diff --git a/README.md b/README.md
index b831ef600d..7843a896f6 100644
--- a/README.md
+++ b/README.md
@@ -283,6 +283,7 @@ Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
1. **[LayoutLMv3](https://huggingface.co/docs/transformers/main/model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
1. **[LayoutXLM](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
1. **[LED](https://huggingface.co/docs/transformers/model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LeViT](https://huggingface.co/docs/transformers/main/model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
1. **[mLUKE](https://huggingface.co/docs/transformers/model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
diff --git a/README_ko.md b/README_ko.md
index 9a5acdc5b0..218e842062 100644
--- a/README_ko.md
+++ b/README_ko.md
@@ -262,6 +262,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
1. **[LayoutLMv3](https://huggingface.co/docs/transformers/main/model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
1. **[LayoutXLM](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
1. **[LED](https://huggingface.co/docs/transformers/model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LeViT](https://huggingface.co/docs/transformers/main/model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
1. **[LXMERT](https://huggingface.co/docs/transformers/model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
diff --git a/README_zh-hans.md b/README_zh-hans.md
index 1c513d1043..8b873c2d40 100644
--- a/README_zh-hans.md
+++ b/README_zh-hans.md
@@ -286,6 +286,7 @@ conda install -c huggingface transformers
1. **[LayoutLMv3](https://huggingface.co/docs/transformers/main/model_doc/layoutlmv3)** (来自 Microsoft Research Asia) 伴随论文 [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) 由 Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei 发布。
1. **[LayoutXLM](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (来自 Microsoft Research Asia) 伴随论文 [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) 由 Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei 发布。
1. **[LED](https://huggingface.co/docs/transformers/model_doc/led)** (来自 AllenAI) 伴随论文 [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) 由 Iz Beltagy, Matthew E. Peters, Arman Cohan 发布。
+1. **[LeViT](https://huggingface.co/docs/transformers/main/model_doc/levit)** (来自 Meta AI) 伴随论文 [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) 由 Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze 发布。
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (来自 AllenAI) 伴随论文 [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) 由 Iz Beltagy, Matthew E. Peters, Arman Cohan 发布。
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (来自 Studio Ousia) 伴随论文 [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) 由 Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto 发布。
1. **[LXMERT](https://huggingface.co/docs/transformers/model_doc/lxmert)** (来自 UNC Chapel Hill) 伴随论文 [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) 由 Hao Tan and Mohit Bansal 发布。
diff --git a/README_zh-hant.md b/README_zh-hant.md
index 8276e2f912..d2ba48d12b 100644
--- a/README_zh-hant.md
+++ b/README_zh-hant.md
@@ -298,6 +298,7 @@ conda install -c huggingface transformers
1. **[LayoutLMv3](https://huggingface.co/docs/transformers/main/model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
1. **[LayoutXLM](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
1. **[LED](https://huggingface.co/docs/transformers/model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LeViT](https://huggingface.co/docs/transformers/main/model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
1. **[LXMERT](https://huggingface.co/docs/transformers/model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
diff --git a/docs/source/en/_toctree.yml b/docs/source/en/_toctree.yml
index cf835c0817..dfa906048f 100644
--- a/docs/source/en/_toctree.yml
+++ b/docs/source/en/_toctree.yml
@@ -248,6 +248,8 @@
title: LayoutXLM
- local: model_doc/led
title: LED
+ - local: model_doc/levit
+ title: LeViT
- local: model_doc/longformer
title: Longformer
- local: model_doc/luke
diff --git a/docs/source/en/index.mdx b/docs/source/en/index.mdx
index 7efc908ae0..d383b3a844 100644
--- a/docs/source/en/index.mdx
+++ b/docs/source/en/index.mdx
@@ -104,6 +104,7 @@ The library currently contains JAX, PyTorch and TensorFlow implementations, pret
1. **[LayoutLMv3](model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
1. **[LayoutXLM](model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
1. **[LED](model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LeViT](model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
1. **[Longformer](model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LUKE](model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
1. **[mLUKE](model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
@@ -225,6 +226,7 @@ Flax), PyTorch, and/or TensorFlow.
| LayoutLMv2 | ✅ | ✅ | ✅ | ❌ | ❌ |
| LayoutLMv3 | ✅ | ✅ | ✅ | ❌ | ❌ |
| LED | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LeViT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Longformer | ✅ | ✅ | ✅ | ✅ | ❌ |
| LUKE | ✅ | ❌ | ✅ | ❌ | ❌ |
| LXMERT | ✅ | ✅ | ✅ | ✅ | ❌ |
diff --git a/docs/source/en/model_doc/levit.mdx b/docs/source/en/model_doc/levit.mdx
new file mode 100644
index 0000000000..4549a5106c
--- /dev/null
+++ b/docs/source/en/model_doc/levit.mdx
@@ -0,0 +1,87 @@
+
+
+# LeViT
+
+## Overview
+
+The LeViT model was proposed in [LeViT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze. LeViT improves the [Vision Transformer (ViT)](vit) in performance and efficiency by a few architectural differences such as activation maps with decreasing resolutions in Transformers and the introduction of an attention bias to integrate positional information.
+
+The abstract from the paper is the following:
+
+*We design a family of image classification architectures that optimize the trade-off between accuracy
+and efficiency in a high-speed regime. Our work exploits recent findings in attention-based architectures,
+which are competitive on highly parallel processing hardware. We revisit principles from the extensive
+literature on convolutional neural networks to apply them to transformers, in particular activation maps
+with decreasing resolutions. We also introduce the attention bias, a new way to integrate positional information
+in vision transformers. As a result, we propose LeVIT: a hybrid neural network for fast inference image classification.
+We consider different measures of efficiency on different hardware platforms, so as to best reflect a wide range of
+application scenarios. Our extensive experiments empirically validate our technical choices and show they are suitable
+to most architectures. Overall, LeViT significantly outperforms existing convnets and vision transformers with respect
+to the speed/accuracy tradeoff. For example, at 80% ImageNet top-1 accuracy, LeViT is 5 times faster than EfficientNet on CPU. *
+
+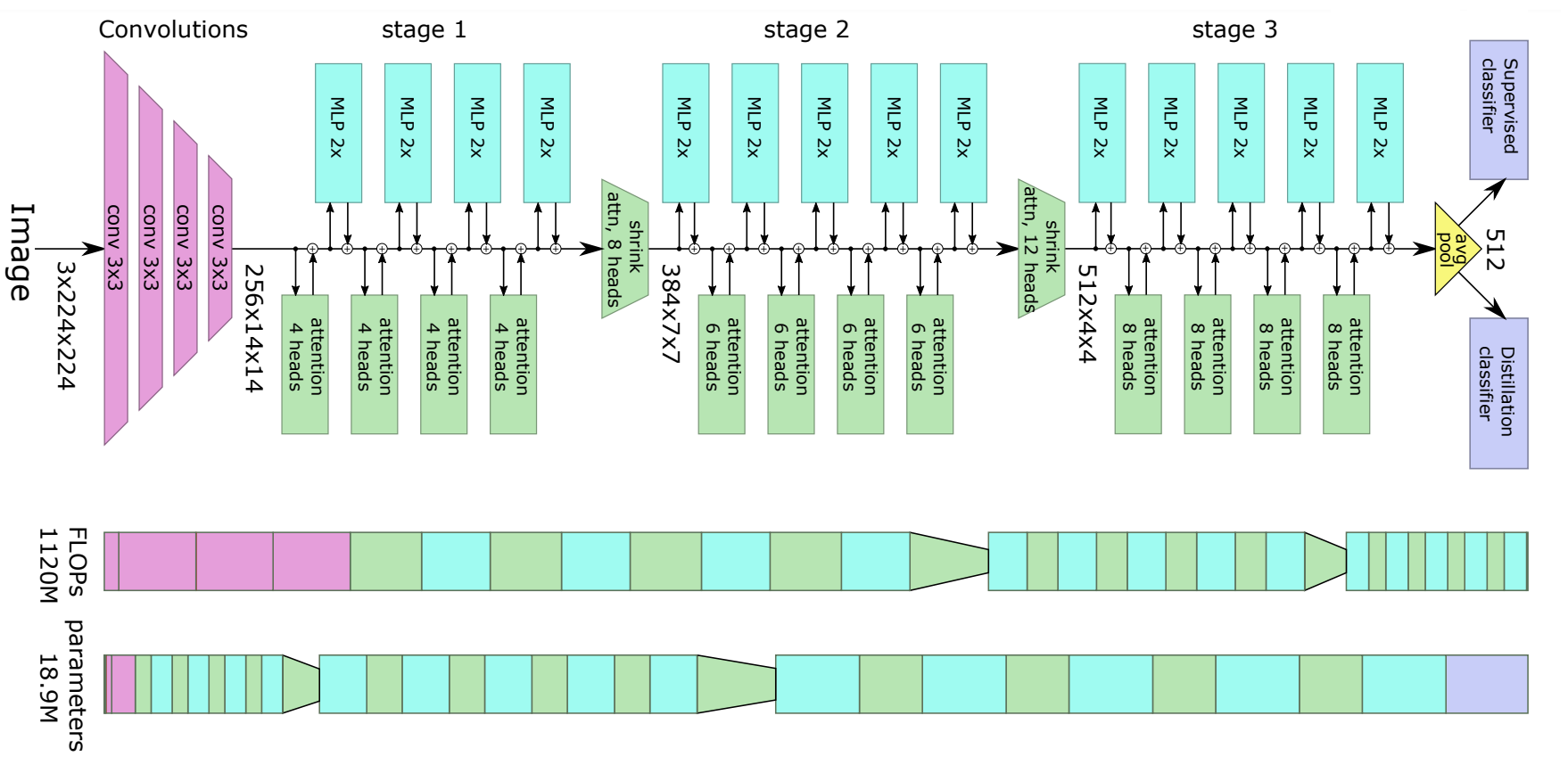 +
+ LeViT Architecture. Taken from the original paper.
+
+Tips:
+
+- Compared to ViT, LeViT models use an additional distillation head to effectively learn from a teacher (which, in the LeViT paper, is a ResNet like-model). The distillation head is learned through backpropagation under supervision of a ResNet like-model. They also draw inspiration from convolution neural networks to use activation maps with decreasing resolutions to increase the efficiency.
+- There are 2 ways to fine-tune distilled models, either (1) in a classic way, by only placing a prediction head on top
+ of the final hidden state and not using the distillation head, or (2) by placing both a prediction head and distillation
+ head on top of the final hidden state. In that case, the prediction head is trained using regular cross-entropy between
+ the prediction of the head and the ground-truth label, while the distillation prediction head is trained using hard distillation
+ (cross-entropy between the prediction of the distillation head and the label predicted by the teacher). At inference time,
+ one takes the average prediction between both heads as final prediction. (2) is also called "fine-tuning with distillation",
+ because one relies on a teacher that has already been fine-tuned on the downstream dataset. In terms of models, (1) corresponds
+ to [`LevitForImageClassification`] and (2) corresponds to [`LevitForImageClassificationWithTeacher`].
+- All released checkpoints were pre-trained and fine-tuned on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k)
+ (also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes). only. No external data was used. This is in
+ contrast with the original ViT model, which used external data like the JFT-300M dataset/Imagenet-21k for
+ pre-training.
+- The authors of LeViT released 5 trained LeViT models, which you can directly plug into [`LevitModel`] or [`LevitForImageClassification`].
+ Techniques like data augmentation, optimization, and regularization were used in order to simulate training on a much larger dataset
+ (while only using ImageNet-1k for pre-training). The 5 variants available are (all trained on images of size 224x224):
+ *facebook/levit-128S*, *facebook/levit-128*, *facebook/levit-192*, *facebook/levit-256* and
+ *facebook/levit-384*. Note that one should use [`LevitFeatureExtractor`] in order to
+ prepare images for the model.
+- [`LevitForImageClassificationWithTeacher`] currently supports only inference and not training or fine-tuning.
+- You can check out demo notebooks regarding inference as well as fine-tuning on custom data [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer)
+ (you can just replace [`ViTFeatureExtractor`] by [`LevitFeatureExtractor`] and [`ViTForImageClassification`] by [`LevitForImageClassification`] or [`LevitForImageClassificationWithTeacher`]).
+
+This model was contributed by [anugunj](https://huggingface.co/anugunj). The original code can be found [here](https://github.com/facebookresearch/LeViT).
+
+
+## LevitConfig
+
+[[autodoc]] LevitConfig
+
+## LevitFeatureExtractor
+
+[[autodoc]] LevitFeatureExtractor
+ - __call__
+
+## LevitModel
+
+[[autodoc]] LevitModel
+ - forward
+
+## LevitForImageClassification
+
+[[autodoc]] LevitForImageClassification
+ - forward
+
+## LevitForImageClassificationWithTeacher
+
+[[autodoc]] LevitForImageClassificationWithTeacher
+ - forward
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index a17253b5e0..b40d95d4d9 100755
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -236,6 +236,7 @@ _import_structure = {
],
"models.layoutxlm": ["LayoutXLMProcessor"],
"models.led": ["LED_PRETRAINED_CONFIG_ARCHIVE_MAP", "LEDConfig", "LEDTokenizer"],
+ "models.levit": ["LEVIT_PRETRAINED_CONFIG_ARCHIVE_MAP", "LevitConfig"],
"models.longformer": ["LONGFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP", "LongformerConfig", "LongformerTokenizer"],
"models.luke": ["LUKE_PRETRAINED_CONFIG_ARCHIVE_MAP", "LukeConfig", "LukeTokenizer"],
"models.lxmert": ["LXMERT_PRETRAINED_CONFIG_ARCHIVE_MAP", "LxmertConfig", "LxmertTokenizer"],
@@ -601,6 +602,7 @@ else:
_import_structure["models.imagegpt"].append("ImageGPTFeatureExtractor")
_import_structure["models.layoutlmv2"].append("LayoutLMv2FeatureExtractor")
_import_structure["models.layoutlmv3"].append("LayoutLMv3FeatureExtractor")
+ _import_structure["models.levit"].append("LevitFeatureExtractor")
_import_structure["models.maskformer"].append("MaskFormerFeatureExtractor")
_import_structure["models.perceiver"].append("PerceiverFeatureExtractor")
_import_structure["models.poolformer"].append("PoolFormerFeatureExtractor")
@@ -1237,6 +1239,15 @@ else:
"LEDPreTrainedModel",
]
)
+ _import_structure["models.levit"].extend(
+ [
+ "LEVIT_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "LevitForImageClassification",
+ "LevitForImageClassificationWithTeacher",
+ "LevitModel",
+ "LevitPreTrainedModel",
+ ]
+ )
_import_structure["models.longformer"].extend(
[
"LONGFORMER_PRETRAINED_MODEL_ARCHIVE_LIST",
@@ -2811,6 +2822,7 @@ if TYPE_CHECKING:
)
from .models.layoutxlm import LayoutXLMProcessor
from .models.led import LED_PRETRAINED_CONFIG_ARCHIVE_MAP, LEDConfig, LEDTokenizer
+ from .models.levit import LEVIT_PRETRAINED_CONFIG_ARCHIVE_MAP, LevitConfig
from .models.longformer import LONGFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP, LongformerConfig, LongformerTokenizer
from .models.luke import LUKE_PRETRAINED_CONFIG_ARCHIVE_MAP, LukeConfig, LukeTokenizer
from .models.lxmert import LXMERT_PRETRAINED_CONFIG_ARCHIVE_MAP, LxmertConfig, LxmertTokenizer
@@ -3123,6 +3135,7 @@ if TYPE_CHECKING:
from .models.imagegpt import ImageGPTFeatureExtractor
from .models.layoutlmv2 import LayoutLMv2FeatureExtractor
from .models.layoutlmv3 import LayoutLMv3FeatureExtractor
+ from .models.levit import LevitFeatureExtractor
from .models.maskformer import MaskFormerFeatureExtractor
from .models.perceiver import PerceiverFeatureExtractor
from .models.poolformer import PoolFormerFeatureExtractor
@@ -3656,6 +3669,13 @@ if TYPE_CHECKING:
LEDModel,
LEDPreTrainedModel,
)
+ from .models.levit import (
+ LEVIT_PRETRAINED_MODEL_ARCHIVE_LIST,
+ LevitForImageClassification,
+ LevitForImageClassificationWithTeacher,
+ LevitModel,
+ LevitPreTrainedModel,
+ )
from .models.longformer import (
LONGFORMER_PRETRAINED_MODEL_ARCHIVE_LIST,
LongformerForMaskedLM,
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index e435265a83..8ceb5014e7 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -73,6 +73,7 @@ from . import (
layoutlmv3,
layoutxlm,
led,
+ levit,
longformer,
luke,
lxmert,
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index dbb19c55aa..1020d8550c 100644
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -76,6 +76,7 @@ CONFIG_MAPPING_NAMES = OrderedDict(
("layoutlmv2", "LayoutLMv2Config"),
("layoutlmv3", "LayoutLMv3Config"),
("led", "LEDConfig"),
+ ("levit", "LevitConfig"),
("longformer", "LongformerConfig"),
("luke", "LukeConfig"),
("lxmert", "LxmertConfig"),
@@ -188,6 +189,7 @@ CONFIG_ARCHIVE_MAP_MAPPING_NAMES = OrderedDict(
("layoutlmv2", "LAYOUTLMV2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("layoutlmv3", "LAYOUTLMV3_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("led", "LED_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("levit", "LEVIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("longformer", "LONGFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("luke", "LUKE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("lxmert", "LXMERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
@@ -302,6 +304,7 @@ MODEL_NAMES_MAPPING = OrderedDict(
("layoutlmv3", "LayoutLMv3"),
("layoutxlm", "LayoutXLM"),
("led", "LED"),
+ ("levit", "LeViT"),
("longformer", "Longformer"),
("luke", "LUKE"),
("lxmert", "LXMERT"),
diff --git a/src/transformers/models/auto/feature_extraction_auto.py b/src/transformers/models/auto/feature_extraction_auto.py
index f398efe360..cbb4b79593 100644
--- a/src/transformers/models/auto/feature_extraction_auto.py
+++ b/src/transformers/models/auto/feature_extraction_auto.py
@@ -53,6 +53,7 @@ FEATURE_EXTRACTOR_MAPPING_NAMES = OrderedDict(
("imagegpt", "ImageGPTFeatureExtractor"),
("layoutlmv2", "LayoutLMv2FeatureExtractor"),
("layoutlmv3", "LayoutLMv3FeatureExtractor"),
+ ("levit", "LevitFeatureExtractor"),
("maskformer", "MaskFormerFeatureExtractor"),
("perceiver", "PerceiverFeatureExtractor"),
("poolformer", "PoolFormerFeatureExtractor"),
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index 61787c3d60..79a7c80ce6 100644
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -75,6 +75,7 @@ MODEL_MAPPING_NAMES = OrderedDict(
("layoutlmv2", "LayoutLMv2Model"),
("layoutlmv3", "LayoutLMv3Model"),
("led", "LEDModel"),
+ ("levit", "LevitModel"),
("longformer", "LongformerModel"),
("luke", "LukeModel"),
("lxmert", "LxmertModel"),
@@ -308,6 +309,7 @@ MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
("data2vec-vision", "Data2VecVisionForImageClassification"),
("deit", ("DeiTForImageClassification", "DeiTForImageClassificationWithTeacher")),
("imagegpt", "ImageGPTForImageClassification"),
+ ("levit", ("LevitForImageClassification", "LevitForImageClassificationWithTeacher")),
(
"perceiver",
(
diff --git a/src/transformers/models/levit/__init__.py b/src/transformers/models/levit/__init__.py
new file mode 100644
index 0000000000..bdbcaed41a
--- /dev/null
+++ b/src/transformers/models/levit/__init__.py
@@ -0,0 +1,75 @@
+# flake8: noqa
+# There's no way to ignore "F401 '...' imported but unused" warnings in this
+# module, but to preserve other warnings. So, don't check this module at all.
