公開された研究論文: [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://huggingface.co/papers/2202.13669)
+1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (AllenAI から) Iz Beltagy, Matthew E. Peters, Arman Cohan から公開された研究論文: [Longformer: The Long-Document Transformer](https://huggingface.co/papers/2004.05150)
+1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (Google AI から) Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang から公開された研究論文: [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://huggingface.co/papers/2112.07916)
+1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (Studio Ousia から) Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto から公開された研究論文: [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://huggingface.co/papers/2010.01057)
+1. **[LXMERT](https://huggingface.co/docs/transformers/model_doc/lxmert)** (UNC Chapel Hill から) Hao Tan and Mohit Bansal から公開された研究論文: [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://huggingface.co/papers/1908.07490)
+1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (Facebook から) Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert から公開された研究論文: [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://huggingface.co/papers/2111.00161)
+1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (Facebook から) Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin から公開された研究論文: [Beyond English-Centric Multilingual Machine Translation](https://huggingface.co/papers/2010.11125)
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Jörg Tiedemann から. [OPUS](http://opus.nlpl.eu/) を使いながら学習された "Machine translation" (マシントランスレーション) モデル. [Marian Framework](https://marian-nmt.github.io/) はMicrosoft Translator Team が現在開発中です.
-1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (Microsoft Research Asia から) Junlong Li, Yiheng Xu, Lei Cui, Furu Wei から公開された研究論文: [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518)
-1. **[Mask2Former](https://huggingface.co/docs/transformers/main/model_doc/mask2former)** (FAIR and UIUC から) Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar. から公開された研究論文 [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527)
-1. **[MaskFormer](https://huggingface.co/docs/transformers/model_doc/maskformer)** (Meta and UIUC から) Bowen Cheng, Alexander G. Schwing, Alexander Kirillov から公開された研究論文: [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278)
-1. **[mBART](https://huggingface.co/docs/transformers/model_doc/mbart)** (Facebook から) Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer から公開された研究論文: [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210)
-1. **[mBART-50](https://huggingface.co/docs/transformers/model_doc/mbart)** (Facebook から) Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan から公開された研究論文: [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401)
-1. **[Megatron-BERT](https://huggingface.co/docs/transformers/model_doc/megatron-bert)** (NVIDIA から) Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro から公開された研究論文: [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053)
-1. **[Megatron-GPT2](https://huggingface.co/docs/transformers/model_doc/megatron_gpt2)** (NVIDIA から) Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro から公開された研究論文: [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053)
-1. **[mLUKE](https://huggingface.co/docs/transformers/model_doc/mluke)** (Studio Ousia から) Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka から公開された研究論文: [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151)
-1. **[MobileBERT](https://huggingface.co/docs/transformers/model_doc/mobilebert)** (CMU/Google Brain から) Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou から公開された研究論文: [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984)
-1. **[MobileNetV1](https://huggingface.co/docs/transformers/model_doc/mobilenet_v1)** (Google Inc. から) Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam から公開された研究論文: [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/abs/1704.04861)
-1. **[MobileNetV2](https://huggingface.co/docs/transformers/model_doc/mobilenet_v2)** (Google Inc. から) Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen から公開された研究論文: [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381)
-1. **[MobileViT](https://huggingface.co/docs/transformers/model_doc/mobilevit)** (Apple から) Sachin Mehta and Mohammad Rastegari から公開された研究論文: [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178)
-1. **[MPNet](https://huggingface.co/docs/transformers/model_doc/mpnet)** (Microsoft Research から) Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu から公開された研究論文: [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297)
-1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (Google AI から) Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel から公開された研究論文: [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934)
-1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (RUC AI Box から) Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen から公開された研究論文: [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131)
-1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (SHI Labs から) Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi から公開された研究論文: [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143)
-1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (Huawei Noah’s Ark Lab から) Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu から公開された研究論文: [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204)
-1. **[NLLB](https://huggingface.co/docs/transformers/model_doc/nllb)** (Meta から) the NLLB team から公開された研究論文: [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672)
-1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (the University of Wisconsin - Madison から) Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh から公開された研究論文: [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902)
-1. **[OneFormer](https://huggingface.co/docs/transformers/main/model_doc/oneformer)** (SHI Labs から) Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi から公開された研究論文: [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220)
-1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (Meta AI から) Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al から公開された研究論文: [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068)
-1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (Google AI から) Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby から公開された研究論文: [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230)
-1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (Google から) Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu から公開された研究論文: [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777)
-1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (Google から) Jason Phang, Yao Zhao, and Peter J. Liu から公開された研究論文: [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347)
-1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (Deepmind から) Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira から公開された研究論文: [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795)
+1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (Microsoft Research Asia から) Junlong Li, Yiheng Xu, Lei Cui, Furu Wei から公開された研究論文: [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://huggingface.co/papers/2110.08518)
+1. **[Mask2Former](https://huggingface.co/docs/transformers/main/model_doc/mask2former)** (FAIR and UIUC から) Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar. から公開された研究論文 [Masked-attention Mask Transformer for Universal Image Segmentation](https://huggingface.co/papers/2112.01527)
+1. **[MaskFormer](https://huggingface.co/docs/transformers/model_doc/maskformer)** (Meta and UIUC から) Bowen Cheng, Alexander G. Schwing, Alexander Kirillov から公開された研究論文: [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://huggingface.co/papers/2107.06278)
+1. **[mBART](https://huggingface.co/docs/transformers/model_doc/mbart)** (Facebook から) Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer から公開された研究論文: [Multilingual Denoising Pre-training for Neural Machine Translation](https://huggingface.co/papers/2001.08210)
+1. **[mBART-50](https://huggingface.co/docs/transformers/model_doc/mbart)** (Facebook から) Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan から公開された研究論文: [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://huggingface.co/papers/2008.00401)
+1. **[Megatron-BERT](https://huggingface.co/docs/transformers/model_doc/megatron-bert)** (NVIDIA から) Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro から公開された研究論文: [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://huggingface.co/papers/1909.08053)
+1. **[Megatron-GPT2](https://huggingface.co/docs/transformers/model_doc/megatron_gpt2)** (NVIDIA から) Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro から公開された研究論文: [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://huggingface.co/papers/1909.08053)
+1. **[mLUKE](https://huggingface.co/docs/transformers/model_doc/mluke)** (Studio Ousia から) Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka から公開された研究論文: [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://huggingface.co/papers/2110.08151)
+1. **[MobileBERT](https://huggingface.co/docs/transformers/model_doc/mobilebert)** (CMU/Google Brain から) Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou から公開された研究論文: [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://huggingface.co/papers/2004.02984)
+1. **[MobileNetV1](https://huggingface.co/docs/transformers/model_doc/mobilenet_v1)** (Google Inc. から) Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam から公開された研究論文: [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://huggingface.co/papers/1704.04861)
+1. **[MobileNetV2](https://huggingface.co/docs/transformers/model_doc/mobilenet_v2)** (Google Inc. から) Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen から公開された研究論文: [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://huggingface.co/papers/1801.04381)
+1. **[MobileViT](https://huggingface.co/docs/transformers/model_doc/mobilevit)** (Apple から) Sachin Mehta and Mohammad Rastegari から公開された研究論文: [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://huggingface.co/papers/2110.02178)
+1. **[MPNet](https://huggingface.co/docs/transformers/model_doc/mpnet)** (Microsoft Research から) Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu から公開された研究論文: [MPNet: Masked and Permuted Pre-training for Language Understanding](https://huggingface.co/papers/2004.09297)
+1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (Google AI から) Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel から公開された研究論文: [mT5: A massively multilingual pre-trained text-to-text transformer](https://huggingface.co/papers/2010.11934)
+1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (RUC AI Box から) Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen から公開された研究論文: [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://huggingface.co/papers/2206.12131)
+1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (SHI Labs から) Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi から公開された研究論文: [Neighborhood Attention Transformer](https://huggingface.co/papers/2204.07143)
+1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (Huawei Noah’s Ark Lab から) Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu から公開された研究論文: [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://huggingface.co/papers/1909.00204)
+1. **[NLLB](https://huggingface.co/docs/transformers/model_doc/nllb)** (Meta から) the NLLB team から公開された研究論文: [No Language Left Behind: Scaling Human-Centered Machine Translation](https://huggingface.co/papers/2207.04672)
+1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (the University of Wisconsin - Madison から) Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh から公開された研究論文: [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://huggingface.co/papers/2102.03902)
+1. **[OneFormer](https://huggingface.co/docs/transformers/main/model_doc/oneformer)** (SHI Labs から) Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi から公開された研究論文: [OneFormer: One Transformer to Rule Universal Image Segmentation](https://huggingface.co/papers/2211.06220)
+1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (Meta AI から) Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al から公開された研究論文: [OPT: Open Pre-trained Transformer Language Models](https://huggingface.co/papers/2205.01068)
+1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (Google AI から) Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby から公開された研究論文: [Simple Open-Vocabulary Object Detection with Vision Transformers](https://huggingface.co/papers/2205.06230)
+1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (Google から) Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu から公開された研究論文: [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://huggingface.co/papers/1912.08777)
+1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (Google から) Jason Phang, Yao Zhao, and Peter J. Liu から公開された研究論文: [Investigating Efficiently Extending Transformers for Long Input Summarization](https://huggingface.co/papers/2208.04347)
+1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (Deepmind から) Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira から公開された研究論文: [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://huggingface.co/papers/2107.14795)
1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (VinAI Research から) Dat Quoc Nguyen and Anh Tuan Nguyen から公開された研究論文: [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/)
-1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (UCLA NLP から) Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang から公開された研究論文: [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333)
-1. **[PoolFormer](https://huggingface.co/docs/transformers/model_doc/poolformer)** (Sea AI Labs から) Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng から公開された研究論文: [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418)
-1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (Microsoft Research から) Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou から公開された研究論文: [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063)
-1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (NVIDIA から) Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius から公開された研究論文: [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602)
-1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (Facebook から) Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela から公開された研究論文: [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401)
-1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (Google Research から) Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang から公開された研究論文: [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909)
-1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (Google Research から) Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya から公開された研究論文: [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451)
-1. **[RegNet](https://huggingface.co/docs/transformers/model_doc/regnet)** (META Platforms から) Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár から公開された研究論文: [Designing Network Design Space](https://arxiv.org/abs/2003.13678)
-1. **[RemBERT](https://huggingface.co/docs/transformers/model_doc/rembert)** (Google Research から) Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder から公開された研究論文: [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821)
-1. **[ResNet](https://huggingface.co/docs/transformers/model_doc/resnet)** (Microsoft Research から) Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun から公開された研究論文: [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385)
-1. **[RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta)** (Facebook から), Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov から公開された研究論文: [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692)
-1. **[RoBERTa-PreLayerNorm](https://huggingface.co/docs/transformers/main/model_doc/roberta-prelayernorm)** (Facebook から) Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli から公開された研究論文: [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://arxiv.org/abs/1904.01038)
+1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (UCLA NLP から) Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang から公開された研究論文: [Unified Pre-training for Program Understanding and Generation](https://huggingface.co/papers/2103.06333)
+1. **[PoolFormer](https://huggingface.co/docs/transformers/model_doc/poolformer)** (Sea AI Labs から) Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng から公開された研究論文: [MetaFormer is Actually What You Need for Vision](https://huggingface.co/papers/2111.11418)
+1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (Microsoft Research から) Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou から公開された研究論文: [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://huggingface.co/papers/2001.04063)
+1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (NVIDIA から) Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius から公開された研究論文: [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://huggingface.co/papers/2004.09602)
+1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (Facebook から) Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela から公開された研究論文: [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://huggingface.co/papers/2005.11401)
+1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (Google Research から) Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang から公開された研究論文: [REALM: Retrieval-Augmented Language Model Pre-Training](https://huggingface.co/papers/2002.08909)
+1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (Google Research から) Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya から公開された研究論文: [Reformer: The Efficient Transformer](https://huggingface.co/papers/2001.04451)
+1. **[RegNet](https://huggingface.co/docs/transformers/model_doc/regnet)** (META Platforms から) Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár から公開された研究論文: [Designing Network Design Space](https://huggingface.co/papers/2003.13678)
+1. **[RemBERT](https://huggingface.co/docs/transformers/model_doc/rembert)** (Google Research から) Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder から公開された研究論文: [Rethinking embedding coupling in pre-trained language models](https://huggingface.co/papers/2010.12821)
+1. **[ResNet](https://huggingface.co/docs/transformers/model_doc/resnet)** (Microsoft Research から) Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun から公開された研究論文: [Deep Residual Learning for Image Recognition](https://huggingface.co/papers/1512.03385)
+1. **[RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta)** (Facebook から), Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov から公開された研究論文: [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://huggingface.co/papers/1907.11692)
+1. **[RoBERTa-PreLayerNorm](https://huggingface.co/docs/transformers/main/model_doc/roberta-prelayernorm)** (Facebook から) Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli から公開された研究論文: [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://huggingface.co/papers/1904.01038)
1. **[RoCBert](https://huggingface.co/docs/transformers/main/model_doc/roc_bert)** (WeChatAI から) HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou から公開された研究論文: [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf)
-1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (ZhuiyiTechnology から), Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu から公開された研究論文: [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864)
-1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (NVIDIA から) Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo から公開された研究論文: [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203)
-1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (ASAPP から) Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi から公開された研究論文: [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870)
-1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (ASAPP から) Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi から公開された研究論文: [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870)
-1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (Facebook から), Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino から公開された研究論文: [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171)
-1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (Facebook から), Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau から公開された研究論文: [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678)
-1. **[Splinter](https://huggingface.co/docs/transformers/model_doc/splinter)** (Tel Aviv University から), Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy から公開された研究論文: [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438)
-1. **[SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (Berkeley から) Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer から公開された研究論文: [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316)
-1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (Microsoft から) Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo から公開された研究論文: [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030)
-1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (Microsoft から) Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo から公開された研究論文: [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883)
-1. **[Swin2SR](https://huggingface.co/docs/transformers/main/model_doc/swin2sr)** (University of Würzburg から) Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte から公開された研究論文: [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345)
-1. **[SwitchTransformers](https://huggingface.co/docs/transformers/main/model_doc/switch_transformers)** (Google から) William Fedus, Barret Zoph, Noam Shazeer から公開された研究論文: [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961)
-1. **[T5](https://huggingface.co/docs/transformers/model_doc/t5)** (Google AI から) Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu から公開された研究論文: [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683)
+1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (ZhuiyiTechnology から), Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu から公開された研究論文: [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://huggingface.co/papers/2104.09864)
+1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (NVIDIA から) Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo から公開された研究論文: [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://huggingface.co/papers/2105.15203)
+1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (ASAPP から) Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi から公開された研究論文: [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://huggingface.co/papers/2109.06870)
+1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (ASAPP から) Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi から公開された研究論文: [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://huggingface.co/papers/2109.06870)
+1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (Facebook から), Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino から公開された研究論文: [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://huggingface.co/papers/2010.05171)
+1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (Facebook から), Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau から公開された研究論文: [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://huggingface.co/papers/2104.06678)
+1. **[Splinter](https://huggingface.co/docs/transformers/model_doc/splinter)** (Tel Aviv University から), Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy から公開された研究論文: [Few-Shot Question Answering by Pretraining Span Selection](https://huggingface.co/papers/2101.00438)
+1. **[SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (Berkeley から) Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer から公開された研究論文: [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://huggingface.co/papers/2006.11316)
+1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (Microsoft から) Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo から公開された研究論文: [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://huggingface.co/papers/2103.14030)
+1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (Microsoft から) Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo から公開された研究論文: [Swin Transformer V2: Scaling Up Capacity and Resolution](https://huggingface.co/papers/2111.09883)
+1. **[Swin2SR](https://huggingface.co/docs/transformers/main/model_doc/swin2sr)** (University of Würzburg から) Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte から公開された研究論文: [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://huggingface.co/papers/2209.11345)
+1. **[SwitchTransformers](https://huggingface.co/docs/transformers/main/model_doc/switch_transformers)** (Google から) William Fedus, Barret Zoph, Noam Shazeer から公開された研究論文: [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://huggingface.co/papers/2101.03961)
+1. **[T5](https://huggingface.co/docs/transformers/model_doc/t5)** (Google AI から) Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu から公開された研究論文: [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://huggingface.co/papers/1910.10683)
1. **[T5v1.1](https://huggingface.co/docs/transformers/model_doc/t5v1.1)** (Google AI から) Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu から公開されたレポジトリー [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511)
-1. **[Table Transformer](https://huggingface.co/docs/transformers/model_doc/table-transformer)** (Microsoft Research から) Brandon Smock, Rohith Pesala, Robin Abraham から公開された研究論文: [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061)
-1. **[TAPAS](https://huggingface.co/docs/transformers/model_doc/tapas)** (Google AI から) Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos から公開された研究論文: [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349)
-1. **[TAPEX](https://huggingface.co/docs/transformers/model_doc/tapex)** (Microsoft Research から) Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou から公開された研究論文: [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653)
+1. **[Table Transformer](https://huggingface.co/docs/transformers/model_doc/table-transformer)** (Microsoft Research から) Brandon Smock, Rohith Pesala, Robin Abraham から公開された研究論文: [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://huggingface.co/papers/2110.00061)
+1. **[TAPAS](https://huggingface.co/docs/transformers/model_doc/tapas)** (Google AI から) Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos から公開された研究論文: [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://huggingface.co/papers/2004.02349)
+1. **[TAPEX](https://huggingface.co/docs/transformers/model_doc/tapex)** (Microsoft Research から) Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou から公開された研究論文: [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://huggingface.co/papers/2107.07653)
1. **[Time Series Transformer](https://huggingface.co/docs/transformers/model_doc/time_series_transformer)** (HuggingFace から).
-1. **[TimeSformer](https://huggingface.co/docs/transformers/main/model_doc/timesformer)** (Facebook から) Gedas Bertasius, Heng Wang, Lorenzo Torresani から公開された研究論文: [Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095)
-1. **[Trajectory Transformer](https://huggingface.co/docs/transformers/model_doc/trajectory_transformers)** (the University of California at Berkeley から) Michael Janner, Qiyang Li, Sergey Levine から公開された研究論文: [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039)
-1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (Google/CMU から) Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov から公開された研究論文: [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860)
-1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (Microsoft から), Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei から公開された研究論文: [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282)
-1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (Google Research から) Yi Tay, Mostafa Dehghani, Vinh Q から公開された研究論文: [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
-1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (Microsoft Research から) Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang から公開された研究論文: [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597)
-1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (Microsoft Research から) Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu から公開された研究論文: [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752)
-1. **[UPerNet](https://huggingface.co/docs/transformers/main/model_doc/upernet)** (Peking University から) Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun. から公開された研究論文 [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221)
-1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (Tsinghua University and Nankai University から) Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu から公開された研究論文: [Visual Attention Network](https://arxiv.org/abs/2202.09741)
-1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (Multimedia Computing Group, Nanjing University から) Zhan Tong, Yibing Song, Jue Wang, Limin Wang から公開された研究論文: [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602)
-1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (NAVER AI Lab/Kakao Enterprise/Kakao Brain から) Wonjae Kim, Bokyung Son, Ildoo Kim から公開された研究論文: [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334)
-1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (Google AI から) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby から公開された研究論文: [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929)
-1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (UCLA NLP から) Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang から公開された研究論文: [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557)
-1. **[ViT Hybrid](https://huggingface.co/docs/transformers/main/model_doc/vit_hybrid)** (Google AI から) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby から公開された研究論文: [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929)
-1. **[ViTMAE](https://huggingface.co/docs/transformers/model_doc/vit_mae)** (Meta AI から) Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick から公開された研究論文: [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377)
-1. **[ViTMSN](https://huggingface.co/docs/transformers/model_doc/vit_msn)** (Meta AI から) Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas から公開された研究論文: [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141)
-1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (Facebook AI から) Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli から公開された研究論文: [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477)
-1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (Facebook AI から) Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino から公開された研究論文: [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171)
-1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (Facebook AI から) Qiantong Xu, Alexei Baevski, Michael Auli から公開された研究論文: [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680)
-1. **[WavLM](https://huggingface.co/docs/transformers/model_doc/wavlm)** (Microsoft Research から) Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei から公開された研究論文: [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900)
+1. **[TimeSformer](https://huggingface.co/docs/transformers/main/model_doc/timesformer)** (Facebook から) Gedas Bertasius, Heng Wang, Lorenzo Torresani から公開された研究論文: [Is Space-Time Attention All You Need for Video Understanding?](https://huggingface.co/papers/2102.05095)
+1. **[Trajectory Transformer](https://huggingface.co/docs/transformers/model_doc/trajectory_transformers)** (the University of California at Berkeley から) Michael Janner, Qiyang Li, Sergey Levine から公開された研究論文: [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://huggingface.co/papers/2106.02039)
+1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (Google/CMU から) Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov から公開された研究論文: [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://huggingface.co/papers/1901.02860)
+1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (Microsoft から), Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei から公開された研究論文: [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://huggingface.co/papers/2109.10282)
+1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (Google Research から) Yi Tay, Mostafa Dehghani, Vinh Q から公開された研究論文: [Unifying Language Learning Paradigms](https://huggingface.co/papers/2205.05131v1) Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
+1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (Microsoft Research から) Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang から公開された研究論文: [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://huggingface.co/papers/2101.07597)
+1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (Microsoft Research から) Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu から公開された研究論文: [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://huggingface.co/papers/2110.05752)
+1. **[UPerNet](https://huggingface.co/docs/transformers/main/model_doc/upernet)** (Peking University から) Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun. から公開された研究論文 [Unified Perceptual Parsing for Scene Understanding](https://huggingface.co/papers/1807.10221)
+1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (Tsinghua University and Nankai University から) Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu から公開された研究論文: [Visual Attention Network](https://huggingface.co/papers/2202.09741)
+1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (Multimedia Computing Group, Nanjing University から) Zhan Tong, Yibing Song, Jue Wang, Limin Wang から公開された研究論文: [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://huggingface.co/papers/2203.12602)
+1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (NAVER AI Lab/Kakao Enterprise/Kakao Brain から) Wonjae Kim, Bokyung Son, Ildoo Kim から公開された研究論文: [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://huggingface.co/papers/2102.03334)
+1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (Google AI から) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby から公開された研究論文: [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://huggingface.co/papers/2010.11929)
+1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (UCLA NLP から) Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang から公開された研究論文: [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://huggingface.co/papers/1908.03557)
+1. **[ViT Hybrid](https://huggingface.co/docs/transformers/main/model_doc/vit_hybrid)** (Google AI から) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby から公開された研究論文: [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://huggingface.co/papers/2010.11929)
+1. **[ViTMAE](https://huggingface.co/docs/transformers/model_doc/vit_mae)** (Meta AI から) Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick から公開された研究論文: [Masked Autoencoders Are Scalable Vision Learners](https://huggingface.co/papers/2111.06377)
+1. **[ViTMSN](https://huggingface.co/docs/transformers/model_doc/vit_msn)** (Meta AI から) Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas から公開された研究論文: [Masked Siamese Networks for Label-Efficient Learning](https://huggingface.co/papers/2204.07141)
+1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (Facebook AI から) Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli から公開された研究論文: [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://huggingface.co/papers/2006.11477)
+1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (Facebook AI から) Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino から公開された研究論文: [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://huggingface.co/papers/2010.05171)
+1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (Facebook AI から) Qiantong Xu, Alexei Baevski, Michael Auli から公開された研究論文: [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://huggingface.co/papers/2109.11680)
+1. **[WavLM](https://huggingface.co/docs/transformers/model_doc/wavlm)** (Microsoft Research から) Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei から公開された研究論文: [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://huggingface.co/papers/2110.13900)
1. **[Whisper](https://huggingface.co/docs/transformers/model_doc/whisper)** (OpenAI から) Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever から公開された研究論文: [Robust Speech Recognition via Large-Scale Weak Supervision](https://cdn.openai.com/papers/whisper.pdf)
-1. **[X-CLIP](https://huggingface.co/docs/transformers/model_doc/xclip)** (Microsoft Research から) Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling から公開された研究論文: [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816)
-1. **[XGLM](https://huggingface.co/docs/transformers/model_doc/xglm)** (From Facebook AI) Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li から公開された研究論文: [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668)
-1. **[XLM](https://huggingface.co/docs/transformers/model_doc/xlm)** (Facebook から) Guillaume Lample and Alexis Conneau から公開された研究論文: [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291)
-1. **[XLM-ProphetNet](https://huggingface.co/docs/transformers/model_doc/xlm-prophetnet)** (Microsoft Research から) Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou から公開された研究論文: [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063)
-1. **[XLM-RoBERTa](https://huggingface.co/docs/transformers/model_doc/xlm-roberta)** (Facebook AI から), Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov から公開された研究論文: [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116)
-1. **[XLM-RoBERTa-XL](https://huggingface.co/docs/transformers/model_doc/xlm-roberta-xl)** (Facebook AI から), Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau から公開された研究論文: [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572)
-1. **[XLNet](https://huggingface.co/docs/transformers/model_doc/xlnet)** (Google/CMU から) Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le から公開された研究論文: [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237)
-1. **[XLS-R](https://huggingface.co/docs/transformers/model_doc/xls_r)** (Facebook AI から) Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli から公開された研究論文: [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296)
-1. **[XLSR-Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/xlsr_wav2vec2)** (Facebook AI から) Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli から公開された研究論文: [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979)
-1. **[YOLOS](https://huggingface.co/docs/transformers/model_doc/yolos)** (Huazhong University of Science & Technology から) Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu から公開された研究論文: [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666)
-1. **[YOSO](https://huggingface.co/docs/transformers/model_doc/yoso)** (the University of Wisconsin - Madison から) Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh から公開された研究論文: [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714)
+1. **[X-CLIP](https://huggingface.co/docs/transformers/model_doc/xclip)** (Microsoft Research から) Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling から公開された研究論文: [Expanding Language-Image Pretrained Models for General Video Recognition](https://huggingface.co/papers/2208.02816)
+1. **[XGLM](https://huggingface.co/docs/transformers/model_doc/xglm)** (From Facebook AI) Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li から公開された研究論文: [Few-shot Learning with Multilingual Language Models](https://huggingface.co/papers/2112.10668)
+1. **[XLM](https://huggingface.co/docs/transformers/model_doc/xlm)** (Facebook から) Guillaume Lample and Alexis Conneau から公開された研究論文: [Cross-lingual Language Model Pretraining](https://huggingface.co/papers/1901.07291)
+1. **[XLM-ProphetNet](https://huggingface.co/docs/transformers/model_doc/xlm-prophetnet)** (Microsoft Research から) Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou から公開された研究論文: [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://huggingface.co/papers/2001.04063)
+1. **[XLM-RoBERTa](https://huggingface.co/docs/transformers/model_doc/xlm-roberta)** (Facebook AI から), Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov から公開された研究論文: [Unsupervised Cross-lingual Representation Learning at Scale](https://huggingface.co/papers/1911.02116)
+1. **[XLM-RoBERTa-XL](https://huggingface.co/docs/transformers/model_doc/xlm-roberta-xl)** (Facebook AI から), Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau から公開された研究論文: [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://huggingface.co/papers/2105.00572)
+1. **[XLNet](https://huggingface.co/docs/transformers/model_doc/xlnet)** (Google/CMU から) Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le から公開された研究論文: [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://huggingface.co/papers/1906.08237)
+1. **[XLS-R](https://huggingface.co/docs/transformers/model_doc/xls_r)** (Facebook AI から) Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli から公開された研究論文: [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://huggingface.co/papers/2111.09296)
+1. **[XLSR-Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/xlsr_wav2vec2)** (Facebook AI から) Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli から公開された研究論文: [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://huggingface.co/papers/2006.13979)
+1. **[YOLOS](https://huggingface.co/docs/transformers/model_doc/yolos)** (Huazhong University of Science & Technology から) Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu から公開された研究論文: [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://huggingface.co/papers/2106.00666)
+1. **[YOSO](https://huggingface.co/docs/transformers/model_doc/yoso)** (the University of Wisconsin - Madison から) Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh から公開された研究論文: [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://huggingface.co/papers/2111.09714)
### サポートされているフレームワーク
diff --git a/docs/source/ja/main_classes/deepspeed.md b/docs/source/ja/main_classes/deepspeed.md
index 52a2cb3d32..b0bc661087 100644
--- a/docs/source/ja/main_classes/deepspeed.md
+++ b/docs/source/ja/main_classes/deepspeed.md
@@ -16,7 +16,7 @@ rendered properly in your Markdown viewer.
# DeepSpeed Integration
-[DeepSpeed](https://github.com/deepspeedai/DeepSpeed) は、[ZeRO 論文](https://arxiv.org/abs/1910.02054) で説明されているすべてを実装します。現在、次のものを完全にサポートしています。
+[DeepSpeed](https://github.com/deepspeedai/DeepSpeed) は、[ZeRO 論文](https://huggingface.co/papers/1910.02054) で説明されているすべてを実装します。現在、次のものを完全にサポートしています。
1. オプティマイザーの状態分割 (ZeRO ステージ 1)
2. 勾配分割 (ZeRO ステージ 2)
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
5. 一連の高速 CUDA 拡張ベースのオプティマイザー
6. CPU および NVMe への ZeRO オフロード
-ZeRO-Offload には独自の専用ペーパーがあります: [ZeRO-Offload: Democratizing Billion-Scale Model Training](https://arxiv.org/abs/2101.06840)。 NVMe サポートについては、論文 [ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning](https://arxiv.org/abs/2104.07857)。
+ZeRO-Offload には独自の専用ペーパーがあります: [ZeRO-Offload: Democratizing Billion-Scale Model Training](https://huggingface.co/papers/2101.06840)。 NVMe サポートについては、論文 [ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning](https://huggingface.co/papers/2104.07857)。
DeepSpeed ZeRO-2 は、その機能が推論には役に立たないため、主にトレーニングのみに使用されます。
@@ -2246,9 +2246,9 @@ RUN_SLOW=1 pytest tests/deepspeed
論文:
-- [ZeRO: 兆パラメータ モデルのトレーニングに向けたメモリの最適化](https://arxiv.org/abs/1910.02054)
-- [ZeRO-Offload: 10 億規模のモデル トレーニングの民主化](https://arxiv.org/abs/2101.06840)
-- [ZeRO-Infinity: 極限スケールの深層学習のための GPU メモリの壁を打ち破る](https://arxiv.org/abs/2104.07857)
+- [ZeRO: 兆パラメータ モデルのトレーニングに向けたメモリの最適化](https://huggingface.co/papers/1910.02054)
+- [ZeRO-Offload: 10 億規模のモデル トレーニングの民主化](https://huggingface.co/papers/2101.06840)
+- [ZeRO-Infinity: 極限スケールの深層学習のための GPU メモリの壁を打ち破る](https://huggingface.co/papers/2104.07857)
最後に、HuggingFace [`Trainer`] は DeepSpeed のみを統合していることを覚えておいてください。
DeepSpeed の使用に関して問題や質問がある場合は、[DeepSpeed GitHub](https://github.com/deepspeedai/DeepSpeed/issues) に問題を提出してください。
diff --git a/docs/source/ja/main_classes/processors.md b/docs/source/ja/main_classes/processors.md
index 63b94af6ea..45333859e8 100644
--- a/docs/source/ja/main_classes/processors.md
+++ b/docs/source/ja/main_classes/processors.md
@@ -78,7 +78,7 @@ QQP、QNLI、RTE、WNLI。
言語を超えたテキスト表現の品質。 XNLI は、[*MultiNLI*](http://www.nyu.edu/projects/bowman/multinli/) に基づくクラウドソースのデータセットです。テキストのペアには、15 個のテキスト含意アノテーションがラベル付けされています。
さまざまな言語 (英語などの高リソース言語とスワヒリ語などの低リソース言語の両方を含む)。
-論文 [XNLI: Evaluating Cross-lingual Sentence Representations](https://arxiv.org/abs/1809.05053) と同時にリリースされました。
+論文 [XNLI: Evaluating Cross-lingual Sentence Representations](https://huggingface.co/papers/1809.05053) と同時にリリースされました。
このライブラリは、XNLI データをロードするプロセッサをホストします。
@@ -92,8 +92,8 @@ QQP、QNLI、RTE、WNLI。
[The Stanford Question Answering Dataset (SQuAD)](https://rajpurkar.github.io/SQuAD-explorer//) は、次のベンチマークです。
質問応答に関するモデルのパフォーマンスを評価します。 v1.1 と v2.0 の 2 つのバージョンが利用可能です。最初のバージョン
-(v1.1) は、論文 [SQuAD: 100,000+ question for Machine Comprehension of Text](https://arxiv.org/abs/1606.05250) とともにリリースされました。 2 番目のバージョン (v2.0) は、論文 [Know What You Don't と同時にリリースされました。
-知っておくべき: SQuAD の答えられない質問](https://arxiv.org/abs/1806.03822)。
+(v1.1) は、論文 [SQuAD: 100,000+ question for Machine Comprehension of Text](https://huggingface.co/papers/1606.05250) とともにリリースされました。 2 番目のバージョン (v2.0) は、論文 [Know What You Don't と同時にリリースされました。
+知っておくべき: SQuAD の答えられない質問](https://huggingface.co/papers/1806.03822)。
このライブラリは、次の 2 つのバージョンのそれぞれのプロセッサをホストします。
diff --git a/docs/source/ja/main_classes/quantization.md b/docs/source/ja/main_classes/quantization.md
index a93d06b257..b511b9dbfc 100644
--- a/docs/source/ja/main_classes/quantization.md
+++ b/docs/source/ja/main_classes/quantization.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
🤗 Transformers には、言語モデルで GPTQ 量子化を実行するための `optimum` API が統合されています。パフォーマンスを大幅に低下させることなく、推論速度を高速化することなく、モデルを 8、4、3、さらには 2 ビットでロードおよび量子化できます。これは、ほとんどの GPU ハードウェアでサポートされています。
量子化モデルの詳細については、以下を確認してください。
-- [GPTQ](https://arxiv.org/pdf/2210.17323.pdf) 論文
+- [GPTQ](https://huggingface.co/papers/2210.17323) 論文
- GPTQ 量子化に関する `optimum` [ガイド](https://huggingface.co/docs/optimum/llm_quantization/usage_guides/quantization)
- バックエンドとして使用される [`AutoGPTQ`](https://github.com/PanQiWei/AutoGPTQ) ライブラリ
@@ -163,7 +163,7 @@ GPTQ を使用してモデルを量子化する方法と、peft を使用して
🤗 Transformers は、`bitsandbytes` で最もよく使用されるモジュールと緊密に統合されています。数行のコードでモデルを 8 ビット精度でロードできます。
これは、`bitsandbytes`の `0.37.0`リリース以降、ほとんどの GPU ハードウェアでサポートされています。
-量子化方法の詳細については、[LLM.int8()](https://arxiv.org/abs/2208.07339) 論文、または [ブログ投稿](https://huggingface.co/blog/hf-bitsandbytes-) をご覧ください。統合)コラボレーションについて。
+量子化方法の詳細については、[LLM.int8()](https://huggingface.co/papers/2208.07339) 論文、または [ブログ投稿](https://huggingface.co/blog/hf-bitsandbytes-) をご覧ください。統合)コラボレーションについて。
`0.39.0`リリース以降、FP4 データ型を活用し、4 ビット量子化を使用して`device_map`をサポートする任意のモデルをロードできます。
@@ -214,7 +214,7 @@ torch.float32
- **`batch_size=1` による高速推論 :** bitsandbytes の `0.40.0` リリース以降、`batch_size=1` では高速推論の恩恵を受けることができます。 [これらのリリース ノート](https://github.com/TimDettmers/bitsandbytes/releases/tag/0.40.0) を確認し、この機能を活用するには`0.40.0`以降のバージョンを使用していることを確認してください。箱の。
-- **トレーニング:** [QLoRA 論文](https://arxiv.org/abs/2305.14314) によると、4 ビット基本モデルをトレーニングする場合 (例: LoRA アダプターを使用)、`bnb_4bit_quant_type='nf4'` を使用する必要があります。 。
+- **トレーニング:** [QLoRA 論文](https://huggingface.co/papers/2305.14314) によると、4 ビット基本モデルをトレーニングする場合 (例: LoRA アダプターを使用)、`bnb_4bit_quant_type='nf4'` を使用する必要があります。 。
- **推論:** 推論の場合、`bnb_4bit_quant_type` はパフォーマンスに大きな影響を与えません。ただし、モデルの重みとの一貫性を保つために、必ず同じ `bnb_4bit_compute_dtype` および `torch_dtype` 引数を使用してください。
diff --git a/docs/source/ja/main_classes/trainer.md b/docs/source/ja/main_classes/trainer.md
index 0a015e1150..57f0a12a7e 100644
--- a/docs/source/ja/main_classes/trainer.md
+++ b/docs/source/ja/main_classes/trainer.md
@@ -291,7 +291,7 @@ export CUDA_VISIBLE_DEVICES=1,0
[`Trainer`] は、トレーニングを劇的に改善する可能性のあるライブラリをサポートするように拡張されました。
時間とはるかに大きなモデルに適合します。
-現在、サードパーティのソリューション [DeepSpeed](https://github.com/deepspeedai/DeepSpeed) および [PyTorch FSDP](https://pytorch.org/docs/stable/fsdp.html) をサポートしています。論文 [ZeRO: メモリの最適化兆パラメータ モデルのトレーニングに向けて、Samyam Rajbhandari、Jeff Rasley、Olatunji Ruwase、Yuxiong He 著](https://arxiv.org/abs/1910.02054)。
+現在、サードパーティのソリューション [DeepSpeed](https://github.com/deepspeedai/DeepSpeed) および [PyTorch FSDP](https://pytorch.org/docs/stable/fsdp.html) をサポートしています。論文 [ZeRO: メモリの最適化兆パラメータ モデルのトレーニングに向けて、Samyam Rajbhandari、Jeff Rasley、Olatunji Ruwase、Yuxiong He 著](https://huggingface.co/papers/1910.02054)。
この提供されるサポートは、この記事の執筆時点では新しくて実験的なものです。 DeepSpeed と PyTorch FSDP のサポートはアクティブであり、それに関する問題は歓迎しますが、FairScale 統合は PyTorch メインに統合されているため、もうサポートしていません ([PyTorch FSDP 統合](#pytorch-fully-sharded-data-parallel))
diff --git a/docs/source/ja/model_doc/albert.md b/docs/source/ja/model_doc/albert.md
index a77e17a640..7824f24599 100644
--- a/docs/source/ja/model_doc/albert.md
+++ b/docs/source/ja/model_doc/albert.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
## 概要
-ALBERTモデルは、「[ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942)」という論文でZhenzhong Lan、Mingda Chen、Sebastian Goodman、Kevin Gimpel、Piyush Sharma、Radu Soricutによって提案されました。BERTのメモリ消費を減らしトレーニングを高速化するためのパラメータ削減技術を2つ示しています:
+ALBERTモデルは、「[ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://huggingface.co/papers/1909.11942)」という論文でZhenzhong Lan、Mingda Chen、Sebastian Goodman、Kevin Gimpel、Piyush Sharma、Radu Soricutによって提案されました。BERTのメモリ消費を減らしトレーニングを高速化するためのパラメータ削減技術を2つ示しています:
- 埋め込み行列を2つの小さな行列に分割する。
- グループ間で分割された繰り返し層を使用する。
diff --git a/docs/source/ja/model_doc/align.md b/docs/source/ja/model_doc/align.md
index 84496e605d..d1ff4d918a 100644
--- a/docs/source/ja/model_doc/align.md
+++ b/docs/source/ja/model_doc/align.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 概要
-ALIGNモデルは、「[Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://arxiv.org/abs/2102.05918)」という論文でChao Jia、Yinfei Yang、Ye Xia、Yi-Ting Chen、Zarana Parekh、Hieu Pham、Quoc V. Le、Yunhsuan Sung、Zhen Li、Tom Duerigによって提案されました。ALIGNはマルチモーダルな視覚言語モデルです。これは画像とテキストの類似度や、ゼロショット画像分類に使用できます。ALIGNは[EfficientNet](efficientnet)を視覚エンコーダーとして、[BERT](bert)をテキストエンコーダーとして搭載したデュアルエンコーダー構造を特徴とし、対照学習によって視覚とテキストの表現を整合させることを学びます。それまでの研究とは異なり、ALIGNは巨大でノイジーなデータセットを活用し、コーパスのスケールを利用して単純な方法ながら最先端の表現を達成できることを示しています。
+ALIGNモデルは、「[Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://huggingface.co/papers/2102.05918)」という論文でChao Jia、Yinfei Yang、Ye Xia、Yi-Ting Chen、Zarana Parekh、Hieu Pham、Quoc V. Le、Yunhsuan Sung、Zhen Li、Tom Duerigによって提案されました。ALIGNはマルチモーダルな視覚言語モデルです。これは画像とテキストの類似度や、ゼロショット画像分類に使用できます。ALIGNは[EfficientNet](efficientnet)を視覚エンコーダーとして、[BERT](bert)をテキストエンコーダーとして搭載したデュアルエンコーダー構造を特徴とし、対照学習によって視覚とテキストの表現を整合させることを学びます。それまでの研究とは異なり、ALIGNは巨大でノイジーなデータセットを活用し、コーパスのスケールを利用して単純な方法ながら最先端の表現を達成できることを示しています。
論文の要旨は以下の通りです:
diff --git a/docs/source/ja/model_doc/altclip.md b/docs/source/ja/model_doc/altclip.md
index 87cf6cc17d..fe721d29bf 100644
--- a/docs/source/ja/model_doc/altclip.md
+++ b/docs/source/ja/model_doc/altclip.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## 概要
-AltCLIPモデルは、「[AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679v2)」という論文でZhongzhi Chen、Guang Liu、Bo-Wen Zhang、Fulong Ye、Qinghong Yang、Ledell Wuによって提案されました。AltCLIP(CLIPの言語エンコーダーの代替)は、様々な画像-テキストペアおよびテキスト-テキストペアでトレーニングされたニューラルネットワークです。CLIPのテキストエンコーダーを事前学習済みの多言語テキストエンコーダーXLM-Rに置き換えることで、ほぼ全てのタスクでCLIPに非常に近い性能を得られ、オリジナルのCLIPの能力を多言語理解などに拡張しました。
+AltCLIPモデルは、「[AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://huggingface.co/papers/2211.06679)」という論文でZhongzhi Chen、Guang Liu、Bo-Wen Zhang、Fulong Ye、Qinghong Yang、Ledell Wuによって提案されました。AltCLIP(CLIPの言語エンコーダーの代替)は、様々な画像-テキストペアおよびテキスト-テキストペアでトレーニングされたニューラルネットワークです。CLIPのテキストエンコーダーを事前学習済みの多言語テキストエンコーダーXLM-Rに置き換えることで、ほぼ全てのタスクでCLIPに非常に近い性能を得られ、オリジナルのCLIPの能力を多言語理解などに拡張しました。
論文の要旨は以下の通りです:
diff --git a/docs/source/ja/model_doc/audio-spectrogram-transformer.md b/docs/source/ja/model_doc/audio-spectrogram-transformer.md
index a5107b14f8..eb0c3cf6e3 100644
--- a/docs/source/ja/model_doc/audio-spectrogram-transformer.md
+++ b/docs/source/ja/model_doc/audio-spectrogram-transformer.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 概要
-Audio Spectrogram Transformerモデルは、[AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778)という論文でYuan Gong、Yu-An Chung、James Glassによって提案されました。これは、音声を画像(スペクトログラム)に変換することで、音声に[Vision Transformer](vit)を適用します。このモデルは音声分類において最先端の結果を得ています。
+Audio Spectrogram Transformerモデルは、[AST: Audio Spectrogram Transformer](https://huggingface.co/papers/2104.01778)という論文でYuan Gong、Yu-An Chung、James Glassによって提案されました。これは、音声を画像(スペクトログラム)に変換することで、音声に[Vision Transformer](vit)を適用します。このモデルは音声分類において最先端の結果を得ています。
論文の要旨は以下の通りです:
@@ -27,7 +27,7 @@ Audio Spectrogram Transformerモデルは、[AST: Audio Spectrogram Transformer]
- Audio Spectrogram Transformerのアーキテクチャ。元論文より抜粋。
+ Audio Spectrogram Transformerのアーキテクチャ。元論文より抜粋。
このモデルは[nielsr](https://huggingface.co/nielsr)より提供されました。
オリジナルのコードは[こちら](https://github.com/YuanGongND/ast)で見ることができます。
@@ -35,7 +35,7 @@ alt="drawing" width="600"/>
## 使用上のヒント
- 独自のデータセットでAudio Spectrogram Transformer(AST)をファインチューニングする場合、入力の正規化(入力の平均を0、標準偏差を0.5にすること)処理することが推奨されます。[`ASTFeatureExtractor`]はこれを処理します。デフォルトではAudioSetの平均と標準偏差を使用していることに注意してください。著者が下流のデータセットの統計をどのように計算しているかは、[`ast/src/get_norm_stats.py`](https://github.com/YuanGongND/ast/blob/master/src/get_norm_stats.py)で確認することができます。
-- ASTは低い学習率が必要であり 著者は[PSLA論文](https://arxiv.org/abs/2102.01243)で提案されたCNNモデルに比べて10倍小さい学習率を使用しています)、素早く収束するため、タスクに適した学習率と学習率スケジューラーを探すことをお勧めします。
+- ASTは低い学習率が必要であり 著者は[PSLA論文](https://huggingface.co/papers/2102.01243)で提案されたCNNモデルに比べて10倍小さい学習率を使用しています)、素早く収束するため、タスクに適した学習率と学習率スケジューラーを探すことをお勧めします。
## 参考資料
diff --git a/docs/source/ja/model_doc/autoformer.md b/docs/source/ja/model_doc/autoformer.md
index b8b0948b96..65c20bfa60 100644
--- a/docs/source/ja/model_doc/autoformer.md
+++ b/docs/source/ja/model_doc/autoformer.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 概要
-Autoformerモデルは、「[Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008)」という論文でHaixu Wu、Jiehui Xu、Jianmin Wang、Mingsheng Longによって提案されました。
+Autoformerモデルは、「[Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://huggingface.co/papers/2106.13008)」という論文でHaixu Wu、Jiehui Xu、Jianmin Wang、Mingsheng Longによって提案されました。
このモデルは、予測プロセス中にトレンドと季節性成分を逐次的に分解できる深層分解アーキテクチャとしてTransformerを増強します。
diff --git a/docs/source/ja/model_doc/bart.md b/docs/source/ja/model_doc/bart.md
index 5c25d6a0c7..6d11c122d9 100644
--- a/docs/source/ja/model_doc/bart.md
+++ b/docs/source/ja/model_doc/bart.md
@@ -31,7 +31,7 @@ rendered properly in your Markdown viewer.
## Overview
Bart モデルは、[BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation、
-翻訳と理解](https://arxiv.org/abs/1910.13461) Mike Lewis、Yinhan Liu、Naman Goyal、Marjan 著
+翻訳と理解](https://huggingface.co/papers/1910.13461) Mike Lewis、Yinhan Liu、Naman Goyal、Marjan 著
ガズビニネジャド、アブデルラフマン・モハメド、オメル・レヴィ、ベス・ストヤノフ、ルーク・ゼトルモイヤー、2019年10月29日。
要約によると、
@@ -65,7 +65,7 @@ Bart モデルは、[BART: Denoising Sequence-to-Sequence Pre-training for Natur
[examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md)。
- Hugging Face `datasets` を使用して [`BartForConditionalGeneration`] をトレーニングする方法の例
オブジェクトは、この [フォーラム ディスカッション](https://discuss.huggingface.co/t/train-bart-for-conditional-generation-e-g-summarization/1904) で見つけることができます。
-- [抽出されたチェックポイント](https://huggingface.co/models?search=distilbart) は、この [論文](https://arxiv.org/abs/2010.13002) で説明されています。
+- [抽出されたチェックポイント](https://huggingface.co/models?search=distilbart) は、この [論文](https://huggingface.co/papers/2010.13002) で説明されています。
## Implementation Notes
@@ -132,7 +132,7 @@ BART を始めるのに役立つ公式 Hugging Face およびコミュニティ
- [テキスト分類タスクガイド(英語版)](../../en/tasks/sequence_classification)
- [質問回答タスク ガイド](../tasks/question_answering)
- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
-- [抽出されたチェックポイント](https://huggingface.co/models?search=distilbart) は、この [論文](https://arxiv.org/abs/2010.13002) で説明されています。
+- [抽出されたチェックポイント](https://huggingface.co/models?search=distilbart) は、この [論文](https://huggingface.co/papers/2010.13002) で説明されています。
## BartConfig
diff --git a/docs/source/ja/model_doc/barthez.md b/docs/source/ja/model_doc/barthez.md
index 94844c3f67..5668772c26 100644
--- a/docs/source/ja/model_doc/barthez.md
+++ b/docs/source/ja/model_doc/barthez.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-BARThez モデルは、Moussa Kamal Eddine、Antoine J.-P によって [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) で提案されました。ティクシエ、ミカリス・ヴァジルジャンニス、10月23日、
+BARThez モデルは、Moussa Kamal Eddine、Antoine J.-P によって [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://huggingface.co/papers/2010.12321) で提案されました。ティクシエ、ミカリス・ヴァジルジャンニス、10月23日、
2020年。
論文の要約:
diff --git a/docs/source/ja/model_doc/bartpho.md b/docs/source/ja/model_doc/bartpho.md
index a9575d821e..3596a91fe1 100644
--- a/docs/source/ja/model_doc/bartpho.md
+++ b/docs/source/ja/model_doc/bartpho.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-BARTpho モデルは、Nguyen Luong Tran、Duong Minh Le、Dat Quoc Nguyen によって [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnam](https://arxiv.org/abs/2109.09701) で提案されました。
+BARTpho モデルは、Nguyen Luong Tran、Duong Minh Le、Dat Quoc Nguyen によって [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnam](https://huggingface.co/papers/2109.09701) で提案されました。
論文の要約は次のとおりです。
diff --git a/docs/source/ja/model_doc/beit.md b/docs/source/ja/model_doc/beit.md
index 948c3bad70..21ccc28c68 100644
--- a/docs/source/ja/model_doc/beit.md
+++ b/docs/source/ja/model_doc/beit.md
@@ -18,11 +18,11 @@ rendered properly in your Markdown viewer.
## Overview
-BEiT モデルは、[BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) で提案されました。
+BEiT モデルは、[BEiT: BERT Pre-Training of Image Transformers](https://huggingface.co/papers/2106.08254) で提案されました。
ハンボ・バオ、リー・ドン、フル・ウェイ。 BERT に触発された BEiT は、自己教師ありの事前トレーニングを作成した最初の論文です。
ビジョン トランスフォーマー (ViT) は、教師付き事前トレーニングよりも優れたパフォーマンスを発揮します。クラスを予測するためにモデルを事前トレーニングするのではなく
-([オリジナルの ViT 論文](https://arxiv.org/abs/2010.11929) で行われたように) 画像の BEiT モデルは、次のように事前トレーニングされています。
-マスクされた OpenAI の [DALL-E モデル](https://arxiv.org/abs/2102.12092) のコードブックからビジュアル トークンを予測します
+([オリジナルの ViT 論文](https://huggingface.co/papers/2010.11929) で行われたように) 画像の BEiT モデルは、次のように事前トレーニングされています。
+マスクされた OpenAI の [DALL-E モデル](https://huggingface.co/papers/2102.12092) のコードブックからビジュアル トークンを予測します
パッチ。
論文の要約は次のとおりです。
@@ -66,7 +66,7 @@ BEiT モデルは、[BEiT: BERT Pre-Training of Image Transformers](https://arxi
- BEiT の事前トレーニング。 元の論文から抜粋。
+ BEiT の事前トレーニング。 元の論文から抜粋。
このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。このモデルの JAX/FLAX バージョンは、
[kamalkraj](https://huggingface.co/kamalkraj) による投稿。元のコードは [ここ](https://github.com/microsoft/unilm/tree/master/beit) にあります。
diff --git a/docs/source/ja/model_doc/bert-generation.md b/docs/source/ja/model_doc/bert-generation.md
index d2c93a4644..bf3b932968 100644
--- a/docs/source/ja/model_doc/bert-generation.md
+++ b/docs/source/ja/model_doc/bert-generation.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## Overview
BertGeneration モデルは、次を使用してシーケンス間のタスクに利用できる BERT モデルです。
-[Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) で提案されている [`EncoderDecoderModel`]
+[Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://huggingface.co/papers/1907.12461) で提案されている [`EncoderDecoderModel`]
タスク、Sascha Rothe、Sishi Nagayan、Aliaksei Severyn 著。
論文の要約は次のとおりです。
diff --git a/docs/source/ja/model_doc/bert.md b/docs/source/ja/model_doc/bert.md
index 6e6947bd04..e0367dcd46 100644
--- a/docs/source/ja/model_doc/bert.md
+++ b/docs/source/ja/model_doc/bert.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
## Overview
-BERT モデルは、Jacob Devlin、Ming-Wei Chang、Kenton Lee、Kristina Toutanova によって [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) で提案されました。それは
+BERT モデルは、Jacob Devlin、Ming-Wei Chang、Kenton Lee、Kristina Toutanova によって [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://huggingface.co/papers/1810.04805) で提案されました。それは
マスクされた言語モデリング目標と次の文の組み合わせを使用して事前トレーニングされた双方向トランスフォーマー
Toronto Book Corpus と Wikipedia からなる大規模なコーパスでの予測。
diff --git a/docs/source/ja/model_doc/big_bird.md b/docs/source/ja/model_doc/big_bird.md
index 960d19146c..d5f4f9d282 100644
--- a/docs/source/ja/model_doc/big_bird.md
+++ b/docs/source/ja/model_doc/big_bird.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-BigBird モデルは、[Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) で提案されました。
+BigBird モデルは、[Big Bird: Transformers for Longer Sequences](https://huggingface.co/papers/2007.14062) で提案されました。
ザヒール、マンジルとグルガネシュ、グルとダベイ、クマール・アヴィナヴァとエインズリー、ジョシュアとアルベルティ、クリスとオンタノン、
サンティアゴとファム、フィリップとラブラ、アニルードとワン、キーファンとヤン、リーなど。 BigBird は注目度が低い
BERT などの Transformer ベースのモデルをさらに長いシーケンスに拡張する、Transformer ベースのモデル。まばらに加えて
diff --git a/docs/source/ja/model_doc/bigbird_pegasus.md b/docs/source/ja/model_doc/bigbird_pegasus.md
index 5314aed1bc..ecee19d6a5 100644
--- a/docs/source/ja/model_doc/bigbird_pegasus.md
+++ b/docs/source/ja/model_doc/bigbird_pegasus.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-BigBird モデルは、[Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) で提案されました。
+BigBird モデルは、[Big Bird: Transformers for Longer Sequences](https://huggingface.co/papers/2007.14062) で提案されました。
ザヒール、マンジルとグルガネシュ、グルとダベイ、クマール・アヴィナヴァとエインズリー、ジョシュアとアルベルティ、クリスとオンタノン、
サンティアゴとファム、フィリップとラブラ、アニルードとワン、キーファンとヤン、リーなど。 BigBird は注目度が低い
BERT などの Transformer ベースのモデルをさらに長いシーケンスに拡張する、Transformer ベースのモデル。まばらに加えて
diff --git a/docs/source/ja/model_doc/bit.md b/docs/source/ja/model_doc/bit.md
index ab0a7a4c68..a9e13e270a 100644
--- a/docs/source/ja/model_doc/bit.md
+++ b/docs/source/ja/model_doc/bit.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-BiT モデルは、Alexander Kolesnikov、Lucas Beyer、Xiaohua Zhai、Joan Puigcerver、Jessica Yung、Sylvain Gelly によって [Big Transfer (BiT): General Visual Representation Learning](https://arxiv.org/abs/1912.11370) で提案されました。ニール・ホールズビー。
+BiT モデルは、Alexander Kolesnikov、Lucas Beyer、Xiaohua Zhai、Joan Puigcerver、Jessica Yung、Sylvain Gelly によって [Big Transfer (BiT): General Visual Representation Learning](https://huggingface.co/papers/1912.11370) で提案されました。ニール・ホールズビー。
BiT は、[ResNet](resnet) のようなアーキテクチャ (具体的には ResNetv2) の事前トレーニングをスケールアップするための簡単なレシピです。この方法により、転移学習が大幅に改善されます。
論文の要約は次のとおりです。
@@ -27,8 +27,8 @@ BiT は、[ResNet](resnet) のようなアーキテクチャ (具体的には Re
## Usage tips
-- BiT モデルは、アーキテクチャの点で ResNetv2 と同等ですが、次の点が異なります: 1) すべてのバッチ正規化層が [グループ正規化](https://arxiv.org/abs/1803.08494) に置き換えられます。
-2) [重みの標準化](https://arxiv.org/abs/1903.10520) は畳み込み層に使用されます。著者らは、両方の組み合わせが大きなバッチサイズでのトレーニングに役立ち、重要な効果があることを示しています。
+- BiT モデルは、アーキテクチャの点で ResNetv2 と同等ですが、次の点が異なります: 1) すべてのバッチ正規化層が [グループ正規化](https://huggingface.co/papers/1803.08494) に置き換えられます。
+2) [重みの標準化](https://huggingface.co/papers/1903.10520) は畳み込み層に使用されます。著者らは、両方の組み合わせが大きなバッチサイズでのトレーニングに役立ち、重要な効果があることを示しています。
転移学習への影響。
このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
diff --git a/docs/source/ja/model_doc/blenderbot-small.md b/docs/source/ja/model_doc/blenderbot-small.md
index ecb9c1174b..97455bddf8 100644
--- a/docs/source/ja/model_doc/blenderbot-small.md
+++ b/docs/source/ja/model_doc/blenderbot-small.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-Blender チャットボット モデルは、[Recipes for building an open-domain chatbot](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller、Emily Dinan、Naman Goyal、Da Ju、Mary Williamson、yinghan Liu、で提案されました。
+Blender チャットボット モデルは、[Recipes for building an open-domain chatbot](https://huggingface.co/papers/2004.13637) Stephen Roller、Emily Dinan、Naman Goyal、Da Ju、Mary Williamson、yinghan Liu、で提案されました。
ジン・シュー、マイル・オット、カート・シャスター、エリック・M・スミス、Y-ラン・ブーロー、ジェイソン・ウェストン、2020年4月30日。
論文の要旨は次のとおりです。
diff --git a/docs/source/ja/model_doc/blenderbot.md b/docs/source/ja/model_doc/blenderbot.md
index f7ee23e755..f2a03e69c9 100644
--- a/docs/source/ja/model_doc/blenderbot.md
+++ b/docs/source/ja/model_doc/blenderbot.md
@@ -20,7 +20,7 @@ rendered properly in your Markdown viewer.
## Overview
-Blender チャットボット モデルは、[Recipes for building an open-domain chatbot](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller、Emily Dinan、Naman Goyal、Da Ju、Mary Williamson、yinghan Liu、で提案されました。
+Blender チャットボット モデルは、[Recipes for building an open-domain chatbot](https://huggingface.co/papers/2004.13637) Stephen Roller、Emily Dinan、Naman Goyal、Da Ju、Mary Williamson、yinghan Liu、で提案されました。
ジン・シュー、マイル・オット、カート・シャスター、エリック・M・スミス、Y-ラン・ブーロー、ジェイソン・ウェストン、2020年4月30日。
論文の要旨は次のとおりです。
@@ -45,7 +45,7 @@ Blender チャットボット モデルは、[Recipes for building an open-domai
## Implementation Notes
-- Blenderbot は、標準の [seq2seq モデル トランスフォーマー](https://arxiv.org/pdf/1706.03762.pdf) ベースのアーキテクチャを使用します。
+- Blenderbot は、標準の [seq2seq モデル トランスフォーマー](https://huggingface.co/papers/1706.03762) ベースのアーキテクチャを使用します。
- 利用可能なチェックポイントは、[モデル ハブ](https://huggingface.co/models?search=blenderbot) で見つけることができます。
- これは *デフォルト* Blenderbot モデル クラスです。ただし、次のような小さなチェックポイントもいくつかあります。
`facebook/blenderbot_small_90M` はアーキテクチャが異なるため、一緒に使用する必要があります。
diff --git a/docs/source/ja/model_doc/blip-2.md b/docs/source/ja/model_doc/blip-2.md
index bd110522e2..52a092ac9a 100644
--- a/docs/source/ja/model_doc/blip-2.md
+++ b/docs/source/ja/model_doc/blip-2.md
@@ -18,9 +18,9 @@ rendered properly in your Markdown viewer.
## Overview
-BLIP-2 モデルは、[BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://arxiv.org/abs/2301.12597) で提案されました。
+BLIP-2 モデルは、[BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://huggingface.co/papers/2301.12597) で提案されました。
Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi.・サバレーゼ、スティーブン・ホイ。 BLIP-2 は、軽量の 12 層 Transformer をトレーニングすることで、フリーズされた事前トレーニング済み画像エンコーダーと大規模言語モデル (LLM) を活用します。
-それらの間にエンコーダーを配置し、さまざまな視覚言語タスクで最先端のパフォーマンスを実現します。最も注目すべき点は、BLIP-2 が 800 億パラメータ モデルである [Flamingo](https://arxiv.org/abs/2204.14198) を 8.7% 改善していることです。
+それらの間にエンコーダーを配置し、さまざまな視覚言語タスクで最先端のパフォーマンスを実現します。最も注目すべき点は、BLIP-2 が 800 億パラメータ モデルである [Flamingo](https://huggingface.co/papers/2204.14198) を 8.7% 改善していることです。
ゼロショット VQAv2 ではトレーニング可能なパラメーターが 54 分の 1 に減少します。
論文の要約は次のとおりです。
@@ -30,7 +30,7 @@ Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi.・サバレーゼ、スティ
- BLIP-2 アーキテクチャ。 元の論文から抜粋。
+ BLIP-2 アーキテクチャ。 元の論文から抜粋。
このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
元のコードは [ここ](https://github.com/salesforce/LAVIS/tree/5ee63d688ba4cebff63acee04adaef2dee9af207) にあります。
diff --git a/docs/source/ja/model_doc/blip.md b/docs/source/ja/model_doc/blip.md
index 8e8550318b..e93c740883 100644
--- a/docs/source/ja/model_doc/blip.md
+++ b/docs/source/ja/model_doc/blip.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-BLIP モデルは、[BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) で Junnan Li、Dongxu Li、Caiming Xiong、Steven Hoi によって提案されました。 。
+BLIP モデルは、[BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://huggingface.co/papers/2201.12086) で Junnan Li、Dongxu Li、Caiming Xiong、Steven Hoi によって提案されました。 。
BLIP は、次のようなさまざまなマルチモーダル タスクを実行できるモデルです。
- 視覚的な質問応答
diff --git a/docs/source/ja/model_doc/bort.md b/docs/source/ja/model_doc/bort.md
index 2b892a35bb..185187219e 100644
--- a/docs/source/ja/model_doc/bort.md
+++ b/docs/source/ja/model_doc/bort.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
## Overview
-BORT モデルは、[Optimal Subarchitecture Extraction for BERT](https://arxiv.org/abs/2010.10499) で提案されました。
+BORT モデルは、[Optimal Subarchitecture Extraction for BERT](https://huggingface.co/papers/2010.10499) で提案されました。
Adrian de Wynter and Daniel J. Perry.これは、BERT のアーキテクチャ パラメータの最適なサブセットです。
著者は「ボルト」と呼んでいます。
diff --git a/docs/source/ja/model_doc/bridgetower.md b/docs/source/ja/model_doc/bridgetower.md
index c210d4666f..116d87caa5 100644
--- a/docs/source/ja/model_doc/bridgetower.md
+++ b/docs/source/ja/model_doc/bridgetower.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-BridgeTower モデルは、Xiao Xu、Chenfei Wu、Shachar Rosenman、Vasudev Lal、Wanxiang Che、Nan Duan [BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning](https://arxiv.org/abs/2206.08657) で提案されました。ドゥアン。このモデルの目標は、
+BridgeTower モデルは、Xiao Xu、Chenfei Wu、Shachar Rosenman、Vasudev Lal、Wanxiang Che、Nan Duan [BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning](https://huggingface.co/papers/2206.08657) で提案されました。ドゥアン。このモデルの目標は、
各ユニモーダル エンコーダとクロスモーダル エンコーダの間のブリッジにより、クロスモーダル エンコーダの各層での包括的かつ詳細な対話が可能になり、追加のパフォーマンスと計算コストがほとんど無視できる程度で、さまざまな下流タスクで優れたパフォーマンスを実現します。
この論文は [AAAI'23](https://aaai.org/Conferences/AAAI-23/) 会議に採択されました。
@@ -35,7 +35,7 @@ BridgeTower モデルは、Xiao Xu、Chenfei Wu、Shachar Rosenman、Vasudev Lal
- ブリッジタワー アーキテクチャ。 元の論文から抜粋。
+ ブリッジタワー アーキテクチャ。 元の論文から抜粋。
このモデルは、[Anahita Bhiwandiwalla](https://huggingface.co/anahita-b)、[Tiep Le](https://huggingface.co/Tile)、[Shaoyen Tseng](https://huggingface.co/shaoyent) 。元のコードは [ここ](https://github.com/microsoft/BridgeTower) にあります。
@@ -124,7 +124,7 @@ BridgeTower は、ビジュアル エンコーダー、テキスト エンコー
- BridgeTower のこの実装では、[`RobertaTokenizer`] を使用してテキスト埋め込みを生成し、OpenAI の CLIP/ViT モデルを使用して視覚的埋め込みを計算します。
- 事前トレーニングされた [bridgeTower-base](https://huggingface.co/BridgeTower/bridgetower-base) および [bridgetower マスクされた言語モデリングと画像テキスト マッチング](https://huggingface.co/BridgeTower/bridgetower--base-itm-mlm) のチェックポイント がリリースされました。
-- 画像検索およびその他の下流タスクにおける BridgeTower のパフォーマンスについては、[表 5](https://arxiv.org/pdf/2206.08657.pdf) を参照してください。
+- 画像検索およびその他の下流タスクにおける BridgeTower のパフォーマンスについては、[表 5](https://huggingface.co/papers/2206.08657) を参照してください。
- このモデルの PyTorch バージョンは、torch 1.10 以降でのみ使用できます。
## BridgeTowerConfig
diff --git a/docs/source/ja/model_doc/bros.md b/docs/source/ja/model_doc/bros.md
index 3749a172a8..def3539585 100644
--- a/docs/source/ja/model_doc/bros.md
+++ b/docs/source/ja/model_doc/bros.md
@@ -14,7 +14,7 @@ specific language governing permissions and limitations under the License.
## Overview
-BROS モデルは、Teakgyu Hon、Donghyun Kim、Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park によって [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://arxiv.org/abs/2108.04539) で提案されました。
+BROS モデルは、Teakgyu Hon、Donghyun Kim、Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park によって [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://huggingface.co/papers/2108.04539) で提案されました。
BROS は *BERT Relying On Spatality* の略です。これは、一連のトークンとその境界ボックスを入力として受け取り、一連の隠れ状態を出力するエンコーダー専用の Transformer モデルです。 BROS は、絶対的な空間情報を使用する代わりに、相対的な空間情報をエンコードします。
diff --git a/docs/source/ja/model_doc/byt5.md b/docs/source/ja/model_doc/byt5.md
index c6796f9818..83f7f0b4ac 100644
--- a/docs/source/ja/model_doc/byt5.md
+++ b/docs/source/ja/model_doc/byt5.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-ByT5 モデルは、[ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir
+ByT5 モデルは、[ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://huggingface.co/papers/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir
Kale, Adam Roberts, Colin Raffel.
論文の要約は次のとおりです。
diff --git a/docs/source/ja/model_doc/camembert.md b/docs/source/ja/model_doc/camembert.md
index 4f59700954..382077613d 100644
--- a/docs/source/ja/model_doc/camembert.md
+++ b/docs/source/ja/model_doc/camembert.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-CamemBERT モデルは、[CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) で提案されました。
+CamemBERT モデルは、[CamemBERT: a Tasty French Language Model](https://huggingface.co/papers/1911.03894) で提案されました。
Louis Martin, Benjamin Muller, Pedro Javier Ortiz Suárez, Yoann Dupont, Laurent Romary, Éric Villemonte de la
Clergerie, Djamé Seddah, and Benoît Sagot. 2019年にリリースされたFacebookのRoBERTaモデルをベースにしたモデルです。
138GBのフランス語テキストでトレーニングされました。
diff --git a/docs/source/ja/model_doc/canine.md b/docs/source/ja/model_doc/canine.md
index b45f1e4f7e..35bd6dc702 100644
--- a/docs/source/ja/model_doc/canine.md
+++ b/docs/source/ja/model_doc/canine.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## Overview
CANINE モデルは、[CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language
-Representation](https://arxiv.org/abs/2103.06874)、Jonathan H. Clark、Dan Garrette、Iulia Turc、John Wieting 著。その
+Representation](https://huggingface.co/papers/2103.06874)、Jonathan H. Clark、Dan Garrette、Iulia Turc、John Wieting 著。その
明示的なトークン化ステップ (バイト ペアなど) を使用せずに Transformer をトレーニングする最初の論文の 1 つ
エンコーディング (BPE、WordPiece または SentencePiece)。代わりに、モデルは Unicode 文字レベルで直接トレーニングされます。
キャラクターレベルでのトレーニングでは必然的にシーケンスの長さが長くなりますが、CANINE はこれを効率的な方法で解決します。
diff --git a/docs/source/ja/model_doc/chinese_clip.md b/docs/source/ja/model_doc/chinese_clip.md
index 68eff8e413..5dac6b3589 100644
--- a/docs/source/ja/model_doc/chinese_clip.md
+++ b/docs/source/ja/model_doc/chinese_clip.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-Chinese-CLIP An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://arxiv.org/abs/2211.01335) で提案されました。周、張周。
+Chinese-CLIP An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://huggingface.co/papers/2211.01335) で提案されました。周、張周。
Chinese-CLIP は、中国語の画像とテキストのペアの大規模なデータセットに対する CLIP (Radford et al., 2021) の実装です。クロスモーダル検索を実行できるほか、ゼロショット画像分類、オープンドメインオブジェクト検出などのビジョンタスクのビジョンバックボーンとしても機能します。オリジナルの中国語-CLIPコードは[このリンクで](https://github.com/OFA-Sys/Chinese-CLIP)。
論文の要約は次のとおりです。
diff --git a/docs/source/ja/model_doc/clap.md b/docs/source/ja/model_doc/clap.md
index f1e08d7601..1a5f2b5dfe 100644
--- a/docs/source/ja/model_doc/clap.md
+++ b/docs/source/ja/model_doc/clap.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## Overview
CLAP モデルは、[Large Scale Contrastive Language-Audio pretraining with
-feature fusion and keyword-to-caption augmentation](https://arxiv.org/pdf/2211.06687.pdf)、Yusong Wu、Ke Chen、Tianyu Zhang、Yuchen Hui、Taylor Berg-Kirkpatrick、Shlomo Dubnov 著。
+feature fusion and keyword-to-caption augmentation](https://huggingface.co/papers/2211.06687)、Yusong Wu、Ke Chen、Tianyu Zhang、Yuchen Hui、Taylor Berg-Kirkpatrick、Shlomo Dubnov 著。
CLAP (Contrastive Language-Audio Pretraining) は、さまざまな (音声、テキスト) ペアでトレーニングされたニューラル ネットワークです。タスクに合わせて直接最適化することなく、音声が与えられた場合に最も関連性の高いテキスト スニペットを予測するように指示できます。 CLAP モデルは、SWINTransformer を使用して log-Mel スペクトログラム入力からオーディオ特徴を取得し、RoBERTa モデルを使用してテキスト特徴を取得します。次に、テキストとオーディオの両方の特徴が、同じ次元の潜在空間に投影されます。投影されたオーディオとテキストの特徴の間のドット積が、同様のスコアとして使用されます。
diff --git a/docs/source/ja/model_doc/clip.md b/docs/source/ja/model_doc/clip.md
index db896c9116..6b21dbd143 100644
--- a/docs/source/ja/model_doc/clip.md
+++ b/docs/source/ja/model_doc/clip.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-CLIP モデルは、Alec Radford、Jong Wook Kim、Chris Hallacy、Aditya Ramesh、Gabriel Goh Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) で提案されました。
+CLIP モデルは、Alec Radford、Jong Wook Kim、Chris Hallacy、Aditya Ramesh、Gabriel Goh Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever [Learning Transferable Visual Models From Natural Language Supervision](https://huggingface.co/papers/2103.00020) で提案されました。
サンディニ・アガルワル、ギリッシュ・サストリー、アマンダ・アスケル、パメラ・ミシュキン、ジャック・クラーク、グレッチェン・クルーガー、イリヤ・サツケヴァー。クリップ
(Contrastive Language-Image Pre-Training) は、さまざまな (画像、テキスト) ペアでトレーニングされたニューラル ネットワークです。かもね
直接最適化することなく、与えられた画像から最も関連性の高いテキスト スニペットを予測するように自然言語で指示されます。
diff --git a/docs/source/ja/model_doc/clipseg.md b/docs/source/ja/model_doc/clipseg.md
index c8bdb0a0e4..8853565fac 100644
--- a/docs/source/ja/model_doc/clipseg.md
+++ b/docs/source/ja/model_doc/clipseg.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-CLIPSeg モデルは、Timo Lüddecke, Alexander Ecker によって [Image Segmentation using Text and Image Prompts](https://arxiv.org/abs/2112.10003) で提案されました。
+CLIPSeg モデルは、Timo Lüddecke, Alexander Ecker によって [Image Segmentation using Text and Image Prompts](https://huggingface.co/papers/2112.10003) で提案されました。
そしてアレクサンダー・エッカー。 CLIPSeg は、ゼロショットおよびワンショット画像セグメンテーションのために、凍結された [CLIP](clip) モデルの上に最小限のデコーダを追加します。
論文の要約は次のとおりです。
@@ -44,7 +44,7 @@ PhraseCut データセット、私たちのシステムは、フリーテキス
- CLIPSeg の概要。 元の論文から抜粋。
+ CLIPSeg の概要。 元の論文から抜粋。
このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
元のコードは [ここ](https://github.com/timojl/clipseg) にあります。
diff --git a/docs/source/ja/model_doc/clvp.md b/docs/source/ja/model_doc/clvp.md
index 0803f5e027..874e0779c7 100644
--- a/docs/source/ja/model_doc/clvp.md
+++ b/docs/source/ja/model_doc/clvp.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-CLVP (Contrastive Language-Voice Pretrained Transformer) モデルは、James Betker によって [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) で提案されました。
+CLVP (Contrastive Language-Voice Pretrained Transformer) モデルは、James Betker によって [Better speech synthesis through scaling](https://huggingface.co/papers/2305.07243) で提案されました。
論文の要約は次のとおりです。
diff --git a/docs/source/ja/model_doc/codegen.md b/docs/source/ja/model_doc/codegen.md
index 78caefe043..28ab376260 100644
--- a/docs/source/ja/model_doc/codegen.md
+++ b/docs/source/ja/model_doc/codegen.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## Overview
-CodeGen モデルは、[A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) で Erik Nijkamp、Bo Pang、林宏明、Lifu Tu、Huan Wang、Yingbo Zhou、Silvio Savarese、Caiming Xiong およびカイミン・ションさん。
+CodeGen モデルは、[A Conversational Paradigm for Program Synthesis](https://huggingface.co/papers/2203.13474) で Erik Nijkamp、Bo Pang、林宏明、Lifu Tu、Huan Wang、Yingbo Zhou、Silvio Savarese、Caiming Xiong およびカイミン・ションさん。
CodeGen は、[The Pile](https://pile.eleuther.ai/)、BigQuery、BigPython で順次トレーニングされたプログラム合成用の自己回帰言語モデルです。
diff --git a/docs/source/ja/model_doc/conditional_detr.md b/docs/source/ja/model_doc/conditional_detr.md
index e2ce65bdca..d0bb090630 100644
--- a/docs/source/ja/model_doc/conditional_detr.md
+++ b/docs/source/ja/model_doc/conditional_detr.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-条件付き DETR モデルは、[Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) で Depu Meng、Xiaokang Chen、Zejia Fan、Gang Zeng、Houqiang Li、Yuhui Yuan、Lei Sun, Jingdong Wang によって提案されました。王京東。条件付き DETR は、高速 DETR トレーニングのための条件付きクロスアテンション メカニズムを提供します。条件付き DETR は DETR よりも 6.7 倍から 10 倍速く収束します。
+条件付き DETR モデルは、[Conditional DETR for Fast Training Convergence](https://huggingface.co/papers/2108.06152) で Depu Meng、Xiaokang Chen、Zejia Fan、Gang Zeng、Houqiang Li、Yuhui Yuan、Lei Sun, Jingdong Wang によって提案されました。王京東。条件付き DETR は、高速 DETR トレーニングのための条件付きクロスアテンション メカニズムを提供します。条件付き DETR は DETR よりも 6.7 倍から 10 倍速く収束します。
論文の要約は次のとおりです。
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
- 条件付き DETR は、元の DETR に比べてはるかに速い収束を示します。 元の論文から引用。
+ 条件付き DETR は、元の DETR に比べてはるかに速い収束を示します。 元の論文から引用。
このモデルは [DepuMeng](https://huggingface.co/DepuMeng) によって寄稿されました。元のコードは [ここ](https://github.com/Atten4Vis/ConditionalDETR) にあります。
diff --git a/docs/source/ja/model_doc/convbert.md b/docs/source/ja/model_doc/convbert.md
index 7d790e4069..c581b715db 100644
--- a/docs/source/ja/model_doc/convbert.md
+++ b/docs/source/ja/model_doc/convbert.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
## Overview
-ConvBERT モデルは、[ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) で Zihang Jiang、Weihao Yu、Daquan Zhou、Yunpeng Chen、Jiashi Feng、Shuicheng Yan によって提案されました。
+ConvBERT モデルは、[ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://huggingface.co/papers/2008.02496) で Zihang Jiang、Weihao Yu、Daquan Zhou、Yunpeng Chen、Jiashi Feng、Shuicheng Yan によって提案されました。
やん。
論文の要約は次のとおりです。
diff --git a/docs/source/ja/model_doc/convnext.md b/docs/source/ja/model_doc/convnext.md
index efbe3bb0f4..336f27709d 100644
--- a/docs/source/ja/model_doc/convnext.md
+++ b/docs/source/ja/model_doc/convnext.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-ConvNeXT モデルは、[A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) で Zhuang Liu、Hanzi Mao、Chao-Yuan Wu、Christoph Feichtenhofer、Trevor Darrell、Saining Xie によって提案されました。
+ConvNeXT モデルは、[A ConvNet for the 2020s](https://huggingface.co/papers/2201.03545) で Zhuang Liu、Hanzi Mao、Chao-Yuan Wu、Christoph Feichtenhofer、Trevor Darrell、Saining Xie によって提案されました。
ConvNeXT は、ビジョン トランスフォーマーの設計からインスピレーションを得た純粋な畳み込みモデル (ConvNet) であり、ビジョン トランスフォーマーよりも優れたパフォーマンスを発揮すると主張しています。
論文の要約は次のとおりです。
@@ -35,7 +35,7 @@ ConvNextと呼ばれます。 ConvNeXts は完全に標準の ConvNet モジュ
- ConvNeXT アーキテクチャ。 元の論文から抜粋。
+ ConvNeXT アーキテクチャ。 元の論文から抜粋。
このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。 TensorFlow バージョンのモデルは [ariG23498](https://github.com/ariG23498) によって提供されました。
[gante](https://github.com/gante)、および [sayakpaul](https://github.com/sayakpaul) (同等の貢献)。元のコードは [こちら](https://github.com/facebookresearch/ConvNeXt) にあります。
diff --git a/docs/source/ja/model_doc/convnextv2.md b/docs/source/ja/model_doc/convnextv2.md
index 9e4d54df24..cadd5e8ca0 100644
--- a/docs/source/ja/model_doc/convnextv2.md
+++ b/docs/source/ja/model_doc/convnextv2.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-ConvNeXt V2 モデルは、Sanghyun Woo、Shobhik Debnath、Ronghang Hu、Xinlei Chen、Zhuang Liu, In So Kweon, Saining Xie. によって [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) で提案されました。
+ConvNeXt V2 モデルは、Sanghyun Woo、Shobhik Debnath、Ronghang Hu、Xinlei Chen、Zhuang Liu, In So Kweon, Saining Xie. によって [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://huggingface.co/papers/2301.00808) で提案されました。
ConvNeXt V2 は、Vision Transformers の設計からインスピレーションを得た純粋な畳み込みモデル (ConvNet) であり、[ConvNeXT](convnext) の後継です。
論文の要約は次のとおりです。
@@ -28,7 +28,7 @@ ConvNeXt V2 は、Vision Transformers の設計からインスピレーション
- ConvNeXt V2 アーキテクチャ。 元の論文から抜粋。
+ ConvNeXt V2 アーキテクチャ。 元の論文から抜粋。
このモデルは [adirik](https://huggingface.co/adirik) によって提供されました。元のコードは [こちら](https://github.com/facebookresearch/ConvNeXt-V2) にあります。
diff --git a/docs/source/ja/model_doc/cpm.md b/docs/source/ja/model_doc/cpm.md
index afac35823e..e10e8af775 100644
--- a/docs/source/ja/model_doc/cpm.md
+++ b/docs/source/ja/model_doc/cpm.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-CPM モデルは、Zhengyan Zhang、Xu Han、Hao Zhou、Pei Ke、Yuxian Gu によって [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) で提案されました。葉徳明、秦裕佳、
+CPM モデルは、Zhengyan Zhang、Xu Han、Hao Zhou、Pei Ke、Yuxian Gu によって [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://huggingface.co/papers/2012.00413) で提案されました。葉徳明、秦裕佳、
Yusheng Su、Haozhe Ji、Jian Guan、Fanchao Qi、Xiaozi Wang、Yanan Zheng、Guoyang Zeng、Huanqi Cao、Shengqi Chen、
Daixuan Li、Zhenbo Sun、Zhiyuan Liu、Minlie Huang、Wentao Han、Jie Tang、Juanzi Li、Xiaoyan Zhu、Maosong Sun。
diff --git a/docs/source/ja/model_doc/ctrl.md b/docs/source/ja/model_doc/ctrl.md
index e20e49d918..508a0d2e43 100644
--- a/docs/source/ja/model_doc/ctrl.md
+++ b/docs/source/ja/model_doc/ctrl.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
## Overview
-CTRL モデルは、Nitish Shirish Keskar*、Bryan McCann*、Lav R. Varshney、Caiming Xiong, Richard Socher によって [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) で提案されました。
+CTRL モデルは、Nitish Shirish Keskar*、Bryan McCann*、Lav R. Varshney、Caiming Xiong, Richard Socher によって [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://huggingface.co/papers/1909.05858) で提案されました。
リチャード・ソーチャー。これは、非常に大規模なコーパスの言語モデリングを使用して事前トレーニングされた因果的 (一方向) トランスフォーマーです
最初のトークンが制御コード (リンク、書籍、Wikipedia など) として予約されている、約 140 GB のテキスト データ。
diff --git a/docs/source/ja/model_doc/cvt.md b/docs/source/ja/model_doc/cvt.md
index 16d39d1b55..ba09273298 100644
--- a/docs/source/ja/model_doc/cvt.md
+++ b/docs/source/ja/model_doc/cvt.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-CvT モデルは、Haping Wu、Bin Xiao、Noel Codella、Mengchen Liu、Xiyang Dai、Lu Yuan、Lei Zhang によって [CvT: Introduction Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) で提案されました。畳み込みビジョン トランスフォーマー (CvT) は、ViT に畳み込みを導入して両方の設計の長所を引き出すことにより、[ビジョン トランスフォーマー (ViT)](vit) のパフォーマンスと効率を向上させます。
+CvT モデルは、Haping Wu、Bin Xiao、Noel Codella、Mengchen Liu、Xiyang Dai、Lu Yuan、Lei Zhang によって [CvT: Introduction Convolutions to Vision Transformers](https://huggingface.co/papers/2103.15808) で提案されました。畳み込みビジョン トランスフォーマー (CvT) は、ViT に畳み込みを導入して両方の設計の長所を引き出すことにより、[ビジョン トランスフォーマー (ViT)](vit) のパフォーマンスと効率を向上させます。
論文の要約は次のとおりです。
diff --git a/docs/source/ja/model_doc/data2vec.md b/docs/source/ja/model_doc/data2vec.md
index c16d913881..b5267aae35 100644
--- a/docs/source/ja/model_doc/data2vec.md
+++ b/docs/source/ja/model_doc/data2vec.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-Data2Vec モデルは、[data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/pdf/2202.03555) で Alexei Baevski、Wei-Ning Hsu、Qiantong Xu、バArun Babu, Jiatao Gu and Michael Auli.
+Data2Vec モデルは、[data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://huggingface.co/papers/2202.03555) で Alexei Baevski、Wei-Ning Hsu、Qiantong Xu、バArun Babu, Jiatao Gu and Michael Auli.
Data2Vec は、テキスト、音声、画像などのさまざまなデータ モダリティにわたる自己教師あり学習のための統一フレームワークを提案します。
重要なのは、事前トレーニングの予測ターゲットは、モダリティ固有のコンテキストに依存しないターゲットではなく、入力のコンテキスト化された潜在表現であることです。
diff --git a/docs/source/ja/model_doc/deberta-v2.md b/docs/source/ja/model_doc/deberta-v2.md
index bdbaf3c21b..279dae3610 100644
--- a/docs/source/ja/model_doc/deberta-v2.md
+++ b/docs/source/ja/model_doc/deberta-v2.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-DeBERTa モデルは、Pengcheng He、Xiaodong Liu、Jianfeng Gao、Weizhu Chen によって [DeBERTa: Decoding-enhanced BERT with Disentangled Attendant](https://arxiv.org/abs/2006.03654) で提案されました。Google のモデルに基づいています。
+DeBERTa モデルは、Pengcheng He、Xiaodong Liu、Jianfeng Gao、Weizhu Chen によって [DeBERTa: Decoding-enhanced BERT with Disentangled Attendant](https://huggingface.co/papers/2006.03654) で提案されました。Google のモデルに基づいています。
2018年にリリースされたBERTモデルと2019年にリリースされたFacebookのRoBERTaモデル。
これは、もつれた注意を解きほぐし、使用されるデータの半分を使用して強化されたマスク デコーダ トレーニングを備えた RoBERTa に基づいて構築されています。
diff --git a/docs/source/ja/model_doc/deberta.md b/docs/source/ja/model_doc/deberta.md
index ef55a64581..8a9440a91f 100644
--- a/docs/source/ja/model_doc/deberta.md
+++ b/docs/source/ja/model_doc/deberta.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-DeBERTa モデルは、Pengcheng He、Xiaodong Liu、Jianfeng Gao、Weizhu Chen によって [DeBERTa: Decoding-enhanced BERT with Disentangled Attendant](https://arxiv.org/abs/2006.03654) で提案されました。Google のモデルに基づいています。
+DeBERTa モデルは、Pengcheng He、Xiaodong Liu、Jianfeng Gao、Weizhu Chen によって [DeBERTa: Decoding-enhanced BERT with Disentangled Attendant](https://huggingface.co/papers/2006.03654) で提案されました。Google のモデルに基づいています。
2018年にリリースされたBERTモデルと2019年にリリースされたFacebookのRoBERTaモデル。
これは、もつれた注意を解きほぐし、使用されるデータの半分を使用して強化されたマスク デコーダ トレーニングを備えた RoBERTa に基づいて構築されています。
diff --git a/docs/source/ja/model_doc/decision_transformer.md b/docs/source/ja/model_doc/decision_transformer.md
index fe37feb5a3..e2dee43cd0 100644
--- a/docs/source/ja/model_doc/decision_transformer.md
+++ b/docs/source/ja/model_doc/decision_transformer.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-Decision Transformer モデルは、[Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) で提案されました。
+Decision Transformer モデルは、[Decision Transformer: Reinforcement Learning via Sequence Modeling](https://huggingface.co/papers/2106.01345) で提案されました。
Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
論文の要約は次のとおりです。
diff --git a/docs/source/ja/model_doc/deformable_detr.md b/docs/source/ja/model_doc/deformable_detr.md
index ccb6ec42f8..3264f3d960 100644
--- a/docs/source/ja/model_doc/deformable_detr.md
+++ b/docs/source/ja/model_doc/deformable_detr.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-変形可能 DETR モデルは、Xizhou Zhu、Weijie Su、Lewei Lu、Bin Li、Xiaogang Wang, Jifeng Dai によって [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) で提案されました
+変形可能 DETR モデルは、Xizhou Zhu、Weijie Su、Lewei Lu、Bin Li、Xiaogang Wang, Jifeng Dai によって [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://huggingface.co/papers/2010.04159) で提案されました
変形可能な DETR は、参照周囲の少数の主要なサンプリング ポイントのみに注目する新しい変形可能なアテンション モジュールを利用することにより、収束の遅さの問題と元の [DETR](detr) の制限された特徴の空間解像度を軽減します。
論文の要約は次のとおりです。
@@ -28,7 +28,7 @@ rendered properly in your Markdown viewer.
- 変形可能な DETR アーキテクチャ。 元の論文から抜粋。
+ 変形可能な DETR アーキテクチャ。 元の論文から抜粋。
このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。元のコードは [ここ](https://github.com/fundamentalvision/Deformable-DETR) にあります。
diff --git a/docs/source/ja/model_doc/deit.md b/docs/source/ja/model_doc/deit.md
index 00fa82e113..ba769dcf0d 100644
--- a/docs/source/ja/model_doc/deit.md
+++ b/docs/source/ja/model_doc/deit.md
@@ -19,8 +19,8 @@ rendered properly in your Markdown viewer.
## Overview
DeiT モデルは、Hugo Touvron、Matthieu Cord、Matthijs Douze、Francisco Massa、Alexandre
-Sablayrolles, Hervé Jégou.によって [Training data-efficient image Transformers & distillation through attention](https://arxiv.org/abs/2012.12877) で提案されました。
-サブレイロール、エルヴェ・ジェグー。 [Dosovitskiy et al., 2020](https://arxiv.org/abs/2010.11929) で紹介された [Vision Transformer (ViT)](vit) は、既存の畳み込みニューラルと同等、またはそれを上回るパフォーマンスを発揮できることを示しました。
+Sablayrolles, Hervé Jégou.によって [Training data-efficient image Transformers & distillation through attention](https://huggingface.co/papers/2012.12877) で提案されました。
+サブレイロール、エルヴェ・ジェグー。 [Dosovitskiy et al., 2020](https://huggingface.co/papers/2010.11929) で紹介された [Vision Transformer (ViT)](vit) は、既存の畳み込みニューラルと同等、またはそれを上回るパフォーマンスを発揮できることを示しました。
Transformer エンコーダ (BERT のような) を使用したネットワーク。ただし、その論文で紹介された ViT モデルには、次のトレーニングが必要でした。
外部データを使用して、数週間にわたる高価なインフラストラクチャ。 DeiT (データ効率の高い画像変換器) はさらに優れています
画像分類用に効率的にトレーニングされたトランスフォーマーにより、必要なデータとコンピューティング リソースがはるかに少なくなります。
diff --git a/docs/source/ja/model_doc/deplot.md b/docs/source/ja/model_doc/deplot.md
index 26871d1e7d..5e125fa9b5 100644
--- a/docs/source/ja/model_doc/deplot.md
+++ b/docs/source/ja/model_doc/deplot.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-DePlot は、Fangyu Liu、Julian Martin Aisenschlos、Francesco Piccinno、Syrine Krichene、Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun. の論文 [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) で提案されました。パン・
+DePlot は、Fangyu Liu、Julian Martin Aisenschlos、Francesco Piccinno、Syrine Krichene、Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun. の論文 [DePlot: One-shot visual language reasoning by plot-to-table translation](https://huggingface.co/papers/2212.10505) で提案されました。パン・
論文の要約には次のように記載されています。
diff --git a/docs/source/ja/model_doc/deta.md b/docs/source/ja/model_doc/deta.md
index 615f839657..7c8a5687ba 100644
--- a/docs/source/ja/model_doc/deta.md
+++ b/docs/source/ja/model_doc/deta.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-DETA モデルは、[NMS Strikes Back](https://arxiv.org/abs/2212.06137) で Jeffrey Ouyang-Zhang、Jang Hyun Cho、Xingyi Zhou、Philipp Krähenbühl によって提案されました。
+DETA モデルは、[NMS Strikes Back](https://huggingface.co/papers/2212.06137) で Jeffrey Ouyang-Zhang、Jang Hyun Cho、Xingyi Zhou、Philipp Krähenbühl によって提案されました。
DETA (Detection Transformers with Assignment の略) は、1 対 1 の 2 部ハンガリアン マッチング損失を置き換えることにより、[Deformable DETR](deformable_detr) を改善します。
非最大抑制 (NMS) を備えた従来の検出器で使用される 1 対多のラベル割り当てを使用します。これにより、最大 2.5 mAP の大幅な増加が得られます。
@@ -29,7 +29,7 @@ DETA (Detection Transformers with Assignment の略) は、1 対 1 の 2 部ハ
- DETA の概要。 元の論文から抜粋。
+ DETA の概要。 元の論文から抜粋。
このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
元のコードは [ここ](https://github.com/jozhang97/DETA) にあります。
diff --git a/docs/source/ja/model_doc/detr.md b/docs/source/ja/model_doc/detr.md
index 3342b123a0..d709d76f04 100644
--- a/docs/source/ja/model_doc/detr.md
+++ b/docs/source/ja/model_doc/detr.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-DETR モデルは、[Transformers を使用したエンドツーエンドのオブジェクト検出](https://arxiv.org/abs/2005.12872) で提案されました。
+DETR モデルは、[Transformers を使用したエンドツーエンドのオブジェクト検出](https://huggingface.co/papers/2005.12872) で提案されました。
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov and Sergey Zagoruyko ルイコ。 DETR
畳み込みバックボーンと、その後にエンドツーエンドでトレーニングできるエンコーダー/デコーダー Transformer で構成されます。
物体の検出。 Faster-R-CNN や Mask-R-CNN などのモデルの複雑さの多くが大幅に簡素化されます。
diff --git a/docs/source/ja/model_doc/dialogpt.md b/docs/source/ja/model_doc/dialogpt.md
index 22ce0c9a09..80e5423785 100644
--- a/docs/source/ja/model_doc/dialogpt.md
+++ b/docs/source/ja/model_doc/dialogpt.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-DialoGPT は、[DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) で Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao,
+DialoGPT は、[DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://huggingface.co/papers/1911.00536) で Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao,
Jianfeng Gao, Jingjing Liu, Bill Dolan.これは、から抽出された 147M 万の会話のようなやりとりでトレーニングされた GPT2 モデルです。
レディット。
diff --git a/docs/source/ja/model_doc/dinat.md b/docs/source/ja/model_doc/dinat.md
index a59b073d46..ee373cdd75 100644
--- a/docs/source/ja/model_doc/dinat.md
+++ b/docs/source/ja/model_doc/dinat.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-DiNAT は [Dilated Neighborhood Attender Transformer](https://arxiv.org/abs/2209.15001) で提案されました。
+DiNAT は [Dilated Neighborhood Attender Transformer](https://huggingface.co/papers/2209.15001) で提案されました。
Ali Hassani and Humphrey Shi.
[NAT](nat) を拡張するために、拡張近隣アテンション パターンを追加してグローバル コンテキストをキャプチャします。
@@ -50,7 +50,7 @@ src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/ma
alt="drawing" width="600"/>
異なる拡張値を使用した近隣アテンション。
-元の論文から抜粋。
+元の論文から抜粋。
このモデルは [Ali Hassani](https://huggingface.co/alihassanijr) によって提供されました。
元のコードは [ここ](https://github.com/SHI-Labs/Neighborhood-Attendance-Transformer) にあります。
diff --git a/docs/source/ja/model_memory_anatomy.md b/docs/source/ja/model_memory_anatomy.md
index 45a383d616..c8b7c90a94 100644
--- a/docs/source/ja/model_memory_anatomy.md
+++ b/docs/source/ja/model_memory_anatomy.md
@@ -193,7 +193,7 @@ Transformerアーキテクチャには、計算強度によって以下の3つ
パフォーマンスのボトルネックを分析する際に、この知識は役立つことがあります。
-この要約は、[Data Movement Is All You Need: Optimizing Transformers 2020に関するケーススタディ](https://arxiv.org/abs/2007.00072)から派生しています。
+この要約は、[Data Movement Is All You Need: Optimizing Transformers 2020に関するケーススタディ](https://huggingface.co/papers/2007.00072)から派生しています。
## Anatomy of Model's Memory
diff --git a/docs/source/ja/model_summary.md b/docs/source/ja/model_summary.md
index 8f8b6af48c..b49bde5c20 100644
--- a/docs/source/ja/model_summary.md
+++ b/docs/source/ja/model_summary.md
@@ -16,7 +16,7 @@ rendered properly in your Markdown viewer.
# The Transformer model family
-2017年に導入されて以来、[元のTransformer](https://arxiv.org/abs/1706.03762)モデルは、自然言語処理(NLP)のタスクを超える多くの新しいエキサイティングなモデルをインスパイアしました。[タンパク質の折りたたまれた構造を予測](https://huggingface.co/blog/deep-learning-with-proteins)するモデル、[チーターを走らせるためのトレーニング](https://huggingface.co/blog/train-decision-transformers)するモデル、そして[時系列予測](https://huggingface.co/blog/time-series-transformers)のためのモデルなどがあります。Transformerのさまざまなバリアントが利用可能ですが、大局を見落とすことがあります。これらのすべてのモデルに共通するのは、元のTransformerアーキテクチャに基づいていることです。一部のモデルはエンコーダまたはデコーダのみを使用し、他のモデルは両方を使用します。これは、Transformerファミリー内のモデルの高レベルの違いをカテゴライズし、調査するための有用な分類法を提供し、以前に出会ったことのないTransformerを理解するのに役立ちます。
+2017年に導入されて以来、[元のTransformer](https://huggingface.co/papers/1706.03762)モデルは、自然言語処理(NLP)のタスクを超える多くの新しいエキサイティングなモデルをインスパイアしました。[タンパク質の折りたたまれた構造を予測](https://huggingface.co/blog/deep-learning-with-proteins)するモデル、[チーターを走らせるためのトレーニング](https://huggingface.co/blog/train-decision-transformers)するモデル、そして[時系列予測](https://huggingface.co/blog/time-series-transformers)のためのモデルなどがあります。Transformerのさまざまなバリアントが利用可能ですが、大局を見落とすことがあります。これらのすべてのモデルに共通するのは、元のTransformerアーキテクチャに基づいていることです。一部のモデルはエンコーダまたはデコーダのみを使用し、他のモデルは両方を使用します。これは、Transformerファミリー内のモデルの高レベルの違いをカテゴライズし、調査するための有用な分類法を提供し、以前に出会ったことのないTransformerを理解するのに役立ちます。
元のTransformerモデルに慣れていないか、リフレッシュが必要な場合は、Hugging Faceコースの[Transformerの動作原理](https://huggingface.co/course/chapter1/4?fw=pt)章をチェックしてください。
@@ -32,7 +32,7 @@ rendered properly in your Markdown viewer.
### Convolutional network
-長い間、畳み込みネットワーク(CNN)はコンピュータビジョンのタスクにおいて支配的なパラダイムでしたが、[ビジョンTransformer](https://arxiv.org/abs/2010.11929)はそのスケーラビリティと効率性を示しました。それでも、一部のCNNの最高の特性、特に特定のタスクにとっては非常に強力な翻訳不変性など、一部のTransformerはアーキテクチャに畳み込みを組み込んでいます。[ConvNeXt](model_doc/convnext)は、畳み込みを現代化するためにTransformerから設計の選択肢を取り入れ、例えば、ConvNeXtは画像をパッチに分割するために重なり合わないスライディングウィンドウと、グローバル受容野を増加させるための大きなカーネルを使用します。ConvNeXtは、メモリ効率を向上させ、パフォーマンスを向上させるためにいくつかのレイヤーデザインの選択肢も提供し、Transformerと競合的になります!
+長い間、畳み込みネットワーク(CNN)はコンピュータビジョンのタスクにおいて支配的なパラダイムでしたが、[ビジョンTransformer](https://huggingface.co/papers/2010.11929)はそのスケーラビリティと効率性を示しました。それでも、一部のCNNの最高の特性、特に特定のタスクにとっては非常に強力な翻訳不変性など、一部のTransformerはアーキテクチャに畳み込みを組み込んでいます。[ConvNeXt](model_doc/convnext)は、畳み込みを現代化するためにTransformerから設計の選択肢を取り入れ、例えば、ConvNeXtは画像をパッチに分割するために重なり合わないスライディングウィンドウと、グローバル受容野を増加させるための大きなカーネルを使用します。ConvNeXtは、メモリ効率を向上させ、パフォーマンスを向上させるためにいくつかのレイヤーデザインの選択肢も提供し、Transformerと競合的になります!
### Encoder[[cv-encoder]]
@@ -59,7 +59,7 @@ BeIT および ViTMAE などの他のビジョンモデルは、BERTの事前ト
[BERT](model_doc/bert) はエンコーダー専用のTransformerで、入力の一部のトークンをランダムにマスクして他のトークンを見ないようにしています。これにより、トークンをマスクした文脈に基づいてマスクされたトークンを予測することが事前トレーニングの目標です。これにより、BERTは入力のより深いかつ豊かな表現を学習するのに左右の文脈を完全に活用できます。しかし、BERTの事前トレーニング戦略にはまだ改善の余地がありました。[RoBERTa](model_doc/roberta) は、トレーニングを長時間行い、より大きなバッチでトレーニングし、事前処理中に一度だけでなく各エポックでトークンをランダムにマスクし、次文予測の目標を削除する新しい事前トレーニングレシピを導入することでこれを改善しました。
-性能を向上させる主要な戦略はモデルのサイズを増やすことですが、大規模なモデルのトレーニングは計算コストがかかります。計算コストを削減する方法の1つは、[DistilBERT](model_doc/distilbert) のような小さなモデルを使用することです。DistilBERTは[知識蒸留](https://arxiv.org/abs/1503.02531) - 圧縮技術 - を使用して、BERTのほぼすべての言語理解機能を保持しながら、より小さなバージョンを作成します。
+性能を向上させる主要な戦略はモデルのサイズを増やすことですが、大規模なモデルのトレーニングは計算コストがかかります。計算コストを削減する方法の1つは、[DistilBERT](model_doc/distilbert) のような小さなモデルを使用することです。DistilBERTは[知識蒸留](https://huggingface.co/papers/1503.02531) - 圧縮技術 - を使用して、BERTのほぼすべての言語理解機能を保持しながら、より小さなバージョンを作成します。
しかし、ほとんどのTransformerモデルは引き続きより多くのパラメータに焦点を当て、トレーニング効率を向上させる新しいモデルが登場しています。[ALBERT](model_doc/albert) は、2つの方法でパラメータの数を減らすことによってメモリ消費量を削減します。大きな語彙埋め込みを2つの小さな行列に分割し、レイヤーがパラメータを共有できるようにします。[DeBERTa](model_doc/deberta) は、単語とその位置を2つのベクトルで別々にエンコードする解かれた注意機構を追加しました。注意はこれらの別々のベクトルから計算されます。単語と位置の埋め込みが含まれる単一のベクトルではなく、[Longformer](model_doc/longformer) は、特に長いシーケンス長のドキュメントを処理するために注意をより効率的にすることに焦点を当てました。固定されたウィンドウサイズの周りの各トークンから計算されるローカルウィンドウ付き注意(特定のタスクトークン(分類のための `[CLS]` など)のみのためのグローバルな注意を含む)の組み合わせを使用して、完全な注意行列ではなく疎な注意行列を作成します。
diff --git a/docs/source/ja/peft.md b/docs/source/ja/peft.md
index c3d195adbd..77dd7be86c 100644
--- a/docs/source/ja/peft.md
+++ b/docs/source/ja/peft.md
@@ -46,7 +46,7 @@ pip install git+https://github.com/huggingface/peft.git
- [Low Rank Adapters](https://huggingface.co/docs/peft/conceptual_guides/lora)
- [IA3](https://huggingface.co/docs/peft/conceptual_guides/ia3)
-- [AdaLoRA](https://arxiv.org/abs/2303.10512)
+- [AdaLoRA](https://huggingface.co/papers/2303.10512)
他のPEFTメソッドを使用したい場合、プロンプト学習やプロンプト調整などについて詳しく知りたい場合、または🤗 PEFTライブラリ全般については、[ドキュメンテーション](https://huggingface.co/docs/peft/index)を参照してください。
diff --git a/docs/source/ja/perf_infer_gpu_many.md b/docs/source/ja/perf_infer_gpu_many.md
index 18a19c849e..6a71c10944 100644
--- a/docs/source/ja/perf_infer_gpu_many.md
+++ b/docs/source/ja/perf_infer_gpu_many.md
@@ -53,7 +53,7 @@ model.to_bettertransformer()
# Use it for training or inference
```
-SDPAは、ハードウェアや問題のサイズなどの特定の設定で[Flash Attention](https://arxiv.org/abs/2205.14135)カーネルを呼び出すこともできます。Flash Attentionを有効にするか、特定の設定(ハードウェア、問題のサイズ)で利用可能かを確認するには、[`torch.nn.kernel.sdpa_kernel`](https://pytorch.org/docs/stable/generated/torch.nn.attention.sdpa_kernel.html)をコンテキストマネージャとして使用します。
+SDPAは、ハードウェアや問題のサイズなどの特定の設定で[Flash Attention](https://huggingface.co/papers/2205.14135)カーネルを呼び出すこともできます。Flash Attentionを有効にするか、特定の設定(ハードウェア、問題のサイズ)で利用可能かを確認するには、[`torch.nn.kernel.sdpa_kernel`](https://pytorch.org/docs/stable/generated/torch.nn.attention.sdpa_kernel.html)をコンテキストマネージャとして使用します。
```diff
diff --git a/docs/source/ja/perf_infer_gpu_one.md b/docs/source/ja/perf_infer_gpu_one.md
index 6a3dc5fa64..374d725a99 100644
--- a/docs/source/ja/perf_infer_gpu_one.md
+++ b/docs/source/ja/perf_infer_gpu_one.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
-Flash Attention 2は、トランスフォーマーベースのモデルのトレーニングと推論速度を大幅に高速化できます。Flash Attention 2は、Tri Dao氏によって[公式のFlash Attentionリポジトリ](https://github.com/Dao-AILab/flash-attention)で導入されました。Flash Attentionに関する科学論文は[こちら](https://arxiv.org/abs/2205.14135)で見ることができます。
+Flash Attention 2は、トランスフォーマーベースのモデルのトレーニングと推論速度を大幅に高速化できます。Flash Attention 2は、Tri Dao氏によって[公式のFlash Attentionリポジトリ](https://github.com/Dao-AILab/flash-attention)で導入されました。Flash Attentionに関する科学論文は[こちら](https://huggingface.co/papers/2205.14135)で見ることができます。
Flash Attention 2を正しくインストールするには、上記のリポジトリに記載されているインストールガイドに従ってください。
@@ -214,7 +214,7 @@ model.to_bettertransformer()
# Use it for training or inference
```
-SDPAは、ハードウェアや問題のサイズに応じて[Flash Attention](https://arxiv.org/abs/2205.14135)カーネルを使用することもできます。Flash Attentionを有効にするか、特定の設定(ハードウェア、問題サイズ)で使用可能かどうかを確認するには、[`torch.nn.attention.sdpa_kernel`](https://pytorch.org/docs/stable/generated/torch.nn.attention.sdpa_kernel.html)をコンテキストマネージャとして使用します。
+SDPAは、ハードウェアや問題のサイズに応じて[Flash Attention](https://huggingface.co/papers/2205.14135)カーネルを使用することもできます。Flash Attentionを有効にするか、特定の設定(ハードウェア、問題サイズ)で使用可能かどうかを確認するには、[`torch.nn.attention.sdpa_kernel`](https://pytorch.org/docs/stable/generated/torch.nn.attention.sdpa_kernel.html)をコンテキストマネージャとして使用します。
```diff
@@ -332,12 +332,12 @@ model_4bit = AutoModelForCausalLM.from_pretrained(
-論文[`LLM.int8():スケーラブルなTransformer向けの8ビット行列乗算`](https://arxiv.org/abs/2208.07339)によれば、Hugging Face統合がHub内のすべてのモデルでわずか数行のコードでサポートされています。このメソッドは、半精度(`float16`および`bfloat16`)の重みの場合に`nn.Linear`サイズを2倍、単精度(`float32`)の重みの場合は4倍に縮小し、外れ値に対してほとんど影響を与えません。
+論文[`LLM.int8():スケーラブルなTransformer向けの8ビット行列乗算`](https://huggingface.co/papers/2208.07339)によれば、Hugging Face統合がHub内のすべてのモデルでわずか数行のコードでサポートされています。このメソッドは、半精度(`float16`および`bfloat16`)の重みの場合に`nn.Linear`サイズを2倍、単精度(`float32`)の重みの場合は4倍に縮小し、外れ値に対してほとんど影響を与えません。

Int8混合精度行列分解は、行列乗算を2つのストリームに分割することによって動作します:(1) システマティックな特徴外れ値ストリームがfp16で行列乗算(0.01%)、(2) int8行列乗算の通常のストリーム(99.9%)。この方法を使用すると、非常に大きなモデルに対して予測の劣化なしにint8推論が可能です。
-このメソッドの詳細については、[論文](https://arxiv.org/abs/2208.07339)または[この統合に関するブログ記事](https://huggingface.co/blog/hf-bitsandbytes-integration)をご確認ください。
+このメソッドの詳細については、[論文](https://huggingface.co/papers/2208.07339)または[この統合に関するブログ記事](https://huggingface.co/blog/hf-bitsandbytes-integration)をご確認ください。

diff --git a/docs/source/ja/perf_train_gpu_many.md b/docs/source/ja/perf_train_gpu_many.md
index 613ccfa20b..6721ba69a9 100644
--- a/docs/source/ja/perf_train_gpu_many.md
+++ b/docs/source/ja/perf_train_gpu_many.md
@@ -317,7 +317,7 @@ VarunaとSageMakerとの実験はまだ行っていませんが、彼らの論
- [DeepSpeed](https://www.deepspeed.ai/tutorials/pipeline/)
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) has an internal implementation - no API.
- [Varuna](https://github.com/microsoft/varuna)
-- [SageMaker](https://arxiv.org/abs/2111.05972) - this is a proprietary solution that can only be used on AWS.
+- [SageMaker](https://huggingface.co/papers/2111.05972) - this is a proprietary solution that can only be used on AWS.
- [OSLO](https://github.com/tunib-ai/oslo) - この実装は、Hugging Face Transformersに基づいています。
🤗 Transformersのステータス: この執筆時点では、いずれのモデルも完全なPP(パイプライン並列処理)をサポートしていません。GPT2モデルとT5モデルは単純なMP(モデル並列処理)サポートを持っています。主な障害は、モデルを`nn.Sequential`に変換できず、すべての入力がテンソルである必要があることです。現在のモデルには、変換を非常に複雑にする多くの機能が含まれており、これらを削除する必要があります。
@@ -334,7 +334,7 @@ OSLOは、`nn.Sequential`の変換なしでTransformersに基づくパイプラ
テンソル並列処理では、各GPUがテンソルのスライスのみを処理し、全体が必要な操作のためにのみ完全なテンソルを集約します。
-このセクションでは、[Megatron-LM](https://github.com/NVIDIA/Megatron-LM)論文からのコンセプトと図を使用します:[GPUクラスタでの効率的な大規模言語モデルトレーニング](https://arxiv.org/abs/2104.04473)。
+このセクションでは、[Megatron-LM](https://github.com/NVIDIA/Megatron-LM)論文からのコンセプトと図を使用します:[GPUクラスタでの効率的な大規模言語モデルトレーニング](https://huggingface.co/papers/2104.04473)。
どのトランスフォーマの主要な構築要素は、完全に接続された`nn.Linear`に続く非線形アクティベーション`GeLU`です。
@@ -365,7 +365,7 @@ SageMakerは、より効率的な処理のためにTPとDPを組み合わせて
実装例:
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)には、モデル固有の内部実装があります。
- [parallelformers](https://github.com/tunib-ai/parallelformers)(現時点では推論のみ)。
-- [SageMaker](https://arxiv.org/abs/2111.05972) - これはAWSでのみ使用できるプロプライエタリなソリューションです。
+- [SageMaker](https://huggingface.co/papers/2111.05972) - これはAWSでのみ使用できるプロプライエタリなソリューションです。
- [OSLO](https://github.com/tunib-ai/oslo)には、Transformersに基づいたテンソル並列実装があります。
🤗 Transformersの状況:
@@ -387,7 +387,7 @@ DeepSpeedの[パイプラインチュートリアル](https://www.deepspeed.ai/t
- [DeepSpeed](https://github.com/deepspeedai/DeepSpeed)
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
- [Varuna](https://github.com/microsoft/varuna)
-- [SageMaker](https://arxiv.org/abs/2111.05972)
+- [SageMaker](https://huggingface.co/papers/2111.05972)
- [OSLO](https://github.com/tunib-ai/oslo)
🤗 Transformersの状況: まだ実装されていません
@@ -406,7 +406,7 @@ DeepSpeedの[パイプラインチュートリアル](https://www.deepspeed.ai/t
- [DeepSpeed](https://github.com/deepspeedai/DeepSpeed) - DeepSpeedには、さらに効率的なDPであるZeRO-DPと呼ばれるものも含まれています。
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
- [Varuna](https://github.com/microsoft/varuna)
-- [SageMaker](https://arxiv.org/abs/2111.05972)
+- [SageMaker](https://huggingface.co/papers/2111.05972)
- [OSLO](https://github.com/tunib-ai/oslo)
🤗 Transformersの状況: まだ実装されていません。PPとTPがないため。
@@ -431,7 +431,7 @@ ZeROステージ3も同様の理由で適していません - より多くのノ
重要な論文:
-- [DeepSpeedとMegatronを使用したMegatron-Turing NLG 530Bのトレーニング](https://arxiv.org/abs/2201.11990)
+- [DeepSpeedとMegatronを使用したMegatron-Turing NLG 530Bのトレーニング](https://huggingface.co/papers/2201.11990)
🤗 Transformersの状況: まだ実装されていません。PPとTPがないため。
@@ -440,7 +440,7 @@ ZeROステージ3も同様の理由で適していません - より多くのノ
[FlexFlow](https://github.com/flexflow/FlexFlow)は、わずかに異なるアプローチで並列化の問題を解決します。
-論文: [Zhihao Jia、Matei Zaharia、Alex Aikenによる "Deep Neural Networksのデータとモデルの並列化を超えて"](https://arxiv.org/abs/1807.05358)
+論文: [Zhihao Jia、Matei Zaharia、Alex Aikenによる "Deep Neural Networksのデータとモデルの並列化を超えて"](https://huggingface.co/papers/1807.05358)
FlexFlowは、サンプル-オペレータ-属性-パラメータの4D並列化を行います。
diff --git a/docs/source/ja/perf_train_gpu_one.md b/docs/source/ja/perf_train_gpu_one.md
index c45737370a..1a82ebb60d 100644
--- a/docs/source/ja/perf_train_gpu_one.md
+++ b/docs/source/ja/perf_train_gpu_one.md
@@ -406,16 +406,16 @@ PyTorchの[pipとcondaビルド](https://pytorch.org/get-started/locally/#start-
関連するほとんどの論文および実装はTensorflow/TPUを中心に構築されています。
-- [GShard: Conditional Computation and Automatic Shardingを活用した巨大モデルのスケーリング](https://arxiv.org/abs/2006.16668)
-- [Switch Transformers: シンプルで効率的なスパース性を備えたトリリオンパラメータモデルへのスケーリング](https://arxiv.org/abs/2101.03961)
+- [GShard: Conditional Computation and Automatic Shardingを活用した巨大モデルのスケーリング](https://huggingface.co/papers/2006.16668)
+- [Switch Transformers: シンプルで効率的なスパース性を備えたトリリオンパラメータモデルへのスケーリング](https://huggingface.co/papers/2101.03961)
- [GLaM: Generalist Language Model (GLaM)](https://ai.googleblog.com/2021/12/more-efficient-in-context-learning-with.html)
-PytorchにはDeepSpeedが構築したものもあります: [DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale](https://arxiv.org/abs/2201.05596)、[Mixture of Experts](https://www.deepspeed.ai/tutorials/mixture-of-experts/) - ブログ記事: [1](https://www.microsoft.com/en-us/research/blog/deepspeed-powers-8x-larger-moe-model-training-with-high-performance/)、[2](https://www.microsoft.com/en-us/research/publication/scalable-and-efficient-moe-training-for-multitask-multilingual-models/)、大規模なTransformerベースの自然言語生成モデルの具体的な展開については、[ブログ記事](https://www.deepspeed.ai/2021/12/09/deepspeed-moe-nlg.html)、[Megatron-Deepspeedブランチ](https://github.com/microsoft/Megatron-DeepSpeed/tree/moe-training)を参照してください。
+PytorchにはDeepSpeedが構築したものもあります: [DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale](https://huggingface.co/papers/2201.05596)、[Mixture of Experts](https://www.deepspeed.ai/tutorials/mixture-of-experts/) - ブログ記事: [1](https://www.microsoft.com/en-us/research/blog/deepspeed-powers-8x-larger-moe-model-training-with-high-performance/)、[2](https://www.microsoft.com/en-us/research/publication/scalable-and-efficient-moe-training-for-multitask-multilingual-models/)、大規模なTransformerベースの自然言語生成モデルの具体的な展開については、[ブログ記事](https://www.deepspeed.ai/2021/12/09/deepspeed-moe-nlg.html)、[Megatron-Deepspeedブランチ](https://github.com/microsoft/Megatron-DeepSpeed/tree/moe-training)を参照してください。
## PyTorchネイティブアテンションとFlash Attentionの使用
-PyTorch 2.0では、ネイティブの[`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html)(SDPA)がリリースされ、[メモリ効率の高いアテンション](https://arxiv.org/abs/2112.05682)や[フラッシュアテンション](https://arxiv.org/abs/2205.14135)などの融合されたGPUカーネルの使用を可能にします。
+PyTorch 2.0では、ネイティブの[`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html)(SDPA)がリリースされ、[メモリ効率の高いアテンション](https://huggingface.co/papers/2112.05682)や[フラッシュアテンション](https://huggingface.co/papers/2205.14135)などの融合されたGPUカーネルの使用を可能にします。
[`optimum`](https://github.com/huggingface/optimum)パッケージをインストールした後、関連する内部モジュールを置き換えて、PyTorchのネイティブアテンションを使用できます。以下のように設定します:
diff --git a/docs/source/ja/tasks/knowledge_distillation_for_image_classification.md b/docs/source/ja/tasks/knowledge_distillation_for_image_classification.md
index 1079121c60..b8d4a569b1 100644
--- a/docs/source/ja/tasks/knowledge_distillation_for_image_classification.md
+++ b/docs/source/ja/tasks/knowledge_distillation_for_image_classification.md
@@ -17,7 +17,7 @@ rendered properly in your Markdown viewer.
[[open-in-colab]]
-知識の蒸留は、より大規模で複雑なモデル (教師) からより小規模で単純なモデル (生徒) に知識を伝達するために使用される手法です。あるモデルから別のモデルに知識を抽出するには、特定のタスク (この場合は画像分類) でトレーニングされた事前トレーニング済み教師モデルを取得し、画像分類でトレーニングされる生徒モデルをランダムに初期化します。次に、学生モデルをトレーニングして、その出力と教師の出力の差を最小限に抑え、動作を模倣します。これは [Distilling the Knowledge in a Neural Network by Hinton et al](https://arxiv.org/abs/1503.02531) で最初に導入されました。このガイドでは、タスク固有の知識の蒸留を行います。これには [Beans データセット](https://huggingface.co/datasets/beans) を使用します。
+知識の蒸留は、より大規模で複雑なモデル (教師) からより小規模で単純なモデル (生徒) に知識を伝達するために使用される手法です。あるモデルから別のモデルに知識を抽出するには、特定のタスク (この場合は画像分類) でトレーニングされた事前トレーニング済み教師モデルを取得し、画像分類でトレーニングされる生徒モデルをランダムに初期化します。次に、学生モデルをトレーニングして、その出力と教師の出力の差を最小限に抑え、動作を模倣します。これは [Distilling the Knowledge in a Neural Network by Hinton et al](https://huggingface.co/papers/1503.02531) で最初に導入されました。このガイドでは、タスク固有の知識の蒸留を行います。これには [Beans データセット](https://huggingface.co/datasets/beans) を使用します。
このガイドでは、[微調整された ViT モデル](https://huggingface.co/merve/vit-mobilenet-beans-224) (教師モデル) を抽出して [MobileNet](https://huggingface.co/google/mobilenet_v2_1.4_224) (学生モデル) 🤗 Transformers の [Trainer API](https://huggingface.co/docs/transformers/en/main_classes/trainer#trainer) を使用します。
diff --git a/docs/source/ja/tasks/video_classification.md b/docs/source/ja/tasks/video_classification.md
index 741356a6f5..e7e7803c94 100644
--- a/docs/source/ja/tasks/video_classification.md
+++ b/docs/source/ja/tasks/video_classification.md
@@ -386,7 +386,7 @@ def compute_metrics(eval_pred):
**評価に関する注意事項**:
-[VideoMAE 論文](https://arxiv.org/abs/2203.12602) では、著者は次の評価戦略を使用しています。彼らはテスト ビデオからのいくつかのクリップでモデルを評価し、それらのクリップにさまざまなクロップを適用して、合計スコアを報告します。ただし、単純さと簡潔さを保つために、このチュートリアルではそれを考慮しません。
+[VideoMAE 論文](https://huggingface.co/papers/2203.12602) では、著者は次の評価戦略を使用しています。彼らはテスト ビデオからのいくつかのクリップでモデルを評価し、それらのクリップにさまざまなクロップを適用して、合計スコアを報告します。ただし、単純さと簡潔さを保つために、このチュートリアルではそれを考慮しません。
また、サンプルをまとめてバッチ処理するために使用される `collate_fn` を定義します。各バッチは、`pixel_values` と `labels` という 2 つのキーで構成されます。
diff --git a/docs/source/ja/tasks_explained.md b/docs/source/ja/tasks_explained.md
index bdfb3ec0ac..f619c2b220 100644
--- a/docs/source/ja/tasks_explained.md
+++ b/docs/source/ja/tasks_explained.md
@@ -121,7 +121,7 @@ ViTが導入した主な変更点は、画像をTransformerに供給する方法
-[Convolution Arithmetic for Deep Learning](https://arxiv.org/abs/1603.07285) からの基本的なパディングやストライドのない畳み込み。
+[Convolution Arithmetic for Deep Learning](https://huggingface.co/papers/1603.07285) からの基本的なパディングやストライドのない畳み込み。
この出力を別の畳み込み層に供給し、各連続した層ごとに、ネットワークはホットドッグやロケットのようなより複雑で抽象的なものを学習します。畳み込み層の間には、特徴の次元を削減し、特徴の位置の変動に対してモデルをより堅牢にするためにプーリング層を追加するのが一般的です。
diff --git a/docs/source/ja/tokenizer_summary.md b/docs/source/ja/tokenizer_summary.md
index 448ad9c871..47afc1f2e0 100644
--- a/docs/source/ja/tokenizer_summary.md
+++ b/docs/source/ja/tokenizer_summary.md
@@ -101,7 +101,7 @@ rendered properly in your Markdown viewer.
### Byte-Pair Encoding(BPE)
-Byte-Pair Encoding(BPE)は、[Neural Machine Translation of Rare Words with Subword Units(Sennrich et al., 2015)](https://arxiv.org/abs/1508.07909)で導入されました。BPEは、トレーニングデータを単語に分割するプリトークナイザに依存しています。プリトークナイゼーションは、空白のトークナイゼーションなど、非常に単純なものであることがあります。例えば、[GPT-2](model_doc/gpt2)、[RoBERTa](model_doc/roberta)です。より高度なプリトークナイゼーションには、ルールベースのトークナイゼーション([XLM](model_doc/xlm)、[FlauBERT](model_doc/flaubert)などが大部分の言語にMosesを使用)や、[GPT](model_doc/gpt)(Spacyとftfyを使用してトレーニングコーパス内の各単語の頻度を数える)などが含まれます。
+Byte-Pair Encoding(BPE)は、[Neural Machine Translation of Rare Words with Subword Units(Sennrich et al., 2015)](https://huggingface.co/papers/1508.07909)で導入されました。BPEは、トレーニングデータを単語に分割するプリトークナイザに依存しています。プリトークナイゼーションは、空白のトークナイゼーションなど、非常に単純なものであることがあります。例えば、[GPT-2](model_doc/gpt2)、[RoBERTa](model_doc/roberta)です。より高度なプリトークナイゼーションには、ルールベースのトークナイゼーション([XLM](model_doc/xlm)、[FlauBERT](model_doc/flaubert)などが大部分の言語にMosesを使用)や、[GPT](model_doc/gpt)(Spacyとftfyを使用してトレーニングコーパス内の各単語の頻度を数える)などが含まれます。
プリトークナイゼーションの後、一意の単語セットが作成され、各単語がトレーニングデータで出現した頻度が決定されます。次に、BPEはベース語彙を作成し、ベース語彙の二つのシンボルから新しいシンボルを形成するためのマージルールを学習します。このプロセスは、語彙が所望の語彙サイズに達するまで続けられます。なお、所望の語彙サイズはトークナイザをトレーニングする前に定義するハイパーパラメータであることに注意してください。
@@ -151,7 +151,7 @@ WordPieceは、[BERT](model_doc/bert)、[DistilBERT](model_doc/distilbert)、お
### Unigram
-Unigramは、[Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates (Kudo, 2018)](https://arxiv.org/pdf/1804.10959.pdf) で導入されたサブワードトークナイゼーションアルゴリズムです。 BPEやWordPieceとは異なり、Unigramはベースボキャブラリを多数のシンボルで初期化し、各シンボルを削減してより小さなボキャブラリを取得します。 ベースボキャブラリは、事前にトークン化されたすべての単語と最も一般的な部分文字列に対応する可能性があります。 Unigramはtransformersのモデルの直接の使用には適していませんが、[SentencePiece](#sentencepiece)と組み合わせて使用されます。
+Unigramは、[Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates (Kudo, 2018)](https://huggingface.co/papers/1804.10959) で導入されたサブワードトークナイゼーションアルゴリズムです。 BPEやWordPieceとは異なり、Unigramはベースボキャブラリを多数のシンボルで初期化し、各シンボルを削減してより小さなボキャブラリを取得します。 ベースボキャブラリは、事前にトークン化されたすべての単語と最も一般的な部分文字列に対応する可能性があります。 Unigramはtransformersのモデルの直接の使用には適していませんが、[SentencePiece](#sentencepiece)と組み合わせて使用されます。
各トレーニングステップで、Unigramアルゴリズムは現在のボキャブラリとユニグラム言語モデルを使用してトレーニングデータ上の損失(通常は対数尤度として定義)を定義します。その後、ボキャブラリ内の各シンボルについて、そのシンボルがボキャブラリから削除された場合に全体の損失がどれだけ増加するかを計算します。 Unigramは、損失の増加が最も低いp(通常は10%または20%)パーセントのシンボルを削除します。つまり、トレーニングデータ全体の損失に最も影響を与えない、最も損失の少ないシンボルを削除します。 このプロセスは、ボキャブラリが望ましいサイズに達するまで繰り返されます。 Unigramアルゴリズムは常にベース文字を保持するため、任意の単語をトークン化できます。
@@ -172,7 +172,7 @@ $$\mathcal{L} = -\sum_{i=1}^{N} \log \left ( \sum_{x \in S(x_{i})} p(x) \right )
### SentencePiece
-これまでに説明したすべてのトークン化アルゴリズムには同じ問題があります。それは、入力テキストが単語を区切るためにスペースを使用していると仮定しているということです。しかし、すべての言語が単語を区切るためにスペースを使用しているわけではありません。この問題を一般的に解決するための1つの方法は、言語固有の前トークナイザーを使用することです(例:[XLM](model_doc/xlm)は特定の中国語、日本語、およびタイ語の前トークナイザーを使用しています)。より一般的にこの問題を解決するために、[SentencePiece:ニューラルテキスト処理のためのシンプルで言語非依存のサブワードトークナイザーおよびデトークナイザー(Kudo et al.、2018)](https://arxiv.org/pdf/1808.06226.pdf) は、入力を生の入力ストリームとして扱い、スペースを使用する文字のセットに含めます。それからBPEまたはunigramアルゴリズムを使用して適切な語彙を構築します。
+これまでに説明したすべてのトークン化アルゴリズムには同じ問題があります。それは、入力テキストが単語を区切るためにスペースを使用していると仮定しているということです。しかし、すべての言語が単語を区切るためにスペースを使用しているわけではありません。この問題を一般的に解決するための1つの方法は、言語固有の前トークナイザーを使用することです(例:[XLM](model_doc/xlm)は特定の中国語、日本語、およびタイ語の前トークナイザーを使用しています)。より一般的にこの問題を解決するために、[SentencePiece:ニューラルテキスト処理のためのシンプルで言語非依存のサブワードトークナイザーおよびデトークナイザー(Kudo et al.、2018)](https://huggingface.co/papers/1808.06226) は、入力を生の入力ストリームとして扱い、スペースを使用する文字のセットに含めます。それからBPEまたはunigramアルゴリズムを使用して適切な語彙を構築します。
たとえば、[`XLNetTokenizer`]はSentencePieceを使用しており、そのために前述の例で`"▁"`文字が語彙に含まれていました。SentencePieceを使用したデコードは非常に簡単で、すべてのトークンを単純に連結し、`"▁"`はスペースに置換されます。
diff --git a/docs/source/ko/bertology.md b/docs/source/ko/bertology.md
index 1f69a03817..37e66402d6 100644
--- a/docs/source/ko/bertology.md
+++ b/docs/source/ko/bertology.md
@@ -21,21 +21,21 @@ BERT와 같은 대규모 트랜스포머의 내부 동작을 조사하는 연구
- BERT는 고전적인 NLP 파이프라인의 재발견 - Ian Tenney, Dipanjan Das, Ellie Pavlick:
- https://arxiv.org/abs/1905.05950
+ https://huggingface.co/papers/1905.05950
- 16개의 헤드가 정말로 1개보다 나은가? - Paul Michel, Omer Levy, Graham Neubig:
- https://arxiv.org/abs/1905.10650
+ https://huggingface.co/papers/1905.10650
- BERT는 무엇을 보는가? BERT의 어텐션 분석 - Kevin Clark, Urvashi Khandelwal, Omer Levy, Christopher D. Manning:
- https://arxiv.org/abs/1906.04341
+ https://huggingface.co/papers/1906.04341
- CAT-probing: 프로그래밍 언어에 대해 사전훈련된 모델이 어떻게 코드 구조를 보는지 알아보기 위한 메트릭 기반 접근 방법:
- https://arxiv.org/abs/2210.04633
+ https://huggingface.co/papers/2210.04633
우리는 이 새로운 연구 분야의 발전을 돕기 위해, BERT/GPT/GPT-2 모델에 내부 표현을 살펴볼 수 있는 몇 가지 기능을 추가했습니다.
이 기능들은 주로 Paul Michel의 훌륭한 작업을 참고하여 개발되었습니다
-(https://arxiv.org/abs/1905.10650):
+(https://huggingface.co/papers/1905.10650):
- BERT/GPT/GPT-2의 모든 은닉 상태에 접근하기,
- BERT/GPT/GPT-2의 각 헤드의 모든 어텐션 가중치에 접근하기,
-- 헤드의 출력 값과 그래디언트를 검색하여 헤드 중요도 점수를 계산하고 https://arxiv.org/abs/1905.10650에서 설명된 대로 헤드를 제거하는 기능을 제공합니다.
+- 헤드의 출력 값과 그래디언트를 검색하여 헤드 중요도 점수를 계산하고 https://huggingface.co/papers/1905.10650에서 설명된 대로 헤드를 제거하는 기능을 제공합니다.
이러한 기능들을 이해하고 직접 사용해볼 수 있도록 [bertology.py](https://github.com/huggingface/transformers-research-projects/tree/main/bertology/run_bertology.py) 예제 스크립트를 추가했습니다. 이 예제 스크립트에서는 GLUE에 대해 사전훈련된 모델에서 정보를 추출하고 모델을 가지치기(prune)해봅니다.
diff --git a/docs/source/ko/generation_strategies.md b/docs/source/ko/generation_strategies.md
index 05f81c008b..a42d067456 100644
--- a/docs/source/ko/generation_strategies.md
+++ b/docs/source/ko/generation_strategies.md
@@ -167,7 +167,7 @@ An increasing sequence: one, two, three, four, five, six, seven, eight, nine, te
### 대조 탐색(Contrastive search)[[contrastive-search]]
-2022년 논문 [A Contrastive Framework for Neural Text Generation](https://arxiv.org/abs/2202.06417)에서 제안된 대조 탐색 디코딩 전략은 반복되지 않으면서도 일관된 긴 출력을 생성하는 데 있어 우수한 결과를 보였습니다. 대조 탐색이 작동하는 방식을 알아보려면 [이 블로그 포스트](https://huggingface.co/blog/introducing-csearch)를 확인하세요. 대조 탐색의 동작을 가능하게 하고 제어하는 두 가지 주요 매개변수는 `penalty_alpha`와 `top_k`입니다:
+2022년 논문 [A Contrastive Framework for Neural Text Generation](https://huggingface.co/papers/2202.06417)에서 제안된 대조 탐색 디코딩 전략은 반복되지 않으면서도 일관된 긴 출력을 생성하는 데 있어 우수한 결과를 보였습니다. 대조 탐색이 작동하는 방식을 알아보려면 [이 블로그 포스트](https://huggingface.co/blog/introducing-csearch)를 확인하세요. 대조 탐색의 동작을 가능하게 하고 제어하는 두 가지 주요 매개변수는 `penalty_alpha`와 `top_k`입니다:
```python
>>> from transformers import AutoTokenizer, AutoModelForCausalLM
@@ -255,7 +255,7 @@ time."\n\nHe added: "I am very proud of the work I have been able to do in the l
### 다양한 빔 탐색 디코딩(Diverse beam search decoding)[[diverse-beam-search-decoding]]
-다양한 빔 탐색(Decoding) 전략은 선택할 수 있는 더 다양한 빔 시퀀스 집합을 생성할 수 있게 해주는 빔 탐색 전략의 확장입니다. 이 방법은 어떻게 작동하는지 알아보려면, [다양한 빔 탐색: 신경 시퀀스 모델에서 다양한 솔루션 디코딩하기](https://arxiv.org/pdf/1610.02424.pdf)를 참조하세요. 이 접근 방식은 세 가지 주요 매개변수를 가지고 있습니다: `num_beams`, `num_beam_groups`, 그리고 `diversity_penalty`. 다양성 패널티는 그룹 간에 출력이 서로 다르게 하기 위한 것이며, 각 그룹 내에서 빔 탐색이 사용됩니다.
+다양한 빔 탐색(Decoding) 전략은 선택할 수 있는 더 다양한 빔 시퀀스 집합을 생성할 수 있게 해주는 빔 탐색 전략의 확장입니다. 이 방법은 어떻게 작동하는지 알아보려면, [다양한 빔 탐색: 신경 시퀀스 모델에서 다양한 솔루션 디코딩하기](https://huggingface.co/papers/1610.02424)를 참조하세요. 이 접근 방식은 세 가지 주요 매개변수를 가지고 있습니다: `num_beams`, `num_beam_groups`, 그리고 `diversity_penalty`. 다양성 패널티는 그룹 간에 출력이 서로 다르게 하기 위한 것이며, 각 그룹 내에서 빔 탐색이 사용됩니다.
```python
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
@@ -293,7 +293,7 @@ culture, and they allow us to design the'
### 추론 디코딩(Speculative Decoding)[[speculative-decoding]]
-추론 디코딩(보조 디코딩(assisted decoding)으로도 알려짐)은 동일한 토크나이저를 사용하는 훨씬 작은 보조 모델을 활용하여 몇 가지 후보 토큰을 생성하는 상위 모델의 디코딩 전략을 수정한 것입니다. 주 모델은 단일 전방 통과로 후보 토큰을 검증함으로써 디코딩 과정을 가속화합니다. `do_sample=True`일 경우, [추론 디코딩 논문](https://arxiv.org/pdf/2211.17192.pdf)에 소개된 토큰 검증과 재샘플링 방식이 사용됩니다.
+추론 디코딩(보조 디코딩(assisted decoding)으로도 알려짐)은 동일한 토크나이저를 사용하는 훨씬 작은 보조 모델을 활용하여 몇 가지 후보 토큰을 생성하는 상위 모델의 디코딩 전략을 수정한 것입니다. 주 모델은 단일 전방 통과로 후보 토큰을 검증함으로써 디코딩 과정을 가속화합니다. `do_sample=True`일 경우, [추론 디코딩 논문](https://huggingface.co/papers/2211.17192)에 소개된 토큰 검증과 재샘플링 방식이 사용됩니다.
현재, 탐욕 검색(greedy search)과 샘플링만이 지원되는 보조 디코딩(assisted decoding) 기능을 통해, 보조 디코딩은 배치 입력을 지원하지 않습니다. 보조 디코딩에 대해 더 알고 싶다면, [이 블로그 포스트](https://huggingface.co/blog/assisted-generation)를 확인해 주세요.
diff --git a/docs/source/ko/index.md b/docs/source/ko/index.md
index bd95cbc0ab..266352500a 100644
--- a/docs/source/ko/index.md
+++ b/docs/source/ko/index.md
@@ -53,163 +53,163 @@ rendered properly in your Markdown viewer.
-1. **[ALBERT](model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
-1. **[BART](model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
-1. **[BARThez](model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
-1. **[BARTpho](model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
-1. **[BEiT](model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
-1. **[BERT](model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
-1. **[BERT For Sequence Generation](model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[ALBERT](model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://huggingface.co/papers/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
+1. **[BART](model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://huggingface.co/papers/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
+1. **[BARThez](model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://huggingface.co/papers/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
+1. **[BARTpho](model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://huggingface.co/papers/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
+1. **[BEiT](model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://huggingface.co/papers/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
+1. **[BERT](model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://huggingface.co/papers/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
+1. **[BERT For Sequence Generation](model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://huggingface.co/papers/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
1. **[BERTweet](model_doc/bertweet)** (from VinAI Research) released with the paper [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) by Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen.
-1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
-1. **[BigBird-RoBERTa](model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
-1. **[Blenderbot](model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
-1. **[BlenderbotSmall](model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://huggingface.co/papers/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[BigBird-RoBERTa](model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://huggingface.co/papers/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[Blenderbot](model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://huggingface.co/papers/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BlenderbotSmall](model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://huggingface.co/papers/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
1. **[BLOOM](model_doc/bloom)** (from BigScience workshop) released by the [BigScience Workshop](https://bigscience.huggingface.co/).
-1. **[BORT](model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
-1. **[ByT5](model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
-1. **[CamemBERT](model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
-1. **[CANINE](model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
-1. **[CLIP](model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
-1. **[CLIPSeg](model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
-1. **[CodeGen](model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
-1. **[Conditional DETR](model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
-1. **[ConvBERT](model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
-1. **[ConvNeXT](model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
-1. **[ConvNeXTV2](model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
-1. **[CPM](model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
-1. **[CTRL](model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
-1. **[CvT](model_doc/cvt)** (from Microsoft) released with the paper [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
-1. **[Data2Vec](model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
-1. **[DeBERTa](model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
-1. **[DeBERTa-v2](model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
-1. **[Decision Transformer](model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
-1. **[Deformable DETR](model_doc/deformable_detr)** (from SenseTime Research) released with the paper [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
-1. **[DeiT](model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
-1. **[DETR](model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
-1. **[DialoGPT](model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
-1. **[DistilBERT](model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers-research-projects/tree/main/distillation) and a German version of DistilBERT.
-1. **[DiT](model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
-1. **[Donut](model_doc/donut)** (from NAVER), released together with the paper [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) by Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park.
-1. **[DPR](model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
-1. **[DPT](master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
-1. **[EfficientNet](model_doc/efficientnet)** (from Google Research) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan and Quoc V. Le.
-1. **[ELECTRA](model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
-1. **[EncoderDecoder](model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
-1. **[ERNIE](model_doc/ernie)** (from Baidu) released with the paper [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223) by Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu.
+1. **[BORT](model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://huggingface.co/papers/2010.10499) by Adrian de Wynter and Daniel J. Perry.
+1. **[ByT5](model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://huggingface.co/papers/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
+1. **[CamemBERT](model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://huggingface.co/papers/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
+1. **[CANINE](model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://huggingface.co/papers/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
+1. **[CLIP](model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://huggingface.co/papers/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
+1. **[CLIPSeg](model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://huggingface.co/papers/2112.10003) by Timo Lüddecke and Alexander Ecker.
+1. **[CodeGen](model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://huggingface.co/papers/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
+1. **[Conditional DETR](model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://huggingface.co/papers/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
+1. **[ConvBERT](model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://huggingface.co/papers/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
+1. **[ConvNeXT](model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://huggingface.co/papers/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
+1. **[ConvNeXTV2](model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://huggingface.co/papers/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
+1. **[CPM](model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://huggingface.co/papers/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
+1. **[CTRL](model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://huggingface.co/papers/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
+1. **[CvT](model_doc/cvt)** (from Microsoft) released with the paper [CvT: Introducing Convolutions to Vision Transformers](https://huggingface.co/papers/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
+1. **[Data2Vec](model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://huggingface.co/papers/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
+1. **[DeBERTa](model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://huggingface.co/papers/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[DeBERTa-v2](model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://huggingface.co/papers/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[Decision Transformer](model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://huggingface.co/papers/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
+1. **[Deformable DETR](model_doc/deformable_detr)** (from SenseTime Research) released with the paper [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://huggingface.co/papers/2010.04159) by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
+1. **[DeiT](model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://huggingface.co/papers/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
+1. **[DETR](model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://huggingface.co/papers/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
+1. **[DialoGPT](model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://huggingface.co/papers/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
+1. **[DistilBERT](model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://huggingface.co/papers/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers-research-projects/tree/main/distillation) and a German version of DistilBERT.
+1. **[DiT](model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://huggingface.co/papers/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
+1. **[Donut](model_doc/donut)** (from NAVER), released together with the paper [OCR-free Document Understanding Transformer](https://huggingface.co/papers/2111.15664) by Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park.
+1. **[DPR](model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://huggingface.co/papers/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
+1. **[DPT](master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://huggingface.co/papers/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
+1. **[EfficientNet](model_doc/efficientnet)** (from Google Research) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://huggingface.co/papers/1905.11946) by Mingxing Tan and Quoc V. Le.
+1. **[ELECTRA](model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://huggingface.co/papers/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
+1. **[EncoderDecoder](model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://huggingface.co/papers/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[ERNIE](model_doc/ernie)** (from Baidu) released with the paper [ERNIE: Enhanced Representation through Knowledge Integration](https://huggingface.co/papers/1904.09223) by Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu.
1. **[ESM](model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2 and ESMFold** were released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
1. **[FLAN-T5](model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
-1. **[FlauBERT](model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
-1. **[FLAVA](model_doc/flava)** (from Facebook AI) released with the paper [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela.
-1. **[FNet](model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
-1. **[Funnel Transformer](model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
-1. **[GLPN](model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
+1. **[FlauBERT](model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://huggingface.co/papers/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
+1. **[FLAVA](model_doc/flava)** (from Facebook AI) released with the paper [FLAVA: A Foundational Language And Vision Alignment Model](https://huggingface.co/papers/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela.
+1. **[FNet](model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://huggingface.co/papers/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
+1. **[Funnel Transformer](model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://huggingface.co/papers/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
+1. **[GLPN](model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://huggingface.co/papers/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
1. **[GPT](model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
1. **[GPT Neo](model_doc/gpt_neo)** (from EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
-1. **[GPT NeoX](model_doc/gpt_neox)** (from EleutherAI) released with the paper [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745) by Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
+1. **[GPT NeoX](model_doc/gpt_neox)** (from EleutherAI) released with the paper [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://huggingface.co/papers/2204.06745) by Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
1. **[GPT NeoX Japanese](model_doc/gpt_neox_japanese)** (from ABEJA) released by Shinya Otani, Takayoshi Makabe, Anuj Arora, and Kyo Hattori.
1. **[GPT-2](model_doc/gpt2)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://openai.com/research/better-language-models/) by Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever.
1. **[GPT-J](model_doc/gptj)** (from EleutherAI) released in the repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
1. **[GPTSAN-japanese](model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
-1. **[GroupViT](model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
-1. **[Hubert](model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
-1. **[I-BERT](model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
+1. **[GroupViT](model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://huggingface.co/papers/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
+1. **[Hubert](model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://huggingface.co/papers/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
+1. **[I-BERT](model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://huggingface.co/papers/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
1. **[ImageGPT](model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
-1. **[Jukebox](model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
-1. **[LayoutLM](model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
-1. **[LayoutLMv2](model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
-1. **[LayoutLMv3](model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
-1. **[LayoutXLM](model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
-1. **[LED](model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
-1. **[LeViT](model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
-1. **[LiLT](model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
-1. **[Longformer](model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
-1. **[LongT5](model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
-1. **[LUKE](model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
-1. **[LXMERT](model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
-1. **[M-CTC-T](model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
-1. **[M2M100](model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
+1. **[Jukebox](model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://huggingface.co/papers/2005.00341) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
+1. **[LayoutLM](model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://huggingface.co/papers/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
+1. **[LayoutLMv2](model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://huggingface.co/papers/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
+1. **[LayoutLMv3](model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://huggingface.co/papers/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
+1. **[LayoutXLM](model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://huggingface.co/papers/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
+1. **[LED](model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://huggingface.co/papers/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LeViT](model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://huggingface.co/papers/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
+1. **[LiLT](model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://huggingface.co/papers/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
+1. **[Longformer](model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://huggingface.co/papers/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LongT5](model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://huggingface.co/papers/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
+1. **[LUKE](model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://huggingface.co/papers/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
+1. **[LXMERT](model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://huggingface.co/papers/1908.07490) by Hao Tan and Mohit Bansal.
+1. **[M-CTC-T](model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://huggingface.co/papers/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
+1. **[M2M100](model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://huggingface.co/papers/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
1. **[MarianMT](model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
-1. **[MarkupLM](model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
-1. **[Mask2Former](model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
-1. **[MaskFormer](model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
-1. **[mBART](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
-1. **[mBART-50](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
-1. **[Megatron-BERT](model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
-1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
-1. **[mLUKE](model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
-1. **[MobileBERT](model_doc/mobilebert)** (from CMU/Google Brain) released with the paper [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou.
-1. **[MobileViT](model_doc/mobilevit)** (from Apple) released with the paper [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari.
-1. **[MPNet](model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
-1. **[MT5](model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
-1. **[MVP](model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
-1. **[Nezha](model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
-1. **[NLLB](model_doc/nllb)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
-1. **[Nyströmformer](model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
-1. **[OneFormer](model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
-1. **[OPT](master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
-1. **[OWL-ViT](model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
-1. **[Pegasus](model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
-1. **[PEGASUS-X](model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao, and Peter J. Liu.
-1. **[Perceiver IO](model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
+1. **[MarkupLM](model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://huggingface.co/papers/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
+1. **[Mask2Former](model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://huggingface.co/papers/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
+1. **[MaskFormer](model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://huggingface.co/papers/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
+1. **[mBART](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://huggingface.co/papers/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
+1. **[mBART-50](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://huggingface.co/papers/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
+1. **[Megatron-BERT](model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://huggingface.co/papers/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://huggingface.co/papers/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[mLUKE](model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://huggingface.co/papers/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
+1. **[MobileBERT](model_doc/mobilebert)** (from CMU/Google Brain) released with the paper [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://huggingface.co/papers/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou.
+1. **[MobileViT](model_doc/mobilevit)** (from Apple) released with the paper [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://huggingface.co/papers/2110.02178) by Sachin Mehta and Mohammad Rastegari.
+1. **[MPNet](model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://huggingface.co/papers/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
+1. **[MT5](model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://huggingface.co/papers/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
+1. **[MVP](model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://huggingface.co/papers/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
+1. **[Nezha](model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://huggingface.co/papers/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
+1. **[NLLB](model_doc/nllb)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://huggingface.co/papers/2207.04672) by the NLLB team.
+1. **[Nyströmformer](model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://huggingface.co/papers/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
+1. **[OneFormer](model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://huggingface.co/papers/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
+1. **[OPT](master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://huggingface.co/papers/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
+1. **[OWL-ViT](model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://huggingface.co/papers/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
+1. **[Pegasus](model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://huggingface.co/papers/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
+1. **[PEGASUS-X](model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://huggingface.co/papers/2208.04347) by Jason Phang, Yao Zhao, and Peter J. Liu.
+1. **[Perceiver IO](model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://huggingface.co/papers/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
1. **[PhoBERT](model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
-1. **[PLBart](model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
-1. **[PoolFormer](model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
-1. **[ProphetNet](model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
-1. **[QDQBert](model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
-1. **[RAG](model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
-1. **[REALM](model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
-1. **[Reformer](model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
-1. **[RegNet](model_doc/regnet)** (from META Platforms) released with the paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
-1. **[RemBERT](model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
-1. **[ResNet](model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
-1. **[RoBERTa](model_doc/roberta)** (from Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
+1. **[PLBart](model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://huggingface.co/papers/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
+1. **[PoolFormer](model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://huggingface.co/papers/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
+1. **[ProphetNet](model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://huggingface.co/papers/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[QDQBert](model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://huggingface.co/papers/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
+1. **[RAG](model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://huggingface.co/papers/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
+1. **[REALM](model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://huggingface.co/papers/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
+1. **[Reformer](model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://huggingface.co/papers/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
+1. **[RegNet](model_doc/regnet)** (from META Platforms) released with the paper [Designing Network Design Space](https://huggingface.co/papers/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
+1. **[RemBERT](model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://huggingface.co/papers/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
+1. **[ResNet](model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://huggingface.co/papers/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
+1. **[RoBERTa](model_doc/roberta)** (from Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://huggingface.co/papers/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
1. **[RoCBert](model_doc/roc_bert)** (from WeChatAI) released with the paper [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
-1. **[RoFormer](model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
-1. **[SegFormer](model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
-1. **[SEW](model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
-1. **[SEW-D](model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
-1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
-1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
-1. **[Splinter](model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
-1. **[SqueezeBERT](model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
-1. **[Swin Transformer](model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
-1. **[Swin Transformer V2](model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
-1. **[T5](model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
+1. **[RoFormer](model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://huggingface.co/papers/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
+1. **[SegFormer](model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://huggingface.co/papers/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
+1. **[SEW](model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://huggingface.co/papers/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SEW-D](model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://huggingface.co/papers/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://huggingface.co/papers/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
+1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://huggingface.co/papers/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
+1. **[Splinter](model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://huggingface.co/papers/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
+1. **[SqueezeBERT](model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://huggingface.co/papers/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
+1. **[Swin Transformer](model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://huggingface.co/papers/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
+1. **[Swin Transformer V2](model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://huggingface.co/papers/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
+1. **[T5](model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://huggingface.co/papers/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[T5v1.1](model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
-1. **[Table Transformer](model_doc/table-transformer)** (from Microsoft Research) released with the paper [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061) by Brandon Smock, Rohith Pesala, Robin Abraham.
-1. **[TAPAS](model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
-1. **[TAPEX](model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
+1. **[Table Transformer](model_doc/table-transformer)** (from Microsoft Research) released with the paper [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://huggingface.co/papers/2110.00061) by Brandon Smock, Rohith Pesala, Robin Abraham.
+1. **[TAPAS](model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://huggingface.co/papers/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
+1. **[TAPEX](model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://huggingface.co/papers/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
1. **[Time Series Transformer](model_doc/time_series_transformer)** (from HuggingFace).
-1. **[Trajectory Transformer](model_doc/trajectory_transformers)** (from the University of California at Berkeley) released with the paper [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine
-1. **[Transformer-XL](model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
-1. **[TrOCR](model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
-1. **[UL2](model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
-1. **[UniSpeech](model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
-1. **[UniSpeechSat](model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
-1. **[VAN](model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
-1. **[VideoMAE](model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
-1. **[ViLT](model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
-1. **[Vision Transformer (ViT)](model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
-1. **[VisualBERT](model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
-1. **[ViTMAE](model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
-1. **[ViTMSN](model_doc/vit_msn)** (from Meta AI) released with the paper [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas.
-1. **[Wav2Vec2](model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
-1. **[Wav2Vec2-Conformer](model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
-1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
-1. **[WavLM](model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
+1. **[Trajectory Transformer](model_doc/trajectory_transformers)** (from the University of California at Berkeley) released with the paper [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://huggingface.co/papers/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine
+1. **[Transformer-XL](model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://huggingface.co/papers/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
+1. **[TrOCR](model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://huggingface.co/papers/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
+1. **[UL2](model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://huggingface.co/papers/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
+1. **[UniSpeech](model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://huggingface.co/papers/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
+1. **[UniSpeechSat](model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://huggingface.co/papers/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
+1. **[VAN](model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://huggingface.co/papers/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
+1. **[VideoMAE](model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://huggingface.co/papers/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
+1. **[ViLT](model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://huggingface.co/papers/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
+1. **[Vision Transformer (ViT)](model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://huggingface.co/papers/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
+1. **[VisualBERT](model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://huggingface.co/papers/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
+1. **[ViTMAE](model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://huggingface.co/papers/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
+1. **[ViTMSN](model_doc/vit_msn)** (from Meta AI) released with the paper [Masked Siamese Networks for Label-Efficient Learning](https://huggingface.co/papers/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas.
+1. **[Wav2Vec2](model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://huggingface.co/papers/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
+1. **[Wav2Vec2-Conformer](model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://huggingface.co/papers/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
+1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://huggingface.co/papers/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
+1. **[WavLM](model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://huggingface.co/papers/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
1. **[Whisper](model_doc/whisper)** (from OpenAI) released with the paper [Robust Speech Recognition via Large-Scale Weak Supervision](https://cdn.openai.com/papers/whisper.pdf) by Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever.
-1. **[X-CLIP](model_doc/xclip)** (from Microsoft Research) released with the paper [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816) by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
-1. **[XGLM](model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
-1. **[XLM](model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau.
-1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
-1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
-1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (from Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
-1. **[XLNet](model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
-1. **[XLS-R](model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
-1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
-1. **[YOLOS](model_doc/yolos)** (from Huazhong University of Science & Technology) released with the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
-1. **[YOSO](model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
+1. **[X-CLIP](model_doc/xclip)** (from Microsoft Research) released with the paper [Expanding Language-Image Pretrained Models for General Video Recognition](https://huggingface.co/papers/2208.02816) by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
+1. **[XGLM](model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://huggingface.co/papers/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
+1. **[XLM](model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://huggingface.co/papers/1901.07291) by Guillaume Lample and Alexis Conneau.
+1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://huggingface.co/papers/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://huggingface.co/papers/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
+1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (from Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://huggingface.co/papers/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
+1. **[XLNet](model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://huggingface.co/papers/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
+1. **[XLS-R](model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://huggingface.co/papers/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
+1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://huggingface.co/papers/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
+1. **[YOLOS](model_doc/yolos)** (from Huazhong University of Science & Technology) released with the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://huggingface.co/papers/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
+1. **[YOSO](model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://huggingface.co/papers/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
### 지원 프레임워크[[supported-framework]]
diff --git a/docs/source/ko/llm_tutorial_optimization.md b/docs/source/ko/llm_tutorial_optimization.md
index 5a95e2d9b5..ec2e34de6d 100644
--- a/docs/source/ko/llm_tutorial_optimization.md
+++ b/docs/source/ko/llm_tutorial_optimization.md
@@ -14,7 +14,7 @@ rendered properly in your Markdown viewer.
GPT3/4, [Falcon](https://huggingface.co/tiiuae/falcon-40b), [Llama](https://huggingface.co/meta-llama/Llama-2-70b-hf)와 같은 대규모 언어 모델의 인간 중심 과제를 해결하는 능력이 빠르게 발전하고 있으며, 현대 지식 기반 산업에서 필수 도구로 자리잡고 있습니다. 그러나 이러한 모델을 실제 과제에 배포하는 것은 여전히 어려운 과제입니다.
-- 인간과 비슷한 텍스트 이해 및 생성 능력을 보이기 위해, 현재 대규모 언어 모델은 수십억 개의 매개변수로 구성되어야 합니다 (참조: [Kaplan et al](https://arxiv.org/abs/2001.08361), [Wei et. al](https://arxiv.org/abs/2206.07682)). 이는 추론을 위한 메모리 요구를 크게 증가시킵니다.
+- 인간과 비슷한 텍스트 이해 및 생성 능력을 보이기 위해, 현재 대규모 언어 모델은 수십억 개의 매개변수로 구성되어야 합니다 (참조: [Kaplan et al](https://huggingface.co/papers/2001.08361), [Wei et. al](https://huggingface.co/papers/2206.07682)). 이는 추론을 위한 메모리 요구를 크게 증가시킵니다.
- 많은 실제 과제에서 대규모 언어 모델은 방대한 맥락 정보를 제공받아야 합니다. 이는 모델이 추론 과정에서 매우 긴 입력 시퀀스를 처리할 수 있어야 한다는 것을 뜻합니다.
이러한 과제의 핵심은 대규모 언어 모델의 계산 및 메모리 활용 능력을 증대시키는 데 있습니다. 특히 방대한 입력 시퀀스를 처리할 때 이러한 능력이 중요합니다.
@@ -25,7 +25,7 @@ GPT3/4, [Falcon](https://huggingface.co/tiiuae/falcon-40b), [Llama](https://hugg
2. **플래시 어텐션:** 플래시 어텐션은 메모리 효율성을 높일 뿐만 아니라 최적화된 GPU 메모리 활용을 통해 효율성을 향상시키는 어텐션 알고리즘의 변형입니다.
-3. **아키텍처 혁신:** 추론 시 대규모 언어 모델은 주로 동일한 방식(긴 입력 맥락을 가진 자기회귀 텍스트 생성 방식)으로 배포되는데, 더 효율적인 추론을 가능하게 하는 특화된 모델 아키텍처가 제안되었습니다. 이러한 모델 아키텍처의 가장 중요한 발전으로는 [Alibi](https://arxiv.org/abs/2108.12409), [Rotary embeddings](https://arxiv.org/abs/2104.09864), [Multi-Query Attention (MQA)](https://arxiv.org/abs/1911.02150), [Grouped-Query-Attention (GQA)]((https://arxiv.org/abs/2305.13245))이 있습니다.
+3. **아키텍처 혁신:** 추론 시 대규모 언어 모델은 주로 동일한 방식(긴 입력 맥락을 가진 자기회귀 텍스트 생성 방식)으로 배포되는데, 더 효율적인 추론을 가능하게 하는 특화된 모델 아키텍처가 제안되었습니다. 이러한 모델 아키텍처의 가장 중요한 발전으로는 [Alibi](https://huggingface.co/papers/2108.12409), [Rotary embeddings](https://huggingface.co/papers/2104.09864), [Multi-Query Attention (MQA)](https://huggingface.co/papers/1911.02150), [Grouped-Query-Attention (GQA)]((https://huggingface.co/papers/2305.13245))이 있습니다.
이 가이드에서는 텐서의 관점에서 자기회귀 생성에 대한 분석을 제공합니다. 낮은 정밀도를 채택하는 것의 장단점을 논의하고, 최신 어텐션 알고리즘을 포괄적으로 탐구하며, 향상된 대규모 언어 모델 아키텍처에 대해 논합니다. 이 과정에서 각 기능의 개선 사항을 보여주는 실용적인 예제를 확인합니다.
@@ -153,7 +153,7 @@ from accelerate.utils import release_memory
release_memory(model)
```
-만약 GPU에 32GB의 VRAM이 없다면 어떻게 될까요? 모델 가중치를 성능에 큰 손실 없이 8비트 또는 4비트로 양자화할 수 있다는 것이 밝혀졌습니다(참고: [Dettmers et al.](https://arxiv.org/abs/2208.07339)). 최근의 [GPTQ 논문](https://arxiv.org/abs/2210.17323) 에서는 모델을 3비트 또는 2비트로 양자화해도 성능 손실이 허용 가능한 수준임을 보여주었습니다🤯.
+만약 GPU에 32GB의 VRAM이 없다면 어떻게 될까요? 모델 가중치를 성능에 큰 손실 없이 8비트 또는 4비트로 양자화할 수 있다는 것이 밝혀졌습니다(참고: [Dettmers et al.](https://huggingface.co/papers/2208.07339)). 최근의 [GPTQ 논문](https://huggingface.co/papers/2210.17323) 에서는 모델을 3비트 또는 2비트로 양자화해도 성능 손실이 허용 가능한 수준임을 보여주었습니다🤯.
너무 자세한 내용은 다루지 않고 설명하자면, 양자화는 가중치의 정밀도를 줄이면서 모델의 추론 결과를 가능한 한 정확하게(즉, bfloat16과 최대한 가깝게) 유지하려고 합니다. 양자화는 특히 텍스트 생성에 잘 작동하는데, 이는 우리가 *가장 가능성 있는 다음 토큰 집합*을 선택하는 것에 초점을 두고 있기 때문이며, 다음 토큰의 *logit* 분포값을 정확하게 예측할 필요는 없기 때문입니다. 핵심은 다음 토큰 *logit* 분포가 대략적으로 동일하게 유지되어 `argmax` 또는 `topk` 연산이 동일한 결과를 제공하는 것입니다.
@@ -296,7 +296,7 @@ $$ \textbf{O} = \text{Attn}(\mathbf{X}) = \mathbf{V} \times \text{Softmax}(\math
대규모 언어 모델의 텍스트 이해 및 생성 능력이 개선되면서 점점 더 복잡한 작업에 사용되고 있습니다. 한때 몇 문장의 번역이나 요약을 처리하던 모델이 이제는 전체 페이지를 처리해야 하게 되면서 광범위한 입력 길이를 처리할 수 있는 능력이 요구되고 있습니다.
-어떻게 하면 큰 입력 길이에 대한 과도한 메모리 요구를 없앨 수 있을까요? \\( QK^T \\) 행렬을 제거하는 새로운 셀프 어텐션 메커니즘을 계산하는 방법이 필요합니다. [Tri Dao et al.](https://arxiv.org/abs/2205.14135)은 바로 이러한 새로운 알고리즘을 개발하였고, 그것이 **플래시 어텐션(Flash Attention)**입니다.
+어떻게 하면 큰 입력 길이에 대한 과도한 메모리 요구를 없앨 수 있을까요? \\( QK^T \\) 행렬을 제거하는 새로운 셀프 어텐션 메커니즘을 계산하는 방법이 필요합니다. [Tri Dao et al.](https://huggingface.co/papers/2205.14135)은 바로 이러한 새로운 알고리즘을 개발하였고, 그것이 **플래시 어텐션(Flash Attention)**입니다.
간단히 말해, 플래시 어텐션은 \\(\mathbf{V} \times \text{Softmax}(\mathbf{QK}^T\\)) 계산을 분할하는데, 여러 번의 소프트맥스 계산을 반복하면서 작은 청크 단위로 출력을 계산합니다:
@@ -304,13 +304,13 @@ $$ \textbf{O}_i \leftarrow s^a_{ij} * \textbf{O}_i + s^b_{ij} * \mathbf{V}_{j} \
여기서 \\( s^a_{ij} \\)와 \\( s^b_{ij} \\)는 각 \\( i \\)와 \\( j \\)에 대해 계산되는 소프트맥스 정규화 통계량입니다.
-플래시 어텐션의 전체 알고리즘은 더 복잡하며, 본 가이드의 범위를 벗어나기 때문에 크게 단순화하였습니다. 여러분은 잘 작성된 [Flash Attention paper](https://arxiv.org/abs/2205.14135) 논문을 참조하여 더 자세한 내용을 확인해 보시기 바랍니다.
+플래시 어텐션의 전체 알고리즘은 더 복잡하며, 본 가이드의 범위를 벗어나기 때문에 크게 단순화하였습니다. 여러분은 잘 작성된 [Flash Attention paper](https://huggingface.co/papers/2205.14135) 논문을 참조하여 더 자세한 내용을 확인해 보시기 바랍니다.
주요 요점은 다음과 같습니다:
> 소프트맥스 정규화 통계량과 몇 가지 스마트한 수학적 방법을 사용함으로써, 플래시 어텐션은 기본 셀프 어텐션 레이어와 **숫자적으로 동일한** 출력을 제공하고 메모리 비용은 \\( N \\)에 따라 선형적으로만 증가합니다.
-공식을 보면, 플래시 어텐션이 더 많은 계산을 필요로 하기 때문에 기본 셀프 어텐션 공식보다 훨씬 느릴 것이라고 생각할 수 있습니다. 실제로 플래시 어텐션은 소프트맥스 정규화 통계량을 지속적으로 다시 계산해야 하기 때문에 일반 어텐션보다 더 많은 FLOP이 필요합니다. (더 자세한 내용은 [논문](https://arxiv.org/abs/2205.14135)을 참조하세요)
+공식을 보면, 플래시 어텐션이 더 많은 계산을 필요로 하기 때문에 기본 셀프 어텐션 공식보다 훨씬 느릴 것이라고 생각할 수 있습니다. 실제로 플래시 어텐션은 소프트맥스 정규화 통계량을 지속적으로 다시 계산해야 하기 때문에 일반 어텐션보다 더 많은 FLOP이 필요합니다. (더 자세한 내용은 [논문](https://huggingface.co/papers/2205.14135)을 참조하세요)
> 그러나 플래시 어텐션은 기본 어텐션보다 추론 속도가 훨씬 빠릅니다. 이는 GPU의 느리고 고대역폭 메모리(VRAM)의 사용량을 크게 줄이고 대신 빠른 온칩 메모리(SRAM)에 집중할 수 있기 때문입니다.
@@ -509,19 +509,19 @@ flush()
대규모 언어 모델이 문장의 순서를 이해하려면 추가적인 *단서*가 필요하며, 이는 일반적으로 *위치 인코딩* (또는 *위치 임베딩*이라고도 함)의 형태로 적용됩니다.
위치 인코딩은 각 토큰의 위치를 숫자 표현으로 인코딩하여 대규모 언어 모델이 문장의 순서를 더 잘 이해할 수 있도록 도와줍니다.
-[*Attention Is All You Need*](https://arxiv.org/abs/1706.03762) 논문의 저자들은 사인 함수 기반의 위치 임베딩 \\( \mathbf{P} = \mathbf{p}_1, \ldots, \mathbf{p}_N \\)을 도입했습니다. 각 벡터 \\( \mathbf{p}_i \\)는 위치 \\( i \\)의 사인 함수로 계산됩니다. 위치 인코딩은 입력 시퀀스 벡터에 단순히 더해져 \\( \mathbf{\hat{X}} = \mathbf{\hat{x}}_1, \ldots, \mathbf{\hat{x}}_N \\) = \\( \mathbf{x}_1 + \mathbf{p}_1, \ldots, \mathbf{x}_N + \mathbf{p}_N \\) 모델이 문장 순서를 더 잘 학습할 수 있도록 합니다.
+[*Attention Is All You Need*](https://huggingface.co/papers/1706.03762) 논문의 저자들은 사인 함수 기반의 위치 임베딩 \\( \mathbf{P} = \mathbf{p}_1, \ldots, \mathbf{p}_N \\)을 도입했습니다. 각 벡터 \\( \mathbf{p}_i \\)는 위치 \\( i \\)의 사인 함수로 계산됩니다. 위치 인코딩은 입력 시퀀스 벡터에 단순히 더해져 \\( \mathbf{\hat{X}} = \mathbf{\hat{x}}_1, \ldots, \mathbf{\hat{x}}_N \\) = \\( \mathbf{x}_1 + \mathbf{p}_1, \ldots, \mathbf{x}_N + \mathbf{p}_N \\) 모델이 문장 순서를 더 잘 학습할 수 있도록 합니다.
-고정된 위치 임베딩 대신 [Devlin et al.](https://arxiv.org/abs/1810.04805)과 같은 다른 연구자들은 학습된 위치 인코딩을 사용했습니다. 이 경우 위치 임베딩 \\( \mathbf{P} \\)은 학습 중에 사용됩니다.
+고정된 위치 임베딩 대신 [Devlin et al.](https://huggingface.co/papers/1810.04805)과 같은 다른 연구자들은 학습된 위치 인코딩을 사용했습니다. 이 경우 위치 임베딩 \\( \mathbf{P} \\)은 학습 중에 사용됩니다.
사인 함수 및 학습된 위치 임베딩은 문장 순서를 대규모 언어 모델에 인코딩하는 주요 방법이었지만, 이러한 위치 인코딩과 관련된 몇 가지 문제가 발견되었습니다:
- 1. 사인 함수와 학습된 위치 임베딩은 모두 절대 위치 임베딩으로, 각 위치 ID \\( 0, \ldots, N \\)에 대해 고유한 임베딩을 인코딩합니다. [Huang et al.](https://arxiv.org/abs/2009.13658) 및 [Su et al.](https://arxiv.org/abs/2104.09864)의 연구에 따르면, 절대 위치 임베딩은 긴 텍스트 입력에 대해 대규모 언어 모델 성능이 저하됩니다. 긴 텍스트 입력의 경우, 모델이 절대 위치 대신 입력 토큰 간의 상대적 위치 거리를 학습하는 것이 유리합니다.
+ 1. 사인 함수와 학습된 위치 임베딩은 모두 절대 위치 임베딩으로, 각 위치 ID \\( 0, \ldots, N \\)에 대해 고유한 임베딩을 인코딩합니다. [Huang et al.](https://huggingface.co/papers/2009.13658) 및 [Su et al.](https://huggingface.co/papers/2104.09864)의 연구에 따르면, 절대 위치 임베딩은 긴 텍스트 입력에 대해 대규모 언어 모델 성능이 저하됩니다. 긴 텍스트 입력의 경우, 모델이 절대 위치 대신 입력 토큰 간의 상대적 위치 거리를 학습하는 것이 유리합니다.
2. 학습된 위치 임베딩을 사용할 때, 대규모 언어 모델은 고정된 입력 길이 \\( N \\)으로 학습되어야 하므로, 학습된 입력 길이보다 더 긴 입력 길이에 대해 추론하는 것이 어렵습니다.
최근에는 위에서 언급한 문제를 해결할 수 있는 상대적 위치 임베딩이 더 인기를 끌고 있습니다. 특히 다음과 같은 방법들이 주목받고 있습니다:
-- [Rotary Position Embedding (RoPE)](https://arxiv.org/abs/2104.09864)
-- [ALiBi](https://arxiv.org/abs/2108.12409)
+- [Rotary Position Embedding (RoPE)](https://huggingface.co/papers/2104.09864)
+- [ALiBi](https://huggingface.co/papers/2108.12409)
*RoPE*와 *ALiBi*는 모두 셀프 어텐션 알고리즘 내에서 직접적으로 문장 순서를 모델에게 알려주는 것이 최선이라고 주장합니다. 이는 단어 토큰이 서로 관계를 맺는 곳이기 때문입니다. 구체적으로, 문장 순서를 \\( \mathbf{QK}^T \\) 계산을 수정하는 방식으로 알려주어야 한다는 것입니다.
@@ -536,21 +536,21 @@ $$ \mathbf{\hat{q}}_i^T \mathbf{\hat{x}}_j = \mathbf{{q}}_i^T \mathbf{R}_{\theta
*RoPE*는 현재 여러 중요한 대규모 언어 모델이 사용되고 있습니다. 예를 들면:
- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
-- [**Llama**](https://arxiv.org/abs/2302.13971)
-- [**PaLM**](https://arxiv.org/abs/2204.02311)
+- [**Llama**](https://huggingface.co/papers/2302.13971)
+- [**PaLM**](https://huggingface.co/papers/2204.02311)
대안으로, *ALiBi*는 훨씬 더 간단한 상대적 위치 인코딩 방식을 제안합니다. 입력 토큰 간의 상대적 거리를 음수인 정수로서 사전 정의된 값 `m`으로 스케일링하여 \\( \mathbf{QK}^T \\) 행렬의 각 쿼리-키 항목에 소프트맥스 계산 직전에 추가합니다.

-[ALiBi](https://arxiv.org/abs/2108.12409) 논문에서 보여주듯이, 이 간단한 상대적 위치 인코딩은 매우 긴 텍스트 입력 시퀀스에서도 모델이 높은 성능을 유지할 수 있게 합니다.
+[ALiBi](https://huggingface.co/papers/2108.12409) 논문에서 보여주듯이, 이 간단한 상대적 위치 인코딩은 매우 긴 텍스트 입력 시퀀스에서도 모델이 높은 성능을 유지할 수 있게 합니다.
*ALiBi*는 현재 여러 중요한 대규모 언어 모델 모델이 사용하고 있습니다. 예를 들면:
- [**MPT**](https://huggingface.co/mosaicml/mpt-30b)
- [**BLOOM**](https://huggingface.co/bigscience/bloom)
-*RoPE*와 *ALiBi* 위치 인코딩은 모두 학습 중에 보지 못한 입력 길이에 대해 확장할 수 있으며, *ALiBi*가 *RoPE*보다 더 잘 확장되는 것으로 나타났습니다. *ALiBi*의 경우, 하삼각 위치 행렬의 값을 입력 시퀀스 길이에 맞추어 증가시키기만 하면 됩니다. *RoPE*의 경우, 학습 중에 사용된 동일한 \\( \theta \\)를 유지하면 학습 중에 보지 못한 매우 긴 텍스트 입력을 전달할 때 성능이 저하됩니다(참고: [Press et al.](https://arxiv.org/abs/2108.12409)). 그러나 커뮤니티는 \\( \theta \\)를 조정하는 몇 가지 효과적인 트릭을 찾아냈으며, 이를 통해 *RoPE* 위치 임베딩이 확장된 텍스트 입력 시퀀스에서도 잘 작동할 수 있게 되었습니다(참고: [here](https://github.com/huggingface/transformers/pull/24653)).
+*RoPE*와 *ALiBi* 위치 인코딩은 모두 학습 중에 보지 못한 입력 길이에 대해 확장할 수 있으며, *ALiBi*가 *RoPE*보다 더 잘 확장되는 것으로 나타났습니다. *ALiBi*의 경우, 하삼각 위치 행렬의 값을 입력 시퀀스 길이에 맞추어 증가시키기만 하면 됩니다. *RoPE*의 경우, 학습 중에 사용된 동일한 \\( \theta \\)를 유지하면 학습 중에 보지 못한 매우 긴 텍스트 입력을 전달할 때 성능이 저하됩니다(참고: [Press et al.](https://huggingface.co/papers/2108.12409)). 그러나 커뮤니티는 \\( \theta \\)를 조정하는 몇 가지 효과적인 트릭을 찾아냈으며, 이를 통해 *RoPE* 위치 임베딩이 확장된 텍스트 입력 시퀀스에서도 잘 작동할 수 있게 되었습니다(참고: [here](https://github.com/huggingface/transformers/pull/24653)).
> RoPE와 ALiBi는 모두 훈련 중에 *학습되지 않는* 상대적 위치 임베딩으로 다음과 같은 직관에 기반합니다:
- 텍스트 입력에 대한 위치 단서는 셀프 어텐션 레이어의 \\( QK^T \\) 행렬에 직접 제공되어야 합니다.
@@ -720,21 +720,21 @@ config = model.config
#### 3.2.2 멀티 쿼리 어텐션 (MQA) [[322-multi-query-attention-mqa]]
-[멀티 쿼리 어텐션 (MQA)](https://arxiv.org/abs/1911.02150)은 Noam Shazeer의 *Fast Transformer Decoding: One Write-Head is All You Need* 논문에서 제안되었습니다. 제목에서 알 수 있듯이, Noam은 `n_head` 키-값 프로젝션 가중치 대신, 모든 어텐션 헤드에서 공유되는 단일 헤드-값 프로젝션 가중치를 사용할 수 있으며, 이를 통해 모델 성능이 크게 저하되지 않는다는 것을 발견했습니다.
+[멀티 쿼리 어텐션 (MQA)](https://huggingface.co/papers/1911.02150)은 Noam Shazeer의 *Fast Transformer Decoding: One Write-Head is All You Need* 논문에서 제안되었습니다. 제목에서 알 수 있듯이, Noam은 `n_head` 키-값 프로젝션 가중치 대신, 모든 어텐션 헤드에서 공유되는 단일 헤드-값 프로젝션 가중치를 사용할 수 있으며, 이를 통해 모델 성능이 크게 저하되지 않는다는 것을 발견했습니다.
> 단일 헤드-값 프로젝션 가중치를 사용함으로써, 키-값 벡터 \\( \mathbf{k}_i, \mathbf{v}_i \\)는 모든 어텐션 헤드에서 동일해야 하며, 이는 캐시에 `n_head` 개 대신 하나의 키-값 프로젝션 쌍만 저장하면 된다는 것을 의미합니다.
대부분의 대규모 언어 모델이 20에서 100 사이의 어텐션 헤드를 사용하기 때문에, MQA는 키-값 캐시의 메모리 소비를 크게 줄입니다. 이 노트북에서 사용된 대규모 언어 모델의 경우, 입력 시퀀스 길이 16000에서 필요한 메모리 소비를 15GB에서 400MB 미만으로 줄일 수 있습니다.
메모리 절감 외에도, MQA는 계산 효율성도 향상시킵니다. 다음과 같이 설명합니다.
-자기회귀 디코딩에서는 큰 키-값 벡터를 다시 로드하고, 현재 키-값 벡터 쌍과 연결한 후 \\( \mathbf{q}_c\mathbf{K}^T \\) 계산에 매 단계마다 입력해야 합니다. 자기회귀 디코딩의 경우, 지속적인 재로드에 필요한 메모리 대역폭이 심각한 시간 병목 현상을 가져올 수 있습니다. 키-값 벡터의 크기를 줄이면 접근해야 하는 메모리 양이 줄어들어 메모리 대역폭 병목 현상이 감소합니다. 자세한 내용은 [Noam의 논문](https://arxiv.org/abs/1911.02150)을 참조하세요.
+자기회귀 디코딩에서는 큰 키-값 벡터를 다시 로드하고, 현재 키-값 벡터 쌍과 연결한 후 \\( \mathbf{q}_c\mathbf{K}^T \\) 계산에 매 단계마다 입력해야 합니다. 자기회귀 디코딩의 경우, 지속적인 재로드에 필요한 메모리 대역폭이 심각한 시간 병목 현상을 가져올 수 있습니다. 키-값 벡터의 크기를 줄이면 접근해야 하는 메모리 양이 줄어들어 메모리 대역폭 병목 현상이 감소합니다. 자세한 내용은 [Noam의 논문](https://huggingface.co/papers/1911.02150)을 참조하세요.
여기서 이해해야 할 중요한 부분은 키-값 어텐션 헤드 수를 1로 줄이는 것이 키-값 캐시를 사용할 때만 의미가 있다는 것입니다. 키-값 캐시 없이 단일 포워드 패스에 대한 모델의 최대 메모리 소비는 변경되지 않으며, 각 어텐션 헤드는 여전히 고유한 쿼리 벡터를 가지므로 각 어텐션 헤드는 여전히 다른 \\( \mathbf{QK}^T \\) 행렬을 가집니다.
MQA는 커뮤니티에서 널리 채택되어 현재 가장 인기 있는 많은 대규모 언어 모델에서 사용되고 있습니다.
- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
-- [**PaLM**](https://arxiv.org/abs/2204.02311)
+- [**PaLM**](https://huggingface.co/papers/2204.02311)
- [**MPT**](https://huggingface.co/mosaicml/mpt-30b)
- [**BLOOM**](https://huggingface.co/bigscience/bloom)
@@ -742,7 +742,7 @@ MQA는 커뮤니티에서 널리 채택되어 현재 가장 인기 있는 많은
#### 3.2.3 그룹 쿼리 어텐션 (GQA) [[323-grouped-query-attention-gqa]]
-[그룹 쿼리 어텐션 (GQA)](https://arxiv.org/abs/2305.13245)은 Google의 Ainslie 등의 연구진들에 의해 제안되었습니다. 그들은 MQA를 사용하는 것이 종종 일반적인 멀티 키-값 헤드 프로젝션을 사용하는 것보다 품질 저하를 가져올 수 있다는 것을 발견했습니다. 이 논문은 쿼리 헤드 프로젝션 가중치의 수를 너무 극단적으로 줄이는 대신, 더 많은 모델 성능을 유지할 수 있다고 주장합니다. 단일 키-값 프로젝션 가중치 대신, `n < n_head` 키-값 프로젝션 가중치를 사용해야 합니다. `n_head`보다 훨씬 작은 `n`값, 예를 들어 2, 4 또는 8을 선택하면, MQA의 거의 모든 메모리 및 속도 이점을 유지하면서 모델 용량을 덜 희생하고 따라서 성능 저하를 줄일 수 있습니다.
+[그룹 쿼리 어텐션 (GQA)](https://huggingface.co/papers/2305.13245)은 Google의 Ainslie 등의 연구진들에 의해 제안되었습니다. 그들은 MQA를 사용하는 것이 종종 일반적인 멀티 키-값 헤드 프로젝션을 사용하는 것보다 품질 저하를 가져올 수 있다는 것을 발견했습니다. 이 논문은 쿼리 헤드 프로젝션 가중치의 수를 너무 극단적으로 줄이는 대신, 더 많은 모델 성능을 유지할 수 있다고 주장합니다. 단일 키-값 프로젝션 가중치 대신, `n < n_head` 키-값 프로젝션 가중치를 사용해야 합니다. `n_head`보다 훨씬 작은 `n`값, 예를 들어 2, 4 또는 8을 선택하면, MQA의 거의 모든 메모리 및 속도 이점을 유지하면서 모델 용량을 덜 희생하고 따라서 성능 저하를 줄일 수 있습니다.
또한, GQA의 저자들은 기존 모델 체크포인트를 원래 사전 학습 계산의 5% 정도의 적은 양으로 GQA 아키텍처로 *업트레이닝*할 수 있음을 발견했습니다. 원래 사전 학습 계산의 5%가 여전히 엄청난 양일 수 있지만, GQA *업트레이닝*은 기존 체크포인트가 더 긴 입력 시퀀스에서도 유용하도록 합니다.
@@ -754,6 +754,6 @@ GQA의 가장 주목할 만한 적용 사례는 [Llama-v2](https://huggingface.c
## 결론 [[conclusion]]
-연구 커뮤니티는 점점 더 큰 대규모 언어 모델의 추론 시간을 가속화하기 위한 새로운 기발한 방법들을 끊임없이 찾아내고 있습니다. 예를 들어, [추측 디코딩](https://arxiv.org/abs/2211.17192)이라는 유망한 연구 방향이 있습니다. 여기서 "쉬운 토큰"은 더 작고 빠른 언어 모델에 의해 생성되고, "어려운 토큰"만 대규모 언어 모델 자체에 의해 생성됩니다. 자세한 내용은 이 노트북의 범위를 벗어나지만, [멋진 블로그 포스트](https://huggingface.co/blog/assisted-generation)에서 읽어볼 수 있습니다.
+연구 커뮤니티는 점점 더 큰 대규모 언어 모델의 추론 시간을 가속화하기 위한 새로운 기발한 방법들을 끊임없이 찾아내고 있습니다. 예를 들어, [추측 디코딩](https://huggingface.co/papers/2211.17192)이라는 유망한 연구 방향이 있습니다. 여기서 "쉬운 토큰"은 더 작고 빠른 언어 모델에 의해 생성되고, "어려운 토큰"만 대규모 언어 모델 자체에 의해 생성됩니다. 자세한 내용은 이 노트북의 범위를 벗어나지만, [멋진 블로그 포스트](https://huggingface.co/blog/assisted-generation)에서 읽어볼 수 있습니다.
GPT3/4, Llama-2-70b, Claude, PaLM과 같은 거대한 대규모 언어 모델이 [Hugging Face Chat](https://huggingface.co/chat/) 또는 ChatGPT와 같은 채팅 인터페이스에서 빠르게 실행될 수 있는 이유는 위에서 언급한 정밀도, 알고리즘, 아키텍처의 개선 덕분입니다. 앞으로 GPU, TPU 등과 같은 가속기는 점점 더 빨라지고 더 많은 메모리를 사용할 것입니다. 따라서 가장 좋은 알고리즘과 아키텍처를 사용하여 최고의 효율을 얻는 것이 중요합니다 🤗
\ No newline at end of file
diff --git a/docs/source/ko/model_doc/altclip.md b/docs/source/ko/model_doc/altclip.md
index 1236bcc9aa..f736ab9c5c 100644
--- a/docs/source/ko/model_doc/altclip.md
+++ b/docs/source/ko/model_doc/altclip.md
@@ -2,7 +2,7 @@
## 개요[[overview]]
-AltCLIP 모델은 Zhongzhi Chen, Guang Liu, Bo-Wen Zhang, Fulong Ye, Qinghong Yang, Ledell Wu의 [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679v2) 논문에서 제안되었습니다. AltCLIP(CLIP의 언어 인코더를 변경하여 언어 기능 확장)은 다양한 이미지-텍스트 및 텍스트-텍스트 쌍으로 훈련된 신경망입니다. CLIP의 텍스트 인코더를 사전 훈련된 다국어 텍스트 인코더 XLM-R로 교체하여, 거의 모든 작업에서 CLIP과 유사한 성능을 얻을 수 있었으며, 원래 CLIP의 다국어 이해와 같은 기능도 확장되었습니다.
+AltCLIP 모델은 Zhongzhi Chen, Guang Liu, Bo-Wen Zhang, Fulong Ye, Qinghong Yang, Ledell Wu의 [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://huggingface.co/papers/2211.06679v2) 논문에서 제안되었습니다. AltCLIP(CLIP의 언어 인코더를 변경하여 언어 기능 확장)은 다양한 이미지-텍스트 및 텍스트-텍스트 쌍으로 훈련된 신경망입니다. CLIP의 텍스트 인코더를 사전 훈련된 다국어 텍스트 인코더 XLM-R로 교체하여, 거의 모든 작업에서 CLIP과 유사한 성능을 얻을 수 있었으며, 원래 CLIP의 다국어 이해와 같은 기능도 확장되었습니다.
논문의 초록은 다음과 같습니다:
diff --git a/docs/source/ko/model_doc/autoformer.md b/docs/source/ko/model_doc/autoformer.md
index e8534ac95c..10aacdb74e 100644
--- a/docs/source/ko/model_doc/autoformer.md
+++ b/docs/source/ko/model_doc/autoformer.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요[[overview]]
-The Autoformer 모델은 Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long가 제안한 [오토포머: 장기 시계열 예측을 위한 자기상관 분해 트랜스포머](https://arxiv.org/abs/2106.13008) 라는 논문에서 소개 되었습니다.
+The Autoformer 모델은 Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long가 제안한 [오토포머: 장기 시계열 예측을 위한 자기상관 분해 트랜스포머](https://huggingface.co/papers/2106.13008) 라는 논문에서 소개 되었습니다.
이 모델은 트랜스포머를 심층 분해 아키텍처로 확장하여, 예측 과정에서 추세와 계절성 요소를 점진적으로 분해할 수 있습니다.
diff --git a/docs/source/ko/model_doc/bart.md b/docs/source/ko/model_doc/bart.md
index 0f7636b3cc..86d97b1310 100644
--- a/docs/source/ko/model_doc/bart.md
+++ b/docs/source/ko/model_doc/bart.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
## 개요 [[overview]]
-Bart 모델은 2019년 10월 29일 Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, Luke Zettlemoyer가 발표한 [BART: 자연어 생성, 번역, 이해를 위한 잡음 제거 seq2seq 사전 훈련](https://arxiv.org/abs/1910.13461)이라는 논문에서 소개되었습니다.
+Bart 모델은 2019년 10월 29일 Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, Luke Zettlemoyer가 발표한 [BART: 자연어 생성, 번역, 이해를 위한 잡음 제거 seq2seq 사전 훈련](https://huggingface.co/papers/1910.13461)이라는 논문에서 소개되었습니다.
논문의 초록에 따르면,
@@ -111,7 +111,7 @@ BART를 시작하는 데 도움이 되는 Hugging Face와 community 자료 목
- [텍스트 분류 작업 가이드](../tasks/sequence_classification)
- [질문 답변 작업 가이드](../tasks/question_answering)
- [인과적 언어 모델링 작업 가이드](../tasks/language_modeling)
-- 이 [논문](https://arxiv.org/abs/2010.13002)은 [증류된 체크포인트](https://huggingface.co/models?search=distilbart)에 대해 설명합니다.
