diff --git a/docs/source/en/model_doc/owlv2.md b/docs/source/en/model_doc/owlv2.md
index 6edc654515..73063c5935 100644
--- a/docs/source/en/model_doc/owlv2.md
+++ b/docs/source/en/model_doc/owlv2.md
@@ -29,12 +29,17 @@ Tips:
- The architecture of OWLv2 is identical to [OWL-ViT](owlvit), however the object detection head now also includes an objectness classifier, which predicts the (query-agnostic) likelihood that a predicted box contains an object (as opposed to background). The objectness score can be used to rank or filter predictions independently of text queries.
- Usage of OWLv2 is identical to [OWL-ViT](owlvit) with a new, updated image processor ([`Owlv2ImageProcessor`]).
+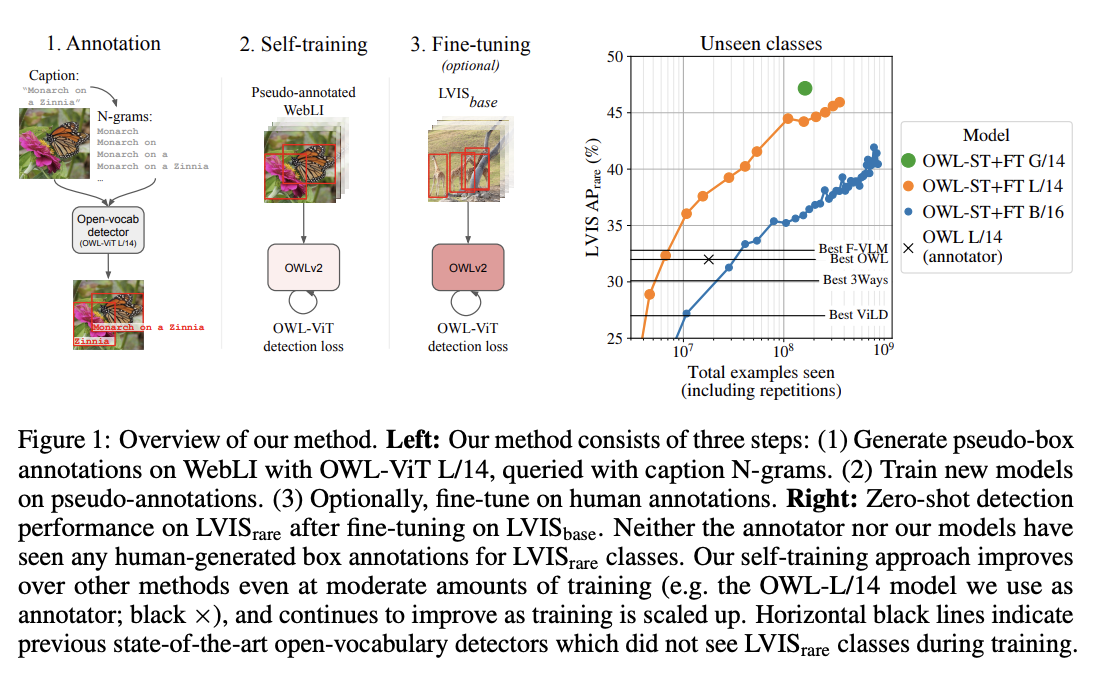 +
+ OWLv2 high-level overview. Taken from the original paper.
+
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
## Usage
-OWL-ViT a zero-shot text-conditioned object detection model. OWL-ViT uses [CLIP](clip) as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
+OWLv2 is, just like its predecessor [OWL-ViT](owlvit), a zero-shot text-conditioned object detection model. OWL-ViT uses [CLIP](clip) as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
[`Owlv2ImageProcessor`] can be used to resize (or rescale) and normalize images for the model and [`CLIPTokenizer`] is used to encode the text. [`Owlv2Processor`] wraps [`Owlv2ImageProcessor`] and [`CLIPTokenizer`] into a single instance to both encode the text and prepare the images. The following example shows how to perform object detection using [`Owlv2Processor`] and [`Owlv2ForObjectDetection`].
