diff --git a/README.md b/README.md
index bdda50acc7..a83ae5dbaa 100644
--- a/README.md
+++ b/README.md
@@ -91,14 +91,21 @@ In Computer Vision:
- [Image classification with ViT](https://huggingface.co/google/vit-base-patch16-224)
- [Object Detection with DETR](https://huggingface.co/facebook/detr-resnet-50)
- [Semantic Segmentation with SegFormer](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
-- [Panoptic Segmentation with DETR](https://huggingface.co/facebook/detr-resnet-50-panoptic)
+- [Panoptic Segmentation with MaskFormer](https://huggingface.co/facebook/maskformer-swin-small-coco)
+- [Depth Estimation with DPT](https://huggingface.co/docs/transformers/model_doc/dpt)
+- [Video Classification with VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)
In Audio:
- [Automatic Speech Recognition with Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base-960h)
- [Keyword Spotting with Wav2Vec2](https://huggingface.co/superb/wav2vec2-base-superb-ks)
+- [Audio Classification with Audio Spectrogram Transformer](https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593)
In Multimodal tasks:
+- [Table Question Answering with TAPAS](https://huggingface.co/google/tapas-base-finetuned-wtq)
- [Visual Question Answering with ViLT](https://huggingface.co/dandelin/vilt-b32-finetuned-vqa)
+- [Zero-shot Image Classification with CLIP](https://huggingface.co/openai/clip-vit-large-patch14)
+- [Document Question Answering with LayoutLM](https://huggingface.co/impira/layoutlm-document-qa)
+- [Zero-shot Video Classification with X-CLIP](https://huggingface.co/docs/transformers/model_doc/xclip)
**[Write With Transformer](https://transformer.huggingface.co)**, built by the Hugging Face team, is the official demo of this repo’s text generation capabilities.
diff --git a/docs/source/en/model_doc/beit.mdx b/docs/source/en/model_doc/beit.mdx
index dea2522fb1..17132ef0ed 100644
--- a/docs/source/en/model_doc/beit.mdx
+++ b/docs/source/en/model_doc/beit.mdx
@@ -67,6 +67,15 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The JAX/FLAX version of this model was
contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/beit).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BEiT.
+
+
+
+- [`BeitForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## BEiT specific outputs
diff --git a/docs/source/en/model_doc/bit.mdx b/docs/source/en/model_doc/bit.mdx
index 7190db9c78..a9b3ff33b7 100644
--- a/docs/source/en/model_doc/bit.mdx
+++ b/docs/source/en/model_doc/bit.mdx
@@ -30,7 +30,6 @@ impact on transfer learning.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/google-research/big_transfer).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BiT.
@@ -45,19 +44,16 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] BitConfig
-
## BitImageProcessor
[[autodoc]] BitImageProcessor
- preprocess
-
## BitModel
[[autodoc]] BitModel
- forward
-
## BitForImageClassification
[[autodoc]] BitForImageClassification
diff --git a/docs/source/en/model_doc/clip.mdx b/docs/source/en/model_doc/clip.mdx
index 943a0f7f5a..790bce6c7f 100644
--- a/docs/source/en/model_doc/clip.mdx
+++ b/docs/source/en/model_doc/clip.mdx
@@ -77,23 +77,14 @@ This model was contributed by [valhalla](https://huggingface.co/valhalla). The o
## Resources
-A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with CLIP. If you're
-interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it.
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with CLIP.
+
+- A blog post on [How to fine-tune CLIP on 10,000 image-text pairs](https://huggingface.co/blog/fine-tune-clip-rsicd).
+- CLIP is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/contrastive-image-text).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it.
The resource should ideally demonstrate something new instead of duplicating an existing resource.
-
-- A blog post on [How to use CLIP to retrieve images from text](https://huggingface.co/blog/fine-tune-clip-rsicd).
-- A blog bost on [How to use CLIP for Japanese text to image generation](https://huggingface.co/blog/japanese-stable-diffusion).
-
-
-
-- A notebook showing [Video to text matching with CLIP for videos](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/X-CLIP/Video_text_matching_with_X_CLIP.ipynb).
-
-
-
-- A notebook showing [Zero shot video classification using CLIP for video](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/X-CLIP/Zero_shot_classify_a_YouTube_video_with_X_CLIP.ipynb).
-
-
## CLIPConfig
[[autodoc]] CLIPConfig
diff --git a/docs/source/en/model_doc/convnext.mdx b/docs/source/en/model_doc/convnext.mdx
index 538c68ea29..857a2adeb2 100644
--- a/docs/source/en/model_doc/convnext.mdx
+++ b/docs/source/en/model_doc/convnext.mdx
@@ -40,16 +40,24 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). TensorFlow version of the model was contributed by [ariG23498](https://github.com/ariG23498),
[gante](https://github.com/gante), and [sayakpaul](https://github.com/sayakpaul) (equal contribution). The original code can be found [here](https://github.com/facebookresearch/ConvNeXt).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ConvNeXT.
+
+
+
+- [`ConvNextForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
## ConvNextConfig
[[autodoc]] ConvNextConfig
-
## ConvNextFeatureExtractor
[[autodoc]] ConvNextFeatureExtractor
-
## ConvNextImageProcessor
[[autodoc]] ConvNextImageProcessor
@@ -60,7 +68,6 @@ This model was contributed by [nielsr](https://huggingface.co/nielsr). TensorFlo
[[autodoc]] ConvNextModel
- forward
-
## ConvNextForImageClassification
[[autodoc]] ConvNextForImageClassification
diff --git a/docs/source/en/model_doc/cvt.mdx b/docs/source/en/model_doc/cvt.mdx
index 873450cf83..9d0fa7ea88 100644
--- a/docs/source/en/model_doc/cvt.mdx
+++ b/docs/source/en/model_doc/cvt.mdx
@@ -38,6 +38,16 @@ Tips:
This model was contributed by [anugunj](https://huggingface.co/anugunj). The original code can be found [here](https://github.com/microsoft/CvT).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with CvT.
+
+
+
+- [`CvtForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
## CvtConfig
[[autodoc]] CvtConfig
diff --git a/docs/source/en/model_doc/data2vec.mdx b/docs/source/en/model_doc/data2vec.mdx
index 8623d64afe..39be094542 100644
--- a/docs/source/en/model_doc/data2vec.mdx
+++ b/docs/source/en/model_doc/data2vec.mdx
@@ -37,9 +37,6 @@ Tips:
- For Data2VecAudio, preprocessing is identical to [`Wav2Vec2Model`], including feature extraction
- For Data2VecText, preprocessing is identical to [`RobertaModel`], including tokenization.
- For Data2VecVision, preprocessing is identical to [`BeitModel`], including feature extraction.
-- To know how a pre-trained Data2Vec vision model can be fine-tuned on the task of image classification, you can check out
-[this notebook](https://colab.research.google.com/github/sayakpaul/TF-2.0-Hacks/blob/master/data2vec_vision_image_classification.ipynb).
-
This model was contributed by [edugp](https://huggingface.co/edugp) and [patrickvonplaten](https://huggingface.co/patrickvonplaten).
[sayakpaul](https://github.com/sayakpaul) and [Rocketknight1](https://github.com/Rocketknight1) contributed Data2Vec for vision in TensorFlow.