+
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...utils import OptionalDependencyNotAvailable, _LazyModule, is_torch_available, is_vision_available
+
+
+_import_structure = {"configuration_levit": ["LEVIT_PRETRAINED_CONFIG_ARCHIVE_MAP", "LevitConfig"]}
+
+try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["feature_extraction_levit"] = ["LevitFeatureExtractor"]
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["modeling_levit"] = [
+ "LEVIT_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "LevitForImageClassification",
+ "LevitForImageClassificationWithTeacher",
+ "LevitModel",
+ "LevitPreTrainedModel",
+ ]
+
+
+if TYPE_CHECKING:
+ from .configuration_levit import LEVIT_PRETRAINED_CONFIG_ARCHIVE_MAP, LevitConfig
+
+ try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .feature_extraction_levit import LevitFeatureExtractor
+
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .modeling_levit import (
+ LEVIT_PRETRAINED_MODEL_ARCHIVE_LIST,
+ LevitForImageClassification,
+ LevitForImageClassificationWithTeacher,
+ LevitModel,
+ LevitPreTrainedModel,
+ )
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/levit/configuration_levit.py b/src/transformers/models/levit/configuration_levit.py
new file mode 100644
index 0000000000..5d75b9fc23
--- /dev/null
+++ b/src/transformers/models/levit/configuration_levit.py
@@ -0,0 +1,122 @@
+# coding=utf-8
+# Copyright 2022 Meta Platforms, Inc. and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" LeViT model configuration"""
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+LEVIT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "facebook/levit-128S": "https://huggingface.co/facebook/levit-128S/resolve/main/config.json",
+ # See all LeViT models at https://huggingface.co/models?filter=levit
+}
+
+
+class LevitConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`LevitModel`]. It is used to instantiate a LeViT
+ model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
+ defaults will yield a similar configuration to that of the LeViT
+ [facebook/levit-base-192](https://huggingface.co/facebook/levit-base-192) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ image_size (`int`, *optional*, defaults to 224):
+ The size of the input image.
+ num_channels (`int`, *optional*, defaults to 3):
+ Number of channels in the input image.
+ kernel_size (`int`, *optional*, defaults to 3):
+ The kernel size for the initial convolution layers of patch embedding.
+ stride (`int`, *optional*, defaults to 2):
+ The stride size for the initial convolution layers of patch embedding.
+ padding (`int`, *optional*, defaults to 1):
+ The padding size for the initial convolution layers of patch embedding.
+ patch_size (`int`, *optional*, defaults to 16):
+ The patch size for embeddings.
+ hidden_sizes (`List[int]`, *optional*, defaults to `[128, 256, 384]`):
+ Dimension of each of the encoder blocks.
+ num_attention_heads (`List[int]`, *optional*, defaults to `[4, 8, 12]`):
+ Number of attention heads for each attention layer in each block of the Transformer encoder.
+ depths (`List[int]`, *optional*, defaults to `[4, 4, 4]`):
+ The number of layers in each encoder block.
+ key_dim (`List[int]`, *optional*, defaults to `[16, 16, 16]`):
+ The size of key in each of the encoder blocks.
+ drop_path_rate (`int`, *optional*, defaults to 0):
+ The dropout probability for stochastic depths, used in the blocks of the Transformer encoder.
+ mlp_ratios (`List[int]`, *optional*, defaults to `[2, 2, 2]`):
+ Ratio of the size of the hidden layer compared to the size of the input layer of the Mix FFNs in the
+ encoder blocks.
+ attention_ratios (`List[int]`, *optional*, defaults to `[2, 2, 2]`):
+ Ratio of the size of the output dimension compared to input dimension of attention layers.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+
+ Example:
+
+ ```python
+ >>> from transformers import LevitModel, LevitConfig
+
+ >>> # Initializing a LeViT levit-base-192 style configuration
+ >>> configuration = LevitConfig()
+
+ >>> # Initializing a model from the levit-base-192 style configuration
+ >>> model = LevitModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+ model_type = "levit"
+
+ def __init__(
+ self,
+ image_size=224,
+ num_channels=3,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ patch_size=16,
+ hidden_sizes=[128, 256, 384],
+ num_attention_heads=[4, 8, 12],
+ depths=[4, 4, 4],
+ key_dim=[16, 16, 16],
+ drop_path_rate=0,
+ mlp_ratio=[2, 2, 2],
+ attention_ratio=[2, 2, 2],
+ initializer_range=0.02,
+ **kwargs
+ ):
+ super().__init__(**kwargs)
+ self.image_size = image_size
+ self.num_channels = num_channels
+ self.kernel_size = kernel_size
+ self.stride = stride
+ self.padding = padding
+ self.hidden_sizes = hidden_sizes
+ self.num_attention_heads = num_attention_heads
+ self.depths = depths
+ self.key_dim = key_dim
+ self.drop_path_rate = drop_path_rate
+ self.patch_size = patch_size
+ self.attention_ratio = attention_ratio
+ self.mlp_ratio = mlp_ratio
+ self.initializer_range = initializer_range
+ self.down_ops = [
+ ["Subsample", key_dim[0], hidden_sizes[0] // key_dim[0], 4, 2, 2],
+ ["Subsample", key_dim[0], hidden_sizes[1] // key_dim[0], 4, 2, 2],
+ ]
diff --git a/src/transformers/models/levit/convert_levit_timm_to_pytorch.py b/src/transformers/models/levit/convert_levit_timm_to_pytorch.py
new file mode 100644
index 0000000000..d9449aad7a
--- /dev/null
+++ b/src/transformers/models/levit/convert_levit_timm_to_pytorch.py
@@ -0,0 +1,181 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Convert LeViT checkpoints from timm."""
+
+
+import argparse
+import json
+from collections import OrderedDict
+from functools import partial
+from pathlib import Path
+
+import torch
+
+import timm
+from huggingface_hub import hf_hub_download
+from transformers import LevitConfig, LevitFeatureExtractor, LevitForImageClassificationWithTeacher
+from transformers.utils import logging
+
+
+logging.set_verbosity_info()
+logger = logging.get_logger()
+
+
+def convert_weight_and_push(
+ hidden_sizes: int, name: str, config: LevitConfig, save_directory: Path, push_to_hub: bool = True
+):
+ print(f"Converting {name}...")
+
+ with torch.no_grad():
+ if hidden_sizes == 128:
+ if name[-1] == "S":
+ from_model = timm.create_model("levit_128s", pretrained=True)
+ else:
+ from_model = timm.create_model("levit_128", pretrained=True)
+ if hidden_sizes == 192:
+ from_model = timm.create_model("levit_192", pretrained=True)
+ if hidden_sizes == 256:
+ from_model = timm.create_model("levit_256", pretrained=True)
+ if hidden_sizes == 384:
+ from_model = timm.create_model("levit_384", pretrained=True)
+
+ from_model.eval()
+ our_model = LevitForImageClassificationWithTeacher(config).eval()
+ huggingface_weights = OrderedDict()
+
+ weights = from_model.state_dict()
+ og_keys = list(from_model.state_dict().keys())
+ new_keys = list(our_model.state_dict().keys())
+ print(len(og_keys), len(new_keys))
+ for i in range(len(og_keys)):
+ huggingface_weights[new_keys[i]] = weights[og_keys[i]]
+ our_model.load_state_dict(huggingface_weights)
+
+ x = torch.randn((2, 3, 224, 224))
+ out1 = from_model(x)
+ out2 = our_model(x).logits
+
+ assert torch.allclose(out1, out2), "The model logits don't match the original one."
+
+ checkpoint_name = name
+ print(checkpoint_name)
+
+ if push_to_hub:
+ our_model.save_pretrained(save_directory / checkpoint_name)
+ feature_extractor = LevitFeatureExtractor()
+ feature_extractor.save_pretrained(save_directory / checkpoint_name)
+
+ print(f"Pushed {checkpoint_name}")
+
+
+def convert_weights_and_push(save_directory: Path, model_name: str = None, push_to_hub: bool = True):
+ filename = "imagenet-1k-id2label.json"
+ num_labels = 1000
+ expected_shape = (1, num_labels)
+
+ repo_id = "datasets/huggingface/label-files"
+ num_labels = num_labels
+ id2label = json.load(open(hf_hub_download(repo_id, filename), "r"))
+ id2label = {int(k): v for k, v in id2label.items()}
+
+ id2label = id2label
+ label2id = {v: k for k, v in id2label.items()}
+
+ ImageNetPreTrainedConfig = partial(LevitConfig, num_labels=num_labels, id2label=id2label, label2id=label2id)
+
+ names_to_hidden_sizes = {
+ "levit-128S": 128,
+ "levit-128": 128,
+ "levit-192": 192,
+ "levit-256": 256,
+ "levit-384": 384,
+ }
+
+ names_to_config = {
+ "levit-128S": ImageNetPreTrainedConfig(
+ hidden_sizes=[128, 256, 384],
+ num_attention_heads=[4, 6, 8],
+ depths=[2, 3, 4],
+ key_dim=[16, 16, 16],
+ drop_path_rate=0,
+ ),
+ "levit-128": ImageNetPreTrainedConfig(
+ hidden_sizes=[128, 256, 384],
+ num_attention_heads=[4, 8, 12],
+ depths=[4, 4, 4],
+ key_dim=[16, 16, 16],
+ drop_path_rate=0,
+ ),
+ "levit-192": ImageNetPreTrainedConfig(
+ hidden_sizes=[192, 288, 384],
+ num_attention_heads=[3, 5, 6],
+ depths=[4, 4, 4],
+ key_dim=[32, 32, 32],
+ drop_path_rate=0,
+ ),
+ "levit-256": ImageNetPreTrainedConfig(
+ hidden_sizes=[256, 384, 512],
+ num_attention_heads=[4, 6, 8],
+ depths=[4, 4, 4],
+ key_dim=[32, 32, 32],
+ drop_path_rate=0,
+ ),
+ "levit-384": ImageNetPreTrainedConfig(
+ hidden_sizes=[384, 512, 768],
+ num_attention_heads=[6, 9, 12],
+ depths=[4, 4, 4],
+ key_dim=[32, 32, 32],
+ drop_path_rate=0.1,
+ ),
+ }
+
+ if model_name:
+ convert_weight_and_push(
+ names_to_hidden_sizes[model_name], model_name, names_to_config[model_name], save_directory, push_to_hub
+ )
+ else:
+ for model_name, config in names_to_config.items():
+ convert_weight_and_push(names_to_hidden_sizes[model_name], model_name, config, save_directory, push_to_hub)
+ return config, expected_shape
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ # Required parameters
+ parser.add_argument(
+ "--model_name",
+ default=None,
+ type=str,
+ help="The name of the model you wish to convert, it must be one of the supported Levit* architecture,",
+ )
+ parser.add_argument(
+ "--pytorch_dump_folder_path",
+ default="levit-dump-folder/",
+ type=Path,
+ required=False,
+ help="Path to the output PyTorch model directory.",
+ )
+ parser.add_argument(
+ "--push_to_hub",
+ default=True,
+ type=bool,
+ required=False,
+ help="If True, push model and feature extractor to the hub.",
+ )
+
+ args = parser.parse_args()
+ pytorch_dump_folder_path: Path = args.pytorch_dump_folder_path
+ pytorch_dump_folder_path.mkdir(exist_ok=True, parents=True)
+ convert_weights_and_push(pytorch_dump_folder_path, args.model_name, args.push_to_hub)
diff --git a/src/transformers/models/levit/feature_extraction_levit.py b/src/transformers/models/levit/feature_extraction_levit.py
new file mode 100644
index 0000000000..b0ac5f6b3d
--- /dev/null
+++ b/src/transformers/models/levit/feature_extraction_levit.py
@@ -0,0 +1,158 @@
+# coding=utf-8
+# Copyright 2022 Meta Platforms, Inc. and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Feature extractor class for LeViT."""
+
+from typing import Optional, Union
+
+import numpy as np
+from PIL import Image
+
+from ...feature_extraction_utils import BatchFeature, FeatureExtractionMixin
+from ...image_utils import (
+ IMAGENET_DEFAULT_MEAN,
+ IMAGENET_DEFAULT_STD,
+ ImageFeatureExtractionMixin,
+ ImageInput,
+ is_torch_tensor,
+)
+from ...utils import TensorType, logging
+
+
+logger = logging.get_logger(__name__)
+
+
+class LevitFeatureExtractor(FeatureExtractionMixin, ImageFeatureExtractionMixin):
+ r"""
+ Constructs a LeViT feature extractor.
+
+ This feature extractor inherits from [`FeatureExtractionMixin`] which contains most of the main methods. Users
+ should refer to this superclass for more information regarding those methods.
+
+ Args:
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Whether to resize the shortest edge of the input to int(256/224 *`size`).
+ size (`int` or `Tuple(int)`, *optional*, defaults to 224):
+ Resize the input to the given size. If a tuple is provided, it should be (width, height). If only an
+ integer is provided, then shorter side of input will be resized to 'size'.
+ resample (`int`, *optional*, defaults to `PIL.Image.BICUBIC`):
+ An optional resampling filter. This can be one of `PIL.Image.NEAREST`, `PIL.Image.BOX`,
+ `PIL.Image.BILINEAR`, `PIL.Image.HAMMING`, `PIL.Image.BICUBIC` or `PIL.Image.LANCZOS`. Only has an effect
+ if `do_resize` is set to `True`.
+ do_center_crop (`bool`, *optional*, defaults to `True`):
+ Whether or not to center crop the input to `size`.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether or not to normalize the input with mean and standard deviation.
+ image_mean (`List[int]`, defaults to `[0.229, 0.224, 0.225]`):
+ The sequence of means for each channel, to be used when normalizing images.
+ image_std (`List[int]`, defaults to `[0.485, 0.456, 0.406]`):
+ The sequence of standard deviations for each channel, to be used when normalizing images.
+ """
+
+ model_input_names = ["pixel_values"]
+
+ def __init__(
+ self,
+ do_resize=True,
+ size=224,
+ resample=Image.BICUBIC,
+ do_center_crop=True,
+ do_normalize=True,
+ image_mean=IMAGENET_DEFAULT_MEAN,
+ image_std=IMAGENET_DEFAULT_STD,
+ **kwargs
+ ):
+ super().__init__(**kwargs)
+ self.do_resize = do_resize
+ self.size = size
+ self.resample = resample
+ self.do_center_crop = do_center_crop
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+
+ def __call__(
+ self, images: ImageInput, return_tensors: Optional[Union[str, TensorType]] = None, **kwargs
+ ) -> BatchFeature:
+ """
+ Main method to prepare for the model one or several image(s).
+
+
+
+ NumPy arrays and PyTorch tensors are converted to PIL images when resizing, so the most efficient is to pass
+ PIL images.
+
+
+
+ Args:
+ images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
+ The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
+ tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a
+ number of channels, H and W are image height and width.
+
+ return_tensors (`str` or [`~utils.TensorType`], *optional*, defaults to `'np'`):
+ If set, will return tensors of a particular framework. Acceptable values are:
+
+ - `'tf'`: Return TensorFlow `tf.constant` objects.
+ - `'pt'`: Return PyTorch `torch.Tensor` objects.
