From 17a7b49bda15353cc49172a0cfeb839a9719e018 Mon Sep 17 00:00:00 2001
From: amyeroberts <22614925+amyeroberts@users.noreply.github.com>
Date: Wed, 30 Nov 2022 14:50:55 +0000
Subject: [PATCH] Update doc examples feature extractor -> image processor
(#20501)
* Update doc example feature extractor -> image processor
* Apply suggestions from code review
---
docs/source/en/autoclass_tutorial.mdx | 20 ++++--
docs/source/en/create_a_model.mdx | 64 ++++++++++++++-----
docs/source/en/glossary.mdx | 2 +-
docs/source/en/main_classes/processors.mdx | 4 +-
docs/source/en/model_doc/beit.mdx | 4 +-
docs/source/en/model_doc/cvt.mdx | 2 +-
docs/source/en/model_doc/deformable_detr.mdx | 2 +-
docs/source/en/model_doc/deit.mdx | 2 +-
docs/source/en/model_doc/detr.mdx | 12 ++--
docs/source/en/model_doc/glpn.mdx | 2 +-
docs/source/en/model_doc/imagegpt.mdx | 2 +-
docs/source/en/model_doc/levit.mdx | 4 +-
docs/source/en/model_doc/maskformer.mdx | 4 +-
docs/source/en/model_doc/mobilenet_v1.mdx | 2 +-
docs/source/en/model_doc/mobilenet_v2.mdx | 2 +-
docs/source/en/model_doc/mobilevit.mdx | 2 +-
docs/source/en/model_doc/poolformer.mdx | 2 +-
docs/source/en/model_doc/regnet.mdx | 2 +-
docs/source/en/model_doc/resnet.mdx | 2 +-
docs/source/en/model_doc/segformer.mdx | 6 +-
docs/source/en/model_doc/swin.mdx | 2 +-
docs/source/en/model_doc/swinv2.mdx | 2 +-
.../source/en/model_doc/table-transformer.mdx | 2 +-
docs/source/en/model_doc/trocr.mdx | 4 +-
docs/source/en/model_doc/videomae.mdx | 2 +-
.../en/model_doc/vision-encoder-decoder.mdx | 14 ++--
docs/source/en/model_doc/visual_bert.mdx | 2 +-
docs/source/en/model_doc/vit.mdx | 4 +-
docs/source/en/model_doc/vit_mae.mdx | 2 +-
docs/source/en/model_doc/yolos.mdx | 2 +-
docs/source/en/philosophy.mdx | 4 +-
docs/source/en/preprocessing.mdx | 22 +++----
docs/source/en/quicktour.mdx | 6 +-
docs/source/en/task_summary.mdx | 10 +--
docs/source/en/tasks/image_classification.mdx | 26 ++++----
.../source/en/tasks/semantic_segmentation.mdx | 10 +--
docs/source/en/troubleshooting.mdx | 2 +-
src/transformers/models/beit/modeling_beit.py | 18 +++---
.../models/beit/modeling_flax_beit.py | 22 +++----
.../modeling_conditional_detr.py | 46 ++++++-------
.../models/convnext/modeling_convnext.py | 6 +-
.../models/convnext/modeling_tf_convnext.py | 16 ++---
src/transformers/models/cvt/modeling_cvt.py | 6 +-
.../models/cvt/modeling_tf_cvt.py | 16 ++---
.../data2vec/modeling_data2vec_vision.py | 12 ++--
.../data2vec/modeling_tf_data2vec_vision.py | 12 ++--
.../modeling_deformable_detr.py | 23 ++++---
src/transformers/models/deit/modeling_deit.py | 18 +++---
.../models/deit/modeling_tf_deit.py | 18 +++---
src/transformers/models/detr/modeling_detr.py | 41 ++++++------
src/transformers/models/dpt/modeling_dpt.py | 18 +++---
src/transformers/models/glpn/modeling_glpn.py | 10 +--
.../models/imagegpt/modeling_imagegpt.py | 24 +++----
.../models/levit/modeling_levit.py | 6 +-
.../models/maskformer/modeling_maskformer.py | 40 ++++++------
.../mobilenet_v1/modeling_mobilenet_v1.py | 6 +-
.../mobilenet_v2/modeling_mobilenet_v2.py | 12 ++--
.../models/mobilevit/modeling_mobilevit.py | 12 ++--
