From 9660e27cd0ada58b60d7e6ea0558c878c5e20580 Mon Sep 17 00:00:00 2001
From: Rockerz <64583161+rajveer43@users.noreply.github.com>
Date: Thu, 7 Dec 2023 00:08:21 +0530
Subject: [PATCH] =?UTF-8?q?Translating=20en/model=5Fdoc=20folder=20docs=20?=
=?UTF-8?q?to=20Japanese(from=20`blip`=20to=20`clap`)=20=F0=9F=87=AF?=
=?UTF-8?q?=F0=9F=87=B5=20(#27673)?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
* Add models
* Add models and update `_toctree.yml`
* Update docs/source/ja/model_doc/chinese_clip.md
Co-authored-by: Steven Liu <59462357+stevhliu@users.noreply.github.com>
* Update docs/source/ja/model_doc/camembert.md
Co-authored-by: Steven Liu <59462357+stevhliu@users.noreply.github.com>
* Update docs/source/ja/model_doc/bros.md
Co-authored-by: Steven Liu <59462357+stevhliu@users.noreply.github.com>
* Update docs/source/ja/model_doc/bros.md
Co-authored-by: Steven Liu <59462357+stevhliu@users.noreply.github.com>
* Update docs/source/ja/model_doc/blip-2.md
Co-authored-by: Steven Liu <59462357+stevhliu@users.noreply.github.com>
* Update docs/source/ja/model_doc/camembert.md
Co-authored-by: Steven Liu <59462357+stevhliu@users.noreply.github.com>
* solve merge conflicts and update paper titles
* Update docs/source/ja/model_doc/bridgetower.md
Co-authored-by: Steven Liu <59462357+stevhliu@users.noreply.github.com>
* Update docs/source/ja/model_doc/canine.md
Co-authored-by: Steven Liu <59462357+stevhliu@users.noreply.github.com>
* Update docs/source/ja/model_doc/chinese_clip.md
Co-authored-by: Steven Liu <59462357+stevhliu@users.noreply.github.com>
* Update the authons name in bros..md
---------
Co-authored-by: Steven Liu <59462357+stevhliu@users.noreply.github.com>
---
docs/source/en/model_doc/biogpt.md | 3 +-
docs/source/ja/_toctree.yml | 22 +++
docs/source/ja/model_doc/bert-generation.md | 2 +-
docs/source/ja/model_doc/biogpt.md | 2 +-
docs/source/ja/model_doc/blenderbot-small.md | 2 +-
docs/source/ja/model_doc/blenderbot.md | 2 +-
docs/source/ja/model_doc/blip-2.md | 90 ++++++++++
docs/source/ja/model_doc/blip.md | 134 +++++++++++++++
docs/source/ja/model_doc/bloom.md | 107 ++++++++++++
docs/source/ja/model_doc/bort.md | 55 ++++++
docs/source/ja/model_doc/bridgetower.md | 171 +++++++++++++++++++
docs/source/ja/model_doc/bros.md | 113 ++++++++++++
docs/source/ja/model_doc/byt5.md | 154 +++++++++++++++++
docs/source/ja/model_doc/camembert.md | 135 +++++++++++++++
docs/source/ja/model_doc/canine.md | 144 ++++++++++++++++
docs/source/ja/model_doc/chinese_clip.md | 112 ++++++++++++
docs/source/ja/model_doc/clap.md | 80 +++++++++
17 files changed, 1322 insertions(+), 6 deletions(-)
create mode 100644 docs/source/ja/model_doc/blip-2.md
create mode 100644 docs/source/ja/model_doc/blip.md
create mode 100644 docs/source/ja/model_doc/bloom.md
create mode 100644 docs/source/ja/model_doc/bort.md
create mode 100644 docs/source/ja/model_doc/bridgetower.md
create mode 100644 docs/source/ja/model_doc/bros.md
create mode 100644 docs/source/ja/model_doc/byt5.md
create mode 100644 docs/source/ja/model_doc/camembert.md
create mode 100644 docs/source/ja/model_doc/canine.md
create mode 100644 docs/source/ja/model_doc/chinese_clip.md
create mode 100644 docs/source/ja/model_doc/clap.md
diff --git a/docs/source/en/model_doc/biogpt.md b/docs/source/en/model_doc/biogpt.md
index 1cac6d1099..20a8e4d9cd 100644
--- a/docs/source/en/model_doc/biogpt.md
+++ b/docs/source/en/model_doc/biogpt.md
@@ -18,8 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-The BioGPT model was proposed in [BioGPT: generative pre-trained transformer for biomedical text generation and mining
-](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9) by Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon and Tie-Yan Liu. BioGPT is a domain-specific generative pre-trained Transformer language model for biomedical text generation and mining. BioGPT follows the Transformer language model backbone, and is pre-trained on 15M PubMed abstracts from scratch.
+The BioGPT model was proposed in [BioGPT: generative pre-trained transformer for biomedical text generation and mining](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9) by Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon and Tie-Yan Liu. BioGPT is a domain-specific generative pre-trained Transformer language model for biomedical text generation and mining. BioGPT follows the Transformer language model backbone, and is pre-trained on 15M PubMed abstracts from scratch.
The abstract from the paper is the following:
diff --git a/docs/source/ja/_toctree.yml b/docs/source/ja/_toctree.yml
index 6c0335082e..5515e1b681 100644
--- a/docs/source/ja/_toctree.yml
+++ b/docs/source/ja/_toctree.yml
@@ -274,6 +274,16 @@
title: Blenderbot
- local: model_doc/blenderbot-small
title: Blenderbot Small
+ - local: model_doc/bloom
+ title: BLOOM
+ - local: model_doc/bort
+ title: BORT
+ - local: model_doc/byt5
+ title: ByT5
+ - local: model_doc/camembert
+ title: CamemBERT
+ - local: model_doc/canine
+ title: CANINE
title: 文章モデル
- isExpanded: false
sections:
@@ -288,6 +298,8 @@
title: Audio Spectrogram Transformer
- local: model_doc/bark
title: Bark
+ - local: model_doc/clap
+ title: CLAP
title: 音声モデル
- isExpanded: false
sections:
@@ -295,6 +307,16 @@
title: ALIGN
- local: model_doc/altclip
title: AltCLIP
+ - local: model_doc/blip
+ title: BLIP
+ - local: model_doc/blip-2
+ title: BLIP-2
+ - local: model_doc/bridgetower
+ title: BridgeTower
+ - local: model_doc/bros
+ title: BROS
+ - local: model_doc/chinese_clip
+ title: Chinese-CLIP
title: マルチモーダルモデル
- isExpanded: false
sections:
diff --git a/docs/source/ja/model_doc/bert-generation.md b/docs/source/ja/model_doc/bert-generation.md
index 8227250bfc..4a25ff5d9b 100644
--- a/docs/source/ja/model_doc/bert-generation.md
+++ b/docs/source/ja/model_doc/bert-generation.md
@@ -19,7 +19,7 @@ rendered properly in your Markdown viewer.
## Overview
BertGeneration モデルは、次を使用してシーケンス間のタスクに利用できる BERT モデルです。
-[シーケンス生成のための事前トレーニング済みチェックポイントの活用](https://arxiv.org/abs/1907.12461) で提案されている [`EncoderDecoderModel`]
+[Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) で提案されている [`EncoderDecoderModel`]
タスク、Sascha Rothe、Sishi Nagayan、Aliaksei Severyn 著。
論文の要約は次のとおりです。
diff --git a/docs/source/ja/model_doc/biogpt.md b/docs/source/ja/model_doc/biogpt.md
index 9732ef7d35..0634062a6b 100644
--- a/docs/source/ja/model_doc/biogpt.md
+++ b/docs/source/ja/model_doc/biogpt.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## Overview
-BioGPT モデルは、[BioGPT: 生物医学テキストの生成とマイニングのための生成事前トレーニング済みトランスフォーマー](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9) by Renqian Luo、Liai Sun、Yingce Xia、 Tao Qin、Sheng Zhang、Hoifung Poon、Tie-Yan Liu。 BioGPT は、生物医学テキストの生成とマイニングのための、ドメイン固有の生成事前トレーニング済み Transformer 言語モデルです。 BioGPT は、Transformer 言語モデルのバックボーンに従い、1,500 万の PubMed 抄録で最初から事前トレーニングされています。
+BioGPT モデルは、[BioGPT: generative pre-trained transformer for biomedical text generation and mining](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9) by Renqian Luo、Liai Sun、Yingce Xia、 Tao Qin、Sheng Zhang、Hoifung Poon、Tie-Yan Liu。 BioGPT は、生物医学テキストの生成とマイニングのための、ドメイン固有の生成事前トレーニング済み Transformer 言語モデルです。 BioGPT は、Transformer 言語モデルのバックボーンに従い、1,500 万の PubMed 抄録で最初から事前トレーニングされています。
論文の要約は次のとおりです。
diff --git a/docs/source/ja/model_doc/blenderbot-small.md b/docs/source/ja/model_doc/blenderbot-small.md
index 2e67653809..ecb9c1174b 100644
--- a/docs/source/ja/model_doc/blenderbot-small.md
+++ b/docs/source/ja/model_doc/blenderbot-small.md
@@ -24,7 +24,7 @@ rendered properly in your Markdown viewer.
## Overview
-Blender チャットボット モデルは、[オープンドメイン チャットボットを構築するためのレシピ](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller、Emily Dinan、Naman Goyal、Da Ju、Mary Williamson、yinghan Liu、で提案されました。
+Blender チャットボット モデルは、[Recipes for building an open-domain chatbot](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller、Emily Dinan、Naman Goyal、Da Ju、Mary Williamson、yinghan Liu、で提案されました。
ジン・シュー、マイル・オット、カート・シャスター、エリック・M・スミス、Y-ラン・ブーロー、ジェイソン・ウェストン、2020年4月30日。
論文の要旨は次のとおりです。
diff --git a/docs/source/ja/model_doc/blenderbot.md b/docs/source/ja/model_doc/blenderbot.md
index 36f8408567..f7ee23e755 100644
--- a/docs/source/ja/model_doc/blenderbot.md
+++ b/docs/source/ja/model_doc/blenderbot.md
@@ -20,7 +20,7 @@ rendered properly in your Markdown viewer.
## Overview
-Blender チャットボット モデルは、[オープンドメイン チャットボットを構築するためのレシピ](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller、Emily Dinan、Naman Goyal、Da Ju、Mary Williamson、yinghan Liu、で提案されました。
+Blender チャットボット モデルは、[Recipes for building an open-domain chatbot](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller、Emily Dinan、Naman Goyal、Da Ju、Mary Williamson、yinghan Liu、で提案されました。
ジン・シュー、マイル・オット、カート・シャスター、エリック・M・スミス、Y-ラン・ブーロー、ジェイソン・ウェストン、2020年4月30日。
論文の要旨は次のとおりです。
diff --git a/docs/source/ja/model_doc/blip-2.md b/docs/source/ja/model_doc/blip-2.md
new file mode 100644
index 0000000000..bd110522e2
--- /dev/null
+++ b/docs/source/ja/model_doc/blip-2.md
@@ -0,0 +1,90 @@
+
+
+# BLIP-2
+
+## Overview
+
+BLIP-2 モデルは、[BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://arxiv.org/abs/2301.12597) で提案されました。
+Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi.・サバレーゼ、スティーブン・ホイ。 BLIP-2 は、軽量の 12 層 Transformer をトレーニングすることで、フリーズされた事前トレーニング済み画像エンコーダーと大規模言語モデル (LLM) を活用します。
+それらの間にエンコーダーを配置し、さまざまな視覚言語タスクで最先端のパフォーマンスを実現します。最も注目すべき点は、BLIP-2 が 800 億パラメータ モデルである [Flamingo](https://arxiv.org/abs/2204.14198) を 8.7% 改善していることです。
+ゼロショット VQAv2 ではトレーニング可能なパラメーターが 54 分の 1 に減少します。
+
+論文の要約は次のとおりです。
+
+*大規模モデルのエンドツーエンドのトレーニングにより、視覚と言語の事前トレーニングのコストはますます法外なものになってきています。この論文では、市販の凍結済み事前トレーニング画像エンコーダと凍結された大規模言語モデルから視覚言語の事前トレーニングをブートストラップする、汎用的で効率的な事前トレーニング戦略である BLIP-2 を提案します。 BLIP-2 は、2 段階で事前トレーニングされた軽量の Querying Transformer でモダリティのギャップを橋渡しします。最初のステージでは、フリーズされた画像エンコーダーから学習する視覚言語表現をブートストラップします。第 2 段階では、凍結された言語モデルから視覚から言語への生成学習をブートストラップします。 BLIP-2 は、既存の方法よりもトレーニング可能なパラメーターが大幅に少ないにもかかわらず、さまざまな視覚言語タスクで最先端のパフォーマンスを実現します。たとえば、私たちのモデルは、トレーニング可能なパラメーターが 54 分の 1 少ないゼロショット VQAv2 で、Flamingo80B を 8.7% 上回っています。また、自然言語の命令に従うことができる、ゼロショット画像からテキストへの生成というモデルの新しい機能も実証します*
+
+ +
+ BLIP-2 アーキテクチャ。 元の論文から抜粋。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
+元のコードは [ここ](https://github.com/salesforce/LAVIS/tree/5ee63d688ba4cebff63acee04adaef2dee9af207) にあります。
+
+## Usage tips
+
+- BLIP-2 は、画像とオプションのテキスト プロンプトを指定して条件付きテキストを生成するために使用できます。推論時には、 [`generate`] メソッドを使用することをお勧めします。
+- [`Blip2Processor`] を使用してモデル用の画像を準備し、予測されたトークン ID をデコードしてテキストに戻すことができます。
+
+## Resources
+
+BLIP-2 の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
+
+- 画像キャプション、ビジュアル質問応答 (VQA)、およびチャットのような会話のための BLIP-2 のデモ ノートブックは、[こちら](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/BLIP-2) にあります。
