From 3c00b885b92fbcd0e7451e56ccf424a2d5a19bbb Mon Sep 17 00:00:00 2001
From: Gustavo Isturiz <48292332+gisturiz@users.noreply.github.com>
Date: Tue, 20 Feb 2024 18:13:15 +0100
Subject: [PATCH] Added image_captioning version in es and included in toctree
file (#29104)
added image_captioning version in es and included in toctree file
---
docs/source/es/_toctree.yml | 2 +
docs/source/es/tasks/image_captioning.md | 266 +++++++++++++++++++++++
2 files changed, 268 insertions(+)
create mode 100644 docs/source/es/tasks/image_captioning.md
diff --git a/docs/source/es/_toctree.yml b/docs/source/es/_toctree.yml
index e9a99b5959..0be8191ecf 100644
--- a/docs/source/es/_toctree.yml
+++ b/docs/source/es/_toctree.yml
@@ -31,6 +31,8 @@
title: Generación de resúmenes
- local: tasks/multiple_choice
title: Selección múltiple
+ - local: tasks/image_captioning
+ title: Subtítulos de imágenes
title: Procesamiento del Lenguaje Natural
- isExpanded: false
sections:
diff --git a/docs/source/es/tasks/image_captioning.md b/docs/source/es/tasks/image_captioning.md
new file mode 100644
index 0000000000..f06f6eda0a
--- /dev/null
+++ b/docs/source/es/tasks/image_captioning.md
@@ -0,0 +1,266 @@
+
+
+# Subtítulos de Imágenes
+
+[[open-in-colab]]
+
+Los subtítulos de imágenes es la tarea de predecir un subtítulo para una imagen dada. Las aplicaciones comunes en el mundo real incluyen
+ayudar a personas con discapacidad visual que les puede ayudar a navegar a través de diferentes situaciones. Por lo tanto, los subtítulos de imágenes
+ayuda a mejorar la accesibilidad del contenido para las personas describiéndoles imágenes.
+
+Esta guía te mostrará cómo:
+
+* Ajustar un modelo de subtítulos de imágenes.
+* Usar el modelo ajustado para inferencia.
+
+Antes de comenzar, asegúrate de tener todas las bibliotecas necesarias instaladas:
+
+```bash
+pip install transformers datasets evaluate -q
+pip install jiwer -q
+```
+
+Te animamos a que inicies sesión en tu cuenta de Hugging Face para que puedas subir y compartir tu modelo con la comunidad. Cuando se te solicite, ingresa tu token para iniciar sesión:
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+## Cargar el conjunto de datos de subtítulos BLIP de Pokémon
+
+Utiliza la biblioteca 🤗 Dataset para cargar un conjunto de datos que consiste en pares {image-caption}. Para crear tu propio conjunto de datos de subtítulos de imágenes
+en PyTorch, puedes seguir [este cuaderno](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/GIT/Fine_tune_GIT_on_an_image_captioning_dataset.ipynb).
+
+```python
+from datasets import load_dataset
+
+ds = load_dataset("lambdalabs/pokemon-blip-captions")
+ds
+```
+```bash
+DatasetDict({
+ train: Dataset({
+ features: ['image', 'text'],
+ num_rows: 833
+ })
+})
+```
+
+El conjunto de datos tiene dos características, `image` y `text`.
+
+
+
+Muchos conjuntos de datos de subtítulos de imágenes contienen múltiples subtítulos por imagen. En esos casos, una estrategia común es muestrear aleatoriamente un subtítulo entre los disponibles durante el entrenamiento.
+
+
+
+Divide el conjunto de entrenamiento del conjunto de datos en un conjunto de entrenamiento y de prueba con el método [`~datasets.Dataset.train_test_split`]:
+
+```python
+ds = ds["train"].train_test_split(test_size=0.1)
+train_ds = ds["train"]
+test_ds = ds["test"]
+```
+
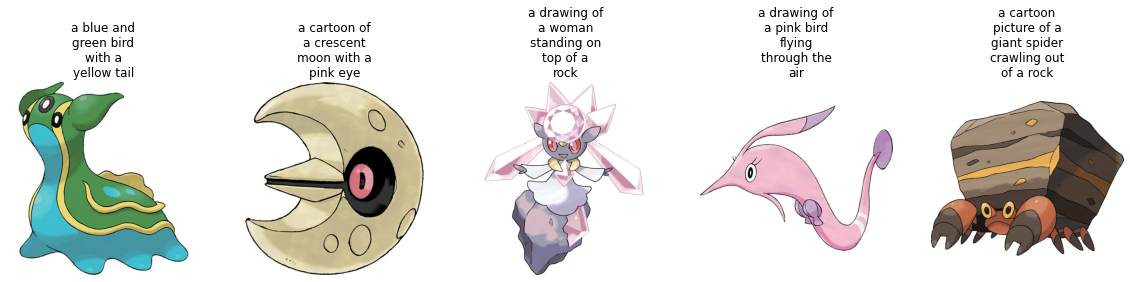
+Vamos a visualizar un par de muestras del conjunto de entrenamiento.
+
+```python
+from textwrap import wrap
+import matplotlib.pyplot as plt
+import numpy as np
+
+
+def plot_images(images, captions):
+ plt.figure(figsize=(20, 20))
+ for i in range(len(images)):
+ ax = plt.subplot(1, len(images), i + 1)
+ caption = captions[i]
+ caption = "\n".join(wrap(caption, 12))
+ plt.title(caption)
+ plt.imshow(images[i])
+ plt.axis("off")
+
+
+sample_images_to_visualize = [np.array(train_ds[i]["image"]) for i in range(5)]
+sample_captions = [train_ds[i]["text"] for i in range(5)]
+plot_images(sample_images_to_visualize, sample_captions)
+```
+
+
+
+
+

+