+- 이 [논문](https://huggingface.co/papers/2010.13002)은 [증류된 체크포인트](https://huggingface.co/models?search=distilbart)에 대해 설명합니다.
## BartConfig[[transformers.BartConfig]]
diff --git a/docs/source/ko/model_doc/barthez.md b/docs/source/ko/model_doc/barthez.md
index 131db38856..4df8eb2cd6 100644
--- a/docs/source/ko/model_doc/barthez.md
+++ b/docs/source/ko/model_doc/barthez.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요 [[overview]]
-BARThez 모델은 2020년 10월 23일, Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis에 의해 [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321)에서 제안되었습니다.
+BARThez 모델은 2020년 10월 23일, Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis에 의해 [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://huggingface.co/papers/2010.12321)에서 제안되었습니다.
이 논문의 초록:
diff --git a/docs/source/ko/model_doc/bartpho.md b/docs/source/ko/model_doc/bartpho.md
index a323c28152..72f4884164 100644
--- a/docs/source/ko/model_doc/bartpho.md
+++ b/docs/source/ko/model_doc/bartpho.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요 [[overview]]
-BARTpho 모델은 Nguyen Luong Tran, Duong Minh Le, Dat Quoc Nguyen에 의해 [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701)에서 제안되었습니다.
+BARTpho 모델은 Nguyen Luong Tran, Duong Minh Le, Dat Quoc Nguyen에 의해 [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://huggingface.co/papers/2109.09701)에서 제안되었습니다.
이 논문의 초록은 다음과 같습니다:
diff --git a/docs/source/ko/model_doc/bert.md b/docs/source/ko/model_doc/bert.md
index 531d3e3dd6..0488a1f9ab 100644
--- a/docs/source/ko/model_doc/bert.md
+++ b/docs/source/ko/model_doc/bert.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
## 개요[[Overview]]
-BERT 모델은 Jacob Devlin. Ming-Wei Chang, Kenton Lee, Kristina Touranova가 제안한 논문 [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805)에서 소개되었습니다. BERT는 사전 학습된 양방향 트랜스포머로, Toronto Book Corpus와 Wikipedia로 구성된 대규모 코퍼스에서 마스킹된 언어 모델링과 다음 문장 예측(Next Sentence Prediction) 목표를 결합해 학습되었습니다.
+BERT 모델은 Jacob Devlin. Ming-Wei Chang, Kenton Lee, Kristina Touranova가 제안한 논문 [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://huggingface.co/papers/1810.04805)에서 소개되었습니다. BERT는 사전 학습된 양방향 트랜스포머로, Toronto Book Corpus와 Wikipedia로 구성된 대규모 코퍼스에서 마스킹된 언어 모델링과 다음 문장 예측(Next Sentence Prediction) 목표를 결합해 학습되었습니다.
해당 논문의 초록입니다:
diff --git a/docs/source/ko/model_doc/blip-2.md b/docs/source/ko/model_doc/blip-2.md
index ae3da11d3a..c9d7b99f81 100644
--- a/docs/source/ko/model_doc/blip-2.md
+++ b/docs/source/ko/model_doc/blip-2.md
@@ -17,7 +17,7 @@ rendered properly in your Markdown viewer.
# BLIP-2[[blip-2]]
## 개요[[overview]]
-BLIP-2 모델은 Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi의 [BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://arxiv.org/abs/2301.12597) 논문에서 제안되었습니다. BLIP-2는 동결된 사전 학습 이미지 인코더와 대규모 언어 모델(LLM)을 연결하는 12층의 경량 Transformer 인코더를 학습시켜, 여러 비전-언어 작업에서 SOTA(현재 최고의 성능)을 달성했습니다. 특히, BLIP-2는 800억 개의 파라미터를 가진 Flamingo 모델보다 제로샷 VQAv2에서 8.7% 더 높은 성능을 기록했으며, 학습 가능한 파라미터 수는 Flamingo보다 54배 적습니다.
+BLIP-2 모델은 Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi의 [BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://huggingface.co/papers/2301.12597) 논문에서 제안되었습니다. BLIP-2는 동결된 사전 학습 이미지 인코더와 대규모 언어 모델(LLM)을 연결하는 12층의 경량 Transformer 인코더를 학습시켜, 여러 비전-언어 작업에서 SOTA(현재 최고의 성능)을 달성했습니다. 특히, BLIP-2는 800억 개의 파라미터를 가진 Flamingo 모델보다 제로샷 VQAv2에서 8.7% 더 높은 성능을 기록했으며, 학습 가능한 파라미터 수는 Flamingo보다 54배 적습니다.
논문의 초록은 다음과 같습니다:
@@ -26,7 +26,7 @@ BLIP-2 모델은 Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi의 [BLIP-2: B
- BLIP-2 구조. 원본 논문 에서 발췌.
+ BLIP-2 구조. 원본 논문 에서 발췌.
이 모델은 [nielsr](https://huggingface.co/nielsr)가 기여했습니다. 원본 코드는 [여기](https://github.com/salesforce/LAVIS/tree/5ee63d688ba4cebff63acee04adaef2dee9af207)에서 확인할 수 있습니다.
diff --git a/docs/source/ko/model_doc/blip.md b/docs/source/ko/model_doc/blip.md
index 27e085315b..6b5a4e8abc 100644
--- a/docs/source/ko/model_doc/blip.md
+++ b/docs/source/ko/model_doc/blip.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요[[overview]]
-BLIP 모델은 Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi의 [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) 논문에서 제안되었습니다.
+BLIP 모델은 Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi의 [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://huggingface.co/papers/2201.12086) 논문에서 제안되었습니다.
BLIP은 여러 멀티모달 작업을 수행할 수 있는 모델입니다:
diff --git a/docs/source/ko/model_doc/chameleon.md b/docs/source/ko/model_doc/chameleon.md
index ac2fa16b77..95c5567763 100644
--- a/docs/source/ko/model_doc/chameleon.md
+++ b/docs/source/ko/model_doc/chameleon.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요 [[overview]]
-Chameleon 모델은 META AI Chameleon 팀의 논문 [Chameleon: Mixed-Modal Early-Fusion Foundation Models](https://arxiv.org/abs/2405.09818v1)에서 제안되었습니다. Chameleon은 벡터 양자화를 사용하여 이미지를 토큰화함으로써 멀티모달 출력을 생성할 수 있는 비전-언어 모델입니다. 이 모델은 교차된 형식을 포함한 이미지와 텍스트를 입력으로 받으며, 텍스트 응답을 생성합니다. 이미지 생성 모듈은 아직 공개되지 않았습니다.
+Chameleon 모델은 META AI Chameleon 팀의 논문 [Chameleon: Mixed-Modal Early-Fusion Foundation Models](https://huggingface.co/papers/2405.09818)에서 제안되었습니다. Chameleon은 벡터 양자화를 사용하여 이미지를 토큰화함으로써 멀티모달 출력을 생성할 수 있는 비전-언어 모델입니다. 이 모델은 교차된 형식을 포함한 이미지와 텍스트를 입력으로 받으며, 텍스트 응답을 생성합니다. 이미지 생성 모듈은 아직 공개되지 않았습니다.
논문의 초록은 다음과 같습니다:
@@ -27,7 +27,7 @@ Chameleon 모델은 META AI Chameleon 팀의 논문 [Chameleon: Mixed-Modal Earl
-Chameleon은 이미지를 이산적인 토큰으로 변환하기 위해 벡터 양자화 모듈을 통합합니다. 이는 자기회귀 transformer를 사용한 이미지 생성을 가능하게 합니다. 원본 논문에서 가져왔습니다.
+Chameleon은 이미지를 이산적인 토큰으로 변환하기 위해 벡터 양자화 모듈을 통합합니다. 이는 자기회귀 transformer를 사용한 이미지 생성을 가능하게 합니다. 원본 논문에서 가져왔습니다.
이 모델은 [joaogante](https://huggingface.co/joaogante)와 [RaushanTurganbay](https://huggingface.co/RaushanTurganbay)가 기여했습니다. 원본 코드는 [여기](https://github.com/facebookresearch/chameleon)에서 찾을 수 있습니다.
diff --git a/docs/source/ko/model_doc/clip.md b/docs/source/ko/model_doc/clip.md
index 5c19a31e10..f1053d1758 100644
--- a/docs/source/ko/model_doc/clip.md
+++ b/docs/source/ko/model_doc/clip.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## 개요[[overview]]
CLIP 모델은 Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh,
-Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever가 제안한 [자연어 지도(supervision)를 통한 전이 가능한 시각 모델 학습](https://arxiv.org/abs/2103.00020)라는 논문에서 소개되었습니다. CLIP(Contrastive Language-Image Pre-Training)은 다양한 이미지와 텍스트 쌍으로 훈련된 신경망 입니다. GPT-2와 3의 제로샷 능력과 유사하게, 해당 작업에 직접적으로 최적화하지 않고도 주어진 이미지에 대해 가장 관련성 있는 텍스트 스니펫을 예측하도록 자연어로 지시할 수 있습니다.
+Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever가 제안한 [자연어 지도(supervision)를 통한 전이 가능한 시각 모델 학습](https://huggingface.co/papers/2103.00020)라는 논문에서 소개되었습니다. CLIP(Contrastive Language-Image Pre-Training)은 다양한 이미지와 텍스트 쌍으로 훈련된 신경망 입니다. GPT-2와 3의 제로샷 능력과 유사하게, 해당 작업에 직접적으로 최적화하지 않고도 주어진 이미지에 대해 가장 관련성 있는 텍스트 스니펫을 예측하도록 자연어로 지시할 수 있습니다.
해당 논문의 초록입니다.
diff --git a/docs/source/ko/model_doc/codegen.md b/docs/source/ko/model_doc/codegen.md
index 264f10e89b..75e69b0b84 100644
--- a/docs/source/ko/model_doc/codegen.md
+++ b/docs/source/ko/model_doc/codegen.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## 개요[[Overview]]
-CodeGen 모델은 Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong이 작성한 논문 [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474)에서 제안되었습니다.
+CodeGen 모델은 Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong이 작성한 논문 [A Conversational Paradigm for Program Synthesis](https://huggingface.co/papers/2203.13474)에서 제안되었습니다.
CodeGen 모델은 프로그램 합성(program synthesis)을 위한 자기회귀(autoregressive) 언어 모델로, [The Pile](https://pile.eleuther.ai/), BigQuery, BigPython 데이터로 순차적으로 학습되었습니다.
diff --git a/docs/source/ko/model_doc/convbert.md b/docs/source/ko/model_doc/convbert.md
index ec64a369b5..c4f0d2ace2 100644
--- a/docs/source/ko/model_doc/convbert.md
+++ b/docs/source/ko/model_doc/convbert.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
## 개요 [[overview]]
-ConvBERT 모델은 Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan에 의해 제안되었으며, 제안 논문 제목은 [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496)입니다.
+ConvBERT 모델은 Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan에 의해 제안되었으며, 제안 논문 제목은 [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://huggingface.co/papers/2008.02496)입니다.
논문의 초록은 다음과 같습니다:
diff --git a/docs/source/ko/model_doc/deberta-v2.md b/docs/source/ko/model_doc/deberta-v2.md
index 2e590ad8a5..bb7bed1434 100644
--- a/docs/source/ko/model_doc/deberta-v2.md
+++ b/docs/source/ko/model_doc/deberta-v2.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## 개요
-DeBERTa 모델은 Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen이 작성한 [DeBERTa: 분리된 어텐션을 활용한 디코딩 강화 BERT](https://arxiv.org/abs/2006.03654)이라는 논문에서 제안되었습니다. 이 모델은 2018년 Google이 발표한 BERT 모델과 2019년 Facebook이 발표한 RoBERTa 모델을 기반으로 합니다.
+DeBERTa 모델은 Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen이 작성한 [DeBERTa: 분리된 어텐션을 활용한 디코딩 강화 BERT](https://huggingface.co/papers/2006.03654)이라는 논문에서 제안되었습니다. 이 모델은 2018년 Google이 발표한 BERT 모델과 2019년 Facebook이 발표한 RoBERTa 모델을 기반으로 합니다.
DeBERTa는 RoBERTa에서 사용된 데이터의 절반만을 사용하여 분리된(disentangled) 어텐션과 향상된 마스크 디코더 학습을 통해 RoBERTa를 개선했습니다.
논문의 초록은 다음과 같습니다:
diff --git a/docs/source/ko/model_doc/deberta.md b/docs/source/ko/model_doc/deberta.md
index 6f82bed033..b471c9327a 100644
--- a/docs/source/ko/model_doc/deberta.md
+++ b/docs/source/ko/model_doc/deberta.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## 개요[[overview]]
-DeBERTa 모델은 Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen이 작성한 [DeBERTa: 분리된 어텐션을 활용한 디코딩 강화 BERT](https://arxiv.org/abs/2006.03654)이라는 논문에서 제안되었습니다. 이 모델은 2018년 Google이 발표한 BERT 모델과 2019년 Facebook이 발표한 RoBERTa 모델을 기반으로 합니다.
+DeBERTa 모델은 Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen이 작성한 [DeBERTa: 분리된 어텐션을 활용한 디코딩 강화 BERT](https://huggingface.co/papers/2006.03654)이라는 논문에서 제안되었습니다. 이 모델은 2018년 Google이 발표한 BERT 모델과 2019년 Facebook이 발표한 RoBERTa 모델을 기반으로 합니다.
DeBERTa는 RoBERTa에서 사용된 데이터의 절반만을 사용하여 분리된(disentangled) 어텐션과 향상된 마스크 디코더 학습을 통해 RoBERTa를 개선했습니다.
논문의 초록은 다음과 같습니다:
diff --git a/docs/source/ko/model_doc/encoder-decoder.md b/docs/source/ko/model_doc/encoder-decoder.md
index c5c5535613..60982cb455 100644
--- a/docs/source/ko/model_doc/encoder-decoder.md
+++ b/docs/source/ko/model_doc/encoder-decoder.md
@@ -20,11 +20,11 @@ rendered properly in your Markdown viewer.
[`EncoderDecoderModel`]은 사전 학습된 자동 인코딩(autoencoding) 모델을 인코더로, 사전 학습된 자가 회귀(autoregressive) 모델을 디코더로 활용하여 시퀀스-투-시퀀스(sequence-to-sequence) 모델을 초기화하는 데 이용됩니다.
-사전 학습된 체크포인트를 활용해 시퀀스-투-시퀀스 모델을 초기화하는 것이 시퀀스 생성(sequence generation) 작업에 효과적이라는 점이 Sascha Rothe, Shashi Narayan, Aliaksei Severyn의 논문 [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461)에서 입증되었습니다.
+사전 학습된 체크포인트를 활용해 시퀀스-투-시퀀스 모델을 초기화하는 것이 시퀀스 생성(sequence generation) 작업에 효과적이라는 점이 Sascha Rothe, Shashi Narayan, Aliaksei Severyn의 논문 [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://huggingface.co/papers/1907.12461)에서 입증되었습니다.
[`EncoderDecoderModel`]이 학습/미세 조정된 후에는 다른 모델과 마찬가지로 저장/불러오기가 가능합니다. 자세한 사용법은 예제를 참고하세요.
-이 아키텍처의 한 가지 응용 사례는 두 개의 사전 학습된 [`BertModel`]을 각각 인코더와 디코더로 활용하여 요약 모델(summarization model)을 구축하는 것입니다. 이는 Yang Liu와 Mirella Lapata의 논문 [Text Summarization with Pretrained Encoders](https://arxiv.org/abs/1908.08345)에서 제시된 바 있습니다.
+이 아키텍처의 한 가지 응용 사례는 두 개의 사전 학습된 [`BertModel`]을 각각 인코더와 디코더로 활용하여 요약 모델(summarization model)을 구축하는 것입니다. 이는 Yang Liu와 Mirella Lapata의 논문 [Text Summarization with Pretrained Encoders](https://huggingface.co/papers/1908.08345)에서 제시된 바 있습니다.
## 모델 설정에서 `EncoderDecoderModel`을 무작위 초기화하기[[Randomly initializing `EncoderDecoderModel` from model configurations.]]
diff --git a/docs/source/ko/model_doc/graphormer.md b/docs/source/ko/model_doc/graphormer.md
index fc6aa2c9e2..9e1a893fc5 100644
--- a/docs/source/ko/model_doc/graphormer.md
+++ b/docs/source/ko/model_doc/graphormer.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## 개요[[overview]]
-Graphormer 모델은 Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu가 제안한 [트랜스포머가 그래프 표현에 있어서 정말 약할까?](https://arxiv.org/abs/2106.05234) 라는 논문에서 소개되었습니다. Graphormer는 그래프 트랜스포머 모델입니다. 텍스트 시퀀스 대신 그래프에서 계산을 수행할 수 있도록 수정되었으며, 전처리와 병합 과정에서 임베딩과 관심 특성을 생성한 후 수정된 어텐션을 사용합니다.
+Graphormer 모델은 Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu가 제안한 [트랜스포머가 그래프 표현에 있어서 정말 약할까?](https://huggingface.co/papers/2106.05234) 라는 논문에서 소개되었습니다. Graphormer는 그래프 트랜스포머 모델입니다. 텍스트 시퀀스 대신 그래프에서 계산을 수행할 수 있도록 수정되었으며, 전처리와 병합 과정에서 임베딩과 관심 특성을 생성한 후 수정된 어텐션을 사용합니다.
해당 논문의 초록입니다:
diff --git a/docs/source/ko/model_doc/informer.md b/docs/source/ko/model_doc/informer.md
index 03722545a5..9482933008 100644
--- a/docs/source/ko/model_doc/informer.md
+++ b/docs/source/ko/model_doc/informer.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요[[overview]]
-The Informer 모델은 Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, Wancai Zhang가 제안한 [Informer: 장기 시퀀스 시계열 예측(LSTF)을 위한 더욱 효율적인 트랜스포머(Beyond Efficient Transformer)](https://arxiv.org/abs/2012.07436)라는 논문에서 소개되었습니다.
+The Informer 모델은 Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, Wancai Zhang가 제안한 [Informer: 장기 시퀀스 시계열 예측(LSTF)을 위한 더욱 효율적인 트랜스포머(Beyond Efficient Transformer)](https://huggingface.co/papers/2012.07436)라는 논문에서 소개되었습니다.
이 방법은 확률적 어텐션 메커니즘을 도입하여 "게으른" 쿼리가 아닌 "활성" 쿼리를 선택하고, 희소 트랜스포머를 제공하여 기존 어텐션의 이차적 계산 및 메모리 요구사항을 완화합니다.
diff --git a/docs/source/ko/model_doc/llama.md b/docs/source/ko/model_doc/llama.md
index 282befac21..3cd5867584 100644
--- a/docs/source/ko/model_doc/llama.md
+++ b/docs/source/ko/model_doc/llama.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요 [[overview]]
-LLaMA 모델은 Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample에 의해 제안된 [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971)에서 소개되었습니다. 이 모델은 7B에서 65B개의 파라미터까지 다양한 크기의 기초 언어 모델을 모아놓은 것입니다.
+LLaMA 모델은 Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample에 의해 제안된 [LLaMA: Open and Efficient Foundation Language Models](https://huggingface.co/papers/2302.13971)에서 소개되었습니다. 이 모델은 7B에서 65B개의 파라미터까지 다양한 크기의 기초 언어 모델을 모아놓은 것입니다.
논문의 초록은 다음과 같습니다:
diff --git a/docs/source/ko/model_doc/llama2.md b/docs/source/ko/model_doc/llama2.md
index 5290f2bb7b..4975b2e4ab 100644
--- a/docs/source/ko/model_doc/llama2.md
+++ b/docs/source/ko/model_doc/llama2.md
@@ -39,7 +39,7 @@ Llama2 모델은 Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Al
🍯 팁:
- Llama2 모델의 가중치는 [이 양식](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)을 작성하여 얻을 수 있습니다.
-- 아키텍처는 처음 버전의 Llama와 매우 유사하며, [이 논문](https://arxiv.org/pdf/2305.13245.pdf)의 내용에 따라 Grouped Query Attention (GQA)이 추가되었습니다.
+- 아키텍처는 처음 버전의 Llama와 매우 유사하며, [이 논문](https://huggingface.co/papers/2305.13245)의 내용에 따라 Grouped Query Attention (GQA)이 추가되었습니다.
- `config.pretraining_tp`를 1과 다른 값으로 설정하면 더 정확하지만 느린 선형 레이어 계산이 활성화되어 원본 로짓과 더 잘 일치하게 됩니다.
- 원래 모델은 `pad_id = -1`을 사용하는데, 이는 패딩 토큰이 없음을 의미합니다. 동일한 로직을 사용할 수 없으므로 `tokenizer.add_special_tokens({"pad_token":""})`를 사용하여 패딩 토큰을 추가하고 이에 따라 토큰 임베딩 크기를 조정해야 합니다. 또한 `model.config.pad_token_id`를 설정해야 합니다. 모델의 `embed_tokens` 레이어는 `self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.config.padding_idx)`로 초기화되어, 패딩 토큰 인코딩이 0을 출력하도록 합니다. 따라서 초기화 시에 전달하는 것을 권장합니다.
- 양식을 작성하고 모델 체크포인트 접근 권한을 얻은 후에는 이미 변환된 체크포인트를 사용할 수 있습니다. 그렇지 않고 자신의 모델을 직접 변환하려는 경우, [변환 스크립트](https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/convert_llama_weights_to_hf.py)를 자유롭게 사용하세요. 스크립트는 다음과 같은 예시의 명령어로 호출할 수 있습니다:
diff --git a/docs/source/ko/model_doc/mamba.md b/docs/source/ko/model_doc/mamba.md
index 404b9b06b4..4c1b898f2d 100644
--- a/docs/source/ko/model_doc/mamba.md
+++ b/docs/source/ko/model_doc/mamba.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요[[overview]]
-맘바(Mamba) 모델은 Albert Gu, Tri Dao가 제안한 [맘바: 선택적 상태 공간을 이용한 선형 시간 시퀀스 모델링](https://arxiv.org/abs/2312.00752)라는 논문에서 소개 되었습니다.
+맘바(Mamba) 모델은 Albert Gu, Tri Dao가 제안한 [맘바: 선택적 상태 공간을 이용한 선형 시간 시퀀스 모델링](https://huggingface.co/papers/2312.00752)라는 논문에서 소개 되었습니다.
이 모델은 `state-space-models`을 기반으로 한 새로운 패러다임 아키텍처입니다. 직관적인 이해를 얻고 싶다면 [이곳](https://srush.github.io/annotated-s4/)을 참고 하세요.
diff --git a/docs/source/ko/model_doc/mamba2.md b/docs/source/ko/model_doc/mamba2.md
index b023914bc1..c6af73ed95 100644
--- a/docs/source/ko/model_doc/mamba2.md
+++ b/docs/source/ko/model_doc/mamba2.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요[[overview]]
-맘바2 모델은 Tri Dao, Albert Gu가 제안한 [트랜스포머는 SSM이다: 구조화된 상태 공간 이중성을 통한 일반화된 모델과 효율적인 알고리즘](https://arxiv.org/abs/2405.21060)라는 논문에서 소개되었습니다. 맘바2는 맘바1과 유사한 상태 공간 모델로, 단순화된 아키텍처에서 더 나은 성능을 보입니다.
+맘바2 모델은 Tri Dao, Albert Gu가 제안한 [트랜스포머는 SSM이다: 구조화된 상태 공간 이중성을 통한 일반화된 모델과 효율적인 알고리즘](https://huggingface.co/papers/2405.21060)라는 논문에서 소개되었습니다. 맘바2는 맘바1과 유사한 상태 공간 모델로, 단순화된 아키텍처에서 더 나은 성능을 보입니다.
해당 논문의 초록입니다:
diff --git a/docs/source/ko/model_doc/patchtsmixer.md b/docs/source/ko/model_doc/patchtsmixer.md
index e1463eb85d..9b799cd7e4 100644
--- a/docs/source/ko/model_doc/patchtsmixer.md
+++ b/docs/source/ko/model_doc/patchtsmixer.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요[[overview]]
-PatchTSMixer 모델은 Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong, Jayant Kalagnanam이 제안한 [TSMixer: 다변량 시계열 예측을 위한 경량 MLP-Mixer 모델](https://arxiv.org/pdf/2306.09364.pdf)이라는 논문에서 소개되었습니다.
+PatchTSMixer 모델은 Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong, Jayant Kalagnanam이 제안한 [TSMixer: 다변량 시계열 예측을 위한 경량 MLP-Mixer 모델](https://huggingface.co/papers/2306.09364)이라는 논문에서 소개되었습니다.
PatchTSMixer는 MLP-Mixer 아키텍처를 기반으로 한 경량 시계열 모델링 접근법입니다. 허깅페이스 구현에서는 PatchTSMixer의 기능을 제공하여 패치, 채널, 숨겨진 특성 간의 경량 혼합을 쉽게 수행하여 효과적인 다변량 시계열 모델링을 가능하게 합니다. 또한 간단한 게이트 어텐션부터 사용자 정의된 더 복잡한 셀프 어텐션 블록까지 다양한 어텐션 메커니즘을 지원합니다. 이 모델은 사전 훈련될 수 있으며 이후 예측, 분류, 회귀와 같은 다양한 다운스트림 작업에 사용될 수 있습니다.
diff --git a/docs/source/ko/model_doc/patchtst.md b/docs/source/ko/model_doc/patchtst.md
index fc9b0eb51e..d8f1b04e50 100644
--- a/docs/source/ko/model_doc/patchtst.md
+++ b/docs/source/ko/model_doc/patchtst.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요[[overview]]
-The PatchTST 모델은 Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam이 제안한 [시계열 하나가 64개의 단어만큼 가치있다: 트랜스포머를 이용한 장기예측](https://arxiv.org/abs/2211.14730)라는 논문에서 소개되었습니다.
+The PatchTST 모델은 Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam이 제안한 [시계열 하나가 64개의 단어만큼 가치있다: 트랜스포머를 이용한 장기예측](https://huggingface.co/papers/2211.14730)라는 논문에서 소개되었습니다.
이 모델은 고수준에서 시계열을 주어진 크기의 패치로 벡터화하고, 결과로 나온 벡터 시퀀스를 트랜스포머를 통해 인코딩한 다음 적절한 헤드를 통해 예측 길이의 예측을 출력합니다. 모델은 다음 그림과 같이 도식화됩니다:
diff --git a/docs/source/ko/model_doc/qwen2_vl.md b/docs/source/ko/model_doc/qwen2_vl.md
index fb4ed27391..5eb6f3bd11 100644
--- a/docs/source/ko/model_doc/qwen2_vl.md
+++ b/docs/source/ko/model_doc/qwen2_vl.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview[[Overview]]
-[Qwen2-VL](https://qwenlm.github.io/blog/qwen2-vl/) 모델은 알리바바 리서치의 Qwen팀에서 개발한 [Qwen-VL](https://arxiv.org/pdf/2308.12966) 모델의 주요 업데이트 버전입니다.
+[Qwen2-VL](https://qwenlm.github.io/blog/qwen2-vl/) 모델은 알리바바 리서치의 Qwen팀에서 개발한 [Qwen-VL](https://huggingface.co/papers/2308.12966) 모델의 주요 업데이트 버전입니다.
블로그의 요약은 다음과 같습니다:
diff --git a/docs/source/ko/model_doc/rag.md b/docs/source/ko/model_doc/rag.md
index 0ae88cc7ac..0610eaa553 100644
--- a/docs/source/ko/model_doc/rag.md
+++ b/docs/source/ko/model_doc/rag.md
@@ -26,7 +26,7 @@ rendered properly in your Markdown viewer.
검색 증강 생성(Retrieval-augmented generation, "RAG") 모델은 사전 훈련된 밀집 검색(DPR)과 시퀀스-투-시퀀스 모델의 장점을 결합합니다. RAG 모델은 문서를 검색하고, 이를 시퀀스-투-시퀀스 모델에 전달한 다음, 주변화(marginalization)를 통해 출력을 생성합니다. 검색기와 시퀀스-투-시퀀스 모듈은 사전 훈련된 모델로 초기화되며, 함께 미세 조정되어 검색과 생성 모두 다운스트림 작업(모델을 특정 태스크에 적용하는 것)에 적응할 수 있게 합니다.
-이 모델은 Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela의 논문 [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401)를 기반으로 합니다.
+이 모델은 Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela의 논문 [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://huggingface.co/papers/2005.11401)를 기반으로 합니다.
논문의 초록은 다음과 같습니다.
diff --git a/docs/source/ko/model_doc/roberta.md b/docs/source/ko/model_doc/roberta.md
index dace24b5f6..e17d7df90c 100644
--- a/docs/source/ko/model_doc/roberta.md
+++ b/docs/source/ko/model_doc/roberta.md
@@ -26,7 +26,7 @@ rendered properly in your Markdown viewer.
## 개요[[overview]]
-RoBERTa 모델은 Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov가 제안한 논문 [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692)에서 소개되었습니다. 이 모델은 2018년에 구글에서 발표한 BERT 모델을 기반으로 합니다.
+RoBERTa 모델은 Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov가 제안한 논문 [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://huggingface.co/papers/1907.11692)에서 소개되었습니다. 이 모델은 2018년에 구글에서 발표한 BERT 모델을 기반으로 합니다.
RoBERTa는 BERT를 기반으로 하며, 주요 하이퍼파라미터를 수정하고, 사전 학습 단계에서 다음 문장 예측(Next Sentence Prediction)을 제거했으며, 훨씬 더 큰 미니 배치 크기와 학습률을 사용하여 학습을 진행했습니다.
diff --git a/docs/source/ko/model_doc/siglip.md b/docs/source/ko/model_doc/siglip.md
index d0eaf93cf0..cc9d93184b 100644
--- a/docs/source/ko/model_doc/siglip.md
+++ b/docs/source/ko/model_doc/siglip.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## 개요[[overview]]
-SigLIP 모델은 Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer의 [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) 논문에서 제안되었습니다. SigLIP은 [CLIP](clip)에서 사용된 손실 함수를 간단한 쌍별 시그모이드 손실(pairwise sigmoid loss)로 대체할 것을 제안합니다. 이는 ImageNet에서 제로샷 분류 정확도 측면에서 더 나은 성능을 보입니다.
+SigLIP 모델은 Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer의 [Sigmoid Loss for Language Image Pre-Training](https://huggingface.co/papers/2303.15343) 논문에서 제안되었습니다. SigLIP은 [CLIP](clip)에서 사용된 손실 함수를 간단한 쌍별 시그모이드 손실(pairwise sigmoid loss)로 대체할 것을 제안합니다. 이는 ImageNet에서 제로샷 분류 정확도 측면에서 더 나은 성능을 보입니다.
논문의 초록은 다음과 같습니다:
@@ -40,7 +40,7 @@ SigLIP 모델은 Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer
- CLIP과 비교한 SigLIP 평가 결과. 원본 논문에서 발췌.
+ CLIP과 비교한 SigLIP 평가 결과. 원본 논문에서 발췌.
이 모델은 [nielsr](https://huggingface.co/nielsr)가 기여했습니다.
원본 코드는 [여기](https://github.com/google-research/big_vision/tree/main)에서 찾을 수 있습니다.
diff --git a/docs/source/ko/model_doc/swin.md b/docs/source/ko/model_doc/swin.md
index 6919d7e997..ba1088210f 100644
--- a/docs/source/ko/model_doc/swin.md
+++ b/docs/source/ko/model_doc/swin.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요 [[overview]]
-Swin Transformer는 Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo가 제안한 논문 [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030)에서 소개되었습니다.
+Swin Transformer는 Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo가 제안한 논문 [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://huggingface.co/papers/2103.14030)에서 소개되었습니다.
논문의 초록은 다음과 같습니다:
@@ -27,7 +27,7 @@ Swin Transformer는 Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang
- Swin Transformer 아키텍처. 원본 논문에서 발췌.
+ Swin Transformer 아키텍처. 원본 논문에서 발췌.
이 모델은 [novice03](https://huggingface.co/novice03)이 기여하였습니다. Tensorflow 버전은 [amyeroberts](https://huggingface.co/amyeroberts)가 기여했습니다. 원본 코드는 [여기](https://github.com/microsoft/Swin-Transformer)에서 확인할 수 있습니다.
diff --git a/docs/source/ko/model_doc/swin2sr.md b/docs/source/ko/model_doc/swin2sr.md
index 931298b959..30149ad31a 100644
--- a/docs/source/ko/model_doc/swin2sr.md
+++ b/docs/source/ko/model_doc/swin2sr.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요 [[overview]]
-Swin2SR 모델은 Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte가 제안한 논문 [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345)에서 소개되었습니다.
+Swin2SR 모델은 Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte가 제안한 논문 [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://huggingface.co/papers/2209.11345)에서 소개되었습니다.
Swin2SR은 [SwinIR](https://github.com/JingyunLiang/SwinIR/) 모델을 개선하고자 [Swin Transformer v2](swinv2) 레이어를 도입함으로써, 훈련 불안정성, 사전 훈련과 미세 조정 간의 해상도 차이, 그리고 데이터 의존성 문제를 완화시킵니다.
논문의 초록은 다음과 같습니다:
@@ -28,7 +28,7 @@ Swin2SR은 [SwinIR](https://github.com/JingyunLiang/SwinIR/) 모델을 개선하
- Swin2SR 아키텍처. 원본 논문에서 발췌.
+ Swin2SR 아키텍처. 원본 논문에서 발췌.
이 모델은 [nielsr](https://huggingface.co/nielsr)가 기여하였습니다.
원본 코드는 [여기](https://github.com/mv-lab/swin2sr)에서 확인할 수 있습니다.
diff --git a/docs/source/ko/model_doc/swinv2.md b/docs/source/ko/model_doc/swinv2.md
index 3bc420a292..40b9268cb2 100644
--- a/docs/source/ko/model_doc/swinv2.md
+++ b/docs/source/ko/model_doc/swinv2.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요 [[overview]]
-Swin Transformer V2는 Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo가 제안한 논문 [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883)에서 소개되었습니다.
+Swin Transformer V2는 Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo가 제안한 논문 [Swin Transformer V2: Scaling Up Capacity and Resolution](https://huggingface.co/papers/2111.09883)에서 소개되었습니다.
논문의 초록은 다음과 같습니다:
diff --git a/docs/source/ko/model_doc/timesformer.md b/docs/source/ko/model_doc/timesformer.md
index aa75cee447..fb2c2ed007 100644
--- a/docs/source/ko/model_doc/timesformer.md
+++ b/docs/source/ko/model_doc/timesformer.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요 [[overview]]
-TimeSformer 모델은 Facebook Research에서 제안한 [TimeSformer: Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095)에서 소개되었습니다. 이 연구는 첫 번째 비디오 Transformer로서, 행동 인식 분야에서 중요한 이정표가 되었습니다. 또한 Transformer 기반의 비디오 이해 및 분류 논문에 많은 영감을 주었습니다.
+TimeSformer 모델은 Facebook Research에서 제안한 [TimeSformer: Is Space-Time Attention All You Need for Video Understanding?](https://huggingface.co/papers/2102.05095)에서 소개되었습니다. 이 연구는 첫 번째 비디오 Transformer로서, 행동 인식 분야에서 중요한 이정표가 되었습니다. 또한 Transformer 기반의 비디오 이해 및 분류 논문에 많은 영감을 주었습니다.
논문의 초록은 다음과 같습니다.
diff --git a/docs/source/ko/model_doc/trajectory_transformer.md b/docs/source/ko/model_doc/trajectory_transformer.md
index ac279eff04..9f72a6f71e 100644
--- a/docs/source/ko/model_doc/trajectory_transformer.md
+++ b/docs/source/ko/model_doc/trajectory_transformer.md
@@ -26,7 +26,7 @@ rendered properly in your Markdown viewer.
## 개요[[overview]]
-Trajectory Transformer 모델은 Michael Janner, Qiyang Li, Sergey Levine이 제안한 [하나의 커다란 시퀀스 모델링 문제로서의 오프라인 강화학습](https://arxiv.org/abs/2106.02039)라는 논문에서 소개되었습니다.
+Trajectory Transformer 모델은 Michael Janner, Qiyang Li, Sergey Levine이 제안한 [하나의 커다란 시퀀스 모델링 문제로서의 오프라인 강화학습](https://huggingface.co/papers/2106.02039)라는 논문에서 소개되었습니다.
해당 논문의 초록입니다:
diff --git a/docs/source/ko/model_doc/vit.md b/docs/source/ko/model_doc/vit.md
index 5f3eb33427..9ec7af81fd 100644
--- a/docs/source/ko/model_doc/vit.md
+++ b/docs/source/ko/model_doc/vit.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요 [[overview]]
-Vision Transformer (ViT) 모델은 Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby가 제안한 논문 [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929)에서 소개되었습니다. 이는 Transformer 인코더를 ImageNet에서 성공적으로 훈련시킨 첫 번째 논문으로, 기존의 잘 알려진 합성곱 신경망(CNN) 구조와 비교해 매우 우수한 결과를 달성했습니다.
+Vision Transformer (ViT) 모델은 Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby가 제안한 논문 [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://huggingface.co/papers/2010.11929)에서 소개되었습니다. 이는 Transformer 인코더를 ImageNet에서 성공적으로 훈련시킨 첫 번째 논문으로, 기존의 잘 알려진 합성곱 신경망(CNN) 구조와 비교해 매우 우수한 결과를 달성했습니다.
논문의 초록은 다음과 같습니다:
@@ -27,7 +27,7 @@ Vision Transformer (ViT) 모델은 Alexey Dosovitskiy, Lucas Beyer, Alexander Ko
- ViT 아키텍처. 원본 논문에서 발췌.
+ ViT 아키텍처. 원본 논문에서 발췌.
원래의 Vision Transformer에 이어, 여러 후속 연구들이 진행되었습니다:
@@ -52,7 +52,7 @@ alt="drawing" width="600"/>
- Vision Transformer는 모든 이미지가 동일한 크기(해상도)여야 하므로, [ViTImageProcessor]를 사용하여 이미지를 모델에 맞게 리사이즈(또는 리스케일)하고 정규화할 수 있습니다.
- 사전 학습이나 미세 조정 시 사용된 패치 해상도와 이미지 해상도는 각 체크포인트의 이름에 반영됩니다. 예를 들어, `google/vit-base-patch16-224`는 패치 해상도가 16x16이고 미세 조정 해상도가 224x224인 기본 크기 아키텍처를 나타냅니다. 모든 체크포인트는 [hub](https://huggingface.co/models?search=vit)에서 확인할 수 있습니다.
- 사용할 수 있는 체크포인트는 (1) [ImageNet-21k](http://www.image-net.org/) (1,400만 개의 이미지와 21,000개의 클래스)에서만 사전 학습되었거나, 또는 (2) [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/) (ILSVRC 2012, 130만 개의 이미지와 1,000개의 클래스)에서 추가로 미세 조정된 경우입니다.
-- Vision Transformer는 224x224 해상도로 사전 학습되었습니다. 미세 조정 시, 사전 학습보다 더 높은 해상도를 사용하는 것이 유리한 경우가 많습니다 ([(Touvron et al., 2019)](https://arxiv.org/abs/1906.06423), [(Kolesnikovet al., 2020)](https://arxiv.org/abs/1912.11370). 더 높은 해상도로 미세 조정하기 위해, 저자들은 원본 이미지에서의 위치에 따라 사전 학습된 위치 임베딩의 2D 보간(interpolation)을 수행합니다.
+- Vision Transformer는 224x224 해상도로 사전 학습되었습니다. 미세 조정 시, 사전 학습보다 더 높은 해상도를 사용하는 것이 유리한 경우가 많습니다 ([(Touvron et al., 2019)](https://huggingface.co/papers/1906.06423), [(Kolesnikovet al., 2020)](https://huggingface.co/papers/1912.11370). 더 높은 해상도로 미세 조정하기 위해, 저자들은 원본 이미지에서의 위치에 따라 사전 학습된 위치 임베딩의 2D 보간(interpolation)을 수행합니다.
- 최고의 결과는 supervised 방식의 사전 학습에서 얻어졌으며, 이는 NLP에서는 해당되지 않는 경우가 많습니다. 저자들은 마스크된 패치 예측(마스크된 언어 모델링에서 영감을 받은 self-supervised 사전 학습 목표)을 사용한 실험도 수행했습니다. 이 접근 방식으로 더 작은 ViT-B/16 모델은 ImageNet에서 79.9%의 정확도를 달성하였으며, 이는 처음부터 학습한 것보다 2% 개선된 결과이지만, 여전히 supervised 사전 학습보다 4% 낮습니다.
### Scaled Dot Product Attention (SDPA) 사용하기 [[using-scaled-dot-product-attention-sdpa]]
diff --git a/docs/source/ko/model_doc/vivit.md b/docs/source/ko/model_doc/vivit.md
index c9eee17cb2..2ae32af044 100644
--- a/docs/source/ko/model_doc/vivit.md
+++ b/docs/source/ko/model_doc/vivit.md
@@ -14,7 +14,7 @@ specific language governing permissions and limitations under the License.
## 개요 [[overview]]
-Vivit 모델은 Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid가 제안한 논문 [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691)에서 소개되었습니다. 이 논문은 비디오 이해를 위한 pure-transformer 기반의 모델 집합 중에서 최초로 성공한 모델 중 하나를 소개합니다.
+Vivit 모델은 Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid가 제안한 논문 [ViViT: A Video Vision Transformer](https://huggingface.co/papers/2103.15691)에서 소개되었습니다. 이 논문은 비디오 이해를 위한 pure-transformer 기반의 모델 집합 중에서 최초로 성공한 모델 중 하나를 소개합니다.
논문의 초록은 다음과 같습니다:
diff --git a/docs/source/ko/model_memory_anatomy.md b/docs/source/ko/model_memory_anatomy.md
index a5c3a0f352..a729b29a7c 100644
--- a/docs/source/ko/model_memory_anatomy.md
+++ b/docs/source/ko/model_memory_anatomy.md
@@ -187,7 +187,7 @@ GPU memory occupied: 14949 MB.
이러한 지식은 성능 병목 현상을 분석할 때 도움이 될 수 있습니다.
-이 내용은 [Data Movement Is All You Need: A Case Study on Optimizing Transformers 2020](https://arxiv.org/abs/2007.00072)을 참고하였습니다.
+이 내용은 [Data Movement Is All You Need: A Case Study on Optimizing Transformers 2020](https://huggingface.co/papers/2007.00072)을 참고하였습니다.
## 모델의 메모리 구조 [[anatomy-of-models-memory]]
diff --git a/docs/source/ko/model_summary.md b/docs/source/ko/model_summary.md
index 568b942533..549ec37473 100644
--- a/docs/source/ko/model_summary.md
+++ b/docs/source/ko/model_summary.md
@@ -16,7 +16,7 @@ rendered properly in your Markdown viewer.
# Transformer 모델군[[the-transformer-model-family]]
-2017년에 소개된 [기본 Transformer](https://arxiv.org/abs/1706.03762) 모델은 자연어 처리(NLP) 작업을 넘어 새롭고 흥미로운 모델들에 영감을 주었습니다. [단백질 접힘 구조 예측](https://huggingface.co/blog/deep-learning-with-proteins), [치타의 달리기 훈련](https://huggingface.co/blog/train-decision-transformers), [시계열 예측](https://huggingface.co/blog/time-series-transformers) 등을 위한 다양한 모델이 생겨났습니다. Transformer의 변형이 너무 많아서, 큰 그림을 놓치기 쉽습니다. 하지만 여기 있는 모든 모델의 공통점은 기본 Trasnformer 아키텍처를 기반으로 한다는 점입니다. 일부 모델은 인코더 또는 디코더만 사용하고, 다른 모델들은 인코더와 디코더를 모두 사용하기도 합니다. 이렇게 Transformer 모델군 내 상위 레벨에서의 차이점을 분류하고 검토하면 유용한 분류 체계를 얻을 수 있으며, 이전에 접해보지 못한 Transformer 모델들 또한 이해하는 데 도움이 될 것입니다.
+2017년에 소개된 [기본 Transformer](https://huggingface.co/papers/1706.03762) 모델은 자연어 처리(NLP) 작업을 넘어 새롭고 흥미로운 모델들에 영감을 주었습니다. [단백질 접힘 구조 예측](https://huggingface.co/blog/deep-learning-with-proteins), [치타의 달리기 훈련](https://huggingface.co/blog/train-decision-transformers), [시계열 예측](https://huggingface.co/blog/time-series-transformers) 등을 위한 다양한 모델이 생겨났습니다. Transformer의 변형이 너무 많아서, 큰 그림을 놓치기 쉽습니다. 하지만 여기 있는 모든 모델의 공통점은 기본 Trasnformer 아키텍처를 기반으로 한다는 점입니다. 일부 모델은 인코더 또는 디코더만 사용하고, 다른 모델들은 인코더와 디코더를 모두 사용하기도 합니다. 이렇게 Transformer 모델군 내 상위 레벨에서의 차이점을 분류하고 검토하면 유용한 분류 체계를 얻을 수 있으며, 이전에 접해보지 못한 Transformer 모델들 또한 이해하는 데 도움이 될 것입니다.
기본 Transformer 모델에 익숙하지 않거나 복습이 필요한 경우, Hugging Face 강의의 [트랜스포머는 어떻게 동작하나요?](https://huggingface.co/course/chapter1/4?fw=pt) 챕터를 확인하세요.
@@ -32,7 +32,7 @@ rendered properly in your Markdown viewer.
### 합성곱 네트워크[[convolutional-network]]
-[Vision Transformer](https://arxiv.org/abs/2010.11929)가 확장성과 효율성을 입증하기 전까지 오랫동안 합성곱 네트워크(CNN)가 컴퓨터 비전 작업의 지배적인 패러다임이었습니다. 그럼에도 불구하고, 이동 불변성(translation invariance)과 같은 CNN의 우수한 부분이 도드라지기 때문에 몇몇 (특히 특정 과업에서의) Transformer 모델은 아키텍처에 합성곱을 통합하기도 했습니다. [ConvNeXt](model_doc/convnext)는 이런 관례를 뒤집어 CNN을 현대화하기 위해 Transformer의 디자인을 차용합니다. 예를 들면 ConvNeXt는 겹치지 않는 슬라이딩 창(sliding window)을 사용하여 이미지를 패치화하고, 더 큰 커널로 전역 수용 필드(global receptive field)를 확장시킵니다. ConvNeXt는 또한 메모리 효율을 높이고 성능을 향상시키기 위해 여러 레이어 설계를 선택하기 때문에 Transformer와 견줄만합니다!
+[Vision Transformer](https://huggingface.co/papers/2010.11929)가 확장성과 효율성을 입증하기 전까지 오랫동안 합성곱 네트워크(CNN)가 컴퓨터 비전 작업의 지배적인 패러다임이었습니다. 그럼에도 불구하고, 이동 불변성(translation invariance)과 같은 CNN의 우수한 부분이 도드라지기 때문에 몇몇 (특히 특정 과업에서의) Transformer 모델은 아키텍처에 합성곱을 통합하기도 했습니다. [ConvNeXt](model_doc/convnext)는 이런 관례를 뒤집어 CNN을 현대화하기 위해 Transformer의 디자인을 차용합니다. 예를 들면 ConvNeXt는 겹치지 않는 슬라이딩 창(sliding window)을 사용하여 이미지를 패치화하고, 더 큰 커널로 전역 수용 필드(global receptive field)를 확장시킵니다. ConvNeXt는 또한 메모리 효율을 높이고 성능을 향상시키기 위해 여러 레이어 설계를 선택하기 때문에 Transformer와 견줄만합니다!
### 인코더[[cv-encoder]]
@@ -58,7 +58,7 @@ BeIT와 ViTMAE와 같은 다른 비전 모델은 BERT의 사전훈련 목표(obj
[BERT](model_doc/bert)는 인코더 전용 Transformer로, 다른 토큰을 보고 소위 "부정 행위"를 저지르는 걸 막기 위해 입력에서 특정 토큰을 임의로 마스킹합니다. 사전훈련의 목표는 컨텍스트를 기반으로 마스킹된 토큰을 예측하는 것입니다. 이를 통해 BERT는 왼쪽과 오른쪽 컨텍스트를 충분히 활용하여 입력에 대해 더 깊고 풍부한 표현을 학습할 수 있습니다. 그러나 BERT의 사전훈련 전략에는 여전히 개선의 여지가 남아 있었습니다. [RoBERTa](model_doc/roberta)는 더 긴 시간 동안 더 큰 배치에 대한 훈련을 포함하고, 전처리 중에 한 번만 마스킹하는 것이 아니라 각 에폭에서 토큰을 임의로 마스킹하고, 다음 문장 예측 목표를 제거하는 새로운 사전훈련 방식을 도입함으로써 이를 개선했습니다.
-성능 개선을 위한 전략으로 모델 크기를 키우는 것이 지배적입니다. 하지만 큰 모델을 훈련하려면 계산 비용이 많이 듭니다. 계산 비용을 줄이는 한 가지 방법은 [DistilBERT](model_doc/distilbert)와 같이 작은 모델을 사용하는 것입니다. DistilBERT는 압축 기법인 [지식 증류(knowledge distillation)](https://arxiv.org/abs/1503.02531)를 사용하여, 거의 모든 언어 이해 능력을 유지하면서 더 작은 버전의 BERT를 만듭니다.
+성능 개선을 위한 전략으로 모델 크기를 키우는 것이 지배적입니다. 하지만 큰 모델을 훈련하려면 계산 비용이 많이 듭니다. 계산 비용을 줄이는 한 가지 방법은 [DistilBERT](model_doc/distilbert)와 같이 작은 모델을 사용하는 것입니다. DistilBERT는 압축 기법인 [지식 증류(knowledge distillation)](https://huggingface.co/papers/1503.02531)를 사용하여, 거의 모든 언어 이해 능력을 유지하면서 더 작은 버전의 BERT를 만듭니다.
그러나 대부분의 Transformer 모델에 더 많은 매개변수를 사용하는 경향이 이어졌고, 이에 따라 훈련 효율성을 개선하는 것에 중점을 둔 새로운 모델이 등장했습니다. [ALBERT](model_doc/albert)는 두 가지 방법으로 매개변수 수를 줄여 메모리 사용량을 줄였습니다. 바로 큰 어휘를 두 개의 작은 행렬로 분리하는 것과 레이어가 매개변수를 공유하도록 하는 것입니다. [DeBERTa](model_doc/deberta)는 단어와 그 위치를 두 개의 벡터로 개별적으로 인코딩하는 분리된(disentangled) 어텐션 메커니즘을 추가했습니다. 어텐션은 단어와 위치 임베딩을 포함하는 단일 벡터 대신 이 별도의 벡터에서 계산됩니다. [Longformer](model_doc/longformer)는 특히 시퀀스 길이가 긴 문서를 처리할 때, 어텐션을 더 효율적으로 만드는 것에 중점을 두었습니다. 지역(local) 윈도우 어텐션(각 토큰 주변의 고정된 윈도우 크기에서만 계산되는 어텐션)과 전역(global) 어텐션(분류를 위해 `[CLS]`와 같은 특정 작업 토큰에만 해당)의 조합을 사용하여 전체(full) 어텐션 행렬 대신 희소(sparse) 어텐션 행렬을 생성합니다.
diff --git a/docs/source/ko/peft.md b/docs/source/ko/peft.md
index d4ef0ba539..7655a2c6b5 100644
--- a/docs/source/ko/peft.md
+++ b/docs/source/ko/peft.md
@@ -44,7 +44,7 @@ pip install git+https://github.com/huggingface/peft.git
- [Low Rank Adapters](https://huggingface.co/docs/peft/conceptual_guides/lora)
- [IA3](https://huggingface.co/docs/peft/conceptual_guides/ia3)
-- [AdaLoRA](https://arxiv.org/abs/2303.10512)
+- [AdaLoRA](https://huggingface.co/papers/2303.10512)
🤗 PEFT와 관련된 다른 방법(예: 프롬프트 훈련 또는 프롬프트 튜닝) 또는 일반적인 🤗 PEFT 라이브러리에 대해 자세히 알아보려면 [문서](https://huggingface.co/docs/peft/index)를 참조하세요.
diff --git a/docs/source/ko/perf_infer_gpu_one.md b/docs/source/ko/perf_infer_gpu_one.md
index d6ddca6cd0..5936c82e07 100644
--- a/docs/source/ko/perf_infer_gpu_one.md
+++ b/docs/source/ko/perf_infer_gpu_one.md
@@ -101,13 +101,13 @@ model_4bit = AutoModelForCausalLM.from_pretrained(
-[`LLM.int8() : 8-bit Matrix Multiplication for Transformers at Scale`](https://arxiv.org/abs/2208.07339) 논문에서 우리는 몇 줄의 코드로 Hub의 모든 모델에 대한 Hugging Face 통합을 지원합니다.
+[`LLM.int8() : 8-bit Matrix Multiplication for Transformers at Scale`](https://huggingface.co/papers/2208.07339) 논문에서 우리는 몇 줄의 코드로 Hub의 모든 모델에 대한 Hugging Face 통합을 지원합니다.
이 방법은 `float16` 및 `bfloat16` 가중치에 대해 `nn.Linear` 크기를 2배로 줄이고, `float32` 가중치에 대해 4배로 줄입니다. 이는 절반 정밀도에서 이상치를 처리함으로써 품질에 거의 영향을 미치지 않습니다.

Int8 혼합 정밀도 행렬 분해는 행렬 곱셈을 두 개의 스트림으로 분리합니다: (1) fp16로 곱해지는 체계적인 특이값 이상치 스트림 행렬(0.01%) 및 (2) int8 행렬 곱셈의 일반적인 스트림(99.9%). 이 방법을 사용하면 매우 큰 모델에 대해 예측 저하 없이 int8 추론이 가능합니다.
-이 방법에 대한 자세한 내용은 [논문](https://arxiv.org/abs/2208.07339)이나 [통합에 관한 블로그 글](https://huggingface.co/blog/hf-bitsandbytes-integration)에서 확인할 수 있습니다.
+이 방법에 대한 자세한 내용은 [논문](https://huggingface.co/papers/2208.07339)이나 [통합에 관한 블로그 글](https://huggingface.co/blog/hf-bitsandbytes-integration)에서 확인할 수 있습니다.

diff --git a/docs/source/ko/perf_train_gpu_many.md b/docs/source/ko/perf_train_gpu_many.md
index b8553ea499..801e06e276 100644
--- a/docs/source/ko/perf_train_gpu_many.md
+++ b/docs/source/ko/perf_train_gpu_many.md
@@ -316,7 +316,7 @@ DP + PP 설정의 전역 배치 크기를 계산하려면 `mbs*chunks*dp_degree`
- [DeepSpeed](https://www.deepspeed.ai/tutorials/pipeline/)
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)은 내부 구현을 가지고 있습니다 - API 없음.
- [Varuna](https://github.com/microsoft/varuna)
-- [SageMaker](https://arxiv.org/abs/2111.05972) - 이는 AWS에서만 사용할 수 있는 소유 솔루션입니다.
+- [SageMaker](https://huggingface.co/papers/2111.05972) - 이는 AWS에서만 사용할 수 있는 소유 솔루션입니다.
- [OSLO](https://github.com/tunib-ai/oslo) - 이는 Hugging Face Transformers를 기반으로 구현된 파이프라인 병렬화입니다.
🤗 Transformers 상태: 이 작성 시점에서 모델 중 어느 것도 완전한 PP를 지원하지 않습니다. GPT2와 T5 모델은 naive MP를 지원합니다. 주요 장애물은 모델을 `nn.Sequential`로 변환하고 모든 입력을 텐서로 가져와야 하는 것을 처리할 수 없기 때문입니다. 현재 모델에는 이러한 변환을 매우 복잡하게 만드는 많은 기능이 포함되어 있어 제거해야 합니다.
@@ -336,7 +336,7 @@ OSLO는 `nn.Sequential`로 변환하지 않고 Transformers를 기반으로 한
텐서 병렬 처리에서는 각 GPU가 텐서의 일부분만 처리하고 전체 텐서가 필요한 연산에 대해서만 전체 텐서를 집계합니다.
-이 섹션에서는 [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) 논문인 [Efficient Large-Scale Language Model Training on GPU Clusters](https://arxiv.org/abs/2104.04473)에서의 개념과 다이어그램을 사용합니다.
+이 섹션에서는 [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) 논문인 [Efficient Large-Scale Language Model Training on GPU Clusters](https://huggingface.co/papers/2104.04473)에서의 개념과 다이어그램을 사용합니다.
Transformer의 주요 구성 요소는 fully connected `nn.Linear`와 비선형 활성화 함수인 `GeLU`입니다.
@@ -367,7 +367,7 @@ SageMaker는 더 효율적인 처리를 위해 TP와 DP를 결합합니다.
구현:
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)은 내부 구현을 가지고 있으므로 모델에 매우 특화되어 있습니다.
- [parallelformers](https://github.com/tunib-ai/parallelformers) (현재는 추론에만 해당)
-- [SageMaker](https://arxiv.org/abs/2111.05972) - 이는 AWS에서만 사용할 수 있는 소유 솔루션입니다.
+- [SageMaker](https://huggingface.co/papers/2111.05972) - 이는 AWS에서만 사용할 수 있는 소유 솔루션입니다.
- [OSLO](https://github.com/tunib-ai/oslo)은 Transformers를 기반으로 한 텐서 병렬 처리 구현을 가지고 있습니다.
🤗 Transformers 현황:
@@ -389,7 +389,7 @@ DeepSpeed [pipeline tutorial](https://www.deepspeed.ai/tutorials/pipeline/)에
- [DeepSpeed](https://github.com/deepspeedai/DeepSpeed)
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
- [Varuna](https://github.com/microsoft/varuna)
-- [SageMaker](https://arxiv.org/abs/2111.05972)
+- [SageMaker](https://huggingface.co/papers/2111.05972)
- [OSLO](https://github.com/tunib-ai/oslo)
🤗 Transformers 현황: 아직 구현되지 않음
@@ -408,7 +408,7 @@ DeepSpeed [pipeline tutorial](https://www.deepspeed.ai/tutorials/pipeline/)에
- [DeepSpeed](https://github.com/deepspeedai/DeepSpeed) - DeepSpeed는 더욱 효율적인 DP인 ZeRO-DP라고도 부릅니다.
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
- [Varuna](https://github.com/microsoft/varuna)
-- [SageMaker](https://arxiv.org/abs/2111.05972)
+- [SageMaker](https://huggingface.co/papers/2111.05972)
- [OSLO](https://github.com/tunib-ai/oslo)
🤗 Transformers 현황: 아직 구현되지 않음. PP와 TP가 없기 때문입니다.
@@ -434,7 +434,7 @@ ZeRO 단계 3도 같은 이유로 좋은 선택이 아닙니다 - 더 많은 노
중요한 논문:
- [Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model](
-https://arxiv.org/abs/2201.11990)
+https://huggingface.co/papers/2201.11990)
🤗 Transformers 현황: 아직 구현되지 않음, PP와 TP가 없기 때문입니다.
@@ -442,7 +442,7 @@ https://arxiv.org/abs/2201.11990)
[FlexFlow](https://github.com/flexflow/FlexFlow)는 약간 다른 방식으로 병렬화 문제를 해결합니다.
-논문: ["Beyond Data and Model Parallelism for Deep Neural Networks" by Zhihao Jia, Matei Zaharia, Alex Aiken](https://arxiv.org/abs/1807.05358)
+논문: ["Beyond Data and Model Parallelism for Deep Neural Networks" by Zhihao Jia, Matei Zaharia, Alex Aiken](https://huggingface.co/papers/1807.05358)
이는 Sample-Operator-Attribute-Parameter를 기반으로 하는 일종의 4D 병렬화를 수행합니다.
diff --git a/docs/source/ko/tasks/knowledge_distillation_for_image_classification.md b/docs/source/ko/tasks/knowledge_distillation_for_image_classification.md
index 37c0cc2508..72cfbcf57a 100644
--- a/docs/source/ko/tasks/knowledge_distillation_for_image_classification.md
+++ b/docs/source/ko/tasks/knowledge_distillation_for_image_classification.md
@@ -17,7 +17,7 @@ rendered properly in your Markdown viewer.
[[open-in-colab]]
-지식 증류(Knowledge distillation)는 더 크고 복잡한 모델(교사)에서 더 작고 간단한 모델(학생)로 지식을 전달하는 기술입니다. 한 모델에서 다른 모델로 지식을 증류하기 위해, 특정 작업(이 경우 이미지 분류)에 대해 학습된 사전 훈련된 교사 모델을 사용하고, 랜덤으로 초기화된 학생 모델을 이미지 분류 작업에 대해 학습합니다. 그다음, 학생 모델이 교사 모델의 출력을 모방하여 두 모델의 출력 차이를 최소화하도록 훈련합니다. 이 기법은 Hinton 등 연구진의 [Distilling the Knowledge in a Neural Network](https://arxiv.org/abs/1503.02531)에서 처음 소개되었습니다. 이 가이드에서는 특정 작업에 맞춘 지식 증류를 수행할 것입니다. 이번에는 [beans dataset](https://huggingface.co/datasets/beans)을 사용할 것입니다.
+지식 증류(Knowledge distillation)는 더 크고 복잡한 모델(교사)에서 더 작고 간단한 모델(학생)로 지식을 전달하는 기술입니다. 한 모델에서 다른 모델로 지식을 증류하기 위해, 특정 작업(이 경우 이미지 분류)에 대해 학습된 사전 훈련된 교사 모델을 사용하고, 랜덤으로 초기화된 학생 모델을 이미지 분류 작업에 대해 학습합니다. 그다음, 학생 모델이 교사 모델의 출력을 모방하여 두 모델의 출력 차이를 최소화하도록 훈련합니다. 이 기법은 Hinton 등 연구진의 [Distilling the Knowledge in a Neural Network](https://huggingface.co/papers/1503.02531)에서 처음 소개되었습니다. 이 가이드에서는 특정 작업에 맞춘 지식 증류를 수행할 것입니다. 이번에는 [beans dataset](https://huggingface.co/datasets/beans)을 사용할 것입니다.
이 가이드는 [미세 조정된 ViT 모델](https://huggingface.co/merve/vit-mobilenet-beans-224) (교사 모델)을 [MobileNet](https://huggingface.co/google/mobilenet_v2_1.4_224) (학생 모델)으로 증류하는 방법을 🤗 Transformers의 [Trainer API](https://huggingface.co/docs/transformers/en/main_classes/trainer#trainer) 를 사용하여 보여줍니다.
diff --git a/docs/source/ko/tasks/video_classification.md b/docs/source/ko/tasks/video_classification.md
index 10569083c0..d39d669f8a 100644
--- a/docs/source/ko/tasks/video_classification.md
+++ b/docs/source/ko/tasks/video_classification.md
@@ -383,7 +383,7 @@ def compute_metrics(eval_pred):
**평가에 대한 참고사항**:
-[VideoMAE 논문](https://arxiv.org/abs/2203.12602)에서 저자는 다음과 같은 평가 전략을 사용합니다. 테스트 영상에서 여러 클립을 선택하고 그 클립에 다양한 크롭을 적용하여 집계 점수를 보고합니다. 그러나 이번 튜토리얼에서는 간단함과 간결함을 위해 해당 전략을 고려하지 않습니다.
+[VideoMAE 논문](https://huggingface.co/papers/2203.12602)에서 저자는 다음과 같은 평가 전략을 사용합니다. 테스트 영상에서 여러 클립을 선택하고 그 클립에 다양한 크롭을 적용하여 집계 점수를 보고합니다. 그러나 이번 튜토리얼에서는 간단함과 간결함을 위해 해당 전략을 고려하지 않습니다.
또한, 예제를 묶어서 배치를 형성하는 `collate_fn`을 정의해야합니다. 각 배치는 `pixel_values`와 `labels`라는 2개의 키로 구성됩니다.
diff --git a/docs/source/ko/tasks_explained.md b/docs/source/ko/tasks_explained.md
index 78c90849bb..57ccd57a79 100644
--- a/docs/source/ko/tasks_explained.md
+++ b/docs/source/ko/tasks_explained.md
@@ -120,7 +120,7 @@ ViT가 도입한 주요 변경 사항은 이미지가 Transformer로 어떻게
-패딩이나 보폭이 없는 기본 합성곱, 딥러닝을 위한 합성곱 연산 가이드
+패딩이나 보폭이 없는 기본 합성곱, 딥러닝을 위한 합성곱 연산 가이드
이 출력을 다른 합성곱 레이어에 전달할 수 있으며, 각 연속적인 레이어를 통해 네트워크는 핫도그나 로켓과 같이 더 복잡하고 추상적인 것을 학습합니다. 합성곱 레이어 사이에 풀링 레이어를 추가하여 차원을 줄이고 특징의 위치 변화에 대해 모델을 더 견고하게 만드는 것이 일반적입니다.
diff --git a/docs/source/ko/tokenizer_summary.md b/docs/source/ko/tokenizer_summary.md
index 0a4ece29a4..1fbd40b99e 100644
--- a/docs/source/ko/tokenizer_summary.md
+++ b/docs/source/ko/tokenizer_summary.md
@@ -127,7 +127,7 @@ rendered properly in your Markdown viewer.
### 바이트 페어 인코딩 (Byte-Pair Encoding, BPE)[[bytepair-encoding-bpe]]
바이트 페어 인코딩(BPE)은 [Neural Machine Translation of Rare Words with Subword Units (Sennrich et
-al., 2015)](https://arxiv.org/abs/1508.07909) 에서 소개되었습니다.
+al., 2015)](https://huggingface.co/papers/1508.07909) 에서 소개되었습니다.
BPE는 훈련 데이터를 단어로 분할하는 사전 토크나이저(pre-tokenizer)에 의존합니다.
사전 토큰화(Pretokenization)에는 [GPT-2](model_doc/gpt2), [Roberta](model_doc/roberta)와 같은 간단한 공백 토큰화가 있습니다.
복잡한 사전 토큰화에는 규칙 기반 토큰화가 해당하는데, 훈련 말뭉치에서 각 단어의 빈도를 계산하기 위해 사용합니다.
@@ -205,7 +205,7 @@ BPE와는 대조적으로 워드피스는 가장 빈도수가 높은 기호 쌍
### 유니그램 (Unigram)[[unigram]]
-유니그램은 [Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates (Kudo, 2018)](https://arxiv.org/pdf/1804.10959.pdf)에서 제안된 서브워드 토큰화 알고리즘입니다.
+유니그램은 [Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates (Kudo, 2018)](https://huggingface.co/papers/1804.10959)에서 제안된 서브워드 토큰화 알고리즘입니다.
BPE나 워드피스와 달리 유니그램은 기본 어휘를 많은 수의 기호로 초기화한 후 각 기호를 점진적으로 줄여 더 작은 어휘를 얻습니다.
예를 들어 기본 어휘는 모든 사전 토큰화된 단어와 가장 일반적인 하위 문자열에 해당할 수 있습니다.
유니그램은 transformers 모델에서 직접적으로 사용되지는 않지만, [SentencePiece](#sentencepiece)와 함께 사용됩니다.
@@ -243,7 +243,7 @@ $$\mathcal{L} = -\sum_{i=1}^{N} \log \left ( \sum_{x \in S(x_{i})} p(x) \right )
지금까지 다룬 토큰화 알고리즘은 동일한 문제를 가집니다: 입력 텍스트는 공백을 사용하여 단어를 구분한다고 가정합니다.
하지만, 모든 언어에서 단어를 구분하기 위해 공백을 사용하지 않습니다.
한가지 가능한 해결방안은 특정 언어에 특화된 사전 토크나이저를 사용하는 것입니다. 예를 들어 [XLM](model_doc/xlm)은 특정 중국어, 일본어, 태국어 사전 토크나이저를 사용합니다.
-이 문제를 일반적인 방법으로 해결하기 위해, [SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing (Kudo et al., 2018)](https://arxiv.org/pdf/1808.06226.pdf)는 입력을 스트림으로 처리해 공백를 하나의 문자로 사용합니다.
+이 문제를 일반적인 방법으로 해결하기 위해, [SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing (Kudo et al., 2018)](https://huggingface.co/papers/1808.06226)는 입력을 스트림으로 처리해 공백를 하나의 문자로 사용합니다.
이후에 BPE 또는 유니그램 알고리즘을 사용해 적절한 어휘를 구성합니다.
[`XLNetTokenizer`]는 센텐스피스를 사용하기 때문에, 위에서 다룬 예시에서 어휘에 `"▁"`가 포함되어있습니다.
diff --git a/docs/source/ko/trainer.md b/docs/source/ko/trainer.md
index 7def9cccd8..072e081a36 100644
--- a/docs/source/ko/trainer.md
+++ b/docs/source/ko/trainer.md
@@ -339,7 +339,7 @@ trainer = trl.SFTTrainer(
trainer.train()
```
-해당 방법에 대한 자세한 내용은 [원본 리포지토리](https://github.com/jiaweizzhao/GaLore) 또는 [논문](https://arxiv.org/abs/2403.03507)을 참고하세요.
+해당 방법에 대한 자세한 내용은 [원본 리포지토리](https://github.com/jiaweizzhao/GaLore) 또는 [논문](https://huggingface.co/papers/2403.03507)을 참고하세요.
현재 GaLore 레이어로 간주되는 Linear 레이어만 훈련 할수 있으며, 저계수 분해를 사용하여 훈련되고 나머지 레이어는 기존 방식으로 최적화됩니다.
diff --git a/docs/source/ms/index.md b/docs/source/ms/index.md
index e0adb8a8a8..d4c7eecd0b 100644
--- a/docs/source/ms/index.md
+++ b/docs/source/ms/index.md
@@ -53,212 +53,212 @@ Dokumentasi disusun kepada lima bahagian:
-1. **[ALBERT](model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
-1. **[ALIGN](model_doc/align)** (from Google Research) released with the paper [Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://arxiv.org/abs/2102.05918) by Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig.
-1. **[AltCLIP](model_doc/altclip)** (from BAAI) released with the paper [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) by Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell.
-1. **[Audio Spectrogram Transformer](model_doc/audio-spectrogram-transformer)** (from MIT) released with the paper [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
-1. **[Autoformer](model_doc/autoformer)** (from Tsinghua University) released with the paper [Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008) by Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long.
-1. **[BART](model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
-1. **[BARThez](model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
-1. **[BARTpho](model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
-1. **[BEiT](model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
-1. **[BERT](model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
-1. **[BERT For Sequence Generation](model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[ALBERT](model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://huggingface.co/papers/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
+1. **[ALIGN](model_doc/align)** (from Google Research) released with the paper [Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://huggingface.co/papers/2102.05918) by Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig.
+1. **[AltCLIP](model_doc/altclip)** (from BAAI) released with the paper [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://huggingface.co/papers/2211.06679) by Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell.
+1. **[Audio Spectrogram Transformer](model_doc/audio-spectrogram-transformer)** (from MIT) released with the paper [AST: Audio Spectrogram Transformer](https://huggingface.co/papers/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
+1. **[Autoformer](model_doc/autoformer)** (from Tsinghua University) released with the paper [Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://huggingface.co/papers/2106.13008) by Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long.
+1. **[BART](model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://huggingface.co/papers/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
+1. **[BARThez](model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://huggingface.co/papers/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
+1. **[BARTpho](model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://huggingface.co/papers/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
+1. **[BEiT](model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://huggingface.co/papers/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
+1. **[BERT](model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://huggingface.co/papers/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
+1. **[BERT For Sequence Generation](model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://huggingface.co/papers/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
1. **[BERTweet](model_doc/bertweet)** (from VinAI Research) released with the paper [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) by Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen.
-1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
-1. **[BigBird-RoBERTa](model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://huggingface.co/papers/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[BigBird-RoBERTa](model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://huggingface.co/papers/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
1. **[BioGpt](model_doc/biogpt)** (from Microsoft Research AI4Science) released with the paper [BioGPT: generative pre-trained transformer for biomedical text generation and mining](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9) by Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon and Tie-Yan Liu.
-1. **[BiT](model_doc/bit)** (from Google AI) released with the paper [Big Transfer (BiT): General Visual Representation Learning](https://arxiv.org/abs/1912.11370) by Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby.
-1. **[Blenderbot](model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
-1. **[BlenderbotSmall](model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
-1. **[BLIP](model_doc/blip)** (from Salesforce) released with the paper [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) by Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
-1. **[BLIP-2](model_doc/blip-2)** (from Salesforce) released with the paper [BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://arxiv.org/abs/2301.12597) by Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi.
+1. **[BiT](model_doc/bit)** (from Google AI) released with the paper [Big Transfer (BiT): General Visual Representation Learning](https://huggingface.co/papers/1912.11370) by Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby.
+1. **[Blenderbot](model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://huggingface.co/papers/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BlenderbotSmall](model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://huggingface.co/papers/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BLIP](model_doc/blip)** (from Salesforce) released with the paper [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://huggingface.co/papers/2201.12086) by Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
+1. **[BLIP-2](model_doc/blip-2)** (from Salesforce) released with the paper [BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://huggingface.co/papers/2301.12597) by Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi.
1. **[BLOOM](model_doc/bloom)** (from BigScience workshop) released by the [BigScience Workshop](https://bigscience.huggingface.co/).
-1. **[BORT](model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
-1. **[BridgeTower](model_doc/bridgetower)** (from Harbin Institute of Technology/Microsoft Research Asia/Intel Labs) released with the paper [BridgeTower: Building Bridges Between Encoders in Vision-Language Representation Learning](https://arxiv.org/abs/2206.08657) by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan.
-1. **[Bros](model_doc/bros)** (from NAVER) released with the paper [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://arxiv.org/abs/2108.04539) by Teakgyu Hong, Donghyun Kim, Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park.
-1. **[ByT5](model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
-1. **[CamemBERT](model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
-1. **[CANINE](model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
-1. **[Chinese-CLIP](model_doc/chinese_clip)** (from OFA-Sys) released with the paper [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://arxiv.org/abs/2211.01335) by An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou.
-1. **[CLAP](model_doc/clap)** (from LAION-AI) released with the paper [Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation](https://arxiv.org/abs/2211.06687) by Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov.
-1. **[CLIP](model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
-1. **[CLIPSeg](model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
-1. **[CodeGen](model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
-1. **[Conditional DETR](model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
-1. **[ConvBERT](model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
-1. **[ConvNeXT](model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
-1. **[ConvNeXTV2](model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
-1. **[CPM](model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
+1. **[BORT](model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://huggingface.co/papers/2010.10499) by Adrian de Wynter and Daniel J. Perry.
+1. **[BridgeTower](model_doc/bridgetower)** (from Harbin Institute of Technology/Microsoft Research Asia/Intel Labs) released with the paper [BridgeTower: Building Bridges Between Encoders in Vision-Language Representation Learning](https://huggingface.co/papers/2206.08657) by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan.
+1. **[Bros](model_doc/bros)** (from NAVER) released with the paper [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://huggingface.co/papers/2108.04539) by Teakgyu Hong, Donghyun Kim, Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park.
+1. **[ByT5](model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://huggingface.co/papers/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
+1. **[CamemBERT](model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://huggingface.co/papers/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
+1. **[CANINE](model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://huggingface.co/papers/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
+1. **[Chinese-CLIP](model_doc/chinese_clip)** (from OFA-Sys) released with the paper [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://huggingface.co/papers/2211.01335) by An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou.
+1. **[CLAP](model_doc/clap)** (from LAION-AI) released with the paper [Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation](https://huggingface.co/papers/2211.06687) by Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov.
+1. **[CLIP](model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://huggingface.co/papers/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
+1. **[CLIPSeg](model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://huggingface.co/papers/2112.10003) by Timo Lüddecke and Alexander Ecker.
+1. **[CodeGen](model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://huggingface.co/papers/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
+1. **[Conditional DETR](model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://huggingface.co/papers/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
+1. **[ConvBERT](model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://huggingface.co/papers/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
+1. **[ConvNeXT](model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://huggingface.co/papers/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
+1. **[ConvNeXTV2](model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://huggingface.co/papers/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
+1. **[CPM](model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://huggingface.co/papers/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
1. **[CPM-Ant](model_doc/cpmant)** (from OpenBMB) released by the [OpenBMB](https://www.openbmb.org/).
-1. **[CTRL](model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
-1. **[CvT](model_doc/cvt)** (from Microsoft) released with the paper [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
-1. **[Data2Vec](model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
-1. **[DeBERTa](model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
-1. **[DeBERTa-v2](model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
-1. **[Decision Transformer](model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
-1. **[Deformable DETR](model_doc/deformable_detr)** (from SenseTime Research) released with the paper [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
-1. **[DeiT](model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
-1. **[DePlot](model_doc/deplot)** (from Google AI) released with the paper [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) by Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.
-1. **[DETA](model_doc/deta)** (from The University of Texas at Austin) released with the paper [NMS Strikes Back](https://arxiv.org/abs/2212.06137) by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
-1. **[DETR](model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
-1. **[DialoGPT](model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
-1. **[DiNAT](model_doc/dinat)** (from SHI Labs) released with the paper [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) by Ali Hassani and Humphrey Shi.
-1. **[DistilBERT](model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers-research-projects/tree/main/distillation) and a German version of DistilBERT.
-1. **[DiT](model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
-1. **[Donut](model_doc/donut)** (from NAVER), released together with the paper [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) by Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park.
-1. **[DPR](model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
-1. **[DPT](master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
-1. **[EfficientFormer](model_doc/efficientformer)** (from Snap Research) released with the paper [EfficientFormer: Vision Transformers at MobileNetSpeed](https://arxiv.org/abs/2206.01191) by Yanyu Li, Geng Yuan, Yang Wen, Ju Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren.
-1. **[EfficientNet](model_doc/efficientnet)** (from Google Brain) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan, Quoc V. Le.
-1. **[ELECTRA](model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
-1. **[EncoderDecoder](model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
-1. **[ERNIE](model_doc/ernie)** (from Baidu) released with the paper [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223) by Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu.
-1. **[ErnieM](model_doc/ernie_m)** (from Baidu) released with the paper [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang.
+1. **[CTRL](model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://huggingface.co/papers/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
+1. **[CvT](model_doc/cvt)** (from Microsoft) released with the paper [CvT: Introducing Convolutions to Vision Transformers](https://huggingface.co/papers/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
+1. **[Data2Vec](model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://huggingface.co/papers/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
+1. **[DeBERTa](model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://huggingface.co/papers/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[DeBERTa-v2](model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://huggingface.co/papers/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[Decision Transformer](model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://huggingface.co/papers/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
+1. **[Deformable DETR](model_doc/deformable_detr)** (from SenseTime Research) released with the paper [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://huggingface.co/papers/2010.04159) by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
+1. **[DeiT](model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://huggingface.co/papers/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
+1. **[DePlot](model_doc/deplot)** (from Google AI) released with the paper [DePlot: One-shot visual language reasoning by plot-to-table translation](https://huggingface.co/papers/2212.10505) by Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.
+1. **[DETA](model_doc/deta)** (from The University of Texas at Austin) released with the paper [NMS Strikes Back](https://huggingface.co/papers/2212.06137) by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
+1. **[DETR](model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://huggingface.co/papers/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
+1. **[DialoGPT](model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://huggingface.co/papers/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
+1. **[DiNAT](model_doc/dinat)** (from SHI Labs) released with the paper [Dilated Neighborhood Attention Transformer](https://huggingface.co/papers/2209.15001) by Ali Hassani and Humphrey Shi.
+1. **[DistilBERT](model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://huggingface.co/papers/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers-research-projects/tree/main/distillation) and a German version of DistilBERT.
+1. **[DiT](model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://huggingface.co/papers/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
+1. **[Donut](model_doc/donut)** (from NAVER), released together with the paper [OCR-free Document Understanding Transformer](https://huggingface.co/papers/2111.15664) by Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park.
+1. **[DPR](model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://huggingface.co/papers/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
+1. **[DPT](master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://huggingface.co/papers/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
+1. **[EfficientFormer](model_doc/efficientformer)** (from Snap Research) released with the paper [EfficientFormer: Vision Transformers at MobileNetSpeed](https://huggingface.co/papers/2206.01191) by Yanyu Li, Geng Yuan, Yang Wen, Ju Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren.
+1. **[EfficientNet](model_doc/efficientnet)** (from Google Brain) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://huggingface.co/papers/1905.11946) by Mingxing Tan, Quoc V. Le.
+1. **[ELECTRA](model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://huggingface.co/papers/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
+1. **[EncoderDecoder](model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://huggingface.co/papers/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[ERNIE](model_doc/ernie)** (from Baidu) released with the paper [ERNIE: Enhanced Representation through Knowledge Integration](https://huggingface.co/papers/1904.09223) by Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu.
+1. **[ErnieM](model_doc/ernie_m)** (from Baidu) released with the paper [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://huggingface.co/papers/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang.
1. **[ESM](model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2 and ESMFold** were released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
1. **[FLAN-T5](model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
1. **[FLAN-UL2](model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
-1. **[FlauBERT](model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
-1. **[FLAVA](model_doc/flava)** (from Facebook AI) released with the paper [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela.
-1. **[FNet](model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
-1. **[FocalNet](model_doc/focalnet)** (from Microsoft Research) released with the paper [Focal Modulation Networks](https://arxiv.org/abs/2203.11926) by Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao.
-1. **[Funnel Transformer](model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
-1. **[GIT](model_doc/git)** (from Microsoft Research) released with the paper [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang.
-1. **[GLPN](model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
+1. **[FlauBERT](model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://huggingface.co/papers/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
+1. **[FLAVA](model_doc/flava)** (from Facebook AI) released with the paper [FLAVA: A Foundational Language And Vision Alignment Model](https://huggingface.co/papers/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela.
+1. **[FNet](model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://huggingface.co/papers/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
+1. **[FocalNet](model_doc/focalnet)** (from Microsoft Research) released with the paper [Focal Modulation Networks](https://huggingface.co/papers/2203.11926) by Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao.
+1. **[Funnel Transformer](model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://huggingface.co/papers/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
+1. **[GIT](model_doc/git)** (from Microsoft Research) released with the paper [GIT: A Generative Image-to-text Transformer for Vision and Language](https://huggingface.co/papers/2205.14100) by Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang.
+1. **[GLPN](model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://huggingface.co/papers/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
1. **[GPT](model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
1. **[GPT Neo](model_doc/gpt_neo)** (from EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
-1. **[GPT NeoX](model_doc/gpt_neox)** (from EleutherAI) released with the paper [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745) by Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
+1. **[GPT NeoX](model_doc/gpt_neox)** (from EleutherAI) released with the paper [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://huggingface.co/papers/2204.06745) by Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
1. **[GPT NeoX Japanese](model_doc/gpt_neox_japanese)** (from ABEJA) released by Shinya Otani, Takayoshi Makabe, Anuj Arora, and Kyo Hattori.
1. **[GPT-2](model_doc/gpt2)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://openai.com/research/better-language-models/) by Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever.
1. **[GPT-J](model_doc/gptj)** (from EleutherAI) released in the repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
1. **[GPT-Sw3](model_doc/gpt-sw3)** (from AI-Sweden) released with the paper [Lessons Learned from GPT-SW3: Building the First Large-Scale Generative Language Model for Swedish](http://www.lrec-conf.org/proceedings/lrec2022/pdf/2022.lrec-1.376.pdf) by Ariel Ekgren, Amaru Cuba Gyllensten, Evangelia Gogoulou, Alice Heiman, Severine Verlinden, Joey Öhman, Fredrik Carlsson, Magnus Sahlgren.
-1. **[GPTBigCode](model_doc/gpt_bigcode)** (from BigCode) released with the paper [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) by Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
+1. **[GPTBigCode](model_doc/gpt_bigcode)** (from BigCode) released with the paper [SantaCoder: don't reach for the stars!](https://huggingface.co/papers/2301.03988) by Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
1. **[GPTSAN-japanese](model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
-1. **[Graphormer](model_doc/graphormer)** (from Microsoft) released with the paper [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) by Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu.
-1. **[GroupViT](model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
-1. **[Hubert](model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
-1. **[I-BERT](model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
+1. **[Graphormer](model_doc/graphormer)** (from Microsoft) released with the paper [Do Transformers Really Perform Bad for Graph Representation?](https://huggingface.co/papers/2106.05234) by Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu.
+1. **[GroupViT](model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://huggingface.co/papers/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
+1. **[Hubert](model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://huggingface.co/papers/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
+1. **[I-BERT](model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://huggingface.co/papers/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
1. **[ImageGPT](model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
-1. **[Informer](model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
-1. **[Jukebox](model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
-1. **[LayoutLM](model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
-1. **[LayoutLMv2](model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
-1. **[LayoutLMv3](model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
-1. **[LayoutXLM](model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
-1. **[LED](model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
-1. **[LeViT](model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
-1. **[LiLT](model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
-1. **[LLaMA](model_doc/llama)** (from The FAIR team of Meta AI) released with the paper [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.
-1. **[Longformer](model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
-1. **[LongT5](model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
-1. **[LUKE](model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
-1. **[LXMERT](model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
-1. **[M-CTC-T](model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
-1. **[M2M100](model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
+1. **[Informer](model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://huggingface.co/papers/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
+1. **[Jukebox](model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://huggingface.co/papers/2005.00341) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
+1. **[LayoutLM](model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://huggingface.co/papers/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
+1. **[LayoutLMv2](model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://huggingface.co/papers/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
+1. **[LayoutLMv3](model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://huggingface.co/papers/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
+1. **[LayoutXLM](model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://huggingface.co/papers/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
+1. **[LED](model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://huggingface.co/papers/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LeViT](model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://huggingface.co/papers/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
+1. **[LiLT](model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://huggingface.co/papers/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
+1. **[LLaMA](model_doc/llama)** (from The FAIR team of Meta AI) released with the paper [LLaMA: Open and Efficient Foundation Language Models](https://huggingface.co/papers/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.
+1. **[Longformer](model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://huggingface.co/papers/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LongT5](model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://huggingface.co/papers/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
+1. **[LUKE](model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://huggingface.co/papers/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
+1. **[LXMERT](model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://huggingface.co/papers/1908.07490) by Hao Tan and Mohit Bansal.
+1. **[M-CTC-T](model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://huggingface.co/papers/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
+1. **[M2M100](model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://huggingface.co/papers/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
1. **[MarianMT](model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
-1. **[MarkupLM](model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
-1. **[Mask2Former](model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
-1. **[MaskFormer](model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
-1. **[MatCha](model_doc/matcha)** (from Google AI) released with the paper [MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering](https://arxiv.org/abs/2212.09662) by Fangyu Liu, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Yasemin Altun, Nigel Collier, Julian Martin Eisenschlos.
-1. **[mBART](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
-1. **[mBART-50](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
-1. **[MEGA](model_doc/mega)** (from Meta/USC/CMU/SJTU) released with the paper [Mega: Moving Average Equipped Gated Attention](https://arxiv.org/abs/2209.10655) by Xuezhe Ma, Chunting Zhou, Xiang Kong, Junxian He, Liangke Gui, Graham Neubig, Jonathan May, and Luke Zettlemoyer.
-1. **[Megatron-BERT](model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
-1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
-1. **[MGP-STR](model_doc/mgp-str)** (from Alibaba Research) released with the paper [Multi-Granularity Prediction for Scene Text Recognition](https://arxiv.org/abs/2209.03592) by Peng Wang, Cheng Da, and Cong Yao.
-1. **[mLUKE](model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
-1. **[MobileBERT](model_doc/mobilebert)** (from CMU/Google Brain) released with the paper [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou.
-1. **[MobileNetV1](model_doc/mobilenet_v1)** (from Google Inc.) released with the paper [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/abs/1704.04861) by Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam.
-1. **[MobileNetV2](model_doc/mobilenet_v2)** (from Google Inc.) released with the paper [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381) by Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen.
-1. **[MobileViT](model_doc/mobilevit)** (from Apple) released with the paper [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari.
-1. **[MPNet](model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
-1. **[MT5](model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
-1. **[MVP](model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
-1. **[NAT](model_doc/nat)** (from SHI Labs) released with the paper [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
-1. **[Nezha](model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
-1. **[NLLB](model_doc/nllb)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
-1. **[NLLB-MOE](model_doc/nllb-moe)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
-1. **[Nyströmformer](model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
-1. **[OneFormer](model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
+1. **[MarkupLM](model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://huggingface.co/papers/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
+1. **[Mask2Former](model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://huggingface.co/papers/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
+1. **[MaskFormer](model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://huggingface.co/papers/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
+1. **[MatCha](model_doc/matcha)** (from Google AI) released with the paper [MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering](https://huggingface.co/papers/2212.09662) by Fangyu Liu, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Yasemin Altun, Nigel Collier, Julian Martin Eisenschlos.
+1. **[mBART](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://huggingface.co/papers/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
+1. **[mBART-50](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://huggingface.co/papers/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
+1. **[MEGA](model_doc/mega)** (from Meta/USC/CMU/SJTU) released with the paper [Mega: Moving Average Equipped Gated Attention](https://huggingface.co/papers/2209.10655) by Xuezhe Ma, Chunting Zhou, Xiang Kong, Junxian He, Liangke Gui, Graham Neubig, Jonathan May, and Luke Zettlemoyer.
+1. **[Megatron-BERT](model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://huggingface.co/papers/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://huggingface.co/papers/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[MGP-STR](model_doc/mgp-str)** (from Alibaba Research) released with the paper [Multi-Granularity Prediction for Scene Text Recognition](https://huggingface.co/papers/2209.03592) by Peng Wang, Cheng Da, and Cong Yao.
+1. **[mLUKE](model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://huggingface.co/papers/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
+1. **[MobileBERT](model_doc/mobilebert)** (from CMU/Google Brain) released with the paper [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://huggingface.co/papers/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou.
+1. **[MobileNetV1](model_doc/mobilenet_v1)** (from Google Inc.) released with the paper [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://huggingface.co/papers/1704.04861) by Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam.
+1. **[MobileNetV2](model_doc/mobilenet_v2)** (from Google Inc.) released with the paper [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://huggingface.co/papers/1801.04381) by Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen.
+1. **[MobileViT](model_doc/mobilevit)** (from Apple) released with the paper [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://huggingface.co/papers/2110.02178) by Sachin Mehta and Mohammad Rastegari.
+1. **[MPNet](model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://huggingface.co/papers/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
+1. **[MT5](model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://huggingface.co/papers/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
+1. **[MVP](model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://huggingface.co/papers/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
+1. **[NAT](model_doc/nat)** (from SHI Labs) released with the paper [Neighborhood Attention Transformer](https://huggingface.co/papers/2204.07143) by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
+1. **[Nezha](model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://huggingface.co/papers/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
+1. **[NLLB](model_doc/nllb)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://huggingface.co/papers/2207.04672) by the NLLB team.
+1. **[NLLB-MOE](model_doc/nllb-moe)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://huggingface.co/papers/2207.04672) by the NLLB team.
+1. **[Nyströmformer](model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://huggingface.co/papers/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
+1. **[OneFormer](model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://huggingface.co/papers/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
1. **[OpenLlama](model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released on GitHub (now removed).
-1. **[OPT](master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
-1. **[OWL-ViT](model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
-1. **[Pegasus](model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
-1. **[PEGASUS-X](model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao, and Peter J. Liu.
-1. **[Perceiver IO](model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
+1. **[OPT](master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://huggingface.co/papers/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
+1. **[OWL-ViT](model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://huggingface.co/papers/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
+1. **[Pegasus](model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://huggingface.co/papers/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
+1. **[PEGASUS-X](model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://huggingface.co/papers/2208.04347) by Jason Phang, Yao Zhao, and Peter J. Liu.
+1. **[Perceiver IO](model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://huggingface.co/papers/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
1. **[PhoBERT](model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
-1. **[Pix2Struct](model_doc/pix2struct)** (from Google) released with the paper [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
-1. **[PLBart](model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
-1. **[PoolFormer](model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
-1. **[ProphetNet](model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
-1. **[QDQBert](model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
-1. **[RAG](model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
-1. **[REALM](model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
-1. **[Reformer](model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
-1. **[RegNet](model_doc/regnet)** (from META Platforms) released with the paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
-1. **[RemBERT](model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
-1. **[ResNet](model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
-1. **[RoBERTa](model_doc/roberta)** (from Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
-1. **[RoBERTa-PreLayerNorm](model_doc/roberta-prelayernorm)** (from Facebook) released with the paper [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://arxiv.org/abs/1904.01038) by Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli.
+1. **[Pix2Struct](model_doc/pix2struct)** (from Google) released with the paper [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://huggingface.co/papers/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
+1. **[PLBart](model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://huggingface.co/papers/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
+1. **[PoolFormer](model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://huggingface.co/papers/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
+1. **[ProphetNet](model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://huggingface.co/papers/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[QDQBert](model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://huggingface.co/papers/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
+1. **[RAG](model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://huggingface.co/papers/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
+1. **[REALM](model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://huggingface.co/papers/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
+1. **[Reformer](model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://huggingface.co/papers/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
+1. **[RegNet](model_doc/regnet)** (from META Platforms) released with the paper [Designing Network Design Space](https://huggingface.co/papers/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
+1. **[RemBERT](model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://huggingface.co/papers/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
+1. **[ResNet](model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://huggingface.co/papers/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
+1. **[RoBERTa](model_doc/roberta)** (from Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://huggingface.co/papers/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
+1. **[RoBERTa-PreLayerNorm](model_doc/roberta-prelayernorm)** (from Facebook) released with the paper [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://huggingface.co/papers/1904.01038) by Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli.
1. **[RoCBert](model_doc/roc_bert)** (from WeChatAI) released with the paper [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
-1. **[RoFormer](model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
+1. **[RoFormer](model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://huggingface.co/papers/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
1. **[RWKV](model_doc/rwkv)** (from Bo Peng), released on [this repo](https://github.com/BlinkDL/RWKV-LM) by Bo Peng.
-1. **[SegFormer](model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
-1. **[Segment Anything](model_doc/sam)** (from Meta AI) released with the paper [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
-1. **[SEW](model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
-1. **[SEW-D](model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
-1. **[SpeechT5](model_doc/speecht5)** (from Microsoft Research) released with the paper [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
-1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
-1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
-1. **[Splinter](model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
-1. **[SqueezeBERT](model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
-1. **[SwiftFormer](model_doc/swiftformer)** (from MBZUAI) released with the paper [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://arxiv.org/abs/2303.15446) by Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan.
-1. **[Swin Transformer](model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
-1. **[Swin Transformer V2](model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
-1. **[Swin2SR](model_doc/swin2sr)** (from University of Würzburg) released with the paper [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
-1. **[SwitchTransformers](model_doc/switch_transformers)** (from Google) released with the paper [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
-1. **[T5](model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
+1. **[SegFormer](model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://huggingface.co/papers/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
+1. **[Segment Anything](model_doc/sam)** (from Meta AI) released with the paper [Segment Anything](https://huggingface.co/papers/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
+1. **[SEW](model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://huggingface.co/papers/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SEW-D](model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://huggingface.co/papers/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SpeechT5](model_doc/speecht5)** (from Microsoft Research) released with the paper [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://huggingface.co/papers/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
+1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://huggingface.co/papers/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
+1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://huggingface.co/papers/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
+1. **[Splinter](model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://huggingface.co/papers/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
+1. **[SqueezeBERT](model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://huggingface.co/papers/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
+1. **[SwiftFormer](model_doc/swiftformer)** (from MBZUAI) released with the paper [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://huggingface.co/papers/2303.15446) by Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan.
+1. **[Swin Transformer](model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://huggingface.co/papers/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
+1. **[Swin Transformer V2](model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://huggingface.co/papers/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
+1. **[Swin2SR](model_doc/swin2sr)** (from University of Würzburg) released with the paper [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://huggingface.co/papers/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
+1. **[SwitchTransformers](model_doc/switch_transformers)** (from Google) released with the paper [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://huggingface.co/papers/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
+1. **[T5](model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://huggingface.co/papers/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[T5v1.1](model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
-1. **[Table Transformer](model_doc/table-transformer)** (from Microsoft Research) released with the paper [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061) by Brandon Smock, Rohith Pesala, Robin Abraham.
-1. **[TAPAS](model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
-1. **[TAPEX](model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
+1. **[Table Transformer](model_doc/table-transformer)** (from Microsoft Research) released with the paper [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://huggingface.co/papers/2110.00061) by Brandon Smock, Rohith Pesala, Robin Abraham.
+1. **[TAPAS](model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://huggingface.co/papers/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
+1. **[TAPEX](model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://huggingface.co/papers/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
1. **[Time Series Transformer](model_doc/time_series_transformer)** (from HuggingFace).
-1. **[TimeSformer](model_doc/timesformer)** (from Facebook) released with the paper [Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095) by Gedas Bertasius, Heng Wang, Lorenzo Torresani.
-1. **[Trajectory Transformer](model_doc/trajectory_transformers)** (from the University of California at Berkeley) released with the paper [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine
-1. **[Transformer-XL](model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
-1. **[TrOCR](model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
-1. **[TVLT](model_doc/tvlt)** (from UNC Chapel Hill) released with the paper [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
-1. **[TVP](model_doc/tvp)** (from Intel) released with the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
-1. **[UL2](model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
-1. **[UniSpeech](model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
-1. **[UniSpeechSat](model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
-1. **[UPerNet](model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
-1. **[VAN](model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
-1. **[VideoMAE](model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
-1. **[ViLT](model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
-1. **[Vision Transformer (ViT)](model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
-1. **[VisualBERT](model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
-1. **[ViT Hybrid](model_doc/vit_hybrid)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
-1. **[ViTMAE](model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
-1. **[ViTMSN](model_doc/vit_msn)** (from Meta AI) released with the paper [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas.
-1. **[Wav2Vec2](model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
-1. **[Wav2Vec2-Conformer](model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
-1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
-1. **[WavLM](model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
+1. **[TimeSformer](model_doc/timesformer)** (from Facebook) released with the paper [Is Space-Time Attention All You Need for Video Understanding?](https://huggingface.co/papers/2102.05095) by Gedas Bertasius, Heng Wang, Lorenzo Torresani.
+1. **[Trajectory Transformer](model_doc/trajectory_transformers)** (from the University of California at Berkeley) released with the paper [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://huggingface.co/papers/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine
+1. **[Transformer-XL](model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://huggingface.co/papers/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
+1. **[TrOCR](model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://huggingface.co/papers/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
+1. **[TVLT](model_doc/tvlt)** (from UNC Chapel Hill) released with the paper [TVLT: Textless Vision-Language Transformer](https://huggingface.co/papers/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
+1. **[TVP](model_doc/tvp)** (from Intel) released with the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://huggingface.co/papers/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
+1. **[UL2](model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://huggingface.co/papers/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
+1. **[UniSpeech](model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://huggingface.co/papers/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
+1. **[UniSpeechSat](model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://huggingface.co/papers/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
+1. **[UPerNet](model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://huggingface.co/papers/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
+1. **[VAN](model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://huggingface.co/papers/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
+1. **[VideoMAE](model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://huggingface.co/papers/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
+1. **[ViLT](model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://huggingface.co/papers/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
+1. **[Vision Transformer (ViT)](model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://huggingface.co/papers/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
+1. **[VisualBERT](model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://huggingface.co/papers/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
+1. **[ViT Hybrid](model_doc/vit_hybrid)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://huggingface.co/papers/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
+1. **[ViTMAE](model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://huggingface.co/papers/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
+1. **[ViTMSN](model_doc/vit_msn)** (from Meta AI) released with the paper [Masked Siamese Networks for Label-Efficient Learning](https://huggingface.co/papers/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas.
+1. **[Wav2Vec2](model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://huggingface.co/papers/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
+1. **[Wav2Vec2-Conformer](model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://huggingface.co/papers/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
+1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://huggingface.co/papers/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
+1. **[WavLM](model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://huggingface.co/papers/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
1. **[Whisper](model_doc/whisper)** (from OpenAI) released with the paper [Robust Speech Recognition via Large-Scale Weak Supervision](https://cdn.openai.com/papers/whisper.pdf) by Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever.
-1. **[X-CLIP](model_doc/xclip)** (from Microsoft Research) released with the paper [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816) by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
+1. **[X-CLIP](model_doc/xclip)** (from Microsoft Research) released with the paper [Expanding Language-Image Pretrained Models for General Video Recognition](https://huggingface.co/papers/2208.02816) by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
1. **[X-MOD](model_doc/xmod)** (from Meta AI) released with the paper [Lifting the Curse of Multilinguality by Pre-training Modular Transformers](http://dx.doi.org/10.18653/v1/2022.naacl-main.255) by Jonas Pfeiffer, Naman Goyal, Xi Lin, Xian Li, James Cross, Sebastian Riedel, Mikel Artetxe.
-1. **[XGLM](model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
-1. **[XLM](model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau.
-1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
-1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
-1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (from Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
-1. **[XLM-V](model_doc/xlm-v)** (from Meta AI) released with the paper [XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models](https://arxiv.org/abs/2301.10472) by Davis Liang, Hila Gonen, Yuning Mao, Rui Hou, Naman Goyal, Marjan Ghazvininejad, Luke Zettlemoyer, Madian Khabsa.
-1. **[XLNet](model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
-1. **[XLS-R](model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
-1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
-1. **[YOLOS](model_doc/yolos)** (from Huazhong University of Science & Technology) released with the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
-1. **[YOSO](model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
+1. **[XGLM](model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://huggingface.co/papers/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
+1. **[XLM](model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://huggingface.co/papers/1901.07291) by Guillaume Lample and Alexis Conneau.
+1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://huggingface.co/papers/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://huggingface.co/papers/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
+1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (from Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://huggingface.co/papers/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
+1. **[XLM-V](model_doc/xlm-v)** (from Meta AI) released with the paper [XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models](https://huggingface.co/papers/2301.10472) by Davis Liang, Hila Gonen, Yuning Mao, Rui Hou, Naman Goyal, Marjan Ghazvininejad, Luke Zettlemoyer, Madian Khabsa.
+1. **[XLNet](model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://huggingface.co/papers/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
+1. **[XLS-R](model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://huggingface.co/papers/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
+1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://huggingface.co/papers/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
+1. **[YOLOS](model_doc/yolos)** (from Huazhong University of Science & Technology) released with the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://huggingface.co/papers/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
+1. **[YOSO](model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://huggingface.co/papers/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
### Rangka kerja yang disokong
diff --git a/docs/source/pt/index.md b/docs/source/pt/index.md
index 365933bd65..66bb29b5cb 100644
--- a/docs/source/pt/index.md
+++ b/docs/source/pt/index.md
@@ -63,121 +63,121 @@ Atualmente a biblioteca contém implementações do PyTorch, TensorFlow e JAX, p
-1. **[ALBERT](model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
-1. **[BART](model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
-1. **[BARThez](model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
-1. **[BARTpho](model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
-1. **[BEiT](model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
-1. **[BERT](model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
+1. **[ALBERT](model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://huggingface.co/papers/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
+1. **[BART](model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://huggingface.co/papers/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
+1. **[BARThez](model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://huggingface.co/papers/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
+1. **[BARTpho](model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://huggingface.co/papers/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
+1. **[BEiT](model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://huggingface.co/papers/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
+1. **[BERT](model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://huggingface.co/papers/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
1. **[BERTweet](model_doc/bertweet)** (from VinAI Research) released with the paper [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) by Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen.
-1. **[BERT For Sequence Generation](model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
-1. **[BigBird-RoBERTa](model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
-1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
-1. **[Blenderbot](model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
-1. **[BlenderbotSmall](model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
-1. **[BORT](model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
-1. **[ByT5](model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
-1. **[CamemBERT](model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
-1. **[CANINE](model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
-1. **[ConvNeXT](model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
-1. **[ConvNeXTV2](model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
-1. **[CLIP](model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
-1. **[ConvBERT](model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
-1. **[CPM](model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
-1. **[CTRL](model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
-1. **[Data2Vec](model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
-1. **[DeBERTa](model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
-1. **[DeBERTa-v2](model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
-1. **[Decision Transformer](model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
-1. **[DiT](model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
-1. **[DeiT](model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
-1. **[DETR](model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
-1. **[DialoGPT](model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
-1. **[DistilBERT](model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers-research-projects/tree/main/distillation) and a German version of DistilBERT.
-1. **[DPR](model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
-1. **[DPT](master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
-1. **[EfficientNet](model_doc/efficientnet)** (from Google Research) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan and Quoc V. Le.
-1. **[EncoderDecoder](model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
-1. **[ELECTRA](model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
-1. **[FlauBERT](model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
-1. **[FNet](model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
-1. **[Funnel Transformer](model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
-1. **[GLPN](model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
+1. **[BERT For Sequence Generation](model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://huggingface.co/papers/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[BigBird-RoBERTa](model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://huggingface.co/papers/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://huggingface.co/papers/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[Blenderbot](model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://huggingface.co/papers/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BlenderbotSmall](model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://huggingface.co/papers/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BORT](model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://huggingface.co/papers/2010.10499) by Adrian de Wynter and Daniel J. Perry.
+1. **[ByT5](model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://huggingface.co/papers/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
+1. **[CamemBERT](model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://huggingface.co/papers/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
+1. **[CANINE](model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://huggingface.co/papers/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
+1. **[ConvNeXT](model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://huggingface.co/papers/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
+1. **[ConvNeXTV2](model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://huggingface.co/papers/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
+1. **[CLIP](model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://huggingface.co/papers/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
+1. **[ConvBERT](model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://huggingface.co/papers/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
+1. **[CPM](model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://huggingface.co/papers/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
+1. **[CTRL](model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://huggingface.co/papers/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
+1. **[Data2Vec](model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://huggingface.co/papers/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
+1. **[DeBERTa](model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://huggingface.co/papers/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[DeBERTa-v2](model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://huggingface.co/papers/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[Decision Transformer](model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://huggingface.co/papers/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
+1. **[DiT](model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://huggingface.co/papers/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
+1. **[DeiT](model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://huggingface.co/papers/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
+1. **[DETR](model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://huggingface.co/papers/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
+1. **[DialoGPT](model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://huggingface.co/papers/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
+1. **[DistilBERT](model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://huggingface.co/papers/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers-research-projects/tree/main/distillation) and a German version of DistilBERT.
+1. **[DPR](model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://huggingface.co/papers/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
+1. **[DPT](master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://huggingface.co/papers/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
+1. **[EfficientNet](model_doc/efficientnet)** (from Google Research) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://huggingface.co/papers/1905.11946) by Mingxing Tan and Quoc V. Le.
+1. **[EncoderDecoder](model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://huggingface.co/papers/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[ELECTRA](model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://huggingface.co/papers/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
+1. **[FlauBERT](model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://huggingface.co/papers/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
+1. **[FNet](model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://huggingface.co/papers/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
+1. **[Funnel Transformer](model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://huggingface.co/papers/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
+1. **[GLPN](model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://huggingface.co/papers/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
1. **[GPT](model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
1. **[GPT-2](model_doc/gpt2)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://openai.com/research/better-language-models/) by Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever.
1. **[GPT-J](model_doc/gptj)** (from EleutherAI) released in the repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
1. **[GPT Neo](model_doc/gpt_neo)** (from EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
1. **[GPTSAN-japanese](model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
-1. **[Hubert](model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
-1. **[I-BERT](model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
+1. **[Hubert](model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://huggingface.co/papers/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
+1. **[I-BERT](model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://huggingface.co/papers/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
1. **[ImageGPT](model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
-1. **[LayoutLM](model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
-1. **[LayoutLMv2](model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
-1. **[LayoutXLM](model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
-1. **[LED](model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
-1. **[Longformer](model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
-1. **[LUKE](model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
-1. **[mLUKE](model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
-1. **[LXMERT](model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
-1. **[M2M100](model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
+1. **[LayoutLM](model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://huggingface.co/papers/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
+1. **[LayoutLMv2](model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://huggingface.co/papers/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
+1. **[LayoutXLM](model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://huggingface.co/papers/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
+1. **[LED](model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://huggingface.co/papers/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[Longformer](model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://huggingface.co/papers/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LUKE](model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://huggingface.co/papers/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
+1. **[mLUKE](model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://huggingface.co/papers/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
+1. **[LXMERT](model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://huggingface.co/papers/1908.07490) by Hao Tan and Mohit Bansal.
+1. **[M2M100](model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://huggingface.co/papers/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
1. **[MarianMT](model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
-1. **[Mask2Former](model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
-1. **[MaskFormer](model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
-1. **[MBart](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
-1. **[MBart-50](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
-1. **[Megatron-BERT](model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
-1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
-1. **[MPNet](model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
-1. **[MT5](model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
-1. **[Nyströmformer](model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
-1. **[OneFormer](model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
-1. **[Pegasus](model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
-1. **[Perceiver IO](model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
+1. **[Mask2Former](model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://huggingface.co/papers/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
+1. **[MaskFormer](model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://huggingface.co/papers/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
+1. **[MBart](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://huggingface.co/papers/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
+1. **[MBart-50](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://huggingface.co/papers/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
+1. **[Megatron-BERT](model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://huggingface.co/papers/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://huggingface.co/papers/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[MPNet](model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://huggingface.co/papers/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
+1. **[MT5](model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://huggingface.co/papers/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
+1. **[Nyströmformer](model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://huggingface.co/papers/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
+1. **[OneFormer](model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://huggingface.co/papers/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
+1. **[Pegasus](model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://huggingface.co/papers/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
+1. **[Perceiver IO](model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://huggingface.co/papers/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
1. **[PhoBERT](model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
-1. **[PLBart](model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
-1. **[PoolFormer](model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
-1. **[ProphetNet](model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
-1. **[QDQBert](model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
-1. **[REALM](model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
-1. **[Reformer](model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
-1. **[RemBERT](model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
-1. **[RegNet](model_doc/regnet)** (from META Platforms) released with the paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
-1. **[ResNet](model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
-1. **[RoBERTa](model_doc/roberta)** (from Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
-1. **[RoFormer](model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
-1. **[SegFormer](model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
-1. **[SEW](model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
-1. **[SEW-D](model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
-1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
-1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
-1. **[Splinter](model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
-1. **[SqueezeBert](model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
-1. **[Swin Transformer](model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
-1. **[T5](model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
+1. **[PLBart](model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://huggingface.co/papers/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
+1. **[PoolFormer](model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://huggingface.co/papers/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
+1. **[ProphetNet](model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://huggingface.co/papers/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[QDQBert](model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://huggingface.co/papers/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
+1. **[REALM](model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://huggingface.co/papers/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
+1. **[Reformer](model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://huggingface.co/papers/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
+1. **[RemBERT](model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://huggingface.co/papers/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
+1. **[RegNet](model_doc/regnet)** (from META Platforms) released with the paper [Designing Network Design Space](https://huggingface.co/papers/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
+1. **[ResNet](model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://huggingface.co/papers/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
+1. **[RoBERTa](model_doc/roberta)** (from Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://huggingface.co/papers/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
+1. **[RoFormer](model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://huggingface.co/papers/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
+1. **[SegFormer](model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://huggingface.co/papers/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
+1. **[SEW](model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://huggingface.co/papers/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SEW-D](model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://huggingface.co/papers/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://huggingface.co/papers/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
+1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://huggingface.co/papers/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
+1. **[Splinter](model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://huggingface.co/papers/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
+1. **[SqueezeBert](model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://huggingface.co/papers/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
+1. **[Swin Transformer](model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://huggingface.co/papers/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
+1. **[T5](model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://huggingface.co/papers/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[T5v1.1](model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
-1. **[TAPAS](model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
-1. **[TAPEX](model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
-1. **[Transformer-XL](model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
-1. **[TrOCR](model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
-1. **[UniSpeech](model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
-1. **[UniSpeechSat](model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
-1. **[VAN](model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
-1. **[ViLT](model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
-1. **[Vision Transformer (ViT)](model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
-1. **[ViTMAE](model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
-1. **[VisualBERT](model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
-1. **[WavLM](model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
-1. **[Wav2Vec2](model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
-1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
-1. **[XGLM](model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
-1. **[XLM](model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau.
-1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
-1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
-1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (from Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
-1. **[XLNet](model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
-1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
-1. **[XLS-R](model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
-1. **[YOSO](model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
+1. **[TAPAS](model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://huggingface.co/papers/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
+1. **[TAPEX](model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://huggingface.co/papers/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
+1. **[Transformer-XL](model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://huggingface.co/papers/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
+1. **[TrOCR](model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://huggingface.co/papers/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
+1. **[UniSpeech](model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://huggingface.co/papers/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
+1. **[UniSpeechSat](model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://huggingface.co/papers/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
+1. **[VAN](model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://huggingface.co/papers/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
+1. **[ViLT](model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://huggingface.co/papers/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
+1. **[Vision Transformer (ViT)](model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://huggingface.co/papers/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
+1. **[ViTMAE](model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://huggingface.co/papers/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
+1. **[VisualBERT](model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://huggingface.co/papers/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
+1. **[WavLM](model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://huggingface.co/papers/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
+1. **[Wav2Vec2](model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://huggingface.co/papers/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
+1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://huggingface.co/papers/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
+1. **[XGLM](model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://huggingface.co/papers/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
+1. **[XLM](model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://huggingface.co/papers/1901.07291) by Guillaume Lample and Alexis Conneau.
+1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://huggingface.co/papers/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://huggingface.co/papers/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
+1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (from Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://huggingface.co/papers/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
+1. **[XLNet](model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://huggingface.co/papers/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
+1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://huggingface.co/papers/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
+1. **[XLS-R](model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://huggingface.co/papers/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
+1. **[YOSO](model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://huggingface.co/papers/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
### Frameworks aceitos
diff --git a/docs/source/zh/bertology.md b/docs/source/zh/bertology.md
index e7df7593a2..54e6057bb9 100644
--- a/docs/source/zh/bertology.md
+++ b/docs/source/zh/bertology.md
@@ -16,18 +16,18 @@ http://www.apache.org/licenses/LICENSE-2.0
- BERT Rediscovers the Classical NLP Pipeline by Ian Tenney, Dipanjan Das, Ellie Pavlick:
- https://arxiv.org/abs/1905.05950
-- Are Sixteen Heads Really Better than One? by Paul Michel, Omer Levy, Graham Neubig: https://arxiv.org/abs/1905.10650
+ https://huggingface.co/papers/1905.05950
+- Are Sixteen Heads Really Better than One? by Paul Michel, Omer Levy, Graham Neubig: https://huggingface.co/papers/1905.10650
- What Does BERT Look At? An Analysis of BERT's Attention by Kevin Clark, Urvashi Khandelwal, Omer Levy, Christopher D.
- Manning: https://arxiv.org/abs/1906.04341
-- CAT-probing: A Metric-based Approach to Interpret How Pre-trained Models for Programming Language Attend Code Structure: https://arxiv.org/abs/2210.04633
+ Manning: https://huggingface.co/papers/1906.04341
+- CAT-probing: A Metric-based Approach to Interpret How Pre-trained Models for Programming Language Attend Code Structure: https://huggingface.co/papers/2210.04633
-为了助力这一新兴领域的发展,我们在BERT/GPT/GPT-2模型中增加了一些附加功能,方便人们访问其内部表示,这些功能主要借鉴了Paul Michel的杰出工作(https://arxiv.org/abs/1905.10650):
+为了助力这一新兴领域的发展,我们在BERT/GPT/GPT-2模型中增加了一些附加功能,方便人们访问其内部表示,这些功能主要借鉴了Paul Michel的杰出工作(https://huggingface.co/papers/1905.10650):
- 访问BERT/GPT/GPT-2的所有隐藏状态,
- 访问BERT/GPT/GPT-2每个注意力头的所有注意力权重,
-- 检索注意力头的输出值和梯度,以便计算头的重要性得分并对头进行剪枝,详情可见论文:https://arxiv.org/abs/1905.10650。
+- 检索注意力头的输出值和梯度,以便计算头的重要性得分并对头进行剪枝,详情可见论文:https://huggingface.co/papers/1905.10650。
为了帮助您理解和使用这些功能,我们添加了一个具体的示例脚本:[bertology.py](https://github.com/huggingface/transformers-research-projects/tree/main/bertology/run_bertology.py),该脚本可以对一个在 GLUE 数据集上预训练的模型进行信息提取与剪枝。
\ No newline at end of file
diff --git a/docs/source/zh/main_classes/deepspeed.md b/docs/source/zh/main_classes/deepspeed.md
index ddc8096d0a..8fa41946b0 100644
--- a/docs/source/zh/main_classes/deepspeed.md
+++ b/docs/source/zh/main_classes/deepspeed.md
@@ -16,7 +16,7 @@ rendered properly in your Markdown viewer.
# DeepSpeed集成
-[DeepSpeed](https://github.com/deepspeedai/DeepSpeed)实现了[ZeRO论文](https://arxiv.org/abs/1910.02054)中描述的所有内容。目前,它提供对以下功能的全面支持:
+[DeepSpeed](https://github.com/deepspeedai/DeepSpeed)实现了[ZeRO论文](https://huggingface.co/papers/1910.02054)中描述的所有内容。目前,它提供对以下功能的全面支持:
1. 优化器状态分区(ZeRO stage 1)
2. 梯度分区(ZeRO stage 2)
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
5. 一系列基于CUDA扩展的快速优化器
6. ZeRO-Offload 到 CPU 和 NVMe
-ZeRO-Offload有其自己的专门论文:[ZeRO-Offload: Democratizing Billion-Scale Model Training](https://arxiv.org/abs/2101.06840)。而NVMe支持在论文[ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning](https://arxiv.org/abs/2104.07857)中进行了描述。
+ZeRO-Offload有其自己的专门论文:[ZeRO-Offload: Democratizing Billion-Scale Model Training](https://huggingface.co/papers/2101.06840)。而NVMe支持在论文[ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning](https://huggingface.co/papers/2104.07857)中进行了描述。
DeepSpeed ZeRO-2主要用于训练,因为它的特性对推理没有用处。
@@ -2093,8 +2093,8 @@ RUN_SLOW=1 pytest tests/deepspeed
论文:
-- [ZeRO: Memory Optimizations Toward Training Trillion Parameter Models](https://arxiv.org/abs/1910.02054)
-- [ZeRO-Offload: Democratizing Billion-Scale Model Training](https://arxiv.org/abs/2101.06840)
-- [ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning](https://arxiv.org/abs/2104.07857)
+- [ZeRO: Memory Optimizations Toward Training Trillion Parameter Models](https://huggingface.co/papers/1910.02054)
+- [ZeRO-Offload: Democratizing Billion-Scale Model Training](https://huggingface.co/papers/2101.06840)
+- [ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning](https://huggingface.co/papers/2104.07857)
最后,请记住,HuggingFace [`Trainer`]仅集成了DeepSpeed,因此如果您在使用DeepSpeed时遇到任何问题或疑问,请在[DeepSpeed GitHub](https://github.com/deepspeedai/DeepSpeed/issues)上提交一个issue。
diff --git a/docs/source/zh/main_classes/processors.md b/docs/source/zh/main_classes/processors.md
index 60167e317a..f7e58a9999 100644
--- a/docs/source/zh/main_classes/processors.md
+++ b/docs/source/zh/main_classes/processors.md
@@ -66,7 +66,7 @@ rendered properly in your Markdown viewer.
[跨语言NLI语料库(XNLI)](https://www.nyu.edu/projects/bowman/xnli/) 是一个评估跨语言文本表示质量的基准测试。XNLI是一个基于[*MultiNLI*](http://www.nyu.edu/projects/bowman/multinli/)的众包数据集:”文本对“被标记为包含15种不同语言(包括英语等高资源语言和斯瓦希里语等低资源语言)的文本蕴涵注释。
-它与论文 [XNLI: Evaluating Cross-lingual Sentence Representations](https://arxiv.org/abs/1809.05053) 一同发布。
+它与论文 [XNLI: Evaluating Cross-lingual Sentence Representations](https://huggingface.co/papers/1809.05053) 一同发布。
该库提供了加载XNLI数据的processor:
@@ -79,7 +79,7 @@ rendered properly in your Markdown viewer.
## SQuAD
-[斯坦福问答数据集(SQuAD)](https://rajpurkar.github.io/SQuAD-explorer//) 是一个评估模型在问答上性能的基准测试。有两个版本,v1.1 和 v2.0。第一个版本(v1.1)与论文 [SQuAD: 100,000+ Questions for Machine Comprehension of Text](https://arxiv.org/abs/1606.05250) 一同发布。第二个版本(v2.0)与论文 [Know What You Don't Know: Unanswerable Questions for SQuAD](https://arxiv.org/abs/1806.03822) 一同发布。
+[斯坦福问答数据集(SQuAD)](https://rajpurkar.github.io/SQuAD-explorer//) 是一个评估模型在问答上性能的基准测试。有两个版本,v1.1 和 v2.0。第一个版本(v1.1)与论文 [SQuAD: 100,000+ Questions for Machine Comprehension of Text](https://huggingface.co/papers/1606.05250) 一同发布。第二个版本(v2.0)与论文 [Know What You Don't Know: Unanswerable Questions for SQuAD](https://huggingface.co/papers/1806.03822) 一同发布。
该库为两个版本各自提供了一个processor:
diff --git a/docs/source/zh/main_classes/quantization.md b/docs/source/zh/main_classes/quantization.md
index d303906a99..0d4bad99af 100644
--- a/docs/source/zh/main_classes/quantization.md
+++ b/docs/source/zh/main_classes/quantization.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## AWQ集成
-AWQ方法已经在[*AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration*论文](https://arxiv.org/abs/2306.00978)中引入。通过AWQ,您可以以4位精度运行模型,同时保留其原始性能(即没有性能降级),并具有比下面介绍的其他量化方法更出色的吞吐量 - 达到与纯`float16`推理相似的吞吐量。
+AWQ方法已经在[*AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration*论文](https://huggingface.co/papers/2306.00978)中引入。通过AWQ,您可以以4位精度运行模型,同时保留其原始性能(即没有性能降级),并具有比下面介绍的其他量化方法更出色的吞吐量 - 达到与纯`float16`推理相似的吞吐量。
我们现在支持使用任何AWQ模型进行推理,这意味着任何人都可以加载和使用在Hub上推送或本地保存的AWQ权重。请注意,使用AWQ需要访问NVIDIA GPU。目前不支持CPU推理。
@@ -118,7 +118,7 @@ model = AutoModelForCausalLM.from_pretrained("TheBloke/zephyr-7B-alpha-AWQ", att
🤗 Transformers已经整合了`optimum` API,用于对语言模型执行GPTQ量化。您可以以8、4、3甚至2位加载和量化您的模型,而性能无明显下降,并且推理速度更快!这受到大多数GPU硬件的支持。
要了解更多关于量化模型的信息,请查看:
-- [GPTQ](https://arxiv.org/pdf/2210.17323.pdf)论文
+- [GPTQ](https://huggingface.co/papers/2210.17323)论文
- `optimum`关于GPTQ量化的[指南](https://huggingface.co/docs/optimum/llm_quantization/usage_guides/quantization)
- 用作后端的[`AutoGPTQ`](https://github.com/PanQiWei/AutoGPTQ)库
@@ -276,7 +276,7 @@ model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", de
🤗 Transformers 与 `bitsandbytes` 上最常用的模块紧密集成。您可以使用几行代码以 8 位精度加载您的模型。
自bitsandbytes的0.37.0版本发布以来,大多数GPU硬件都支持这一点。
-在[LLM.int8()](https://arxiv.org/abs/2208.07339)论文中了解更多关于量化方法的信息,或者在[博客文章](https://huggingface.co/blog/hf-bitsandbytes-integration)中了解关于合作的更多信息。
+在[LLM.int8()](https://huggingface.co/papers/2208.07339)论文中了解更多关于量化方法的信息,或者在[博客文章](https://huggingface.co/blog/hf-bitsandbytes-integration)中了解关于合作的更多信息。
自其“0.39.0”版本发布以来,您可以使用FP4数据类型,通过4位量化加载任何支持“device_map”的模型。
@@ -329,7 +329,7 @@ torch.float32
- **使用 `batch_size=1` 实现更快的推理:** 自 `bitsandbytes` 的 `0.40.0` 版本以来,设置 `batch_size=1`,您可以从快速推理中受益。请查看 [这些发布说明](https://github.com/TimDettmers/bitsandbytes/releases/tag/0.40.0) ,并确保使用大于 `0.40.0` 的版本以直接利用此功能。
-- **训练:** 根据 [QLoRA 论文](https://arxiv.org/abs/2305.14314),对于4位基模型训练(使用 LoRA 适配器),应使用 `bnb_4bit_quant_type='nf4'`。
+- **训练:** 根据 [QLoRA 论文](https://huggingface.co/papers/2305.14314),对于4位基模型训练(使用 LoRA 适配器),应使用 `bnb_4bit_quant_type='nf4'`。
- **推理:** 对于推理,`bnb_4bit_quant_type` 对性能影响不大。但是为了与模型的权重保持一致,请确保使用相同的 `bnb_4bit_compute_dtype` 和 `torch_dtype` 参数。
diff --git a/docs/source/zh/main_classes/trainer.md b/docs/source/zh/main_classes/trainer.md
index 16d6c6606b..c176ae870f 100644
--- a/docs/source/zh/main_classes/trainer.md
+++ b/docs/source/zh/main_classes/trainer.md
@@ -281,7 +281,7 @@ export CUDA_VISIBLE_DEVICES=1,0
[`Trainer`] 已经被扩展,以支持可能显著提高训练时间并适应更大模型的库。
-目前,它支持第三方解决方案 [DeepSpeed](https://github.com/deepspeedai/DeepSpeed) 和 [PyTorch FSDP](https://pytorch.org/docs/stable/fsdp.html),它们实现了论文 [ZeRO: Memory Optimizations Toward Training Trillion Parameter Models, by Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, Yuxiong He](https://arxiv.org/abs/1910.02054) 的部分内容。
+目前,它支持第三方解决方案 [DeepSpeed](https://github.com/deepspeedai/DeepSpeed) 和 [PyTorch FSDP](https://pytorch.org/docs/stable/fsdp.html),它们实现了论文 [ZeRO: Memory Optimizations Toward Training Trillion Parameter Models, by Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, Yuxiong He](https://huggingface.co/papers/1910.02054) 的部分内容。
截至撰写本文,此提供的支持是新的且实验性的。尽管我们欢迎围绕 DeepSpeed 和 PyTorch FSDP 的issues,但我们不再支持 FairScale 集成,因为它已经集成到了 PyTorch 主线(参见 [PyTorch FSDP 集成](#pytorch-fully-sharded-data-parallel))。
diff --git a/docs/source/zh/peft.md b/docs/source/zh/peft.md
index de7ae6d155..f00ae5ca39 100644
--- a/docs/source/zh/peft.md
+++ b/docs/source/zh/peft.md
@@ -44,7 +44,7 @@ Transformers原生支持一些PEFT方法,这意味着你可以加载本地存
- [Low Rank Adapters](https://huggingface.co/docs/peft/conceptual_guides/lora)
- [IA3](https://huggingface.co/docs/peft/conceptual_guides/ia3)
-- [AdaLoRA](https://arxiv.org/abs/2303.10512)
+- [AdaLoRA](https://huggingface.co/papers/2303.10512)
如果你想使用其他PEFT方法,例如提示学习或提示微调,或者关于通用的 🤗 PEFT库,请参阅[文档](https://huggingface.co/docs/peft/index)。
diff --git a/docs/source/zh/tokenizer_summary.md b/docs/source/zh/tokenizer_summary.md
index c349154f96..3191b37b84 100644
--- a/docs/source/zh/tokenizer_summary.md
+++ b/docs/source/zh/tokenizer_summary.md
@@ -122,7 +122,7 @@ token应该附着在前面那个token的后面,不带空格的附着(分词
### Byte-Pair Encoding (BPE)
Byte-Pair Encoding (BPE)来自于[Neural Machine Translation of Rare Words with Subword Units (Sennrich et
-al., 2015)](https://arxiv.org/abs/1508.07909)。BPE依赖于一个预分词器,这个预分词器会将训练数据分割成单词。预分词可以是简单的
+al., 2015)](https://huggingface.co/papers/1508.07909)。BPE依赖于一个预分词器,这个预分词器会将训练数据分割成单词。预分词可以是简单的
空格分词,像::[GPT-2](model_doc/gpt2),[RoBERTa](model_doc/roberta)。更加先进的预分词方式包括了基于规则的分词,像: [XLM](model_doc/xlm),[FlauBERT](model_doc/flaubert),FlauBERT在大多数语言使用了Moses,或者[GPT](model_doc/gpt),GPT
使用了Spacy和ftfy,统计了训练语料库中每个单词的频次。
@@ -194,7 +194,7 @@ WordPiece不会选择出现频次最大的符号对,而是选择了加入到
### Unigram
Unigram是一个子词分词器算法,介绍见[Subword Regularization: Improving Neural Network Translation
-Models with Multiple Subword Candidates (Kudo, 2018)](https://arxiv.org/pdf/1804.10959.pdf)。和BPE或者WordPiece相比较
+Models with Multiple Subword Candidates (Kudo, 2018)](https://huggingface.co/papers/1804.10959)。和BPE或者WordPiece相比较
,Unigram使用大量的符号来初始化它的基础字典,然后逐渐的精简每个符号来获得一个更小的词典。举例来看基础词典能够对应所有的预分词
的单词以及最常见的子字符串。Unigram没有直接用在任何transformers的任何模型中,但是和[SentencePiece](#sentencepiece)一起联合使用。
@@ -224,7 +224,7 @@ $$\mathcal{L} = -\sum_{i=1}^{N} \log \left ( \sum_{x \in S(x_{i})} p(x) \right )
目前为止描述的所有分词算法都有相同的问题:它们都假设输入的文本使用空格来分开单词。然而,不是所有的语言都使用空格来分开单词。
一个可能的解决方案是使用某种语言特定的预分词器。像:[XLM](model_doc/xlm)使用了一个特定的中文、日语和Thai的预分词器。
为了更加广泛的解决这个问题,[SentencePiece: A simple and language independent subword tokenizer and
-detokenizer for Neural Text Processing (Kudo et al., 2018)](https://arxiv.org/pdf/1808.06226.pdf)
+detokenizer for Neural Text Processing (Kudo et al., 2018)](https://huggingface.co/papers/1808.06226)
将输入文本看作一个原始的输入流,因此使用的符合集合中也包括了空格。SentencePiece然后会使用BPE或者unigram算法来产生合适的
词典。
diff --git a/examples/flax/language-modeling/README.md b/examples/flax/language-modeling/README.md
index 9e2dee3621..441661795e 100644
--- a/examples/flax/language-modeling/README.md
+++ b/examples/flax/language-modeling/README.md
@@ -26,7 +26,7 @@ way which enables simple and efficient model parallelism.
## Masked language modeling
In the following, we demonstrate how to train a bi-directional transformer model
-using masked language modeling objective as introduced in [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805).
+using masked language modeling objective as introduced in [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://huggingface.co/papers/1810.04805).
More specifically, we demonstrate how JAX/Flax can be leveraged
to pre-train [**`FacebookAI/roberta-base`**](https://huggingface.co/FacebookAI/roberta-base)
in Norwegian on a single TPUv3-8 pod.
@@ -229,7 +229,7 @@ look at [this](https://colab.research.google.com/github/huggingface/notebooks/bl
## T5-like span-masked language modeling
In the following, we demonstrate how to train a T5 model using the span-masked language model
-objective as proposed in the [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683).
+objective as proposed in the [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://huggingface.co/papers/1910.10683).
More specifically, we demonstrate how JAX/Flax can be leveraged
to pre-train [**`google/t5-v1_1-base`**](https://huggingface.co/google/t5-v1_1-base)
in Norwegian on a single TPUv3-8 pod.
@@ -341,7 +341,7 @@ Training statistics can be accessed on directly on the 🤗 [hub](https://huggin
## BART: Denoising language modeling
In the following, we demonstrate how to train a BART model
-using denoising language modeling objective as introduced in [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461).
+using denoising language modeling objective as introduced in [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://huggingface.co/papers/1910.13461).
More specifically, we demonstrate how JAX/Flax can be leveraged
to pre-train [**`bart-base`**](https://huggingface.co/facebook/bart-base)
in Norwegian on a single TPUv3-8 pod.
diff --git a/examples/flax/language-modeling/run_bart_dlm_flax.py b/examples/flax/language-modeling/run_bart_dlm_flax.py
index 2bbb66a24a..1c5299ebc9 100644
--- a/examples/flax/language-modeling/run_bart_dlm_flax.py
+++ b/examples/flax/language-modeling/run_bart_dlm_flax.py
@@ -265,7 +265,7 @@ class FlaxDataCollatorForBartDenoisingLM:
Data collator used for BART denoising language modeling. The code is largely copied from
``__.
For more information on how BART denoising language modeling works, one can take a look
- at the `official paper `__
+ at the `official paper `__
or the `official code for preprocessing `__ .
Args:
tokenizer (:class:`~transformers.PreTrainedTokenizer` or :class:`~transformers.PreTrainedTokenizerFast`):
diff --git a/examples/flax/language-modeling/run_t5_mlm_flax.py b/examples/flax/language-modeling/run_t5_mlm_flax.py
index b376c26d32..afe4d202b8 100755
--- a/examples/flax/language-modeling/run_t5_mlm_flax.py
+++ b/examples/flax/language-modeling/run_t5_mlm_flax.py
@@ -309,7 +309,7 @@ class FlaxDataCollatorForT5MLM:
Data collator used for T5 span-masked language modeling.
It is made sure that after masking the inputs are of length `data_args.max_seq_length` and targets are also of fixed length.
For more information on how T5 span-masked language modeling works, one can take a look
- at the `official paper `__
+ at the `official paper `__
or the `official code for preprocessing `__ .
Args:
diff --git a/examples/legacy/question-answering/README.md b/examples/legacy/question-answering/README.md
index 339837c94f..39d65e9176 100644
--- a/examples/legacy/question-answering/README.md
+++ b/examples/legacy/question-answering/README.md
@@ -6,12 +6,12 @@ models which were pre-trained on the same training data (BooksCorpus and English
training, but with different relative position embeddings.
* `zhiheng-huang/bert-base-uncased-embedding-relative-key`, trained from scratch with relative embedding proposed by
-Shaw et al., [Self-Attention with Relative Position Representations](https://arxiv.org/abs/1803.02155)
+Shaw et al., [Self-Attention with Relative Position Representations](https://huggingface.co/papers/1803.02155)
* `zhiheng-huang/bert-base-uncased-embedding-relative-key-query`, trained from scratch with relative embedding method 4
-in Huang et al. [Improve Transformer Models with Better Relative Position Embeddings](https://arxiv.org/abs/2009.13658)
+in Huang et al. [Improve Transformer Models with Better Relative Position Embeddings](https://huggingface.co/papers/2009.13658)
* `zhiheng-huang/bert-large-uncased-whole-word-masking-embedding-relative-key-query`, fine-tuned from model
`google-bert/bert-large-uncased-whole-word-masking` with 3 additional epochs with relative embedding method 4 in Huang et al.
-[Improve Transformer Models with Better Relative Position Embeddings](https://arxiv.org/abs/2009.13658)
+[Improve Transformer Models with Better Relative Position Embeddings](https://huggingface.co/papers/2009.13658)
##### Base models fine-tuning
diff --git a/examples/modular-transformers/configuration_my_new_model.py b/examples/modular-transformers/configuration_my_new_model.py
index 863217d304..bdf142d8d3 100644
--- a/examples/modular-transformers/configuration_my_new_model.py
+++ b/examples/modular-transformers/configuration_my_new_model.py
@@ -37,7 +37,7 @@ class MyNewModelConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
diff --git a/examples/modular-transformers/configuration_new_model.py b/examples/modular-transformers/configuration_new_model.py
index f9954a3c7a..110e0176f6 100644
--- a/examples/modular-transformers/configuration_new_model.py
+++ b/examples/modular-transformers/configuration_new_model.py
@@ -35,7 +35,7 @@ class NewModelConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
head_dim (`int`, *optional*, defaults to 256):
The attention head dimension.
diff --git a/examples/modular-transformers/modeling_add_function.py b/examples/modular-transformers/modeling_add_function.py
index acf140f025..ee52f883e4 100644
--- a/examples/modular-transformers/modeling_add_function.py
+++ b/examples/modular-transformers/modeling_add_function.py
@@ -53,7 +53,7 @@ class TestAttention(nn.Module):
Adapted from transformers.models.mistral.modeling_mistral.MistralAttention:
The input dimension here is attention_hidden_size = 2 * hidden_size, and head_dim = attention_hidden_size // num_heads.
The extra factor of 2 comes from the input being the concatenation of original_hidden_states with the output of the previous (mamba) layer
- (see fig. 2 in https://arxiv.org/pdf/2405.16712).
+ (see fig. 2 in https://huggingface.co/papers/2405.16712).
Additionally, replaced
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim) with
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim/2)
diff --git a/examples/modular-transformers/modeling_dummy.py b/examples/modular-transformers/modeling_dummy.py
index e513e27497..6ea859ee2f 100644
--- a/examples/modular-transformers/modeling_dummy.py
+++ b/examples/modular-transformers/modeling_dummy.py
@@ -388,7 +388,7 @@ DUMMY_INPUTS_DOCSTRING = r"""
`past_key_values`).
If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
- 1 indicates the head is **not masked**,
diff --git a/examples/modular-transformers/modeling_dummy_bert.py b/examples/modular-transformers/modeling_dummy_bert.py
index 5543a60c8d..5b2c9f9383 100644
--- a/examples/modular-transformers/modeling_dummy_bert.py
+++ b/examples/modular-transformers/modeling_dummy_bert.py
@@ -845,7 +845,7 @@ class DummyBertModel(DummyBertPreTrainedModel):
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in [Attention is
- all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
+ all you need](https://huggingface.co/papers/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
To behave as an decoder the model needs to be initialized with the `is_decoder` argument of the configuration set
diff --git a/examples/modular-transformers/modeling_multimodal1.py b/examples/modular-transformers/modeling_multimodal1.py
index 5f1a083321..3d4b01ebd8 100644
--- a/examples/modular-transformers/modeling_multimodal1.py
+++ b/examples/modular-transformers/modeling_multimodal1.py
@@ -388,7 +388,7 @@ MULTIMODAL1_TEXT_INPUTS_DOCSTRING = r"""
`past_key_values`).
If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
- 1 indicates the head is **not masked**,
diff --git a/examples/modular-transformers/modeling_my_new_model2.py b/examples/modular-transformers/modeling_my_new_model2.py
index df794c7873..7a5176138f 100644
--- a/examples/modular-transformers/modeling_my_new_model2.py
+++ b/examples/modular-transformers/modeling_my_new_model2.py
@@ -386,7 +386,7 @@ MY_NEW_MODEL2_INPUTS_DOCSTRING = r"""
`past_key_values`).
If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
- 1 indicates the head is **not masked**,
diff --git a/examples/modular-transformers/modeling_roberta.py b/examples/modular-transformers/modeling_roberta.py
index 2aa5a94a6a..7f2b1e7d71 100644
--- a/examples/modular-transformers/modeling_roberta.py
+++ b/examples/modular-transformers/modeling_roberta.py
@@ -848,7 +848,7 @@ class RobertaModel(RobertaPreTrainedModel):
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in [Attention is
- all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
+ all you need](https://huggingface.co/papers/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
To behave as an decoder the model needs to be initialized with the `is_decoder` argument of the configuration set
diff --git a/examples/modular-transformers/modeling_super.py b/examples/modular-transformers/modeling_super.py
index 4b23c6cb16..4d3308d115 100644
--- a/examples/modular-transformers/modeling_super.py
+++ b/examples/modular-transformers/modeling_super.py
@@ -389,7 +389,7 @@ SUPER_INPUTS_DOCSTRING = r"""
`past_key_values`).
If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
- 1 indicates the head is **not masked**,
diff --git a/examples/pytorch/image-pretraining/README.md b/examples/pytorch/image-pretraining/README.md
index 88c71e643e..5a5e83af8d 100644
--- a/examples/pytorch/image-pretraining/README.md
+++ b/examples/pytorch/image-pretraining/README.md
@@ -25,12 +25,12 @@ NOTE: If you encounter problems/have suggestions for improvement, open an issue
## SimMIM
-The `run_mim.py` script can be used to pre-train any Transformer-based vision model in the library (concretely, any model supported by the `AutoModelForMaskedImageModeling` API) for masked image modeling as proposed in [SimMIM: A Simple Framework for Masked Image Modeling](https://arxiv.org/abs/2111.09886) using PyTorch.
+The `run_mim.py` script can be used to pre-train any Transformer-based vision model in the library (concretely, any model supported by the `AutoModelForMaskedImageModeling` API) for masked image modeling as proposed in [SimMIM: A Simple Framework for Masked Image Modeling](https://huggingface.co/papers/2111.09886) using PyTorch.
- SimMIM framework. Taken from the original paper.
+ SimMIM framework. Taken from the original paper.
The goal for the model is to predict raw pixel values for the masked patches, using just a linear layer as prediction head. The model is trained using a simple L1 loss.
@@ -145,7 +145,7 @@ python run_mim.py \
## MAE
-The `run_mae.py` script can be used to pre-train a Vision Transformer as a masked autoencoder (MAE), as proposed in [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377). The script can be used to train a `ViTMAEForPreTraining` model in the Transformers library, using PyTorch. After self-supervised pre-training, one can load the weights of the encoder directly into a `ViTForImageClassification`. The MAE method allows for learning high-capacity models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data.
+The `run_mae.py` script can be used to pre-train a Vision Transformer as a masked autoencoder (MAE), as proposed in [Masked Autoencoders Are Scalable Vision Learners](https://huggingface.co/papers/2111.06377). The script can be used to train a `ViTMAEForPreTraining` model in the Transformers library, using PyTorch. After self-supervised pre-training, one can load the weights of the encoder directly into a `ViTForImageClassification`. The MAE method allows for learning high-capacity models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data.
The goal for the model is to predict raw pixel values for the masked patches. As the model internally masks patches and learns to reconstruct them, there's no need for any labels. The model uses the mean squared error (MSE) between the reconstructed and original images in the pixel space.
@@ -182,14 +182,14 @@ python run_mae.py \
Here we set:
- `mask_ratio` to 0.75 (to mask 75% of the patches for each image)
- `norm_pix_loss` to use normalized pixel values as target (the authors reported better representations with this enabled)
-- `base_learning_rate` to 1.5e-4. Note that the effective learning rate is computed by the [linear schedule](https://arxiv.org/abs/1706.02677): `lr` = `blr` * total training batch size / 256. The total training batch size is computed as `training_args.train_batch_size` * `training_args.gradient_accumulation_steps` * `training_args.world_size`.
+- `base_learning_rate` to 1.5e-4. Note that the effective learning rate is computed by the [linear schedule](https://huggingface.co/papers/1706.02677): `lr` = `blr` * total training batch size / 256. The total training batch size is computed as `training_args.train_batch_size` * `training_args.gradient_accumulation_steps` * `training_args.world_size`.
This replicates the same hyperparameters as used in the original implementation, as shown in the table below.
- Original hyperparameters. Taken from the original paper.
+ Original hyperparameters. Taken from the original paper.
Alternatively, one can decide to further pre-train an already pre-trained (or fine-tuned) checkpoint from the [hub](https://huggingface.co/). This can be done by setting the `model_name_or_path` argument to "facebook/vit-mae-base" for example.
diff --git a/examples/pytorch/image-pretraining/run_mae.py b/examples/pytorch/image-pretraining/run_mae.py
index 35cad47957..997356fe4e 100644
--- a/examples/pytorch/image-pretraining/run_mae.py
+++ b/examples/pytorch/image-pretraining/run_mae.py
@@ -37,7 +37,7 @@ from transformers.utils import check_min_version, send_example_telemetry
from transformers.utils.versions import require_version
-""" Pre-training a 🤗 ViT model as an MAE (masked autoencoder), as proposed in https://arxiv.org/abs/2111.06377."""
+""" Pre-training a 🤗 ViT model as an MAE (masked autoencoder), as proposed in https://huggingface.co/papers/2111.06377."""
logger = logging.getLogger(__name__)
diff --git a/examples/pytorch/language-modeling/README.md b/examples/pytorch/language-modeling/README.md
index e1b2beddf4..8623a77d5f 100644
--- a/examples/pytorch/language-modeling/README.md
+++ b/examples/pytorch/language-modeling/README.md
@@ -75,7 +75,7 @@ python run_clm_no_trainer.py \
### GPT-2/GPT and causal language modeling with fill-in-the middle objective
-The following example fine-tunes GPT-2 on WikiText-2 but using the Fill-in-middle training objective. FIM objective was proposed in [Efficient Training of Language Models to Fill in the Middle](https://arxiv.org/abs/2207.14255). They showed that autoregressive language models can learn to infill text after applying a straightforward transformation to the dataset, which simply moves a span of text from the middle of a document to its end.
+The following example fine-tunes GPT-2 on WikiText-2 but using the Fill-in-middle training objective. FIM objective was proposed in [Efficient Training of Language Models to Fill in the Middle](https://huggingface.co/papers/2207.14255). They showed that autoregressive language models can learn to infill text after applying a straightforward transformation to the dataset, which simply moves a span of text from the middle of a document to its end.
We're using the raw WikiText-2 (no tokens were replaced before the tokenization). The loss here is that of causal language modeling.
diff --git a/examples/pytorch/speech-pretraining/README.md b/examples/pytorch/speech-pretraining/README.md
index d0126634d2..a7364c780d 100644
--- a/examples/pytorch/speech-pretraining/README.md
+++ b/examples/pytorch/speech-pretraining/README.md
@@ -21,7 +21,7 @@ limitations under the License.
The script [`run_speech_wav2vec2_pretraining_no_trainer.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py) can be used to pre-train a [Wav2Vec2](https://huggingface.co/transformers/model_doc/wav2vec2.html?highlight=wav2vec2) model from scratch.
-In the script [`run_speech_wav2vec2_pretraining_no_trainer`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py), a Wav2Vec2 model is pre-trained on audio data alone using [Wav2Vec2's contrastive loss objective](https://arxiv.org/abs/2006.11477).
+In the script [`run_speech_wav2vec2_pretraining_no_trainer`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py), a Wav2Vec2 model is pre-trained on audio data alone using [Wav2Vec2's contrastive loss objective](https://huggingface.co/papers/2006.11477).
The following examples show how to fine-tune a `"base"`-sized Wav2Vec2 model as well as a `"large"`-sized Wav2Vec2 model using [`accelerate`](https://github.com/huggingface/accelerate).
diff --git a/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py b/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py
index 3bb7fe7bdc..111706412a 100755
--- a/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py
+++ b/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py
@@ -314,7 +314,7 @@ class DataCollatorForWav2Vec2Pretraining:
mask_time_prob (:obj:`float`, `optional`, defaults to :obj:`0.65`):
Percentage (between 0 and 1) of all feature vectors along the time axis which will be masked for the contrastive task.
Note that overlap between masked sequences may decrease the actual percentage of masked vectors.
- The default value is taken from the original wav2vec 2.0 article (https://arxiv.org/abs/2006.11477),
+ The default value is taken from the original wav2vec 2.0 article (https://huggingface.co/papers/2006.11477),
and results in about 49 percent of each sequence being masked on average.
mask_time_length (:obj:`int`, `optional`, defaults to :obj:`10`):
Length of each vector mask span to mask along the time axis in the contrastive task. The default value
diff --git a/examples/pytorch/speech-recognition/README.md b/examples/pytorch/speech-recognition/README.md
index 4990219f42..d0e898b8b7 100644
--- a/examples/pytorch/speech-recognition/README.md
+++ b/examples/pytorch/speech-recognition/README.md
@@ -493,7 +493,7 @@ Note that we have added a randomly initialized _adapter layer_ to `wav2vec2-base
`encoder_add_adapter=True`. This adapter sub-samples the output sequence of
`wav2vec2-base` along the time dimension. By default, a single
output vector of `wav2vec2-base` has a receptive field of *ca.* 25ms (*cf.*
-Section *4.2* of the [official Wav2Vec2 paper](https://arxiv.org/pdf/2006.11477.pdf)), which represents a little less a single character. On the other hand, BART
+Section *4.2* of the [official Wav2Vec2 paper](https://huggingface.co/papers/2006.11477)), which represents a little less a single character. On the other hand, BART
makes use of a sentence-piece tokenizer as an input processor, so that a single
hidden vector of `bart-base` represents *ca.* 4 characters. To better align the
receptive field of the *Wav2Vec2* output vectors with *BART*'s hidden-states in the cross-attention
diff --git a/examples/tensorflow/language-modeling-tpu/README.md b/examples/tensorflow/language-modeling-tpu/README.md
index 25381f86d0..0c068df8f2 100644
--- a/examples/tensorflow/language-modeling-tpu/README.md
+++ b/examples/tensorflow/language-modeling-tpu/README.md
@@ -8,7 +8,7 @@ This example will demonstrate pre-training language models at the 100M-1B parame
We've tried to ensure that all the practices we show you here are scalable, though - with relatively few changes, the code could be scaled up to much larger models.
-Google's gargantuan [PaLM model](https://arxiv.org/abs/2204.02311), with
+Google's gargantuan [PaLM model](https://huggingface.co/papers/2204.02311), with
over 500B parameters, is a good example of how far you can go with pure TPU training, though gathering the dataset and the budget to train at that scale is not an easy task!
### Table of contents
diff --git a/src/transformers/activations.py b/src/transformers/activations.py
index 2dab2fb32c..423e3cee87 100644
--- a/src/transformers/activations.py
+++ b/src/transformers/activations.py
@@ -27,7 +27,7 @@ logger = logging.get_logger(__name__)
class PytorchGELUTanh(nn.Module):
"""
A fast C implementation of the tanh approximation of the GeLU activation function. See
- https://arxiv.org/abs/1606.08415.
+ https://huggingface.co/papers/1606.08415.
This implementation is equivalent to NewGELU and FastGELU but much faster. However, it is not an exact numerical
match due to rounding errors.
@@ -40,7 +40,7 @@ class PytorchGELUTanh(nn.Module):
class NewGELUActivation(nn.Module):
"""
Implementation of the GELU activation function currently in Google BERT repo (identical to OpenAI GPT). Also see
- the Gaussian Error Linear Units paper: https://arxiv.org/abs/1606.08415
+ the Gaussian Error Linear Units paper: https://huggingface.co/papers/1606.08415
"""
def forward(self, input: Tensor) -> Tensor:
@@ -52,7 +52,7 @@ class GELUActivation(nn.Module):
Original Implementation of the GELU activation function in Google BERT repo when initially created. For
information: OpenAI GPT's GELU is slightly different (and gives slightly different results): 0.5 * x * (1 +
torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3)))) This is now written in C in nn.functional
- Also see the Gaussian Error Linear Units paper: https://arxiv.org/abs/1606.08415
+ Also see the Gaussian Error Linear Units paper: https://huggingface.co/papers/1606.08415
"""
def __init__(self, use_gelu_python: bool = False):
@@ -91,13 +91,13 @@ class ClippedGELUActivation(nn.Module):
"""
Clip the range of possible GeLU outputs between [min, max]. This is especially useful for quantization purpose, as
it allows mapping negatives values in the GeLU spectrum. For more information on this trick, please refer to
- https://arxiv.org/abs/2004.09602.
+ https://huggingface.co/papers/2004.09602.
Gaussian Error Linear Unit. Original Implementation of the gelu activation function in Google Bert repo when
initially created.
For information: OpenAI GPT's gelu is slightly different (and gives slightly different results): 0.5 * x * (1 +
- torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3)))). See https://arxiv.org/abs/1606.08415
+ torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3)))). See https://huggingface.co/papers/1606.08415
"""
def __init__(self, min: float, max: float):
@@ -130,7 +130,7 @@ class AccurateGELUActivation(nn.Module):
class MishActivation(nn.Module):
"""
- See Mish: A Self-Regularized Non-Monotonic Activation Function (Misra., https://arxiv.org/abs/1908.08681). Also
+ See Mish: A Self-Regularized Non-Monotonic Activation Function (Misra., https://huggingface.co/papers/1908.08681). Also
visit the official repository for the paper: https://github.com/digantamisra98/Mish
"""
@@ -157,7 +157,7 @@ class LinearActivation(nn.Module):
class LaplaceActivation(nn.Module):
"""
Applies elementwise activation based on Laplace function, introduced in MEGA as an attention activation. See
- https://arxiv.org/abs/2209.10655
+ https://huggingface.co/papers/2209.10655
Inspired by squared relu, but with bounded range and gradient for better stability
"""
@@ -169,7 +169,7 @@ class LaplaceActivation(nn.Module):
class ReLUSquaredActivation(nn.Module):
"""
- Applies the relu^2 activation introduced in https://arxiv.org/abs/2109.08668v2
+ Applies the relu^2 activation introduced in https://huggingface.co/papers/2109.08668v2
"""
def forward(self, input):
diff --git a/src/transformers/activations_tf.py b/src/transformers/activations_tf.py
index d12b73ea45..8dccf6c4f4 100644
--- a/src/transformers/activations_tf.py
+++ b/src/transformers/activations_tf.py
@@ -36,7 +36,7 @@ def _gelu(x):
Gaussian Error Linear Unit. Original Implementation of the gelu activation function in Google Bert repo when
initially created. For information: OpenAI GPT's gelu is slightly different (and gives slightly different results):
0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3)))) Also see
- https://arxiv.org/abs/1606.08415
+ https://huggingface.co/papers/1606.08415
"""
x = tf.convert_to_tensor(x)
cdf = 0.5 * (1.0 + tf.math.erf(x / tf.cast(tf.sqrt(2.0), x.dtype)))
@@ -46,7 +46,7 @@ def _gelu(x):
def _gelu_new(x):
"""
- Gaussian Error Linear Unit. This is a smoother version of the GELU. Original paper: https://arxiv.org/abs/1606.0841
+ Gaussian Error Linear Unit. This is a smoother version of the GELU. Original paper: https://huggingface.co/papers/1606.0841
Args:
x: float Tensor to perform activation
@@ -86,19 +86,19 @@ def gelu_10(x):
"""
Clip the range of possible GeLU outputs between [-10, 10]. This is especially useful for quantization purpose, as
it allows mapping 2 negatives values in the GeLU spectrum. For more information on this trick, please refer to
- https://arxiv.org/abs/2004.09602
+ https://huggingface.co/papers/2004.09602
Gaussian Error Linear Unit. Original Implementation of the gelu activation function in Google Bert repo when
initially created. For information: OpenAI GPT's gelu is slightly different (and gives slightly different results):
0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3)))) Also see
- https://arxiv.org/abs/1606.08415 :param x: :return:
+ https://huggingface.co/papers/1606.08415 :param x: :return:
"""
return tf.clip_by_value(_gelu(x), -10, 10)
def glu(x, axis=-1):
"""
- Gated Linear Unit. Implementation as defined in the original paper (see https://arxiv.org/abs/1612.08083), where
+ Gated Linear Unit. Implementation as defined in the original paper (see https://huggingface.co/papers/1612.08083), where
the input `x` is split in two halves across a dimension (`axis`), A and B, returning A * sigmoid(B).
Args:
diff --git a/src/transformers/cache_utils.py b/src/transformers/cache_utils.py
index 55f5010fbb..453d4a44bb 100644
--- a/src/transformers/cache_utils.py
+++ b/src/transformers/cache_utils.py
@@ -843,7 +843,7 @@ class OffloadedCache(DynamicCache):
class QuantizedCache(DynamicCache):
"""
- A quantizer cache similar to what is described in the [KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache paper](https://arxiv.org/abs/2402.02750).
+ A quantizer cache similar to what is described in the [KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache paper](https://huggingface.co/papers/2402.02750).
It allows the model to generate longer sequence length without allocating too much memory for Key and Value cache by applying quantization.
The cache has two types of storage, one for original precision and one for the quantized cache. A `residual length` is set as a maximum capacity for the
diff --git a/src/transformers/generation/beam_search.py b/src/transformers/generation/beam_search.py
index f5850a864c..f783784a4a 100644
--- a/src/transformers/generation/beam_search.py
+++ b/src/transformers/generation/beam_search.py
@@ -154,7 +154,7 @@ class BeamSearchScorer(BeamScorer):
[`~transformers.BeamSearchScorer.finalize`].
num_beam_groups (`int`, *optional*, defaults to 1):
Number of groups to divide `num_beams` into in order to ensure diversity among different groups of beams.
- See [this paper](https://arxiv.org/pdf/1610.02424.pdf) for more details.
+ See [this paper](https://huggingface.co/papers/1610.02424) for more details.
max_length (`int`, *optional*):
The maximum length of the sequence to be generated.
"""
@@ -448,7 +448,7 @@ class ConstrainedBeamSearchScorer(BeamScorer):
[`~transformers.BeamSearchScorer.finalize`].
num_beam_groups (`int`, *optional*, defaults to 1):
Number of groups to divide `num_beams` into in order to ensure diversity among different groups of beams.
- See [this paper](https://arxiv.org/pdf/1610.02424.pdf) for more details.
+ See [this paper](https://huggingface.co/papers/1610.02424) for more details.
max_length (`int`, *optional*):
The maximum length of the sequence to be generated.
"""
diff --git a/src/transformers/generation/candidate_generator.py b/src/transformers/generation/candidate_generator.py
index bb92220305..b82cdd12f8 100644
--- a/src/transformers/generation/candidate_generator.py
+++ b/src/transformers/generation/candidate_generator.py
@@ -678,7 +678,7 @@ class AssistantToTargetTranslator:
Translates token ids and logits between assistant and target model vocabularies. This class is used to handle
vocabulary mismatches when using different tokenizers for the assistant and target models in speculative decoding,
as introduced in the paper "Lossless Speculative Decoding Algorithms for Heterogeneous Vocabularies"
- (https://www.arxiv.org/abs/2502.05202).
+ (https://huggingface.co/papers/2502.05202).
It maintains mappings between the two vocabularies and handles token/logit conversion.
Args:
diff --git a/src/transformers/generation/configuration_utils.py b/src/transformers/generation/configuration_utils.py
index c886b51cf5..e7e77a8cd6 100644
--- a/src/transformers/generation/configuration_utils.py
+++ b/src/transformers/generation/configuration_utils.py
@@ -160,7 +160,7 @@ class GenerationConfig(PushToHubMixin):
Number of beams for beam search. 1 means no beam search.
num_beam_groups (`int`, *optional*, defaults to 1):
Number of groups to divide `num_beams` into in order to ensure diversity among different groups of beams.
- [this paper](https://arxiv.org/pdf/1610.02424.pdf) for more details.
+ [this paper](https://huggingface.co/papers/1610.02424) for more details.
penalty_alpha (`float`, *optional*):
The values balance the model confidence and the degeneration penalty in contrastive search decoding.
dola_layers (`str` or `List[int]`, *optional*):
@@ -171,7 +171,7 @@ class GenerationConfig(PushToHubMixin):
If a list of integers, it must contain the indices of the layers to use for candidate premature layers in DoLa.
The 0-th layer is the word embedding layer of the model. Set to `'low'` to improve long-answer reasoning tasks,
`'high'` to improve short-answer tasks. Check the [documentation](https://github.com/huggingface/transformers/blob/main/docs/source/en/generation_strategies.md)
- or [the paper](https://arxiv.org/abs/2309.03883) for more details.
+ or [the paper](https://huggingface.co/papers/2309.03883) for more details.
> Parameters that control the cache
@@ -216,25 +216,25 @@ class GenerationConfig(PushToHubMixin):
the expected conditional probability of predicting a random token next, given the partial text already
generated. If set to float < 1, the smallest set of the most locally typical tokens with probabilities that
add up to `typical_p` or higher are kept for generation. See [this
- paper](https://arxiv.org/pdf/2202.00666.pdf) for more details.
+ paper](https://huggingface.co/papers/2202.00666) for more details.
epsilon_cutoff (`float`, *optional*, defaults to 0.0):
If set to float strictly between 0 and 1, only tokens with a conditional probability greater than
`epsilon_cutoff` will be sampled. In the paper, suggested values range from 3e-4 to 9e-4, depending on the
size of the model. See [Truncation Sampling as Language Model
- Desmoothing](https://arxiv.org/abs/2210.15191) for more details.
+ Desmoothing](https://huggingface.co/papers/2210.15191) for more details.
eta_cutoff (`float`, *optional*, defaults to 0.0):
Eta sampling is a hybrid of locally typical sampling and epsilon sampling. If set to float strictly between
0 and 1, a token is only considered if it is greater than either `eta_cutoff` or `sqrt(eta_cutoff) *
exp(-entropy(softmax(next_token_logits)))`. The latter term is intuitively the expected next token
probability, scaled by `sqrt(eta_cutoff)`. In the paper, suggested values range from 3e-4 to 2e-3,
depending on the size of the model. See [Truncation Sampling as Language Model
- Desmoothing](https://arxiv.org/abs/2210.15191) for more details.
+ Desmoothing](https://huggingface.co/papers/2210.15191) for more details.
diversity_penalty (`float`, *optional*, defaults to 0.0):
This value is subtracted from a beam's score if it generates a token same as any beam from other group at a
particular time. Note that `diversity_penalty` is only effective if `group beam search` is enabled.
repetition_penalty (`float`, *optional*, defaults to 1.0):
The parameter for repetition penalty. 1.0 means no penalty. See [this
- paper](https://arxiv.org/pdf/1909.05858.pdf) for more details.
+ paper](https://huggingface.co/papers/1909.05858) for more details.
encoder_repetition_penalty (`float`, *optional*, defaults to 1.0):
The parameter for encoder_repetition_penalty. An exponential penalty on sequences that are not in the
original input. 1.0 means no penalty.
@@ -358,7 +358,7 @@ class GenerationConfig(PushToHubMixin):
(defined by `num_assistant_tokens`) is not yet reached. The assistant's confidence threshold is adjusted throughout the speculative iterations to reduce the number of unnecessary draft and target forward passes, biased towards avoiding false negatives.
`assistant_confidence_threshold` value is persistent over multiple generation calls with the same assistant model.
It is an unsupervised version of the dynamic speculation lookahead
- from Dynamic Speculation Lookahead Accelerates Speculative Decoding of Large Language Models .
+ from Dynamic Speculation Lookahead Accelerates Speculative Decoding of Large Language Models .
prompt_lookup_num_tokens (`int`, *optional*):
The number of tokens to be output as candidate tokens.
max_matching_ngram_size (`int`, *optional*):
@@ -1396,7 +1396,7 @@ class BaseWatermarkingConfig(ABC):
class WatermarkingConfig(BaseWatermarkingConfig):
"""
Class that holds arguments for watermark generation and should be passed into `GenerationConfig` during `generate`.
- See [this paper](https://arxiv.org/abs/2306.04634) for more details on the arguments.
+ See [this paper](https://huggingface.co/papers/2306.04634) for more details on the arguments.
Accepts the following keys:
- greenlist_ratio (`float`):
diff --git a/src/transformers/generation/logits_process.py b/src/transformers/generation/logits_process.py
index a6c6766b75..b0a1cfcb29 100644
--- a/src/transformers/generation/logits_process.py
+++ b/src/transformers/generation/logits_process.py
@@ -300,7 +300,7 @@ class RepetitionPenaltyLogitsProcessor(LogitsProcessor):
most once per token. Note that, for decoder-only models like most LLMs, the considered tokens include the prompt
by default.
- In the original [paper](https://arxiv.org/pdf/1909.05858.pdf), the authors suggest the use of a penalty of around
+ In the original [paper](https://huggingface.co/papers/1909.05858), the authors suggest the use of a penalty of around
1.2 to achieve a good balance between truthful generation and lack of repetition. To penalize and reduce
repetition, use `penalty` values above 1.0, where a higher value penalizes more strongly. To reward and encourage
repetition, use `penalty` values between 0.0 and 1.0, where a lower value rewards more strongly.
@@ -628,7 +628,7 @@ class TypicalLogitsWarper(LogitsProcessor):
whose log probability is close to the entropy of the token probability distribution. This means that the most
likely tokens may be discarded in the process.
- See [Typical Decoding for Natural Language Generation](https://arxiv.org/abs/2202.00666) for more information.
+ See [Typical Decoding for Natural Language Generation](https://huggingface.co/papers/2202.00666) for more information.
Args:
mass (`float`, *optional*, defaults to 0.9):
@@ -714,7 +714,7 @@ class EpsilonLogitsWarper(LogitsProcessor):
r"""
[`LogitsProcessor`] that performs epsilon-sampling, i.e. restricting to tokens with `prob >= epsilon`. Takes the
largest min_tokens_to_keep tokens if no tokens satisfy this constraint. See [Truncation Sampling as Language Model
- Desmoothing](https://arxiv.org/abs/2210.15191) for more information.
+ Desmoothing](https://huggingface.co/papers/2210.15191) for more information.
Args:
epsilon (`float`):
@@ -786,7 +786,7 @@ class EtaLogitsWarper(LogitsProcessor):
the token probabilities, i.e. `eta := min(epsilon, sqrt(epsilon * e^-entropy(probabilities)))`. Takes the largest
min_tokens_to_keep tokens if no tokens satisfy this constraint. It addresses the issue of poor quality in long
samples of text generated by neural language models leading to more coherent and fluent text. See [Truncation
- Sampling as Language Model Desmoothing](https://arxiv.org/abs/2210.15191) for more information. Note: `do_sample`
+ Sampling as Language Model Desmoothing](https://huggingface.co/papers/2210.15191) for more information. Note: `do_sample`
must be set to `True` for this `LogitsProcessor` to work.
@@ -1329,7 +1329,7 @@ class NoBadWordsLogitsProcessor(SequenceBiasLogitsProcessor):
class PrefixConstrainedLogitsProcessor(LogitsProcessor):
r"""
[`LogitsProcessor`] that enforces constrained generation and is useful for prefix-conditioned constrained
- generation. See [Autoregressive Entity Retrieval](https://arxiv.org/abs/2010.00904) for more information.
+ generation. See [Autoregressive Entity Retrieval](https://huggingface.co/papers/2010.00904) for more information.
Args:
prefix_allowed_tokens_fn (`Callable[[int, torch.Tensor], List[int]]`):
@@ -1403,7 +1403,7 @@ class HammingDiversityLogitsProcessor(LogitsProcessor):
[`LogitsProcessor`] that enforces diverse beam search.
Note that this logits processor is only effective for [`PreTrainedModel.group_beam_search`]. See [Diverse Beam
- Search: Decoding Diverse Solutions from Neural Sequence Models](https://arxiv.org/pdf/1610.02424.pdf) for more
+ Search: Decoding Diverse Solutions from Neural Sequence Models](https://huggingface.co/papers/1610.02424) for more
details.
Traditional beam search often generates very similar sequences across different beams.
@@ -1419,7 +1419,7 @@ class HammingDiversityLogitsProcessor(LogitsProcessor):
Number of beams for beam search. 1 means no beam search.
num_beam_groups (`int`):
Number of groups to divide `num_beams` into in order to ensure diversity among different groups of beams.
- [this paper](https://arxiv.org/pdf/1610.02424.pdf) for more details.
+ [this paper](https://huggingface.co/papers/1610.02424) for more details.
Examples:
@@ -1899,7 +1899,7 @@ class WhisperTimeStampLogitsProcessor(LogitsProcessor):
potential tokens.
- See [the paper](https://arxiv.org/abs/2212.04356) for more information.
+ See [the paper](https://huggingface.co/papers/2212.04356) for more information.
Args:
generate_config (`GenerateConfig`):
@@ -2095,7 +2095,7 @@ class ClassifierFreeGuidanceLogitsProcessor(LogitsProcessor):
correspond to the unconditional logits (predicted from an empty or 'null' prompt). The processor computes a
weighted average across the conditional and unconditional logits, parameterised by the `guidance_scale`.
- See [the paper](https://arxiv.org/abs/2306.05284) for more information.
+ See [the paper](https://huggingface.co/papers/2306.05284) for more information.
@@ -2203,7 +2203,7 @@ class UnbatchedClassifierFreeGuidanceLogitsProcessor(LogitsProcessor):
from prompt conditional and prompt unconditional (or negative) logits, parameterized by the `guidance_scale`.
The unconditional scores are computed internally by prompting `model` with the `unconditional_ids` branch.
- See [the paper](https://arxiv.org/abs/2306.17806) for more information.
+ See [the paper](https://huggingface.co/papers/2306.17806) for more information.
Args:
guidance_scale (`float`):
@@ -2370,7 +2370,7 @@ class WatermarkLogitsProcessor(LogitsProcessor):
The text generated by this `LogitsProcessor` can be detected using `WatermarkDetector`. See [`~WatermarkDetector.__call__`] for details,
- See [the paper](https://arxiv.org/abs/2306.04634) for more information.
+ See [the paper](https://huggingface.co/papers/2306.04634) for more information.
Args:
vocab_size (`int`):
diff --git a/src/transformers/generation/tf_logits_process.py b/src/transformers/generation/tf_logits_process.py
index 8302319d98..49c4a55f8e 100644
--- a/src/transformers/generation/tf_logits_process.py
+++ b/src/transformers/generation/tf_logits_process.py
@@ -242,7 +242,7 @@ class TFRepetitionPenaltyLogitsProcessor(TFLogitsProcessor):
Args:
repetition_penalty (`float`):
The parameter for repetition penalty. 1.0 means no penalty. See [this
- paper](https://arxiv.org/pdf/1909.05858.pdf) for more details.
+ paper](https://huggingface.co/papers/1909.05858) for more details.
"""
def __init__(self, penalty: float):
diff --git a/src/transformers/generation/utils.py b/src/transformers/generation/utils.py
index 4a549fc215..7be31637bf 100644
--- a/src/transformers/generation/utils.py
+++ b/src/transformers/generation/utils.py
@@ -2293,7 +2293,7 @@ class GenerationMixin(ContinuousMixin):
`input_ids`. It has to return a list with the allowed tokens for the next generation step conditioned
on the batch ID `batch_id` and the previously generated tokens `inputs_ids`. This argument is useful
for constrained generation conditioned on the prefix, as described in [Autoregressive Entity
- Retrieval](https://arxiv.org/abs/2010.00904).
+ Retrieval](https://huggingface.co/papers/2010.00904).
synced_gpus (`bool`, *optional*):
Whether to continue running the while loop until max_length. Unless overridden, this flag will be set
to `True` if using `FullyShardedDataParallel` or DeepSpeed ZeRO Stage 3 with multiple GPUs to avoid
@@ -2883,7 +2883,7 @@ class GenerationMixin(ContinuousMixin):
Generates sequences of token ids for models with a language modeling head using **dola decoding** and can be
used for decoder-only text models.
The method is based on the paper "DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language
- Models" (https://arxiv.org/abs/2309.03883) in ICLR 2024.
+ Models" (https://huggingface.co/papers/2309.03883) in ICLR 2024.
Parameters:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
@@ -4905,7 +4905,7 @@ class GenerationMixin(ContinuousMixin):
# 3. Select the accepted tokens. There are two possible cases:
# Case 1: `do_sample=True` and we have logits for the candidates (originally from speculative decoding)
- # 👉 Apply algorithm 1 from the speculative decoding paper (https://arxiv.org/pdf/2211.17192.pdf).
+ # 👉 Apply algorithm 1 from the speculative decoding paper (https://huggingface.co/papers/2211.17192).
if do_sample and candidate_logits is not None:
valid_tokens, n_matches = _speculative_sampling(
candidate_input_ids,
@@ -5094,7 +5094,7 @@ def _speculative_sampling(
is_done_candidate,
):
"""
- Applies sampling as in the speculative decoding paper (https://arxiv.org/pdf/2211.17192.pdf, algorithm 1). Returns
+ Applies sampling as in the speculative decoding paper (https://huggingface.co/papers/2211.17192, algorithm 1). Returns
the selected tokens, as well as the number of candidate matches.
NOTE: Unless otherwise stated, the variable names match those in the paper.
diff --git a/src/transformers/generation/watermarking.py b/src/transformers/generation/watermarking.py
index 139d8cf2c7..759e46631d 100644
--- a/src/transformers/generation/watermarking.py
+++ b/src/transformers/generation/watermarking.py
@@ -77,7 +77,7 @@ class WatermarkDetector:
the correct device that was used during text generation, the correct watermarking arguments and the correct tokenizer vocab size.
The code was based on the [original repo](https://github.com/jwkirchenbauer/lm-watermarking/tree/main).
- See [the paper](https://arxiv.org/abs/2306.04634) for more information.
+ See [the paper](https://huggingface.co/papers/2306.04634) for more information.
Args:
model_config (`PretrainedConfig`):
diff --git a/src/transformers/integrations/peft.py b/src/transformers/integrations/peft.py
index 8a1652748f..90ddd68c26 100644
--- a/src/transformers/integrations/peft.py
+++ b/src/transformers/integrations/peft.py
@@ -53,7 +53,7 @@ class PeftAdapterMixin:
that anyone can load, train and run with this mixin class:
- Low Rank Adapters (LoRA): https://huggingface.co/docs/peft/conceptual_guides/lora
- IA3: https://huggingface.co/docs/peft/conceptual_guides/ia3
- - AdaLora: https://arxiv.org/abs/2303.10512
+ - AdaLora: https://huggingface.co/papers/2303.10512
Other PEFT models such as prompt tuning, prompt learning are out of scope as these adapters are not "injectable"
into a torch module. For using these methods, please refer to the usage guide of PEFT library.
diff --git a/src/transformers/integrations/tensor_parallel.py b/src/transformers/integrations/tensor_parallel.py
index b0946ee771..83ce593437 100644
--- a/src/transformers/integrations/tensor_parallel.py
+++ b/src/transformers/integrations/tensor_parallel.py
@@ -647,7 +647,7 @@ class SequenceParallel(TensorParallelLayer):
`RMSNorm python implementation `__
This style implements the operation that is described in the paper
- `Reducing Activation Recomputation in Large Transformer Models `__
+ `Reducing Activation Recomputation in Large Transformer Models `__
If the input passed in to this ``nn.Module`` is a :class:`torch.Tensor`, it assumes that the input is already sharded
on the sequence dimension and converts the input to a :class:`DTensor` sharded on the sequence dimension. If the input
diff --git a/src/transformers/loss/loss_for_object_detection.py b/src/transformers/loss/loss_for_object_detection.py
index 0481312af8..877141f022 100644
--- a/src/transformers/loss/loss_for_object_detection.py
+++ b/src/transformers/loss/loss_for_object_detection.py
@@ -53,7 +53,7 @@ def dice_loss(inputs, targets, num_boxes):
def sigmoid_focal_loss(inputs, targets, num_boxes, alpha: float = 0.25, gamma: float = 2):
"""
- Loss used in RetinaNet for dense detection: https://arxiv.org/abs/1708.02002.
+ Loss used in RetinaNet for dense detection: https://huggingface.co/papers/1708.02002.
Args:
inputs (`torch.FloatTensor` of arbitrary shape):
diff --git a/src/transformers/loss/loss_grounding_dino.py b/src/transformers/loss/loss_grounding_dino.py
index 0b5e4f6054..0294f93232 100644
--- a/src/transformers/loss/loss_grounding_dino.py
+++ b/src/transformers/loss/loss_grounding_dino.py
@@ -33,7 +33,7 @@ def sigmoid_focal_loss(
gamma: float = 2,
):
"""
- Loss used in RetinaNet for dense detection: https://arxiv.org/abs/1708.02002.
+ Loss used in RetinaNet for dense detection: https://huggingface.co/papers/1708.02002.
Args:
inputs (`torch.FloatTensor` of arbitrary shape):
diff --git a/src/transformers/modelcard.py b/src/transformers/modelcard.py
index da5c407778..5cc9ba8e3b 100644
--- a/src/transformers/modelcard.py
+++ b/src/transformers/modelcard.py
@@ -83,7 +83,7 @@ class ModelCard:
Please read the following paper for details and explanation on the sections: "Model Cards for Model Reporting" by
Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer,
- Inioluwa Deborah Raji and Timnit Gebru for the proposal behind model cards. Link: https://arxiv.org/abs/1810.03993
+ Inioluwa Deborah Raji and Timnit Gebru for the proposal behind model cards. Link: https://huggingface.co/papers/1810.03993
Note: A model card can be loaded and saved to disk.
"""
@@ -92,7 +92,7 @@ class ModelCard:
warnings.warn(
"The class `ModelCard` is deprecated and will be removed in version 5 of Transformers", FutureWarning
)
- # Recommended attributes from https://arxiv.org/abs/1810.03993 (see papers)
+ # Recommended attributes from https://huggingface.co/papers/1810.03993 (see papers)
self.model_details = kwargs.pop("model_details", {})
self.intended_use = kwargs.pop("intended_use", {})
self.factors = kwargs.pop("factors", {})
diff --git a/src/transformers/modeling_rope_utils.py b/src/transformers/modeling_rope_utils.py
index ccb961edea..e84c2c4a79 100644
--- a/src/transformers/modeling_rope_utils.py
+++ b/src/transformers/modeling_rope_utils.py
@@ -228,7 +228,7 @@ def _compute_yarn_parameters(
) -> tuple["torch.Tensor", float]:
"""
Computes the inverse frequencies with NTK scaling. Please refer to the
- [original paper](https://arxiv.org/abs/2309.00071)
+ [original paper](https://huggingface.co/papers/2309.00071)
Args:
config ([`~transformers.PretrainedConfig`]):
The model configuration.
diff --git a/src/transformers/modeling_utils.py b/src/transformers/modeling_utils.py
index 64d5737545..e1668ffd7c 100644
--- a/src/transformers/modeling_utils.py
+++ b/src/transformers/modeling_utils.py
@@ -1881,7 +1881,7 @@ class ModuleUtilsMixin:
Get number of (optionally, non-embeddings) floating-point operations for the forward and backward passes of a
batch with this transformer model. Default approximation neglects the quadratic dependency on the number of
tokens (valid if `12 * d_model << sequence_length`) as laid out in [this
- paper](https://arxiv.org/pdf/2001.08361.pdf) section 2.1. Should be overridden for transformers with parameter
+ paper](https://huggingface.co/papers/2001.08361) section 2.1. Should be overridden for transformers with parameter
re-use e.g. Albert or Universal Transformers, or if doing long-range modeling with very high sequence lengths.
Args:
diff --git a/src/transformers/models/albert/configuration_albert.py b/src/transformers/models/albert/configuration_albert.py
index 6dd34ac6b0..b60c19d504 100644
--- a/src/transformers/models/albert/configuration_albert.py
+++ b/src/transformers/models/albert/configuration_albert.py
@@ -71,9 +71,9 @@ class AlbertConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
pad_token_id (`int`, *optional*, defaults to 0):
Padding token id.
bos_token_id (`int`, *optional*, defaults to 2):
diff --git a/src/transformers/models/align/configuration_align.py b/src/transformers/models/align/configuration_align.py
index a22ab1dc40..31121b5a71 100644
--- a/src/transformers/models/align/configuration_align.py
+++ b/src/transformers/models/align/configuration_align.py
@@ -71,9 +71,9 @@ class AlignTextConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models). Only
relevant if `config.is_decoder=True`.
diff --git a/src/transformers/models/altclip/configuration_altclip.py b/src/transformers/models/altclip/configuration_altclip.py
index 3c8e91bd47..4f1392e6c8 100755
--- a/src/transformers/models/altclip/configuration_altclip.py
+++ b/src/transformers/models/altclip/configuration_altclip.py
@@ -70,9 +70,9 @@ class AltCLIPTextConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models). Only
relevant if `config.is_decoder=True`.
diff --git a/src/transformers/models/altclip/modeling_altclip.py b/src/transformers/models/altclip/modeling_altclip.py
index 5637bc6dee..4c86159b2c 100755
--- a/src/transformers/models/altclip/modeling_altclip.py
+++ b/src/transformers/models/altclip/modeling_altclip.py
@@ -1134,7 +1134,7 @@ class AltCLIPVisionModel(AltCLIPPreTrainedModel):
to `True`. To be used in a Seq2Seq model, the model needs to initialized with both `is_decoder` argument and
`add_cross_attention` set to `True`; an `encoder_hidden_states` is then expected as an input to the forward pass.
- .. _*Attention is all you need*: https://arxiv.org/abs/1706.03762
+ .. _*Attention is all you need*: https://huggingface.co/papers/1706.03762
"""
)
class AltRobertaModel(AltCLIPPreTrainedModel):
diff --git a/src/transformers/models/aria/configuration_aria.py b/src/transformers/models/aria/configuration_aria.py
index 761dd2f722..1d0e1d3c5f 100644
--- a/src/transformers/models/aria/configuration_aria.py
+++ b/src/transformers/models/aria/configuration_aria.py
@@ -50,7 +50,7 @@ class AriaTextConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
diff --git a/src/transformers/models/aria/modular_aria.py b/src/transformers/models/aria/modular_aria.py
index b8ae65d1d5..f9de23cfa1 100644
--- a/src/transformers/models/aria/modular_aria.py
+++ b/src/transformers/models/aria/modular_aria.py
@@ -121,7 +121,7 @@ class AriaTextConfig(LlamaConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
diff --git a/src/transformers/models/autoformer/modeling_autoformer.py b/src/transformers/models/autoformer/modeling_autoformer.py
index 0a41692f69..dd3fbf57ea 100644
--- a/src/transformers/models/autoformer/modeling_autoformer.py
+++ b/src/transformers/models/autoformer/modeling_autoformer.py
@@ -1032,7 +1032,7 @@ class AutoformerEncoder(AutoformerPreTrainedModel):
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
to_drop = False
if self.training:
dropout_probability = torch.rand([])
@@ -1218,7 +1218,7 @@ class AutoformerDecoder(AutoformerPreTrainedModel):
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
diff --git a/src/transformers/models/bamba/configuration_bamba.py b/src/transformers/models/bamba/configuration_bamba.py
index 5255f7cdf5..efa9d5f3d0 100644
--- a/src/transformers/models/bamba/configuration_bamba.py
+++ b/src/transformers/models/bamba/configuration_bamba.py
@@ -54,7 +54,7 @@ class BambaConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `8`.
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to `8`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
initializer_range (`float`, *optional*, defaults to 0.02):
diff --git a/src/transformers/models/bart/configuration_bart.py b/src/transformers/models/bart/configuration_bart.py
index 8561b4b8b4..90781feab3 100644
--- a/src/transformers/models/bart/configuration_bart.py
+++ b/src/transformers/models/bart/configuration_bart.py
@@ -75,10 +75,10 @@ class BartConfig(PretrainedConfig):
init_std (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
encoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
decoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
scale_embedding (`bool`, *optional*, defaults to `False`):
Scale embeddings by diving by sqrt(d_model).
diff --git a/src/transformers/models/bart/modeling_bart.py b/src/transformers/models/bart/modeling_bart.py
index 2442baa243..15c90e64d8 100755
--- a/src/transformers/models/bart/modeling_bart.py
+++ b/src/transformers/models/bart/modeling_bart.py
@@ -865,7 +865,7 @@ class BartEncoder(BartPreTrainedModel):
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
to_drop = False
if self.training:
dropout_probability = torch.rand([])
@@ -1129,7 +1129,7 @@ class BartDecoder(BartPreTrainedModel):
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
@@ -1283,7 +1283,7 @@ class BartModel(BartPreTrainedModel):
be used by default.
If you want to change padding behavior, you should read [`modeling_bart._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules in the decoder. Mask values selected in `[0,
@@ -1456,7 +1456,7 @@ class BartForConditionalGeneration(BartPreTrainedModel, GenerationMixin):
be used by default.
If you want to change padding behavior, you should read [`modeling_bart._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules in the decoder. Mask values selected in `[0,
@@ -1642,7 +1642,7 @@ class BartForSequenceClassification(BartPreTrainedModel):
be used by default.
If you want to change padding behavior, you should read [`modeling_bart._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules in the decoder. Mask values selected in `[0,
@@ -1788,7 +1788,7 @@ class BartForQuestionAnswering(BartPreTrainedModel):
be used by default.
If you want to change padding behavior, you should read [`modeling_bart._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules in the decoder. Mask values selected in `[0,
diff --git a/src/transformers/models/bart/modeling_flax_bart.py b/src/transformers/models/bart/modeling_flax_bart.py
index f04ab551e3..a2d3e44c56 100644
--- a/src/transformers/models/bart/modeling_flax_bart.py
+++ b/src/transformers/models/bart/modeling_flax_bart.py
@@ -122,7 +122,7 @@ BART_INPUTS_DOCSTRING = r"""
be used by default.
If you want to change padding behavior, you should modify to your needs. See diagram 1 in [the
- paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
+ paper](https://huggingface.co/papers/1910.13461) for more information on the default strategy.
position_ids (`numpy.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.max_position_embeddings - 1]`.
@@ -199,7 +199,7 @@ BART_DECODE_INPUTS_DOCSTRING = r"""
be used by default.
If you want to change padding behavior, you should modify to your needs. See diagram 1 in [the
- paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
+ paper](https://huggingface.co/papers/1910.13461) for more information on the default strategy.
decoder_position_ids (`numpy.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each decoder input sequence tokens in the position embeddings. Selected in the
range `[0, config.max_position_embeddings - 1]`.
@@ -478,7 +478,7 @@ class FlaxBartEncoderLayerCollection(nn.Module):
for encoder_layer in self.layers:
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if not deterministic and (dropout_probability < self.layerdrop): # skip the layer
layer_outputs = (None, None)
@@ -624,7 +624,7 @@ class FlaxBartDecoderLayerCollection(nn.Module):
for decoder_layer in self.layers:
if output_hidden_states:
all_hidden_states += (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if not deterministic and (dropout_probability < self.layerdrop):
layer_outputs = (None, None, None)
diff --git a/src/transformers/models/bart/modeling_tf_bart.py b/src/transformers/models/bart/modeling_tf_bart.py
index 7ab9817986..e345807d9d 100644
--- a/src/transformers/models/bart/modeling_tf_bart.py
+++ b/src/transformers/models/bart/modeling_tf_bart.py
@@ -860,7 +860,7 @@ class TFBartEncoder(keras.layers.Layer):
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if training and (dropout_probability < self.layerdrop): # skip the layer
continue
@@ -1069,7 +1069,7 @@ class TFBartDecoder(keras.layers.Layer):
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
diff --git a/src/transformers/models/beit/modeling_beit.py b/src/transformers/models/beit/modeling_beit.py
index 24e16ee8bf..69d9e991a5 100755
--- a/src/transformers/models/beit/modeling_beit.py
+++ b/src/transformers/models/beit/modeling_beit.py
@@ -576,7 +576,7 @@ class BeitRelativePositionBias(nn.Module):
def generate_relative_position_index(self, window_size: Tuple[int, int]) -> torch.Tensor:
"""
This method creates the relative position index, modified to support arbitrary window sizes,
- as introduced in [MiDaS v3.1](https://arxiv.org/abs/2307.14460).
+ as introduced in [MiDaS v3.1](https://huggingface.co/papers/2307.14460).
"""
num_relative_distance = (2 * window_size[0] - 1) * (2 * window_size[1] - 1) + 3
# cls to token & token 2 cls & cls to cls
@@ -1155,7 +1155,7 @@ class BeitPyramidPoolingModule(nn.Module):
class BeitUperHead(nn.Module):
"""
Unified Perceptual Parsing for Scene Understanding. This head is the implementation of
- [UPerNet](https://arxiv.org/abs/1807.10221).
+ [UPerNet](https://huggingface.co/papers/1807.10221).
Based on OpenMMLab's implementation, found in https://github.com/open-mmlab/mmsegmentation.
"""
@@ -1240,7 +1240,7 @@ class BeitUperHead(nn.Module):
class BeitFCNHead(nn.Module):
"""
Fully Convolution Networks for Semantic Segmentation. This head is implemented of
- [FCNNet](https://arxiv.org/abs/1411.4038>).
+ [FCNNet](https://huggingface.co/papers/1411.4038>).