@@ -48,6 +45,17 @@ The original code (for NLP and Speech) can be found [here](https://github.com/py
The original code for vision can be found [here](https://github.com/facebookresearch/data2vec_vision/tree/main/beit).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Data2Vec.
+
+
+
+- [`Data2VecVisionForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+- To fine-tune [`TFData2VecVisionForImageClassification`] on a custom dataset, see [this notebook](https://colab.research.google.com/github/sayakpaul/TF-2.0-Hacks/blob/master/data2vec_vision_image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
## Data2VecTextConfig
[[autodoc]] Data2VecTextConfig
diff --git a/docs/source/en/model_doc/deformable_detr.mdx b/docs/source/en/model_doc/deformable_detr.mdx
index 30683bce17..32cb68746d 100644
--- a/docs/source/en/model_doc/deformable_detr.mdx
+++ b/docs/source/en/model_doc/deformable_detr.mdx
@@ -24,7 +24,7 @@ The abstract from the paper is the following:
Tips:
- One can use [`DeformableDetrImageProcessor`] to prepare images (and optional targets) for the model.
-- Training Deformable DETR is equivalent to training the original [DETR](detr) model. Demo notebooks can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR).
+- Training Deformable DETR is equivalent to training the original [DETR](detr) model. See the [resources](#resources) section below for demo notebooks.
 @@ -33,6 +33,16 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/fundamentalvision/Deformable-DETR).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Deformable DETR.
+
+
+
+- Demo notebooks regarding inference + fine-tuning on a custom dataset for [`DeformableDetrForObjectDetection`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Deformable-DETR).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
## DeformableDetrImageProcessor
[[autodoc]] DeformableDetrImageProcessor
@@ -47,18 +57,15 @@ This model was contributed by [nielsr](https://huggingface.co/nielsr). The origi
- pad_and_create_pixel_mask
- post_process_object_detection
-
## DeformableDetrConfig
[[autodoc]] DeformableDetrConfig
-
## DeformableDetrModel
[[autodoc]] DeformableDetrModel
- forward
-
## DeformableDetrForObjectDetection
[[autodoc]] DeformableDetrForObjectDetection
diff --git a/docs/source/en/model_doc/deit.mdx b/docs/source/en/model_doc/deit.mdx
index 45e9f598f9..0640a13391 100644
--- a/docs/source/en/model_doc/deit.mdx
+++ b/docs/source/en/model_doc/deit.mdx
@@ -71,6 +71,19 @@ Tips:
This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version of this model was added by [amyeroberts](https://huggingface.co/amyeroberts).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DeiT.
+
+
+
+- [`DeiTForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+Besides that:
+
+- [`DeiTForMaskedImageModeling`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## DeiTConfig
diff --git a/docs/source/en/model_doc/detr.mdx b/docs/source/en/model_doc/detr.mdx
index 28defdf791..872a7d4387 100644
--- a/docs/source/en/model_doc/detr.mdx
+++ b/docs/source/en/model_doc/detr.mdx
@@ -37,9 +37,6 @@ baselines.*
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/facebookresearch/detr).
-The quickest way to get started with DETR is by checking the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR) (which showcase both inference and
-fine-tuning on custom data).
-
Here's a TLDR explaining how [`~transformers.DetrForObjectDetection`] works:
First, an image is sent through a pre-trained convolutional backbone (in the paper, the authors use
@@ -153,6 +150,15 @@ outputs of the model using one of the postprocessing methods of [`~transformers.
be be provided to either `CocoEvaluator` or `PanopticEvaluator`, which allow you to calculate metrics like
mean Average Precision (mAP) and Panoptic Quality (PQ). The latter objects are implemented in the [original repository](https://github.com/facebookresearch/detr). See the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR) for more info regarding evaluation.
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DETR.
+
+
+
+- All example notebooks illustrating fine-tuning [`DetrForObjectDetection`] and [`DetrForSegmentation`] on a custom dataset an be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## DETR specific outputs
diff --git a/docs/source/en/model_doc/dinat.mdx b/docs/source/en/model_doc/dinat.mdx
index c8cebd921e..1f6577e21a 100644
--- a/docs/source/en/model_doc/dinat.mdx
+++ b/docs/source/en/model_doc/dinat.mdx
@@ -61,12 +61,20 @@ Taken from the original paper.
+
+- [`DinatForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## DinatConfig
[[autodoc]] DinatConfig
-
## DinatModel
[[autodoc]] DinatModel
diff --git a/docs/source/en/model_doc/dit.mdx b/docs/source/en/model_doc/dit.mdx
index e3830ce7c3..4843ca71f5 100644
--- a/docs/source/en/model_doc/dit.mdx
+++ b/docs/source/en/model_doc/dit.mdx
@@ -64,4 +64,14 @@ A notebook that illustrates inference for document image classification can be f
As DiT's architecture is equivalent to that of BEiT, one can refer to [BEiT's documentation page](beit) for all tips, code examples and notebooks.
-This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/dit).
\ No newline at end of file
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/dit).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DiT.
+
+
+
+- [`BeitForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
\ No newline at end of file
diff --git a/docs/source/en/model_doc/dpt.mdx b/docs/source/en/model_doc/dpt.mdx
index 46049d7a05..705dc680e6 100644
--- a/docs/source/en/model_doc/dpt.mdx
+++ b/docs/source/en/model_doc/dpt.mdx
@@ -28,37 +28,40 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/isl-org/DPT).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DPT.
+
+- Demo notebooks for [`DPTForDepthEstimation`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DPT).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
## DPTConfig
[[autodoc]] DPTConfig
-
## DPTFeatureExtractor
[[autodoc]] DPTFeatureExtractor
- __call__
- post_process_semantic_segmentation
-
## DPTImageProcessor
[[autodoc]] DPTImageProcessor
- preprocess
- post_process_semantic_segmentation
-
## DPTModel
[[autodoc]] DPTModel
- forward
-
## DPTForDepthEstimation
[[autodoc]] DPTForDepthEstimation
- forward
-
## DPTForSemanticSegmentation
[[autodoc]] DPTForSemanticSegmentation
diff --git a/docs/source/en/model_doc/glpn.mdx b/docs/source/en/model_doc/glpn.mdx
index 5d087de2fb..fe39dbb948 100644
--- a/docs/source/en/model_doc/glpn.mdx
+++ b/docs/source/en/model_doc/glpn.mdx
@@ -31,7 +31,6 @@ The abstract from the paper is the following:
Tips:
-- A notebook illustrating inference with [`GLPNForDepthEstimation`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/GLPN/GLPN_inference_(depth_estimation).ipynb).
- One can use [`GLPNImageProcessor`] to prepare images for the model.
@@ -33,6 +33,16 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/fundamentalvision/Deformable-DETR).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Deformable DETR.
