diff --git a/docs/source/en/hpo_train.md b/docs/source/en/hpo_train.md
index c516c501f8..49dde04fe6 100644
--- a/docs/source/en/hpo_train.md
+++ b/docs/source/en/hpo_train.md
@@ -15,7 +15,7 @@ rendered properly in your Markdown viewer.
# Hyperparameter Search using Trainer API
-🤗 Transformers provides a [`Trainer`] class optimized for training 🤗 Transformers models, making it easier to start training without manually writing your own training loop. The [`Trainer`] provides API for hyperparameter search. This doc shows how to enable it in example.
+🤗 Transformers provides a [`Trainer`] class optimized for training 🤗 Transformers models, making it easier to start training without manually writing your own training loop. The [`Trainer`] provides API for hyperparameter search. This doc shows how to enable it in example.
## Hyperparameter Search backend
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
you should install them before using them as the hyperparameter search backend
```bash
-pip install optuna/sigopt/wandb/ray[tune]
+pip install optuna/sigopt/wandb/ray[tune]
```
## How to enable Hyperparameter search in example
@@ -112,7 +112,7 @@ Create a [`Trainer`] with your `model_init` function, training arguments, traini
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... model_init=model_init,
... data_collator=data_collator,
... )
diff --git a/docs/source/en/model_doc/mamba.md b/docs/source/en/model_doc/mamba.md
index 94eb2e2c2d..317948331e 100644
--- a/docs/source/en/model_doc/mamba.md
+++ b/docs/source/en/model_doc/mamba.md
@@ -39,8 +39,8 @@ The original code can be found [here](https://github.com/state-spaces/mamba).
# Usage
-### A simple generation example:
-```python
+### A simple generation example:
+```python
from transformers import MambaConfig, MambaForCausalLM, AutoTokenizer
import torch
@@ -55,7 +55,7 @@ print(tokenizer.batch_decode(out))
### Peft finetuning
The slow version is not very stable for training, and the fast one needs `float32`!
-```python
+```python
from datasets import load_dataset
from trl import SFTTrainer
from peft import LoraConfig
@@ -80,7 +80,7 @@ lora_config = LoraConfig(
)
trainer = SFTTrainer(
model=model,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
args=training_args,
peft_config=lora_config,
train_dataset=dataset,
diff --git a/docs/source/en/quicktour.md b/docs/source/en/quicktour.md
index fb1689cce7..f6fc66f4b6 100755
--- a/docs/source/en/quicktour.md
+++ b/docs/source/en/quicktour.md
@@ -111,7 +111,7 @@ Load an audio dataset (see the 🤗 Datasets [Quick Start](https://huggingface.c
>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train") # doctest: +IGNORE_RESULT
```
-You need to make sure the sampling rate of the dataset matches the sampling
+You need to make sure the sampling rate of the dataset matches the sampling
rate [`facebook/wav2vec2-base-960h`](https://huggingface.co/facebook/wav2vec2-base-960h) was trained on:
```py
@@ -174,7 +174,7 @@ If you can't find a model for your use-case, you'll need to finetune a pretraine
-Under the hood, the [`AutoModelForSequenceClassification`] and [`AutoTokenizer`] classes work together to power the [`pipeline`] you used above. An [AutoClass](./model_doc/auto) is a shortcut that automatically retrieves the architecture of a pretrained model from its name or path. You only need to select the appropriate `AutoClass` for your task and it's associated preprocessing class.
+Under the hood, the [`AutoModelForSequenceClassification`] and [`AutoTokenizer`] classes work together to power the [`pipeline`] you used above. An [AutoClass](./model_doc/auto) is a shortcut that automatically retrieves the architecture of a pretrained model from its name or path. You only need to select the appropriate `AutoClass` for your task and it's associated preprocessing class.
Let's return to the example from the previous section and see how you can use the `AutoClass` to replicate the results of the [`pipeline`].
@@ -485,7 +485,7 @@ Now gather all these classes in [`Trainer`]:
... args=training_args,
... train_dataset=dataset["train"],
... eval_dataset=dataset["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... ) # doctest: +SKIP
```
@@ -502,7 +502,7 @@ For tasks - like translation or summarization - that use a sequence-to-sequence
-You can customize the training loop behavior by subclassing the methods inside [`Trainer`]. This allows you to customize features such as the loss function, optimizer, and scheduler. Take a look at the [`Trainer`] reference for which methods can be subclassed.
+You can customize the training loop behavior by subclassing the methods inside [`Trainer`]. This allows you to customize features such as the loss function, optimizer, and scheduler. Take a look at the [`Trainer`] reference for which methods can be subclassed.
The other way to customize the training loop is by using [Callbacks](./main_classes/callback). You can use callbacks to integrate with other libraries and inspect the training loop to report on progress or stop the training early. Callbacks do not modify anything in the training loop itself. To customize something like the loss function, you need to subclass the [`Trainer`] instead.
diff --git a/docs/source/en/tasks/asr.md b/docs/source/en/tasks/asr.md
index 2ddd972c3d..f3e068444c 100644
--- a/docs/source/en/tasks/asr.md
+++ b/docs/source/en/tasks/asr.md
@@ -281,7 +281,7 @@ At this point, only three steps remain:
... args=training_args,
... train_dataset=encoded_minds["train"],
... eval_dataset=encoded_minds["test"],
-... tokenizer=processor,
+... processing_class=processor,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
@@ -368,4 +368,4 @@ Get the predicted `input_ids` with the highest probability, and use the processo
['I WOUL LIKE O SET UP JOINT ACOUNT WTH Y PARTNER']
```
-
\ No newline at end of file
+
diff --git a/docs/source/en/tasks/audio_classification.md b/docs/source/en/tasks/audio_classification.md
index 4610e86d6a..59d6a175da 100644
--- a/docs/source/en/tasks/audio_classification.md
+++ b/docs/source/en/tasks/audio_classification.md
@@ -98,8 +98,8 @@ Take a look at an example now:
There are two fields:
-- `audio`: a 1-dimensional `array` of the speech signal that must be called to load and resample the audio file.
-- `intent_class`: represents the class id of the speaker's intent.
+- `audio`: a 1-dimensional `array` of the speech signal that must be called to load and resample the audio file.
+- `intent_class`: represents the class id of the speaker's intent.
To make it easier for the model to get the label name from the label id, create a dictionary that maps the label name to an integer and vice versa:
@@ -235,7 +235,7 @@ At this point, only three steps remain:
... args=training_args,
... train_dataset=encoded_minds["train"],
... eval_dataset=encoded_minds["test"],
-... tokenizer=feature_extractor,
+... processing_class=feature_extractor,
... compute_metrics=compute_metrics,
... )
@@ -321,4 +321,4 @@ Get the class with the highest probability, and use the model's `id2label` mappi
'cash_deposit'
```
-
\ No newline at end of file
+
diff --git a/docs/source/en/tasks/document_question_answering.md b/docs/source/en/tasks/document_question_answering.md
index 54c0cd5aef..d83e025c40 100644
--- a/docs/source/en/tasks/document_question_answering.md
+++ b/docs/source/en/tasks/document_question_answering.md
@@ -420,7 +420,7 @@ Finally, bring everything together, and call [`~Trainer.train`]:
... data_collator=data_collator,
... train_dataset=encoded_train_dataset,
... eval_dataset=encoded_test_dataset,
-... tokenizer=processor,
+... processing_class=processor,
... )
>>> trainer.train()
@@ -489,4 +489,4 @@ which token is at the end of the answer. Both have shape (batch_size, sequence_l
>>> processor.tokenizer.decode(encoding.input_ids.squeeze()[predicted_start_idx : predicted_end_idx + 1])
'lee a. waller'
-```
\ No newline at end of file
+```
diff --git a/docs/source/en/tasks/image_classification.md b/docs/source/en/tasks/image_classification.md
index 279216443b..514ec3fbfe 100644
--- a/docs/source/en/tasks/image_classification.md
+++ b/docs/source/en/tasks/image_classification.md
@@ -317,7 +317,7 @@ At this point, only three steps remain:
... data_collator=data_collator,
... train_dataset=food["train"],
... eval_dataset=food["test"],
-... tokenizer=image_processor,
+... processing_class=image_processor,
... compute_metrics=compute_metrics,
... )
diff --git a/docs/source/en/tasks/knowledge_distillation_for_image_classification.md b/docs/source/en/tasks/knowledge_distillation_for_image_classification.md
index f856e35b17..530e92d81f 100644
--- a/docs/source/en/tasks/knowledge_distillation_for_image_classification.md
+++ b/docs/source/en/tasks/knowledge_distillation_for_image_classification.md
@@ -19,9 +19,9 @@ rendered properly in your Markdown viewer.
Knowledge distillation is a technique used to transfer knowledge from a larger, more complex model (teacher) to a smaller, simpler model (student). To distill knowledge from one model to another, we take a pre-trained teacher model trained on a certain task (image classification for this case) and randomly initialize a student model to be trained on image classification. Next, we train the student model to minimize the difference between it's outputs and the teacher's outputs, thus making it mimic the behavior. It was first introduced in [Distilling the Knowledge in a Neural Network by Hinton et al](https://arxiv.org/abs/1503.02531). In this guide, we will do task-specific knowledge distillation. We will use the [beans dataset](https://huggingface.co/datasets/beans) for this.
-This guide demonstrates how you can distill a [fine-tuned ViT model](https://huggingface.co/merve/vit-mobilenet-beans-224) (teacher model) to a [MobileNet](https://huggingface.co/google/mobilenet_v2_1.4_224) (student model) using the [Trainer API](https://huggingface.co/docs/transformers/en/main_classes/trainer#trainer) of 🤗 Transformers.
+This guide demonstrates how you can distill a [fine-tuned ViT model](https://huggingface.co/merve/vit-mobilenet-beans-224) (teacher model) to a [MobileNet](https://huggingface.co/google/mobilenet_v2_1.4_224) (student model) using the [Trainer API](https://huggingface.co/docs/transformers/en/main_classes/trainer#trainer) of 🤗 Transformers.
-Let's install the libraries needed for distillation and evaluating the process.
+Let's install the libraries needed for distillation and evaluating the process.
```bash
pip install transformers datasets accelerate tensorboard evaluate --upgrade
@@ -29,7 +29,7 @@ pip install transformers datasets accelerate tensorboard evaluate --upgrade
In this example, we are using the `merve/beans-vit-224` model as teacher model. It's an image classification model, based on `google/vit-base-patch16-224-in21k` fine-tuned on beans dataset. We will distill this model to a randomly initialized MobileNetV2.
-We will now load the dataset.
+We will now load the dataset.
```python
from datasets import load_dataset
@@ -37,7 +37,7 @@ from datasets import load_dataset
dataset = load_dataset("beans")
```
-We can use an image processor from either of the models, as in this case they return the same output with same resolution. We will use the `map()` method of `dataset` to apply the preprocessing to every split of the dataset.
+We can use an image processor from either of the models, as in this case they return the same output with same resolution. We will use the `map()` method of `dataset` to apply the preprocessing to every split of the dataset.
```python
from transformers import AutoImageProcessor
@@ -93,7 +93,7 @@ class ImageDistilTrainer(Trainer):
return (loss, student_output) if return_outputs else loss
```
-We will now login to Hugging Face Hub so we can push our model to the Hugging Face Hub through the `Trainer`.
+We will now login to Hugging Face Hub so we can push our model to the Hugging Face Hub through the `Trainer`.
```python
from huggingface_hub import notebook_login
@@ -101,7 +101,7 @@ from huggingface_hub import notebook_login
notebook_login()
```
-Let's set the `TrainingArguments`, the teacher model and the student model.
+Let's set the `TrainingArguments`, the teacher model and the student model.
```python
from transformers import AutoModelForImageClassification, MobileNetV2Config, MobileNetV2ForImageClassification
@@ -164,7 +164,7 @@ trainer = ImageDistilTrainer(
train_dataset=processed_datasets["train"],
eval_dataset=processed_datasets["validation"],
data_collator=data_collator,
- tokenizer=teacher_processor,
+ processing_class=teacher_processor,
compute_metrics=compute_metrics,
temperature=5,
lambda_param=0.5
diff --git a/docs/source/en/tasks/multiple_choice.md b/docs/source/en/tasks/multiple_choice.md
index fc63c35425..06eb45eda9 100644
--- a/docs/source/en/tasks/multiple_choice.md
+++ b/docs/source/en/tasks/multiple_choice.md
@@ -270,7 +270,7 @@ At this point, only three steps remain:
... args=training_args,
... train_dataset=tokenized_swag["train"],
... eval_dataset=tokenized_swag["validation"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=DataCollatorForMultipleChoice(tokenizer=tokenizer),
... compute_metrics=compute_metrics,
... )
diff --git a/docs/source/en/tasks/object_detection.md b/docs/source/en/tasks/object_detection.md
index dfad80b949..fdc81896bc 100644
--- a/docs/source/en/tasks/object_detection.md
+++ b/docs/source/en/tasks/object_detection.md
@@ -340,7 +340,7 @@ with `pixel_values`, a tensor with `pixel_mask`, and `labels`.
[ 0.0741, 0.0741, 0.0741, ..., 0.0741, 0.0741, 0.0741],
[ 0.0741, 0.0741, 0.0741, ..., 0.0741, 0.0741, 0.0741],
[ 0.0741, 0.0741, 0.0741, ..., 0.0741, 0.0741, 0.0741]],
-
+
[[ 1.6232, 1.6408, 1.6583, ..., 0.8704, 1.0105, 1.1331],
[ 1.6408, 1.6583, 1.6758, ..., 0.8529, 0.9930, 1.0980],
[ 1.6933, 1.6933, 1.7108, ..., 0.8179, 0.9580, 1.0630],
@@ -348,7 +348,7 @@ with `pixel_values`, a tensor with `pixel_mask`, and `labels`.
[ 0.2052, 0.2052, 0.2052, ..., 0.2052, 0.2052, 0.2052],
[ 0.2052, 0.2052, 0.2052, ..., 0.2052, 0.2052, 0.2052],
[ 0.2052, 0.2052, 0.2052, ..., 0.2052, 0.2052, 0.2052]],
-
+
[[ 1.8905, 1.9080, 1.9428, ..., -0.1487, -0.0964, -0.0615],
[ 1.9254, 1.9428, 1.9603, ..., -0.1661, -0.1138, -0.0790],
[ 1.9777, 1.9777, 1.9951, ..., -0.2010, -0.1138, -0.0790],
@@ -569,7 +569,7 @@ Finally, bring everything together, and call [`~transformers.Trainer.train`]:
... args=training_args,
... train_dataset=cppe5["train"],
... eval_dataset=cppe5["validation"],
-... tokenizer=image_processor,
+... processing_class=image_processor,
... data_collator=collate_fn,
... compute_metrics=eval_compute_metrics_fn,
... )
diff --git a/docs/source/en/tasks/question_answering.md b/docs/source/en/tasks/question_answering.md
index 367e35b121..998010e67c 100644
--- a/docs/source/en/tasks/question_answering.md
+++ b/docs/source/en/tasks/question_answering.md
@@ -225,7 +225,7 @@ At this point, only three steps remain:
... args=training_args,
... train_dataset=tokenized_squad["train"],
... eval_dataset=tokenized_squad["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... )
diff --git a/docs/source/en/tasks/sequence_classification.md b/docs/source/en/tasks/sequence_classification.md
index 572d6493ba..27516ace1c 100644
--- a/docs/source/en/tasks/sequence_classification.md
+++ b/docs/source/en/tasks/sequence_classification.md
@@ -190,7 +190,7 @@ At this point, only three steps remain:
... args=training_args,
... train_dataset=tokenized_imdb["train"],
... eval_dataset=tokenized_imdb["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
diff --git a/docs/source/en/tasks/summarization.md b/docs/source/en/tasks/summarization.md
index b79415996c..7d7ecf1fba 100644
--- a/docs/source/en/tasks/summarization.md
+++ b/docs/source/en/tasks/summarization.md
@@ -214,7 +214,7 @@ At this point, only three steps remain:
... args=training_args,
... train_dataset=tokenized_billsum["train"],
... eval_dataset=tokenized_billsum["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
diff --git a/docs/source/en/tasks/text-to-speech.md b/docs/source/en/tasks/text-to-speech.md
index ad8c43a28e..188d4ea5f9 100644
--- a/docs/source/en/tasks/text-to-speech.md
+++ b/docs/source/en/tasks/text-to-speech.md
@@ -18,13 +18,13 @@ rendered properly in your Markdown viewer.
[[open-in-colab]]
-Text-to-speech (TTS) is the task of creating natural-sounding speech from text, where the speech can be generated in multiple
-languages and for multiple speakers. Several text-to-speech models are currently available in 🤗 Transformers, such as
-[Bark](../model_doc/bark), [MMS](../model_doc/mms), [VITS](../model_doc/vits) and [SpeechT5](../model_doc/speecht5).
+Text-to-speech (TTS) is the task of creating natural-sounding speech from text, where the speech can be generated in multiple
+languages and for multiple speakers. Several text-to-speech models are currently available in 🤗 Transformers, such as
+[Bark](../model_doc/bark), [MMS](../model_doc/mms), [VITS](../model_doc/vits) and [SpeechT5](../model_doc/speecht5).
-You can easily generate audio using the `"text-to-audio"` pipeline (or its alias - `"text-to-speech"`). Some models, like Bark,
+You can easily generate audio using the `"text-to-audio"` pipeline (or its alias - `"text-to-speech"`). Some models, like Bark,
can also be conditioned to generate non-verbal communications such as laughing, sighing and crying, or even add music.
-Here's an example of how you would use the `"text-to-speech"` pipeline with Bark:
+Here's an example of how you would use the `"text-to-speech"` pipeline with Bark:
```py
>>> from transformers import pipeline
@@ -34,18 +34,18 @@ Here's an example of how you would use the `"text-to-speech"` pipeline with Bark
>>> output = pipe(text)
```
-Here's a code snippet you can use to listen to the resulting audio in a notebook:
+Here's a code snippet you can use to listen to the resulting audio in a notebook:
```python
>>> from IPython.display import Audio
>>> Audio(output["audio"], rate=output["sampling_rate"])
```
-For more examples on what Bark and other pretrained TTS models can do, refer to our
-[Audio course](https://huggingface.co/learn/audio-course/chapter6/pre-trained_models).
+For more examples on what Bark and other pretrained TTS models can do, refer to our
+[Audio course](https://huggingface.co/learn/audio-course/chapter6/pre-trained_models).
-If you are looking to fine-tune a TTS model, the only text-to-speech models currently available in 🤗 Transformers
-are [SpeechT5](model_doc/speecht5) and [FastSpeech2Conformer](model_doc/fastspeech2_conformer), though more will be added in the future. SpeechT5 is pre-trained on a combination of speech-to-text and text-to-speech data, allowing it to learn a unified space of hidden representations shared by both text and speech. This means that the same pre-trained model can be fine-tuned for different tasks. Furthermore, SpeechT5 supports multiple speakers through x-vector speaker embeddings.
+If you are looking to fine-tune a TTS model, the only text-to-speech models currently available in 🤗 Transformers
+are [SpeechT5](model_doc/speecht5) and [FastSpeech2Conformer](model_doc/fastspeech2_conformer), though more will be added in the future. SpeechT5 is pre-trained on a combination of speech-to-text and text-to-speech data, allowing it to learn a unified space of hidden representations shared by both text and speech. This means that the same pre-trained model can be fine-tuned for different tasks. Furthermore, SpeechT5 supports multiple speakers through x-vector speaker embeddings.
The remainder of this guide illustrates how to:
@@ -66,7 +66,7 @@ pip install git+https://github.com/huggingface/transformers.git
-To follow this guide you will need a GPU. If you're working in a notebook, run the following line to check if a GPU is available:
+To follow this guide you will need a GPU. If you're working in a notebook, run the following line to check if a GPU is available:
```bash
!nvidia-smi
@@ -90,13 +90,13 @@ We encourage you to log in to your Hugging Face account to upload and share your
## Load the dataset
-[VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) is a large-scale multilingual speech corpus consisting of
-data sourced from 2009-2020 European Parliament event recordings. It contains labelled audio-transcription data for 15
-European languages. In this guide, we are using the Dutch language subset, feel free to pick another subset.
+[VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) is a large-scale multilingual speech corpus consisting of
+data sourced from 2009-2020 European Parliament event recordings. It contains labelled audio-transcription data for 15
+European languages. In this guide, we are using the Dutch language subset, feel free to pick another subset.
-Note that VoxPopuli or any other automated speech recognition (ASR) dataset may not be the most suitable
-option for training TTS models. The features that make it beneficial for ASR, such as excessive background noise, are
-typically undesirable in TTS. However, finding top-quality, multilingual, and multi-speaker TTS datasets can be quite
+Note that VoxPopuli or any other automated speech recognition (ASR) dataset may not be the most suitable
+option for training TTS models. The features that make it beneficial for ASR, such as excessive background noise, are
+typically undesirable in TTS. However, finding top-quality, multilingual, and multi-speaker TTS datasets can be quite
challenging.
Let's load the data:
@@ -109,7 +109,7 @@ Let's load the data:
20968
```
-20968 examples should be sufficient for fine-tuning. SpeechT5 expects audio data to have a sampling rate of 16 kHz, so
+20968 examples should be sufficient for fine-tuning. SpeechT5 expects audio data to have a sampling rate of 16 kHz, so
make sure the examples in the dataset meet this requirement:
```py
@@ -118,7 +118,7 @@ dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
## Preprocess the data
-Let's begin by defining the model checkpoint to use and loading the appropriate processor:
+Let's begin by defining the model checkpoint to use and loading the appropriate processor:
```py
>>> from transformers import SpeechT5Processor
@@ -127,7 +127,7 @@ Let's begin by defining the model checkpoint to use and loading the appropriate
>>> processor = SpeechT5Processor.from_pretrained(checkpoint)
```
-### Text cleanup for SpeechT5 tokenization
+### Text cleanup for SpeechT5 tokenization
Start by cleaning up the text data. You'll need the tokenizer part of the processor to process the text:
@@ -135,18 +135,18 @@ Start by cleaning up the text data. You'll need the tokenizer part of the proces
>>> tokenizer = processor.tokenizer
```
-The dataset examples contain `raw_text` and `normalized_text` features. When deciding which feature to use as the text input,
-consider that the SpeechT5 tokenizer doesn't have any tokens for numbers. In `normalized_text` the numbers are written
+The dataset examples contain `raw_text` and `normalized_text` features. When deciding which feature to use as the text input,
+consider that the SpeechT5 tokenizer doesn't have any tokens for numbers. In `normalized_text` the numbers are written
out as text. Thus, it is a better fit, and we recommend using `normalized_text` as input text.
-Because SpeechT5 was trained on the English language, it may not recognize certain characters in the Dutch dataset. If
-left as is, these characters will be converted to `` tokens. However, in Dutch, certain characters like `à` are
+Because SpeechT5 was trained on the English language, it may not recognize certain characters in the Dutch dataset. If
+left as is, these characters will be converted to `` tokens. However, in Dutch, certain characters like `à` are
used to stress syllables. In order to preserve the meaning of the text, we can replace this character with a regular `a`.
-To identify unsupported tokens, extract all unique characters in the dataset using the `SpeechT5Tokenizer` which
-works with characters as tokens. To do this, write the `extract_all_chars` mapping function that concatenates
-the transcriptions from all examples into one string and converts it to a set of characters.
-Make sure to set `batched=True` and `batch_size=-1` in `dataset.map()` so that all transcriptions are available at once for
+To identify unsupported tokens, extract all unique characters in the dataset using the `SpeechT5Tokenizer` which
+works with characters as tokens. To do this, write the `extract_all_chars` mapping function that concatenates
+the transcriptions from all examples into one string and converts it to a set of characters.
+Make sure to set `batched=True` and `batch_size=-1` in `dataset.map()` so that all transcriptions are available at once for
the mapping function.
```py
@@ -168,8 +168,8 @@ the mapping function.
>>> tokenizer_vocab = {k for k, _ in tokenizer.get_vocab().items()}
```
-Now you have two sets of characters: one with the vocabulary from the dataset and one with the vocabulary from the tokenizer.
-To identify any unsupported characters in the dataset, you can take the difference between these two sets. The resulting
+Now you have two sets of characters: one with the vocabulary from the dataset and one with the vocabulary from the tokenizer.
+To identify any unsupported characters in the dataset, you can take the difference between these two sets. The resulting
set will contain the characters that are in the dataset but not in the tokenizer.
```py
@@ -177,7 +177,7 @@ set will contain the characters that are in the dataset but not in the tokenizer
{' ', 'à', 'ç', 'è', 'ë', 'í', 'ï', 'ö', 'ü'}
```
-To handle the unsupported characters identified in the previous step, define a function that maps these characters to
+To handle the unsupported characters identified in the previous step, define a function that maps these characters to
valid tokens. Note that spaces are already replaced by `▁` in the tokenizer and don't need to be handled separately.
```py
@@ -206,9 +206,9 @@ Now that you have dealt with special characters in the text, it's time to shift
### Speakers
-The VoxPopuli dataset includes speech from multiple speakers, but how many speakers are represented in the dataset? To
-determine this, we can count the number of unique speakers and the number of examples each speaker contributes to the dataset.
-With a total of 20,968 examples in the dataset, this information will give us a better understanding of the distribution of
+The VoxPopuli dataset includes speech from multiple speakers, but how many speakers are represented in the dataset? To
+determine this, we can count the number of unique speakers and the number of examples each speaker contributes to the dataset.
+With a total of 20,968 examples in the dataset, this information will give us a better understanding of the distribution of
speakers and examples in the data.
```py
@@ -236,9 +236,9 @@ By plotting a histogram you can get a sense of how much data there is for each s
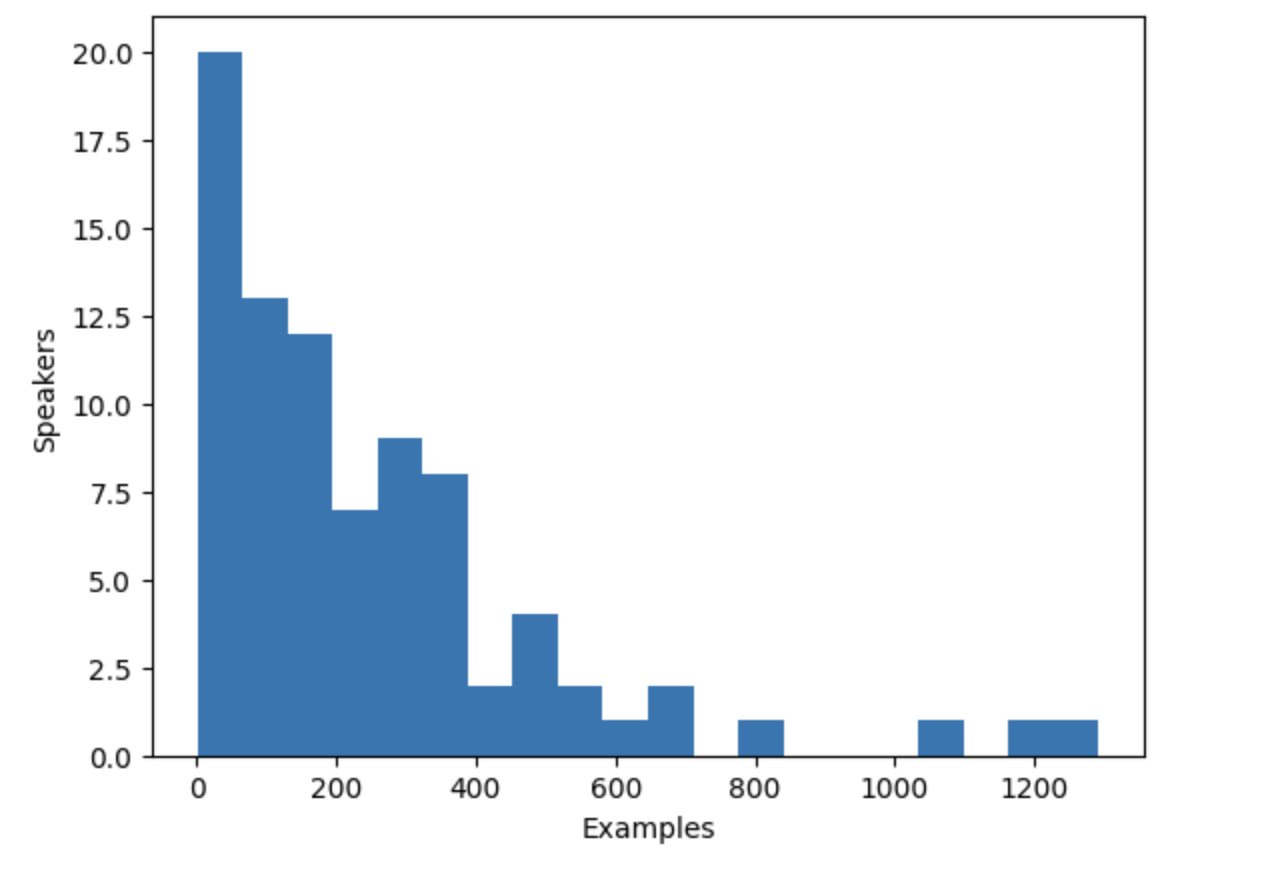 -The histogram reveals that approximately one-third of the speakers in the dataset have fewer than 100 examples, while
-around ten speakers have more than 500 examples. To improve training efficiency and balance the dataset, we can limit
-the data to speakers with between 100 and 400 examples.
+The histogram reveals that approximately one-third of the speakers in the dataset have fewer than 100 examples, while
+around ten speakers have more than 500 examples. To improve training efficiency and balance the dataset, we can limit
+the data to speakers with between 100 and 400 examples.
```py
>>> def select_speaker(speaker_id):
@@ -248,14 +248,14 @@ the data to speakers with between 100 and 400 examples.
>>> dataset = dataset.filter(select_speaker, input_columns=["speaker_id"])
```
-Let's check how many speakers remain:
+Let's check how many speakers remain:
```py
>>> len(set(dataset["speaker_id"]))
42
```
-Let's see how many examples are left:
+Let's see how many examples are left:
```py
>>> len(dataset)
@@ -264,18 +264,18 @@ Let's see how many examples are left:
You are left with just under 10,000 examples from approximately 40 unique speakers, which should be sufficient.
-Note that some speakers with few examples may actually have more audio available if the examples are long. However,
-determining the total amount of audio for each speaker requires scanning through the entire dataset, which is a
+Note that some speakers with few examples may actually have more audio available if the examples are long. However,
+determining the total amount of audio for each speaker requires scanning through the entire dataset, which is a
time-consuming process that involves loading and decoding each audio file. As such, we have chosen to skip this step here.
### Speaker embeddings
-To enable the TTS model to differentiate between multiple speakers, you'll need to create a speaker embedding for each example.
+To enable the TTS model to differentiate between multiple speakers, you'll need to create a speaker embedding for each example.
The speaker embedding is an additional input into the model that captures a particular speaker's voice characteristics.
-To generate these speaker embeddings, use the pre-trained [spkrec-xvect-voxceleb](https://huggingface.co/speechbrain/spkrec-xvect-voxceleb)
-model from SpeechBrain.
+To generate these speaker embeddings, use the pre-trained [spkrec-xvect-voxceleb](https://huggingface.co/speechbrain/spkrec-xvect-voxceleb)
+model from SpeechBrain.
-Create a function `create_speaker_embedding()` that takes an input audio waveform and outputs a 512-element vector
+Create a function `create_speaker_embedding()` that takes an input audio waveform and outputs a 512-element vector
containing the corresponding speaker embedding.
```py
@@ -301,17 +301,17 @@ containing the corresponding speaker embedding.
... return speaker_embeddings
```
-It's important to note that the `speechbrain/spkrec-xvect-voxceleb` model was trained on English speech from the VoxCeleb
-dataset, whereas the training examples in this guide are in Dutch. While we believe that this model will still generate
+It's important to note that the `speechbrain/spkrec-xvect-voxceleb` model was trained on English speech from the VoxCeleb
+dataset, whereas the training examples in this guide are in Dutch. While we believe that this model will still generate
reasonable speaker embeddings for our Dutch dataset, this assumption may not hold true in all cases.
-For optimal results, we recommend training an X-vector model on the target speech first. This will ensure that the model
+For optimal results, we recommend training an X-vector model on the target speech first. This will ensure that the model
is better able to capture the unique voice characteristics present in the Dutch language.
### Processing the dataset
-Finally, let's process the data into the format the model expects. Create a `prepare_dataset` function that takes in a
-single example and uses the `SpeechT5Processor` object to tokenize the input text and load the target audio into a log-mel spectrogram.
+Finally, let's process the data into the format the model expects. Create a `prepare_dataset` function that takes in a
+single example and uses the `SpeechT5Processor` object to tokenize the input text and load the target audio into a log-mel spectrogram.
It should also add the speaker embeddings as an additional input.
```py
@@ -363,8 +363,8 @@ The labels should be a log-mel spectrogram with 80 mel bins.
-The histogram reveals that approximately one-third of the speakers in the dataset have fewer than 100 examples, while
-around ten speakers have more than 500 examples. To improve training efficiency and balance the dataset, we can limit
-the data to speakers with between 100 and 400 examples.
+The histogram reveals that approximately one-third of the speakers in the dataset have fewer than 100 examples, while
+around ten speakers have more than 500 examples. To improve training efficiency and balance the dataset, we can limit
+the data to speakers with between 100 and 400 examples.
```py
>>> def select_speaker(speaker_id):
@@ -248,14 +248,14 @@ the data to speakers with between 100 and 400 examples.
>>> dataset = dataset.filter(select_speaker, input_columns=["speaker_id"])
```
-Let's check how many speakers remain:
+Let's check how many speakers remain:
```py
>>> len(set(dataset["speaker_id"]))
42
```
-Let's see how many examples are left:
+Let's see how many examples are left:
```py
>>> len(dataset)
@@ -264,18 +264,18 @@ Let's see how many examples are left:
You are left with just under 10,000 examples from approximately 40 unique speakers, which should be sufficient.
-Note that some speakers with few examples may actually have more audio available if the examples are long. However,
-determining the total amount of audio for each speaker requires scanning through the entire dataset, which is a
+Note that some speakers with few examples may actually have more audio available if the examples are long. However,
+determining the total amount of audio for each speaker requires scanning through the entire dataset, which is a
time-consuming process that involves loading and decoding each audio file. As such, we have chosen to skip this step here.
### Speaker embeddings
-To enable the TTS model to differentiate between multiple speakers, you'll need to create a speaker embedding for each example.
+To enable the TTS model to differentiate between multiple speakers, you'll need to create a speaker embedding for each example.
The speaker embedding is an additional input into the model that captures a particular speaker's voice characteristics.
-To generate these speaker embeddings, use the pre-trained [spkrec-xvect-voxceleb](https://huggingface.co/speechbrain/spkrec-xvect-voxceleb)
-model from SpeechBrain.
+To generate these speaker embeddings, use the pre-trained [spkrec-xvect-voxceleb](https://huggingface.co/speechbrain/spkrec-xvect-voxceleb)
+model from SpeechBrain.
-Create a function `create_speaker_embedding()` that takes an input audio waveform and outputs a 512-element vector
+Create a function `create_speaker_embedding()` that takes an input audio waveform and outputs a 512-element vector
containing the corresponding speaker embedding.
```py
@@ -301,17 +301,17 @@ containing the corresponding speaker embedding.
... return speaker_embeddings
```
-It's important to note that the `speechbrain/spkrec-xvect-voxceleb` model was trained on English speech from the VoxCeleb
-dataset, whereas the training examples in this guide are in Dutch. While we believe that this model will still generate
+It's important to note that the `speechbrain/spkrec-xvect-voxceleb` model was trained on English speech from the VoxCeleb
+dataset, whereas the training examples in this guide are in Dutch. While we believe that this model will still generate
reasonable speaker embeddings for our Dutch dataset, this assumption may not hold true in all cases.
-For optimal results, we recommend training an X-vector model on the target speech first. This will ensure that the model
+For optimal results, we recommend training an X-vector model on the target speech first. This will ensure that the model
is better able to capture the unique voice characteristics present in the Dutch language.
### Processing the dataset
-Finally, let's process the data into the format the model expects. Create a `prepare_dataset` function that takes in a
-single example and uses the `SpeechT5Processor` object to tokenize the input text and load the target audio into a log-mel spectrogram.
+Finally, let's process the data into the format the model expects. Create a `prepare_dataset` function that takes in a
+single example and uses the `SpeechT5Processor` object to tokenize the input text and load the target audio into a log-mel spectrogram.
It should also add the speaker embeddings as an additional input.
```py
@@ -363,8 +363,8 @@ The labels should be a log-mel spectrogram with 80 mel bins.
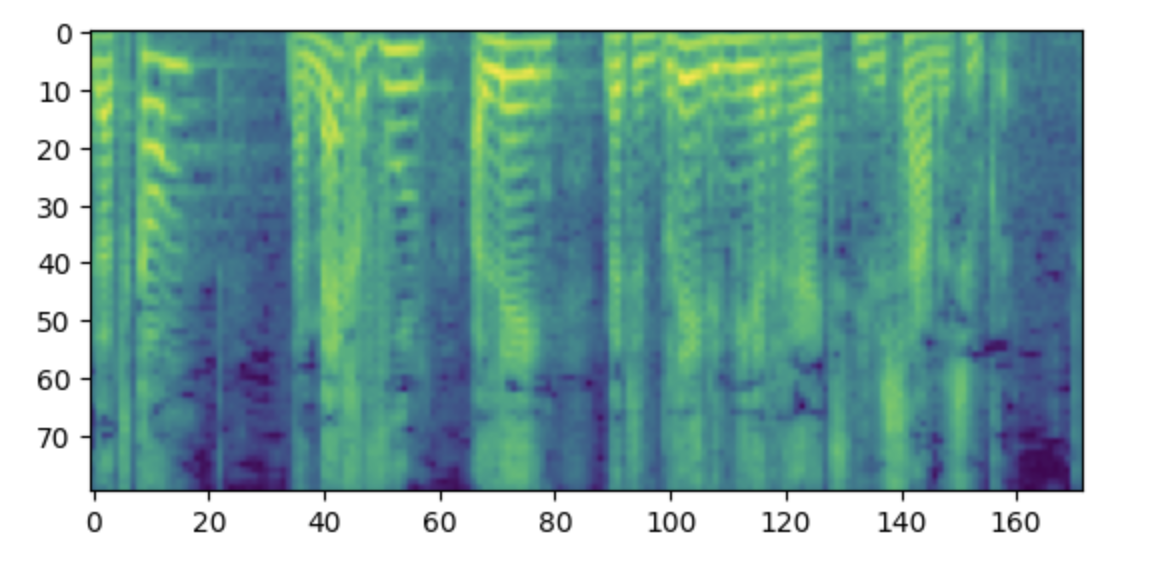 -Side note: If you find this spectrogram confusing, it may be due to your familiarity with the convention of placing low frequencies
-at the bottom and high frequencies at the top of a plot. However, when plotting spectrograms as an image using the matplotlib library,
+Side note: If you find this spectrogram confusing, it may be due to your familiarity with the convention of placing low frequencies
+at the bottom and high frequencies at the top of a plot. However, when plotting spectrograms as an image using the matplotlib library,
the y-axis is flipped and the spectrograms appear upside down.
Now apply the processing function to the entire dataset. This will take between 5 and 10 minutes.
@@ -373,7 +373,7 @@ Now apply the processing function to the entire dataset. This will take between
>>> dataset = dataset.map(prepare_dataset, remove_columns=dataset.column_names)
```
-You'll see a warning saying that some examples in the dataset are longer than the maximum input length the model can handle (600 tokens).
+You'll see a warning saying that some examples in the dataset are longer than the maximum input length the model can handle (600 tokens).
Remove those examples from the dataset. Here we go even further and to allow for larger batch sizes we remove anything over 200 tokens.
```py
@@ -387,7 +387,7 @@ Remove those examples from the dataset. Here we go even further and to allow for
8259
```
-Next, create a basic train/test split:
+Next, create a basic train/test split:
```py
>>> dataset = dataset.train_test_split(test_size=0.1)
@@ -395,8 +395,8 @@ Next, create a basic train/test split:
### Data collator
-In order to combine multiple examples into a batch, you need to define a custom data collator. This collator will pad shorter sequences with padding
-tokens, ensuring that all examples have the same length. For the spectrogram labels, the padded portions are replaced with the special value `-100`. This special value
+In order to combine multiple examples into a batch, you need to define a custom data collator. This collator will pad shorter sequences with padding
+tokens, ensuring that all examples have the same length. For the spectrogram labels, the padded portions are replaced with the special value `-100`. This special value
instructs the model to ignore that part of the spectrogram when calculating the spectrogram loss.
```py
@@ -437,18 +437,18 @@ instructs the model to ignore that part of the spectrogram when calculating the
... return batch
```
-In SpeechT5, the input to the decoder part of the model is reduced by a factor 2. In other words, it throws away every
-other timestep from the target sequence. The decoder then predicts a sequence that is twice as long. Since the original
-target sequence length may be odd, the data collator makes sure to round the maximum length of the batch down to be a
+In SpeechT5, the input to the decoder part of the model is reduced by a factor 2. In other words, it throws away every
+other timestep from the target sequence. The decoder then predicts a sequence that is twice as long. Since the original
+target sequence length may be odd, the data collator makes sure to round the maximum length of the batch down to be a
multiple of 2.