.../models/mobilevit/modeling_tf_mobilevit.py | 12 ++--
.../models/perceiver/modeling_perceiver.py | 24 +++----
.../models/poolformer/modeling_poolformer.py | 6 +-
.../models/regnet/modeling_regnet.py | 6 +-
.../models/regnet/modeling_tf_regnet.py | 6 +-
.../models/resnet/modeling_resnet.py | 6 +-
.../models/resnet/modeling_tf_resnet.py | 6 +-
.../models/segformer/modeling_segformer.py | 10 +--
.../models/segformer/modeling_tf_segformer.py | 12 ++--
src/transformers/models/swin/modeling_swin.py | 12 ++--
.../models/swin/modeling_tf_swin.py | 12 ++--
.../models/swinv2/modeling_swinv2.py | 12 ++--
.../modeling_table_transformer.py | 25 ++++----
.../models/trocr/processing_trocr.py | 2 +-
src/transformers/models/van/modeling_van.py | 6 +-
.../models/videomae/modeling_videomae.py | 22 +++----
.../modeling_flax_vision_encoder_decoder.py | 26 ++++----
.../modeling_flax_vision_text_dual_encoder.py | 4 +-
.../models/vit/modeling_flax_vit.py | 16 ++---
.../models/vit/modeling_tf_vit.py | 6 +-
src/transformers/models/vit/modeling_vit.py | 12 ++--
.../models/vit_mae/modeling_tf_vit_mae.py | 16 ++---
.../models/vit_mae/modeling_vit_mae.py | 16 ++---
.../models/vit_msn/modeling_vit_msn.py | 16 ++---
.../models/yolos/modeling_yolos.py | 20 +++---
templates/adding_a_new_model/README.md | 4 +-
84 files changed, 497 insertions(+), 458 deletions(-)
diff --git a/docs/source/en/autoclass_tutorial.mdx b/docs/source/en/autoclass_tutorial.mdx
index 00ad93881b..6b44e41a85 100644
--- a/docs/source/en/autoclass_tutorial.mdx
+++ b/docs/source/en/autoclass_tutorial.mdx
@@ -23,6 +23,7 @@ Remember, architecture refers to the skeleton of the model and checkpoints are t
In this tutorial, learn to:
* Load a pretrained tokenizer.
+* Load a pretrained image processor
* Load a pretrained feature extractor.
* Load a pretrained processor.
* Load a pretrained model.
@@ -49,9 +50,20 @@ Then tokenize your input as shown below:
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
+## AutoImageProcessor
+
+For vision tasks, an image processor processes the image into the correct input format.
+
+```py
+>>> from transformers import AutoImageProcessor
+
+>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
+```
+
+
## AutoFeatureExtractor
-For audio and vision tasks, a feature extractor processes the audio signal or image into the correct input format.
+For audio tasks, a feature extractor processes the audio signal the correct input format.
Load a feature extractor with [`AutoFeatureExtractor.from_pretrained`]:
@@ -65,7 +77,7 @@ Load a feature extractor with [`AutoFeatureExtractor.from_pretrained`]:
## AutoProcessor
-Multimodal tasks require a processor that combines two types of preprocessing tools. For example, the [LayoutLMV2](model_doc/layoutlmv2) model requires a feature extractor to handle images and a tokenizer to handle text; a processor combines both of them.
+Multimodal tasks require a processor that combines two types of preprocessing tools. For example, the [LayoutLMV2](model_doc/layoutlmv2) model requires an image processor to handle images and a tokenizer to handle text; a processor combines both of them.
