diff --git a/.gitignore b/.gitignore
index 965fbeec77..cf81834636 100644
--- a/.gitignore
+++ b/.gitignore
@@ -160,4 +160,7 @@ tags
.pre-commit*
# .lock
-*.lock
\ No newline at end of file
+*.lock
+
+# DS_Store (MacOS)
+.DS_Store
\ No newline at end of file
diff --git a/docs/source/model_doc/auto.mdx b/docs/source/model_doc/auto.mdx
index 21bda43196..20a73c7e4c 100644
--- a/docs/source/model_doc/auto.mdx
+++ b/docs/source/model_doc/auto.mdx
@@ -142,6 +142,10 @@ Likewise, if your `NewModel` is a subclass of [`PreTrainedModel`], make sure its
[[autodoc]] AutoModelForAudioXVector
+## AutoModelForMaskedImageModeling
+
+[[autodoc]] AutoModelForMaskedImageModeling
+
## AutoModelForObjectDetection
[[autodoc]] AutoModelForObjectDetection
diff --git a/docs/source/model_doc/deit.mdx b/docs/source/model_doc/deit.mdx
index 1887d2ea70..e03920e93e 100644
--- a/docs/source/model_doc/deit.mdx
+++ b/docs/source/model_doc/deit.mdx
@@ -86,6 +86,11 @@ This model was contributed by [nielsr](https://huggingface.co/nielsr).
[[autodoc]] DeiTModel
- forward
+## DeiTForMaskedImageModeling
+
+[[autodoc]] DeiTForMaskedImageModeling
+ - forward
+
## DeiTForImageClassification
[[autodoc]] DeiTForImageClassification
diff --git a/docs/source/model_doc/swin.mdx b/docs/source/model_doc/swin.mdx
index fe56a73b32..c1fd4e86d3 100644
--- a/docs/source/model_doc/swin.mdx
+++ b/docs/source/model_doc/swin.mdx
@@ -53,6 +53,10 @@ This model was contributed by [novice03](https://huggingface.co/novice03>). The
[[autodoc]] SwinModel
- forward
+## SwinForMaskedImageModeling
+
+[[autodoc]] SwinForMaskedImageModeling
+ - forward
## SwinForImageClassification
diff --git a/docs/source/model_doc/vit.mdx b/docs/source/model_doc/vit.mdx
index 03d204ff75..37c469f6aa 100644
--- a/docs/source/model_doc/vit.mdx
+++ b/docs/source/model_doc/vit.mdx
@@ -103,6 +103,11 @@ go to him!
[[autodoc]] ViTModel
- forward
+## ViTForMaskedImageModeling
+
+[[autodoc]] ViTForMaskedImageModeling
+ - forward
+
## ViTForImageClassification
[[autodoc]] ViTForImageClassification
diff --git a/examples/pytorch/image-pretraining/README.md b/examples/pytorch/image-pretraining/README.md
index ff77b03e72..814f160a34 100644
--- a/examples/pytorch/image-pretraining/README.md
+++ b/examples/pytorch/image-pretraining/README.md
@@ -16,13 +16,140 @@ limitations under the License.
# Image pretraining examples
+This directory contains Python scripts that allow you to pre-train Transformer-based vision models (like [ViT](https://huggingface.co/docs/transformers/model_doc/vit), [Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)) on your own data, after which you can easily load the weights into a [`AutoModelForImageClassification`](https://huggingface.co/docs/transformers/model_doc/auto#transformers.AutoModelForImageClassification). It currently includes scripts for:
+- [SimMIM](#simmim) (by Microsoft Research)
+- [MAE](#mae) (by Facebook AI).
+
NOTE: If you encounter problems/have suggestions for improvement, open an issue on Github and tag @NielsRogge.
-This directory contains a script, `run_mae.py`, that can be used to pre-train a Vision Transformer as a masked autoencoder (MAE), as proposed in [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377). The script can be used to train a `ViTMAEForPreTraining` model in the Transformers library, using PyTorch. After self-supervised pre-training, one can load the weights of the encoder directly into a `ViTForImageClassification`. The MAE method allows for learning high-capacity models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data.
+
+## SimMIM
+
+The `run_mim.py` script can be used to pre-train any Transformer-based vision model in the library (concretly, any model supported by the `AutoModelForMaskedImageModeling` API) for masked image modeling as proposed in [SimMIM: A Simple Framework for Masked Image Modeling](https://arxiv.org/abs/2111.09886) using PyTorch.
+
+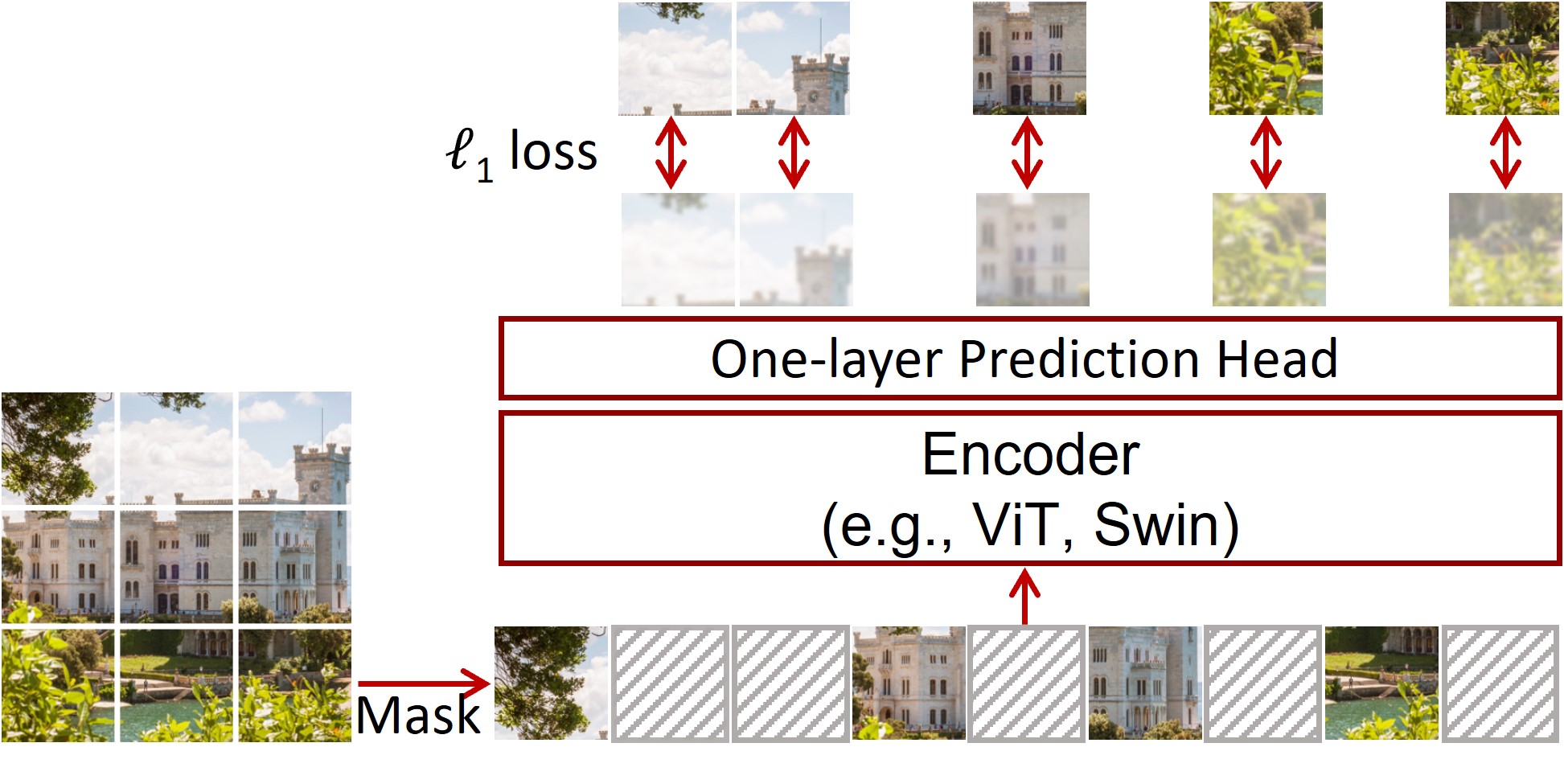 +
+ SimMIM framework. Taken from the original paper.
+
+The goal for the model is to predict raw pixel values for the masked patches, using just a linear layer as prediction head. The model is trained using a simple L1 loss.
+
+### Using datasets from 🤗 datasets
+
+Here we show how to pre-train a `ViT` from scratch for masked image modeling on the [cifar10](https://huggingface.co/datasets/cifar10) dataset.
+
+Alternatively, one can decide to further pre-train an already pre-trained (or fine-tuned) checkpoint from the [hub](https://huggingface.co/). This can be done by setting the `model_name_or_path` argument to "google/vit-base-patch16-224-in21k" for example (and not specifying the `model_type` argument).
+
+```bash
+!python run_mim.py \
+ --model_type vit \
+ --output_dir ./outputs/ \
+ --overwrite_output_dir \
+ --remove_unused_columns False \
+ --label_names bool_masked_pos \
+ --do_train \
+ --do_eval \
+ --learning_rate 2e-5 \
+ --weight_decay 0.05 \
+ --num_train_epochs 100 \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 8 \
+ --logging_strategy steps \
+ --logging_steps 10 \
+ --evaluation_strategy epoch \
+ --save_strategy epoch \
+ --load_best_model_at_end True \
+ --save_total_limit 3 \
+ --seed 1337
+```
+
+Here, we train for 100 epochs with a learning rate of 2e-5. Note that the SimMIM authors used a more sophisticated learning rate schedule, see the [config files](https://github.com/microsoft/SimMIM/blob/main/configs/vit_base__800ep/simmim_pretrain__vit_base__img224__800ep.yaml) for more info. One can easily tweak the script to include this learning rate schedule (several learning rate schedulers are supported via the [training arguments](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments)).
+
+We can also for instance replicate the pre-training of a Swin Transformer using the same architecture as used by the SimMIM authors. For this, we first create a custom configuration and save it locally:
+
+```python
+from transformers import SwinConfig
+
+IMAGE_SIZE = 192
+PATCH_SIZE = 4
+EMBED_DIM = 128
+DEPTHS = [2, 2, 18, 2]
+NUM_HEADS = [4, 8, 16, 32]
+WINDOW_SIZE = 6
+
+config = SwinConfig(
+ image_size=IMAGE_SIZE,
+ patch_size=PATCH_SIZE,
+ embed_dim=EMBED_DIM,
+ depths=DEPTHS,
+ num_heads=NUM_HEADS,
+ window_size=WINDOW_SIZE,
+)
+config.save_pretrained("path_to_config")
+```
+
+Next, we can run the script by providing the path to this custom configuration (replace `path_to_config` below with your path):
+
+```bash
+!python run_mim.py \
+ --config_name_or_path path_to_config \
+ --model_type swin \
+ --output_dir ./outputs/ \
+ --overwrite_output_dir \
+ --remove_unused_columns False \
+ --label_names bool_masked_pos \
+ --do_train \
+ --do_eval \
+ --learning_rate 2e-5 \
+ --num_train_epochs 5 \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 8 \
+ --logging_strategy steps \
+ --logging_steps 10 \
+ --evaluation_strategy epoch \
+ --save_strategy epoch \
+ --load_best_model_at_end True \
+ --save_total_limit 3 \
+ --seed 1337
+```
+
+This will train a Swin Transformer from scratch.
+
+### Using your own data
+
+To use your own dataset, the training script expects the following directory structure:
+
+```bash
+root/dog/xxx.png
+root/dog/xxy.png
+root/dog/[...]/xxz.png
+
+root/cat/123.png
+root/cat/nsdf3.png
+root/cat/[...]/asd932_.png
+```
+
+Note that you can put images in dummy subfolders, whose names will be ignored by default (as labels aren't required). You can also just place all images into a single dummy subfolder. Once you've prepared your dataset, you can run the script like this:
+
+```bash
+python run_mim.py \
+ --model_type vit \
+ --dataset_name nateraw/image-folder \
+ --train_dir \
+ --output_dir ./outputs/ \
+ --remove_unused_columns False \
+ --label_names bool_masked_pos \
+ --do_train \
+ --do_eval
+```
+
+## MAE
+
+The `run_mae.py` script can be used to pre-train a Vision Transformer as a masked autoencoder (MAE), as proposed in [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377). The script can be used to train a `ViTMAEForPreTraining` model in the Transformers library, using PyTorch. After self-supervised pre-training, one can load the weights of the encoder directly into a `ViTForImageClassification`. The MAE method allows for learning high-capacity models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data.
The goal for the model is to predict raw pixel values for the masked patches. As the model internally masks patches and learns to reconstruct them, there's no need for any labels. The model uses the mean squared error (MSE) between the reconstructed and original images in the pixel space.
-## Using datasets from 🤗 `datasets`
+### Using datasets from 🤗 `datasets`
One can use the following command to pre-train a `ViTMAEForPreTraining` model from scratch on the [cifar10](https://huggingface.co/datasets/cifar10) dataset:
@@ -67,7 +194,7 @@ alt="drawing" width="300"/>
Alternatively, one can decide to further pre-train an already pre-trained (or fine-tuned) checkpoint from the [hub](https://huggingface.co/). This can be done by setting the `model_name_or_path` argument to "facebook/vit-mae-base" for example.
-## Using your own data
+### Using your own data
To use your own dataset, the training script expects the following directory structure:
@@ -95,7 +222,7 @@ python run_mae.py \
--do_eval
```
-### 💡 The above will split the train dir into training and evaluation sets
+#### 💡 The above will split the train dir into training and evaluation sets
- To control the split amount, use the `--train_val_split` flag.
- To provide your own validation split in its own directory, you can pass the `--validation_dir ` flag.
@@ -122,7 +249,7 @@ $ huggingface-cli login
3. When running the script, pass the following arguments:
```bash
-python run_mae.py \
+python run_xxx.py \
--push_to_hub \
--push_to_hub_model_id \
...
diff --git a/examples/pytorch/image-pretraining/run_mim.py b/examples/pytorch/image-pretraining/run_mim.py
new file mode 100644
index 0000000000..d235a0394d
--- /dev/null
+++ b/examples/pytorch/image-pretraining/run_mim.py
@@ -0,0 +1,448 @@
+#!/usr/bin/env python
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+
+import logging
+import os
+import sys
+from dataclasses import dataclass, field
+from typing import Optional
+
+import numpy as np
+import torch
+from datasets import load_dataset
+from torchvision.transforms import Compose, Lambda, Normalize, RandomHorizontalFlip, RandomResizedCrop, ToTensor
+
+import transformers
+from transformers import (
+ CONFIG_MAPPING,
+ FEATURE_EXTRACTOR_MAPPING,
+ MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING,
+ AutoConfig,
+ AutoFeatureExtractor,
+ AutoModelForMaskedImageModeling,
+ HfArgumentParser,
+ Trainer,
+ TrainingArguments,
+)
+from transformers.trainer_utils import get_last_checkpoint
+from transformers.utils import check_min_version
+from transformers.utils.versions import require_version
+
+
+""" Pre-training a 🤗 Transformers model for simple masked image modeling (SimMIM).
+Any model supported by the AutoModelForMaskedImageModeling API can be used.
+"""
+
+logger = logging.getLogger(__name__)
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.17.0.dev0")
+
+require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/image-pretraining/requirements.txt")
+
+MODEL_CONFIG_CLASSES = list(MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ Using `HfArgumentParser` we can turn this class into argparse arguments to be able to
+ specify them on the command line.
+ """
+
+ dataset_name: Optional[str] = field(
+ default="cifar10", metadata={"help": "Name of a dataset from the datasets package"}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ image_column_name: Optional[str] = field(
+ default=None,
+ metadata={"help": "The column name of the images in the files. If not set, will try to use 'image' or 'img'."},
+ )
+ train_dir: Optional[str] = field(default=None, metadata={"help": "A folder containing the training data."})
+ validation_dir: Optional[str] = field(default=None, metadata={"help": "A folder containing the validation data."})
+ train_val_split: Optional[float] = field(
+ default=0.15, metadata={"help": "Percent to split off of train for validation."}
+ )
+ mask_patch_size: int = field(default=32, metadata={"help": "The size of the square patches to use for masking."})
+ mask_ratio: float = field(
+ default=0.6,
+ metadata={"help": "Percentage of patches to mask."},
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ },
+ )
+
+ def __post_init__(self):
+ data_files = dict()
+ if self.train_dir is not None:
+ data_files["train"] = self.train_dir
+ if self.validation_dir is not None:
+ data_files["val"] = self.validation_dir
+ self.data_files = data_files if data_files else None
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/feature extractor we are going to pre-train.
