From 7df4b90c760804295cd4c23a0840055b772898ee Mon Sep 17 00:00:00 2001
From: NielsRogge <48327001+NielsRogge@users.noreply.github.com>
Date: Wed, 22 Dec 2021 14:18:03 +0100
Subject: [PATCH] Fix Perceiver docs (#14879)
---
docs/source/model_doc/perceiver.mdx | 2 +-
.../models/perceiver/modeling_perceiver.py | 17 ++++++++++++++++-
2 files changed, 17 insertions(+), 2 deletions(-)
diff --git a/docs/source/model_doc/perceiver.mdx b/docs/source/model_doc/perceiver.mdx
index b474074e8b..0dbfd3e004 100644
--- a/docs/source/model_doc/perceiver.mdx
+++ b/docs/source/model_doc/perceiver.mdx
@@ -72,7 +72,7 @@ size of 262 byte IDs).
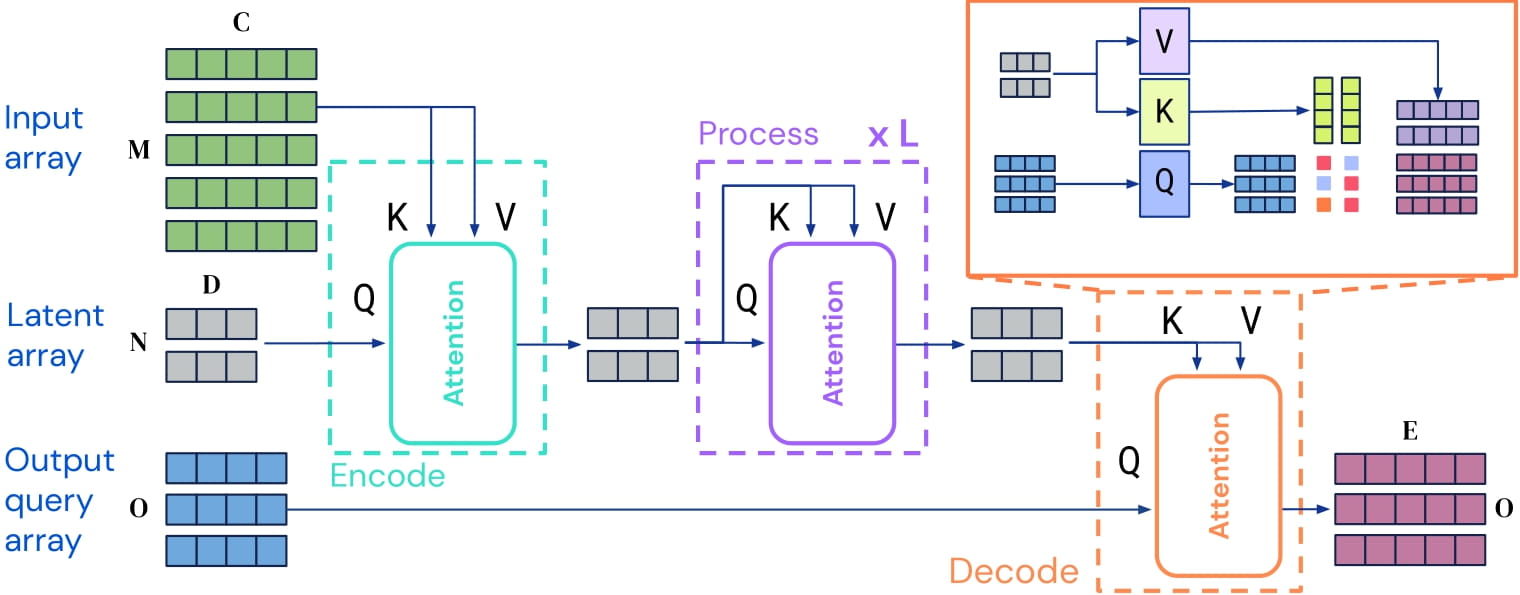 - Perceiver IO architecture. Taken from the [original paper](https://arxiv.org/abs/2105.15203)
+ Perceiver IO architecture. Taken from the original paper
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
[here](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
diff --git a/src/transformers/models/perceiver/modeling_perceiver.py b/src/transformers/models/perceiver/modeling_perceiver.py
index 5cfef2effb..c412f7f360 100755
--- a/src/transformers/models/perceiver/modeling_perceiver.py
+++ b/src/transformers/models/perceiver/modeling_perceiver.py
@@ -1881,14 +1881,29 @@ class PerceiverForMultimodalAutoencoding(PerceiverPreTrainedModel):
```python
>>> from transformers import PerceiverForMultimodalAutoencoding
>>> import torch
+ >>> import numpy as np
+ >>> # create multimodal inputs
>>> images = torch.randn((1, 16, 3, 224, 224))
>>> audio = torch.randn((1, 30720, 1))
>>> inputs = dict(image=images, audio=audio, label=torch.zeros((images.shape[0], 700)))
>>> model = PerceiverForMultimodalAutoencoding.from_pretrained('deepmind/multimodal-perceiver')
- >>> outputs = model(inputs=inputs)
+ >>> # in the Perceiver IO paper, videos are auto-encoded in chunks
+ >>> # each chunk subsamples different index dimensions of the image and audio modality decoder queries
+ >>> nchunks = 128
+ >>> image_chunk_size = np.prod((16, 224, 224)) // nchunks
+ >>> audio_chunk_size = audio.shape[1] // model.config.samples_per_patch // nchunks
+ >>> # process the first chunk
+ >>> chunk_idx = 0
+ >>> subsampling = {
+ ... "image": torch.arange(image_chunk_size * chunk_idx, image_chunk_size * (chunk_idx + 1)),