+
+
+
+- Demo notebooks regarding inference + fine-tuning on a custom dataset for [`DeformableDetrForObjectDetection`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Deformable-DETR).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
## DeformableDetrImageProcessor
[[autodoc]] DeformableDetrImageProcessor
@@ -47,18 +57,15 @@ This model was contributed by [nielsr](https://huggingface.co/nielsr). The origi
- pad_and_create_pixel_mask
- post_process_object_detection
-
## DeformableDetrConfig
[[autodoc]] DeformableDetrConfig
-
## DeformableDetrModel
[[autodoc]] DeformableDetrModel
- forward
-
## DeformableDetrForObjectDetection
[[autodoc]] DeformableDetrForObjectDetection
diff --git a/docs/source/en/model_doc/deit.mdx b/docs/source/en/model_doc/deit.mdx
index 45e9f598f9..0640a13391 100644
--- a/docs/source/en/model_doc/deit.mdx
+++ b/docs/source/en/model_doc/deit.mdx
@@ -71,6 +71,19 @@ Tips:
This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version of this model was added by [amyeroberts](https://huggingface.co/amyeroberts).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DeiT.
+
+
+
+- [`DeiTForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+Besides that:
+
+- [`DeiTForMaskedImageModeling`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## DeiTConfig
diff --git a/docs/source/en/model_doc/detr.mdx b/docs/source/en/model_doc/detr.mdx
index 28defdf791..872a7d4387 100644
--- a/docs/source/en/model_doc/detr.mdx
+++ b/docs/source/en/model_doc/detr.mdx
@@ -37,9 +37,6 @@ baselines.*
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/facebookresearch/detr).
-The quickest way to get started with DETR is by checking the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR) (which showcase both inference and
-fine-tuning on custom data).
-
Here's a TLDR explaining how [`~transformers.DetrForObjectDetection`] works:
First, an image is sent through a pre-trained convolutional backbone (in the paper, the authors use
@@ -153,6 +150,15 @@ outputs of the model using one of the postprocessing methods of [`~transformers.
be be provided to either `CocoEvaluator` or `PanopticEvaluator`, which allow you to calculate metrics like
mean Average Precision (mAP) and Panoptic Quality (PQ). The latter objects are implemented in the [original repository](https://github.com/facebookresearch/detr). See the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR) for more info regarding evaluation.
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DETR.
+
+
+
+- All example notebooks illustrating fine-tuning [`DetrForObjectDetection`] and [`DetrForSegmentation`] on a custom dataset an be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## DETR specific outputs
diff --git a/docs/source/en/model_doc/dinat.mdx b/docs/source/en/model_doc/dinat.mdx
index c8cebd921e..1f6577e21a 100644
--- a/docs/source/en/model_doc/dinat.mdx
+++ b/docs/source/en/model_doc/dinat.mdx
@@ -61,12 +61,20 @@ Taken from the original paper.
+
+- [`DinatForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## DinatConfig
[[autodoc]] DinatConfig
-
## DinatModel
[[autodoc]] DinatModel
diff --git a/docs/source/en/model_doc/dit.mdx b/docs/source/en/model_doc/dit.mdx
index e3830ce7c3..4843ca71f5 100644
--- a/docs/source/en/model_doc/dit.mdx
+++ b/docs/source/en/model_doc/dit.mdx
@@ -64,4 +64,14 @@ A notebook that illustrates inference for document image classification can be f
As DiT's architecture is equivalent to that of BEiT, one can refer to [BEiT's documentation page](beit) for all tips, code examples and notebooks.
-This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/dit).
\ No newline at end of file
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/dit).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DiT.
+
+
+
+- [`BeitForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
\ No newline at end of file
diff --git a/docs/source/en/model_doc/dpt.mdx b/docs/source/en/model_doc/dpt.mdx
index 46049d7a05..705dc680e6 100644
--- a/docs/source/en/model_doc/dpt.mdx
+++ b/docs/source/en/model_doc/dpt.mdx
@@ -28,37 +28,40 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/isl-org/DPT).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DPT.
+
+- Demo notebooks for [`DPTForDepthEstimation`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DPT).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
## DPTConfig
[[autodoc]] DPTConfig
-
## DPTFeatureExtractor
[[autodoc]] DPTFeatureExtractor
- __call__
- post_process_semantic_segmentation
-
## DPTImageProcessor
[[autodoc]] DPTImageProcessor
- preprocess
- post_process_semantic_segmentation
-
## DPTModel
[[autodoc]] DPTModel
- forward
-
## DPTForDepthEstimation
[[autodoc]] DPTForDepthEstimation
- forward
-
## DPTForSemanticSegmentation
[[autodoc]] DPTForSemanticSegmentation
diff --git a/docs/source/en/model_doc/glpn.mdx b/docs/source/en/model_doc/glpn.mdx
index 5d087de2fb..fe39dbb948 100644
--- a/docs/source/en/model_doc/glpn.mdx
+++ b/docs/source/en/model_doc/glpn.mdx
@@ -31,7 +31,6 @@ The abstract from the paper is the following:
Tips:
-- A notebook illustrating inference with [`GLPNForDepthEstimation`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/GLPN/GLPN_inference_(depth_estimation).ipynb).
- One can use [`GLPNImageProcessor`] to prepare images for the model.
 This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/vinvino02/GLPDepth).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with GLPN.
+
+- Demo notebooks for [`GLPNForDepthEstimation`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/GLPN).
+
## GLPNConfig
[[autodoc]] GLPNConfig
diff --git a/docs/source/en/model_doc/groupvit.mdx b/docs/source/en/model_doc/groupvit.mdx
index 8c955a2e30..200ec7ccb8 100644
--- a/docs/source/en/model_doc/groupvit.mdx
+++ b/docs/source/en/model_doc/groupvit.mdx
@@ -24,11 +24,16 @@ The abstract from the paper is the following:
Tips:
- You may specify `output_segmentation=True` in the forward of `GroupViTModel` to get the segmentation logits of input texts.
-- The quickest way to get started with GroupViT is by checking the [example notebooks](https://github.com/xvjiarui/GroupViT/blob/main/demo/GroupViT_hf_inference_notebook.ipynb) (which showcase zero-shot segmentation inference). One can also check out the [HuggingFace Spaces demo](https://huggingface.co/spaces/xvjiarui/GroupViT) to play with GroupViT.
This model was contributed by [xvjiarui](https://huggingface.co/xvjiarui). The TensorFlow version was contributed by [ariG23498](https://huggingface.co/ariG23498) with the help of [Yih-Dar SHIEH](https://huggingface.co/ydshieh), [Amy Roberts](https://huggingface.co/amyeroberts), and [Joao Gante](https://huggingface.co/joaogante).
The original code can be found [here](https://github.com/NVlabs/GroupViT).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with GroupViT.
+
+- The quickest way to get started with GroupViT is by checking the [example notebooks](https://github.com/xvjiarui/GroupViT/blob/main/demo/GroupViT_hf_inference_notebook.ipynb) (which showcase zero-shot segmentation inference).
+- One can also check out the [HuggingFace Spaces demo](https://huggingface.co/spaces/xvjiarui/GroupViT) to play with GroupViT.
## GroupViTConfig
diff --git a/docs/source/en/model_doc/imagegpt.mdx b/docs/source/en/model_doc/imagegpt.mdx
index ec265d1488..baee48b96e 100644
--- a/docs/source/en/model_doc/imagegpt.mdx
+++ b/docs/source/en/model_doc/imagegpt.mdx
@@ -38,8 +38,6 @@ This model was contributed by [nielsr](https://huggingface.co/nielsr), based on
Tips:
-- Demo notebooks for ImageGPT can be found
- [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ImageGPT).
