diff --git a/docs/source/en/_toctree.yml b/docs/source/en/_toctree.yml
index 8018e0275d..f18e54eea0 100644
--- a/docs/source/en/_toctree.yml
+++ b/docs/source/en/_toctree.yml
@@ -183,6 +183,8 @@
title: DeepSpeed Integration
- local: main_classes/feature_extractor
title: Feature Extractor
+ - local: main_classes/image_processor
+ title: Image Processor
title: Main Classes
- sections:
- isExpanded: false
diff --git a/docs/source/en/internal/image_processing_utils.mdx b/docs/source/en/internal/image_processing_utils.mdx
index 6450913053..6a35736464 100644
--- a/docs/source/en/internal/image_processing_utils.mdx
+++ b/docs/source/en/internal/image_processing_utils.mdx
@@ -29,6 +29,6 @@ Most of those are only useful if you are studying the code of the image processo
[[autodoc]] image_transforms.to_pil_image
-## ImageProcessorMixin
+## ImageProcessingMixin
-[[autodoc]] image_processing_utils.ImageProcessorMixin
+[[autodoc]] image_processing_utils.ImageProcessingMixin
diff --git a/docs/source/en/main_classes/image_processor.mdx b/docs/source/en/main_classes/image_processor.mdx
new file mode 100644
index 0000000000..6a10839721
--- /dev/null
+++ b/docs/source/en/main_classes/image_processor.mdx
@@ -0,0 +1,30 @@
+
+
+# Image Processor
+
+An image processor is in charge of preparing input features for vision models and post processing their outputs. This includes transformations such as resizing, normalization, and conversion to PyTorch, TensorFlow, Flax and Numpy tensors. It may also include model specific post-processing such as converting logits to segmentation masks.
+
+
+## ImageProcessingMixin
+
+[[autodoc]] image_processing_utils.ImageProcessingMixin
+ - from_pretrained
+ - save_pretrained
+
+## BatchFeature
+
+[[autodoc]] BatchFeature
+
+## BaseImageProcessor
+
+[[autodoc]] image_processing_utils.BaseImageProcessor
diff --git a/docs/source/en/model_doc/auto.mdx b/docs/source/en/model_doc/auto.mdx
index a6426eb3c2..79ad20bd80 100644
--- a/docs/source/en/model_doc/auto.mdx
+++ b/docs/source/en/model_doc/auto.mdx
@@ -66,6 +66,10 @@ Likewise, if your `NewModel` is a subclass of [`PreTrainedModel`], make sure its
[[autodoc]] AutoFeatureExtractor
+## AutoImageProcessor
+
+[[autodoc]] AutoImageProcessor
+
## AutoProcessor
[[autodoc]] AutoProcessor
diff --git a/docs/source/en/model_doc/beit.mdx b/docs/source/en/model_doc/beit.mdx
index 689eadc70a..82e4a3a159 100644
--- a/docs/source/en/model_doc/beit.mdx
+++ b/docs/source/en/model_doc/beit.mdx
@@ -60,7 +60,7 @@ Tips:
position embeddings.
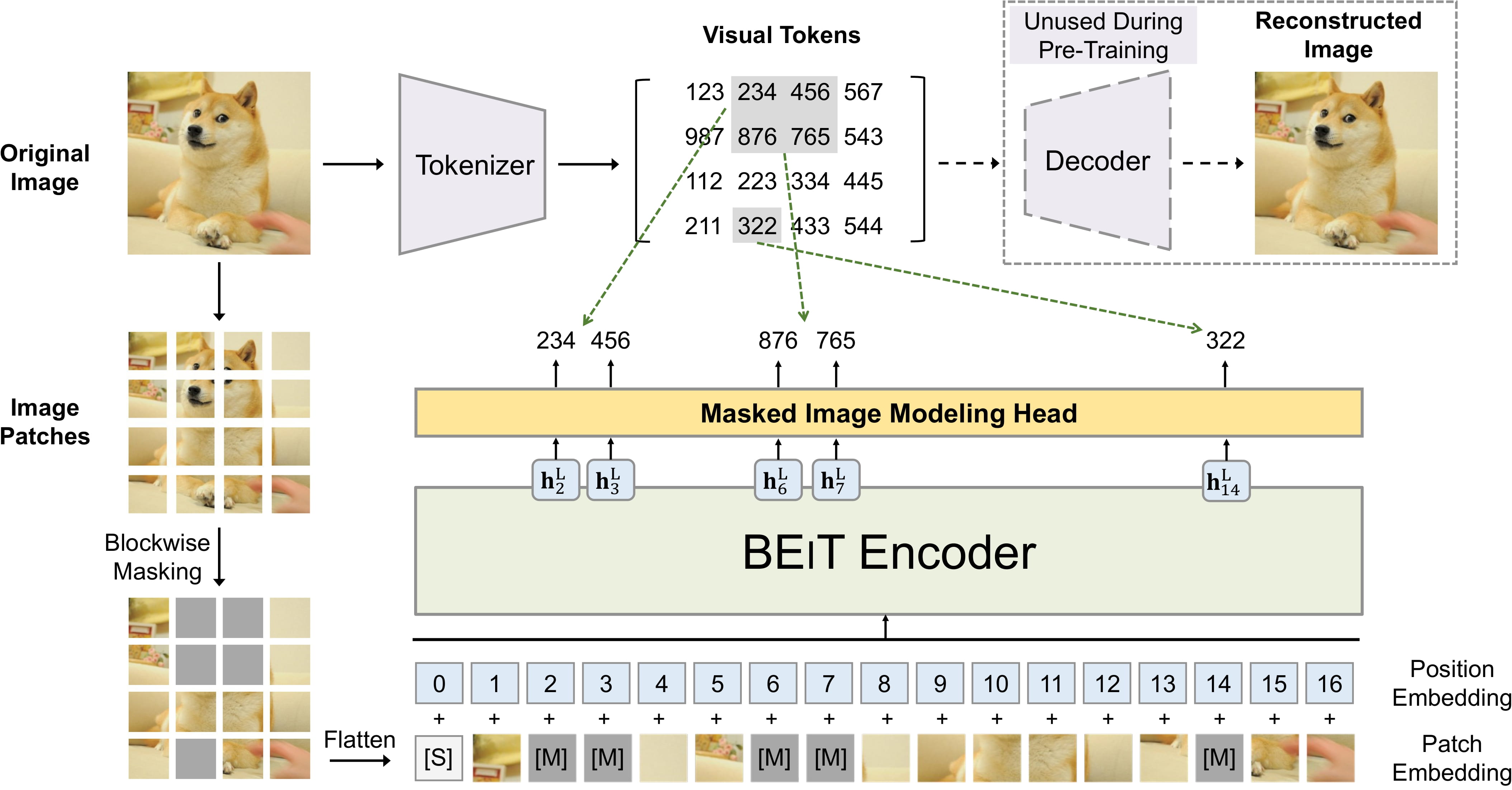 +alt="drawing" width="600"/>
BEiT pre-training. Taken from the original paper.
@@ -84,6 +84,12 @@ contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code
- __call__
- post_process_semantic_segmentation
+## BeitImageProcessor
+
+[[autodoc]] BeitImageProcessor
+ - preprocess
+ - post_process_semantic_segmentation
+
## BeitModel
[[autodoc]] BeitModel
diff --git a/docs/source/en/model_doc/clip.mdx b/docs/source/en/model_doc/clip.mdx
index 0ab0ec7689..080c80e709 100644
--- a/docs/source/en/model_doc/clip.mdx
+++ b/docs/source/en/model_doc/clip.mdx
@@ -100,6 +100,11 @@ This model was contributed by [valhalla](https://huggingface.co/valhalla). The o
[[autodoc]] CLIPTokenizerFast
+## CLIPImageProcessor
+
+[[autodoc]] CLIPImageProcessor
+ - preprocess
+
## CLIPFeatureExtractor
[[autodoc]] CLIPFeatureExtractor
diff --git a/docs/source/en/model_doc/convnext.mdx b/docs/source/en/model_doc/convnext.mdx
index 732e0eb7a5..538c68ea29 100644
--- a/docs/source/en/model_doc/convnext.mdx
+++ b/docs/source/en/model_doc/convnext.mdx
@@ -33,7 +33,7 @@ Tips:
- See the code examples below each model regarding usage.
+alt="drawing" width="600"/>
BEiT pre-training. Taken from the original paper.
@@ -84,6 +84,12 @@ contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code
- __call__
- post_process_semantic_segmentation
+## BeitImageProcessor
+
+[[autodoc]] BeitImageProcessor
+ - preprocess
+ - post_process_semantic_segmentation
+
## BeitModel
[[autodoc]] BeitModel
diff --git a/docs/source/en/model_doc/clip.mdx b/docs/source/en/model_doc/clip.mdx
index 0ab0ec7689..080c80e709 100644
--- a/docs/source/en/model_doc/clip.mdx
+++ b/docs/source/en/model_doc/clip.mdx
@@ -100,6 +100,11 @@ This model was contributed by [valhalla](https://huggingface.co/valhalla). The o
[[autodoc]] CLIPTokenizerFast
+## CLIPImageProcessor
+
+[[autodoc]] CLIPImageProcessor
+ - preprocess
+
## CLIPFeatureExtractor
[[autodoc]] CLIPFeatureExtractor
diff --git a/docs/source/en/model_doc/convnext.mdx b/docs/source/en/model_doc/convnext.mdx
index 732e0eb7a5..538c68ea29 100644
--- a/docs/source/en/model_doc/convnext.mdx
+++ b/docs/source/en/model_doc/convnext.mdx
@@ -33,7 +33,7 @@ Tips:
- See the code examples below each model regarding usage.
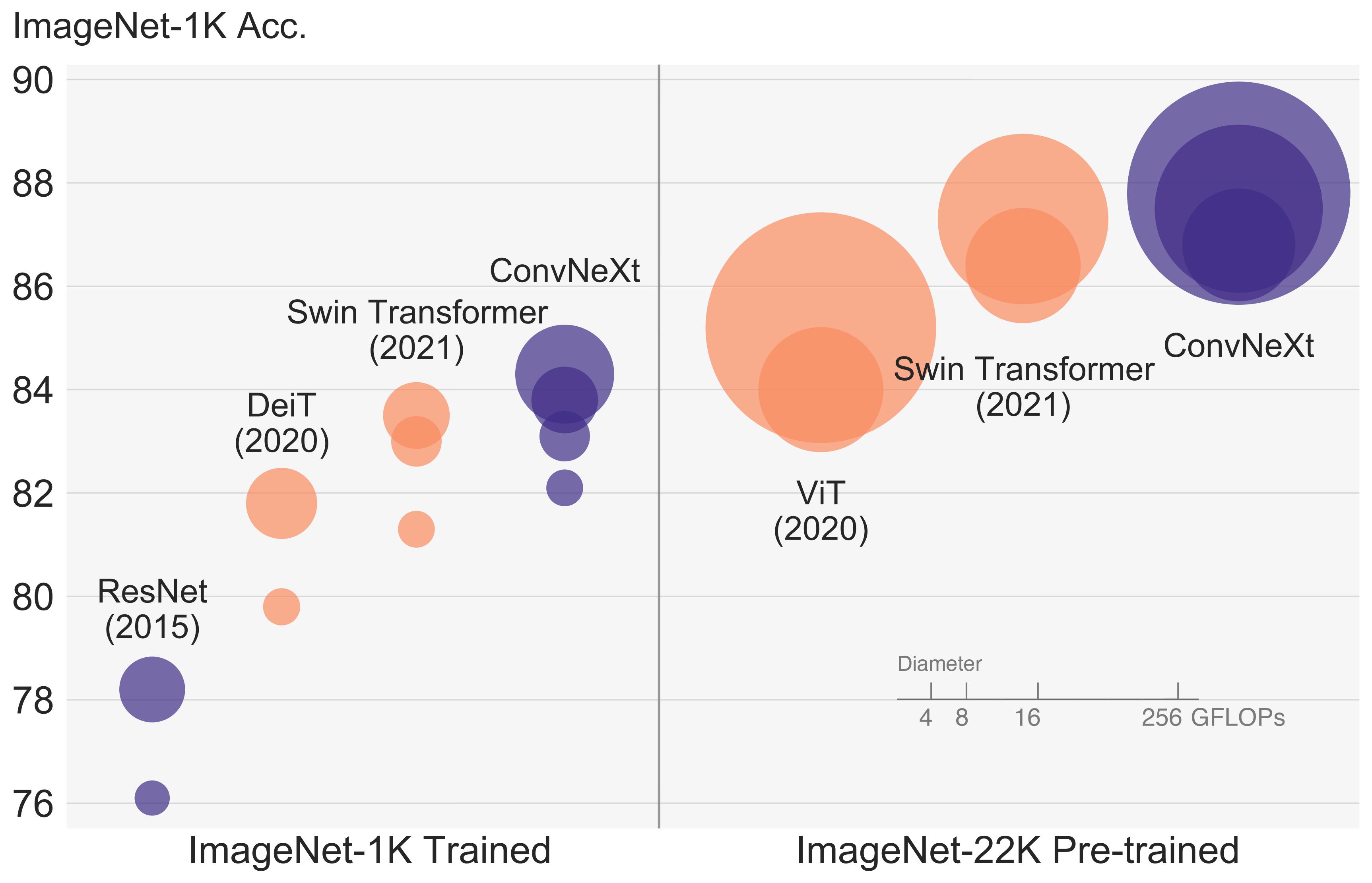 +alt="drawing" width="600"/>
ConvNeXT architecture. Taken from the original paper.
@@ -50,6 +50,11 @@ This model was contributed by [nielsr](https://huggingface.co/nielsr). TensorFlo
[[autodoc]] ConvNextFeatureExtractor
+## ConvNextImageProcessor
+
+[[autodoc]] ConvNextImageProcessor
+ - preprocess
+
## ConvNextModel
[[autodoc]] ConvNextModel
@@ -71,4 +76,4 @@ This model was contributed by [nielsr](https://huggingface.co/nielsr). TensorFlo
## TFConvNextForImageClassification
[[autodoc]] TFConvNextForImageClassification
- - call
\ No newline at end of file
+ - call
diff --git a/docs/source/en/model_doc/deit.mdx b/docs/source/en/model_doc/deit.mdx
index c66e619778..fa2cce8df5 100644
--- a/docs/source/en/model_doc/deit.mdx
+++ b/docs/source/en/model_doc/deit.mdx
@@ -81,6 +81,11 @@ This model was contributed by [nielsr](https://huggingface.co/nielsr). The Tenso
[[autodoc]] DeiTFeatureExtractor
- __call__
+## DeiTImageProcessor
+
+[[autodoc]] DeiTImageProcessor
+ - preprocess
+
## DeiTModel
[[autodoc]] DeiTModel
diff --git a/docs/source/en/model_doc/dpt.mdx b/docs/source/en/model_doc/dpt.mdx
index fec1801661..46049d7a05 100644
--- a/docs/source/en/model_doc/dpt.mdx
+++ b/docs/source/en/model_doc/dpt.mdx
@@ -22,7 +22,7 @@ The abstract from the paper is the following:
*We introduce dense vision transformers, an architecture that leverages vision transformers in place of convolutional networks as a backbone for dense prediction tasks. We assemble tokens from various stages of the vision transformer into image-like representations at various resolutions and progressively combine them into full-resolution predictions using a convolutional decoder. The transformer backbone processes representations at a constant and relatively high resolution and has a global receptive field at every stage. These properties allow the dense vision transformer to provide finer-grained and more globally coherent predictions when compared to fully-convolutional networks. Our experiments show that this architecture yields substantial improvements on dense prediction tasks, especially when a large amount of training data is available. For monocular depth estimation, we observe an improvement of up to 28% in relative performance when compared to a state-of-the-art fully-convolutional network. When applied to semantic segmentation, dense vision transformers set a new state of the art on ADE20K with 49.02% mIoU. We further show that the architecture can be fine-tuned on smaller datasets such as NYUv2, KITTI, and Pascal Context where it also sets the new state of the art.*
+alt="drawing" width="600"/>
ConvNeXT architecture. Taken from the original paper.
@@ -50,6 +50,11 @@ This model was contributed by [nielsr](https://huggingface.co/nielsr). TensorFlo
[[autodoc]] ConvNextFeatureExtractor
+## ConvNextImageProcessor
+
+[[autodoc]] ConvNextImageProcessor
+ - preprocess
+
## ConvNextModel
[[autodoc]] ConvNextModel
@@ -71,4 +76,4 @@ This model was contributed by [nielsr](https://huggingface.co/nielsr). TensorFlo
## TFConvNextForImageClassification
[[autodoc]] TFConvNextForImageClassification
- - call
\ No newline at end of file
+ - call
diff --git a/docs/source/en/model_doc/deit.mdx b/docs/source/en/model_doc/deit.mdx
index c66e619778..fa2cce8df5 100644
--- a/docs/source/en/model_doc/deit.mdx
+++ b/docs/source/en/model_doc/deit.mdx
@@ -81,6 +81,11 @@ This model was contributed by [nielsr](https://huggingface.co/nielsr). The Tenso
[[autodoc]] DeiTFeatureExtractor
- __call__
+## DeiTImageProcessor
+
+[[autodoc]] DeiTImageProcessor
+ - preprocess
+
## DeiTModel
[[autodoc]] DeiTModel
diff --git a/docs/source/en/model_doc/dpt.mdx b/docs/source/en/model_doc/dpt.mdx
index fec1801661..46049d7a05 100644
--- a/docs/source/en/model_doc/dpt.mdx
+++ b/docs/source/en/model_doc/dpt.mdx
@@ -22,7 +22,7 @@ The abstract from the paper is the following:
*We introduce dense vision transformers, an architecture that leverages vision transformers in place of convolutional networks as a backbone for dense prediction tasks. We assemble tokens from various stages of the vision transformer into image-like representations at various resolutions and progressively combine them into full-resolution predictions using a convolutional decoder. The transformer backbone processes representations at a constant and relatively high resolution and has a global receptive field at every stage. These properties allow the dense vision transformer to provide finer-grained and more globally coherent predictions when compared to fully-convolutional networks. Our experiments show that this architecture yields substantial improvements on dense prediction tasks, especially when a large amount of training data is available. For monocular depth estimation, we observe an improvement of up to 28% in relative performance when compared to a state-of-the-art fully-convolutional network. When applied to semantic segmentation, dense vision transformers set a new state of the art on ADE20K with 49.02% mIoU. We further show that the architecture can be fine-tuned on smaller datasets such as NYUv2, KITTI, and Pascal Context where it also sets the new state of the art.*
 +alt="drawing" width="600"/>
DPT architecture. Taken from the original paper.
@@ -40,6 +40,13 @@ This model was contributed by [nielsr](https://huggingface.co/nielsr). The origi
- post_process_semantic_segmentation
+## DPTImageProcessor
+
+[[autodoc]] DPTImageProcessor
+ - preprocess
+ - post_process_semantic_segmentation
+
+
## DPTModel
[[autodoc]] DPTModel
@@ -55,4 +62,4 @@ This model was contributed by [nielsr](https://huggingface.co/nielsr). The origi
## DPTForSemanticSegmentation
[[autodoc]] DPTForSemanticSegmentation
- - forward
\ No newline at end of file
+ - forward
diff --git a/docs/source/en/model_doc/flava.mdx b/docs/source/en/model_doc/flava.mdx
index 91c456ff4b..4df11a5758 100644
--- a/docs/source/en/model_doc/flava.mdx
+++ b/docs/source/en/model_doc/flava.mdx
@@ -16,17 +16,17 @@ specific language governing permissions and limitations under the License.
The FLAVA model was proposed in [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela and is accepted at CVPR 2022.
-The paper aims at creating a single unified foundation model which can work across vision, language
+The paper aims at creating a single unified foundation model which can work across vision, language
as well as vision-and-language multimodal tasks.
The abstract from the paper is the following:
-*State-of-the-art vision and vision-and-language models rely on large-scale visio-linguistic pretraining for obtaining good performance on a variety
-of downstream tasks. Generally, such models are often either cross-modal (contrastive) or multi-modal
-(with earlier fusion) but not both; and they often only target specific modalities or tasks. A promising
-direction would be to use a single holistic universal model, as a "foundation", that targets all modalities
-at once -- a true vision and language foundation model should be good at vision tasks, language tasks, and
-cross- and multi-modal vision and language tasks. We introduce FLAVA as such a model and demonstrate
+*State-of-the-art vision and vision-and-language models rely on large-scale visio-linguistic pretraining for obtaining good performance on a variety
+of downstream tasks. Generally, such models are often either cross-modal (contrastive) or multi-modal
+(with earlier fusion) but not both; and they often only target specific modalities or tasks. A promising
+direction would be to use a single holistic universal model, as a "foundation", that targets all modalities
+at once -- a true vision and language foundation model should be good at vision tasks, language tasks, and
+cross- and multi-modal vision and language tasks. We introduce FLAVA as such a model and demonstrate
impressive performance on a wide range of 35 tasks spanning these target modalities.*
@@ -61,6 +61,11 @@ This model was contributed by [aps](https://huggingface.co/aps). The original co
[[autodoc]] FlavaFeatureExtractor
+## FlavaImageProcessor
+
+[[autodoc]] FlavaImageProcessor
+ - preprocess
+
## FlavaForPreTraining
[[autodoc]] FlavaForPreTraining
diff --git a/docs/source/en/model_doc/glpn.mdx b/docs/source/en/model_doc/glpn.mdx
index 428aede4de..e1479ac7a8 100644
--- a/docs/source/en/model_doc/glpn.mdx
+++ b/docs/source/en/model_doc/glpn.mdx
@@ -35,7 +35,7 @@ Tips:
- One can use [`GLPNFeatureExtractor`] to prepare images for the model.
+alt="drawing" width="600"/>
DPT architecture. Taken from the original paper.
@@ -40,6 +40,13 @@ This model was contributed by [nielsr](https://huggingface.co/nielsr). The origi
- post_process_semantic_segmentation
+## DPTImageProcessor
+
+[[autodoc]] DPTImageProcessor
+ - preprocess
+ - post_process_semantic_segmentation
+
+
## DPTModel
[[autodoc]] DPTModel
@@ -55,4 +62,4 @@ This model was contributed by [nielsr](https://huggingface.co/nielsr). The origi
## DPTForSemanticSegmentation
[[autodoc]] DPTForSemanticSegmentation
- - forward
\ No newline at end of file
+ - forward
diff --git a/docs/source/en/model_doc/flava.mdx b/docs/source/en/model_doc/flava.mdx
index 91c456ff4b..4df11a5758 100644
--- a/docs/source/en/model_doc/flava.mdx
+++ b/docs/source/en/model_doc/flava.mdx
@@ -16,17 +16,17 @@ specific language governing permissions and limitations under the License.
The FLAVA model was proposed in [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela and is accepted at CVPR 2022.
-The paper aims at creating a single unified foundation model which can work across vision, language
+The paper aims at creating a single unified foundation model which can work across vision, language
as well as vision-and-language multimodal tasks.
The abstract from the paper is the following:
-*State-of-the-art vision and vision-and-language models rely on large-scale visio-linguistic pretraining for obtaining good performance on a variety
-of downstream tasks. Generally, such models are often either cross-modal (contrastive) or multi-modal
-(with earlier fusion) but not both; and they often only target specific modalities or tasks. A promising
-direction would be to use a single holistic universal model, as a "foundation", that targets all modalities
-at once -- a true vision and language foundation model should be good at vision tasks, language tasks, and
-cross- and multi-modal vision and language tasks. We introduce FLAVA as such a model and demonstrate
+*State-of-the-art vision and vision-and-language models rely on large-scale visio-linguistic pretraining for obtaining good performance on a variety
+of downstream tasks. Generally, such models are often either cross-modal (contrastive) or multi-modal
+(with earlier fusion) but not both; and they often only target specific modalities or tasks. A promising
+direction would be to use a single holistic universal model, as a "foundation", that targets all modalities
+at once -- a true vision and language foundation model should be good at vision tasks, language tasks, and
+cross- and multi-modal vision and language tasks. We introduce FLAVA as such a model and demonstrate
impressive performance on a wide range of 35 tasks spanning these target modalities.*
@@ -61,6 +61,11 @@ This model was contributed by [aps](https://huggingface.co/aps). The original co
[[autodoc]] FlavaFeatureExtractor
+## FlavaImageProcessor
+
+[[autodoc]] FlavaImageProcessor
+ - preprocess
+
## FlavaForPreTraining
[[autodoc]] FlavaForPreTraining
diff --git a/docs/source/en/model_doc/glpn.mdx b/docs/source/en/model_doc/glpn.mdx
index 428aede4de..e1479ac7a8 100644
--- a/docs/source/en/model_doc/glpn.mdx
+++ b/docs/source/en/model_doc/glpn.mdx
@@ -35,7 +35,7 @@ Tips:
- One can use [`GLPNFeatureExtractor`] to prepare images for the model.
 +alt="drawing" width="600"/>
Summary of the approach. Taken from the original paper.
@@ -50,6 +50,11 @@ This model was contributed by [nielsr](https://huggingface.co/nielsr). The origi
[[autodoc]] GLPNFeatureExtractor
- __call__
+## GLPNImageProcessor
+
+[[autodoc]] GLPNImageProcessor
+ - preprocess
+
## GLPNModel
[[autodoc]] GLPNModel
@@ -58,4 +63,4 @@ This model was contributed by [nielsr](https://huggingface.co/nielsr). The origi
## GLPNForDepthEstimation
[[autodoc]] GLPNForDepthEstimation
- - forward
\ No newline at end of file
+ - forward
diff --git a/docs/source/en/model_doc/imagegpt.mdx b/docs/source/en/model_doc/imagegpt.mdx
index 679cdfd30a..8e6624b7aa 100644
--- a/docs/source/en/model_doc/imagegpt.mdx
+++ b/docs/source/en/model_doc/imagegpt.mdx
@@ -29,7 +29,7 @@ competitive with self-supervised benchmarks on ImageNet when substituting pixels
top-1 accuracy on a linear probe of our features.*
+alt="drawing" width="600"/>
Summary of the approach. Taken from the original paper.
@@ -50,6 +50,11 @@ This model was contributed by [nielsr](https://huggingface.co/nielsr). The origi
[[autodoc]] GLPNFeatureExtractor
- __call__
+## GLPNImageProcessor
+
+[[autodoc]] GLPNImageProcessor
+ - preprocess
+
## GLPNModel
[[autodoc]] GLPNModel
@@ -58,4 +63,4 @@ This model was contributed by [nielsr](https://huggingface.co/nielsr). The origi
## GLPNForDepthEstimation
[[autodoc]] GLPNForDepthEstimation
- - forward
\ No newline at end of file
+ - forward
diff --git a/docs/source/en/model_doc/imagegpt.mdx b/docs/source/en/model_doc/imagegpt.mdx
index 679cdfd30a..8e6624b7aa 100644
--- a/docs/source/en/model_doc/imagegpt.mdx
+++ b/docs/source/en/model_doc/imagegpt.mdx
@@ -29,7 +29,7 @@ competitive with self-supervised benchmarks on ImageNet when substituting pixels
top-1 accuracy on a linear probe of our features.*
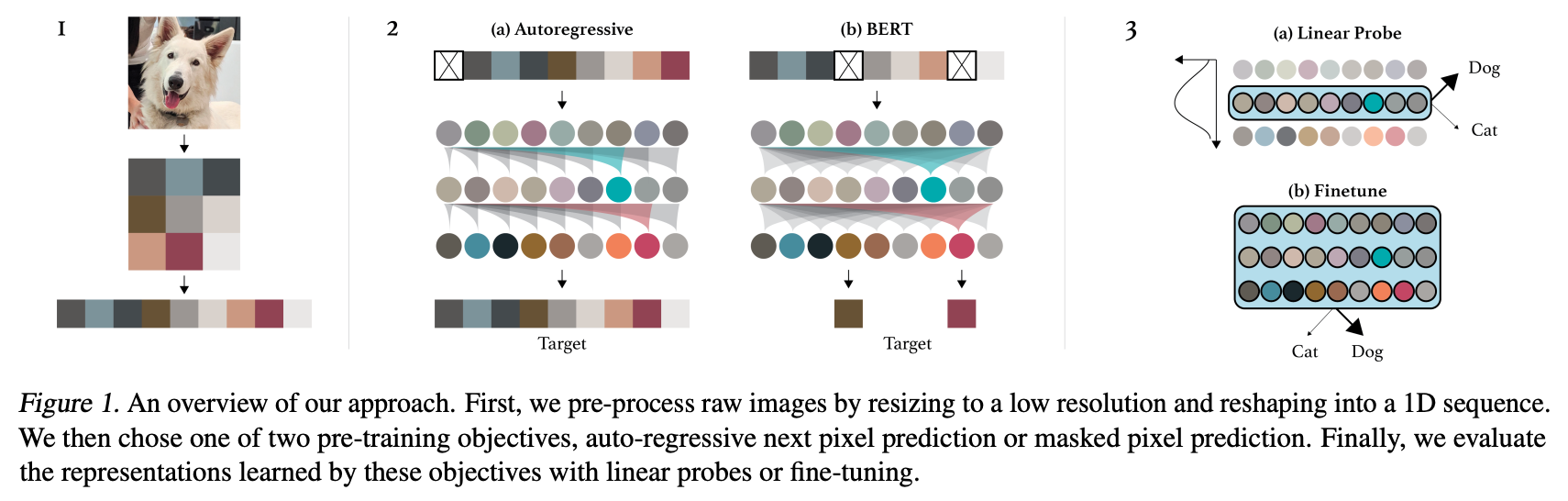 +alt="drawing" width="600"/>
Summary of the approach. Taken from the [original paper](https://cdn.openai.com/papers/Generative_Pretraining_from_Pixels_V2.pdf).