-```py
+```py
>>> data_collator = TTSDataCollatorWithPadding(processor=processor)
```
## Train the model
-Load the pre-trained model from the same checkpoint as you used for loading the processor:
+Load the pre-trained model from the same checkpoint as you used for loading the processor:
```py
>>> from transformers import SpeechT5ForTextToSpeech
@@ -458,11 +458,11 @@ Load the pre-trained model from the same checkpoint as you used for loading the
The `use_cache=True` option is incompatible with gradient checkpointing. Disable it for training.
-```py
+```py
>>> model.config.use_cache = False
```
-Define the training arguments. Here we are not computing any evaluation metrics during the training process. Instead, we'll
+Define the training arguments. Here we are not computing any evaluation metrics during the training process. Instead, we'll
only look at the loss:
```python
@@ -501,19 +501,19 @@ Instantiate the `Trainer` object and pass the model, dataset, and data collator
... train_dataset=dataset["train"],
... eval_dataset=dataset["test"],
... data_collator=data_collator,
-... tokenizer=processor,
+... processing_class=processor,
... )
```
-And with that, you're ready to start training! Training will take several hours. Depending on your GPU,
-it is possible that you will encounter a CUDA "out-of-memory" error when you start training. In this case, you can reduce
+And with that, you're ready to start training! Training will take several hours. Depending on your GPU,
+it is possible that you will encounter a CUDA "out-of-memory" error when you start training. In this case, you can reduce
the `per_device_train_batch_size` incrementally by factors of 2 and increase `gradient_accumulation_steps` by 2x to compensate.
```py
>>> trainer.train()
```
-To be able to use your checkpoint with a pipeline, make sure to save the processor with the checkpoint:
+To be able to use your checkpoint with a pipeline, make sure to save the processor with the checkpoint:
```py
>>> processor.save_pretrained("YOUR_ACCOUNT_NAME/speecht5_finetuned_voxpopuli_nl")
@@ -530,8 +530,8 @@ Push the final model to the 🤗 Hub:
### Inference with a pipeline
Great, now that you've fine-tuned a model, you can use it for inference!
-First, let's see how you can use it with a corresponding pipeline. Let's create a `"text-to-speech"` pipeline with your
-checkpoint:
+First, let's see how you can use it with a corresponding pipeline. Let's create a `"text-to-speech"` pipeline with your
+checkpoint:
```py
>>> from transformers import pipeline
@@ -545,14 +545,14 @@ Pick a piece of text in Dutch you'd like narrated, e.g.:
>>> text = "hallo allemaal, ik praat nederlands. groetjes aan iedereen!"
```
-To use SpeechT5 with the pipeline, you'll need a speaker embedding. Let's get it from an example in the test dataset:
+To use SpeechT5 with the pipeline, you'll need a speaker embedding. Let's get it from an example in the test dataset:
```py
>>> example = dataset["test"][304]
>>> speaker_embeddings = torch.tensor(example["speaker_embeddings"]).unsqueeze(0)
```
-Now you can pass the text and speaker embeddings to the pipeline, and it will take care of the rest:
+Now you can pass the text and speaker embeddings to the pipeline, and it will take care of the rest:
```py
>>> forward_params = {"speaker_embeddings": speaker_embeddings}
@@ -567,40 +567,40 @@ You can then listen to the result:
```py
>>> from IPython.display import Audio
->>> Audio(output['audio'], rate=output['sampling_rate'])
+>>> Audio(output['audio'], rate=output['sampling_rate'])
```
### Run inference manually
-You can achieve the same inference results without using the pipeline, however, more steps will be required.
+You can achieve the same inference results without using the pipeline, however, more steps will be required.
-Load the model from the 🤗 Hub:
+Load the model from the 🤗 Hub:
```py
>>> model = SpeechT5ForTextToSpeech.from_pretrained("YOUR_ACCOUNT/speecht5_finetuned_voxpopuli_nl")
```
-Pick an example from the test dataset to obtain a speaker embedding.
+Pick an example from the test dataset obtain a speaker embedding.
-```py
+```py
>>> example = dataset["test"][304]
>>> speaker_embeddings = torch.tensor(example["speaker_embeddings"]).unsqueeze(0)
```
Define the input text and tokenize it.
-```py
+```py
>>> text = "hallo allemaal, ik praat nederlands. groetjes aan iedereen!"
>>> inputs = processor(text=text, return_tensors="pt")
```
-Create a spectrogram with your model:
+Create a spectrogram with your model:
```py
>>> spectrogram = model.generate_speech(inputs["input_ids"], speaker_embeddings)
```
-Visualize the spectrogram, if you'd like to:
+Visualize the spectrogram, if you'd like to:
```py
>>> plt.figure()
@@ -623,15 +623,15 @@ Finally, use the vocoder to turn the spectrogram into sound.
>>> Audio(speech.numpy(), rate=16000)
```
-In our experience, obtaining satisfactory results from this model can be challenging. The quality of the speaker
-embeddings appears to be a significant factor. Since SpeechT5 was pre-trained with English x-vectors, it performs best
+In our experience, obtaining satisfactory results from this model can be challenging. The quality of the speaker
+embeddings appears to be a significant factor. Since SpeechT5 was pre-trained with English x-vectors, it performs best
when using English speaker embeddings. If the synthesized speech sounds poor, try using a different speaker embedding.
-Increasing the training duration is also likely to enhance the quality of the results. Even so, the speech clearly is Dutch instead of English, and it does
+Increasing the training duration is also likely to enhance the quality of the results. Even so, the speech clearly is Dutch instead of English, and it does
capture the voice characteristics of the speaker (compare to the original audio in the example).
-Another thing to experiment with is the model's configuration. For example, try using `config.reduction_factor = 1` to
+Another thing to experiment with is the model's configuration. For example, try using `config.reduction_factor = 1` to
see if this improves the results.
-Finally, it is essential to consider ethical considerations. Although TTS technology has numerous useful applications, it
-may also be used for malicious purposes, such as impersonating someone's voice without their knowledge or consent. Please
+Finally, it is essential to consider ethical considerations. Although TTS technology has numerous useful applications, it
+may also be used for malicious purposes, such as impersonating someone's voice without their knowledge or consent. Please
use TTS judiciously and responsibly.
diff --git a/docs/source/en/tasks/token_classification.md b/docs/source/en/tasks/token_classification.md
index 444d842172..b93dd0cbe2 100644
--- a/docs/source/en/tasks/token_classification.md
+++ b/docs/source/en/tasks/token_classification.md
@@ -296,7 +296,7 @@ At this point, only three steps remain:
... args=training_args,
... train_dataset=tokenized_wnut["train"],
... eval_dataset=tokenized_wnut["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
diff --git a/docs/source/en/tasks/translation.md b/docs/source/en/tasks/translation.md
index a4b544fe68..426ba1c340 100644
--- a/docs/source/en/tasks/translation.md
+++ b/docs/source/en/tasks/translation.md
@@ -221,7 +221,7 @@ At this point, only three steps remain:
... args=training_args,
... train_dataset=tokenized_books["train"],
... eval_dataset=tokenized_books["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
diff --git a/docs/source/en/tasks/video_classification.md b/docs/source/en/tasks/video_classification.md
index 15b3b7a969..c268de1786 100644
--- a/docs/source/en/tasks/video_classification.md
+++ b/docs/source/en/tasks/video_classification.md
@@ -61,7 +61,7 @@ Start by loading a subset of the [UCF-101 dataset](https://www.crcv.ucf.edu/data
After the subset has been downloaded, you need to extract the compressed archive:
-```py
+```py
>>> import tarfile
>>> with tarfile.open(file_path) as t:
@@ -106,13 +106,13 @@ UCF101_subset/
You can then count the number of total videos.
-```py
+```py
>>> import pathlib
>>> dataset_root_path = "UCF101_subset"
>>> dataset_root_path = pathlib.Path(dataset_root_path)
```
-```py
+```py
>>> video_count_train = len(list(dataset_root_path.glob("train/*/*.avi")))
>>> video_count_val = len(list(dataset_root_path.glob("val/*/*.avi")))
>>> video_count_test = len(list(dataset_root_path.glob("test/*/*.avi")))
@@ -120,7 +120,7 @@ You can then count the number of total videos.
>>> print(f"Total videos: {video_total}")
```
-```py
+```py
>>> all_video_file_paths = (
... list(dataset_root_path.glob("train/*/*.avi"))
... + list(dataset_root_path.glob("val/*/*.avi"))
@@ -148,9 +148,9 @@ For the validation and evaluation splits, you wouldn't want to have video clips
Next up, you will derive the set of labels present in the dataset. Also, create two dictionaries that'll be helpful when initializing the model:
* `label2id`: maps the class names to integers.
-* `id2label`: maps the integers to class names.
+* `id2label`: maps the integers to class names.
-```py
+```py
>>> class_labels = sorted({str(path).split("/")[2] for path in all_video_file_paths})
>>> label2id = {label: i for i, label in enumerate(class_labels)}
>>> id2label = {i: label for label, i in label2id.items()}
@@ -166,7 +166,7 @@ There are 10 unique classes. For each class, there are 30 videos in the training
Instantiate a video classification model from a pretrained checkpoint and its associated image processor. The model's encoder comes with pre-trained parameters, and the classification head is randomly initialized. The image processor will come in handy when writing the preprocessing pipeline for our dataset.
-```py
+```py
>>> from transformers import VideoMAEImageProcessor, VideoMAEForVideoClassification
>>> model_ckpt = "MCG-NJU/videomae-base"
@@ -191,13 +191,13 @@ You should probably TRAIN this model on a down-stream task to be able to use it
The warning is telling us we are throwing away some weights (e.g. the weights and bias of the `classifier` layer) and randomly initializing some others (the weights and bias of a new `classifier` layer). This is expected in this case, because we are adding a new head for which we don't have pretrained weights, so the library warns us we should fine-tune this model before using it for inference, which is exactly what we are going to do.
-**Note** that [this checkpoint](https://huggingface.co/MCG-NJU/videomae-base-finetuned-kinetics) leads to better performance on this task as the checkpoint was obtained by fine-tuning on a similar downstream task having considerable domain overlap. You can check out [this checkpoint](https://huggingface.co/sayakpaul/videomae-base-finetuned-kinetics-finetuned-ucf101-subset) which was obtained by fine-tuning `MCG-NJU/videomae-base-finetuned-kinetics`.
+**Note** that [this checkpoint](https://huggingface.co/MCG-NJU/videomae-base-finetuned-kinetics) leads to better performance on this task as the checkpoint was obtained fine-tuning on a similar downstream task having considerable domain overlap. You can check out [this checkpoint](https://huggingface.co/sayakpaul/videomae-base-finetuned-kinetics-finetuned-ucf101-subset) which was obtained by fine-tuning `MCG-NJU/videomae-base-finetuned-kinetics`.
## Prepare the datasets for training
-For preprocessing the videos, you will leverage the [PyTorchVideo library](https://pytorchvideo.org/). Start by importing the dependencies we need.
+For preprocessing the videos, you will leverage the [PyTorchVideo library](https://pytorchvideo.org/). Start by importing the dependencies we need.
-```py
+```py
>>> import pytorchvideo.data
>>> from pytorchvideo.transforms import (
@@ -218,7 +218,7 @@ For preprocessing the videos, you will leverage the [PyTorchVideo library](https
... )
```
-For the training dataset transformations, use a combination of uniform temporal subsampling, pixel normalization, random cropping, and random horizontal flipping. For the validation and evaluation dataset transformations, keep the same transformation chain except for random cropping and horizontal flipping. To learn more about the details of these transformations check out the [official documentation of PyTorchVideo](https://pytorchvideo.org).
+For the training dataset transformations, use a combination of uniform temporal subsampling, pixel normalization, random cropping, and random horizontal flipping. For the validation and evaluation dataset transformations, keep the same transformation chain except for random cropping and horizontal flipping. To learn more about the details of these transformations check out the [official documentation of PyTorchVideo](https://pytorchvideo.org).
Use the `image_processor` associated with the pre-trained model to obtain the following information:
@@ -243,9 +243,9 @@ Start by defining some constants.
>>> clip_duration = num_frames_to_sample * sample_rate / fps
```
-Now, define the dataset-specific transformations and the datasets respectively. Starting with the training set:
+Now, define the dataset-specific transformations and the datasets respectively. Starting with the training set:
-```py
+```py
>>> train_transform = Compose(
... [
... ApplyTransformToKey(
@@ -272,9 +272,9 @@ Now, define the dataset-specific transformations and the datasets respectively.
... )
```
-The same sequence of workflow can be applied to the validation and evaluation sets:
+The same sequence of workflow can be applied to the validation and evaluation sets:
-```py
+```py
>>> val_transform = Compose(
... [
... ApplyTransformToKey(
@@ -306,7 +306,7 @@ The same sequence of workflow can be applied to the validation and evaluation se
... )
```
-**Note**: The above dataset pipelines are taken from the [official PyTorchVideo example](https://pytorchvideo.org/docs/tutorial_classification#dataset). We're using the [`pytorchvideo.data.Ucf101()`](https://pytorchvideo.readthedocs.io/en/latest/api/data/data.html#pytorchvideo.data.Ucf101) function because it's tailored for the UCF-101 dataset. Under the hood, it returns a [`pytorchvideo.data.labeled_video_dataset.LabeledVideoDataset`](https://pytorchvideo.readthedocs.io/en/latest/api/data/data.html#pytorchvideo.data.LabeledVideoDataset) object. `LabeledVideoDataset` class is the base class for all things video in the PyTorchVideo dataset. So, if you want to use a custom dataset not supported off-the-shelf by PyTorchVideo, you can extend the `LabeledVideoDataset` class accordingly. Refer to the `data` API [documentation to](https://pytorchvideo.readthedocs.io/en/latest/api/data/data.html) learn more. Also, if your dataset follows a similar structure (as shown above), then using the `pytorchvideo.data.Ucf101()` should work just fine.
+**Note**: The above dataset pipelines are taken from the [official PyTorchVideo example](https://pytorchvideo.org/docs/tutorial_classification#dataset). We're using the [`pytorchvideo.data.Ucf101()`](https://pytorchvideo.readthedocs.io/en/latest/api/data/data.html#pytorchvideo.data.Ucf101) function because it's tailored for the UCF-101 dataset. Under the hood, it returns a [`pytorchvideo.data.labeled_video_dataset.LabeledVideoDataset`](https://pytorchvideo.readthedocs.io/en/latest/api/data/data.html#pytorchvideo.data.LabeledVideoDataset) object. `LabeledVideoDataset` class is the base class for all things video in the PyTorchVideo dataset. So, if you want to use a custom dataset not supported off-the-shelf by PyTorchVideo, you can extend the `LabeledVideoDataset` class accordingly. Refer to the `data` API [documentation to](https://pytorchvideo.readthedocs.io/en/latest/api/data/data.html) learn more. Also, if your dataset follows a similar structure (as shown above), then using the `pytorchvideo.data.Ucf101()` should work just fine.
You can access the `num_videos` argument to know the number of videos in the dataset.
@@ -315,9 +315,9 @@ You can access the `num_videos` argument to know the number of videos in the dat
# (300, 30, 75)
```
-## Visualize the preprocessed video for better debugging
+## Visualize the preprocessed video for better debugging
-```py
+```py
>>> import imageio
>>> import numpy as np
>>> from IPython.display import Image
@@ -330,7 +330,7 @@ You can access the `num_videos` argument to know the number of videos in the dat
>>> def create_gif(video_tensor, filename="sample.gif"):
... """Prepares a GIF from a video tensor.
-...
+...
... The video tensor is expected to have the following shape:
... (num_frames, num_channels, height, width).
... """
@@ -357,14 +357,14 @@ You can access the `num_videos` argument to know the number of videos in the dat
-Side note: If you find this spectrogram confusing, it may be due to your familiarity with the convention of placing low frequencies
-at the bottom and high frequencies at the top of a plot. However, when plotting spectrograms as an image using the matplotlib library,
+Side note: If you find this spectrogram confusing, it may be due to your familiarity with the convention of placing low frequencies
+at the bottom and high frequencies at the top of a plot. However, when plotting spectrograms as an image using the matplotlib library,
the y-axis is flipped and the spectrograms appear upside down.
Now apply the processing function to the entire dataset. This will take between 5 and 10 minutes.
@@ -373,7 +373,7 @@ Now apply the processing function to the entire dataset. This will take between
>>> dataset = dataset.map(prepare_dataset, remove_columns=dataset.column_names)
```
-You'll see a warning saying that some examples in the dataset are longer than the maximum input length the model can handle (600 tokens).
+You'll see a warning saying that some examples in the dataset are longer than the maximum input length the model can handle (600 tokens).
Remove those examples from the dataset. Here we go even further and to allow for larger batch sizes we remove anything over 200 tokens.
```py
@@ -387,7 +387,7 @@ Remove those examples from the dataset. Here we go even further and to allow for
8259
```
-Next, create a basic train/test split:
+Next, create a basic train/test split:
```py
>>> dataset = dataset.train_test_split(test_size=0.1)
@@ -395,8 +395,8 @@ Next, create a basic train/test split:
### Data collator
-In order to combine multiple examples into a batch, you need to define a custom data collator. This collator will pad shorter sequences with padding
-tokens, ensuring that all examples have the same length. For the spectrogram labels, the padded portions are replaced with the special value `-100`. This special value
+In order to combine multiple examples into a batch, you need to define a custom data collator. This collator will pad shorter sequences with padding
+tokens, ensuring that all examples have the same length. For the spectrogram labels, the padded portions are replaced with the special value `-100`. This special value
instructs the model to ignore that part of the spectrogram when calculating the spectrogram loss.
```py
@@ -437,18 +437,18 @@ instructs the model to ignore that part of the spectrogram when calculating the
... return batch
```
-In SpeechT5, the input to the decoder part of the model is reduced by a factor 2. In other words, it throws away every
-other timestep from the target sequence. The decoder then predicts a sequence that is twice as long. Since the original
-target sequence length may be odd, the data collator makes sure to round the maximum length of the batch down to be a
+In SpeechT5, the input to the decoder part of the model is reduced by a factor 2. In other words, it throws away every
+other timestep from the target sequence. The decoder then predicts a sequence that is twice as long. Since the original
+target sequence length may be odd, the data collator makes sure to round the maximum length of the batch down to be a
multiple of 2.
-```py
+```py
>>> data_collator = TTSDataCollatorWithPadding(processor=processor)
```
## Train the model
-Load the pre-trained model from the same checkpoint as you used for loading the processor:
+Load the pre-trained model from the same checkpoint as you used for loading the processor:
```py
>>> from transformers import SpeechT5ForTextToSpeech
@@ -458,11 +458,11 @@ Load the pre-trained model from the same checkpoint as you used for loading the
The `use_cache=True` option is incompatible with gradient checkpointing. Disable it for training.
-```py
+```py
>>> model.config.use_cache = False
```
-Define the training arguments. Here we are not computing any evaluation metrics during the training process. Instead, we'll
+Define the training arguments. Here we are not computing any evaluation metrics during the training process. Instead, we'll
only look at the loss:
```python
@@ -501,19 +501,19 @@ Instantiate the `Trainer` object and pass the model, dataset, and data collator
... train_dataset=dataset["train"],
... eval_dataset=dataset["test"],
... data_collator=data_collator,
-... tokenizer=processor,
+... processing_class=processor,
... )
```
-And with that, you're ready to start training! Training will take several hours. Depending on your GPU,
-it is possible that you will encounter a CUDA "out-of-memory" error when you start training. In this case, you can reduce
+And with that, you're ready to start training! Training will take several hours. Depending on your GPU,
+it is possible that you will encounter a CUDA "out-of-memory" error when you start training. In this case, you can reduce
the `per_device_train_batch_size` incrementally by factors of 2 and increase `gradient_accumulation_steps` by 2x to compensate.
```py
>>> trainer.train()
```
-To be able to use your checkpoint with a pipeline, make sure to save the processor with the checkpoint:
+To be able to use your checkpoint with a pipeline, make sure to save the processor with the checkpoint:
```py
>>> processor.save_pretrained("YOUR_ACCOUNT_NAME/speecht5_finetuned_voxpopuli_nl")
@@ -530,8 +530,8 @@ Push the final model to the 🤗 Hub:
### Inference with a pipeline
Great, now that you've fine-tuned a model, you can use it for inference!
-First, let's see how you can use it with a corresponding pipeline. Let's create a `"text-to-speech"` pipeline with your
-checkpoint:
+First, let's see how you can use it with a corresponding pipeline. Let's create a `"text-to-speech"` pipeline with your
+checkpoint:
```py
>>> from transformers import pipeline
@@ -545,14 +545,14 @@ Pick a piece of text in Dutch you'd like narrated, e.g.:
>>> text = "hallo allemaal, ik praat nederlands. groetjes aan iedereen!"
```
-To use SpeechT5 with the pipeline, you'll need a speaker embedding. Let's get it from an example in the test dataset:
+To use SpeechT5 with the pipeline, you'll need a speaker embedding. Let's get it from an example in the test dataset:
```py
>>> example = dataset["test"][304]
>>> speaker_embeddings = torch.tensor(example["speaker_embeddings"]).unsqueeze(0)
```
-Now you can pass the text and speaker embeddings to the pipeline, and it will take care of the rest:
+Now you can pass the text and speaker embeddings to the pipeline, and it will take care of the rest:
```py
>>> forward_params = {"speaker_embeddings": speaker_embeddings}
@@ -567,40 +567,40 @@ You can then listen to the result:
```py
>>> from IPython.display import Audio
->>> Audio(output['audio'], rate=output['sampling_rate'])
+>>> Audio(output['audio'], rate=output['sampling_rate'])
```
### Run inference manually
-You can achieve the same inference results without using the pipeline, however, more steps will be required.
+You can achieve the same inference results without using the pipeline, however, more steps will be required.
-Load the model from the 🤗 Hub:
+Load the model from the 🤗 Hub:
```py
>>> model = SpeechT5ForTextToSpeech.from_pretrained("YOUR_ACCOUNT/speecht5_finetuned_voxpopuli_nl")
```
-Pick an example from the test dataset to obtain a speaker embedding.
+Pick an example from the test dataset obtain a speaker embedding.
-```py
+```py
>>> example = dataset["test"][304]
>>> speaker_embeddings = torch.tensor(example["speaker_embeddings"]).unsqueeze(0)
```
Define the input text and tokenize it.
-```py
+```py
>>> text = "hallo allemaal, ik praat nederlands. groetjes aan iedereen!"
>>> inputs = processor(text=text, return_tensors="pt")
```
-Create a spectrogram with your model:
+Create a spectrogram with your model:
```py
>>> spectrogram = model.generate_speech(inputs["input_ids"], speaker_embeddings)
```
-Visualize the spectrogram, if you'd like to:
+Visualize the spectrogram, if you'd like to:
```py
>>> plt.figure()
@@ -623,15 +623,15 @@ Finally, use the vocoder to turn the spectrogram into sound.
>>> Audio(speech.numpy(), rate=16000)
```
-In our experience, obtaining satisfactory results from this model can be challenging. The quality of the speaker
-embeddings appears to be a significant factor. Since SpeechT5 was pre-trained with English x-vectors, it performs best
+In our experience, obtaining satisfactory results from this model can be challenging. The quality of the speaker
+embeddings appears to be a significant factor. Since SpeechT5 was pre-trained with English x-vectors, it performs best
when using English speaker embeddings. If the synthesized speech sounds poor, try using a different speaker embedding.
-Increasing the training duration is also likely to enhance the quality of the results. Even so, the speech clearly is Dutch instead of English, and it does
+Increasing the training duration is also likely to enhance the quality of the results. Even so, the speech clearly is Dutch instead of English, and it does
capture the voice characteristics of the speaker (compare to the original audio in the example).
-Another thing to experiment with is the model's configuration. For example, try using `config.reduction_factor = 1` to
+Another thing to experiment with is the model's configuration. For example, try using `config.reduction_factor = 1` to
see if this improves the results.
-Finally, it is essential to consider ethical considerations. Although TTS technology has numerous useful applications, it
-may also be used for malicious purposes, such as impersonating someone's voice without their knowledge or consent. Please
+Finally, it is essential to consider ethical considerations. Although TTS technology has numerous useful applications, it
+may also be used for malicious purposes, such as impersonating someone's voice without their knowledge or consent. Please
use TTS judiciously and responsibly.
diff --git a/docs/source/en/tasks/token_classification.md b/docs/source/en/tasks/token_classification.md
index 444d842172..b93dd0cbe2 100644
--- a/docs/source/en/tasks/token_classification.md
+++ b/docs/source/en/tasks/token_classification.md
@@ -296,7 +296,7 @@ At this point, only three steps remain:
... args=training_args,
... train_dataset=tokenized_wnut["train"],
... eval_dataset=tokenized_wnut["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
diff --git a/docs/source/en/tasks/translation.md b/docs/source/en/tasks/translation.md
index a4b544fe68..426ba1c340 100644
--- a/docs/source/en/tasks/translation.md
+++ b/docs/source/en/tasks/translation.md
@@ -221,7 +221,7 @@ At this point, only three steps remain:
... args=training_args,
... train_dataset=tokenized_books["train"],
... eval_dataset=tokenized_books["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
diff --git a/docs/source/en/tasks/video_classification.md b/docs/source/en/tasks/video_classification.md
index 15b3b7a969..c268de1786 100644
--- a/docs/source/en/tasks/video_classification.md
+++ b/docs/source/en/tasks/video_classification.md
@@ -61,7 +61,7 @@ Start by loading a subset of the [UCF-101 dataset](https://www.crcv.ucf.edu/data
After the subset has been downloaded, you need to extract the compressed archive:
-```py
+```py
>>> import tarfile
>>> with tarfile.open(file_path) as t:
@@ -106,13 +106,13 @@ UCF101_subset/
You can then count the number of total videos.
-```py
+```py
>>> import pathlib
>>> dataset_root_path = "UCF101_subset"
>>> dataset_root_path = pathlib.Path(dataset_root_path)
```
-```py
+```py
>>> video_count_train = len(list(dataset_root_path.glob("train/*/*.avi")))
>>> video_count_val = len(list(dataset_root_path.glob("val/*/*.avi")))
>>> video_count_test = len(list(dataset_root_path.glob("test/*/*.avi")))
@@ -120,7 +120,7 @@ You can then count the number of total videos.
>>> print(f"Total videos: {video_total}")
```
-```py
+```py
>>> all_video_file_paths = (
... list(dataset_root_path.glob("train/*/*.avi"))
... + list(dataset_root_path.glob("val/*/*.avi"))
@@ -148,9 +148,9 @@ For the validation and evaluation splits, you wouldn't want to have video clips
Next up, you will derive the set of labels present in the dataset. Also, create two dictionaries that'll be helpful when initializing the model:
* `label2id`: maps the class names to integers.
-* `id2label`: maps the integers to class names.
+* `id2label`: maps the integers to class names.
-```py
+```py
>>> class_labels = sorted({str(path).split("/")[2] for path in all_video_file_paths})
>>> label2id = {label: i for i, label in enumerate(class_labels)}
>>> id2label = {i: label for label, i in label2id.items()}
@@ -166,7 +166,7 @@ There are 10 unique classes. For each class, there are 30 videos in the training
Instantiate a video classification model from a pretrained checkpoint and its associated image processor. The model's encoder comes with pre-trained parameters, and the classification head is randomly initialized. The image processor will come in handy when writing the preprocessing pipeline for our dataset.
-```py
+```py
>>> from transformers import VideoMAEImageProcessor, VideoMAEForVideoClassification
>>> model_ckpt = "MCG-NJU/videomae-base"
@@ -191,13 +191,13 @@ You should probably TRAIN this model on a down-stream task to be able to use it
The warning is telling us we are throwing away some weights (e.g. the weights and bias of the `classifier` layer) and randomly initializing some others (the weights and bias of a new `classifier` layer). This is expected in this case, because we are adding a new head for which we don't have pretrained weights, so the library warns us we should fine-tune this model before using it for inference, which is exactly what we are going to do.
-**Note** that [this checkpoint](https://huggingface.co/MCG-NJU/videomae-base-finetuned-kinetics) leads to better performance on this task as the checkpoint was obtained by fine-tuning on a similar downstream task having considerable domain overlap. You can check out [this checkpoint](https://huggingface.co/sayakpaul/videomae-base-finetuned-kinetics-finetuned-ucf101-subset) which was obtained by fine-tuning `MCG-NJU/videomae-base-finetuned-kinetics`.
+**Note** that [this checkpoint](https://huggingface.co/MCG-NJU/videomae-base-finetuned-kinetics) leads to better performance on this task as the checkpoint was obtained fine-tuning on a similar downstream task having considerable domain overlap. You can check out [this checkpoint](https://huggingface.co/sayakpaul/videomae-base-finetuned-kinetics-finetuned-ucf101-subset) which was obtained by fine-tuning `MCG-NJU/videomae-base-finetuned-kinetics`.
## Prepare the datasets for training
-For preprocessing the videos, you will leverage the [PyTorchVideo library](https://pytorchvideo.org/). Start by importing the dependencies we need.
+For preprocessing the videos, you will leverage the [PyTorchVideo library](https://pytorchvideo.org/). Start by importing the dependencies we need.
-```py
+```py
>>> import pytorchvideo.data
>>> from pytorchvideo.transforms import (
@@ -218,7 +218,7 @@ For preprocessing the videos, you will leverage the [PyTorchVideo library](https
... )
```
-For the training dataset transformations, use a combination of uniform temporal subsampling, pixel normalization, random cropping, and random horizontal flipping. For the validation and evaluation dataset transformations, keep the same transformation chain except for random cropping and horizontal flipping. To learn more about the details of these transformations check out the [official documentation of PyTorchVideo](https://pytorchvideo.org).
+For the training dataset transformations, use a combination of uniform temporal subsampling, pixel normalization, random cropping, and random horizontal flipping. For the validation and evaluation dataset transformations, keep the same transformation chain except for random cropping and horizontal flipping. To learn more about the details of these transformations check out the [official documentation of PyTorchVideo](https://pytorchvideo.org).
Use the `image_processor` associated with the pre-trained model to obtain the following information:
@@ -243,9 +243,9 @@ Start by defining some constants.
>>> clip_duration = num_frames_to_sample * sample_rate / fps
```
-Now, define the dataset-specific transformations and the datasets respectively. Starting with the training set:
+Now, define the dataset-specific transformations and the datasets respectively. Starting with the training set:
-```py
+```py
>>> train_transform = Compose(
... [
... ApplyTransformToKey(
@@ -272,9 +272,9 @@ Now, define the dataset-specific transformations and the datasets respectively.
... )
```
-The same sequence of workflow can be applied to the validation and evaluation sets:
+The same sequence of workflow can be applied to the validation and evaluation sets:
-```py
+```py
>>> val_transform = Compose(
... [
... ApplyTransformToKey(
@@ -306,7 +306,7 @@ The same sequence of workflow can be applied to the validation and evaluation se
... )
```
-**Note**: The above dataset pipelines are taken from the [official PyTorchVideo example](https://pytorchvideo.org/docs/tutorial_classification#dataset). We're using the [`pytorchvideo.data.Ucf101()`](https://pytorchvideo.readthedocs.io/en/latest/api/data/data.html#pytorchvideo.data.Ucf101) function because it's tailored for the UCF-101 dataset. Under the hood, it returns a [`pytorchvideo.data.labeled_video_dataset.LabeledVideoDataset`](https://pytorchvideo.readthedocs.io/en/latest/api/data/data.html#pytorchvideo.data.LabeledVideoDataset) object. `LabeledVideoDataset` class is the base class for all things video in the PyTorchVideo dataset. So, if you want to use a custom dataset not supported off-the-shelf by PyTorchVideo, you can extend the `LabeledVideoDataset` class accordingly. Refer to the `data` API [documentation to](https://pytorchvideo.readthedocs.io/en/latest/api/data/data.html) learn more. Also, if your dataset follows a similar structure (as shown above), then using the `pytorchvideo.data.Ucf101()` should work just fine.
+**Note**: The above dataset pipelines are taken from the [official PyTorchVideo example](https://pytorchvideo.org/docs/tutorial_classification#dataset). We're using the [`pytorchvideo.data.Ucf101()`](https://pytorchvideo.readthedocs.io/en/latest/api/data/data.html#pytorchvideo.data.Ucf101) function because it's tailored for the UCF-101 dataset. Under the hood, it returns a [`pytorchvideo.data.labeled_video_dataset.LabeledVideoDataset`](https://pytorchvideo.readthedocs.io/en/latest/api/data/data.html#pytorchvideo.data.LabeledVideoDataset) object. `LabeledVideoDataset` class is the base class for all things video in the PyTorchVideo dataset. So, if you want to use a custom dataset not supported off-the-shelf by PyTorchVideo, you can extend the `LabeledVideoDataset` class accordingly. Refer to the `data` API [documentation to](https://pytorchvideo.readthedocs.io/en/latest/api/data/data.html) learn more. Also, if your dataset follows a similar structure (as shown above), then using the `pytorchvideo.data.Ucf101()` should work just fine.
You can access the `num_videos` argument to know the number of videos in the dataset.
@@ -315,9 +315,9 @@ You can access the `num_videos` argument to know the number of videos in the dat
# (300, 30, 75)
```
-## Visualize the preprocessed video for better debugging
+## Visualize the preprocessed video for better debugging
-```py
+```py
>>> import imageio
>>> import numpy as np
>>> from IPython.display import Image
@@ -330,7 +330,7 @@ You can access the `num_videos` argument to know the number of videos in the dat
>>> def create_gif(video_tensor, filename="sample.gif"):
... """Prepares a GIF from a video tensor.
-...
+...
... The video tensor is expected to have the following shape:
... (num_frames, num_channels, height, width).
... """
@@ -357,14 +357,14 @@ You can access the `num_videos` argument to know the number of videos in the dat
 -## Train the model
+## Train the model
Leverage [`Trainer`](https://huggingface.co/docs/transformers/main_classes/trainer) from 🤗 Transformers for training the model. To instantiate a `Trainer`, you need to define the training configuration and an evaluation metric. The most important is the [`TrainingArguments`](https://huggingface.co/transformers/main_classes/trainer.html#transformers.TrainingArguments), which is a class that contains all the attributes to configure the training. It requires an output folder name, which will be used to save the checkpoints of the model. It also helps sync all the information in the model repository on 🤗 Hub.
Most of the training arguments are self-explanatory, but one that is quite important here is `remove_unused_columns=False`. This one will drop any features not used by the model's call function. By default it's `True` because usually it's ideal to drop unused feature columns, making it easier to unpack inputs into the model's call function. But, in this case, you need the unused features ('video' in particular) in order to create `pixel_values` (which is a mandatory key our model expects in its inputs).
-```py
+```py
>>> from transformers import TrainingArguments, Trainer
>>> model_name = model_ckpt.split("/")[-1]
@@ -388,7 +388,7 @@ Most of the training arguments are self-explanatory, but one that is quite impor
... )
```
-The dataset returned by `pytorchvideo.data.Ucf101()` doesn't implement the `__len__` method. As such, we must define `max_steps` when instantiating `TrainingArguments`.
+The dataset returned by `pytorchvideo.data.Ucf101()` doesn't implement the `__len__` method. As such, we must define `max_steps` when instantiating `TrainingArguments`.
Next, you need to define a function to compute the metrics from the predictions, which will use the `metric` you'll load now. The only preprocessing you have to do is to take the argmax of our predicted logits:
@@ -409,7 +409,7 @@ In the [VideoMAE paper](https://arxiv.org/abs/2203.12602), the authors use the f
Also, define a `collate_fn`, which will be used to batch examples together. Each batch consists of 2 keys, namely `pixel_values` and `labels`.
-```py
+```py
>>> def collate_fn(examples):
... # permute to (num_frames, num_channels, height, width)
... pixel_values = torch.stack(
@@ -421,13 +421,13 @@ Also, define a `collate_fn`, which will be used to batch examples together. Each
Then you just pass all of this along with the datasets to `Trainer`:
-```py
+```py
>>> trainer = Trainer(
... model,
... args,
... train_dataset=train_dataset,
... eval_dataset=val_dataset,
-... tokenizer=image_processor,
+... processing_class=image_processor,
... compute_metrics=compute_metrics,
... data_collator=collate_fn,
... )
@@ -437,7 +437,7 @@ You might wonder why you passed along the `image_processor` as a tokenizer when
Now fine-tune our model by calling the `train` method:
-```py
+```py
>>> train_results = trainer.train()
```
@@ -453,7 +453,7 @@ Great, now that you have fine-tuned a model, you can use it for inference!
Load a video for inference:
-```py
+```py
>>> sample_test_video = next(iter(test_dataset))
```
@@ -507,10 +507,10 @@ Now, pass your input to the model and return the `logits`:
>>> logits = run_inference(trained_model, sample_test_video["video"])
```
-Decoding the `logits`, we get:
+Decoding the `logits`, we get:
-```py
+```py
>>> predicted_class_idx = logits.argmax(-1).item()
>>> print("Predicted class:", model.config.id2label[predicted_class_idx])
# Predicted class: BasketballDunk
-```
\ No newline at end of file
+```
diff --git a/docs/source/en/tasks/visual_question_answering.md b/docs/source/en/tasks/visual_question_answering.md
index c45f12dbc1..7083d8c98b 100644
--- a/docs/source/en/tasks/visual_question_answering.md
+++ b/docs/source/en/tasks/visual_question_answering.md
@@ -18,14 +18,14 @@ rendered properly in your Markdown viewer.
[[open-in-colab]]
-Visual Question Answering (VQA) is the task of answering open-ended questions based on an image.
-The input to models supporting this task is typically a combination of an image and a question, and the output is an
+Visual Question Answering (VQA) is the task of answering open-ended questions based on an image.
+The input to models supporting this task is typically a combination of an image and a question, and the output is an
answer expressed in natural language.
Some noteworthy use case examples for VQA include:
* Accessibility applications for visually impaired individuals.
* Education: posing questions about visual materials presented in lectures or textbooks. VQA can also be utilized in interactive museum exhibits or historical sites.
-* Customer service and e-commerce: VQA can enhance user experience by letting users ask questions about products.
+* Customer service and e-commerce: VQA can enhance user experience by letting users ask questions about products.
* Image retrieval: VQA models can be used to retrieve images with specific characteristics. For example, the user can ask "Is there a dog?" to find all images with dogs from a set of images.
In this guide you'll learn how to:
@@ -36,15 +36,15 @@ In this guide you'll learn how to:
## Fine-tuning ViLT
-ViLT model incorporates text embeddings into a Vision Transformer (ViT), allowing it to have a minimal design for
-Vision-and-Language Pre-training (VLP). This model can be used for several downstream tasks. For the VQA task, a classifier
-head is placed on top (a linear layer on top of the final hidden state of the `[CLS]` token) and randomly initialized.
+ViLT model incorporates text embeddings into a Vision Transformer (ViT), allowing it to have a minimal design for
+Vision-and-Language Pre-training (VLP). This model can be used for several downstream tasks. For the VQA task, a classifier
+head is placed on top (a linear layer on top of the final hidden state of the `[CLS]` token) and randomly initialized.
Visual Question Answering is thus treated as a **classification problem**.
-More recent models, such as BLIP, BLIP-2, and InstructBLIP, treat VQA as a generative task. Later in this guide we
-illustrate how to use them for zero-shot VQA inference.
+More recent models, such as BLIP, BLIP-2, and InstructBLIP, treat VQA as a generative task. Later in this guide we
+illustrate how to use them for zero-shot VQA inference.
-Before you begin, make sure you have all the necessary libraries installed.
+Before you begin, make sure you have all the necessary libraries installed.
```bash
pip install -q transformers datasets
@@ -67,15 +67,15 @@ Let's define the model checkpoint as a global variable.
## Load the data
-For illustration purposes, in this guide we use a very small sample of the annotated visual question answering `Graphcore/vqa` dataset.
+For illustration purposes, in this guide we use a very small sample of the annotated visual question answering `Graphcore/vqa` dataset.
You can find the full dataset on [🤗 Hub](https://huggingface.co/datasets/Graphcore/vqa).
-As an alternative to the [`Graphcore/vqa` dataset](https://huggingface.co/datasets/Graphcore/vqa), you can download the
-same data manually from the official [VQA dataset page](https://visualqa.org/download.html). If you prefer to follow the
+As an alternative to the [`Graphcore/vqa` dataset](https://huggingface.co/datasets/Graphcore/vqa), you can download the
+same data manually from the official [VQA dataset page](https://visualqa.org/download.html). If you prefer to follow the
tutorial with your custom data, check out how to [Create an image dataset](https://huggingface.co/docs/datasets/image_dataset#loading-script)
-guide in the 🤗 Datasets documentation.
+guide in the 🤗 Datasets documentation.
-Let's load the first 200 examples from the validation split and explore the dataset's features:
+Let's load the first 200 examples from the validation split and explore the dataset's features:
```python
>>> from datasets import load_dataset
@@ -104,20 +104,20 @@ Let's take a look at an example to understand the dataset's features:
0.30000001192092896]}}
```
-The features relevant to the task include:
+The features relevant to the task include:
* `question`: the question to be answered from the image
* `image_id`: the path to the image the question refers to
* `label`: the annotations
-We can remove the rest of the features as they won't be necessary:
+We can remove the rest of the features as they won't be necessary:
-```py
+```py
>>> dataset = dataset.remove_columns(['question_type', 'question_id', 'answer_type'])
```
-As you can see, the `label` feature contains several answers to the same question (called `ids` here) collected by different human annotators.
-This is because the answer to a question can be subjective. In this case, the question is "where is he looking?". Some people
-annotated this with "down", others with "at table", another one with "skateboard", etc.
+As you can see, the `label` feature contains several answers to the same question (called `ids` here) collected by different human annotators.
+This is because the answer to a question can be subjective. In this case, the question is "where is he looking?". Some people
+annotated this with "down", others with "at table", another one with "skateboard", etc.