+ """
+
+ model_name_or_path: str = field(
+ default=None,
+ metadata={
+ "help": "The model checkpoint for weights initialization. Can be a local path to a pytorch_model.bin or a "
+ "checkpoint identifier on the hub. "
+ "Don't set if you want to train a model from scratch."
+ },
+ )
+ model_type: Optional[str] = field(
+ default=None,
+ metadata={"help": "If training from scratch, pass a model type from the list: " + ", ".join(MODEL_TYPES)},
+ )
+ config_name_or_path: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ config_overrides: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": "Override some existing default config settings when a model is trained from scratch. Example: "
+ "n_embd=10,resid_pdrop=0.2,scale_attn_weights=false,summary_type=cls_index"
+ },
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store (cache) the pretrained models/datasets downloaded from the hub"},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ feature_extractor_name: str = field(default=None, metadata={"help": "Name or path of preprocessor config."})
+ use_auth_token: bool = field(
+ default=False,
+ metadata={
+ "help": "Will use the token generated when running `transformers-cli login` (necessary to use this script "
+ "with private models)."
+ },
+ )
+ image_size: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": "The size (resolution) of each image. If not specified, will use `image_size` of the configuration."
+ },
+ )
+ patch_size: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": "The size (resolution) of each patch. If not specified, will use `patch_size` of the configuration."
+ },
+ )
+ encoder_stride: Optional[int] = field(
+ default=None,
+ metadata={"help": "Stride to use for the encoder."},
+ )
+
+
+class MaskGenerator:
+ """
+ A class to generate boolean masks for the pretraining task.
+
+ A mask is a 1D tensor of shape (model_patch_size**2,) where the value is either 0 or 1,
+ where 1 indicates "masked".
+ """
+
+ def __init__(self, input_size=192, mask_patch_size=32, model_patch_size=4, mask_ratio=0.6):
+ self.input_size = input_size
+ self.mask_patch_size = mask_patch_size
+ self.model_patch_size = model_patch_size
+ self.mask_ratio = mask_ratio
+
+ if self.input_size % self.mask_patch_size != 0:
+ raise ValueError("Input size must be divisible by mask patch size")
+ if self.mask_patch_size % self.model_patch_size != 0:
+ raise ValueError("Mask patch size must be divisible by model patch size")
+
+ self.rand_size = self.input_size // self.mask_patch_size
+ self.scale = self.mask_patch_size // self.model_patch_size
+
+ self.token_count = self.rand_size**2
+ self.mask_count = int(np.ceil(self.token_count * self.mask_ratio))
+
+ def __call__(self):
+ mask_idx = np.random.permutation(self.token_count)[: self.mask_count]
+ mask = np.zeros(self.token_count, dtype=int)
+ mask[mask_idx] = 1
+
+ mask = mask.reshape((self.rand_size, self.rand_size))
+ mask = mask.repeat(self.scale, axis=0).repeat(self.scale, axis=1)
+
+ return torch.tensor(mask.flatten())
+
+
+def collate_fn(examples):
+ pixel_values = torch.stack([example["pixel_values"] for example in examples])
+ mask = torch.stack([example["mask"] for example in examples])
+ return {"pixel_values": pixel_values, "bool_masked_pos": mask}
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+ transformers.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
+ + f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
+ )
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Detecting last checkpoint.
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # Initialize our dataset.
+ ds = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ data_files=data_args.data_files,
+ cache_dir=model_args.cache_dir,
+ )
+
+ # If we don't have a validation split, split off a percentage of train as validation.
+ data_args.train_val_split = None if "validation" in ds.keys() else data_args.train_val_split
+ if isinstance(data_args.train_val_split, float) and data_args.train_val_split > 0.0:
+ split = ds["train"].train_test_split(data_args.train_val_split)
+ ds["train"] = split["train"]
+ ds["validation"] = split["test"]
+
+ # Create config
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ config_kwargs = {
+ "cache_dir": model_args.cache_dir,
+ "revision": model_args.model_revision,
+ "use_auth_token": True if model_args.use_auth_token else None,
+ }
+ if model_args.config_name_or_path:
+ config = AutoConfig.from_pretrained(model_args.config_name_or_path, **config_kwargs)
+ elif model_args.model_name_or_path:
+ config = AutoConfig.from_pretrained(model_args.model_name_or_path, **config_kwargs)
+ else:
+ config = CONFIG_MAPPING[model_args.model_type]()
+ logger.warning("You are instantiating a new config instance from scratch.")
+ if model_args.config_overrides is not None:
+ logger.info(f"Overriding config: {model_args.config_overrides}")
+ config.update_from_string(model_args.config_overrides)
+ logger.info(f"New config: {config}")
+
+ # make sure the decoder_type is "simmim" (only relevant for BEiT)
+ if hasattr(config, "decoder_type"):
+ config.decoder_type = "simmim"
+
+ # adapt config
+ model_args.image_size = model_args.image_size if model_args.image_size is not None else config.image_size
+ model_args.patch_size = model_args.patch_size if model_args.patch_size is not None else config.patch_size
+ model_args.encoder_stride = (
+ model_args.encoder_stride if model_args.encoder_stride is not None else config.encoder_stride
+ )
+
+ config.update(
+ {
+ "image_size": model_args.image_size,
+ "patch_size": model_args.patch_size,
+ "encoder_stride": model_args.encoder_stride,
+ }
+ )
+
+ # create feature extractor
+ if model_args.feature_extractor_name:
+ feature_extractor = AutoFeatureExtractor.from_pretrained(model_args.feature_extractor_name, **config_kwargs)
+ elif model_args.model_name_or_path:
+ feature_extractor = AutoFeatureExtractor.from_pretrained(model_args.model_name_or_path, **config_kwargs)
+ else:
+ FEATURE_EXTRACTOR_TYPES = {
+ conf.model_type: feature_extractor_class
+ for conf, feature_extractor_class in FEATURE_EXTRACTOR_MAPPING.items()
+ }
+ feature_extractor = FEATURE_EXTRACTOR_TYPES[model_args.model_type]()
+
+ # create model
+ if model_args.model_name_or_path:
+ model = AutoModelForMaskedImageModeling.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ use_auth_token=True if model_args.use_auth_token else None,
+ )
+ else:
+ logger.info("Training new model from scratch")
+ model = AutoModelForMaskedImageModeling.from_config(config)
+
+ if training_args.do_train:
+ column_names = ds["train"].column_names
+ else:
+ column_names = ds["validation"].column_names
+
+ if data_args.image_column_name is not None:
+ image_column_name = data_args.image_column_name
+ elif "image" in column_names:
+ image_column_name = "image"
+ elif "img" in column_names:
+ image_column_name = "img"
+ else:
+ image_column_name = column_names[0]
+
+ # transformations as done in original SimMIM paper
+ # source: https://github.com/microsoft/SimMIM/blob/main/data/data_simmim.py
+ transforms = Compose(
+ [
+ Lambda(lambda img: img.convert("RGB") if img.mode != "RGB" else img),
+ RandomResizedCrop(model_args.image_size, scale=(0.67, 1.0), ratio=(3.0 / 4.0, 4.0 / 3.0)),
+ RandomHorizontalFlip(),
+ ToTensor(),
+ Normalize(mean=feature_extractor.image_mean, std=feature_extractor.image_std),
+ ]
+ )
+
+ # create mask generator
+ mask_generator = MaskGenerator(
+ input_size=model_args.image_size,
+ mask_patch_size=data_args.mask_patch_size,
+ model_patch_size=model_args.patch_size,
+ mask_ratio=data_args.mask_ratio,
+ )
+
+ def preprocess_images(examples):
+ """Preprocess a batch of images by applying transforms + creating a corresponding mask, indicating
+ which patches to mask."""
+
+ examples["pixel_values"] = [transforms(image) for image in examples[image_column_name]]
+ examples["mask"] = [mask_generator() for i in range(len(examples[image_column_name]))]
+
+ return examples
+
+ if training_args.do_train:
+ if "train" not in ds:
+ raise ValueError("--do_train requires a train dataset")
+ if data_args.max_train_samples is not None:
+ ds["train"] = ds["train"].shuffle(seed=training_args.seed).select(range(data_args.max_train_samples))
+ # Set the training transforms
+ ds["train"].set_transform(preprocess_images)
+
+ if training_args.do_eval:
+ if "validation" not in ds:
+ raise ValueError("--do_eval requires a validation dataset")
+ if data_args.max_eval_samples is not None:
+ ds["validation"] = (
+ ds["validation"].shuffle(seed=training_args.seed).select(range(data_args.max_eval_samples))
+ )
+ # Set the validation transforms
+ ds["validation"].set_transform(preprocess_images)
+
+ # Initialize our trainer
+ trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=ds["train"] if training_args.do_train else None,
+ eval_dataset=ds["validation"] if training_args.do_eval else None,
+ tokenizer=feature_extractor,
+ data_collator=collate_fn,
+ )
+
+ # Training
+ if training_args.do_train:
+ checkpoint = None
+ if training_args.resume_from_checkpoint is not None:
+ checkpoint = training_args.resume_from_checkpoint
+ elif last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ trainer.save_model()
+ trainer.log_metrics("train", train_result.metrics)
+ trainer.save_metrics("train", train_result.metrics)
+ trainer.save_state()
+
+ # Evaluation
+ if training_args.do_eval:
+ metrics = trainer.evaluate()
+ trainer.log_metrics("eval", metrics)
+ trainer.save_metrics("eval", metrics)
+
+ # Write model card and (optionally) push to hub
+ kwargs = {
+ "finetuned_from": model_args.model_name_or_path,
+ "tasks": "masked-image-modeling",
+ "dataset": data_args.dataset_name,
+ "tags": ["masked-image-modeling"],
+ }
+ if training_args.push_to_hub:
+ trainer.push_to_hub(**kwargs)
+ else:
+ trainer.create_model_card(**kwargs)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index 8efc520dc0..d0cc27ad95 100755
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -670,6 +670,7 @@ if is_torch_available():
"MODEL_FOR_CTC_MAPPING",
"MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING",
"MODEL_FOR_IMAGE_SEGMENTATION_MAPPING",
+ "MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING",
"MODEL_FOR_MASKED_LM_MAPPING",
"MODEL_FOR_MULTIPLE_CHOICE_MAPPING",
"MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING",
@@ -692,6 +693,7 @@ if is_torch_available():
"AutoModelForCTC",
"AutoModelForImageClassification",
"AutoModelForImageSegmentation",
+ "AutoModelForMaskedImageModeling",
"AutoModelForMaskedLM",
"AutoModelForMultipleChoice",
"AutoModelForNextSentencePrediction",
@@ -892,6 +894,7 @@ if is_torch_available():
"DEIT_PRETRAINED_MODEL_ARCHIVE_LIST",
"DeiTForImageClassification",
"DeiTForImageClassificationWithTeacher",
+ "DeiTForMaskedImageModeling",
"DeiTModel",
"DeiTPreTrainedModel",
]
@@ -1375,6 +1378,7 @@ if is_torch_available():
[
"SWIN_PRETRAINED_MODEL_ARCHIVE_LIST",
"SwinForImageClassification",
+ "SwinForMaskedImageModeling",
"SwinModel",
"SwinPreTrainedModel",
]
@@ -1456,6 +1460,7 @@ if is_torch_available():
[
"VIT_PRETRAINED_MODEL_ARCHIVE_LIST",
"ViTForImageClassification",
+ "ViTForMaskedImageModeling",
"ViTModel",
"ViTPreTrainedModel",
]
@@ -2822,6 +2827,7 @@ if TYPE_CHECKING:
MODEL_FOR_CTC_MAPPING,
MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING,
MODEL_FOR_IMAGE_SEGMENTATION_MAPPING,
+ MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING,
MODEL_FOR_MASKED_LM_MAPPING,
MODEL_FOR_MULTIPLE_CHOICE_MAPPING,
MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING,
@@ -2844,6 +2850,7 @@ if TYPE_CHECKING:
AutoModelForCTC,
AutoModelForImageClassification,
AutoModelForImageSegmentation,
+ AutoModelForMaskedImageModeling,
AutoModelForMaskedLM,
AutoModelForMultipleChoice,
AutoModelForNextSentencePrediction,
@@ -3010,6 +3017,7 @@ if TYPE_CHECKING:
DEIT_PRETRAINED_MODEL_ARCHIVE_LIST,
DeiTForImageClassification,
DeiTForImageClassificationWithTeacher,
+ DeiTForMaskedImageModeling,
DeiTModel,
DeiTPreTrainedModel,
)
@@ -3412,6 +3420,7 @@ if TYPE_CHECKING:
from .models.swin import (
SWIN_PRETRAINED_MODEL_ARCHIVE_LIST,
SwinForImageClassification,
+ SwinForMaskedImageModeling,
SwinModel,
SwinPreTrainedModel,
)
@@ -3477,6 +3486,7 @@ if TYPE_CHECKING:
from .models.vit import (
VIT_PRETRAINED_MODEL_ARCHIVE_LIST,
ViTForImageClassification,
+ ViTForMaskedImageModeling,
ViTModel,
ViTPreTrainedModel,
)
diff --git a/src/transformers/models/auto/__init__.py b/src/transformers/models/auto/__init__.py
index 9e39f38d09..18701a4275 100644
--- a/src/transformers/models/auto/__init__.py
+++ b/src/transformers/models/auto/__init__.py
@@ -37,6 +37,7 @@ if is_torch_available():
"MODEL_FOR_CTC_MAPPING",
"MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING",
"MODEL_FOR_IMAGE_SEGMENTATION_MAPPING",
+ "MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING",
"MODEL_FOR_MASKED_LM_MAPPING",
"MODEL_FOR_MULTIPLE_CHOICE_MAPPING",
"MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING",
@@ -60,6 +61,7 @@ if is_torch_available():
"AutoModelForCTC",
"AutoModelForImageClassification",
"AutoModelForImageSegmentation",
+ "AutoModelForMaskedImageModeling",
"AutoModelForMaskedLM",
"AutoModelForMultipleChoice",
"AutoModelForNextSentencePrediction",
@@ -153,6 +155,7 @@ if TYPE_CHECKING:
MODEL_FOR_CTC_MAPPING,
MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING,
MODEL_FOR_IMAGE_SEGMENTATION_MAPPING,
+ MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING,
MODEL_FOR_MASKED_LM_MAPPING,
MODEL_FOR_MULTIPLE_CHOICE_MAPPING,
MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING,
@@ -176,6 +179,7 @@ if TYPE_CHECKING:
AutoModelForCTC,
AutoModelForImageClassification,
AutoModelForImageSegmentation,
+ AutoModelForMaskedImageModeling,
AutoModelForMaskedLM,
AutoModelForMultipleChoice,
AutoModelForNextSentencePrediction,
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index 5e8c8149dd..8c3946e62f 100644
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -251,6 +251,15 @@ MODEL_FOR_CAUSAL_LM_MAPPING_NAMES = OrderedDict(
]
)
+MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING_NAMES = OrderedDict(
+ [
+ ("vit", "ViTForMaskedImageModeling"),
+ ("deit", "DeiTForMaskedImageModeling"),
+ ("swin", "SwinForMaskedImageModeling"),
+ ]
+)
+
+
MODEL_FOR_CAUSAL_IMAGE_MODELING_MAPPING_NAMES = OrderedDict(
# Model for Causal Image Modeling mapping
[
@@ -621,6 +630,9 @@ MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING = _LazyAutoMapping(
)
MODEL_FOR_VISION_2_SEQ_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_VISION_2_SEQ_MAPPING_NAMES)
MODEL_FOR_MASKED_LM_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_MASKED_LM_MAPPING_NAMES)
+MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING_NAMES
+)
MODEL_FOR_OBJECT_DETECTION_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_OBJECT_DETECTION_MAPPING_NAMES)
MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING = _LazyAutoMapping(
CONFIG_MAPPING_NAMES, MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING_NAMES
@@ -823,6 +835,13 @@ class AutoModelForAudioXVector(_BaseAutoModelClass):
AutoModelForAudioXVector = auto_class_update(AutoModelForAudioXVector, head_doc="audio retrieval via x-vector")
+class AutoModelForMaskedImageModeling(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING
+
+
+AutoModelForMaskedImageModeling = auto_class_update(AutoModelForMaskedImageModeling, head_doc="masked image modeling")
+
+
class AutoModelWithLMHead(_AutoModelWithLMHead):
@classmethod
def from_config(cls, config):
diff --git a/src/transformers/models/beit/configuration_beit.py b/src/transformers/models/beit/configuration_beit.py
index ebc46ee313..a611e1b453 100644
--- a/src/transformers/models/beit/configuration_beit.py
+++ b/src/transformers/models/beit/configuration_beit.py
@@ -48,19 +48,19 @@ class BeitConfig(PretrainedConfig):
hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
`"relu"`, `"selu"` and `"gelu_new"` are supported.