- ImageGPT is almost exactly the same as [GPT-2](gpt2), with the exception that a different activation
function is used (namely "quick gelu"), and the layer normalization layers don't mean center the inputs. ImageGPT
also doesn't have tied input- and output embeddings.
@@ -71,6 +69,17 @@ Tips:
| MiT-b4 | [3, 8, 27, 3] | [64, 128, 320, 512] | 768 | 62.6 | 83.6 |
| MiT-b5 | [3, 6, 40, 3] | [64, 128, 320, 512] | 768 | 82.0 | 83.8 |
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ImageGPT.
+
+
+
+- Demo notebooks for ImageGPT can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ImageGPT).
+- [`ImageGPTForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
## ImageGPTConfig
[[autodoc]] ImageGPTConfig
diff --git a/docs/source/en/model_doc/levit.mdx b/docs/source/en/model_doc/levit.mdx
index 0a64471b34..69c2e00c0b 100644
--- a/docs/source/en/model_doc/levit.mdx
+++ b/docs/source/en/model_doc/levit.mdx
@@ -61,6 +61,15 @@ Tips:
This model was contributed by [anugunj](https://huggingface.co/anugunj). The original code can be found [here](https://github.com/facebookresearch/LeViT).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LeViT.
+
+
+
+- [`LevitForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## LevitConfig
diff --git a/docs/source/en/model_doc/lilt.mdx b/docs/source/en/model_doc/lilt.mdx
index 9b80c1bc09..f29a8d67a3 100644
--- a/docs/source/en/model_doc/lilt.mdx
+++ b/docs/source/en/model_doc/lilt.mdx
@@ -37,7 +37,6 @@ model.push_to_hub("name_of_repo_on_the_hub")
- When preparing data for the model, make sure to use the token vocabulary that corresponds to the RoBERTa checkpoint you combined with the Layout Transformer.
- As [lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-roberta-en-base) uses the same vocabulary as [LayoutLMv3](layoutlmv3), one can use [`LayoutLMv3TokenizerFast`] to prepare data for the model.
The same is true for [lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-infoxlm-base): one can use [`LayoutXLMTokenizerFast`] for that model.
-- Demo notebooks for LiLT can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LiLT).
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/vinvino02/GLPDepth).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with GLPN.
+
+- Demo notebooks for [`GLPNForDepthEstimation`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/GLPN).
+
## GLPNConfig
[[autodoc]] GLPNConfig
diff --git a/docs/source/en/model_doc/groupvit.mdx b/docs/source/en/model_doc/groupvit.mdx
index 8c955a2e30..200ec7ccb8 100644
--- a/docs/source/en/model_doc/groupvit.mdx
+++ b/docs/source/en/model_doc/groupvit.mdx
@@ -24,11 +24,16 @@ The abstract from the paper is the following:
Tips:
- You may specify `output_segmentation=True` in the forward of `GroupViTModel` to get the segmentation logits of input texts.
-- The quickest way to get started with GroupViT is by checking the [example notebooks](https://github.com/xvjiarui/GroupViT/blob/main/demo/GroupViT_hf_inference_notebook.ipynb) (which showcase zero-shot segmentation inference). One can also check out the [HuggingFace Spaces demo](https://huggingface.co/spaces/xvjiarui/GroupViT) to play with GroupViT.
This model was contributed by [xvjiarui](https://huggingface.co/xvjiarui). The TensorFlow version was contributed by [ariG23498](https://huggingface.co/ariG23498) with the help of [Yih-Dar SHIEH](https://huggingface.co/ydshieh), [Amy Roberts](https://huggingface.co/amyeroberts), and [Joao Gante](https://huggingface.co/joaogante).
The original code can be found [here](https://github.com/NVlabs/GroupViT).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with GroupViT.
+
+- The quickest way to get started with GroupViT is by checking the [example notebooks](https://github.com/xvjiarui/GroupViT/blob/main/demo/GroupViT_hf_inference_notebook.ipynb) (which showcase zero-shot segmentation inference).
+- One can also check out the [HuggingFace Spaces demo](https://huggingface.co/spaces/xvjiarui/GroupViT) to play with GroupViT.
## GroupViTConfig
diff --git a/docs/source/en/model_doc/imagegpt.mdx b/docs/source/en/model_doc/imagegpt.mdx
index ec265d1488..baee48b96e 100644
--- a/docs/source/en/model_doc/imagegpt.mdx
+++ b/docs/source/en/model_doc/imagegpt.mdx
@@ -38,8 +38,6 @@ This model was contributed by [nielsr](https://huggingface.co/nielsr), based on
Tips:
-- Demo notebooks for ImageGPT can be found
- [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ImageGPT).
- ImageGPT is almost exactly the same as [GPT-2](gpt2), with the exception that a different activation
function is used (namely "quick gelu"), and the layer normalization layers don't mean center the inputs. ImageGPT
also doesn't have tied input- and output embeddings.
@@ -71,6 +69,17 @@ Tips:
| MiT-b4 | [3, 8, 27, 3] | [64, 128, 320, 512] | 768 | 62.6 | 83.6 |
| MiT-b5 | [3, 6, 40, 3] | [64, 128, 320, 512] | 768 | 82.0 | 83.8 |
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ImageGPT.
+
+
+
+- Demo notebooks for ImageGPT can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ImageGPT).
+- [`ImageGPTForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
## ImageGPTConfig
[[autodoc]] ImageGPTConfig
diff --git a/docs/source/en/model_doc/levit.mdx b/docs/source/en/model_doc/levit.mdx
index 0a64471b34..69c2e00c0b 100644
--- a/docs/source/en/model_doc/levit.mdx
+++ b/docs/source/en/model_doc/levit.mdx
@@ -61,6 +61,15 @@ Tips:
This model was contributed by [anugunj](https://huggingface.co/anugunj). The original code can be found [here](https://github.com/facebookresearch/LeViT).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LeViT.
+
+
+
+- [`LevitForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## LevitConfig
diff --git a/docs/source/en/model_doc/lilt.mdx b/docs/source/en/model_doc/lilt.mdx
index 9b80c1bc09..f29a8d67a3 100644
--- a/docs/source/en/model_doc/lilt.mdx
+++ b/docs/source/en/model_doc/lilt.mdx
@@ -37,7 +37,6 @@ model.push_to_hub("name_of_repo_on_the_hub")
- When preparing data for the model, make sure to use the token vocabulary that corresponds to the RoBERTa checkpoint you combined with the Layout Transformer.
- As [lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-roberta-en-base) uses the same vocabulary as [LayoutLMv3](layoutlmv3), one can use [`LayoutLMv3TokenizerFast`] to prepare data for the model.
The same is true for [lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-infoxlm-base): one can use [`LayoutXLMTokenizerFast`] for that model.
-- Demo notebooks for LiLT can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LiLT).
