-This model is in maintenance mode only, so we won't accept any new PRs changing its code.
+This model is in maintenance mode only, we don't accept any new PRs changing its code.
If you run into any issues running this model, please reinstall the last version that supported this model: v4.30.0.
You can do so by running the following command: `pip install -U transformers==4.30.0`.
@@ -49,7 +49,7 @@ on the weakly-supervised WikiSQL denotation accuracy to 89.5% (+2.3%), the WikiT
to 74.5% (+3.5%), and the TabFact accuracy to 84.2% (+3.2%). To our knowledge, this is the first work to exploit table pre-training via synthetic executable programs
and to achieve new state-of-the-art results on various downstream tasks.*
-Tips:
+## Usage tips
- TAPEX is a generative (seq2seq) model. One can directly plug in the weights of TAPEX into a BART model.
- TAPEX has checkpoints on the hub that are either pre-trained only, or fine-tuned on WTQ, SQA, WikiSQL and TabFact.
@@ -58,7 +58,7 @@ Tips:
- TAPEX has its own tokenizer, that allows to prepare all data for the model easily. One can pass Pandas DataFrames and strings to the tokenizer,
and it will automatically create the `input_ids` and `attention_mask` (as shown in the usage examples below).
-## Usage: inference
+### Usage: inference
Below, we illustrate how to use TAPEX for table question answering. As one can see, one can directly plug in the weights of TAPEX into a BART model.
We use the [Auto API](auto), which will automatically instantiate the appropriate tokenizer ([`TapexTokenizer`]) and model ([`BartForConditionalGeneration`]) for us,
@@ -135,6 +135,12 @@ benchmark for table fact checking (it achieves 84% accuracy). The code example b
Refused
```
+
+
+TAPEX architecture is the same as BART, except for tokenization. Refer to [BART documentation](bart) for information on
+configuration classes and their parameters. TAPEX-specific tokenizer is documented below.
+
+
## TapexTokenizer
diff --git a/docs/source/en/model_doc/time_series_transformer.md b/docs/source/en/model_doc/time_series_transformer.md
index 208798aa1c..c5bfcfc15e 100644
--- a/docs/source/en/model_doc/time_series_transformer.md
+++ b/docs/source/en/model_doc/time_series_transformer.md
@@ -16,18 +16,12 @@ rendered properly in your Markdown viewer.
# Time Series Transformer
-
-
-This is a recently introduced model so the API hasn't been tested extensively. There may be some bugs or slight
-breaking changes to fix it in the future. If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title).
-
-
-
## Overview
The Time Series Transformer model is a vanilla encoder-decoder Transformer for time series forecasting.
+This model was contributed by [kashif](https://huggingface.co/kashif).
-Tips:
+## Usage tips
- Similar to other models in the library, [`TimeSeriesTransformerModel`] is the raw Transformer without any head on top, and [`TimeSeriesTransformerForPrediction`]
adds a distribution head on top of the former, which can be used for time-series forecasting. Note that this is a so-called probabilistic forecasting model, not a
@@ -56,9 +50,6 @@ of the context as initial input for the decoder).
- At inference time, we give the final value of the `past_values` as input to the decoder. Next, we can sample from the model to make a prediction at the next time step,
which is then fed to the decoder in order to make the next prediction (also called autoregressive generation).
-
-This model was contributed by [kashif](https://huggingface.co/kashif).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
@@ -70,13 +61,11 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] TimeSeriesTransformerConfig
-
## TimeSeriesTransformerModel
[[autodoc]] TimeSeriesTransformerModel
- forward
-
## TimeSeriesTransformerForPrediction
[[autodoc]] TimeSeriesTransformerForPrediction
diff --git a/docs/source/en/model_doc/timesformer.md b/docs/source/en/model_doc/timesformer.md
index d87fde4fb2..fe75bee5b2 100644
--- a/docs/source/en/model_doc/timesformer.md
+++ b/docs/source/en/model_doc/timesformer.md
@@ -25,14 +25,15 @@ The abstract from the paper is the following:
*We present a convolution-free approach to video classification built exclusively on self-attention over space and time. Our method, named "TimeSformer," adapts the standard Transformer architecture to video by enabling spatiotemporal feature learning directly from a sequence of frame-level patches. Our experimental study compares different self-attention schemes and suggests that "divided attention," where temporal attention and spatial attention are separately applied within each block, leads to the best video classification accuracy among the design choices considered. Despite the radically new design, TimeSformer achieves state-of-the-art results on several action recognition benchmarks, including the best reported accuracy on Kinetics-400 and Kinetics-600. Finally, compared to 3D convolutional networks, our model is faster to train, it can achieve dramatically higher test efficiency (at a small drop in accuracy), and it can also be applied to much longer video clips (over one minute long). Code and models are available at: [this https URL](https://github.com/facebookresearch/TimeSformer).*
-Tips:
-
-There are many pretrained variants. Select your pretrained model based on the dataset it is trained on. Moreover, the number of input frames per clip changes based on the model size so you should consider this parameter while selecting your pretrained model.
-
This model was contributed by [fcakyon](https://huggingface.co/fcakyon).
The original code can be found [here](https://github.com/facebookresearch/TimeSformer).
-## Documentation resources
+## Usage tips
+
+There are many pretrained variants. Select your pretrained model based on the dataset it is trained on. Moreover,
+the number of input frames per clip changes based on the model size so you should consider this parameter while selecting your pretrained model.
+
+## Resources
- [Video classification task guide](../tasks/video_classification)
diff --git a/docs/source/en/model_doc/trajectory_transformer.md b/docs/source/en/model_doc/trajectory_transformer.md
index 548642f7bb..4561625587 100644
--- a/docs/source/en/model_doc/trajectory_transformer.md
+++ b/docs/source/en/model_doc/trajectory_transformer.md
@@ -43,19 +43,18 @@ in offline RL algorithms. We demonstrate the flexibility of this approach across
imitation learning, goal-conditioned RL, and offline RL. Further, we show that this approach can be combined with
existing model-free algorithms to yield a state-of-the-art planner in sparse-reward, long-horizon tasks.*
-Tips:
+This model was contributed by [CarlCochet](https://huggingface.co/CarlCochet). The original code can be found [here](https://github.com/jannerm/trajectory-transformer).
+
+## Usage tips
This Transformer is used for deep reinforcement learning. To use it, you need to create sequences from
actions, states and rewards from all previous timesteps. This model will treat all these elements together
as one big sequence (a trajectory).
-This model was contributed by [CarlCochet](https://huggingface.co/CarlCochet). The original code can be found [here](https://github.com/jannerm/trajectory-transformer).
-
## TrajectoryTransformerConfig
[[autodoc]] TrajectoryTransformerConfig
-
## TrajectoryTransformerModel
[[autodoc]] TrajectoryTransformerModel
diff --git a/docs/source/en/model_doc/transfo-xl.md b/docs/source/en/model_doc/transfo-xl.md
index beb5ba2fea..d75e3a37b9 100644
--- a/docs/source/en/model_doc/transfo-xl.md
+++ b/docs/source/en/model_doc/transfo-xl.md
@@ -45,7 +45,9 @@ bpc/perplexity to 0.99 on enwiki8, 1.08 on text8, 18.3 on WikiText-103, 21.8 on
Treebank (without finetuning). When trained only on WikiText-103, Transformer-XL manages to generate reasonably
coherent, novel text articles with thousands of tokens.*
-Tips:
+This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/kimiyoung/transformer-xl).
+
+## Usage tips
- Transformer-XL uses relative sinusoidal positional embeddings. Padding can be done on the left or on the right. The
original implementation trains on SQuAD with padding on the left, therefore the padding defaults are set to left.
@@ -54,7 +56,6 @@ Tips:
- Basically, the hidden states of the previous segment are concatenated to the current input to compute the attention scores. This allows the model to pay attention to information that was in the previous segment as well as the current one. By stacking multiple attention layers, the receptive field can be increased to multiple previous segments.
- This changes the positional embeddings to positional relative embeddings (as the regular positional embeddings would give the same results in the current input and the current hidden state at a given position) and needs to make some adjustments in the way attention scores are computed.
-This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/kimiyoung/transformer-xl).
@@ -62,7 +63,7 @@ TransformerXL does **not** work with *torch.nn.DataParallel* due to a bug in PyT
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Causal language modeling task guide](../tasks/language_modeling)
@@ -86,6 +87,9 @@ TransformerXL does **not** work with *torch.nn.DataParallel* due to a bug in PyT
[[autodoc]] models.transfo_xl.modeling_tf_transfo_xl.TFTransfoXLLMHeadModelOutput
+
+
+
## TransfoXLModel
[[autodoc]] TransfoXLModel
@@ -101,6 +105,9 @@ TransformerXL does **not** work with *torch.nn.DataParallel* due to a bug in PyT
[[autodoc]] TransfoXLForSequenceClassification
- forward
+
+
+
## TFTransfoXLModel
[[autodoc]] TFTransfoXLModel
@@ -116,6 +123,9 @@ TransformerXL does **not** work with *torch.nn.DataParallel* due to a bug in PyT
[[autodoc]] TFTransfoXLForSequenceClassification
- call
+
+
+
## Internal Layers
[[autodoc]] AdaptiveEmbedding
diff --git a/docs/source/en/model_doc/trocr.md b/docs/source/en/model_doc/trocr.md
index bfab93ad66..c471a13bbd 100644
--- a/docs/source/en/model_doc/trocr.md
+++ b/docs/source/en/model_doc/trocr.md
@@ -43,7 +43,7 @@ Please refer to the [`VisionEncoderDecoder`] class on how to use this model.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
[here](https://github.com/microsoft/unilm/tree/6f60612e7cc86a2a1ae85c47231507a587ab4e01/trocr).
-Tips:
+## Usage tips
- The quickest way to get started with TrOCR is by checking the [tutorial
notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/TrOCR), which show how to use the model
diff --git a/docs/source/en/model_doc/tvlt.md b/docs/source/en/model_doc/tvlt.md
index 5ddb6badb7..f09ea8af86 100644
--- a/docs/source/en/model_doc/tvlt.md
+++ b/docs/source/en/model_doc/tvlt.md
@@ -25,14 +25,6 @@ The abstract from the paper is the following:
*In this work, we present the Textless Vision-Language Transformer (TVLT), where homogeneous transformer blocks take raw visual and audio inputs for vision-and-language representation learning with minimal modality-specific design, and do not use text-specific modules such as tokenization or automatic speech recognition (ASR). TVLT is trained by reconstructing masked patches of continuous video frames and audio spectrograms (masked autoencoding) and contrastive modeling to align video and audio. TVLT attains performance comparable to its text-based counterpart on various multimodal tasks, such as visual question answering, image retrieval, video retrieval, and multimodal sentiment analysis, with 28x faster inference speed and only 1/3 of the parameters. Our findings suggest the possibility of learning compact and efficient visual-linguistic representations from low-level visual and audio signals without assuming the prior existence of text.*
-Tips:
-
-- TVLT is a model that takes both `pixel_values` and `audio_values` as input. One can use [`TvltProcessor`] to prepare data for the model.
- This processor wraps an image processor (for the image/video modality) and an audio feature extractor (for the audio modality) into one.
-- TVLT is trained with images/videos and audios of various sizes: the authors resize and crop the input images/videos to 224 and limit the length of audio spectrogram to 2048. To make batching of videos and audios possible, the authors use a `pixel_mask` that indicates which pixels are real/padding and `audio_mask` that indicates which audio values are real/padding.
-- The design of TVLT is very similar to that of a standard Vision Transformer (ViT) and masked autoencoder (MAE) as in [ViTMAE](vitmae). The difference is that the model includes embedding layers for the audio modality.
-- The PyTorch version of this model is only available in torch 1.10 and higher.
-
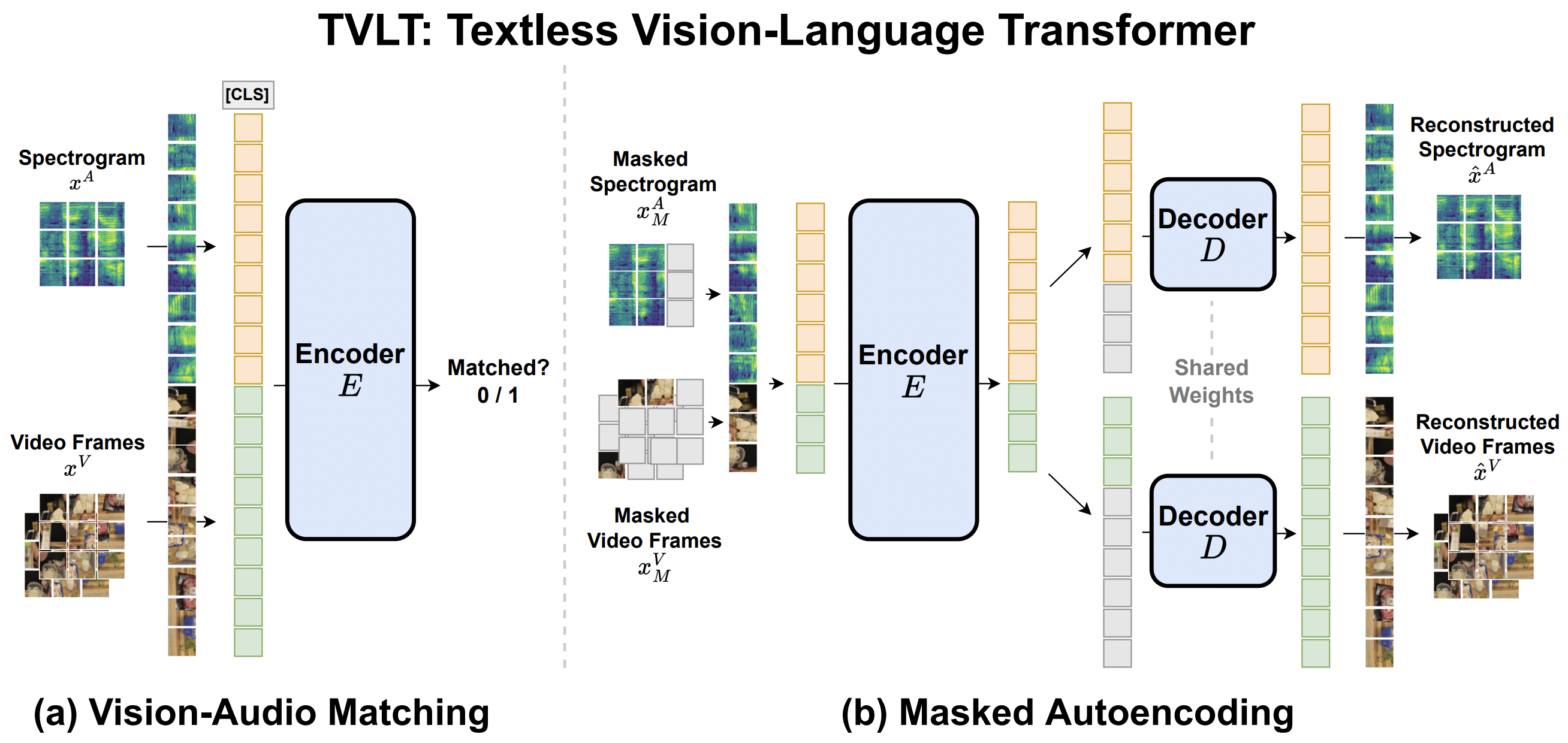 @@ -42,6 +34,14 @@ alt="drawing" width="600"/>
The original code can be found [here](https://github.com/zinengtang/TVLT). This model was contributed by [Zineng Tang](https://huggingface.co/ZinengTang).
+## Usage tips
+
+- TVLT is a model that takes both `pixel_values` and `audio_values` as input. One can use [`TvltProcessor`] to prepare data for the model.
+ This processor wraps an image processor (for the image/video modality) and an audio feature extractor (for the audio modality) into one.
+- TVLT is trained with images/videos and audios of various sizes: the authors resize and crop the input images/videos to 224 and limit the length of audio spectrogram to 2048. To make batching of videos and audios possible, the authors use a `pixel_mask` that indicates which pixels are real/padding and `audio_mask` that indicates which audio values are real/padding.
+- The design of TVLT is very similar to that of a standard Vision Transformer (ViT) and masked autoencoder (MAE) as in [ViTMAE](vitmae). The difference is that the model includes embedding layers for the audio modality.
+- The PyTorch version of this model is only available in torch 1.10 and higher.
+
## TvltConfig
[[autodoc]] TvltConfig
diff --git a/docs/source/en/model_doc/ul2.md b/docs/source/en/model_doc/ul2.md
index 3863f23a7d..f4d01c40b0 100644
--- a/docs/source/en/model_doc/ul2.md
+++ b/docs/source/en/model_doc/ul2.md
@@ -24,12 +24,20 @@ The abstract from the paper is the following:
*Existing pre-trained models are generally geared towards a particular class of problems. To date, there seems to be still no consensus on what the right architecture and pre-training setup should be. This paper presents a unified framework for pre-training models that are universally effective across datasets and setups. We begin by disentangling architectural archetypes with pre-training objectives -- two concepts that are commonly conflated. Next, we present a generalized and unified perspective for self-supervision in NLP and show how different pre-training objectives can be cast as one another and how interpolating between different objectives can be effective. We then propose Mixture-of-Denoisers (MoD), a pre-training objective that combines diverse pre-training paradigms together. We furthermore introduce a notion of mode switching, wherein downstream fine-tuning is associated with specific pre-training schemes. We conduct extensive ablative experiments to compare multiple pre-training objectives and find that our method pushes the Pareto-frontier by outperforming T5 and/or GPT-like models across multiple diverse setups. Finally, by scaling our model up to 20B parameters, we achieve SOTA performance on 50 well-established supervised NLP tasks ranging from language generation (with automated and human evaluation), language understanding, text classification, question answering, commonsense reasoning, long text reasoning, structured knowledge grounding and information retrieval. Our model also achieve strong results at in-context learning, outperforming 175B GPT-3 on zero-shot SuperGLUE and tripling the performance of T5-XXL on one-shot summarization.*
-Tips:
+This model was contributed by [DanielHesslow](https://huggingface.co/Seledorn). The original code can be found [here](https://github.com/google-research/google-research/tree/master/ul2).
+
+## Usage tips
- UL2 is an encoder-decoder model pre-trained on a mixture of denoising functions as well as fine-tuned on an array of downstream tasks.
- UL2 has the same architecture as [T5v1.1](t5v1.1) but uses the Gated-SiLU activation function instead of Gated-GELU.
- The authors release checkpoints of one architecture which can be seen [here](https://huggingface.co/google/ul2)
-The original code can be found [here](https://github.com/google-research/google-research/tree/master/ul2).
+
+
+As UL2 has the same architecture as T5v1.1, refer to [T5's documentation page](t5) for API reference, tips, code examples and notebooks.
+
+
+
+
+
-This model was contributed by [DanielHesslow](https://huggingface.co/Seledorn).
diff --git a/docs/source/en/model_doc/umt5.md b/docs/source/en/model_doc/umt5.md
index 4e6375bd46..6a7498c243 100644
--- a/docs/source/en/model_doc/umt5.md
+++ b/docs/source/en/model_doc/umt5.md
@@ -33,13 +33,6 @@ The abstract from the paper is the following:
*Pretrained multilingual large language models have typically used heuristic temperature-based sampling to balance between different languages. However previous work has not systematically evaluated the efficacy of different pretraining language distributions across model scales. In this paper, we propose a new sampling method, UniMax, that delivers more uniform coverage of head languages while mitigating overfitting on tail languages by explicitly capping the number of repeats over each language's corpus. We perform an extensive series of ablations testing a range of sampling strategies on a suite of multilingual benchmarks, while varying model scale. We find that UniMax outperforms standard temperature-based sampling, and the benefits persist as scale increases. As part of our contribution, we release: (i) an improved and refreshed mC4 multilingual corpus consisting of 29 trillion characters across 107 languages, and (ii) a suite of pretrained umT5 model checkpoints trained with UniMax sampling.*
-Tips:
-
-- UMT5 was only pre-trained on [mC4](https://huggingface.co/datasets/mc4) excluding any supervised training.
-Therefore, this model has to be fine-tuned before it is usable on a downstream task, unlike the original T5 model.
-- Since umT5 was pre-trained in an unsupervise manner, there's no real advantage to using a task prefix during single-task
-fine-tuning. If you are doing multi-task fine-tuning, you should use a prefix.
-
Google has released the following variants:
- [google/umt5-small](https://huggingface.co/google/umt5-small)
@@ -50,7 +43,12 @@ Google has released the following variants:
This model was contributed by [agemagician](https://huggingface.co/agemagician) and [stefan-it](https://huggingface.co/stefan-it). The original code can be
found [here](https://github.com/google-research/t5x).
-One can refer to [T5's documentation page](t5) for more tips, code examples and notebooks.
+## Usage tips
+
+- UMT5 was only pre-trained on [mC4](https://huggingface.co/datasets/mc4) excluding any supervised training.
+Therefore, this model has to be fine-tuned before it is usable on a downstream task, unlike the original T5 model.
+- Since umT5 was pre-trained in an unsupervise manner, there's no real advantage to using a task prefix during single-task
+fine-tuning. If you are doing multi-task fine-tuning, you should use a prefix.
## Differences with mT5?
`UmT5` is based on mT5, with a non-shared relative positional bias that is computed for each layer. This means that the model set `has_relative_bias` for each layer.
@@ -73,6 +71,11 @@ The conversion script is also different because the model was saved in t5x's lat
['nyone who drink a alcohol A A. This I']
```
+
+
+Refer to [T5's documentation page](t5) for more tips, code examples and notebooks.
+
+
## UMT5Config
[[autodoc]] UMT5Config
diff --git a/docs/source/en/model_doc/unispeech-sat.md b/docs/source/en/model_doc/unispeech-sat.md
index 25489d9eef..e2a2114811 100644
--- a/docs/source/en/model_doc/unispeech-sat.md
+++ b/docs/source/en/model_doc/unispeech-sat.md
@@ -37,7 +37,10 @@ state-of-the-art performance in universal representation learning, especially fo
tasks. An ablation study is performed verifying the efficacy of each proposed method. Finally, we scale up training
dataset to 94 thousand hours public audio data and achieve further performance improvement in all SUPERB tasks.*
-Tips:
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
+found [here](https://github.com/microsoft/UniSpeech/tree/main/UniSpeech-SAT).
+
+## Usage tips
- UniSpeechSat is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
Please use [`Wav2Vec2Processor`] for the feature extraction.
@@ -45,10 +48,7 @@ Tips:
decoded using [`Wav2Vec2CTCTokenizer`].
- UniSpeechSat performs especially well on speaker verification, speaker identification, and speaker diarization tasks.
-This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
-found [here](https://github.com/microsoft/UniSpeech/tree/main/UniSpeech-SAT).
-
-## Documentation resources
+## Resources
- [Audio classification task guide](../tasks/audio_classification)
- [Automatic speech recognition task guide](../tasks/asr)
diff --git a/docs/source/en/model_doc/unispeech.md b/docs/source/en/model_doc/unispeech.md
index 8338aa1bda..2b2b13bed5 100644
--- a/docs/source/en/model_doc/unispeech.md
+++ b/docs/source/en/model_doc/unispeech.md
@@ -33,17 +33,17 @@ recognition by a maximum of 13.4% and 17.8% relative phone error rate reductions
testing languages). The transferability of UniSpeech is also demonstrated on a domain-shift speech recognition task,
i.e., a relative word error rate reduction of 6% against the previous approach.*
-Tips:
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
+found [here](https://github.com/microsoft/UniSpeech/tree/main/UniSpeech).
+
+## Usage tips
- UniSpeech is a speech model that accepts a float array corresponding to the raw waveform of the speech signal. Please
use [`Wav2Vec2Processor`] for the feature extraction.
- UniSpeech model can be fine-tuned using connectionist temporal classification (CTC) so the model output has to be
decoded using [`Wav2Vec2CTCTokenizer`].
-This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
-found [here](https://github.com/microsoft/UniSpeech/tree/main/UniSpeech).
-
-## Documentation resources
+## Resources
- [Audio classification task guide](../tasks/audio_classification)
- [Automatic speech recognition task guide](../tasks/asr)
diff --git a/docs/source/en/model_doc/upernet.md b/docs/source/en/model_doc/upernet.md
index db651acaa4..418c3ef178 100644
--- a/docs/source/en/model_doc/upernet.md
+++ b/docs/source/en/model_doc/upernet.md
@@ -33,17 +33,7 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code is based on OpenMMLab's mmsegmentation [here](https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/uper_head.py).
-## Resources
-
-A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with UPerNet.
-
-- Demo notebooks for UPerNet can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/UPerNet).
-- [`UperNetForSemanticSegmentation`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/semantic-segmentation) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/semantic_segmentation.ipynb).
-- See also: [Semantic segmentation task guide](../tasks/semantic_segmentation)
-
-If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
-
-## Usage
+## Usage examples
UPerNet is a general framework for semantic segmentation. It can be used with any vision backbone, like so:
@@ -69,6 +59,16 @@ model = UperNetForSemanticSegmentation(config)
Note that this will randomly initialize all the weights of the model.
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with UPerNet.
+
+- Demo notebooks for UPerNet can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/UPerNet).
+- [`UperNetForSemanticSegmentation`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/semantic-segmentation) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/semantic_segmentation.ipynb).
+- See also: [Semantic segmentation task guide](../tasks/semantic_segmentation)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
## UperNetConfig
[[autodoc]] UperNetConfig
diff --git a/docs/source/en/model_doc/van.md b/docs/source/en/model_doc/van.md
index b9539602d3..83e4959b30 100644
--- a/docs/source/en/model_doc/van.md
+++ b/docs/source/en/model_doc/van.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
-This model is in maintenance mode only, so we won't accept any new PRs changing its code.
+This model is in maintenance mode only, we don't accept any new PRs changing its code.
If you run into any issues running this model, please reinstall the last version that supported this model: v4.30.0.
You can do so by running the following command: `pip install -U transformers==4.30.0`.
@@ -60,13 +60,11 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] VanConfig
-
## VanModel
[[autodoc]] VanModel
- forward
-
## VanForImageClassification
[[autodoc]] VanForImageClassification
diff --git a/docs/source/en/model_doc/videomae.md b/docs/source/en/model_doc/videomae.md
index 5a3620040a..75eb961738 100644
--- a/docs/source/en/model_doc/videomae.md
+++ b/docs/source/en/model_doc/videomae.md
@@ -25,11 +25,6 @@ The abstract from the paper is the following:
*Pre-training video transformers on extra large-scale datasets is generally required to achieve premier performance on relatively small datasets. In this paper, we show that video masked autoencoders (VideoMAE) are data-efficient learners for self-supervised video pre-training (SSVP). We are inspired by the recent ImageMAE and propose customized video tube masking and reconstruction. These simple designs turn out to be effective for overcoming information leakage caused by the temporal correlation during video reconstruction. We obtain three important findings on SSVP: (1) An extremely high proportion of masking ratio (i.e., 90% to 95%) still yields favorable performance of VideoMAE. The temporally redundant video content enables higher masking ratio than that of images. (2) VideoMAE achieves impressive results on very small datasets (i.e., around 3k-4k videos) without using any extra data. This is partially ascribed to the challenging task of video reconstruction to enforce high-level structure learning. (3) VideoMAE shows that data quality is more important than data quantity for SSVP. Domain shift between pre-training and target datasets are important issues in SSVP. Notably, our VideoMAE with the vanilla ViT backbone can achieve 83.9% on Kinects-400, 75.3% on Something-Something V2, 90.8% on UCF101, and 61.1% on HMDB51 without using any extra data.*
-Tips:
-
-- One can use [`VideoMAEImageProcessor`] to prepare videos for the model. It will resize + normalize all frames of a video for you.
-- [`VideoMAEForPreTraining`] includes the decoder on top for self-supervised pre-training.
-
@@ -42,6 +34,14 @@ alt="drawing" width="600"/>
The original code can be found [here](https://github.com/zinengtang/TVLT). This model was contributed by [Zineng Tang](https://huggingface.co/ZinengTang).
+## Usage tips
+
+- TVLT is a model that takes both `pixel_values` and `audio_values` as input. One can use [`TvltProcessor`] to prepare data for the model.
+ This processor wraps an image processor (for the image/video modality) and an audio feature extractor (for the audio modality) into one.
+- TVLT is trained with images/videos and audios of various sizes: the authors resize and crop the input images/videos to 224 and limit the length of audio spectrogram to 2048. To make batching of videos and audios possible, the authors use a `pixel_mask` that indicates which pixels are real/padding and `audio_mask` that indicates which audio values are real/padding.
+- The design of TVLT is very similar to that of a standard Vision Transformer (ViT) and masked autoencoder (MAE) as in [ViTMAE](vitmae). The difference is that the model includes embedding layers for the audio modality.
+- The PyTorch version of this model is only available in torch 1.10 and higher.