@@ -69,6 +74,10 @@ Detected a photo of a cat with confidence 0.614 at location [341.67, 17.54, 642.
Detected a photo of a cat with confidence 0.665 at location [6.75, 38.97, 326.62, 354.85]
```
+## Resources
+
+A demo notebook on using OWLv2 for zero- and one-shot (image-guided) object detection can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/OWLv2).
+
## Owlv2Config
[[autodoc]] Owlv2Config
diff --git a/docs/source/en/model_doc/owlvit.md b/docs/source/en/model_doc/owlvit.md
index b18b80b405..712d0f62d7 100644
--- a/docs/source/en/model_doc/owlvit.md
+++ b/docs/source/en/model_doc/owlvit.md
@@ -24,6 +24,13 @@ The abstract from the paper is the following:
*Combining simple architectures with large-scale pre-training has led to massive improvements in image classification. For object detection, pre-training and scaling approaches are less well established, especially in the long-tailed and open-vocabulary setting, where training data is relatively scarce. In this paper, we propose a strong recipe for transferring image-text models to open-vocabulary object detection. We use a standard Vision Transformer architecture with minimal modifications, contrastive image-text pre-training, and end-to-end detection fine-tuning. Our analysis of the scaling properties of this setup shows that increasing image-level pre-training and model size yield consistent improvements on the downstream detection task. We provide the adaptation strategies and regularizations needed to attain very strong performance on zero-shot text-conditioned and one-shot image-conditioned object detection. Code and models are available on GitHub.*
+
+
+ OWLv2 high-level overview. Taken from the original paper.
+
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
## Usage
-OWL-ViT a zero-shot text-conditioned object detection model. OWL-ViT uses [CLIP](clip) as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
+OWLv2 is, just like its predecessor [OWL-ViT](owlvit), a zero-shot text-conditioned object detection model. OWL-ViT uses [CLIP](clip) as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
[`Owlv2ImageProcessor`] can be used to resize (or rescale) and normalize images for the model and [`CLIPTokenizer`] is used to encode the text. [`Owlv2Processor`] wraps [`Owlv2ImageProcessor`] and [`CLIPTokenizer`] into a single instance to both encode the text and prepare the images. The following example shows how to perform object detection using [`Owlv2Processor`] and [`Owlv2ForObjectDetection`].
@@ -69,6 +74,10 @@ Detected a photo of a cat with confidence 0.614 at location [341.67, 17.54, 642.
Detected a photo of a cat with confidence 0.665 at location [6.75, 38.97, 326.62, 354.85]
```
+## Resources
+
+A demo notebook on using OWLv2 for zero- and one-shot (image-guided) object detection can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/OWLv2).
+
## Owlv2Config
[[autodoc]] Owlv2Config