@@ -81,6 +81,11 @@ Tips:
- __call__
+## ImageGPTImageProcessor
+
+[[autodoc]] ImageGPTImageProcessor
+ - preprocess
+
## ImageGPTModel
[[autodoc]] ImageGPTModel
@@ -97,4 +102,4 @@ Tips:
[[autodoc]] ImageGPTForImageClassification
- - forward
\ No newline at end of file
+ - forward
diff --git a/docs/source/en/model_doc/layoutlmv2.mdx b/docs/source/en/model_doc/layoutlmv2.mdx
index e40a3cfc8d..dc225d768d 100644
--- a/docs/source/en/model_doc/layoutlmv2.mdx
+++ b/docs/source/en/model_doc/layoutlmv2.mdx
@@ -45,7 +45,7 @@ RVL-CDIP (0.9443 -> 0.9564), and DocVQA (0.7295 -> 0.8672). The pre-trained Layo
this https URL.*
LayoutLMv2 depends on `detectron2`, `torchvision` and `tesseract`. Run the
-following to install them:
+following to install them:
```
python -m pip install 'git+https://github.com/facebookresearch/detectron2.git'
python -m pip install torchvision tesseract
@@ -275,6 +275,11 @@ print(encoding.keys())
[[autodoc]] LayoutLMv2FeatureExtractor
- __call__
+## LayoutLMv2ImageProcessor
+
+[[autodoc]] LayoutLMv2ImageProcessor
+ - preprocess
+
## LayoutLMv2Tokenizer
[[autodoc]] LayoutLMv2Tokenizer
diff --git a/docs/source/en/model_doc/layoutlmv3.mdx b/docs/source/en/model_doc/layoutlmv3.mdx
index 2d425900e3..d49ee1819a 100644
--- a/docs/source/en/model_doc/layoutlmv3.mdx
+++ b/docs/source/en/model_doc/layoutlmv3.mdx
@@ -73,6 +73,11 @@ LayoutLMv3 is nearly identical to LayoutLMv2, so we've also included LayoutLMv2
[[autodoc]] LayoutLMv3FeatureExtractor
- __call__
+## LayoutLMv3ImageProcessor
+
+[[autodoc]] LayoutLMv3ImageProcessor
+ - preprocess
+
## LayoutLMv3Tokenizer
[[autodoc]] LayoutLMv3Tokenizer
diff --git a/docs/source/en/model_doc/levit.mdx b/docs/source/en/model_doc/levit.mdx
index 4549a5106c..1ebe93ff3f 100644
--- a/docs/source/en/model_doc/levit.mdx
+++ b/docs/source/en/model_doc/levit.mdx
@@ -19,18 +19,18 @@ The LeViT model was proposed in [LeViT: Introducing Convolutions to Vision Trans
The abstract from the paper is the following:
*We design a family of image classification architectures that optimize the trade-off between accuracy
-and efficiency in a high-speed regime. Our work exploits recent findings in attention-based architectures,
-which are competitive on highly parallel processing hardware. We revisit principles from the extensive
-literature on convolutional neural networks to apply them to transformers, in particular activation maps
+and efficiency in a high-speed regime. Our work exploits recent findings in attention-based architectures,
+which are competitive on highly parallel processing hardware. We revisit principles from the extensive
+literature on convolutional neural networks to apply them to transformers, in particular activation maps
with decreasing resolutions. We also introduce the attention bias, a new way to integrate positional information
-in vision transformers. As a result, we propose LeVIT: a hybrid neural network for fast inference image classification.
-We consider different measures of efficiency on different hardware platforms, so as to best reflect a wide range of
-application scenarios. Our extensive experiments empirically validate our technical choices and show they are suitable
-to most architectures. Overall, LeViT significantly outperforms existing convnets and vision transformers with respect
+in vision transformers. As a result, we propose LeVIT: a hybrid neural network for fast inference image classification.
+We consider different measures of efficiency on different hardware platforms, so as to best reflect a wide range of
+application scenarios. Our extensive experiments empirically validate our technical choices and show they are suitable
+to most architectures. Overall, LeViT significantly outperforms existing convnets and vision transformers with respect
to the speed/accuracy tradeoff. For example, at 80% ImageNet top-1 accuracy, LeViT is 5 times faster than EfficientNet on CPU. *
+alt="drawing" width="600"/>
Summary of the approach. Taken from the [original paper](https://cdn.openai.com/papers/Generative_Pretraining_from_Pixels_V2.pdf).
@@ -81,6 +81,11 @@ Tips:
- __call__
+## ImageGPTImageProcessor
+
+[[autodoc]] ImageGPTImageProcessor
+ - preprocess
+
## ImageGPTModel
[[autodoc]] ImageGPTModel
@@ -97,4 +102,4 @@ Tips:
[[autodoc]] ImageGPTForImageClassification
- - forward
\ No newline at end of file
+ - forward
diff --git a/docs/source/en/model_doc/layoutlmv2.mdx b/docs/source/en/model_doc/layoutlmv2.mdx
index e40a3cfc8d..dc225d768d 100644
--- a/docs/source/en/model_doc/layoutlmv2.mdx
+++ b/docs/source/en/model_doc/layoutlmv2.mdx
@@ -45,7 +45,7 @@ RVL-CDIP (0.9443 -> 0.9564), and DocVQA (0.7295 -> 0.8672). The pre-trained Layo
this https URL.*
LayoutLMv2 depends on `detectron2`, `torchvision` and `tesseract`. Run the
-following to install them:
+following to install them:
```
python -m pip install 'git+https://github.com/facebookresearch/detectron2.git'
python -m pip install torchvision tesseract
@@ -275,6 +275,11 @@ print(encoding.keys())
[[autodoc]] LayoutLMv2FeatureExtractor
- __call__
+## LayoutLMv2ImageProcessor
+
+[[autodoc]] LayoutLMv2ImageProcessor
+ - preprocess
+
## LayoutLMv2Tokenizer
[[autodoc]] LayoutLMv2Tokenizer
diff --git a/docs/source/en/model_doc/layoutlmv3.mdx b/docs/source/en/model_doc/layoutlmv3.mdx
index 2d425900e3..d49ee1819a 100644
--- a/docs/source/en/model_doc/layoutlmv3.mdx
+++ b/docs/source/en/model_doc/layoutlmv3.mdx
@@ -73,6 +73,11 @@ LayoutLMv3 is nearly identical to LayoutLMv2, so we've also included LayoutLMv2
[[autodoc]] LayoutLMv3FeatureExtractor
- __call__
+## LayoutLMv3ImageProcessor
+
+[[autodoc]] LayoutLMv3ImageProcessor
+ - preprocess
+
## LayoutLMv3Tokenizer
[[autodoc]] LayoutLMv3Tokenizer
diff --git a/docs/source/en/model_doc/levit.mdx b/docs/source/en/model_doc/levit.mdx
index 4549a5106c..1ebe93ff3f 100644
--- a/docs/source/en/model_doc/levit.mdx
+++ b/docs/source/en/model_doc/levit.mdx
@@ -19,18 +19,18 @@ The LeViT model was proposed in [LeViT: Introducing Convolutions to Vision Trans
The abstract from the paper is the following:
*We design a family of image classification architectures that optimize the trade-off between accuracy
-and efficiency in a high-speed regime. Our work exploits recent findings in attention-based architectures,
-which are competitive on highly parallel processing hardware. We revisit principles from the extensive
-literature on convolutional neural networks to apply them to transformers, in particular activation maps
+and efficiency in a high-speed regime. Our work exploits recent findings in attention-based architectures,
+which are competitive on highly parallel processing hardware. We revisit principles from the extensive
+literature on convolutional neural networks to apply them to transformers, in particular activation maps
with decreasing resolutions. We also introduce the attention bias, a new way to integrate positional information
-in vision transformers. As a result, we propose LeVIT: a hybrid neural network for fast inference image classification.
-We consider different measures of efficiency on different hardware platforms, so as to best reflect a wide range of
-application scenarios. Our extensive experiments empirically validate our technical choices and show they are suitable
-to most architectures. Overall, LeViT significantly outperforms existing convnets and vision transformers with respect
+in vision transformers. As a result, we propose LeVIT: a hybrid neural network for fast inference image classification.
+We consider different measures of efficiency on different hardware platforms, so as to best reflect a wide range of
+application scenarios. Our extensive experiments empirically validate our technical choices and show they are suitable
+to most architectures. Overall, LeViT significantly outperforms existing convnets and vision transformers with respect
to the speed/accuracy tradeoff. For example, at 80% ImageNet top-1 accuracy, LeViT is 5 times faster than EfficientNet on CPU. *
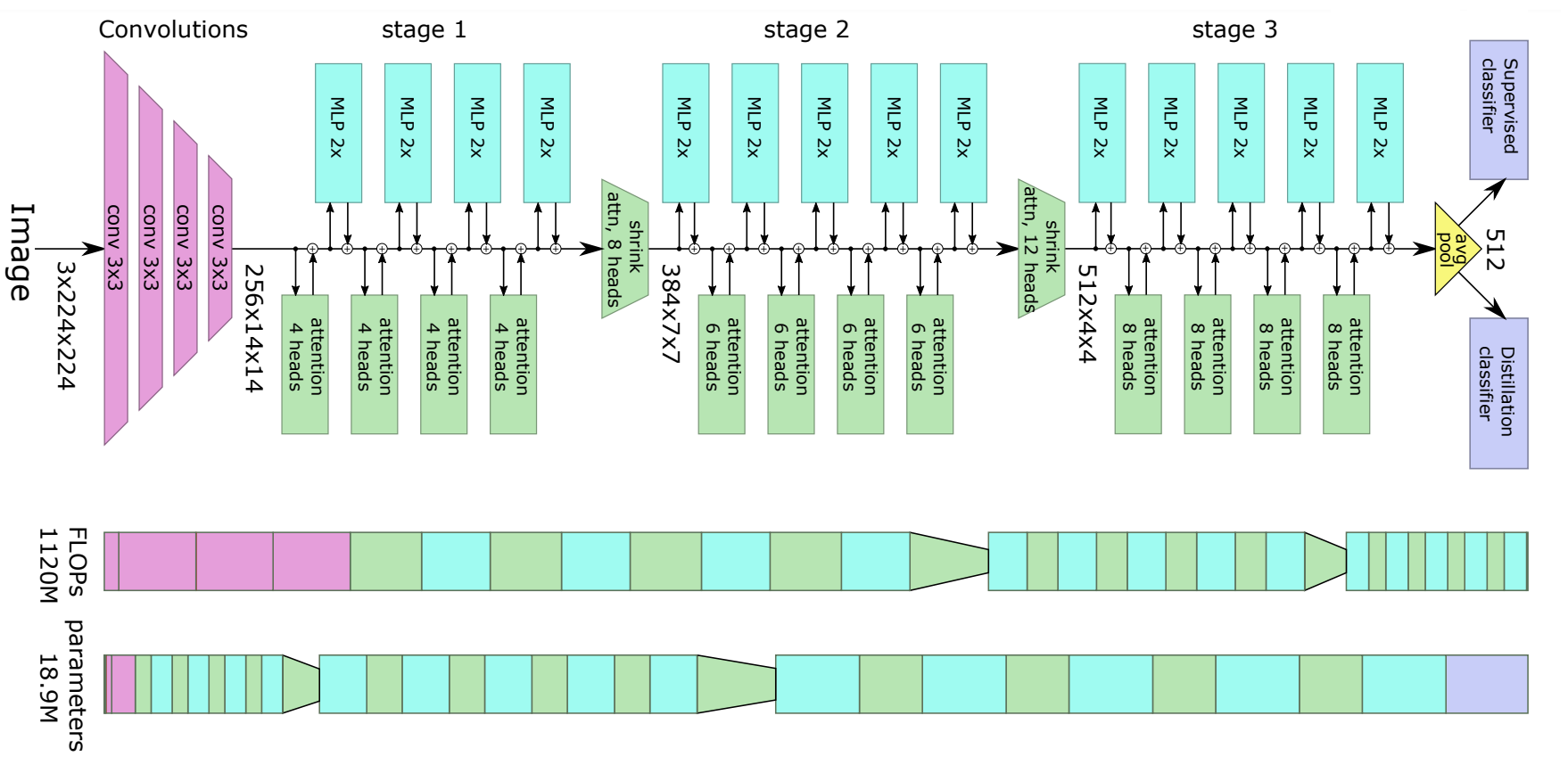 +alt="drawing" width="600"/>
LeViT Architecture. Taken from the original paper.
@@ -38,25 +38,25 @@ Tips:
- Compared to ViT, LeViT models use an additional distillation head to effectively learn from a teacher (which, in the LeViT paper, is a ResNet like-model). The distillation head is learned through backpropagation under supervision of a ResNet like-model. They also draw inspiration from convolution neural networks to use activation maps with decreasing resolutions to increase the efficiency.
- There are 2 ways to fine-tune distilled models, either (1) in a classic way, by only placing a prediction head on top
- of the final hidden state and not using the distillation head, or (2) by placing both a prediction head and distillation
- head on top of the final hidden state. In that case, the prediction head is trained using regular cross-entropy between
- the prediction of the head and the ground-truth label, while the distillation prediction head is trained using hard distillation
- (cross-entropy between the prediction of the distillation head and the label predicted by the teacher). At inference time,
- one takes the average prediction between both heads as final prediction. (2) is also called "fine-tuning with distillation",
- because one relies on a teacher that has already been fine-tuned on the downstream dataset. In terms of models, (1) corresponds
+ of the final hidden state and not using the distillation head, or (2) by placing both a prediction head and distillation
+ head on top of the final hidden state. In that case, the prediction head is trained using regular cross-entropy between
+ the prediction of the head and the ground-truth label, while the distillation prediction head is trained using hard distillation
+ (cross-entropy between the prediction of the distillation head and the label predicted by the teacher). At inference time,
+ one takes the average prediction between both heads as final prediction. (2) is also called "fine-tuning with distillation",
+ because one relies on a teacher that has already been fine-tuned on the downstream dataset. In terms of models, (1) corresponds
to [`LevitForImageClassification`] and (2) corresponds to [`LevitForImageClassificationWithTeacher`].
-- All released checkpoints were pre-trained and fine-tuned on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k)
+- All released checkpoints were pre-trained and fine-tuned on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k)
(also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes). only. No external data was used. This is in
contrast with the original ViT model, which used external data like the JFT-300M dataset/Imagenet-21k for
pre-training.
-- The authors of LeViT released 5 trained LeViT models, which you can directly plug into [`LevitModel`] or [`LevitForImageClassification`].
+- The authors of LeViT released 5 trained LeViT models, which you can directly plug into [`LevitModel`] or [`LevitForImageClassification`].
Techniques like data augmentation, optimization, and regularization were used in order to simulate training on a much larger dataset
(while only using ImageNet-1k for pre-training). The 5 variants available are (all trained on images of size 224x224):
*facebook/levit-128S*, *facebook/levit-128*, *facebook/levit-192*, *facebook/levit-256* and
*facebook/levit-384*. Note that one should use [`LevitFeatureExtractor`] in order to
prepare images for the model.
- [`LevitForImageClassificationWithTeacher`] currently supports only inference and not training or fine-tuning.
-- You can check out demo notebooks regarding inference as well as fine-tuning on custom data [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer)
+- You can check out demo notebooks regarding inference as well as fine-tuning on custom data [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer)
(you can just replace [`ViTFeatureExtractor`] by [`LevitFeatureExtractor`] and [`ViTForImageClassification`] by [`LevitForImageClassification`] or [`LevitForImageClassificationWithTeacher`]).
This model was contributed by [anugunj](https://huggingface.co/anugunj). The original code can be found [here](https://github.com/facebookresearch/LeViT).
@@ -71,6 +71,12 @@ This model was contributed by [anugunj](https://huggingface.co/anugunj). The ori
[[autodoc]] LevitFeatureExtractor
- __call__
+## LevitImageProcessor
+
+ [[autodoc]] LevitImageProcessor
+ - preprocess
+
+
## LevitModel
[[autodoc]] LevitModel
diff --git a/docs/source/en/model_doc/mobilevit.mdx b/docs/source/en/model_doc/mobilevit.mdx
index 818f8432af..1b73b1e439 100644
--- a/docs/source/en/model_doc/mobilevit.mdx
+++ b/docs/source/en/model_doc/mobilevit.mdx
@@ -14,7 +14,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The MobileViT model was proposed in [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari. MobileViT introduces a new layer that replaces local processing in convolutions with global processing using transformers.
+The MobileViT model was proposed in [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari. MobileViT introduces a new layer that replaces local processing in convolutions with global processing using transformers.
The abstract from the paper is the following:
@@ -25,10 +25,10 @@ Tips:
- MobileViT is more like a CNN than a Transformer model. It does not work on sequence data but on batches of images. Unlike ViT, there are no embeddings. The backbone model outputs a feature map. You can follow [this tutorial](https://keras.io/examples/vision/mobilevit) for a lightweight introduction.
- One can use [`MobileViTFeatureExtractor`] to prepare images for the model. Note that if you do your own preprocessing, the pretrained checkpoints expect images to be in BGR pixel order (not RGB).
- The available image classification checkpoints are pre-trained on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k) (also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes).
-- The segmentation model uses a [DeepLabV3](https://arxiv.org/abs/1706.05587) head. The available semantic segmentation checkpoints are pre-trained on [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/).
-- As the name suggests MobileViT was designed to be performant and efficient on mobile phones. The TensorFlow versions of the MobileViT models are fully compatible with [TensorFlow Lite](https://www.tensorflow.org/lite).
+- The segmentation model uses a [DeepLabV3](https://arxiv.org/abs/1706.05587) head. The available semantic segmentation checkpoints are pre-trained on [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/).
+- As the name suggests MobileViT was designed to be performant and efficient on mobile phones. The TensorFlow versions of the MobileViT models are fully compatible with [TensorFlow Lite](https://www.tensorflow.org/lite).
- You can use the following code to convert a MobileViT checkpoint (be it image classification or semantic segmentation) to generate a
+ You can use the following code to convert a MobileViT checkpoint (be it image classification or semantic segmentation) to generate a
TensorFlow Lite model:
```py
@@ -52,7 +52,7 @@ with open(tflite_filename, "wb") as f:
```
The resulting model will be just **about an MB** making it a good fit for mobile applications where resources and network
- bandwidth can be constrained.
+ bandwidth can be constrained.
This model was contributed by [matthijs](https://huggingface.co/Matthijs). The TensorFlow version of the model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code and weights can be found [here](https://github.com/apple/ml-cvnets).
@@ -68,6 +68,12 @@ This model was contributed by [matthijs](https://huggingface.co/Matthijs). The T
- __call__
- post_process_semantic_segmentation
+## MobileViTImageProcessor
+
+[[autodoc]] MobileViTImageProcessor
+ - preprocess
+ - post_process_semantic_segmentation
+
## MobileViTModel
[[autodoc]] MobileViTModel
@@ -86,14 +92,14 @@ This model was contributed by [matthijs](https://huggingface.co/Matthijs). The T
## TFMobileViTModel
[[autodoc]] TFMobileViTModel
- - call
+ - call
## TFMobileViTForImageClassification
[[autodoc]] TFMobileViTForImageClassification
- - call
+ - call
## TFMobileViTForSemanticSegmentation
[[autodoc]] TFMobileViTForSemanticSegmentation
- - call
+ - call
diff --git a/docs/source/en/model_doc/perceiver.mdx b/docs/source/en/model_doc/perceiver.mdx
index 0dbfd3e004..52a928472c 100644
--- a/docs/source/en/model_doc/perceiver.mdx
+++ b/docs/source/en/model_doc/perceiver.mdx
@@ -70,7 +70,7 @@ vocabulary size of the model, i.e. creating logits of shape `(batch_size, 2048,
size of 262 byte IDs).
+alt="drawing" width="600"/>
LeViT Architecture. Taken from the original paper.
@@ -38,25 +38,25 @@ Tips:
- Compared to ViT, LeViT models use an additional distillation head to effectively learn from a teacher (which, in the LeViT paper, is a ResNet like-model). The distillation head is learned through backpropagation under supervision of a ResNet like-model. They also draw inspiration from convolution neural networks to use activation maps with decreasing resolutions to increase the efficiency.
- There are 2 ways to fine-tune distilled models, either (1) in a classic way, by only placing a prediction head on top
- of the final hidden state and not using the distillation head, or (2) by placing both a prediction head and distillation
- head on top of the final hidden state. In that case, the prediction head is trained using regular cross-entropy between
- the prediction of the head and the ground-truth label, while the distillation prediction head is trained using hard distillation
- (cross-entropy between the prediction of the distillation head and the label predicted by the teacher). At inference time,
- one takes the average prediction between both heads as final prediction. (2) is also called "fine-tuning with distillation",
- because one relies on a teacher that has already been fine-tuned on the downstream dataset. In terms of models, (1) corresponds
+ of the final hidden state and not using the distillation head, or (2) by placing both a prediction head and distillation
+ head on top of the final hidden state. In that case, the prediction head is trained using regular cross-entropy between
+ the prediction of the head and the ground-truth label, while the distillation prediction head is trained using hard distillation
+ (cross-entropy between the prediction of the distillation head and the label predicted by the teacher). At inference time,
+ one takes the average prediction between both heads as final prediction. (2) is also called "fine-tuning with distillation",
+ because one relies on a teacher that has already been fine-tuned on the downstream dataset. In terms of models, (1) corresponds
to [`LevitForImageClassification`] and (2) corresponds to [`LevitForImageClassificationWithTeacher`].
-- All released checkpoints were pre-trained and fine-tuned on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k)
+- All released checkpoints were pre-trained and fine-tuned on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k)
(also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes). only. No external data was used. This is in
contrast with the original ViT model, which used external data like the JFT-300M dataset/Imagenet-21k for
pre-training.
-- The authors of LeViT released 5 trained LeViT models, which you can directly plug into [`LevitModel`] or [`LevitForImageClassification`].
+- The authors of LeViT released 5 trained LeViT models, which you can directly plug into [`LevitModel`] or [`LevitForImageClassification`].
Techniques like data augmentation, optimization, and regularization were used in order to simulate training on a much larger dataset
(while only using ImageNet-1k for pre-training). The 5 variants available are (all trained on images of size 224x224):
*facebook/levit-128S*, *facebook/levit-128*, *facebook/levit-192*, *facebook/levit-256* and
*facebook/levit-384*. Note that one should use [`LevitFeatureExtractor`] in order to
prepare images for the model.
- [`LevitForImageClassificationWithTeacher`] currently supports only inference and not training or fine-tuning.
-- You can check out demo notebooks regarding inference as well as fine-tuning on custom data [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer)
+- You can check out demo notebooks regarding inference as well as fine-tuning on custom data [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer)
(you can just replace [`ViTFeatureExtractor`] by [`LevitFeatureExtractor`] and [`ViTForImageClassification`] by [`LevitForImageClassification`] or [`LevitForImageClassificationWithTeacher`]).
This model was contributed by [anugunj](https://huggingface.co/anugunj). The original code can be found [here](https://github.com/facebookresearch/LeViT).
@@ -71,6 +71,12 @@ This model was contributed by [anugunj](https://huggingface.co/anugunj). The ori
[[autodoc]] LevitFeatureExtractor
- __call__
+## LevitImageProcessor
+
+ [[autodoc]] LevitImageProcessor
+ - preprocess
+
+
## LevitModel
[[autodoc]] LevitModel
diff --git a/docs/source/en/model_doc/mobilevit.mdx b/docs/source/en/model_doc/mobilevit.mdx
index 818f8432af..1b73b1e439 100644
--- a/docs/source/en/model_doc/mobilevit.mdx
+++ b/docs/source/en/model_doc/mobilevit.mdx
@@ -14,7 +14,7 @@ specific language governing permissions and limitations under the License.
## Overview
-The MobileViT model was proposed in [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari. MobileViT introduces a new layer that replaces local processing in convolutions with global processing using transformers.
+The MobileViT model was proposed in [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari. MobileViT introduces a new layer that replaces local processing in convolutions with global processing using transformers.
The abstract from the paper is the following:
@@ -25,10 +25,10 @@ Tips:
- MobileViT is more like a CNN than a Transformer model. It does not work on sequence data but on batches of images. Unlike ViT, there are no embeddings. The backbone model outputs a feature map. You can follow [this tutorial](https://keras.io/examples/vision/mobilevit) for a lightweight introduction.
- One can use [`MobileViTFeatureExtractor`] to prepare images for the model. Note that if you do your own preprocessing, the pretrained checkpoints expect images to be in BGR pixel order (not RGB).
- The available image classification checkpoints are pre-trained on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k) (also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes).
-- The segmentation model uses a [DeepLabV3](https://arxiv.org/abs/1706.05587) head. The available semantic segmentation checkpoints are pre-trained on [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/).
-- As the name suggests MobileViT was designed to be performant and efficient on mobile phones. The TensorFlow versions of the MobileViT models are fully compatible with [TensorFlow Lite](https://www.tensorflow.org/lite).
+- The segmentation model uses a [DeepLabV3](https://arxiv.org/abs/1706.05587) head. The available semantic segmentation checkpoints are pre-trained on [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/).
+- As the name suggests MobileViT was designed to be performant and efficient on mobile phones. The TensorFlow versions of the MobileViT models are fully compatible with [TensorFlow Lite](https://www.tensorflow.org/lite).
- You can use the following code to convert a MobileViT checkpoint (be it image classification or semantic segmentation) to generate a
+ You can use the following code to convert a MobileViT checkpoint (be it image classification or semantic segmentation) to generate a
TensorFlow Lite model:
```py
@@ -52,7 +52,7 @@ with open(tflite_filename, "wb") as f:
```
The resulting model will be just **about an MB** making it a good fit for mobile applications where resources and network
- bandwidth can be constrained.
+ bandwidth can be constrained.
This model was contributed by [matthijs](https://huggingface.co/Matthijs). The TensorFlow version of the model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code and weights can be found [here](https://github.com/apple/ml-cvnets).
@@ -68,6 +68,12 @@ This model was contributed by [matthijs](https://huggingface.co/Matthijs). The T
- __call__
- post_process_semantic_segmentation
+## MobileViTImageProcessor
+
+[[autodoc]] MobileViTImageProcessor
+ - preprocess
+ - post_process_semantic_segmentation
+
## MobileViTModel
[[autodoc]] MobileViTModel
@@ -86,14 +92,14 @@ This model was contributed by [matthijs](https://huggingface.co/Matthijs). The T
## TFMobileViTModel
[[autodoc]] TFMobileViTModel
- - call
+ - call
## TFMobileViTForImageClassification
[[autodoc]] TFMobileViTForImageClassification
- - call
+ - call
## TFMobileViTForSemanticSegmentation
[[autodoc]] TFMobileViTForSemanticSegmentation
- - call
+ - call
diff --git a/docs/source/en/model_doc/perceiver.mdx b/docs/source/en/model_doc/perceiver.mdx
index 0dbfd3e004..52a928472c 100644
--- a/docs/source/en/model_doc/perceiver.mdx
+++ b/docs/source/en/model_doc/perceiver.mdx
@@ -70,7 +70,7 @@ vocabulary size of the model, i.e. creating logits of shape `(batch_size, 2048,
size of 262 byte IDs).