Take a look at the image and consider which answer would you give:
@@ -132,14 +132,14 @@ Take a look at the image and consider which answer would you give:
-## Train the model
+## Train the model
Leverage [`Trainer`](https://huggingface.co/docs/transformers/main_classes/trainer) from 🤗 Transformers for training the model. To instantiate a `Trainer`, you need to define the training configuration and an evaluation metric. The most important is the [`TrainingArguments`](https://huggingface.co/transformers/main_classes/trainer.html#transformers.TrainingArguments), which is a class that contains all the attributes to configure the training. It requires an output folder name, which will be used to save the checkpoints of the model. It also helps sync all the information in the model repository on 🤗 Hub.
Most of the training arguments are self-explanatory, but one that is quite important here is `remove_unused_columns=False`. This one will drop any features not used by the model's call function. By default it's `True` because usually it's ideal to drop unused feature columns, making it easier to unpack inputs into the model's call function. But, in this case, you need the unused features ('video' in particular) in order to create `pixel_values` (which is a mandatory key our model expects in its inputs).
-```py
+```py
>>> from transformers import TrainingArguments, Trainer
>>> model_name = model_ckpt.split("/")[-1]
@@ -388,7 +388,7 @@ Most of the training arguments are self-explanatory, but one that is quite impor
... )
```
-The dataset returned by `pytorchvideo.data.Ucf101()` doesn't implement the `__len__` method. As such, we must define `max_steps` when instantiating `TrainingArguments`.
+The dataset returned by `pytorchvideo.data.Ucf101()` doesn't implement the `__len__` method. As such, we must define `max_steps` when instantiating `TrainingArguments`.
Next, you need to define a function to compute the metrics from the predictions, which will use the `metric` you'll load now. The only preprocessing you have to do is to take the argmax of our predicted logits:
@@ -409,7 +409,7 @@ In the [VideoMAE paper](https://arxiv.org/abs/2203.12602), the authors use the f
Also, define a `collate_fn`, which will be used to batch examples together. Each batch consists of 2 keys, namely `pixel_values` and `labels`.
-```py
+```py
>>> def collate_fn(examples):
... # permute to (num_frames, num_channels, height, width)
... pixel_values = torch.stack(
@@ -421,13 +421,13 @@ Also, define a `collate_fn`, which will be used to batch examples together. Each
Then you just pass all of this along with the datasets to `Trainer`:
-```py
+```py
>>> trainer = Trainer(
... model,
... args,
... train_dataset=train_dataset,
... eval_dataset=val_dataset,
-... tokenizer=image_processor,
+... processing_class=image_processor,
... compute_metrics=compute_metrics,
... data_collator=collate_fn,
... )
@@ -437,7 +437,7 @@ You might wonder why you passed along the `image_processor` as a tokenizer when
Now fine-tune our model by calling the `train` method:
-```py
+```py
>>> train_results = trainer.train()
```
@@ -453,7 +453,7 @@ Great, now that you have fine-tuned a model, you can use it for inference!
Load a video for inference:
-```py
+```py
>>> sample_test_video = next(iter(test_dataset))
```
@@ -507,10 +507,10 @@ Now, pass your input to the model and return the `logits`:
>>> logits = run_inference(trained_model, sample_test_video["video"])
```
-Decoding the `logits`, we get:
+Decoding the `logits`, we get:
-```py
+```py
>>> predicted_class_idx = logits.argmax(-1).item()
>>> print("Predicted class:", model.config.id2label[predicted_class_idx])
# Predicted class: BasketballDunk
-```
\ No newline at end of file
+```
diff --git a/docs/source/en/tasks/visual_question_answering.md b/docs/source/en/tasks/visual_question_answering.md
index c45f12dbc1..7083d8c98b 100644
--- a/docs/source/en/tasks/visual_question_answering.md
+++ b/docs/source/en/tasks/visual_question_answering.md
@@ -18,14 +18,14 @@ rendered properly in your Markdown viewer.
[[open-in-colab]]
-Visual Question Answering (VQA) is the task of answering open-ended questions based on an image.
-The input to models supporting this task is typically a combination of an image and a question, and the output is an
+Visual Question Answering (VQA) is the task of answering open-ended questions based on an image.
+The input to models supporting this task is typically a combination of an image and a question, and the output is an
answer expressed in natural language.
Some noteworthy use case examples for VQA include:
* Accessibility applications for visually impaired individuals.
* Education: posing questions about visual materials presented in lectures or textbooks. VQA can also be utilized in interactive museum exhibits or historical sites.
-* Customer service and e-commerce: VQA can enhance user experience by letting users ask questions about products.
+* Customer service and e-commerce: VQA can enhance user experience by letting users ask questions about products.
* Image retrieval: VQA models can be used to retrieve images with specific characteristics. For example, the user can ask "Is there a dog?" to find all images with dogs from a set of images.
In this guide you'll learn how to:
@@ -36,15 +36,15 @@ In this guide you'll learn how to:
## Fine-tuning ViLT
-ViLT model incorporates text embeddings into a Vision Transformer (ViT), allowing it to have a minimal design for
-Vision-and-Language Pre-training (VLP). This model can be used for several downstream tasks. For the VQA task, a classifier
-head is placed on top (a linear layer on top of the final hidden state of the `[CLS]` token) and randomly initialized.
+ViLT model incorporates text embeddings into a Vision Transformer (ViT), allowing it to have a minimal design for
+Vision-and-Language Pre-training (VLP). This model can be used for several downstream tasks. For the VQA task, a classifier
+head is placed on top (a linear layer on top of the final hidden state of the `[CLS]` token) and randomly initialized.
Visual Question Answering is thus treated as a **classification problem**.
-More recent models, such as BLIP, BLIP-2, and InstructBLIP, treat VQA as a generative task. Later in this guide we
-illustrate how to use them for zero-shot VQA inference.
+More recent models, such as BLIP, BLIP-2, and InstructBLIP, treat VQA as a generative task. Later in this guide we
+illustrate how to use them for zero-shot VQA inference.
-Before you begin, make sure you have all the necessary libraries installed.
+Before you begin, make sure you have all the necessary libraries installed.
```bash
pip install -q transformers datasets
@@ -67,15 +67,15 @@ Let's define the model checkpoint as a global variable.
## Load the data
-For illustration purposes, in this guide we use a very small sample of the annotated visual question answering `Graphcore/vqa` dataset.
+For illustration purposes, in this guide we use a very small sample of the annotated visual question answering `Graphcore/vqa` dataset.
You can find the full dataset on [🤗 Hub](https://huggingface.co/datasets/Graphcore/vqa).
-As an alternative to the [`Graphcore/vqa` dataset](https://huggingface.co/datasets/Graphcore/vqa), you can download the
-same data manually from the official [VQA dataset page](https://visualqa.org/download.html). If you prefer to follow the
+As an alternative to the [`Graphcore/vqa` dataset](https://huggingface.co/datasets/Graphcore/vqa), you can download the
+same data manually from the official [VQA dataset page](https://visualqa.org/download.html). If you prefer to follow the
tutorial with your custom data, check out how to [Create an image dataset](https://huggingface.co/docs/datasets/image_dataset#loading-script)
-guide in the 🤗 Datasets documentation.
+guide in the 🤗 Datasets documentation.
-Let's load the first 200 examples from the validation split and explore the dataset's features:
+Let's load the first 200 examples from the validation split and explore the dataset's features:
```python
>>> from datasets import load_dataset
@@ -104,20 +104,20 @@ Let's take a look at an example to understand the dataset's features:
0.30000001192092896]}}
```
-The features relevant to the task include:
+The features relevant to the task include:
* `question`: the question to be answered from the image
* `image_id`: the path to the image the question refers to
* `label`: the annotations
-We can remove the rest of the features as they won't be necessary:
+We can remove the rest of the features as they won't be necessary:
-```py
+```py
>>> dataset = dataset.remove_columns(['question_type', 'question_id', 'answer_type'])
```
-As you can see, the `label` feature contains several answers to the same question (called `ids` here) collected by different human annotators.
-This is because the answer to a question can be subjective. In this case, the question is "where is he looking?". Some people
-annotated this with "down", others with "at table", another one with "skateboard", etc.
+As you can see, the `label` feature contains several answers to the same question (called `ids` here) collected by different human annotators.
+This is because the answer to a question can be subjective. In this case, the question is "where is he looking?". Some people
+annotated this with "down", others with "at table", another one with "skateboard", etc.
Take a look at the image and consider which answer would you give:
@@ -132,14 +132,14 @@ Take a look at the image and consider which answer would you give:
 -Due to the questions' and answers' ambiguity, datasets like this are treated as a multi-label classification problem (as
-multiple answers are possibly valid). Moreover, rather than just creating a one-hot encoded vector, one creates a
+Due to the questions' and answers' ambiguity, datasets like this are treated as a multi-label classification problem (as
+multiple answers are possibly valid). Moreover, rather than just creating a one-hot encoded vector, one creates a
soft encoding, based on the number of times a certain answer appeared in the annotations.
-For instance, in the example above, because the answer "down" is selected way more often than other answers, it has a
-score (called `weight` in the dataset) of 1.0, and the rest of the answers have scores < 1.0.
+For instance, in the example above, because the answer "down" is selected way more often than other answers, it has a
+score (called `weight` in the dataset) of 1.0, and the rest of the answers have scores < 1.0.
-To later instantiate the model with an appropriate classification head, let's create two dictionaries: one that maps
+To later instantiate the model with an appropriate classification head, let's create two dictionaries: one that maps
the label name to an integer and vice versa:
```py
@@ -150,10 +150,10 @@ the label name to an integer and vice versa:
>>> unique_labels = list(set(flattened_labels))
>>> label2id = {label: idx for idx, label in enumerate(unique_labels)}
->>> id2label = {idx: label for label, idx in label2id.items()}
+>>> id2label = {idx: label for label, idx in label2id.items()}
```
-Now that we have the mappings, we can replace the string answers with their ids, and flatten the dataset for a more convenient further preprocessing.
+Now that we have the mappings, we can replace the string answers with their ids, and flatten the dataset for a more convenient further preprocessing.
```python
>>> def replace_ids(inputs):
@@ -172,21 +172,21 @@ Now that we have the mappings, we can replace the string answers with their ids,
## Preprocessing data
-The next step is to load a ViLT processor to prepare the image and text data for the model.
+The next step is to load a ViLT processor to prepare the image and text data for the model.
[`ViltProcessor`] wraps a BERT tokenizer and ViLT image processor into a convenient single processor:
-```py
+```py
>>> from transformers import ViltProcessor
>>> processor = ViltProcessor.from_pretrained(model_checkpoint)
```
-To preprocess the data we need to encode the images and questions using the [`ViltProcessor`]. The processor will use
-the [`BertTokenizerFast`] to tokenize the text and create `input_ids`, `attention_mask` and `token_type_ids` for the text data.
+To preprocess the data we need to encode the images and questions using the [`ViltProcessor`]. The processor will use
+the [`BertTokenizerFast`] to tokenize the text and create `input_ids`, `attention_mask` and `token_type_ids` for the text data.
As for images, the processor will leverage [`ViltImageProcessor`] to resize and normalize the image, and create `pixel_values` and `pixel_mask`.
-All these preprocessing steps are done under the hood, we only need to call the `processor`. However, we still need to
-prepare the target labels. In this representation, each element corresponds to a possible answer (label). For correct answers, the element holds
+All these preprocessing steps are done under the hood, we only need to call the `processor`. However, we still need to
+prepare the target labels. In this representation, each element corresponds to a possible answer (label). For correct answers, the element holds
their respective score (weight), while the remaining elements are set to zero.
The following function applies the `processor` to the images and questions and formats the labels as described above:
@@ -197,13 +197,13 @@ The following function applies the `processor` to the images and questions and f
>>> def preprocess_data(examples):
... image_paths = examples['image_id']
... images = [Image.open(image_path) for image_path in image_paths]
-... texts = examples['question']
+... texts = examples['question']
... encoding = processor(images, texts, padding="max_length", truncation=True, return_tensors="pt")
... for k, v in encoding.items():
... encoding[k] = v.squeeze()
-
+
... targets = []
... for labels, scores in zip(examples['label.ids'], examples['label.weights']):
@@ -211,15 +211,15 @@ The following function applies the `processor` to the images and questions and f
... for label, score in zip(labels, scores):
... target[label] = score
-
+
... targets.append(target)
... encoding["labels"] = targets
-
+
... return encoding
```
-To apply the preprocessing function over the entire dataset, use 🤗 Datasets [`~datasets.map`] function. You can speed up `map` by
+To apply the preprocessing function over the entire dataset, use 🤗 Datasets [`~datasets.map`] function. You can speed up `map` by
setting `batched=True` to process multiple elements of the dataset at once. At this point, feel free to remove the columns you don't need.
```py
@@ -241,7 +241,7 @@ As a final step, create a batch of examples using [`DefaultDataCollator`]:
## Train the model
-You’re ready to start training your model now! Load ViLT with [`ViltForQuestionAnswering`]. Specify the number of labels
+You’re ready to start training your model now! Load ViLT with [`ViltForQuestionAnswering`]. Specify the number of labels
along with the label mappings:
```py
@@ -282,14 +282,14 @@ At this point, only three steps remain:
... args=training_args,
... data_collator=data_collator,
... train_dataset=processed_dataset,
-... tokenizer=processor,
+... processing_class=processor,
... )
```
3. Call [`~Trainer.train`] to finetune your model.
```py
->>> trainer.train()
+>>> trainer.train()
```
Once training is completed, share your model to the Hub with the [`~Trainer.push_to_hub`] method to share your final model on the 🤗 Hub:
@@ -309,7 +309,7 @@ way to try out your fine-tuned model for inference is to use it in a [`Pipeline`
>>> pipe = pipeline("visual-question-answering", model="MariaK/vilt_finetuned_200")
```
-The model in this guide has only been trained on 200 examples, so don't expect a lot from it. Let's see if it at least
+The model in this guide has only been trained on 200 examples, so don't expect a lot from it. Let's see if it at least
learned something from the data and take the first example from the dataset to illustrate inference:
```py
@@ -352,13 +352,13 @@ Predicted answer: down
## Zero-shot VQA
-The previous model treated VQA as a classification task. Some recent models, such as BLIP, BLIP-2, and InstructBLIP approach
-VQA as a generative task. Let's take [BLIP-2](../model_doc/blip-2) as an example. It introduced a new visual-language pre-training
-paradigm in which any combination of pre-trained vision encoder and LLM can be used (learn more in the [BLIP-2 blog post](https://huggingface.co/blog/blip-2)).
-This enables achieving state-of-the-art results on multiple visual-language tasks including visual question answering.
+The previous model treated VQA as a classification task. Some recent models, such as BLIP, BLIP-2, and InstructBLIP approach
+VQA as a generative task. Let's take [BLIP-2](../model_doc/blip-2) as an example. It introduced a new visual-language pre-training
+paradigm in which any combination of pre-trained vision encoder and LLM can be used (learn more in the [BLIP-2 blog post](https://huggingface.co/blog/blip-2)).
+This enables achieving state-of-the-art results on multiple visual-language tasks including visual question answering.
-Let's illustrate how you can use this model for VQA. First, let's load the model. Here we'll explicitly send the model to a
-GPU, if available, which we didn't need to do earlier when training, as [`Trainer`] handles this automatically:
+Let's illustrate how you can use this model for VQA. First, let's load the model. Here we'll explicitly send the model to a
+GPU, if available, which we didn't need to do earlier when training, as [`Trainer`] handles this automatically:
```py
>>> from transformers import AutoProcessor, Blip2ForConditionalGeneration
@@ -370,9 +370,9 @@ GPU, if available, which we didn't need to do earlier when training, as [`Traine
>>> model.to(device)
```
-The model takes image and text as input, so let's use the exact same image/question pair from the first example in the VQA dataset:
+The model takes image and text as input, so let's use the exact same image/question pair from the first example in the VQA dataset:
-```py
+```py
>>> example = dataset[0]
>>> image = Image.open(example['image_id'])
>>> question = example['question']
@@ -381,7 +381,7 @@ The model takes image and text as input, so let's use the exact same image/quest
To use BLIP-2 for visual question answering task, the textual prompt has to follow a specific format: `Question: {} Answer:`.
```py
->>> prompt = f"Question: {question} Answer:"
+>>> prompt = f"Question: {question} Answer:"
```
Now we need to preprocess the image/prompt with the model's processor, pass the processed input through the model, and decode the output:
@@ -392,10 +392,9 @@ Now we need to preprocess the image/prompt with the model's processor, pass the
>>> generated_ids = model.generate(**inputs, max_new_tokens=10)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
>>> print(generated_text)
-"He is looking at the crowd"
+"He is looking at the crowd"
```
-As you can see, the model recognized the crowd, and the direction of the face (looking down), however, it seems to miss
-the fact the crowd is behind the skater. Still, in cases where acquiring human-annotated datasets is not feasible, this
+As you can see, the model recognized the crowd, and the direction of the face (looking down), however, it seems to miss
+the fact the crowd is behind the skater. Still, in cases where acquiring human-annotated datasets is not feasible, this
approach can quickly produce useful results.
-
diff --git a/docs/source/en/trainer.md b/docs/source/en/trainer.md
index 812c5fe1a2..f9ea333769 100644
--- a/docs/source/en/trainer.md
+++ b/docs/source/en/trainer.md
@@ -81,7 +81,7 @@ trainer = Trainer(
args=training_args,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
@@ -153,7 +153,7 @@ from transformers import TrainerCallback
class EarlyStoppingCallback(TrainerCallback):
def __init__(self, num_steps=10):
self.num_steps = num_steps
-
+
def on_step_end(self, args, state, control, **kwargs):
if state.global_step >= self.num_steps:
return {"should_training_stop": True}
@@ -171,7 +171,7 @@ trainer = Trainer(
args=training_args,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
callback=[EarlyStoppingCallback()],
@@ -289,7 +289,7 @@ tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_config(config).to(0)
trainer = trl.SFTTrainer(
- model=model,
+ model=model,
args=args,
train_dataset=train_dataset,
dataset_text_field='text',
@@ -327,7 +327,7 @@ tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_config(config).to(0)
trainer = trl.SFTTrainer(
- model=model,
+ model=model,
args=args,
train_dataset=train_dataset,
dataset_text_field='text',
@@ -370,7 +370,7 @@ tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_config(config).to(0)
trainer = trl.SFTTrainer(
- model=model,
+ model=model,
args=args,
train_dataset=train_dataset,
dataset_text_field='text',
@@ -419,8 +419,8 @@ The kernel supports the Llama, Gemma, Mistral, and Mixtral model architectures.
## LOMO optimizer
-The LOMO optimizers have been introduced in [Full Parameter Fine-Tuning for Large Language Models with Limited Resources](https://hf.co/papers/2306.09782) and [AdaLomo: Low-memory Optimization with Adaptive Learning Rate](https://hf.co/papers/2310.10195).
-They both consist of an efficient full-parameter fine-tuning method. These optimizers fuse the gradient computation and the parameter update in one step to reduce memory usage. Supported optimizers for LOMO are `"lomo"` and `"adalomo"`. First either install LOMO from pypi `pip install lomo-optim` or install it from source with `pip install git+https://github.com/OpenLMLab/LOMO.git`.
+The LOMO optimizers have been introduced in [Full Parameter Fine-Tuning for Large Language Models with Limited Resources](https://hf.co/papers/2306.09782) and [AdaLomo: Low-memory Optimization with Adaptive Learning Rate](https://hf.co/papers/2310.10195).
+They both consist of an efficient full-parameter fine-tuning method. These optimizers fuse the gradient computation and the parameter update in one step to reduce memory usage. Supported optimizers for LOMO are `"lomo"` and `"adalomo"`. First either install LOMO from pypi `pip install lomo-optim` or install it from source with `pip install git+https://github.com/OpenLMLab/LOMO.git`.
@@ -457,7 +457,7 @@ tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, low_cpu_mem_usage=True).to(0)
trainer = trl.SFTTrainer(
- model=model,
+ model=model,
args=args,
train_dataset=train_dataset,
dataset_text_field='text',
@@ -579,8 +579,8 @@ To use Accelerate with [`Trainer`], run the [`accelerate.config`](https://huggin
```yml
-compute_environment: LOCAL_MACHINE
-distributed_type: MULTI_GPU
+compute_environment: LOCAL_MACHINE
+distributed_type: MULTI_GPU
downcast_bf16: 'no'
gpu_ids: all
machine_rank: 0 #change rank as per the node
@@ -654,8 +654,8 @@ use_cpu: false
```yml
-compute_environment: LOCAL_MACHINE
-deepspeed_config:
+compute_environment: LOCAL_MACHINE
+deepspeed_config:
gradient_accumulation_steps: 1
gradient_clipping: 0.7
offload_optimizer_device: cpu
diff --git a/docs/source/es/tasks/asr.md b/docs/source/es/tasks/asr.md
index 7d3133af47..41e9f82e35 100644
--- a/docs/source/es/tasks/asr.md
+++ b/docs/source/es/tasks/asr.md
@@ -276,7 +276,7 @@ En este punto, solo quedan tres pasos:
... args=training_args,
... train_dataset=encoded_minds["train"],
... eval_dataset=encoded_minds["test"],
-... tokenizer=processor.feature_extractor,
+... processing_class=processor.feature_extractor,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
diff --git a/docs/source/es/tasks/image_classification.md b/docs/source/es/tasks/image_classification.md
index 4e3696c505..1bea468842 100644
--- a/docs/source/es/tasks/image_classification.md
+++ b/docs/source/es/tasks/image_classification.md
@@ -160,7 +160,7 @@ Al llegar a este punto, solo quedan tres pasos:
... data_collator=data_collator,
... train_dataset=food["train"],
... eval_dataset=food["test"],
-... tokenizer=image_processor,
+... processing_class=image_processor,
... )
>>> trainer.train()
diff --git a/docs/source/es/tasks/multiple_choice.md b/docs/source/es/tasks/multiple_choice.md
index 959416f149..32df3401d7 100644
--- a/docs/source/es/tasks/multiple_choice.md
+++ b/docs/source/es/tasks/multiple_choice.md
@@ -225,7 +225,7 @@ En este punto, solo quedan tres pasos:
... args=training_args,
... train_dataset=tokenized_swag["train"],
... eval_dataset=tokenized_swag["validation"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=DataCollatorForMultipleChoice(tokenizer=tokenizer),
... )
diff --git a/docs/source/es/tasks/question_answering.md b/docs/source/es/tasks/question_answering.md
index ca43aac9ae..42a6e4b6e1 100644
--- a/docs/source/es/tasks/question_answering.md
+++ b/docs/source/es/tasks/question_answering.md
@@ -195,7 +195,7 @@ En este punto, solo quedan tres pasos:
... args=training_args,
... train_dataset=tokenized_squad["train"],
... eval_dataset=tokenized_squad["validation"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... )
diff --git a/docs/source/es/tasks/summarization.md b/docs/source/es/tasks/summarization.md
index e6a9532f66..c9060cba6b 100644
--- a/docs/source/es/tasks/summarization.md
+++ b/docs/source/es/tasks/summarization.md
@@ -155,7 +155,7 @@ En este punto, solo faltan tres pasos:
... args=training_args,
... train_dataset=tokenized_billsum["train"],
... eval_dataset=tokenized_billsum["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... )
diff --git a/docs/source/es/trainer.md b/docs/source/es/trainer.md
index 57fcaa6290..dab83e9a9d 100644
--- a/docs/source/es/trainer.md
+++ b/docs/source/es/trainer.md
@@ -14,7 +14,7 @@ rendered properly in your Markdown viewer.
-->
-# El Trainer
+# El Trainer
El [`Trainer`] es un bucle completo de entrenamiento y evaluación para modelos de PyTorch implementado en la biblioteca Transformers. Solo necesitas pasarle las piezas necesarias para el entrenamiento (modelo, tokenizador, conjunto de datos, función de evaluación, hiperparámetros de entrenamiento, etc.), y la clase [`Trainer`] se encarga del resto. Esto facilita comenzar a entrenar más rápido sin tener que escribir manualmente tu propio bucle de entrenamiento. Pero al mismo tiempo, [`Trainer`] es muy personalizable y ofrece una gran cantidad de opciones de entrenamiento para que puedas adaptarlo a tus necesidades exactas de entrenamiento.
@@ -79,7 +79,7 @@ trainer = Trainer(
args=training_args,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
@@ -151,7 +151,7 @@ from transformers import TrainerCallback
class EarlyStoppingCallback(TrainerCallback):
def __init__(self, num_steps=10):
self.num_steps = num_steps
-
+
def on_step_end(self, args, state, control, **kwargs):
if state.global_step >= self.num_steps:
return {"should_training_stop": True}
@@ -169,7 +169,7 @@ trainer = Trainer(
args=training_args,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
callback=[EarlyStoppingCallback()],
@@ -265,8 +265,8 @@ Para usar Accelerate con [`Trainer`], ejecuta el comando [`accelerate.config`](h
```yml
-compute_environment: LOCAL_MACHINE
-distributed_type: MULTI_GPU
+compute_environment: LOCAL_MACHINE
+distributed_type: MULTI_GPU
downcast_bf16: 'no'
gpu_ids: all
machine_rank: 0 #change rank as per the node
@@ -337,8 +337,8 @@ use_cpu: false
```yml
-compute_environment: LOCAL_MACHINE
-deepspeed_config:
+compute_environment: LOCAL_MACHINE
+deepspeed_config:
gradient_accumulation_steps: 1
gradient_clipping: 0.7
offload_optimizer_device: cpu
@@ -406,4 +406,4 @@ accelerate launch --num_processes=2 \
--overwrite_output_dir
```
-Consulta el tutorial [Lanzamiento de tus scripts con Accelerate](https://huggingface.co/docs/accelerate/basic_tutorials/launch) para obtener más información sobre `accelerate_launch` y las configuraciones personalizadas.
\ No newline at end of file
+Consulta el tutorial [Lanzamiento de tus scripts con Accelerate](https://huggingface.co/docs/accelerate/basic_tutorials/launch) para obtener más información sobre `accelerate_launch` y las configuraciones personalizadas.
diff --git a/docs/source/fr/quicktour.md b/docs/source/fr/quicktour.md
index df0233ae82..3cc2a8c5fa 100644
--- a/docs/source/fr/quicktour.md
+++ b/docs/source/fr/quicktour.md
@@ -169,7 +169,7 @@ Si vous ne parvenez pas à trouver un modèle adapté à votre cas d'utilisation
-Les classes [`AutoModelForSequenceClassification`] et [`AutoTokenizer`] fonctionnent ensemble pour créer un [`pipeline`] comme celui que vous avez utilisé ci-dessus. Une [AutoClass](./model_doc/auto) est un raccourci qui récupère automatiquement l'architecture d'un modèle pré-entraîné à partir de son nom ou de son emplacement. Il vous suffit de sélectionner l'`AutoClass` appropriée à votre tâche et la classe de prétraitement qui lui est associée.
+Les classes [`AutoModelForSequenceClassification`] et [`AutoTokenizer`] fonctionnent ensemble pour créer un [`pipeline`] comme celui que vous avez utilisé ci-dessus. Une [AutoClass](./model_doc/auto) est un raccourci qui récupère automatiquement l'architecture d'un modèle pré-entraîné à partir de son nom ou de son emplacement. Il vous suffit de sélectionner l'`AutoClass` appropriée à votre tâche et la classe de prétraitement qui lui est associée.
Reprenons l'exemple de la section précédente et voyons comment vous pouvez utiliser l'`AutoClass` pour reproduire les résultats du [`pipeline`].
@@ -479,7 +479,7 @@ Maintenant, rassemblez tous ces éléments dans un [`Trainer`] :
... args=training_args,
... train_dataset=dataset["train"],
... eval_dataset=dataset["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... ) # doctest: +SKIP
```
@@ -496,7 +496,7 @@ Pour les tâches - comme la traduction ou la génération de résumé - qui util
-Vous pouvez personnaliser le comportement de la boucle d'apprentissage en redéfinissant les méthodes à l'intérieur de [`Trainer`]. Cela vous permet de personnaliser des caractéristiques telles que la fonction de perte, l'optimiseur et le planificateur. Consultez la documentation de [`Trainer`] pour savoir quelles méthodes peuvent être redéfinies.
+Vous pouvez personnaliser le comportement de la boucle d'apprentissage en redéfinissant les méthodes à l'intérieur de [`Trainer`]. Cela vous permet de personnaliser des caractéristiques telles que la fonction de perte, l'optimiseur et le planificateur. Consultez la documentation de [`Trainer`] pour savoir quelles méthodes peuvent être redéfinies.
L'autre moyen de personnaliser la boucle d'apprentissage est d'utiliser les [Callbacks](./main_classes/callback). Vous pouvez utiliser les callbacks pour intégrer d'autres bibliothèques et inspecter la boucle d'apprentissage afin de suivre la progression ou d'arrêter l'apprentissage plus tôt. Les callbacks ne modifient rien dans la boucle d'apprentissage elle-même. Pour personnaliser quelque chose comme la fonction de perte, vous devez redéfinir le [`Trainer`] à la place.
diff --git a/docs/source/ja/hpo_train.md b/docs/source/ja/hpo_train.md
index 85da3616f8..90591daf8b 100644
--- a/docs/source/ja/hpo_train.md
+++ b/docs/source/ja/hpo_train.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
これらを使用する前に、ハイパーパラメーター検索バックエンドをインストールする必要があります。
```bash
-pip install optuna/sigopt/wandb/ray[tune]
+pip install optuna/sigopt/wandb/ray[tune]
```
## How to enable Hyperparameter search in example
@@ -119,7 +119,7 @@ Wandbについては、[object_parameter](https://docs.wandb.ai/guides/sweeps/co
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... model_init=model_init,
... data_collator=data_collator,
... )
@@ -142,9 +142,3 @@ Wandbについては、[object_parameter](https://docs.wandb.ai/guides/sweeps/co
## Hyperparameter search For DDP finetune
現在、DDP(Distributed Data Parallel)のためのハイパーパラメーター検索は、Optuna と SigOpt に対して有効になっています。ランクゼロプロセスのみが検索トライアルを生成し、他のランクに引数を渡します。
-
-
-
-
-
-
diff --git a/docs/source/ja/quicktour.md b/docs/source/ja/quicktour.md
index 0e20d1eee9..e03dea33cb 100644
--- a/docs/source/ja/quicktour.md
+++ b/docs/source/ja/quicktour.md
@@ -516,7 +516,7 @@ tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
... args=training_args,
... train_dataset=dataset["train"],
... eval_dataset=dataset["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... ) # doctest: +SKIP
```
diff --git a/docs/source/ja/tasks/asr.md b/docs/source/ja/tasks/asr.md
index 9226f5b414..ebefeba831 100644
--- a/docs/source/ja/tasks/asr.md
+++ b/docs/source/ja/tasks/asr.md
@@ -148,7 +148,7 @@ MInDS-14 データセットのサンプリング レートは 8000kHz です (
... return batch
```
-データセット全体に前処理関数を適用するには、🤗 Datasets [`~datasets.Dataset.map`] 関数を使用します。 `num_proc` パラメータを使用してプロセスの数を増やすことで、`map` を高速化できます。 [`~datasets.Dataset.remove_columns`] メソッドを使用して、不要な列を削除します。
+データセット全体に前処理関数を適用するには、🤗 Datasets [`~datasets.Dataset.map`] 関数を使用します。 `num_proc` パラメータを使用してプロセスの数を増やすことで、`map` を高速化できます。 [`~datasets.Dataset.remove_columns`] メソッドを使用して、不要な列を削除します。
```py
>>> encoded_minds = minds.map(prepare_dataset, remove_columns=minds.column_names["train"], num_proc=4)
@@ -281,7 +281,7 @@ MInDS-14 データセットのサンプリング レートは 8000kHz です (
... args=training_args,
... train_dataset=encoded_minds["train"],
... eval_dataset=encoded_minds["test"],
-... tokenizer=processor,
+... processing_class=processor,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
diff --git a/docs/source/ja/tasks/audio_classification.md b/docs/source/ja/tasks/audio_classification.md
index d32050072f..aa38d12d4e 100644
--- a/docs/source/ja/tasks/audio_classification.md
+++ b/docs/source/ja/tasks/audio_classification.md
@@ -233,7 +233,7 @@ MInDS-14 データセットのサンプリング レートは 8000khz です (
... args=training_args,
... train_dataset=encoded_minds["train"],
... eval_dataset=encoded_minds["test"],
-... tokenizer=feature_extractor,
+... processing_class=feature_extractor,
... compute_metrics=compute_metrics,
... )
@@ -320,4 +320,4 @@ MInDS-14 データセットのサンプリング レートは 8000khz です (
'cash_deposit'
```
-
\ No newline at end of file
+
diff --git a/docs/source/ja/tasks/document_question_answering.md b/docs/source/ja/tasks/document_question_answering.md
index 847ec8441c..f07cc6dff2 100644
--- a/docs/source/ja/tasks/document_question_answering.md
+++ b/docs/source/ja/tasks/document_question_answering.md
@@ -364,7 +364,7 @@ end_index 18
自分で実装したい場合は、[質問応答の章](https://huggingface.co/course/chapter7/7?fw=pt#postprocessing) を確認してください。
インスピレーションを得るためにハグフェイスコースの。
-## Train
+## Train
おめでとう!このガイドの最も難しい部分を無事にナビゲートできたので、独自のモデルをトレーニングする準備が整いました。
トレーニングには次の手順が含まれます。
@@ -423,7 +423,7 @@ end_index 18
... data_collator=data_collator,
... train_dataset=encoded_train_dataset,
... eval_dataset=encoded_test_dataset,
-... tokenizer=processor,
+... processing_class=processor,
... )
>>> trainer.train()
diff --git a/docs/source/ja/tasks/image_classification.md b/docs/source/ja/tasks/image_classification.md
index 2202dc3a4f..013dfc286d 100644
--- a/docs/source/ja/tasks/image_classification.md
+++ b/docs/source/ja/tasks/image_classification.md
@@ -323,7 +323,7 @@ food["test"].set_transform(preprocess_val)
... data_collator=data_collator,
... train_dataset=food["train"],
... eval_dataset=food["test"],
-... tokenizer=image_processor,
+... processing_class=image_processor,
... compute_metrics=compute_metrics,
... )
@@ -551,4 +551,3 @@ Epoch 5/5
-
diff --git a/docs/source/ja/tasks/knowledge_distillation_for_image_classification.md b/docs/source/ja/tasks/knowledge_distillation_for_image_classification.md
index 30c0dbbf06..1079121c60 100644
--- a/docs/source/ja/tasks/knowledge_distillation_for_image_classification.md
+++ b/docs/source/ja/tasks/knowledge_distillation_for_image_classification.md
@@ -165,7 +165,7 @@ trainer = ImageDistilTrainer(
train_dataset=processed_datasets["train"],
eval_dataset=processed_datasets["validation"],
data_collator=data_collator,
- tokenizer=teacher_extractor,
+ processing_class=teacher_extractor,
compute_metrics=compute_metrics,
temperature=5,
lambda_param=0.5
diff --git a/docs/source/ja/tasks/multiple_choice.md b/docs/source/ja/tasks/multiple_choice.md
index 98e258f161..075a7a2cb7 100644
--- a/docs/source/ja/tasks/multiple_choice.md
+++ b/docs/source/ja/tasks/multiple_choice.md
@@ -271,7 +271,7 @@ tokenized_swag = swag.map(preprocess_function, batched=True)
... args=training_args,
... train_dataset=tokenized_swag["train"],
... eval_dataset=tokenized_swag["validation"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=DataCollatorForMultipleChoice(tokenizer=tokenizer),
... compute_metrics=compute_metrics,
... )
diff --git a/docs/source/ja/tasks/object_detection.md b/docs/source/ja/tasks/object_detection.md
index 1b1bfb3f81..31e8effa54 100644
--- a/docs/source/ja/tasks/object_detection.md
+++ b/docs/source/ja/tasks/object_detection.md
@@ -371,7 +371,7 @@ DETR モデルをトレーニングできる「ラベル」。画像プロセッ
... args=training_args,
... data_collator=collate_fn,
... train_dataset=cppe5["train"],
-... tokenizer=image_processor,
+... processing_class=image_processor,
... )
>>> trainer.train()
diff --git a/docs/source/ja/tasks/question_answering.md b/docs/source/ja/tasks/question_answering.md
index b039272f45..9217c211e6 100644
--- a/docs/source/ja/tasks/question_answering.md
+++ b/docs/source/ja/tasks/question_answering.md
@@ -227,7 +227,7 @@ pip install transformers datasets evaluate
... args=training_args,
... train_dataset=tokenized_squad["train"],
... eval_dataset=tokenized_squad["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... )
diff --git a/docs/source/ja/tasks/summarization.md b/docs/source/ja/tasks/summarization.md
index 74152d5dbd..6784696e6c 100644
--- a/docs/source/ja/tasks/summarization.md
+++ b/docs/source/ja/tasks/summarization.md
@@ -216,7 +216,7 @@ pip install transformers datasets evaluate rouge_score
... args=training_args,
... train_dataset=tokenized_billsum["train"],
... eval_dataset=tokenized_billsum["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
diff --git a/docs/source/ja/tasks/text-to-speech.md b/docs/source/ja/tasks/text-to-speech.md
index b302a19a0d..669d15730e 100644
--- a/docs/source/ja/tasks/text-to-speech.md
+++ b/docs/source/ja/tasks/text-to-speech.md
@@ -125,7 +125,7 @@ dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
>>> processor = SpeechT5Processor.from_pretrained(checkpoint)
```
-### Text cleanup for SpeechT5 tokenization
+### Text cleanup for SpeechT5 tokenization
まずはテキストデータをクリーンアップすることから始めます。テキストを処理するには、プロセッサのトークナイザー部分が必要です。
@@ -442,7 +442,7 @@ SpeechT5 では、モデルのデコーダ部分への入力が 2 分の 1 に
ターゲット シーケンスの長さが奇数である可能性がある場合、データ照合機能はバッチの最大長を切り捨てて、
2の倍数。
-```py
+```py
>>> data_collator = TTSDataCollatorWithPadding(processor=processor)
```
@@ -458,7 +458,7 @@ SpeechT5 では、モデルのデコーダ部分への入力が 2 分の 1 に
`use_cache=True`オプションは、勾配チェックポイントと互換性がありません。トレーニングのために無効にします。
-```py
+```py
>>> model.config.use_cache = False
```
@@ -501,7 +501,7 @@ SpeechT5 では、モデルのデコーダ部分への入力が 2 分の 1 に
... train_dataset=dataset["train"],
... eval_dataset=dataset["test"],
... data_collator=data_collator,
-... tokenizer=processor,
+... processing_class=processor,
... )
```
これで、トレーニングを開始する準備が整いました。トレーニングには数時間かかります。 GPU に応じて、
@@ -567,7 +567,7 @@ SpeechT5 では、モデルのデコーダ部分への入力が 2 分の 1 に
```py
>>> from IPython.display import Audio
->>> Audio(output['audio'], rate=output['sampling_rate'])
+>>> Audio(output['audio'], rate=output['sampling_rate'])
```
### Run inference manually
@@ -583,14 +583,14 @@ SpeechT5 では、モデルのデコーダ部分への入力が 2 分の 1 に
テスト データセットから例を選択して、スピーカーの埋め込みを取得します。
-```py
+```py
>>> example = dataset["test"][304]
>>> speaker_embeddings = torch.tensor(example["speaker_embeddings"]).unsqueeze(0)
```
入力テキストを定義し、トークン化します。
-```py
+```py
>>> text = "hallo allemaal, ik praat nederlands. groetjes aan iedereen!"
>>> inputs = processor(text=text, return_tensors="pt")
```
diff --git a/docs/source/ja/tasks/token_classification.md b/docs/source/ja/tasks/token_classification.md
index a7f5097f68..4389aeacb5 100644
--- a/docs/source/ja/tasks/token_classification.md
+++ b/docs/source/ja/tasks/token_classification.md
@@ -295,7 +295,7 @@ pip install transformers datasets evaluate seqeval
... args=training_args,
... train_dataset=tokenized_wnut["train"],
... eval_dataset=tokenized_wnut["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
diff --git a/docs/source/ja/tasks/translation.md b/docs/source/ja/tasks/translation.md
index eb67604f9e..7fa45eac9c 100644
--- a/docs/source/ja/tasks/translation.md
+++ b/docs/source/ja/tasks/translation.md
@@ -220,7 +220,7 @@ pip install transformers datasets evaluate sacrebleu
... args=training_args,
... train_dataset=tokenized_books["train"],
... eval_dataset=tokenized_books["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
diff --git a/docs/source/ja/tasks/video_classification.md b/docs/source/ja/tasks/video_classification.md
index ecfae843f2..741356a6f5 100644
--- a/docs/source/ja/tasks/video_classification.md
+++ b/docs/source/ja/tasks/video_classification.md
@@ -61,7 +61,7 @@ pip install -q pytorchvideo transformers evaluate
サブセットをダウンロードした後、圧縮アーカイブを抽出する必要があります。
-```py
+```py
>>> import tarfile
>>> with tarfile.open(file_path) as t:
@@ -127,7 +127,7 @@ UCF101_subset/
* `id2label`: 整数をクラス名にマッピングします。
-```py
+```py
>>> class_labels = sorted({str(path).split("/")[2] for path in all_video_file_paths})
>>> label2id = {label: i for i, label in enumerate(class_labels)}
>>> id2label = {i: label for label, i in label2id.items()}
@@ -143,7 +143,7 @@ UCF101_subset/
事前トレーニングされたチェックポイントとそれに関連する画像プロセッサからビデオ分類モデルをインスタンス化します。モデルのエンコーダーには事前トレーニングされたパラメーターが付属しており、分類ヘッドはランダムに初期化されます。画像プロセッサは、データセットの前処理パイプラインを作成するときに役立ちます。
-```py
+```py
>>> from transformers import VideoMAEImageProcessor, VideoMAEForVideoClassification
>>> model_ckpt = "MCG-NJU/videomae-base"
@@ -175,7 +175,7 @@ You should probably TRAIN this model on a down-stream task to be able to use it
ビデオの前処理には、[PyTorchVideo ライブラリ](https://pytorchvideo.org/) を利用します。まず、必要な依存関係をインポートします。
-```py
+```py
>>> import pytorchvideo.data
>>> from pytorchvideo.transforms import (
@@ -224,7 +224,7 @@ You should probably TRAIN this model on a down-stream task to be able to use it
次に、データセット固有の変換とデータセットをそれぞれ定義します。トレーニングセットから始めます:
-```py
+```py
>>> train_transform = Compose(
... [
... ApplyTransformToKey(
@@ -254,7 +254,7 @@ You should probably TRAIN this model on a down-stream task to be able to use it
同じ一連のワークフローを検証セットと評価セットに適用できます。
-```py
+```py
>>> val_transform = Compose(
... [
... ApplyTransformToKey(
@@ -297,9 +297,9 @@ You should probably TRAIN this model on a down-stream task to be able to use it
# (300, 30, 75)
```
-## Visualize the preprocessed video for better debugging
+## Visualize the preprocessed video for better debugging
-```py
+```py
>>> import imageio
>>> import numpy as np
>>> from IPython.display import Image
@@ -312,7 +312,7 @@ You should probably TRAIN this model on a down-stream task to be able to use it
>>> def create_gif(video_tensor, filename="sample.gif"):
... """Prepares a GIF from a video tensor.