Args:
config (BeitConfig): Configuration.
diff --git a/src/transformers/models/bert/configuration_bert.py b/src/transformers/models/bert/configuration_bert.py
index f307100a95..e7e51d3295 100644
--- a/src/transformers/models/bert/configuration_bert.py
+++ b/src/transformers/models/bert/configuration_bert.py
@@ -68,9 +68,9 @@ class BertConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
is_decoder (`bool`, *optional*, defaults to `False`):
Whether the model is used as a decoder or not. If `False`, the model is used as an encoder.
use_cache (`bool`, *optional*, defaults to `True`):
diff --git a/src/transformers/models/bert/modeling_bert.py b/src/transformers/models/bert/modeling_bert.py
index dd738ea96e..f5fc09ce23 100755
--- a/src/transformers/models/bert/modeling_bert.py
+++ b/src/transformers/models/bert/modeling_bert.py
@@ -853,7 +853,7 @@ class BertForPreTrainingOutput(ModelOutput):
custom_intro="""
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in [Attention is
- all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
+ all you need](https://huggingface.co/papers/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
To behave as an decoder the model needs to be initialized with the `is_decoder` argument of the configuration set
diff --git a/src/transformers/models/bert_generation/configuration_bert_generation.py b/src/transformers/models/bert_generation/configuration_bert_generation.py
index 1abe7c1a1c..e6cf054cc5 100644
--- a/src/transformers/models/bert_generation/configuration_bert_generation.py
+++ b/src/transformers/models/bert_generation/configuration_bert_generation.py
@@ -63,9 +63,9 @@ class BertGenerationConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models). Only
relevant if `config.is_decoder=True`.
diff --git a/src/transformers/models/bert_generation/modeling_bert_generation.py b/src/transformers/models/bert_generation/modeling_bert_generation.py
index 6dee1db6fb..308a8f31ef 100755
--- a/src/transformers/models/bert_generation/modeling_bert_generation.py
+++ b/src/transformers/models/bert_generation/modeling_bert_generation.py
@@ -612,11 +612,11 @@ class BertGenerationEncoder(BertGenerationPreTrainedModel):
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in [Attention is
- all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
+ all you need](https://huggingface.co/papers/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
This model should be used when leveraging Bert or Roberta checkpoints for the [`EncoderDecoderModel`] class as
- described in [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461)
+ described in [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://huggingface.co/papers/1907.12461)
by Sascha Rothe, Shashi Narayan, and Aliaksei Severyn.
To behave as an decoder the model needs to be initialized with the `is_decoder` argument of the configuration set
diff --git a/src/transformers/models/big_bird/modeling_big_bird.py b/src/transformers/models/big_bird/modeling_big_bird.py
index 2106c07e7d..a6f6fbf1f2 100755
--- a/src/transformers/models/big_bird/modeling_big_bird.py
+++ b/src/transformers/models/big_bird/modeling_big_bird.py
@@ -1833,7 +1833,7 @@ class BigBirdModel(BigBirdPreTrainedModel):
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in [Attention is
- all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
+ all you need](https://huggingface.co/papers/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
To behave as an decoder the model needs to be initialized with the `is_decoder` argument of the configuration set
diff --git a/src/transformers/models/bigbird_pegasus/configuration_bigbird_pegasus.py b/src/transformers/models/bigbird_pegasus/configuration_bigbird_pegasus.py
index 0dc765ce8f..29b481c78a 100644
--- a/src/transformers/models/bigbird_pegasus/configuration_bigbird_pegasus.py
+++ b/src/transformers/models/bigbird_pegasus/configuration_bigbird_pegasus.py
@@ -74,10 +74,10 @@ class BigBirdPegasusConfig(PretrainedConfig):
init_std (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
encoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
decoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models).
diff --git a/src/transformers/models/bigbird_pegasus/modeling_bigbird_pegasus.py b/src/transformers/models/bigbird_pegasus/modeling_bigbird_pegasus.py
index d49d4e65bd..ce26a24f84 100755
--- a/src/transformers/models/bigbird_pegasus/modeling_bigbird_pegasus.py
+++ b/src/transformers/models/bigbird_pegasus/modeling_bigbird_pegasus.py
@@ -1937,7 +1937,7 @@ class BigBirdPegasusEncoder(BigBirdPegasusPreTrainedModel):
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
to_drop = False
if self.training:
dropout_probability = torch.rand([])
@@ -2289,7 +2289,7 @@ class BigBirdPegasusDecoder(BigBirdPegasusPreTrainedModel):
f" {head_mask.size()[0]}."
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
@@ -2430,7 +2430,7 @@ class BigBirdPegasusModel(BigBirdPegasusPreTrainedModel):
If you want to change padding behavior, you should read
[`modeling_bigbird_pegasus._prepare_decoder_attention_mask`] and modify to your needs. See diagram 1 in
- [the paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
+ [the paper](https://huggingface.co/papers/1910.13461) for more information on the default strategy.
decoder_head_mask (`torch.Tensor` of shape `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the attention modules in the decoder. Mask values selected in `[0, 1]`:
@@ -2593,7 +2593,7 @@ class BigBirdPegasusForConditionalGeneration(BigBirdPegasusPreTrainedModel, Gene
If you want to change padding behavior, you should read
[`modeling_bigbird_pegasus._prepare_decoder_attention_mask`] and modify to your needs. See diagram 1 in
- [the paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
+ [the paper](https://huggingface.co/papers/1910.13461) for more information on the default strategy.
decoder_head_mask (`torch.Tensor` of shape `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the attention modules in the decoder. Mask values selected in `[0, 1]`:
@@ -2750,7 +2750,7 @@ class BigBirdPegasusForSequenceClassification(BigBirdPegasusPreTrainedModel):
If you want to change padding behavior, you should read
[`modeling_bigbird_pegasus._prepare_decoder_attention_mask`] and modify to your needs. See diagram 1 in
- [the paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
+ [the paper](https://huggingface.co/papers/1910.13461) for more information on the default strategy.
decoder_head_mask (`torch.Tensor` of shape `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the attention modules in the decoder. Mask values selected in `[0, 1]`:
@@ -2884,7 +2884,7 @@ class BigBirdPegasusForQuestionAnswering(BigBirdPegasusPreTrainedModel):
If you want to change padding behavior, you should read
[`modeling_bigbird_pegasus._prepare_decoder_attention_mask`] and modify to your needs. See diagram 1 in
- [the paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
+ [the paper](https://huggingface.co/papers/1910.13461) for more information on the default strategy.
decoder_head_mask (`torch.Tensor` of shape `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the attention modules in the decoder. Mask values selected in `[0, 1]`:
diff --git a/src/transformers/models/biogpt/configuration_biogpt.py b/src/transformers/models/biogpt/configuration_biogpt.py
index b338092edd..e773290efc 100644
--- a/src/transformers/models/biogpt/configuration_biogpt.py
+++ b/src/transformers/models/biogpt/configuration_biogpt.py
@@ -64,7 +64,7 @@ class BioGptConfig(PretrainedConfig):
Whether or not the model should return the last key/values attentions (not used by all models). Only
relevant if `config.is_decoder=True`.
layerdrop (`float`, *optional*, defaults to 0.0):
- Please refer to the paper about LayerDrop: https://arxiv.org/abs/1909.11556 for further details
+ Please refer to the paper about LayerDrop: https://huggingface.co/papers/1909.11556 for further details
activation_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for activations inside the fully connected layer.
pad_token_id (`int`, *optional*, defaults to 1):
diff --git a/src/transformers/models/biogpt/modeling_biogpt.py b/src/transformers/models/biogpt/modeling_biogpt.py
index f12eeac697..06447e67ab 100755
--- a/src/transformers/models/biogpt/modeling_biogpt.py
+++ b/src/transformers/models/biogpt/modeling_biogpt.py
@@ -638,7 +638,7 @@ class BioGptModel(BioGptPreTrainedModel):
next_decoder_cache = () if use_cache else None
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
diff --git a/src/transformers/models/biogpt/modular_biogpt.py b/src/transformers/models/biogpt/modular_biogpt.py
index 78d6da134b..d7ba7bf617 100644
--- a/src/transformers/models/biogpt/modular_biogpt.py
+++ b/src/transformers/models/biogpt/modular_biogpt.py
@@ -465,7 +465,7 @@ class BioGptModel(BioGptPreTrainedModel):
next_decoder_cache = () if use_cache else None
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
diff --git a/src/transformers/models/bit/modeling_bit.py b/src/transformers/models/bit/modeling_bit.py
index f1a6ee34e7..8adb812820 100644
--- a/src/transformers/models/bit/modeling_bit.py
+++ b/src/transformers/models/bit/modeling_bit.py
@@ -85,7 +85,7 @@ class WeightStandardizedConv2d(nn.Conv2d):
"""Conv2d with Weight Standardization. Includes TensorFlow compatible SAME padding. Used for ViT Hybrid model.
Paper: [Micro-Batch Training with Batch-Channel Normalization and Weight
- Standardization](https://arxiv.org/abs/1903.10520v2)
+ Standardization](https://huggingface.co/papers/1903.10520v2)
"""
def __init__(
diff --git a/src/transformers/models/bitnet/configuration_bitnet.py b/src/transformers/models/bitnet/configuration_bitnet.py
index 87177bab98..6df31b5b82 100644
--- a/src/transformers/models/bitnet/configuration_bitnet.py
+++ b/src/transformers/models/bitnet/configuration_bitnet.py
@@ -49,7 +49,7 @@ class BitNetConfig(PretrainedConfig):
`num_key_value_heads=1 the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
hidden_act (`str` or `function`, *optional*, defaults to `"relu2"`):
The non-linear activation function (function or string) in the decoder.
diff --git a/src/transformers/models/blenderbot/configuration_blenderbot.py b/src/transformers/models/blenderbot/configuration_blenderbot.py
index 5030ad04c2..4428799137 100644
--- a/src/transformers/models/blenderbot/configuration_blenderbot.py
+++ b/src/transformers/models/blenderbot/configuration_blenderbot.py
@@ -73,10 +73,10 @@ class BlenderbotConfig(PretrainedConfig):
init_std (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
encoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
decoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
scale_embedding (`bool`, *optional*, defaults to `False`):
Scale embeddings by diving by sqrt(d_model).
diff --git a/src/transformers/models/blenderbot/modeling_blenderbot.py b/src/transformers/models/blenderbot/modeling_blenderbot.py
index 4c001a3544..b72a333edb 100755
--- a/src/transformers/models/blenderbot/modeling_blenderbot.py
+++ b/src/transformers/models/blenderbot/modeling_blenderbot.py
@@ -815,7 +815,7 @@ class BlenderbotEncoder(BlenderbotPreTrainedModel):
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
to_drop = False
if self.training:
dropout_probability = torch.rand([])
@@ -1082,7 +1082,7 @@ class BlenderbotDecoder(BlenderbotPreTrainedModel):
f" {head_mask.size()[0]}."
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
diff --git a/src/transformers/models/blenderbot/modeling_flax_blenderbot.py b/src/transformers/models/blenderbot/modeling_flax_blenderbot.py
index 835cb6814a..a977083e69 100644
--- a/src/transformers/models/blenderbot/modeling_flax_blenderbot.py
+++ b/src/transformers/models/blenderbot/modeling_flax_blenderbot.py
@@ -108,7 +108,7 @@ BLENDERBOT_INPUTS_DOCSTRING = r"""
be used by default.
If you want to change padding behavior, you should modify to your needs. See diagram 1 in [the
- paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
+ paper](https://huggingface.co/papers/1910.13461) for more information on the default strategy.
position_ids (`numpy.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.max_position_embeddings - 1]`.
@@ -185,7 +185,7 @@ BLENDERBOT_DECODE_INPUTS_DOCSTRING = r"""
be used by default.
If you want to change padding behavior, you should modify to your needs. See diagram 1 in [the
- paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
+ paper](https://huggingface.co/papers/1910.13461) for more information on the default strategy.
decoder_position_ids (`numpy.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each decoder input sequence tokens in the position embeddings. Selected in the
range `[0, config.max_position_embeddings - 1]`.
@@ -468,7 +468,7 @@ class FlaxBlenderbotEncoderLayerCollection(nn.Module):
for encoder_layer in self.layers:
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if not deterministic and (dropout_probability < self.layerdrop): # skip the layer
layer_outputs = (None, None)
@@ -617,7 +617,7 @@ class FlaxBlenderbotDecoderLayerCollection(nn.Module):
for decoder_layer in self.layers:
if output_hidden_states:
all_hidden_states += (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if not deterministic and (dropout_probability < self.layerdrop):
layer_outputs = (None, None, None)
diff --git a/src/transformers/models/blenderbot/modeling_tf_blenderbot.py b/src/transformers/models/blenderbot/modeling_tf_blenderbot.py
index f3476cb925..f4eaec2cee 100644
--- a/src/transformers/models/blenderbot/modeling_tf_blenderbot.py
+++ b/src/transformers/models/blenderbot/modeling_tf_blenderbot.py
@@ -807,7 +807,7 @@ class TFBlenderbotEncoder(keras.layers.Layer):
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if training and (dropout_probability < self.layerdrop): # skip the layer
continue
@@ -1028,7 +1028,7 @@ class TFBlenderbotDecoder(keras.layers.Layer):
),
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
dropout_probability = random.uniform(0, 1)
diff --git a/src/transformers/models/blenderbot_small/configuration_blenderbot_small.py b/src/transformers/models/blenderbot_small/configuration_blenderbot_small.py
index a2174767de..6d43b975e5 100644
--- a/src/transformers/models/blenderbot_small/configuration_blenderbot_small.py
+++ b/src/transformers/models/blenderbot_small/configuration_blenderbot_small.py
@@ -73,10 +73,10 @@ class BlenderbotSmallConfig(PretrainedConfig):
init_std (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
encoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
decoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
scale_embedding (`bool`, *optional*, defaults to `False`):
Scale embeddings by diving by sqrt(d_model).
diff --git a/src/transformers/models/blenderbot_small/modeling_blenderbot_small.py b/src/transformers/models/blenderbot_small/modeling_blenderbot_small.py
index 49cff8f620..31fcf9febb 100755
--- a/src/transformers/models/blenderbot_small/modeling_blenderbot_small.py
+++ b/src/transformers/models/blenderbot_small/modeling_blenderbot_small.py
@@ -802,7 +802,7 @@ class BlenderbotSmallEncoder(BlenderbotSmallPreTrainedModel):
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
to_drop = False
if self.training:
dropout_probability = torch.rand([])
@@ -1065,7 +1065,7 @@ class BlenderbotSmallDecoder(BlenderbotSmallPreTrainedModel):
f" {head_mask.size()[0]}."
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
diff --git a/src/transformers/models/blenderbot_small/modeling_flax_blenderbot_small.py b/src/transformers/models/blenderbot_small/modeling_flax_blenderbot_small.py
index 1e6a3a727a..5b845702ff 100644
--- a/src/transformers/models/blenderbot_small/modeling_flax_blenderbot_small.py
+++ b/src/transformers/models/blenderbot_small/modeling_flax_blenderbot_small.py
@@ -119,7 +119,7 @@ BLENDERBOT_SMALL_INPUTS_DOCSTRING = r"""
be used by default.
If you want to change padding behavior, you should modify to your needs. See diagram 1 in [the
- paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
+ paper](https://huggingface.co/papers/1910.13461) for more information on the default strategy.
position_ids (`numpy.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.max_position_embeddings - 1]`.
@@ -196,7 +196,7 @@ BLENDERBOT_SMALL_DECODE_INPUTS_DOCSTRING = r"""
be used by default.
If you want to change padding behavior, you should modify to your needs. See diagram 1 in [the
- paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
+ paper](https://huggingface.co/papers/1910.13461) for more information on the default strategy.
decoder_position_ids (`numpy.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each decoder input sequence tokens in the position embeddings. Selected in the
range `[0, config.max_position_embeddings - 1]`.
@@ -480,7 +480,7 @@ class FlaxBlenderbotSmallEncoderLayerCollection(nn.Module):
for encoder_layer in self.layers:
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if not deterministic and (dropout_probability < self.layerdrop): # skip the layer
layer_outputs = (None, None)
@@ -629,7 +629,7 @@ class FlaxBlenderbotSmallDecoderLayerCollection(nn.Module):
for decoder_layer in self.layers:
if output_hidden_states:
all_hidden_states += (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if not deterministic and (dropout_probability < self.layerdrop):
layer_outputs = (None, None, None)
diff --git a/src/transformers/models/blenderbot_small/modeling_tf_blenderbot_small.py b/src/transformers/models/blenderbot_small/modeling_tf_blenderbot_small.py
index 4de9828083..b871d5bb82 100644
--- a/src/transformers/models/blenderbot_small/modeling_tf_blenderbot_small.py
+++ b/src/transformers/models/blenderbot_small/modeling_tf_blenderbot_small.py
@@ -813,7 +813,7 @@ class TFBlenderbotSmallEncoder(keras.layers.Layer):
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if training and (dropout_probability < self.layerdrop): # skip the layer
continue
@@ -1031,7 +1031,7 @@ class TFBlenderbotSmallDecoder(keras.layers.Layer):
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
dropout_probability = random.uniform(0, 1)
diff --git a/src/transformers/models/blip/configuration_blip.py b/src/transformers/models/blip/configuration_blip.py
index c46cd2a08b..35dde07367 100644
--- a/src/transformers/models/blip/configuration_blip.py
+++ b/src/transformers/models/blip/configuration_blip.py
@@ -75,7 +75,7 @@ class BlipTextConfig(PretrainedConfig):
label_smoothing (float, *optional*):
A float in [0.0, 1.0]. Specifies the amount of smoothing when computing the loss, where 0.0 means no smoothing. The targets
become a mixture of the original ground truth and a uniform distribution as described in
- `Rethinking the Inception Architecture for Computer Vision `__. Default: :math:`0.0`.
+ `Rethinking the Inception Architecture for Computer Vision `__. Default: :math:`0.0`.
Example:
@@ -251,7 +251,7 @@ class BlipConfig(PretrainedConfig):
label_smoothing (float, optional, *optional*, defaults to 0.0):
A float in [0.0, 1.0]. Specifies the amount of smoothing when computing the loss, where 0.0 means no smoothing. The targets
become a mixture of the original ground truth and a uniform distribution as described in
- `Rethinking the Inception Architecture for Computer Vision `__. Default: :math:`0.0`.
+ `Rethinking the Inception Architecture for Computer Vision `__. Default: :math:`0.0`.
kwargs (*optional*):
Dictionary of keyword arguments.
diff --git a/src/transformers/models/blip/modeling_blip_text.py b/src/transformers/models/blip/modeling_blip_text.py
index ffbca32eb9..7b19c20b2d 100644
--- a/src/transformers/models/blip/modeling_blip_text.py
+++ b/src/transformers/models/blip/modeling_blip_text.py
@@ -561,7 +561,7 @@ class BlipTextModel(BlipTextPreTrainedModel):
"""
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in [Attention is
- all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
+ all you need](https://huggingface.co/papers/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin. argument and `is_decoder` set to `True`; an
`encoder_hidden_states` is then expected as an input to the forward pass.
"""
diff --git a/src/transformers/models/blip/modeling_tf_blip_text.py b/src/transformers/models/blip/modeling_tf_blip_text.py
index 6414bfa3b7..5ddf23670c 100644
--- a/src/transformers/models/blip/modeling_tf_blip_text.py
+++ b/src/transformers/models/blip/modeling_tf_blip_text.py
@@ -730,7 +730,7 @@ class TFBlipTextModel(TFBlipTextPreTrainedModel):
"""
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in [Attention is
- all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
+ all you need](https://huggingface.co/papers/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin. argument and `is_decoder` set to `True`; an
`encoder_hidden_states` is then expected as an input to the forward pass.
"""
diff --git a/src/transformers/models/blip_2/configuration_blip_2.py b/src/transformers/models/blip_2/configuration_blip_2.py
index c4ce602548..9b4a48a21c 100644
--- a/src/transformers/models/blip_2/configuration_blip_2.py
+++ b/src/transformers/models/blip_2/configuration_blip_2.py
@@ -149,9 +149,9 @@ class Blip2QFormerConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
cross_attention_frequency (`int`, *optional*, defaults to 2):
The frequency of adding cross-attention to the Transformer layers.
encoder_hidden_size (`int`, *optional*, defaults to 1408):
diff --git a/src/transformers/models/bloom/modeling_bloom.py b/src/transformers/models/bloom/modeling_bloom.py
index bdba37a73b..9c35c9c68d 100644
--- a/src/transformers/models/bloom/modeling_bloom.py
+++ b/src/transformers/models/bloom/modeling_bloom.py
@@ -54,7 +54,7 @@ logger = logging.get_logger(__name__)
def build_alibi_tensor(attention_mask: torch.Tensor, num_heads: int, dtype: torch.dtype) -> torch.Tensor:
"""
- Link to paper: https://arxiv.org/abs/2108.12409 Alibi tensor is not causal as the original paper mentions, it
+ Link to paper: https://huggingface.co/papers/2108.12409 Alibi tensor is not causal as the original paper mentions, it
relies on a translation invariance of softmax for quick implementation: with l being a tensor, and a fixed value
`softmax(l+a) = softmax(l)`. Based on
https://github.com/ofirpress/attention_with_linear_biases/blob/a35aaca144e0eb6b789dfcb46784c4b8e31b7983/fairseq/models/transformer.py#L742
diff --git a/src/transformers/models/bloom/modeling_flax_bloom.py b/src/transformers/models/bloom/modeling_flax_bloom.py
index d0b2f084d3..0c002728f6 100644
--- a/src/transformers/models/bloom/modeling_flax_bloom.py
+++ b/src/transformers/models/bloom/modeling_flax_bloom.py
@@ -114,7 +114,7 @@ def build_alibi_tensor(attention_mask: jnp.ndarray, num_heads: int, dtype: Optio
relies on a translation invariance of softmax for quick implementation: with l being a tensor, and a fixed value
`softmax(l+a) = softmax(l)`. Based on
https://github.com/ofirpress/attention_with_linear_biases/blob/a35aaca144e0eb6b789dfcb46784c4b8e31b7983/fairseq/models/transformer.py#L742
- Link to paper: https://arxiv.org/abs/2108.12409
+ Link to paper: https://huggingface.co/papers/2108.12409
Args:
attention_mask (`jnp.ndarray`):
diff --git a/src/transformers/models/bridgetower/configuration_bridgetower.py b/src/transformers/models/bridgetower/configuration_bridgetower.py
index 6a3d9072de..72881b22c3 100644
--- a/src/transformers/models/bridgetower/configuration_bridgetower.py
+++ b/src/transformers/models/bridgetower/configuration_bridgetower.py
@@ -136,9 +136,9 @@ class BridgeTowerTextConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
is_decoder (`bool`, *optional*, defaults to `False`):
Whether the model is used as a decoder or not. If `False`, the model is used as an encoder.
use_cache (`bool`, *optional*, defaults to `True`):
diff --git a/src/transformers/models/bridgetower/modeling_bridgetower.py b/src/transformers/models/bridgetower/modeling_bridgetower.py
index e9ba3f272c..52ada3b0ac 100644
--- a/src/transformers/models/bridgetower/modeling_bridgetower.py
+++ b/src/transformers/models/bridgetower/modeling_bridgetower.py
@@ -1010,7 +1010,7 @@ class BridgeTowerVisionModel(BridgeTowerPreTrainedModel):
to `True`. To be used in a Seq2Seq model, the model needs to initialized with both `is_decoder` argument and
`add_cross_attention` set to `True`; an `encoder_hidden_states` is then expected as an input to the forward pass.
- .. _*Attention is all you need*: https://arxiv.org/abs/1706.03762
+ .. _*Attention is all you need*: https://huggingface.co/papers/1706.03762
"""
)
class BridgeTowerTextModel(BridgeTowerPreTrainedModel):
diff --git a/src/transformers/models/camembert/configuration_camembert.py b/src/transformers/models/camembert/configuration_camembert.py
index 140006381d..3979e54874 100644
--- a/src/transformers/models/camembert/configuration_camembert.py
+++ b/src/transformers/models/camembert/configuration_camembert.py
@@ -68,9 +68,9 @@ class CamembertConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
is_decoder (`bool`, *optional*, defaults to `False`):
Whether the model is used as a decoder or not. If `False`, the model is used as an encoder.
use_cache (`bool`, *optional*, defaults to `True`):
diff --git a/src/transformers/models/camembert/modeling_camembert.py b/src/transformers/models/camembert/modeling_camembert.py
index 733f313078..b8b855db67 100644
--- a/src/transformers/models/camembert/modeling_camembert.py
+++ b/src/transformers/models/camembert/modeling_camembert.py
@@ -769,7 +769,7 @@ class CamembertModel(CamembertPreTrainedModel):
`True`. To be used in a Seq2Seq model, the model needs to initialized with both `is_decoder` argument and
`add_cross_attention` set to `True`; an `encoder_hidden_states` is then expected as an input to the forward pass.
- .. _*Attention is all you need*: https://arxiv.org/abs/1706.03762
+ .. _*Attention is all you need*: https://huggingface.co/papers/1706.03762
"""
diff --git a/src/transformers/models/chameleon/configuration_chameleon.py b/src/transformers/models/chameleon/configuration_chameleon.py
index 7760f55b7c..efb6da999d 100644
--- a/src/transformers/models/chameleon/configuration_chameleon.py
+++ b/src/transformers/models/chameleon/configuration_chameleon.py
@@ -126,7 +126,7 @@ class ChameleonConfig(PretrainedConfig):
`num_key_value_heads=1 the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
diff --git a/src/transformers/models/chameleon/modeling_chameleon.py b/src/transformers/models/chameleon/modeling_chameleon.py
index 63ec521882..ad01558c6f 100644
--- a/src/transformers/models/chameleon/modeling_chameleon.py
+++ b/src/transformers/models/chameleon/modeling_chameleon.py
@@ -855,7 +855,8 @@ class ChameleonPreTrainedModel(PreTrainedModel):
custom_intro="""
The VQ-VAE model used in Chameleon for encoding/decoding images into discrete tokens.
This model follows the "Make-a-scene: Scene-based text-to-image generation with human priors" paper from
- [ Oran Gafni, Adam Polyak, Oron Ashual, Shelly Sheynin, Devi Parikh, and Yaniv Taigman](https://arxiv.org/abs/2203.13131).
+ [ Oran Gafni, Adam Polyak, Oron Ashual, Shelly Sheynin, Devi Parikh, and Yaniv
+ Taigman](https://huggingface.co/papers/2203.13131).
"""
)
class ChameleonVQVAE(ChameleonPreTrainedModel):
diff --git a/src/transformers/models/chinese_clip/configuration_chinese_clip.py b/src/transformers/models/chinese_clip/configuration_chinese_clip.py
index 53c5e62175..e47509a364 100644
--- a/src/transformers/models/chinese_clip/configuration_chinese_clip.py
+++ b/src/transformers/models/chinese_clip/configuration_chinese_clip.py
@@ -79,9 +79,9 @@ class ChineseCLIPTextConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models). Only
relevant if `config.is_decoder=True`.
diff --git a/src/transformers/models/chinese_clip/modeling_chinese_clip.py b/src/transformers/models/chinese_clip/modeling_chinese_clip.py
index bc1421e715..0a5527ca8a 100644
--- a/src/transformers/models/chinese_clip/modeling_chinese_clip.py
+++ b/src/transformers/models/chinese_clip/modeling_chinese_clip.py
@@ -1011,7 +1011,7 @@ class ChineseCLIPTextModel(ChineseCLIPPreTrainedModel):
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in [Attention is
- all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
+ all you need](https://huggingface.co/papers/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
To behave as an decoder the model needs to be initialized with the `is_decoder` argument of the configuration set
diff --git a/src/transformers/models/clap/configuration_clap.py b/src/transformers/models/clap/configuration_clap.py
index c5b7d3b7a2..1ee09d08a6 100644
--- a/src/transformers/models/clap/configuration_clap.py
+++ b/src/transformers/models/clap/configuration_clap.py
@@ -61,9 +61,9 @@ class ClapTextConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
is_decoder (`bool`, *optional*, defaults to `False`):
Whether the model is used as a decoder or not. If `False`, the model is used as an encoder.
use_cache (`bool`, *optional*, defaults to `True`):
diff --git a/src/transformers/models/clap/modeling_clap.py b/src/transformers/models/clap/modeling_clap.py
index a088490717..a382982e2f 100644
--- a/src/transformers/models/clap/modeling_clap.py
+++ b/src/transformers/models/clap/modeling_clap.py
@@ -1653,7 +1653,7 @@ class ClapAudioModel(ClapPreTrainedModel):
to `True`. To be used in a Seq2Seq model, the model needs to initialized with both `is_decoder` argument and
`add_cross_attention` set to `True`; an `encoder_hidden_states` is then expected as an input to the forward pass.
- .. _*Attention is all you need*: https://arxiv.org/abs/1706.03762
+ .. _*Attention is all you need*: https://huggingface.co/papers/1706.03762
"""
)
class ClapTextModel(ClapPreTrainedModel):
diff --git a/src/transformers/models/clvp/modeling_clvp.py b/src/transformers/models/clvp/modeling_clvp.py
index 677858fe80..24520791f1 100644
--- a/src/transformers/models/clvp/modeling_clvp.py
+++ b/src/transformers/models/clvp/modeling_clvp.py
@@ -242,7 +242,7 @@ class ClvpRMSNorm(nn.Module):
class ClvpRotaryPositionalEmbedding(nn.Module):
"""
Rotary Position Embedding Class for CLVP. It was proposed in the paper 'ROFORMER: ENHANCED TRANSFORMER WITH ROTARY
- POSITION EMBEDDING', Please see https://arxiv.org/pdf/2104.09864v1.pdf .
+ POSITION EMBEDDING', Please see https://huggingface.co/papers/2104.09864v1.pdf .
"""
def __init__(self, config):
diff --git a/src/transformers/models/cohere/configuration_cohere.py b/src/transformers/models/cohere/configuration_cohere.py
index 3e257448bc..ba5de252d1 100644
--- a/src/transformers/models/cohere/configuration_cohere.py
+++ b/src/transformers/models/cohere/configuration_cohere.py
@@ -57,7 +57,7 @@ class CohereConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
diff --git a/src/transformers/models/cohere2/configuration_cohere2.py b/src/transformers/models/cohere2/configuration_cohere2.py
index 8da5a81c09..8d8d3aa982 100644
--- a/src/transformers/models/cohere2/configuration_cohere2.py
+++ b/src/transformers/models/cohere2/configuration_cohere2.py
@@ -53,7 +53,7 @@ class Cohere2Config(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
diff --git a/src/transformers/models/cohere2/modular_cohere2.py b/src/transformers/models/cohere2/modular_cohere2.py
index 7153b1e547..5139611ff5 100644
--- a/src/transformers/models/cohere2/modular_cohere2.py
+++ b/src/transformers/models/cohere2/modular_cohere2.py
@@ -75,7 +75,7 @@ class Cohere2Config(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
diff --git a/src/transformers/models/colpali/modeling_colpali.py b/src/transformers/models/colpali/modeling_colpali.py
index 79cb24a8a5..82eda38072 100644
--- a/src/transformers/models/colpali/modeling_colpali.py
+++ b/src/transformers/models/colpali/modeling_colpali.py
@@ -101,7 +101,7 @@ class ColPaliForRetrievalOutput(ModelOutput):
single model that can take into account both the textual and visual content (layout, charts, etc.) of a document.
ColPali is part of the ColVision model family, which was first introduced in the following paper:
- [*ColPali: Efficient Document Retrieval with Vision Language Models*](https://arxiv.org/abs/2407.01449).
+ [*ColPali: Efficient Document Retrieval with Vision Language Models*](https://huggingface.co/papers/2407.01449).
"""
)
class ColPaliForRetrieval(ColPaliPreTrainedModel):
diff --git a/src/transformers/models/colqwen2/modeling_colqwen2.py b/src/transformers/models/colqwen2/modeling_colqwen2.py
index c4fdc63567..1982f9e136 100644
--- a/src/transformers/models/colqwen2/modeling_colqwen2.py
+++ b/src/transformers/models/colqwen2/modeling_colqwen2.py
@@ -108,7 +108,7 @@ class ColQwen2ForRetrievalOutput(ModelOutput):
a single model that can take into account both the textual and visual content (layout, charts, ...) of a document.
ColQwen2 is part of the ColVision model family, which was introduced with ColPali in the following paper:
- [*ColPali: Efficient Document Retrieval with Vision Language Models*](https://arxiv.org/abs/2407.01449).
+ [*ColPali: Efficient Document Retrieval with Vision Language Models*](https://huggingface.co/papers/2407.01449).
"""
)
class ColQwen2ForRetrieval(ColQwen2PreTrainedModel):
diff --git a/src/transformers/models/colqwen2/modular_colqwen2.py b/src/transformers/models/colqwen2/modular_colqwen2.py
index 43c4cc5308..a2357f6bef 100644
--- a/src/transformers/models/colqwen2/modular_colqwen2.py
+++ b/src/transformers/models/colqwen2/modular_colqwen2.py
@@ -277,7 +277,7 @@ class ColQwen2ForRetrievalOutput(ModelOutput):
a single model that can take into account both the textual and visual content (layout, charts, ...) of a document.
ColQwen2 is part of the ColVision model family, which was introduced with ColPali in the following paper:
- [*ColPali: Efficient Document Retrieval with Vision Language Models*](https://arxiv.org/abs/2407.01449).
+ [*ColPali: Efficient Document Retrieval with Vision Language Models*](https://huggingface.co/papers/2407.01449).
"""
)
class ColQwen2ForRetrieval(ColPaliForRetrieval):
diff --git a/src/transformers/models/conditional_detr/configuration_conditional_detr.py b/src/transformers/models/conditional_detr/configuration_conditional_detr.py
index 8cef8b7461..b85ef10556 100644
--- a/src/transformers/models/conditional_detr/configuration_conditional_detr.py
+++ b/src/transformers/models/conditional_detr/configuration_conditional_detr.py
@@ -79,10 +79,10 @@ class ConditionalDetrConfig(PretrainedConfig):
init_xavier_std (`float`, *optional*, defaults to 1):
The scaling factor used for the Xavier initialization gain in the HM Attention map module.
encoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
decoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
auxiliary_loss (`bool`, *optional*, defaults to `False`):
Whether auxiliary decoding losses (loss at each decoder layer) are to be used.
diff --git a/src/transformers/models/conditional_detr/modeling_conditional_detr.py b/src/transformers/models/conditional_detr/modeling_conditional_detr.py
index 0b63dd3330..dfde0d9548 100644
--- a/src/transformers/models/conditional_detr/modeling_conditional_detr.py
+++ b/src/transformers/models/conditional_detr/modeling_conditional_detr.py
@@ -1135,7 +1135,7 @@ class ConditionalDetrEncoder(ConditionalDetrPreTrainedModel):
for i, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
to_drop = False
if self.training:
dropout_probability = torch.rand([])
@@ -1284,7 +1284,7 @@ class ConditionalDetrDecoder(ConditionalDetrPreTrainedModel):
query_sine_embed_before_transformation = gen_sine_position_embeddings(obj_center, self.config.d_model)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
diff --git a/src/transformers/models/cpmant/modeling_cpmant.py b/src/transformers/models/cpmant/modeling_cpmant.py
index e437672aa5..ff7ec67453 100755
--- a/src/transformers/models/cpmant/modeling_cpmant.py
+++ b/src/transformers/models/cpmant/modeling_cpmant.py
@@ -36,7 +36,7 @@ logger = logging.get_logger(__name__)
class CpmAntLayerNorm(nn.Module):
"""
- We use Root Mean Square (RMS) Layer Normalization, please see https://arxiv.org/abs/1910.07467 for details."
+ We use Root Mean Square (RMS) Layer Normalization, please see https://huggingface.co/papers/1910.07467 for details."
"""
def __init__(self, config: CpmAntConfig):
diff --git a/src/transformers/models/csm/configuration_csm.py b/src/transformers/models/csm/configuration_csm.py
index 56a60cda24..7882ac0fbf 100644
--- a/src/transformers/models/csm/configuration_csm.py
+++ b/src/transformers/models/csm/configuration_csm.py
@@ -55,7 +55,7 @@ class CsmDepthDecoderConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
@@ -236,7 +236,7 @@ class CsmConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf).
+ paper](https://huggingface.co/papers/2305.13245).
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the backbone model Transformer decoder.
max_position_embeddings (`int`, *optional*, defaults to 2048):
diff --git a/src/transformers/models/d_fine/modeling_d_fine.py b/src/transformers/models/d_fine/modeling_d_fine.py
index 573c3f3d29..439bf9d20f 100644
--- a/src/transformers/models/d_fine/modeling_d_fine.py
+++ b/src/transformers/models/d_fine/modeling_d_fine.py
@@ -2069,7 +2069,7 @@ class DFineEncoder(nn.Module):
class DFineHybridEncoder(nn.Module):
"""
Decoder consisting of a projection layer, a set of `DFineEncoder`, a top-down Feature Pyramid Network
- (FPN) and a bottom-up Path Aggregation Network (PAN). More details on the paper: https://arxiv.org/abs/2304.08069
+ (FPN) and a bottom-up Path Aggregation Network (PAN). More details on the paper: https://huggingface.co/papers/2304.08069
Args:
config: DFineConfig
diff --git a/src/transformers/models/dac/modeling_dac.py b/src/transformers/models/dac/modeling_dac.py
index 519a4bcd44..ff94bb8603 100644
--- a/src/transformers/models/dac/modeling_dac.py
+++ b/src/transformers/models/dac/modeling_dac.py
@@ -105,7 +105,7 @@ class DacVectorQuantize(nn.Module):
Implementation of VQ similar to Karpathy's repo (https://github.com/karpathy/deep-vector-quantization)
Additionally uses following tricks from improved VQGAN
- (https://arxiv.org/pdf/2110.04627.pdf):
+ (https://huggingface.co/papers/2110.04627):
1. Factorized codes: Perform nearest neighbor lookup in low-dimensional space
for improved codebook usage
2. l2-normalized codes: Converts euclidean distance to cosine similarity which
@@ -264,7 +264,7 @@ class DacDecoderBlock(nn.Module):
class DacResidualVectorQuantize(nn.Module):
"""
- ResidualVectorQuantize block - Introduced in SoundStream: An end2end neural audio codec (https://arxiv.org/abs/2107.03312)
+ ResidualVectorQuantize block - Introduced in SoundStream: An end2end neural audio codec (https://huggingface.co/papers/2107.03312)
"""
def __init__(self, config: DacConfig):
diff --git a/src/transformers/models/data2vec/configuration_data2vec_audio.py b/src/transformers/models/data2vec/configuration_data2vec_audio.py
index bab37cc6c1..36ed814bb7 100644
--- a/src/transformers/models/data2vec/configuration_data2vec_audio.py
+++ b/src/transformers/models/data2vec/configuration_data2vec_audio.py
@@ -60,7 +60,7 @@ class Data2VecAudioConfig(PretrainedConfig):
final_dropout (`float`, *optional*, defaults to 0.1):
The dropout probability for the final projection layer of [`Data2VecAudioForCTC`].
layerdrop (`float`, *optional*, defaults to 0.1):
- The LayerDrop probability. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556) for more
+ The LayerDrop probability. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556) for more
details.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
@@ -252,7 +252,7 @@ class Data2VecAudioConfig(PretrainedConfig):
f" `len(config.conv_kernel) = {len(self.conv_kernel)}`."
)
- # fine-tuning config parameters for SpecAugment: https://arxiv.org/abs/1904.08779
+ # fine-tuning config parameters for SpecAugment: https://huggingface.co/papers/1904.08779
self.mask_time_prob = mask_time_prob
self.mask_time_length = mask_time_length
self.mask_time_min_masks = mask_time_min_masks
diff --git a/src/transformers/models/data2vec/configuration_data2vec_text.py b/src/transformers/models/data2vec/configuration_data2vec_text.py
index a00985f6e7..f9518d67bf 100644
--- a/src/transformers/models/data2vec/configuration_data2vec_text.py
+++ b/src/transformers/models/data2vec/configuration_data2vec_text.py
@@ -67,9 +67,9 @@ class Data2VecTextConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
is_decoder (`bool`, *optional*, defaults to `False`):
Whether the model is used as a decoder or not. If `False`, the model is used as an encoder.
use_cache (`bool`, *optional*, defaults to `True`):
diff --git a/src/transformers/models/data2vec/modeling_data2vec_audio.py b/src/transformers/models/data2vec/modeling_data2vec_audio.py
index eafcbff89a..1968749fd8 100755
--- a/src/transformers/models/data2vec/modeling_data2vec_audio.py
+++ b/src/transformers/models/data2vec/modeling_data2vec_audio.py
@@ -435,7 +435,7 @@ class Data2VecAudioEncoder(nn.Module):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = torch.rand([])
skip_the_layer = True if self.training and (dropout_probability < self.config.layerdrop) else False
@@ -631,7 +631,7 @@ def _compute_mask_indices(
) -> np.ndarray:
"""
Computes random mask spans for a given shape. Used to implement [SpecAugment: A Simple Data Augmentation Method for
- ASR](https://arxiv.org/abs/1904.08779). Note that this method is not optimized to run on TPU and should be run on
+ ASR](https://huggingface.co/papers/1904.08779). Note that this method is not optimized to run on TPU and should be run on
CPU as part of the preprocessing during training.
Args:
@@ -778,7 +778,7 @@ class Data2VecAudioModel(Data2VecAudioPreTrainedModel):
):
"""
Masks extracted features along time axis and/or along feature axis according to
- [SpecAugment](https://arxiv.org/abs/1904.08779).
+ [SpecAugment](https://huggingface.co/papers/1904.08779).
"""
# `config.apply_spec_augment` can set masking to False
diff --git a/src/transformers/models/data2vec/modeling_data2vec_text.py b/src/transformers/models/data2vec/modeling_data2vec_text.py
index a1d747476d..d957e64235 100644
--- a/src/transformers/models/data2vec/modeling_data2vec_text.py
+++ b/src/transformers/models/data2vec/modeling_data2vec_text.py
@@ -610,7 +610,7 @@ class Data2VecTextModel(Data2VecTextPreTrainedModel):
to `True`. To be used in a Seq2Seq model, the model needs to initialized with both `is_decoder` argument and
`add_cross_attention` set to `True`; an `encoder_hidden_states` is then expected as an input to the forward pass.
- .. _*Attention is all you need*: https://arxiv.org/abs/1706.03762
+ .. _*Attention is all you need*: https://huggingface.co/papers/1706.03762
"""
diff --git a/src/transformers/models/data2vec/modeling_data2vec_vision.py b/src/transformers/models/data2vec/modeling_data2vec_vision.py
index 33dae045d4..18f589773f 100644
--- a/src/transformers/models/data2vec/modeling_data2vec_vision.py
+++ b/src/transformers/models/data2vec/modeling_data2vec_vision.py
@@ -579,7 +579,7 @@ class Data2VecVisionRelativePositionBias(nn.Module):
def generate_relative_position_index(self, window_size: Tuple[int, int]) -> torch.Tensor:
"""
This method creates the relative position index, modified to support arbitrary window sizes,
- as introduced in [MiDaS v3.1](https://arxiv.org/abs/2307.14460).
+ as introduced in [MiDaS v3.1](https://huggingface.co/papers/2307.14460).
"""
num_relative_distance = (2 * window_size[0] - 1) * (2 * window_size[1] - 1) + 3
# cls to token & token 2 cls & cls to cls
@@ -1070,7 +1070,7 @@ class Data2VecVisionPyramidPoolingModule(nn.Module):
class Data2VecVisionUperHead(nn.Module):
"""
Unified Perceptual Parsing for Scene Understanding. This head is the implementation of
- [UPerNet](https://arxiv.org/abs/1807.10221).
+ [UPerNet](https://huggingface.co/papers/1807.10221).
Based on OpenMMLab's implementation, found in https://github.com/open-mmlab/mmsegmentation.
"""
@@ -1156,7 +1156,7 @@ class Data2VecVisionUperHead(nn.Module):
class Data2VecVisionFCNHead(nn.Module):
"""
Fully Convolution Networks for Semantic Segmentation. This head is implemented of
- [FCNNet](https://arxiv.org/abs/1411.4038>).
+ [FCNNet](https://huggingface.co/papers/1411.4038>).
Args:
config (Data2VecVisionConfig): Configuration.
diff --git a/src/transformers/models/data2vec/modeling_tf_data2vec_vision.py b/src/transformers/models/data2vec/modeling_tf_data2vec_vision.py
index 9a41ed6fb0..8f8558889d 100644
--- a/src/transformers/models/data2vec/modeling_tf_data2vec_vision.py
+++ b/src/transformers/models/data2vec/modeling_tf_data2vec_vision.py
@@ -1336,7 +1336,7 @@ class TFData2VecVisionPyramidPoolingModule(keras.layers.Layer):
class TFData2VecVisionUperHead(keras.layers.Layer):
"""
Unified Perceptual Parsing for Scene Understanding. This head is the implementation of
- [UPerNet](https://arxiv.org/abs/1807.10221).
+ [UPerNet](https://huggingface.co/papers/1807.10221).
Based on OpenMMLab's implementation, found in https://github.com/open-mmlab/mmsegmentation.
"""
@@ -1446,7 +1446,7 @@ class TFData2VecVisionUperHead(keras.layers.Layer):
class TFData2VecVisionFCNHead(keras.layers.Layer):
"""
Fully Convolution Networks for Semantic Segmentation. This head is implemented from
- [FCNNet](https://arxiv.org/abs/1411.4038).
+ [FCNNet](https://huggingface.co/papers/1411.4038).
Args:
config (Data2VecVisionConfig): Configuration.
diff --git a/src/transformers/models/dbrx/modeling_dbrx.py b/src/transformers/models/dbrx/modeling_dbrx.py
index 0a530e87ae..725397a122 100644
--- a/src/transformers/models/dbrx/modeling_dbrx.py
+++ b/src/transformers/models/dbrx/modeling_dbrx.py
@@ -130,7 +130,7 @@ def load_balancing_loss_func(
) -> torch.Tensor:
r"""Computes auxiliary load balancing loss as in Switch Transformer - implemented in Pytorch.
- See Switch Transformer (https://arxiv.org/abs/2101.03961) for more details. This function implements the loss
+ See Switch Transformer (https://huggingface.co/papers/2101.03961) for more details. This function implements the loss
function presented in equations (4) - (6) of the paper. It aims at penalizing cases where the routing between
experts is too unbalanced.
diff --git a/src/transformers/models/deberta/modeling_tf_deberta.py b/src/transformers/models/deberta/modeling_tf_deberta.py
index afc8ba2abb..f2ab00622f 100644
--- a/src/transformers/models/deberta/modeling_tf_deberta.py
+++ b/src/transformers/models/deberta/modeling_tf_deberta.py
@@ -1147,7 +1147,7 @@ class TFDebertaPreTrainedModel(TFPreTrainedModel):
DEBERTA_START_DOCSTRING = r"""
The DeBERTa model was proposed in [DeBERTa: Decoding-enhanced BERT with Disentangled
- Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen. It's build
+ Attention](https://huggingface.co/papers/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen. It's build
on top of BERT/RoBERTa with two improvements, i.e. disentangled attention and enhanced mask decoder. With those two
improvements, it out perform BERT/RoBERTa on a majority of tasks with 80GB pretraining data.
diff --git a/src/transformers/models/deberta_v2/modeling_tf_deberta_v2.py b/src/transformers/models/deberta_v2/modeling_tf_deberta_v2.py
index 899564eef0..4abd334b12 100644
--- a/src/transformers/models/deberta_v2/modeling_tf_deberta_v2.py
+++ b/src/transformers/models/deberta_v2/modeling_tf_deberta_v2.py
@@ -1255,7 +1255,7 @@ class TFDebertaV2PreTrainedModel(TFPreTrainedModel):
DEBERTA_START_DOCSTRING = r"""
The DeBERTa model was proposed in [DeBERTa: Decoding-enhanced BERT with Disentangled
- Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen. It's build
+ Attention](https://huggingface.co/papers/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen. It's build
on top of BERT/RoBERTa with two improvements, i.e. disentangled attention and enhanced mask decoder. With those two
improvements, it out perform BERT/RoBERTa on a majority of tasks with 80GB pretraining data.
diff --git a/src/transformers/models/decision_transformer/modeling_decision_transformer.py b/src/transformers/models/decision_transformer/modeling_decision_transformer.py
index c577d6f17c..84844a77a7 100755
--- a/src/transformers/models/decision_transformer/modeling_decision_transformer.py
+++ b/src/transformers/models/decision_transformer/modeling_decision_transformer.py
@@ -795,7 +795,7 @@ class DecisionTransformerModel(DecisionTransformerPreTrainedModel):
"""
The model builds upon the GPT2 architecture to perform autoregressive prediction of actions in an offline RL
- setting. Refer to the paper for more details: https://arxiv.org/abs/2106.01345
+ setting. Refer to the paper for more details: https://huggingface.co/papers/2106.01345
"""
diff --git a/src/transformers/models/deepseek_v3/configuration_deepseek_v3.py b/src/transformers/models/deepseek_v3/configuration_deepseek_v3.py
index 4372cad67f..0b885f8d5a 100644
--- a/src/transformers/models/deepseek_v3/configuration_deepseek_v3.py
+++ b/src/transformers/models/deepseek_v3/configuration_deepseek_v3.py
@@ -53,7 +53,7 @@ class DeepseekV3Config(PretrainedConfig):
`num_key_value_heads=1 the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
n_shared_experts (`int`, *optional*, defaults to 1):
Number of shared experts.
diff --git a/src/transformers/models/deformable_detr/configuration_deformable_detr.py b/src/transformers/models/deformable_detr/configuration_deformable_detr.py
index 05bd0f906a..7e6b94d7d3 100644
--- a/src/transformers/models/deformable_detr/configuration_deformable_detr.py
+++ b/src/transformers/models/deformable_detr/configuration_deformable_detr.py
@@ -74,7 +74,7 @@ class DeformableDetrConfig(PretrainedConfig):
init_xavier_std (`float`, *optional*, defaults to 1):
The scaling factor used for the Xavier initialization gain in the HM Attention map module.
encoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
auxiliary_loss (`bool`, *optional*, defaults to `False`):
Whether auxiliary decoding losses (loss at each decoder layer) are to be used.
diff --git a/src/transformers/models/deit/modeling_deit.py b/src/transformers/models/deit/modeling_deit.py
index 05bacf8155..07df603a94 100644
--- a/src/transformers/models/deit/modeling_deit.py
+++ b/src/transformers/models/deit/modeling_deit.py
@@ -587,7 +587,7 @@ class DeiTPooler(nn.Module):
@auto_docstring(
custom_intro="""
- DeiT Model with a decoder on top for masked image modeling, as proposed in [SimMIM](https://arxiv.org/abs/2111.09886).
+ DeiT Model with a decoder on top for masked image modeling, as proposed in [SimMIM](https://huggingface.co/papers/2111.09886).
diff --git a/src/transformers/models/deit/modeling_tf_deit.py b/src/transformers/models/deit/modeling_tf_deit.py
index 49c9526803..b052d32f03 100644
--- a/src/transformers/models/deit/modeling_tf_deit.py
+++ b/src/transformers/models/deit/modeling_tf_deit.py
@@ -892,7 +892,7 @@ class TFDeitDecoder(keras.layers.Layer):
@add_start_docstrings(
"DeiT Model with a decoder on top for masked image modeling, as proposed in"
- " [SimMIM](https://arxiv.org/abs/2111.09886).",
+ " [SimMIM](https://huggingface.co/papers/2111.09886).",
DEIT_START_DOCSTRING,
)
class TFDeiTForMaskedImageModeling(TFDeiTPreTrainedModel):
diff --git a/src/transformers/models/deprecated/deta/configuration_deta.py b/src/transformers/models/deprecated/deta/configuration_deta.py
index 558bf59679..90c779a8ee 100644
--- a/src/transformers/models/deprecated/deta/configuration_deta.py
+++ b/src/transformers/models/deprecated/deta/configuration_deta.py
@@ -78,7 +78,7 @@ class DetaConfig(PretrainedConfig):
init_xavier_std (`float`, *optional*, defaults to 1):
The scaling factor used for the Xavier initialization gain in the HM Attention map module.
encoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
auxiliary_loss (`bool`, *optional*, defaults to `False`):
Whether auxiliary decoding losses (loss at each decoder layer) are to be used.
diff --git a/src/transformers/models/deprecated/deta/modeling_deta.py b/src/transformers/models/deprecated/deta/modeling_deta.py
index ef4f0da573..69810c3889 100644
--- a/src/transformers/models/deprecated/deta/modeling_deta.py
+++ b/src/transformers/models/deprecated/deta/modeling_deta.py
@@ -2110,7 +2110,7 @@ def dice_loss(inputs, targets, num_boxes):
def sigmoid_focal_loss(inputs, targets, num_boxes, alpha: float = 0.25, gamma: float = 2):
"""
- Loss used in RetinaNet for dense detection: https://arxiv.org/abs/1708.02002.
+ Loss used in RetinaNet for dense detection: https://huggingface.co/papers/1708.02002.
Args:
inputs (`torch.FloatTensor` of arbitrary shape):
diff --git a/src/transformers/models/deprecated/gptsan_japanese/configuration_gptsan_japanese.py b/src/transformers/models/deprecated/gptsan_japanese/configuration_gptsan_japanese.py
index cd56581009..a7d1e23e08 100644
--- a/src/transformers/models/deprecated/gptsan_japanese/configuration_gptsan_japanese.py
+++ b/src/transformers/models/deprecated/gptsan_japanese/configuration_gptsan_japanese.py
@@ -67,7 +67,7 @@ class GPTSanJapaneseConfig(PretrainedConfig):
during training.
router_dtype (`str`, *optional*, default to `"float32"`):
The `dtype` used for the routers. It is preferable to keep the `dtype` to `"float32"` as specified in the
- *selective precision* discussion in [the paper](https://arxiv.org/abs/2101.03961).
+ *selective precision* discussion in [the paper](https://huggingface.co/papers/2101.03961).
router_ignore_padding_tokens (`bool`, *optional*, defaults to `False`):
Whether to ignore padding tokens when routing.
output_hidden_states (`bool`, *optional*, default to `False`):
diff --git a/src/transformers/models/deprecated/gptsan_japanese/modeling_gptsan_japanese.py b/src/transformers/models/deprecated/gptsan_japanese/modeling_gptsan_japanese.py
index 17da733be9..d387b86875 100644
--- a/src/transformers/models/deprecated/gptsan_japanese/modeling_gptsan_japanese.py
+++ b/src/transformers/models/deprecated/gptsan_japanese/modeling_gptsan_japanese.py
@@ -49,7 +49,7 @@ def router_z_loss_func(router_logits: torch.Tensor) -> float:
r"""
Compute the router z-loss implemented in PyTorch.
- The router z-loss was introduced in [Designing Effective Sparse Expert Models](https://arxiv.org/abs/2202.08906).
+ The router z-loss was introduced in [Designing Effective Sparse Expert Models](https://huggingface.co/papers/2202.08906).
It encourages router logits to remain small in an effort to improve stability.
Args:
@@ -69,7 +69,7 @@ def load_balancing_loss_func(router_probs: torch.Tensor, expert_indices: torch.T
r"""
Computes auxiliary load balancing loss as in Switch Transformer - implemented in Pytorch.
- See Switch Transformer (https://arxiv.org/abs/2101.03961) for more details. This function implements the loss
+ See Switch Transformer (https://huggingface.co/papers/2101.03961) for more details. This function implements the loss
function presented in equations (4) - (6) of the paper. It aims at penalizing cases where the routing between
experts is too unbalanced.
@@ -142,8 +142,8 @@ class GPTSanJapaneseTop1Router(nn.Module):
"""
Router using tokens choose top-1 experts assignment.
- This router uses the same mechanism as in Switch Transformer (https://arxiv.org/abs/2101.03961) and V-MoE
- (https://arxiv.org/abs/2106.05974): tokens choose their top experts. Items are sorted by router_probs and then
+ This router uses the same mechanism as in Switch Transformer (https://huggingface.co/papers/2101.03961) and V-MoE
+ (https://huggingface.co/papers/2106.05974): tokens choose their top experts. Items are sorted by router_probs and then
routed to their choice of expert until the expert's expert_capacity is reached. **There is no guarantee that each
token is processed by an expert**, or that each expert receives at least one token.
@@ -174,7 +174,7 @@ class GPTSanJapaneseTop1Router(nn.Module):
This is used later for computing router z-loss.
"""
# float32 is used to ensure stability. See the discussion of "selective precision" in
- # https://arxiv.org/abs/2101.03961.
+ # https://huggingface.co/papers/2101.03961.
# We also store the previous dtype to cast back the output to the previous dtype
self.input_dtype = hidden_states.dtype
hidden_states = hidden_states.to(self.dtype)
diff --git a/src/transformers/models/deprecated/graphormer/configuration_graphormer.py b/src/transformers/models/deprecated/graphormer/configuration_graphormer.py
index 1ecde152e4..81c13c6a80 100644
--- a/src/transformers/models/deprecated/graphormer/configuration_graphormer.py
+++ b/src/transformers/models/deprecated/graphormer/configuration_graphormer.py
@@ -78,7 +78,7 @@ class GraphormerConfig(PretrainedConfig):
activation_dropout (`float`, *optional*, defaults to 0.1):
The dropout probability for the activation of the linear transformer layer.
layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
bias (`bool`, *optional*, defaults to `True`):
Uses bias in the attention module - unsupported at the moment.
diff --git a/src/transformers/models/deprecated/graphormer/modeling_graphormer.py b/src/transformers/models/deprecated/graphormer/modeling_graphormer.py
index b30caa51e2..21e001c1f7 100755
--- a/src/transformers/models/deprecated/graphormer/modeling_graphormer.py
+++ b/src/transformers/models/deprecated/graphormer/modeling_graphormer.py
@@ -135,7 +135,7 @@ class LayerDropModuleList(nn.ModuleList):
From:
https://github.com/facebookresearch/fairseq/blob/dd0079bde7f678b0cd0715cbd0ae68d661b7226d/fairseq/modules/layer_drop.py
A LayerDrop implementation based on [`torch.nn.ModuleList`]. LayerDrop as described in
- https://arxiv.org/abs/1909.11556.
+ https://huggingface.co/papers/1909.11556.
We refresh the choice of which layers to drop every time we iterate over the LayerDropModuleList instance. During
evaluation we always iterate over all layers.
diff --git a/src/transformers/models/deprecated/jukebox/configuration_jukebox.py b/src/transformers/models/deprecated/jukebox/configuration_jukebox.py
index d10cbc2d82..c1d8a78e3e 100644
--- a/src/transformers/models/deprecated/jukebox/configuration_jukebox.py
+++ b/src/transformers/models/deprecated/jukebox/configuration_jukebox.py
@@ -394,7 +394,7 @@ class JukeboxVQVAEConfig(PretrainedConfig):
Number of hierarchical levels that used in the VQVAE.
lmu (`float`, *optional*, defaults to 0.99):
Used in the codebook update, exponential moving average coefficient. For more detail refer to Appendix A.1
- of the original [VQVAE paper](https://arxiv.org/pdf/1711.00937v2.pdf)
+ of the original [VQVAE paper](https://huggingface.co/papers/1711.00937v2.pdf)
multipliers (`List[int]`, *optional*, defaults to `[2, 1, 1]`):
Depth and width multipliers used for each level. Used on the `res_conv_width` and `res_conv_depth`
res_conv_depth (`int`, *optional*, defaults to 4):
diff --git a/src/transformers/models/deprecated/jukebox/modeling_jukebox.py b/src/transformers/models/deprecated/jukebox/modeling_jukebox.py
index f1a6ef7093..11064c1e46 100755
--- a/src/transformers/models/deprecated/jukebox/modeling_jukebox.py
+++ b/src/transformers/models/deprecated/jukebox/modeling_jukebox.py
@@ -592,7 +592,7 @@ JUKEBOX_START_DOCSTRING = r"""
@add_start_docstrings(
"""The Hierarchical VQ-VAE model used in Jukebox. This model follows the Hierarchical VQVAE paper from [Will Williams, Sam
-Ringer, Tom Ash, John Hughes, David MacLeod, Jamie Dougherty](https://arxiv.org/abs/2002.08111).
+Ringer, Tom Ash, John Hughes, David MacLeod, Jamie Dougherty](https://huggingface.co/papers/2002.08111).
""",
JUKEBOX_START_DOCSTRING,
diff --git a/src/transformers/models/deprecated/mctct/modeling_mctct.py b/src/transformers/models/deprecated/mctct/modeling_mctct.py
index e873111cb2..5f80743c4d 100755
--- a/src/transformers/models/deprecated/mctct/modeling_mctct.py
+++ b/src/transformers/models/deprecated/mctct/modeling_mctct.py
@@ -55,7 +55,7 @@ _CTC_EXPECTED_LOSS = 1885.65
class MCTCTConv1dSubsampler(nn.Module):
"""
Convolutional subsampler: a stack of 1D convolution (along temporal dimension) followed by non-linear activation
- via gated linear units (https://arxiv.org/abs/1911.08460)
+ via gated linear units (https://huggingface.co/papers/1911.08460)
"""
def __init__(self, config):
@@ -585,7 +585,7 @@ class MCTCTEncoder(MCTCTPreTrainedModel):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = torch.rand([])
skip_the_layer = True if self.training and (dropout_probability < self.config.layerdrop) else False
diff --git a/src/transformers/models/deprecated/mega/modeling_mega.py b/src/transformers/models/deprecated/mega/modeling_mega.py
index 2c4a848df5..b73fa9c020 100644
--- a/src/transformers/models/deprecated/mega/modeling_mega.py
+++ b/src/transformers/models/deprecated/mega/modeling_mega.py
@@ -319,7 +319,7 @@ class MegaMultiDimensionDampedEma(nn.Module):
"""
Mega's Exponential Moving Average layer, largely left unmodified from the original repo with the exception of
variable names and moving away from the stateful representation of incremental decoding state. See
- "https://arxiv.org/abs/2209.10655" for more details.
+ "https://huggingface.co/papers/2209.10655" for more details.
"""
def __init__(self, config: MegaConfig):
@@ -784,7 +784,7 @@ class MegaGatedCrossAttention(nn.Module):
class MegaMovingAverageGatedAttention(nn.Module):
"""
- Pure PyTorch implementation of Mega block; see https://arxiv.org/abs/2209.10655 and original fairseq implementation
+ Pure PyTorch implementation of Mega block; see https://huggingface.co/papers/2209.10655 and original fairseq implementation
at https://github.com/facebookresearch/mega (copyright Meta Research, licensed under MIT License)
Differences from original implementation include hidden state refactor and fixed inconsistency with additive /
@@ -1457,7 +1457,7 @@ class MegaModel(MegaPreTrainedModel):
`is_decoder=True` and `bidirectional=False` argument as well as `add_cross_attention` set to `True`; an
`encoder_hidden_states` is then expected as an input to the forward pass.
- .. _*Mega: Moving Average Equipped Gated Attention*: https://arxiv.org/abs/2209.10655
+ .. _*Mega: Moving Average Equipped Gated Attention*: https://huggingface.co/papers/2209.10655
"""
diff --git a/src/transformers/models/deprecated/nezha/modeling_nezha.py b/src/transformers/models/deprecated/nezha/modeling_nezha.py
index 7be52bee58..73655d4647 100644
--- a/src/transformers/models/deprecated/nezha/modeling_nezha.py
+++ b/src/transformers/models/deprecated/nezha/modeling_nezha.py
@@ -836,7 +836,7 @@ class NezhaModel(NezhaPreTrainedModel):
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in [Attention is
- all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
+ all you need](https://huggingface.co/papers/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
To behave as an decoder the model needs to be initialized with the `is_decoder` argument of the configuration set
diff --git a/src/transformers/models/deprecated/open_llama/modeling_open_llama.py b/src/transformers/models/deprecated/open_llama/modeling_open_llama.py
index 79d79ea546..e3726fd9a2 100644
--- a/src/transformers/models/deprecated/open_llama/modeling_open_llama.py
+++ b/src/transformers/models/deprecated/open_llama/modeling_open_llama.py
@@ -475,7 +475,7 @@ OPEN_LLAMA_INPUTS_DOCSTRING = r"""
`past_key_values`).
If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
- 1 indicates the head is **not masked**,
diff --git a/src/transformers/models/deprecated/qdqbert/modeling_qdqbert.py b/src/transformers/models/deprecated/qdqbert/modeling_qdqbert.py
index 8b68a4e426..fdeeb424ab 100755
--- a/src/transformers/models/deprecated/qdqbert/modeling_qdqbert.py
+++ b/src/transformers/models/deprecated/qdqbert/modeling_qdqbert.py
@@ -821,7 +821,7 @@ class QDQBertModel(QDQBertPreTrainedModel):
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in [Attention is
- all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
+ all you need](https://huggingface.co/papers/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
To behave as an decoder the model needs to be initialized with the `is_decoder` argument of the configuration set
diff --git a/src/transformers/models/deprecated/speech_to_text_2/configuration_speech_to_text_2.py b/src/transformers/models/deprecated/speech_to_text_2/configuration_speech_to_text_2.py
index 2afd79feb2..a7cde92274 100644
--- a/src/transformers/models/deprecated/speech_to_text_2/configuration_speech_to_text_2.py
+++ b/src/transformers/models/deprecated/speech_to_text_2/configuration_speech_to_text_2.py
@@ -55,9 +55,9 @@ class Speech2Text2Config(PretrainedConfig):
The dropout ratio for activations inside the fully connected layer.
init_std (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
- https://arxiv.org/abs/1909.11556>`__ for more details.
+ https://huggingface.co/papers/1909.11556>`__ for more details.
decoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models).
diff --git a/src/transformers/models/deprecated/speech_to_text_2/modeling_speech_to_text_2.py b/src/transformers/models/deprecated/speech_to_text_2/modeling_speech_to_text_2.py
index 6f1dd18d97..4d1d4c3da1 100755
--- a/src/transformers/models/deprecated/speech_to_text_2/modeling_speech_to_text_2.py
+++ b/src/transformers/models/deprecated/speech_to_text_2/modeling_speech_to_text_2.py
@@ -602,7 +602,7 @@ class Speech2Text2Decoder(Speech2Text2PreTrainedModel):
f" {head_mask.size()[0]}."
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
diff --git a/src/transformers/models/deprecated/van/modeling_van.py b/src/transformers/models/deprecated/van/modeling_van.py
index 1da03cb544..8a48858852 100644
--- a/src/transformers/models/deprecated/van/modeling_van.py
+++ b/src/transformers/models/deprecated/van/modeling_van.py
@@ -86,7 +86,7 @@ class VanOverlappingPatchEmbedder(nn.Module):
"""
Downsamples the input using a patchify operation with a `stride` of 4 by default making adjacent windows overlap by
half of the area. From [PVTv2: Improved Baselines with Pyramid Vision
- Transformer](https://arxiv.org/abs/2106.13797).
+ Transformer](https://huggingface.co/papers/2106.13797).
"""
def __init__(self, in_channels: int, hidden_size: int, patch_size: int = 7, stride: int = 4):
@@ -105,7 +105,7 @@ class VanOverlappingPatchEmbedder(nn.Module):
class VanMlpLayer(nn.Module):
"""
MLP with depth-wise convolution, from [PVTv2: Improved Baselines with Pyramid Vision
- Transformer](https://arxiv.org/abs/2106.13797).
+ Transformer](https://huggingface.co/papers/2106.13797).
"""
def __init__(
diff --git a/src/transformers/models/deprecated/xlm_prophetnet/configuration_xlm_prophetnet.py b/src/transformers/models/deprecated/xlm_prophetnet/configuration_xlm_prophetnet.py
index 2d7751d954..59f42577c5 100644
--- a/src/transformers/models/deprecated/xlm_prophetnet/configuration_xlm_prophetnet.py
+++ b/src/transformers/models/deprecated/xlm_prophetnet/configuration_xlm_prophetnet.py
@@ -81,10 +81,10 @@ class XLMProphetNetConfig(PretrainedConfig):
token.
num_buckets (`int`, *optional*, defaults to 32)
The number of buckets to use for each attention layer. This is for relative position calculation. See the
- [T5 paper](see https://arxiv.org/abs/1910.10683) for more details.
+ [T5 paper](see https://huggingface.co/papers/1910.10683) for more details.
relative_max_distance (`int`, *optional*, defaults to 128)
Relative distances greater than this number will be put into the last same bucket. This is for relative
- position calculation. See the [T5 paper](see https://arxiv.org/abs/1910.10683) for more details.
+ position calculation. See the [T5 paper](see https://huggingface.co/papers/1910.10683) for more details.
disable_ngram_loss (`bool`, *optional*, defaults to `False`):
Whether be trained predicting only the next first token.
eps (`float`, *optional*, defaults to 0.0):
diff --git a/src/transformers/models/detr/configuration_detr.py b/src/transformers/models/detr/configuration_detr.py
index d0373505bb..976b937312 100644
--- a/src/transformers/models/detr/configuration_detr.py
+++ b/src/transformers/models/detr/configuration_detr.py
@@ -79,10 +79,10 @@ class DetrConfig(PretrainedConfig):
init_xavier_std (`float`, *optional*, defaults to 1):
The scaling factor used for the Xavier initialization gain in the HM Attention map module.
encoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
decoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
auxiliary_loss (`bool`, *optional*, defaults to `False`):
Whether auxiliary decoding losses (loss at each decoder layer) are to be used.
diff --git a/src/transformers/models/detr/modeling_detr.py b/src/transformers/models/detr/modeling_detr.py
index c23258fad1..dd6264d183 100644
--- a/src/transformers/models/detr/modeling_detr.py
+++ b/src/transformers/models/detr/modeling_detr.py
@@ -894,7 +894,7 @@ class DetrEncoder(DetrPreTrainedModel):
for i, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
to_drop = False
if self.training:
dropout_probability = torch.rand([])
@@ -1037,7 +1037,7 @@ class DetrDecoder(DetrPreTrainedModel):
all_cross_attentions = () if (output_attentions and encoder_hidden_states is not None) else None
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
diff --git a/src/transformers/models/diffllama/configuration_diffllama.py b/src/transformers/models/diffllama/configuration_diffllama.py
index 3e0b918e90..d0b32c9724 100644
--- a/src/transformers/models/diffllama/configuration_diffllama.py
+++ b/src/transformers/models/diffllama/configuration_diffllama.py
@@ -49,7 +49,7 @@ class DiffLlamaConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
diff --git a/src/transformers/models/dpr/configuration_dpr.py b/src/transformers/models/dpr/configuration_dpr.py
index 7e4b97c97a..03b1690024 100644
--- a/src/transformers/models/dpr/configuration_dpr.py
+++ b/src/transformers/models/dpr/configuration_dpr.py
@@ -67,9 +67,9 @@ class DPRConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
projection_dim (`int`, *optional*, defaults to 0):
Dimension of the projection for the context and question encoders. If it is set to zero (default), then no
projection is done.
diff --git a/src/transformers/models/electra/configuration_electra.py b/src/transformers/models/electra/configuration_electra.py
index c88b44532e..f12756d976 100644
--- a/src/transformers/models/electra/configuration_electra.py
+++ b/src/transformers/models/electra/configuration_electra.py
@@ -92,9 +92,9 @@ class ElectraConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models). Only
relevant if `config.is_decoder=True`.
diff --git a/src/transformers/models/emu3/configuration_emu3.py b/src/transformers/models/emu3/configuration_emu3.py
index 509150df8d..22ab66f6d0 100644
--- a/src/transformers/models/emu3/configuration_emu3.py
+++ b/src/transformers/models/emu3/configuration_emu3.py
@@ -139,7 +139,7 @@ class Emu3TextConfig(PretrainedConfig):
`num_key_value_heads=1 the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
diff --git a/src/transformers/models/emu3/modeling_emu3.py b/src/transformers/models/emu3/modeling_emu3.py
index 995e9cac7d..348c0ea8d7 100644
--- a/src/transformers/models/emu3/modeling_emu3.py
+++ b/src/transformers/models/emu3/modeling_emu3.py
@@ -959,7 +959,8 @@ class Emu3VQVAEDecoder(nn.Module):
custom_intro="""
The VQ-VAE model used in Emu3 for encoding/decoding images into discrete tokens.
This model follows the "Make-a-scene: Scene-based text-to-image generation with human priors" paper from
- [ Oran Gafni, Adam Polyak, Oron Ashual, Shelly Sheynin, Devi Parikh, and Yaniv Taigman](https://arxiv.org/abs/2203.13131).
+ [ Oran Gafni, Adam Polyak, Oron Ashual, Shelly Sheynin, Devi Parikh, and Yaniv
+ Taigman](https://huggingface.co/papers/2203.13131).
"""
)
class Emu3VQVAE(PreTrainedModel):
diff --git a/src/transformers/models/emu3/modular_emu3.py b/src/transformers/models/emu3/modular_emu3.py
index d6e34eb14a..58461f8bd6 100644
--- a/src/transformers/models/emu3/modular_emu3.py
+++ b/src/transformers/models/emu3/modular_emu3.py
@@ -693,7 +693,8 @@ class Emu3VQVAEDecoder(nn.Module):
custom_intro="""
The VQ-VAE model used in Emu3 for encoding/decoding images into discrete tokens.
This model follows the "Make-a-scene: Scene-based text-to-image generation with human priors" paper from
- [ Oran Gafni, Adam Polyak, Oron Ashual, Shelly Sheynin, Devi Parikh, and Yaniv Taigman](https://arxiv.org/abs/2203.13131).
+ [ Oran Gafni, Adam Polyak, Oron Ashual, Shelly Sheynin, Devi Parikh, and Yaniv
+ Taigman](https://huggingface.co/papers/2203.13131).
"""
)
class Emu3VQVAE(PreTrainedModel):
diff --git a/src/transformers/models/encoder_decoder/modeling_flax_encoder_decoder.py b/src/transformers/models/encoder_decoder/modeling_flax_encoder_decoder.py
index c37e7d3537..38551ddc20 100644
--- a/src/transformers/models/encoder_decoder/modeling_flax_encoder_decoder.py
+++ b/src/transformers/models/encoder_decoder/modeling_flax_encoder_decoder.py
@@ -46,7 +46,7 @@ ENCODER_DECODER_START_DOCSTRING = r"""
The effectiveness of initializing sequence-to-sequence models with pretrained checkpoints for sequence generation
tasks was shown in [Leveraging Pre-trained Checkpoints for Sequence Generation
- Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn. Michael Matena, Yanqi
+ Tasks](https://huggingface.co/papers/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn. Michael Matena, Yanqi
Zhou, Wei Li, Peter J. Liu.
After such an Encoder Decoder model has been trained/fine-tuned, it can be saved/loaded just like any other models
diff --git a/src/transformers/models/encoder_decoder/modeling_tf_encoder_decoder.py b/src/transformers/models/encoder_decoder/modeling_tf_encoder_decoder.py
index 9926f8d10f..bf375dbd40 100644
--- a/src/transformers/models/encoder_decoder/modeling_tf_encoder_decoder.py
+++ b/src/transformers/models/encoder_decoder/modeling_tf_encoder_decoder.py
@@ -67,7 +67,7 @@ ENCODER_DECODER_START_DOCSTRING = r"""
The effectiveness of initializing sequence-to-sequence models with pretrained checkpoints for sequence generation
tasks was shown in [Leveraging Pre-trained Checkpoints for Sequence Generation
- Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn. Michael Matena, Yanqi
+ Tasks](https://huggingface.co/papers/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn. Michael Matena, Yanqi
Zhou, Wei Li, Peter J. Liu.
After such an Encoder Decoder model has been trained/fine-tuned, it can be saved/loaded just like any other models
diff --git a/src/transformers/models/ernie/configuration_ernie.py b/src/transformers/models/ernie/configuration_ernie.py
index e212292c48..abf300f0ce 100644
--- a/src/transformers/models/ernie/configuration_ernie.py
+++ b/src/transformers/models/ernie/configuration_ernie.py
@@ -74,9 +74,9 @@ class ErnieConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models). Only
relevant if `config.is_decoder=True`.
diff --git a/src/transformers/models/ernie/modeling_ernie.py b/src/transformers/models/ernie/modeling_ernie.py
index c07627fa79..bd52f56cf5 100644
--- a/src/transformers/models/ernie/modeling_ernie.py
+++ b/src/transformers/models/ernie/modeling_ernie.py
@@ -696,7 +696,7 @@ class ErnieForPreTrainingOutput(ModelOutput):
custom_intro="""
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in [Attention is
- all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
+ all you need](https://huggingface.co/papers/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
To behave as an decoder the model needs to be initialized with the `is_decoder` argument of the configuration set
diff --git a/src/transformers/models/esm/configuration_esm.py b/src/transformers/models/esm/configuration_esm.py
index ac56bc8d78..a7d8efab64 100644
--- a/src/transformers/models/esm/configuration_esm.py
+++ b/src/transformers/models/esm/configuration_esm.py
@@ -69,9 +69,9 @@ class EsmConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query", "rotary"`.
For positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
is_decoder (`bool`, *optional*, defaults to `False`):
Whether the model is used as a decoder or not. If `False`, the model is used as an encoder.
use_cache (`bool`, *optional*, defaults to `True`):
diff --git a/src/transformers/models/esm/modeling_esm.py b/src/transformers/models/esm/modeling_esm.py
index 7505268bb3..3af89dcfc3 100755
--- a/src/transformers/models/esm/modeling_esm.py
+++ b/src/transformers/models/esm/modeling_esm.py
@@ -827,7 +827,7 @@ class EsmModel(EsmPreTrainedModel):
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in [Attention is
- all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
+ all you need](https://huggingface.co/papers/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
To behave as an decoder the model needs to be initialized with the `is_decoder` argument of the configuration set
diff --git a/src/transformers/models/esm/modeling_tf_esm.py b/src/transformers/models/esm/modeling_tf_esm.py
index 71698486da..53b7e273ba 100644
--- a/src/transformers/models/esm/modeling_tf_esm.py
+++ b/src/transformers/models/esm/modeling_tf_esm.py
@@ -874,7 +874,7 @@ class TFEsmMainLayer(keras.layers.Layer):
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in [Attention is
- all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
+ all you need](https://huggingface.co/papers/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
To behave as an decoder the model needs to be initialized with the `is_decoder` argument of the configuration set
diff --git a/src/transformers/models/falcon_h1/configuration_falcon_h1.py b/src/transformers/models/falcon_h1/configuration_falcon_h1.py
index 94ca7f848d..4b10b2e3f2 100644
--- a/src/transformers/models/falcon_h1/configuration_falcon_h1.py
+++ b/src/transformers/models/falcon_h1/configuration_falcon_h1.py
@@ -51,7 +51,7 @@ class FalconH1Config(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `8`.
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to `8`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
initializer_range (`float`, *optional*, defaults to 0.02):
diff --git a/src/transformers/models/fastspeech2_conformer/modeling_fastspeech2_conformer.py b/src/transformers/models/fastspeech2_conformer/modeling_fastspeech2_conformer.py
index ed78a8a7e5..473e09ab20 100644
--- a/src/transformers/models/fastspeech2_conformer/modeling_fastspeech2_conformer.py
+++ b/src/transformers/models/fastspeech2_conformer/modeling_fastspeech2_conformer.py
@@ -141,7 +141,7 @@ def length_regulator(encoded_embeddings, duration_labels, speaking_speed=1.0):
Length regulator for feed-forward Transformer.
This is the length regulator module described in `FastSpeech: Fast, Robust and Controllable Text to Speech`
- https://arxiv.org/pdf/1905.09263.pdf. The length regulator expands char or phoneme-level embedding features to
+ https://huggingface.co/papers/1905.09263. The length regulator expands char or phoneme-level embedding features to
frame-level by repeating each feature based on the corresponding predicted durations.
Args:
@@ -188,7 +188,7 @@ class FastSpeech2ConformerDurationPredictor(nn.Module):
Duration predictor module.
This is a module of duration predictor described in the paper 'FastSpeech: Fast, Robust and Controllable Text to
- Speech' https://arxiv.org/pdf/1905.09263.pdf The duration predictor predicts a duration of each frame in log domain
+ Speech' https://huggingface.co/papers/1905.09263 The duration predictor predicts a duration of each frame in log domain
from the hidden embeddings of encoder.
Note:
@@ -411,7 +411,7 @@ class FastSpeech2ConformerVarianceEmbedding(nn.Module):
class FastSpeech2ConformerAttention(nn.Module):
"""
Multi-Head attention layer with relative position encoding. Details can be found in
- https://github.com/espnet/espnet/pull/2816. Paper: https://arxiv.org/abs/1901.02860.
+ https://github.com/espnet/espnet/pull/2816. Paper: https://huggingface.co/papers/1901.02860.
"""
def __init__(self, config: FastSpeech2ConformerConfig, module_config):
@@ -431,7 +431,7 @@ class FastSpeech2ConformerAttention(nn.Module):
# linear transformation for positional encoding
self.linear_pos = nn.Linear(self.hidden_size, self.hidden_size, bias=False)
# these two learnable bias are used in matrix c and matrix d
- # as described in https://arxiv.org/abs/1901.02860 Section 3.3
+ # as described in https://huggingface.co/papers/1901.02860 Section 3.3
self.pos_bias_u = nn.Parameter(torch.Tensor(self.num_heads, self.head_dim))
self.pos_bias_v = nn.Parameter(torch.Tensor(self.num_heads, self.head_dim))
@@ -484,7 +484,7 @@ class FastSpeech2ConformerAttention(nn.Module):
# compute attention score
# first compute matrix a and matrix c
- # as described in https://arxiv.org/abs/1901.02860 Section 3.3
+ # as described in https://huggingface.co/papers/1901.02860 Section 3.3
# (batch_size, head, time1, time2)
matrix_ac = torch.matmul(query_with_bias_u, key_states.permute(0, 2, 3, 1))
@@ -686,7 +686,7 @@ class FastSpeech2ConformerMultiLayeredConv1d(nn.Module):
This is a module of multi-layered conv1d designed to replace positionwise feed-forward network in Transformer
block, which is introduced in 'FastSpeech: Fast, Robust and Controllable Text to Speech'
- https://arxiv.org/pdf/1905.09263.pdf
+ https://huggingface.co/papers/1905.09263
"""
def __init__(self, config: FastSpeech2ConformerConfig, module_config):
@@ -730,7 +730,7 @@ class FastSpeech2ConformerRelPositionalEncoding(nn.Module):
"""
Args:
Relative positional encoding module (new implementation). Details can be found in
- https://github.com/espnet/espnet/pull/2816. See : Appendix Batch in https://arxiv.org/abs/1901.02860
+ https://github.com/espnet/espnet/pull/2816. See : Appendix Batch in https://huggingface.co/papers/1901.02860
config (`FastSpeech2ConformerConfig`):
FastSpeech2ConformerConfig instance.
module_config (`dict`):
@@ -774,7 +774,7 @@ class FastSpeech2ConformerRelPositionalEncoding(nn.Module):
# Reserve the order of positive indices and concat both positive and
# negative indices. This is used to support the shifting trick
- # as in https://arxiv.org/abs/1901.02860
+ # as in https://huggingface.co/papers/1901.02860
pos_enc_positive = torch.flip(pos_enc_positive, [0]).unsqueeze(0)
pos_enc_negative = pos_enc_negative[1:].unsqueeze(0)
pos_enc = torch.cat([pos_enc_positive, pos_enc_negative], dim=1)
@@ -1046,7 +1046,7 @@ class FastSpeech2ConformerModel(FastSpeech2ConformerPreTrainedModel):
FastSpeech 2 module.
This is a module of FastSpeech 2 described in 'FastSpeech 2: Fast and High-Quality End-to-End Text to Speech'
- https://arxiv.org/abs/2006.04558. Instead of quantized pitch and energy, we use token-averaged value introduced in
+ https://huggingface.co/papers/2006.04558. Instead of quantized pitch and energy, we use token-averaged value introduced in
FastPitch: Parallel Text-to-speech with Pitch Prediction. The encoder and decoder are Conformers instead of regular
Transformers.
"""
diff --git a/src/transformers/models/flava/configuration_flava.py b/src/transformers/models/flava/configuration_flava.py
index 4f9a47b4d1..65520d48af 100644
--- a/src/transformers/models/flava/configuration_flava.py
+++ b/src/transformers/models/flava/configuration_flava.py
@@ -151,9 +151,9 @@ class FlavaTextConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
hidden_size (`int`, *optional*, defaults to 768):
Dimensionality of the encoder layers and the pooler layer.
num_hidden_layers (`int`, *optional*, defaults to 12):
diff --git a/src/transformers/models/fnet/modeling_fnet.py b/src/transformers/models/fnet/modeling_fnet.py
index 0a88a7b9fd..b2e8572efe 100755
--- a/src/transformers/models/fnet/modeling_fnet.py
+++ b/src/transformers/models/fnet/modeling_fnet.py
@@ -441,7 +441,7 @@ class FNetModel(FNetPreTrainedModel):
"""
The model can behave as an encoder, following the architecture described in [FNet: Mixing Tokens with Fourier
- Transforms](https://arxiv.org/abs/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
+ Transforms](https://huggingface.co/papers/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
"""
diff --git a/src/transformers/models/focalnet/modeling_focalnet.py b/src/transformers/models/focalnet/modeling_focalnet.py
index 37292f0687..6a9e38411c 100644
--- a/src/transformers/models/focalnet/modeling_focalnet.py
+++ b/src/transformers/models/focalnet/modeling_focalnet.py
@@ -711,7 +711,7 @@ class FocalNetModel(FocalNetPreTrainedModel):
custom_intro="""
FocalNet Model with a decoder on top for masked image modeling.
- This follows the same implementation as in [SimMIM](https://arxiv.org/abs/2111.09886).
+ This follows the same implementation as in [SimMIM](https://huggingface.co/papers/2111.09886).
diff --git a/src/transformers/models/fsmt/modeling_fsmt.py b/src/transformers/models/fsmt/modeling_fsmt.py
index 39f65179b8..6be3ae909a 100644
--- a/src/transformers/models/fsmt/modeling_fsmt.py
+++ b/src/transformers/models/fsmt/modeling_fsmt.py
@@ -23,7 +23,7 @@
# - David Grangier
# - Kyra Yee
#
-# Paper: Facebook FAIR's WMT19 News Translation Task Submission https://arxiv.org/abs/1907.06616
+# Paper: Facebook FAIR's WMT19 News Translation Task Submission https://huggingface.co/papers/1907.06616
#
"""PyTorch Fairseq model, ported from https://github.com/pytorch/fairseq/tree/master/examples/wmt19"""
@@ -425,7 +425,7 @@ class FSMTEncoder(nn.Module):
x = x.transpose(0, 1) # T x B x C -> B x T x C
encoder_states += (x,)
x = x.transpose(0, 1) # B x T x C -> T x B x C
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = torch.rand([])
if self.training and (dropout_probability < self.layerdrop): # skip the layer
attn = None
@@ -666,7 +666,7 @@ class FSMTDecoder(nn.Module):
f" {head_mask.size()[0]}."
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
x = x.transpose(0, 1)
all_hidden_states += (x,)
diff --git a/src/transformers/models/funnel/modeling_funnel.py b/src/transformers/models/funnel/modeling_funnel.py
index b77e802a20..8e1f8d8d27 100644
--- a/src/transformers/models/funnel/modeling_funnel.py
+++ b/src/transformers/models/funnel/modeling_funnel.py
@@ -207,7 +207,7 @@ class FunnelAttentionStructure(nn.Module):
For the relative shift attention, it returns all possible vectors R used in the paper, appendix A.2.1, final
formula.
- Paper link: https://arxiv.org/abs/2006.03236
+ Paper link: https://huggingface.co/papers/2006.03236
"""
d_model = self.config.d_model
if self.config.attention_type == "factorized":
@@ -454,7 +454,7 @@ class FunnelRelMultiheadAttention(nn.Module):
"""Relative attention score for the positional encodings"""
# q_head has shape batch_size x sea_len x n_head x d_head
if self.config.attention_type == "factorized":
- # Notations from the paper, appending A.2.2, final formula (https://arxiv.org/abs/2006.03236)
+ # Notations from the paper, appending A.2.2, final formula (https://huggingface.co/papers/2006.03236)
# phi and pi have shape seq_len x d_model, psi and omega have shape context_len x d_model
phi, pi, psi, omega = position_embeds
# Shape n_head x d_head
@@ -473,7 +473,7 @@ class FunnelRelMultiheadAttention(nn.Module):
)
else:
shift = 2 if q_head.shape[1] != context_len else 1
- # Notations from the paper, appending A.2.1, final formula (https://arxiv.org/abs/2006.03236)
+ # Notations from the paper, appending A.2.1, final formula (https://huggingface.co/papers/2006.03236)
# Grab the proper positional encoding, shape max_rel_len x d_model
r = position_embeds[self.block_index][shift - 1]
# Shape n_head x d_head
diff --git a/src/transformers/models/funnel/modeling_tf_funnel.py b/src/transformers/models/funnel/modeling_tf_funnel.py
index 0f8e76b99f..8c14417089 100644
--- a/src/transformers/models/funnel/modeling_tf_funnel.py
+++ b/src/transformers/models/funnel/modeling_tf_funnel.py
@@ -169,7 +169,7 @@ class TFFunnelAttentionStructure:
For the relative shift attention, it returns all possible vectors R used in the paper, appendix A.2.1, final
formula.
- Paper link: https://arxiv.org/abs/2006.03236
+ Paper link: https://huggingface.co/papers/2006.03236
"""
if self.attention_type == "factorized":
# Notations from the paper, appending A.2.2, final formula.
@@ -443,7 +443,7 @@ class TFFunnelRelMultiheadAttention(keras.layers.Layer):
"""Relative attention score for the positional encodings"""
# q_head has shape batch_size x sea_len x n_head x d_head
if self.attention_type == "factorized":
- # Notations from the paper, appending A.2.2, final formula (https://arxiv.org/abs/2006.03236)
+ # Notations from the paper, appending A.2.2, final formula (https://huggingface.co/papers/2006.03236)
# phi and pi have shape seq_len x d_model, psi and omega have shape context_len x d_model
phi, pi, psi, omega = position_embeds
# Shape n_head x d_head
@@ -461,7 +461,7 @@ class TFFunnelRelMultiheadAttention(keras.layers.Layer):
"bind,jd->bnij", q_r_attention_2, omega
)
else:
- # Notations from the paper, appending A.2.1, final formula (https://arxiv.org/abs/2006.03236)
+ # Notations from the paper, appending A.2.1, final formula (https://huggingface.co/papers/2006.03236)
# Grab the proper positional encoding, shape max_rel_len x d_model
if shape_list(q_head)[1] != context_len:
shift = 2
@@ -1112,7 +1112,7 @@ class TFFunnelForPreTrainingOutput(ModelOutput):
FUNNEL_START_DOCSTRING = r"""
The Funnel Transformer model was proposed in [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient
- Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
+ Language Processing](https://huggingface.co/papers/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
This model inherits from [`TFPreTrainedModel`]. Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
diff --git a/src/transformers/models/gemma/configuration_gemma.py b/src/transformers/models/gemma/configuration_gemma.py
index d8f26d3845..363af5c3ff 100644
--- a/src/transformers/models/gemma/configuration_gemma.py
+++ b/src/transformers/models/gemma/configuration_gemma.py
@@ -48,7 +48,7 @@ class GemmaConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
head_dim (`int`, *optional*, defaults to 256):
The attention head dimension.
diff --git a/src/transformers/models/gemma/modeling_flax_gemma.py b/src/transformers/models/gemma/modeling_flax_gemma.py
index 237e92d949..49b3ffc68a 100644
--- a/src/transformers/models/gemma/modeling_flax_gemma.py
+++ b/src/transformers/models/gemma/modeling_flax_gemma.py
@@ -98,7 +98,7 @@ GEMMA_INPUTS_DOCSTRING = r"""
`past_key_values`).
If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
- 1 indicates the head is **not masked**,
diff --git a/src/transformers/models/gemma/modular_gemma.py b/src/transformers/models/gemma/modular_gemma.py
index b10bd51f0c..f9f10e816c 100644
--- a/src/transformers/models/gemma/modular_gemma.py
+++ b/src/transformers/models/gemma/modular_gemma.py
@@ -75,7 +75,7 @@ class GemmaConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
head_dim (`int`, *optional*, defaults to 256):
The attention head dimension.
diff --git a/src/transformers/models/gemma2/configuration_gemma2.py b/src/transformers/models/gemma2/configuration_gemma2.py
index c1390bf205..95ca6df873 100644
--- a/src/transformers/models/gemma2/configuration_gemma2.py
+++ b/src/transformers/models/gemma2/configuration_gemma2.py
@@ -48,7 +48,7 @@ class Gemma2Config(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
head_dim (`int`, *optional*, defaults to 256):
The attention head dimension.
diff --git a/src/transformers/models/gemma2/modular_gemma2.py b/src/transformers/models/gemma2/modular_gemma2.py
index f35fdefac6..5ce710a6ac 100644
--- a/src/transformers/models/gemma2/modular_gemma2.py
+++ b/src/transformers/models/gemma2/modular_gemma2.py
@@ -72,7 +72,7 @@ class Gemma2Config(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
head_dim (`int`, *optional*, defaults to 256):
The attention head dimension.
diff --git a/src/transformers/models/gemma3/configuration_gemma3.py b/src/transformers/models/gemma3/configuration_gemma3.py
index d6935cfef7..895058f465 100644
--- a/src/transformers/models/gemma3/configuration_gemma3.py
+++ b/src/transformers/models/gemma3/configuration_gemma3.py
@@ -56,7 +56,7 @@ class Gemma3TextConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
head_dim (`int`, *optional*, defaults to 256):
The attention head dimension.
diff --git a/src/transformers/models/gemma3/modular_gemma3.py b/src/transformers/models/gemma3/modular_gemma3.py
index 3c1f5b0d5f..f298d2736e 100644
--- a/src/transformers/models/gemma3/modular_gemma3.py
+++ b/src/transformers/models/gemma3/modular_gemma3.py
@@ -83,7 +83,7 @@ class Gemma3TextConfig(Gemma2Config, PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
head_dim (`int`, *optional*, defaults to 256):
The attention head dimension.
diff --git a/src/transformers/models/git/configuration_git.py b/src/transformers/models/git/configuration_git.py
index 6266f0f45d..86c85854ff 100644
--- a/src/transformers/models/git/configuration_git.py
+++ b/src/transformers/models/git/configuration_git.py
@@ -143,9 +143,9 @@ class GitConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models).
num_image_with_embedding (`int`, *optional*):
diff --git a/src/transformers/models/glm/configuration_glm.py b/src/transformers/models/glm/configuration_glm.py
index 94b7eb528f..4d61dc6fa1 100644
--- a/src/transformers/models/glm/configuration_glm.py
+++ b/src/transformers/models/glm/configuration_glm.py
@@ -43,7 +43,7 @@ class GlmConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
partial_rotary_factor (`float`, *optional*, defaults to 0.5): The factor of the partial rotary position.
head_dim (`int`, *optional*, defaults to 128):
diff --git a/src/transformers/models/glm4/configuration_glm4.py b/src/transformers/models/glm4/configuration_glm4.py
index 7ed2fbf0ee..46dc929826 100644
--- a/src/transformers/models/glm4/configuration_glm4.py
+++ b/src/transformers/models/glm4/configuration_glm4.py
@@ -43,7 +43,7 @@ class Glm4Config(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
partial_rotary_factor (`float`, *optional*, defaults to 0.5): The factor of the partial rotary position.
head_dim (`int`, *optional*, defaults to 128):
diff --git a/src/transformers/models/glpn/modeling_glpn.py b/src/transformers/models/glpn/modeling_glpn.py
index b9bb0dba2a..e23b86f076 100755
--- a/src/transformers/models/glpn/modeling_glpn.py
+++ b/src/transformers/models/glpn/modeling_glpn.py
@@ -97,7 +97,7 @@ class GLPNOverlapPatchEmbeddings(nn.Module):
# Copied from transformers.models.segformer.modeling_segformer.SegformerEfficientSelfAttention
class GLPNEfficientSelfAttention(nn.Module):
"""SegFormer's efficient self-attention mechanism. Employs the sequence reduction process introduced in the [PvT
- paper](https://arxiv.org/abs/2102.12122)."""
+ paper](https://huggingface.co/papers/2102.12122)."""
def __init__(self, config, hidden_size, num_attention_heads, sequence_reduction_ratio):
super().__init__()
@@ -480,7 +480,7 @@ class GLPNModel(GLPNPreTrainedModel):
class GLPNSelectiveFeatureFusion(nn.Module):
"""
- Selective Feature Fusion module, as explained in the [paper](https://arxiv.org/abs/2201.07436) (section 3.4). This
+ Selective Feature Fusion module, as explained in the [paper](https://huggingface.co/papers/2201.07436) (section 3.4). This
module adaptively selects and integrates local and global features by attaining an attention map for each feature.
"""
@@ -571,7 +571,7 @@ class GLPNDecoder(nn.Module):
class SiLogLoss(nn.Module):
r"""
- Implements the Scale-invariant log scale loss [Eigen et al., 2014](https://arxiv.org/abs/1406.2283).
+ Implements the Scale-invariant log scale loss [Eigen et al., 2014](https://huggingface.co/papers/1406.2283).
$$L=\frac{1}{n} \sum_{i} d_{i}^{2}-\frac{1}{2 n^{2}}\left(\sum_{i} d_{i}^{2}\right)$$ where $d_{i}=\log y_{i}-\log
y_{i}^{*}$.
diff --git a/src/transformers/models/granite/configuration_granite.py b/src/transformers/models/granite/configuration_granite.py
index c7f3240260..61d3ba9e7b 100644
--- a/src/transformers/models/granite/configuration_granite.py
+++ b/src/transformers/models/granite/configuration_granite.py
@@ -55,7 +55,7 @@ class GraniteConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
diff --git a/src/transformers/models/granite_speech/modeling_granite_speech.py b/src/transformers/models/granite_speech/modeling_granite_speech.py
index bfce41e6fa..abcb3cfce2 100644
--- a/src/transformers/models/granite_speech/modeling_granite_speech.py
+++ b/src/transformers/models/granite_speech/modeling_granite_speech.py
@@ -126,7 +126,7 @@ class GraniteSpeechConformerFeedForward(nn.Module):
class GraniteSpeechConformerAttention(nn.Module):
"""Attention for conformer blocks using Shaw's relative positional embeddings.
- See the following [paper](https://arxiv.org/pdf/1803.02155) for more details.
+ See the following [paper](https://huggingface.co/papers/1803.02155) for more details.
"""
def __init__(self, config: GraniteSpeechEncoderConfig):
diff --git a/src/transformers/models/granitemoe/configuration_granitemoe.py b/src/transformers/models/granitemoe/configuration_granitemoe.py
index cb1c30da5a..0fb8dbe16f 100644
--- a/src/transformers/models/granitemoe/configuration_granitemoe.py
+++ b/src/transformers/models/granitemoe/configuration_granitemoe.py
@@ -55,7 +55,7 @@ class GraniteMoeConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
diff --git a/src/transformers/models/granitemoe/modeling_granitemoe.py b/src/transformers/models/granitemoe/modeling_granitemoe.py
index a3a314a6ab..e55e188bca 100644
--- a/src/transformers/models/granitemoe/modeling_granitemoe.py
+++ b/src/transformers/models/granitemoe/modeling_granitemoe.py
@@ -51,7 +51,7 @@ def load_balancing_loss_func(
r"""
Computes auxiliary load balancing loss as in Switch Transformer - implemented in Pytorch.
- See Switch Transformer (https://arxiv.org/abs/2101.03961) for more details. This function implements the loss
+ See Switch Transformer (https://huggingface.co/papers/2101.03961) for more details. This function implements the loss
function presented in equations (4) - (6) of the paper. It aims at penalizing cases where the routing between
experts is too unbalanced.
diff --git a/src/transformers/models/granitemoehybrid/configuration_granitemoehybrid.py b/src/transformers/models/granitemoehybrid/configuration_granitemoehybrid.py
index cd38fc8f9e..9e77959104 100644
--- a/src/transformers/models/granitemoehybrid/configuration_granitemoehybrid.py
+++ b/src/transformers/models/granitemoehybrid/configuration_granitemoehybrid.py
@@ -50,7 +50,7 @@ class GraniteMoeHybridConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
diff --git a/src/transformers/models/granitemoehybrid/modeling_granitemoehybrid.py b/src/transformers/models/granitemoehybrid/modeling_granitemoehybrid.py
index d6ff36bf32..032081bc04 100644
--- a/src/transformers/models/granitemoehybrid/modeling_granitemoehybrid.py
+++ b/src/transformers/models/granitemoehybrid/modeling_granitemoehybrid.py
@@ -1521,7 +1521,7 @@ def load_balancing_loss_func(
r"""
Computes auxiliary load balancing loss as in Switch Transformer - implemented in Pytorch.
- See Switch Transformer (https://arxiv.org/abs/2101.03961) for more details. This function implements the loss
+ See Switch Transformer (https://huggingface.co/papers/2101.03961) for more details. This function implements the loss
function presented in equations (4) - (6) of the paper. It aims at penalizing cases where the routing between
experts is too unbalanced.
diff --git a/src/transformers/models/granitemoeshared/configuration_granitemoeshared.py b/src/transformers/models/granitemoeshared/configuration_granitemoeshared.py
index dc71da6a5f..cd1c4a5ca6 100644
--- a/src/transformers/models/granitemoeshared/configuration_granitemoeshared.py
+++ b/src/transformers/models/granitemoeshared/configuration_granitemoeshared.py
@@ -55,7 +55,7 @@ class GraniteMoeSharedConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
diff --git a/src/transformers/models/granitemoeshared/modeling_granitemoeshared.py b/src/transformers/models/granitemoeshared/modeling_granitemoeshared.py
index dc429aa55b..139535b009 100644
--- a/src/transformers/models/granitemoeshared/modeling_granitemoeshared.py
+++ b/src/transformers/models/granitemoeshared/modeling_granitemoeshared.py
@@ -848,7 +848,7 @@ def load_balancing_loss_func(
r"""
Computes auxiliary load balancing loss as in Switch Transformer - implemented in Pytorch.
- See Switch Transformer (https://arxiv.org/abs/2101.03961) for more details. This function implements the loss
+ See Switch Transformer (https://huggingface.co/papers/2101.03961) for more details. This function implements the loss
function presented in equations (4) - (6) of the paper. It aims at penalizing cases where the routing between
experts is too unbalanced.
diff --git a/src/transformers/models/helium/configuration_helium.py b/src/transformers/models/helium/configuration_helium.py
index fe3a5d95d1..9bb4d8d887 100644
--- a/src/transformers/models/helium/configuration_helium.py
+++ b/src/transformers/models/helium/configuration_helium.py
@@ -43,7 +43,7 @@ class HeliumConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
head_dim (`int`, *optional*, defaults to 128):
The attention head dimension.
diff --git a/src/transformers/models/hubert/configuration_hubert.py b/src/transformers/models/hubert/configuration_hubert.py
index 36d41bfc57..486487da3d 100644
--- a/src/transformers/models/hubert/configuration_hubert.py
+++ b/src/transformers/models/hubert/configuration_hubert.py
@@ -60,7 +60,7 @@ class HubertConfig(PretrainedConfig):
final_dropout (`float`, *optional*, defaults to 0.1):
The dropout probability for the final projection layer of [`Wav2Vec2ForCTC`].
layerdrop (`float`, *optional*, defaults to 0.1):
- The LayerDrop probability. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556) for more
+ The LayerDrop probability. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556) for more
details.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
@@ -103,7 +103,7 @@ class HubertConfig(PretrainedConfig):
apply_spec_augment (`bool`, *optional*, defaults to `True`):
Whether to apply *SpecAugment* data augmentation to the outputs of the feature encoder. For reference see
[SpecAugment: A Simple Data Augmentation Method for Automatic Speech
- Recognition](https://arxiv.org/abs/1904.08779).
+ Recognition](https://huggingface.co/papers/1904.08779).
mask_time_prob (`float`, *optional*, defaults to 0.05):
Percentage (between 0 and 1) of all feature vectors along the time axis which will be masked. The masking
procedure generates ''mask_time_prob*len(time_axis)/mask_time_length'' independent masks over the axis. If
@@ -244,7 +244,7 @@ class HubertConfig(PretrainedConfig):
f" `len(config.conv_kernel) = {len(self.conv_kernel)}`."
)
- # fine-tuning config parameters for SpecAugment: https://arxiv.org/abs/1904.08779
+ # fine-tuning config parameters for SpecAugment: https://huggingface.co/papers/1904.08779
self.apply_spec_augment = apply_spec_augment
self.mask_time_prob = mask_time_prob
self.mask_time_length = mask_time_length
diff --git a/src/transformers/models/hubert/modeling_hubert.py b/src/transformers/models/hubert/modeling_hubert.py
index 115345407e..15f874c40a 100755
--- a/src/transformers/models/hubert/modeling_hubert.py
+++ b/src/transformers/models/hubert/modeling_hubert.py
@@ -495,7 +495,7 @@ class HubertEncoder(nn.Module):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = torch.rand([])
skip_the_layer = True if self.training and (dropout_probability < self.config.layerdrop) else False
@@ -668,7 +668,7 @@ class HubertEncoderStableLayerNorm(nn.Module):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = torch.rand([])
skip_the_layer = True if self.training and (dropout_probability < self.config.layerdrop) else False
@@ -810,7 +810,7 @@ def _compute_mask_indices(
) -> np.ndarray:
"""
Computes random mask spans for a given shape. Used to implement [SpecAugment: A Simple Data Augmentation Method for
- ASR](https://arxiv.org/abs/1904.08779). Note that this method is not optimized to run on TPU and should be run on
+ ASR](https://huggingface.co/papers/1904.08779). Note that this method is not optimized to run on TPU and should be run on
CPU as part of the preprocessing during training.
Args:
@@ -948,7 +948,7 @@ class HubertModel(HubertPreTrainedModel):
):
"""
Masks extracted features along time axis and/or along feature axis according to
- [SpecAugment](https://arxiv.org/abs/1904.08779).
+ [SpecAugment](https://huggingface.co/papers/1904.08779).
"""
# `config.apply_spec_augment` can set masking to False
diff --git a/src/transformers/models/hubert/modeling_tf_hubert.py b/src/transformers/models/hubert/modeling_tf_hubert.py
index 8664db8a42..d12c343de6 100644
--- a/src/transformers/models/hubert/modeling_tf_hubert.py
+++ b/src/transformers/models/hubert/modeling_tf_hubert.py
@@ -1030,7 +1030,7 @@ class TFHubertEncoder(keras.layers.Layer):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = np.random.uniform(0, 1)
if training and (dropout_probability < self.config.layerdrop): # skip the layer
continue
@@ -1112,7 +1112,7 @@ class TFHubertEncoderStableLayerNorm(keras.layers.Layer):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = np.random.uniform(0, 1)
if training and (dropout_probability < self.config.layerdrop): # skip the layer
continue
@@ -1208,7 +1208,7 @@ class TFHubertMainLayer(keras.layers.Layer):
def _mask_hidden_states(self, hidden_states: tf.Tensor, mask_time_indices: tf.Tensor | None = None):
"""
Masks extracted features along time axis and/or along feature axis according to
- [SpecAugment](https://arxiv.org/abs/1904.08779).
+ [SpecAugment](https://huggingface.co/papers/1904.08779).
"""
batch_size, sequence_length, hidden_size = shape_list(hidden_states)
diff --git a/src/transformers/models/ibert/configuration_ibert.py b/src/transformers/models/ibert/configuration_ibert.py
index 1d36cf70b7..963e6e6c9e 100644
--- a/src/transformers/models/ibert/configuration_ibert.py
+++ b/src/transformers/models/ibert/configuration_ibert.py
@@ -68,9 +68,9 @@ class IBertConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
quant_mode (`bool`, *optional*, defaults to `False`):
Whether to quantize the model or not.
force_dequant (`str`, *optional*, defaults to `"none"`):
diff --git a/src/transformers/models/ibert/modeling_ibert.py b/src/transformers/models/ibert/modeling_ibert.py
index 9d322e5eca..006bfcc40b 100644
--- a/src/transformers/models/ibert/modeling_ibert.py
+++ b/src/transformers/models/ibert/modeling_ibert.py
@@ -657,7 +657,7 @@ class IBertModel(IBertPreTrainedModel):
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in [Attention is
- all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
+ all you need](https://huggingface.co/papers/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
"""
diff --git a/src/transformers/models/idefics/modeling_tf_idefics.py b/src/transformers/models/idefics/modeling_tf_idefics.py
index 057988d992..4f4ef97aa5 100644
--- a/src/transformers/models/idefics/modeling_tf_idefics.py
+++ b/src/transformers/models/idefics/modeling_tf_idefics.py
@@ -1118,7 +1118,7 @@ LLAMA_INPUTS_DOCSTRING = r"""
`past_key_values`).
If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
- 1 indicates the head is **not masked**,
diff --git a/src/transformers/models/idefics2/image_processing_idefics2.py b/src/transformers/models/idefics2/image_processing_idefics2.py
index 02fc697a86..197e2fbf3f 100644
--- a/src/transformers/models/idefics2/image_processing_idefics2.py
+++ b/src/transformers/models/idefics2/image_processing_idefics2.py
@@ -182,7 +182,7 @@ class Idefics2ImageProcessor(BaseImageProcessor):
sample in the batch, such that the returned tensor is of shape (batch_size, max_num_images, num_channels, max_height, max_width).
do_image_splitting (`bool`, *optional*, defaults to `False`):
Whether to split the image into a sequence 4 equal sub-images concatenated with the original image. That
- strategy was first introduced in https://arxiv.org/abs/2311.06607.
+ strategy was first introduced in https://huggingface.co/papers/2311.06607.
"""
model_input_names = ["pixel_values", "pixel_attention_mask"]
@@ -440,7 +440,7 @@ class Idefics2ImageProcessor(BaseImageProcessor):
Whether or not to pad the images to the largest height and width in the batch.
do_image_splitting (`bool`, *optional*, defaults to `self.do_image_splitting`):
Whether to split the image into a sequence 4 equal sub-images concatenated with the original image. That
- strategy was first introduced in https://arxiv.org/abs/2311.06607.
+ strategy was first introduced in https://huggingface.co/papers/2311.06607.
return_tensors (`str` or `TensorType`, *optional*):
The type of tensors to return. Can be one of:
- Unset: Return a list of `np.ndarray`.
diff --git a/src/transformers/models/idefics2/modeling_idefics2.py b/src/transformers/models/idefics2/modeling_idefics2.py
index 4607051b19..663a4b43a3 100644
--- a/src/transformers/models/idefics2/modeling_idefics2.py
+++ b/src/transformers/models/idefics2/modeling_idefics2.py
@@ -119,7 +119,7 @@ class Idefics2VisionEmbeddings(nn.Module):
This is a modified version of `siglip.modelign_siglip.SiglipVisionEmbeddings` to enable images of variable
resolution.
- The modifications are adapted from [Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution](https://arxiv.org/abs/2307.06304)
+ The modifications are adapted from [Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution](https://huggingface.co/papers/2307.06304)
which allows treating images in their native aspect ratio and without the need to resize them to the same
fixed size. In particular, we start from the original pre-trained SigLIP model
(which uses images of fixed-size square images) and adapt it by training on images of variable resolutions.
diff --git a/src/transformers/models/idefics3/modeling_idefics3.py b/src/transformers/models/idefics3/modeling_idefics3.py
index 99ea7fd0d3..70c803268a 100644
--- a/src/transformers/models/idefics3/modeling_idefics3.py
+++ b/src/transformers/models/idefics3/modeling_idefics3.py
@@ -120,7 +120,7 @@ class Idefics3VisionEmbeddings(nn.Module):
This is a modified version of `siglip.modelign_siglip.SiglipVisionEmbeddings` to enable images of variable
resolution.
- The modifications are adapted from [Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution](https://arxiv.org/abs/2307.06304)
+ The modifications are adapted from [Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution](https://huggingface.co/papers/2307.06304)
which allows treating images in their native aspect ratio and without the need to resize them to the same
fixed size. In particular, we start from the original pre-trained SigLIP model
(which uses images of fixed-size square images) and adapt it by training on images of variable resolutions.
diff --git a/src/transformers/models/informer/modeling_informer.py b/src/transformers/models/informer/modeling_informer.py
index 330bc620bc..e0cd58eec7 100644
--- a/src/transformers/models/informer/modeling_informer.py
+++ b/src/transformers/models/informer/modeling_informer.py
@@ -1076,7 +1076,7 @@ class InformerEncoder(InformerPreTrainedModel):
for idx, (encoder_layer, conv_layer) in enumerate(zip(self.layers, self.conv_layers)):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
to_drop = False
if self.training:
dropout_probability = torch.rand([])
@@ -1291,7 +1291,7 @@ class InformerDecoder(InformerPreTrainedModel):
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
diff --git a/src/transformers/models/informer/modular_informer.py b/src/transformers/models/informer/modular_informer.py
index 15bcb8d38a..183ba27c3a 100644
--- a/src/transformers/models/informer/modular_informer.py
+++ b/src/transformers/models/informer/modular_informer.py
@@ -600,7 +600,7 @@ class InformerEncoder(TimeSeriesTransformerEncoder):
for idx, (encoder_layer, conv_layer) in enumerate(zip(self.layers, self.conv_layers)):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
to_drop = False
if self.training:
dropout_probability = torch.rand([])
diff --git a/src/transformers/models/instructblip/configuration_instructblip.py b/src/transformers/models/instructblip/configuration_instructblip.py
index 04c32d552d..4206e174fa 100644
--- a/src/transformers/models/instructblip/configuration_instructblip.py
+++ b/src/transformers/models/instructblip/configuration_instructblip.py
@@ -149,9 +149,9 @@ class InstructBlipQFormerConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
cross_attention_frequency (`int`, *optional*, defaults to 2):
The frequency of adding cross-attention to the Transformer layers.
encoder_hidden_size (`int`, *optional*, defaults to 1408):
diff --git a/src/transformers/models/instructblipvideo/configuration_instructblipvideo.py b/src/transformers/models/instructblipvideo/configuration_instructblipvideo.py
index d761139596..7ad1653a37 100644
--- a/src/transformers/models/instructblipvideo/configuration_instructblipvideo.py
+++ b/src/transformers/models/instructblipvideo/configuration_instructblipvideo.py
@@ -155,9 +155,9 @@ class InstructBlipVideoQFormerConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
cross_attention_frequency (`int`, *optional*, defaults to 2):
The frequency of adding cross-attention to the Transformer layers.
encoder_hidden_size (`int`, *optional*, defaults to 1408):
diff --git a/src/transformers/models/jamba/configuration_jamba.py b/src/transformers/models/jamba/configuration_jamba.py
index 5980a28e4a..a557562ea0 100644
--- a/src/transformers/models/jamba/configuration_jamba.py
+++ b/src/transformers/models/jamba/configuration_jamba.py
@@ -56,7 +56,7 @@ class JambaConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `8`.
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to `8`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
initializer_range (`float`, *optional*, defaults to 0.02):
diff --git a/src/transformers/models/jamba/modeling_jamba.py b/src/transformers/models/jamba/modeling_jamba.py
index d60190161e..70e6855972 100755
--- a/src/transformers/models/jamba/modeling_jamba.py
+++ b/src/transformers/models/jamba/modeling_jamba.py
@@ -73,7 +73,7 @@ def load_balancing_loss_func(
r"""
Computes auxiliary load balancing loss as in Switch Transformer - implemented in Pytorch.
- See Switch Transformer (https://arxiv.org/abs/2101.03961) for more details. This function implements the loss
+ See Switch Transformer (https://huggingface.co/papers/2101.03961) for more details. This function implements the loss
function presented in equations (4) - (6) of the paper. It aims at penalizing cases where the routing between
experts is too unbalanced.
diff --git a/src/transformers/models/janus/modeling_janus.py b/src/transformers/models/janus/modeling_janus.py
index a526ce5d7a..6455c41eb1 100644
--- a/src/transformers/models/janus/modeling_janus.py
+++ b/src/transformers/models/janus/modeling_janus.py
@@ -946,7 +946,8 @@ class JanusVQVAEDecoder(nn.Module):
custom_intro="""
The VQ-VAE model used in Janus for encoding/decoding images into discrete tokens.
This model follows the "Make-a-scene: Scene-based text-to-image generation with human priors" paper from
- [ Oran Gafni, Adam Polyak, Oron Ashual, Shelly Sheynin, Devi Parikh, and Yaniv Taigman](https://arxiv.org/abs/2203.13131).
+ [ Oran Gafni, Adam Polyak, Oron Ashual, Shelly Sheynin, Devi Parikh, and Yaniv
+ Taigman](https://huggingface.co/papers/2203.13131).
"""
)
class JanusVQVAE(JanusPreTrainedModel):
diff --git a/src/transformers/models/jetmoe/modeling_jetmoe.py b/src/transformers/models/jetmoe/modeling_jetmoe.py
index 788b2066b5..8afe851bd2 100644
--- a/src/transformers/models/jetmoe/modeling_jetmoe.py
+++ b/src/transformers/models/jetmoe/modeling_jetmoe.py
@@ -56,7 +56,7 @@ def load_balancing_loss_func(
r"""
Computes auxiliary load balancing loss as in Switch Transformer - implemented in Pytorch.
- See Switch Transformer (https://arxiv.org/abs/2101.03961) for more details. This function implements the loss
+ See Switch Transformer (https://huggingface.co/papers/2101.03961) for more details. This function implements the loss
function presented in equations (4) - (6) of the paper. It aims at penalizing cases where the routing between
experts is too unbalanced.
diff --git a/src/transformers/models/kosmos2/configuration_kosmos2.py b/src/transformers/models/kosmos2/configuration_kosmos2.py
index 85695e250c..56b26eb171 100644
--- a/src/transformers/models/kosmos2/configuration_kosmos2.py
+++ b/src/transformers/models/kosmos2/configuration_kosmos2.py
@@ -56,7 +56,7 @@ class Kosmos2TextConfig(PretrainedConfig):
activation_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for activations inside the fully connected layer.
layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
layer_norm_eps (`float`, *optional*, defaults to 1e-05):
The epsilon used by the layer normalization layers.
diff --git a/src/transformers/models/kosmos2/modeling_kosmos2.py b/src/transformers/models/kosmos2/modeling_kosmos2.py
index ebf578fedf..745563ad12 100644
--- a/src/transformers/models/kosmos2/modeling_kosmos2.py
+++ b/src/transformers/models/kosmos2/modeling_kosmos2.py
@@ -1128,7 +1128,7 @@ class Kosmos2TextTransformer(nn.Module):
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
diff --git a/src/transformers/models/layoutlm/configuration_layoutlm.py b/src/transformers/models/layoutlm/configuration_layoutlm.py
index 0f5fdf1d90..d053e5e57c 100644
--- a/src/transformers/models/layoutlm/configuration_layoutlm.py
+++ b/src/transformers/models/layoutlm/configuration_layoutlm.py
@@ -70,9 +70,9 @@ class LayoutLMConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models). Only
relevant if `config.is_decoder=True`.
diff --git a/src/transformers/models/layoutlmv3/modeling_layoutlmv3.py b/src/transformers/models/layoutlmv3/modeling_layoutlmv3.py
index 3605001d8a..9e1569d11f 100644
--- a/src/transformers/models/layoutlmv3/modeling_layoutlmv3.py
+++ b/src/transformers/models/layoutlmv3/modeling_layoutlmv3.py
@@ -251,7 +251,7 @@ class LayoutLMv3SelfAttention(nn.Module):
def cogview_attention(self, attention_scores, alpha=32):
"""
- https://arxiv.org/abs/2105.13290 Section 2.4 Stabilization of training: Precision Bottleneck Relaxation
+ https://huggingface.co/papers/2105.13290 Section 2.4 Stabilization of training: Precision Bottleneck Relaxation
(PB-Relax). A replacement of the original nn.Softmax(dim=-1)(attention_scores). Seems the new attention_probs
will result in a slower speed and a little bias. Can use torch.allclose(standard_attention_probs,
cogview_attention_probs, atol=1e-08) for comparison. The smaller atol (e.g., 1e-08), the better.
@@ -278,7 +278,7 @@ class LayoutLMv3SelfAttention(nn.Module):
# Take the dot product between "query" and "key" to get the raw attention scores.
# The attention scores QT K/√d could be significantly larger than input elements, and result in overflow.
- # Changing the computational order into QT(K/√d) alleviates the problem. (https://arxiv.org/pdf/2105.13290.pdf)
+ # Changing the computational order into QT(K/√d) alleviates the problem. (https://huggingface.co/papers/2105.13290)
attention_scores = torch.matmul(query_layer / math.sqrt(self.attention_head_size), key_layer.transpose(-1, -2))
if self.has_relative_attention_bias and self.has_spatial_attention_bias:
diff --git a/src/transformers/models/layoutlmv3/modeling_tf_layoutlmv3.py b/src/transformers/models/layoutlmv3/modeling_tf_layoutlmv3.py
index 4cdd15d5e4..d145b51b3c 100644
--- a/src/transformers/models/layoutlmv3/modeling_tf_layoutlmv3.py
+++ b/src/transformers/models/layoutlmv3/modeling_tf_layoutlmv3.py
@@ -343,7 +343,7 @@ class TFLayoutLMv3SelfAttention(keras.layers.Layer):
def cogview_attention(self, attention_scores: tf.Tensor, alpha: Union[float, int] = 32):
"""
- https://arxiv.org/abs/2105.13290 Section 2.4 Stabilization of training: Precision Bottleneck Relaxation
+ https://huggingface.co/papers/2105.13290 Section 2.4 Stabilization of training: Precision Bottleneck Relaxation
(PB-Relax). A replacement of the original keras.layers.Softmax(axis=-1)(attention_scores). Seems the new
attention_probs will result in a slower speed and a little bias. Can use
tf.debugging.assert_near(standard_attention_probs, cogview_attention_probs, atol=1e-08) for comparison. The
diff --git a/src/transformers/models/led/configuration_led.py b/src/transformers/models/led/configuration_led.py
index d51c0dc4aa..0dcc3ecce4 100644
--- a/src/transformers/models/led/configuration_led.py
+++ b/src/transformers/models/led/configuration_led.py
@@ -70,10 +70,10 @@ class LEDConfig(PretrainedConfig):
init_std (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
encoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
decoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models)
diff --git a/src/transformers/models/led/modeling_led.py b/src/transformers/models/led/modeling_led.py
index e6e21ce897..1783fe06ec 100755
--- a/src/transformers/models/led/modeling_led.py
+++ b/src/transformers/models/led/modeling_led.py
@@ -1584,7 +1584,7 @@ class LEDEncoder(LEDPreTrainedModel):
important for task-specific finetuning because it makes the model more flexible at representing the
task. For example, for classification, the token should be given global attention. For QA, all
question tokens should also have global attention. Please refer to the [Longformer
- paper](https://arxiv.org/abs/2004.05150) for more details. Mask values selected in `[0, 1]`:
+ paper](https://huggingface.co/papers/2004.05150) for more details. Mask values selected in `[0, 1]`:
- 0 for local attention (a sliding window attention),
- 1 for global attention (tokens that attend to all other tokens, and all other tokens attend to them).
@@ -1674,7 +1674,7 @@ class LEDEncoder(LEDPreTrainedModel):
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = torch.rand([])
if self.training and (dropout_probability < self.layerdrop): # skip the layer
@@ -1807,7 +1807,7 @@ class LEDDecoder(LEDPreTrainedModel):
for task-specific finetuning because it makes the model more flexible at representing the task. For
example, for classification, the token should be given global attention. For QA, all question
tokens should also have global attention. Please refer to the [Longformer
- paper](https://arxiv.org/abs/2004.05150) for more details. Mask values selected in `[0, 1]`:
+ paper](https://huggingface.co/papers/2004.05150) for more details. Mask values selected in `[0, 1]`:
- 0 for local attention (a sliding window attention),
- 1 for global attention (tokens that attend to all other tokens, and all other tokens attend to them).
@@ -1933,7 +1933,7 @@ class LEDDecoder(LEDPreTrainedModel):
f" {head_mask.size()[0]}."
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
@@ -2066,7 +2066,7 @@ class LEDModel(LEDPreTrainedModel):
be used by default.
If you want to change padding behavior, you should read [`modeling_led._prepare_decoder_inputs`] and modify
- to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more information on the
+ to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more information on the
default strategy.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules in the decoder. Mask values selected in `[0,
@@ -2080,7 +2080,7 @@ class LEDModel(LEDPreTrainedModel):
important for task-specific finetuning because it makes the model more flexible at representing the task.
For example, for classification, the token should be given global attention. For QA, all question
tokens should also have global attention. Please refer to the [Longformer
- paper](https://arxiv.org/abs/2004.05150) for more details. Mask values selected in `[0, 1]`:
+ paper](https://huggingface.co/papers/2004.05150) for more details. Mask values selected in `[0, 1]`:
- 0 for local attention (a sliding window attention),
- 1 for global attention (tokens that attend to all other tokens, and all other tokens attend to them).
@@ -2236,7 +2236,7 @@ class LEDForConditionalGeneration(LEDPreTrainedModel, GenerationMixin):
be used by default.
If you want to change padding behavior, you should read [`modeling_led._prepare_decoder_inputs`] and modify
- to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more information on the
+ to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more information on the
default strategy.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules in the decoder. Mask values selected in `[0,
@@ -2250,7 +2250,7 @@ class LEDForConditionalGeneration(LEDPreTrainedModel, GenerationMixin):
important for task-specific finetuning because it makes the model more flexible at representing the task.
For example, for classification, the token should be given global attention. For QA, all question
tokens should also have global attention. Please refer to the [Longformer
- paper](https://arxiv.org/abs/2004.05150) for more details. Mask values selected in `[0, 1]`:
+ paper](https://huggingface.co/papers/2004.05150) for more details. Mask values selected in `[0, 1]`:
- 0 for local attention (a sliding window attention),
- 1 for global attention (tokens that attend to all other tokens, and all other tokens attend to them).
@@ -2442,7 +2442,7 @@ class LEDForSequenceClassification(LEDPreTrainedModel):
be used by default.
If you want to change padding behavior, you should read [`modeling_led._prepare_decoder_inputs`] and modify
- to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more information on the
+ to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more information on the
default strategy.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules in the decoder. Mask values selected in `[0,
@@ -2456,7 +2456,7 @@ class LEDForSequenceClassification(LEDPreTrainedModel):
important for task-specific finetuning because it makes the model more flexible at representing the task.
For example, for classification, the token should be given global attention. For QA, all question
tokens should also have global attention. Please refer to the [Longformer
- paper](https://arxiv.org/abs/2004.05150) for more details. Mask values selected in `[0, 1]`:
+ paper](https://huggingface.co/papers/2004.05150) for more details. Mask values selected in `[0, 1]`:
- 0 for local attention (a sliding window attention),
- 1 for global attention (tokens that attend to all other tokens, and all other tokens attend to them).
@@ -2594,7 +2594,7 @@ class LEDForQuestionAnswering(LEDPreTrainedModel):
be used by default.
If you want to change padding behavior, you should read [`modeling_led._prepare_decoder_inputs`] and modify
- to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more information on the
+ to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more information on the
default strategy.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules in the decoder. Mask values selected in `[0,
@@ -2608,7 +2608,7 @@ class LEDForQuestionAnswering(LEDPreTrainedModel):
important for task-specific finetuning because it makes the model more flexible at representing the task.
For example, for classification, the token should be given global attention. For QA, all question
tokens should also have global attention. Please refer to the [Longformer
- paper](https://arxiv.org/abs/2004.05150) for more details. Mask values selected in `[0, 1]`:
+ paper](https://huggingface.co/papers/2004.05150) for more details. Mask values selected in `[0, 1]`:
- 0 for local attention (a sliding window attention),
- 1 for global attention (tokens that attend to all other tokens, and all other tokens attend to them).
diff --git a/src/transformers/models/led/modeling_tf_led.py b/src/transformers/models/led/modeling_tf_led.py
index 25f7a2e5f5..c867cebe36 100644
--- a/src/transformers/models/led/modeling_tf_led.py
+++ b/src/transformers/models/led/modeling_tf_led.py
@@ -1878,7 +1878,7 @@ class TFLEDEncoder(keras.layers.Layer):
if output_hidden_states:
hidden_states_to_add = self.compute_hidden_states(hidden_states, padding_len)
encoder_states = encoder_states + (hidden_states_to_add,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if training and (dropout_probability < self.layerdrop): # skip the layer
continue
@@ -2149,7 +2149,7 @@ class TFLEDDecoder(keras.layers.Layer):
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
dropout_probability = random.uniform(0, 1)
diff --git a/src/transformers/models/lilt/configuration_lilt.py b/src/transformers/models/lilt/configuration_lilt.py
index 30f32cca4a..940fad4aa8 100644
--- a/src/transformers/models/lilt/configuration_lilt.py
+++ b/src/transformers/models/lilt/configuration_lilt.py
@@ -61,9 +61,9 @@ class LiltConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
classifier_dropout (`float`, *optional*):
The dropout ratio for the classification head.
channel_shrink_ratio (`int`, *optional*, defaults to 4):
diff --git a/src/transformers/models/llama/configuration_llama.py b/src/transformers/models/llama/configuration_llama.py
index 1bca828270..3399ab6489 100644
--- a/src/transformers/models/llama/configuration_llama.py
+++ b/src/transformers/models/llama/configuration_llama.py
@@ -52,7 +52,7 @@ class LlamaConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
diff --git a/src/transformers/models/llama/modeling_flax_llama.py b/src/transformers/models/llama/modeling_flax_llama.py
index 14bc16ede6..c3cf79e705 100644
--- a/src/transformers/models/llama/modeling_flax_llama.py
+++ b/src/transformers/models/llama/modeling_flax_llama.py
@@ -104,7 +104,7 @@ LLAMA_INPUTS_DOCSTRING = r"""
`past_key_values`).
If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
- 1 indicates the head is **not masked**,
diff --git a/src/transformers/models/llama4/modeling_llama4.py b/src/transformers/models/llama4/modeling_llama4.py
index fe77ea4a58..e6308d37c4 100644
--- a/src/transformers/models/llama4/modeling_llama4.py
+++ b/src/transformers/models/llama4/modeling_llama4.py
@@ -325,7 +325,7 @@ class Llama4TextAttention(nn.Module):
query_states = self.qk_norm(query_states)
key_states = self.qk_norm(key_states)
- # Use temperature tuning from https://arxiv.org/abs/2501.19399) to NoROPE layers
+ # Use temperature tuning from https://huggingface.co/papers/2501.19399) to NoROPE layers
if self.attn_temperature_tuning and not self.use_rope:
attn_scales = (
torch.log(torch.floor((cache_position.float() + 1.0) / self.floor_scale) + 1.0) * self.attn_scale + 1.0
diff --git a/src/transformers/models/llava_next/image_processing_llava_next.py b/src/transformers/models/llava_next/image_processing_llava_next.py
index a1c26183c9..1e8ef6cf3b 100644
--- a/src/transformers/models/llava_next/image_processing_llava_next.py
+++ b/src/transformers/models/llava_next/image_processing_llava_next.py
@@ -108,7 +108,7 @@ def expand_to_square(image: np.array, background_color, input_data_format) -> np
class LlavaNextImageProcessor(BaseImageProcessor):
r"""
Constructs a LLaVa-NeXT image processor. Based on [`CLIPImageProcessor`] with incorporation of additional techniques
- for processing high resolution images as explained in the [LLaVa paper](https://arxiv.org/abs/2310.03744).
+ for processing high resolution images as explained in the [LLaVa paper](https://huggingface.co/papers/2310.03744).
Args:
do_resize (`bool`, *optional*, defaults to `True`):
diff --git a/src/transformers/models/longformer/modeling_longformer.py b/src/transformers/models/longformer/modeling_longformer.py
index ea178f3594..dc0f161511 100755
--- a/src/transformers/models/longformer/modeling_longformer.py
+++ b/src/transformers/models/longformer/modeling_longformer.py
@@ -1417,7 +1417,7 @@ class LongformerModel(LongformerPreTrainedModel):
"""
This class copied code from [`RobertaModel`] and overwrote standard self-attention with longformer self-attention
to provide the ability to process long sequences following the self-attention approach described in [Longformer:
- the Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, and Arman Cohan.
+ the Long-Document Transformer](https://huggingface.co/papers/2004.05150) by Iz Beltagy, Matthew E. Peters, and Arman Cohan.
Longformer self-attention combines a local (sliding window) and global attention to extend to long documents
without the O(n^2) increase in memory and compute.
@@ -1549,7 +1549,7 @@ class LongformerModel(LongformerPreTrainedModel):
attention attends to all other tokens, and all other tokens attend to them. This is important for
task-specific finetuning because it makes the model more flexible at representing the task. For example,
for classification, the token should be given global attention. For QA, all question tokens should also
- have global attention. Please refer to the [Longformer paper](https://arxiv.org/abs/2004.05150) for more
+ have global attention. Please refer to the [Longformer paper](https://huggingface.co/papers/2004.05150) for more
details. Mask values selected in `[0, 1]`:
- 0 for local attention (a sliding window attention),
@@ -1701,7 +1701,7 @@ class LongformerForMaskedLM(LongformerPreTrainedModel):
attention attends to all other tokens, and all other tokens attend to them. This is important for
task-specific finetuning because it makes the model more flexible at representing the task. For example,
for classification, the token should be given global attention. For QA, all question tokens should also
- have global attention. Please refer to the [Longformer paper](https://arxiv.org/abs/2004.05150) for more
+ have global attention. Please refer to the [Longformer paper](https://huggingface.co/papers/2004.05150) for more
details. Mask values selected in `[0, 1]`:
- 0 for local attention (a sliding window attention),
@@ -1814,7 +1814,7 @@ class LongformerForSequenceClassification(LongformerPreTrainedModel):
attention attends to all other tokens, and all other tokens attend to them. This is important for
task-specific finetuning because it makes the model more flexible at representing the task. For example,
for classification, the token should be given global attention. For QA, all question tokens should also
- have global attention. Please refer to the [Longformer paper](https://arxiv.org/abs/2004.05150) for more
+ have global attention. Please refer to the [Longformer paper](https://huggingface.co/papers/2004.05150) for more
details. Mask values selected in `[0, 1]`:
- 0 for local attention (a sliding window attention),
@@ -1938,7 +1938,7 @@ class LongformerForQuestionAnswering(LongformerPreTrainedModel):
attention attends to all other tokens, and all other tokens attend to them. This is important for
task-specific finetuning because it makes the model more flexible at representing the task. For example,
for classification, the token should be given global attention. For QA, all question tokens should also
- have global attention. Please refer to the [Longformer paper](https://arxiv.org/abs/2004.05150) for more
+ have global attention. Please refer to the [Longformer paper](https://huggingface.co/papers/2004.05150) for more
details. Mask values selected in `[0, 1]`:
- 0 for local attention (a sliding window attention),
@@ -2068,7 +2068,7 @@ class LongformerForTokenClassification(LongformerPreTrainedModel):
attention attends to all other tokens, and all other tokens attend to them. This is important for
task-specific finetuning because it makes the model more flexible at representing the task. For example,
for classification, the token should be given global attention. For QA, all question tokens should also
- have global attention. Please refer to the [Longformer paper](https://arxiv.org/abs/2004.05150) for more
+ have global attention. Please refer to the [Longformer paper](https://huggingface.co/papers/2004.05150) for more
details. Mask values selected in `[0, 1]`:
- 0 for local attention (a sliding window attention),
@@ -2164,7 +2164,7 @@ class LongformerForMultipleChoice(LongformerPreTrainedModel):
attention attends to all other tokens, and all other tokens attend to them. This is important for
task-specific finetuning because it makes the model more flexible at representing the task. For example,
for classification, the token should be given global attention. For QA, all question tokens should also
- have global attention. Please refer to the [Longformer paper](https://arxiv.org/abs/2004.05150) for more
+ have global attention. Please refer to the [Longformer paper](https://huggingface.co/papers/2004.05150) for more
details. Mask values selected in `[0, 1]`:
- 0 for local attention (a sliding window attention),
diff --git a/src/transformers/models/longformer/modeling_tf_longformer.py b/src/transformers/models/longformer/modeling_tf_longformer.py
index 9280838de0..bb0f5279bd 100644
--- a/src/transformers/models/longformer/modeling_tf_longformer.py
+++ b/src/transformers/models/longformer/modeling_tf_longformer.py
@@ -2061,7 +2061,7 @@ LONGFORMER_INPUTS_DOCSTRING = r"""
attention attends to all other tokens, and all other tokens attend to them. This is important for
task-specific finetuning because it makes the model more flexible at representing the task. For example,
for classification, the token should be given global attention. For QA, all question tokens should also
- have global attention. Please refer to the [Longformer paper](https://arxiv.org/abs/2004.05150) for more
+ have global attention. Please refer to the [Longformer paper](https://huggingface.co/papers/2004.05150) for more
details. Mask values selected in `[0, 1]`:
- 0 for local attention (a sliding window attention),
@@ -2110,7 +2110,7 @@ class TFLongformerModel(TFLongformerPreTrainedModel):
This class copies code from [`TFRobertaModel`] and overwrites standard self-attention with longformer
self-attention to provide the ability to process long sequences following the self-attention approach described in
- [Longformer: the Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, and
+ [Longformer: the Long-Document Transformer](https://huggingface.co/papers/2004.05150) by Iz Beltagy, Matthew E. Peters, and
Arman Cohan. Longformer self-attention combines a local (sliding window) and global attention to extend to long
documents without the O(n^2) increase in memory and compute.
diff --git a/src/transformers/models/longt5/modeling_flax_longt5.py b/src/transformers/models/longt5/modeling_flax_longt5.py
index b9a341349f..2674c225e5 100644
--- a/src/transformers/models/longt5/modeling_flax_longt5.py
+++ b/src/transformers/models/longt5/modeling_flax_longt5.py
@@ -90,7 +90,7 @@ def _split_into_blocks(x: jnp.ndarray, block_len: int, axis: int) -> jnp.ndarray
def _concatenate_3_blocks(x: jnp.ndarray, block_axis: int, sequence_axis: int, pad_value: int = 0) -> jnp.ndarray:
"""Concatenate three consecutive blocks for each input block for local attentiont.
- For more information, see: https://arxiv.org/pdf/2112.07916.pdf.
+ For more information, see: https://huggingface.co/papers/2112.07916.
"""
num_blocks = x.shape[block_axis]
@@ -1587,7 +1587,7 @@ LONGT5_DECODE_INPUTS_DOCSTRING = r"""
be used by default.
If you want to change padding behavior, you should modify to your needs. See diagram 1 in [the
- paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
+ paper](https://huggingface.co/papers/1910.13461) for more information on the default strategy.
past_key_values (`Dict[str, np.ndarray]`, *optional*, returned by `init_cache` or when passing previous `past_key_values`):
Dictionary of pre-computed hidden-states (key and values in the attention blocks) that can be used for fast
auto-regressive decoding. Pre-computed key and value hidden-states are of shape *[batch_size, max_length]*.
@@ -1970,7 +1970,7 @@ class FlaxLongT5PreTrainedModel(FlaxPreTrainedModel):
LONGT5_START_DOCSTRING = r"""
The LongT5 model was proposed in [LongT5: Efficient Text-To-Text Transformer for Long
- Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo
+ Sequences](https://huggingface.co/papers/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo
Ni, Yun-Hsuan Sung and Yinfei Yang. It's an encoder-decoder transformer pre-trained in a text-to-text denoising
generative setting. LongT5 model is an extension of T5 model, and it enables using one of the two different
efficient attention mechanisms - (1) Local attention, or (2) Transient-Global attention.
diff --git a/src/transformers/models/longt5/modeling_longt5.py b/src/transformers/models/longt5/modeling_longt5.py
index 62e696e811..35d9cb30a9 100644
--- a/src/transformers/models/longt5/modeling_longt5.py
+++ b/src/transformers/models/longt5/modeling_longt5.py
@@ -93,7 +93,7 @@ def _split_into_blocks(x: torch.Tensor, block_len: int, dim: int) -> torch.Tenso
def _concatenate_3_blocks(x: torch.Tensor, block_dim: int, sequence_dim: int, pad_value: int = 0) -> torch.Tensor:
"""Concatenate three consecutive blocks for each input block for local attentiont.
- For more information, see: https://arxiv.org/pdf/2112.07916.pdf.
+ For more information, see: https://huggingface.co/papers/2112.07916.
"""
num_blocks = x.shape[block_dim]
@@ -231,7 +231,7 @@ class LongT5LayerNorm(nn.Module):
def forward(self, hidden_states):
# LongT5 uses a layer_norm which only scales and doesn't shift, which is also known as Root Mean
- # Square Layer Normalization https://arxiv.org/abs/1910.07467 thus variance is calculated
+ # Square Layer Normalization https://huggingface.co/papers/1910.07467 thus variance is calculated
# w/o mean and there is no bias. Additionally we want to make sure that the accumulation for
# half-precision inputs is done in fp32
diff --git a/src/transformers/models/luke/configuration_luke.py b/src/transformers/models/luke/configuration_luke.py
index 3d4640a9fd..fbac7c36d7 100644
--- a/src/transformers/models/luke/configuration_luke.py
+++ b/src/transformers/models/luke/configuration_luke.py
@@ -68,7 +68,7 @@ class LukeConfig(PretrainedConfig):
use_entity_aware_attention (`bool`, *optional*, defaults to `True`):
Whether or not the model should use the entity-aware self-attention mechanism proposed in [LUKE: Deep
Contextualized Entity Representations with Entity-aware Self-attention (Yamada et
- al.)](https://arxiv.org/abs/2010.01057).
+ al.)](https://huggingface.co/papers/2010.01057).
classifier_dropout (`float`, *optional*):
The dropout ratio for the classification head.
pad_token_id (`int`, *optional*, defaults to 1):
diff --git a/src/transformers/models/lxmert/modeling_tf_lxmert.py b/src/transformers/models/lxmert/modeling_tf_lxmert.py
index 0efea46329..637646ae2f 100644
--- a/src/transformers/models/lxmert/modeling_tf_lxmert.py
+++ b/src/transformers/models/lxmert/modeling_tf_lxmert.py
@@ -980,7 +980,7 @@ class TFLxmertPreTrainedModel(TFPreTrainedModel):
LXMERT_START_DOCSTRING = r"""
The LXMERT model was proposed in [LXMERT: Learning Cross-Modality Encoder Representations from
- Transformers](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal. It's a vision and language transformer
+ Transformers](https://huggingface.co/papers/1908.07490) by Hao Tan and Mohit Bansal. It's a vision and language transformer
model, pre-trained on a variety of multi-modal datasets comprising of GQA, VQAv2.0, MCSCOCO captions, and Visual
genome, using a combination of masked language modeling, region of interest feature regression, cross entropy loss
for question answering attribute prediction, and object tag prediction.
diff --git a/src/transformers/models/m2m_100/configuration_m2m_100.py b/src/transformers/models/m2m_100/configuration_m2m_100.py
index 8b2ae78c1f..620641f1cf 100644
--- a/src/transformers/models/m2m_100/configuration_m2m_100.py
+++ b/src/transformers/models/m2m_100/configuration_m2m_100.py
@@ -74,10 +74,10 @@ class M2M100Config(PretrainedConfig):
init_std (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
encoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
decoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models).
diff --git a/src/transformers/models/m2m_100/modeling_m2m_100.py b/src/transformers/models/m2m_100/modeling_m2m_100.py
index f348867272..0b19afb8f0 100755
--- a/src/transformers/models/m2m_100/modeling_m2m_100.py
+++ b/src/transformers/models/m2m_100/modeling_m2m_100.py
@@ -876,7 +876,7 @@ class M2M100Encoder(M2M100PreTrainedModel):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = torch.rand([])
skip_the_layer = True if self.training and (dropout_probability < self.layerdrop) else False
@@ -1135,7 +1135,7 @@ class M2M100Decoder(M2M100PreTrainedModel):
if output_hidden_states:
all_hidden_states += (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = torch.rand([])
skip_the_layer = True if self.training and (dropout_probability < self.layerdrop) else False
diff --git a/src/transformers/models/marian/configuration_marian.py b/src/transformers/models/marian/configuration_marian.py
index 19073b91a6..0e0468c50b 100644
--- a/src/transformers/models/marian/configuration_marian.py
+++ b/src/transformers/models/marian/configuration_marian.py
@@ -72,10 +72,10 @@ class MarianConfig(PretrainedConfig):
init_std (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
encoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
decoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
scale_embedding (`bool`, *optional*, defaults to `False`):
Scale embeddings by diving by sqrt(d_model).
diff --git a/src/transformers/models/marian/modeling_flax_marian.py b/src/transformers/models/marian/modeling_flax_marian.py
index 2436158806..bcd2ab5f32 100644
--- a/src/transformers/models/marian/modeling_flax_marian.py
+++ b/src/transformers/models/marian/modeling_flax_marian.py
@@ -121,7 +121,7 @@ MARIAN_INPUTS_DOCSTRING = r"""
be used by default.
If you want to change padding behavior, you should modify to your needs. See diagram 1 in [the
- paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
+ paper](https://huggingface.co/papers/1910.13461) for more information on the default strategy.
position_ids (`numpy.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.max_position_embeddings - 1]`.
@@ -198,7 +198,7 @@ MARIAN_DECODE_INPUTS_DOCSTRING = r"""
be used by default.
If you want to change padding behavior, you should modify to your needs. See diagram 1 in [the
- paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
+ paper](https://huggingface.co/papers/1910.13461) for more information on the default strategy.
decoder_position_ids (`numpy.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each decoder input sequence tokens in the position embeddings. Selected in the
range `[0, config.max_position_embeddings - 1]`.
@@ -492,7 +492,7 @@ class FlaxMarianEncoderLayerCollection(nn.Module):
for encoder_layer in self.layers:
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if not deterministic and (dropout_probability < self.layerdrop): # skip the layer
layer_outputs = (None, None)
@@ -641,7 +641,7 @@ class FlaxMarianDecoderLayerCollection(nn.Module):
for decoder_layer in self.layers:
if output_hidden_states:
all_hidden_states += (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if not deterministic and (dropout_probability < self.layerdrop):
layer_outputs = (None, None, None)
diff --git a/src/transformers/models/marian/modeling_marian.py b/src/transformers/models/marian/modeling_marian.py
index a604820f2c..18c435a393 100755
--- a/src/transformers/models/marian/modeling_marian.py
+++ b/src/transformers/models/marian/modeling_marian.py
@@ -821,7 +821,7 @@ class MarianEncoder(MarianPreTrainedModel):
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
to_drop = False
if self.training:
dropout_probability = torch.rand([])
@@ -1079,7 +1079,7 @@ class MarianDecoder(MarianPreTrainedModel):
f" {head_mask.size()[0]}."
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
diff --git a/src/transformers/models/marian/modeling_tf_marian.py b/src/transformers/models/marian/modeling_tf_marian.py
index 9884b6d7e9..3a92dea6df 100644
--- a/src/transformers/models/marian/modeling_tf_marian.py
+++ b/src/transformers/models/marian/modeling_tf_marian.py
@@ -843,7 +843,7 @@ class TFMarianEncoder(keras.layers.Layer):
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if training and (dropout_probability < self.layerdrop): # skip the layer
continue
@@ -1059,7 +1059,7 @@ class TFMarianDecoder(keras.layers.Layer):
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
dropout_probability = random.uniform(0, 1)
diff --git a/src/transformers/models/mask2former/modeling_mask2former.py b/src/transformers/models/mask2former/modeling_mask2former.py
index 7650cfcd0f..0ff091059a 100644
--- a/src/transformers/models/mask2former/modeling_mask2former.py
+++ b/src/transformers/models/mask2former/modeling_mask2former.py
@@ -1374,7 +1374,7 @@ class Mask2FormerPixelLevelModule(nn.Module):
def __init__(self, config: Mask2FormerConfig):
"""
Pixel Level Module proposed in [Masked-attention Mask Transformer for Universal Image
- Segmentation](https://arxiv.org/abs/2112.01527). It runs the input image through a backbone and a pixel
+ Segmentation](https://huggingface.co/papers/2112.01527). It runs the input image through a backbone and a pixel
decoder, generating multi-scale feature maps and pixel embeddings.
Args:
diff --git a/src/transformers/models/maskformer/modeling_maskformer.py b/src/transformers/models/maskformer/modeling_maskformer.py
index 4745e153c2..6d3742a253 100644
--- a/src/transformers/models/maskformer/modeling_maskformer.py
+++ b/src/transformers/models/maskformer/modeling_maskformer.py
@@ -296,7 +296,7 @@ def sigmoid_focal_loss(
inputs: Tensor, labels: Tensor, num_masks: int, alpha: float = 0.25, gamma: float = 2
) -> Tensor:
r"""
- Focal loss proposed in [Focal Loss for Dense Object Detection](https://arxiv.org/abs/1708.02002) originally used in
+ Focal loss proposed in [Focal Loss for Dense Object Detection](https://huggingface.co/papers/1708.02002) originally used in
RetinaNet. The loss is computed as follows:
$$ \mathcal{L}_{\text{focal loss} = -(1 - p_t)^{\gamma}\log{(p_t)} $$
@@ -734,7 +734,7 @@ class DetrDecoder(nn.Module):
all_cross_attentions = () if (output_attentions and encoder_hidden_states is not None) else None
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
@@ -1215,7 +1215,7 @@ class MaskFormerPixelDecoder(nn.Module):
def __init__(self, *args, feature_size: int = 256, mask_feature_size: int = 256, **kwargs):
r"""
Pixel Decoder Module proposed in [Per-Pixel Classification is Not All You Need for Semantic
- Segmentation](https://arxiv.org/abs/2107.06278). It first runs the backbone's features into a Feature Pyramid
+ Segmentation](https://huggingface.co/papers/2107.06278). It first runs the backbone's features into a Feature Pyramid
Network creating a list of feature maps. Then, it projects the last one to the correct `mask_size`.
Args:
@@ -1342,7 +1342,7 @@ class MaskFormerPixelLevelModule(nn.Module):
def __init__(self, config: MaskFormerConfig):
"""
Pixel Level Module proposed in [Per-Pixel Classification is Not All You Need for Semantic
- Segmentation](https://arxiv.org/abs/2107.06278). It runs the input image through a backbone and a pixel
+ Segmentation](https://huggingface.co/papers/2107.06278). It runs the input image through a backbone and a pixel
decoder, generating an image feature map and pixel embeddings.
Args:
diff --git a/src/transformers/models/mbart/configuration_mbart.py b/src/transformers/models/mbart/configuration_mbart.py
index 76941cb02f..104e7e00d9 100644
--- a/src/transformers/models/mbart/configuration_mbart.py
+++ b/src/transformers/models/mbart/configuration_mbart.py
@@ -74,10 +74,10 @@ class MBartConfig(PretrainedConfig):
init_std (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
encoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
decoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
scale_embedding (`bool`, *optional*, defaults to `False`):
Scale embeddings by diving by sqrt(d_model).
diff --git a/src/transformers/models/mbart/modeling_flax_mbart.py b/src/transformers/models/mbart/modeling_flax_mbart.py
index 1e019f5199..f369e39e49 100644
--- a/src/transformers/models/mbart/modeling_flax_mbart.py
+++ b/src/transformers/models/mbart/modeling_flax_mbart.py
@@ -122,7 +122,7 @@ MBART_INPUTS_DOCSTRING = r"""
be used by default.
If you want to change padding behavior, you should modify to your needs. See diagram 1 in [the
- paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
+ paper](https://huggingface.co/papers/1910.13461) for more information on the default strategy.
position_ids (`numpy.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.max_position_embeddings - 1]`.
@@ -199,7 +199,7 @@ MBART_DECODE_INPUTS_DOCSTRING = r"""
be used by default.
If you want to change padding behavior, you should modify to your needs. See diagram 1 in [the
- paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
+ paper](https://huggingface.co/papers/1910.13461) for more information on the default strategy.
decoder_position_ids (`numpy.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each decoder input sequence tokens in the position embeddings. Selected in the
range `[0, config.max_position_embeddings - 1]`.
@@ -491,7 +491,7 @@ class FlaxMBartEncoderLayerCollection(nn.Module):
for encoder_layer in self.layers:
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if not deterministic and (dropout_probability < self.layerdrop): # skip the layer
layer_outputs = (None, None)
@@ -639,7 +639,7 @@ class FlaxMBartDecoderLayerCollection(nn.Module):
for decoder_layer in self.layers:
if output_hidden_states:
all_hidden_states += (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if not deterministic and (dropout_probability < self.layerdrop):
layer_outputs = (None, None, None)
diff --git a/src/transformers/models/mbart/modeling_mbart.py b/src/transformers/models/mbart/modeling_mbart.py
index 4f3253eeb4..785f751142 100755
--- a/src/transformers/models/mbart/modeling_mbart.py
+++ b/src/transformers/models/mbart/modeling_mbart.py
@@ -856,7 +856,7 @@ class MBartEncoder(MBartPreTrainedModel):
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
to_drop = False
if self.training:
dropout_probability = torch.rand([])
@@ -1122,7 +1122,7 @@ class MBartDecoder(MBartPreTrainedModel):
f" {attn_mask.size()[0]}."
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
@@ -1606,7 +1606,7 @@ class MBartForSequenceClassification(MBartPreTrainedModel):
be used by default.
If you want to change padding behavior, you should read [`modeling_bart._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules in the decoder. Mask values selected in `[0,
@@ -1753,7 +1753,7 @@ class MBartForQuestionAnswering(MBartPreTrainedModel):
be used by default.
If you want to change padding behavior, you should read [`modeling_bart._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules in the decoder. Mask values selected in `[0,
diff --git a/src/transformers/models/mbart/modeling_tf_mbart.py b/src/transformers/models/mbart/modeling_tf_mbart.py
index 16c53caa3f..54c90bf011 100644
--- a/src/transformers/models/mbart/modeling_tf_mbart.py
+++ b/src/transformers/models/mbart/modeling_tf_mbart.py
@@ -837,7 +837,7 @@ class TFMBartEncoder(keras.layers.Layer):
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if training and (dropout_probability < self.layerdrop): # skip the layer
continue
@@ -1066,7 +1066,7 @@ class TFMBartDecoder(keras.layers.Layer):
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
dropout_probability = random.uniform(0, 1)
diff --git a/src/transformers/models/megatron_bert/configuration_megatron_bert.py b/src/transformers/models/megatron_bert/configuration_megatron_bert.py
index db81a10a47..1505388e29 100644
--- a/src/transformers/models/megatron_bert/configuration_megatron_bert.py
+++ b/src/transformers/models/megatron_bert/configuration_megatron_bert.py
@@ -63,9 +63,9 @@ class MegatronBertConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
is_decoder (`bool`, *optional*, defaults to `False`):
Whether the model is used as a decoder or not. If `False`, the model is used as an encoder.
use_cache (`bool`, *optional*, defaults to `True`):
diff --git a/src/transformers/models/megatron_bert/modeling_megatron_bert.py b/src/transformers/models/megatron_bert/modeling_megatron_bert.py
index 557cdb1fee..b195b2841c 100755
--- a/src/transformers/models/megatron_bert/modeling_megatron_bert.py
+++ b/src/transformers/models/megatron_bert/modeling_megatron_bert.py
@@ -751,7 +751,7 @@ class MegatronBertModel(MegatronBertPreTrainedModel):
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in [Attention is
- all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
+ all you need](https://huggingface.co/papers/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
To behave as an decoder the model needs to be initialized with the `is_decoder` argument of the configuration set
diff --git a/src/transformers/models/mimi/configuration_mimi.py b/src/transformers/models/mimi/configuration_mimi.py
index 4d5a1b0078..a36b5e7101 100644
--- a/src/transformers/models/mimi/configuration_mimi.py
+++ b/src/transformers/models/mimi/configuration_mimi.py
@@ -96,7 +96,7 @@ class MimiConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `8`.
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to `8`.
head_dim (`int`, *optional*, defaults to `hidden_size // num_attention_heads`):
The attention head dimension.
hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
diff --git a/src/transformers/models/mimi/modeling_mimi.py b/src/transformers/models/mimi/modeling_mimi.py
index 4d7b92979a..451e9c790a 100644
--- a/src/transformers/models/mimi/modeling_mimi.py
+++ b/src/transformers/models/mimi/modeling_mimi.py
@@ -377,7 +377,7 @@ class MimiEncoder(nn.Module):
class MimiLayerScale(nn.Module):
- """Layer scale from [Touvron et al 2021] (https://arxiv.org/pdf/2103.17239.pdf).
+ """Layer scale from [Touvron et al 2021] (https://huggingface.co/papers/2103.17239).
This rescales diagonally the residual outputs close to 0, with a learnt scale.
"""
@@ -926,7 +926,7 @@ class MimiTransformerModel(nn.Module):
`past_key_values`).
If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
- 1 indicates the head is **not masked**,
diff --git a/src/transformers/models/minimax/configuration_minimax.py b/src/transformers/models/minimax/configuration_minimax.py
index b8ec562de0..86369db078 100644
--- a/src/transformers/models/minimax/configuration_minimax.py
+++ b/src/transformers/models/minimax/configuration_minimax.py
@@ -52,7 +52,7 @@ class MiniMaxConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `8`.
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to `8`.
head_dim (`int`, *optional*, defaults to `hidden_size // num_attention_heads`):
The attention head dimension.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
diff --git a/src/transformers/models/minimax/modeling_minimax.py b/src/transformers/models/minimax/modeling_minimax.py
index 18d2e4df7d..5ac3f98f1d 100644
--- a/src/transformers/models/minimax/modeling_minimax.py
+++ b/src/transformers/models/minimax/modeling_minimax.py
@@ -799,7 +799,7 @@ def load_balancing_loss_func(
r"""
Computes auxiliary load balancing loss as in Switch Transformer - implemented in Pytorch.
- See Switch Transformer (https://arxiv.org/abs/2101.03961) for more details. This function implements the loss
+ See Switch Transformer (https://huggingface.co/papers/2101.03961) for more details. This function implements the loss
function presented in equations (4) - (6) of the paper. It aims at penalizing cases where the routing between
experts is too unbalanced.
diff --git a/src/transformers/models/minimax/modular_minimax.py b/src/transformers/models/minimax/modular_minimax.py
index 0028dcbfb6..e0d3ef892c 100644
--- a/src/transformers/models/minimax/modular_minimax.py
+++ b/src/transformers/models/minimax/modular_minimax.py
@@ -77,7 +77,7 @@ class MiniMaxConfig(MixtralConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `8`.
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to `8`.
head_dim (`int`, *optional*, defaults to `hidden_size // num_attention_heads`):
The attention head dimension.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
diff --git a/src/transformers/models/mistral/configuration_mistral.py b/src/transformers/models/mistral/configuration_mistral.py
index 5a3cac5225..893853a07c 100644
--- a/src/transformers/models/mistral/configuration_mistral.py
+++ b/src/transformers/models/mistral/configuration_mistral.py
@@ -52,7 +52,7 @@ class MistralConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `8`.
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to `8`.
head_dim (`int`, *optional*, defaults to `hidden_size // num_attention_heads`):
The attention head dimension.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
diff --git a/src/transformers/models/mistral/modeling_flax_mistral.py b/src/transformers/models/mistral/modeling_flax_mistral.py
index f50c55bbd3..6785a7b46a 100644
--- a/src/transformers/models/mistral/modeling_flax_mistral.py
+++ b/src/transformers/models/mistral/modeling_flax_mistral.py
@@ -103,7 +103,7 @@ MISTRAL_INPUTS_DOCSTRING = r"""
`past_key_values`).
If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
- 1 indicates the head is **not masked**,
diff --git a/src/transformers/models/mistral/modeling_tf_mistral.py b/src/transformers/models/mistral/modeling_tf_mistral.py
index 52f076a05a..f6d2289ff2 100644
--- a/src/transformers/models/mistral/modeling_tf_mistral.py
+++ b/src/transformers/models/mistral/modeling_tf_mistral.py
@@ -713,7 +713,7 @@ MISTRAL_INPUTS_DOCSTRING = r"""
`past_key_values`).
If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
- 1 indicates the head is **not masked**,
diff --git a/src/transformers/models/mixtral/configuration_mixtral.py b/src/transformers/models/mixtral/configuration_mixtral.py
index ef2d870c1b..35ae3f10db 100644
--- a/src/transformers/models/mixtral/configuration_mixtral.py
+++ b/src/transformers/models/mixtral/configuration_mixtral.py
@@ -52,7 +52,7 @@ class MixtralConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `8`.
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to `8`.
head_dim (`int`, *optional*, defaults to `hidden_size // num_attention_heads`):
The attention head dimension.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
diff --git a/src/transformers/models/mixtral/modeling_mixtral.py b/src/transformers/models/mixtral/modeling_mixtral.py
index 9147538f73..5e3e39f621 100644
--- a/src/transformers/models/mixtral/modeling_mixtral.py
+++ b/src/transformers/models/mixtral/modeling_mixtral.py
@@ -597,7 +597,7 @@ def load_balancing_loss_func(
r"""
Computes auxiliary load balancing loss as in Switch Transformer - implemented in Pytorch.
- See Switch Transformer (https://arxiv.org/abs/2101.03961) for more details. This function implements the loss
+ See Switch Transformer (https://huggingface.co/papers/2101.03961) for more details. This function implements the loss
function presented in equations (4) - (6) of the paper. It aims at penalizing cases where the routing between
experts is too unbalanced.
diff --git a/src/transformers/models/mixtral/modular_mixtral.py b/src/transformers/models/mixtral/modular_mixtral.py
index 7132a4165f..288bc21247 100644
--- a/src/transformers/models/mixtral/modular_mixtral.py
+++ b/src/transformers/models/mixtral/modular_mixtral.py
@@ -60,7 +60,7 @@ def load_balancing_loss_func(
r"""
Computes auxiliary load balancing loss as in Switch Transformer - implemented in Pytorch.
- See Switch Transformer (https://arxiv.org/abs/2101.03961) for more details. This function implements the loss
+ See Switch Transformer (https://huggingface.co/papers/2101.03961) for more details. This function implements the loss
function presented in equations (4) - (6) of the paper. It aims at penalizing cases where the routing between
experts is too unbalanced.
diff --git a/src/transformers/models/mlcd/modeling_mlcd.py b/src/transformers/models/mlcd/modeling_mlcd.py
index ad943fd9c5..84ee78433b 100644
--- a/src/transformers/models/mlcd/modeling_mlcd.py
+++ b/src/transformers/models/mlcd/modeling_mlcd.py
@@ -225,9 +225,9 @@ class MLCDAttention(nn.Module):
"""Multi-headed attention from 'Attention Is All You Need' paper
Multi-headed attention with RoPE. Refer to papers:
- Attention is all you need:
- https://arxiv.org/abs/1706.03762
+ https://huggingface.co/papers/1706.03762
- RoFormer: Enhanced Transformer with Rotary Position Embedding:
- https://arxiv.org/abs/2104.09864
+ https://huggingface.co/papers/2104.09864
"""
def __init__(self, config: MLCDVisionConfig):
diff --git a/src/transformers/models/mlcd/modular_mlcd.py b/src/transformers/models/mlcd/modular_mlcd.py
index 6186cbbbb4..1dad06b3c8 100644
--- a/src/transformers/models/mlcd/modular_mlcd.py
+++ b/src/transformers/models/mlcd/modular_mlcd.py
@@ -190,9 +190,9 @@ class MLCDVisionEmbeddings(CLIPVisionEmbeddings):
class MLCDAttention(CLIPAttention):
"""Multi-headed attention with RoPE. Refer to papers:
- Attention is all you need:
- https://arxiv.org/abs/1706.03762
+ https://huggingface.co/papers/1706.03762
- RoFormer: Enhanced Transformer with Rotary Position Embedding:
- https://arxiv.org/abs/2104.09864
+ https://huggingface.co/papers/2104.09864
"""
def __init__(self, config: MLCDVisionConfig):
diff --git a/src/transformers/models/mobilebert/modeling_mobilebert.py b/src/transformers/models/mobilebert/modeling_mobilebert.py
index 7c0c18a8df..6cfd569f00 100644
--- a/src/transformers/models/mobilebert/modeling_mobilebert.py
+++ b/src/transformers/models/mobilebert/modeling_mobilebert.py
@@ -190,7 +190,7 @@ class MobileBertEmbeddings(nn.Module):
if self.trigram_input:
# From the paper MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited
- # Devices (https://arxiv.org/abs/2004.02984)
+ # Devices (https://huggingface.co/papers/2004.02984)
#
# The embedding table in BERT models accounts for a substantial proportion of model size. To compress
# the embedding layer, we reduce the embedding dimension to 128 in MobileBERT.
@@ -714,7 +714,7 @@ class MobileBertForPreTrainingOutput(ModelOutput):
@auto_docstring
class MobileBertModel(MobileBertPreTrainedModel):
"""
- https://arxiv.org/pdf/2004.02984.pdf
+ https://huggingface.co/papers/2004.02984
"""
def __init__(self, config, add_pooling_layer=True):
diff --git a/src/transformers/models/mobilebert/modeling_tf_mobilebert.py b/src/transformers/models/mobilebert/modeling_tf_mobilebert.py
index e85c079025..fff35745bf 100644
--- a/src/transformers/models/mobilebert/modeling_tf_mobilebert.py
+++ b/src/transformers/models/mobilebert/modeling_tf_mobilebert.py
@@ -240,7 +240,7 @@ class TFMobileBertEmbeddings(keras.layers.Layer):
if self.trigram_input:
# From the paper MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited
- # Devices (https://arxiv.org/abs/2004.02984)
+ # Devices (https://huggingface.co/papers/2004.02984)
#
# The embedding table in BERT models accounts for a substantial proportion of model size. To compress
# the embedding layer, we reduce the embedding dimension to 128 in MobileBERT.
diff --git a/src/transformers/models/mobilenet_v2/modeling_mobilenet_v2.py b/src/transformers/models/mobilenet_v2/modeling_mobilenet_v2.py
index f3cfc9098d..cc3173896c 100755
--- a/src/transformers/models/mobilenet_v2/modeling_mobilenet_v2.py
+++ b/src/transformers/models/mobilenet_v2/modeling_mobilenet_v2.py
@@ -632,7 +632,7 @@ class MobileNetV2ForImageClassification(MobileNetV2PreTrainedModel):
class MobileNetV2DeepLabV3Plus(nn.Module):
"""
The neural network from the paper "Encoder-Decoder with Atrous Separable Convolution for Semantic Image
- Segmentation" https://arxiv.org/abs/1802.02611
+ Segmentation" https://huggingface.co/papers/1802.02611
"""
def __init__(self, config: MobileNetV2Config) -> None:
diff --git a/src/transformers/models/mobilevit/modeling_mobilevit.py b/src/transformers/models/mobilevit/modeling_mobilevit.py
index b642f5c12e..459bb61391 100755
--- a/src/transformers/models/mobilevit/modeling_mobilevit.py
+++ b/src/transformers/models/mobilevit/modeling_mobilevit.py
@@ -121,7 +121,7 @@ class MobileViTConvLayer(nn.Module):
class MobileViTInvertedResidual(nn.Module):
"""
- Inverted residual block (MobileNetv2): https://arxiv.org/abs/1801.04381
+ Inverted residual block (MobileNetv2): https://huggingface.co/papers/1801.04381
"""
def __init__(
@@ -352,7 +352,7 @@ class MobileViTTransformer(nn.Module):
class MobileViTLayer(nn.Module):
"""
- MobileViT block: https://arxiv.org/abs/2110.02178
+ MobileViT block: https://huggingface.co/papers/2110.02178
"""
def __init__(
@@ -831,7 +831,7 @@ class MobileViTASPPPooling(nn.Module):
class MobileViTASPP(nn.Module):
"""
- ASPP module defined in DeepLab papers: https://arxiv.org/abs/1606.00915, https://arxiv.org/abs/1706.05587
+ ASPP module defined in DeepLab papers: https://huggingface.co/papers/1606.00915, https://huggingface.co/papers/1706.05587
"""
def __init__(self, config: MobileViTConfig) -> None:
@@ -890,7 +890,7 @@ class MobileViTASPP(nn.Module):
class MobileViTDeepLabV3(nn.Module):
"""
- DeepLabv3 architecture: https://arxiv.org/abs/1706.05587
+ DeepLabv3 architecture: https://huggingface.co/papers/1706.05587
"""
def __init__(self, config: MobileViTConfig) -> None:
diff --git a/src/transformers/models/mobilevit/modeling_tf_mobilevit.py b/src/transformers/models/mobilevit/modeling_tf_mobilevit.py
index 76397f160b..d19470c68f 100644
--- a/src/transformers/models/mobilevit/modeling_tf_mobilevit.py
+++ b/src/transformers/models/mobilevit/modeling_tf_mobilevit.py
@@ -155,7 +155,7 @@ class TFMobileViTConvLayer(keras.layers.Layer):
class TFMobileViTInvertedResidual(keras.layers.Layer):
"""
- Inverted residual block (MobileNetv2): https://arxiv.org/abs/1801.04381
+ Inverted residual block (MobileNetv2): https://huggingface.co/papers/1801.04381
"""
def __init__(
@@ -487,7 +487,7 @@ class TFMobileViTTransformer(keras.layers.Layer):
class TFMobileViTLayer(keras.layers.Layer):
"""
- MobileViT block: https://arxiv.org/abs/2110.02178
+ MobileViT block: https://huggingface.co/papers/2110.02178
"""
def __init__(
@@ -1125,7 +1125,7 @@ class TFMobileViTASPPPooling(keras.layers.Layer):
class TFMobileViTASPP(keras.layers.Layer):
"""
- ASPP module defined in DeepLab papers: https://arxiv.org/abs/1606.00915, https://arxiv.org/abs/1706.05587
+ ASPP module defined in DeepLab papers: https://huggingface.co/papers/1606.00915, https://huggingface.co/papers/1706.05587
"""
def __init__(self, config: MobileViTConfig, **kwargs) -> None:
@@ -1208,7 +1208,7 @@ class TFMobileViTASPP(keras.layers.Layer):
class TFMobileViTDeepLabV3(keras.layers.Layer):
"""
- DeepLabv3 architecture: https://arxiv.org/abs/1706.05587
+ DeepLabv3 architecture: https://huggingface.co/papers/1706.05587
"""
def __init__(self, config: MobileViTConfig, **kwargs) -> None:
diff --git a/src/transformers/models/mobilevitv2/modeling_mobilevitv2.py b/src/transformers/models/mobilevitv2/modeling_mobilevitv2.py
index 7f800bfd34..b60177abf3 100644
--- a/src/transformers/models/mobilevitv2/modeling_mobilevitv2.py
+++ b/src/transformers/models/mobilevitv2/modeling_mobilevitv2.py
@@ -126,7 +126,7 @@ class MobileViTV2ConvLayer(nn.Module):
# Copied from transformers.models.mobilevit.modeling_mobilevit.MobileViTInvertedResidual with MobileViT->MobileViTV2
class MobileViTV2InvertedResidual(nn.Module):
"""
- Inverted residual block (MobileNetv2): https://arxiv.org/abs/1801.04381
+ Inverted residual block (MobileNetv2): https://huggingface.co/papers/1801.04381
"""
def __init__(
@@ -199,7 +199,7 @@ class MobileViTV2MobileNetLayer(nn.Module):
class MobileViTV2LinearSelfAttention(nn.Module):
"""
This layer applies a self-attention with linear complexity, as described in MobileViTV2 paper:
- https://arxiv.org/abs/2206.02680
+ https://huggingface.co/papers/2206.02680
Args:
config (`MobileVitv2Config`):
@@ -353,7 +353,7 @@ class MobileViTV2Transformer(nn.Module):
class MobileViTV2Layer(nn.Module):
"""
- MobileViTV2 layer: https://arxiv.org/abs/2206.02680
+ MobileViTV2 layer: https://huggingface.co/papers/2206.02680
"""
def __init__(
@@ -785,7 +785,7 @@ class MobileViTV2ASPPPooling(nn.Module):
class MobileViTV2ASPP(nn.Module):
"""
- ASPP module defined in DeepLab papers: https://arxiv.org/abs/1606.00915, https://arxiv.org/abs/1706.05587
+ ASPP module defined in DeepLab papers: https://huggingface.co/papers/1606.00915, https://huggingface.co/papers/1706.05587
"""
def __init__(self, config: MobileViTV2Config) -> None:
@@ -846,7 +846,7 @@ class MobileViTV2ASPP(nn.Module):
# Copied from transformers.models.mobilevit.modeling_mobilevit.MobileViTDeepLabV3 with MobileViT->MobileViTV2
class MobileViTV2DeepLabV3(nn.Module):
"""
- DeepLabv3 architecture: https://arxiv.org/abs/1706.05587
+ DeepLabv3 architecture: https://huggingface.co/papers/1706.05587
"""
def __init__(self, config: MobileViTV2Config) -> None:
diff --git a/src/transformers/models/moonshine/configuration_moonshine.py b/src/transformers/models/moonshine/configuration_moonshine.py
index dba0d973af..ef77126917 100644
--- a/src/transformers/models/moonshine/configuration_moonshine.py
+++ b/src/transformers/models/moonshine/configuration_moonshine.py
@@ -54,7 +54,7 @@ class MoonshineConfig(PretrainedConfig):
`encoder_num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
decoder_num_key_value_heads (`int`, *optional*):
This is the number of key_value heads that should be used to implement Grouped Query Attention. If
@@ -62,7 +62,7 @@ class MoonshineConfig(PretrainedConfig):
`decoder_num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`decoder_num_attention_heads`.
pad_head_dim_to_multiple_of (`int`, *optional*):
Pad head dimension in encoder and decoder to the next multiple of this value. Necessary for using certain
diff --git a/src/transformers/models/moonshine/modeling_moonshine.py b/src/transformers/models/moonshine/modeling_moonshine.py
index a3aebaed9a..0987bf2d0f 100644
--- a/src/transformers/models/moonshine/modeling_moonshine.py
+++ b/src/transformers/models/moonshine/modeling_moonshine.py
@@ -825,7 +825,7 @@ def _compute_mask_indices(
) -> np.ndarray:
"""
Computes random mask spans for a given shape. Used to implement [SpecAugment: A Simple Data Augmentation Method for
- ASR](https://arxiv.org/abs/1904.08779). Note that this method is not optimized to run on TPU and should be run on
+ ASR](https://huggingface.co/papers/1904.08779). Note that this method is not optimized to run on TPU and should be run on
CPU as part of the preprocessing during training.
Args:
@@ -971,7 +971,7 @@ class MoonshineModel(MoonshinePreTrainedModel):
):
"""
Masks extracted features along time axis and/or along feature axis according to
- [SpecAugment](https://arxiv.org/abs/1904.08779).
+ [SpecAugment](https://huggingface.co/papers/1904.08779).
"""
# `config.apply_spec_augment` can set masking to False
@@ -1054,7 +1054,7 @@ class MoonshineModel(MoonshinePreTrainedModel):
`past_key_values`).
If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
- 1 indicates the head is **not masked**,
@@ -1230,7 +1230,7 @@ class MoonshineForConditionalGeneration(MoonshinePreTrainedModel, GenerationMixi
`past_key_values`).
If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
- 1 indicates the head is **not masked**,
diff --git a/src/transformers/models/moonshine/modular_moonshine.py b/src/transformers/models/moonshine/modular_moonshine.py
index f99de20eb0..7b400ab5b9 100644
--- a/src/transformers/models/moonshine/modular_moonshine.py
+++ b/src/transformers/models/moonshine/modular_moonshine.py
@@ -76,7 +76,7 @@ class MoonshineConfig(PretrainedConfig):
`encoder_num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
decoder_num_key_value_heads (`int`, *optional*):
This is the number of key_value heads that should be used to implement Grouped Query Attention. If
@@ -84,7 +84,7 @@ class MoonshineConfig(PretrainedConfig):
`decoder_num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`decoder_num_attention_heads`.
pad_head_dim_to_multiple_of (`int`, *optional*):
Pad head dimension in encoder and decoder to the next multiple of this value. Necessary for using certain
@@ -870,7 +870,7 @@ class MoonshineModel(WhisperModel):
`past_key_values`).
If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
- 1 indicates the head is **not masked**,
@@ -1030,7 +1030,7 @@ class MoonshineForConditionalGeneration(MoonshinePreTrainedModel, GenerationMixi
`past_key_values`).
If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
- 1 indicates the head is **not masked**,
diff --git a/src/transformers/models/moshi/configuration_moshi.py b/src/transformers/models/moshi/configuration_moshi.py
index 02b82ee5ed..ca2837017b 100644
--- a/src/transformers/models/moshi/configuration_moshi.py
+++ b/src/transformers/models/moshi/configuration_moshi.py
@@ -48,7 +48,7 @@ class MoshiDepthConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `num_attention_heads`.
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to `num_attention_heads`.
audio_vocab_size (`int`, *optional*, defaults to 2048):
Vocabulary size of the audio part of model. Defines the number of different tokens that can be
represented by the `audio_codes` passed when calling the Moshi models.
@@ -172,7 +172,7 @@ class MoshiConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `num_attention_heads`.
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to `num_attention_heads`.
audio_vocab_size (`int`, *optional*):
Vocabulary size of the audio part of model. Defines the number of different tokens that can be
represented by the `audio_codes` passed when calling the Moshi models.
diff --git a/src/transformers/models/moshi/modeling_moshi.py b/src/transformers/models/moshi/modeling_moshi.py
index 7e71eb2ce2..50608d609c 100644
--- a/src/transformers/models/moshi/modeling_moshi.py
+++ b/src/transformers/models/moshi/modeling_moshi.py
@@ -919,7 +919,7 @@ class MoshiDepthDecoder(MoshiPreTrainedModel, GenerationMixin):
`past_key_values`).
If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
- 1 indicates the head is **not masked**,
diff --git a/src/transformers/models/mpt/modeling_mpt.py b/src/transformers/models/mpt/modeling_mpt.py
index 10e91c988a..5f7fd05cf8 100644
--- a/src/transformers/models/mpt/modeling_mpt.py
+++ b/src/transformers/models/mpt/modeling_mpt.py
@@ -42,7 +42,7 @@ logger = logging.get_logger(__name__)
def build_mpt_alibi_tensor(num_heads, sequence_length, alibi_bias_max=8, device=None):
r"""
- Link to paper: https://arxiv.org/abs/2108.12409 - Alibi tensor is not causal as the original paper mentions, it
+ Link to paper: https://huggingface.co/papers/2108.12409 - Alibi tensor is not causal as the original paper mentions, it
relies on a translation invariance of softmax for quick implementation. This implementation has been copied from
the alibi implementation of MPT source code that led to slightly different results than the Bloom alibi:
https://huggingface.co/mosaicml/mpt-7b/blob/main/attention.py#L292
diff --git a/src/transformers/models/mt5/modeling_mt5.py b/src/transformers/models/mt5/modeling_mt5.py
index 6b488b66d2..1d31d9ebb8 100644
--- a/src/transformers/models/mt5/modeling_mt5.py
+++ b/src/transformers/models/mt5/modeling_mt5.py
@@ -131,7 +131,7 @@ class MT5LayerNorm(nn.Module):
def forward(self, hidden_states):
# MT5 uses a layer_norm which only scales and doesn't shift, which is also known as Root Mean
- # Square Layer Normalization https://arxiv.org/abs/1910.07467 thus variance is calculated
+ # Square Layer Normalization https://huggingface.co/papers/1910.07467 thus variance is calculated
# w/o mean and there is no bias. Additionally we want to make sure that the accumulation for
# half-precision inputs is done in fp32
diff --git a/src/transformers/models/musicgen/configuration_musicgen.py b/src/transformers/models/musicgen/configuration_musicgen.py
index e5079eb1ed..1618af7e43 100644
--- a/src/transformers/models/musicgen/configuration_musicgen.py
+++ b/src/transformers/models/musicgen/configuration_musicgen.py
@@ -60,7 +60,7 @@ class MusicgenDecoderConfig(PretrainedConfig):
initializer_factor (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
scale_embedding (`bool`, *optional*, defaults to `False`):
Scale embeddings by diving by sqrt(hidden_size).
diff --git a/src/transformers/models/musicgen/modeling_musicgen.py b/src/transformers/models/musicgen/modeling_musicgen.py
index 42b0567133..9f0ddc6c9d 100644
--- a/src/transformers/models/musicgen/modeling_musicgen.py
+++ b/src/transformers/models/musicgen/modeling_musicgen.py
@@ -610,7 +610,7 @@ class MusicgenDecoder(MusicgenPreTrainedModel):
f" {attn_mask.size()[0]}."
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
dropout_probability = random.uniform(0, 1)
diff --git a/src/transformers/models/musicgen_melody/configuration_musicgen_melody.py b/src/transformers/models/musicgen_melody/configuration_musicgen_melody.py
index 24c8a17faa..c4285151c4 100644
--- a/src/transformers/models/musicgen_melody/configuration_musicgen_melody.py
+++ b/src/transformers/models/musicgen_melody/configuration_musicgen_melody.py
@@ -47,7 +47,7 @@ class MusicgenMelodyDecoderConfig(PretrainedConfig):
num_attention_heads (`int`, *optional*, defaults to 16):
Number of attention heads for each attention layer in the Transformer block.
layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
use_cache (`bool`, *optional*, defaults to `True`):
Whether the model should return the last key/values attentions (not used by all models)
diff --git a/src/transformers/models/musicgen_melody/modeling_musicgen_melody.py b/src/transformers/models/musicgen_melody/modeling_musicgen_melody.py
index 4e1ea39e75..3343cf2333 100644
--- a/src/transformers/models/musicgen_melody/modeling_musicgen_melody.py
+++ b/src/transformers/models/musicgen_melody/modeling_musicgen_melody.py
@@ -587,7 +587,7 @@ class MusicgenMelodyDecoder(MusicgenMelodyPreTrainedModel):
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
dropout_probability = random.uniform(0, 1)
diff --git a/src/transformers/models/mvp/configuration_mvp.py b/src/transformers/models/mvp/configuration_mvp.py
index a270461db4..c216e53ed8 100644
--- a/src/transformers/models/mvp/configuration_mvp.py
+++ b/src/transformers/models/mvp/configuration_mvp.py
@@ -69,10 +69,10 @@ class MvpConfig(PretrainedConfig):
init_std (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
encoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
decoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
scale_embedding (`bool`, *optional*, defaults to `False`):
Scale embeddings by diving by sqrt(d_model).
diff --git a/src/transformers/models/mvp/modeling_mvp.py b/src/transformers/models/mvp/modeling_mvp.py
index 29874999e0..6f823b2887 100644
--- a/src/transformers/models/mvp/modeling_mvp.py
+++ b/src/transformers/models/mvp/modeling_mvp.py
@@ -672,7 +672,7 @@ class MvpEncoder(MvpPreTrainedModel):
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
to_drop = False
if self.training:
dropout_probability = torch.rand([])
@@ -925,7 +925,7 @@ class MvpDecoder(MvpPreTrainedModel):
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
@@ -1076,7 +1076,7 @@ class MvpModel(MvpPreTrainedModel):
be used by default.
If you want to change padding behavior, you should read [`modeling_mvp._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules in the decoder. Mask values selected in `[0,
@@ -1244,7 +1244,7 @@ class MvpForConditionalGeneration(MvpPreTrainedModel, GenerationMixin):
be used by default.
If you want to change padding behavior, you should read [`modeling_mvp._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules in the decoder. Mask values selected in `[0,
@@ -1416,7 +1416,7 @@ class MvpForSequenceClassification(MvpPreTrainedModel):
be used by default.
If you want to change padding behavior, you should read [`modeling_mvp._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules in the decoder. Mask values selected in `[0,
@@ -1589,7 +1589,7 @@ class MvpForQuestionAnswering(MvpPreTrainedModel):
be used by default.
If you want to change padding behavior, you should read [`modeling_mvp._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules in the decoder. Mask values selected in `[0,
diff --git a/src/transformers/models/nemotron/configuration_nemotron.py b/src/transformers/models/nemotron/configuration_nemotron.py
index e52d6d1448..0a15bb96b0 100644
--- a/src/transformers/models/nemotron/configuration_nemotron.py
+++ b/src/transformers/models/nemotron/configuration_nemotron.py
@@ -53,7 +53,7 @@ class NemotronConfig(PretrainedConfig):
`num_key_value_heads=1 the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
hidden_act (`str` or `function`, *optional*, defaults to `"relu2"`):
The non-linear activation function (function or string) in the decoder.
diff --git a/src/transformers/models/nllb_moe/configuration_nllb_moe.py b/src/transformers/models/nllb_moe/configuration_nllb_moe.py
index f161930d90..61cb2197c8 100644
--- a/src/transformers/models/nllb_moe/configuration_nllb_moe.py
+++ b/src/transformers/models/nllb_moe/configuration_nllb_moe.py
@@ -67,10 +67,10 @@ class NllbMoeConfig(PretrainedConfig):
init_std (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
encoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
decoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
second_expert_policy ( `str`, *optional*, default to `"all"`):
The policy used for the sampling the probability of being sampled to a second expert for each token.
@@ -94,7 +94,7 @@ class NllbMoeConfig(PretrainedConfig):
Frequency of the sparse layers in the decoder. 4 means that one out of 4 layers will be sparse.
router_dtype (`str`, *optional*, default to `"float32"`):
The `dtype` used for the routers. It is preferable to keep the `dtype` to `"float32"` as specified in the
- *selective precision* discussion in [the paper](https://arxiv.org/abs/2101.03961).
+ *selective precision* discussion in [the paper](https://huggingface.co/papers/2101.03961).
router_ignore_padding_tokens (`bool`, *optional*, defaults to `False`):
Whether to ignore padding tokens when routing. if `False`, the padding tokens are not routed to any
experts.
diff --git a/src/transformers/models/nllb_moe/modeling_nllb_moe.py b/src/transformers/models/nllb_moe/modeling_nllb_moe.py
index 6d7bd6c985..a9642e9737 100644
--- a/src/transformers/models/nllb_moe/modeling_nllb_moe.py
+++ b/src/transformers/models/nllb_moe/modeling_nllb_moe.py
@@ -95,7 +95,7 @@ def load_balancing_loss_func(router_probs: torch.Tensor, expert_indices: torch.T
r"""
Computes auxiliary load balancing loss as in Switch Transformer - implemented in Pytorch.
- See Switch Transformer (https://arxiv.org/abs/2101.03961) for more details. This function implements the loss
+ See Switch Transformer (https://huggingface.co/papers/2101.03961) for more details. This function implements the loss
function presented in equations (4) - (6) of the paper. It aims at penalizing cases where the routing between
experts is too unbalanced.
@@ -1013,7 +1013,7 @@ class NllbMoeEncoder(NllbMoePreTrainedModel):
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = torch.rand([])
if self.training and (dropout_probability < self.layerdrop): # skip the layer
layer_outputs = (None, None, None)
@@ -1285,7 +1285,7 @@ class NllbMoeDecoder(NllbMoePreTrainedModel):
if output_hidden_states:
all_hidden_states += (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = torch.rand([])
skip_the_layer = True if self.training and (dropout_probability < self.layerdrop) else False
diff --git a/src/transformers/models/olmo/configuration_olmo.py b/src/transformers/models/olmo/configuration_olmo.py
index 2c2da01463..a1bf0971b5 100644
--- a/src/transformers/models/olmo/configuration_olmo.py
+++ b/src/transformers/models/olmo/configuration_olmo.py
@@ -54,7 +54,7 @@ class OlmoConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
diff --git a/src/transformers/models/olmo2/configuration_olmo2.py b/src/transformers/models/olmo2/configuration_olmo2.py
index 96ed3993ed..c7a0dabaf4 100644
--- a/src/transformers/models/olmo2/configuration_olmo2.py
+++ b/src/transformers/models/olmo2/configuration_olmo2.py
@@ -36,7 +36,7 @@ class Olmo2Config(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
diff --git a/src/transformers/models/olmo2/modular_olmo2.py b/src/transformers/models/olmo2/modular_olmo2.py
index 22d716f855..9772a2b727 100644
--- a/src/transformers/models/olmo2/modular_olmo2.py
+++ b/src/transformers/models/olmo2/modular_olmo2.py
@@ -50,7 +50,7 @@ class Olmo2Config(OlmoConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
diff --git a/src/transformers/models/olmoe/configuration_olmoe.py b/src/transformers/models/olmoe/configuration_olmoe.py
index 7997659737..864d06b64d 100644
--- a/src/transformers/models/olmoe/configuration_olmoe.py
+++ b/src/transformers/models/olmoe/configuration_olmoe.py
@@ -43,7 +43,7 @@ class OlmoeConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
diff --git a/src/transformers/models/olmoe/modeling_olmoe.py b/src/transformers/models/olmoe/modeling_olmoe.py
index 88f884dc2e..374e941c02 100644
--- a/src/transformers/models/olmoe/modeling_olmoe.py
+++ b/src/transformers/models/olmoe/modeling_olmoe.py
@@ -49,7 +49,7 @@ def load_balancing_loss_func(
r"""
Computes auxiliary load balancing loss as in Switch Transformer - implemented in Pytorch.