Load a processor with [`AutoProcessor.from_pretrained`]:
@@ -103,7 +115,7 @@ TensorFlow and Flax checkpoints are not affected, and can be loaded within PyTor
-Generally, we recommend using the `AutoTokenizer` class and the `AutoModelFor` class to load pretrained instances of models. This will ensure you load the correct architecture every time. In the next [tutorial](preprocessing), learn how to use your newly loaded tokenizer, feature extractor and processor to preprocess a dataset for fine-tuning.
+Generally, we recommend using the `AutoTokenizer` class and the `AutoModelFor` class to load pretrained instances of models. This will ensure you load the correct architecture every time. In the next [tutorial](preprocessing), learn how to use your newly loaded tokenizer, image processor, feature extractor and processor to preprocess a dataset for fine-tuning.
Finally, the `TFAutoModelFor` classes let you load a pretrained model for a given task (see [here](model_doc/auto) for a complete list of available tasks). For example, load a model for sequence classification with [`TFAutoModelForSequenceClassification.from_pretrained`]:
@@ -122,6 +134,6 @@ Easily reuse the same checkpoint to load an architecture for a different task:
>>> model = TFAutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")
```
-Generally, we recommend using the `AutoTokenizer` class and the `TFAutoModelFor` class to load pretrained instances of models. This will ensure you load the correct architecture every time. In the next [tutorial](preprocessing), learn how to use your newly loaded tokenizer, feature extractor and processor to preprocess a dataset for fine-tuning.
+Generally, we recommend using the `AutoTokenizer` class and the `TFAutoModelFor` class to load pretrained instances of models. This will ensure you load the correct architecture every time. In the next [tutorial](preprocessing), learn how to use your newly loaded tokenizer, image processor, feature extractor and processor to preprocess a dataset for fine-tuning.
diff --git a/docs/source/en/create_a_model.mdx b/docs/source/en/create_a_model.mdx
index 51d2b2cb90..b0bafa4589 100644
--- a/docs/source/en/create_a_model.mdx
+++ b/docs/source/en/create_a_model.mdx
@@ -17,7 +17,8 @@ An [`AutoClass`](model_doc/auto) automatically infers the model architecture and
- Load and customize a model configuration.
- Create a model architecture.
- Create a slow and fast tokenizer for text.
-- Create a feature extractor for audio or image tasks.
+- Create an image processor for vision tasks.
+- Create a feature extractor for audio tasks.
- Create a processor for multimodal tasks.
## Configuration
@@ -244,21 +245,21 @@ By default, [`AutoTokenizer`] will try to load a fast tokenizer. You can disable
-## Feature Extractor
+## Image Processor
-A feature extractor processes audio or image inputs. It inherits from the base [`~feature_extraction_utils.FeatureExtractionMixin`] class, and may also inherit from the [`ImageFeatureExtractionMixin`] class for processing image features or the [`SequenceFeatureExtractor`] class for processing audio inputs.
+An image processor processes vision inputs. It inherits from the base [`~image_processing_utils.ImageProcessingMixin`] class.
-Depending on whether you are working on an audio or vision task, create a feature extractor associated with the model you're using. For example, create a default [`ViTFeatureExtractor`] if you are using [ViT](model_doc/vit) for image classification:
+To use, create an image processor associated with the model you're using. For example, create a default [`ViTImageProcessor`] if you are using [ViT](model_doc/vit) for image classification:
```py
->>> from transformers import ViTFeatureExtractor
+>>> from transformers import ViTImageProcessor
->>> vit_extractor = ViTFeatureExtractor()
+>>> vit_extractor = ViTImageProcessor()
>>> print(vit_extractor)
-ViTFeatureExtractor {
+ViTImageProcessor {
"do_normalize": true,
"do_resize": true,
- "feature_extractor_type": "ViTFeatureExtractor",
+ "feature_extractor_type": "ViTImageProcessor",
"image_mean": [
0.5,
0.5,
@@ -276,21 +277,21 @@ ViTFeatureExtractor {
-If you aren't looking for any customization, just use the `from_pretrained` method to load a model's default feature extractor parameters.