-...
+...
... The video tensor is expected to have the following shape:
... (num_frames, num_channels, height, width).
... """
@@ -339,13 +339,13 @@ You should probably TRAIN this model on a down-stream task to be able to use it
-## Train the model
+## Train the model
🤗 Transformers の [`Trainer`](https://huggingface.co/docs/transformers/main_classes/trainer) をモデルのトレーニングに利用します。 `Trainer`をインスタンス化するには、トレーニング構成と評価メトリクスを定義する必要があります。最も重要なのは [`TrainingArguments`](https://huggingface.co/transformers/main_classes/trainer.html#transformers.TrainingArguments) で、これはトレーニングを構成するためのすべての属性を含むクラスです。モデルのチェックポイントを保存するために使用される出力フォルダー名が必要です。また、🤗 Hub 上のモデル リポジトリ内のすべての情報を同期するのにも役立ちます。
トレーニング引数のほとんどは一目瞭然ですが、ここで非常に重要なのは`remove_unused_columns=False`です。これにより、モデルの呼び出し関数で使用されない機能が削除されます。デフォルトでは`True`です。これは、通常、未使用の特徴列を削除し、モデルの呼び出し関数への入力を解凍しやすくすることが理想的であるためです。ただし、この場合、`pixel_values` (モデルが入力で期待する必須キーです) を作成するには、未使用の機能 (特に`video`) が必要です。
-```py
+```py
>>> from transformers import TrainingArguments, Trainer
>>> model_name = model_ckpt.split("/")[-1]
@@ -391,7 +391,7 @@ def compute_metrics(eval_pred):
また、サンプルをまとめてバッチ処理するために使用される `collate_fn` を定義します。各バッチは、`pixel_values` と `labels` という 2 つのキーで構成されます。
-```py
+```py
>>> def collate_fn(examples):
... # permute to (num_frames, num_channels, height, width)
... pixel_values = torch.stack(
@@ -403,13 +403,13 @@ def compute_metrics(eval_pred):
次に、これらすべてをデータセットとともに`Trainer`に渡すだけです。
-```py
+```py
>>> trainer = Trainer(
... model,
... args,
... train_dataset=train_dataset,
... eval_dataset=val_dataset,
-... tokenizer=image_processor,
+... processing_class=image_processor,
... compute_metrics=compute_metrics,
... data_collator=collate_fn,
... )
@@ -419,7 +419,7 @@ def compute_metrics(eval_pred):
次に、`train` メソッドを呼び出してモデルを微調整します。
-```py
+```py
>>> train_results = trainer.train()
```
@@ -435,7 +435,7 @@ def compute_metrics(eval_pred):
推論のためにビデオをロードします。
-```py
+```py
>>> sample_test_video = next(iter(test_dataset))
```
@@ -491,7 +491,7 @@ def compute_metrics(eval_pred):
`logits` をデコードすると、次のようになります。
-```py
+```py
>>> predicted_class_idx = logits.argmax(-1).item()
>>> print("Predicted class:", model.config.id2label[predicted_class_idx])
# Predicted class: BasketballDunk
diff --git a/docs/source/ja/tasks/visual_question_answering.md b/docs/source/ja/tasks/visual_question_answering.md
index f6c2989693..3231cba5e3 100644
--- a/docs/source/ja/tasks/visual_question_answering.md
+++ b/docs/source/ja/tasks/visual_question_answering.md
@@ -110,7 +110,7 @@ Dataset({
残りの機能は必要ないので削除できます。
-```py
+```py
>>> dataset = dataset.remove_columns(['question_type', 'question_id', 'answer_type'])
```
@@ -150,7 +150,7 @@ Dataset({
>>> unique_labels = list(set(flattened_labels))
>>> label2id = {label: idx for idx, label in enumerate(unique_labels)}
->>> id2label = {idx: label for label, idx in label2id.items()}
+>>> id2label = {idx: label for label, idx in label2id.items()}
```
マッピングができたので、文字列の回答をその ID に置き換え、さらに前処理をより便利にするためにデータセットをフラット化することができます。
@@ -175,7 +175,7 @@ Dataset({
次のステップでは、ViLT プロセッサをロードして、モデルの画像データとテキスト データを準備します。
[`ViltProcessor`] は、BERT トークナイザーと ViLT 画像プロセッサを便利な単一プロセッサにラップします。
-```py
+```py
>>> from transformers import ViltProcessor
>>> processor = ViltProcessor.from_pretrained(model_checkpoint)
@@ -197,13 +197,13 @@ Dataset({
>>> def preprocess_data(examples):
... image_paths = examples['image_id']
... images = [Image.open(image_path) for image_path in image_paths]
-... texts = examples['question']
+... texts = examples['question']
... encoding = processor(images, texts, padding="max_length", truncation=True, return_tensors="pt")
... for k, v in encoding.items():
... encoding[k] = v.squeeze()
-
+
... targets = []
... for labels, scores in zip(examples['label.ids'], examples['label.weights']):
@@ -211,11 +211,11 @@ Dataset({
... for label, score in zip(labels, scores):
... target[label] = score
-
+
... targets.append(target)
... encoding["labels"] = targets
-
+
... return encoding
```
@@ -284,14 +284,14 @@ Dataset({
... args=training_args,
... data_collator=data_collator,
... train_dataset=processed_dataset,
-... tokenizer=processor,
+... processing_class=processor,
... )
```
3. [`~Trainer.train`] を呼び出してモデルを微調整します。
```py
->>> trainer.train()
+>>> trainer.train()
```
トレーニングが完了したら、 [`~Trainer.push_to_hub`] メソッドを使用してモデルをハブに共有し、🤗 ハブで最終モデルを共有します。
@@ -376,7 +376,7 @@ GPU (利用可能な場合)。これは [`Trainer`] が自動的に処理する
モデルは画像とテキストを入力として受け取るため、VQA データセットの最初の例とまったく同じ画像と質問のペアを使用してみましょう。
-```py
+```py
>>> example = dataset[0]
>>> image = Image.open(example['image_id'])
>>> question = example['question']
@@ -386,7 +386,7 @@ GPU (利用可能な場合)。これは [`Trainer`] が自動的に処理する
```py
->>> prompt = f"Question: {question} Answer:"
+>>> prompt = f"Question: {question} Answer:"
```
次に、モデルのプロセッサで画像/プロンプトを前処理し、処理された入力をモデルに渡し、出力をデコードする必要があります。
@@ -397,7 +397,7 @@ GPU (利用可能な場合)。これは [`Trainer`] が自動的に処理する
>>> generated_ids = model.generate(**inputs, max_new_tokens=10)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
>>> print(generated_text)
-"He is looking at the crowd"
+"He is looking at the crowd"
```
ご覧のとおり、モデルは群衆と顔の向き (下を向いている) を認識しましたが、見逃しているようです。
diff --git a/docs/source/ko/hpo_train.md b/docs/source/ko/hpo_train.md
index 58bacd55ff..c0982db5e0 100644
--- a/docs/source/ko/hpo_train.md
+++ b/docs/source/ko/hpo_train.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
하이퍼파라미터 탐색 백엔드로 사용하기 전에 아래의 명령어를 사용하여 라이브러리들을 설치하세요.
```bash
-pip install optuna/sigopt/wandb/ray[tune]
+pip install optuna/sigopt/wandb/ray[tune]
```
## 예제에서 하이퍼파라미터 탐색을 활성화하는 방법 [[how-to-enable-hyperparameter-search-in-example]]
@@ -100,7 +100,7 @@ wandb의 경우, 해당 [object_parameter](https://docs.wandb.ai/guides/sweeps/c
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... model_init=model_init,
... data_collator=data_collator,
... )
diff --git a/docs/source/ko/quicktour.md b/docs/source/ko/quicktour.md
index 0dc4887b88..06f44e6fd2 100644
--- a/docs/source/ko/quicktour.md
+++ b/docs/source/ko/quicktour.md
@@ -486,7 +486,7 @@ tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
... args=training_args,
... train_dataset=dataset["train"],
... eval_dataset=dataset["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... ) # doctest: +SKIP
```
@@ -554,4 +554,4 @@ tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
## 다음 단계는 무엇인가요? [[whats-next]]
-🤗 Transformers 둘러보기를 모두 읽으셨다면, 가이드를 살펴보고 더 구체적인 것을 수행하는 방법을 알아보세요. 이를테면 커스텀 모델 구축하는 방법, 과업에 알맞게 모델을 미세조정하는 방법, 스크립트로 모델 훈련하는 방법 등이 있습니다. 🤗 Transformers 핵심 개념에 대해 더 알아보려면 커피 한 잔 들고 개념 가이드를 살펴보세요!
\ No newline at end of file
+🤗 Transformers 둘러보기를 모두 읽으셨다면, 가이드를 살펴보고 더 구체적인 것을 수행하는 방법을 알아보세요. 이를테면 커스텀 모델 구축하는 방법, 과업에 알맞게 모델을 미세조정하는 방법, 스크립트로 모델 훈련하는 방법 등이 있습니다. 🤗 Transformers 핵심 개념에 대해 더 알아보려면 커피 한 잔 들고 개념 가이드를 살펴보세요!
diff --git a/docs/source/ko/tasks/asr.md b/docs/source/ko/tasks/asr.md
index 2247537678..d1e4a5e1d9 100644
--- a/docs/source/ko/tasks/asr.md
+++ b/docs/source/ko/tasks/asr.md
@@ -20,7 +20,7 @@ rendered properly in your Markdown viewer.
-자동 음성 인식(Automatic Speech Recognition, ASR)은 음성 신호를 텍스트로 변환하여 음성 입력 시퀀스를 텍스트 출력에 매핑합니다.
+자동 음성 인식(Automatic Speech Recognition, ASR)은 음성 신호를 텍스트로 변환하여 음성 입력 시퀀스를 텍스트 출력에 매핑합니다.
Siri와 Alexa와 같은 가상 어시스턴트는 ASR 모델을 사용하여 일상적으로 사용자를 돕고 있으며, 회의 중 라이브 캡션 및 메모 작성과 같은 유용한 사용자 친화적 응용 프로그램도 많이 있습니다.
이 가이드에서 소개할 내용은 아래와 같습니다:
@@ -50,7 +50,7 @@ Hugging Face 계정에 로그인하면 모델을 업로드하고 커뮤니티에
## MInDS-14 데이터 세트 가져오기[[load-minds-14-dataset]]
-먼저, 🤗 Datasets 라이브러리에서 [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) 데이터 세트의 일부분을 가져오세요.
+먼저, 🤗 Datasets 라이브러리에서 [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) 데이터 세트의 일부분을 가져오세요.
이렇게 하면 전체 데이터 세트에 대한 훈련에 시간을 들이기 전에 모든 것이 작동하는지 실험하고 검증할 수 있습니다.
```py
@@ -198,7 +198,7 @@ MInDS-14 데이터 세트의 샘플링 레이트는 8000kHz이므로([데이터
## 평가하기[[evaluate]]
-훈련 중에 평가 지표를 포함하면 모델의 성능을 평가하는 데 도움이 되는 경우가 많습니다. 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) 라이브러리를 사용하면 평가 방법을 빠르게 불러올 수 있습니다.
+훈련 중에 평가 지표를 포함하면 모델의 성능을 평가하는 데 도움이 되는 경우가 많습니다. 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) 라이브러리를 사용하면 평가 방법을 빠르게 불러올 수 있습니다.
이 작업에서는 [단어 오류율(Word Error Rate, WER)](https://huggingface.co/spaces/evaluate-metric/wer) 평가 지표를 가져옵니다.
(평가 지표를 불러오고 계산하는 방법은 🤗 Evaluate [둘러보기](https://huggingface.co/docs/evaluate/a_quick_tour)를 참조하세요):
@@ -285,7 +285,7 @@ MInDS-14 데이터 세트의 샘플링 레이트는 8000kHz이므로([데이터
... args=training_args,
... train_dataset=encoded_minds["train"],
... eval_dataset=encoded_minds["test"],
-... tokenizer=processor.feature_extractor,
+... processing_class=processor.feature_extractor,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
@@ -372,4 +372,4 @@ MInDS-14 데이터 세트의 샘플링 레이트는 8000kHz이므로([데이터
['I WOUL LIKE O SET UP JOINT ACOUNT WTH Y PARTNER']
```
-
\ No newline at end of file
+
diff --git a/docs/source/ko/tasks/audio_classification.md b/docs/source/ko/tasks/audio_classification.md
index 73932100b0..936b4eb198 100644
--- a/docs/source/ko/tasks/audio_classification.md
+++ b/docs/source/ko/tasks/audio_classification.md
@@ -235,7 +235,7 @@ MinDS-14 데이터 세트의 샘플링 속도는 8000khz이므로(이 정보는
... args=training_args,
... train_dataset=encoded_minds["train"],
... eval_dataset=encoded_minds["test"],
-... tokenizer=feature_extractor,
+... processing_class=feature_extractor,
... compute_metrics=compute_metrics,
... )
@@ -321,4 +321,4 @@ For a more in-depth example of how to finetune a model for audio classification,
'cash_deposit'
```
-
\ No newline at end of file
+
diff --git a/docs/source/ko/tasks/document_question_answering.md b/docs/source/ko/tasks/document_question_answering.md
index 3d943ab96e..6c2d04f4ee 100644
--- a/docs/source/ko/tasks/document_question_answering.md
+++ b/docs/source/ko/tasks/document_question_answering.md
@@ -18,8 +18,8 @@ rendered properly in your Markdown viewer.
[[open-in-colab]]
-문서 시각적 질의 응답(Document Visual Question Answering)이라고도 하는
-문서 질의 응답(Document Question Answering)은 문서 이미지에 대한 질문에 답변을 주는 태스크입니다.
+문서 시각적 질의 응답(Document Visual Question Answering)이라고도 하는
+문서 질의 응답(Document Question Answering)은 문서 이미지에 대한 질문에 답변을 주는 태스크입니다.
이 태스크를 지원하는 모델의 입력은 일반적으로 이미지와 질문의 조합이고, 출력은 자연어로 된 답변입니다. 이러한 모델은 텍스트, 단어의 위치(바운딩 박스), 이미지 등 다양한 모달리티를 활용합니다.
이 가이드는 다음 내용을 설명합니다:
@@ -72,7 +72,7 @@ pip install -q pytesseract
## 데이터 불러오기 [[load-the-data]]
-이 가이드에서는 🤗 Hub에서 찾을 수 있는 전처리된 DocVQA의 작은 샘플을 사용합니다.
+이 가이드에서는 🤗 Hub에서 찾을 수 있는 전처리된 DocVQA의 작은 샘플을 사용합니다.
DocVQA의 전체 데이터 세트를 사용하고 싶다면, [DocVQA homepage](https://rrc.cvc.uab.es/?ch=17)에 가입 후 다운로드 할 수 있습니다. 전체 데이터 세트를 다운로드 했다면, 이 가이드를 계속 진행하기 위해 [🤗 dataset에 파일을 가져오는 방법](https://huggingface.co/docs/datasets/loading#local-and-remote-files)을 확인하세요.
```py
@@ -124,9 +124,9 @@ DatasetDict({
>>> updated_dataset = updated_dataset.filter(lambda x: len(x["words"]) + len(x["question"].split()) < 512)
```
-이 시점에서 이 데이터 세트의 OCR 특성도 제거해 보겠습니다. OCR 특성은 다른 모델을 미세 조정하기 위한 것으로, 이 가이드에서 사용하는 모델의 입력 요구 사항과 일치하지 않기 때문에 이 특성을 사용하기 위해서는 일부 처리가 필요합니다.
+이 시점에서 이 데이터 세트의 OCR 특성도 제거해 보겠습니다. OCR 특성은 다른 모델을 미세 조정하기 위한 것으로, 이 가이드에서 사용하는 모델의 입력 요구 사항과 일치하지 않기 때문에 이 특성을 사용하기 위해서는 일부 처리가 필요합니다.
대신, 원본 데이터에 [`LayoutLMv2Processor`]를 사용하여 OCR 및 토큰화를 모두 수행할 수 있습니다.
-이렇게 하면 모델이 요구하는 입력을 얻을 수 있습니다.
+이렇게 하면 모델이 요구하는 입력을 얻을 수 있습니다.
이미지를 수동으로 처리하려면, [`LayoutLMv2` model documentation](../model_doc/layoutlmv2)에서 모델이 요구하는 입력 포맷을 확인해보세요.
```py
@@ -186,7 +186,7 @@ DatasetDict({
### 텍스트 데이터 전처리 [[preprocessing-text-data]]
이미지에 OCR을 적용했으면 데이터 세트의 텍스트 부분을 모델에 맞게 인코딩해야 합니다.
-이 인코딩에는 이전 단계에서 가져온 단어와 박스를 토큰 수준의 `input_ids`, `attention_mask`, `token_type_ids` 및 `bbox`로 변환하는 작업이 포함됩니다.
+이 인코딩에는 이전 단계에서 가져온 단어와 박스를 토큰 수준의 `input_ids`, `attention_mask`, `token_type_ids` 및 `bbox`로 변환하는 작업이 포함됩니다.
텍스트를 전처리하려면 프로세서의 `tokenizer`가 필요합니다.
```py
@@ -197,8 +197,8 @@ DatasetDict({
레이블 추가를 위해서, 먼저 더 큰 리스트(단어 리스트)에서 하위 리스트(단어로 분할된 답변)을 찾을 수 있는 헬퍼 함수를 정의합니다.
-이 함수는 `words_list`와 `answer_list`, 이렇게 두 리스트를 입력으로 받습니다.
-그런 다음 `words_list`를 반복하여 `words_list`의 현재 단어(words_list[i])가 `answer_list`의 첫 번째 단어(answer_list[0])와 같은지,
+이 함수는 `words_list`와 `answer_list`, 이렇게 두 리스트를 입력으로 받습니다.
+그런 다음 `words_list`를 반복하여 `words_list`의 현재 단어(words_list[i])가 `answer_list`의 첫 번째 단어(answer_list[0])와 같은지,
현재 단어에서 시작해 `answer_list`와 같은 길이만큼의 `words_list`의 하위 리스트가 `answer_list`와 일치하는지 확인합니다.
이 조건이 참이라면 일치하는 항목을 발견했음을 의미하며, 함수는 일치 항목, 시작 인덱스(idx) 및 종료 인덱스(idx + len(answer_list) - 1)를 기록합니다. 일치하는 항목이 두 개 이상 발견되면 함수는 첫 번째 항목만 반환합니다. 일치하는 항목이 없다면 함수는 (`None`, 0, 0)을 반환합니다.
@@ -349,7 +349,7 @@ end_index 18
## 훈련 [[train]]
-축하합니다! 이 가이드의 가장 어려운 부분을 성공적으로 처리했으니 이제 나만의 모델을 훈련할 준비가 되었습니다.
+축하합니다! 이 가이드의 가장 어려운 부분을 성공적으로 처리했으니 이제 나만의 모델을 훈련할 준비가 되었습니다.
훈련은 다음과 같은 단계로 이루어져 있습니다:
* 전처리에서의 동일한 체크포인트를 사용하기 위해 [`AutoModelForDocumentQuestionAnswering`]으로 모델을 가져옵니다.
* [`TrainingArguments`]로 훈련 하이퍼파라미터를 정합니다.
@@ -406,7 +406,7 @@ end_index 18
... data_collator=data_collator,
... train_dataset=encoded_train_dataset,
... eval_dataset=encoded_test_dataset,
-... tokenizer=processor,
+... processing_class=processor,
... )
>>> trainer.train()
@@ -421,7 +421,7 @@ end_index 18
## 추론 [[inference]]
-이제 LayoutLMv2 모델을 미세 조정하고 🤗 Hub에 업로드했으니 추론에도 사용할 수 있습니다.
+이제 LayoutLMv2 모델을 미세 조정하고 🤗 Hub에 업로드했으니 추론에도 사용할 수 있습니다.
추론을 위해 미세 조정된 모델을 사용해 보는 가장 간단한 방법은 [`Pipeline`]을 사용하는 것 입니다.
예를 들어 보겠습니다:
@@ -473,4 +473,4 @@ end_index 18
>>> processor.tokenizer.decode(encoding.input_ids.squeeze()[predicted_start_idx : predicted_end_idx + 1])
'lee a. waller'
-```
\ No newline at end of file
+```
diff --git a/docs/source/ko/tasks/image_classification.md b/docs/source/ko/tasks/image_classification.md
index 91ff3a9ca9..4955bd6cdf 100644
--- a/docs/source/ko/tasks/image_classification.md
+++ b/docs/source/ko/tasks/image_classification.md
@@ -157,7 +157,7 @@ Hugging Face 계정에 로그인하여 모델을 업로드하고 커뮤니티에
과적합을 방지하고 모델을 보다 견고하게 만들기 위해 데이터 세트의 훈련 부분에 데이터 증강을 추가합니다.
여기서 Keras 전처리 레이어로 훈련 데이터에 대한 변환(데이터 증강 포함)과
-검증 데이터에 대한 변환(중앙 크로핑, 크기 조정, 정규화만)을 정의합니다.
+검증 데이터에 대한 변환(중앙 크로핑, 크기 조정, 정규화만)을 정의합니다.
`tf.image` 또는 다른 원하는 라이브러리를 사용할 수 있습니다.
```py
@@ -241,7 +241,7 @@ food["test"].set_transform(preprocess_val)
## 평가[[evaluate]]
훈련 중에 평가 지표를 포함하면 모델의 성능을 평가하는 데 도움이 되는 경우가 많습니다.
-🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) 라이브러리로 평가 방법을 빠르게 가져올 수 있습니다. 이 작업에서는
+🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) 라이브러리로 평가 방법을 빠르게 가져올 수 있습니다. 이 작업에서는
[accuracy](https://huggingface.co/spaces/evaluate-metric/accuracy) 평가 지표를 가져옵니다. (🤗 Evaluate [빠른 둘러보기](https://huggingface.co/docs/evaluate/a_quick_tour)를 참조하여 평가 지표를 가져오고 계산하는 방법에 대해 자세히 알아보세요):
```py
@@ -317,7 +317,7 @@ food["test"].set_transform(preprocess_val)
... data_collator=data_collator,
... train_dataset=food["train"],
... eval_dataset=food["test"],
-... tokenizer=image_processor,
+... processing_class=image_processor,
... compute_metrics=compute_metrics,
... )
@@ -404,7 +404,7 @@ TensorFlow에서 모델을 미세 조정하려면 다음 단계를 따르세요:
```
예측에서 정확도를 계산하고 모델을 🤗 Hub로 푸시하려면 [Keras callbacks](../main_classes/keras_callbacks)를 사용하세요.
-`compute_metrics` 함수를 [KerasMetricCallback](../main_classes/keras_callbacks#transformers.KerasMetricCallback)에 전달하고,
+`compute_metrics` 함수를 [KerasMetricCallback](../main_classes/keras_callbacks#transformers.KerasMetricCallback)에 전달하고,
[PushToHubCallback](../main_classes/keras_callbacks#transformers.PushToHubCallback)을 사용하여 모델을 업로드합니다:
```py
diff --git a/docs/source/ko/tasks/multiple_choice.md b/docs/source/ko/tasks/multiple_choice.md
index 607bc04747..f2755da4a8 100644
--- a/docs/source/ko/tasks/multiple_choice.md
+++ b/docs/source/ko/tasks/multiple_choice.md
@@ -270,7 +270,7 @@ tokenized_swag = swag.map(preprocess_function, batched=True)
... args=training_args,
... train_dataset=tokenized_swag["train"],
... eval_dataset=tokenized_swag["validation"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=DataCollatorForMultipleChoice(tokenizer=tokenizer),
... compute_metrics=compute_metrics,
... )
diff --git a/docs/source/ko/tasks/object_detection.md b/docs/source/ko/tasks/object_detection.md
index 2b92d7edb5..e027ad65a9 100644
--- a/docs/source/ko/tasks/object_detection.md
+++ b/docs/source/ko/tasks/object_detection.md
@@ -361,7 +361,7 @@ DatasetDict({
... args=training_args,
... data_collator=collate_fn,
... train_dataset=cppe5["train"],
-... tokenizer=image_processor,
+... processing_class=image_processor,
... )
>>> trainer.train()
diff --git a/docs/source/ko/tasks/question_answering.md b/docs/source/ko/tasks/question_answering.md
index cebd9e1a78..8309dd7d75 100644
--- a/docs/source/ko/tasks/question_answering.md
+++ b/docs/source/ko/tasks/question_answering.md
@@ -223,7 +223,7 @@ pip install transformers datasets evaluate
... args=training_args,
... train_dataset=tokenized_squad["train"],
... eval_dataset=tokenized_squad["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... )
diff --git a/docs/source/ko/tasks/sequence_classification.md b/docs/source/ko/tasks/sequence_classification.md
index b9812e63b0..11dae1a965 100644
--- a/docs/source/ko/tasks/sequence_classification.md
+++ b/docs/source/ko/tasks/sequence_classification.md
@@ -190,7 +190,7 @@ tokenized_imdb = imdb.map(preprocess_function, batched=True)
... args=training_args,
... train_dataset=tokenized_imdb["train"],
... eval_dataset=tokenized_imdb["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
diff --git a/docs/source/ko/tasks/summarization.md b/docs/source/ko/tasks/summarization.md
index 501aaae726..a2b2b1fbc9 100644
--- a/docs/source/ko/tasks/summarization.md
+++ b/docs/source/ko/tasks/summarization.md
@@ -223,7 +223,7 @@ Hugging Face 계정에 로그인하면 모델을 업로드하고 커뮤니티에
... args=training_args,
... train_dataset=tokenized_billsum["train"],
... eval_dataset=tokenized_billsum["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
diff --git a/docs/source/ko/tasks/token_classification.md b/docs/source/ko/tasks/token_classification.md
index e32a18e1ee..a65503092c 100644
--- a/docs/source/ko/tasks/token_classification.md
+++ b/docs/source/ko/tasks/token_classification.md
@@ -107,7 +107,7 @@ Hugging Face 계정에 로그인하여 모델을 업로드하고 커뮤니티에
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
```
-위의 예제 `tokens` 필드를 보면 입력이 이미 토큰화된 것처럼 보입니다. 그러나 실제로 입력은 아직 토큰화되지 않았으므로 단어를 하위 단어로 토큰화하기 위해 `is_split_into_words=True`를 설정해야 합니다. 예제로 확인합니다:
+위의 예제 `tokens` 필드를 보면 입력이 이미 토큰화된 것처럼 보입니다. 그러나 실제로 입력은 아직 토큰화되지 않았으므로 단어를 하위 단어로 토큰화하기 위해 `is_split_into_words=True`를 설정해야 합니다. 예제로 확인합니다:
```py
>>> example = wnut["train"][0]
@@ -294,7 +294,7 @@ Hugging Face 계정에 로그인하여 모델을 업로드하고 커뮤니티에
... args=training_args,
... train_dataset=tokenized_wnut["train"],
... eval_dataset=tokenized_wnut["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
@@ -405,8 +405,8 @@ TensorFlow에서 모델을 파인 튜닝하려면, 먼저 옵티마이저 함수
-토큰 분류를 위한 모델을 파인 튜닝하는 자세한 예제는 다음
-[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb)
+토큰 분류를 위한 모델을 파인 튜닝하는 자세한 예제는 다음
+[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb)
또는 [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb)를 참조하세요.
diff --git a/docs/source/ko/tasks/translation.md b/docs/source/ko/tasks/translation.md
index 88dbb405e1..5b4eaaa612 100644
--- a/docs/source/ko/tasks/translation.md
+++ b/docs/source/ko/tasks/translation.md
@@ -221,7 +221,7 @@ pip install transformers datasets evaluate sacrebleu
... args=training_args,
... train_dataset=tokenized_books["train"],
... eval_dataset=tokenized_books["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
diff --git a/docs/source/ko/tasks/video_classification.md b/docs/source/ko/tasks/video_classification.md
index f18ef918fa..10569083c0 100644
--- a/docs/source/ko/tasks/video_classification.md
+++ b/docs/source/ko/tasks/video_classification.md
@@ -61,7 +61,7 @@ pip install -q pytorchvideo transformers evaluate
```
데이터 세트의 하위 집합이 다운로드 되면, 압축된 파일의 압축을 해제해야 합니다:
-```py
+```py
>>> import tarfile
>>> with tarfile.open(file_path) as t:
@@ -124,9 +124,9 @@ UCF101_subset/
그 다음으로, 데이터 세트에 존재하는 라벨을 추출합니다. 또한, 모델을 초기화할 때 도움이 될 딕셔너리(dictionary data type)를 생성합니다.
* `label2id`: 클래스 이름을 정수에 매핑합니다.
-* `id2label`: 정수를 클래스 이름에 매핑합니다.
+* `id2label`: 정수를 클래스 이름에 매핑합니다.
-```py
+```py
>>> class_labels = sorted({str(path).split("/")[2] for path in all_video_file_paths})
>>> label2id = {label: i for i, label in enumerate(class_labels)}
>>> id2label = {i: label for label, i in label2id.items()}
@@ -142,7 +142,7 @@ UCF101_subset/
사전 훈련된 체크포인트와 체크포인트에 연관된 이미지 프로세서를 사용하여 영상 분류 모델을 인스턴스화합니다. 모델의 인코더에는 미리 학습된 매개변수가 제공되며, 분류 헤드(데이터를 분류하는 마지막 레이어)는 무작위로 초기화됩니다. 데이터 세트의 전처리 파이프라인을 작성할 때는 이미지 프로세서가 유용합니다.
-```py
+```py
>>> from transformers import VideoMAEImageProcessor, VideoMAEForVideoClassification
>>> model_ckpt = "MCG-NJU/videomae-base"
@@ -174,7 +174,7 @@ You should probably TRAIN this model on a down-stream task to be able to use it
영상 전처리를 위해 [PyTorchVideo 라이브러리](https://pytorchvideo.org/)를 활용할 것입니다. 필요한 종속성을 가져오는 것으로 시작하세요.
-```py
+```py
>>> import pytorchvideo.data
>>> from pytorchvideo.transforms import (
@@ -223,7 +223,7 @@ You should probably TRAIN this model on a down-stream task to be able to use it
이제 데이터 세트에 특화된 전처리(transform)과 데이터 세트 자체를 정의합니다. 먼저 훈련 데이터 세트로 시작합니다:
-```py
+```py
>>> train_transform = Compose(
... [
... ApplyTransformToKey(
@@ -252,7 +252,7 @@ You should probably TRAIN this model on a down-stream task to be able to use it
같은 방식의 작업 흐름을 검증과 평가 세트에도 적용할 수 있습니다.
-```py
+```py
>>> val_transform = Compose(
... [
... ApplyTransformToKey(
@@ -296,7 +296,7 @@ You should probably TRAIN this model on a down-stream task to be able to use it
## 더 나은 디버깅을 위해 전처리 영상 시각화하기[[visualize-the-preprocessed-video-for-better-debugging]]
-```py
+```py
>>> import imageio
>>> import numpy as np
>>> from IPython.display import Image
@@ -309,7 +309,7 @@ You should probably TRAIN this model on a down-stream task to be able to use it
>>> def create_gif(video_tensor, filename="sample.gif"):
... """Prepares a GIF from a video tensor.
-...
+...
... The video tensor is expected to have the following shape:
... (num_frames, num_channels, height, width).
... """
@@ -336,13 +336,13 @@ You should probably TRAIN this model on a down-stream task to be able to use it
-## 모델 훈련하기[[train-the-model]]
+## 모델 훈련하기[[train-the-model]]
🤗 Transformers의 [`Trainer`](https://huggingface.co/docs/transformers/main_classes/trainer)를 사용하여 모델을 훈련시켜보세요. `Trainer`를 인스턴스화하려면 훈련 설정과 평가 지표를 정의해야 합니다. 가장 중요한 것은 [`TrainingArguments`](https://huggingface.co/transformers/main_classes/trainer.html#transformers.TrainingArguments)입니다. 이 클래스는 훈련을 구성하는 모든 속성을 포함하며, 훈련 중 체크포인트를 저장할 출력 폴더 이름을 필요로 합니다. 또한 🤗 Hub의 모델 저장소의 모든 정보를 동기화하는 데 도움이 됩니다.
대부분의 훈련 인수는 따로 설명할 필요는 없습니다. 하지만 여기에서 중요한 인수는 `remove_unused_columns=False` 입니다. 이 인자는 모델의 호출 함수에서 사용되지 않는 모든 속성 열(columns)을 삭제합니다. 기본값은 일반적으로 True입니다. 이는 사용되지 않는 기능 열을 삭제하는 것이 이상적이며, 입력을 모델의 호출 함수로 풀기(unpack)가 쉬워지기 때문입니다. 하지만 이 경우에는 `pixel_values`(모델의 입력으로 필수적인 키)를 생성하기 위해 사용되지 않는 기능('video'가 특히 그렇습니다)이 필요합니다. 따라서 remove_unused_columns을 False로 설정해야 합니다.
-```py
+```py
>>> from transformers import TrainingArguments, Trainer
>>> model_name = model_ckpt.split("/")[-1]
@@ -387,7 +387,7 @@ def compute_metrics(eval_pred):
또한, 예제를 묶어서 배치를 형성하는 `collate_fn`을 정의해야합니다. 각 배치는 `pixel_values`와 `labels`라는 2개의 키로 구성됩니다.
-```py
+```py
>>> def collate_fn(examples):
... # permute to (num_frames, num_channels, height, width)
... pixel_values = torch.stack(
@@ -399,13 +399,13 @@ def compute_metrics(eval_pred):
그런 다음 이 모든 것을 데이터 세트와 함께 `Trainer`에 전달하기만 하면 됩니다:
-```py
+```py
>>> trainer = Trainer(
... model,
... args,
... train_dataset=train_dataset,
... eval_dataset=val_dataset,
-... tokenizer=image_processor,
+... processing_class=image_processor,
... compute_metrics=compute_metrics,
... data_collator=collate_fn,
... )
@@ -415,7 +415,7 @@ def compute_metrics(eval_pred):
`train` 메소드를 호출하여 모델을 미세 조정하세요:
-```py
+```py
>>> train_results = trainer.train()
```
@@ -429,7 +429,7 @@ def compute_metrics(eval_pred):
좋습니다. 이제 미세 조정된 모델을 추론하는 데 사용할 수 있습니다.
추론에 사용할 영상을 불러오세요:
-```py
+```py
>>> sample_test_video = next(iter(test_dataset))
```
@@ -485,7 +485,7 @@ def compute_metrics(eval_pred):
`logits`을 디코딩하면, 우리는 다음 결과를 얻을 수 있습니다:
-```py
+```py
>>> predicted_class_idx = logits.argmax(-1).item()
>>> print("Predicted class:", model.config.id2label[predicted_class_idx])
# Predicted class: BasketballDunk
diff --git a/docs/source/ko/tasks/visual_question_answering.md b/docs/source/ko/tasks/visual_question_answering.md
index f8560b14f9..9bc87c071e 100644
--- a/docs/source/ko/tasks/visual_question_answering.md
+++ b/docs/source/ko/tasks/visual_question_answering.md
@@ -35,7 +35,7 @@ VQA의 주요 사용 사례는 다음과 같습니다:
## ViLT 미세 조정 [[finetuning-vilt]]
ViLT는 Vision Transformer (ViT) 내에 텍스트 임베딩을 포함하여 비전/자연어 사전훈련(VLP; Vision-and-Language Pretraining)을 위한 기본 디자인을 제공합니다.
-ViLT 모델은 비전 트랜스포머(ViT)에 텍스트 임베딩을 넣어 비전/언어 사전훈련(VLP; Vision-and-Language Pre-training)을 위한 기본적인 디자인을 갖췄습니다. 이 모델은 여러 다운스트림 작업에 사용할 수 있습니다. VQA 태스크에서는 (`[CLS]` 토큰의 최종 은닉 상태 위에 선형 레이어인) 분류 헤더가 있으며 무작위로 초기화됩니다.
+ViLT 모델은 비전 트랜스포머(ViT)에 텍스트 임베딩을 넣어 비전/언어 사전훈련(VLP; Vision-and-Language Pre-training)을 위한 기본적인 디자인을 갖췄습니다. 이 모델은 여러 다운스트림 작업에 사용할 수 있습니다. VQA 태스크에서는 (`[CLS]` 토큰의 최종 은닉 상태 위에 선형 레이어인) 분류 헤더가 있으며 무작위로 초기화됩니다.
따라서 여기에서 시각적 질의응답은 **분류 문제**로 취급됩니다.
최근의 BLIP, BLIP-2, InstructBLIP와 같은 모델들은 VQA를 생성형 작업으로 간주합니다. 가이드의 후반부에서는 이런 모델들을 사용하여 제로샷 VQA 추론을 하는 방법에 대해 설명하겠습니다.
@@ -104,7 +104,7 @@ Dataset({
나머지 특성들은 필요하지 않기 때문에 삭제해도 됩니다:
-```py
+```py
>>> dataset = dataset.remove_columns(['question_type', 'question_id', 'answer_type'])
```
@@ -137,7 +137,7 @@ Dataset({
>>> unique_labels = list(set(flattened_labels))
>>> label2id = {label: idx for idx, label in enumerate(unique_labels)}
->>> id2label = {idx: label for label, idx in label2id.items()}
+>>> id2label = {idx: label for label, idx in label2id.items()}
```
이제 매핑이 완료되었으므로 문자열 답변을 해당 id로 교체하고, 데이터세트의 더 편리한 후처리를 위해 편평화 할 수 있습니다.
@@ -159,10 +159,10 @@ Dataset({
## 데이터 전처리 [[preprocessing-data]]
-다음 단계는 모델을 위해 이미지와 텍스트 데이터를 준비하기 위해 ViLT 프로세서를 가져오는 것입니다.
+다음 단계는 모델을 위해 이미지와 텍스트 데이터를 준비하기 위해 ViLT 프로세서를 가져오는 것입니다.
[`ViltProcessor`]는 BERT 토크나이저와 ViLT 이미지 프로세서를 편리하게 하나의 프로세서로 묶습니다:
-```py
+```py
>>> from transformers import ViltProcessor
>>> processor = ViltProcessor.from_pretrained(model_checkpoint)
@@ -181,13 +181,13 @@ Dataset({
>>> def preprocess_data(examples):
... image_paths = examples['image_id']
... images = [Image.open(image_path) for image_path in image_paths]
-... texts = examples['question']
+... texts = examples['question']
... encoding = processor(images, texts, padding="max_length", truncation=True, return_tensors="pt")
... for k, v in encoding.items():
... encoding[k] = v.squeeze()
-
+
... targets = []
... for labels, scores in zip(examples['label.ids'], examples['label.weights']):
@@ -195,11 +195,11 @@ Dataset({
... for label, score in zip(labels, scores):
... target[label] = score
-
+
... targets.append(target)
... encoding["labels"] = targets
-
+
... return encoding
```
@@ -264,14 +264,14 @@ Dataset({
... args=training_args,
... data_collator=data_collator,
... train_dataset=processed_dataset,
-... tokenizer=processor,
+... processing_class=processor,
... )
```
3. [`~Trainer.train`]을 호출하여 모델을 미세 조정하세요:
```py
->>> trainer.train()
+>>> trainer.train()
```
훈련이 완료되면, [`~Trainer.push_to_hub`] 메소드를 사용하여 🤗 Hub에 모델을 공유하세요:
@@ -349,7 +349,7 @@ Predicted answer: down
모델은 이미지와 텍스트를 입력으로 받으므로, VQA 데이터세트의 첫 번째 예제에서와 동일한 이미지/질문 쌍을 사용해 보겠습니다:
-```py
+```py
>>> example = dataset[0]
>>> image = Image.open(example['image_id'])
>>> question = example['question']
@@ -358,7 +358,7 @@ Predicted answer: down
BLIP-2를 시각적 질의응답 작업에 사용하려면 텍스트 프롬프트가 `Question: {} Answer:` 형식을 따라야 합니다.