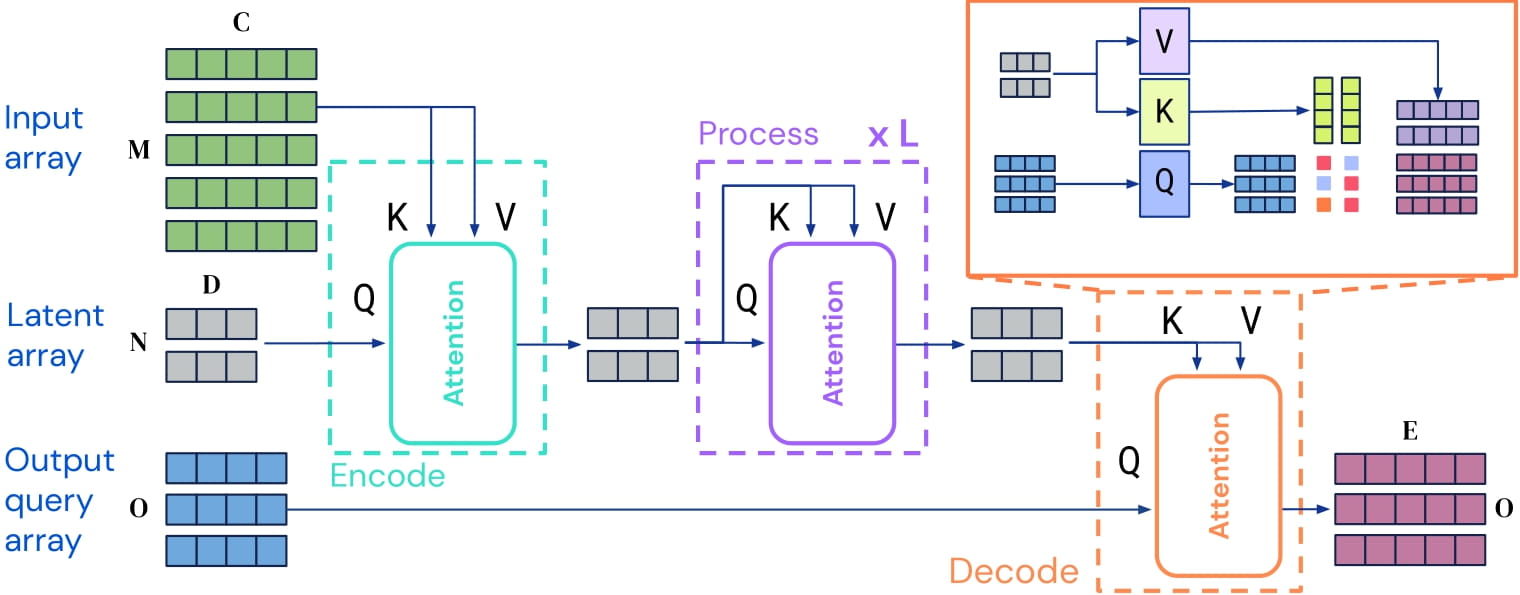 +alt="drawing" width="600"/>
Perceiver IO architecture. Taken from the original paper
@@ -83,8 +83,8 @@ Tips:
notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Perceiver).
- Refer to the [blog post](https://huggingface.co/blog/perceiver) if you want to fully understand how the model works and
is implemented in the library. Note that the models available in the library only showcase some examples of what you can do
-with the Perceiver. There are many more use cases, including question answering, named-entity recognition, object detection,
-audio classification, video classification, etc.
+with the Perceiver. There are many more use cases, including question answering, named-entity recognition, object detection,
+audio classification, video classification, etc.
**Note**:
@@ -114,6 +114,11 @@ audio classification, video classification, etc.
[[autodoc]] PerceiverFeatureExtractor
- __call__
+## PerceiverImageProcessor
+
+[[autodoc]] PerceiverImageProcessor
+ - preprocess
+
## PerceiverTextPreprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverTextPreprocessor
diff --git a/docs/source/en/model_doc/poolformer.mdx b/docs/source/en/model_doc/poolformer.mdx
index ac06bb63db..1b5727311e 100644
--- a/docs/source/en/model_doc/poolformer.mdx
+++ b/docs/source/en/model_doc/poolformer.mdx
@@ -50,12 +50,17 @@ This model was contributed by [heytanay](https://huggingface.co/heytanay). The o
[[autodoc]] PoolFormerFeatureExtractor
- __call__
+## PoolFormerImageProcessor
+
+[[autodoc]] PoolFormerImageProcessor
+ - preprocess
+
## PoolFormerModel
[[autodoc]] PoolFormerModel
- forward
-
+
## PoolFormerForImageClassification
[[autodoc]] PoolFormerForImageClassification
- - forward
\ No newline at end of file
+ - forward
diff --git a/docs/source/en/model_doc/segformer.mdx b/docs/source/en/model_doc/segformer.mdx
index f165150683..5dc8da5d19 100644
--- a/docs/source/en/model_doc/segformer.mdx
+++ b/docs/source/en/model_doc/segformer.mdx
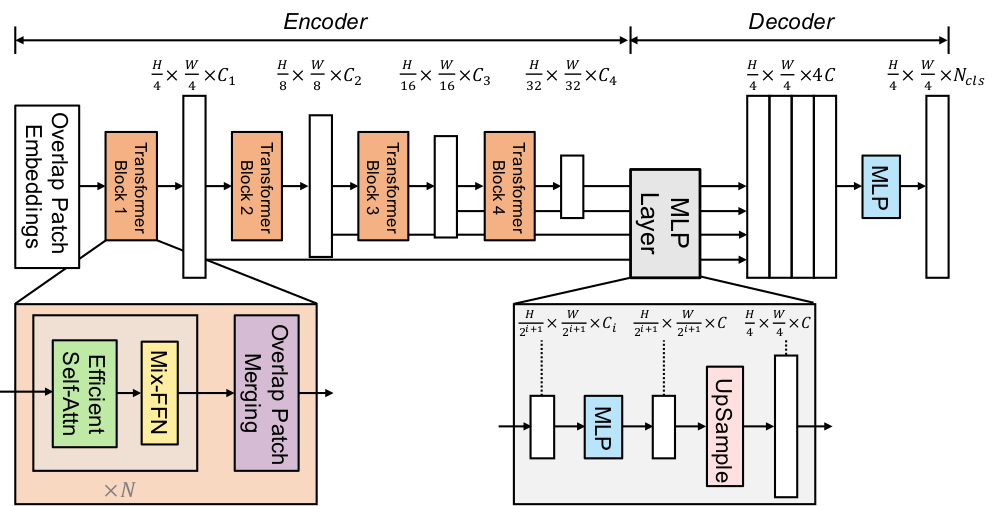
@@ -36,7 +36,7 @@ The figure below illustrates the architecture of SegFormer. Taken from the [orig
+alt="drawing" width="600"/>
Perceiver IO architecture. Taken from the original paper
@@ -83,8 +83,8 @@ Tips:
notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Perceiver).
- Refer to the [blog post](https://huggingface.co/blog/perceiver) if you want to fully understand how the model works and
is implemented in the library. Note that the models available in the library only showcase some examples of what you can do
-with the Perceiver. There are many more use cases, including question answering, named-entity recognition, object detection,
-audio classification, video classification, etc.
+with the Perceiver. There are many more use cases, including question answering, named-entity recognition, object detection,
+audio classification, video classification, etc.
**Note**:
@@ -114,6 +114,11 @@ audio classification, video classification, etc.
[[autodoc]] PerceiverFeatureExtractor
- __call__
+## PerceiverImageProcessor
+
+[[autodoc]] PerceiverImageProcessor
+ - preprocess
+
## PerceiverTextPreprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverTextPreprocessor
diff --git a/docs/source/en/model_doc/poolformer.mdx b/docs/source/en/model_doc/poolformer.mdx
index ac06bb63db..1b5727311e 100644
--- a/docs/source/en/model_doc/poolformer.mdx
+++ b/docs/source/en/model_doc/poolformer.mdx
@@ -50,12 +50,17 @@ This model was contributed by [heytanay](https://huggingface.co/heytanay). The o
[[autodoc]] PoolFormerFeatureExtractor
- __call__
+## PoolFormerImageProcessor
+
+[[autodoc]] PoolFormerImageProcessor
+ - preprocess
+
## PoolFormerModel
[[autodoc]] PoolFormerModel
- forward
-
+
## PoolFormerForImageClassification
[[autodoc]] PoolFormerForImageClassification
- - forward
\ No newline at end of file
+ - forward
diff --git a/docs/source/en/model_doc/segformer.mdx b/docs/source/en/model_doc/segformer.mdx
index f165150683..5dc8da5d19 100644
--- a/docs/source/en/model_doc/segformer.mdx
+++ b/docs/source/en/model_doc/segformer.mdx
@@ -36,7 +36,7 @@ The figure below illustrates the architecture of SegFormer. Taken from the [orig
 -This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version
of the model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/NVlabs/SegFormer).
Tips:
@@ -55,7 +55,7 @@ Tips:
- TensorFlow users should refer to [this repository](https://github.com/deep-diver/segformer-tf-transformers) that shows off-the-shelf inference and fine-tuning.
- One can also check out [this interactive demo on Hugging Face Spaces](https://huggingface.co/spaces/chansung/segformer-tf-transformers)
to try out a SegFormer model on custom images.
-- SegFormer works on any input size, as it pads the input to be divisible by `config.patch_sizes`.
+- SegFormer works on any input size, as it pads the input to be divisible by `config.patch_sizes`.
- One can use [`SegformerFeatureExtractor`] to prepare images and corresponding segmentation maps
for the model. Note that this feature extractor is fairly basic and does not include all data augmentations used in
the original paper. The original preprocessing pipelines (for the ADE20k dataset for instance) can be found [here](https://github.com/NVlabs/SegFormer/blob/master/local_configs/_base_/datasets/ade20k_repeat.py). The most
@@ -95,6 +95,12 @@ SegFormer's results on the segmentation datasets like ADE20k, refer to the [pape
- __call__
- post_process_semantic_segmentation
+## SegformerImageProcessor
+
+[[autodoc]] SegformerImageProcessor
+ - preprocess
+ - post_process_semantic_segmentation
+
## SegformerModel
[[autodoc]] SegformerModel
@@ -123,14 +129,14 @@ SegFormer's results on the segmentation datasets like ADE20k, refer to the [pape
## TFSegformerModel
[[autodoc]] TFSegformerModel
- - call
+ - call
## TFSegformerForImageClassification
[[autodoc]] TFSegformerForImageClassification
- - call
+ - call
## TFSegformerForSemanticSegmentation
[[autodoc]] TFSegformerForSemanticSegmentation
- - call
+ - call
diff --git a/docs/source/en/model_doc/videomae.mdx b/docs/source/en/model_doc/videomae.mdx
index c319944dc8..b6f86f39dc 100644
--- a/docs/source/en/model_doc/videomae.mdx
+++ b/docs/source/en/model_doc/videomae.mdx
@@ -27,7 +27,7 @@ Tips:
- [`VideoMAEForPreTraining`] includes the decoder on top for self-supervised pre-training.
-This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version
of the model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/NVlabs/SegFormer).
Tips:
@@ -55,7 +55,7 @@ Tips:
- TensorFlow users should refer to [this repository](https://github.com/deep-diver/segformer-tf-transformers) that shows off-the-shelf inference and fine-tuning.
- One can also check out [this interactive demo on Hugging Face Spaces](https://huggingface.co/spaces/chansung/segformer-tf-transformers)
to try out a SegFormer model on custom images.
-- SegFormer works on any input size, as it pads the input to be divisible by `config.patch_sizes`.
+- SegFormer works on any input size, as it pads the input to be divisible by `config.patch_sizes`.
- One can use [`SegformerFeatureExtractor`] to prepare images and corresponding segmentation maps
for the model. Note that this feature extractor is fairly basic and does not include all data augmentations used in
the original paper. The original preprocessing pipelines (for the ADE20k dataset for instance) can be found [here](https://github.com/NVlabs/SegFormer/blob/master/local_configs/_base_/datasets/ade20k_repeat.py). The most
@@ -95,6 +95,12 @@ SegFormer's results on the segmentation datasets like ADE20k, refer to the [pape
- __call__
- post_process_semantic_segmentation
+## SegformerImageProcessor
+
+[[autodoc]] SegformerImageProcessor
+ - preprocess
+ - post_process_semantic_segmentation
+
## SegformerModel
[[autodoc]] SegformerModel
@@ -123,14 +129,14 @@ SegFormer's results on the segmentation datasets like ADE20k, refer to the [pape
## TFSegformerModel
[[autodoc]] TFSegformerModel
- - call
+ - call
## TFSegformerForImageClassification
[[autodoc]] TFSegformerForImageClassification
- - call
+ - call
## TFSegformerForSemanticSegmentation
[[autodoc]] TFSegformerForSemanticSegmentation
- - call
+ - call
diff --git a/docs/source/en/model_doc/videomae.mdx b/docs/source/en/model_doc/videomae.mdx
index c319944dc8..b6f86f39dc 100644
--- a/docs/source/en/model_doc/videomae.mdx
+++ b/docs/source/en/model_doc/videomae.mdx
@@ -27,7 +27,7 @@ Tips:
- [`VideoMAEForPreTraining`] includes the decoder on top for self-supervised pre-training.
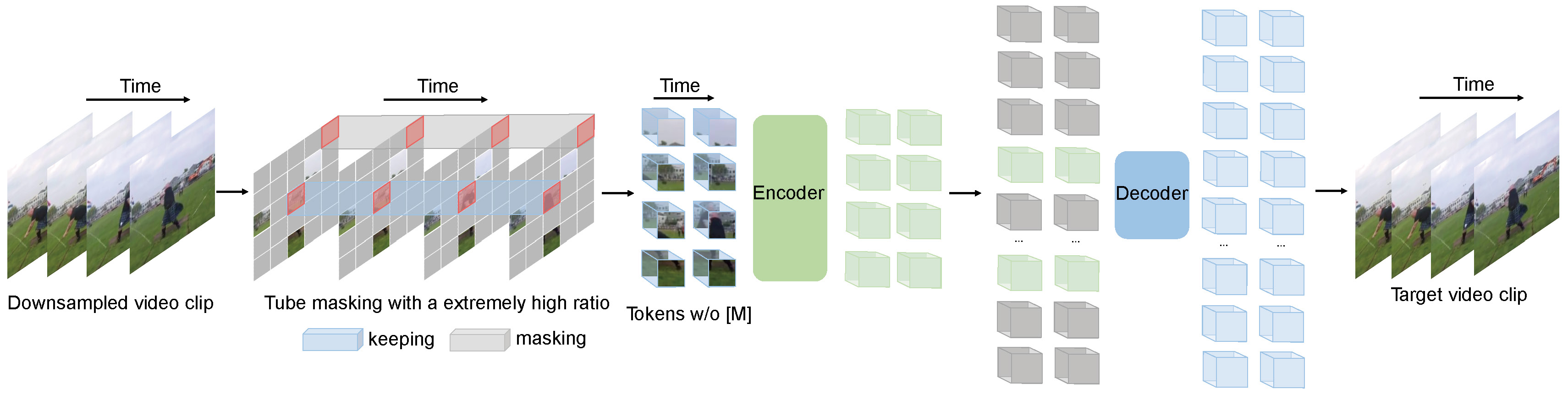 +alt="drawing" width="600"/>
VideoMAE pre-training. Taken from the original paper.
@@ -44,6 +44,11 @@ The original code can be found [here](https://github.com/MCG-NJU/VideoMAE).
[[autodoc]] VideoMAEFeatureExtractor
- __call__
+## VideoMAEImageProcessor
+
+[[autodoc]] VideoMAEImageProcessor
+ - preprocess
+
## VideoMAEModel
[[autodoc]] VideoMAEModel
@@ -57,4 +62,4 @@ The original code can be found [here](https://github.com/MCG-NJU/VideoMAE).
## VideoMAEForVideoClassification
[[autodoc]] transformers.VideoMAEForVideoClassification
- - forward
\ No newline at end of file
+ - forward
diff --git a/docs/source/en/model_doc/vilt.mdx b/docs/source/en/model_doc/vilt.mdx
index d02f376ebd..7c8653e1a3 100644
--- a/docs/source/en/model_doc/vilt.mdx
+++ b/docs/source/en/model_doc/vilt.mdx
@@ -38,12 +38,12 @@ Tips:
This processor wraps a feature extractor (for the image modality) and a tokenizer (for the language modality) into one.
- ViLT is trained with images of various sizes: the authors resize the shorter edge of input images to 384 and limit the longer edge to
under 640 while preserving the aspect ratio. To make batching of images possible, the authors use a `pixel_mask` that indicates
- which pixel values are real and which are padding. [`ViltProcessor`] automatically creates this for you.
-- The design of ViLT is very similar to that of a standard Vision Transformer (ViT). The only difference is that the model includes
+ which pixel values are real and which are padding. [`ViltProcessor`] automatically creates this for you.
+- The design of ViLT is very similar to that of a standard Vision Transformer (ViT). The only difference is that the model includes
additional embedding layers for the language modality.
+alt="drawing" width="600"/>
VideoMAE pre-training. Taken from the original paper.
@@ -44,6 +44,11 @@ The original code can be found [here](https://github.com/MCG-NJU/VideoMAE).
[[autodoc]] VideoMAEFeatureExtractor
- __call__
+## VideoMAEImageProcessor
+
+[[autodoc]] VideoMAEImageProcessor
+ - preprocess
+
## VideoMAEModel
[[autodoc]] VideoMAEModel
@@ -57,4 +62,4 @@ The original code can be found [here](https://github.com/MCG-NJU/VideoMAE).
## VideoMAEForVideoClassification
[[autodoc]] transformers.VideoMAEForVideoClassification
- - forward
\ No newline at end of file
+ - forward
diff --git a/docs/source/en/model_doc/vilt.mdx b/docs/source/en/model_doc/vilt.mdx
index d02f376ebd..7c8653e1a3 100644
--- a/docs/source/en/model_doc/vilt.mdx
+++ b/docs/source/en/model_doc/vilt.mdx
@@ -38,12 +38,12 @@ Tips:
This processor wraps a feature extractor (for the image modality) and a tokenizer (for the language modality) into one.
- ViLT is trained with images of various sizes: the authors resize the shorter edge of input images to 384 and limit the longer edge to
under 640 while preserving the aspect ratio. To make batching of images possible, the authors use a `pixel_mask` that indicates
- which pixel values are real and which are padding. [`ViltProcessor`] automatically creates this for you.
-- The design of ViLT is very similar to that of a standard Vision Transformer (ViT). The only difference is that the model includes
+ which pixel values are real and which are padding. [`ViltProcessor`] automatically creates this for you.
+- The design of ViLT is very similar to that of a standard Vision Transformer (ViT). The only difference is that the model includes
additional embedding layers for the language modality.
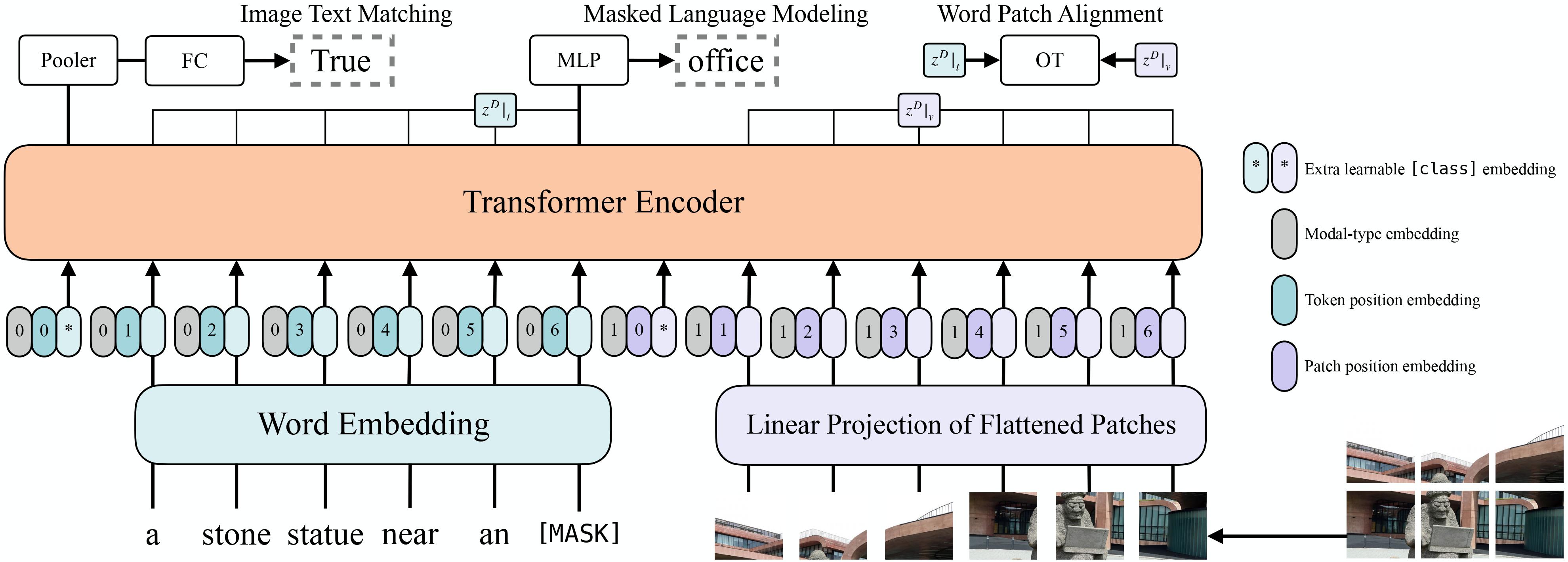 +alt="drawing" width="600"/>
ViLT architecture. Taken from the original paper.
@@ -63,6 +63,11 @@ Tips:
[[autodoc]] ViltFeatureExtractor
- __call__
+## ViltImageProcessor
+
+[[autodoc]] ViltImageProcessor
+ - preprocess
+
## ViltProcessor
[[autodoc]] ViltProcessor
diff --git a/docs/source/en/model_doc/vit.mdx b/docs/source/en/model_doc/vit.mdx
index 5978d4518e..9b3a5a1e16 100644
--- a/docs/source/en/model_doc/vit.mdx
+++ b/docs/source/en/model_doc/vit.mdx
@@ -57,7 +57,7 @@ Tips:
improvement of 2% to training from scratch, but still 4% behind supervised pre-training.
+alt="drawing" width="600"/>
ViLT architecture. Taken from the original paper.
@@ -63,6 +63,11 @@ Tips:
[[autodoc]] ViltFeatureExtractor
- __call__
+## ViltImageProcessor
+
+[[autodoc]] ViltImageProcessor
+ - preprocess
+
## ViltProcessor
[[autodoc]] ViltProcessor
diff --git a/docs/source/en/model_doc/vit.mdx b/docs/source/en/model_doc/vit.mdx
index 5978d4518e..9b3a5a1e16 100644
--- a/docs/source/en/model_doc/vit.mdx
+++ b/docs/source/en/model_doc/vit.mdx
@@ -57,7 +57,7 @@ Tips:
improvement of 2% to training from scratch, but still 4% behind supervised pre-training.
 +alt="drawing" width="600"/>
ViT architecture. Taken from the original paper.
@@ -96,6 +96,12 @@ go to him!
[[autodoc]] ViTFeatureExtractor
- __call__
+
+## ViTImageProcessor
+
+[[autodoc]] ViTImageProcessor
+ - preprocess
+
## ViTModel
[[autodoc]] ViTModel
diff --git a/docs/source/en/preprocessing.mdx b/docs/source/en/preprocessing.mdx
index 541885c452..ebbe7b5a80 100644
--- a/docs/source/en/preprocessing.mdx
+++ b/docs/source/en/preprocessing.mdx
@@ -17,7 +17,8 @@ specific language governing permissions and limitations under the License.
Before you can train a model on a dataset, it needs to be preprocessed into the expected model input format. Whether your data is text, images, or audio, they need to be converted and assembled into batches of tensors. 🤗 Transformers provides a set of preprocessing classes to help prepare your data for the model. In this tutorial, you'll learn that for:
* Text, use a [Tokenizer](./main_classes/tokenizer) to convert text into a sequence of tokens, create a numerical representation of the tokens, and assemble them into tensors.
-* Computer vision and speech, use a [Feature extractor](./main_classes/feature_extractor) to extract sequential features from audio waveforms and images and convert them into tensors.
+* Image inputs use a [ImageProcessor](./main_classes/image) to convert images into tensors.
+* Speech and audio, use a [Feature extractor](./main_classes/feature_extractor) to extract sequential features from audio waveforms and convert them into tensors.
* Multimodal inputs, use a [Processor](./main_classes/processors) to combine a tokenizer and a feature extractor.
