German electra model card v3 update (#7089)
* changed eval table model order * Update install * update mc
This commit is contained in:
@@ -7,73 +7,66 @@ tags:
|
|||||||
- commoncrawl
|
- commoncrawl
|
||||||
- uncased
|
- uncased
|
||||||
- umlaute
|
- umlaute
|
||||||
|
- umlauts
|
||||||
|
- german
|
||||||
|
- deutsch
|
||||||
---
|
---
|
||||||
|
|
||||||
# German Electra Uncased
|
# German Electra Uncased
|
||||||
<img width="300px" src="https://raw.githubusercontent.com/German-NLP-Group/german-transformer-training/master/model_cards/german-electra-logo.png">
|
<img width="300px" src="https://raw.githubusercontent.com/German-NLP-Group/german-transformer-training/master/model_cards/german-electra-logo.png">
|
||||||
[¹]
|
[¹]
|
||||||
|
|
||||||
|
|
||||||
# Model Info
|
# Model Info
|
||||||
|
|
||||||
This Model is suitable for Training on many downstream tasks in German (Q&A, Sentiment Analysis, etc.).
|
This Model is suitable for Training on many downstream tasks in German (Q&A, Sentiment Analysis, etc.).
|
||||||
|
|
||||||
It can be used as a drop-in Replacement for **BERT** in most down-stream tasks (**ELECTRA** is even implemented as an extended **BERT** Class).
|
It can be used as a drop-in Replacement for **BERT** in most down-stream tasks (**ELECTRA** is even implemented as an extended **BERT** Class).
|
||||||
|
|
||||||
At the time of release (August 2020) this Model is the best performing publicly available German NLP Model on various German Evaluation Metrics (CONLL03-DE, GermEval18 Coarse, GermEval18 Fine). For GermEval18 Coarse results see below. More will be published soon.
|
At the time of release (August 2020) this Model is the best performing publicly available German NLP Model on various German Evaluation Metrics (CONLL03-DE, GermEval18 Coarse, GermEval18 Fine). For GermEval18 Coarse results see below. More will be published soon.
|
||||||
|
|
||||||
|
# Installation
|
||||||
|
This model has the special feature that it is **uncased** but does **not strip accents**.
|
||||||
|
This possibility was added by us with [PR #6280](https://github.com/huggingface/transformers/pull/6280).
|
||||||
|
To use it you have to use Transformers version 3.1.0 or newer.
|
||||||
|
|
||||||
## Installation
|
```bash
|
||||||
|
pip install transformers -U
|
||||||
|
```
|
||||||
|
|
||||||
---
|
# Uncase and Umlauts ('Ö', 'Ä', 'Ü')
|
||||||
This model is **uncased** but does not use **strip accents**.
|
|
||||||
The necessary parameter is `strip_accents=False`.
|
|
||||||
|
|
||||||
This needs to be set for the tokenizer otherwise the model will perform slightly worse.
|
|
||||||
It was added to Transformers with [PR #6280](https://github.com/huggingface/transformers/pull/6280).
|
|
||||||
|
|
||||||
Since Transformers has not been released since the PR #6280 was merged, you have to install directly from source:
|
|
||||||
|
|
||||||
`pip install git+https://github.com/huggingface/transformers.git -U`
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
|
|
||||||
## Uncase and Umlauts ('Ö', 'Ä', 'Ü')
|
|
||||||
This model is uncased. This helps especially for domains where colloquial terms with uncorrect capitalization is often used.
|
This model is uncased. This helps especially for domains where colloquial terms with uncorrect capitalization is often used.
|
||||||
|
|
||||||
The special characters 'ö', 'ü', 'ä' are included through the `strip_accent=False` option, as this leads to an improved precision.
|
The special characters 'ö', 'ü', 'ä' are included through the `strip_accent=False` option, as this leads to an improved precision.