- hidden_dropout_prob (`float`, *optional*, defaults to 0.1):
+ hidden_dropout_prob (`float`, *optional*, defaults to 0.0):
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
- attention_probs_dropout_prob (`float`, *optional*, defaults to 0.1):
+ attention_probs_dropout_prob (`float`, *optional*, defaults to 0.0):
The dropout ratio for the attention probabilities.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
layer_norm_eps (`float`, *optional*, defaults to 1e-12):
The epsilon used by the layer normalization layers.
- image_size (`int`, *optional*, defaults to `224`):
+ image_size (`int`, *optional*, defaults to 224):
The size (resolution) of each image.
- patch_size (`int`, *optional*, defaults to `16`):
+ patch_size (`int`, *optional*, defaults to 16):
The size (resolution) of each patch.
- num_channels (`int`, *optional*, defaults to `3`):
+ num_channels (`int`, *optional*, defaults to 3):
The number of input channels.
use_mask_token (`bool`, *optional*, defaults to `False`):
Whether to use a mask token for masked image modeling.
diff --git a/src/transformers/models/beit/modeling_beit.py b/src/transformers/models/beit/modeling_beit.py
index d42e4abc8e..9e9c3393a9 100755
--- a/src/transformers/models/beit/modeling_beit.py
+++ b/src/transformers/models/beit/modeling_beit.py
@@ -1,5 +1,5 @@
# coding=utf-8
-# Copyright 2021 Google AI, Ross Wightman, The HuggingFace Inc. team. All rights reserved.
+# Copyright 2021 Microsoft Research and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
diff --git a/src/transformers/models/deit/__init__.py b/src/transformers/models/deit/__init__.py
index a637cde38b..a9fddc5af8 100644
--- a/src/transformers/models/deit/__init__.py
+++ b/src/transformers/models/deit/__init__.py
@@ -32,6 +32,7 @@ if is_torch_available():
"DEIT_PRETRAINED_MODEL_ARCHIVE_LIST",
"DeiTForImageClassification",
"DeiTForImageClassificationWithTeacher",
+ "DeiTForMaskedImageModeling",
"DeiTModel",
"DeiTPreTrainedModel",
]
@@ -48,6 +49,7 @@ if TYPE_CHECKING:
DEIT_PRETRAINED_MODEL_ARCHIVE_LIST,
DeiTForImageClassification,
DeiTForImageClassificationWithTeacher,
+ DeiTForMaskedImageModeling,
DeiTModel,
DeiTPreTrainedModel,
)
diff --git a/src/transformers/models/deit/configuration_deit.py b/src/transformers/models/deit/configuration_deit.py
index 4e5968cf1e..616e1288e0 100644
--- a/src/transformers/models/deit/configuration_deit.py
+++ b/src/transformers/models/deit/configuration_deit.py
@@ -66,7 +66,8 @@ class DeiTConfig(PretrainedConfig):
The number of input channels.
qkv_bias (`bool`, *optional*, defaults to `True`):
Whether to add a bias to the queries, keys and values.
-
+ encoder_stride (`int`, `optional`, defaults to 16):
+ Factor to increase the spatial resolution by in the decoder head for masked image modeling.
Example:
@@ -100,6 +101,7 @@ class DeiTConfig(PretrainedConfig):
patch_size=16,
num_channels=3,
qkv_bias=True,
+ encoder_stride=16,
**kwargs
):
super().__init__(**kwargs)
@@ -113,8 +115,8 @@ class DeiTConfig(PretrainedConfig):
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.initializer_range = initializer_range
self.layer_norm_eps = layer_norm_eps
-
self.image_size = image_size
self.patch_size = patch_size
self.num_channels = num_channels
self.qkv_bias = qkv_bias
+ self.encoder_stride = encoder_stride
diff --git a/src/transformers/models/deit/modeling_deit.py b/src/transformers/models/deit/modeling_deit.py
index 3a8d7cd0a9..5e9dca45e7 100644
--- a/src/transformers/models/deit/modeling_deit.py
+++ b/src/transformers/models/deit/modeling_deit.py
@@ -33,7 +33,7 @@ from ...file_utils import (
add_start_docstrings_to_model_forward,
replace_return_docstrings,
)
-from ...modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling, SequenceClassifierOutput
+from ...modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling, MaskedLMOutput, SequenceClassifierOutput
from ...modeling_utils import PreTrainedModel, find_pruneable_heads_and_indices, prune_linear_layer
from ...utils import logging
from .configuration_deit import DeiTConfig
@@ -73,15 +73,16 @@ def to_2tuple(x):
class DeiTEmbeddings(nn.Module):
"""
- Construct the CLS token, distillation token, position and patch embeddings.
+ Construct the CLS token, distillation token, position and patch embeddings. Optionally, also the mask token.
"""
- def __init__(self, config):
+ def __init__(self, config, use_mask_token=False):
super().__init__()
self.cls_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size))
self.distillation_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size))
+ self.mask_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size)) if use_mask_token else None
self.patch_embeddings = PatchEmbeddings(
image_size=config.image_size,
patch_size=config.patch_size,
@@ -92,9 +93,15 @@ class DeiTEmbeddings(nn.Module):
self.position_embeddings = nn.Parameter(torch.zeros(1, num_patches + 2, config.hidden_size))
self.dropout = nn.Dropout(config.hidden_dropout_prob)
- def forward(self, pixel_values):
- batch_size = pixel_values.shape[0]
+ def forward(self, pixel_values, bool_masked_pos=None):
embeddings = self.patch_embeddings(pixel_values)
+ batch_size, seq_len, _ = embeddings.size()
+
+ if bool_masked_pos is not None:
+ mask_tokens = self.mask_token.expand(batch_size, seq_len, -1)
+ # replace the masked visual tokens by mask_tokens
+ mask = bool_masked_pos.unsqueeze(-1).type_as(mask_tokens)
+ embeddings = embeddings * (1.0 - mask) + mask_tokens * mask
cls_tokens = self.cls_token.expand(batch_size, -1, -1)
distillation_tokens = self.distillation_token.expand(batch_size, -1, -1)
@@ -396,10 +403,6 @@ class DeiTPreTrainedModel(PreTrainedModel):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
- elif isinstance(module, nn.Embedding):
- module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
- if module.padding_idx is not None:
- module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
@@ -448,11 +451,11 @@ DEIT_INPUTS_DOCSTRING = r"""
DEIT_START_DOCSTRING,
)
class DeiTModel(DeiTPreTrainedModel):
- def __init__(self, config, add_pooling_layer=True):
+ def __init__(self, config, add_pooling_layer=True, use_mask_token=False):
super().__init__(config)
self.config = config
- self.embeddings = DeiTEmbeddings(config)
+ self.embeddings = DeiTEmbeddings(config, use_mask_token=use_mask_token)
self.encoder = DeiTEncoder(config)
self.layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
@@ -484,6 +487,7 @@ class DeiTModel(DeiTPreTrainedModel):
def forward(
self,
pixel_values=None,
+ bool_masked_pos=None,
head_mask=None,
output_attentions=None,
output_hidden_states=None,
@@ -505,7 +509,7 @@ class DeiTModel(DeiTPreTrainedModel):
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
- embedding_output = self.embeddings(pixel_values)
+ embedding_output = self.embeddings(pixel_values, bool_masked_pos=bool_masked_pos)
encoder_outputs = self.encoder(
embedding_output,
@@ -545,6 +549,105 @@ class DeiTPooler(nn.Module):
return pooled_output
+@add_start_docstrings(
+ "DeiT Model with a decoder on top for masked image modeling, as proposed in `SimMIM `__.",
+ DEIT_START_DOCSTRING,
+)
+class DeiTForMaskedImageModeling(DeiTPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+
+ self.deit = DeiTModel(config, add_pooling_layer=False, use_mask_token=True)
+
+ self.decoder = nn.Sequential(
+ nn.Conv2d(in_channels=config.hidden_size, out_channels=config.encoder_stride**2 * 3, kernel_size=1),
+ nn.PixelShuffle(config.encoder_stride),
+ )
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(DEIT_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=MaskedLMOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ pixel_values=None,
+ bool_masked_pos=None,
+ head_mask=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ ):
+ r"""
+ bool_masked_pos (`torch.BoolTensor` of shape `(batch_size, num_patches)`):
+ Boolean masked positions. Indicates which patches are masked (1) and which aren't (0).
+
+ Returns:
+
+ Examples:
+ ```python
+ >>> from transformers import DeiTFeatureExtractor, DeiTForMaskedImageModeling
+ >>> from PIL import Image
+ >>> import requests
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> feature_extractor = DeiTFeatureExtractor.from_pretrained("google/vit-base-patch16-224-in21k")
+ >>> model = DeiTForMaskedImageModeling.from_pretrained("google/vit-base-patch16-224-in21k")
+
+ >>> inputs = feature_extractor(images=image, return_tensors="pt")
+
+ >>> outputs = model(**inputs)
+ >>> last_hidden_states = outputs.last_hidden_state
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.deit(
+ pixel_values,
+ bool_masked_pos=bool_masked_pos,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ sequence_output = outputs[0]
+
+ # Reshape to (batch_size, num_channels, height, width)
+ sequence_output = sequence_output[:, 1:-1]
+ batch_size, sequence_length, num_channels = sequence_output.shape
+ height = width = int(sequence_length**0.5)
+ sequence_output = sequence_output.permute(0, 2, 1).reshape(batch_size, num_channels, height, width)
+
+ # Reconstruct pixel values
+ reconstructed_pixel_values = self.decoder(sequence_output)
+
+ masked_im_loss = None
+ if bool_masked_pos is not None:
+ size = self.config.image_size // self.config.patch_size
+ bool_masked_pos = bool_masked_pos.reshape(-1, size, size)
+ mask = (
+ bool_masked_pos.repeat_interleave(self.config.patch_size, 1)
+ .repeat_interleave(self.config.patch_size, 2)
+ .unsqueeze(1)
+ .contiguous()
+ )
+ reconstruction_loss = nn.functional.l1_loss(pixel_values, reconstructed_pixel_values, reduction="none")
+ masked_im_loss = (reconstruction_loss * mask).sum() / (mask.sum() + 1e-5) / self.config.num_channels
+
+ if not return_dict:
+ output = (reconstructed_pixel_values,) + outputs[2:]
+ return ((masked_im_loss,) + output) if masked_im_loss is not None else output
+
+ return MaskedLMOutput(
+ loss=masked_im_loss,
+ logits=reconstructed_pixel_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
@add_start_docstrings(
"""
DeiT Model transformer with an image classification head on top (a linear layer on top of the final hidden state of
diff --git a/src/transformers/models/swin/__init__.py b/src/transformers/models/swin/__init__.py
index c1d8bdf9ac..a93f35512c 100644
--- a/src/transformers/models/swin/__init__.py
+++ b/src/transformers/models/swin/__init__.py
@@ -30,6 +30,7 @@ if is_torch_available():
_import_structure["modeling_swin"] = [
"SWIN_PRETRAINED_MODEL_ARCHIVE_LIST",
"SwinForImageClassification",
+ "SwinForMaskedImageModeling",
"SwinModel",
"SwinPreTrainedModel",
]
@@ -42,6 +43,7 @@ if TYPE_CHECKING:
from .modeling_swin import (
SWIN_PRETRAINED_MODEL_ARCHIVE_LIST,
SwinForImageClassification,
+ SwinForMaskedImageModeling,
SwinModel,
SwinPreTrainedModel,
)
diff --git a/src/transformers/models/swin/configuration_swin.py b/src/transformers/models/swin/configuration_swin.py
index 7b70c26926..8749ed3d75 100644
--- a/src/transformers/models/swin/configuration_swin.py
+++ b/src/transformers/models/swin/configuration_swin.py
@@ -73,6 +73,8 @@ class SwinConfig(PretrainedConfig):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
layer_norm_eps (`float`, *optional*, defaults to 1e-12):
The epsilon used by the layer normalization layers.
+ encoder_stride (`int`, `optional`, defaults to 32):
+ Factor to increase the spatial resolution by in the decoder head for masked image modeling.
Example:
@@ -113,6 +115,7 @@ class SwinConfig(PretrainedConfig):
patch_norm=True,
initializer_range=0.02,
layer_norm_eps=1e-5,
+ encoder_stride=32,
**kwargs
):
super().__init__(**kwargs)
@@ -122,6 +125,7 @@ class SwinConfig(PretrainedConfig):
self.num_channels = num_channels
self.embed_dim = embed_dim
self.depths = depths
+ self.num_layers = len(depths)
self.num_heads = num_heads
self.window_size = window_size
self.mlp_ratio = mlp_ratio
@@ -134,6 +138,7 @@ class SwinConfig(PretrainedConfig):
self.path_norm = patch_norm
self.layer_norm_eps = layer_norm_eps
self.initializer_range = initializer_range
+ self.encoder_stride = encoder_stride
# we set the hidden_size attribute in order to make Swin work with VisionEncoderDecoderModel
# this indicates the channel dimension after the last stage of the model
self.hidden_size = embed_dim * 8
diff --git a/src/transformers/models/swin/modeling_swin.py b/src/transformers/models/swin/modeling_swin.py
index 2266750647..5b31b433f5 100644
--- a/src/transformers/models/swin/modeling_swin.py
+++ b/src/transformers/models/swin/modeling_swin.py
@@ -24,8 +24,13 @@ from torch import nn
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
from ...activations import ACT2FN
-from ...file_utils import add_code_sample_docstrings, add_start_docstrings, add_start_docstrings_to_model_forward
-from ...modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling, SequenceClassifierOutput
+from ...file_utils import (
+ add_code_sample_docstrings,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ replace_return_docstrings,
+)
+from ...modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling, MaskedLMOutput, SequenceClassifierOutput
from ...modeling_utils import PreTrainedModel, find_pruneable_heads_and_indices, prune_linear_layer
from ...utils import logging
from .configuration_swin import SwinConfig
@@ -100,10 +105,10 @@ def drop_path(input, drop_prob=0.0, training=False, scale_by_keep=True):
class SwinEmbeddings(nn.Module):
"""
- Construct the patch and position embeddings.
+ Construct the patch and position embeddings. Optionally, also the mask token.
"""
- def __init__(self, config):
+ def __init__(self, config, use_mask_token=False):
super().__init__()
self.patch_embeddings = SwinPatchEmbeddings(
@@ -114,6 +119,7 @@ class SwinEmbeddings(nn.Module):
)
num_patches = self.patch_embeddings.num_patches
self.patch_grid = self.patch_embeddings.grid_size
+ self.mask_token = nn.Parameter(torch.zeros(1, 1, config.embed_dim)) if use_mask_token else None
if config.use_absolute_embeddings:
self.position_embeddings = nn.Parameter(torch.zeros(1, num_patches + 1, config.embed_dim))
@@ -123,9 +129,16 @@ class SwinEmbeddings(nn.Module):
self.norm = nn.LayerNorm(config.embed_dim)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
- def forward(self, pixel_values):
+ def forward(self, pixel_values, bool_masked_pos=None):
embeddings = self.patch_embeddings(pixel_values)
embeddings = self.norm(embeddings)
+ batch_size, seq_len, _ = embeddings.size()
+
+ if bool_masked_pos is not None:
+ mask_tokens = self.mask_token.expand(batch_size, seq_len, -1)
+ # replace the masked visual tokens by mask_tokens
+ mask = bool_masked_pos.unsqueeze(-1).type_as(mask_tokens)
+ embeddings = embeddings * (1.0 - mask) + mask_tokens * mask
if self.position_embeddings is not None:
embeddings = embeddings + self.position_embeddings
@@ -616,7 +629,7 @@ class SwinPreTrainedModel(PreTrainedModel):
def _init_weights(self, module):
"""Initialize the weights"""
- if isinstance(module, nn.Linear):
+ if isinstance(module, (nn.Linear, nn.Conv2d)):
# Slightly different from the TF version which uses truncated_normal for initialization
# cf https://github.com/pytorch/pytorch/pull/5617
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
@@ -669,13 +682,13 @@ SWIN_INPUTS_DOCSTRING = r"""
SWIN_START_DOCSTRING,
)
class SwinModel(SwinPreTrainedModel):
- def __init__(self, config, add_pooling_layer=True):
+ def __init__(self, config, add_pooling_layer=True, use_mask_token=False):
super().__init__(config)
self.config = config
self.num_layers = len(config.depths)
self.num_features = int(config.embed_dim * 2 ** (self.num_layers - 1))
- self.embeddings = SwinEmbeddings(config)
+ self.embeddings = SwinEmbeddings(config, use_mask_token=use_mask_token)
self.encoder = SwinEncoder(config, self.embeddings.patch_grid)
self.layernorm = nn.LayerNorm(self.num_features, eps=config.layer_norm_eps)
@@ -707,6 +720,7 @@ class SwinModel(SwinPreTrainedModel):
def forward(
self,
pixel_values=None,
+ bool_masked_pos=None,
head_mask=None,
output_attentions=None,
output_hidden_states=None,
@@ -728,7 +742,7 @@ class SwinModel(SwinPreTrainedModel):
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, len(self.config.depths))
- embedding_output = self.embeddings(pixel_values)
+ embedding_output = self.embeddings(pixel_values, bool_masked_pos=bool_masked_pos)
encoder_outputs = self.encoder(
embedding_output,
@@ -757,6 +771,106 @@ class SwinModel(SwinPreTrainedModel):
)
+@add_start_docstrings(
+ "Swin Model with a decoder on top for masked image modeling, as proposed in `SimMIM `__.",
+ SWIN_START_DOCSTRING,
+)
+class SwinForMaskedImageModeling(SwinPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+
+ self.swin = SwinModel(config, add_pooling_layer=False, use_mask_token=True)
+
+ num_features = int(config.embed_dim * 2 ** (config.num_layers - 1))
+ self.decoder = nn.Sequential(
+ nn.Conv2d(in_channels=num_features, out_channels=config.encoder_stride**2 * 3, kernel_size=1),
+ nn.PixelShuffle(config.encoder_stride),
+ )
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(SWIN_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=MaskedLMOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ pixel_values=None,
+ bool_masked_pos=None,
+ head_mask=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ ):
+ r"""
+ bool_masked_pos (`torch.BoolTensor` of shape `(batch_size, num_patches)`):
+ Boolean masked positions. Indicates which patches are masked (1) and which aren't (0).