```py
->>> prompt = f"Question: {question} Answer:"
+>>> prompt = f"Question: {question} Answer:"
```
이제 모델의 프로세서로 이미지/프롬프트를 전처리하고, 처리된 입력을 모델을 통해 전달하고, 출력을 디코드해야 합니다:
@@ -369,7 +369,7 @@ BLIP-2를 시각적 질의응답 작업에 사용하려면 텍스트 프롬프
>>> generated_ids = model.generate(**inputs, max_new_tokens=10)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
>>> print(generated_text)
-"He is looking at the crowd"
+"He is looking at the crowd"
```
보시다시피 모델은 군중을 인식하고, 얼굴의 방향(아래쪽을 보고 있음)을 인식했지만, 군중이 스케이터 뒤에 있다는 사실을 놓쳤습니다. 그러나 사람이 직접 라벨링한 데이터셋을 얻을 수 없는 경우에, 이 접근법은 빠르게 유용한 결과를 생성할 수 있습니다.
diff --git a/docs/source/pt/tasks/sequence_classification.md b/docs/source/pt/tasks/sequence_classification.md
index e7776894f8..a2e6865c92 100644
--- a/docs/source/pt/tasks/sequence_classification.md
+++ b/docs/source/pt/tasks/sequence_classification.md
@@ -134,7 +134,7 @@ Nesse ponto, restam apenas três passos:
... args=training_args,
... train_dataset=tokenized_imdb["train"],
... eval_dataset=tokenized_imdb["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... )
@@ -213,4 +213,4 @@ Chame o método [`fit`](https://keras.io/api/models/model_training_apis/#fit-met
Para obter um exemplo mais aprofundado de como executar o fine-tuning de um modelo para classificação de texto, dê uma olhada nesse [notebook utilizando PyTorch](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb) ou nesse [notebook utilizando TensorFlow](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb).
-
\ No newline at end of file
+
diff --git a/docs/source/pt/tasks/token_classification.md b/docs/source/pt/tasks/token_classification.md
index d4d6bf4dd9..45ce0d8742 100644
--- a/docs/source/pt/tasks/token_classification.md
+++ b/docs/source/pt/tasks/token_classification.md
@@ -193,7 +193,7 @@ Nesse ponto, restam apenas três passos:
... args=training_args,
... train_dataset=tokenized_wnut["train"],
... eval_dataset=tokenized_wnut["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... )
@@ -269,4 +269,4 @@ Chame o método [`fit`](https://keras.io/api/models/model_training_apis/#fit-met
Para obter um exemplo mais aprofundado de como executar o fine-tuning de um modelo para classificação de tokens, dê uma olhada nesse [notebook utilizando PyTorch](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb) ou nesse [notebook utilizando TensorFlow](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb).
-
\ No newline at end of file
+
diff --git a/docs/source/te/quicktour.md b/docs/source/te/quicktour.md
index 96ac046cf6..67e530f35f 100644
--- a/docs/source/te/quicktour.md
+++ b/docs/source/te/quicktour.md
@@ -142,7 +142,7 @@ label: NEGATIVE, with score: 0.5309
```
-
+
ముందుగా శిక్షణ పొందిన మోడల్ను లోడ్ చేయడానికి [`AutoModelForSequenceClassification`] మరియు [`AutoTokenizer`]ని ఉపయోగించండి మరియు దాని అనుబంధిత టోకెనైజర్ (తదుపరి విభాగంలో `AutoClass`పై మరిన్ని):
```py
@@ -154,7 +154,7 @@ label: NEGATIVE, with score: 0.5309
ముందుగా శిక్షణ పొందిన మోడల్ను లోడ్ చేయడానికి [`TFAutoModelForSequenceClassification`] మరియు [`AutoTokenizer`]ని ఉపయోగించండి మరియు దాని అనుబంధిత టోకెనైజర్ (తదుపరి విభాగంలో `TFAutoClass`పై మరిన్ని):
-
+
```py
>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
@@ -329,7 +329,7 @@ tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
మీ మోడల్ చక్కగా ట్యూన్ చేయబడిన తర్వాత, మీరు దానిని [`PreTrainedModel.save_pretrained`]ని ఉపయోగించి దాని టోకెనైజర్తో సేవ్ చేయవచ్చు:
-
+
```py
>>> pt_save_directory = "./pt_save_pretrained"
>>> tokenizer.save_pretrained(pt_save_directory) # doctest: +IGNORE_RESULT
@@ -344,7 +344,7 @@ tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
మీ మోడల్ చక్కగా ట్యూన్ చేయబడిన తర్వాత, మీరు దానిని [`TFPreTrainedModel.save_pretrained`]ని ఉపయోగించి దాని టోకెనైజర్తో సేవ్ చేయవచ్చు:
-
+
```py
>>> tf_save_directory = "./tf_save_pretrained"
>>> tokenizer.save_pretrained(tf_save_directory) # doctest: +IGNORE_RESULT
@@ -395,7 +395,7 @@ tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
[`AutoModel.from_config`]తో మీ అనుకూల కాన్ఫిగరేషన్ నుండి మోడల్ను సృష్టించండి:
-
+
```py
>>> from transformers import AutoModel
@@ -404,7 +404,7 @@ tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
[`TFAutoModel.from_config`]తో మీ అనుకూల కాన్ఫిగరేషన్ నుండి మోడల్ను సృష్టించండి:
-
+
```py
>>> from transformers import TFAutoModel
@@ -465,7 +465,7 @@ tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
```
ఆపై దానిని [`~datasets.Dataset.map`]తో మొత్తం డేటాసెట్లో వర్తింపజేయండి:
-
+
```py
>>> dataset = dataset.map(tokenize_dataset, batched=True)
```
@@ -488,7 +488,7 @@ tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
... args=training_args,
... train_dataset=dataset["train"],
... eval_dataset=dataset["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... ) # doctest: +SKIP
```
diff --git a/docs/source/zh/hpo_train.md b/docs/source/zh/hpo_train.md
index 182940c359..907be0a21f 100644
--- a/docs/source/zh/hpo_train.md
+++ b/docs/source/zh/hpo_train.md
@@ -15,7 +15,7 @@ rendered properly in your Markdown viewer.
# 使用Trainer API进行超参数搜索
-🤗 Transformers库提供了一个优化过的[`Trainer`]类,用于训练🤗 Transformers模型,相比于手动编写自己的训练循环,这更容易开始训练。[`Trainer`]提供了超参数搜索的API。本文档展示了如何在示例中启用它。
+🤗 Transformers库提供了一个优化过的[`Trainer`]类,用于训练🤗 Transformers模型,相比于手动编写自己的训练循环,这更容易开始训练。[`Trainer`]提供了超参数搜索的API。本文档展示了如何在示例中启用它。
## 超参数搜索后端
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
在使用它们之前,您应该先安装它们作为超参数搜索后端。
```bash
-pip install optuna/sigopt/wandb/ray[tune]
+pip install optuna/sigopt/wandb/ray[tune]
```
## 如何在示例中启用超参数搜索
@@ -115,7 +115,7 @@ Optuna提供了多目标HPO。您可以在`hyperparameter_search`中传递`direc
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... model_init=model_init,
... data_collator=data_collator,
... )
@@ -136,4 +136,4 @@ Optuna提供了多目标HPO。您可以在`hyperparameter_search`中传递`direc
```
## 针对DDP微调的超参数搜索
-目前,Optuna和Sigopt已启用针对DDP的超参数搜索。只有rank-zero进程会进行超参数搜索并将参数传递给其他进程。
\ No newline at end of file
+目前,Optuna和Sigopt已启用针对DDP的超参数搜索。只有rank-zero进程会进行超参数搜索并将参数传递给其他进程。
diff --git a/docs/source/zh/quicktour.md b/docs/source/zh/quicktour.md
index 9760a69769..acc5953971 100644
--- a/docs/source/zh/quicktour.md
+++ b/docs/source/zh/quicktour.md
@@ -476,7 +476,7 @@ tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
... args=training_args,
... train_dataset=dataset["train"],
... eval_dataset=dataset["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... ) # doctest: +SKIP
```
diff --git a/docs/source/zh/tasks/asr.md b/docs/source/zh/tasks/asr.md
index b4366d7204..a4fdbd308e 100644
--- a/docs/source/zh/tasks/asr.md
+++ b/docs/source/zh/tasks/asr.md
@@ -298,7 +298,7 @@ Wav2Vec2 分词器仅训练了大写字符,因此您需要确保文本与分
... args=training_args,
... train_dataset=encoded_minds["train"],
... eval_dataset=encoded_minds["test"],
-... tokenizer=processor,
+... processing_class=processor,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
@@ -389,4 +389,4 @@ Wav2Vec2 分词器仅训练了大写字符,因此您需要确保文本与分
['I WOUL LIKE O SET UP JOINT ACOUNT WTH Y PARTNER']
```
-
\ No newline at end of file
+
diff --git a/examples/legacy/seq2seq/finetune_trainer.py b/examples/legacy/seq2seq/finetune_trainer.py
index e269bc2474..5ede86ee08 100755
--- a/examples/legacy/seq2seq/finetune_trainer.py
+++ b/examples/legacy/seq2seq/finetune_trainer.py
@@ -302,7 +302,7 @@ def main():
tokenizer, data_args, model.config.decoder_start_token_id, training_args.tpu_num_cores
),
compute_metrics=compute_metrics_fn,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
)
all_metrics = {}
diff --git a/examples/pytorch/audio-classification/run_audio_classification.py b/examples/pytorch/audio-classification/run_audio_classification.py
index 61df8ce990..009a1f6372 100644
--- a/examples/pytorch/audio-classification/run_audio_classification.py
+++ b/examples/pytorch/audio-classification/run_audio_classification.py
@@ -394,7 +394,7 @@ def main():
train_dataset=raw_datasets["train"] if training_args.do_train else None,
eval_dataset=raw_datasets["eval"] if training_args.do_eval else None,
compute_metrics=compute_metrics,
- tokenizer=feature_extractor,
+ processing_class=feature_extractor,
)
# Training
diff --git a/examples/pytorch/image-classification/run_image_classification.py b/examples/pytorch/image-classification/run_image_classification.py
index 01ed9938c4..0a9789426c 100755
--- a/examples/pytorch/image-classification/run_image_classification.py
+++ b/examples/pytorch/image-classification/run_image_classification.py
@@ -396,7 +396,7 @@ def main():
train_dataset=dataset["train"] if training_args.do_train else None,
eval_dataset=dataset["validation"] if training_args.do_eval else None,
compute_metrics=compute_metrics,
- tokenizer=image_processor,
+ processing_class=image_processor,
data_collator=collate_fn,
)
diff --git a/examples/pytorch/image-pretraining/run_mae.py b/examples/pytorch/image-pretraining/run_mae.py
index 4ec195f925..46863cbbf1 100644
--- a/examples/pytorch/image-pretraining/run_mae.py
+++ b/examples/pytorch/image-pretraining/run_mae.py
@@ -364,7 +364,7 @@ def main():
args=training_args,
train_dataset=ds["train"] if training_args.do_train else None,
eval_dataset=ds["validation"] if training_args.do_eval else None,
- tokenizer=image_processor,
+ processing_class=image_processor,
data_collator=collate_fn,
)
diff --git a/examples/pytorch/image-pretraining/run_mim.py b/examples/pytorch/image-pretraining/run_mim.py
index b6c0ca899e..3912c69344 100644
--- a/examples/pytorch/image-pretraining/run_mim.py
+++ b/examples/pytorch/image-pretraining/run_mim.py
@@ -443,7 +443,7 @@ def main():
args=training_args,
train_dataset=ds["train"] if training_args.do_train else None,
eval_dataset=ds["validation"] if training_args.do_eval else None,
- tokenizer=image_processor,
+ processing_class=image_processor,
data_collator=collate_fn,
)
diff --git a/examples/pytorch/instance-segmentation/run_instance_segmentation.py b/examples/pytorch/instance-segmentation/run_instance_segmentation.py
index 22152c6fad..aeb78f95d2 100644
--- a/examples/pytorch/instance-segmentation/run_instance_segmentation.py
+++ b/examples/pytorch/instance-segmentation/run_instance_segmentation.py
@@ -445,7 +445,7 @@ def main():
args=training_args,
train_dataset=dataset["train"] if training_args.do_train else None,
eval_dataset=dataset["validation"] if training_args.do_eval else None,
- tokenizer=image_processor,
+ processing_class=image_processor,
data_collator=collate_fn,
compute_metrics=compute_metrics,
)
diff --git a/examples/pytorch/language-modeling/run_clm.py b/examples/pytorch/language-modeling/run_clm.py
index 74fae865c9..656571eb37 100755
--- a/examples/pytorch/language-modeling/run_clm.py
+++ b/examples/pytorch/language-modeling/run_clm.py
@@ -586,7 +586,7 @@ def main():
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
# Data collator will default to DataCollatorWithPadding, so we change it.
data_collator=default_data_collator,
compute_metrics=compute_metrics if training_args.do_eval and not is_torch_xla_available() else None,
diff --git a/examples/pytorch/language-modeling/run_fim.py b/examples/pytorch/language-modeling/run_fim.py
index eb670ae44e..154fc15183 100644
--- a/examples/pytorch/language-modeling/run_fim.py
+++ b/examples/pytorch/language-modeling/run_fim.py
@@ -793,7 +793,7 @@ def main():
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
# Data collator will default to DataCollatorWithPadding, so we change it.
data_collator=default_data_collator,
compute_metrics=compute_metrics if training_args.do_eval and not is_torch_tpu_available() else None,
diff --git a/examples/pytorch/language-modeling/run_mlm.py b/examples/pytorch/language-modeling/run_mlm.py
index 34cefa833f..d021318ae0 100755
--- a/examples/pytorch/language-modeling/run_mlm.py
+++ b/examples/pytorch/language-modeling/run_mlm.py
@@ -622,7 +622,7 @@ def main():
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics if training_args.do_eval and not is_torch_xla_available() else None,
preprocess_logits_for_metrics=preprocess_logits_for_metrics
diff --git a/examples/pytorch/language-modeling/run_plm.py b/examples/pytorch/language-modeling/run_plm.py
index 237a1ddbd0..0a207b8047 100755
--- a/examples/pytorch/language-modeling/run_plm.py
+++ b/examples/pytorch/language-modeling/run_plm.py
@@ -519,7 +519,7 @@ def main():
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
- tokenizer=tokenizer,
+ processing_classtokenizer=tokenizer,
data_collator=data_collator,
)
diff --git a/examples/pytorch/multiple-choice/run_swag.py b/examples/pytorch/multiple-choice/run_swag.py
index 6dc5f97641..ac5db5f6b0 100755
--- a/examples/pytorch/multiple-choice/run_swag.py
+++ b/examples/pytorch/multiple-choice/run_swag.py
@@ -440,7 +440,7 @@ def main():
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
diff --git a/examples/pytorch/object-detection/run_object_detection.py b/examples/pytorch/object-detection/run_object_detection.py
index 74d87bc5d1..0aea1a11c1 100644
--- a/examples/pytorch/object-detection/run_object_detection.py
+++ b/examples/pytorch/object-detection/run_object_detection.py
@@ -488,7 +488,7 @@ def main():
args=training_args,
train_dataset=dataset["train"] if training_args.do_train else None,
eval_dataset=dataset["validation"] if training_args.do_eval else None,
- tokenizer=image_processor,
+ processing_class=image_processor,
data_collator=collate_fn,
compute_metrics=eval_compute_metrics_fn,
)
diff --git a/examples/pytorch/question-answering/run_qa.py b/examples/pytorch/question-answering/run_qa.py
index ac6fcd249b..bb0a645592 100755
--- a/examples/pytorch/question-answering/run_qa.py
+++ b/examples/pytorch/question-answering/run_qa.py
@@ -640,7 +640,7 @@ def main():
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
eval_examples=eval_examples if training_args.do_eval else None,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
post_process_function=post_processing_function,
compute_metrics=compute_metrics,
diff --git a/examples/pytorch/question-answering/run_qa_beam_search.py b/examples/pytorch/question-answering/run_qa_beam_search.py
index 23c9080f20..b3d9ee1e9c 100755
--- a/examples/pytorch/question-answering/run_qa_beam_search.py
+++ b/examples/pytorch/question-answering/run_qa_beam_search.py
@@ -666,7 +666,7 @@ def main():
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
eval_examples=eval_examples if training_args.do_eval else None,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
post_process_function=post_processing_function,
compute_metrics=compute_metrics,
diff --git a/examples/pytorch/question-answering/run_seq2seq_qa.py b/examples/pytorch/question-answering/run_seq2seq_qa.py
index d4e1844f3a..7cf50cf94a 100644
--- a/examples/pytorch/question-answering/run_seq2seq_qa.py
+++ b/examples/pytorch/question-answering/run_seq2seq_qa.py
@@ -663,7 +663,7 @@ def main():
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
eval_examples=eval_examples if training_args.do_eval else None,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
post_process_function=post_processing_function,
diff --git a/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py b/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py
index 9d3c29ed8c..4c119dcbb4 100644
--- a/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py
+++ b/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py
@@ -403,7 +403,7 @@ def main():
train_dataset=dataset["train"] if training_args.do_train else None,
eval_dataset=dataset["validation"] if training_args.do_eval else None,
compute_metrics=compute_metrics,
- tokenizer=image_processor,
+ processing_class=image_processor,
data_collator=default_data_collator,
)
diff --git a/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py b/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py
index 62166012c7..ff5da5ed49 100755
--- a/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py
+++ b/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py
@@ -751,7 +751,7 @@ def main():
compute_metrics=compute_metrics,
train_dataset=vectorized_datasets["train"] if training_args.do_train else None,
eval_dataset=vectorized_datasets["eval"] if training_args.do_eval else None,
- tokenizer=processor,
+ processing_class=processor,
preprocess_logits_for_metrics=preprocess_logits_for_metrics,
)
diff --git a/examples/pytorch/speech-recognition/run_speech_recognition_ctc_adapter.py b/examples/pytorch/speech-recognition/run_speech_recognition_ctc_adapter.py
index 144ae30166..66a75ca5d0 100755
--- a/examples/pytorch/speech-recognition/run_speech_recognition_ctc_adapter.py
+++ b/examples/pytorch/speech-recognition/run_speech_recognition_ctc_adapter.py
@@ -747,7 +747,7 @@ def main():
compute_metrics=compute_metrics,
train_dataset=vectorized_datasets["train"] if training_args.do_train else None,
eval_dataset=vectorized_datasets["eval"] if training_args.do_eval else None,
- tokenizer=processor,
+ processing_class=processor,
)
# 8. Finally, we can start training
diff --git a/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py b/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py
index a83502ed80..8740ec5f88 100755
--- a/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py
+++ b/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py
@@ -569,7 +569,7 @@ def main():
args=training_args,
train_dataset=vectorized_datasets["train"] if training_args.do_train else None,
eval_dataset=vectorized_datasets["eval"] if training_args.do_eval else None,
- tokenizer=feature_extractor,
+ processing_class=feature_extractor,
data_collator=data_collator,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
)
diff --git a/examples/pytorch/summarization/run_summarization.py b/examples/pytorch/summarization/run_summarization.py
index a4d6f616b7..9a25d94405 100755
--- a/examples/pytorch/summarization/run_summarization.py
+++ b/examples/pytorch/summarization/run_summarization.py
@@ -677,7 +677,7 @@ def main():
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
)
diff --git a/examples/pytorch/text-classification/run_classification.py b/examples/pytorch/text-classification/run_classification.py
index 9fd11e05b1..a440a48110 100755
--- a/examples/pytorch/text-classification/run_classification.py
+++ b/examples/pytorch/text-classification/run_classification.py
@@ -674,7 +674,7 @@ def main():
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
compute_metrics=compute_metrics,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
)
diff --git a/examples/pytorch/text-classification/run_glue.py b/examples/pytorch/text-classification/run_glue.py
index 8292389bf8..4284fdf12f 100755
--- a/examples/pytorch/text-classification/run_glue.py
+++ b/examples/pytorch/text-classification/run_glue.py
@@ -531,7 +531,7 @@ def main():
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
compute_metrics=compute_metrics,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
)
diff --git a/examples/pytorch/text-classification/run_xnli.py b/examples/pytorch/text-classification/run_xnli.py
index 1c6c85f4ba..6578e96dc9 100755
--- a/examples/pytorch/text-classification/run_xnli.py
+++ b/examples/pytorch/text-classification/run_xnli.py
@@ -393,7 +393,7 @@ def main():
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
compute_metrics=compute_metrics,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
)
diff --git a/examples/pytorch/token-classification/run_ner.py b/examples/pytorch/token-classification/run_ner.py
index b8ef21d6ec..ef1c0ac917 100755
--- a/examples/pytorch/token-classification/run_ner.py
+++ b/examples/pytorch/token-classification/run_ner.py
@@ -567,7 +567,7 @@ def main():
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
diff --git a/examples/pytorch/translation/run_translation.py b/examples/pytorch/translation/run_translation.py
index c23cf8a431..4e16401018 100755
--- a/examples/pytorch/translation/run_translation.py
+++ b/examples/pytorch/translation/run_translation.py
@@ -597,7 +597,7 @@ def main():
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
)
diff --git a/src/transformers/integrations/integration_utils.py b/src/transformers/integrations/integration_utils.py
index 40298f9c6f..5f0ac55d0e 100755
--- a/src/transformers/integrations/integration_utils.py
+++ b/src/transformers/integrations/integration_utils.py
@@ -915,7 +915,7 @@ class WandbCallback(TrainerCallback):
if self._log_model.is_enabled and self._initialized and state.is_world_process_zero:
from ..trainer import Trainer
- fake_trainer = Trainer(args=args, model=model, tokenizer=tokenizer)
+ fake_trainer = Trainer(args=args, model=model, processing_class=tokenizer)
with tempfile.TemporaryDirectory() as temp_dir:
fake_trainer.save_model(temp_dir)
metadata = (
@@ -2112,7 +2112,7 @@ class DVCLiveCallback(TrainerCallback):
from transformers.trainer import Trainer
if self._log_model is True:
- fake_trainer = Trainer(args=args, model=kwargs.get("model"), tokenizer=kwargs.get("tokenizer"))
+ fake_trainer = Trainer(args=args, model=kwargs.get("model"), processing_class=kwargs.get("tokenizer"))
name = "best" if args.load_best_model_at_end else "last"
output_dir = os.path.join(args.output_dir, name)
fake_trainer.save_model(output_dir)
diff --git a/src/transformers/trainer.py b/src/transformers/trainer.py
index 5b5afee248..6ca4520fca 100755
--- a/src/transformers/trainer.py
+++ b/src/transformers/trainer.py
@@ -60,7 +60,9 @@ from .configuration_utils import PretrainedConfig
from .data.data_collator import DataCollator, DataCollatorWithPadding, default_data_collator
from .debug_utils import DebugOption, DebugUnderflowOverflow
from .feature_extraction_sequence_utils import SequenceFeatureExtractor
+from .feature_extraction_utils import FeatureExtractionMixin
from .hyperparameter_search import ALL_HYPERPARAMETER_SEARCH_BACKENDS, default_hp_search_backend
+from .image_processing_utils import BaseImageProcessor
from .integrations.deepspeed import deepspeed_init, deepspeed_load_checkpoint, is_deepspeed_available
from .integrations.tpu import tpu_spmd_dataloader
from .modelcard import TrainingSummary
@@ -70,6 +72,7 @@ from .models.auto.modeling_auto import (
MODEL_MAPPING_NAMES,
)
from .optimization import Adafactor, get_scheduler
+from .processing_utils import ProcessorMixin
from .pytorch_utils import (
ALL_LAYERNORM_LAYERS,
is_torch_greater_or_equal_than_1_13,
@@ -308,8 +311,8 @@ class Trainer:
`output_dir` set to a directory named *tmp_trainer* in the current directory if not provided.
data_collator (`DataCollator`, *optional*):
The function to use to form a batch from a list of elements of `train_dataset` or `eval_dataset`. Will
- default to [`default_data_collator`] if no `tokenizer` is provided, an instance of
- [`DataCollatorWithPadding`] otherwise.
+ default to [`default_data_collator`] if no `processing_class` is provided, an instance of
+ [`DataCollatorWithPadding`] otherwise if the processing_class is a feature extractor or tokenizer.
train_dataset (Union[`torch.utils.data.Dataset`, `torch.utils.data.IterableDataset`, `datasets.Dataset`], *optional*):
The dataset to use for training. If it is a [`~datasets.Dataset`], columns not accepted by the
`model.forward()` method are automatically removed.
@@ -327,6 +330,12 @@ class Trainer:
The tokenizer used to preprocess the data. If provided, will be used to automatically pad the inputs to the
maximum length when batching inputs, and it will be saved along the model to make it easier to rerun an
interrupted training or reuse the fine-tuned model.
+ This is now deprecated.
+ processing_class (`PreTrainedTokenizerBase` or `BaseImageProcessor` or `FeatureExtractionMixin` or `ProcessorMixin`, *optional*):
+ Processing class used to process the data. If provided, will be used to automatically process the inputs
+ for the model, and it will be saved along the model to make it easier to rerun an interrupted training or
+ reuse the fine-tuned model.
+ This supercedes the `tokenizer` argument, which is now deprecated.
model_init (`Callable[[], PreTrainedModel]`, *optional*):
A function that instantiates the model to be used. If provided, each call to [`~Trainer.train`] will start
from a new instance of the model as given by this function.
@@ -384,6 +393,9 @@ class Trainer:
train_dataset: Optional[Union[Dataset, IterableDataset, "datasets.Dataset"]] = None,
eval_dataset: Optional[Union[Dataset, Dict[str, Dataset], "datasets.Dataset"]] = None,
tokenizer: Optional[PreTrainedTokenizerBase] = None,
+ processing_class: Optional[
+ Union[PreTrainedTokenizerBase, BaseImageProcessor, FeatureExtractionMixin, ProcessorMixin]
+ ] = None,
model_init: Optional[Callable[[], PreTrainedModel]] = None,
compute_metrics: Optional[Callable[[EvalPrediction], Dict]] = None,
callbacks: Optional[List[TrainerCallback]] = None,
@@ -425,6 +437,17 @@ class Trainer:
# force device and distributed setup init explicitly
args._setup_devices
+ if tokenizer is not None:
+ if processing_class is not None:
+ raise ValueError(
+ "You cannot specify both `tokenizer` and `processing_class` at the same time. Please use `processing_class`."
+ )
+ warnings.warn(
+ "`tokenizer` is now deprecated and will be removed in v5, please use `processing_class` instead.",
+ FutureWarning,
+ )
+ processing_class = tokenizer
+
if model is None:
if model_init is not None:
self.model_init = model_init
@@ -541,14 +564,15 @@ class Trainer:
self.place_model_on_device = False
default_collator = (
- DataCollatorWithPadding(tokenizer)
- if tokenizer is not None and isinstance(tokenizer, (PreTrainedTokenizerBase, SequenceFeatureExtractor))
+ DataCollatorWithPadding(processing_class)
+ if processing_class is not None
+ and isinstance(processing_class, (PreTrainedTokenizerBase, SequenceFeatureExtractor))
else default_data_collator
)
self.data_collator = data_collator if data_collator is not None else default_collator
self.train_dataset = train_dataset
self.eval_dataset = eval_dataset
- self.tokenizer = tokenizer
+ self.processing_class = processing_class
# Bnb Quantized models doesn't support `.to` operation.
if (
@@ -600,7 +624,7 @@ class Trainer:
default_callbacks = DEFAULT_CALLBACKS + get_reporting_integration_callbacks(self.args.report_to)
callbacks = default_callbacks if callbacks is None else default_callbacks + callbacks
self.callback_handler = CallbackHandler(
- callbacks, self.model, self.tokenizer, self.optimizer, self.lr_scheduler
+ callbacks, self.model, self.processing_class, self.optimizer, self.lr_scheduler
)
self.add_callback(PrinterCallback if self.args.disable_tqdm else DEFAULT_PROGRESS_CALLBACK)
@@ -728,6 +752,11 @@ class Trainer:
xs.set_global_mesh(xs.Mesh(np.array(range(num_devices)), (num_devices, 1), axis_names=("fsdp", "tensor")))
self.is_fsdp_xla_v1_enabled = self.is_fsdp_xla_enabled and not self.is_fsdp_xla_v2_enabled
+ @property
+ def tokenizer(self) -> Optional[PreTrainedTokenizerBase]:
+ logger.warning("Trainer.tokenizer is now deprecated. You should use Trainer.processing_class instead.")
+ return self.processing_class
+
def _activate_neftune(self, model):
r"""
Activates the neftune as presented in this code: https://github.com/neelsjain/NEFTune and paper:
@@ -887,7 +916,9 @@ class Trainer:
)
else:
lengths = None
- model_input_name = self.tokenizer.model_input_names[0] if self.tokenizer is not None else None
+ model_input_name = (
+ self.processing_class.model_input_names[0] if self.processing_class is not None else None
+ )
return LengthGroupedSampler(
self.args.train_batch_size * self.args.gradient_accumulation_steps,
dataset=self.train_dataset,
@@ -3699,8 +3730,8 @@ class Trainer:
safe_serialization=self.args.save_safetensors,
state_dict=xm._maybe_convert_to_cpu(model.state_dict()),
)
- if self.tokenizer is not None and self.args.should_save:
- self.tokenizer.save_pretrained(output_dir)
+ if self.processing_class is not None and self.args.should_save:
+ self.processing_class.save_pretrained(output_dir)
def _save(self, output_dir: Optional[str] = None, state_dict=None):
# If we are executing this function, we are the process zero, so we don't check for that.
@@ -3732,8 +3763,8 @@ class Trainer:
output_dir, state_dict=state_dict, safe_serialization=self.args.save_safetensors
)
- if self.tokenizer is not None:
- self.tokenizer.save_pretrained(output_dir)
+ if self.processing_class is not None:
+ self.processing_class.save_pretrained(output_dir)
# Good practice: save your training arguments together with the trained model
torch.save(self.args, os.path.join(output_dir, TRAINING_ARGS_NAME))
@@ -4442,9 +4473,9 @@ class Trainer:
for modeling_file in modeling_files:
if os.path.isfile(os.path.join(checkpoint_folder, modeling_file)):
shutil.copy(os.path.join(checkpoint_folder, modeling_file), os.path.join(output_dir, modeling_file))
- # Saving the tokenizer is fast and we don't know how many files it may have spawned, so we resave it to be sure.
- if self.tokenizer is not None:
- self.tokenizer.save_pretrained(output_dir)
+ # Saving the processing class is fast and we don't know how many files it may have spawned, so we resave it to be sure.
+ if self.processing_class is not None:
+ self.processing_class.save_pretrained(output_dir)
# Same for the training arguments
torch.save(self.args, os.path.join(output_dir, TRAINING_ARGS_NAME))
@@ -4499,7 +4530,7 @@ class Trainer:
**kwargs,
) -> str:
"""
- Upload `self.model` and `self.tokenizer` to the 🤗 model hub on the repo `self.args.hub_model_id`.
+ Upload `self.model` and `self.processing_class` to the 🤗 model hub on the repo `self.args.hub_model_id`.
Parameters:
commit_message (`str`, *optional*, defaults to `"End of training"`):
diff --git a/src/transformers/trainer_callback.py b/src/transformers/trainer_callback.py
index d457a65993..405874acf8 100644
--- a/src/transformers/trainer_callback.py
+++ b/src/transformers/trainer_callback.py
@@ -272,7 +272,9 @@ class TrainerCallback:
model ([`PreTrainedModel`] or `torch.nn.Module`):
The model being trained.
tokenizer ([`PreTrainedTokenizer`]):
- The tokenizer used for encoding the data.
+ The tokenizer used for encoding the data. This is deprecated in favour of `processing_class`.
+ processing_class ([`PreTrainedTokenizer` or `BaseImageProcessor` or `ProcessorMixin` or `FeatureExtractionMixin`]):
+ The processing class used for encoding the data. Can be a tokenizer, a processor, an image processor or a feature extractor.
optimizer (`torch.optim.Optimizer`):
The optimizer used for the training steps.
lr_scheduler (`torch.optim.lr_scheduler.LambdaLR`):
@@ -403,12 +405,12 @@ class TrainerCallback:
class CallbackHandler(TrainerCallback):
"""Internal class that just calls the list of callbacks in order."""
- def __init__(self, callbacks, model, tokenizer, optimizer, lr_scheduler):
+ def __init__(self, callbacks, model, processing_class, optimizer, lr_scheduler):
self.callbacks = []
for cb in callbacks:
self.add_callback(cb)
self.model = model
- self.tokenizer = tokenizer
+ self.processing_class = processing_class
self.optimizer = optimizer
self.lr_scheduler = lr_scheduler
self.train_dataloader = None
@@ -518,7 +520,7 @@ class CallbackHandler(TrainerCallback):
state,
control,
model=self.model,
- tokenizer=self.tokenizer,
+ processing_class=self.processing_class,
optimizer=self.optimizer,
lr_scheduler=self.lr_scheduler,
train_dataloader=self.train_dataloader,
diff --git a/src/transformers/trainer_seq2seq.py b/src/transformers/trainer_seq2seq.py
index abc45cffe4..241bea7860 100644
--- a/src/transformers/trainer_seq2seq.py
+++ b/src/transformers/trainer_seq2seq.py
@@ -29,7 +29,10 @@ from .utils import logging
if TYPE_CHECKING:
from .data.data_collator import DataCollator
+ from .feature_extraction_utils import FeatureExtractionMixin
+ from .image_processing_utils import BaseImageProcessor
from .modeling_utils import PreTrainedModel
+ from .processing_utils import ProcessorMixin
from .tokenization_utils_base import PreTrainedTokenizerBase
from .trainer_callback import TrainerCallback
from .trainer_utils import EvalPrediction, PredictionOutput
@@ -48,6 +51,9 @@ class Seq2SeqTrainer(Trainer):
train_dataset: Optional[Dataset] = None,
eval_dataset: Optional[Union[Dataset, Dict[str, Dataset]]] = None,
tokenizer: Optional["PreTrainedTokenizerBase"] = None,
+ processing_class: Optional[
+ Union["PreTrainedTokenizerBase", "BaseImageProcessor", "FeatureExtractionMixin", "ProcessorMixin"]
+ ] = None,
model_init: Optional[Callable[[], "PreTrainedModel"]] = None,
compute_metrics: Optional[Callable[["EvalPrediction"], Dict]] = None,
callbacks: Optional[List["TrainerCallback"]] = None,
@@ -61,6 +67,7 @@ class Seq2SeqTrainer(Trainer):
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
+ processing_class=processing_class,
model_init=model_init,
compute_metrics=compute_metrics,
callbacks=callbacks,
diff --git a/src/transformers/training_args.py b/src/transformers/training_args.py
index b314d7855d..26da84dfe2 100644
--- a/src/transformers/training_args.py
+++ b/src/transformers/training_args.py
@@ -683,9 +683,9 @@ class TrainingArguments:
hub_strategy (`str` or [`~trainer_utils.HubStrategy`], *optional*, defaults to `"every_save"`):
Defines the scope of what is pushed to the Hub and when. Possible values are:
- - `"end"`: push the model, its configuration, the tokenizer (if passed along to the [`Trainer`]) and a
+ - `"end"`: push the model, its configuration, the processing class e.g. tokenizer (if passed along to the [`Trainer`]) and a
draft of a model card when the [`~Trainer.save_model`] method is called.
- - `"every_save"`: push the model, its configuration, the tokenizer (if passed along to the [`Trainer`]) and
+ - `"every_save"`: push the model, its configuration, the processing class e.g. tokenizer (if passed along to the [`Trainer`]) and
a draft of a model card each time there is a model save. The pushes are asynchronous to not block
training, and in case the save are very frequent, a new push is only attempted if the previous one is
finished. A last push is made with the final model at the end of training.
@@ -2854,9 +2854,9 @@ class TrainingArguments:
strategy (`str` or [`~trainer_utils.HubStrategy`], *optional*, defaults to `"every_save"`):
Defines the scope of what is pushed to the Hub and when. Possible values are:
- - `"end"`: push the model, its configuration, the tokenizer (if passed along to the [`Trainer`]) and a
+ - `"end"`: push the model, its configuration, the processing_class e.g. tokenizer (if passed along to the [`Trainer`]) and a
draft of a model card when the [`~Trainer.save_model`] method is called.
- - `"every_save"`: push the model, its configuration, the tokenizer (if passed along to the [`Trainer`])
+ - `"every_save"`: push the model, its configuration, the processing_class e.g. tokenizer (if passed along to the [`Trainer`])
and
a draft of a model card each time there is a model save. The pushes are asynchronous to not block
training, and in case the save are very frequent, a new push is only attempted if the previous one is
diff --git a/templates/adding_a_new_example_script/{{cookiecutter.directory_name}}/run_{{cookiecutter.example_shortcut}}.py b/templates/adding_a_new_example_script/{{cookiecutter.directory_name}}/run_{{cookiecutter.example_shortcut}}.py
index 0b27b49212..c2b753c103 100755
--- a/templates/adding_a_new_example_script/{{cookiecutter.directory_name}}/run_{{cookiecutter.example_shortcut}}.py
+++ b/templates/adding_a_new_example_script/{{cookiecutter.directory_name}}/run_{{cookiecutter.example_shortcut}}.py
@@ -450,7 +450,7 @@ def main():
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
)
diff --git a/tests/deepspeed/test_deepspeed.py b/tests/deepspeed/test_deepspeed.py
index b635833706..8eaa00bc76 100644
--- a/tests/deepspeed/test_deepspeed.py
+++ b/tests/deepspeed/test_deepspeed.py
@@ -1036,7 +1036,7 @@ class TrainerIntegrationDeepSpeed(TrainerIntegrationDeepSpeedWithCustomConfig, T
trainer = Trainer(
model=model,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
diff --git a/tests/sagemaker/scripts/pytorch/run_glue_model_parallelism.py b/tests/sagemaker/scripts/pytorch/run_glue_model_parallelism.py
index b050b1ca5a..2e3d9fdc7f 100644
--- a/tests/sagemaker/scripts/pytorch/run_glue_model_parallelism.py
+++ b/tests/sagemaker/scripts/pytorch/run_glue_model_parallelism.py
@@ -455,7 +455,7 @@ def main():
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
compute_metrics=compute_metrics,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
)
diff --git a/tests/test_tokenization_common.py b/tests/test_tokenization_common.py
index 342254dfbd..8020b0e711 100644
--- a/tests/test_tokenization_common.py
+++ b/tests/test_tokenization_common.py
@@ -4293,7 +4293,7 @@ class TokenizerTesterMixin:
# Load tokenizer from a folder without legacy files
tokenizer = self.rust_tokenizer_class.from_pretrained(tmp_dir)
training_args = TrainingArguments(output_dir=tmp_dir, do_train=True, no_cuda=True)
- trainer = Trainer(model=model, args=training_args, tokenizer=tokenizer)
+ trainer = Trainer(model=model, args=training_args, processing_class=tokenizer)
# Should not raise an error
trainer.save_model(os.path.join(tmp_dir, "checkpoint"))
diff --git a/tests/trainer/test_trainer.py b/tests/trainer/test_trainer.py
index 0035ff7de8..6ce961257d 100644
--- a/tests/trainer/test_trainer.py
+++ b/tests/trainer/test_trainer.py
@@ -38,6 +38,9 @@ from parameterized import parameterized
from requests.exceptions import HTTPError
from transformers import (
+ AutoFeatureExtractor,
+ AutoImageProcessor,
+ AutoProcessor,
AutoTokenizer,
IntervalStrategy,
PretrainedConfig,
@@ -1059,14 +1062,14 @@ class TrainerIntegrationTest(TestCasePlus, TrainerIntegrationCommon):
max_steps=10,
use_cpu=True,
)
- trainer = Trainer(tiny_model, args, tokenizer=tokenizer, train_dataset=train_dataset)
+ trainer = Trainer(tiny_model, args, processing_class=tokenizer, train_dataset=train_dataset)
trainer.train()
parameters = dict(tiny_model.named_parameters())
state = dataclasses.asdict(trainer.state)
# Reinitialize trainer
- trainer = Trainer(tiny_model, args, tokenizer=tokenizer, train_dataset=train_dataset)
+ trainer = Trainer(tiny_model, args, processing_class=tokenizer, train_dataset=train_dataset)
checkpoint = os.path.join(tmpdir, "checkpoint-5")
@@ -3786,6 +3789,98 @@ class TrainerIntegrationTest(TestCasePlus, TrainerIntegrationCommon):
_ = trainer.evaluate()
_ = trainer.predict(eval_dataset)
+ def test_trainer_saves_tokenizer(self):
+ MODEL_ID = "google-bert/bert-base-uncased"
+ tokenizer = AutoTokenizer.from_pretrained(MODEL_ID, use_fast=False)
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ config = RegressionModelConfig(a=1.5, b=2.5)
+ trainer = Trainer(
+ model=RegressionPreTrainedModel(config),
+ args=TrainingArguments(output_dir=tmp_dir),
+ processing_class=tokenizer,
+ )
+ trainer.save_model()
+
+ reloaded_tokenizer = AutoTokenizer.from_pretrained(tmp_dir)
+
+ # For tokenizers, there isn't a direct to_dict method and the properties stored in the configs e.g.