+
## TvltConfig
[[autodoc]] TvltConfig
diff --git a/docs/source/en/model_doc/ul2.md b/docs/source/en/model_doc/ul2.md
index 3863f23a7d..f4d01c40b0 100644
--- a/docs/source/en/model_doc/ul2.md
+++ b/docs/source/en/model_doc/ul2.md
@@ -24,12 +24,20 @@ The abstract from the paper is the following:
*Existing pre-trained models are generally geared towards a particular class of problems. To date, there seems to be still no consensus on what the right architecture and pre-training setup should be. This paper presents a unified framework for pre-training models that are universally effective across datasets and setups. We begin by disentangling architectural archetypes with pre-training objectives -- two concepts that are commonly conflated. Next, we present a generalized and unified perspective for self-supervision in NLP and show how different pre-training objectives can be cast as one another and how interpolating between different objectives can be effective. We then propose Mixture-of-Denoisers (MoD), a pre-training objective that combines diverse pre-training paradigms together. We furthermore introduce a notion of mode switching, wherein downstream fine-tuning is associated with specific pre-training schemes. We conduct extensive ablative experiments to compare multiple pre-training objectives and find that our method pushes the Pareto-frontier by outperforming T5 and/or GPT-like models across multiple diverse setups. Finally, by scaling our model up to 20B parameters, we achieve SOTA performance on 50 well-established supervised NLP tasks ranging from language generation (with automated and human evaluation), language understanding, text classification, question answering, commonsense reasoning, long text reasoning, structured knowledge grounding and information retrieval. Our model also achieve strong results at in-context learning, outperforming 175B GPT-3 on zero-shot SuperGLUE and tripling the performance of T5-XXL on one-shot summarization.*
-Tips:
+This model was contributed by [DanielHesslow](https://huggingface.co/Seledorn). The original code can be found [here](https://github.com/google-research/google-research/tree/master/ul2).
+
+## Usage tips
- UL2 is an encoder-decoder model pre-trained on a mixture of denoising functions as well as fine-tuned on an array of downstream tasks.
- UL2 has the same architecture as [T5v1.1](t5v1.1) but uses the Gated-SiLU activation function instead of Gated-GELU.
- The authors release checkpoints of one architecture which can be seen [here](https://huggingface.co/google/ul2)
-The original code can be found [here](https://github.com/google-research/google-research/tree/master/ul2).
+
+
+As UL2 has the same architecture as T5v1.1, refer to [T5's documentation page](t5) for API reference, tips, code examples and notebooks.
+
+
+
+
+
-This model was contributed by [DanielHesslow](https://huggingface.co/Seledorn).
diff --git a/docs/source/en/model_doc/umt5.md b/docs/source/en/model_doc/umt5.md
index 4e6375bd46..6a7498c243 100644
--- a/docs/source/en/model_doc/umt5.md
+++ b/docs/source/en/model_doc/umt5.md
@@ -33,13 +33,6 @@ The abstract from the paper is the following:
*Pretrained multilingual large language models have typically used heuristic temperature-based sampling to balance between different languages. However previous work has not systematically evaluated the efficacy of different pretraining language distributions across model scales. In this paper, we propose a new sampling method, UniMax, that delivers more uniform coverage of head languages while mitigating overfitting on tail languages by explicitly capping the number of repeats over each language's corpus. We perform an extensive series of ablations testing a range of sampling strategies on a suite of multilingual benchmarks, while varying model scale. We find that UniMax outperforms standard temperature-based sampling, and the benefits persist as scale increases. As part of our contribution, we release: (i) an improved and refreshed mC4 multilingual corpus consisting of 29 trillion characters across 107 languages, and (ii) a suite of pretrained umT5 model checkpoints trained with UniMax sampling.*
-Tips:
-
-- UMT5 was only pre-trained on [mC4](https://huggingface.co/datasets/mc4) excluding any supervised training.
-Therefore, this model has to be fine-tuned before it is usable on a downstream task, unlike the original T5 model.
-- Since umT5 was pre-trained in an unsupervise manner, there's no real advantage to using a task prefix during single-task
-fine-tuning. If you are doing multi-task fine-tuning, you should use a prefix.
-
Google has released the following variants:
- [google/umt5-small](https://huggingface.co/google/umt5-small)
@@ -50,7 +43,12 @@ Google has released the following variants:
This model was contributed by [agemagician](https://huggingface.co/agemagician) and [stefan-it](https://huggingface.co/stefan-it). The original code can be
found [here](https://github.com/google-research/t5x).
-One can refer to [T5's documentation page](t5) for more tips, code examples and notebooks.
+## Usage tips
+
+- UMT5 was only pre-trained on [mC4](https://huggingface.co/datasets/mc4) excluding any supervised training.
+Therefore, this model has to be fine-tuned before it is usable on a downstream task, unlike the original T5 model.
+- Since umT5 was pre-trained in an unsupervise manner, there's no real advantage to using a task prefix during single-task
+fine-tuning. If you are doing multi-task fine-tuning, you should use a prefix.
## Differences with mT5?
`UmT5` is based on mT5, with a non-shared relative positional bias that is computed for each layer. This means that the model set `has_relative_bias` for each layer.
@@ -73,6 +71,11 @@ The conversion script is also different because the model was saved in t5x's lat
['nyone who drink a alcohol A A. This I']
```
+
+
+Refer to [T5's documentation page](t5) for more tips, code examples and notebooks.
+
+
## UMT5Config
[[autodoc]] UMT5Config
diff --git a/docs/source/en/model_doc/unispeech-sat.md b/docs/source/en/model_doc/unispeech-sat.md
index 25489d9eef..e2a2114811 100644
--- a/docs/source/en/model_doc/unispeech-sat.md
+++ b/docs/source/en/model_doc/unispeech-sat.md
@@ -37,7 +37,10 @@ state-of-the-art performance in universal representation learning, especially fo
tasks. An ablation study is performed verifying the efficacy of each proposed method. Finally, we scale up training
dataset to 94 thousand hours public audio data and achieve further performance improvement in all SUPERB tasks.*
-Tips:
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
+found [here](https://github.com/microsoft/UniSpeech/tree/main/UniSpeech-SAT).
+
+## Usage tips
- UniSpeechSat is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
Please use [`Wav2Vec2Processor`] for the feature extraction.
@@ -45,10 +48,7 @@ Tips:
decoded using [`Wav2Vec2CTCTokenizer`].
- UniSpeechSat performs especially well on speaker verification, speaker identification, and speaker diarization tasks.
-This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
-found [here](https://github.com/microsoft/UniSpeech/tree/main/UniSpeech-SAT).
-
-## Documentation resources
+## Resources
- [Audio classification task guide](../tasks/audio_classification)
- [Automatic speech recognition task guide](../tasks/asr)
diff --git a/docs/source/en/model_doc/unispeech.md b/docs/source/en/model_doc/unispeech.md
index 8338aa1bda..2b2b13bed5 100644
--- a/docs/source/en/model_doc/unispeech.md
+++ b/docs/source/en/model_doc/unispeech.md
@@ -33,17 +33,17 @@ recognition by a maximum of 13.4% and 17.8% relative phone error rate reductions
testing languages). The transferability of UniSpeech is also demonstrated on a domain-shift speech recognition task,
i.e., a relative word error rate reduction of 6% against the previous approach.*
-Tips:
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
+found [here](https://github.com/microsoft/UniSpeech/tree/main/UniSpeech).
+
+## Usage tips
- UniSpeech is a speech model that accepts a float array corresponding to the raw waveform of the speech signal. Please
use [`Wav2Vec2Processor`] for the feature extraction.
- UniSpeech model can be fine-tuned using connectionist temporal classification (CTC) so the model output has to be
decoded using [`Wav2Vec2CTCTokenizer`].
-This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
-found [here](https://github.com/microsoft/UniSpeech/tree/main/UniSpeech).
-
-## Documentation resources
+## Resources
- [Audio classification task guide](../tasks/audio_classification)
- [Automatic speech recognition task guide](../tasks/asr)
diff --git a/docs/source/en/model_doc/upernet.md b/docs/source/en/model_doc/upernet.md
index db651acaa4..418c3ef178 100644
--- a/docs/source/en/model_doc/upernet.md
+++ b/docs/source/en/model_doc/upernet.md
@@ -33,17 +33,7 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code is based on OpenMMLab's mmsegmentation [here](https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/uper_head.py).
-## Resources
-
-A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with UPerNet.
-
-- Demo notebooks for UPerNet can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/UPerNet).
-- [`UperNetForSemanticSegmentation`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/semantic-segmentation) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/semantic_segmentation.ipynb).
-- See also: [Semantic segmentation task guide](../tasks/semantic_segmentation)
-
-If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
-
-## Usage
+## Usage examples
UPerNet is a general framework for semantic segmentation. It can be used with any vision backbone, like so:
@@ -69,6 +59,16 @@ model = UperNetForSemanticSegmentation(config)
Note that this will randomly initialize all the weights of the model.
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with UPerNet.
+
+- Demo notebooks for UPerNet can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/UPerNet).
+- [`UperNetForSemanticSegmentation`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/semantic-segmentation) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/semantic_segmentation.ipynb).
+- See also: [Semantic segmentation task guide](../tasks/semantic_segmentation)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
## UperNetConfig
[[autodoc]] UperNetConfig
diff --git a/docs/source/en/model_doc/van.md b/docs/source/en/model_doc/van.md
index b9539602d3..83e4959b30 100644
--- a/docs/source/en/model_doc/van.md
+++ b/docs/source/en/model_doc/van.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
-This model is in maintenance mode only, so we won't accept any new PRs changing its code.
+This model is in maintenance mode only, we don't accept any new PRs changing its code.
If you run into any issues running this model, please reinstall the last version that supported this model: v4.30.0.
You can do so by running the following command: `pip install -U transformers==4.30.0`.
@@ -60,13 +60,11 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] VanConfig
-
## VanModel
[[autodoc]] VanModel
- forward
-
## VanForImageClassification
[[autodoc]] VanForImageClassification
diff --git a/docs/source/en/model_doc/videomae.md b/docs/source/en/model_doc/videomae.md
index 5a3620040a..75eb961738 100644
--- a/docs/source/en/model_doc/videomae.md
+++ b/docs/source/en/model_doc/videomae.md
@@ -25,11 +25,6 @@ The abstract from the paper is the following:
*Pre-training video transformers on extra large-scale datasets is generally required to achieve premier performance on relatively small datasets. In this paper, we show that video masked autoencoders (VideoMAE) are data-efficient learners for self-supervised video pre-training (SSVP). We are inspired by the recent ImageMAE and propose customized video tube masking and reconstruction. These simple designs turn out to be effective for overcoming information leakage caused by the temporal correlation during video reconstruction. We obtain three important findings on SSVP: (1) An extremely high proportion of masking ratio (i.e., 90% to 95%) still yields favorable performance of VideoMAE. The temporally redundant video content enables higher masking ratio than that of images. (2) VideoMAE achieves impressive results on very small datasets (i.e., around 3k-4k videos) without using any extra data. This is partially ascribed to the challenging task of video reconstruction to enforce high-level structure learning. (3) VideoMAE shows that data quality is more important than data quantity for SSVP. Domain shift between pre-training and target datasets are important issues in SSVP. Notably, our VideoMAE with the vanilla ViT backbone can achieve 83.9% on Kinects-400, 75.3% on Something-Something V2, 90.8% on UCF101, and 61.1% on HMDB51 without using any extra data.*
-Tips:
-
-- One can use [`VideoMAEImageProcessor`] to prepare videos for the model. It will resize + normalize all frames of a video for you.
-- [`VideoMAEForPreTraining`] includes the decoder on top for self-supervised pre-training.
-
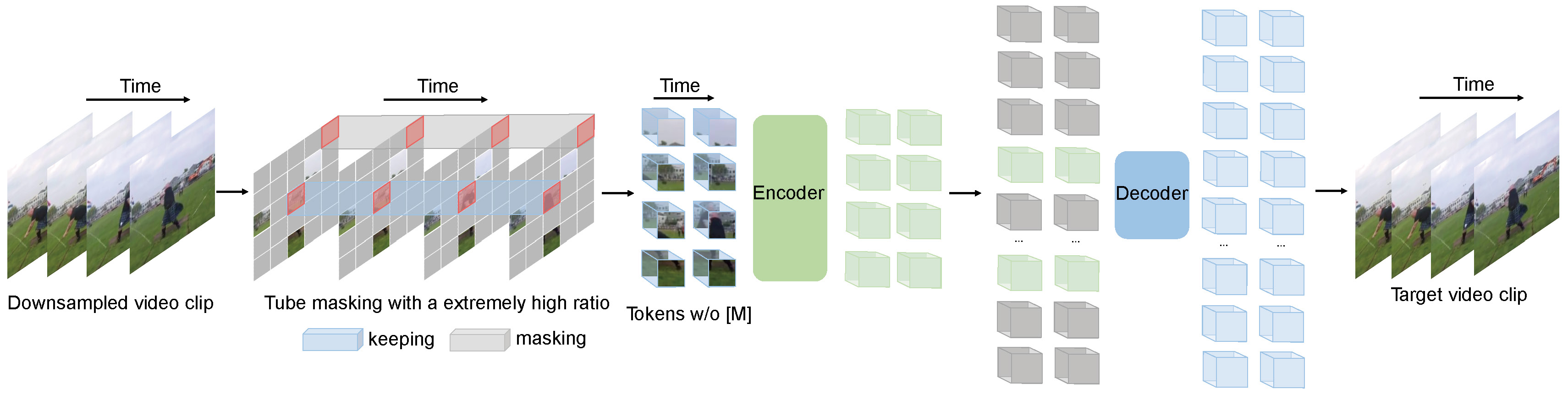 @@ -50,7 +45,6 @@ to fine-tune a VideoMAE model on a custom dataset.
- [Video classification task guide](../tasks/video_classification)
- [A 🤗 Space](https://huggingface.co/spaces/sayakpaul/video-classification-ucf101-subset) showing how to perform inference with a video classification model.
-
## VideoMAEConfig
[[autodoc]] VideoMAEConfig
@@ -72,6 +66,8 @@ to fine-tune a VideoMAE model on a custom dataset.
## VideoMAEForPreTraining
+`VideoMAEForPreTraining` includes the decoder on top for self-supervised pre-training.
+
[[autodoc]] transformers.VideoMAEForPreTraining
- forward
diff --git a/docs/source/en/model_doc/vilt.md b/docs/source/en/model_doc/vilt.md
index 2e2f4a140d..2b0ac022da 100644
--- a/docs/source/en/model_doc/vilt.md
+++ b/docs/source/en/model_doc/vilt.md
@@ -34,7 +34,14 @@ Vision-and-Language Transformer (ViLT), monolithic in the sense that the process
simplified to just the same convolution-free manner that we process textual inputs. We show that ViLT is up to tens of
times faster than previous VLP models, yet with competitive or better downstream task performance.*
-Tips:
+
@@ -50,7 +45,6 @@ to fine-tune a VideoMAE model on a custom dataset.
- [Video classification task guide](../tasks/video_classification)
- [A 🤗 Space](https://huggingface.co/spaces/sayakpaul/video-classification-ucf101-subset) showing how to perform inference with a video classification model.
-
## VideoMAEConfig
[[autodoc]] VideoMAEConfig
@@ -72,6 +66,8 @@ to fine-tune a VideoMAE model on a custom dataset.
## VideoMAEForPreTraining
+`VideoMAEForPreTraining` includes the decoder on top for self-supervised pre-training.
+
[[autodoc]] transformers.VideoMAEForPreTraining
- forward
diff --git a/docs/source/en/model_doc/vilt.md b/docs/source/en/model_doc/vilt.md
index 2e2f4a140d..2b0ac022da 100644
--- a/docs/source/en/model_doc/vilt.md
+++ b/docs/source/en/model_doc/vilt.md
@@ -34,7 +34,14 @@ Vision-and-Language Transformer (ViLT), monolithic in the sense that the process
simplified to just the same convolution-free manner that we process textual inputs. We show that ViLT is up to tens of
times faster than previous VLP models, yet with competitive or better downstream task performance.*
-Tips:
+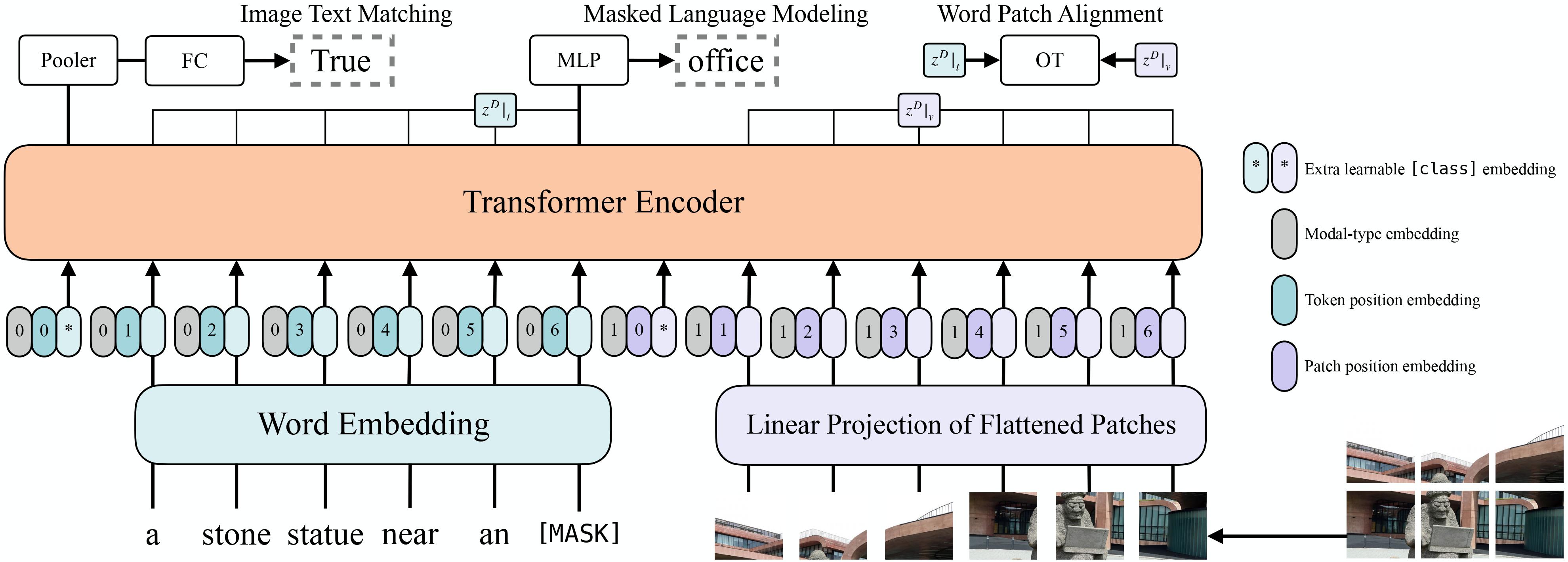 +
+ ViLT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/dandelin/ViLT).
+
+## Usage tips
- The quickest way to get started with ViLT is by checking the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ViLT)
(which showcase both inference and fine-tuning on custom data).
@@ -45,17 +52,6 @@ Tips:
which pixel values are real and which are padding. [`ViltProcessor`] automatically creates this for you.
- The design of ViLT is very similar to that of a standard Vision Transformer (ViT). The only difference is that the model includes
additional embedding layers for the language modality.
-
-
-
- ViLT architecture. Taken from the original paper.
-
-This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/dandelin/ViLT).
-
-
-Tips:
-
- The PyTorch version of this model is only available in torch 1.10 and higher.
## ViltConfig
diff --git a/docs/source/en/model_doc/vision-encoder-decoder.md b/docs/source/en/model_doc/vision-encoder-decoder.md
index 0beeaeae10..89d89896a2 100644
--- a/docs/source/en/model_doc/vision-encoder-decoder.md
+++ b/docs/source/en/model_doc/vision-encoder-decoder.md
@@ -151,20 +151,32 @@ were contributed by [ydshieh](https://github.com/ydshieh).
[[autodoc]] VisionEncoderDecoderConfig
+
+
+
## VisionEncoderDecoderModel
[[autodoc]] VisionEncoderDecoderModel
- forward
- from_encoder_decoder_pretrained
+
+
+
## TFVisionEncoderDecoderModel
[[autodoc]] TFVisionEncoderDecoderModel
- call
- from_encoder_decoder_pretrained
+
+
+
## FlaxVisionEncoderDecoderModel
[[autodoc]] FlaxVisionEncoderDecoderModel
- __call__
- from_encoder_decoder_pretrained
+
+
+
diff --git a/docs/source/en/model_doc/vision-text-dual-encoder.md b/docs/source/en/model_doc/vision-text-dual-encoder.md
index 6fa9728cac..7cb68a2618 100644
--- a/docs/source/en/model_doc/vision-text-dual-encoder.md
+++ b/docs/source/en/model_doc/vision-text-dual-encoder.md
@@ -36,17 +36,29 @@ new zero-shot vision tasks such as image classification or retrieval.
[[autodoc]] VisionTextDualEncoderProcessor
+
+
+
## VisionTextDualEncoderModel
[[autodoc]] VisionTextDualEncoderModel
- forward
+
+
+
## FlaxVisionTextDualEncoderModel
[[autodoc]] FlaxVisionTextDualEncoderModel
- __call__
+
+
+
## TFVisionTextDualEncoderModel
[[autodoc]] TFVisionTextDualEncoderModel
- call
+
+
+
diff --git a/docs/source/en/model_doc/visual_bert.md b/docs/source/en/model_doc/visual_bert.md
index 7d84c0d9fa..1db218f1a5 100644
--- a/docs/source/en/model_doc/visual_bert.md
+++ b/docs/source/en/model_doc/visual_bert.md
@@ -32,7 +32,9 @@ simpler. Further analysis demonstrates that VisualBERT can ground elements of la
explicit supervision and is even sensitive to syntactic relationships, tracking, for example, associations between
verbs and image regions corresponding to their arguments.*
-Tips:
+This model was contributed by [gchhablani](https://huggingface.co/gchhablani). The original code can be found [here](https://github.com/uclanlp/visualbert).
+
+## Usage tips
1. Most of the checkpoints provided work with the [`VisualBertForPreTraining`] configuration. Other
checkpoints provided are the fine-tuned checkpoints for down-stream tasks - VQA ('visualbert-vqa'), VCR
@@ -43,8 +45,6 @@ Tips:
We do not provide the detector and its weights as a part of the package, but it will be available in the research
projects, and the states can be loaded directly into the detector provided.
-## Usage
-
VisualBERT is a multi-modal vision and language model. It can be used for visual question answering, multiple choice,
visual reasoning and region-to-phrase correspondence tasks. VisualBERT uses a BERT-like transformer to prepare
embeddings for image-text pairs. Both the text and visual features are then projected to a latent space with identical
@@ -92,8 +92,6 @@ The following example shows how to get the last hidden state using [`VisualBertM
>>> last_hidden_state = outputs.last_hidden_state
```
-This model was contributed by [gchhablani](https://huggingface.co/gchhablani). The original code can be found [here](https://github.com/uclanlp/visualbert).
-
## VisualBertConfig
[[autodoc]] VisualBertConfig
diff --git a/docs/source/en/model_doc/vit.md b/docs/source/en/model_doc/vit.md
index 409580d094..25c3a6c8f5 100644
--- a/docs/source/en/model_doc/vit.md
+++ b/docs/source/en/model_doc/vit.md
@@ -24,7 +24,6 @@ Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minder
Uszkoreit, Neil Houlsby. It's the first paper that successfully trains a Transformer encoder on ImageNet, attaining
very good results compared to familiar convolutional architectures.
-
The abstract from the paper is the following:
*While the Transformer architecture has become the de-facto standard for natural language processing tasks, its
@@ -36,30 +35,6 @@ data and transferred to multiple mid-sized or small image recognition benchmarks
Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring
substantially fewer computational resources to train.*
-Tips:
-
-- Demo notebooks regarding inference as well as fine-tuning ViT on custom data can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer).
-- To feed images to the Transformer encoder, each image is split into a sequence of fixed-size non-overlapping patches,
- which are then linearly embedded. A [CLS] token is added to serve as representation of an entire image, which can be
- used for classification. The authors also add absolute position embeddings, and feed the resulting sequence of
- vectors to a standard Transformer encoder.
-- As the Vision Transformer expects each image to be of the same size (resolution), one can use
- [`ViTImageProcessor`] to resize (or rescale) and normalize images for the model.
-- Both the patch resolution and image resolution used during pre-training or fine-tuning are reflected in the name of
- each checkpoint. For example, `google/vit-base-patch16-224` refers to a base-sized architecture with patch
- resolution of 16x16 and fine-tuning resolution of 224x224. All checkpoints can be found on the [hub](https://huggingface.co/models?search=vit).
-- The available checkpoints are either (1) pre-trained on [ImageNet-21k](http://www.image-net.org/) (a collection of
- 14 million images and 21k classes) only, or (2) also fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/) (also referred to as ILSVRC 2012, a collection of 1.3 million
- images and 1,000 classes).
-- The Vision Transformer was pre-trained using a resolution of 224x224. During fine-tuning, it is often beneficial to
- use a higher resolution than pre-training [(Touvron et al., 2019)](https://arxiv.org/abs/1906.06423), [(Kolesnikov
- et al., 2020)](https://arxiv.org/abs/1912.11370). In order to fine-tune at higher resolution, the authors perform
- 2D interpolation of the pre-trained position embeddings, according to their location in the original image.
-- The best results are obtained with supervised pre-training, which is not the case in NLP. The authors also performed
- an experiment with a self-supervised pre-training objective, namely masked patched prediction (inspired by masked
- language modeling). With this approach, the smaller ViT-B/16 model achieves 79.9% accuracy on ImageNet, a significant
- improvement of 2% to training from scratch, but still 4% behind supervised pre-training.
-
+
+ ViLT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/dandelin/ViLT).
+
+## Usage tips
- The quickest way to get started with ViLT is by checking the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ViLT)
(which showcase both inference and fine-tuning on custom data).
@@ -45,17 +52,6 @@ Tips:
which pixel values are real and which are padding. [`ViltProcessor`] automatically creates this for you.
- The design of ViLT is very similar to that of a standard Vision Transformer (ViT). The only difference is that the model includes
additional embedding layers for the language modality.
-
-
-
- ViLT architecture. Taken from the original paper.
-
-This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/dandelin/ViLT).
-
-
-Tips:
-
- The PyTorch version of this model is only available in torch 1.10 and higher.
## ViltConfig
diff --git a/docs/source/en/model_doc/vision-encoder-decoder.md b/docs/source/en/model_doc/vision-encoder-decoder.md
index 0beeaeae10..89d89896a2 100644
--- a/docs/source/en/model_doc/vision-encoder-decoder.md
+++ b/docs/source/en/model_doc/vision-encoder-decoder.md
@@ -151,20 +151,32 @@ were contributed by [ydshieh](https://github.com/ydshieh).
[[autodoc]] VisionEncoderDecoderConfig
+
+
+
## VisionEncoderDecoderModel
[[autodoc]] VisionEncoderDecoderModel
- forward
- from_encoder_decoder_pretrained
+
+
+
## TFVisionEncoderDecoderModel
[[autodoc]] TFVisionEncoderDecoderModel
- call
- from_encoder_decoder_pretrained
+
+
+
## FlaxVisionEncoderDecoderModel
[[autodoc]] FlaxVisionEncoderDecoderModel
- __call__
- from_encoder_decoder_pretrained
+
+
+
diff --git a/docs/source/en/model_doc/vision-text-dual-encoder.md b/docs/source/en/model_doc/vision-text-dual-encoder.md
index 6fa9728cac..7cb68a2618 100644
--- a/docs/source/en/model_doc/vision-text-dual-encoder.md
+++ b/docs/source/en/model_doc/vision-text-dual-encoder.md
@@ -36,17 +36,29 @@ new zero-shot vision tasks such as image classification or retrieval.
[[autodoc]] VisionTextDualEncoderProcessor
+
+
+
## VisionTextDualEncoderModel
[[autodoc]] VisionTextDualEncoderModel
- forward
+
+
+
## FlaxVisionTextDualEncoderModel
[[autodoc]] FlaxVisionTextDualEncoderModel
- __call__
+
+
+
## TFVisionTextDualEncoderModel
[[autodoc]] TFVisionTextDualEncoderModel
- call
+
+
+
diff --git a/docs/source/en/model_doc/visual_bert.md b/docs/source/en/model_doc/visual_bert.md
index 7d84c0d9fa..1db218f1a5 100644
--- a/docs/source/en/model_doc/visual_bert.md
+++ b/docs/source/en/model_doc/visual_bert.md
@@ -32,7 +32,9 @@ simpler. Further analysis demonstrates that VisualBERT can ground elements of la
explicit supervision and is even sensitive to syntactic relationships, tracking, for example, associations between
verbs and image regions corresponding to their arguments.*
-Tips:
+This model was contributed by [gchhablani](https://huggingface.co/gchhablani). The original code can be found [here](https://github.com/uclanlp/visualbert).
+
+## Usage tips
1. Most of the checkpoints provided work with the [`VisualBertForPreTraining`] configuration. Other
checkpoints provided are the fine-tuned checkpoints for down-stream tasks - VQA ('visualbert-vqa'), VCR
@@ -43,8 +45,6 @@ Tips:
We do not provide the detector and its weights as a part of the package, but it will be available in the research
projects, and the states can be loaded directly into the detector provided.
-## Usage
-
VisualBERT is a multi-modal vision and language model. It can be used for visual question answering, multiple choice,
visual reasoning and region-to-phrase correspondence tasks. VisualBERT uses a BERT-like transformer to prepare
embeddings for image-text pairs. Both the text and visual features are then projected to a latent space with identical
@@ -92,8 +92,6 @@ The following example shows how to get the last hidden state using [`VisualBertM
>>> last_hidden_state = outputs.last_hidden_state
```
-This model was contributed by [gchhablani](https://huggingface.co/gchhablani). The original code can be found [here](https://github.com/uclanlp/visualbert).