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index 54b4b42fec..c07836075b 100644
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -125,11 +125,13 @@ _import_structure = {
"ALL_PRETRAINED_CONFIG_ARCHIVE_MAP",
"CONFIG_MAPPING",
"FEATURE_EXTRACTOR_MAPPING",
+ "IMAGE_PROCESSOR_MAPPING",
"MODEL_NAMES_MAPPING",
"PROCESSOR_MAPPING",
"TOKENIZER_MAPPING",
"AutoConfig",
"AutoFeatureExtractor",
+ "AutoImageProcessor",
"AutoProcessor",
"AutoTokenizer",
],
@@ -251,6 +253,7 @@ _import_structure = {
"LAYOUTLMV2_PRETRAINED_CONFIG_ARCHIVE_MAP",
"LayoutLMv2Config",
"LayoutLMv2FeatureExtractor",
+ "LayoutLMv2ImageProcessor",
"LayoutLMv2Processor",
"LayoutLMv2Tokenizer",
],
@@ -258,6 +261,7 @@ _import_structure = {
"LAYOUTLMV3_PRETRAINED_CONFIG_ARCHIVE_MAP",
"LayoutLMv3Config",
"LayoutLMv3FeatureExtractor",
+ "LayoutLMv3ImageProcessor",
"LayoutLMv3Processor",
"LayoutLMv3Tokenizer",
],
@@ -375,7 +379,13 @@ _import_structure = {
],
"models.van": ["VAN_PRETRAINED_CONFIG_ARCHIVE_MAP", "VanConfig"],
"models.videomae": ["VIDEOMAE_PRETRAINED_CONFIG_ARCHIVE_MAP", "VideoMAEConfig"],
- "models.vilt": ["VILT_PRETRAINED_CONFIG_ARCHIVE_MAP", "ViltConfig", "ViltFeatureExtractor", "ViltProcessor"],
+ "models.vilt": [
+ "VILT_PRETRAINED_CONFIG_ARCHIVE_MAP",
+ "ViltConfig",
+ "ViltFeatureExtractor",
+ "ViltImageProcessor",
+ "ViltProcessor",
+ ],
"models.vision_encoder_decoder": ["VisionEncoderDecoderConfig"],
"models.vision_text_dual_encoder": ["VisionTextDualEncoderConfig", "VisionTextDualEncoderProcessor"],
"models.visual_bert": ["VISUAL_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP", "VisualBertConfig"],
@@ -689,35 +699,34 @@ except OptionalDependencyNotAvailable:
name for name in dir(dummy_vision_objects) if not name.startswith("_")
]
else:
- _import_structure["image_processing_utils"] = ["ImageProcessorMixin"]
+ _import_structure["image_processing_utils"] = ["ImageProcessingMixin"]
_import_structure["image_transforms"] = ["rescale", "resize", "to_pil_image"]
_import_structure["image_utils"] = ["ImageFeatureExtractionMixin"]
- _import_structure["models.beit"].append("BeitFeatureExtractor")
- _import_structure["models.clip"].append("CLIPFeatureExtractor")
- _import_structure["models.convnext"].append("ConvNextFeatureExtractor")
+ _import_structure["models.beit"].extend(["BeitFeatureExtractor", "BeitImageProcessor"])
+ _import_structure["models.clip"].extend(["CLIPFeatureExtractor", "CLIPImageProcessor"])
+ _import_structure["models.convnext"].extend(["ConvNextFeatureExtractor", "ConvNextImageProcessor"])
_import_structure["models.deformable_detr"].append("DeformableDetrFeatureExtractor")
- _import_structure["models.deit"].append("DeiTFeatureExtractor")
+ _import_structure["models.deit"].extend(["DeiTFeatureExtractor", "DeiTImageProcessor"])
_import_structure["models.detr"].append("DetrFeatureExtractor")
_import_structure["models.conditional_detr"].append("ConditionalDetrFeatureExtractor")
_import_structure["models.donut"].append("DonutFeatureExtractor")
- _import_structure["models.dpt"].append("DPTFeatureExtractor")
- _import_structure["models.flava"].extend(["FlavaFeatureExtractor", "FlavaProcessor"])
- _import_structure["models.glpn"].append("GLPNFeatureExtractor")
- _import_structure["models.imagegpt"].append("ImageGPTFeatureExtractor")
- _import_structure["models.layoutlmv2"].append("LayoutLMv2FeatureExtractor")
- _import_structure["models.layoutlmv3"].append("LayoutLMv3FeatureExtractor")
- _import_structure["models.levit"].append("LevitFeatureExtractor")
+ _import_structure["models.dpt"].extend(["DPTFeatureExtractor", "DPTImageProcessor"])
+ _import_structure["models.flava"].extend(["FlavaFeatureExtractor", "FlavaProcessor", "FlavaImageProcessor"])
+ _import_structure["models.glpn"].extend(["GLPNFeatureExtractor", "GLPNImageProcessor"])
+ _import_structure["models.imagegpt"].extend(["ImageGPTFeatureExtractor", "ImageGPTImageProcessor"])
+ _import_structure["models.layoutlmv2"].extend(["LayoutLMv2FeatureExtractor", "LayoutLMv2ImageProcessor"])
+ _import_structure["models.layoutlmv3"].extend(["LayoutLMv3FeatureExtractor", "LayoutLMv3ImageProcessor"])
+ _import_structure["models.levit"].extend(["LevitFeatureExtractor", "LevitImageProcessor"])
_import_structure["models.maskformer"].append("MaskFormerFeatureExtractor")
- _import_structure["models.mobilevit"].append("MobileViTFeatureExtractor")
+ _import_structure["models.mobilevit"].extend(["MobileViTFeatureExtractor", "MobileViTImageProcessor"])
_import_structure["models.owlvit"].append("OwlViTFeatureExtractor")
- _import_structure["models.perceiver"].append("PerceiverFeatureExtractor")
- _import_structure["models.poolformer"].append("PoolFormerFeatureExtractor")
- _import_structure["models.segformer"].append("SegformerFeatureExtractor")
- _import_structure["models.videomae"].append("VideoMAEFeatureExtractor")
- _import_structure["models.vilt"].append("ViltFeatureExtractor")
- _import_structure["models.vilt"].append("ViltProcessor")
- _import_structure["models.vit"].append("ViTFeatureExtractor")
- _import_structure["models.yolos"].append("YolosFeatureExtractor")
+ _import_structure["models.perceiver"].extend(["PerceiverFeatureExtractor", "PerceiverImageProcessor"])
+ _import_structure["models.poolformer"].extend(["PoolFormerFeatureExtractor", "PoolFormerImageProcessor"])
+ _import_structure["models.segformer"].extend(["SegformerFeatureExtractor", "SegformerImageProcessor"])
+ _import_structure["models.videomae"].extend(["VideoMAEFeatureExtractor", "VideoMAEImageProcessor"])
+ _import_structure["models.vilt"].extend(["ViltFeatureExtractor", "ViltImageProcessor", "ViltProcessor"])
+ _import_structure["models.vit"].extend(["ViTFeatureExtractor", "ViTImageProcessor"])
+ _import_structure["models.yolos"].extend(["YolosFeatureExtractor"])
# Timm-backed objects
try:
@@ -3220,11 +3229,13 @@ if TYPE_CHECKING:
ALL_PRETRAINED_CONFIG_ARCHIVE_MAP,
CONFIG_MAPPING,
FEATURE_EXTRACTOR_MAPPING,
+ IMAGE_PROCESSOR_MAPPING,
MODEL_NAMES_MAPPING,
PROCESSOR_MAPPING,
TOKENIZER_MAPPING,
AutoConfig,
AutoFeatureExtractor,
+ AutoImageProcessor,
AutoProcessor,
AutoTokenizer,
)
@@ -3337,6 +3348,7 @@ if TYPE_CHECKING:
LAYOUTLMV2_PRETRAINED_CONFIG_ARCHIVE_MAP,
LayoutLMv2Config,
LayoutLMv2FeatureExtractor,
+ LayoutLMv2ImageProcessor,
LayoutLMv2Processor,
LayoutLMv2Tokenizer,
)
@@ -3344,6 +3356,7 @@ if TYPE_CHECKING:
LAYOUTLMV3_PRETRAINED_CONFIG_ARCHIVE_MAP,
LayoutLMv3Config,
LayoutLMv3FeatureExtractor,
+ LayoutLMv3ImageProcessor,
LayoutLMv3Processor,
LayoutLMv3Tokenizer,
)
@@ -3441,7 +3454,13 @@ if TYPE_CHECKING:
from .models.unispeech_sat import UNISPEECH_SAT_PRETRAINED_CONFIG_ARCHIVE_MAP, UniSpeechSatConfig
from .models.van import VAN_PRETRAINED_CONFIG_ARCHIVE_MAP, VanConfig
from .models.videomae import VIDEOMAE_PRETRAINED_CONFIG_ARCHIVE_MAP, VideoMAEConfig
- from .models.vilt import VILT_PRETRAINED_CONFIG_ARCHIVE_MAP, ViltConfig, ViltFeatureExtractor, ViltProcessor
+ from .models.vilt import (
+ VILT_PRETRAINED_CONFIG_ARCHIVE_MAP,
+ ViltConfig,
+ ViltFeatureExtractor,
+ ViltImageProcessor,
+ ViltProcessor,
+ )
from .models.vision_encoder_decoder import VisionEncoderDecoderConfig
from .models.vision_text_dual_encoder import VisionTextDualEncoderConfig, VisionTextDualEncoderProcessor
from .models.visual_bert import VISUAL_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP, VisualBertConfig
@@ -3716,33 +3735,33 @@ if TYPE_CHECKING:
except OptionalDependencyNotAvailable:
from .utils.dummy_vision_objects import *
else:
- from .image_processing_utils import ImageProcessorMixin
+ from .image_processing_utils import ImageProcessingMixin
from .image_transforms import rescale, resize, to_pil_image
from .image_utils import ImageFeatureExtractionMixin
- from .models.beit import BeitFeatureExtractor
- from .models.clip import CLIPFeatureExtractor
+ from .models.beit import BeitFeatureExtractor, BeitImageProcessor
+ from .models.clip import CLIPFeatureExtractor, CLIPImageProcessor
from .models.conditional_detr import ConditionalDetrFeatureExtractor
- from .models.convnext import ConvNextFeatureExtractor
+ from .models.convnext import ConvNextFeatureExtractor, ConvNextImageProcessor
from .models.deformable_detr import DeformableDetrFeatureExtractor
- from .models.deit import DeiTFeatureExtractor
+ from .models.deit import DeiTFeatureExtractor, DeiTImageProcessor
from .models.detr import DetrFeatureExtractor
from .models.donut import DonutFeatureExtractor
- from .models.dpt import DPTFeatureExtractor
- from .models.flava import FlavaFeatureExtractor, FlavaProcessor
- from .models.glpn import GLPNFeatureExtractor
- from .models.imagegpt import ImageGPTFeatureExtractor
- from .models.layoutlmv2 import LayoutLMv2FeatureExtractor
- from .models.layoutlmv3 import LayoutLMv3FeatureExtractor
- from .models.levit import LevitFeatureExtractor
+ from .models.dpt import DPTFeatureExtractor, DPTImageProcessor
+ from .models.flava import FlavaFeatureExtractor, FlavaImageProcessor, FlavaProcessor
+ from .models.glpn import GLPNFeatureExtractor, GLPNImageProcessor
+ from .models.imagegpt import ImageGPTFeatureExtractor, ImageGPTImageProcessor
+ from .models.layoutlmv2 import LayoutLMv2FeatureExtractor, LayoutLMv2ImageProcessor
+ from .models.layoutlmv3 import LayoutLMv3FeatureExtractor, LayoutLMv3ImageProcessor
+ from .models.levit import LevitFeatureExtractor, LevitImageProcessor
from .models.maskformer import MaskFormerFeatureExtractor
- from .models.mobilevit import MobileViTFeatureExtractor
+ from .models.mobilevit import MobileViTFeatureExtractor, MobileViTImageProcessor
from .models.owlvit import OwlViTFeatureExtractor
- from .models.perceiver import PerceiverFeatureExtractor
- from .models.poolformer import PoolFormerFeatureExtractor
- from .models.segformer import SegformerFeatureExtractor
- from .models.videomae import VideoMAEFeatureExtractor
- from .models.vilt import ViltFeatureExtractor, ViltProcessor
- from .models.vit import ViTFeatureExtractor
+ from .models.perceiver import PerceiverFeatureExtractor, PerceiverImageProcessor
+ from .models.poolformer import PoolFormerFeatureExtractor, PoolFormerImageProcessor
+ from .models.segformer import SegformerFeatureExtractor, SegformerImageProcessor
+ from .models.videomae import VideoMAEFeatureExtractor, VideoMAEImageProcessor
+ from .models.vilt import ViltFeatureExtractor, ViltImageProcessor, ViltProcessor
+ from .models.vit import ViTFeatureExtractor, ViTImageProcessor
from .models.yolos import YolosFeatureExtractor
# Modeling
diff --git a/src/transformers/commands/add_new_model_like.py b/src/transformers/commands/add_new_model_like.py
index a5d4e97ffd..2af7688073 100644
--- a/src/transformers/commands/add_new_model_like.py
+++ b/src/transformers/commands/add_new_model_like.py
@@ -389,6 +389,7 @@ SPECIAL_PATTERNS = {
"_CHECKPOINT_FOR_DOC =": "checkpoint",
"_CONFIG_FOR_DOC =": "config_class",
"_TOKENIZER_FOR_DOC =": "tokenizer_class",
+ "_IMAGE_PROCESSOR_FOR_DOC =": "image_processor_class",
"_FEAT_EXTRACTOR_FOR_DOC =": "feature_extractor_class",
"_PROCESSOR_FOR_DOC =": "processor_class",
}
diff --git a/src/transformers/commands/pt_to_tf.py b/src/transformers/commands/pt_to_tf.py
index 76d4984ade..62996b0513 100644
--- a/src/transformers/commands/pt_to_tf.py
+++ b/src/transformers/commands/pt_to_tf.py
@@ -24,10 +24,12 @@ import huggingface_hub
from .. import (
FEATURE_EXTRACTOR_MAPPING,
+ IMAGE_PROCESSOR_MAPPING,
PROCESSOR_MAPPING,
TOKENIZER_MAPPING,
AutoConfig,
AutoFeatureExtractor,
+ AutoImageProcessor,
AutoProcessor,
AutoTokenizer,
is_datasets_available,
@@ -202,6 +204,8 @@ class PTtoTFCommand(BaseTransformersCLICommand):
processor = AutoProcessor.from_pretrained(self._local_dir)
if model_config_class in TOKENIZER_MAPPING and processor.tokenizer.pad_token is None:
processor.tokenizer.pad_token = processor.tokenizer.eos_token
+ elif model_config_class in IMAGE_PROCESSOR_MAPPING:
+ processor = AutoImageProcessor.from_pretrained(self._local_dir)
elif model_config_class in FEATURE_EXTRACTOR_MAPPING:
processor = AutoFeatureExtractor.from_pretrained(self._local_dir)
elif model_config_class in TOKENIZER_MAPPING:
diff --git a/src/transformers/image_processing_utils.py b/src/transformers/image_processing_utils.py
index bdd30ecc04..7f73eff1e2 100644
--- a/src/transformers/image_processing_utils.py
+++ b/src/transformers/image_processing_utils.py
@@ -13,17 +13,31 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-from typing import Dict, Iterable, Optional, Union
+import copy
+import json
+import os
+from typing import Any, Dict, Iterable, Optional, Tuple, Union
+import numpy as np
+
+from .dynamic_module_utils import custom_object_save
from .feature_extraction_utils import BatchFeature as BaseBatchFeature
-from .feature_extraction_utils import FeatureExtractionMixin
-from .utils import logging
+from .utils import (
+ IMAGE_PROCESSOR_NAME,
+ PushToHubMixin,
+ cached_file,
+ copy_func,
+ download_url,
+ is_offline_mode,
+ is_remote_url,
+ logging,
+)
logger = logging.get_logger(__name__)
-# TODO: Move BatchFeature to be imported by both feature_extraction_utils and image_processing_utils
+# TODO: Move BatchFeature to be imported by both image_processing_utils and image_processing_utils
# We override the class string here, but logic is the same.
class BatchFeature(BaseBatchFeature):
r"""
@@ -40,12 +54,381 @@ class BatchFeature(BaseBatchFeature):
"""
-# We use aliasing whilst we phase out the old API. Once feature extractors for vision models
-# are deprecated, ImageProcessor mixin will be implemented. Any shared logic will be abstracted out.
-ImageProcessorMixin = FeatureExtractionMixin
+# TODO: (Amy) - factor out the common parts of this and the feature extractor
+class ImageProcessingMixin(PushToHubMixin):
+ """
+ This is an image processor mixin used to provide saving/loading functionality for sequential and image feature
+ extractors.
+ """
+
+ _auto_class = None
+
+ def __init__(self, **kwargs):
+ """Set elements of `kwargs` as attributes."""
+ # Pop "processor_class" as it should be saved as private attribute
+ self._processor_class = kwargs.pop("processor_class", None)
+ # Additional attributes without default values
+ for key, value in kwargs.items():
+ try:
+ setattr(self, key, value)
+ except AttributeError as err:
+ logger.error(f"Can't set {key} with value {value} for {self}")
+ raise err
+
+ def _set_processor_class(self, processor_class: str):
+ """Sets processor class as an attribute."""
+ self._processor_class = processor_class
+
+ @classmethod
+ def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs):
+ r"""
+ Instantiate a type of [`~image_processing_utils.ImageProcessingMixin`] from an image processor.
+
+ Args:
+ pretrained_model_name_or_path (`str` or `os.PathLike`):
+ This can be either:
+
+ - a string, the *model id* of a pretrained image_processor hosted inside a model repo on
+ huggingface.co. Valid model ids can be located at the root-level, like `bert-base-uncased`, or
+ namespaced under a user or organization name, like `dbmdz/bert-base-german-cased`.
+ - a path to a *directory* containing a image processor file saved using the
+ [`~image_processing_utils.ImageProcessingMixin.save_pretrained`] method, e.g.,
+ `./my_model_directory/`.
+ - a path or url to a saved image processor JSON *file*, e.g.,
+ `./my_model_directory/preprocessor_config.json`.
+ cache_dir (`str` or `os.PathLike`, *optional*):
+ Path to a directory in which a downloaded pretrained model image processor should be cached if the
+ standard cache should not be used.
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force to (re-)download the image processor files and override the cached versions if
+ they exist.
+ resume_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to delete incompletely received file. Attempts to resume the download if such a file
+ exists.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}.` The proxies are used on each request.
+ use_auth_token (`str` or `bool`, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, or not specified, will use
+ the token generated when running `huggingface-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
-class BaseImageProcessor(ImageProcessorMixin):
+
+
+ To test a pull request you made on the Hub, you can pass `revision="refs/pr/".
+
+
+
+ return_unused_kwargs (`bool`, *optional*, defaults to `False`):
+ If `False`, then this function returns just the final image processor object. If `True`, then this
+ functions returns a `Tuple(image_processor, unused_kwargs)` where *unused_kwargs* is a dictionary
+ consisting of the key/value pairs whose keys are not image processor attributes: i.e., the part of
+ `kwargs` which has not been used to update `image_processor` and is otherwise ignored.
+ kwargs (`Dict[str, Any]`, *optional*):
+ The values in kwargs of any keys which are image processor attributes will be used to override the
+ loaded values. Behavior concerning key/value pairs whose keys are *not* image processor attributes is
+ controlled by the `return_unused_kwargs` keyword parameter.
+
+ Returns:
+ A image processor of type [`~image_processing_utils.ImageProcessingMixin`].
+
+ Examples:
+
+ ```python
+ # We can't instantiate directly the base class *ImageProcessingMixin* so let's show the examples on a
+ # derived class: *CLIPImageProcessor*
+ image_processor = CLIPImageProcessor.from_pretrained(
+ "openai/clip-vit-base-patch32"
+ ) # Download image_processing_config from huggingface.co and cache.
+ image_processor = CLIPImageProcessor.from_pretrained(
+ "./test/saved_model/"
+ ) # E.g. image processor (or model) was saved using *save_pretrained('./test/saved_model/')*
+ image_processor = CLIPImageProcessor.from_pretrained("./test/saved_model/preprocessor_config.json")
+ image_processor = CLIPImageProcessor.from_pretrained(
+ "openai/clip-vit-base-patch32", do_normalize=False, foo=False
+ )
+ assert image_processor.do_normalize is False
+ image_processor, unused_kwargs = CLIPImageProcessor.from_pretrained(
+ "openai/clip-vit-base-patch32", do_normalize=False, foo=False, return_unused_kwargs=True
+ )
+ assert image_processor.do_normalize is False
+ assert unused_kwargs == {"foo": False}
+ ```"""
+ image_processor_dict, kwargs = cls.get_image_processor_dict(pretrained_model_name_or_path, **kwargs)
+
+ return cls.from_dict(image_processor_dict, **kwargs)
+
+ def save_pretrained(self, save_directory: Union[str, os.PathLike], push_to_hub: bool = False, **kwargs):
+ """
+ Save an image processor object to the directory `save_directory`, so that it can be re-loaded using the
+ [`~image_processing_utils.ImageProcessingMixin.from_pretrained`] class method.
+
+ Args:
+ save_directory (`str` or `os.PathLike`):
+ Directory where the image processor JSON file will be saved (will be created if it does not exist).
+ push_to_hub (`bool`, *optional*, defaults to `False`):
+ Whether or not to push your model to the Hugging Face model hub after saving it. You can specify the
+ repository you want to push to with `repo_id` (will default to the name of `save_directory` in your
+ namespace).
+ kwargs:
+ Additional key word arguments passed along to the [`~utils.PushToHubMixin.push_to_hub`] method.
+ """
+ if os.path.isfile(save_directory):
+ raise AssertionError(f"Provided path ({save_directory}) should be a directory, not a file")
+
+ os.makedirs(save_directory, exist_ok=True)
+
+ if push_to_hub:
+ commit_message = kwargs.pop("commit_message", None)
+ repo_id = kwargs.pop("repo_id", save_directory.split(os.path.sep)[-1])
+ repo_id, token = self._create_repo(repo_id, **kwargs)
+ files_timestamps = self._get_files_timestamps(save_directory)
+
+ # If we have a custom config, we copy the file defining it in the folder and set the attributes so it can be
+ # loaded from the Hub.
+ if self._auto_class is not None:
+ custom_object_save(self, save_directory, config=self)
+
+ # If we save using the predefined names, we can load using `from_pretrained`
+ output_image_processor_file = os.path.join(save_directory, IMAGE_PROCESSOR_NAME)
+
+ self.to_json_file(output_image_processor_file)
+ logger.info(f"Image processor saved in {output_image_processor_file}")
+
+ if push_to_hub:
+ self._upload_modified_files(
+ save_directory, repo_id, files_timestamps, commit_message=commit_message, token=token
+ )
+
+ return [output_image_processor_file]
+
+ @classmethod
+ def get_image_processor_dict(
+ cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs
+ ) -> Tuple[Dict[str, Any], Dict[str, Any]]:
+ """
+ From a `pretrained_model_name_or_path`, resolve to a dictionary of parameters, to be used for instantiating a
+ image processor of type [`~image_processor_utils.ImageProcessingMixin`] using `from_dict`.
+
+ Parameters:
+ pretrained_model_name_or_path (`str` or `os.PathLike`):
+ The identifier of the pre-trained checkpoint from which we want the dictionary of parameters.
+
+ Returns:
+ `Tuple[Dict, Dict]`: The dictionary(ies) that will be used to instantiate the image processor object.
+ """
+ cache_dir = kwargs.pop("cache_dir", None)
+ force_download = kwargs.pop("force_download", False)
+ resume_download = kwargs.pop("resume_download", False)
+ proxies = kwargs.pop("proxies", None)
+ use_auth_token = kwargs.pop("use_auth_token", None)
+ local_files_only = kwargs.pop("local_files_only", False)
+ revision = kwargs.pop("revision", None)
+
+ from_pipeline = kwargs.pop("_from_pipeline", None)
+ from_auto_class = kwargs.pop("_from_auto", False)
+
+ user_agent = {"file_type": "image processor", "from_auto_class": from_auto_class}
+ if from_pipeline is not None:
+ user_agent["using_pipeline"] = from_pipeline
+
+ if is_offline_mode() and not local_files_only:
+ logger.info("Offline mode: forcing local_files_only=True")
+ local_files_only = True
+
+ pretrained_model_name_or_path = str(pretrained_model_name_or_path)
+ is_local = os.path.isdir(pretrained_model_name_or_path)
+ if os.path.isdir(pretrained_model_name_or_path):
+ image_processor_file = os.path.join(pretrained_model_name_or_path, IMAGE_PROCESSOR_NAME)
+ if os.path.isfile(pretrained_model_name_or_path):
+ resolved_image_processor_file = pretrained_model_name_or_path
+ is_local = True
+ elif is_remote_url(pretrained_model_name_or_path):
+ image_processor_file = pretrained_model_name_or_path
+ resolved_image_processor_file = download_url(pretrained_model_name_or_path)
+ else:
+ image_processor_file = IMAGE_PROCESSOR_NAME
+ try:
+ # Load from local folder or from cache or download from model Hub and cache
+ resolved_image_processor_file = cached_file(
+ pretrained_model_name_or_path,
+ image_processor_file,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ proxies=proxies,
+ resume_download=resume_download,
+ local_files_only=local_files_only,
+ use_auth_token=use_auth_token,
+ user_agent=user_agent,
+ revision=revision,
+ )
+ except EnvironmentError:
+ # Raise any environment error raise by `cached_file`. It will have a helpful error message adapted to
+ # the original exception.
+ raise
+ except Exception:
+ # For any other exception, we throw a generic error.
+ raise EnvironmentError(
+ f"Can't load image processor for '{pretrained_model_name_or_path}'. If you were trying to load"
+ " it from 'https://huggingface.co/models', make sure you don't have a local directory with the"
+ f" same name. Otherwise, make sure '{pretrained_model_name_or_path}' is the correct path to a"
+ f" directory containing a {IMAGE_PROCESSOR_NAME} file"
+ )
+
+ try:
+ # Load image_processor dict
+ with open(resolved_image_processor_file, "r", encoding="utf-8") as reader:
+ text = reader.read()
+ image_processor_dict = json.loads(text)
+
+ except json.JSONDecodeError:
+ raise EnvironmentError(
+ f"It looks like the config file at '{resolved_image_processor_file}' is not a valid JSON file."
+ )
+
+ if is_local:
+ logger.info(f"loading configuration file {resolved_image_processor_file}")
+ else:
+ logger.info(
+ f"loading configuration file {image_processor_file} from cache at {resolved_image_processor_file}"
+ )
+
+ return image_processor_dict, kwargs
+
+ @classmethod
+ def from_dict(cls, image_processor_dict: Dict[str, Any], **kwargs):
+ """
+ Instantiates a type of [`~image_processing_utils.ImageProcessingMixin`] from a Python dictionary of parameters.
+
+ Args:
+ image_processor_dict (`Dict[str, Any]`):
+ Dictionary that will be used to instantiate the image processor object. Such a dictionary can be
+ retrieved from a pretrained checkpoint by leveraging the
+ [`~image_processing_utils.ImageProcessingMixin.to_dict`] method.
+ kwargs (`Dict[str, Any]`):
+ Additional parameters from which to initialize the image processor object.
+
+ Returns:
+ [`~image_processing_utils.ImageProcessingMixin`]: The image processor object instantiated from those
+ parameters.
+ """
+ return_unused_kwargs = kwargs.pop("return_unused_kwargs", False)
+
+ image_processor = cls(**image_processor_dict)
+
+ # Update image_processor with kwargs if needed
+ to_remove = []
+ for key, value in kwargs.items():
+ if hasattr(image_processor, key):
+ setattr(image_processor, key, value)
+ to_remove.append(key)
+ for key in to_remove:
+ kwargs.pop(key, None)
+
+ logger.info(f"Image processor {image_processor}")
+ if return_unused_kwargs:
+ return image_processor, kwargs
+ else:
+ return image_processor
+
+ def to_dict(self) -> Dict[str, Any]:
+ """
+ Serializes this instance to a Python dictionary.
+
+ Returns:
+ `Dict[str, Any]`: Dictionary of all the attributes that make up this image processor instance.
+ """
+ output = copy.deepcopy(self.__dict__)
+ output["image_processor_type"] = self.__class__.__name__
+
+ return output
+
+ @classmethod
+ def from_json_file(cls, json_file: Union[str, os.PathLike]):
+ """
+ Instantiates a image processor of type [`~image_processing_utils.ImageProcessingMixin`] from the path to a JSON
+ file of parameters.
+
+ Args:
+ json_file (`str` or `os.PathLike`):
+ Path to the JSON file containing the parameters.
+
+ Returns:
+ A image processor of type [`~image_processing_utils.ImageProcessingMixin`]: The image_processor object
+ instantiated from that JSON file.
+ """
+ with open(json_file, "r", encoding="utf-8") as reader:
+ text = reader.read()
+ image_processor_dict = json.loads(text)
+ return cls(**image_processor_dict)
+
+ def to_json_string(self) -> str:
+ """
+ Serializes this instance to a JSON string.
+
+ Returns:
+ `str`: String containing all the attributes that make up this feature_extractor instance in JSON format.
+ """
+ dictionary = self.to_dict()
+
+ for key, value in dictionary.items():
+ if isinstance(value, np.ndarray):
+ dictionary[key] = value.tolist()
+
+ # make sure private name "_processor_class" is correctly
+ # saved as "processor_class"
+ _processor_class = dictionary.pop("_processor_class", None)
+ if _processor_class is not None:
+ dictionary["processor_class"] = _processor_class
+
+ return json.dumps(dictionary, indent=2, sort_keys=True) + "\n"
+
+ def to_json_file(self, json_file_path: Union[str, os.PathLike]):
+ """
+ Save this instance to a JSON file.
+
+ Args:
+ json_file_path (`str` or `os.PathLike`):
+ Path to the JSON file in which this image_processor instance's parameters will be saved.
+ """
+ with open(json_file_path, "w", encoding="utf-8") as writer:
+ writer.write(self.to_json_string())
+
+ def __repr__(self):
+ return f"{self.__class__.__name__} {self.to_json_string()}"
+
+ @classmethod
+ def register_for_auto_class(cls, auto_class="AutoImageProcessor"):
+ """
+ Register this class with a given auto class. This should only be used for custom image processors as the ones
+ in the library are already mapped with `AutoImageProcessor `.
+
+
+
+ This API is experimental and may have some slight breaking changes in the next releases.
+
+
+
+ Args:
+ auto_class (`str` or `type`, *optional*, defaults to `"AutoImageProcessor "`):
+ The auto class to register this new image processor with.
+ """
+ if not isinstance(auto_class, str):
+ auto_class = auto_class.__name__
+
+ import transformers.models.auto as auto_module
+
+ if not hasattr(auto_module, auto_class):
+ raise ValueError(f"{auto_class} is not a valid auto class.")
+
+ cls._auto_class = auto_class
+
+
+class BaseImageProcessor(ImageProcessingMixin):
def __init__(self, **kwargs):
super().__init__(**kwargs)
@@ -65,7 +448,7 @@ def get_size_dict(
) -> dict:
"""
Converts the old size parameter in the config into the new dict expected in the config. This is to ensure backwards
- compatibility with the old feature extractor configs and removes ambiguity over whether the tuple is in (height,
+ compatibility with the old image processor configs and removes ambiguity over whether the tuple is in (height,
width) or (width, height) format.