+ - `'np'`: Return NumPy `np.ndarray` objects.
+ - `'jax'`: Return JAX `jnp.ndarray` objects.
+
+ Returns:
+ [`BatchFeature`]: A [`BatchFeature`] with the following fields:
+
+ - **pixel_values** -- Pixel values to be fed to a model, of shape (batch_size, num_channels, height,
+ width).
+ """
+ # Input type checking for clearer error
+ valid_images = False
+
+ # Check that images has a valid type
+ if isinstance(images, (Image.Image, np.ndarray)) or is_torch_tensor(images):
+ valid_images = True
+ elif isinstance(images, (list, tuple)):
+ if len(images) == 0 or isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]):
+ valid_images = True
+
+ if not valid_images:
+ raise ValueError(
+ "Images must of type `PIL.Image.Image`, `np.ndarray` or `torch.Tensor` (single example), "
+ "`List[PIL.Image.Image]`, `List[np.ndarray]` or `List[torch.Tensor]` (batch of examples)."
+ )
+
+ is_batched = bool(
+ isinstance(images, (list, tuple))
+ and (isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]))
+ )
+
+ if not is_batched:
+ images = [images]
+
+ # transformations (resizing + center cropping + normalization)
+ if self.do_resize and self.size is not None:
+ size_ = int((256 / 224) * self.size)
+ images = [
+ self.resize(image=image, size=size_, resample=self.resample, default_to_square=False)
+ for image in images
+ ]
+ if self.do_center_crop:
+ images = [self.center_crop(image=image, size=self.size) for image in images]
+ if self.do_normalize:
+ images = [self.normalize(image=image, mean=self.image_mean, std=self.image_std) for image in images]
+
+ # return as BatchFeature
+ data = {"pixel_values": images}
+ encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
+
+ return encoded_inputs
diff --git a/src/transformers/models/levit/modeling_levit.py b/src/transformers/models/levit/modeling_levit.py
new file mode 100644
index 0000000000..b04a98317d
--- /dev/null
+++ b/src/transformers/models/levit/modeling_levit.py
@@ -0,0 +1,738 @@
+# coding=utf-8
+# Copyright 2022 Meta Platforms, Inc. and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch LeViT model."""
+
+import itertools
+from dataclasses import dataclass
+from typing import Optional, Tuple
+
+import torch
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+
+from ...modeling_outputs import (
+ BaseModelOutputWithNoAttention,
+ BaseModelOutputWithPoolingAndNoAttention,
+ ImageClassifierOutputWithNoAttention,
+ ModelOutput,
+)
+from ...modeling_utils import PreTrainedModel
+from ...utils import add_code_sample_docstrings, add_start_docstrings, add_start_docstrings_to_model_forward, logging
+from .configuration_levit import LevitConfig
+
+
+logger = logging.get_logger(__name__)
+
+# General docstring
+_CONFIG_FOR_DOC = "LevitConfig"
+_FEAT_EXTRACTOR_FOR_DOC = "LevitFeatureExtractor"
+
+# Base docstring
+_CHECKPOINT_FOR_DOC = "facebook/levit-128S"
+_EXPECTED_OUTPUT_SHAPE = [1, 16, 384]
+
+# Image classification docstring
+_IMAGE_CLASS_CHECKPOINT = "facebook/levit-128S"
+_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
+
+LEVIT_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "facebook/levit-128S",
+ # See all LeViT models at https://huggingface.co/models?filter=levit
+]
+
+
+@dataclass
+class LevitForImageClassificationWithTeacherOutput(ModelOutput):
+ """
+ Output type of [`LevitForImageClassificationWithTeacher`].
+
+ Args:
+ logits (`torch.FloatTensor` of shape `(batch_size, config.num_labels)`):
+ Prediction scores as the average of the `cls_logits` and `distillation_logits`.
+ cls_logits (`torch.FloatTensor` of shape `(batch_size, config.num_labels)`):
+ Prediction scores of the classification head (i.e. the linear layer on top of the final hidden state of the
+ class token).
+ distillation_logits (`torch.FloatTensor` of shape `(batch_size, config.num_labels)`):
+ Prediction scores of the distillation head (i.e. the linear layer on top of the final hidden state of the
+ distillation token).
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
+ shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the model at the output of each layer
+ plus the initial embedding outputs.
+ """
+
+ logits: torch.FloatTensor = None
+ cls_logits: torch.FloatTensor = None
+ distillation_logits: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+
+
+class LevitConvEmbeddings(nn.Module):
+ """
+ LeViT Conv Embeddings with Batch Norm, used in the initial patch embedding layer.
+ """
+
+ def __init__(
+ self, in_channels, out_channels, kernel_size, stride, padding, dilation=1, groups=1, bn_weight_init=1
+ ):
+ super().__init__()
+ self.convolution = nn.Conv2d(
+ in_channels, out_channels, kernel_size, stride, padding, dilation=dilation, groups=groups, bias=False
+ )
+ self.batch_norm = nn.BatchNorm2d(out_channels)
+
+ def forward(self, embeddings):
+ embeddings = self.convolution(embeddings)
+ embeddings = self.batch_norm(embeddings)
+ return embeddings
+
+
+class LevitPatchEmbeddings(nn.Module):
+ """
+ LeViT patch embeddings, for final embeddings to be passed to transformer blocks. It consists of multiple
+ `LevitConvEmbeddings`.
+ """
+
+ def __init__(self, config):
+ super().__init__()
+ self.embedding_layer_1 = LevitConvEmbeddings(
+ config.num_channels, config.hidden_sizes[0] // 8, config.kernel_size, config.stride, config.padding
+ )
+ self.activation_layer_1 = nn.Hardswish()
+
+ self.embedding_layer_2 = LevitConvEmbeddings(
+ config.hidden_sizes[0] // 8, config.hidden_sizes[0] // 4, config.kernel_size, config.stride, config.padding
+ )
+ self.activation_layer_2 = nn.Hardswish()
+
+ self.embedding_layer_3 = LevitConvEmbeddings(
+ config.hidden_sizes[0] // 4, config.hidden_sizes[0] // 2, config.kernel_size, config.stride, config.padding
+ )
+ self.activation_layer_3 = nn.Hardswish()
+
+ self.embedding_layer_4 = LevitConvEmbeddings(
+ config.hidden_sizes[0] // 2, config.hidden_sizes[0], config.kernel_size, config.stride, config.padding
+ )
+
+ def forward(self, pixel_values):
+ embeddings = self.embedding_layer_1(pixel_values)
+ embeddings = self.activation_layer_1(embeddings)
+ embeddings = self.embedding_layer_2(embeddings)
+ embeddings = self.activation_layer_2(embeddings)
+ embeddings = self.embedding_layer_3(embeddings)
+ embeddings = self.activation_layer_3(embeddings)
+ embeddings = self.embedding_layer_4(embeddings)
+ return embeddings.flatten(2).transpose(1, 2)
+
+
+class MLPLayerWithBN(nn.Module):
+ def __init__(self, input_dim, output_dim, bn_weight_init=1):
+ super().__init__()
+ self.linear = nn.Linear(in_features=input_dim, out_features=output_dim, bias=False)
+ self.batch_norm = nn.BatchNorm1d(output_dim)
+
+ def forward(self, hidden_state):
+ hidden_state = self.linear(hidden_state)
+ hidden_state = self.batch_norm(hidden_state.flatten(0, 1)).reshape_as(hidden_state)
+ return hidden_state
+
+
+class LevitSubsample(nn.Module):
+ def __init__(self, stride, resolution):
+ super().__init__()
+ self.stride = stride
+ self.resolution = resolution
+
+ def forward(self, hidden_state):
+ batch_size, _, channels = hidden_state.shape
+ hidden_state = hidden_state.view(batch_size, self.resolution, self.resolution, channels)[
+ :, :: self.stride, :: self.stride
+ ].reshape(batch_size, -1, channels)
+ return hidden_state
+
+
+class LevitAttention(nn.Module):
+ def __init__(self, hidden_sizes, key_dim, num_attention_heads, attention_ratio, resolution):
+ super().__init__()
+ self.num_attention_heads = num_attention_heads
+ self.scale = key_dim**-0.5
+ self.key_dim = key_dim
+ self.attention_ratio = attention_ratio
+ self.out_dim_keys_values = attention_ratio * key_dim * num_attention_heads + key_dim * num_attention_heads * 2
+ self.out_dim_projection = attention_ratio * key_dim * num_attention_heads
+
+ self.queries_keys_values = MLPLayerWithBN(hidden_sizes, self.out_dim_keys_values)
+ self.activation = nn.Hardswish()
+ self.projection = MLPLayerWithBN(self.out_dim_projection, hidden_sizes, bn_weight_init=0)
+
+ points = list(itertools.product(range(resolution), range(resolution)))
+ len_points = len(points)
+ attention_offsets, indices = {}, []
+ for p1 in points:
+ for p2 in points:
+ offset = (abs(p1[0] - p2[0]), abs(p1[1] - p2[1]))
+ if offset not in attention_offsets:
+ attention_offsets[offset] = len(attention_offsets)
+ indices.append(attention_offsets[offset])
+
+ self.attention_bias_cache = {}
+ self.attention_biases = torch.nn.Parameter(torch.zeros(num_attention_heads, len(attention_offsets)))
+ self.register_buffer("attention_bias_idxs", torch.LongTensor(indices).view(len_points, len_points))
+
+ @torch.no_grad()
+ def train(self, mode=True):
+ super().train(mode)
+ if mode and self.attention_bias_cache:
+ self.attention_bias_cache = {} # clear ab cache
+
+ def get_attention_biases(self, device):
+ if self.training:
+ return self.attention_biases[:, self.attention_bias_idxs]
+ else:
+ device_key = str(device)
+ if device_key not in self.attention_bias_cache:
+ self.attention_bias_cache[device_key] = self.attention_biases[:, self.attention_bias_idxs]
+ return self.attention_bias_cache[device_key]
+
+ def forward(self, hidden_state):
+ batch_size, seq_length, _ = hidden_state.shape
+ queries_keys_values = self.queries_keys_values(hidden_state)
+ query, key, value = queries_keys_values.view(batch_size, seq_length, self.num_attention_heads, -1).split(
+ [self.key_dim, self.key_dim, self.attention_ratio * self.key_dim], dim=3
+ )
+ query = query.permute(0, 2, 1, 3)
+ key = key.permute(0, 2, 1, 3)
+ value = value.permute(0, 2, 1, 3)
+
+ attention = query @ key.transpose(-2, -1) * self.scale + self.get_attention_biases(hidden_state.device)
+ attention = attention.softmax(dim=-1)
+ hidden_state = (attention @ value).transpose(1, 2).reshape(batch_size, seq_length, self.out_dim_projection)
+ hidden_state = self.projection(self.activation(hidden_state))
+ return hidden_state
+
+
+class LevitAttentionSubsample(nn.Module):
+ def __init__(
+ self,
+ input_dim,
+ output_dim,
+ key_dim,
+ num_attention_heads,
+ attention_ratio,
+ stride,
+ resolution_in,
+ resolution_out,
+ ):
+ super().__init__()
+ self.num_attention_heads = num_attention_heads
+ self.scale = key_dim**-0.5
+ self.key_dim = key_dim
+ self.attention_ratio = attention_ratio
+ self.out_dim_keys_values = attention_ratio * key_dim * num_attention_heads + key_dim * num_attention_heads
+ self.out_dim_projection = attention_ratio * key_dim * num_attention_heads
+ self.resolution_out = resolution_out
+ # resolution_in is the intial resolution, resoloution_out is final resolution after downsampling
+ self.keys_values = MLPLayerWithBN(input_dim, self.out_dim_keys_values)
+ self.queries_subsample = LevitSubsample(stride, resolution_in)
+ self.queries = MLPLayerWithBN(input_dim, key_dim * num_attention_heads)
+ self.activation = nn.Hardswish()
+ self.projection = MLPLayerWithBN(self.out_dim_projection, output_dim)
+
+ self.attention_bias_cache = {}
+
+ points = list(itertools.product(range(resolution_in), range(resolution_in)))
+ points_ = list(itertools.product(range(resolution_out), range(resolution_out)))
+ len_points, len_points_ = len(points), len(points_)
+ attention_offsets, indices = {}, []
+ for p1 in points_:
+ for p2 in points:
+ size = 1
+ offset = (abs(p1[0] * stride - p2[0] + (size - 1) / 2), abs(p1[1] * stride - p2[1] + (size - 1) / 2))
+ if offset not in attention_offsets:
+ attention_offsets[offset] = len(attention_offsets)
+ indices.append(attention_offsets[offset])
+
+ self.attention_biases = torch.nn.Parameter(torch.zeros(num_attention_heads, len(attention_offsets)))
+ self.register_buffer("attention_bias_idxs", torch.LongTensor(indices).view(len_points_, len_points))
+
+ @torch.no_grad()
+ def train(self, mode=True):
+ super().train(mode)
+ if mode and self.attention_bias_cache:
+ self.attention_bias_cache = {} # clear ab cache
+
+ def get_attention_biases(self, device):
+ if self.training:
+ return self.attention_biases[:, self.attention_bias_idxs]
+ else:
+ device_key = str(device)
+ if device_key not in self.attention_bias_cache:
+ self.attention_bias_cache[device_key] = self.attention_biases[:, self.attention_bias_idxs]
+ return self.attention_bias_cache[device_key]
+
+ def forward(self, hidden_state):
+ batch_size, seq_length, _ = hidden_state.shape
+ key, value = (
+ self.keys_values(hidden_state)
+ .view(batch_size, seq_length, self.num_attention_heads, -1)
+ .split([self.key_dim, self.attention_ratio * self.key_dim], dim=3)
+ )
+ key = key.permute(0, 2, 1, 3)
+ value = value.permute(0, 2, 1, 3)
+
+ query = self.queries(self.queries_subsample(hidden_state))
+ query = query.view(batch_size, self.resolution_out**2, self.num_attention_heads, self.key_dim).permute(
+ 0, 2, 1, 3
+ )
+
+ attention = query @ key.transpose(-2, -1) * self.scale + self.get_attention_biases(hidden_state.device)
+ attention = attention.softmax(dim=-1)
+ hidden_state = (attention @ value).transpose(1, 2).reshape(batch_size, -1, self.out_dim_projection)
+ hidden_state = self.projection(self.activation(hidden_state))
+ return hidden_state
+
+
+class LevitMLPLayer(nn.Module):
+ """
+ MLP Layer with `2X` expansion in contrast to ViT with `4X`.
+ """
+
+ def __init__(self, input_dim, hidden_dim):
+ super().__init__()
+ self.linear_up = MLPLayerWithBN(input_dim, hidden_dim)
+ self.activation = nn.Hardswish()
+ self.linear_down = MLPLayerWithBN(hidden_dim, input_dim)
+
+ def forward(self, hidden_state):
+ hidden_state = self.linear_up(hidden_state)
+ hidden_state = self.activation(hidden_state)
+ hidden_state = self.linear_down(hidden_state)
+ return hidden_state
+
+
+class LevitResidualLayer(nn.Module):
+ """
+ Residual Block for LeViT
+ """
+
+ def __init__(self, module, drop_rate):
+ super().__init__()
+ self.module = module
+ self.drop_rate = drop_rate
+
+ def forward(self, hidden_state):
+ if self.training and self.drop_rate > 0:
+ rnd = torch.rand(hidden_state.size(0), 1, 1, device=hidden_state.device)
+ rnd = rnd.ge_(self.drop_rate).div(1 - self.drop_rate).detach()
+ hidden_state = hidden_state + self.module(hidden_state) * rnd
+ return hidden_state
+ else:
+ hidden_state = hidden_state + self.module(hidden_state)
+ return hidden_state
+
+
+class LevitStage(nn.Module):
+ """
+ LeViT Stage consisting of `LevitMLPLayer` and `LevitAttention` layers.
+ """
+
+ def __init__(
+ self,
+ config,
+ idx,
+ hidden_sizes,
+ key_dim,
+ depths,
+ num_attention_heads,
+ attention_ratio,
+ mlp_ratio,
+ down_ops,
+ resolution_in,
+ ):
+ super().__init__()
+ self.layers = []
+ self.config = config
+ self.resolution_in = resolution_in
+ # resolution_in is the intial resolution, resolution_out is final resolution after downsampling
+ for _ in range(depths):
+ self.layers.append(
+ LevitResidualLayer(
+ LevitAttention(hidden_sizes, key_dim, num_attention_heads, attention_ratio, resolution_in),
+ self.config.drop_path_rate,
+ )
+ )
+ if mlp_ratio > 0:
+ hidden_dim = hidden_sizes * mlp_ratio
+ self.layers.append(
+ LevitResidualLayer(LevitMLPLayer(hidden_sizes, hidden_dim), self.config.drop_path_rate)
+ )
+
+ if down_ops[0] == "Subsample":
+ self.resolution_out = (self.resolution_in - 1) // down_ops[5] + 1
+ self.layers.append(
+ LevitAttentionSubsample(
+ *self.config.hidden_sizes[idx : idx + 2],
+ key_dim=down_ops[1],
+ num_attention_heads=down_ops[2],
+ attention_ratio=down_ops[3],
+ stride=down_ops[5],
+ resolution_in=resolution_in,
+ resolution_out=self.resolution_out,
+ )
+ )
+ self.resolution_in = self.resolution_out
+ if down_ops[4] > 0:
+ hidden_dim = self.config.hidden_sizes[idx + 1] * down_ops[4]
+ self.layers.append(
+ LevitResidualLayer(
+ LevitMLPLayer(self.config.hidden_sizes[idx + 1], hidden_dim), self.config.drop_path_rate
+ )
+ )
+
+ self.layers = nn.ModuleList(self.layers)
+
+ def get_resolution(self):
+ return self.resolution_in
+
+ def forward(self, hidden_state):
+ for layer in self.layers:
+ hidden_state = layer(hidden_state)
+ return hidden_state
+
+
+class LevitEncoder(nn.Module):
+ """
+ LeViT Encoder consisting of multiple `LevitStage` stages.