+ # saved tokens change overtime, so we check that two tokenizers are equal by comparing their encoded outputs
+ test_sentence = "This is a test sentence"
+ self.assertListEqual(
+ tokenizer(test_sentence, padding="max_length").input_ids,
+ reloaded_tokenizer(test_sentence, padding="max_length").input_ids,
+ )
+
+ def test_trainer_saves_image_processor(self):
+ MODEL_ID = "openai/clip-vit-base-patch32"
+ image_processor = AutoImageProcessor.from_pretrained(MODEL_ID)
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ config = RegressionModelConfig(a=1.5, b=2.5)
+ trainer = Trainer(
+ model=RegressionPreTrainedModel(config),
+ args=TrainingArguments(output_dir=tmp_dir),
+ processing_class=image_processor,
+ )
+ trainer.save_model()
+ reloaded_image_processor = AutoImageProcessor.from_pretrained(tmp_dir)
+
+ self.assertDictEqual(image_processor.to_dict(), reloaded_image_processor.to_dict())
+
+ def test_trainer_saves_feature_extractor(self):
+ MODEL_ID = "facebook/wav2vec2-base-960h"
+ feature_extractor = AutoFeatureExtractor.from_pretrained(MODEL_ID)
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ config = RegressionModelConfig(a=1.5, b=2.5)
+ trainer = Trainer(
+ model=RegressionPreTrainedModel(config),
+ args=TrainingArguments(output_dir=tmp_dir),
+ processing_class=feature_extractor,
+ )
+ trainer.save_model()
+
+ reloaded_feature_extractor = AutoFeatureExtractor.from_pretrained(tmp_dir)
+
+ self.assertDictEqual(feature_extractor.to_dict(), reloaded_feature_extractor.to_dict())
+
+ def test_trainer_saves_processor(self):
+ MODEL_ID = "openai/clip-vit-base-patch32"
+ image_processor = AutoImageProcessor.from_pretrained(MODEL_ID)
+ tokenizer = AutoTokenizer.from_pretrained(MODEL_ID, use_fast=False)
+ processor = AutoProcessor.from_pretrained(MODEL_ID)
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ config = RegressionModelConfig(a=1.5, b=2.5)
+ trainer = Trainer(
+ model=RegressionPreTrainedModel(config),
+ args=TrainingArguments(output_dir=tmp_dir),
+ processing_class=processor,
+ )
+ trainer.save_model()
+
+ reloaded_processor = AutoProcessor.from_pretrained(tmp_dir)
+ reloaded_image_processor = AutoImageProcessor.from_pretrained(tmp_dir)
+ reloaded_tokenizer = AutoTokenizer.from_pretrained(tmp_dir)
+
+ self.assertDictEqual(reloaded_processor.to_dict(), processor.to_dict())
+
+ image_processor_dict = image_processor.to_dict()
+ reloaded_image_processor_dict = reloaded_image_processor.to_dict()
+ # When the processor is saved in the trainer, the _processor_class gets set in the reload_image_processor dict
+ image_processor_dict.pop("_processor_class")
+ reloaded_image_processor_dict.pop("_processor_class")
+ self.assertDictEqual(image_processor_dict, reloaded_image_processor_dict)
+
+ # For tokenizers, there isn't a direct to_dict method and the properties stored in the configs e.g.
+ # saved tokens change overtime, so we check that two tokenizers are equal by comparing their encoded outputs
+ test_sentence = "This is a test sentence"
+ self.assertListEqual(
+ tokenizer(test_sentence, padding="max_length").input_ids,
+ reloaded_tokenizer(test_sentence, padding="max_length").input_ids,
+ )
+
@require_torch
@is_staging_test
diff --git a/tests/trainer/test_trainer_seq2seq.py b/tests/trainer/test_trainer_seq2seq.py
index a4b38aecb2..30dd2ed460 100644
--- a/tests/trainer/test_trainer_seq2seq.py
+++ b/tests/trainer/test_trainer_seq2seq.py
@@ -129,7 +129,7 @@ class Seq2seqTrainerTester(TestCasePlus):
compute_metrics=_compute_metrics,
train_dataset=train_dataset,
eval_dataset=val_dataset,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
)
# start training
@@ -158,7 +158,7 @@ class Seq2seqTrainerTester(TestCasePlus):
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
compute_metrics=lambda x: {"samples": x[0].shape[0]},
)
@@ -199,7 +199,7 @@ class Seq2seqTrainerTester(TestCasePlus):
_ = Seq2SeqTrainer(
model=model,
args=training_args,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
compute_metrics=lambda x: {"samples": x[0].shape[0]},
)
-Due to the questions' and answers' ambiguity, datasets like this are treated as a multi-label classification problem (as
-multiple answers are possibly valid). Moreover, rather than just creating a one-hot encoded vector, one creates a
+Due to the questions' and answers' ambiguity, datasets like this are treated as a multi-label classification problem (as
+multiple answers are possibly valid). Moreover, rather than just creating a one-hot encoded vector, one creates a
soft encoding, based on the number of times a certain answer appeared in the annotations.
-For instance, in the example above, because the answer "down" is selected way more often than other answers, it has a
-score (called `weight` in the dataset) of 1.0, and the rest of the answers have scores < 1.0.
+For instance, in the example above, because the answer "down" is selected way more often than other answers, it has a
+score (called `weight` in the dataset) of 1.0, and the rest of the answers have scores < 1.0.
-To later instantiate the model with an appropriate classification head, let's create two dictionaries: one that maps
+To later instantiate the model with an appropriate classification head, let's create two dictionaries: one that maps
the label name to an integer and vice versa:
```py
@@ -150,10 +150,10 @@ the label name to an integer and vice versa:
>>> unique_labels = list(set(flattened_labels))
>>> label2id = {label: idx for idx, label in enumerate(unique_labels)}
->>> id2label = {idx: label for label, idx in label2id.items()}
+>>> id2label = {idx: label for label, idx in label2id.items()}
```
-Now that we have the mappings, we can replace the string answers with their ids, and flatten the dataset for a more convenient further preprocessing.
+Now that we have the mappings, we can replace the string answers with their ids, and flatten the dataset for a more convenient further preprocessing.
```python
>>> def replace_ids(inputs):
@@ -172,21 +172,21 @@ Now that we have the mappings, we can replace the string answers with their ids,
## Preprocessing data
-The next step is to load a ViLT processor to prepare the image and text data for the model.
+The next step is to load a ViLT processor to prepare the image and text data for the model.
[`ViltProcessor`] wraps a BERT tokenizer and ViLT image processor into a convenient single processor:
-```py
+```py
>>> from transformers import ViltProcessor
>>> processor = ViltProcessor.from_pretrained(model_checkpoint)
```
-To preprocess the data we need to encode the images and questions using the [`ViltProcessor`]. The processor will use
-the [`BertTokenizerFast`] to tokenize the text and create `input_ids`, `attention_mask` and `token_type_ids` for the text data.
+To preprocess the data we need to encode the images and questions using the [`ViltProcessor`]. The processor will use
+the [`BertTokenizerFast`] to tokenize the text and create `input_ids`, `attention_mask` and `token_type_ids` for the text data.
As for images, the processor will leverage [`ViltImageProcessor`] to resize and normalize the image, and create `pixel_values` and `pixel_mask`.
-All these preprocessing steps are done under the hood, we only need to call the `processor`. However, we still need to
-prepare the target labels. In this representation, each element corresponds to a possible answer (label). For correct answers, the element holds
+All these preprocessing steps are done under the hood, we only need to call the `processor`. However, we still need to
+prepare the target labels. In this representation, each element corresponds to a possible answer (label). For correct answers, the element holds
their respective score (weight), while the remaining elements are set to zero.
The following function applies the `processor` to the images and questions and formats the labels as described above:
@@ -197,13 +197,13 @@ The following function applies the `processor` to the images and questions and f
>>> def preprocess_data(examples):
... image_paths = examples['image_id']
... images = [Image.open(image_path) for image_path in image_paths]
-... texts = examples['question']
+... texts = examples['question']
... encoding = processor(images, texts, padding="max_length", truncation=True, return_tensors="pt")
... for k, v in encoding.items():
... encoding[k] = v.squeeze()
-
+
... targets = []
... for labels, scores in zip(examples['label.ids'], examples['label.weights']):
@@ -211,15 +211,15 @@ The following function applies the `processor` to the images and questions and f
... for label, score in zip(labels, scores):
... target[label] = score
-
+
... targets.append(target)
... encoding["labels"] = targets
-
+
... return encoding
```
-To apply the preprocessing function over the entire dataset, use 🤗 Datasets [`~datasets.map`] function. You can speed up `map` by
+To apply the preprocessing function over the entire dataset, use 🤗 Datasets [`~datasets.map`] function. You can speed up `map` by
setting `batched=True` to process multiple elements of the dataset at once. At this point, feel free to remove the columns you don't need.
```py
@@ -241,7 +241,7 @@ As a final step, create a batch of examples using [`DefaultDataCollator`]:
## Train the model
-You’re ready to start training your model now! Load ViLT with [`ViltForQuestionAnswering`]. Specify the number of labels
+You’re ready to start training your model now! Load ViLT with [`ViltForQuestionAnswering`]. Specify the number of labels
along with the label mappings:
```py
@@ -282,14 +282,14 @@ At this point, only three steps remain:
... args=training_args,
... data_collator=data_collator,
... train_dataset=processed_dataset,
-... tokenizer=processor,
+... processing_class=processor,
... )
```
3. Call [`~Trainer.train`] to finetune your model.
```py
->>> trainer.train()
+>>> trainer.train()
```
Once training is completed, share your model to the Hub with the [`~Trainer.push_to_hub`] method to share your final model on the 🤗 Hub:
@@ -309,7 +309,7 @@ way to try out your fine-tuned model for inference is to use it in a [`Pipeline`
>>> pipe = pipeline("visual-question-answering", model="MariaK/vilt_finetuned_200")
```
-The model in this guide has only been trained on 200 examples, so don't expect a lot from it. Let's see if it at least
+The model in this guide has only been trained on 200 examples, so don't expect a lot from it. Let's see if it at least
learned something from the data and take the first example from the dataset to illustrate inference:
```py
@@ -352,13 +352,13 @@ Predicted answer: down
## Zero-shot VQA
-The previous model treated VQA as a classification task. Some recent models, such as BLIP, BLIP-2, and InstructBLIP approach
-VQA as a generative task. Let's take [BLIP-2](../model_doc/blip-2) as an example. It introduced a new visual-language pre-training
-paradigm in which any combination of pre-trained vision encoder and LLM can be used (learn more in the [BLIP-2 blog post](https://huggingface.co/blog/blip-2)).
-This enables achieving state-of-the-art results on multiple visual-language tasks including visual question answering.
+The previous model treated VQA as a classification task. Some recent models, such as BLIP, BLIP-2, and InstructBLIP approach
+VQA as a generative task. Let's take [BLIP-2](../model_doc/blip-2) as an example. It introduced a new visual-language pre-training
+paradigm in which any combination of pre-trained vision encoder and LLM can be used (learn more in the [BLIP-2 blog post](https://huggingface.co/blog/blip-2)).
+This enables achieving state-of-the-art results on multiple visual-language tasks including visual question answering.
-Let's illustrate how you can use this model for VQA. First, let's load the model. Here we'll explicitly send the model to a
-GPU, if available, which we didn't need to do earlier when training, as [`Trainer`] handles this automatically:
+Let's illustrate how you can use this model for VQA. First, let's load the model. Here we'll explicitly send the model to a
+GPU, if available, which we didn't need to do earlier when training, as [`Trainer`] handles this automatically:
```py
>>> from transformers import AutoProcessor, Blip2ForConditionalGeneration
@@ -370,9 +370,9 @@ GPU, if available, which we didn't need to do earlier when training, as [`Traine
>>> model.to(device)
```
-The model takes image and text as input, so let's use the exact same image/question pair from the first example in the VQA dataset:
+The model takes image and text as input, so let's use the exact same image/question pair from the first example in the VQA dataset:
-```py
+```py
>>> example = dataset[0]
>>> image = Image.open(example['image_id'])
>>> question = example['question']
@@ -381,7 +381,7 @@ The model takes image and text as input, so let's use the exact same image/quest
To use BLIP-2 for visual question answering task, the textual prompt has to follow a specific format: `Question: {} Answer:`.
```py
->>> prompt = f"Question: {question} Answer:"
+>>> prompt = f"Question: {question} Answer:"
```
Now we need to preprocess the image/prompt with the model's processor, pass the processed input through the model, and decode the output:
@@ -392,10 +392,9 @@ Now we need to preprocess the image/prompt with the model's processor, pass the
>>> generated_ids = model.generate(**inputs, max_new_tokens=10)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
>>> print(generated_text)
-"He is looking at the crowd"
+"He is looking at the crowd"
```
-As you can see, the model recognized the crowd, and the direction of the face (looking down), however, it seems to miss
-the fact the crowd is behind the skater. Still, in cases where acquiring human-annotated datasets is not feasible, this
+As you can see, the model recognized the crowd, and the direction of the face (looking down), however, it seems to miss
+the fact the crowd is behind the skater. Still, in cases where acquiring human-annotated datasets is not feasible, this
approach can quickly produce useful results.
-
diff --git a/docs/source/en/trainer.md b/docs/source/en/trainer.md
index 812c5fe1a2..f9ea333769 100644
--- a/docs/source/en/trainer.md
+++ b/docs/source/en/trainer.md
@@ -81,7 +81,7 @@ trainer = Trainer(
args=training_args,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
@@ -153,7 +153,7 @@ from transformers import TrainerCallback
class EarlyStoppingCallback(TrainerCallback):
def __init__(self, num_steps=10):
self.num_steps = num_steps
-
+
def on_step_end(self, args, state, control, **kwargs):
if state.global_step >= self.num_steps:
return {"should_training_stop": True}
@@ -171,7 +171,7 @@ trainer = Trainer(
args=training_args,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
callback=[EarlyStoppingCallback()],
@@ -289,7 +289,7 @@ tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_config(config).to(0)
trainer = trl.SFTTrainer(
- model=model,
+ model=model,
args=args,
train_dataset=train_dataset,
dataset_text_field='text',
@@ -327,7 +327,7 @@ tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_config(config).to(0)
trainer = trl.SFTTrainer(
- model=model,
+ model=model,
args=args,
train_dataset=train_dataset,
dataset_text_field='text',
@@ -370,7 +370,7 @@ tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_config(config).to(0)
trainer = trl.SFTTrainer(
- model=model,
+ model=model,
args=args,
train_dataset=train_dataset,
dataset_text_field='text',
@@ -419,8 +419,8 @@ The kernel supports the Llama, Gemma, Mistral, and Mixtral model architectures.
## LOMO optimizer
-The LOMO optimizers have been introduced in [Full Parameter Fine-Tuning for Large Language Models with Limited Resources](https://hf.co/papers/2306.09782) and [AdaLomo: Low-memory Optimization with Adaptive Learning Rate](https://hf.co/papers/2310.10195).
-They both consist of an efficient full-parameter fine-tuning method. These optimizers fuse the gradient computation and the parameter update in one step to reduce memory usage. Supported optimizers for LOMO are `"lomo"` and `"adalomo"`. First either install LOMO from pypi `pip install lomo-optim` or install it from source with `pip install git+https://github.com/OpenLMLab/LOMO.git`.
+The LOMO optimizers have been introduced in [Full Parameter Fine-Tuning for Large Language Models with Limited Resources](https://hf.co/papers/2306.09782) and [AdaLomo: Low-memory Optimization with Adaptive Learning Rate](https://hf.co/papers/2310.10195).
+They both consist of an efficient full-parameter fine-tuning method. These optimizers fuse the gradient computation and the parameter update in one step to reduce memory usage. Supported optimizers for LOMO are `"lomo"` and `"adalomo"`. First either install LOMO from pypi `pip install lomo-optim` or install it from source with `pip install git+https://github.com/OpenLMLab/LOMO.git`.
@@ -457,7 +457,7 @@ tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, low_cpu_mem_usage=True).to(0)
trainer = trl.SFTTrainer(
- model=model,
+ model=model,
args=args,
train_dataset=train_dataset,
dataset_text_field='text',
@@ -579,8 +579,8 @@ To use Accelerate with [`Trainer`], run the [`accelerate.config`](https://huggin
```yml
-compute_environment: LOCAL_MACHINE
-distributed_type: MULTI_GPU
+compute_environment: LOCAL_MACHINE
+distributed_type: MULTI_GPU
downcast_bf16: 'no'
gpu_ids: all
machine_rank: 0 #change rank as per the node
@@ -654,8 +654,8 @@ use_cpu: false
```yml
-compute_environment: LOCAL_MACHINE
-deepspeed_config:
+compute_environment: LOCAL_MACHINE
+deepspeed_config:
gradient_accumulation_steps: 1
gradient_clipping: 0.7
offload_optimizer_device: cpu
diff --git a/docs/source/es/tasks/asr.md b/docs/source/es/tasks/asr.md
index 7d3133af47..41e9f82e35 100644
--- a/docs/source/es/tasks/asr.md
+++ b/docs/source/es/tasks/asr.md
@@ -276,7 +276,7 @@ En este punto, solo quedan tres pasos:
... args=training_args,
... train_dataset=encoded_minds["train"],
... eval_dataset=encoded_minds["test"],
-... tokenizer=processor.feature_extractor,
+... processing_class=processor.feature_extractor,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
diff --git a/docs/source/es/tasks/image_classification.md b/docs/source/es/tasks/image_classification.md
index 4e3696c505..1bea468842 100644
--- a/docs/source/es/tasks/image_classification.md
+++ b/docs/source/es/tasks/image_classification.md
@@ -160,7 +160,7 @@ Al llegar a este punto, solo quedan tres pasos:
... data_collator=data_collator,
... train_dataset=food["train"],
... eval_dataset=food["test"],
-... tokenizer=image_processor,
+... processing_class=image_processor,
... )
>>> trainer.train()
diff --git a/docs/source/es/tasks/multiple_choice.md b/docs/source/es/tasks/multiple_choice.md
index 959416f149..32df3401d7 100644
--- a/docs/source/es/tasks/multiple_choice.md
+++ b/docs/source/es/tasks/multiple_choice.md
@@ -225,7 +225,7 @@ En este punto, solo quedan tres pasos:
... args=training_args,
... train_dataset=tokenized_swag["train"],
... eval_dataset=tokenized_swag["validation"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=DataCollatorForMultipleChoice(tokenizer=tokenizer),
... )
diff --git a/docs/source/es/tasks/question_answering.md b/docs/source/es/tasks/question_answering.md
index ca43aac9ae..42a6e4b6e1 100644
--- a/docs/source/es/tasks/question_answering.md
+++ b/docs/source/es/tasks/question_answering.md
@@ -195,7 +195,7 @@ En este punto, solo quedan tres pasos:
... args=training_args,
... train_dataset=tokenized_squad["train"],
... eval_dataset=tokenized_squad["validation"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... )
diff --git a/docs/source/es/tasks/summarization.md b/docs/source/es/tasks/summarization.md
index e6a9532f66..c9060cba6b 100644
--- a/docs/source/es/tasks/summarization.md
+++ b/docs/source/es/tasks/summarization.md
@@ -155,7 +155,7 @@ En este punto, solo faltan tres pasos:
... args=training_args,
... train_dataset=tokenized_billsum["train"],
... eval_dataset=tokenized_billsum["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... )
diff --git a/docs/source/es/trainer.md b/docs/source/es/trainer.md
index 57fcaa6290..dab83e9a9d 100644
--- a/docs/source/es/trainer.md
+++ b/docs/source/es/trainer.md
@@ -14,7 +14,7 @@ rendered properly in your Markdown viewer.
-->
-# El Trainer
+# El Trainer
El [`Trainer`] es un bucle completo de entrenamiento y evaluación para modelos de PyTorch implementado en la biblioteca Transformers. Solo necesitas pasarle las piezas necesarias para el entrenamiento (modelo, tokenizador, conjunto de datos, función de evaluación, hiperparámetros de entrenamiento, etc.), y la clase [`Trainer`] se encarga del resto. Esto facilita comenzar a entrenar más rápido sin tener que escribir manualmente tu propio bucle de entrenamiento. Pero al mismo tiempo, [`Trainer`] es muy personalizable y ofrece una gran cantidad de opciones de entrenamiento para que puedas adaptarlo a tus necesidades exactas de entrenamiento.
@@ -79,7 +79,7 @@ trainer = Trainer(
args=training_args,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
@@ -151,7 +151,7 @@ from transformers import TrainerCallback
class EarlyStoppingCallback(TrainerCallback):
def __init__(self, num_steps=10):
self.num_steps = num_steps
-
+
def on_step_end(self, args, state, control, **kwargs):
if state.global_step >= self.num_steps:
return {"should_training_stop": True}
@@ -169,7 +169,7 @@ trainer = Trainer(
args=training_args,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
callback=[EarlyStoppingCallback()],
@@ -265,8 +265,8 @@ Para usar Accelerate con [`Trainer`], ejecuta el comando [`accelerate.config`](h
```yml
-compute_environment: LOCAL_MACHINE
-distributed_type: MULTI_GPU
+compute_environment: LOCAL_MACHINE
+distributed_type: MULTI_GPU
downcast_bf16: 'no'
gpu_ids: all
machine_rank: 0 #change rank as per the node
@@ -337,8 +337,8 @@ use_cpu: false
```yml
-compute_environment: LOCAL_MACHINE
-deepspeed_config:
+compute_environment: LOCAL_MACHINE
+deepspeed_config:
gradient_accumulation_steps: 1
gradient_clipping: 0.7
offload_optimizer_device: cpu
@@ -406,4 +406,4 @@ accelerate launch --num_processes=2 \
--overwrite_output_dir
```
-Consulta el tutorial [Lanzamiento de tus scripts con Accelerate](https://huggingface.co/docs/accelerate/basic_tutorials/launch) para obtener más información sobre `accelerate_launch` y las configuraciones personalizadas.
\ No newline at end of file
+Consulta el tutorial [Lanzamiento de tus scripts con Accelerate](https://huggingface.co/docs/accelerate/basic_tutorials/launch) para obtener más información sobre `accelerate_launch` y las configuraciones personalizadas.
diff --git a/docs/source/fr/quicktour.md b/docs/source/fr/quicktour.md
index df0233ae82..3cc2a8c5fa 100644
--- a/docs/source/fr/quicktour.md
+++ b/docs/source/fr/quicktour.md
@@ -169,7 +169,7 @@ Si vous ne parvenez pas à trouver un modèle adapté à votre cas d'utilisation
-Les classes [`AutoModelForSequenceClassification`] et [`AutoTokenizer`] fonctionnent ensemble pour créer un [`pipeline`] comme celui que vous avez utilisé ci-dessus. Une [AutoClass](./model_doc/auto) est un raccourci qui récupère automatiquement l'architecture d'un modèle pré-entraîné à partir de son nom ou de son emplacement. Il vous suffit de sélectionner l'`AutoClass` appropriée à votre tâche et la classe de prétraitement qui lui est associée.
+Les classes [`AutoModelForSequenceClassification`] et [`AutoTokenizer`] fonctionnent ensemble pour créer un [`pipeline`] comme celui que vous avez utilisé ci-dessus. Une [AutoClass](./model_doc/auto) est un raccourci qui récupère automatiquement l'architecture d'un modèle pré-entraîné à partir de son nom ou de son emplacement. Il vous suffit de sélectionner l'`AutoClass` appropriée à votre tâche et la classe de prétraitement qui lui est associée.
Reprenons l'exemple de la section précédente et voyons comment vous pouvez utiliser l'`AutoClass` pour reproduire les résultats du [`pipeline`].
@@ -479,7 +479,7 @@ Maintenant, rassemblez tous ces éléments dans un [`Trainer`] :
... args=training_args,
... train_dataset=dataset["train"],
... eval_dataset=dataset["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... ) # doctest: +SKIP
```
@@ -496,7 +496,7 @@ Pour les tâches - comme la traduction ou la génération de résumé - qui util
-Vous pouvez personnaliser le comportement de la boucle d'apprentissage en redéfinissant les méthodes à l'intérieur de [`Trainer`]. Cela vous permet de personnaliser des caractéristiques telles que la fonction de perte, l'optimiseur et le planificateur. Consultez la documentation de [`Trainer`] pour savoir quelles méthodes peuvent être redéfinies.
+Vous pouvez personnaliser le comportement de la boucle d'apprentissage en redéfinissant les méthodes à l'intérieur de [`Trainer`]. Cela vous permet de personnaliser des caractéristiques telles que la fonction de perte, l'optimiseur et le planificateur. Consultez la documentation de [`Trainer`] pour savoir quelles méthodes peuvent être redéfinies.
L'autre moyen de personnaliser la boucle d'apprentissage est d'utiliser les [Callbacks](./main_classes/callback). Vous pouvez utiliser les callbacks pour intégrer d'autres bibliothèques et inspecter la boucle d'apprentissage afin de suivre la progression ou d'arrêter l'apprentissage plus tôt. Les callbacks ne modifient rien dans la boucle d'apprentissage elle-même. Pour personnaliser quelque chose comme la fonction de perte, vous devez redéfinir le [`Trainer`] à la place.
diff --git a/docs/source/ja/hpo_train.md b/docs/source/ja/hpo_train.md
index 85da3616f8..90591daf8b 100644
--- a/docs/source/ja/hpo_train.md
+++ b/docs/source/ja/hpo_train.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
これらを使用する前に、ハイパーパラメーター検索バックエンドをインストールする必要があります。
```bash
-pip install optuna/sigopt/wandb/ray[tune]
+pip install optuna/sigopt/wandb/ray[tune]
```
## How to enable Hyperparameter search in example
@@ -119,7 +119,7 @@ Wandbについては、[object_parameter](https://docs.wandb.ai/guides/sweeps/co
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... model_init=model_init,
... data_collator=data_collator,
... )
@@ -142,9 +142,3 @@ Wandbについては、[object_parameter](https://docs.wandb.ai/guides/sweeps/co
## Hyperparameter search For DDP finetune
現在、DDP(Distributed Data Parallel)のためのハイパーパラメーター検索は、Optuna と SigOpt に対して有効になっています。ランクゼロプロセスのみが検索トライアルを生成し、他のランクに引数を渡します。
-
-
-
-
-
-
diff --git a/docs/source/ja/quicktour.md b/docs/source/ja/quicktour.md
index 0e20d1eee9..e03dea33cb 100644
--- a/docs/source/ja/quicktour.md
+++ b/docs/source/ja/quicktour.md
@@ -516,7 +516,7 @@ tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
... args=training_args,
... train_dataset=dataset["train"],
... eval_dataset=dataset["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... ) # doctest: +SKIP
```
diff --git a/docs/source/ja/tasks/asr.md b/docs/source/ja/tasks/asr.md
index 9226f5b414..ebefeba831 100644
--- a/docs/source/ja/tasks/asr.md
+++ b/docs/source/ja/tasks/asr.md
@@ -148,7 +148,7 @@ MInDS-14 データセットのサンプリング レートは 8000kHz です (
... return batch
```
-データセット全体に前処理関数を適用するには、🤗 Datasets [`~datasets.Dataset.map`] 関数を使用します。 `num_proc` パラメータを使用してプロセスの数を増やすことで、`map` を高速化できます。 [`~datasets.Dataset.remove_columns`] メソッドを使用して、不要な列を削除します。
+データセット全体に前処理関数を適用するには、🤗 Datasets [`~datasets.Dataset.map`] 関数を使用します。 `num_proc` パラメータを使用してプロセスの数を増やすことで、`map` を高速化できます。 [`~datasets.Dataset.remove_columns`] メソッドを使用して、不要な列を削除します。
```py
>>> encoded_minds = minds.map(prepare_dataset, remove_columns=minds.column_names["train"], num_proc=4)
@@ -281,7 +281,7 @@ MInDS-14 データセットのサンプリング レートは 8000kHz です (
... args=training_args,
... train_dataset=encoded_minds["train"],
... eval_dataset=encoded_minds["test"],
-... tokenizer=processor,
+... processing_class=processor,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
diff --git a/docs/source/ja/tasks/audio_classification.md b/docs/source/ja/tasks/audio_classification.md
index d32050072f..aa38d12d4e 100644
--- a/docs/source/ja/tasks/audio_classification.md
+++ b/docs/source/ja/tasks/audio_classification.md
@@ -233,7 +233,7 @@ MInDS-14 データセットのサンプリング レートは 8000khz です (
... args=training_args,
... train_dataset=encoded_minds["train"],
... eval_dataset=encoded_minds["test"],
-... tokenizer=feature_extractor,
+... processing_class=feature_extractor,
... compute_metrics=compute_metrics,
... )
@@ -320,4 +320,4 @@ MInDS-14 データセットのサンプリング レートは 8000khz です (
'cash_deposit'
```
-
\ No newline at end of file
+
diff --git a/docs/source/ja/tasks/document_question_answering.md b/docs/source/ja/tasks/document_question_answering.md
index 847ec8441c..f07cc6dff2 100644
--- a/docs/source/ja/tasks/document_question_answering.md
+++ b/docs/source/ja/tasks/document_question_answering.md
@@ -364,7 +364,7 @@ end_index 18
自分で実装したい場合は、[質問応答の章](https://huggingface.co/course/chapter7/7?fw=pt#postprocessing) を確認してください。
インスピレーションを得るためにハグフェイスコースの。
-## Train
+## Train
おめでとう!このガイドの最も難しい部分を無事にナビゲートできたので、独自のモデルをトレーニングする準備が整いました。
トレーニングには次の手順が含まれます。
@@ -423,7 +423,7 @@ end_index 18
... data_collator=data_collator,
... train_dataset=encoded_train_dataset,
... eval_dataset=encoded_test_dataset,
-... tokenizer=processor,
+... processing_class=processor,
... )
>>> trainer.train()
diff --git a/docs/source/ja/tasks/image_classification.md b/docs/source/ja/tasks/image_classification.md
index 2202dc3a4f..013dfc286d 100644
--- a/docs/source/ja/tasks/image_classification.md
+++ b/docs/source/ja/tasks/image_classification.md
@@ -323,7 +323,7 @@ food["test"].set_transform(preprocess_val)
... data_collator=data_collator,
... train_dataset=food["train"],
... eval_dataset=food["test"],
-... tokenizer=image_processor,
+... processing_class=image_processor,
... compute_metrics=compute_metrics,
... )
@@ -551,4 +551,3 @@ Epoch 5/5
-
diff --git a/docs/source/ja/tasks/knowledge_distillation_for_image_classification.md b/docs/source/ja/tasks/knowledge_distillation_for_image_classification.md
index 30c0dbbf06..1079121c60 100644
--- a/docs/source/ja/tasks/knowledge_distillation_for_image_classification.md
+++ b/docs/source/ja/tasks/knowledge_distillation_for_image_classification.md
@@ -165,7 +165,7 @@ trainer = ImageDistilTrainer(
train_dataset=processed_datasets["train"],
eval_dataset=processed_datasets["validation"],
data_collator=data_collator,
- tokenizer=teacher_extractor,
+ processing_class=teacher_extractor,
compute_metrics=compute_metrics,
temperature=5,
lambda_param=0.5
diff --git a/docs/source/ja/tasks/multiple_choice.md b/docs/source/ja/tasks/multiple_choice.md
index 98e258f161..075a7a2cb7 100644
--- a/docs/source/ja/tasks/multiple_choice.md
+++ b/docs/source/ja/tasks/multiple_choice.md
@@ -271,7 +271,7 @@ tokenized_swag = swag.map(preprocess_function, batched=True)
... args=training_args,
... train_dataset=tokenized_swag["train"],
... eval_dataset=tokenized_swag["validation"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=DataCollatorForMultipleChoice(tokenizer=tokenizer),
... compute_metrics=compute_metrics,
... )
diff --git a/docs/source/ja/tasks/object_detection.md b/docs/source/ja/tasks/object_detection.md
index 1b1bfb3f81..31e8effa54 100644
--- a/docs/source/ja/tasks/object_detection.md
+++ b/docs/source/ja/tasks/object_detection.md
@@ -371,7 +371,7 @@ DETR モデルをトレーニングできる「ラベル」。画像プロセッ
... args=training_args,
... data_collator=collate_fn,
... train_dataset=cppe5["train"],
-... tokenizer=image_processor,
+... processing_class=image_processor,
... )
>>> trainer.train()
diff --git a/docs/source/ja/tasks/question_answering.md b/docs/source/ja/tasks/question_answering.md
index b039272f45..9217c211e6 100644
--- a/docs/source/ja/tasks/question_answering.md
+++ b/docs/source/ja/tasks/question_answering.md
@@ -227,7 +227,7 @@ pip install transformers datasets evaluate
... args=training_args,
... train_dataset=tokenized_squad["train"],
... eval_dataset=tokenized_squad["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... )
diff --git a/docs/source/ja/tasks/summarization.md b/docs/source/ja/tasks/summarization.md
index 74152d5dbd..6784696e6c 100644
--- a/docs/source/ja/tasks/summarization.md
+++ b/docs/source/ja/tasks/summarization.md
@@ -216,7 +216,7 @@ pip install transformers datasets evaluate rouge_score
... args=training_args,
... train_dataset=tokenized_billsum["train"],
... eval_dataset=tokenized_billsum["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
diff --git a/docs/source/ja/tasks/text-to-speech.md b/docs/source/ja/tasks/text-to-speech.md
index b302a19a0d..669d15730e 100644
--- a/docs/source/ja/tasks/text-to-speech.md
+++ b/docs/source/ja/tasks/text-to-speech.md
@@ -125,7 +125,7 @@ dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
>>> processor = SpeechT5Processor.from_pretrained(checkpoint)
```
-### Text cleanup for SpeechT5 tokenization
+### Text cleanup for SpeechT5 tokenization
まずはテキストデータをクリーンアップすることから始めます。テキストを処理するには、プロセッサのトークナイザー部分が必要です。
@@ -442,7 +442,7 @@ SpeechT5 では、モデルのデコーダ部分への入力が 2 分の 1 に
ターゲット シーケンスの長さが奇数である可能性がある場合、データ照合機能はバッチの最大長を切り捨てて、
2の倍数。
-```py
+```py
>>> data_collator = TTSDataCollatorWithPadding(processor=processor)
```
@@ -458,7 +458,7 @@ SpeechT5 では、モデルのデコーダ部分への入力が 2 分の 1 に
`use_cache=True`オプションは、勾配チェックポイントと互換性がありません。トレーニングのために無効にします。
-```py
+```py
>>> model.config.use_cache = False
```
@@ -501,7 +501,7 @@ SpeechT5 では、モデルのデコーダ部分への入力が 2 分の 1 に
... train_dataset=dataset["train"],
... eval_dataset=dataset["test"],
... data_collator=data_collator,
-... tokenizer=processor,
+... processing_class=processor,
... )
```
これで、トレーニングを開始する準備が整いました。トレーニングには数時間かかります。 GPU に応じて、
@@ -567,7 +567,7 @@ SpeechT5 では、モデルのデコーダ部分への入力が 2 分の 1 に
```py
>>> from IPython.display import Audio
->>> Audio(output['audio'], rate=output['sampling_rate'])
+>>> Audio(output['audio'], rate=output['sampling_rate'])
```
### Run inference manually
@@ -583,14 +583,14 @@ SpeechT5 では、モデルのデコーダ部分への入力が 2 分の 1 に
テスト データセットから例を選択して、スピーカーの埋め込みを取得します。
-```py
+```py
>>> example = dataset["test"][304]
>>> speaker_embeddings = torch.tensor(example["speaker_embeddings"]).unsqueeze(0)
```
入力テキストを定義し、トークン化します。
-```py
+```py
>>> text = "hallo allemaal, ik praat nederlands. groetjes aan iedereen!"
>>> inputs = processor(text=text, return_tensors="pt")
```
diff --git a/docs/source/ja/tasks/token_classification.md b/docs/source/ja/tasks/token_classification.md
index a7f5097f68..4389aeacb5 100644
--- a/docs/source/ja/tasks/token_classification.md
+++ b/docs/source/ja/tasks/token_classification.md
@@ -295,7 +295,7 @@ pip install transformers datasets evaluate seqeval
... args=training_args,
... train_dataset=tokenized_wnut["train"],
... eval_dataset=tokenized_wnut["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
diff --git a/docs/source/ja/tasks/translation.md b/docs/source/ja/tasks/translation.md
index eb67604f9e..7fa45eac9c 100644
--- a/docs/source/ja/tasks/translation.md
+++ b/docs/source/ja/tasks/translation.md
@@ -220,7 +220,7 @@ pip install transformers datasets evaluate sacrebleu
... args=training_args,
... train_dataset=tokenized_books["train"],
... eval_dataset=tokenized_books["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
diff --git a/docs/source/ja/tasks/video_classification.md b/docs/source/ja/tasks/video_classification.md
index ecfae843f2..741356a6f5 100644
--- a/docs/source/ja/tasks/video_classification.md
+++ b/docs/source/ja/tasks/video_classification.md
@@ -61,7 +61,7 @@ pip install -q pytorchvideo transformers evaluate
サブセットをダウンロードした後、圧縮アーカイブを抽出する必要があります。
-```py
+```py
>>> import tarfile
>>> with tarfile.open(file_path) as t:
@@ -127,7 +127,7 @@ UCF101_subset/
* `id2label`: 整数をクラス名にマッピングします。
-```py
+```py
>>> class_labels = sorted({str(path).split("/")[2] for path in all_video_file_paths})
>>> label2id = {label: i for i, label in enumerate(class_labels)}
>>> id2label = {i: label for label, i in label2id.items()}
@@ -143,7 +143,7 @@ UCF101_subset/
事前トレーニングされたチェックポイントとそれに関連する画像プロセッサからビデオ分類モデルをインスタンス化します。モデルのエンコーダーには事前トレーニングされたパラメーターが付属しており、分類ヘッドはランダムに初期化されます。画像プロセッサは、データセットの前処理パイプラインを作成するときに役立ちます。
-```py
+```py
>>> from transformers import VideoMAEImageProcessor, VideoMAEForVideoClassification
>>> model_ckpt = "MCG-NJU/videomae-base"
@@ -175,7 +175,7 @@ You should probably TRAIN this model on a down-stream task to be able to use it
ビデオの前処理には、[PyTorchVideo ライブラリ](https://pytorchvideo.org/) を利用します。まず、必要な依存関係をインポートします。
-```py
+```py
>>> import pytorchvideo.data
>>> from pytorchvideo.transforms import (
@@ -224,7 +224,7 @@ You should probably TRAIN this model on a down-stream task to be able to use it
次に、データセット固有の変換とデータセットをそれぞれ定義します。トレーニングセットから始めます:
-```py
+```py
>>> train_transform = Compose(
... [
... ApplyTransformToKey(
@@ -254,7 +254,7 @@ You should probably TRAIN this model on a down-stream task to be able to use it
同じ一連のワークフローを検証セットと評価セットに適用できます。
-```py
+```py
>>> val_transform = Compose(
... [
... ApplyTransformToKey(
@@ -297,9 +297,9 @@ You should probably TRAIN this model on a down-stream task to be able to use it
# (300, 30, 75)
```
-## Visualize the preprocessed video for better debugging
+## Visualize the preprocessed video for better debugging
-```py
+```py
>>> import imageio
>>> import numpy as np
>>> from IPython.display import Image
@@ -312,7 +312,7 @@ You should probably TRAIN this model on a down-stream task to be able to use it
>>> def create_gif(video_tensor, filename="sample.gif"):
... """Prepares a GIF from a video tensor.
-...
+...
... The video tensor is expected to have the following shape:
... (num_frames, num_channels, height, width).