- See Switch Transformer (https://arxiv.org/abs/2101.03961) for more details. This function implements the loss
+ See Switch Transformer (https://huggingface.co/papers/2101.03961) for more details. This function implements the loss
function presented in equations (4) - (6) of the paper. It aims at penalizing cases where the routing between
experts is too unbalanced.
diff --git a/src/transformers/models/omdet_turbo/modeling_omdet_turbo.py b/src/transformers/models/omdet_turbo/modeling_omdet_turbo.py
index a5ae345e5d..59e6cec142 100644
--- a/src/transformers/models/omdet_turbo/modeling_omdet_turbo.py
+++ b/src/transformers/models/omdet_turbo/modeling_omdet_turbo.py
@@ -650,7 +650,7 @@ class OmDetTurboEncoder(nn.Module):
class OmDetTurboHybridEncoder(nn.Module):
"""
Encoder consisting of channel projection layers, a set of `OmDetTurboEncoder`, a top-down Feature Pyramid Network
- (FPN) and a bottom-up Path Aggregation Network (PAN). More details on the paper: https://arxiv.org/abs/2304.08069
+ (FPN) and a bottom-up Path Aggregation Network (PAN). More details on the paper: https://huggingface.co/papers/2304.08069
Args:
config: OmDetTurboConfig
diff --git a/src/transformers/models/oneformer/modeling_oneformer.py b/src/transformers/models/oneformer/modeling_oneformer.py
index b45e4219e8..219b1a972b 100644
--- a/src/transformers/models/oneformer/modeling_oneformer.py
+++ b/src/transformers/models/oneformer/modeling_oneformer.py
@@ -1473,7 +1473,7 @@ class OneFormerPixelLevelModule(nn.Module):
def __init__(self, config: OneFormerConfig):
"""
Pixel Level Module proposed in [Masked-attention Mask Transformer for Universal Image
- Segmentation](https://arxiv.org/abs/2112.01527). It runs the input image through a backbone and a pixel
+ Segmentation](https://huggingface.co/papers/2112.01527). It runs the input image through a backbone and a pixel
decoder, generating multi-scale feature maps and pixel embeddings.
Args:
diff --git a/src/transformers/models/opt/configuration_opt.py b/src/transformers/models/opt/configuration_opt.py
index 8f8838ad9e..58c2569d4e 100644
--- a/src/transformers/models/opt/configuration_opt.py
+++ b/src/transformers/models/opt/configuration_opt.py
@@ -60,7 +60,7 @@ class OPTConfig(PretrainedConfig):
attention_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for the attention probabilities.
layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556) for more
+ The LayerDrop probability. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556) for more
details.
init_std (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
diff --git a/src/transformers/models/opt/modeling_opt.py b/src/transformers/models/opt/modeling_opt.py
index eef54b02ec..b03e9bb452 100644
--- a/src/transformers/models/opt/modeling_opt.py
+++ b/src/transformers/models/opt/modeling_opt.py
@@ -663,7 +663,7 @@ class OPTDecoder(OPTPreTrainedModel):
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
diff --git a/src/transformers/models/pegasus/configuration_pegasus.py b/src/transformers/models/pegasus/configuration_pegasus.py
index 23bff5d771..3c27f7d44d 100644
--- a/src/transformers/models/pegasus/configuration_pegasus.py
+++ b/src/transformers/models/pegasus/configuration_pegasus.py
@@ -65,10 +65,10 @@ class PegasusConfig(PretrainedConfig):
init_std (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
encoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
decoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
scale_embedding (`bool`, *optional*, defaults to `False`):
Scale embeddings by diving by sqrt(d_model).
diff --git a/src/transformers/models/pegasus/modeling_flax_pegasus.py b/src/transformers/models/pegasus/modeling_flax_pegasus.py
index 89b8450312..5bbe62c856 100644
--- a/src/transformers/models/pegasus/modeling_flax_pegasus.py
+++ b/src/transformers/models/pegasus/modeling_flax_pegasus.py
@@ -117,7 +117,7 @@ PEGASUS_INPUTS_DOCSTRING = r"""
be used by default.
If you want to change padding behavior, you should modify to your needs. See diagram 1 in [the
- paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
+ paper](https://huggingface.co/papers/1910.13461) for more information on the default strategy.
position_ids (`numpy.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.max_position_embeddings - 1]`.
@@ -190,7 +190,7 @@ PEGASUS_DECODE_INPUTS_DOCSTRING = r"""
be used by default.
If you want to change padding behavior, you should modify to your needs. See diagram 1 in [the
- paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
+ paper](https://huggingface.co/papers/1910.13461) for more information on the default strategy.
decoder_position_ids (`numpy.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each decoder input sequence tokens in the position embeddings. Selected in the
range `[0, config.max_position_embeddings - 1]`.
@@ -484,7 +484,7 @@ class FlaxPegasusEncoderLayerCollection(nn.Module):
for encoder_layer in self.layers:
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if not deterministic and (dropout_probability < self.layerdrop): # skip the layer
layer_outputs = (None, None)
@@ -633,7 +633,7 @@ class FlaxPegasusDecoderLayerCollection(nn.Module):
for decoder_layer in self.layers:
if output_hidden_states:
all_hidden_states += (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if not deterministic and (dropout_probability < self.layerdrop):
layer_outputs = (None, None, None)
diff --git a/src/transformers/models/pegasus/modeling_pegasus.py b/src/transformers/models/pegasus/modeling_pegasus.py
index 303ae89fd0..d723e4c644 100755
--- a/src/transformers/models/pegasus/modeling_pegasus.py
+++ b/src/transformers/models/pegasus/modeling_pegasus.py
@@ -835,7 +835,7 @@ class PegasusEncoder(PegasusPreTrainedModel):
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
to_drop = False
if self.training:
dropout_probability = torch.rand([])
@@ -1127,7 +1127,7 @@ class PegasusDecoder(PegasusPreTrainedModel):
f" {head_mask.size()[0]}."
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
diff --git a/src/transformers/models/pegasus/modeling_tf_pegasus.py b/src/transformers/models/pegasus/modeling_tf_pegasus.py
index 15176c92b0..c584e6da94 100644
--- a/src/transformers/models/pegasus/modeling_tf_pegasus.py
+++ b/src/transformers/models/pegasus/modeling_tf_pegasus.py
@@ -847,7 +847,7 @@ class TFPegasusEncoder(keras.layers.Layer):
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if training and (dropout_probability < self.layerdrop): # skip the layer
continue
@@ -1069,7 +1069,7 @@ class TFPegasusDecoder(keras.layers.Layer):
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
dropout_probability = random.uniform(0, 1)
diff --git a/src/transformers/models/pegasus/tokenization_pegasus.py b/src/transformers/models/pegasus/tokenization_pegasus.py
index c338e0fac1..19b5f5aaa5 100644
--- a/src/transformers/models/pegasus/tokenization_pegasus.py
+++ b/src/transformers/models/pegasus/tokenization_pegasus.py
@@ -65,12 +65,12 @@ class PegasusTokenizer(PreTrainedTokenizer):
The token used for masking single token values. This is the token used when training this model with masked
language modeling (MLM). This is the token that the PEGASUS encoder will try to predict during pretraining.
It corresponds to *[MASK2]* in [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive
- Summarization](https://arxiv.org/pdf/1912.08777.pdf).
+ Summarization](https://huggingface.co/papers/1912.08777).
mask_token_sent (`str`, *optional*, defaults to `""`):
The token used for masking whole target sentences. This is the token used when training this model with gap
sentences generation (GSG). This is the sentence that the PEGASUS decoder will try to predict during
pretraining. It corresponds to *[MASK1]* in [PEGASUS: Pre-training with Extracted Gap-sentences for
- Abstractive Summarization](https://arxiv.org/pdf/1912.08777.pdf).
+ Abstractive Summarization](https://huggingface.co/papers/1912.08777).
additional_special_tokens (`List[str]`, *optional*):
Additional special tokens used by the tokenizer. If no additional_special_tokens are provided and
are used as additional special tokens corresponding to the [original PEGASUS
diff --git a/src/transformers/models/pegasus/tokenization_pegasus_fast.py b/src/transformers/models/pegasus/tokenization_pegasus_fast.py
index 657390ec77..3105d6f109 100644
--- a/src/transformers/models/pegasus/tokenization_pegasus_fast.py
+++ b/src/transformers/models/pegasus/tokenization_pegasus_fast.py
@@ -67,12 +67,12 @@ class PegasusTokenizerFast(PreTrainedTokenizerFast):
The token used for masking single token values. This is the token used when training this model with masked
language modeling (MLM). This is the token that the PEGASUS encoder will try to predict during pretraining.
It corresponds to *[MASK2]* in [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive
- Summarization](https://arxiv.org/pdf/1912.08777.pdf).
+ Summarization](https://huggingface.co/papers/1912.08777).
mask_token_sent (`str`, *optional*, defaults to `""`):
The token used for masking whole target sentences. This is the token used when training this model with gap
sentences generation (GSG). This is the sentence that the PEGASUS decoder will try to predict during
pretraining. It corresponds to *[MASK1]* in [PEGASUS: Pre-training with Extracted Gap-sentences for
- Abstractive Summarization](https://arxiv.org/pdf/1912.08777.pdf).
+ Abstractive Summarization](https://huggingface.co/papers/1912.08777).
additional_special_tokens (`List[str]`, *optional*):
Additional special tokens used by the tokenizer. If no additional_special_tokens are provided and
are used as additional special tokens corresponding to the [original PEGASUS
diff --git a/src/transformers/models/pegasus_x/configuration_pegasus_x.py b/src/transformers/models/pegasus_x/configuration_pegasus_x.py
index c92f5662b5..626389c448 100644
--- a/src/transformers/models/pegasus_x/configuration_pegasus_x.py
+++ b/src/transformers/models/pegasus_x/configuration_pegasus_x.py
@@ -65,10 +65,10 @@ class PegasusXConfig(PretrainedConfig):
init_std (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
encoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
decoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models)
diff --git a/src/transformers/models/pegasus_x/modeling_pegasus_x.py b/src/transformers/models/pegasus_x/modeling_pegasus_x.py
index bf94379cca..40d7d1db73 100755
--- a/src/transformers/models/pegasus_x/modeling_pegasus_x.py
+++ b/src/transformers/models/pegasus_x/modeling_pegasus_x.py
@@ -1138,7 +1138,7 @@ class PegasusXEncoder(PegasusXPreTrainedModel):
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
to_drop = False
if self.training:
dropout_probability = torch.rand([])
@@ -1380,7 +1380,7 @@ class PegasusXDecoder(PegasusXPreTrainedModel):
next_decoder_cache = None
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
diff --git a/src/transformers/models/phi/configuration_phi.py b/src/transformers/models/phi/configuration_phi.py
index bd6eb48003..222722e19b 100644
--- a/src/transformers/models/phi/configuration_phi.py
+++ b/src/transformers/models/phi/configuration_phi.py
@@ -51,7 +51,7 @@ class PhiConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
resid_pdrop (`float`, *optional*, defaults to 0.0):
Dropout probability for mlp outputs.
diff --git a/src/transformers/models/phi3/configuration_phi3.py b/src/transformers/models/phi3/configuration_phi3.py
index 4b91cbcd14..a9009e837d 100644
--- a/src/transformers/models/phi3/configuration_phi3.py
+++ b/src/transformers/models/phi3/configuration_phi3.py
@@ -50,7 +50,7 @@ class Phi3Config(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
resid_pdrop (`float`, *optional*, defaults to 0.0):
Dropout probability for mlp outputs.
diff --git a/src/transformers/models/phi4_multimodal/configuration_phi4_multimodal.py b/src/transformers/models/phi4_multimodal/configuration_phi4_multimodal.py
index fee669feb8..3b6c2ca1d9 100644
--- a/src/transformers/models/phi4_multimodal/configuration_phi4_multimodal.py
+++ b/src/transformers/models/phi4_multimodal/configuration_phi4_multimodal.py
@@ -269,7 +269,7 @@ class Phi4MultimodalConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
resid_pdrop (`float`, *optional*, defaults to 0.0):
Dropout probability for mlp outputs.
diff --git a/src/transformers/models/phi4_multimodal/modular_phi4_multimodal.py b/src/transformers/models/phi4_multimodal/modular_phi4_multimodal.py
index 76925919eb..62fb4e1d50 100644
--- a/src/transformers/models/phi4_multimodal/modular_phi4_multimodal.py
+++ b/src/transformers/models/phi4_multimodal/modular_phi4_multimodal.py
@@ -305,7 +305,7 @@ class Phi4MultimodalConfig(Phi3Config):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
resid_pdrop (`float`, *optional*, defaults to 0.0):
Dropout probability for mlp outputs.
diff --git a/src/transformers/models/phimoe/configuration_phimoe.py b/src/transformers/models/phimoe/configuration_phimoe.py
index f30ed7435c..5fea626c30 100644
--- a/src/transformers/models/phimoe/configuration_phimoe.py
+++ b/src/transformers/models/phimoe/configuration_phimoe.py
@@ -49,7 +49,7 @@ class PhimoeConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `8`.
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to `8`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
max_position_embeddings (`int`, *optional*, defaults to `4096*32`):
diff --git a/src/transformers/models/phimoe/modeling_phimoe.py b/src/transformers/models/phimoe/modeling_phimoe.py
index e81d38e2d8..bcb8b7f0f7 100644
--- a/src/transformers/models/phimoe/modeling_phimoe.py
+++ b/src/transformers/models/phimoe/modeling_phimoe.py
@@ -61,7 +61,7 @@ def load_balancing_loss_func(
r"""
Computes auxiliary load balancing loss as in Switch Transformer - implemented in Pytorch.
- See Switch Transformer (https://arxiv.org/abs/2101.03961) for more details. This function implements the loss
+ See Switch Transformer (https://huggingface.co/papers/2101.03961) for more details. This function implements the loss
function presented in equations (4) - (6) of the paper. It aims at penalizing cases where the routing between
experts is too unbalanced.
@@ -593,7 +593,7 @@ class MultiplierProcessor(torch.autograd.Function):
def sparsemixer(scores, jitter_eps, training, top_k=2):
"""
Sparse mixer function to select top-k experts and compute multipliers.
- Based on the paper: https://arxiv.org/pdf/2409.12136
+ Based on the paper: https://huggingface.co/papers/2409.12136
We first replace the TopK(·) function as random sampling of discrete variables
in model training. Then, following Liu et al. (2023a) and Liu et al. (2023b), we apply Heun's
third order method to approximate the expert routing gradient and construct a modified
diff --git a/src/transformers/models/pix2struct/image_processing_pix2struct.py b/src/transformers/models/pix2struct/image_processing_pix2struct.py
index f052521236..ff303bf069 100644
--- a/src/transformers/models/pix2struct/image_processing_pix2struct.py
+++ b/src/transformers/models/pix2struct/image_processing_pix2struct.py
@@ -201,7 +201,7 @@ class Pix2StructImageProcessor(BaseImageProcessor):
The patch size to use for the image. According to Pix2Struct paper and code, the patch size is 16x16.
max_patches (`int`, *optional*, defaults to 2048):
The maximum number of patches to extract from the image as per the [Pix2Struct
- paper](https://arxiv.org/pdf/2210.03347.pdf).
+ paper](https://huggingface.co/papers/2210.03347).
is_vqa (`bool`, *optional*, defaults to `False`):
Whether or not the image processor is for the VQA task. If `True` and `header_text` is passed in, text is
rendered onto the input images.
diff --git a/src/transformers/models/pix2struct/modeling_pix2struct.py b/src/transformers/models/pix2struct/modeling_pix2struct.py
index f9a5b00218..65088ec424 100644
--- a/src/transformers/models/pix2struct/modeling_pix2struct.py
+++ b/src/transformers/models/pix2struct/modeling_pix2struct.py
@@ -69,7 +69,7 @@ class Pix2StructLayerNorm(nn.Module):
def forward(self, hidden_states):
# T5 uses a layer_norm which only scales and doesn't shift, which is also known as Root Mean
- # Square Layer Normalization https://arxiv.org/abs/1910.07467 thus variance is calculated
+ # Square Layer Normalization https://huggingface.co/papers/1910.07467 thus variance is calculated
# w/o mean and there is no bias. Additionally we want to make sure that the accumulation for
# half-precision inputs is done in fp32
@@ -527,7 +527,7 @@ class Pix2StructVisionModel(Pix2StructPreTrainedModel):
flattened_patches (`torch.FloatTensor` of shape `(batch_size, sequence_length, num_channels x patch_height x patch_width)`):
Flattened and padded pixel values. These values can be obtained using [`AutoImageProcessor`]. See
[`Pix2StructVisionImageProcessor.__call__`] for details. Check the [original
- paper](https://arxiv.org/abs/2210.03347) (figure 5) for more details.
+ paper](https://huggingface.co/papers/2210.03347) (figure 5) for more details.
Example:
diff --git a/src/transformers/models/plbart/configuration_plbart.py b/src/transformers/models/plbart/configuration_plbart.py
index 141bdde47f..a605f9a1c8 100644
--- a/src/transformers/models/plbart/configuration_plbart.py
+++ b/src/transformers/models/plbart/configuration_plbart.py
@@ -71,10 +71,10 @@ class PLBartConfig(PretrainedConfig):
init_std (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
encoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
decoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
scale_embedding (`bool`, *optional*, defaults to `True`):
Scale embeddings by diving by sqrt(d_model).
diff --git a/src/transformers/models/plbart/modeling_plbart.py b/src/transformers/models/plbart/modeling_plbart.py
index 695a0ed458..6399653cd0 100644
--- a/src/transformers/models/plbart/modeling_plbart.py
+++ b/src/transformers/models/plbart/modeling_plbart.py
@@ -673,7 +673,7 @@ class PLBartEncoder(PLBartPreTrainedModel):
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
to_drop = False
if self.training:
dropout_probability = torch.rand([])
@@ -1056,7 +1056,7 @@ class PLBartDecoder(PLBartPreTrainedModel):
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
diff --git a/src/transformers/models/pop2piano/modeling_pop2piano.py b/src/transformers/models/pop2piano/modeling_pop2piano.py
index c63b4df774..f48ada2be8 100644
--- a/src/transformers/models/pop2piano/modeling_pop2piano.py
+++ b/src/transformers/models/pop2piano/modeling_pop2piano.py
@@ -71,7 +71,7 @@ class Pop2PianoLayerNorm(nn.Module):
def forward(self, hidden_states):
# Pop2Piano uses a layer_norm which only scales and doesn't shift, which is also known as Root Mean
- # Square Layer Normalization https://arxiv.org/abs/1910.07467 thus variance is calculated
+ # Square Layer Normalization https://huggingface.co/papers/1910.07467 thus variance is calculated
# w/o mean and there is no bias. Additionally we want to make sure that the accumulation for
# half-precision inputs is done in fp32
diff --git a/src/transformers/models/prophetnet/configuration_prophetnet.py b/src/transformers/models/prophetnet/configuration_prophetnet.py
index 1219e1faac..32cf31153e 100644
--- a/src/transformers/models/prophetnet/configuration_prophetnet.py
+++ b/src/transformers/models/prophetnet/configuration_prophetnet.py
@@ -80,10 +80,10 @@ class ProphetNetConfig(PretrainedConfig):
token.
num_buckets (`int`, *optional*, defaults to 32)
The number of buckets to use for each attention layer. This is for relative position calculation. See the
- [T5 paper](see https://arxiv.org/abs/1910.10683) for more details.
+ [T5 paper](see https://huggingface.co/papers/1910.10683) for more details.
relative_max_distance (`int`, *optional*, defaults to 128)
Relative distances greater than this number will be put into the last same bucket. This is for relative
- position calculation. See the [T5 paper](see https://arxiv.org/abs/1910.10683) for more details.
+ position calculation. See the [T5 paper](see https://huggingface.co/papers/1910.10683) for more details.
disable_ngram_loss (`bool`, *optional*, defaults to `False`):
Whether be trained predicting only the next first token.
eps (`float`, *optional*, defaults to 0.0):
diff --git a/src/transformers/models/pvt/modeling_pvt.py b/src/transformers/models/pvt/modeling_pvt.py
index a299ad8729..ea81df51eb 100755
--- a/src/transformers/models/pvt/modeling_pvt.py
+++ b/src/transformers/models/pvt/modeling_pvt.py
@@ -155,7 +155,7 @@ class PvtSelfOutput(nn.Module):
class PvtEfficientSelfAttention(nn.Module):
- """Efficient self-attention mechanism with reduction of the sequence [PvT paper](https://arxiv.org/abs/2102.12122)."""
+ """Efficient self-attention mechanism with reduction of the sequence [PvT paper](https://huggingface.co/papers/2102.12122)."""
def __init__(
self, config: PvtConfig, hidden_size: int, num_attention_heads: int, sequences_reduction_ratio: float
diff --git a/src/transformers/models/qwen2/configuration_qwen2.py b/src/transformers/models/qwen2/configuration_qwen2.py
index fcba4b4a66..e4c99a4fbc 100644
--- a/src/transformers/models/qwen2/configuration_qwen2.py
+++ b/src/transformers/models/qwen2/configuration_qwen2.py
@@ -51,7 +51,7 @@ class Qwen2Config(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `32`.
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to `32`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
max_position_embeddings (`int`, *optional*, defaults to 32768):
diff --git a/src/transformers/models/qwen2_5_omni/configuration_qwen2_5_omni.py b/src/transformers/models/qwen2_5_omni/configuration_qwen2_5_omni.py
index 197ab8e78a..a0ad1b0fb7 100644
--- a/src/transformers/models/qwen2_5_omni/configuration_qwen2_5_omni.py
+++ b/src/transformers/models/qwen2_5_omni/configuration_qwen2_5_omni.py
@@ -239,7 +239,7 @@ class Qwen2_5OmniTextConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `32`.
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to `32`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
max_position_embeddings (`int`, *optional*, defaults to 32768):
@@ -586,7 +586,7 @@ class Qwen2_5OmniTalkerConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `32`.
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to `32`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
max_position_embeddings (`int`, *optional*, defaults to 32768):
diff --git a/src/transformers/models/qwen2_5_omni/modeling_qwen2_5_omni.py b/src/transformers/models/qwen2_5_omni/modeling_qwen2_5_omni.py
index 313d69e0ed..896b408116 100644
--- a/src/transformers/models/qwen2_5_omni/modeling_qwen2_5_omni.py
+++ b/src/transformers/models/qwen2_5_omni/modeling_qwen2_5_omni.py
@@ -2871,7 +2871,7 @@ class SqueezeExcitationRes2NetBlock(nn.Module):
class ECAPA_TimeDelayNet(torch.nn.Module):
"""An implementation of the speaker embedding model in a paper.
"ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in
- TDNN Based Speaker Verification" (https://arxiv.org/abs/2005.07143).
+ TDNN Based Speaker Verification" (https://huggingface.co/papers/2005.07143).
"""
def __init__(self, config: Qwen2_5OmniDiTConfig):
@@ -3236,7 +3236,7 @@ class SnakeBeta(nn.Module):
- beta - trainable parameter that controls magnitude
References:
- This activation function is a modified version based on this paper by Liu Ziyin, Tilman Hartwig, Masahito Ueda:
- https://arxiv.org/abs/2006.08195
+ https://huggingface.co/papers/2006.08195
"""
def __init__(self, in_features, alpha=1.0):
diff --git a/src/transformers/models/qwen2_5_omni/modular_qwen2_5_omni.py b/src/transformers/models/qwen2_5_omni/modular_qwen2_5_omni.py
index 2f18921df2..5af995b137 100644
--- a/src/transformers/models/qwen2_5_omni/modular_qwen2_5_omni.py
+++ b/src/transformers/models/qwen2_5_omni/modular_qwen2_5_omni.py
@@ -278,7 +278,7 @@ class Qwen2_5OmniTextConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `32`.
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to `32`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
max_position_embeddings (`int`, *optional*, defaults to 32768):
@@ -625,7 +625,7 @@ class Qwen2_5OmniTalkerConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `32`.
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to `32`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
max_position_embeddings (`int`, *optional*, defaults to 32768):
@@ -3175,7 +3175,7 @@ class SqueezeExcitationRes2NetBlock(nn.Module):
class ECAPA_TimeDelayNet(torch.nn.Module):
"""An implementation of the speaker embedding model in a paper.
"ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in
- TDNN Based Speaker Verification" (https://arxiv.org/abs/2005.07143).
+ TDNN Based Speaker Verification" (https://huggingface.co/papers/2005.07143).
"""
def __init__(self, config: Qwen2_5OmniDiTConfig):
@@ -3504,7 +3504,7 @@ class SnakeBeta(nn.Module):
- beta - trainable parameter that controls magnitude
References:
- This activation function is a modified version based on this paper by Liu Ziyin, Tilman Hartwig, Masahito Ueda:
- https://arxiv.org/abs/2006.08195
+ https://huggingface.co/papers/2006.08195
"""
def __init__(self, in_features, alpha=1.0):
diff --git a/src/transformers/models/qwen2_5_vl/configuration_qwen2_5_vl.py b/src/transformers/models/qwen2_5_vl/configuration_qwen2_5_vl.py
index be91b5b4ee..37ad9238aa 100644
--- a/src/transformers/models/qwen2_5_vl/configuration_qwen2_5_vl.py
+++ b/src/transformers/models/qwen2_5_vl/configuration_qwen2_5_vl.py
@@ -95,7 +95,7 @@ class Qwen2_5_VLTextConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `32`.
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to `32`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
max_position_embeddings (`int`, *optional*, defaults to 32768):
diff --git a/src/transformers/models/qwen2_audio/configuration_qwen2_audio.py b/src/transformers/models/qwen2_audio/configuration_qwen2_audio.py
index 23a1c699dd..ef95f19ed2 100644
--- a/src/transformers/models/qwen2_audio/configuration_qwen2_audio.py
+++ b/src/transformers/models/qwen2_audio/configuration_qwen2_audio.py
@@ -44,7 +44,7 @@ class Qwen2AudioEncoderConfig(PretrainedConfig):
encoder_ffn_dim (`int`, *optional*, defaults to 5120):
Dimensionality of the "intermediate" (often named feed-forward) layer in encoder.
encoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
d_model (`int`, *optional*, defaults to 1280):
Dimensionality of the layers.
diff --git a/src/transformers/models/qwen2_audio/modeling_qwen2_audio.py b/src/transformers/models/qwen2_audio/modeling_qwen2_audio.py
index 1f7b144798..99be5b7f5c 100644
--- a/src/transformers/models/qwen2_audio/modeling_qwen2_audio.py
+++ b/src/transformers/models/qwen2_audio/modeling_qwen2_audio.py
@@ -425,7 +425,7 @@ class Qwen2AudioEncoder(Qwen2AudioPreTrainedModel):
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
to_drop = False
if self.training:
dropout_probability = torch.rand([])
diff --git a/src/transformers/models/qwen2_moe/configuration_qwen2_moe.py b/src/transformers/models/qwen2_moe/configuration_qwen2_moe.py
index c279463e9d..b03f692dd9 100644
--- a/src/transformers/models/qwen2_moe/configuration_qwen2_moe.py
+++ b/src/transformers/models/qwen2_moe/configuration_qwen2_moe.py
@@ -50,7 +50,7 @@ class Qwen2MoeConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `32`.
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to `32`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
max_position_embeddings (`int`, *optional*, defaults to 32768):
diff --git a/src/transformers/models/qwen2_moe/modeling_qwen2_moe.py b/src/transformers/models/qwen2_moe/modeling_qwen2_moe.py
index 7f81c331cc..86091759f3 100644
--- a/src/transformers/models/qwen2_moe/modeling_qwen2_moe.py
+++ b/src/transformers/models/qwen2_moe/modeling_qwen2_moe.py
@@ -66,7 +66,7 @@ def load_balancing_loss_func(
r"""
Computes auxiliary load balancing loss as in Switch Transformer - implemented in Pytorch.
- See Switch Transformer (https://arxiv.org/abs/2101.03961) for more details. This function implements the loss
+ See Switch Transformer (https://huggingface.co/papers/2101.03961) for more details. This function implements the loss
function presented in equations (4) - (6) of the paper. It aims at penalizing cases where the routing between
experts is too unbalanced.
diff --git a/src/transformers/models/qwen2_vl/configuration_qwen2_vl.py b/src/transformers/models/qwen2_vl/configuration_qwen2_vl.py
index db1c089608..e3f8ea7e2f 100644
--- a/src/transformers/models/qwen2_vl/configuration_qwen2_vl.py
+++ b/src/transformers/models/qwen2_vl/configuration_qwen2_vl.py
@@ -84,7 +84,7 @@ class Qwen2VLTextConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `32`.
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to `32`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
max_position_embeddings (`int`, *optional*, defaults to 32768):
diff --git a/src/transformers/models/qwen3/configuration_qwen3.py b/src/transformers/models/qwen3/configuration_qwen3.py
index 032c611f86..77fbdb4e09 100644
--- a/src/transformers/models/qwen3/configuration_qwen3.py
+++ b/src/transformers/models/qwen3/configuration_qwen3.py
@@ -51,7 +51,7 @@ class Qwen3Config(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `32`.
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to `32`.
head_dim (`int`, *optional*, defaults to 128):
The attention head dimension.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
diff --git a/src/transformers/models/qwen3_moe/configuration_qwen3_moe.py b/src/transformers/models/qwen3_moe/configuration_qwen3_moe.py
index e0d6978047..908e7ed9f9 100644
--- a/src/transformers/models/qwen3_moe/configuration_qwen3_moe.py
+++ b/src/transformers/models/qwen3_moe/configuration_qwen3_moe.py
@@ -50,7 +50,8 @@ class Qwen3MoeConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `32`.
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to `32`.
+
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
max_position_embeddings (`int`, *optional*, defaults to 32768):
diff --git a/src/transformers/models/qwen3_moe/modeling_qwen3_moe.py b/src/transformers/models/qwen3_moe/modeling_qwen3_moe.py
index d4ba6c3656..98b714c726 100644
--- a/src/transformers/models/qwen3_moe/modeling_qwen3_moe.py
+++ b/src/transformers/models/qwen3_moe/modeling_qwen3_moe.py
@@ -603,7 +603,7 @@ def load_balancing_loss_func(
r"""
Computes auxiliary load balancing loss as in Switch Transformer - implemented in Pytorch.
- See Switch Transformer (https://arxiv.org/abs/2101.03961) for more details. This function implements the loss
+ See Switch Transformer (https://huggingface.co/papers/2101.03961) for more details. This function implements the loss
function presented in equations (4) - (6) of the paper. It aims at penalizing cases where the routing between
experts is too unbalanced.
diff --git a/src/transformers/models/rag/modeling_rag.py b/src/transformers/models/rag/modeling_rag.py
index e2456afafa..b246b50b12 100644
--- a/src/transformers/models/rag/modeling_rag.py
+++ b/src/transformers/models/rag/modeling_rag.py
@@ -221,7 +221,7 @@ class RetrievAugLMOutput(ModelOutput):
@auto_docstring(
custom_intro="""
RAG models were released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP
- Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandra Piktus et al.
+ Tasks](https://huggingface.co/papers/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandra Piktus et al.
RAG is a retriever augmented model and encapsulate three components: a question encoder, a dataset retriever and a
generator, the encoder and generator are trainable while the retriever is just an indexed dataset.
@@ -1446,7 +1446,7 @@ class RagTokenForGeneration(RagPreTrainedModel, GenerationMixin):
`batch_id`. It has to return a list with the allowed tokens for the next generation step conditioned on
the previously generated tokens `inputs_ids` and the batch ID `batch_id`. This argument is useful for
constrained generation conditioned on the prefix, as described in [Autoregressive Entity
- Retrieval](https://arxiv.org/abs/2010.00904).
+ Retrieval](https://huggingface.co/papers/2010.00904).
logits_processor (`LogitsProcessorList`, *optional*):
Custom logits processors that complement the default logits processors built from arguments and a
model's config. If a logit processor is passed that is already created with the arguments or a model's
diff --git a/src/transformers/models/rag/modeling_tf_rag.py b/src/transformers/models/rag/modeling_tf_rag.py
index 79fa08c6c5..650e591dc2 100644
--- a/src/transformers/models/rag/modeling_tf_rag.py
+++ b/src/transformers/models/rag/modeling_tf_rag.py
@@ -218,7 +218,7 @@ class TFRetrievAugLMOutput(ModelOutput):
class TFRagPreTrainedModel(TFPreTrainedModel):
r"""
RAG models were released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP
- Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandra Piktus et al.
+ Tasks](https://huggingface.co/papers/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandra Piktus et al.
RAG is a retriever augmented model and encapsulate three components: a question encoder, a dataset retriever and a
generator, the encoder and generator are trainable while the retriever is just an indexed dataset.
@@ -881,7 +881,7 @@ class TFRagTokenForGeneration(TFRagPreTrainedModel, TFCausalLanguageModelingLoss
`torch.nn.functional.log_softmax`.
labels (`tf.Tensor` or `np.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the cross entropy classification loss according to Rag-Token model formulation See
- https://arxiv.org/pdf/2005.11401.pdf Section 2.1 for details about Rag-Token formulation. Indices should be
+ https://huggingface.co/papers/2005.11401 Section 2.1 for details about Rag-Token formulation. Indices should be
in `[0, ..., config.vocab_size - 1]`.
reduce_loss (`bool`, *optional*):
Only relevant if `labels` is passed. If `True`, the NLL loss is reduced using the `tf.Tensor.sum`
@@ -1395,7 +1395,7 @@ class TFRagSequenceForGeneration(TFRagPreTrainedModel, TFCausalLanguageModelingL
the loss.
labels (`tf.Tensor` or `np.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the cross entropy classification loss according to Rag-Sequence model formulation See
- https://arxiv.org/pdf/2005.11401.pdf Section 2.1 for details about Rag-Sequence formulation. Indices should
+ https://huggingface.co/papers/2005.11401 Section 2.1 for details about Rag-Sequence formulation. Indices should
be in `[0, ..., config.vocab_size - 1]`.
reduce_loss (`bool`, *optional*):
Only relevant if `labels` is passed. If `True`, the NLL loss is reduced using the `tf.Tensor.sum`
diff --git a/src/transformers/models/reformer/modeling_reformer.py b/src/transformers/models/reformer/modeling_reformer.py
index 3422fbad2b..3fd77f8fb4 100755
--- a/src/transformers/models/reformer/modeling_reformer.py
+++ b/src/transformers/models/reformer/modeling_reformer.py
@@ -602,7 +602,7 @@ class LSHSelfAttention(nn.Module, EfficientAttentionMixin):
def _hash_vectors(self, vectors, num_hashes, attention_mask, increase_num_buckets=False):
batch_size = vectors.shape[0]
- # See https://arxiv.org/pdf/1509.02897.pdf
+ # See https://huggingface.co/papers/1509.02897
# We sample a different random rotation for each round of hashing to
# decrease the probability of hash misses.
if isinstance(self.num_buckets, int):
@@ -778,7 +778,7 @@ class LSHSelfAttention(nn.Module, EfficientAttentionMixin):
del mask
# Self mask is ALWAYS applied.
- # From the reformer paper (https://arxiv.org/pdf/2001.04451.pdf):
+ # From the reformer paper (https://huggingface.co/papers/2001.04451):
# " While attention to the future is not allowed, typical implementations of the
# Transformer do allow a position to attend to itself.
# Such behavior is undesirable in a shared-QK formulation because the dot-product
diff --git a/src/transformers/models/regnet/convert_regnet_to_pytorch.py b/src/transformers/models/regnet/convert_regnet_to_pytorch.py
index ab8b34500d..51c0e3a4a0 100644
--- a/src/transformers/models/regnet/convert_regnet_to_pytorch.py
+++ b/src/transformers/models/regnet/convert_regnet_to_pytorch.py
@@ -305,7 +305,7 @@ def convert_weights_and_push(save_directory: Path, model_name: Optional[str] = N
"regnet-y-320": ImageNetPreTrainedConfig(
depths=[2, 5, 12, 1], hidden_sizes=[232, 696, 1392, 3712], groups_width=232
),
- # models created by SEER -> https://arxiv.org/abs/2202.08360
+ # models created by SEER -> https://huggingface.co/papers/2202.08360
"regnet-y-320-seer": RegNetConfig(depths=[2, 5, 12, 1], hidden_sizes=[232, 696, 1392, 3712], groups_width=232),
"regnet-y-640-seer": RegNetConfig(depths=[2, 5, 12, 1], hidden_sizes=[328, 984, 1968, 4920], groups_width=328),
"regnet-y-1280-seer": RegNetConfig(
diff --git a/src/transformers/models/regnet/modeling_flax_regnet.py b/src/transformers/models/regnet/modeling_flax_regnet.py
index 8d2921ea14..90f16560c7 100644
--- a/src/transformers/models/regnet/modeling_flax_regnet.py
+++ b/src/transformers/models/regnet/modeling_flax_regnet.py
@@ -212,7 +212,7 @@ class FlaxRegNetSELayerCollection(nn.Module):
class FlaxRegNetSELayer(nn.Module):
"""
- Squeeze and Excitation layer (SE) proposed in [Squeeze-and-Excitation Networks](https://arxiv.org/abs/1709.01507).
+ Squeeze and Excitation layer (SE) proposed in [Squeeze-and-Excitation Networks](https://huggingface.co/papers/1709.01507).
"""
in_channels: int
diff --git a/src/transformers/models/regnet/modeling_regnet.py b/src/transformers/models/regnet/modeling_regnet.py
index b510e3565a..aeb333e8b0 100644
--- a/src/transformers/models/regnet/modeling_regnet.py
+++ b/src/transformers/models/regnet/modeling_regnet.py
@@ -108,7 +108,7 @@ class RegNetShortCut(nn.Module):
class RegNetSELayer(nn.Module):
"""
- Squeeze and Excitation layer (SE) proposed in [Squeeze-and-Excitation Networks](https://arxiv.org/abs/1709.01507).
+ Squeeze and Excitation layer (SE) proposed in [Squeeze-and-Excitation Networks](https://huggingface.co/papers/1709.01507).
"""
def __init__(self, in_channels: int, reduced_channels: int):
diff --git a/src/transformers/models/regnet/modeling_tf_regnet.py b/src/transformers/models/regnet/modeling_tf_regnet.py
index 7e0cc5d562..07f7058659 100644
--- a/src/transformers/models/regnet/modeling_tf_regnet.py
+++ b/src/transformers/models/regnet/modeling_tf_regnet.py
@@ -170,7 +170,7 @@ class TFRegNetShortCut(keras.layers.Layer):
class TFRegNetSELayer(keras.layers.Layer):
"""
- Squeeze and Excitation layer (SE) proposed in [Squeeze-and-Excitation Networks](https://arxiv.org/abs/1709.01507).
+ Squeeze and Excitation layer (SE) proposed in [Squeeze-and-Excitation Networks](https://huggingface.co/papers/1709.01507).
"""
def __init__(self, in_channels: int, reduced_channels: int, **kwargs):
diff --git a/src/transformers/models/rembert/modeling_rembert.py b/src/transformers/models/rembert/modeling_rembert.py
index 6a8ba4bf11..ab1953659d 100755
--- a/src/transformers/models/rembert/modeling_rembert.py
+++ b/src/transformers/models/rembert/modeling_rembert.py
@@ -655,7 +655,7 @@ class RemBertPreTrainedModel(PreTrainedModel):
custom_intro="""
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in [Attention is
- all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
+ all you need](https://huggingface.co/papers/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
To behave as an decoder the model needs to be initialized with the `is_decoder` argument of the configuration set
diff --git a/src/transformers/models/roberta/configuration_roberta.py b/src/transformers/models/roberta/configuration_roberta.py
index 2e2221738a..04917804a2 100644
--- a/src/transformers/models/roberta/configuration_roberta.py
+++ b/src/transformers/models/roberta/configuration_roberta.py
@@ -68,9 +68,9 @@ class RobertaConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
is_decoder (`bool`, *optional*, defaults to `False`):
Whether the model is used as a decoder or not. If `False`, the model is used as an encoder.
use_cache (`bool`, *optional*, defaults to `True`):
diff --git a/src/transformers/models/roberta/modeling_roberta.py b/src/transformers/models/roberta/modeling_roberta.py
index a88cf0c9c6..937931376d 100644
--- a/src/transformers/models/roberta/modeling_roberta.py
+++ b/src/transformers/models/roberta/modeling_roberta.py
@@ -705,7 +705,7 @@ class RobertaPreTrainedModel(PreTrainedModel):
custom_intro="""
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in [Attention is
- all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
+ all you need](https://huggingface.co/papers/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
To behave as an decoder the model needs to be initialized with the `is_decoder` argument of the configuration set
diff --git a/src/transformers/models/roberta_prelayernorm/configuration_roberta_prelayernorm.py b/src/transformers/models/roberta_prelayernorm/configuration_roberta_prelayernorm.py
index a5685db407..72bc808c45 100644
--- a/src/transformers/models/roberta_prelayernorm/configuration_roberta_prelayernorm.py
+++ b/src/transformers/models/roberta_prelayernorm/configuration_roberta_prelayernorm.py
@@ -69,9 +69,9 @@ class RobertaPreLayerNormConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
is_decoder (`bool`, *optional*, defaults to `False`):
Whether the model is used as a decoder or not. If `False`, the model is used as an encoder.
use_cache (`bool`, *optional*, defaults to `True`):
diff --git a/src/transformers/models/roberta_prelayernorm/modeling_roberta_prelayernorm.py b/src/transformers/models/roberta_prelayernorm/modeling_roberta_prelayernorm.py
index 0f3aeaf4d0..a91491f2bd 100644
--- a/src/transformers/models/roberta_prelayernorm/modeling_roberta_prelayernorm.py
+++ b/src/transformers/models/roberta_prelayernorm/modeling_roberta_prelayernorm.py
@@ -600,7 +600,7 @@ class RobertaPreLayerNormPreTrainedModel(PreTrainedModel):
to `True`. To be used in a Seq2Seq model, the model needs to initialized with both `is_decoder` argument and
`add_cross_attention` set to `True`; an `encoder_hidden_states` is then expected as an input to the forward pass.
- .. _*Attention is all you need*: https://arxiv.org/abs/1706.03762
+ .. _*Attention is all you need*: https://huggingface.co/papers/1706.03762
"""
)
class RobertaPreLayerNormModel(RobertaPreLayerNormPreTrainedModel):
diff --git a/src/transformers/models/roc_bert/configuration_roc_bert.py b/src/transformers/models/roc_bert/configuration_roc_bert.py
index 4bf53bf338..75f83e11a7 100644
--- a/src/transformers/models/roc_bert/configuration_roc_bert.py
+++ b/src/transformers/models/roc_bert/configuration_roc_bert.py
@@ -68,9 +68,9 @@ class RoCBertConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
classifier_dropout (`float`, *optional*):
The dropout ratio for the classification head.
enable_pronunciation (`bool`, *optional*, defaults to `True`):
diff --git a/src/transformers/models/roc_bert/modeling_roc_bert.py b/src/transformers/models/roc_bert/modeling_roc_bert.py
index 42e9fb94e4..f154de671d 100644
--- a/src/transformers/models/roc_bert/modeling_roc_bert.py
+++ b/src/transformers/models/roc_bert/modeling_roc_bert.py
@@ -768,7 +768,7 @@ class RoCBertPreTrainedModel(PreTrainedModel):
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in [Attention is
- all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
+ all you need](https://huggingface.co/papers/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
To behave as an decoder the model needs to be initialized with the `is_decoder` argument of the configuration set
diff --git a/src/transformers/models/roformer/modeling_roformer.py b/src/transformers/models/roformer/modeling_roformer.py
index 1fdccf7284..a675a39738 100644
--- a/src/transformers/models/roformer/modeling_roformer.py
+++ b/src/transformers/models/roformer/modeling_roformer.py
@@ -798,7 +798,7 @@ class RoFormerPreTrainedModel(PreTrainedModel):
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in [Attention is
- all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
+ all you need](https://huggingface.co/papers/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
To behave as an decoder the model needs to be initialized with the `is_decoder` argument of the configuration set
diff --git a/src/transformers/models/rt_detr/modeling_rt_detr.py b/src/transformers/models/rt_detr/modeling_rt_detr.py
index 59bcf08578..5301187408 100644
--- a/src/transformers/models/rt_detr/modeling_rt_detr.py
+++ b/src/transformers/models/rt_detr/modeling_rt_detr.py
@@ -1129,7 +1129,7 @@ class RTDetrEncoder(nn.Module):
class RTDetrHybridEncoder(nn.Module):
"""
Decoder consisting of a projection layer, a set of `RTDetrEncoder`, a top-down Feature Pyramid Network
- (FPN) and a bottom-up Path Aggregation Network (PAN). More details on the paper: https://arxiv.org/abs/2304.08069
+ (FPN) and a bottom-up Path Aggregation Network (PAN). More details on the paper: https://huggingface.co/papers/2304.08069
Args:
config: RTDetrConfig
diff --git a/src/transformers/models/rt_detr_v2/modeling_rt_detr_v2.py b/src/transformers/models/rt_detr_v2/modeling_rt_detr_v2.py
index d8a145d645..b076cfcc98 100644
--- a/src/transformers/models/rt_detr_v2/modeling_rt_detr_v2.py
+++ b/src/transformers/models/rt_detr_v2/modeling_rt_detr_v2.py
@@ -931,7 +931,7 @@ class RTDetrV2Encoder(nn.Module):
class RTDetrV2HybridEncoder(nn.Module):
"""
Decoder consisting of a projection layer, a set of `RTDetrV2Encoder`, a top-down Feature Pyramid Network
- (FPN) and a bottom-up Path Aggregation Network (PAN). More details on the paper: https://arxiv.org/abs/2304.08069
+ (FPN) and a bottom-up Path Aggregation Network (PAN). More details on the paper: https://huggingface.co/papers/2304.08069
Args:
config: RTDetrV2Config
diff --git a/src/transformers/models/sam/modeling_sam.py b/src/transformers/models/sam/modeling_sam.py
index f49280e717..b6af50ba88 100644
--- a/src/transformers/models/sam/modeling_sam.py
+++ b/src/transformers/models/sam/modeling_sam.py
@@ -1399,10 +1399,10 @@ class SamModel(SamPreTrainedModel):
"best" mask, by specifying `multimask_output=False`.
attention_similarity (`torch.FloatTensor`, *optional*):
Attention similarity tensor, to be provided to the mask decoder for target-guided attention in case the
- model is used for personalization as introduced in [PerSAM](https://arxiv.org/abs/2305.03048).
+ model is used for personalization as introduced in [PerSAM](https://huggingface.co/papers/2305.03048).
target_embedding (`torch.FloatTensor`, *optional*):
Embedding of the target concept, to be provided to the mask decoder for target-semantic prompting in case
- the model is used for personalization as introduced in [PerSAM](https://arxiv.org/abs/2305.03048).
+ the model is used for personalization as introduced in [PerSAM](https://huggingface.co/papers/2305.03048).
Example:
diff --git a/src/transformers/models/sam_hq/modeling_sam_hq.py b/src/transformers/models/sam_hq/modeling_sam_hq.py
index 0a77f996cd..d0f78bb6ce 100644
--- a/src/transformers/models/sam_hq/modeling_sam_hq.py
+++ b/src/transformers/models/sam_hq/modeling_sam_hq.py
@@ -1522,10 +1522,10 @@ class SamHQModel(SamHQPreTrainedModel):
This is specific to SAM-HQ's architecture.
attention_similarity (`torch.FloatTensor`, *optional*):
Attention similarity tensor, to be provided to the mask decoder for target-guided attention in case the
- model is used for personalization as introduced in [PerSAM](https://arxiv.org/abs/2305.03048).
+ model is used for personalization as introduced in [PerSAM](https://huggingface.co/papers/2305.03048).
target_embedding (`torch.FloatTensor`, *optional*):
Embedding of the target concept, to be provided to the mask decoder for target-semantic prompting in case
- the model is used for personalization as introduced in [PerSAM](https://arxiv.org/abs/2305.03048).
+ the model is used for personalization as introduced in [PerSAM](https://huggingface.co/papers/2305.03048).
intermediate_embeddings (`List[torch.FloatTensor]`, *optional*):
Intermediate embeddings from vision encoder's non-windowed blocks, used by SAM-HQ for enhanced mask quality.
Required when providing pre-computed image_embeddings instead of pixel_values.
diff --git a/src/transformers/models/sam_hq/modular_sam_hq.py b/src/transformers/models/sam_hq/modular_sam_hq.py
index e57eaffbb9..584c2824d9 100644
--- a/src/transformers/models/sam_hq/modular_sam_hq.py
+++ b/src/transformers/models/sam_hq/modular_sam_hq.py
@@ -550,10 +550,10 @@ class SamHQModel(SamModel):
This is specific to SAM-HQ's architecture.
attention_similarity (`torch.FloatTensor`, *optional*):
Attention similarity tensor, to be provided to the mask decoder for target-guided attention in case the
- model is used for personalization as introduced in [PerSAM](https://arxiv.org/abs/2305.03048).
+ model is used for personalization as introduced in [PerSAM](https://huggingface.co/papers/2305.03048).
target_embedding (`torch.FloatTensor`, *optional*):
Embedding of the target concept, to be provided to the mask decoder for target-semantic prompting in case
- the model is used for personalization as introduced in [PerSAM](https://arxiv.org/abs/2305.03048).
+ the model is used for personalization as introduced in [PerSAM](https://huggingface.co/papers/2305.03048).
intermediate_embeddings (`List[torch.FloatTensor]`, *optional*):
Intermediate embeddings from vision encoder's non-windowed blocks, used by SAM-HQ for enhanced mask quality.
Required when providing pre-computed image_embeddings instead of pixel_values.
diff --git a/src/transformers/models/seamless_m4t/configuration_seamless_m4t.py b/src/transformers/models/seamless_m4t/configuration_seamless_m4t.py
index f406264b03..25715352db 100644
--- a/src/transformers/models/seamless_m4t/configuration_seamless_m4t.py
+++ b/src/transformers/models/seamless_m4t/configuration_seamless_m4t.py
@@ -58,10 +58,10 @@ class SeamlessM4TConfig(PretrainedConfig):
is_encoder_decoder (`bool`, *optional*, defaults to `True`):
Whether the model is used as an encoder/decoder or not.
encoder_layerdrop (`float`, *optional*, defaults to 0.05):
- The LayerDrop probability for the encoders. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the encoders. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
decoder_layerdrop (`float`, *optional*, defaults to 0.05):
- The LayerDrop probability for the decoders. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the decoders. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
activation_function (`str` or `function`, *optional*, defaults to `"relu"`):
The non-linear activation function (function or string) in the decoder and feed-forward layers. If string,
@@ -118,7 +118,7 @@ class SeamlessM4TConfig(PretrainedConfig):
Add an adapter layer on top of the speech encoder.
speech_encoder_layerdrop (`float`, *optional*, defaults to 0.1):
The LayerDrop probability for the speech encoder. See the [LayerDrop paper](see
- https://arxiv.org/abs/1909.11556) for more details.
+ https://huggingface.co/papers/1909.11556) for more details.
feature_projection_input_dim (`int`, *optional*, defaults to 160):
Input dimension of the input feature projection of the speech encoder, i.e the dimension after processing
input audios with [`SeamlessM4TFeatureExtractor`].
diff --git a/src/transformers/models/seamless_m4t/modeling_seamless_m4t.py b/src/transformers/models/seamless_m4t/modeling_seamless_m4t.py
index 42f3e4b577..64a8451ce5 100755
--- a/src/transformers/models/seamless_m4t/modeling_seamless_m4t.py
+++ b/src/transformers/models/seamless_m4t/modeling_seamless_m4t.py
@@ -69,7 +69,7 @@ SEAMLESS_M4T_COMMON_CUSTOM_ARGS = r"""
be used by default.
If you want to change padding behavior, you should read [`modeling_bart._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
inputs_embeds (`torch.FloatTensor` of shape`(batch_size, sequence_length, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
@@ -260,7 +260,7 @@ class SeamlessM4TConformerPositionalConvEmbedding(nn.Module):
# Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerRotaryPositionalEmbedding with Wav2Vec2->SeamlessM4T, num_attention_heads->speech_encoder_attention_heads
class SeamlessM4TConformerRotaryPositionalEmbedding(nn.Module):
"""Rotary positional embedding
- Reference : https://blog.eleuther.ai/rotary-embeddings/ Paper: https://arxiv.org/pdf/2104.09864.pdf
+ Reference : https://blog.eleuther.ai/rotary-embeddings/ Paper: https://huggingface.co/papers/2104.09864
"""
def __init__(self, config):
@@ -328,7 +328,7 @@ class SeamlessM4TConformerRelPositionalEmbedding(nn.Module):
# Reverse the order of positive indices and concat both positive and
# negative indices. This is used to support the shifting trick
- # as in https://arxiv.org/abs/1901.02860
+ # as in https://huggingface.co/papers/1901.02860
pe_positive = torch.flip(pe_positive, [0]).unsqueeze(0)
pe_negative = pe_negative[1:].unsqueeze(0)
pe = torch.cat([pe_positive, pe_negative], dim=1)
@@ -482,7 +482,7 @@ class SeamlessM4TConformerSelfAttention(nn.Module):
# linear transformation for positional encoding
self.linear_pos = nn.Linear(config.hidden_size, config.hidden_size, bias=False)
# these two learnable bias are used in matrix c and matrix d
- # as described in https://arxiv.org/abs/1901.02860 Section 3.3
+ # as described in https://huggingface.co/papers/1901.02860 Section 3.3
self.pos_bias_u = nn.Parameter(torch.zeros(self.num_heads, self.head_size))
self.pos_bias_v = nn.Parameter(torch.zeros(self.num_heads, self.head_size))
@@ -525,7 +525,7 @@ class SeamlessM4TConformerSelfAttention(nn.Module):
" 'relative'"
)
# apply relative_position_embeddings to qk scores
- # as proposed in Transformer_XL: https://arxiv.org/abs/1901.02860
+ # as proposed in Transformer_XL: https://huggingface.co/papers/1901.02860
scores = self._apply_relative_embeddings(
query=query, key=key, relative_position_embeddings=relative_position_embeddings
)
@@ -587,7 +587,7 @@ class SeamlessM4TConformerSelfAttention(nn.Module):
q_with_bias_v = (query + self.pos_bias_v).transpose(1, 2)
# 3. attention score: first compute matrix a and matrix c
- # as described in https://arxiv.org/abs/1901.02860 Section 3.3
+ # as described in https://huggingface.co/papers/1901.02860 Section 3.3
# => (batch, head, time1, time2)
scores_ac = torch.matmul(q_with_bias_u, key.transpose(-2, -1))
@@ -611,7 +611,7 @@ class SeamlessM4TConformerSelfAttention(nn.Module):
class SeamlessM4TConformerEncoderLayer(nn.Module):
- """Conformer block based on https://arxiv.org/abs/2005.08100."""
+ """Conformer block based on https://huggingface.co/papers/2005.08100."""
# Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerEncoderLayer.__init__ with Wav2Vec2->SeamlessM4T, attention_dropout->speech_encoder_dropout, torch.nn->nn
def __init__(self, config):
@@ -735,7 +735,7 @@ class SeamlessM4TConformerEncoder(nn.Module):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = torch.rand([])
skip_the_layer = (
@@ -1681,7 +1681,7 @@ class SeamlessM4TEncoder(SeamlessM4TPreTrainedModel):
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
to_drop = False
if self.training:
dropout_probability = torch.rand([])
@@ -1856,7 +1856,7 @@ class SeamlessM4TDecoder(SeamlessM4TPreTrainedModel):
next_decoder_cache = () if use_cache else None
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
@@ -2705,7 +2705,7 @@ class SeamlessM4TForTextToText(SeamlessM4TPreTrainedModel, GenerationMixin):
`input_ids`. It has to return a list with the allowed tokens for the next generation step conditioned
on the batch ID `batch_id` and the previously generated tokens `inputs_ids`. This argument is useful
for constrained generation conditioned on the prefix, as described in [Autoregressive Entity
- Retrieval](https://arxiv.org/abs/2010.00904).
+ Retrieval](https://huggingface.co/papers/2010.00904).
synced_gpus (`bool`, *optional*, defaults to `False`):
Whether to continue running the while loop until max_length (needed to avoid deadlocking with
`FullyShardedDataParallel` and DeepSpeed ZeRO Stage 3).
@@ -2977,7 +2977,7 @@ class SeamlessM4TForSpeechToText(SeamlessM4TPreTrainedModel, GenerationMixin):
`input_ids`. It has to return a list with the allowed tokens for the next generation step conditioned
on the batch ID `batch_id` and the previously generated tokens `inputs_ids`. This argument is useful
for constrained generation conditioned on the prefix, as described in [Autoregressive Entity
- Retrieval](https://arxiv.org/abs/2010.00904).
+ Retrieval](https://huggingface.co/papers/2010.00904).
synced_gpus (`bool`, *optional*, defaults to `False`):
Whether to continue running the while loop until max_length (needed to avoid deadlocking with
`FullyShardedDataParallel` and DeepSpeed ZeRO Stage 3).
diff --git a/src/transformers/models/seamless_m4t_v2/configuration_seamless_m4t_v2.py b/src/transformers/models/seamless_m4t_v2/configuration_seamless_m4t_v2.py
index d29eaf4540..5c5c34d6aa 100644
--- a/src/transformers/models/seamless_m4t_v2/configuration_seamless_m4t_v2.py
+++ b/src/transformers/models/seamless_m4t_v2/configuration_seamless_m4t_v2.py
@@ -62,10 +62,10 @@ class SeamlessM4Tv2Config(PretrainedConfig):
is_encoder_decoder (`bool`, *optional*, defaults to `True`):
Whether the model is used as an encoder/decoder or not.
encoder_layerdrop (`float`, *optional*, defaults to 0.05):
- The LayerDrop probability for the encoders. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the encoders. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
decoder_layerdrop (`float`, *optional*, defaults to 0.05):
- The LayerDrop probability for the decoders. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the decoders. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
activation_function (`str` or `function`, *optional*, defaults to `"relu"`):
The non-linear activation function (function or string) in the decoder and feed-forward layers. If string,
@@ -122,7 +122,7 @@ class SeamlessM4Tv2Config(PretrainedConfig):
Add an adapter layer on top of the speech encoder.
speech_encoder_layerdrop (`float`, *optional*, defaults to 0.1):
The LayerDrop probability for the speech encoder. See the [LayerDrop paper](see
- https://arxiv.org/abs/1909.11556) for more details.
+ https://huggingface.co/papers/1909.11556) for more details.
feature_projection_input_dim (`int`, *optional*, defaults to 160):
Input dimension of the input feature projection of the speech encoder, i.e the dimension after processing
input audios with [`SeamlessM4TFeatureExtractor`].
@@ -138,7 +138,7 @@ class SeamlessM4Tv2Config(PretrainedConfig):
position_embeddings_type (`str`, *optional*, defaults to `"relative_key"`):
Can be specified to `relative_key`. If left to `None`, no relative position embedding is applied. Only
applied to the speech encoder. For more information on `"relative_key"`, please refer to [Self-Attention
- with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
conv_depthwise_kernel_size (`int`, *optional*, defaults to 31):
Kernel size of convolutional depthwise 1D layer in Conformer blocks. Only applied to the speech encoder.
left_max_position_embeddings (`int`, *optional*, defaults to 64):
diff --git a/src/transformers/models/seamless_m4t_v2/modeling_seamless_m4t_v2.py b/src/transformers/models/seamless_m4t_v2/modeling_seamless_m4t_v2.py
index c62b97fb89..6bf730003a 100644
--- a/src/transformers/models/seamless_m4t_v2/modeling_seamless_m4t_v2.py
+++ b/src/transformers/models/seamless_m4t_v2/modeling_seamless_m4t_v2.py
@@ -66,7 +66,7 @@ SEAMLESS_M4T_V2_COMMON_CUSTOM_ARGS = r"""
be used by default.
If you want to change padding behavior, you should read [`modeling_bart._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
inputs_embeds (`torch.FloatTensor` of shape`(batch_size, sequence_length, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
@@ -335,7 +335,8 @@ class SeamlessM4Tv2ConformerFeedForward(nn.Module):
class SeamlessM4Tv2ConformerConvolutionModule(nn.Module):
"""Convolution block used in the conformer block. Uses a causal depthwise convolution similar to that
- described in Section 2.1 of `https://doi.org/10.48550/arxiv.1609.03499"""
+ described in Section 2.1 of https://huggingface.co/papers/1609.03499
+ """
def __init__(self, config):
super().__init__()
@@ -489,7 +490,7 @@ class SeamlessM4Tv2ConformerSelfAttention(nn.Module):
class SeamlessM4Tv2ConformerEncoderLayer(nn.Module):
- """Conformer block based on https://arxiv.org/abs/2005.08100."""
+ """Conformer block based on https://huggingface.co/papers/2005.08100."""
# Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerEncoderLayer.__init__ with Wav2Vec2->SeamlessM4Tv2, attention_dropout->speech_encoder_dropout, torch.nn->nn
def __init__(self, config):
@@ -636,7 +637,7 @@ class SeamlessM4Tv2ConformerEncoder(nn.Module):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = torch.rand([])
skip_the_layer = (
@@ -1749,7 +1750,7 @@ class SeamlessM4Tv2Encoder(SeamlessM4Tv2PreTrainedModel):
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
to_drop = False
if self.training:
dropout_probability = torch.rand([])
@@ -1925,7 +1926,7 @@ class SeamlessM4Tv2Decoder(SeamlessM4Tv2PreTrainedModel):
next_decoder_cache = () if use_cache else None
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
@@ -2128,7 +2129,7 @@ class SeamlessM4Tv2TextToUnitDecoder(SeamlessM4Tv2PreTrainedModel):
all_self_attns = () if output_attentions else None
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
@@ -2949,7 +2950,7 @@ class SeamlessM4Tv2ForTextToText(SeamlessM4Tv2PreTrainedModel, GenerationMixin):
`input_ids`. It has to return a list with the allowed tokens for the next generation step conditioned
on the batch ID `batch_id` and the previously generated tokens `inputs_ids`. This argument is useful
for constrained generation conditioned on the prefix, as described in [Autoregressive Entity
- Retrieval](https://arxiv.org/abs/2010.00904).
+ Retrieval](https://huggingface.co/papers/2010.00904).
synced_gpus (`bool`, *optional*, defaults to `False`):
Whether to continue running the while loop until max_length (needed to avoid deadlocking with
`FullyShardedDataParallel` and DeepSpeed ZeRO Stage 3).
@@ -3231,7 +3232,7 @@ class SeamlessM4Tv2ForSpeechToText(SeamlessM4Tv2PreTrainedModel, GenerationMixin
`input_ids`. It has to return a list with the allowed tokens for the next generation step conditioned
on the batch ID `batch_id` and the previously generated tokens `inputs_ids`. This argument is useful
for constrained generation conditioned on the prefix, as described in [Autoregressive Entity
- Retrieval](https://arxiv.org/abs/2010.00904).
+ Retrieval](https://huggingface.co/papers/2010.00904).
synced_gpus (`bool`, *optional*, defaults to `False`):
Whether to continue running the while loop until max_length (needed to avoid deadlocking with
`FullyShardedDataParallel` and DeepSpeed ZeRO Stage 3).
diff --git a/src/transformers/models/segformer/modeling_segformer.py b/src/transformers/models/segformer/modeling_segformer.py
index 81df26dc69..f5e08b9303 100755
--- a/src/transformers/models/segformer/modeling_segformer.py
+++ b/src/transformers/models/segformer/modeling_segformer.py
@@ -123,7 +123,7 @@ class SegformerOverlapPatchEmbeddings(nn.Module):
class SegformerEfficientSelfAttention(nn.Module):
"""SegFormer's efficient self-attention mechanism. Employs the sequence reduction process introduced in the [PvT
- paper](https://arxiv.org/abs/2102.12122)."""
+ paper](https://huggingface.co/papers/2102.12122)."""
def __init__(self, config, hidden_size, num_attention_heads, sequence_reduction_ratio):
super().__init__()
diff --git a/src/transformers/models/segformer/modeling_tf_segformer.py b/src/transformers/models/segformer/modeling_tf_segformer.py
index bad72cdf2b..3c084f237e 100644
--- a/src/transformers/models/segformer/modeling_tf_segformer.py
+++ b/src/transformers/models/segformer/modeling_tf_segformer.py
@@ -115,7 +115,7 @@ class TFSegformerOverlapPatchEmbeddings(keras.layers.Layer):
class TFSegformerEfficientSelfAttention(keras.layers.Layer):
"""SegFormer's efficient self-attention mechanism. Employs the sequence reduction process introduced in the [PvT
- paper](https://arxiv.org/abs/2102.12122)."""
+ paper](https://huggingface.co/papers/2102.12122)."""
def __init__(
self,
diff --git a/src/transformers/models/seggpt/image_processing_seggpt.py b/src/transformers/models/seggpt/image_processing_seggpt.py
index b469586de8..3ccb42ee7a 100644
--- a/src/transformers/models/seggpt/image_processing_seggpt.py
+++ b/src/transformers/models/seggpt/image_processing_seggpt.py
@@ -45,7 +45,7 @@ if is_vision_available():
logger = logging.get_logger(__name__)
-# See https://arxiv.org/pdf/2212.02499.pdf at 3.1 Redefining Output Spaces as "Images" - Semantic Segmentation from PAINTER paper
+# See https://huggingface.co/papers/2212.02499 at 3.1 Redefining Output Spaces as "Images" - Semantic Segmentation from PAINTER paper
# Taken from https://github.com/Abdullah-Meda/Painter/blob/main/Painter/data/coco_semseg/gen_color_coco_panoptic_segm.py#L31
def build_palette(num_labels: int) -> List[Tuple[int, int]]:
base = int(num_labels ** (1 / 3)) + 1
diff --git a/src/transformers/models/sew/configuration_sew.py b/src/transformers/models/sew/configuration_sew.py
index aff4e37542..b8cb804039 100644
--- a/src/transformers/models/sew/configuration_sew.py
+++ b/src/transformers/models/sew/configuration_sew.py
@@ -61,7 +61,7 @@ class SEWConfig(PretrainedConfig):
final_dropout (`float`, *optional*, defaults to 0.1):
The dropout probability for the final projection layer of [`SEWForCTC`].
layerdrop (`float`, *optional*, defaults to 0.1):
- The LayerDrop probability. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556) for more
+ The LayerDrop probability. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556) for more
details.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
@@ -96,7 +96,7 @@ class SEWConfig(PretrainedConfig):
apply_spec_augment (`bool`, *optional*, defaults to `True`):
Whether to apply *SpecAugment* data augmentation to the outputs of the feature encoder. For reference see
[SpecAugment: A Simple Data Augmentation Method for Automatic Speech
- Recognition](https://arxiv.org/abs/1904.08779).
+ Recognition](https://huggingface.co/papers/1904.08779).
mask_time_prob (`float`, *optional*, defaults to 0.05):
Percentage (between 0 and 1) of all feature vectors along the time axis which will be masked. The masking
procedure generates ''mask_time_prob*len(time_axis)/mask_time_length'' independent masks over the axis. If
@@ -231,7 +231,7 @@ class SEWConfig(PretrainedConfig):
f"= {len(self.conv_stride)}`, `len(config.conv_kernel) = {len(self.conv_kernel)}`."
)
- # fine-tuning config parameters for SpecAugment: https://arxiv.org/abs/1904.08779
+ # fine-tuning config parameters for SpecAugment: https://huggingface.co/papers/1904.08779
self.apply_spec_augment = apply_spec_augment
self.mask_time_prob = mask_time_prob
self.mask_time_length = mask_time_length
diff --git a/src/transformers/models/sew/modeling_sew.py b/src/transformers/models/sew/modeling_sew.py
index 330cd99a7b..f68e9a2078 100644
--- a/src/transformers/models/sew/modeling_sew.py
+++ b/src/transformers/models/sew/modeling_sew.py
@@ -515,7 +515,7 @@ class SEWEncoder(nn.Module):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = torch.rand([])
skip_the_layer = True if self.training and (dropout_probability < self.config.layerdrop) else False
@@ -635,7 +635,7 @@ def _compute_mask_indices(
) -> np.ndarray:
"""
Computes random mask spans for a given shape. Used to implement [SpecAugment: A Simple Data Augmentation Method for
- ASR](https://arxiv.org/abs/1904.08779). Note that this method is not optimized to run on TPU and should be run on
+ ASR](https://huggingface.co/papers/1904.08779). Note that this method is not optimized to run on TPU and should be run on
CPU as part of the preprocessing during training.
Args:
@@ -775,7 +775,7 @@ class SEWModel(SEWPreTrainedModel):
):
"""
Masks extracted features along time axis and/or along feature axis according to
- [SpecAugment](https://arxiv.org/abs/1904.08779).
+ [SpecAugment](https://huggingface.co/papers/1904.08779).
"""
# `config.apply_spec_augment` can set masking to False
diff --git a/src/transformers/models/sew/modular_sew.py b/src/transformers/models/sew/modular_sew.py
index b3aa3e01b6..1f7d9f1b43 100644
--- a/src/transformers/models/sew/modular_sew.py
+++ b/src/transformers/models/sew/modular_sew.py
@@ -224,7 +224,7 @@ class SEWEncoder(nn.Module):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = torch.rand([])
skip_the_layer = True if self.training and (dropout_probability < self.config.layerdrop) else False
@@ -365,7 +365,7 @@ class SEWModel(SEWPreTrainedModel):
):
"""
Masks extracted features along time axis and/or along feature axis according to
- [SpecAugment](https://arxiv.org/abs/1904.08779).
+ [SpecAugment](https://huggingface.co/papers/1904.08779).
"""
# `config.apply_spec_augment` can set masking to False
diff --git a/src/transformers/models/sew_d/configuration_sew_d.py b/src/transformers/models/sew_d/configuration_sew_d.py
index b965c85662..c23b12f6ac 100644
--- a/src/transformers/models/sew_d/configuration_sew_d.py
+++ b/src/transformers/models/sew_d/configuration_sew_d.py
@@ -109,7 +109,7 @@ class SEWDConfig(PretrainedConfig):
apply_spec_augment (`bool`, *optional*, defaults to `True`):
Whether to apply *SpecAugment* data augmentation to the outputs of the feature encoder. For reference see
[SpecAugment: A Simple Data Augmentation Method for Automatic Speech
- Recognition](https://arxiv.org/abs/1904.08779).
+ Recognition](https://huggingface.co/papers/1904.08779).
mask_time_prob (`float`, *optional*, defaults to 0.05):
Percentage (between 0 and 1) of all feature vectors along the time axis which will be masked. The masking
procedure generates ''mask_time_prob*len(time_axis)/mask_time_length'' independent masks over the axis. If
@@ -258,7 +258,7 @@ class SEWDConfig(PretrainedConfig):
f"= {len(self.conv_stride)}`, `len(config.conv_kernel) = {len(self.conv_kernel)}`."
)
- # fine-tuning config parameters for SpecAugment: https://arxiv.org/abs/1904.08779
+ # fine-tuning config parameters for SpecAugment: https://huggingface.co/papers/1904.08779
self.apply_spec_augment = apply_spec_augment
self.mask_time_prob = mask_time_prob
self.mask_time_length = mask_time_length
diff --git a/src/transformers/models/sew_d/modeling_sew_d.py b/src/transformers/models/sew_d/modeling_sew_d.py
index 27ab17799a..92da0e0935 100644
--- a/src/transformers/models/sew_d/modeling_sew_d.py
+++ b/src/transformers/models/sew_d/modeling_sew_d.py
@@ -49,7 +49,7 @@ def _compute_mask_indices(
) -> np.ndarray:
"""
Computes random mask spans for a given shape. Used to implement [SpecAugment: A Simple Data Augmentation Method for
- ASR](https://arxiv.org/abs/1904.08779). Note that this method is not optimized to run on TPU and should be run on
+ ASR](https://huggingface.co/papers/1904.08779). Note that this method is not optimized to run on TPU and should be run on
CPU as part of the preprocessing during training.
Args:
@@ -1299,7 +1299,7 @@ class SEWDModel(SEWDPreTrainedModel):
):
"""
Masks extracted features along time axis and/or along feature axis according to
- [SpecAugment](https://arxiv.org/abs/1904.08779).
+ [SpecAugment](https://huggingface.co/papers/1904.08779).
"""
# `config.apply_spec_augment` can set masking to False
diff --git a/src/transformers/models/smolvlm/modeling_smolvlm.py b/src/transformers/models/smolvlm/modeling_smolvlm.py
index 5b472cb5c2..090cbd3637 100644
--- a/src/transformers/models/smolvlm/modeling_smolvlm.py
+++ b/src/transformers/models/smolvlm/modeling_smolvlm.py
@@ -75,7 +75,7 @@ class SmolVLMVisionEmbeddings(nn.Module):
This is a modified version of `siglip.modelign_siglip.SiglipVisionEmbeddings` to enable images of variable
resolution.
- The modifications are adapted from [Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution](https://arxiv.org/abs/2307.06304)
+ The modifications are adapted from [Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution](https://huggingface.co/papers/2307.06304)
which allows treating images in their native aspect ratio and without the need to resize them to the same
fixed size. In particular, we start from the original pre-trained SigLIP model
(which uses images of fixed-size square images) and adapt it by training on images of variable resolutions.
diff --git a/src/transformers/models/speech_encoder_decoder/modeling_flax_speech_encoder_decoder.py b/src/transformers/models/speech_encoder_decoder/modeling_flax_speech_encoder_decoder.py
index e266460346..97325f2d66 100644
--- a/src/transformers/models/speech_encoder_decoder/modeling_flax_speech_encoder_decoder.py
+++ b/src/transformers/models/speech_encoder_decoder/modeling_flax_speech_encoder_decoder.py
@@ -46,11 +46,11 @@ SPEECH_ENCODER_DECODER_START_DOCSTRING = r"""
The effectiveness of initializing sequence-to-sequence models with pretrained checkpoints for sequence generation
tasks was shown in [Leveraging Pre-trained Checkpoints for Sequence Generation
- Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn. Michael Matena, Yanqi
+ Tasks](https://huggingface.co/papers/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn. Michael Matena, Yanqi
Zhou, Wei Li, Peter J. Liu.
Additionally, in [Large-Scale Self- and Semi-Supervised Learning for Speech
- Translation](https://arxiv.org/abs/2104.06678) it is shown how leveraging large pretrained speech models for speech
+ Translation](https://huggingface.co/papers/2104.06678) it is shown how leveraging large pretrained speech models for speech
translation yields a significant performance improvement.
After such an Speech-Encoder Decoder model has been trained/fine-tuned, it can be saved/loaded just like any other
diff --git a/src/transformers/models/speech_to_text/configuration_speech_to_text.py b/src/transformers/models/speech_to_text/configuration_speech_to_text.py
index fef4069e4e..27a0995a0b 100644
--- a/src/transformers/models/speech_to_text/configuration_speech_to_text.py
+++ b/src/transformers/models/speech_to_text/configuration_speech_to_text.py
@@ -49,10 +49,10 @@ class Speech2TextConfig(PretrainedConfig):
decoder_attention_heads (`int`, *optional*, defaults to 4):
Number of attention heads for each attention layer in the Transformer decoder.
encoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the encoder. See the [LayerDrop paper](https://arxiv.org/abs/1909.11556) for
+ The LayerDrop probability for the encoder. See the [LayerDrop paper](https://huggingface.co/papers/1909.11556) for
more details.
decoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the decoder. See the [LayerDrop paper](https://arxiv.org/abs/1909.11556) for
+ The LayerDrop probability for the decoder. See the [LayerDrop paper](https://huggingface.co/papers/1909.11556) for
more details.
use_cache (`bool`, *optional*, defaults to `True`):
Whether the model should return the last key/values attentions (not used by all models).
diff --git a/src/transformers/models/speech_to_text/modeling_speech_to_text.py b/src/transformers/models/speech_to_text/modeling_speech_to_text.py
index aa4ea81071..b1c07dba9e 100755
--- a/src/transformers/models/speech_to_text/modeling_speech_to_text.py
+++ b/src/transformers/models/speech_to_text/modeling_speech_to_text.py
@@ -73,7 +73,7 @@ def shift_tokens_right(input_ids: torch.Tensor, pad_token_id: int, decoder_start
class Conv1dSubsampler(nn.Module):
"""
Convolutional subsampler: a stack of 1D convolution (along temporal dimension) followed by non-linear activation
- via gated linear units (https://arxiv.org/abs/1911.08460)
+ via gated linear units (https://huggingface.co/papers/1911.08460)
"""
def __init__(self, config):
@@ -683,7 +683,7 @@ class Speech2TextEncoder(Speech2TextPreTrainedModel):
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
to_drop = False
if self.training:
dropout_probability = torch.rand([])
@@ -931,7 +931,7 @@ class Speech2TextDecoder(Speech2TextPreTrainedModel):
f" {head_mask.size()[0]}."
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
@@ -1141,7 +1141,7 @@ class Speech2TextModel(Speech2TextPreTrainedModel):
If you want to change padding behavior, you should read
[`modeling_speech_to_text._prepare_decoder_attention_mask`] and modify to your needs. See diagram 1 in [the
- paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
+ paper](https://huggingface.co/papers/1910.13461) for more information on the default strategy.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules. Mask values selected in `[0, 1]`:
@@ -1303,7 +1303,7 @@ class Speech2TextForConditionalGeneration(Speech2TextPreTrainedModel, Generation
If you want to change padding behavior, you should read
[`modeling_speech_to_text._prepare_decoder_attention_mask`] and modify to your needs. See diagram 1 in [the
- paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
+ paper](https://huggingface.co/papers/1910.13461) for more information on the default strategy.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules. Mask values selected in `[0, 1]`:
diff --git a/src/transformers/models/speech_to_text/modeling_tf_speech_to_text.py b/src/transformers/models/speech_to_text/modeling_tf_speech_to_text.py
index 858079f5b6..33fe931486 100755
--- a/src/transformers/models/speech_to_text/modeling_tf_speech_to_text.py
+++ b/src/transformers/models/speech_to_text/modeling_tf_speech_to_text.py
@@ -118,7 +118,7 @@ def _expand_mask(mask: tf.Tensor, tgt_len: Optional[int] = None):
class TFConv1dSubsampler(keras.layers.Layer):
"""
Convolutional subsampler: a stack of 1D convolution (along temporal dimension) followed by non-linear activation
- via gated linear units (https://arxiv.org/abs/1911.08460)
+ via gated linear units (https://huggingface.co/papers/1911.08460)
"""
def __init__(self, config: Speech2TextConfig, **kwargs):
@@ -913,7 +913,7 @@ class TFSpeech2TextEncoder(keras.layers.Layer):
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if training and (dropout_probability < self.layerdrop): # skip the layer
continue
@@ -1132,7 +1132,7 @@ class TFSpeech2TextDecoder(keras.layers.Layer):
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
dropout_probability = random.uniform(0, 1)
diff --git a/src/transformers/models/speecht5/configuration_speecht5.py b/src/transformers/models/speecht5/configuration_speecht5.py
index 7af0dc222e..3a0ac5dcc9 100644
--- a/src/transformers/models/speecht5/configuration_speecht5.py
+++ b/src/transformers/models/speecht5/configuration_speecht5.py
@@ -47,7 +47,7 @@ class SpeechT5Config(PretrainedConfig):
encoder_ffn_dim (`int`, *optional*, defaults to 3072):
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
encoder_layerdrop (`float`, *optional*, defaults to 0.1):
- The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
decoder_layers (`int`, *optional*, defaults to 6):
Number of hidden layers in the Transformer decoder.
@@ -56,7 +56,7 @@ class SpeechT5Config(PretrainedConfig):
decoder_ffn_dim (`int`, *optional*, defaults to 3072):
Dimensionality of the "intermediate" (often named feed-forward) layer in the Transformer decoder.
decoder_layerdrop (`float`, *optional*, defaults to 0.1):
- The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
@@ -105,7 +105,7 @@ class SpeechT5Config(PretrainedConfig):
apply_spec_augment (`bool`, *optional*, defaults to `True`):
Whether to apply *SpecAugment* data augmentation to the outputs of the speech encoder pre-net. For
reference see [SpecAugment: A Simple Data Augmentation Method for Automatic Speech
- Recognition](https://arxiv.org/abs/1904.08779).
+ Recognition](https://huggingface.co/papers/1904.08779).
mask_time_prob (`float`, *optional*, defaults to 0.05):
Percentage (between 0 and 1) of all feature vectors along the time axis which will be masked. The masking
procedure generates ''mask_time_prob*len(time_axis)/mask_time_length'' independent masks over the axis. If
@@ -291,7 +291,7 @@ class SpeechT5Config(PretrainedConfig):
f" `len(config.conv_kernel) = {len(self.conv_kernel)}`."
)
- # fine-tuning config parameters for SpecAugment: https://arxiv.org/abs/1904.08779
+ # fine-tuning config parameters for SpecAugment: https://huggingface.co/papers/1904.08779
self.apply_spec_augment = apply_spec_augment
self.mask_time_prob = mask_time_prob
self.mask_time_length = mask_time_length
diff --git a/src/transformers/models/speecht5/modeling_speecht5.py b/src/transformers/models/speecht5/modeling_speecht5.py
index 5004dd037c..9967e2b045 100644
--- a/src/transformers/models/speecht5/modeling_speecht5.py
+++ b/src/transformers/models/speecht5/modeling_speecht5.py
@@ -96,7 +96,7 @@ def _compute_mask_indices(
) -> np.ndarray:
"""
Computes random mask spans for a given shape. Used to implement [SpecAugment: A Simple Data Augmentation Method for
- ASR](https://arxiv.org/abs/1904.08779). Note that this method is not optimized to run on TPU and should be run on
+ ASR](https://huggingface.co/papers/1904.08779). Note that this method is not optimized to run on TPU and should be run on
CPU as part of the preprocessing during training.
Args:
@@ -398,7 +398,7 @@ class SpeechT5PositionalConvEmbedding(nn.Module):
class SpeechT5ScaledPositionalEncoding(nn.Module):
"""
- Scaled positional encoding, see §3.2 in https://arxiv.org/abs/1809.08895
+ Scaled positional encoding, see §3.2 in https://huggingface.co/papers/1809.08895
"""
def __init__(self, dropout, dim, max_len=5000):
@@ -610,7 +610,7 @@ class SpeechT5SpeechEncoderPrenet(nn.Module):
):
"""
Masks extracted features along time axis and/or along feature axis according to
- [SpecAugment](https://arxiv.org/abs/1904.08779).
+ [SpecAugment](https://huggingface.co/papers/1904.08779).
"""
# `config.apply_spec_augment` can set masking to False
@@ -682,7 +682,7 @@ class SpeechT5SpeechDecoderPrenet(nn.Module):
input_values: torch.Tensor,
speaker_embeddings: Optional[torch.Tensor] = None,
):
- # Dropout is always applied, even when evaluating. See §2.2 in https://arxiv.org/abs/1712.05884.
+ # Dropout is always applied, even when evaluating. See §2.2 in https://huggingface.co/papers/1712.05884.
inputs_embeds = input_values
for layer in self.layers:
@@ -1330,7 +1330,7 @@ class SpeechT5Encoder(SpeechT5PreTrainedModel):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
skip_the_layer = False
if self.training:
dropout_probability = torch.rand([])
@@ -1626,7 +1626,7 @@ class SpeechT5Decoder(SpeechT5PreTrainedModel):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
skip_the_layer = False
if self.training:
dropout_probability = torch.rand([])
@@ -1840,7 +1840,7 @@ class SpeechT5DecoderWithoutPrenet(SpeechT5PreTrainedModel):
class SpeechT5GuidedMultiheadAttentionLoss(nn.Module):
"""
Guided attention loss from the paper [Efficiently Trainable Text-to-Speech System Based on Deep Convolutional
- Networks with Guided Attention](https://arxiv.org/abs/1710.08969), adapted for multi-head attention.
+ Networks with Guided Attention](https://huggingface.co/papers/1710.08969), adapted for multi-head attention.
"""
def __init__(self, config: SpeechT5Config):
@@ -2041,7 +2041,7 @@ class SpeechT5Model(SpeechT5PreTrainedModel):
also be used by default.
If you want to change padding behavior, you should read [`SpeechT5Decoder._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules. Mask values selected in `[0, 1]`:
@@ -2206,7 +2206,7 @@ class SpeechT5ForSpeechToText(SpeechT5PreTrainedModel, GenerationMixin):
also be used by default.
If you want to change padding behavior, you should read [`SpeechT5Decoder._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules. Mask values selected in `[0, 1]`:
@@ -2535,7 +2535,7 @@ class SpeechT5ForTextToSpeech(SpeechT5PreTrainedModel):
also be used by default.
If you want to change padding behavior, you should read [`SpeechT5Decoder._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules. Mask values selected in `[0, 1]`:
@@ -2886,7 +2886,7 @@ class SpeechT5ForSpeechToSpeech(SpeechT5PreTrainedModel):
also be used by default.
If you want to change padding behavior, you should read [`SpeechT5Decoder._prepare_decoder_attention_mask`]
- and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ and modify to your needs. See diagram 1 in [the paper](https://huggingface.co/papers/1910.13461) for more
information on the default strategy.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules. Mask values selected in `[0, 1]`:
diff --git a/src/transformers/models/splinter/modeling_splinter.py b/src/transformers/models/splinter/modeling_splinter.py
index 6498947325..372c678edf 100755
--- a/src/transformers/models/splinter/modeling_splinter.py
+++ b/src/transformers/models/splinter/modeling_splinter.py
@@ -537,7 +537,7 @@ class SplinterPreTrainedModel(PreTrainedModel):
class SplinterModel(SplinterPreTrainedModel):
"""
The model is an encoder (with only self-attention) following the architecture described in [Attention is all you
- need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones,
+ need](https://huggingface.co/papers/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones,
Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
"""
diff --git a/src/transformers/models/stablelm/configuration_stablelm.py b/src/transformers/models/stablelm/configuration_stablelm.py
index a30f9510c4..b9a2193aa8 100644
--- a/src/transformers/models/stablelm/configuration_stablelm.py
+++ b/src/transformers/models/stablelm/configuration_stablelm.py
@@ -52,7 +52,7 @@ class StableLmConfig(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to
`num_attention_heads`.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string).
diff --git a/src/transformers/models/starcoder2/configuration_starcoder2.py b/src/transformers/models/starcoder2/configuration_starcoder2.py
index b58e8ddf1a..2e5dad5570 100644
--- a/src/transformers/models/starcoder2/configuration_starcoder2.py
+++ b/src/transformers/models/starcoder2/configuration_starcoder2.py
@@ -51,7 +51,7 @@ class Starcoder2Config(PretrainedConfig):
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `8`.
+ paper](https://huggingface.co/papers/2305.13245). If it is not specified, will default to `8`.
hidden_act (`str` or `function`, *optional*, defaults to `"gelu_pytorch_tanh"`):
The non-linear activation function (function or string) in the decoder.
max_position_embeddings (`int`, *optional*, defaults to 4096):
diff --git a/src/transformers/models/superglue/modeling_superglue.py b/src/transformers/models/superglue/modeling_superglue.py
index 7b1f335f7f..d5d5fbb47f 100644
--- a/src/transformers/models/superglue/modeling_superglue.py
+++ b/src/transformers/models/superglue/modeling_superglue.py
@@ -582,7 +582,7 @@ class SuperGlueForKeypointMatching(SuperGluePreTrainedModel):
Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew
Rabinovich. SuperGlue: Learning Feature Matching with Graph Neural
- Networks. In CVPR, 2020. https://arxiv.org/abs/1911.11763
+ Networks. In CVPR, 2020. https://huggingface.co/papers/1911.11763
"""
def __init__(self, config: SuperGlueConfig) -> None:
diff --git a/src/transformers/models/superpoint/modeling_superpoint.py b/src/transformers/models/superpoint/modeling_superpoint.py
index 58dd7ade98..a0077b3e04 100644
--- a/src/transformers/models/superpoint/modeling_superpoint.py
+++ b/src/transformers/models/superpoint/modeling_superpoint.py
@@ -363,7 +363,7 @@ class SuperPointForKeypointDetection(SuperPointPreTrainedModel):
"""
SuperPoint model. It consists of a SuperPointEncoder, a SuperPointInterestPointDecoder and a
SuperPointDescriptorDecoder. SuperPoint was proposed in `SuperPoint: Self-Supervised Interest Point Detection and
- Description `__ by Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. It
+ Description `__ by Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. It
is a fully convolutional neural network that extracts keypoints and descriptors from an image. It is trained in a
self-supervised manner, using a combination of a photometric loss and a loss based on the homographic adaptation of
keypoints. It is made of a convolutional encoder and two decoders: one for keypoints and one for descriptors.
diff --git a/src/transformers/models/swin/modeling_swin.py b/src/transformers/models/swin/modeling_swin.py
index 31373ec370..72d3b27e45 100644
--- a/src/transformers/models/swin/modeling_swin.py
+++ b/src/transformers/models/swin/modeling_swin.py
@@ -1030,7 +1030,7 @@ class SwinModel(SwinPreTrainedModel):
@auto_docstring(
custom_intro="""
- Swin Model with a decoder on top for masked image modeling, as proposed in [SimMIM](https://arxiv.org/abs/2111.09886).
+ Swin Model with a decoder on top for masked image modeling, as proposed in [SimMIM](https://huggingface.co/papers/2111.09886).
diff --git a/src/transformers/models/swin/modeling_tf_swin.py b/src/transformers/models/swin/modeling_tf_swin.py
index 6929f58c88..a627d133d6 100644
--- a/src/transformers/models/swin/modeling_tf_swin.py
+++ b/src/transformers/models/swin/modeling_tf_swin.py
@@ -1430,7 +1430,7 @@ class TFSwinDecoder(keras.layers.Layer):
@add_start_docstrings(
"Swin Model with a decoder on top for masked image modeling, as proposed in"
- " [SimMIM](https://arxiv.org/abs/2111.09886).",
+ " [SimMIM](https://huggingface.co/papers/2111.09886).",
SWIN_START_DOCSTRING,
)
class TFSwinForMaskedImageModeling(TFSwinPreTrainedModel):
diff --git a/src/transformers/models/swinv2/modeling_swinv2.py b/src/transformers/models/swinv2/modeling_swinv2.py
index ea340d730c..e3ed52baad 100644
--- a/src/transformers/models/swinv2/modeling_swinv2.py
+++ b/src/transformers/models/swinv2/modeling_swinv2.py
@@ -1088,7 +1088,7 @@ class Swinv2Model(Swinv2PreTrainedModel):
@auto_docstring(
custom_intro="""
Swinv2 Model with a decoder on top for masked image modeling, as proposed in
- [SimMIM](https://arxiv.org/abs/2111.09886).
+ [SimMIM](https://huggingface.co/papers/2111.09886).
diff --git a/src/transformers/models/switch_transformers/configuration_switch_transformers.py b/src/transformers/models/switch_transformers/configuration_switch_transformers.py
index 093148f601..1b8d42e1d6 100644
--- a/src/transformers/models/switch_transformers/configuration_switch_transformers.py
+++ b/src/transformers/models/switch_transformers/configuration_switch_transformers.py
@@ -63,7 +63,7 @@ class SwitchTransformersConfig(PretrainedConfig):
Amount of noise to add to the router.
router_dtype (`str`, *optional*, default to `"float32"`):
The `dtype` used for the routers. It is preferable to keep the `dtype` to `"float32"` as specified in the
- *selective precision* discussion in [the paper](https://arxiv.org/abs/2101.03961).
+ *selective precision* discussion in [the paper](https://huggingface.co/papers/2101.03961).
router_ignore_padding_tokens (`bool`, *optional*, defaults to `False`):
Whether to ignore padding tokens when routing.
relative_attention_num_buckets (`int`, *optional*, defaults to 32):
diff --git a/src/transformers/models/switch_transformers/modeling_switch_transformers.py b/src/transformers/models/switch_transformers/modeling_switch_transformers.py
index d2db7781d2..b4694d3e32 100644
--- a/src/transformers/models/switch_transformers/modeling_switch_transformers.py
+++ b/src/transformers/models/switch_transformers/modeling_switch_transformers.py
@@ -66,7 +66,7 @@ def router_z_loss_func(router_logits: torch.Tensor) -> float:
r"""
Compute the router z-loss implemented in PyTorch.
- The router z-loss was introduced in [Designing Effective Sparse Expert Models](https://arxiv.org/abs/2202.08906).
+ The router z-loss was introduced in [Designing Effective Sparse Expert Models](https://huggingface.co/papers/2202.08906).
It encourages router logits to remain small in an effort to improve stability.
Args:
@@ -86,7 +86,7 @@ def load_balancing_loss_func(router_probs: torch.Tensor, expert_indices: torch.T
r"""
Computes auxiliary load balancing loss as in Switch Transformer - implemented in Pytorch.
- See Switch Transformer (https://arxiv.org/abs/2101.03961) for more details. This function implements the loss
+ See Switch Transformer (https://huggingface.co/papers/2101.03961) for more details. This function implements the loss
function presented in equations (4) - (6) of the paper. It aims at penalizing cases where the routing between
experts is too unbalanced.
@@ -125,8 +125,8 @@ class SwitchTransformersTop1Router(nn.Module):
"""
Router using tokens choose top-1 experts assignment.
- This router uses the same mechanism as in Switch Transformer (https://arxiv.org/abs/2101.03961) and V-MoE
- (https://arxiv.org/abs/2106.05974): tokens choose their top experts. Items are sorted by router_probs and then
+ This router uses the same mechanism as in Switch Transformer (https://huggingface.co/papers/2101.03961) and V-MoE
+ (https://huggingface.co/papers/2106.05974): tokens choose their top experts. Items are sorted by router_probs and then
routed to their choice of expert until the expert's expert_capacity is reached. **There is no guarantee that each
token is processed by an expert**, or that each expert receives at least one token.
@@ -157,7 +157,7 @@ class SwitchTransformersTop1Router(nn.Module):
This is used later for computing router z-loss.
"""
# float32 is used to ensure stability. See the discussion of "selective precision" in
- # https://arxiv.org/abs/2101.03961.
+ # https://huggingface.co/papers/2101.03961.
# We also store the previous dtype to cast back the output to the previous dtype
self.input_dtype = hidden_states.dtype
hidden_states = hidden_states.to(self.dtype)
@@ -226,7 +226,7 @@ class SwitchTransformersLayerNorm(nn.Module):
def forward(self, hidden_states):
# SwitchTransformers uses a layer_norm which only scales and doesn't shift, which is also known as Root Mean
- # Square Layer Normalization https://arxiv.org/abs/1910.07467 thus variance is calculated
+ # Square Layer Normalization https://huggingface.co/papers/1910.07467 thus variance is calculated
# w/o mean and there is no bias. Additionally we want to make sure that the accumulation for
# half-precision inputs is done in fp32
diff --git a/src/transformers/models/t5/modeling_flax_t5.py b/src/transformers/models/t5/modeling_flax_t5.py
index 1fa8da5c2d..b5ce477682 100644
--- a/src/transformers/models/t5/modeling_flax_t5.py
+++ b/src/transformers/models/t5/modeling_flax_t5.py
@@ -850,7 +850,7 @@ T5_DECODE_INPUTS_DOCSTRING = r"""
be used by default.
If you want to change padding behavior, you should modify to your needs. See diagram 1 in [the
- paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
+ paper](https://huggingface.co/papers/1910.13461) for more information on the default strategy.
past_key_values (`Dict[str, np.ndarray]`, *optional*, returned by `init_cache` or when passing previous `past_key_values`):
Dictionary of pre-computed hidden-states (key and values in the attention blocks) that can be used for fast
auto-regressive decoding. Pre-computed key and value hidden-states are of shape *[batch_size, max_length]*.
@@ -1232,7 +1232,7 @@ class FlaxT5PreTrainedModel(FlaxPreTrainedModel):
T5_START_DOCSTRING = r"""
The T5 model was proposed in [Exploring the Limits of Transfer Learning with a Unified Text-to-Text
- Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan
+ Transformer](https://huggingface.co/papers/1910.10683) by Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan
Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu. It's an encoder decoder transformer pre-trained in a
text-to-text denoising generative setting.
diff --git a/src/transformers/models/t5/modeling_t5.py b/src/transformers/models/t5/modeling_t5.py
index 466b725bce..94c90dbfe0 100644
--- a/src/transformers/models/t5/modeling_t5.py
+++ b/src/transformers/models/t5/modeling_t5.py
@@ -246,7 +246,7 @@ class T5LayerNorm(nn.Module):
def forward(self, hidden_states):
# T5 uses a layer_norm which only scales and doesn't shift, which is also known as Root Mean
- # Square Layer Normalization https://arxiv.org/abs/1910.07467 thus variance is calculated
+ # Square Layer Normalization https://huggingface.co/papers/1910.07467 thus variance is calculated
# w/o mean and there is no bias. Additionally we want to make sure that the accumulation for
# half-precision inputs is done in fp32
diff --git a/src/transformers/models/t5/modeling_tf_t5.py b/src/transformers/models/t5/modeling_tf_t5.py
index 84f5b2a636..ab25938bb0 100644
--- a/src/transformers/models/t5/modeling_tf_t5.py
+++ b/src/transformers/models/t5/modeling_tf_t5.py
@@ -990,7 +990,7 @@ class TFT5PreTrainedModel(TFPreTrainedModel):
T5_START_DOCSTRING = r"""
The T5 model was proposed in [Exploring the Limits of Transfer Learning with a Unified Text-to-Text
- Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan
+ Transformer](https://huggingface.co/papers/1910.10683) by Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan
Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu. It's an encoder decoder transformer pre-trained in a
text-to-text denoising generative setting.
diff --git a/src/transformers/models/table_transformer/configuration_table_transformer.py b/src/transformers/models/table_transformer/configuration_table_transformer.py
index 39eef3fced..6c091f5ef7 100644
--- a/src/transformers/models/table_transformer/configuration_table_transformer.py
+++ b/src/transformers/models/table_transformer/configuration_table_transformer.py
@@ -79,10 +79,10 @@ class TableTransformerConfig(PretrainedConfig):
init_xavier_std (`float`, *optional*, defaults to 1):
The scaling factor used for the Xavier initialization gain in the HM Attention map module.
encoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
decoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
auxiliary_loss (`bool`, *optional*, defaults to `False`):
Whether auxiliary decoding losses (loss at each decoder layer) are to be used.
diff --git a/src/transformers/models/table_transformer/modeling_table_transformer.py b/src/transformers/models/table_transformer/modeling_table_transformer.py
index 7793331bf2..d86966a82d 100644
--- a/src/transformers/models/table_transformer/modeling_table_transformer.py
+++ b/src/transformers/models/table_transformer/modeling_table_transformer.py
@@ -835,7 +835,7 @@ class TableTransformerEncoder(TableTransformerPreTrainedModel):
for encoder_layer in self.layers:
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
to_drop = False
if self.training:
dropout_probability = torch.rand([])
@@ -981,7 +981,7 @@ class TableTransformerDecoder(TableTransformerPreTrainedModel):
all_cross_attentions = () if (output_attentions and encoder_hidden_states is not None) else None
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
diff --git a/src/transformers/models/tapas/modeling_tapas.py b/src/transformers/models/tapas/modeling_tapas.py
index 35295ebf88..5ac999f3ca 100644
--- a/src/transformers/models/tapas/modeling_tapas.py
+++ b/src/transformers/models/tapas/modeling_tapas.py
@@ -729,7 +729,7 @@ class TapasModel(TapasPreTrainedModel):
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in [Attention is
- all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
+ all you need](https://huggingface.co/papers/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
"""
diff --git a/src/transformers/models/time_series_transformer/modeling_time_series_transformer.py b/src/transformers/models/time_series_transformer/modeling_time_series_transformer.py
index dc960efbbc..d610148911 100644
--- a/src/transformers/models/time_series_transformer/modeling_time_series_transformer.py
+++ b/src/transformers/models/time_series_transformer/modeling_time_series_transformer.py
@@ -847,7 +847,7 @@ class TimeSeriesTransformerEncoder(TimeSeriesTransformerPreTrainedModel):
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
to_drop = False
if self.training:
dropout_probability = torch.rand([])
@@ -1058,7 +1058,7 @@ class TimeSeriesTransformerDecoder(TimeSeriesTransformerPreTrainedModel):
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
diff --git a/src/transformers/models/trocr/configuration_trocr.py b/src/transformers/models/trocr/configuration_trocr.py
index 6c3aabbe19..c7d1e316b1 100644
--- a/src/transformers/models/trocr/configuration_trocr.py
+++ b/src/transformers/models/trocr/configuration_trocr.py
@@ -59,7 +59,7 @@ class TrOCRConfig(PretrainedConfig):
init_std (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
decoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models).
diff --git a/src/transformers/models/trocr/modeling_trocr.py b/src/transformers/models/trocr/modeling_trocr.py
index 152243da08..7a75ffcbea 100644
--- a/src/transformers/models/trocr/modeling_trocr.py
+++ b/src/transformers/models/trocr/modeling_trocr.py
@@ -633,7 +633,7 @@ class TrOCRDecoder(TrOCRPreTrainedModel):
f" {head_mask.size()[0]}."
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
diff --git a/src/transformers/models/udop/modeling_udop.py b/src/transformers/models/udop/modeling_udop.py
index 9089c2daa8..537f87641c 100644
--- a/src/transformers/models/udop/modeling_udop.py
+++ b/src/transformers/models/udop/modeling_udop.py
@@ -351,7 +351,7 @@ class UdopLayerNorm(nn.Module):
def forward(self, hidden_states):
# Udop uses a layer_norm which only scales and doesn't shift, which is also known as Root Mean
- # Square Layer Normalization https://arxiv.org/abs/1910.07467 thus variance is calculated
+ # Square Layer Normalization https://huggingface.co/papers/1910.07467 thus variance is calculated
# w/o mean and there is no bias. Additionally we want to make sure that the accumulation for
# half-precision inputs is done in fp32
diff --git a/src/transformers/models/umt5/modeling_umt5.py b/src/transformers/models/umt5/modeling_umt5.py
index e45d63aba7..f8bc1642c3 100644
--- a/src/transformers/models/umt5/modeling_umt5.py
+++ b/src/transformers/models/umt5/modeling_umt5.py
@@ -68,7 +68,7 @@ class UMT5LayerNorm(nn.Module):
def forward(self, hidden_states):
# UMT5 uses a layer_norm which only scales and doesn't shift, which is also known as Root Mean
- # Square Layer Normalization https://arxiv.org/abs/1910.07467 thus variance is calculated
+ # Square Layer Normalization https://huggingface.co/papers/1910.07467 thus variance is calculated
# w/o mean and there is no bias. Additionally we want to make sure that the accumulation for
# half-precision inputs is done in fp32
diff --git a/src/transformers/models/unispeech/configuration_unispeech.py b/src/transformers/models/unispeech/configuration_unispeech.py
index 8ddf93edbe..f304e566e8 100644
--- a/src/transformers/models/unispeech/configuration_unispeech.py
+++ b/src/transformers/models/unispeech/configuration_unispeech.py
@@ -65,7 +65,7 @@ class UniSpeechConfig(PretrainedConfig):
final_dropout (`float`, *optional*, defaults to 0.1):
The dropout probability for the final projection layer of [`UniSpeechForCTC`].
layerdrop (`float`, *optional*, defaults to 0.1):
- The LayerDrop probability. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556) for more
+ The LayerDrop probability. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556) for more
details.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
@@ -102,7 +102,7 @@ class UniSpeechConfig(PretrainedConfig):
apply_spec_augment (`bool`, *optional*, defaults to `True`):
Whether to apply *SpecAugment* data augmentation to the outputs of the feature encoder. For reference see
[SpecAugment: A Simple Data Augmentation Method for Automatic Speech
- Recognition](https://arxiv.org/abs/1904.08779).
+ Recognition](https://huggingface.co/papers/1904.08779).
mask_time_prob (`float`, *optional*, defaults to 0.05):
Percentage (between 0 and 1) of all feature vectors along the time axis which will be masked. The masking
procedure generates ''mask_time_prob*len(time_axis)/mask_time_length'' independent masks over the axis. If
@@ -275,7 +275,7 @@ class UniSpeechConfig(PretrainedConfig):
f" `len(config.conv_kernel) = {len(self.conv_kernel)}`."
)
- # fine-tuning config parameters for SpecAugment: https://arxiv.org/abs/1904.08779
+ # fine-tuning config parameters for SpecAugment: https://huggingface.co/papers/1904.08779
self.apply_spec_augment = apply_spec_augment
self.mask_time_prob = mask_time_prob
self.mask_time_length = mask_time_length
diff --git a/src/transformers/models/unispeech/modeling_unispeech.py b/src/transformers/models/unispeech/modeling_unispeech.py
index 4fdce328e9..4f5fa3805a 100755
--- a/src/transformers/models/unispeech/modeling_unispeech.py
+++ b/src/transformers/models/unispeech/modeling_unispeech.py
@@ -62,7 +62,7 @@ class UniSpeechForPreTrainingOutput(ModelOutput):
Args:
loss (*optional*, returned when model is in train mode, `torch.FloatTensor` of shape `(1,)`):
Total loss as the sum of the contrastive loss (L_m) and the diversity loss (L_d) as stated in the [official
- paper](https://arxiv.org/pdf/2006.11477.pdf) . (classification) loss.
+ paper](https://huggingface.co/papers/2006.11477) . (classification) loss.
projected_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.proj_codevector_dim)`):
Hidden-states of the model projected to *config.proj_codevector_dim* that can be used to predict the masked
projected quantized states.
@@ -534,7 +534,7 @@ class UniSpeechEncoder(nn.Module):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = torch.rand([])
skip_the_layer = True if self.training and (dropout_probability < self.config.layerdrop) else False
@@ -707,7 +707,7 @@ class UniSpeechEncoderStableLayerNorm(nn.Module):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = torch.rand([])
skip_the_layer = True if self.training and (dropout_probability < self.config.layerdrop) else False
@@ -772,7 +772,7 @@ class UniSpeechEncoderStableLayerNorm(nn.Module):
class UniSpeechGumbelVectorQuantizer(nn.Module):
"""
Vector quantization using gumbel softmax. See `[CATEGORICAL REPARAMETERIZATION WITH
- GUMBEL-SOFTMAX](https://arxiv.org/pdf/1611.01144.pdf) for more information.
+ GUMBEL-SOFTMAX](https://huggingface.co/papers/1611.01144) for more information.
"""
def __init__(self, config):
@@ -922,7 +922,7 @@ def _compute_mask_indices(
) -> np.ndarray:
"""
Computes random mask spans for a given shape. Used to implement [SpecAugment: A Simple Data Augmentation Method for
- ASR](https://arxiv.org/abs/1904.08779). Note that this method is not optimized to run on TPU and should be run on
+ ASR](https://huggingface.co/papers/1904.08779). Note that this method is not optimized to run on TPU and should be run on
CPU as part of the preprocessing during training.
Args:
@@ -1062,7 +1062,7 @@ class UniSpeechModel(UniSpeechPreTrainedModel):
):
"""
Masks extracted features along time axis and/or along feature axis according to
- [SpecAugment](https://arxiv.org/abs/1904.08779).
+ [SpecAugment](https://huggingface.co/papers/1904.08779).
"""
# `config.apply_spec_augment` can set masking to False
diff --git a/src/transformers/models/unispeech/modular_unispeech.py b/src/transformers/models/unispeech/modular_unispeech.py
index 5a9133089a..884e031d26 100644
--- a/src/transformers/models/unispeech/modular_unispeech.py
+++ b/src/transformers/models/unispeech/modular_unispeech.py
@@ -50,7 +50,7 @@ class UniSpeechForPreTrainingOutput(ModelOutput):
Args:
loss (*optional*, returned when model is in train mode, `torch.FloatTensor` of shape `(1,)`):
Total loss as the sum of the contrastive loss (L_m) and the diversity loss (L_d) as stated in the [official
- paper](https://arxiv.org/pdf/2006.11477.pdf) . (classification) loss.
+ paper](https://huggingface.co/papers/2006.11477) . (classification) loss.
projected_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.proj_codevector_dim)`):
Hidden-states of the model projected to *config.proj_codevector_dim* that can be used to predict the masked
projected quantized states.
diff --git a/src/transformers/models/unispeech_sat/configuration_unispeech_sat.py b/src/transformers/models/unispeech_sat/configuration_unispeech_sat.py
index de81639d62..24996c825e 100644
--- a/src/transformers/models/unispeech_sat/configuration_unispeech_sat.py
+++ b/src/transformers/models/unispeech_sat/configuration_unispeech_sat.py
@@ -66,7 +66,7 @@ class UniSpeechSatConfig(PretrainedConfig):
final_dropout (`float`, *optional*, defaults to 0.1):
The dropout probability for the final projection layer of [`UniSpeechSatForCTC`].
layerdrop (`float`, *optional*, defaults to 0.1):
- The LayerDrop probability. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556) for more
+ The LayerDrop probability. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556) for more
details.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
@@ -103,7 +103,7 @@ class UniSpeechSatConfig(PretrainedConfig):
apply_spec_augment (`bool`, *optional*, defaults to `True`):
Whether to apply *SpecAugment* data augmentation to the outputs of the feature encoder. For reference see
[SpecAugment: A Simple Data Augmentation Method for Automatic Speech
- Recognition](https://arxiv.org/abs/1904.08779).
+ Recognition](https://huggingface.co/papers/1904.08779).
mask_time_prob (`float`, *optional*, defaults to 0.05):
Percentage (between 0 and 1) of all feature vectors along the time axis which will be masked. The masking
procedure generates ''mask_time_prob*len(time_axis)/mask_time_length'' independent masks over the axis. If
@@ -287,7 +287,7 @@ class UniSpeechSatConfig(PretrainedConfig):
f" `len(config.conv_kernel) = {len(self.conv_kernel)}`."
)
- # fine-tuning config parameters for SpecAugment: https://arxiv.org/abs/1904.08779
+ # fine-tuning config parameters for SpecAugment: https://huggingface.co/papers/1904.08779
self.apply_spec_augment = apply_spec_augment
self.mask_time_prob = mask_time_prob
self.mask_time_length = mask_time_length
diff --git a/src/transformers/models/unispeech_sat/modeling_unispeech_sat.py b/src/transformers/models/unispeech_sat/modeling_unispeech_sat.py
index 50ee4c198d..1a84b2e6d2 100755
--- a/src/transformers/models/unispeech_sat/modeling_unispeech_sat.py
+++ b/src/transformers/models/unispeech_sat/modeling_unispeech_sat.py
@@ -64,7 +64,7 @@ class UniSpeechSatForPreTrainingOutput(ModelOutput):
Args:
loss (*optional*, returned when model is in train mode, `torch.FloatTensor` of shape `(1,)`):
Total loss as the sum of the contrastive loss (L_m) and the diversity loss (L_d) as stated in the [official
- paper](https://arxiv.org/pdf/2006.11477.pdf) . (classification) loss.
+ paper](https://huggingface.co/papers/2006.11477) . (classification) loss.
projected_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.proj_codevector_dim)`):
Hidden-states of the model projected to *config.proj_codevector_dim* that can be used to predict the masked
projected quantized states.
@@ -537,7 +537,7 @@ class UniSpeechSatEncoder(nn.Module):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = torch.rand([])
skip_the_layer = True if self.training and (dropout_probability < self.config.layerdrop) else False
@@ -710,7 +710,7 @@ class UniSpeechSatEncoderStableLayerNorm(nn.Module):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = torch.rand([])
skip_the_layer = True if self.training and (dropout_probability < self.config.layerdrop) else False
@@ -775,7 +775,7 @@ class UniSpeechSatEncoderStableLayerNorm(nn.Module):
class UniSpeechSatGumbelVectorQuantizer(nn.Module):
"""
Vector quantization using gumbel softmax. See `[CATEGORICAL REPARAMETERIZATION WITH
- GUMBEL-SOFTMAX](https://arxiv.org/pdf/1611.01144.pdf) for more information.
+ GUMBEL-SOFTMAX](https://huggingface.co/papers/1611.01144) for more information.
"""
def __init__(self, config):
@@ -925,7 +925,7 @@ def _compute_mask_indices(
) -> np.ndarray:
"""
Computes random mask spans for a given shape. Used to implement [SpecAugment: A Simple Data Augmentation Method for
- ASR](https://arxiv.org/abs/1904.08779). Note that this method is not optimized to run on TPU and should be run on
+ ASR](https://huggingface.co/papers/1904.08779). Note that this method is not optimized to run on TPU and should be run on
CPU as part of the preprocessing during training.
Args:
@@ -1064,7 +1064,7 @@ class UniSpeechSatModel(UniSpeechSatPreTrainedModel):
):
"""
Masks extracted features along time axis and/or along feature axis according to
- [SpecAugment](https://arxiv.org/abs/1904.08779).
+ [SpecAugment](https://huggingface.co/papers/1904.08779).
"""
# `config.apply_spec_augment` can set masking to False
diff --git a/src/transformers/models/unispeech_sat/modular_unispeech_sat.py b/src/transformers/models/unispeech_sat/modular_unispeech_sat.py
index f86c397a04..57e8da9e4d 100644
--- a/src/transformers/models/unispeech_sat/modular_unispeech_sat.py
+++ b/src/transformers/models/unispeech_sat/modular_unispeech_sat.py
@@ -55,7 +55,7 @@ class UniSpeechSatForPreTrainingOutput(ModelOutput):
Args:
loss (*optional*, returned when model is in train mode, `torch.FloatTensor` of shape `(1,)`):
Total loss as the sum of the contrastive loss (L_m) and the diversity loss (L_d) as stated in the [official
- paper](https://arxiv.org/pdf/2006.11477.pdf) . (classification) loss.
+ paper](https://huggingface.co/papers/2006.11477) . (classification) loss.
projected_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.proj_codevector_dim)`):
Hidden-states of the model projected to *config.proj_codevector_dim* that can be used to predict the masked
projected quantized states.
diff --git a/src/transformers/models/univnet/modeling_univnet.py b/src/transformers/models/univnet/modeling_univnet.py
index e000aecbc4..712b531e5e 100644
--- a/src/transformers/models/univnet/modeling_univnet.py
+++ b/src/transformers/models/univnet/modeling_univnet.py
@@ -277,7 +277,7 @@ class UnivNetLvcResidualBlock(nn.Module):
"""
Performs location-variable convolution operation on the input sequence (hidden_states) using the local
convolution kernel. This was introduced in [LVCNet: Efficient Condition-Dependent Modeling Network for Waveform
- Generation](https://arxiv.org/abs/2102.10815) by Zhen Zheng, Jianzong Wang, Ning Cheng, and Jing Xiao.
+ Generation](https://huggingface.co/papers/2102.10815) by Zhen Zheng, Jianzong Wang, Ning Cheng, and Jing Xiao.
Time: 414 μs ± 309 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each), test on NVIDIA V100.
diff --git a/src/transformers/models/upernet/modeling_upernet.py b/src/transformers/models/upernet/modeling_upernet.py
index 1e192be807..9954555f1f 100644
--- a/src/transformers/models/upernet/modeling_upernet.py
+++ b/src/transformers/models/upernet/modeling_upernet.py
@@ -120,7 +120,7 @@ class UperNetPyramidPoolingModule(nn.Module):
class UperNetHead(nn.Module):
"""
Unified Perceptual Parsing for Scene Understanding. This head is the implementation of
- [UPerNet](https://arxiv.org/abs/1807.10221).
+ [UPerNet](https://huggingface.co/papers/1807.10221).
"""
def __init__(self, config, in_channels):
@@ -204,7 +204,7 @@ class UperNetHead(nn.Module):
class UperNetFCNHead(nn.Module):
"""
Fully Convolution Networks for Semantic Segmentation. This head is the implementation of
- [FCNNet](https://arxiv.org/abs/1411.4038>).
+ [FCNNet](https://huggingface.co/papers/1411.4038>).
Args:
config:
diff --git a/src/transformers/models/vision_encoder_decoder/modeling_flax_vision_encoder_decoder.py b/src/transformers/models/vision_encoder_decoder/modeling_flax_vision_encoder_decoder.py
index 4d96a68bc1..53424220e8 100644
--- a/src/transformers/models/vision_encoder_decoder/modeling_flax_vision_encoder_decoder.py
+++ b/src/transformers/models/vision_encoder_decoder/modeling_flax_vision_encoder_decoder.py
@@ -46,11 +46,11 @@ VISION_ENCODER_DECODER_START_DOCSTRING = r"""
The effectiveness of initializing sequence-to-sequence models with pretrained checkpoints for sequence generation
tasks was shown in [Leveraging Pre-trained Checkpoints for Sequence Generation
- Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn. Michael Matena, Yanqi
+ Tasks](https://huggingface.co/papers/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn. Michael Matena, Yanqi
Zhou, Wei Li, Peter J. Liu.
Additionally, in [TrOCR: Transformer-based Optical Character Recognition with Pre-trained
- Models](https://arxiv.org/abs/2109.10282) it is shown how leveraging large pretrained vision models for optical
+ Models](https://huggingface.co/papers/2109.10282) it is shown how leveraging large pretrained vision models for optical
character recognition (OCR) yields a significant performance improvement.
After such a Vision-Encoder-Text-Decoder model has been trained/fine-tuned, it can be saved/loaded just like any
diff --git a/src/transformers/models/vision_encoder_decoder/modeling_tf_vision_encoder_decoder.py b/src/transformers/models/vision_encoder_decoder/modeling_tf_vision_encoder_decoder.py
index 29d855728a..f8597701a8 100644
--- a/src/transformers/models/vision_encoder_decoder/modeling_tf_vision_encoder_decoder.py
+++ b/src/transformers/models/vision_encoder_decoder/modeling_tf_vision_encoder_decoder.py
@@ -59,11 +59,11 @@ VISION_ENCODER_DECODER_START_DOCSTRING = r"""
The effectiveness of initializing sequence-to-sequence models with pretrained checkpoints for sequence generation
tasks was shown in [Leveraging Pre-trained Checkpoints for Sequence Generation
- Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn. Michael Matena, Yanqi
+ Tasks](https://huggingface.co/papers/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn. Michael Matena, Yanqi
Zhou, Wei Li, Peter J. Liu.
Additionally, in [TrOCR: Transformer-based Optical Character Recognition with Pre-trained
- Models](https://arxiv.org/abs/2109.10282) it is shown how leveraging large pretrained vision models for optical
+ Models](https://huggingface.co/papers/2109.10282) it is shown how leveraging large pretrained vision models for optical
character recognition (OCR) yields a significant performance improvement.
After such a Vision-Encoder-Text-Decoder model has been trained/fine-tuned, it can be saved/loaded just like any
diff --git a/src/transformers/models/vision_text_dual_encoder/modeling_flax_vision_text_dual_encoder.py b/src/transformers/models/vision_text_dual_encoder/modeling_flax_vision_text_dual_encoder.py
index 020efb3c5c..fca25c0429 100644
--- a/src/transformers/models/vision_text_dual_encoder/modeling_flax_vision_text_dual_encoder.py
+++ b/src/transformers/models/vision_text_dual_encoder/modeling_flax_vision_text_dual_encoder.py
@@ -40,7 +40,7 @@ VISION_TEXT_DUAL_ENCODER_START_DOCSTRING = r"""
via the [`~FlaxAutoModel.from_pretrained`] method. The projection layers are automatically added to the model and
should be fine-tuned on a downstream task, like contrastive image-text modeling.
- In [LiT: Zero-Shot Transfer with Locked-image Text Tuning](https://arxiv.org/abs/2111.07991) it is shown how
+ In [LiT: Zero-Shot Transfer with Locked-image Text Tuning](https://huggingface.co/papers/2111.07991) it is shown how
leveraging pre-trained (locked/frozen) image and text model for contrastive learning yields significant improvement
on new zero-shot vision tasks such as image classification or retrieval.
diff --git a/src/transformers/models/vision_text_dual_encoder/modeling_tf_vision_text_dual_encoder.py b/src/transformers/models/vision_text_dual_encoder/modeling_tf_vision_text_dual_encoder.py
index 6ce382a74b..7d4b9613ae 100644
--- a/src/transformers/models/vision_text_dual_encoder/modeling_tf_vision_text_dual_encoder.py
+++ b/src/transformers/models/vision_text_dual_encoder/modeling_tf_vision_text_dual_encoder.py
@@ -47,7 +47,7 @@ VISION_TEXT_DUAL_ENCODER_START_DOCSTRING = r"""
via the [`~TFAutoModel.from_pretrained`] method. The projection layers are automatically added to the model and
should be fine-tuned on a downstream task, like contrastive image-text modeling.
- In [LiT: Zero-Shot Transfer with Locked-image Text Tuning](https://arxiv.org/abs/2111.07991) it is shown how
+ In [LiT: Zero-Shot Transfer with Locked-image Text Tuning](https://huggingface.co/papers/2111.07991) it is shown how
leveraging pre-trained (locked/frozen) image and text model for contrastive learning yields significant improvement
on new zero-shot vision tasks such as image classification or retrieval.
diff --git a/src/transformers/models/visual_bert/modeling_visual_bert.py b/src/transformers/models/visual_bert/modeling_visual_bert.py
index da46d412e6..84e375ad22 100755
--- a/src/transformers/models/visual_bert/modeling_visual_bert.py
+++ b/src/transformers/models/visual_bert/modeling_visual_bert.py
@@ -556,7 +556,7 @@ class VisualBertForPreTrainingOutput(ModelOutput):
@auto_docstring(
custom_intro="""
The model can behave as an encoder (with only self-attention) following the architecture described in [Attention is
- all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
+ all you need](https://huggingface.co/papers/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
"""
)
diff --git a/src/transformers/models/vit/modeling_vit.py b/src/transformers/models/vit/modeling_vit.py
index e8a9958fc5..b057958166 100644
--- a/src/transformers/models/vit/modeling_vit.py
+++ b/src/transformers/models/vit/modeling_vit.py
@@ -593,7 +593,7 @@ class ViTPooler(nn.Module):
@auto_docstring(
custom_intro="""
- ViT Model with a decoder on top for masked image modeling, as proposed in [SimMIM](https://arxiv.org/abs/2111.09886).
+ ViT Model with a decoder on top for masked image modeling, as proposed in [SimMIM](https://huggingface.co/papers/2111.09886).
diff --git a/src/transformers/models/vits/configuration_vits.py b/src/transformers/models/vits/configuration_vits.py
index 6de2591b0f..2d33601885 100644
--- a/src/transformers/models/vits/configuration_vits.py
+++ b/src/transformers/models/vits/configuration_vits.py
@@ -48,7 +48,7 @@ class VitsConfig(PretrainedConfig):
ffn_dim (`int`, *optional*, defaults to 768):
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
layerdrop (`float`, *optional*, defaults to 0.1):
- The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
ffn_kernel_size (`int`, *optional*, defaults to 3):
Kernel size of the 1D convolution layers used by the feed-forward network in the Transformer encoder.
diff --git a/src/transformers/models/vits/modeling_vits.py b/src/transformers/models/vits/modeling_vits.py
index 3acca4036b..ac95b93331 100644
--- a/src/transformers/models/vits/modeling_vits.py
+++ b/src/transformers/models/vits/modeling_vits.py
@@ -1139,7 +1139,7 @@ class VitsEncoder(nn.Module):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = np.random.uniform(0, 1)
skip_the_layer = self.training and (dropout_probability < self.layerdrop)
diff --git a/src/transformers/models/wav2vec2/configuration_wav2vec2.py b/src/transformers/models/wav2vec2/configuration_wav2vec2.py
index b1702ae22e..4598e7c255 100644
--- a/src/transformers/models/wav2vec2/configuration_wav2vec2.py
+++ b/src/transformers/models/wav2vec2/configuration_wav2vec2.py
@@ -61,7 +61,7 @@ class Wav2Vec2Config(PretrainedConfig):
final_dropout (`float`, *optional*, defaults to 0.1):
The dropout probability for the final projection layer of [`Wav2Vec2ForCTC`].
layerdrop (`float`, *optional*, defaults to 0.1):
- The LayerDrop probability. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556) for more
+ The LayerDrop probability. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556) for more
details.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
@@ -102,7 +102,7 @@ class Wav2Vec2Config(PretrainedConfig):
apply_spec_augment (`bool`, *optional*, defaults to `True`):
Whether to apply *SpecAugment* data augmentation to the outputs of the feature encoder. For reference see
[SpecAugment: A Simple Data Augmentation Method for Automatic Speech
- Recognition](https://arxiv.org/abs/1904.08779).
+ Recognition](https://huggingface.co/papers/1904.08779).
mask_time_prob (`float`, *optional*, defaults to 0.05):
Percentage (between 0 and 1) of all feature vectors along the time axis which will be masked. The masking
procedure generates ''mask_time_prob*len(time_axis)/mask_time_length'' independent masks over the axis. If
@@ -299,7 +299,7 @@ class Wav2Vec2Config(PretrainedConfig):
f" `len(config.conv_kernel) = {len(self.conv_kernel)}`."
)
- # fine-tuning config parameters for SpecAugment: https://arxiv.org/abs/1904.08779
+ # fine-tuning config parameters for SpecAugment: https://huggingface.co/papers/1904.08779
self.apply_spec_augment = apply_spec_augment
self.mask_time_prob = mask_time_prob
self.mask_time_length = mask_time_length
diff --git a/src/transformers/models/wav2vec2/modeling_flax_wav2vec2.py b/src/transformers/models/wav2vec2/modeling_flax_wav2vec2.py
index ee188888d7..b4127201d2 100644
--- a/src/transformers/models/wav2vec2/modeling_flax_wav2vec2.py
+++ b/src/transformers/models/wav2vec2/modeling_flax_wav2vec2.py
@@ -79,7 +79,7 @@ class FlaxWav2Vec2ForPreTrainingOutput(ModelOutput):
Args:
loss (*optional*, returned when model is in train mode, `jnp.ndarray` of shape `(1,)`):
Total loss as the sum of the contrastive loss (L_m) and the diversity loss (L_d) as stated in the [official
- paper](https://arxiv.org/pdf/2006.11477.pdf) . (classification) loss.
+ paper](https://huggingface.co/papers/2006.11477) . (classification) loss.
projected_states (`jnp.ndarray` of shape `(batch_size, sequence_length, config.proj_codevector_dim)`):
Hidden-states of the model projected to *config.proj_codevector_dim* that can be used to predict the masked
projected quantized states.
@@ -115,7 +115,7 @@ def _compute_mask_indices(
) -> np.ndarray:
"""
Computes random mask spans for a given shape. Used to implement [SpecAugment: A Simple Data Augmentation Method for
- ASR](https://arxiv.org/abs/1904.08779). Note that this method is not optimized to run on TPU and should be run on
+ ASR](https://huggingface.co/papers/1904.08779). Note that this method is not optimized to run on TPU and should be run on
CPU as part of the preprocessing during training.
Args:
@@ -214,7 +214,7 @@ def _sample_negative_indices(features_shape: Tuple, num_negatives: int, attentio
WAV2VEC2_START_DOCSTRING = r"""
Wav2Vec2 was proposed in [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech
- Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael
+ Representations](https://huggingface.co/papers/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael
Auli.
This model inherits from [`FlaxPreTrainedModel`]. Check the superclass documentation for the generic methods the
@@ -701,7 +701,7 @@ class FlaxWav2Vec2StableLayerNormEncoder(nn.Module):
class FlaxWav2Vec2GumbelVectorQuantizer(nn.Module):
"""
Vector quantization using gumbel softmax. See [CATEGORICAL REPARAMETERIZATION WITH
- GUMBEL-SOFTMAX](https://arxiv.org/pdf/1611.01144.pdf) for more information.
+ GUMBEL-SOFTMAX](https://huggingface.co/papers/1611.01144) for more information.
"""
config: Wav2Vec2Config
diff --git a/src/transformers/models/wav2vec2/modeling_tf_wav2vec2.py b/src/transformers/models/wav2vec2/modeling_tf_wav2vec2.py
index 1e71728de5..5ba5462d71 100644
--- a/src/transformers/models/wav2vec2/modeling_tf_wav2vec2.py
+++ b/src/transformers/models/wav2vec2/modeling_tf_wav2vec2.py
@@ -1054,7 +1054,7 @@ class TFWav2Vec2Encoder(keras.layers.Layer):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = np.random.uniform(0, 1)
if training and (dropout_probability < self.config.layerdrop): # skip the layer
continue
@@ -1135,7 +1135,7 @@ class TFWav2Vec2EncoderStableLayerNorm(keras.layers.Layer):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = np.random.uniform(0, 1)
if training and (dropout_probability < self.config.layerdrop): # skip the layer
continue
@@ -1231,7 +1231,7 @@ class TFWav2Vec2MainLayer(keras.layers.Layer):
def _mask_hidden_states(self, hidden_states: tf.Tensor, mask_time_indices: tf.Tensor | None = None):
"""
Masks extracted features along time axis and/or along feature axis according to
- [SpecAugment](https://arxiv.org/abs/1904.08779).
+ [SpecAugment](https://huggingface.co/papers/1904.08779).
"""
batch_size, sequence_length, hidden_size = shape_list(hidden_states)
diff --git a/src/transformers/models/wav2vec2/modeling_wav2vec2.py b/src/transformers/models/wav2vec2/modeling_wav2vec2.py
index 6a66a21eec..ecde2d66e3 100755
--- a/src/transformers/models/wav2vec2/modeling_wav2vec2.py
+++ b/src/transformers/models/wav2vec2/modeling_wav2vec2.py
@@ -82,7 +82,7 @@ class Wav2Vec2ForPreTrainingOutput(ModelOutput):
Args:
loss (*optional*, returned when `sample_negative_indices` are passed, `torch.FloatTensor` of shape `(1,)`):
Total loss as the sum of the contrastive loss (L_m) and the diversity loss (L_d) as stated in the [official
- paper](https://arxiv.org/pdf/2006.11477.pdf) . (classification) loss.
+ paper](https://huggingface.co/papers/2006.11477) . (classification) loss.
projected_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.proj_codevector_dim)`):
Hidden-states of the model projected to *config.proj_codevector_dim* that can be used to predict the masked
projected quantized states.
@@ -101,9 +101,9 @@ class Wav2Vec2ForPreTrainingOutput(ModelOutput):
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
contrastive_loss (*optional*, returned when `sample_negative_indices` are passed, `torch.FloatTensor` of shape `(1,)`):
- The contrastive loss (L_m) as stated in the [official paper](https://arxiv.org/pdf/2006.11477.pdf) .
+ The contrastive loss (L_m) as stated in the [official paper](https://huggingface.co/papers/2006.11477) .
diversity_loss (*optional*, returned when `sample_negative_indices` are passed, `torch.FloatTensor` of shape `(1,)`):
- The diversity loss (L_d) as stated in the [official paper](https://arxiv.org/pdf/2006.11477.pdf) .
+ The diversity loss (L_d) as stated in the [official paper](https://huggingface.co/papers/2006.11477) .
"""
loss: Optional[torch.FloatTensor] = None
@@ -125,7 +125,7 @@ def _compute_mask_indices(
) -> np.ndarray:
"""
Computes random mask spans for a given shape. Used to implement [SpecAugment: A Simple Data Augmentation Method for
- ASR](https://arxiv.org/abs/1904.08779). Note that this method is not optimized to run on TPU and should be run on
+ ASR](https://huggingface.co/papers/1904.08779). Note that this method is not optimized to run on TPU and should be run on
CPU as part of the preprocessing during training.
Args:
@@ -772,7 +772,7 @@ class Wav2Vec2Encoder(nn.Module):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = torch.rand([])
skip_the_layer = True if self.training and (dropout_probability < self.config.layerdrop) else False
@@ -875,7 +875,7 @@ class Wav2Vec2EncoderStableLayerNorm(nn.Module):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = torch.rand([])
skip_the_layer = True if self.training and (dropout_probability < self.config.layerdrop) else False
@@ -941,7 +941,7 @@ class Wav2Vec2EncoderStableLayerNorm(nn.Module):
class Wav2Vec2GumbelVectorQuantizer(nn.Module):
"""
Vector quantization using gumbel softmax. See `[CATEGORICAL REPARAMETERIZATION WITH
- GUMBEL-SOFTMAX](https://arxiv.org/pdf/1611.01144.pdf) for more information.
+ GUMBEL-SOFTMAX](https://huggingface.co/papers/1611.01144) for more information.
"""
def __init__(self, config):
@@ -1453,7 +1453,7 @@ class Wav2Vec2Model(Wav2Vec2PreTrainedModel):
):
"""
Masks extracted features along time axis and/or along feature axis according to
- [SpecAugment](https://arxiv.org/abs/1904.08779).
+ [SpecAugment](https://huggingface.co/papers/1904.08779).
"""
# `config.apply_spec_augment` can set masking to False
@@ -1730,7 +1730,7 @@ class Wav2Vec2ForPreTraining(Wav2Vec2PreTrainedModel):
).permute(2, 0, 1, 3)
# 4. compute logits, corresponding to `logs = sim(c_t, [q_t, \sim{q}_t]) / \kappa`
- # of equation (3) in https://arxiv.org/pdf/2006.11477.pdf
+ # of equation (3) in https://huggingface.co/papers/2006.11477
logits = self.compute_contrastive_logits(
quantized_features[None, :],
negative_quantized_features,
diff --git a/src/transformers/models/wav2vec2_bert/configuration_wav2vec2_bert.py b/src/transformers/models/wav2vec2_bert/configuration_wav2vec2_bert.py
index c4af932213..62799ef055 100644
--- a/src/transformers/models/wav2vec2_bert/configuration_wav2vec2_bert.py
+++ b/src/transformers/models/wav2vec2_bert/configuration_wav2vec2_bert.py
@@ -63,7 +63,7 @@ class Wav2Vec2BertConfig(PretrainedConfig):
final_dropout (`float`, *optional*, defaults to 0.1):
The dropout probability for the final projection layer of [`Wav2Vec2BertForCTC`].
layerdrop (`float`, *optional*, defaults to 0.1):
- The LayerDrop probability. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556) for more
+ The LayerDrop probability. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556) for more
details.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
@@ -72,7 +72,7 @@ class Wav2Vec2BertConfig(PretrainedConfig):
apply_spec_augment (`bool`, *optional*, defaults to `True`):
Whether to apply *SpecAugment* data augmentation to the outputs of the feature encoder. For reference see
[SpecAugment: A Simple Data Augmentation Method for Automatic Speech
- Recognition](https://arxiv.org/abs/1904.08779).
+ Recognition](https://huggingface.co/papers/1904.08779).
mask_time_prob (`float`, *optional*, defaults to 0.05):
Percentage (between 0 and 1) of all feature vectors along the time axis which will be masked. The masking
procedure generates `mask_time_prob*len(time_axis)/mask_time_length ``independent masks over the axis. If
@@ -148,7 +148,7 @@ class Wav2Vec2BertConfig(PretrainedConfig):
- `rotary`, for rotary position embeddings.
- `relative`, for relative position embeddings.
- `relative_key`, for relative position embeddings as defined by Shaw in [Self-Attention
- with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
If left to `None`, no relative position embeddings is applied.
rotary_embedding_base (`int`, *optional*, defaults to 10000):
If `"rotary"` position embeddings are used, defines the size of the embedding base.
@@ -269,7 +269,7 @@ class Wav2Vec2BertConfig(PretrainedConfig):
self.conv_depthwise_kernel_size = conv_depthwise_kernel_size
self.conformer_conv_dropout = conformer_conv_dropout
- # fine-tuning config parameters for SpecAugment: https://arxiv.org/abs/1904.08779
+ # fine-tuning config parameters for SpecAugment: https://huggingface.co/papers/1904.08779
self.apply_spec_augment = apply_spec_augment
self.mask_time_prob = mask_time_prob
self.mask_time_length = mask_time_length
diff --git a/src/transformers/models/wav2vec2_bert/modeling_wav2vec2_bert.py b/src/transformers/models/wav2vec2_bert/modeling_wav2vec2_bert.py
index ba606c0028..f7c666b9d3 100644
--- a/src/transformers/models/wav2vec2_bert/modeling_wav2vec2_bert.py
+++ b/src/transformers/models/wav2vec2_bert/modeling_wav2vec2_bert.py
@@ -32,7 +32,7 @@ from .configuration_wav2vec2_bert import Wav2Vec2BertConfig
class Wav2Vec2BertRotaryPositionalEmbedding(nn.Module):
"""Rotary positional embedding
- Reference : https://blog.eleuther.ai/rotary-embeddings/ Paper: https://arxiv.org/pdf/2104.09864.pdf
+ Reference : https://blog.eleuther.ai/rotary-embeddings/ Paper: https://huggingface.co/papers/2104.09864
"""
def __init__(self, config):
@@ -100,7 +100,7 @@ class Wav2Vec2BertRelPositionalEmbedding(nn.Module):
# Reverse the order of positive indices and concat both positive and
# negative indices. This is used to support the shifting trick
- # as in https://arxiv.org/abs/1901.02860
+ # as in https://huggingface.co/papers/1901.02860
pe_positive = torch.flip(pe_positive, [0]).unsqueeze(0)
pe_negative = pe_negative[1:].unsqueeze(0)
pe = torch.cat([pe_positive, pe_negative], dim=1)
@@ -249,7 +249,7 @@ class Wav2Vec2BertSelfAttention(nn.Module):
# linear transformation for positional encoding
self.linear_pos = nn.Linear(hidden_size, hidden_size, bias=False)
# these two learnable bias are used in matrix c and matrix d
- # as described in https://arxiv.org/abs/1901.02860 Section 3.3
+ # as described in https://huggingface.co/papers/1901.02860 Section 3.3
self.pos_bias_u = nn.Parameter(torch.zeros(self.num_heads, self.head_size))
self.pos_bias_v = nn.Parameter(torch.zeros(self.num_heads, self.head_size))
@@ -297,7 +297,7 @@ class Wav2Vec2BertSelfAttention(nn.Module):
" 'relative'"
)
# apply relative_position_embeddings to qk scores
- # as proposed in Transformer_XL: https://arxiv.org/abs/1901.02860
+ # as proposed in Transformer_XL: https://huggingface.co/papers/1901.02860
scores = self._apply_relative_embeddings(
query=query, key=key, relative_position_embeddings=relative_position_embeddings
)
@@ -371,7 +371,7 @@ class Wav2Vec2BertSelfAttention(nn.Module):
q_with_bias_v = (query + self.pos_bias_v).transpose(1, 2)
# 3. attention score: first compute matrix a and matrix c
- # as described in https://arxiv.org/abs/1901.02860 Section 3.3
+ # as described in https://huggingface.co/papers/1901.02860 Section 3.3
# => (batch, head, time1, time2)
scores_ac = torch.matmul(q_with_bias_u, key.transpose(-2, -1))
@@ -395,7 +395,7 @@ class Wav2Vec2BertSelfAttention(nn.Module):
class Wav2Vec2BertEncoderLayer(nn.Module):
- """Conformer block based on https://arxiv.org/abs/2005.08100."""
+ """Conformer block based on https://huggingface.co/papers/2005.08100."""
def __init__(self, config):
super().__init__()
@@ -514,7 +514,7 @@ class Wav2Vec2BertEncoder(nn.Module):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = torch.rand([])
skip_the_layer = True if self.training and (dropout_probability < self.config.layerdrop) else False
@@ -812,7 +812,7 @@ def _compute_mask_indices(
) -> np.ndarray:
"""
Computes random mask spans for a given shape. Used to implement [SpecAugment: A Simple Data Augmentation Method for
- ASR](https://arxiv.org/abs/1904.08779). Note that this method is not optimized to run on TPU and should be run on
+ ASR](https://huggingface.co/papers/1904.08779). Note that this method is not optimized to run on TPU and should be run on
CPU as part of the preprocessing during training.
Args:
@@ -955,7 +955,7 @@ class Wav2Vec2BertModel(Wav2Vec2BertPreTrainedModel):
):
"""
Masks extracted features along time axis and/or along feature axis according to
- [SpecAugment](https://arxiv.org/abs/1904.08779).
+ [SpecAugment](https://huggingface.co/papers/1904.08779).
"""
# `config.apply_spec_augment` can set masking to False
diff --git a/src/transformers/models/wav2vec2_bert/modular_wav2vec2_bert.py b/src/transformers/models/wav2vec2_bert/modular_wav2vec2_bert.py
index 1b4693e978..6dd421ff85 100644
--- a/src/transformers/models/wav2vec2_bert/modular_wav2vec2_bert.py
+++ b/src/transformers/models/wav2vec2_bert/modular_wav2vec2_bert.py
@@ -205,7 +205,7 @@ class Wav2Vec2BertSelfAttention(Wav2Vec2ConformerSelfAttention, nn.Module):
# linear transformation for positional encoding
self.linear_pos = nn.Linear(hidden_size, hidden_size, bias=False)
# these two learnable bias are used in matrix c and matrix d
- # as described in https://arxiv.org/abs/1901.02860 Section 3.3
+ # as described in https://huggingface.co/papers/1901.02860 Section 3.3
self.pos_bias_u = nn.Parameter(torch.zeros(self.num_heads, self.head_size))
self.pos_bias_v = nn.Parameter(torch.zeros(self.num_heads, self.head_size))
@@ -253,7 +253,7 @@ class Wav2Vec2BertSelfAttention(Wav2Vec2ConformerSelfAttention, nn.Module):
" 'relative'"
)
# apply relative_position_embeddings to qk scores
- # as proposed in Transformer_XL: https://arxiv.org/abs/1901.02860
+ # as proposed in Transformer_XL: https://huggingface.co/papers/1901.02860
scores = self._apply_relative_embeddings(
query=query, key=key, relative_position_embeddings=relative_position_embeddings
)
@@ -293,7 +293,7 @@ class Wav2Vec2BertSelfAttention(Wav2Vec2ConformerSelfAttention, nn.Module):
class Wav2Vec2BertEncoderLayer(nn.Module):
- """Conformer block based on https://arxiv.org/abs/2005.08100."""
+ """Conformer block based on https://huggingface.co/papers/2005.08100."""
def __init__(self, config):
super().__init__()
@@ -412,7 +412,7 @@ class Wav2Vec2BertEncoder(nn.Module):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = torch.rand([])
skip_the_layer = True if self.training and (dropout_probability < self.config.layerdrop) else False
diff --git a/src/transformers/models/wav2vec2_conformer/configuration_wav2vec2_conformer.py b/src/transformers/models/wav2vec2_conformer/configuration_wav2vec2_conformer.py
index d33adb90d6..b8a894e876 100644
--- a/src/transformers/models/wav2vec2_conformer/configuration_wav2vec2_conformer.py
+++ b/src/transformers/models/wav2vec2_conformer/configuration_wav2vec2_conformer.py
@@ -62,7 +62,7 @@ class Wav2Vec2ConformerConfig(PretrainedConfig):
final_dropout (`float`, *optional*, defaults to 0.1):
The dropout probability for the final projection layer of [`Wav2Vec2ConformerForCTC`].
layerdrop (`float`, *optional*, defaults to 0.1):
- The LayerDrop probability. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556) for more
+ The LayerDrop probability. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556) for more
details.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
@@ -99,7 +99,7 @@ class Wav2Vec2ConformerConfig(PretrainedConfig):
apply_spec_augment (`bool`, *optional*, defaults to `True`):
Whether to apply *SpecAugment* data augmentation to the outputs of the feature encoder. For reference see
[SpecAugment: A Simple Data Augmentation Method for Automatic Speech
- Recognition](https://arxiv.org/abs/1904.08779).
+ Recognition](https://huggingface.co/papers/1904.08779).
mask_time_prob (`float`, *optional*, defaults to 0.05):
Percentage (between 0 and 1) of all feature vectors along the time axis which will be masked. The masking
procedure generates ''mask_time_prob*len(time_axis)/mask_time_length'' independent masks over the axis. If
@@ -313,7 +313,7 @@ class Wav2Vec2ConformerConfig(PretrainedConfig):
self.conv_depthwise_kernel_size = conv_depthwise_kernel_size
self.conformer_conv_dropout = conformer_conv_dropout
- # fine-tuning config parameters for SpecAugment: https://arxiv.org/abs/1904.08779
+ # fine-tuning config parameters for SpecAugment: https://huggingface.co/papers/1904.08779
self.apply_spec_augment = apply_spec_augment
self.mask_time_prob = mask_time_prob
self.mask_time_length = mask_time_length
diff --git a/src/transformers/models/wav2vec2_conformer/modeling_wav2vec2_conformer.py b/src/transformers/models/wav2vec2_conformer/modeling_wav2vec2_conformer.py
index af02fa91ee..f481a02c7f 100644
--- a/src/transformers/models/wav2vec2_conformer/modeling_wav2vec2_conformer.py
+++ b/src/transformers/models/wav2vec2_conformer/modeling_wav2vec2_conformer.py
@@ -42,7 +42,7 @@ class Wav2Vec2ConformerForPreTrainingOutput(ModelOutput):
Args:
loss (*optional*, returned when `sample_negative_indices` are passed, `torch.FloatTensor` of shape `(1,)`):
Total loss as the sum of the contrastive loss (L_m) and the diversity loss (L_d) as stated in the [official
- paper](https://arxiv.org/pdf/2006.11477.pdf) . (classification) loss.
+ paper](https://huggingface.co/papers/2006.11477) . (classification) loss.
projected_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.proj_codevector_dim)`):
Hidden-states of the model projected to *config.proj_codevector_dim* that can be used to predict the masked
projected quantized states.
@@ -61,9 +61,9 @@ class Wav2Vec2ConformerForPreTrainingOutput(ModelOutput):
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
contrastive_loss (*optional*, returned when `sample_negative_indices` are passed, `torch.FloatTensor` of shape `(1,)`):
- The contrastive loss (L_m) as stated in the [official paper](https://arxiv.org/pdf/2006.11477.pdf) .
+ The contrastive loss (L_m) as stated in the [official paper](https://huggingface.co/papers/2006.11477) .
diversity_loss (*optional*, returned when `sample_negative_indices` are passed, `torch.FloatTensor` of shape `(1,)`):
- The diversity loss (L_d) as stated in the [official paper](https://arxiv.org/pdf/2006.11477.pdf) .
+ The diversity loss (L_d) as stated in the [official paper](https://huggingface.co/papers/2006.11477) .
"""
loss: Optional[torch.FloatTensor] = None
@@ -134,7 +134,7 @@ class Wav2Vec2ConformerPositionalConvEmbedding(nn.Module):
class Wav2Vec2ConformerRotaryPositionalEmbedding(nn.Module):
"""Rotary positional embedding
- Reference : https://blog.eleuther.ai/rotary-embeddings/ Paper: https://arxiv.org/pdf/2104.09864.pdf
+ Reference : https://blog.eleuther.ai/rotary-embeddings/ Paper: https://huggingface.co/papers/2104.09864
"""
def __init__(self, config):
@@ -201,7 +201,7 @@ class Wav2Vec2ConformerRelPositionalEmbedding(nn.Module):
# Reverse the order of positive indices and concat both positive and
# negative indices. This is used to support the shifting trick
- # as in https://arxiv.org/abs/1901.02860
+ # as in https://huggingface.co/papers/1901.02860
pe_positive = torch.flip(pe_positive, [0]).unsqueeze(0)
pe_negative = pe_negative[1:].unsqueeze(0)
pe = torch.cat([pe_positive, pe_negative], dim=1)
@@ -457,7 +457,7 @@ class Wav2Vec2ConformerSelfAttention(nn.Module):
# linear transformation for positional encoding
self.linear_pos = nn.Linear(config.hidden_size, config.hidden_size, bias=False)
# these two learnable bias are used in matrix c and matrix d
- # as described in https://arxiv.org/abs/1901.02860 Section 3.3
+ # as described in https://huggingface.co/papers/1901.02860 Section 3.3
self.pos_bias_u = nn.Parameter(torch.zeros(self.num_heads, self.head_size))
self.pos_bias_v = nn.Parameter(torch.zeros(self.num_heads, self.head_size))
@@ -499,7 +499,7 @@ class Wav2Vec2ConformerSelfAttention(nn.Module):
" 'relative'"
)
# apply relative_position_embeddings to qk scores
- # as proposed in Transformer_XL: https://arxiv.org/abs/1901.02860
+ # as proposed in Transformer_XL: https://huggingface.co/papers/1901.02860
scores = self._apply_relative_embeddings(
query=query, key=key, relative_position_embeddings=relative_position_embeddings
)
@@ -559,7 +559,7 @@ class Wav2Vec2ConformerSelfAttention(nn.Module):
q_with_bias_v = (query + self.pos_bias_v).transpose(1, 2)
# 3. attention score: first compute matrix a and matrix c
- # as described in https://arxiv.org/abs/1901.02860 Section 3.3
+ # as described in https://huggingface.co/papers/1901.02860 Section 3.3
# => (batch, head, time1, time2)
scores_ac = torch.matmul(q_with_bias_u, key.transpose(-2, -1))
@@ -583,7 +583,7 @@ class Wav2Vec2ConformerSelfAttention(nn.Module):
class Wav2Vec2ConformerEncoderLayer(nn.Module):
- """Conformer block based on https://arxiv.org/abs/2005.08100."""
+ """Conformer block based on https://huggingface.co/papers/2005.08100."""
def __init__(self, config):
super().__init__()
@@ -703,7 +703,7 @@ class Wav2Vec2ConformerEncoder(nn.Module):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = torch.rand([])
skip_the_layer = True if self.training and (dropout_probability < self.config.layerdrop) else False
@@ -748,7 +748,7 @@ class Wav2Vec2ConformerEncoder(nn.Module):
class Wav2Vec2ConformerGumbelVectorQuantizer(nn.Module):
"""
Vector quantization using gumbel softmax. See `[CATEGORICAL REPARAMETERIZATION WITH
- GUMBEL-SOFTMAX](https://arxiv.org/pdf/1611.01144.pdf) for more information.
+ GUMBEL-SOFTMAX](https://huggingface.co/papers/1611.01144) for more information.
"""
def __init__(self, config):
@@ -974,7 +974,7 @@ def _compute_mask_indices(
) -> np.ndarray:
"""
Computes random mask spans for a given shape. Used to implement [SpecAugment: A Simple Data Augmentation Method for
- ASR](https://arxiv.org/abs/1904.08779). Note that this method is not optimized to run on TPU and should be run on
+ ASR](https://huggingface.co/papers/1904.08779). Note that this method is not optimized to run on TPU and should be run on
CPU as part of the preprocessing during training.
Args:
@@ -1121,7 +1121,7 @@ class Wav2Vec2ConformerModel(Wav2Vec2ConformerPreTrainedModel):
):
"""
Masks extracted features along time axis and/or along feature axis according to
- [SpecAugment](https://arxiv.org/abs/1904.08779).
+ [SpecAugment](https://huggingface.co/papers/1904.08779).
"""
# `config.apply_spec_augment` can set masking to False
@@ -1386,7 +1386,7 @@ class Wav2Vec2ConformerForPreTraining(Wav2Vec2ConformerPreTrainedModel):
).permute(2, 0, 1, 3)
# 4. compute logits, corresponding to `logs = sim(c_t, [q_t, \sim{q}_t]) / \kappa`
- # of equation (3) in https://arxiv.org/pdf/2006.11477.pdf
+ # of equation (3) in https://huggingface.co/papers/2006.11477
logits = self.compute_contrastive_logits(
quantized_features[None, :],
negative_quantized_features,
diff --git a/src/transformers/models/wav2vec2_conformer/modular_wav2vec2_conformer.py b/src/transformers/models/wav2vec2_conformer/modular_wav2vec2_conformer.py
index c95280ce68..4b066b09a7 100644
--- a/src/transformers/models/wav2vec2_conformer/modular_wav2vec2_conformer.py
+++ b/src/transformers/models/wav2vec2_conformer/modular_wav2vec2_conformer.py
@@ -42,7 +42,7 @@ class Wav2Vec2ConformerForPreTrainingOutput(ModelOutput):
Args:
loss (*optional*, returned when `sample_negative_indices` are passed, `torch.FloatTensor` of shape `(1,)`):
Total loss as the sum of the contrastive loss (L_m) and the diversity loss (L_d) as stated in the [official
- paper](https://arxiv.org/pdf/2006.11477.pdf) . (classification) loss.
+ paper](https://huggingface.co/papers/2006.11477) . (classification) loss.
projected_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.proj_codevector_dim)`):
Hidden-states of the model projected to *config.proj_codevector_dim* that can be used to predict the masked
projected quantized states.
@@ -61,9 +61,9 @@ class Wav2Vec2ConformerForPreTrainingOutput(ModelOutput):
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
contrastive_loss (*optional*, returned when `sample_negative_indices` are passed, `torch.FloatTensor` of shape `(1,)`):
- The contrastive loss (L_m) as stated in the [official paper](https://arxiv.org/pdf/2006.11477.pdf) .
+ The contrastive loss (L_m) as stated in the [official paper](https://huggingface.co/papers/2006.11477) .
diversity_loss (*optional*, returned when `sample_negative_indices` are passed, `torch.FloatTensor` of shape `(1,)`):
- The diversity loss (L_d) as stated in the [official paper](https://arxiv.org/pdf/2006.11477.pdf) .
+ The diversity loss (L_d) as stated in the [official paper](https://huggingface.co/papers/2006.11477) .
"""
loss: Optional[torch.FloatTensor] = None
@@ -82,7 +82,7 @@ class Wav2Vec2ConformerPositionalConvEmbedding(Wav2Vec2PositionalConvEmbedding):
class Wav2Vec2ConformerRotaryPositionalEmbedding(nn.Module):
"""Rotary positional embedding
- Reference : https://blog.eleuther.ai/rotary-embeddings/ Paper: https://arxiv.org/pdf/2104.09864.pdf
+ Reference : https://blog.eleuther.ai/rotary-embeddings/ Paper: https://huggingface.co/papers/2104.09864
"""
def __init__(self, config):
@@ -149,7 +149,7 @@ class Wav2Vec2ConformerRelPositionalEmbedding(nn.Module):
# Reverse the order of positive indices and concat both positive and
# negative indices. This is used to support the shifting trick
- # as in https://arxiv.org/abs/1901.02860
+ # as in https://huggingface.co/papers/1901.02860
pe_positive = torch.flip(pe_positive, [0]).unsqueeze(0)
pe_negative = pe_negative[1:].unsqueeze(0)
pe = torch.cat([pe_positive, pe_negative], dim=1)
@@ -259,7 +259,7 @@ class Wav2Vec2ConformerSelfAttention(nn.Module):
# linear transformation for positional encoding
self.linear_pos = nn.Linear(config.hidden_size, config.hidden_size, bias=False)
# these two learnable bias are used in matrix c and matrix d
- # as described in https://arxiv.org/abs/1901.02860 Section 3.3
+ # as described in https://huggingface.co/papers/1901.02860 Section 3.3
self.pos_bias_u = nn.Parameter(torch.zeros(self.num_heads, self.head_size))
self.pos_bias_v = nn.Parameter(torch.zeros(self.num_heads, self.head_size))
@@ -301,7 +301,7 @@ class Wav2Vec2ConformerSelfAttention(nn.Module):
" 'relative'"
)
# apply relative_position_embeddings to qk scores
- # as proposed in Transformer_XL: https://arxiv.org/abs/1901.02860
+ # as proposed in Transformer_XL: https://huggingface.co/papers/1901.02860
scores = self._apply_relative_embeddings(
query=query, key=key, relative_position_embeddings=relative_position_embeddings
)
@@ -361,7 +361,7 @@ class Wav2Vec2ConformerSelfAttention(nn.Module):
q_with_bias_v = (query + self.pos_bias_v).transpose(1, 2)
# 3. attention score: first compute matrix a and matrix c
- # as described in https://arxiv.org/abs/1901.02860 Section 3.3
+ # as described in https://huggingface.co/papers/1901.02860 Section 3.3
# => (batch, head, time1, time2)
scores_ac = torch.matmul(q_with_bias_u, key.transpose(-2, -1))
@@ -385,7 +385,7 @@ class Wav2Vec2ConformerSelfAttention(nn.Module):
class Wav2Vec2ConformerEncoderLayer(nn.Module):
- """Conformer block based on https://arxiv.org/abs/2005.08100."""
+ """Conformer block based on https://huggingface.co/papers/2005.08100."""
def __init__(self, config):
super().__init__()
@@ -505,7 +505,7 @@ class Wav2Vec2ConformerEncoder(nn.Module):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = torch.rand([])
skip_the_layer = True if self.training and (dropout_probability < self.config.layerdrop) else False
diff --git a/src/transformers/models/wavlm/configuration_wavlm.py b/src/transformers/models/wavlm/configuration_wavlm.py
index 11eb1f081a..62f9ae92d2 100644
--- a/src/transformers/models/wavlm/configuration_wavlm.py
+++ b/src/transformers/models/wavlm/configuration_wavlm.py
@@ -60,7 +60,7 @@ class WavLMConfig(PretrainedConfig):
final_dropout (`float`, *optional*, defaults to 0.1):
The dropout probability for the final projection layer of [`WavLMForCTC`].
layerdrop (`float`, *optional*, defaults to 0.1):
- The LayerDrop probability. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556) for more
+ The LayerDrop probability. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556) for more
details.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
@@ -99,7 +99,7 @@ class WavLMConfig(PretrainedConfig):
apply_spec_augment (`bool`, *optional*, defaults to `True`):
Whether to apply *SpecAugment* data augmentation to the outputs of the feature encoder. For reference see
[SpecAugment: A Simple Data Augmentation Method for Automatic Speech
- Recognition](https://arxiv.org/abs/1904.08779).
+ Recognition](https://huggingface.co/papers/1904.08779).
mask_time_prob (`float`, *optional*, defaults to 0.05):
Probability of each feature vector along the time axis to be chosen as the start of the vector span to be
masked. Approximately `mask_time_prob * sequence_length // mask_time_length` feature vectors will be masked
@@ -292,7 +292,7 @@ class WavLMConfig(PretrainedConfig):
f" `len(config.conv_kernel) = {len(self.conv_kernel)}`."
)
- # fine-tuning config parameters for SpecAugment: https://arxiv.org/abs/1904.08779
+ # fine-tuning config parameters for SpecAugment: https://huggingface.co/papers/1904.08779
self.apply_spec_augment = apply_spec_augment
self.mask_time_prob = mask_time_prob
self.mask_time_length = mask_time_length
diff --git a/src/transformers/models/wavlm/modeling_wavlm.py b/src/transformers/models/wavlm/modeling_wavlm.py
index 11670ea7d2..07e6cb4efc 100755
--- a/src/transformers/models/wavlm/modeling_wavlm.py
+++ b/src/transformers/models/wavlm/modeling_wavlm.py
@@ -412,7 +412,7 @@ class WavLMEncoder(nn.Module):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = torch.rand([])
skip_the_layer = self.training and i > 0 and (dropout_probability < self.config.layerdrop)
@@ -497,7 +497,7 @@ class WavLMEncoderStableLayerNorm(nn.Module):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = torch.rand([])
skip_the_layer = self.training and i > 0 and (dropout_probability < self.config.layerdrop)
@@ -542,7 +542,7 @@ class WavLMEncoderStableLayerNorm(nn.Module):
class WavLMGumbelVectorQuantizer(nn.Module):
"""
Vector quantization using gumbel softmax. See [CATEGORICAL REPARAMETERIZATION WITH
- GUMBEL-SOFTMAX](https://arxiv.org/pdf/1611.01144.pdf) for more information.
+ GUMBEL-SOFTMAX](https://huggingface.co/papers/1611.01144) for more information.
"""
def __init__(self, config):
@@ -870,7 +870,7 @@ def _compute_mask_indices(
) -> np.ndarray:
"""
Computes random mask spans for a given shape. Used to implement [SpecAugment: A Simple Data Augmentation Method for
- ASR](https://arxiv.org/abs/1904.08779). Note that this method is not optimized to run on TPU and should be run on
+ ASR](https://huggingface.co/papers/1904.08779). Note that this method is not optimized to run on TPU and should be run on
CPU as part of the preprocessing during training.
Args:
@@ -1032,7 +1032,7 @@ class WavLMModel(WavLMPreTrainedModel):
):
"""
Masks extracted features along time axis and/or along feature axis according to
- [SpecAugment](https://arxiv.org/abs/1904.08779).
+ [SpecAugment](https://huggingface.co/papers/1904.08779).
"""
# `config.apply_spec_augment` can set masking to False
diff --git a/src/transformers/models/wavlm/modular_wavlm.py b/src/transformers/models/wavlm/modular_wavlm.py
index 1ff9d5052c..7a8464449c 100644
--- a/src/transformers/models/wavlm/modular_wavlm.py
+++ b/src/transformers/models/wavlm/modular_wavlm.py
@@ -323,7 +323,7 @@ class WavLMEncoder(nn.Module):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = torch.rand([])
skip_the_layer = self.training and i > 0 and (dropout_probability < self.config.layerdrop)
@@ -408,7 +408,7 @@ class WavLMEncoderStableLayerNorm(nn.Module):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = torch.rand([])
skip_the_layer = self.training and i > 0 and (dropout_probability < self.config.layerdrop)
@@ -453,7 +453,7 @@ class WavLMEncoderStableLayerNorm(nn.Module):
class WavLMGumbelVectorQuantizer(nn.Module):
"""
Vector quantization using gumbel softmax. See [CATEGORICAL REPARAMETERIZATION WITH
- GUMBEL-SOFTMAX](https://arxiv.org/pdf/1611.01144.pdf) for more information.
+ GUMBEL-SOFTMAX](https://huggingface.co/papers/1611.01144) for more information.
"""
def __init__(self, config):
diff --git a/src/transformers/models/whisper/configuration_whisper.py b/src/transformers/models/whisper/configuration_whisper.py
index 3a1489a4ec..bc15e92566 100644
--- a/src/transformers/models/whisper/configuration_whisper.py
+++ b/src/transformers/models/whisper/configuration_whisper.py
@@ -88,10 +88,10 @@ class WhisperConfig(PretrainedConfig):
decoder_ffn_dim (`int`, *optional*, defaults to 1536):
Dimensionality of the "intermediate" (often named feed-forward) layer in decoder.
encoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
decoder_layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
decoder_start_token_id (`int`, *optional*, defaults to 50257):
Corresponds to the "<|startoftranscript|>" token, which is automatically used when no `decoder_input_ids`
@@ -143,7 +143,7 @@ class WhisperConfig(PretrainedConfig):
apply_spec_augment (`bool`, *optional*, defaults to `False`):
Whether to apply *SpecAugment* data augmentation to the outputs of the feature encoder. For reference see
[SpecAugment: A Simple Data Augmentation Method for Automatic Speech
- Recognition](https://arxiv.org/abs/1904.08779).
+ Recognition](https://huggingface.co/papers/1904.08779).
mask_time_prob (`float`, *optional*, defaults to 0.05):
Percentage (between 0 and 1) of all feature vectors along the time axis which will be masked. The masking
procedure generates `mask_time_prob*len(time_axis)/mask_time_length` independent masks over the axis. If
@@ -263,7 +263,7 @@ class WhisperConfig(PretrainedConfig):
self.classifier_proj_size = classifier_proj_size
self.use_weighted_layer_sum = use_weighted_layer_sum
- # fine-tuning config parameters for SpecAugment: https://arxiv.org/abs/1904.08779
+ # fine-tuning config parameters for SpecAugment: https://huggingface.co/papers/1904.08779
self.apply_spec_augment = apply_spec_augment
self.mask_time_prob = mask_time_prob
self.mask_time_length = mask_time_length
diff --git a/src/transformers/models/whisper/generation_whisper.py b/src/transformers/models/whisper/generation_whisper.py
index e4a1d1db30..cdcf0d8ac0 100644
--- a/src/transformers/models/whisper/generation_whisper.py
+++ b/src/transformers/models/whisper/generation_whisper.py
@@ -414,7 +414,7 @@ class WhisperGenerationMixin(GenerationMixin):
`input_ids`. It has to return a list with the allowed tokens for the next generation step conditioned
on the batch ID `batch_id` and the previously generated tokens `inputs_ids`. This argument is useful
for constrained generation conditioned on the prefix, as described in [Autoregressive Entity
- Retrieval](https://arxiv.org/abs/2010.00904).
+ Retrieval](https://huggingface.co/papers/2010.00904).
synced_gpus (`bool`, *optional*, defaults to `False`):
Whether to continue running the while loop until max_length (needed to avoid deadlocking with
`FullyShardedDataParallel` and DeepSpeed ZeRO Stage 3).
diff --git a/src/transformers/models/whisper/modeling_flax_whisper.py b/src/transformers/models/whisper/modeling_flax_whisper.py
index decc393dfc..97891615c3 100644
--- a/src/transformers/models/whisper/modeling_flax_whisper.py
+++ b/src/transformers/models/whisper/modeling_flax_whisper.py
@@ -116,7 +116,7 @@ WHISPER_INPUTS_DOCSTRING = r"""
decoder_attention_mask (`numpy.ndarray` of shape `(batch_size, target_sequence_length)`, *optional*):
Default behavior: generate a tensor that ignores pad tokens in `decoder_input_ids`. Causal mask will also
be used by default. If you want to change padding behavior, you should modify to your needs. See diagram 1
- in [the paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
+ in [the paper](https://huggingface.co/papers/1910.13461) for more information on the default strategy.
position_ids (`numpy.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Whisper does not use `position_ids` in the encoder as `input_features` is always the same size and doesn't
use masking, but this argument is preserved for compatibility. By default the silence in the input log mel
@@ -171,7 +171,7 @@ WHISPER_DECODE_INPUTS_DOCSTRING = r"""
decoder_attention_mask (`numpy.ndarray` of shape `(batch_size, target_sequence_length)`, *optional*):
Default behavior: generate a tensor that ignores pad tokens in `decoder_input_ids`. Causal mask will also
be used by default. If you want to change padding behavior, you should modify to your needs. See diagram 1
- in [the paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
+ in [the paper](https://huggingface.co/papers/1910.13461) for more information on the default strategy.
decoder_position_ids (`numpy.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each decoder input sequence tokens in the position embeddings. Selected in the
range `[0, config.max_position_embeddings - 1]`.
@@ -439,7 +439,7 @@ class FlaxWhisperEncoderLayerCollection(nn.Module):
for encoder_layer in self.layers:
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if not deterministic and (dropout_probability < self.layerdrop): # skip the layer
layer_outputs = (None, None)
@@ -595,7 +595,7 @@ class FlaxWhisperDecoderLayerCollection(nn.Module):
for decoder_layer in self.layers:
if output_hidden_states:
all_hidden_states += (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if not deterministic and (dropout_probability < self.layerdrop):
layer_outputs = (None, None, None)
diff --git a/src/transformers/models/whisper/modeling_tf_whisper.py b/src/transformers/models/whisper/modeling_tf_whisper.py
index ffe49551ef..9778e22399 100644
--- a/src/transformers/models/whisper/modeling_tf_whisper.py
+++ b/src/transformers/models/whisper/modeling_tf_whisper.py
@@ -621,7 +621,7 @@ WHISPER_INPUTS_DOCSTRING = r"""
If you want to change padding behavior, you should read
[`modeling_whisper._prepare_decoder_attention_mask`] and modify to your needs. See diagram 1 in [the
- paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
+ paper](https://huggingface.co/papers/1910.13461) for more information on the default strategy.
head_mask (`tf.Tensor` of shape `(encoder_layers, encoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the attention modules in the encoder. Mask values selected in `[0, 1]`:
@@ -784,7 +784,7 @@ class TFWhisperEncoder(keras.layers.Layer):
for idx, encoder_layer in enumerate(self.encoder_layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if training and (dropout_probability < self.layerdrop): # skip the layer
continue
@@ -1020,7 +1020,7 @@ class TFWhisperDecoder(keras.layers.Layer):
)
for idx, decoder_layer in enumerate(self.decoder_layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
dropout_probability = random.uniform(0, 1)
diff --git a/src/transformers/models/whisper/modeling_whisper.py b/src/transformers/models/whisper/modeling_whisper.py
index 7bb07a6c1c..9d55199fcc 100644
--- a/src/transformers/models/whisper/modeling_whisper.py
+++ b/src/transformers/models/whisper/modeling_whisper.py
@@ -89,7 +89,7 @@ def _compute_mask_indices(
) -> np.ndarray:
"""
Computes random mask spans for a given shape. Used to implement [SpecAugment: A Simple Data Augmentation Method for
- ASR](https://arxiv.org/abs/1904.08779). Note that this method is not optimized to run on TPU and should be run on
+ ASR](https://huggingface.co/papers/1904.08779). Note that this method is not optimized to run on TPU and should be run on
CPU as part of the preprocessing during training.
Args:
@@ -703,7 +703,7 @@ class WhisperEncoder(WhisperPreTrainedModel):
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
to_drop = False
if self.training:
dropout_probability = torch.rand([])
@@ -956,7 +956,7 @@ class WhisperDecoder(WhisperPreTrainedModel):
f" {head_mask.size()[0]}."
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
@@ -1061,7 +1061,7 @@ class WhisperModel(WhisperPreTrainedModel):
):
"""
Masks extracted features along time axis and/or along feature axis according to
- [SpecAugment](https://arxiv.org/abs/1904.08779).
+ [SpecAugment](https://huggingface.co/papers/1904.08779).
"""
# `config.apply_spec_augment` can set masking to False
@@ -1141,7 +1141,7 @@ class WhisperModel(WhisperPreTrainedModel):
If you want to change padding behavior, you should read
[`modeling_whisper._prepare_decoder_attention_mask`] and modify to your needs. See diagram 1 in [the BART
- paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
+ paper](https://huggingface.co/papers/1910.13461) for more information on the default strategy.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules. Mask values selected in `[0, 1]`:
@@ -1311,7 +1311,7 @@ class WhisperForConditionalGeneration(WhisperGenerationMixin, WhisperPreTrainedM
If you want to change padding behavior, you should read
[`modeling_whisper._prepare_decoder_attention_mask`] and modify to your needs. See diagram 1 in [the BART
- paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
+ paper](https://huggingface.co/papers/1910.13461) for more information on the default strategy.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules. Mask values selected in `[0, 1]`:
diff --git a/src/transformers/models/xglm/configuration_xglm.py b/src/transformers/models/xglm/configuration_xglm.py
index da5ded4916..d8a3be370b 100644
--- a/src/transformers/models/xglm/configuration_xglm.py
+++ b/src/transformers/models/xglm/configuration_xglm.py
@@ -57,7 +57,7 @@ class XGLMConfig(PretrainedConfig):
activation_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for activations inside the fully connected layer.
layerdrop (`float`, *optional*, defaults to 0.0):
- The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://huggingface.co/papers/1909.11556)
for more details.
init_std (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
diff --git a/src/transformers/models/xglm/modeling_flax_xglm.py b/src/transformers/models/xglm/modeling_flax_xglm.py
index 96f797ea58..d98af5f3e9 100644
--- a/src/transformers/models/xglm/modeling_flax_xglm.py
+++ b/src/transformers/models/xglm/modeling_flax_xglm.py
@@ -413,7 +413,7 @@ class FlaxXGLMDecoderLayerCollection(nn.Module):
for decoder_layer in self.layers:
if output_hidden_states:
all_hidden_states += (hidden_states,)
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if not deterministic and (dropout_probability < self.layerdrop):
layer_outputs = (None, None, None)
diff --git a/src/transformers/models/xglm/modeling_tf_xglm.py b/src/transformers/models/xglm/modeling_tf_xglm.py
index dc9f82900a..4acf2bfe7f 100644
--- a/src/transformers/models/xglm/modeling_tf_xglm.py
+++ b/src/transformers/models/xglm/modeling_tf_xglm.py
@@ -597,7 +597,7 @@ class TFXGLMMainLayer(keras.layers.Layer):
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
diff --git a/src/transformers/models/xglm/modeling_xglm.py b/src/transformers/models/xglm/modeling_xglm.py
index e9f3f63c96..28bd37731f 100755
--- a/src/transformers/models/xglm/modeling_xglm.py
+++ b/src/transformers/models/xglm/modeling_xglm.py
@@ -537,7 +537,7 @@ class XGLMModel(XGLMPreTrainedModel):
f" {head_mask.size()[0]}."
)
for idx, decoder_layer in enumerate(self.layers):
- # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ # add LayerDrop (see https://huggingface.co/papers/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
diff --git a/src/transformers/models/xlm_roberta/configuration_xlm_roberta.py b/src/transformers/models/xlm_roberta/configuration_xlm_roberta.py
index 33bdaacf40..97d6245cb1 100644
--- a/src/transformers/models/xlm_roberta/configuration_xlm_roberta.py
+++ b/src/transformers/models/xlm_roberta/configuration_xlm_roberta.py
@@ -69,9 +69,9 @@ class XLMRobertaConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
is_decoder (`bool`, *optional*, defaults to `False`):
Whether the model is used as a decoder or not. If `False`, the model is used as an encoder.
use_cache (`bool`, *optional*, defaults to `True`):
diff --git a/src/transformers/models/xlm_roberta_xl/configuration_xlm_roberta_xl.py b/src/transformers/models/xlm_roberta_xl/configuration_xlm_roberta_xl.py
index 90a7fc6d1b..4111a61d4e 100644
--- a/src/transformers/models/xlm_roberta_xl/configuration_xlm_roberta_xl.py
+++ b/src/transformers/models/xlm_roberta_xl/configuration_xlm_roberta_xl.py
@@ -68,9 +68,9 @@ class XLMRobertaXLConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models). Only
relevant if `config.is_decoder=True`.
diff --git a/src/transformers/models/xmod/configuration_xmod.py b/src/transformers/models/xmod/configuration_xmod.py
index 1cb4482ee4..41bad38a45 100644
--- a/src/transformers/models/xmod/configuration_xmod.py
+++ b/src/transformers/models/xmod/configuration_xmod.py
@@ -68,9 +68,9 @@ class XmodConfig(PretrainedConfig):
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
- [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
- with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
is_decoder (`bool`, *optional*, defaults to `False`):
Whether the model is used as a decoder or not. If `False`, the model is used as an encoder.
use_cache (`bool`, *optional*, defaults to `True`):
diff --git a/src/transformers/models/xmod/modeling_xmod.py b/src/transformers/models/xmod/modeling_xmod.py
index 646c952fde..aac258d6a4 100644
--- a/src/transformers/models/xmod/modeling_xmod.py
+++ b/src/transformers/models/xmod/modeling_xmod.py
@@ -701,7 +701,7 @@ class XmodPreTrainedModel(PreTrainedModel):
to `True`. To be used in a Seq2Seq model, the model needs to initialized with both `is_decoder` argument and
`add_cross_attention` set to `True`; an `encoder_hidden_states` is then expected as an input to the forward pass.
- .. _*Attention is all you need*: https://arxiv.org/abs/1706.03762
+ .. _*Attention is all you need*: https://huggingface.co/papers/1706.03762
"""
)
class XmodModel(XmodPreTrainedModel):
diff --git a/src/transformers/models/zamba/configuration_zamba.py b/src/transformers/models/zamba/configuration_zamba.py
index e51d0e4ef4..3de9a19d1b 100644
--- a/src/transformers/models/zamba/configuration_zamba.py
+++ b/src/transformers/models/zamba/configuration_zamba.py
@@ -60,7 +60,7 @@ class ZambaConfig(PretrainedConfig):
`num_key_value_heads=1 the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf).
+ paper](https://huggingface.co/papers/2305.13245).
n_mamba_heads (`int`, *optional*, defaults to 2):
Number of mamba heads for each mamba layer.
hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
diff --git a/src/transformers/models/zamba/modeling_zamba.py b/src/transformers/models/zamba/modeling_zamba.py
index 7733decd01..ae00519790 100644
--- a/src/transformers/models/zamba/modeling_zamba.py
+++ b/src/transformers/models/zamba/modeling_zamba.py
@@ -225,7 +225,7 @@ class ZambaAttention(nn.Module):
Adapted from transformers.models.mistral.modeling_mistral.MistralAttention:
The input dimension here is attention_hidden_size = 2 * hidden_size, and head_dim = attention_hidden_size // num_heads.
The extra factor of 2 comes from the input being the concatenation of original_hidden_states with the output of the previous (mamba) layer
- (see fig. 2 in https://arxiv.org/pdf/2405.16712).
+ (see fig. 2 in https://huggingface.co/papers/2405.16712).
Additionally, replaced
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim) with
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim/2)
@@ -608,7 +608,7 @@ class ZambaAttentionDecoderLayer(nn.Module):
original_hidden_states (`torch.FloatTensor`): word embedding output of shape `(batch, seq_len, embed_dim)`.
This is concatenated with `hidden_states` (which is the output of the previous (mamba) layer). The
concatenated tensor is then used as input of the pre-attention RMSNorm
- (see fig. 2 in https://arxiv.org/pdf/2405.16712).
+ (see fig. 2 in https://huggingface.co/papers/2405.16712).
layer_idx (`int`): layer_idx in the forward pass. Used to distinguish Zamba's tied transformer layers.
attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
`(batch, sequence_length)` where padding elements are indicated by 0.
@@ -684,8 +684,8 @@ class ZambaMambaDecoderLayer(nn.Module):
residual = hidden_states
- # `transformer_hidden_states` is the output from shared transformer + linear layer (see fig. 2 in https://arxiv.org/pdf/2405.16712).
- # `transformer_hidden_states` is then added to the input to the mamba layer below (as described in eq. (6) of https://arxiv.org/pdf/2405.16712).
+ # `transformer_hidden_states` is the output from shared transformer + linear layer (see fig. 2 in https://huggingface.co/papers/2405.16712).
+ # `transformer_hidden_states` is then added to the input to the mamba layer below (as described in eq. (6) of https://huggingface.co/papers/2405.16712).
hidden_states = (
hidden_states + transformer_hidden_states if transformer_hidden_states is not None else hidden_states
)
diff --git a/src/transformers/models/zamba2/configuration_zamba2.py b/src/transformers/models/zamba2/configuration_zamba2.py
index 1392eab1b3..f7e8f818aa 100644
--- a/src/transformers/models/zamba2/configuration_zamba2.py
+++ b/src/transformers/models/zamba2/configuration_zamba2.py
@@ -80,7 +80,7 @@ class Zamba2Config(PretrainedConfig):
`num_key_value_heads=1 the model will use Multi Query Attention (MQA) otherwise GQA is used. When
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
by meanpooling all the original heads within that group. For more details, check out [this
- paper](https://arxiv.org/pdf/2305.13245.pdf).
+ paper](https://huggingface.co/papers/2305.13245).
attention_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for the attention probabilities.
num_mem_blocks (`int`, *optional*, defaults to 1):
diff --git a/src/transformers/models/zamba2/modeling_zamba2.py b/src/transformers/models/zamba2/modeling_zamba2.py
index b2aed16823..dd7b6fde58 100644
--- a/src/transformers/models/zamba2/modeling_zamba2.py
+++ b/src/transformers/models/zamba2/modeling_zamba2.py
@@ -325,7 +325,7 @@ class Zamba2Attention(nn.Module):
Adapted from transformers.models.mistral.modeling_mistral.MistralAttention:
The input dimension here is attention_hidden_size = 2 * hidden_size, and head_dim = attention_hidden_size // num_heads.
The extra factor of 2 comes from the input being the concatenation of original_hidden_states with the output of the previous (mamba) layer
- (see fig. 2 in https://arxiv.org/pdf/2405.16712).
+ (see fig. 2 in https://huggingface.co/papers/2405.16712).
Additionally, replaced
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim) with
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim/2)
@@ -335,13 +335,13 @@ class Zamba2Attention(nn.Module):
Adapted from transformers.models.mistral.modeling_mistral.MistralAttention:
The input dimension here is attention_hidden_size = 2 * hidden_size, and head_dim = attention_hidden_size // num_heads.
The extra factor of 2 comes from the input being the concatenation of original_hidden_states with the output of the previous (mamba) layer
- (see fig. 2 in https://arxiv.org/pdf/2405.16712).
+ (see fig. 2 in https://huggingface.co/papers/2405.16712).
Additionally, replaced
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim) with
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim/2)
Finally, this attention layer contributes to tied transformer blocks aimed to increasing compute without increasing model size. Because this
layer is tied, un-tied adapters (formally the same as LoRA but used in the base model) modules are added to the q, k, v projectors to increase
- expressivity with a small memory overhead (see Fig. 2 of https://arxiv.org/pdf/2411.15242).
+ expressivity with a small memory overhead (see Fig. 2 of https://huggingface.co/papers/2411.15242).
"""
def __init__(
@@ -1008,7 +1008,7 @@ class Zamba2AttentionDecoderLayer(nn.Module):
original_hidden_states (`torch.FloatTensor`): word embedding output of shape `(batch, seq_len, embed_dim)`.
This is concatenated with `hidden_states` (which is the output of the previous (mamba) layer). The
concatenated tensor is then used as input of the pre-attention RMSNorm
- (see fig. 2 in https://arxiv.org/pdf/2405.16712).
+ (see fig. 2 in https://huggingface.co/papers/2405.16712).
attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
`(batch, sequence_length)` where padding elements are indicated by 0.
past_key_value (`Zamba2HybridDynamicCache`, *optional*): cached past key and value projection states
@@ -1084,8 +1084,8 @@ class Zamba2MambaDecoderLayer(nn.Module):
residual = hidden_states
- # `transformer_hidden_states` is the output from shared transformer + linear layer (see fig. 2 in https://arxiv.org/pdf/2405.16712).
- # `transformer_hidden_states` is then added to the input to the mamba layer below (as described in eq. (6) of https://arxiv.org/pdf/2405.16712).
+ # `transformer_hidden_states` is the output from shared transformer + linear layer (see fig. 2 in https://huggingface.co/papers/2405.16712).
+ # `transformer_hidden_states` is then added to the input to the mamba layer below (as described in eq. (6) of https://huggingface.co/papers/2405.16712).
hidden_states = (
hidden_states + transformer_hidden_states if transformer_hidden_states is not None else hidden_states
)
diff --git a/src/transformers/models/zamba2/modular_zamba2.py b/src/transformers/models/zamba2/modular_zamba2.py
index c4e14dd148..241a4bc393 100644
--- a/src/transformers/models/zamba2/modular_zamba2.py
+++ b/src/transformers/models/zamba2/modular_zamba2.py
@@ -186,13 +186,13 @@ class Zamba2Attention(ZambaAttention):
Adapted from transformers.models.mistral.modeling_mistral.MistralAttention:
The input dimension here is attention_hidden_size = 2 * hidden_size, and head_dim = attention_hidden_size // num_heads.
The extra factor of 2 comes from the input being the concatenation of original_hidden_states with the output of the previous (mamba) layer
- (see fig. 2 in https://arxiv.org/pdf/2405.16712).
+ (see fig. 2 in https://huggingface.co/papers/2405.16712).
Additionally, replaced
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim) with
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim/2)
Finally, this attention layer contributes to tied transformer blocks aimed to increasing compute without increasing model size. Because this
layer is tied, un-tied adapters (formally the same as LoRA but used in the base model) modules are added to the q, k, v projectors to increase
- expressivity with a small memory overhead (see Fig. 2 of https://arxiv.org/pdf/2411.15242).
+ expressivity with a small memory overhead (see Fig. 2 of https://huggingface.co/papers/2411.15242).
"""
def __init__(
@@ -785,7 +785,7 @@ class Zamba2AttentionDecoderLayer(ZambaAttentionDecoderLayer):
original_hidden_states (`torch.FloatTensor`): word embedding output of shape `(batch, seq_len, embed_dim)`.
This is concatenated with `hidden_states` (which is the output of the previous (mamba) layer). The
concatenated tensor is then used as input of the pre-attention RMSNorm
- (see fig. 2 in https://arxiv.org/pdf/2405.16712).
+ (see fig. 2 in https://huggingface.co/papers/2405.16712).
attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
`(batch, sequence_length)` where padding elements are indicated by 0.
past_key_value (`Zamba2HybridDynamicCache`, *optional*): cached past key and value projection states
diff --git a/src/transformers/optimization.py b/src/transformers/optimization.py
index ffeebaed5d..dd1d35a0b1 100644
--- a/src/transformers/optimization.py
+++ b/src/transformers/optimization.py
@@ -608,7 +608,7 @@ class Adafactor(Optimizer):
AdaFactor pytorch implementation can be used as a drop in replacement for Adam original fairseq code:
https://github.com/pytorch/fairseq/blob/master/fairseq/optim/adafactor.py
- Paper: *Adafactor: Adaptive Learning Rates with Sublinear Memory Cost* https://arxiv.org/abs/1804.04235 Note that
+ Paper: *Adafactor: Adaptive Learning Rates with Sublinear Memory Cost* https://huggingface.co/papers/1804.04235 Note that
this optimizer internally adjusts the learning rate depending on the `scale_parameter`, `relative_step` and
`warmup_init` options. To use a manual (external) learning rate schedule you should set `scale_parameter=False` and
`relative_step=False`.
@@ -642,7 +642,7 @@ class Adafactor(Optimizer):
- Training without LR warmup or clip_threshold is not recommended.
- use scheduled LR warm-up to fixed LR
- - use clip_threshold=1.0 (https://arxiv.org/abs/1804.04235)
+ - use clip_threshold=1.0 (https://huggingface.co/papers/1804.04235)
- Disable relative updates
- Use scale_parameter=False
- Additional optimizer operations like gradient clipping should not be used alongside Adafactor
diff --git a/src/transformers/optimization_tf.py b/src/transformers/optimization_tf.py
index 4da4ecc901..cfd49613af 100644
--- a/src/transformers/optimization_tf.py
+++ b/src/transformers/optimization_tf.py
@@ -182,7 +182,7 @@ class AdamWeightDecay(Adam):
Adam enables L2 weight decay and clip_by_global_norm on gradients. Just adding the square of the weights to the
loss function is *not* the correct way of using L2 regularization/weight decay with Adam, since that will interact
with the m and v parameters in strange ways as shown in [Decoupled Weight Decay
- Regularization](https://arxiv.org/abs/1711.05101).
+ Regularization](https://huggingface.co/papers/1711.05101).
Instead we want to decay the weights in a manner that doesn't interact with the m/v parameters. This is equivalent
to adding the square of the weights to the loss with plain (non-momentum) SGD.
@@ -198,7 +198,7 @@ class AdamWeightDecay(Adam):
The epsilon parameter in Adam, which is a small constant for numerical stability.
amsgrad (`bool`, *optional*, defaults to `False`):
Whether to apply AMSGrad variant of this algorithm or not, see [On the Convergence of Adam and
- Beyond](https://arxiv.org/abs/1904.09237).
+ Beyond](https://huggingface.co/papers/1904.09237).
weight_decay_rate (`float`, *optional*, defaults to 0.0):
The weight decay to apply.
include_in_weight_decay (`List[str]`, *optional*):
diff --git a/src/transformers/quantizers/quantizer_auto_round.py b/src/transformers/quantizers/quantizer_auto_round.py
index f2d95abb64..94071b71a9 100644
--- a/src/transformers/quantizers/quantizer_auto_round.py
+++ b/src/transformers/quantizers/quantizer_auto_round.py
@@ -31,7 +31,7 @@ logger = logging.get_logger(__name__)
class AutoRoundQuantizer(HfQuantizer):
"""
- Quantizer of the AutoRound method. (https://arxiv.org/pdf/2309.05516)
+ Quantizer of the AutoRound method. (https://huggingface.co/papers/2309.05516)
"""
# AutoRound requires data calibration - we support only inference
diff --git a/src/transformers/quantizers/quantizer_awq.py b/src/transformers/quantizers/quantizer_awq.py
index ee6c636020..9d69c62997 100644
--- a/src/transformers/quantizers/quantizer_awq.py
+++ b/src/transformers/quantizers/quantizer_awq.py
@@ -34,7 +34,7 @@ logger = logging.get_logger(__name__)
class AwqQuantizer(HfQuantizer):
"""
- 4-bit quantization for Activation-aware Weight Quantization(AWQ) (https://arxiv.org/abs/2306.00978)
+ 4-bit quantization for Activation-aware Weight Quantization(AWQ) (https://huggingface.co/papers/2306.00978)
"""
# AWQ requires data calibration - we support only inference
diff --git a/src/transformers/quantizers/quantizer_bitnet.py b/src/transformers/quantizers/quantizer_bitnet.py
index 4df34d22a7..ae80843366 100644
--- a/src/transformers/quantizers/quantizer_bitnet.py
+++ b/src/transformers/quantizers/quantizer_bitnet.py
@@ -34,7 +34,7 @@ class BitNetHfQuantizer(HfQuantizer):
1.58-bit quantization from BitNet quantization method:
Before loading: it converts the linear layers into BitLinear layers during loading.