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## Blip2Config
+
+[[autodoc]] Blip2Config
+ - from_vision_qformer_text_configs
+
+## Blip2VisionConfig
+
+[[autodoc]] Blip2VisionConfig
+
+## Blip2QFormerConfig
+
+[[autodoc]] Blip2QFormerConfig
+
+## Blip2Processor
+
+[[autodoc]] Blip2Processor
+
+## Blip2VisionModel
+
+[[autodoc]] Blip2VisionModel
+ - forward
+
+## Blip2QFormerModel
+
+[[autodoc]] Blip2QFormerModel
+ - forward
+
+## Blip2Model
+
+[[autodoc]] Blip2Model
+ - forward
+ - get_text_features
+ - get_image_features
+ - get_qformer_features
+
+## Blip2ForConditionalGeneration
+
+[[autodoc]] Blip2ForConditionalGeneration
+ - forward
+ - generate
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/blip.md b/docs/source/ja/model_doc/blip.md
new file mode 100644
index 0000000000..c145af701f
--- /dev/null
+++ b/docs/source/ja/model_doc/blip.md
@@ -0,0 +1,134 @@
+
+
+# BLIP
+
+## Overview
+
+BLIP モデルは、[BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) で Junnan Li、Dongxu Li、Caiming Xiong、Steven Hoi によって提案されました。 。
+
+BLIP は、次のようなさまざまなマルチモーダル タスクを実行できるモデルです。
+- 視覚的な質問応答
+- 画像とテキストの検索(画像とテキストのマッチング)
+- 画像キャプション
+
+論文の要約は次のとおりです。
+
+*視覚言語事前トレーニング (VLP) により、多くの視覚言語タスクのパフォーマンスが向上しました。
+ただし、既存の事前トレーニング済みモデルのほとんどは、理解ベースのタスクまたは世代ベースのタスクのいずれかでのみ優れています。さらに、最適ではない監視ソースである Web から収集されたノイズの多い画像とテキストのペアを使用してデータセットをスケールアップすることで、パフォーマンスの向上が大幅に達成されました。この論文では、視覚言語の理解と生成タスクの両方に柔軟に移行する新しい VLP フレームワークである BLIP を提案します。 BLIP は、キャプションをブートストラップすることでノイズの多い Web データを効果的に利用します。キャプショナーが合成キャプションを生成し、フィルターがノイズの多いキャプションを除去します。画像テキスト検索 (平均再現率 +2.7%@1)、画像キャプション作成 (CIDEr で +2.8%)、VQA ( VQA スコアは +1.6%)。 BLIP は、ゼロショット方式でビデオ言語タスクに直接転送した場合にも、強力な一般化能力を発揮します。コード、モデル、データセットがリリースされています。*
+
+
+
+このモデルは [ybelkada](https://huggingface.co/ybelkada) によって提供されました。
+元のコードは [ここ](https://github.com/salesforce/BLIP) にあります。
+
+## Resources
+
+- [Jupyter ノートブック](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_blip.ipynb) カスタム データセットの画像キャプション用に BLIP を微調整する方法
+
+## BlipConfig
+
+[[autodoc]] BlipConfig
+ - from_text_vision_configs
+
+## BlipTextConfig
+
+[[autodoc]] BlipTextConfig
+
+## BlipVisionConfig
+
+[[autodoc]] BlipVisionConfig
+
+## BlipProcessor
+
+[[autodoc]] BlipProcessor
+
+## BlipImageProcessor
+
+[[autodoc]] BlipImageProcessor
+ - preprocess
+
+
+
+
+## BlipModel
+
+[[autodoc]] BlipModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## BlipTextModel
+
+[[autodoc]] BlipTextModel
+ - forward
+
+## BlipVisionModel
+
+[[autodoc]] BlipVisionModel
+ - forward
+
+## BlipForConditionalGeneration
+
+[[autodoc]] BlipForConditionalGeneration
+ - forward
+
+## BlipForImageTextRetrieval
+
+[[autodoc]] BlipForImageTextRetrieval
+ - forward
+
+## BlipForQuestionAnswering
+
+[[autodoc]] BlipForQuestionAnswering
+ - forward
+
+
+
+
+## TFBlipModel
+
+[[autodoc]] TFBlipModel
+ - call
+ - get_text_features
+ - get_image_features
+
+## TFBlipTextModel
+
+[[autodoc]] TFBlipTextModel
+ - call
+
+## TFBlipVisionModel
+
+[[autodoc]] TFBlipVisionModel
+ - call
+
+## TFBlipForConditionalGeneration
+
+[[autodoc]] TFBlipForConditionalGeneration
+ - call
+
+## TFBlipForImageTextRetrieval
+
+[[autodoc]] TFBlipForImageTextRetrieval
+ - call
+
+## TFBlipForQuestionAnswering
+
+[[autodoc]] TFBlipForQuestionAnswering
+ - call
+
+
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/bloom.md b/docs/source/ja/model_doc/bloom.md
new file mode 100644
index 0000000000..1ac9396fa8
--- /dev/null
+++ b/docs/source/ja/model_doc/bloom.md
@@ -0,0 +1,107 @@
+
+
+# BLOOM
+
+## Overview
+
+BLOOM モデルは、[BigScience Workshop](https://bigscience.huggingface.co/) を通じてさまざまなバージョンで提案されています。 BigScience は、研究者が時間とリソースをプールして共同でより高い効果を達成する他のオープン サイエンス イニシアチブからインスピレーションを得ています。
+BLOOM のアーキテクチャは基本的に GPT3 (次のトークン予測のための自己回帰モデル) に似ていますが、46 の異なる言語と 13 のプログラミング言語でトレーニングされています。
+モデルのいくつかの小さいバージョンが同じデータセットでトレーニングされています。 BLOOM は次のバージョンで利用できます。
+
+- [bloom-560m](https://huggingface.co/bigscience/bloom-560m)
+- [bloom-1b1](https://huggingface.co/bigscience/bloom-1b1)
+- [bloom-1b7](https://huggingface.co/bigscience/bloom-1b7)
+- [bloom-3b](https://huggingface.co/bigscience/bloom-3b)
+- [bloom-7b1](https://huggingface.co/bigscience/bloom-7b1)
+- [bloom](https://huggingface.co/bigscience/bloom) (176B parameters)
+
+## Resources
+
+BLOOM を使い始めるのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+
+
+- [`BloomForCausalLM`] これによってサポートされています [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#gpt-2gpt-and-causal-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
+
+以下も参照してください。
+- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
+- [テキスト分類タスクガイド](../tasks/sequence_classification)
+- [トークン分類タスクガイド](../tasks/token_classification)
+- [質問回答タスク ガイド](../tasks/question_answering)
+
+
+⚡️ 推論
+- に関するブログ [最適化の話: ブルーム推論](https://huggingface.co/blog/bloom-inference-optimization)。
+- に関するブログ [DeepSpeed と Accelerate を使用した信じられないほど高速な BLOOM 推論](https://huggingface.co/blog/bloom-inference-pytorch-scripts)。
+
+⚙️トレーニング
+- に関するブログ [BLOOM トレーニングの背後にあるテクノロジー](https://huggingface.co/blog/bloom-megatron-deepspeed)。
+
+## BloomConfig
+
+[[autodoc]] BloomConfig
+ - all
+
+## BloomTokenizerFast
+
+[[autodoc]] BloomTokenizerFast
+ - all
+
+
+
+
+
+## BloomModel
+
+[[autodoc]] BloomModel
+ - forward
+
+## BloomForCausalLM
+
+[[autodoc]] BloomForCausalLM
+ - forward
+
+## BloomForSequenceClassification
+
+[[autodoc]] BloomForSequenceClassification
+ - forward
+
+## BloomForTokenClassification
+
+[[autodoc]] BloomForTokenClassification
+ - forward
+
+## BloomForQuestionAnswering
+
+[[autodoc]] BloomForQuestionAnswering
+ - forward
+
+
+
+
+## FlaxBloomModel
+
+[[autodoc]] FlaxBloomModel
+ - __call__
+
+## FlaxBloomForCausalLM
+
+[[autodoc]] FlaxBloomForCausalLM
+ - __call__
+
+
+
diff --git a/docs/source/ja/model_doc/bort.md b/docs/source/ja/model_doc/bort.md
new file mode 100644
index 0000000000..2b892a35bb
--- /dev/null
+++ b/docs/source/ja/model_doc/bort.md
@@ -0,0 +1,55 @@
+
+
+# BORT
+
+
+
+このモデルはメンテナンス モードのみであり、コードを変更する新しい PR は受け付けられません。
+
+このモデルの実行中に問題が発生した場合は、このモデルをサポートしていた最後のバージョン (v4.30.0) を再インストールしてください。
+これを行うには、コマンド `pip install -U Transformers==4.30.0` を実行します。
+
+
+
+## Overview
+
+BORT モデルは、[Optimal Subarchitecture Extraction for BERT](https://arxiv.org/abs/2010.10499) で提案されました。
+Adrian de Wynter and Daniel J. Perry.これは、BERT のアーキテクチャ パラメータの最適なサブセットです。
+著者は「ボルト」と呼んでいます。
+
+論文の要約は次のとおりです。
+
+*Devlin らから BERT アーキテクチャのアーキテクチャ パラメータの最適なサブセットを抽出します。 (2018)
+ニューラル アーキテクチャ検索のアルゴリズムにおける最近の画期的な技術を適用します。この最適なサブセットを次のように呼びます。
+"Bort" は明らかに小さく、有効 (つまり、埋め込み層を考慮しない) サイズは 5.5% です。
+オリジナルの BERT 大規模アーキテクチャ、およびネット サイズの 16%。 Bort は 288 GPU 時間で事前トレーニングすることもできます。
+最高パフォーマンスの BERT パラメトリック アーキテクチャ バリアントである RoBERTa-large の事前トレーニングに必要な時間の 1.2%
+(Liu et al., 2019)、同じマシンで BERT-large をトレーニングするのに必要な GPU 時間の世界記録の約 33%
+ハードウェア。また、CPU 上で 7.9 倍高速であるだけでなく、他の圧縮バージョンよりもパフォーマンスが優れています。
+アーキテクチャ、および一部の非圧縮バリアント: 0.3% ~ 31% のパフォーマンス向上が得られます。
+BERT-large に関して、複数の公開自然言語理解 (NLU) ベンチマークにおける絶対的な評価。*
+
+このモデルは [stefan-it](https://huggingface.co/stefan-it) によって提供されました。元のコードは[ここ](https://github.com/alexa/bort/)にあります。
+
+## Usage tips
+
+- BORT のモデル アーキテクチャは BERT に基づいています。詳細については、[BERT のドキュメント ページ](bert) を参照してください。
+ モデルの API リファレンスと使用例。
+- BORT は BERT トークナイザーの代わりに RoBERTa トークナイザーを使用します。トークナイザーの API リファレンスと使用例については、[RoBERTa のドキュメント ページ](roberta) を参照してください。
+- BORT には、 [Agora](https://adewynter.github.io/notes/bort_algorithms_and_applications.html#fine-tuning-with-algebraic-topology) と呼ばれる特定の微調整アルゴリズムが必要です。
+ 残念ながらまだオープンソース化されていません。誰かが実装しようとすると、コミュニティにとって非常に役立ちます。
+ BORT の微調整を機能させるためのアルゴリズム。
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/bridgetower.md b/docs/source/ja/model_doc/bridgetower.md
new file mode 100644
index 0000000000..12be1fcc26
--- /dev/null
+++ b/docs/source/ja/model_doc/bridgetower.md
@@ -0,0 +1,171 @@
+
+
+# BridgeTower
+
+## Overview
+
+BridgeTower モデルは、Xiao Xu、Chenfei Wu、Shachar Rosenman、Vasudev Lal、Wanxiang Che、Nan Duan [BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning](https://arxiv.org/abs/2206.08657) で提案されました。ドゥアン。このモデルの目標は、
+各ユニモーダル エンコーダとクロスモーダル エンコーダの間のブリッジにより、クロスモーダル エンコーダの各層での包括的かつ詳細な対話が可能になり、追加のパフォーマンスと計算コストがほとんど無視できる程度で、さまざまな下流タスクで優れたパフォーマンスを実現します。
+
+この論文は [AAAI'23](https://aaai.org/Conferences/AAAI-23/) 会議に採択されました。
+
+論文の要約は次のとおりです。
+
+*TWO-TOWER アーキテクチャを備えたビジョン言語 (VL) モデルは、近年の視覚言語表現学習の主流となっています。
+現在の VL モデルは、軽量のユニモーダル エンコーダーを使用して、ディープ クロスモーダル エンコーダーで両方のモダリティを同時に抽出、位置合わせ、融合することを学習するか、事前にトレーニングされたディープ ユニモーダル エンコーダーから最終層のユニモーダル表現を上部のクロスモーダルエンコーダー。
+どちらのアプローチも、視覚言語表現の学習を制限し、モデルのパフォーマンスを制限する可能性があります。この論文では、ユニモーダル エンコーダの最上位層とクロスモーダル エンコーダの各層の間の接続を構築する複数のブリッジ層を導入する BRIDGETOWER を提案します。
+これにより、効果的なボトムアップのクロスモーダル調整と、クロスモーダル エンコーダー内の事前トレーニング済みユニモーダル エンコーダーのさまざまなセマンティック レベルの視覚表現とテキスト表現の間の融合が可能になります。 BRIDGETOWER は 4M 画像のみで事前トレーニングされており、さまざまな下流の視覚言語タスクで最先端のパフォーマンスを実現します。
+特に、VQAv2 テスト標準セットでは、BRIDGETOWER は 78.73% の精度を達成し、同じ事前トレーニング データとほぼ無視できる追加パラメータと計算コストで以前の最先端モデル METER を 1.09% 上回りました。
+特に、モデルをさらにスケーリングすると、BRIDGETOWER は 81.15% の精度を達成し、桁違いに大きなデータセットで事前トレーニングされたモデルを上回りました。*
+
+
+
+ BLIP-2 アーキテクチャ。 元の論文から抜粋。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
+元のコードは [ここ](https://github.com/salesforce/LAVIS/tree/5ee63d688ba4cebff63acee04adaef2dee9af207) にあります。
+
+## Usage tips
+
+- BLIP-2 は、画像とオプションのテキスト プロンプトを指定して条件付きテキストを生成するために使用できます。推論時には、 [`generate`] メソッドを使用することをお勧めします。
+- [`Blip2Processor`] を使用してモデル用の画像を準備し、予測されたトークン ID をデコードしてテキストに戻すことができます。
+
+## Resources
+
+BLIP-2 の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
+
+- 画像キャプション、ビジュアル質問応答 (VQA)、およびチャットのような会話のための BLIP-2 のデモ ノートブックは、[こちら](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/BLIP-2) にあります。
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## Blip2Config
+
+[[autodoc]] Blip2Config
+ - from_vision_qformer_text_configs
+
+## Blip2VisionConfig
+
+[[autodoc]] Blip2VisionConfig
+
+## Blip2QFormerConfig
+
+[[autodoc]] Blip2QFormerConfig
+
+## Blip2Processor
+
+[[autodoc]] Blip2Processor
+
+## Blip2VisionModel
+
+[[autodoc]] Blip2VisionModel
+ - forward
+
+## Blip2QFormerModel
+
+[[autodoc]] Blip2QFormerModel
+ - forward
+
+## Blip2Model
+
+[[autodoc]] Blip2Model
+ - forward
+ - get_text_features
+ - get_image_features
+ - get_qformer_features
+
+## Blip2ForConditionalGeneration
+
+[[autodoc]] Blip2ForConditionalGeneration
+ - forward
+ - generate
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/blip.md b/docs/source/ja/model_doc/blip.md
new file mode 100644
index 0000000000..c145af701f
--- /dev/null
+++ b/docs/source/ja/model_doc/blip.md
@@ -0,0 +1,134 @@
+
+
+# BLIP
+
+## Overview
+
+BLIP モデルは、[BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) で Junnan Li、Dongxu Li、Caiming Xiong、Steven Hoi によって提案されました。 。
+