... """
@@ -339,13 +339,13 @@ You should probably TRAIN this model on a down-stream task to be able to use it
-## Train the model
+## Train the model
🤗 Transformers の [`Trainer`](https://huggingface.co/docs/transformers/main_classes/trainer) をモデルのトレーニングに利用します。 `Trainer`をインスタンス化するには、トレーニング構成と評価メトリクスを定義する必要があります。最も重要なのは [`TrainingArguments`](https://huggingface.co/transformers/main_classes/trainer.html#transformers.TrainingArguments) で、これはトレーニングを構成するためのすべての属性を含むクラスです。モデルのチェックポイントを保存するために使用される出力フォルダー名が必要です。また、🤗 Hub 上のモデル リポジトリ内のすべての情報を同期するのにも役立ちます。
トレーニング引数のほとんどは一目瞭然ですが、ここで非常に重要なのは`remove_unused_columns=False`です。これにより、モデルの呼び出し関数で使用されない機能が削除されます。デフォルトでは`True`です。これは、通常、未使用の特徴列を削除し、モデルの呼び出し関数への入力を解凍しやすくすることが理想的であるためです。ただし、この場合、`pixel_values` (モデルが入力で期待する必須キーです) を作成するには、未使用の機能 (特に`video`) が必要です。
-```py
+```py
>>> from transformers import TrainingArguments, Trainer
>>> model_name = model_ckpt.split("/")[-1]
@@ -391,7 +391,7 @@ def compute_metrics(eval_pred):
また、サンプルをまとめてバッチ処理するために使用される `collate_fn` を定義します。各バッチは、`pixel_values` と `labels` という 2 つのキーで構成されます。
-```py
+```py
>>> def collate_fn(examples):
... # permute to (num_frames, num_channels, height, width)
... pixel_values = torch.stack(
@@ -403,13 +403,13 @@ def compute_metrics(eval_pred):
次に、これらすべてをデータセットとともに`Trainer`に渡すだけです。
-```py
+```py
>>> trainer = Trainer(
... model,
... args,
... train_dataset=train_dataset,
... eval_dataset=val_dataset,
-... tokenizer=image_processor,
+... processing_class=image_processor,
... compute_metrics=compute_metrics,
... data_collator=collate_fn,
... )
@@ -419,7 +419,7 @@ def compute_metrics(eval_pred):
次に、`train` メソッドを呼び出してモデルを微調整します。
-```py
+```py
>>> train_results = trainer.train()
```
@@ -435,7 +435,7 @@ def compute_metrics(eval_pred):
推論のためにビデオをロードします。
-```py
+```py
>>> sample_test_video = next(iter(test_dataset))
```
@@ -491,7 +491,7 @@ def compute_metrics(eval_pred):
`logits` をデコードすると、次のようになります。
-```py
+```py
>>> predicted_class_idx = logits.argmax(-1).item()
>>> print("Predicted class:", model.config.id2label[predicted_class_idx])
# Predicted class: BasketballDunk
diff --git a/docs/source/ja/tasks/visual_question_answering.md b/docs/source/ja/tasks/visual_question_answering.md
index f6c2989693..3231cba5e3 100644
--- a/docs/source/ja/tasks/visual_question_answering.md
+++ b/docs/source/ja/tasks/visual_question_answering.md
@@ -110,7 +110,7 @@ Dataset({
残りの機能は必要ないので削除できます。
-```py
+```py
>>> dataset = dataset.remove_columns(['question_type', 'question_id', 'answer_type'])
```
@@ -150,7 +150,7 @@ Dataset({
>>> unique_labels = list(set(flattened_labels))
>>> label2id = {label: idx for idx, label in enumerate(unique_labels)}
->>> id2label = {idx: label for label, idx in label2id.items()}
+>>> id2label = {idx: label for label, idx in label2id.items()}
```
マッピングができたので、文字列の回答をその ID に置き換え、さらに前処理をより便利にするためにデータセットをフラット化することができます。
@@ -175,7 +175,7 @@ Dataset({
次のステップでは、ViLT プロセッサをロードして、モデルの画像データとテキスト データを準備します。
[`ViltProcessor`] は、BERT トークナイザーと ViLT 画像プロセッサを便利な単一プロセッサにラップします。
-```py
+```py
>>> from transformers import ViltProcessor
>>> processor = ViltProcessor.from_pretrained(model_checkpoint)
@@ -197,13 +197,13 @@ Dataset({
>>> def preprocess_data(examples):
... image_paths = examples['image_id']
... images = [Image.open(image_path) for image_path in image_paths]
-... texts = examples['question']
+... texts = examples['question']
... encoding = processor(images, texts, padding="max_length", truncation=True, return_tensors="pt")
... for k, v in encoding.items():
... encoding[k] = v.squeeze()
-
+
... targets = []
... for labels, scores in zip(examples['label.ids'], examples['label.weights']):
@@ -211,11 +211,11 @@ Dataset({
... for label, score in zip(labels, scores):
... target[label] = score
-
+
... targets.append(target)
... encoding["labels"] = targets
-
+
... return encoding
```
@@ -284,14 +284,14 @@ Dataset({
... args=training_args,
... data_collator=data_collator,
... train_dataset=processed_dataset,
-... tokenizer=processor,
+... processing_class=processor,
... )
```
3. [`~Trainer.train`] を呼び出してモデルを微調整します。
```py
->>> trainer.train()
+>>> trainer.train()
```
トレーニングが完了したら、 [`~Trainer.push_to_hub`] メソッドを使用してモデルをハブに共有し、🤗 ハブで最終モデルを共有します。
@@ -376,7 +376,7 @@ GPU (利用可能な場合)。これは [`Trainer`] が自動的に処理する
モデルは画像とテキストを入力として受け取るため、VQA データセットの最初の例とまったく同じ画像と質問のペアを使用してみましょう。
-```py
+```py
>>> example = dataset[0]
>>> image = Image.open(example['image_id'])
>>> question = example['question']
@@ -386,7 +386,7 @@ GPU (利用可能な場合)。これは [`Trainer`] が自動的に処理する
```py
->>> prompt = f"Question: {question} Answer:"
+>>> prompt = f"Question: {question} Answer:"
```
次に、モデルのプロセッサで画像/プロンプトを前処理し、処理された入力をモデルに渡し、出力をデコードする必要があります。
@@ -397,7 +397,7 @@ GPU (利用可能な場合)。これは [`Trainer`] が自動的に処理する
>>> generated_ids = model.generate(**inputs, max_new_tokens=10)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
>>> print(generated_text)
-"He is looking at the crowd"
+"He is looking at the crowd"
```
ご覧のとおり、モデルは群衆と顔の向き (下を向いている) を認識しましたが、見逃しているようです。
diff --git a/docs/source/ko/hpo_train.md b/docs/source/ko/hpo_train.md
index 58bacd55ff..c0982db5e0 100644
--- a/docs/source/ko/hpo_train.md
+++ b/docs/source/ko/hpo_train.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
하이퍼파라미터 탐색 백엔드로 사용하기 전에 아래의 명령어를 사용하여 라이브러리들을 설치하세요.
```bash
-pip install optuna/sigopt/wandb/ray[tune]
+pip install optuna/sigopt/wandb/ray[tune]
```
## 예제에서 하이퍼파라미터 탐색을 활성화하는 방법 [[how-to-enable-hyperparameter-search-in-example]]
@@ -100,7 +100,7 @@ wandb의 경우, 해당 [object_parameter](https://docs.wandb.ai/guides/sweeps/c
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... model_init=model_init,
... data_collator=data_collator,
... )
diff --git a/docs/source/ko/quicktour.md b/docs/source/ko/quicktour.md
index 0dc4887b88..06f44e6fd2 100644
--- a/docs/source/ko/quicktour.md
+++ b/docs/source/ko/quicktour.md
@@ -486,7 +486,7 @@ tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
... args=training_args,
... train_dataset=dataset["train"],
... eval_dataset=dataset["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... ) # doctest: +SKIP
```
@@ -554,4 +554,4 @@ tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
## 다음 단계는 무엇인가요? [[whats-next]]
-🤗 Transformers 둘러보기를 모두 읽으셨다면, 가이드를 살펴보고 더 구체적인 것을 수행하는 방법을 알아보세요. 이를테면 커스텀 모델 구축하는 방법, 과업에 알맞게 모델을 미세조정하는 방법, 스크립트로 모델 훈련하는 방법 등이 있습니다. 🤗 Transformers 핵심 개념에 대해 더 알아보려면 커피 한 잔 들고 개념 가이드를 살펴보세요!
\ No newline at end of file
+🤗 Transformers 둘러보기를 모두 읽으셨다면, 가이드를 살펴보고 더 구체적인 것을 수행하는 방법을 알아보세요. 이를테면 커스텀 모델 구축하는 방법, 과업에 알맞게 모델을 미세조정하는 방법, 스크립트로 모델 훈련하는 방법 등이 있습니다. 🤗 Transformers 핵심 개념에 대해 더 알아보려면 커피 한 잔 들고 개념 가이드를 살펴보세요!
diff --git a/docs/source/ko/tasks/asr.md b/docs/source/ko/tasks/asr.md
index 2247537678..d1e4a5e1d9 100644
--- a/docs/source/ko/tasks/asr.md
+++ b/docs/source/ko/tasks/asr.md
@@ -20,7 +20,7 @@ rendered properly in your Markdown viewer.
-자동 음성 인식(Automatic Speech Recognition, ASR)은 음성 신호를 텍스트로 변환하여 음성 입력 시퀀스를 텍스트 출력에 매핑합니다.
+자동 음성 인식(Automatic Speech Recognition, ASR)은 음성 신호를 텍스트로 변환하여 음성 입력 시퀀스를 텍스트 출력에 매핑합니다.
Siri와 Alexa와 같은 가상 어시스턴트는 ASR 모델을 사용하여 일상적으로 사용자를 돕고 있으며, 회의 중 라이브 캡션 및 메모 작성과 같은 유용한 사용자 친화적 응용 프로그램도 많이 있습니다.
이 가이드에서 소개할 내용은 아래와 같습니다:
@@ -50,7 +50,7 @@ Hugging Face 계정에 로그인하면 모델을 업로드하고 커뮤니티에
## MInDS-14 데이터 세트 가져오기[[load-minds-14-dataset]]
-먼저, 🤗 Datasets 라이브러리에서 [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) 데이터 세트의 일부분을 가져오세요.
+먼저, 🤗 Datasets 라이브러리에서 [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) 데이터 세트의 일부분을 가져오세요.
이렇게 하면 전체 데이터 세트에 대한 훈련에 시간을 들이기 전에 모든 것이 작동하는지 실험하고 검증할 수 있습니다.
```py
@@ -198,7 +198,7 @@ MInDS-14 데이터 세트의 샘플링 레이트는 8000kHz이므로([데이터
## 평가하기[[evaluate]]
-훈련 중에 평가 지표를 포함하면 모델의 성능을 평가하는 데 도움이 되는 경우가 많습니다. 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) 라이브러리를 사용하면 평가 방법을 빠르게 불러올 수 있습니다.
+훈련 중에 평가 지표를 포함하면 모델의 성능을 평가하는 데 도움이 되는 경우가 많습니다. 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) 라이브러리를 사용하면 평가 방법을 빠르게 불러올 수 있습니다.
이 작업에서는 [단어 오류율(Word Error Rate, WER)](https://huggingface.co/spaces/evaluate-metric/wer) 평가 지표를 가져옵니다.
(평가 지표를 불러오고 계산하는 방법은 🤗 Evaluate [둘러보기](https://huggingface.co/docs/evaluate/a_quick_tour)를 참조하세요):
@@ -285,7 +285,7 @@ MInDS-14 데이터 세트의 샘플링 레이트는 8000kHz이므로([데이터
... args=training_args,
... train_dataset=encoded_minds["train"],
... eval_dataset=encoded_minds["test"],
-... tokenizer=processor.feature_extractor,
+... processing_class=processor.feature_extractor,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
@@ -372,4 +372,4 @@ MInDS-14 데이터 세트의 샘플링 레이트는 8000kHz이므로([데이터
['I WOUL LIKE O SET UP JOINT ACOUNT WTH Y PARTNER']
```
-
\ No newline at end of file
+
diff --git a/docs/source/ko/tasks/audio_classification.md b/docs/source/ko/tasks/audio_classification.md
index 73932100b0..936b4eb198 100644
--- a/docs/source/ko/tasks/audio_classification.md
+++ b/docs/source/ko/tasks/audio_classification.md
@@ -235,7 +235,7 @@ MinDS-14 데이터 세트의 샘플링 속도는 8000khz이므로(이 정보는
... args=training_args,
... train_dataset=encoded_minds["train"],
... eval_dataset=encoded_minds["test"],
-... tokenizer=feature_extractor,
+... processing_class=feature_extractor,
... compute_metrics=compute_metrics,
... )
@@ -321,4 +321,4 @@ For a more in-depth example of how to finetune a model for audio classification,
'cash_deposit'
```
-
\ No newline at end of file
+
diff --git a/docs/source/ko/tasks/document_question_answering.md b/docs/source/ko/tasks/document_question_answering.md
index 3d943ab96e..6c2d04f4ee 100644
--- a/docs/source/ko/tasks/document_question_answering.md
+++ b/docs/source/ko/tasks/document_question_answering.md
@@ -18,8 +18,8 @@ rendered properly in your Markdown viewer.
[[open-in-colab]]
-문서 시각적 질의 응답(Document Visual Question Answering)이라고도 하는
-문서 질의 응답(Document Question Answering)은 문서 이미지에 대한 질문에 답변을 주는 태스크입니다.
+문서 시각적 질의 응답(Document Visual Question Answering)이라고도 하는
+문서 질의 응답(Document Question Answering)은 문서 이미지에 대한 질문에 답변을 주는 태스크입니다.
이 태스크를 지원하는 모델의 입력은 일반적으로 이미지와 질문의 조합이고, 출력은 자연어로 된 답변입니다. 이러한 모델은 텍스트, 단어의 위치(바운딩 박스), 이미지 등 다양한 모달리티를 활용합니다.
이 가이드는 다음 내용을 설명합니다:
@@ -72,7 +72,7 @@ pip install -q pytesseract
## 데이터 불러오기 [[load-the-data]]
-이 가이드에서는 🤗 Hub에서 찾을 수 있는 전처리된 DocVQA의 작은 샘플을 사용합니다.
+이 가이드에서는 🤗 Hub에서 찾을 수 있는 전처리된 DocVQA의 작은 샘플을 사용합니다.
DocVQA의 전체 데이터 세트를 사용하고 싶다면, [DocVQA homepage](https://rrc.cvc.uab.es/?ch=17)에 가입 후 다운로드 할 수 있습니다. 전체 데이터 세트를 다운로드 했다면, 이 가이드를 계속 진행하기 위해 [🤗 dataset에 파일을 가져오는 방법](https://huggingface.co/docs/datasets/loading#local-and-remote-files)을 확인하세요.
```py
@@ -124,9 +124,9 @@ DatasetDict({
>>> updated_dataset = updated_dataset.filter(lambda x: len(x["words"]) + len(x["question"].split()) < 512)
```
-이 시점에서 이 데이터 세트의 OCR 특성도 제거해 보겠습니다. OCR 특성은 다른 모델을 미세 조정하기 위한 것으로, 이 가이드에서 사용하는 모델의 입력 요구 사항과 일치하지 않기 때문에 이 특성을 사용하기 위해서는 일부 처리가 필요합니다.
+이 시점에서 이 데이터 세트의 OCR 특성도 제거해 보겠습니다. OCR 특성은 다른 모델을 미세 조정하기 위한 것으로, 이 가이드에서 사용하는 모델의 입력 요구 사항과 일치하지 않기 때문에 이 특성을 사용하기 위해서는 일부 처리가 필요합니다.
대신, 원본 데이터에 [`LayoutLMv2Processor`]를 사용하여 OCR 및 토큰화를 모두 수행할 수 있습니다.
-이렇게 하면 모델이 요구하는 입력을 얻을 수 있습니다.
+이렇게 하면 모델이 요구하는 입력을 얻을 수 있습니다.
이미지를 수동으로 처리하려면, [`LayoutLMv2` model documentation](../model_doc/layoutlmv2)에서 모델이 요구하는 입력 포맷을 확인해보세요.
```py
@@ -186,7 +186,7 @@ DatasetDict({
### 텍스트 데이터 전처리 [[preprocessing-text-data]]
이미지에 OCR을 적용했으면 데이터 세트의 텍스트 부분을 모델에 맞게 인코딩해야 합니다.
-이 인코딩에는 이전 단계에서 가져온 단어와 박스를 토큰 수준의 `input_ids`, `attention_mask`, `token_type_ids` 및 `bbox`로 변환하는 작업이 포함됩니다.
+이 인코딩에는 이전 단계에서 가져온 단어와 박스를 토큰 수준의 `input_ids`, `attention_mask`, `token_type_ids` 및 `bbox`로 변환하는 작업이 포함됩니다.
텍스트를 전처리하려면 프로세서의 `tokenizer`가 필요합니다.
```py
@@ -197,8 +197,8 @@ DatasetDict({
레이블 추가를 위해서, 먼저 더 큰 리스트(단어 리스트)에서 하위 리스트(단어로 분할된 답변)을 찾을 수 있는 헬퍼 함수를 정의합니다.
-이 함수는 `words_list`와 `answer_list`, 이렇게 두 리스트를 입력으로 받습니다.
-그런 다음 `words_list`를 반복하여 `words_list`의 현재 단어(words_list[i])가 `answer_list`의 첫 번째 단어(answer_list[0])와 같은지,
+이 함수는 `words_list`와 `answer_list`, 이렇게 두 리스트를 입력으로 받습니다.
+그런 다음 `words_list`를 반복하여 `words_list`의 현재 단어(words_list[i])가 `answer_list`의 첫 번째 단어(answer_list[0])와 같은지,
현재 단어에서 시작해 `answer_list`와 같은 길이만큼의 `words_list`의 하위 리스트가 `answer_list`와 일치하는지 확인합니다.
이 조건이 참이라면 일치하는 항목을 발견했음을 의미하며, 함수는 일치 항목, 시작 인덱스(idx) 및 종료 인덱스(idx + len(answer_list) - 1)를 기록합니다. 일치하는 항목이 두 개 이상 발견되면 함수는 첫 번째 항목만 반환합니다. 일치하는 항목이 없다면 함수는 (`None`, 0, 0)을 반환합니다.
@@ -349,7 +349,7 @@ end_index 18
## 훈련 [[train]]
-축하합니다! 이 가이드의 가장 어려운 부분을 성공적으로 처리했으니 이제 나만의 모델을 훈련할 준비가 되었습니다.
+축하합니다! 이 가이드의 가장 어려운 부분을 성공적으로 처리했으니 이제 나만의 모델을 훈련할 준비가 되었습니다.
훈련은 다음과 같은 단계로 이루어져 있습니다:
* 전처리에서의 동일한 체크포인트를 사용하기 위해 [`AutoModelForDocumentQuestionAnswering`]으로 모델을 가져옵니다.
* [`TrainingArguments`]로 훈련 하이퍼파라미터를 정합니다.
@@ -406,7 +406,7 @@ end_index 18
... data_collator=data_collator,
... train_dataset=encoded_train_dataset,
... eval_dataset=encoded_test_dataset,
-... tokenizer=processor,
+... processing_class=processor,
... )
>>> trainer.train()
@@ -421,7 +421,7 @@ end_index 18
## 추론 [[inference]]
-이제 LayoutLMv2 모델을 미세 조정하고 🤗 Hub에 업로드했으니 추론에도 사용할 수 있습니다.
+이제 LayoutLMv2 모델을 미세 조정하고 🤗 Hub에 업로드했으니 추론에도 사용할 수 있습니다.
추론을 위해 미세 조정된 모델을 사용해 보는 가장 간단한 방법은 [`Pipeline`]을 사용하는 것 입니다.
예를 들어 보겠습니다:
@@ -473,4 +473,4 @@ end_index 18
>>> processor.tokenizer.decode(encoding.input_ids.squeeze()[predicted_start_idx : predicted_end_idx + 1])
'lee a. waller'
-```
\ No newline at end of file
+```
diff --git a/docs/source/ko/tasks/image_classification.md b/docs/source/ko/tasks/image_classification.md
index 91ff3a9ca9..4955bd6cdf 100644
--- a/docs/source/ko/tasks/image_classification.md
+++ b/docs/source/ko/tasks/image_classification.md
@@ -157,7 +157,7 @@ Hugging Face 계정에 로그인하여 모델을 업로드하고 커뮤니티에
과적합을 방지하고 모델을 보다 견고하게 만들기 위해 데이터 세트의 훈련 부분에 데이터 증강을 추가합니다.
여기서 Keras 전처리 레이어로 훈련 데이터에 대한 변환(데이터 증강 포함)과
-검증 데이터에 대한 변환(중앙 크로핑, 크기 조정, 정규화만)을 정의합니다.
+검증 데이터에 대한 변환(중앙 크로핑, 크기 조정, 정규화만)을 정의합니다.
`tf.image` 또는 다른 원하는 라이브러리를 사용할 수 있습니다.
```py
@@ -241,7 +241,7 @@ food["test"].set_transform(preprocess_val)
## 평가[[evaluate]]
훈련 중에 평가 지표를 포함하면 모델의 성능을 평가하는 데 도움이 되는 경우가 많습니다.
-🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) 라이브러리로 평가 방법을 빠르게 가져올 수 있습니다. 이 작업에서는
+🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) 라이브러리로 평가 방법을 빠르게 가져올 수 있습니다. 이 작업에서는
[accuracy](https://huggingface.co/spaces/evaluate-metric/accuracy) 평가 지표를 가져옵니다. (🤗 Evaluate [빠른 둘러보기](https://huggingface.co/docs/evaluate/a_quick_tour)를 참조하여 평가 지표를 가져오고 계산하는 방법에 대해 자세히 알아보세요):
```py
@@ -317,7 +317,7 @@ food["test"].set_transform(preprocess_val)
... data_collator=data_collator,
... train_dataset=food["train"],
... eval_dataset=food["test"],
-... tokenizer=image_processor,
+... processing_class=image_processor,
... compute_metrics=compute_metrics,
... )
@@ -404,7 +404,7 @@ TensorFlow에서 모델을 미세 조정하려면 다음 단계를 따르세요:
```
예측에서 정확도를 계산하고 모델을 🤗 Hub로 푸시하려면 [Keras callbacks](../main_classes/keras_callbacks)를 사용하세요.
-`compute_metrics` 함수를 [KerasMetricCallback](../main_classes/keras_callbacks#transformers.KerasMetricCallback)에 전달하고,
+`compute_metrics` 함수를 [KerasMetricCallback](../main_classes/keras_callbacks#transformers.KerasMetricCallback)에 전달하고,
[PushToHubCallback](../main_classes/keras_callbacks#transformers.PushToHubCallback)을 사용하여 모델을 업로드합니다:
```py
diff --git a/docs/source/ko/tasks/multiple_choice.md b/docs/source/ko/tasks/multiple_choice.md
index 607bc04747..f2755da4a8 100644
--- a/docs/source/ko/tasks/multiple_choice.md
+++ b/docs/source/ko/tasks/multiple_choice.md
@@ -270,7 +270,7 @@ tokenized_swag = swag.map(preprocess_function, batched=True)
... args=training_args,
... train_dataset=tokenized_swag["train"],
... eval_dataset=tokenized_swag["validation"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=DataCollatorForMultipleChoice(tokenizer=tokenizer),
... compute_metrics=compute_metrics,
... )
diff --git a/docs/source/ko/tasks/object_detection.md b/docs/source/ko/tasks/object_detection.md
index 2b92d7edb5..e027ad65a9 100644
--- a/docs/source/ko/tasks/object_detection.md
+++ b/docs/source/ko/tasks/object_detection.md
@@ -361,7 +361,7 @@ DatasetDict({
... args=training_args,
... data_collator=collate_fn,
... train_dataset=cppe5["train"],
-... tokenizer=image_processor,
+... processing_class=image_processor,
... )
>>> trainer.train()
diff --git a/docs/source/ko/tasks/question_answering.md b/docs/source/ko/tasks/question_answering.md
index cebd9e1a78..8309dd7d75 100644
--- a/docs/source/ko/tasks/question_answering.md
+++ b/docs/source/ko/tasks/question_answering.md
@@ -223,7 +223,7 @@ pip install transformers datasets evaluate
... args=training_args,
... train_dataset=tokenized_squad["train"],
... eval_dataset=tokenized_squad["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... )
diff --git a/docs/source/ko/tasks/sequence_classification.md b/docs/source/ko/tasks/sequence_classification.md
index b9812e63b0..11dae1a965 100644
--- a/docs/source/ko/tasks/sequence_classification.md
+++ b/docs/source/ko/tasks/sequence_classification.md
@@ -190,7 +190,7 @@ tokenized_imdb = imdb.map(preprocess_function, batched=True)
... args=training_args,
... train_dataset=tokenized_imdb["train"],
... eval_dataset=tokenized_imdb["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
diff --git a/docs/source/ko/tasks/summarization.md b/docs/source/ko/tasks/summarization.md
index 501aaae726..a2b2b1fbc9 100644
--- a/docs/source/ko/tasks/summarization.md
+++ b/docs/source/ko/tasks/summarization.md
@@ -223,7 +223,7 @@ Hugging Face 계정에 로그인하면 모델을 업로드하고 커뮤니티에
... args=training_args,
... train_dataset=tokenized_billsum["train"],
... eval_dataset=tokenized_billsum["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
diff --git a/docs/source/ko/tasks/token_classification.md b/docs/source/ko/tasks/token_classification.md
index e32a18e1ee..a65503092c 100644
--- a/docs/source/ko/tasks/token_classification.md
+++ b/docs/source/ko/tasks/token_classification.md
@@ -107,7 +107,7 @@ Hugging Face 계정에 로그인하여 모델을 업로드하고 커뮤니티에
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
```
-위의 예제 `tokens` 필드를 보면 입력이 이미 토큰화된 것처럼 보입니다. 그러나 실제로 입력은 아직 토큰화되지 않았으므로 단어를 하위 단어로 토큰화하기 위해 `is_split_into_words=True`를 설정해야 합니다. 예제로 확인합니다:
+위의 예제 `tokens` 필드를 보면 입력이 이미 토큰화된 것처럼 보입니다. 그러나 실제로 입력은 아직 토큰화되지 않았으므로 단어를 하위 단어로 토큰화하기 위해 `is_split_into_words=True`를 설정해야 합니다. 예제로 확인합니다:
```py
>>> example = wnut["train"][0]
@@ -294,7 +294,7 @@ Hugging Face 계정에 로그인하여 모델을 업로드하고 커뮤니티에
... args=training_args,
... train_dataset=tokenized_wnut["train"],
... eval_dataset=tokenized_wnut["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
@@ -405,8 +405,8 @@ TensorFlow에서 모델을 파인 튜닝하려면, 먼저 옵티마이저 함수
-토큰 분류를 위한 모델을 파인 튜닝하는 자세한 예제는 다음
-[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb)
+토큰 분류를 위한 모델을 파인 튜닝하는 자세한 예제는 다음
+[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb)
또는 [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb)를 참조하세요.
diff --git a/docs/source/ko/tasks/translation.md b/docs/source/ko/tasks/translation.md
index 88dbb405e1..5b4eaaa612 100644
--- a/docs/source/ko/tasks/translation.md
+++ b/docs/source/ko/tasks/translation.md
@@ -221,7 +221,7 @@ pip install transformers datasets evaluate sacrebleu
... args=training_args,
... train_dataset=tokenized_books["train"],
... eval_dataset=tokenized_books["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
diff --git a/docs/source/ko/tasks/video_classification.md b/docs/source/ko/tasks/video_classification.md
index f18ef918fa..10569083c0 100644
--- a/docs/source/ko/tasks/video_classification.md
+++ b/docs/source/ko/tasks/video_classification.md
@@ -61,7 +61,7 @@ pip install -q pytorchvideo transformers evaluate
```
데이터 세트의 하위 집합이 다운로드 되면, 압축된 파일의 압축을 해제해야 합니다:
-```py
+```py
>>> import tarfile
>>> with tarfile.open(file_path) as t:
@@ -124,9 +124,9 @@ UCF101_subset/
그 다음으로, 데이터 세트에 존재하는 라벨을 추출합니다. 또한, 모델을 초기화할 때 도움이 될 딕셔너리(dictionary data type)를 생성합니다.
* `label2id`: 클래스 이름을 정수에 매핑합니다.
-* `id2label`: 정수를 클래스 이름에 매핑합니다.
+* `id2label`: 정수를 클래스 이름에 매핑합니다.
-```py
+```py
>>> class_labels = sorted({str(path).split("/")[2] for path in all_video_file_paths})
>>> label2id = {label: i for i, label in enumerate(class_labels)}
>>> id2label = {i: label for label, i in label2id.items()}
@@ -142,7 +142,7 @@ UCF101_subset/
사전 훈련된 체크포인트와 체크포인트에 연관된 이미지 프로세서를 사용하여 영상 분류 모델을 인스턴스화합니다. 모델의 인코더에는 미리 학습된 매개변수가 제공되며, 분류 헤드(데이터를 분류하는 마지막 레이어)는 무작위로 초기화됩니다. 데이터 세트의 전처리 파이프라인을 작성할 때는 이미지 프로세서가 유용합니다.
-```py
+```py
>>> from transformers import VideoMAEImageProcessor, VideoMAEForVideoClassification
>>> model_ckpt = "MCG-NJU/videomae-base"
@@ -174,7 +174,7 @@ You should probably TRAIN this model on a down-stream task to be able to use it
영상 전처리를 위해 [PyTorchVideo 라이브러리](https://pytorchvideo.org/)를 활용할 것입니다. 필요한 종속성을 가져오는 것으로 시작하세요.
-```py
+```py
>>> import pytorchvideo.data
>>> from pytorchvideo.transforms import (
@@ -223,7 +223,7 @@ You should probably TRAIN this model on a down-stream task to be able to use it
이제 데이터 세트에 특화된 전처리(transform)과 데이터 세트 자체를 정의합니다. 먼저 훈련 데이터 세트로 시작합니다:
-```py
+```py
>>> train_transform = Compose(
... [
... ApplyTransformToKey(
@@ -252,7 +252,7 @@ You should probably TRAIN this model on a down-stream task to be able to use it
같은 방식의 작업 흐름을 검증과 평가 세트에도 적용할 수 있습니다.
-```py
+```py
>>> val_transform = Compose(
... [
... ApplyTransformToKey(
@@ -296,7 +296,7 @@ You should probably TRAIN this model on a down-stream task to be able to use it
## 더 나은 디버깅을 위해 전처리 영상 시각화하기[[visualize-the-preprocessed-video-for-better-debugging]]
-```py
+```py
>>> import imageio
>>> import numpy as np
>>> from IPython.display import Image
@@ -309,7 +309,7 @@ You should probably TRAIN this model on a down-stream task to be able to use it
>>> def create_gif(video_tensor, filename="sample.gif"):
... """Prepares a GIF from a video tensor.
-...
+...
... The video tensor is expected to have the following shape:
... (num_frames, num_channels, height, width).
... """
@@ -336,13 +336,13 @@ You should probably TRAIN this model on a down-stream task to be able to use it
-## 모델 훈련하기[[train-the-model]]
+## 모델 훈련하기[[train-the-model]]
🤗 Transformers의 [`Trainer`](https://huggingface.co/docs/transformers/main_classes/trainer)를 사용하여 모델을 훈련시켜보세요. `Trainer`를 인스턴스화하려면 훈련 설정과 평가 지표를 정의해야 합니다. 가장 중요한 것은 [`TrainingArguments`](https://huggingface.co/transformers/main_classes/trainer.html#transformers.TrainingArguments)입니다. 이 클래스는 훈련을 구성하는 모든 속성을 포함하며, 훈련 중 체크포인트를 저장할 출력 폴더 이름을 필요로 합니다. 또한 🤗 Hub의 모델 저장소의 모든 정보를 동기화하는 데 도움이 됩니다.
대부분의 훈련 인수는 따로 설명할 필요는 없습니다. 하지만 여기에서 중요한 인수는 `remove_unused_columns=False` 입니다. 이 인자는 모델의 호출 함수에서 사용되지 않는 모든 속성 열(columns)을 삭제합니다. 기본값은 일반적으로 True입니다. 이는 사용되지 않는 기능 열을 삭제하는 것이 이상적이며, 입력을 모델의 호출 함수로 풀기(unpack)가 쉬워지기 때문입니다. 하지만 이 경우에는 `pixel_values`(모델의 입력으로 필수적인 키)를 생성하기 위해 사용되지 않는 기능('video'가 특히 그렇습니다)이 필요합니다. 따라서 remove_unused_columns을 False로 설정해야 합니다.
-```py
+```py
>>> from transformers import TrainingArguments, Trainer
>>> model_name = model_ckpt.split("/")[-1]
@@ -387,7 +387,7 @@ def compute_metrics(eval_pred):
또한, 예제를 묶어서 배치를 형성하는 `collate_fn`을 정의해야합니다. 각 배치는 `pixel_values`와 `labels`라는 2개의 키로 구성됩니다.
-```py
+```py
>>> def collate_fn(examples):
... # permute to (num_frames, num_channels, height, width)
... pixel_values = torch.stack(
@@ -399,13 +399,13 @@ def compute_metrics(eval_pred):
그런 다음 이 모든 것을 데이터 세트와 함께 `Trainer`에 전달하기만 하면 됩니다:
-```py
+```py
>>> trainer = Trainer(
... model,
... args,
... train_dataset=train_dataset,
... eval_dataset=val_dataset,
-... tokenizer=image_processor,
+... processing_class=image_processor,
... compute_metrics=compute_metrics,
... data_collator=collate_fn,
... )
@@ -415,7 +415,7 @@ def compute_metrics(eval_pred):
`train` 메소드를 호출하여 모델을 미세 조정하세요:
-```py
+```py
>>> train_results = trainer.train()
```
@@ -429,7 +429,7 @@ def compute_metrics(eval_pred):
좋습니다. 이제 미세 조정된 모델을 추론하는 데 사용할 수 있습니다.
추론에 사용할 영상을 불러오세요:
-```py
+```py
>>> sample_test_video = next(iter(test_dataset))
```
@@ -485,7 +485,7 @@ def compute_metrics(eval_pred):
`logits`을 디코딩하면, 우리는 다음 결과를 얻을 수 있습니다:
-```py
+```py
>>> predicted_class_idx = logits.argmax(-1).item()
>>> print("Predicted class:", model.config.id2label[predicted_class_idx])
# Predicted class: BasketballDunk
diff --git a/docs/source/ko/tasks/visual_question_answering.md b/docs/source/ko/tasks/visual_question_answering.md
index f8560b14f9..9bc87c071e 100644
--- a/docs/source/ko/tasks/visual_question_answering.md
+++ b/docs/source/ko/tasks/visual_question_answering.md
@@ -35,7 +35,7 @@ VQA의 주요 사용 사례는 다음과 같습니다:
## ViLT 미세 조정 [[finetuning-vilt]]
ViLT는 Vision Transformer (ViT) 내에 텍스트 임베딩을 포함하여 비전/자연어 사전훈련(VLP; Vision-and-Language Pretraining)을 위한 기본 디자인을 제공합니다.
-ViLT 모델은 비전 트랜스포머(ViT)에 텍스트 임베딩을 넣어 비전/언어 사전훈련(VLP; Vision-and-Language Pre-training)을 위한 기본적인 디자인을 갖췄습니다. 이 모델은 여러 다운스트림 작업에 사용할 수 있습니다. VQA 태스크에서는 (`[CLS]` 토큰의 최종 은닉 상태 위에 선형 레이어인) 분류 헤더가 있으며 무작위로 초기화됩니다.
+ViLT 모델은 비전 트랜스포머(ViT)에 텍스트 임베딩을 넣어 비전/언어 사전훈련(VLP; Vision-and-Language Pre-training)을 위한 기본적인 디자인을 갖췄습니다. 이 모델은 여러 다운스트림 작업에 사용할 수 있습니다. VQA 태스크에서는 (`[CLS]` 토큰의 최종 은닉 상태 위에 선형 레이어인) 분류 헤더가 있으며 무작위로 초기화됩니다.
따라서 여기에서 시각적 질의응답은 **분류 문제**로 취급됩니다.
최근의 BLIP, BLIP-2, InstructBLIP와 같은 모델들은 VQA를 생성형 작업으로 간주합니다. 가이드의 후반부에서는 이런 모델들을 사용하여 제로샷 VQA 추론을 하는 방법에 대해 설명하겠습니다.
@@ -104,7 +104,7 @@ Dataset({
나머지 특성들은 필요하지 않기 때문에 삭제해도 됩니다:
-```py
+```py
>>> dataset = dataset.remove_columns(['question_type', 'question_id', 'answer_type'])
```
@@ -137,7 +137,7 @@ Dataset({
>>> unique_labels = list(set(flattened_labels))
>>> label2id = {label: idx for idx, label in enumerate(unique_labels)}
->>> id2label = {idx: label for label, idx in label2id.items()}
+>>> id2label = {idx: label for label, idx in label2id.items()}
```
이제 매핑이 완료되었으므로 문자열 답변을 해당 id로 교체하고, 데이터세트의 더 편리한 후처리를 위해 편평화 할 수 있습니다.
@@ -159,10 +159,10 @@ Dataset({
## 데이터 전처리 [[preprocessing-data]]
-다음 단계는 모델을 위해 이미지와 텍스트 데이터를 준비하기 위해 ViLT 프로세서를 가져오는 것입니다.
+다음 단계는 모델을 위해 이미지와 텍스트 데이터를 준비하기 위해 ViLT 프로세서를 가져오는 것입니다.
[`ViltProcessor`]는 BERT 토크나이저와 ViLT 이미지 프로세서를 편리하게 하나의 프로세서로 묶습니다:
-```py
+```py
>>> from transformers import ViltProcessor
>>> processor = ViltProcessor.from_pretrained(model_checkpoint)
@@ -181,13 +181,13 @@ Dataset({
>>> def preprocess_data(examples):
... image_paths = examples['image_id']
... images = [Image.open(image_path) for image_path in image_paths]
-... texts = examples['question']
+... texts = examples['question']
... encoding = processor(images, texts, padding="max_length", truncation=True, return_tensors="pt")
... for k, v in encoding.items():
... encoding[k] = v.squeeze()
-
+
... targets = []
... for labels, scores in zip(examples['label.ids'], examples['label.weights']):
@@ -195,11 +195,11 @@ Dataset({
... for label, score in zip(labels, scores):
... target[label] = score
-
+
... targets.append(target)
... encoding["labels"] = targets
-
+
... return encoding
```
@@ -264,14 +264,14 @@ Dataset({
... args=training_args,
... data_collator=data_collator,
... train_dataset=processed_dataset,
-... tokenizer=processor,
+... processing_class=processor,
... )
```
3. [`~Trainer.train`]을 호출하여 모델을 미세 조정하세요:
```py
->>> trainer.train()
+>>> trainer.train()
```
훈련이 완료되면, [`~Trainer.push_to_hub`] 메소드를 사용하여 🤗 Hub에 모델을 공유하세요:
@@ -349,7 +349,7 @@ Predicted answer: down
모델은 이미지와 텍스트를 입력으로 받으므로, VQA 데이터세트의 첫 번째 예제에서와 동일한 이미지/질문 쌍을 사용해 보겠습니다:
-```py
+```py
>>> example = dataset[0]
>>> image = Image.open(example['image_id'])
>>> question = example['question']
@@ -358,7 +358,7 @@ Predicted answer: down
BLIP-2를 시각적 질의응답 작업에 사용하려면 텍스트 프롬프트가 `Question: {} Answer:` 형식을 따라야 합니다.
```py
->>> prompt = f"Question: {question} Answer:"
+>>> prompt = f"Question: {question} Answer:"
```
이제 모델의 프로세서로 이미지/프롬프트를 전처리하고, 처리된 입력을 모델을 통해 전달하고, 출력을 디코드해야 합니다:
@@ -369,7 +369,7 @@ BLIP-2를 시각적 질의응답 작업에 사용하려면 텍스트 프롬프
>>> generated_ids = model.generate(**inputs, max_new_tokens=10)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
>>> print(generated_text)
-"He is looking at the crowd"
+"He is looking at the crowd"
```
보시다시피 모델은 군중을 인식하고, 얼굴의 방향(아래쪽을 보고 있음)을 인식했지만, 군중이 스케이터 뒤에 있다는 사실을 놓쳤습니다. 그러나 사람이 직접 라벨링한 데이터셋을 얻을 수 없는 경우에, 이 접근법은 빠르게 유용한 결과를 생성할 수 있습니다.
diff --git a/docs/source/pt/tasks/sequence_classification.md b/docs/source/pt/tasks/sequence_classification.md
index e7776894f8..a2e6865c92 100644
--- a/docs/source/pt/tasks/sequence_classification.md
+++ b/docs/source/pt/tasks/sequence_classification.md
@@ -134,7 +134,7 @@ Nesse ponto, restam apenas três passos:
... args=training_args,
... train_dataset=tokenized_imdb["train"],
... eval_dataset=tokenized_imdb["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... )
@@ -213,4 +213,4 @@ Chame o método [`fit`](https://keras.io/api/models/model_training_apis/#fit-met
Para obter um exemplo mais aprofundado de como executar o fine-tuning de um modelo para classificação de texto, dê uma olhada nesse [notebook utilizando PyTorch](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb) ou nesse [notebook utilizando TensorFlow](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb).
-
\ No newline at end of file
+
diff --git a/docs/source/pt/tasks/token_classification.md b/docs/source/pt/tasks/token_classification.md
index d4d6bf4dd9..45ce0d8742 100644
--- a/docs/source/pt/tasks/token_classification.md
+++ b/docs/source/pt/tasks/token_classification.md
@@ -193,7 +193,7 @@ Nesse ponto, restam apenas três passos:
... args=training_args,
... train_dataset=tokenized_wnut["train"],
... eval_dataset=tokenized_wnut["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... )
@@ -269,4 +269,4 @@ Chame o método [`fit`](https://keras.io/api/models/model_training_apis/#fit-met
Para obter um exemplo mais aprofundado de como executar o fine-tuning de um modelo para classificação de tokens, dê uma olhada nesse [notebook utilizando PyTorch](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb) ou nesse [notebook utilizando TensorFlow](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb).