- Check out the paper introducing this method : https://arxiv.org/pdf/2402.17764
+ Check out the paper introducing this method: https://huggingface.co/papers/2402.17764
"""
requires_parameters_quantization = False
diff --git a/src/transformers/trainer.py b/src/transformers/trainer.py
index 7ec12010a8..e945e04fcb 100755
--- a/src/transformers/trainer.py
+++ b/src/transformers/trainer.py
@@ -821,7 +821,7 @@ class Trainer:
def _activate_neftune(self, model):
r"""
Activates the neftune as presented in this code: https://github.com/neelsjain/NEFTune and paper:
- https://arxiv.org/abs/2310.05914
+ https://huggingface.co/papers/2310.05914
"""
unwrapped_model = self.accelerator.unwrap_model(model)
diff --git a/src/transformers/training_args.py b/src/transformers/training_args.py
index 2f4a745273..37a1db5761 100644
--- a/src/transformers/training_args.py
+++ b/src/transformers/training_args.py
@@ -765,12 +765,12 @@ class TrainingArguments:
neftune_noise_alpha (`Optional[float]`):
If not `None`, this will activate NEFTune noise embeddings. This can drastically improve model performance
- for instruction fine-tuning. Check out the [original paper](https://arxiv.org/abs/2310.05914) and the
+ for instruction fine-tuning. Check out the [original paper](https://huggingface.co/papers/2310.05914) and the
[original code](https://github.com/neelsjain/NEFTune). Support transformers `PreTrainedModel` and also
`PeftModel` from peft. The original paper used values in the range [5.0, 15.0].
optim_target_modules (`Union[str, List[str]]`, *optional*):
The target modules to optimize, i.e. the module names that you would like to train.
- Currently used for the GaLore algorithm (https://arxiv.org/abs/2403.03507) and APOLLO algorithm (https://arxiv.org/abs/2412.05270).
+ Currently used for the GaLore algorithm (https://huggingface.co/papers/2403.03507) and APOLLO algorithm (https://huggingface.co/papers/2412.05270).
See GaLore implementation (https://github.com/jiaweizzhao/GaLore) and APOLLO implementation (https://github.com/zhuhanqing/APOLLO) for more details.
You need to make sure to pass a valid GaLore or APOLLO optimizer, e.g., one of: "apollo_adamw", "galore_adamw", "galore_adamw_8bit", "galore_adafactor" and make sure that the target modules are `nn.Linear` modules only.
@@ -1489,7 +1489,7 @@ class TrainingArguments:
neftune_noise_alpha: Optional[float] = field(
default=None,
metadata={
- "help": "Activates neftune noise embeddings into the model. NEFTune has been proven to drastically improve model performances for instruction fine-tuning. Check out the original paper here: https://arxiv.org/abs/2310.05914 and the original code here: https://github.com/neelsjain/NEFTune. Only supported for `PreTrainedModel` and `PeftModel` classes."
+ "help": "Activates neftune noise embeddings into the model. NEFTune has been proven to drastically improve model performances for instruction fine-tuning. Check out the original paper here: https://huggingface.co/papers/2310.05914 and the original code here: https://github.com/neelsjain/NEFTune. Only supported for `PreTrainedModel` and `PeftModel` classes."
},
)
diff --git a/src/transformers/utils/quantization_config.py b/src/transformers/utils/quantization_config.py
index 9f53953112..0085b4ae0d 100644
--- a/src/transformers/utils/quantization_config.py
+++ b/src/transformers/utils/quantization_config.py
@@ -418,7 +418,7 @@ class BitsAndBytesConfig(QuantizationConfigMixin):
`bitsandbytes`.
llm_int8_threshold (`float`, *optional*, defaults to 6.0):
This corresponds to the outlier threshold for outlier detection as described in `LLM.int8() : 8-bit Matrix
- Multiplication for Transformers at Scale` paper: https://arxiv.org/abs/2208.07339 Any hidden states value
+ Multiplication for Transformers at Scale` paper: https://huggingface.co/papers/2208.07339 Any hidden states value
that is above this threshold will be considered an outlier and the operation on those values will be done
in fp16. Values are usually normally distributed, that is, most values are in the range [-3.5, 3.5], but
there are some exceptional systematic outliers that are very differently distributed for large models.
diff --git a/tests/repo_utils/test_check_copies.py b/tests/repo_utils/test_check_copies.py
index 826f1b5956..f6ae669c4c 100644
--- a/tests/repo_utils/test_check_copies.py
+++ b/tests/repo_utils/test_check_copies.py
@@ -373,11 +373,11 @@ class CopyCheckTester(unittest.TestCase):
md_list = (
"1. **[ALBERT](https://huggingface.co/transformers/model_doc/albert.html)** (from Google Research and the"
" Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for"
- " Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong"
+ " Self-supervised Learning of Language Representations](https://huggingface.co/papers/1909.11942), by Zhenzhong"
" Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.\n1."
" **[DistilBERT](https://huggingface.co/transformers/model_doc/distilbert.html)** (from HuggingFace),"
" released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and"
- " lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same"
+ " lighter](https://huggingface.co/papers/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same"
" method has been applied to compress GPT2 into"
" [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/distillation), RoBERTa into"
" [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/distillation),"
@@ -385,23 +385,23 @@ class CopyCheckTester(unittest.TestCase):
" [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/distillation) and a German"
" version of DistilBERT.\n1. **[ELECTRA](https://huggingface.co/transformers/model_doc/electra.html)**"
" (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders"
- " as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang"
+ " as discriminators rather than generators](https://huggingface.co/papers/2003.10555) by Kevin Clark, Minh-Thang"
" Luong, Quoc V. Le, Christopher D. Manning."
)
localized_md_list = (
"1. **[ALBERT](https://huggingface.co/transformers/model_doc/albert.html)** (来自 Google Research and the"
" Toyota Technological Institute at Chicago) 伴随论文 [ALBERT: A Lite BERT for Self-supervised Learning of"
- " Language Representations](https://arxiv.org/abs/1909.11942), 由 Zhenzhong Lan, Mingda Chen, Sebastian"
+ " Language Representations](https://huggingface.co/papers/1909.11942), 由 Zhenzhong Lan, Mingda Chen, Sebastian"
" Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut 发布。\n"
)
converted_md_list_sample = (
"1. **[ALBERT](https://huggingface.co/transformers/model_doc/albert.html)** (来自 Google Research and the"
" Toyota Technological Institute at Chicago) 伴随论文 [ALBERT: A Lite BERT for Self-supervised Learning of"
- " Language Representations](https://arxiv.org/abs/1909.11942), 由 Zhenzhong Lan, Mingda Chen, Sebastian"
+ " Language Representations](https://huggingface.co/papers/1909.11942), 由 Zhenzhong Lan, Mingda Chen, Sebastian"
" Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut 发布。\n1."
" **[DistilBERT](https://huggingface.co/transformers/model_doc/distilbert.html)** (来自 HuggingFace) 伴随论文"
" [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and"
- " lighter](https://arxiv.org/abs/1910.01108) 由 Victor Sanh, Lysandre Debut and Thomas Wolf 发布。 The same"
+ " lighter](https://huggingface.co/papers/1910.01108) 由 Victor Sanh, Lysandre Debut and Thomas Wolf 发布。 The same"
" method has been applied to compress GPT2 into"
" [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/distillation), RoBERTa into"
" [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/distillation),"
@@ -409,7 +409,7 @@ class CopyCheckTester(unittest.TestCase):
" [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/distillation) and a German"
" version of DistilBERT.\n1. **[ELECTRA](https://huggingface.co/transformers/model_doc/electra.html)** (来自"
" Google Research/Stanford University) 伴随论文 [ELECTRA: Pre-training text encoders as discriminators rather"
- " than generators](https://arxiv.org/abs/2003.10555) 由 Kevin Clark, Minh-Thang Luong, Quoc V. Le,"
+ " than generators](https://huggingface.co/papers/2003.10555) 由 Kevin Clark, Minh-Thang Luong, Quoc V. Le,"
" Christopher D. Manning 发布。\n"
)
@@ -430,19 +430,19 @@ class CopyCheckTester(unittest.TestCase):
link_changed_md_list = (
"1. **[ALBERT](https://huggingface.co/transformers/model_doc/albert.html)** (from Google Research and the"
" Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for"
- " Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong"
+ " Self-supervised Learning of Language Representations](https://huggingface.co/papers/1909.11942), by Zhenzhong"
" Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut."
)
link_unchanged_md_list = (
"1. **[ALBERT](https://huggingface.co/transformers/main/model_doc/albert.html)** (来自 Google Research and"
" the Toyota Technological Institute at Chicago) 伴随论文 [ALBERT: A Lite BERT for Self-supervised Learning of"
- " Language Representations](https://arxiv.org/abs/1909.11942), 由 Zhenzhong Lan, Mingda Chen, Sebastian"
+ " Language Representations](https://huggingface.co/papers/1909.11942), 由 Zhenzhong Lan, Mingda Chen, Sebastian"
" Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut 发布。\n"
)
converted_md_list_sample = (
"1. **[ALBERT](https://huggingface.co/transformers/model_doc/albert.html)** (来自 Google Research and the"
" Toyota Technological Institute at Chicago) 伴随论文 [ALBERT: A Lite BERT for Self-supervised Learning of"
- " Language Representations](https://arxiv.org/abs/1909.11942), 由 Zhenzhong Lan, Mingda Chen, Sebastian"
+ " Language Representations](https://huggingface.co/papers/1909.11942), 由 Zhenzhong Lan, Mingda Chen, Sebastian"
" Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut 发布。\n"
)
diff --git a/tests/utils/test_model_card.py b/tests/utils/test_model_card.py
index 1b3ca30400..16dec39081 100644
--- a/tests/utils/test_model_card.py
+++ b/tests/utils/test_model_card.py
@@ -33,13 +33,13 @@ class ModelCardTester(unittest.TestCase):
"metrics": "BLEU and ROUGE-1",
"evaluation_data": {
"Datasets": {"BLEU": "My-great-dataset-v1", "ROUGE-1": "My-short-dataset-v2.1"},
- "Preprocessing": "See details on https://arxiv.org/pdf/1810.03993.pdf",
+ "Preprocessing": "See details on https://huggingface.co/papers/1810.03993",
},
"training_data": {
"Dataset": "English Wikipedia dump dated 2018-12-01",
"Preprocessing": (
"Using SentencePiece vocabulary of size 52k tokens. See details on"
- " https://arxiv.org/pdf/1810.03993.pdf"
+ " https://huggingface.co/papers/1810.03993"
),
},
"quantitative_analyses": {"BLEU": 55.1, "ROUGE-1": 76},
 - Deformable DETR architecture. Taken from the original paper.
+ Deformable DETR architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/fundamentalvision/Deformable-DETR).
diff --git a/docs/source/en/model_doc/deit.md b/docs/source/en/model_doc/deit.md
index 57cfee1f11..c2f0f17c06 100644
--- a/docs/source/en/model_doc/deit.md
+++ b/docs/source/en/model_doc/deit.md
@@ -25,8 +25,8 @@ rendered properly in your Markdown viewer.
## Overview
-The DeiT model was proposed in [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre
-Sablayrolles, Hervé Jégou. The [Vision Transformer (ViT)](vit) introduced in [Dosovitskiy et al., 2020](https://arxiv.org/abs/2010.11929) has shown that one can match or even outperform existing convolutional neural
+The DeiT model was proposed in [Training data-efficient image transformers & distillation through attention](https://huggingface.co/papers/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre
+Sablayrolles, Hervé Jégou. The [Vision Transformer (ViT)](vit) introduced in [Dosovitskiy et al., 2020](https://huggingface.co/papers/2010.11929) has shown that one can match or even outperform existing convolutional neural
networks using a Transformer encoder (BERT-like). However, the ViT models introduced in that paper required training on
expensive infrastructure for multiple weeks, using external data. DeiT (data-efficient image transformers) are more
efficiently trained transformers for image classification, requiring far less data and far less computing resources
diff --git a/docs/source/en/model_doc/deplot.md b/docs/source/en/model_doc/deplot.md
index d3c0de7b7f..28a5c70940 100644
--- a/docs/source/en/model_doc/deplot.md
+++ b/docs/source/en/model_doc/deplot.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-DePlot was proposed in the paper [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) from Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.
+DePlot was proposed in the paper [DePlot: One-shot visual language reasoning by plot-to-table translation](https://huggingface.co/papers/2212.10505) from Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.
The abstract of the paper states the following:
diff --git a/docs/source/en/model_doc/depth_anything_v2.md b/docs/source/en/model_doc/depth_anything_v2.md
index c98017d2bb..413273b05d 100644
--- a/docs/source/en/model_doc/depth_anything_v2.md
+++ b/docs/source/en/model_doc/depth_anything_v2.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-Depth Anything V2 was introduced in [the paper of the same name](https://arxiv.org/abs/2406.09414) by Lihe Yang et al. It uses the same architecture as the original [Depth Anything model](depth_anything), but uses synthetic data and a larger capacity teacher model to achieve much finer and robust depth predictions.
+Depth Anything V2 was introduced in [the paper of the same name](https://huggingface.co/papers/2406.09414) by Lihe Yang et al. It uses the same architecture as the original [Depth Anything model](depth_anything), but uses synthetic data and a larger capacity teacher model to achieve much finer and robust depth predictions.
The abstract from the paper is the following:
@@ -27,7 +27,7 @@ The abstract from the paper is the following:
- Deformable DETR architecture. Taken from the original paper.
+ Deformable DETR architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/fundamentalvision/Deformable-DETR).
diff --git a/docs/source/en/model_doc/deit.md b/docs/source/en/model_doc/deit.md
index 57cfee1f11..c2f0f17c06 100644
--- a/docs/source/en/model_doc/deit.md
+++ b/docs/source/en/model_doc/deit.md
@@ -25,8 +25,8 @@ rendered properly in your Markdown viewer.
## Overview
-The DeiT model was proposed in [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre
-Sablayrolles, Hervé Jégou. The [Vision Transformer (ViT)](vit) introduced in [Dosovitskiy et al., 2020](https://arxiv.org/abs/2010.11929) has shown that one can match or even outperform existing convolutional neural
+The DeiT model was proposed in [Training data-efficient image transformers & distillation through attention](https://huggingface.co/papers/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre
+Sablayrolles, Hervé Jégou. The [Vision Transformer (ViT)](vit) introduced in [Dosovitskiy et al., 2020](https://huggingface.co/papers/2010.11929) has shown that one can match or even outperform existing convolutional neural
networks using a Transformer encoder (BERT-like). However, the ViT models introduced in that paper required training on
expensive infrastructure for multiple weeks, using external data. DeiT (data-efficient image transformers) are more
efficiently trained transformers for image classification, requiring far less data and far less computing resources
diff --git a/docs/source/en/model_doc/deplot.md b/docs/source/en/model_doc/deplot.md
index d3c0de7b7f..28a5c70940 100644
--- a/docs/source/en/model_doc/deplot.md
+++ b/docs/source/en/model_doc/deplot.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-DePlot was proposed in the paper [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) from Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.
+DePlot was proposed in the paper [DePlot: One-shot visual language reasoning by plot-to-table translation](https://huggingface.co/papers/2212.10505) from Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.
The abstract of the paper states the following:
diff --git a/docs/source/en/model_doc/depth_anything_v2.md b/docs/source/en/model_doc/depth_anything_v2.md
index c98017d2bb..413273b05d 100644
--- a/docs/source/en/model_doc/depth_anything_v2.md
+++ b/docs/source/en/model_doc/depth_anything_v2.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-Depth Anything V2 was introduced in [the paper of the same name](https://arxiv.org/abs/2406.09414) by Lihe Yang et al. It uses the same architecture as the original [Depth Anything model](depth_anything), but uses synthetic data and a larger capacity teacher model to achieve much finer and robust depth predictions.
+Depth Anything V2 was introduced in [the paper of the same name](https://huggingface.co/papers/2406.09414) by Lihe Yang et al. It uses the same architecture as the original [Depth Anything model](depth_anything), but uses synthetic data and a larger capacity teacher model to achieve much finer and robust depth predictions.
The abstract from the paper is the following:
@@ -27,7 +27,7 @@ The abstract from the paper is the following:
 - Depth Anything overview. Taken from the original paper.
+ Depth Anything overview. Taken from the original paper.
The Depth Anything models were contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/DepthAnything/Depth-Anything-V2).
diff --git a/docs/source/en/model_doc/depth_pro.md b/docs/source/en/model_doc/depth_pro.md
index 42fd725a9a..84f350a2a0 100644
--- a/docs/source/en/model_doc/depth_pro.md
+++ b/docs/source/en/model_doc/depth_pro.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The DepthPro model was proposed in [Depth Pro: Sharp Monocular Metric Depth in Less Than a Second](https://arxiv.org/abs/2410.02073) by Aleksei Bochkovskii, Amaël Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan R. Richter, Vladlen Koltun.
+The DepthPro model was proposed in [Depth Pro: Sharp Monocular Metric Depth in Less Than a Second](https://huggingface.co/papers/2410.02073) by Aleksei Bochkovskii, Amaël Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan R. Richter, Vladlen Koltun.
DepthPro is a foundation model for zero-shot metric monocular depth estimation, designed to generate high-resolution depth maps with remarkable sharpness and fine-grained details. It employs a multi-scale Vision Transformer (ViT)-based architecture, where images are downsampled, divided into patches, and processed using a shared Dinov2 encoder. The extracted patch-level features are merged, upsampled, and refined using a DPT-like fusion stage, enabling precise depth estimation.
@@ -78,7 +78,7 @@ The DepthPro model processes an input image by first downsampling it at multiple
- Depth Anything overview. Taken from the original paper.
+ Depth Anything overview. Taken from the original paper.
The Depth Anything models were contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/DepthAnything/Depth-Anything-V2).
diff --git a/docs/source/en/model_doc/depth_pro.md b/docs/source/en/model_doc/depth_pro.md
index 42fd725a9a..84f350a2a0 100644
--- a/docs/source/en/model_doc/depth_pro.md
+++ b/docs/source/en/model_doc/depth_pro.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The DepthPro model was proposed in [Depth Pro: Sharp Monocular Metric Depth in Less Than a Second](https://arxiv.org/abs/2410.02073) by Aleksei Bochkovskii, Amaël Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan R. Richter, Vladlen Koltun.
+The DepthPro model was proposed in [Depth Pro: Sharp Monocular Metric Depth in Less Than a Second](https://huggingface.co/papers/2410.02073) by Aleksei Bochkovskii, Amaël Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan R. Richter, Vladlen Koltun.
DepthPro is a foundation model for zero-shot metric monocular depth estimation, designed to generate high-resolution depth maps with remarkable sharpness and fine-grained details. It employs a multi-scale Vision Transformer (ViT)-based architecture, where images are downsampled, divided into patches, and processed using a shared Dinov2 encoder. The extracted patch-level features are merged, upsampled, and refined using a DPT-like fusion stage, enabling precise depth estimation.
@@ -78,7 +78,7 @@ The DepthPro model processes an input image by first downsampling it at multiple
 - DepthPro architecture. Taken from the original paper.
+ DepthPro architecture. Taken from the original paper.
The `DepthProForDepthEstimation` model uses a `DepthProEncoder`, for encoding the input image and a `FeatureFusionStage` for fusing the output features from encoder.
@@ -151,7 +151,7 @@ On a local benchmark (A100-40GB, PyTorch 2.3.0, OS Ubuntu 22.04) with `float32`
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DepthPro:
-- Research Paper: [Depth Pro: Sharp Monocular Metric Depth in Less Than a Second](https://arxiv.org/pdf/2410.02073)
+- Research Paper: [Depth Pro: Sharp Monocular Metric Depth in Less Than a Second](https://huggingface.co/papers/2410.02073)
- Official Implementation: [apple/ml-depth-pro](https://github.com/apple/ml-depth-pro)
- DepthPro Inference Notebook: [DepthPro Inference](https://github.com/qubvel/transformers-notebooks/blob/main/notebooks/DepthPro_inference.ipynb)
- DepthPro for Super Resolution and Image Segmentation
diff --git a/docs/source/en/model_doc/deta.md b/docs/source/en/model_doc/deta.md
index e3859341a7..c151734f92 100644
--- a/docs/source/en/model_doc/deta.md
+++ b/docs/source/en/model_doc/deta.md
@@ -30,7 +30,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The DETA model was proposed in [NMS Strikes Back](https://arxiv.org/abs/2212.06137) by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
+The DETA model was proposed in [NMS Strikes Back](https://huggingface.co/papers/2212.06137) by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
DETA (short for Detection Transformers with Assignment) improves [Deformable DETR](deformable_detr) by replacing the one-to-one bipartite Hungarian matching loss
with one-to-many label assignments used in traditional detectors with non-maximum suppression (NMS). This leads to significant gains of up to 2.5 mAP.
@@ -41,7 +41,7 @@ The abstract from the paper is the following:
- DepthPro architecture. Taken from the original paper.
+ DepthPro architecture. Taken from the original paper.
The `DepthProForDepthEstimation` model uses a `DepthProEncoder`, for encoding the input image and a `FeatureFusionStage` for fusing the output features from encoder.
@@ -151,7 +151,7 @@ On a local benchmark (A100-40GB, PyTorch 2.3.0, OS Ubuntu 22.04) with `float32`
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DepthPro:
-- Research Paper: [Depth Pro: Sharp Monocular Metric Depth in Less Than a Second](https://arxiv.org/pdf/2410.02073)
+- Research Paper: [Depth Pro: Sharp Monocular Metric Depth in Less Than a Second](https://huggingface.co/papers/2410.02073)
- Official Implementation: [apple/ml-depth-pro](https://github.com/apple/ml-depth-pro)
- DepthPro Inference Notebook: [DepthPro Inference](https://github.com/qubvel/transformers-notebooks/blob/main/notebooks/DepthPro_inference.ipynb)
- DepthPro for Super Resolution and Image Segmentation
diff --git a/docs/source/en/model_doc/deta.md b/docs/source/en/model_doc/deta.md
index e3859341a7..c151734f92 100644
--- a/docs/source/en/model_doc/deta.md
+++ b/docs/source/en/model_doc/deta.md
@@ -30,7 +30,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The DETA model was proposed in [NMS Strikes Back](https://arxiv.org/abs/2212.06137) by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
+The DETA model was proposed in [NMS Strikes Back](https://huggingface.co/papers/2212.06137) by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
DETA (short for Detection Transformers with Assignment) improves [Deformable DETR](deformable_detr) by replacing the one-to-one bipartite Hungarian matching loss
with one-to-many label assignments used in traditional detectors with non-maximum suppression (NMS). This leads to significant gains of up to 2.5 mAP.
@@ -41,7 +41,7 @@ The abstract from the paper is the following:
 - Visualization of attention maps of various models trained with vs. without registers. Taken from the original paper.
+ Visualization of attention maps of various models trained with vs. without registers. Taken from the original paper.
Tips:
diff --git a/docs/source/en/model_doc/dpr.md b/docs/source/en/model_doc/dpr.md
index 0f6b19c900..4b3d3f4a26 100644
--- a/docs/source/en/model_doc/dpr.md
+++ b/docs/source/en/model_doc/dpr.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
Dense Passage Retrieval (DPR) is a set of tools and models for state-of-the-art open-domain Q&A research. It was
-introduced in [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by
+introduced in [Dense Passage Retrieval for Open-Domain Question Answering](https://huggingface.co/papers/2004.04906) by
Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, Wen-tau Yih.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/dpt.md b/docs/source/en/model_doc/dpt.md
index 95e422dee8..1699207973 100644
--- a/docs/source/en/model_doc/dpt.md
+++ b/docs/source/en/model_doc/dpt.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The DPT model was proposed in [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
+The DPT model was proposed in [Vision Transformers for Dense Prediction](https://huggingface.co/papers/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
DPT is a model that leverages the [Vision Transformer (ViT)](vit) as backbone for dense prediction tasks like semantic segmentation and depth estimation.
The abstract from the paper is the following:
@@ -34,7 +34,7 @@ The abstract from the paper is the following:
- Visualization of attention maps of various models trained with vs. without registers. Taken from the original paper.
+ Visualization of attention maps of various models trained with vs. without registers. Taken from the original paper.
Tips:
diff --git a/docs/source/en/model_doc/dpr.md b/docs/source/en/model_doc/dpr.md
index 0f6b19c900..4b3d3f4a26 100644
--- a/docs/source/en/model_doc/dpr.md
+++ b/docs/source/en/model_doc/dpr.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
Dense Passage Retrieval (DPR) is a set of tools and models for state-of-the-art open-domain Q&A research. It was
-introduced in [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by
+introduced in [Dense Passage Retrieval for Open-Domain Question Answering](https://huggingface.co/papers/2004.04906) by
Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, Wen-tau Yih.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/dpt.md b/docs/source/en/model_doc/dpt.md
index 95e422dee8..1699207973 100644
--- a/docs/source/en/model_doc/dpt.md
+++ b/docs/source/en/model_doc/dpt.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The DPT model was proposed in [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
+The DPT model was proposed in [Vision Transformers for Dense Prediction](https://huggingface.co/papers/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
DPT is a model that leverages the [Vision Transformer (ViT)](vit) as backbone for dense prediction tasks like semantic segmentation and depth estimation.
The abstract from the paper is the following:
@@ -34,7 +34,7 @@ The abstract from the paper is the following:
 - DPT architecture. Taken from the original paper.
+ DPT architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/isl-org/DPT).
diff --git a/docs/source/en/model_doc/efficientformer.md b/docs/source/en/model_doc/efficientformer.md
index f05ccacc3d..31b1d37f0f 100644
--- a/docs/source/en/model_doc/efficientformer.md
+++ b/docs/source/en/model_doc/efficientformer.md
@@ -31,7 +31,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The EfficientFormer model was proposed in [EfficientFormer: Vision Transformers at MobileNet Speed](https://arxiv.org/abs/2206.01191)
+The EfficientFormer model was proposed in [EfficientFormer: Vision Transformers at MobileNet Speed](https://huggingface.co/papers/2206.01191)
by Yanyu Li, Geng Yuan, Yang Wen, Eric Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren. EfficientFormer proposes a
dimension-consistent pure transformer that can be run on mobile devices for dense prediction tasks like image classification, object
detection and semantic segmentation.
diff --git a/docs/source/en/model_doc/efficientnet.md b/docs/source/en/model_doc/efficientnet.md
index 17a96aeb5a..e11eab612c 100644
--- a/docs/source/en/model_doc/efficientnet.md
+++ b/docs/source/en/model_doc/efficientnet.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The EfficientNet model was proposed in [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946)
+The EfficientNet model was proposed in [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://huggingface.co/papers/1905.11946)
by Mingxing Tan and Quoc V. Le. EfficientNets are a family of image classification models, which achieve state-of-the-art accuracy, yet being an order-of-magnitude smaller and faster than previous models.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/emu3.md b/docs/source/en/model_doc/emu3.md
index 20b8a5e1cd..5f51566084 100644
--- a/docs/source/en/model_doc/emu3.md
+++ b/docs/source/en/model_doc/emu3.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Emu3 model was proposed in [Emu3: Next-Token Prediction is All You Need](https://arxiv.org/abs/2409.18869) by Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, Yingli Zhao, Yulong Ao, Xuebin Min, Tao Li, Boya Wu, Bo Zhao, Bowen Zhang, Liangdong Wang, Guang Liu, Zheqi He, Xi Yang, Jingjing Liu, Yonghua Lin, Tiejun Huang, Zhongyuan Wang.
+The Emu3 model was proposed in [Emu3: Next-Token Prediction is All You Need](https://huggingface.co/papers/2409.18869) by Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, Yingli Zhao, Yulong Ao, Xuebin Min, Tao Li, Boya Wu, Bo Zhao, Bowen Zhang, Liangdong Wang, Guang Liu, Zheqi He, Xi Yang, Jingjing Liu, Yonghua Lin, Tiejun Huang, Zhongyuan Wang.
Emu3 is a multimodal LLM that uses vector quantization to tokenize images into discrete tokens. Discretized image tokens are later fused with text token ids for image and text generation. The model can additionally generate images by predicting image token ids.
diff --git a/docs/source/en/model_doc/encodec.md b/docs/source/en/model_doc/encodec.md
index 893954d5cf..06ce1e2faf 100644
--- a/docs/source/en/model_doc/encodec.md
+++ b/docs/source/en/model_doc/encodec.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The EnCodec neural codec model was proposed in [High Fidelity Neural Audio Compression](https://arxiv.org/abs/2210.13438) by Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi.
+The EnCodec neural codec model was proposed in [High Fidelity Neural Audio Compression](https://huggingface.co/papers/2210.13438) by Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/encoder-decoder.md b/docs/source/en/model_doc/encoder-decoder.md
index d0a676fb33..f697c213b7 100644
--- a/docs/source/en/model_doc/encoder-decoder.md
+++ b/docs/source/en/model_doc/encoder-decoder.md
@@ -30,14 +30,14 @@ The [`EncoderDecoderModel`] can be used to initialize a sequence-to-sequence mod
pretrained autoencoding model as the encoder and any pretrained autoregressive model as the decoder.
The effectiveness of initializing sequence-to-sequence models with pretrained checkpoints for sequence generation tasks
-was shown in [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by
+was shown in [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://huggingface.co/papers/1907.12461) by
Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
After such an [`EncoderDecoderModel`] has been trained/fine-tuned, it can be saved/loaded just like
any other models (see the examples for more information).
An application of this architecture could be to leverage two pretrained [`BertModel`] as the encoder
-and decoder for a summarization model as was shown in: [Text Summarization with Pretrained Encoders](https://arxiv.org/abs/1908.08345) by Yang Liu and Mirella Lapata.
+and decoder for a summarization model as was shown in: [Text Summarization with Pretrained Encoders](https://huggingface.co/papers/1908.08345) by Yang Liu and Mirella Lapata.
## Randomly initializing `EncoderDecoderModel` from model configurations.
diff --git a/docs/source/en/model_doc/ernie.md b/docs/source/en/model_doc/ernie.md
index 82f2a0d5ba..596a7b1f4b 100644
--- a/docs/source/en/model_doc/ernie.md
+++ b/docs/source/en/model_doc/ernie.md
@@ -22,8 +22,8 @@ rendered properly in your Markdown viewer.
## Overview
ERNIE is a series of powerful models proposed by baidu, especially in Chinese tasks,
-including [ERNIE1.0](https://arxiv.org/abs/1904.09223), [ERNIE2.0](https://ojs.aaai.org/index.php/AAAI/article/view/6428),
-[ERNIE3.0](https://arxiv.org/abs/2107.02137), [ERNIE-Gram](https://arxiv.org/abs/2010.12148), [ERNIE-health](https://arxiv.org/abs/2110.07244), etc.
+including [ERNIE1.0](https://huggingface.co/papers/1904.09223), [ERNIE2.0](https://ojs.aaai.org/index.php/AAAI/article/view/6428),
+[ERNIE3.0](https://huggingface.co/papers/2107.02137), [ERNIE-Gram](https://huggingface.co/papers/2010.12148), [ERNIE-health](https://huggingface.co/papers/2110.07244), etc.
These models are contributed by [nghuyong](https://huggingface.co/nghuyong) and the official code can be found in [PaddleNLP](https://github.com/PaddlePaddle/PaddleNLP) (in PaddlePaddle).
diff --git a/docs/source/en/model_doc/ernie_m.md b/docs/source/en/model_doc/ernie_m.md
index 3ce3b40c44..292fce2ac3 100644
--- a/docs/source/en/model_doc/ernie_m.md
+++ b/docs/source/en/model_doc/ernie_m.md
@@ -31,7 +31,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
The ErnieM model was proposed in [ERNIE-M: Enhanced Multilingual Representation by Aligning
-Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun,
+Cross-lingual Semantics with Monolingual Corpora](https://huggingface.co/papers/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun,
Hao Tian, Hua Wu, Haifeng Wang.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/fastspeech2_conformer.md b/docs/source/en/model_doc/fastspeech2_conformer.md
index aeb055ceae..f6abf6125f 100644
--- a/docs/source/en/model_doc/fastspeech2_conformer.md
+++ b/docs/source/en/model_doc/fastspeech2_conformer.md
@@ -18,7 +18,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The FastSpeech2Conformer model was proposed with the paper [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
+The FastSpeech2Conformer model was proposed with the paper [Recent Developments On Espnet Toolkit Boosted By Conformer](https://huggingface.co/papers/2010.13956) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
The abstract from the original FastSpeech2 paper is the following:
diff --git a/docs/source/en/model_doc/flan-t5.md b/docs/source/en/model_doc/flan-t5.md
index 0e3b9ba073..8f6f413894 100644
--- a/docs/source/en/model_doc/flan-t5.md
+++ b/docs/source/en/model_doc/flan-t5.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-FLAN-T5 was released in the paper [Scaling Instruction-Finetuned Language Models](https://arxiv.org/pdf/2210.11416.pdf) - it is an enhanced version of T5 that has been finetuned in a mixture of tasks.
+FLAN-T5 was released in the paper [Scaling Instruction-Finetuned Language Models](https://huggingface.co/papers/2210.11416) - it is an enhanced version of T5 that has been finetuned in a mixture of tasks.
One can directly use FLAN-T5 weights without finetuning the model:
diff --git a/docs/source/en/model_doc/flaubert.md b/docs/source/en/model_doc/flaubert.md
index 59ab44ebff..f921cfdce1 100644
--- a/docs/source/en/model_doc/flaubert.md
+++ b/docs/source/en/model_doc/flaubert.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The FlauBERT model was proposed in the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le et al. It's a transformer model pretrained using a masked language
+The FlauBERT model was proposed in the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://huggingface.co/papers/1912.05372) by Hang Le et al. It's a transformer model pretrained using a masked language
modeling (MLM) objective (like BERT).
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/flava.md b/docs/source/en/model_doc/flava.md
index c809be7358..9360bb7a97 100644
--- a/docs/source/en/model_doc/flava.md
+++ b/docs/source/en/model_doc/flava.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The FLAVA model was proposed in [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela and is accepted at CVPR 2022.
+The FLAVA model was proposed in [FLAVA: A Foundational Language And Vision Alignment Model](https://huggingface.co/papers/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela and is accepted at CVPR 2022.
The paper aims at creating a single unified foundation model which can work across vision, language
as well as vision-and-language multimodal tasks.
diff --git a/docs/source/en/model_doc/fnet.md b/docs/source/en/model_doc/fnet.md
index fcf75e21ca..5d1a7d498c 100644
--- a/docs/source/en/model_doc/fnet.md
+++ b/docs/source/en/model_doc/fnet.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The FNet model was proposed in [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by
+The FNet model was proposed in [FNet: Mixing Tokens with Fourier Transforms](https://huggingface.co/papers/2105.03824) by
James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon. The model replaces the self-attention layer in a BERT
model with a fourier transform which returns only the real parts of the transform. The model is significantly faster
than the BERT model because it has fewer parameters and is more memory efficient. The model achieves about 92-97%
diff --git a/docs/source/en/model_doc/focalnet.md b/docs/source/en/model_doc/focalnet.md
index 5312cae4ff..02cd9e173d 100644
--- a/docs/source/en/model_doc/focalnet.md
+++ b/docs/source/en/model_doc/focalnet.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The FocalNet model was proposed in [Focal Modulation Networks](https://arxiv.org/abs/2203.11926) by Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao.
+The FocalNet model was proposed in [Focal Modulation Networks](https://huggingface.co/papers/2203.11926) by Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao.
FocalNets completely replace self-attention (used in models like [ViT](vit) and [Swin](swin)) by a focal modulation mechanism for modeling token interactions in vision.
The authors claim that FocalNets outperform self-attention based models with similar computational costs on the tasks of image classification, object detection, and segmentation.
diff --git a/docs/source/en/model_doc/fsmt.md b/docs/source/en/model_doc/fsmt.md
index 9419dce71e..acce6979ba 100644
--- a/docs/source/en/model_doc/fsmt.md
+++ b/docs/source/en/model_doc/fsmt.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-FSMT (FairSeq MachineTranslation) models were introduced in [Facebook FAIR's WMT19 News Translation Task Submission](https://arxiv.org/abs/1907.06616) by Nathan Ng, Kyra Yee, Alexei Baevski, Myle Ott, Michael Auli, Sergey Edunov.
+FSMT (FairSeq MachineTranslation) models were introduced in [Facebook FAIR's WMT19 News Translation Task Submission](https://huggingface.co/papers/1907.06616) by Nathan Ng, Kyra Yee, Alexei Baevski, Myle Ott, Michael Auli, Sergey Edunov.
The abstract of the paper is the following:
diff --git a/docs/source/en/model_doc/funnel.md b/docs/source/en/model_doc/funnel.md
index 96050a153d..8eb35ea1d3 100644
--- a/docs/source/en/model_doc/funnel.md
+++ b/docs/source/en/model_doc/funnel.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
The Funnel Transformer model was proposed in the paper [Funnel-Transformer: Filtering out Sequential Redundancy for
-Efficient Language Processing](https://arxiv.org/abs/2006.03236). It is a bidirectional transformer model, like
+Efficient Language Processing](https://huggingface.co/papers/2006.03236). It is a bidirectional transformer model, like
BERT, but with a pooling operation after each block of layers, a bit like in traditional convolutional neural networks
(CNN) in computer vision.
diff --git a/docs/source/en/model_doc/git.md b/docs/source/en/model_doc/git.md
index 825b73c5c5..c1b7dba820 100644
--- a/docs/source/en/model_doc/git.md
+++ b/docs/source/en/model_doc/git.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The GIT model was proposed in [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by
+The GIT model was proposed in [GIT: A Generative Image-to-text Transformer for Vision and Language](https://huggingface.co/papers/2205.14100) by
Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang. GIT is a decoder-only Transformer
that leverages [CLIP](clip)'s vision encoder to condition the model on vision inputs besides text. The model obtains state-of-the-art results on
image captioning and visual question answering benchmarks.
@@ -34,7 +34,7 @@ The abstract from the paper is the following:
- DPT architecture. Taken from the original paper.
+ DPT architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/isl-org/DPT).
diff --git a/docs/source/en/model_doc/efficientformer.md b/docs/source/en/model_doc/efficientformer.md
index f05ccacc3d..31b1d37f0f 100644
--- a/docs/source/en/model_doc/efficientformer.md
+++ b/docs/source/en/model_doc/efficientformer.md
@@ -31,7 +31,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The EfficientFormer model was proposed in [EfficientFormer: Vision Transformers at MobileNet Speed](https://arxiv.org/abs/2206.01191)
+The EfficientFormer model was proposed in [EfficientFormer: Vision Transformers at MobileNet Speed](https://huggingface.co/papers/2206.01191)
by Yanyu Li, Geng Yuan, Yang Wen, Eric Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren. EfficientFormer proposes a
dimension-consistent pure transformer that can be run on mobile devices for dense prediction tasks like image classification, object
detection and semantic segmentation.
diff --git a/docs/source/en/model_doc/efficientnet.md b/docs/source/en/model_doc/efficientnet.md
index 17a96aeb5a..e11eab612c 100644
--- a/docs/source/en/model_doc/efficientnet.md
+++ b/docs/source/en/model_doc/efficientnet.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The EfficientNet model was proposed in [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946)
+The EfficientNet model was proposed in [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://huggingface.co/papers/1905.11946)
by Mingxing Tan and Quoc V. Le. EfficientNets are a family of image classification models, which achieve state-of-the-art accuracy, yet being an order-of-magnitude smaller and faster than previous models.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/emu3.md b/docs/source/en/model_doc/emu3.md
index 20b8a5e1cd..5f51566084 100644
--- a/docs/source/en/model_doc/emu3.md
+++ b/docs/source/en/model_doc/emu3.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Emu3 model was proposed in [Emu3: Next-Token Prediction is All You Need](https://arxiv.org/abs/2409.18869) by Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, Yingli Zhao, Yulong Ao, Xuebin Min, Tao Li, Boya Wu, Bo Zhao, Bowen Zhang, Liangdong Wang, Guang Liu, Zheqi He, Xi Yang, Jingjing Liu, Yonghua Lin, Tiejun Huang, Zhongyuan Wang.
+The Emu3 model was proposed in [Emu3: Next-Token Prediction is All You Need](https://huggingface.co/papers/2409.18869) by Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, Yingli Zhao, Yulong Ao, Xuebin Min, Tao Li, Boya Wu, Bo Zhao, Bowen Zhang, Liangdong Wang, Guang Liu, Zheqi He, Xi Yang, Jingjing Liu, Yonghua Lin, Tiejun Huang, Zhongyuan Wang.
Emu3 is a multimodal LLM that uses vector quantization to tokenize images into discrete tokens. Discretized image tokens are later fused with text token ids for image and text generation. The model can additionally generate images by predicting image token ids.
diff --git a/docs/source/en/model_doc/encodec.md b/docs/source/en/model_doc/encodec.md
index 893954d5cf..06ce1e2faf 100644
--- a/docs/source/en/model_doc/encodec.md
+++ b/docs/source/en/model_doc/encodec.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The EnCodec neural codec model was proposed in [High Fidelity Neural Audio Compression](https://arxiv.org/abs/2210.13438) by Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi.
+The EnCodec neural codec model was proposed in [High Fidelity Neural Audio Compression](https://huggingface.co/papers/2210.13438) by Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/encoder-decoder.md b/docs/source/en/model_doc/encoder-decoder.md
index d0a676fb33..f697c213b7 100644
--- a/docs/source/en/model_doc/encoder-decoder.md
+++ b/docs/source/en/model_doc/encoder-decoder.md
@@ -30,14 +30,14 @@ The [`EncoderDecoderModel`] can be used to initialize a sequence-to-sequence mod
pretrained autoencoding model as the encoder and any pretrained autoregressive model as the decoder.
The effectiveness of initializing sequence-to-sequence models with pretrained checkpoints for sequence generation tasks
-was shown in [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by
+was shown in [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://huggingface.co/papers/1907.12461) by
Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
After such an [`EncoderDecoderModel`] has been trained/fine-tuned, it can be saved/loaded just like
any other models (see the examples for more information).
An application of this architecture could be to leverage two pretrained [`BertModel`] as the encoder
-and decoder for a summarization model as was shown in: [Text Summarization with Pretrained Encoders](https://arxiv.org/abs/1908.08345) by Yang Liu and Mirella Lapata.
+and decoder for a summarization model as was shown in: [Text Summarization with Pretrained Encoders](https://huggingface.co/papers/1908.08345) by Yang Liu and Mirella Lapata.
## Randomly initializing `EncoderDecoderModel` from model configurations.
diff --git a/docs/source/en/model_doc/ernie.md b/docs/source/en/model_doc/ernie.md
index 82f2a0d5ba..596a7b1f4b 100644
--- a/docs/source/en/model_doc/ernie.md
+++ b/docs/source/en/model_doc/ernie.md
@@ -22,8 +22,8 @@ rendered properly in your Markdown viewer.
## Overview
ERNIE is a series of powerful models proposed by baidu, especially in Chinese tasks,
-including [ERNIE1.0](https://arxiv.org/abs/1904.09223), [ERNIE2.0](https://ojs.aaai.org/index.php/AAAI/article/view/6428),
-[ERNIE3.0](https://arxiv.org/abs/2107.02137), [ERNIE-Gram](https://arxiv.org/abs/2010.12148), [ERNIE-health](https://arxiv.org/abs/2110.07244), etc.
+including [ERNIE1.0](https://huggingface.co/papers/1904.09223), [ERNIE2.0](https://ojs.aaai.org/index.php/AAAI/article/view/6428),
+[ERNIE3.0](https://huggingface.co/papers/2107.02137), [ERNIE-Gram](https://huggingface.co/papers/2010.12148), [ERNIE-health](https://huggingface.co/papers/2110.07244), etc.
These models are contributed by [nghuyong](https://huggingface.co/nghuyong) and the official code can be found in [PaddleNLP](https://github.com/PaddlePaddle/PaddleNLP) (in PaddlePaddle).
diff --git a/docs/source/en/model_doc/ernie_m.md b/docs/source/en/model_doc/ernie_m.md
index 3ce3b40c44..292fce2ac3 100644
--- a/docs/source/en/model_doc/ernie_m.md
+++ b/docs/source/en/model_doc/ernie_m.md
@@ -31,7 +31,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
The ErnieM model was proposed in [ERNIE-M: Enhanced Multilingual Representation by Aligning
-Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun,
+Cross-lingual Semantics with Monolingual Corpora](https://huggingface.co/papers/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun,
Hao Tian, Hua Wu, Haifeng Wang.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/fastspeech2_conformer.md b/docs/source/en/model_doc/fastspeech2_conformer.md
index aeb055ceae..f6abf6125f 100644
--- a/docs/source/en/model_doc/fastspeech2_conformer.md
+++ b/docs/source/en/model_doc/fastspeech2_conformer.md
@@ -18,7 +18,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The FastSpeech2Conformer model was proposed with the paper [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
+The FastSpeech2Conformer model was proposed with the paper [Recent Developments On Espnet Toolkit Boosted By Conformer](https://huggingface.co/papers/2010.13956) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
The abstract from the original FastSpeech2 paper is the following:
diff --git a/docs/source/en/model_doc/flan-t5.md b/docs/source/en/model_doc/flan-t5.md
index 0e3b9ba073..8f6f413894 100644
--- a/docs/source/en/model_doc/flan-t5.md
+++ b/docs/source/en/model_doc/flan-t5.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-FLAN-T5 was released in the paper [Scaling Instruction-Finetuned Language Models](https://arxiv.org/pdf/2210.11416.pdf) - it is an enhanced version of T5 that has been finetuned in a mixture of tasks.
+FLAN-T5 was released in the paper [Scaling Instruction-Finetuned Language Models](https://huggingface.co/papers/2210.11416) - it is an enhanced version of T5 that has been finetuned in a mixture of tasks.
One can directly use FLAN-T5 weights without finetuning the model:
diff --git a/docs/source/en/model_doc/flaubert.md b/docs/source/en/model_doc/flaubert.md
index 59ab44ebff..f921cfdce1 100644
--- a/docs/source/en/model_doc/flaubert.md
+++ b/docs/source/en/model_doc/flaubert.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The FlauBERT model was proposed in the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le et al. It's a transformer model pretrained using a masked language
+The FlauBERT model was proposed in the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://huggingface.co/papers/1912.05372) by Hang Le et al. It's a transformer model pretrained using a masked language
modeling (MLM) objective (like BERT).
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/flava.md b/docs/source/en/model_doc/flava.md
index c809be7358..9360bb7a97 100644
--- a/docs/source/en/model_doc/flava.md
+++ b/docs/source/en/model_doc/flava.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The FLAVA model was proposed in [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela and is accepted at CVPR 2022.
+The FLAVA model was proposed in [FLAVA: A Foundational Language And Vision Alignment Model](https://huggingface.co/papers/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela and is accepted at CVPR 2022.
The paper aims at creating a single unified foundation model which can work across vision, language
as well as vision-and-language multimodal tasks.
diff --git a/docs/source/en/model_doc/fnet.md b/docs/source/en/model_doc/fnet.md
index fcf75e21ca..5d1a7d498c 100644
--- a/docs/source/en/model_doc/fnet.md
+++ b/docs/source/en/model_doc/fnet.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The FNet model was proposed in [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by
+The FNet model was proposed in [FNet: Mixing Tokens with Fourier Transforms](https://huggingface.co/papers/2105.03824) by
James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon. The model replaces the self-attention layer in a BERT
model with a fourier transform which returns only the real parts of the transform. The model is significantly faster
than the BERT model because it has fewer parameters and is more memory efficient. The model achieves about 92-97%
diff --git a/docs/source/en/model_doc/focalnet.md b/docs/source/en/model_doc/focalnet.md
index 5312cae4ff..02cd9e173d 100644
--- a/docs/source/en/model_doc/focalnet.md
+++ b/docs/source/en/model_doc/focalnet.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The FocalNet model was proposed in [Focal Modulation Networks](https://arxiv.org/abs/2203.11926) by Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao.
+The FocalNet model was proposed in [Focal Modulation Networks](https://huggingface.co/papers/2203.11926) by Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao.
FocalNets completely replace self-attention (used in models like [ViT](vit) and [Swin](swin)) by a focal modulation mechanism for modeling token interactions in vision.
The authors claim that FocalNets outperform self-attention based models with similar computational costs on the tasks of image classification, object detection, and segmentation.
diff --git a/docs/source/en/model_doc/fsmt.md b/docs/source/en/model_doc/fsmt.md
index 9419dce71e..acce6979ba 100644
--- a/docs/source/en/model_doc/fsmt.md
+++ b/docs/source/en/model_doc/fsmt.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-FSMT (FairSeq MachineTranslation) models were introduced in [Facebook FAIR's WMT19 News Translation Task Submission](https://arxiv.org/abs/1907.06616) by Nathan Ng, Kyra Yee, Alexei Baevski, Myle Ott, Michael Auli, Sergey Edunov.
+FSMT (FairSeq MachineTranslation) models were introduced in [Facebook FAIR's WMT19 News Translation Task Submission](https://huggingface.co/papers/1907.06616) by Nathan Ng, Kyra Yee, Alexei Baevski, Myle Ott, Michael Auli, Sergey Edunov.
The abstract of the paper is the following:
diff --git a/docs/source/en/model_doc/funnel.md b/docs/source/en/model_doc/funnel.md
index 96050a153d..8eb35ea1d3 100644
--- a/docs/source/en/model_doc/funnel.md
+++ b/docs/source/en/model_doc/funnel.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
The Funnel Transformer model was proposed in the paper [Funnel-Transformer: Filtering out Sequential Redundancy for
-Efficient Language Processing](https://arxiv.org/abs/2006.03236). It is a bidirectional transformer model, like
+Efficient Language Processing](https://huggingface.co/papers/2006.03236). It is a bidirectional transformer model, like
BERT, but with a pooling operation after each block of layers, a bit like in traditional convolutional neural networks
(CNN) in computer vision.
diff --git a/docs/source/en/model_doc/git.md b/docs/source/en/model_doc/git.md
index 825b73c5c5..c1b7dba820 100644
--- a/docs/source/en/model_doc/git.md
+++ b/docs/source/en/model_doc/git.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The GIT model was proposed in [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by
+The GIT model was proposed in [GIT: A Generative Image-to-text Transformer for Vision and Language](https://huggingface.co/papers/2205.14100) by
Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang. GIT is a decoder-only Transformer
that leverages [CLIP](clip)'s vision encoder to condition the model on vision inputs besides text. The model obtains state-of-the-art results on
image captioning and visual question answering benchmarks.
@@ -34,7 +34,7 @@ The abstract from the paper is the following:
 - GIT architecture. Taken from the original paper.
+ GIT architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/microsoft/GenerativeImage2Text).
diff --git a/docs/source/en/model_doc/glm.md b/docs/source/en/model_doc/glm.md
index cfcd549d14..bf5b95ac14 100644
--- a/docs/source/en/model_doc/glm.md
+++ b/docs/source/en/model_doc/glm.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
The GLM Model was proposed
-in [ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools](https://arxiv.org/html/2406.12793v1)
+in [ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools](https://huggingface.co/papers/2406.12793)
by GLM Team, THUDM & ZhipuAI.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/glpn.md b/docs/source/en/model_doc/glpn.md
index 95ecc36bf5..4a4433626f 100644
--- a/docs/source/en/model_doc/glpn.md
+++ b/docs/source/en/model_doc/glpn.md
@@ -29,7 +29,7 @@ breaking changes to fix it in the future. If you see something strange, file a [
## Overview
-The GLPN model was proposed in [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
+The GLPN model was proposed in [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://huggingface.co/papers/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
GLPN combines [SegFormer](segformer)'s hierarchical mix-Transformer with a lightweight decoder for monocular depth estimation. The proposed decoder shows better performance than the previously proposed decoders, with considerably
less computational complexity.
@@ -40,7 +40,7 @@ The abstract from the paper is the following:
- GIT architecture. Taken from the original paper.
+ GIT architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/microsoft/GenerativeImage2Text).
diff --git a/docs/source/en/model_doc/glm.md b/docs/source/en/model_doc/glm.md
index cfcd549d14..bf5b95ac14 100644
--- a/docs/source/en/model_doc/glm.md
+++ b/docs/source/en/model_doc/glm.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
The GLM Model was proposed
-in [ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools](https://arxiv.org/html/2406.12793v1)
+in [ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools](https://huggingface.co/papers/2406.12793)
by GLM Team, THUDM & ZhipuAI.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/glpn.md b/docs/source/en/model_doc/glpn.md
index 95ecc36bf5..4a4433626f 100644
--- a/docs/source/en/model_doc/glpn.md
+++ b/docs/source/en/model_doc/glpn.md
@@ -29,7 +29,7 @@ breaking changes to fix it in the future. If you see something strange, file a [
## Overview
-The GLPN model was proposed in [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
+The GLPN model was proposed in [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://huggingface.co/papers/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
GLPN combines [SegFormer](segformer)'s hierarchical mix-Transformer with a lightweight decoder for monocular depth estimation. The proposed decoder shows better performance than the previously proposed decoders, with considerably
less computational complexity.
@@ -40,7 +40,7 @@ The abstract from the paper is the following:
 - Summary of the approach. Taken from the original paper.
+ Summary of the approach. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/vinvino02/GLPDepth).
diff --git a/docs/source/en/model_doc/got_ocr2.md b/docs/source/en/model_doc/got_ocr2.md
index c7a73659e8..6f15f2526f 100644
--- a/docs/source/en/model_doc/got_ocr2.md
+++ b/docs/source/en/model_doc/got_ocr2.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The GOT-OCR2 model was proposed in [General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model](https://arxiv.org/abs/2409.01704) by Haoran Wei, Chenglong Liu, Jinyue Chen, Jia Wang, Lingyu Kong, Yanming Xu, Zheng Ge, Liang Zhao, Jianjian Sun, Yuang Peng, Chunrui Han, Xiangyu Zhang.
+The GOT-OCR2 model was proposed in [General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model](https://huggingface.co/papers/2409.01704) by Haoran Wei, Chenglong Liu, Jinyue Chen, Jia Wang, Lingyu Kong, Yanming Xu, Zheng Ge, Liang Zhao, Jianjian Sun, Yuang Peng, Chunrui Han, Xiangyu Zhang.
The abstract from the paper is the following:
@@ -31,7 +31,7 @@ The abstract from the paper is the following:
- Summary of the approach. Taken from the original paper.
+ Summary of the approach. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/vinvino02/GLPDepth).
diff --git a/docs/source/en/model_doc/got_ocr2.md b/docs/source/en/model_doc/got_ocr2.md
index c7a73659e8..6f15f2526f 100644
--- a/docs/source/en/model_doc/got_ocr2.md
+++ b/docs/source/en/model_doc/got_ocr2.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The GOT-OCR2 model was proposed in [General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model](https://arxiv.org/abs/2409.01704) by Haoran Wei, Chenglong Liu, Jinyue Chen, Jia Wang, Lingyu Kong, Yanming Xu, Zheng Ge, Liang Zhao, Jianjian Sun, Yuang Peng, Chunrui Han, Xiangyu Zhang.
+The GOT-OCR2 model was proposed in [General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model](https://huggingface.co/papers/2409.01704) by Haoran Wei, Chenglong Liu, Jinyue Chen, Jia Wang, Lingyu Kong, Yanming Xu, Zheng Ge, Liang Zhao, Jianjian Sun, Yuang Peng, Chunrui Han, Xiangyu Zhang.
The abstract from the paper is the following:
@@ -31,7 +31,7 @@ The abstract from the paper is the following:
 - GOT-OCR2 training stages. Taken from the original paper.
+ GOT-OCR2 training stages. Taken from the original paper.
Tips:
diff --git a/docs/source/en/model_doc/gpt_bigcode.md b/docs/source/en/model_doc/gpt_bigcode.md
index 3620281893..9e25f3c19e 100644
--- a/docs/source/en/model_doc/gpt_bigcode.md
+++ b/docs/source/en/model_doc/gpt_bigcode.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The GPTBigCode model was proposed in [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) by BigCode. The listed authors are: Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
+The GPTBigCode model was proposed in [SantaCoder: don't reach for the stars!](https://huggingface.co/papers/2301.03988) by BigCode. The listed authors are: Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/granite_speech.md b/docs/source/en/model_doc/granite_speech.md
index 212c3d1499..be5714a3ab 100644
--- a/docs/source/en/model_doc/granite_speech.md
+++ b/docs/source/en/model_doc/granite_speech.md
@@ -23,11 +23,11 @@ rendered properly in your Markdown viewer.
## Overview
The Granite Speech model is a multimodal language model, consisting of a speech encoder, speech projector, large language model, and LoRA adapter(s). More details regarding each component for the current (Granite 3.2 Speech) model architecture may be found below.
-1. Speech Encoder: A [Conformer](https://arxiv.org/abs/2005.08100) encoder trained with Connectionist Temporal Classification (CTC) on character-level targets on ASR corpora. The encoder uses block-attention and self-conditioned CTC from the middle layer.
+1. Speech Encoder: A [Conformer](https://huggingface.co/papers/2005.08100) encoder trained with Connectionist Temporal Classification (CTC) on character-level targets on ASR corpora. The encoder uses block-attention and self-conditioned CTC from the middle layer.
2. Speech Projector: A query transformer (q-former) operating on the outputs of the last encoder block. The encoder and projector temporally downsample the audio features to be merged into the multimodal embeddings to be processed by the llm.
-3. Large Language Model: The Granite Speech model leverages Granite LLMs, which were originally proposed in [this paper](https://arxiv.org/abs/2408.13359).
+3. Large Language Model: The Granite Speech model leverages Granite LLMs, which were originally proposed in [this paper](https://huggingface.co/papers/2408.13359).
4. LoRA adapter(s): The Granite Speech model contains a modality specific LoRA, which will be enabled when audio features are provided, and disabled otherwise.
diff --git a/docs/source/en/model_doc/granitemoe.md b/docs/source/en/model_doc/granitemoe.md
index 56ba5d936c..3334008f0c 100644
--- a/docs/source/en/model_doc/granitemoe.md
+++ b/docs/source/en/model_doc/granitemoe.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The GraniteMoe model was proposed in [Power Scheduler: A Batch Size and Token Number Agnostic Learning Rate Scheduler](https://arxiv.org/abs/2408.13359) by Yikang Shen, Matthew Stallone, Mayank Mishra, Gaoyuan Zhang, Shawn Tan, Aditya Prasad, Adriana Meza Soria, David D. Cox and Rameswar Panda.
+The GraniteMoe model was proposed in [Power Scheduler: A Batch Size and Token Number Agnostic Learning Rate Scheduler](https://huggingface.co/papers/2408.13359) by Yikang Shen, Matthew Stallone, Mayank Mishra, Gaoyuan Zhang, Shawn Tan, Aditya Prasad, Adriana Meza Soria, David D. Cox and Rameswar Panda.
PowerMoE-3B is a 3B sparse Mixture-of-Experts (sMoE) language model trained with the Power learning rate scheduler. It sparsely activates 800M parameters for each token. It is trained on a mix of open-source and proprietary datasets. PowerMoE-3B has shown promising results compared to other dense models with 2x activate parameters across various benchmarks, including natural language multi-choices, code generation, and math reasoning.
diff --git a/docs/source/en/model_doc/granitemoeshared.md b/docs/source/en/model_doc/granitemoeshared.md
index 38eb7daf8c..54a956c0f3 100644
--- a/docs/source/en/model_doc/granitemoeshared.md
+++ b/docs/source/en/model_doc/granitemoeshared.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## Overview
-The GraniteMoe model was proposed in [Power Scheduler: A Batch Size and Token Number Agnostic Learning Rate Scheduler](https://arxiv.org/abs/2408.13359) by Yikang Shen, Matthew Stallone, Mayank Mishra, Gaoyuan Zhang, Shawn Tan, Aditya Prasad, Adriana Meza Soria, David D. Cox and Rameswar Panda.
+The GraniteMoe model was proposed in [Power Scheduler: A Batch Size and Token Number Agnostic Learning Rate Scheduler](https://huggingface.co/papers/2408.13359) by Yikang Shen, Matthew Stallone, Mayank Mishra, Gaoyuan Zhang, Shawn Tan, Aditya Prasad, Adriana Meza Soria, David D. Cox and Rameswar Panda.
Additionally this class GraniteMoeSharedModel adds shared experts for Moe.
diff --git a/docs/source/en/model_doc/graphormer.md b/docs/source/en/model_doc/graphormer.md
index 0d88134d4b..b602bc9b0d 100644
--- a/docs/source/en/model_doc/graphormer.md
+++ b/docs/source/en/model_doc/graphormer.md
@@ -28,7 +28,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The Graphormer model was proposed in [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) by
+The Graphormer model was proposed in [Do Transformers Really Perform Bad for Graph Representation?](https://huggingface.co/papers/2106.05234) by
Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen and Tie-Yan Liu. It is a Graph Transformer model, modified to allow computations on graphs instead of text sequences by generating embeddings and features of interest during preprocessing and collation, then using a modified attention.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/grounding-dino.md b/docs/source/en/model_doc/grounding-dino.md
index 0222243519..145913da63 100644
--- a/docs/source/en/model_doc/grounding-dino.md
+++ b/docs/source/en/model_doc/grounding-dino.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Grounding DINO model was proposed in [Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection](https://arxiv.org/abs/2303.05499) by Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang. Grounding DINO extends a closed-set object detection model with a text encoder, enabling open-set object detection. The model achieves remarkable results, such as 52.5 AP on COCO zero-shot.
+The Grounding DINO model was proposed in [Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection](https://huggingface.co/papers/2303.05499) by Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang. Grounding DINO extends a closed-set object detection model with a text encoder, enabling open-set object detection. The model achieves remarkable results, such as 52.5 AP on COCO zero-shot.
The abstract from the paper is the following:
@@ -31,7 +31,7 @@ The abstract from the paper is the following:
- GOT-OCR2 training stages. Taken from the original paper.
+ GOT-OCR2 training stages. Taken from the original paper.
Tips:
diff --git a/docs/source/en/model_doc/gpt_bigcode.md b/docs/source/en/model_doc/gpt_bigcode.md
index 3620281893..9e25f3c19e 100644
--- a/docs/source/en/model_doc/gpt_bigcode.md
+++ b/docs/source/en/model_doc/gpt_bigcode.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The GPTBigCode model was proposed in [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) by BigCode. The listed authors are: Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
+The GPTBigCode model was proposed in [SantaCoder: don't reach for the stars!](https://huggingface.co/papers/2301.03988) by BigCode. The listed authors are: Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/granite_speech.md b/docs/source/en/model_doc/granite_speech.md
index 212c3d1499..be5714a3ab 100644
--- a/docs/source/en/model_doc/granite_speech.md
+++ b/docs/source/en/model_doc/granite_speech.md
@@ -23,11 +23,11 @@ rendered properly in your Markdown viewer.
## Overview
The Granite Speech model is a multimodal language model, consisting of a speech encoder, speech projector, large language model, and LoRA adapter(s). More details regarding each component for the current (Granite 3.2 Speech) model architecture may be found below.
-1. Speech Encoder: A [Conformer](https://arxiv.org/abs/2005.08100) encoder trained with Connectionist Temporal Classification (CTC) on character-level targets on ASR corpora. The encoder uses block-attention and self-conditioned CTC from the middle layer.
+1. Speech Encoder: A [Conformer](https://huggingface.co/papers/2005.08100) encoder trained with Connectionist Temporal Classification (CTC) on character-level targets on ASR corpora. The encoder uses block-attention and self-conditioned CTC from the middle layer.
2. Speech Projector: A query transformer (q-former) operating on the outputs of the last encoder block. The encoder and projector temporally downsample the audio features to be merged into the multimodal embeddings to be processed by the llm.
-3. Large Language Model: The Granite Speech model leverages Granite LLMs, which were originally proposed in [this paper](https://arxiv.org/abs/2408.13359).
+3. Large Language Model: The Granite Speech model leverages Granite LLMs, which were originally proposed in [this paper](https://huggingface.co/papers/2408.13359).
4. LoRA adapter(s): The Granite Speech model contains a modality specific LoRA, which will be enabled when audio features are provided, and disabled otherwise.
diff --git a/docs/source/en/model_doc/granitemoe.md b/docs/source/en/model_doc/granitemoe.md
index 56ba5d936c..3334008f0c 100644
--- a/docs/source/en/model_doc/granitemoe.md
+++ b/docs/source/en/model_doc/granitemoe.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The GraniteMoe model was proposed in [Power Scheduler: A Batch Size and Token Number Agnostic Learning Rate Scheduler](https://arxiv.org/abs/2408.13359) by Yikang Shen, Matthew Stallone, Mayank Mishra, Gaoyuan Zhang, Shawn Tan, Aditya Prasad, Adriana Meza Soria, David D. Cox and Rameswar Panda.
+The GraniteMoe model was proposed in [Power Scheduler: A Batch Size and Token Number Agnostic Learning Rate Scheduler](https://huggingface.co/papers/2408.13359) by Yikang Shen, Matthew Stallone, Mayank Mishra, Gaoyuan Zhang, Shawn Tan, Aditya Prasad, Adriana Meza Soria, David D. Cox and Rameswar Panda.
PowerMoE-3B is a 3B sparse Mixture-of-Experts (sMoE) language model trained with the Power learning rate scheduler. It sparsely activates 800M parameters for each token. It is trained on a mix of open-source and proprietary datasets. PowerMoE-3B has shown promising results compared to other dense models with 2x activate parameters across various benchmarks, including natural language multi-choices, code generation, and math reasoning.
diff --git a/docs/source/en/model_doc/granitemoeshared.md b/docs/source/en/model_doc/granitemoeshared.md
index 38eb7daf8c..54a956c0f3 100644
--- a/docs/source/en/model_doc/granitemoeshared.md
+++ b/docs/source/en/model_doc/granitemoeshared.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## Overview
-The GraniteMoe model was proposed in [Power Scheduler: A Batch Size and Token Number Agnostic Learning Rate Scheduler](https://arxiv.org/abs/2408.13359) by Yikang Shen, Matthew Stallone, Mayank Mishra, Gaoyuan Zhang, Shawn Tan, Aditya Prasad, Adriana Meza Soria, David D. Cox and Rameswar Panda.
+The GraniteMoe model was proposed in [Power Scheduler: A Batch Size and Token Number Agnostic Learning Rate Scheduler](https://huggingface.co/papers/2408.13359) by Yikang Shen, Matthew Stallone, Mayank Mishra, Gaoyuan Zhang, Shawn Tan, Aditya Prasad, Adriana Meza Soria, David D. Cox and Rameswar Panda.
Additionally this class GraniteMoeSharedModel adds shared experts for Moe.
diff --git a/docs/source/en/model_doc/graphormer.md b/docs/source/en/model_doc/graphormer.md
index 0d88134d4b..b602bc9b0d 100644
--- a/docs/source/en/model_doc/graphormer.md
+++ b/docs/source/en/model_doc/graphormer.md
@@ -28,7 +28,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The Graphormer model was proposed in [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) by
+The Graphormer model was proposed in [Do Transformers Really Perform Bad for Graph Representation?](https://huggingface.co/papers/2106.05234) by
Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen and Tie-Yan Liu. It is a Graph Transformer model, modified to allow computations on graphs instead of text sequences by generating embeddings and features of interest during preprocessing and collation, then using a modified attention.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/grounding-dino.md b/docs/source/en/model_doc/grounding-dino.md
index 0222243519..145913da63 100644
--- a/docs/source/en/model_doc/grounding-dino.md
+++ b/docs/source/en/model_doc/grounding-dino.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Grounding DINO model was proposed in [Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection](https://arxiv.org/abs/2303.05499) by Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang. Grounding DINO extends a closed-set object detection model with a text encoder, enabling open-set object detection. The model achieves remarkable results, such as 52.5 AP on COCO zero-shot.
+The Grounding DINO model was proposed in [Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection](https://huggingface.co/papers/2303.05499) by Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang. Grounding DINO extends a closed-set object detection model with a text encoder, enabling open-set object detection. The model achieves remarkable results, such as 52.5 AP on COCO zero-shot.
The abstract from the paper is the following:
@@ -31,7 +31,7 @@ The abstract from the paper is the following:
 - Grounding DINO overview. Taken from the original paper.
+ Grounding DINO overview. Taken from the original paper.
This model was contributed by [EduardoPacheco](https://huggingface.co/EduardoPacheco) and [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/IDEA-Research/GroundingDINO).
@@ -85,7 +85,7 @@ Detected a cat with confidence 0.426 at location [11.74, 51.55, 316.51, 473.22]
## Grounded SAM
-One can combine Grounding DINO with the [Segment Anything](sam) model for text-based mask generation as introduced in [Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks](https://arxiv.org/abs/2401.14159). You can refer to this [demo notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Grounding%20DINO/GroundingDINO_with_Segment_Anything.ipynb) 🌍 for details.
+One can combine Grounding DINO with the [Segment Anything](sam) model for text-based mask generation as introduced in [Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks](https://huggingface.co/papers/2401.14159). You can refer to this [demo notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Grounding%20DINO/GroundingDINO_with_Segment_Anything.ipynb) 🌍 for details.
- Grounding DINO overview. Taken from the original paper.
+ Grounding DINO overview. Taken from the original paper.
This model was contributed by [EduardoPacheco](https://huggingface.co/EduardoPacheco) and [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/IDEA-Research/GroundingDINO).
@@ -85,7 +85,7 @@ Detected a cat with confidence 0.426 at location [11.74, 51.55, 316.51, 473.22]
## Grounded SAM
-One can combine Grounding DINO with the [Segment Anything](sam) model for text-based mask generation as introduced in [Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks](https://arxiv.org/abs/2401.14159). You can refer to this [demo notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Grounding%20DINO/GroundingDINO_with_Segment_Anything.ipynb) 🌍 for details.
+One can combine Grounding DINO with the [Segment Anything](sam) model for text-based mask generation as introduced in [Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks](https://huggingface.co/papers/2401.14159). You can refer to this [demo notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Grounding%20DINO/GroundingDINO_with_Segment_Anything.ipynb) 🌍 for details.
 diff --git a/docs/source/en/model_doc/groupvit.md b/docs/source/en/model_doc/groupvit.md
index c77a51d8b1..dbe83b64c8 100644
--- a/docs/source/en/model_doc/groupvit.md
+++ b/docs/source/en/model_doc/groupvit.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The GroupViT model was proposed in [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
+The GroupViT model was proposed in [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://huggingface.co/papers/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
Inspired by [CLIP](clip), GroupViT is a vision-language model that can perform zero-shot semantic segmentation on any given vocabulary categories.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/hgnet_v2.md b/docs/source/en/model_doc/hgnet_v2.md
index 7c868608f4..a2e594b5f9 100644
--- a/docs/source/en/model_doc/hgnet_v2.md
+++ b/docs/source/en/model_doc/hgnet_v2.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## Overview
A HGNet-V2 (High Performance GPU Net) image classification model.
-HGNet arhtictecture was proposed in [HGNET: A Hierarchical Feature Guided Network for Occupancy Flow Field Prediction](https://arxiv.org/abs/2407.01097) by
+HGNet arhtictecture was proposed in [HGNET: A Hierarchical Feature Guided Network for Occupancy Flow Field Prediction](https://huggingface.co/papers/2407.01097) by
Zhan Chen, Chen Tang, Lu Xiong
The abstract from the HGNET paper is the following:
diff --git a/docs/source/en/model_doc/hiera.md b/docs/source/en/model_doc/hiera.md
index a82eec950a..9d20f34670 100644
--- a/docs/source/en/model_doc/hiera.md
+++ b/docs/source/en/model_doc/hiera.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-Hiera was proposed in [Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles](https://arxiv.org/abs/2306.00989) by Chaitanya Ryali, Yuan-Ting Hu, Daniel Bolya, Chen Wei, Haoqi Fan, Po-Yao Huang, Vaibhav Aggarwal, Arkabandhu Chowdhury, Omid Poursaeed, Judy Hoffman, Jitendra Malik, Yanghao Li, Christoph Feichtenhofer
+Hiera was proposed in [Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles](https://huggingface.co/papers/2306.00989) by Chaitanya Ryali, Yuan-Ting Hu, Daniel Bolya, Chen Wei, Haoqi Fan, Po-Yao Huang, Vaibhav Aggarwal, Arkabandhu Chowdhury, Omid Poursaeed, Judy Hoffman, Jitendra Malik, Yanghao Li, Christoph Feichtenhofer
The paper introduces "Hiera," a hierarchical Vision Transformer that simplifies the architecture of modern hierarchical vision transformers by removing unnecessary components without compromising on accuracy or efficiency. Unlike traditional transformers that add complex vision-specific components to improve supervised classification performance, Hiera demonstrates that such additions, often termed "bells-and-whistles," are not essential for high accuracy. By leveraging a strong visual pretext task (MAE) for pretraining, Hiera retains simplicity and achieves superior accuracy and speed both in inference and training across various image and video recognition tasks. The approach suggests that spatial biases required for vision tasks can be effectively learned through proper pretraining, eliminating the need for added architectural complexity.
@@ -33,7 +33,7 @@ The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/groupvit.md b/docs/source/en/model_doc/groupvit.md
index c77a51d8b1..dbe83b64c8 100644
--- a/docs/source/en/model_doc/groupvit.md
+++ b/docs/source/en/model_doc/groupvit.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The GroupViT model was proposed in [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
+The GroupViT model was proposed in [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://huggingface.co/papers/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
Inspired by [CLIP](clip), GroupViT is a vision-language model that can perform zero-shot semantic segmentation on any given vocabulary categories.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/hgnet_v2.md b/docs/source/en/model_doc/hgnet_v2.md
index 7c868608f4..a2e594b5f9 100644
--- a/docs/source/en/model_doc/hgnet_v2.md
+++ b/docs/source/en/model_doc/hgnet_v2.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## Overview
A HGNet-V2 (High Performance GPU Net) image classification model.
-HGNet arhtictecture was proposed in [HGNET: A Hierarchical Feature Guided Network for Occupancy Flow Field Prediction](https://arxiv.org/abs/2407.01097) by
+HGNet arhtictecture was proposed in [HGNET: A Hierarchical Feature Guided Network for Occupancy Flow Field Prediction](https://huggingface.co/papers/2407.01097) by
Zhan Chen, Chen Tang, Lu Xiong
The abstract from the HGNET paper is the following:
diff --git a/docs/source/en/model_doc/hiera.md b/docs/source/en/model_doc/hiera.md
index a82eec950a..9d20f34670 100644
--- a/docs/source/en/model_doc/hiera.md
+++ b/docs/source/en/model_doc/hiera.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-Hiera was proposed in [Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles](https://arxiv.org/abs/2306.00989) by Chaitanya Ryali, Yuan-Ting Hu, Daniel Bolya, Chen Wei, Haoqi Fan, Po-Yao Huang, Vaibhav Aggarwal, Arkabandhu Chowdhury, Omid Poursaeed, Judy Hoffman, Jitendra Malik, Yanghao Li, Christoph Feichtenhofer
+Hiera was proposed in [Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles](https://huggingface.co/papers/2306.00989) by Chaitanya Ryali, Yuan-Ting Hu, Daniel Bolya, Chen Wei, Haoqi Fan, Po-Yao Huang, Vaibhav Aggarwal, Arkabandhu Chowdhury, Omid Poursaeed, Judy Hoffman, Jitendra Malik, Yanghao Li, Christoph Feichtenhofer
The paper introduces "Hiera," a hierarchical Vision Transformer that simplifies the architecture of modern hierarchical vision transformers by removing unnecessary components without compromising on accuracy or efficiency. Unlike traditional transformers that add complex vision-specific components to improve supervised classification performance, Hiera demonstrates that such additions, often termed "bells-and-whistles," are not essential for high accuracy. By leveraging a strong visual pretext task (MAE) for pretraining, Hiera retains simplicity and achieves superior accuracy and speed both in inference and training across various image and video recognition tasks. The approach suggests that spatial biases required for vision tasks can be effectively learned through proper pretraining, eliminating the need for added architectural complexity.
@@ -33,7 +33,7 @@ The abstract from the paper is the following:
 - Hiera architecture. Taken from the original paper.
+ Hiera architecture. Taken from the original paper.
This model was a joint contribution by [EduardoPacheco](https://huggingface.co/EduardoPacheco) and [namangarg110](https://huggingface.co/namangarg110). The original code can be found [here] (https://github.com/facebookresearch/hiera).
diff --git a/docs/source/en/model_doc/hubert.md b/docs/source/en/model_doc/hubert.md
index 98f00867bd..17255fa8d4 100644
--- a/docs/source/en/model_doc/hubert.md
+++ b/docs/source/en/model_doc/hubert.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-Hubert was proposed in [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan
+Hubert was proposed in [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://huggingface.co/papers/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan
Salakhutdinov, Abdelrahman Mohamed.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/ibert.md b/docs/source/en/model_doc/ibert.md
index 8c43eeddaf..34893c6c1d 100644
--- a/docs/source/en/model_doc/ibert.md
+++ b/docs/source/en/model_doc/ibert.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The I-BERT model was proposed in [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by
+The I-BERT model was proposed in [I-BERT: Integer-only BERT Quantization](https://huggingface.co/papers/2101.01321) by
Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney and Kurt Keutzer. It's a quantized version of RoBERTa running
inference up to four times faster.
diff --git a/docs/source/en/model_doc/idefics2.md b/docs/source/en/model_doc/idefics2.md
index 8de2c92d56..24d3fd23c7 100644
--- a/docs/source/en/model_doc/idefics2.md
+++ b/docs/source/en/model_doc/idefics2.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Idefics2 model was proposed in [What matters when building vision-language models?](https://arxiv.org/abs/2405.02246) by Léo Tronchon, Hugo Laurencon, Victor Sanh. The accompanying blog post can be found [here](https://huggingface.co/blog/idefics2).
+The Idefics2 model was proposed in [What matters when building vision-language models?](https://huggingface.co/papers/2405.02246) by Léo Tronchon, Hugo Laurencon, Victor Sanh. The accompanying blog post can be found [here](https://huggingface.co/blog/idefics2).
Idefics2 is an open multimodal model that accepts arbitrary sequences of image and text inputs and produces text
outputs. The model can answer questions about images, describe visual content, create stories grounded on multiple
@@ -39,7 +39,7 @@ The abstract from the paper is the following:
- Hiera architecture. Taken from the original paper.
+ Hiera architecture. Taken from the original paper.
This model was a joint contribution by [EduardoPacheco](https://huggingface.co/EduardoPacheco) and [namangarg110](https://huggingface.co/namangarg110). The original code can be found [here] (https://github.com/facebookresearch/hiera).
diff --git a/docs/source/en/model_doc/hubert.md b/docs/source/en/model_doc/hubert.md
index 98f00867bd..17255fa8d4 100644
--- a/docs/source/en/model_doc/hubert.md
+++ b/docs/source/en/model_doc/hubert.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-Hubert was proposed in [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan
+Hubert was proposed in [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://huggingface.co/papers/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan
Salakhutdinov, Abdelrahman Mohamed.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/ibert.md b/docs/source/en/model_doc/ibert.md
index 8c43eeddaf..34893c6c1d 100644
--- a/docs/source/en/model_doc/ibert.md
+++ b/docs/source/en/model_doc/ibert.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The I-BERT model was proposed in [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by
+The I-BERT model was proposed in [I-BERT: Integer-only BERT Quantization](https://huggingface.co/papers/2101.01321) by
Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney and Kurt Keutzer. It's a quantized version of RoBERTa running
inference up to four times faster.
diff --git a/docs/source/en/model_doc/idefics2.md b/docs/source/en/model_doc/idefics2.md
index 8de2c92d56..24d3fd23c7 100644
--- a/docs/source/en/model_doc/idefics2.md
+++ b/docs/source/en/model_doc/idefics2.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Idefics2 model was proposed in [What matters when building vision-language models?](https://arxiv.org/abs/2405.02246) by Léo Tronchon, Hugo Laurencon, Victor Sanh. The accompanying blog post can be found [here](https://huggingface.co/blog/idefics2).
+The Idefics2 model was proposed in [What matters when building vision-language models?](https://huggingface.co/papers/2405.02246) by Léo Tronchon, Hugo Laurencon, Victor Sanh. The accompanying blog post can be found [here](https://huggingface.co/blog/idefics2).
Idefics2 is an open multimodal model that accepts arbitrary sequences of image and text inputs and produces text
outputs. The model can answer questions about images, describe visual content, create stories grounded on multiple
@@ -39,7 +39,7 @@ The abstract from the paper is the following:
 - Idefics2 architecture. Taken from the original paper.
+ Idefics2 architecture. Taken from the original paper.
This model was contributed by [amyeroberts](https://huggingface.co/amyeroberts).
The original code can be found [here](https://huggingface.co/HuggingFaceM4/idefics2).
diff --git a/docs/source/en/model_doc/ijepa.md b/docs/source/en/model_doc/ijepa.md
index d350114781..02c05b0bdd 100644
--- a/docs/source/en/model_doc/ijepa.md
+++ b/docs/source/en/model_doc/ijepa.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The I-JEPA model was proposed in [Image-based Joint-Embedding Predictive Architecture](https://arxiv.org/abs/2301.08243) by Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, Nicolas Ballas.
+The I-JEPA model was proposed in [Image-based Joint-Embedding Predictive Architecture](https://huggingface.co/papers/2301.08243) by Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, Nicolas Ballas.
I-JEPA is a self-supervised learning method that predicts the representations of one part of an image based on other parts of the same image. This approach focuses on learning semantic features without relying on pre-defined invariances from hand-crafted data transformations, which can bias specific tasks, or on filling in pixel-level details, which often leads to less meaningful representations.
The abstract from the paper is the following:
@@ -34,7 +34,7 @@ This paper demonstrates an approach for learning highly semantic image represent
- Idefics2 architecture. Taken from the original paper.
+ Idefics2 architecture. Taken from the original paper.
This model was contributed by [amyeroberts](https://huggingface.co/amyeroberts).
The original code can be found [here](https://huggingface.co/HuggingFaceM4/idefics2).
diff --git a/docs/source/en/model_doc/ijepa.md b/docs/source/en/model_doc/ijepa.md
index d350114781..02c05b0bdd 100644
--- a/docs/source/en/model_doc/ijepa.md
+++ b/docs/source/en/model_doc/ijepa.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The I-JEPA model was proposed in [Image-based Joint-Embedding Predictive Architecture](https://arxiv.org/abs/2301.08243) by Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, Nicolas Ballas.
+The I-JEPA model was proposed in [Image-based Joint-Embedding Predictive Architecture](https://huggingface.co/papers/2301.08243) by Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, Nicolas Ballas.
I-JEPA is a self-supervised learning method that predicts the representations of one part of an image based on other parts of the same image. This approach focuses on learning semantic features without relying on pre-defined invariances from hand-crafted data transformations, which can bias specific tasks, or on filling in pixel-level details, which often leads to less meaningful representations.
The abstract from the paper is the following:
@@ -34,7 +34,7 @@ This paper demonstrates an approach for learning highly semantic image represent
 - I-JEPA architecture. Taken from the original paper.
+ I-JEPA architecture. Taken from the original paper.
This model was contributed by [jmtzt](https://huggingface.co/jmtzt).
The original code can be found [here](https://github.com/facebookresearch/ijepa).
diff --git a/docs/source/en/model_doc/informer.md b/docs/source/en/model_doc/informer.md
index 1dfc397db7..d511d0f498 100644
--- a/docs/source/en/model_doc/informer.md
+++ b/docs/source/en/model_doc/informer.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Informer model was proposed in [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
+The Informer model was proposed in [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://huggingface.co/papers/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
This method introduces a Probabilistic Attention mechanism to select the "active" queries rather than the "lazy" queries and provides a sparse Transformer thus mitigating the quadratic compute and memory requirements of vanilla attention.
diff --git a/docs/source/en/model_doc/instructblip.md b/docs/source/en/model_doc/instructblip.md
index 944e8888fc..c297ca0ac4 100644
--- a/docs/source/en/model_doc/instructblip.md
+++ b/docs/source/en/model_doc/instructblip.md
@@ -18,7 +18,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The InstructBLIP model was proposed in [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
+The InstructBLIP model was proposed in [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://huggingface.co/papers/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
InstructBLIP leverages the [BLIP-2](blip2) architecture for visual instruction tuning.
The abstract from the paper is the following:
@@ -28,7 +28,7 @@ The abstract from the paper is the following:
- I-JEPA architecture. Taken from the original paper.
+ I-JEPA architecture. Taken from the original paper.
This model was contributed by [jmtzt](https://huggingface.co/jmtzt).
The original code can be found [here](https://github.com/facebookresearch/ijepa).
diff --git a/docs/source/en/model_doc/informer.md b/docs/source/en/model_doc/informer.md
index 1dfc397db7..d511d0f498 100644
--- a/docs/source/en/model_doc/informer.md
+++ b/docs/source/en/model_doc/informer.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Informer model was proposed in [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
+The Informer model was proposed in [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://huggingface.co/papers/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
This method introduces a Probabilistic Attention mechanism to select the "active" queries rather than the "lazy" queries and provides a sparse Transformer thus mitigating the quadratic compute and memory requirements of vanilla attention.
diff --git a/docs/source/en/model_doc/instructblip.md b/docs/source/en/model_doc/instructblip.md
index 944e8888fc..c297ca0ac4 100644
--- a/docs/source/en/model_doc/instructblip.md
+++ b/docs/source/en/model_doc/instructblip.md
@@ -18,7 +18,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The InstructBLIP model was proposed in [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
+The InstructBLIP model was proposed in [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://huggingface.co/papers/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
InstructBLIP leverages the [BLIP-2](blip2) architecture for visual instruction tuning.
The abstract from the paper is the following:
@@ -28,7 +28,7 @@ The abstract from the paper is the following:
 - InstructBLIP architecture. Taken from the original paper.
+ InstructBLIP architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/salesforce/LAVIS/tree/main/projects/instructblip).
diff --git a/docs/source/en/model_doc/instructblipvideo.md b/docs/source/en/model_doc/instructblipvideo.md
index fd728c35bb..d0b4dc3cc0 100644
--- a/docs/source/en/model_doc/instructblipvideo.md
+++ b/docs/source/en/model_doc/instructblipvideo.md
@@ -18,7 +18,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The InstructBLIPVideo is an extension of the models proposed in [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
+The InstructBLIPVideo is an extension of the models proposed in [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://huggingface.co/papers/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
InstructBLIPVideo uses the same architecture as [InstructBLIP](instructblip) and works with the same checkpoints as [InstructBLIP](instructblip). The only difference is the ability to process videos.
The abstract from the paper is the following:
@@ -28,7 +28,7 @@ The abstract from the paper is the following:
- InstructBLIP architecture. Taken from the original paper.
+ InstructBLIP architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/salesforce/LAVIS/tree/main/projects/instructblip).
diff --git a/docs/source/en/model_doc/instructblipvideo.md b/docs/source/en/model_doc/instructblipvideo.md
index fd728c35bb..d0b4dc3cc0 100644
--- a/docs/source/en/model_doc/instructblipvideo.md
+++ b/docs/source/en/model_doc/instructblipvideo.md
@@ -18,7 +18,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The InstructBLIPVideo is an extension of the models proposed in [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
+The InstructBLIPVideo is an extension of the models proposed in [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://huggingface.co/papers/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
InstructBLIPVideo uses the same architecture as [InstructBLIP](instructblip) and works with the same checkpoints as [InstructBLIP](instructblip). The only difference is the ability to process videos.
The abstract from the paper is the following:
@@ -28,7 +28,7 @@ The abstract from the paper is the following:
 - Overview of tasks that KOSMOS-2 can handle. Taken from the original paper.
+ Overview of tasks that KOSMOS-2 can handle. Taken from the original paper.
## Example
diff --git a/docs/source/en/model_doc/layoutlm.md b/docs/source/en/model_doc/layoutlm.md
index 51cc52b7f4..86c5c7c1fc 100644
--- a/docs/source/en/model_doc/layoutlm.md
+++ b/docs/source/en/model_doc/layoutlm.md
@@ -26,7 +26,7 @@ rendered properly in your Markdown viewer.
## Overview
The LayoutLM model was proposed in the paper [LayoutLM: Pre-training of Text and Layout for Document Image
-Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, and
+Understanding](https://huggingface.co/papers/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, and
Ming Zhou. It's a simple but effective pretraining method of text and layout for document image understanding and
information extraction tasks, such as form understanding and receipt understanding. It obtains state-of-the-art results
on several downstream tasks:
diff --git a/docs/source/en/model_doc/layoutlmv2.md b/docs/source/en/model_doc/layoutlmv2.md
index af20687571..b6c6242e45 100644
--- a/docs/source/en/model_doc/layoutlmv2.md
+++ b/docs/source/en/model_doc/layoutlmv2.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The LayoutLMV2 model was proposed in [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu,
+The LayoutLMV2 model was proposed in [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://huggingface.co/papers/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu,
Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou. LayoutLMV2 improves [LayoutLM](layoutlm) to obtain
state-of-the-art results across several document image understanding benchmarks:
@@ -34,7 +34,7 @@ state-of-the-art results across several document image understanding benchmarks:
documents for testing).
- document image classification: the [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/) dataset (a collection of
400,000 images belonging to one of 16 classes).
-- document visual question answering: the [DocVQA](https://arxiv.org/abs/2007.00398) dataset (a collection of 50,000
+- document visual question answering: the [DocVQA](https://huggingface.co/papers/2007.00398) dataset (a collection of 50,000
questions defined on 12,000+ document images).
The abstract from the paper is the following:
@@ -65,7 +65,7 @@ python -m pip install torchvision tesseract
- The main difference between LayoutLMv1 and LayoutLMv2 is that the latter incorporates visual embeddings during
pre-training (while LayoutLMv1 only adds visual embeddings during fine-tuning).
- LayoutLMv2 adds both a relative 1D attention bias as well as a spatial 2D attention bias to the attention scores in
- the self-attention layers. Details can be found on page 5 of the [paper](https://arxiv.org/abs/2012.14740).
+ the self-attention layers. Details can be found on page 5 of the [paper](https://huggingface.co/papers/2012.14740).
- Demo notebooks on how to use the LayoutLMv2 model on RVL-CDIP, FUNSD, DocVQA, CORD can be found [here](https://github.com/NielsRogge/Transformers-Tutorials).
- LayoutLMv2 uses Facebook AI's [Detectron2](https://github.com/facebookresearch/detectron2/) package for its visual
backbone. See [this link](https://detectron2.readthedocs.io/en/latest/tutorials/install.html) for installation
diff --git a/docs/source/en/model_doc/layoutlmv3.md b/docs/source/en/model_doc/layoutlmv3.md
index 07200be361..cbf6709727 100644
--- a/docs/source/en/model_doc/layoutlmv3.md
+++ b/docs/source/en/model_doc/layoutlmv3.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-The LayoutLMv3 model was proposed in [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
+The LayoutLMv3 model was proposed in [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://huggingface.co/papers/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
LayoutLMv3 simplifies [LayoutLMv2](layoutlmv2) by using patch embeddings (as in [ViT](vit)) instead of leveraging a CNN backbone, and pre-trains the model on 3 objectives: masked language modeling (MLM), masked image modeling (MIM)
and word-patch alignment (WPA).
@@ -29,7 +29,7 @@ The abstract from the paper is the following:
- Overview of tasks that KOSMOS-2 can handle. Taken from the original paper.
+ Overview of tasks that KOSMOS-2 can handle. Taken from the original paper.
## Example
diff --git a/docs/source/en/model_doc/layoutlm.md b/docs/source/en/model_doc/layoutlm.md
index 51cc52b7f4..86c5c7c1fc 100644
--- a/docs/source/en/model_doc/layoutlm.md
+++ b/docs/source/en/model_doc/layoutlm.md
@@ -26,7 +26,7 @@ rendered properly in your Markdown viewer.
## Overview
The LayoutLM model was proposed in the paper [LayoutLM: Pre-training of Text and Layout for Document Image
-Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, and
+Understanding](https://huggingface.co/papers/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, and
Ming Zhou. It's a simple but effective pretraining method of text and layout for document image understanding and
information extraction tasks, such as form understanding and receipt understanding. It obtains state-of-the-art results
on several downstream tasks:
diff --git a/docs/source/en/model_doc/layoutlmv2.md b/docs/source/en/model_doc/layoutlmv2.md
index af20687571..b6c6242e45 100644
--- a/docs/source/en/model_doc/layoutlmv2.md
+++ b/docs/source/en/model_doc/layoutlmv2.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The LayoutLMV2 model was proposed in [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu,
+The LayoutLMV2 model was proposed in [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://huggingface.co/papers/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu,
Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou. LayoutLMV2 improves [LayoutLM](layoutlm) to obtain
state-of-the-art results across several document image understanding benchmarks:
@@ -34,7 +34,7 @@ state-of-the-art results across several document image understanding benchmarks:
documents for testing).
- document image classification: the [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/) dataset (a collection of
400,000 images belonging to one of 16 classes).
-- document visual question answering: the [DocVQA](https://arxiv.org/abs/2007.00398) dataset (a collection of 50,000
+- document visual question answering: the [DocVQA](https://huggingface.co/papers/2007.00398) dataset (a collection of 50,000
questions defined on 12,000+ document images).
The abstract from the paper is the following:
@@ -65,7 +65,7 @@ python -m pip install torchvision tesseract
- The main difference between LayoutLMv1 and LayoutLMv2 is that the latter incorporates visual embeddings during
pre-training (while LayoutLMv1 only adds visual embeddings during fine-tuning).
- LayoutLMv2 adds both a relative 1D attention bias as well as a spatial 2D attention bias to the attention scores in
- the self-attention layers. Details can be found on page 5 of the [paper](https://arxiv.org/abs/2012.14740).
+ the self-attention layers. Details can be found on page 5 of the [paper](https://huggingface.co/papers/2012.14740).
- Demo notebooks on how to use the LayoutLMv2 model on RVL-CDIP, FUNSD, DocVQA, CORD can be found [here](https://github.com/NielsRogge/Transformers-Tutorials).
- LayoutLMv2 uses Facebook AI's [Detectron2](https://github.com/facebookresearch/detectron2/) package for its visual
backbone. See [this link](https://detectron2.readthedocs.io/en/latest/tutorials/install.html) for installation
diff --git a/docs/source/en/model_doc/layoutlmv3.md b/docs/source/en/model_doc/layoutlmv3.md
index 07200be361..cbf6709727 100644
--- a/docs/source/en/model_doc/layoutlmv3.md
+++ b/docs/source/en/model_doc/layoutlmv3.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-The LayoutLMv3 model was proposed in [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
+The LayoutLMv3 model was proposed in [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://huggingface.co/papers/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
LayoutLMv3 simplifies [LayoutLMv2](layoutlmv2) by using patch embeddings (as in [ViT](vit)) instead of leveraging a CNN backbone, and pre-trains the model on 3 objectives: masked language modeling (MLM), masked image modeling (MIM)
and word-patch alignment (WPA).
@@ -29,7 +29,7 @@ The abstract from the paper is the following:
 - LayoutLMv3 architecture. Taken from the original paper.
+ LayoutLMv3 architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version of this model was added by [chriskoo](https://huggingface.co/chriskoo), [tokec](https://huggingface.co/tokec), and [lre](https://huggingface.co/lre). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/layoutlmv3).
diff --git a/docs/source/en/model_doc/layoutxlm.md b/docs/source/en/model_doc/layoutxlm.md
index 96e0a4d4bf..32f453fb6f 100644
--- a/docs/source/en/model_doc/layoutxlm.md
+++ b/docs/source/en/model_doc/layoutxlm.md
@@ -22,8 +22,8 @@ rendered properly in your Markdown viewer.
## Overview
-LayoutXLM was proposed in [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha
-Zhang, Furu Wei. It's a multilingual extension of the [LayoutLMv2 model](https://arxiv.org/abs/2012.14740) trained
+LayoutXLM was proposed in [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://huggingface.co/papers/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha
+Zhang, Furu Wei. It's a multilingual extension of the [LayoutLMv2 model](https://huggingface.co/papers/2012.14740) trained
on 53 languages.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/led.md b/docs/source/en/model_doc/led.md
index 729d5666d8..e0d44107bc 100644
--- a/docs/source/en/model_doc/led.md
+++ b/docs/source/en/model_doc/led.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The LED model was proposed in [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz
+The LED model was proposed in [Longformer: The Long-Document Transformer](https://huggingface.co/papers/2004.05150) by Iz
Beltagy, Matthew E. Peters, Arman Cohan.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/levit.md b/docs/source/en/model_doc/levit.md
index f794f7902f..7596980ecd 100644
--- a/docs/source/en/model_doc/levit.md
+++ b/docs/source/en/model_doc/levit.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The LeViT model was proposed in [LeViT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze. LeViT improves the [Vision Transformer (ViT)](vit) in performance and efficiency by a few architectural differences such as activation maps with decreasing resolutions in Transformers and the introduction of an attention bias to integrate positional information.
+The LeViT model was proposed in [LeViT: Introducing Convolutions to Vision Transformers](https://huggingface.co/papers/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze. LeViT improves the [Vision Transformer (ViT)](vit) in performance and efficiency by a few architectural differences such as activation maps with decreasing resolutions in Transformers and the introduction of an attention bias to integrate positional information.
The abstract from the paper is the following:
@@ -40,7 +40,7 @@ to the speed/accuracy tradeoff. For example, at 80% ImageNet top-1 accuracy, LeV
- LayoutLMv3 architecture. Taken from the original paper.
+ LayoutLMv3 architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version of this model was added by [chriskoo](https://huggingface.co/chriskoo), [tokec](https://huggingface.co/tokec), and [lre](https://huggingface.co/lre). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/layoutlmv3).
diff --git a/docs/source/en/model_doc/layoutxlm.md b/docs/source/en/model_doc/layoutxlm.md
index 96e0a4d4bf..32f453fb6f 100644
--- a/docs/source/en/model_doc/layoutxlm.md
+++ b/docs/source/en/model_doc/layoutxlm.md
@@ -22,8 +22,8 @@ rendered properly in your Markdown viewer.
## Overview
-LayoutXLM was proposed in [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha
-Zhang, Furu Wei. It's a multilingual extension of the [LayoutLMv2 model](https://arxiv.org/abs/2012.14740) trained
+LayoutXLM was proposed in [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://huggingface.co/papers/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha
+Zhang, Furu Wei. It's a multilingual extension of the [LayoutLMv2 model](https://huggingface.co/papers/2012.14740) trained
on 53 languages.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/led.md b/docs/source/en/model_doc/led.md
index 729d5666d8..e0d44107bc 100644
--- a/docs/source/en/model_doc/led.md
+++ b/docs/source/en/model_doc/led.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The LED model was proposed in [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz
+The LED model was proposed in [Longformer: The Long-Document Transformer](https://huggingface.co/papers/2004.05150) by Iz
Beltagy, Matthew E. Peters, Arman Cohan.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/levit.md b/docs/source/en/model_doc/levit.md
index f794f7902f..7596980ecd 100644
--- a/docs/source/en/model_doc/levit.md
+++ b/docs/source/en/model_doc/levit.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The LeViT model was proposed in [LeViT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze. LeViT improves the [Vision Transformer (ViT)](vit) in performance and efficiency by a few architectural differences such as activation maps with decreasing resolutions in Transformers and the introduction of an attention bias to integrate positional information.
+The LeViT model was proposed in [LeViT: Introducing Convolutions to Vision Transformers](https://huggingface.co/papers/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze. LeViT improves the [Vision Transformer (ViT)](vit) in performance and efficiency by a few architectural differences such as activation maps with decreasing resolutions in Transformers and the introduction of an attention bias to integrate positional information.
The abstract from the paper is the following:
@@ -40,7 +40,7 @@ to the speed/accuracy tradeoff. For example, at 80% ImageNet top-1 accuracy, LeV
 - LeViT Architecture. Taken from the original paper.
+ LeViT Architecture. Taken from the original paper.
This model was contributed by [anugunj](https://huggingface.co/anugunj). The original code can be found [here](https://github.com/facebookresearch/LeViT).
diff --git a/docs/source/en/model_doc/lilt.md b/docs/source/en/model_doc/lilt.md
index 2474d854e0..57e8cac28f 100644
--- a/docs/source/en/model_doc/lilt.md
+++ b/docs/source/en/model_doc/lilt.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The LiLT model was proposed in [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
+The LiLT model was proposed in [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://huggingface.co/papers/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
LiLT allows to combine any pre-trained RoBERTa text encoder with a lightweight Layout Transformer, to enable [LayoutLM](layoutlm)-like document understanding for many
languages.
@@ -33,7 +33,7 @@ The abstract from the paper is the following:
- LeViT Architecture. Taken from the original paper.
+ LeViT Architecture. Taken from the original paper.
This model was contributed by [anugunj](https://huggingface.co/anugunj). The original code can be found [here](https://github.com/facebookresearch/LeViT).
diff --git a/docs/source/en/model_doc/lilt.md b/docs/source/en/model_doc/lilt.md
index 2474d854e0..57e8cac28f 100644
--- a/docs/source/en/model_doc/lilt.md
+++ b/docs/source/en/model_doc/lilt.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The LiLT model was proposed in [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
+The LiLT model was proposed in [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://huggingface.co/papers/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
LiLT allows to combine any pre-trained RoBERTa text encoder with a lightweight Layout Transformer, to enable [LayoutLM](layoutlm)-like document understanding for many
languages.
@@ -33,7 +33,7 @@ The abstract from the paper is the following:
 - LiLT architecture. Taken from the original paper.
+ LiLT architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/jpwang/lilt).
diff --git a/docs/source/en/model_doc/llava.md b/docs/source/en/model_doc/llava.md
index d4cc90d2ec..ae1d3c92b1 100644
--- a/docs/source/en/model_doc/llava.md
+++ b/docs/source/en/model_doc/llava.md
@@ -26,7 +26,7 @@ rendered properly in your Markdown viewer.
LLaVa is an open-source chatbot trained by fine-tuning LlamA/Vicuna on GPT-generated multimodal instruction-following data. It is an auto-regressive language model, based on the transformer architecture. In other words, it is an multi-modal version of LLMs fine-tuned for chat / instructions.
-The LLaVa model was proposed in [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) and improved in [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/pdf/2310.03744) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
+The LLaVa model was proposed in [Visual Instruction Tuning](https://huggingface.co/papers/2304.08485) and improved in [Improved Baselines with Visual Instruction Tuning](https://huggingface.co/papers/2310.03744) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
The abstract from the paper is the following:
@@ -35,7 +35,7 @@ The abstract from the paper is the following:
- LiLT architecture. Taken from the original paper.
+ LiLT architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/jpwang/lilt).
diff --git a/docs/source/en/model_doc/llava.md b/docs/source/en/model_doc/llava.md
index d4cc90d2ec..ae1d3c92b1 100644
--- a/docs/source/en/model_doc/llava.md
+++ b/docs/source/en/model_doc/llava.md
@@ -26,7 +26,7 @@ rendered properly in your Markdown viewer.
LLaVa is an open-source chatbot trained by fine-tuning LlamA/Vicuna on GPT-generated multimodal instruction-following data. It is an auto-regressive language model, based on the transformer architecture. In other words, it is an multi-modal version of LLMs fine-tuned for chat / instructions.
-The LLaVa model was proposed in [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) and improved in [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/pdf/2310.03744) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
+The LLaVa model was proposed in [Visual Instruction Tuning](https://huggingface.co/papers/2304.08485) and improved in [Improved Baselines with Visual Instruction Tuning](https://huggingface.co/papers/2310.03744) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
The abstract from the paper is the following:
@@ -35,7 +35,7 @@ The abstract from the paper is the following:
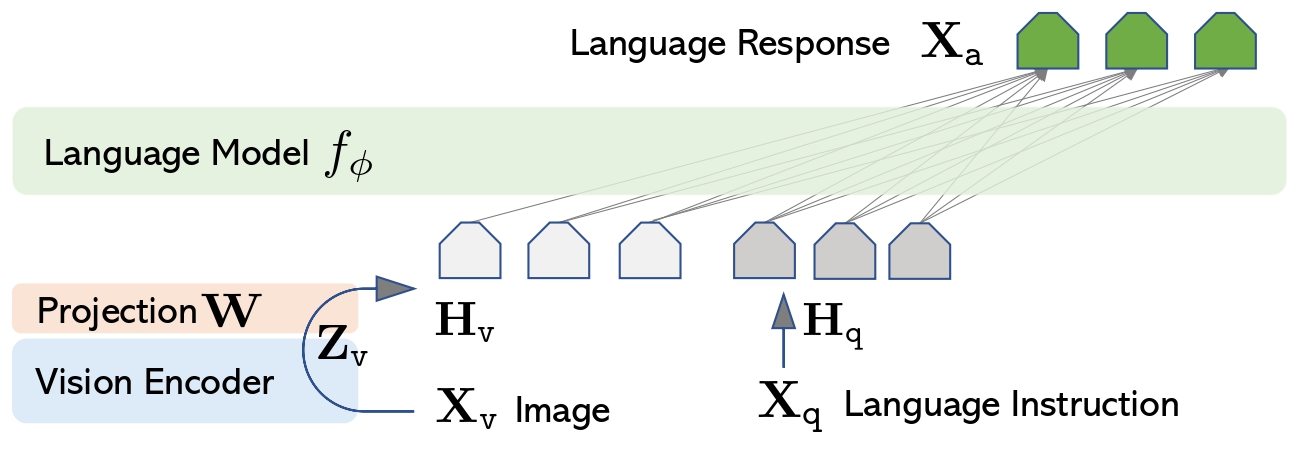 - LLaVa architecture. Taken from the original paper.
+ LLaVa architecture. Taken from the original paper.
This model was contributed by [ArthurZ](https://huggingface.co/ArthurZ) and [ybelkada](https://huggingface.co/ybelkada).
The original code can be found [here](https://github.com/haotian-liu/LLaVA/tree/main/llava).
diff --git a/docs/source/en/model_doc/llava_next.md b/docs/source/en/model_doc/llava_next.md
index cfc60d074c..e4bb26f9c0 100644
--- a/docs/source/en/model_doc/llava_next.md
+++ b/docs/source/en/model_doc/llava_next.md
@@ -43,7 +43,7 @@ Along with performance improvements, LLaVA-NeXT maintains the minimalist design
- LLaVa architecture. Taken from the original paper.
+ LLaVa architecture. Taken from the original paper.
This model was contributed by [ArthurZ](https://huggingface.co/ArthurZ) and [ybelkada](https://huggingface.co/ybelkada).
The original code can be found [here](https://github.com/haotian-liu/LLaVA/tree/main/llava).
diff --git a/docs/source/en/model_doc/llava_next.md b/docs/source/en/model_doc/llava_next.md
index cfc60d074c..e4bb26f9c0 100644
--- a/docs/source/en/model_doc/llava_next.md
+++ b/docs/source/en/model_doc/llava_next.md
@@ -43,7 +43,7 @@ Along with performance improvements, LLaVA-NeXT maintains the minimalist design
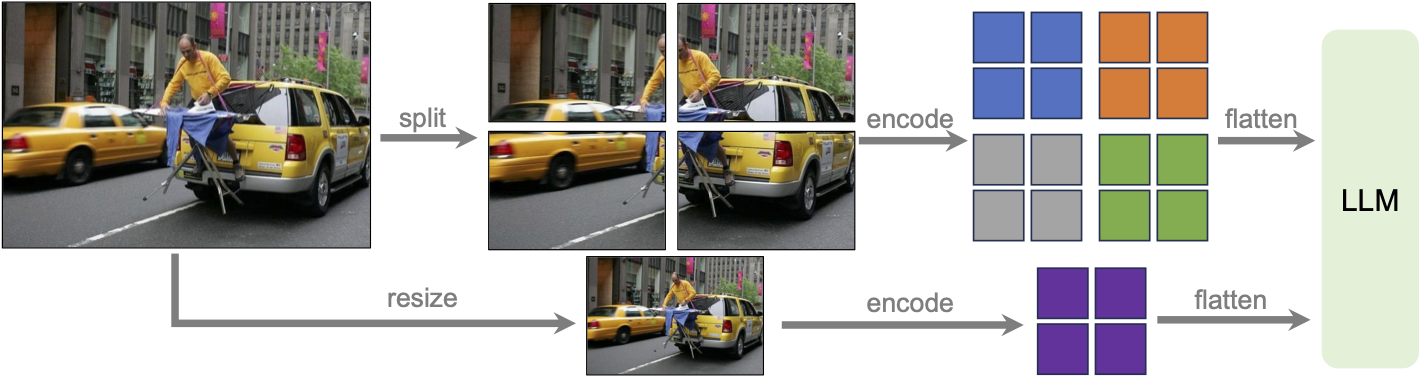 - LLaVa-NeXT incorporates a higher input resolution by encoding various patches of the input image. Taken from the original paper.
+ LLaVa-NeXT incorporates a higher input resolution by encoding various patches of the input image. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/haotian-liu/LLaVA/tree/main).
diff --git a/docs/source/en/model_doc/llava_next_video.md b/docs/source/en/model_doc/llava_next_video.md
index aa61121162..b3e42698c6 100644
--- a/docs/source/en/model_doc/llava_next_video.md
+++ b/docs/source/en/model_doc/llava_next_video.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
The LLaVa-NeXT-Video model was proposed in [LLaVA-NeXT: A Strong Zero-shot Video Understanding Model
](https://llava-vl.github.io/blog/2024-04-30-llava-next-video/) by Yuanhan Zhang, Bo Li, Haotian Liu, Yong Jae Lee, Liangke Gui, Di Fu, Jiashi Feng, Ziwei Liu, Chunyuan Li. LLaVa-NeXT-Video improves upon [LLaVa-NeXT](llava_next) by fine-tuning on a mix if video and image dataset thus increasing the model's performance on videos.
-[LLaVA-NeXT](llava_next) surprisingly has strong performance in understanding video content in zero-shot fashion with the AnyRes technique that it uses. The AnyRes technique naturally represents a high-resolution image into multiple images. This technique is naturally generalizable to represent videos because videos can be considered as a set of frames (similar to a set of images in LLaVa-NeXT). The current version of LLaVA-NeXT makes use of AnyRes and trains with supervised fine-tuning (SFT) on top of LLaVA-Next on video data to achieves better video understanding capabilities.The model is a current SOTA among open-source models on [VideoMME bench](https://arxiv.org/abs/2405.21075).
+[LLaVA-NeXT](llava_next) surprisingly has strong performance in understanding video content in zero-shot fashion with the AnyRes technique that it uses. The AnyRes technique naturally represents a high-resolution image into multiple images. This technique is naturally generalizable to represent videos because videos can be considered as a set of frames (similar to a set of images in LLaVa-NeXT). The current version of LLaVA-NeXT makes use of AnyRes and trains with supervised fine-tuning (SFT) on top of LLaVA-Next on video data to achieves better video understanding capabilities.The model is a current SOTA among open-source models on [VideoMME bench](https://huggingface.co/papers/2405.21075).
The introduction from the blog is the following:
diff --git a/docs/source/en/model_doc/llava_onevision.md b/docs/source/en/model_doc/llava_onevision.md
index da3359f7e3..a8b63c9016 100644
--- a/docs/source/en/model_doc/llava_onevision.md
+++ b/docs/source/en/model_doc/llava_onevision.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The LLaVA-OneVision model was proposed in [LLaVA-OneVision: Easy Visual Task Transfer](https://arxiv.org/abs/2408.03326) by
- LLaVa-NeXT incorporates a higher input resolution by encoding various patches of the input image. Taken from the original paper.
+ LLaVa-NeXT incorporates a higher input resolution by encoding various patches of the input image. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/haotian-liu/LLaVA/tree/main).
diff --git a/docs/source/en/model_doc/llava_next_video.md b/docs/source/en/model_doc/llava_next_video.md
index aa61121162..b3e42698c6 100644
--- a/docs/source/en/model_doc/llava_next_video.md
+++ b/docs/source/en/model_doc/llava_next_video.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
The LLaVa-NeXT-Video model was proposed in [LLaVA-NeXT: A Strong Zero-shot Video Understanding Model
](https://llava-vl.github.io/blog/2024-04-30-llava-next-video/) by Yuanhan Zhang, Bo Li, Haotian Liu, Yong Jae Lee, Liangke Gui, Di Fu, Jiashi Feng, Ziwei Liu, Chunyuan Li. LLaVa-NeXT-Video improves upon [LLaVa-NeXT](llava_next) by fine-tuning on a mix if video and image dataset thus increasing the model's performance on videos.
-[LLaVA-NeXT](llava_next) surprisingly has strong performance in understanding video content in zero-shot fashion with the AnyRes technique that it uses. The AnyRes technique naturally represents a high-resolution image into multiple images. This technique is naturally generalizable to represent videos because videos can be considered as a set of frames (similar to a set of images in LLaVa-NeXT). The current version of LLaVA-NeXT makes use of AnyRes and trains with supervised fine-tuning (SFT) on top of LLaVA-Next on video data to achieves better video understanding capabilities.The model is a current SOTA among open-source models on [VideoMME bench](https://arxiv.org/abs/2405.21075).
+[LLaVA-NeXT](llava_next) surprisingly has strong performance in understanding video content in zero-shot fashion with the AnyRes technique that it uses. The AnyRes technique naturally represents a high-resolution image into multiple images. This technique is naturally generalizable to represent videos because videos can be considered as a set of frames (similar to a set of images in LLaVa-NeXT). The current version of LLaVA-NeXT makes use of AnyRes and trains with supervised fine-tuning (SFT) on top of LLaVA-Next on video data to achieves better video understanding capabilities.The model is a current SOTA among open-source models on [VideoMME bench](https://huggingface.co/papers/2405.21075).
The introduction from the blog is the following:
diff --git a/docs/source/en/model_doc/llava_onevision.md b/docs/source/en/model_doc/llava_onevision.md
index da3359f7e3..a8b63c9016 100644
--- a/docs/source/en/model_doc/llava_onevision.md
+++ b/docs/source/en/model_doc/llava_onevision.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The LLaVA-OneVision model was proposed in [LLaVA-OneVision: Easy Visual Task Transfer](https://arxiv.org/abs/2408.03326) by 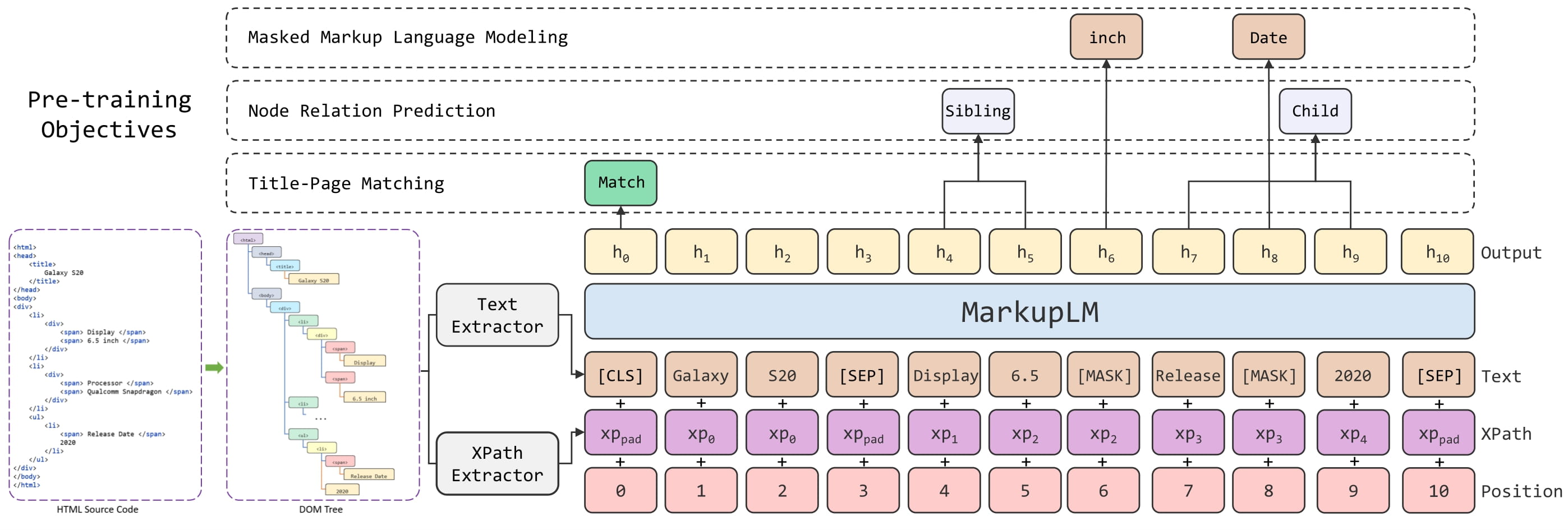 - MarkupLM architecture. Taken from the original paper.
+ MarkupLM architecture. Taken from the original paper.
## Usage: MarkupLMProcessor
diff --git a/docs/source/en/model_doc/mask2former.md b/docs/source/en/model_doc/mask2former.md
index 37a2603c68..f27fd5948f 100644
--- a/docs/source/en/model_doc/mask2former.md
+++ b/docs/source/en/model_doc/mask2former.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Mask2Former model was proposed in [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar. Mask2Former is a unified framework for panoptic, instance and semantic segmentation and features significant performance and efficiency improvements over [MaskFormer](maskformer).
+The Mask2Former model was proposed in [Masked-attention Mask Transformer for Universal Image Segmentation](https://huggingface.co/papers/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar. Mask2Former is a unified framework for panoptic, instance and semantic segmentation and features significant performance and efficiency improvements over [MaskFormer](maskformer).
The abstract from the paper is the following:
@@ -31,7 +31,7 @@ of semantics defines a task. While only the semantics of each task differ, curre
- MarkupLM architecture. Taken from the original paper.
+ MarkupLM architecture. Taken from the original paper.
## Usage: MarkupLMProcessor
diff --git a/docs/source/en/model_doc/mask2former.md b/docs/source/en/model_doc/mask2former.md
index 37a2603c68..f27fd5948f 100644
--- a/docs/source/en/model_doc/mask2former.md
+++ b/docs/source/en/model_doc/mask2former.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Mask2Former model was proposed in [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar. Mask2Former is a unified framework for panoptic, instance and semantic segmentation and features significant performance and efficiency improvements over [MaskFormer](maskformer).
+The Mask2Former model was proposed in [Masked-attention Mask Transformer for Universal Image Segmentation](https://huggingface.co/papers/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar. Mask2Former is a unified framework for panoptic, instance and semantic segmentation and features significant performance and efficiency improvements over [MaskFormer](maskformer).
The abstract from the paper is the following:
@@ -31,7 +31,7 @@ of semantics defines a task. While only the semantics of each task differ, curre
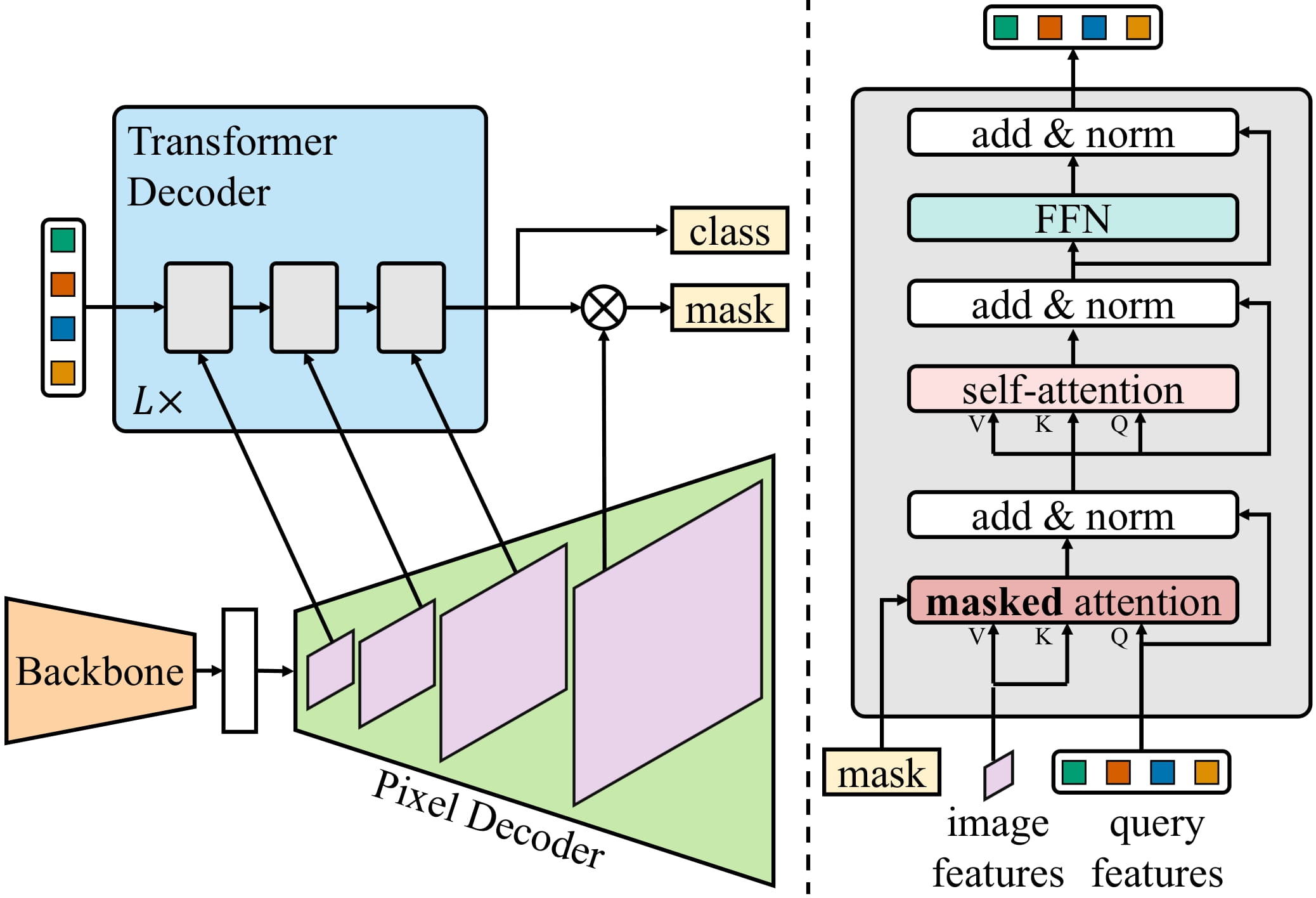 - Mask2Former architecture. Taken from the original paper.
+ Mask2Former architecture. Taken from the original paper.
This model was contributed by [Shivalika Singh](https://huggingface.co/shivi) and [Alara Dirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/facebookresearch/Mask2Former).
diff --git a/docs/source/en/model_doc/maskformer.md b/docs/source/en/model_doc/maskformer.md
index 0adbbf2285..fcfe11ec55 100644
--- a/docs/source/en/model_doc/maskformer.md
+++ b/docs/source/en/model_doc/maskformer.md
@@ -29,13 +29,13 @@ breaking changes to fix it in the future. If you see something strange, file a [
## Overview
-The MaskFormer model was proposed in [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov. MaskFormer addresses semantic segmentation with a mask classification paradigm instead of performing classic pixel-level classification.
+The MaskFormer model was proposed in [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://huggingface.co/papers/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov. MaskFormer addresses semantic segmentation with a mask classification paradigm instead of performing classic pixel-level classification.
The abstract from the paper is the following:
*Modern approaches typically formulate semantic segmentation as a per-pixel classification task, while instance-level segmentation is handled with an alternative mask classification. Our key insight: mask classification is sufficiently general to solve both semantic- and instance-level segmentation tasks in a unified manner using the exact same model, loss, and training procedure. Following this observation, we propose MaskFormer, a simple mask classification model which predicts a set of binary masks, each associated with a single global class label prediction. Overall, the proposed mask classification-based method simplifies the landscape of effective approaches to semantic and panoptic segmentation tasks and shows excellent empirical results. In particular, we observe that MaskFormer outperforms per-pixel classification baselines when the number of classes is large. Our mask classification-based method outperforms both current state-of-the-art semantic (55.6 mIoU on ADE20K) and panoptic segmentation (52.7 PQ on COCO) models.*
-The figure below illustrates the architecture of MaskFormer. Taken from the [original paper](https://arxiv.org/abs/2107.06278).
+The figure below illustrates the architecture of MaskFormer. Taken from the [original paper](https://huggingface.co/papers/2107.06278).
- Mask2Former architecture. Taken from the original paper.
+ Mask2Former architecture. Taken from the original paper.
This model was contributed by [Shivalika Singh](https://huggingface.co/shivi) and [Alara Dirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/facebookresearch/Mask2Former).
diff --git a/docs/source/en/model_doc/maskformer.md b/docs/source/en/model_doc/maskformer.md
index 0adbbf2285..fcfe11ec55 100644
--- a/docs/source/en/model_doc/maskformer.md
+++ b/docs/source/en/model_doc/maskformer.md
@@ -29,13 +29,13 @@ breaking changes to fix it in the future. If you see something strange, file a [
## Overview
-The MaskFormer model was proposed in [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov. MaskFormer addresses semantic segmentation with a mask classification paradigm instead of performing classic pixel-level classification.
+The MaskFormer model was proposed in [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://huggingface.co/papers/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov. MaskFormer addresses semantic segmentation with a mask classification paradigm instead of performing classic pixel-level classification.
The abstract from the paper is the following:
*Modern approaches typically formulate semantic segmentation as a per-pixel classification task, while instance-level segmentation is handled with an alternative mask classification. Our key insight: mask classification is sufficiently general to solve both semantic- and instance-level segmentation tasks in a unified manner using the exact same model, loss, and training procedure. Following this observation, we propose MaskFormer, a simple mask classification model which predicts a set of binary masks, each associated with a single global class label prediction. Overall, the proposed mask classification-based method simplifies the landscape of effective approaches to semantic and panoptic segmentation tasks and shows excellent empirical results. In particular, we observe that MaskFormer outperforms per-pixel classification baselines when the number of classes is large. Our mask classification-based method outperforms both current state-of-the-art semantic (55.6 mIoU on ADE20K) and panoptic segmentation (52.7 PQ on COCO) models.*
-The figure below illustrates the architecture of MaskFormer. Taken from the [original paper](https://arxiv.org/abs/2107.06278).
+The figure below illustrates the architecture of MaskFormer. Taken from the [original paper](https://huggingface.co/papers/2107.06278).
 diff --git a/docs/source/en/model_doc/matcha.md b/docs/source/en/model_doc/matcha.md
index f3c618953b..7dc5660db6 100644
--- a/docs/source/en/model_doc/matcha.md
+++ b/docs/source/en/model_doc/matcha.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-MatCha has been proposed in the paper [MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering](https://arxiv.org/abs/2212.09662), from Fangyu Liu, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Yasemin Altun, Nigel Collier, Julian Martin Eisenschlos.
+MatCha has been proposed in the paper [MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering](https://huggingface.co/papers/2212.09662), from Fangyu Liu, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Yasemin Altun, Nigel Collier, Julian Martin Eisenschlos.
The abstract of the paper states the following:
diff --git a/docs/source/en/model_doc/mctct.md b/docs/source/en/model_doc/mctct.md
index a755f5a027..beb381f6a0 100644
--- a/docs/source/en/model_doc/mctct.md
+++ b/docs/source/en/model_doc/mctct.md
@@ -31,7 +31,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The M-CTC-T model was proposed in [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert. The model is a 1B-param transformer encoder, with a CTC head over 8065 character labels and a language identification head over 60 language ID labels. It is trained on Common Voice (version 6.1, December 2020 release) and VoxPopuli. After training on Common Voice and VoxPopuli, the model is trained on Common Voice only. The labels are unnormalized character-level transcripts (punctuation and capitalization are not removed). The model takes as input Mel filterbank features from a 16Khz audio signal.
+The M-CTC-T model was proposed in [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://huggingface.co/papers/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert. The model is a 1B-param transformer encoder, with a CTC head over 8065 character labels and a language identification head over 60 language ID labels. It is trained on Common Voice (version 6.1, December 2020 release) and VoxPopuli. After training on Common Voice and VoxPopuli, the model is trained on Common Voice only. The labels are unnormalized character-level transcripts (punctuation and capitalization are not removed). The model takes as input Mel filterbank features from a 16Khz audio signal.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/mega.md b/docs/source/en/model_doc/mega.md
index 4e8ccd4b29..080d8de529 100644
--- a/docs/source/en/model_doc/mega.md
+++ b/docs/source/en/model_doc/mega.md
@@ -30,7 +30,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The MEGA model was proposed in [Mega: Moving Average Equipped Gated Attention](https://arxiv.org/abs/2209.10655) by Xuezhe Ma, Chunting Zhou, Xiang Kong, Junxian He, Liangke Gui, Graham Neubig, Jonathan May, and Luke Zettlemoyer.
+The MEGA model was proposed in [Mega: Moving Average Equipped Gated Attention](https://huggingface.co/papers/2209.10655) by Xuezhe Ma, Chunting Zhou, Xiang Kong, Junxian He, Liangke Gui, Graham Neubig, Jonathan May, and Luke Zettlemoyer.
MEGA proposes a new approach to self-attention with each encoder layer having a multi-headed exponential moving average in addition to a single head of standard dot-product attention, giving the attention mechanism
stronger positional biases. This allows MEGA to perform competitively to Transformers on standard benchmarks including LRA
while also having significantly fewer parameters. MEGA's compute efficiency allows it to scale to very long sequences, making it an
diff --git a/docs/source/en/model_doc/megatron-bert.md b/docs/source/en/model_doc/megatron-bert.md
index b032655f75..8d3ba12295 100644
--- a/docs/source/en/model_doc/megatron-bert.md
+++ b/docs/source/en/model_doc/megatron-bert.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
The MegatronBERT model was proposed in [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model
-Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley,
+Parallelism](https://huggingface.co/papers/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley,
Jared Casper and Bryan Catanzaro.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/megatron_gpt2.md b/docs/source/en/model_doc/megatron_gpt2.md
index 7e0ee3cb9e..fc90474663 100644
--- a/docs/source/en/model_doc/megatron_gpt2.md
+++ b/docs/source/en/model_doc/megatron_gpt2.md
@@ -26,7 +26,7 @@ rendered properly in your Markdown viewer.
## Overview
The MegatronGPT2 model was proposed in [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model
-Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley,
+Parallelism](https://huggingface.co/papers/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley,
Jared Casper and Bryan Catanzaro.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/mgp-str.md b/docs/source/en/model_doc/mgp-str.md
index 168e5bd104..b98a34874e 100644
--- a/docs/source/en/model_doc/mgp-str.md
+++ b/docs/source/en/model_doc/mgp-str.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MGP-STR model was proposed in [Multi-Granularity Prediction for Scene Text Recognition](https://arxiv.org/abs/2209.03592) by Peng Wang, Cheng Da, and Cong Yao. MGP-STR is a conceptually **simple** yet **powerful** vision Scene Text Recognition (STR) model, which is built upon the [Vision Transformer (ViT)](vit). To integrate linguistic knowledge, Multi-Granularity Prediction (MGP) strategy is proposed to inject information from the language modality into the model in an implicit way.
+The MGP-STR model was proposed in [Multi-Granularity Prediction for Scene Text Recognition](https://huggingface.co/papers/2209.03592) by Peng Wang, Cheng Da, and Cong Yao. MGP-STR is a conceptually **simple** yet **powerful** vision Scene Text Recognition (STR) model, which is built upon the [Vision Transformer (ViT)](vit). To integrate linguistic knowledge, Multi-Granularity Prediction (MGP) strategy is proposed to inject information from the language modality into the model in an implicit way.
The abstract from the paper is the following:
@@ -31,7 +31,7 @@ The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/matcha.md b/docs/source/en/model_doc/matcha.md
index f3c618953b..7dc5660db6 100644
--- a/docs/source/en/model_doc/matcha.md
+++ b/docs/source/en/model_doc/matcha.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-MatCha has been proposed in the paper [MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering](https://arxiv.org/abs/2212.09662), from Fangyu Liu, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Yasemin Altun, Nigel Collier, Julian Martin Eisenschlos.
+MatCha has been proposed in the paper [MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering](https://huggingface.co/papers/2212.09662), from Fangyu Liu, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Yasemin Altun, Nigel Collier, Julian Martin Eisenschlos.
The abstract of the paper states the following:
diff --git a/docs/source/en/model_doc/mctct.md b/docs/source/en/model_doc/mctct.md
index a755f5a027..beb381f6a0 100644
--- a/docs/source/en/model_doc/mctct.md
+++ b/docs/source/en/model_doc/mctct.md
@@ -31,7 +31,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The M-CTC-T model was proposed in [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert. The model is a 1B-param transformer encoder, with a CTC head over 8065 character labels and a language identification head over 60 language ID labels. It is trained on Common Voice (version 6.1, December 2020 release) and VoxPopuli. After training on Common Voice and VoxPopuli, the model is trained on Common Voice only. The labels are unnormalized character-level transcripts (punctuation and capitalization are not removed). The model takes as input Mel filterbank features from a 16Khz audio signal.
+The M-CTC-T model was proposed in [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://huggingface.co/papers/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert. The model is a 1B-param transformer encoder, with a CTC head over 8065 character labels and a language identification head over 60 language ID labels. It is trained on Common Voice (version 6.1, December 2020 release) and VoxPopuli. After training on Common Voice and VoxPopuli, the model is trained on Common Voice only. The labels are unnormalized character-level transcripts (punctuation and capitalization are not removed). The model takes as input Mel filterbank features from a 16Khz audio signal.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/mega.md b/docs/source/en/model_doc/mega.md
index 4e8ccd4b29..080d8de529 100644
--- a/docs/source/en/model_doc/mega.md
+++ b/docs/source/en/model_doc/mega.md
@@ -30,7 +30,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The MEGA model was proposed in [Mega: Moving Average Equipped Gated Attention](https://arxiv.org/abs/2209.10655) by Xuezhe Ma, Chunting Zhou, Xiang Kong, Junxian He, Liangke Gui, Graham Neubig, Jonathan May, and Luke Zettlemoyer.
+The MEGA model was proposed in [Mega: Moving Average Equipped Gated Attention](https://huggingface.co/papers/2209.10655) by Xuezhe Ma, Chunting Zhou, Xiang Kong, Junxian He, Liangke Gui, Graham Neubig, Jonathan May, and Luke Zettlemoyer.
MEGA proposes a new approach to self-attention with each encoder layer having a multi-headed exponential moving average in addition to a single head of standard dot-product attention, giving the attention mechanism
stronger positional biases. This allows MEGA to perform competitively to Transformers on standard benchmarks including LRA
while also having significantly fewer parameters. MEGA's compute efficiency allows it to scale to very long sequences, making it an
diff --git a/docs/source/en/model_doc/megatron-bert.md b/docs/source/en/model_doc/megatron-bert.md
index b032655f75..8d3ba12295 100644
--- a/docs/source/en/model_doc/megatron-bert.md
+++ b/docs/source/en/model_doc/megatron-bert.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
The MegatronBERT model was proposed in [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model
-Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley,
+Parallelism](https://huggingface.co/papers/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley,
Jared Casper and Bryan Catanzaro.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/megatron_gpt2.md b/docs/source/en/model_doc/megatron_gpt2.md
index 7e0ee3cb9e..fc90474663 100644
--- a/docs/source/en/model_doc/megatron_gpt2.md
+++ b/docs/source/en/model_doc/megatron_gpt2.md
@@ -26,7 +26,7 @@ rendered properly in your Markdown viewer.
## Overview
The MegatronGPT2 model was proposed in [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model
-Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley,
+Parallelism](https://huggingface.co/papers/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley,
Jared Casper and Bryan Catanzaro.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/mgp-str.md b/docs/source/en/model_doc/mgp-str.md
index 168e5bd104..b98a34874e 100644
--- a/docs/source/en/model_doc/mgp-str.md
+++ b/docs/source/en/model_doc/mgp-str.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MGP-STR model was proposed in [Multi-Granularity Prediction for Scene Text Recognition](https://arxiv.org/abs/2209.03592) by Peng Wang, Cheng Da, and Cong Yao. MGP-STR is a conceptually **simple** yet **powerful** vision Scene Text Recognition (STR) model, which is built upon the [Vision Transformer (ViT)](vit). To integrate linguistic knowledge, Multi-Granularity Prediction (MGP) strategy is proposed to inject information from the language modality into the model in an implicit way.
+The MGP-STR model was proposed in [Multi-Granularity Prediction for Scene Text Recognition](https://huggingface.co/papers/2209.03592) by Peng Wang, Cheng Da, and Cong Yao. MGP-STR is a conceptually **simple** yet **powerful** vision Scene Text Recognition (STR) model, which is built upon the [Vision Transformer (ViT)](vit). To integrate linguistic knowledge, Multi-Granularity Prediction (MGP) strategy is proposed to inject information from the language modality into the model in an implicit way.
The abstract from the paper is the following:
@@ -31,7 +31,7 @@ The abstract from the paper is the following:
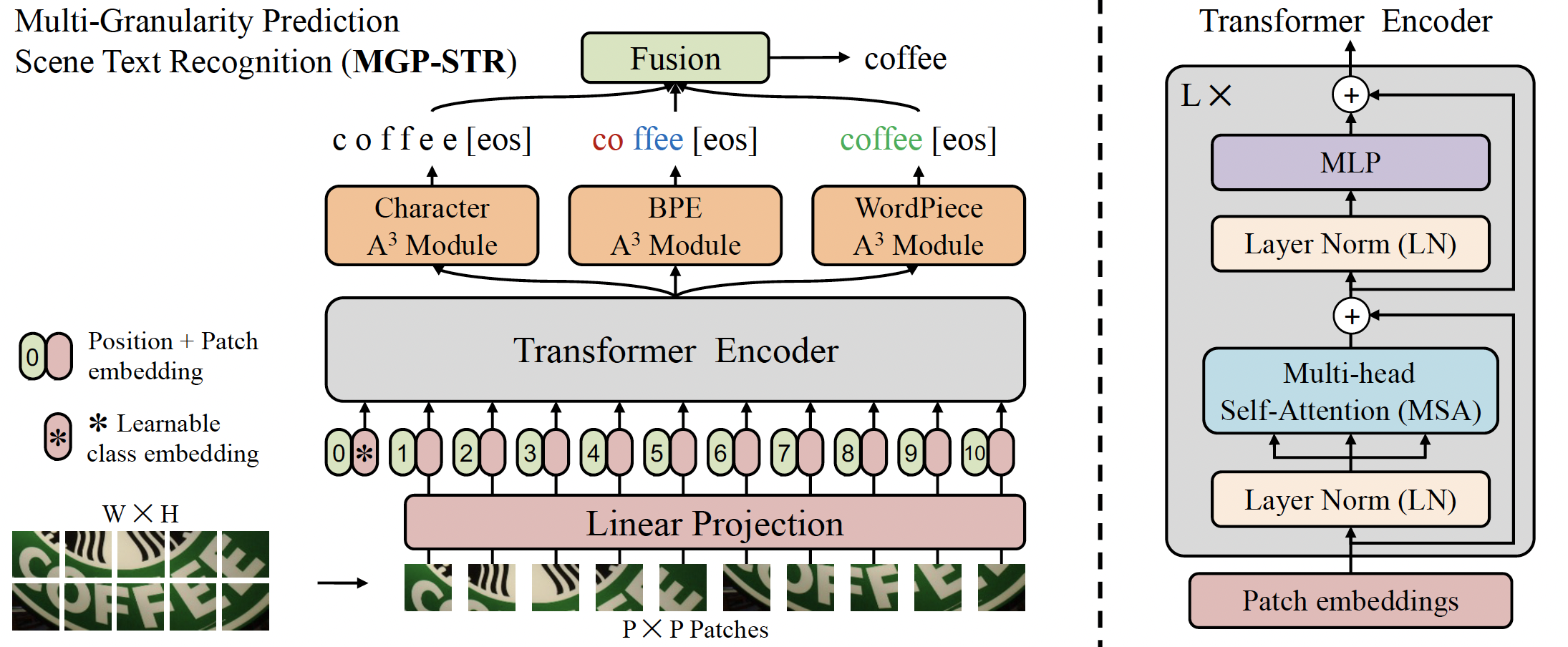 - MGP-STR architecture. Taken from the original paper.
+ MGP-STR architecture. Taken from the original paper.
MGP-STR is trained on two synthetic datasets [MJSynth]((http://www.robots.ox.ac.uk/~vgg/data/text/)) (MJ) and [SynthText](http://www.robots.ox.ac.uk/~vgg/data/scenetext/) (ST) without fine-tuning on other datasets. It achieves state-of-the-art results on six standard Latin scene text benchmarks, including 3 regular text datasets (IC13, SVT, IIIT) and 3 irregular ones (IC15, SVTP, CUTE).
This model was contributed by [yuekun](https://huggingface.co/yuekun). The original code can be found [here](https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/OCR/MGP-STR).
diff --git a/docs/source/en/model_doc/minimax.md b/docs/source/en/model_doc/minimax.md
index 7ae1ca6700..d4b9e56f0b 100644
--- a/docs/source/en/model_doc/minimax.md
+++ b/docs/source/en/model_doc/minimax.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MiniMax-Text-01 model was proposed in [MiniMax-01: Scaling Foundation Models with Lightning Attention](https://arxiv.org/abs/2501.08313) by MiniMax, Aonian Li, Bangwei Gong, Bo Yang, Boji Shan, Chang Liu, Cheng Zhu, Chunhao Zhang, Congchao Guo, Da Chen, Dong Li, Enwei Jiao, Gengxin Li, Guojun Zhang, Haohai Sun, Houze Dong, Jiadai Zhu, Jiaqi Zhuang, Jiayuan Song, Jin Zhu, Jingtao Han, Jingyang Li, Junbin Xie, Junhao Xu, Junjie Yan, Kaishun Zhang, Kecheng Xiao, Kexi Kang, Le Han, Leyang Wang, Lianfei Yu, Liheng Feng, Lin Zheng, Linbo Chai, Long Xing, Meizhi Ju, Mingyuan Chi, Mozhi Zhang, Peikai Huang, Pengcheng Niu, Pengfei Li, Pengyu Zhao, Qi Yang, Qidi Xu, Qiexiang Wang, Qin Wang, Qiuhui Li, Ruitao Leng, Shengmin Shi, Shuqi Yu, Sichen Li, Songquan Zhu, Tao Huang, Tianrun Liang, Weigao Sun, Weixuan Sun, Weiyu Cheng, Wenkai Li, Xiangjun Song, Xiao Su, Xiaodong Han, Xinjie Zhang, Xinzhu Hou, Xu Min, Xun Zou, Xuyang Shen, Yan Gong, Yingjie Zhu, Yipeng Zhou, Yiran Zhong, Yongyi Hu, Yuanxiang Fan, Yue Yu, Yufeng Yang, Yuhao Li, Yunan Huang, Yunji Li, Yunpeng Huang, Yunzhi Xu, Yuxin Mao, Zehan Li, Zekang Li, Zewei Tao, Zewen Ying, Zhaoyang Cong, Zhen Qin, Zhenhua Fan, Zhihang Yu, Zhuo Jiang, Zijia Wu.
+The MiniMax-Text-01 model was proposed in [MiniMax-01: Scaling Foundation Models with Lightning Attention](https://huggingface.co/papers/2501.08313) by MiniMax, Aonian Li, Bangwei Gong, Bo Yang, Boji Shan, Chang Liu, Cheng Zhu, Chunhao Zhang, Congchao Guo, Da Chen, Dong Li, Enwei Jiao, Gengxin Li, Guojun Zhang, Haohai Sun, Houze Dong, Jiadai Zhu, Jiaqi Zhuang, Jiayuan Song, Jin Zhu, Jingtao Han, Jingyang Li, Junbin Xie, Junhao Xu, Junjie Yan, Kaishun Zhang, Kecheng Xiao, Kexi Kang, Le Han, Leyang Wang, Lianfei Yu, Liheng Feng, Lin Zheng, Linbo Chai, Long Xing, Meizhi Ju, Mingyuan Chi, Mozhi Zhang, Peikai Huang, Pengcheng Niu, Pengfei Li, Pengyu Zhao, Qi Yang, Qidi Xu, Qiexiang Wang, Qin Wang, Qiuhui Li, Ruitao Leng, Shengmin Shi, Shuqi Yu, Sichen Li, Songquan Zhu, Tao Huang, Tianrun Liang, Weigao Sun, Weixuan Sun, Weiyu Cheng, Wenkai Li, Xiangjun Song, Xiao Su, Xiaodong Han, Xinjie Zhang, Xinzhu Hou, Xu Min, Xun Zou, Xuyang Shen, Yan Gong, Yingjie Zhu, Yipeng Zhou, Yiran Zhong, Yongyi Hu, Yuanxiang Fan, Yue Yu, Yufeng Yang, Yuhao Li, Yunan Huang, Yunji Li, Yunpeng Huang, Yunzhi Xu, Yuxin Mao, Zehan Li, Zekang Li, Zewei Tao, Zewen Ying, Zhaoyang Cong, Zhen Qin, Zhenhua Fan, Zhihang Yu, Zhuo Jiang, Zijia Wu.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/mluke.md b/docs/source/en/model_doc/mluke.md
index aae607def6..3472ebc220 100644
--- a/docs/source/en/model_doc/mluke.md
+++ b/docs/source/en/model_doc/mluke.md
@@ -22,8 +22,8 @@ rendered properly in your Markdown viewer.
## Overview
-The mLUKE model was proposed in [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka. It's a multilingual extension
-of the [LUKE model](https://arxiv.org/abs/2010.01057) trained on the basis of XLM-RoBERTa.
+The mLUKE model was proposed in [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://huggingface.co/papers/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka. It's a multilingual extension
+of the [LUKE model](https://huggingface.co/papers/2010.01057) trained on the basis of XLM-RoBERTa.
It is based on XLM-RoBERTa and adds entity embeddings, which helps improve performance on various downstream tasks
involving reasoning about entities such as named entity recognition, extractive question answering, relation
diff --git a/docs/source/en/model_doc/mms.md b/docs/source/en/model_doc/mms.md
index 480d5bc8dd..53b73f8295 100644
--- a/docs/source/en/model_doc/mms.md
+++ b/docs/source/en/model_doc/mms.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MMS model was proposed in [Scaling Speech Technology to 1,000+ Languages](https://arxiv.org/abs/2305.13516)
+The MMS model was proposed in [Scaling Speech Technology to 1,000+ Languages](https://huggingface.co/papers/2305.13516)
by Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, Alexei Baevski, Yossi Adi, Xiaohui Zhang, Wei-Ning Hsu, Alexis Conneau, Michael Auli
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/mobilevit.md b/docs/source/en/model_doc/mobilevit.md
index c9054b59cb..6fb69649ee 100644
--- a/docs/source/en/model_doc/mobilevit.md
+++ b/docs/source/en/model_doc/mobilevit.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MobileViT model was proposed in [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari. MobileViT introduces a new layer that replaces local processing in convolutions with global processing using transformers.
+The MobileViT model was proposed in [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://huggingface.co/papers/2110.02178) by Sachin Mehta and Mohammad Rastegari. MobileViT introduces a new layer that replaces local processing in convolutions with global processing using transformers.
The abstract from the paper is the following:
@@ -36,7 +36,7 @@ This model was contributed by [matthijs](https://huggingface.co/Matthijs). The T
- MobileViT is more like a CNN than a Transformer model. It does not work on sequence data but on batches of images. Unlike ViT, there are no embeddings. The backbone model outputs a feature map. You can follow [this tutorial](https://keras.io/examples/vision/mobilevit) for a lightweight introduction.
- One can use [`MobileViTImageProcessor`] to prepare images for the model. Note that if you do your own preprocessing, the pretrained checkpoints expect images to be in BGR pixel order (not RGB).
- The available image classification checkpoints are pre-trained on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k) (also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes).
-- The segmentation model uses a [DeepLabV3](https://arxiv.org/abs/1706.05587) head. The available semantic segmentation checkpoints are pre-trained on [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/).
+- The segmentation model uses a [DeepLabV3](https://huggingface.co/papers/1706.05587) head. The available semantic segmentation checkpoints are pre-trained on [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/).
- As the name suggests MobileViT was designed to be performant and efficient on mobile phones. The TensorFlow versions of the MobileViT models are fully compatible with [TensorFlow Lite](https://www.tensorflow.org/lite).
You can use the following code to convert a MobileViT checkpoint (be it image classification or semantic segmentation) to generate a
diff --git a/docs/source/en/model_doc/mobilevitv2.md b/docs/source/en/model_doc/mobilevitv2.md
index b654966685..9c20fb6e96 100644
--- a/docs/source/en/model_doc/mobilevitv2.md
+++ b/docs/source/en/model_doc/mobilevitv2.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MobileViTV2 model was proposed in [Separable Self-attention for Mobile Vision Transformers](https://arxiv.org/abs/2206.02680) by Sachin Mehta and Mohammad Rastegari.
+The MobileViTV2 model was proposed in [Separable Self-attention for Mobile Vision Transformers](https://huggingface.co/papers/2206.02680) by Sachin Mehta and Mohammad Rastegari.
MobileViTV2 is the second version of MobileViT, constructed by replacing the multi-headed self-attention in MobileViT with separable self-attention.
@@ -38,7 +38,7 @@ The original code can be found [here](https://github.com/apple/ml-cvnets).
- MobileViTV2 is more like a CNN than a Transformer model. It does not work on sequence data but on batches of images. Unlike ViT, there are no embeddings. The backbone model outputs a feature map.
- One can use [`MobileViTImageProcessor`] to prepare images for the model. Note that if you do your own preprocessing, the pretrained checkpoints expect images to be in BGR pixel order (not RGB).
- The available image classification checkpoints are pre-trained on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k) (also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes).
-- The segmentation model uses a [DeepLabV3](https://arxiv.org/abs/1706.05587) head. The available semantic segmentation checkpoints are pre-trained on [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/).
+- The segmentation model uses a [DeepLabV3](https://huggingface.co/papers/1706.05587) head. The available semantic segmentation checkpoints are pre-trained on [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/).
## MobileViTV2Config
diff --git a/docs/source/en/model_doc/mpnet.md b/docs/source/en/model_doc/mpnet.md
index cf84e2b410..caddc635cb 100644
--- a/docs/source/en/model_doc/mpnet.md
+++ b/docs/source/en/model_doc/mpnet.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MPNet model was proposed in [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
+The MPNet model was proposed in [MPNet: Masked and Permuted Pre-training for Language Understanding](https://huggingface.co/papers/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
MPNet adopts a novel pre-training method, named masked and permuted language modeling, to inherit the advantages of
masked language modeling and permuted language modeling for natural language understanding.
diff --git a/docs/source/en/model_doc/mra.md b/docs/source/en/model_doc/mra.md
index a5490d5d37..9faa9a2616 100644
--- a/docs/source/en/model_doc/mra.md
+++ b/docs/source/en/model_doc/mra.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MRA model was proposed in [Multi Resolution Analysis (MRA) for Approximate Self-Attention](https://arxiv.org/abs/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, and Vikas Singh.
+The MRA model was proposed in [Multi Resolution Analysis (MRA) for Approximate Self-Attention](https://huggingface.co/papers/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, and Vikas Singh.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/mt5.md b/docs/source/en/model_doc/mt5.md
index d4af9f538c..d6b9ef99cb 100644
--- a/docs/source/en/model_doc/mt5.md
+++ b/docs/source/en/model_doc/mt5.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The mT5 model was presented in [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya
+The mT5 model was presented in [mT5: A massively multilingual pre-trained text-to-text transformer](https://huggingface.co/papers/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya
Siddhant, Aditya Barua, Colin Raffel.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/musicgen.md b/docs/source/en/model_doc/musicgen.md
index 917347af10..ff7645bcea 100644
--- a/docs/source/en/model_doc/musicgen.md
+++ b/docs/source/en/model_doc/musicgen.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MusicGen model was proposed in the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284)
+The MusicGen model was proposed in the paper [Simple and Controllable Music Generation](https://huggingface.co/papers/2306.05284)
by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
MusicGen is a single stage auto-regressive Transformer model capable of generating high-quality music samples conditioned
diff --git a/docs/source/en/model_doc/musicgen_melody.md b/docs/source/en/model_doc/musicgen_melody.md
index eea1a184e8..3e4bbabc6c 100644
--- a/docs/source/en/model_doc/musicgen_melody.md
+++ b/docs/source/en/model_doc/musicgen_melody.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MusicGen Melody model was proposed in [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
+The MusicGen Melody model was proposed in [Simple and Controllable Music Generation](https://huggingface.co/papers/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
MusicGen Melody is a single stage auto-regressive Transformer model capable of generating high-quality music samples conditioned on text descriptions or audio prompts. The text descriptions are passed through a frozen text encoder model to obtain a sequence of hidden-state representations. MusicGen is then trained to predict discrete audio tokens, or *audio codes*, conditioned on these hidden-states. These audio tokens are then decoded using an audio compression model, such as EnCodec, to recover the audio waveform.
diff --git a/docs/source/en/model_doc/mvp.md b/docs/source/en/model_doc/mvp.md
index d732977167..d2dcdeb301 100644
--- a/docs/source/en/model_doc/mvp.md
+++ b/docs/source/en/model_doc/mvp.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MVP model was proposed in [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
+The MVP model was proposed in [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://huggingface.co/papers/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
According to the abstract,
@@ -39,7 +39,7 @@ This model was contributed by [Tianyi Tang](https://huggingface.co/StevenTang).
- We have released a series of models [here](https://huggingface.co/models?filter=mvp), including MVP, MVP with task-specific prompts, and multi-task pre-trained variants.
- If you want to use a model without prompts (standard Transformer), you can load it through `MvpForConditionalGeneration.from_pretrained('RUCAIBox/mvp')`.
- If you want to use a model with task-specific prompts, such as summarization, you can load it through `MvpForConditionalGeneration.from_pretrained('RUCAIBox/mvp-summarization')`.
-- Our model supports lightweight prompt tuning following [Prefix-tuning](https://arxiv.org/abs/2101.00190) with method `set_lightweight_tuning()`.
+- Our model supports lightweight prompt tuning following [Prefix-tuning](https://huggingface.co/papers/2101.00190) with method `set_lightweight_tuning()`.
## Usage examples
@@ -86,7 +86,7 @@ For data-to-text generation, it is an example to use MVP and multi-task pre-trai
['Iron Man is a fictional superhero appearing in American comic books published by Marvel Comics.']
```
-For lightweight tuning, *i.e.*, fixing the model and only tuning prompts, you can load MVP with randomly initialized prompts or with task-specific prompts. Our code also supports Prefix-tuning with BART following the [original paper](https://arxiv.org/abs/2101.00190).
+For lightweight tuning, *i.e.*, fixing the model and only tuning prompts, you can load MVP with randomly initialized prompts or with task-specific prompts. Our code also supports Prefix-tuning with BART following the [original paper](https://huggingface.co/papers/2101.00190).
```python
>>> from transformers import MvpForConditionalGeneration
diff --git a/docs/source/en/model_doc/myt5.md b/docs/source/en/model_doc/myt5.md
index c8b46f4351..cb406e9d7d 100644
--- a/docs/source/en/model_doc/myt5.md
+++ b/docs/source/en/model_doc/myt5.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-The myt5 model was proposed in [MYTE: Morphology-Driven Byte Encoding for Better and Fairer Multilingual Language Modeling](https://arxiv.org/pdf/2403.10691.pdf) by Tomasz Limisiewicz, Terra Blevins, Hila Gonen, Orevaoghene Ahia, and Luke Zettlemoyer.
+The myt5 model was proposed in [MYTE: Morphology-Driven Byte Encoding for Better and Fairer Multilingual Language Modeling](https://huggingface.co/papers/2403.10691) by Tomasz Limisiewicz, Terra Blevins, Hila Gonen, Orevaoghene Ahia, and Luke Zettlemoyer.
MyT5 (**My**te **T5**) is a multilingual language model based on T5 architecture.
The model uses a **m**orphologically-driven **byte** (**MYTE**) representation described in our paper.
**MYTE** uses codepoints corresponding to morphemes in contrast to characters used in UTF-8 encoding.
diff --git a/docs/source/en/model_doc/nat.md b/docs/source/en/model_doc/nat.md
index c7725ed7a5..86a935f9f6 100644
--- a/docs/source/en/model_doc/nat.md
+++ b/docs/source/en/model_doc/nat.md
@@ -30,7 +30,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-NAT was proposed in [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143)
+NAT was proposed in [Neighborhood Attention Transformer](https://huggingface.co/papers/2204.07143)
by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
It is a hierarchical vision transformer based on Neighborhood Attention, a sliding-window self attention pattern.
@@ -53,7 +53,7 @@ src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/ma
alt="drawing" width="600"/>
Neighborhood Attention compared to other attention patterns.
-Taken from the original paper.
+Taken from the original paper.
This model was contributed by [Ali Hassani](https://huggingface.co/alihassanijr).
The original code can be found [here](https://github.com/SHI-Labs/Neighborhood-Attention-Transformer).
diff --git a/docs/source/en/model_doc/nemotron.md b/docs/source/en/model_doc/nemotron.md
index 13b1b9be2f..761ad33fde 100644
--- a/docs/source/en/model_doc/nemotron.md
+++ b/docs/source/en/model_doc/nemotron.md
@@ -44,9 +44,9 @@ NVIDIA NeMo is an end-to-end, cloud-native platform to build, customize, and dep
### Minitron 4B Base
-Minitron is a family of small language models (SLMs) obtained by pruning NVIDIA's [Nemotron-4 15B](https://arxiv.org/abs/2402.16819) model. We prune model embedding size, attention heads, and MLP intermediate dimension, following which, we perform continued training with distillation to arrive at the final models.
+Minitron is a family of small language models (SLMs) obtained by pruning NVIDIA's [Nemotron-4 15B](https://huggingface.co/papers/2402.16819) model. We prune model embedding size, attention heads, and MLP intermediate dimension, following which, we perform continued training with distillation to arrive at the final models.
-Deriving the Minitron 8B and 4B models from the base 15B model using our approach requires up to **40x fewer training tokens** per model compared to training from scratch; this results in **compute cost savings of 1.8x** for training the full model family (15B, 8B, and 4B). Minitron models exhibit up to a 16% improvement in MMLU scores compared to training from scratch, perform comparably to other community models such as Mistral 7B, Gemma 7B and Llama-3 8B, and outperform state-of-the-art compression techniques from the literature. Please refer to our [arXiv paper](https://arxiv.org/abs/2407.14679) for more details.
+Deriving the Minitron 8B and 4B models from the base 15B model using our approach requires up to **40x fewer training tokens** per model compared to training from scratch; this results in **compute cost savings of 1.8x** for training the full model family (15B, 8B, and 4B). Minitron models exhibit up to a 16% improvement in MMLU scores compared to training from scratch, perform comparably to other community models such as Mistral 7B, Gemma 7B and Llama-3 8B, and outperform state-of-the-art compression techniques from the literature. Please refer to our [arXiv paper](https://huggingface.co/papers/2407.14679) for more details.
Minitron models are for research and development only.
@@ -84,7 +84,7 @@ Minitron is released under the [NVIDIA Open Model License Agreement](https://dev
### Evaluation Results
-*5-shot performance.* Language Understanding evaluated using [Massive Multitask Language Understanding](https://arxiv.org/abs/2009.03300):
+*5-shot performance.* Language Understanding evaluated using [Massive Multitask Language Understanding](https://huggingface.co/papers/2009.03300):
| Average |
| :---- |
@@ -103,7 +103,7 @@ Minitron is released under the [NVIDIA Open Model License Agreement](https://dev
| :------------- |
| 23.3 |
-Please refer to our [paper](https://arxiv.org/abs/2407.14679) for the full set of results.
+Please refer to our [paper](https://huggingface.co/papers/2407.14679) for the full set of results.
### Citation
diff --git a/docs/source/en/model_doc/nezha.md b/docs/source/en/model_doc/nezha.md
index dc815e0ecc..edbadcb220 100644
--- a/docs/source/en/model_doc/nezha.md
+++ b/docs/source/en/model_doc/nezha.md
@@ -30,7 +30,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The Nezha model was proposed in [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei et al.
+The Nezha model was proposed in [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://huggingface.co/papers/1909.00204) by Junqiu Wei et al.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/nllb-moe.md b/docs/source/en/model_doc/nllb-moe.md
index fc8c8c9211..4e5af4fb18 100644
--- a/docs/source/en/model_doc/nllb-moe.md
+++ b/docs/source/en/model_doc/nllb-moe.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The NLLB model was presented in [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by Marta R. Costa-jussà, James Cross, Onur Çelebi,
+The NLLB model was presented in [No Language Left Behind: Scaling Human-Centered Machine Translation](https://huggingface.co/papers/2207.04672) by Marta R. Costa-jussà, James Cross, Onur Çelebi,
Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula,
Loic Barrault, Gabriel Mejia Gonzalez, Prangthip Hansanti, John Hoffman, Semarley Jarrett, Kaushik Ram Sadagopan, Dirk Rowe, Shannon Spruit, Chau Tran, Pierre Andrews,
Necip Fazil Ayan, Shruti Bhosale, Sergey Edunov, Angela Fan, Cynthia Gao, Vedanuj Goswami, Francisco Guzmán, Philipp Koehn, Alexandre Mourachko, Christophe Ropers,
diff --git a/docs/source/en/model_doc/nllb.md b/docs/source/en/model_doc/nllb.md
index 4ba2737779..483d590016 100644
--- a/docs/source/en/model_doc/nllb.md
+++ b/docs/source/en/model_doc/nllb.md
@@ -65,7 +65,7 @@ For more details, feel free to check the linked [PR](https://github.com/huggingf
## Overview
-The NLLB model was presented in [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by Marta R. Costa-jussà, James Cross, Onur Çelebi,
+The NLLB model was presented in [No Language Left Behind: Scaling Human-Centered Machine Translation](https://huggingface.co/papers/2207.04672) by Marta R. Costa-jussà, James Cross, Onur Çelebi,
Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula,
Loic Barrault, Gabriel Mejia Gonzalez, Prangthip Hansanti, John Hoffman, Semarley Jarrett, Kaushik Ram Sadagopan, Dirk Rowe, Shannon Spruit, Chau Tran, Pierre Andrews,
Necip Fazil Ayan, Shruti Bhosale, Sergey Edunov, Angela Fan, Cynthia Gao, Vedanuj Goswami, Francisco Guzmán, Philipp Koehn, Alexandre Mourachko, Christophe Ropers,
diff --git a/docs/source/en/model_doc/nougat.md b/docs/source/en/model_doc/nougat.md
index 06b12b5ee8..c3d6ef54f4 100644
--- a/docs/source/en/model_doc/nougat.md
+++ b/docs/source/en/model_doc/nougat.md
@@ -24,7 +24,7 @@ specific language governing permissions and limitations under the License. -->
## Overview
-The Nougat model was proposed in [Nougat: Neural Optical Understanding for Academic Documents](https://arxiv.org/abs/2308.13418) by
+The Nougat model was proposed in [Nougat: Neural Optical Understanding for Academic Documents](https://huggingface.co/papers/2308.13418) by
Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic. Nougat uses the same architecture as [Donut](donut), meaning an image Transformer
encoder and an autoregressive text Transformer decoder to translate scientific PDFs to markdown, enabling easier access to them.
@@ -35,7 +35,7 @@ The abstract from the paper is the following:
- MGP-STR architecture. Taken from the original paper.
+ MGP-STR architecture. Taken from the original paper.
MGP-STR is trained on two synthetic datasets [MJSynth]((http://www.robots.ox.ac.uk/~vgg/data/text/)) (MJ) and [SynthText](http://www.robots.ox.ac.uk/~vgg/data/scenetext/) (ST) without fine-tuning on other datasets. It achieves state-of-the-art results on six standard Latin scene text benchmarks, including 3 regular text datasets (IC13, SVT, IIIT) and 3 irregular ones (IC15, SVTP, CUTE).
This model was contributed by [yuekun](https://huggingface.co/yuekun). The original code can be found [here](https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/OCR/MGP-STR).
diff --git a/docs/source/en/model_doc/minimax.md b/docs/source/en/model_doc/minimax.md
index 7ae1ca6700..d4b9e56f0b 100644
--- a/docs/source/en/model_doc/minimax.md
+++ b/docs/source/en/model_doc/minimax.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MiniMax-Text-01 model was proposed in [MiniMax-01: Scaling Foundation Models with Lightning Attention](https://arxiv.org/abs/2501.08313) by MiniMax, Aonian Li, Bangwei Gong, Bo Yang, Boji Shan, Chang Liu, Cheng Zhu, Chunhao Zhang, Congchao Guo, Da Chen, Dong Li, Enwei Jiao, Gengxin Li, Guojun Zhang, Haohai Sun, Houze Dong, Jiadai Zhu, Jiaqi Zhuang, Jiayuan Song, Jin Zhu, Jingtao Han, Jingyang Li, Junbin Xie, Junhao Xu, Junjie Yan, Kaishun Zhang, Kecheng Xiao, Kexi Kang, Le Han, Leyang Wang, Lianfei Yu, Liheng Feng, Lin Zheng, Linbo Chai, Long Xing, Meizhi Ju, Mingyuan Chi, Mozhi Zhang, Peikai Huang, Pengcheng Niu, Pengfei Li, Pengyu Zhao, Qi Yang, Qidi Xu, Qiexiang Wang, Qin Wang, Qiuhui Li, Ruitao Leng, Shengmin Shi, Shuqi Yu, Sichen Li, Songquan Zhu, Tao Huang, Tianrun Liang, Weigao Sun, Weixuan Sun, Weiyu Cheng, Wenkai Li, Xiangjun Song, Xiao Su, Xiaodong Han, Xinjie Zhang, Xinzhu Hou, Xu Min, Xun Zou, Xuyang Shen, Yan Gong, Yingjie Zhu, Yipeng Zhou, Yiran Zhong, Yongyi Hu, Yuanxiang Fan, Yue Yu, Yufeng Yang, Yuhao Li, Yunan Huang, Yunji Li, Yunpeng Huang, Yunzhi Xu, Yuxin Mao, Zehan Li, Zekang Li, Zewei Tao, Zewen Ying, Zhaoyang Cong, Zhen Qin, Zhenhua Fan, Zhihang Yu, Zhuo Jiang, Zijia Wu.
+The MiniMax-Text-01 model was proposed in [MiniMax-01: Scaling Foundation Models with Lightning Attention](https://huggingface.co/papers/2501.08313) by MiniMax, Aonian Li, Bangwei Gong, Bo Yang, Boji Shan, Chang Liu, Cheng Zhu, Chunhao Zhang, Congchao Guo, Da Chen, Dong Li, Enwei Jiao, Gengxin Li, Guojun Zhang, Haohai Sun, Houze Dong, Jiadai Zhu, Jiaqi Zhuang, Jiayuan Song, Jin Zhu, Jingtao Han, Jingyang Li, Junbin Xie, Junhao Xu, Junjie Yan, Kaishun Zhang, Kecheng Xiao, Kexi Kang, Le Han, Leyang Wang, Lianfei Yu, Liheng Feng, Lin Zheng, Linbo Chai, Long Xing, Meizhi Ju, Mingyuan Chi, Mozhi Zhang, Peikai Huang, Pengcheng Niu, Pengfei Li, Pengyu Zhao, Qi Yang, Qidi Xu, Qiexiang Wang, Qin Wang, Qiuhui Li, Ruitao Leng, Shengmin Shi, Shuqi Yu, Sichen Li, Songquan Zhu, Tao Huang, Tianrun Liang, Weigao Sun, Weixuan Sun, Weiyu Cheng, Wenkai Li, Xiangjun Song, Xiao Su, Xiaodong Han, Xinjie Zhang, Xinzhu Hou, Xu Min, Xun Zou, Xuyang Shen, Yan Gong, Yingjie Zhu, Yipeng Zhou, Yiran Zhong, Yongyi Hu, Yuanxiang Fan, Yue Yu, Yufeng Yang, Yuhao Li, Yunan Huang, Yunji Li, Yunpeng Huang, Yunzhi Xu, Yuxin Mao, Zehan Li, Zekang Li, Zewei Tao, Zewen Ying, Zhaoyang Cong, Zhen Qin, Zhenhua Fan, Zhihang Yu, Zhuo Jiang, Zijia Wu.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/mluke.md b/docs/source/en/model_doc/mluke.md
index aae607def6..3472ebc220 100644
--- a/docs/source/en/model_doc/mluke.md
+++ b/docs/source/en/model_doc/mluke.md
@@ -22,8 +22,8 @@ rendered properly in your Markdown viewer.
## Overview
-The mLUKE model was proposed in [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka. It's a multilingual extension
-of the [LUKE model](https://arxiv.org/abs/2010.01057) trained on the basis of XLM-RoBERTa.
+The mLUKE model was proposed in [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://huggingface.co/papers/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka. It's a multilingual extension
+of the [LUKE model](https://huggingface.co/papers/2010.01057) trained on the basis of XLM-RoBERTa.
It is based on XLM-RoBERTa and adds entity embeddings, which helps improve performance on various downstream tasks
involving reasoning about entities such as named entity recognition, extractive question answering, relation
diff --git a/docs/source/en/model_doc/mms.md b/docs/source/en/model_doc/mms.md
index 480d5bc8dd..53b73f8295 100644
--- a/docs/source/en/model_doc/mms.md
+++ b/docs/source/en/model_doc/mms.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MMS model was proposed in [Scaling Speech Technology to 1,000+ Languages](https://arxiv.org/abs/2305.13516)
+The MMS model was proposed in [Scaling Speech Technology to 1,000+ Languages](https://huggingface.co/papers/2305.13516)
by Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, Alexei Baevski, Yossi Adi, Xiaohui Zhang, Wei-Ning Hsu, Alexis Conneau, Michael Auli
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/mobilevit.md b/docs/source/en/model_doc/mobilevit.md
index c9054b59cb..6fb69649ee 100644
--- a/docs/source/en/model_doc/mobilevit.md
+++ b/docs/source/en/model_doc/mobilevit.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MobileViT model was proposed in [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari. MobileViT introduces a new layer that replaces local processing in convolutions with global processing using transformers.
+The MobileViT model was proposed in [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://huggingface.co/papers/2110.02178) by Sachin Mehta and Mohammad Rastegari. MobileViT introduces a new layer that replaces local processing in convolutions with global processing using transformers.
The abstract from the paper is the following:
@@ -36,7 +36,7 @@ This model was contributed by [matthijs](https://huggingface.co/Matthijs). The T
- MobileViT is more like a CNN than a Transformer model. It does not work on sequence data but on batches of images. Unlike ViT, there are no embeddings. The backbone model outputs a feature map. You can follow [this tutorial](https://keras.io/examples/vision/mobilevit) for a lightweight introduction.
- One can use [`MobileViTImageProcessor`] to prepare images for the model. Note that if you do your own preprocessing, the pretrained checkpoints expect images to be in BGR pixel order (not RGB).
- The available image classification checkpoints are pre-trained on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k) (also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes).
-- The segmentation model uses a [DeepLabV3](https://arxiv.org/abs/1706.05587) head. The available semantic segmentation checkpoints are pre-trained on [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/).
+- The segmentation model uses a [DeepLabV3](https://huggingface.co/papers/1706.05587) head. The available semantic segmentation checkpoints are pre-trained on [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/).
- As the name suggests MobileViT was designed to be performant and efficient on mobile phones. The TensorFlow versions of the MobileViT models are fully compatible with [TensorFlow Lite](https://www.tensorflow.org/lite).
You can use the following code to convert a MobileViT checkpoint (be it image classification or semantic segmentation) to generate a
diff --git a/docs/source/en/model_doc/mobilevitv2.md b/docs/source/en/model_doc/mobilevitv2.md
index b654966685..9c20fb6e96 100644
--- a/docs/source/en/model_doc/mobilevitv2.md
+++ b/docs/source/en/model_doc/mobilevitv2.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MobileViTV2 model was proposed in [Separable Self-attention for Mobile Vision Transformers](https://arxiv.org/abs/2206.02680) by Sachin Mehta and Mohammad Rastegari.
+The MobileViTV2 model was proposed in [Separable Self-attention for Mobile Vision Transformers](https://huggingface.co/papers/2206.02680) by Sachin Mehta and Mohammad Rastegari.
MobileViTV2 is the second version of MobileViT, constructed by replacing the multi-headed self-attention in MobileViT with separable self-attention.
@@ -38,7 +38,7 @@ The original code can be found [here](https://github.com/apple/ml-cvnets).
- MobileViTV2 is more like a CNN than a Transformer model. It does not work on sequence data but on batches of images. Unlike ViT, there are no embeddings. The backbone model outputs a feature map.
- One can use [`MobileViTImageProcessor`] to prepare images for the model. Note that if you do your own preprocessing, the pretrained checkpoints expect images to be in BGR pixel order (not RGB).
- The available image classification checkpoints are pre-trained on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k) (also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes).
-- The segmentation model uses a [DeepLabV3](https://arxiv.org/abs/1706.05587) head. The available semantic segmentation checkpoints are pre-trained on [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/).
+- The segmentation model uses a [DeepLabV3](https://huggingface.co/papers/1706.05587) head. The available semantic segmentation checkpoints are pre-trained on [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/).
## MobileViTV2Config
diff --git a/docs/source/en/model_doc/mpnet.md b/docs/source/en/model_doc/mpnet.md
index cf84e2b410..caddc635cb 100644
--- a/docs/source/en/model_doc/mpnet.md
+++ b/docs/source/en/model_doc/mpnet.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MPNet model was proposed in [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
+The MPNet model was proposed in [MPNet: Masked and Permuted Pre-training for Language Understanding](https://huggingface.co/papers/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
MPNet adopts a novel pre-training method, named masked and permuted language modeling, to inherit the advantages of
masked language modeling and permuted language modeling for natural language understanding.
diff --git a/docs/source/en/model_doc/mra.md b/docs/source/en/model_doc/mra.md
index a5490d5d37..9faa9a2616 100644
--- a/docs/source/en/model_doc/mra.md
+++ b/docs/source/en/model_doc/mra.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MRA model was proposed in [Multi Resolution Analysis (MRA) for Approximate Self-Attention](https://arxiv.org/abs/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, and Vikas Singh.
+The MRA model was proposed in [Multi Resolution Analysis (MRA) for Approximate Self-Attention](https://huggingface.co/papers/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, and Vikas Singh.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/mt5.md b/docs/source/en/model_doc/mt5.md
index d4af9f538c..d6b9ef99cb 100644
--- a/docs/source/en/model_doc/mt5.md
+++ b/docs/source/en/model_doc/mt5.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The mT5 model was presented in [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya
+The mT5 model was presented in [mT5: A massively multilingual pre-trained text-to-text transformer](https://huggingface.co/papers/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya
Siddhant, Aditya Barua, Colin Raffel.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/musicgen.md b/docs/source/en/model_doc/musicgen.md
index 917347af10..ff7645bcea 100644
--- a/docs/source/en/model_doc/musicgen.md
+++ b/docs/source/en/model_doc/musicgen.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MusicGen model was proposed in the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284)
+The MusicGen model was proposed in the paper [Simple and Controllable Music Generation](https://huggingface.co/papers/2306.05284)
by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
MusicGen is a single stage auto-regressive Transformer model capable of generating high-quality music samples conditioned
diff --git a/docs/source/en/model_doc/musicgen_melody.md b/docs/source/en/model_doc/musicgen_melody.md
index eea1a184e8..3e4bbabc6c 100644
--- a/docs/source/en/model_doc/musicgen_melody.md
+++ b/docs/source/en/model_doc/musicgen_melody.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MusicGen Melody model was proposed in [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
+The MusicGen Melody model was proposed in [Simple and Controllable Music Generation](https://huggingface.co/papers/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
MusicGen Melody is a single stage auto-regressive Transformer model capable of generating high-quality music samples conditioned on text descriptions or audio prompts. The text descriptions are passed through a frozen text encoder model to obtain a sequence of hidden-state representations. MusicGen is then trained to predict discrete audio tokens, or *audio codes*, conditioned on these hidden-states. These audio tokens are then decoded using an audio compression model, such as EnCodec, to recover the audio waveform.
diff --git a/docs/source/en/model_doc/mvp.md b/docs/source/en/model_doc/mvp.md
index d732977167..d2dcdeb301 100644
--- a/docs/source/en/model_doc/mvp.md
+++ b/docs/source/en/model_doc/mvp.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The MVP model was proposed in [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
+The MVP model was proposed in [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://huggingface.co/papers/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
According to the abstract,
@@ -39,7 +39,7 @@ This model was contributed by [Tianyi Tang](https://huggingface.co/StevenTang).
- We have released a series of models [here](https://huggingface.co/models?filter=mvp), including MVP, MVP with task-specific prompts, and multi-task pre-trained variants.
- If you want to use a model without prompts (standard Transformer), you can load it through `MvpForConditionalGeneration.from_pretrained('RUCAIBox/mvp')`.
- If you want to use a model with task-specific prompts, such as summarization, you can load it through `MvpForConditionalGeneration.from_pretrained('RUCAIBox/mvp-summarization')`.
-- Our model supports lightweight prompt tuning following [Prefix-tuning](https://arxiv.org/abs/2101.00190) with method `set_lightweight_tuning()`.
+- Our model supports lightweight prompt tuning following [Prefix-tuning](https://huggingface.co/papers/2101.00190) with method `set_lightweight_tuning()`.
## Usage examples
@@ -86,7 +86,7 @@ For data-to-text generation, it is an example to use MVP and multi-task pre-trai
['Iron Man is a fictional superhero appearing in American comic books published by Marvel Comics.']
```
-For lightweight tuning, *i.e.*, fixing the model and only tuning prompts, you can load MVP with randomly initialized prompts or with task-specific prompts. Our code also supports Prefix-tuning with BART following the [original paper](https://arxiv.org/abs/2101.00190).
+For lightweight tuning, *i.e.*, fixing the model and only tuning prompts, you can load MVP with randomly initialized prompts or with task-specific prompts. Our code also supports Prefix-tuning with BART following the [original paper](https://huggingface.co/papers/2101.00190).
```python
>>> from transformers import MvpForConditionalGeneration
diff --git a/docs/source/en/model_doc/myt5.md b/docs/source/en/model_doc/myt5.md
index c8b46f4351..cb406e9d7d 100644
--- a/docs/source/en/model_doc/myt5.md
+++ b/docs/source/en/model_doc/myt5.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-The myt5 model was proposed in [MYTE: Morphology-Driven Byte Encoding for Better and Fairer Multilingual Language Modeling](https://arxiv.org/pdf/2403.10691.pdf) by Tomasz Limisiewicz, Terra Blevins, Hila Gonen, Orevaoghene Ahia, and Luke Zettlemoyer.
+The myt5 model was proposed in [MYTE: Morphology-Driven Byte Encoding for Better and Fairer Multilingual Language Modeling](https://huggingface.co/papers/2403.10691) by Tomasz Limisiewicz, Terra Blevins, Hila Gonen, Orevaoghene Ahia, and Luke Zettlemoyer.
MyT5 (**My**te **T5**) is a multilingual language model based on T5 architecture.
The model uses a **m**orphologically-driven **byte** (**MYTE**) representation described in our paper.
**MYTE** uses codepoints corresponding to morphemes in contrast to characters used in UTF-8 encoding.
diff --git a/docs/source/en/model_doc/nat.md b/docs/source/en/model_doc/nat.md
index c7725ed7a5..86a935f9f6 100644
--- a/docs/source/en/model_doc/nat.md
+++ b/docs/source/en/model_doc/nat.md
@@ -30,7 +30,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-NAT was proposed in [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143)
+NAT was proposed in [Neighborhood Attention Transformer](https://huggingface.co/papers/2204.07143)
by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
It is a hierarchical vision transformer based on Neighborhood Attention, a sliding-window self attention pattern.
@@ -53,7 +53,7 @@ src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/ma
alt="drawing" width="600"/>
Neighborhood Attention compared to other attention patterns.
-Taken from the original paper.
+Taken from the original paper.
This model was contributed by [Ali Hassani](https://huggingface.co/alihassanijr).
The original code can be found [here](https://github.com/SHI-Labs/Neighborhood-Attention-Transformer).
diff --git a/docs/source/en/model_doc/nemotron.md b/docs/source/en/model_doc/nemotron.md
index 13b1b9be2f..761ad33fde 100644
--- a/docs/source/en/model_doc/nemotron.md
+++ b/docs/source/en/model_doc/nemotron.md
@@ -44,9 +44,9 @@ NVIDIA NeMo is an end-to-end, cloud-native platform to build, customize, and dep
### Minitron 4B Base
-Minitron is a family of small language models (SLMs) obtained by pruning NVIDIA's [Nemotron-4 15B](https://arxiv.org/abs/2402.16819) model. We prune model embedding size, attention heads, and MLP intermediate dimension, following which, we perform continued training with distillation to arrive at the final models.
+Minitron is a family of small language models (SLMs) obtained by pruning NVIDIA's [Nemotron-4 15B](https://huggingface.co/papers/2402.16819) model. We prune model embedding size, attention heads, and MLP intermediate dimension, following which, we perform continued training with distillation to arrive at the final models.
-Deriving the Minitron 8B and 4B models from the base 15B model using our approach requires up to **40x fewer training tokens** per model compared to training from scratch; this results in **compute cost savings of 1.8x** for training the full model family (15B, 8B, and 4B). Minitron models exhibit up to a 16% improvement in MMLU scores compared to training from scratch, perform comparably to other community models such as Mistral 7B, Gemma 7B and Llama-3 8B, and outperform state-of-the-art compression techniques from the literature. Please refer to our [arXiv paper](https://arxiv.org/abs/2407.14679) for more details.
+Deriving the Minitron 8B and 4B models from the base 15B model using our approach requires up to **40x fewer training tokens** per model compared to training from scratch; this results in **compute cost savings of 1.8x** for training the full model family (15B, 8B, and 4B). Minitron models exhibit up to a 16% improvement in MMLU scores compared to training from scratch, perform comparably to other community models such as Mistral 7B, Gemma 7B and Llama-3 8B, and outperform state-of-the-art compression techniques from the literature. Please refer to our [arXiv paper](https://huggingface.co/papers/2407.14679) for more details.
Minitron models are for research and development only.
@@ -84,7 +84,7 @@ Minitron is released under the [NVIDIA Open Model License Agreement](https://dev
### Evaluation Results
-*5-shot performance.* Language Understanding evaluated using [Massive Multitask Language Understanding](https://arxiv.org/abs/2009.03300):
+*5-shot performance.* Language Understanding evaluated using [Massive Multitask Language Understanding](https://huggingface.co/papers/2009.03300):
| Average |
| :---- |
@@ -103,7 +103,7 @@ Minitron is released under the [NVIDIA Open Model License Agreement](https://dev
| :------------- |
| 23.3 |
-Please refer to our [paper](https://arxiv.org/abs/2407.14679) for the full set of results.
+Please refer to our [paper](https://huggingface.co/papers/2407.14679) for the full set of results.
### Citation
diff --git a/docs/source/en/model_doc/nezha.md b/docs/source/en/model_doc/nezha.md
index dc815e0ecc..edbadcb220 100644
--- a/docs/source/en/model_doc/nezha.md
+++ b/docs/source/en/model_doc/nezha.md
@@ -30,7 +30,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The Nezha model was proposed in [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei et al.
+The Nezha model was proposed in [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://huggingface.co/papers/1909.00204) by Junqiu Wei et al.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/nllb-moe.md b/docs/source/en/model_doc/nllb-moe.md
index fc8c8c9211..4e5af4fb18 100644
--- a/docs/source/en/model_doc/nllb-moe.md
+++ b/docs/source/en/model_doc/nllb-moe.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The NLLB model was presented in [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by Marta R. Costa-jussà, James Cross, Onur Çelebi,
+The NLLB model was presented in [No Language Left Behind: Scaling Human-Centered Machine Translation](https://huggingface.co/papers/2207.04672) by Marta R. Costa-jussà, James Cross, Onur Çelebi,
Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula,
Loic Barrault, Gabriel Mejia Gonzalez, Prangthip Hansanti, John Hoffman, Semarley Jarrett, Kaushik Ram Sadagopan, Dirk Rowe, Shannon Spruit, Chau Tran, Pierre Andrews,
Necip Fazil Ayan, Shruti Bhosale, Sergey Edunov, Angela Fan, Cynthia Gao, Vedanuj Goswami, Francisco Guzmán, Philipp Koehn, Alexandre Mourachko, Christophe Ropers,
diff --git a/docs/source/en/model_doc/nllb.md b/docs/source/en/model_doc/nllb.md
index 4ba2737779..483d590016 100644
--- a/docs/source/en/model_doc/nllb.md
+++ b/docs/source/en/model_doc/nllb.md
@@ -65,7 +65,7 @@ For more details, feel free to check the linked [PR](https://github.com/huggingf
## Overview
-The NLLB model was presented in [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by Marta R. Costa-jussà, James Cross, Onur Çelebi,
+The NLLB model was presented in [No Language Left Behind: Scaling Human-Centered Machine Translation](https://huggingface.co/papers/2207.04672) by Marta R. Costa-jussà, James Cross, Onur Çelebi,
Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula,
Loic Barrault, Gabriel Mejia Gonzalez, Prangthip Hansanti, John Hoffman, Semarley Jarrett, Kaushik Ram Sadagopan, Dirk Rowe, Shannon Spruit, Chau Tran, Pierre Andrews,
Necip Fazil Ayan, Shruti Bhosale, Sergey Edunov, Angela Fan, Cynthia Gao, Vedanuj Goswami, Francisco Guzmán, Philipp Koehn, Alexandre Mourachko, Christophe Ropers,
diff --git a/docs/source/en/model_doc/nougat.md b/docs/source/en/model_doc/nougat.md
index 06b12b5ee8..c3d6ef54f4 100644
--- a/docs/source/en/model_doc/nougat.md
+++ b/docs/source/en/model_doc/nougat.md
@@ -24,7 +24,7 @@ specific language governing permissions and limitations under the License. -->
## Overview
-The Nougat model was proposed in [Nougat: Neural Optical Understanding for Academic Documents](https://arxiv.org/abs/2308.13418) by
+The Nougat model was proposed in [Nougat: Neural Optical Understanding for Academic Documents](https://huggingface.co/papers/2308.13418) by
Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic. Nougat uses the same architecture as [Donut](donut), meaning an image Transformer
encoder and an autoregressive text Transformer decoder to translate scientific PDFs to markdown, enabling easier access to them.
@@ -35,7 +35,7 @@ The abstract from the paper is the following:
 - Nougat high-level overview. Taken from the original paper.
+ Nougat high-level overview. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
[here](https://github.com/facebookresearch/nougat).
diff --git a/docs/source/en/model_doc/nystromformer.md b/docs/source/en/model_doc/nystromformer.md
index b4c017b35f..f368a77a3c 100644
--- a/docs/source/en/model_doc/nystromformer.md
+++ b/docs/source/en/model_doc/nystromformer.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Nyströmformer model was proposed in [*Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention*](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn
+The Nyströmformer model was proposed in [*Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention*](https://huggingface.co/papers/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn
Fung, Yin Li, and Vikas Singh.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/olmo.md b/docs/source/en/model_doc/olmo.md
index 8d722185c3..c0d227cb54 100644
--- a/docs/source/en/model_doc/olmo.md
+++ b/docs/source/en/model_doc/olmo.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The OLMo model was proposed in [OLMo: Accelerating the Science of Language Models](https://arxiv.org/abs/2402.00838) by Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Raghavi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E. Peters, Valentina Pyatkin, Abhilasha Ravichander, Dustin Schwenk, Saurabh Shah, Will Smith, Emma Strubell, Nishant Subramani, Mitchell Wortsman, Pradeep Dasigi, Nathan Lambert, Kyle Richardson, Luke Zettlemoyer, Jesse Dodge, Kyle Lo, Luca Soldaini, Noah A. Smith, Hannaneh Hajishirzi.
+The OLMo model was proposed in [OLMo: Accelerating the Science of Language Models](https://huggingface.co/papers/2402.00838) by Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Raghavi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E. Peters, Valentina Pyatkin, Abhilasha Ravichander, Dustin Schwenk, Saurabh Shah, Will Smith, Emma Strubell, Nishant Subramani, Mitchell Wortsman, Pradeep Dasigi, Nathan Lambert, Kyle Richardson, Luke Zettlemoyer, Jesse Dodge, Kyle Lo, Luca Soldaini, Noah A. Smith, Hannaneh Hajishirzi.
OLMo is a series of **O**pen **L**anguage **Mo**dels designed to enable the science of language models. The OLMo models are trained on the Dolma dataset. We release all code, checkpoints, logs (coming soon), and details involved in training these models.
diff --git a/docs/source/en/model_doc/olmoe.md b/docs/source/en/model_doc/olmoe.md
index 6496e44c1b..701d1b7c2f 100644
--- a/docs/source/en/model_doc/olmoe.md
+++ b/docs/source/en/model_doc/olmoe.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The OLMoE model was proposed in [OLMoE: Open Mixture-of-Experts Language Models](https://arxiv.org/abs/2409.02060) by Niklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, Pete Walsh, Oyvind Tafjord, Nathan Lambert, Yuling Gu, Shane Arora, Akshita Bhagia, Dustin Schwenk, David Wadden, Alexander Wettig, Binyuan Hui, Tim Dettmers, Douwe Kiela, Ali Farhadi, Noah A. Smith, Pang Wei Koh, Amanpreet Singh, Hannaneh Hajishirzi.