-
## VisualBertConfig
[[autodoc]] VisualBertConfig
diff --git a/docs/source/en/model_doc/vit.md b/docs/source/en/model_doc/vit.md
index 409580d094..25c3a6c8f5 100644
--- a/docs/source/en/model_doc/vit.md
+++ b/docs/source/en/model_doc/vit.md
@@ -24,7 +24,6 @@ Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minder
Uszkoreit, Neil Houlsby. It's the first paper that successfully trains a Transformer encoder on ImageNet, attaining
very good results compared to familiar convolutional architectures.
-
The abstract from the paper is the following:
*While the Transformer architecture has become the de-facto standard for natural language processing tasks, its
@@ -36,30 +35,6 @@ data and transferred to multiple mid-sized or small image recognition benchmarks
Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring
substantially fewer computational resources to train.*
-Tips:
-
-- Demo notebooks regarding inference as well as fine-tuning ViT on custom data can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer).
-- To feed images to the Transformer encoder, each image is split into a sequence of fixed-size non-overlapping patches,
- which are then linearly embedded. A [CLS] token is added to serve as representation of an entire image, which can be
- used for classification. The authors also add absolute position embeddings, and feed the resulting sequence of
- vectors to a standard Transformer encoder.
-- As the Vision Transformer expects each image to be of the same size (resolution), one can use
- [`ViTImageProcessor`] to resize (or rescale) and normalize images for the model.
-- Both the patch resolution and image resolution used during pre-training or fine-tuning are reflected in the name of
- each checkpoint. For example, `google/vit-base-patch16-224` refers to a base-sized architecture with patch
- resolution of 16x16 and fine-tuning resolution of 224x224. All checkpoints can be found on the [hub](https://huggingface.co/models?search=vit).
-- The available checkpoints are either (1) pre-trained on [ImageNet-21k](http://www.image-net.org/) (a collection of
- 14 million images and 21k classes) only, or (2) also fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/) (also referred to as ILSVRC 2012, a collection of 1.3 million
- images and 1,000 classes).
-- The Vision Transformer was pre-trained using a resolution of 224x224. During fine-tuning, it is often beneficial to
- use a higher resolution than pre-training [(Touvron et al., 2019)](https://arxiv.org/abs/1906.06423), [(Kolesnikov
- et al., 2020)](https://arxiv.org/abs/1912.11370). In order to fine-tune at higher resolution, the authors perform
- 2D interpolation of the pre-trained position embeddings, according to their location in the original image.
-- The best results are obtained with supervised pre-training, which is not the case in NLP. The authors also performed
- an experiment with a self-supervised pre-training objective, namely masked patched prediction (inspired by masked
- language modeling). With this approach, the smaller ViT-B/16 model achieves 79.9% accuracy on ImageNet, a significant
- improvement of 2% to training from scratch, but still 4% behind supervised pre-training.
-
 @@ -87,28 +62,35 @@ Following the original Vision Transformer, some follow-up works have been made:
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code (written in JAX) can be
found [here](https://github.com/google-research/vision_transformer).
-Note that we converted the weights from Ross Wightman's [timm library](https://github.com/rwightman/pytorch-image-models), who already converted the weights from JAX to PyTorch. Credits
-go to him!
-
-## Resources
-
-A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViT.
-
-
-
-- [`ViTForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
-- A blog on fine-tuning [`ViTForImageClassification`] on a custom dataset can be found [here](https://huggingface.co/blog/fine-tune-vit).
-- More demo notebooks to fine-tune [`ViTForImageClassification`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer).
-- [Image classification task guide](../tasks/image_classification)
-
-Besides that:
-
-- [`ViTForMaskedImageModeling`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining).
-
-If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+Note that we converted the weights from Ross Wightman's [timm library](https://github.com/rwightman/pytorch-image-models),
+who already converted the weights from JAX to PyTorch. Credits go to him!
+
+## Usage tips
+
+- To feed images to the Transformer encoder, each image is split into a sequence of fixed-size non-overlapping patches,
+ which are then linearly embedded. A [CLS] token is added to serve as representation of an entire image, which can be
+ used for classification. The authors also add absolute position embeddings, and feed the resulting sequence of
+ vectors to a standard Transformer encoder.
+- As the Vision Transformer expects each image to be of the same size (resolution), one can use
+ [`ViTImageProcessor`] to resize (or rescale) and normalize images for the model.
+- Both the patch resolution and image resolution used during pre-training or fine-tuning are reflected in the name of
+ each checkpoint. For example, `google/vit-base-patch16-224` refers to a base-sized architecture with patch
+ resolution of 16x16 and fine-tuning resolution of 224x224. All checkpoints can be found on the [hub](https://huggingface.co/models?search=vit).
+- The available checkpoints are either (1) pre-trained on [ImageNet-21k](http://www.image-net.org/) (a collection of
+ 14 million images and 21k classes) only, or (2) also fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/) (also referred to as ILSVRC 2012, a collection of 1.3 million
+ images and 1,000 classes).
+- The Vision Transformer was pre-trained using a resolution of 224x224. During fine-tuning, it is often beneficial to
+ use a higher resolution than pre-training [(Touvron et al., 2019)](https://arxiv.org/abs/1906.06423), [(Kolesnikov
+ et al., 2020)](https://arxiv.org/abs/1912.11370). In order to fine-tune at higher resolution, the authors perform
+ 2D interpolation of the pre-trained position embeddings, according to their location in the original image.
+- The best results are obtained with supervised pre-training, which is not the case in NLP. The authors also performed
+ an experiment with a self-supervised pre-training objective, namely masked patched prediction (inspired by masked
+ language modeling). With this approach, the smaller ViT-B/16 model achieves 79.9% accuracy on ImageNet, a significant
+ improvement of 2% to training from scratch, but still 4% behind supervised pre-training.
## Resources
+Demo notebooks regarding inference as well as fine-tuning ViT on custom data can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer).
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViT. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
`ViTForImageClassification` is supported by:
@@ -134,7 +116,6 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
- A blog post on [Deploying Hugging Face ViT on Vertex AI](https://huggingface.co/blog/deploy-vertex-ai)
- A blog post on [Deploying Hugging Face ViT on Kubernetes with TF Serving](https://huggingface.co/blog/deploy-tfserving-kubernetes)
-
## ViTConfig
[[autodoc]] ViTConfig
@@ -144,12 +125,14 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] ViTFeatureExtractor
- __call__
-
## ViTImageProcessor
[[autodoc]] ViTImageProcessor
- preprocess
+
+
+
## ViTModel
[[autodoc]] ViTModel
@@ -165,6 +148,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] ViTForImageClassification
- forward
+
+
+
## TFViTModel
[[autodoc]] TFViTModel
@@ -175,6 +161,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] TFViTForImageClassification
- call
+
+
+
## FlaxVitModel
[[autodoc]] FlaxViTModel
@@ -184,3 +173,6 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] FlaxViTForImageClassification
- __call__
+
+
+
diff --git a/docs/source/en/model_doc/vit_hybrid.md b/docs/source/en/model_doc/vit_hybrid.md
index 84969cd0f6..52c0d35bc1 100644
--- a/docs/source/en/model_doc/vit_hybrid.md
+++ b/docs/source/en/model_doc/vit_hybrid.md
@@ -25,7 +25,6 @@ Uszkoreit, Neil Houlsby. It's the first paper that successfully trains a Transfo
very good results compared to familiar convolutional architectures. ViT hybrid is a slight variant of the [plain Vision Transformer](vit),
by leveraging a convolutional backbone (specifically, [BiT](bit)) whose features are used as initial "tokens" for the Transformer.
-
The abstract from the paper is the following:
*While the Transformer architecture has become the de-facto standard for natural language processing tasks, its
@@ -40,7 +39,6 @@ substantially fewer computational resources to train.*
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code (written in JAX) can be
found [here](https://github.com/google-research/vision_transformer).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViT Hybrid.
@@ -52,7 +50,6 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
-
## ViTHybridConfig
[[autodoc]] ViTHybridConfig
diff --git a/docs/source/en/model_doc/vit_mae.md b/docs/source/en/model_doc/vit_mae.md
index c14cc7e57c..27d6d26816 100644
--- a/docs/source/en/model_doc/vit_mae.md
+++ b/docs/source/en/model_doc/vit_mae.md
@@ -32,7 +32,15 @@ enables us to train large models efficiently and effectively: we accelerate trai
models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data. Transfer performance in downstream
tasks outperforms supervised pre-training and shows promising scaling behavior.*
-Tips:
+
@@ -87,28 +62,35 @@ Following the original Vision Transformer, some follow-up works have been made:
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code (written in JAX) can be
found [here](https://github.com/google-research/vision_transformer).
-Note that we converted the weights from Ross Wightman's [timm library](https://github.com/rwightman/pytorch-image-models), who already converted the weights from JAX to PyTorch. Credits
-go to him!
-
-## Resources
-
-A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViT.
-
-
-
-- [`ViTForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
-- A blog on fine-tuning [`ViTForImageClassification`] on a custom dataset can be found [here](https://huggingface.co/blog/fine-tune-vit).
-- More demo notebooks to fine-tune [`ViTForImageClassification`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer).
-- [Image classification task guide](../tasks/image_classification)
-
-Besides that:
-
-- [`ViTForMaskedImageModeling`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining).
-
-If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+Note that we converted the weights from Ross Wightman's [timm library](https://github.com/rwightman/pytorch-image-models),
+who already converted the weights from JAX to PyTorch. Credits go to him!
+
+## Usage tips
+
+- To feed images to the Transformer encoder, each image is split into a sequence of fixed-size non-overlapping patches,
+ which are then linearly embedded. A [CLS] token is added to serve as representation of an entire image, which can be
+ used for classification. The authors also add absolute position embeddings, and feed the resulting sequence of
+ vectors to a standard Transformer encoder.
+- As the Vision Transformer expects each image to be of the same size (resolution), one can use
+ [`ViTImageProcessor`] to resize (or rescale) and normalize images for the model.
+- Both the patch resolution and image resolution used during pre-training or fine-tuning are reflected in the name of
+ each checkpoint. For example, `google/vit-base-patch16-224` refers to a base-sized architecture with patch
+ resolution of 16x16 and fine-tuning resolution of 224x224. All checkpoints can be found on the [hub](https://huggingface.co/models?search=vit).
+- The available checkpoints are either (1) pre-trained on [ImageNet-21k](http://www.image-net.org/) (a collection of
+ 14 million images and 21k classes) only, or (2) also fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/) (also referred to as ILSVRC 2012, a collection of 1.3 million
+ images and 1,000 classes).
+- The Vision Transformer was pre-trained using a resolution of 224x224. During fine-tuning, it is often beneficial to
+ use a higher resolution than pre-training [(Touvron et al., 2019)](https://arxiv.org/abs/1906.06423), [(Kolesnikov
+ et al., 2020)](https://arxiv.org/abs/1912.11370). In order to fine-tune at higher resolution, the authors perform
+ 2D interpolation of the pre-trained position embeddings, according to their location in the original image.
+- The best results are obtained with supervised pre-training, which is not the case in NLP. The authors also performed
+ an experiment with a self-supervised pre-training objective, namely masked patched prediction (inspired by masked
+ language modeling). With this approach, the smaller ViT-B/16 model achieves 79.9% accuracy on ImageNet, a significant
+ improvement of 2% to training from scratch, but still 4% behind supervised pre-training.
## Resources
+Demo notebooks regarding inference as well as fine-tuning ViT on custom data can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer).
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViT. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
`ViTForImageClassification` is supported by:
@@ -134,7 +116,6 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
- A blog post on [Deploying Hugging Face ViT on Vertex AI](https://huggingface.co/blog/deploy-vertex-ai)
- A blog post on [Deploying Hugging Face ViT on Kubernetes with TF Serving](https://huggingface.co/blog/deploy-tfserving-kubernetes)
-
## ViTConfig
[[autodoc]] ViTConfig
@@ -144,12 +125,14 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] ViTFeatureExtractor
- __call__
-
## ViTImageProcessor
[[autodoc]] ViTImageProcessor
- preprocess
+
+
+
## ViTModel
[[autodoc]] ViTModel
@@ -165,6 +148,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] ViTForImageClassification
- forward
+
+
+
## TFViTModel
[[autodoc]] TFViTModel
@@ -175,6 +161,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] TFViTForImageClassification
- call
+
+
+
## FlaxVitModel
[[autodoc]] FlaxViTModel
@@ -184,3 +173,6 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] FlaxViTForImageClassification
- __call__
+
+
+
diff --git a/docs/source/en/model_doc/vit_hybrid.md b/docs/source/en/model_doc/vit_hybrid.md
index 84969cd0f6..52c0d35bc1 100644
--- a/docs/source/en/model_doc/vit_hybrid.md
+++ b/docs/source/en/model_doc/vit_hybrid.md
@@ -25,7 +25,6 @@ Uszkoreit, Neil Houlsby. It's the first paper that successfully trains a Transfo
very good results compared to familiar convolutional architectures. ViT hybrid is a slight variant of the [plain Vision Transformer](vit),
by leveraging a convolutional backbone (specifically, [BiT](bit)) whose features are used as initial "tokens" for the Transformer.
-
The abstract from the paper is the following:
*While the Transformer architecture has become the de-facto standard for natural language processing tasks, its
@@ -40,7 +39,6 @@ substantially fewer computational resources to train.*
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code (written in JAX) can be
found [here](https://github.com/google-research/vision_transformer).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViT Hybrid.
@@ -52,7 +50,6 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
-
## ViTHybridConfig
[[autodoc]] ViTHybridConfig
diff --git a/docs/source/en/model_doc/vit_mae.md b/docs/source/en/model_doc/vit_mae.md
index c14cc7e57c..27d6d26816 100644
--- a/docs/source/en/model_doc/vit_mae.md
+++ b/docs/source/en/model_doc/vit_mae.md
@@ -32,7 +32,15 @@ enables us to train large models efficiently and effectively: we accelerate trai
models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data. Transfer performance in downstream
tasks outperforms supervised pre-training and shows promising scaling behavior.*
-Tips:
+ +
+ MAE architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). TensorFlow version of the model was contributed by [sayakpaul](https://github.com/sayakpaul) and
+[ariG23498](https://github.com/ariG23498) (equal contribution). The original code can be found [here](https://github.com/facebookresearch/mae).
+
+## Usage tips
- MAE (masked auto encoding) is a method for self-supervised pre-training of Vision Transformers (ViTs). The pre-training objective is relatively simple:
by masking a large portion (75%) of the image patches, the model must reconstruct raw pixel values. One can use [`ViTMAEForPreTraining`] for this purpose.
@@ -44,14 +52,6 @@ consists of Transformer blocks) takes as input. Each mask token is a shared, lea
sin/cos position embeddings are added both to the input of the encoder and the decoder.
- For a visual understanding of how MAEs work you can check out this [post](https://keras.io/examples/vision/masked_image_modeling/).
-
-
- MAE architecture. Taken from the original paper.
-
-This model was contributed by [nielsr](https://huggingface.co/nielsr). TensorFlow version of the model was contributed by [sayakpaul](https://github.com/sayakpaul) and
-[ariG23498](https://github.com/ariG23498) (equal contribution). The original code can be found [here](https://github.com/facebookresearch/mae).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViTMAE.
@@ -65,26 +65,31 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] ViTMAEConfig
+
+
## ViTMAEModel
[[autodoc]] ViTMAEModel
- forward
-
## ViTMAEForPreTraining
[[autodoc]] transformers.ViTMAEForPreTraining
- forward
+
+
## TFViTMAEModel
[[autodoc]] TFViTMAEModel
- call
-
## TFViTMAEForPreTraining
[[autodoc]] transformers.TFViTMAEForPreTraining
- call
+
+
+
diff --git a/docs/source/en/model_doc/vit_msn.md b/docs/source/en/model_doc/vit_msn.md
index ded0245194..666b7dd0df 100644
--- a/docs/source/en/model_doc/vit_msn.md
+++ b/docs/source/en/model_doc/vit_msn.md
@@ -33,7 +33,13 @@ while producing representations of a high semantic level that perform competitiv
on ImageNet-1K, with only 5,000 annotated images, our base MSN model achieves 72.4% top-1 accuracy,
and with 1% of ImageNet-1K labels, we achieve 75.7% top-1 accuracy, setting a new state-of-the-art for self-supervised learning on this benchmark.*
-Tips:
+
+
+ MAE architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). TensorFlow version of the model was contributed by [sayakpaul](https://github.com/sayakpaul) and
+[ariG23498](https://github.com/ariG23498) (equal contribution). The original code can be found [here](https://github.com/facebookresearch/mae).
+
+## Usage tips
- MAE (masked auto encoding) is a method for self-supervised pre-training of Vision Transformers (ViTs). The pre-training objective is relatively simple:
by masking a large portion (75%) of the image patches, the model must reconstruct raw pixel values. One can use [`ViTMAEForPreTraining`] for this purpose.
@@ -44,14 +52,6 @@ consists of Transformer blocks) takes as input. Each mask token is a shared, lea
sin/cos position embeddings are added both to the input of the encoder and the decoder.
- For a visual understanding of how MAEs work you can check out this [post](https://keras.io/examples/vision/masked_image_modeling/).
-
-
- MAE architecture. Taken from the original paper.
-
-This model was contributed by [nielsr](https://huggingface.co/nielsr). TensorFlow version of the model was contributed by [sayakpaul](https://github.com/sayakpaul) and
-[ariG23498](https://github.com/ariG23498) (equal contribution). The original code can be found [here](https://github.com/facebookresearch/mae).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViTMAE.
@@ -65,26 +65,31 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] ViTMAEConfig
+
+
## ViTMAEModel
[[autodoc]] ViTMAEModel
- forward
-
## ViTMAEForPreTraining
[[autodoc]] transformers.ViTMAEForPreTraining
- forward
+
+
## TFViTMAEModel
[[autodoc]] TFViTMAEModel
- call
-
## TFViTMAEForPreTraining
[[autodoc]] transformers.TFViTMAEForPreTraining
- call
+
+
+
diff --git a/docs/source/en/model_doc/vit_msn.md b/docs/source/en/model_doc/vit_msn.md
index ded0245194..666b7dd0df 100644
--- a/docs/source/en/model_doc/vit_msn.md
+++ b/docs/source/en/model_doc/vit_msn.md
@@ -33,7 +33,13 @@ while producing representations of a high semantic level that perform competitiv
on ImageNet-1K, with only 5,000 annotated images, our base MSN model achieves 72.4% top-1 accuracy,
and with 1% of ImageNet-1K labels, we achieve 75.7% top-1 accuracy, setting a new state-of-the-art for self-supervised learning on this benchmark.*
-Tips:
+ +
+ MSN architecture. Taken from the original paper.
+
+This model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/facebookresearch/msn).
+
+## Usage tips
- MSN (masked siamese networks) is a method for self-supervised pre-training of Vision Transformers (ViTs). The pre-training
objective is to match the prototypes assigned to the unmasked views of the images to that of the masked views of the same images.
@@ -43,13 +49,6 @@ use the [`ViTMSNForImageClassification`] class which is initialized from [`ViTMS
- MSN is particularly useful in the low-shot and extreme low-shot regimes. Notably, it achieves 75.7% top-1 accuracy with only 1% of ImageNet-1K
labels when fine-tuned.
-
-
-
- MSN architecture. Taken from the original paper.
-
-This model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/facebookresearch/msn).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViT MSN.
@@ -65,13 +64,11 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] ViTMSNConfig
-
## ViTMSNModel
[[autodoc]] ViTMSNModel
- forward
-
## ViTMSNForImageClassification
[[autodoc]] ViTMSNForImageClassification
diff --git a/docs/source/en/model_doc/vitdet.md b/docs/source/en/model_doc/vitdet.md
index 657e467ee3..81bf787d6c 100644
--- a/docs/source/en/model_doc/vitdet.md
+++ b/docs/source/en/model_doc/vitdet.md
@@ -21,13 +21,12 @@ The abstract from the paper is the following:
*We explore the plain, non-hierarchical Vision Transformer (ViT) as a backbone network for object detection. This design enables the original ViT architecture to be fine-tuned for object detection without needing to redesign a hierarchical backbone for pre-training. With minimal adaptations for fine-tuning, our plain-backbone detector can achieve competitive results. Surprisingly, we observe: (i) it is sufficient to build a simple feature pyramid from a single-scale feature map (without the common FPN design) and (ii) it is sufficient to use window attention (without shifting) aided with very few cross-window propagation blocks. With plain ViT backbones pre-trained as Masked Autoencoders (MAE), our detector, named ViTDet, can compete with the previous leading methods that were all based on hierarchical backbones, reaching up to 61.3 AP_box on the COCO dataset using only ImageNet-1K pre-training. We hope our study will draw attention to research on plain-backbone detectors.*
-Tips:
-
-- For the moment, only the backbone is available.
-
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/facebookresearch/detectron2/tree/main/projects/ViTDet).
+Tips:
+
+- At the moment, only the backbone is available.
## VitDetConfig
diff --git a/docs/source/en/model_doc/vitmatte.md b/docs/source/en/model_doc/vitmatte.md
index 479b398f80..5a6d501030 100644
--- a/docs/source/en/model_doc/vitmatte.md
+++ b/docs/source/en/model_doc/vitmatte.md
@@ -21,10 +21,6 @@ The abstract from the paper is the following:
*Recently, plain vision Transformers (ViTs) have shown impressive performance on various computer vision tasks, thanks to their strong modeling capacity and large-scale pretraining. However, they have not yet conquered the problem of image matting. We hypothesize that image matting could also be boosted by ViTs and present a new efficient and robust ViT-based matting system, named ViTMatte. Our method utilizes (i) a hybrid attention mechanism combined with a convolution neck to help ViTs achieve an excellent performance-computation trade-off in matting tasks. (ii) Additionally, we introduce the detail capture module, which just consists of simple lightweight convolutions to complement the detailed information required by matting. To the best of our knowledge, ViTMatte is the first work to unleash the potential of ViT on image matting with concise adaptation. It inherits many superior properties from ViT to matting, including various pretraining strategies, concise architecture design, and flexible inference strategies. We evaluate ViTMatte on Composition-1k and Distinctions-646, the most commonly used benchmark for image matting, our method achieves state-of-the-art performance and outperforms prior matting works by a large margin.*
-Tips:
-
-- The model expects both the image and trimap (concatenated) as input. One can use [`ViTMatteImageProcessor`] for this purpose.
-
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/hustvl/ViTMatte).
@@ -39,6 +35,10 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
- A demo notebook regarding inference with [`VitMatteForImageMatting`], including background replacement, can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ViTMatte).
+
+
+The model expects both the image and trimap (concatenated) as input. Use [`ViTMatteImageProcessor`] for this purpose.
+
## VitMatteConfig
diff --git a/docs/source/en/model_doc/vits.md b/docs/source/en/model_doc/vits.md
index 1b57df4027..73001d82ed 100644
--- a/docs/source/en/model_doc/vits.md
+++ b/docs/source/en/model_doc/vits.md
@@ -16,7 +16,6 @@ specific language governing permissions and limitations under the License.
The VITS model was proposed in [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103) by Jaehyeon Kim, Jungil Kong, Juhee Son.
-
VITS (**V**ariational **I**nference with adversarial learning for end-to-end **T**ext-to-**S**peech) is an end-to-end
speech synthesis model that predicts a speech waveform conditional on an input text sequence. It is a conditional variational
autoencoder (VAE) comprised of a posterior encoder, decoder, and conditional prior.
@@ -42,7 +41,7 @@ as these checkpoints use the same architecture and a slightly modified tokenizer
This model was contributed by [Matthijs](https://huggingface.co/Matthijs) and [sanchit-gandhi](https://huggingface.co/sanchit-gandhi). The original code can be found [here](https://github.com/jaywalnut310/vits).
-## Model Usage
+## Usage examples
Both the VITS and MMS-TTS checkpoints can be used with the same API. Since the flow-based model is non-deterministic, it
is good practice to set a seed to ensure reproducibility of the outputs. For languages with a Roman alphabet,
diff --git a/docs/source/en/model_doc/vivit.md b/docs/source/en/model_doc/vivit.md
index 755629a767..4426493a0f 100644
--- a/docs/source/en/model_doc/vivit.md
+++ b/docs/source/en/model_doc/vivit.md
@@ -21,7 +21,6 @@ The abstract from the paper is the following:
*We present pure-transformer based models for video classification, drawing upon the recent success of such models in image classification. Our model extracts spatio-temporal tokens from the input video, which are then encoded by a series of transformer layers. In order to handle the long sequences of tokens encountered in video, we propose several, efficient variants of our model which factorise the spatial- and temporal-dimensions of the input. Although transformer-based models are known to only be effective when large training datasets are available, we show how we can effectively regularise the model during training and leverage pretrained image models to be able to train on comparatively small datasets. We conduct thorough ablation studies, and achieve state-of-the-art results on multiple video classification benchmarks including Kinetics 400 and 600, Epic Kitchens, Something-Something v2 and Moments in Time, outperforming prior methods based on deep 3D convolutional networks.*
-
This model was contributed by [jegormeister](https://huggingface.co/jegormeister). The original code (written in JAX) can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/vivit).
## VivitConfig
diff --git a/docs/source/en/model_doc/wav2vec2-conformer.md b/docs/source/en/model_doc/wav2vec2-conformer.md
index 87e255cd0c..c32c03bb0c 100644
--- a/docs/source/en/model_doc/wav2vec2-conformer.md
+++ b/docs/source/en/model_doc/wav2vec2-conformer.md
@@ -24,7 +24,10 @@ The official results of the model can be found in Table 3 and Table 4 of the pap
The Wav2Vec2-Conformer weights were released by the Meta AI team within the [Fairseq library](https://github.com/pytorch/fairseq/blob/main/examples/wav2vec/README.md#pre-trained-models).
-Tips:
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten).
+The original code can be found [here](https://github.com/pytorch/fairseq/tree/main/examples/wav2vec).
+
+## Usage tips
- Wav2Vec2-Conformer follows the same architecture as Wav2Vec2, but replaces the *Attention*-block with a *Conformer*-block
as introduced in [Conformer: Convolution-augmented Transformer for Speech Recognition](https://arxiv.org/abs/2005.08100).
@@ -34,10 +37,7 @@ an improved word error rate.
- Wav2Vec2-Conformer can use either no relative position embeddings, Transformer-XL-like position embeddings, or
rotary position embeddings by setting the correct `config.position_embeddings_type`.
-This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten).
-The original code can be found [here](https://github.com/pytorch/fairseq/tree/main/examples/wav2vec).
-
-## Documentation resources
+## Resources
- [Audio classification task guide](../tasks/audio_classification)
- [Automatic speech recognition task guide](../tasks/asr)
diff --git a/docs/source/en/model_doc/wav2vec2.md b/docs/source/en/model_doc/wav2vec2.md
index 3a67f66d9d..81d8f332ac 100644
--- a/docs/source/en/model_doc/wav2vec2.md
+++ b/docs/source/en/model_doc/wav2vec2.md
@@ -31,14 +31,14 @@ of the art on the 100 hour subset while using 100 times less labeled data. Using
pre-training on 53k hours of unlabeled data still achieves 4.8/8.2 WER. This demonstrates the feasibility of speech
recognition with limited amounts of labeled data.*
-Tips:
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten).
+
+## Usage tips
- Wav2Vec2 is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
- Wav2Vec2 model was trained using connectionist temporal classification (CTC) so the model output has to be decoded
using [`Wav2Vec2CTCTokenizer`].
-This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Wav2Vec2. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
@@ -167,6 +167,9 @@ Otherwise, [`~Wav2Vec2ProcessorWithLM.batch_decode`] performance will be slower
[[autodoc]] models.wav2vec2.modeling_flax_wav2vec2.FlaxWav2Vec2ForPreTrainingOutput
+
+
+
## Wav2Vec2Model
[[autodoc]] Wav2Vec2Model
@@ -198,6 +201,9 @@ Otherwise, [`~Wav2Vec2ProcessorWithLM.batch_decode`] performance will be slower
[[autodoc]] Wav2Vec2ForPreTraining
- forward
+
+
+
## TFWav2Vec2Model
[[autodoc]] TFWav2Vec2Model
@@ -213,6 +219,9 @@ Otherwise, [`~Wav2Vec2ProcessorWithLM.batch_decode`] performance will be slower
[[autodoc]] TFWav2Vec2ForCTC
- call
+
+
+
## FlaxWav2Vec2Model
[[autodoc]] FlaxWav2Vec2Model
@@ -227,3 +236,6 @@ Otherwise, [`~Wav2Vec2ProcessorWithLM.batch_decode`] performance will be slower
[[autodoc]] FlaxWav2Vec2ForPreTraining
- __call__
+
+
+
diff --git a/docs/source/en/model_doc/wav2vec2_phoneme.md b/docs/source/en/model_doc/wav2vec2_phoneme.md
index a852bef637..93e0656f49 100644
--- a/docs/source/en/model_doc/wav2vec2_phoneme.md
+++ b/docs/source/en/model_doc/wav2vec2_phoneme.md
@@ -31,7 +31,13 @@ mapping phonemes of the training languages to the target language using articula
this simple method significantly outperforms prior work which introduced task-specific architectures and used only part
of a monolingually pretrained model.*
-Tips:
+Relevant checkpoints can be found under https://huggingface.co/models?other=phoneme-recognition.