+
+ Returns:
+
+ Examples:
+ ```python
+ >>> from transformers import AutoFeatureExtractor, SwinForMaskedImageModeling
+ >>> from PIL import Image
+ >>> import requests
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/swin-tiny-patch4-window7-224")
+ >>> model = SwinForMaskedImageModeling.from_pretrained("microsoft/swin-tiny-patch4-window7-224")
+
+ >>> inputs = feature_extractor(images=image, return_tensors="pt")
+
+ >>> outputs = model(**inputs)
+ >>> last_hidden_states = outputs.last_hidden_state
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.swin(
+ pixel_values,
+ bool_masked_pos=bool_masked_pos,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ sequence_output = outputs[0]
+
+ # Reshape to (batch_size, num_channels, height, width)
+ sequence_output = sequence_output.transpose(1, 2)
+ batch_size, num_channels, sequence_length = sequence_output.shape
+ height = width = int(sequence_length**0.5)
+ sequence_output = sequence_output.reshape(batch_size, num_channels, height, width)
+
+ # Reconstruct pixel values
+ reconstructed_pixel_values = self.decoder(sequence_output)
+
+ masked_im_loss = None
+ if bool_masked_pos is not None:
+ size = self.config.image_size // self.config.patch_size
+ bool_masked_pos = bool_masked_pos.reshape(-1, size, size)
+ mask = (
+ bool_masked_pos.repeat_interleave(self.config.patch_size, 1)
+ .repeat_interleave(self.config.patch_size, 2)
+ .unsqueeze(1)
+ .contiguous()
+ )
+ reconstruction_loss = nn.functional.l1_loss(pixel_values, reconstructed_pixel_values, reduction="none")
+ masked_im_loss = (reconstruction_loss * mask).sum() / (mask.sum() + 1e-5) / self.config.num_channels
+
+ if not return_dict:
+ output = (reconstructed_pixel_values,) + outputs[2:]
+ return ((masked_im_loss,) + output) if masked_im_loss is not None else output
+
+ return MaskedLMOutput(
+ loss=masked_im_loss,
+ logits=reconstructed_pixel_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
@add_start_docstrings(
"""
Swin Model transformer with an image classification head on top (a linear layer on top of the final hidden state of
diff --git a/src/transformers/models/vit/__init__.py b/src/transformers/models/vit/__init__.py
index 09b91776cd..92c3681a4c 100644
--- a/src/transformers/models/vit/__init__.py
+++ b/src/transformers/models/vit/__init__.py
@@ -31,6 +31,7 @@ if is_torch_available():
_import_structure["modeling_vit"] = [
"VIT_PRETRAINED_MODEL_ARCHIVE_LIST",
"ViTForImageClassification",
+ "ViTForMaskedImageModeling",
"ViTModel",
"ViTPreTrainedModel",
]
@@ -59,6 +60,7 @@ if TYPE_CHECKING:
from .modeling_vit import (
VIT_PRETRAINED_MODEL_ARCHIVE_LIST,
ViTForImageClassification,
+ ViTForMaskedImageModeling,
ViTModel,
ViTPreTrainedModel,
)
diff --git a/src/transformers/models/vit/configuration_vit.py b/src/transformers/models/vit/configuration_vit.py
index b31be121fb..c8902fa9c0 100644
--- a/src/transformers/models/vit/configuration_vit.py
+++ b/src/transformers/models/vit/configuration_vit.py
@@ -65,7 +65,8 @@ class ViTConfig(PretrainedConfig):
The number of input channels.
qkv_bias (`bool`, *optional*, defaults to `True`):
Whether to add a bias to the queries, keys and values.
-
+ encoder_stride (`int`, `optional`, defaults to 16):
+ Factor to increase the spatial resolution by in the decoder head for masked image modeling.
Example:
@@ -99,6 +100,7 @@ class ViTConfig(PretrainedConfig):
patch_size=16,
num_channels=3,
qkv_bias=True,
+ encoder_stride=16,
**kwargs
):
super().__init__(**kwargs)
@@ -112,8 +114,8 @@ class ViTConfig(PretrainedConfig):
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.initializer_range = initializer_range
self.layer_norm_eps = layer_norm_eps
-
self.image_size = image_size
self.patch_size = patch_size
self.num_channels = num_channels
self.qkv_bias = qkv_bias
+ self.encoder_stride = encoder_stride
diff --git a/src/transformers/models/vit/modeling_vit.py b/src/transformers/models/vit/modeling_vit.py
index 747a25d1dd..773be1b6cf 100644
--- a/src/transformers/models/vit/modeling_vit.py
+++ b/src/transformers/models/vit/modeling_vit.py
@@ -24,8 +24,13 @@ from torch import nn
from torch.nn import CrossEntropyLoss, MSELoss
from ...activations import ACT2FN
-from ...file_utils import add_code_sample_docstrings, add_start_docstrings, add_start_docstrings_to_model_forward
-from ...modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling, SequenceClassifierOutput
+from ...file_utils import (
+ add_code_sample_docstrings,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ replace_return_docstrings,
+)
+from ...modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling, MaskedLMOutput, SequenceClassifierOutput
from ...modeling_utils import PreTrainedModel, find_pruneable_heads_and_indices, prune_linear_layer
from ...utils import logging
from .configuration_vit import ViTConfig
@@ -67,14 +72,15 @@ def to_2tuple(x):
class ViTEmbeddings(nn.Module):
"""
- Construct the CLS token, position and patch embeddings.
+ Construct the CLS token, position and patch embeddings. Optionally, also the mask token.
"""
- def __init__(self, config):
+ def __init__(self, config, use_mask_token=False):
super().__init__()
self.cls_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size))
+ self.mask_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size)) if use_mask_token else None
self.patch_embeddings = PatchEmbeddings(
image_size=config.image_size,
patch_size=config.patch_size,
@@ -117,10 +123,17 @@ class ViTEmbeddings(nn.Module):
patch_pos_embed = patch_pos_embed.permute(0, 2, 3, 1).view(1, -1, dim)
return torch.cat((class_pos_embed.unsqueeze(0), patch_pos_embed), dim=1)
- def forward(self, pixel_values, interpolate_pos_encoding=False):
+ def forward(self, pixel_values, bool_masked_pos=None, interpolate_pos_encoding=False):
batch_size, num_channels, height, width = pixel_values.shape
embeddings = self.patch_embeddings(pixel_values, interpolate_pos_encoding=interpolate_pos_encoding)
+ batch_size, seq_len, _ = embeddings.size()
+ if bool_masked_pos is not None:
+ mask_tokens = self.mask_token.expand(batch_size, seq_len, -1)
+ # replace the masked visual tokens by mask_tokens
+ mask = bool_masked_pos.unsqueeze(-1).type_as(mask_tokens)
+ embeddings = embeddings * (1.0 - mask) + mask_tokens * mask
+
# add the [CLS] token to the embedded patch tokens
cls_tokens = self.cls_token.expand(batch_size, -1, -1)
embeddings = torch.cat((cls_tokens, embeddings), dim=1)
@@ -422,10 +435,6 @@ class ViTPreTrainedModel(PreTrainedModel):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
- elif isinstance(module, nn.Embedding):
- module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
- if module.padding_idx is not None:
- module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
@@ -476,11 +485,11 @@ VIT_INPUTS_DOCSTRING = r"""
VIT_START_DOCSTRING,
)
class ViTModel(ViTPreTrainedModel):
- def __init__(self, config, add_pooling_layer=True):
+ def __init__(self, config, add_pooling_layer=True, use_mask_token=False):
super().__init__(config)
self.config = config
- self.embeddings = ViTEmbeddings(config)
+ self.embeddings = ViTEmbeddings(config, use_mask_token=use_mask_token)
self.encoder = ViTEncoder(config)
self.layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
@@ -512,6 +521,7 @@ class ViTModel(ViTPreTrainedModel):
def forward(
self,
pixel_values=None,
+ bool_masked_pos=None,
head_mask=None,
output_attentions=None,
output_hidden_states=None,
@@ -534,7 +544,9 @@ class ViTModel(ViTPreTrainedModel):
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
- embedding_output = self.embeddings(pixel_values, interpolate_pos_encoding=interpolate_pos_encoding)
+ embedding_output = self.embeddings(
+ pixel_values, bool_masked_pos=bool_masked_pos, interpolate_pos_encoding=interpolate_pos_encoding
+ )
encoder_outputs = self.encoder(
embedding_output,
@@ -573,6 +585,107 @@ class ViTPooler(nn.Module):
return pooled_output
+@add_start_docstrings(
+ "ViT Model with a decoder on top for masked image modeling, as proposed in `SimMIM `__.",
+ VIT_START_DOCSTRING,
+)
+class ViTForMaskedImageModeling(ViTPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+
+ self.vit = ViTModel(config, add_pooling_layer=False, use_mask_token=True)
+
+ self.decoder = nn.Sequential(
+ nn.Conv2d(in_channels=config.hidden_size, out_channels=config.encoder_stride**2 * 3, kernel_size=1),
+ nn.PixelShuffle(config.encoder_stride),
+ )
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(VIT_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=MaskedLMOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ pixel_values=None,
+ bool_masked_pos=None,
+ head_mask=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ interpolate_pos_encoding=None,
+ return_dict=None,
+ ):
+ r"""
+ bool_masked_pos (`torch.BoolTensor` of shape `(batch_size, num_patches)`):
+ Boolean masked positions. Indicates which patches are masked (1) and which aren't (0).
+
+ Returns:
+
+ Examples:
+ ```python
+ >>> from transformers import ViTFeatureExtractor, ViTForMaskedImageModeling
+ >>> from PIL import Image
+ >>> import requests
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> feature_extractor = ViTFeatureExtractor.from_pretrained("google/vit-base-patch16-224-in21k")
+ >>> model = ViTForMaskedImageModeling.from_pretrained("google/vit-base-patch16-224-in21k")
+
+ >>> inputs = feature_extractor(images=image, return_tensors="pt")
+
+ >>> outputs = model(**inputs)
+ >>> last_hidden_states = outputs.last_hidden_state
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.vit(
+ pixel_values,
+ bool_masked_pos=bool_masked_pos,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ interpolate_pos_encoding=interpolate_pos_encoding,
+ return_dict=return_dict,
+ )
+
+ sequence_output = outputs[0]
+
+ # Reshape to (batch_size, num_channels, height, width)
+ sequence_output = sequence_output[:, 1:]
+ batch_size, sequence_length, num_channels = sequence_output.shape
+ height = width = int(sequence_length**0.5)
+ sequence_output = sequence_output.permute(0, 2, 1).reshape(batch_size, num_channels, height, width)
+
+ # Reconstruct pixel values
+ reconstructed_pixel_values = self.decoder(sequence_output)
+
+ masked_im_loss = None
+ if bool_masked_pos is not None:
+ size = self.config.image_size // self.config.patch_size
+ bool_masked_pos = bool_masked_pos.reshape(-1, size, size)
+ mask = (
+ bool_masked_pos.repeat_interleave(self.config.patch_size, 1)
+ .repeat_interleave(self.config.patch_size, 2)
+ .unsqueeze(1)
+ .contiguous()
+ )
+ reconstruction_loss = nn.functional.l1_loss(pixel_values, reconstructed_pixel_values, reduction="none")
+ masked_im_loss = (reconstruction_loss * mask).sum() / (mask.sum() + 1e-5) / self.config.num_channels
+
+ if not return_dict:
+ output = (reconstructed_pixel_values,) + outputs[2:]
+ return ((masked_im_loss,) + output) if masked_im_loss is not None else output
+
+ return MaskedLMOutput(
+ loss=masked_im_loss,
+ logits=reconstructed_pixel_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
@add_start_docstrings(
"""
ViT Model transformer with an image classification head on top (a linear layer on top of the final hidden state of
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index be08c8f0e2..4facca5740 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -362,6 +362,9 @@ MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING = None
MODEL_FOR_IMAGE_SEGMENTATION_MAPPING = None
+MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING = None
+
+
MODEL_FOR_MASKED_LM_MAPPING = None
@@ -460,6 +463,13 @@ class AutoModelForImageSegmentation(metaclass=DummyObject):
requires_backends(self, ["torch"])
+class AutoModelForMaskedImageModeling(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
class AutoModelForMaskedLM(metaclass=DummyObject):
_backends = ["torch"]
@@ -1305,6 +1315,13 @@ class DeiTForImageClassificationWithTeacher(metaclass=DummyObject):
requires_backends(self, ["torch"])
+class DeiTForMaskedImageModeling(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
class DeiTModel(metaclass=DummyObject):
_backends = ["torch"]
@@ -3449,6 +3466,13 @@ class SwinForImageClassification(metaclass=DummyObject):
requires_backends(self, ["torch"])
+class SwinForMaskedImageModeling(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
class SwinModel(metaclass=DummyObject):
_backends = ["torch"]
@@ -3782,6 +3806,13 @@ class ViTForImageClassification(metaclass=DummyObject):
requires_backends(self, ["torch"])
+class ViTForMaskedImageModeling(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
class ViTModel(metaclass=DummyObject):
_backends = ["torch"]
diff --git a/tests/test_modeling_common.py b/tests/test_modeling_common.py
index d9ef068777..17888bcfac 100755
--- a/tests/test_modeling_common.py
+++ b/tests/test_modeling_common.py
@@ -72,6 +72,7 @@ if is_torch_available():
MODEL_FOR_CAUSAL_IMAGE_MODELING_MAPPING,
MODEL_FOR_CAUSAL_LM_MAPPING,
MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING,
+ MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING,
MODEL_FOR_MASKED_LM_MAPPING,
MODEL_FOR_MULTIPLE_CHOICE_MAPPING,
MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING,
@@ -165,6 +166,11 @@ class ModelTesterMixin:
inputs_dict["labels"] = torch.zeros(
(self.model_tester.batch_size, self.model_tester.seq_length), dtype=torch.long, device=torch_device
)
+ elif model_class in get_values(MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING):
+ num_patches = self.model_tester.image_size // self.model_tester.patch_size
+ inputs_dict["bool_masked_pos"] = torch.zeros(
+ (self.model_tester.batch_size, num_patches**2), dtype=torch.long, device=torch_device
+ )
return inputs_dict
def test_save_load(self):
diff --git a/tests/test_modeling_deit.py b/tests/test_modeling_deit.py
index 925dbc6b0e..d829e59b8e 100644
--- a/tests/test_modeling_deit.py
+++ b/tests/test_modeling_deit.py
@@ -35,6 +35,7 @@ if is_torch_available():
MODEL_MAPPING,
DeiTForImageClassification,
DeiTForImageClassificationWithTeacher,
+ DeiTForMaskedImageModeling,
DeiTModel,
)
from transformers.models.deit.modeling_deit import DEIT_PRETRAINED_MODEL_ARCHIVE_LIST, to_2tuple
@@ -67,6 +68,7 @@ class DeiTModelTester:
initializer_range=0.02,
num_labels=3,
scope=None,
+ encoder_stride=2,
):
self.parent = parent
self.batch_size = batch_size
@@ -85,6 +87,7 @@ class DeiTModelTester:
self.type_sequence_label_size = type_sequence_label_size
self.initializer_range = initializer_range
self.scope = scope
+ self.encoder_stride = encoder_stride
def prepare_config_and_inputs(self):
pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
@@ -111,6 +114,7 @@ class DeiTModelTester:
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
is_decoder=False,
initializer_range=self.initializer_range,
+ encoder_stride=self.encoder_stride,
)
def create_and_check_model(self, config, pixel_values, labels):
@@ -155,6 +159,7 @@ class DeiTModelTest(ModelTesterMixin, unittest.TestCase):
DeiTModel,
DeiTForImageClassification,
DeiTForImageClassificationWithTeacher,
+ DeiTForMaskedImageModeling,
)
if is_torch_available()
else ()
diff --git a/tests/test_modeling_swin.py b/tests/test_modeling_swin.py
index 173f7ffc3a..edfff892f5 100644
--- a/tests/test_modeling_swin.py
+++ b/tests/test_modeling_swin.py
@@ -31,7 +31,7 @@ if is_torch_available():
import torch
from torch import nn
- from transformers import SwinForImageClassification, SwinModel
+ from transformers import SwinForImageClassification, SwinForMaskedImageModeling, SwinModel
from transformers.models.swin.modeling_swin import SWIN_PRETRAINED_MODEL_ARCHIVE_LIST, to_2tuple
if is_vision_available():
@@ -74,6 +74,7 @@ class SwinModelTester:
scope=None,
use_labels=True,
type_sequence_label_size=10,
+ encoder_stride=2,
):
self.parent = parent
self.batch_size = batch_size
@@ -98,6 +99,7 @@ class SwinModelTester:
self.scope = scope
self.use_labels = use_labels
self.type_sequence_label_size = type_sequence_label_size
+ self.encoder_stride = encoder_stride
def prepare_config_and_inputs(self):
pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
@@ -129,6 +131,7 @@ class SwinModelTester:
path_norm=self.patch_norm,
layer_norm_eps=self.layer_norm_eps,
initializer_range=self.initializer_range,
+ encoder_stride=self.encoder_stride,
)
def create_and_check_model(self, config, pixel_values, labels):
@@ -169,6 +172,7 @@ class SwinModelTest(ModelTesterMixin, unittest.TestCase):
(
SwinModel,
SwinForImageClassification,
+ SwinForMaskedImageModeling,
)
if is_torch_available()
else ()
diff --git a/tests/test_modeling_vit.py b/tests/test_modeling_vit.py
index ac96f553e4..e0c38d7b4c 100644
--- a/tests/test_modeling_vit.py
+++ b/tests/test_modeling_vit.py
@@ -30,7 +30,7 @@ if is_torch_available():
import torch
from torch import nn
- from transformers import ViTForImageClassification, ViTModel
+ from transformers import ViTForImageClassification, ViTForMaskedImageModeling, ViTModel
from transformers.models.vit.modeling_vit import VIT_PRETRAINED_MODEL_ARCHIVE_LIST, to_2tuple
@@ -61,6 +61,7 @@ class ViTModelTester:
initializer_range=0.02,
num_labels=3,
scope=None,
+ encoder_stride=2,
):
self.parent = parent
self.batch_size = batch_size
@@ -79,6 +80,7 @@ class ViTModelTester:
self.type_sequence_label_size = type_sequence_label_size
self.initializer_range = initializer_range
self.scope = scope
+ self.encoder_stride = encoder_stride
def prepare_config_and_inputs(self):
pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
@@ -105,6 +107,7 @@ class ViTModelTester:
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
is_decoder=False,
initializer_range=self.initializer_range,
+ encoder_stride=self.encoder_stride,
)
def create_and_check_model(self, config, pixel_values, labels):
@@ -148,6 +151,7 @@ class ViTModelTest(ModelTesterMixin, unittest.TestCase):
(
ViTModel,
ViTForImageClassification,
+ ViTForMaskedImageModeling,
)
if is_torch_available()
else ()
+
+ SimMIM framework. Taken from the original paper.
