Update notebook link and fix few working issues.
Signed-off-by: Morgan Funtowicz <morgan@huggingface.co>
This commit is contained in:
@@ -32,7 +32,7 @@
|
||||
"was not well suited for the kind of hardware we're currently leveraging due to bad parallelization capabilities. \n",
|
||||
"\n",
|
||||
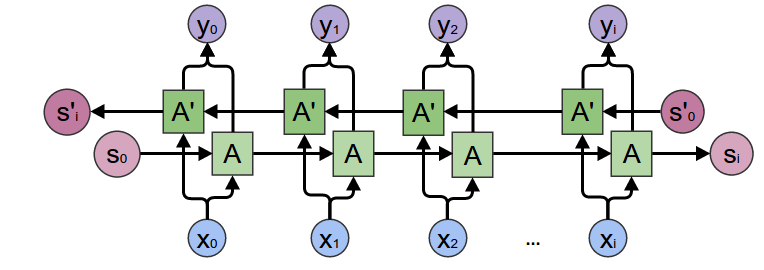
"Some extensions were provided by the academic community, such as Bidirectional RNN ([Schuster & Paliwal., 1997](https://www.researchgate.net/publication/3316656_Bidirectional_recurrent_neural_networks), [Graves & al., 2005](https://mediatum.ub.tum.de/doc/1290195/file.pdf)), \n",
|
||||
"which can be seen as a concatenation of two sequential process, on going forward, the other one going backward over the sequence input.\n",
|
||||
"which can be seen as a concatenation of two sequential process, one going forward, the other one going backward over the sequence input.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
@@ -49,8 +49,7 @@
|
||||
"on translation tasks but it quickly extended to almost all the tasks RNNs were State-of-the-Art at that time.\n",
|
||||
"\n",
|
||||
"One advantage of Transformer over its RNN counterpart was its non sequential attention model. Remember, the RNNs had to\n",
|
||||
"iterate over each element of the input sequence one-by-one and carry an \"updatable-state\" between each hop. With Transformer\n",
|
||||
"the, the model is able to look at every position in the sequence, at the same time, in one operation.\n",
|
||||
"iterate over each element of the input sequence one-by-one and carry an \"updatable-state\" between each hop. With Transformer, the model is able to look at every position in the sequence, at the same time, in one operation.\n",
|
||||
"\n",
|
||||
"For a deep-dive into the Transformer architecture, [The Annotated Transformer](https://nlp.seas.harvard.edu/2018/04/03/attention.html#encoder-and-decoder-stacks) \n",
|
||||
"will drive you along all the details of the paper.\n",
|
||||
@@ -68,7 +67,7 @@
|
||||
"source": [
|
||||
"## Getting started with transformers\n",
|
||||
"\n",
|
||||
"For the rest of this notebook, we will use a BERT model, as it's the most simple and there are plenty of content about it\n",
|
||||
"For the rest of this notebook, we will use the [BERT (Devlin & al., 2018)](https://arxiv.org/abs/1810.04805) architecture, as it's the most simple and there are plenty of content about it\n",
|
||||
"over the internet, it will be easy to dig more over this architecture if you want to.\n",
|
||||
"\n",
|
||||
"The transformers library allows you to benefits from large, pretrained language models without requiring a huge and costly computational\n",
|
||||
|
||||
@@ -11,7 +11,7 @@ Pull Request and we'll review it so it can be included here.
|
||||
|
||||
| Notebook | Description | |
|
||||
|:----------|:-------------:|------:|
|
||||
| [Getting Started Tokenizers](01-training_tokenizers.ipynb) | How to train and use your very own tokenizer |[](https://colab.research.google.com/github/huggingface/transformers/blob/docker-notebooks/notebooks/01-training-tokenizers.ipynb) |
|
||||
| [Getting Started Tokenizers](01-training-tokenizers.ipynb) | How to train and use your very own tokenizer |[](https://colab.research.google.com/github/huggingface/transformers/blob/docker-notebooks/notebooks/01-training-tokenizers.ipynb) |
|
||||
| [Getting Started Transformers](02-transformers.ipynb) | How to easily start using transformers | [](https://colab.research.google.com/github/huggingface/transformers/blob/docker-notebooks/notebooks/01-training-tokenizers.ipynb) |
|
||||
| [How to use Pipelines](03-pipelines.ipynb) | Simple and efficient way to use State-of-the-Art models on downstream tasks through transformers | [](https://colab.research.google.com/github/huggingface/transformers/blob/docker-notebooks/notebooks/01-training-tokenizers.ipynb) |
|
||||
| [How to train a language model](https://github.com/huggingface/blog/blob/master/notebooks/01_how_to_train.ipynb)| Highlight all the steps to effectively train Transformer model on custom data | [](https://colab.research.google.com/github/huggingface/blog/blob/master/notebooks/01_how_to_train.ipynb)|
|
||||
|
||||
Reference in New Issue
Block a user