+BLIP は、次のようなさまざまなマルチモーダル タスクを実行できるモデルです。
+- 視覚的な質問応答
+- 画像とテキストの検索(画像とテキストのマッチング)
+- 画像キャプション
+
+論文の要約は次のとおりです。
+
+*視覚言語事前トレーニング (VLP) により、多くの視覚言語タスクのパフォーマンスが向上しました。
+ただし、既存の事前トレーニング済みモデルのほとんどは、理解ベースのタスクまたは世代ベースのタスクのいずれかでのみ優れています。さらに、最適ではない監視ソースである Web から収集されたノイズの多い画像とテキストのペアを使用してデータセットをスケールアップすることで、パフォーマンスの向上が大幅に達成されました。この論文では、視覚言語の理解と生成タスクの両方に柔軟に移行する新しい VLP フレームワークである BLIP を提案します。 BLIP は、キャプションをブートストラップすることでノイズの多い Web データを効果的に利用します。キャプショナーが合成キャプションを生成し、フィルターがノイズの多いキャプションを除去します。画像テキスト検索 (平均再現率 +2.7%@1)、画像キャプション作成 (CIDEr で +2.8%)、VQA ( VQA スコアは +1.6%)。 BLIP は、ゼロショット方式でビデオ言語タスクに直接転送した場合にも、強力な一般化能力を発揮します。コード、モデル、データセットがリリースされています。*
+
+
+
+このモデルは [ybelkada](https://huggingface.co/ybelkada) によって提供されました。
+元のコードは [ここ](https://github.com/salesforce/BLIP) にあります。
+
+## Resources
+
+- [Jupyter ノートブック](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_blip.ipynb) カスタム データセットの画像キャプション用に BLIP を微調整する方法
+
+## BlipConfig
+
+[[autodoc]] BlipConfig
+ - from_text_vision_configs
+
+## BlipTextConfig
+
+[[autodoc]] BlipTextConfig
+
+## BlipVisionConfig
+
+[[autodoc]] BlipVisionConfig
+
+## BlipProcessor
+
+[[autodoc]] BlipProcessor
+
+## BlipImageProcessor
+
+[[autodoc]] BlipImageProcessor
+ - preprocess
+
+
+
+
+## BlipModel
+
+[[autodoc]] BlipModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## BlipTextModel
+
+[[autodoc]] BlipTextModel
+ - forward
+
+## BlipVisionModel
+
+[[autodoc]] BlipVisionModel
+ - forward
+
+## BlipForConditionalGeneration
+
+[[autodoc]] BlipForConditionalGeneration
+ - forward
+
+## BlipForImageTextRetrieval
+
+[[autodoc]] BlipForImageTextRetrieval
+ - forward
+
+## BlipForQuestionAnswering
+
+[[autodoc]] BlipForQuestionAnswering
+ - forward
+
+
+
+
+## TFBlipModel
+
+[[autodoc]] TFBlipModel
+ - call
+ - get_text_features
+ - get_image_features
+
+## TFBlipTextModel
+
+[[autodoc]] TFBlipTextModel
+ - call
+
+## TFBlipVisionModel
+
+[[autodoc]] TFBlipVisionModel
+ - call
+
+## TFBlipForConditionalGeneration
+
+[[autodoc]] TFBlipForConditionalGeneration
+ - call
+
+## TFBlipForImageTextRetrieval
+
+[[autodoc]] TFBlipForImageTextRetrieval
+ - call
+
+## TFBlipForQuestionAnswering
+
+[[autodoc]] TFBlipForQuestionAnswering
+ - call
+
+
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/bloom.md b/docs/source/ja/model_doc/bloom.md
new file mode 100644
index 0000000000..1ac9396fa8
--- /dev/null
+++ b/docs/source/ja/model_doc/bloom.md
@@ -0,0 +1,107 @@
+
+
+# BLOOM
+
+## Overview
+
+BLOOM モデルは、[BigScience Workshop](https://bigscience.huggingface.co/) を通じてさまざまなバージョンで提案されています。 BigScience は、研究者が時間とリソースをプールして共同でより高い効果を達成する他のオープン サイエンス イニシアチブからインスピレーションを得ています。
+BLOOM のアーキテクチャは基本的に GPT3 (次のトークン予測のための自己回帰モデル) に似ていますが、46 の異なる言語と 13 のプログラミング言語でトレーニングされています。
+モデルのいくつかの小さいバージョンが同じデータセットでトレーニングされています。 BLOOM は次のバージョンで利用できます。
+
+- [bloom-560m](https://huggingface.co/bigscience/bloom-560m)
+- [bloom-1b1](https://huggingface.co/bigscience/bloom-1b1)
+- [bloom-1b7](https://huggingface.co/bigscience/bloom-1b7)
+- [bloom-3b](https://huggingface.co/bigscience/bloom-3b)
+- [bloom-7b1](https://huggingface.co/bigscience/bloom-7b1)
+- [bloom](https://huggingface.co/bigscience/bloom) (176B parameters)
+
+## Resources
+
+BLOOM を使い始めるのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+
+
+- [`BloomForCausalLM`] これによってサポートされています [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#gpt-2gpt-and-causal-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
+
+以下も参照してください。
+- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
+- [テキスト分類タスクガイド](../tasks/sequence_classification)
+- [トークン分類タスクガイド](../tasks/token_classification)
+- [質問回答タスク ガイド](../tasks/question_answering)
+
+
+⚡️ 推論
+- に関するブログ [最適化の話: ブルーム推論](https://huggingface.co/blog/bloom-inference-optimization)。
+- に関するブログ [DeepSpeed と Accelerate を使用した信じられないほど高速な BLOOM 推論](https://huggingface.co/blog/bloom-inference-pytorch-scripts)。
+
+⚙️トレーニング
+- に関するブログ [BLOOM トレーニングの背後にあるテクノロジー](https://huggingface.co/blog/bloom-megatron-deepspeed)。
+
+## BloomConfig
+
+[[autodoc]] BloomConfig
+ - all
+
+## BloomTokenizerFast
+
+[[autodoc]] BloomTokenizerFast
+ - all
+
+
+
+
+
+## BloomModel
+
+[[autodoc]] BloomModel
+ - forward
+
+## BloomForCausalLM
+
+[[autodoc]] BloomForCausalLM
+ - forward
+
+## BloomForSequenceClassification
+
+[[autodoc]] BloomForSequenceClassification
+ - forward
+
+## BloomForTokenClassification
+
+[[autodoc]] BloomForTokenClassification
+ - forward
+
+## BloomForQuestionAnswering
+
+[[autodoc]] BloomForQuestionAnswering
+ - forward
+
+
+
+
+## FlaxBloomModel
+
+[[autodoc]] FlaxBloomModel
+ - __call__
+
+## FlaxBloomForCausalLM
+
+[[autodoc]] FlaxBloomForCausalLM
+ - __call__
+
+
+
diff --git a/docs/source/ja/model_doc/bort.md b/docs/source/ja/model_doc/bort.md
new file mode 100644
index 0000000000..2b892a35bb
--- /dev/null
+++ b/docs/source/ja/model_doc/bort.md
@@ -0,0 +1,55 @@
+
+
+# BORT
+
+
+
+このモデルはメンテナンス モードのみであり、コードを変更する新しい PR は受け付けられません。
+
+このモデルの実行中に問題が発生した場合は、このモデルをサポートしていた最後のバージョン (v4.30.0) を再インストールしてください。
+これを行うには、コマンド `pip install -U Transformers==4.30.0` を実行します。
+
+
+
+## Overview
+
+BORT モデルは、[Optimal Subarchitecture Extraction for BERT](https://arxiv.org/abs/2010.10499) で提案されました。
+Adrian de Wynter and Daniel J. Perry.これは、BERT のアーキテクチャ パラメータの最適なサブセットです。
+著者は「ボルト」と呼んでいます。
+
+論文の要約は次のとおりです。
+
+*Devlin らから BERT アーキテクチャのアーキテクチャ パラメータの最適なサブセットを抽出します。 (2018)
+ニューラル アーキテクチャ検索のアルゴリズムにおける最近の画期的な技術を適用します。この最適なサブセットを次のように呼びます。
+"Bort" は明らかに小さく、有効 (つまり、埋め込み層を考慮しない) サイズは 5.5% です。
+オリジナルの BERT 大規模アーキテクチャ、およびネット サイズの 16%。 Bort は 288 GPU 時間で事前トレーニングすることもできます。
+最高パフォーマンスの BERT パラメトリック アーキテクチャ バリアントである RoBERTa-large の事前トレーニングに必要な時間の 1.2%
+(Liu et al., 2019)、同じマシンで BERT-large をトレーニングするのに必要な GPU 時間の世界記録の約 33%
+ハードウェア。また、CPU 上で 7.9 倍高速であるだけでなく、他の圧縮バージョンよりもパフォーマンスが優れています。
+アーキテクチャ、および一部の非圧縮バリアント: 0.3% ~ 31% のパフォーマンス向上が得られます。
+BERT-large に関して、複数の公開自然言語理解 (NLU) ベンチマークにおける絶対的な評価。*
+
+このモデルは [stefan-it](https://huggingface.co/stefan-it) によって提供されました。元のコードは[ここ](https://github.com/alexa/bort/)にあります。
+
+## Usage tips
+
+- BORT のモデル アーキテクチャは BERT に基づいています。詳細については、[BERT のドキュメント ページ](bert) を参照してください。
+ モデルの API リファレンスと使用例。
+- BORT は BERT トークナイザーの代わりに RoBERTa トークナイザーを使用します。トークナイザーの API リファレンスと使用例については、[RoBERTa のドキュメント ページ](roberta) を参照してください。
+- BORT には、 [Agora](https://adewynter.github.io/notes/bort_algorithms_and_applications.html#fine-tuning-with-algebraic-topology) と呼ばれる特定の微調整アルゴリズムが必要です。
+ 残念ながらまだオープンソース化されていません。誰かが実装しようとすると、コミュニティにとって非常に役立ちます。
+ BORT の微調整を機能させるためのアルゴリズム。
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/bridgetower.md b/docs/source/ja/model_doc/bridgetower.md
new file mode 100644
index 0000000000..12be1fcc26
--- /dev/null
+++ b/docs/source/ja/model_doc/bridgetower.md
@@ -0,0 +1,171 @@
+
+
+# BridgeTower
+
+## Overview
+
+BridgeTower モデルは、Xiao Xu、Chenfei Wu、Shachar Rosenman、Vasudev Lal、Wanxiang Che、Nan Duan [BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning](https://arxiv.org/abs/2206.08657) で提案されました。ドゥアン。このモデルの目標は、
+各ユニモーダル エンコーダとクロスモーダル エンコーダの間のブリッジにより、クロスモーダル エンコーダの各層での包括的かつ詳細な対話が可能になり、追加のパフォーマンスと計算コストがほとんど無視できる程度で、さまざまな下流タスクで優れたパフォーマンスを実現します。
+
+この論文は [AAAI'23](https://aaai.org/Conferences/AAAI-23/) 会議に採択されました。
+
+論文の要約は次のとおりです。
+
+*TWO-TOWER アーキテクチャを備えたビジョン言語 (VL) モデルは、近年の視覚言語表現学習の主流となっています。
+現在の VL モデルは、軽量のユニモーダル エンコーダーを使用して、ディープ クロスモーダル エンコーダーで両方のモダリティを同時に抽出、位置合わせ、融合することを学習するか、事前にトレーニングされたディープ ユニモーダル エンコーダーから最終層のユニモーダル表現を上部のクロスモーダルエンコーダー。
+どちらのアプローチも、視覚言語表現の学習を制限し、モデルのパフォーマンスを制限する可能性があります。この論文では、ユニモーダル エンコーダの最上位層とクロスモーダル エンコーダの各層の間の接続を構築する複数のブリッジ層を導入する BRIDGETOWER を提案します。
+これにより、効果的なボトムアップのクロスモーダル調整と、クロスモーダル エンコーダー内の事前トレーニング済みユニモーダル エンコーダーのさまざまなセマンティック レベルの視覚表現とテキスト表現の間の融合が可能になります。 BRIDGETOWER は 4M 画像のみで事前トレーニングされており、さまざまな下流の視覚言語タスクで最先端のパフォーマンスを実現します。
+特に、VQAv2 テスト標準セットでは、BRIDGETOWER は 78.73% の精度を達成し、同じ事前トレーニング データとほぼ無視できる追加パラメータと計算コストで以前の最先端モデル METER を 1.09% 上回りました。
+特に、モデルをさらにスケーリングすると、BRIDGETOWER は 81.15% の精度を達成し、桁違いに大きなデータセットで事前トレーニングされたモデルを上回りました。*
+
+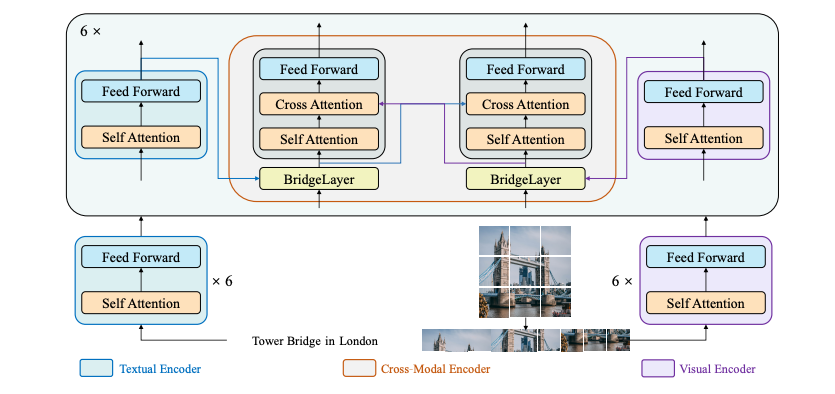 +
+ ブリッジタワー アーキテクチャ。 元の論文から抜粋。
+
+このモデルは、[Anahita Bhiwandiwalla](https://huggingface.co/anahita-b)、[Tiep Le](https://huggingface.co/Tile)、[Shaoyen Tseng](https://huggingface.co/shaoyent)。元のコードは [ここ](https://github.com/microsoft/BridgeTower) にあります。
+
+## Usage tips and examples
+
+BridgeTower は、ビジュアル エンコーダー、テキスト エンコーダー、および複数の軽量ブリッジ レイヤーを備えたクロスモーダル エンコーダーで構成されます。
+このアプローチの目標は、各ユニモーダル エンコーダーとクロスモーダル エンコーダーの間にブリッジを構築し、クロスモーダル エンコーダーの各層で包括的かつ詳細な対話を可能にすることでした。
+原則として、提案されたアーキテクチャでは、任意のビジュアル、テキスト、またはクロスモーダル エンコーダを適用できます。
+
+[`BridgeTowerProcessor`] は、[`RobertaTokenizer`] と [`BridgeTowerImageProcessor`] を単一のインスタンスにラップし、両方の機能を実現します。
+テキストをエンコードし、画像をそれぞれ用意します。
+
+次の例は、[`BridgeTowerProcessor`] と [`BridgeTowerForContrastiveLearning`] を使用して対照学習を実行する方法を示しています。
+
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForContrastiveLearning
+>>> import requests
+>>> from PIL import Image
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
+
+>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
+>>> model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
+
+>>> # forward pass
+>>> scores = dict()
+>>> for text in texts:
+... # prepare inputs
+... encoding = processor(image, text, return_tensors="pt")
+... outputs = model(**encoding)
+... scores[text] = outputs
+```
+
+次の例は、[`BridgeTowerProcessor`] と [`BridgeTowerForImageAndTextRetrieval`] を使用して画像テキストの取得を実行する方法を示しています。
+
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
+>>> import requests
+>>> from PIL import Image
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
+
+>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+>>> model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+
+>>> # forward pass
+>>> scores = dict()
+>>> for text in texts:
+... # prepare inputs
+... encoding = processor(image, text, return_tensors="pt")
+... outputs = model(**encoding)
+... scores[text] = outputs.logits[0, 1].item()
+```
+
+次の例は、[`BridgeTowerProcessor`] と [`BridgeTowerForMaskedLM`] を使用してマスクされた言語モデリングを実行する方法を示しています。
+
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
+>>> from PIL import Image
+>>> import requests
+
+>>> url = "http://images.cocodataset.org/val2017/000000360943.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
+>>> text = "a looking out of the window"
+
+>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+>>> model = BridgeTowerForMaskedLM.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+
+>>> # prepare inputs
+>>> encoding = processor(image, text, return_tensors="pt")
+
+>>> # forward pass
+>>> outputs = model(**encoding)
+
+>>> results = processor.decode(outputs.logits.argmax(dim=-1).squeeze(0).tolist())
+
+>>> print(results)
+.a cat looking out of the window.