+
+The goal for the model is to predict raw pixel values for the masked patches, using just a linear layer as prediction head. The model is trained using a simple L1 loss.
+
+### Using datasets from 🤗 datasets
+
+Here we show how to pre-train a `ViT` from scratch for masked image modeling on the [cifar10](https://huggingface.co/datasets/cifar10) dataset.
+
+Alternatively, one can decide to further pre-train an already pre-trained (or fine-tuned) checkpoint from the [hub](https://huggingface.co/). This can be done by setting the `model_name_or_path` argument to "google/vit-base-patch16-224-in21k" for example (and not specifying the `model_type` argument).
+
+```bash
+!python run_mim.py \
+ --model_type vit \
+ --output_dir ./outputs/ \
+ --overwrite_output_dir \
+ --remove_unused_columns False \
+ --label_names bool_masked_pos \
+ --do_train \
+ --do_eval \
+ --learning_rate 2e-5 \
+ --weight_decay 0.05 \
+ --num_train_epochs 100 \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 8 \
+ --logging_strategy steps \
+ --logging_steps 10 \
+ --evaluation_strategy epoch \
+ --save_strategy epoch \
+ --load_best_model_at_end True \
+ --save_total_limit 3 \
+ --seed 1337
+```
+
+Here, we train for 100 epochs with a learning rate of 2e-5. Note that the SimMIM authors used a more sophisticated learning rate schedule, see the [config files](https://github.com/microsoft/SimMIM/blob/main/configs/vit_base__800ep/simmim_pretrain__vit_base__img224__800ep.yaml) for more info. One can easily tweak the script to include this learning rate schedule (several learning rate schedulers are supported via the [training arguments](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments)).
+
+We can also for instance replicate the pre-training of a Swin Transformer using the same architecture as used by the SimMIM authors. For this, we first create a custom configuration and save it locally:
+
+```python
+from transformers import SwinConfig
+
+IMAGE_SIZE = 192
+PATCH_SIZE = 4
+EMBED_DIM = 128
+DEPTHS = [2, 2, 18, 2]
+NUM_HEADS = [4, 8, 16, 32]
+WINDOW_SIZE = 6
+
+config = SwinConfig(
+ image_size=IMAGE_SIZE,
+ patch_size=PATCH_SIZE,
+ embed_dim=EMBED_DIM,
+ depths=DEPTHS,
+ num_heads=NUM_HEADS,
+ window_size=WINDOW_SIZE,
+)
+config.save_pretrained("path_to_config")
+```
+
+Next, we can run the script by providing the path to this custom configuration (replace `path_to_config` below with your path):
+
+```bash
+!python run_mim.py \
+ --config_name_or_path path_to_config \
+ --model_type swin \
+ --output_dir ./outputs/ \
+ --overwrite_output_dir \
+ --remove_unused_columns False \
+ --label_names bool_masked_pos \
+ --do_train \
+ --do_eval \
+ --learning_rate 2e-5 \
+ --num_train_epochs 5 \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 8 \
+ --logging_strategy steps \
+ --logging_steps 10 \
+ --evaluation_strategy epoch \
+ --save_strategy epoch \
+ --load_best_model_at_end True \
+ --save_total_limit 3 \
+ --seed 1337
+```
+
+This will train a Swin Transformer from scratch.
+
+### Using your own data
+
+To use your own dataset, the training script expects the following directory structure:
+
+```bash
+root/dog/xxx.png
+root/dog/xxy.png
+root/dog/[...]/xxz.png
+
+root/cat/123.png
+root/cat/nsdf3.png
+root/cat/[...]/asd932_.png
+```
+
+Note that you can put images in dummy subfolders, whose names will be ignored by default (as labels aren't required). You can also just place all images into a single dummy subfolder. Once you've prepared your dataset, you can run the script like this:
+
+```bash
+python run_mim.py \
+ --model_type vit \
+ --dataset_name nateraw/image-folder \
+ --train_dir \
+ --output_dir ./outputs/ \
+ --remove_unused_columns False \
+ --label_names bool_masked_pos \
+ --do_train \
+ --do_eval
+```
+
+## MAE
+
+The `run_mae.py` script can be used to pre-train a Vision Transformer as a masked autoencoder (MAE), as proposed in [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377). The script can be used to train a `ViTMAEForPreTraining` model in the Transformers library, using PyTorch. After self-supervised pre-training, one can load the weights of the encoder directly into a `ViTForImageClassification`. The MAE method allows for learning high-capacity models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data.
The goal for the model is to predict raw pixel values for the masked patches. As the model internally masks patches and learns to reconstruct them, there's no need for any labels. The model uses the mean squared error (MSE) between the reconstructed and original images in the pixel space.
-## Using datasets from 🤗 `datasets`
+### Using datasets from 🤗 `datasets`
One can use the following command to pre-train a `ViTMAEForPreTraining` model from scratch on the [cifar10](https://huggingface.co/datasets/cifar10) dataset:
@@ -67,7 +194,7 @@ alt="drawing" width="300"/>
Alternatively, one can decide to further pre-train an already pre-trained (or fine-tuned) checkpoint from the [hub](https://huggingface.co/). This can be done by setting the `model_name_or_path` argument to "facebook/vit-mae-base" for example.
-## Using your own data
+### Using your own data
To use your own dataset, the training script expects the following directory structure:
@@ -95,7 +222,7 @@ python run_mae.py \
--do_eval
```
-### 💡 The above will split the train dir into training and evaluation sets
+#### 💡 The above will split the train dir into training and evaluation sets
- To control the split amount, use the `--train_val_split` flag.
- To provide your own validation split in its own directory, you can pass the `--validation_dir ` flag.
@@ -122,7 +249,7 @@ $ huggingface-cli login
3. When running the script, pass the following arguments:
```bash
-python run_mae.py \
+python run_xxx.py \
--push_to_hub \
--push_to_hub_model_id \
...
diff --git a/examples/pytorch/image-pretraining/run_mim.py b/examples/pytorch/image-pretraining/run_mim.py
new file mode 100644
index 0000000000..d235a0394d
--- /dev/null
+++ b/examples/pytorch/image-pretraining/run_mim.py
@@ -0,0 +1,448 @@
+#!/usr/bin/env python
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+
+import logging
+import os
+import sys
+from dataclasses import dataclass, field
+from typing import Optional
+
+import numpy as np
+import torch
+from datasets import load_dataset
+from torchvision.transforms import Compose, Lambda, Normalize, RandomHorizontalFlip, RandomResizedCrop, ToTensor
+
+import transformers
+from transformers import (
+ CONFIG_MAPPING,
+ FEATURE_EXTRACTOR_MAPPING,
+ MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING,
+ AutoConfig,
+ AutoFeatureExtractor,
+ AutoModelForMaskedImageModeling,
+ HfArgumentParser,
+ Trainer,
+ TrainingArguments,
+)
+from transformers.trainer_utils import get_last_checkpoint
+from transformers.utils import check_min_version
+from transformers.utils.versions import require_version
+
+
+""" Pre-training a 🤗 Transformers model for simple masked image modeling (SimMIM).
+Any model supported by the AutoModelForMaskedImageModeling API can be used.
+"""
+
+logger = logging.getLogger(__name__)
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.17.0.dev0")
+
+require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/image-pretraining/requirements.txt")
+
+MODEL_CONFIG_CLASSES = list(MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ Using `HfArgumentParser` we can turn this class into argparse arguments to be able to
+ specify them on the command line.
+ """
+
+ dataset_name: Optional[str] = field(
+ default="cifar10", metadata={"help": "Name of a dataset from the datasets package"}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ image_column_name: Optional[str] = field(
+ default=None,
+ metadata={"help": "The column name of the images in the files. If not set, will try to use 'image' or 'img'."},
+ )
+ train_dir: Optional[str] = field(default=None, metadata={"help": "A folder containing the training data."})
+ validation_dir: Optional[str] = field(default=None, metadata={"help": "A folder containing the validation data."})
+ train_val_split: Optional[float] = field(
+ default=0.15, metadata={"help": "Percent to split off of train for validation."}
+ )
+ mask_patch_size: int = field(default=32, metadata={"help": "The size of the square patches to use for masking."})
+ mask_ratio: float = field(
+ default=0.6,
+ metadata={"help": "Percentage of patches to mask."},
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ },
+ )
+
+ def __post_init__(self):
+ data_files = dict()
+ if self.train_dir is not None:
+ data_files["train"] = self.train_dir
+ if self.validation_dir is not None:
+ data_files["val"] = self.validation_dir
+ self.data_files = data_files if data_files else None
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/feature extractor we are going to pre-train.
+ """
+
+ model_name_or_path: str = field(
+ default=None,
+ metadata={
+ "help": "The model checkpoint for weights initialization. Can be a local path to a pytorch_model.bin or a "
+ "checkpoint identifier on the hub. "
+ "Don't set if you want to train a model from scratch."
+ },
+ )
+ model_type: Optional[str] = field(
+ default=None,
+ metadata={"help": "If training from scratch, pass a model type from the list: " + ", ".join(MODEL_TYPES)},
+ )
+ config_name_or_path: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ config_overrides: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": "Override some existing default config settings when a model is trained from scratch. Example: "
+ "n_embd=10,resid_pdrop=0.2,scale_attn_weights=false,summary_type=cls_index"
+ },
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store (cache) the pretrained models/datasets downloaded from the hub"},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ feature_extractor_name: str = field(default=None, metadata={"help": "Name or path of preprocessor config."})
+ use_auth_token: bool = field(
+ default=False,
+ metadata={
+ "help": "Will use the token generated when running `transformers-cli login` (necessary to use this script "
+ "with private models)."
+ },
+ )
+ image_size: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": "The size (resolution) of each image. If not specified, will use `image_size` of the configuration."
+ },
+ )
+ patch_size: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": "The size (resolution) of each patch. If not specified, will use `patch_size` of the configuration."
+ },
+ )
+ encoder_stride: Optional[int] = field(
+ default=None,
+ metadata={"help": "Stride to use for the encoder."},
+ )
+
+
+class MaskGenerator:
+ """
+ A class to generate boolean masks for the pretraining task.
+
+ A mask is a 1D tensor of shape (model_patch_size**2,) where the value is either 0 or 1,
+ where 1 indicates "masked".
+ """
+
+ def __init__(self, input_size=192, mask_patch_size=32, model_patch_size=4, mask_ratio=0.6):
+ self.input_size = input_size
+ self.mask_patch_size = mask_patch_size
+ self.model_patch_size = model_patch_size
+ self.mask_ratio = mask_ratio
+
+ if self.input_size % self.mask_patch_size != 0:
+ raise ValueError("Input size must be divisible by mask patch size")
+ if self.mask_patch_size % self.model_patch_size != 0:
+ raise ValueError("Mask patch size must be divisible by model patch size")
+
+ self.rand_size = self.input_size // self.mask_patch_size
+ self.scale = self.mask_patch_size // self.model_patch_size
+
+ self.token_count = self.rand_size**2
+ self.mask_count = int(np.ceil(self.token_count * self.mask_ratio))
+
+ def __call__(self):
+ mask_idx = np.random.permutation(self.token_count)[: self.mask_count]
+ mask = np.zeros(self.token_count, dtype=int)
+ mask[mask_idx] = 1
+
+ mask = mask.reshape((self.rand_size, self.rand_size))
+ mask = mask.repeat(self.scale, axis=0).repeat(self.scale, axis=1)
+
+ return torch.tensor(mask.flatten())
+
+
+def collate_fn(examples):
+ pixel_values = torch.stack([example["pixel_values"] for example in examples])
+ mask = torch.stack([example["mask"] for example in examples])
+ return {"pixel_values": pixel_values, "bool_masked_pos": mask}
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+ transformers.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
+ + f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
+ )
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Detecting last checkpoint.
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # Initialize our dataset.
+ ds = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ data_files=data_args.data_files,
+ cache_dir=model_args.cache_dir,
+ )
+
+ # If we don't have a validation split, split off a percentage of train as validation.
+ data_args.train_val_split = None if "validation" in ds.keys() else data_args.train_val_split
+ if isinstance(data_args.train_val_split, float) and data_args.train_val_split > 0.0:
+ split = ds["train"].train_test_split(data_args.train_val_split)
+ ds["train"] = split["train"]
+ ds["validation"] = split["test"]
+
+ # Create config
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ config_kwargs = {
+ "cache_dir": model_args.cache_dir,
+ "revision": model_args.model_revision,
+ "use_auth_token": True if model_args.use_auth_token else None,
+ }
+ if model_args.config_name_or_path:
+ config = AutoConfig.from_pretrained(model_args.config_name_or_path, **config_kwargs)
+ elif model_args.model_name_or_path:
+ config = AutoConfig.from_pretrained(model_args.model_name_or_path, **config_kwargs)
+ else:
+ config = CONFIG_MAPPING[model_args.model_type]()
+ logger.warning("You are instantiating a new config instance from scratch.")