- If `size` is tuple, it is converted to `{"height": size[0], "width": size[1]}` or `{"height": size[1], "width":
@@ -119,3 +502,9 @@ def get_size_dict(
f" or ('shortest_edge',) got {size}. Setting as {size_dict}.",
)
return size_dict
+
+
+ImageProcessingMixin.push_to_hub = copy_func(ImageProcessingMixin.push_to_hub)
+ImageProcessingMixin.push_to_hub.__doc__ = ImageProcessingMixin.push_to_hub.__doc__.format(
+ object="image processor", object_class="AutoImageProcessor", object_files="image processor file"
+)
diff --git a/src/transformers/models/auto/__init__.py b/src/transformers/models/auto/__init__.py
index acb0fa8b0f..a1a1356eb0 100644
--- a/src/transformers/models/auto/__init__.py
+++ b/src/transformers/models/auto/__init__.py
@@ -31,6 +31,7 @@ _import_structure = {
"auto_factory": ["get_values"],
"configuration_auto": ["ALL_PRETRAINED_CONFIG_ARCHIVE_MAP", "CONFIG_MAPPING", "MODEL_NAMES_MAPPING", "AutoConfig"],
"feature_extraction_auto": ["FEATURE_EXTRACTOR_MAPPING", "AutoFeatureExtractor"],
+ "image_processing_auto": ["IMAGE_PROCESSOR_MAPPING", "AutoImageProcessor"],
"processing_auto": ["PROCESSOR_MAPPING", "AutoProcessor"],
"tokenization_auto": ["TOKENIZER_MAPPING", "AutoTokenizer"],
}
@@ -184,6 +185,7 @@ if TYPE_CHECKING:
from .auto_factory import get_values
from .configuration_auto import ALL_PRETRAINED_CONFIG_ARCHIVE_MAP, CONFIG_MAPPING, MODEL_NAMES_MAPPING, AutoConfig
from .feature_extraction_auto import FEATURE_EXTRACTOR_MAPPING, AutoFeatureExtractor
+ from .image_processing_auto import IMAGE_PROCESSOR_MAPPING, AutoImageProcessor
from .processing_auto import PROCESSOR_MAPPING, AutoProcessor
from .tokenization_auto import TOKENIZER_MAPPING, AutoTokenizer
diff --git a/src/transformers/models/auto/image_processing_auto.py b/src/transformers/models/auto/image_processing_auto.py
new file mode 100644
index 0000000000..776be93136
--- /dev/null
+++ b/src/transformers/models/auto/image_processing_auto.py
@@ -0,0 +1,358 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" AutoImageProcessor class."""
+import importlib
+import json
+import os
+from collections import OrderedDict
+from typing import Dict, Optional, Union
+
+# Build the list of all image processors
+from ...configuration_utils import PretrainedConfig
+from ...dynamic_module_utils import get_class_from_dynamic_module
+from ...image_processing_utils import ImageProcessingMixin
+from ...utils import CONFIG_NAME, IMAGE_PROCESSOR_NAME, get_file_from_repo, logging
+from .auto_factory import _LazyAutoMapping
+from .configuration_auto import (
+ CONFIG_MAPPING_NAMES,
+ AutoConfig,
+ model_type_to_module_name,
+ replace_list_option_in_docstrings,
+)
+
+
+logger = logging.get_logger(__name__)
+
+IMAGE_PROCESSOR_MAPPING_NAMES = OrderedDict(
+ [
+ ("beit", "BeitImageProcessor"),
+ ("clip", "CLIPImageProcessor"),
+ ("convnext", "ConvNextImageProcessor"),
+ ("cvt", "ConvNextImageProcessor"),
+ ("data2vec-vision", "BeitImageProcessor"),
+ ("deit", "DeiTImageProcessor"),
+ ("dpt", "DPTImageProcessor"),
+ ("flava", "FlavaImageProcessor"),
+ ("glpn", "GLPNImageProcessor"),
+ ("groupvit", "CLIPImageProcessor"),
+ ("imagegpt", "ImageGPTImageProcessor"),
+ ("layoutlmv2", "LayoutLMv2ImageProcessor"),
+ ("layoutlmv3", "LayoutLMv3ImageProcessor"),
+ ("levit", "LevitImageProcessor"),
+ ("mobilevit", "MobileViTImageProcessor"),
+ ("perceiver", "PerceiverImageProcessor"),
+ ("poolformer", "PoolFormerImageProcessor"),
+ ("regnet", "ConvNextImageProcessor"),
+ ("resnet", "ConvNextImageProcessor"),
+ ("segformer", "SegformerImageProcessor"),
+ ("swin", "ViTImageProcessor"),
+ ("swinv2", "ViTImageProcessor"),
+ ("van", "ConvNextImageProcessor"),
+ ("videomae", "VideoMAEImageProcessor"),
+ ("vilt", "ViltImageProcessor"),
+ ("vit", "ViTImageProcessor"),
+ ("vit_mae", "ViTImageProcessor"),
+ ("vit_msn", "ViTImageProcessor"),
+ ("xclip", "CLIPImageProcessor"),
+ ]
+)
+
+IMAGE_PROCESSOR_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, IMAGE_PROCESSOR_MAPPING_NAMES)
+
+
+def image_processor_class_from_name(class_name: str):
+ for module_name, extractors in IMAGE_PROCESSOR_MAPPING_NAMES.items():
+ if class_name in extractors:
+ module_name = model_type_to_module_name(module_name)
+
+ module = importlib.import_module(f".{module_name}", "transformers.models")
+ try:
+ return getattr(module, class_name)
+ except AttributeError:
+ continue
+
+ for _, extractor in IMAGE_PROCESSOR_MAPPING._extra_content.items():
+ if getattr(extractor, "__name__", None) == class_name:
+ return extractor
+
+ # We did not fine the class, but maybe it's because a dep is missing. In that case, the class will be in the main
+ # init and we return the proper dummy to get an appropriate error message.
+ main_module = importlib.import_module("transformers")
+ if hasattr(main_module, class_name):
+ return getattr(main_module, class_name)
+
+ return None
+
+
+def get_image_processor_config(
+ pretrained_model_name_or_path: Union[str, os.PathLike],
+ cache_dir: Optional[Union[str, os.PathLike]] = None,
+ force_download: bool = False,
+ resume_download: bool = False,
+ proxies: Optional[Dict[str, str]] = None,
+ use_auth_token: Optional[Union[bool, str]] = None,
+ revision: Optional[str] = None,
+ local_files_only: bool = False,
+ **kwargs,
+):
+ """
+ Loads the image processor configuration from a pretrained model imag processor configuration. # FIXME
+
+ Args:
+ pretrained_model_name_or_path (`str` or `os.PathLike`):
+ This can be either:
+
+ - a string, the *model id* of a pretrained model configuration hosted inside a model repo on
+ huggingface.co. Valid model ids can be located at the root-level, like `bert-base-uncased`, or namespaced
+ under a user or organization name, like `dbmdz/bert-base-german-cased`.
+ - a path to a *directory* containing a configuration file saved using the
+ [`~PreTrainedTokenizer.save_pretrained`] method, e.g., `./my_model_directory/`.
+
+ cache_dir (`str` or `os.PathLike`, *optional*):
+ Path to a directory in which a downloaded pretrained model configuration should be cached if the standard
+ cache should not be used.
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force to (re-)download the configuration files and override the cached versions if they
+ exist.
+ resume_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to delete incompletely received file. Attempts to resume the download if such a file exists.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}.` The proxies are used on each request.
+ use_auth_token (`str` or *bool*, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
+ when running `huggingface-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+ local_files_only (`bool`, *optional*, defaults to `False`):
+ If `True`, will only try to load the image processor configuration from local files.
+
+
+
+ Passing `use_auth_token=True` is required when you want to use a private model.
+
+
+
+ Returns:
+ `Dict`: The configuration of the image processor.
+
+ Examples:
+
+ ```python
+ # Download configuration from huggingface.co and cache.
+ image_processor_config = get_image_processor_config("bert-base-uncased")
+ # This model does not have a image processor config so the result will be an empty dict.
+ image_processor_config = get_image_processor_config("xlm-roberta-base")
+
+ # Save a pretrained image processor locally and you can reload its config
+ from transformers import AutoTokenizer
+
+ image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
+ image_processor.save_pretrained("image-processor-test")
+ image_processor_config = get_image_processor_config("image-processor-test")
+ ```"""
+ resolved_config_file = get_file_from_repo(
+ pretrained_model_name_or_path,
+ IMAGE_PROCESSOR_NAME,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ resume_download=resume_download,
+ proxies=proxies,
+ use_auth_token=use_auth_token,
+ revision=revision,
+ local_files_only=local_files_only,
+ )
+ if resolved_config_file is None:
+ logger.info(
+ "Could not locate the image processor configuration file, will try to use the model config instead."
+ )
+ return {}
+
+ with open(resolved_config_file, encoding="utf-8") as reader:
+ return json.load(reader)
+
+
+class AutoImageProcessor:
+ r"""
+ This is a generic image processor class that will be instantiated as one of the image processor classes of the
+ library when created with the [`AutoImageProcessor.from_pretrained`] class method.
+
+ This class cannot be instantiated directly using `__init__()` (throws an error).
+ """
+
+ def __init__(self):
+ raise EnvironmentError(
+ "AutoImageProcessor is designed to be instantiated "
+ "using the `AutoImageProcessor.from_pretrained(pretrained_model_name_or_path)` method."
+ )
+
+ @classmethod
+ @replace_list_option_in_docstrings(IMAGE_PROCESSOR_MAPPING_NAMES)
+ def from_pretrained(cls, pretrained_model_name_or_path, **kwargs):
+ r"""
+ Instantiate one of the image processor classes of the library from a pretrained model vocabulary.
+
+ The image processor class to instantiate is selected based on the `model_type` property of the config object
+ (either passed as an argument or loaded from `pretrained_model_name_or_path` if possible), or when it's
+ missing, by falling back to using pattern matching on `pretrained_model_name_or_path`:
+
+ List options
+
+ Params:
+ pretrained_model_name_or_path (`str` or `os.PathLike`):
+ This can be either:
+
+ - a string, the *model id* of a pretrained image_processor hosted inside a model repo on
+ huggingface.co. Valid model ids can be located at the root-level, like `bert-base-uncased`, or
+ namespaced under a user or organization name, like `dbmdz/bert-base-german-cased`.
+ - a path to a *directory* containing a image processor file saved using the
+ [`~image_processing_utils.ImageProcessingMixin.save_pretrained`] method, e.g.,
+ `./my_model_directory/`.
+ - a path or url to a saved image processor JSON *file*, e.g.,
+ `./my_model_directory/preprocessor_config.json`.
+ cache_dir (`str` or `os.PathLike`, *optional*):
+ Path to a directory in which a downloaded pretrained model image processor should be cached if the
+ standard cache should not be used.
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force to (re-)download the image processor files and override the cached versions if
+ they exist.
+ resume_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to delete incompletely received file. Attempts to resume the download if such a file
+ exists.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}.` The proxies are used on each request.
+ use_auth_token (`str` or *bool*, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
+ when running `huggingface-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+ return_unused_kwargs (`bool`, *optional*, defaults to `False`):
+ If `False`, then this function returns just the final image processor object. If `True`, then this
+ functions returns a `Tuple(image_processor, unused_kwargs)` where *unused_kwargs* is a dictionary
+ consisting of the key/value pairs whose keys are not image processor attributes: i.e., the part of
+ `kwargs` which has not been used to update `image_processor` and is otherwise ignored.
+ trust_remote_code (`bool`, *optional*, defaults to `False`):
+ Whether or not to allow for custom models defined on the Hub in their own modeling files. This option
+ should only be set to `True` for repositories you trust and in which you have read the code, as it will
+ execute code present on the Hub on your local machine.
+ kwargs (`Dict[str, Any]`, *optional*):
+ The values in kwargs of any keys which are image processor attributes will be used to override the
+ loaded values. Behavior concerning key/value pairs whose keys are *not* image processor attributes is
+ controlled by the `return_unused_kwargs` keyword parameter.
+
+
+
+ Passing `use_auth_token=True` is required when you want to use a private model.
+
+
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoImageProcessor
+
+ >>> # Download image processor from huggingface.co and cache.
+ >>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
+
+ >>> # If image processor files are in a directory (e.g. image processor was saved using *save_pretrained('./test/saved_model/')*)
+ >>> image_processor = AutoImageProcessor.from_pretrained("./test/saved_model/")
+ ```"""
+ config = kwargs.pop("config", None)
+ trust_remote_code = kwargs.pop("trust_remote_code", False)
+ kwargs["_from_auto"] = True
+
+ config_dict, _ = ImageProcessingMixin.get_image_processor_dict(pretrained_model_name_or_path, **kwargs)
+ image_processor_class = config_dict.get("image_processor_type", None)
+ image_processor_auto_map = None
+ if "AutoImageProcessor" in config_dict.get("auto_map", {}):
+ image_processor_auto_map = config_dict["auto_map"]["AutoImageProcessor"]
+
+ # If we still don't have the image processor class, check if we're loading from a previous feature extractor config
+ # and if so, infer the image processor class from there.
+ if image_processor_class is None and image_processor_auto_map is None:
+ feature_extractor_class = config_dict.pop("feature_extractor_type", None)
+ if feature_extractor_class is not None:
+ logger.warning(
+ "Could not find image processor class in the image processor config or the model config. Loading"
+ " based on pattern matching with the model's feature extractor configuration."
+ )
+ image_processor_class = feature_extractor_class.replace("FeatureExtractor", "ImageProcessor")
+ if "AutoFeatureExtractor" in config_dict.get("auto_map", {}):
+ feature_extractor_auto_map = config_dict["auto_map"]["AutoFeatureExtractor"]
+ image_processor_auto_map = feature_extractor_auto_map.replace("FeatureExtractor", "ImageProcessor")
+ logger.warning(
+ "Could not find image processor auto map in the image processor config or the model config."
+ " Loading based on pattern matching with the model's feature extractor configuration."
+ )
+
+ # If we don't find the image processor class in the image processor config, let's try the model config.
+ if image_processor_class is None and image_processor_auto_map is None:
+ if not isinstance(config, PretrainedConfig):
+ config = AutoConfig.from_pretrained(pretrained_model_name_or_path, **kwargs)
+ # It could be in `config.image_processor_type``
+ image_processor_class = getattr(config, "image_processor_type", None)
+ if hasattr(config, "auto_map") and "AutoImageProcessor" in config.auto_map:
+ image_processor_auto_map = config.auto_map["AutoImageProcessor"]
+
+ if image_processor_class is not None:
+ # If we have custom code for a image processor, we get the proper class.
+ if image_processor_auto_map is not None:
+ if not trust_remote_code:
+ raise ValueError(
+ f"Loading {pretrained_model_name_or_path} requires you to execute the image processor file "
+ "in that repo on your local machine. Make sure you have read the code there to avoid "
+ "malicious use, then set the option `trust_remote_code=True` to remove this error."
+ )
+ if kwargs.get("revision", None) is None:
+ logger.warning(
+ "Explicitly passing a `revision` is encouraged when loading a image processor with custom "
+ "code to ensure no malicious code has been contributed in a newer revision."
+ )
+
+ module_file, class_name = image_processor_auto_map.split(".")
+ image_processor_class = get_class_from_dynamic_module(
+ pretrained_model_name_or_path, module_file + ".py", class_name, **kwargs
+ )
+ else:
+ image_processor_class = image_processor_class_from_name(image_processor_class)
+
+ return image_processor_class.from_dict(config_dict, **kwargs)
+ # Last try: we use the IMAGE_PROCESSOR_MAPPING.
+ elif type(config) in IMAGE_PROCESSOR_MAPPING:
+ image_processor_class = IMAGE_PROCESSOR_MAPPING[type(config)]
+ return image_processor_class.from_dict(config_dict, **kwargs)
+
+ raise ValueError(
+ f"Unrecognized image processor in {pretrained_model_name_or_path}. Should have a "
+ f"`image_processor_type` key in its {IMAGE_PROCESSOR_NAME} of {CONFIG_NAME}, or one of the following "
+ f"`model_type` keys in its {CONFIG_NAME}: {', '.join(c for c in IMAGE_PROCESSOR_MAPPING_NAMES.keys())}"
+ )
+
+ @staticmethod
+ def register(config_class, image_processor_class):
+ """
+ Register a new image processor for this class.
+
+ Args:
+ config_class ([`PretrainedConfig`]):
+ The configuration corresponding to the model to register.
+ image_processor_class ([`ImageProcessingMixin`]): The image processor to register.
+ """
+ IMAGE_PROCESSOR_MAPPING.register(config_class, image_processor_class)
diff --git a/src/transformers/models/auto/processing_auto.py b/src/transformers/models/auto/processing_auto.py
index f7bb87e25e..06d44ab33e 100644
--- a/src/transformers/models/auto/processing_auto.py
+++ b/src/transformers/models/auto/processing_auto.py
@@ -22,6 +22,7 @@ from collections import OrderedDict
from ...configuration_utils import PretrainedConfig
from ...dynamic_module_utils import get_class_from_dynamic_module
from ...feature_extraction_utils import FeatureExtractionMixin
+from ...image_processing_utils import ImageProcessingMixin
from ...tokenization_utils import TOKENIZER_CONFIG_FILE
from ...utils import FEATURE_EXTRACTOR_NAME, get_file_from_repo, logging
from .auto_factory import _LazyAutoMapping
@@ -32,6 +33,7 @@ from .configuration_auto import (
replace_list_option_in_docstrings,
)
from .feature_extraction_auto import AutoFeatureExtractor
+from .image_processing_auto import AutoImageProcessor
from .tokenization_auto import AutoTokenizer
@@ -189,11 +191,18 @@ class AutoProcessor:
get_file_from_repo_kwargs = {
key: kwargs[key] for key in inspect.signature(get_file_from_repo).parameters.keys() if key in kwargs
}
- # Let's start by checking whether the processor class is saved in a feature extractor
+ # Let's start by checking whether the processor class is saved in an image processor
preprocessor_config_file = get_file_from_repo(
pretrained_model_name_or_path, FEATURE_EXTRACTOR_NAME, **get_file_from_repo_kwargs
)
if preprocessor_config_file is not None:
+ config_dict, _ = ImageProcessingMixin.get_image_processor_dict(pretrained_model_name_or_path, **kwargs)
+ processor_class = config_dict.get("processor_class", None)
+ if "AutoProcessor" in config_dict.get("auto_map", {}):
+ processor_auto_map = config_dict["auto_map"]["AutoProcessor"]
+
+ # If not found, let's check whether the processor class is saved in a feature extractor config
+ if preprocessor_config_file is not None and processor_class is None:
config_dict, _ = FeatureExtractionMixin.get_feature_extractor_dict(pretrained_model_name_or_path, **kwargs)
processor_class = config_dict.get("processor_class", None)
if "AutoProcessor" in config_dict.get("auto_map", {}):
@@ -261,6 +270,13 @@ class AutoProcessor:
pretrained_model_name_or_path, trust_remote_code=trust_remote_code, **kwargs
)
except Exception:
+ try:
+ return AutoImageProcessor.from_pretrained(
+ pretrained_model_name_or_path, trust_remote_code=trust_remote_code, **kwargs
+ )
+ except Exception:
+ pass
+
try:
return AutoFeatureExtractor.from_pretrained(
pretrained_model_name_or_path, trust_remote_code=trust_remote_code, **kwargs
diff --git a/src/transformers/models/beit/__init__.py b/src/transformers/models/beit/__init__.py
index 40818fff90..9f625fe54d 100644
--- a/src/transformers/models/beit/__init__.py
+++ b/src/transformers/models/beit/__init__.py
@@ -36,6 +36,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_beit"] = ["BeitFeatureExtractor"]
+ _import_structure["image_processing_beit"] = ["BeitImageProcessor"]
try:
if not is_torch_available():
@@ -76,6 +77,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_beit import BeitFeatureExtractor
+ from .image_processing_beit import BeitImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/models/clip/__init__.py b/src/transformers/models/clip/__init__.py
index 637d78b0da..e9bfd63844 100644
--- a/src/transformers/models/clip/__init__.py
+++ b/src/transformers/models/clip/__init__.py
@@ -55,6 +55,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_clip"] = ["CLIPFeatureExtractor"]
+ _import_structure["image_processing_clip"] = ["CLIPImageProcessor"]
try:
if not is_torch_available():
@@ -126,6 +127,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_clip import CLIPFeatureExtractor
+ from .image_processing_clip import CLIPImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/models/convnext/__init__.py b/src/transformers/models/convnext/__init__.py
index 93000d5c66..109f79daea 100644
--- a/src/transformers/models/convnext/__init__.py
+++ b/src/transformers/models/convnext/__init__.py
@@ -38,6 +38,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_convnext"] = ["ConvNextFeatureExtractor"]
+ _import_structure["image_processing_convnext"] = ["ConvNextImageProcessor"]
try:
if not is_torch_available():
@@ -74,6 +75,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_convnext import ConvNextFeatureExtractor
+ from .image_processing_convnext import ConvNextImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/models/deit/__init__.py b/src/transformers/models/deit/__init__.py
index 78e3bda84e..c9932c26e2 100644
--- a/src/transformers/models/deit/__init__.py
+++ b/src/transformers/models/deit/__init__.py
@@ -35,6 +35,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_deit"] = ["DeiTFeatureExtractor"]
+ _import_structure["image_processing_deit"] = ["DeiTImageProcessor"]
try:
if not is_torch_available():
@@ -77,6 +78,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_deit import DeiTFeatureExtractor
+ from .image_processing_deit import DeiTImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/models/dpt/__init__.py b/src/transformers/models/dpt/__init__.py
index 1df82ab628..b1467adb0b 100644
--- a/src/transformers/models/dpt/__init__.py
+++ b/src/transformers/models/dpt/__init__.py
@@ -30,6 +30,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_dpt"] = ["DPTFeatureExtractor"]
+ _import_structure["image_processing_dpt"] = ["DPTImageProcessor"]
try:
if not is_torch_available():
@@ -56,6 +57,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_dpt import DPTFeatureExtractor
+ from .image_processing_dpt import DPTImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/models/flava/__init__.py b/src/transformers/models/flava/__init__.py
index 29d8240032..356504bf4f 100644
--- a/src/transformers/models/flava/__init__.py
+++ b/src/transformers/models/flava/__init__.py
@@ -38,6 +38,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_flava"] = ["FlavaFeatureExtractor"]
+ _import_structure["image_processing_flava"] = ["FlavaImageProcessor"]
_import_structure["processing_flava"] = ["FlavaProcessor"]
try:
@@ -74,6 +75,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_flava import FlavaFeatureExtractor
+ from .image_processing_flava import FlavaImageProcessor
from .processing_flava import FlavaProcessor
try:
diff --git a/src/transformers/models/glpn/__init__.py b/src/transformers/models/glpn/__init__.py
index aa667afff6..f16ee4a5a6 100644
--- a/src/transformers/models/glpn/__init__.py
+++ b/src/transformers/models/glpn/__init__.py
@@ -30,6 +30,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_glpn"] = ["GLPNFeatureExtractor"]
+ _import_structure["image_processing_glpn"] = ["GLPNImageProcessor"]
try:
if not is_torch_available():
@@ -56,6 +57,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_glpn import GLPNFeatureExtractor
+ from .image_processing_glpn import GLPNImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/models/imagegpt/__init__.py b/src/transformers/models/imagegpt/__init__.py
index c2189a3ce1..8a7ed9669d 100644
--- a/src/transformers/models/imagegpt/__init__.py
+++ b/src/transformers/models/imagegpt/__init__.py
@@ -32,6 +32,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_imagegpt"] = ["ImageGPTFeatureExtractor"]
+ _import_structure["image_processing_imagegpt"] = ["ImageGPTImageProcessor"]
try:
if not is_torch_available():
@@ -59,6 +60,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_imagegpt import ImageGPTFeatureExtractor
+ from .image_processing_imagegpt import ImageGPTImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/models/layoutlmv2/__init__.py b/src/transformers/models/layoutlmv2/__init__.py
index beaacb8158..5da6a96142 100644
--- a/src/transformers/models/layoutlmv2/__init__.py
+++ b/src/transformers/models/layoutlmv2/__init__.py
@@ -48,6 +48,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_layoutlmv2"] = ["LayoutLMv2FeatureExtractor"]
+ _import_structure["image_processing_layoutlmv2"] = ["LayoutLMv2ImageProcessor"]
try:
if not is_torch_available():
@@ -84,7 +85,7 @@ if TYPE_CHECKING:
except OptionalDependencyNotAvailable:
pass
else:
- from .feature_extraction_layoutlmv2 import LayoutLMv2FeatureExtractor
+ from .feature_extraction_layoutlmv2 import LayoutLMv2FeatureExtractor, LayoutLMv2ImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/models/layoutlmv3/__init__.py b/src/transformers/models/layoutlmv3/__init__.py
index 68a07362dc..927a940676 100644
--- a/src/transformers/models/layoutlmv3/__init__.py
+++ b/src/transformers/models/layoutlmv3/__init__.py
@@ -83,6 +83,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_layoutlmv3"] = ["LayoutLMv3FeatureExtractor"]
+ _import_structure["image_processing_layoutlmv3"] = ["LayoutLMv3ImageProcessor"]
if TYPE_CHECKING:
@@ -139,6 +140,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_layoutlmv3 import LayoutLMv3FeatureExtractor
+ from .image_processing_layoutlmv3 import LayoutLMv3ImageProcessor
else:
import sys
diff --git a/src/transformers/models/levit/__init__.py b/src/transformers/models/levit/__init__.py
index ea848f12a2..f42fb02ad0 100644
--- a/src/transformers/models/levit/__init__.py
+++ b/src/transformers/models/levit/__init__.py
@@ -29,6 +29,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_levit"] = ["LevitFeatureExtractor"]
+ _import_structure["image_processing_levit"] = ["LevitImageProcessor"]
try:
if not is_torch_available():
@@ -55,6 +56,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_levit import LevitFeatureExtractor
+ from .image_processing_levit import LevitImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/models/mobilevit/__init__.py b/src/transformers/models/mobilevit/__init__.py
index e1e088f693..d0d8962b4e 100644
--- a/src/transformers/models/mobilevit/__init__.py
+++ b/src/transformers/models/mobilevit/__init__.py
@@ -37,6 +37,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_mobilevit"] = ["MobileViTFeatureExtractor"]
+ _import_structure["image_processing_mobilevit"] = ["MobileViTImageProcessor"]
try:
if not is_torch_available():
@@ -76,6 +77,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_mobilevit import MobileViTFeatureExtractor
+ from .image_processing_mobilevit import MobileViTImageProcessor
try:
if not is_torch_available():
@@ -91,14 +93,6 @@ if TYPE_CHECKING:
MobileViTPreTrainedModel,
)
- try:
- if not is_vision_available():
- raise OptionalDependencyNotAvailable()
- except OptionalDependencyNotAvailable:
- pass
- else:
- from .feature_extraction_mobilevit import MobileViTFeatureExtractor
-
try:
if not is_tf_available():
raise OptionalDependencyNotAvailable()
diff --git a/src/transformers/models/perceiver/__init__.py b/src/transformers/models/perceiver/__init__.py
index 107c62f2eb..120d4a36fb 100644
--- a/src/transformers/models/perceiver/__init__.py
+++ b/src/transformers/models/perceiver/__init__.py
@@ -38,6 +38,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_perceiver"] = ["PerceiverFeatureExtractor"]
+ _import_structure["image_processing_perceiver"] = ["PerceiverImageProcessor"]
try:
if not is_torch_available():
@@ -71,6 +72,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_perceiver import PerceiverFeatureExtractor
+ from .image_processing_perceiver import PerceiverImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/models/poolformer/__init__.py b/src/transformers/models/poolformer/__init__.py
index 7cb5e4acac..947ac753fb 100644
--- a/src/transformers/models/poolformer/__init__.py
+++ b/src/transformers/models/poolformer/__init__.py
@@ -30,6 +30,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_poolformer"] = ["PoolFormerFeatureExtractor"]
+ _import_structure["image_processing_poolformer"] = ["PoolFormerImageProcessor"]
try:
if not is_torch_available():
@@ -55,6 +56,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_poolformer import PoolFormerFeatureExtractor
+ from .image_processing_poolformer import PoolFormerImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/models/segformer/__init__.py b/src/transformers/models/segformer/__init__.py
index 7b8b60651d..0d0aeb80ca 100644
--- a/src/transformers/models/segformer/__init__.py