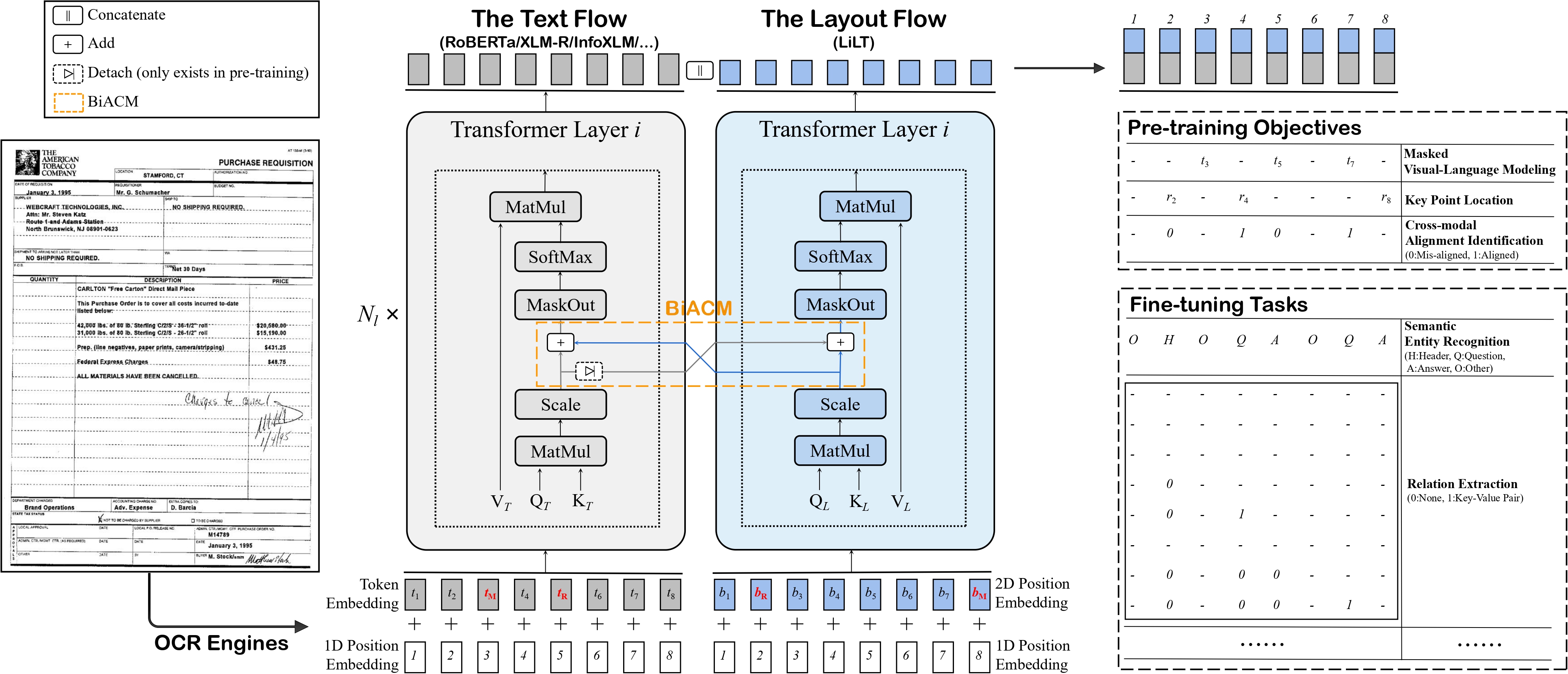 @@ -47,6 +46,13 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/jpwang/lilt).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LiLT.
+
+- Demo notebooks for LiLT can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LiLT).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## LiltConfig
diff --git a/docs/source/en/model_doc/mobilenet_v1.mdx b/docs/source/en/model_doc/mobilenet_v1.mdx
index 48627954ce..48795896f0 100644
--- a/docs/source/en/model_doc/mobilenet_v1.mdx
+++ b/docs/source/en/model_doc/mobilenet_v1.mdx
@@ -44,6 +44,16 @@ Unsupported features:
This model was contributed by [matthijs](https://huggingface.co/Matthijs). The original code and weights can be found [here](https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet_v1.md).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with MobileNetV1.
+
+
+
+- [`MobileNetV1ForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
## MobileNetV1Config
[[autodoc]] MobileNetV1Config
diff --git a/docs/source/en/model_doc/mobilenet_v2.mdx b/docs/source/en/model_doc/mobilenet_v2.mdx
index 6b9dde63b8..6f179f3cee 100644
--- a/docs/source/en/model_doc/mobilenet_v2.mdx
+++ b/docs/source/en/model_doc/mobilenet_v2.mdx
@@ -48,6 +48,16 @@ Unsupported features:
This model was contributed by [matthijs](https://huggingface.co/Matthijs). The original code and weights can be found [here for the main model](https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet) and [here for DeepLabV3+](https://github.com/tensorflow/models/tree/master/research/deeplab).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with MobileNetV2.
+
+
+
+- [`MobileNetV2ForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
## MobileNetV2Config
[[autodoc]] MobileNetV2Config
diff --git a/docs/source/en/model_doc/mobilevit.mdx b/docs/source/en/model_doc/mobilevit.mdx
index c7de403a80..6c0b5b6aae 100644
--- a/docs/source/en/model_doc/mobilevit.mdx
+++ b/docs/source/en/model_doc/mobilevit.mdx
@@ -57,6 +57,15 @@ with open(tflite_filename, "wb") as f:
This model was contributed by [matthijs](https://huggingface.co/Matthijs). The TensorFlow version of the model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code and weights can be found [here](https://github.com/apple/ml-cvnets).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with MobileViT.
+
+
+
+- [`MobileViTForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## MobileViTConfig
diff --git a/docs/source/en/model_doc/nat.mdx b/docs/source/en/model_doc/nat.mdx
index 43b59fb471..636b984c6a 100644
--- a/docs/source/en/model_doc/nat.mdx
+++ b/docs/source/en/model_doc/nat.mdx
@@ -56,6 +56,15 @@ Taken from the original paper.
+
+- [`NatForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## NatConfig
diff --git a/docs/source/en/model_doc/poolformer.mdx b/docs/source/en/model_doc/poolformer.mdx
index e047626261..be3aa29849 100644
--- a/docs/source/en/model_doc/poolformer.mdx
+++ b/docs/source/en/model_doc/poolformer.mdx
@@ -41,6 +41,16 @@ Tips:
This model was contributed by [heytanay](https://huggingface.co/heytanay). The original code can be found [here](https://github.com/sail-sg/poolformer).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with PoolFormer.
+
+
+
+- [`PoolFormerForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
## PoolFormerConfig
[[autodoc]] PoolFormerConfig
diff --git a/docs/source/en/model_doc/regnet.mdx b/docs/source/en/model_doc/regnet.mdx
index a426ad8fa1..62d030452a 100644
--- a/docs/source/en/model_doc/regnet.mdx
+++ b/docs/source/en/model_doc/regnet.mdx
@@ -31,6 +31,15 @@ This model was contributed by [Francesco](https://huggingface.co/Francesco). The
was contributed by [sayakpaul](https://huggingface.com/sayakpaul) and [ariG23498](https://huggingface.com/ariG23498).
The original code can be found [here](https://github.com/facebookresearch/pycls).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with RegNet.
