Update model card: new performance chart (#2864)
* Update model performance for correct German conll03 dataset * Adjust text * Adjust line spacing
This commit is contained in:
@@ -1,6 +1,6 @@
|
|||||||
---
|
---
|
||||||
language: german
|
language: german
|
||||||
thumbnail: https://thumb.tildacdn.com/tild3330-3735-4461-b133-656238643834/-/format/webp/deepset_performance.png
|
thumbnail: https://thumb.tildacdn.com/tild3162-6462-4566-b663-376630376138/-/format/webp/Screenshot_from_2020.png
|
||||||
---
|
---
|
||||||
|
|
||||||
# German BERT
|
# German BERT
|
||||||
@@ -42,12 +42,12 @@ During training we monitored the loss and evaluated different model checkpoints
|
|||||||
- CONLL03: Seq f1 score for NER
|
- CONLL03: Seq f1 score for NER
|
||||||
- 10kGNAD: Accuracy for document classification
|
- 10kGNAD: Accuracy for document classification
|
||||||
|
|
||||||
Even without thorough hyperparameter tuning, we observed quite stable learning especially for our German model. Multiple restarts with different seeds produced quite similar results.
|
Even without thorough hyperparameter tuning, we observed quite stable learning especially for our German model. Multiple restarts with different seeds produced quite similar results.
|
||||||

|
|
||||||
|

|
||||||
While outperforming on 4 out of 5 task we wondered why the German BERT model did not outperform on CONLL03-de. So we compared English BERT with multilingual on CONLL03-en and found them to perform similar as well.
|
|
||||||
|
|
||||||
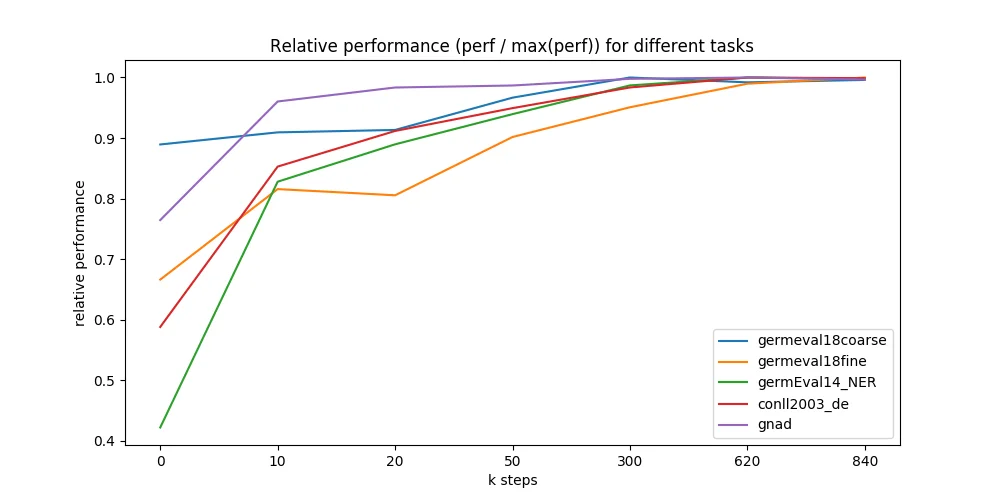
We further evaluated different points during the 9 days of pre-training and were astonished how fast the model converges to the maximally reachable performance. We ran all 5 downstream tasks on 7 different model checkpoints - taken at 0 up to 840k training steps (x-axis in figure below). Most checkpoints are taken from early training where we expected most performance changes. Surprisingly, even a randomly initialized BERT can be trained only on labeled downstream datasets and reach good performance (blue line, GermEval 2018 Coarse task, 795 kB trainset size).
|
We further evaluated different points during the 9 days of pre-training and were astonished how fast the model converges to the maximally reachable performance. We ran all 5 downstream tasks on 7 different model checkpoints - taken at 0 up to 840k training steps (x-axis in figure below). Most checkpoints are taken from early training where we expected most performance changes. Surprisingly, even a randomly initialized BERT can be trained only on labeled downstream datasets and reach good performance (blue line, GermEval 2018 Coarse task, 795 kB trainset size).
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
## Authors
|
## Authors
|
||||||
|
|||||||
Reference in New Issue
Block a user