+```
+
+チップ:
+
+- BridgeTower のこの実装では、[`RobertaTokenizer`] を使用してテキスト埋め込みを生成し、OpenAI の CLIP/ViT モデルを使用して視覚的埋め込みを計算します。
+- 事前トレーニングされた [bridgeTower-base](https://huggingface.co/BridgeTower/bridgetower-base) および [bridgetower マスクされた言語モデリングと画像テキスト マッチング](https://huggingface.co/BridgeTower/bridgetower--base-itm-mlm) のチェックポイント がリリースされました。
+- 画像検索およびその他の下流タスクにおける BridgeTower のパフォーマンスについては、[表 5](https://arxiv.org/pdf/2206.08657.pdf) を参照してください。
+- このモデルの PyTorch バージョンは、torch 1.10 以降でのみ使用できます。
+
+## BridgeTowerConfig
+
+[[autodoc]] BridgeTowerConfig
+
+## BridgeTowerTextConfig
+
+[[autodoc]] BridgeTowerTextConfig
+
+## BridgeTowerVisionConfig
+
+[[autodoc]] BridgeTowerVisionConfig
+
+## BridgeTowerImageProcessor
+
+[[autodoc]] BridgeTowerImageProcessor
+ - preprocess
+
+## BridgeTowerProcessor
+
+[[autodoc]] BridgeTowerProcessor
+ - __call__
+
+## BridgeTowerModel
+
+[[autodoc]] BridgeTowerModel
+ - forward
+
+## BridgeTowerForContrastiveLearning
+
+[[autodoc]] BridgeTowerForContrastiveLearning
+ - forward
+
+## BridgeTowerForMaskedLM
+
+[[autodoc]] BridgeTowerForMaskedLM
+ - forward
+
+## BridgeTowerForImageAndTextRetrieval
+
+[[autodoc]] BridgeTowerForImageAndTextRetrieval
+ - forward
+
diff --git a/docs/source/ja/model_doc/bros.md b/docs/source/ja/model_doc/bros.md
new file mode 100644
index 0000000000..3749a172a8
--- /dev/null
+++ b/docs/source/ja/model_doc/bros.md
@@ -0,0 +1,113 @@
+
+
+# BROS
+
+## Overview
+
+BROS モデルは、Teakgyu Hon、Donghyun Kim、Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park によって [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://arxiv.org/abs/2108.04539) で提案されました。
+
+BROS は *BERT Relying On Spatality* の略です。これは、一連のトークンとその境界ボックスを入力として受け取り、一連の隠れ状態を出力するエンコーダー専用の Transformer モデルです。 BROS は、絶対的な空間情報を使用する代わりに、相対的な空間情報をエンコードします。
+
+BERT で使用されるトークンマスク言語モデリング目標 (TMLM) と新しいエリアマスク言語モデリング目標 (AMLM) の 2 つの目標で事前トレーニングされています。
+TMLM では、トークンはランダムにマスクされ、モデルは空間情報と他のマスクされていないトークンを使用してマスクされたトークンを予測します。
+AMLM は TMLM の 2D バージョンです。テキスト トークンをランダムにマスクし、TMLM と同じ情報で予測しますが、テキスト ブロック (領域) をマスクします。
+
+`BrosForTokenClassification`には、BrosModel の上に単純な線形層があります。各トークンのラベルを予測します。
+`BrosSpadeEEForTokenClassification`には、BrosModel の上に`initial_token_classifier`と`subsequent_token_classifier`があります。 `initial_token_classifier` は各エンティティの最初のトークンを予測するために使用され、`subsequent_token_classifier` はエンティティ内の次のトークンを予測するために使用されます。 `BrosSpadeELForTokenClassification`には BrosModel の上に`entity_linker`があります。 `entity_linker` は 2 つのエンティティ間の関係を予測するために使用されます。
+
+`BrosForTokenClassification`と`BrosSpadeEEForTokenClassification`は基本的に同じジョブを実行します。ただし、`BrosForTokenClassification`は入力トークンが完全にシリアル化されていることを前提としています (トークンは 2D 空間に存在するため、これは非常に困難な作業です)。一方、`BrosSpadeEEForTokenClassification`は 1 つのトークンから次の接続トークンを予測するため、シリアル化エラーの処理をより柔軟に行うことができます。
+
+`BrosSpadeELForTokenClassification` はエンティティ内のリンク タスクを実行します。これら 2 つのエンティティが何らかの関係を共有する場合、(あるエンティティの) 1 つのトークンから (別のエンティティの) 別のトークンへの関係を予測します。
+
+BROS は、明示的な視覚機能に依存せずに、FUNSD、SROIE、CORD、SciTSR などの Key Information Extraction (KIE) ベンチマークで同等以上の結果を達成します。
+
+論文の要約は次のとおりです。
+
+*文書画像からの重要情報抽出 (KIE) には、2 次元 (2D) 空間におけるテキストの文脈的および空間的意味論を理解する必要があります。最近の研究の多くは、文書画像の視覚的特徴とテキストおよびそのレイアウトを組み合わせることに重点を置いた事前トレーニング済み言語モデルを開発することで、この課題を解決しようとしています。一方、このペーパーでは、テキストとレイアウトの効果的な組み合わせという基本に立ち返ってこの問題に取り組みます。具体的には、BROS (BERT Relying On Spatality) という名前の事前トレーニング済み言語モデルを提案します。この言語モデルは、2D 空間内のテキストの相対位置をエンコードし、エリア マスキング戦略を使用してラベルのないドキュメントから学習します。 2D 空間内のテキストを理解するためのこの最適化されたトレーニング スキームにより、BROS は、視覚的な特徴に依存することなく、4 つの KIE ベンチマーク (FUNSD、SROIE*、CORD、および SciTSR) で以前の方法と比較して同等以上のパフォーマンスを示しました。また、この論文では、KIE タスクにおける 2 つの現実世界の課題 ((1) 間違ったテキスト順序によるエラーの最小化、および (2) 少数の下流例からの効率的な学習) を明らかにし、以前の方法に対する BROS の優位性を実証します。*
+
+このモデルは [jinho8345](https://huggingface.co/jinho8345) によって寄稿されました。元のコードは [ここ](https://github.com/clovaai/bros) にあります。
+
+## Usage tips and examples
+
+- [`~transformers.BrosModel.forward`] には、`input_ids` と `bbox` (バウンディング ボックス) が必要です。各境界ボックスは、(x0、y0、x1、y1) 形式 (左上隅、右下隅) である必要があります。境界ボックスの取得は外部 OCR システムに依存します。 「x」座標はドキュメント画像の幅で正規化する必要があり、「y」座標はドキュメント画像の高さで正規化する必要があります。
+
+```python
+def expand_and_normalize_bbox(bboxes, doc_width, doc_height):
+ # here, bboxes are numpy array
+
+ # Normalize bbox -> 0 ~ 1
+ bboxes[:, [0, 2]] = bboxes[:, [0, 2]] / width
+ bboxes[:, [1, 3]] = bboxes[:, [1, 3]] / height
+```
+
+- [`~transformers.BrosForTokenClassification.forward`、`~transformers.BrosSpadeEEForTokenClassification.forward`、`~transformers.BrosSpadeEEForTokenClassification.forward`] では、損失計算に `input_ids` と `bbox` だけでなく `box_first_token_mask` も必要です。これは、各ボックスの先頭以外のトークンを除外するためのマスクです。このマスクは、単語から `input_ids` を作成するときに境界ボックスの開始トークン インデックスを保存することで取得できます。次のコードで`box_first_token_mask`を作成できます。
+
+```python
+def make_box_first_token_mask(bboxes, words, tokenizer, max_seq_length=512):
+
+ box_first_token_mask = np.zeros(max_seq_length, dtype=np.bool_)
+
+ # encode(tokenize) each word from words (List[str])
+ input_ids_list: List[List[int]] = [tokenizer.encode(e, add_special_tokens=False) for e in words]
+
+ # get the length of each box
+ tokens_length_list: List[int] = [len(l) for l in input_ids_list]
+
+ box_end_token_indices = np.array(list(itertools.accumulate(tokens_length_list)))
+ box_start_token_indices = box_end_token_indices - np.array(tokens_length_list)
+
+ # filter out the indices that are out of max_seq_length
+ box_end_token_indices = box_end_token_indices[box_end_token_indices < max_seq_length - 1]
+ if len(box_start_token_indices) > len(box_end_token_indices):
+ box_start_token_indices = box_start_token_indices[: len(box_end_token_indices)]
+
+ # set box_start_token_indices to True
+ box_first_token_mask[box_start_token_indices] = True
+
+ return box_first_token_mask
+
+```
+
+## Resources
+
+- デモ スクリプトは [こちら](https://github.com/clovaai/bros) にあります。
+
+## BrosConfig
+
+[[autodoc]] BrosConfig
+
+## BrosProcessor
+
+[[autodoc]] BrosProcessor
+ - __call__
+
+## BrosModel
+
+[[autodoc]] BrosModel
+ - forward
+
+
+## BrosForTokenClassification
+
+[[autodoc]] BrosForTokenClassification
+ - forward
+
+## BrosSpadeEEForTokenClassification
+
+[[autodoc]] BrosSpadeEEForTokenClassification
+ - forward
+
+## BrosSpadeELForTokenClassification
+
+[[autodoc]] BrosSpadeELForTokenClassification
+ - forward
diff --git a/docs/source/ja/model_doc/byt5.md b/docs/source/ja/model_doc/byt5.md
new file mode 100644
index 0000000000..c6796f9818
--- /dev/null
+++ b/docs/source/ja/model_doc/byt5.md
@@ -0,0 +1,154 @@
+
+
+# ByT5
+
+## Overview
+
+ByT5 モデルは、[ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir
+Kale, Adam Roberts, Colin Raffel.
+
+論文の要約は次のとおりです。
+
+*最も広く使用されている事前トレーニング済み言語モデルは、単語またはサブワード単位に対応するトークンのシーケンスで動作します。
+テキストをトークンのシーケンスとしてエンコードするには、トークナイザーが必要です。トークナイザーは通常、
+モデル。代わりに生のテキスト (バイトまたは文字) を直接操作するトークンフリー モデルには多くの利点があります。
+すぐに使用できるあらゆる言語のテキストを処理でき、ノイズに対してより堅牢であり、技術的負債を最小限に抑えます。
+複雑でエラーが発生しやすいテキスト前処理パイプラインを削除します。バイトまたは文字列がトークンより長いため
+トークンフリー モデルに関する過去の研究では、シーケンスのコストを償却するように設計された新しいモデル アーキテクチャが導入されることがよくありました。
+生のテキストを直接操作します。この論文では、標準的な Transformer アーキテクチャが次のようなもので使用できることを示します。
+バイトシーケンスを処理するための最小限の変更。パラメータ数の観点からトレードオフを注意深く特徴付けます。
+FLOP のトレーニングと推論速度を調べ、バイトレベルのモデルがトークンレベルと競合できることを示します。
+対応者。また、バイトレベルのモデルはノイズに対して大幅に堅牢であり、より優れたパフォーマンスを発揮することも示しています。
+スペルと発音に敏感なタスク。私たちの貢献の一環として、新しいセットをリリースします。
+T5 アーキテクチャに基づいた事前トレーニング済みのバイトレベルの Transformer モデルと、そこで使用されるすべてのコードとデータ
+実験。*
+
+このモデルは、[patrickvonplaten](https://huggingface.co/patrickvonplaten) によって提供されました。元のコードは次のとおりです
+[ここ](https://github.com/google-research/byt5) にあります。
+
+
+
+ByT5 のアーキテクチャは T5v1.1 モデルに基づいています。API リファレンスについては、[T5v1.1 のドキュメント ページ](t5v1.1) を参照してください。彼らは
+モデルの入力を準備する方法が異なるだけです。以下のコード例を参照してください。
+
+
+
+ByT5 は教師なしで事前トレーニングされているため、単一タスク中にタスク プレフィックスを使用する利点はありません。
+微調整。マルチタスクの微調整を行う場合は、プレフィックスを使用する必要があります。
+
+## Usage Examples
+
+ByT5 は生の UTF-8 バイトで動作するため、トークナイザーなしで使用できます。
+
+```python
+>>> from transformers import T5ForConditionalGeneration
+>>> import torch
+
+>>> model = T5ForConditionalGeneration.from_pretrained("google/byt5-small")
+
+>>> num_special_tokens = 3
+>>> # Model has 3 special tokens which take up the input ids 0,1,2 of ByT5.
+>>> # => Need to shift utf-8 character encodings by 3 before passing ids to model.
+
+>>> input_ids = torch.tensor([list("Life is like a box of chocolates.".encode("utf-8"))]) + num_special_tokens
+
+>>> labels = torch.tensor([list("La vie est comme une boîte de chocolat.".encode("utf-8"))]) + num_special_tokens
+
+>>> loss = model(input_ids, labels=labels).loss
+>>> loss.item()
+2.66
+```
+
+ただし、バッチ推論とトレーニングの場合は、トークナイザーを使用することをお勧めします。
+
+
+```python
+>>> from transformers import T5ForConditionalGeneration, AutoTokenizer
+
+>>> model = T5ForConditionalGeneration.from_pretrained("google/byt5-small")
+>>> tokenizer = AutoTokenizer.from_pretrained("google/byt5-small")
+
+>>> model_inputs = tokenizer(
+... ["Life is like a box of chocolates.", "Today is Monday."], padding="longest", return_tensors="pt"
+... )
+>>> labels_dict = tokenizer(
+... ["La vie est comme une boîte de chocolat.", "Aujourd'hui c'est lundi."], padding="longest", return_tensors="pt"
+... )
+>>> labels = labels_dict.input_ids
+
+>>> loss = model(**model_inputs, labels=labels).loss
+>>> loss.item()
+17.9
+```
+
+[T5](t5) と同様に、ByT5 はスパンマスクノイズ除去タスクでトレーニングされました。しかし、
+モデルはキャラクターに直接作用するため、事前トレーニングタスクは少し複雑です
+違う。のいくつかの文字を破損してみましょう
+`"The dog chases a ball in the park."`という文を入力し、ByT5 に予測してもらいます。
+わたしたちのため。
+
+```python
+>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
+>>> import torch
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google/byt5-base")
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("google/byt5-base")
+
+>>> input_ids_prompt = "The dog chases a ball in the park."
+>>> input_ids = tokenizer(input_ids_prompt).input_ids
+
+>>> # Note that we cannot add "{extra_id_...}" to the string directly
+>>> # as the Byte tokenizer would incorrectly merge the tokens
+>>> # For ByT5, we need to work directly on the character level
+>>> # Contrary to T5, ByT5 does not use sentinel tokens for masking, but instead
+>>> # uses final utf character ids.
+>>> # UTF-8 is represented by 8 bits and ByT5 has 3 special tokens.
+>>> # => There are 2**8+2 = 259 input ids and mask tokens count down from index 258.
+>>> # => mask to "The dog [258]a ball [257]park."
+
+>>> input_ids = torch.tensor([input_ids[:8] + [258] + input_ids[14:21] + [257] + input_ids[28:]])
+>>> input_ids
+tensor([[ 87, 107, 104, 35, 103, 114, 106, 35, 258, 35, 100, 35, 101, 100, 111, 111, 257, 35, 115, 100, 117, 110, 49, 1]])
+
+>>> # ByT5 produces only one char at a time so we need to produce many more output characters here -> set `max_length=100`.