|
||||||
|
|
||||||
## Creators
|
# Creators
|
||||||
This model was trained and open sourced in conjunction with the [**German NLP Group**](https://github.com/German-NLP-Group) in equal parts by:
|
This model was trained and open sourced in conjunction with the [**German NLP Group**](https://github.com/German-NLP-Group) in equal parts by:
|
||||||
- [**Philip May**](https://eniak.de) - [T-Systems on site services GmbH](https://www.t-systems-onsite.de/)
|
- [**Philip May**](https://eniak.de) - [T-Systems on site services GmbH](https://www.t-systems-onsite.de/)
|
||||||
- [**Philipp Reißel**](https://www.reissel.eu) - [ambeRoad](https://amberoad.de/)
|
- [**Philipp Reißel**](https://www.reissel.eu) - [ambeRoad](https://amberoad.de/)
|
||||||
|
|
||||||
## Evaluation: GermEval18 Coarse
|
# Evaluation: GermEval18 Coarse
|
||||||
|
|
||||||
| Model Name |</br>F1 macro<br/> Mean | </br>F1 macro<br/>Median | </br>F1 macro<br/>Std |
|
| Model Name | F1 macro<br/>Mean | F1 macro<br/>Median | F1 macro<br/>Std |
|
||||||
|---|---|---|---|
|
|---|---|---|---|
|
||||||
| <span style="color:red">**ELECTRA-base-german-uncased** (this model) | <span style="color:red">**0.778** | **0.778** | **0.00392** |
|
|
||||||
| dbmdz/bert-base-german-uncased | 0.770 | 0.770 | 0.00572 |
|
|
||||||
| dbmdz/bert-base-german-cased | 0.765 | 0.765 | 0.00523 |
|
|
||||||
| bert-base-german-cased | 0.762 | 0.761 | 0.00597 |
|
|
||||||
| distilbert-base-german-cased | 0.752 | 0.752 | 0.00341 |
|
|
||||||
| dbmdz/electra-base-german-europeana-cased-discriminator | 0.745 | 0.745 | 0.00498 |
|
|
||||||
| dbmdz-bert-base-german-europeana-uncased | 0.736 | 0.737 | 0.00476 |
|
|
||||||
| dbmdz-bert-base-german-europeana-cased | 0.727 | 0.729 | 0.00674 |
|
| dbmdz-bert-base-german-europeana-cased | 0.727 | 0.729 | 0.00674 |
|
||||||
|
| dbmdz-bert-base-german-europeana-uncased | 0.736 | 0.737 | 0.00476 |
|
||||||
|
| dbmdz/electra-base-german-europeana-cased-discriminator | 0.745 | 0.745 | 0.00498 |
|
||||||
|
| distilbert-base-german-cased | 0.752 | 0.752 | 0.00341 |
|
||||||
|
| bert-base-german-cased | 0.762 | 0.761 | 0.00597 |
|
||||||
|
| dbmdz/bert-base-german-cased | 0.765 | 0.765 | 0.00523 |
|
||||||
|
| dbmdz/bert-base-german-uncased | 0.770 | 0.770 | 0.00572 |
|
||||||
|
| **ELECTRA-base-german-uncased (this model)** | **0.778** | **0.778** | **0.00392** |
|
||||||
|
|
||||||
- (1): Hyperparameters taken from the [FARM project](https://farm.deepset.ai/) "[germEval18Coarse_config.json](https://github.com/deepset-ai/FARM/blob/master/experiments/german-bert2.0-eval/germEval18Coarse_config.json)"
|
- (1): Hyperparameters taken from the [FARM project](https://farm.deepset.ai/) "[germEval18Coarse_config.json](https://github.com/deepset-ai/FARM/blob/master/experiments/german-bert2.0-eval/germEval18Coarse_config.json)"
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
## Checkpoint evaluation
|
# Checkpoint evaluation
|
||||||
Since it it not guaranteed that the last checkpoint is the best, we evaluated the checkpoints on GermEval18. We found that the last checkpoint is indeed the best. The training was stable and did not overfit the text corpus. Below is a boxplot chart showing the different checkpoints.
|
Since it it not guaranteed that the last checkpoint is the best, we evaluated the checkpoints on GermEval18. We found that the last checkpoint is indeed the best. The training was stable and did not overfit the text corpus. Below is a boxplot chart showing the different checkpoints.