+The OLMoE model was proposed in [OLMoE: Open Mixture-of-Experts Language Models](https://huggingface.co/papers/2409.02060) by Niklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, Pete Walsh, Oyvind Tafjord, Nathan Lambert, Yuling Gu, Shane Arora, Akshita Bhagia, Dustin Schwenk, David Wadden, Alexander Wettig, Binyuan Hui, Tim Dettmers, Douwe Kiela, Ali Farhadi, Noah A. Smith, Pang Wei Koh, Amanpreet Singh, Hannaneh Hajishirzi.
OLMoE is a series of **O**pen **L**anguage **Mo**dels using sparse **M**ixture-**o**f-**E**xperts designed to enable the science of language models. We release all code, checkpoints, logs, and details involved in training these models.
diff --git a/docs/source/en/model_doc/omdet-turbo.md b/docs/source/en/model_doc/omdet-turbo.md
index d73fef2d8b..b4fc6adef3 100644
--- a/docs/source/en/model_doc/omdet-turbo.md
+++ b/docs/source/en/model_doc/omdet-turbo.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The OmDet-Turbo model was proposed in [Real-time Transformer-based Open-Vocabulary Detection with Efficient Fusion Head](https://arxiv.org/abs/2403.06892) by Tiancheng Zhao, Peng Liu, Xuan He, Lu Zhang, Kyusong Lee. OmDet-Turbo incorporates components from RT-DETR and introduces a swift multimodal fusion module to achieve real-time open-vocabulary object detection capabilities while maintaining high accuracy. The base model achieves performance of up to 100.2 FPS and 53.4 AP on COCO zero-shot.
+The OmDet-Turbo model was proposed in [Real-time Transformer-based Open-Vocabulary Detection with Efficient Fusion Head](https://huggingface.co/papers/2403.06892) by Tiancheng Zhao, Peng Liu, Xuan He, Lu Zhang, Kyusong Lee. OmDet-Turbo incorporates components from RT-DETR and introduces a swift multimodal fusion module to achieve real-time open-vocabulary object detection capabilities while maintaining high accuracy. The base model achieves performance of up to 100.2 FPS and 53.4 AP on COCO zero-shot.
The abstract from the paper is the following:
@@ -30,7 +30,7 @@ The abstract from the paper is the following:
- Nougat high-level overview. Taken from the original paper.
+ Nougat high-level overview. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
[here](https://github.com/facebookresearch/nougat).
diff --git a/docs/source/en/model_doc/nystromformer.md b/docs/source/en/model_doc/nystromformer.md
index b4c017b35f..f368a77a3c 100644
--- a/docs/source/en/model_doc/nystromformer.md
+++ b/docs/source/en/model_doc/nystromformer.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Nyströmformer model was proposed in [*Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention*](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn
+The Nyströmformer model was proposed in [*Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention*](https://huggingface.co/papers/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn
Fung, Yin Li, and Vikas Singh.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/olmo.md b/docs/source/en/model_doc/olmo.md
index 8d722185c3..c0d227cb54 100644
--- a/docs/source/en/model_doc/olmo.md
+++ b/docs/source/en/model_doc/olmo.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The OLMo model was proposed in [OLMo: Accelerating the Science of Language Models](https://arxiv.org/abs/2402.00838) by Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Raghavi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E. Peters, Valentina Pyatkin, Abhilasha Ravichander, Dustin Schwenk, Saurabh Shah, Will Smith, Emma Strubell, Nishant Subramani, Mitchell Wortsman, Pradeep Dasigi, Nathan Lambert, Kyle Richardson, Luke Zettlemoyer, Jesse Dodge, Kyle Lo, Luca Soldaini, Noah A. Smith, Hannaneh Hajishirzi.
+The OLMo model was proposed in [OLMo: Accelerating the Science of Language Models](https://huggingface.co/papers/2402.00838) by Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Raghavi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E. Peters, Valentina Pyatkin, Abhilasha Ravichander, Dustin Schwenk, Saurabh Shah, Will Smith, Emma Strubell, Nishant Subramani, Mitchell Wortsman, Pradeep Dasigi, Nathan Lambert, Kyle Richardson, Luke Zettlemoyer, Jesse Dodge, Kyle Lo, Luca Soldaini, Noah A. Smith, Hannaneh Hajishirzi.
OLMo is a series of **O**pen **L**anguage **Mo**dels designed to enable the science of language models. The OLMo models are trained on the Dolma dataset. We release all code, checkpoints, logs (coming soon), and details involved in training these models.
diff --git a/docs/source/en/model_doc/olmoe.md b/docs/source/en/model_doc/olmoe.md
index 6496e44c1b..701d1b7c2f 100644
--- a/docs/source/en/model_doc/olmoe.md
+++ b/docs/source/en/model_doc/olmoe.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The OLMoE model was proposed in [OLMoE: Open Mixture-of-Experts Language Models](https://arxiv.org/abs/2409.02060) by Niklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, Pete Walsh, Oyvind Tafjord, Nathan Lambert, Yuling Gu, Shane Arora, Akshita Bhagia, Dustin Schwenk, David Wadden, Alexander Wettig, Binyuan Hui, Tim Dettmers, Douwe Kiela, Ali Farhadi, Noah A. Smith, Pang Wei Koh, Amanpreet Singh, Hannaneh Hajishirzi.
+The OLMoE model was proposed in [OLMoE: Open Mixture-of-Experts Language Models](https://huggingface.co/papers/2409.02060) by Niklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, Pete Walsh, Oyvind Tafjord, Nathan Lambert, Yuling Gu, Shane Arora, Akshita Bhagia, Dustin Schwenk, David Wadden, Alexander Wettig, Binyuan Hui, Tim Dettmers, Douwe Kiela, Ali Farhadi, Noah A. Smith, Pang Wei Koh, Amanpreet Singh, Hannaneh Hajishirzi.
OLMoE is a series of **O**pen **L**anguage **Mo**dels using sparse **M**ixture-**o**f-**E**xperts designed to enable the science of language models. We release all code, checkpoints, logs, and details involved in training these models.
diff --git a/docs/source/en/model_doc/omdet-turbo.md b/docs/source/en/model_doc/omdet-turbo.md
index d73fef2d8b..b4fc6adef3 100644
--- a/docs/source/en/model_doc/omdet-turbo.md
+++ b/docs/source/en/model_doc/omdet-turbo.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The OmDet-Turbo model was proposed in [Real-time Transformer-based Open-Vocabulary Detection with Efficient Fusion Head](https://arxiv.org/abs/2403.06892) by Tiancheng Zhao, Peng Liu, Xuan He, Lu Zhang, Kyusong Lee. OmDet-Turbo incorporates components from RT-DETR and introduces a swift multimodal fusion module to achieve real-time open-vocabulary object detection capabilities while maintaining high accuracy. The base model achieves performance of up to 100.2 FPS and 53.4 AP on COCO zero-shot.
+The OmDet-Turbo model was proposed in [Real-time Transformer-based Open-Vocabulary Detection with Efficient Fusion Head](https://huggingface.co/papers/2403.06892) by Tiancheng Zhao, Peng Liu, Xuan He, Lu Zhang, Kyusong Lee. OmDet-Turbo incorporates components from RT-DETR and introduces a swift multimodal fusion module to achieve real-time open-vocabulary object detection capabilities while maintaining high accuracy. The base model achieves performance of up to 100.2 FPS and 53.4 AP on COCO zero-shot.
The abstract from the paper is the following:
@@ -30,7 +30,7 @@ The abstract from the paper is the following:
 - OmDet-Turbo architecture overview. Taken from the original paper.
+ OmDet-Turbo architecture overview. Taken from the original paper.
This model was contributed by [yonigozlan](https://huggingface.co/yonigozlan).
The original code can be found [here](https://github.com/om-ai-lab/OmDet).
diff --git a/docs/source/en/model_doc/oneformer.md b/docs/source/en/model_doc/oneformer.md
index f1c1de7912..c0dcfd8800 100644
--- a/docs/source/en/model_doc/oneformer.md
+++ b/docs/source/en/model_doc/oneformer.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The OneFormer model was proposed in [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi. OneFormer is a universal image segmentation framework that can be trained on a single panoptic dataset to perform semantic, instance, and panoptic segmentation tasks. OneFormer uses a task token to condition the model on the task in focus, making the architecture task-guided for training, and task-dynamic for inference.
+The OneFormer model was proposed in [OneFormer: One Transformer to Rule Universal Image Segmentation](https://huggingface.co/papers/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi. OneFormer is a universal image segmentation framework that can be trained on a single panoptic dataset to perform semantic, instance, and panoptic segmentation tasks. OneFormer uses a task token to condition the model on the task in focus, making the architecture task-guided for training, and task-dynamic for inference.
- OmDet-Turbo architecture overview. Taken from the original paper.
+ OmDet-Turbo architecture overview. Taken from the original paper.
This model was contributed by [yonigozlan](https://huggingface.co/yonigozlan).
The original code can be found [here](https://github.com/om-ai-lab/OmDet).
diff --git a/docs/source/en/model_doc/oneformer.md b/docs/source/en/model_doc/oneformer.md
index f1c1de7912..c0dcfd8800 100644
--- a/docs/source/en/model_doc/oneformer.md
+++ b/docs/source/en/model_doc/oneformer.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The OneFormer model was proposed in [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi. OneFormer is a universal image segmentation framework that can be trained on a single panoptic dataset to perform semantic, instance, and panoptic segmentation tasks. OneFormer uses a task token to condition the model on the task in focus, making the architecture task-guided for training, and task-dynamic for inference.
+The OneFormer model was proposed in [OneFormer: One Transformer to Rule Universal Image Segmentation](https://huggingface.co/papers/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi. OneFormer is a universal image segmentation framework that can be trained on a single panoptic dataset to perform semantic, instance, and panoptic segmentation tasks. OneFormer uses a task token to condition the model on the task in focus, making the architecture task-guided for training, and task-dynamic for inference.
 @@ -30,7 +30,7 @@ The abstract from the paper is the following:
*Universal Image Segmentation is not a new concept. Past attempts to unify image segmentation in the last decades include scene parsing, panoptic segmentation, and, more recently, new panoptic architectures. However, such panoptic architectures do not truly unify image segmentation because they need to be trained individually on the semantic, instance, or panoptic segmentation to achieve the best performance. Ideally, a truly universal framework should be trained only once and achieve SOTA performance across all three image segmentation tasks. To that end, we propose OneFormer, a universal image segmentation framework that unifies segmentation with a multi-task train-once design. We first propose a task-conditioned joint training strategy that enables training on ground truths of each domain (semantic, instance, and panoptic segmentation) within a single multi-task training process. Secondly, we introduce a task token to condition our model on the task at hand, making our model task-dynamic to support multi-task training and inference. Thirdly, we propose using a query-text contrastive loss during training to establish better inter-task and inter-class distinctions. Notably, our single OneFormer model outperforms specialized Mask2Former models across all three segmentation tasks on ADE20k, CityScapes, and COCO, despite the latter being trained on each of the three tasks individually with three times the resources. With new ConvNeXt and DiNAT backbones, we observe even more performance improvement. We believe OneFormer is a significant step towards making image segmentation more universal and accessible.*
-The figure below illustrates the architecture of OneFormer. Taken from the [original paper](https://arxiv.org/abs/2211.06220).
+The figure below illustrates the architecture of OneFormer. Taken from the [original paper](https://huggingface.co/papers/2211.06220).
@@ -30,7 +30,7 @@ The abstract from the paper is the following:
*Universal Image Segmentation is not a new concept. Past attempts to unify image segmentation in the last decades include scene parsing, panoptic segmentation, and, more recently, new panoptic architectures. However, such panoptic architectures do not truly unify image segmentation because they need to be trained individually on the semantic, instance, or panoptic segmentation to achieve the best performance. Ideally, a truly universal framework should be trained only once and achieve SOTA performance across all three image segmentation tasks. To that end, we propose OneFormer, a universal image segmentation framework that unifies segmentation with a multi-task train-once design. We first propose a task-conditioned joint training strategy that enables training on ground truths of each domain (semantic, instance, and panoptic segmentation) within a single multi-task training process. Secondly, we introduce a task token to condition our model on the task at hand, making our model task-dynamic to support multi-task training and inference. Thirdly, we propose using a query-text contrastive loss during training to establish better inter-task and inter-class distinctions. Notably, our single OneFormer model outperforms specialized Mask2Former models across all three segmentation tasks on ADE20k, CityScapes, and COCO, despite the latter being trained on each of the three tasks individually with three times the resources. With new ConvNeXt and DiNAT backbones, we observe even more performance improvement. We believe OneFormer is a significant step towards making image segmentation more universal and accessible.*
-The figure below illustrates the architecture of OneFormer. Taken from the [original paper](https://arxiv.org/abs/2211.06220).
+The figure below illustrates the architecture of OneFormer. Taken from the [original paper](https://huggingface.co/papers/2211.06220).
 diff --git a/docs/source/en/model_doc/opt.md b/docs/source/en/model_doc/opt.md
index 8d72403aba..93db673065 100644
--- a/docs/source/en/model_doc/opt.md
+++ b/docs/source/en/model_doc/opt.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
## Overview
-The OPT model was proposed in [Open Pre-trained Transformer Language Models](https://arxiv.org/pdf/2205.01068) by Meta AI.
+The OPT model was proposed in [Open Pre-trained Transformer Language Models](https://huggingface.co/papers/2205.01068) by Meta AI.
OPT is a series of open-sourced large causal language models which perform similar in performance to GPT3.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/owlv2.md b/docs/source/en/model_doc/owlv2.md
index f01a5c5906..b7ab61cc98 100644
--- a/docs/source/en/model_doc/owlv2.md
+++ b/docs/source/en/model_doc/owlv2.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-OWLv2 was proposed in [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby. OWLv2 scales up [OWL-ViT](owlvit) using self-training, which uses an existing detector to generate pseudo-box annotations on image-text pairs. This results in large gains over the previous state-of-the-art for zero-shot object detection.
+OWLv2 was proposed in [Scaling Open-Vocabulary Object Detection](https://huggingface.co/papers/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby. OWLv2 scales up [OWL-ViT](owlvit) using self-training, which uses an existing detector to generate pseudo-box annotations on image-text pairs. This results in large gains over the previous state-of-the-art for zero-shot object detection.
The abstract from the paper is the following:
@@ -31,7 +31,7 @@ The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/opt.md b/docs/source/en/model_doc/opt.md
index 8d72403aba..93db673065 100644
--- a/docs/source/en/model_doc/opt.md
+++ b/docs/source/en/model_doc/opt.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
## Overview
-The OPT model was proposed in [Open Pre-trained Transformer Language Models](https://arxiv.org/pdf/2205.01068) by Meta AI.
+The OPT model was proposed in [Open Pre-trained Transformer Language Models](https://huggingface.co/papers/2205.01068) by Meta AI.
OPT is a series of open-sourced large causal language models which perform similar in performance to GPT3.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/owlv2.md b/docs/source/en/model_doc/owlv2.md
index f01a5c5906..b7ab61cc98 100644
--- a/docs/source/en/model_doc/owlv2.md
+++ b/docs/source/en/model_doc/owlv2.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-OWLv2 was proposed in [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby. OWLv2 scales up [OWL-ViT](owlvit) using self-training, which uses an existing detector to generate pseudo-box annotations on image-text pairs. This results in large gains over the previous state-of-the-art for zero-shot object detection.
+OWLv2 was proposed in [Scaling Open-Vocabulary Object Detection](https://huggingface.co/papers/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby. OWLv2 scales up [OWL-ViT](owlvit) using self-training, which uses an existing detector to generate pseudo-box annotations on image-text pairs. This results in large gains over the previous state-of-the-art for zero-shot object detection.
The abstract from the paper is the following:
@@ -31,7 +31,7 @@ The abstract from the paper is the following:
 - OWLv2 high-level overview. Taken from the original paper.
+ OWLv2 high-level overview. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
diff --git a/docs/source/en/model_doc/owlvit.md b/docs/source/en/model_doc/owlvit.md
index bbcfe0de9f..a69eee88c1 100644
--- a/docs/source/en/model_doc/owlvit.md
+++ b/docs/source/en/model_doc/owlvit.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The OWL-ViT (short for Vision Transformer for Open-World Localization) was proposed in [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby. OWL-ViT is an open-vocabulary object detection network trained on a variety of (image, text) pairs. It can be used to query an image with one or multiple text queries to search for and detect target objects described in text.
+The OWL-ViT (short for Vision Transformer for Open-World Localization) was proposed in [Simple Open-Vocabulary Object Detection with Vision Transformers](https://huggingface.co/papers/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby. OWL-ViT is an open-vocabulary object detection network trained on a variety of (image, text) pairs. It can be used to query an image with one or multiple text queries to search for and detect target objects described in text.
The abstract from the paper is the following:
@@ -31,7 +31,7 @@ The abstract from the paper is the following:
- OWLv2 high-level overview. Taken from the original paper.
+ OWLv2 high-level overview. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
diff --git a/docs/source/en/model_doc/owlvit.md b/docs/source/en/model_doc/owlvit.md
index bbcfe0de9f..a69eee88c1 100644
--- a/docs/source/en/model_doc/owlvit.md
+++ b/docs/source/en/model_doc/owlvit.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The OWL-ViT (short for Vision Transformer for Open-World Localization) was proposed in [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby. OWL-ViT is an open-vocabulary object detection network trained on a variety of (image, text) pairs. It can be used to query an image with one or multiple text queries to search for and detect target objects described in text.
+The OWL-ViT (short for Vision Transformer for Open-World Localization) was proposed in [Simple Open-Vocabulary Object Detection with Vision Transformers](https://huggingface.co/papers/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby. OWL-ViT is an open-vocabulary object detection network trained on a variety of (image, text) pairs. It can be used to query an image with one or multiple text queries to search for and detect target objects described in text.
The abstract from the paper is the following:
@@ -31,7 +31,7 @@ The abstract from the paper is the following:
 - OWL-ViT architecture. Taken from the original paper.
+ OWL-ViT architecture. Taken from the original paper.
This model was contributed by [adirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
diff --git a/docs/source/en/model_doc/patchtsmixer.md b/docs/source/en/model_doc/patchtsmixer.md
index dd678dd401..3093206793 100644
--- a/docs/source/en/model_doc/patchtsmixer.md
+++ b/docs/source/en/model_doc/patchtsmixer.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The PatchTSMixer model was proposed in [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf) by Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong and Jayant Kalagnanam.
+The PatchTSMixer model was proposed in [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://huggingface.co/papers/2306.09364) by Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong and Jayant Kalagnanam.
PatchTSMixer is a lightweight time-series modeling approach based on the MLP-Mixer architecture. In this HuggingFace implementation, we provide PatchTSMixer's capabilities to effortlessly facilitate lightweight mixing across patches, channels, and hidden features for effective multivariate time-series modeling. It also supports various attention mechanisms starting from simple gated attention to more complex self-attention blocks that can be customized accordingly. The model can be pretrained and subsequently used for various downstream tasks such as forecasting, classification and regression.
diff --git a/docs/source/en/model_doc/patchtst.md b/docs/source/en/model_doc/patchtst.md
index c55ba33342..5d9a2f402e 100644
--- a/docs/source/en/model_doc/patchtst.md
+++ b/docs/source/en/model_doc/patchtst.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The PatchTST model was proposed in [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/abs/2211.14730) by Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong and Jayant Kalagnanam.
+The PatchTST model was proposed in [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://huggingface.co/papers/2211.14730) by Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong and Jayant Kalagnanam.
At a high level the model vectorizes time series into patches of a given size and encodes the resulting sequence of vectors via a Transformer that then outputs the prediction length forecast via an appropriate head. The model is illustrated in the following figure:
diff --git a/docs/source/en/model_doc/pegasus_x.md b/docs/source/en/model_doc/pegasus_x.md
index 97e50601b7..379e0362bb 100644
--- a/docs/source/en/model_doc/pegasus_x.md
+++ b/docs/source/en/model_doc/pegasus_x.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The PEGASUS-X model was proposed in [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao and Peter J. Liu.
+The PEGASUS-X model was proposed in [Investigating Efficiently Extending Transformers for Long Input Summarization](https://huggingface.co/papers/2208.04347) by Jason Phang, Yao Zhao and Peter J. Liu.
PEGASUS-X (PEGASUS eXtended) extends the PEGASUS models for long input summarization through additional long input pretraining and using staggered block-local attention with global tokens in the encoder.
diff --git a/docs/source/en/model_doc/perceiver.md b/docs/source/en/model_doc/perceiver.md
index 629f185953..eb930bd4bd 100644
--- a/docs/source/en/model_doc/perceiver.md
+++ b/docs/source/en/model_doc/perceiver.md
@@ -23,11 +23,11 @@ rendered properly in your Markdown viewer.
## Overview
The Perceiver IO model was proposed in [Perceiver IO: A General Architecture for Structured Inputs &
-Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch,
+Outputs](https://huggingface.co/papers/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch,
Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M.
Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
-Perceiver IO is a generalization of [Perceiver](https://arxiv.org/abs/2103.03206) to handle arbitrary outputs in
+Perceiver IO is a generalization of [Perceiver](https://huggingface.co/papers/2103.03206) to handle arbitrary outputs in
addition to arbitrary inputs. The original Perceiver only produced a single classification label. In addition to
classification labels, Perceiver IO can produce (for example) language, optical flow, and multimodal videos with audio.
This is done using the same building blocks as the original Perceiver. The computational complexity of Perceiver IO is
@@ -80,7 +80,7 @@ size of 262 byte IDs).
- OWL-ViT architecture. Taken from the original paper.
+ OWL-ViT architecture. Taken from the original paper.
This model was contributed by [adirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
diff --git a/docs/source/en/model_doc/patchtsmixer.md b/docs/source/en/model_doc/patchtsmixer.md
index dd678dd401..3093206793 100644
--- a/docs/source/en/model_doc/patchtsmixer.md
+++ b/docs/source/en/model_doc/patchtsmixer.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The PatchTSMixer model was proposed in [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf) by Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong and Jayant Kalagnanam.
+The PatchTSMixer model was proposed in [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://huggingface.co/papers/2306.09364) by Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong and Jayant Kalagnanam.
PatchTSMixer is a lightweight time-series modeling approach based on the MLP-Mixer architecture. In this HuggingFace implementation, we provide PatchTSMixer's capabilities to effortlessly facilitate lightweight mixing across patches, channels, and hidden features for effective multivariate time-series modeling. It also supports various attention mechanisms starting from simple gated attention to more complex self-attention blocks that can be customized accordingly. The model can be pretrained and subsequently used for various downstream tasks such as forecasting, classification and regression.
diff --git a/docs/source/en/model_doc/patchtst.md b/docs/source/en/model_doc/patchtst.md
index c55ba33342..5d9a2f402e 100644
--- a/docs/source/en/model_doc/patchtst.md
+++ b/docs/source/en/model_doc/patchtst.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The PatchTST model was proposed in [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/abs/2211.14730) by Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong and Jayant Kalagnanam.
+The PatchTST model was proposed in [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://huggingface.co/papers/2211.14730) by Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong and Jayant Kalagnanam.
At a high level the model vectorizes time series into patches of a given size and encodes the resulting sequence of vectors via a Transformer that then outputs the prediction length forecast via an appropriate head. The model is illustrated in the following figure:
diff --git a/docs/source/en/model_doc/pegasus_x.md b/docs/source/en/model_doc/pegasus_x.md
index 97e50601b7..379e0362bb 100644
--- a/docs/source/en/model_doc/pegasus_x.md
+++ b/docs/source/en/model_doc/pegasus_x.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The PEGASUS-X model was proposed in [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao and Peter J. Liu.
+The PEGASUS-X model was proposed in [Investigating Efficiently Extending Transformers for Long Input Summarization](https://huggingface.co/papers/2208.04347) by Jason Phang, Yao Zhao and Peter J. Liu.
PEGASUS-X (PEGASUS eXtended) extends the PEGASUS models for long input summarization through additional long input pretraining and using staggered block-local attention with global tokens in the encoder.
diff --git a/docs/source/en/model_doc/perceiver.md b/docs/source/en/model_doc/perceiver.md
index 629f185953..eb930bd4bd 100644
--- a/docs/source/en/model_doc/perceiver.md
+++ b/docs/source/en/model_doc/perceiver.md
@@ -23,11 +23,11 @@ rendered properly in your Markdown viewer.
## Overview
The Perceiver IO model was proposed in [Perceiver IO: A General Architecture for Structured Inputs &
-Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch,
+Outputs](https://huggingface.co/papers/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch,
Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M.
Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
-Perceiver IO is a generalization of [Perceiver](https://arxiv.org/abs/2103.03206) to handle arbitrary outputs in
+Perceiver IO is a generalization of [Perceiver](https://huggingface.co/papers/2103.03206) to handle arbitrary outputs in
addition to arbitrary inputs. The original Perceiver only produced a single classification label. In addition to
classification labels, Perceiver IO can produce (for example) language, optical flow, and multimodal videos with audio.
This is done using the same building blocks as the original Perceiver. The computational complexity of Perceiver IO is
@@ -80,7 +80,7 @@ size of 262 byte IDs).
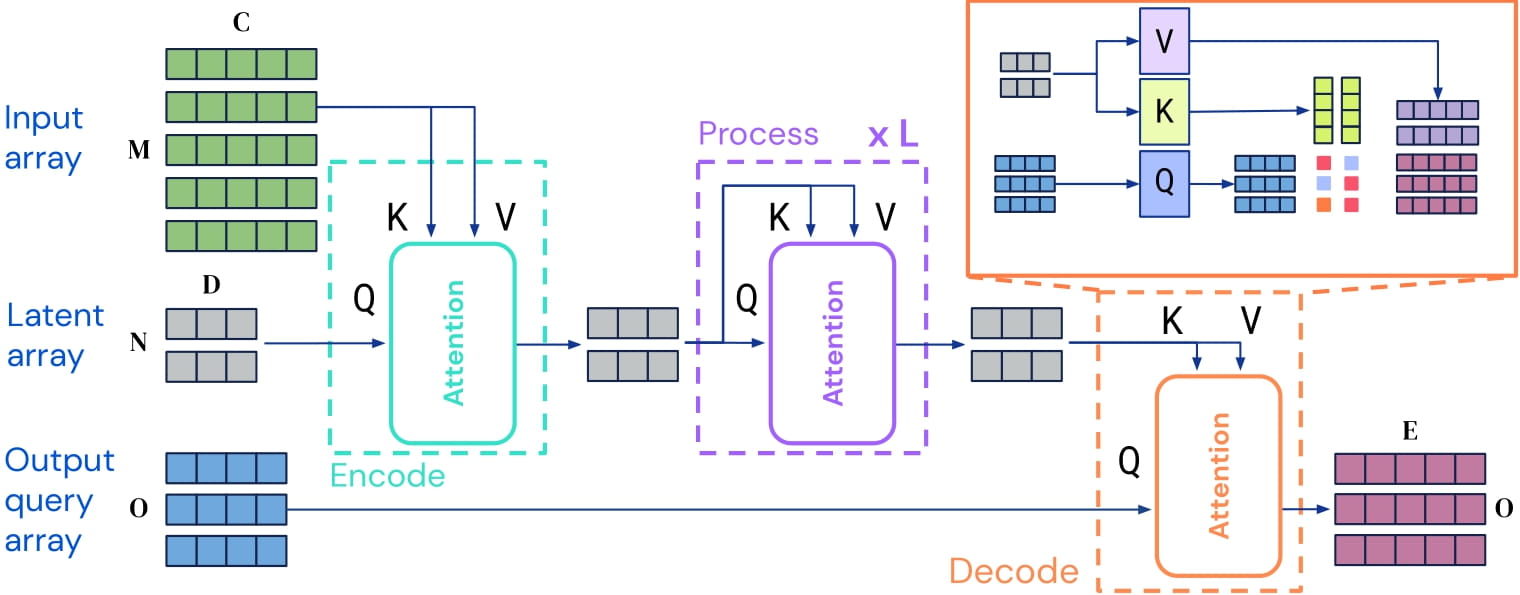 - Perceiver IO architecture. Taken from the original paper
+ Perceiver IO architecture. Taken from the original paper
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
[here](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
diff --git a/docs/source/en/model_doc/phi3.md b/docs/source/en/model_doc/phi3.md
index 82973d39c0..41753bff5b 100644
--- a/docs/source/en/model_doc/phi3.md
+++ b/docs/source/en/model_doc/phi3.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Phi-3 model was proposed in [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/abs/2404.14219) by Microsoft.
+The Phi-3 model was proposed in [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://huggingface.co/papers/2404.14219) by Microsoft.
### Summary
diff --git a/docs/source/en/model_doc/phimoe.md b/docs/source/en/model_doc/phimoe.md
index 6728248f2e..8395021411 100644
--- a/docs/source/en/model_doc/phimoe.md
+++ b/docs/source/en/model_doc/phimoe.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The PhiMoE model was proposed in [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/abs/2404.14219) by Microsoft.
+The PhiMoE model was proposed in [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://huggingface.co/papers/2404.14219) by Microsoft.
### Summary
diff --git a/docs/source/en/model_doc/pix2struct.md b/docs/source/en/model_doc/pix2struct.md
index e912cc96cd..b03e73d246 100644
--- a/docs/source/en/model_doc/pix2struct.md
+++ b/docs/source/en/model_doc/pix2struct.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Pix2Struct model was proposed in [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
+The Pix2Struct model was proposed in [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://huggingface.co/papers/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/plbart.md b/docs/source/en/model_doc/plbart.md
index d57ee8ed99..a885924530 100644
--- a/docs/source/en/model_doc/plbart.md
+++ b/docs/source/en/model_doc/plbart.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The PLBART model was proposed in [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
+The PLBART model was proposed in [Unified Pre-training for Program Understanding and Generation](https://huggingface.co/papers/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
This is a BART-like model which can be used to perform code-summarization, code-generation, and code-translation tasks. The pre-trained model `plbart-base` has been trained using multilingual denoising task
on Java, Python and English.
@@ -50,7 +50,7 @@ model is multilingual it expects the sequences in a different format. A special
source and target text. The source text format is `X [eos, src_lang_code]` where `X` is the source text. The
target text format is `[tgt_lang_code] X [eos]`. `bos` is never used.
-However, for fine-tuning, in some cases no language token is provided in cases where a single language is used. Please refer to [the paper](https://arxiv.org/abs/2103.06333) to learn more about this.
+However, for fine-tuning, in some cases no language token is provided in cases where a single language is used. Please refer to [the paper](https://huggingface.co/papers/2103.06333) to learn more about this.
In cases where the language code is needed, the regular [`~PLBartTokenizer.__call__`] will encode source text format
when you pass texts as the first argument or with the keyword argument `text`, and will encode target text format if
diff --git a/docs/source/en/model_doc/poolformer.md b/docs/source/en/model_doc/poolformer.md
index 60573162d6..46c84d04fa 100644
--- a/docs/source/en/model_doc/poolformer.md
+++ b/docs/source/en/model_doc/poolformer.md
@@ -22,13 +22,13 @@ rendered properly in your Markdown viewer.
## Overview
-The PoolFormer model was proposed in [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Sea AI Labs. Instead of designing complicated token mixer to achieve SOTA performance, the target of this work is to demonstrate the competence of transformer models largely stem from the general architecture MetaFormer.
+The PoolFormer model was proposed in [MetaFormer is Actually What You Need for Vision](https://huggingface.co/papers/2111.11418) by Sea AI Labs. Instead of designing complicated token mixer to achieve SOTA performance, the target of this work is to demonstrate the competence of transformer models largely stem from the general architecture MetaFormer.
The abstract from the paper is the following:
*Transformers have shown great potential in computer vision tasks. A common belief is their attention-based token mixer module contributes most to their competence. However, recent works show the attention-based module in transformers can be replaced by spatial MLPs and the resulted models still perform quite well. Based on this observation, we hypothesize that the general architecture of the transformers, instead of the specific token mixer module, is more essential to the model's performance. To verify this, we deliberately replace the attention module in transformers with an embarrassingly simple spatial pooling operator to conduct only the most basic token mixing. Surprisingly, we observe that the derived model, termed as PoolFormer, achieves competitive performance on multiple computer vision tasks. For example, on ImageNet-1K, PoolFormer achieves 82.1% top-1 accuracy, surpassing well-tuned vision transformer/MLP-like baselines DeiT-B/ResMLP-B24 by 0.3%/1.1% accuracy with 35%/52% fewer parameters and 48%/60% fewer MACs. The effectiveness of PoolFormer verifies our hypothesis and urges us to initiate the concept of "MetaFormer", a general architecture abstracted from transformers without specifying the token mixer. Based on the extensive experiments, we argue that MetaFormer is the key player in achieving superior results for recent transformer and MLP-like models on vision tasks. This work calls for more future research dedicated to improving MetaFormer instead of focusing on the token mixer modules. Additionally, our proposed PoolFormer could serve as a starting baseline for future MetaFormer architecture design.*
-The figure below illustrates the architecture of PoolFormer. Taken from the [original paper](https://arxiv.org/abs/2111.11418).
+The figure below illustrates the architecture of PoolFormer. Taken from the [original paper](https://huggingface.co/papers/2111.11418).
- Perceiver IO architecture. Taken from the original paper
+ Perceiver IO architecture. Taken from the original paper
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
[here](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
diff --git a/docs/source/en/model_doc/phi3.md b/docs/source/en/model_doc/phi3.md
index 82973d39c0..41753bff5b 100644
--- a/docs/source/en/model_doc/phi3.md
+++ b/docs/source/en/model_doc/phi3.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Phi-3 model was proposed in [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/abs/2404.14219) by Microsoft.
+The Phi-3 model was proposed in [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://huggingface.co/papers/2404.14219) by Microsoft.
### Summary
diff --git a/docs/source/en/model_doc/phimoe.md b/docs/source/en/model_doc/phimoe.md
index 6728248f2e..8395021411 100644
--- a/docs/source/en/model_doc/phimoe.md
+++ b/docs/source/en/model_doc/phimoe.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The PhiMoE model was proposed in [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/abs/2404.14219) by Microsoft.
+The PhiMoE model was proposed in [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://huggingface.co/papers/2404.14219) by Microsoft.
### Summary
diff --git a/docs/source/en/model_doc/pix2struct.md b/docs/source/en/model_doc/pix2struct.md
index e912cc96cd..b03e73d246 100644
--- a/docs/source/en/model_doc/pix2struct.md
+++ b/docs/source/en/model_doc/pix2struct.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Pix2Struct model was proposed in [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
+The Pix2Struct model was proposed in [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://huggingface.co/papers/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/plbart.md b/docs/source/en/model_doc/plbart.md
index d57ee8ed99..a885924530 100644
--- a/docs/source/en/model_doc/plbart.md
+++ b/docs/source/en/model_doc/plbart.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The PLBART model was proposed in [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
+The PLBART model was proposed in [Unified Pre-training for Program Understanding and Generation](https://huggingface.co/papers/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
This is a BART-like model which can be used to perform code-summarization, code-generation, and code-translation tasks. The pre-trained model `plbart-base` has been trained using multilingual denoising task
on Java, Python and English.
@@ -50,7 +50,7 @@ model is multilingual it expects the sequences in a different format. A special
source and target text. The source text format is `X [eos, src_lang_code]` where `X` is the source text. The
target text format is `[tgt_lang_code] X [eos]`. `bos` is never used.
-However, for fine-tuning, in some cases no language token is provided in cases where a single language is used. Please refer to [the paper](https://arxiv.org/abs/2103.06333) to learn more about this.
+However, for fine-tuning, in some cases no language token is provided in cases where a single language is used. Please refer to [the paper](https://huggingface.co/papers/2103.06333) to learn more about this.
In cases where the language code is needed, the regular [`~PLBartTokenizer.__call__`] will encode source text format
when you pass texts as the first argument or with the keyword argument `text`, and will encode target text format if
diff --git a/docs/source/en/model_doc/poolformer.md b/docs/source/en/model_doc/poolformer.md
index 60573162d6..46c84d04fa 100644
--- a/docs/source/en/model_doc/poolformer.md
+++ b/docs/source/en/model_doc/poolformer.md
@@ -22,13 +22,13 @@ rendered properly in your Markdown viewer.
## Overview
-The PoolFormer model was proposed in [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Sea AI Labs. Instead of designing complicated token mixer to achieve SOTA performance, the target of this work is to demonstrate the competence of transformer models largely stem from the general architecture MetaFormer.
+The PoolFormer model was proposed in [MetaFormer is Actually What You Need for Vision](https://huggingface.co/papers/2111.11418) by Sea AI Labs. Instead of designing complicated token mixer to achieve SOTA performance, the target of this work is to demonstrate the competence of transformer models largely stem from the general architecture MetaFormer.
The abstract from the paper is the following:
*Transformers have shown great potential in computer vision tasks. A common belief is their attention-based token mixer module contributes most to their competence. However, recent works show the attention-based module in transformers can be replaced by spatial MLPs and the resulted models still perform quite well. Based on this observation, we hypothesize that the general architecture of the transformers, instead of the specific token mixer module, is more essential to the model's performance. To verify this, we deliberately replace the attention module in transformers with an embarrassingly simple spatial pooling operator to conduct only the most basic token mixing. Surprisingly, we observe that the derived model, termed as PoolFormer, achieves competitive performance on multiple computer vision tasks. For example, on ImageNet-1K, PoolFormer achieves 82.1% top-1 accuracy, surpassing well-tuned vision transformer/MLP-like baselines DeiT-B/ResMLP-B24 by 0.3%/1.1% accuracy with 35%/52% fewer parameters and 48%/60% fewer MACs. The effectiveness of PoolFormer verifies our hypothesis and urges us to initiate the concept of "MetaFormer", a general architecture abstracted from transformers without specifying the token mixer. Based on the extensive experiments, we argue that MetaFormer is the key player in achieving superior results for recent transformer and MLP-like models on vision tasks. This work calls for more future research dedicated to improving MetaFormer instead of focusing on the token mixer modules. Additionally, our proposed PoolFormer could serve as a starting baseline for future MetaFormer architecture design.*
-The figure below illustrates the architecture of PoolFormer. Taken from the [original paper](https://arxiv.org/abs/2111.11418).
+The figure below illustrates the architecture of PoolFormer. Taken from the [original paper](https://huggingface.co/papers/2111.11418).
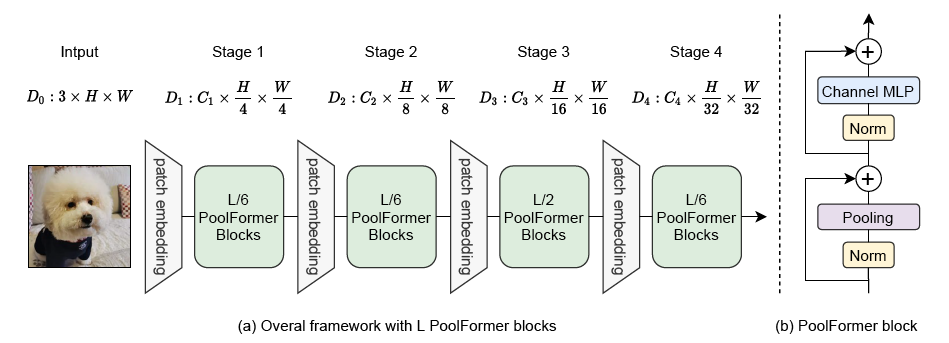 diff --git a/docs/source/en/model_doc/pop2piano.md b/docs/source/en/model_doc/pop2piano.md
index a9554b4924..6f78233d2c 100644
--- a/docs/source/en/model_doc/pop2piano.md
+++ b/docs/source/en/model_doc/pop2piano.md
@@ -18,14 +18,14 @@ specific language governing permissions and limitations under the License.
## Overview
-The Pop2Piano model was proposed in [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi and Kyogu Lee.
+The Pop2Piano model was proposed in [Pop2Piano : Pop Audio-based Piano Cover Generation](https://huggingface.co/papers/2211.00895) by Jongho Choi and Kyogu Lee.
Piano covers of pop music are widely enjoyed, but generating them from music is not a trivial task. It requires great
expertise with playing piano as well as knowing different characteristics and melodies of a song. With Pop2Piano you
can directly generate a cover from a song's audio waveform. It is the first model to directly generate a piano cover
from pop audio without melody and chord extraction modules.
-Pop2Piano is an encoder-decoder Transformer model based on [T5](https://arxiv.org/pdf/1910.10683.pdf). The input audio
+Pop2Piano is an encoder-decoder Transformer model based on [T5](https://huggingface.co/papers/1910.10683). The input audio
is transformed to its waveform and passed to the encoder, which transforms it to a latent representation. The decoder
uses these latent representations to generate token ids in an autoregressive way. Each token id corresponds to one of four
different token types: time, velocity, note and 'special'. The token ids are then decoded to their equivalent MIDI file.
diff --git a/docs/source/en/model_doc/prompt_depth_anything.md b/docs/source/en/model_doc/prompt_depth_anything.md
index 910298fa8c..271fc4e2c0 100644
--- a/docs/source/en/model_doc/prompt_depth_anything.md
+++ b/docs/source/en/model_doc/prompt_depth_anything.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Prompt Depth Anything model was introduced in [Prompting Depth Anything for 4K Resolution Accurate Metric Depth Estimation](https://arxiv.org/abs/2412.14015) by Haotong Lin, Sida Peng, Jingxiao Chen, Songyou Peng, Jiaming Sun, Minghuan Liu, Hujun Bao, Jiashi Feng, Xiaowei Zhou, Bingyi Kang.
+The Prompt Depth Anything model was introduced in [Prompting Depth Anything for 4K Resolution Accurate Metric Depth Estimation](https://huggingface.co/papers/2412.14015) by Haotong Lin, Sida Peng, Jingxiao Chen, Songyou Peng, Jiaming Sun, Minghuan Liu, Hujun Bao, Jiashi Feng, Xiaowei Zhou, Bingyi Kang.
The abstract from the paper is as follows:
@@ -28,7 +28,7 @@ The abstract from the paper is as follows:
diff --git a/docs/source/en/model_doc/pop2piano.md b/docs/source/en/model_doc/pop2piano.md
index a9554b4924..6f78233d2c 100644
--- a/docs/source/en/model_doc/pop2piano.md
+++ b/docs/source/en/model_doc/pop2piano.md
@@ -18,14 +18,14 @@ specific language governing permissions and limitations under the License.
## Overview
-The Pop2Piano model was proposed in [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi and Kyogu Lee.
+The Pop2Piano model was proposed in [Pop2Piano : Pop Audio-based Piano Cover Generation](https://huggingface.co/papers/2211.00895) by Jongho Choi and Kyogu Lee.
Piano covers of pop music are widely enjoyed, but generating them from music is not a trivial task. It requires great
expertise with playing piano as well as knowing different characteristics and melodies of a song. With Pop2Piano you
can directly generate a cover from a song's audio waveform. It is the first model to directly generate a piano cover
from pop audio without melody and chord extraction modules.
-Pop2Piano is an encoder-decoder Transformer model based on [T5](https://arxiv.org/pdf/1910.10683.pdf). The input audio
+Pop2Piano is an encoder-decoder Transformer model based on [T5](https://huggingface.co/papers/1910.10683). The input audio
is transformed to its waveform and passed to the encoder, which transforms it to a latent representation. The decoder
uses these latent representations to generate token ids in an autoregressive way. Each token id corresponds to one of four
different token types: time, velocity, note and 'special'. The token ids are then decoded to their equivalent MIDI file.
diff --git a/docs/source/en/model_doc/prompt_depth_anything.md b/docs/source/en/model_doc/prompt_depth_anything.md
index 910298fa8c..271fc4e2c0 100644
--- a/docs/source/en/model_doc/prompt_depth_anything.md
+++ b/docs/source/en/model_doc/prompt_depth_anything.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Prompt Depth Anything model was introduced in [Prompting Depth Anything for 4K Resolution Accurate Metric Depth Estimation](https://arxiv.org/abs/2412.14015) by Haotong Lin, Sida Peng, Jingxiao Chen, Songyou Peng, Jiaming Sun, Minghuan Liu, Hujun Bao, Jiashi Feng, Xiaowei Zhou, Bingyi Kang.
+The Prompt Depth Anything model was introduced in [Prompting Depth Anything for 4K Resolution Accurate Metric Depth Estimation](https://huggingface.co/papers/2412.14015) by Haotong Lin, Sida Peng, Jingxiao Chen, Songyou Peng, Jiaming Sun, Minghuan Liu, Hujun Bao, Jiashi Feng, Xiaowei Zhou, Bingyi Kang.
The abstract from the paper is as follows:
@@ -28,7 +28,7 @@ The abstract from the paper is as follows:
 - Prompt Depth Anything overview. Taken from the original paper.
+ Prompt Depth Anything overview. Taken from the original paper.
## Usage example
diff --git a/docs/source/en/model_doc/prophetnet.md b/docs/source/en/model_doc/prophetnet.md
index b768fef72a..9085886cde 100644
--- a/docs/source/en/model_doc/prophetnet.md
+++ b/docs/source/en/model_doc/prophetnet.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The ProphetNet model was proposed in [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei
+The ProphetNet model was proposed in [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://huggingface.co/papers/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei
Zhang, Ming Zhou on 13 Jan, 2020.
ProphetNet is an encoder-decoder model and can predict n-future tokens for "ngram" language modeling instead of just
diff --git a/docs/source/en/model_doc/pvt.md b/docs/source/en/model_doc/pvt.md
index daa4806bc3..4b221c9791 100644
--- a/docs/source/en/model_doc/pvt.md
+++ b/docs/source/en/model_doc/pvt.md
@@ -19,7 +19,7 @@ specific language governing permissions and limitations under the License.
## Overview
The PVT model was proposed in
-[Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/abs/2102.12122)
+[Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://huggingface.co/papers/2102.12122)
by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao. The PVT is a type of
vision transformer that utilizes a pyramid structure to make it an effective backbone for dense prediction tasks. Specifically
it allows for more fine-grained inputs (4 x 4 pixels per patch) to be used, while simultaneously shrinking the sequence length
diff --git a/docs/source/en/model_doc/pvt_v2.md b/docs/source/en/model_doc/pvt_v2.md
index deac614d38..b8ebe9198a 100644
--- a/docs/source/en/model_doc/pvt_v2.md
+++ b/docs/source/en/model_doc/pvt_v2.md
@@ -19,11 +19,11 @@ specific language governing permissions and limitations under the License.
## Overview
The PVTv2 model was proposed in
-[PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. As an improved variant of PVT, it eschews position embeddings, relying instead on positional information encoded through zero-padding and overlapping patch embeddings. This lack of reliance on position embeddings simplifies the architecture, and enables running inference at any resolution without needing to interpolate them.
+[PVT v2: Improved Baselines with Pyramid Vision Transformer](https://huggingface.co/papers/2106.13797) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. As an improved variant of PVT, it eschews position embeddings, relying instead on positional information encoded through zero-padding and overlapping patch embeddings. This lack of reliance on position embeddings simplifies the architecture, and enables running inference at any resolution without needing to interpolate them.
-The PVTv2 encoder structure has been successfully deployed to achieve state-of-the-art scores in [Segformer](https://arxiv.org/abs/2105.15203) for semantic segmentation, [GLPN](https://arxiv.org/abs/2201.07436) for monocular depth, and [Panoptic Segformer](https://arxiv.org/abs/2109.03814) for panoptic segmentation.
+The PVTv2 encoder structure has been successfully deployed to achieve state-of-the-art scores in [Segformer](https://huggingface.co/papers/2105.15203) for semantic segmentation, [GLPN](https://huggingface.co/papers/2201.07436) for monocular depth, and [Panoptic Segformer](https://huggingface.co/papers/2109.03814) for panoptic segmentation.
-PVTv2 belongs to a family of models called [hierarchical transformers](https://natecibik.medium.com/the-rise-of-vision-transformers-f623c980419f) , which make adaptations to transformer layers in order to generate multi-scale feature maps. Unlike the columnal structure of Vision Transformer ([ViT](https://arxiv.org/abs/2010.11929)) which loses fine-grained detail, multi-scale feature maps are known preserve this detail and aid performance in dense prediction tasks. In the case of PVTv2, this is achieved by generating image patch tokens using 2D convolution with overlapping kernels in each encoder layer.
+PVTv2 belongs to a family of models called [hierarchical transformers](https://natecibik.medium.com/the-rise-of-vision-transformers-f623c980419f) , which make adaptations to transformer layers in order to generate multi-scale feature maps. Unlike the columnal structure of Vision Transformer ([ViT](https://huggingface.co/papers/2010.11929)) which loses fine-grained detail, multi-scale feature maps are known preserve this detail and aid performance in dense prediction tasks. In the case of PVTv2, this is achieved by generating image patch tokens using 2D convolution with overlapping kernels in each encoder layer.
The multi-scale features of hierarchical transformers allow them to be easily swapped in for traditional workhorse computer vision backbone models like ResNet in larger architectures. Both Segformer and Panoptic Segformer demonstrated that configurations using PVTv2 for a backbone consistently outperformed those with similarly sized ResNet backbones.
@@ -39,8 +39,8 @@ This model was contributed by [FoamoftheSea](https://huggingface.co/FoamoftheSea
## Usage tips
-- [PVTv2](https://arxiv.org/abs/2106.13797) is a hierarchical transformer model which has demonstrated powerful performance in image classification and multiple other tasks, used as a backbone for semantic segmentation in [Segformer](https://arxiv.org/abs/2105.15203), monocular depth estimation in [GLPN](https://arxiv.org/abs/2201.07436), and panoptic segmentation in [Panoptic Segformer](https://arxiv.org/abs/2109.03814), consistently showing higher performance than similar ResNet configurations.
-- Hierarchical transformers like PVTv2 achieve superior data and parameter efficiency on image data compared with pure transformer architectures by incorporating design elements of convolutional neural networks (CNNs) into their encoders. This creates a best-of-both-worlds architecture that infuses the useful inductive biases of CNNs like translation equivariance and locality into the network while still enjoying the benefits of dynamic data response and global relationship modeling provided by the self-attention mechanism of [transformers](https://arxiv.org/abs/1706.03762).
+- [PVTv2](https://huggingface.co/papers/2106.13797) is a hierarchical transformer model which has demonstrated powerful performance in image classification and multiple other tasks, used as a backbone for semantic segmentation in [Segformer](https://huggingface.co/papers/2105.15203), monocular depth estimation in [GLPN](https://huggingface.co/papers/2201.07436), and panoptic segmentation in [Panoptic Segformer](https://huggingface.co/papers/2109.03814), consistently showing higher performance than similar ResNet configurations.
+- Hierarchical transformers like PVTv2 achieve superior data and parameter efficiency on image data compared with pure transformer architectures by incorporating design elements of convolutional neural networks (CNNs) into their encoders. This creates a best-of-both-worlds architecture that infuses the useful inductive biases of CNNs like translation equivariance and locality into the network while still enjoying the benefits of dynamic data response and global relationship modeling provided by the self-attention mechanism of [transformers](https://huggingface.co/papers/1706.03762).
- PVTv2 uses overlapping patch embeddings to create multi-scale feature maps, which are infused with location information using zero-padding and depth-wise convolutions.
- To reduce the complexity in the attention layers, PVTv2 performs a spatial reduction on the hidden states using either strided 2D convolution (SRA) or fixed-size average pooling (Linear SRA). Although inherently more lossy, Linear SRA provides impressive performance with a linear complexity with respect to image size. To use Linear SRA in the self-attention layers, set `linear_attention=True` in the `PvtV2Config`.
- [`PvtV2Model`] is the hierarchical transformer encoder (which is also often referred to as Mix Transformer or MiT in the literature). [`PvtV2ForImageClassification`] adds a simple classifier head on top to perform Image Classification. [`PvtV2Backbone`] can be used with the [`AutoBackbone`] system in larger architectures like Deformable DETR.
diff --git a/docs/source/en/model_doc/qdqbert.md b/docs/source/en/model_doc/qdqbert.md
index 4c1a485b11..64e00d6a43 100644
--- a/docs/source/en/model_doc/qdqbert.md
+++ b/docs/source/en/model_doc/qdqbert.md
@@ -31,7 +31,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
The QDQBERT model can be referenced in [Integer Quantization for Deep Learning Inference: Principles and Empirical
-Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius
+Evaluation](https://huggingface.co/papers/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius
Micikevicius.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/qwen2_audio.md b/docs/source/en/model_doc/qwen2_audio.md
index 03a54f3893..22e1effd27 100644
--- a/docs/source/en/model_doc/qwen2_audio.md
+++ b/docs/source/en/model_doc/qwen2_audio.md
@@ -29,7 +29,7 @@ The Qwen2-Audio is the new model series of large audio-language models from the
* voice chat: users can freely engage in voice interactions with Qwen2-Audio without text input
* audio analysis: users could provide audio and text instructions for analysis during the interaction
-It was proposed in [Qwen2-Audio Technical Report](https://arxiv.org/abs/2407.10759) by Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, Chang Zhou, Jingren Zhou.
+It was proposed in [Qwen2-Audio Technical Report](https://huggingface.co/papers/2407.10759) by Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, Chang Zhou, Jingren Zhou.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/qwen2_vl.md b/docs/source/en/model_doc/qwen2_vl.md
index c6bf692f9d..39ddbdc006 100644
--- a/docs/source/en/model_doc/qwen2_vl.md
+++ b/docs/source/en/model_doc/qwen2_vl.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The [Qwen2-VL](https://qwenlm.github.io/blog/qwen2-vl/) model is a major update to [Qwen-VL](https://arxiv.org/pdf/2308.12966) from the Qwen team at Alibaba Research.
+The [Qwen2-VL](https://qwenlm.github.io/blog/qwen2-vl/) model is a major update to [Qwen-VL](https://huggingface.co/papers/2308.12966) from the Qwen team at Alibaba Research.
The abstract from the blog is the following:
diff --git a/docs/source/en/model_doc/rag.md b/docs/source/en/model_doc/rag.md
index 8b65da43a2..425d5c70d1 100644
--- a/docs/source/en/model_doc/rag.md
+++ b/docs/source/en/model_doc/rag.md
@@ -29,7 +29,7 @@ sequence-to-sequence models. RAG models retrieve documents, pass them to a seq2s
outputs. The retriever and seq2seq modules are initialized from pretrained models, and fine-tuned jointly, allowing
both retrieval and generation to adapt to downstream tasks.
-It is based on the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir
+It is based on the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://huggingface.co/papers/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir
Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/realm.md b/docs/source/en/model_doc/realm.md
index b5b9102c2c..efff6717d8 100644
--- a/docs/source/en/model_doc/realm.md
+++ b/docs/source/en/model_doc/realm.md
@@ -30,7 +30,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The REALM model was proposed in [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang. It's a
+The REALM model was proposed in [REALM: Retrieval-Augmented Language Model Pre-Training](https://huggingface.co/papers/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang. It's a
retrieval-augmented language model that firstly retrieves documents from a textual knowledge corpus and then
utilizes retrieved documents to process question answering tasks.
diff --git a/docs/source/en/model_doc/reformer.md b/docs/source/en/model_doc/reformer.md
index 7e403599fd..e65c725d90 100644
--- a/docs/source/en/model_doc/reformer.md
+++ b/docs/source/en/model_doc/reformer.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Reformer model was proposed in the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451.pdf) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
+The Reformer model was proposed in the paper [Reformer: The Efficient Transformer](https://huggingface.co/papers/2001.04451.pdf) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
The abstract from the paper is the following:
@@ -93,7 +93,7 @@ length* of the `input_ids`.
In Locality sensitive hashing (LSH) self attention the key and query projection weights are tied. Therefore, the key
query embedding vectors are also tied. LSH self attention uses the locality sensitive hashing mechanism proposed in
-[Practical and Optimal LSH for Angular Distance](https://arxiv.org/abs/1509.02897) to assign each of the tied key
+[Practical and Optimal LSH for Angular Distance](https://huggingface.co/papers/1509.02897) to assign each of the tied key
query embedding vectors to one of `config.num_buckets` possible buckets. The premise is that the more "similar"
key query embedding vectors (in terms of *cosine similarity*) are to each other, the more likely they are assigned to
the same bucket.
@@ -105,7 +105,7 @@ each of length `config.lsh_chunk_length`. For each chunk, the query embedding ve
(which are tied to themselves) and to the key embedding vectors of `config.lsh_num_chunks_before` previous
neighboring chunks and `config.lsh_num_chunks_after` following neighboring chunks.
-For more information, see the [original Paper](https://arxiv.org/abs/2001.04451) or this great [blog post](https://www.pragmatic.ml/reformer-deep-dive/).
+For more information, see the [original Paper](https://huggingface.co/papers/2001.04451) or this great [blog post](https://www.pragmatic.ml/reformer-deep-dive/).
Note that `config.num_buckets` can also be factorized into a list \\((n_{\text{buckets}}^1,
n_{\text{buckets}}^2)\\). This way instead of assigning the query key embedding vectors to one of \\((1,\ldots,
diff --git a/docs/source/en/model_doc/regnet.md b/docs/source/en/model_doc/regnet.md
index f292fe0df2..a86176bcf2 100644
--- a/docs/source/en/model_doc/regnet.md
+++ b/docs/source/en/model_doc/regnet.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The RegNet model was proposed in [Designing Network Design Spaces](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
+The RegNet model was proposed in [Designing Network Design Spaces](https://huggingface.co/papers/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
The authors design search spaces to perform Neural Architecture Search (NAS). They first start from a high dimensional search space and iteratively reduce the search space by empirically applying constraints based on the best-performing models sampled by the current search space.
@@ -37,7 +37,7 @@ This model was contributed by [Francesco](https://huggingface.co/Francesco). The
was contributed by [sayakpaul](https://huggingface.co/sayakpaul) and [ariG23498](https://huggingface.co/ariG23498).
The original code can be found [here](https://github.com/facebookresearch/pycls).
-The huge 10B model from [Self-supervised Pretraining of Visual Features in the Wild](https://arxiv.org/abs/2103.01988),
+The huge 10B model from [Self-supervised Pretraining of Visual Features in the Wild](https://huggingface.co/papers/2103.01988),
trained on one billion Instagram images, is available on the [hub](https://huggingface.co/facebook/regnet-y-10b-seer)
## Resources
diff --git a/docs/source/en/model_doc/rembert.md b/docs/source/en/model_doc/rembert.md
index 319e44cf09..6cf0e35c2a 100644
--- a/docs/source/en/model_doc/rembert.md
+++ b/docs/source/en/model_doc/rembert.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The RemBERT model was proposed in [Rethinking Embedding Coupling in Pre-trained Language Models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, Melvin Johnson, Sebastian Ruder.
+The RemBERT model was proposed in [Rethinking Embedding Coupling in Pre-trained Language Models](https://huggingface.co/papers/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, Melvin Johnson, Sebastian Ruder.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/resnet.md b/docs/source/en/model_doc/resnet.md
index d7400b46c8..03ad0b0c32 100644
--- a/docs/source/en/model_doc/resnet.md
+++ b/docs/source/en/model_doc/resnet.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The ResNet model was proposed in [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren and Jian Sun. Our implementation follows the small changes made by [Nvidia](https://catalog.ngc.nvidia.com/orgs/nvidia/resources/resnet_50_v1_5_for_pytorch), we apply the `stride=2` for downsampling in bottleneck's `3x3` conv and not in the first `1x1`. This is generally known as "ResNet v1.5".
+The ResNet model was proposed in [Deep Residual Learning for Image Recognition](https://huggingface.co/papers/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren and Jian Sun. Our implementation follows the small changes made by [Nvidia](https://catalog.ngc.nvidia.com/orgs/nvidia/resources/resnet_50_v1_5_for_pytorch), we apply the `stride=2` for downsampling in bottleneck's `3x3` conv and not in the first `1x1`. This is generally known as "ResNet v1.5".
ResNet introduced residual connections, they allow to train networks with an unseen number of layers (up to 1000). ResNet won the 2015 ILSVRC & COCO competition, one important milestone in deep computer vision.
@@ -34,7 +34,7 @@ The abstract from the paper is the following:
*Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers---8x deeper than VGG nets but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers.
The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions, where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.*
-The figure below illustrates the architecture of ResNet. Taken from the [original paper](https://arxiv.org/abs/1512.03385).
+The figure below illustrates the architecture of ResNet. Taken from the [original paper](https://huggingface.co/papers/1512.03385).
- Prompt Depth Anything overview. Taken from the original paper.
+ Prompt Depth Anything overview. Taken from the original paper.
## Usage example
diff --git a/docs/source/en/model_doc/prophetnet.md b/docs/source/en/model_doc/prophetnet.md
index b768fef72a..9085886cde 100644
--- a/docs/source/en/model_doc/prophetnet.md
+++ b/docs/source/en/model_doc/prophetnet.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The ProphetNet model was proposed in [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei
+The ProphetNet model was proposed in [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://huggingface.co/papers/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei
Zhang, Ming Zhou on 13 Jan, 2020.
ProphetNet is an encoder-decoder model and can predict n-future tokens for "ngram" language modeling instead of just
diff --git a/docs/source/en/model_doc/pvt.md b/docs/source/en/model_doc/pvt.md
index daa4806bc3..4b221c9791 100644
--- a/docs/source/en/model_doc/pvt.md
+++ b/docs/source/en/model_doc/pvt.md
@@ -19,7 +19,7 @@ specific language governing permissions and limitations under the License.
## Overview
The PVT model was proposed in
-[Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/abs/2102.12122)
+[Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://huggingface.co/papers/2102.12122)
by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao. The PVT is a type of
vision transformer that utilizes a pyramid structure to make it an effective backbone for dense prediction tasks. Specifically
it allows for more fine-grained inputs (4 x 4 pixels per patch) to be used, while simultaneously shrinking the sequence length
diff --git a/docs/source/en/model_doc/pvt_v2.md b/docs/source/en/model_doc/pvt_v2.md
index deac614d38..b8ebe9198a 100644
--- a/docs/source/en/model_doc/pvt_v2.md
+++ b/docs/source/en/model_doc/pvt_v2.md
@@ -19,11 +19,11 @@ specific language governing permissions and limitations under the License.
## Overview
The PVTv2 model was proposed in
-[PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. As an improved variant of PVT, it eschews position embeddings, relying instead on positional information encoded through zero-padding and overlapping patch embeddings. This lack of reliance on position embeddings simplifies the architecture, and enables running inference at any resolution without needing to interpolate them.
+[PVT v2: Improved Baselines with Pyramid Vision Transformer](https://huggingface.co/papers/2106.13797) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. As an improved variant of PVT, it eschews position embeddings, relying instead on positional information encoded through zero-padding and overlapping patch embeddings. This lack of reliance on position embeddings simplifies the architecture, and enables running inference at any resolution without needing to interpolate them.
-The PVTv2 encoder structure has been successfully deployed to achieve state-of-the-art scores in [Segformer](https://arxiv.org/abs/2105.15203) for semantic segmentation, [GLPN](https://arxiv.org/abs/2201.07436) for monocular depth, and [Panoptic Segformer](https://arxiv.org/abs/2109.03814) for panoptic segmentation.
+The PVTv2 encoder structure has been successfully deployed to achieve state-of-the-art scores in [Segformer](https://huggingface.co/papers/2105.15203) for semantic segmentation, [GLPN](https://huggingface.co/papers/2201.07436) for monocular depth, and [Panoptic Segformer](https://huggingface.co/papers/2109.03814) for panoptic segmentation.
-PVTv2 belongs to a family of models called [hierarchical transformers](https://natecibik.medium.com/the-rise-of-vision-transformers-f623c980419f) , which make adaptations to transformer layers in order to generate multi-scale feature maps. Unlike the columnal structure of Vision Transformer ([ViT](https://arxiv.org/abs/2010.11929)) which loses fine-grained detail, multi-scale feature maps are known preserve this detail and aid performance in dense prediction tasks. In the case of PVTv2, this is achieved by generating image patch tokens using 2D convolution with overlapping kernels in each encoder layer.
+PVTv2 belongs to a family of models called [hierarchical transformers](https://natecibik.medium.com/the-rise-of-vision-transformers-f623c980419f) , which make adaptations to transformer layers in order to generate multi-scale feature maps. Unlike the columnal structure of Vision Transformer ([ViT](https://huggingface.co/papers/2010.11929)) which loses fine-grained detail, multi-scale feature maps are known preserve this detail and aid performance in dense prediction tasks. In the case of PVTv2, this is achieved by generating image patch tokens using 2D convolution with overlapping kernels in each encoder layer.
The multi-scale features of hierarchical transformers allow them to be easily swapped in for traditional workhorse computer vision backbone models like ResNet in larger architectures. Both Segformer and Panoptic Segformer demonstrated that configurations using PVTv2 for a backbone consistently outperformed those with similarly sized ResNet backbones.
@@ -39,8 +39,8 @@ This model was contributed by [FoamoftheSea](https://huggingface.co/FoamoftheSea
## Usage tips
-- [PVTv2](https://arxiv.org/abs/2106.13797) is a hierarchical transformer model which has demonstrated powerful performance in image classification and multiple other tasks, used as a backbone for semantic segmentation in [Segformer](https://arxiv.org/abs/2105.15203), monocular depth estimation in [GLPN](https://arxiv.org/abs/2201.07436), and panoptic segmentation in [Panoptic Segformer](https://arxiv.org/abs/2109.03814), consistently showing higher performance than similar ResNet configurations.
-- Hierarchical transformers like PVTv2 achieve superior data and parameter efficiency on image data compared with pure transformer architectures by incorporating design elements of convolutional neural networks (CNNs) into their encoders. This creates a best-of-both-worlds architecture that infuses the useful inductive biases of CNNs like translation equivariance and locality into the network while still enjoying the benefits of dynamic data response and global relationship modeling provided by the self-attention mechanism of [transformers](https://arxiv.org/abs/1706.03762).
+- [PVTv2](https://huggingface.co/papers/2106.13797) is a hierarchical transformer model which has demonstrated powerful performance in image classification and multiple other tasks, used as a backbone for semantic segmentation in [Segformer](https://huggingface.co/papers/2105.15203), monocular depth estimation in [GLPN](https://huggingface.co/papers/2201.07436), and panoptic segmentation in [Panoptic Segformer](https://huggingface.co/papers/2109.03814), consistently showing higher performance than similar ResNet configurations.
+- Hierarchical transformers like PVTv2 achieve superior data and parameter efficiency on image data compared with pure transformer architectures by incorporating design elements of convolutional neural networks (CNNs) into their encoders. This creates a best-of-both-worlds architecture that infuses the useful inductive biases of CNNs like translation equivariance and locality into the network while still enjoying the benefits of dynamic data response and global relationship modeling provided by the self-attention mechanism of [transformers](https://huggingface.co/papers/1706.03762).
- PVTv2 uses overlapping patch embeddings to create multi-scale feature maps, which are infused with location information using zero-padding and depth-wise convolutions.
- To reduce the complexity in the attention layers, PVTv2 performs a spatial reduction on the hidden states using either strided 2D convolution (SRA) or fixed-size average pooling (Linear SRA). Although inherently more lossy, Linear SRA provides impressive performance with a linear complexity with respect to image size. To use Linear SRA in the self-attention layers, set `linear_attention=True` in the `PvtV2Config`.
- [`PvtV2Model`] is the hierarchical transformer encoder (which is also often referred to as Mix Transformer or MiT in the literature). [`PvtV2ForImageClassification`] adds a simple classifier head on top to perform Image Classification. [`PvtV2Backbone`] can be used with the [`AutoBackbone`] system in larger architectures like Deformable DETR.
diff --git a/docs/source/en/model_doc/qdqbert.md b/docs/source/en/model_doc/qdqbert.md
index 4c1a485b11..64e00d6a43 100644
--- a/docs/source/en/model_doc/qdqbert.md
+++ b/docs/source/en/model_doc/qdqbert.md
@@ -31,7 +31,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
The QDQBERT model can be referenced in [Integer Quantization for Deep Learning Inference: Principles and Empirical
-Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius
+Evaluation](https://huggingface.co/papers/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius
Micikevicius.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/qwen2_audio.md b/docs/source/en/model_doc/qwen2_audio.md
index 03a54f3893..22e1effd27 100644
--- a/docs/source/en/model_doc/qwen2_audio.md
+++ b/docs/source/en/model_doc/qwen2_audio.md
@@ -29,7 +29,7 @@ The Qwen2-Audio is the new model series of large audio-language models from the
* voice chat: users can freely engage in voice interactions with Qwen2-Audio without text input
* audio analysis: users could provide audio and text instructions for analysis during the interaction
-It was proposed in [Qwen2-Audio Technical Report](https://arxiv.org/abs/2407.10759) by Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, Chang Zhou, Jingren Zhou.
+It was proposed in [Qwen2-Audio Technical Report](https://huggingface.co/papers/2407.10759) by Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, Chang Zhou, Jingren Zhou.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/qwen2_vl.md b/docs/source/en/model_doc/qwen2_vl.md
index c6bf692f9d..39ddbdc006 100644
--- a/docs/source/en/model_doc/qwen2_vl.md
+++ b/docs/source/en/model_doc/qwen2_vl.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The [Qwen2-VL](https://qwenlm.github.io/blog/qwen2-vl/) model is a major update to [Qwen-VL](https://arxiv.org/pdf/2308.12966) from the Qwen team at Alibaba Research.
+The [Qwen2-VL](https://qwenlm.github.io/blog/qwen2-vl/) model is a major update to [Qwen-VL](https://huggingface.co/papers/2308.12966) from the Qwen team at Alibaba Research.
The abstract from the blog is the following:
diff --git a/docs/source/en/model_doc/rag.md b/docs/source/en/model_doc/rag.md
index 8b65da43a2..425d5c70d1 100644
--- a/docs/source/en/model_doc/rag.md
+++ b/docs/source/en/model_doc/rag.md
@@ -29,7 +29,7 @@ sequence-to-sequence models. RAG models retrieve documents, pass them to a seq2s
outputs. The retriever and seq2seq modules are initialized from pretrained models, and fine-tuned jointly, allowing
both retrieval and generation to adapt to downstream tasks.
-It is based on the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir
+It is based on the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://huggingface.co/papers/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir
Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/realm.md b/docs/source/en/model_doc/realm.md
index b5b9102c2c..efff6717d8 100644
--- a/docs/source/en/model_doc/realm.md
+++ b/docs/source/en/model_doc/realm.md
@@ -30,7 +30,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The REALM model was proposed in [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang. It's a
+The REALM model was proposed in [REALM: Retrieval-Augmented Language Model Pre-Training](https://huggingface.co/papers/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang. It's a
retrieval-augmented language model that firstly retrieves documents from a textual knowledge corpus and then
utilizes retrieved documents to process question answering tasks.
diff --git a/docs/source/en/model_doc/reformer.md b/docs/source/en/model_doc/reformer.md
index 7e403599fd..e65c725d90 100644
--- a/docs/source/en/model_doc/reformer.md
+++ b/docs/source/en/model_doc/reformer.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Reformer model was proposed in the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451.pdf) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
+The Reformer model was proposed in the paper [Reformer: The Efficient Transformer](https://huggingface.co/papers/2001.04451.pdf) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
The abstract from the paper is the following:
@@ -93,7 +93,7 @@ length* of the `input_ids`.
In Locality sensitive hashing (LSH) self attention the key and query projection weights are tied. Therefore, the key
query embedding vectors are also tied. LSH self attention uses the locality sensitive hashing mechanism proposed in
-[Practical and Optimal LSH for Angular Distance](https://arxiv.org/abs/1509.02897) to assign each of the tied key
+[Practical and Optimal LSH for Angular Distance](https://huggingface.co/papers/1509.02897) to assign each of the tied key
query embedding vectors to one of `config.num_buckets` possible buckets. The premise is that the more "similar"
key query embedding vectors (in terms of *cosine similarity*) are to each other, the more likely they are assigned to
the same bucket.
@@ -105,7 +105,7 @@ each of length `config.lsh_chunk_length`. For each chunk, the query embedding ve
(which are tied to themselves) and to the key embedding vectors of `config.lsh_num_chunks_before` previous
neighboring chunks and `config.lsh_num_chunks_after` following neighboring chunks.
-For more information, see the [original Paper](https://arxiv.org/abs/2001.04451) or this great [blog post](https://www.pragmatic.ml/reformer-deep-dive/).
+For more information, see the [original Paper](https://huggingface.co/papers/2001.04451) or this great [blog post](https://www.pragmatic.ml/reformer-deep-dive/).
Note that `config.num_buckets` can also be factorized into a list \\((n_{\text{buckets}}^1,
n_{\text{buckets}}^2)\\). This way instead of assigning the query key embedding vectors to one of \\((1,\ldots,
diff --git a/docs/source/en/model_doc/regnet.md b/docs/source/en/model_doc/regnet.md
index f292fe0df2..a86176bcf2 100644
--- a/docs/source/en/model_doc/regnet.md
+++ b/docs/source/en/model_doc/regnet.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The RegNet model was proposed in [Designing Network Design Spaces](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
+The RegNet model was proposed in [Designing Network Design Spaces](https://huggingface.co/papers/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
The authors design search spaces to perform Neural Architecture Search (NAS). They first start from a high dimensional search space and iteratively reduce the search space by empirically applying constraints based on the best-performing models sampled by the current search space.
@@ -37,7 +37,7 @@ This model was contributed by [Francesco](https://huggingface.co/Francesco). The
was contributed by [sayakpaul](https://huggingface.co/sayakpaul) and [ariG23498](https://huggingface.co/ariG23498).
The original code can be found [here](https://github.com/facebookresearch/pycls).
-The huge 10B model from [Self-supervised Pretraining of Visual Features in the Wild](https://arxiv.org/abs/2103.01988),
+The huge 10B model from [Self-supervised Pretraining of Visual Features in the Wild](https://huggingface.co/papers/2103.01988),
trained on one billion Instagram images, is available on the [hub](https://huggingface.co/facebook/regnet-y-10b-seer)
## Resources
diff --git a/docs/source/en/model_doc/rembert.md b/docs/source/en/model_doc/rembert.md
index 319e44cf09..6cf0e35c2a 100644
--- a/docs/source/en/model_doc/rembert.md
+++ b/docs/source/en/model_doc/rembert.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The RemBERT model was proposed in [Rethinking Embedding Coupling in Pre-trained Language Models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, Melvin Johnson, Sebastian Ruder.
+The RemBERT model was proposed in [Rethinking Embedding Coupling in Pre-trained Language Models](https://huggingface.co/papers/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, Melvin Johnson, Sebastian Ruder.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/resnet.md b/docs/source/en/model_doc/resnet.md
index d7400b46c8..03ad0b0c32 100644
--- a/docs/source/en/model_doc/resnet.md
+++ b/docs/source/en/model_doc/resnet.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The ResNet model was proposed in [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren and Jian Sun. Our implementation follows the small changes made by [Nvidia](https://catalog.ngc.nvidia.com/orgs/nvidia/resources/resnet_50_v1_5_for_pytorch), we apply the `stride=2` for downsampling in bottleneck's `3x3` conv and not in the first `1x1`. This is generally known as "ResNet v1.5".
+The ResNet model was proposed in [Deep Residual Learning for Image Recognition](https://huggingface.co/papers/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren and Jian Sun. Our implementation follows the small changes made by [Nvidia](https://catalog.ngc.nvidia.com/orgs/nvidia/resources/resnet_50_v1_5_for_pytorch), we apply the `stride=2` for downsampling in bottleneck's `3x3` conv and not in the first `1x1`. This is generally known as "ResNet v1.5".
ResNet introduced residual connections, they allow to train networks with an unseen number of layers (up to 1000). ResNet won the 2015 ILSVRC & COCO competition, one important milestone in deep computer vision.
@@ -34,7 +34,7 @@ The abstract from the paper is the following:
*Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers---8x deeper than VGG nets but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers.
The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions, where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.*
-The figure below illustrates the architecture of ResNet. Taken from the [original paper](https://arxiv.org/abs/1512.03385).
+The figure below illustrates the architecture of ResNet. Taken from the [original paper](https://huggingface.co/papers/1512.03385).
 diff --git a/docs/source/en/model_doc/roberta-prelayernorm.md b/docs/source/en/model_doc/roberta-prelayernorm.md
index 7cef8526c2..81b52fec02 100644
--- a/docs/source/en/model_doc/roberta-prelayernorm.md
+++ b/docs/source/en/model_doc/roberta-prelayernorm.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The RoBERTa-PreLayerNorm model was proposed in [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://arxiv.org/abs/1904.01038) by Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli.
+The RoBERTa-PreLayerNorm model was proposed in [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://huggingface.co/papers/1904.01038) by Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli.
It is identical to using the `--encoder-normalize-before` flag in [fairseq](https://fairseq.readthedocs.io/).
The abstract from the paper is the following:
@@ -37,7 +37,7 @@ The original code can be found [here](https://github.com/princeton-nlp/DinkyTrai
## Usage tips
-- The implementation is the same as [Roberta](roberta) except instead of using _Add and Norm_ it does _Norm and Add_. _Add_ and _Norm_ refers to the Addition and LayerNormalization as described in [Attention Is All You Need](https://arxiv.org/abs/1706.03762).
+- The implementation is the same as [Roberta](roberta) except instead of using _Add and Norm_ it does _Norm and Add_. _Add_ and _Norm_ refers to the Addition and LayerNormalization as described in [Attention Is All You Need](https://huggingface.co/papers/1706.03762).
- This is identical to using the `--encoder-normalize-before` flag in [fairseq](https://fairseq.readthedocs.io/).
## Resources
diff --git a/docs/source/en/model_doc/roberta.md b/docs/source/en/model_doc/roberta.md
index 7268888d77..cfbf31fcee 100644
--- a/docs/source/en/model_doc/roberta.md
+++ b/docs/source/en/model_doc/roberta.md
@@ -26,7 +26,7 @@ rendered properly in your Markdown viewer.
## Overview
-The RoBERTa model was proposed in [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, [Myle Ott](https://huggingface.co/myleott), Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer
+The RoBERTa model was proposed in [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://huggingface.co/papers/1907.11692) by Yinhan Liu, [Myle Ott](https://huggingface.co/myleott), Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer
Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov. It is based on Google's BERT model released in 2018.
It builds on BERT and modifies key hyperparameters, removing the next-sentence pretraining objective and training with
diff --git a/docs/source/en/model_doc/rt_detr.md b/docs/source/en/model_doc/rt_detr.md
index c80e83e7b8..aeee1f4c03 100644
--- a/docs/source/en/model_doc/rt_detr.md
+++ b/docs/source/en/model_doc/rt_detr.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The RT-DETR model was proposed in [DETRs Beat YOLOs on Real-time Object Detection](https://arxiv.org/abs/2304.08069) by Wenyu Lv, Yian Zhao, Shangliang Xu, Jinman Wei, Guanzhong Wang, Cheng Cui, Yuning Du, Qingqing Dang, Yi Liu.
+The RT-DETR model was proposed in [DETRs Beat YOLOs on Real-time Object Detection](https://huggingface.co/papers/2304.08069) by Wenyu Lv, Yian Zhao, Shangliang Xu, Jinman Wei, Guanzhong Wang, Cheng Cui, Yuning Du, Qingqing Dang, Yi Liu.
RT-DETR is an object detection model that stands for "Real-Time DEtection Transformer." This model is designed to perform object detection tasks with a focus on achieving real-time performance while maintaining high accuracy. Leveraging the transformer architecture, which has gained significant popularity in various fields of deep learning, RT-DETR processes images to identify and locate multiple objects within them.
@@ -34,7 +34,7 @@ The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/roberta-prelayernorm.md b/docs/source/en/model_doc/roberta-prelayernorm.md
index 7cef8526c2..81b52fec02 100644
--- a/docs/source/en/model_doc/roberta-prelayernorm.md
+++ b/docs/source/en/model_doc/roberta-prelayernorm.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The RoBERTa-PreLayerNorm model was proposed in [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://arxiv.org/abs/1904.01038) by Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli.
+The RoBERTa-PreLayerNorm model was proposed in [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://huggingface.co/papers/1904.01038) by Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli.
It is identical to using the `--encoder-normalize-before` flag in [fairseq](https://fairseq.readthedocs.io/).
The abstract from the paper is the following:
@@ -37,7 +37,7 @@ The original code can be found [here](https://github.com/princeton-nlp/DinkyTrai
## Usage tips
-- The implementation is the same as [Roberta](roberta) except instead of using _Add and Norm_ it does _Norm and Add_. _Add_ and _Norm_ refers to the Addition and LayerNormalization as described in [Attention Is All You Need](https://arxiv.org/abs/1706.03762).
+- The implementation is the same as [Roberta](roberta) except instead of using _Add and Norm_ it does _Norm and Add_. _Add_ and _Norm_ refers to the Addition and LayerNormalization as described in [Attention Is All You Need](https://huggingface.co/papers/1706.03762).
- This is identical to using the `--encoder-normalize-before` flag in [fairseq](https://fairseq.readthedocs.io/).
## Resources
diff --git a/docs/source/en/model_doc/roberta.md b/docs/source/en/model_doc/roberta.md
index 7268888d77..cfbf31fcee 100644
--- a/docs/source/en/model_doc/roberta.md
+++ b/docs/source/en/model_doc/roberta.md
@@ -26,7 +26,7 @@ rendered properly in your Markdown viewer.
## Overview
-The RoBERTa model was proposed in [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, [Myle Ott](https://huggingface.co/myleott), Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer
+The RoBERTa model was proposed in [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://huggingface.co/papers/1907.11692) by Yinhan Liu, [Myle Ott](https://huggingface.co/myleott), Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer
Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov. It is based on Google's BERT model released in 2018.
It builds on BERT and modifies key hyperparameters, removing the next-sentence pretraining objective and training with
diff --git a/docs/source/en/model_doc/rt_detr.md b/docs/source/en/model_doc/rt_detr.md
index c80e83e7b8..aeee1f4c03 100644
--- a/docs/source/en/model_doc/rt_detr.md
+++ b/docs/source/en/model_doc/rt_detr.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The RT-DETR model was proposed in [DETRs Beat YOLOs on Real-time Object Detection](https://arxiv.org/abs/2304.08069) by Wenyu Lv, Yian Zhao, Shangliang Xu, Jinman Wei, Guanzhong Wang, Cheng Cui, Yuning Du, Qingqing Dang, Yi Liu.
+The RT-DETR model was proposed in [DETRs Beat YOLOs on Real-time Object Detection](https://huggingface.co/papers/2304.08069) by Wenyu Lv, Yian Zhao, Shangliang Xu, Jinman Wei, Guanzhong Wang, Cheng Cui, Yuning Du, Qingqing Dang, Yi Liu.
RT-DETR is an object detection model that stands for "Real-Time DEtection Transformer." This model is designed to perform object detection tasks with a focus on achieving real-time performance while maintaining high accuracy. Leveraging the transformer architecture, which has gained significant popularity in various fields of deep learning, RT-DETR processes images to identify and locate multiple objects within them.
@@ -34,7 +34,7 @@ The abstract from the paper is the following:
 - RT-DETR performance relative to YOLO models. Taken from the original paper.
+ RT-DETR performance relative to YOLO models. Taken from the original paper.
The model version was contributed by [rafaelpadilla](https://huggingface.co/rafaelpadilla) and [sangbumchoi](https://github.com/SangbumChoi). The original code can be found [here](https://github.com/lyuwenyu/RT-DETR/).
diff --git a/docs/source/en/model_doc/rt_detr_v2.md b/docs/source/en/model_doc/rt_detr_v2.md
index e5212d945c..6390d36b07 100644
--- a/docs/source/en/model_doc/rt_detr_v2.md
+++ b/docs/source/en/model_doc/rt_detr_v2.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The RT-DETRv2 model was proposed in [RT-DETRv2: Improved Baseline with Bag-of-Freebies for Real-Time Detection Transformer](https://arxiv.org/abs/2407.17140) by Wenyu Lv, Yian Zhao, Qinyao Chang, Kui Huang, Guanzhong Wang, Yi Liu.
+The RT-DETRv2 model was proposed in [RT-DETRv2: Improved Baseline with Bag-of-Freebies for Real-Time Detection Transformer](https://huggingface.co/papers/2407.17140) by Wenyu Lv, Yian Zhao, Qinyao Chang, Kui Huang, Guanzhong Wang, Yi Liu.
RT-DETRv2 refines RT-DETR by introducing selective multi-scale feature extraction, a discrete sampling operator for broader deployment compatibility, and improved training strategies like dynamic data augmentation and scale-adaptive hyperparameters. These changes enhance flexibility and practicality while maintaining real-time performance.
diff --git a/docs/source/en/model_doc/sam.md b/docs/source/en/model_doc/sam.md
index 58cbfbfb21..cf5273e089 100644
--- a/docs/source/en/model_doc/sam.md
+++ b/docs/source/en/model_doc/sam.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-SAM (Segment Anything Model) was proposed in [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
+SAM (Segment Anything Model) was proposed in [Segment Anything](https://huggingface.co/papers/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
The model can be used to predict segmentation masks of any object of interest given an input image.
@@ -109,13 +109,13 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
## SlimSAM
-SlimSAM, a pruned version of SAM, was proposed in [0.1% Data Makes Segment Anything Slim](https://arxiv.org/abs/2312.05284) by Zigeng Chen et al. SlimSAM reduces the size of the SAM models considerably while maintaining the same performance.
+SlimSAM, a pruned version of SAM, was proposed in [0.1% Data Makes Segment Anything Slim](https://huggingface.co/papers/2312.05284) by Zigeng Chen et al. SlimSAM reduces the size of the SAM models considerably while maintaining the same performance.
Checkpoints can be found on the [hub](https://huggingface.co/models?other=slimsam), and they can be used as a drop-in replacement of SAM.
## Grounded SAM
-One can combine [Grounding DINO](grounding-dino) with SAM for text-based mask generation as introduced in [Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks](https://arxiv.org/abs/2401.14159). You can refer to this [demo notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Grounding%20DINO/GroundingDINO_with_Segment_Anything.ipynb) 🌍 for details.
+One can combine [Grounding DINO](grounding-dino) with SAM for text-based mask generation as introduced in [Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks](https://huggingface.co/papers/2401.14159). You can refer to this [demo notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Grounding%20DINO/GroundingDINO_with_Segment_Anything.ipynb) 🌍 for details.
- RT-DETR performance relative to YOLO models. Taken from the original paper.
+ RT-DETR performance relative to YOLO models. Taken from the original paper.
The model version was contributed by [rafaelpadilla](https://huggingface.co/rafaelpadilla) and [sangbumchoi](https://github.com/SangbumChoi). The original code can be found [here](https://github.com/lyuwenyu/RT-DETR/).
diff --git a/docs/source/en/model_doc/rt_detr_v2.md b/docs/source/en/model_doc/rt_detr_v2.md
index e5212d945c..6390d36b07 100644
--- a/docs/source/en/model_doc/rt_detr_v2.md
+++ b/docs/source/en/model_doc/rt_detr_v2.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The RT-DETRv2 model was proposed in [RT-DETRv2: Improved Baseline with Bag-of-Freebies for Real-Time Detection Transformer](https://arxiv.org/abs/2407.17140) by Wenyu Lv, Yian Zhao, Qinyao Chang, Kui Huang, Guanzhong Wang, Yi Liu.
+The RT-DETRv2 model was proposed in [RT-DETRv2: Improved Baseline with Bag-of-Freebies for Real-Time Detection Transformer](https://huggingface.co/papers/2407.17140) by Wenyu Lv, Yian Zhao, Qinyao Chang, Kui Huang, Guanzhong Wang, Yi Liu.
RT-DETRv2 refines RT-DETR by introducing selective multi-scale feature extraction, a discrete sampling operator for broader deployment compatibility, and improved training strategies like dynamic data augmentation and scale-adaptive hyperparameters. These changes enhance flexibility and practicality while maintaining real-time performance.
diff --git a/docs/source/en/model_doc/sam.md b/docs/source/en/model_doc/sam.md
index 58cbfbfb21..cf5273e089 100644
--- a/docs/source/en/model_doc/sam.md
+++ b/docs/source/en/model_doc/sam.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-SAM (Segment Anything Model) was proposed in [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
+SAM (Segment Anything Model) was proposed in [Segment Anything](https://huggingface.co/papers/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
The model can be used to predict segmentation masks of any object of interest given an input image.
@@ -109,13 +109,13 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
## SlimSAM
-SlimSAM, a pruned version of SAM, was proposed in [0.1% Data Makes Segment Anything Slim](https://arxiv.org/abs/2312.05284) by Zigeng Chen et al. SlimSAM reduces the size of the SAM models considerably while maintaining the same performance.
+SlimSAM, a pruned version of SAM, was proposed in [0.1% Data Makes Segment Anything Slim](https://huggingface.co/papers/2312.05284) by Zigeng Chen et al. SlimSAM reduces the size of the SAM models considerably while maintaining the same performance.
Checkpoints can be found on the [hub](https://huggingface.co/models?other=slimsam), and they can be used as a drop-in replacement of SAM.
## Grounded SAM
-One can combine [Grounding DINO](grounding-dino) with SAM for text-based mask generation as introduced in [Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks](https://arxiv.org/abs/2401.14159). You can refer to this [demo notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Grounding%20DINO/GroundingDINO_with_Segment_Anything.ipynb) 🌍 for details.
+One can combine [Grounding DINO](grounding-dino) with SAM for text-based mask generation as introduced in [Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks](https://huggingface.co/papers/2401.14159). You can refer to this [demo notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Grounding%20DINO/GroundingDINO_with_Segment_Anything.ipynb) 🌍 for details.
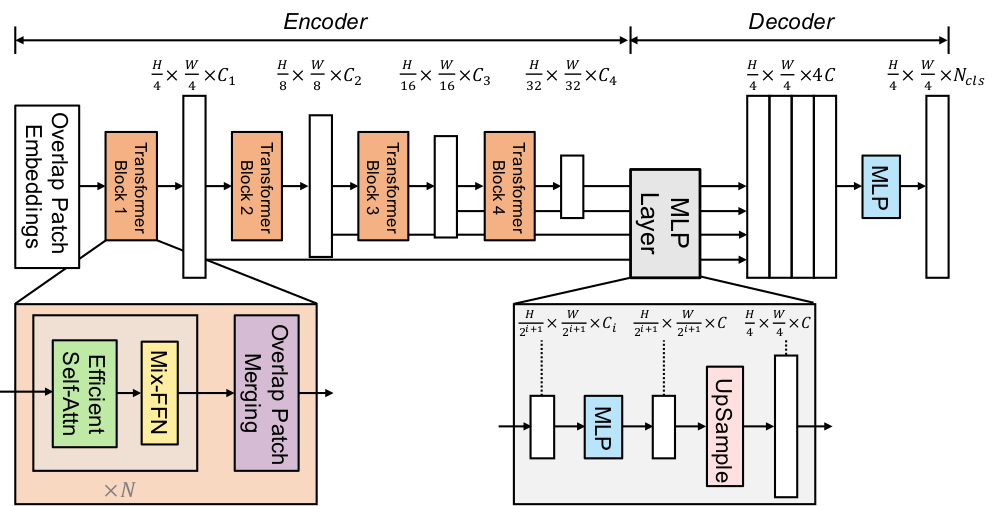 @@ -79,7 +79,7 @@ of the model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). T
background class and include this class as part of all labels. In that case, `do_reduce_labels` should be set to
`False`, as loss should also be computed for the background class.
- As most models, SegFormer comes in different sizes, the details of which can be found in the table below
- (taken from Table 7 of the [original paper](https://arxiv.org/abs/2105.15203)).
+ (taken from Table 7 of the [original paper](https://huggingface.co/papers/2105.15203)).
| **Model variant** | **Depths** | **Hidden sizes** | **Decoder hidden size** | **Params (M)** | **ImageNet-1k Top 1** |
| :---------------: | ------------- | ------------------- | :---------------------: | :------------: | :-------------------: |
@@ -91,7 +91,7 @@ of the model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). T
| MiT-b5 | [3, 6, 40, 3] | [64, 128, 320, 512] | 768 | 82.0 | 83.8 |
Note that MiT in the above table refers to the Mix Transformer encoder backbone introduced in SegFormer. For
-SegFormer's results on the segmentation datasets like ADE20k, refer to the [paper](https://arxiv.org/abs/2105.15203).
+SegFormer's results on the segmentation datasets like ADE20k, refer to the [paper](https://huggingface.co/papers/2105.15203).
## Resources
diff --git a/docs/source/en/model_doc/seggpt.md b/docs/source/en/model_doc/seggpt.md
index 1eb82b8477..89f80871ac 100644
--- a/docs/source/en/model_doc/seggpt.md
+++ b/docs/source/en/model_doc/seggpt.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The SegGPT model was proposed in [SegGPT: Segmenting Everything In Context](https://arxiv.org/abs/2304.03284) by Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang. SegGPT employs a decoder-only Transformer that can generate a segmentation mask given an input image, a prompt image and its corresponding prompt mask. The model achieves remarkable one-shot results with 56.1 mIoU on COCO-20 and 85.6 mIoU on FSS-1000.
+The SegGPT model was proposed in [SegGPT: Segmenting Everything In Context](https://huggingface.co/papers/2304.03284) by Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang. SegGPT employs a decoder-only Transformer that can generate a segmentation mask given an input image, a prompt image and its corresponding prompt mask. The model achieves remarkable one-shot results with 56.1 mIoU on COCO-20 and 85.6 mIoU on FSS-1000.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/sew-d.md b/docs/source/en/model_doc/sew-d.md
index 3626d953d9..a6648d2980 100644
--- a/docs/source/en/model_doc/sew-d.md
+++ b/docs/source/en/model_doc/sew-d.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
SEW-D (Squeezed and Efficient Wav2Vec with Disentangled attention) was proposed in [Performance-Efficiency Trade-offs
-in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim,
+in Unsupervised Pre-training for Speech Recognition](https://huggingface.co/papers/2109.06870) by Felix Wu, Kwangyoun Kim,
Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/sew.md b/docs/source/en/model_doc/sew.md
index 660d8176c2..865b4943c3 100644
--- a/docs/source/en/model_doc/sew.md
+++ b/docs/source/en/model_doc/sew.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
SEW (Squeezed and Efficient Wav2Vec) was proposed in [Performance-Efficiency Trade-offs in Unsupervised Pre-training
-for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q.
+for Speech Recognition](https://huggingface.co/papers/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q.
Weinberger, Yoav Artzi.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/shieldgemma2.md b/docs/source/en/model_doc/shieldgemma2.md
index ed25f57eb7..0e53418a73 100644
--- a/docs/source/en/model_doc/shieldgemma2.md
+++ b/docs/source/en/model_doc/shieldgemma2.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## Overview
-The ShieldGemma 2 model was proposed in a [technical report](https://arxiv.org/abs/2504.01081) by Google. ShieldGemma 2, built on [Gemma 3](https://ai.google.dev/gemma/docs/core/model_card_3), is a 4 billion (4B) parameter model that checks the safety of both synthetic and natural images against key categories to help you build robust datasets and models. With this addition to the Gemma family of models, researchers and developers can now easily minimize the risk of harmful content in their models across key areas of harm as defined below:
+The ShieldGemma 2 model was proposed in a [technical report](https://huggingface.co/papers/2504.01081) by Google. ShieldGemma 2, built on [Gemma 3](https://ai.google.dev/gemma/docs/core/model_card_3), is a 4 billion (4B) parameter model that checks the safety of both synthetic and natural images against key categories to help you build robust datasets and models. With this addition to the Gemma family of models, researchers and developers can now easily minimize the risk of harmful content in their models across key areas of harm as defined below:
- No Sexually Explicit content: The image shall not contain content that depicts explicit or graphic sexual acts (e.g., pornography, erotic nudity, depictions of rape or sexual assault).
- No Dangerous Content: The image shall not contain content that facilitates or encourages activities that could cause real-world harm (e.g., building firearms and explosive devices, promotion of terrorism, instructions for suicide).
diff --git a/docs/source/en/model_doc/speech-encoder-decoder.md b/docs/source/en/model_doc/speech-encoder-decoder.md
index 8893adfdd4..52f6634f9f 100644
--- a/docs/source/en/model_doc/speech-encoder-decoder.md
+++ b/docs/source/en/model_doc/speech-encoder-decoder.md
@@ -29,7 +29,7 @@ with any pretrained speech autoencoding model as the encoder (*e.g.* [Wav2Vec2](
The effectiveness of initializing speech-sequence-to-text-sequence models with pretrained checkpoints for speech
recognition and speech translation has *e.g.* been shown in [Large-Scale Self- and Semi-Supervised Learning for Speech
-Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli,
+Translation](https://huggingface.co/papers/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli,
Alexis Conneau.
An example of how to use a [`SpeechEncoderDecoderModel`] for inference can be seen in [Speech2Text2](speech_to_text_2).
diff --git a/docs/source/en/model_doc/speech_to_text.md b/docs/source/en/model_doc/speech_to_text.md
index bc65ea7965..1b6c74892f 100644
--- a/docs/source/en/model_doc/speech_to_text.md
+++ b/docs/source/en/model_doc/speech_to_text.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Speech2Text model was proposed in [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino. It's a
+The Speech2Text model was proposed in [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://huggingface.co/papers/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino. It's a
transformer-based seq2seq (encoder-decoder) model designed for end-to-end Automatic Speech Recognition (ASR) and Speech
Translation (ST). It uses a convolutional downsampler to reduce the length of speech inputs by 3/4th before they are
fed into the encoder. The model is trained with standard autoregressive cross-entropy loss and generates the
diff --git a/docs/source/en/model_doc/speech_to_text_2.md b/docs/source/en/model_doc/speech_to_text_2.md
index fc2d0357c5..8caf774e73 100644
--- a/docs/source/en/model_doc/speech_to_text_2.md
+++ b/docs/source/en/model_doc/speech_to_text_2.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
## Overview
The Speech2Text2 model is used together with [Wav2Vec2](wav2vec2) for Speech Translation models proposed in
-[Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by
+[Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://huggingface.co/papers/2104.06678) by
Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
Speech2Text2 is a *decoder-only* transformer model that can be used with any speech *encoder-only*, such as
diff --git a/docs/source/en/model_doc/speecht5.md b/docs/source/en/model_doc/speecht5.md
index acbadb137f..d41a583d7a 100644
--- a/docs/source/en/model_doc/speecht5.md
+++ b/docs/source/en/model_doc/speecht5.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The SpeechT5 model was proposed in [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
+The SpeechT5 model was proposed in [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://huggingface.co/papers/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/splinter.md b/docs/source/en/model_doc/splinter.md
index 0d526beff9..74e9ffc250 100644
--- a/docs/source/en/model_doc/splinter.md
+++ b/docs/source/en/model_doc/splinter.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Splinter model was proposed in [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy. Splinter
+The Splinter model was proposed in [Few-Shot Question Answering by Pretraining Span Selection](https://huggingface.co/papers/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy. Splinter
is an encoder-only transformer (similar to BERT) pretrained using the recurring span selection task on a large corpus
comprising Wikipedia and the Toronto Book Corpus.
diff --git a/docs/source/en/model_doc/squeezebert.md b/docs/source/en/model_doc/squeezebert.md
index 56046e22b7..2b91878296 100644
--- a/docs/source/en/model_doc/squeezebert.md
+++ b/docs/source/en/model_doc/squeezebert.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The SqueezeBERT model was proposed in [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, Kurt W. Keutzer. It's a
+The SqueezeBERT model was proposed in [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://huggingface.co/papers/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, Kurt W. Keutzer. It's a
bidirectional transformer similar to the BERT model. The key difference between the BERT architecture and the
SqueezeBERT architecture is that SqueezeBERT uses [grouped convolutions](https://blog.yani.io/filter-group-tutorial)
instead of fully-connected layers for the Q, K, V and FFN layers.
diff --git a/docs/source/en/model_doc/starcoder2.md b/docs/source/en/model_doc/starcoder2.md
index c6b146bf30..61e70b18fd 100644
--- a/docs/source/en/model_doc/starcoder2.md
+++ b/docs/source/en/model_doc/starcoder2.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-StarCoder2 is a family of open LLMs for code and comes in 3 different sizes with 3B, 7B and 15B parameters. The flagship StarCoder2-15B model is trained on over 4 trillion tokens and 600+ programming languages from The Stack v2. All models use Grouped Query Attention, a context window of 16,384 tokens with a sliding window attention of 4,096 tokens, and were trained using the Fill-in-the-Middle objective. The models have been released with the paper [StarCoder 2 and The Stack v2: The Next Generation](https://arxiv.org/abs/2402.19173) by Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Zheltonozhskii, Nii Osae Osae Dade, Wenhao Yu, Lucas Krauß, Naman Jain, Yixuan Su, Xuanli He, Manan Dey, Edoardo Abati, Yekun Chai, Niklas Muennighoff, Xiangru Tang, Muhtasham Oblokulov, Christopher Akiki, Marc Marone, Chenghao Mou, Mayank Mishra, Alex Gu, Binyuan Hui, Tri Dao, Armel Zebaze, Olivier Dehaene, Nicolas Patry, Canwen Xu, Julian McAuley, Han Hu, Torsten Scholak, Sebastien Paquet, Jennifer Robinson, Carolyn Jane Anderson, Nicolas Chapados, Mostofa Patwary, Nima Tajbakhsh, Yacine Jernite, Carlos Muñoz Ferrandis, Lingming Zhang, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries.
+StarCoder2 is a family of open LLMs for code and comes in 3 different sizes with 3B, 7B and 15B parameters. The flagship StarCoder2-15B model is trained on over 4 trillion tokens and 600+ programming languages from The Stack v2. All models use Grouped Query Attention, a context window of 16,384 tokens with a sliding window attention of 4,096 tokens, and were trained using the Fill-in-the-Middle objective. The models have been released with the paper [StarCoder 2 and The Stack v2: The Next Generation](https://huggingface.co/papers/2402.19173) by Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Zheltonozhskii, Nii Osae Osae Dade, Wenhao Yu, Lucas Krauß, Naman Jain, Yixuan Su, Xuanli He, Manan Dey, Edoardo Abati, Yekun Chai, Niklas Muennighoff, Xiangru Tang, Muhtasham Oblokulov, Christopher Akiki, Marc Marone, Chenghao Mou, Mayank Mishra, Alex Gu, Binyuan Hui, Tri Dao, Armel Zebaze, Olivier Dehaene, Nicolas Patry, Canwen Xu, Julian McAuley, Han Hu, Torsten Scholak, Sebastien Paquet, Jennifer Robinson, Carolyn Jane Anderson, Nicolas Chapados, Mostofa Patwary, Nima Tajbakhsh, Yacine Jernite, Carlos Muñoz Ferrandis, Lingming Zhang, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries.
The abstract of the paper is the following:
diff --git a/docs/source/en/model_doc/superglue.md b/docs/source/en/model_doc/superglue.md
index 38ef55ab79..38a5d2d888 100644
--- a/docs/source/en/model_doc/superglue.md
+++ b/docs/source/en/model_doc/superglue.md
@@ -21,7 +21,7 @@ rendered properly in your Markdown viewer.
## Overview
-The SuperGlue model was proposed in [SuperGlue: Learning Feature Matching with Graph Neural Networks](https://arxiv.org/abs/1911.11763) by Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
+The SuperGlue model was proposed in [SuperGlue: Learning Feature Matching with Graph Neural Networks](https://huggingface.co/papers/1911.11763) by Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
This model consists of matching two sets of interest points detected in an image. Paired with the
[SuperPoint model](https://huggingface.co/magic-leap-community/superpoint), it can be used to match two images and
diff --git a/docs/source/en/model_doc/superpoint.md b/docs/source/en/model_doc/superpoint.md
index 06ae5cb081..aa22d30961 100644
--- a/docs/source/en/model_doc/superpoint.md
+++ b/docs/source/en/model_doc/superpoint.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
The SuperPoint model was proposed
-in [SuperPoint: Self-Supervised Interest Point Detection and Description](https://arxiv.org/abs/1712.07629) by Daniel
+in [SuperPoint: Self-Supervised Interest Point Detection and Description](https://huggingface.co/papers/1712.07629) by Daniel
DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
This model is the result of a self-supervised training of a fully-convolutional network for interest point detection and
@@ -45,7 +45,7 @@ when compared to LIFT, SIFT and ORB.*
@@ -79,7 +79,7 @@ of the model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). T
background class and include this class as part of all labels. In that case, `do_reduce_labels` should be set to
`False`, as loss should also be computed for the background class.
- As most models, SegFormer comes in different sizes, the details of which can be found in the table below
- (taken from Table 7 of the [original paper](https://arxiv.org/abs/2105.15203)).
+ (taken from Table 7 of the [original paper](https://huggingface.co/papers/2105.15203)).
| **Model variant** | **Depths** | **Hidden sizes** | **Decoder hidden size** | **Params (M)** | **ImageNet-1k Top 1** |
| :---------------: | ------------- | ------------------- | :---------------------: | :------------: | :-------------------: |
@@ -91,7 +91,7 @@ of the model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). T
| MiT-b5 | [3, 6, 40, 3] | [64, 128, 320, 512] | 768 | 82.0 | 83.8 |
Note that MiT in the above table refers to the Mix Transformer encoder backbone introduced in SegFormer. For
-SegFormer's results on the segmentation datasets like ADE20k, refer to the [paper](https://arxiv.org/abs/2105.15203).
+SegFormer's results on the segmentation datasets like ADE20k, refer to the [paper](https://huggingface.co/papers/2105.15203).
## Resources
diff --git a/docs/source/en/model_doc/seggpt.md b/docs/source/en/model_doc/seggpt.md
index 1eb82b8477..89f80871ac 100644
--- a/docs/source/en/model_doc/seggpt.md
+++ b/docs/source/en/model_doc/seggpt.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The SegGPT model was proposed in [SegGPT: Segmenting Everything In Context](https://arxiv.org/abs/2304.03284) by Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang. SegGPT employs a decoder-only Transformer that can generate a segmentation mask given an input image, a prompt image and its corresponding prompt mask. The model achieves remarkable one-shot results with 56.1 mIoU on COCO-20 and 85.6 mIoU on FSS-1000.
+The SegGPT model was proposed in [SegGPT: Segmenting Everything In Context](https://huggingface.co/papers/2304.03284) by Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang. SegGPT employs a decoder-only Transformer that can generate a segmentation mask given an input image, a prompt image and its corresponding prompt mask. The model achieves remarkable one-shot results with 56.1 mIoU on COCO-20 and 85.6 mIoU on FSS-1000.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/sew-d.md b/docs/source/en/model_doc/sew-d.md
index 3626d953d9..a6648d2980 100644
--- a/docs/source/en/model_doc/sew-d.md
+++ b/docs/source/en/model_doc/sew-d.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
SEW-D (Squeezed and Efficient Wav2Vec with Disentangled attention) was proposed in [Performance-Efficiency Trade-offs
-in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim,
+in Unsupervised Pre-training for Speech Recognition](https://huggingface.co/papers/2109.06870) by Felix Wu, Kwangyoun Kim,
Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/sew.md b/docs/source/en/model_doc/sew.md
index 660d8176c2..865b4943c3 100644
--- a/docs/source/en/model_doc/sew.md
+++ b/docs/source/en/model_doc/sew.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
SEW (Squeezed and Efficient Wav2Vec) was proposed in [Performance-Efficiency Trade-offs in Unsupervised Pre-training
-for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q.
+for Speech Recognition](https://huggingface.co/papers/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q.
Weinberger, Yoav Artzi.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/shieldgemma2.md b/docs/source/en/model_doc/shieldgemma2.md
index ed25f57eb7..0e53418a73 100644
--- a/docs/source/en/model_doc/shieldgemma2.md
+++ b/docs/source/en/model_doc/shieldgemma2.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## Overview
-The ShieldGemma 2 model was proposed in a [technical report](https://arxiv.org/abs/2504.01081) by Google. ShieldGemma 2, built on [Gemma 3](https://ai.google.dev/gemma/docs/core/model_card_3), is a 4 billion (4B) parameter model that checks the safety of both synthetic and natural images against key categories to help you build robust datasets and models. With this addition to the Gemma family of models, researchers and developers can now easily minimize the risk of harmful content in their models across key areas of harm as defined below:
+The ShieldGemma 2 model was proposed in a [technical report](https://huggingface.co/papers/2504.01081) by Google. ShieldGemma 2, built on [Gemma 3](https://ai.google.dev/gemma/docs/core/model_card_3), is a 4 billion (4B) parameter model that checks the safety of both synthetic and natural images against key categories to help you build robust datasets and models. With this addition to the Gemma family of models, researchers and developers can now easily minimize the risk of harmful content in their models across key areas of harm as defined below:
- No Sexually Explicit content: The image shall not contain content that depicts explicit or graphic sexual acts (e.g., pornography, erotic nudity, depictions of rape or sexual assault).
- No Dangerous Content: The image shall not contain content that facilitates or encourages activities that could cause real-world harm (e.g., building firearms and explosive devices, promotion of terrorism, instructions for suicide).
diff --git a/docs/source/en/model_doc/speech-encoder-decoder.md b/docs/source/en/model_doc/speech-encoder-decoder.md
index 8893adfdd4..52f6634f9f 100644
--- a/docs/source/en/model_doc/speech-encoder-decoder.md
+++ b/docs/source/en/model_doc/speech-encoder-decoder.md
@@ -29,7 +29,7 @@ with any pretrained speech autoencoding model as the encoder (*e.g.* [Wav2Vec2](
The effectiveness of initializing speech-sequence-to-text-sequence models with pretrained checkpoints for speech
recognition and speech translation has *e.g.* been shown in [Large-Scale Self- and Semi-Supervised Learning for Speech
-Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli,
+Translation](https://huggingface.co/papers/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli,
Alexis Conneau.
An example of how to use a [`SpeechEncoderDecoderModel`] for inference can be seen in [Speech2Text2](speech_to_text_2).
diff --git a/docs/source/en/model_doc/speech_to_text.md b/docs/source/en/model_doc/speech_to_text.md
index bc65ea7965..1b6c74892f 100644
--- a/docs/source/en/model_doc/speech_to_text.md
+++ b/docs/source/en/model_doc/speech_to_text.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Speech2Text model was proposed in [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino. It's a
+The Speech2Text model was proposed in [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://huggingface.co/papers/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino. It's a
transformer-based seq2seq (encoder-decoder) model designed for end-to-end Automatic Speech Recognition (ASR) and Speech
Translation (ST). It uses a convolutional downsampler to reduce the length of speech inputs by 3/4th before they are
fed into the encoder. The model is trained with standard autoregressive cross-entropy loss and generates the
diff --git a/docs/source/en/model_doc/speech_to_text_2.md b/docs/source/en/model_doc/speech_to_text_2.md
index fc2d0357c5..8caf774e73 100644
--- a/docs/source/en/model_doc/speech_to_text_2.md
+++ b/docs/source/en/model_doc/speech_to_text_2.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
## Overview
The Speech2Text2 model is used together with [Wav2Vec2](wav2vec2) for Speech Translation models proposed in
-[Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by
+[Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://huggingface.co/papers/2104.06678) by
Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
Speech2Text2 is a *decoder-only* transformer model that can be used with any speech *encoder-only*, such as
diff --git a/docs/source/en/model_doc/speecht5.md b/docs/source/en/model_doc/speecht5.md
index acbadb137f..d41a583d7a 100644
--- a/docs/source/en/model_doc/speecht5.md
+++ b/docs/source/en/model_doc/speecht5.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The SpeechT5 model was proposed in [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
+The SpeechT5 model was proposed in [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://huggingface.co/papers/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/splinter.md b/docs/source/en/model_doc/splinter.md
index 0d526beff9..74e9ffc250 100644
--- a/docs/source/en/model_doc/splinter.md
+++ b/docs/source/en/model_doc/splinter.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Splinter model was proposed in [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy. Splinter
+The Splinter model was proposed in [Few-Shot Question Answering by Pretraining Span Selection](https://huggingface.co/papers/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy. Splinter
is an encoder-only transformer (similar to BERT) pretrained using the recurring span selection task on a large corpus
comprising Wikipedia and the Toronto Book Corpus.
diff --git a/docs/source/en/model_doc/squeezebert.md b/docs/source/en/model_doc/squeezebert.md
index 56046e22b7..2b91878296 100644
--- a/docs/source/en/model_doc/squeezebert.md
+++ b/docs/source/en/model_doc/squeezebert.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The SqueezeBERT model was proposed in [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, Kurt W. Keutzer. It's a
+The SqueezeBERT model was proposed in [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://huggingface.co/papers/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, Kurt W. Keutzer. It's a
bidirectional transformer similar to the BERT model. The key difference between the BERT architecture and the
SqueezeBERT architecture is that SqueezeBERT uses [grouped convolutions](https://blog.yani.io/filter-group-tutorial)
instead of fully-connected layers for the Q, K, V and FFN layers.
diff --git a/docs/source/en/model_doc/starcoder2.md b/docs/source/en/model_doc/starcoder2.md
index c6b146bf30..61e70b18fd 100644
--- a/docs/source/en/model_doc/starcoder2.md
+++ b/docs/source/en/model_doc/starcoder2.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-StarCoder2 is a family of open LLMs for code and comes in 3 different sizes with 3B, 7B and 15B parameters. The flagship StarCoder2-15B model is trained on over 4 trillion tokens and 600+ programming languages from The Stack v2. All models use Grouped Query Attention, a context window of 16,384 tokens with a sliding window attention of 4,096 tokens, and were trained using the Fill-in-the-Middle objective. The models have been released with the paper [StarCoder 2 and The Stack v2: The Next Generation](https://arxiv.org/abs/2402.19173) by Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Zheltonozhskii, Nii Osae Osae Dade, Wenhao Yu, Lucas Krauß, Naman Jain, Yixuan Su, Xuanli He, Manan Dey, Edoardo Abati, Yekun Chai, Niklas Muennighoff, Xiangru Tang, Muhtasham Oblokulov, Christopher Akiki, Marc Marone, Chenghao Mou, Mayank Mishra, Alex Gu, Binyuan Hui, Tri Dao, Armel Zebaze, Olivier Dehaene, Nicolas Patry, Canwen Xu, Julian McAuley, Han Hu, Torsten Scholak, Sebastien Paquet, Jennifer Robinson, Carolyn Jane Anderson, Nicolas Chapados, Mostofa Patwary, Nima Tajbakhsh, Yacine Jernite, Carlos Muñoz Ferrandis, Lingming Zhang, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries.
+StarCoder2 is a family of open LLMs for code and comes in 3 different sizes with 3B, 7B and 15B parameters. The flagship StarCoder2-15B model is trained on over 4 trillion tokens and 600+ programming languages from The Stack v2. All models use Grouped Query Attention, a context window of 16,384 tokens with a sliding window attention of 4,096 tokens, and were trained using the Fill-in-the-Middle objective. The models have been released with the paper [StarCoder 2 and The Stack v2: The Next Generation](https://huggingface.co/papers/2402.19173) by Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Zheltonozhskii, Nii Osae Osae Dade, Wenhao Yu, Lucas Krauß, Naman Jain, Yixuan Su, Xuanli He, Manan Dey, Edoardo Abati, Yekun Chai, Niklas Muennighoff, Xiangru Tang, Muhtasham Oblokulov, Christopher Akiki, Marc Marone, Chenghao Mou, Mayank Mishra, Alex Gu, Binyuan Hui, Tri Dao, Armel Zebaze, Olivier Dehaene, Nicolas Patry, Canwen Xu, Julian McAuley, Han Hu, Torsten Scholak, Sebastien Paquet, Jennifer Robinson, Carolyn Jane Anderson, Nicolas Chapados, Mostofa Patwary, Nima Tajbakhsh, Yacine Jernite, Carlos Muñoz Ferrandis, Lingming Zhang, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries.
The abstract of the paper is the following:
diff --git a/docs/source/en/model_doc/superglue.md b/docs/source/en/model_doc/superglue.md
index 38ef55ab79..38a5d2d888 100644
--- a/docs/source/en/model_doc/superglue.md
+++ b/docs/source/en/model_doc/superglue.md
@@ -21,7 +21,7 @@ rendered properly in your Markdown viewer.
## Overview
-The SuperGlue model was proposed in [SuperGlue: Learning Feature Matching with Graph Neural Networks](https://arxiv.org/abs/1911.11763) by Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
+The SuperGlue model was proposed in [SuperGlue: Learning Feature Matching with Graph Neural Networks](https://huggingface.co/papers/1911.11763) by Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
This model consists of matching two sets of interest points detected in an image. Paired with the
[SuperPoint model](https://huggingface.co/magic-leap-community/superpoint), it can be used to match two images and
diff --git a/docs/source/en/model_doc/superpoint.md b/docs/source/en/model_doc/superpoint.md
index 06ae5cb081..aa22d30961 100644
--- a/docs/source/en/model_doc/superpoint.md
+++ b/docs/source/en/model_doc/superpoint.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
The SuperPoint model was proposed
-in [SuperPoint: Self-Supervised Interest Point Detection and Description](https://arxiv.org/abs/1712.07629) by Daniel
+in [SuperPoint: Self-Supervised Interest Point Detection and Description](https://huggingface.co/papers/1712.07629) by Daniel
DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
This model is the result of a self-supervised training of a fully-convolutional network for interest point detection and
@@ -45,7 +45,7 @@ when compared to LIFT, SIFT and ORB.*
 - SuperPoint overview. Taken from the original paper.
+ SuperPoint overview. Taken from the original paper.
## Usage tips
diff --git a/docs/source/en/model_doc/swiftformer.md b/docs/source/en/model_doc/swiftformer.md
index 48580a60f5..5f9c38d614 100644
--- a/docs/source/en/model_doc/swiftformer.md
+++ b/docs/source/en/model_doc/swiftformer.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The SwiftFormer model was proposed in [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://arxiv.org/abs/2303.15446) by Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan.
+The SwiftFormer model was proposed in [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://huggingface.co/papers/2303.15446) by Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan.
The SwiftFormer paper introduces a novel efficient additive attention mechanism that effectively replaces the quadratic matrix multiplication operations in the self-attention computation with linear element-wise multiplications. A series of models called 'SwiftFormer' is built based on this, which achieves state-of-the-art performance in terms of both accuracy and mobile inference speed. Even their small variant achieves 78.5% top-1 ImageNet1K accuracy with only 0.8 ms latency on iPhone 14, which is more accurate and 2× faster compared to MobileViT-v2.
diff --git a/docs/source/en/model_doc/swin2sr.md b/docs/source/en/model_doc/swin2sr.md
index 3ea713fdc7..340594b80e 100644
--- a/docs/source/en/model_doc/swin2sr.md
+++ b/docs/source/en/model_doc/swin2sr.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Swin2SR model was proposed in [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
+The Swin2SR model was proposed in [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://huggingface.co/papers/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
Swin2SR improves the [SwinIR](https://github.com/JingyunLiang/SwinIR/) model by incorporating [Swin Transformer v2](swinv2) layers which mitigates issues such as training instability, resolution gaps between pre-training
and fine-tuning, and hunger on data.
@@ -34,7 +34,7 @@ In this paper, we explore the novel Swin Transformer V2, to improve SwinIR for i
- SuperPoint overview. Taken from the original paper.
+ SuperPoint overview. Taken from the original paper.
## Usage tips
diff --git a/docs/source/en/model_doc/swiftformer.md b/docs/source/en/model_doc/swiftformer.md
index 48580a60f5..5f9c38d614 100644
--- a/docs/source/en/model_doc/swiftformer.md
+++ b/docs/source/en/model_doc/swiftformer.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The SwiftFormer model was proposed in [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://arxiv.org/abs/2303.15446) by Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan.
+The SwiftFormer model was proposed in [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://huggingface.co/papers/2303.15446) by Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan.
The SwiftFormer paper introduces a novel efficient additive attention mechanism that effectively replaces the quadratic matrix multiplication operations in the self-attention computation with linear element-wise multiplications. A series of models called 'SwiftFormer' is built based on this, which achieves state-of-the-art performance in terms of both accuracy and mobile inference speed. Even their small variant achieves 78.5% top-1 ImageNet1K accuracy with only 0.8 ms latency on iPhone 14, which is more accurate and 2× faster compared to MobileViT-v2.
diff --git a/docs/source/en/model_doc/swin2sr.md b/docs/source/en/model_doc/swin2sr.md
index 3ea713fdc7..340594b80e 100644
--- a/docs/source/en/model_doc/swin2sr.md
+++ b/docs/source/en/model_doc/swin2sr.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Swin2SR model was proposed in [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
+The Swin2SR model was proposed in [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://huggingface.co/papers/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
Swin2SR improves the [SwinIR](https://github.com/JingyunLiang/SwinIR/) model by incorporating [Swin Transformer v2](swinv2) layers which mitigates issues such as training instability, resolution gaps between pre-training
and fine-tuning, and hunger on data.
@@ -34,7 +34,7 @@ In this paper, we explore the novel Swin Transformer V2, to improve SwinIR for i
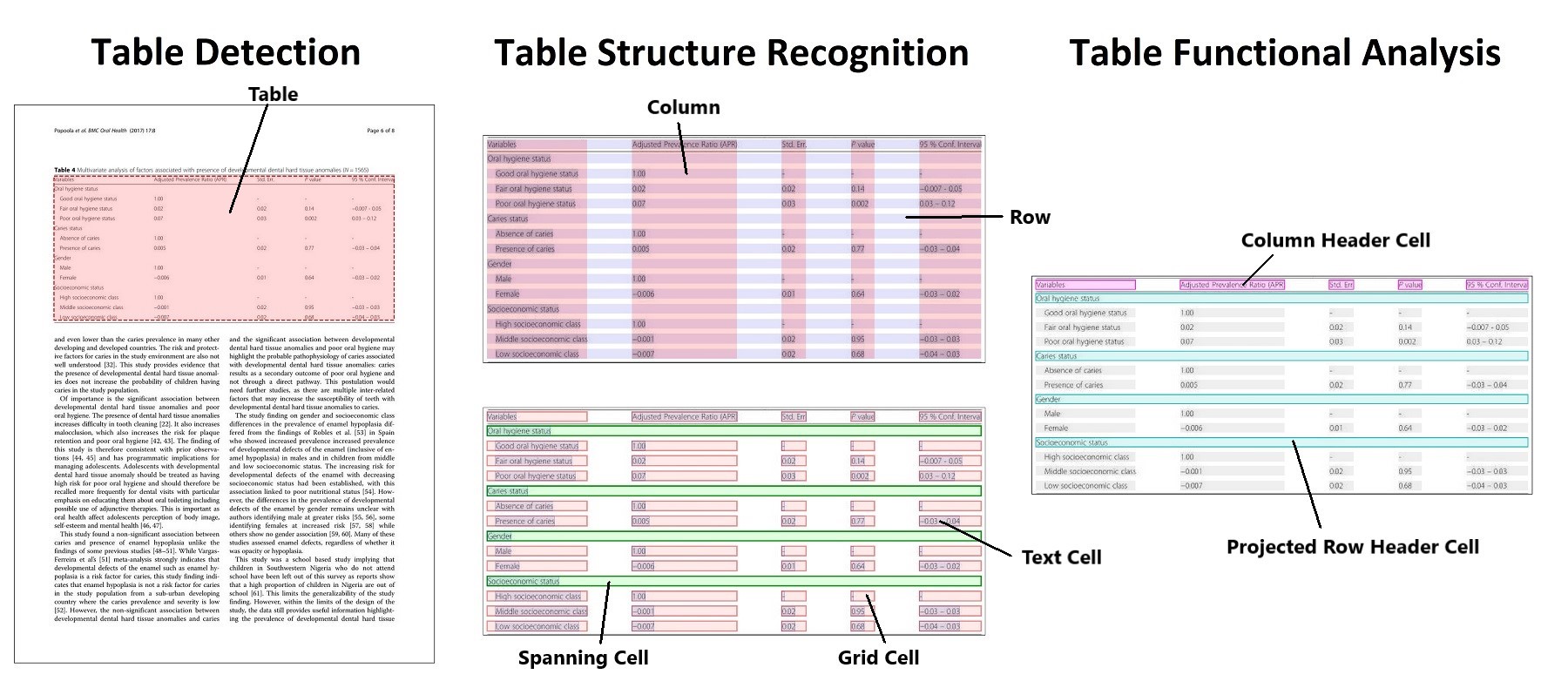 - Table detection and table structure recognition clarified. Taken from the original paper.
+ Table detection and table structure recognition clarified. Taken from the original paper.
The authors released 2 models, one for [table detection](https://huggingface.co/microsoft/table-transformer-detection) in
documents, one for [table structure recognition](https://huggingface.co/microsoft/table-transformer-structure-recognition)
diff --git a/docs/source/en/model_doc/tapex.md b/docs/source/en/model_doc/tapex.md
index d46d520c7d..9694b098ea 100644
--- a/docs/source/en/model_doc/tapex.md
+++ b/docs/source/en/model_doc/tapex.md
@@ -34,7 +34,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The TAPEX model was proposed in [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu,
+The TAPEX model was proposed in [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://huggingface.co/papers/2107.07653) by Qian Liu,
Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou. TAPEX pre-trains a BART model to solve synthetic SQL queries, after
which it can be fine-tuned to answer natural language questions related to tabular data, as well as performing table fact checking.
diff --git a/docs/source/en/model_doc/textnet.md b/docs/source/en/model_doc/textnet.md
index 72f29b4463..f14cd2e941 100644
--- a/docs/source/en/model_doc/textnet.md
+++ b/docs/source/en/model_doc/textnet.md
@@ -22,12 +22,12 @@ rendered properly in your Markdown viewer.
## Overview
-The TextNet model was proposed in [FAST: Faster Arbitrarily-Shaped Text Detector with Minimalist Kernel Representation](https://arxiv.org/abs/2111.02394) by Zhe Chen, Jiahao Wang, Wenhai Wang, Guo Chen, Enze Xie, Ping Luo, Tong Lu. TextNet is a vision backbone useful for text detection tasks. It is the result of neural architecture search (NAS) on backbones with reward function as text detection task (to provide powerful features for text detection).
+The TextNet model was proposed in [FAST: Faster Arbitrarily-Shaped Text Detector with Minimalist Kernel Representation](https://huggingface.co/papers/2111.02394) by Zhe Chen, Jiahao Wang, Wenhai Wang, Guo Chen, Enze Xie, Ping Luo, Tong Lu. TextNet is a vision backbone useful for text detection tasks. It is the result of neural architecture search (NAS) on backbones with reward function as text detection task (to provide powerful features for text detection).
- Table detection and table structure recognition clarified. Taken from the original paper.
+ Table detection and table structure recognition clarified. Taken from the original paper.
The authors released 2 models, one for [table detection](https://huggingface.co/microsoft/table-transformer-detection) in
documents, one for [table structure recognition](https://huggingface.co/microsoft/table-transformer-structure-recognition)
diff --git a/docs/source/en/model_doc/tapex.md b/docs/source/en/model_doc/tapex.md
index d46d520c7d..9694b098ea 100644
--- a/docs/source/en/model_doc/tapex.md
+++ b/docs/source/en/model_doc/tapex.md
@@ -34,7 +34,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The TAPEX model was proposed in [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu,
+The TAPEX model was proposed in [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://huggingface.co/papers/2107.07653) by Qian Liu,
Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou. TAPEX pre-trains a BART model to solve synthetic SQL queries, after
which it can be fine-tuned to answer natural language questions related to tabular data, as well as performing table fact checking.
diff --git a/docs/source/en/model_doc/textnet.md b/docs/source/en/model_doc/textnet.md
index 72f29b4463..f14cd2e941 100644
--- a/docs/source/en/model_doc/textnet.md
+++ b/docs/source/en/model_doc/textnet.md
@@ -22,12 +22,12 @@ rendered properly in your Markdown viewer.
## Overview
-The TextNet model was proposed in [FAST: Faster Arbitrarily-Shaped Text Detector with Minimalist Kernel Representation](https://arxiv.org/abs/2111.02394) by Zhe Chen, Jiahao Wang, Wenhai Wang, Guo Chen, Enze Xie, Ping Luo, Tong Lu. TextNet is a vision backbone useful for text detection tasks. It is the result of neural architecture search (NAS) on backbones with reward function as text detection task (to provide powerful features for text detection).
+The TextNet model was proposed in [FAST: Faster Arbitrarily-Shaped Text Detector with Minimalist Kernel Representation](https://huggingface.co/papers/2111.02394) by Zhe Chen, Jiahao Wang, Wenhai Wang, Guo Chen, Enze Xie, Ping Luo, Tong Lu. TextNet is a vision backbone useful for text detection tasks. It is the result of neural architecture search (NAS) on backbones with reward function as text detection task (to provide powerful features for text detection).
 - TextNet backbone as part of FAST. Taken from the original paper.
+ TextNet backbone as part of FAST. Taken from the original paper.
This model was contributed by [Raghavan](https://huggingface.co/Raghavan), [jadechoghari](https://huggingface.co/jadechoghari) and [nielsr](https://huggingface.co/nielsr).
diff --git a/docs/source/en/model_doc/timesformer.md b/docs/source/en/model_doc/timesformer.md
index c01f64efa7..c39a63a668 100644
--- a/docs/source/en/model_doc/timesformer.md
+++ b/docs/source/en/model_doc/timesformer.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The TimeSformer model was proposed in [TimeSformer: Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095) by Facebook Research.
+The TimeSformer model was proposed in [TimeSformer: Is Space-Time Attention All You Need for Video Understanding?](https://huggingface.co/papers/2102.05095) by Facebook Research.
This work is a milestone in action-recognition field being the first video transformer. It inspired many transformer based video understanding and classification papers.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/trajectory_transformer.md b/docs/source/en/model_doc/trajectory_transformer.md
index 0c8fc29e01..a2353c9414 100644
--- a/docs/source/en/model_doc/trajectory_transformer.md
+++ b/docs/source/en/model_doc/trajectory_transformer.md
@@ -31,7 +31,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The Trajectory Transformer model was proposed in [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine.
+The Trajectory Transformer model was proposed in [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://huggingface.co/papers/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/transfo-xl.md b/docs/source/en/model_doc/transfo-xl.md
index 4d4f68ab07..66f249f24e 100644
--- a/docs/source/en/model_doc/transfo-xl.md
+++ b/docs/source/en/model_doc/transfo-xl.md
@@ -61,7 +61,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The Transformer-XL model was proposed in [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan
+The Transformer-XL model was proposed in [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://huggingface.co/papers/1901.02860) by Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan
Salakhutdinov. It's a causal (uni-directional) transformer with relative positioning (sinusoïdal) embeddings which can
reuse previously computed hidden-states to attend to longer context (memory). This model also uses adaptive softmax
inputs and outputs (tied).
diff --git a/docs/source/en/model_doc/trocr.md b/docs/source/en/model_doc/trocr.md
index 0d0fb6ca24..420398376a 100644
--- a/docs/source/en/model_doc/trocr.md
+++ b/docs/source/en/model_doc/trocr.md
@@ -22,7 +22,7 @@ specific language governing permissions and limitations under the License. -->
## Overview
The TrOCR model was proposed in [TrOCR: Transformer-based Optical Character Recognition with Pre-trained
-Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang,
+Models](https://huggingface.co/papers/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang,
Zhoujun Li, Furu Wei. TrOCR consists of an image Transformer encoder and an autoregressive text Transformer decoder to
perform [optical character recognition (OCR)](https://en.wikipedia.org/wiki/Optical_character_recognition).
@@ -40,7 +40,7 @@ tasks.*
- TextNet backbone as part of FAST. Taken from the original paper.
+ TextNet backbone as part of FAST. Taken from the original paper.
This model was contributed by [Raghavan](https://huggingface.co/Raghavan), [jadechoghari](https://huggingface.co/jadechoghari) and [nielsr](https://huggingface.co/nielsr).
diff --git a/docs/source/en/model_doc/timesformer.md b/docs/source/en/model_doc/timesformer.md
index c01f64efa7..c39a63a668 100644
--- a/docs/source/en/model_doc/timesformer.md
+++ b/docs/source/en/model_doc/timesformer.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The TimeSformer model was proposed in [TimeSformer: Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095) by Facebook Research.
+The TimeSformer model was proposed in [TimeSformer: Is Space-Time Attention All You Need for Video Understanding?](https://huggingface.co/papers/2102.05095) by Facebook Research.
This work is a milestone in action-recognition field being the first video transformer. It inspired many transformer based video understanding and classification papers.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/trajectory_transformer.md b/docs/source/en/model_doc/trajectory_transformer.md
index 0c8fc29e01..a2353c9414 100644
--- a/docs/source/en/model_doc/trajectory_transformer.md
+++ b/docs/source/en/model_doc/trajectory_transformer.md
@@ -31,7 +31,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The Trajectory Transformer model was proposed in [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine.
+The Trajectory Transformer model was proposed in [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://huggingface.co/papers/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/transfo-xl.md b/docs/source/en/model_doc/transfo-xl.md
index 4d4f68ab07..66f249f24e 100644
--- a/docs/source/en/model_doc/transfo-xl.md
+++ b/docs/source/en/model_doc/transfo-xl.md
@@ -61,7 +61,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The Transformer-XL model was proposed in [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan
+The Transformer-XL model was proposed in [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://huggingface.co/papers/1901.02860) by Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan
Salakhutdinov. It's a causal (uni-directional) transformer with relative positioning (sinusoïdal) embeddings which can
reuse previously computed hidden-states to attend to longer context (memory). This model also uses adaptive softmax
inputs and outputs (tied).
diff --git a/docs/source/en/model_doc/trocr.md b/docs/source/en/model_doc/trocr.md
index 0d0fb6ca24..420398376a 100644
--- a/docs/source/en/model_doc/trocr.md
+++ b/docs/source/en/model_doc/trocr.md
@@ -22,7 +22,7 @@ specific language governing permissions and limitations under the License. -->
## Overview
The TrOCR model was proposed in [TrOCR: Transformer-based Optical Character Recognition with Pre-trained
-Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang,
+Models](https://huggingface.co/papers/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang,
Zhoujun Li, Furu Wei. TrOCR consists of an image Transformer encoder and an autoregressive text Transformer decoder to
perform [optical character recognition (OCR)](https://en.wikipedia.org/wiki/Optical_character_recognition).
@@ -40,7 +40,7 @@ tasks.*
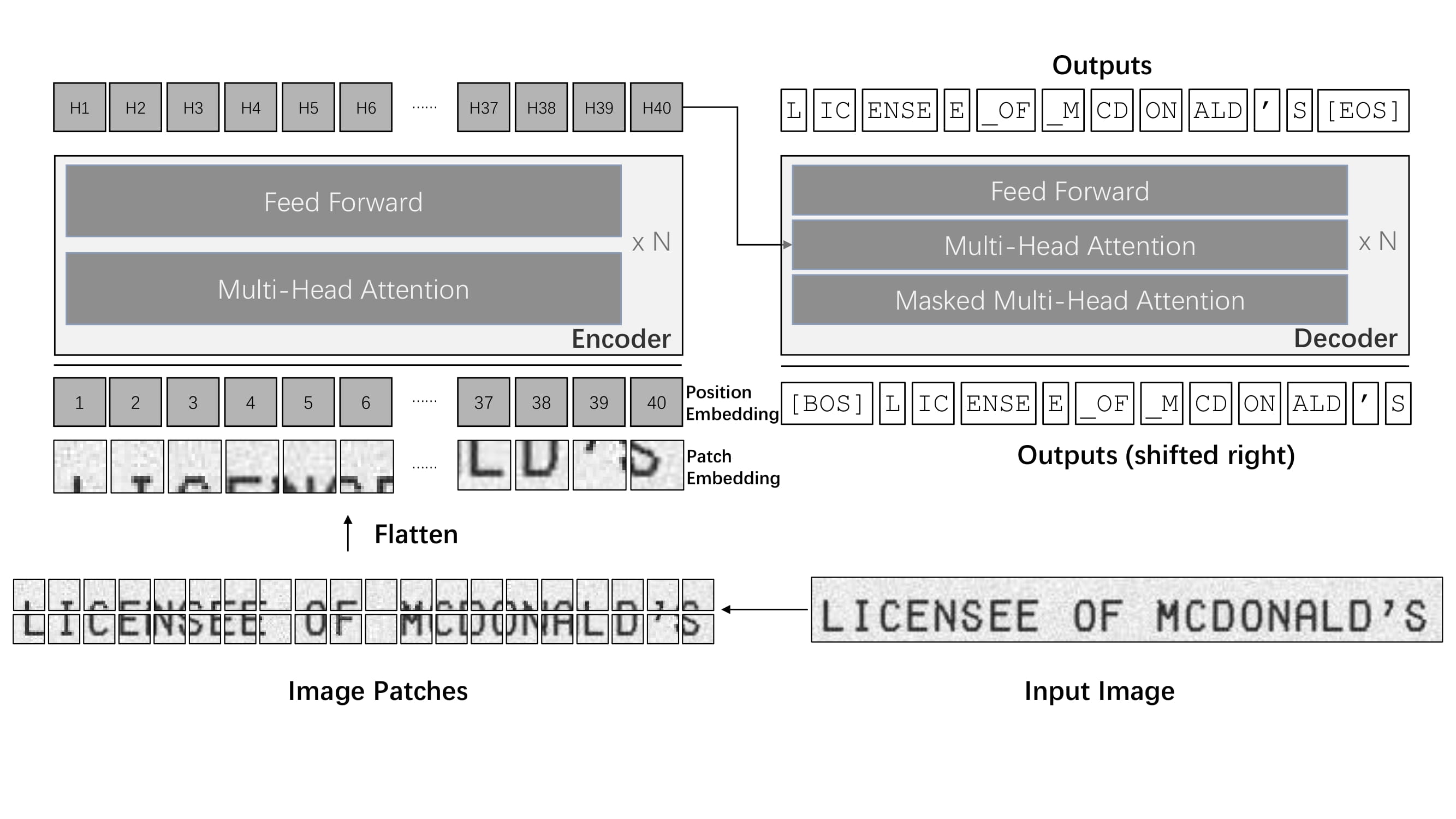 - TrOCR architecture. Taken from the original paper.
+ TrOCR architecture. Taken from the original paper.
Please refer to the [`VisionEncoderDecoder`] class on how to use this model.
diff --git a/docs/source/en/model_doc/tvlt.md b/docs/source/en/model_doc/tvlt.md
index f1a97dfcd8..949c8549f5 100644
--- a/docs/source/en/model_doc/tvlt.md
+++ b/docs/source/en/model_doc/tvlt.md
@@ -30,7 +30,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The TVLT model was proposed in [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156)
+The TVLT model was proposed in [TVLT: Textless Vision-Language Transformer](https://huggingface.co/papers/2209.14156)
by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal (the first three authors contributed equally). The Textless Vision-Language Transformer (TVLT) is a model that uses raw visual and audio inputs for vision-and-language representation learning, without using text-specific modules such as tokenization or automatic speech recognition (ASR). It can perform various audiovisual and vision-language tasks like retrieval, question answering, etc.
The abstract from the paper is the following:
@@ -42,7 +42,7 @@ The abstract from the paper is the following:
alt="drawing" width="600"/>
- TVLT architecture. Taken from the original paper.
+ TVLT architecture. Taken from the original paper.
The original code can be found [here](https://github.com/zinengtang/TVLT). This model was contributed by [Zineng Tang](https://huggingface.co/ZinengTang).
diff --git a/docs/source/en/model_doc/tvp.md b/docs/source/en/model_doc/tvp.md
index cadb6e71f0..1b83ebfa6d 100644
--- a/docs/source/en/model_doc/tvp.md
+++ b/docs/source/en/model_doc/tvp.md
@@ -18,7 +18,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The text-visual prompting (TVP) framework was proposed in the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
+The text-visual prompting (TVP) framework was proposed in the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://huggingface.co/papers/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
The abstract from the paper is the following:
@@ -29,7 +29,7 @@ This research addresses temporal video grounding (TVG), which is the process of
- TrOCR architecture. Taken from the original paper.
+ TrOCR architecture. Taken from the original paper.
Please refer to the [`VisionEncoderDecoder`] class on how to use this model.
diff --git a/docs/source/en/model_doc/tvlt.md b/docs/source/en/model_doc/tvlt.md
index f1a97dfcd8..949c8549f5 100644
--- a/docs/source/en/model_doc/tvlt.md
+++ b/docs/source/en/model_doc/tvlt.md
@@ -30,7 +30,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The TVLT model was proposed in [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156)
+The TVLT model was proposed in [TVLT: Textless Vision-Language Transformer](https://huggingface.co/papers/2209.14156)
by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal (the first three authors contributed equally). The Textless Vision-Language Transformer (TVLT) is a model that uses raw visual and audio inputs for vision-and-language representation learning, without using text-specific modules such as tokenization or automatic speech recognition (ASR). It can perform various audiovisual and vision-language tasks like retrieval, question answering, etc.
The abstract from the paper is the following:
@@ -42,7 +42,7 @@ The abstract from the paper is the following:
alt="drawing" width="600"/>
- TVLT architecture. Taken from the original paper.
+ TVLT architecture. Taken from the original paper.
The original code can be found [here](https://github.com/zinengtang/TVLT). This model was contributed by [Zineng Tang](https://huggingface.co/ZinengTang).
diff --git a/docs/source/en/model_doc/tvp.md b/docs/source/en/model_doc/tvp.md
index cadb6e71f0..1b83ebfa6d 100644
--- a/docs/source/en/model_doc/tvp.md
+++ b/docs/source/en/model_doc/tvp.md
@@ -18,7 +18,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The text-visual prompting (TVP) framework was proposed in the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
+The text-visual prompting (TVP) framework was proposed in the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://huggingface.co/papers/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
The abstract from the paper is the following:
@@ -29,7 +29,7 @@ This research addresses temporal video grounding (TVG), which is the process of
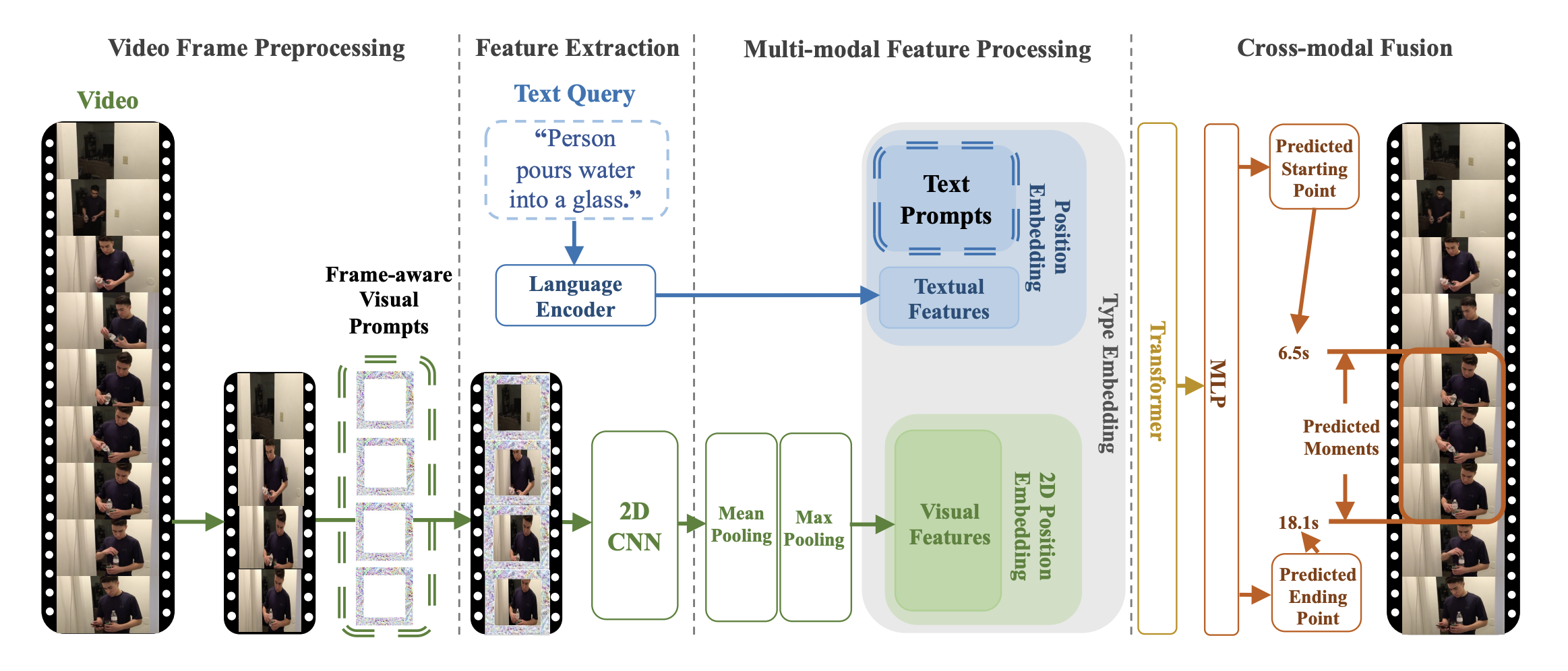 - TVP architecture. Taken from the original paper.
+ TVP architecture. Taken from the original paper.
This model was contributed by [Jiqing Feng](https://huggingface.co/Jiqing). The original code can be found [here](https://github.com/intel/TVP).
@@ -162,7 +162,7 @@ Tips:
- This implementation of TVP uses [`BertTokenizer`] to generate text embeddings and Resnet-50 model to compute visual embeddings.
- Checkpoints for pre-trained [tvp-base](https://huggingface.co/Intel/tvp-base) is released.
-- Please refer to [Table 2](https://arxiv.org/pdf/2303.04995.pdf) for TVP's performance on Temporal Video Grounding task.
+- Please refer to [Table 2](https://huggingface.co/papers/2303.04995) for TVP's performance on Temporal Video Grounding task.
## TvpConfig
diff --git a/docs/source/en/model_doc/udop.md b/docs/source/en/model_doc/udop.md
index b63bc11a53..fd2a70d7ec 100644
--- a/docs/source/en/model_doc/udop.md
+++ b/docs/source/en/model_doc/udop.md
@@ -18,7 +18,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The UDOP model was proposed in [Unifying Vision, Text, and Layout for Universal Document Processing](https://arxiv.org/abs/2212.02623) by Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal.
+The UDOP model was proposed in [Unifying Vision, Text, and Layout for Universal Document Processing](https://huggingface.co/papers/2212.02623) by Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal.
UDOP adopts an encoder-decoder Transformer architecture based on [T5](t5) for document AI tasks like document image classification, document parsing and document visual question answering.
The abstract from the paper is the following:
@@ -28,7 +28,7 @@ We propose Universal Document Processing (UDOP), a foundation Document AI model
- TVP architecture. Taken from the original paper.
+ TVP architecture. Taken from the original paper.
This model was contributed by [Jiqing Feng](https://huggingface.co/Jiqing). The original code can be found [here](https://github.com/intel/TVP).
@@ -162,7 +162,7 @@ Tips:
- This implementation of TVP uses [`BertTokenizer`] to generate text embeddings and Resnet-50 model to compute visual embeddings.
- Checkpoints for pre-trained [tvp-base](https://huggingface.co/Intel/tvp-base) is released.
-- Please refer to [Table 2](https://arxiv.org/pdf/2303.04995.pdf) for TVP's performance on Temporal Video Grounding task.
+- Please refer to [Table 2](https://huggingface.co/papers/2303.04995) for TVP's performance on Temporal Video Grounding task.
## TvpConfig
diff --git a/docs/source/en/model_doc/udop.md b/docs/source/en/model_doc/udop.md
index b63bc11a53..fd2a70d7ec 100644
--- a/docs/source/en/model_doc/udop.md
+++ b/docs/source/en/model_doc/udop.md
@@ -18,7 +18,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The UDOP model was proposed in [Unifying Vision, Text, and Layout for Universal Document Processing](https://arxiv.org/abs/2212.02623) by Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal.
+The UDOP model was proposed in [Unifying Vision, Text, and Layout for Universal Document Processing](https://huggingface.co/papers/2212.02623) by Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal.
UDOP adopts an encoder-decoder Transformer architecture based on [T5](t5) for document AI tasks like document image classification, document parsing and document visual question answering.
The abstract from the paper is the following:
@@ -28,7 +28,7 @@ We propose Universal Document Processing (UDOP), a foundation Document AI model
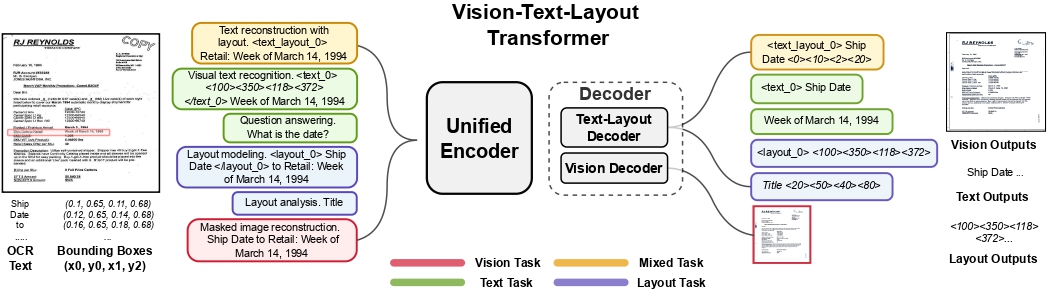 - UDOP architecture. Taken from the original paper.
+ UDOP architecture. Taken from the original paper.
## Usage tips
@@ -64,7 +64,7 @@ One can use [`UdopProcessor`] to prepare images and text for the model, which ta
- If using an own OCR engine of choice, one recommendation is Azure's [Read API](https://learn.microsoft.com/en-us/azure/ai-services/computer-vision/how-to/call-read-api), which supports so-called line segments. Use of segment position embeddings typically results in better performance.
- At inference time, it's recommended to use the `generate` method to autoregressively generate text given a document image.
-- The model has been pre-trained on both self-supervised and supervised objectives. One can use the various task prefixes (prompts) used during pre-training to test out the out-of-the-box capabilities. For instance, the model can be prompted with "Question answering. What is the date?", as "Question answering." is the task prefix used during pre-training for DocVQA. Refer to the [paper](https://arxiv.org/abs/2212.02623) (table 1) for all task prefixes.
+- The model has been pre-trained on both self-supervised and supervised objectives. One can use the various task prefixes (prompts) used during pre-training to test out the out-of-the-box capabilities. For instance, the model can be prompted with "Question answering. What is the date?", as "Question answering." is the task prefix used during pre-training for DocVQA. Refer to the [paper](https://huggingface.co/papers/2212.02623) (table 1) for all task prefixes.
- One can also fine-tune [`UdopEncoderModel`], which is the encoder-only part of UDOP, which can be seen as a LayoutLMv3-like Transformer encoder. For discriminative tasks, one can just add a linear classifier on top of it and fine-tune it on a labeled dataset.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
diff --git a/docs/source/en/model_doc/ul2.md b/docs/source/en/model_doc/ul2.md
index 18743a2842..b3c1a22260 100644
--- a/docs/source/en/model_doc/ul2.md
+++ b/docs/source/en/model_doc/ul2.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The T5 model was presented in [Unifying Language Learning Paradigms](https://arxiv.org/pdf/2205.05131v1.pdf) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler.
+The T5 model was presented in [Unifying Language Learning Paradigms](https://huggingface.co/papers/2205.05131) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/unispeech-sat.md b/docs/source/en/model_doc/unispeech-sat.md
index c526bb434d..8d0adb8e78 100644
--- a/docs/source/en/model_doc/unispeech-sat.md
+++ b/docs/source/en/model_doc/unispeech-sat.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
The UniSpeech-SAT model was proposed in [UniSpeech-SAT: Universal Speech Representation Learning with Speaker Aware
-Pre-Training](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen,
+Pre-Training](https://huggingface.co/papers/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen,
Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu .
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/unispeech.md b/docs/source/en/model_doc/unispeech.md
index 9f23656b22..a83f7600d5 100644
--- a/docs/source/en/model_doc/unispeech.md
+++ b/docs/source/en/model_doc/unispeech.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The UniSpeech model was proposed in [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael
+The UniSpeech model was proposed in [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://huggingface.co/papers/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael
Zeng, Xuedong Huang .
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/univnet.md b/docs/source/en/model_doc/univnet.md
index 3671471152..57492dcd68 100644
--- a/docs/source/en/model_doc/univnet.md
+++ b/docs/source/en/model_doc/univnet.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The UnivNet model was proposed in [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kin, and Juntae Kim.
+The UnivNet model was proposed in [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://huggingface.co/papers/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kin, and Juntae Kim.
The UnivNet model is a generative adversarial network (GAN) trained to synthesize high fidelity speech waveforms. The UnivNet model shared in `transformers` is the *generator*, which maps a conditioning log-mel spectrogram and optional noise sequence to a speech waveform (e.g. a vocoder). Only the generator is required for inference. The *discriminator* used to train the `generator` is not implemented.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/upernet.md b/docs/source/en/model_doc/upernet.md
index a2c96582f2..e215ec8621 100644
--- a/docs/source/en/model_doc/upernet.md
+++ b/docs/source/en/model_doc/upernet.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The UPerNet model was proposed in [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221)
+The UPerNet model was proposed in [Unified Perceptual Parsing for Scene Understanding](https://huggingface.co/papers/1807.10221)
by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun. UPerNet is a general framework to effectively segment
a wide range of concepts from images, leveraging any vision backbone like [ConvNeXt](convnext) or [Swin](swin).
@@ -33,7 +33,7 @@ The abstract from the paper is the following:
- UDOP architecture. Taken from the original paper.
+ UDOP architecture. Taken from the original paper.
## Usage tips
@@ -64,7 +64,7 @@ One can use [`UdopProcessor`] to prepare images and text for the model, which ta
- If using an own OCR engine of choice, one recommendation is Azure's [Read API](https://learn.microsoft.com/en-us/azure/ai-services/computer-vision/how-to/call-read-api), which supports so-called line segments. Use of segment position embeddings typically results in better performance.
- At inference time, it's recommended to use the `generate` method to autoregressively generate text given a document image.
-- The model has been pre-trained on both self-supervised and supervised objectives. One can use the various task prefixes (prompts) used during pre-training to test out the out-of-the-box capabilities. For instance, the model can be prompted with "Question answering. What is the date?", as "Question answering." is the task prefix used during pre-training for DocVQA. Refer to the [paper](https://arxiv.org/abs/2212.02623) (table 1) for all task prefixes.
+- The model has been pre-trained on both self-supervised and supervised objectives. One can use the various task prefixes (prompts) used during pre-training to test out the out-of-the-box capabilities. For instance, the model can be prompted with "Question answering. What is the date?", as "Question answering." is the task prefix used during pre-training for DocVQA. Refer to the [paper](https://huggingface.co/papers/2212.02623) (table 1) for all task prefixes.
- One can also fine-tune [`UdopEncoderModel`], which is the encoder-only part of UDOP, which can be seen as a LayoutLMv3-like Transformer encoder. For discriminative tasks, one can just add a linear classifier on top of it and fine-tune it on a labeled dataset.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
diff --git a/docs/source/en/model_doc/ul2.md b/docs/source/en/model_doc/ul2.md
index 18743a2842..b3c1a22260 100644
--- a/docs/source/en/model_doc/ul2.md
+++ b/docs/source/en/model_doc/ul2.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The T5 model was presented in [Unifying Language Learning Paradigms](https://arxiv.org/pdf/2205.05131v1.pdf) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler.
+The T5 model was presented in [Unifying Language Learning Paradigms](https://huggingface.co/papers/2205.05131) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/unispeech-sat.md b/docs/source/en/model_doc/unispeech-sat.md
index c526bb434d..8d0adb8e78 100644
--- a/docs/source/en/model_doc/unispeech-sat.md
+++ b/docs/source/en/model_doc/unispeech-sat.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
The UniSpeech-SAT model was proposed in [UniSpeech-SAT: Universal Speech Representation Learning with Speaker Aware
-Pre-Training](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen,
+Pre-Training](https://huggingface.co/papers/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen,
Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu .
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/unispeech.md b/docs/source/en/model_doc/unispeech.md
index 9f23656b22..a83f7600d5 100644
--- a/docs/source/en/model_doc/unispeech.md
+++ b/docs/source/en/model_doc/unispeech.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The UniSpeech model was proposed in [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael
+The UniSpeech model was proposed in [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://huggingface.co/papers/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael
Zeng, Xuedong Huang .
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/univnet.md b/docs/source/en/model_doc/univnet.md
index 3671471152..57492dcd68 100644
--- a/docs/source/en/model_doc/univnet.md
+++ b/docs/source/en/model_doc/univnet.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The UnivNet model was proposed in [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kin, and Juntae Kim.
+The UnivNet model was proposed in [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://huggingface.co/papers/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kin, and Juntae Kim.
The UnivNet model is a generative adversarial network (GAN) trained to synthesize high fidelity speech waveforms. The UnivNet model shared in `transformers` is the *generator*, which maps a conditioning log-mel spectrogram and optional noise sequence to a speech waveform (e.g. a vocoder). Only the generator is required for inference. The *discriminator* used to train the `generator` is not implemented.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/upernet.md b/docs/source/en/model_doc/upernet.md
index a2c96582f2..e215ec8621 100644
--- a/docs/source/en/model_doc/upernet.md
+++ b/docs/source/en/model_doc/upernet.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The UPerNet model was proposed in [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221)
+The UPerNet model was proposed in [Unified Perceptual Parsing for Scene Understanding](https://huggingface.co/papers/1807.10221)
by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun. UPerNet is a general framework to effectively segment
a wide range of concepts from images, leveraging any vision backbone like [ConvNeXt](convnext) or [Swin](swin).
@@ -33,7 +33,7 @@ The abstract from the paper is the following:
 - UPerNet framework. Taken from the original paper.
+ UPerNet framework. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code is based on OpenMMLab's mmsegmentation [here](https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/uper_head.py).
diff --git a/docs/source/en/model_doc/van.md b/docs/source/en/model_doc/van.md
index 1df6a4640b..0a25691823 100644
--- a/docs/source/en/model_doc/van.md
+++ b/docs/source/en/model_doc/van.md
@@ -31,7 +31,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The VAN model was proposed in [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
+The VAN model was proposed in [Visual Attention Network](https://huggingface.co/papers/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
This paper introduces a new attention layer based on convolution operations able to capture both local and distant relationships. This is done by combining normal and large kernel convolution layers. The latter uses a dilated convolution to capture distant correlations.
@@ -43,7 +43,7 @@ Tips:
- VAN does not have an embedding layer, thus the `hidden_states` will have a length equal to the number of stages.
-The figure below illustrates the architecture of a Visual Attention Layer. Taken from the [original paper](https://arxiv.org/abs/2202.09741).
+The figure below illustrates the architecture of a Visual Attention Layer. Taken from the [original paper](https://huggingface.co/papers/2202.09741).
- UPerNet framework. Taken from the original paper.
+ UPerNet framework. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code is based on OpenMMLab's mmsegmentation [here](https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/uper_head.py).
diff --git a/docs/source/en/model_doc/van.md b/docs/source/en/model_doc/van.md
index 1df6a4640b..0a25691823 100644
--- a/docs/source/en/model_doc/van.md
+++ b/docs/source/en/model_doc/van.md
@@ -31,7 +31,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The VAN model was proposed in [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
+The VAN model was proposed in [Visual Attention Network](https://huggingface.co/papers/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
This paper introduces a new attention layer based on convolution operations able to capture both local and distant relationships. This is done by combining normal and large kernel convolution layers. The latter uses a dilated convolution to capture distant correlations.
@@ -43,7 +43,7 @@ Tips:
- VAN does not have an embedding layer, thus the `hidden_states` will have a length equal to the number of stages.
-The figure below illustrates the architecture of a Visual Attention Layer. Taken from the [original paper](https://arxiv.org/abs/2202.09741).
+The figure below illustrates the architecture of a Visual Attention Layer. Taken from the [original paper](https://huggingface.co/papers/2202.09741).
 diff --git a/docs/source/en/model_doc/video_llava.md b/docs/source/en/model_doc/video_llava.md
index 9eaed2e7d5..a9282bdad0 100644
--- a/docs/source/en/model_doc/video_llava.md
+++ b/docs/source/en/model_doc/video_llava.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
Video-LLaVa is an open-source multimodal LLM trained by fine-tuning LlamA/Vicuna on multimodal instruction-following data generated by Llava1.5 and VideChat. It is an auto-regressive language model, based on the transformer architecture. Video-LLaVa unifies visual representations to the language feature space, and enables an LLM to perform visual reasoning capabilities on both images and videos simultaneously.
-The Video-LLaVA model was proposed in [Video-LLaVA: Learning United Visual Representation by Alignment Before Projection](https://arxiv.org/abs/2311.10122) by Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munang Ning, Peng Jin, Li Yuan.
+The Video-LLaVA model was proposed in [Video-LLaVA: Learning United Visual Representation by Alignment Before Projection](https://huggingface.co/papers/2311.10122) by Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munang Ning, Peng Jin, Li Yuan.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/videomae.md b/docs/source/en/model_doc/videomae.md
index be048d5b73..ac3d6c044e 100644
--- a/docs/source/en/model_doc/videomae.md
+++ b/docs/source/en/model_doc/videomae.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The VideoMAE model was proposed in [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
+The VideoMAE model was proposed in [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://huggingface.co/papers/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
VideoMAE extends masked auto encoders ([MAE](vit_mae)) to video, claiming state-of-the-art performance on several video classification benchmarks.
The abstract from the paper is the following:
@@ -34,7 +34,7 @@ The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/video_llava.md b/docs/source/en/model_doc/video_llava.md
index 9eaed2e7d5..a9282bdad0 100644
--- a/docs/source/en/model_doc/video_llava.md
+++ b/docs/source/en/model_doc/video_llava.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
Video-LLaVa is an open-source multimodal LLM trained by fine-tuning LlamA/Vicuna on multimodal instruction-following data generated by Llava1.5 and VideChat. It is an auto-regressive language model, based on the transformer architecture. Video-LLaVa unifies visual representations to the language feature space, and enables an LLM to perform visual reasoning capabilities on both images and videos simultaneously.
-The Video-LLaVA model was proposed in [Video-LLaVA: Learning United Visual Representation by Alignment Before Projection](https://arxiv.org/abs/2311.10122) by Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munang Ning, Peng Jin, Li Yuan.
+The Video-LLaVA model was proposed in [Video-LLaVA: Learning United Visual Representation by Alignment Before Projection](https://huggingface.co/papers/2311.10122) by Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munang Ning, Peng Jin, Li Yuan.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/videomae.md b/docs/source/en/model_doc/videomae.md
index be048d5b73..ac3d6c044e 100644
--- a/docs/source/en/model_doc/videomae.md
+++ b/docs/source/en/model_doc/videomae.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The VideoMAE model was proposed in [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
+The VideoMAE model was proposed in [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://huggingface.co/papers/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
VideoMAE extends masked auto encoders ([MAE](vit_mae)) to video, claiming state-of-the-art performance on several video classification benchmarks.
The abstract from the paper is the following:
@@ -34,7 +34,7 @@ The abstract from the paper is the following:
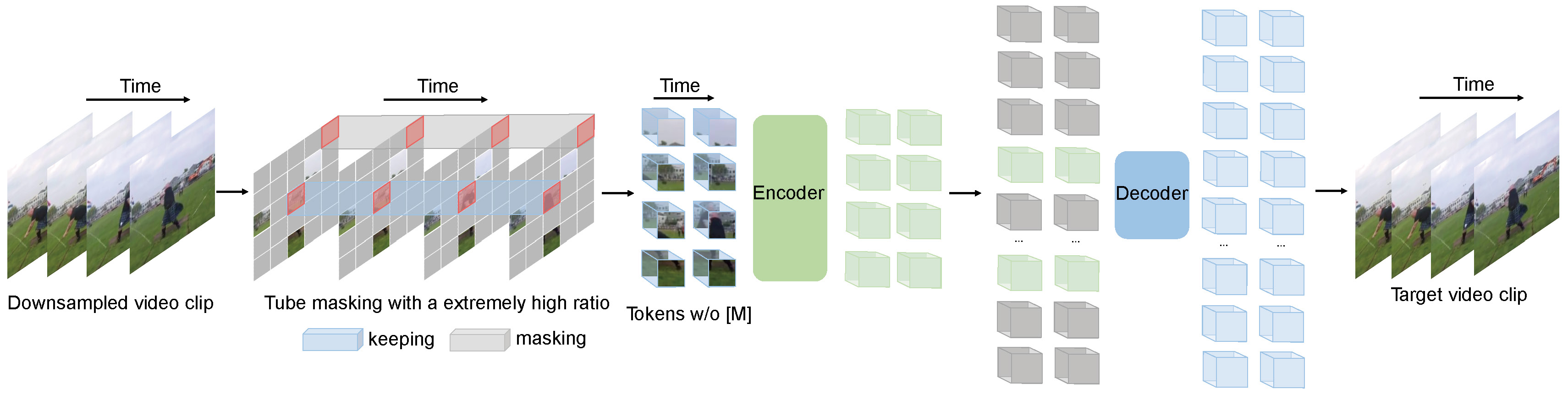 - VideoMAE pre-training. Taken from the original paper.
+ VideoMAE pre-training. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/MCG-NJU/VideoMAE).
diff --git a/docs/source/en/model_doc/vilt.md b/docs/source/en/model_doc/vilt.md
index ea598cbbe2..19146e3846 100644
--- a/docs/source/en/model_doc/vilt.md
+++ b/docs/source/en/model_doc/vilt.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The ViLT model was proposed in [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334)
+The ViLT model was proposed in [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://huggingface.co/papers/2102.03334)
by Wonjae Kim, Bokyung Son, Ildoo Kim. ViLT incorporates text embeddings into a Vision Transformer (ViT), allowing it to have a minimal design
for Vision-and-Language Pre-training (VLP).
@@ -41,7 +41,7 @@ times faster than previous VLP models, yet with competitive or better downstream
- VideoMAE pre-training. Taken from the original paper.
+ VideoMAE pre-training. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/MCG-NJU/VideoMAE).
diff --git a/docs/source/en/model_doc/vilt.md b/docs/source/en/model_doc/vilt.md
index ea598cbbe2..19146e3846 100644
--- a/docs/source/en/model_doc/vilt.md
+++ b/docs/source/en/model_doc/vilt.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The ViLT model was proposed in [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334)
+The ViLT model was proposed in [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://huggingface.co/papers/2102.03334)
by Wonjae Kim, Bokyung Son, Ildoo Kim. ViLT incorporates text embeddings into a Vision Transformer (ViT), allowing it to have a minimal design
for Vision-and-Language Pre-training (VLP).
@@ -41,7 +41,7 @@ times faster than previous VLP models, yet with competitive or better downstream
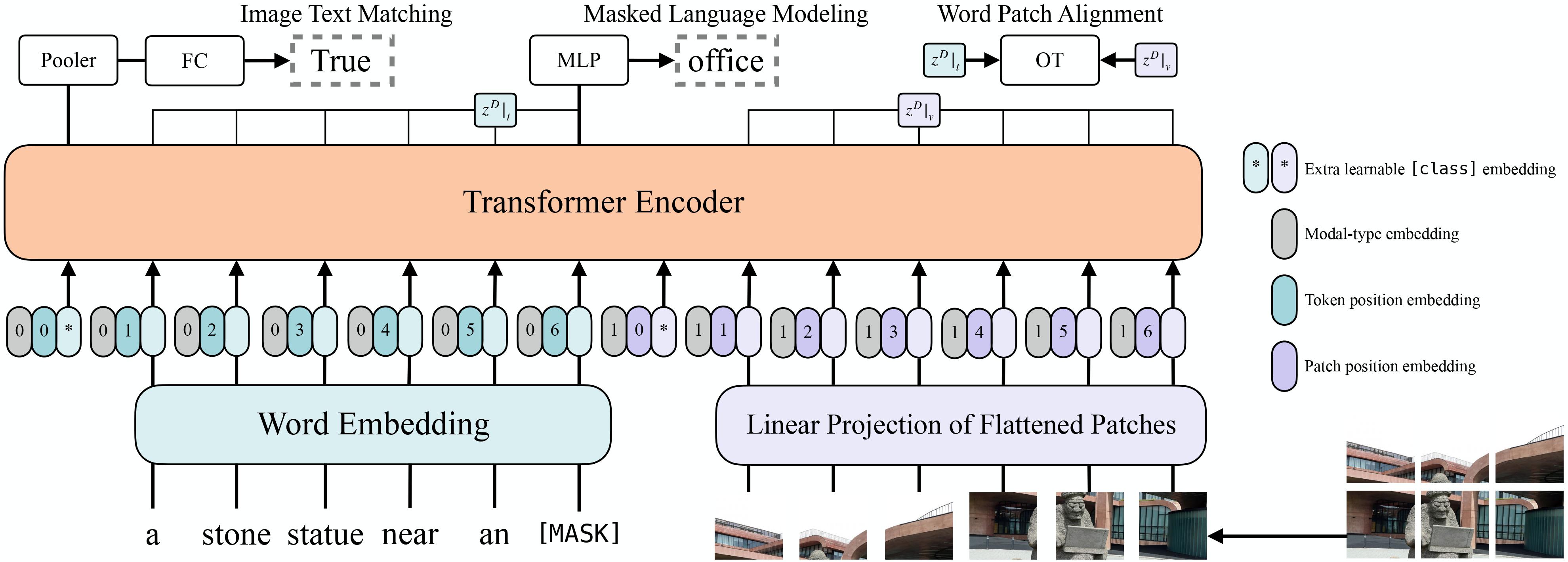 - ViLT architecture. Taken from the original paper.
+ ViLT architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/dandelin/ViLT).
diff --git a/docs/source/en/model_doc/vipllava.md b/docs/source/en/model_doc/vipllava.md
index 8edf154026..c60b172045 100644
--- a/docs/source/en/model_doc/vipllava.md
+++ b/docs/source/en/model_doc/vipllava.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The VipLlava model was proposed in [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://arxiv.org/abs/2312.00784) by Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee.
+The VipLlava model was proposed in [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://huggingface.co/papers/2312.00784) by Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee.
VipLlava enhances the training protocol of Llava by marking images and interact with the model using natural cues like a "red bounding box" or "pointed arrow" during training.
diff --git a/docs/source/en/model_doc/vision-encoder-decoder.md b/docs/source/en/model_doc/vision-encoder-decoder.md
index 0534085861..53c573be47 100644
--- a/docs/source/en/model_doc/vision-encoder-decoder.md
+++ b/docs/source/en/model_doc/vision-encoder-decoder.md
@@ -32,7 +32,7 @@ pretrained Transformer-based vision model as the encoder (*e.g.* [ViT](vit), [BE
and any pretrained language model as the decoder (*e.g.* [RoBERTa](roberta), [GPT2](gpt2), [BERT](bert), [DistilBERT](distilbert)).
The effectiveness of initializing image-to-text-sequence models with pretrained checkpoints has been shown in (for
-example) [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang,
+example) [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://huggingface.co/papers/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang,
Zhoujun Li, Furu Wei.
After such a [`VisionEncoderDecoderModel`] has been trained/fine-tuned, it can be saved/loaded just like any other models (see the examples below
diff --git a/docs/source/en/model_doc/vision-text-dual-encoder.md b/docs/source/en/model_doc/vision-text-dual-encoder.md
index b9d6db38d5..3106cb0ac3 100644
--- a/docs/source/en/model_doc/vision-text-dual-encoder.md
+++ b/docs/source/en/model_doc/vision-text-dual-encoder.md
@@ -33,7 +33,7 @@ to a shared latent space. The projection layers are randomly initialized so the
downstream task. This model can be used to align the vision-text embeddings using CLIP like contrastive image-text
training and then can be used for zero-shot vision tasks such image-classification or retrieval.
-In [LiT: Zero-Shot Transfer with Locked-image Text Tuning](https://arxiv.org/abs/2111.07991) it is shown how
+In [LiT: Zero-Shot Transfer with Locked-image Text Tuning](https://huggingface.co/papers/2111.07991) it is shown how
leveraging pre-trained (locked/frozen) image and text model for contrastive learning yields significant improvement on
new zero-shot vision tasks such as image classification or retrieval.
diff --git a/docs/source/en/model_doc/visual_bert.md b/docs/source/en/model_doc/visual_bert.md
index 265d482c19..02c98ba3d9 100644
--- a/docs/source/en/model_doc/visual_bert.md
+++ b/docs/source/en/model_doc/visual_bert.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The VisualBERT model was proposed in [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
+The VisualBERT model was proposed in [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://huggingface.co/papers/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
VisualBERT is a neural network trained on a variety of (image, text) pairs.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/vit_hybrid.md b/docs/source/en/model_doc/vit_hybrid.md
index a79fadd255..c268c2fad3 100644
--- a/docs/source/en/model_doc/vit_hybrid.md
+++ b/docs/source/en/model_doc/vit_hybrid.md
@@ -32,7 +32,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
The hybrid Vision Transformer (ViT) model was proposed in [An Image is Worth 16x16 Words: Transformers for Image Recognition
-at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk
+at Scale](https://huggingface.co/papers/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk
Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob
Uszkoreit, Neil Houlsby. It's the first paper that successfully trains a Transformer encoder on ImageNet, attaining
very good results compared to familiar convolutional architectures. ViT hybrid is a slight variant of the [plain Vision Transformer](vit),
diff --git a/docs/source/en/model_doc/vit_msn.md b/docs/source/en/model_doc/vit_msn.md
index a3aadef0e9..8835f01cd8 100644
--- a/docs/source/en/model_doc/vit_msn.md
+++ b/docs/source/en/model_doc/vit_msn.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The ViTMSN model was proposed in [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes,
+The ViTMSN model was proposed in [Masked Siamese Networks for Label-Efficient Learning](https://huggingface.co/papers/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes,
Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas. The paper presents a joint-embedding architecture to match the prototypes
of masked patches with that of the unmasked patches. With this setup, their method yields excellent performance in the low-shot and extreme low-shot
regimes.
@@ -41,7 +41,7 @@ and with 1% of ImageNet-1K labels, we achieve 75.7% top-1 accuracy, setting a ne
- ViLT architecture. Taken from the original paper.
+ ViLT architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/dandelin/ViLT).
diff --git a/docs/source/en/model_doc/vipllava.md b/docs/source/en/model_doc/vipllava.md
index 8edf154026..c60b172045 100644
--- a/docs/source/en/model_doc/vipllava.md
+++ b/docs/source/en/model_doc/vipllava.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The VipLlava model was proposed in [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://arxiv.org/abs/2312.00784) by Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee.
+The VipLlava model was proposed in [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://huggingface.co/papers/2312.00784) by Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee.
VipLlava enhances the training protocol of Llava by marking images and interact with the model using natural cues like a "red bounding box" or "pointed arrow" during training.
diff --git a/docs/source/en/model_doc/vision-encoder-decoder.md b/docs/source/en/model_doc/vision-encoder-decoder.md
index 0534085861..53c573be47 100644
--- a/docs/source/en/model_doc/vision-encoder-decoder.md
+++ b/docs/source/en/model_doc/vision-encoder-decoder.md
@@ -32,7 +32,7 @@ pretrained Transformer-based vision model as the encoder (*e.g.* [ViT](vit), [BE
and any pretrained language model as the decoder (*e.g.* [RoBERTa](roberta), [GPT2](gpt2), [BERT](bert), [DistilBERT](distilbert)).
The effectiveness of initializing image-to-text-sequence models with pretrained checkpoints has been shown in (for
-example) [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang,
+example) [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://huggingface.co/papers/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang,
Zhoujun Li, Furu Wei.
After such a [`VisionEncoderDecoderModel`] has been trained/fine-tuned, it can be saved/loaded just like any other models (see the examples below
diff --git a/docs/source/en/model_doc/vision-text-dual-encoder.md b/docs/source/en/model_doc/vision-text-dual-encoder.md
index b9d6db38d5..3106cb0ac3 100644
--- a/docs/source/en/model_doc/vision-text-dual-encoder.md
+++ b/docs/source/en/model_doc/vision-text-dual-encoder.md
@@ -33,7 +33,7 @@ to a shared latent space. The projection layers are randomly initialized so the
downstream task. This model can be used to align the vision-text embeddings using CLIP like contrastive image-text
training and then can be used for zero-shot vision tasks such image-classification or retrieval.
-In [LiT: Zero-Shot Transfer with Locked-image Text Tuning](https://arxiv.org/abs/2111.07991) it is shown how
+In [LiT: Zero-Shot Transfer with Locked-image Text Tuning](https://huggingface.co/papers/2111.07991) it is shown how
leveraging pre-trained (locked/frozen) image and text model for contrastive learning yields significant improvement on
new zero-shot vision tasks such as image classification or retrieval.
diff --git a/docs/source/en/model_doc/visual_bert.md b/docs/source/en/model_doc/visual_bert.md
index 265d482c19..02c98ba3d9 100644
--- a/docs/source/en/model_doc/visual_bert.md
+++ b/docs/source/en/model_doc/visual_bert.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The VisualBERT model was proposed in [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
+The VisualBERT model was proposed in [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://huggingface.co/papers/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
VisualBERT is a neural network trained on a variety of (image, text) pairs.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/vit_hybrid.md b/docs/source/en/model_doc/vit_hybrid.md
index a79fadd255..c268c2fad3 100644
--- a/docs/source/en/model_doc/vit_hybrid.md
+++ b/docs/source/en/model_doc/vit_hybrid.md
@@ -32,7 +32,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
The hybrid Vision Transformer (ViT) model was proposed in [An Image is Worth 16x16 Words: Transformers for Image Recognition
-at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk
+at Scale](https://huggingface.co/papers/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk
Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob
Uszkoreit, Neil Houlsby. It's the first paper that successfully trains a Transformer encoder on ImageNet, attaining
very good results compared to familiar convolutional architectures. ViT hybrid is a slight variant of the [plain Vision Transformer](vit),
diff --git a/docs/source/en/model_doc/vit_msn.md b/docs/source/en/model_doc/vit_msn.md
index a3aadef0e9..8835f01cd8 100644
--- a/docs/source/en/model_doc/vit_msn.md
+++ b/docs/source/en/model_doc/vit_msn.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The ViTMSN model was proposed in [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes,
+The ViTMSN model was proposed in [Masked Siamese Networks for Label-Efficient Learning](https://huggingface.co/papers/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes,
Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas. The paper presents a joint-embedding architecture to match the prototypes
of masked patches with that of the unmasked patches. With this setup, their method yields excellent performance in the low-shot and extreme low-shot
regimes.
@@ -41,7 +41,7 @@ and with 1% of ImageNet-1K labels, we achieve 75.7% top-1 accuracy, setting a ne
 - MSN architecture. Taken from the original paper.
+ MSN architecture. Taken from the original paper.
This model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/facebookresearch/msn).
diff --git a/docs/source/en/model_doc/vitdet.md b/docs/source/en/model_doc/vitdet.md
index d569e71d90..738d83461b 100644
--- a/docs/source/en/model_doc/vitdet.md
+++ b/docs/source/en/model_doc/vitdet.md
@@ -18,7 +18,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The ViTDet model was proposed in [Exploring Plain Vision Transformer Backbones for Object Detection](https://arxiv.org/abs/2203.16527) by Yanghao Li, Hanzi Mao, Ross Girshick, Kaiming He.
+The ViTDet model was proposed in [Exploring Plain Vision Transformer Backbones for Object Detection](https://huggingface.co/papers/2203.16527) by Yanghao Li, Hanzi Mao, Ross Girshick, Kaiming He.
VitDet leverages the plain [Vision Transformer](vit) for the task of object detection.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/vitmatte.md b/docs/source/en/model_doc/vitmatte.md
index 566c296229..f661de1622 100644
--- a/docs/source/en/model_doc/vitmatte.md
+++ b/docs/source/en/model_doc/vitmatte.md
@@ -18,7 +18,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The ViTMatte model was proposed in [Boosting Image Matting with Pretrained Plain Vision Transformers](https://arxiv.org/abs/2305.15272) by Jingfeng Yao, Xinggang Wang, Shusheng Yang, Baoyuan Wang.
+The ViTMatte model was proposed in [Boosting Image Matting with Pretrained Plain Vision Transformers](https://huggingface.co/papers/2305.15272) by Jingfeng Yao, Xinggang Wang, Shusheng Yang, Baoyuan Wang.
ViTMatte leverages plain [Vision Transformers](vit) for the task of image matting, which is the process of accurately estimating the foreground object in images and videos.
The abstract from the paper is the following:
@@ -31,7 +31,7 @@ The original code can be found [here](https://github.com/hustvl/ViTMatte).
- MSN architecture. Taken from the original paper.
+ MSN architecture. Taken from the original paper.
This model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/facebookresearch/msn).
diff --git a/docs/source/en/model_doc/vitdet.md b/docs/source/en/model_doc/vitdet.md
index d569e71d90..738d83461b 100644
--- a/docs/source/en/model_doc/vitdet.md
+++ b/docs/source/en/model_doc/vitdet.md
@@ -18,7 +18,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The ViTDet model was proposed in [Exploring Plain Vision Transformer Backbones for Object Detection](https://arxiv.org/abs/2203.16527) by Yanghao Li, Hanzi Mao, Ross Girshick, Kaiming He.
+The ViTDet model was proposed in [Exploring Plain Vision Transformer Backbones for Object Detection](https://huggingface.co/papers/2203.16527) by Yanghao Li, Hanzi Mao, Ross Girshick, Kaiming He.
VitDet leverages the plain [Vision Transformer](vit) for the task of object detection.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/vitmatte.md b/docs/source/en/model_doc/vitmatte.md
index 566c296229..f661de1622 100644
--- a/docs/source/en/model_doc/vitmatte.md
+++ b/docs/source/en/model_doc/vitmatte.md
@@ -18,7 +18,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The ViTMatte model was proposed in [Boosting Image Matting with Pretrained Plain Vision Transformers](https://arxiv.org/abs/2305.15272) by Jingfeng Yao, Xinggang Wang, Shusheng Yang, Baoyuan Wang.
+The ViTMatte model was proposed in [Boosting Image Matting with Pretrained Plain Vision Transformers](https://huggingface.co/papers/2305.15272) by Jingfeng Yao, Xinggang Wang, Shusheng Yang, Baoyuan Wang.
ViTMatte leverages plain [Vision Transformers](vit) for the task of image matting, which is the process of accurately estimating the foreground object in images and videos.
The abstract from the paper is the following:
@@ -31,7 +31,7 @@ The original code can be found [here](https://github.com/hustvl/ViTMatte).
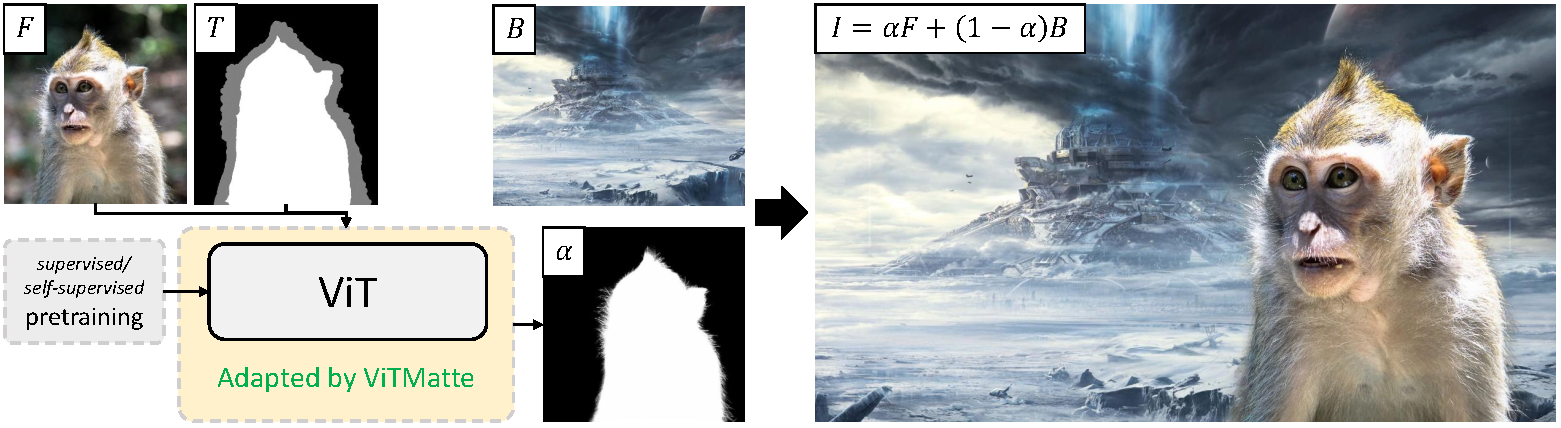 - ViTMatte high-level overview. Taken from the original paper.
+ ViTMatte high-level overview. Taken from the original paper.
## Resources
diff --git a/docs/source/en/model_doc/vitpose.md b/docs/source/en/model_doc/vitpose.md
index 02471ad39e..7a417cc213 100644
--- a/docs/source/en/model_doc/vitpose.md
+++ b/docs/source/en/model_doc/vitpose.md
@@ -18,7 +18,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The ViTPose model was proposed in [ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation](https://arxiv.org/abs/2204.12484) by Yufei Xu, Jing Zhang, Qiming Zhang, Dacheng Tao. ViTPose employs a standard, non-hierarchical [Vision Transformer](vit) as backbone for the task of keypoint estimation. A simple decoder head is added on top to predict the heatmaps from a given image. Despite its simplicity, the model gets state-of-the-art results on the challenging MS COCO Keypoint Detection benchmark. The model was further improved in [ViTPose++: Vision Transformer for Generic Body Pose Estimation](https://arxiv.org/abs/2212.04246) where the authors employ
+The ViTPose model was proposed in [ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation](https://huggingface.co/papers/2204.12484) by Yufei Xu, Jing Zhang, Qiming Zhang, Dacheng Tao. ViTPose employs a standard, non-hierarchical [Vision Transformer](vit) as backbone for the task of keypoint estimation. A simple decoder head is added on top to predict the heatmaps from a given image. Despite its simplicity, the model gets state-of-the-art results on the challenging MS COCO Keypoint Detection benchmark. The model was further improved in [ViTPose++: Vision Transformer for Generic Body Pose Estimation](https://huggingface.co/papers/2212.04246) where the authors employ
a mixture-of-experts (MoE) module in the ViT backbone along with pre-training on more data, which further enhances the performance.
The abstract from the paper is the following:
@@ -28,7 +28,7 @@ The abstract from the paper is the following:
- ViTMatte high-level overview. Taken from the original paper.
+ ViTMatte high-level overview. Taken from the original paper.
## Resources
diff --git a/docs/source/en/model_doc/vitpose.md b/docs/source/en/model_doc/vitpose.md
index 02471ad39e..7a417cc213 100644
--- a/docs/source/en/model_doc/vitpose.md
+++ b/docs/source/en/model_doc/vitpose.md
@@ -18,7 +18,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The ViTPose model was proposed in [ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation](https://arxiv.org/abs/2204.12484) by Yufei Xu, Jing Zhang, Qiming Zhang, Dacheng Tao. ViTPose employs a standard, non-hierarchical [Vision Transformer](vit) as backbone for the task of keypoint estimation. A simple decoder head is added on top to predict the heatmaps from a given image. Despite its simplicity, the model gets state-of-the-art results on the challenging MS COCO Keypoint Detection benchmark. The model was further improved in [ViTPose++: Vision Transformer for Generic Body Pose Estimation](https://arxiv.org/abs/2212.04246) where the authors employ
+The ViTPose model was proposed in [ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation](https://huggingface.co/papers/2204.12484) by Yufei Xu, Jing Zhang, Qiming Zhang, Dacheng Tao. ViTPose employs a standard, non-hierarchical [Vision Transformer](vit) as backbone for the task of keypoint estimation. A simple decoder head is added on top to predict the heatmaps from a given image. Despite its simplicity, the model gets state-of-the-art results on the challenging MS COCO Keypoint Detection benchmark. The model was further improved in [ViTPose++: Vision Transformer for Generic Body Pose Estimation](https://huggingface.co/papers/2212.04246) where the authors employ
a mixture-of-experts (MoE) module in the ViT backbone along with pre-training on more data, which further enhances the performance.
The abstract from the paper is the following:
@@ -28,7 +28,7 @@ The abstract from the paper is the following:
 - ViTPose architecture. Taken from the original paper.