+>>> output_ids = model.generate(input_ids, max_length=100)[0].tolist()
+>>> output_ids
+[0, 258, 108, 118, 35, 119, 107, 104, 35, 114, 113, 104, 35, 122, 107, 114, 35, 103, 114, 104, 118, 257, 35, 108, 113, 35, 119, 107, 104, 35, 103, 108, 118, 102, 114, 256, 108, 113, 35, 119, 107, 104, 35, 115, 100, 117, 110, 49, 35, 87, 107, 104, 35, 103, 114, 106, 35, 108, 118, 35, 119, 107, 104, 35, 114, 113, 104, 35, 122, 107, 114, 35, 103, 114, 104, 118, 35, 100, 35, 101, 100, 111, 111, 35, 108, 113, 255, 35, 108, 113, 35, 119, 107, 104, 35, 115, 100, 117, 110, 49]
+
+>>> # ^- Note how 258 descends to 257, 256, 255
+
+>>> # Now we need to split on the sentinel tokens, let's write a short loop for this
+>>> output_ids_list = []
+>>> start_token = 0
+>>> sentinel_token = 258
+>>> while sentinel_token in output_ids:
+... split_idx = output_ids.index(sentinel_token)
+... output_ids_list.append(output_ids[start_token:split_idx])
+... start_token = split_idx
+... sentinel_token -= 1
+
+>>> output_ids_list.append(output_ids[start_token:])
+>>> output_string = tokenizer.batch_decode(output_ids_list)
+>>> output_string
+['', 'is the one who does', ' in the disco', 'in the park. The dog is the one who does a ball in', ' in the park.']
+```
+
+## ByT5Tokenizer
+
+[[autodoc]] ByT5Tokenizer
+
+詳細については、[`ByT5Tokenizer`] を参照してください。
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/camembert.md b/docs/source/ja/model_doc/camembert.md
new file mode 100644
index 0000000000..db8e0aa936
--- /dev/null
+++ b/docs/source/ja/model_doc/camembert.md
@@ -0,0 +1,135 @@
+
+
+# CamemBERT
+
+## Overview
+
+CamemBERT モデルは、[CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) で提案されました。
+Louis Martin, Benjamin Muller, Pedro Javier Ortiz Suárez, Yoann Dupont, Laurent Romary, Éric Villemonte de la
+Clergerie, Djamé Seddah, and Benoît Sagot. 2019年にリリースされたFacebookのRoBERTaモデルをベースにしたモデルです。
+138GBのフランス語テキストでトレーニングされました。
+
+論文の要約は次のとおりです。
+
+*事前トレーニングされた言語モデルは現在、自然言語処理で広く普及しています。成功にもかかわらず、利用可能なほとんどの
+モデルは英語のデータ、または複数言語のデータの連結でトレーニングされています。これにより、
+このようなモデルの実際の使用は、英語を除くすべての言語で非常に限られています。フランス人にとってこの問題に対処することを目指して、
+Bi-direction Encoders for Transformers (BERT) のフランス語版である CamemBERT をリリースします。測定します
+複数の下流タスク、つまり品詞タグ付けにおける多言語モデルと比較した CamemBERT のパフォーマンス
+依存関係解析、固有表現認識、自然言語推論。 CamemBERT は最先端技術を向上させます
+検討されているほとんどのタスクに対応します。私たちは、研究と
+フランス語 NLP の下流アプリケーション。*
+
+このモデルは [camembert](https://huggingface.co/camembert) によって提供されました。元のコードは [ここ](https://camembert-model.fr/) にあります。
+
+
+
+
+この実装はRoBERTaと同じです。使用例については[RoBERTaのドキュメント](roberta)も参照してください。
+入力と出力に関する情報として。
+
+
+
+## Resources
+
+- [テキスト分類タスクガイド](../tasks/sequence_classification)
+- [トークン分類タスクガイド](../tasks/token_classification)
+- [質問回答タスク ガイド](../tasks/question_answering)
+- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
+- [マスク言語モデリング タスク ガイド](../tasks/masked_language_modeling)
+- [多肢選択タスク ガイド](../tasks/multiple_choice)
+
+## CamembertConfig
+
+[[autodoc]] CamembertConfig
+
+## CamembertTokenizer
+
+[[autodoc]] CamembertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## CamembertTokenizerFast
+
+[[autodoc]] CamembertTokenizerFast
+
+
+
+
+## CamembertModel
+
+[[autodoc]] CamembertModel
+
+## CamembertForCausalLM
+
+[[autodoc]] CamembertForCausalLM
+
+## CamembertForMaskedLM
+
+[[autodoc]] CamembertForMaskedLM
+
+## CamembertForSequenceClassification
+
+[[autodoc]] CamembertForSequenceClassification
+
+## CamembertForMultipleChoice
+
+[[autodoc]] CamembertForMultipleChoice
+
+## CamembertForTokenClassification
+
+[[autodoc]] CamembertForTokenClassification
+
+## CamembertForQuestionAnswering
+
+[[autodoc]] CamembertForQuestionAnswering
+
+
+
+
+## TFCamembertModel
+
+[[autodoc]] TFCamembertModel
+
+## TFCamembertForCasualLM
+
+[[autodoc]] TFCamembertForCausalLM
+
+## TFCamembertForMaskedLM
+
+[[autodoc]] TFCamembertForMaskedLM
+
+## TFCamembertForSequenceClassification
+
+[[autodoc]] TFCamembertForSequenceClassification
+
+## TFCamembertForMultipleChoice
+
+[[autodoc]] TFCamembertForMultipleChoice
+
+## TFCamembertForTokenClassification
+
+[[autodoc]] TFCamembertForTokenClassification
+
+## TFCamembertForQuestionAnswering
+
+[[autodoc]] TFCamembertForQuestionAnswering
+
+
+
diff --git a/docs/source/ja/model_doc/canine.md b/docs/source/ja/model_doc/canine.md
new file mode 100644
index 0000000000..18af699967
--- /dev/null
+++ b/docs/source/ja/model_doc/canine.md
@@ -0,0 +1,144 @@
+
+
+# CANINE
+
+## Overview
+
+CANINE モデルは、[CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language
+Representation](https://arxiv.org/abs/2103.06874)、Jonathan H. Clark、Dan Garrette、Iulia Turc、John Wieting 著。その
+明示的なトークン化ステップ (バイト ペアなど) を使用せずに Transformer をトレーニングする最初の論文の 1 つ
+エンコーディング (BPE、WordPiece または SentencePiece)。代わりに、モデルは Unicode 文字レベルで直接トレーニングされます。
+キャラクターレベルでのトレーニングでは必然的にシーケンスの長さが長くなりますが、CANINE はこれを効率的な方法で解決します。
+ディープ Transformer エンコーダを適用する前に、ダウンサンプリング戦略を実行します。
+
+論文の要約は次のとおりです。
+
+*パイプライン NLP システムは、エンドツーエンドのニューラル モデリングに大部分が取って代わられていますが、一般的に使用されているほぼすべてのモデルは
+依然として明示的なトークン化手順が必要です。最近のトークン化アプローチはデータ由来のサブワードに基づいていますが、
+レキシコンは手動で作成されたトークナイザーよりも脆弱ではありませんが、これらの技術はすべての言語に等しく適しているわけではありません。
+言語や固定語彙の使用により、モデルの適応能力が制限される可能性があります。この論文では、CANINE を紹介します。
+明示的なトークン化や語彙を使用せずに、文字シーケンスを直接操作するニューラル エンコーダーと、
+文字に直接作用するか、オプションでサブワードをソフト誘導バイアスとして使用する事前トレーニング戦略。
+よりきめの細かい入力を効果的かつ効率的に使用するために、CANINE はダウンサンプリングを組み合わせて、入力を削減します。
+コンテキストをエンコードするディープトランスフォーマースタックを備えたシーケンスの長さ。 CANINE は、同等の mBERT モデルよりも次の点で優れています。
+TyDi QA の 2.8 F1 は、モデル パラメータが 28% 少ないにもかかわらず、困難な多言語ベンチマークです。*
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。元のコードは [ここ](https://github.com/google-research/language/tree/master/language/canine) にあります。
+
+## Usage tips
+
+- CANINE は内部で少なくとも 3 つの Transformer エンコーダーを使用します: 2 つの「浅い」エンコーダー (単一のエンコーダーのみで構成)
+ レイヤー) と 1 つの「ディープ」エンコーダー (通常の BERT エンコーダー)。まず、「浅い」エンコーダを使用してコンテキストを設定します。
+ ローカル アテンションを使用した文字の埋め込み。次に、ダウンサンプリングの後、「ディープ」エンコーダーが適用されます。ついに、
+ アップサンプリング後、「浅い」エンコーダを使用して最終的な文字埋め込みが作成されます。アップと
+ ダウンサンプリングについては論文に記載されています。
+- CANINE は、デフォルトで 2048 文字の最大シーケンス長を使用します。 [`CanineTokenizer`] を使用できます
+ モデル用のテキストを準備します。
+- 特別な [CLS] トークンの最終的な非表示状態の上に線形レイヤーを配置することで分類を行うことができます。
+ (事前定義された Unicode コード ポイントがあります)。ただし、トークン分類タスクの場合は、ダウンサンプリングされたシーケンス
+ トークンは、元の文字シーケンスの長さ (2048) と一致するように再度アップサンプリングする必要があります。の
+ 詳細については、論文を参照してください。
+
+モデルのチェックポイント:
+
+ - [google/canine-c](https://huggingface.co/google/canine-c): 自己回帰文字損失で事前トレーニング済み、
+ 12 レイヤー、768 隠し、12 ヘッド、121M パラメーター (サイズ ~500 MB)。
+ - [google/canine-s](https://huggingface.co/google/canine-s): サブワード損失で事前トレーニング済み、12 層、
+ 768 個の非表示、12 ヘッド、121M パラメーター (サイズ ~500 MB)。
+
+## Usage example
+
+CANINE は生の文字で動作するため、**トークナイザーなし**で使用できます。
+
+```python
+>>> from transformers import CanineModel
+>>> import torch
+
+>>> model = CanineModel.from_pretrained("google/canine-c") # model pre-trained with autoregressive character loss
+
+>>> text = "hello world"
+>>> # use Python's built-in ord() function to turn each character into its unicode code point id
+>>> input_ids = torch.tensor([[ord(char) for char in text]])
+
+>>> outputs = model(input_ids) # forward pass
+>>> pooled_output = outputs.pooler_output
+>>> sequence_output = outputs.last_hidden_state
+```
+
+ただし、バッチ推論とトレーニングの場合は、トークナイザーを使用することをお勧めします(すべてをパディング/切り詰めるため)
+シーケンスを同じ長さにします):
+
+```python
+>>> from transformers import CanineTokenizer, CanineModel
+
+>>> model = CanineModel.from_pretrained("google/canine-c")
+>>> tokenizer = CanineTokenizer.from_pretrained("google/canine-c")
+
+>>> inputs = ["Life is like a box of chocolates.", "You never know what you gonna get."]