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten)
+
+The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
+
+## Usage tips
- Wav2Vec2Phoneme uses the exact same architecture as Wav2Vec2
- Wav2Vec2Phoneme is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
@@ -39,17 +45,16 @@ Tips:
decoded using [`Wav2Vec2PhonemeCTCTokenizer`].
- Wav2Vec2Phoneme can be fine-tuned on multiple language at once and decode unseen languages in a single forward pass
to a sequence of phonemes
-- By default the model outputs a sequence of phonemes. In order to transform the phonemes to a sequence of words one
+- By default, the model outputs a sequence of phonemes. In order to transform the phonemes to a sequence of words one
should make use of a dictionary and language model.
-Relevant checkpoints can be found under https://huggingface.co/models?other=phoneme-recognition.
-This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten)
+
-The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
-
-Wav2Vec2Phoneme's architecture is based on the Wav2Vec2 model, so one can refer to [`Wav2Vec2`]'s documentation page except for the tokenizer.
+Wav2Vec2Phoneme's architecture is based on the Wav2Vec2 model, for API reference, check out [`Wav2Vec2`](wav2vec2)'s documentation page
+except for the tokenizer.
+
## Wav2Vec2PhonemeCTCTokenizer
diff --git a/docs/source/en/model_doc/wavlm.md b/docs/source/en/model_doc/wavlm.md
index 2754304d82..13f6298075 100644
--- a/docs/source/en/model_doc/wavlm.md
+++ b/docs/source/en/model_doc/wavlm.md
@@ -35,7 +35,12 @@ additional overlapped utterances are created unsupervisely and incorporated duri
the training dataset from 60k hours to 94k hours. WavLM Large achieves state-of-the-art performance on the SUPERB
benchmark, and brings significant improvements for various speech processing tasks on their representative benchmarks.*
-Tips:
+Relevant checkpoints can be found under https://huggingface.co/models?other=wavlm.
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
+found [here](https://github.com/microsoft/unilm/tree/master/wavlm).
+
+## Usage tips
- WavLM is a speech model that accepts a float array corresponding to the raw waveform of the speech signal. Please use
[`Wav2Vec2Processor`] for the feature extraction.
@@ -43,12 +48,7 @@ Tips:
using [`Wav2Vec2CTCTokenizer`].
- WavLM performs especially well on speaker verification, speaker identification, and speaker diarization tasks.
-Relevant checkpoints can be found under https://huggingface.co/models?other=wavlm.
-
-This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
-found [here](https://github.com/microsoft/unilm/tree/master/wavlm).
-
-## Documentation resources
+## Resources
- [Audio classification task guide](../tasks/audio_classification)
- [Automatic speech recognition task guide](../tasks/asr)
diff --git a/docs/source/en/model_doc/whisper.md b/docs/source/en/model_doc/whisper.md
index 2f1cfc5e22..4ea7e94381 100644
--- a/docs/source/en/model_doc/whisper.md
+++ b/docs/source/en/model_doc/whisper.md
@@ -24,18 +24,16 @@ The abstract from the paper is the following:
*We study the capabilities of speech processing systems trained simply to predict large amounts of transcripts of audio on the internet. When scaled to 680,000 hours of multilingual and multitask supervision, the resulting models generalize well to standard benchmarks and are often competitive with prior fully supervised results but in a zeroshot transfer setting without the need for any finetuning. When compared to humans, the models approach their accuracy and robustness. We are releasing models and inference code to serve as a foundation for further work on robust speech processing.*
+This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ). The Tensorflow version of this model was contributed by [amyeroberts](https://huggingface.co/amyeroberts).
+The original code can be found [here](https://github.com/openai/whisper).
-Tips:
+## Usage tips
- The model usually performs well without requiring any finetuning.
- The architecture follows a classic encoder-decoder architecture, which means that it relies on the [`~generation.GenerationMixin.generate`] function for inference.
- Inference is currently only implemented for short-form i.e. audio is pre-segmented into <=30s segments. Long-form (including timestamps) will be implemented in a future release.
- One can use [`WhisperProcessor`] to prepare audio for the model, and decode the predicted ID's back into text.
-This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ). The Tensorflow version of this model was contributed by [amyeroberts](https://huggingface.co/amyeroberts).
-The original code can be found [here](https://github.com/openai/whisper).
-
-
## WhisperConfig
[[autodoc]] WhisperConfig
@@ -76,6 +74,9 @@ The original code can be found [here](https://github.com/openai/whisper).
- batch_decode
- decode
+
+
+
## WhisperModel
[[autodoc]] WhisperModel
@@ -98,6 +99,8 @@ The original code can be found [here](https://github.com/openai/whisper).
[[autodoc]] WhisperForAudioClassification
- forward
+
+
## TFWhisperModel
@@ -109,6 +112,8 @@ The original code can be found [here](https://github.com/openai/whisper).
[[autodoc]] TFWhisperForConditionalGeneration
- call
+
+
## FlaxWhisperModel
@@ -125,3 +130,6 @@ The original code can be found [here](https://github.com/openai/whisper).
[[autodoc]] FlaxWhisperForAudioClassification
- __call__
+
+
+
diff --git a/docs/source/en/model_doc/xglm.md b/docs/source/en/model_doc/xglm.md
index 1b184c17e8..470e42c747 100644
--- a/docs/source/en/model_doc/xglm.md
+++ b/docs/source/en/model_doc/xglm.md
@@ -42,7 +42,7 @@ in social value tasks such as hate speech detection in five languages and find i
This model was contributed by [Suraj](https://huggingface.co/valhalla). The original code can be found [here](https://github.com/pytorch/fairseq/tree/main/examples/xglm).
-## Documentation resources
+## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
@@ -62,6 +62,9 @@ This model was contributed by [Suraj](https://huggingface.co/valhalla). The orig
[[autodoc]] XGLMTokenizerFast
+
+
+
## XGLMModel
[[autodoc]] XGLMModel
@@ -72,6 +75,9 @@ This model was contributed by [Suraj](https://huggingface.co/valhalla). The orig
[[autodoc]] XGLMForCausalLM
- forward
+
+
+
## TFXGLMModel
[[autodoc]] TFXGLMModel
@@ -82,6 +88,9 @@ This model was contributed by [Suraj](https://huggingface.co/valhalla). The orig
[[autodoc]] TFXGLMForCausalLM
- call
+
+
+
## FlaxXGLMModel
[[autodoc]] FlaxXGLMModel
@@ -90,4 +99,7 @@ This model was contributed by [Suraj](https://huggingface.co/valhalla). The orig
## FlaxXGLMForCausalLM
[[autodoc]] FlaxXGLMForCausalLM
- - __call__
\ No newline at end of file
+ - __call__
+
+
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/xlm-prophetnet.md b/docs/source/en/model_doc/xlm-prophetnet.md
index 5e7ba5b7e3..7a61aeb3e3 100644
--- a/docs/source/en/model_doc/xlm-prophetnet.md
+++ b/docs/source/en/model_doc/xlm-prophetnet.md
@@ -36,7 +36,7 @@ Zhang, Ming Zhou on 13 Jan, 2020.
XLM-ProphetNet is an encoder-decoder model and can predict n-future tokens for "ngram" language modeling instead of
just the next token. Its architecture is identical to ProhpetNet, but the model was trained on the multi-lingual
-"wiki100" Wikipedia dump.
+"wiki100" Wikipedia dump. XLM-ProphetNet's model architecture and pretraining objective is same as ProphetNet, but XLM-ProphetNet was pre-trained on the cross-lingual dataset XGLUE.
The abstract from the paper is the following:
@@ -52,11 +52,7 @@ state-of-the-art results on all these datasets compared to the models using the
The Authors' code can be found [here](https://github.com/microsoft/ProphetNet).
-Tips:
-
-- XLM-ProphetNet's model architecture and pretraining objective is same as ProphetNet, but XLM-ProphetNet was pre-trained on the cross-lingual dataset XGLUE.
-
-## Documentation resources
+## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
- [Translation task guide](../tasks/translation)
diff --git a/docs/source/en/model_doc/xlm-roberta-xl.md b/docs/source/en/model_doc/xlm-roberta-xl.md
index b659294607..f9cb78c0bf 100644
--- a/docs/source/en/model_doc/xlm-roberta-xl.md
+++ b/docs/source/en/model_doc/xlm-roberta-xl.md
@@ -24,15 +24,15 @@ The abstract from the paper is the following:
*Recent work has demonstrated the effectiveness of cross-lingual language model pretraining for cross-lingual understanding. In this study, we present the results of two larger multilingual masked language models, with 3.5B and 10.7B parameters. Our two new models dubbed XLM-R XL and XLM-R XXL outperform XLM-R by 1.8% and 2.4% average accuracy on XNLI. Our model also outperforms the RoBERTa-Large model on several English tasks of the GLUE benchmark by 0.3% on average while handling 99 more languages. This suggests pretrained models with larger capacity may obtain both strong performance on high-resource languages while greatly improving low-resource languages. We make our code and models publicly available.*
-Tips:
-
-- XLM-RoBERTa-XL is a multilingual model trained on 100 different languages. Unlike some XLM multilingual models, it does
- not require `lang` tensors to understand which language is used, and should be able to determine the correct
- language from the input ids.
-
This model was contributed by [Soonhwan-Kwon](https://github.com/Soonhwan-Kwon) and [stefan-it](https://huggingface.co/stefan-it). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/xlmr).
-## Documentation resources
+## Usage tips
+
+XLM-RoBERTa-XL is a multilingual model trained on 100 different languages. Unlike some XLM multilingual models, it does
+not require `lang` tensors to understand which language is used, and should be able to determine the correct
+language from the input ids.
+
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
diff --git a/docs/source/en/model_doc/xlm-roberta.md b/docs/source/en/model_doc/xlm-roberta.md
index 935003156f..5854001523 100644
--- a/docs/source/en/model_doc/xlm-roberta.md
+++ b/docs/source/en/model_doc/xlm-roberta.md
@@ -46,16 +46,14 @@ languages at scale. Finally, we show, for the first time, the possibility of mul
per-language performance; XLM-Ris very competitive with strong monolingual models on the GLUE and XNLI benchmarks. We
will make XLM-R code, data, and models publicly available.*
-Tips:
+This model was contributed by [stefan-it](https://huggingface.co/stefan-it). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/xlmr).
+
+## Usage tips
- XLM-RoBERTa is a multilingual model trained on 100 different languages. Unlike some XLM multilingual models, it does
not require `lang` tensors to understand which language is used, and should be able to determine the correct
language from the input ids.
- Uses RoBERTa tricks on the XLM approach, but does not use the translation language modeling objective. It only uses masked language modeling on sentences coming from one language.
-- This implementation is the same as RoBERTa. Refer to the [documentation of RoBERTa](roberta) for usage examples
- as well as the information relative to the inputs and outputs.
-
-This model was contributed by [stefan-it](https://huggingface.co/stefan-it). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/xlmr).
## Resources
@@ -110,6 +108,11 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
- A blog post on how to [Deploy Serverless XLM RoBERTa on AWS Lambda](https://www.philschmid.de/multilingual-serverless-xlm-roberta-with-huggingface).
+
+
+This implementation is the same as RoBERTa. Refer to the [documentation of RoBERTa](roberta) for usage examples as well as the information relative to the inputs and outputs.
+
+
## XLMRobertaConfig
[[autodoc]] XLMRobertaConfig
@@ -126,6 +129,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] XLMRobertaTokenizerFast
+
+
+
## XLMRobertaModel
[[autodoc]] XLMRobertaModel
@@ -161,6 +167,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] XLMRobertaForQuestionAnswering
- forward
+
+
+
## TFXLMRobertaModel
[[autodoc]] TFXLMRobertaModel
@@ -196,6 +205,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] TFXLMRobertaForQuestionAnswering
- call
+
+
+
## FlaxXLMRobertaModel
[[autodoc]] FlaxXLMRobertaModel
@@ -230,3 +242,6 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] FlaxXLMRobertaForQuestionAnswering
- __call__
+
+
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/xlm-v.md b/docs/source/en/model_doc/xlm-v.md
index 38bed0dc46..049a1f35ad 100644
--- a/docs/source/en/model_doc/xlm-v.md
+++ b/docs/source/en/model_doc/xlm-v.md
@@ -35,7 +35,10 @@ a multilingual language model with a one million token vocabulary. XLM-V outperf
tested on ranging from natural language inference (XNLI), question answering (MLQA, XQuAD, TyDiQA), and
named entity recognition (WikiAnn) to low-resource tasks (Americas NLI, MasakhaNER).*
-Tips:
+This model was contributed by [stefan-it](https://huggingface.co/stefan-it), including detailed experiments with XLM-V on downstream tasks.
+The experiments repository can be found [here](https://github.com/stefan-it/xlm-v-experiments).
+
+## Usage tips
- XLM-V is compatible with the XLM-RoBERTa model architecture, only model weights from [`fairseq`](https://github.com/facebookresearch/fairseq)
library had to be converted.
@@ -43,5 +46,7 @@ Tips:
A XLM-V (base size) model is available under the [`facebook/xlm-v-base`](https://huggingface.co/facebook/xlm-v-base) identifier.
-This model was contributed by [stefan-it](https://huggingface.co/stefan-it), including detailed experiments with XLM-V on downstream tasks.
-The experiments repository can be found [here](https://github.com/stefan-it/xlm-v-experiments).
+
+
+XLM-V architecture is the same as XLM-RoBERTa, refer to [XLM-RoBERTa documentation](xlm-roberta) for API reference, and examples.
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/xlm.md b/docs/source/en/model_doc/xlm.md
index 8b5b31a2db..0ee11c6add 100644
--- a/docs/source/en/model_doc/xlm.md
+++ b/docs/source/en/model_doc/xlm.md
@@ -46,7 +46,9 @@ obtain 34.3 BLEU on WMT'16 German-English, improving the previous state of the a
machine translation, we obtain a new state of the art of 38.5 BLEU on WMT'16 Romanian-English, outperforming the
previous best approach by more than 4 BLEU. Our code and pretrained models will be made publicly available.*
-Tips:
+This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/facebookresearch/XLM/).
+
+## Usage tips
- XLM has many different checkpoints, which were trained using different objectives: CLM, MLM or TLM. Make sure to
select the correct objective for your task (e.g. MLM checkpoints are not suitable for generation).
@@ -57,9 +59,7 @@ Tips:
* Masked language modeling (MLM) which is like RoBERTa. One of the languages is selected for each training sample, and the model input is a sentence of 256 tokens, that may span over several documents in one of those languages, with dynamic masking of the tokens.
* A combination of MLM and translation language modeling (TLM). This consists of concatenating a sentence in two different languages, with random masking. To predict one of the masked tokens, the model can use both, the surrounding context in language 1 and the context given by language 2.
-This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/facebookresearch/XLM/).
-
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
@@ -84,6 +84,9 @@ This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The o
[[autodoc]] models.xlm.modeling_xlm.XLMForQuestionAnsweringOutput
+
+
+
## XLMModel
[[autodoc]] XLMModel
@@ -119,6 +122,9 @@ This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The o
[[autodoc]] XLMForQuestionAnswering
- forward
+
+
+
## TFXLMModel
[[autodoc]] TFXLMModel
@@ -148,3 +154,8 @@ This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The o
[[autodoc]] TFXLMForQuestionAnsweringSimple
- call
+
+
+
+
+
diff --git a/docs/source/en/model_doc/xlnet.md b/docs/source/en/model_doc/xlnet.md
index 3685728cd7..d2209c3d55 100644
--- a/docs/source/en/model_doc/xlnet.md
+++ b/docs/source/en/model_doc/xlnet.md
@@ -44,7 +44,9 @@ formulation. Furthermore, XLNet integrates ideas from Transformer-XL, the state-
pretraining. Empirically, under comparable experiment settings, XLNet outperforms BERT on 20 tasks, often by a large
margin, including question answering, natural language inference, sentiment analysis, and document ranking.*
-Tips:
+This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/zihangdai/xlnet/).
+
+## Usage tips
- The specific attention pattern can be controlled at training and test time using the `perm_mask` input.
- Due to the difficulty of training a fully auto-regressive model over various factorization order, XLNet is pretrained
@@ -56,9 +58,7 @@ Tips:
- XLNet is not a traditional autoregressive model but uses a training strategy that builds on that. It permutes the tokens in the sentence, then allows the model to use the last n tokens to predict the token n+1. Since this is all done with a mask, the sentence is actually fed in the model in the right order, but instead of masking the first n tokens for n+1, XLNet uses a mask that hides the previous tokens in some given permutation of 1,…,sequence length.
- XLNet also uses the same recurrence mechanism as Transformer-XL to build long-term dependencies.
-This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/zihangdai/xlnet/).
-
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
@@ -110,6 +110,9 @@ This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The o
[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetForQuestionAnsweringSimpleOutput
+
+
+
## XLNetModel
[[autodoc]] XLNetModel
@@ -145,6 +148,9 @@ This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The o
[[autodoc]] XLNetForQuestionAnswering
- forward
+
+
+
## TFXLNetModel
[[autodoc]] TFXLNetModel
@@ -174,3 +180,6 @@ This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The o
[[autodoc]] TFXLNetForQuestionAnsweringSimple
- call
+
+
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/xls_r.md b/docs/source/en/model_doc/xls_r.md
index 8e22004244..2226c813e7 100644
--- a/docs/source/en/model_doc/xls_r.md
+++ b/docs/source/en/model_doc/xls_r.md
@@ -34,14 +34,18 @@ language identification. Moreover, we show that with sufficient model size, cros
English-only pretraining when translating English speech into other languages, a setting which favors monolingual
pretraining. We hope XLS-R can help to improve speech processing tasks for many more languages of the world.*
-Tips:
+Relevant checkpoints can be found under https://huggingface.co/models?other=xls_r.
+
+The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
+
+## Usage tips
- XLS-R is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
- XLS-R model was trained using connectionist temporal classification (CTC) so the model output has to be decoded using
[`Wav2Vec2CTCTokenizer`].
-Relevant checkpoints can be found under https://huggingface.co/models?other=xls_r.
+
-XLS-R's architecture is based on the Wav2Vec2 model, so one can refer to [Wav2Vec2's documentation page](wav2vec2).
+XLS-R's architecture is based on the Wav2Vec2 model, refer to [Wav2Vec2's documentation page](wav2vec2) for API reference.
-The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/xlsr_wav2vec2.md b/docs/source/en/model_doc/xlsr_wav2vec2.md
index 643d37416d..d1b5444c24 100644
--- a/docs/source/en/model_doc/xlsr_wav2vec2.md
+++ b/docs/source/en/model_doc/xlsr_wav2vec2.md
@@ -34,12 +34,16 @@ individual models. Analysis shows that the latent discrete speech representation
increased sharing for related languages. We hope to catalyze research in low-resource speech understanding by releasing
XLSR-53, a large model pretrained in 53 languages.*
-Tips:
+The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
+
+## Usage tips
- XLSR-Wav2Vec2 is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
- XLSR-Wav2Vec2 model was trained using connectionist temporal classification (CTC) so the model output has to be
decoded using [`Wav2Vec2CTCTokenizer`].
+
+
XLSR-Wav2Vec2's architecture is based on the Wav2Vec2 model, so one can refer to [Wav2Vec2's documentation page](wav2vec2).
-The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
+
diff --git a/docs/source/en/model_doc/xmod.md b/docs/source/en/model_doc/xmod.md
index 5a3409bbc4..47797fa649 100644
--- a/docs/source/en/model_doc/xmod.md
+++ b/docs/source/en/model_doc/xmod.md
@@ -25,13 +25,15 @@ The abstract from the paper is the following:
*Multilingual pre-trained models are known to suffer from the curse of multilinguality, which causes per-language performance to drop as they cover more languages. We address this issue by introducing language-specific modules, which allows us to grow the total capacity of the model, while keeping the total number of trainable parameters per language constant. In contrast with prior work that learns language-specific components post-hoc, we pre-train the modules of our Cross-lingual Modular (X-MOD) models from the start. Our experiments on natural language inference, named entity recognition and question answering show that our approach not only mitigates the negative interference between languages, but also enables positive transfer, resulting in improved monolingual and cross-lingual performance. Furthermore, our approach enables adding languages post-hoc with no measurable drop in performance, no longer limiting the model usage to the set of pre-trained languages.*
+This model was contributed by [jvamvas](https://huggingface.co/jvamvas).
+The original code can be found [here](https://github.com/facebookresearch/fairseq/tree/58cc6cca18f15e6d56e3f60c959fe4f878960a60/fairseq/models/xmod) and the original documentation is found [here](https://github.com/facebookresearch/fairseq/tree/58cc6cca18f15e6d56e3f60c959fe4f878960a60/examples/xmod).
+
+## Usage tips
+
Tips:
- X-MOD is similar to [XLM-R](xlm-roberta), but a difference is that the input language needs to be specified so that the correct language adapter can be activated.
- The main models – base and large – have adapters for 81 languages.
-This model was contributed by [jvamvas](https://huggingface.co/jvamvas).
-The original code can be found [here](https://github.com/facebookresearch/fairseq/tree/58cc6cca18f15e6d56e3f60c959fe4f878960a60/fairseq/models/xmod) and the original documentation is found [here](https://github.com/facebookresearch/fairseq/tree/58cc6cca18f15e6d56e3f60c959fe4f878960a60/examples/xmod).
-
## Adapter Usage
### Input language
diff --git a/docs/source/en/model_doc/yolos.md b/docs/source/en/model_doc/yolos.md
index 6185c3a067..5386c373ac 100644
--- a/docs/source/en/model_doc/yolos.md
+++ b/docs/source/en/model_doc/yolos.md
@@ -25,10 +25,6 @@ The abstract from the paper is the following:
*Can Transformer perform 2D object- and region-level recognition from a pure sequence-to-sequence perspective with minimal knowledge about the 2D spatial structure? To answer this question, we present You Only Look at One Sequence (YOLOS), a series of object detection models based on the vanilla Vision Transformer with the fewest possible modifications, region priors, as well as inductive biases of the target task. We find that YOLOS pre-trained on the mid-sized ImageNet-1k dataset only can already achieve quite competitive performance on the challenging COCO object detection benchmark, e.g., YOLOS-Base directly adopted from BERT-Base architecture can obtain 42.0 box AP on COCO val. We also discuss the impacts as well as limitations of current pre-train schemes and model scaling strategies for Transformer in vision through YOLOS.*
-Tips:
-
-- One can use [`YolosImageProcessor`] for preparing images (and optional targets) for the model. Contrary to [DETR](detr), YOLOS doesn't require a `pixel_mask` to be created.
-
+
+ MSN architecture. Taken from the original paper.
+
+This model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/facebookresearch/msn).
+
+## Usage tips
- MSN (masked siamese networks) is a method for self-supervised pre-training of Vision Transformers (ViTs). The pre-training
objective is to match the prototypes assigned to the unmasked views of the images to that of the masked views of the same images.
@@ -43,13 +49,6 @@ use the [`ViTMSNForImageClassification`] class which is initialized from [`ViTMS
- MSN is particularly useful in the low-shot and extreme low-shot regimes. Notably, it achieves 75.7% top-1 accuracy with only 1% of ImageNet-1K
labels when fine-tuned.
-
-
-
- MSN architecture. Taken from the original paper.
-
-This model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/facebookresearch/msn).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViT MSN.
@@ -65,13 +64,11 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] ViTMSNConfig
-
## ViTMSNModel
[[autodoc]] ViTMSNModel
- forward
-
## ViTMSNForImageClassification
[[autodoc]] ViTMSNForImageClassification
diff --git a/docs/source/en/model_doc/vitdet.md b/docs/source/en/model_doc/vitdet.md
index 657e467ee3..81bf787d6c 100644
--- a/docs/source/en/model_doc/vitdet.md
+++ b/docs/source/en/model_doc/vitdet.md
@@ -21,13 +21,12 @@ The abstract from the paper is the following:
*We explore the plain, non-hierarchical Vision Transformer (ViT) as a backbone network for object detection. This design enables the original ViT architecture to be fine-tuned for object detection without needing to redesign a hierarchical backbone for pre-training. With minimal adaptations for fine-tuning, our plain-backbone detector can achieve competitive results. Surprisingly, we observe: (i) it is sufficient to build a simple feature pyramid from a single-scale feature map (without the common FPN design) and (ii) it is sufficient to use window attention (without shifting) aided with very few cross-window propagation blocks. With plain ViT backbones pre-trained as Masked Autoencoders (MAE), our detector, named ViTDet, can compete with the previous leading methods that were all based on hierarchical backbones, reaching up to 61.3 AP_box on the COCO dataset using only ImageNet-1K pre-training. We hope our study will draw attention to research on plain-backbone detectors.*
-Tips:
-
-- For the moment, only the backbone is available.
-
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/facebookresearch/detectron2/tree/main/projects/ViTDet).
+Tips:
+
+- At the moment, only the backbone is available.
## VitDetConfig
diff --git a/docs/source/en/model_doc/vitmatte.md b/docs/source/en/model_doc/vitmatte.md
index 479b398f80..5a6d501030 100644
--- a/docs/source/en/model_doc/vitmatte.md
+++ b/docs/source/en/model_doc/vitmatte.md
@@ -21,10 +21,6 @@ The abstract from the paper is the following:
*Recently, plain vision Transformers (ViTs) have shown impressive performance on various computer vision tasks, thanks to their strong modeling capacity and large-scale pretraining. However, they have not yet conquered the problem of image matting. We hypothesize that image matting could also be boosted by ViTs and present a new efficient and robust ViT-based matting system, named ViTMatte. Our method utilizes (i) a hybrid attention mechanism combined with a convolution neck to help ViTs achieve an excellent performance-computation trade-off in matting tasks. (ii) Additionally, we introduce the detail capture module, which just consists of simple lightweight convolutions to complement the detailed information required by matting. To the best of our knowledge, ViTMatte is the first work to unleash the potential of ViT on image matting with concise adaptation. It inherits many superior properties from ViT to matting, including various pretraining strategies, concise architecture design, and flexible inference strategies. We evaluate ViTMatte on Composition-1k and Distinctions-646, the most commonly used benchmark for image matting, our method achieves state-of-the-art performance and outperforms prior matting works by a large margin.*
-Tips:
-
-- The model expects both the image and trimap (concatenated) as input. One can use [`ViTMatteImageProcessor`] for this purpose.
-
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/hustvl/ViTMatte).
@@ -39,6 +35,10 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
- A demo notebook regarding inference with [`VitMatteForImageMatting`], including background replacement, can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ViTMatte).
+
+
+The model expects both the image and trimap (concatenated) as input. Use [`ViTMatteImageProcessor`] for this purpose.
+
## VitMatteConfig
diff --git a/docs/source/en/model_doc/vits.md b/docs/source/en/model_doc/vits.md
index 1b57df4027..73001d82ed 100644
--- a/docs/source/en/model_doc/vits.md
+++ b/docs/source/en/model_doc/vits.md
@@ -16,7 +16,6 @@ specific language governing permissions and limitations under the License.
The VITS model was proposed in [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103) by Jaehyeon Kim, Jungil Kong, Juhee Son.
-
VITS (**V**ariational **I**nference with adversarial learning for end-to-end **T**ext-to-**S**peech) is an end-to-end
speech synthesis model that predicts a speech waveform conditional on an input text sequence. It is a conditional variational
autoencoder (VAE) comprised of a posterior encoder, decoder, and conditional prior.
@@ -42,7 +41,7 @@ as these checkpoints use the same architecture and a slightly modified tokenizer
This model was contributed by [Matthijs](https://huggingface.co/Matthijs) and [sanchit-gandhi](https://huggingface.co/sanchit-gandhi). The original code can be found [here](https://github.com/jaywalnut310/vits).
-## Model Usage
+## Usage examples
Both the VITS and MMS-TTS checkpoints can be used with the same API. Since the flow-based model is non-deterministic, it
is good practice to set a seed to ensure reproducibility of the outputs. For languages with a Roman alphabet,
diff --git a/docs/source/en/model_doc/vivit.md b/docs/source/en/model_doc/vivit.md
index 755629a767..4426493a0f 100644
--- a/docs/source/en/model_doc/vivit.md
+++ b/docs/source/en/model_doc/vivit.md
@@ -21,7 +21,6 @@ The abstract from the paper is the following:
*We present pure-transformer based models for video classification, drawing upon the recent success of such models in image classification. Our model extracts spatio-temporal tokens from the input video, which are then encoded by a series of transformer layers. In order to handle the long sequences of tokens encountered in video, we propose several, efficient variants of our model which factorise the spatial- and temporal-dimensions of the input. Although transformer-based models are known to only be effective when large training datasets are available, we show how we can effectively regularise the model during training and leverage pretrained image models to be able to train on comparatively small datasets. We conduct thorough ablation studies, and achieve state-of-the-art results on multiple video classification benchmarks including Kinetics 400 and 600, Epic Kitchens, Something-Something v2 and Moments in Time, outperforming prior methods based on deep 3D convolutional networks.*
-
This model was contributed by [jegormeister](https://huggingface.co/jegormeister). The original code (written in JAX) can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/vivit).
## VivitConfig
diff --git a/docs/source/en/model_doc/wav2vec2-conformer.md b/docs/source/en/model_doc/wav2vec2-conformer.md
index 87e255cd0c..c32c03bb0c 100644
--- a/docs/source/en/model_doc/wav2vec2-conformer.md
+++ b/docs/source/en/model_doc/wav2vec2-conformer.md
@@ -24,7 +24,10 @@ The official results of the model can be found in Table 3 and Table 4 of the pap
The Wav2Vec2-Conformer weights were released by the Meta AI team within the [Fairseq library](https://github.com/pytorch/fairseq/blob/main/examples/wav2vec/README.md#pre-trained-models).