+
+
+
+- [`RegNetForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## RegNetConfig
diff --git a/docs/source/en/model_doc/resnet.mdx b/docs/source/en/model_doc/resnet.mdx
index ce1799e8d4..031066b69b 100644
--- a/docs/source/en/model_doc/resnet.mdx
+++ b/docs/source/en/model_doc/resnet.mdx
@@ -33,6 +33,16 @@ The figure below illustrates the architecture of ResNet. Taken from the [origina
This model was contributed by [Francesco](https://huggingface.co/Francesco). The TensorFlow version of this model was added by [amyeroberts](https://huggingface.co/amyeroberts). The original code can be found [here](https://github.com/KaimingHe/deep-residual-networks).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ResNet.
+
+
+
+- [`ResNetForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
## ResNetConfig
[[autodoc]] ResNetConfig
diff --git a/docs/source/en/model_doc/segformer.mdx b/docs/source/en/model_doc/segformer.mdx
index 76a02c27f4..5c494e4747 100644
--- a/docs/source/en/model_doc/segformer.mdx
+++ b/docs/source/en/model_doc/segformer.mdx
@@ -84,6 +84,22 @@ Tips:
Note that MiT in the above table refers to the Mix Transformer encoder backbone introduced in SegFormer. For
SegFormer's results on the segmentation datasets like ADE20k, refer to the [paper](https://arxiv.org/abs/2105.15203).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with SegFormer.
+
+
+
+- [`SegformerForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+Semantic segmentation:
+
+- [`SegformerForSemanticSegmentation`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/semantic-segmentation).
+- A blog on fine-tuning SegFormer on a custom dataset can be found [here](https://huggingface.co/blog/fine-tune-segformer).
+- More demo notebooks on SegFormer (both inference + fine-tuning on a custom dataset) can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/SegFormer).
+- [`TFSegformerForSemanticSegmentation`] is supported by this [example notebook](https://github.com/huggingface/notebooks/blob/main/examples/semantic_segmentation-tf.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## SegformerConfig
diff --git a/docs/source/en/model_doc/swin.mdx b/docs/source/en/model_doc/swin.mdx
index 503a141084..1bb4fb88d8 100644
--- a/docs/source/en/model_doc/swin.mdx
+++ b/docs/source/en/model_doc/swin.mdx
@@ -45,6 +45,20 @@ alt="drawing" width="600"/>
This model was contributed by [novice03](https://huggingface.co/novice03). The Tensorflow version of this model was contributed by [amyeroberts](https://huggingface.co/amyeroberts). The original code can be found [here](https://github.com/microsoft/Swin-Transformer).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Swin Transformer.
+
+
+
+- [`SwinForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+Besides that:
+
+- [`SwinForMaskedImageModeling`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
## SwinConfig
[[autodoc]] SwinConfig
diff --git a/docs/source/en/model_doc/swinv2.mdx b/docs/source/en/model_doc/swinv2.mdx
index 576f1a142a..c4378583c4 100644
--- a/docs/source/en/model_doc/swinv2.mdx
+++ b/docs/source/en/model_doc/swinv2.mdx
@@ -26,6 +26,19 @@ Tips:
This model was contributed by [nandwalritik](https://huggingface.co/nandwalritik).
The original code can be found [here](https://github.com/microsoft/Swin-Transformer).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Swin Transformer v2.
+
+
+
+- [`Swinv2ForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+Besides that:
+
+- [`Swinv2ForMaskedImageModeling`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## Swinv2Config
diff --git a/docs/source/en/model_doc/van.mdx b/docs/source/en/model_doc/van.mdx
index 9fc05ab3e7..1f5507244c 100644
--- a/docs/source/en/model_doc/van.mdx
+++ b/docs/source/en/model_doc/van.mdx
@@ -32,6 +32,15 @@ The figure below illustrates the architecture of a Visual Aattention Layer. Take
This model was contributed by [Francesco](https://huggingface.co/Francesco). The original code can be found [here](https://github.com/Visual-Attention-Network/VAN-Classification).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with VAN.
+
+
+
+- [`VanForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## VanConfig
diff --git a/docs/source/en/model_doc/vit.mdx b/docs/source/en/model_doc/vit.mdx
index de31278dfe..45ed3f1878 100644
--- a/docs/source/en/model_doc/vit.mdx
+++ b/docs/source/en/model_doc/vit.mdx
@@ -86,6 +86,21 @@ found [here](https://github.com/google-research/vision_transformer).
Note that we converted the weights from Ross Wightman's [timm library](https://github.com/rwightman/pytorch-image-models), who already converted the weights from JAX to PyTorch. Credits
go to him!
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViT.
+
+
+
+- [`ViTForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+- A blog on fine-tuning [`ViTForImageClassification`] on a custom dataset can be found [here](https://huggingface.co/blog/fine-tune-vit).
+- More demo notebooks to fine-tune [`ViTForImageClassification`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer).
+
+Besides that:
+
+- [`ViTForMaskedImageModeling`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## Resources
diff --git a/docs/source/en/model_doc/vit_mae.mdx b/docs/source/en/model_doc/vit_mae.mdx
index 4544237070..714a68e152 100644
--- a/docs/source/en/model_doc/vit_mae.mdx
+++ b/docs/source/en/model_doc/vit_mae.mdx
@@ -32,9 +32,6 @@ Tips:
- MAE (masked auto encoding) is a method for self-supervised pre-training of Vision Transformers (ViTs). The pre-training objective is relatively simple:
by masking a large portion (75%) of the image patches, the model must reconstruct raw pixel values. One can use [`ViTMAEForPreTraining`] for this purpose.
-- An example Python script that illustrates how to pre-train [`ViTMAEForPreTraining`] from scratch can be found [here](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining).
-One can easily tweak it for their own use case.
-- A notebook that illustrates how to visualize reconstructed pixel values with [`ViTMAEForPreTraining`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/ViTMAE/ViT_MAE_visualization_demo.ipynb).
- After pre-training, one "throws away" the decoder used to reconstruct pixels, and one uses the encoder for fine-tuning/linear probing. This means that after
fine-tuning, one can directly plug in the weights into a [`ViTForImageClassification`].
- One can use [`ViTImageProcessor`] to prepare images for the model. See the code examples for more info.
@@ -51,6 +48,14 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). TensorFlow version of the model was contributed by [sayakpaul](https://github.com/sayakpaul) and
[ariG23498](https://github.com/ariG23498) (equal contribution). The original code can be found [here](https://github.com/facebookresearch/mae).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViTMAE.
+
+- [`ViTMAEForPreTraining`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining), allowing you to pre-train the model from scratch/further pre-train the model on custom data.
+- A notebook that illustrates how to visualize reconstructed pixel values with [`ViTMAEForPreTraining`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/ViTMAE/ViT_MAE_visualization_demo.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## ViTMAEConfig
diff --git a/docs/source/en/model_doc/vit_msn.mdx b/docs/source/en/model_doc/vit_msn.mdx
index 07faed51e6..47c1f69e2b 100644
--- a/docs/source/en/model_doc/vit_msn.mdx
+++ b/docs/source/en/model_doc/vit_msn.mdx
@@ -46,6 +46,15 @@ labels when fine-tuned.
This model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/facebookresearch/msn).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViT MSN.