+>>> encoding = tokenizer(inputs, padding="longest", truncation=True, return_tensors="pt")
+
+>>> outputs = model(**encoding) # forward pass
+>>> pooled_output = outputs.pooler_output
+>>> sequence_output = outputs.last_hidden_state
+```
+
+## Resources
+
+- [テキスト分類タスクガイド](../tasks/sequence_classification)
+- [トークン分類タスクガイド](../tasks/token_classification)
+- [質問回答タスク ガイド](../tasks/question_answering)
+- [多肢選択タスク ガイド](../tasks/multiple_choice)
+
+## CanineConfig
+
+[[autodoc]] CanineConfig
+
+## CanineTokenizer
+
+[[autodoc]] CanineTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+
+## CANINE specific outputs
+
+[[autodoc]] models.canine.modeling_canine.CanineModelOutputWithPooling
+
+## CanineModel
+
+[[autodoc]] CanineModel
+ - forward
+
+## CanineForSequenceClassification
+
+[[autodoc]] CanineForSequenceClassification
+ - forward
+
+## CanineForMultipleChoice
+
+[[autodoc]] CanineForMultipleChoice
+ - forward
+
+## CanineForTokenClassification
+
+[[autodoc]] CanineForTokenClassification
+ - forward
+
+## CanineForQuestionAnswering
+
+[[autodoc]] CanineForQuestionAnswering
+ - forward
diff --git a/docs/source/ja/model_doc/chinese_clip.md b/docs/source/ja/model_doc/chinese_clip.md
new file mode 100644
index 0000000000..8d7dc401d2
--- /dev/null
+++ b/docs/source/ja/model_doc/chinese_clip.md
@@ -0,0 +1,112 @@
+
+
+# Chinese-CLIP
+
+## Overview
+
+Chinese-CLIP An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://arxiv.org/abs/2211.01335) で提案されました。周、張周。
+Chinese-CLIP は、中国語の画像とテキストのペアの大規模なデータセットに対する CLIP (Radford et al., 2021) の実装です。クロスモーダル検索を実行できるほか、ゼロショット画像分類、オープンドメインオブジェクト検出などのビジョンタスクのビジョンバックボーンとしても機能します。オリジナルの中国語-CLIPコードは[このリンクで](https://github.com/OFA-Sys/Chinese-CLIP)。
+
+論文の要約は次のとおりです。
+
+*CLIP の大成功 (Radford et al., 2021) により、視覚言語の事前訓練のための対照学習の研究と応用が促進されました。この研究では、ほとんどのデータが公開されているデータセットから取得された中国語の画像とテキストのペアの大規模なデータセットを構築し、新しいデータセットで中国語の CLIP モデルを事前トレーニングします。当社では、7,700 万から 9 億 5,800 万のパラメータにわたる、複数のサイズの 5 つの中国 CLIP モデルを開発しています。さらに、モデルのパフォーマンスを向上させるために、最初に画像エンコーダーをフリーズさせてモデルをトレーニングし、次にすべてのパラメーターを最適化してトレーニングする 2 段階の事前トレーニング方法を提案します。私たちの包括的な実験では、中国の CLIP がゼロショット学習と微調整のセットアップで MUGE、Flickr30K-CN、および COCO-CN 上で最先端のパフォーマンスを達成でき、ゼロで競争力のあるパフォーマンスを達成できることを実証しています。 - ELEVATER ベンチマークでの評価に基づくショット画像の分類 (Li et al., 2022)。コード、事前トレーニング済みモデル、デモがリリースされました。*
+
+Chinese-CLIP モデルは、[OFA-Sys](https://huggingface.co/OFA-Sys) によって提供されました。
+
+## Usage example
+
+以下のコード スニペットは、画像とテキストの特徴と類似性を計算する方法を示しています。
+
+```python
+>>> from PIL import Image
+>>> import requests
+>>> from transformers import ChineseCLIPProcessor, ChineseCLIPModel
+
+>>> model = ChineseCLIPModel.from_pretrained("OFA-Sys/chinese-clip-vit-base-patch16")
+>>> processor = ChineseCLIPProcessor.from_pretrained("OFA-Sys/chinese-clip-vit-base-patch16")
+
+>>> url = "https://clip-cn-beijing.oss-cn-beijing.aliyuncs.com/pokemon.jpeg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> # Squirtle, Bulbasaur, Charmander, Pikachu in English
+>>> texts = ["杰尼龟", "妙蛙种子", "小火龙", "皮卡丘"]
+
+>>> # compute image feature
+>>> inputs = processor(images=image, return_tensors="pt")
+>>> image_features = model.get_image_features(**inputs)
+>>> image_features = image_features / image_features.norm(p=2, dim=-1, keepdim=True) # normalize
+
+>>> # compute text features
+>>> inputs = processor(text=texts, padding=True, return_tensors="pt")
+>>> text_features = model.get_text_features(**inputs)
+>>> text_features = text_features / text_features.norm(p=2, dim=-1, keepdim=True) # normalize
+
+>>> # compute image-text similarity scores
+>>> inputs = processor(text=texts, images=image, return_tensors="pt", padding=True)
+>>> outputs = model(**inputs)
+>>> logits_per_image = outputs.logits_per_image # this is the image-text similarity score
+>>> probs = logits_per_image.softmax(dim=1) # probs: [[1.2686e-03, 5.4499e-02, 6.7968e-04, 9.4355e-01]]
+```
+
+現在、次のスケールの事前トレーニング済み Chinese-CLIP モデルが 🤗 Hub で利用可能です。
+
+- [OFA-Sys/chinese-clip-vit-base-patch16](https://huggingface.co/OFA-Sys/chinese-clip-vit-base-patch16)
+- [OFA-Sys/chinese-clip-vit-large-patch14](https://huggingface.co/OFA-Sys/chinese-clip-vit-large-patch14)
+- [OFA-Sys/chinese-clip-vit-large-patch14-336px](https://huggingface.co/OFA-Sys/chinese-clip-vit-large-patch14-336px)
+- [OFA-Sys/chinese-clip-vit-huge-patch14](https://huggingface.co/OFA-Sys/chinese-clip-vit-huge-patch14)
+
+## ChineseCLIPConfig
+
+[[autodoc]] ChineseCLIPConfig
+ - from_text_vision_configs
+
+## ChineseCLIPTextConfig
+
+[[autodoc]] ChineseCLIPTextConfig
+
+## ChineseCLIPVisionConfig
+
+[[autodoc]] ChineseCLIPVisionConfig
+
+## ChineseCLIPImageProcessor
+
+[[autodoc]] ChineseCLIPImageProcessor
+ - preprocess
+
+## ChineseCLIPFeatureExtractor
+
+[[autodoc]] ChineseCLIPFeatureExtractor
+
+## ChineseCLIPProcessor
+
+[[autodoc]] ChineseCLIPProcessor
+
+## ChineseCLIPModel
+
+[[autodoc]] ChineseCLIPModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## ChineseCLIPTextModel
+
+[[autodoc]] ChineseCLIPTextModel
+ - forward
+
+## ChineseCLIPVisionModel
+
+[[autodoc]] ChineseCLIPVisionModel
+ - forward
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/clap.md b/docs/source/ja/model_doc/clap.md
new file mode 100644
index 0000000000..f1e08d7601
--- /dev/null
+++ b/docs/source/ja/model_doc/clap.md
@@ -0,0 +1,80 @@
+
+
+# CLAP
+
+## Overview
+
+CLAP モデルは、[Large Scale Contrastive Language-Audio pretraining with
+feature fusion and keyword-to-caption augmentation](https://arxiv.org/pdf/2211.06687.pdf)、Yusong Wu、Ke Chen、Tianyu Zhang、Yuchen Hui、Taylor Berg-Kirkpatrick、Shlomo Dubnov 著。
+
+CLAP (Contrastive Language-Audio Pretraining) は、さまざまな (音声、テキスト) ペアでトレーニングされたニューラル ネットワークです。タスクに合わせて直接最適化することなく、音声が与えられた場合に最も関連性の高いテキスト スニペットを予測するように指示できます。 CLAP モデルは、SWINTransformer を使用して log-Mel スペクトログラム入力からオーディオ特徴を取得し、RoBERTa モデルを使用してテキスト特徴を取得します。次に、テキストとオーディオの両方の特徴が、同じ次元の潜在空間に投影されます。投影されたオーディオとテキストの特徴の間のドット積が、同様のスコアとして使用されます。
+
+論文の要約は次のとおりです。
+
+*対照学習は、マルチモーダル表現学習の分野で目覚ましい成功を収めています。この論文では、音声データと自然言語記述を組み合わせて音声表現を開発する、対照的な言語音声事前トレーニングのパイプラインを提案します。この目標を達成するために、私たちはまず、さまざまなデータ ソースからの 633,526 個の音声とテキストのペアの大規模なコレクションである LAION-Audio-630K をリリースします。次に、さまざまなオーディオ エンコーダとテキスト エンコーダを考慮して、対照的な言語とオーディオの事前トレーニング モデルを構築します。機能融合メカニズムとキーワードからキャプションへの拡張をモデル設計に組み込んで、モデルが可変長の音声入力を処理できるようにし、パフォーマンスを向上させます。 3 番目に、包括的な実験を実行して、テキストから音声への取得、ゼロショット音声分類、教師付き音声分類の 3 つのタスクにわたってモデルを評価します。結果は、私たちのモデルがテキストから音声への検索タスクにおいて優れたパフォーマンスを達成していることを示しています。オーディオ分類タスクでは、モデルはゼロショット設定で最先端のパフォーマンスを達成し、非ゼロショット設定でもモデルの結果に匹敵するパフォーマンスを得ることができます。 LAION-オーディオ-6*
+
+このモデルは、[Younes Belkada](https://huggingface.co/ybelkada) および [Arthur Zucker](https://huggingface.co/ArthurZ) によって提供されました。
+元のコードは [こちら](https://github.com/LAION-AI/Clap) にあります。
+
+## ClapConfig
+
+[[autodoc]] ClapConfig
+ - from_text_audio_configs
+
+## ClapTextConfig
+
+[[autodoc]] ClapTextConfig
+
+## ClapAudioConfig
+
+[[autodoc]] ClapAudioConfig
+
+## ClapFeatureExtractor
+
+[[autodoc]] ClapFeatureExtractor
+
+## ClapProcessor
+
+[[autodoc]] ClapProcessor
+
+## ClapModel
+
+[[autodoc]] ClapModel
+ - forward
+ - get_text_features
+ - get_audio_features
+
+## ClapTextModel
+
+[[autodoc]] ClapTextModel
+ - forward
+
+## ClapTextModelWithProjection
+
+[[autodoc]] ClapTextModelWithProjection
+ - forward
+
+## ClapAudioModel
+
+[[autodoc]] ClapAudioModel
+ - forward
+
+## ClapAudioModelWithProjection
+
+[[autodoc]] ClapAudioModelWithProjection
+ - forward
+
\ No newline at end of file
+
+ ブリッジタワー アーキテクチャ。 元の論文から抜粋。
+
+このモデルは、[Anahita Bhiwandiwalla](https://huggingface.co/anahita-b)、[Tiep Le](https://huggingface.co/Tile)、[Shaoyen Tseng](https://huggingface.co/shaoyent)。元のコードは [ここ](https://github.com/microsoft/BridgeTower) にあります。
+
+## Usage tips and examples
+
+BridgeTower は、ビジュアル エンコーダー、テキスト エンコーダー、および複数の軽量ブリッジ レイヤーを備えたクロスモーダル エンコーダーで構成されます。
+このアプローチの目標は、各ユニモーダル エンコーダーとクロスモーダル エンコーダーの間にブリッジを構築し、クロスモーダル エンコーダーの各層で包括的かつ詳細な対話を可能にすることでした。
+原則として、提案されたアーキテクチャでは、任意のビジュアル、テキスト、またはクロスモーダル エンコーダを適用できます。
+
+[`BridgeTowerProcessor`] は、[`RobertaTokenizer`] と [`BridgeTowerImageProcessor`] を単一のインスタンスにラップし、両方の機能を実現します。
+テキストをエンコードし、画像をそれぞれ用意します。
+
+次の例は、[`BridgeTowerProcessor`] と [`BridgeTowerForContrastiveLearning`] を使用して対照学習を実行する方法を示しています。
+
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForContrastiveLearning
+>>> import requests
+>>> from PIL import Image
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
+
+>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
+>>> model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
+
+>>> # forward pass
+>>> scores = dict()
+>>> for text in texts:
+... # prepare inputs
+... encoding = processor(image, text, return_tensors="pt")
+... outputs = model(**encoding)
+... scores[text] = outputs
+```
+
+次の例は、[`BridgeTowerProcessor`] と [`BridgeTowerForImageAndTextRetrieval`] を使用して画像テキストの取得を実行する方法を示しています。
+
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
+>>> import requests
+>>> from PIL import Image
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
+
+>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+>>> model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+
+>>> # forward pass
+>>> scores = dict()
+>>> for text in texts:
+... # prepare inputs
+... encoding = processor(image, text, return_tensors="pt")
+... outputs = model(**encoding)
+... scores[text] = outputs.logits[0, 1].item()
+```
+
+次の例は、[`BridgeTowerProcessor`] と [`BridgeTowerForMaskedLM`] を使用してマスクされた言語モデリングを実行する方法を示しています。
+
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
+>>> from PIL import Image
+>>> import requests
+
+>>> url = "http://images.cocodataset.org/val2017/000000360943.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
+>>> text = "a looking out of the window"
+
+>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+>>> model = BridgeTowerForMaskedLM.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+
+>>> # prepare inputs
+>>> encoding = processor(image, text, return_tensors="pt")
+
+>>> # forward pass
+>>> outputs = model(**encoding)
+
+>>> results = processor.decode(outputs.logits.argmax(dim=-1).squeeze(0).tolist())
+
+>>> print(results)
+.a cat looking out of the window.
+```
+
+チップ:
+
+- BridgeTower のこの実装では、[`RobertaTokenizer`] を使用してテキスト埋め込みを生成し、OpenAI の CLIP/ViT モデルを使用して視覚的埋め込みを計算します。
+- 事前トレーニングされた [bridgeTower-base](https://huggingface.co/BridgeTower/bridgetower-base) および [bridgetower マスクされた言語モデリングと画像テキスト マッチング](https://huggingface.co/BridgeTower/bridgetower--base-itm-mlm) のチェックポイント がリリースされました。
+- 画像検索およびその他の下流タスクにおける BridgeTower のパフォーマンスについては、[表 5](https://arxiv.org/pdf/2206.08657.pdf) を参照してください。
+- このモデルの PyTorch バージョンは、torch 1.10 以降でのみ使用できます。
+
+## BridgeTowerConfig
+
+[[autodoc]] BridgeTowerConfig
+
+## BridgeTowerTextConfig
+
+[[autodoc]] BridgeTowerTextConfig
+
+## BridgeTowerVisionConfig
+
+[[autodoc]] BridgeTowerVisionConfig
+
+## BridgeTowerImageProcessor
+
+[[autodoc]] BridgeTowerImageProcessor
+ - preprocess
+
+## BridgeTowerProcessor
+
+[[autodoc]] BridgeTowerProcessor
+ - __call__
+
+## BridgeTowerModel
+
+[[autodoc]] BridgeTowerModel
+ - forward
+
+## BridgeTowerForContrastiveLearning
+
+[[autodoc]] BridgeTowerForContrastiveLearning
+ - forward
+
+## BridgeTowerForMaskedLM
+
+[[autodoc]] BridgeTowerForMaskedLM
+ - forward
+
+## BridgeTowerForImageAndTextRetrieval
+
+[[autodoc]] BridgeTowerForImageAndTextRetrieval
+ - forward
+
diff --git a/docs/source/ja/model_doc/bros.md b/docs/source/ja/model_doc/bros.md
new file mode 100644
index 0000000000..3749a172a8
--- /dev/null
+++ b/docs/source/ja/model_doc/bros.md
@@ -0,0 +1,113 @@
+
+
+# BROS
+
+## Overview
+
+BROS モデルは、Teakgyu Hon、Donghyun Kim、Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park によって [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://arxiv.org/abs/2108.04539) で提案されました。
+
+BROS は *BERT Relying On Spatality* の略です。これは、一連のトークンとその境界ボックスを入力として受け取り、一連の隠れ状態を出力するエンコーダー専用の Transformer モデルです。 BROS は、絶対的な空間情報を使用する代わりに、相対的な空間情報をエンコードします。
+
+BERT で使用されるトークンマスク言語モデリング目標 (TMLM) と新しいエリアマスク言語モデリング目標 (AMLM) の 2 つの目標で事前トレーニングされています。
+TMLM では、トークンはランダムにマスクされ、モデルは空間情報と他のマスクされていないトークンを使用してマスクされたトークンを予測します。
+AMLM は TMLM の 2D バージョンです。テキスト トークンをランダムにマスクし、TMLM と同じ情報で予測しますが、テキスト ブロック (領域) をマスクします。
+
+`BrosForTokenClassification`には、BrosModel の上に単純な線形層があります。各トークンのラベルを予測します。
+`BrosSpadeEEForTokenClassification`には、BrosModel の上に`initial_token_classifier`と`subsequent_token_classifier`があります。 `initial_token_classifier` は各エンティティの最初のトークンを予測するために使用され、`subsequent_token_classifier` はエンティティ内の次のトークンを予測するために使用されます。 `BrosSpadeELForTokenClassification`には BrosModel の上に`entity_linker`があります。 `entity_linker` は 2 つのエンティティ間の関係を予測するために使用されます。
+
+`BrosForTokenClassification`と`BrosSpadeEEForTokenClassification`は基本的に同じジョブを実行します。ただし、`BrosForTokenClassification`は入力トークンが完全にシリアル化されていることを前提としています (トークンは 2D 空間に存在するため、これは非常に困難な作業です)。一方、`BrosSpadeEEForTokenClassification`は 1 つのトークンから次の接続トークンを予測するため、シリアル化エラーの処理をより柔軟に行うことができます。
+
+`BrosSpadeELForTokenClassification` はエンティティ内のリンク タスクを実行します。これら 2 つのエンティティが何らかの関係を共有する場合、(あるエンティティの) 1 つのトークンから (別のエンティティの) 別のトークンへの関係を予測します。
+
+BROS は、明示的な視覚機能に依存せずに、FUNSD、SROIE、CORD、SciTSR などの Key Information Extraction (KIE) ベンチマークで同等以上の結果を達成します。
+
+論文の要約は次のとおりです。
+
+*文書画像からの重要情報抽出 (KIE) には、2 次元 (2D) 空間におけるテキストの文脈的および空間的意味論を理解する必要があります。最近の研究の多くは、文書画像の視覚的特徴とテキストおよびそのレイアウトを組み合わせることに重点を置いた事前トレーニング済み言語モデルを開発することで、この課題を解決しようとしています。一方、このペーパーでは、テキストとレイアウトの効果的な組み合わせという基本に立ち返ってこの問題に取り組みます。具体的には、BROS (BERT Relying On Spatality) という名前の事前トレーニング済み言語モデルを提案します。この言語モデルは、2D 空間内のテキストの相対位置をエンコードし、エリア マスキング戦略を使用してラベルのないドキュメントから学習します。 2D 空間内のテキストを理解するためのこの最適化されたトレーニング スキームにより、BROS は、視覚的な特徴に依存することなく、4 つの KIE ベンチマーク (FUNSD、SROIE*、CORD、および SciTSR) で以前の方法と比較して同等以上のパフォーマンスを示しました。また、この論文では、KIE タスクにおける 2 つの現実世界の課題 ((1) 間違ったテキスト順序によるエラーの最小化、および (2) 少数の下流例からの効率的な学習) を明らかにし、以前の方法に対する BROS の優位性を実証します。*
+
+このモデルは [jinho8345](https://huggingface.co/jinho8345) によって寄稿されました。元のコードは [ここ](https://github.com/clovaai/bros) にあります。
+
+## Usage tips and examples
+
+- [`~transformers.BrosModel.forward`] には、`input_ids` と `bbox` (バウンディング ボックス) が必要です。各境界ボックスは、(x0、y0、x1、y1) 形式 (左上隅、右下隅) である必要があります。境界ボックスの取得は外部 OCR システムに依存します。 「x」座標はドキュメント画像の幅で正規化する必要があり、「y」座標はドキュメント画像の高さで正規化する必要があります。
+
+```python
+def expand_and_normalize_bbox(bboxes, doc_width, doc_height):
+ # here, bboxes are numpy array
+
+ # Normalize bbox -> 0 ~ 1
+ bboxes[:, [0, 2]] = bboxes[:, [0, 2]] / width
+ bboxes[:, [1, 3]] = bboxes[:, [1, 3]] / height
+```
+
+- [`~transformers.BrosForTokenClassification.forward`、`~transformers.BrosSpadeEEForTokenClassification.forward`、`~transformers.BrosSpadeEEForTokenClassification.forward`] では、損失計算に `input_ids` と `bbox` だけでなく `box_first_token_mask` も必要です。これは、各ボックスの先頭以外のトークンを除外するためのマスクです。このマスクは、単語から `input_ids` を作成するときに境界ボックスの開始トークン インデックスを保存することで取得できます。次のコードで`box_first_token_mask`を作成できます。
+
+```python
+def make_box_first_token_mask(bboxes, words, tokenizer, max_seq_length=512):
+
+ box_first_token_mask = np.zeros(max_seq_length, dtype=np.bool_)
+
+ # encode(tokenize) each word from words (List[str])
+ input_ids_list: List[List[int]] = [tokenizer.encode(e, add_special_tokens=False) for e in words]
+
+ # get the length of each box
+ tokens_length_list: List[int] = [len(l) for l in input_ids_list]
+
+ box_end_token_indices = np.array(list(itertools.accumulate(tokens_length_list)))
+ box_start_token_indices = box_end_token_indices - np.array(tokens_length_list)
+
+ # filter out the indices that are out of max_seq_length
+ box_end_token_indices = box_end_token_indices[box_end_token_indices < max_seq_length - 1]
+ if len(box_start_token_indices) > len(box_end_token_indices):
+ box_start_token_indices = box_start_token_indices[: len(box_end_token_indices)]
+
+ # set box_start_token_indices to True
+ box_first_token_mask[box_start_token_indices] = True
+
+ return box_first_token_mask
+
+```
+
+## Resources
+
+- デモ スクリプトは [こちら](https://github.com/clovaai/bros) にあります。
+
+## BrosConfig
+
+[[autodoc]] BrosConfig
+
+## BrosProcessor
+
+[[autodoc]] BrosProcessor
+ - __call__
+
+## BrosModel
+
+[[autodoc]] BrosModel
+ - forward
+
+
+## BrosForTokenClassification
+
+[[autodoc]] BrosForTokenClassification
+ - forward
+
+## BrosSpadeEEForTokenClassification
+
+[[autodoc]] BrosSpadeEEForTokenClassification
+ - forward
+
+## BrosSpadeELForTokenClassification
+
+[[autodoc]] BrosSpadeELForTokenClassification
+ - forward
diff --git a/docs/source/ja/model_doc/byt5.md b/docs/source/ja/model_doc/byt5.md
new file mode 100644
index 0000000000..c6796f9818
--- /dev/null
+++ b/docs/source/ja/model_doc/byt5.md
@@ -0,0 +1,154 @@
+
+
+# ByT5
+
+## Overview
+
+ByT5 モデルは、[ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir
+Kale, Adam Roberts, Colin Raffel.