-Tips:
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten).
+The original code can be found [here](https://github.com/pytorch/fairseq/tree/main/examples/wav2vec).
+
+## Usage tips
- Wav2Vec2-Conformer follows the same architecture as Wav2Vec2, but replaces the *Attention*-block with a *Conformer*-block
as introduced in [Conformer: Convolution-augmented Transformer for Speech Recognition](https://arxiv.org/abs/2005.08100).
@@ -34,10 +37,7 @@ an improved word error rate.
- Wav2Vec2-Conformer can use either no relative position embeddings, Transformer-XL-like position embeddings, or
rotary position embeddings by setting the correct `config.position_embeddings_type`.
-This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten).
-The original code can be found [here](https://github.com/pytorch/fairseq/tree/main/examples/wav2vec).
-
-## Documentation resources
+## Resources
- [Audio classification task guide](../tasks/audio_classification)
- [Automatic speech recognition task guide](../tasks/asr)
diff --git a/docs/source/en/model_doc/wav2vec2.md b/docs/source/en/model_doc/wav2vec2.md
index 3a67f66d9d..81d8f332ac 100644
--- a/docs/source/en/model_doc/wav2vec2.md
+++ b/docs/source/en/model_doc/wav2vec2.md
@@ -31,14 +31,14 @@ of the art on the 100 hour subset while using 100 times less labeled data. Using
pre-training on 53k hours of unlabeled data still achieves 4.8/8.2 WER. This demonstrates the feasibility of speech
recognition with limited amounts of labeled data.*
-Tips:
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten).
+
+## Usage tips
- Wav2Vec2 is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
- Wav2Vec2 model was trained using connectionist temporal classification (CTC) so the model output has to be decoded
using [`Wav2Vec2CTCTokenizer`].
-This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Wav2Vec2. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
@@ -167,6 +167,9 @@ Otherwise, [`~Wav2Vec2ProcessorWithLM.batch_decode`] performance will be slower
[[autodoc]] models.wav2vec2.modeling_flax_wav2vec2.FlaxWav2Vec2ForPreTrainingOutput
+
+
+
## Wav2Vec2Model
[[autodoc]] Wav2Vec2Model
@@ -198,6 +201,9 @@ Otherwise, [`~Wav2Vec2ProcessorWithLM.batch_decode`] performance will be slower
[[autodoc]] Wav2Vec2ForPreTraining
- forward
+
+
+
## TFWav2Vec2Model
[[autodoc]] TFWav2Vec2Model
@@ -213,6 +219,9 @@ Otherwise, [`~Wav2Vec2ProcessorWithLM.batch_decode`] performance will be slower
[[autodoc]] TFWav2Vec2ForCTC
- call
+
+
+
## FlaxWav2Vec2Model
[[autodoc]] FlaxWav2Vec2Model
@@ -227,3 +236,6 @@ Otherwise, [`~Wav2Vec2ProcessorWithLM.batch_decode`] performance will be slower
[[autodoc]] FlaxWav2Vec2ForPreTraining
- __call__
+
+
+
diff --git a/docs/source/en/model_doc/wav2vec2_phoneme.md b/docs/source/en/model_doc/wav2vec2_phoneme.md
index a852bef637..93e0656f49 100644
--- a/docs/source/en/model_doc/wav2vec2_phoneme.md
+++ b/docs/source/en/model_doc/wav2vec2_phoneme.md
@@ -31,7 +31,13 @@ mapping phonemes of the training languages to the target language using articula
this simple method significantly outperforms prior work which introduced task-specific architectures and used only part
of a monolingually pretrained model.*
-Tips:
+Relevant checkpoints can be found under https://huggingface.co/models?other=phoneme-recognition.
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten)
+
+The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
+
+## Usage tips
- Wav2Vec2Phoneme uses the exact same architecture as Wav2Vec2
- Wav2Vec2Phoneme is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
@@ -39,17 +45,16 @@ Tips:
decoded using [`Wav2Vec2PhonemeCTCTokenizer`].
- Wav2Vec2Phoneme can be fine-tuned on multiple language at once and decode unseen languages in a single forward pass
to a sequence of phonemes
-- By default the model outputs a sequence of phonemes. In order to transform the phonemes to a sequence of words one
+- By default, the model outputs a sequence of phonemes. In order to transform the phonemes to a sequence of words one
should make use of a dictionary and language model.
-Relevant checkpoints can be found under https://huggingface.co/models?other=phoneme-recognition.
-This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten)
+
-The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
-
-Wav2Vec2Phoneme's architecture is based on the Wav2Vec2 model, so one can refer to [`Wav2Vec2`]'s documentation page except for the tokenizer.
+Wav2Vec2Phoneme's architecture is based on the Wav2Vec2 model, for API reference, check out [`Wav2Vec2`](wav2vec2)'s documentation page
+except for the tokenizer.
+
## Wav2Vec2PhonemeCTCTokenizer
diff --git a/docs/source/en/model_doc/wavlm.md b/docs/source/en/model_doc/wavlm.md
index 2754304d82..13f6298075 100644
--- a/docs/source/en/model_doc/wavlm.md
+++ b/docs/source/en/model_doc/wavlm.md
@@ -35,7 +35,12 @@ additional overlapped utterances are created unsupervisely and incorporated duri
the training dataset from 60k hours to 94k hours. WavLM Large achieves state-of-the-art performance on the SUPERB
benchmark, and brings significant improvements for various speech processing tasks on their representative benchmarks.*
-Tips:
+Relevant checkpoints can be found under https://huggingface.co/models?other=wavlm.
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
+found [here](https://github.com/microsoft/unilm/tree/master/wavlm).
+
+## Usage tips
- WavLM is a speech model that accepts a float array corresponding to the raw waveform of the speech signal. Please use
[`Wav2Vec2Processor`] for the feature extraction.
@@ -43,12 +48,7 @@ Tips:
using [`Wav2Vec2CTCTokenizer`].
- WavLM performs especially well on speaker verification, speaker identification, and speaker diarization tasks.
-Relevant checkpoints can be found under https://huggingface.co/models?other=wavlm.
-
-This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
-found [here](https://github.com/microsoft/unilm/tree/master/wavlm).
-
-## Documentation resources
+## Resources
- [Audio classification task guide](../tasks/audio_classification)
- [Automatic speech recognition task guide](../tasks/asr)
diff --git a/docs/source/en/model_doc/whisper.md b/docs/source/en/model_doc/whisper.md
index 2f1cfc5e22..4ea7e94381 100644
--- a/docs/source/en/model_doc/whisper.md
+++ b/docs/source/en/model_doc/whisper.md
@@ -24,18 +24,16 @@ The abstract from the paper is the following:
*We study the capabilities of speech processing systems trained simply to predict large amounts of transcripts of audio on the internet. When scaled to 680,000 hours of multilingual and multitask supervision, the resulting models generalize well to standard benchmarks and are often competitive with prior fully supervised results but in a zeroshot transfer setting without the need for any finetuning. When compared to humans, the models approach their accuracy and robustness. We are releasing models and inference code to serve as a foundation for further work on robust speech processing.*
+This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ). The Tensorflow version of this model was contributed by [amyeroberts](https://huggingface.co/amyeroberts).
+The original code can be found [here](https://github.com/openai/whisper).
-Tips:
+## Usage tips
- The model usually performs well without requiring any finetuning.
- The architecture follows a classic encoder-decoder architecture, which means that it relies on the [`~generation.GenerationMixin.generate`] function for inference.
- Inference is currently only implemented for short-form i.e. audio is pre-segmented into <=30s segments. Long-form (including timestamps) will be implemented in a future release.
- One can use [`WhisperProcessor`] to prepare audio for the model, and decode the predicted ID's back into text.
-This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ). The Tensorflow version of this model was contributed by [amyeroberts](https://huggingface.co/amyeroberts).
-The original code can be found [here](https://github.com/openai/whisper).
-
-
## WhisperConfig
[[autodoc]] WhisperConfig
@@ -76,6 +74,9 @@ The original code can be found [here](https://github.com/openai/whisper).
- batch_decode
- decode
+
+
+
## WhisperModel
[[autodoc]] WhisperModel
@@ -98,6 +99,8 @@ The original code can be found [here](https://github.com/openai/whisper).
[[autodoc]] WhisperForAudioClassification
- forward
+
+
## TFWhisperModel
@@ -109,6 +112,8 @@ The original code can be found [here](https://github.com/openai/whisper).
[[autodoc]] TFWhisperForConditionalGeneration
- call
+
+
## FlaxWhisperModel
@@ -125,3 +130,6 @@ The original code can be found [here](https://github.com/openai/whisper).
[[autodoc]] FlaxWhisperForAudioClassification
- __call__
+
+
+
diff --git a/docs/source/en/model_doc/xglm.md b/docs/source/en/model_doc/xglm.md
index 1b184c17e8..470e42c747 100644
--- a/docs/source/en/model_doc/xglm.md
+++ b/docs/source/en/model_doc/xglm.md
@@ -42,7 +42,7 @@ in social value tasks such as hate speech detection in five languages and find i
This model was contributed by [Suraj](https://huggingface.co/valhalla). The original code can be found [here](https://github.com/pytorch/fairseq/tree/main/examples/xglm).
-## Documentation resources
+## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
@@ -62,6 +62,9 @@ This model was contributed by [Suraj](https://huggingface.co/valhalla). The orig
[[autodoc]] XGLMTokenizerFast
+
+
+
## XGLMModel
[[autodoc]] XGLMModel
@@ -72,6 +75,9 @@ This model was contributed by [Suraj](https://huggingface.co/valhalla). The orig
[[autodoc]] XGLMForCausalLM
- forward
+
+
+
## TFXGLMModel
[[autodoc]] TFXGLMModel
@@ -82,6 +88,9 @@ This model was contributed by [Suraj](https://huggingface.co/valhalla). The orig
[[autodoc]] TFXGLMForCausalLM
- call
+
+
+
## FlaxXGLMModel
[[autodoc]] FlaxXGLMModel
@@ -90,4 +99,7 @@ This model was contributed by [Suraj](https://huggingface.co/valhalla). The orig
## FlaxXGLMForCausalLM
[[autodoc]] FlaxXGLMForCausalLM
- - __call__
\ No newline at end of file
+ - __call__
+
+
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/xlm-prophetnet.md b/docs/source/en/model_doc/xlm-prophetnet.md
index 5e7ba5b7e3..7a61aeb3e3 100644
--- a/docs/source/en/model_doc/xlm-prophetnet.md
+++ b/docs/source/en/model_doc/xlm-prophetnet.md
@@ -36,7 +36,7 @@ Zhang, Ming Zhou on 13 Jan, 2020.
XLM-ProphetNet is an encoder-decoder model and can predict n-future tokens for "ngram" language modeling instead of
just the next token. Its architecture is identical to ProhpetNet, but the model was trained on the multi-lingual
-"wiki100" Wikipedia dump.
+"wiki100" Wikipedia dump. XLM-ProphetNet's model architecture and pretraining objective is same as ProphetNet, but XLM-ProphetNet was pre-trained on the cross-lingual dataset XGLUE.
The abstract from the paper is the following:
@@ -52,11 +52,7 @@ state-of-the-art results on all these datasets compared to the models using the
The Authors' code can be found [here](https://github.com/microsoft/ProphetNet).
-Tips:
-
-- XLM-ProphetNet's model architecture and pretraining objective is same as ProphetNet, but XLM-ProphetNet was pre-trained on the cross-lingual dataset XGLUE.
-
-## Documentation resources
+## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
- [Translation task guide](../tasks/translation)
diff --git a/docs/source/en/model_doc/xlm-roberta-xl.md b/docs/source/en/model_doc/xlm-roberta-xl.md
index b659294607..f9cb78c0bf 100644
--- a/docs/source/en/model_doc/xlm-roberta-xl.md
+++ b/docs/source/en/model_doc/xlm-roberta-xl.md
@@ -24,15 +24,15 @@ The abstract from the paper is the following:
*Recent work has demonstrated the effectiveness of cross-lingual language model pretraining for cross-lingual understanding. In this study, we present the results of two larger multilingual masked language models, with 3.5B and 10.7B parameters. Our two new models dubbed XLM-R XL and XLM-R XXL outperform XLM-R by 1.8% and 2.4% average accuracy on XNLI. Our model also outperforms the RoBERTa-Large model on several English tasks of the GLUE benchmark by 0.3% on average while handling 99 more languages. This suggests pretrained models with larger capacity may obtain both strong performance on high-resource languages while greatly improving low-resource languages. We make our code and models publicly available.*
-Tips:
-
-- XLM-RoBERTa-XL is a multilingual model trained on 100 different languages. Unlike some XLM multilingual models, it does
- not require `lang` tensors to understand which language is used, and should be able to determine the correct
- language from the input ids.
-
This model was contributed by [Soonhwan-Kwon](https://github.com/Soonhwan-Kwon) and [stefan-it](https://huggingface.co/stefan-it). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/xlmr).
-## Documentation resources
+## Usage tips
+
+XLM-RoBERTa-XL is a multilingual model trained on 100 different languages. Unlike some XLM multilingual models, it does
+not require `lang` tensors to understand which language is used, and should be able to determine the correct
+language from the input ids.
+
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
diff --git a/docs/source/en/model_doc/xlm-roberta.md b/docs/source/en/model_doc/xlm-roberta.md
index 935003156f..5854001523 100644
--- a/docs/source/en/model_doc/xlm-roberta.md
+++ b/docs/source/en/model_doc/xlm-roberta.md
@@ -46,16 +46,14 @@ languages at scale. Finally, we show, for the first time, the possibility of mul
per-language performance; XLM-Ris very competitive with strong monolingual models on the GLUE and XNLI benchmarks. We
will make XLM-R code, data, and models publicly available.*
-Tips:
+This model was contributed by [stefan-it](https://huggingface.co/stefan-it). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/xlmr).
+
+## Usage tips
- XLM-RoBERTa is a multilingual model trained on 100 different languages. Unlike some XLM multilingual models, it does
not require `lang` tensors to understand which language is used, and should be able to determine the correct
language from the input ids.
- Uses RoBERTa tricks on the XLM approach, but does not use the translation language modeling objective. It only uses masked language modeling on sentences coming from one language.
-- This implementation is the same as RoBERTa. Refer to the [documentation of RoBERTa](roberta) for usage examples
- as well as the information relative to the inputs and outputs.
-
-This model was contributed by [stefan-it](https://huggingface.co/stefan-it). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/xlmr).
## Resources
@@ -110,6 +108,11 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
- A blog post on how to [Deploy Serverless XLM RoBERTa on AWS Lambda](https://www.philschmid.de/multilingual-serverless-xlm-roberta-with-huggingface).
+
+
+This implementation is the same as RoBERTa. Refer to the [documentation of RoBERTa](roberta) for usage examples as well as the information relative to the inputs and outputs.
+
+
## XLMRobertaConfig
[[autodoc]] XLMRobertaConfig
@@ -126,6 +129,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] XLMRobertaTokenizerFast
+
+
+
## XLMRobertaModel
[[autodoc]] XLMRobertaModel
@@ -161,6 +167,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] XLMRobertaForQuestionAnswering
- forward
+
+
+
## TFXLMRobertaModel
[[autodoc]] TFXLMRobertaModel
@@ -196,6 +205,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] TFXLMRobertaForQuestionAnswering
- call
+
+
+
## FlaxXLMRobertaModel
[[autodoc]] FlaxXLMRobertaModel
@@ -230,3 +242,6 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] FlaxXLMRobertaForQuestionAnswering
- __call__
+
+
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/xlm-v.md b/docs/source/en/model_doc/xlm-v.md
index 38bed0dc46..049a1f35ad 100644
--- a/docs/source/en/model_doc/xlm-v.md
+++ b/docs/source/en/model_doc/xlm-v.md
@@ -35,7 +35,10 @@ a multilingual language model with a one million token vocabulary. XLM-V outperf
tested on ranging from natural language inference (XNLI), question answering (MLQA, XQuAD, TyDiQA), and
named entity recognition (WikiAnn) to low-resource tasks (Americas NLI, MasakhaNER).*
-Tips:
+This model was contributed by [stefan-it](https://huggingface.co/stefan-it), including detailed experiments with XLM-V on downstream tasks.
+The experiments repository can be found [here](https://github.com/stefan-it/xlm-v-experiments).
+
+## Usage tips
- XLM-V is compatible with the XLM-RoBERTa model architecture, only model weights from [`fairseq`](https://github.com/facebookresearch/fairseq)
library had to be converted.
@@ -43,5 +46,7 @@ Tips:
A XLM-V (base size) model is available under the [`facebook/xlm-v-base`](https://huggingface.co/facebook/xlm-v-base) identifier.
-This model was contributed by [stefan-it](https://huggingface.co/stefan-it), including detailed experiments with XLM-V on downstream tasks.
-The experiments repository can be found [here](https://github.com/stefan-it/xlm-v-experiments).
+
+
+XLM-V architecture is the same as XLM-RoBERTa, refer to [XLM-RoBERTa documentation](xlm-roberta) for API reference, and examples.
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/xlm.md b/docs/source/en/model_doc/xlm.md
index 8b5b31a2db..0ee11c6add 100644
--- a/docs/source/en/model_doc/xlm.md
+++ b/docs/source/en/model_doc/xlm.md
@@ -46,7 +46,9 @@ obtain 34.3 BLEU on WMT'16 German-English, improving the previous state of the a
machine translation, we obtain a new state of the art of 38.5 BLEU on WMT'16 Romanian-English, outperforming the
previous best approach by more than 4 BLEU. Our code and pretrained models will be made publicly available.*
-Tips:
+This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/facebookresearch/XLM/).
+
+## Usage tips
- XLM has many different checkpoints, which were trained using different objectives: CLM, MLM or TLM. Make sure to
select the correct objective for your task (e.g. MLM checkpoints are not suitable for generation).
@@ -57,9 +59,7 @@ Tips:
* Masked language modeling (MLM) which is like RoBERTa. One of the languages is selected for each training sample, and the model input is a sentence of 256 tokens, that may span over several documents in one of those languages, with dynamic masking of the tokens.
* A combination of MLM and translation language modeling (TLM). This consists of concatenating a sentence in two different languages, with random masking. To predict one of the masked tokens, the model can use both, the surrounding context in language 1 and the context given by language 2.
-This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/facebookresearch/XLM/).
-
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
@@ -84,6 +84,9 @@ This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The o
[[autodoc]] models.xlm.modeling_xlm.XLMForQuestionAnsweringOutput
+
+
+
## XLMModel
[[autodoc]] XLMModel
@@ -119,6 +122,9 @@ This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The o
[[autodoc]] XLMForQuestionAnswering
- forward
+
+
+
## TFXLMModel
[[autodoc]] TFXLMModel
@@ -148,3 +154,8 @@ This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The o
[[autodoc]] TFXLMForQuestionAnsweringSimple
- call
+
+
+
+
+
diff --git a/docs/source/en/model_doc/xlnet.md b/docs/source/en/model_doc/xlnet.md
index 3685728cd7..d2209c3d55 100644
--- a/docs/source/en/model_doc/xlnet.md
+++ b/docs/source/en/model_doc/xlnet.md
@@ -44,7 +44,9 @@ formulation. Furthermore, XLNet integrates ideas from Transformer-XL, the state-
pretraining. Empirically, under comparable experiment settings, XLNet outperforms BERT on 20 tasks, often by a large
margin, including question answering, natural language inference, sentiment analysis, and document ranking.*
-Tips:
+This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/zihangdai/xlnet/).
+
+## Usage tips
- The specific attention pattern can be controlled at training and test time using the `perm_mask` input.
- Due to the difficulty of training a fully auto-regressive model over various factorization order, XLNet is pretrained
@@ -56,9 +58,7 @@ Tips:
- XLNet is not a traditional autoregressive model but uses a training strategy that builds on that. It permutes the tokens in the sentence, then allows the model to use the last n tokens to predict the token n+1. Since this is all done with a mask, the sentence is actually fed in the model in the right order, but instead of masking the first n tokens for n+1, XLNet uses a mask that hides the previous tokens in some given permutation of 1,…,sequence length.
- XLNet also uses the same recurrence mechanism as Transformer-XL to build long-term dependencies.
-This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/zihangdai/xlnet/).
-
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
@@ -110,6 +110,9 @@ This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The o
[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetForQuestionAnsweringSimpleOutput
+
+
+
## XLNetModel
[[autodoc]] XLNetModel
@@ -145,6 +148,9 @@ This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The o
[[autodoc]] XLNetForQuestionAnswering
- forward
+
+
+
## TFXLNetModel
[[autodoc]] TFXLNetModel
@@ -174,3 +180,6 @@ This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The o
[[autodoc]] TFXLNetForQuestionAnsweringSimple
- call
+
+
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/xls_r.md b/docs/source/en/model_doc/xls_r.md
index 8e22004244..2226c813e7 100644
--- a/docs/source/en/model_doc/xls_r.md
+++ b/docs/source/en/model_doc/xls_r.md
@@ -34,14 +34,18 @@ language identification. Moreover, we show that with sufficient model size, cros
English-only pretraining when translating English speech into other languages, a setting which favors monolingual
pretraining. We hope XLS-R can help to improve speech processing tasks for many more languages of the world.*
-Tips:
+Relevant checkpoints can be found under https://huggingface.co/models?other=xls_r.
+
+The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
+
+## Usage tips
- XLS-R is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
- XLS-R model was trained using connectionist temporal classification (CTC) so the model output has to be decoded using
[`Wav2Vec2CTCTokenizer`].
-Relevant checkpoints can be found under https://huggingface.co/models?other=xls_r.
+
-XLS-R's architecture is based on the Wav2Vec2 model, so one can refer to [Wav2Vec2's documentation page](wav2vec2).
+XLS-R's architecture is based on the Wav2Vec2 model, refer to [Wav2Vec2's documentation page](wav2vec2) for API reference.
-The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/xlsr_wav2vec2.md b/docs/source/en/model_doc/xlsr_wav2vec2.md
index 643d37416d..d1b5444c24 100644
--- a/docs/source/en/model_doc/xlsr_wav2vec2.md
+++ b/docs/source/en/model_doc/xlsr_wav2vec2.md
@@ -34,12 +34,16 @@ individual models. Analysis shows that the latent discrete speech representation
increased sharing for related languages. We hope to catalyze research in low-resource speech understanding by releasing
XLSR-53, a large model pretrained in 53 languages.*
-Tips:
+The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
+
+## Usage tips
- XLSR-Wav2Vec2 is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
- XLSR-Wav2Vec2 model was trained using connectionist temporal classification (CTC) so the model output has to be
decoded using [`Wav2Vec2CTCTokenizer`].
+
+
XLSR-Wav2Vec2's architecture is based on the Wav2Vec2 model, so one can refer to [Wav2Vec2's documentation page](wav2vec2).
-The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
+
diff --git a/docs/source/en/model_doc/xmod.md b/docs/source/en/model_doc/xmod.md
index 5a3409bbc4..47797fa649 100644
--- a/docs/source/en/model_doc/xmod.md
+++ b/docs/source/en/model_doc/xmod.md
@@ -25,13 +25,15 @@ The abstract from the paper is the following:
*Multilingual pre-trained models are known to suffer from the curse of multilinguality, which causes per-language performance to drop as they cover more languages. We address this issue by introducing language-specific modules, which allows us to grow the total capacity of the model, while keeping the total number of trainable parameters per language constant. In contrast with prior work that learns language-specific components post-hoc, we pre-train the modules of our Cross-lingual Modular (X-MOD) models from the start. Our experiments on natural language inference, named entity recognition and question answering show that our approach not only mitigates the negative interference between languages, but also enables positive transfer, resulting in improved monolingual and cross-lingual performance. Furthermore, our approach enables adding languages post-hoc with no measurable drop in performance, no longer limiting the model usage to the set of pre-trained languages.*
+This model was contributed by [jvamvas](https://huggingface.co/jvamvas).
+The original code can be found [here](https://github.com/facebookresearch/fairseq/tree/58cc6cca18f15e6d56e3f60c959fe4f878960a60/fairseq/models/xmod) and the original documentation is found [here](https://github.com/facebookresearch/fairseq/tree/58cc6cca18f15e6d56e3f60c959fe4f878960a60/examples/xmod).
+
+## Usage tips
+
Tips:
- X-MOD is similar to [XLM-R](xlm-roberta), but a difference is that the input language needs to be specified so that the correct language adapter can be activated.
- The main models – base and large – have adapters for 81 languages.
-This model was contributed by [jvamvas](https://huggingface.co/jvamvas).
-The original code can be found [here](https://github.com/facebookresearch/fairseq/tree/58cc6cca18f15e6d56e3f60c959fe4f878960a60/fairseq/models/xmod) and the original documentation is found [here](https://github.com/facebookresearch/fairseq/tree/58cc6cca18f15e6d56e3f60c959fe4f878960a60/examples/xmod).
-
## Adapter Usage
### Input language
diff --git a/docs/source/en/model_doc/yolos.md b/docs/source/en/model_doc/yolos.md
index 6185c3a067..5386c373ac 100644
--- a/docs/source/en/model_doc/yolos.md
+++ b/docs/source/en/model_doc/yolos.md
@@ -25,10 +25,6 @@ The abstract from the paper is the following:
*Can Transformer perform 2D object- and region-level recognition from a pure sequence-to-sequence perspective with minimal knowledge about the 2D spatial structure? To answer this question, we present You Only Look at One Sequence (YOLOS), a series of object detection models based on the vanilla Vision Transformer with the fewest possible modifications, region priors, as well as inductive biases of the target task. We find that YOLOS pre-trained on the mid-sized ImageNet-1k dataset only can already achieve quite competitive performance on the challenging COCO object detection benchmark, e.g., YOLOS-Base directly adopted from BERT-Base architecture can obtain 42.0 box AP on COCO val. We also discuss the impacts as well as limitations of current pre-train schemes and model scaling strategies for Transformer in vision through YOLOS.*
-Tips:
-
-- One can use [`YolosImageProcessor`] for preparing images (and optional targets) for the model. Contrary to [DETR](detr), YOLOS doesn't require a `pixel_mask` to be created.
-
 @@ -47,6 +43,12 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+
+Use [`YolosImageProcessor`] for preparing images (and optional targets) for the model. Contrary to [DETR](detr), YOLOS doesn't require a `pixel_mask` to be created.
+
+
+
## YolosConfig
[[autodoc]] YolosConfig
@@ -65,13 +67,11 @@ If you're interested in submitting a resource to be included here, please feel f
- pad
- post_process_object_detection
-
## YolosModel
[[autodoc]] YolosModel
- forward
-
## YolosForObjectDetection
[[autodoc]] YolosForObjectDetection
diff --git a/docs/source/en/model_doc/yoso.md b/docs/source/en/model_doc/yoso.md
index 4b98cd348c..a3dfa3fed8 100644
--- a/docs/source/en/model_doc/yoso.md
+++ b/docs/source/en/model_doc/yoso.md
@@ -37,7 +37,9 @@ length where we see favorable performance relative to a standard pretrained Tran
for evaluating performance on long sequences, our method achieves results consistent with softmax self-attention but with sizable
speed-ups and memory savings and often outperforms other efficient self-attention methods. Our code is available at this https URL*
-Tips:
+This model was contributed by [novice03](https://huggingface.co/novice03). The original code can be found [here](https://github.com/mlpen/YOSO).
+
+## Usage tips
- The YOSO attention algorithm is implemented through custom CUDA kernels, functions written in CUDA C++ that can be executed multiple times
in parallel on a GPU.
@@ -52,9 +54,7 @@ alt="drawing" width="600"/>
YOSO Attention Algorithm. Taken from the original paper.
-This model was contributed by [novice03](https://huggingface.co/novice03). The original code can be found [here](https://github.com/mlpen/YOSO).
-
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
@@ -66,19 +66,16 @@ This model was contributed by [novice03](https://huggingface.co/novice03). The o
[[autodoc]] YosoConfig
-
## YosoModel
[[autodoc]] YosoModel
- forward
-
## YosoForMaskedLM
[[autodoc]] YosoForMaskedLM
- forward
-
## YosoForSequenceClassification
[[autodoc]] YosoForSequenceClassification
@@ -89,13 +86,11 @@ This model was contributed by [novice03](https://huggingface.co/novice03). The o
[[autodoc]] YosoForMultipleChoice
- forward
-
## YosoForTokenClassification
[[autodoc]] YosoForTokenClassification
- forward
-
## YosoForQuestionAnswering
[[autodoc]] YosoForQuestionAnswering
@@ -47,6 +43,12 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+
+Use [`YolosImageProcessor`] for preparing images (and optional targets) for the model. Contrary to [DETR](detr), YOLOS doesn't require a `pixel_mask` to be created.
+
+
+
## YolosConfig
[[autodoc]] YolosConfig
@@ -65,13 +67,11 @@ If you're interested in submitting a resource to be included here, please feel f
- pad
- post_process_object_detection
-
## YolosModel
[[autodoc]] YolosModel
- forward
-
## YolosForObjectDetection
[[autodoc]] YolosForObjectDetection
diff --git a/docs/source/en/model_doc/yoso.md b/docs/source/en/model_doc/yoso.md
index 4b98cd348c..a3dfa3fed8 100644
--- a/docs/source/en/model_doc/yoso.md
+++ b/docs/source/en/model_doc/yoso.md
@@ -37,7 +37,9 @@ length where we see favorable performance relative to a standard pretrained Tran
for evaluating performance on long sequences, our method achieves results consistent with softmax self-attention but with sizable
speed-ups and memory savings and often outperforms other efficient self-attention methods. Our code is available at this https URL*
-Tips:
+This model was contributed by [novice03](https://huggingface.co/novice03). The original code can be found [here](https://github.com/mlpen/YOSO).