+ """
+
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ resolution = self.config.image_size // self.config.patch_size
+ self.stages = []
+ self.config.down_ops.append([""])
+
+ for stage_idx in range(len(config.depths)):
+ stage = LevitStage(
+ config,
+ stage_idx,
+ config.hidden_sizes[stage_idx],
+ config.key_dim[stage_idx],
+ config.depths[stage_idx],
+ config.num_attention_heads[stage_idx],
+ config.attention_ratio[stage_idx],
+ config.mlp_ratio[stage_idx],
+ config.down_ops[stage_idx],
+ resolution,
+ )
+ resolution = stage.get_resolution()
+ self.stages.append(stage)
+
+ self.stages = nn.ModuleList(self.stages)
+
+ def forward(self, hidden_state, output_hidden_states=False, return_dict=True):
+ all_hidden_states = () if output_hidden_states else None
+
+ for stage in self.stages:
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_state,)
+ hidden_state = stage(hidden_state)
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_state,)
+ if not return_dict:
+ return tuple(v for v in [hidden_state, all_hidden_states] if v is not None)
+
+ return BaseModelOutputWithNoAttention(last_hidden_state=hidden_state, hidden_states=all_hidden_states)
+
+
+class LevitClassificationLayer(nn.Module):
+ """
+ LeViT Classification Layer
+ """
+
+ def __init__(self, input_dim, output_dim):
+ super().__init__()
+ self.batch_norm = nn.BatchNorm1d(input_dim)
+ self.linear = nn.Linear(input_dim, output_dim)
+
+ def forward(self, hidden_state):
+ hidden_state = self.batch_norm(hidden_state)
+ logits = self.linear(hidden_state)
+ return logits
+
+
+class LevitPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = LevitConfig
+ base_model_prefix = "levit"
+ main_input_name = "pixel_values"
+ supports_gradient_checkpointing = True
+
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ if isinstance(module, (nn.Linear, nn.Conv2d)):
+ # Slightly different from the TF version which uses truncated_normal for initialization
+ # cf https://github.com/pytorch/pytorch/pull/5617
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, (nn.BatchNorm1d, nn.BatchNorm2d)):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, LevitModel):
+ module.gradient_checkpointing = value
+
+
+LEVIT_START_DOCSTRING = r"""
+ This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it
+ as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
+ behavior.
+
+ Parameters:
+ config ([`LevitConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+LEVIT_INPUTS_DOCSTRING = r"""
+ Args:
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
+ [`AutoFeatureExtractor.__call__`] for details.
+
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ "The bare Levit model outputting raw features without any specific head on top.",
+ LEVIT_START_DOCSTRING,
+)
+class LevitModel(LevitPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.config = config
+ self.patch_embeddings = LevitPatchEmbeddings(config)
+ self.encoder = LevitEncoder(config)
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(LEVIT_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ processor_class=_FEAT_EXTRACTOR_FOR_DOC,
+ checkpoint=_CHECKPOINT_FOR_DOC,
+ output_type=BaseModelOutputWithPoolingAndNoAttention,
+ config_class=_CONFIG_FOR_DOC,
+ modality="vision",
+ expected_output=_EXPECTED_OUTPUT_SHAPE,
+ )
+ def forward(
+ self,
+ pixel_values: torch.FloatTensor = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ):
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if pixel_values is None:
+ raise ValueError("You have to specify pixel_values")
+
+ embeddings = self.patch_embeddings(pixel_values)
+ encoder_outputs = self.encoder(
+ embeddings,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ last_hidden_state = encoder_outputs[0]
+
+ # global average pooling, (batch_size, seq_length, hidden_sizes) -> (batch_size, hidden_sizes)
+ pooled_output = last_hidden_state.mean(dim=1)
+
+ if not return_dict:
+ return (last_hidden_state, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPoolingAndNoAttention(
+ last_hidden_state=last_hidden_state,
+ pooler_output=pooled_output,
+ hidden_states=encoder_outputs.hidden_states,
+ )
+
+
+@add_start_docstrings(
+ """
+ Levit Model with an image classification head on top (a linear layer on top of the pooled features), e.g. for
+ ImageNet.
+ """,
+ LEVIT_START_DOCSTRING,
+)
+class LevitForImageClassification(LevitPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.config = config
+ self.num_labels = config.num_labels
+ self.levit = LevitModel(config)
+
+ # Classifier head
+ self.classifier = (
+ LevitClassificationLayer(config.hidden_sizes[-1], config.num_labels)
+ if config.num_labels > 0
+ else torch.nn.Identity()
+ )
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(LEVIT_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ processor_class=_FEAT_EXTRACTOR_FOR_DOC,
+ checkpoint=_IMAGE_CLASS_CHECKPOINT,
+ output_type=ImageClassifierOutputWithNoAttention,
+ config_class=_CONFIG_FOR_DOC,
+ expected_output=_IMAGE_CLASS_EXPECTED_OUTPUT,
+ )
+ def forward(
+ self,
+ pixel_values: torch.FloatTensor = None,
+ labels: Optional[torch.LongTensor] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ):
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the image classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.levit(pixel_values, output_hidden_states=output_hidden_states, return_dict=return_dict)
+
+ sequence_output = outputs[0]
+ sequence_output = sequence_output.mean(1)
+ logits = self.classifier(sequence_output)
+
+ loss = None
+ if labels is not None:
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = "regression"
+ elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
+ self.config.problem_type = "single_label_classification"
+ else:
+ self.config.problem_type = "multi_label_classification"
+
+ if self.config.problem_type == "regression":
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(logits, labels)
+ elif self.config.problem_type == "single_label_classification":
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == "multi_label_classification":
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(logits, labels)
+ if not return_dict:
+ output = (logits,) + outputs[2:]
+ return ((loss,) + output) if loss is not None else output
+
+ return ImageClassifierOutputWithNoAttention(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ )
+
+
+@add_start_docstrings(
+ """
+ LeViT Model transformer with image classification heads on top (a linear layer on top of the final hidden state and
+ a linear layer on top of the final hidden state of the distillation token) e.g. for ImageNet. .. warning::
+ This model supports inference-only. Fine-tuning with distillation (i.e. with a teacher) is not yet
+ supported.
+ """,
+ LEVIT_START_DOCSTRING,
+)
+class LevitForImageClassificationWithTeacher(LevitPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.config = config
+ self.num_labels = config.num_labels
+ self.levit = LevitModel(config)
+
+ # Classifier head
+ self.classifier = (
+ LevitClassificationLayer(config.hidden_sizes[-1], config.num_labels)
+ if config.num_labels > 0
+ else torch.nn.Identity()
+ )
+ self.classifier_distill = (
+ LevitClassificationLayer(config.hidden_sizes[-1], config.num_labels)
+ if config.num_labels > 0
+ else torch.nn.Identity()
+ )
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(LEVIT_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ processor_class=_FEAT_EXTRACTOR_FOR_DOC,
+ checkpoint=_IMAGE_CLASS_CHECKPOINT,
+ output_type=LevitForImageClassificationWithTeacherOutput,
+ config_class=_CONFIG_FOR_DOC,
+ expected_output=_IMAGE_CLASS_EXPECTED_OUTPUT,
+ )
+ def forward(
+ self,
+ pixel_values: torch.FloatTensor = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ):
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.levit(pixel_values, output_hidden_states=output_hidden_states, return_dict=return_dict)
+
+ sequence_output = outputs[0]
+ sequence_output = sequence_output.mean(1)
+ cls_logits, distill_logits = self.classifier(sequence_output), self.classifier_distill(sequence_output)
+ logits = (cls_logits + distill_logits) / 2
+
+ if not return_dict:
+ output = (logits, cls_logits, distill_logits) + outputs[2:]
+ return output
+
+ return LevitForImageClassificationWithTeacherOutput(
+ logits=logits,
+ cls_logits=cls_logits,
+ distillation_logits=distill_logits,
+ hidden_states=outputs.hidden_states,
+ )
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index e25185b1a1..4b7e06e635 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -2474,6 +2474,37 @@ class LEDPreTrainedModel(metaclass=DummyObject):
requires_backends(self, ["torch"])
+LEVIT_PRETRAINED_MODEL_ARCHIVE_LIST = None
+
+
+class LevitForImageClassification(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class LevitForImageClassificationWithTeacher(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class LevitModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class LevitPreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
LONGFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = None
diff --git a/src/transformers/utils/dummy_vision_objects.py b/src/transformers/utils/dummy_vision_objects.py
index add3fada5b..63e7450be4 100644
--- a/src/transformers/utils/dummy_vision_objects.py
+++ b/src/transformers/utils/dummy_vision_objects.py
@@ -101,6 +101,13 @@ class LayoutLMv3FeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class LevitFeatureExtractor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class MaskFormerFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
diff --git a/tests/models/levit/__init__.py b/tests/models/levit/__init__.py
new file mode 100644
index 0000000000..e69de29bb2
diff --git a/tests/models/levit/test_feature_extraction_levit.py b/tests/models/levit/test_feature_extraction_levit.py
new file mode 100644
index 0000000000..98a704b97a
--- /dev/null
+++ b/tests/models/levit/test_feature_extraction_levit.py
@@ -0,0 +1,195 @@
+# coding=utf-8
+# Copyright 2022 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+import numpy as np
+
+from transformers.testing_utils import require_torch, require_vision
+from transformers.utils import is_torch_available, is_vision_available
+
+from ...test_feature_extraction_common import FeatureExtractionSavingTestMixin, prepare_image_inputs
+
+
+if is_torch_available():
+ import torch
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import LevitFeatureExtractor
+
+
+class LevitFeatureExtractionTester(unittest.TestCase):
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ image_size=18,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=18,
+ do_center_crop=True,
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.do_center_crop = do_center_crop
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+
+ def prepare_feat_extract_dict(self):
+ return {
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ "do_normalize": self.do_normalize,
+ "do_resize": self.do_resize,
+ "do_center_crop": self.do_center_crop,
+ "size": self.size,
+ }
+
+
+@require_torch
+@require_vision
+class LevitFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.TestCase):
+
+ feature_extraction_class = LevitFeatureExtractor if is_vision_available() else None
+
+ def setUp(self):
+ self.feature_extract_tester = LevitFeatureExtractionTester(self)
+
+ @property
+ def feat_extract_dict(self):
+ return self.feature_extract_tester.prepare_feat_extract_dict()
+
+ def test_feat_extract_properties(self):
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ self.assertTrue(hasattr(feature_extractor, "image_mean"))
+ self.assertTrue(hasattr(feature_extractor, "image_std"))
+ self.assertTrue(hasattr(feature_extractor, "do_normalize"))
+ self.assertTrue(hasattr(feature_extractor, "do_resize"))
+ self.assertTrue(hasattr(feature_extractor, "do_center_crop"))
+ self.assertTrue(hasattr(feature_extractor, "size"))
+
+ def test_batch_feature(self):
+ pass
+
+ def test_call_pil(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random PIL images
+ image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False)
+ for image in image_inputs:
+ self.assertIsInstance(image, Image.Image)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ # Test batched
+ encoded_images = feature_extractor(image_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ def test_call_numpy(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random numpy tensors
+ image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False, numpify=True)
+ for image in image_inputs:
+ self.assertIsInstance(image, np.ndarray)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ # Test batched
+ encoded_images = feature_extractor(image_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ def test_call_pytorch(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random PyTorch tensors
+ image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False, torchify=True)
+ for image in image_inputs:
+ self.assertIsInstance(image, torch.Tensor)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ # Test batched
+ encoded_images = feature_extractor(image_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
diff --git a/tests/models/levit/test_modeling_levit.py b/tests/models/levit/test_modeling_levit.py
new file mode 100644
index 0000000000..69fb0d0e00
--- /dev/null
+++ b/tests/models/levit/test_modeling_levit.py
@@ -0,0 +1,423 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch LeViT model. """
+
+
+import inspect
+import unittest
+import warnings
+from math import ceil, floor
+
+from transformers import LevitConfig
+from transformers.file_utils import cached_property, is_torch_available, is_vision_available
+from transformers.models.auto import get_values
+from transformers.testing_utils import require_torch, require_vision, slow, torch_device
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING,
+ MODEL_MAPPING,
+ LevitForImageClassification,
+ LevitForImageClassificationWithTeacher,
+ LevitModel,
+ )
+ from transformers.models.levit.modeling_levit import LEVIT_PRETRAINED_MODEL_ARCHIVE_LIST
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import LevitFeatureExtractor
+
+
+class LevitConfigTester(ConfigTester):
+ def create_and_test_config_common_properties(self):
+ config = self.config_class(**self.inputs_dict)
+ self.parent.assertTrue(hasattr(config, "hidden_sizes"))
+ self.parent.assertTrue(hasattr(config, "num_attention_heads"))
+
+
+class LevitModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ image_size=64,
+ num_channels=3,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ patch_size=16,
+ hidden_sizes=[128, 256, 384],
+ num_attention_heads=[4, 6, 8],
+ depths=[2, 3, 4],
+ key_dim=[16, 16, 16],
+ drop_path_rate=0,
+ mlp_ratio=[2, 2, 2],
+ attention_ratio=[2, 2, 2],
+ initializer_range=0.02,
+ is_training=True,
+ use_labels=True,
+ num_labels=2, # Check
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.num_channels = num_channels
+ self.kernel_size = kernel_size
+ self.stride = stride
+ self.padding = padding
+ self.hidden_sizes = hidden_sizes
+ self.num_attention_heads = num_attention_heads
+ self.depths = depths
+ self.key_dim = key_dim
+ self.drop_path_rate = drop_path_rate
+ self.patch_size = patch_size
+ self.attention_ratio = attention_ratio
+ self.mlp_ratio = mlp_ratio
+ self.initializer_range = initializer_range
+ self.down_ops = [
+ ["Subsample", key_dim[0], hidden_sizes[0] // key_dim[0], 4, 2, 2],
+ ["Subsample", key_dim[0], hidden_sizes[1] // key_dim[0], 4, 2, 2],
+ ]
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.num_labels = num_labels
+ self.initializer_range = initializer_range
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size], self.num_labels)
+
+ config = self.get_config()
+ return config, pixel_values, labels
+
+ def get_config(self):
+ return LevitConfig(
+ image_size=self.image_size,
+ num_channels=self.num_channels,
+ kernel_size=self.kernel_size,
+ stride=self.stride,
+ padding=self.padding,
+ patch_size=self.patch_size,
+ hidden_sizes=self.hidden_sizes,
+ num_attention_heads=self.num_attention_heads,
+ depths=self.depths,
+ key_dim=self.key_dim,
+ drop_path_rate=self.drop_path_rate,
+ mlp_ratio=self.mlp_ratio,
+ attention_ratio=self.attention_ratio,
+ initializer_range=self.initializer_range,
+ down_ops=self.down_ops,
+ )
+
+ def create_and_check_model(self, config, pixel_values, labels):
+ model = LevitModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ image_size = (self.image_size, self.image_size)
+ height, width = image_size[0], image_size[1]
+ for _ in range(4):
+ height = floor(((height + 2 * self.padding - self.kernel_size) / self.stride) + 1)
+ width = floor(((width + 2 * self.padding - self.kernel_size) / self.stride) + 1)
+ self.parent.assertEqual(
+ result.last_hidden_state.shape,
+ (self.batch_size, ceil(height / 4) * ceil(width / 4), self.hidden_sizes[-1]),
+ )
+
+ def create_and_check_for_image_classification(self, config, pixel_values, labels):
+ config.num_labels = self.num_labels
+ model = LevitForImageClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values, labels=labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values, labels = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class LevitModelTest(ModelTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as Levit does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (
+ (LevitModel, LevitForImageClassification, LevitForImageClassificationWithTeacher)
+ if is_torch_available()
+ else ()
+ )
+
+ test_pruning = False
+ test_torchscript = False
+ test_resize_embeddings = False
+ test_head_masking = False
+ has_attentions = False
+
+ def setUp(self):
+ self.model_tester = LevitModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=LevitConfig, has_text_modality=False, hidden_size=37)
+
+ def test_config(self):
+ self.create_and_test_config_common_properties()
+ self.config_tester.create_and_test_config_to_json_string()
+ self.config_tester.create_and_test_config_to_json_file()
+ self.config_tester.create_and_test_config_from_and_save_pretrained()
+ self.config_tester.create_and_test_config_with_num_labels()
+ self.config_tester.check_config_can_be_init_without_params()
+ self.config_tester.check_config_arguments_init()
+
+ def create_and_test_config_common_properties(self):
+ return
+
+ @unittest.skip(reason="Levit does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="Levit does not support input and output embeddings")
+ def test_model_common_attributes(self):
+ pass
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_hidden_states_output(self):
+ def check_hidden_states_output(inputs_dict, config, model_class):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ hidden_states = outputs.hidden_states
+
+ expected_num_layers = len(self.model_tester.depths) + 1
+ self.assertEqual(len(hidden_states), expected_num_layers)
+
+ image_size = (self.model_tester.image_size, self.model_tester.image_size)
+ height, width = image_size[0], image_size[1]
+ for _ in range(4):
+ height = floor(
+ (
+ (height + 2 * self.model_tester.padding - self.model_tester.kernel_size)
+ / self.model_tester.stride
+ )
+ + 1
+ )
+ width = floor(
+ (
+ (width + 2 * self.model_tester.padding - self.model_tester.kernel_size)
+ / self.model_tester.stride
+ )
+ + 1
+ )
+ # verify the first hidden states (first block)
+ self.assertListEqual(
+ list(hidden_states[0].shape[-2:]),
+ [
+ height * width,
+ self.model_tester.hidden_sizes[0],
+ ],
+ )
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_hidden_states"] = True
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ # check that output_hidden_states also work using config
+ del inputs_dict["output_hidden_states"]
+ config.output_hidden_states = True
+
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ inputs_dict = super()._prepare_for_class(inputs_dict, model_class, return_labels=return_labels)
+
+ if return_labels:
+ if model_class.__name__ == "LevitForImageClassificationWithTeacher":
+ del inputs_dict["labels"]
+
+ return inputs_dict
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_for_image_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_image_classification(*config_and_inputs)
+
+ # special case for LevitForImageClassificationWithTeacher model
+ def test_training(self):
+ if not self.model_tester.is_training:
+ return
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ for model_class in self.all_model_classes:
+ # LevitForImageClassificationWithTeacher supports inference-only
+ if (
+ model_class in get_values(MODEL_MAPPING)
+ or model_class.__name__ == "LevitForImageClassificationWithTeacher"
+ ):
+ continue
+ model = model_class(config)
+ model.to(torch_device)
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ def test_training_gradient_checkpointing(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ if not self.model_tester.is_training:
+ return
+
+ config.use_cache = False
+ config.return_dict = True
+
+ for model_class in self.all_model_classes:
+ if model_class in get_values(MODEL_MAPPING) or not model_class.supports_gradient_checkpointing:
+ continue
+ # LevitForImageClassificationWithTeacher supports inference-only
+ if model_class.__name__ == "LevitForImageClassificationWithTeacher":
+ continue
+ model = model_class(config)
+ model.gradient_checkpointing_enable()
+ model.to(torch_device)
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ def test_problem_types(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ problem_types = [
+ {"title": "multi_label_classification", "num_labels": 2, "dtype": torch.float},
+ {"title": "single_label_classification", "num_labels": 1, "dtype": torch.long},
+ {"title": "regression", "num_labels": 1, "dtype": torch.float},
+ ]
+
+ for model_class in self.all_model_classes:
+ if (
+ model_class
+ not in [
+ *get_values(MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING),
+ ]
+ or model_class.__name__ == "LevitForImageClassificationWithTeacher"
+ ):
+ continue
+
+ for problem_type in problem_types:
+ with self.subTest(msg=f"Testing {model_class} with {problem_type['title']}"):
+
+ config.problem_type = problem_type["title"]
+ config.num_labels = problem_type["num_labels"]
+
+ model = model_class(config)
+ model.to(torch_device)
+ model.train()
+
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+
+ if problem_type["num_labels"] > 1:
+ inputs["labels"] = inputs["labels"].unsqueeze(1).repeat(1, problem_type["num_labels"])
+
+ inputs["labels"] = inputs["labels"].to(problem_type["dtype"])
+
+ # This tests that we do not trigger the warning form PyTorch "Using a target size that is different
+ # to the input size. This will likely lead to incorrect results due to broadcasting. Please ensure
+ # they have the same size." which is a symptom something in wrong for the regression problem.