+
+論文の要約は次のとおりです。
+
+*最も広く使用されている事前トレーニング済み言語モデルは、単語またはサブワード単位に対応するトークンのシーケンスで動作します。
+テキストをトークンのシーケンスとしてエンコードするには、トークナイザーが必要です。トークナイザーは通常、
+モデル。代わりに生のテキスト (バイトまたは文字) を直接操作するトークンフリー モデルには多くの利点があります。
+すぐに使用できるあらゆる言語のテキストを処理でき、ノイズに対してより堅牢であり、技術的負債を最小限に抑えます。
+複雑でエラーが発生しやすいテキスト前処理パイプラインを削除します。バイトまたは文字列がトークンより長いため
+トークンフリー モデルに関する過去の研究では、シーケンスのコストを償却するように設計された新しいモデル アーキテクチャが導入されることがよくありました。
+生のテキストを直接操作します。この論文では、標準的な Transformer アーキテクチャが次のようなもので使用できることを示します。
+バイトシーケンスを処理するための最小限の変更。パラメータ数の観点からトレードオフを注意深く特徴付けます。
+FLOP のトレーニングと推論速度を調べ、バイトレベルのモデルがトークンレベルと競合できることを示します。
+対応者。また、バイトレベルのモデルはノイズに対して大幅に堅牢であり、より優れたパフォーマンスを発揮することも示しています。
+スペルと発音に敏感なタスク。私たちの貢献の一環として、新しいセットをリリースします。
+T5 アーキテクチャに基づいた事前トレーニング済みのバイトレベルの Transformer モデルと、そこで使用されるすべてのコードとデータ
+実験。*
+
+このモデルは、[patrickvonplaten](https://huggingface.co/patrickvonplaten) によって提供されました。元のコードは次のとおりです
+[ここ](https://github.com/google-research/byt5) にあります。
+
+
+
+ByT5 のアーキテクチャは T5v1.1 モデルに基づいています。API リファレンスについては、[T5v1.1 のドキュメント ページ](t5v1.1) を参照してください。彼らは
+モデルの入力を準備する方法が異なるだけです。以下のコード例を参照してください。
+
+
+
+ByT5 は教師なしで事前トレーニングされているため、単一タスク中にタスク プレフィックスを使用する利点はありません。
+微調整。マルチタスクの微調整を行う場合は、プレフィックスを使用する必要があります。
+
+## Usage Examples
+
+ByT5 は生の UTF-8 バイトで動作するため、トークナイザーなしで使用できます。
+
+```python
+>>> from transformers import T5ForConditionalGeneration
+>>> import torch
+
+>>> model = T5ForConditionalGeneration.from_pretrained("google/byt5-small")
+
+>>> num_special_tokens = 3
+>>> # Model has 3 special tokens which take up the input ids 0,1,2 of ByT5.
+>>> # => Need to shift utf-8 character encodings by 3 before passing ids to model.
+
+>>> input_ids = torch.tensor([list("Life is like a box of chocolates.".encode("utf-8"))]) + num_special_tokens
+
+>>> labels = torch.tensor([list("La vie est comme une boîte de chocolat.".encode("utf-8"))]) + num_special_tokens
+
+>>> loss = model(input_ids, labels=labels).loss
+>>> loss.item()
+2.66
+```
+
+ただし、バッチ推論とトレーニングの場合は、トークナイザーを使用することをお勧めします。
+
+
+```python
+>>> from transformers import T5ForConditionalGeneration, AutoTokenizer
+
+>>> model = T5ForConditionalGeneration.from_pretrained("google/byt5-small")
+>>> tokenizer = AutoTokenizer.from_pretrained("google/byt5-small")
+
+>>> model_inputs = tokenizer(
+... ["Life is like a box of chocolates.", "Today is Monday."], padding="longest", return_tensors="pt"
+... )
+>>> labels_dict = tokenizer(
+... ["La vie est comme une boîte de chocolat.", "Aujourd'hui c'est lundi."], padding="longest", return_tensors="pt"
+... )
+>>> labels = labels_dict.input_ids
+
+>>> loss = model(**model_inputs, labels=labels).loss
+>>> loss.item()
+17.9
+```
+
+[T5](t5) と同様に、ByT5 はスパンマスクノイズ除去タスクでトレーニングされました。しかし、
+モデルはキャラクターに直接作用するため、事前トレーニングタスクは少し複雑です
+違う。のいくつかの文字を破損してみましょう
+`"The dog chases a ball in the park."`という文を入力し、ByT5 に予測してもらいます。
+わたしたちのため。
+
+```python
+>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
+>>> import torch
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google/byt5-base")
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("google/byt5-base")
+
+>>> input_ids_prompt = "The dog chases a ball in the park."
+>>> input_ids = tokenizer(input_ids_prompt).input_ids
+
+>>> # Note that we cannot add "{extra_id_...}" to the string directly
+>>> # as the Byte tokenizer would incorrectly merge the tokens
+>>> # For ByT5, we need to work directly on the character level
+>>> # Contrary to T5, ByT5 does not use sentinel tokens for masking, but instead
+>>> # uses final utf character ids.
+>>> # UTF-8 is represented by 8 bits and ByT5 has 3 special tokens.
+>>> # => There are 2**8+2 = 259 input ids and mask tokens count down from index 258.
+>>> # => mask to "The dog [258]a ball [257]park."
+
+>>> input_ids = torch.tensor([input_ids[:8] + [258] + input_ids[14:21] + [257] + input_ids[28:]])
+>>> input_ids
+tensor([[ 87, 107, 104, 35, 103, 114, 106, 35, 258, 35, 100, 35, 101, 100, 111, 111, 257, 35, 115, 100, 117, 110, 49, 1]])
+
+>>> # ByT5 produces only one char at a time so we need to produce many more output characters here -> set `max_length=100`.
+>>> output_ids = model.generate(input_ids, max_length=100)[0].tolist()
+>>> output_ids
+[0, 258, 108, 118, 35, 119, 107, 104, 35, 114, 113, 104, 35, 122, 107, 114, 35, 103, 114, 104, 118, 257, 35, 108, 113, 35, 119, 107, 104, 35, 103, 108, 118, 102, 114, 256, 108, 113, 35, 119, 107, 104, 35, 115, 100, 117, 110, 49, 35, 87, 107, 104, 35, 103, 114, 106, 35, 108, 118, 35, 119, 107, 104, 35, 114, 113, 104, 35, 122, 107, 114, 35, 103, 114, 104, 118, 35, 100, 35, 101, 100, 111, 111, 35, 108, 113, 255, 35, 108, 113, 35, 119, 107, 104, 35, 115, 100, 117, 110, 49]
+
+>>> # ^- Note how 258 descends to 257, 256, 255
+
+>>> # Now we need to split on the sentinel tokens, let's write a short loop for this
+>>> output_ids_list = []
+>>> start_token = 0
+>>> sentinel_token = 258
+>>> while sentinel_token in output_ids:
+... split_idx = output_ids.index(sentinel_token)
+... output_ids_list.append(output_ids[start_token:split_idx])
+... start_token = split_idx
+... sentinel_token -= 1
+
+>>> output_ids_list.append(output_ids[start_token:])
+>>> output_string = tokenizer.batch_decode(output_ids_list)
+>>> output_string
+['', 'is the one who does', ' in the disco', 'in the park. The dog is the one who does a ball in', ' in the park.']
+```
+
+## ByT5Tokenizer
+
+[[autodoc]] ByT5Tokenizer
+
+詳細については、[`ByT5Tokenizer`] を参照してください。
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/camembert.md b/docs/source/ja/model_doc/camembert.md
new file mode 100644
index 0000000000..db8e0aa936
--- /dev/null
+++ b/docs/source/ja/model_doc/camembert.md
@@ -0,0 +1,135 @@
+
+
+# CamemBERT
+
+## Overview
+
+CamemBERT モデルは、[CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) で提案されました。
+Louis Martin, Benjamin Muller, Pedro Javier Ortiz Suárez, Yoann Dupont, Laurent Romary, Éric Villemonte de la
+Clergerie, Djamé Seddah, and Benoît Sagot. 2019年にリリースされたFacebookのRoBERTaモデルをベースにしたモデルです。
+138GBのフランス語テキストでトレーニングされました。
+
+論文の要約は次のとおりです。
+
+*事前トレーニングされた言語モデルは現在、自然言語処理で広く普及しています。成功にもかかわらず、利用可能なほとんどの
+モデルは英語のデータ、または複数言語のデータの連結でトレーニングされています。これにより、
+このようなモデルの実際の使用は、英語を除くすべての言語で非常に限られています。フランス人にとってこの問題に対処することを目指して、
+Bi-direction Encoders for Transformers (BERT) のフランス語版である CamemBERT をリリースします。測定します
+複数の下流タスク、つまり品詞タグ付けにおける多言語モデルと比較した CamemBERT のパフォーマンス
+依存関係解析、固有表現認識、自然言語推論。 CamemBERT は最先端技術を向上させます
+検討されているほとんどのタスクに対応します。私たちは、研究と
+フランス語 NLP の下流アプリケーション。*
+
+このモデルは [camembert](https://huggingface.co/camembert) によって提供されました。元のコードは [ここ](https://camembert-model.fr/) にあります。
+
+
+
+
+この実装はRoBERTaと同じです。使用例については[RoBERTaのドキュメント](roberta)も参照してください。
+入力と出力に関する情報として。
+
+
+
+## Resources
+
+- [テキスト分類タスクガイド](../tasks/sequence_classification)
+- [トークン分類タスクガイド](../tasks/token_classification)
+- [質問回答タスク ガイド](../tasks/question_answering)
+- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
+- [マスク言語モデリング タスク ガイド](../tasks/masked_language_modeling)
+- [多肢選択タスク ガイド](../tasks/multiple_choice)
+
+## CamembertConfig
+
+[[autodoc]] CamembertConfig
+
+## CamembertTokenizer
+
+[[autodoc]] CamembertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## CamembertTokenizerFast
+
+[[autodoc]] CamembertTokenizerFast
+
+
+
+
+## CamembertModel
+
+[[autodoc]] CamembertModel
+
+## CamembertForCausalLM
+
+[[autodoc]] CamembertForCausalLM
+
+## CamembertForMaskedLM
+
+[[autodoc]] CamembertForMaskedLM
+
+## CamembertForSequenceClassification
+
+[[autodoc]] CamembertForSequenceClassification
+
+## CamembertForMultipleChoice
+
+[[autodoc]] CamembertForMultipleChoice
+
+## CamembertForTokenClassification
+
+[[autodoc]] CamembertForTokenClassification
+
+## CamembertForQuestionAnswering
+
+[[autodoc]] CamembertForQuestionAnswering
+
+
+
+
+## TFCamembertModel
+
+[[autodoc]] TFCamembertModel
+
+## TFCamembertForCasualLM
+
+[[autodoc]] TFCamembertForCausalLM
+
+## TFCamembertForMaskedLM
+
+[[autodoc]] TFCamembertForMaskedLM
+
+## TFCamembertForSequenceClassification
+
+[[autodoc]] TFCamembertForSequenceClassification
+
+## TFCamembertForMultipleChoice
+
+[[autodoc]] TFCamembertForMultipleChoice
+
+## TFCamembertForTokenClassification
+
+[[autodoc]] TFCamembertForTokenClassification
+
+## TFCamembertForQuestionAnswering
+
+[[autodoc]] TFCamembertForQuestionAnswering
+
+
+
diff --git a/docs/source/ja/model_doc/canine.md b/docs/source/ja/model_doc/canine.md
new file mode 100644
index 0000000000..18af699967
--- /dev/null
+++ b/docs/source/ja/model_doc/canine.md
@@ -0,0 +1,144 @@
+
+
+# CANINE
+
+## Overview
+
+CANINE モデルは、[CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language
+Representation](https://arxiv.org/abs/2103.06874)、Jonathan H. Clark、Dan Garrette、Iulia Turc、John Wieting 著。その
+明示的なトークン化ステップ (バイト ペアなど) を使用せずに Transformer をトレーニングする最初の論文の 1 つ
+エンコーディング (BPE、WordPiece または SentencePiece)。代わりに、モデルは Unicode 文字レベルで直接トレーニングされます。
+キャラクターレベルでのトレーニングでは必然的にシーケンスの長さが長くなりますが、CANINE はこれを効率的な方法で解決します。
+ディープ Transformer エンコーダを適用する前に、ダウンサンプリング戦略を実行します。
+
+論文の要約は次のとおりです。
+
+*パイプライン NLP システムは、エンドツーエンドのニューラル モデリングに大部分が取って代わられていますが、一般的に使用されているほぼすべてのモデルは
+依然として明示的なトークン化手順が必要です。最近のトークン化アプローチはデータ由来のサブワードに基づいていますが、
+レキシコンは手動で作成されたトークナイザーよりも脆弱ではありませんが、これらの技術はすべての言語に等しく適しているわけではありません。
+言語や固定語彙の使用により、モデルの適応能力が制限される可能性があります。この論文では、CANINE を紹介します。
+明示的なトークン化や語彙を使用せずに、文字シーケンスを直接操作するニューラル エンコーダーと、
+文字に直接作用するか、オプションでサブワードをソフト誘導バイアスとして使用する事前トレーニング戦略。
+よりきめの細かい入力を効果的かつ効率的に使用するために、CANINE はダウンサンプリングを組み合わせて、入力を削減します。
+コンテキストをエンコードするディープトランスフォーマースタックを備えたシーケンスの長さ。 CANINE は、同等の mBERT モデルよりも次の点で優れています。
+TyDi QA の 2.8 F1 は、モデル パラメータが 28% 少ないにもかかわらず、困難な多言語ベンチマークです。*
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。元のコードは [ここ](https://github.com/google-research/language/tree/master/language/canine) にあります。
+
+## Usage tips
+
+- CANINE は内部で少なくとも 3 つの Transformer エンコーダーを使用します: 2 つの「浅い」エンコーダー (単一のエンコーダーのみで構成)
+ レイヤー) と 1 つの「ディープ」エンコーダー (通常の BERT エンコーダー)。まず、「浅い」エンコーダを使用してコンテキストを設定します。
+ ローカル アテンションを使用した文字の埋め込み。次に、ダウンサンプリングの後、「ディープ」エンコーダーが適用されます。ついに、
+ アップサンプリング後、「浅い」エンコーダを使用して最終的な文字埋め込みが作成されます。アップと
+ ダウンサンプリングについては論文に記載されています。
+- CANINE は、デフォルトで 2048 文字の最大シーケンス長を使用します。 [`CanineTokenizer`] を使用できます
+ モデル用のテキストを準備します。
+- 特別な [CLS] トークンの最終的な非表示状態の上に線形レイヤーを配置することで分類を行うことができます。
+ (事前定義された Unicode コード ポイントがあります)。ただし、トークン分類タスクの場合は、ダウンサンプリングされたシーケンス
+ トークンは、元の文字シーケンスの長さ (2048) と一致するように再度アップサンプリングする必要があります。の
+ 詳細については、論文を参照してください。
+
+モデルのチェックポイント:
+
+ - [google/canine-c](https://huggingface.co/google/canine-c): 自己回帰文字損失で事前トレーニング済み、
+ 12 レイヤー、768 隠し、12 ヘッド、121M パラメーター (サイズ ~500 MB)。
+ - [google/canine-s](https://huggingface.co/google/canine-s): サブワード損失で事前トレーニング済み、12 層、
+ 768 個の非表示、12 ヘッド、121M パラメーター (サイズ ~500 MB)。
+
+## Usage example
+
+CANINE は生の文字で動作するため、**トークナイザーなし**で使用できます。
+
+```python
+>>> from transformers import CanineModel
+>>> import torch
+
+>>> model = CanineModel.from_pretrained("google/canine-c") # model pre-trained with autoregressive character loss
+
+>>> text = "hello world"
+>>> # use Python's built-in ord() function to turn each character into its unicode code point id
+>>> input_ids = torch.tensor([[ord(char) for char in text]])
+
+>>> outputs = model(input_ids) # forward pass
+>>> pooled_output = outputs.pooler_output
+>>> sequence_output = outputs.last_hidden_state
+```
+
+ただし、バッチ推論とトレーニングの場合は、トークナイザーを使用することをお勧めします(すべてをパディング/切り詰めるため)
+シーケンスを同じ長さにします):
+
+```python
+>>> from transformers import CanineTokenizer, CanineModel
+
+>>> model = CanineModel.from_pretrained("google/canine-c")
+>>> tokenizer = CanineTokenizer.from_pretrained("google/canine-c")
+
+>>> inputs = ["Life is like a box of chocolates.", "You never know what you gonna get."]