+ ViTPose architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr) and [sangbumchoi](https://github.com/SangbumChoi).
The original code can be found [here](https://github.com/ViTAE-Transformer/ViTPose).
@@ -95,7 +95,7 @@ image_pose_result = pose_results[0] # results for first image
### ViTPose++ models
-The best [checkpoints](https://huggingface.co/collections/usyd-community/vitpose-677fcfd0a0b2b5c8f79c4335) are those of the [ViTPose++ paper](https://arxiv.org/abs/2212.04246). ViTPose++ models employ a so-called [Mixture-of-Experts (MoE)](https://huggingface.co/blog/moe) architecture for the ViT backbone, resulting in better performance.
+The best [checkpoints](https://huggingface.co/collections/usyd-community/vitpose-677fcfd0a0b2b5c8f79c4335) are those of the [ViTPose++ paper](https://huggingface.co/papers/2212.04246). ViTPose++ models employ a so-called [Mixture-of-Experts (MoE)](https://huggingface.co/blog/moe) architecture for the ViT backbone, resulting in better performance.
The ViTPose+ checkpoints use 6 experts, hence 6 different dataset indices can be passed.
An overview of the various dataset indices is provided below:
diff --git a/docs/source/en/model_doc/vivit.md b/docs/source/en/model_doc/vivit.md
index a2cba9793e..cf32c749e2 100644
--- a/docs/source/en/model_doc/vivit.md
+++ b/docs/source/en/model_doc/vivit.md
@@ -20,7 +20,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The Vivit model was proposed in [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
+The Vivit model was proposed in [ViViT: A Video Vision Transformer](https://huggingface.co/papers/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
The paper proposes one of the first successful pure-transformer based set of models for video understanding.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/wav2vec2-conformer.md b/docs/source/en/model_doc/wav2vec2-conformer.md
index f84e6b3711..fa304b3a86 100644
--- a/docs/source/en/model_doc/wav2vec2-conformer.md
+++ b/docs/source/en/model_doc/wav2vec2-conformer.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Wav2Vec2-Conformer was added to an updated version of [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
+The Wav2Vec2-Conformer was added to an updated version of [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://huggingface.co/papers/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
The official results of the model can be found in Table 3 and Table 4 of the paper.
@@ -36,7 +36,7 @@ Note: Meta (FAIR) released a new version of [Wav2Vec2-BERT 2.0](https://huggingf
## Usage tips
- Wav2Vec2-Conformer follows the same architecture as Wav2Vec2, but replaces the *Attention*-block with a *Conformer*-block
- as introduced in [Conformer: Convolution-augmented Transformer for Speech Recognition](https://arxiv.org/abs/2005.08100).
+ as introduced in [Conformer: Convolution-augmented Transformer for Speech Recognition](https://huggingface.co/papers/2005.08100).
- For the same number of layers, Wav2Vec2-Conformer requires more parameters than Wav2Vec2, but also yields
an improved word error rate.
- Wav2Vec2-Conformer uses the same tokenizer and feature extractor as Wav2Vec2.
diff --git a/docs/source/en/model_doc/wav2vec2.md b/docs/source/en/model_doc/wav2vec2.md
index a5fedef0f7..d884f44b1e 100644
--- a/docs/source/en/model_doc/wav2vec2.md
+++ b/docs/source/en/model_doc/wav2vec2.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Wav2Vec2 model was proposed in [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
+The Wav2Vec2 model was proposed in [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://huggingface.co/papers/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/wav2vec2_phoneme.md b/docs/source/en/model_doc/wav2vec2_phoneme.md
index c5c1edd6ac..863bdafca3 100644
--- a/docs/source/en/model_doc/wav2vec2_phoneme.md
+++ b/docs/source/en/model_doc/wav2vec2_phoneme.md
@@ -26,7 +26,7 @@ rendered properly in your Markdown viewer.
## Overview
The Wav2Vec2Phoneme model was proposed in [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition (Xu et al.,
-2021](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
+2021)](https://huggingface.co/papers/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/wavlm.md b/docs/source/en/model_doc/wavlm.md
index 54947e2f15..7dfe6f26bb 100644
--- a/docs/source/en/model_doc/wavlm.md
+++ b/docs/source/en/model_doc/wavlm.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The WavLM model was proposed in [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen,
+The WavLM model was proposed in [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://huggingface.co/papers/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen,
Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu,
Michael Zeng, Furu Wei.
diff --git a/docs/source/en/model_doc/xclip.md b/docs/source/en/model_doc/xclip.md
index 62f0c3aa2e..ca78a68ae2 100644
--- a/docs/source/en/model_doc/xclip.md
+++ b/docs/source/en/model_doc/xclip.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The X-CLIP model was proposed in [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816) by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
+The X-CLIP model was proposed in [Expanding Language-Image Pretrained Models for General Video Recognition](https://huggingface.co/papers/2208.02816) by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
X-CLIP is a minimal extension of [CLIP](clip) for video. The model consists of a text encoder, a cross-frame vision encoder, a multi-frame integration Transformer, and a video-specific prompt generator.
The abstract from the paper is the following:
@@ -36,7 +36,7 @@ Tips:
- ViTPose architecture. Taken from the original paper.
+ ViTPose architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr) and [sangbumchoi](https://github.com/SangbumChoi).
The original code can be found [here](https://github.com/ViTAE-Transformer/ViTPose).
@@ -95,7 +95,7 @@ image_pose_result = pose_results[0] # results for first image
### ViTPose++ models
-The best [checkpoints](https://huggingface.co/collections/usyd-community/vitpose-677fcfd0a0b2b5c8f79c4335) are those of the [ViTPose++ paper](https://arxiv.org/abs/2212.04246). ViTPose++ models employ a so-called [Mixture-of-Experts (MoE)](https://huggingface.co/blog/moe) architecture for the ViT backbone, resulting in better performance.
+The best [checkpoints](https://huggingface.co/collections/usyd-community/vitpose-677fcfd0a0b2b5c8f79c4335) are those of the [ViTPose++ paper](https://huggingface.co/papers/2212.04246). ViTPose++ models employ a so-called [Mixture-of-Experts (MoE)](https://huggingface.co/blog/moe) architecture for the ViT backbone, resulting in better performance.
The ViTPose+ checkpoints use 6 experts, hence 6 different dataset indices can be passed.
An overview of the various dataset indices is provided below:
diff --git a/docs/source/en/model_doc/vivit.md b/docs/source/en/model_doc/vivit.md
index a2cba9793e..cf32c749e2 100644
--- a/docs/source/en/model_doc/vivit.md
+++ b/docs/source/en/model_doc/vivit.md
@@ -20,7 +20,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The Vivit model was proposed in [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
+The Vivit model was proposed in [ViViT: A Video Vision Transformer](https://huggingface.co/papers/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
The paper proposes one of the first successful pure-transformer based set of models for video understanding.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/wav2vec2-conformer.md b/docs/source/en/model_doc/wav2vec2-conformer.md
index f84e6b3711..fa304b3a86 100644
--- a/docs/source/en/model_doc/wav2vec2-conformer.md
+++ b/docs/source/en/model_doc/wav2vec2-conformer.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Wav2Vec2-Conformer was added to an updated version of [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
+The Wav2Vec2-Conformer was added to an updated version of [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://huggingface.co/papers/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
The official results of the model can be found in Table 3 and Table 4 of the paper.
@@ -36,7 +36,7 @@ Note: Meta (FAIR) released a new version of [Wav2Vec2-BERT 2.0](https://huggingf
## Usage tips
- Wav2Vec2-Conformer follows the same architecture as Wav2Vec2, but replaces the *Attention*-block with a *Conformer*-block
- as introduced in [Conformer: Convolution-augmented Transformer for Speech Recognition](https://arxiv.org/abs/2005.08100).
+ as introduced in [Conformer: Convolution-augmented Transformer for Speech Recognition](https://huggingface.co/papers/2005.08100).
- For the same number of layers, Wav2Vec2-Conformer requires more parameters than Wav2Vec2, but also yields
an improved word error rate.
- Wav2Vec2-Conformer uses the same tokenizer and feature extractor as Wav2Vec2.
diff --git a/docs/source/en/model_doc/wav2vec2.md b/docs/source/en/model_doc/wav2vec2.md
index a5fedef0f7..d884f44b1e 100644
--- a/docs/source/en/model_doc/wav2vec2.md
+++ b/docs/source/en/model_doc/wav2vec2.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
## Overview
-The Wav2Vec2 model was proposed in [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
+The Wav2Vec2 model was proposed in [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://huggingface.co/papers/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/wav2vec2_phoneme.md b/docs/source/en/model_doc/wav2vec2_phoneme.md
index c5c1edd6ac..863bdafca3 100644
--- a/docs/source/en/model_doc/wav2vec2_phoneme.md
+++ b/docs/source/en/model_doc/wav2vec2_phoneme.md
@@ -26,7 +26,7 @@ rendered properly in your Markdown viewer.
## Overview
The Wav2Vec2Phoneme model was proposed in [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition (Xu et al.,
-2021](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
+2021)](https://huggingface.co/papers/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/wavlm.md b/docs/source/en/model_doc/wavlm.md
index 54947e2f15..7dfe6f26bb 100644
--- a/docs/source/en/model_doc/wavlm.md
+++ b/docs/source/en/model_doc/wavlm.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The WavLM model was proposed in [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen,
+The WavLM model was proposed in [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://huggingface.co/papers/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen,
Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu,
Michael Zeng, Furu Wei.
diff --git a/docs/source/en/model_doc/xclip.md b/docs/source/en/model_doc/xclip.md
index 62f0c3aa2e..ca78a68ae2 100644
--- a/docs/source/en/model_doc/xclip.md
+++ b/docs/source/en/model_doc/xclip.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The X-CLIP model was proposed in [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816) by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
+The X-CLIP model was proposed in [Expanding Language-Image Pretrained Models for General Video Recognition](https://huggingface.co/papers/2208.02816) by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
X-CLIP is a minimal extension of [CLIP](clip) for video. The model consists of a text encoder, a cross-frame vision encoder, a multi-frame integration Transformer, and a video-specific prompt generator.
The abstract from the paper is the following:
@@ -36,7 +36,7 @@ Tips:
 - X-CLIP architecture. Taken from the original paper.
+ X-CLIP architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/microsoft/VideoX/tree/master/X-CLIP).
diff --git a/docs/source/en/model_doc/xglm.md b/docs/source/en/model_doc/xglm.md
index 4032de2cd7..6c0c180727 100644
--- a/docs/source/en/model_doc/xglm.md
+++ b/docs/source/en/model_doc/xglm.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The XGLM model was proposed in [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668)
+The XGLM model was proposed in [Few-shot Learning with Multilingual Language Models](https://huggingface.co/papers/2112.10668)
by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal,
Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo,
Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
diff --git a/docs/source/en/model_doc/xlm-prophetnet.md b/docs/source/en/model_doc/xlm-prophetnet.md
index 046904d885..5d11a532f2 100644
--- a/docs/source/en/model_doc/xlm-prophetnet.md
+++ b/docs/source/en/model_doc/xlm-prophetnet.md
@@ -43,7 +43,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The XLM-ProphetNet model was proposed in [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei
+The XLM-ProphetNet model was proposed in [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://huggingface.co/papers/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei
Zhang, Ming Zhou on 13 Jan, 2020.
XLM-ProphetNet is an encoder-decoder model and can predict n-future tokens for "ngram" language modeling instead of
diff --git a/docs/source/en/model_doc/xlm-v.md b/docs/source/en/model_doc/xlm-v.md
index 69badfe2e6..05b4a42593 100644
--- a/docs/source/en/model_doc/xlm-v.md
+++ b/docs/source/en/model_doc/xlm-v.md
@@ -26,7 +26,7 @@ rendered properly in your Markdown viewer.
## Overview
XLM-V is multilingual language model with a one million token vocabulary trained on 2.5TB of data from Common Crawl (same as XLM-R).
-It was introduced in the [XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models](https://arxiv.org/abs/2301.10472)
+It was introduced in the [XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models](https://huggingface.co/papers/2301.10472)
paper by Davis Liang, Hila Gonen, Yuning Mao, Rui Hou, Naman Goyal, Marjan Ghazvininejad, Luke Zettlemoyer and Madian Khabsa.
From the abstract of the XLM-V paper:
diff --git a/docs/source/en/model_doc/xlnet.md b/docs/source/en/model_doc/xlnet.md
index 0b90de75cc..e35851d5d2 100644
--- a/docs/source/en/model_doc/xlnet.md
+++ b/docs/source/en/model_doc/xlnet.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The XLNet model was proposed in [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov,
+The XLNet model was proposed in [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://huggingface.co/papers/1906.08237) by Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov,
Quoc V. Le. XLnet is an extension of the Transformer-XL model pre-trained using an autoregressive method to learn
bidirectional contexts by maximizing the expected likelihood over all permutations of the input sequence factorization
order.
diff --git a/docs/source/en/model_doc/xls_r.md b/docs/source/en/model_doc/xls_r.md
index d24d88907e..238c703f3e 100644
--- a/docs/source/en/model_doc/xls_r.md
+++ b/docs/source/en/model_doc/xls_r.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The XLS-R model was proposed in [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman
+The XLS-R model was proposed in [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://huggingface.co/papers/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman
Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/xlsr_wav2vec2.md b/docs/source/en/model_doc/xlsr_wav2vec2.md
index f88b0dc9e1..eceea3be20 100644
--- a/docs/source/en/model_doc/xlsr_wav2vec2.md
+++ b/docs/source/en/model_doc/xlsr_wav2vec2.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The XLSR-Wav2Vec2 model was proposed in [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael
+The XLSR-Wav2Vec2 model was proposed in [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://huggingface.co/papers/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael
Auli.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/yolos.md b/docs/source/en/model_doc/yolos.md
index c4a9e21228..9eaf56d2be 100644
--- a/docs/source/en/model_doc/yolos.md
+++ b/docs/source/en/model_doc/yolos.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The YOLOS model was proposed in [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
+The YOLOS model was proposed in [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://huggingface.co/papers/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
YOLOS proposes to just leverage the plain [Vision Transformer (ViT)](vit) for object detection, inspired by DETR. It turns out that a base-sized encoder-only Transformer can also achieve 42 AP on COCO, similar to DETR and much more complex frameworks such as Faster R-CNN.
The abstract from the paper is the following:
@@ -34,7 +34,7 @@ The abstract from the paper is the following:
- X-CLIP architecture. Taken from the original paper.
+ X-CLIP architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/microsoft/VideoX/tree/master/X-CLIP).
diff --git a/docs/source/en/model_doc/xglm.md b/docs/source/en/model_doc/xglm.md
index 4032de2cd7..6c0c180727 100644
--- a/docs/source/en/model_doc/xglm.md
+++ b/docs/source/en/model_doc/xglm.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The XGLM model was proposed in [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668)
+The XGLM model was proposed in [Few-shot Learning with Multilingual Language Models](https://huggingface.co/papers/2112.10668)
by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal,
Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo,
Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
diff --git a/docs/source/en/model_doc/xlm-prophetnet.md b/docs/source/en/model_doc/xlm-prophetnet.md
index 046904d885..5d11a532f2 100644
--- a/docs/source/en/model_doc/xlm-prophetnet.md
+++ b/docs/source/en/model_doc/xlm-prophetnet.md
@@ -43,7 +43,7 @@ You can do so by running the following command: `pip install -U transformers==4.
## Overview
-The XLM-ProphetNet model was proposed in [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei
+The XLM-ProphetNet model was proposed in [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://huggingface.co/papers/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei
Zhang, Ming Zhou on 13 Jan, 2020.
XLM-ProphetNet is an encoder-decoder model and can predict n-future tokens for "ngram" language modeling instead of
diff --git a/docs/source/en/model_doc/xlm-v.md b/docs/source/en/model_doc/xlm-v.md
index 69badfe2e6..05b4a42593 100644
--- a/docs/source/en/model_doc/xlm-v.md
+++ b/docs/source/en/model_doc/xlm-v.md
@@ -26,7 +26,7 @@ rendered properly in your Markdown viewer.
## Overview
XLM-V is multilingual language model with a one million token vocabulary trained on 2.5TB of data from Common Crawl (same as XLM-R).
-It was introduced in the [XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models](https://arxiv.org/abs/2301.10472)
+It was introduced in the [XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models](https://huggingface.co/papers/2301.10472)
paper by Davis Liang, Hila Gonen, Yuning Mao, Rui Hou, Naman Goyal, Marjan Ghazvininejad, Luke Zettlemoyer and Madian Khabsa.
From the abstract of the XLM-V paper:
diff --git a/docs/source/en/model_doc/xlnet.md b/docs/source/en/model_doc/xlnet.md
index 0b90de75cc..e35851d5d2 100644
--- a/docs/source/en/model_doc/xlnet.md
+++ b/docs/source/en/model_doc/xlnet.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## Overview
-The XLNet model was proposed in [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov,
+The XLNet model was proposed in [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://huggingface.co/papers/1906.08237) by Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov,
Quoc V. Le. XLnet is an extension of the Transformer-XL model pre-trained using an autoregressive method to learn
bidirectional contexts by maximizing the expected likelihood over all permutations of the input sequence factorization
order.
diff --git a/docs/source/en/model_doc/xls_r.md b/docs/source/en/model_doc/xls_r.md
index d24d88907e..238c703f3e 100644
--- a/docs/source/en/model_doc/xls_r.md
+++ b/docs/source/en/model_doc/xls_r.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The XLS-R model was proposed in [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman
+The XLS-R model was proposed in [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://huggingface.co/papers/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman
Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/xlsr_wav2vec2.md b/docs/source/en/model_doc/xlsr_wav2vec2.md
index f88b0dc9e1..eceea3be20 100644
--- a/docs/source/en/model_doc/xlsr_wav2vec2.md
+++ b/docs/source/en/model_doc/xlsr_wav2vec2.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
## Overview
-The XLSR-Wav2Vec2 model was proposed in [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael
+The XLSR-Wav2Vec2 model was proposed in [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://huggingface.co/papers/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael
Auli.
The abstract from the paper is the following:
diff --git a/docs/source/en/model_doc/yolos.md b/docs/source/en/model_doc/yolos.md
index c4a9e21228..9eaf56d2be 100644
--- a/docs/source/en/model_doc/yolos.md
+++ b/docs/source/en/model_doc/yolos.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-The YOLOS model was proposed in [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
+The YOLOS model was proposed in [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://huggingface.co/papers/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
YOLOS proposes to just leverage the plain [Vision Transformer (ViT)](vit) for object detection, inspired by DETR. It turns out that a base-sized encoder-only Transformer can also achieve 42 AP on COCO, similar to DETR and much more complex frameworks such as Faster R-CNN.
The abstract from the paper is the following:
@@ -34,7 +34,7 @@ The abstract from the paper is the following:
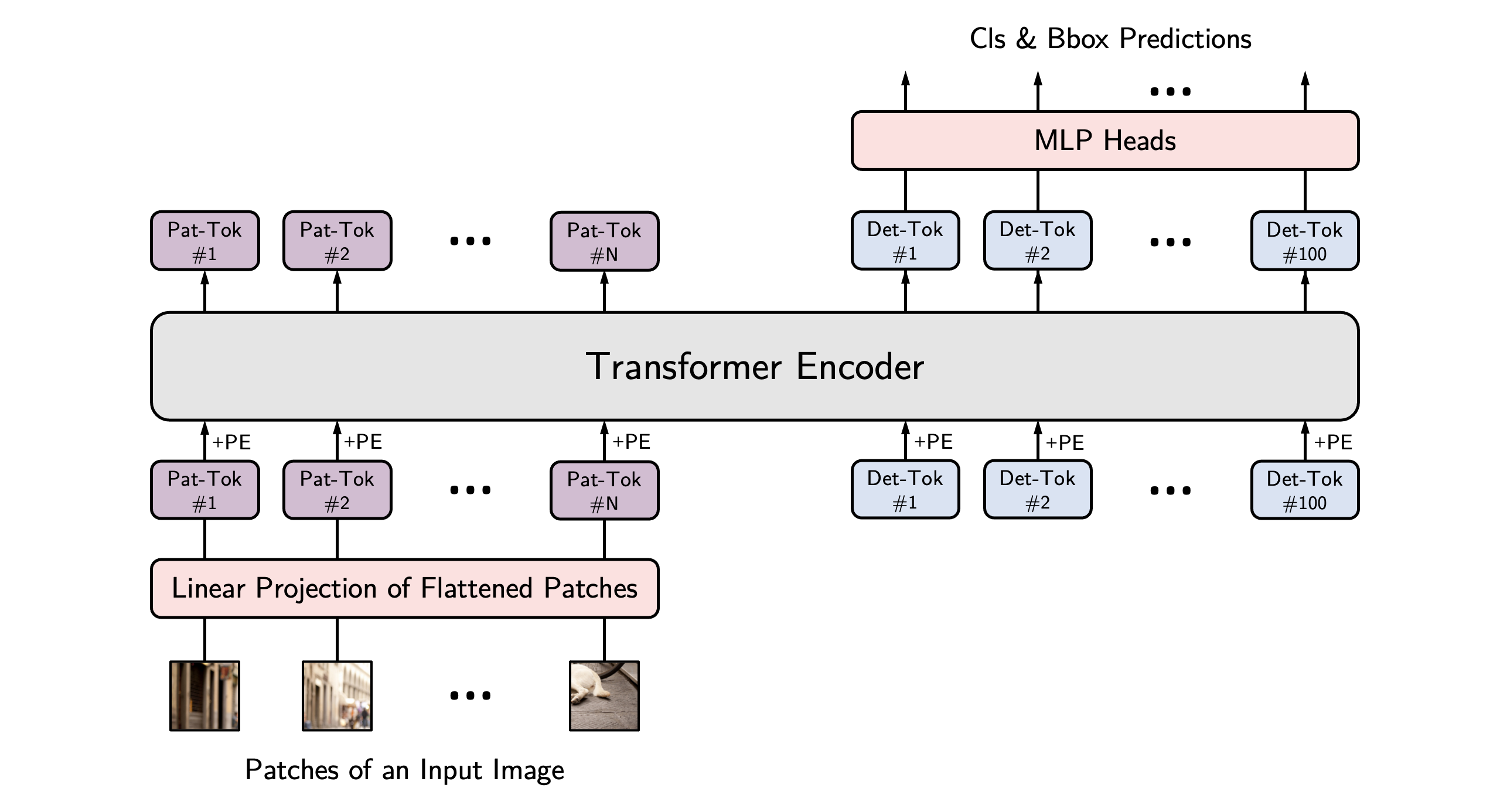 - YOLOS architecture. Taken from the original paper.
+ YOLOS architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/hustvl/YOLOS).
diff --git a/docs/source/en/model_doc/yoso.md b/docs/source/en/model_doc/yoso.md
index c9fbb11b1e..344fad9e12 100644
--- a/docs/source/en/model_doc/yoso.md
+++ b/docs/source/en/model_doc/yoso.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The YOSO model was proposed in [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714)
+The YOSO model was proposed in [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://huggingface.co/papers/2111.09714)
by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh. YOSO approximates standard softmax self-attention
via a Bernoulli sampling scheme based on Locality Sensitive Hashing (LSH). In principle, all the Bernoulli random variables can be sampled with
a single hash.
@@ -56,7 +56,7 @@ does not require compiling CUDA kernels.
- YOLOS architecture. Taken from the original paper.
+ YOLOS architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/hustvl/YOLOS).
diff --git a/docs/source/en/model_doc/yoso.md b/docs/source/en/model_doc/yoso.md
index c9fbb11b1e..344fad9e12 100644
--- a/docs/source/en/model_doc/yoso.md
+++ b/docs/source/en/model_doc/yoso.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## Overview
-The YOSO model was proposed in [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714)
+The YOSO model was proposed in [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://huggingface.co/papers/2111.09714)
by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh. YOSO approximates standard softmax self-attention
via a Bernoulli sampling scheme based on Locality Sensitive Hashing (LSH). In principle, all the Bernoulli random variables can be sampled with
a single hash.
@@ -56,7 +56,7 @@ does not require compiling CUDA kernels.
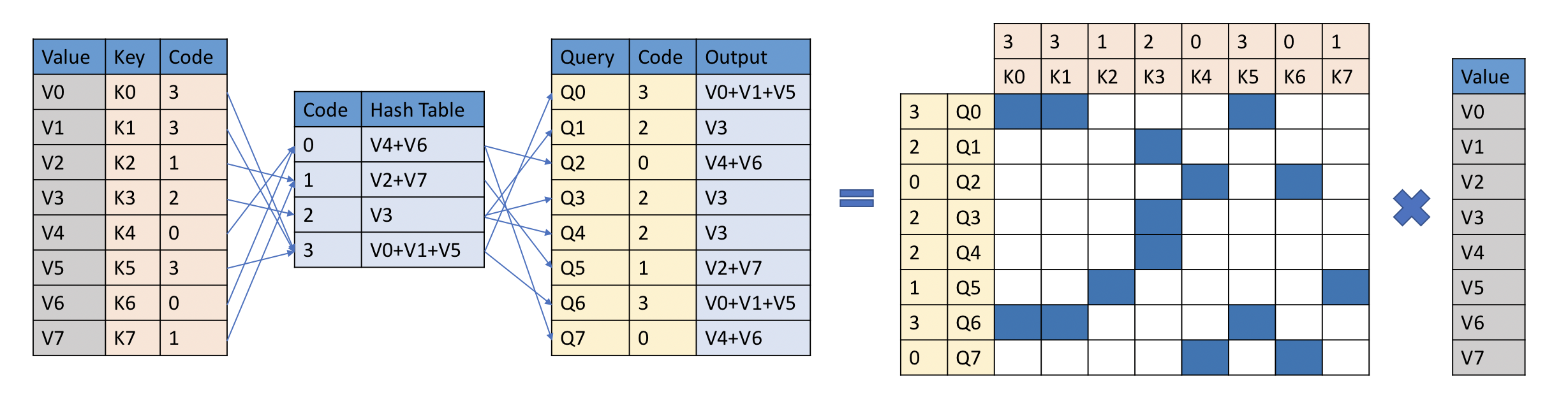 - YOSO Attention Algorithm. Taken from the original paper.
+ YOSO Attention Algorithm. Taken from the original paper.
## Resources
diff --git a/docs/source/en/model_memory_anatomy.md b/docs/source/en/model_memory_anatomy.md
index 44c197aae5..7ef53f4056 100644
--- a/docs/source/en/model_memory_anatomy.md
+++ b/docs/source/en/model_memory_anatomy.md
@@ -204,7 +204,7 @@ Transformers architecture includes 3 main groups of operations grouped below by
This knowledge can be helpful to know when analyzing performance bottlenecks.
-This summary is derived from [Data Movement Is All You Need: A Case Study on Optimizing Transformers 2020](https://arxiv.org/abs/2007.00072)
+This summary is derived from [Data Movement Is All You Need: A Case Study on Optimizing Transformers 2020](https://huggingface.co/papers/2007.00072)
## Anatomy of Model's Memory
diff --git a/docs/source/en/model_summary.md b/docs/source/en/model_summary.md
index c7efc4c00d..0836f27283 100644
--- a/docs/source/en/model_summary.md
+++ b/docs/source/en/model_summary.md
@@ -16,7 +16,7 @@ rendered properly in your Markdown viewer.
# The Transformer model family
-Since its introduction in 2017, the [original Transformer](https://arxiv.org/abs/1706.03762) model (see the [Annotated Transformer](http://nlp.seas.harvard.edu/2018/04/03/attention.html) blog post for a gentle technical introduction) has inspired many new and exciting models that extend beyond natural language processing (NLP) tasks. There are models for [predicting the folded structure of proteins](https://huggingface.co/blog/deep-learning-with-proteins), [training a cheetah to run](https://huggingface.co/blog/train-decision-transformers), and [time series forecasting](https://huggingface.co/blog/time-series-transformers). With so many Transformer variants available, it can be easy to miss the bigger picture. What all these models have in common is they're based on the original Transformer architecture. Some models only use the encoder or decoder, while others use both. This provides a useful taxonomy to categorize and examine the high-level differences within models in the Transformer family, and it'll help you understand Transformers you haven't encountered before.
+Since its introduction in 2017, the [original Transformer](https://huggingface.co/papers/1706.03762) model (see the [Annotated Transformer](http://nlp.seas.harvard.edu/2018/04/03/attention.html) blog post for a gentle technical introduction) has inspired many new and exciting models that extend beyond natural language processing (NLP) tasks. There are models for [predicting the folded structure of proteins](https://huggingface.co/blog/deep-learning-with-proteins), [training a cheetah to run](https://huggingface.co/blog/train-decision-transformers), and [time series forecasting](https://huggingface.co/blog/time-series-transformers). With so many Transformer variants available, it can be easy to miss the bigger picture. What all these models have in common is they're based on the original Transformer architecture. Some models only use the encoder or decoder, while others use both. This provides a useful taxonomy to categorize and examine the high-level differences within models in the Transformer family, and it'll help you understand Transformers you haven't encountered before.
If you aren't familiar with the original Transformer model or need a refresher, check out the [How do Transformers work](https://huggingface.co/course/chapter1/4?fw=pt) chapter from the Hugging Face course.
@@ -32,7 +32,7 @@ If you aren't familiar with the original Transformer model or need a refresher,
### Convolutional network
-For a long time, convolutional networks (CNNs) were the dominant paradigm for computer vision tasks until the [Vision Transformer](https://arxiv.org/abs/2010.11929) demonstrated its scalability and efficiency. Even then, some of a CNN's best qualities, like translation invariance, are so powerful (especially for certain tasks) that some Transformers incorporate convolutions in their architecture. [ConvNeXt](model_doc/convnext) flipped this exchange around and incorporated design choices from Transformers to modernize a CNN. For example, ConvNeXt uses non-overlapping sliding windows to patchify an image and a larger kernel to increase its global receptive field. ConvNeXt also makes several layer design choices to be more memory-efficient and improve performance, so it competes favorably with Transformers!
+For a long time, convolutional networks (CNNs) were the dominant paradigm for computer vision tasks until the [Vision Transformer](https://huggingface.co/papers/2010.11929) demonstrated its scalability and efficiency. Even then, some of a CNN's best qualities, like translation invariance, are so powerful (especially for certain tasks) that some Transformers incorporate convolutions in their architecture. [ConvNeXt](model_doc/convnext) flipped this exchange around and incorporated design choices from Transformers to modernize a CNN. For example, ConvNeXt uses non-overlapping sliding windows to patchify an image and a larger kernel to increase its global receptive field. ConvNeXt also makes several layer design choices to be more memory-efficient and improve performance, so it competes favorably with Transformers!
### Encoder[[cv-encoder]]
@@ -58,7 +58,7 @@ Vision models commonly use an encoder (also known as a backbone) to extract impo
[BERT](model_doc/bert) is an encoder-only Transformer that randomly masks certain tokens in the input to avoid seeing other tokens, which would allow it to "cheat". The pretraining objective is to predict the masked token based on the context. This allows BERT to fully use the left and right contexts to help it learn a deeper and richer representation of the inputs. However, there was still room for improvement in BERT's pretraining strategy. [RoBERTa](model_doc/roberta) improved upon this by introducing a new pretraining recipe that includes training for longer and on larger batches, randomly masking tokens at each epoch instead of just once during preprocessing, and removing the next-sentence prediction objective.
-The dominant strategy to improve performance is to increase the model size. But training large models is computationally expensive. One way to reduce computational costs is using a smaller model like [DistilBERT](model_doc/distilbert). DistilBERT uses [knowledge distillation](https://arxiv.org/abs/1503.02531) - a compression technique - to create a smaller version of BERT while keeping nearly all of its language understanding capabilities.
+The dominant strategy to improve performance is to increase the model size. But training large models is computationally expensive. One way to reduce computational costs is using a smaller model like [DistilBERT](model_doc/distilbert). DistilBERT uses [knowledge distillation](https://huggingface.co/papers/1503.02531) - a compression technique - to create a smaller version of BERT while keeping nearly all of its language understanding capabilities.
However, most Transformer models continued to trend towards more parameters, leading to new models focused on improving training efficiency. [ALBERT](model_doc/albert) reduces memory consumption by lowering the number of parameters in two ways: separating the larger vocabulary embedding into two smaller matrices and allowing layers to share parameters. [DeBERTa](model_doc/deberta) added a disentangled attention mechanism where the word and its position are separately encoded in two vectors. The attention is computed from these separate vectors instead of a single vector containing the word and position embeddings. [Longformer](model_doc/longformer) also focused on making attention more efficient, especially for processing documents with longer sequence lengths. It uses a combination of local windowed attention (attention only calculated from fixed window size around each token) and global attention (only for specific task tokens like `[CLS]` for classification) to create a sparse attention matrix instead of a full attention matrix.
diff --git a/docs/source/en/quantization/aqlm.md b/docs/source/en/quantization/aqlm.md
index 9c9b6ac071..49bd7f89bc 100644
--- a/docs/source/en/quantization/aqlm.md
+++ b/docs/source/en/quantization/aqlm.md
@@ -16,7 +16,7 @@ rendered properly in your Markdown viewer.
# AQLM
-Additive Quantization of Language Models ([AQLM](https://arxiv.org/abs/2401.06118)) quantizes multiple weights together and takes advantage of interdependencies between them. AQLM represents groups of 8-16 weights as a sum of multiple vector codes.
+Additive Quantization of Language Models ([AQLM](https://huggingface.co/papers/2401.06118)) quantizes multiple weights together and takes advantage of interdependencies between them. AQLM represents groups of 8-16 weights as a sum of multiple vector codes.
AQLM also supports fine-tuning with [LoRA](https://huggingface.co/docs/peft/package_reference/lora) with the [PEFT](https://huggingface.co/docs/peft) library, and is fully compatible with [torch.compile](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) for even faster inference and training.
diff --git a/docs/source/en/quantization/bitnet.md b/docs/source/en/quantization/bitnet.md
index 5f713a20d3..922210b213 100644
--- a/docs/source/en/quantization/bitnet.md
+++ b/docs/source/en/quantization/bitnet.md
@@ -16,7 +16,7 @@ rendered properly in your Markdown viewer.
# BitNet
-[BitNet](https://arxiv.org/abs/2402.17764) replaces traditional linear layers in Multi-Head Attention and feed-forward networks with specialized BitLinear layers. The BitLinear layers quantize the weights using ternary precision (with values of -1, 0, and 1) and quantize the activations to 8-bit precision.
+[BitNet](https://huggingface.co/papers/2402.17764) replaces traditional linear layers in Multi-Head Attention and feed-forward networks with specialized BitLinear layers. The BitLinear layers quantize the weights using ternary precision (with values of -1, 0, and 1) and quantize the activations to 8-bit precision.
- YOSO Attention Algorithm. Taken from the original paper.
+ YOSO Attention Algorithm. Taken from the original paper.
## Resources
diff --git a/docs/source/en/model_memory_anatomy.md b/docs/source/en/model_memory_anatomy.md
index 44c197aae5..7ef53f4056 100644
--- a/docs/source/en/model_memory_anatomy.md
+++ b/docs/source/en/model_memory_anatomy.md
@@ -204,7 +204,7 @@ Transformers architecture includes 3 main groups of operations grouped below by
This knowledge can be helpful to know when analyzing performance bottlenecks.
-This summary is derived from [Data Movement Is All You Need: A Case Study on Optimizing Transformers 2020](https://arxiv.org/abs/2007.00072)
+This summary is derived from [Data Movement Is All You Need: A Case Study on Optimizing Transformers 2020](https://huggingface.co/papers/2007.00072)
## Anatomy of Model's Memory
diff --git a/docs/source/en/model_summary.md b/docs/source/en/model_summary.md
index c7efc4c00d..0836f27283 100644
--- a/docs/source/en/model_summary.md
+++ b/docs/source/en/model_summary.md
@@ -16,7 +16,7 @@ rendered properly in your Markdown viewer.
# The Transformer model family
-Since its introduction in 2017, the [original Transformer](https://arxiv.org/abs/1706.03762) model (see the [Annotated Transformer](http://nlp.seas.harvard.edu/2018/04/03/attention.html) blog post for a gentle technical introduction) has inspired many new and exciting models that extend beyond natural language processing (NLP) tasks. There are models for [predicting the folded structure of proteins](https://huggingface.co/blog/deep-learning-with-proteins), [training a cheetah to run](https://huggingface.co/blog/train-decision-transformers), and [time series forecasting](https://huggingface.co/blog/time-series-transformers). With so many Transformer variants available, it can be easy to miss the bigger picture. What all these models have in common is they're based on the original Transformer architecture. Some models only use the encoder or decoder, while others use both. This provides a useful taxonomy to categorize and examine the high-level differences within models in the Transformer family, and it'll help you understand Transformers you haven't encountered before.
+Since its introduction in 2017, the [original Transformer](https://huggingface.co/papers/1706.03762) model (see the [Annotated Transformer](http://nlp.seas.harvard.edu/2018/04/03/attention.html) blog post for a gentle technical introduction) has inspired many new and exciting models that extend beyond natural language processing (NLP) tasks. There are models for [predicting the folded structure of proteins](https://huggingface.co/blog/deep-learning-with-proteins), [training a cheetah to run](https://huggingface.co/blog/train-decision-transformers), and [time series forecasting](https://huggingface.co/blog/time-series-transformers). With so many Transformer variants available, it can be easy to miss the bigger picture. What all these models have in common is they're based on the original Transformer architecture. Some models only use the encoder or decoder, while others use both. This provides a useful taxonomy to categorize and examine the high-level differences within models in the Transformer family, and it'll help you understand Transformers you haven't encountered before.
If you aren't familiar with the original Transformer model or need a refresher, check out the [How do Transformers work](https://huggingface.co/course/chapter1/4?fw=pt) chapter from the Hugging Face course.
@@ -32,7 +32,7 @@ If you aren't familiar with the original Transformer model or need a refresher,
### Convolutional network
-For a long time, convolutional networks (CNNs) were the dominant paradigm for computer vision tasks until the [Vision Transformer](https://arxiv.org/abs/2010.11929) demonstrated its scalability and efficiency. Even then, some of a CNN's best qualities, like translation invariance, are so powerful (especially for certain tasks) that some Transformers incorporate convolutions in their architecture. [ConvNeXt](model_doc/convnext) flipped this exchange around and incorporated design choices from Transformers to modernize a CNN. For example, ConvNeXt uses non-overlapping sliding windows to patchify an image and a larger kernel to increase its global receptive field. ConvNeXt also makes several layer design choices to be more memory-efficient and improve performance, so it competes favorably with Transformers!
+For a long time, convolutional networks (CNNs) were the dominant paradigm for computer vision tasks until the [Vision Transformer](https://huggingface.co/papers/2010.11929) demonstrated its scalability and efficiency. Even then, some of a CNN's best qualities, like translation invariance, are so powerful (especially for certain tasks) that some Transformers incorporate convolutions in their architecture. [ConvNeXt](model_doc/convnext) flipped this exchange around and incorporated design choices from Transformers to modernize a CNN. For example, ConvNeXt uses non-overlapping sliding windows to patchify an image and a larger kernel to increase its global receptive field. ConvNeXt also makes several layer design choices to be more memory-efficient and improve performance, so it competes favorably with Transformers!
### Encoder[[cv-encoder]]
@@ -58,7 +58,7 @@ Vision models commonly use an encoder (also known as a backbone) to extract impo
[BERT](model_doc/bert) is an encoder-only Transformer that randomly masks certain tokens in the input to avoid seeing other tokens, which would allow it to "cheat". The pretraining objective is to predict the masked token based on the context. This allows BERT to fully use the left and right contexts to help it learn a deeper and richer representation of the inputs. However, there was still room for improvement in BERT's pretraining strategy. [RoBERTa](model_doc/roberta) improved upon this by introducing a new pretraining recipe that includes training for longer and on larger batches, randomly masking tokens at each epoch instead of just once during preprocessing, and removing the next-sentence prediction objective.
-The dominant strategy to improve performance is to increase the model size. But training large models is computationally expensive. One way to reduce computational costs is using a smaller model like [DistilBERT](model_doc/distilbert). DistilBERT uses [knowledge distillation](https://arxiv.org/abs/1503.02531) - a compression technique - to create a smaller version of BERT while keeping nearly all of its language understanding capabilities.
+The dominant strategy to improve performance is to increase the model size. But training large models is computationally expensive. One way to reduce computational costs is using a smaller model like [DistilBERT](model_doc/distilbert). DistilBERT uses [knowledge distillation](https://huggingface.co/papers/1503.02531) - a compression technique - to create a smaller version of BERT while keeping nearly all of its language understanding capabilities.
However, most Transformer models continued to trend towards more parameters, leading to new models focused on improving training efficiency. [ALBERT](model_doc/albert) reduces memory consumption by lowering the number of parameters in two ways: separating the larger vocabulary embedding into two smaller matrices and allowing layers to share parameters. [DeBERTa](model_doc/deberta) added a disentangled attention mechanism where the word and its position are separately encoded in two vectors. The attention is computed from these separate vectors instead of a single vector containing the word and position embeddings. [Longformer](model_doc/longformer) also focused on making attention more efficient, especially for processing documents with longer sequence lengths. It uses a combination of local windowed attention (attention only calculated from fixed window size around each token) and global attention (only for specific task tokens like `[CLS]` for classification) to create a sparse attention matrix instead of a full attention matrix.
diff --git a/docs/source/en/quantization/aqlm.md b/docs/source/en/quantization/aqlm.md
index 9c9b6ac071..49bd7f89bc 100644
--- a/docs/source/en/quantization/aqlm.md
+++ b/docs/source/en/quantization/aqlm.md
@@ -16,7 +16,7 @@ rendered properly in your Markdown viewer.
# AQLM
-Additive Quantization of Language Models ([AQLM](https://arxiv.org/abs/2401.06118)) quantizes multiple weights together and takes advantage of interdependencies between them. AQLM represents groups of 8-16 weights as a sum of multiple vector codes.
+Additive Quantization of Language Models ([AQLM](https://huggingface.co/papers/2401.06118)) quantizes multiple weights together and takes advantage of interdependencies between them. AQLM represents groups of 8-16 weights as a sum of multiple vector codes.
AQLM also supports fine-tuning with [LoRA](https://huggingface.co/docs/peft/package_reference/lora) with the [PEFT](https://huggingface.co/docs/peft) library, and is fully compatible with [torch.compile](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) for even faster inference and training.
diff --git a/docs/source/en/quantization/bitnet.md b/docs/source/en/quantization/bitnet.md
index 5f713a20d3..922210b213 100644
--- a/docs/source/en/quantization/bitnet.md
+++ b/docs/source/en/quantization/bitnet.md
@@ -16,7 +16,7 @@ rendered properly in your Markdown viewer.
# BitNet
-[BitNet](https://arxiv.org/abs/2402.17764) replaces traditional linear layers in Multi-Head Attention and feed-forward networks with specialized BitLinear layers. The BitLinear layers quantize the weights using ternary precision (with values of -1, 0, and 1) and quantize the activations to 8-bit precision.
+[BitNet](https://huggingface.co/papers/2402.17764) replaces traditional linear layers in Multi-Head Attention and feed-forward networks with specialized BitLinear layers. The BitLinear layers quantize the weights using ternary precision (with values of -1, 0, and 1) and quantize the activations to 8-bit precision.
 @@ -27,7 +27,7 @@ BitNet models can't be quantized on the fly. They need to be quantized during pr
1. Compute the average of the absolute values of the weight matrix and use as a scale.
2. Divide the weights by the scale, round the values, constrain them between -1 and 1, and rescale them to continue in full precision.
-3. Activations are quantized to a specified bit-width (8-bit) using [absmax](https://arxiv.org/pdf/2208.07339) quantization (symmetric per channel quantization). This involves scaling the activations into a range of [−128,127].
+3. Activations are quantized to a specified bit-width (8-bit) using [absmax](https://huggingface.co/papers/2208.07339) quantization (symmetric per channel quantization). This involves scaling the activations into a range of [−128,127].
Refer to this [PR](https://github.com/huggingface/nanotron/pull/180) to pretrain or fine-tune a 1.58-bit model with [Nanotron](https://github.com/huggingface/nanotron). For fine-tuning, convert a model from the Hugging Face to Nanotron format. Find the conversion steps in this [PR](https://github.com/huggingface/nanotron/pull/174).
diff --git a/docs/source/en/quantization/higgs.md b/docs/source/en/quantization/higgs.md
index 11c42b208c..07f6e2b31f 100644
--- a/docs/source/en/quantization/higgs.md
+++ b/docs/source/en/quantization/higgs.md
@@ -16,7 +16,7 @@ rendered properly in your Markdown viewer.
# HIGGS
-[HIGGS](https://arxiv.org/abs/2411.17525) is a zero-shot quantization algorithm that combines Hadamard preprocessing with MSE-Optimal quantization grids to achieve lower quantization error and state-of-the-art performance.
+[HIGGS](https://huggingface.co/papers/2411.17525) is a zero-shot quantization algorithm that combines Hadamard preprocessing with MSE-Optimal quantization grids to achieve lower quantization error and state-of-the-art performance.
Runtime support for HIGGS is implemented through the [FLUTE](https://github.com/HanGuo97/flute) library. Only the 70B and 405B variants of Llama 3 and Llama 3.0, and the 8B and 27B variants of Gemma 2 are currently supported. HIGGS also doesn't support quantized training and backward passes in general at the moment.
diff --git a/docs/source/en/quantization/vptq.md b/docs/source/en/quantization/vptq.md
index af082c5f2f..392895e0ea 100644
--- a/docs/source/en/quantization/vptq.md
+++ b/docs/source/en/quantization/vptq.md
@@ -69,4 +69,4 @@ VPTQ achieves better accuracy and higher throughput with lower quantization over
See an example demo of VPTQ on the VPTQ Online Demo [Space](https://huggingface.co/spaces/microsoft/VPTQ) or try running the VPTQ inference [notebook](https://colab.research.google.com/github/microsoft/VPTQ/blob/main/notebooks/vptq_example.ipynb).
-For more information, read the VPTQ [paper](https://arxiv.org/pdf/2409.17066).
+For more information, read the VPTQ [paper](https://huggingface.co/papers/2409.17066).
diff --git a/docs/source/en/tasks/knowledge_distillation_for_image_classification.md b/docs/source/en/tasks/knowledge_distillation_for_image_classification.md
index c1ccafb6fc..4d1e735bd7 100644
--- a/docs/source/en/tasks/knowledge_distillation_for_image_classification.md
+++ b/docs/source/en/tasks/knowledge_distillation_for_image_classification.md
@@ -17,7 +17,7 @@ rendered properly in your Markdown viewer.
[[open-in-colab]]
-Knowledge distillation is a technique used to transfer knowledge from a larger, more complex model (teacher) to a smaller, simpler model (student). To distill knowledge from one model to another, we take a pre-trained teacher model trained on a certain task (image classification for this case) and randomly initialize a student model to be trained on image classification. Next, we train the student model to minimize the difference between its outputs and the teacher's outputs, thus making it mimic the behavior. It was first introduced in [Distilling the Knowledge in a Neural Network by Hinton et al](https://arxiv.org/abs/1503.02531). In this guide, we will do task-specific knowledge distillation. We will use the [beans dataset](https://huggingface.co/datasets/beans) for this.
+Knowledge distillation is a technique used to transfer knowledge from a larger, more complex model (teacher) to a smaller, simpler model (student). To distill knowledge from one model to another, we take a pre-trained teacher model trained on a certain task (image classification for this case) and randomly initialize a student model to be trained on image classification. Next, we train the student model to minimize the difference between its outputs and the teacher's outputs, thus making it mimic the behavior. It was first introduced in [Distilling the Knowledge in a Neural Network by Hinton et al](https://huggingface.co/papers/1503.02531). In this guide, we will do task-specific knowledge distillation. We will use the [beans dataset](https://huggingface.co/datasets/beans) for this.
This guide demonstrates how you can distill a [fine-tuned ViT model](https://huggingface.co/merve/vit-mobilenet-beans-224) (teacher model) to a [MobileNet](https://huggingface.co/google/mobilenet_v2_1.4_224) (student model) using the [Trainer API](https://huggingface.co/docs/transformers/en/main_classes/trainer#trainer) of 🤗 Transformers.
diff --git a/docs/source/en/tasks/video_classification.md b/docs/source/en/tasks/video_classification.md
index c268de1786..7a8c6ba45d 100644
--- a/docs/source/en/tasks/video_classification.md
+++ b/docs/source/en/tasks/video_classification.md
@@ -405,7 +405,7 @@ def compute_metrics(eval_pred):
**A note on evaluation**:
-In the [VideoMAE paper](https://arxiv.org/abs/2203.12602), the authors use the following evaluation strategy. They evaluate the model on several clips from test videos and apply different crops to those clips and report the aggregate score. However, in the interest of simplicity and brevity, we don't consider that in this tutorial.
+In the [VideoMAE paper](https://huggingface.co/papers/2203.12602), the authors use the following evaluation strategy. They evaluate the model on several clips from test videos and apply different crops to those clips and report the aggregate score. However, in the interest of simplicity and brevity, we don't consider that in this tutorial.
Also, define a `collate_fn`, which will be used to batch examples together. Each batch consists of 2 keys, namely `pixel_values` and `labels`.
diff --git a/docs/source/en/tasks_explained.md b/docs/source/en/tasks_explained.md
index 1cc60ba096..afdfb86989 100644
--- a/docs/source/en/tasks_explained.md
+++ b/docs/source/en/tasks_explained.md
@@ -120,7 +120,7 @@ This section briefly explains convolutions, but it'd be helpful to have a prior
@@ -27,7 +27,7 @@ BitNet models can't be quantized on the fly. They need to be quantized during pr
1. Compute the average of the absolute values of the weight matrix and use as a scale.
2. Divide the weights by the scale, round the values, constrain them between -1 and 1, and rescale them to continue in full precision.
-3. Activations are quantized to a specified bit-width (8-bit) using [absmax](https://arxiv.org/pdf/2208.07339) quantization (symmetric per channel quantization). This involves scaling the activations into a range of [−128,127].
+3. Activations are quantized to a specified bit-width (8-bit) using [absmax](https://huggingface.co/papers/2208.07339) quantization (symmetric per channel quantization). This involves scaling the activations into a range of [−128,127].
Refer to this [PR](https://github.com/huggingface/nanotron/pull/180) to pretrain or fine-tune a 1.58-bit model with [Nanotron](https://github.com/huggingface/nanotron). For fine-tuning, convert a model from the Hugging Face to Nanotron format. Find the conversion steps in this [PR](https://github.com/huggingface/nanotron/pull/174).
diff --git a/docs/source/en/quantization/higgs.md b/docs/source/en/quantization/higgs.md
index 11c42b208c..07f6e2b31f 100644
--- a/docs/source/en/quantization/higgs.md
+++ b/docs/source/en/quantization/higgs.md
@@ -16,7 +16,7 @@ rendered properly in your Markdown viewer.
# HIGGS
-[HIGGS](https://arxiv.org/abs/2411.17525) is a zero-shot quantization algorithm that combines Hadamard preprocessing with MSE-Optimal quantization grids to achieve lower quantization error and state-of-the-art performance.
+[HIGGS](https://huggingface.co/papers/2411.17525) is a zero-shot quantization algorithm that combines Hadamard preprocessing with MSE-Optimal quantization grids to achieve lower quantization error and state-of-the-art performance.
Runtime support for HIGGS is implemented through the [FLUTE](https://github.com/HanGuo97/flute) library. Only the 70B and 405B variants of Llama 3 and Llama 3.0, and the 8B and 27B variants of Gemma 2 are currently supported. HIGGS also doesn't support quantized training and backward passes in general at the moment.
diff --git a/docs/source/en/quantization/vptq.md b/docs/source/en/quantization/vptq.md
index af082c5f2f..392895e0ea 100644
--- a/docs/source/en/quantization/vptq.md
+++ b/docs/source/en/quantization/vptq.md
@@ -69,4 +69,4 @@ VPTQ achieves better accuracy and higher throughput with lower quantization over
See an example demo of VPTQ on the VPTQ Online Demo [Space](https://huggingface.co/spaces/microsoft/VPTQ) or try running the VPTQ inference [notebook](https://colab.research.google.com/github/microsoft/VPTQ/blob/main/notebooks/vptq_example.ipynb).
-For more information, read the VPTQ [paper](https://arxiv.org/pdf/2409.17066).
+For more information, read the VPTQ [paper](https://huggingface.co/papers/2409.17066).
diff --git a/docs/source/en/tasks/knowledge_distillation_for_image_classification.md b/docs/source/en/tasks/knowledge_distillation_for_image_classification.md
index c1ccafb6fc..4d1e735bd7 100644
--- a/docs/source/en/tasks/knowledge_distillation_for_image_classification.md
+++ b/docs/source/en/tasks/knowledge_distillation_for_image_classification.md
@@ -17,7 +17,7 @@ rendered properly in your Markdown viewer.
[[open-in-colab]]
-Knowledge distillation is a technique used to transfer knowledge from a larger, more complex model (teacher) to a smaller, simpler model (student). To distill knowledge from one model to another, we take a pre-trained teacher model trained on a certain task (image classification for this case) and randomly initialize a student model to be trained on image classification. Next, we train the student model to minimize the difference between its outputs and the teacher's outputs, thus making it mimic the behavior. It was first introduced in [Distilling the Knowledge in a Neural Network by Hinton et al](https://arxiv.org/abs/1503.02531). In this guide, we will do task-specific knowledge distillation. We will use the [beans dataset](https://huggingface.co/datasets/beans) for this.
+Knowledge distillation is a technique used to transfer knowledge from a larger, more complex model (teacher) to a smaller, simpler model (student). To distill knowledge from one model to another, we take a pre-trained teacher model trained on a certain task (image classification for this case) and randomly initialize a student model to be trained on image classification. Next, we train the student model to minimize the difference between its outputs and the teacher's outputs, thus making it mimic the behavior. It was first introduced in [Distilling the Knowledge in a Neural Network by Hinton et al](https://huggingface.co/papers/1503.02531). In this guide, we will do task-specific knowledge distillation. We will use the [beans dataset](https://huggingface.co/datasets/beans) for this.
This guide demonstrates how you can distill a [fine-tuned ViT model](https://huggingface.co/merve/vit-mobilenet-beans-224) (teacher model) to a [MobileNet](https://huggingface.co/google/mobilenet_v2_1.4_224) (student model) using the [Trainer API](https://huggingface.co/docs/transformers/en/main_classes/trainer#trainer) of 🤗 Transformers.
diff --git a/docs/source/en/tasks/video_classification.md b/docs/source/en/tasks/video_classification.md
index c268de1786..7a8c6ba45d 100644
--- a/docs/source/en/tasks/video_classification.md
+++ b/docs/source/en/tasks/video_classification.md
@@ -405,7 +405,7 @@ def compute_metrics(eval_pred):
**A note on evaluation**:
-In the [VideoMAE paper](https://arxiv.org/abs/2203.12602), the authors use the following evaluation strategy. They evaluate the model on several clips from test videos and apply different crops to those clips and report the aggregate score. However, in the interest of simplicity and brevity, we don't consider that in this tutorial.
+In the [VideoMAE paper](https://huggingface.co/papers/2203.12602), the authors use the following evaluation strategy. They evaluate the model on several clips from test videos and apply different crops to those clips and report the aggregate score. However, in the interest of simplicity and brevity, we don't consider that in this tutorial.
Also, define a `collate_fn`, which will be used to batch examples together. Each batch consists of 2 keys, namely `pixel_values` and `labels`.
diff --git a/docs/source/en/tasks_explained.md b/docs/source/en/tasks_explained.md
index 1cc60ba096..afdfb86989 100644
--- a/docs/source/en/tasks_explained.md
+++ b/docs/source/en/tasks_explained.md
@@ -120,7 +120,7 @@ This section briefly explains convolutions, but it'd be helpful to have a prior
 -A basic convolution without padding or stride, taken from A guide to convolution arithmetic for deep learning.
+A basic convolution without padding or stride, taken from A guide to convolution arithmetic for deep learning.
You can feed this output to another convolutional layer, and with each successive layer, the network learns more complex and abstract things like hotdogs or rockets. Between convolutional layers, it is common to add a pooling layer to reduce dimensionality and make the model more robust to variations of a feature's position.
diff --git a/docs/source/en/tokenizer_summary.md b/docs/source/en/tokenizer_summary.md
index c5f12dd20d..801948f35d 100644
--- a/docs/source/en/tokenizer_summary.md
+++ b/docs/source/en/tokenizer_summary.md
@@ -140,7 +140,7 @@ on.
### Byte-Pair Encoding (BPE)
Byte-Pair Encoding (BPE) was introduced in [Neural Machine Translation of Rare Words with Subword Units (Sennrich et
-al., 2015)](https://arxiv.org/abs/1508.07909). BPE relies on a pre-tokenizer that splits the training data into
+al., 2015)](https://huggingface.co/papers/1508.07909). BPE relies on a pre-tokenizer that splits the training data into
words. Pretokenization can be as simple as space tokenization, e.g. [GPT-2](model_doc/gpt2), [RoBERTa](model_doc/roberta). More advanced pre-tokenization include rule-based tokenization, e.g. [XLM](model_doc/xlm),
[FlauBERT](model_doc/flaubert) which uses Moses for most languages, or [GPT](model_doc/openai-gpt) which uses
spaCy and ftfy, to count the frequency of each word in the training corpus.
@@ -230,7 +230,7 @@ to ensure it's _worth it_.
### Unigram
Unigram is a subword tokenization algorithm introduced in [Subword Regularization: Improving Neural Network Translation
-Models with Multiple Subword Candidates (Kudo, 2018)](https://arxiv.org/pdf/1804.10959.pdf). In contrast to BPE or
+Models with Multiple Subword Candidates (Kudo, 2018)](https://huggingface.co/papers/1804.10959). In contrast to BPE or
WordPiece, Unigram initializes its base vocabulary to a large number of symbols and progressively trims down each
symbol to obtain a smaller vocabulary. The base vocabulary could for instance correspond to all pre-tokenized words and
the most common substrings. Unigram is not used directly for any of the models in the transformers, but it's used in
@@ -270,7 +270,7 @@ All tokenization algorithms described so far have the same problem: It is assume
separate words. However, not all languages use spaces to separate words. One possible solution is to use language
specific pre-tokenizers, *e.g.* [XLM](model_doc/xlm) uses a specific Chinese, Japanese, and Thai pre-tokenizer.
To solve this problem more generally, [SentencePiece: A simple and language independent subword tokenizer and
-detokenizer for Neural Text Processing (Kudo et al., 2018)](https://arxiv.org/pdf/1808.06226.pdf) treats the input
+detokenizer for Neural Text Processing (Kudo et al., 2018)](https://huggingface.co/papers/1808.06226) treats the input
as a raw input stream, thus including the space in the set of characters to use. It then uses the BPE or unigram
algorithm to construct the appropriate vocabulary.
diff --git a/docs/source/es/bertology.md b/docs/source/es/bertology.md
index c62e5aaf97..19ae1444ae 100644
--- a/docs/source/es/bertology.md
+++ b/docs/source/es/bertology.md
@@ -21,21 +21,21 @@ Hay un creciente campo de estudio empeñado en la investigación del funcionamie
- BERT Rediscovers the Classical NLP Pipeline por Ian Tenney, Dipanjan Das, Ellie Pavlick:
- https://arxiv.org/abs/1905.05950
-- Are Sixteen Heads Really Better than One? por Paul Michel, Omer Levy, Graham Neubig: https://arxiv.org/abs/1905.10650
+ https://huggingface.co/papers/1905.05950
+- Are Sixteen Heads Really Better than One? por Paul Michel, Omer Levy, Graham Neubig: https://huggingface.co/papers/1905.10650
- What Does BERT Look At? An Analysis of BERT's Attention por Kevin Clark, Urvashi Khandelwal, Omer Levy, Christopher D.
- Manning: https://arxiv.org/abs/1906.04341
-- CAT-probing: A Metric-based Approach to Interpret How Pre-trained Models for Programming Language Attend Code Structure: https://arxiv.org/abs/2210.04633
+ Manning: https://huggingface.co/papers/1906.04341
+- CAT-probing: A Metric-based Approach to Interpret How Pre-trained Models for Programming Language Attend Code Structure: https://huggingface.co/papers/2210.04633
Para asistir al desarrollo de este nuevo campo, hemos incluido algunas features adicionales en los modelos BERT/GPT/GPT-2 para
ayudar a acceder a las representaciones internas, principalmente adaptado de la gran obra de Paul Michel
-(https://arxiv.org/abs/1905.10650):
+(https://huggingface.co/papers/1905.10650):
- accediendo a todos los hidden-states de BERT/GPT/GPT-2,
- accediendo a todos los pesos de atención para cada head de BERT/GPT/GPT-2,
- adquiriendo los valores de salida y gradientes de las heads para poder computar la métrica de importancia de las heads y realizar la poda de heads como se explica
- en https://arxiv.org/abs/1905.10650.
+ en https://huggingface.co/papers/1905.10650.
Para ayudarte a entender y usar estas features, hemos añadido un script específico de ejemplo: [bertology.py](https://github.com/huggingface/transformers-research-projects/tree/main/bertology/run_bertology.py) mientras extraes información y cortas un modelo pre-entrenado en
GLUE.
diff --git a/docs/source/es/glossary.md b/docs/source/es/glossary.md
index 790fa1fecb..3debcdbd35 100644
--- a/docs/source/es/glossary.md
+++ b/docs/source/es/glossary.md
@@ -147,7 +147,7 @@ El proceso de seleccionar y transformar datos crudos en un conjunto de caracter
En cada bloque de atención residual en los transformadores, la capa de autoatención suele ir seguida de 2 capas de avance. El tamaño de embedding intermedio de las capas de avance suele ser mayor que el tamaño oculto del modelo (por ejemplo, para `google-bert/bert-base-uncased`).
-Para una entrada de tamaño `[batch_size, sequence_length]`, la memoria requerida para almacenar los embeddings intermedios de avance `[batch_size, sequence_length, config.intermediate_size]` puede representar una gran fracción del uso de memoria. Los autores de [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) observaron que, dado que el cálculo es independiente de la dimensión `sequence_length`, es matemáticamente equivalente calcular los embeddings de salida de ambas capas de avance `[batch_size, config.hidden_size]_0, ..., [batch_size, config.hidden_size]_n` individualmente y concatenarlos después a `[batch_size, sequence_length, config.hidden_size]` con `n = sequence_length`, lo que intercambia el aumento del tiempo de cálculo por una reducción en el uso de memoria, pero produce un resultado matemáticamente **equivalente**.
+Para una entrada de tamaño `[batch_size, sequence_length]`, la memoria requerida para almacenar los embeddings intermedios de avance `[batch_size, sequence_length, config.intermediate_size]` puede representar una gran fracción del uso de memoria. Los autores de [Reformer: The Efficient Transformer](https://huggingface.co/papers/2001.04451) observaron que, dado que el cálculo es independiente de la dimensión `sequence_length`, es matemáticamente equivalente calcular los embeddings de salida de ambas capas de avance `[batch_size, config.hidden_size]_0, ..., [batch_size, config.hidden_size]_n` individualmente y concatenarlos después a `[batch_size, sequence_length, config.hidden_size]` con `n = sequence_length`, lo que intercambia el aumento del tiempo de cálculo por una reducción en el uso de memoria, pero produce un resultado matemáticamente **equivalente**.
Para modelos que utilizan la función [`apply_chunking_to_forward`], el `chunk_size` define el número de embeddings de salida que se calculan en paralelo y, por lo tanto, define el equilibrio entre la complejidad de memoria y tiempo. Si `chunk_size` se establece en 0, no se realiza ninguna fragmentación de avance.
@@ -183,7 +183,7 @@ Los IDs de entrada a menudo son los únicos parámetros necesarios que se deben
-A basic convolution without padding or stride, taken from A guide to convolution arithmetic for deep learning.
+A basic convolution without padding or stride, taken from A guide to convolution arithmetic for deep learning.
You can feed this output to another convolutional layer, and with each successive layer, the network learns more complex and abstract things like hotdogs or rockets. Between convolutional layers, it is common to add a pooling layer to reduce dimensionality and make the model more robust to variations of a feature's position.
diff --git a/docs/source/en/tokenizer_summary.md b/docs/source/en/tokenizer_summary.md
index c5f12dd20d..801948f35d 100644
--- a/docs/source/en/tokenizer_summary.md
+++ b/docs/source/en/tokenizer_summary.md
@@ -140,7 +140,7 @@ on.
### Byte-Pair Encoding (BPE)
Byte-Pair Encoding (BPE) was introduced in [Neural Machine Translation of Rare Words with Subword Units (Sennrich et
-al., 2015)](https://arxiv.org/abs/1508.07909). BPE relies on a pre-tokenizer that splits the training data into
+al., 2015)](https://huggingface.co/papers/1508.07909). BPE relies on a pre-tokenizer that splits the training data into
words. Pretokenization can be as simple as space tokenization, e.g. [GPT-2](model_doc/gpt2), [RoBERTa](model_doc/roberta). More advanced pre-tokenization include rule-based tokenization, e.g. [XLM](model_doc/xlm),
[FlauBERT](model_doc/flaubert) which uses Moses for most languages, or [GPT](model_doc/openai-gpt) which uses
spaCy and ftfy, to count the frequency of each word in the training corpus.
@@ -230,7 +230,7 @@ to ensure it's _worth it_.
### Unigram
Unigram is a subword tokenization algorithm introduced in [Subword Regularization: Improving Neural Network Translation
-Models with Multiple Subword Candidates (Kudo, 2018)](https://arxiv.org/pdf/1804.10959.pdf). In contrast to BPE or
+Models with Multiple Subword Candidates (Kudo, 2018)](https://huggingface.co/papers/1804.10959). In contrast to BPE or
WordPiece, Unigram initializes its base vocabulary to a large number of symbols and progressively trims down each
symbol to obtain a smaller vocabulary. The base vocabulary could for instance correspond to all pre-tokenized words and
the most common substrings. Unigram is not used directly for any of the models in the transformers, but it's used in
@@ -270,7 +270,7 @@ All tokenization algorithms described so far have the same problem: It is assume
separate words. However, not all languages use spaces to separate words. One possible solution is to use language
specific pre-tokenizers, *e.g.* [XLM](model_doc/xlm) uses a specific Chinese, Japanese, and Thai pre-tokenizer.
To solve this problem more generally, [SentencePiece: A simple and language independent subword tokenizer and
-detokenizer for Neural Text Processing (Kudo et al., 2018)](https://arxiv.org/pdf/1808.06226.pdf) treats the input
+detokenizer for Neural Text Processing (Kudo et al., 2018)](https://huggingface.co/papers/1808.06226) treats the input
as a raw input stream, thus including the space in the set of characters to use. It then uses the BPE or unigram
algorithm to construct the appropriate vocabulary.
diff --git a/docs/source/es/bertology.md b/docs/source/es/bertology.md
index c62e5aaf97..19ae1444ae 100644
--- a/docs/source/es/bertology.md
+++ b/docs/source/es/bertology.md
@@ -21,21 +21,21 @@ Hay un creciente campo de estudio empeñado en la investigación del funcionamie
- BERT Rediscovers the Classical NLP Pipeline por Ian Tenney, Dipanjan Das, Ellie Pavlick:
- https://arxiv.org/abs/1905.05950
-- Are Sixteen Heads Really Better than One? por Paul Michel, Omer Levy, Graham Neubig: https://arxiv.org/abs/1905.10650
+ https://huggingface.co/papers/1905.05950
+- Are Sixteen Heads Really Better than One? por Paul Michel, Omer Levy, Graham Neubig: https://huggingface.co/papers/1905.10650
- What Does BERT Look At? An Analysis of BERT's Attention por Kevin Clark, Urvashi Khandelwal, Omer Levy, Christopher D.
- Manning: https://arxiv.org/abs/1906.04341
-- CAT-probing: A Metric-based Approach to Interpret How Pre-trained Models for Programming Language Attend Code Structure: https://arxiv.org/abs/2210.04633
+ Manning: https://huggingface.co/papers/1906.04341
+- CAT-probing: A Metric-based Approach to Interpret How Pre-trained Models for Programming Language Attend Code Structure: https://huggingface.co/papers/2210.04633
Para asistir al desarrollo de este nuevo campo, hemos incluido algunas features adicionales en los modelos BERT/GPT/GPT-2 para
ayudar a acceder a las representaciones internas, principalmente adaptado de la gran obra de Paul Michel
-(https://arxiv.org/abs/1905.10650):
+(https://huggingface.co/papers/1905.10650):
- accediendo a todos los hidden-states de BERT/GPT/GPT-2,
- accediendo a todos los pesos de atención para cada head de BERT/GPT/GPT-2,
- adquiriendo los valores de salida y gradientes de las heads para poder computar la métrica de importancia de las heads y realizar la poda de heads como se explica
- en https://arxiv.org/abs/1905.10650.
+ en https://huggingface.co/papers/1905.10650.
Para ayudarte a entender y usar estas features, hemos añadido un script específico de ejemplo: [bertology.py](https://github.com/huggingface/transformers-research-projects/tree/main/bertology/run_bertology.py) mientras extraes información y cortas un modelo pre-entrenado en
GLUE.
diff --git a/docs/source/es/glossary.md b/docs/source/es/glossary.md
index 790fa1fecb..3debcdbd35 100644
--- a/docs/source/es/glossary.md
+++ b/docs/source/es/glossary.md
@@ -147,7 +147,7 @@ El proceso de seleccionar y transformar datos crudos en un conjunto de caracter
En cada bloque de atención residual en los transformadores, la capa de autoatención suele ir seguida de 2 capas de avance. El tamaño de embedding intermedio de las capas de avance suele ser mayor que el tamaño oculto del modelo (por ejemplo, para `google-bert/bert-base-uncased`).
-Para una entrada de tamaño `[batch_size, sequence_length]`, la memoria requerida para almacenar los embeddings intermedios de avance `[batch_size, sequence_length, config.intermediate_size]` puede representar una gran fracción del uso de memoria. Los autores de [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) observaron que, dado que el cálculo es independiente de la dimensión `sequence_length`, es matemáticamente equivalente calcular los embeddings de salida de ambas capas de avance `[batch_size, config.hidden_size]_0, ..., [batch_size, config.hidden_size]_n` individualmente y concatenarlos después a `[batch_size, sequence_length, config.hidden_size]` con `n = sequence_length`, lo que intercambia el aumento del tiempo de cálculo por una reducción en el uso de memoria, pero produce un resultado matemáticamente **equivalente**.
+Para una entrada de tamaño `[batch_size, sequence_length]`, la memoria requerida para almacenar los embeddings intermedios de avance `[batch_size, sequence_length, config.intermediate_size]` puede representar una gran fracción del uso de memoria. Los autores de [Reformer: The Efficient Transformer](https://huggingface.co/papers/2001.04451) observaron que, dado que el cálculo es independiente de la dimensión `sequence_length`, es matemáticamente equivalente calcular los embeddings de salida de ambas capas de avance `[batch_size, config.hidden_size]_0, ..., [batch_size, config.hidden_size]_n` individualmente y concatenarlos después a `[batch_size, sequence_length, config.hidden_size]` con `n = sequence_length`, lo que intercambia el aumento del tiempo de cálculo por una reducción en el uso de memoria, pero produce un resultado matemáticamente **equivalente**.
Para modelos que utilizan la función [`apply_chunking_to_forward`], el `chunk_size` define el número de embeddings de salida que se calculan en paralelo y, por lo tanto, define el equilibrio entre la complejidad de memoria y tiempo. Si `chunk_size` se establece en 0, no se realiza ninguna fragmentación de avance.
@@ -183,7 +183,7 @@ Los IDs de entrada a menudo son los únicos parámetros necesarios que se deben
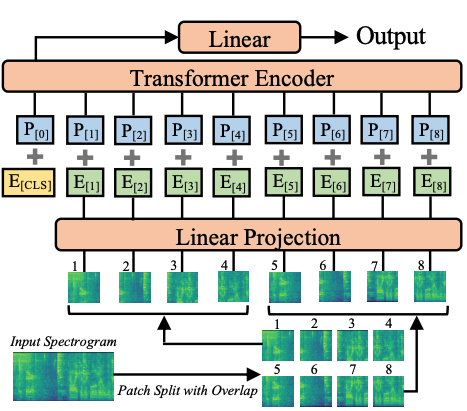 - Audio Spectrogram Transformerのアーキテクチャ。元論文より抜粋。
+ Audio Spectrogram Transformerのアーキテクチャ。元論文より抜粋。
このモデルは[nielsr](https://huggingface.co/nielsr)より提供されました。
オリジナルのコードは[こちら](https://github.com/YuanGongND/ast)で見ることができます。
@@ -35,7 +35,7 @@ alt="drawing" width="600"/>
## 使用上のヒント
- 独自のデータセットでAudio Spectrogram Transformer(AST)をファインチューニングする場合、入力の正規化(入力の平均を0、標準偏差を0.5にすること)処理することが推奨されます。[`ASTFeatureExtractor`]はこれを処理します。デフォルトではAudioSetの平均と標準偏差を使用していることに注意してください。著者が下流のデータセットの統計をどのように計算しているかは、[`ast/src/get_norm_stats.py`](https://github.com/YuanGongND/ast/blob/master/src/get_norm_stats.py)で確認することができます。
-- ASTは低い学習率が必要であり 著者は[PSLA論文](https://arxiv.org/abs/2102.01243)で提案されたCNNモデルに比べて10倍小さい学習率を使用しています)、素早く収束するため、タスクに適した学習率と学習率スケジューラーを探すことをお勧めします。
+- ASTは低い学習率が必要であり 著者は[PSLA論文](https://huggingface.co/papers/2102.01243)で提案されたCNNモデルに比べて10倍小さい学習率を使用しています)、素早く収束するため、タスクに適した学習率と学習率スケジューラーを探すことをお勧めします。
## 参考資料
diff --git a/docs/source/ja/model_doc/autoformer.md b/docs/source/ja/model_doc/autoformer.md
index b8b0948b96..65c20bfa60 100644
--- a/docs/source/ja/model_doc/autoformer.md
+++ b/docs/source/ja/model_doc/autoformer.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 概要
-Autoformerモデルは、「[Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008)」という論文でHaixu Wu、Jiehui Xu、Jianmin Wang、Mingsheng Longによって提案されました。
+Autoformerモデルは、「[Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://huggingface.co/papers/2106.13008)」という論文でHaixu Wu、Jiehui Xu、Jianmin Wang、Mingsheng Longによって提案されました。
このモデルは、予測プロセス中にトレンドと季節性成分を逐次的に分解できる深層分解アーキテクチャとしてTransformerを増強します。
diff --git a/docs/source/ja/model_doc/bart.md b/docs/source/ja/model_doc/bart.md
index 5c25d6a0c7..6d11c122d9 100644
--- a/docs/source/ja/model_doc/bart.md
+++ b/docs/source/ja/model_doc/bart.md
@@ -31,7 +31,7 @@ rendered properly in your Markdown viewer.
## Overview
Bart モデルは、[BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation、
-翻訳と理解](https://arxiv.org/abs/1910.13461) Mike Lewis、Yinhan Liu、Naman Goyal、Marjan 著
+翻訳と理解](https://huggingface.co/papers/1910.13461) Mike Lewis、Yinhan Liu、Naman Goyal、Marjan 著
ガズビニネジャド、アブデルラフマン・モハメド、オメル・レヴィ、ベス・ストヤノフ、ルーク・ゼトルモイヤー、2019年10月29日。
要約によると、
@@ -65,7 +65,7 @@ Bart モデルは、[BART: Denoising Sequence-to-Sequence Pre-training for Natur
[examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md)。
- Hugging Face `datasets` を使用して [`BartForConditionalGeneration`] をトレーニングする方法の例
オブジェクトは、この [フォーラム ディスカッション](https://discuss.huggingface.co/t/train-bart-for-conditional-generation-e-g-summarization/1904) で見つけることができます。
-- [抽出されたチェックポイント](https://huggingface.co/models?search=distilbart) は、この [論文](https://arxiv.org/abs/2010.13002) で説明されています。
+- [抽出されたチェックポイント](https://huggingface.co/models?search=distilbart) は、この [論文](https://huggingface.co/papers/2010.13002) で説明されています。
## Implementation Notes
@@ -132,7 +132,7 @@ BART を始めるのに役立つ公式 Hugging Face およびコミュニティ
- [テキスト分類タスクガイド(英語版)](../../en/tasks/sequence_classification)
- [質問回答タスク ガイド](../tasks/question_answering)
- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
-- [抽出されたチェックポイント](https://huggingface.co/models?search=distilbart) は、この [論文](https://arxiv.org/abs/2010.13002) で説明されています。
+- [抽出されたチェックポイント](https://huggingface.co/models?search=distilbart) は、この [論文](https://huggingface.co/papers/2010.13002) で説明されています。
## BartConfig
diff --git a/docs/source/ja/model_doc/barthez.md b/docs/source/ja/model_doc/barthez.md
index 94844c3f67..5668772c26 100644
--- a/docs/source/ja/model_doc/barthez.md
+++ b/docs/source/ja/model_doc/barthez.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-BARThez モデルは、Moussa Kamal Eddine、Antoine J.-P によって [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) で提案されました。ティクシエ、ミカリス・ヴァジルジャンニス、10月23日、
+BARThez モデルは、Moussa Kamal Eddine、Antoine J.-P によって [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://huggingface.co/papers/2010.12321) で提案されました。ティクシエ、ミカリス・ヴァジルジャンニス、10月23日、
2020年。
論文の要約:
diff --git a/docs/source/ja/model_doc/bartpho.md b/docs/source/ja/model_doc/bartpho.md
index a9575d821e..3596a91fe1 100644
--- a/docs/source/ja/model_doc/bartpho.md
+++ b/docs/source/ja/model_doc/bartpho.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-BARTpho モデルは、Nguyen Luong Tran、Duong Minh Le、Dat Quoc Nguyen によって [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnam](https://arxiv.org/abs/2109.09701) で提案されました。
+BARTpho モデルは、Nguyen Luong Tran、Duong Minh Le、Dat Quoc Nguyen によって [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnam](https://huggingface.co/papers/2109.09701) で提案されました。
論文の要約は次のとおりです。
diff --git a/docs/source/ja/model_doc/beit.md b/docs/source/ja/model_doc/beit.md
index 948c3bad70..21ccc28c68 100644
--- a/docs/source/ja/model_doc/beit.md
+++ b/docs/source/ja/model_doc/beit.md
@@ -18,11 +18,11 @@ rendered properly in your Markdown viewer.
## Overview
-BEiT モデルは、[BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) で提案されました。
+BEiT モデルは、[BEiT: BERT Pre-Training of Image Transformers](https://huggingface.co/papers/2106.08254) で提案されました。
ハンボ・バオ、リー・ドン、フル・ウェイ。 BERT に触発された BEiT は、自己教師ありの事前トレーニングを作成した最初の論文です。
ビジョン トランスフォーマー (ViT) は、教師付き事前トレーニングよりも優れたパフォーマンスを発揮します。クラスを予測するためにモデルを事前トレーニングするのではなく
-([オリジナルの ViT 論文](https://arxiv.org/abs/2010.11929) で行われたように) 画像の BEiT モデルは、次のように事前トレーニングされています。
-マスクされた OpenAI の [DALL-E モデル](https://arxiv.org/abs/2102.12092) のコードブックからビジュアル トークンを予測します
+([オリジナルの ViT 論文](https://huggingface.co/papers/2010.11929) で行われたように) 画像の BEiT モデルは、次のように事前トレーニングされています。
+マスクされた OpenAI の [DALL-E モデル](https://huggingface.co/papers/2102.12092) のコードブックからビジュアル トークンを予測します
パッチ。
論文の要約は次のとおりです。
@@ -66,7 +66,7 @@ BEiT モデルは、[BEiT: BERT Pre-Training of Image Transformers](https://arxi
- Audio Spectrogram Transformerのアーキテクチャ。元論文より抜粋。
+ Audio Spectrogram Transformerのアーキテクチャ。元論文より抜粋。
このモデルは[nielsr](https://huggingface.co/nielsr)より提供されました。
オリジナルのコードは[こちら](https://github.com/YuanGongND/ast)で見ることができます。
@@ -35,7 +35,7 @@ alt="drawing" width="600"/>
## 使用上のヒント
- 独自のデータセットでAudio Spectrogram Transformer(AST)をファインチューニングする場合、入力の正規化(入力の平均を0、標準偏差を0.5にすること)処理することが推奨されます。[`ASTFeatureExtractor`]はこれを処理します。デフォルトではAudioSetの平均と標準偏差を使用していることに注意してください。著者が下流のデータセットの統計をどのように計算しているかは、[`ast/src/get_norm_stats.py`](https://github.com/YuanGongND/ast/blob/master/src/get_norm_stats.py)で確認することができます。
-- ASTは低い学習率が必要であり 著者は[PSLA論文](https://arxiv.org/abs/2102.01243)で提案されたCNNモデルに比べて10倍小さい学習率を使用しています)、素早く収束するため、タスクに適した学習率と学習率スケジューラーを探すことをお勧めします。
+- ASTは低い学習率が必要であり 著者は[PSLA論文](https://huggingface.co/papers/2102.01243)で提案されたCNNモデルに比べて10倍小さい学習率を使用しています)、素早く収束するため、タスクに適した学習率と学習率スケジューラーを探すことをお勧めします。
## 参考資料
diff --git a/docs/source/ja/model_doc/autoformer.md b/docs/source/ja/model_doc/autoformer.md
index b8b0948b96..65c20bfa60 100644
--- a/docs/source/ja/model_doc/autoformer.md
+++ b/docs/source/ja/model_doc/autoformer.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 概要
-Autoformerモデルは、「[Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008)」という論文でHaixu Wu、Jiehui Xu、Jianmin Wang、Mingsheng Longによって提案されました。
+Autoformerモデルは、「[Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://huggingface.co/papers/2106.13008)」という論文でHaixu Wu、Jiehui Xu、Jianmin Wang、Mingsheng Longによって提案されました。
このモデルは、予測プロセス中にトレンドと季節性成分を逐次的に分解できる深層分解アーキテクチャとしてTransformerを増強します。
diff --git a/docs/source/ja/model_doc/bart.md b/docs/source/ja/model_doc/bart.md
index 5c25d6a0c7..6d11c122d9 100644
--- a/docs/source/ja/model_doc/bart.md
+++ b/docs/source/ja/model_doc/bart.md
@@ -31,7 +31,7 @@ rendered properly in your Markdown viewer.
## Overview
Bart モデルは、[BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation、
-翻訳と理解](https://arxiv.org/abs/1910.13461) Mike Lewis、Yinhan Liu、Naman Goyal、Marjan 著
+翻訳と理解](https://huggingface.co/papers/1910.13461) Mike Lewis、Yinhan Liu、Naman Goyal、Marjan 著
ガズビニネジャド、アブデルラフマン・モハメド、オメル・レヴィ、ベス・ストヤノフ、ルーク・ゼトルモイヤー、2019年10月29日。
要約によると、
@@ -65,7 +65,7 @@ Bart モデルは、[BART: Denoising Sequence-to-Sequence Pre-training for Natur
[examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md)。
- Hugging Face `datasets` を使用して [`BartForConditionalGeneration`] をトレーニングする方法の例
オブジェクトは、この [フォーラム ディスカッション](https://discuss.huggingface.co/t/train-bart-for-conditional-generation-e-g-summarization/1904) で見つけることができます。
-- [抽出されたチェックポイント](https://huggingface.co/models?search=distilbart) は、この [論文](https://arxiv.org/abs/2010.13002) で説明されています。
+- [抽出されたチェックポイント](https://huggingface.co/models?search=distilbart) は、この [論文](https://huggingface.co/papers/2010.13002) で説明されています。
## Implementation Notes
@@ -132,7 +132,7 @@ BART を始めるのに役立つ公式 Hugging Face およびコミュニティ
- [テキスト分類タスクガイド(英語版)](../../en/tasks/sequence_classification)
- [質問回答タスク ガイド](../tasks/question_answering)
- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
-- [抽出されたチェックポイント](https://huggingface.co/models?search=distilbart) は、この [論文](https://arxiv.org/abs/2010.13002) で説明されています。
+- [抽出されたチェックポイント](https://huggingface.co/models?search=distilbart) は、この [論文](https://huggingface.co/papers/2010.13002) で説明されています。
## BartConfig
diff --git a/docs/source/ja/model_doc/barthez.md b/docs/source/ja/model_doc/barthez.md
index 94844c3f67..5668772c26 100644
--- a/docs/source/ja/model_doc/barthez.md
+++ b/docs/source/ja/model_doc/barthez.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-BARThez モデルは、Moussa Kamal Eddine、Antoine J.-P によって [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) で提案されました。ティクシエ、ミカリス・ヴァジルジャンニス、10月23日、
+BARThez モデルは、Moussa Kamal Eddine、Antoine J.-P によって [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://huggingface.co/papers/2010.12321) で提案されました。ティクシエ、ミカリス・ヴァジルジャンニス、10月23日、
2020年。
論文の要約:
diff --git a/docs/source/ja/model_doc/bartpho.md b/docs/source/ja/model_doc/bartpho.md
index a9575d821e..3596a91fe1 100644
--- a/docs/source/ja/model_doc/bartpho.md
+++ b/docs/source/ja/model_doc/bartpho.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-BARTpho モデルは、Nguyen Luong Tran、Duong Minh Le、Dat Quoc Nguyen によって [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnam](https://arxiv.org/abs/2109.09701) で提案されました。
+BARTpho モデルは、Nguyen Luong Tran、Duong Minh Le、Dat Quoc Nguyen によって [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnam](https://huggingface.co/papers/2109.09701) で提案されました。
論文の要約は次のとおりです。
diff --git a/docs/source/ja/model_doc/beit.md b/docs/source/ja/model_doc/beit.md
index 948c3bad70..21ccc28c68 100644
--- a/docs/source/ja/model_doc/beit.md
+++ b/docs/source/ja/model_doc/beit.md
@@ -18,11 +18,11 @@ rendered properly in your Markdown viewer.
## Overview
-BEiT モデルは、[BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) で提案されました。
+BEiT モデルは、[BEiT: BERT Pre-Training of Image Transformers](https://huggingface.co/papers/2106.08254) で提案されました。
ハンボ・バオ、リー・ドン、フル・ウェイ。 BERT に触発された BEiT は、自己教師ありの事前トレーニングを作成した最初の論文です。
ビジョン トランスフォーマー (ViT) は、教師付き事前トレーニングよりも優れたパフォーマンスを発揮します。クラスを予測するためにモデルを事前トレーニングするのではなく
-([オリジナルの ViT 論文](https://arxiv.org/abs/2010.11929) で行われたように) 画像の BEiT モデルは、次のように事前トレーニングされています。
-マスクされた OpenAI の [DALL-E モデル](https://arxiv.org/abs/2102.12092) のコードブックからビジュアル トークンを予測します
+([オリジナルの ViT 論文](https://huggingface.co/papers/2010.11929) で行われたように) 画像の BEiT モデルは、次のように事前トレーニングされています。
+マスクされた OpenAI の [DALL-E モデル](https://huggingface.co/papers/2102.12092) のコードブックからビジュアル トークンを予測します
パッチ。
論文の要約は次のとおりです。
@@ -66,7 +66,7 @@ BEiT モデルは、[BEiT: BERT Pre-Training of Image Transformers](https://arxi
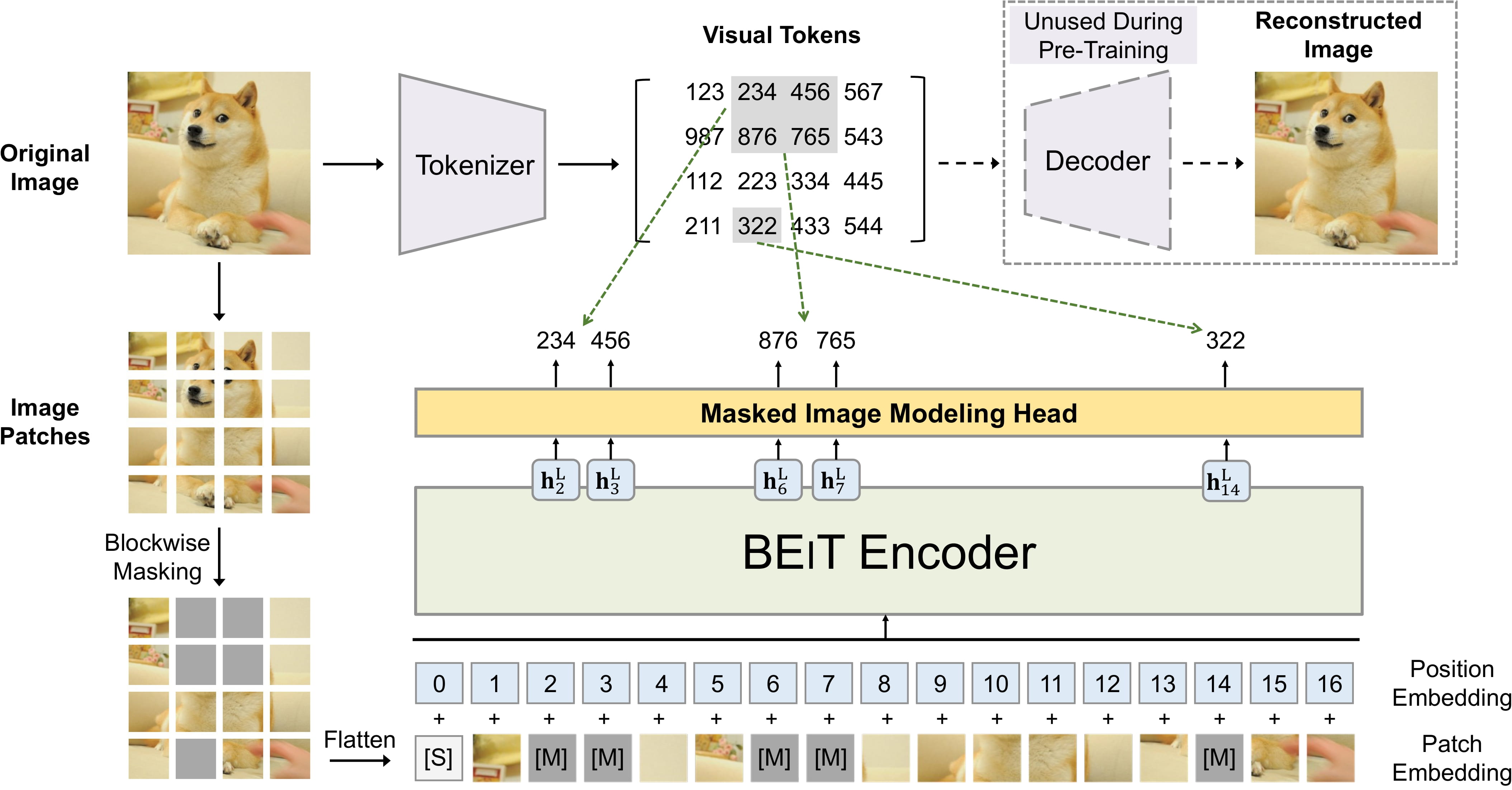 - BEiT の事前トレーニング。 元の論文から抜粋。
+ BEiT の事前トレーニング。 元の論文から抜粋。
このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。このモデルの JAX/FLAX バージョンは、
[kamalkraj](https://huggingface.co/kamalkraj) による投稿。元のコードは [ここ](https://github.com/microsoft/unilm/tree/master/beit) にあります。
diff --git a/docs/source/ja/model_doc/bert-generation.md b/docs/source/ja/model_doc/bert-generation.md
index d2c93a4644..bf3b932968 100644
--- a/docs/source/ja/model_doc/bert-generation.md
+++ b/docs/source/ja/model_doc/bert-generation.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## Overview
BertGeneration モデルは、次を使用してシーケンス間のタスクに利用できる BERT モデルです。
-[Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) で提案されている [`EncoderDecoderModel`]
+[Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://huggingface.co/papers/1907.12461) で提案されている [`EncoderDecoderModel`]
タスク、Sascha Rothe、Sishi Nagayan、Aliaksei Severyn 著。
論文の要約は次のとおりです。
diff --git a/docs/source/ja/model_doc/bert.md b/docs/source/ja/model_doc/bert.md
index 6e6947bd04..e0367dcd46 100644
--- a/docs/source/ja/model_doc/bert.md
+++ b/docs/source/ja/model_doc/bert.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
## Overview
-BERT モデルは、Jacob Devlin、Ming-Wei Chang、Kenton Lee、Kristina Toutanova によって [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) で提案されました。それは
+BERT モデルは、Jacob Devlin、Ming-Wei Chang、Kenton Lee、Kristina Toutanova によって [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://huggingface.co/papers/1810.04805) で提案されました。それは
マスクされた言語モデリング目標と次の文の組み合わせを使用して事前トレーニングされた双方向トランスフォーマー
Toronto Book Corpus と Wikipedia からなる大規模なコーパスでの予測。
diff --git a/docs/source/ja/model_doc/big_bird.md b/docs/source/ja/model_doc/big_bird.md
index 960d19146c..d5f4f9d282 100644
--- a/docs/source/ja/model_doc/big_bird.md
+++ b/docs/source/ja/model_doc/big_bird.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-BigBird モデルは、[Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) で提案されました。
+BigBird モデルは、[Big Bird: Transformers for Longer Sequences](https://huggingface.co/papers/2007.14062) で提案されました。
ザヒール、マンジルとグルガネシュ、グルとダベイ、クマール・アヴィナヴァとエインズリー、ジョシュアとアルベルティ、クリスとオンタノン、
サンティアゴとファム、フィリップとラブラ、アニルードとワン、キーファンとヤン、リーなど。 BigBird は注目度が低い
BERT などの Transformer ベースのモデルをさらに長いシーケンスに拡張する、Transformer ベースのモデル。まばらに加えて
diff --git a/docs/source/ja/model_doc/bigbird_pegasus.md b/docs/source/ja/model_doc/bigbird_pegasus.md
index 5314aed1bc..ecee19d6a5 100644
--- a/docs/source/ja/model_doc/bigbird_pegasus.md
+++ b/docs/source/ja/model_doc/bigbird_pegasus.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-BigBird モデルは、[Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) で提案されました。
+BigBird モデルは、[Big Bird: Transformers for Longer Sequences](https://huggingface.co/papers/2007.14062) で提案されました。
ザヒール、マンジルとグルガネシュ、グルとダベイ、クマール・アヴィナヴァとエインズリー、ジョシュアとアルベルティ、クリスとオンタノン、
サンティアゴとファム、フィリップとラブラ、アニルードとワン、キーファンとヤン、リーなど。 BigBird は注目度が低い
BERT などの Transformer ベースのモデルをさらに長いシーケンスに拡張する、Transformer ベースのモデル。まばらに加えて
diff --git a/docs/source/ja/model_doc/bit.md b/docs/source/ja/model_doc/bit.md
index ab0a7a4c68..a9e13e270a 100644
--- a/docs/source/ja/model_doc/bit.md
+++ b/docs/source/ja/model_doc/bit.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-BiT モデルは、Alexander Kolesnikov、Lucas Beyer、Xiaohua Zhai、Joan Puigcerver、Jessica Yung、Sylvain Gelly によって [Big Transfer (BiT): General Visual Representation Learning](https://arxiv.org/abs/1912.11370) で提案されました。ニール・ホールズビー。
+BiT モデルは、Alexander Kolesnikov、Lucas Beyer、Xiaohua Zhai、Joan Puigcerver、Jessica Yung、Sylvain Gelly によって [Big Transfer (BiT): General Visual Representation Learning](https://huggingface.co/papers/1912.11370) で提案されました。ニール・ホールズビー。
BiT は、[ResNet](resnet) のようなアーキテクチャ (具体的には ResNetv2) の事前トレーニングをスケールアップするための簡単なレシピです。この方法により、転移学習が大幅に改善されます。
論文の要約は次のとおりです。
@@ -27,8 +27,8 @@ BiT は、[ResNet](resnet) のようなアーキテクチャ (具体的には Re
## Usage tips
-- BiT モデルは、アーキテクチャの点で ResNetv2 と同等ですが、次の点が異なります: 1) すべてのバッチ正規化層が [グループ正規化](https://arxiv.org/abs/1803.08494) に置き換えられます。
-2) [重みの標準化](https://arxiv.org/abs/1903.10520) は畳み込み層に使用されます。著者らは、両方の組み合わせが大きなバッチサイズでのトレーニングに役立ち、重要な効果があることを示しています。
+- BiT モデルは、アーキテクチャの点で ResNetv2 と同等ですが、次の点が異なります: 1) すべてのバッチ正規化層が [グループ正規化](https://huggingface.co/papers/1803.08494) に置き換えられます。
+2) [重みの標準化](https://huggingface.co/papers/1903.10520) は畳み込み層に使用されます。著者らは、両方の組み合わせが大きなバッチサイズでのトレーニングに役立ち、重要な効果があることを示しています。
転移学習への影響。
このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
diff --git a/docs/source/ja/model_doc/blenderbot-small.md b/docs/source/ja/model_doc/blenderbot-small.md
index ecb9c1174b..97455bddf8 100644
--- a/docs/source/ja/model_doc/blenderbot-small.md
+++ b/docs/source/ja/model_doc/blenderbot-small.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-Blender チャットボット モデルは、[Recipes for building an open-domain chatbot](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller、Emily Dinan、Naman Goyal、Da Ju、Mary Williamson、yinghan Liu、で提案されました。
+Blender チャットボット モデルは、[Recipes for building an open-domain chatbot](https://huggingface.co/papers/2004.13637) Stephen Roller、Emily Dinan、Naman Goyal、Da Ju、Mary Williamson、yinghan Liu、で提案されました。
ジン・シュー、マイル・オット、カート・シャスター、エリック・M・スミス、Y-ラン・ブーロー、ジェイソン・ウェストン、2020年4月30日。
論文の要旨は次のとおりです。
diff --git a/docs/source/ja/model_doc/blenderbot.md b/docs/source/ja/model_doc/blenderbot.md
index f7ee23e755..f2a03e69c9 100644
--- a/docs/source/ja/model_doc/blenderbot.md
+++ b/docs/source/ja/model_doc/blenderbot.md
@@ -20,7 +20,7 @@ rendered properly in your Markdown viewer.
## Overview
-Blender チャットボット モデルは、[Recipes for building an open-domain chatbot](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller、Emily Dinan、Naman Goyal、Da Ju、Mary Williamson、yinghan Liu、で提案されました。
+Blender チャットボット モデルは、[Recipes for building an open-domain chatbot](https://huggingface.co/papers/2004.13637) Stephen Roller、Emily Dinan、Naman Goyal、Da Ju、Mary Williamson、yinghan Liu、で提案されました。
ジン・シュー、マイル・オット、カート・シャスター、エリック・M・スミス、Y-ラン・ブーロー、ジェイソン・ウェストン、2020年4月30日。
論文の要旨は次のとおりです。
@@ -45,7 +45,7 @@ Blender チャットボット モデルは、[Recipes for building an open-domai
## Implementation Notes
-- Blenderbot は、標準の [seq2seq モデル トランスフォーマー](https://arxiv.org/pdf/1706.03762.pdf) ベースのアーキテクチャを使用します。
+- Blenderbot は、標準の [seq2seq モデル トランスフォーマー](https://huggingface.co/papers/1706.03762) ベースのアーキテクチャを使用します。
- 利用可能なチェックポイントは、[モデル ハブ](https://huggingface.co/models?search=blenderbot) で見つけることができます。
- これは *デフォルト* Blenderbot モデル クラスです。ただし、次のような小さなチェックポイントもいくつかあります。
`facebook/blenderbot_small_90M` はアーキテクチャが異なるため、一緒に使用する必要があります。
diff --git a/docs/source/ja/model_doc/blip-2.md b/docs/source/ja/model_doc/blip-2.md
index bd110522e2..52a092ac9a 100644
--- a/docs/source/ja/model_doc/blip-2.md
+++ b/docs/source/ja/model_doc/blip-2.md
@@ -18,9 +18,9 @@ rendered properly in your Markdown viewer.
## Overview
-BLIP-2 モデルは、[BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://arxiv.org/abs/2301.12597) で提案されました。
+BLIP-2 モデルは、[BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://huggingface.co/papers/2301.12597) で提案されました。
Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi.・サバレーゼ、スティーブン・ホイ。 BLIP-2 は、軽量の 12 層 Transformer をトレーニングすることで、フリーズされた事前トレーニング済み画像エンコーダーと大規模言語モデル (LLM) を活用します。
-それらの間にエンコーダーを配置し、さまざまな視覚言語タスクで最先端のパフォーマンスを実現します。最も注目すべき点は、BLIP-2 が 800 億パラメータ モデルである [Flamingo](https://arxiv.org/abs/2204.14198) を 8.7% 改善していることです。
+それらの間にエンコーダーを配置し、さまざまな視覚言語タスクで最先端のパフォーマンスを実現します。最も注目すべき点は、BLIP-2 が 800 億パラメータ モデルである [Flamingo](https://huggingface.co/papers/2204.14198) を 8.7% 改善していることです。
ゼロショット VQAv2 ではトレーニング可能なパラメーターが 54 分の 1 に減少します。
論文の要約は次のとおりです。
@@ -30,7 +30,7 @@ Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi.・サバレーゼ、スティ
- BEiT の事前トレーニング。 元の論文から抜粋。
+ BEiT の事前トレーニング。 元の論文から抜粋。
このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。このモデルの JAX/FLAX バージョンは、
[kamalkraj](https://huggingface.co/kamalkraj) による投稿。元のコードは [ここ](https://github.com/microsoft/unilm/tree/master/beit) にあります。
diff --git a/docs/source/ja/model_doc/bert-generation.md b/docs/source/ja/model_doc/bert-generation.md
index d2c93a4644..bf3b932968 100644
--- a/docs/source/ja/model_doc/bert-generation.md
+++ b/docs/source/ja/model_doc/bert-generation.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## Overview
BertGeneration モデルは、次を使用してシーケンス間のタスクに利用できる BERT モデルです。
-[Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) で提案されている [`EncoderDecoderModel`]
+[Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://huggingface.co/papers/1907.12461) で提案されている [`EncoderDecoderModel`]
タスク、Sascha Rothe、Sishi Nagayan、Aliaksei Severyn 著。
論文の要約は次のとおりです。
diff --git a/docs/source/ja/model_doc/bert.md b/docs/source/ja/model_doc/bert.md
index 6e6947bd04..e0367dcd46 100644
--- a/docs/source/ja/model_doc/bert.md
+++ b/docs/source/ja/model_doc/bert.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
## Overview
-BERT モデルは、Jacob Devlin、Ming-Wei Chang、Kenton Lee、Kristina Toutanova によって [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) で提案されました。それは
+BERT モデルは、Jacob Devlin、Ming-Wei Chang、Kenton Lee、Kristina Toutanova によって [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://huggingface.co/papers/1810.04805) で提案されました。それは
マスクされた言語モデリング目標と次の文の組み合わせを使用して事前トレーニングされた双方向トランスフォーマー
Toronto Book Corpus と Wikipedia からなる大規模なコーパスでの予測。
diff --git a/docs/source/ja/model_doc/big_bird.md b/docs/source/ja/model_doc/big_bird.md
index 960d19146c..d5f4f9d282 100644
--- a/docs/source/ja/model_doc/big_bird.md
+++ b/docs/source/ja/model_doc/big_bird.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-BigBird モデルは、[Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) で提案されました。
+BigBird モデルは、[Big Bird: Transformers for Longer Sequences](https://huggingface.co/papers/2007.14062) で提案されました。
ザヒール、マンジルとグルガネシュ、グルとダベイ、クマール・アヴィナヴァとエインズリー、ジョシュアとアルベルティ、クリスとオンタノン、
サンティアゴとファム、フィリップとラブラ、アニルードとワン、キーファンとヤン、リーなど。 BigBird は注目度が低い
BERT などの Transformer ベースのモデルをさらに長いシーケンスに拡張する、Transformer ベースのモデル。まばらに加えて
diff --git a/docs/source/ja/model_doc/bigbird_pegasus.md b/docs/source/ja/model_doc/bigbird_pegasus.md
index 5314aed1bc..ecee19d6a5 100644
--- a/docs/source/ja/model_doc/bigbird_pegasus.md
+++ b/docs/source/ja/model_doc/bigbird_pegasus.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-BigBird モデルは、[Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) で提案されました。
+BigBird モデルは、[Big Bird: Transformers for Longer Sequences](https://huggingface.co/papers/2007.14062) で提案されました。
ザヒール、マンジルとグルガネシュ、グルとダベイ、クマール・アヴィナヴァとエインズリー、ジョシュアとアルベルティ、クリスとオンタノン、
サンティアゴとファム、フィリップとラブラ、アニルードとワン、キーファンとヤン、リーなど。 BigBird は注目度が低い
BERT などの Transformer ベースのモデルをさらに長いシーケンスに拡張する、Transformer ベースのモデル。まばらに加えて
diff --git a/docs/source/ja/model_doc/bit.md b/docs/source/ja/model_doc/bit.md
index ab0a7a4c68..a9e13e270a 100644
--- a/docs/source/ja/model_doc/bit.md
+++ b/docs/source/ja/model_doc/bit.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-BiT モデルは、Alexander Kolesnikov、Lucas Beyer、Xiaohua Zhai、Joan Puigcerver、Jessica Yung、Sylvain Gelly によって [Big Transfer (BiT): General Visual Representation Learning](https://arxiv.org/abs/1912.11370) で提案されました。ニール・ホールズビー。
+BiT モデルは、Alexander Kolesnikov、Lucas Beyer、Xiaohua Zhai、Joan Puigcerver、Jessica Yung、Sylvain Gelly によって [Big Transfer (BiT): General Visual Representation Learning](https://huggingface.co/papers/1912.11370) で提案されました。ニール・ホールズビー。
BiT は、[ResNet](resnet) のようなアーキテクチャ (具体的には ResNetv2) の事前トレーニングをスケールアップするための簡単なレシピです。この方法により、転移学習が大幅に改善されます。
論文の要約は次のとおりです。
@@ -27,8 +27,8 @@ BiT は、[ResNet](resnet) のようなアーキテクチャ (具体的には Re
## Usage tips
-- BiT モデルは、アーキテクチャの点で ResNetv2 と同等ですが、次の点が異なります: 1) すべてのバッチ正規化層が [グループ正規化](https://arxiv.org/abs/1803.08494) に置き換えられます。
-2) [重みの標準化](https://arxiv.org/abs/1903.10520) は畳み込み層に使用されます。著者らは、両方の組み合わせが大きなバッチサイズでのトレーニングに役立ち、重要な効果があることを示しています。
+- BiT モデルは、アーキテクチャの点で ResNetv2 と同等ですが、次の点が異なります: 1) すべてのバッチ正規化層が [グループ正規化](https://huggingface.co/papers/1803.08494) に置き換えられます。
+2) [重みの標準化](https://huggingface.co/papers/1903.10520) は畳み込み層に使用されます。著者らは、両方の組み合わせが大きなバッチサイズでのトレーニングに役立ち、重要な効果があることを示しています。
転移学習への影響。
このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
diff --git a/docs/source/ja/model_doc/blenderbot-small.md b/docs/source/ja/model_doc/blenderbot-small.md
index ecb9c1174b..97455bddf8 100644
--- a/docs/source/ja/model_doc/blenderbot-small.md
+++ b/docs/source/ja/model_doc/blenderbot-small.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-Blender チャットボット モデルは、[Recipes for building an open-domain chatbot](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller、Emily Dinan、Naman Goyal、Da Ju、Mary Williamson、yinghan Liu、で提案されました。
+Blender チャットボット モデルは、[Recipes for building an open-domain chatbot](https://huggingface.co/papers/2004.13637) Stephen Roller、Emily Dinan、Naman Goyal、Da Ju、Mary Williamson、yinghan Liu、で提案されました。
ジン・シュー、マイル・オット、カート・シャスター、エリック・M・スミス、Y-ラン・ブーロー、ジェイソン・ウェストン、2020年4月30日。
論文の要旨は次のとおりです。
diff --git a/docs/source/ja/model_doc/blenderbot.md b/docs/source/ja/model_doc/blenderbot.md
index f7ee23e755..f2a03e69c9 100644
--- a/docs/source/ja/model_doc/blenderbot.md
+++ b/docs/source/ja/model_doc/blenderbot.md
@@ -20,7 +20,7 @@ rendered properly in your Markdown viewer.
## Overview
-Blender チャットボット モデルは、[Recipes for building an open-domain chatbot](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller、Emily Dinan、Naman Goyal、Da Ju、Mary Williamson、yinghan Liu、で提案されました。
+Blender チャットボット モデルは、[Recipes for building an open-domain chatbot](https://huggingface.co/papers/2004.13637) Stephen Roller、Emily Dinan、Naman Goyal、Da Ju、Mary Williamson、yinghan Liu、で提案されました。
ジン・シュー、マイル・オット、カート・シャスター、エリック・M・スミス、Y-ラン・ブーロー、ジェイソン・ウェストン、2020年4月30日。
論文の要旨は次のとおりです。
@@ -45,7 +45,7 @@ Blender チャットボット モデルは、[Recipes for building an open-domai
## Implementation Notes
-- Blenderbot は、標準の [seq2seq モデル トランスフォーマー](https://arxiv.org/pdf/1706.03762.pdf) ベースのアーキテクチャを使用します。
+- Blenderbot は、標準の [seq2seq モデル トランスフォーマー](https://huggingface.co/papers/1706.03762) ベースのアーキテクチャを使用します。
- 利用可能なチェックポイントは、[モデル ハブ](https://huggingface.co/models?search=blenderbot) で見つけることができます。
- これは *デフォルト* Blenderbot モデル クラスです。ただし、次のような小さなチェックポイントもいくつかあります。
`facebook/blenderbot_small_90M` はアーキテクチャが異なるため、一緒に使用する必要があります。
diff --git a/docs/source/ja/model_doc/blip-2.md b/docs/source/ja/model_doc/blip-2.md
index bd110522e2..52a092ac9a 100644
--- a/docs/source/ja/model_doc/blip-2.md
+++ b/docs/source/ja/model_doc/blip-2.md
@@ -18,9 +18,9 @@ rendered properly in your Markdown viewer.
## Overview
-BLIP-2 モデルは、[BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://arxiv.org/abs/2301.12597) で提案されました。
+BLIP-2 モデルは、[BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://huggingface.co/papers/2301.12597) で提案されました。
Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi.・サバレーゼ、スティーブン・ホイ。 BLIP-2 は、軽量の 12 層 Transformer をトレーニングすることで、フリーズされた事前トレーニング済み画像エンコーダーと大規模言語モデル (LLM) を活用します。
-それらの間にエンコーダーを配置し、さまざまな視覚言語タスクで最先端のパフォーマンスを実現します。最も注目すべき点は、BLIP-2 が 800 億パラメータ モデルである [Flamingo](https://arxiv.org/abs/2204.14198) を 8.7% 改善していることです。
+それらの間にエンコーダーを配置し、さまざまな視覚言語タスクで最先端のパフォーマンスを実現します。最も注目すべき点は、BLIP-2 が 800 億パラメータ モデルである [Flamingo](https://huggingface.co/papers/2204.14198) を 8.7% 改善していることです。
ゼロショット VQAv2 ではトレーニング可能なパラメーターが 54 分の 1 に減少します。
論文の要約は次のとおりです。
@@ -30,7 +30,7 @@ Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi.・サバレーゼ、スティ
 - BLIP-2 アーキテクチャ。 元の論文から抜粋。
+ BLIP-2 アーキテクチャ。 元の論文から抜粋。
このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
元のコードは [ここ](https://github.com/salesforce/LAVIS/tree/5ee63d688ba4cebff63acee04adaef2dee9af207) にあります。
diff --git a/docs/source/ja/model_doc/blip.md b/docs/source/ja/model_doc/blip.md
index 8e8550318b..e93c740883 100644
--- a/docs/source/ja/model_doc/blip.md
+++ b/docs/source/ja/model_doc/blip.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-BLIP モデルは、[BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) で Junnan Li、Dongxu Li、Caiming Xiong、Steven Hoi によって提案されました。 。
+BLIP モデルは、[BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://huggingface.co/papers/2201.12086) で Junnan Li、Dongxu Li、Caiming Xiong、Steven Hoi によって提案されました。 。
BLIP は、次のようなさまざまなマルチモーダル タスクを実行できるモデルです。
- 視覚的な質問応答
diff --git a/docs/source/ja/model_doc/bort.md b/docs/source/ja/model_doc/bort.md
index 2b892a35bb..185187219e 100644
--- a/docs/source/ja/model_doc/bort.md
+++ b/docs/source/ja/model_doc/bort.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
## Overview
-BORT モデルは、[Optimal Subarchitecture Extraction for BERT](https://arxiv.org/abs/2010.10499) で提案されました。
+BORT モデルは、[Optimal Subarchitecture Extraction for BERT](https://huggingface.co/papers/2010.10499) で提案されました。
Adrian de Wynter and Daniel J. Perry.これは、BERT のアーキテクチャ パラメータの最適なサブセットです。
著者は「ボルト」と呼んでいます。
diff --git a/docs/source/ja/model_doc/bridgetower.md b/docs/source/ja/model_doc/bridgetower.md
index c210d4666f..116d87caa5 100644
--- a/docs/source/ja/model_doc/bridgetower.md
+++ b/docs/source/ja/model_doc/bridgetower.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-BridgeTower モデルは、Xiao Xu、Chenfei Wu、Shachar Rosenman、Vasudev Lal、Wanxiang Che、Nan Duan [BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning](https://arxiv.org/abs/2206.08657) で提案されました。ドゥアン。このモデルの目標は、
+BridgeTower モデルは、Xiao Xu、Chenfei Wu、Shachar Rosenman、Vasudev Lal、Wanxiang Che、Nan Duan [BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning](https://huggingface.co/papers/2206.08657) で提案されました。ドゥアン。このモデルの目標は、
各ユニモーダル エンコーダとクロスモーダル エンコーダの間のブリッジにより、クロスモーダル エンコーダの各層での包括的かつ詳細な対話が可能になり、追加のパフォーマンスと計算コストがほとんど無視できる程度で、さまざまな下流タスクで優れたパフォーマンスを実現します。
この論文は [AAAI'23](https://aaai.org/Conferences/AAAI-23/) 会議に採択されました。
@@ -35,7 +35,7 @@ BridgeTower モデルは、Xiao Xu、Chenfei Wu、Shachar Rosenman、Vasudev Lal
- BLIP-2 アーキテクチャ。 元の論文から抜粋。
+ BLIP-2 アーキテクチャ。 元の論文から抜粋。
このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
元のコードは [ここ](https://github.com/salesforce/LAVIS/tree/5ee63d688ba4cebff63acee04adaef2dee9af207) にあります。
diff --git a/docs/source/ja/model_doc/blip.md b/docs/source/ja/model_doc/blip.md
index 8e8550318b..e93c740883 100644
--- a/docs/source/ja/model_doc/blip.md
+++ b/docs/source/ja/model_doc/blip.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-BLIP モデルは、[BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) で Junnan Li、Dongxu Li、Caiming Xiong、Steven Hoi によって提案されました。 。
+BLIP モデルは、[BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://huggingface.co/papers/2201.12086) で Junnan Li、Dongxu Li、Caiming Xiong、Steven Hoi によって提案されました。 。
BLIP は、次のようなさまざまなマルチモーダル タスクを実行できるモデルです。
- 視覚的な質問応答
diff --git a/docs/source/ja/model_doc/bort.md b/docs/source/ja/model_doc/bort.md
index 2b892a35bb..185187219e 100644
--- a/docs/source/ja/model_doc/bort.md
+++ b/docs/source/ja/model_doc/bort.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
## Overview
-BORT モデルは、[Optimal Subarchitecture Extraction for BERT](https://arxiv.org/abs/2010.10499) で提案されました。
+BORT モデルは、[Optimal Subarchitecture Extraction for BERT](https://huggingface.co/papers/2010.10499) で提案されました。
Adrian de Wynter and Daniel J. Perry.これは、BERT のアーキテクチャ パラメータの最適なサブセットです。
著者は「ボルト」と呼んでいます。
diff --git a/docs/source/ja/model_doc/bridgetower.md b/docs/source/ja/model_doc/bridgetower.md
index c210d4666f..116d87caa5 100644
--- a/docs/source/ja/model_doc/bridgetower.md
+++ b/docs/source/ja/model_doc/bridgetower.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-BridgeTower モデルは、Xiao Xu、Chenfei Wu、Shachar Rosenman、Vasudev Lal、Wanxiang Che、Nan Duan [BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning](https://arxiv.org/abs/2206.08657) で提案されました。ドゥアン。このモデルの目標は、
+BridgeTower モデルは、Xiao Xu、Chenfei Wu、Shachar Rosenman、Vasudev Lal、Wanxiang Che、Nan Duan [BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning](https://huggingface.co/papers/2206.08657) で提案されました。ドゥアン。このモデルの目標は、
各ユニモーダル エンコーダとクロスモーダル エンコーダの間のブリッジにより、クロスモーダル エンコーダの各層での包括的かつ詳細な対話が可能になり、追加のパフォーマンスと計算コストがほとんど無視できる程度で、さまざまな下流タスクで優れたパフォーマンスを実現します。
この論文は [AAAI'23](https://aaai.org/Conferences/AAAI-23/) 会議に採択されました。
@@ -35,7 +35,7 @@ BridgeTower モデルは、Xiao Xu、Chenfei Wu、Shachar Rosenman、Vasudev Lal
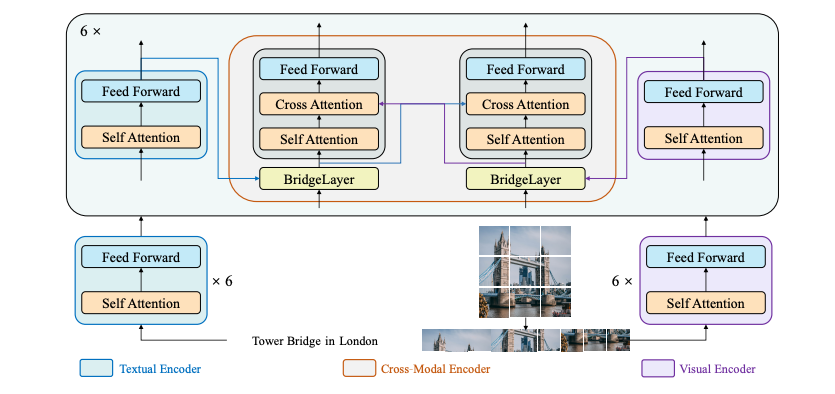 - ブリッジタワー アーキテクチャ。 元の論文から抜粋。
+ ブリッジタワー アーキテクチャ。 元の論文から抜粋。
このモデルは、[Anahita Bhiwandiwalla](https://huggingface.co/anahita-b)、[Tiep Le](https://huggingface.co/Tile)、[Shaoyen Tseng](https://huggingface.co/shaoyent) 。元のコードは [ここ](https://github.com/microsoft/BridgeTower) にあります。
@@ -124,7 +124,7 @@ BridgeTower は、ビジュアル エンコーダー、テキスト エンコー
- BridgeTower のこの実装では、[`RobertaTokenizer`] を使用してテキスト埋め込みを生成し、OpenAI の CLIP/ViT モデルを使用して視覚的埋め込みを計算します。
- 事前トレーニングされた [bridgeTower-base](https://huggingface.co/BridgeTower/bridgetower-base) および [bridgetower マスクされた言語モデリングと画像テキスト マッチング](https://huggingface.co/BridgeTower/bridgetower--base-itm-mlm) のチェックポイント がリリースされました。
-- 画像検索およびその他の下流タスクにおける BridgeTower のパフォーマンスについては、[表 5](https://arxiv.org/pdf/2206.08657.pdf) を参照してください。
+- 画像検索およびその他の下流タスクにおける BridgeTower のパフォーマンスについては、[表 5](https://huggingface.co/papers/2206.08657) を参照してください。
- このモデルの PyTorch バージョンは、torch 1.10 以降でのみ使用できます。
## BridgeTowerConfig
diff --git a/docs/source/ja/model_doc/bros.md b/docs/source/ja/model_doc/bros.md
index 3749a172a8..def3539585 100644
--- a/docs/source/ja/model_doc/bros.md
+++ b/docs/source/ja/model_doc/bros.md
@@ -14,7 +14,7 @@ specific language governing permissions and limitations under the License.
## Overview
-BROS モデルは、Teakgyu Hon、Donghyun Kim、Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park によって [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://arxiv.org/abs/2108.04539) で提案されました。
+BROS モデルは、Teakgyu Hon、Donghyun Kim、Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park によって [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://huggingface.co/papers/2108.04539) で提案されました。
BROS は *BERT Relying On Spatality* の略です。これは、一連のトークンとその境界ボックスを入力として受け取り、一連の隠れ状態を出力するエンコーダー専用の Transformer モデルです。 BROS は、絶対的な空間情報を使用する代わりに、相対的な空間情報をエンコードします。
diff --git a/docs/source/ja/model_doc/byt5.md b/docs/source/ja/model_doc/byt5.md
index c6796f9818..83f7f0b4ac 100644
--- a/docs/source/ja/model_doc/byt5.md
+++ b/docs/source/ja/model_doc/byt5.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-ByT5 モデルは、[ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir
+ByT5 モデルは、[ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://huggingface.co/papers/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir
Kale, Adam Roberts, Colin Raffel.
論文の要約は次のとおりです。
diff --git a/docs/source/ja/model_doc/camembert.md b/docs/source/ja/model_doc/camembert.md
index 4f59700954..382077613d 100644
--- a/docs/source/ja/model_doc/camembert.md
+++ b/docs/source/ja/model_doc/camembert.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-CamemBERT モデルは、[CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) で提案されました。
+CamemBERT モデルは、[CamemBERT: a Tasty French Language Model](https://huggingface.co/papers/1911.03894) で提案されました。
Louis Martin, Benjamin Muller, Pedro Javier Ortiz Suárez, Yoann Dupont, Laurent Romary, Éric Villemonte de la
Clergerie, Djamé Seddah, and Benoît Sagot. 2019年にリリースされたFacebookのRoBERTaモデルをベースにしたモデルです。
138GBのフランス語テキストでトレーニングされました。
diff --git a/docs/source/ja/model_doc/canine.md b/docs/source/ja/model_doc/canine.md
index b45f1e4f7e..35bd6dc702 100644
--- a/docs/source/ja/model_doc/canine.md
+++ b/docs/source/ja/model_doc/canine.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## Overview
CANINE モデルは、[CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language
-Representation](https://arxiv.org/abs/2103.06874)、Jonathan H. Clark、Dan Garrette、Iulia Turc、John Wieting 著。その
+Representation](https://huggingface.co/papers/2103.06874)、Jonathan H. Clark、Dan Garrette、Iulia Turc、John Wieting 著。その
明示的なトークン化ステップ (バイト ペアなど) を使用せずに Transformer をトレーニングする最初の論文の 1 つ
エンコーディング (BPE、WordPiece または SentencePiece)。代わりに、モデルは Unicode 文字レベルで直接トレーニングされます。
キャラクターレベルでのトレーニングでは必然的にシーケンスの長さが長くなりますが、CANINE はこれを効率的な方法で解決します。
diff --git a/docs/source/ja/model_doc/chinese_clip.md b/docs/source/ja/model_doc/chinese_clip.md
index 68eff8e413..5dac6b3589 100644
--- a/docs/source/ja/model_doc/chinese_clip.md
+++ b/docs/source/ja/model_doc/chinese_clip.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-Chinese-CLIP An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://arxiv.org/abs/2211.01335) で提案されました。周、張周。
+Chinese-CLIP An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://huggingface.co/papers/2211.01335) で提案されました。周、張周。
Chinese-CLIP は、中国語の画像とテキストのペアの大規模なデータセットに対する CLIP (Radford et al., 2021) の実装です。クロスモーダル検索を実行できるほか、ゼロショット画像分類、オープンドメインオブジェクト検出などのビジョンタスクのビジョンバックボーンとしても機能します。オリジナルの中国語-CLIPコードは[このリンクで](https://github.com/OFA-Sys/Chinese-CLIP)。
論文の要約は次のとおりです。
diff --git a/docs/source/ja/model_doc/clap.md b/docs/source/ja/model_doc/clap.md
index f1e08d7601..1a5f2b5dfe 100644
--- a/docs/source/ja/model_doc/clap.md
+++ b/docs/source/ja/model_doc/clap.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## Overview
CLAP モデルは、[Large Scale Contrastive Language-Audio pretraining with
-feature fusion and keyword-to-caption augmentation](https://arxiv.org/pdf/2211.06687.pdf)、Yusong Wu、Ke Chen、Tianyu Zhang、Yuchen Hui、Taylor Berg-Kirkpatrick、Shlomo Dubnov 著。
+feature fusion and keyword-to-caption augmentation](https://huggingface.co/papers/2211.06687)、Yusong Wu、Ke Chen、Tianyu Zhang、Yuchen Hui、Taylor Berg-Kirkpatrick、Shlomo Dubnov 著。
CLAP (Contrastive Language-Audio Pretraining) は、さまざまな (音声、テキスト) ペアでトレーニングされたニューラル ネットワークです。タスクに合わせて直接最適化することなく、音声が与えられた場合に最も関連性の高いテキスト スニペットを予測するように指示できます。 CLAP モデルは、SWINTransformer を使用して log-Mel スペクトログラム入力からオーディオ特徴を取得し、RoBERTa モデルを使用してテキスト特徴を取得します。次に、テキストとオーディオの両方の特徴が、同じ次元の潜在空間に投影されます。投影されたオーディオとテキストの特徴の間のドット積が、同様のスコアとして使用されます。
diff --git a/docs/source/ja/model_doc/clip.md b/docs/source/ja/model_doc/clip.md
index db896c9116..6b21dbd143 100644
--- a/docs/source/ja/model_doc/clip.md
+++ b/docs/source/ja/model_doc/clip.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-CLIP モデルは、Alec Radford、Jong Wook Kim、Chris Hallacy、Aditya Ramesh、Gabriel Goh Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) で提案されました。
+CLIP モデルは、Alec Radford、Jong Wook Kim、Chris Hallacy、Aditya Ramesh、Gabriel Goh Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever [Learning Transferable Visual Models From Natural Language Supervision](https://huggingface.co/papers/2103.00020) で提案されました。
サンディニ・アガルワル、ギリッシュ・サストリー、アマンダ・アスケル、パメラ・ミシュキン、ジャック・クラーク、グレッチェン・クルーガー、イリヤ・サツケヴァー。クリップ
(Contrastive Language-Image Pre-Training) は、さまざまな (画像、テキスト) ペアでトレーニングされたニューラル ネットワークです。かもね
直接最適化することなく、与えられた画像から最も関連性の高いテキスト スニペットを予測するように自然言語で指示されます。
diff --git a/docs/source/ja/model_doc/clipseg.md b/docs/source/ja/model_doc/clipseg.md
index c8bdb0a0e4..8853565fac 100644
--- a/docs/source/ja/model_doc/clipseg.md
+++ b/docs/source/ja/model_doc/clipseg.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-CLIPSeg モデルは、Timo Lüddecke, Alexander Ecker によって [Image Segmentation using Text and Image Prompts](https://arxiv.org/abs/2112.10003) で提案されました。
+CLIPSeg モデルは、Timo Lüddecke, Alexander Ecker によって [Image Segmentation using Text and Image Prompts](https://huggingface.co/papers/2112.10003) で提案されました。
そしてアレクサンダー・エッカー。 CLIPSeg は、ゼロショットおよびワンショット画像セグメンテーションのために、凍結された [CLIP](clip) モデルの上に最小限のデコーダを追加します。
論文の要約は次のとおりです。
@@ -44,7 +44,7 @@ PhraseCut データセット、私たちのシステムは、フリーテキス
- ブリッジタワー アーキテクチャ。 元の論文から抜粋。
+ ブリッジタワー アーキテクチャ。 元の論文から抜粋。
このモデルは、[Anahita Bhiwandiwalla](https://huggingface.co/anahita-b)、[Tiep Le](https://huggingface.co/Tile)、[Shaoyen Tseng](https://huggingface.co/shaoyent) 。元のコードは [ここ](https://github.com/microsoft/BridgeTower) にあります。
@@ -124,7 +124,7 @@ BridgeTower は、ビジュアル エンコーダー、テキスト エンコー
- BridgeTower のこの実装では、[`RobertaTokenizer`] を使用してテキスト埋め込みを生成し、OpenAI の CLIP/ViT モデルを使用して視覚的埋め込みを計算します。
- 事前トレーニングされた [bridgeTower-base](https://huggingface.co/BridgeTower/bridgetower-base) および [bridgetower マスクされた言語モデリングと画像テキスト マッチング](https://huggingface.co/BridgeTower/bridgetower--base-itm-mlm) のチェックポイント がリリースされました。
-- 画像検索およびその他の下流タスクにおける BridgeTower のパフォーマンスについては、[表 5](https://arxiv.org/pdf/2206.08657.pdf) を参照してください。
+- 画像検索およびその他の下流タスクにおける BridgeTower のパフォーマンスについては、[表 5](https://huggingface.co/papers/2206.08657) を参照してください。
- このモデルの PyTorch バージョンは、torch 1.10 以降でのみ使用できます。
## BridgeTowerConfig
diff --git a/docs/source/ja/model_doc/bros.md b/docs/source/ja/model_doc/bros.md
index 3749a172a8..def3539585 100644
--- a/docs/source/ja/model_doc/bros.md
+++ b/docs/source/ja/model_doc/bros.md
@@ -14,7 +14,7 @@ specific language governing permissions and limitations under the License.
## Overview
-BROS モデルは、Teakgyu Hon、Donghyun Kim、Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park によって [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://arxiv.org/abs/2108.04539) で提案されました。
+BROS モデルは、Teakgyu Hon、Donghyun Kim、Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park によって [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://huggingface.co/papers/2108.04539) で提案されました。
BROS は *BERT Relying On Spatality* の略です。これは、一連のトークンとその境界ボックスを入力として受け取り、一連の隠れ状態を出力するエンコーダー専用の Transformer モデルです。 BROS は、絶対的な空間情報を使用する代わりに、相対的な空間情報をエンコードします。
diff --git a/docs/source/ja/model_doc/byt5.md b/docs/source/ja/model_doc/byt5.md
index c6796f9818..83f7f0b4ac 100644
--- a/docs/source/ja/model_doc/byt5.md
+++ b/docs/source/ja/model_doc/byt5.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-ByT5 モデルは、[ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir
+ByT5 モデルは、[ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://huggingface.co/papers/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir
Kale, Adam Roberts, Colin Raffel.
論文の要約は次のとおりです。
diff --git a/docs/source/ja/model_doc/camembert.md b/docs/source/ja/model_doc/camembert.md
index 4f59700954..382077613d 100644
--- a/docs/source/ja/model_doc/camembert.md
+++ b/docs/source/ja/model_doc/camembert.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-CamemBERT モデルは、[CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) で提案されました。
+CamemBERT モデルは、[CamemBERT: a Tasty French Language Model](https://huggingface.co/papers/1911.03894) で提案されました。
Louis Martin, Benjamin Muller, Pedro Javier Ortiz Suárez, Yoann Dupont, Laurent Romary, Éric Villemonte de la
Clergerie, Djamé Seddah, and Benoît Sagot. 2019年にリリースされたFacebookのRoBERTaモデルをベースにしたモデルです。
138GBのフランス語テキストでトレーニングされました。
diff --git a/docs/source/ja/model_doc/canine.md b/docs/source/ja/model_doc/canine.md
index b45f1e4f7e..35bd6dc702 100644
--- a/docs/source/ja/model_doc/canine.md
+++ b/docs/source/ja/model_doc/canine.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## Overview
CANINE モデルは、[CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language
-Representation](https://arxiv.org/abs/2103.06874)、Jonathan H. Clark、Dan Garrette、Iulia Turc、John Wieting 著。その
+Representation](https://huggingface.co/papers/2103.06874)、Jonathan H. Clark、Dan Garrette、Iulia Turc、John Wieting 著。その
明示的なトークン化ステップ (バイト ペアなど) を使用せずに Transformer をトレーニングする最初の論文の 1 つ
エンコーディング (BPE、WordPiece または SentencePiece)。代わりに、モデルは Unicode 文字レベルで直接トレーニングされます。
キャラクターレベルでのトレーニングでは必然的にシーケンスの長さが長くなりますが、CANINE はこれを効率的な方法で解決します。
diff --git a/docs/source/ja/model_doc/chinese_clip.md b/docs/source/ja/model_doc/chinese_clip.md
index 68eff8e413..5dac6b3589 100644
--- a/docs/source/ja/model_doc/chinese_clip.md
+++ b/docs/source/ja/model_doc/chinese_clip.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-Chinese-CLIP An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://arxiv.org/abs/2211.01335) で提案されました。周、張周。
+Chinese-CLIP An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://huggingface.co/papers/2211.01335) で提案されました。周、張周。
Chinese-CLIP は、中国語の画像とテキストのペアの大規模なデータセットに対する CLIP (Radford et al., 2021) の実装です。クロスモーダル検索を実行できるほか、ゼロショット画像分類、オープンドメインオブジェクト検出などのビジョンタスクのビジョンバックボーンとしても機能します。オリジナルの中国語-CLIPコードは[このリンクで](https://github.com/OFA-Sys/Chinese-CLIP)。
論文の要約は次のとおりです。
diff --git a/docs/source/ja/model_doc/clap.md b/docs/source/ja/model_doc/clap.md
index f1e08d7601..1a5f2b5dfe 100644
--- a/docs/source/ja/model_doc/clap.md
+++ b/docs/source/ja/model_doc/clap.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## Overview
CLAP モデルは、[Large Scale Contrastive Language-Audio pretraining with
-feature fusion and keyword-to-caption augmentation](https://arxiv.org/pdf/2211.06687.pdf)、Yusong Wu、Ke Chen、Tianyu Zhang、Yuchen Hui、Taylor Berg-Kirkpatrick、Shlomo Dubnov 著。
+feature fusion and keyword-to-caption augmentation](https://huggingface.co/papers/2211.06687)、Yusong Wu、Ke Chen、Tianyu Zhang、Yuchen Hui、Taylor Berg-Kirkpatrick、Shlomo Dubnov 著。
CLAP (Contrastive Language-Audio Pretraining) は、さまざまな (音声、テキスト) ペアでトレーニングされたニューラル ネットワークです。タスクに合わせて直接最適化することなく、音声が与えられた場合に最も関連性の高いテキスト スニペットを予測するように指示できます。 CLAP モデルは、SWINTransformer を使用して log-Mel スペクトログラム入力からオーディオ特徴を取得し、RoBERTa モデルを使用してテキスト特徴を取得します。次に、テキストとオーディオの両方の特徴が、同じ次元の潜在空間に投影されます。投影されたオーディオとテキストの特徴の間のドット積が、同様のスコアとして使用されます。
diff --git a/docs/source/ja/model_doc/clip.md b/docs/source/ja/model_doc/clip.md
index db896c9116..6b21dbd143 100644
--- a/docs/source/ja/model_doc/clip.md
+++ b/docs/source/ja/model_doc/clip.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-CLIP モデルは、Alec Radford、Jong Wook Kim、Chris Hallacy、Aditya Ramesh、Gabriel Goh Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) で提案されました。
+CLIP モデルは、Alec Radford、Jong Wook Kim、Chris Hallacy、Aditya Ramesh、Gabriel Goh Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever [Learning Transferable Visual Models From Natural Language Supervision](https://huggingface.co/papers/2103.00020) で提案されました。
サンディニ・アガルワル、ギリッシュ・サストリー、アマンダ・アスケル、パメラ・ミシュキン、ジャック・クラーク、グレッチェン・クルーガー、イリヤ・サツケヴァー。クリップ
(Contrastive Language-Image Pre-Training) は、さまざまな (画像、テキスト) ペアでトレーニングされたニューラル ネットワークです。かもね
直接最適化することなく、与えられた画像から最も関連性の高いテキスト スニペットを予測するように自然言語で指示されます。
diff --git a/docs/source/ja/model_doc/clipseg.md b/docs/source/ja/model_doc/clipseg.md
index c8bdb0a0e4..8853565fac 100644
--- a/docs/source/ja/model_doc/clipseg.md
+++ b/docs/source/ja/model_doc/clipseg.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-CLIPSeg モデルは、Timo Lüddecke, Alexander Ecker によって [Image Segmentation using Text and Image Prompts](https://arxiv.org/abs/2112.10003) で提案されました。
+CLIPSeg モデルは、Timo Lüddecke, Alexander Ecker によって [Image Segmentation using Text and Image Prompts](https://huggingface.co/papers/2112.10003) で提案されました。
そしてアレクサンダー・エッカー。 CLIPSeg は、ゼロショットおよびワンショット画像セグメンテーションのために、凍結された [CLIP](clip) モデルの上に最小限のデコーダを追加します。
論文の要約は次のとおりです。
@@ -44,7 +44,7 @@ PhraseCut データセット、私たちのシステムは、フリーテキス
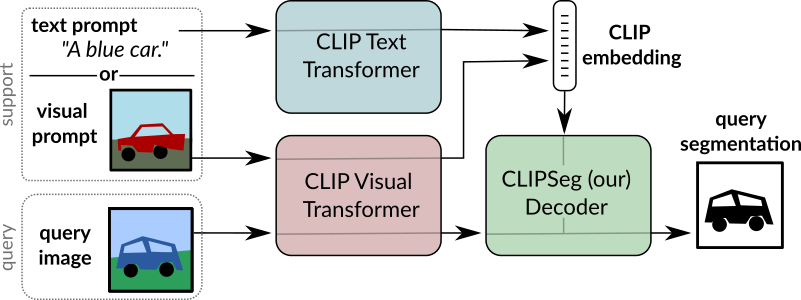 - CLIPSeg の概要。 元の論文から抜粋。
+ CLIPSeg の概要。 元の論文から抜粋。
このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
元のコードは [ここ](https://github.com/timojl/clipseg) にあります。
diff --git a/docs/source/ja/model_doc/clvp.md b/docs/source/ja/model_doc/clvp.md
index 0803f5e027..874e0779c7 100644
--- a/docs/source/ja/model_doc/clvp.md
+++ b/docs/source/ja/model_doc/clvp.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-CLVP (Contrastive Language-Voice Pretrained Transformer) モデルは、James Betker によって [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) で提案されました。
+CLVP (Contrastive Language-Voice Pretrained Transformer) モデルは、James Betker によって [Better speech synthesis through scaling](https://huggingface.co/papers/2305.07243) で提案されました。
論文の要約は次のとおりです。
diff --git a/docs/source/ja/model_doc/codegen.md b/docs/source/ja/model_doc/codegen.md
index 78caefe043..28ab376260 100644
--- a/docs/source/ja/model_doc/codegen.md
+++ b/docs/source/ja/model_doc/codegen.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## Overview
-CodeGen モデルは、[A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) で Erik Nijkamp、Bo Pang、林宏明、Lifu Tu、Huan Wang、Yingbo Zhou、Silvio Savarese、Caiming Xiong およびカイミン・ションさん。
+CodeGen モデルは、[A Conversational Paradigm for Program Synthesis](https://huggingface.co/papers/2203.13474) で Erik Nijkamp、Bo Pang、林宏明、Lifu Tu、Huan Wang、Yingbo Zhou、Silvio Savarese、Caiming Xiong およびカイミン・ションさん。
CodeGen は、[The Pile](https://pile.eleuther.ai/)、BigQuery、BigPython で順次トレーニングされたプログラム合成用の自己回帰言語モデルです。
diff --git a/docs/source/ja/model_doc/conditional_detr.md b/docs/source/ja/model_doc/conditional_detr.md
index e2ce65bdca..d0bb090630 100644
--- a/docs/source/ja/model_doc/conditional_detr.md
+++ b/docs/source/ja/model_doc/conditional_detr.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-条件付き DETR モデルは、[Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) で Depu Meng、Xiaokang Chen、Zejia Fan、Gang Zeng、Houqiang Li、Yuhui Yuan、Lei Sun, Jingdong Wang によって提案されました。王京東。条件付き DETR は、高速 DETR トレーニングのための条件付きクロスアテンション メカニズムを提供します。条件付き DETR は DETR よりも 6.7 倍から 10 倍速く収束します。
+条件付き DETR モデルは、[Conditional DETR for Fast Training Convergence](https://huggingface.co/papers/2108.06152) で Depu Meng、Xiaokang Chen、Zejia Fan、Gang Zeng、Houqiang Li、Yuhui Yuan、Lei Sun, Jingdong Wang によって提案されました。王京東。条件付き DETR は、高速 DETR トレーニングのための条件付きクロスアテンション メカニズムを提供します。条件付き DETR は DETR よりも 6.7 倍から 10 倍速く収束します。
論文の要約は次のとおりです。
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
- CLIPSeg の概要。 元の論文から抜粋。
+ CLIPSeg の概要。 元の論文から抜粋。
このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
元のコードは [ここ](https://github.com/timojl/clipseg) にあります。
diff --git a/docs/source/ja/model_doc/clvp.md b/docs/source/ja/model_doc/clvp.md
index 0803f5e027..874e0779c7 100644
--- a/docs/source/ja/model_doc/clvp.md
+++ b/docs/source/ja/model_doc/clvp.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-CLVP (Contrastive Language-Voice Pretrained Transformer) モデルは、James Betker によって [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) で提案されました。
+CLVP (Contrastive Language-Voice Pretrained Transformer) モデルは、James Betker によって [Better speech synthesis through scaling](https://huggingface.co/papers/2305.07243) で提案されました。
論文の要約は次のとおりです。
diff --git a/docs/source/ja/model_doc/codegen.md b/docs/source/ja/model_doc/codegen.md
index 78caefe043..28ab376260 100644
--- a/docs/source/ja/model_doc/codegen.md
+++ b/docs/source/ja/model_doc/codegen.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## Overview
-CodeGen モデルは、[A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) で Erik Nijkamp、Bo Pang、林宏明、Lifu Tu、Huan Wang、Yingbo Zhou、Silvio Savarese、Caiming Xiong およびカイミン・ションさん。
+CodeGen モデルは、[A Conversational Paradigm for Program Synthesis](https://huggingface.co/papers/2203.13474) で Erik Nijkamp、Bo Pang、林宏明、Lifu Tu、Huan Wang、Yingbo Zhou、Silvio Savarese、Caiming Xiong およびカイミン・ションさん。
CodeGen は、[The Pile](https://pile.eleuther.ai/)、BigQuery、BigPython で順次トレーニングされたプログラム合成用の自己回帰言語モデルです。
diff --git a/docs/source/ja/model_doc/conditional_detr.md b/docs/source/ja/model_doc/conditional_detr.md
index e2ce65bdca..d0bb090630 100644
--- a/docs/source/ja/model_doc/conditional_detr.md
+++ b/docs/source/ja/model_doc/conditional_detr.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-条件付き DETR モデルは、[Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) で Depu Meng、Xiaokang Chen、Zejia Fan、Gang Zeng、Houqiang Li、Yuhui Yuan、Lei Sun, Jingdong Wang によって提案されました。王京東。条件付き DETR は、高速 DETR トレーニングのための条件付きクロスアテンション メカニズムを提供します。条件付き DETR は DETR よりも 6.7 倍から 10 倍速く収束します。
+条件付き DETR モデルは、[Conditional DETR for Fast Training Convergence](https://huggingface.co/papers/2108.06152) で Depu Meng、Xiaokang Chen、Zejia Fan、Gang Zeng、Houqiang Li、Yuhui Yuan、Lei Sun, Jingdong Wang によって提案されました。王京東。条件付き DETR は、高速 DETR トレーニングのための条件付きクロスアテンション メカニズムを提供します。条件付き DETR は DETR よりも 6.7 倍から 10 倍速く収束します。
論文の要約は次のとおりです。
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
 - 条件付き DETR は、元の DETR に比べてはるかに速い収束を示します。 元の論文から引用。
+ 条件付き DETR は、元の DETR に比べてはるかに速い収束を示します。 元の論文から引用。
このモデルは [DepuMeng](https://huggingface.co/DepuMeng) によって寄稿されました。元のコードは [ここ](https://github.com/Atten4Vis/ConditionalDETR) にあります。
diff --git a/docs/source/ja/model_doc/convbert.md b/docs/source/ja/model_doc/convbert.md
index 7d790e4069..c581b715db 100644
--- a/docs/source/ja/model_doc/convbert.md
+++ b/docs/source/ja/model_doc/convbert.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
## Overview
-ConvBERT モデルは、[ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) で Zihang Jiang、Weihao Yu、Daquan Zhou、Yunpeng Chen、Jiashi Feng、Shuicheng Yan によって提案されました。
+ConvBERT モデルは、[ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://huggingface.co/papers/2008.02496) で Zihang Jiang、Weihao Yu、Daquan Zhou、Yunpeng Chen、Jiashi Feng、Shuicheng Yan によって提案されました。
やん。
論文の要約は次のとおりです。
diff --git a/docs/source/ja/model_doc/convnext.md b/docs/source/ja/model_doc/convnext.md
index efbe3bb0f4..336f27709d 100644
--- a/docs/source/ja/model_doc/convnext.md
+++ b/docs/source/ja/model_doc/convnext.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-ConvNeXT モデルは、[A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) で Zhuang Liu、Hanzi Mao、Chao-Yuan Wu、Christoph Feichtenhofer、Trevor Darrell、Saining Xie によって提案されました。
+ConvNeXT モデルは、[A ConvNet for the 2020s](https://huggingface.co/papers/2201.03545) で Zhuang Liu、Hanzi Mao、Chao-Yuan Wu、Christoph Feichtenhofer、Trevor Darrell、Saining Xie によって提案されました。
ConvNeXT は、ビジョン トランスフォーマーの設計からインスピレーションを得た純粋な畳み込みモデル (ConvNet) であり、ビジョン トランスフォーマーよりも優れたパフォーマンスを発揮すると主張しています。
論文の要約は次のとおりです。
@@ -35,7 +35,7 @@ ConvNextと呼ばれます。 ConvNeXts は完全に標準の ConvNet モジュ
- 条件付き DETR は、元の DETR に比べてはるかに速い収束を示します。 元の論文から引用。
+ 条件付き DETR は、元の DETR に比べてはるかに速い収束を示します。 元の論文から引用。
このモデルは [DepuMeng](https://huggingface.co/DepuMeng) によって寄稿されました。元のコードは [ここ](https://github.com/Atten4Vis/ConditionalDETR) にあります。
diff --git a/docs/source/ja/model_doc/convbert.md b/docs/source/ja/model_doc/convbert.md
index 7d790e4069..c581b715db 100644
--- a/docs/source/ja/model_doc/convbert.md
+++ b/docs/source/ja/model_doc/convbert.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
## Overview
-ConvBERT モデルは、[ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) で Zihang Jiang、Weihao Yu、Daquan Zhou、Yunpeng Chen、Jiashi Feng、Shuicheng Yan によって提案されました。
+ConvBERT モデルは、[ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://huggingface.co/papers/2008.02496) で Zihang Jiang、Weihao Yu、Daquan Zhou、Yunpeng Chen、Jiashi Feng、Shuicheng Yan によって提案されました。
やん。
論文の要約は次のとおりです。
diff --git a/docs/source/ja/model_doc/convnext.md b/docs/source/ja/model_doc/convnext.md
index efbe3bb0f4..336f27709d 100644
--- a/docs/source/ja/model_doc/convnext.md
+++ b/docs/source/ja/model_doc/convnext.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-ConvNeXT モデルは、[A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) で Zhuang Liu、Hanzi Mao、Chao-Yuan Wu、Christoph Feichtenhofer、Trevor Darrell、Saining Xie によって提案されました。
+ConvNeXT モデルは、[A ConvNet for the 2020s](https://huggingface.co/papers/2201.03545) で Zhuang Liu、Hanzi Mao、Chao-Yuan Wu、Christoph Feichtenhofer、Trevor Darrell、Saining Xie によって提案されました。
ConvNeXT は、ビジョン トランスフォーマーの設計からインスピレーションを得た純粋な畳み込みモデル (ConvNet) であり、ビジョン トランスフォーマーよりも優れたパフォーマンスを発揮すると主張しています。
論文の要約は次のとおりです。
@@ -35,7 +35,7 @@ ConvNextと呼ばれます。 ConvNeXts は完全に標準の ConvNet モジュ
 - ConvNeXT アーキテクチャ。 元の論文から抜粋。
+ ConvNeXT アーキテクチャ。 元の論文から抜粋。
このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。 TensorFlow バージョンのモデルは [ariG23498](https://github.com/ariG23498) によって提供されました。
[gante](https://github.com/gante)、および [sayakpaul](https://github.com/sayakpaul) (同等の貢献)。元のコードは [こちら](https://github.com/facebookresearch/ConvNeXt) にあります。
diff --git a/docs/source/ja/model_doc/convnextv2.md b/docs/source/ja/model_doc/convnextv2.md
index 9e4d54df24..cadd5e8ca0 100644
--- a/docs/source/ja/model_doc/convnextv2.md
+++ b/docs/source/ja/model_doc/convnextv2.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-ConvNeXt V2 モデルは、Sanghyun Woo、Shobhik Debnath、Ronghang Hu、Xinlei Chen、Zhuang Liu, In So Kweon, Saining Xie. によって [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) で提案されました。
+ConvNeXt V2 モデルは、Sanghyun Woo、Shobhik Debnath、Ronghang Hu、Xinlei Chen、Zhuang Liu, In So Kweon, Saining Xie. によって [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://huggingface.co/papers/2301.00808) で提案されました。
ConvNeXt V2 は、Vision Transformers の設計からインスピレーションを得た純粋な畳み込みモデル (ConvNet) であり、[ConvNeXT](convnext) の後継です。
論文の要約は次のとおりです。
@@ -28,7 +28,7 @@ ConvNeXt V2 は、Vision Transformers の設計からインスピレーション
- ConvNeXT アーキテクチャ。 元の論文から抜粋。
+ ConvNeXT アーキテクチャ。 元の論文から抜粋。
このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。 TensorFlow バージョンのモデルは [ariG23498](https://github.com/ariG23498) によって提供されました。
[gante](https://github.com/gante)、および [sayakpaul](https://github.com/sayakpaul) (同等の貢献)。元のコードは [こちら](https://github.com/facebookresearch/ConvNeXt) にあります。
diff --git a/docs/source/ja/model_doc/convnextv2.md b/docs/source/ja/model_doc/convnextv2.md
index 9e4d54df24..cadd5e8ca0 100644
--- a/docs/source/ja/model_doc/convnextv2.md
+++ b/docs/source/ja/model_doc/convnextv2.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-ConvNeXt V2 モデルは、Sanghyun Woo、Shobhik Debnath、Ronghang Hu、Xinlei Chen、Zhuang Liu, In So Kweon, Saining Xie. によって [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) で提案されました。
+ConvNeXt V2 モデルは、Sanghyun Woo、Shobhik Debnath、Ronghang Hu、Xinlei Chen、Zhuang Liu, In So Kweon, Saining Xie. によって [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://huggingface.co/papers/2301.00808) で提案されました。
ConvNeXt V2 は、Vision Transformers の設計からインスピレーションを得た純粋な畳み込みモデル (ConvNet) であり、[ConvNeXT](convnext) の後継です。
論文の要約は次のとおりです。
@@ -28,7 +28,7 @@ ConvNeXt V2 は、Vision Transformers の設計からインスピレーション
 - ConvNeXt V2 アーキテクチャ。 元の論文から抜粋。
+ ConvNeXt V2 アーキテクチャ。 元の論文から抜粋。
このモデルは [adirik](https://huggingface.co/adirik) によって提供されました。元のコードは [こちら](https://github.com/facebookresearch/ConvNeXt-V2) にあります。
diff --git a/docs/source/ja/model_doc/cpm.md b/docs/source/ja/model_doc/cpm.md
index afac35823e..e10e8af775 100644
--- a/docs/source/ja/model_doc/cpm.md
+++ b/docs/source/ja/model_doc/cpm.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-CPM モデルは、Zhengyan Zhang、Xu Han、Hao Zhou、Pei Ke、Yuxian Gu によって [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) で提案されました。葉徳明、秦裕佳、
+CPM モデルは、Zhengyan Zhang、Xu Han、Hao Zhou、Pei Ke、Yuxian Gu によって [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://huggingface.co/papers/2012.00413) で提案されました。葉徳明、秦裕佳、
Yusheng Su、Haozhe Ji、Jian Guan、Fanchao Qi、Xiaozi Wang、Yanan Zheng、Guoyang Zeng、Huanqi Cao、Shengqi Chen、
Daixuan Li、Zhenbo Sun、Zhiyuan Liu、Minlie Huang、Wentao Han、Jie Tang、Juanzi Li、Xiaoyan Zhu、Maosong Sun。
diff --git a/docs/source/ja/model_doc/ctrl.md b/docs/source/ja/model_doc/ctrl.md
index e20e49d918..508a0d2e43 100644
--- a/docs/source/ja/model_doc/ctrl.md
+++ b/docs/source/ja/model_doc/ctrl.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
## Overview
-CTRL モデルは、Nitish Shirish Keskar*、Bryan McCann*、Lav R. Varshney、Caiming Xiong, Richard Socher によって [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) で提案されました。
+CTRL モデルは、Nitish Shirish Keskar*、Bryan McCann*、Lav R. Varshney、Caiming Xiong, Richard Socher によって [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://huggingface.co/papers/1909.05858) で提案されました。
リチャード・ソーチャー。これは、非常に大規模なコーパスの言語モデリングを使用して事前トレーニングされた因果的 (一方向) トランスフォーマーです
最初のトークンが制御コード (リンク、書籍、Wikipedia など) として予約されている、約 140 GB のテキスト データ。
diff --git a/docs/source/ja/model_doc/cvt.md b/docs/source/ja/model_doc/cvt.md
index 16d39d1b55..ba09273298 100644
--- a/docs/source/ja/model_doc/cvt.md
+++ b/docs/source/ja/model_doc/cvt.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-CvT モデルは、Haping Wu、Bin Xiao、Noel Codella、Mengchen Liu、Xiyang Dai、Lu Yuan、Lei Zhang によって [CvT: Introduction Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) で提案されました。畳み込みビジョン トランスフォーマー (CvT) は、ViT に畳み込みを導入して両方の設計の長所を引き出すことにより、[ビジョン トランスフォーマー (ViT)](vit) のパフォーマンスと効率を向上させます。
+CvT モデルは、Haping Wu、Bin Xiao、Noel Codella、Mengchen Liu、Xiyang Dai、Lu Yuan、Lei Zhang によって [CvT: Introduction Convolutions to Vision Transformers](https://huggingface.co/papers/2103.15808) で提案されました。畳み込みビジョン トランスフォーマー (CvT) は、ViT に畳み込みを導入して両方の設計の長所を引き出すことにより、[ビジョン トランスフォーマー (ViT)](vit) のパフォーマンスと効率を向上させます。
論文の要約は次のとおりです。
diff --git a/docs/source/ja/model_doc/data2vec.md b/docs/source/ja/model_doc/data2vec.md
index c16d913881..b5267aae35 100644
--- a/docs/source/ja/model_doc/data2vec.md
+++ b/docs/source/ja/model_doc/data2vec.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-Data2Vec モデルは、[data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/pdf/2202.03555) で Alexei Baevski、Wei-Ning Hsu、Qiantong Xu、バArun Babu, Jiatao Gu and Michael Auli.
+Data2Vec モデルは、[data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://huggingface.co/papers/2202.03555) で Alexei Baevski、Wei-Ning Hsu、Qiantong Xu、バArun Babu, Jiatao Gu and Michael Auli.
Data2Vec は、テキスト、音声、画像などのさまざまなデータ モダリティにわたる自己教師あり学習のための統一フレームワークを提案します。
重要なのは、事前トレーニングの予測ターゲットは、モダリティ固有のコンテキストに依存しないターゲットではなく、入力のコンテキスト化された潜在表現であることです。
diff --git a/docs/source/ja/model_doc/deberta-v2.md b/docs/source/ja/model_doc/deberta-v2.md
index bdbaf3c21b..279dae3610 100644
--- a/docs/source/ja/model_doc/deberta-v2.md
+++ b/docs/source/ja/model_doc/deberta-v2.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-DeBERTa モデルは、Pengcheng He、Xiaodong Liu、Jianfeng Gao、Weizhu Chen によって [DeBERTa: Decoding-enhanced BERT with Disentangled Attendant](https://arxiv.org/abs/2006.03654) で提案されました。Google のモデルに基づいています。
+DeBERTa モデルは、Pengcheng He、Xiaodong Liu、Jianfeng Gao、Weizhu Chen によって [DeBERTa: Decoding-enhanced BERT with Disentangled Attendant](https://huggingface.co/papers/2006.03654) で提案されました。Google のモデルに基づいています。
2018年にリリースされたBERTモデルと2019年にリリースされたFacebookのRoBERTaモデル。
これは、もつれた注意を解きほぐし、使用されるデータの半分を使用して強化されたマスク デコーダ トレーニングを備えた RoBERTa に基づいて構築されています。
diff --git a/docs/source/ja/model_doc/deberta.md b/docs/source/ja/model_doc/deberta.md
index ef55a64581..8a9440a91f 100644
--- a/docs/source/ja/model_doc/deberta.md
+++ b/docs/source/ja/model_doc/deberta.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-DeBERTa モデルは、Pengcheng He、Xiaodong Liu、Jianfeng Gao、Weizhu Chen によって [DeBERTa: Decoding-enhanced BERT with Disentangled Attendant](https://arxiv.org/abs/2006.03654) で提案されました。Google のモデルに基づいています。
+DeBERTa モデルは、Pengcheng He、Xiaodong Liu、Jianfeng Gao、Weizhu Chen によって [DeBERTa: Decoding-enhanced BERT with Disentangled Attendant](https://huggingface.co/papers/2006.03654) で提案されました。Google のモデルに基づいています。
2018年にリリースされたBERTモデルと2019年にリリースされたFacebookのRoBERTaモデル。
これは、もつれた注意を解きほぐし、使用されるデータの半分を使用して強化されたマスク デコーダ トレーニングを備えた RoBERTa に基づいて構築されています。
diff --git a/docs/source/ja/model_doc/decision_transformer.md b/docs/source/ja/model_doc/decision_transformer.md
index fe37feb5a3..e2dee43cd0 100644
--- a/docs/source/ja/model_doc/decision_transformer.md
+++ b/docs/source/ja/model_doc/decision_transformer.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-Decision Transformer モデルは、[Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) で提案されました。
+Decision Transformer モデルは、[Decision Transformer: Reinforcement Learning via Sequence Modeling](https://huggingface.co/papers/2106.01345) で提案されました。
Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
論文の要約は次のとおりです。
diff --git a/docs/source/ja/model_doc/deformable_detr.md b/docs/source/ja/model_doc/deformable_detr.md
index ccb6ec42f8..3264f3d960 100644
--- a/docs/source/ja/model_doc/deformable_detr.md
+++ b/docs/source/ja/model_doc/deformable_detr.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-変形可能 DETR モデルは、Xizhou Zhu、Weijie Su、Lewei Lu、Bin Li、Xiaogang Wang, Jifeng Dai によって [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) で提案されました
+変形可能 DETR モデルは、Xizhou Zhu、Weijie Su、Lewei Lu、Bin Li、Xiaogang Wang, Jifeng Dai によって [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://huggingface.co/papers/2010.04159) で提案されました
変形可能な DETR は、参照周囲の少数の主要なサンプリング ポイントのみに注目する新しい変形可能なアテンション モジュールを利用することにより、収束の遅さの問題と元の [DETR](detr) の制限された特徴の空間解像度を軽減します。
論文の要約は次のとおりです。
@@ -28,7 +28,7 @@ rendered properly in your Markdown viewer.
- ConvNeXt V2 アーキテクチャ。 元の論文から抜粋。
+ ConvNeXt V2 アーキテクチャ。 元の論文から抜粋。
このモデルは [adirik](https://huggingface.co/adirik) によって提供されました。元のコードは [こちら](https://github.com/facebookresearch/ConvNeXt-V2) にあります。
diff --git a/docs/source/ja/model_doc/cpm.md b/docs/source/ja/model_doc/cpm.md
index afac35823e..e10e8af775 100644
--- a/docs/source/ja/model_doc/cpm.md
+++ b/docs/source/ja/model_doc/cpm.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-CPM モデルは、Zhengyan Zhang、Xu Han、Hao Zhou、Pei Ke、Yuxian Gu によって [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) で提案されました。葉徳明、秦裕佳、
+CPM モデルは、Zhengyan Zhang、Xu Han、Hao Zhou、Pei Ke、Yuxian Gu によって [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://huggingface.co/papers/2012.00413) で提案されました。葉徳明、秦裕佳、
Yusheng Su、Haozhe Ji、Jian Guan、Fanchao Qi、Xiaozi Wang、Yanan Zheng、Guoyang Zeng、Huanqi Cao、Shengqi Chen、
Daixuan Li、Zhenbo Sun、Zhiyuan Liu、Minlie Huang、Wentao Han、Jie Tang、Juanzi Li、Xiaoyan Zhu、Maosong Sun。
diff --git a/docs/source/ja/model_doc/ctrl.md b/docs/source/ja/model_doc/ctrl.md
index e20e49d918..508a0d2e43 100644
--- a/docs/source/ja/model_doc/ctrl.md
+++ b/docs/source/ja/model_doc/ctrl.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
## Overview
-CTRL モデルは、Nitish Shirish Keskar*、Bryan McCann*、Lav R. Varshney、Caiming Xiong, Richard Socher によって [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) で提案されました。
+CTRL モデルは、Nitish Shirish Keskar*、Bryan McCann*、Lav R. Varshney、Caiming Xiong, Richard Socher によって [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://huggingface.co/papers/1909.05858) で提案されました。
リチャード・ソーチャー。これは、非常に大規模なコーパスの言語モデリングを使用して事前トレーニングされた因果的 (一方向) トランスフォーマーです
最初のトークンが制御コード (リンク、書籍、Wikipedia など) として予約されている、約 140 GB のテキスト データ。
diff --git a/docs/source/ja/model_doc/cvt.md b/docs/source/ja/model_doc/cvt.md
index 16d39d1b55..ba09273298 100644
--- a/docs/source/ja/model_doc/cvt.md
+++ b/docs/source/ja/model_doc/cvt.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-CvT モデルは、Haping Wu、Bin Xiao、Noel Codella、Mengchen Liu、Xiyang Dai、Lu Yuan、Lei Zhang によって [CvT: Introduction Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) で提案されました。畳み込みビジョン トランスフォーマー (CvT) は、ViT に畳み込みを導入して両方の設計の長所を引き出すことにより、[ビジョン トランスフォーマー (ViT)](vit) のパフォーマンスと効率を向上させます。
+CvT モデルは、Haping Wu、Bin Xiao、Noel Codella、Mengchen Liu、Xiyang Dai、Lu Yuan、Lei Zhang によって [CvT: Introduction Convolutions to Vision Transformers](https://huggingface.co/papers/2103.15808) で提案されました。畳み込みビジョン トランスフォーマー (CvT) は、ViT に畳み込みを導入して両方の設計の長所を引き出すことにより、[ビジョン トランスフォーマー (ViT)](vit) のパフォーマンスと効率を向上させます。
論文の要約は次のとおりです。
diff --git a/docs/source/ja/model_doc/data2vec.md b/docs/source/ja/model_doc/data2vec.md
index c16d913881..b5267aae35 100644
--- a/docs/source/ja/model_doc/data2vec.md
+++ b/docs/source/ja/model_doc/data2vec.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-Data2Vec モデルは、[data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/pdf/2202.03555) で Alexei Baevski、Wei-Ning Hsu、Qiantong Xu、バArun Babu, Jiatao Gu and Michael Auli.
+Data2Vec モデルは、[data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://huggingface.co/papers/2202.03555) で Alexei Baevski、Wei-Ning Hsu、Qiantong Xu、バArun Babu, Jiatao Gu and Michael Auli.
Data2Vec は、テキスト、音声、画像などのさまざまなデータ モダリティにわたる自己教師あり学習のための統一フレームワークを提案します。
重要なのは、事前トレーニングの予測ターゲットは、モダリティ固有のコンテキストに依存しないターゲットではなく、入力のコンテキスト化された潜在表現であることです。
diff --git a/docs/source/ja/model_doc/deberta-v2.md b/docs/source/ja/model_doc/deberta-v2.md
index bdbaf3c21b..279dae3610 100644
--- a/docs/source/ja/model_doc/deberta-v2.md
+++ b/docs/source/ja/model_doc/deberta-v2.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-DeBERTa モデルは、Pengcheng He、Xiaodong Liu、Jianfeng Gao、Weizhu Chen によって [DeBERTa: Decoding-enhanced BERT with Disentangled Attendant](https://arxiv.org/abs/2006.03654) で提案されました。Google のモデルに基づいています。
+DeBERTa モデルは、Pengcheng He、Xiaodong Liu、Jianfeng Gao、Weizhu Chen によって [DeBERTa: Decoding-enhanced BERT with Disentangled Attendant](https://huggingface.co/papers/2006.03654) で提案されました。Google のモデルに基づいています。
2018年にリリースされたBERTモデルと2019年にリリースされたFacebookのRoBERTaモデル。
これは、もつれた注意を解きほぐし、使用されるデータの半分を使用して強化されたマスク デコーダ トレーニングを備えた RoBERTa に基づいて構築されています。
diff --git a/docs/source/ja/model_doc/deberta.md b/docs/source/ja/model_doc/deberta.md
index ef55a64581..8a9440a91f 100644
--- a/docs/source/ja/model_doc/deberta.md
+++ b/docs/source/ja/model_doc/deberta.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-DeBERTa モデルは、Pengcheng He、Xiaodong Liu、Jianfeng Gao、Weizhu Chen によって [DeBERTa: Decoding-enhanced BERT with Disentangled Attendant](https://arxiv.org/abs/2006.03654) で提案されました。Google のモデルに基づいています。
+DeBERTa モデルは、Pengcheng He、Xiaodong Liu、Jianfeng Gao、Weizhu Chen によって [DeBERTa: Decoding-enhanced BERT with Disentangled Attendant](https://huggingface.co/papers/2006.03654) で提案されました。Google のモデルに基づいています。
2018年にリリースされたBERTモデルと2019年にリリースされたFacebookのRoBERTaモデル。
これは、もつれた注意を解きほぐし、使用されるデータの半分を使用して強化されたマスク デコーダ トレーニングを備えた RoBERTa に基づいて構築されています。
diff --git a/docs/source/ja/model_doc/decision_transformer.md b/docs/source/ja/model_doc/decision_transformer.md
index fe37feb5a3..e2dee43cd0 100644
--- a/docs/source/ja/model_doc/decision_transformer.md
+++ b/docs/source/ja/model_doc/decision_transformer.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-Decision Transformer モデルは、[Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) で提案されました。
+Decision Transformer モデルは、[Decision Transformer: Reinforcement Learning via Sequence Modeling](https://huggingface.co/papers/2106.01345) で提案されました。
Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
論文の要約は次のとおりです。
diff --git a/docs/source/ja/model_doc/deformable_detr.md b/docs/source/ja/model_doc/deformable_detr.md
index ccb6ec42f8..3264f3d960 100644
--- a/docs/source/ja/model_doc/deformable_detr.md
+++ b/docs/source/ja/model_doc/deformable_detr.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-変形可能 DETR モデルは、Xizhou Zhu、Weijie Su、Lewei Lu、Bin Li、Xiaogang Wang, Jifeng Dai によって [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) で提案されました
+変形可能 DETR モデルは、Xizhou Zhu、Weijie Su、Lewei Lu、Bin Li、Xiaogang Wang, Jifeng Dai によって [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://huggingface.co/papers/2010.04159) で提案されました
変形可能な DETR は、参照周囲の少数の主要なサンプリング ポイントのみに注目する新しい変形可能なアテンション モジュールを利用することにより、収束の遅さの問題と元の [DETR](detr) の制限された特徴の空間解像度を軽減します。
論文の要約は次のとおりです。
@@ -28,7 +28,7 @@ rendered properly in your Markdown viewer.
 - 変形可能な DETR アーキテクチャ。 元の論文から抜粋。
+ 変形可能な DETR アーキテクチャ。 元の論文から抜粋。
このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。元のコードは [ここ](https://github.com/fundamentalvision/Deformable-DETR) にあります。
diff --git a/docs/source/ja/model_doc/deit.md b/docs/source/ja/model_doc/deit.md
index 00fa82e113..ba769dcf0d 100644
--- a/docs/source/ja/model_doc/deit.md
+++ b/docs/source/ja/model_doc/deit.md
@@ -19,8 +19,8 @@ rendered properly in your Markdown viewer.
## Overview
DeiT モデルは、Hugo Touvron、Matthieu Cord、Matthijs Douze、Francisco Massa、Alexandre
-Sablayrolles, Hervé Jégou.によって [Training data-efficient image Transformers & distillation through attention](https://arxiv.org/abs/2012.12877) で提案されました。
-サブレイロール、エルヴェ・ジェグー。 [Dosovitskiy et al., 2020](https://arxiv.org/abs/2010.11929) で紹介された [Vision Transformer (ViT)](vit) は、既存の畳み込みニューラルと同等、またはそれを上回るパフォーマンスを発揮できることを示しました。
+Sablayrolles, Hervé Jégou.によって [Training data-efficient image Transformers & distillation through attention](https://huggingface.co/papers/2012.12877) で提案されました。
+サブレイロール、エルヴェ・ジェグー。 [Dosovitskiy et al., 2020](https://huggingface.co/papers/2010.11929) で紹介された [Vision Transformer (ViT)](vit) は、既存の畳み込みニューラルと同等、またはそれを上回るパフォーマンスを発揮できることを示しました。
Transformer エンコーダ (BERT のような) を使用したネットワーク。ただし、その論文で紹介された ViT モデルには、次のトレーニングが必要でした。
外部データを使用して、数週間にわたる高価なインフラストラクチャ。 DeiT (データ効率の高い画像変換器) はさらに優れています
画像分類用に効率的にトレーニングされたトランスフォーマーにより、必要なデータとコンピューティング リソースがはるかに少なくなります。
diff --git a/docs/source/ja/model_doc/deplot.md b/docs/source/ja/model_doc/deplot.md
index 26871d1e7d..5e125fa9b5 100644
--- a/docs/source/ja/model_doc/deplot.md
+++ b/docs/source/ja/model_doc/deplot.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-DePlot は、Fangyu Liu、Julian Martin Aisenschlos、Francesco Piccinno、Syrine Krichene、Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun. の論文 [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) で提案されました。パン・
+DePlot は、Fangyu Liu、Julian Martin Aisenschlos、Francesco Piccinno、Syrine Krichene、Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun. の論文 [DePlot: One-shot visual language reasoning by plot-to-table translation](https://huggingface.co/papers/2212.10505) で提案されました。パン・
論文の要約には次のように記載されています。
diff --git a/docs/source/ja/model_doc/deta.md b/docs/source/ja/model_doc/deta.md
index 615f839657..7c8a5687ba 100644
--- a/docs/source/ja/model_doc/deta.md
+++ b/docs/source/ja/model_doc/deta.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-DETA モデルは、[NMS Strikes Back](https://arxiv.org/abs/2212.06137) で Jeffrey Ouyang-Zhang、Jang Hyun Cho、Xingyi Zhou、Philipp Krähenbühl によって提案されました。
+DETA モデルは、[NMS Strikes Back](https://huggingface.co/papers/2212.06137) で Jeffrey Ouyang-Zhang、Jang Hyun Cho、Xingyi Zhou、Philipp Krähenbühl によって提案されました。
DETA (Detection Transformers with Assignment の略) は、1 対 1 の 2 部ハンガリアン マッチング損失を置き換えることにより、[Deformable DETR](deformable_detr) を改善します。
非最大抑制 (NMS) を備えた従来の検出器で使用される 1 対多のラベル割り当てを使用します。これにより、最大 2.5 mAP の大幅な増加が得られます。
@@ -29,7 +29,7 @@ DETA (Detection Transformers with Assignment の略) は、1 対 1 の 2 部ハ
- 変形可能な DETR アーキテクチャ。 元の論文から抜粋。
+ 変形可能な DETR アーキテクチャ。 元の論文から抜粋。
このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。元のコードは [ここ](https://github.com/fundamentalvision/Deformable-DETR) にあります。
diff --git a/docs/source/ja/model_doc/deit.md b/docs/source/ja/model_doc/deit.md
index 00fa82e113..ba769dcf0d 100644
--- a/docs/source/ja/model_doc/deit.md
+++ b/docs/source/ja/model_doc/deit.md
@@ -19,8 +19,8 @@ rendered properly in your Markdown viewer.
## Overview
DeiT モデルは、Hugo Touvron、Matthieu Cord、Matthijs Douze、Francisco Massa、Alexandre
-Sablayrolles, Hervé Jégou.によって [Training data-efficient image Transformers & distillation through attention](https://arxiv.org/abs/2012.12877) で提案されました。
-サブレイロール、エルヴェ・ジェグー。 [Dosovitskiy et al., 2020](https://arxiv.org/abs/2010.11929) で紹介された [Vision Transformer (ViT)](vit) は、既存の畳み込みニューラルと同等、またはそれを上回るパフォーマンスを発揮できることを示しました。
+Sablayrolles, Hervé Jégou.によって [Training data-efficient image Transformers & distillation through attention](https://huggingface.co/papers/2012.12877) で提案されました。
+サブレイロール、エルヴェ・ジェグー。 [Dosovitskiy et al., 2020](https://huggingface.co/papers/2010.11929) で紹介された [Vision Transformer (ViT)](vit) は、既存の畳み込みニューラルと同等、またはそれを上回るパフォーマンスを発揮できることを示しました。
Transformer エンコーダ (BERT のような) を使用したネットワーク。ただし、その論文で紹介された ViT モデルには、次のトレーニングが必要でした。
外部データを使用して、数週間にわたる高価なインフラストラクチャ。 DeiT (データ効率の高い画像変換器) はさらに優れています
画像分類用に効率的にトレーニングされたトランスフォーマーにより、必要なデータとコンピューティング リソースがはるかに少なくなります。
diff --git a/docs/source/ja/model_doc/deplot.md b/docs/source/ja/model_doc/deplot.md
index 26871d1e7d..5e125fa9b5 100644
--- a/docs/source/ja/model_doc/deplot.md
+++ b/docs/source/ja/model_doc/deplot.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-DePlot は、Fangyu Liu、Julian Martin Aisenschlos、Francesco Piccinno、Syrine Krichene、Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun. の論文 [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) で提案されました。パン・
+DePlot は、Fangyu Liu、Julian Martin Aisenschlos、Francesco Piccinno、Syrine Krichene、Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun. の論文 [DePlot: One-shot visual language reasoning by plot-to-table translation](https://huggingface.co/papers/2212.10505) で提案されました。パン・
論文の要約には次のように記載されています。
diff --git a/docs/source/ja/model_doc/deta.md b/docs/source/ja/model_doc/deta.md
index 615f839657..7c8a5687ba 100644
--- a/docs/source/ja/model_doc/deta.md
+++ b/docs/source/ja/model_doc/deta.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-DETA モデルは、[NMS Strikes Back](https://arxiv.org/abs/2212.06137) で Jeffrey Ouyang-Zhang、Jang Hyun Cho、Xingyi Zhou、Philipp Krähenbühl によって提案されました。
+DETA モデルは、[NMS Strikes Back](https://huggingface.co/papers/2212.06137) で Jeffrey Ouyang-Zhang、Jang Hyun Cho、Xingyi Zhou、Philipp Krähenbühl によって提案されました。
DETA (Detection Transformers with Assignment の略) は、1 対 1 の 2 部ハンガリアン マッチング損失を置き換えることにより、[Deformable DETR](deformable_detr) を改善します。
非最大抑制 (NMS) を備えた従来の検出器で使用される 1 対多のラベル割り当てを使用します。これにより、最大 2.5 mAP の大幅な増加が得られます。
@@ -29,7 +29,7 @@ DETA (Detection Transformers with Assignment の略) は、1 対 1 の 2 部ハ
 - DETA の概要。 元の論文から抜粋。
+ DETA の概要。 元の論文から抜粋。
このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
元のコードは [ここ](https://github.com/jozhang97/DETA) にあります。
diff --git a/docs/source/ja/model_doc/detr.md b/docs/source/ja/model_doc/detr.md
index 3342b123a0..d709d76f04 100644
--- a/docs/source/ja/model_doc/detr.md
+++ b/docs/source/ja/model_doc/detr.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-DETR モデルは、[Transformers を使用したエンドツーエンドのオブジェクト検出](https://arxiv.org/abs/2005.12872) で提案されました。
+DETR モデルは、[Transformers を使用したエンドツーエンドのオブジェクト検出](https://huggingface.co/papers/2005.12872) で提案されました。
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov and Sergey Zagoruyko ルイコ。 DETR
畳み込みバックボーンと、その後にエンドツーエンドでトレーニングできるエンコーダー/デコーダー Transformer で構成されます。
物体の検出。 Faster-R-CNN や Mask-R-CNN などのモデルの複雑さの多くが大幅に簡素化されます。
diff --git a/docs/source/ja/model_doc/dialogpt.md b/docs/source/ja/model_doc/dialogpt.md
index 22ce0c9a09..80e5423785 100644
--- a/docs/source/ja/model_doc/dialogpt.md
+++ b/docs/source/ja/model_doc/dialogpt.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-DialoGPT は、[DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) で Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao,
+DialoGPT は、[DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://huggingface.co/papers/1911.00536) で Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao,
Jianfeng Gao, Jingjing Liu, Bill Dolan.これは、から抽出された 147M 万の会話のようなやりとりでトレーニングされた GPT2 モデルです。
レディット。
diff --git a/docs/source/ja/model_doc/dinat.md b/docs/source/ja/model_doc/dinat.md
index a59b073d46..ee373cdd75 100644
--- a/docs/source/ja/model_doc/dinat.md
+++ b/docs/source/ja/model_doc/dinat.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-DiNAT は [Dilated Neighborhood Attender Transformer](https://arxiv.org/abs/2209.15001) で提案されました。
+DiNAT は [Dilated Neighborhood Attender Transformer](https://huggingface.co/papers/2209.15001) で提案されました。
Ali Hassani and Humphrey Shi.
[NAT](nat) を拡張するために、拡張近隣アテンション パターンを追加してグローバル コンテキストをキャプチャします。
@@ -50,7 +50,7 @@ src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/ma
alt="drawing" width="600"/>
異なる拡張値を使用した近隣アテンション。
-元の論文から抜粋。
+元の論文から抜粋。
このモデルは [Ali Hassani](https://huggingface.co/alihassanijr) によって提供されました。
元のコードは [ここ](https://github.com/SHI-Labs/Neighborhood-Attendance-Transformer) にあります。
diff --git a/docs/source/ja/model_memory_anatomy.md b/docs/source/ja/model_memory_anatomy.md
index 45a383d616..c8b7c90a94 100644
--- a/docs/source/ja/model_memory_anatomy.md
+++ b/docs/source/ja/model_memory_anatomy.md
@@ -193,7 +193,7 @@ Transformerアーキテクチャには、計算強度によって以下の3つ
パフォーマンスのボトルネックを分析する際に、この知識は役立つことがあります。
-この要約は、[Data Movement Is All You Need: Optimizing Transformers 2020に関するケーススタディ](https://arxiv.org/abs/2007.00072)から派生しています。
+この要約は、[Data Movement Is All You Need: Optimizing Transformers 2020に関するケーススタディ](https://huggingface.co/papers/2007.00072)から派生しています。
## Anatomy of Model's Memory
diff --git a/docs/source/ja/model_summary.md b/docs/source/ja/model_summary.md
index 8f8b6af48c..b49bde5c20 100644
--- a/docs/source/ja/model_summary.md
+++ b/docs/source/ja/model_summary.md
@@ -16,7 +16,7 @@ rendered properly in your Markdown viewer.
# The Transformer model family
-2017年に導入されて以来、[元のTransformer](https://arxiv.org/abs/1706.03762)モデルは、自然言語処理(NLP)のタスクを超える多くの新しいエキサイティングなモデルをインスパイアしました。[タンパク質の折りたたまれた構造を予測](https://huggingface.co/blog/deep-learning-with-proteins)するモデル、[チーターを走らせるためのトレーニング](https://huggingface.co/blog/train-decision-transformers)するモデル、そして[時系列予測](https://huggingface.co/blog/time-series-transformers)のためのモデルなどがあります。Transformerのさまざまなバリアントが利用可能ですが、大局を見落とすことがあります。これらのすべてのモデルに共通するのは、元のTransformerアーキテクチャに基づいていることです。一部のモデルはエンコーダまたはデコーダのみを使用し、他のモデルは両方を使用します。これは、Transformerファミリー内のモデルの高レベルの違いをカテゴライズし、調査するための有用な分類法を提供し、以前に出会ったことのないTransformerを理解するのに役立ちます。
+2017年に導入されて以来、[元のTransformer](https://huggingface.co/papers/1706.03762)モデルは、自然言語処理(NLP)のタスクを超える多くの新しいエキサイティングなモデルをインスパイアしました。[タンパク質の折りたたまれた構造を予測](https://huggingface.co/blog/deep-learning-with-proteins)するモデル、[チーターを走らせるためのトレーニング](https://huggingface.co/blog/train-decision-transformers)するモデル、そして[時系列予測](https://huggingface.co/blog/time-series-transformers)のためのモデルなどがあります。Transformerのさまざまなバリアントが利用可能ですが、大局を見落とすことがあります。これらのすべてのモデルに共通するのは、元のTransformerアーキテクチャに基づいていることです。一部のモデルはエンコーダまたはデコーダのみを使用し、他のモデルは両方を使用します。これは、Transformerファミリー内のモデルの高レベルの違いをカテゴライズし、調査するための有用な分類法を提供し、以前に出会ったことのないTransformerを理解するのに役立ちます。
元のTransformerモデルに慣れていないか、リフレッシュが必要な場合は、Hugging Faceコースの[Transformerの動作原理](https://huggingface.co/course/chapter1/4?fw=pt)章をチェックしてください。
@@ -32,7 +32,7 @@ rendered properly in your Markdown viewer.
### Convolutional network
-長い間、畳み込みネットワーク(CNN)はコンピュータビジョンのタスクにおいて支配的なパラダイムでしたが、[ビジョンTransformer](https://arxiv.org/abs/2010.11929)はそのスケーラビリティと効率性を示しました。それでも、一部のCNNの最高の特性、特に特定のタスクにとっては非常に強力な翻訳不変性など、一部のTransformerはアーキテクチャに畳み込みを組み込んでいます。[ConvNeXt](model_doc/convnext)は、畳み込みを現代化するためにTransformerから設計の選択肢を取り入れ、例えば、ConvNeXtは画像をパッチに分割するために重なり合わないスライディングウィンドウと、グローバル受容野を増加させるための大きなカーネルを使用します。ConvNeXtは、メモリ効率を向上させ、パフォーマンスを向上させるためにいくつかのレイヤーデザインの選択肢も提供し、Transformerと競合的になります!
+長い間、畳み込みネットワーク(CNN)はコンピュータビジョンのタスクにおいて支配的なパラダイムでしたが、[ビジョンTransformer](https://huggingface.co/papers/2010.11929)はそのスケーラビリティと効率性を示しました。それでも、一部のCNNの最高の特性、特に特定のタスクにとっては非常に強力な翻訳不変性など、一部のTransformerはアーキテクチャに畳み込みを組み込んでいます。[ConvNeXt](model_doc/convnext)は、畳み込みを現代化するためにTransformerから設計の選択肢を取り入れ、例えば、ConvNeXtは画像をパッチに分割するために重なり合わないスライディングウィンドウと、グローバル受容野を増加させるための大きなカーネルを使用します。ConvNeXtは、メモリ効率を向上させ、パフォーマンスを向上させるためにいくつかのレイヤーデザインの選択肢も提供し、Transformerと競合的になります!