+ # See https://github.com/huggingface/transformers/issues/11780
+ with warnings.catch_warnings(record=True) as warning_list:
+ loss = model(**inputs).loss
+ for w in warning_list:
+ if "Using a target size that is different to the input size" in str(w.message):
+ raise ValueError(
+ f"Something is going wrong in the regression problem: intercepted {w.message}"
+ )
+
+ loss.backward()
+
+ @slow
+ def test_model_from_pretrained(self):
+ for model_name in LEVIT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ model = LevitModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_torch
+@require_vision
+class LevitModelIntegrationTest(unittest.TestCase):
+ @cached_property
+ def default_feature_extractor(self):
+ return LevitFeatureExtractor.from_pretrained(LEVIT_PRETRAINED_MODEL_ARCHIVE_LIST[0])
+
+ @slow
+ def test_inference_image_classification_head(self):
+ model = LevitForImageClassificationWithTeacher.from_pretrained(LEVIT_PRETRAINED_MODEL_ARCHIVE_LIST[0]).to(
+ torch_device
+ )
+
+ feature_extractor = self.default_feature_extractor
+ image = prepare_img()
+ inputs = feature_extractor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the logits
+ expected_shape = torch.Size((1, 1000))
+ self.assertEqual(outputs.logits.shape, expected_shape)
+
+ expected_slice = torch.tensor([0.0096, -1.0084, -1.4318]).to(torch_device)
+
+ self.assertTrue(torch.allclose(outputs.logits[0, :3], expected_slice, atol=1e-4))
+
+ LeViT Architecture. Taken from the original paper.
+
+Tips:
+
+- Compared to ViT, LeViT models use an additional distillation head to effectively learn from a teacher (which, in the LeViT paper, is a ResNet like-model). The distillation head is learned through backpropagation under supervision of a ResNet like-model. They also draw inspiration from convolution neural networks to use activation maps with decreasing resolutions to increase the efficiency.
+- There are 2 ways to fine-tune distilled models, either (1) in a classic way, by only placing a prediction head on top
+ of the final hidden state and not using the distillation head, or (2) by placing both a prediction head and distillation
+ head on top of the final hidden state. In that case, the prediction head is trained using regular cross-entropy between
+ the prediction of the head and the ground-truth label, while the distillation prediction head is trained using hard distillation
+ (cross-entropy between the prediction of the distillation head and the label predicted by the teacher). At inference time,
+ one takes the average prediction between both heads as final prediction. (2) is also called "fine-tuning with distillation",
+ because one relies on a teacher that has already been fine-tuned on the downstream dataset. In terms of models, (1) corresponds
+ to [`LevitForImageClassification`] and (2) corresponds to [`LevitForImageClassificationWithTeacher`].
+- All released checkpoints were pre-trained and fine-tuned on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k)
+ (also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes). only. No external data was used. This is in
+ contrast with the original ViT model, which used external data like the JFT-300M dataset/Imagenet-21k for
+ pre-training.
+- The authors of LeViT released 5 trained LeViT models, which you can directly plug into [`LevitModel`] or [`LevitForImageClassification`].
+ Techniques like data augmentation, optimization, and regularization were used in order to simulate training on a much larger dataset
+ (while only using ImageNet-1k for pre-training). The 5 variants available are (all trained on images of size 224x224):
+ *facebook/levit-128S*, *facebook/levit-128*, *facebook/levit-192*, *facebook/levit-256* and
+ *facebook/levit-384*. Note that one should use [`LevitFeatureExtractor`] in order to
+ prepare images for the model.
+- [`LevitForImageClassificationWithTeacher`] currently supports only inference and not training or fine-tuning.
+- You can check out demo notebooks regarding inference as well as fine-tuning on custom data [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer)
+ (you can just replace [`ViTFeatureExtractor`] by [`LevitFeatureExtractor`] and [`ViTForImageClassification`] by [`LevitForImageClassification`] or [`LevitForImageClassificationWithTeacher`]).
+
+This model was contributed by [anugunj](https://huggingface.co/anugunj). The original code can be found [here](https://github.com/facebookresearch/LeViT).
+
+
+## LevitConfig
+
+[[autodoc]] LevitConfig
+
+## LevitFeatureExtractor
+
+[[autodoc]] LevitFeatureExtractor
+ - __call__
+
+## LevitModel
+
+[[autodoc]] LevitModel
+ - forward
+
+## LevitForImageClassification
+
+[[autodoc]] LevitForImageClassification
+ - forward
+
+## LevitForImageClassificationWithTeacher
+
+[[autodoc]] LevitForImageClassificationWithTeacher
+ - forward
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index a17253b5e0..b40d95d4d9 100755
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -236,6 +236,7 @@ _import_structure = {
],
"models.layoutxlm": ["LayoutXLMProcessor"],
"models.led": ["LED_PRETRAINED_CONFIG_ARCHIVE_MAP", "LEDConfig", "LEDTokenizer"],
+ "models.levit": ["LEVIT_PRETRAINED_CONFIG_ARCHIVE_MAP", "LevitConfig"],
"models.longformer": ["LONGFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP", "LongformerConfig", "LongformerTokenizer"],
"models.luke": ["LUKE_PRETRAINED_CONFIG_ARCHIVE_MAP", "LukeConfig", "LukeTokenizer"],
"models.lxmert": ["LXMERT_PRETRAINED_CONFIG_ARCHIVE_MAP", "LxmertConfig", "LxmertTokenizer"],
@@ -601,6 +602,7 @@ else:
_import_structure["models.imagegpt"].append("ImageGPTFeatureExtractor")
_import_structure["models.layoutlmv2"].append("LayoutLMv2FeatureExtractor")
_import_structure["models.layoutlmv3"].append("LayoutLMv3FeatureExtractor")
+ _import_structure["models.levit"].append("LevitFeatureExtractor")
_import_structure["models.maskformer"].append("MaskFormerFeatureExtractor")
_import_structure["models.perceiver"].append("PerceiverFeatureExtractor")
_import_structure["models.poolformer"].append("PoolFormerFeatureExtractor")
@@ -1237,6 +1239,15 @@ else:
"LEDPreTrainedModel",
]
)
+ _import_structure["models.levit"].extend(
+ [
+ "LEVIT_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "LevitForImageClassification",
+ "LevitForImageClassificationWithTeacher",
+ "LevitModel",
+ "LevitPreTrainedModel",
+ ]
+ )
_import_structure["models.longformer"].extend(
[
"LONGFORMER_PRETRAINED_MODEL_ARCHIVE_LIST",
@@ -2811,6 +2822,7 @@ if TYPE_CHECKING:
)
from .models.layoutxlm import LayoutXLMProcessor
from .models.led import LED_PRETRAINED_CONFIG_ARCHIVE_MAP, LEDConfig, LEDTokenizer
+ from .models.levit import LEVIT_PRETRAINED_CONFIG_ARCHIVE_MAP, LevitConfig
from .models.longformer import LONGFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP, LongformerConfig, LongformerTokenizer
from .models.luke import LUKE_PRETRAINED_CONFIG_ARCHIVE_MAP, LukeConfig, LukeTokenizer
from .models.lxmert import LXMERT_PRETRAINED_CONFIG_ARCHIVE_MAP, LxmertConfig, LxmertTokenizer
@@ -3123,6 +3135,7 @@ if TYPE_CHECKING:
from .models.imagegpt import ImageGPTFeatureExtractor
from .models.layoutlmv2 import LayoutLMv2FeatureExtractor
from .models.layoutlmv3 import LayoutLMv3FeatureExtractor
+ from .models.levit import LevitFeatureExtractor
from .models.maskformer import MaskFormerFeatureExtractor
from .models.perceiver import PerceiverFeatureExtractor
from .models.poolformer import PoolFormerFeatureExtractor
@@ -3656,6 +3669,13 @@ if TYPE_CHECKING:
LEDModel,
LEDPreTrainedModel,
)
+ from .models.levit import (
+ LEVIT_PRETRAINED_MODEL_ARCHIVE_LIST,
+ LevitForImageClassification,
+ LevitForImageClassificationWithTeacher,
+ LevitModel,
+ LevitPreTrainedModel,
+ )
from .models.longformer import (
LONGFORMER_PRETRAINED_MODEL_ARCHIVE_LIST,
LongformerForMaskedLM,
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index e435265a83..8ceb5014e7 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -73,6 +73,7 @@ from . import (
layoutlmv3,
layoutxlm,
led,
+ levit,
longformer,
luke,
lxmert,
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index dbb19c55aa..1020d8550c 100644
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -76,6 +76,7 @@ CONFIG_MAPPING_NAMES = OrderedDict(
("layoutlmv2", "LayoutLMv2Config"),
("layoutlmv3", "LayoutLMv3Config"),
("led", "LEDConfig"),
+ ("levit", "LevitConfig"),
("longformer", "LongformerConfig"),
("luke", "LukeConfig"),
("lxmert", "LxmertConfig"),
@@ -188,6 +189,7 @@ CONFIG_ARCHIVE_MAP_MAPPING_NAMES = OrderedDict(
("layoutlmv2", "LAYOUTLMV2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("layoutlmv3", "LAYOUTLMV3_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("led", "LED_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("levit", "LEVIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("longformer", "LONGFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("luke", "LUKE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("lxmert", "LXMERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
@@ -302,6 +304,7 @@ MODEL_NAMES_MAPPING = OrderedDict(
("layoutlmv3", "LayoutLMv3"),
("layoutxlm", "LayoutXLM"),
("led", "LED"),
+ ("levit", "LeViT"),
("longformer", "Longformer"),
("luke", "LUKE"),
("lxmert", "LXMERT"),
diff --git a/src/transformers/models/auto/feature_extraction_auto.py b/src/transformers/models/auto/feature_extraction_auto.py
index f398efe360..cbb4b79593 100644
--- a/src/transformers/models/auto/feature_extraction_auto.py
+++ b/src/transformers/models/auto/feature_extraction_auto.py
@@ -53,6 +53,7 @@ FEATURE_EXTRACTOR_MAPPING_NAMES = OrderedDict(
("imagegpt", "ImageGPTFeatureExtractor"),
("layoutlmv2", "LayoutLMv2FeatureExtractor"),
("layoutlmv3", "LayoutLMv3FeatureExtractor"),
+ ("levit", "LevitFeatureExtractor"),
("maskformer", "MaskFormerFeatureExtractor"),
("perceiver", "PerceiverFeatureExtractor"),
("poolformer", "PoolFormerFeatureExtractor"),
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index 61787c3d60..79a7c80ce6 100644
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -75,6 +75,7 @@ MODEL_MAPPING_NAMES = OrderedDict(
("layoutlmv2", "LayoutLMv2Model"),
("layoutlmv3", "LayoutLMv3Model"),
("led", "LEDModel"),
+ ("levit", "LevitModel"),
("longformer", "LongformerModel"),
("luke", "LukeModel"),
("lxmert", "LxmertModel"),
@@ -308,6 +309,7 @@ MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
("data2vec-vision", "Data2VecVisionForImageClassification"),
("deit", ("DeiTForImageClassification", "DeiTForImageClassificationWithTeacher")),
("imagegpt", "ImageGPTForImageClassification"),
+ ("levit", ("LevitForImageClassification", "LevitForImageClassificationWithTeacher")),
(
"perceiver",
(
diff --git a/src/transformers/models/levit/__init__.py b/src/transformers/models/levit/__init__.py
new file mode 100644
index 0000000000..bdbcaed41a
--- /dev/null
+++ b/src/transformers/models/levit/__init__.py
@@ -0,0 +1,75 @@
+# flake8: noqa
+# There's no way to ignore "F401 '...' imported but unused" warnings in this
+# module, but to preserve other warnings. So, don't check this module at all.
+
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...utils import OptionalDependencyNotAvailable, _LazyModule, is_torch_available, is_vision_available
+
+
+_import_structure = {"configuration_levit": ["LEVIT_PRETRAINED_CONFIG_ARCHIVE_MAP", "LevitConfig"]}
+
+try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["feature_extraction_levit"] = ["LevitFeatureExtractor"]
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["modeling_levit"] = [
+ "LEVIT_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "LevitForImageClassification",
+ "LevitForImageClassificationWithTeacher",
+ "LevitModel",
+ "LevitPreTrainedModel",
+ ]
+
+
+if TYPE_CHECKING:
+ from .configuration_levit import LEVIT_PRETRAINED_CONFIG_ARCHIVE_MAP, LevitConfig
+
+ try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .feature_extraction_levit import LevitFeatureExtractor
+
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .modeling_levit import (
+ LEVIT_PRETRAINED_MODEL_ARCHIVE_LIST,
+ LevitForImageClassification,
+ LevitForImageClassificationWithTeacher,
+ LevitModel,
+ LevitPreTrainedModel,
+ )
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/levit/configuration_levit.py b/src/transformers/models/levit/configuration_levit.py
new file mode 100644
index 0000000000..5d75b9fc23
--- /dev/null
+++ b/src/transformers/models/levit/configuration_levit.py
@@ -0,0 +1,122 @@
+# coding=utf-8
+# Copyright 2022 Meta Platforms, Inc. and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" LeViT model configuration"""
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+LEVIT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "facebook/levit-128S": "https://huggingface.co/facebook/levit-128S/resolve/main/config.json",
+ # See all LeViT models at https://huggingface.co/models?filter=levit
+}
+
+
+class LevitConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`LevitModel`]. It is used to instantiate a LeViT
+ model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
+ defaults will yield a similar configuration to that of the LeViT
+ [facebook/levit-base-192](https://huggingface.co/facebook/levit-base-192) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ image_size (`int`, *optional*, defaults to 224):
+ The size of the input image.
+ num_channels (`int`, *optional*, defaults to 3):
+ Number of channels in the input image.
+ kernel_size (`int`, *optional*, defaults to 3):
+ The kernel size for the initial convolution layers of patch embedding.
+ stride (`int`, *optional*, defaults to 2):
+ The stride size for the initial convolution layers of patch embedding.
+ padding (`int`, *optional*, defaults to 1):
+ The padding size for the initial convolution layers of patch embedding.
+ patch_size (`int`, *optional*, defaults to 16):
+ The patch size for embeddings.