+++ b/src/transformers/models/segformer/__init__.py
@@ -37,6 +37,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_segformer"] = ["SegformerFeatureExtractor"]
+ _import_structure["image_processing_segformer"] = ["SegformerImageProcessor"]
try:
if not is_torch_available():
@@ -80,6 +81,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_segformer import SegformerFeatureExtractor
+ from .image_processing_segformer import SegformerImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/models/videomae/__init__.py b/src/transformers/models/videomae/__init__.py
index fb239c6063..a363004406 100644
--- a/src/transformers/models/videomae/__init__.py
+++ b/src/transformers/models/videomae/__init__.py
@@ -45,6 +45,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_videomae"] = ["VideoMAEFeatureExtractor"]
+ _import_structure["image_processing_videomae"] = ["VideoMAEImageProcessor"]
if TYPE_CHECKING:
from .configuration_videomae import VIDEOMAE_PRETRAINED_CONFIG_ARCHIVE_MAP, VideoMAEConfig
@@ -70,6 +71,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_videomae import VideoMAEFeatureExtractor
+ from .image_processing_videomae import VideoMAEImageProcessor
else:
import sys
diff --git a/src/transformers/models/vilt/__init__.py b/src/transformers/models/vilt/__init__.py
index d05318202b..436a3a56d7 100644
--- a/src/transformers/models/vilt/__init__.py
+++ b/src/transformers/models/vilt/__init__.py
@@ -30,6 +30,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_vilt"] = ["ViltFeatureExtractor"]
+ _import_structure["image_processing_vilt"] = ["ViltImageProcessor"]
_import_structure["processing_vilt"] = ["ViltProcessor"]
try:
@@ -61,6 +62,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_vilt import ViltFeatureExtractor
+ from .image_processing_vilt import ViltImageProcessor
from .processing_vilt import ViltProcessor
try:
diff --git a/src/transformers/models/vit/__init__.py b/src/transformers/models/vit/__init__.py
index b30a9ec15d..cda977d617 100644
--- a/src/transformers/models/vit/__init__.py
+++ b/src/transformers/models/vit/__init__.py
@@ -36,6 +36,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_vit"] = ["ViTFeatureExtractor"]
+ _import_structure["image_processing_vit"] = ["ViTImageProcessor"]
try:
if not is_torch_available():
@@ -85,6 +86,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_vit import ViTFeatureExtractor
+ from .image_processing_vit import ViTImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/utils/dummy_vision_objects.py b/src/transformers/utils/dummy_vision_objects.py
index a3112c4454..829d704086 100644
--- a/src/transformers/utils/dummy_vision_objects.py
+++ b/src/transformers/utils/dummy_vision_objects.py
@@ -3,7 +3,7 @@
from ..utils import DummyObject, requires_backends
-class ImageProcessorMixin(metaclass=DummyObject):
+class ImageProcessingMixin(metaclass=DummyObject):
_backends = ["vision"]
def __init__(self, *args, **kwargs):
@@ -36,6 +36,13 @@ class BeitFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class BeitImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class CLIPFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -43,6 +50,13 @@ class CLIPFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class CLIPImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class ConditionalDetrFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -57,6 +71,13 @@ class ConvNextFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class ConvNextImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class DeformableDetrFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -71,6 +92,13 @@ class DeiTFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class DeiTImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class DetrFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -92,6 +120,13 @@ class DPTFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class DPTImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class FlavaFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -99,6 +134,13 @@ class FlavaFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class FlavaImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class FlavaProcessor(metaclass=DummyObject):
_backends = ["vision"]
@@ -113,6 +155,13 @@ class GLPNFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class GLPNImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class ImageGPTFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -120,6 +169,13 @@ class ImageGPTFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class ImageGPTImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class LayoutLMv2FeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -127,6 +183,13 @@ class LayoutLMv2FeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class LayoutLMv2ImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class LayoutLMv3FeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -134,6 +197,13 @@ class LayoutLMv3FeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class LayoutLMv3ImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class LevitFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -141,6 +211,13 @@ class LevitFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class LevitImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class MaskFormerFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -155,6 +232,13 @@ class MobileViTFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class MobileViTImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class OwlViTFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -169,6 +253,13 @@ class PerceiverFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class PerceiverImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class PoolFormerFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -176,6 +267,13 @@ class PoolFormerFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class PoolFormerImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class SegformerFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -183,6 +281,13 @@ class SegformerFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class SegformerImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class VideoMAEFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -190,6 +295,13 @@ class VideoMAEFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class VideoMAEImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class ViltFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -197,6 +309,13 @@ class ViltFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class ViltImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class ViltProcessor(metaclass=DummyObject):
_backends = ["vision"]
@@ -211,6 +330,13 @@ class ViTFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class ViTImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class YolosFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
diff --git a/tests/models/auto/test_image_processing_auto.py b/tests/models/auto/test_image_processing_auto.py
new file mode 100644
index 0000000000..3d2009d5c8
--- /dev/null
+++ b/tests/models/auto/test_image_processing_auto.py
@@ -0,0 +1,167 @@
+# coding=utf-8
+# Copyright 2021 the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import json
+import sys
+import tempfile
+import unittest
+from pathlib import Path
+
+from transformers import (
+ CONFIG_MAPPING,
+ IMAGE_PROCESSOR_MAPPING,
+ AutoConfig,
+ AutoImageProcessor,
+ CLIPConfig,
+ CLIPImageProcessor,
+)
+from transformers.testing_utils import DUMMY_UNKNOWN_IDENTIFIER
+
+
+sys.path.append(str(Path(__file__).parent.parent.parent.parent / "utils"))
+
+from test_module.custom_configuration import CustomConfig # noqa E402
+from test_module.custom_image_processing import CustomImageProcessor # noqa E402
+
+
+class AutoImageProcessorTest(unittest.TestCase):
+ def test_image_processor_from_model_shortcut(self):
+ config = AutoImageProcessor.from_pretrained("openai/clip-vit-base-patch32")
+ self.assertIsInstance(config, CLIPImageProcessor)
+
+ def test_image_processor_from_local_directory_from_key(self):
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ processor_tmpfile = Path(tmpdirname) / "preprocessor_config.json"
+ config_tmpfile = Path(tmpdirname) / "config.json"
+ json.dump(
+ {"image_processor_type": "CLIPImageProcessor", "processor_class": "CLIPProcessor"},
+ open(processor_tmpfile, "w"),
+ )
+ json.dump({"model_type": "clip"}, open(config_tmpfile, "w"))
+
+ config = AutoImageProcessor.from_pretrained(tmpdirname)
+ self.assertIsInstance(config, CLIPImageProcessor)
+
+ def test_image_processor_from_local_directory_from_feature_extractor_key(self):
+ # Ensure we can load the image processor from the feature extractor config
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ processor_tmpfile = Path(tmpdirname) / "preprocessor_config.json"
+ config_tmpfile = Path(tmpdirname) / "config.json"
+ json.dump(
+ {"feature_extractor_type": "CLIPFeatureExtractor", "processor_class": "CLIPProcessor"},
+ open(processor_tmpfile, "w"),
+ )
+ json.dump({"model_type": "clip"}, open(config_tmpfile, "w"))
+
+ config = AutoImageProcessor.from_pretrained(tmpdirname)
+ self.assertIsInstance(config, CLIPImageProcessor)
+
+ def test_image_processor_from_local_directory_from_config(self):
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model_config = CLIPConfig()
+
+ # Create a dummy config file with image_proceesor_type
+ processor_tmpfile = Path(tmpdirname) / "preprocessor_config.json"
+ config_tmpfile = Path(tmpdirname) / "config.json"
+ json.dump(
+ {"image_processor_type": "CLIPImageProcessor", "processor_class": "CLIPProcessor"},
+ open(processor_tmpfile, "w"),
+ )
+ json.dump({"model_type": "clip"}, open(config_tmpfile, "w"))
+
+ # remove image_processor_type to make sure config.json alone is enough to load image processor locally
+ config_dict = AutoImageProcessor.from_pretrained(tmpdirname).to_dict()
+
+ config_dict.pop("image_processor_type")
+ config = CLIPImageProcessor(**config_dict)
+
+ # save in new folder
+ model_config.save_pretrained(tmpdirname)
+ config.save_pretrained(tmpdirname)
+
+ config = AutoImageProcessor.from_pretrained(tmpdirname)
+
+ # make sure private variable is not incorrectly saved
+ dict_as_saved = json.loads(config.to_json_string())
+ self.assertTrue("_processor_class" not in dict_as_saved)
+
+ self.assertIsInstance(config, CLIPImageProcessor)
+
+ def test_image_processor_from_local_file(self):
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ processor_tmpfile = Path(tmpdirname) / "preprocessor_config.json"
+ json.dump(
+ {"image_processor_type": "CLIPImageProcessor", "processor_class": "CLIPProcessor"},
+ open(processor_tmpfile, "w"),
+ )
+
+ config = AutoImageProcessor.from_pretrained(processor_tmpfile)
+ self.assertIsInstance(config, CLIPImageProcessor)
+
+ def test_repo_not_found(self):
+ with self.assertRaisesRegex(
+ EnvironmentError, "clip-base is not a local folder and is not a valid model identifier"
+ ):
+ _ = AutoImageProcessor.from_pretrained("clip-base")
+
+ def test_revision_not_found(self):
+ with self.assertRaisesRegex(
+ EnvironmentError, r"aaaaaa is not a valid git identifier \(branch name, tag name or commit id\)"
+ ):
+ _ = AutoImageProcessor.from_pretrained(DUMMY_UNKNOWN_IDENTIFIER, revision="aaaaaa")
+
+ def test_image_processor_not_found(self):
+ with self.assertRaisesRegex(
+ EnvironmentError,
+ "hf-internal-testing/config-no-model does not appear to have a file named preprocessor_config.json.",
+ ):
+ _ = AutoImageProcessor.from_pretrained("hf-internal-testing/config-no-model")
+
+ def test_from_pretrained_dynamic_image_processor(self):
+ model = AutoImageProcessor.from_pretrained(
+ "hf-internal-testing/test_dynamic_image_processor", trust_remote_code=True
+ )
+ self.assertEqual(model.__class__.__name__, "NewImageProcessor")
+
+ def test_new_image_processor_registration(self):
+ try:
+ AutoConfig.register("custom", CustomConfig)
+ AutoImageProcessor.register(CustomConfig, CustomImageProcessor)
+ # Trying to register something existing in the Transformers library will raise an error
+ with self.assertRaises(ValueError):
+ AutoImageProcessor.register(CLIPConfig, CLIPImageProcessor)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ processor_tmpfile = Path(tmpdirname) / "preprocessor_config.json"
+ config_tmpfile = Path(tmpdirname) / "config.json"
+ json.dump(
+ {"feature_extractor_type": "CLIPFeatureExtractor", "processor_class": "CLIPProcessor"},
+ open(processor_tmpfile, "w"),
+ )
+ json.dump({"model_type": "clip"}, open(config_tmpfile, "w"))
+
+ image_processor = CustomImageProcessor.from_pretrained(tmpdirname)
+
+ # Now that the config is registered, it can be used as any other config with the auto-API
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ image_processor.save_pretrained(tmp_dir)
+ new_image_processor = AutoImageProcessor.from_pretrained(tmp_dir)
+ self.assertIsInstance(new_image_processor, CustomImageProcessor)
+
+ finally:
+ if "custom" in CONFIG_MAPPING._extra_content:
+ del CONFIG_MAPPING._extra_content["custom"]
+ if CustomConfig in IMAGE_PROCESSOR_MAPPING._extra_content:
+ del IMAGE_PROCESSOR_MAPPING._extra_content[CustomConfig]
diff --git a/utils/test_module/custom_image_processing.py b/utils/test_module/custom_image_processing.py
new file mode 100644
index 0000000000..e4984854ad
--- /dev/null
+++ b/utils/test_module/custom_image_processing.py
@@ -0,0 +1,5 @@
+from transformers import CLIPImageProcessor
+
+
+class CustomImageProcessor(CLIPImageProcessor):
+ pass
+alt="drawing" width="600"/>
ViT architecture. Taken from the original paper.
@@ -96,6 +96,12 @@ go to him!
[[autodoc]] ViTFeatureExtractor
- __call__
+
+## ViTImageProcessor
+
+[[autodoc]] ViTImageProcessor
+ - preprocess
+
## ViTModel
[[autodoc]] ViTModel
diff --git a/docs/source/en/preprocessing.mdx b/docs/source/en/preprocessing.mdx
index 541885c452..ebbe7b5a80 100644
--- a/docs/source/en/preprocessing.mdx
+++ b/docs/source/en/preprocessing.mdx
@@ -17,7 +17,8 @@ specific language governing permissions and limitations under the License.
Before you can train a model on a dataset, it needs to be preprocessed into the expected model input format. Whether your data is text, images, or audio, they need to be converted and assembled into batches of tensors. 🤗 Transformers provides a set of preprocessing classes to help prepare your data for the model. In this tutorial, you'll learn that for:
* Text, use a [Tokenizer](./main_classes/tokenizer) to convert text into a sequence of tokens, create a numerical representation of the tokens, and assemble them into tensors.
-* Computer vision and speech, use a [Feature extractor](./main_classes/feature_extractor) to extract sequential features from audio waveforms and images and convert them into tensors.
+* Image inputs use a [ImageProcessor](./main_classes/image) to convert images into tensors.
+* Speech and audio, use a [Feature extractor](./main_classes/feature_extractor) to extract sequential features from audio waveforms and convert them into tensors.
* Multimodal inputs, use a [Processor](./main_classes/processors) to combine a tokenizer and a feature extractor.
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index 54b4b42fec..c07836075b 100644
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -125,11 +125,13 @@ _import_structure = {
"ALL_PRETRAINED_CONFIG_ARCHIVE_MAP",
"CONFIG_MAPPING",
"FEATURE_EXTRACTOR_MAPPING",
+ "IMAGE_PROCESSOR_MAPPING",
"MODEL_NAMES_MAPPING",
"PROCESSOR_MAPPING",
"TOKENIZER_MAPPING",
"AutoConfig",
"AutoFeatureExtractor",
+ "AutoImageProcessor",
"AutoProcessor",
"AutoTokenizer",
],
@@ -251,6 +253,7 @@ _import_structure = {
"LAYOUTLMV2_PRETRAINED_CONFIG_ARCHIVE_MAP",
"LayoutLMv2Config",
"LayoutLMv2FeatureExtractor",
+ "LayoutLMv2ImageProcessor",
"LayoutLMv2Processor",
"LayoutLMv2Tokenizer",
],
@@ -258,6 +261,7 @@ _import_structure = {
"LAYOUTLMV3_PRETRAINED_CONFIG_ARCHIVE_MAP",
"LayoutLMv3Config",
"LayoutLMv3FeatureExtractor",
+ "LayoutLMv3ImageProcessor",
"LayoutLMv3Processor",
"LayoutLMv3Tokenizer",
],
@@ -375,7 +379,13 @@ _import_structure = {
],
"models.van": ["VAN_PRETRAINED_CONFIG_ARCHIVE_MAP", "VanConfig"],
"models.videomae": ["VIDEOMAE_PRETRAINED_CONFIG_ARCHIVE_MAP", "VideoMAEConfig"],
- "models.vilt": ["VILT_PRETRAINED_CONFIG_ARCHIVE_MAP", "ViltConfig", "ViltFeatureExtractor", "ViltProcessor"],
+ "models.vilt": [
+ "VILT_PRETRAINED_CONFIG_ARCHIVE_MAP",
+ "ViltConfig",
+ "ViltFeatureExtractor",
+ "ViltImageProcessor",
+ "ViltProcessor",
+ ],
"models.vision_encoder_decoder": ["VisionEncoderDecoderConfig"],
"models.vision_text_dual_encoder": ["VisionTextDualEncoderConfig", "VisionTextDualEncoderProcessor"],
"models.visual_bert": ["VISUAL_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP", "VisualBertConfig"],
@@ -689,35 +699,34 @@ except OptionalDependencyNotAvailable:
name for name in dir(dummy_vision_objects) if not name.startswith("_")
]
else:
- _import_structure["image_processing_utils"] = ["ImageProcessorMixin"]
+ _import_structure["image_processing_utils"] = ["ImageProcessingMixin"]
_import_structure["image_transforms"] = ["rescale", "resize", "to_pil_image"]
_import_structure["image_utils"] = ["ImageFeatureExtractionMixin"]
- _import_structure["models.beit"].append("BeitFeatureExtractor")
- _import_structure["models.clip"].append("CLIPFeatureExtractor")
- _import_structure["models.convnext"].append("ConvNextFeatureExtractor")
+ _import_structure["models.beit"].extend(["BeitFeatureExtractor", "BeitImageProcessor"])
+ _import_structure["models.clip"].extend(["CLIPFeatureExtractor", "CLIPImageProcessor"])
+ _import_structure["models.convnext"].extend(["ConvNextFeatureExtractor", "ConvNextImageProcessor"])
_import_structure["models.deformable_detr"].append("DeformableDetrFeatureExtractor")
- _import_structure["models.deit"].append("DeiTFeatureExtractor")
+ _import_structure["models.deit"].extend(["DeiTFeatureExtractor", "DeiTImageProcessor"])
_import_structure["models.detr"].append("DetrFeatureExtractor")
_import_structure["models.conditional_detr"].append("ConditionalDetrFeatureExtractor")
_import_structure["models.donut"].append("DonutFeatureExtractor")
- _import_structure["models.dpt"].append("DPTFeatureExtractor")
- _import_structure["models.flava"].extend(["FlavaFeatureExtractor", "FlavaProcessor"])
- _import_structure["models.glpn"].append("GLPNFeatureExtractor")
- _import_structure["models.imagegpt"].append("ImageGPTFeatureExtractor")
- _import_structure["models.layoutlmv2"].append("LayoutLMv2FeatureExtractor")
- _import_structure["models.layoutlmv3"].append("LayoutLMv3FeatureExtractor")
- _import_structure["models.levit"].append("LevitFeatureExtractor")
+ _import_structure["models.dpt"].extend(["DPTFeatureExtractor", "DPTImageProcessor"])
+ _import_structure["models.flava"].extend(["FlavaFeatureExtractor", "FlavaProcessor", "FlavaImageProcessor"])
+ _import_structure["models.glpn"].extend(["GLPNFeatureExtractor", "GLPNImageProcessor"])
+ _import_structure["models.imagegpt"].extend(["ImageGPTFeatureExtractor", "ImageGPTImageProcessor"])
+ _import_structure["models.layoutlmv2"].extend(["LayoutLMv2FeatureExtractor", "LayoutLMv2ImageProcessor"])
+ _import_structure["models.layoutlmv3"].extend(["LayoutLMv3FeatureExtractor", "LayoutLMv3ImageProcessor"])
+ _import_structure["models.levit"].extend(["LevitFeatureExtractor", "LevitImageProcessor"])
_import_structure["models.maskformer"].append("MaskFormerFeatureExtractor")
- _import_structure["models.mobilevit"].append("MobileViTFeatureExtractor")
+ _import_structure["models.mobilevit"].extend(["MobileViTFeatureExtractor", "MobileViTImageProcessor"])
_import_structure["models.owlvit"].append("OwlViTFeatureExtractor")
- _import_structure["models.perceiver"].append("PerceiverFeatureExtractor")
- _import_structure["models.poolformer"].append("PoolFormerFeatureExtractor")
- _import_structure["models.segformer"].append("SegformerFeatureExtractor")
- _import_structure["models.videomae"].append("VideoMAEFeatureExtractor")
- _import_structure["models.vilt"].append("ViltFeatureExtractor")
- _import_structure["models.vilt"].append("ViltProcessor")
- _import_structure["models.vit"].append("ViTFeatureExtractor")
- _import_structure["models.yolos"].append("YolosFeatureExtractor")
+ _import_structure["models.perceiver"].extend(["PerceiverFeatureExtractor", "PerceiverImageProcessor"])
+ _import_structure["models.poolformer"].extend(["PoolFormerFeatureExtractor", "PoolFormerImageProcessor"])
+ _import_structure["models.segformer"].extend(["SegformerFeatureExtractor", "SegformerImageProcessor"])
+ _import_structure["models.videomae"].extend(["VideoMAEFeatureExtractor", "VideoMAEImageProcessor"])
+ _import_structure["models.vilt"].extend(["ViltFeatureExtractor", "ViltImageProcessor", "ViltProcessor"])
+ _import_structure["models.vit"].extend(["ViTFeatureExtractor", "ViTImageProcessor"])
+ _import_structure["models.yolos"].extend(["YolosFeatureExtractor"])
# Timm-backed objects
try:
@@ -3220,11 +3229,13 @@ if TYPE_CHECKING:
ALL_PRETRAINED_CONFIG_ARCHIVE_MAP,
CONFIG_MAPPING,
FEATURE_EXTRACTOR_MAPPING,
+ IMAGE_PROCESSOR_MAPPING,
MODEL_NAMES_MAPPING,
PROCESSOR_MAPPING,
TOKENIZER_MAPPING,
AutoConfig,
AutoFeatureExtractor,
+ AutoImageProcessor,
AutoProcessor,
AutoTokenizer,
)
@@ -3337,6 +3348,7 @@ if TYPE_CHECKING:
LAYOUTLMV2_PRETRAINED_CONFIG_ARCHIVE_MAP,
LayoutLMv2Config,
LayoutLMv2FeatureExtractor,
+ LayoutLMv2ImageProcessor,
LayoutLMv2Processor,
LayoutLMv2Tokenizer,
)
@@ -3344,6 +3356,7 @@ if TYPE_CHECKING:
LAYOUTLMV3_PRETRAINED_CONFIG_ARCHIVE_MAP,
LayoutLMv3Config,
LayoutLMv3FeatureExtractor,
+ LayoutLMv3ImageProcessor,
LayoutLMv3Processor,
LayoutLMv3Tokenizer,
)
@@ -3441,7 +3454,13 @@ if TYPE_CHECKING:
from .models.unispeech_sat import UNISPEECH_SAT_PRETRAINED_CONFIG_ARCHIVE_MAP, UniSpeechSatConfig
from .models.van import VAN_PRETRAINED_CONFIG_ARCHIVE_MAP, VanConfig
from .models.videomae import VIDEOMAE_PRETRAINED_CONFIG_ARCHIVE_MAP, VideoMAEConfig
- from .models.vilt import VILT_PRETRAINED_CONFIG_ARCHIVE_MAP, ViltConfig, ViltFeatureExtractor, ViltProcessor
+ from .models.vilt import (
+ VILT_PRETRAINED_CONFIG_ARCHIVE_MAP,
+ ViltConfig,
+ ViltFeatureExtractor,
+ ViltImageProcessor,
+ ViltProcessor,
+ )
from .models.vision_encoder_decoder import VisionEncoderDecoderConfig
from .models.vision_text_dual_encoder import VisionTextDualEncoderConfig, VisionTextDualEncoderProcessor
from .models.visual_bert import VISUAL_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP, VisualBertConfig
@@ -3716,33 +3735,33 @@ if TYPE_CHECKING:
except OptionalDependencyNotAvailable:
from .utils.dummy_vision_objects import *
else:
- from .image_processing_utils import ImageProcessorMixin
+ from .image_processing_utils import ImageProcessingMixin
from .image_transforms import rescale, resize, to_pil_image
from .image_utils import ImageFeatureExtractionMixin
- from .models.beit import BeitFeatureExtractor
- from .models.clip import CLIPFeatureExtractor
+ from .models.beit import BeitFeatureExtractor, BeitImageProcessor
+ from .models.clip import CLIPFeatureExtractor, CLIPImageProcessor
from .models.conditional_detr import ConditionalDetrFeatureExtractor
- from .models.convnext import ConvNextFeatureExtractor
+ from .models.convnext import ConvNextFeatureExtractor, ConvNextImageProcessor
from .models.deformable_detr import DeformableDetrFeatureExtractor
- from .models.deit import DeiTFeatureExtractor
+ from .models.deit import DeiTFeatureExtractor, DeiTImageProcessor
from .models.detr import DetrFeatureExtractor
from .models.donut import DonutFeatureExtractor
- from .models.dpt import DPTFeatureExtractor
- from .models.flava import FlavaFeatureExtractor, FlavaProcessor
- from .models.glpn import GLPNFeatureExtractor
- from .models.imagegpt import ImageGPTFeatureExtractor
- from .models.layoutlmv2 import LayoutLMv2FeatureExtractor
- from .models.layoutlmv3 import LayoutLMv3FeatureExtractor
- from .models.levit import LevitFeatureExtractor
+ from .models.dpt import DPTFeatureExtractor, DPTImageProcessor
+ from .models.flava import FlavaFeatureExtractor, FlavaImageProcessor, FlavaProcessor
+ from .models.glpn import GLPNFeatureExtractor, GLPNImageProcessor
+ from .models.imagegpt import ImageGPTFeatureExtractor, ImageGPTImageProcessor
+ from .models.layoutlmv2 import LayoutLMv2FeatureExtractor, LayoutLMv2ImageProcessor
+ from .models.layoutlmv3 import LayoutLMv3FeatureExtractor, LayoutLMv3ImageProcessor
+ from .models.levit import LevitFeatureExtractor, LevitImageProcessor
from .models.maskformer import MaskFormerFeatureExtractor
- from .models.mobilevit import MobileViTFeatureExtractor
+ from .models.mobilevit import MobileViTFeatureExtractor, MobileViTImageProcessor
from .models.owlvit import OwlViTFeatureExtractor
- from .models.perceiver import PerceiverFeatureExtractor
- from .models.poolformer import PoolFormerFeatureExtractor
- from .models.segformer import SegformerFeatureExtractor
- from .models.videomae import VideoMAEFeatureExtractor
- from .models.vilt import ViltFeatureExtractor, ViltProcessor
- from .models.vit import ViTFeatureExtractor
+ from .models.perceiver import PerceiverFeatureExtractor, PerceiverImageProcessor
+ from .models.poolformer import PoolFormerFeatureExtractor, PoolFormerImageProcessor
+ from .models.segformer import SegformerFeatureExtractor, SegformerImageProcessor
+ from .models.videomae import VideoMAEFeatureExtractor, VideoMAEImageProcessor
+ from .models.vilt import ViltFeatureExtractor, ViltImageProcessor, ViltProcessor
+ from .models.vit import ViTFeatureExtractor, ViTImageProcessor
from .models.yolos import YolosFeatureExtractor
# Modeling
diff --git a/src/transformers/commands/add_new_model_like.py b/src/transformers/commands/add_new_model_like.py
index a5d4e97ffd..2af7688073 100644
--- a/src/transformers/commands/add_new_model_like.py
+++ b/src/transformers/commands/add_new_model_like.py
@@ -389,6 +389,7 @@ SPECIAL_PATTERNS = {
"_CHECKPOINT_FOR_DOC =": "checkpoint",
"_CONFIG_FOR_DOC =": "config_class",
"_TOKENIZER_FOR_DOC =": "tokenizer_class",
+ "_IMAGE_PROCESSOR_FOR_DOC =": "image_processor_class",
"_FEAT_EXTRACTOR_FOR_DOC =": "feature_extractor_class",
"_PROCESSOR_FOR_DOC =": "processor_class",
}
diff --git a/src/transformers/commands/pt_to_tf.py b/src/transformers/commands/pt_to_tf.py
index 76d4984ade..62996b0513 100644
--- a/src/transformers/commands/pt_to_tf.py
+++ b/src/transformers/commands/pt_to_tf.py
@@ -24,10 +24,12 @@ import huggingface_hub
from .. import (
FEATURE_EXTRACTOR_MAPPING,
+ IMAGE_PROCESSOR_MAPPING,
PROCESSOR_MAPPING,
TOKENIZER_MAPPING,
AutoConfig,
AutoFeatureExtractor,
+ AutoImageProcessor,
AutoProcessor,
AutoTokenizer,
is_datasets_available,
@@ -202,6 +204,8 @@ class PTtoTFCommand(BaseTransformersCLICommand):
processor = AutoProcessor.from_pretrained(self._local_dir)
if model_config_class in TOKENIZER_MAPPING and processor.tokenizer.pad_token is None:
processor.tokenizer.pad_token = processor.tokenizer.eos_token
+ elif model_config_class in IMAGE_PROCESSOR_MAPPING:
+ processor = AutoImageProcessor.from_pretrained(self._local_dir)
elif model_config_class in FEATURE_EXTRACTOR_MAPPING:
processor = AutoFeatureExtractor.from_pretrained(self._local_dir)
elif model_config_class in TOKENIZER_MAPPING:
diff --git a/src/transformers/image_processing_utils.py b/src/transformers/image_processing_utils.py
index bdd30ecc04..7f73eff1e2 100644
--- a/src/transformers/image_processing_utils.py
+++ b/src/transformers/image_processing_utils.py
@@ -13,17 +13,31 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-from typing import Dict, Iterable, Optional, Union
+import copy
+import json
+import os
+from typing import Any, Dict, Iterable, Optional, Tuple, Union
+import numpy as np
+
+from .dynamic_module_utils import custom_object_save
from .feature_extraction_utils import BatchFeature as BaseBatchFeature
-from .feature_extraction_utils import FeatureExtractionMixin
-from .utils import logging
+from .utils import (
+ IMAGE_PROCESSOR_NAME,
+ PushToHubMixin,
+ cached_file,
+ copy_func,
+ download_url,
+ is_offline_mode,
+ is_remote_url,
+ logging,
+)
logger = logging.get_logger(__name__)
-# TODO: Move BatchFeature to be imported by both feature_extraction_utils and image_processing_utils
+# TODO: Move BatchFeature to be imported by both image_processing_utils and image_processing_utils
# We override the class string here, but logic is the same.
class BatchFeature(BaseBatchFeature):
r"""
@@ -40,12 +54,381 @@ class BatchFeature(BaseBatchFeature):
"""
-# We use aliasing whilst we phase out the old API. Once feature extractors for vision models
-# are deprecated, ImageProcessor mixin will be implemented. Any shared logic will be abstracted out.