+
+
+
+- [`ViTMSNForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## ViTMSNConfig
diff --git a/docs/source/en/model_doc/xclip.mdx b/docs/source/en/model_doc/xclip.mdx
index 96832f46e5..a49ed8b913 100644
--- a/docs/source/en/model_doc/xclip.mdx
+++ b/docs/source/en/model_doc/xclip.mdx
@@ -24,7 +24,6 @@ The abstract from the paper is the following:
Tips:
- Usage of X-CLIP is identical to [CLIP](clip).
-- Demo notebooks for X-CLIP can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/X-CLIP).
@@ -47,6 +46,13 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/jpwang/lilt).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LiLT.
+
+- Demo notebooks for LiLT can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LiLT).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## LiltConfig
diff --git a/docs/source/en/model_doc/mobilenet_v1.mdx b/docs/source/en/model_doc/mobilenet_v1.mdx
index 48627954ce..48795896f0 100644
--- a/docs/source/en/model_doc/mobilenet_v1.mdx
+++ b/docs/source/en/model_doc/mobilenet_v1.mdx
@@ -44,6 +44,16 @@ Unsupported features:
This model was contributed by [matthijs](https://huggingface.co/Matthijs). The original code and weights can be found [here](https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet_v1.md).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with MobileNetV1.
+
+
+
+- [`MobileNetV1ForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
## MobileNetV1Config
[[autodoc]] MobileNetV1Config
diff --git a/docs/source/en/model_doc/mobilenet_v2.mdx b/docs/source/en/model_doc/mobilenet_v2.mdx
index 6b9dde63b8..6f179f3cee 100644
--- a/docs/source/en/model_doc/mobilenet_v2.mdx
+++ b/docs/source/en/model_doc/mobilenet_v2.mdx
@@ -48,6 +48,16 @@ Unsupported features:
This model was contributed by [matthijs](https://huggingface.co/Matthijs). The original code and weights can be found [here for the main model](https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet) and [here for DeepLabV3+](https://github.com/tensorflow/models/tree/master/research/deeplab).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with MobileNetV2.
+
+
+
+- [`MobileNetV2ForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
## MobileNetV2Config
[[autodoc]] MobileNetV2Config
diff --git a/docs/source/en/model_doc/mobilevit.mdx b/docs/source/en/model_doc/mobilevit.mdx
index c7de403a80..6c0b5b6aae 100644
--- a/docs/source/en/model_doc/mobilevit.mdx
+++ b/docs/source/en/model_doc/mobilevit.mdx
@@ -57,6 +57,15 @@ with open(tflite_filename, "wb") as f:
This model was contributed by [matthijs](https://huggingface.co/Matthijs). The TensorFlow version of the model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code and weights can be found [here](https://github.com/apple/ml-cvnets).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with MobileViT.
+
+
+
+- [`MobileViTForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## MobileViTConfig
diff --git a/docs/source/en/model_doc/nat.mdx b/docs/source/en/model_doc/nat.mdx
index 43b59fb471..636b984c6a 100644
--- a/docs/source/en/model_doc/nat.mdx
+++ b/docs/source/en/model_doc/nat.mdx
@@ -56,6 +56,15 @@ Taken from the original paper.
+
+- [`NatForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## NatConfig
diff --git a/docs/source/en/model_doc/poolformer.mdx b/docs/source/en/model_doc/poolformer.mdx
index e047626261..be3aa29849 100644
--- a/docs/source/en/model_doc/poolformer.mdx
+++ b/docs/source/en/model_doc/poolformer.mdx
@@ -41,6 +41,16 @@ Tips:
This model was contributed by [heytanay](https://huggingface.co/heytanay). The original code can be found [here](https://github.com/sail-sg/poolformer).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with PoolFormer.
+
+
+
+- [`PoolFormerForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
## PoolFormerConfig
[[autodoc]] PoolFormerConfig
diff --git a/docs/source/en/model_doc/regnet.mdx b/docs/source/en/model_doc/regnet.mdx
index a426ad8fa1..62d030452a 100644
--- a/docs/source/en/model_doc/regnet.mdx
+++ b/docs/source/en/model_doc/regnet.mdx
@@ -31,6 +31,15 @@ This model was contributed by [Francesco](https://huggingface.co/Francesco). The
was contributed by [sayakpaul](https://huggingface.com/sayakpaul) and [ariG23498](https://huggingface.com/ariG23498).
The original code can be found [here](https://github.com/facebookresearch/pycls).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with RegNet.
+
+
+
+- [`RegNetForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## RegNetConfig
diff --git a/docs/source/en/model_doc/resnet.mdx b/docs/source/en/model_doc/resnet.mdx
index ce1799e8d4..031066b69b 100644
--- a/docs/source/en/model_doc/resnet.mdx
+++ b/docs/source/en/model_doc/resnet.mdx
@@ -33,6 +33,16 @@ The figure below illustrates the architecture of ResNet. Taken from the [origina
This model was contributed by [Francesco](https://huggingface.co/Francesco). The TensorFlow version of this model was added by [amyeroberts](https://huggingface.co/amyeroberts). The original code can be found [here](https://github.com/KaimingHe/deep-residual-networks).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ResNet.
+
+
+
+- [`ResNetForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
## ResNetConfig
[[autodoc]] ResNetConfig
diff --git a/docs/source/en/model_doc/segformer.mdx b/docs/source/en/model_doc/segformer.mdx
index 76a02c27f4..5c494e4747 100644
--- a/docs/source/en/model_doc/segformer.mdx
+++ b/docs/source/en/model_doc/segformer.mdx
@@ -84,6 +84,22 @@ Tips:
Note that MiT in the above table refers to the Mix Transformer encoder backbone introduced in SegFormer. For
SegFormer's results on the segmentation datasets like ADE20k, refer to the [paper](https://arxiv.org/abs/2105.15203).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with SegFormer.
+
+
+
+- [`SegformerForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+Semantic segmentation:
+
+- [`SegformerForSemanticSegmentation`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/semantic-segmentation).
+- A blog on fine-tuning SegFormer on a custom dataset can be found [here](https://huggingface.co/blog/fine-tune-segformer).
+- More demo notebooks on SegFormer (both inference + fine-tuning on a custom dataset) can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/SegFormer).
+- [`TFSegformerForSemanticSegmentation`] is supported by this [example notebook](https://github.com/huggingface/notebooks/blob/main/examples/semantic_segmentation-tf.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## SegformerConfig
diff --git a/docs/source/en/model_doc/swin.mdx b/docs/source/en/model_doc/swin.mdx
index 503a141084..1bb4fb88d8 100644
--- a/docs/source/en/model_doc/swin.mdx
+++ b/docs/source/en/model_doc/swin.mdx
@@ -45,6 +45,20 @@ alt="drawing" width="600"/>
This model was contributed by [novice03](https://huggingface.co/novice03). The Tensorflow version of this model was contributed by [amyeroberts](https://huggingface.co/amyeroberts). The original code can be found [here](https://github.com/microsoft/Swin-Transformer).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Swin Transformer.
+
+
+
+- [`SwinForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+Besides that:
+
+- [`SwinForMaskedImageModeling`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
## SwinConfig
[[autodoc]] SwinConfig
diff --git a/docs/source/en/model_doc/swinv2.mdx b/docs/source/en/model_doc/swinv2.mdx
index 576f1a142a..c4378583c4 100644
--- a/docs/source/en/model_doc/swinv2.mdx
+++ b/docs/source/en/model_doc/swinv2.mdx
@@ -26,6 +26,19 @@ Tips:
This model was contributed by [nandwalritik](https://huggingface.co/nandwalritik).