+
+## Usage tips
- The YOSO attention algorithm is implemented through custom CUDA kernels, functions written in CUDA C++ that can be executed multiple times
in parallel on a GPU.
@@ -52,9 +54,7 @@ alt="drawing" width="600"/>
YOSO Attention Algorithm. Taken from the original paper.
-This model was contributed by [novice03](https://huggingface.co/novice03). The original code can be found [here](https://github.com/mlpen/YOSO).
-
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
@@ -66,19 +66,16 @@ This model was contributed by [novice03](https://huggingface.co/novice03). The o
[[autodoc]] YosoConfig
-
## YosoModel
[[autodoc]] YosoModel
- forward
-
## YosoForMaskedLM
[[autodoc]] YosoForMaskedLM
- forward
-
## YosoForSequenceClassification
[[autodoc]] YosoForSequenceClassification
@@ -89,13 +86,11 @@ This model was contributed by [novice03](https://huggingface.co/novice03). The o
[[autodoc]] YosoForMultipleChoice
- forward
-
## YosoForTokenClassification
[[autodoc]] YosoForTokenClassification
- forward
-
## YosoForQuestionAnswering
[[autodoc]] YosoForQuestionAnswering
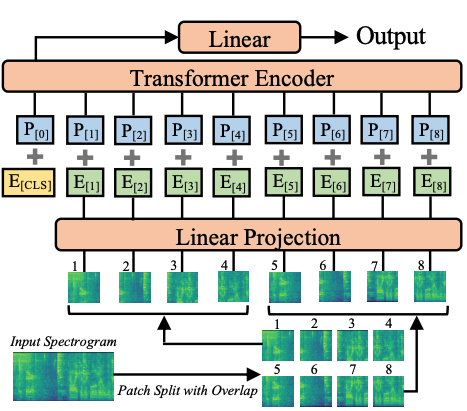 @@ -43,6 +34,15 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/YuanGongND/ast).
+## Usage tips
+
+- When fine-tuning the Audio Spectrogram Transformer (AST) on your own dataset, it's recommended to take care of the input normalization (to make
+sure the input has mean of 0 and std of 0.5). [`ASTFeatureExtractor`] takes care of this. Note that it uses the AudioSet
+mean and std by default. You can check [`ast/src/get_norm_stats.py`](https://github.com/YuanGongND/ast/blob/master/src/get_norm_stats.py) to see how
+the authors compute the stats for a downstream dataset.
+- Note that the AST needs a low learning rate (the authors use a 10 times smaller learning rate compared to their CNN model proposed in the
+[PSLA paper](https://arxiv.org/abs/2102.01243)) and converges quickly, so please search for a suitable learning rate and learning rate scheduler for your task.
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with the Audio Spectrogram Transformer.
diff --git a/docs/source/en/model_doc/autoformer.md b/docs/source/en/model_doc/autoformer.md
index 20977c71ca..bb423e941c 100644
--- a/docs/source/en/model_doc/autoformer.md
+++ b/docs/source/en/model_doc/autoformer.md
@@ -39,13 +39,11 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] AutoformerConfig
-
## AutoformerModel
[[autodoc]] AutoformerModel
- forward
-
## AutoformerForPrediction
[[autodoc]] AutoformerForPrediction
diff --git a/docs/source/en/model_doc/bark.md b/docs/source/en/model_doc/bark.md
index e287df13fe..0d9127d917 100644
--- a/docs/source/en/model_doc/bark.md
+++ b/docs/source/en/model_doc/bark.md
@@ -14,8 +14,7 @@ specific language governing permissions and limitations under the License.
## Overview
-Bark is a transformer-based text-to-speech model proposed by Suno AI in [suno-ai/bark](https://github.com/suno-ai/bark).
-
+Bark is a transformer-based text-to-speech model proposed by Suno AI in [suno-ai/bark](https://github.com/suno-ai/bark).
Bark is made of 4 main models:
@@ -26,6 +25,9 @@ Bark is made of 4 main models:
It should be noted that each of the first three modules can support conditional speaker embeddings to condition the output sound according to specific predefined voice.
+This model was contributed by [Yoach Lacombe (ylacombe)](https://huggingface.co/ylacombe) and [Sanchit Gandhi (sanchit-gandhi)](https://github.com/sanchit-gandhi).
+The original code can be found [here](https://github.com/suno-ai/bark).
+
### Optimizing Bark
Bark can be optimized with just a few extra lines of code, which **significantly reduces its memory footprint** and **accelerates inference**.
@@ -86,7 +88,7 @@ model.enable_cpu_offload()
Find out more on inference optimization techniques [here](https://huggingface.co/docs/transformers/perf_infer_gpu_one).
-### Tips
+### Usage tips
Suno offers a library of voice presets in a number of languages [here](https://suno-ai.notion.site/8b8e8749ed514b0cbf3f699013548683?v=bc67cff786b04b50b3ceb756fd05f68c).
These presets are also uploaded in the hub [here](https://huggingface.co/suno/bark-small/tree/main/speaker_embeddings) or [here](https://huggingface.co/suno/bark/tree/main/speaker_embeddings).
@@ -142,11 +144,6 @@ To save the audio, simply take the sample rate from the model config and some sc
>>> write_wav("bark_generation.wav", sample_rate, audio_array)
```
-
-This model was contributed by [Yoach Lacombe (ylacombe)](https://huggingface.co/ylacombe) and [Sanchit Gandhi (sanchit-gandhi)](https://github.com/sanchit-gandhi).
-The original code can be found [here](https://github.com/suno-ai/bark).
-
-
## BarkConfig
[[autodoc]] BarkConfig
diff --git a/docs/source/en/model_doc/bart.md b/docs/source/en/model_doc/bart.md
index dcf149fd85..7986228915 100644
--- a/docs/source/en/model_doc/bart.md
+++ b/docs/source/en/model_doc/bart.md
@@ -25,9 +25,6 @@ rendered properly in your Markdown viewer.
-**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) and assign
-@patrickvonplaten
-
## Overview
The Bart model was proposed in [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation,
@@ -45,7 +42,9 @@ According to the abstract,
state-of-the-art results on a range of abstractive dialogue, question answering, and summarization tasks, with gains
of up to 6 ROUGE.
-Tips:
+This model was contributed by [sshleifer](https://huggingface.co/sshleifer). The authors' code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/bart).
+
+## Usage tips:
- BART is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
@@ -57,18 +56,6 @@ Tips:
* permute sentences
* rotate the document to make it start at a specific token
-This model was contributed by [sshleifer](https://huggingface.co/sshleifer). The Authors' code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/bart).
-
-
-### Examples
-
-- Examples and scripts for fine-tuning BART and other models for sequence to sequence tasks can be found in
- [examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md).
-- An example of how to train [`BartForConditionalGeneration`] with a Hugging Face `datasets`
- object can be found in this [forum discussion](https://discuss.huggingface.co/t/train-bart-for-conditional-generation-e-g-summarization/1904).
-- [Distilled checkpoints](https://huggingface.co/models?search=distilbart) are described in this [paper](https://arxiv.org/abs/2010.13002).
-
-
## Implementation Notes
- Bart doesn't use `token_type_ids` for sequence classification. Use [`BartTokenizer`] or
@@ -112,6 +99,7 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
- [`BartForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization.ipynb).
- [`TFBartForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization-tf.ipynb).
- [`FlaxBartForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/summarization).
+- An example of how to train [`BartForConditionalGeneration`] with a Hugging Face `datasets` object can be found in this [forum discussion](https://discuss.huggingface.co/t/train-bart-for-conditional-generation-e-g-summarization/1904)
- [Summarization](https://huggingface.co/course/chapter7/5?fw=pt#summarization) chapter of the 🤗 Hugging Face course.
- [Summarization task guide](../tasks/summarization)
@@ -134,6 +122,7 @@ See also:
- [Text classification task guide](../tasks/sequence_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
+- [Distilled checkpoints](https://huggingface.co/models?search=distilbart) are described in this [paper](https://arxiv.org/abs/2010.13002).
## BartConfig
@@ -150,6 +139,10 @@ See also:
[[autodoc]] BartTokenizerFast
- all
+
+
@@ -43,6 +34,15 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/YuanGongND/ast).
+## Usage tips
+
+- When fine-tuning the Audio Spectrogram Transformer (AST) on your own dataset, it's recommended to take care of the input normalization (to make
+sure the input has mean of 0 and std of 0.5). [`ASTFeatureExtractor`] takes care of this. Note that it uses the AudioSet
+mean and std by default. You can check [`ast/src/get_norm_stats.py`](https://github.com/YuanGongND/ast/blob/master/src/get_norm_stats.py) to see how
+the authors compute the stats for a downstream dataset.
+- Note that the AST needs a low learning rate (the authors use a 10 times smaller learning rate compared to their CNN model proposed in the
+[PSLA paper](https://arxiv.org/abs/2102.01243)) and converges quickly, so please search for a suitable learning rate and learning rate scheduler for your task.
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with the Audio Spectrogram Transformer.
diff --git a/docs/source/en/model_doc/autoformer.md b/docs/source/en/model_doc/autoformer.md
index 20977c71ca..bb423e941c 100644
--- a/docs/source/en/model_doc/autoformer.md
+++ b/docs/source/en/model_doc/autoformer.md
@@ -39,13 +39,11 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] AutoformerConfig
-
## AutoformerModel
[[autodoc]] AutoformerModel
- forward
-
## AutoformerForPrediction
[[autodoc]] AutoformerForPrediction
diff --git a/docs/source/en/model_doc/bark.md b/docs/source/en/model_doc/bark.md
index e287df13fe..0d9127d917 100644
--- a/docs/source/en/model_doc/bark.md
+++ b/docs/source/en/model_doc/bark.md
@@ -14,8 +14,7 @@ specific language governing permissions and limitations under the License.
## Overview
-Bark is a transformer-based text-to-speech model proposed by Suno AI in [suno-ai/bark](https://github.com/suno-ai/bark).
-
+Bark is a transformer-based text-to-speech model proposed by Suno AI in [suno-ai/bark](https://github.com/suno-ai/bark).
Bark is made of 4 main models:
@@ -26,6 +25,9 @@ Bark is made of 4 main models:
It should be noted that each of the first three modules can support conditional speaker embeddings to condition the output sound according to specific predefined voice.
+This model was contributed by [Yoach Lacombe (ylacombe)](https://huggingface.co/ylacombe) and [Sanchit Gandhi (sanchit-gandhi)](https://github.com/sanchit-gandhi).
+The original code can be found [here](https://github.com/suno-ai/bark).
+
### Optimizing Bark
Bark can be optimized with just a few extra lines of code, which **significantly reduces its memory footprint** and **accelerates inference**.
@@ -86,7 +88,7 @@ model.enable_cpu_offload()
Find out more on inference optimization techniques [here](https://huggingface.co/docs/transformers/perf_infer_gpu_one).
-### Tips
+### Usage tips
Suno offers a library of voice presets in a number of languages [here](https://suno-ai.notion.site/8b8e8749ed514b0cbf3f699013548683?v=bc67cff786b04b50b3ceb756fd05f68c).
These presets are also uploaded in the hub [here](https://huggingface.co/suno/bark-small/tree/main/speaker_embeddings) or [here](https://huggingface.co/suno/bark/tree/main/speaker_embeddings).
@@ -142,11 +144,6 @@ To save the audio, simply take the sample rate from the model config and some sc
>>> write_wav("bark_generation.wav", sample_rate, audio_array)
```
-
-This model was contributed by [Yoach Lacombe (ylacombe)](https://huggingface.co/ylacombe) and [Sanchit Gandhi (sanchit-gandhi)](https://github.com/sanchit-gandhi).
-The original code can be found [here](https://github.com/suno-ai/bark).
-
-
## BarkConfig
[[autodoc]] BarkConfig
diff --git a/docs/source/en/model_doc/bart.md b/docs/source/en/model_doc/bart.md
index dcf149fd85..7986228915 100644
--- a/docs/source/en/model_doc/bart.md
+++ b/docs/source/en/model_doc/bart.md
@@ -25,9 +25,6 @@ rendered properly in your Markdown viewer.
-**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) and assign
-@patrickvonplaten
-
## Overview
The Bart model was proposed in [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation,
@@ -45,7 +42,9 @@ According to the abstract,
state-of-the-art results on a range of abstractive dialogue, question answering, and summarization tasks, with gains
of up to 6 ROUGE.
-Tips:
+This model was contributed by [sshleifer](https://huggingface.co/sshleifer). The authors' code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/bart).
+
+## Usage tips:
- BART is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
@@ -57,18 +56,6 @@ Tips:
* permute sentences
* rotate the document to make it start at a specific token
-This model was contributed by [sshleifer](https://huggingface.co/sshleifer). The Authors' code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/bart).
-
-
-### Examples
-
-- Examples and scripts for fine-tuning BART and other models for sequence to sequence tasks can be found in
- [examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md).
-- An example of how to train [`BartForConditionalGeneration`] with a Hugging Face `datasets`
- object can be found in this [forum discussion](https://discuss.huggingface.co/t/train-bart-for-conditional-generation-e-g-summarization/1904).
-- [Distilled checkpoints](https://huggingface.co/models?search=distilbart) are described in this [paper](https://arxiv.org/abs/2010.13002).
-
-
## Implementation Notes
- Bart doesn't use `token_type_ids` for sequence classification. Use [`BartTokenizer`] or
@@ -112,6 +99,7 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
- [`BartForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization.ipynb).
- [`TFBartForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization-tf.ipynb).
- [`FlaxBartForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/summarization).
+- An example of how to train [`BartForConditionalGeneration`] with a Hugging Face `datasets` object can be found in this [forum discussion](https://discuss.huggingface.co/t/train-bart-for-conditional-generation-e-g-summarization/1904)
- [Summarization](https://huggingface.co/course/chapter7/5?fw=pt#summarization) chapter of the 🤗 Hugging Face course.
- [Summarization task guide](../tasks/summarization)
@@ -134,6 +122,7 @@ See also:
- [Text classification task guide](../tasks/sequence_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
+- [Distilled checkpoints](https://huggingface.co/models?search=distilbart) are described in this [paper](https://arxiv.org/abs/2010.13002).
## BartConfig
@@ -150,6 +139,10 @@ See also:
[[autodoc]] BartTokenizerFast
- all
+
+ @@ -40,6 +35,11 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/salesforce/LAVIS/tree/5ee63d688ba4cebff63acee04adaef2dee9af207).
+## Usage tips
+
+- BLIP-2 can be used for conditional text generation given an image and an optional text prompt. At inference time, it's recommended to use the [`generate`] method.
+- One can use [`Blip2Processor`] to prepare images for the model, and decode the predicted tokens ID's back to text.
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BLIP-2.
diff --git a/docs/source/en/model_doc/blip.md b/docs/source/en/model_doc/blip.md
index 8afed63311..bc122c942a 100644
--- a/docs/source/en/model_doc/blip.md
+++ b/docs/source/en/model_doc/blip.md
@@ -20,7 +20,7 @@ rendered properly in your Markdown viewer.
The BLIP model was proposed in [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) by Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
-BLIP is a model that is able to perform various multi-modal tasks including
+BLIP is a model that is able to perform various multi-modal tasks including:
- Visual Question Answering
- Image-Text retrieval (Image-text matching)
- Image Captioning
@@ -39,7 +39,6 @@ The original code can be found [here](https://github.com/salesforce/BLIP).
- [Jupyter notebook](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_blip.ipynb) on how to fine-tune BLIP for image captioning on a custom dataset
-
## BlipConfig
[[autodoc]] BlipConfig
@@ -57,12 +56,14 @@ The original code can be found [here](https://github.com/salesforce/BLIP).
[[autodoc]] BlipProcessor
-
## BlipImageProcessor
[[autodoc]] BlipImageProcessor
- preprocess
+
@@ -40,6 +35,11 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/salesforce/LAVIS/tree/5ee63d688ba4cebff63acee04adaef2dee9af207).
+## Usage tips
+
+- BLIP-2 can be used for conditional text generation given an image and an optional text prompt. At inference time, it's recommended to use the [`generate`] method.
+- One can use [`Blip2Processor`] to prepare images for the model, and decode the predicted tokens ID's back to text.
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BLIP-2.
diff --git a/docs/source/en/model_doc/blip.md b/docs/source/en/model_doc/blip.md
index 8afed63311..bc122c942a 100644
--- a/docs/source/en/model_doc/blip.md
+++ b/docs/source/en/model_doc/blip.md
@@ -20,7 +20,7 @@ rendered properly in your Markdown viewer.
The BLIP model was proposed in [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) by Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
-BLIP is a model that is able to perform various multi-modal tasks including
+BLIP is a model that is able to perform various multi-modal tasks including:
- Visual Question Answering
- Image-Text retrieval (Image-text matching)
- Image Captioning
@@ -39,7 +39,6 @@ The original code can be found [here](https://github.com/salesforce/BLIP).
- [Jupyter notebook](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_blip.ipynb) on how to fine-tune BLIP for image captioning on a custom dataset
-
## BlipConfig
[[autodoc]] BlipConfig
@@ -57,12 +56,14 @@ The original code can be found [here](https://github.com/salesforce/BLIP).
[[autodoc]] BlipProcessor
-
## BlipImageProcessor
[[autodoc]] BlipImageProcessor
- preprocess
+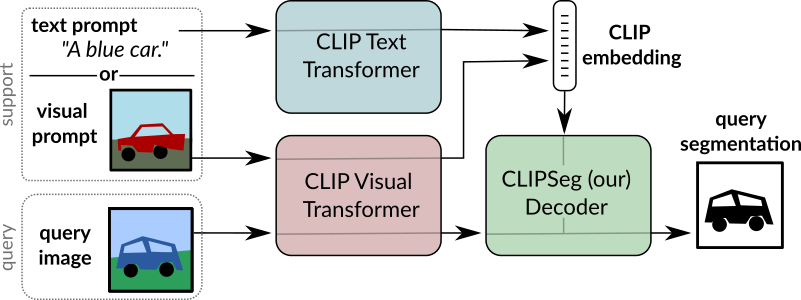 @@ -56,6 +49,13 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/timojl/clipseg).
+## Usage tips
+
+- [`CLIPSegForImageSegmentation`] adds a decoder on top of [`CLIPSegModel`]. The latter is identical to [`CLIPModel`].
+- [`CLIPSegForImageSegmentation`] can generate image segmentations based on arbitrary prompts at test time. A prompt can be either a text
+(provided to the model as `input_ids`) or an image (provided to the model as `conditional_pixel_values`). One can also provide custom
+conditional embeddings (provided to the model as `conditional_embeddings`).
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with CLIPSeg. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
diff --git a/docs/source/en/model_doc/code_llama.md b/docs/source/en/model_doc/code_llama.md
index a60cf16415..38d50c8733 100644
--- a/docs/source/en/model_doc/code_llama.md
+++ b/docs/source/en/model_doc/code_llama.md
@@ -24,7 +24,11 @@ The abstract from the paper is the following:
*We release Code Llama, a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models, infilling capabilities, support for large input contexts, and zero-shot instruction following ability for programming tasks. We provide multiple flavors to cover a wide range of applications: foundation models (Code Llama), Python specializations (Code Llama - Python), and instruction-following models (Code Llama - Instruct) with 7B, 13B and 34B parameters each. All models are trained on sequences of 16k tokens and show improvements on inputs with up to 100k tokens. 7B and 13B Code Llama and Code Llama - Instruct variants support infilling based on surrounding content. Code Llama reaches state-of-the-art performance among open models on several code benchmarks, with scores of up to 53% and 55% on HumanEval and MBPP, respectively. Notably, Code Llama - Python 7B outperforms Llama 2 70B on HumanEval and MBPP, and all our models outperform every other publicly available model on MultiPL-E. We release Code Llama under a permissive license that allows for both research and commercial use.*
-Check out all Code Llama models [here](https://huggingface.co/models?search=code_llama) and the officially released ones in the [codellama org](https://huggingface.co/codellama).
+Check out all Code Llama model checkpoints [here](https://huggingface.co/models?search=code_llama) and the officially released ones in the [codellama org](https://huggingface.co/codellama).
+
+This model was contributed by [ArthurZucker](https://huggingface.co/ArthurZ). The original code of the authors can be found [here](https://github.com/facebookresearch/llama).
+
+## Usage tips and examples
@@ -56,6 +49,13 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/timojl/clipseg).
+## Usage tips
+
+- [`CLIPSegForImageSegmentation`] adds a decoder on top of [`CLIPSegModel`]. The latter is identical to [`CLIPModel`].
+- [`CLIPSegForImageSegmentation`] can generate image segmentations based on arbitrary prompts at test time. A prompt can be either a text
+(provided to the model as `input_ids`) or an image (provided to the model as `conditional_pixel_values`). One can also provide custom
+conditional embeddings (provided to the model as `conditional_embeddings`).
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with CLIPSeg. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
diff --git a/docs/source/en/model_doc/code_llama.md b/docs/source/en/model_doc/code_llama.md
index a60cf16415..38d50c8733 100644
--- a/docs/source/en/model_doc/code_llama.md
+++ b/docs/source/en/model_doc/code_llama.md
@@ -24,7 +24,11 @@ The abstract from the paper is the following:
*We release Code Llama, a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models, infilling capabilities, support for large input contexts, and zero-shot instruction following ability for programming tasks. We provide multiple flavors to cover a wide range of applications: foundation models (Code Llama), Python specializations (Code Llama - Python), and instruction-following models (Code Llama - Instruct) with 7B, 13B and 34B parameters each. All models are trained on sequences of 16k tokens and show improvements on inputs with up to 100k tokens. 7B and 13B Code Llama and Code Llama - Instruct variants support infilling based on surrounding content. Code Llama reaches state-of-the-art performance among open models on several code benchmarks, with scores of up to 53% and 55% on HumanEval and MBPP, respectively. Notably, Code Llama - Python 7B outperforms Llama 2 70B on HumanEval and MBPP, and all our models outperform every other publicly available model on MultiPL-E. We release Code Llama under a permissive license that allows for both research and commercial use.*
-Check out all Code Llama models [here](https://huggingface.co/models?search=code_llama) and the officially released ones in the [codellama org](https://huggingface.co/codellama).
+Check out all Code Llama model checkpoints [here](https://huggingface.co/models?search=code_llama) and the officially released ones in the [codellama org](https://huggingface.co/codellama).
+
+This model was contributed by [ArthurZucker](https://huggingface.co/ArthurZ). The original code of the authors can be found [here](https://github.com/facebookresearch/llama).
+
+## Usage tips and examples
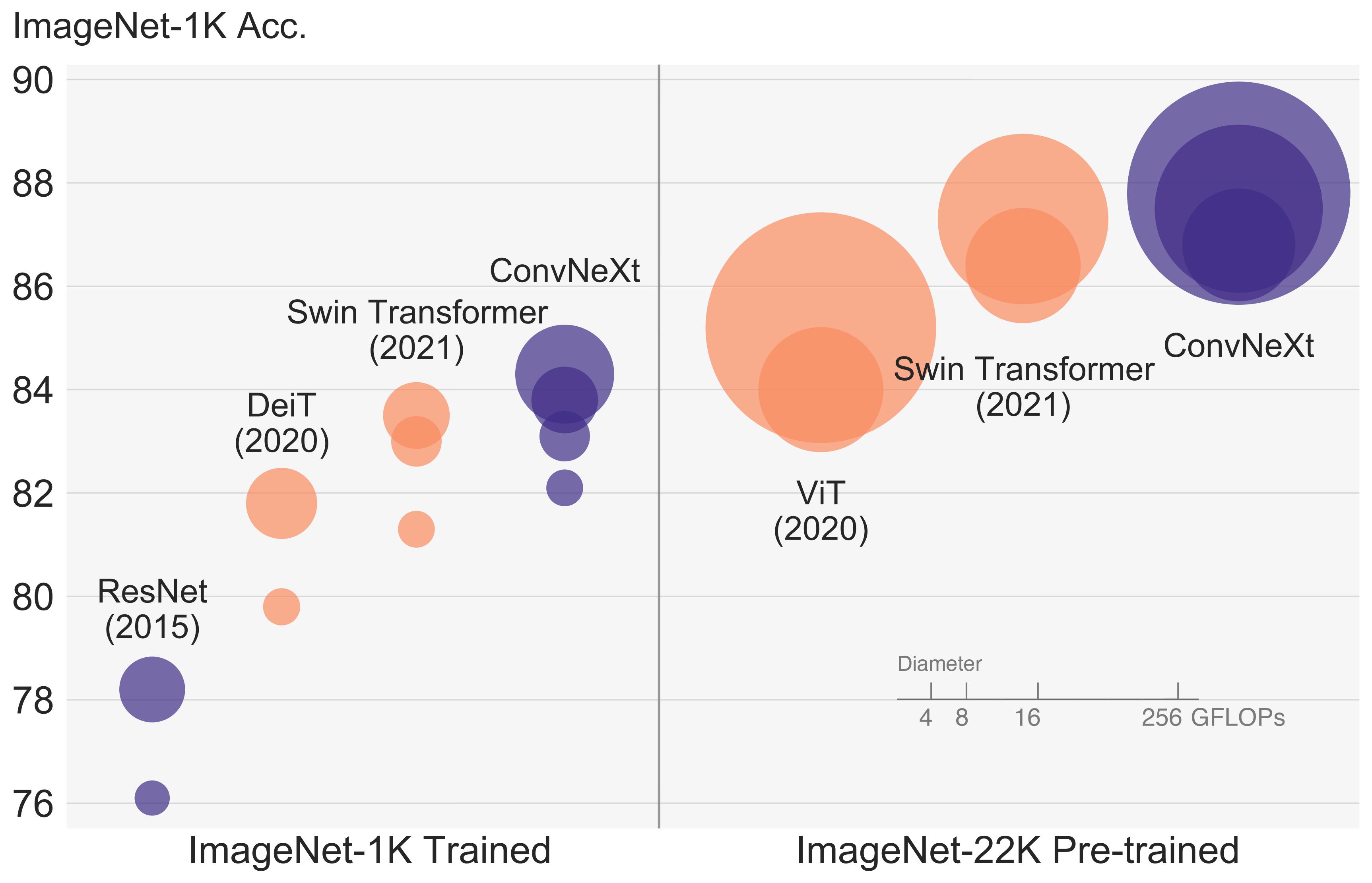 @@ -68,6 +64,9 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] ConvNextImageProcessor
- preprocess
+
@@ -68,6 +64,9 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] ConvNextImageProcessor
- preprocess
+ diff --git a/docs/source/en/model_doc/cpm.md b/docs/source/en/model_doc/cpm.md
index a2ecf1a1e0..129c4ed3a3 100644
--- a/docs/source/en/model_doc/cpm.md
+++ b/docs/source/en/model_doc/cpm.md
@@ -37,7 +37,14 @@ NLP tasks in the settings of few-shot (even zero-shot) learning.*
This model was contributed by [canwenxu](https://huggingface.co/canwenxu). The original implementation can be found
here: https://github.com/TsinghuaAI/CPM-Generate
-Note: We only have a tokenizer here, since the model architecture is the same as GPT-2.
+
+
diff --git a/docs/source/en/model_doc/cpm.md b/docs/source/en/model_doc/cpm.md
index a2ecf1a1e0..129c4ed3a3 100644
--- a/docs/source/en/model_doc/cpm.md
+++ b/docs/source/en/model_doc/cpm.md
@@ -37,7 +37,14 @@ NLP tasks in the settings of few-shot (even zero-shot) learning.*
This model was contributed by [canwenxu](https://huggingface.co/canwenxu). The original implementation can be found
here: https://github.com/TsinghuaAI/CPM-Generate
-Note: We only have a tokenizer here, since the model architecture is the same as GPT-2.
+
+ @@ -37,6 +32,10 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/fundamentalvision/Deformable-DETR).
+## Usage tips
+
+- Training Deformable DETR is equivalent to training the original [DETR](detr) model. See the [resources](#resources) section below for demo notebooks.
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Deformable DETR.
diff --git a/docs/source/en/model_doc/deit.md b/docs/source/en/model_doc/deit.md
index ef32e05ebd..7d9918a45e 100644
--- a/docs/source/en/model_doc/deit.md
+++ b/docs/source/en/model_doc/deit.md
@@ -16,13 +16,6 @@ rendered properly in your Markdown viewer.
# DeiT
-
@@ -37,6 +32,10 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/fundamentalvision/Deformable-DETR).
+## Usage tips
+
+- Training Deformable DETR is equivalent to training the original [DETR](detr) model. See the [resources](#resources) section below for demo notebooks.
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Deformable DETR.
diff --git a/docs/source/en/model_doc/deit.md b/docs/source/en/model_doc/deit.md
index ef32e05ebd..7d9918a45e 100644
--- a/docs/source/en/model_doc/deit.md
+++ b/docs/source/en/model_doc/deit.md
@@ -16,13 +16,6 @@ rendered properly in your Markdown viewer.