-
\ No newline at end of file
+
diff --git a/docs/source/te/quicktour.md b/docs/source/te/quicktour.md
index 96ac046cf6..67e530f35f 100644
--- a/docs/source/te/quicktour.md
+++ b/docs/source/te/quicktour.md
@@ -142,7 +142,7 @@ label: NEGATIVE, with score: 0.5309
```
-
+
ముందుగా శిక్షణ పొందిన మోడల్ను లోడ్ చేయడానికి [`AutoModelForSequenceClassification`] మరియు [`AutoTokenizer`]ని ఉపయోగించండి మరియు దాని అనుబంధిత టోకెనైజర్ (తదుపరి విభాగంలో `AutoClass`పై మరిన్ని):
```py
@@ -154,7 +154,7 @@ label: NEGATIVE, with score: 0.5309
ముందుగా శిక్షణ పొందిన మోడల్ను లోడ్ చేయడానికి [`TFAutoModelForSequenceClassification`] మరియు [`AutoTokenizer`]ని ఉపయోగించండి మరియు దాని అనుబంధిత టోకెనైజర్ (తదుపరి విభాగంలో `TFAutoClass`పై మరిన్ని):
-
+
```py
>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
@@ -329,7 +329,7 @@ tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
మీ మోడల్ చక్కగా ట్యూన్ చేయబడిన తర్వాత, మీరు దానిని [`PreTrainedModel.save_pretrained`]ని ఉపయోగించి దాని టోకెనైజర్తో సేవ్ చేయవచ్చు:
-
+
```py
>>> pt_save_directory = "./pt_save_pretrained"
>>> tokenizer.save_pretrained(pt_save_directory) # doctest: +IGNORE_RESULT
@@ -344,7 +344,7 @@ tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
మీ మోడల్ చక్కగా ట్యూన్ చేయబడిన తర్వాత, మీరు దానిని [`TFPreTrainedModel.save_pretrained`]ని ఉపయోగించి దాని టోకెనైజర్తో సేవ్ చేయవచ్చు:
-
+
```py
>>> tf_save_directory = "./tf_save_pretrained"
>>> tokenizer.save_pretrained(tf_save_directory) # doctest: +IGNORE_RESULT
@@ -395,7 +395,7 @@ tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
[`AutoModel.from_config`]తో మీ అనుకూల కాన్ఫిగరేషన్ నుండి మోడల్ను సృష్టించండి:
-
+
```py
>>> from transformers import AutoModel
@@ -404,7 +404,7 @@ tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
[`TFAutoModel.from_config`]తో మీ అనుకూల కాన్ఫిగరేషన్ నుండి మోడల్ను సృష్టించండి:
-
+
```py
>>> from transformers import TFAutoModel
@@ -465,7 +465,7 @@ tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
```
ఆపై దానిని [`~datasets.Dataset.map`]తో మొత్తం డేటాసెట్లో వర్తింపజేయండి:
-
+
```py
>>> dataset = dataset.map(tokenize_dataset, batched=True)
```
@@ -488,7 +488,7 @@ tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
... args=training_args,
... train_dataset=dataset["train"],
... eval_dataset=dataset["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... ) # doctest: +SKIP
```
diff --git a/docs/source/zh/hpo_train.md b/docs/source/zh/hpo_train.md
index 182940c359..907be0a21f 100644
--- a/docs/source/zh/hpo_train.md
+++ b/docs/source/zh/hpo_train.md
@@ -15,7 +15,7 @@ rendered properly in your Markdown viewer.
# 使用Trainer API进行超参数搜索
-🤗 Transformers库提供了一个优化过的[`Trainer`]类,用于训练🤗 Transformers模型,相比于手动编写自己的训练循环,这更容易开始训练。[`Trainer`]提供了超参数搜索的API。本文档展示了如何在示例中启用它。
+🤗 Transformers库提供了一个优化过的[`Trainer`]类,用于训练🤗 Transformers模型,相比于手动编写自己的训练循环,这更容易开始训练。[`Trainer`]提供了超参数搜索的API。本文档展示了如何在示例中启用它。
## 超参数搜索后端
@@ -25,7 +25,7 @@ rendered properly in your Markdown viewer.
在使用它们之前,您应该先安装它们作为超参数搜索后端。
```bash
-pip install optuna/sigopt/wandb/ray[tune]
+pip install optuna/sigopt/wandb/ray[tune]
```
## 如何在示例中启用超参数搜索
@@ -115,7 +115,7 @@ Optuna提供了多目标HPO。您可以在`hyperparameter_search`中传递`direc
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... model_init=model_init,
... data_collator=data_collator,
... )
@@ -136,4 +136,4 @@ Optuna提供了多目标HPO。您可以在`hyperparameter_search`中传递`direc
```
## 针对DDP微调的超参数搜索
-目前,Optuna和Sigopt已启用针对DDP的超参数搜索。只有rank-zero进程会进行超参数搜索并将参数传递给其他进程。
\ No newline at end of file
+目前,Optuna和Sigopt已启用针对DDP的超参数搜索。只有rank-zero进程会进行超参数搜索并将参数传递给其他进程。
diff --git a/docs/source/zh/quicktour.md b/docs/source/zh/quicktour.md
index 9760a69769..acc5953971 100644
--- a/docs/source/zh/quicktour.md
+++ b/docs/source/zh/quicktour.md
@@ -476,7 +476,7 @@ tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
... args=training_args,
... train_dataset=dataset["train"],
... eval_dataset=dataset["test"],
-... tokenizer=tokenizer,
+... processing_class=tokenizer,
... data_collator=data_collator,
... ) # doctest: +SKIP
```
diff --git a/docs/source/zh/tasks/asr.md b/docs/source/zh/tasks/asr.md
index b4366d7204..a4fdbd308e 100644
--- a/docs/source/zh/tasks/asr.md
+++ b/docs/source/zh/tasks/asr.md
@@ -298,7 +298,7 @@ Wav2Vec2 分词器仅训练了大写字符,因此您需要确保文本与分
... args=training_args,
... train_dataset=encoded_minds["train"],
... eval_dataset=encoded_minds["test"],
-... tokenizer=processor,
+... processing_class=processor,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
@@ -389,4 +389,4 @@ Wav2Vec2 分词器仅训练了大写字符,因此您需要确保文本与分
['I WOUL LIKE O SET UP JOINT ACOUNT WTH Y PARTNER']
```
-
\ No newline at end of file
+
diff --git a/examples/legacy/seq2seq/finetune_trainer.py b/examples/legacy/seq2seq/finetune_trainer.py
index e269bc2474..5ede86ee08 100755
--- a/examples/legacy/seq2seq/finetune_trainer.py
+++ b/examples/legacy/seq2seq/finetune_trainer.py
@@ -302,7 +302,7 @@ def main():
tokenizer, data_args, model.config.decoder_start_token_id, training_args.tpu_num_cores
),
compute_metrics=compute_metrics_fn,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
)
all_metrics = {}
diff --git a/examples/pytorch/audio-classification/run_audio_classification.py b/examples/pytorch/audio-classification/run_audio_classification.py
index 61df8ce990..009a1f6372 100644
--- a/examples/pytorch/audio-classification/run_audio_classification.py
+++ b/examples/pytorch/audio-classification/run_audio_classification.py
@@ -394,7 +394,7 @@ def main():
train_dataset=raw_datasets["train"] if training_args.do_train else None,
eval_dataset=raw_datasets["eval"] if training_args.do_eval else None,
compute_metrics=compute_metrics,
- tokenizer=feature_extractor,
+ processing_class=feature_extractor,
)
# Training
diff --git a/examples/pytorch/image-classification/run_image_classification.py b/examples/pytorch/image-classification/run_image_classification.py
index 01ed9938c4..0a9789426c 100755
--- a/examples/pytorch/image-classification/run_image_classification.py
+++ b/examples/pytorch/image-classification/run_image_classification.py
@@ -396,7 +396,7 @@ def main():
train_dataset=dataset["train"] if training_args.do_train else None,
eval_dataset=dataset["validation"] if training_args.do_eval else None,
compute_metrics=compute_metrics,
- tokenizer=image_processor,
+ processing_class=image_processor,
data_collator=collate_fn,
)
diff --git a/examples/pytorch/image-pretraining/run_mae.py b/examples/pytorch/image-pretraining/run_mae.py
index 4ec195f925..46863cbbf1 100644
--- a/examples/pytorch/image-pretraining/run_mae.py
+++ b/examples/pytorch/image-pretraining/run_mae.py
@@ -364,7 +364,7 @@ def main():
args=training_args,
train_dataset=ds["train"] if training_args.do_train else None,
eval_dataset=ds["validation"] if training_args.do_eval else None,
- tokenizer=image_processor,
+ processing_class=image_processor,
data_collator=collate_fn,
)
diff --git a/examples/pytorch/image-pretraining/run_mim.py b/examples/pytorch/image-pretraining/run_mim.py
index b6c0ca899e..3912c69344 100644
--- a/examples/pytorch/image-pretraining/run_mim.py
+++ b/examples/pytorch/image-pretraining/run_mim.py
@@ -443,7 +443,7 @@ def main():
args=training_args,
train_dataset=ds["train"] if training_args.do_train else None,
eval_dataset=ds["validation"] if training_args.do_eval else None,
- tokenizer=image_processor,
+ processing_class=image_processor,
data_collator=collate_fn,
)
diff --git a/examples/pytorch/instance-segmentation/run_instance_segmentation.py b/examples/pytorch/instance-segmentation/run_instance_segmentation.py
index 22152c6fad..aeb78f95d2 100644
--- a/examples/pytorch/instance-segmentation/run_instance_segmentation.py
+++ b/examples/pytorch/instance-segmentation/run_instance_segmentation.py
@@ -445,7 +445,7 @@ def main():
args=training_args,
train_dataset=dataset["train"] if training_args.do_train else None,
eval_dataset=dataset["validation"] if training_args.do_eval else None,
- tokenizer=image_processor,
+ processing_class=image_processor,
data_collator=collate_fn,
compute_metrics=compute_metrics,
)
diff --git a/examples/pytorch/language-modeling/run_clm.py b/examples/pytorch/language-modeling/run_clm.py
index 74fae865c9..656571eb37 100755
--- a/examples/pytorch/language-modeling/run_clm.py
+++ b/examples/pytorch/language-modeling/run_clm.py
@@ -586,7 +586,7 @@ def main():
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
# Data collator will default to DataCollatorWithPadding, so we change it.
data_collator=default_data_collator,
compute_metrics=compute_metrics if training_args.do_eval and not is_torch_xla_available() else None,
diff --git a/examples/pytorch/language-modeling/run_fim.py b/examples/pytorch/language-modeling/run_fim.py
index eb670ae44e..154fc15183 100644
--- a/examples/pytorch/language-modeling/run_fim.py
+++ b/examples/pytorch/language-modeling/run_fim.py
@@ -793,7 +793,7 @@ def main():
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
# Data collator will default to DataCollatorWithPadding, so we change it.
data_collator=default_data_collator,
compute_metrics=compute_metrics if training_args.do_eval and not is_torch_tpu_available() else None,
diff --git a/examples/pytorch/language-modeling/run_mlm.py b/examples/pytorch/language-modeling/run_mlm.py
index 34cefa833f..d021318ae0 100755
--- a/examples/pytorch/language-modeling/run_mlm.py
+++ b/examples/pytorch/language-modeling/run_mlm.py
@@ -622,7 +622,7 @@ def main():
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics if training_args.do_eval and not is_torch_xla_available() else None,
preprocess_logits_for_metrics=preprocess_logits_for_metrics
diff --git a/examples/pytorch/language-modeling/run_plm.py b/examples/pytorch/language-modeling/run_plm.py
index 237a1ddbd0..0a207b8047 100755
--- a/examples/pytorch/language-modeling/run_plm.py
+++ b/examples/pytorch/language-modeling/run_plm.py
@@ -519,7 +519,7 @@ def main():
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
- tokenizer=tokenizer,
+ processing_classtokenizer=tokenizer,
data_collator=data_collator,
)
diff --git a/examples/pytorch/multiple-choice/run_swag.py b/examples/pytorch/multiple-choice/run_swag.py
index 6dc5f97641..ac5db5f6b0 100755
--- a/examples/pytorch/multiple-choice/run_swag.py
+++ b/examples/pytorch/multiple-choice/run_swag.py
@@ -440,7 +440,7 @@ def main():
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
diff --git a/examples/pytorch/object-detection/run_object_detection.py b/examples/pytorch/object-detection/run_object_detection.py
index 74d87bc5d1..0aea1a11c1 100644
--- a/examples/pytorch/object-detection/run_object_detection.py
+++ b/examples/pytorch/object-detection/run_object_detection.py
@@ -488,7 +488,7 @@ def main():
args=training_args,
train_dataset=dataset["train"] if training_args.do_train else None,
eval_dataset=dataset["validation"] if training_args.do_eval else None,
- tokenizer=image_processor,
+ processing_class=image_processor,
data_collator=collate_fn,
compute_metrics=eval_compute_metrics_fn,
)
diff --git a/examples/pytorch/question-answering/run_qa.py b/examples/pytorch/question-answering/run_qa.py
index ac6fcd249b..bb0a645592 100755
--- a/examples/pytorch/question-answering/run_qa.py
+++ b/examples/pytorch/question-answering/run_qa.py
@@ -640,7 +640,7 @@ def main():
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
eval_examples=eval_examples if training_args.do_eval else None,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
post_process_function=post_processing_function,
compute_metrics=compute_metrics,
diff --git a/examples/pytorch/question-answering/run_qa_beam_search.py b/examples/pytorch/question-answering/run_qa_beam_search.py
index 23c9080f20..b3d9ee1e9c 100755
--- a/examples/pytorch/question-answering/run_qa_beam_search.py
+++ b/examples/pytorch/question-answering/run_qa_beam_search.py
@@ -666,7 +666,7 @@ def main():
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
eval_examples=eval_examples if training_args.do_eval else None,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
post_process_function=post_processing_function,
compute_metrics=compute_metrics,
diff --git a/examples/pytorch/question-answering/run_seq2seq_qa.py b/examples/pytorch/question-answering/run_seq2seq_qa.py
index d4e1844f3a..7cf50cf94a 100644
--- a/examples/pytorch/question-answering/run_seq2seq_qa.py
+++ b/examples/pytorch/question-answering/run_seq2seq_qa.py
@@ -663,7 +663,7 @@ def main():
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
eval_examples=eval_examples if training_args.do_eval else None,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
post_process_function=post_processing_function,
diff --git a/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py b/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py
index 9d3c29ed8c..4c119dcbb4 100644
--- a/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py
+++ b/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py
@@ -403,7 +403,7 @@ def main():
train_dataset=dataset["train"] if training_args.do_train else None,
eval_dataset=dataset["validation"] if training_args.do_eval else None,
compute_metrics=compute_metrics,
- tokenizer=image_processor,
+ processing_class=image_processor,
data_collator=default_data_collator,
)
diff --git a/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py b/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py
index 62166012c7..ff5da5ed49 100755
--- a/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py
+++ b/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py
@@ -751,7 +751,7 @@ def main():
compute_metrics=compute_metrics,
train_dataset=vectorized_datasets["train"] if training_args.do_train else None,
eval_dataset=vectorized_datasets["eval"] if training_args.do_eval else None,
- tokenizer=processor,
+ processing_class=processor,
preprocess_logits_for_metrics=preprocess_logits_for_metrics,
)
diff --git a/examples/pytorch/speech-recognition/run_speech_recognition_ctc_adapter.py b/examples/pytorch/speech-recognition/run_speech_recognition_ctc_adapter.py
index 144ae30166..66a75ca5d0 100755
--- a/examples/pytorch/speech-recognition/run_speech_recognition_ctc_adapter.py
+++ b/examples/pytorch/speech-recognition/run_speech_recognition_ctc_adapter.py
@@ -747,7 +747,7 @@ def main():
compute_metrics=compute_metrics,
train_dataset=vectorized_datasets["train"] if training_args.do_train else None,
eval_dataset=vectorized_datasets["eval"] if training_args.do_eval else None,
- tokenizer=processor,
+ processing_class=processor,
)
# 8. Finally, we can start training
diff --git a/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py b/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py
index a83502ed80..8740ec5f88 100755
--- a/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py
+++ b/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py
@@ -569,7 +569,7 @@ def main():
args=training_args,
train_dataset=vectorized_datasets["train"] if training_args.do_train else None,
eval_dataset=vectorized_datasets["eval"] if training_args.do_eval else None,
- tokenizer=feature_extractor,
+ processing_class=feature_extractor,
data_collator=data_collator,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
)
diff --git a/examples/pytorch/summarization/run_summarization.py b/examples/pytorch/summarization/run_summarization.py
index a4d6f616b7..9a25d94405 100755
--- a/examples/pytorch/summarization/run_summarization.py
+++ b/examples/pytorch/summarization/run_summarization.py
@@ -677,7 +677,7 @@ def main():
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
)
diff --git a/examples/pytorch/text-classification/run_classification.py b/examples/pytorch/text-classification/run_classification.py
index 9fd11e05b1..a440a48110 100755
--- a/examples/pytorch/text-classification/run_classification.py
+++ b/examples/pytorch/text-classification/run_classification.py
@@ -674,7 +674,7 @@ def main():
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
compute_metrics=compute_metrics,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
)
diff --git a/examples/pytorch/text-classification/run_glue.py b/examples/pytorch/text-classification/run_glue.py
index 8292389bf8..4284fdf12f 100755
--- a/examples/pytorch/text-classification/run_glue.py
+++ b/examples/pytorch/text-classification/run_glue.py
@@ -531,7 +531,7 @@ def main():
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
compute_metrics=compute_metrics,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
)
diff --git a/examples/pytorch/text-classification/run_xnli.py b/examples/pytorch/text-classification/run_xnli.py
index 1c6c85f4ba..6578e96dc9 100755
--- a/examples/pytorch/text-classification/run_xnli.py
+++ b/examples/pytorch/text-classification/run_xnli.py
@@ -393,7 +393,7 @@ def main():
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
compute_metrics=compute_metrics,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
)
diff --git a/examples/pytorch/token-classification/run_ner.py b/examples/pytorch/token-classification/run_ner.py
index b8ef21d6ec..ef1c0ac917 100755
--- a/examples/pytorch/token-classification/run_ner.py
+++ b/examples/pytorch/token-classification/run_ner.py
@@ -567,7 +567,7 @@ def main():
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
diff --git a/examples/pytorch/translation/run_translation.py b/examples/pytorch/translation/run_translation.py
index c23cf8a431..4e16401018 100755
--- a/examples/pytorch/translation/run_translation.py
+++ b/examples/pytorch/translation/run_translation.py
@@ -597,7 +597,7 @@ def main():
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
)
diff --git a/src/transformers/integrations/integration_utils.py b/src/transformers/integrations/integration_utils.py
index 40298f9c6f..5f0ac55d0e 100755
--- a/src/transformers/integrations/integration_utils.py
+++ b/src/transformers/integrations/integration_utils.py
@@ -915,7 +915,7 @@ class WandbCallback(TrainerCallback):
if self._log_model.is_enabled and self._initialized and state.is_world_process_zero:
from ..trainer import Trainer
- fake_trainer = Trainer(args=args, model=model, tokenizer=tokenizer)
+ fake_trainer = Trainer(args=args, model=model, processing_class=tokenizer)
with tempfile.TemporaryDirectory() as temp_dir:
fake_trainer.save_model(temp_dir)
metadata = (
@@ -2112,7 +2112,7 @@ class DVCLiveCallback(TrainerCallback):
from transformers.trainer import Trainer
if self._log_model is True:
- fake_trainer = Trainer(args=args, model=kwargs.get("model"), tokenizer=kwargs.get("tokenizer"))
+ fake_trainer = Trainer(args=args, model=kwargs.get("model"), processing_class=kwargs.get("tokenizer"))
name = "best" if args.load_best_model_at_end else "last"
output_dir = os.path.join(args.output_dir, name)
fake_trainer.save_model(output_dir)
diff --git a/src/transformers/trainer.py b/src/transformers/trainer.py
index 5b5afee248..6ca4520fca 100755
--- a/src/transformers/trainer.py
+++ b/src/transformers/trainer.py
@@ -60,7 +60,9 @@ from .configuration_utils import PretrainedConfig
from .data.data_collator import DataCollator, DataCollatorWithPadding, default_data_collator
from .debug_utils import DebugOption, DebugUnderflowOverflow
from .feature_extraction_sequence_utils import SequenceFeatureExtractor
+from .feature_extraction_utils import FeatureExtractionMixin
from .hyperparameter_search import ALL_HYPERPARAMETER_SEARCH_BACKENDS, default_hp_search_backend
+from .image_processing_utils import BaseImageProcessor
from .integrations.deepspeed import deepspeed_init, deepspeed_load_checkpoint, is_deepspeed_available
from .integrations.tpu import tpu_spmd_dataloader
from .modelcard import TrainingSummary
@@ -70,6 +72,7 @@ from .models.auto.modeling_auto import (
MODEL_MAPPING_NAMES,
)
from .optimization import Adafactor, get_scheduler
+from .processing_utils import ProcessorMixin
from .pytorch_utils import (
ALL_LAYERNORM_LAYERS,
is_torch_greater_or_equal_than_1_13,
@@ -308,8 +311,8 @@ class Trainer:
`output_dir` set to a directory named *tmp_trainer* in the current directory if not provided.
data_collator (`DataCollator`, *optional*):
The function to use to form a batch from a list of elements of `train_dataset` or `eval_dataset`. Will
- default to [`default_data_collator`] if no `tokenizer` is provided, an instance of
- [`DataCollatorWithPadding`] otherwise.
+ default to [`default_data_collator`] if no `processing_class` is provided, an instance of
+ [`DataCollatorWithPadding`] otherwise if the processing_class is a feature extractor or tokenizer.
train_dataset (Union[`torch.utils.data.Dataset`, `torch.utils.data.IterableDataset`, `datasets.Dataset`], *optional*):
The dataset to use for training. If it is a [`~datasets.Dataset`], columns not accepted by the
`model.forward()` method are automatically removed.
@@ -327,6 +330,12 @@ class Trainer:
The tokenizer used to preprocess the data. If provided, will be used to automatically pad the inputs to the
maximum length when batching inputs, and it will be saved along the model to make it easier to rerun an
interrupted training or reuse the fine-tuned model.
+ This is now deprecated.
+ processing_class (`PreTrainedTokenizerBase` or `BaseImageProcessor` or `FeatureExtractionMixin` or `ProcessorMixin`, *optional*):
+ Processing class used to process the data. If provided, will be used to automatically process the inputs
+ for the model, and it will be saved along the model to make it easier to rerun an interrupted training or
+ reuse the fine-tuned model.
+ This supercedes the `tokenizer` argument, which is now deprecated.
model_init (`Callable[[], PreTrainedModel]`, *optional*):
A function that instantiates the model to be used. If provided, each call to [`~Trainer.train`] will start
from a new instance of the model as given by this function.
@@ -384,6 +393,9 @@ class Trainer:
train_dataset: Optional[Union[Dataset, IterableDataset, "datasets.Dataset"]] = None,
eval_dataset: Optional[Union[Dataset, Dict[str, Dataset], "datasets.Dataset"]] = None,
tokenizer: Optional[PreTrainedTokenizerBase] = None,
+ processing_class: Optional[
+ Union[PreTrainedTokenizerBase, BaseImageProcessor, FeatureExtractionMixin, ProcessorMixin]
+ ] = None,
model_init: Optional[Callable[[], PreTrainedModel]] = None,
compute_metrics: Optional[Callable[[EvalPrediction], Dict]] = None,
callbacks: Optional[List[TrainerCallback]] = None,
@@ -425,6 +437,17 @@ class Trainer:
# force device and distributed setup init explicitly
args._setup_devices
+ if tokenizer is not None:
+ if processing_class is not None:
+ raise ValueError(
+ "You cannot specify both `tokenizer` and `processing_class` at the same time. Please use `processing_class`."
+ )
+ warnings.warn(
+ "`tokenizer` is now deprecated and will be removed in v5, please use `processing_class` instead.",
+ FutureWarning,
+ )
+ processing_class = tokenizer
+
if model is None:
if model_init is not None:
self.model_init = model_init
@@ -541,14 +564,15 @@ class Trainer:
self.place_model_on_device = False
default_collator = (
- DataCollatorWithPadding(tokenizer)
- if tokenizer is not None and isinstance(tokenizer, (PreTrainedTokenizerBase, SequenceFeatureExtractor))
+ DataCollatorWithPadding(processing_class)
+ if processing_class is not None
+ and isinstance(processing_class, (PreTrainedTokenizerBase, SequenceFeatureExtractor))
else default_data_collator
)
self.data_collator = data_collator if data_collator is not None else default_collator
self.train_dataset = train_dataset
self.eval_dataset = eval_dataset
- self.tokenizer = tokenizer
+ self.processing_class = processing_class
# Bnb Quantized models doesn't support `.to` operation.
if (
@@ -600,7 +624,7 @@ class Trainer:
default_callbacks = DEFAULT_CALLBACKS + get_reporting_integration_callbacks(self.args.report_to)
callbacks = default_callbacks if callbacks is None else default_callbacks + callbacks
self.callback_handler = CallbackHandler(
- callbacks, self.model, self.tokenizer, self.optimizer, self.lr_scheduler
+ callbacks, self.model, self.processing_class, self.optimizer, self.lr_scheduler
)
self.add_callback(PrinterCallback if self.args.disable_tqdm else DEFAULT_PROGRESS_CALLBACK)
@@ -728,6 +752,11 @@ class Trainer:
xs.set_global_mesh(xs.Mesh(np.array(range(num_devices)), (num_devices, 1), axis_names=("fsdp", "tensor")))
self.is_fsdp_xla_v1_enabled = self.is_fsdp_xla_enabled and not self.is_fsdp_xla_v2_enabled
+ @property
+ def tokenizer(self) -> Optional[PreTrainedTokenizerBase]:
+ logger.warning("Trainer.tokenizer is now deprecated. You should use Trainer.processing_class instead.")
+ return self.processing_class
+
def _activate_neftune(self, model):
r"""
Activates the neftune as presented in this code: https://github.com/neelsjain/NEFTune and paper:
@@ -887,7 +916,9 @@ class Trainer:
)
else:
lengths = None
- model_input_name = self.tokenizer.model_input_names[0] if self.tokenizer is not None else None
+ model_input_name = (
+ self.processing_class.model_input_names[0] if self.processing_class is not None else None
+ )
return LengthGroupedSampler(
self.args.train_batch_size * self.args.gradient_accumulation_steps,
dataset=self.train_dataset,
@@ -3699,8 +3730,8 @@ class Trainer:
safe_serialization=self.args.save_safetensors,
state_dict=xm._maybe_convert_to_cpu(model.state_dict()),
)
- if self.tokenizer is not None and self.args.should_save:
- self.tokenizer.save_pretrained(output_dir)
+ if self.processing_class is not None and self.args.should_save:
+ self.processing_class.save_pretrained(output_dir)
def _save(self, output_dir: Optional[str] = None, state_dict=None):
# If we are executing this function, we are the process zero, so we don't check for that.
@@ -3732,8 +3763,8 @@ class Trainer:
output_dir, state_dict=state_dict, safe_serialization=self.args.save_safetensors
)
- if self.tokenizer is not None:
- self.tokenizer.save_pretrained(output_dir)
+ if self.processing_class is not None:
+ self.processing_class.save_pretrained(output_dir)
# Good practice: save your training arguments together with the trained model
torch.save(self.args, os.path.join(output_dir, TRAINING_ARGS_NAME))
@@ -4442,9 +4473,9 @@ class Trainer:
for modeling_file in modeling_files:
if os.path.isfile(os.path.join(checkpoint_folder, modeling_file)):
shutil.copy(os.path.join(checkpoint_folder, modeling_file), os.path.join(output_dir, modeling_file))
- # Saving the tokenizer is fast and we don't know how many files it may have spawned, so we resave it to be sure.
- if self.tokenizer is not None:
- self.tokenizer.save_pretrained(output_dir)
+ # Saving the processing class is fast and we don't know how many files it may have spawned, so we resave it to be sure.
+ if self.processing_class is not None:
+ self.processing_class.save_pretrained(output_dir)
# Same for the training arguments
torch.save(self.args, os.path.join(output_dir, TRAINING_ARGS_NAME))
@@ -4499,7 +4530,7 @@ class Trainer:
**kwargs,
) -> str:
"""
- Upload `self.model` and `self.tokenizer` to the 🤗 model hub on the repo `self.args.hub_model_id`.
+ Upload `self.model` and `self.processing_class` to the 🤗 model hub on the repo `self.args.hub_model_id`.
Parameters:
commit_message (`str`, *optional*, defaults to `"End of training"`):
diff --git a/src/transformers/trainer_callback.py b/src/transformers/trainer_callback.py
index d457a65993..405874acf8 100644
--- a/src/transformers/trainer_callback.py
+++ b/src/transformers/trainer_callback.py
@@ -272,7 +272,9 @@ class TrainerCallback:
model ([`PreTrainedModel`] or `torch.nn.Module`):
The model being trained.
tokenizer ([`PreTrainedTokenizer`]):
- The tokenizer used for encoding the data.
+ The tokenizer used for encoding the data. This is deprecated in favour of `processing_class`.
+ processing_class ([`PreTrainedTokenizer` or `BaseImageProcessor` or `ProcessorMixin` or `FeatureExtractionMixin`]):
+ The processing class used for encoding the data. Can be a tokenizer, a processor, an image processor or a feature extractor.
optimizer (`torch.optim.Optimizer`):
The optimizer used for the training steps.
lr_scheduler (`torch.optim.lr_scheduler.LambdaLR`):
@@ -403,12 +405,12 @@ class TrainerCallback:
class CallbackHandler(TrainerCallback):
"""Internal class that just calls the list of callbacks in order."""
- def __init__(self, callbacks, model, tokenizer, optimizer, lr_scheduler):
+ def __init__(self, callbacks, model, processing_class, optimizer, lr_scheduler):
self.callbacks = []
for cb in callbacks:
self.add_callback(cb)
self.model = model
- self.tokenizer = tokenizer
+ self.processing_class = processing_class
self.optimizer = optimizer
self.lr_scheduler = lr_scheduler
self.train_dataloader = None
@@ -518,7 +520,7 @@ class CallbackHandler(TrainerCallback):
state,
control,
model=self.model,
- tokenizer=self.tokenizer,
+ processing_class=self.processing_class,
optimizer=self.optimizer,
lr_scheduler=self.lr_scheduler,
train_dataloader=self.train_dataloader,
diff --git a/src/transformers/trainer_seq2seq.py b/src/transformers/trainer_seq2seq.py
index abc45cffe4..241bea7860 100644
--- a/src/transformers/trainer_seq2seq.py
+++ b/src/transformers/trainer_seq2seq.py
@@ -29,7 +29,10 @@ from .utils import logging
if TYPE_CHECKING:
from .data.data_collator import DataCollator
+ from .feature_extraction_utils import FeatureExtractionMixin
+ from .image_processing_utils import BaseImageProcessor
from .modeling_utils import PreTrainedModel
+ from .processing_utils import ProcessorMixin
from .tokenization_utils_base import PreTrainedTokenizerBase
from .trainer_callback import TrainerCallback
from .trainer_utils import EvalPrediction, PredictionOutput
@@ -48,6 +51,9 @@ class Seq2SeqTrainer(Trainer):
train_dataset: Optional[Dataset] = None,
eval_dataset: Optional[Union[Dataset, Dict[str, Dataset]]] = None,
tokenizer: Optional["PreTrainedTokenizerBase"] = None,
+ processing_class: Optional[
+ Union["PreTrainedTokenizerBase", "BaseImageProcessor", "FeatureExtractionMixin", "ProcessorMixin"]
+ ] = None,
model_init: Optional[Callable[[], "PreTrainedModel"]] = None,
compute_metrics: Optional[Callable[["EvalPrediction"], Dict]] = None,
callbacks: Optional[List["TrainerCallback"]] = None,
@@ -61,6 +67,7 @@ class Seq2SeqTrainer(Trainer):
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
+ processing_class=processing_class,
model_init=model_init,
compute_metrics=compute_metrics,
callbacks=callbacks,
diff --git a/src/transformers/training_args.py b/src/transformers/training_args.py
index b314d7855d..26da84dfe2 100644
--- a/src/transformers/training_args.py
+++ b/src/transformers/training_args.py
@@ -683,9 +683,9 @@ class TrainingArguments:
hub_strategy (`str` or [`~trainer_utils.HubStrategy`], *optional*, defaults to `"every_save"`):
Defines the scope of what is pushed to the Hub and when. Possible values are:
- - `"end"`: push the model, its configuration, the tokenizer (if passed along to the [`Trainer`]) and a
+ - `"end"`: push the model, its configuration, the processing class e.g. tokenizer (if passed along to the [`Trainer`]) and a
draft of a model card when the [`~Trainer.save_model`] method is called.
- - `"every_save"`: push the model, its configuration, the tokenizer (if passed along to the [`Trainer`]) and
+ - `"every_save"`: push the model, its configuration, the processing class e.g. tokenizer (if passed along to the [`Trainer`]) and
a draft of a model card each time there is a model save. The pushes are asynchronous to not block
training, and in case the save are very frequent, a new push is only attempted if the previous one is
finished. A last push is made with the final model at the end of training.
@@ -2854,9 +2854,9 @@ class TrainingArguments:
strategy (`str` or [`~trainer_utils.HubStrategy`], *optional*, defaults to `"every_save"`):
Defines the scope of what is pushed to the Hub and when. Possible values are:
- - `"end"`: push the model, its configuration, the tokenizer (if passed along to the [`Trainer`]) and a
+ - `"end"`: push the model, its configuration, the processing_class e.g. tokenizer (if passed along to the [`Trainer`]) and a
draft of a model card when the [`~Trainer.save_model`] method is called.
- - `"every_save"`: push the model, its configuration, the tokenizer (if passed along to the [`Trainer`])
+ - `"every_save"`: push the model, its configuration, the processing_class e.g. tokenizer (if passed along to the [`Trainer`])
and
a draft of a model card each time there is a model save. The pushes are asynchronous to not block
training, and in case the save are very frequent, a new push is only attempted if the previous one is
diff --git a/templates/adding_a_new_example_script/{{cookiecutter.directory_name}}/run_{{cookiecutter.example_shortcut}}.py b/templates/adding_a_new_example_script/{{cookiecutter.directory_name}}/run_{{cookiecutter.example_shortcut}}.py
index 0b27b49212..c2b753c103 100755
--- a/templates/adding_a_new_example_script/{{cookiecutter.directory_name}}/run_{{cookiecutter.example_shortcut}}.py
+++ b/templates/adding_a_new_example_script/{{cookiecutter.directory_name}}/run_{{cookiecutter.example_shortcut}}.py
@@ -450,7 +450,7 @@ def main():
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
)
diff --git a/tests/deepspeed/test_deepspeed.py b/tests/deepspeed/test_deepspeed.py
index b635833706..8eaa00bc76 100644
--- a/tests/deepspeed/test_deepspeed.py
+++ b/tests/deepspeed/test_deepspeed.py
@@ -1036,7 +1036,7 @@ class TrainerIntegrationDeepSpeed(TrainerIntegrationDeepSpeedWithCustomConfig, T
trainer = Trainer(
model=model,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
diff --git a/tests/sagemaker/scripts/pytorch/run_glue_model_parallelism.py b/tests/sagemaker/scripts/pytorch/run_glue_model_parallelism.py
index b050b1ca5a..2e3d9fdc7f 100644
--- a/tests/sagemaker/scripts/pytorch/run_glue_model_parallelism.py
+++ b/tests/sagemaker/scripts/pytorch/run_glue_model_parallelism.py
@@ -455,7 +455,7 @@ def main():
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
compute_metrics=compute_metrics,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
)
diff --git a/tests/test_tokenization_common.py b/tests/test_tokenization_common.py
index 342254dfbd..8020b0e711 100644
--- a/tests/test_tokenization_common.py
+++ b/tests/test_tokenization_common.py
@@ -4293,7 +4293,7 @@ class TokenizerTesterMixin:
# Load tokenizer from a folder without legacy files
tokenizer = self.rust_tokenizer_class.from_pretrained(tmp_dir)
training_args = TrainingArguments(output_dir=tmp_dir, do_train=True, no_cuda=True)
- trainer = Trainer(model=model, args=training_args, tokenizer=tokenizer)
+ trainer = Trainer(model=model, args=training_args, processing_class=tokenizer)
# Should not raise an error
trainer.save_model(os.path.join(tmp_dir, "checkpoint"))
diff --git a/tests/trainer/test_trainer.py b/tests/trainer/test_trainer.py
index 0035ff7de8..6ce961257d 100644
--- a/tests/trainer/test_trainer.py
+++ b/tests/trainer/test_trainer.py
@@ -38,6 +38,9 @@ from parameterized import parameterized
from requests.exceptions import HTTPError
from transformers import (
+ AutoFeatureExtractor,
+ AutoImageProcessor,
+ AutoProcessor,
AutoTokenizer,
IntervalStrategy,
PretrainedConfig,
@@ -1059,14 +1062,14 @@ class TrainerIntegrationTest(TestCasePlus, TrainerIntegrationCommon):
max_steps=10,
use_cpu=True,
)
- trainer = Trainer(tiny_model, args, tokenizer=tokenizer, train_dataset=train_dataset)
+ trainer = Trainer(tiny_model, args, processing_class=tokenizer, train_dataset=train_dataset)
trainer.train()
parameters = dict(tiny_model.named_parameters())
state = dataclasses.asdict(trainer.state)
# Reinitialize trainer
- trainer = Trainer(tiny_model, args, tokenizer=tokenizer, train_dataset=train_dataset)
+ trainer = Trainer(tiny_model, args, processing_class=tokenizer, train_dataset=train_dataset)
checkpoint = os.path.join(tmpdir, "checkpoint-5")
@@ -3786,6 +3789,98 @@ class TrainerIntegrationTest(TestCasePlus, TrainerIntegrationCommon):
_ = trainer.evaluate()
_ = trainer.predict(eval_dataset)
+ def test_trainer_saves_tokenizer(self):
+ MODEL_ID = "google-bert/bert-base-uncased"
+ tokenizer = AutoTokenizer.from_pretrained(MODEL_ID, use_fast=False)
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ config = RegressionModelConfig(a=1.5, b=2.5)
+ trainer = Trainer(
+ model=RegressionPreTrainedModel(config),
+ args=TrainingArguments(output_dir=tmp_dir),
+ processing_class=tokenizer,
+ )
+ trainer.save_model()
+
+ reloaded_tokenizer = AutoTokenizer.from_pretrained(tmp_dir)
+
+ # For tokenizers, there isn't a direct to_dict method and the properties stored in the configs e.g.
+ # saved tokens change overtime, so we check that two tokenizers are equal by comparing their encoded outputs
+ test_sentence = "This is a test sentence"
+ self.assertListEqual(
+ tokenizer(test_sentence, padding="max_length").input_ids,
+ reloaded_tokenizer(test_sentence, padding="max_length").input_ids,
+ )
+
+ def test_trainer_saves_image_processor(self):
+ MODEL_ID = "openai/clip-vit-base-patch32"
+ image_processor = AutoImageProcessor.from_pretrained(MODEL_ID)
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ config = RegressionModelConfig(a=1.5, b=2.5)
+ trainer = Trainer(
+ model=RegressionPreTrainedModel(config),
+ args=TrainingArguments(output_dir=tmp_dir),
+ processing_class=image_processor,
+ )
+ trainer.save_model()
+ reloaded_image_processor = AutoImageProcessor.from_pretrained(tmp_dir)
+
+ self.assertDictEqual(image_processor.to_dict(), reloaded_image_processor.to_dict())
+
+ def test_trainer_saves_feature_extractor(self):
+ MODEL_ID = "facebook/wav2vec2-base-960h"
+ feature_extractor = AutoFeatureExtractor.from_pretrained(MODEL_ID)
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ config = RegressionModelConfig(a=1.5, b=2.5)
+ trainer = Trainer(
+ model=RegressionPreTrainedModel(config),
+ args=TrainingArguments(output_dir=tmp_dir),
+ processing_class=feature_extractor,
+ )
+ trainer.save_model()
+
+ reloaded_feature_extractor = AutoFeatureExtractor.from_pretrained(tmp_dir)
+
+ self.assertDictEqual(feature_extractor.to_dict(), reloaded_feature_extractor.to_dict())
+
+ def test_trainer_saves_processor(self):
+ MODEL_ID = "openai/clip-vit-base-patch32"
+ image_processor = AutoImageProcessor.from_pretrained(MODEL_ID)
+ tokenizer = AutoTokenizer.from_pretrained(MODEL_ID, use_fast=False)
+ processor = AutoProcessor.from_pretrained(MODEL_ID)
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ config = RegressionModelConfig(a=1.5, b=2.5)
+ trainer = Trainer(
+ model=RegressionPreTrainedModel(config),
+ args=TrainingArguments(output_dir=tmp_dir),
+ processing_class=processor,
+ )
+ trainer.save_model()
+
+ reloaded_processor = AutoProcessor.from_pretrained(tmp_dir)
+ reloaded_image_processor = AutoImageProcessor.from_pretrained(tmp_dir)
+ reloaded_tokenizer = AutoTokenizer.from_pretrained(tmp_dir)
+
+ self.assertDictEqual(reloaded_processor.to_dict(), processor.to_dict())
+
+ image_processor_dict = image_processor.to_dict()
+ reloaded_image_processor_dict = reloaded_image_processor.to_dict()
+ # When the processor is saved in the trainer, the _processor_class gets set in the reload_image_processor dict
+ image_processor_dict.pop("_processor_class")
+ reloaded_image_processor_dict.pop("_processor_class")
+ self.assertDictEqual(image_processor_dict, reloaded_image_processor_dict)
+
+ # For tokenizers, there isn't a direct to_dict method and the properties stored in the configs e.g.
+ # saved tokens change overtime, so we check that two tokenizers are equal by comparing their encoded outputs
+ test_sentence = "This is a test sentence"
+ self.assertListEqual(
+ tokenizer(test_sentence, padding="max_length").input_ids,
+ reloaded_tokenizer(test_sentence, padding="max_length").input_ids,
+ )
+
@require_torch
@is_staging_test
diff --git a/tests/trainer/test_trainer_seq2seq.py b/tests/trainer/test_trainer_seq2seq.py
index a4b38aecb2..30dd2ed460 100644
--- a/tests/trainer/test_trainer_seq2seq.py
+++ b/tests/trainer/test_trainer_seq2seq.py
@@ -129,7 +129,7 @@ class Seq2seqTrainerTester(TestCasePlus):
compute_metrics=_compute_metrics,
train_dataset=train_dataset,
eval_dataset=val_dataset,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
)
# start training
@@ -158,7 +158,7 @@ class Seq2seqTrainerTester(TestCasePlus):
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
compute_metrics=lambda x: {"samples": x[0].shape[0]},
)
@@ -199,7 +199,7 @@ class Seq2seqTrainerTester(TestCasePlus):
_ = Seq2SeqTrainer(
model=model,
args=training_args,
- tokenizer=tokenizer,
+ processing_class=tokenizer,
data_collator=data_collator,
compute_metrics=lambda x: {"samples": x[0].shape[0]},
)