-ImageProcessorMixin = FeatureExtractionMixin
+# TODO: (Amy) - factor out the common parts of this and the feature extractor
+class ImageProcessingMixin(PushToHubMixin):
+ """
+ This is an image processor mixin used to provide saving/loading functionality for sequential and image feature
+ extractors.
+ """
+
+ _auto_class = None
+
+ def __init__(self, **kwargs):
+ """Set elements of `kwargs` as attributes."""
+ # Pop "processor_class" as it should be saved as private attribute
+ self._processor_class = kwargs.pop("processor_class", None)
+ # Additional attributes without default values
+ for key, value in kwargs.items():
+ try:
+ setattr(self, key, value)
+ except AttributeError as err:
+ logger.error(f"Can't set {key} with value {value} for {self}")
+ raise err
+
+ def _set_processor_class(self, processor_class: str):
+ """Sets processor class as an attribute."""
+ self._processor_class = processor_class
+
+ @classmethod
+ def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs):
+ r"""
+ Instantiate a type of [`~image_processing_utils.ImageProcessingMixin`] from an image processor.
+
+ Args:
+ pretrained_model_name_or_path (`str` or `os.PathLike`):
+ This can be either:
+
+ - a string, the *model id* of a pretrained image_processor hosted inside a model repo on
+ huggingface.co. Valid model ids can be located at the root-level, like `bert-base-uncased`, or
+ namespaced under a user or organization name, like `dbmdz/bert-base-german-cased`.
+ - a path to a *directory* containing a image processor file saved using the
+ [`~image_processing_utils.ImageProcessingMixin.save_pretrained`] method, e.g.,
+ `./my_model_directory/`.
+ - a path or url to a saved image processor JSON *file*, e.g.,
+ `./my_model_directory/preprocessor_config.json`.
+ cache_dir (`str` or `os.PathLike`, *optional*):
+ Path to a directory in which a downloaded pretrained model image processor should be cached if the
+ standard cache should not be used.
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force to (re-)download the image processor files and override the cached versions if
+ they exist.
+ resume_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to delete incompletely received file. Attempts to resume the download if such a file
+ exists.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}.` The proxies are used on each request.
+ use_auth_token (`str` or `bool`, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, or not specified, will use
+ the token generated when running `huggingface-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
-class BaseImageProcessor(ImageProcessorMixin):
+
+
+ To test a pull request you made on the Hub, you can pass `revision="refs/pr/".
+
+
+
+ return_unused_kwargs (`bool`, *optional*, defaults to `False`):
+ If `False`, then this function returns just the final image processor object. If `True`, then this
+ functions returns a `Tuple(image_processor, unused_kwargs)` where *unused_kwargs* is a dictionary
+ consisting of the key/value pairs whose keys are not image processor attributes: i.e., the part of
+ `kwargs` which has not been used to update `image_processor` and is otherwise ignored.
+ kwargs (`Dict[str, Any]`, *optional*):
+ The values in kwargs of any keys which are image processor attributes will be used to override the
+ loaded values. Behavior concerning key/value pairs whose keys are *not* image processor attributes is
+ controlled by the `return_unused_kwargs` keyword parameter.
+
+ Returns:
+ A image processor of type [`~image_processing_utils.ImageProcessingMixin`].
+
+ Examples:
+
+ ```python
+ # We can't instantiate directly the base class *ImageProcessingMixin* so let's show the examples on a
+ # derived class: *CLIPImageProcessor*
+ image_processor = CLIPImageProcessor.from_pretrained(
+ "openai/clip-vit-base-patch32"
+ ) # Download image_processing_config from huggingface.co and cache.
+ image_processor = CLIPImageProcessor.from_pretrained(
+ "./test/saved_model/"
+ ) # E.g. image processor (or model) was saved using *save_pretrained('./test/saved_model/')*
+ image_processor = CLIPImageProcessor.from_pretrained("./test/saved_model/preprocessor_config.json")
+ image_processor = CLIPImageProcessor.from_pretrained(
+ "openai/clip-vit-base-patch32", do_normalize=False, foo=False
+ )
+ assert image_processor.do_normalize is False
+ image_processor, unused_kwargs = CLIPImageProcessor.from_pretrained(
+ "openai/clip-vit-base-patch32", do_normalize=False, foo=False, return_unused_kwargs=True
+ )
+ assert image_processor.do_normalize is False
+ assert unused_kwargs == {"foo": False}
+ ```"""
+ image_processor_dict, kwargs = cls.get_image_processor_dict(pretrained_model_name_or_path, **kwargs)
+
+ return cls.from_dict(image_processor_dict, **kwargs)
+
+ def save_pretrained(self, save_directory: Union[str, os.PathLike], push_to_hub: bool = False, **kwargs):
+ """
+ Save an image processor object to the directory `save_directory`, so that it can be re-loaded using the
+ [`~image_processing_utils.ImageProcessingMixin.from_pretrained`] class method.
+
+ Args:
+ save_directory (`str` or `os.PathLike`):
+ Directory where the image processor JSON file will be saved (will be created if it does not exist).
+ push_to_hub (`bool`, *optional*, defaults to `False`):
+ Whether or not to push your model to the Hugging Face model hub after saving it. You can specify the
+ repository you want to push to with `repo_id` (will default to the name of `save_directory` in your
+ namespace).
+ kwargs:
+ Additional key word arguments passed along to the [`~utils.PushToHubMixin.push_to_hub`] method.
+ """
+ if os.path.isfile(save_directory):
+ raise AssertionError(f"Provided path ({save_directory}) should be a directory, not a file")
+
+ os.makedirs(save_directory, exist_ok=True)
+
+ if push_to_hub:
+ commit_message = kwargs.pop("commit_message", None)
+ repo_id = kwargs.pop("repo_id", save_directory.split(os.path.sep)[-1])
+ repo_id, token = self._create_repo(repo_id, **kwargs)
+ files_timestamps = self._get_files_timestamps(save_directory)
+
+ # If we have a custom config, we copy the file defining it in the folder and set the attributes so it can be
+ # loaded from the Hub.
+ if self._auto_class is not None:
+ custom_object_save(self, save_directory, config=self)
+
+ # If we save using the predefined names, we can load using `from_pretrained`
+ output_image_processor_file = os.path.join(save_directory, IMAGE_PROCESSOR_NAME)
+
+ self.to_json_file(output_image_processor_file)
+ logger.info(f"Image processor saved in {output_image_processor_file}")
+
+ if push_to_hub:
+ self._upload_modified_files(
+ save_directory, repo_id, files_timestamps, commit_message=commit_message, token=token
+ )
+
+ return [output_image_processor_file]
+
+ @classmethod
+ def get_image_processor_dict(
+ cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs
+ ) -> Tuple[Dict[str, Any], Dict[str, Any]]:
+ """
+ From a `pretrained_model_name_or_path`, resolve to a dictionary of parameters, to be used for instantiating a
+ image processor of type [`~image_processor_utils.ImageProcessingMixin`] using `from_dict`.
+
+ Parameters:
+ pretrained_model_name_or_path (`str` or `os.PathLike`):
+ The identifier of the pre-trained checkpoint from which we want the dictionary of parameters.
+
+ Returns:
+ `Tuple[Dict, Dict]`: The dictionary(ies) that will be used to instantiate the image processor object.
+ """
+ cache_dir = kwargs.pop("cache_dir", None)
+ force_download = kwargs.pop("force_download", False)
+ resume_download = kwargs.pop("resume_download", False)
+ proxies = kwargs.pop("proxies", None)
+ use_auth_token = kwargs.pop("use_auth_token", None)
+ local_files_only = kwargs.pop("local_files_only", False)
+ revision = kwargs.pop("revision", None)
+
+ from_pipeline = kwargs.pop("_from_pipeline", None)
+ from_auto_class = kwargs.pop("_from_auto", False)
+
+ user_agent = {"file_type": "image processor", "from_auto_class": from_auto_class}
+ if from_pipeline is not None:
+ user_agent["using_pipeline"] = from_pipeline
+
+ if is_offline_mode() and not local_files_only:
+ logger.info("Offline mode: forcing local_files_only=True")
+ local_files_only = True
+
+ pretrained_model_name_or_path = str(pretrained_model_name_or_path)
+ is_local = os.path.isdir(pretrained_model_name_or_path)
+ if os.path.isdir(pretrained_model_name_or_path):
+ image_processor_file = os.path.join(pretrained_model_name_or_path, IMAGE_PROCESSOR_NAME)
+ if os.path.isfile(pretrained_model_name_or_path):
+ resolved_image_processor_file = pretrained_model_name_or_path
+ is_local = True
+ elif is_remote_url(pretrained_model_name_or_path):
+ image_processor_file = pretrained_model_name_or_path
+ resolved_image_processor_file = download_url(pretrained_model_name_or_path)
+ else:
+ image_processor_file = IMAGE_PROCESSOR_NAME
+ try:
+ # Load from local folder or from cache or download from model Hub and cache
+ resolved_image_processor_file = cached_file(
+ pretrained_model_name_or_path,
+ image_processor_file,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ proxies=proxies,
+ resume_download=resume_download,
+ local_files_only=local_files_only,
+ use_auth_token=use_auth_token,
+ user_agent=user_agent,
+ revision=revision,
+ )
+ except EnvironmentError:
+ # Raise any environment error raise by `cached_file`. It will have a helpful error message adapted to
+ # the original exception.
+ raise
+ except Exception:
+ # For any other exception, we throw a generic error.
+ raise EnvironmentError(
+ f"Can't load image processor for '{pretrained_model_name_or_path}'. If you were trying to load"
+ " it from 'https://huggingface.co/models', make sure you don't have a local directory with the"
+ f" same name. Otherwise, make sure '{pretrained_model_name_or_path}' is the correct path to a"
+ f" directory containing a {IMAGE_PROCESSOR_NAME} file"
+ )
+
+ try:
+ # Load image_processor dict
+ with open(resolved_image_processor_file, "r", encoding="utf-8") as reader:
+ text = reader.read()
+ image_processor_dict = json.loads(text)
+
+ except json.JSONDecodeError:
+ raise EnvironmentError(
+ f"It looks like the config file at '{resolved_image_processor_file}' is not a valid JSON file."
+ )
+
+ if is_local:
+ logger.info(f"loading configuration file {resolved_image_processor_file}")
+ else:
+ logger.info(
+ f"loading configuration file {image_processor_file} from cache at {resolved_image_processor_file}"
+ )
+
+ return image_processor_dict, kwargs
+
+ @classmethod
+ def from_dict(cls, image_processor_dict: Dict[str, Any], **kwargs):
+ """
+ Instantiates a type of [`~image_processing_utils.ImageProcessingMixin`] from a Python dictionary of parameters.
+
+ Args:
+ image_processor_dict (`Dict[str, Any]`):
+ Dictionary that will be used to instantiate the image processor object. Such a dictionary can be
+ retrieved from a pretrained checkpoint by leveraging the
+ [`~image_processing_utils.ImageProcessingMixin.to_dict`] method.
+ kwargs (`Dict[str, Any]`):
+ Additional parameters from which to initialize the image processor object.
+
+ Returns:
+ [`~image_processing_utils.ImageProcessingMixin`]: The image processor object instantiated from those
+ parameters.
+ """
+ return_unused_kwargs = kwargs.pop("return_unused_kwargs", False)
+
+ image_processor = cls(**image_processor_dict)
+
+ # Update image_processor with kwargs if needed
+ to_remove = []
+ for key, value in kwargs.items():
+ if hasattr(image_processor, key):
+ setattr(image_processor, key, value)
+ to_remove.append(key)
+ for key in to_remove:
+ kwargs.pop(key, None)
+
+ logger.info(f"Image processor {image_processor}")
+ if return_unused_kwargs:
+ return image_processor, kwargs
+ else:
+ return image_processor
+
+ def to_dict(self) -> Dict[str, Any]:
+ """
+ Serializes this instance to a Python dictionary.
+
+ Returns:
+ `Dict[str, Any]`: Dictionary of all the attributes that make up this image processor instance.
+ """
+ output = copy.deepcopy(self.__dict__)
+ output["image_processor_type"] = self.__class__.__name__
+
+ return output
+
+ @classmethod
+ def from_json_file(cls, json_file: Union[str, os.PathLike]):
+ """
+ Instantiates a image processor of type [`~image_processing_utils.ImageProcessingMixin`] from the path to a JSON
+ file of parameters.
+
+ Args:
+ json_file (`str` or `os.PathLike`):
+ Path to the JSON file containing the parameters.
+
+ Returns:
+ A image processor of type [`~image_processing_utils.ImageProcessingMixin`]: The image_processor object
+ instantiated from that JSON file.
+ """
+ with open(json_file, "r", encoding="utf-8") as reader:
+ text = reader.read()
+ image_processor_dict = json.loads(text)
+ return cls(**image_processor_dict)
+
+ def to_json_string(self) -> str:
+ """
+ Serializes this instance to a JSON string.
+
+ Returns:
+ `str`: String containing all the attributes that make up this feature_extractor instance in JSON format.
+ """
+ dictionary = self.to_dict()
+
+ for key, value in dictionary.items():
+ if isinstance(value, np.ndarray):
+ dictionary[key] = value.tolist()
+
+ # make sure private name "_processor_class" is correctly
+ # saved as "processor_class"
+ _processor_class = dictionary.pop("_processor_class", None)
+ if _processor_class is not None:
+ dictionary["processor_class"] = _processor_class
+
+ return json.dumps(dictionary, indent=2, sort_keys=True) + "\n"
+
+ def to_json_file(self, json_file_path: Union[str, os.PathLike]):
+ """
+ Save this instance to a JSON file.
+
+ Args:
+ json_file_path (`str` or `os.PathLike`):
+ Path to the JSON file in which this image_processor instance's parameters will be saved.
+ """
+ with open(json_file_path, "w", encoding="utf-8") as writer:
+ writer.write(self.to_json_string())
+
+ def __repr__(self):
+ return f"{self.__class__.__name__} {self.to_json_string()}"
+
+ @classmethod
+ def register_for_auto_class(cls, auto_class="AutoImageProcessor"):
+ """
+ Register this class with a given auto class. This should only be used for custom image processors as the ones
+ in the library are already mapped with `AutoImageProcessor `.
+
+
+
+ This API is experimental and may have some slight breaking changes in the next releases.
+
+
+
+ Args:
+ auto_class (`str` or `type`, *optional*, defaults to `"AutoImageProcessor "`):
+ The auto class to register this new image processor with.
+ """
+ if not isinstance(auto_class, str):
+ auto_class = auto_class.__name__
+
+ import transformers.models.auto as auto_module
+
+ if not hasattr(auto_module, auto_class):
+ raise ValueError(f"{auto_class} is not a valid auto class.")
+
+ cls._auto_class = auto_class
+
+
+class BaseImageProcessor(ImageProcessingMixin):
def __init__(self, **kwargs):
super().__init__(**kwargs)
@@ -65,7 +448,7 @@ def get_size_dict(
) -> dict:
"""
Converts the old size parameter in the config into the new dict expected in the config. This is to ensure backwards
- compatibility with the old feature extractor configs and removes ambiguity over whether the tuple is in (height,
+ compatibility with the old image processor configs and removes ambiguity over whether the tuple is in (height,
width) or (width, height) format.
- If `size` is tuple, it is converted to `{"height": size[0], "width": size[1]}` or `{"height": size[1], "width":
@@ -119,3 +502,9 @@ def get_size_dict(
f" or ('shortest_edge',) got {size}. Setting as {size_dict}.",
)
return size_dict
+
+
+ImageProcessingMixin.push_to_hub = copy_func(ImageProcessingMixin.push_to_hub)
+ImageProcessingMixin.push_to_hub.__doc__ = ImageProcessingMixin.push_to_hub.__doc__.format(
+ object="image processor", object_class="AutoImageProcessor", object_files="image processor file"
+)
diff --git a/src/transformers/models/auto/__init__.py b/src/transformers/models/auto/__init__.py
index acb0fa8b0f..a1a1356eb0 100644
--- a/src/transformers/models/auto/__init__.py
+++ b/src/transformers/models/auto/__init__.py
@@ -31,6 +31,7 @@ _import_structure = {
"auto_factory": ["get_values"],
"configuration_auto": ["ALL_PRETRAINED_CONFIG_ARCHIVE_MAP", "CONFIG_MAPPING", "MODEL_NAMES_MAPPING", "AutoConfig"],
"feature_extraction_auto": ["FEATURE_EXTRACTOR_MAPPING", "AutoFeatureExtractor"],
+ "image_processing_auto": ["IMAGE_PROCESSOR_MAPPING", "AutoImageProcessor"],
"processing_auto": ["PROCESSOR_MAPPING", "AutoProcessor"],
"tokenization_auto": ["TOKENIZER_MAPPING", "AutoTokenizer"],
}
@@ -184,6 +185,7 @@ if TYPE_CHECKING:
from .auto_factory import get_values
from .configuration_auto import ALL_PRETRAINED_CONFIG_ARCHIVE_MAP, CONFIG_MAPPING, MODEL_NAMES_MAPPING, AutoConfig
from .feature_extraction_auto import FEATURE_EXTRACTOR_MAPPING, AutoFeatureExtractor
+ from .image_processing_auto import IMAGE_PROCESSOR_MAPPING, AutoImageProcessor
from .processing_auto import PROCESSOR_MAPPING, AutoProcessor
from .tokenization_auto import TOKENIZER_MAPPING, AutoTokenizer
diff --git a/src/transformers/models/auto/image_processing_auto.py b/src/transformers/models/auto/image_processing_auto.py
new file mode 100644
index 0000000000..776be93136
--- /dev/null
+++ b/src/transformers/models/auto/image_processing_auto.py
@@ -0,0 +1,358 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" AutoImageProcessor class."""
+import importlib
+import json
+import os
+from collections import OrderedDict
+from typing import Dict, Optional, Union
+
+# Build the list of all image processors
+from ...configuration_utils import PretrainedConfig
+from ...dynamic_module_utils import get_class_from_dynamic_module
+from ...image_processing_utils import ImageProcessingMixin
+from ...utils import CONFIG_NAME, IMAGE_PROCESSOR_NAME, get_file_from_repo, logging
+from .auto_factory import _LazyAutoMapping
+from .configuration_auto import (
+ CONFIG_MAPPING_NAMES,
+ AutoConfig,
+ model_type_to_module_name,
+ replace_list_option_in_docstrings,
+)
+
+
+logger = logging.get_logger(__name__)
+
+IMAGE_PROCESSOR_MAPPING_NAMES = OrderedDict(
+ [
+ ("beit", "BeitImageProcessor"),
+ ("clip", "CLIPImageProcessor"),
+ ("convnext", "ConvNextImageProcessor"),
+ ("cvt", "ConvNextImageProcessor"),
+ ("data2vec-vision", "BeitImageProcessor"),
+ ("deit", "DeiTImageProcessor"),
+ ("dpt", "DPTImageProcessor"),
+ ("flava", "FlavaImageProcessor"),
+ ("glpn", "GLPNImageProcessor"),
+ ("groupvit", "CLIPImageProcessor"),
+ ("imagegpt", "ImageGPTImageProcessor"),
+ ("layoutlmv2", "LayoutLMv2ImageProcessor"),
+ ("layoutlmv3", "LayoutLMv3ImageProcessor"),
+ ("levit", "LevitImageProcessor"),
+ ("mobilevit", "MobileViTImageProcessor"),
+ ("perceiver", "PerceiverImageProcessor"),
+ ("poolformer", "PoolFormerImageProcessor"),
+ ("regnet", "ConvNextImageProcessor"),
+ ("resnet", "ConvNextImageProcessor"),
+ ("segformer", "SegformerImageProcessor"),
+ ("swin", "ViTImageProcessor"),
+ ("swinv2", "ViTImageProcessor"),
+ ("van", "ConvNextImageProcessor"),
+ ("videomae", "VideoMAEImageProcessor"),
+ ("vilt", "ViltImageProcessor"),
+ ("vit", "ViTImageProcessor"),
+ ("vit_mae", "ViTImageProcessor"),
+ ("vit_msn", "ViTImageProcessor"),
+ ("xclip", "CLIPImageProcessor"),
+ ]
+)
+
+IMAGE_PROCESSOR_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, IMAGE_PROCESSOR_MAPPING_NAMES)
+
+
+def image_processor_class_from_name(class_name: str):
+ for module_name, extractors in IMAGE_PROCESSOR_MAPPING_NAMES.items():
+ if class_name in extractors:
+ module_name = model_type_to_module_name(module_name)
+
+ module = importlib.import_module(f".{module_name}", "transformers.models")
+ try:
+ return getattr(module, class_name)
+ except AttributeError:
+ continue
+
+ for _, extractor in IMAGE_PROCESSOR_MAPPING._extra_content.items():
+ if getattr(extractor, "__name__", None) == class_name:
+ return extractor
+
+ # We did not fine the class, but maybe it's because a dep is missing. In that case, the class will be in the main
+ # init and we return the proper dummy to get an appropriate error message.
+ main_module = importlib.import_module("transformers")
+ if hasattr(main_module, class_name):
+ return getattr(main_module, class_name)
+
+ return None
+
+
+def get_image_processor_config(
+ pretrained_model_name_or_path: Union[str, os.PathLike],
+ cache_dir: Optional[Union[str, os.PathLike]] = None,
+ force_download: bool = False,
+ resume_download: bool = False,
+ proxies: Optional[Dict[str, str]] = None,
+ use_auth_token: Optional[Union[bool, str]] = None,
+ revision: Optional[str] = None,
+ local_files_only: bool = False,
+ **kwargs,
+):
+ """
+ Loads the image processor configuration from a pretrained model imag processor configuration. # FIXME
+
+ Args:
+ pretrained_model_name_or_path (`str` or `os.PathLike`):
+ This can be either:
+
+ - a string, the *model id* of a pretrained model configuration hosted inside a model repo on
+ huggingface.co. Valid model ids can be located at the root-level, like `bert-base-uncased`, or namespaced
+ under a user or organization name, like `dbmdz/bert-base-german-cased`.
+ - a path to a *directory* containing a configuration file saved using the
+ [`~PreTrainedTokenizer.save_pretrained`] method, e.g., `./my_model_directory/`.
+
+ cache_dir (`str` or `os.PathLike`, *optional*):
+ Path to a directory in which a downloaded pretrained model configuration should be cached if the standard
+ cache should not be used.
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force to (re-)download the configuration files and override the cached versions if they
+ exist.
+ resume_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to delete incompletely received file. Attempts to resume the download if such a file exists.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}.` The proxies are used on each request.
+ use_auth_token (`str` or *bool*, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
+ when running `huggingface-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+ local_files_only (`bool`, *optional*, defaults to `False`):
+ If `True`, will only try to load the image processor configuration from local files.
+
+
+
+ Passing `use_auth_token=True` is required when you want to use a private model.
+
+
+
+ Returns:
+ `Dict`: The configuration of the image processor.
+
+ Examples:
+
+ ```python
+ # Download configuration from huggingface.co and cache.
+ image_processor_config = get_image_processor_config("bert-base-uncased")
+ # This model does not have a image processor config so the result will be an empty dict.
+ image_processor_config = get_image_processor_config("xlm-roberta-base")
+
+ # Save a pretrained image processor locally and you can reload its config
+ from transformers import AutoTokenizer
+
+ image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
+ image_processor.save_pretrained("image-processor-test")
+ image_processor_config = get_image_processor_config("image-processor-test")
+ ```"""
+ resolved_config_file = get_file_from_repo(
+ pretrained_model_name_or_path,
+ IMAGE_PROCESSOR_NAME,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ resume_download=resume_download,
+ proxies=proxies,
+ use_auth_token=use_auth_token,
+ revision=revision,
+ local_files_only=local_files_only,
+ )
+ if resolved_config_file is None:
+ logger.info(
+ "Could not locate the image processor configuration file, will try to use the model config instead."
+ )
+ return {}
+
+ with open(resolved_config_file, encoding="utf-8") as reader:
+ return json.load(reader)
+
+
+class AutoImageProcessor:
+ r"""
+ This is a generic image processor class that will be instantiated as one of the image processor classes of the
+ library when created with the [`AutoImageProcessor.from_pretrained`] class method.
+
+ This class cannot be instantiated directly using `__init__()` (throws an error).
+ """
+
+ def __init__(self):
+ raise EnvironmentError(
+ "AutoImageProcessor is designed to be instantiated "
+ "using the `AutoImageProcessor.from_pretrained(pretrained_model_name_or_path)` method."
+ )
+
+ @classmethod
+ @replace_list_option_in_docstrings(IMAGE_PROCESSOR_MAPPING_NAMES)
+ def from_pretrained(cls, pretrained_model_name_or_path, **kwargs):
+ r"""
+ Instantiate one of the image processor classes of the library from a pretrained model vocabulary.
+
+ The image processor class to instantiate is selected based on the `model_type` property of the config object
+ (either passed as an argument or loaded from `pretrained_model_name_or_path` if possible), or when it's
+ missing, by falling back to using pattern matching on `pretrained_model_name_or_path`:
+
+ List options
+
+ Params:
+ pretrained_model_name_or_path (`str` or `os.PathLike`):
+ This can be either:
+
+ - a string, the *model id* of a pretrained image_processor hosted inside a model repo on
+ huggingface.co. Valid model ids can be located at the root-level, like `bert-base-uncased`, or
+ namespaced under a user or organization name, like `dbmdz/bert-base-german-cased`.
+ - a path to a *directory* containing a image processor file saved using the
+ [`~image_processing_utils.ImageProcessingMixin.save_pretrained`] method, e.g.,
+ `./my_model_directory/`.
+ - a path or url to a saved image processor JSON *file*, e.g.,
+ `./my_model_directory/preprocessor_config.json`.
+ cache_dir (`str` or `os.PathLike`, *optional*):
+ Path to a directory in which a downloaded pretrained model image processor should be cached if the
+ standard cache should not be used.
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force to (re-)download the image processor files and override the cached versions if
+ they exist.
+ resume_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to delete incompletely received file. Attempts to resume the download if such a file
+ exists.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}.` The proxies are used on each request.
+ use_auth_token (`str` or *bool*, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
+ when running `huggingface-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+ return_unused_kwargs (`bool`, *optional*, defaults to `False`):
+ If `False`, then this function returns just the final image processor object. If `True`, then this
+ functions returns a `Tuple(image_processor, unused_kwargs)` where *unused_kwargs* is a dictionary
+ consisting of the key/value pairs whose keys are not image processor attributes: i.e., the part of
+ `kwargs` which has not been used to update `image_processor` and is otherwise ignored.
+ trust_remote_code (`bool`, *optional*, defaults to `False`):
+ Whether or not to allow for custom models defined on the Hub in their own modeling files. This option
+ should only be set to `True` for repositories you trust and in which you have read the code, as it will
+ execute code present on the Hub on your local machine.
+ kwargs (`Dict[str, Any]`, *optional*):
+ The values in kwargs of any keys which are image processor attributes will be used to override the
+ loaded values. Behavior concerning key/value pairs whose keys are *not* image processor attributes is
+ controlled by the `return_unused_kwargs` keyword parameter.
+
+
+
+ Passing `use_auth_token=True` is required when you want to use a private model.
+
+
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoImageProcessor
+
+ >>> # Download image processor from huggingface.co and cache.