# DeiT
-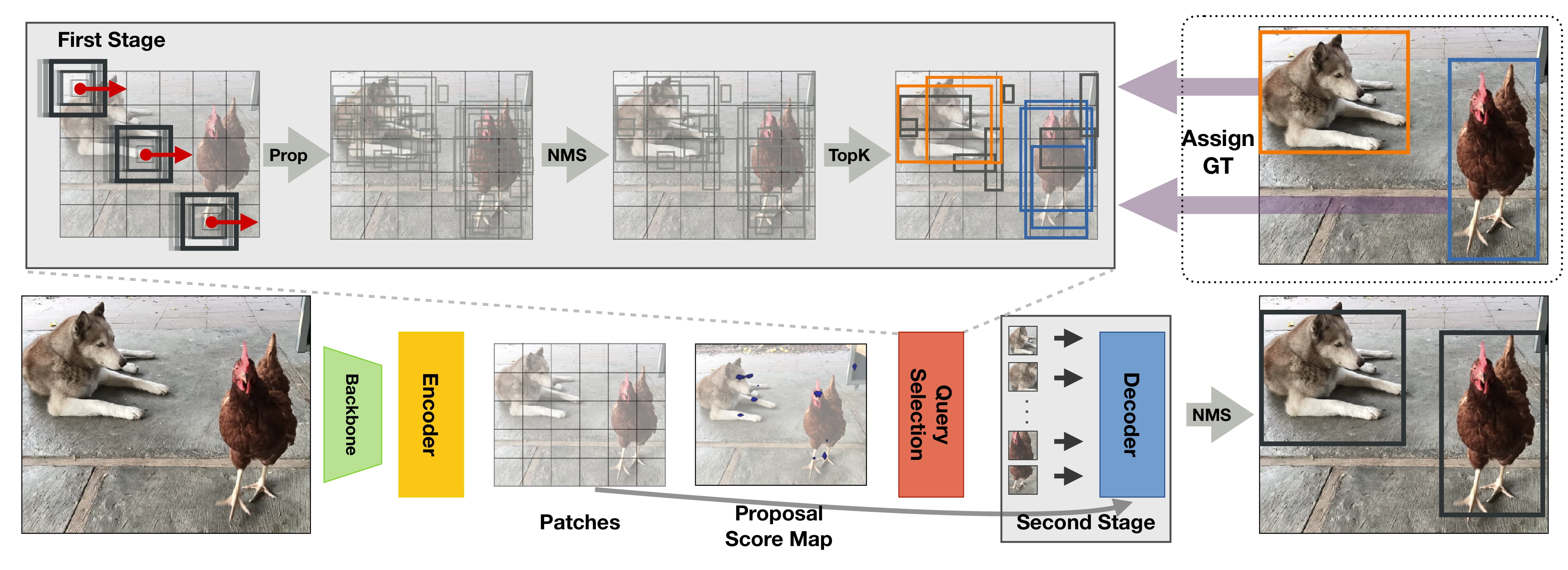 @@ -51,20 +47,17 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] DetaConfig
-
## DetaImageProcessor
[[autodoc]] DetaImageProcessor
- preprocess
- post_process_object_detection
-
## DetaModel
[[autodoc]] DetaModel
- forward
-
## DetaForObjectDetection
[[autodoc]] DetaForObjectDetection
diff --git a/docs/source/en/model_doc/detr.md b/docs/source/en/model_doc/detr.md
index 2c03a0f8b8..c36bd4380e 100644
--- a/docs/source/en/model_doc/detr.md
+++ b/docs/source/en/model_doc/detr.md
@@ -41,6 +41,8 @@ baselines.*
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/facebookresearch/detr).
+## How DETR works
+
Here's a TLDR explaining how [`~transformers.DetrForObjectDetection`] works:
First, an image is sent through a pre-trained convolutional backbone (in the paper, the authors use
@@ -79,7 +81,7 @@ where one first trains a [`~transformers.DetrForObjectDetection`] model to detec
the mask head for 25 epochs. Experimentally, these two approaches give similar results. Note that predicting boxes is
required for the training to be possible, since the Hungarian matching is computed using distances between boxes.
-Tips:
+## Usage tips
- DETR uses so-called **object queries** to detect objects in an image. The number of queries determines the maximum
number of objects that can be detected in a single image, and is set to 100 by default (see parameter
@@ -165,14 +167,6 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
-## DETR specific outputs
-
-[[autodoc]] models.detr.modeling_detr.DetrModelOutput
-
-[[autodoc]] models.detr.modeling_detr.DetrObjectDetectionOutput
-
-[[autodoc]] models.detr.modeling_detr.DetrSegmentationOutput
-
## DetrConfig
[[autodoc]] DetrConfig
@@ -195,6 +189,14 @@ If you're interested in submitting a resource to be included here, please feel f
- post_process_instance_segmentation
- post_process_panoptic_segmentation
+## DETR specific outputs
+
+[[autodoc]] models.detr.modeling_detr.DetrModelOutput
+
+[[autodoc]] models.detr.modeling_detr.DetrObjectDetectionOutput
+
+[[autodoc]] models.detr.modeling_detr.DetrSegmentationOutput
+
## DetrModel
[[autodoc]] DetrModel
diff --git a/docs/source/en/model_doc/dialogpt.md b/docs/source/en/model_doc/dialogpt.md
index 70929409b2..558b91d76d 100644
--- a/docs/source/en/model_doc/dialogpt.md
+++ b/docs/source/en/model_doc/dialogpt.md
@@ -32,7 +32,9 @@ that leverage DialoGPT generate more relevant, contentful and context-consistent
systems. The pre-trained model and training pipeline are publicly released to facilitate research into neural response
generation and the development of more intelligent open-domain dialogue systems.*
-Tips:
+The original code can be found [here](https://github.com/microsoft/DialoGPT).
+
+## Usage tips
- DialoGPT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather
than the left.
@@ -47,7 +49,8 @@ follow the OpenAI GPT-2 to model a multiturn dialogue session as a long text and
modeling. We first concatenate all dialog turns within a dialogue session into a long text x_1,..., x_N (N is the
sequence length), ended by the end-of-text token.* For more information please confer to the original paper.
+
@@ -51,20 +47,17 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] DetaConfig
-
## DetaImageProcessor
[[autodoc]] DetaImageProcessor
- preprocess
- post_process_object_detection
-
## DetaModel
[[autodoc]] DetaModel
- forward
-
## DetaForObjectDetection
[[autodoc]] DetaForObjectDetection
diff --git a/docs/source/en/model_doc/detr.md b/docs/source/en/model_doc/detr.md
index 2c03a0f8b8..c36bd4380e 100644
--- a/docs/source/en/model_doc/detr.md
+++ b/docs/source/en/model_doc/detr.md
@@ -41,6 +41,8 @@ baselines.*
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/facebookresearch/detr).
+## How DETR works
+
Here's a TLDR explaining how [`~transformers.DetrForObjectDetection`] works:
First, an image is sent through a pre-trained convolutional backbone (in the paper, the authors use
@@ -79,7 +81,7 @@ where one first trains a [`~transformers.DetrForObjectDetection`] model to detec
the mask head for 25 epochs. Experimentally, these two approaches give similar results. Note that predicting boxes is
required for the training to be possible, since the Hungarian matching is computed using distances between boxes.
-Tips:
+## Usage tips
- DETR uses so-called **object queries** to detect objects in an image. The number of queries determines the maximum
number of objects that can be detected in a single image, and is set to 100 by default (see parameter
@@ -165,14 +167,6 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
-## DETR specific outputs
-
-[[autodoc]] models.detr.modeling_detr.DetrModelOutput
-
-[[autodoc]] models.detr.modeling_detr.DetrObjectDetectionOutput
-
-[[autodoc]] models.detr.modeling_detr.DetrSegmentationOutput
-
## DetrConfig
[[autodoc]] DetrConfig
@@ -195,6 +189,14 @@ If you're interested in submitting a resource to be included here, please feel f
- post_process_instance_segmentation
- post_process_panoptic_segmentation
+## DETR specific outputs
+
+[[autodoc]] models.detr.modeling_detr.DetrModelOutput
+
+[[autodoc]] models.detr.modeling_detr.DetrObjectDetectionOutput
+
+[[autodoc]] models.detr.modeling_detr.DetrSegmentationOutput
+
## DetrModel
[[autodoc]] DetrModel
diff --git a/docs/source/en/model_doc/dialogpt.md b/docs/source/en/model_doc/dialogpt.md
index 70929409b2..558b91d76d 100644
--- a/docs/source/en/model_doc/dialogpt.md
+++ b/docs/source/en/model_doc/dialogpt.md
@@ -32,7 +32,9 @@ that leverage DialoGPT generate more relevant, contentful and context-consistent
systems. The pre-trained model and training pipeline are publicly released to facilitate research into neural response
generation and the development of more intelligent open-domain dialogue systems.*
-Tips:
+The original code can be found [here](https://github.com/microsoft/DialoGPT).
+
+## Usage tips
- DialoGPT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather
than the left.
@@ -47,7 +49,8 @@ follow the OpenAI GPT-2 to model a multiturn dialogue session as a long text and
modeling. We first concatenate all dialog turns within a dialogue session into a long text x_1,..., x_N (N is the
sequence length), ended by the end-of-text token.* For more information please confer to the original paper.
+ @@ -65,6 +54,17 @@ Taken from the original paper.
+
@@ -65,6 +54,17 @@ Taken from the original paper.
+ @@ -40,6 +35,10 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/microsoft/GenerativeImage2Text).
+## Usage tips
+
+- GIT is implemented in a very similar way to GPT-2, the only difference being that the model is also conditioned on `pixel_values`.
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with GIT.
diff --git a/docs/source/en/model_doc/glpn.md b/docs/source/en/model_doc/glpn.md
index be9a7d2d79..b57d1a7ccd 100644
--- a/docs/source/en/model_doc/glpn.md
+++ b/docs/source/en/model_doc/glpn.md
@@ -33,10 +33,6 @@ The abstract from the paper is the following:
*Depth estimation from a single image is an important task that can be applied to various fields in computer vision, and has grown rapidly with the development of convolutional neural networks. In this paper, we propose a novel structure and training strategy for monocular depth estimation to further improve the prediction accuracy of the network. We deploy a hierarchical transformer encoder to capture and convey the global context, and design a lightweight yet powerful decoder to generate an estimated depth map while considering local connectivity. By constructing connected paths between multi-scale local features and the global decoding stream with our proposed selective feature fusion module, the network can integrate both representations and recover fine details. In addition, the proposed decoder shows better performance than the previously proposed decoders, with considerably less computational complexity. Furthermore, we improve the depth-specific augmentation method by utilizing an important observation in depth estimation to enhance the model. Our network achieves state-of-the-art performance over the challenging depth dataset NYU Depth V2. Extensive experiments have been conducted to validate and show the effectiveness of the proposed approach. Finally, our model shows better generalisation ability and robustness than other comparative models.*
-Tips:
-
-- One can use [`GLPNImageProcessor`] to prepare images for the model.
-
@@ -40,6 +35,10 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/microsoft/GenerativeImage2Text).
+## Usage tips
+
+- GIT is implemented in a very similar way to GPT-2, the only difference being that the model is also conditioned on `pixel_values`.
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with GIT.
diff --git a/docs/source/en/model_doc/glpn.md b/docs/source/en/model_doc/glpn.md
index be9a7d2d79..b57d1a7ccd 100644
--- a/docs/source/en/model_doc/glpn.md
+++ b/docs/source/en/model_doc/glpn.md
@@ -33,10 +33,6 @@ The abstract from the paper is the following:
*Depth estimation from a single image is an important task that can be applied to various fields in computer vision, and has grown rapidly with the development of convolutional neural networks. In this paper, we propose a novel structure and training strategy for monocular depth estimation to further improve the prediction accuracy of the network. We deploy a hierarchical transformer encoder to capture and convey the global context, and design a lightweight yet powerful decoder to generate an estimated depth map while considering local connectivity. By constructing connected paths between multi-scale local features and the global decoding stream with our proposed selective feature fusion module, the network can integrate both representations and recover fine details. In addition, the proposed decoder shows better performance than the previously proposed decoders, with considerably less computational complexity. Furthermore, we improve the depth-specific augmentation method by utilizing an important observation in depth estimation to enhance the model. Our network achieves state-of-the-art performance over the challenging depth dataset NYU Depth V2. Extensive experiments have been conducted to validate and show the effectiveness of the proposed approach. Finally, our model shows better generalisation ability and robustness than other comparative models.*
-Tips:
-
-- One can use [`GLPNImageProcessor`] to prepare images for the model.
-
 diff --git a/docs/source/en/model_doc/gpt-sw3.md b/docs/source/en/model_doc/gpt-sw3.md
index 286cac12c9..f4d34a0721 100644
--- a/docs/source/en/model_doc/gpt-sw3.md
+++ b/docs/source/en/model_doc/gpt-sw3.md
@@ -32,12 +32,8 @@ causal language modeling (CLM) objective utilizing the NeMo Megatron GPT impleme
This model was contributed by [AI Sweden](https://huggingface.co/AI-Sweden).
-The implementation uses the [GPT2Model](https://huggingface.co/docs/transformers/model_doc/gpt2) coupled
-with our `GPTSw3Tokenizer`. This means that `AutoTokenizer` and `AutoModelForCausalLM` map to our tokenizer
-implementation and the corresponding GPT2 model implementation respectively.
-*Note that sentencepiece is required to use our tokenizer and can be installed with:* `pip install transformers[sentencepiece]` or `pip install sentencepiece`
+## Usage example
-Example usage:
```python
>>> from transformers import AutoTokenizer, AutoModelForCausalLM
@@ -52,12 +48,21 @@ Example usage:
Träd är fina för att de är färgstarka. Men ibland är det fint
```
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Causal language modeling task guide](../tasks/language_modeling)
+
diff --git a/docs/source/en/model_doc/gpt-sw3.md b/docs/source/en/model_doc/gpt-sw3.md
index 286cac12c9..f4d34a0721 100644
--- a/docs/source/en/model_doc/gpt-sw3.md
+++ b/docs/source/en/model_doc/gpt-sw3.md
@@ -32,12 +32,8 @@ causal language modeling (CLM) objective utilizing the NeMo Megatron GPT impleme
This model was contributed by [AI Sweden](https://huggingface.co/AI-Sweden).
-The implementation uses the [GPT2Model](https://huggingface.co/docs/transformers/model_doc/gpt2) coupled
-with our `GPTSw3Tokenizer`. This means that `AutoTokenizer` and `AutoModelForCausalLM` map to our tokenizer
-implementation and the corresponding GPT2 model implementation respectively.
-*Note that sentencepiece is required to use our tokenizer and can be installed with:* `pip install transformers[sentencepiece]` or `pip install sentencepiece`
+## Usage example
-Example usage:
```python
>>> from transformers import AutoTokenizer, AutoModelForCausalLM
@@ -52,12 +48,21 @@ Example usage:
Träd är fina för att de är färgstarka. Men ibland är det fint
```
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Causal language modeling task guide](../tasks/language_modeling)
+ @@ -33,6 +29,9 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/salesforce/LAVIS/tree/main/projects/instructblip).
+## Usage tips
+
+InstructBLIP uses the same architecture as [BLIP-2](blip2) with a tiny but important difference: it also feeds the text prompt (instruction) to the Q-Former.
## InstructBlipConfig
diff --git a/docs/source/en/model_doc/jukebox.md b/docs/source/en/model_doc/jukebox.md
index 24a80164a2..a6d865d86c 100644
--- a/docs/source/en/model_doc/jukebox.md
+++ b/docs/source/en/model_doc/jukebox.md
@@ -32,7 +32,11 @@ The metadata such as *artist, genre and timing* are passed to each prior, in the

-Tips:
+This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ).
+The original code can be found [here](https://github.com/openai/jukebox).
+
+## Usage tips
+
- This model only supports inference. This is for a few reasons, mostly because it requires a crazy amount of memory to train. Feel free to open a PR and add what's missing to have a full integration with the hugging face traineer!
- This model is very slow, and takes 8h to generate a minute long audio using the 5b top prior on a V100 GPU. In order automaticallay handle the device on which the model should execute, use `accelerate`.
- Contrary to the paper, the order of the priors goes from `0` to `1` as it felt more intuitive : we sample starting from `0`.
@@ -67,14 +71,12 @@ The original code can be found [here](https://github.com/openai/jukebox).
- upsample
- _sample
-
## JukeboxPrior
[[autodoc]] JukeboxPrior
- sample
- forward
-
## JukeboxVQVAE
[[autodoc]] JukeboxVQVAE
diff --git a/docs/source/en/model_doc/layoutlm.md b/docs/source/en/model_doc/layoutlm.md
index ebf6b1a4b4..34b429fb73 100644
--- a/docs/source/en/model_doc/layoutlm.md
+++ b/docs/source/en/model_doc/layoutlm.md
@@ -46,7 +46,7 @@ document-level pretraining. It achieves new state-of-the-art results in several
understanding (from 70.72 to 79.27), receipt understanding (from 94.02 to 95.24) and document image classification
(from 93.07 to 94.42).*
-Tips:
+## Usage tips
- In addition to *input_ids*, [`~transformers.LayoutLMModel.forward`] also expects the input `bbox`, which are
the bounding boxes (i.e. 2D-positions) of the input tokens. These can be obtained using an external OCR engine such
@@ -123,6 +123,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] LayoutLMTokenizerFast
+
@@ -33,6 +29,9 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/salesforce/LAVIS/tree/main/projects/instructblip).
+## Usage tips
+
+InstructBLIP uses the same architecture as [BLIP-2](blip2) with a tiny but important difference: it also feeds the text prompt (instruction) to the Q-Former.
## InstructBlipConfig
diff --git a/docs/source/en/model_doc/jukebox.md b/docs/source/en/model_doc/jukebox.md
index 24a80164a2..a6d865d86c 100644
--- a/docs/source/en/model_doc/jukebox.md
+++ b/docs/source/en/model_doc/jukebox.md
@@ -32,7 +32,11 @@ The metadata such as *artist, genre and timing* are passed to each prior, in the

-Tips:
+This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ).
+The original code can be found [here](https://github.com/openai/jukebox).
+
+## Usage tips
+
- This model only supports inference. This is for a few reasons, mostly because it requires a crazy amount of memory to train. Feel free to open a PR and add what's missing to have a full integration with the hugging face traineer!
- This model is very slow, and takes 8h to generate a minute long audio using the 5b top prior on a V100 GPU. In order automaticallay handle the device on which the model should execute, use `accelerate`.
- Contrary to the paper, the order of the priors goes from `0` to `1` as it felt more intuitive : we sample starting from `0`.
@@ -67,14 +71,12 @@ The original code can be found [here](https://github.com/openai/jukebox).
- upsample
- _sample
-
## JukeboxPrior
[[autodoc]] JukeboxPrior
- sample
- forward
-
## JukeboxVQVAE
[[autodoc]] JukeboxVQVAE
diff --git a/docs/source/en/model_doc/layoutlm.md b/docs/source/en/model_doc/layoutlm.md
index ebf6b1a4b4..34b429fb73 100644
--- a/docs/source/en/model_doc/layoutlm.md
+++ b/docs/source/en/model_doc/layoutlm.md
@@ -46,7 +46,7 @@ document-level pretraining. It achieves new state-of-the-art results in several
understanding (from 70.72 to 79.27), receipt understanding (from 94.02 to 95.24) and document image classification
(from 93.07 to 94.42).*
-Tips:
+## Usage tips
- In addition to *input_ids*, [`~transformers.LayoutLMModel.forward`] also expects the input `bbox`, which are
the bounding boxes (i.e. 2D-positions) of the input tokens. These can be obtained using an external OCR engine such
@@ -123,6 +123,9 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
[[autodoc]] LayoutLMTokenizerFast
+ @@ -43,6 +33,14 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version of this model was added by [chriskoo](https://huggingface.co/chriskoo), [tokec](https://huggingface.co/tokec), and [lre](https://huggingface.co/lre). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/layoutlmv3).
+## Usage tips
+
+- In terms of data processing, LayoutLMv3 is identical to its predecessor [LayoutLMv2](layoutlmv2), except that:
+ - images need to be resized and normalized with channels in regular RGB format. LayoutLMv2 on the other hand normalizes the images internally and expects the channels in BGR format.
+ - text is tokenized using byte-pair encoding (BPE), as opposed to WordPiece.
+ Due to these differences in data preprocessing, one can use [`LayoutLMv3Processor`] which internally combines a [`LayoutLMv3ImageProcessor`] (for the image modality) and a [`LayoutLMv3Tokenizer`]/[`LayoutLMv3TokenizerFast`] (for the text modality) to prepare all data for the model.
+- Regarding usage of [`LayoutLMv3Processor`], we refer to the [usage guide](layoutlmv2#usage-layoutlmv2processor) of its predecessor.
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LayoutLMv3. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
@@ -53,6 +51,9 @@ LayoutLMv3 is nearly identical to LayoutLMv2, so we've also included LayoutLMv2
@@ -43,6 +33,14 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version of this model was added by [chriskoo](https://huggingface.co/chriskoo), [tokec](https://huggingface.co/tokec), and [lre](https://huggingface.co/lre). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/layoutlmv3).
+## Usage tips
+
+- In terms of data processing, LayoutLMv3 is identical to its predecessor [LayoutLMv2](layoutlmv2), except that:
+ - images need to be resized and normalized with channels in regular RGB format. LayoutLMv2 on the other hand normalizes the images internally and expects the channels in BGR format.
+ - text is tokenized using byte-pair encoding (BPE), as opposed to WordPiece.
+ Due to these differences in data preprocessing, one can use [`LayoutLMv3Processor`] which internally combines a [`LayoutLMv3ImageProcessor`] (for the image modality) and a [`LayoutLMv3Tokenizer`]/[`LayoutLMv3TokenizerFast`] (for the text modality) to prepare all data for the model.
+- Regarding usage of [`LayoutLMv3Processor`], we refer to the [usage guide](layoutlmv2#usage-layoutlmv2processor) of its predecessor.
+
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LayoutLMv3. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
@@ -53,6 +51,9 @@ LayoutLMv3 is nearly identical to LayoutLMv2, so we've also included LayoutLMv2
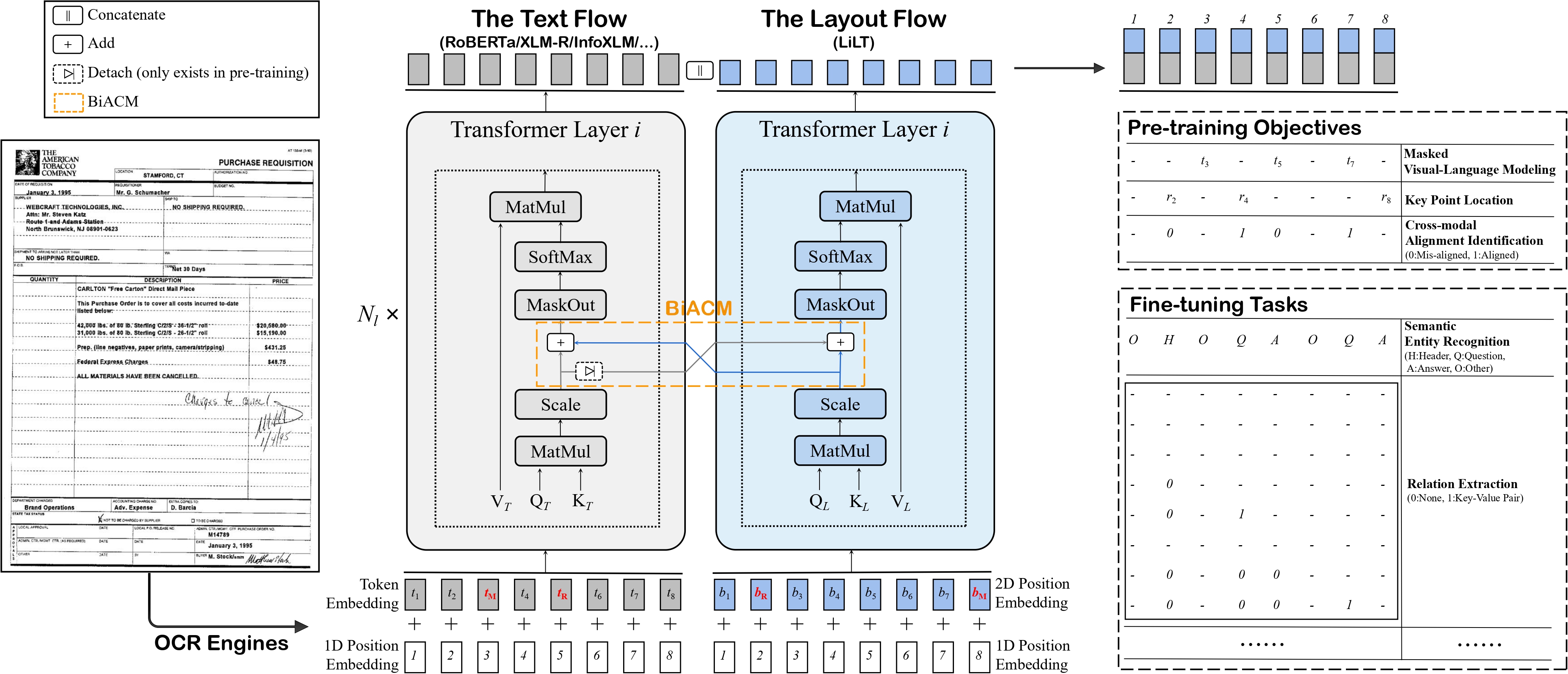 +
+ LiLT architecture. Taken from the
+
+ LiLT architecture. Taken from the 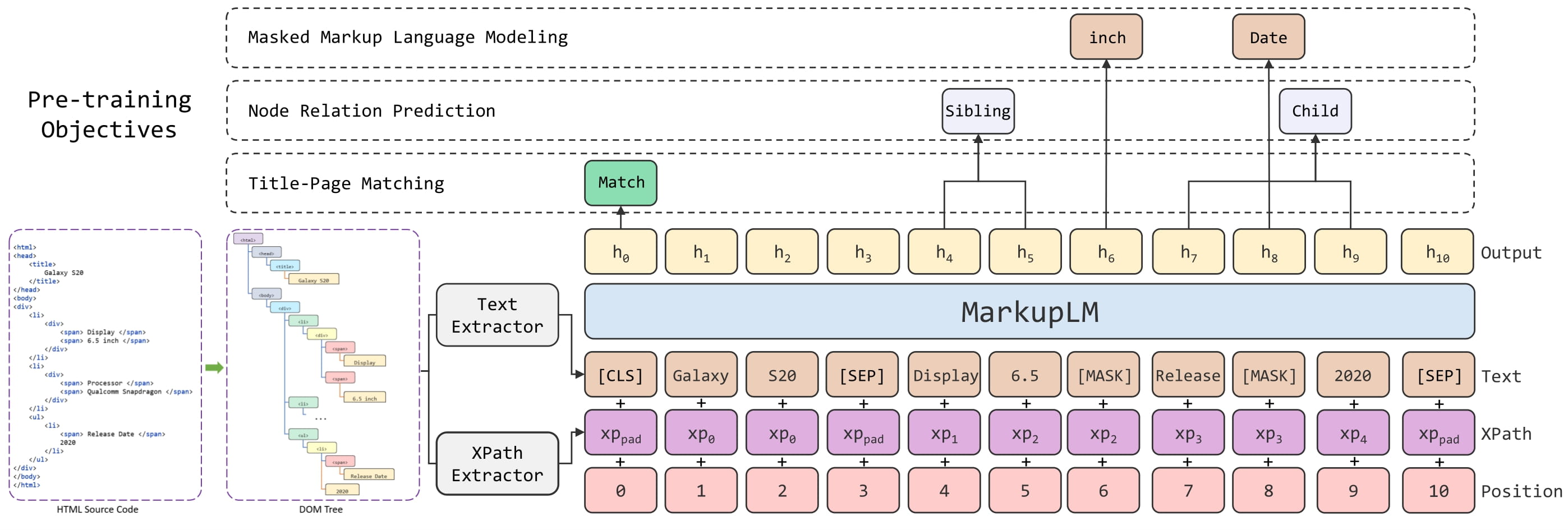 MarkupLM architecture. Taken from the
MarkupLM architecture. Taken from the 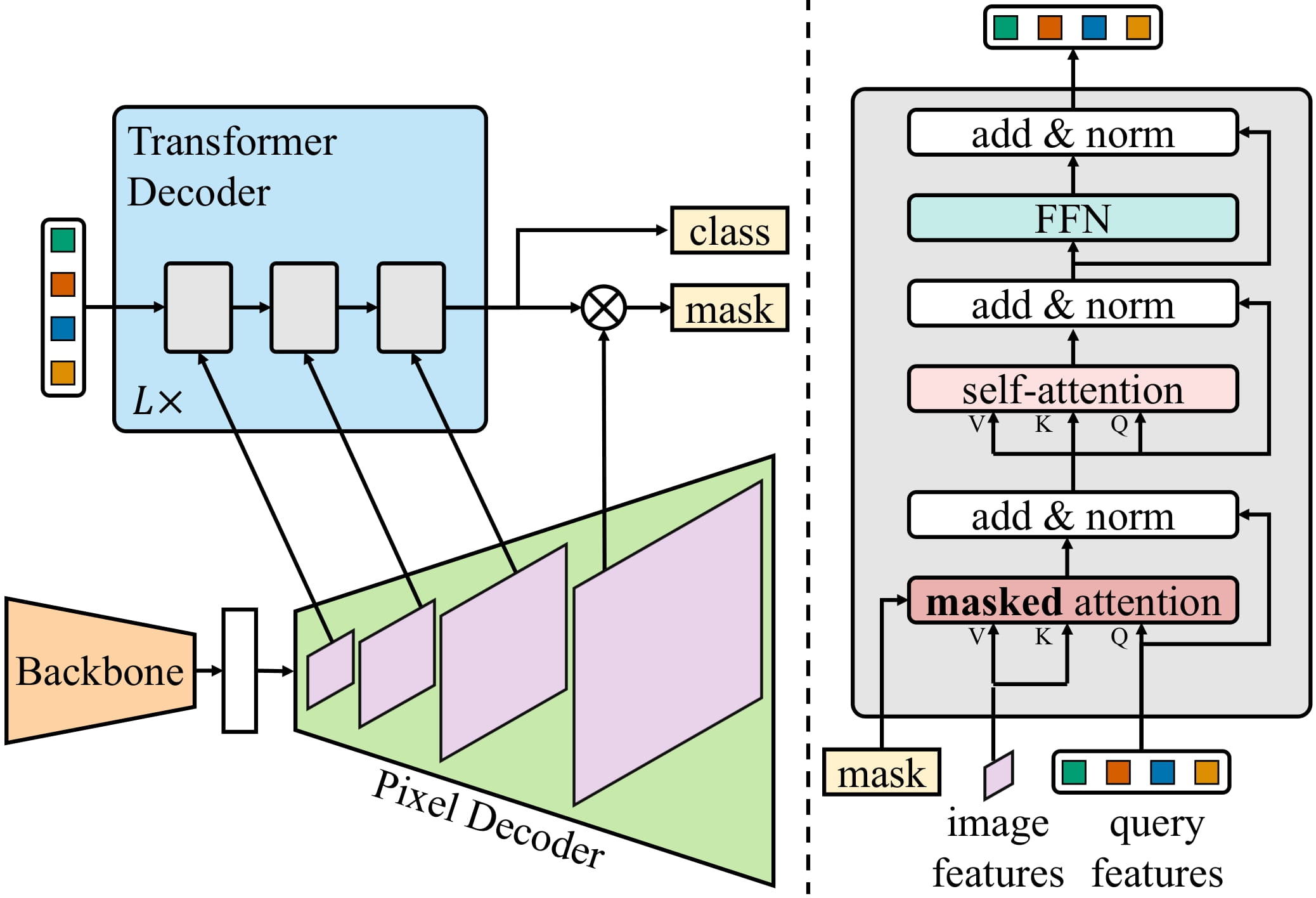 Mask2Former architecture. Taken from the
Mask2Former architecture. Taken from the  +
+This model was contributed by [francesco](https://huggingface.co/francesco). The original code can be found [here](https://github.com/facebookresearch/MaskFormer).