+ if model_args.config_overrides is not None:
+ logger.info(f"Overriding config: {model_args.config_overrides}")
+ config.update_from_string(model_args.config_overrides)
+ logger.info(f"New config: {config}")
+
+ # make sure the decoder_type is "simmim" (only relevant for BEiT)
+ if hasattr(config, "decoder_type"):
+ config.decoder_type = "simmim"
+
+ # adapt config
+ model_args.image_size = model_args.image_size if model_args.image_size is not None else config.image_size
+ model_args.patch_size = model_args.patch_size if model_args.patch_size is not None else config.patch_size
+ model_args.encoder_stride = (
+ model_args.encoder_stride if model_args.encoder_stride is not None else config.encoder_stride
+ )
+
+ config.update(
+ {
+ "image_size": model_args.image_size,
+ "patch_size": model_args.patch_size,
+ "encoder_stride": model_args.encoder_stride,
+ }
+ )
+
+ # create feature extractor
+ if model_args.feature_extractor_name:
+ feature_extractor = AutoFeatureExtractor.from_pretrained(model_args.feature_extractor_name, **config_kwargs)
+ elif model_args.model_name_or_path:
+ feature_extractor = AutoFeatureExtractor.from_pretrained(model_args.model_name_or_path, **config_kwargs)
+ else:
+ FEATURE_EXTRACTOR_TYPES = {
+ conf.model_type: feature_extractor_class
+ for conf, feature_extractor_class in FEATURE_EXTRACTOR_MAPPING.items()
+ }
+ feature_extractor = FEATURE_EXTRACTOR_TYPES[model_args.model_type]()
+
+ # create model
+ if model_args.model_name_or_path:
+ model = AutoModelForMaskedImageModeling.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ use_auth_token=True if model_args.use_auth_token else None,
+ )
+ else:
+ logger.info("Training new model from scratch")
+ model = AutoModelForMaskedImageModeling.from_config(config)
+
+ if training_args.do_train:
+ column_names = ds["train"].column_names
+ else:
+ column_names = ds["validation"].column_names
+
+ if data_args.image_column_name is not None:
+ image_column_name = data_args.image_column_name
+ elif "image" in column_names:
+ image_column_name = "image"
+ elif "img" in column_names:
+ image_column_name = "img"
+ else:
+ image_column_name = column_names[0]
+
+ # transformations as done in original SimMIM paper
+ # source: https://github.com/microsoft/SimMIM/blob/main/data/data_simmim.py
+ transforms = Compose(
+ [
+ Lambda(lambda img: img.convert("RGB") if img.mode != "RGB" else img),
+ RandomResizedCrop(model_args.image_size, scale=(0.67, 1.0), ratio=(3.0 / 4.0, 4.0 / 3.0)),
+ RandomHorizontalFlip(),
+ ToTensor(),
+ Normalize(mean=feature_extractor.image_mean, std=feature_extractor.image_std),
+ ]
+ )
+
+ # create mask generator
+ mask_generator = MaskGenerator(
+ input_size=model_args.image_size,
+ mask_patch_size=data_args.mask_patch_size,
+ model_patch_size=model_args.patch_size,
+ mask_ratio=data_args.mask_ratio,
+ )
+
+ def preprocess_images(examples):
+ """Preprocess a batch of images by applying transforms + creating a corresponding mask, indicating
+ which patches to mask."""
+
+ examples["pixel_values"] = [transforms(image) for image in examples[image_column_name]]
+ examples["mask"] = [mask_generator() for i in range(len(examples[image_column_name]))]
+
+ return examples
+
+ if training_args.do_train:
+ if "train" not in ds:
+ raise ValueError("--do_train requires a train dataset")
+ if data_args.max_train_samples is not None:
+ ds["train"] = ds["train"].shuffle(seed=training_args.seed).select(range(data_args.max_train_samples))
+ # Set the training transforms
+ ds["train"].set_transform(preprocess_images)
+
+ if training_args.do_eval:
+ if "validation" not in ds:
+ raise ValueError("--do_eval requires a validation dataset")
+ if data_args.max_eval_samples is not None:
+ ds["validation"] = (
+ ds["validation"].shuffle(seed=training_args.seed).select(range(data_args.max_eval_samples))
+ )
+ # Set the validation transforms
+ ds["validation"].set_transform(preprocess_images)
+
+ # Initialize our trainer
+ trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=ds["train"] if training_args.do_train else None,
+ eval_dataset=ds["validation"] if training_args.do_eval else None,
+ tokenizer=feature_extractor,
+ data_collator=collate_fn,
+ )
+
+ # Training
+ if training_args.do_train:
+ checkpoint = None
+ if training_args.resume_from_checkpoint is not None:
+ checkpoint = training_args.resume_from_checkpoint
+ elif last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ trainer.save_model()
+ trainer.log_metrics("train", train_result.metrics)
+ trainer.save_metrics("train", train_result.metrics)
+ trainer.save_state()
+
+ # Evaluation
+ if training_args.do_eval:
+ metrics = trainer.evaluate()
+ trainer.log_metrics("eval", metrics)
+ trainer.save_metrics("eval", metrics)
+
+ # Write model card and (optionally) push to hub
+ kwargs = {
+ "finetuned_from": model_args.model_name_or_path,
+ "tasks": "masked-image-modeling",
+ "dataset": data_args.dataset_name,
+ "tags": ["masked-image-modeling"],
+ }
+ if training_args.push_to_hub:
+ trainer.push_to_hub(**kwargs)
+ else:
+ trainer.create_model_card(**kwargs)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index 8efc520dc0..d0cc27ad95 100755
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -670,6 +670,7 @@ if is_torch_available():
"MODEL_FOR_CTC_MAPPING",
"MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING",
"MODEL_FOR_IMAGE_SEGMENTATION_MAPPING",
+ "MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING",
"MODEL_FOR_MASKED_LM_MAPPING",
"MODEL_FOR_MULTIPLE_CHOICE_MAPPING",
"MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING",
@@ -692,6 +693,7 @@ if is_torch_available():
"AutoModelForCTC",
"AutoModelForImageClassification",
"AutoModelForImageSegmentation",
+ "AutoModelForMaskedImageModeling",
"AutoModelForMaskedLM",
"AutoModelForMultipleChoice",
"AutoModelForNextSentencePrediction",
@@ -892,6 +894,7 @@ if is_torch_available():
"DEIT_PRETRAINED_MODEL_ARCHIVE_LIST",
"DeiTForImageClassification",
"DeiTForImageClassificationWithTeacher",
+ "DeiTForMaskedImageModeling",
"DeiTModel",
"DeiTPreTrainedModel",
]
@@ -1375,6 +1378,7 @@ if is_torch_available():
[
"SWIN_PRETRAINED_MODEL_ARCHIVE_LIST",
"SwinForImageClassification",
+ "SwinForMaskedImageModeling",
"SwinModel",
"SwinPreTrainedModel",
]
@@ -1456,6 +1460,7 @@ if is_torch_available():
[
"VIT_PRETRAINED_MODEL_ARCHIVE_LIST",
"ViTForImageClassification",
+ "ViTForMaskedImageModeling",
"ViTModel",
"ViTPreTrainedModel",
]
@@ -2822,6 +2827,7 @@ if TYPE_CHECKING:
MODEL_FOR_CTC_MAPPING,
MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING,
MODEL_FOR_IMAGE_SEGMENTATION_MAPPING,
+ MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING,
MODEL_FOR_MASKED_LM_MAPPING,
MODEL_FOR_MULTIPLE_CHOICE_MAPPING,
MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING,
@@ -2844,6 +2850,7 @@ if TYPE_CHECKING:
AutoModelForCTC,
AutoModelForImageClassification,
AutoModelForImageSegmentation,
+ AutoModelForMaskedImageModeling,
AutoModelForMaskedLM,
AutoModelForMultipleChoice,
AutoModelForNextSentencePrediction,
@@ -3010,6 +3017,7 @@ if TYPE_CHECKING:
DEIT_PRETRAINED_MODEL_ARCHIVE_LIST,
DeiTForImageClassification,
DeiTForImageClassificationWithTeacher,
+ DeiTForMaskedImageModeling,
DeiTModel,
DeiTPreTrainedModel,
)
@@ -3412,6 +3420,7 @@ if TYPE_CHECKING:
from .models.swin import (
SWIN_PRETRAINED_MODEL_ARCHIVE_LIST,
SwinForImageClassification,
+ SwinForMaskedImageModeling,
SwinModel,
SwinPreTrainedModel,
)
@@ -3477,6 +3486,7 @@ if TYPE_CHECKING:
from .models.vit import (
VIT_PRETRAINED_MODEL_ARCHIVE_LIST,
ViTForImageClassification,
+ ViTForMaskedImageModeling,
ViTModel,
ViTPreTrainedModel,
)
diff --git a/src/transformers/models/auto/__init__.py b/src/transformers/models/auto/__init__.py
index 9e39f38d09..18701a4275 100644
--- a/src/transformers/models/auto/__init__.py
+++ b/src/transformers/models/auto/__init__.py
@@ -37,6 +37,7 @@ if is_torch_available():
"MODEL_FOR_CTC_MAPPING",
"MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING",
"MODEL_FOR_IMAGE_SEGMENTATION_MAPPING",
+ "MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING",
"MODEL_FOR_MASKED_LM_MAPPING",
"MODEL_FOR_MULTIPLE_CHOICE_MAPPING",
"MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING",
@@ -60,6 +61,7 @@ if is_torch_available():
"AutoModelForCTC",
"AutoModelForImageClassification",
"AutoModelForImageSegmentation",
+ "AutoModelForMaskedImageModeling",
"AutoModelForMaskedLM",
"AutoModelForMultipleChoice",
"AutoModelForNextSentencePrediction",
@@ -153,6 +155,7 @@ if TYPE_CHECKING:
MODEL_FOR_CTC_MAPPING,
MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING,
MODEL_FOR_IMAGE_SEGMENTATION_MAPPING,
+ MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING,
MODEL_FOR_MASKED_LM_MAPPING,
MODEL_FOR_MULTIPLE_CHOICE_MAPPING,
MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING,
@@ -176,6 +179,7 @@ if TYPE_CHECKING:
AutoModelForCTC,
AutoModelForImageClassification,
AutoModelForImageSegmentation,
+ AutoModelForMaskedImageModeling,
AutoModelForMaskedLM,
AutoModelForMultipleChoice,
AutoModelForNextSentencePrediction,
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index 5e8c8149dd..8c3946e62f 100644
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -251,6 +251,15 @@ MODEL_FOR_CAUSAL_LM_MAPPING_NAMES = OrderedDict(
]
)
+MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING_NAMES = OrderedDict(
+ [
+ ("vit", "ViTForMaskedImageModeling"),
+ ("deit", "DeiTForMaskedImageModeling"),
+ ("swin", "SwinForMaskedImageModeling"),
+ ]
+)
+
+
MODEL_FOR_CAUSAL_IMAGE_MODELING_MAPPING_NAMES = OrderedDict(
# Model for Causal Image Modeling mapping
[
@@ -621,6 +630,9 @@ MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING = _LazyAutoMapping(
)
MODEL_FOR_VISION_2_SEQ_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_VISION_2_SEQ_MAPPING_NAMES)
MODEL_FOR_MASKED_LM_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_MASKED_LM_MAPPING_NAMES)
+MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING_NAMES
+)
MODEL_FOR_OBJECT_DETECTION_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_OBJECT_DETECTION_MAPPING_NAMES)
MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING = _LazyAutoMapping(
CONFIG_MAPPING_NAMES, MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING_NAMES
@@ -823,6 +835,13 @@ class AutoModelForAudioXVector(_BaseAutoModelClass):
AutoModelForAudioXVector = auto_class_update(AutoModelForAudioXVector, head_doc="audio retrieval via x-vector")
+class AutoModelForMaskedImageModeling(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING
+
+
+AutoModelForMaskedImageModeling = auto_class_update(AutoModelForMaskedImageModeling, head_doc="masked image modeling")
+
+
class AutoModelWithLMHead(_AutoModelWithLMHead):
@classmethod
def from_config(cls, config):
diff --git a/src/transformers/models/beit/configuration_beit.py b/src/transformers/models/beit/configuration_beit.py
index ebc46ee313..a611e1b453 100644
--- a/src/transformers/models/beit/configuration_beit.py
+++ b/src/transformers/models/beit/configuration_beit.py
@@ -48,19 +48,19 @@ class BeitConfig(PretrainedConfig):
hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
`"relu"`, `"selu"` and `"gelu_new"` are supported.
- hidden_dropout_prob (`float`, *optional*, defaults to 0.1):
+ hidden_dropout_prob (`float`, *optional*, defaults to 0.0):
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
- attention_probs_dropout_prob (`float`, *optional*, defaults to 0.1):
+ attention_probs_dropout_prob (`float`, *optional*, defaults to 0.0):
The dropout ratio for the attention probabilities.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
layer_norm_eps (`float`, *optional*, defaults to 1e-12):
The epsilon used by the layer normalization layers.
- image_size (`int`, *optional*, defaults to `224`):
+ image_size (`int`, *optional*, defaults to 224):
The size (resolution) of each image.
- patch_size (`int`, *optional*, defaults to `16`):
+ patch_size (`int`, *optional*, defaults to 16):
The size (resolution) of each patch.
- num_channels (`int`, *optional*, defaults to `3`):
+ num_channels (`int`, *optional*, defaults to 3):
The number of input channels.
use_mask_token (`bool`, *optional*, defaults to `False`):
Whether to use a mask token for masked image modeling.
diff --git a/src/transformers/models/beit/modeling_beit.py b/src/transformers/models/beit/modeling_beit.py
index d42e4abc8e..9e9c3393a9 100755
--- a/src/transformers/models/beit/modeling_beit.py
+++ b/src/transformers/models/beit/modeling_beit.py
@@ -1,5 +1,5 @@
# coding=utf-8
-# Copyright 2021 Google AI, Ross Wightman, The HuggingFace Inc. team. All rights reserved.
+# Copyright 2021 Microsoft Research and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
diff --git a/src/transformers/models/deit/__init__.py b/src/transformers/models/deit/__init__.py
index a637cde38b..a9fddc5af8 100644
--- a/src/transformers/models/deit/__init__.py
+++ b/src/transformers/models/deit/__init__.py
@@ -32,6 +32,7 @@ if is_torch_available():
"DEIT_PRETRAINED_MODEL_ARCHIVE_LIST",
"DeiTForImageClassification",
"DeiTForImageClassificationWithTeacher",
+ "DeiTForMaskedImageModeling",
"DeiTModel",
"DeiTPreTrainedModel",
]
@@ -48,6 +49,7 @@ if TYPE_CHECKING:
DEIT_PRETRAINED_MODEL_ARCHIVE_LIST,
DeiTForImageClassification,
DeiTForImageClassificationWithTeacher,
+ DeiTForMaskedImageModeling,
DeiTModel,
DeiTPreTrainedModel,
)
diff --git a/src/transformers/models/deit/configuration_deit.py b/src/transformers/models/deit/configuration_deit.py
index 4e5968cf1e..616e1288e0 100644
--- a/src/transformers/models/deit/configuration_deit.py
+++ b/src/transformers/models/deit/configuration_deit.py
@@ -66,7 +66,8 @@ class DeiTConfig(PretrainedConfig):
The number of input channels.
qkv_bias (`bool`, *optional*, defaults to `True`):
Whether to add a bias to the queries, keys and values.
-
+ encoder_stride (`int`, `optional`, defaults to 16):
+ Factor to increase the spatial resolution by in the decoder head for masked image modeling.
Example:
@@ -100,6 +101,7 @@ class DeiTConfig(PretrainedConfig):
patch_size=16,
num_channels=3,
qkv_bias=True,
+ encoder_stride=16,
**kwargs
):
super().__init__(**kwargs)
@@ -113,8 +115,8 @@ class DeiTConfig(PretrainedConfig):
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.initializer_range = initializer_range
self.layer_norm_eps = layer_norm_eps
-
self.image_size = image_size
self.patch_size = patch_size
self.num_channels = num_channels
self.qkv_bias = qkv_bias
+ self.encoder_stride = encoder_stride
diff --git a/src/transformers/models/deit/modeling_deit.py b/src/transformers/models/deit/modeling_deit.py
index 3a8d7cd0a9..5e9dca45e7 100644
--- a/src/transformers/models/deit/modeling_deit.py
+++ b/src/transformers/models/deit/modeling_deit.py
@@ -33,7 +33,7 @@ from ...file_utils import (
add_start_docstrings_to_model_forward,
replace_return_docstrings,
)
-from ...modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling, SequenceClassifierOutput
+from ...modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling, MaskedLMOutput, SequenceClassifierOutput
from ...modeling_utils import PreTrainedModel, find_pruneable_heads_and_indices, prune_linear_layer
from ...utils import logging
from .configuration_deit import DeiTConfig
@@ -73,15 +73,16 @@ def to_2tuple(x):
class DeiTEmbeddings(nn.Module):
"""
- Construct the CLS token, distillation token, position and patch embeddings.