+ >>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
+
+ >>> # If image processor files are in a directory (e.g. image processor was saved using *save_pretrained('./test/saved_model/')*)
+ >>> image_processor = AutoImageProcessor.from_pretrained("./test/saved_model/")
+ ```"""
+ config = kwargs.pop("config", None)
+ trust_remote_code = kwargs.pop("trust_remote_code", False)
+ kwargs["_from_auto"] = True
+
+ config_dict, _ = ImageProcessingMixin.get_image_processor_dict(pretrained_model_name_or_path, **kwargs)
+ image_processor_class = config_dict.get("image_processor_type", None)
+ image_processor_auto_map = None
+ if "AutoImageProcessor" in config_dict.get("auto_map", {}):
+ image_processor_auto_map = config_dict["auto_map"]["AutoImageProcessor"]
+
+ # If we still don't have the image processor class, check if we're loading from a previous feature extractor config
+ # and if so, infer the image processor class from there.
+ if image_processor_class is None and image_processor_auto_map is None:
+ feature_extractor_class = config_dict.pop("feature_extractor_type", None)
+ if feature_extractor_class is not None:
+ logger.warning(
+ "Could not find image processor class in the image processor config or the model config. Loading"
+ " based on pattern matching with the model's feature extractor configuration."
+ )
+ image_processor_class = feature_extractor_class.replace("FeatureExtractor", "ImageProcessor")
+ if "AutoFeatureExtractor" in config_dict.get("auto_map", {}):
+ feature_extractor_auto_map = config_dict["auto_map"]["AutoFeatureExtractor"]
+ image_processor_auto_map = feature_extractor_auto_map.replace("FeatureExtractor", "ImageProcessor")
+ logger.warning(
+ "Could not find image processor auto map in the image processor config or the model config."
+ " Loading based on pattern matching with the model's feature extractor configuration."
+ )
+
+ # If we don't find the image processor class in the image processor config, let's try the model config.
+ if image_processor_class is None and image_processor_auto_map is None:
+ if not isinstance(config, PretrainedConfig):
+ config = AutoConfig.from_pretrained(pretrained_model_name_or_path, **kwargs)
+ # It could be in `config.image_processor_type``
+ image_processor_class = getattr(config, "image_processor_type", None)
+ if hasattr(config, "auto_map") and "AutoImageProcessor" in config.auto_map:
+ image_processor_auto_map = config.auto_map["AutoImageProcessor"]
+
+ if image_processor_class is not None:
+ # If we have custom code for a image processor, we get the proper class.
+ if image_processor_auto_map is not None:
+ if not trust_remote_code:
+ raise ValueError(
+ f"Loading {pretrained_model_name_or_path} requires you to execute the image processor file "
+ "in that repo on your local machine. Make sure you have read the code there to avoid "
+ "malicious use, then set the option `trust_remote_code=True` to remove this error."
+ )
+ if kwargs.get("revision", None) is None:
+ logger.warning(
+ "Explicitly passing a `revision` is encouraged when loading a image processor with custom "
+ "code to ensure no malicious code has been contributed in a newer revision."
+ )
+
+ module_file, class_name = image_processor_auto_map.split(".")
+ image_processor_class = get_class_from_dynamic_module(
+ pretrained_model_name_or_path, module_file + ".py", class_name, **kwargs
+ )
+ else:
+ image_processor_class = image_processor_class_from_name(image_processor_class)
+
+ return image_processor_class.from_dict(config_dict, **kwargs)
+ # Last try: we use the IMAGE_PROCESSOR_MAPPING.
+ elif type(config) in IMAGE_PROCESSOR_MAPPING:
+ image_processor_class = IMAGE_PROCESSOR_MAPPING[type(config)]
+ return image_processor_class.from_dict(config_dict, **kwargs)
+
+ raise ValueError(
+ f"Unrecognized image processor in {pretrained_model_name_or_path}. Should have a "
+ f"`image_processor_type` key in its {IMAGE_PROCESSOR_NAME} of {CONFIG_NAME}, or one of the following "
+ f"`model_type` keys in its {CONFIG_NAME}: {', '.join(c for c in IMAGE_PROCESSOR_MAPPING_NAMES.keys())}"
+ )
+
+ @staticmethod
+ def register(config_class, image_processor_class):
+ """
+ Register a new image processor for this class.
+
+ Args:
+ config_class ([`PretrainedConfig`]):
+ The configuration corresponding to the model to register.
+ image_processor_class ([`ImageProcessingMixin`]): The image processor to register.
+ """
+ IMAGE_PROCESSOR_MAPPING.register(config_class, image_processor_class)
diff --git a/src/transformers/models/auto/processing_auto.py b/src/transformers/models/auto/processing_auto.py
index f7bb87e25e..06d44ab33e 100644
--- a/src/transformers/models/auto/processing_auto.py
+++ b/src/transformers/models/auto/processing_auto.py
@@ -22,6 +22,7 @@ from collections import OrderedDict
from ...configuration_utils import PretrainedConfig
from ...dynamic_module_utils import get_class_from_dynamic_module
from ...feature_extraction_utils import FeatureExtractionMixin
+from ...image_processing_utils import ImageProcessingMixin
from ...tokenization_utils import TOKENIZER_CONFIG_FILE
from ...utils import FEATURE_EXTRACTOR_NAME, get_file_from_repo, logging
from .auto_factory import _LazyAutoMapping
@@ -32,6 +33,7 @@ from .configuration_auto import (
replace_list_option_in_docstrings,
)
from .feature_extraction_auto import AutoFeatureExtractor
+from .image_processing_auto import AutoImageProcessor
from .tokenization_auto import AutoTokenizer
@@ -189,11 +191,18 @@ class AutoProcessor:
get_file_from_repo_kwargs = {
key: kwargs[key] for key in inspect.signature(get_file_from_repo).parameters.keys() if key in kwargs
}
- # Let's start by checking whether the processor class is saved in a feature extractor
+ # Let's start by checking whether the processor class is saved in an image processor
preprocessor_config_file = get_file_from_repo(
pretrained_model_name_or_path, FEATURE_EXTRACTOR_NAME, **get_file_from_repo_kwargs
)
if preprocessor_config_file is not None:
+ config_dict, _ = ImageProcessingMixin.get_image_processor_dict(pretrained_model_name_or_path, **kwargs)
+ processor_class = config_dict.get("processor_class", None)
+ if "AutoProcessor" in config_dict.get("auto_map", {}):
+ processor_auto_map = config_dict["auto_map"]["AutoProcessor"]
+
+ # If not found, let's check whether the processor class is saved in a feature extractor config
+ if preprocessor_config_file is not None and processor_class is None:
config_dict, _ = FeatureExtractionMixin.get_feature_extractor_dict(pretrained_model_name_or_path, **kwargs)
processor_class = config_dict.get("processor_class", None)
if "AutoProcessor" in config_dict.get("auto_map", {}):
@@ -261,6 +270,13 @@ class AutoProcessor:
pretrained_model_name_or_path, trust_remote_code=trust_remote_code, **kwargs
)
except Exception:
+ try:
+ return AutoImageProcessor.from_pretrained(
+ pretrained_model_name_or_path, trust_remote_code=trust_remote_code, **kwargs
+ )
+ except Exception:
+ pass
+
try:
return AutoFeatureExtractor.from_pretrained(
pretrained_model_name_or_path, trust_remote_code=trust_remote_code, **kwargs
diff --git a/src/transformers/models/beit/__init__.py b/src/transformers/models/beit/__init__.py
index 40818fff90..9f625fe54d 100644
--- a/src/transformers/models/beit/__init__.py
+++ b/src/transformers/models/beit/__init__.py
@@ -36,6 +36,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_beit"] = ["BeitFeatureExtractor"]
+ _import_structure["image_processing_beit"] = ["BeitImageProcessor"]
try:
if not is_torch_available():
@@ -76,6 +77,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_beit import BeitFeatureExtractor
+ from .image_processing_beit import BeitImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/models/clip/__init__.py b/src/transformers/models/clip/__init__.py
index 637d78b0da..e9bfd63844 100644
--- a/src/transformers/models/clip/__init__.py
+++ b/src/transformers/models/clip/__init__.py
@@ -55,6 +55,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_clip"] = ["CLIPFeatureExtractor"]
+ _import_structure["image_processing_clip"] = ["CLIPImageProcessor"]
try:
if not is_torch_available():
@@ -126,6 +127,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_clip import CLIPFeatureExtractor
+ from .image_processing_clip import CLIPImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/models/convnext/__init__.py b/src/transformers/models/convnext/__init__.py
index 93000d5c66..109f79daea 100644
--- a/src/transformers/models/convnext/__init__.py
+++ b/src/transformers/models/convnext/__init__.py
@@ -38,6 +38,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_convnext"] = ["ConvNextFeatureExtractor"]
+ _import_structure["image_processing_convnext"] = ["ConvNextImageProcessor"]
try:
if not is_torch_available():
@@ -74,6 +75,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_convnext import ConvNextFeatureExtractor
+ from .image_processing_convnext import ConvNextImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/models/deit/__init__.py b/src/transformers/models/deit/__init__.py
index 78e3bda84e..c9932c26e2 100644
--- a/src/transformers/models/deit/__init__.py
+++ b/src/transformers/models/deit/__init__.py
@@ -35,6 +35,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_deit"] = ["DeiTFeatureExtractor"]
+ _import_structure["image_processing_deit"] = ["DeiTImageProcessor"]
try:
if not is_torch_available():
@@ -77,6 +78,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_deit import DeiTFeatureExtractor
+ from .image_processing_deit import DeiTImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/models/dpt/__init__.py b/src/transformers/models/dpt/__init__.py
index 1df82ab628..b1467adb0b 100644
--- a/src/transformers/models/dpt/__init__.py
+++ b/src/transformers/models/dpt/__init__.py
@@ -30,6 +30,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_dpt"] = ["DPTFeatureExtractor"]
+ _import_structure["image_processing_dpt"] = ["DPTImageProcessor"]
try:
if not is_torch_available():
@@ -56,6 +57,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_dpt import DPTFeatureExtractor
+ from .image_processing_dpt import DPTImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/models/flava/__init__.py b/src/transformers/models/flava/__init__.py
index 29d8240032..356504bf4f 100644
--- a/src/transformers/models/flava/__init__.py
+++ b/src/transformers/models/flava/__init__.py
@@ -38,6 +38,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_flava"] = ["FlavaFeatureExtractor"]
+ _import_structure["image_processing_flava"] = ["FlavaImageProcessor"]
_import_structure["processing_flava"] = ["FlavaProcessor"]
try:
@@ -74,6 +75,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_flava import FlavaFeatureExtractor
+ from .image_processing_flava import FlavaImageProcessor
from .processing_flava import FlavaProcessor
try:
diff --git a/src/transformers/models/glpn/__init__.py b/src/transformers/models/glpn/__init__.py
index aa667afff6..f16ee4a5a6 100644
--- a/src/transformers/models/glpn/__init__.py
+++ b/src/transformers/models/glpn/__init__.py
@@ -30,6 +30,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_glpn"] = ["GLPNFeatureExtractor"]
+ _import_structure["image_processing_glpn"] = ["GLPNImageProcessor"]
try:
if not is_torch_available():
@@ -56,6 +57,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_glpn import GLPNFeatureExtractor
+ from .image_processing_glpn import GLPNImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/models/imagegpt/__init__.py b/src/transformers/models/imagegpt/__init__.py
index c2189a3ce1..8a7ed9669d 100644
--- a/src/transformers/models/imagegpt/__init__.py
+++ b/src/transformers/models/imagegpt/__init__.py
@@ -32,6 +32,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_imagegpt"] = ["ImageGPTFeatureExtractor"]
+ _import_structure["image_processing_imagegpt"] = ["ImageGPTImageProcessor"]
try:
if not is_torch_available():
@@ -59,6 +60,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_imagegpt import ImageGPTFeatureExtractor
+ from .image_processing_imagegpt import ImageGPTImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/models/layoutlmv2/__init__.py b/src/transformers/models/layoutlmv2/__init__.py
index beaacb8158..5da6a96142 100644
--- a/src/transformers/models/layoutlmv2/__init__.py
+++ b/src/transformers/models/layoutlmv2/__init__.py
@@ -48,6 +48,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_layoutlmv2"] = ["LayoutLMv2FeatureExtractor"]
+ _import_structure["image_processing_layoutlmv2"] = ["LayoutLMv2ImageProcessor"]
try:
if not is_torch_available():
@@ -84,7 +85,7 @@ if TYPE_CHECKING:
except OptionalDependencyNotAvailable:
pass
else:
- from .feature_extraction_layoutlmv2 import LayoutLMv2FeatureExtractor
+ from .feature_extraction_layoutlmv2 import LayoutLMv2FeatureExtractor, LayoutLMv2ImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/models/layoutlmv3/__init__.py b/src/transformers/models/layoutlmv3/__init__.py
index 68a07362dc..927a940676 100644
--- a/src/transformers/models/layoutlmv3/__init__.py
+++ b/src/transformers/models/layoutlmv3/__init__.py
@@ -83,6 +83,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_layoutlmv3"] = ["LayoutLMv3FeatureExtractor"]
+ _import_structure["image_processing_layoutlmv3"] = ["LayoutLMv3ImageProcessor"]
if TYPE_CHECKING:
@@ -139,6 +140,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_layoutlmv3 import LayoutLMv3FeatureExtractor
+ from .image_processing_layoutlmv3 import LayoutLMv3ImageProcessor
else:
import sys
diff --git a/src/transformers/models/levit/__init__.py b/src/transformers/models/levit/__init__.py
index ea848f12a2..f42fb02ad0 100644
--- a/src/transformers/models/levit/__init__.py
+++ b/src/transformers/models/levit/__init__.py
@@ -29,6 +29,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_levit"] = ["LevitFeatureExtractor"]
+ _import_structure["image_processing_levit"] = ["LevitImageProcessor"]
try:
if not is_torch_available():
@@ -55,6 +56,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_levit import LevitFeatureExtractor
+ from .image_processing_levit import LevitImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/models/mobilevit/__init__.py b/src/transformers/models/mobilevit/__init__.py
index e1e088f693..d0d8962b4e 100644
--- a/src/transformers/models/mobilevit/__init__.py
+++ b/src/transformers/models/mobilevit/__init__.py
@@ -37,6 +37,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_mobilevit"] = ["MobileViTFeatureExtractor"]
+ _import_structure["image_processing_mobilevit"] = ["MobileViTImageProcessor"]
try:
if not is_torch_available():
@@ -76,6 +77,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_mobilevit import MobileViTFeatureExtractor
+ from .image_processing_mobilevit import MobileViTImageProcessor
try:
if not is_torch_available():
@@ -91,14 +93,6 @@ if TYPE_CHECKING:
MobileViTPreTrainedModel,
)
- try:
- if not is_vision_available():
- raise OptionalDependencyNotAvailable()
- except OptionalDependencyNotAvailable:
- pass
- else:
- from .feature_extraction_mobilevit import MobileViTFeatureExtractor
-
try:
if not is_tf_available():
raise OptionalDependencyNotAvailable()
diff --git a/src/transformers/models/perceiver/__init__.py b/src/transformers/models/perceiver/__init__.py
index 107c62f2eb..120d4a36fb 100644
--- a/src/transformers/models/perceiver/__init__.py
+++ b/src/transformers/models/perceiver/__init__.py
@@ -38,6 +38,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_perceiver"] = ["PerceiverFeatureExtractor"]
+ _import_structure["image_processing_perceiver"] = ["PerceiverImageProcessor"]
try:
if not is_torch_available():
@@ -71,6 +72,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_perceiver import PerceiverFeatureExtractor
+ from .image_processing_perceiver import PerceiverImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/models/poolformer/__init__.py b/src/transformers/models/poolformer/__init__.py
index 7cb5e4acac..947ac753fb 100644
--- a/src/transformers/models/poolformer/__init__.py
+++ b/src/transformers/models/poolformer/__init__.py
@@ -30,6 +30,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_poolformer"] = ["PoolFormerFeatureExtractor"]
+ _import_structure["image_processing_poolformer"] = ["PoolFormerImageProcessor"]
try:
if not is_torch_available():
@@ -55,6 +56,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_poolformer import PoolFormerFeatureExtractor
+ from .image_processing_poolformer import PoolFormerImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/models/segformer/__init__.py b/src/transformers/models/segformer/__init__.py
index 7b8b60651d..0d0aeb80ca 100644
--- a/src/transformers/models/segformer/__init__.py
+++ b/src/transformers/models/segformer/__init__.py
@@ -37,6 +37,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_segformer"] = ["SegformerFeatureExtractor"]
+ _import_structure["image_processing_segformer"] = ["SegformerImageProcessor"]
try:
if not is_torch_available():
@@ -80,6 +81,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_segformer import SegformerFeatureExtractor
+ from .image_processing_segformer import SegformerImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/models/videomae/__init__.py b/src/transformers/models/videomae/__init__.py
index fb239c6063..a363004406 100644
--- a/src/transformers/models/videomae/__init__.py
+++ b/src/transformers/models/videomae/__init__.py
@@ -45,6 +45,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_videomae"] = ["VideoMAEFeatureExtractor"]
+ _import_structure["image_processing_videomae"] = ["VideoMAEImageProcessor"]
if TYPE_CHECKING:
from .configuration_videomae import VIDEOMAE_PRETRAINED_CONFIG_ARCHIVE_MAP, VideoMAEConfig
@@ -70,6 +71,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_videomae import VideoMAEFeatureExtractor
+ from .image_processing_videomae import VideoMAEImageProcessor
else:
import sys
diff --git a/src/transformers/models/vilt/__init__.py b/src/transformers/models/vilt/__init__.py
index d05318202b..436a3a56d7 100644
--- a/src/transformers/models/vilt/__init__.py
+++ b/src/transformers/models/vilt/__init__.py
@@ -30,6 +30,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_vilt"] = ["ViltFeatureExtractor"]
+ _import_structure["image_processing_vilt"] = ["ViltImageProcessor"]
_import_structure["processing_vilt"] = ["ViltProcessor"]
try:
@@ -61,6 +62,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_vilt import ViltFeatureExtractor
+ from .image_processing_vilt import ViltImageProcessor
from .processing_vilt import ViltProcessor
try:
diff --git a/src/transformers/models/vit/__init__.py b/src/transformers/models/vit/__init__.py
index b30a9ec15d..cda977d617 100644
--- a/src/transformers/models/vit/__init__.py
+++ b/src/transformers/models/vit/__init__.py
@@ -36,6 +36,7 @@ except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_vit"] = ["ViTFeatureExtractor"]
+ _import_structure["image_processing_vit"] = ["ViTImageProcessor"]
try:
if not is_torch_available():
@@ -85,6 +86,7 @@ if TYPE_CHECKING:
pass
else:
from .feature_extraction_vit import ViTFeatureExtractor
+ from .image_processing_vit import ViTImageProcessor
try:
if not is_torch_available():
diff --git a/src/transformers/utils/dummy_vision_objects.py b/src/transformers/utils/dummy_vision_objects.py
index a3112c4454..829d704086 100644
--- a/src/transformers/utils/dummy_vision_objects.py
+++ b/src/transformers/utils/dummy_vision_objects.py
@@ -3,7 +3,7 @@
from ..utils import DummyObject, requires_backends
-class ImageProcessorMixin(metaclass=DummyObject):
+class ImageProcessingMixin(metaclass=DummyObject):
_backends = ["vision"]
def __init__(self, *args, **kwargs):
@@ -36,6 +36,13 @@ class BeitFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class BeitImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class CLIPFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -43,6 +50,13 @@ class CLIPFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class CLIPImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class ConditionalDetrFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -57,6 +71,13 @@ class ConvNextFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class ConvNextImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class DeformableDetrFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -71,6 +92,13 @@ class DeiTFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class DeiTImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class DetrFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -92,6 +120,13 @@ class DPTFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class DPTImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class FlavaFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -99,6 +134,13 @@ class FlavaFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class FlavaImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class FlavaProcessor(metaclass=DummyObject):
_backends = ["vision"]
@@ -113,6 +155,13 @@ class GLPNFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class GLPNImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class ImageGPTFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -120,6 +169,13 @@ class ImageGPTFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class ImageGPTImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class LayoutLMv2FeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -127,6 +183,13 @@ class LayoutLMv2FeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class LayoutLMv2ImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class LayoutLMv3FeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -134,6 +197,13 @@ class LayoutLMv3FeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class LayoutLMv3ImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class LevitFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -141,6 +211,13 @@ class LevitFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class LevitImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class MaskFormerFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -155,6 +232,13 @@ class MobileViTFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class MobileViTImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class OwlViTFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -169,6 +253,13 @@ class PerceiverFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class PerceiverImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class PoolFormerFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -176,6 +267,13 @@ class PoolFormerFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class PoolFormerImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class SegformerFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -183,6 +281,13 @@ class SegformerFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class SegformerImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class VideoMAEFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -190,6 +295,13 @@ class VideoMAEFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class VideoMAEImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class ViltFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
@@ -197,6 +309,13 @@ class ViltFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class ViltImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class ViltProcessor(metaclass=DummyObject):
_backends = ["vision"]
@@ -211,6 +330,13 @@ class ViTFeatureExtractor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class ViTImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class YolosFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
diff --git a/tests/models/auto/test_image_processing_auto.py b/tests/models/auto/test_image_processing_auto.py
new file mode 100644
index 0000000000..3d2009d5c8
--- /dev/null
+++ b/tests/models/auto/test_image_processing_auto.py
@@ -0,0 +1,167 @@
+# coding=utf-8
+# Copyright 2021 the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import json
+import sys
+import tempfile
+import unittest
+from pathlib import Path
+
+from transformers import (
+ CONFIG_MAPPING,
+ IMAGE_PROCESSOR_MAPPING,
+ AutoConfig,
+ AutoImageProcessor,
+ CLIPConfig,
+ CLIPImageProcessor,
+)
+from transformers.testing_utils import DUMMY_UNKNOWN_IDENTIFIER
+
+
+sys.path.append(str(Path(__file__).parent.parent.parent.parent / "utils"))
+
+from test_module.custom_configuration import CustomConfig # noqa E402
+from test_module.custom_image_processing import CustomImageProcessor # noqa E402
+
+
+class AutoImageProcessorTest(unittest.TestCase):
+ def test_image_processor_from_model_shortcut(self):
+ config = AutoImageProcessor.from_pretrained("openai/clip-vit-base-patch32")
+ self.assertIsInstance(config, CLIPImageProcessor)
+
+ def test_image_processor_from_local_directory_from_key(self):
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ processor_tmpfile = Path(tmpdirname) / "preprocessor_config.json"
+ config_tmpfile = Path(tmpdirname) / "config.json"
+ json.dump(
+ {"image_processor_type": "CLIPImageProcessor", "processor_class": "CLIPProcessor"},
+ open(processor_tmpfile, "w"),
+ )
+ json.dump({"model_type": "clip"}, open(config_tmpfile, "w"))
+
+ config = AutoImageProcessor.from_pretrained(tmpdirname)
+ self.assertIsInstance(config, CLIPImageProcessor)
+
+ def test_image_processor_from_local_directory_from_feature_extractor_key(self):
+ # Ensure we can load the image processor from the feature extractor config
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ processor_tmpfile = Path(tmpdirname) / "preprocessor_config.json"
+ config_tmpfile = Path(tmpdirname) / "config.json"
+ json.dump(
+ {"feature_extractor_type": "CLIPFeatureExtractor", "processor_class": "CLIPProcessor"},
+ open(processor_tmpfile, "w"),
+ )
+ json.dump({"model_type": "clip"}, open(config_tmpfile, "w"))
+
+ config = AutoImageProcessor.from_pretrained(tmpdirname)
+ self.assertIsInstance(config, CLIPImageProcessor)
+
+ def test_image_processor_from_local_directory_from_config(self):
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model_config = CLIPConfig()
+
+ # Create a dummy config file with image_proceesor_type
+ processor_tmpfile = Path(tmpdirname) / "preprocessor_config.json"
+ config_tmpfile = Path(tmpdirname) / "config.json"
+ json.dump(
+ {"image_processor_type": "CLIPImageProcessor", "processor_class": "CLIPProcessor"},
+ open(processor_tmpfile, "w"),
+ )
+ json.dump({"model_type": "clip"}, open(config_tmpfile, "w"))
+
+ # remove image_processor_type to make sure config.json alone is enough to load image processor locally
+ config_dict = AutoImageProcessor.from_pretrained(tmpdirname).to_dict()
+
+ config_dict.pop("image_processor_type")
+ config = CLIPImageProcessor(**config_dict)
+
+ # save in new folder
+ model_config.save_pretrained(tmpdirname)
+ config.save_pretrained(tmpdirname)
+
+ config = AutoImageProcessor.from_pretrained(tmpdirname)
+
+ # make sure private variable is not incorrectly saved
+ dict_as_saved = json.loads(config.to_json_string())
+ self.assertTrue("_processor_class" not in dict_as_saved)
+
+ self.assertIsInstance(config, CLIPImageProcessor)
+
+ def test_image_processor_from_local_file(self):
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ processor_tmpfile = Path(tmpdirname) / "preprocessor_config.json"
+ json.dump(
+ {"image_processor_type": "CLIPImageProcessor", "processor_class": "CLIPProcessor"},
+ open(processor_tmpfile, "w"),
+ )
+
+ config = AutoImageProcessor.from_pretrained(processor_tmpfile)
+ self.assertIsInstance(config, CLIPImageProcessor)
+
+ def test_repo_not_found(self):
+ with self.assertRaisesRegex(
+ EnvironmentError, "clip-base is not a local folder and is not a valid model identifier"
+ ):
+ _ = AutoImageProcessor.from_pretrained("clip-base")
+
+ def test_revision_not_found(self):
+ with self.assertRaisesRegex(
+ EnvironmentError, r"aaaaaa is not a valid git identifier \(branch name, tag name or commit id\)"
+ ):
+ _ = AutoImageProcessor.from_pretrained(DUMMY_UNKNOWN_IDENTIFIER, revision="aaaaaa")
+
+ def test_image_processor_not_found(self):
+ with self.assertRaisesRegex(
+ EnvironmentError,
+ "hf-internal-testing/config-no-model does not appear to have a file named preprocessor_config.json.",
+ ):
+ _ = AutoImageProcessor.from_pretrained("hf-internal-testing/config-no-model")
+
+ def test_from_pretrained_dynamic_image_processor(self):
+ model = AutoImageProcessor.from_pretrained(
+ "hf-internal-testing/test_dynamic_image_processor", trust_remote_code=True
+ )
+ self.assertEqual(model.__class__.__name__, "NewImageProcessor")
+
+ def test_new_image_processor_registration(self):
+ try:
+ AutoConfig.register("custom", CustomConfig)
+ AutoImageProcessor.register(CustomConfig, CustomImageProcessor)
+ # Trying to register something existing in the Transformers library will raise an error
+ with self.assertRaises(ValueError):
+ AutoImageProcessor.register(CLIPConfig, CLIPImageProcessor)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ processor_tmpfile = Path(tmpdirname) / "preprocessor_config.json"
+ config_tmpfile = Path(tmpdirname) / "config.json"
+ json.dump(
+ {"feature_extractor_type": "CLIPFeatureExtractor", "processor_class": "CLIPProcessor"},
+ open(processor_tmpfile, "w"),
+ )
+ json.dump({"model_type": "clip"}, open(config_tmpfile, "w"))
+
+ image_processor = CustomImageProcessor.from_pretrained(tmpdirname)
+
+ # Now that the config is registered, it can be used as any other config with the auto-API
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ image_processor.save_pretrained(tmp_dir)
+ new_image_processor = AutoImageProcessor.from_pretrained(tmp_dir)
+ self.assertIsInstance(new_image_processor, CustomImageProcessor)
+
+ finally:
+ if "custom" in CONFIG_MAPPING._extra_content:
+ del CONFIG_MAPPING._extra_content["custom"]
+ if CustomConfig in IMAGE_PROCESSOR_MAPPING._extra_content:
+ del IMAGE_PROCESSOR_MAPPING._extra_content[CustomConfig]
diff --git a/utils/test_module/custom_image_processing.py b/utils/test_module/custom_image_processing.py
new file mode 100644
index 0000000000..e4984854ad
--- /dev/null
+++ b/utils/test_module/custom_image_processing.py
@@ -0,0 +1,5 @@
+from transformers import CLIPImageProcessor
+
+
+class CustomImageProcessor(CLIPImageProcessor):
+ pass