+ hidden_sizes (`List[int]`, *optional*, defaults to `[128, 256, 384]`):
+ Dimension of each of the encoder blocks.
+ num_attention_heads (`List[int]`, *optional*, defaults to `[4, 8, 12]`):
+ Number of attention heads for each attention layer in each block of the Transformer encoder.
+ depths (`List[int]`, *optional*, defaults to `[4, 4, 4]`):
+ The number of layers in each encoder block.
+ key_dim (`List[int]`, *optional*, defaults to `[16, 16, 16]`):
+ The size of key in each of the encoder blocks.
+ drop_path_rate (`int`, *optional*, defaults to 0):
+ The dropout probability for stochastic depths, used in the blocks of the Transformer encoder.
+ mlp_ratios (`List[int]`, *optional*, defaults to `[2, 2, 2]`):
+ Ratio of the size of the hidden layer compared to the size of the input layer of the Mix FFNs in the
+ encoder blocks.
+ attention_ratios (`List[int]`, *optional*, defaults to `[2, 2, 2]`):
+ Ratio of the size of the output dimension compared to input dimension of attention layers.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+
+ Example:
+
+ ```python
+ >>> from transformers import LevitModel, LevitConfig
+
+ >>> # Initializing a LeViT levit-base-192 style configuration
+ >>> configuration = LevitConfig()
+
+ >>> # Initializing a model from the levit-base-192 style configuration
+ >>> model = LevitModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+ model_type = "levit"
+
+ def __init__(
+ self,
+ image_size=224,
+ num_channels=3,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ patch_size=16,
+ hidden_sizes=[128, 256, 384],
+ num_attention_heads=[4, 8, 12],
+ depths=[4, 4, 4],
+ key_dim=[16, 16, 16],
+ drop_path_rate=0,
+ mlp_ratio=[2, 2, 2],
+ attention_ratio=[2, 2, 2],
+ initializer_range=0.02,
+ **kwargs
+ ):
+ super().__init__(**kwargs)
+ self.image_size = image_size
+ self.num_channels = num_channels
+ self.kernel_size = kernel_size
+ self.stride = stride
+ self.padding = padding
+ self.hidden_sizes = hidden_sizes
+ self.num_attention_heads = num_attention_heads
+ self.depths = depths
+ self.key_dim = key_dim
+ self.drop_path_rate = drop_path_rate
+ self.patch_size = patch_size
+ self.attention_ratio = attention_ratio
+ self.mlp_ratio = mlp_ratio
+ self.initializer_range = initializer_range
+ self.down_ops = [
+ ["Subsample", key_dim[0], hidden_sizes[0] // key_dim[0], 4, 2, 2],
+ ["Subsample", key_dim[0], hidden_sizes[1] // key_dim[0], 4, 2, 2],
+ ]
diff --git a/src/transformers/models/levit/convert_levit_timm_to_pytorch.py b/src/transformers/models/levit/convert_levit_timm_to_pytorch.py
new file mode 100644
index 0000000000..d9449aad7a
--- /dev/null
+++ b/src/transformers/models/levit/convert_levit_timm_to_pytorch.py
@@ -0,0 +1,181 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Convert LeViT checkpoints from timm."""
+
+
+import argparse
+import json
+from collections import OrderedDict
+from functools import partial
+from pathlib import Path
+
+import torch
+
+import timm
+from huggingface_hub import hf_hub_download
+from transformers import LevitConfig, LevitFeatureExtractor, LevitForImageClassificationWithTeacher
+from transformers.utils import logging
+
+
+logging.set_verbosity_info()
+logger = logging.get_logger()
+
+
+def convert_weight_and_push(
+ hidden_sizes: int, name: str, config: LevitConfig, save_directory: Path, push_to_hub: bool = True
+):
+ print(f"Converting {name}...")
+
+ with torch.no_grad():
+ if hidden_sizes == 128:
+ if name[-1] == "S":
+ from_model = timm.create_model("levit_128s", pretrained=True)
+ else:
+ from_model = timm.create_model("levit_128", pretrained=True)
+ if hidden_sizes == 192:
+ from_model = timm.create_model("levit_192", pretrained=True)
+ if hidden_sizes == 256:
+ from_model = timm.create_model("levit_256", pretrained=True)
+ if hidden_sizes == 384:
+ from_model = timm.create_model("levit_384", pretrained=True)
+
+ from_model.eval()
+ our_model = LevitForImageClassificationWithTeacher(config).eval()
+ huggingface_weights = OrderedDict()
+
+ weights = from_model.state_dict()
+ og_keys = list(from_model.state_dict().keys())
+ new_keys = list(our_model.state_dict().keys())
+ print(len(og_keys), len(new_keys))
+ for i in range(len(og_keys)):
+ huggingface_weights[new_keys[i]] = weights[og_keys[i]]
+ our_model.load_state_dict(huggingface_weights)
+
+ x = torch.randn((2, 3, 224, 224))
+ out1 = from_model(x)
+ out2 = our_model(x).logits
+
+ assert torch.allclose(out1, out2), "The model logits don't match the original one."
+
+ checkpoint_name = name
+ print(checkpoint_name)
+
+ if push_to_hub:
+ our_model.save_pretrained(save_directory / checkpoint_name)
+ feature_extractor = LevitFeatureExtractor()
+ feature_extractor.save_pretrained(save_directory / checkpoint_name)
+
+ print(f"Pushed {checkpoint_name}")
+
+
+def convert_weights_and_push(save_directory: Path, model_name: str = None, push_to_hub: bool = True):
+ filename = "imagenet-1k-id2label.json"
+ num_labels = 1000
+ expected_shape = (1, num_labels)
+
+ repo_id = "datasets/huggingface/label-files"
+ num_labels = num_labels
+ id2label = json.load(open(hf_hub_download(repo_id, filename), "r"))
+ id2label = {int(k): v for k, v in id2label.items()}
+
+ id2label = id2label
+ label2id = {v: k for k, v in id2label.items()}
+
+ ImageNetPreTrainedConfig = partial(LevitConfig, num_labels=num_labels, id2label=id2label, label2id=label2id)
+
+ names_to_hidden_sizes = {
+ "levit-128S": 128,
+ "levit-128": 128,
+ "levit-192": 192,
+ "levit-256": 256,
+ "levit-384": 384,
+ }
+
+ names_to_config = {
+ "levit-128S": ImageNetPreTrainedConfig(
+ hidden_sizes=[128, 256, 384],
+ num_attention_heads=[4, 6, 8],
+ depths=[2, 3, 4],
+ key_dim=[16, 16, 16],
+ drop_path_rate=0,
+ ),
+ "levit-128": ImageNetPreTrainedConfig(
+ hidden_sizes=[128, 256, 384],
+ num_attention_heads=[4, 8, 12],
+ depths=[4, 4, 4],
+ key_dim=[16, 16, 16],
+ drop_path_rate=0,
+ ),
+ "levit-192": ImageNetPreTrainedConfig(
+ hidden_sizes=[192, 288, 384],
+ num_attention_heads=[3, 5, 6],
+ depths=[4, 4, 4],
+ key_dim=[32, 32, 32],
+ drop_path_rate=0,
+ ),
+ "levit-256": ImageNetPreTrainedConfig(
+ hidden_sizes=[256, 384, 512],
+ num_attention_heads=[4, 6, 8],
+ depths=[4, 4, 4],
+ key_dim=[32, 32, 32],
+ drop_path_rate=0,
+ ),
+ "levit-384": ImageNetPreTrainedConfig(
+ hidden_sizes=[384, 512, 768],
+ num_attention_heads=[6, 9, 12],
+ depths=[4, 4, 4],
+ key_dim=[32, 32, 32],
+ drop_path_rate=0.1,
+ ),
+ }
+
+ if model_name:
+ convert_weight_and_push(
+ names_to_hidden_sizes[model_name], model_name, names_to_config[model_name], save_directory, push_to_hub
+ )
+ else:
+ for model_name, config in names_to_config.items():
+ convert_weight_and_push(names_to_hidden_sizes[model_name], model_name, config, save_directory, push_to_hub)
+ return config, expected_shape
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ # Required parameters
+ parser.add_argument(
+ "--model_name",
+ default=None,
+ type=str,
+ help="The name of the model you wish to convert, it must be one of the supported Levit* architecture,",
+ )
+ parser.add_argument(
+ "--pytorch_dump_folder_path",
+ default="levit-dump-folder/",
+ type=Path,
+ required=False,
+ help="Path to the output PyTorch model directory.",
+ )
+ parser.add_argument(
+ "--push_to_hub",
+ default=True,
+ type=bool,
+ required=False,
+ help="If True, push model and feature extractor to the hub.",
+ )
+
+ args = parser.parse_args()
+ pytorch_dump_folder_path: Path = args.pytorch_dump_folder_path
+ pytorch_dump_folder_path.mkdir(exist_ok=True, parents=True)
+ convert_weights_and_push(pytorch_dump_folder_path, args.model_name, args.push_to_hub)
diff --git a/src/transformers/models/levit/feature_extraction_levit.py b/src/transformers/models/levit/feature_extraction_levit.py
new file mode 100644
index 0000000000..b0ac5f6b3d
--- /dev/null
+++ b/src/transformers/models/levit/feature_extraction_levit.py
@@ -0,0 +1,158 @@
+# coding=utf-8
+# Copyright 2022 Meta Platforms, Inc. and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Feature extractor class for LeViT."""
+
+from typing import Optional, Union
+
+import numpy as np
+from PIL import Image
+
+from ...feature_extraction_utils import BatchFeature, FeatureExtractionMixin
+from ...image_utils import (
+ IMAGENET_DEFAULT_MEAN,
+ IMAGENET_DEFAULT_STD,
+ ImageFeatureExtractionMixin,
+ ImageInput,
+ is_torch_tensor,
+)
+from ...utils import TensorType, logging
+
+
+logger = logging.get_logger(__name__)
+
+
+class LevitFeatureExtractor(FeatureExtractionMixin, ImageFeatureExtractionMixin):
+ r"""
+ Constructs a LeViT feature extractor.
+
+ This feature extractor inherits from [`FeatureExtractionMixin`] which contains most of the main methods. Users
+ should refer to this superclass for more information regarding those methods.
+
+ Args:
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Whether to resize the shortest edge of the input to int(256/224 *`size`).
+ size (`int` or `Tuple(int)`, *optional*, defaults to 224):
+ Resize the input to the given size. If a tuple is provided, it should be (width, height). If only an
+ integer is provided, then shorter side of input will be resized to 'size'.
+ resample (`int`, *optional*, defaults to `PIL.Image.BICUBIC`):
+ An optional resampling filter. This can be one of `PIL.Image.NEAREST`, `PIL.Image.BOX`,
+ `PIL.Image.BILINEAR`, `PIL.Image.HAMMING`, `PIL.Image.BICUBIC` or `PIL.Image.LANCZOS`. Only has an effect
+ if `do_resize` is set to `True`.
+ do_center_crop (`bool`, *optional*, defaults to `True`):
+ Whether or not to center crop the input to `size`.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether or not to normalize the input with mean and standard deviation.
+ image_mean (`List[int]`, defaults to `[0.229, 0.224, 0.225]`):
+ The sequence of means for each channel, to be used when normalizing images.
+ image_std (`List[int]`, defaults to `[0.485, 0.456, 0.406]`):
+ The sequence of standard deviations for each channel, to be used when normalizing images.
+ """
+
+ model_input_names = ["pixel_values"]
+
+ def __init__(
+ self,
+ do_resize=True,
+ size=224,
+ resample=Image.BICUBIC,
+ do_center_crop=True,
+ do_normalize=True,
+ image_mean=IMAGENET_DEFAULT_MEAN,
+ image_std=IMAGENET_DEFAULT_STD,
+ **kwargs
+ ):
+ super().__init__(**kwargs)
+ self.do_resize = do_resize
+ self.size = size
+ self.resample = resample
+ self.do_center_crop = do_center_crop
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+
+ def __call__(
+ self, images: ImageInput, return_tensors: Optional[Union[str, TensorType]] = None, **kwargs
+ ) -> BatchFeature:
+ """
+ Main method to prepare for the model one or several image(s).
+
+
+
+ NumPy arrays and PyTorch tensors are converted to PIL images when resizing, so the most efficient is to pass
+ PIL images.
+
+
+
+ Args:
+ images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
+ The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
+ tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a
+ number of channels, H and W are image height and width.
+
+ return_tensors (`str` or [`~utils.TensorType`], *optional*, defaults to `'np'`):
+ If set, will return tensors of a particular framework. Acceptable values are:
+
+ - `'tf'`: Return TensorFlow `tf.constant` objects.
+ - `'pt'`: Return PyTorch `torch.Tensor` objects.
+ - `'np'`: Return NumPy `np.ndarray` objects.
+ - `'jax'`: Return JAX `jnp.ndarray` objects.
+
+ Returns:
+ [`BatchFeature`]: A [`BatchFeature`] with the following fields:
+
+ - **pixel_values** -- Pixel values to be fed to a model, of shape (batch_size, num_channels, height,
+ width).
+ """
+ # Input type checking for clearer error
+ valid_images = False
+
+ # Check that images has a valid type
+ if isinstance(images, (Image.Image, np.ndarray)) or is_torch_tensor(images):
+ valid_images = True
+ elif isinstance(images, (list, tuple)):
+ if len(images) == 0 or isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]):
+ valid_images = True
+
+ if not valid_images:
+ raise ValueError(
+ "Images must of type `PIL.Image.Image`, `np.ndarray` or `torch.Tensor` (single example), "
+ "`List[PIL.Image.Image]`, `List[np.ndarray]` or `List[torch.Tensor]` (batch of examples)."
+ )
+
+ is_batched = bool(
+ isinstance(images, (list, tuple))
+ and (isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]))
+ )
+
+ if not is_batched:
+ images = [images]
+
+ # transformations (resizing + center cropping + normalization)
+ if self.do_resize and self.size is not None:
+ size_ = int((256 / 224) * self.size)
+ images = [
+ self.resize(image=image, size=size_, resample=self.resample, default_to_square=False)
+ for image in images
+ ]
+ if self.do_center_crop:
+ images = [self.center_crop(image=image, size=self.size) for image in images]
+ if self.do_normalize:
+ images = [self.normalize(image=image, mean=self.image_mean, std=self.image_std) for image in images]
+
+ # return as BatchFeature
+ data = {"pixel_values": images}
+ encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
+
+ return encoded_inputs
diff --git a/src/transformers/models/levit/modeling_levit.py b/src/transformers/models/levit/modeling_levit.py
new file mode 100644
index 0000000000..b04a98317d
--- /dev/null
+++ b/src/transformers/models/levit/modeling_levit.py
@@ -0,0 +1,738 @@
+# coding=utf-8
+# Copyright 2022 Meta Platforms, Inc. and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch LeViT model."""
+
+import itertools
+from dataclasses import dataclass
+from typing import Optional, Tuple
+
+import torch
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+
+from ...modeling_outputs import (
+ BaseModelOutputWithNoAttention,
+ BaseModelOutputWithPoolingAndNoAttention,
+ ImageClassifierOutputWithNoAttention,
+ ModelOutput,
+)
+from ...modeling_utils import PreTrainedModel
+from ...utils import add_code_sample_docstrings, add_start_docstrings, add_start_docstrings_to_model_forward, logging
+from .configuration_levit import LevitConfig
+
+
+logger = logging.get_logger(__name__)
+
+# General docstring
+_CONFIG_FOR_DOC = "LevitConfig"
+_FEAT_EXTRACTOR_FOR_DOC = "LevitFeatureExtractor"
+
+# Base docstring
+_CHECKPOINT_FOR_DOC = "facebook/levit-128S"
+_EXPECTED_OUTPUT_SHAPE = [1, 16, 384]
+
+# Image classification docstring
+_IMAGE_CLASS_CHECKPOINT = "facebook/levit-128S"
+_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
+
+LEVIT_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "facebook/levit-128S",
+ # See all LeViT models at https://huggingface.co/models?filter=levit
+]
+
+
+@dataclass
+class LevitForImageClassificationWithTeacherOutput(ModelOutput):
+ """
+ Output type of [`LevitForImageClassificationWithTeacher`].
+
+ Args:
+ logits (`torch.FloatTensor` of shape `(batch_size, config.num_labels)`):
+ Prediction scores as the average of the `cls_logits` and `distillation_logits`.
+ cls_logits (`torch.FloatTensor` of shape `(batch_size, config.num_labels)`):
+ Prediction scores of the classification head (i.e. the linear layer on top of the final hidden state of the
+ class token).
+ distillation_logits (`torch.FloatTensor` of shape `(batch_size, config.num_labels)`):
+ Prediction scores of the distillation head (i.e. the linear layer on top of the final hidden state of the
+ distillation token).
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
+ shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the model at the output of each layer
+ plus the initial embedding outputs.
+ """
+
+ logits: torch.FloatTensor = None
+ cls_logits: torch.FloatTensor = None
+ distillation_logits: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+
+
+class LevitConvEmbeddings(nn.Module):
+ """
+ LeViT Conv Embeddings with Batch Norm, used in the initial patch embedding layer.
+ """
+
+ def __init__(
+ self, in_channels, out_channels, kernel_size, stride, padding, dilation=1, groups=1, bn_weight_init=1
+ ):
+ super().__init__()
+ self.convolution = nn.Conv2d(
+ in_channels, out_channels, kernel_size, stride, padding, dilation=dilation, groups=groups, bias=False
+ )
+ self.batch_norm = nn.BatchNorm2d(out_channels)
+
+ def forward(self, embeddings):
+ embeddings = self.convolution(embeddings)
+ embeddings = self.batch_norm(embeddings)
+ return embeddings
+
+
+class LevitPatchEmbeddings(nn.Module):
+ """
+ LeViT patch embeddings, for final embeddings to be passed to transformer blocks. It consists of multiple
+ `LevitConvEmbeddings`.