|
||||||
|
|
||||||
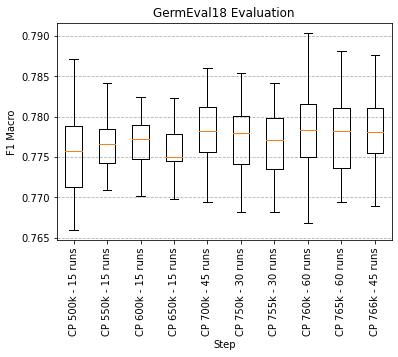
|

|
||||||
|
|
||||||
## Pre-training details
|
# Pre-training details
|
||||||
|
|
||||||
### Data
|
## Data
|
||||||
- Cleaned Common Crawl Corpus 2019-09 German: [CC_net](https://github.com/facebookresearch/cc_net) (Only head coprus and filtered for language_score > 0.98) - 62 GB
|
- Cleaned Common Crawl Corpus 2019-09 German: [CC_net](https://github.com/facebookresearch/cc_net) (Only head coprus and filtered for language_score > 0.98) - 62 GB
|
||||||
- German Wikipedia Article Pages Dump (20200701) - 5.5 GB
|
- German Wikipedia Article Pages Dump (20200701) - 5.5 GB
|
||||||
- German Wikipedia Talk Pages Dump (20200620) - 1.1 GB
|
- German Wikipedia Talk Pages Dump (20200620) - 1.1 GB
|
||||||
@@ -84,7 +77,7 @@ The sentences were split with [SojaMo](https://github.com/tsproisl/SoMaJo). We t
|
|||||||
|
|
||||||
More Details can be found here [Preperaing Datasets for German Electra Github](https://github.com/German-NLP-Group/german-transformer-training)
|
More Details can be found here [Preperaing Datasets for German Electra Github](https://github.com/German-NLP-Group/german-transformer-training)
|
||||||
|
|
||||||
### Electra Branch no_strip_accents
|
## Electra Branch no_strip_accents
|
||||||
Because we do not want to stip accents in our training data we made a change to Electra and used this repo [Electra no_strip_accents](https://github.com/PhilipMay/electra/tree/no_strip_accents) (branch `no_strip_accents`). Then created the tf dataset with:
|
Because we do not want to stip accents in our training data we made a change to Electra and used this repo [Electra no_strip_accents](https://github.com/PhilipMay/electra/tree/no_strip_accents) (branch `no_strip_accents`). Then created the tf dataset with:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
@@ -92,11 +85,9 @@ python build_pretraining_dataset.py --corpus-dir <corpus_dir> --vocab-file <dir>
|
|||||||
```
|
```
|
||||||
|
|
||||||
## The training
|
## The training
|
||||||
|
|
||||||
The training itself can be performed with the Original Electra Repo (No special case for this needed).
|
The training itself can be performed with the Original Electra Repo (No special case for this needed).
|
||||||
We run it with the following Config:
|
We run it with the following Config:
|
||||||
|
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
<summary>The exact Training Config</summary>
|
<summary>The exact Training Config</summary>
|
||||||
<br/>debug False
|
<br/>debug False
|
||||||
@@ -143,7 +134,6 @@ We run it with the following Config:
|
|||||||
<br/>vocab_file gs://XXX
|
<br/>vocab_file gs://XXX
|
||||||
<br/>vocab_size 32767
|
<br/>vocab_size 32767
|
||||||
<br/>weight_decay_rate 0.01
|
<br/>weight_decay_rate 0.01
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
|

|
||||||
@@ -155,7 +145,7 @@ Special thanks to [Stefan Schweter](https://github.com/stefan-it) for your feedb
|
|||||||
|
|
||||||
[¹]: Source for the picture [Pinterest](https://www.pinterest.cl/pin/371828512984142193/)
|
[¹]: Source for the picture [Pinterest](https://www.pinterest.cl/pin/371828512984142193/)
|
||||||
|
|
||||||
## Negative Results
|
# Negative Results
|
||||||
We tried the following approaches which we found had no positive influence:
|
We tried the following approaches which we found had no positive influence:
|
||||||
|
|
||||||
- **Increased Vocab Size**: Leads to more parameters and thus reduced examples/sec while no visible Performance gains were measured
|
- **Increased Vocab Size**: Leads to more parameters and thus reduced examples/sec while no visible Performance gains were measured
|
||||||
|
|||||||
Reference in New Issue
Block a user