### Encoder[[cv-encoder]]
@@ -59,7 +59,7 @@ BeIT および ViTMAE などの他のビジョンモデルは、BERTの事前ト
[BERT](model_doc/bert) はエンコーダー専用のTransformerで、入力の一部のトークンをランダムにマスクして他のトークンを見ないようにしています。これにより、トークンをマスクした文脈に基づいてマスクされたトークンを予測することが事前トレーニングの目標です。これにより、BERTは入力のより深いかつ豊かな表現を学習するのに左右の文脈を完全に活用できます。しかし、BERTの事前トレーニング戦略にはまだ改善の余地がありました。[RoBERTa](model_doc/roberta) は、トレーニングを長時間行い、より大きなバッチでトレーニングし、事前処理中に一度だけでなく各エポックでトークンをランダムにマスクし、次文予測の目標を削除する新しい事前トレーニングレシピを導入することでこれを改善しました。
-性能を向上させる主要な戦略はモデルのサイズを増やすことですが、大規模なモデルのトレーニングは計算コストがかかります。計算コストを削減する方法の1つは、[DistilBERT](model_doc/distilbert) のような小さなモデルを使用することです。DistilBERTは[知識蒸留](https://arxiv.org/abs/1503.02531) - 圧縮技術 - を使用して、BERTのほぼすべての言語理解機能を保持しながら、より小さなバージョンを作成します。
+性能を向上させる主要な戦略はモデルのサイズを増やすことですが、大規模なモデルのトレーニングは計算コストがかかります。計算コストを削減する方法の1つは、[DistilBERT](model_doc/distilbert) のような小さなモデルを使用することです。DistilBERTは[知識蒸留](https://huggingface.co/papers/1503.02531) - 圧縮技術 - を使用して、BERTのほぼすべての言語理解機能を保持しながら、より小さなバージョンを作成します。
しかし、ほとんどのTransformerモデルは引き続きより多くのパラメータに焦点を当て、トレーニング効率を向上させる新しいモデルが登場しています。[ALBERT](model_doc/albert) は、2つの方法でパラメータの数を減らすことによってメモリ消費量を削減します。大きな語彙埋め込みを2つの小さな行列に分割し、レイヤーがパラメータを共有できるようにします。[DeBERTa](model_doc/deberta) は、単語とその位置を2つのベクトルで別々にエンコードする解かれた注意機構を追加しました。注意はこれらの別々のベクトルから計算されます。単語と位置の埋め込みが含まれる単一のベクトルではなく、[Longformer](model_doc/longformer) は、特に長いシーケンス長のドキュメントを処理するために注意をより効率的にすることに焦点を当てました。固定されたウィンドウサイズの周りの各トークンから計算されるローカルウィンドウ付き注意(特定のタスクトークン(分類のための `[CLS]` など)のみのためのグローバルな注意を含む)の組み合わせを使用して、完全な注意行列ではなく疎な注意行列を作成します。
diff --git a/docs/source/ja/peft.md b/docs/source/ja/peft.md
index c3d195adbd..77dd7be86c 100644
--- a/docs/source/ja/peft.md
+++ b/docs/source/ja/peft.md
@@ -46,7 +46,7 @@ pip install git+https://github.com/huggingface/peft.git
- [Low Rank Adapters](https://huggingface.co/docs/peft/conceptual_guides/lora)
- [IA3](https://huggingface.co/docs/peft/conceptual_guides/ia3)
-- [AdaLoRA](https://arxiv.org/abs/2303.10512)
+- [AdaLoRA](https://huggingface.co/papers/2303.10512)
他のPEFTメソッドを使用したい場合、プロンプト学習やプロンプト調整などについて詳しく知りたい場合、または🤗 PEFTライブラリ全般については、[ドキュメンテーション](https://huggingface.co/docs/peft/index)を参照してください。
diff --git a/docs/source/ja/perf_infer_gpu_many.md b/docs/source/ja/perf_infer_gpu_many.md
index 18a19c849e..6a71c10944 100644
--- a/docs/source/ja/perf_infer_gpu_many.md
+++ b/docs/source/ja/perf_infer_gpu_many.md
@@ -53,7 +53,7 @@ model.to_bettertransformer()
# Use it for training or inference
```
-SDPAは、ハードウェアや問題のサイズなどの特定の設定で[Flash Attention](https://arxiv.org/abs/2205.14135)カーネルを呼び出すこともできます。Flash Attentionを有効にするか、特定の設定(ハードウェア、問題のサイズ)で利用可能かを確認するには、[`torch.nn.kernel.sdpa_kernel`](https://pytorch.org/docs/stable/generated/torch.nn.attention.sdpa_kernel.html)をコンテキストマネージャとして使用します。
+SDPAは、ハードウェアや問題のサイズなどの特定の設定で[Flash Attention](https://huggingface.co/papers/2205.14135)カーネルを呼び出すこともできます。Flash Attentionを有効にするか、特定の設定(ハードウェア、問題のサイズ)で利用可能かを確認するには、[`torch.nn.kernel.sdpa_kernel`](https://pytorch.org/docs/stable/generated/torch.nn.attention.sdpa_kernel.html)をコンテキストマネージャとして使用します。
```diff
diff --git a/docs/source/ja/perf_infer_gpu_one.md b/docs/source/ja/perf_infer_gpu_one.md
index 6a3dc5fa64..374d725a99 100644
--- a/docs/source/ja/perf_infer_gpu_one.md
+++ b/docs/source/ja/perf_infer_gpu_one.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
-Flash Attention 2は、トランスフォーマーベースのモデルのトレーニングと推論速度を大幅に高速化できます。Flash Attention 2は、Tri Dao氏によって[公式のFlash Attentionリポジトリ](https://github.com/Dao-AILab/flash-attention)で導入されました。Flash Attentionに関する科学論文は[こちら](https://arxiv.org/abs/2205.14135)で見ることができます。
+Flash Attention 2は、トランスフォーマーベースのモデルのトレーニングと推論速度を大幅に高速化できます。Flash Attention 2は、Tri Dao氏によって[公式のFlash Attentionリポジトリ](https://github.com/Dao-AILab/flash-attention)で導入されました。Flash Attentionに関する科学論文は[こちら](https://huggingface.co/papers/2205.14135)で見ることができます。
Flash Attention 2を正しくインストールするには、上記のリポジトリに記載されているインストールガイドに従ってください。
@@ -214,7 +214,7 @@ model.to_bettertransformer()
# Use it for training or inference
```
-SDPAは、ハードウェアや問題のサイズに応じて[Flash Attention](https://arxiv.org/abs/2205.14135)カーネルを使用することもできます。Flash Attentionを有効にするか、特定の設定(ハードウェア、問題サイズ)で使用可能かどうかを確認するには、[`torch.nn.attention.sdpa_kernel`](https://pytorch.org/docs/stable/generated/torch.nn.attention.sdpa_kernel.html)をコンテキストマネージャとして使用します。
+SDPAは、ハードウェアや問題のサイズに応じて[Flash Attention](https://huggingface.co/papers/2205.14135)カーネルを使用することもできます。Flash Attentionを有効にするか、特定の設定(ハードウェア、問題サイズ)で使用可能かどうかを確認するには、[`torch.nn.attention.sdpa_kernel`](https://pytorch.org/docs/stable/generated/torch.nn.attention.sdpa_kernel.html)をコンテキストマネージャとして使用します。
```diff
@@ -332,12 +332,12 @@ model_4bit = AutoModelForCausalLM.from_pretrained(
-論文[`LLM.int8():スケーラブルなTransformer向けの8ビット行列乗算`](https://arxiv.org/abs/2208.07339)によれば、Hugging Face統合がHub内のすべてのモデルでわずか数行のコードでサポートされています。このメソッドは、半精度(`float16`および`bfloat16`)の重みの場合に`nn.Linear`サイズを2倍、単精度(`float32`)の重みの場合は4倍に縮小し、外れ値に対してほとんど影響を与えません。
+論文[`LLM.int8():スケーラブルなTransformer向けの8ビット行列乗算`](https://huggingface.co/papers/2208.07339)によれば、Hugging Face統合がHub内のすべてのモデルでわずか数行のコードでサポートされています。このメソッドは、半精度(`float16`および`bfloat16`)の重みの場合に`nn.Linear`サイズを2倍、単精度(`float32`)の重みの場合は4倍に縮小し、外れ値に対してほとんど影響を与えません。

Int8混合精度行列分解は、行列乗算を2つのストリームに分割することによって動作します:(1) システマティックな特徴外れ値ストリームがfp16で行列乗算(0.01%)、(2) int8行列乗算の通常のストリーム(99.9%)。この方法を使用すると、非常に大きなモデルに対して予測の劣化なしにint8推論が可能です。
-このメソッドの詳細については、[論文](https://arxiv.org/abs/2208.07339)または[この統合に関するブログ記事](https://huggingface.co/blog/hf-bitsandbytes-integration)をご確認ください。
+このメソッドの詳細については、[論文](https://huggingface.co/papers/2208.07339)または[この統合に関するブログ記事](https://huggingface.co/blog/hf-bitsandbytes-integration)をご確認ください。

diff --git a/docs/source/ja/perf_train_gpu_many.md b/docs/source/ja/perf_train_gpu_many.md
index 613ccfa20b..6721ba69a9 100644
--- a/docs/source/ja/perf_train_gpu_many.md
+++ b/docs/source/ja/perf_train_gpu_many.md
@@ -317,7 +317,7 @@ VarunaとSageMakerとの実験はまだ行っていませんが、彼らの論
- [DeepSpeed](https://www.deepspeed.ai/tutorials/pipeline/)
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) has an internal implementation - no API.
- [Varuna](https://github.com/microsoft/varuna)
-- [SageMaker](https://arxiv.org/abs/2111.05972) - this is a proprietary solution that can only be used on AWS.
+- [SageMaker](https://huggingface.co/papers/2111.05972) - this is a proprietary solution that can only be used on AWS.
- [OSLO](https://github.com/tunib-ai/oslo) - この実装は、Hugging Face Transformersに基づいています。
🤗 Transformersのステータス: この執筆時点では、いずれのモデルも完全なPP(パイプライン並列処理)をサポートしていません。GPT2モデルとT5モデルは単純なMP(モデル並列処理)サポートを持っています。主な障害は、モデルを`nn.Sequential`に変換できず、すべての入力がテンソルである必要があることです。現在のモデルには、変換を非常に複雑にする多くの機能が含まれており、これらを削除する必要があります。
@@ -334,7 +334,7 @@ OSLOは、`nn.Sequential`の変換なしでTransformersに基づくパイプラ
テンソル並列処理では、各GPUがテンソルのスライスのみを処理し、全体が必要な操作のためにのみ完全なテンソルを集約します。
-このセクションでは、[Megatron-LM](https://github.com/NVIDIA/Megatron-LM)論文からのコンセプトと図を使用します:[GPUクラスタでの効率的な大規模言語モデルトレーニング](https://arxiv.org/abs/2104.04473)。
+このセクションでは、[Megatron-LM](https://github.com/NVIDIA/Megatron-LM)論文からのコンセプトと図を使用します:[GPUクラスタでの効率的な大規模言語モデルトレーニング](https://huggingface.co/papers/2104.04473)。
どのトランスフォーマの主要な構築要素は、完全に接続された`nn.Linear`に続く非線形アクティベーション`GeLU`です。
@@ -365,7 +365,7 @@ SageMakerは、より効率的な処理のためにTPとDPを組み合わせて
実装例:
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)には、モデル固有の内部実装があります。
- [parallelformers](https://github.com/tunib-ai/parallelformers)(現時点では推論のみ)。
-- [SageMaker](https://arxiv.org/abs/2111.05972) - これはAWSでのみ使用できるプロプライエタリなソリューションです。
+- [SageMaker](https://huggingface.co/papers/2111.05972) - これはAWSでのみ使用できるプロプライエタリなソリューションです。
- [OSLO](https://github.com/tunib-ai/oslo)には、Transformersに基づいたテンソル並列実装があります。
🤗 Transformersの状況:
@@ -387,7 +387,7 @@ DeepSpeedの[パイプラインチュートリアル](https://www.deepspeed.ai/t
- [DeepSpeed](https://github.com/deepspeedai/DeepSpeed)
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
- [Varuna](https://github.com/microsoft/varuna)
-- [SageMaker](https://arxiv.org/abs/2111.05972)
+- [SageMaker](https://huggingface.co/papers/2111.05972)
- [OSLO](https://github.com/tunib-ai/oslo)
🤗 Transformersの状況: まだ実装されていません
@@ -406,7 +406,7 @@ DeepSpeedの[パイプラインチュートリアル](https://www.deepspeed.ai/t
- [DeepSpeed](https://github.com/deepspeedai/DeepSpeed) - DeepSpeedには、さらに効率的なDPであるZeRO-DPと呼ばれるものも含まれています。
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
- [Varuna](https://github.com/microsoft/varuna)
-- [SageMaker](https://arxiv.org/abs/2111.05972)
+- [SageMaker](https://huggingface.co/papers/2111.05972)
- [OSLO](https://github.com/tunib-ai/oslo)
🤗 Transformersの状況: まだ実装されていません。PPとTPがないため。
@@ -431,7 +431,7 @@ ZeROステージ3も同様の理由で適していません - より多くのノ
重要な論文:
-- [DeepSpeedとMegatronを使用したMegatron-Turing NLG 530Bのトレーニング](https://arxiv.org/abs/2201.11990)
+- [DeepSpeedとMegatronを使用したMegatron-Turing NLG 530Bのトレーニング](https://huggingface.co/papers/2201.11990)
🤗 Transformersの状況: まだ実装されていません。PPとTPがないため。
@@ -440,7 +440,7 @@ ZeROステージ3も同様の理由で適していません - より多くのノ
[FlexFlow](https://github.com/flexflow/FlexFlow)は、わずかに異なるアプローチで並列化の問題を解決します。
-論文: [Zhihao Jia、Matei Zaharia、Alex Aikenによる "Deep Neural Networksのデータとモデルの並列化を超えて"](https://arxiv.org/abs/1807.05358)
+論文: [Zhihao Jia、Matei Zaharia、Alex Aikenによる "Deep Neural Networksのデータとモデルの並列化を超えて"](https://huggingface.co/papers/1807.05358)
FlexFlowは、サンプル-オペレータ-属性-パラメータの4D並列化を行います。
diff --git a/docs/source/ja/perf_train_gpu_one.md b/docs/source/ja/perf_train_gpu_one.md
index c45737370a..1a82ebb60d 100644
--- a/docs/source/ja/perf_train_gpu_one.md
+++ b/docs/source/ja/perf_train_gpu_one.md
@@ -406,16 +406,16 @@ PyTorchの[pipとcondaビルド](https://pytorch.org/get-started/locally/#start-
関連するほとんどの論文および実装はTensorflow/TPUを中心に構築されています。
-- [GShard: Conditional Computation and Automatic Shardingを活用した巨大モデルのスケーリング](https://arxiv.org/abs/2006.16668)
-- [Switch Transformers: シンプルで効率的なスパース性を備えたトリリオンパラメータモデルへのスケーリング](https://arxiv.org/abs/2101.03961)
+- [GShard: Conditional Computation and Automatic Shardingを活用した巨大モデルのスケーリング](https://huggingface.co/papers/2006.16668)
+- [Switch Transformers: シンプルで効率的なスパース性を備えたトリリオンパラメータモデルへのスケーリング](https://huggingface.co/papers/2101.03961)
- [GLaM: Generalist Language Model (GLaM)](https://ai.googleblog.com/2021/12/more-efficient-in-context-learning-with.html)
-PytorchにはDeepSpeedが構築したものもあります: [DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale](https://arxiv.org/abs/2201.05596)、[Mixture of Experts](https://www.deepspeed.ai/tutorials/mixture-of-experts/) - ブログ記事: [1](https://www.microsoft.com/en-us/research/blog/deepspeed-powers-8x-larger-moe-model-training-with-high-performance/)、[2](https://www.microsoft.com/en-us/research/publication/scalable-and-efficient-moe-training-for-multitask-multilingual-models/)、大規模なTransformerベースの自然言語生成モデルの具体的な展開については、[ブログ記事](https://www.deepspeed.ai/2021/12/09/deepspeed-moe-nlg.html)、[Megatron-Deepspeedブランチ](https://github.com/microsoft/Megatron-DeepSpeed/tree/moe-training)を参照してください。
+PytorchにはDeepSpeedが構築したものもあります: [DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale](https://huggingface.co/papers/2201.05596)、[Mixture of Experts](https://www.deepspeed.ai/tutorials/mixture-of-experts/) - ブログ記事: [1](https://www.microsoft.com/en-us/research/blog/deepspeed-powers-8x-larger-moe-model-training-with-high-performance/)、[2](https://www.microsoft.com/en-us/research/publication/scalable-and-efficient-moe-training-for-multitask-multilingual-models/)、大規模なTransformerベースの自然言語生成モデルの具体的な展開については、[ブログ記事](https://www.deepspeed.ai/2021/12/09/deepspeed-moe-nlg.html)、[Megatron-Deepspeedブランチ](https://github.com/microsoft/Megatron-DeepSpeed/tree/moe-training)を参照してください。
## PyTorchネイティブアテンションとFlash Attentionの使用
-PyTorch 2.0では、ネイティブの[`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html)(SDPA)がリリースされ、[メモリ効率の高いアテンション](https://arxiv.org/abs/2112.05682)や[フラッシュアテンション](https://arxiv.org/abs/2205.14135)などの融合されたGPUカーネルの使用を可能にします。
+PyTorch 2.0では、ネイティブの[`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html)(SDPA)がリリースされ、[メモリ効率の高いアテンション](https://huggingface.co/papers/2112.05682)や[フラッシュアテンション](https://huggingface.co/papers/2205.14135)などの融合されたGPUカーネルの使用を可能にします。
[`optimum`](https://github.com/huggingface/optimum)パッケージをインストールした後、関連する内部モジュールを置き換えて、PyTorchのネイティブアテンションを使用できます。以下のように設定します:
diff --git a/docs/source/ja/tasks/knowledge_distillation_for_image_classification.md b/docs/source/ja/tasks/knowledge_distillation_for_image_classification.md
index 1079121c60..b8d4a569b1 100644
--- a/docs/source/ja/tasks/knowledge_distillation_for_image_classification.md
+++ b/docs/source/ja/tasks/knowledge_distillation_for_image_classification.md
@@ -17,7 +17,7 @@ rendered properly in your Markdown viewer.
[[open-in-colab]]
-知識の蒸留は、より大規模で複雑なモデル (教師) からより小規模で単純なモデル (生徒) に知識を伝達するために使用される手法です。あるモデルから別のモデルに知識を抽出するには、特定のタスク (この場合は画像分類) でトレーニングされた事前トレーニング済み教師モデルを取得し、画像分類でトレーニングされる生徒モデルをランダムに初期化します。次に、学生モデルをトレーニングして、その出力と教師の出力の差を最小限に抑え、動作を模倣します。これは [Distilling the Knowledge in a Neural Network by Hinton et al](https://arxiv.org/abs/1503.02531) で最初に導入されました。このガイドでは、タスク固有の知識の蒸留を行います。これには [Beans データセット](https://huggingface.co/datasets/beans) を使用します。
+知識の蒸留は、より大規模で複雑なモデル (教師) からより小規模で単純なモデル (生徒) に知識を伝達するために使用される手法です。あるモデルから別のモデルに知識を抽出するには、特定のタスク (この場合は画像分類) でトレーニングされた事前トレーニング済み教師モデルを取得し、画像分類でトレーニングされる生徒モデルをランダムに初期化します。次に、学生モデルをトレーニングして、その出力と教師の出力の差を最小限に抑え、動作を模倣します。これは [Distilling the Knowledge in a Neural Network by Hinton et al](https://huggingface.co/papers/1503.02531) で最初に導入されました。このガイドでは、タスク固有の知識の蒸留を行います。これには [Beans データセット](https://huggingface.co/datasets/beans) を使用します。
このガイドでは、[微調整された ViT モデル](https://huggingface.co/merve/vit-mobilenet-beans-224) (教師モデル) を抽出して [MobileNet](https://huggingface.co/google/mobilenet_v2_1.4_224) (学生モデル) 🤗 Transformers の [Trainer API](https://huggingface.co/docs/transformers/en/main_classes/trainer#trainer) を使用します。
diff --git a/docs/source/ja/tasks/video_classification.md b/docs/source/ja/tasks/video_classification.md
index 741356a6f5..e7e7803c94 100644
--- a/docs/source/ja/tasks/video_classification.md
+++ b/docs/source/ja/tasks/video_classification.md
@@ -386,7 +386,7 @@ def compute_metrics(eval_pred):
**評価に関する注意事項**:
-[VideoMAE 論文](https://arxiv.org/abs/2203.12602) では、著者は次の評価戦略を使用しています。彼らはテスト ビデオからのいくつかのクリップでモデルを評価し、それらのクリップにさまざまなクロップを適用して、合計スコアを報告します。ただし、単純さと簡潔さを保つために、このチュートリアルではそれを考慮しません。
+[VideoMAE 論文](https://huggingface.co/papers/2203.12602) では、著者は次の評価戦略を使用しています。彼らはテスト ビデオからのいくつかのクリップでモデルを評価し、それらのクリップにさまざまなクロップを適用して、合計スコアを報告します。ただし、単純さと簡潔さを保つために、このチュートリアルではそれを考慮しません。
また、サンプルをまとめてバッチ処理するために使用される `collate_fn` を定義します。各バッチは、`pixel_values` と `labels` という 2 つのキーで構成されます。
diff --git a/docs/source/ja/tasks_explained.md b/docs/source/ja/tasks_explained.md
index bdfb3ec0ac..f619c2b220 100644
--- a/docs/source/ja/tasks_explained.md
+++ b/docs/source/ja/tasks_explained.md
@@ -121,7 +121,7 @@ ViTが導入した主な変更点は、画像をTransformerに供給する方法
- DETA の概要。 元の論文から抜粋。
+ DETA の概要。 元の論文から抜粋。
このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
元のコードは [ここ](https://github.com/jozhang97/DETA) にあります。
diff --git a/docs/source/ja/model_doc/detr.md b/docs/source/ja/model_doc/detr.md
index 3342b123a0..d709d76f04 100644
--- a/docs/source/ja/model_doc/detr.md
+++ b/docs/source/ja/model_doc/detr.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-DETR モデルは、[Transformers を使用したエンドツーエンドのオブジェクト検出](https://arxiv.org/abs/2005.12872) で提案されました。
+DETR モデルは、[Transformers を使用したエンドツーエンドのオブジェクト検出](https://huggingface.co/papers/2005.12872) で提案されました。
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov and Sergey Zagoruyko ルイコ。 DETR
畳み込みバックボーンと、その後にエンドツーエンドでトレーニングできるエンコーダー/デコーダー Transformer で構成されます。
物体の検出。 Faster-R-CNN や Mask-R-CNN などのモデルの複雑さの多くが大幅に簡素化されます。
diff --git a/docs/source/ja/model_doc/dialogpt.md b/docs/source/ja/model_doc/dialogpt.md
index 22ce0c9a09..80e5423785 100644
--- a/docs/source/ja/model_doc/dialogpt.md
+++ b/docs/source/ja/model_doc/dialogpt.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-DialoGPT は、[DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) で Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao,
+DialoGPT は、[DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://huggingface.co/papers/1911.00536) で Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao,
Jianfeng Gao, Jingjing Liu, Bill Dolan.これは、から抽出された 147M 万の会話のようなやりとりでトレーニングされた GPT2 モデルです。
レディット。
diff --git a/docs/source/ja/model_doc/dinat.md b/docs/source/ja/model_doc/dinat.md
index a59b073d46..ee373cdd75 100644
--- a/docs/source/ja/model_doc/dinat.md
+++ b/docs/source/ja/model_doc/dinat.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-DiNAT は [Dilated Neighborhood Attender Transformer](https://arxiv.org/abs/2209.15001) で提案されました。
+DiNAT は [Dilated Neighborhood Attender Transformer](https://huggingface.co/papers/2209.15001) で提案されました。
Ali Hassani and Humphrey Shi.
[NAT](nat) を拡張するために、拡張近隣アテンション パターンを追加してグローバル コンテキストをキャプチャします。
@@ -50,7 +50,7 @@ src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/ma
alt="drawing" width="600"/>
異なる拡張値を使用した近隣アテンション。
-元の論文から抜粋。
+元の論文から抜粋。
このモデルは [Ali Hassani](https://huggingface.co/alihassanijr) によって提供されました。
元のコードは [ここ](https://github.com/SHI-Labs/Neighborhood-Attendance-Transformer) にあります。
diff --git a/docs/source/ja/model_memory_anatomy.md b/docs/source/ja/model_memory_anatomy.md
index 45a383d616..c8b7c90a94 100644
--- a/docs/source/ja/model_memory_anatomy.md
+++ b/docs/source/ja/model_memory_anatomy.md
@@ -193,7 +193,7 @@ Transformerアーキテクチャには、計算強度によって以下の3つ
パフォーマンスのボトルネックを分析する際に、この知識は役立つことがあります。
-この要約は、[Data Movement Is All You Need: Optimizing Transformers 2020に関するケーススタディ](https://arxiv.org/abs/2007.00072)から派生しています。
+この要約は、[Data Movement Is All You Need: Optimizing Transformers 2020に関するケーススタディ](https://huggingface.co/papers/2007.00072)から派生しています。
## Anatomy of Model's Memory
diff --git a/docs/source/ja/model_summary.md b/docs/source/ja/model_summary.md
index 8f8b6af48c..b49bde5c20 100644
--- a/docs/source/ja/model_summary.md
+++ b/docs/source/ja/model_summary.md
@@ -16,7 +16,7 @@ rendered properly in your Markdown viewer.
# The Transformer model family
-2017年に導入されて以来、[元のTransformer](https://arxiv.org/abs/1706.03762)モデルは、自然言語処理(NLP)のタスクを超える多くの新しいエキサイティングなモデルをインスパイアしました。[タンパク質の折りたたまれた構造を予測](https://huggingface.co/blog/deep-learning-with-proteins)するモデル、[チーターを走らせるためのトレーニング](https://huggingface.co/blog/train-decision-transformers)するモデル、そして[時系列予測](https://huggingface.co/blog/time-series-transformers)のためのモデルなどがあります。Transformerのさまざまなバリアントが利用可能ですが、大局を見落とすことがあります。これらのすべてのモデルに共通するのは、元のTransformerアーキテクチャに基づいていることです。一部のモデルはエンコーダまたはデコーダのみを使用し、他のモデルは両方を使用します。これは、Transformerファミリー内のモデルの高レベルの違いをカテゴライズし、調査するための有用な分類法を提供し、以前に出会ったことのないTransformerを理解するのに役立ちます。
+2017年に導入されて以来、[元のTransformer](https://huggingface.co/papers/1706.03762)モデルは、自然言語処理(NLP)のタスクを超える多くの新しいエキサイティングなモデルをインスパイアしました。[タンパク質の折りたたまれた構造を予測](https://huggingface.co/blog/deep-learning-with-proteins)するモデル、[チーターを走らせるためのトレーニング](https://huggingface.co/blog/train-decision-transformers)するモデル、そして[時系列予測](https://huggingface.co/blog/time-series-transformers)のためのモデルなどがあります。Transformerのさまざまなバリアントが利用可能ですが、大局を見落とすことがあります。これらのすべてのモデルに共通するのは、元のTransformerアーキテクチャに基づいていることです。一部のモデルはエンコーダまたはデコーダのみを使用し、他のモデルは両方を使用します。これは、Transformerファミリー内のモデルの高レベルの違いをカテゴライズし、調査するための有用な分類法を提供し、以前に出会ったことのないTransformerを理解するのに役立ちます。
元のTransformerモデルに慣れていないか、リフレッシュが必要な場合は、Hugging Faceコースの[Transformerの動作原理](https://huggingface.co/course/chapter1/4?fw=pt)章をチェックしてください。
@@ -32,7 +32,7 @@ rendered properly in your Markdown viewer.
### Convolutional network
-長い間、畳み込みネットワーク(CNN)はコンピュータビジョンのタスクにおいて支配的なパラダイムでしたが、[ビジョンTransformer](https://arxiv.org/abs/2010.11929)はそのスケーラビリティと効率性を示しました。それでも、一部のCNNの最高の特性、特に特定のタスクにとっては非常に強力な翻訳不変性など、一部のTransformerはアーキテクチャに畳み込みを組み込んでいます。[ConvNeXt](model_doc/convnext)は、畳み込みを現代化するためにTransformerから設計の選択肢を取り入れ、例えば、ConvNeXtは画像をパッチに分割するために重なり合わないスライディングウィンドウと、グローバル受容野を増加させるための大きなカーネルを使用します。ConvNeXtは、メモリ効率を向上させ、パフォーマンスを向上させるためにいくつかのレイヤーデザインの選択肢も提供し、Transformerと競合的になります!
+長い間、畳み込みネットワーク(CNN)はコンピュータビジョンのタスクにおいて支配的なパラダイムでしたが、[ビジョンTransformer](https://huggingface.co/papers/2010.11929)はそのスケーラビリティと効率性を示しました。それでも、一部のCNNの最高の特性、特に特定のタスクにとっては非常に強力な翻訳不変性など、一部のTransformerはアーキテクチャに畳み込みを組み込んでいます。[ConvNeXt](model_doc/convnext)は、畳み込みを現代化するためにTransformerから設計の選択肢を取り入れ、例えば、ConvNeXtは画像をパッチに分割するために重なり合わないスライディングウィンドウと、グローバル受容野を増加させるための大きなカーネルを使用します。ConvNeXtは、メモリ効率を向上させ、パフォーマンスを向上させるためにいくつかのレイヤーデザインの選択肢も提供し、Transformerと競合的になります!
### Encoder[[cv-encoder]]
@@ -59,7 +59,7 @@ BeIT および ViTMAE などの他のビジョンモデルは、BERTの事前ト
[BERT](model_doc/bert) はエンコーダー専用のTransformerで、入力の一部のトークンをランダムにマスクして他のトークンを見ないようにしています。これにより、トークンをマスクした文脈に基づいてマスクされたトークンを予測することが事前トレーニングの目標です。これにより、BERTは入力のより深いかつ豊かな表現を学習するのに左右の文脈を完全に活用できます。しかし、BERTの事前トレーニング戦略にはまだ改善の余地がありました。[RoBERTa](model_doc/roberta) は、トレーニングを長時間行い、より大きなバッチでトレーニングし、事前処理中に一度だけでなく各エポックでトークンをランダムにマスクし、次文予測の目標を削除する新しい事前トレーニングレシピを導入することでこれを改善しました。
-性能を向上させる主要な戦略はモデルのサイズを増やすことですが、大規模なモデルのトレーニングは計算コストがかかります。計算コストを削減する方法の1つは、[DistilBERT](model_doc/distilbert) のような小さなモデルを使用することです。DistilBERTは[知識蒸留](https://arxiv.org/abs/1503.02531) - 圧縮技術 - を使用して、BERTのほぼすべての言語理解機能を保持しながら、より小さなバージョンを作成します。
+性能を向上させる主要な戦略はモデルのサイズを増やすことですが、大規模なモデルのトレーニングは計算コストがかかります。計算コストを削減する方法の1つは、[DistilBERT](model_doc/distilbert) のような小さなモデルを使用することです。DistilBERTは[知識蒸留](https://huggingface.co/papers/1503.02531) - 圧縮技術 - を使用して、BERTのほぼすべての言語理解機能を保持しながら、より小さなバージョンを作成します。
しかし、ほとんどのTransformerモデルは引き続きより多くのパラメータに焦点を当て、トレーニング効率を向上させる新しいモデルが登場しています。[ALBERT](model_doc/albert) は、2つの方法でパラメータの数を減らすことによってメモリ消費量を削減します。大きな語彙埋め込みを2つの小さな行列に分割し、レイヤーがパラメータを共有できるようにします。[DeBERTa](model_doc/deberta) は、単語とその位置を2つのベクトルで別々にエンコードする解かれた注意機構を追加しました。注意はこれらの別々のベクトルから計算されます。単語と位置の埋め込みが含まれる単一のベクトルではなく、[Longformer](model_doc/longformer) は、特に長いシーケンス長のドキュメントを処理するために注意をより効率的にすることに焦点を当てました。固定されたウィンドウサイズの周りの各トークンから計算されるローカルウィンドウ付き注意(特定のタスクトークン(分類のための `[CLS]` など)のみのためのグローバルな注意を含む)の組み合わせを使用して、完全な注意行列ではなく疎な注意行列を作成します。
diff --git a/docs/source/ja/peft.md b/docs/source/ja/peft.md
index c3d195adbd..77dd7be86c 100644
--- a/docs/source/ja/peft.md
+++ b/docs/source/ja/peft.md
@@ -46,7 +46,7 @@ pip install git+https://github.com/huggingface/peft.git
- [Low Rank Adapters](https://huggingface.co/docs/peft/conceptual_guides/lora)
- [IA3](https://huggingface.co/docs/peft/conceptual_guides/ia3)
-- [AdaLoRA](https://arxiv.org/abs/2303.10512)
+- [AdaLoRA](https://huggingface.co/papers/2303.10512)
他のPEFTメソッドを使用したい場合、プロンプト学習やプロンプト調整などについて詳しく知りたい場合、または🤗 PEFTライブラリ全般については、[ドキュメンテーション](https://huggingface.co/docs/peft/index)を参照してください。
diff --git a/docs/source/ja/perf_infer_gpu_many.md b/docs/source/ja/perf_infer_gpu_many.md
index 18a19c849e..6a71c10944 100644
--- a/docs/source/ja/perf_infer_gpu_many.md
+++ b/docs/source/ja/perf_infer_gpu_many.md
@@ -53,7 +53,7 @@ model.to_bettertransformer()
# Use it for training or inference
```
-SDPAは、ハードウェアや問題のサイズなどの特定の設定で[Flash Attention](https://arxiv.org/abs/2205.14135)カーネルを呼び出すこともできます。Flash Attentionを有効にするか、特定の設定(ハードウェア、問題のサイズ)で利用可能かを確認するには、[`torch.nn.kernel.sdpa_kernel`](https://pytorch.org/docs/stable/generated/torch.nn.attention.sdpa_kernel.html)をコンテキストマネージャとして使用します。
+SDPAは、ハードウェアや問題のサイズなどの特定の設定で[Flash Attention](https://huggingface.co/papers/2205.14135)カーネルを呼び出すこともできます。Flash Attentionを有効にするか、特定の設定(ハードウェア、問題のサイズ)で利用可能かを確認するには、[`torch.nn.kernel.sdpa_kernel`](https://pytorch.org/docs/stable/generated/torch.nn.attention.sdpa_kernel.html)をコンテキストマネージャとして使用します。
```diff
diff --git a/docs/source/ja/perf_infer_gpu_one.md b/docs/source/ja/perf_infer_gpu_one.md
index 6a3dc5fa64..374d725a99 100644
--- a/docs/source/ja/perf_infer_gpu_one.md
+++ b/docs/source/ja/perf_infer_gpu_one.md
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
-Flash Attention 2は、トランスフォーマーベースのモデルのトレーニングと推論速度を大幅に高速化できます。Flash Attention 2は、Tri Dao氏によって[公式のFlash Attentionリポジトリ](https://github.com/Dao-AILab/flash-attention)で導入されました。Flash Attentionに関する科学論文は[こちら](https://arxiv.org/abs/2205.14135)で見ることができます。
+Flash Attention 2は、トランスフォーマーベースのモデルのトレーニングと推論速度を大幅に高速化できます。Flash Attention 2は、Tri Dao氏によって[公式のFlash Attentionリポジトリ](https://github.com/Dao-AILab/flash-attention)で導入されました。Flash Attentionに関する科学論文は[こちら](https://huggingface.co/papers/2205.14135)で見ることができます。
Flash Attention 2を正しくインストールするには、上記のリポジトリに記載されているインストールガイドに従ってください。
@@ -214,7 +214,7 @@ model.to_bettertransformer()
# Use it for training or inference
```
-SDPAは、ハードウェアや問題のサイズに応じて[Flash Attention](https://arxiv.org/abs/2205.14135)カーネルを使用することもできます。Flash Attentionを有効にするか、特定の設定(ハードウェア、問題サイズ)で使用可能かどうかを確認するには、[`torch.nn.attention.sdpa_kernel`](https://pytorch.org/docs/stable/generated/torch.nn.attention.sdpa_kernel.html)をコンテキストマネージャとして使用します。
+SDPAは、ハードウェアや問題のサイズに応じて[Flash Attention](https://huggingface.co/papers/2205.14135)カーネルを使用することもできます。Flash Attentionを有効にするか、特定の設定(ハードウェア、問題サイズ)で使用可能かどうかを確認するには、[`torch.nn.attention.sdpa_kernel`](https://pytorch.org/docs/stable/generated/torch.nn.attention.sdpa_kernel.html)をコンテキストマネージャとして使用します。
```diff
@@ -332,12 +332,12 @@ model_4bit = AutoModelForCausalLM.from_pretrained(
-論文[`LLM.int8():スケーラブルなTransformer向けの8ビット行列乗算`](https://arxiv.org/abs/2208.07339)によれば、Hugging Face統合がHub内のすべてのモデルでわずか数行のコードでサポートされています。このメソッドは、半精度(`float16`および`bfloat16`)の重みの場合に`nn.Linear`サイズを2倍、単精度(`float32`)の重みの場合は4倍に縮小し、外れ値に対してほとんど影響を与えません。
+論文[`LLM.int8():スケーラブルなTransformer向けの8ビット行列乗算`](https://huggingface.co/papers/2208.07339)によれば、Hugging Face統合がHub内のすべてのモデルでわずか数行のコードでサポートされています。このメソッドは、半精度(`float16`および`bfloat16`)の重みの場合に`nn.Linear`サイズを2倍、単精度(`float32`)の重みの場合は4倍に縮小し、外れ値に対してほとんど影響を与えません。

Int8混合精度行列分解は、行列乗算を2つのストリームに分割することによって動作します:(1) システマティックな特徴外れ値ストリームがfp16で行列乗算(0.01%)、(2) int8行列乗算の通常のストリーム(99.9%)。この方法を使用すると、非常に大きなモデルに対して予測の劣化なしにint8推論が可能です。
-このメソッドの詳細については、[論文](https://arxiv.org/abs/2208.07339)または[この統合に関するブログ記事](https://huggingface.co/blog/hf-bitsandbytes-integration)をご確認ください。
+このメソッドの詳細については、[論文](https://huggingface.co/papers/2208.07339)または[この統合に関するブログ記事](https://huggingface.co/blog/hf-bitsandbytes-integration)をご確認ください。

diff --git a/docs/source/ja/perf_train_gpu_many.md b/docs/source/ja/perf_train_gpu_many.md
index 613ccfa20b..6721ba69a9 100644
--- a/docs/source/ja/perf_train_gpu_many.md
+++ b/docs/source/ja/perf_train_gpu_many.md
@@ -317,7 +317,7 @@ VarunaとSageMakerとの実験はまだ行っていませんが、彼らの論
- [DeepSpeed](https://www.deepspeed.ai/tutorials/pipeline/)
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) has an internal implementation - no API.
- [Varuna](https://github.com/microsoft/varuna)
-- [SageMaker](https://arxiv.org/abs/2111.05972) - this is a proprietary solution that can only be used on AWS.
+- [SageMaker](https://huggingface.co/papers/2111.05972) - this is a proprietary solution that can only be used on AWS.
- [OSLO](https://github.com/tunib-ai/oslo) - この実装は、Hugging Face Transformersに基づいています。
🤗 Transformersのステータス: この執筆時点では、いずれのモデルも完全なPP(パイプライン並列処理)をサポートしていません。GPT2モデルとT5モデルは単純なMP(モデル並列処理)サポートを持っています。主な障害は、モデルを`nn.Sequential`に変換できず、すべての入力がテンソルである必要があることです。現在のモデルには、変換を非常に複雑にする多くの機能が含まれており、これらを削除する必要があります。
@@ -334,7 +334,7 @@ OSLOは、`nn.Sequential`の変換なしでTransformersに基づくパイプラ
テンソル並列処理では、各GPUがテンソルのスライスのみを処理し、全体が必要な操作のためにのみ完全なテンソルを集約します。
-このセクションでは、[Megatron-LM](https://github.com/NVIDIA/Megatron-LM)論文からのコンセプトと図を使用します:[GPUクラスタでの効率的な大規模言語モデルトレーニング](https://arxiv.org/abs/2104.04473)。
+このセクションでは、[Megatron-LM](https://github.com/NVIDIA/Megatron-LM)論文からのコンセプトと図を使用します:[GPUクラスタでの効率的な大規模言語モデルトレーニング](https://huggingface.co/papers/2104.04473)。
どのトランスフォーマの主要な構築要素は、完全に接続された`nn.Linear`に続く非線形アクティベーション`GeLU`です。
@@ -365,7 +365,7 @@ SageMakerは、より効率的な処理のためにTPとDPを組み合わせて
実装例:
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)には、モデル固有の内部実装があります。
- [parallelformers](https://github.com/tunib-ai/parallelformers)(現時点では推論のみ)。
-- [SageMaker](https://arxiv.org/abs/2111.05972) - これはAWSでのみ使用できるプロプライエタリなソリューションです。
+- [SageMaker](https://huggingface.co/papers/2111.05972) - これはAWSでのみ使用できるプロプライエタリなソリューションです。
- [OSLO](https://github.com/tunib-ai/oslo)には、Transformersに基づいたテンソル並列実装があります。
🤗 Transformersの状況:
@@ -387,7 +387,7 @@ DeepSpeedの[パイプラインチュートリアル](https://www.deepspeed.ai/t
- [DeepSpeed](https://github.com/deepspeedai/DeepSpeed)
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
- [Varuna](https://github.com/microsoft/varuna)
-- [SageMaker](https://arxiv.org/abs/2111.05972)
+- [SageMaker](https://huggingface.co/papers/2111.05972)
- [OSLO](https://github.com/tunib-ai/oslo)
🤗 Transformersの状況: まだ実装されていません
@@ -406,7 +406,7 @@ DeepSpeedの[パイプラインチュートリアル](https://www.deepspeed.ai/t
- [DeepSpeed](https://github.com/deepspeedai/DeepSpeed) - DeepSpeedには、さらに効率的なDPであるZeRO-DPと呼ばれるものも含まれています。
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
- [Varuna](https://github.com/microsoft/varuna)
-- [SageMaker](https://arxiv.org/abs/2111.05972)
+- [SageMaker](https://huggingface.co/papers/2111.05972)
- [OSLO](https://github.com/tunib-ai/oslo)
🤗 Transformersの状況: まだ実装されていません。PPとTPがないため。
@@ -431,7 +431,7 @@ ZeROステージ3も同様の理由で適していません - より多くのノ
重要な論文:
-- [DeepSpeedとMegatronを使用したMegatron-Turing NLG 530Bのトレーニング](https://arxiv.org/abs/2201.11990)
+- [DeepSpeedとMegatronを使用したMegatron-Turing NLG 530Bのトレーニング](https://huggingface.co/papers/2201.11990)
🤗 Transformersの状況: まだ実装されていません。PPとTPがないため。
@@ -440,7 +440,7 @@ ZeROステージ3も同様の理由で適していません - より多くのノ
[FlexFlow](https://github.com/flexflow/FlexFlow)は、わずかに異なるアプローチで並列化の問題を解決します。
-論文: [Zhihao Jia、Matei Zaharia、Alex Aikenによる "Deep Neural Networksのデータとモデルの並列化を超えて"](https://arxiv.org/abs/1807.05358)
+論文: [Zhihao Jia、Matei Zaharia、Alex Aikenによる "Deep Neural Networksのデータとモデルの並列化を超えて"](https://huggingface.co/papers/1807.05358)
FlexFlowは、サンプル-オペレータ-属性-パラメータの4D並列化を行います。
diff --git a/docs/source/ja/perf_train_gpu_one.md b/docs/source/ja/perf_train_gpu_one.md
index c45737370a..1a82ebb60d 100644
--- a/docs/source/ja/perf_train_gpu_one.md
+++ b/docs/source/ja/perf_train_gpu_one.md
@@ -406,16 +406,16 @@ PyTorchの[pipとcondaビルド](https://pytorch.org/get-started/locally/#start-
関連するほとんどの論文および実装はTensorflow/TPUを中心に構築されています。
-- [GShard: Conditional Computation and Automatic Shardingを活用した巨大モデルのスケーリング](https://arxiv.org/abs/2006.16668)
-- [Switch Transformers: シンプルで効率的なスパース性を備えたトリリオンパラメータモデルへのスケーリング](https://arxiv.org/abs/2101.03961)
+- [GShard: Conditional Computation and Automatic Shardingを活用した巨大モデルのスケーリング](https://huggingface.co/papers/2006.16668)
+- [Switch Transformers: シンプルで効率的なスパース性を備えたトリリオンパラメータモデルへのスケーリング](https://huggingface.co/papers/2101.03961)
- [GLaM: Generalist Language Model (GLaM)](https://ai.googleblog.com/2021/12/more-efficient-in-context-learning-with.html)
-PytorchにはDeepSpeedが構築したものもあります: [DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale](https://arxiv.org/abs/2201.05596)、[Mixture of Experts](https://www.deepspeed.ai/tutorials/mixture-of-experts/) - ブログ記事: [1](https://www.microsoft.com/en-us/research/blog/deepspeed-powers-8x-larger-moe-model-training-with-high-performance/)、[2](https://www.microsoft.com/en-us/research/publication/scalable-and-efficient-moe-training-for-multitask-multilingual-models/)、大規模なTransformerベースの自然言語生成モデルの具体的な展開については、[ブログ記事](https://www.deepspeed.ai/2021/12/09/deepspeed-moe-nlg.html)、[Megatron-Deepspeedブランチ](https://github.com/microsoft/Megatron-DeepSpeed/tree/moe-training)を参照してください。
+PytorchにはDeepSpeedが構築したものもあります: [DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale](https://huggingface.co/papers/2201.05596)、[Mixture of Experts](https://www.deepspeed.ai/tutorials/mixture-of-experts/) - ブログ記事: [1](https://www.microsoft.com/en-us/research/blog/deepspeed-powers-8x-larger-moe-model-training-with-high-performance/)、[2](https://www.microsoft.com/en-us/research/publication/scalable-and-efficient-moe-training-for-multitask-multilingual-models/)、大規模なTransformerベースの自然言語生成モデルの具体的な展開については、[ブログ記事](https://www.deepspeed.ai/2021/12/09/deepspeed-moe-nlg.html)、[Megatron-Deepspeedブランチ](https://github.com/microsoft/Megatron-DeepSpeed/tree/moe-training)を参照してください。
## PyTorchネイティブアテンションとFlash Attentionの使用
-PyTorch 2.0では、ネイティブの[`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html)(SDPA)がリリースされ、[メモリ効率の高いアテンション](https://arxiv.org/abs/2112.05682)や[フラッシュアテンション](https://arxiv.org/abs/2205.14135)などの融合されたGPUカーネルの使用を可能にします。
+PyTorch 2.0では、ネイティブの[`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html)(SDPA)がリリースされ、[メモリ効率の高いアテンション](https://huggingface.co/papers/2112.05682)や[フラッシュアテンション](https://huggingface.co/papers/2205.14135)などの融合されたGPUカーネルの使用を可能にします。
[`optimum`](https://github.com/huggingface/optimum)パッケージをインストールした後、関連する内部モジュールを置き換えて、PyTorchのネイティブアテンションを使用できます。以下のように設定します:
diff --git a/docs/source/ja/tasks/knowledge_distillation_for_image_classification.md b/docs/source/ja/tasks/knowledge_distillation_for_image_classification.md
index 1079121c60..b8d4a569b1 100644
--- a/docs/source/ja/tasks/knowledge_distillation_for_image_classification.md
+++ b/docs/source/ja/tasks/knowledge_distillation_for_image_classification.md
@@ -17,7 +17,7 @@ rendered properly in your Markdown viewer.
[[open-in-colab]]
-知識の蒸留は、より大規模で複雑なモデル (教師) からより小規模で単純なモデル (生徒) に知識を伝達するために使用される手法です。あるモデルから別のモデルに知識を抽出するには、特定のタスク (この場合は画像分類) でトレーニングされた事前トレーニング済み教師モデルを取得し、画像分類でトレーニングされる生徒モデルをランダムに初期化します。次に、学生モデルをトレーニングして、その出力と教師の出力の差を最小限に抑え、動作を模倣します。これは [Distilling the Knowledge in a Neural Network by Hinton et al](https://arxiv.org/abs/1503.02531) で最初に導入されました。このガイドでは、タスク固有の知識の蒸留を行います。これには [Beans データセット](https://huggingface.co/datasets/beans) を使用します。
+知識の蒸留は、より大規模で複雑なモデル (教師) からより小規模で単純なモデル (生徒) に知識を伝達するために使用される手法です。あるモデルから別のモデルに知識を抽出するには、特定のタスク (この場合は画像分類) でトレーニングされた事前トレーニング済み教師モデルを取得し、画像分類でトレーニングされる生徒モデルをランダムに初期化します。次に、学生モデルをトレーニングして、その出力と教師の出力の差を最小限に抑え、動作を模倣します。これは [Distilling the Knowledge in a Neural Network by Hinton et al](https://huggingface.co/papers/1503.02531) で最初に導入されました。このガイドでは、タスク固有の知識の蒸留を行います。これには [Beans データセット](https://huggingface.co/datasets/beans) を使用します。
このガイドでは、[微調整された ViT モデル](https://huggingface.co/merve/vit-mobilenet-beans-224) (教師モデル) を抽出して [MobileNet](https://huggingface.co/google/mobilenet_v2_1.4_224) (学生モデル) 🤗 Transformers の [Trainer API](https://huggingface.co/docs/transformers/en/main_classes/trainer#trainer) を使用します。
diff --git a/docs/source/ja/tasks/video_classification.md b/docs/source/ja/tasks/video_classification.md
index 741356a6f5..e7e7803c94 100644
--- a/docs/source/ja/tasks/video_classification.md
+++ b/docs/source/ja/tasks/video_classification.md
@@ -386,7 +386,7 @@ def compute_metrics(eval_pred):
**評価に関する注意事項**:
-[VideoMAE 論文](https://arxiv.org/abs/2203.12602) では、著者は次の評価戦略を使用しています。彼らはテスト ビデオからのいくつかのクリップでモデルを評価し、それらのクリップにさまざまなクロップを適用して、合計スコアを報告します。ただし、単純さと簡潔さを保つために、このチュートリアルではそれを考慮しません。
+[VideoMAE 論文](https://huggingface.co/papers/2203.12602) では、著者は次の評価戦略を使用しています。彼らはテスト ビデオからのいくつかのクリップでモデルを評価し、それらのクリップにさまざまなクロップを適用して、合計スコアを報告します。ただし、単純さと簡潔さを保つために、このチュートリアルではそれを考慮しません。
また、サンプルをまとめてバッチ処理するために使用される `collate_fn` を定義します。各バッチは、`pixel_values` と `labels` という 2 つのキーで構成されます。
diff --git a/docs/source/ja/tasks_explained.md b/docs/source/ja/tasks_explained.md
index bdfb3ec0ac..f619c2b220 100644
--- a/docs/source/ja/tasks_explained.md
+++ b/docs/source/ja/tasks_explained.md
@@ -121,7 +121,7 @@ ViTが導入した主な変更点は、画像をTransformerに供給する方法
 -Chameleon은 이미지를 이산적인 토큰으로 변환하기 위해 벡터 양자화 모듈을 통합합니다. 이는 자기회귀 transformer를 사용한 이미지 생성을 가능하게 합니다. 원본 논문에서 가져왔습니다.
+Chameleon은 이미지를 이산적인 토큰으로 변환하기 위해 벡터 양자화 모듈을 통합합니다. 이는 자기회귀 transformer를 사용한 이미지 생성을 가능하게 합니다. 원본 논문에서 가져왔습니다.
이 모델은 [joaogante](https://huggingface.co/joaogante)와 [RaushanTurganbay](https://huggingface.co/RaushanTurganbay)가 기여했습니다. 원본 코드는 [여기](https://github.com/facebookresearch/chameleon)에서 찾을 수 있습니다.
diff --git a/docs/source/ko/model_doc/clip.md b/docs/source/ko/model_doc/clip.md
index 5c19a31e10..f1053d1758 100644
--- a/docs/source/ko/model_doc/clip.md
+++ b/docs/source/ko/model_doc/clip.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## 개요[[overview]]
CLIP 모델은 Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh,
-Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever가 제안한 [자연어 지도(supervision)를 통한 전이 가능한 시각 모델 학습](https://arxiv.org/abs/2103.00020)라는 논문에서 소개되었습니다. CLIP(Contrastive Language-Image Pre-Training)은 다양한 이미지와 텍스트 쌍으로 훈련된 신경망 입니다. GPT-2와 3의 제로샷 능력과 유사하게, 해당 작업에 직접적으로 최적화하지 않고도 주어진 이미지에 대해 가장 관련성 있는 텍스트 스니펫을 예측하도록 자연어로 지시할 수 있습니다.
+Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever가 제안한 [자연어 지도(supervision)를 통한 전이 가능한 시각 모델 학습](https://huggingface.co/papers/2103.00020)라는 논문에서 소개되었습니다. CLIP(Contrastive Language-Image Pre-Training)은 다양한 이미지와 텍스트 쌍으로 훈련된 신경망 입니다. GPT-2와 3의 제로샷 능력과 유사하게, 해당 작업에 직접적으로 최적화하지 않고도 주어진 이미지에 대해 가장 관련성 있는 텍스트 스니펫을 예측하도록 자연어로 지시할 수 있습니다.
해당 논문의 초록입니다.
diff --git a/docs/source/ko/model_doc/codegen.md b/docs/source/ko/model_doc/codegen.md
index 264f10e89b..75e69b0b84 100644
--- a/docs/source/ko/model_doc/codegen.md
+++ b/docs/source/ko/model_doc/codegen.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## 개요[[Overview]]
-CodeGen 모델은 Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong이 작성한 논문 [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474)에서 제안되었습니다.
+CodeGen 모델은 Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong이 작성한 논문 [A Conversational Paradigm for Program Synthesis](https://huggingface.co/papers/2203.13474)에서 제안되었습니다.
CodeGen 모델은 프로그램 합성(program synthesis)을 위한 자기회귀(autoregressive) 언어 모델로, [The Pile](https://pile.eleuther.ai/), BigQuery, BigPython 데이터로 순차적으로 학습되었습니다.
diff --git a/docs/source/ko/model_doc/convbert.md b/docs/source/ko/model_doc/convbert.md
index ec64a369b5..c4f0d2ace2 100644
--- a/docs/source/ko/model_doc/convbert.md
+++ b/docs/source/ko/model_doc/convbert.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
## 개요 [[overview]]
-ConvBERT 모델은 Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan에 의해 제안되었으며, 제안 논문 제목은 [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496)입니다.
+ConvBERT 모델은 Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan에 의해 제안되었으며, 제안 논문 제목은 [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://huggingface.co/papers/2008.02496)입니다.
논문의 초록은 다음과 같습니다:
diff --git a/docs/source/ko/model_doc/deberta-v2.md b/docs/source/ko/model_doc/deberta-v2.md
index 2e590ad8a5..bb7bed1434 100644
--- a/docs/source/ko/model_doc/deberta-v2.md
+++ b/docs/source/ko/model_doc/deberta-v2.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## 개요
-DeBERTa 모델은 Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen이 작성한 [DeBERTa: 분리된 어텐션을 활용한 디코딩 강화 BERT](https://arxiv.org/abs/2006.03654)이라는 논문에서 제안되었습니다. 이 모델은 2018년 Google이 발표한 BERT 모델과 2019년 Facebook이 발표한 RoBERTa 모델을 기반으로 합니다.
+DeBERTa 모델은 Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen이 작성한 [DeBERTa: 분리된 어텐션을 활용한 디코딩 강화 BERT](https://huggingface.co/papers/2006.03654)이라는 논문에서 제안되었습니다. 이 모델은 2018년 Google이 발표한 BERT 모델과 2019년 Facebook이 발표한 RoBERTa 모델을 기반으로 합니다.
DeBERTa는 RoBERTa에서 사용된 데이터의 절반만을 사용하여 분리된(disentangled) 어텐션과 향상된 마스크 디코더 학습을 통해 RoBERTa를 개선했습니다.
논문의 초록은 다음과 같습니다:
diff --git a/docs/source/ko/model_doc/deberta.md b/docs/source/ko/model_doc/deberta.md
index 6f82bed033..b471c9327a 100644
--- a/docs/source/ko/model_doc/deberta.md
+++ b/docs/source/ko/model_doc/deberta.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## 개요[[overview]]
-DeBERTa 모델은 Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen이 작성한 [DeBERTa: 분리된 어텐션을 활용한 디코딩 강화 BERT](https://arxiv.org/abs/2006.03654)이라는 논문에서 제안되었습니다. 이 모델은 2018년 Google이 발표한 BERT 모델과 2019년 Facebook이 발표한 RoBERTa 모델을 기반으로 합니다.
+DeBERTa 모델은 Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen이 작성한 [DeBERTa: 분리된 어텐션을 활용한 디코딩 강화 BERT](https://huggingface.co/papers/2006.03654)이라는 논문에서 제안되었습니다. 이 모델은 2018년 Google이 발표한 BERT 모델과 2019년 Facebook이 발표한 RoBERTa 모델을 기반으로 합니다.
DeBERTa는 RoBERTa에서 사용된 데이터의 절반만을 사용하여 분리된(disentangled) 어텐션과 향상된 마스크 디코더 학습을 통해 RoBERTa를 개선했습니다.
논문의 초록은 다음과 같습니다:
diff --git a/docs/source/ko/model_doc/encoder-decoder.md b/docs/source/ko/model_doc/encoder-decoder.md
index c5c5535613..60982cb455 100644
--- a/docs/source/ko/model_doc/encoder-decoder.md
+++ b/docs/source/ko/model_doc/encoder-decoder.md
@@ -20,11 +20,11 @@ rendered properly in your Markdown viewer.
[`EncoderDecoderModel`]은 사전 학습된 자동 인코딩(autoencoding) 모델을 인코더로, 사전 학습된 자가 회귀(autoregressive) 모델을 디코더로 활용하여 시퀀스-투-시퀀스(sequence-to-sequence) 모델을 초기화하는 데 이용됩니다.
-사전 학습된 체크포인트를 활용해 시퀀스-투-시퀀스 모델을 초기화하는 것이 시퀀스 생성(sequence generation) 작업에 효과적이라는 점이 Sascha Rothe, Shashi Narayan, Aliaksei Severyn의 논문 [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461)에서 입증되었습니다.
+사전 학습된 체크포인트를 활용해 시퀀스-투-시퀀스 모델을 초기화하는 것이 시퀀스 생성(sequence generation) 작업에 효과적이라는 점이 Sascha Rothe, Shashi Narayan, Aliaksei Severyn의 논문 [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://huggingface.co/papers/1907.12461)에서 입증되었습니다.
[`EncoderDecoderModel`]이 학습/미세 조정된 후에는 다른 모델과 마찬가지로 저장/불러오기가 가능합니다. 자세한 사용법은 예제를 참고하세요.
-이 아키텍처의 한 가지 응용 사례는 두 개의 사전 학습된 [`BertModel`]을 각각 인코더와 디코더로 활용하여 요약 모델(summarization model)을 구축하는 것입니다. 이는 Yang Liu와 Mirella Lapata의 논문 [Text Summarization with Pretrained Encoders](https://arxiv.org/abs/1908.08345)에서 제시된 바 있습니다.
+이 아키텍처의 한 가지 응용 사례는 두 개의 사전 학습된 [`BertModel`]을 각각 인코더와 디코더로 활용하여 요약 모델(summarization model)을 구축하는 것입니다. 이는 Yang Liu와 Mirella Lapata의 논문 [Text Summarization with Pretrained Encoders](https://huggingface.co/papers/1908.08345)에서 제시된 바 있습니다.
## 모델 설정에서 `EncoderDecoderModel`을 무작위 초기화하기[[Randomly initializing `EncoderDecoderModel` from model configurations.]]
diff --git a/docs/source/ko/model_doc/graphormer.md b/docs/source/ko/model_doc/graphormer.md
index fc6aa2c9e2..9e1a893fc5 100644
--- a/docs/source/ko/model_doc/graphormer.md
+++ b/docs/source/ko/model_doc/graphormer.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## 개요[[overview]]
-Graphormer 모델은 Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu가 제안한 [트랜스포머가 그래프 표현에 있어서 정말 약할까?](https://arxiv.org/abs/2106.05234) 라는 논문에서 소개되었습니다. Graphormer는 그래프 트랜스포머 모델입니다. 텍스트 시퀀스 대신 그래프에서 계산을 수행할 수 있도록 수정되었으며, 전처리와 병합 과정에서 임베딩과 관심 특성을 생성한 후 수정된 어텐션을 사용합니다.
+Graphormer 모델은 Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu가 제안한 [트랜스포머가 그래프 표현에 있어서 정말 약할까?](https://huggingface.co/papers/2106.05234) 라는 논문에서 소개되었습니다. Graphormer는 그래프 트랜스포머 모델입니다. 텍스트 시퀀스 대신 그래프에서 계산을 수행할 수 있도록 수정되었으며, 전처리와 병합 과정에서 임베딩과 관심 특성을 생성한 후 수정된 어텐션을 사용합니다.
해당 논문의 초록입니다:
diff --git a/docs/source/ko/model_doc/informer.md b/docs/source/ko/model_doc/informer.md
index 03722545a5..9482933008 100644
--- a/docs/source/ko/model_doc/informer.md
+++ b/docs/source/ko/model_doc/informer.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요[[overview]]
-The Informer 모델은 Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, Wancai Zhang가 제안한 [Informer: 장기 시퀀스 시계열 예측(LSTF)을 위한 더욱 효율적인 트랜스포머(Beyond Efficient Transformer)](https://arxiv.org/abs/2012.07436)라는 논문에서 소개되었습니다.
+The Informer 모델은 Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, Wancai Zhang가 제안한 [Informer: 장기 시퀀스 시계열 예측(LSTF)을 위한 더욱 효율적인 트랜스포머(Beyond Efficient Transformer)](https://huggingface.co/papers/2012.07436)라는 논문에서 소개되었습니다.
이 방법은 확률적 어텐션 메커니즘을 도입하여 "게으른" 쿼리가 아닌 "활성" 쿼리를 선택하고, 희소 트랜스포머를 제공하여 기존 어텐션의 이차적 계산 및 메모리 요구사항을 완화합니다.
diff --git a/docs/source/ko/model_doc/llama.md b/docs/source/ko/model_doc/llama.md
index 282befac21..3cd5867584 100644
--- a/docs/source/ko/model_doc/llama.md
+++ b/docs/source/ko/model_doc/llama.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요 [[overview]]
-LLaMA 모델은 Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample에 의해 제안된 [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971)에서 소개되었습니다. 이 모델은 7B에서 65B개의 파라미터까지 다양한 크기의 기초 언어 모델을 모아놓은 것입니다.
+LLaMA 모델은 Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample에 의해 제안된 [LLaMA: Open and Efficient Foundation Language Models](https://huggingface.co/papers/2302.13971)에서 소개되었습니다. 이 모델은 7B에서 65B개의 파라미터까지 다양한 크기의 기초 언어 모델을 모아놓은 것입니다.
논문의 초록은 다음과 같습니다:
diff --git a/docs/source/ko/model_doc/llama2.md b/docs/source/ko/model_doc/llama2.md
index 5290f2bb7b..4975b2e4ab 100644
--- a/docs/source/ko/model_doc/llama2.md
+++ b/docs/source/ko/model_doc/llama2.md
@@ -39,7 +39,7 @@ Llama2 모델은 Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Al
🍯 팁:
- Llama2 모델의 가중치는 [이 양식](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)을 작성하여 얻을 수 있습니다.
-- 아키텍처는 처음 버전의 Llama와 매우 유사하며, [이 논문](https://arxiv.org/pdf/2305.13245.pdf)의 내용에 따라 Grouped Query Attention (GQA)이 추가되었습니다.
+- 아키텍처는 처음 버전의 Llama와 매우 유사하며, [이 논문](https://huggingface.co/papers/2305.13245)의 내용에 따라 Grouped Query Attention (GQA)이 추가되었습니다.
- `config.pretraining_tp`를 1과 다른 값으로 설정하면 더 정확하지만 느린 선형 레이어 계산이 활성화되어 원본 로짓과 더 잘 일치하게 됩니다.
- 원래 모델은 `pad_id = -1`을 사용하는데, 이는 패딩 토큰이 없음을 의미합니다. 동일한 로직을 사용할 수 없으므로 `tokenizer.add_special_tokens({"pad_token":"
-Chameleon은 이미지를 이산적인 토큰으로 변환하기 위해 벡터 양자화 모듈을 통합합니다. 이는 자기회귀 transformer를 사용한 이미지 생성을 가능하게 합니다. 원본 논문에서 가져왔습니다.
+Chameleon은 이미지를 이산적인 토큰으로 변환하기 위해 벡터 양자화 모듈을 통합합니다. 이는 자기회귀 transformer를 사용한 이미지 생성을 가능하게 합니다. 원본 논문에서 가져왔습니다.
이 모델은 [joaogante](https://huggingface.co/joaogante)와 [RaushanTurganbay](https://huggingface.co/RaushanTurganbay)가 기여했습니다. 원본 코드는 [여기](https://github.com/facebookresearch/chameleon)에서 찾을 수 있습니다.
diff --git a/docs/source/ko/model_doc/clip.md b/docs/source/ko/model_doc/clip.md
index 5c19a31e10..f1053d1758 100644
--- a/docs/source/ko/model_doc/clip.md
+++ b/docs/source/ko/model_doc/clip.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## 개요[[overview]]
CLIP 모델은 Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh,
-Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever가 제안한 [자연어 지도(supervision)를 통한 전이 가능한 시각 모델 학습](https://arxiv.org/abs/2103.00020)라는 논문에서 소개되었습니다. CLIP(Contrastive Language-Image Pre-Training)은 다양한 이미지와 텍스트 쌍으로 훈련된 신경망 입니다. GPT-2와 3의 제로샷 능력과 유사하게, 해당 작업에 직접적으로 최적화하지 않고도 주어진 이미지에 대해 가장 관련성 있는 텍스트 스니펫을 예측하도록 자연어로 지시할 수 있습니다.
+Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever가 제안한 [자연어 지도(supervision)를 통한 전이 가능한 시각 모델 학습](https://huggingface.co/papers/2103.00020)라는 논문에서 소개되었습니다. CLIP(Contrastive Language-Image Pre-Training)은 다양한 이미지와 텍스트 쌍으로 훈련된 신경망 입니다. GPT-2와 3의 제로샷 능력과 유사하게, 해당 작업에 직접적으로 최적화하지 않고도 주어진 이미지에 대해 가장 관련성 있는 텍스트 스니펫을 예측하도록 자연어로 지시할 수 있습니다.
해당 논문의 초록입니다.
diff --git a/docs/source/ko/model_doc/codegen.md b/docs/source/ko/model_doc/codegen.md
index 264f10e89b..75e69b0b84 100644
--- a/docs/source/ko/model_doc/codegen.md
+++ b/docs/source/ko/model_doc/codegen.md
@@ -22,7 +22,7 @@ rendered properly in your Markdown viewer.
## 개요[[Overview]]
-CodeGen 모델은 Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong이 작성한 논문 [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474)에서 제안되었습니다.
+CodeGen 모델은 Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong이 작성한 논문 [A Conversational Paradigm for Program Synthesis](https://huggingface.co/papers/2203.13474)에서 제안되었습니다.
CodeGen 모델은 프로그램 합성(program synthesis)을 위한 자기회귀(autoregressive) 언어 모델로, [The Pile](https://pile.eleuther.ai/), BigQuery, BigPython 데이터로 순차적으로 학습되었습니다.
diff --git a/docs/source/ko/model_doc/convbert.md b/docs/source/ko/model_doc/convbert.md
index ec64a369b5..c4f0d2ace2 100644
--- a/docs/source/ko/model_doc/convbert.md
+++ b/docs/source/ko/model_doc/convbert.md
@@ -27,7 +27,7 @@ rendered properly in your Markdown viewer.
## 개요 [[overview]]
-ConvBERT 모델은 Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan에 의해 제안되었으며, 제안 논문 제목은 [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496)입니다.
+ConvBERT 모델은 Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan에 의해 제안되었으며, 제안 논문 제목은 [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://huggingface.co/papers/2008.02496)입니다.
논문의 초록은 다음과 같습니다:
diff --git a/docs/source/ko/model_doc/deberta-v2.md b/docs/source/ko/model_doc/deberta-v2.md
index 2e590ad8a5..bb7bed1434 100644
--- a/docs/source/ko/model_doc/deberta-v2.md
+++ b/docs/source/ko/model_doc/deberta-v2.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## 개요
-DeBERTa 모델은 Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen이 작성한 [DeBERTa: 분리된 어텐션을 활용한 디코딩 강화 BERT](https://arxiv.org/abs/2006.03654)이라는 논문에서 제안되었습니다. 이 모델은 2018년 Google이 발표한 BERT 모델과 2019년 Facebook이 발표한 RoBERTa 모델을 기반으로 합니다.
+DeBERTa 모델은 Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen이 작성한 [DeBERTa: 분리된 어텐션을 활용한 디코딩 강화 BERT](https://huggingface.co/papers/2006.03654)이라는 논문에서 제안되었습니다. 이 모델은 2018년 Google이 발표한 BERT 모델과 2019년 Facebook이 발표한 RoBERTa 모델을 기반으로 합니다.
DeBERTa는 RoBERTa에서 사용된 데이터의 절반만을 사용하여 분리된(disentangled) 어텐션과 향상된 마스크 디코더 학습을 통해 RoBERTa를 개선했습니다.
논문의 초록은 다음과 같습니다:
diff --git a/docs/source/ko/model_doc/deberta.md b/docs/source/ko/model_doc/deberta.md
index 6f82bed033..b471c9327a 100644
--- a/docs/source/ko/model_doc/deberta.md
+++ b/docs/source/ko/model_doc/deberta.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## 개요[[overview]]
-DeBERTa 모델은 Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen이 작성한 [DeBERTa: 분리된 어텐션을 활용한 디코딩 강화 BERT](https://arxiv.org/abs/2006.03654)이라는 논문에서 제안되었습니다. 이 모델은 2018년 Google이 발표한 BERT 모델과 2019년 Facebook이 발표한 RoBERTa 모델을 기반으로 합니다.
+DeBERTa 모델은 Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen이 작성한 [DeBERTa: 분리된 어텐션을 활용한 디코딩 강화 BERT](https://huggingface.co/papers/2006.03654)이라는 논문에서 제안되었습니다. 이 모델은 2018년 Google이 발표한 BERT 모델과 2019년 Facebook이 발표한 RoBERTa 모델을 기반으로 합니다.
DeBERTa는 RoBERTa에서 사용된 데이터의 절반만을 사용하여 분리된(disentangled) 어텐션과 향상된 마스크 디코더 학습을 통해 RoBERTa를 개선했습니다.
논문의 초록은 다음과 같습니다:
diff --git a/docs/source/ko/model_doc/encoder-decoder.md b/docs/source/ko/model_doc/encoder-decoder.md
index c5c5535613..60982cb455 100644
--- a/docs/source/ko/model_doc/encoder-decoder.md
+++ b/docs/source/ko/model_doc/encoder-decoder.md
@@ -20,11 +20,11 @@ rendered properly in your Markdown viewer.
[`EncoderDecoderModel`]은 사전 학습된 자동 인코딩(autoencoding) 모델을 인코더로, 사전 학습된 자가 회귀(autoregressive) 모델을 디코더로 활용하여 시퀀스-투-시퀀스(sequence-to-sequence) 모델을 초기화하는 데 이용됩니다.
-사전 학습된 체크포인트를 활용해 시퀀스-투-시퀀스 모델을 초기화하는 것이 시퀀스 생성(sequence generation) 작업에 효과적이라는 점이 Sascha Rothe, Shashi Narayan, Aliaksei Severyn의 논문 [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461)에서 입증되었습니다.
+사전 학습된 체크포인트를 활용해 시퀀스-투-시퀀스 모델을 초기화하는 것이 시퀀스 생성(sequence generation) 작업에 효과적이라는 점이 Sascha Rothe, Shashi Narayan, Aliaksei Severyn의 논문 [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://huggingface.co/papers/1907.12461)에서 입증되었습니다.
[`EncoderDecoderModel`]이 학습/미세 조정된 후에는 다른 모델과 마찬가지로 저장/불러오기가 가능합니다. 자세한 사용법은 예제를 참고하세요.
-이 아키텍처의 한 가지 응용 사례는 두 개의 사전 학습된 [`BertModel`]을 각각 인코더와 디코더로 활용하여 요약 모델(summarization model)을 구축하는 것입니다. 이는 Yang Liu와 Mirella Lapata의 논문 [Text Summarization with Pretrained Encoders](https://arxiv.org/abs/1908.08345)에서 제시된 바 있습니다.
+이 아키텍처의 한 가지 응용 사례는 두 개의 사전 학습된 [`BertModel`]을 각각 인코더와 디코더로 활용하여 요약 모델(summarization model)을 구축하는 것입니다. 이는 Yang Liu와 Mirella Lapata의 논문 [Text Summarization with Pretrained Encoders](https://huggingface.co/papers/1908.08345)에서 제시된 바 있습니다.
## 모델 설정에서 `EncoderDecoderModel`을 무작위 초기화하기[[Randomly initializing `EncoderDecoderModel` from model configurations.]]
diff --git a/docs/source/ko/model_doc/graphormer.md b/docs/source/ko/model_doc/graphormer.md
index fc6aa2c9e2..9e1a893fc5 100644
--- a/docs/source/ko/model_doc/graphormer.md
+++ b/docs/source/ko/model_doc/graphormer.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
## 개요[[overview]]
-Graphormer 모델은 Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu가 제안한 [트랜스포머가 그래프 표현에 있어서 정말 약할까?](https://arxiv.org/abs/2106.05234) 라는 논문에서 소개되었습니다. Graphormer는 그래프 트랜스포머 모델입니다. 텍스트 시퀀스 대신 그래프에서 계산을 수행할 수 있도록 수정되었으며, 전처리와 병합 과정에서 임베딩과 관심 특성을 생성한 후 수정된 어텐션을 사용합니다.
+Graphormer 모델은 Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu가 제안한 [트랜스포머가 그래프 표현에 있어서 정말 약할까?](https://huggingface.co/papers/2106.05234) 라는 논문에서 소개되었습니다. Graphormer는 그래프 트랜스포머 모델입니다. 텍스트 시퀀스 대신 그래프에서 계산을 수행할 수 있도록 수정되었으며, 전처리와 병합 과정에서 임베딩과 관심 특성을 생성한 후 수정된 어텐션을 사용합니다.
해당 논문의 초록입니다:
diff --git a/docs/source/ko/model_doc/informer.md b/docs/source/ko/model_doc/informer.md
index 03722545a5..9482933008 100644
--- a/docs/source/ko/model_doc/informer.md
+++ b/docs/source/ko/model_doc/informer.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요[[overview]]
-The Informer 모델은 Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, Wancai Zhang가 제안한 [Informer: 장기 시퀀스 시계열 예측(LSTF)을 위한 더욱 효율적인 트랜스포머(Beyond Efficient Transformer)](https://arxiv.org/abs/2012.07436)라는 논문에서 소개되었습니다.
+The Informer 모델은 Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, Wancai Zhang가 제안한 [Informer: 장기 시퀀스 시계열 예측(LSTF)을 위한 더욱 효율적인 트랜스포머(Beyond Efficient Transformer)](https://huggingface.co/papers/2012.07436)라는 논문에서 소개되었습니다.
이 방법은 확률적 어텐션 메커니즘을 도입하여 "게으른" 쿼리가 아닌 "활성" 쿼리를 선택하고, 희소 트랜스포머를 제공하여 기존 어텐션의 이차적 계산 및 메모리 요구사항을 완화합니다.
diff --git a/docs/source/ko/model_doc/llama.md b/docs/source/ko/model_doc/llama.md
index 282befac21..3cd5867584 100644
--- a/docs/source/ko/model_doc/llama.md
+++ b/docs/source/ko/model_doc/llama.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요 [[overview]]
-LLaMA 모델은 Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample에 의해 제안된 [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971)에서 소개되었습니다. 이 모델은 7B에서 65B개의 파라미터까지 다양한 크기의 기초 언어 모델을 모아놓은 것입니다.
+LLaMA 모델은 Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample에 의해 제안된 [LLaMA: Open and Efficient Foundation Language Models](https://huggingface.co/papers/2302.13971)에서 소개되었습니다. 이 모델은 7B에서 65B개의 파라미터까지 다양한 크기의 기초 언어 모델을 모아놓은 것입니다.
논문의 초록은 다음과 같습니다:
diff --git a/docs/source/ko/model_doc/llama2.md b/docs/source/ko/model_doc/llama2.md
index 5290f2bb7b..4975b2e4ab 100644
--- a/docs/source/ko/model_doc/llama2.md
+++ b/docs/source/ko/model_doc/llama2.md
@@ -39,7 +39,7 @@ Llama2 모델은 Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Al
🍯 팁:
- Llama2 모델의 가중치는 [이 양식](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)을 작성하여 얻을 수 있습니다.
-- 아키텍처는 처음 버전의 Llama와 매우 유사하며, [이 논문](https://arxiv.org/pdf/2305.13245.pdf)의 내용에 따라 Grouped Query Attention (GQA)이 추가되었습니다.
+- 아키텍처는 처음 버전의 Llama와 매우 유사하며, [이 논문](https://huggingface.co/papers/2305.13245)의 내용에 따라 Grouped Query Attention (GQA)이 추가되었습니다.
- `config.pretraining_tp`를 1과 다른 값으로 설정하면 더 정확하지만 느린 선형 레이어 계산이 활성화되어 원본 로짓과 더 잘 일치하게 됩니다.
- 원래 모델은 `pad_id = -1`을 사용하는데, 이는 패딩 토큰이 없음을 의미합니다. 동일한 로직을 사용할 수 없으므로 `tokenizer.add_special_tokens({"pad_token":" - CLIP과 비교한 SigLIP 평가 결과. 원본 논문에서 발췌.
+ CLIP과 비교한 SigLIP 평가 결과. 원본 논문에서 발췌.
이 모델은 [nielsr](https://huggingface.co/nielsr)가 기여했습니다.
원본 코드는 [여기](https://github.com/google-research/big_vision/tree/main)에서 찾을 수 있습니다.
diff --git a/docs/source/ko/model_doc/swin.md b/docs/source/ko/model_doc/swin.md
index 6919d7e997..ba1088210f 100644
--- a/docs/source/ko/model_doc/swin.md
+++ b/docs/source/ko/model_doc/swin.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요 [[overview]]
-Swin Transformer는 Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo가 제안한 논문 [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030)에서 소개되었습니다.
+Swin Transformer는 Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo가 제안한 논문 [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://huggingface.co/papers/2103.14030)에서 소개되었습니다.
논문의 초록은 다음과 같습니다:
@@ -27,7 +27,7 @@ Swin Transformer는 Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang
- CLIP과 비교한 SigLIP 평가 결과. 원본 논문에서 발췌.
+ CLIP과 비교한 SigLIP 평가 결과. 원본 논문에서 발췌.
이 모델은 [nielsr](https://huggingface.co/nielsr)가 기여했습니다.
원본 코드는 [여기](https://github.com/google-research/big_vision/tree/main)에서 찾을 수 있습니다.
diff --git a/docs/source/ko/model_doc/swin.md b/docs/source/ko/model_doc/swin.md
index 6919d7e997..ba1088210f 100644
--- a/docs/source/ko/model_doc/swin.md
+++ b/docs/source/ko/model_doc/swin.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요 [[overview]]
-Swin Transformer는 Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo가 제안한 논문 [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030)에서 소개되었습니다.
+Swin Transformer는 Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo가 제안한 논문 [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://huggingface.co/papers/2103.14030)에서 소개되었습니다.
논문의 초록은 다음과 같습니다:
@@ -27,7 +27,7 @@ Swin Transformer는 Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang
 - Swin Transformer 아키텍처. 원본 논문에서 발췌.
+ Swin Transformer 아키텍처. 원본 논문에서 발췌.
이 모델은 [novice03](https://huggingface.co/novice03)이 기여하였습니다. Tensorflow 버전은 [amyeroberts](https://huggingface.co/amyeroberts)가 기여했습니다. 원본 코드는 [여기](https://github.com/microsoft/Swin-Transformer)에서 확인할 수 있습니다.
diff --git a/docs/source/ko/model_doc/swin2sr.md b/docs/source/ko/model_doc/swin2sr.md
index 931298b959..30149ad31a 100644
--- a/docs/source/ko/model_doc/swin2sr.md
+++ b/docs/source/ko/model_doc/swin2sr.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요 [[overview]]
-Swin2SR 모델은 Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte가 제안한 논문 [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345)에서 소개되었습니다.
+Swin2SR 모델은 Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte가 제안한 논문 [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://huggingface.co/papers/2209.11345)에서 소개되었습니다.
Swin2SR은 [SwinIR](https://github.com/JingyunLiang/SwinIR/) 모델을 개선하고자 [Swin Transformer v2](swinv2) 레이어를 도입함으로써, 훈련 불안정성, 사전 훈련과 미세 조정 간의 해상도 차이, 그리고 데이터 의존성 문제를 완화시킵니다.
논문의 초록은 다음과 같습니다:
@@ -28,7 +28,7 @@ Swin2SR은 [SwinIR](https://github.com/JingyunLiang/SwinIR/) 모델을 개선하
- Swin Transformer 아키텍처. 원본 논문에서 발췌.
+ Swin Transformer 아키텍처. 원본 논문에서 발췌.
이 모델은 [novice03](https://huggingface.co/novice03)이 기여하였습니다. Tensorflow 버전은 [amyeroberts](https://huggingface.co/amyeroberts)가 기여했습니다. 원본 코드는 [여기](https://github.com/microsoft/Swin-Transformer)에서 확인할 수 있습니다.
diff --git a/docs/source/ko/model_doc/swin2sr.md b/docs/source/ko/model_doc/swin2sr.md
index 931298b959..30149ad31a 100644
--- a/docs/source/ko/model_doc/swin2sr.md
+++ b/docs/source/ko/model_doc/swin2sr.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요 [[overview]]
-Swin2SR 모델은 Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte가 제안한 논문 [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345)에서 소개되었습니다.
+Swin2SR 모델은 Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte가 제안한 논문 [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://huggingface.co/papers/2209.11345)에서 소개되었습니다.
Swin2SR은 [SwinIR](https://github.com/JingyunLiang/SwinIR/) 모델을 개선하고자 [Swin Transformer v2](swinv2) 레이어를 도입함으로써, 훈련 불안정성, 사전 훈련과 미세 조정 간의 해상도 차이, 그리고 데이터 의존성 문제를 완화시킵니다.
논문의 초록은 다음과 같습니다:
@@ -28,7 +28,7 @@ Swin2SR은 [SwinIR](https://github.com/JingyunLiang/SwinIR/) 모델을 개선하
 - Swin2SR 아키텍처. 원본 논문에서 발췌.
+ Swin2SR 아키텍처. 원본 논문에서 발췌.
이 모델은 [nielsr](https://huggingface.co/nielsr)가 기여하였습니다.
원본 코드는 [여기](https://github.com/mv-lab/swin2sr)에서 확인할 수 있습니다.
diff --git a/docs/source/ko/model_doc/swinv2.md b/docs/source/ko/model_doc/swinv2.md
index 3bc420a292..40b9268cb2 100644
--- a/docs/source/ko/model_doc/swinv2.md
+++ b/docs/source/ko/model_doc/swinv2.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요 [[overview]]
-Swin Transformer V2는 Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo가 제안한 논문 [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883)에서 소개되었습니다.
+Swin Transformer V2는 Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo가 제안한 논문 [Swin Transformer V2: Scaling Up Capacity and Resolution](https://huggingface.co/papers/2111.09883)에서 소개되었습니다.
논문의 초록은 다음과 같습니다:
diff --git a/docs/source/ko/model_doc/timesformer.md b/docs/source/ko/model_doc/timesformer.md
index aa75cee447..fb2c2ed007 100644
--- a/docs/source/ko/model_doc/timesformer.md
+++ b/docs/source/ko/model_doc/timesformer.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요 [[overview]]
-TimeSformer 모델은 Facebook Research에서 제안한 [TimeSformer: Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095)에서 소개되었습니다. 이 연구는 첫 번째 비디오 Transformer로서, 행동 인식 분야에서 중요한 이정표가 되었습니다. 또한 Transformer 기반의 비디오 이해 및 분류 논문에 많은 영감을 주었습니다.
+TimeSformer 모델은 Facebook Research에서 제안한 [TimeSformer: Is Space-Time Attention All You Need for Video Understanding?](https://huggingface.co/papers/2102.05095)에서 소개되었습니다. 이 연구는 첫 번째 비디오 Transformer로서, 행동 인식 분야에서 중요한 이정표가 되었습니다. 또한 Transformer 기반의 비디오 이해 및 분류 논문에 많은 영감을 주었습니다.
논문의 초록은 다음과 같습니다.
diff --git a/docs/source/ko/model_doc/trajectory_transformer.md b/docs/source/ko/model_doc/trajectory_transformer.md
index ac279eff04..9f72a6f71e 100644
--- a/docs/source/ko/model_doc/trajectory_transformer.md
+++ b/docs/source/ko/model_doc/trajectory_transformer.md
@@ -26,7 +26,7 @@ rendered properly in your Markdown viewer.
## 개요[[overview]]
-Trajectory Transformer 모델은 Michael Janner, Qiyang Li, Sergey Levine이 제안한 [하나의 커다란 시퀀스 모델링 문제로서의 오프라인 강화학습](https://arxiv.org/abs/2106.02039)라는 논문에서 소개되었습니다.
+Trajectory Transformer 모델은 Michael Janner, Qiyang Li, Sergey Levine이 제안한 [하나의 커다란 시퀀스 모델링 문제로서의 오프라인 강화학습](https://huggingface.co/papers/2106.02039)라는 논문에서 소개되었습니다.
해당 논문의 초록입니다:
diff --git a/docs/source/ko/model_doc/vit.md b/docs/source/ko/model_doc/vit.md
index 5f3eb33427..9ec7af81fd 100644
--- a/docs/source/ko/model_doc/vit.md
+++ b/docs/source/ko/model_doc/vit.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요 [[overview]]
-Vision Transformer (ViT) 모델은 Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby가 제안한 논문 [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929)에서 소개되었습니다. 이는 Transformer 인코더를 ImageNet에서 성공적으로 훈련시킨 첫 번째 논문으로, 기존의 잘 알려진 합성곱 신경망(CNN) 구조와 비교해 매우 우수한 결과를 달성했습니다.
+Vision Transformer (ViT) 모델은 Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby가 제안한 논문 [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://huggingface.co/papers/2010.11929)에서 소개되었습니다. 이는 Transformer 인코더를 ImageNet에서 성공적으로 훈련시킨 첫 번째 논문으로, 기존의 잘 알려진 합성곱 신경망(CNN) 구조와 비교해 매우 우수한 결과를 달성했습니다.
논문의 초록은 다음과 같습니다:
@@ -27,7 +27,7 @@ Vision Transformer (ViT) 모델은 Alexey Dosovitskiy, Lucas Beyer, Alexander Ko
- Swin2SR 아키텍처. 원본 논문에서 발췌.
+ Swin2SR 아키텍처. 원본 논문에서 발췌.
이 모델은 [nielsr](https://huggingface.co/nielsr)가 기여하였습니다.
원본 코드는 [여기](https://github.com/mv-lab/swin2sr)에서 확인할 수 있습니다.
diff --git a/docs/source/ko/model_doc/swinv2.md b/docs/source/ko/model_doc/swinv2.md
index 3bc420a292..40b9268cb2 100644
--- a/docs/source/ko/model_doc/swinv2.md
+++ b/docs/source/ko/model_doc/swinv2.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요 [[overview]]
-Swin Transformer V2는 Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo가 제안한 논문 [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883)에서 소개되었습니다.
+Swin Transformer V2는 Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo가 제안한 논문 [Swin Transformer V2: Scaling Up Capacity and Resolution](https://huggingface.co/papers/2111.09883)에서 소개되었습니다.
논문의 초록은 다음과 같습니다:
diff --git a/docs/source/ko/model_doc/timesformer.md b/docs/source/ko/model_doc/timesformer.md
index aa75cee447..fb2c2ed007 100644
--- a/docs/source/ko/model_doc/timesformer.md
+++ b/docs/source/ko/model_doc/timesformer.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요 [[overview]]
-TimeSformer 모델은 Facebook Research에서 제안한 [TimeSformer: Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095)에서 소개되었습니다. 이 연구는 첫 번째 비디오 Transformer로서, 행동 인식 분야에서 중요한 이정표가 되었습니다. 또한 Transformer 기반의 비디오 이해 및 분류 논문에 많은 영감을 주었습니다.
+TimeSformer 모델은 Facebook Research에서 제안한 [TimeSformer: Is Space-Time Attention All You Need for Video Understanding?](https://huggingface.co/papers/2102.05095)에서 소개되었습니다. 이 연구는 첫 번째 비디오 Transformer로서, 행동 인식 분야에서 중요한 이정표가 되었습니다. 또한 Transformer 기반의 비디오 이해 및 분류 논문에 많은 영감을 주었습니다.
논문의 초록은 다음과 같습니다.
diff --git a/docs/source/ko/model_doc/trajectory_transformer.md b/docs/source/ko/model_doc/trajectory_transformer.md
index ac279eff04..9f72a6f71e 100644
--- a/docs/source/ko/model_doc/trajectory_transformer.md
+++ b/docs/source/ko/model_doc/trajectory_transformer.md
@@ -26,7 +26,7 @@ rendered properly in your Markdown viewer.
## 개요[[overview]]
-Trajectory Transformer 모델은 Michael Janner, Qiyang Li, Sergey Levine이 제안한 [하나의 커다란 시퀀스 모델링 문제로서의 오프라인 강화학습](https://arxiv.org/abs/2106.02039)라는 논문에서 소개되었습니다.
+Trajectory Transformer 모델은 Michael Janner, Qiyang Li, Sergey Levine이 제안한 [하나의 커다란 시퀀스 모델링 문제로서의 오프라인 강화학습](https://huggingface.co/papers/2106.02039)라는 논문에서 소개되었습니다.
해당 논문의 초록입니다:
diff --git a/docs/source/ko/model_doc/vit.md b/docs/source/ko/model_doc/vit.md
index 5f3eb33427..9ec7af81fd 100644
--- a/docs/source/ko/model_doc/vit.md
+++ b/docs/source/ko/model_doc/vit.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 개요 [[overview]]
-Vision Transformer (ViT) 모델은 Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby가 제안한 논문 [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929)에서 소개되었습니다. 이는 Transformer 인코더를 ImageNet에서 성공적으로 훈련시킨 첫 번째 논문으로, 기존의 잘 알려진 합성곱 신경망(CNN) 구조와 비교해 매우 우수한 결과를 달성했습니다.
+Vision Transformer (ViT) 모델은 Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby가 제안한 논문 [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://huggingface.co/papers/2010.11929)에서 소개되었습니다. 이는 Transformer 인코더를 ImageNet에서 성공적으로 훈련시킨 첫 번째 논문으로, 기존의 잘 알려진 합성곱 신경망(CNN) 구조와 비교해 매우 우수한 결과를 달성했습니다.
논문의 초록은 다음과 같습니다:
@@ -27,7 +27,7 @@ Vision Transformer (ViT) 모델은 Alexey Dosovitskiy, Lucas Beyer, Alexander Ko
 - ViT 아키텍처. 원본 논문에서 발췌.
+ ViT 아키텍처. 원본 논문에서 발췌.
원래의 Vision Transformer에 이어, 여러 후속 연구들이 진행되었습니다:
@@ -52,7 +52,7 @@ alt="drawing" width="600"/>
- Vision Transformer는 모든 이미지가 동일한 크기(해상도)여야 하므로, [ViTImageProcessor]를 사용하여 이미지를 모델에 맞게 리사이즈(또는 리스케일)하고 정규화할 수 있습니다.
- 사전 학습이나 미세 조정 시 사용된 패치 해상도와 이미지 해상도는 각 체크포인트의 이름에 반영됩니다. 예를 들어, `google/vit-base-patch16-224`는 패치 해상도가 16x16이고 미세 조정 해상도가 224x224인 기본 크기 아키텍처를 나타냅니다. 모든 체크포인트는 [hub](https://huggingface.co/models?search=vit)에서 확인할 수 있습니다.
- 사용할 수 있는 체크포인트는 (1) [ImageNet-21k](http://www.image-net.org/) (1,400만 개의 이미지와 21,000개의 클래스)에서만 사전 학습되었거나, 또는 (2) [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/) (ILSVRC 2012, 130만 개의 이미지와 1,000개의 클래스)에서 추가로 미세 조정된 경우입니다.
-- Vision Transformer는 224x224 해상도로 사전 학습되었습니다. 미세 조정 시, 사전 학습보다 더 높은 해상도를 사용하는 것이 유리한 경우가 많습니다 ([(Touvron et al., 2019)](https://arxiv.org/abs/1906.06423), [(Kolesnikovet al., 2020)](https://arxiv.org/abs/1912.11370). 더 높은 해상도로 미세 조정하기 위해, 저자들은 원본 이미지에서의 위치에 따라 사전 학습된 위치 임베딩의 2D 보간(interpolation)을 수행합니다.
+- Vision Transformer는 224x224 해상도로 사전 학습되었습니다. 미세 조정 시, 사전 학습보다 더 높은 해상도를 사용하는 것이 유리한 경우가 많습니다 ([(Touvron et al., 2019)](https://huggingface.co/papers/1906.06423), [(Kolesnikovet al., 2020)](https://huggingface.co/papers/1912.11370). 더 높은 해상도로 미세 조정하기 위해, 저자들은 원본 이미지에서의 위치에 따라 사전 학습된 위치 임베딩의 2D 보간(interpolation)을 수행합니다.
- 최고의 결과는 supervised 방식의 사전 학습에서 얻어졌으며, 이는 NLP에서는 해당되지 않는 경우가 많습니다. 저자들은 마스크된 패치 예측(마스크된 언어 모델링에서 영감을 받은 self-supervised 사전 학습 목표)을 사용한 실험도 수행했습니다. 이 접근 방식으로 더 작은 ViT-B/16 모델은 ImageNet에서 79.9%의 정확도를 달성하였으며, 이는 처음부터 학습한 것보다 2% 개선된 결과이지만, 여전히 supervised 사전 학습보다 4% 낮습니다.
### Scaled Dot Product Attention (SDPA) 사용하기 [[using-scaled-dot-product-attention-sdpa]]
diff --git a/docs/source/ko/model_doc/vivit.md b/docs/source/ko/model_doc/vivit.md
index c9eee17cb2..2ae32af044 100644
--- a/docs/source/ko/model_doc/vivit.md
+++ b/docs/source/ko/model_doc/vivit.md
@@ -14,7 +14,7 @@ specific language governing permissions and limitations under the License.
## 개요 [[overview]]
-Vivit 모델은 Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid가 제안한 논문 [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691)에서 소개되었습니다. 이 논문은 비디오 이해를 위한 pure-transformer 기반의 모델 집합 중에서 최초로 성공한 모델 중 하나를 소개합니다.
+Vivit 모델은 Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid가 제안한 논문 [ViViT: A Video Vision Transformer](https://huggingface.co/papers/2103.15691)에서 소개되었습니다. 이 논문은 비디오 이해를 위한 pure-transformer 기반의 모델 집합 중에서 최초로 성공한 모델 중 하나를 소개합니다.
논문의 초록은 다음과 같습니다:
diff --git a/docs/source/ko/model_memory_anatomy.md b/docs/source/ko/model_memory_anatomy.md
index a5c3a0f352..a729b29a7c 100644
--- a/docs/source/ko/model_memory_anatomy.md
+++ b/docs/source/ko/model_memory_anatomy.md
@@ -187,7 +187,7 @@ GPU memory occupied: 14949 MB.
이러한 지식은 성능 병목 현상을 분석할 때 도움이 될 수 있습니다.
-이 내용은 [Data Movement Is All You Need: A Case Study on Optimizing Transformers 2020](https://arxiv.org/abs/2007.00072)을 참고하였습니다.
+이 내용은 [Data Movement Is All You Need: A Case Study on Optimizing Transformers 2020](https://huggingface.co/papers/2007.00072)을 참고하였습니다.
## 모델의 메모리 구조 [[anatomy-of-models-memory]]
diff --git a/docs/source/ko/model_summary.md b/docs/source/ko/model_summary.md
index 568b942533..549ec37473 100644
--- a/docs/source/ko/model_summary.md
+++ b/docs/source/ko/model_summary.md
@@ -16,7 +16,7 @@ rendered properly in your Markdown viewer.
# Transformer 모델군[[the-transformer-model-family]]
-2017년에 소개된 [기본 Transformer](https://arxiv.org/abs/1706.03762) 모델은 자연어 처리(NLP) 작업을 넘어 새롭고 흥미로운 모델들에 영감을 주었습니다. [단백질 접힘 구조 예측](https://huggingface.co/blog/deep-learning-with-proteins), [치타의 달리기 훈련](https://huggingface.co/blog/train-decision-transformers), [시계열 예측](https://huggingface.co/blog/time-series-transformers) 등을 위한 다양한 모델이 생겨났습니다. Transformer의 변형이 너무 많아서, 큰 그림을 놓치기 쉽습니다. 하지만 여기 있는 모든 모델의 공통점은 기본 Trasnformer 아키텍처를 기반으로 한다는 점입니다. 일부 모델은 인코더 또는 디코더만 사용하고, 다른 모델들은 인코더와 디코더를 모두 사용하기도 합니다. 이렇게 Transformer 모델군 내 상위 레벨에서의 차이점을 분류하고 검토하면 유용한 분류 체계를 얻을 수 있으며, 이전에 접해보지 못한 Transformer 모델들 또한 이해하는 데 도움이 될 것입니다.
+2017년에 소개된 [기본 Transformer](https://huggingface.co/papers/1706.03762) 모델은 자연어 처리(NLP) 작업을 넘어 새롭고 흥미로운 모델들에 영감을 주었습니다. [단백질 접힘 구조 예측](https://huggingface.co/blog/deep-learning-with-proteins), [치타의 달리기 훈련](https://huggingface.co/blog/train-decision-transformers), [시계열 예측](https://huggingface.co/blog/time-series-transformers) 등을 위한 다양한 모델이 생겨났습니다. Transformer의 변형이 너무 많아서, 큰 그림을 놓치기 쉽습니다. 하지만 여기 있는 모든 모델의 공통점은 기본 Trasnformer 아키텍처를 기반으로 한다는 점입니다. 일부 모델은 인코더 또는 디코더만 사용하고, 다른 모델들은 인코더와 디코더를 모두 사용하기도 합니다. 이렇게 Transformer 모델군 내 상위 레벨에서의 차이점을 분류하고 검토하면 유용한 분류 체계를 얻을 수 있으며, 이전에 접해보지 못한 Transformer 모델들 또한 이해하는 데 도움이 될 것입니다.
기본 Transformer 모델에 익숙하지 않거나 복습이 필요한 경우, Hugging Face 강의의 [트랜스포머는 어떻게 동작하나요?](https://huggingface.co/course/chapter1/4?fw=pt) 챕터를 확인하세요.
@@ -32,7 +32,7 @@ rendered properly in your Markdown viewer.
### 합성곱 네트워크[[convolutional-network]]
-[Vision Transformer](https://arxiv.org/abs/2010.11929)가 확장성과 효율성을 입증하기 전까지 오랫동안 합성곱 네트워크(CNN)가 컴퓨터 비전 작업의 지배적인 패러다임이었습니다. 그럼에도 불구하고, 이동 불변성(translation invariance)과 같은 CNN의 우수한 부분이 도드라지기 때문에 몇몇 (특히 특정 과업에서의) Transformer 모델은 아키텍처에 합성곱을 통합하기도 했습니다. [ConvNeXt](model_doc/convnext)는 이런 관례를 뒤집어 CNN을 현대화하기 위해 Transformer의 디자인을 차용합니다. 예를 들면 ConvNeXt는 겹치지 않는 슬라이딩 창(sliding window)을 사용하여 이미지를 패치화하고, 더 큰 커널로 전역 수용 필드(global receptive field)를 확장시킵니다. ConvNeXt는 또한 메모리 효율을 높이고 성능을 향상시키기 위해 여러 레이어 설계를 선택하기 때문에 Transformer와 견줄만합니다!
+[Vision Transformer](https://huggingface.co/papers/2010.11929)가 확장성과 효율성을 입증하기 전까지 오랫동안 합성곱 네트워크(CNN)가 컴퓨터 비전 작업의 지배적인 패러다임이었습니다. 그럼에도 불구하고, 이동 불변성(translation invariance)과 같은 CNN의 우수한 부분이 도드라지기 때문에 몇몇 (특히 특정 과업에서의) Transformer 모델은 아키텍처에 합성곱을 통합하기도 했습니다. [ConvNeXt](model_doc/convnext)는 이런 관례를 뒤집어 CNN을 현대화하기 위해 Transformer의 디자인을 차용합니다. 예를 들면 ConvNeXt는 겹치지 않는 슬라이딩 창(sliding window)을 사용하여 이미지를 패치화하고, 더 큰 커널로 전역 수용 필드(global receptive field)를 확장시킵니다. ConvNeXt는 또한 메모리 효율을 높이고 성능을 향상시키기 위해 여러 레이어 설계를 선택하기 때문에 Transformer와 견줄만합니다!
### 인코더[[cv-encoder]]
@@ -58,7 +58,7 @@ BeIT와 ViTMAE와 같은 다른 비전 모델은 BERT의 사전훈련 목표(obj
[BERT](model_doc/bert)는 인코더 전용 Transformer로, 다른 토큰을 보고 소위 "부정 행위"를 저지르는 걸 막기 위해 입력에서 특정 토큰을 임의로 마스킹합니다. 사전훈련의 목표는 컨텍스트를 기반으로 마스킹된 토큰을 예측하는 것입니다. 이를 통해 BERT는 왼쪽과 오른쪽 컨텍스트를 충분히 활용하여 입력에 대해 더 깊고 풍부한 표현을 학습할 수 있습니다. 그러나 BERT의 사전훈련 전략에는 여전히 개선의 여지가 남아 있었습니다. [RoBERTa](model_doc/roberta)는 더 긴 시간 동안 더 큰 배치에 대한 훈련을 포함하고, 전처리 중에 한 번만 마스킹하는 것이 아니라 각 에폭에서 토큰을 임의로 마스킹하고, 다음 문장 예측 목표를 제거하는 새로운 사전훈련 방식을 도입함으로써 이를 개선했습니다.
-성능 개선을 위한 전략으로 모델 크기를 키우는 것이 지배적입니다. 하지만 큰 모델을 훈련하려면 계산 비용이 많이 듭니다. 계산 비용을 줄이는 한 가지 방법은 [DistilBERT](model_doc/distilbert)와 같이 작은 모델을 사용하는 것입니다. DistilBERT는 압축 기법인 [지식 증류(knowledge distillation)](https://arxiv.org/abs/1503.02531)를 사용하여, 거의 모든 언어 이해 능력을 유지하면서 더 작은 버전의 BERT를 만듭니다.
+성능 개선을 위한 전략으로 모델 크기를 키우는 것이 지배적입니다. 하지만 큰 모델을 훈련하려면 계산 비용이 많이 듭니다. 계산 비용을 줄이는 한 가지 방법은 [DistilBERT](model_doc/distilbert)와 같이 작은 모델을 사용하는 것입니다. DistilBERT는 압축 기법인 [지식 증류(knowledge distillation)](https://huggingface.co/papers/1503.02531)를 사용하여, 거의 모든 언어 이해 능력을 유지하면서 더 작은 버전의 BERT를 만듭니다.
그러나 대부분의 Transformer 모델에 더 많은 매개변수를 사용하는 경향이 이어졌고, 이에 따라 훈련 효율성을 개선하는 것에 중점을 둔 새로운 모델이 등장했습니다. [ALBERT](model_doc/albert)는 두 가지 방법으로 매개변수 수를 줄여 메모리 사용량을 줄였습니다. 바로 큰 어휘를 두 개의 작은 행렬로 분리하는 것과 레이어가 매개변수를 공유하도록 하는 것입니다. [DeBERTa](model_doc/deberta)는 단어와 그 위치를 두 개의 벡터로 개별적으로 인코딩하는 분리된(disentangled) 어텐션 메커니즘을 추가했습니다. 어텐션은 단어와 위치 임베딩을 포함하는 단일 벡터 대신 이 별도의 벡터에서 계산됩니다. [Longformer](model_doc/longformer)는 특히 시퀀스 길이가 긴 문서를 처리할 때, 어텐션을 더 효율적으로 만드는 것에 중점을 두었습니다. 지역(local) 윈도우 어텐션(각 토큰 주변의 고정된 윈도우 크기에서만 계산되는 어텐션)과 전역(global) 어텐션(분류를 위해 `[CLS]`와 같은 특정 작업 토큰에만 해당)의 조합을 사용하여 전체(full) 어텐션 행렬 대신 희소(sparse) 어텐션 행렬을 생성합니다.
diff --git a/docs/source/ko/peft.md b/docs/source/ko/peft.md
index d4ef0ba539..7655a2c6b5 100644
--- a/docs/source/ko/peft.md
+++ b/docs/source/ko/peft.md
@@ -44,7 +44,7 @@ pip install git+https://github.com/huggingface/peft.git
- [Low Rank Adapters](https://huggingface.co/docs/peft/conceptual_guides/lora)
- [IA3](https://huggingface.co/docs/peft/conceptual_guides/ia3)
-- [AdaLoRA](https://arxiv.org/abs/2303.10512)
+- [AdaLoRA](https://huggingface.co/papers/2303.10512)
🤗 PEFT와 관련된 다른 방법(예: 프롬프트 훈련 또는 프롬프트 튜닝) 또는 일반적인 🤗 PEFT 라이브러리에 대해 자세히 알아보려면 [문서](https://huggingface.co/docs/peft/index)를 참조하세요.
diff --git a/docs/source/ko/perf_infer_gpu_one.md b/docs/source/ko/perf_infer_gpu_one.md
index d6ddca6cd0..5936c82e07 100644
--- a/docs/source/ko/perf_infer_gpu_one.md
+++ b/docs/source/ko/perf_infer_gpu_one.md
@@ -101,13 +101,13 @@ model_4bit = AutoModelForCausalLM.from_pretrained(
-[`LLM.int8() : 8-bit Matrix Multiplication for Transformers at Scale`](https://arxiv.org/abs/2208.07339) 논문에서 우리는 몇 줄의 코드로 Hub의 모든 모델에 대한 Hugging Face 통합을 지원합니다.
+[`LLM.int8() : 8-bit Matrix Multiplication for Transformers at Scale`](https://huggingface.co/papers/2208.07339) 논문에서 우리는 몇 줄의 코드로 Hub의 모든 모델에 대한 Hugging Face 통합을 지원합니다.
이 방법은 `float16` 및 `bfloat16` 가중치에 대해 `nn.Linear` 크기를 2배로 줄이고, `float32` 가중치에 대해 4배로 줄입니다. 이는 절반 정밀도에서 이상치를 처리함으로써 품질에 거의 영향을 미치지 않습니다.

Int8 혼합 정밀도 행렬 분해는 행렬 곱셈을 두 개의 스트림으로 분리합니다: (1) fp16로 곱해지는 체계적인 특이값 이상치 스트림 행렬(0.01%) 및 (2) int8 행렬 곱셈의 일반적인 스트림(99.9%). 이 방법을 사용하면 매우 큰 모델에 대해 예측 저하 없이 int8 추론이 가능합니다.
-이 방법에 대한 자세한 내용은 [논문](https://arxiv.org/abs/2208.07339)이나 [통합에 관한 블로그 글](https://huggingface.co/blog/hf-bitsandbytes-integration)에서 확인할 수 있습니다.
+이 방법에 대한 자세한 내용은 [논문](https://huggingface.co/papers/2208.07339)이나 [통합에 관한 블로그 글](https://huggingface.co/blog/hf-bitsandbytes-integration)에서 확인할 수 있습니다.

diff --git a/docs/source/ko/perf_train_gpu_many.md b/docs/source/ko/perf_train_gpu_many.md
index b8553ea499..801e06e276 100644
--- a/docs/source/ko/perf_train_gpu_many.md
+++ b/docs/source/ko/perf_train_gpu_many.md
@@ -316,7 +316,7 @@ DP + PP 설정의 전역 배치 크기를 계산하려면 `mbs*chunks*dp_degree`
- [DeepSpeed](https://www.deepspeed.ai/tutorials/pipeline/)
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)은 내부 구현을 가지고 있습니다 - API 없음.
- [Varuna](https://github.com/microsoft/varuna)
-- [SageMaker](https://arxiv.org/abs/2111.05972) - 이는 AWS에서만 사용할 수 있는 소유 솔루션입니다.
+- [SageMaker](https://huggingface.co/papers/2111.05972) - 이는 AWS에서만 사용할 수 있는 소유 솔루션입니다.
- [OSLO](https://github.com/tunib-ai/oslo) - 이는 Hugging Face Transformers를 기반으로 구현된 파이프라인 병렬화입니다.
🤗 Transformers 상태: 이 작성 시점에서 모델 중 어느 것도 완전한 PP를 지원하지 않습니다. GPT2와 T5 모델은 naive MP를 지원합니다. 주요 장애물은 모델을 `nn.Sequential`로 변환하고 모든 입력을 텐서로 가져와야 하는 것을 처리할 수 없기 때문입니다. 현재 모델에는 이러한 변환을 매우 복잡하게 만드는 많은 기능이 포함되어 있어 제거해야 합니다.
@@ -336,7 +336,7 @@ OSLO는 `nn.Sequential`로 변환하지 않고 Transformers를 기반으로 한
텐서 병렬 처리에서는 각 GPU가 텐서의 일부분만 처리하고 전체 텐서가 필요한 연산에 대해서만 전체 텐서를 집계합니다.
-이 섹션에서는 [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) 논문인 [Efficient Large-Scale Language Model Training on GPU Clusters](https://arxiv.org/abs/2104.04473)에서의 개념과 다이어그램을 사용합니다.
+이 섹션에서는 [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) 논문인 [Efficient Large-Scale Language Model Training on GPU Clusters](https://huggingface.co/papers/2104.04473)에서의 개념과 다이어그램을 사용합니다.
Transformer의 주요 구성 요소는 fully connected `nn.Linear`와 비선형 활성화 함수인 `GeLU`입니다.
@@ -367,7 +367,7 @@ SageMaker는 더 효율적인 처리를 위해 TP와 DP를 결합합니다.
구현:
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)은 내부 구현을 가지고 있으므로 모델에 매우 특화되어 있습니다.
- [parallelformers](https://github.com/tunib-ai/parallelformers) (현재는 추론에만 해당)
-- [SageMaker](https://arxiv.org/abs/2111.05972) - 이는 AWS에서만 사용할 수 있는 소유 솔루션입니다.
+- [SageMaker](https://huggingface.co/papers/2111.05972) - 이는 AWS에서만 사용할 수 있는 소유 솔루션입니다.
- [OSLO](https://github.com/tunib-ai/oslo)은 Transformers를 기반으로 한 텐서 병렬 처리 구현을 가지고 있습니다.
🤗 Transformers 현황:
@@ -389,7 +389,7 @@ DeepSpeed [pipeline tutorial](https://www.deepspeed.ai/tutorials/pipeline/)에
- [DeepSpeed](https://github.com/deepspeedai/DeepSpeed)
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
- [Varuna](https://github.com/microsoft/varuna)
-- [SageMaker](https://arxiv.org/abs/2111.05972)
+- [SageMaker](https://huggingface.co/papers/2111.05972)
- [OSLO](https://github.com/tunib-ai/oslo)
🤗 Transformers 현황: 아직 구현되지 않음
@@ -408,7 +408,7 @@ DeepSpeed [pipeline tutorial](https://www.deepspeed.ai/tutorials/pipeline/)에
- [DeepSpeed](https://github.com/deepspeedai/DeepSpeed) - DeepSpeed는 더욱 효율적인 DP인 ZeRO-DP라고도 부릅니다.
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
- [Varuna](https://github.com/microsoft/varuna)
-- [SageMaker](https://arxiv.org/abs/2111.05972)
+- [SageMaker](https://huggingface.co/papers/2111.05972)
- [OSLO](https://github.com/tunib-ai/oslo)
🤗 Transformers 현황: 아직 구현되지 않음. PP와 TP가 없기 때문입니다.
@@ -434,7 +434,7 @@ ZeRO 단계 3도 같은 이유로 좋은 선택이 아닙니다 - 더 많은 노
중요한 논문:
- [Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model](
-https://arxiv.org/abs/2201.11990)
+https://huggingface.co/papers/2201.11990)
🤗 Transformers 현황: 아직 구현되지 않음, PP와 TP가 없기 때문입니다.
@@ -442,7 +442,7 @@ https://arxiv.org/abs/2201.11990)
[FlexFlow](https://github.com/flexflow/FlexFlow)는 약간 다른 방식으로 병렬화 문제를 해결합니다.
-논문: ["Beyond Data and Model Parallelism for Deep Neural Networks" by Zhihao Jia, Matei Zaharia, Alex Aiken](https://arxiv.org/abs/1807.05358)
+논문: ["Beyond Data and Model Parallelism for Deep Neural Networks" by Zhihao Jia, Matei Zaharia, Alex Aiken](https://huggingface.co/papers/1807.05358)
이는 Sample-Operator-Attribute-Parameter를 기반으로 하는 일종의 4D 병렬화를 수행합니다.
diff --git a/docs/source/ko/tasks/knowledge_distillation_for_image_classification.md b/docs/source/ko/tasks/knowledge_distillation_for_image_classification.md
index 37c0cc2508..72cfbcf57a 100644
--- a/docs/source/ko/tasks/knowledge_distillation_for_image_classification.md
+++ b/docs/source/ko/tasks/knowledge_distillation_for_image_classification.md
@@ -17,7 +17,7 @@ rendered properly in your Markdown viewer.
[[open-in-colab]]
-지식 증류(Knowledge distillation)는 더 크고 복잡한 모델(교사)에서 더 작고 간단한 모델(학생)로 지식을 전달하는 기술입니다. 한 모델에서 다른 모델로 지식을 증류하기 위해, 특정 작업(이 경우 이미지 분류)에 대해 학습된 사전 훈련된 교사 모델을 사용하고, 랜덤으로 초기화된 학생 모델을 이미지 분류 작업에 대해 학습합니다. 그다음, 학생 모델이 교사 모델의 출력을 모방하여 두 모델의 출력 차이를 최소화하도록 훈련합니다. 이 기법은 Hinton 등 연구진의 [Distilling the Knowledge in a Neural Network](https://arxiv.org/abs/1503.02531)에서 처음 소개되었습니다. 이 가이드에서는 특정 작업에 맞춘 지식 증류를 수행할 것입니다. 이번에는 [beans dataset](https://huggingface.co/datasets/beans)을 사용할 것입니다.
+지식 증류(Knowledge distillation)는 더 크고 복잡한 모델(교사)에서 더 작고 간단한 모델(학생)로 지식을 전달하는 기술입니다. 한 모델에서 다른 모델로 지식을 증류하기 위해, 특정 작업(이 경우 이미지 분류)에 대해 학습된 사전 훈련된 교사 모델을 사용하고, 랜덤으로 초기화된 학생 모델을 이미지 분류 작업에 대해 학습합니다. 그다음, 학생 모델이 교사 모델의 출력을 모방하여 두 모델의 출력 차이를 최소화하도록 훈련합니다. 이 기법은 Hinton 등 연구진의 [Distilling the Knowledge in a Neural Network](https://huggingface.co/papers/1503.02531)에서 처음 소개되었습니다. 이 가이드에서는 특정 작업에 맞춘 지식 증류를 수행할 것입니다. 이번에는 [beans dataset](https://huggingface.co/datasets/beans)을 사용할 것입니다.
이 가이드는 [미세 조정된 ViT 모델](https://huggingface.co/merve/vit-mobilenet-beans-224) (교사 모델)을 [MobileNet](https://huggingface.co/google/mobilenet_v2_1.4_224) (학생 모델)으로 증류하는 방법을 🤗 Transformers의 [Trainer API](https://huggingface.co/docs/transformers/en/main_classes/trainer#trainer) 를 사용하여 보여줍니다.
diff --git a/docs/source/ko/tasks/video_classification.md b/docs/source/ko/tasks/video_classification.md
index 10569083c0..d39d669f8a 100644
--- a/docs/source/ko/tasks/video_classification.md
+++ b/docs/source/ko/tasks/video_classification.md
@@ -383,7 +383,7 @@ def compute_metrics(eval_pred):
**평가에 대한 참고사항**:
-[VideoMAE 논문](https://arxiv.org/abs/2203.12602)에서 저자는 다음과 같은 평가 전략을 사용합니다. 테스트 영상에서 여러 클립을 선택하고 그 클립에 다양한 크롭을 적용하여 집계 점수를 보고합니다. 그러나 이번 튜토리얼에서는 간단함과 간결함을 위해 해당 전략을 고려하지 않습니다.
+[VideoMAE 논문](https://huggingface.co/papers/2203.12602)에서 저자는 다음과 같은 평가 전략을 사용합니다. 테스트 영상에서 여러 클립을 선택하고 그 클립에 다양한 크롭을 적용하여 집계 점수를 보고합니다. 그러나 이번 튜토리얼에서는 간단함과 간결함을 위해 해당 전략을 고려하지 않습니다.
또한, 예제를 묶어서 배치를 형성하는 `collate_fn`을 정의해야합니다. 각 배치는 `pixel_values`와 `labels`라는 2개의 키로 구성됩니다.
diff --git a/docs/source/ko/tasks_explained.md b/docs/source/ko/tasks_explained.md
index 78c90849bb..57ccd57a79 100644
--- a/docs/source/ko/tasks_explained.md
+++ b/docs/source/ko/tasks_explained.md
@@ -120,7 +120,7 @@ ViT가 도입한 주요 변경 사항은 이미지가 Transformer로 어떻게
- ViT 아키텍처. 원본 논문에서 발췌.
+ ViT 아키텍처. 원본 논문에서 발췌.
원래의 Vision Transformer에 이어, 여러 후속 연구들이 진행되었습니다:
@@ -52,7 +52,7 @@ alt="drawing" width="600"/>
- Vision Transformer는 모든 이미지가 동일한 크기(해상도)여야 하므로, [ViTImageProcessor]를 사용하여 이미지를 모델에 맞게 리사이즈(또는 리스케일)하고 정규화할 수 있습니다.
- 사전 학습이나 미세 조정 시 사용된 패치 해상도와 이미지 해상도는 각 체크포인트의 이름에 반영됩니다. 예를 들어, `google/vit-base-patch16-224`는 패치 해상도가 16x16이고 미세 조정 해상도가 224x224인 기본 크기 아키텍처를 나타냅니다. 모든 체크포인트는 [hub](https://huggingface.co/models?search=vit)에서 확인할 수 있습니다.
- 사용할 수 있는 체크포인트는 (1) [ImageNet-21k](http://www.image-net.org/) (1,400만 개의 이미지와 21,000개의 클래스)에서만 사전 학습되었거나, 또는 (2) [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/) (ILSVRC 2012, 130만 개의 이미지와 1,000개의 클래스)에서 추가로 미세 조정된 경우입니다.
-- Vision Transformer는 224x224 해상도로 사전 학습되었습니다. 미세 조정 시, 사전 학습보다 더 높은 해상도를 사용하는 것이 유리한 경우가 많습니다 ([(Touvron et al., 2019)](https://arxiv.org/abs/1906.06423), [(Kolesnikovet al., 2020)](https://arxiv.org/abs/1912.11370). 더 높은 해상도로 미세 조정하기 위해, 저자들은 원본 이미지에서의 위치에 따라 사전 학습된 위치 임베딩의 2D 보간(interpolation)을 수행합니다.
+- Vision Transformer는 224x224 해상도로 사전 학습되었습니다. 미세 조정 시, 사전 학습보다 더 높은 해상도를 사용하는 것이 유리한 경우가 많습니다 ([(Touvron et al., 2019)](https://huggingface.co/papers/1906.06423), [(Kolesnikovet al., 2020)](https://huggingface.co/papers/1912.11370). 더 높은 해상도로 미세 조정하기 위해, 저자들은 원본 이미지에서의 위치에 따라 사전 학습된 위치 임베딩의 2D 보간(interpolation)을 수행합니다.
- 최고의 결과는 supervised 방식의 사전 학습에서 얻어졌으며, 이는 NLP에서는 해당되지 않는 경우가 많습니다. 저자들은 마스크된 패치 예측(마스크된 언어 모델링에서 영감을 받은 self-supervised 사전 학습 목표)을 사용한 실험도 수행했습니다. 이 접근 방식으로 더 작은 ViT-B/16 모델은 ImageNet에서 79.9%의 정확도를 달성하였으며, 이는 처음부터 학습한 것보다 2% 개선된 결과이지만, 여전히 supervised 사전 학습보다 4% 낮습니다.
### Scaled Dot Product Attention (SDPA) 사용하기 [[using-scaled-dot-product-attention-sdpa]]
diff --git a/docs/source/ko/model_doc/vivit.md b/docs/source/ko/model_doc/vivit.md
index c9eee17cb2..2ae32af044 100644
--- a/docs/source/ko/model_doc/vivit.md
+++ b/docs/source/ko/model_doc/vivit.md
@@ -14,7 +14,7 @@ specific language governing permissions and limitations under the License.
## 개요 [[overview]]
-Vivit 모델은 Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid가 제안한 논문 [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691)에서 소개되었습니다. 이 논문은 비디오 이해를 위한 pure-transformer 기반의 모델 집합 중에서 최초로 성공한 모델 중 하나를 소개합니다.
+Vivit 모델은 Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid가 제안한 논문 [ViViT: A Video Vision Transformer](https://huggingface.co/papers/2103.15691)에서 소개되었습니다. 이 논문은 비디오 이해를 위한 pure-transformer 기반의 모델 집합 중에서 최초로 성공한 모델 중 하나를 소개합니다.
논문의 초록은 다음과 같습니다:
diff --git a/docs/source/ko/model_memory_anatomy.md b/docs/source/ko/model_memory_anatomy.md
index a5c3a0f352..a729b29a7c 100644
--- a/docs/source/ko/model_memory_anatomy.md
+++ b/docs/source/ko/model_memory_anatomy.md
@@ -187,7 +187,7 @@ GPU memory occupied: 14949 MB.
이러한 지식은 성능 병목 현상을 분석할 때 도움이 될 수 있습니다.
-이 내용은 [Data Movement Is All You Need: A Case Study on Optimizing Transformers 2020](https://arxiv.org/abs/2007.00072)을 참고하였습니다.
+이 내용은 [Data Movement Is All You Need: A Case Study on Optimizing Transformers 2020](https://huggingface.co/papers/2007.00072)을 참고하였습니다.
## 모델의 메모리 구조 [[anatomy-of-models-memory]]
diff --git a/docs/source/ko/model_summary.md b/docs/source/ko/model_summary.md
index 568b942533..549ec37473 100644
--- a/docs/source/ko/model_summary.md
+++ b/docs/source/ko/model_summary.md
@@ -16,7 +16,7 @@ rendered properly in your Markdown viewer.
# Transformer 모델군[[the-transformer-model-family]]
-2017년에 소개된 [기본 Transformer](https://arxiv.org/abs/1706.03762) 모델은 자연어 처리(NLP) 작업을 넘어 새롭고 흥미로운 모델들에 영감을 주었습니다. [단백질 접힘 구조 예측](https://huggingface.co/blog/deep-learning-with-proteins), [치타의 달리기 훈련](https://huggingface.co/blog/train-decision-transformers), [시계열 예측](https://huggingface.co/blog/time-series-transformers) 등을 위한 다양한 모델이 생겨났습니다. Transformer의 변형이 너무 많아서, 큰 그림을 놓치기 쉽습니다. 하지만 여기 있는 모든 모델의 공통점은 기본 Trasnformer 아키텍처를 기반으로 한다는 점입니다. 일부 모델은 인코더 또는 디코더만 사용하고, 다른 모델들은 인코더와 디코더를 모두 사용하기도 합니다. 이렇게 Transformer 모델군 내 상위 레벨에서의 차이점을 분류하고 검토하면 유용한 분류 체계를 얻을 수 있으며, 이전에 접해보지 못한 Transformer 모델들 또한 이해하는 데 도움이 될 것입니다.
+2017년에 소개된 [기본 Transformer](https://huggingface.co/papers/1706.03762) 모델은 자연어 처리(NLP) 작업을 넘어 새롭고 흥미로운 모델들에 영감을 주었습니다. [단백질 접힘 구조 예측](https://huggingface.co/blog/deep-learning-with-proteins), [치타의 달리기 훈련](https://huggingface.co/blog/train-decision-transformers), [시계열 예측](https://huggingface.co/blog/time-series-transformers) 등을 위한 다양한 모델이 생겨났습니다. Transformer의 변형이 너무 많아서, 큰 그림을 놓치기 쉽습니다. 하지만 여기 있는 모든 모델의 공통점은 기본 Trasnformer 아키텍처를 기반으로 한다는 점입니다. 일부 모델은 인코더 또는 디코더만 사용하고, 다른 모델들은 인코더와 디코더를 모두 사용하기도 합니다. 이렇게 Transformer 모델군 내 상위 레벨에서의 차이점을 분류하고 검토하면 유용한 분류 체계를 얻을 수 있으며, 이전에 접해보지 못한 Transformer 모델들 또한 이해하는 데 도움이 될 것입니다.
기본 Transformer 모델에 익숙하지 않거나 복습이 필요한 경우, Hugging Face 강의의 [트랜스포머는 어떻게 동작하나요?](https://huggingface.co/course/chapter1/4?fw=pt) 챕터를 확인하세요.
@@ -32,7 +32,7 @@ rendered properly in your Markdown viewer.
### 합성곱 네트워크[[convolutional-network]]
-[Vision Transformer](https://arxiv.org/abs/2010.11929)가 확장성과 효율성을 입증하기 전까지 오랫동안 합성곱 네트워크(CNN)가 컴퓨터 비전 작업의 지배적인 패러다임이었습니다. 그럼에도 불구하고, 이동 불변성(translation invariance)과 같은 CNN의 우수한 부분이 도드라지기 때문에 몇몇 (특히 특정 과업에서의) Transformer 모델은 아키텍처에 합성곱을 통합하기도 했습니다. [ConvNeXt](model_doc/convnext)는 이런 관례를 뒤집어 CNN을 현대화하기 위해 Transformer의 디자인을 차용합니다. 예를 들면 ConvNeXt는 겹치지 않는 슬라이딩 창(sliding window)을 사용하여 이미지를 패치화하고, 더 큰 커널로 전역 수용 필드(global receptive field)를 확장시킵니다. ConvNeXt는 또한 메모리 효율을 높이고 성능을 향상시키기 위해 여러 레이어 설계를 선택하기 때문에 Transformer와 견줄만합니다!
+[Vision Transformer](https://huggingface.co/papers/2010.11929)가 확장성과 효율성을 입증하기 전까지 오랫동안 합성곱 네트워크(CNN)가 컴퓨터 비전 작업의 지배적인 패러다임이었습니다. 그럼에도 불구하고, 이동 불변성(translation invariance)과 같은 CNN의 우수한 부분이 도드라지기 때문에 몇몇 (특히 특정 과업에서의) Transformer 모델은 아키텍처에 합성곱을 통합하기도 했습니다. [ConvNeXt](model_doc/convnext)는 이런 관례를 뒤집어 CNN을 현대화하기 위해 Transformer의 디자인을 차용합니다. 예를 들면 ConvNeXt는 겹치지 않는 슬라이딩 창(sliding window)을 사용하여 이미지를 패치화하고, 더 큰 커널로 전역 수용 필드(global receptive field)를 확장시킵니다. ConvNeXt는 또한 메모리 효율을 높이고 성능을 향상시키기 위해 여러 레이어 설계를 선택하기 때문에 Transformer와 견줄만합니다!
### 인코더[[cv-encoder]]
@@ -58,7 +58,7 @@ BeIT와 ViTMAE와 같은 다른 비전 모델은 BERT의 사전훈련 목표(obj
[BERT](model_doc/bert)는 인코더 전용 Transformer로, 다른 토큰을 보고 소위 "부정 행위"를 저지르는 걸 막기 위해 입력에서 특정 토큰을 임의로 마스킹합니다. 사전훈련의 목표는 컨텍스트를 기반으로 마스킹된 토큰을 예측하는 것입니다. 이를 통해 BERT는 왼쪽과 오른쪽 컨텍스트를 충분히 활용하여 입력에 대해 더 깊고 풍부한 표현을 학습할 수 있습니다. 그러나 BERT의 사전훈련 전략에는 여전히 개선의 여지가 남아 있었습니다. [RoBERTa](model_doc/roberta)는 더 긴 시간 동안 더 큰 배치에 대한 훈련을 포함하고, 전처리 중에 한 번만 마스킹하는 것이 아니라 각 에폭에서 토큰을 임의로 마스킹하고, 다음 문장 예측 목표를 제거하는 새로운 사전훈련 방식을 도입함으로써 이를 개선했습니다.
-성능 개선을 위한 전략으로 모델 크기를 키우는 것이 지배적입니다. 하지만 큰 모델을 훈련하려면 계산 비용이 많이 듭니다. 계산 비용을 줄이는 한 가지 방법은 [DistilBERT](model_doc/distilbert)와 같이 작은 모델을 사용하는 것입니다. DistilBERT는 압축 기법인 [지식 증류(knowledge distillation)](https://arxiv.org/abs/1503.02531)를 사용하여, 거의 모든 언어 이해 능력을 유지하면서 더 작은 버전의 BERT를 만듭니다.
+성능 개선을 위한 전략으로 모델 크기를 키우는 것이 지배적입니다. 하지만 큰 모델을 훈련하려면 계산 비용이 많이 듭니다. 계산 비용을 줄이는 한 가지 방법은 [DistilBERT](model_doc/distilbert)와 같이 작은 모델을 사용하는 것입니다. DistilBERT는 압축 기법인 [지식 증류(knowledge distillation)](https://huggingface.co/papers/1503.02531)를 사용하여, 거의 모든 언어 이해 능력을 유지하면서 더 작은 버전의 BERT를 만듭니다.
그러나 대부분의 Transformer 모델에 더 많은 매개변수를 사용하는 경향이 이어졌고, 이에 따라 훈련 효율성을 개선하는 것에 중점을 둔 새로운 모델이 등장했습니다. [ALBERT](model_doc/albert)는 두 가지 방법으로 매개변수 수를 줄여 메모리 사용량을 줄였습니다. 바로 큰 어휘를 두 개의 작은 행렬로 분리하는 것과 레이어가 매개변수를 공유하도록 하는 것입니다. [DeBERTa](model_doc/deberta)는 단어와 그 위치를 두 개의 벡터로 개별적으로 인코딩하는 분리된(disentangled) 어텐션 메커니즘을 추가했습니다. 어텐션은 단어와 위치 임베딩을 포함하는 단일 벡터 대신 이 별도의 벡터에서 계산됩니다. [Longformer](model_doc/longformer)는 특히 시퀀스 길이가 긴 문서를 처리할 때, 어텐션을 더 효율적으로 만드는 것에 중점을 두었습니다. 지역(local) 윈도우 어텐션(각 토큰 주변의 고정된 윈도우 크기에서만 계산되는 어텐션)과 전역(global) 어텐션(분류를 위해 `[CLS]`와 같은 특정 작업 토큰에만 해당)의 조합을 사용하여 전체(full) 어텐션 행렬 대신 희소(sparse) 어텐션 행렬을 생성합니다.
diff --git a/docs/source/ko/peft.md b/docs/source/ko/peft.md
index d4ef0ba539..7655a2c6b5 100644
--- a/docs/source/ko/peft.md
+++ b/docs/source/ko/peft.md
@@ -44,7 +44,7 @@ pip install git+https://github.com/huggingface/peft.git
- [Low Rank Adapters](https://huggingface.co/docs/peft/conceptual_guides/lora)
- [IA3](https://huggingface.co/docs/peft/conceptual_guides/ia3)
-- [AdaLoRA](https://arxiv.org/abs/2303.10512)
+- [AdaLoRA](https://huggingface.co/papers/2303.10512)
🤗 PEFT와 관련된 다른 방법(예: 프롬프트 훈련 또는 프롬프트 튜닝) 또는 일반적인 🤗 PEFT 라이브러리에 대해 자세히 알아보려면 [문서](https://huggingface.co/docs/peft/index)를 참조하세요.
diff --git a/docs/source/ko/perf_infer_gpu_one.md b/docs/source/ko/perf_infer_gpu_one.md
index d6ddca6cd0..5936c82e07 100644
--- a/docs/source/ko/perf_infer_gpu_one.md
+++ b/docs/source/ko/perf_infer_gpu_one.md
@@ -101,13 +101,13 @@ model_4bit = AutoModelForCausalLM.from_pretrained(
-[`LLM.int8() : 8-bit Matrix Multiplication for Transformers at Scale`](https://arxiv.org/abs/2208.07339) 논문에서 우리는 몇 줄의 코드로 Hub의 모든 모델에 대한 Hugging Face 통합을 지원합니다.
+[`LLM.int8() : 8-bit Matrix Multiplication for Transformers at Scale`](https://huggingface.co/papers/2208.07339) 논문에서 우리는 몇 줄의 코드로 Hub의 모든 모델에 대한 Hugging Face 통합을 지원합니다.
이 방법은 `float16` 및 `bfloat16` 가중치에 대해 `nn.Linear` 크기를 2배로 줄이고, `float32` 가중치에 대해 4배로 줄입니다. 이는 절반 정밀도에서 이상치를 처리함으로써 품질에 거의 영향을 미치지 않습니다.

Int8 혼합 정밀도 행렬 분해는 행렬 곱셈을 두 개의 스트림으로 분리합니다: (1) fp16로 곱해지는 체계적인 특이값 이상치 스트림 행렬(0.01%) 및 (2) int8 행렬 곱셈의 일반적인 스트림(99.9%). 이 방법을 사용하면 매우 큰 모델에 대해 예측 저하 없이 int8 추론이 가능합니다.
-이 방법에 대한 자세한 내용은 [논문](https://arxiv.org/abs/2208.07339)이나 [통합에 관한 블로그 글](https://huggingface.co/blog/hf-bitsandbytes-integration)에서 확인할 수 있습니다.
+이 방법에 대한 자세한 내용은 [논문](https://huggingface.co/papers/2208.07339)이나 [통합에 관한 블로그 글](https://huggingface.co/blog/hf-bitsandbytes-integration)에서 확인할 수 있습니다.

diff --git a/docs/source/ko/perf_train_gpu_many.md b/docs/source/ko/perf_train_gpu_many.md
index b8553ea499..801e06e276 100644
--- a/docs/source/ko/perf_train_gpu_many.md
+++ b/docs/source/ko/perf_train_gpu_many.md
@@ -316,7 +316,7 @@ DP + PP 설정의 전역 배치 크기를 계산하려면 `mbs*chunks*dp_degree`
- [DeepSpeed](https://www.deepspeed.ai/tutorials/pipeline/)
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)은 내부 구현을 가지고 있습니다 - API 없음.
- [Varuna](https://github.com/microsoft/varuna)
-- [SageMaker](https://arxiv.org/abs/2111.05972) - 이는 AWS에서만 사용할 수 있는 소유 솔루션입니다.
+- [SageMaker](https://huggingface.co/papers/2111.05972) - 이는 AWS에서만 사용할 수 있는 소유 솔루션입니다.
- [OSLO](https://github.com/tunib-ai/oslo) - 이는 Hugging Face Transformers를 기반으로 구현된 파이프라인 병렬화입니다.
🤗 Transformers 상태: 이 작성 시점에서 모델 중 어느 것도 완전한 PP를 지원하지 않습니다. GPT2와 T5 모델은 naive MP를 지원합니다. 주요 장애물은 모델을 `nn.Sequential`로 변환하고 모든 입력을 텐서로 가져와야 하는 것을 처리할 수 없기 때문입니다. 현재 모델에는 이러한 변환을 매우 복잡하게 만드는 많은 기능이 포함되어 있어 제거해야 합니다.
@@ -336,7 +336,7 @@ OSLO는 `nn.Sequential`로 변환하지 않고 Transformers를 기반으로 한
텐서 병렬 처리에서는 각 GPU가 텐서의 일부분만 처리하고 전체 텐서가 필요한 연산에 대해서만 전체 텐서를 집계합니다.
-이 섹션에서는 [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) 논문인 [Efficient Large-Scale Language Model Training on GPU Clusters](https://arxiv.org/abs/2104.04473)에서의 개념과 다이어그램을 사용합니다.
+이 섹션에서는 [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) 논문인 [Efficient Large-Scale Language Model Training on GPU Clusters](https://huggingface.co/papers/2104.04473)에서의 개념과 다이어그램을 사용합니다.
Transformer의 주요 구성 요소는 fully connected `nn.Linear`와 비선형 활성화 함수인 `GeLU`입니다.
@@ -367,7 +367,7 @@ SageMaker는 더 효율적인 처리를 위해 TP와 DP를 결합합니다.
구현:
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)은 내부 구현을 가지고 있으므로 모델에 매우 특화되어 있습니다.
- [parallelformers](https://github.com/tunib-ai/parallelformers) (현재는 추론에만 해당)
-- [SageMaker](https://arxiv.org/abs/2111.05972) - 이는 AWS에서만 사용할 수 있는 소유 솔루션입니다.
+- [SageMaker](https://huggingface.co/papers/2111.05972) - 이는 AWS에서만 사용할 수 있는 소유 솔루션입니다.
- [OSLO](https://github.com/tunib-ai/oslo)은 Transformers를 기반으로 한 텐서 병렬 처리 구현을 가지고 있습니다.
🤗 Transformers 현황:
@@ -389,7 +389,7 @@ DeepSpeed [pipeline tutorial](https://www.deepspeed.ai/tutorials/pipeline/)에
- [DeepSpeed](https://github.com/deepspeedai/DeepSpeed)
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
- [Varuna](https://github.com/microsoft/varuna)
-- [SageMaker](https://arxiv.org/abs/2111.05972)
+- [SageMaker](https://huggingface.co/papers/2111.05972)
- [OSLO](https://github.com/tunib-ai/oslo)
🤗 Transformers 현황: 아직 구현되지 않음
@@ -408,7 +408,7 @@ DeepSpeed [pipeline tutorial](https://www.deepspeed.ai/tutorials/pipeline/)에
- [DeepSpeed](https://github.com/deepspeedai/DeepSpeed) - DeepSpeed는 더욱 효율적인 DP인 ZeRO-DP라고도 부릅니다.
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
- [Varuna](https://github.com/microsoft/varuna)
-- [SageMaker](https://arxiv.org/abs/2111.05972)
+- [SageMaker](https://huggingface.co/papers/2111.05972)
- [OSLO](https://github.com/tunib-ai/oslo)
🤗 Transformers 현황: 아직 구현되지 않음. PP와 TP가 없기 때문입니다.
@@ -434,7 +434,7 @@ ZeRO 단계 3도 같은 이유로 좋은 선택이 아닙니다 - 더 많은 노
중요한 논문:
- [Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model](
-https://arxiv.org/abs/2201.11990)
+https://huggingface.co/papers/2201.11990)
🤗 Transformers 현황: 아직 구현되지 않음, PP와 TP가 없기 때문입니다.
@@ -442,7 +442,7 @@ https://arxiv.org/abs/2201.11990)
[FlexFlow](https://github.com/flexflow/FlexFlow)는 약간 다른 방식으로 병렬화 문제를 해결합니다.
-논문: ["Beyond Data and Model Parallelism for Deep Neural Networks" by Zhihao Jia, Matei Zaharia, Alex Aiken](https://arxiv.org/abs/1807.05358)
+논문: ["Beyond Data and Model Parallelism for Deep Neural Networks" by Zhihao Jia, Matei Zaharia, Alex Aiken](https://huggingface.co/papers/1807.05358)
이는 Sample-Operator-Attribute-Parameter를 기반으로 하는 일종의 4D 병렬화를 수행합니다.
diff --git a/docs/source/ko/tasks/knowledge_distillation_for_image_classification.md b/docs/source/ko/tasks/knowledge_distillation_for_image_classification.md
index 37c0cc2508..72cfbcf57a 100644
--- a/docs/source/ko/tasks/knowledge_distillation_for_image_classification.md
+++ b/docs/source/ko/tasks/knowledge_distillation_for_image_classification.md
@@ -17,7 +17,7 @@ rendered properly in your Markdown viewer.
[[open-in-colab]]
-지식 증류(Knowledge distillation)는 더 크고 복잡한 모델(교사)에서 더 작고 간단한 모델(학생)로 지식을 전달하는 기술입니다. 한 모델에서 다른 모델로 지식을 증류하기 위해, 특정 작업(이 경우 이미지 분류)에 대해 학습된 사전 훈련된 교사 모델을 사용하고, 랜덤으로 초기화된 학생 모델을 이미지 분류 작업에 대해 학습합니다. 그다음, 학생 모델이 교사 모델의 출력을 모방하여 두 모델의 출력 차이를 최소화하도록 훈련합니다. 이 기법은 Hinton 등 연구진의 [Distilling the Knowledge in a Neural Network](https://arxiv.org/abs/1503.02531)에서 처음 소개되었습니다. 이 가이드에서는 특정 작업에 맞춘 지식 증류를 수행할 것입니다. 이번에는 [beans dataset](https://huggingface.co/datasets/beans)을 사용할 것입니다.
+지식 증류(Knowledge distillation)는 더 크고 복잡한 모델(교사)에서 더 작고 간단한 모델(학생)로 지식을 전달하는 기술입니다. 한 모델에서 다른 모델로 지식을 증류하기 위해, 특정 작업(이 경우 이미지 분류)에 대해 학습된 사전 훈련된 교사 모델을 사용하고, 랜덤으로 초기화된 학생 모델을 이미지 분류 작업에 대해 학습합니다. 그다음, 학생 모델이 교사 모델의 출력을 모방하여 두 모델의 출력 차이를 최소화하도록 훈련합니다. 이 기법은 Hinton 등 연구진의 [Distilling the Knowledge in a Neural Network](https://huggingface.co/papers/1503.02531)에서 처음 소개되었습니다. 이 가이드에서는 특정 작업에 맞춘 지식 증류를 수행할 것입니다. 이번에는 [beans dataset](https://huggingface.co/datasets/beans)을 사용할 것입니다.
이 가이드는 [미세 조정된 ViT 모델](https://huggingface.co/merve/vit-mobilenet-beans-224) (교사 모델)을 [MobileNet](https://huggingface.co/google/mobilenet_v2_1.4_224) (학생 모델)으로 증류하는 방법을 🤗 Transformers의 [Trainer API](https://huggingface.co/docs/transformers/en/main_classes/trainer#trainer) 를 사용하여 보여줍니다.
diff --git a/docs/source/ko/tasks/video_classification.md b/docs/source/ko/tasks/video_classification.md
index 10569083c0..d39d669f8a 100644
--- a/docs/source/ko/tasks/video_classification.md
+++ b/docs/source/ko/tasks/video_classification.md
@@ -383,7 +383,7 @@ def compute_metrics(eval_pred):
**평가에 대한 참고사항**:
-[VideoMAE 논문](https://arxiv.org/abs/2203.12602)에서 저자는 다음과 같은 평가 전략을 사용합니다. 테스트 영상에서 여러 클립을 선택하고 그 클립에 다양한 크롭을 적용하여 집계 점수를 보고합니다. 그러나 이번 튜토리얼에서는 간단함과 간결함을 위해 해당 전략을 고려하지 않습니다.
+[VideoMAE 논문](https://huggingface.co/papers/2203.12602)에서 저자는 다음과 같은 평가 전략을 사용합니다. 테스트 영상에서 여러 클립을 선택하고 그 클립에 다양한 크롭을 적용하여 집계 점수를 보고합니다. 그러나 이번 튜토리얼에서는 간단함과 간결함을 위해 해당 전략을 고려하지 않습니다.
또한, 예제를 묶어서 배치를 형성하는 `collate_fn`을 정의해야합니다. 각 배치는 `pixel_values`와 `labels`라는 2개의 키로 구성됩니다.
diff --git a/docs/source/ko/tasks_explained.md b/docs/source/ko/tasks_explained.md
index 78c90849bb..57ccd57a79 100644
--- a/docs/source/ko/tasks_explained.md
+++ b/docs/source/ko/tasks_explained.md
@@ -120,7 +120,7 @@ ViT가 도입한 주요 변경 사항은 이미지가 Transformer로 어떻게
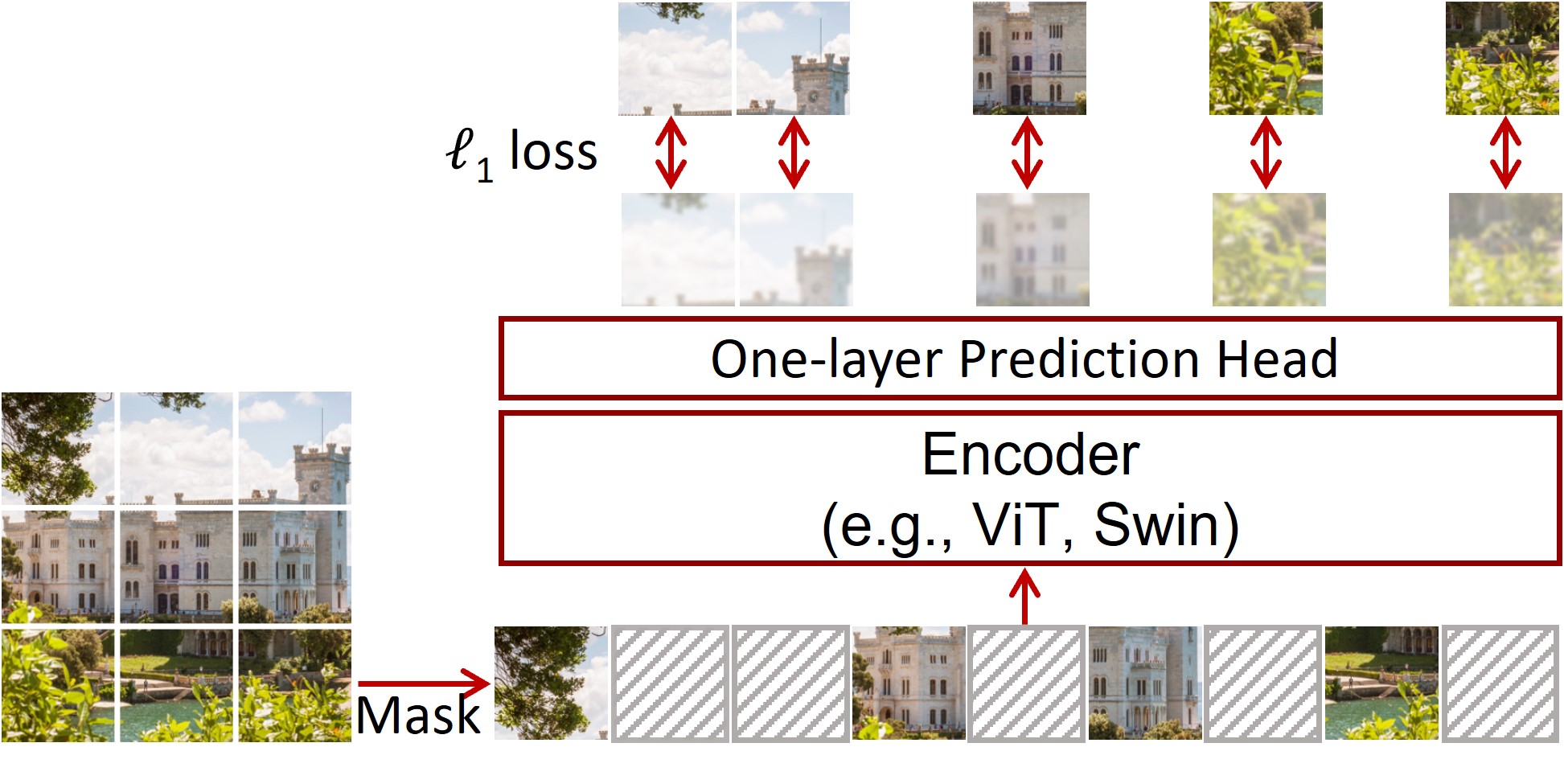 - SimMIM framework. Taken from the original paper.
+ SimMIM framework. Taken from the original paper.
The goal for the model is to predict raw pixel values for the masked patches, using just a linear layer as prediction head. The model is trained using a simple L1 loss.
@@ -145,7 +145,7 @@ python run_mim.py \
## MAE
-The `run_mae.py` script can be used to pre-train a Vision Transformer as a masked autoencoder (MAE), as proposed in [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377). The script can be used to train a `ViTMAEForPreTraining` model in the Transformers library, using PyTorch. After self-supervised pre-training, one can load the weights of the encoder directly into a `ViTForImageClassification`. The MAE method allows for learning high-capacity models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data.
+The `run_mae.py` script can be used to pre-train a Vision Transformer as a masked autoencoder (MAE), as proposed in [Masked Autoencoders Are Scalable Vision Learners](https://huggingface.co/papers/2111.06377). The script can be used to train a `ViTMAEForPreTraining` model in the Transformers library, using PyTorch. After self-supervised pre-training, one can load the weights of the encoder directly into a `ViTForImageClassification`. The MAE method allows for learning high-capacity models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data.
The goal for the model is to predict raw pixel values for the masked patches. As the model internally masks patches and learns to reconstruct them, there's no need for any labels. The model uses the mean squared error (MSE) between the reconstructed and original images in the pixel space.
@@ -182,14 +182,14 @@ python run_mae.py \
Here we set:
- `mask_ratio` to 0.75 (to mask 75% of the patches for each image)
- `norm_pix_loss` to use normalized pixel values as target (the authors reported better representations with this enabled)
-- `base_learning_rate` to 1.5e-4. Note that the effective learning rate is computed by the [linear schedule](https://arxiv.org/abs/1706.02677): `lr` = `blr` * total training batch size / 256. The total training batch size is computed as `training_args.train_batch_size` * `training_args.gradient_accumulation_steps` * `training_args.world_size`.
+- `base_learning_rate` to 1.5e-4. Note that the effective learning rate is computed by the [linear schedule](https://huggingface.co/papers/1706.02677): `lr` = `blr` * total training batch size / 256. The total training batch size is computed as `training_args.train_batch_size` * `training_args.gradient_accumulation_steps` * `training_args.world_size`.
This replicates the same hyperparameters as used in the original implementation, as shown in the table below.
- SimMIM framework. Taken from the original paper.
+ SimMIM framework. Taken from the original paper.
The goal for the model is to predict raw pixel values for the masked patches, using just a linear layer as prediction head. The model is trained using a simple L1 loss.
@@ -145,7 +145,7 @@ python run_mim.py \
## MAE
-The `run_mae.py` script can be used to pre-train a Vision Transformer as a masked autoencoder (MAE), as proposed in [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377). The script can be used to train a `ViTMAEForPreTraining` model in the Transformers library, using PyTorch. After self-supervised pre-training, one can load the weights of the encoder directly into a `ViTForImageClassification`. The MAE method allows for learning high-capacity models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data.
+The `run_mae.py` script can be used to pre-train a Vision Transformer as a masked autoencoder (MAE), as proposed in [Masked Autoencoders Are Scalable Vision Learners](https://huggingface.co/papers/2111.06377). The script can be used to train a `ViTMAEForPreTraining` model in the Transformers library, using PyTorch. After self-supervised pre-training, one can load the weights of the encoder directly into a `ViTForImageClassification`. The MAE method allows for learning high-capacity models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data.
The goal for the model is to predict raw pixel values for the masked patches. As the model internally masks patches and learns to reconstruct them, there's no need for any labels. The model uses the mean squared error (MSE) between the reconstructed and original images in the pixel space.
@@ -182,14 +182,14 @@ python run_mae.py \
Here we set:
- `mask_ratio` to 0.75 (to mask 75% of the patches for each image)
- `norm_pix_loss` to use normalized pixel values as target (the authors reported better representations with this enabled)
-- `base_learning_rate` to 1.5e-4. Note that the effective learning rate is computed by the [linear schedule](https://arxiv.org/abs/1706.02677): `lr` = `blr` * total training batch size / 256. The total training batch size is computed as `training_args.train_batch_size` * `training_args.gradient_accumulation_steps` * `training_args.world_size`.
+- `base_learning_rate` to 1.5e-4. Note that the effective learning rate is computed by the [linear schedule](https://huggingface.co/papers/1706.02677): `lr` = `blr` * total training batch size / 256. The total training batch size is computed as `training_args.train_batch_size` * `training_args.gradient_accumulation_steps` * `training_args.world_size`.
This replicates the same hyperparameters as used in the original implementation, as shown in the table below.
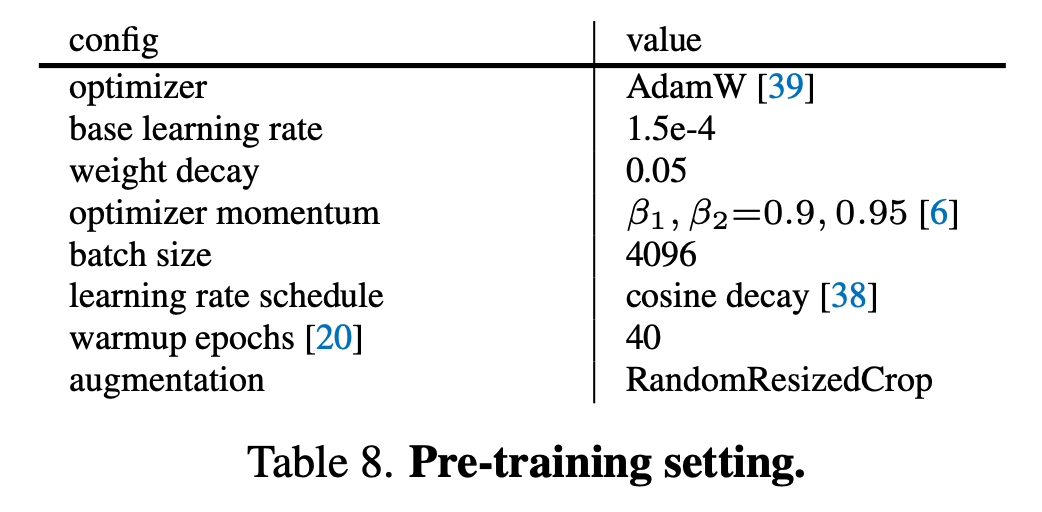 - Original hyperparameters. Taken from the original paper.
+ Original hyperparameters. Taken from the original paper.
Alternatively, one can decide to further pre-train an already pre-trained (or fine-tuned) checkpoint from the [hub](https://huggingface.co/). This can be done by setting the `model_name_or_path` argument to "facebook/vit-mae-base" for example.
diff --git a/examples/pytorch/image-pretraining/run_mae.py b/examples/pytorch/image-pretraining/run_mae.py
index 35cad47957..997356fe4e 100644
--- a/examples/pytorch/image-pretraining/run_mae.py
+++ b/examples/pytorch/image-pretraining/run_mae.py
@@ -37,7 +37,7 @@ from transformers.utils import check_min_version, send_example_telemetry
from transformers.utils.versions import require_version
-""" Pre-training a 🤗 ViT model as an MAE (masked autoencoder), as proposed in https://arxiv.org/abs/2111.06377."""
+""" Pre-training a 🤗 ViT model as an MAE (masked autoencoder), as proposed in https://huggingface.co/papers/2111.06377."""
logger = logging.getLogger(__name__)
diff --git a/examples/pytorch/language-modeling/README.md b/examples/pytorch/language-modeling/README.md
index e1b2beddf4..8623a77d5f 100644
--- a/examples/pytorch/language-modeling/README.md
+++ b/examples/pytorch/language-modeling/README.md
@@ -75,7 +75,7 @@ python run_clm_no_trainer.py \
### GPT-2/GPT and causal language modeling with fill-in-the middle objective
-The following example fine-tunes GPT-2 on WikiText-2 but using the Fill-in-middle training objective. FIM objective was proposed in [Efficient Training of Language Models to Fill in the Middle](https://arxiv.org/abs/2207.14255). They showed that autoregressive language models can learn to infill text after applying a straightforward transformation to the dataset, which simply moves a span of text from the middle of a document to its end.
+The following example fine-tunes GPT-2 on WikiText-2 but using the Fill-in-middle training objective. FIM objective was proposed in [Efficient Training of Language Models to Fill in the Middle](https://huggingface.co/papers/2207.14255). They showed that autoregressive language models can learn to infill text after applying a straightforward transformation to the dataset, which simply moves a span of text from the middle of a document to its end.
We're using the raw WikiText-2 (no tokens were replaced before the tokenization). The loss here is that of causal language modeling.
diff --git a/examples/pytorch/speech-pretraining/README.md b/examples/pytorch/speech-pretraining/README.md
index d0126634d2..a7364c780d 100644
--- a/examples/pytorch/speech-pretraining/README.md
+++ b/examples/pytorch/speech-pretraining/README.md
@@ -21,7 +21,7 @@ limitations under the License.
The script [`run_speech_wav2vec2_pretraining_no_trainer.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py) can be used to pre-train a [Wav2Vec2](https://huggingface.co/transformers/model_doc/wav2vec2.html?highlight=wav2vec2) model from scratch.
-In the script [`run_speech_wav2vec2_pretraining_no_trainer`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py), a Wav2Vec2 model is pre-trained on audio data alone using [Wav2Vec2's contrastive loss objective](https://arxiv.org/abs/2006.11477).
+In the script [`run_speech_wav2vec2_pretraining_no_trainer`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py), a Wav2Vec2 model is pre-trained on audio data alone using [Wav2Vec2's contrastive loss objective](https://huggingface.co/papers/2006.11477).
The following examples show how to fine-tune a `"base"`-sized Wav2Vec2 model as well as a `"large"`-sized Wav2Vec2 model using [`accelerate`](https://github.com/huggingface/accelerate).
diff --git a/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py b/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py
index 3bb7fe7bdc..111706412a 100755
--- a/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py
+++ b/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py
@@ -314,7 +314,7 @@ class DataCollatorForWav2Vec2Pretraining:
mask_time_prob (:obj:`float`, `optional`, defaults to :obj:`0.65`):
Percentage (between 0 and 1) of all feature vectors along the time axis which will be masked for the contrastive task.
Note that overlap between masked sequences may decrease the actual percentage of masked vectors.
- The default value is taken from the original wav2vec 2.0 article (https://arxiv.org/abs/2006.11477),
+ The default value is taken from the original wav2vec 2.0 article (https://huggingface.co/papers/2006.11477),
and results in about 49 percent of each sequence being masked on average.
mask_time_length (:obj:`int`, `optional`, defaults to :obj:`10`):
Length of each vector mask span to mask along the time axis in the contrastive task. The default value
diff --git a/examples/pytorch/speech-recognition/README.md b/examples/pytorch/speech-recognition/README.md
index 4990219f42..d0e898b8b7 100644
--- a/examples/pytorch/speech-recognition/README.md
+++ b/examples/pytorch/speech-recognition/README.md
@@ -493,7 +493,7 @@ Note that we have added a randomly initialized _adapter layer_ to `wav2vec2-base
`encoder_add_adapter=True`. This adapter sub-samples the output sequence of
`wav2vec2-base` along the time dimension. By default, a single
output vector of `wav2vec2-base` has a receptive field of *ca.* 25ms (*cf.*
-Section *4.2* of the [official Wav2Vec2 paper](https://arxiv.org/pdf/2006.11477.pdf)), which represents a little less a single character. On the other hand, BART
+Section *4.2* of the [official Wav2Vec2 paper](https://huggingface.co/papers/2006.11477)), which represents a little less a single character. On the other hand, BART
makes use of a sentence-piece tokenizer as an input processor, so that a single
hidden vector of `bart-base` represents *ca.* 4 characters. To better align the
receptive field of the *Wav2Vec2* output vectors with *BART*'s hidden-states in the cross-attention
diff --git a/examples/tensorflow/language-modeling-tpu/README.md b/examples/tensorflow/language-modeling-tpu/README.md
index 25381f86d0..0c068df8f2 100644
--- a/examples/tensorflow/language-modeling-tpu/README.md
+++ b/examples/tensorflow/language-modeling-tpu/README.md
@@ -8,7 +8,7 @@ This example will demonstrate pre-training language models at the 100M-1B parame
We've tried to ensure that all the practices we show you here are scalable, though - with relatively few changes, the code could be scaled up to much larger models.
-Google's gargantuan [PaLM model](https://arxiv.org/abs/2204.02311), with
+Google's gargantuan [PaLM model](https://huggingface.co/papers/2204.02311), with
over 500B parameters, is a good example of how far you can go with pure TPU training, though gathering the dataset and the budget to train at that scale is not an easy task!
### Table of contents
diff --git a/src/transformers/activations.py b/src/transformers/activations.py
index 2dab2fb32c..423e3cee87 100644
--- a/src/transformers/activations.py
+++ b/src/transformers/activations.py
@@ -27,7 +27,7 @@ logger = logging.get_logger(__name__)
class PytorchGELUTanh(nn.Module):
"""
A fast C implementation of the tanh approximation of the GeLU activation function. See
- https://arxiv.org/abs/1606.08415.
+ https://huggingface.co/papers/1606.08415.
This implementation is equivalent to NewGELU and FastGELU but much faster. However, it is not an exact numerical
match due to rounding errors.
@@ -40,7 +40,7 @@ class PytorchGELUTanh(nn.Module):
class NewGELUActivation(nn.Module):
"""
Implementation of the GELU activation function currently in Google BERT repo (identical to OpenAI GPT). Also see
- the Gaussian Error Linear Units paper: https://arxiv.org/abs/1606.08415
+ the Gaussian Error Linear Units paper: https://huggingface.co/papers/1606.08415
"""
def forward(self, input: Tensor) -> Tensor:
@@ -52,7 +52,7 @@ class GELUActivation(nn.Module):
Original Implementation of the GELU activation function in Google BERT repo when initially created. For
information: OpenAI GPT's GELU is slightly different (and gives slightly different results): 0.5 * x * (1 +
torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3)))) This is now written in C in nn.functional
- Also see the Gaussian Error Linear Units paper: https://arxiv.org/abs/1606.08415
+ Also see the Gaussian Error Linear Units paper: https://huggingface.co/papers/1606.08415
"""
def __init__(self, use_gelu_python: bool = False):
@@ -91,13 +91,13 @@ class ClippedGELUActivation(nn.Module):
"""
Clip the range of possible GeLU outputs between [min, max]. This is especially useful for quantization purpose, as
it allows mapping negatives values in the GeLU spectrum. For more information on this trick, please refer to
- https://arxiv.org/abs/2004.09602.
+ https://huggingface.co/papers/2004.09602.
Gaussian Error Linear Unit. Original Implementation of the gelu activation function in Google Bert repo when
initially created.
For information: OpenAI GPT's gelu is slightly different (and gives slightly different results): 0.5 * x * (1 +
- torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3)))). See https://arxiv.org/abs/1606.08415
+ torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3)))). See https://huggingface.co/papers/1606.08415
"""
def __init__(self, min: float, max: float):
@@ -130,7 +130,7 @@ class AccurateGELUActivation(nn.Module):
class MishActivation(nn.Module):
"""
- See Mish: A Self-Regularized Non-Monotonic Activation Function (Misra., https://arxiv.org/abs/1908.08681). Also
+ See Mish: A Self-Regularized Non-Monotonic Activation Function (Misra., https://huggingface.co/papers/1908.08681). Also
visit the official repository for the paper: https://github.com/digantamisra98/Mish
"""
@@ -157,7 +157,7 @@ class LinearActivation(nn.Module):
class LaplaceActivation(nn.Module):
"""
Applies elementwise activation based on Laplace function, introduced in MEGA as an attention activation. See
- https://arxiv.org/abs/2209.10655
+ https://huggingface.co/papers/2209.10655
Inspired by squared relu, but with bounded range and gradient for better stability
"""
@@ -169,7 +169,7 @@ class LaplaceActivation(nn.Module):
class ReLUSquaredActivation(nn.Module):
"""
- Applies the relu^2 activation introduced in https://arxiv.org/abs/2109.08668v2
+ Applies the relu^2 activation introduced in https://huggingface.co/papers/2109.08668v2
"""
def forward(self, input):
diff --git a/src/transformers/activations_tf.py b/src/transformers/activations_tf.py
index d12b73ea45..8dccf6c4f4 100644
--- a/src/transformers/activations_tf.py
+++ b/src/transformers/activations_tf.py
@@ -36,7 +36,7 @@ def _gelu(x):
Gaussian Error Linear Unit. Original Implementation of the gelu activation function in Google Bert repo when
initially created. For information: OpenAI GPT's gelu is slightly different (and gives slightly different results):
0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3)))) Also see
- https://arxiv.org/abs/1606.08415
+ https://huggingface.co/papers/1606.08415
"""
x = tf.convert_to_tensor(x)
cdf = 0.5 * (1.0 + tf.math.erf(x / tf.cast(tf.sqrt(2.0), x.dtype)))
@@ -46,7 +46,7 @@ def _gelu(x):
def _gelu_new(x):
"""
- Gaussian Error Linear Unit. This is a smoother version of the GELU. Original paper: https://arxiv.org/abs/1606.0841
+ Gaussian Error Linear Unit. This is a smoother version of the GELU. Original paper: https://huggingface.co/papers/1606.0841
Args:
x: float Tensor to perform activation
@@ -86,19 +86,19 @@ def gelu_10(x):
"""
Clip the range of possible GeLU outputs between [-10, 10]. This is especially useful for quantization purpose, as
it allows mapping 2 negatives values in the GeLU spectrum. For more information on this trick, please refer to
- https://arxiv.org/abs/2004.09602
+ https://huggingface.co/papers/2004.09602
Gaussian Error Linear Unit. Original Implementation of the gelu activation function in Google Bert repo when
initially created. For information: OpenAI GPT's gelu is slightly different (and gives slightly different results):
0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3)))) Also see
- https://arxiv.org/abs/1606.08415 :param x: :return:
+ https://huggingface.co/papers/1606.08415 :param x: :return:
"""
return tf.clip_by_value(_gelu(x), -10, 10)
def glu(x, axis=-1):
"""
- Gated Linear Unit. Implementation as defined in the original paper (see https://arxiv.org/abs/1612.08083), where
+ Gated Linear Unit. Implementation as defined in the original paper (see https://huggingface.co/papers/1612.08083), where
the input `x` is split in two halves across a dimension (`axis`), A and B, returning A * sigmoid(B).
Args:
diff --git a/src/transformers/cache_utils.py b/src/transformers/cache_utils.py
index 55f5010fbb..453d4a44bb 100644
--- a/src/transformers/cache_utils.py
+++ b/src/transformers/cache_utils.py
@@ -843,7 +843,7 @@ class OffloadedCache(DynamicCache):
class QuantizedCache(DynamicCache):
"""
- A quantizer cache similar to what is described in the [KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache paper](https://arxiv.org/abs/2402.02750).
+ A quantizer cache similar to what is described in the [KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache paper](https://huggingface.co/papers/2402.02750).
It allows the model to generate longer sequence length without allocating too much memory for Key and Value cache by applying quantization.
The cache has two types of storage, one for original precision and one for the quantized cache. A `residual length` is set as a maximum capacity for the
diff --git a/src/transformers/generation/beam_search.py b/src/transformers/generation/beam_search.py
index f5850a864c..f783784a4a 100644
--- a/src/transformers/generation/beam_search.py
+++ b/src/transformers/generation/beam_search.py
@@ -154,7 +154,7 @@ class BeamSearchScorer(BeamScorer):
[`~transformers.BeamSearchScorer.finalize`].
num_beam_groups (`int`, *optional*, defaults to 1):
Number of groups to divide `num_beams` into in order to ensure diversity among different groups of beams.
- See [this paper](https://arxiv.org/pdf/1610.02424.pdf) for more details.
+ See [this paper](https://huggingface.co/papers/1610.02424) for more details.
max_length (`int`, *optional*):
The maximum length of the sequence to be generated.
"""
@@ -448,7 +448,7 @@ class ConstrainedBeamSearchScorer(BeamScorer):
[`~transformers.BeamSearchScorer.finalize`].
num_beam_groups (`int`, *optional*, defaults to 1):
Number of groups to divide `num_beams` into in order to ensure diversity among different groups of beams.
- See [this paper](https://arxiv.org/pdf/1610.02424.pdf) for more details.
+ See [this paper](https://huggingface.co/papers/1610.02424) for more details.
max_length (`int`, *optional*):
The maximum length of the sequence to be generated.
"""
diff --git a/src/transformers/generation/candidate_generator.py b/src/transformers/generation/candidate_generator.py
index bb92220305..b82cdd12f8 100644
--- a/src/transformers/generation/candidate_generator.py
+++ b/src/transformers/generation/candidate_generator.py
@@ -678,7 +678,7 @@ class AssistantToTargetTranslator:
Translates token ids and logits between assistant and target model vocabularies. This class is used to handle
vocabulary mismatches when using different tokenizers for the assistant and target models in speculative decoding,
as introduced in the paper "Lossless Speculative Decoding Algorithms for Heterogeneous Vocabularies"
- (https://www.arxiv.org/abs/2502.05202).
+ (https://huggingface.co/papers/2502.05202).
It maintains mappings between the two vocabularies and handles token/logit conversion.
Args:
diff --git a/src/transformers/generation/configuration_utils.py b/src/transformers/generation/configuration_utils.py
index c886b51cf5..e7e77a8cd6 100644
--- a/src/transformers/generation/configuration_utils.py
+++ b/src/transformers/generation/configuration_utils.py
@@ -160,7 +160,7 @@ class GenerationConfig(PushToHubMixin):
Number of beams for beam search. 1 means no beam search.
num_beam_groups (`int`, *optional*, defaults to 1):
Number of groups to divide `num_beams` into in order to ensure diversity among different groups of beams.
- [this paper](https://arxiv.org/pdf/1610.02424.pdf) for more details.
+ [this paper](https://huggingface.co/papers/1610.02424) for more details.
penalty_alpha (`float`, *optional*):
The values balance the model confidence and the degeneration penalty in contrastive search decoding.
dola_layers (`str` or `List[int]`, *optional*):
@@ -171,7 +171,7 @@ class GenerationConfig(PushToHubMixin):
If a list of integers, it must contain the indices of the layers to use for candidate premature layers in DoLa.
The 0-th layer is the word embedding layer of the model. Set to `'low'` to improve long-answer reasoning tasks,
`'high'` to improve short-answer tasks. Check the [documentation](https://github.com/huggingface/transformers/blob/main/docs/source/en/generation_strategies.md)
- or [the paper](https://arxiv.org/abs/2309.03883) for more details.
+ or [the paper](https://huggingface.co/papers/2309.03883) for more details.
> Parameters that control the cache
@@ -216,25 +216,25 @@ class GenerationConfig(PushToHubMixin):
the expected conditional probability of predicting a random token next, given the partial text already
generated. If set to float < 1, the smallest set of the most locally typical tokens with probabilities that
add up to `typical_p` or higher are kept for generation. See [this
- paper](https://arxiv.org/pdf/2202.00666.pdf) for more details.
+ paper](https://huggingface.co/papers/2202.00666) for more details.
epsilon_cutoff (`float`, *optional*, defaults to 0.0):
If set to float strictly between 0 and 1, only tokens with a conditional probability greater than
`epsilon_cutoff` will be sampled. In the paper, suggested values range from 3e-4 to 9e-4, depending on the
size of the model. See [Truncation Sampling as Language Model
- Desmoothing](https://arxiv.org/abs/2210.15191) for more details.
+ Desmoothing](https://huggingface.co/papers/2210.15191) for more details.
eta_cutoff (`float`, *optional*, defaults to 0.0):
Eta sampling is a hybrid of locally typical sampling and epsilon sampling. If set to float strictly between
0 and 1, a token is only considered if it is greater than either `eta_cutoff` or `sqrt(eta_cutoff) *
exp(-entropy(softmax(next_token_logits)))`. The latter term is intuitively the expected next token
probability, scaled by `sqrt(eta_cutoff)`. In the paper, suggested values range from 3e-4 to 2e-3,
depending on the size of the model. See [Truncation Sampling as Language Model
- Desmoothing](https://arxiv.org/abs/2210.15191) for more details.
+ Desmoothing](https://huggingface.co/papers/2210.15191) for more details.
diversity_penalty (`float`, *optional*, defaults to 0.0):
This value is subtracted from a beam's score if it generates a token same as any beam from other group at a
particular time. Note that `diversity_penalty` is only effective if `group beam search` is enabled.
repetition_penalty (`float`, *optional*, defaults to 1.0):
The parameter for repetition penalty. 1.0 means no penalty. See [this
- paper](https://arxiv.org/pdf/1909.05858.pdf) for more details.
+ paper](https://huggingface.co/papers/1909.05858) for more details.
encoder_repetition_penalty (`float`, *optional*, defaults to 1.0):
The parameter for encoder_repetition_penalty. An exponential penalty on sequences that are not in the
original input. 1.0 means no penalty.
@@ -358,7 +358,7 @@ class GenerationConfig(PushToHubMixin):
(defined by `num_assistant_tokens`) is not yet reached. The assistant's confidence threshold is adjusted throughout the speculative iterations to reduce the number of unnecessary draft and target forward passes, biased towards avoiding false negatives.
`assistant_confidence_threshold` value is persistent over multiple generation calls with the same assistant model.
It is an unsupervised version of the dynamic speculation lookahead
- from Dynamic Speculation Lookahead Accelerates Speculative Decoding of Large Language Models
- Original hyperparameters. Taken from the original paper.
+ Original hyperparameters. Taken from the original paper.
Alternatively, one can decide to further pre-train an already pre-trained (or fine-tuned) checkpoint from the [hub](https://huggingface.co/). This can be done by setting the `model_name_or_path` argument to "facebook/vit-mae-base" for example.
diff --git a/examples/pytorch/image-pretraining/run_mae.py b/examples/pytorch/image-pretraining/run_mae.py
index 35cad47957..997356fe4e 100644
--- a/examples/pytorch/image-pretraining/run_mae.py
+++ b/examples/pytorch/image-pretraining/run_mae.py
@@ -37,7 +37,7 @@ from transformers.utils import check_min_version, send_example_telemetry
from transformers.utils.versions import require_version
-""" Pre-training a 🤗 ViT model as an MAE (masked autoencoder), as proposed in https://arxiv.org/abs/2111.06377."""
+""" Pre-training a 🤗 ViT model as an MAE (masked autoencoder), as proposed in https://huggingface.co/papers/2111.06377."""
logger = logging.getLogger(__name__)
diff --git a/examples/pytorch/language-modeling/README.md b/examples/pytorch/language-modeling/README.md
index e1b2beddf4..8623a77d5f 100644
--- a/examples/pytorch/language-modeling/README.md
+++ b/examples/pytorch/language-modeling/README.md
@@ -75,7 +75,7 @@ python run_clm_no_trainer.py \
### GPT-2/GPT and causal language modeling with fill-in-the middle objective
-The following example fine-tunes GPT-2 on WikiText-2 but using the Fill-in-middle training objective. FIM objective was proposed in [Efficient Training of Language Models to Fill in the Middle](https://arxiv.org/abs/2207.14255). They showed that autoregressive language models can learn to infill text after applying a straightforward transformation to the dataset, which simply moves a span of text from the middle of a document to its end.
+The following example fine-tunes GPT-2 on WikiText-2 but using the Fill-in-middle training objective. FIM objective was proposed in [Efficient Training of Language Models to Fill in the Middle](https://huggingface.co/papers/2207.14255). They showed that autoregressive language models can learn to infill text after applying a straightforward transformation to the dataset, which simply moves a span of text from the middle of a document to its end.
We're using the raw WikiText-2 (no tokens were replaced before the tokenization). The loss here is that of causal language modeling.
diff --git a/examples/pytorch/speech-pretraining/README.md b/examples/pytorch/speech-pretraining/README.md
index d0126634d2..a7364c780d 100644
--- a/examples/pytorch/speech-pretraining/README.md
+++ b/examples/pytorch/speech-pretraining/README.md
@@ -21,7 +21,7 @@ limitations under the License.
The script [`run_speech_wav2vec2_pretraining_no_trainer.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py) can be used to pre-train a [Wav2Vec2](https://huggingface.co/transformers/model_doc/wav2vec2.html?highlight=wav2vec2) model from scratch.
-In the script [`run_speech_wav2vec2_pretraining_no_trainer`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py), a Wav2Vec2 model is pre-trained on audio data alone using [Wav2Vec2's contrastive loss objective](https://arxiv.org/abs/2006.11477).
+In the script [`run_speech_wav2vec2_pretraining_no_trainer`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py), a Wav2Vec2 model is pre-trained on audio data alone using [Wav2Vec2's contrastive loss objective](https://huggingface.co/papers/2006.11477).
The following examples show how to fine-tune a `"base"`-sized Wav2Vec2 model as well as a `"large"`-sized Wav2Vec2 model using [`accelerate`](https://github.com/huggingface/accelerate).
diff --git a/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py b/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py
index 3bb7fe7bdc..111706412a 100755
--- a/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py
+++ b/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py
@@ -314,7 +314,7 @@ class DataCollatorForWav2Vec2Pretraining:
mask_time_prob (:obj:`float`, `optional`, defaults to :obj:`0.65`):
Percentage (between 0 and 1) of all feature vectors along the time axis which will be masked for the contrastive task.
Note that overlap between masked sequences may decrease the actual percentage of masked vectors.
- The default value is taken from the original wav2vec 2.0 article (https://arxiv.org/abs/2006.11477),
+ The default value is taken from the original wav2vec 2.0 article (https://huggingface.co/papers/2006.11477),
and results in about 49 percent of each sequence being masked on average.
mask_time_length (:obj:`int`, `optional`, defaults to :obj:`10`):
Length of each vector mask span to mask along the time axis in the contrastive task. The default value
diff --git a/examples/pytorch/speech-recognition/README.md b/examples/pytorch/speech-recognition/README.md
index 4990219f42..d0e898b8b7 100644
--- a/examples/pytorch/speech-recognition/README.md
+++ b/examples/pytorch/speech-recognition/README.md
@@ -493,7 +493,7 @@ Note that we have added a randomly initialized _adapter layer_ to `wav2vec2-base
`encoder_add_adapter=True`. This adapter sub-samples the output sequence of
`wav2vec2-base` along the time dimension. By default, a single
output vector of `wav2vec2-base` has a receptive field of *ca.* 25ms (*cf.*
-Section *4.2* of the [official Wav2Vec2 paper](https://arxiv.org/pdf/2006.11477.pdf)), which represents a little less a single character. On the other hand, BART
+Section *4.2* of the [official Wav2Vec2 paper](https://huggingface.co/papers/2006.11477)), which represents a little less a single character. On the other hand, BART
makes use of a sentence-piece tokenizer as an input processor, so that a single
hidden vector of `bart-base` represents *ca.* 4 characters. To better align the
receptive field of the *Wav2Vec2* output vectors with *BART*'s hidden-states in the cross-attention
diff --git a/examples/tensorflow/language-modeling-tpu/README.md b/examples/tensorflow/language-modeling-tpu/README.md
index 25381f86d0..0c068df8f2 100644
--- a/examples/tensorflow/language-modeling-tpu/README.md
+++ b/examples/tensorflow/language-modeling-tpu/README.md
@@ -8,7 +8,7 @@ This example will demonstrate pre-training language models at the 100M-1B parame
We've tried to ensure that all the practices we show you here are scalable, though - with relatively few changes, the code could be scaled up to much larger models.
-Google's gargantuan [PaLM model](https://arxiv.org/abs/2204.02311), with
+Google's gargantuan [PaLM model](https://huggingface.co/papers/2204.02311), with
over 500B parameters, is a good example of how far you can go with pure TPU training, though gathering the dataset and the budget to train at that scale is not an easy task!
### Table of contents
diff --git a/src/transformers/activations.py b/src/transformers/activations.py
index 2dab2fb32c..423e3cee87 100644
--- a/src/transformers/activations.py
+++ b/src/transformers/activations.py
@@ -27,7 +27,7 @@ logger = logging.get_logger(__name__)
class PytorchGELUTanh(nn.Module):
"""
A fast C implementation of the tanh approximation of the GeLU activation function. See
- https://arxiv.org/abs/1606.08415.
+ https://huggingface.co/papers/1606.08415.
This implementation is equivalent to NewGELU and FastGELU but much faster. However, it is not an exact numerical
match due to rounding errors.
@@ -40,7 +40,7 @@ class PytorchGELUTanh(nn.Module):
class NewGELUActivation(nn.Module):
"""
Implementation of the GELU activation function currently in Google BERT repo (identical to OpenAI GPT). Also see
- the Gaussian Error Linear Units paper: https://arxiv.org/abs/1606.08415
+ the Gaussian Error Linear Units paper: https://huggingface.co/papers/1606.08415
"""
def forward(self, input: Tensor) -> Tensor:
@@ -52,7 +52,7 @@ class GELUActivation(nn.Module):
Original Implementation of the GELU activation function in Google BERT repo when initially created. For
information: OpenAI GPT's GELU is slightly different (and gives slightly different results): 0.5 * x * (1 +
torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3)))) This is now written in C in nn.functional
- Also see the Gaussian Error Linear Units paper: https://arxiv.org/abs/1606.08415
+ Also see the Gaussian Error Linear Units paper: https://huggingface.co/papers/1606.08415
"""
def __init__(self, use_gelu_python: bool = False):
@@ -91,13 +91,13 @@ class ClippedGELUActivation(nn.Module):
"""
Clip the range of possible GeLU outputs between [min, max]. This is especially useful for quantization purpose, as
it allows mapping negatives values in the GeLU spectrum. For more information on this trick, please refer to
- https://arxiv.org/abs/2004.09602.
+ https://huggingface.co/papers/2004.09602.
Gaussian Error Linear Unit. Original Implementation of the gelu activation function in Google Bert repo when
initially created.
For information: OpenAI GPT's gelu is slightly different (and gives slightly different results): 0.5 * x * (1 +
- torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3)))). See https://arxiv.org/abs/1606.08415
+ torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3)))). See https://huggingface.co/papers/1606.08415
"""
def __init__(self, min: float, max: float):
@@ -130,7 +130,7 @@ class AccurateGELUActivation(nn.Module):
class MishActivation(nn.Module):
"""
- See Mish: A Self-Regularized Non-Monotonic Activation Function (Misra., https://arxiv.org/abs/1908.08681). Also
+ See Mish: A Self-Regularized Non-Monotonic Activation Function (Misra., https://huggingface.co/papers/1908.08681). Also
visit the official repository for the paper: https://github.com/digantamisra98/Mish
"""
@@ -157,7 +157,7 @@ class LinearActivation(nn.Module):
class LaplaceActivation(nn.Module):
"""
Applies elementwise activation based on Laplace function, introduced in MEGA as an attention activation. See
- https://arxiv.org/abs/2209.10655
+ https://huggingface.co/papers/2209.10655
Inspired by squared relu, but with bounded range and gradient for better stability
"""
@@ -169,7 +169,7 @@ class LaplaceActivation(nn.Module):
class ReLUSquaredActivation(nn.Module):
"""
- Applies the relu^2 activation introduced in https://arxiv.org/abs/2109.08668v2
+ Applies the relu^2 activation introduced in https://huggingface.co/papers/2109.08668v2
"""
def forward(self, input):
diff --git a/src/transformers/activations_tf.py b/src/transformers/activations_tf.py
index d12b73ea45..8dccf6c4f4 100644
--- a/src/transformers/activations_tf.py
+++ b/src/transformers/activations_tf.py
@@ -36,7 +36,7 @@ def _gelu(x):
Gaussian Error Linear Unit. Original Implementation of the gelu activation function in Google Bert repo when
initially created. For information: OpenAI GPT's gelu is slightly different (and gives slightly different results):
0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3)))) Also see
- https://arxiv.org/abs/1606.08415
+ https://huggingface.co/papers/1606.08415
"""
x = tf.convert_to_tensor(x)
cdf = 0.5 * (1.0 + tf.math.erf(x / tf.cast(tf.sqrt(2.0), x.dtype)))
@@ -46,7 +46,7 @@ def _gelu(x):
def _gelu_new(x):
"""
- Gaussian Error Linear Unit. This is a smoother version of the GELU. Original paper: https://arxiv.org/abs/1606.0841
+ Gaussian Error Linear Unit. This is a smoother version of the GELU. Original paper: https://huggingface.co/papers/1606.0841
Args:
x: float Tensor to perform activation
@@ -86,19 +86,19 @@ def gelu_10(x):
"""
Clip the range of possible GeLU outputs between [-10, 10]. This is especially useful for quantization purpose, as
it allows mapping 2 negatives values in the GeLU spectrum. For more information on this trick, please refer to
- https://arxiv.org/abs/2004.09602
+ https://huggingface.co/papers/2004.09602
Gaussian Error Linear Unit. Original Implementation of the gelu activation function in Google Bert repo when
initially created. For information: OpenAI GPT's gelu is slightly different (and gives slightly different results):
0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3)))) Also see
- https://arxiv.org/abs/1606.08415 :param x: :return:
+ https://huggingface.co/papers/1606.08415 :param x: :return:
"""
return tf.clip_by_value(_gelu(x), -10, 10)
def glu(x, axis=-1):
"""
- Gated Linear Unit. Implementation as defined in the original paper (see https://arxiv.org/abs/1612.08083), where
+ Gated Linear Unit. Implementation as defined in the original paper (see https://huggingface.co/papers/1612.08083), where
the input `x` is split in two halves across a dimension (`axis`), A and B, returning A * sigmoid(B).
Args:
diff --git a/src/transformers/cache_utils.py b/src/transformers/cache_utils.py
index 55f5010fbb..453d4a44bb 100644
--- a/src/transformers/cache_utils.py
+++ b/src/transformers/cache_utils.py
@@ -843,7 +843,7 @@ class OffloadedCache(DynamicCache):
class QuantizedCache(DynamicCache):
"""
- A quantizer cache similar to what is described in the [KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache paper](https://arxiv.org/abs/2402.02750).
+ A quantizer cache similar to what is described in the [KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache paper](https://huggingface.co/papers/2402.02750).
It allows the model to generate longer sequence length without allocating too much memory for Key and Value cache by applying quantization.
The cache has two types of storage, one for original precision and one for the quantized cache. A `residual length` is set as a maximum capacity for the
diff --git a/src/transformers/generation/beam_search.py b/src/transformers/generation/beam_search.py
index f5850a864c..f783784a4a 100644
--- a/src/transformers/generation/beam_search.py
+++ b/src/transformers/generation/beam_search.py
@@ -154,7 +154,7 @@ class BeamSearchScorer(BeamScorer):
[`~transformers.BeamSearchScorer.finalize`].
num_beam_groups (`int`, *optional*, defaults to 1):
Number of groups to divide `num_beams` into in order to ensure diversity among different groups of beams.
- See [this paper](https://arxiv.org/pdf/1610.02424.pdf) for more details.
+ See [this paper](https://huggingface.co/papers/1610.02424) for more details.
max_length (`int`, *optional*):
The maximum length of the sequence to be generated.
"""
@@ -448,7 +448,7 @@ class ConstrainedBeamSearchScorer(BeamScorer):
[`~transformers.BeamSearchScorer.finalize`].
num_beam_groups (`int`, *optional*, defaults to 1):
Number of groups to divide `num_beams` into in order to ensure diversity among different groups of beams.
- See [this paper](https://arxiv.org/pdf/1610.02424.pdf) for more details.
+ See [this paper](https://huggingface.co/papers/1610.02424) for more details.
max_length (`int`, *optional*):
The maximum length of the sequence to be generated.
"""
diff --git a/src/transformers/generation/candidate_generator.py b/src/transformers/generation/candidate_generator.py
index bb92220305..b82cdd12f8 100644
--- a/src/transformers/generation/candidate_generator.py
+++ b/src/transformers/generation/candidate_generator.py
@@ -678,7 +678,7 @@ class AssistantToTargetTranslator:
Translates token ids and logits between assistant and target model vocabularies. This class is used to handle
vocabulary mismatches when using different tokenizers for the assistant and target models in speculative decoding,
as introduced in the paper "Lossless Speculative Decoding Algorithms for Heterogeneous Vocabularies"
- (https://www.arxiv.org/abs/2502.05202).
+ (https://huggingface.co/papers/2502.05202).
It maintains mappings between the two vocabularies and handles token/logit conversion.
Args:
diff --git a/src/transformers/generation/configuration_utils.py b/src/transformers/generation/configuration_utils.py
index c886b51cf5..e7e77a8cd6 100644
--- a/src/transformers/generation/configuration_utils.py
+++ b/src/transformers/generation/configuration_utils.py
@@ -160,7 +160,7 @@ class GenerationConfig(PushToHubMixin):
Number of beams for beam search. 1 means no beam search.
num_beam_groups (`int`, *optional*, defaults to 1):
Number of groups to divide `num_beams` into in order to ensure diversity among different groups of beams.
- [this paper](https://arxiv.org/pdf/1610.02424.pdf) for more details.
+ [this paper](https://huggingface.co/papers/1610.02424) for more details.
penalty_alpha (`float`, *optional*):
The values balance the model confidence and the degeneration penalty in contrastive search decoding.
dola_layers (`str` or `List[int]`, *optional*):
@@ -171,7 +171,7 @@ class GenerationConfig(PushToHubMixin):
If a list of integers, it must contain the indices of the layers to use for candidate premature layers in DoLa.
The 0-th layer is the word embedding layer of the model. Set to `'low'` to improve long-answer reasoning tasks,
`'high'` to improve short-answer tasks. Check the [documentation](https://github.com/huggingface/transformers/blob/main/docs/source/en/generation_strategies.md)
- or [the paper](https://arxiv.org/abs/2309.03883) for more details.
+ or [the paper](https://huggingface.co/papers/2309.03883) for more details.
> Parameters that control the cache
@@ -216,25 +216,25 @@ class GenerationConfig(PushToHubMixin):
the expected conditional probability of predicting a random token next, given the partial text already
generated. If set to float < 1, the smallest set of the most locally typical tokens with probabilities that
add up to `typical_p` or higher are kept for generation. See [this
- paper](https://arxiv.org/pdf/2202.00666.pdf) for more details.
+ paper](https://huggingface.co/papers/2202.00666) for more details.
epsilon_cutoff (`float`, *optional*, defaults to 0.0):
If set to float strictly between 0 and 1, only tokens with a conditional probability greater than
`epsilon_cutoff` will be sampled. In the paper, suggested values range from 3e-4 to 9e-4, depending on the
size of the model. See [Truncation Sampling as Language Model
- Desmoothing](https://arxiv.org/abs/2210.15191) for more details.
+ Desmoothing](https://huggingface.co/papers/2210.15191) for more details.
eta_cutoff (`float`, *optional*, defaults to 0.0):
Eta sampling is a hybrid of locally typical sampling and epsilon sampling. If set to float strictly between
0 and 1, a token is only considered if it is greater than either `eta_cutoff` or `sqrt(eta_cutoff) *
exp(-entropy(softmax(next_token_logits)))`. The latter term is intuitively the expected next token
probability, scaled by `sqrt(eta_cutoff)`. In the paper, suggested values range from 3e-4 to 2e-3,
depending on the size of the model. See [Truncation Sampling as Language Model
- Desmoothing](https://arxiv.org/abs/2210.15191) for more details.
+ Desmoothing](https://huggingface.co/papers/2210.15191) for more details.
diversity_penalty (`float`, *optional*, defaults to 0.0):
This value is subtracted from a beam's score if it generates a token same as any beam from other group at a
particular time. Note that `diversity_penalty` is only effective if `group beam search` is enabled.
repetition_penalty (`float`, *optional*, defaults to 1.0):
The parameter for repetition penalty. 1.0 means no penalty. See [this
- paper](https://arxiv.org/pdf/1909.05858.pdf) for more details.
+ paper](https://huggingface.co/papers/1909.05858) for more details.
encoder_repetition_penalty (`float`, *optional*, defaults to 1.0):
The parameter for encoder_repetition_penalty. An exponential penalty on sequences that are not in the
original input. 1.0 means no penalty.
@@ -358,7 +358,7 @@ class GenerationConfig(PushToHubMixin):
(defined by `num_assistant_tokens`) is not yet reached. The assistant's confidence threshold is adjusted throughout the speculative iterations to reduce the number of unnecessary draft and target forward passes, biased towards avoiding false negatives.
`assistant_confidence_threshold` value is persistent over multiple generation calls with the same assistant model.
It is an unsupervised version of the dynamic speculation lookahead
- from Dynamic Speculation Lookahead Accelerates Speculative Decoding of Large Language Models