diff --git a/docs/source/en/model_doc/owlvit.md b/docs/source/en/model_doc/owlvit.md
index b18b80b405..712d0f62d7 100644
--- a/docs/source/en/model_doc/owlvit.md
+++ b/docs/source/en/model_doc/owlvit.md
@@ -24,6 +24,13 @@ The abstract from the paper is the following:
*Combining simple architectures with large-scale pre-training has led to massive improvements in image classification. For object detection, pre-training and scaling approaches are less well established, especially in the long-tailed and open-vocabulary setting, where training data is relatively scarce. In this paper, we propose a strong recipe for transferring image-text models to open-vocabulary object detection. We use a standard Vision Transformer architecture with minimal modifications, contrastive image-text pre-training, and end-to-end detection fine-tuning. Our analysis of the scaling properties of this setup shows that increasing image-level pre-training and model size yield consistent improvements on the downstream detection task. We provide the adaptation strategies and regularizations needed to attain very strong performance on zero-shot text-conditioned and one-shot image-conditioned object detection. Code and models are available on GitHub.*
+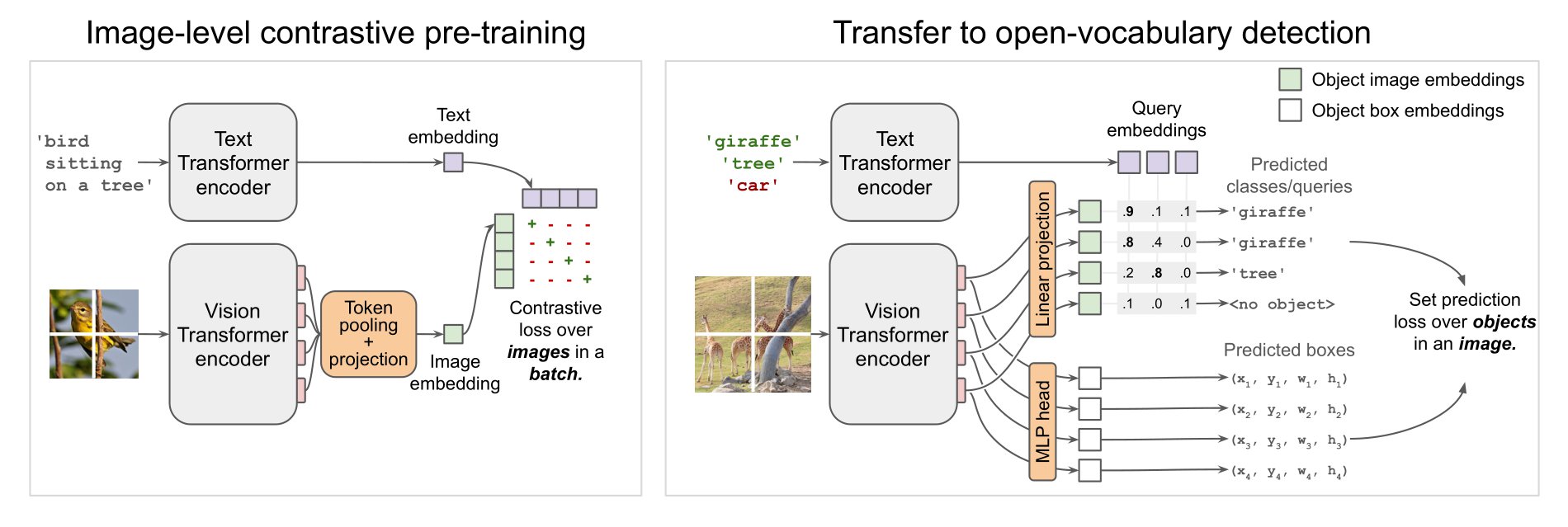 +
+ OWL-ViT architecture. Taken from the original paper.
+
+This model was contributed by [adirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
+
## Usage
OWL-ViT is a zero-shot text-conditioned object detection model. OWL-ViT uses [CLIP](clip) as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
@@ -61,7 +68,9 @@ Detected a photo of a cat with confidence 0.707 at location [324.97, 20.44, 640.
Detected a photo of a cat with confidence 0.717 at location [1.46, 55.26, 315.55, 472.17]
```
-This model was contributed by [adirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
+## Resources
+
+A demo notebook on using OWL-ViT for zero- and one-shot (image-guided) object detection can be found [here](https://github.com/huggingface/notebooks/blob/main/examples/zeroshot_object_detection_with_owlvit.ipynb).
## OwlViTConfig
+
+ OWL-ViT architecture. Taken from the original paper.
+
+This model was contributed by [adirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
+
## Usage
OWL-ViT is a zero-shot text-conditioned object detection model. OWL-ViT uses [CLIP](clip) as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
@@ -61,7 +68,9 @@ Detected a photo of a cat with confidence 0.707 at location [324.97, 20.44, 640.
Detected a photo of a cat with confidence 0.717 at location [1.46, 55.26, 315.55, 472.17]
```
-This model was contributed by [adirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
+## Resources
+
+A demo notebook on using OWL-ViT for zero- and one-shot (image-guided) object detection can be found [here](https://github.com/huggingface/notebooks/blob/main/examples/zeroshot_object_detection_with_owlvit.ipynb).
## OwlViTConfig