+ ... "audio": torch.arange(audio_chunk_size * chunk_idx, audio_chunk_size * (chunk_idx + 1)),
+ ... "label": None,
+ ... }
+
+ >>> outputs = model(inputs=inputs, subsampled_output_points=subsampling)
>>> logits = outputs.logits
```"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
- Perceiver IO architecture. Taken from the [original paper](https://arxiv.org/abs/2105.15203)
+ Perceiver IO architecture. Taken from the original paper
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
[here](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
diff --git a/src/transformers/models/perceiver/modeling_perceiver.py b/src/transformers/models/perceiver/modeling_perceiver.py
index 5cfef2effb..c412f7f360 100755
--- a/src/transformers/models/perceiver/modeling_perceiver.py
+++ b/src/transformers/models/perceiver/modeling_perceiver.py
@@ -1881,14 +1881,29 @@ class PerceiverForMultimodalAutoencoding(PerceiverPreTrainedModel):
```python
>>> from transformers import PerceiverForMultimodalAutoencoding
>>> import torch
+ >>> import numpy as np
+ >>> # create multimodal inputs
>>> images = torch.randn((1, 16, 3, 224, 224))
>>> audio = torch.randn((1, 30720, 1))
>>> inputs = dict(image=images, audio=audio, label=torch.zeros((images.shape[0], 700)))
>>> model = PerceiverForMultimodalAutoencoding.from_pretrained('deepmind/multimodal-perceiver')
- >>> outputs = model(inputs=inputs)
+ >>> # in the Perceiver IO paper, videos are auto-encoded in chunks
+ >>> # each chunk subsamples different index dimensions of the image and audio modality decoder queries
+ >>> nchunks = 128
+ >>> image_chunk_size = np.prod((16, 224, 224)) // nchunks
+ >>> audio_chunk_size = audio.shape[1] // model.config.samples_per_patch // nchunks
+ >>> # process the first chunk
+ >>> chunk_idx = 0
+ >>> subsampling = {
+ ... "image": torch.arange(image_chunk_size * chunk_idx, image_chunk_size * (chunk_idx + 1)),
+ ... "audio": torch.arange(audio_chunk_size * chunk_idx, audio_chunk_size * (chunk_idx + 1)),
+ ... "label": None,
+ ... }
+
+ >>> outputs = model(inputs=inputs, subsampled_output_points=subsampling)
>>> logits = outputs.logits
```"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict