Update README.md
- I added an example using the model with pipelines to show that we have set```{"use_fast": False}``` in the tokenizer.
- I added a Colab to play with the model and pipelines
- I added a Colab to discover Huggingface pipelines at the end of the document
This commit is contained in:
committed by
 Julien Chaumond
Julien Chaumond
parent
cc6775cdf5
commit
7df12d7bf8
@@ -89,7 +89,37 @@ The model was trained on a Tesla P100 GPU and 25GB of RAM with the following com
|
||||
|
||||
So, yes, this version is even more accurate.
|
||||
|
||||
### Model in action (in a Colab Notebook)
|
||||
### Model in action
|
||||
|
||||
Fast usage with **pipelines**:
|
||||
|
||||
```python
|
||||
from transformers import *
|
||||
|
||||
# Important!: By now the QA pipeline is not compatible with fast tokenizer, but they are working on it. So that pass the object to the tokenizer {"use_fast": False} as in the following example:
|
||||
|
||||
nlp = pipeline(
|
||||
'question-answering',
|
||||
model='mrm8488/distill-bert-base-spanish-wwm-cased-finetuned-spa-squad2-es',
|
||||
tokenizer=(
|
||||
'mrm8488/distill-bert-base-spanish-wwm-cased-finetuned-spa-squad2-es',
|
||||
{"use_fast": False}
|
||||
)
|
||||
)
|
||||
|
||||
nlp(
|
||||
{
|
||||
'question': '¿Para qué lenguaje está trabajando?',
|
||||
'context': 'Manuel Romero está colaborando activamente con huggingface/transformers ' +
|
||||
'para traer el poder de las últimas técnicas de procesamiento de lenguaje natural al idioma español'
|
||||
}
|
||||
)
|
||||
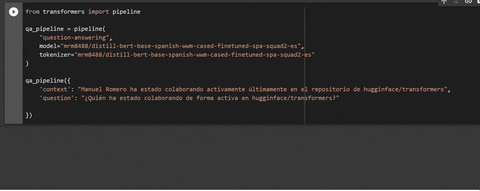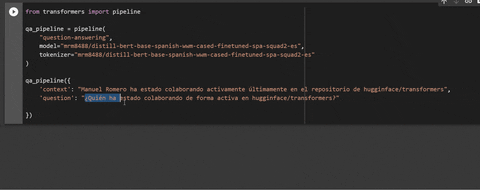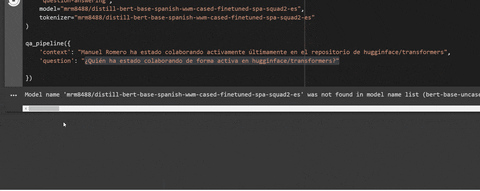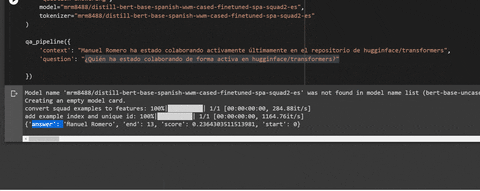
# Output: {'answer': 'español', 'end': 169, 'score': 0.67530957344621, 'start': 163}
|
||||
```
|
||||
|
||||
Play with this model and ```pipelines``` in a Colab:
|
||||
|
||||
<a href="https://colab.research.google.com/github/mrm8488/shared_colab_notebooks/blob/master/Using_Spanish_BERT_fine_tuned_for_Q%26A_pipelines.ipynb" target="_parent"><img src="https://camo.githubusercontent.com/52feade06f2fecbf006889a904d221e6a730c194/68747470733a2f2f636f6c61622e72657365617263682e676f6f676c652e636f6d2f6173736574732f636f6c61622d62616467652e737667" alt="Open In Colab" data-canonical-src="https://colab.research.google.com/assets/colab-badge.svg"></a>
|
||||
|
||||
<details>
|
||||
|
||||
@@ -100,13 +130,12 @@ So, yes, this version is even more accurate.
|
||||
2. Run predictions:
|
||||
|
||||

|
||||
|
||||
3. Using **Pipelines**
|
||||
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
More about ``` Huggingface pipelines```? check this Colab out:
|
||||
|
||||
<a href="https://colab.research.google.com/github/mrm8488/shared_colab_notebooks/blob/master/Huggingface_pipelines_demo.ipynb" target="_parent"><img src="https://camo.githubusercontent.com/52feade06f2fecbf006889a904d221e6a730c194/68747470733a2f2f636f6c61622e72657365617263682e676f6f676c652e636f6d2f6173736574732f636f6c61622d62616467652e737667" alt="Open In Colab" data-canonical-src="https://colab.research.google.com/assets/colab-badge.svg"></a>
|
||||
|
||||
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
|
||||
|
||||
> Made with <span style="color: #e25555;">♥</span> in Spain
|
||||
|
||||
Reference in New Issue
Block a user