+>>> encoding = tokenizer(inputs, padding="longest", truncation=True, return_tensors="pt")
+
+>>> outputs = model(**encoding) # forward pass
+>>> pooled_output = outputs.pooler_output
+>>> sequence_output = outputs.last_hidden_state
+```
+
+## Resources
+
+- [テキスト分類タスクガイド](../tasks/sequence_classification)
+- [トークン分類タスクガイド](../tasks/token_classification)
+- [質問回答タスク ガイド](../tasks/question_answering)
+- [多肢選択タスク ガイド](../tasks/multiple_choice)
+
+## CanineConfig
+
+[[autodoc]] CanineConfig
+
+## CanineTokenizer
+
+[[autodoc]] CanineTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+
+## CANINE specific outputs
+
+[[autodoc]] models.canine.modeling_canine.CanineModelOutputWithPooling
+
+## CanineModel
+
+[[autodoc]] CanineModel
+ - forward
+
+## CanineForSequenceClassification
+
+[[autodoc]] CanineForSequenceClassification
+ - forward
+
+## CanineForMultipleChoice
+
+[[autodoc]] CanineForMultipleChoice
+ - forward
+
+## CanineForTokenClassification
+
+[[autodoc]] CanineForTokenClassification
+ - forward
+
+## CanineForQuestionAnswering
+
+[[autodoc]] CanineForQuestionAnswering
+ - forward
diff --git a/docs/source/ja/model_doc/chinese_clip.md b/docs/source/ja/model_doc/chinese_clip.md
new file mode 100644
index 0000000000..8d7dc401d2
--- /dev/null
+++ b/docs/source/ja/model_doc/chinese_clip.md
@@ -0,0 +1,112 @@
+
+
+# Chinese-CLIP
+
+## Overview
+
+Chinese-CLIP An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://arxiv.org/abs/2211.01335) で提案されました。周、張周。
+Chinese-CLIP は、中国語の画像とテキストのペアの大規模なデータセットに対する CLIP (Radford et al., 2021) の実装です。クロスモーダル検索を実行できるほか、ゼロショット画像分類、オープンドメインオブジェクト検出などのビジョンタスクのビジョンバックボーンとしても機能します。オリジナルの中国語-CLIPコードは[このリンクで](https://github.com/OFA-Sys/Chinese-CLIP)。
+
+論文の要約は次のとおりです。
+
+*CLIP の大成功 (Radford et al., 2021) により、視覚言語の事前訓練のための対照学習の研究と応用が促進されました。この研究では、ほとんどのデータが公開されているデータセットから取得された中国語の画像とテキストのペアの大規模なデータセットを構築し、新しいデータセットで中国語の CLIP モデルを事前トレーニングします。当社では、7,700 万から 9 億 5,800 万のパラメータにわたる、複数のサイズの 5 つの中国 CLIP モデルを開発しています。さらに、モデルのパフォーマンスを向上させるために、最初に画像エンコーダーをフリーズさせてモデルをトレーニングし、次にすべてのパラメーターを最適化してトレーニングする 2 段階の事前トレーニング方法を提案します。私たちの包括的な実験では、中国の CLIP がゼロショット学習と微調整のセットアップで MUGE、Flickr30K-CN、および COCO-CN 上で最先端のパフォーマンスを達成でき、ゼロで競争力のあるパフォーマンスを達成できることを実証しています。 - ELEVATER ベンチマークでの評価に基づくショット画像の分類 (Li et al., 2022)。コード、事前トレーニング済みモデル、デモがリリースされました。*
+
+Chinese-CLIP モデルは、[OFA-Sys](https://huggingface.co/OFA-Sys) によって提供されました。
+
+## Usage example
+
+以下のコード スニペットは、画像とテキストの特徴と類似性を計算する方法を示しています。
+
+```python
+>>> from PIL import Image
+>>> import requests
+>>> from transformers import ChineseCLIPProcessor, ChineseCLIPModel
+
+>>> model = ChineseCLIPModel.from_pretrained("OFA-Sys/chinese-clip-vit-base-patch16")
+>>> processor = ChineseCLIPProcessor.from_pretrained("OFA-Sys/chinese-clip-vit-base-patch16")
+
+>>> url = "https://clip-cn-beijing.oss-cn-beijing.aliyuncs.com/pokemon.jpeg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> # Squirtle, Bulbasaur, Charmander, Pikachu in English
+>>> texts = ["杰尼龟", "妙蛙种子", "小火龙", "皮卡丘"]
+
+>>> # compute image feature
+>>> inputs = processor(images=image, return_tensors="pt")
+>>> image_features = model.get_image_features(**inputs)
+>>> image_features = image_features / image_features.norm(p=2, dim=-1, keepdim=True) # normalize
+
+>>> # compute text features
+>>> inputs = processor(text=texts, padding=True, return_tensors="pt")
+>>> text_features = model.get_text_features(**inputs)
+>>> text_features = text_features / text_features.norm(p=2, dim=-1, keepdim=True) # normalize
+
+>>> # compute image-text similarity scores
+>>> inputs = processor(text=texts, images=image, return_tensors="pt", padding=True)
+>>> outputs = model(**inputs)
+>>> logits_per_image = outputs.logits_per_image # this is the image-text similarity score
+>>> probs = logits_per_image.softmax(dim=1) # probs: [[1.2686e-03, 5.4499e-02, 6.7968e-04, 9.4355e-01]]
+```
+
+現在、次のスケールの事前トレーニング済み Chinese-CLIP モデルが 🤗 Hub で利用可能です。
+
+- [OFA-Sys/chinese-clip-vit-base-patch16](https://huggingface.co/OFA-Sys/chinese-clip-vit-base-patch16)
+- [OFA-Sys/chinese-clip-vit-large-patch14](https://huggingface.co/OFA-Sys/chinese-clip-vit-large-patch14)
+- [OFA-Sys/chinese-clip-vit-large-patch14-336px](https://huggingface.co/OFA-Sys/chinese-clip-vit-large-patch14-336px)
+- [OFA-Sys/chinese-clip-vit-huge-patch14](https://huggingface.co/OFA-Sys/chinese-clip-vit-huge-patch14)
+
+## ChineseCLIPConfig
+
+[[autodoc]] ChineseCLIPConfig
+ - from_text_vision_configs
+
+## ChineseCLIPTextConfig
+
+[[autodoc]] ChineseCLIPTextConfig
+
+## ChineseCLIPVisionConfig
+
+[[autodoc]] ChineseCLIPVisionConfig
+
+## ChineseCLIPImageProcessor
+
+[[autodoc]] ChineseCLIPImageProcessor
+ - preprocess
+
+## ChineseCLIPFeatureExtractor
+
+[[autodoc]] ChineseCLIPFeatureExtractor
+
+## ChineseCLIPProcessor
+
+[[autodoc]] ChineseCLIPProcessor
+
+## ChineseCLIPModel
+
+[[autodoc]] ChineseCLIPModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## ChineseCLIPTextModel
+
+[[autodoc]] ChineseCLIPTextModel
+ - forward
+
+## ChineseCLIPVisionModel
+
+[[autodoc]] ChineseCLIPVisionModel
+ - forward
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/clap.md b/docs/source/ja/model_doc/clap.md
new file mode 100644
index 0000000000..f1e08d7601
--- /dev/null
+++ b/docs/source/ja/model_doc/clap.md
@@ -0,0 +1,80 @@
+
+
+# CLAP
+
+## Overview
+
+CLAP モデルは、[Large Scale Contrastive Language-Audio pretraining with
+feature fusion and keyword-to-caption augmentation](https://arxiv.org/pdf/2211.06687.pdf)、Yusong Wu、Ke Chen、Tianyu Zhang、Yuchen Hui、Taylor Berg-Kirkpatrick、Shlomo Dubnov 著。
+
+CLAP (Contrastive Language-Audio Pretraining) は、さまざまな (音声、テキスト) ペアでトレーニングされたニューラル ネットワークです。タスクに合わせて直接最適化することなく、音声が与えられた場合に最も関連性の高いテキスト スニペットを予測するように指示できます。 CLAP モデルは、SWINTransformer を使用して log-Mel スペクトログラム入力からオーディオ特徴を取得し、RoBERTa モデルを使用してテキスト特徴を取得します。次に、テキストとオーディオの両方の特徴が、同じ次元の潜在空間に投影されます。投影されたオーディオとテキストの特徴の間のドット積が、同様のスコアとして使用されます。
+
+論文の要約は次のとおりです。
+
+*対照学習は、マルチモーダル表現学習の分野で目覚ましい成功を収めています。この論文では、音声データと自然言語記述を組み合わせて音声表現を開発する、対照的な言語音声事前トレーニングのパイプラインを提案します。この目標を達成するために、私たちはまず、さまざまなデータ ソースからの 633,526 個の音声とテキストのペアの大規模なコレクションである LAION-Audio-630K をリリースします。次に、さまざまなオーディオ エンコーダとテキスト エンコーダを考慮して、対照的な言語とオーディオの事前トレーニング モデルを構築します。機能融合メカニズムとキーワードからキャプションへの拡張をモデル設計に組み込んで、モデルが可変長の音声入力を処理できるようにし、パフォーマンスを向上させます。 3 番目に、包括的な実験を実行して、テキストから音声への取得、ゼロショット音声分類、教師付き音声分類の 3 つのタスクにわたってモデルを評価します。結果は、私たちのモデルがテキストから音声への検索タスクにおいて優れたパフォーマンスを達成していることを示しています。オーディオ分類タスクでは、モデルはゼロショット設定で最先端のパフォーマンスを達成し、非ゼロショット設定でもモデルの結果に匹敵するパフォーマンスを得ることができます。 LAION-オーディオ-6*
+
+このモデルは、[Younes Belkada](https://huggingface.co/ybelkada) および [Arthur Zucker](https://huggingface.co/ArthurZ) によって提供されました。
+元のコードは [こちら](https://github.com/LAION-AI/Clap) にあります。
+
+## ClapConfig
+
+[[autodoc]] ClapConfig
+ - from_text_audio_configs
+
+## ClapTextConfig
+
+[[autodoc]] ClapTextConfig
+
+## ClapAudioConfig
+
+[[autodoc]] ClapAudioConfig
+
+## ClapFeatureExtractor
+
+[[autodoc]] ClapFeatureExtractor
+
+## ClapProcessor
+
+[[autodoc]] ClapProcessor
+
+## ClapModel
+
+[[autodoc]] ClapModel
+ - forward
+ - get_text_features
+ - get_audio_features
+
+## ClapTextModel
+
+[[autodoc]] ClapTextModel
+ - forward
+
+## ClapTextModelWithProjection
+
+[[autodoc]] ClapTextModelWithProjection
+ - forward
+
+## ClapAudioModel
+
+[[autodoc]] ClapAudioModel
+ - forward
+
+## ClapAudioModelWithProjection
+
+[[autodoc]] ClapAudioModelWithProjection
+ - forward
+
\ No newline at end of file