+ """
+
+ def __init__(self, config):
+ super().__init__()
+ self.embedding_layer_1 = LevitConvEmbeddings(
+ config.num_channels, config.hidden_sizes[0] // 8, config.kernel_size, config.stride, config.padding
+ )
+ self.activation_layer_1 = nn.Hardswish()
+
+ self.embedding_layer_2 = LevitConvEmbeddings(
+ config.hidden_sizes[0] // 8, config.hidden_sizes[0] // 4, config.kernel_size, config.stride, config.padding
+ )
+ self.activation_layer_2 = nn.Hardswish()
+
+ self.embedding_layer_3 = LevitConvEmbeddings(
+ config.hidden_sizes[0] // 4, config.hidden_sizes[0] // 2, config.kernel_size, config.stride, config.padding
+ )
+ self.activation_layer_3 = nn.Hardswish()
+
+ self.embedding_layer_4 = LevitConvEmbeddings(
+ config.hidden_sizes[0] // 2, config.hidden_sizes[0], config.kernel_size, config.stride, config.padding
+ )
+
+ def forward(self, pixel_values):
+ embeddings = self.embedding_layer_1(pixel_values)
+ embeddings = self.activation_layer_1(embeddings)
+ embeddings = self.embedding_layer_2(embeddings)
+ embeddings = self.activation_layer_2(embeddings)
+ embeddings = self.embedding_layer_3(embeddings)
+ embeddings = self.activation_layer_3(embeddings)
+ embeddings = self.embedding_layer_4(embeddings)
+ return embeddings.flatten(2).transpose(1, 2)
+
+
+class MLPLayerWithBN(nn.Module):
+ def __init__(self, input_dim, output_dim, bn_weight_init=1):
+ super().__init__()
+ self.linear = nn.Linear(in_features=input_dim, out_features=output_dim, bias=False)
+ self.batch_norm = nn.BatchNorm1d(output_dim)
+
+ def forward(self, hidden_state):
+ hidden_state = self.linear(hidden_state)
+ hidden_state = self.batch_norm(hidden_state.flatten(0, 1)).reshape_as(hidden_state)
+ return hidden_state
+
+
+class LevitSubsample(nn.Module):
+ def __init__(self, stride, resolution):
+ super().__init__()
+ self.stride = stride
+ self.resolution = resolution
+
+ def forward(self, hidden_state):
+ batch_size, _, channels = hidden_state.shape
+ hidden_state = hidden_state.view(batch_size, self.resolution, self.resolution, channels)[
+ :, :: self.stride, :: self.stride
+ ].reshape(batch_size, -1, channels)
+ return hidden_state
+
+
+class LevitAttention(nn.Module):
+ def __init__(self, hidden_sizes, key_dim, num_attention_heads, attention_ratio, resolution):
+ super().__init__()
+ self.num_attention_heads = num_attention_heads
+ self.scale = key_dim**-0.5
+ self.key_dim = key_dim
+ self.attention_ratio = attention_ratio
+ self.out_dim_keys_values = attention_ratio * key_dim * num_attention_heads + key_dim * num_attention_heads * 2
+ self.out_dim_projection = attention_ratio * key_dim * num_attention_heads
+
+ self.queries_keys_values = MLPLayerWithBN(hidden_sizes, self.out_dim_keys_values)
+ self.activation = nn.Hardswish()
+ self.projection = MLPLayerWithBN(self.out_dim_projection, hidden_sizes, bn_weight_init=0)
+
+ points = list(itertools.product(range(resolution), range(resolution)))
+ len_points = len(points)
+ attention_offsets, indices = {}, []
+ for p1 in points:
+ for p2 in points:
+ offset = (abs(p1[0] - p2[0]), abs(p1[1] - p2[1]))
+ if offset not in attention_offsets:
+ attention_offsets[offset] = len(attention_offsets)
+ indices.append(attention_offsets[offset])
+
+ self.attention_bias_cache = {}
+ self.attention_biases = torch.nn.Parameter(torch.zeros(num_attention_heads, len(attention_offsets)))
+ self.register_buffer("attention_bias_idxs", torch.LongTensor(indices).view(len_points, len_points))
+
+ @torch.no_grad()
+ def train(self, mode=True):
+ super().train(mode)
+ if mode and self.attention_bias_cache:
+ self.attention_bias_cache = {} # clear ab cache
+
+ def get_attention_biases(self, device):
+ if self.training:
+ return self.attention_biases[:, self.attention_bias_idxs]
+ else:
+ device_key = str(device)
+ if device_key not in self.attention_bias_cache:
+ self.attention_bias_cache[device_key] = self.attention_biases[:, self.attention_bias_idxs]
+ return self.attention_bias_cache[device_key]
+
+ def forward(self, hidden_state):
+ batch_size, seq_length, _ = hidden_state.shape
+ queries_keys_values = self.queries_keys_values(hidden_state)
+ query, key, value = queries_keys_values.view(batch_size, seq_length, self.num_attention_heads, -1).split(
+ [self.key_dim, self.key_dim, self.attention_ratio * self.key_dim], dim=3
+ )
+ query = query.permute(0, 2, 1, 3)
+ key = key.permute(0, 2, 1, 3)
+ value = value.permute(0, 2, 1, 3)
+
+ attention = query @ key.transpose(-2, -1) * self.scale + self.get_attention_biases(hidden_state.device)
+ attention = attention.softmax(dim=-1)
+ hidden_state = (attention @ value).transpose(1, 2).reshape(batch_size, seq_length, self.out_dim_projection)
+ hidden_state = self.projection(self.activation(hidden_state))
+ return hidden_state
+
+
+class LevitAttentionSubsample(nn.Module):
+ def __init__(
+ self,
+ input_dim,
+ output_dim,
+ key_dim,
+ num_attention_heads,
+ attention_ratio,
+ stride,
+ resolution_in,
+ resolution_out,
+ ):
+ super().__init__()
+ self.num_attention_heads = num_attention_heads
+ self.scale = key_dim**-0.5
+ self.key_dim = key_dim
+ self.attention_ratio = attention_ratio
+ self.out_dim_keys_values = attention_ratio * key_dim * num_attention_heads + key_dim * num_attention_heads
+ self.out_dim_projection = attention_ratio * key_dim * num_attention_heads
+ self.resolution_out = resolution_out
+ # resolution_in is the intial resolution, resoloution_out is final resolution after downsampling
+ self.keys_values = MLPLayerWithBN(input_dim, self.out_dim_keys_values)
+ self.queries_subsample = LevitSubsample(stride, resolution_in)
+ self.queries = MLPLayerWithBN(input_dim, key_dim * num_attention_heads)
+ self.activation = nn.Hardswish()
+ self.projection = MLPLayerWithBN(self.out_dim_projection, output_dim)
+
+ self.attention_bias_cache = {}
+
+ points = list(itertools.product(range(resolution_in), range(resolution_in)))
+ points_ = list(itertools.product(range(resolution_out), range(resolution_out)))
+ len_points, len_points_ = len(points), len(points_)
+ attention_offsets, indices = {}, []
+ for p1 in points_:
+ for p2 in points:
+ size = 1
+ offset = (abs(p1[0] * stride - p2[0] + (size - 1) / 2), abs(p1[1] * stride - p2[1] + (size - 1) / 2))
+ if offset not in attention_offsets:
+ attention_offsets[offset] = len(attention_offsets)
+ indices.append(attention_offsets[offset])
+
+ self.attention_biases = torch.nn.Parameter(torch.zeros(num_attention_heads, len(attention_offsets)))
+ self.register_buffer("attention_bias_idxs", torch.LongTensor(indices).view(len_points_, len_points))
+
+ @torch.no_grad()
+ def train(self, mode=True):
+ super().train(mode)
+ if mode and self.attention_bias_cache:
+ self.attention_bias_cache = {} # clear ab cache
+
+ def get_attention_biases(self, device):
+ if self.training:
+ return self.attention_biases[:, self.attention_bias_idxs]
+ else:
+ device_key = str(device)
+ if device_key not in self.attention_bias_cache:
+ self.attention_bias_cache[device_key] = self.attention_biases[:, self.attention_bias_idxs]
+ return self.attention_bias_cache[device_key]
+
+ def forward(self, hidden_state):
+ batch_size, seq_length, _ = hidden_state.shape
+ key, value = (
+ self.keys_values(hidden_state)
+ .view(batch_size, seq_length, self.num_attention_heads, -1)
+ .split([self.key_dim, self.attention_ratio * self.key_dim], dim=3)
+ )
+ key = key.permute(0, 2, 1, 3)
+ value = value.permute(0, 2, 1, 3)
+
+ query = self.queries(self.queries_subsample(hidden_state))
+ query = query.view(batch_size, self.resolution_out**2, self.num_attention_heads, self.key_dim).permute(
+ 0, 2, 1, 3
+ )
+
+ attention = query @ key.transpose(-2, -1) * self.scale + self.get_attention_biases(hidden_state.device)
+ attention = attention.softmax(dim=-1)
+ hidden_state = (attention @ value).transpose(1, 2).reshape(batch_size, -1, self.out_dim_projection)
+ hidden_state = self.projection(self.activation(hidden_state))
+ return hidden_state
+
+
+class LevitMLPLayer(nn.Module):
+ """
+ MLP Layer with `2X` expansion in contrast to ViT with `4X`.
+ """
+
+ def __init__(self, input_dim, hidden_dim):
+ super().__init__()
+ self.linear_up = MLPLayerWithBN(input_dim, hidden_dim)
+ self.activation = nn.Hardswish()
+ self.linear_down = MLPLayerWithBN(hidden_dim, input_dim)
+
+ def forward(self, hidden_state):
+ hidden_state = self.linear_up(hidden_state)
+ hidden_state = self.activation(hidden_state)
+ hidden_state = self.linear_down(hidden_state)
+ return hidden_state
+
+
+class LevitResidualLayer(nn.Module):
+ """
+ Residual Block for LeViT
+ """
+
+ def __init__(self, module, drop_rate):
+ super().__init__()
+ self.module = module
+ self.drop_rate = drop_rate
+
+ def forward(self, hidden_state):
+ if self.training and self.drop_rate > 0:
+ rnd = torch.rand(hidden_state.size(0), 1, 1, device=hidden_state.device)
+ rnd = rnd.ge_(self.drop_rate).div(1 - self.drop_rate).detach()
+ hidden_state = hidden_state + self.module(hidden_state) * rnd
+ return hidden_state
+ else:
+ hidden_state = hidden_state + self.module(hidden_state)
+ return hidden_state
+
+
+class LevitStage(nn.Module):
+ """
+ LeViT Stage consisting of `LevitMLPLayer` and `LevitAttention` layers.
+ """
+
+ def __init__(
+ self,
+ config,
+ idx,
+ hidden_sizes,
+ key_dim,
+ depths,
+ num_attention_heads,
+ attention_ratio,
+ mlp_ratio,
+ down_ops,
+ resolution_in,
+ ):
+ super().__init__()
+ self.layers = []
+ self.config = config
+ self.resolution_in = resolution_in
+ # resolution_in is the intial resolution, resolution_out is final resolution after downsampling
+ for _ in range(depths):
+ self.layers.append(
+ LevitResidualLayer(
+ LevitAttention(hidden_sizes, key_dim, num_attention_heads, attention_ratio, resolution_in),
+ self.config.drop_path_rate,
+ )
+ )
+ if mlp_ratio > 0:
+ hidden_dim = hidden_sizes * mlp_ratio
+ self.layers.append(
+ LevitResidualLayer(LevitMLPLayer(hidden_sizes, hidden_dim), self.config.drop_path_rate)
+ )
+
+ if down_ops[0] == "Subsample":
+ self.resolution_out = (self.resolution_in - 1) // down_ops[5] + 1
+ self.layers.append(
+ LevitAttentionSubsample(
+ *self.config.hidden_sizes[idx : idx + 2],
+ key_dim=down_ops[1],
+ num_attention_heads=down_ops[2],
+ attention_ratio=down_ops[3],
+ stride=down_ops[5],
+ resolution_in=resolution_in,
+ resolution_out=self.resolution_out,
+ )
+ )
+ self.resolution_in = self.resolution_out
+ if down_ops[4] > 0:
+ hidden_dim = self.config.hidden_sizes[idx + 1] * down_ops[4]
+ self.layers.append(
+ LevitResidualLayer(
+ LevitMLPLayer(self.config.hidden_sizes[idx + 1], hidden_dim), self.config.drop_path_rate
+ )
+ )
+
+ self.layers = nn.ModuleList(self.layers)
+
+ def get_resolution(self):
+ return self.resolution_in
+
+ def forward(self, hidden_state):
+ for layer in self.layers:
+ hidden_state = layer(hidden_state)
+ return hidden_state
+
+
+class LevitEncoder(nn.Module):
+ """
+ LeViT Encoder consisting of multiple `LevitStage` stages.
+ """
+
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ resolution = self.config.image_size // self.config.patch_size
+ self.stages = []
+ self.config.down_ops.append([""])
+
+ for stage_idx in range(len(config.depths)):
+ stage = LevitStage(
+ config,
+ stage_idx,
+ config.hidden_sizes[stage_idx],
+ config.key_dim[stage_idx],
+ config.depths[stage_idx],
+ config.num_attention_heads[stage_idx],
+ config.attention_ratio[stage_idx],
+ config.mlp_ratio[stage_idx],
+ config.down_ops[stage_idx],
+ resolution,
+ )
+ resolution = stage.get_resolution()
+ self.stages.append(stage)
+
+ self.stages = nn.ModuleList(self.stages)
+
+ def forward(self, hidden_state, output_hidden_states=False, return_dict=True):
+ all_hidden_states = () if output_hidden_states else None
+
+ for stage in self.stages:
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_state,)
+ hidden_state = stage(hidden_state)
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_state,)
+ if not return_dict:
+ return tuple(v for v in [hidden_state, all_hidden_states] if v is not None)
+
+ return BaseModelOutputWithNoAttention(last_hidden_state=hidden_state, hidden_states=all_hidden_states)
+
+
+class LevitClassificationLayer(nn.Module):
+ """
+ LeViT Classification Layer
+ """
+
+ def __init__(self, input_dim, output_dim):
+ super().__init__()
+ self.batch_norm = nn.BatchNorm1d(input_dim)
+ self.linear = nn.Linear(input_dim, output_dim)
+
+ def forward(self, hidden_state):
+ hidden_state = self.batch_norm(hidden_state)
+ logits = self.linear(hidden_state)
+ return logits
+
+
+class LevitPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = LevitConfig
+ base_model_prefix = "levit"
+ main_input_name = "pixel_values"
+ supports_gradient_checkpointing = True
+
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ if isinstance(module, (nn.Linear, nn.Conv2d)):
+ # Slightly different from the TF version which uses truncated_normal for initialization
+ # cf https://github.com/pytorch/pytorch/pull/5617
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, (nn.BatchNorm1d, nn.BatchNorm2d)):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, LevitModel):
+ module.gradient_checkpointing = value
+
+
+LEVIT_START_DOCSTRING = r"""
+ This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it
+ as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
+ behavior.
+
+ Parameters:
+ config ([`LevitConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+LEVIT_INPUTS_DOCSTRING = r"""
+ Args:
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
+ [`AutoFeatureExtractor.__call__`] for details.
+
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ "The bare Levit model outputting raw features without any specific head on top.",
+ LEVIT_START_DOCSTRING,
+)
+class LevitModel(LevitPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.config = config
+ self.patch_embeddings = LevitPatchEmbeddings(config)
+ self.encoder = LevitEncoder(config)
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(LEVIT_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ processor_class=_FEAT_EXTRACTOR_FOR_DOC,
+ checkpoint=_CHECKPOINT_FOR_DOC,
+ output_type=BaseModelOutputWithPoolingAndNoAttention,
+ config_class=_CONFIG_FOR_DOC,
+ modality="vision",
+ expected_output=_EXPECTED_OUTPUT_SHAPE,
+ )
+ def forward(
+ self,
+ pixel_values: torch.FloatTensor = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ):
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if pixel_values is None:
+ raise ValueError("You have to specify pixel_values")
+
+ embeddings = self.patch_embeddings(pixel_values)
+ encoder_outputs = self.encoder(
+ embeddings,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ last_hidden_state = encoder_outputs[0]
+
+ # global average pooling, (batch_size, seq_length, hidden_sizes) -> (batch_size, hidden_sizes)
+ pooled_output = last_hidden_state.mean(dim=1)
+
+ if not return_dict:
+ return (last_hidden_state, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPoolingAndNoAttention(
+ last_hidden_state=last_hidden_state,
+ pooler_output=pooled_output,
+ hidden_states=encoder_outputs.hidden_states,
+ )
+
+
+@add_start_docstrings(
+ """
+ Levit Model with an image classification head on top (a linear layer on top of the pooled features), e.g. for
+ ImageNet.