+ Construct the CLS token, distillation token, position and patch embeddings. Optionally, also the mask token.
"""
- def __init__(self, config):
+ def __init__(self, config, use_mask_token=False):
super().__init__()
self.cls_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size))
self.distillation_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size))
+ self.mask_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size)) if use_mask_token else None
self.patch_embeddings = PatchEmbeddings(
image_size=config.image_size,
patch_size=config.patch_size,
@@ -92,9 +93,15 @@ class DeiTEmbeddings(nn.Module):
self.position_embeddings = nn.Parameter(torch.zeros(1, num_patches + 2, config.hidden_size))
self.dropout = nn.Dropout(config.hidden_dropout_prob)
- def forward(self, pixel_values):
- batch_size = pixel_values.shape[0]
+ def forward(self, pixel_values, bool_masked_pos=None):
embeddings = self.patch_embeddings(pixel_values)
+ batch_size, seq_len, _ = embeddings.size()
+
+ if bool_masked_pos is not None:
+ mask_tokens = self.mask_token.expand(batch_size, seq_len, -1)
+ # replace the masked visual tokens by mask_tokens
+ mask = bool_masked_pos.unsqueeze(-1).type_as(mask_tokens)
+ embeddings = embeddings * (1.0 - mask) + mask_tokens * mask
cls_tokens = self.cls_token.expand(batch_size, -1, -1)
distillation_tokens = self.distillation_token.expand(batch_size, -1, -1)
@@ -396,10 +403,6 @@ class DeiTPreTrainedModel(PreTrainedModel):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
- elif isinstance(module, nn.Embedding):
- module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
- if module.padding_idx is not None:
- module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
@@ -448,11 +451,11 @@ DEIT_INPUTS_DOCSTRING = r"""
DEIT_START_DOCSTRING,
)
class DeiTModel(DeiTPreTrainedModel):
- def __init__(self, config, add_pooling_layer=True):
+ def __init__(self, config, add_pooling_layer=True, use_mask_token=False):
super().__init__(config)
self.config = config
- self.embeddings = DeiTEmbeddings(config)
+ self.embeddings = DeiTEmbeddings(config, use_mask_token=use_mask_token)
self.encoder = DeiTEncoder(config)
self.layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
@@ -484,6 +487,7 @@ class DeiTModel(DeiTPreTrainedModel):
def forward(
self,
pixel_values=None,
+ bool_masked_pos=None,
head_mask=None,
output_attentions=None,
output_hidden_states=None,
@@ -505,7 +509,7 @@ class DeiTModel(DeiTPreTrainedModel):
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
- embedding_output = self.embeddings(pixel_values)
+ embedding_output = self.embeddings(pixel_values, bool_masked_pos=bool_masked_pos)
encoder_outputs = self.encoder(
embedding_output,
@@ -545,6 +549,105 @@ class DeiTPooler(nn.Module):
return pooled_output
+@add_start_docstrings(
+ "DeiT Model with a decoder on top for masked image modeling, as proposed in `SimMIM `__.",
+ DEIT_START_DOCSTRING,
+)
+class DeiTForMaskedImageModeling(DeiTPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+
+ self.deit = DeiTModel(config, add_pooling_layer=False, use_mask_token=True)
+
+ self.decoder = nn.Sequential(
+ nn.Conv2d(in_channels=config.hidden_size, out_channels=config.encoder_stride**2 * 3, kernel_size=1),
+ nn.PixelShuffle(config.encoder_stride),
+ )
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(DEIT_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=MaskedLMOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ pixel_values=None,
+ bool_masked_pos=None,
+ head_mask=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ ):
+ r"""
+ bool_masked_pos (`torch.BoolTensor` of shape `(batch_size, num_patches)`):
+ Boolean masked positions. Indicates which patches are masked (1) and which aren't (0).
+
+ Returns:
+
+ Examples:
+ ```python
+ >>> from transformers import DeiTFeatureExtractor, DeiTForMaskedImageModeling
+ >>> from PIL import Image
+ >>> import requests
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> feature_extractor = DeiTFeatureExtractor.from_pretrained("google/vit-base-patch16-224-in21k")
+ >>> model = DeiTForMaskedImageModeling.from_pretrained("google/vit-base-patch16-224-in21k")
+
+ >>> inputs = feature_extractor(images=image, return_tensors="pt")
+
+ >>> outputs = model(**inputs)
+ >>> last_hidden_states = outputs.last_hidden_state
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.deit(
+ pixel_values,
+ bool_masked_pos=bool_masked_pos,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ sequence_output = outputs[0]
+
+ # Reshape to (batch_size, num_channels, height, width)
+ sequence_output = sequence_output[:, 1:-1]
+ batch_size, sequence_length, num_channels = sequence_output.shape
+ height = width = int(sequence_length**0.5)
+ sequence_output = sequence_output.permute(0, 2, 1).reshape(batch_size, num_channels, height, width)
+
+ # Reconstruct pixel values
+ reconstructed_pixel_values = self.decoder(sequence_output)
+
+ masked_im_loss = None
+ if bool_masked_pos is not None:
+ size = self.config.image_size // self.config.patch_size
+ bool_masked_pos = bool_masked_pos.reshape(-1, size, size)
+ mask = (
+ bool_masked_pos.repeat_interleave(self.config.patch_size, 1)
+ .repeat_interleave(self.config.patch_size, 2)
+ .unsqueeze(1)
+ .contiguous()
+ )
+ reconstruction_loss = nn.functional.l1_loss(pixel_values, reconstructed_pixel_values, reduction="none")
+ masked_im_loss = (reconstruction_loss * mask).sum() / (mask.sum() + 1e-5) / self.config.num_channels
+
+ if not return_dict:
+ output = (reconstructed_pixel_values,) + outputs[2:]
+ return ((masked_im_loss,) + output) if masked_im_loss is not None else output
+
+ return MaskedLMOutput(
+ loss=masked_im_loss,
+ logits=reconstructed_pixel_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
@add_start_docstrings(
"""
DeiT Model transformer with an image classification head on top (a linear layer on top of the final hidden state of
diff --git a/src/transformers/models/swin/__init__.py b/src/transformers/models/swin/__init__.py
index c1d8bdf9ac..a93f35512c 100644
--- a/src/transformers/models/swin/__init__.py
+++ b/src/transformers/models/swin/__init__.py
@@ -30,6 +30,7 @@ if is_torch_available():
_import_structure["modeling_swin"] = [
"SWIN_PRETRAINED_MODEL_ARCHIVE_LIST",
"SwinForImageClassification",
+ "SwinForMaskedImageModeling",
"SwinModel",
"SwinPreTrainedModel",
]
@@ -42,6 +43,7 @@ if TYPE_CHECKING:
from .modeling_swin import (
SWIN_PRETRAINED_MODEL_ARCHIVE_LIST,
SwinForImageClassification,
+ SwinForMaskedImageModeling,
SwinModel,
SwinPreTrainedModel,
)
diff --git a/src/transformers/models/swin/configuration_swin.py b/src/transformers/models/swin/configuration_swin.py
index 7b70c26926..8749ed3d75 100644
--- a/src/transformers/models/swin/configuration_swin.py
+++ b/src/transformers/models/swin/configuration_swin.py
@@ -73,6 +73,8 @@ class SwinConfig(PretrainedConfig):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
layer_norm_eps (`float`, *optional*, defaults to 1e-12):
The epsilon used by the layer normalization layers.
+ encoder_stride (`int`, `optional`, defaults to 32):
+ Factor to increase the spatial resolution by in the decoder head for masked image modeling.
Example:
@@ -113,6 +115,7 @@ class SwinConfig(PretrainedConfig):
patch_norm=True,
initializer_range=0.02,
layer_norm_eps=1e-5,
+ encoder_stride=32,
**kwargs
):
super().__init__(**kwargs)
@@ -122,6 +125,7 @@ class SwinConfig(PretrainedConfig):
self.num_channels = num_channels
self.embed_dim = embed_dim
self.depths = depths
+ self.num_layers = len(depths)
self.num_heads = num_heads
self.window_size = window_size
self.mlp_ratio = mlp_ratio
@@ -134,6 +138,7 @@ class SwinConfig(PretrainedConfig):
self.path_norm = patch_norm
self.layer_norm_eps = layer_norm_eps
self.initializer_range = initializer_range
+ self.encoder_stride = encoder_stride
# we set the hidden_size attribute in order to make Swin work with VisionEncoderDecoderModel
# this indicates the channel dimension after the last stage of the model
self.hidden_size = embed_dim * 8
diff --git a/src/transformers/models/swin/modeling_swin.py b/src/transformers/models/swin/modeling_swin.py
index 2266750647..5b31b433f5 100644
--- a/src/transformers/models/swin/modeling_swin.py
+++ b/src/transformers/models/swin/modeling_swin.py
@@ -24,8 +24,13 @@ from torch import nn
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
from ...activations import ACT2FN
-from ...file_utils import add_code_sample_docstrings, add_start_docstrings, add_start_docstrings_to_model_forward
-from ...modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling, SequenceClassifierOutput
+from ...file_utils import (
+ add_code_sample_docstrings,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ replace_return_docstrings,
+)
+from ...modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling, MaskedLMOutput, SequenceClassifierOutput
from ...modeling_utils import PreTrainedModel, find_pruneable_heads_and_indices, prune_linear_layer
from ...utils import logging
from .configuration_swin import SwinConfig
@@ -100,10 +105,10 @@ def drop_path(input, drop_prob=0.0, training=False, scale_by_keep=True):
class SwinEmbeddings(nn.Module):
"""
- Construct the patch and position embeddings.
+ Construct the patch and position embeddings. Optionally, also the mask token.
"""
- def __init__(self, config):
+ def __init__(self, config, use_mask_token=False):
super().__init__()
self.patch_embeddings = SwinPatchEmbeddings(
@@ -114,6 +119,7 @@ class SwinEmbeddings(nn.Module):
)
num_patches = self.patch_embeddings.num_patches
self.patch_grid = self.patch_embeddings.grid_size
+ self.mask_token = nn.Parameter(torch.zeros(1, 1, config.embed_dim)) if use_mask_token else None
if config.use_absolute_embeddings:
self.position_embeddings = nn.Parameter(torch.zeros(1, num_patches + 1, config.embed_dim))
@@ -123,9 +129,16 @@ class SwinEmbeddings(nn.Module):
self.norm = nn.LayerNorm(config.embed_dim)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
- def forward(self, pixel_values):
+ def forward(self, pixel_values, bool_masked_pos=None):
embeddings = self.patch_embeddings(pixel_values)
embeddings = self.norm(embeddings)
+ batch_size, seq_len, _ = embeddings.size()
+
+ if bool_masked_pos is not None:
+ mask_tokens = self.mask_token.expand(batch_size, seq_len, -1)
+ # replace the masked visual tokens by mask_tokens
+ mask = bool_masked_pos.unsqueeze(-1).type_as(mask_tokens)
+ embeddings = embeddings * (1.0 - mask) + mask_tokens * mask
if self.position_embeddings is not None:
embeddings = embeddings + self.position_embeddings
@@ -616,7 +629,7 @@ class SwinPreTrainedModel(PreTrainedModel):
def _init_weights(self, module):
"""Initialize the weights"""
- if isinstance(module, nn.Linear):
+ if isinstance(module, (nn.Linear, nn.Conv2d)):
# Slightly different from the TF version which uses truncated_normal for initialization
# cf https://github.com/pytorch/pytorch/pull/5617
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
@@ -669,13 +682,13 @@ SWIN_INPUTS_DOCSTRING = r"""
SWIN_START_DOCSTRING,
)
class SwinModel(SwinPreTrainedModel):
- def __init__(self, config, add_pooling_layer=True):
+ def __init__(self, config, add_pooling_layer=True, use_mask_token=False):
super().__init__(config)
self.config = config
self.num_layers = len(config.depths)
self.num_features = int(config.embed_dim * 2 ** (self.num_layers - 1))
- self.embeddings = SwinEmbeddings(config)
+ self.embeddings = SwinEmbeddings(config, use_mask_token=use_mask_token)
self.encoder = SwinEncoder(config, self.embeddings.patch_grid)
self.layernorm = nn.LayerNorm(self.num_features, eps=config.layer_norm_eps)
@@ -707,6 +720,7 @@ class SwinModel(SwinPreTrainedModel):
def forward(
self,
pixel_values=None,
+ bool_masked_pos=None,
head_mask=None,
output_attentions=None,
output_hidden_states=None,
@@ -728,7 +742,7 @@ class SwinModel(SwinPreTrainedModel):
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, len(self.config.depths))
- embedding_output = self.embeddings(pixel_values)
+ embedding_output = self.embeddings(pixel_values, bool_masked_pos=bool_masked_pos)
encoder_outputs = self.encoder(
embedding_output,
@@ -757,6 +771,106 @@ class SwinModel(SwinPreTrainedModel):
)
+@add_start_docstrings(
+ "Swin Model with a decoder on top for masked image modeling, as proposed in `SimMIM `__.",
+ SWIN_START_DOCSTRING,
+)
+class SwinForMaskedImageModeling(SwinPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+
+ self.swin = SwinModel(config, add_pooling_layer=False, use_mask_token=True)
+
+ num_features = int(config.embed_dim * 2 ** (config.num_layers - 1))
+ self.decoder = nn.Sequential(
+ nn.Conv2d(in_channels=num_features, out_channels=config.encoder_stride**2 * 3, kernel_size=1),
+ nn.PixelShuffle(config.encoder_stride),
+ )
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(SWIN_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=MaskedLMOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ pixel_values=None,
+ bool_masked_pos=None,
+ head_mask=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ ):
+ r"""
+ bool_masked_pos (`torch.BoolTensor` of shape `(batch_size, num_patches)`):
+ Boolean masked positions. Indicates which patches are masked (1) and which aren't (0).
+
+ Returns:
+
+ Examples:
+ ```python
+ >>> from transformers import AutoFeatureExtractor, SwinForMaskedImageModeling
+ >>> from PIL import Image
+ >>> import requests
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/swin-tiny-patch4-window7-224")
+ >>> model = SwinForMaskedImageModeling.from_pretrained("microsoft/swin-tiny-patch4-window7-224")
+
+ >>> inputs = feature_extractor(images=image, return_tensors="pt")
+
+ >>> outputs = model(**inputs)
+ >>> last_hidden_states = outputs.last_hidden_state
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.swin(
+ pixel_values,
+ bool_masked_pos=bool_masked_pos,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ sequence_output = outputs[0]
+
+ # Reshape to (batch_size, num_channels, height, width)
+ sequence_output = sequence_output.transpose(1, 2)
+ batch_size, num_channels, sequence_length = sequence_output.shape
+ height = width = int(sequence_length**0.5)
+ sequence_output = sequence_output.reshape(batch_size, num_channels, height, width)
+
+ # Reconstruct pixel values
+ reconstructed_pixel_values = self.decoder(sequence_output)
+
+ masked_im_loss = None
+ if bool_masked_pos is not None:
+ size = self.config.image_size // self.config.patch_size
+ bool_masked_pos = bool_masked_pos.reshape(-1, size, size)
+ mask = (
+ bool_masked_pos.repeat_interleave(self.config.patch_size, 1)
+ .repeat_interleave(self.config.patch_size, 2)
+ .unsqueeze(1)
+ .contiguous()
+ )
+ reconstruction_loss = nn.functional.l1_loss(pixel_values, reconstructed_pixel_values, reduction="none")
+ masked_im_loss = (reconstruction_loss * mask).sum() / (mask.sum() + 1e-5) / self.config.num_channels
+
+ if not return_dict:
+ output = (reconstructed_pixel_values,) + outputs[2:]
+ return ((masked_im_loss,) + output) if masked_im_loss is not None else output
+
+ return MaskedLMOutput(
+ loss=masked_im_loss,
+ logits=reconstructed_pixel_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
@add_start_docstrings(
"""
Swin Model transformer with an image classification head on top (a linear layer on top of the final hidden state of
diff --git a/src/transformers/models/vit/__init__.py b/src/transformers/models/vit/__init__.py
index 09b91776cd..92c3681a4c 100644
--- a/src/transformers/models/vit/__init__.py
+++ b/src/transformers/models/vit/__init__.py
@@ -31,6 +31,7 @@ if is_torch_available():
_import_structure["modeling_vit"] = [
"VIT_PRETRAINED_MODEL_ARCHIVE_LIST",
"ViTForImageClassification",
+ "ViTForMaskedImageModeling",
"ViTModel",
"ViTPreTrainedModel",
]
@@ -59,6 +60,7 @@ if TYPE_CHECKING:
from .modeling_vit import (
VIT_PRETRAINED_MODEL_ARCHIVE_LIST,
ViTForImageClassification,
+ ViTForMaskedImageModeling,
ViTModel,
ViTPreTrainedModel,
)
diff --git a/src/transformers/models/vit/configuration_vit.py b/src/transformers/models/vit/configuration_vit.py
index b31be121fb..c8902fa9c0 100644
--- a/src/transformers/models/vit/configuration_vit.py
+++ b/src/transformers/models/vit/configuration_vit.py
@@ -65,7 +65,8 @@ class ViTConfig(PretrainedConfig):
The number of input channels.
qkv_bias (`bool`, *optional*, defaults to `True`):
Whether to add a bias to the queries, keys and values.