+
+## Usage tips
+
- MaskFormer's Transformer decoder is identical to the decoder of [DETR](detr). During training, the authors of DETR did find it helpful to use auxiliary losses in the decoder, especially to help the model output the correct number of objects of each class. If you set the parameter `use_auxilary_loss` of [`MaskFormerConfig`] to `True`, then prediction feedforward neural networks and Hungarian losses are added after each decoder layer (with the FFNs sharing parameters).
- If you want to train the model in a distributed environment across multiple nodes, then one should update the
`get_num_masks` function inside in the `MaskFormerLoss` class of `modeling_maskformer.py`. When training on multiple nodes, this should be
@@ -39,12 +46,6 @@ Tips:
- One can use [`MaskFormerImageProcessor`] to prepare images for the model and optional targets for the model.
- To get the final segmentation, depending on the task, you can call [`~MaskFormerImageProcessor.post_process_semantic_segmentation`] or [`~MaskFormerImageProcessor.post_process_panoptic_segmentation`]. Both tasks can be solved using [`MaskFormerForInstanceSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
-The figure below illustrates the architecture of MaskFormer. Taken from the [original paper](https://arxiv.org/abs/2107.06278).
-
-
+
+This model was contributed by [francesco](https://huggingface.co/francesco). The original code can be found [here](https://github.com/facebookresearch/MaskFormer).
+
+## Usage tips
+
- MaskFormer's Transformer decoder is identical to the decoder of [DETR](detr). During training, the authors of DETR did find it helpful to use auxiliary losses in the decoder, especially to help the model output the correct number of objects of each class. If you set the parameter `use_auxilary_loss` of [`MaskFormerConfig`] to `True`, then prediction feedforward neural networks and Hungarian losses are added after each decoder layer (with the FFNs sharing parameters).
- If you want to train the model in a distributed environment across multiple nodes, then one should update the
`get_num_masks` function inside in the `MaskFormerLoss` class of `modeling_maskformer.py`. When training on multiple nodes, this should be
@@ -39,12 +46,6 @@ Tips:
- One can use [`MaskFormerImageProcessor`] to prepare images for the model and optional targets for the model.
- To get the final segmentation, depending on the task, you can call [`~MaskFormerImageProcessor.post_process_semantic_segmentation`] or [`~MaskFormerImageProcessor.post_process_panoptic_segmentation`]. Both tasks can be solved using [`MaskFormerForInstanceSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
-The figure below illustrates the architecture of MaskFormer. Taken from the [original paper](https://arxiv.org/abs/2107.06278).
-
- +
+This model was contributed by [Jitesh Jain](https://huggingface.co/praeclarumjj3). The original code can be found [here](https://github.com/SHI-Labs/OneFormer).
+
+## Usage tips
+
- OneFormer requires two inputs during inference: *image* and *task token*.
- During training, OneFormer only uses panoptic annotations.
- If you want to train the model in a distributed environment across multiple nodes, then one should update the
@@ -35,12 +42,6 @@ Tips:
- One can use [`OneFormerProcessor`] to prepare input images and task inputs for the model and optional targets for the model. [`OneformerProcessor`] wraps [`OneFormerImageProcessor`] and [`CLIPTokenizer`] into a single instance to both prepare the images and encode the task inputs.
- To get the final segmentation, depending on the task, you can call [`~OneFormerProcessor.post_process_semantic_segmentation`] or [`~OneFormerImageProcessor.post_process_instance_segmentation`] or [`~OneFormerImageProcessor.post_process_panoptic_segmentation`]. All three tasks can be solved using [`OneFormerForUniversalSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
-The figure below illustrates the architecture of OneFormer. Taken from the [original paper](https://arxiv.org/abs/2211.06220).
-
-
+
+This model was contributed by [Jitesh Jain](https://huggingface.co/praeclarumjj3). The original code can be found [here](https://github.com/SHI-Labs/OneFormer).
+
+## Usage tips
+
- OneFormer requires two inputs during inference: *image* and *task token*.
- During training, OneFormer only uses panoptic annotations.
- If you want to train the model in a distributed environment across multiple nodes, then one should update the
@@ -35,12 +42,6 @@ Tips:
- One can use [`OneFormerProcessor`] to prepare input images and task inputs for the model and optional targets for the model. [`OneformerProcessor`] wraps [`OneFormerImageProcessor`] and [`CLIPTokenizer`] into a single instance to both prepare the images and encode the task inputs.
- To get the final segmentation, depending on the task, you can call [`~OneFormerProcessor.post_process_semantic_segmentation`] or [`~OneFormerImageProcessor.post_process_instance_segmentation`] or [`~OneFormerImageProcessor.post_process_panoptic_segmentation`]. All three tasks can be solved using [`OneFormerForUniversalSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
-The figure below illustrates the architecture of OneFormer. Taken from the [original paper](https://arxiv.org/abs/2211.06220).
-
-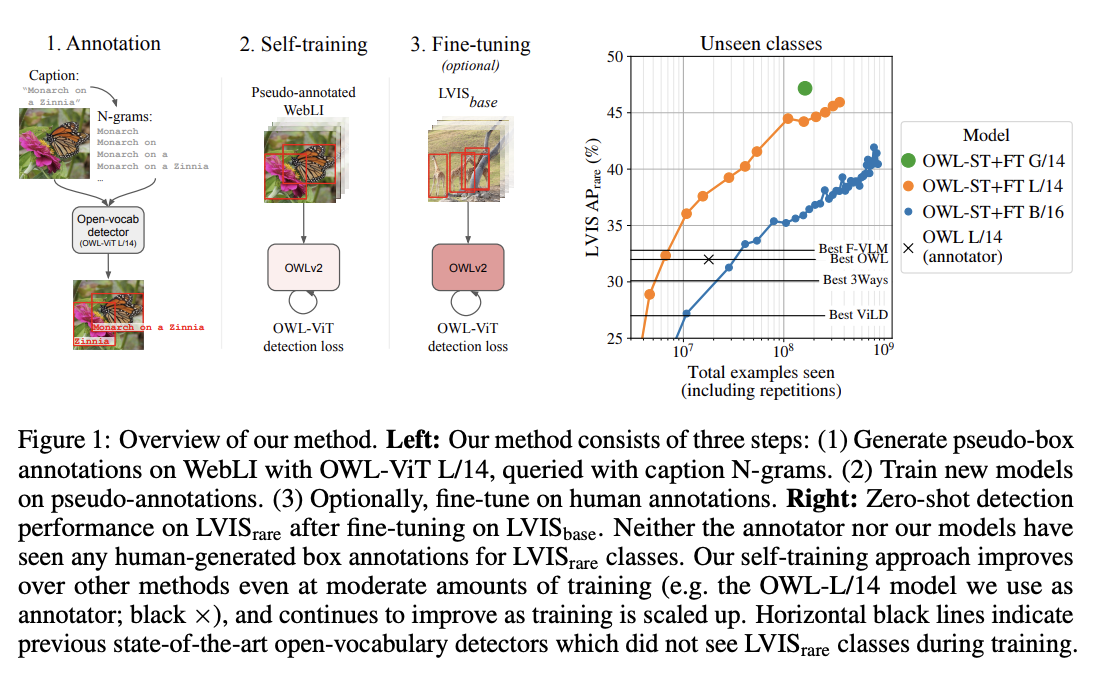 @@ -37,13 +32,12 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
-## Usage
+## Usage example
OWLv2 is, just like its predecessor [OWL-ViT](owlvit), a zero-shot text-conditioned object detection model. OWL-ViT uses [CLIP](clip) as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
[`Owlv2ImageProcessor`] can be used to resize (or rescale) and normalize images for the model and [`CLIPTokenizer`] is used to encode the text. [`Owlv2Processor`] wraps [`Owlv2ImageProcessor`] and [`CLIPTokenizer`] into a single instance to both encode the text and prepare the images. The following example shows how to perform object detection using [`Owlv2Processor`] and [`Owlv2ForObjectDetection`].
-
```python
>>> import requests
>>> from PIL import Image
@@ -76,7 +70,15 @@ Detected a photo of a cat with confidence 0.665 at location [6.75, 38.97, 326.62
## Resources
-A demo notebook on using OWLv2 for zero- and one-shot (image-guided) object detection can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/OWLv2).
+- A demo notebook on using OWLv2 for zero- and one-shot (image-guided) object detection can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/OWLv2).
+- [Zero-shot object detection task guide](../tasks/zero_shot_object_detection)
+
+
@@ -37,13 +32,12 @@ alt="drawing" width="600"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
-## Usage
+## Usage example
OWLv2 is, just like its predecessor [OWL-ViT](owlvit), a zero-shot text-conditioned object detection model. OWL-ViT uses [CLIP](clip) as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
[`Owlv2ImageProcessor`] can be used to resize (or rescale) and normalize images for the model and [`CLIPTokenizer`] is used to encode the text. [`Owlv2Processor`] wraps [`Owlv2ImageProcessor`] and [`CLIPTokenizer`] into a single instance to both encode the text and prepare the images. The following example shows how to perform object detection using [`Owlv2Processor`] and [`Owlv2ForObjectDetection`].
-
```python
>>> import requests
>>> from PIL import Image
@@ -76,7 +70,15 @@ Detected a photo of a cat with confidence 0.665 at location [6.75, 38.97, 326.62
## Resources
-A demo notebook on using OWLv2 for zero- and one-shot (image-guided) object detection can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/OWLv2).
+- A demo notebook on using OWLv2 for zero- and one-shot (image-guided) object detection can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/OWLv2).
+- [Zero-shot object detection task guide](../tasks/zero_shot_object_detection)
+
+ +This model was contributed by [heytanay](https://huggingface.co/heytanay). The original code can be found [here](https://github.com/sail-sg/poolformer).
-Tips:
+## Usage tips
- PoolFormer has a hierarchical architecture, where instead of Attention, a simple Average Pooling layer is present. All checkpoints of the model can be found on the [hub](https://huggingface.co/models?other=poolformer).
- One can use [`PoolFormerImageProcessor`] to prepare images for the model.
@@ -43,8 +44,6 @@ Tips:
| m36 | [6, 6, 18, 6] | [96, 192, 384, 768] | 56 | 82.1 |
| m48 | [8, 8, 24, 8] | [96, 192, 384, 768] | 73 | 82.5 |
-This model was contributed by [heytanay](https://huggingface.co/heytanay). The original code can be found [here](https://github.com/sail-sg/poolformer).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with PoolFormer.
diff --git a/docs/source/en/model_doc/pop2piano.md b/docs/source/en/model_doc/pop2piano.md
index 95fd83f192..8e52eda70c 100644
--- a/docs/source/en/model_doc/pop2piano.md
+++ b/docs/source/en/model_doc/pop2piano.md
@@ -32,7 +32,6 @@ is transformed to its waveform and passed to the encoder, which transforms it to
uses these latent representations to generate token ids in an autoregressive way. Each token id corresponds to one of four
different token types: time, velocity, note and 'special'. The token ids are then decoded to their equivalent MIDI file.
-
The abstract from the paper is the following:
*Piano covers of pop music are enjoyed by many people. However, the
@@ -49,22 +48,21 @@ directly from pop audio without using melody and chord extraction
modules. We show that Pop2Piano, trained with our dataset, is capable
of producing plausible piano covers.*
+This model was contributed by [Susnato Dhar](https://huggingface.co/susnato).
+The original code can be found [here](https://github.com/sweetcocoa/pop2piano).
-Tips:
+## Usage tips
-1. To use Pop2Piano, you will need to install the 🤗 Transformers library, as well as the following third party modules:
+* To use Pop2Piano, you will need to install the 🤗 Transformers library, as well as the following third party modules:
```
pip install pretty-midi==0.2.9 essentia==2.1b6.dev1034 librosa scipy
```
Please note that you may need to restart your runtime after installation.
-2. Pop2Piano is an Encoder-Decoder based model like T5.
-3. Pop2Piano can be used to generate midi-audio files for a given audio sequence.
-4. Choosing different composers in `Pop2PianoForConditionalGeneration.generate()` can lead to variety of different results.
-5. Setting the sampling rate to 44.1 kHz when loading the audio file can give good performance.
-6. Though Pop2Piano was mainly trained on Korean Pop music, it also does pretty well on other Western Pop or Hip Hop songs.
-
-This model was contributed by [Susnato Dhar](https://huggingface.co/susnato).
-The original code can be found [here](https://github.com/sweetcocoa/pop2piano).
+* Pop2Piano is an Encoder-Decoder based model like T5.
+* Pop2Piano can be used to generate midi-audio files for a given audio sequence.
+* Choosing different composers in `Pop2PianoForConditionalGeneration.generate()` can lead to variety of different results.
+* Setting the sampling rate to 44.1 kHz when loading the audio file can give good performance.
+* Though Pop2Piano was mainly trained on Korean Pop music, it also does pretty well on other Western Pop or Hip Hop songs.
## Examples
diff --git a/docs/source/en/model_doc/prophetnet.md b/docs/source/en/model_doc/prophetnet.md
index 6ab0937da7..7e63e0c088 100644
--- a/docs/source/en/model_doc/prophetnet.md
+++ b/docs/source/en/model_doc/prophetnet.md
@@ -25,10 +25,6 @@ rendered properly in your Markdown viewer.
-
-**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) and assign
-@patrickvonplaten
-
## Overview
The ProphetNet model was proposed in [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei
@@ -49,15 +45,15 @@ dataset (160GB) respectively. Then we conduct experiments on CNN/DailyMail, Giga
abstractive summarization and question generation tasks. Experimental results show that ProphetNet achieves new
state-of-the-art results on all these datasets compared to the models using the same scale pretraining corpus.*
-Tips:
+The Authors' code can be found [here](https://github.com/microsoft/ProphetNet).
+
+## Usage tips
- ProphetNet is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
- The model architecture is based on the original Transformer, but replaces the “standard” self-attention mechanism in the decoder by a a main self-attention mechanism and a self and n-stream (predict) self-attention mechanism.
-The Authors' code can be found [here](https://github.com/microsoft/ProphetNet).
-
-## Documentation resources
+## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
- [Translation task guide](../tasks/translation)
diff --git a/docs/source/en/model_doc/qdqbert.md b/docs/source/en/model_doc/qdqbert.md
index 62a0e01084..9ee42ff3b4 100644
--- a/docs/source/en/model_doc/qdqbert.md
+++ b/docs/source/en/model_doc/qdqbert.md
@@ -32,22 +32,18 @@ by processors with high-throughput integer math pipelines. We also present a wor
able to maintain accuracy within 1% of the floating-point baseline on all networks studied, including models that are
more difficult to quantize, such as MobileNets and BERT-large.*
-Tips:
+This model was contributed by [shangz](https://huggingface.co/shangz).
+
+## Usage tips
- QDQBERT model adds fake quantization operations (pair of QuantizeLinear/DequantizeLinear ops) to (i) linear layer
inputs and weights, (ii) matmul inputs, (iii) residual add inputs, in BERT model.
-
- QDQBERT requires the dependency of [Pytorch Quantization Toolkit](https://github.com/NVIDIA/TensorRT/tree/master/tools/pytorch-quantization). To install `pip install pytorch-quantization --extra-index-url https://pypi.ngc.nvidia.com`
-
- QDQBERT model can be loaded from any checkpoint of HuggingFace BERT model (for example *bert-base-uncased*), and
perform Quantization Aware Training/Post Training Quantization.
-
- A complete example of using QDQBERT model to perform Quatization Aware Training and Post Training Quantization for
SQUAD task can be found at [transformers/examples/research_projects/quantization-qdqbert/](examples/research_projects/quantization-qdqbert/).
-This model was contributed by [shangz](https://huggingface.co/shangz).
-
-
### Set default quantizers
QDQBERT model adds fake quantization operations (pair of QuantizeLinear/DequantizeLinear ops) to BERT by
@@ -118,7 +114,7 @@ the instructions in [torch.onnx](https://pytorch.org/docs/stable/onnx.html). Exa
>>> torch.onnx.export(...)
```
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
diff --git a/docs/source/en/model_doc/rag.md b/docs/source/en/model_doc/rag.md
index b467c6169f..1891efe742 100644
--- a/docs/source/en/model_doc/rag.md
+++ b/docs/source/en/model_doc/rag.md
@@ -52,8 +52,12 @@ parametric-only seq2seq baseline.*
This model was contributed by [ola13](https://huggingface.co/ola13).
-Tips:
-- Retrieval-augmented generation (“RAG”) models combine the powers of pretrained dense retrieval (DPR) and Seq2Seq models. RAG models retrieve docs, pass them to a seq2seq model, then marginalize to generate outputs. The retriever and seq2seq modules are initialized from pretrained models, and fine-tuned jointly, allowing both retrieval and generation to adapt to downstream tasks.
+## Usage tips
+
+Retrieval-augmented generation ("RAG") models combine the powers of pretrained dense retrieval (DPR) and Seq2Seq models.
+RAG models retrieve docs, pass them to a seq2seq model, then marginalize to generate outputs. The retriever and seq2seq
+modules are initialized from pretrained models, and fine-tuned jointly, allowing both retrieval and generation to adapt
+to downstream tasks.
## RagConfig
@@ -73,6 +77,9 @@ Tips:
[[autodoc]] RagRetriever
+
+This model was contributed by [heytanay](https://huggingface.co/heytanay). The original code can be found [here](https://github.com/sail-sg/poolformer).
-Tips:
+## Usage tips
- PoolFormer has a hierarchical architecture, where instead of Attention, a simple Average Pooling layer is present. All checkpoints of the model can be found on the [hub](https://huggingface.co/models?other=poolformer).
- One can use [`PoolFormerImageProcessor`] to prepare images for the model.
@@ -43,8 +44,6 @@ Tips:
| m36 | [6, 6, 18, 6] | [96, 192, 384, 768] | 56 | 82.1 |
| m48 | [8, 8, 24, 8] | [96, 192, 384, 768] | 73 | 82.5 |
-This model was contributed by [heytanay](https://huggingface.co/heytanay). The original code can be found [here](https://github.com/sail-sg/poolformer).
-
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with PoolFormer.
diff --git a/docs/source/en/model_doc/pop2piano.md b/docs/source/en/model_doc/pop2piano.md
index 95fd83f192..8e52eda70c 100644
--- a/docs/source/en/model_doc/pop2piano.md
+++ b/docs/source/en/model_doc/pop2piano.md
@@ -32,7 +32,6 @@ is transformed to its waveform and passed to the encoder, which transforms it to
uses these latent representations to generate token ids in an autoregressive way. Each token id corresponds to one of four
different token types: time, velocity, note and 'special'. The token ids are then decoded to their equivalent MIDI file.
-
The abstract from the paper is the following:
*Piano covers of pop music are enjoyed by many people. However, the
@@ -49,22 +48,21 @@ directly from pop audio without using melody and chord extraction
modules. We show that Pop2Piano, trained with our dataset, is capable
of producing plausible piano covers.*
+This model was contributed by [Susnato Dhar](https://huggingface.co/susnato).
+The original code can be found [here](https://github.com/sweetcocoa/pop2piano).
-Tips:
+## Usage tips
-1. To use Pop2Piano, you will need to install the 🤗 Transformers library, as well as the following third party modules:
+* To use Pop2Piano, you will need to install the 🤗 Transformers library, as well as the following third party modules:
```
pip install pretty-midi==0.2.9 essentia==2.1b6.dev1034 librosa scipy
```
Please note that you may need to restart your runtime after installation.
-2. Pop2Piano is an Encoder-Decoder based model like T5.
-3. Pop2Piano can be used to generate midi-audio files for a given audio sequence.
-4. Choosing different composers in `Pop2PianoForConditionalGeneration.generate()` can lead to variety of different results.
-5. Setting the sampling rate to 44.1 kHz when loading the audio file can give good performance.
-6. Though Pop2Piano was mainly trained on Korean Pop music, it also does pretty well on other Western Pop or Hip Hop songs.
-
-This model was contributed by [Susnato Dhar](https://huggingface.co/susnato).
-The original code can be found [here](https://github.com/sweetcocoa/pop2piano).
+* Pop2Piano is an Encoder-Decoder based model like T5.
+* Pop2Piano can be used to generate midi-audio files for a given audio sequence.
+* Choosing different composers in `Pop2PianoForConditionalGeneration.generate()` can lead to variety of different results.
+* Setting the sampling rate to 44.1 kHz when loading the audio file can give good performance.
+* Though Pop2Piano was mainly trained on Korean Pop music, it also does pretty well on other Western Pop or Hip Hop songs.
## Examples
diff --git a/docs/source/en/model_doc/prophetnet.md b/docs/source/en/model_doc/prophetnet.md
index 6ab0937da7..7e63e0c088 100644
--- a/docs/source/en/model_doc/prophetnet.md
+++ b/docs/source/en/model_doc/prophetnet.md
@@ -25,10 +25,6 @@ rendered properly in your Markdown viewer.
-
-**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) and assign
-@patrickvonplaten
-
## Overview
The ProphetNet model was proposed in [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei
@@ -49,15 +45,15 @@ dataset (160GB) respectively. Then we conduct experiments on CNN/DailyMail, Giga
abstractive summarization and question generation tasks. Experimental results show that ProphetNet achieves new
state-of-the-art results on all these datasets compared to the models using the same scale pretraining corpus.*
-Tips:
+The Authors' code can be found [here](https://github.com/microsoft/ProphetNet).
+
+## Usage tips
- ProphetNet is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
- The model architecture is based on the original Transformer, but replaces the “standard” self-attention mechanism in the decoder by a a main self-attention mechanism and a self and n-stream (predict) self-attention mechanism.
-The Authors' code can be found [here](https://github.com/microsoft/ProphetNet).
-
-## Documentation resources
+## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
- [Translation task guide](../tasks/translation)
diff --git a/docs/source/en/model_doc/qdqbert.md b/docs/source/en/model_doc/qdqbert.md
index 62a0e01084..9ee42ff3b4 100644
--- a/docs/source/en/model_doc/qdqbert.md
+++ b/docs/source/en/model_doc/qdqbert.md
@@ -32,22 +32,18 @@ by processors with high-throughput integer math pipelines. We also present a wor
able to maintain accuracy within 1% of the floating-point baseline on all networks studied, including models that are
more difficult to quantize, such as MobileNets and BERT-large.*
-Tips:
+This model was contributed by [shangz](https://huggingface.co/shangz).
+
+## Usage tips
- QDQBERT model adds fake quantization operations (pair of QuantizeLinear/DequantizeLinear ops) to (i) linear layer
inputs and weights, (ii) matmul inputs, (iii) residual add inputs, in BERT model.
-
- QDQBERT requires the dependency of [Pytorch Quantization Toolkit](https://github.com/NVIDIA/TensorRT/tree/master/tools/pytorch-quantization). To install `pip install pytorch-quantization --extra-index-url https://pypi.ngc.nvidia.com`
-
- QDQBERT model can be loaded from any checkpoint of HuggingFace BERT model (for example *bert-base-uncased*), and
perform Quantization Aware Training/Post Training Quantization.
-
- A complete example of using QDQBERT model to perform Quatization Aware Training and Post Training Quantization for
SQUAD task can be found at [transformers/examples/research_projects/quantization-qdqbert/](examples/research_projects/quantization-qdqbert/).
-This model was contributed by [shangz](https://huggingface.co/shangz).
-
-
### Set default quantizers
QDQBERT model adds fake quantization operations (pair of QuantizeLinear/DequantizeLinear ops) to BERT by
@@ -118,7 +114,7 @@ the instructions in [torch.onnx](https://pytorch.org/docs/stable/onnx.html). Exa
>>> torch.onnx.export(...)
```
-## Documentation resources
+## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
diff --git a/docs/source/en/model_doc/rag.md b/docs/source/en/model_doc/rag.md
index b467c6169f..1891efe742 100644
--- a/docs/source/en/model_doc/rag.md
+++ b/docs/source/en/model_doc/rag.md
@@ -52,8 +52,12 @@ parametric-only seq2seq baseline.*
This model was contributed by [ola13](https://huggingface.co/ola13).
-Tips:
-- Retrieval-augmented generation (“RAG”) models combine the powers of pretrained dense retrieval (DPR) and Seq2Seq models. RAG models retrieve docs, pass them to a seq2seq model, then marginalize to generate outputs. The retriever and seq2seq modules are initialized from pretrained models, and fine-tuned jointly, allowing both retrieval and generation to adapt to downstream tasks.
+## Usage tips
+
+Retrieval-augmented generation ("RAG") models combine the powers of pretrained dense retrieval (DPR) and Seq2Seq models.
+RAG models retrieve docs, pass them to a seq2seq model, then marginalize to generate outputs. The retriever and seq2seq
+modules are initialized from pretrained models, and fine-tuned jointly, allowing both retrieval and generation to adapt
+to downstream tasks.
## RagConfig
@@ -73,6 +77,9 @@ Tips:
[[autodoc]] RagRetriever
+ @@ -52,30 +48,35 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] ResNetConfig
+
@@ -52,30 +48,35 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] ResNetConfig
+ @@ -48,6 +43,10 @@ alt="drawing" width="600"/>
This model was contributed by [novice03](https://huggingface.co/novice03). The Tensorflow version of this model was contributed by [amyeroberts](https://huggingface.co/amyeroberts). The original code can be found [here](https://github.com/microsoft/Swin-Transformer).
+## Usage tips
+
+- Swin pads the inputs supporting any input height and width (if divisible by `32`).
+- Swin can be used as a *backbone*. When `output_hidden_states = True`, it will output both `hidden_states` and `reshaped_hidden_states`. The `reshaped_hidden_states` have a shape of `(batch, num_channels, height, width)` rather than `(batch_size, sequence_length, num_channels)`.
## Resources
@@ -68,6 +67,8 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] SwinConfig
+
@@ -48,6 +43,10 @@ alt="drawing" width="600"/>
This model was contributed by [novice03](https://huggingface.co/novice03). The Tensorflow version of this model was contributed by [amyeroberts](https://huggingface.co/amyeroberts). The original code can be found [here](https://github.com/microsoft/Swin-Transformer).
+## Usage tips
+
+- Swin pads the inputs supporting any input height and width (if divisible by `32`).
+- Swin can be used as a *backbone*. When `output_hidden_states = True`, it will output both `hidden_states` and `reshaped_hidden_states`. The `reshaped_hidden_states` have a shape of `(batch, num_channels, height, width)` rather than `(batch_size, sequence_length, num_channels)`.
## Resources
@@ -68,6 +67,8 @@ If you're interested in submitting a resource to be included here, please feel f
[[autodoc]] SwinConfig
+ Table detection and table structure recognition clarified. Taken from the
Table detection and table structure recognition clarified. Taken from the