+ """,
+ LEVIT_START_DOCSTRING,
+)
+class LevitForImageClassification(LevitPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.config = config
+ self.num_labels = config.num_labels
+ self.levit = LevitModel(config)
+
+ # Classifier head
+ self.classifier = (
+ LevitClassificationLayer(config.hidden_sizes[-1], config.num_labels)
+ if config.num_labels > 0
+ else torch.nn.Identity()
+ )
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(LEVIT_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ processor_class=_FEAT_EXTRACTOR_FOR_DOC,
+ checkpoint=_IMAGE_CLASS_CHECKPOINT,
+ output_type=ImageClassifierOutputWithNoAttention,
+ config_class=_CONFIG_FOR_DOC,
+ expected_output=_IMAGE_CLASS_EXPECTED_OUTPUT,
+ )
+ def forward(
+ self,
+ pixel_values: torch.FloatTensor = None,
+ labels: Optional[torch.LongTensor] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ):
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the image classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.levit(pixel_values, output_hidden_states=output_hidden_states, return_dict=return_dict)
+
+ sequence_output = outputs[0]
+ sequence_output = sequence_output.mean(1)
+ logits = self.classifier(sequence_output)
+
+ loss = None
+ if labels is not None:
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = "regression"
+ elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
+ self.config.problem_type = "single_label_classification"
+ else:
+ self.config.problem_type = "multi_label_classification"
+
+ if self.config.problem_type == "regression":
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(logits, labels)
+ elif self.config.problem_type == "single_label_classification":
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == "multi_label_classification":
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(logits, labels)
+ if not return_dict:
+ output = (logits,) + outputs[2:]
+ return ((loss,) + output) if loss is not None else output
+
+ return ImageClassifierOutputWithNoAttention(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ )
+
+
+@add_start_docstrings(
+ """
+ LeViT Model transformer with image classification heads on top (a linear layer on top of the final hidden state and
+ a linear layer on top of the final hidden state of the distillation token) e.g. for ImageNet. .. warning::
+ This model supports inference-only. Fine-tuning with distillation (i.e. with a teacher) is not yet
+ supported.
+ """,
+ LEVIT_START_DOCSTRING,
+)
+class LevitForImageClassificationWithTeacher(LevitPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.config = config
+ self.num_labels = config.num_labels
+ self.levit = LevitModel(config)
+
+ # Classifier head
+ self.classifier = (
+ LevitClassificationLayer(config.hidden_sizes[-1], config.num_labels)
+ if config.num_labels > 0
+ else torch.nn.Identity()
+ )
+ self.classifier_distill = (
+ LevitClassificationLayer(config.hidden_sizes[-1], config.num_labels)
+ if config.num_labels > 0
+ else torch.nn.Identity()
+ )
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(LEVIT_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ processor_class=_FEAT_EXTRACTOR_FOR_DOC,
+ checkpoint=_IMAGE_CLASS_CHECKPOINT,
+ output_type=LevitForImageClassificationWithTeacherOutput,
+ config_class=_CONFIG_FOR_DOC,
+ expected_output=_IMAGE_CLASS_EXPECTED_OUTPUT,
+ )
+ def forward(
+ self,
+ pixel_values: torch.FloatTensor = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ):
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.levit(pixel_values, output_hidden_states=output_hidden_states, return_dict=return_dict)
+
+ sequence_output = outputs[0]
+ sequence_output = sequence_output.mean(1)
+ cls_logits, distill_logits = self.classifier(sequence_output), self.classifier_distill(sequence_output)
+ logits = (cls_logits + distill_logits) / 2
+
+ if not return_dict:
+ output = (logits, cls_logits, distill_logits) + outputs[2:]
+ return output
+
+ return LevitForImageClassificationWithTeacherOutput(
+ logits=logits,
+ cls_logits=cls_logits,
+ distillation_logits=distill_logits,
+ hidden_states=outputs.hidden_states,
+ )
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index e25185b1a1..4b7e06e635 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -2474,6 +2474,37 @@ class LEDPreTrainedModel(metaclass=DummyObject):
requires_backends(self, ["torch"])
+LEVIT_PRETRAINED_MODEL_ARCHIVE_LIST = None
+
+
+class LevitForImageClassification(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class LevitForImageClassificationWithTeacher(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class LevitModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class LevitPreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
LONGFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = None
diff --git a/src/transformers/utils/dummy_vision_objects.py b/src/transformers/utils/dummy_vision_objects.py
index add3fada5b..63e7450be4 100644
--- a/src/transformers/utils/dummy_vision_objects.py
+++ b/src/transformers/utils/dummy_vision_objects.py
@@ -101,6 +101,13 @@ class LayoutLMv3FeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class LevitFeatureExtractor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class MaskFormerFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
diff --git a/tests/models/levit/__init__.py b/tests/models/levit/__init__.py
new file mode 100644
index 0000000000..e69de29bb2
diff --git a/tests/models/levit/test_feature_extraction_levit.py b/tests/models/levit/test_feature_extraction_levit.py
new file mode 100644
index 0000000000..98a704b97a
--- /dev/null
+++ b/tests/models/levit/test_feature_extraction_levit.py
@@ -0,0 +1,195 @@
+# coding=utf-8
+# Copyright 2022 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+import numpy as np
+
+from transformers.testing_utils import require_torch, require_vision
+from transformers.utils import is_torch_available, is_vision_available
+
+from ...test_feature_extraction_common import FeatureExtractionSavingTestMixin, prepare_image_inputs
+
+
+if is_torch_available():
+ import torch
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import LevitFeatureExtractor
+
+
+class LevitFeatureExtractionTester(unittest.TestCase):
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ image_size=18,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=18,
+ do_center_crop=True,
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.do_center_crop = do_center_crop
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+
+ def prepare_feat_extract_dict(self):
+ return {
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ "do_normalize": self.do_normalize,
+ "do_resize": self.do_resize,
+ "do_center_crop": self.do_center_crop,
+ "size": self.size,
+ }
+
+
+@require_torch
+@require_vision
+class LevitFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.TestCase):
+
+ feature_extraction_class = LevitFeatureExtractor if is_vision_available() else None
+
+ def setUp(self):
+ self.feature_extract_tester = LevitFeatureExtractionTester(self)
+
+ @property
+ def feat_extract_dict(self):
+ return self.feature_extract_tester.prepare_feat_extract_dict()
+
+ def test_feat_extract_properties(self):
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ self.assertTrue(hasattr(feature_extractor, "image_mean"))
+ self.assertTrue(hasattr(feature_extractor, "image_std"))
+ self.assertTrue(hasattr(feature_extractor, "do_normalize"))
+ self.assertTrue(hasattr(feature_extractor, "do_resize"))
+ self.assertTrue(hasattr(feature_extractor, "do_center_crop"))
+ self.assertTrue(hasattr(feature_extractor, "size"))
+
+ def test_batch_feature(self):
+ pass
+
+ def test_call_pil(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random PIL images
+ image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False)
+ for image in image_inputs:
+ self.assertIsInstance(image, Image.Image)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ # Test batched
+ encoded_images = feature_extractor(image_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ def test_call_numpy(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random numpy tensors
+ image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False, numpify=True)
+ for image in image_inputs:
+ self.assertIsInstance(image, np.ndarray)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ # Test batched
+ encoded_images = feature_extractor(image_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ def test_call_pytorch(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random PyTorch tensors
+ image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False, torchify=True)
+ for image in image_inputs:
+ self.assertIsInstance(image, torch.Tensor)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ # Test batched
+ encoded_images = feature_extractor(image_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
diff --git a/tests/models/levit/test_modeling_levit.py b/tests/models/levit/test_modeling_levit.py
new file mode 100644
index 0000000000..69fb0d0e00
--- /dev/null
+++ b/tests/models/levit/test_modeling_levit.py
@@ -0,0 +1,423 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch LeViT model. """
+
+
+import inspect
+import unittest
+import warnings
+from math import ceil, floor
+
+from transformers import LevitConfig
+from transformers.file_utils import cached_property, is_torch_available, is_vision_available
+from transformers.models.auto import get_values
+from transformers.testing_utils import require_torch, require_vision, slow, torch_device
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING,
+ MODEL_MAPPING,
+ LevitForImageClassification,
+ LevitForImageClassificationWithTeacher,
+ LevitModel,
+ )
+ from transformers.models.levit.modeling_levit import LEVIT_PRETRAINED_MODEL_ARCHIVE_LIST
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import LevitFeatureExtractor
+
+
+class LevitConfigTester(ConfigTester):
+ def create_and_test_config_common_properties(self):
+ config = self.config_class(**self.inputs_dict)
+ self.parent.assertTrue(hasattr(config, "hidden_sizes"))
+ self.parent.assertTrue(hasattr(config, "num_attention_heads"))
+
+
+class LevitModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ image_size=64,
+ num_channels=3,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ patch_size=16,
+ hidden_sizes=[128, 256, 384],
+ num_attention_heads=[4, 6, 8],
+ depths=[2, 3, 4],
+ key_dim=[16, 16, 16],
+ drop_path_rate=0,
+ mlp_ratio=[2, 2, 2],
+ attention_ratio=[2, 2, 2],
+ initializer_range=0.02,
+ is_training=True,
+ use_labels=True,
+ num_labels=2, # Check
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.num_channels = num_channels
+ self.kernel_size = kernel_size
+ self.stride = stride
+ self.padding = padding
+ self.hidden_sizes = hidden_sizes
+ self.num_attention_heads = num_attention_heads
+ self.depths = depths
+ self.key_dim = key_dim
+ self.drop_path_rate = drop_path_rate
+ self.patch_size = patch_size
+ self.attention_ratio = attention_ratio
+ self.mlp_ratio = mlp_ratio
+ self.initializer_range = initializer_range
+ self.down_ops = [
+ ["Subsample", key_dim[0], hidden_sizes[0] // key_dim[0], 4, 2, 2],
+ ["Subsample", key_dim[0], hidden_sizes[1] // key_dim[0], 4, 2, 2],
+ ]
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.num_labels = num_labels
+ self.initializer_range = initializer_range
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size], self.num_labels)
+
+ config = self.get_config()
+ return config, pixel_values, labels
+
+ def get_config(self):
+ return LevitConfig(
+ image_size=self.image_size,
+ num_channels=self.num_channels,
+ kernel_size=self.kernel_size,
+ stride=self.stride,
+ padding=self.padding,
+ patch_size=self.patch_size,
+ hidden_sizes=self.hidden_sizes,
+ num_attention_heads=self.num_attention_heads,
+ depths=self.depths,
+ key_dim=self.key_dim,
+ drop_path_rate=self.drop_path_rate,
+ mlp_ratio=self.mlp_ratio,
+ attention_ratio=self.attention_ratio,
+ initializer_range=self.initializer_range,
+ down_ops=self.down_ops,
+ )
+
+ def create_and_check_model(self, config, pixel_values, labels):
+ model = LevitModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ image_size = (self.image_size, self.image_size)
+ height, width = image_size[0], image_size[1]
+ for _ in range(4):
+ height = floor(((height + 2 * self.padding - self.kernel_size) / self.stride) + 1)
+ width = floor(((width + 2 * self.padding - self.kernel_size) / self.stride) + 1)
+ self.parent.assertEqual(
+ result.last_hidden_state.shape,
+ (self.batch_size, ceil(height / 4) * ceil(width / 4), self.hidden_sizes[-1]),
+ )
+
+ def create_and_check_for_image_classification(self, config, pixel_values, labels):
+ config.num_labels = self.num_labels
+ model = LevitForImageClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values, labels=labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values, labels = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class LevitModelTest(ModelTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as Levit does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (
+ (LevitModel, LevitForImageClassification, LevitForImageClassificationWithTeacher)
+ if is_torch_available()
+ else ()
+ )
+
+ test_pruning = False
+ test_torchscript = False
+ test_resize_embeddings = False
+ test_head_masking = False
+ has_attentions = False
+
+ def setUp(self):
+ self.model_tester = LevitModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=LevitConfig, has_text_modality=False, hidden_size=37)
+
+ def test_config(self):
+ self.create_and_test_config_common_properties()
+ self.config_tester.create_and_test_config_to_json_string()
+ self.config_tester.create_and_test_config_to_json_file()
+ self.config_tester.create_and_test_config_from_and_save_pretrained()
+ self.config_tester.create_and_test_config_with_num_labels()
+ self.config_tester.check_config_can_be_init_without_params()
+ self.config_tester.check_config_arguments_init()
+
+ def create_and_test_config_common_properties(self):
+ return
+
+ @unittest.skip(reason="Levit does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="Levit does not support input and output embeddings")
+ def test_model_common_attributes(self):
+ pass
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_hidden_states_output(self):
+ def check_hidden_states_output(inputs_dict, config, model_class):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ hidden_states = outputs.hidden_states
+
+ expected_num_layers = len(self.model_tester.depths) + 1
+ self.assertEqual(len(hidden_states), expected_num_layers)
+
+ image_size = (self.model_tester.image_size, self.model_tester.image_size)
+ height, width = image_size[0], image_size[1]
+ for _ in range(4):
+ height = floor(
+ (
+ (height + 2 * self.model_tester.padding - self.model_tester.kernel_size)
+ / self.model_tester.stride
+ )
+ + 1
+ )
+ width = floor(
+ (
+ (width + 2 * self.model_tester.padding - self.model_tester.kernel_size)
+ / self.model_tester.stride
+ )
+ + 1
+ )
+ # verify the first hidden states (first block)
+ self.assertListEqual(
+ list(hidden_states[0].shape[-2:]),
+ [
+ height * width,
+ self.model_tester.hidden_sizes[0],
+ ],
+ )
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_hidden_states"] = True
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ # check that output_hidden_states also work using config
+ del inputs_dict["output_hidden_states"]
+ config.output_hidden_states = True
+
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ inputs_dict = super()._prepare_for_class(inputs_dict, model_class, return_labels=return_labels)
+
+ if return_labels:
+ if model_class.__name__ == "LevitForImageClassificationWithTeacher":
+ del inputs_dict["labels"]
+
+ return inputs_dict
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_for_image_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_image_classification(*config_and_inputs)
+
+ # special case for LevitForImageClassificationWithTeacher model
+ def test_training(self):
+ if not self.model_tester.is_training:
+ return
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ for model_class in self.all_model_classes:
+ # LevitForImageClassificationWithTeacher supports inference-only
+ if (
+ model_class in get_values(MODEL_MAPPING)
+ or model_class.__name__ == "LevitForImageClassificationWithTeacher"
+ ):
+ continue
+ model = model_class(config)
+ model.to(torch_device)
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ def test_training_gradient_checkpointing(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ if not self.model_tester.is_training:
+ return
+
+ config.use_cache = False
+ config.return_dict = True
+
+ for model_class in self.all_model_classes:
+ if model_class in get_values(MODEL_MAPPING) or not model_class.supports_gradient_checkpointing:
+ continue
+ # LevitForImageClassificationWithTeacher supports inference-only
+ if model_class.__name__ == "LevitForImageClassificationWithTeacher":
+ continue
+ model = model_class(config)
+ model.gradient_checkpointing_enable()
+ model.to(torch_device)
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ def test_problem_types(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ problem_types = [
+ {"title": "multi_label_classification", "num_labels": 2, "dtype": torch.float},
+ {"title": "single_label_classification", "num_labels": 1, "dtype": torch.long},
+ {"title": "regression", "num_labels": 1, "dtype": torch.float},
+ ]
+
+ for model_class in self.all_model_classes:
+ if (
+ model_class
+ not in [
+ *get_values(MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING),
+ ]
+ or model_class.__name__ == "LevitForImageClassificationWithTeacher"
+ ):
+ continue
+
+ for problem_type in problem_types:
+ with self.subTest(msg=f"Testing {model_class} with {problem_type['title']}"):
+
+ config.problem_type = problem_type["title"]
+ config.num_labels = problem_type["num_labels"]
+
+ model = model_class(config)
+ model.to(torch_device)
+ model.train()
+
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+
+ if problem_type["num_labels"] > 1:
+ inputs["labels"] = inputs["labels"].unsqueeze(1).repeat(1, problem_type["num_labels"])
+
+ inputs["labels"] = inputs["labels"].to(problem_type["dtype"])
+
+ # This tests that we do not trigger the warning form PyTorch "Using a target size that is different
+ # to the input size. This will likely lead to incorrect results due to broadcasting. Please ensure
+ # they have the same size." which is a symptom something in wrong for the regression problem.
+ # See https://github.com/huggingface/transformers/issues/11780
+ with warnings.catch_warnings(record=True) as warning_list:
+ loss = model(**inputs).loss
+ for w in warning_list:
+ if "Using a target size that is different to the input size" in str(w.message):
+ raise ValueError(
+ f"Something is going wrong in the regression problem: intercepted {w.message}"
+ )
+
+ loss.backward()
+
+ @slow
+ def test_model_from_pretrained(self):
+ for model_name in LEVIT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ model = LevitModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_torch
+@require_vision
+class LevitModelIntegrationTest(unittest.TestCase):
+ @cached_property
+ def default_feature_extractor(self):
+ return LevitFeatureExtractor.from_pretrained(LEVIT_PRETRAINED_MODEL_ARCHIVE_LIST[0])
+
+ @slow
+ def test_inference_image_classification_head(self):
+ model = LevitForImageClassificationWithTeacher.from_pretrained(LEVIT_PRETRAINED_MODEL_ARCHIVE_LIST[0]).to(
+ torch_device
+ )
+
+ feature_extractor = self.default_feature_extractor
+ image = prepare_img()
+ inputs = feature_extractor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the logits
+ expected_shape = torch.Size((1, 1000))
+ self.assertEqual(outputs.logits.shape, expected_shape)
+
+ expected_slice = torch.tensor([0.0096, -1.0084, -1.4318]).to(torch_device)
+
+ self.assertTrue(torch.allclose(outputs.logits[0, :3], expected_slice, atol=1e-4))