-
+ encoder_stride (`int`, `optional`, defaults to 16):
+ Factor to increase the spatial resolution by in the decoder head for masked image modeling.
Example:
@@ -99,6 +100,7 @@ class ViTConfig(PretrainedConfig):
patch_size=16,
num_channels=3,
qkv_bias=True,
+ encoder_stride=16,
**kwargs
):
super().__init__(**kwargs)
@@ -112,8 +114,8 @@ class ViTConfig(PretrainedConfig):
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.initializer_range = initializer_range
self.layer_norm_eps = layer_norm_eps
-
self.image_size = image_size
self.patch_size = patch_size
self.num_channels = num_channels
self.qkv_bias = qkv_bias
+ self.encoder_stride = encoder_stride
diff --git a/src/transformers/models/vit/modeling_vit.py b/src/transformers/models/vit/modeling_vit.py
index 747a25d1dd..773be1b6cf 100644
--- a/src/transformers/models/vit/modeling_vit.py
+++ b/src/transformers/models/vit/modeling_vit.py
@@ -24,8 +24,13 @@ from torch import nn
from torch.nn import CrossEntropyLoss, MSELoss
from ...activations import ACT2FN
-from ...file_utils import add_code_sample_docstrings, add_start_docstrings, add_start_docstrings_to_model_forward
-from ...modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling, SequenceClassifierOutput
+from ...file_utils import (
+ add_code_sample_docstrings,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ replace_return_docstrings,
+)
+from ...modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling, MaskedLMOutput, SequenceClassifierOutput
from ...modeling_utils import PreTrainedModel, find_pruneable_heads_and_indices, prune_linear_layer
from ...utils import logging
from .configuration_vit import ViTConfig
@@ -67,14 +72,15 @@ def to_2tuple(x):
class ViTEmbeddings(nn.Module):
"""
- Construct the CLS token, position and patch embeddings.
+ Construct the CLS token, position and patch embeddings. Optionally, also the mask token.
"""
- def __init__(self, config):
+ def __init__(self, config, use_mask_token=False):
super().__init__()
self.cls_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size))
+ self.mask_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size)) if use_mask_token else None
self.patch_embeddings = PatchEmbeddings(
image_size=config.image_size,
patch_size=config.patch_size,
@@ -117,10 +123,17 @@ class ViTEmbeddings(nn.Module):
patch_pos_embed = patch_pos_embed.permute(0, 2, 3, 1).view(1, -1, dim)
return torch.cat((class_pos_embed.unsqueeze(0), patch_pos_embed), dim=1)
- def forward(self, pixel_values, interpolate_pos_encoding=False):
+ def forward(self, pixel_values, bool_masked_pos=None, interpolate_pos_encoding=False):
batch_size, num_channels, height, width = pixel_values.shape
embeddings = self.patch_embeddings(pixel_values, interpolate_pos_encoding=interpolate_pos_encoding)
+ batch_size, seq_len, _ = embeddings.size()
+ if bool_masked_pos is not None:
+ mask_tokens = self.mask_token.expand(batch_size, seq_len, -1)
+ # replace the masked visual tokens by mask_tokens
+ mask = bool_masked_pos.unsqueeze(-1).type_as(mask_tokens)
+ embeddings = embeddings * (1.0 - mask) + mask_tokens * mask
+
# add the [CLS] token to the embedded patch tokens
cls_tokens = self.cls_token.expand(batch_size, -1, -1)
embeddings = torch.cat((cls_tokens, embeddings), dim=1)
@@ -422,10 +435,6 @@ class ViTPreTrainedModel(PreTrainedModel):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
- elif isinstance(module, nn.Embedding):
- module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
- if module.padding_idx is not None:
- module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
@@ -476,11 +485,11 @@ VIT_INPUTS_DOCSTRING = r"""
VIT_START_DOCSTRING,
)
class ViTModel(ViTPreTrainedModel):
- def __init__(self, config, add_pooling_layer=True):
+ def __init__(self, config, add_pooling_layer=True, use_mask_token=False):
super().__init__(config)
self.config = config
- self.embeddings = ViTEmbeddings(config)
+ self.embeddings = ViTEmbeddings(config, use_mask_token=use_mask_token)
self.encoder = ViTEncoder(config)
self.layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
@@ -512,6 +521,7 @@ class ViTModel(ViTPreTrainedModel):
def forward(
self,
pixel_values=None,
+ bool_masked_pos=None,
head_mask=None,
output_attentions=None,
output_hidden_states=None,
@@ -534,7 +544,9 @@ class ViTModel(ViTPreTrainedModel):
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
- embedding_output = self.embeddings(pixel_values, interpolate_pos_encoding=interpolate_pos_encoding)
+ embedding_output = self.embeddings(
+ pixel_values, bool_masked_pos=bool_masked_pos, interpolate_pos_encoding=interpolate_pos_encoding
+ )
encoder_outputs = self.encoder(
embedding_output,
@@ -573,6 +585,107 @@ class ViTPooler(nn.Module):
return pooled_output
+@add_start_docstrings(
+ "ViT Model with a decoder on top for masked image modeling, as proposed in `SimMIM `__.",
+ VIT_START_DOCSTRING,
+)
+class ViTForMaskedImageModeling(ViTPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+
+ self.vit = ViTModel(config, add_pooling_layer=False, use_mask_token=True)
+
+ self.decoder = nn.Sequential(
+ nn.Conv2d(in_channels=config.hidden_size, out_channels=config.encoder_stride**2 * 3, kernel_size=1),
+ nn.PixelShuffle(config.encoder_stride),
+ )
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(VIT_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=MaskedLMOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ pixel_values=None,
+ bool_masked_pos=None,
+ head_mask=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ interpolate_pos_encoding=None,
+ return_dict=None,
+ ):
+ r"""
+ bool_masked_pos (`torch.BoolTensor` of shape `(batch_size, num_patches)`):
+ Boolean masked positions. Indicates which patches are masked (1) and which aren't (0).
+
+ Returns:
+
+ Examples:
+ ```python
+ >>> from transformers import ViTFeatureExtractor, ViTForMaskedImageModeling
+ >>> from PIL import Image
+ >>> import requests
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> feature_extractor = ViTFeatureExtractor.from_pretrained("google/vit-base-patch16-224-in21k")
+ >>> model = ViTForMaskedImageModeling.from_pretrained("google/vit-base-patch16-224-in21k")
+
+ >>> inputs = feature_extractor(images=image, return_tensors="pt")
+
+ >>> outputs = model(**inputs)
+ >>> last_hidden_states = outputs.last_hidden_state
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.vit(
+ pixel_values,
+ bool_masked_pos=bool_masked_pos,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ interpolate_pos_encoding=interpolate_pos_encoding,
+ return_dict=return_dict,
+ )
+
+ sequence_output = outputs[0]
+
+ # Reshape to (batch_size, num_channels, height, width)
+ sequence_output = sequence_output[:, 1:]
+ batch_size, sequence_length, num_channels = sequence_output.shape
+ height = width = int(sequence_length**0.5)
+ sequence_output = sequence_output.permute(0, 2, 1).reshape(batch_size, num_channels, height, width)
+
+ # Reconstruct pixel values
+ reconstructed_pixel_values = self.decoder(sequence_output)
+
+ masked_im_loss = None
+ if bool_masked_pos is not None:
+ size = self.config.image_size // self.config.patch_size
+ bool_masked_pos = bool_masked_pos.reshape(-1, size, size)
+ mask = (
+ bool_masked_pos.repeat_interleave(self.config.patch_size, 1)
+ .repeat_interleave(self.config.patch_size, 2)
+ .unsqueeze(1)
+ .contiguous()
+ )
+ reconstruction_loss = nn.functional.l1_loss(pixel_values, reconstructed_pixel_values, reduction="none")
+ masked_im_loss = (reconstruction_loss * mask).sum() / (mask.sum() + 1e-5) / self.config.num_channels
+
+ if not return_dict:
+ output = (reconstructed_pixel_values,) + outputs[2:]
+ return ((masked_im_loss,) + output) if masked_im_loss is not None else output
+
+ return MaskedLMOutput(
+ loss=masked_im_loss,
+ logits=reconstructed_pixel_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
@add_start_docstrings(
"""
ViT Model transformer with an image classification head on top (a linear layer on top of the final hidden state of
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index be08c8f0e2..4facca5740 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -362,6 +362,9 @@ MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING = None
MODEL_FOR_IMAGE_SEGMENTATION_MAPPING = None
+MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING = None
+
+
MODEL_FOR_MASKED_LM_MAPPING = None
@@ -460,6 +463,13 @@ class AutoModelForImageSegmentation(metaclass=DummyObject):
requires_backends(self, ["torch"])
+class AutoModelForMaskedImageModeling(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
class AutoModelForMaskedLM(metaclass=DummyObject):
_backends = ["torch"]
@@ -1305,6 +1315,13 @@ class DeiTForImageClassificationWithTeacher(metaclass=DummyObject):
requires_backends(self, ["torch"])
+class DeiTForMaskedImageModeling(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
class DeiTModel(metaclass=DummyObject):
_backends = ["torch"]
@@ -3449,6 +3466,13 @@ class SwinForImageClassification(metaclass=DummyObject):
requires_backends(self, ["torch"])
+class SwinForMaskedImageModeling(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
class SwinModel(metaclass=DummyObject):
_backends = ["torch"]
@@ -3782,6 +3806,13 @@ class ViTForImageClassification(metaclass=DummyObject):
requires_backends(self, ["torch"])
+class ViTForMaskedImageModeling(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
class ViTModel(metaclass=DummyObject):
_backends = ["torch"]
diff --git a/tests/test_modeling_common.py b/tests/test_modeling_common.py
index d9ef068777..17888bcfac 100755
--- a/tests/test_modeling_common.py
+++ b/tests/test_modeling_common.py
@@ -72,6 +72,7 @@ if is_torch_available():
MODEL_FOR_CAUSAL_IMAGE_MODELING_MAPPING,
MODEL_FOR_CAUSAL_LM_MAPPING,
MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING,
+ MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING,
MODEL_FOR_MASKED_LM_MAPPING,
MODEL_FOR_MULTIPLE_CHOICE_MAPPING,
MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING,
@@ -165,6 +166,11 @@ class ModelTesterMixin:
inputs_dict["labels"] = torch.zeros(
(self.model_tester.batch_size, self.model_tester.seq_length), dtype=torch.long, device=torch_device
)
+ elif model_class in get_values(MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING):
+ num_patches = self.model_tester.image_size // self.model_tester.patch_size
+ inputs_dict["bool_masked_pos"] = torch.zeros(
+ (self.model_tester.batch_size, num_patches**2), dtype=torch.long, device=torch_device
+ )
return inputs_dict
def test_save_load(self):
diff --git a/tests/test_modeling_deit.py b/tests/test_modeling_deit.py
index 925dbc6b0e..d829e59b8e 100644
--- a/tests/test_modeling_deit.py
+++ b/tests/test_modeling_deit.py
@@ -35,6 +35,7 @@ if is_torch_available():
MODEL_MAPPING,
DeiTForImageClassification,
DeiTForImageClassificationWithTeacher,
+ DeiTForMaskedImageModeling,
DeiTModel,
)
from transformers.models.deit.modeling_deit import DEIT_PRETRAINED_MODEL_ARCHIVE_LIST, to_2tuple
@@ -67,6 +68,7 @@ class DeiTModelTester:
initializer_range=0.02,
num_labels=3,
scope=None,
+ encoder_stride=2,
):
self.parent = parent
self.batch_size = batch_size
@@ -85,6 +87,7 @@ class DeiTModelTester:
self.type_sequence_label_size = type_sequence_label_size
self.initializer_range = initializer_range
self.scope = scope
+ self.encoder_stride = encoder_stride
def prepare_config_and_inputs(self):
pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
@@ -111,6 +114,7 @@ class DeiTModelTester:
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
is_decoder=False,
initializer_range=self.initializer_range,
+ encoder_stride=self.encoder_stride,
)
def create_and_check_model(self, config, pixel_values, labels):
@@ -155,6 +159,7 @@ class DeiTModelTest(ModelTesterMixin, unittest.TestCase):
DeiTModel,
DeiTForImageClassification,
DeiTForImageClassificationWithTeacher,
+ DeiTForMaskedImageModeling,
)
if is_torch_available()
else ()
diff --git a/tests/test_modeling_swin.py b/tests/test_modeling_swin.py
index 173f7ffc3a..edfff892f5 100644
--- a/tests/test_modeling_swin.py
+++ b/tests/test_modeling_swin.py
@@ -31,7 +31,7 @@ if is_torch_available():
import torch
from torch import nn
- from transformers import SwinForImageClassification, SwinModel
+ from transformers import SwinForImageClassification, SwinForMaskedImageModeling, SwinModel
from transformers.models.swin.modeling_swin import SWIN_PRETRAINED_MODEL_ARCHIVE_LIST, to_2tuple
if is_vision_available():
@@ -74,6 +74,7 @@ class SwinModelTester:
scope=None,
use_labels=True,
type_sequence_label_size=10,
+ encoder_stride=2,
):
self.parent = parent
self.batch_size = batch_size
@@ -98,6 +99,7 @@ class SwinModelTester:
self.scope = scope
self.use_labels = use_labels
self.type_sequence_label_size = type_sequence_label_size
+ self.encoder_stride = encoder_stride
def prepare_config_and_inputs(self):
pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
@@ -129,6 +131,7 @@ class SwinModelTester:
path_norm=self.patch_norm,
layer_norm_eps=self.layer_norm_eps,
initializer_range=self.initializer_range,
+ encoder_stride=self.encoder_stride,
)
def create_and_check_model(self, config, pixel_values, labels):
@@ -169,6 +172,7 @@ class SwinModelTest(ModelTesterMixin, unittest.TestCase):
(
SwinModel,
SwinForImageClassification,
+ SwinForMaskedImageModeling,
)
if is_torch_available()
else ()
diff --git a/tests/test_modeling_vit.py b/tests/test_modeling_vit.py
index ac96f553e4..e0c38d7b4c 100644
--- a/tests/test_modeling_vit.py
+++ b/tests/test_modeling_vit.py
@@ -30,7 +30,7 @@ if is_torch_available():
import torch
from torch import nn
- from transformers import ViTForImageClassification, ViTModel
+ from transformers import ViTForImageClassification, ViTForMaskedImageModeling, ViTModel
from transformers.models.vit.modeling_vit import VIT_PRETRAINED_MODEL_ARCHIVE_LIST, to_2tuple
@@ -61,6 +61,7 @@ class ViTModelTester:
initializer_range=0.02,
num_labels=3,
scope=None,
+ encoder_stride=2,
):
self.parent = parent
self.batch_size = batch_size
@@ -79,6 +80,7 @@ class ViTModelTester:
self.type_sequence_label_size = type_sequence_label_size
self.initializer_range = initializer_range
self.scope = scope
+ self.encoder_stride = encoder_stride
def prepare_config_and_inputs(self):
pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
@@ -105,6 +107,7 @@ class ViTModelTester:
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
is_decoder=False,
initializer_range=self.initializer_range,
+ encoder_stride=self.encoder_stride,
)
def create_and_check_model(self, config, pixel_values, labels):
@@ -148,6 +151,7 @@ class ViTModelTest(ModelTesterMixin, unittest.TestCase):
(
ViTModel,
ViTForImageClassification,
+ ViTForMaskedImageModeling,
)
if is_torch_available()
else ()