diff --git a/docs/source/en/main_classes/trainer.md b/docs/source/en/main_classes/trainer.md
index 462cea55dc..e9a93bbff7 100644
--- a/docs/source/en/main_classes/trainer.md
+++ b/docs/source/en/main_classes/trainer.md
@@ -740,3 +740,27 @@ Sections that were moved:
| Gradient Clipping
| Getting The Model Weights Out
]
+
+## Boost your fine-tuning performances using NEFTune
+
+
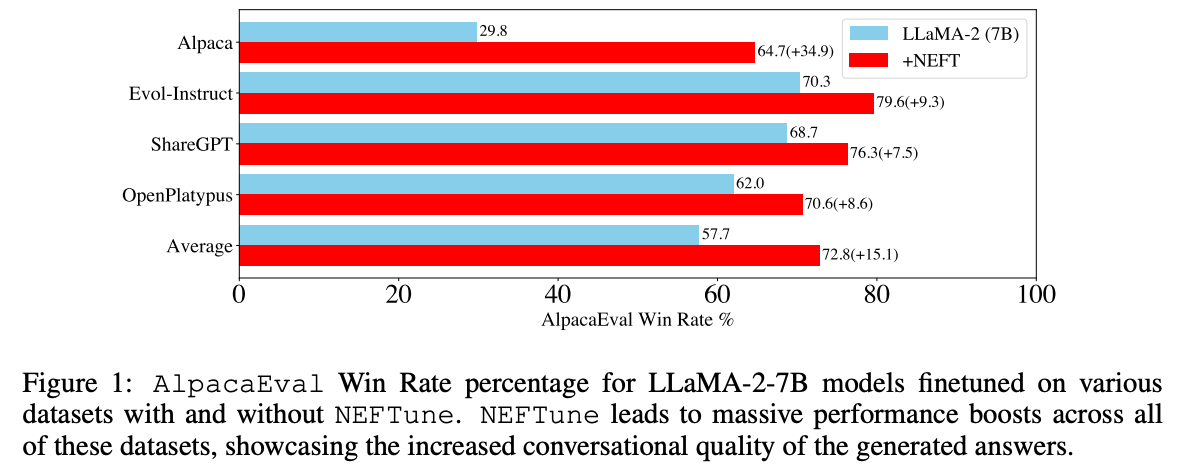
+NEFTune is a technique to boost the performance of chat models and was introduced by the paper “NEFTune: Noisy Embeddings Improve Instruction Finetuning” from Jain et al. it consists of adding noise to the embedding vectors during training. According to the abstract of the paper:
+
+> Standard finetuning of LLaMA-2-7B using Alpaca achieves 29.79% on AlpacaEval, which rises to 64.69% using noisy embeddings. NEFTune also improves over strong baselines on modern instruction datasets. Models trained with Evol-Instruct see a 10% improvement, with ShareGPT an 8% improvement, and with OpenPlatypus an 8% improvement. Even powerful models further refined with RLHF such as LLaMA-2-Chat benefit from additional training with NEFTune.
+
+
+
+