The original code can be found [here](https://github.com/microsoft/Swin-Transformer).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Swin Transformer v2.
+
+
+
+- [`Swinv2ForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+Besides that:
+
+- [`Swinv2ForMaskedImageModeling`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## Swinv2Config
diff --git a/docs/source/en/model_doc/van.mdx b/docs/source/en/model_doc/van.mdx
index 9fc05ab3e7..1f5507244c 100644
--- a/docs/source/en/model_doc/van.mdx
+++ b/docs/source/en/model_doc/van.mdx
@@ -32,6 +32,15 @@ The figure below illustrates the architecture of a Visual Aattention Layer. Take
This model was contributed by [Francesco](https://huggingface.co/Francesco). The original code can be found [here](https://github.com/Visual-Attention-Network/VAN-Classification).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with VAN.
+
+
+
+- [`VanForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## VanConfig
diff --git a/docs/source/en/model_doc/vit.mdx b/docs/source/en/model_doc/vit.mdx
index de31278dfe..45ed3f1878 100644
--- a/docs/source/en/model_doc/vit.mdx
+++ b/docs/source/en/model_doc/vit.mdx
@@ -86,6 +86,21 @@ found [here](https://github.com/google-research/vision_transformer).
Note that we converted the weights from Ross Wightman's [timm library](https://github.com/rwightman/pytorch-image-models), who already converted the weights from JAX to PyTorch. Credits
go to him!
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViT.
+
+
+
+- [`ViTForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+- A blog on fine-tuning [`ViTForImageClassification`] on a custom dataset can be found [here](https://huggingface.co/blog/fine-tune-vit).
+- More demo notebooks to fine-tune [`ViTForImageClassification`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer).
+
+Besides that:
+
+- [`ViTForMaskedImageModeling`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## Resources
diff --git a/docs/source/en/model_doc/vit_mae.mdx b/docs/source/en/model_doc/vit_mae.mdx
index 4544237070..714a68e152 100644
--- a/docs/source/en/model_doc/vit_mae.mdx
+++ b/docs/source/en/model_doc/vit_mae.mdx
@@ -32,9 +32,6 @@ Tips:
- MAE (masked auto encoding) is a method for self-supervised pre-training of Vision Transformers (ViTs). The pre-training objective is relatively simple:
by masking a large portion (75%) of the image patches, the model must reconstruct raw pixel values. One can use [`ViTMAEForPreTraining`] for this purpose.
-- An example Python script that illustrates how to pre-train [`ViTMAEForPreTraining`] from scratch can be found [here](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining).
-One can easily tweak it for their own use case.
-- A notebook that illustrates how to visualize reconstructed pixel values with [`ViTMAEForPreTraining`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/ViTMAE/ViT_MAE_visualization_demo.ipynb).
- After pre-training, one "throws away" the decoder used to reconstruct pixels, and one uses the encoder for fine-tuning/linear probing. This means that after
fine-tuning, one can directly plug in the weights into a [`ViTForImageClassification`].
- One can use [`ViTImageProcessor`] to prepare images for the model. See the code examples for more info.
@@ -51,6 +48,14 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). TensorFlow version of the model was contributed by [sayakpaul](https://github.com/sayakpaul) and
[ariG23498](https://github.com/ariG23498) (equal contribution). The original code can be found [here](https://github.com/facebookresearch/mae).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViTMAE.
+
+- [`ViTMAEForPreTraining`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining), allowing you to pre-train the model from scratch/further pre-train the model on custom data.
+- A notebook that illustrates how to visualize reconstructed pixel values with [`ViTMAEForPreTraining`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/ViTMAE/ViT_MAE_visualization_demo.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## ViTMAEConfig
diff --git a/docs/source/en/model_doc/vit_msn.mdx b/docs/source/en/model_doc/vit_msn.mdx
index 07faed51e6..47c1f69e2b 100644
--- a/docs/source/en/model_doc/vit_msn.mdx
+++ b/docs/source/en/model_doc/vit_msn.mdx
@@ -46,6 +46,15 @@ labels when fine-tuned.
This model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/facebookresearch/msn).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViT MSN.
+
+
+
+- [`ViTMSNForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## ViTMSNConfig
diff --git a/docs/source/en/model_doc/xclip.mdx b/docs/source/en/model_doc/xclip.mdx
index 96832f46e5..a49ed8b913 100644
--- a/docs/source/en/model_doc/xclip.mdx
+++ b/docs/source/en/model_doc/xclip.mdx
@@ -24,7 +24,6 @@ The abstract from the paper is the following:
Tips:
- Usage of X-CLIP is identical to [CLIP](clip).
-- Demo notebooks for X-CLIP can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/X-CLIP).
 @@ -34,6 +33,13 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/microsoft/VideoX/tree/master/X-CLIP).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with X-CLIP.
+
+- Demo notebooks for X-CLIP can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/X-CLIP).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## XCLIPProcessor
diff --git a/docs/source/en/model_doc/yolos.mdx b/docs/source/en/model_doc/yolos.mdx
index 838517ea76..66533bacfb 100644
--- a/docs/source/en/model_doc/yolos.mdx
+++ b/docs/source/en/model_doc/yolos.mdx
@@ -24,7 +24,6 @@ The abstract from the paper is the following:
Tips:
- One can use [`YolosImageProcessor`] for preparing images (and optional targets) for the model. Contrary to [DETR](detr), YOLOS doesn't require a `pixel_mask` to be created.
-- Demo notebooks (regarding inference and fine-tuning on custom data) can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/YOLOS).
@@ -34,6 +33,13 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/microsoft/VideoX/tree/master/X-CLIP).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with X-CLIP.
+
+- Demo notebooks for X-CLIP can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/X-CLIP).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## XCLIPProcessor
diff --git a/docs/source/en/model_doc/yolos.mdx b/docs/source/en/model_doc/yolos.mdx
index 838517ea76..66533bacfb 100644
--- a/docs/source/en/model_doc/yolos.mdx
+++ b/docs/source/en/model_doc/yolos.mdx
@@ -24,7 +24,6 @@ The abstract from the paper is the following:
Tips:
- One can use [`YolosImageProcessor`] for preparing images (and optional targets) for the model. Contrary to [DETR](detr), YOLOS doesn't require a `pixel_mask` to be created.
-- Demo notebooks (regarding inference and fine-tuning on custom data) can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/YOLOS).
 @@ -33,6 +32,16 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/hustvl/YOLOS).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with YOLOS.
+
+
+
+- All example notebooks illustrating inference + fine-tuning [`YolosForObjectDetection`] on a custom dataset can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/YOLOS).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
## YolosConfig
[[autodoc]] YolosConfig
@@ -33,6 +32,16 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/hustvl/YOLOS).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with YOLOS.
+
+
+
+- All example notebooks illustrating inference + fine-tuning [`YolosForObjectDetection`] on a custom dataset can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/YOLOS).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
## YolosConfig
[[autodoc]] YolosConfig