+If you aren't looking for any customization, just use the `from_pretrained` method to load a model's default image processor parameters.
-Modify any of the [`ViTFeatureExtractor`] parameters to create your custom feature extractor:
+Modify any of the [`ViTImageProcessor`] parameters to create your custom image processor:
```py
->>> from transformers import ViTFeatureExtractor
+>>> from transformers import ViTImageProcessor
->>> my_vit_extractor = ViTFeatureExtractor(resample="PIL.Image.BOX", do_normalize=False, image_mean=[0.3, 0.3, 0.3])
+>>> my_vit_extractor = ViTImageProcessor(resample="PIL.Image.BOX", do_normalize=False, image_mean=[0.3, 0.3, 0.3])
>>> print(my_vit_extractor)
-ViTFeatureExtractor {
+ViTImageProcessor {
"do_normalize": false,
"do_resize": true,
- "feature_extractor_type": "ViTFeatureExtractor",
+ "feature_extractor_type": "ViTImageProcessor",
"image_mean": [
0.3,
0.3,
@@ -306,7 +307,11 @@ ViTFeatureExtractor {
}
```
-For audio inputs, you can create a [`Wav2Vec2FeatureExtractor`] and customize the parameters in a similar way:
+## Feature Extractor
+
+A feature extractor processes audio inputs. It inherits from the base [`~feature_extraction_utils.FeatureExtractionMixin`] class, and may also inherit from the [`SequenceFeatureExtractor`] class for processing audio inputs.
+
+To use, create a feature extractor associated with the model you're using. For example, create a default [`Wav2Vec2FeatureExtractor`] if you are using [Wav2Vec2](model_doc/wav2vec2) for audio classification:
```py
>>> from transformers import Wav2Vec2FeatureExtractor
@@ -324,9 +329,34 @@ Wav2Vec2FeatureExtractor {
}
```
+
+
+If you aren't looking for any customization, just use the `from_pretrained` method to load a model's default feature extractor parameters.
+
+
+
+Modify any of the [`Wav2Vec2FeatureExtractor`] parameters to create your custom feature extractor:
+
+```py
+>>> from transformers import Wav2Vec2FeatureExtractor
+
+>>> w2v2_extractor = Wav2Vec2FeatureExtractor(sampling_rate=8000, do_normalize=False)
+>>> print(w2v2_extractor)
+Wav2Vec2FeatureExtractor {
+ "do_normalize": false,
+ "feature_extractor_type": "Wav2Vec2FeatureExtractor",
+ "feature_size": 1,
+ "padding_side": "right",
+ "padding_value": 0.0,
+ "return_attention_mask": false,
+ "sampling_rate": 8000
+}
+```
+
+
## Processor
-For models that support multimodal tasks, 🤗 Transformers offers a processor class that conveniently wraps a feature extractor and tokenizer into a single object. For example, let's use the [`Wav2Vec2Processor`] for an automatic speech recognition task (ASR). ASR transcribes audio to text, so you will need a feature extractor and a tokenizer.
+For models that support multimodal tasks, 🤗 Transformers offers a processor class that conveniently wraps processing classes such as a feature extractor and a tokenizer into a single object. For example, let's use the [`Wav2Vec2Processor`] for an automatic speech recognition task (ASR). ASR transcribes audio to text, so you will need a feature extractor and a tokenizer.
Create a feature extractor to handle the audio inputs:
@@ -352,4 +382,4 @@ Combine the feature extractor and tokenizer in [`Wav2Vec2Processor`]:
>>> processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
```
-With two basic classes - configuration and model - and an additional preprocessing class (tokenizer, feature extractor, or processor), you can create any of the models supported by 🤗 Transformers. Each of these base classes are configurable, allowing you to use the specific attributes you want. You can easily setup a model for training or modify an existing pretrained model to fine-tune.
\ No newline at end of file
+With two basic classes - configuration and model - and an additional preprocessing class (tokenizer, image processor, feature extractor, or processor), you can create any of the models supported by 🤗 Transformers. Each of these base classes are configurable, allowing you to use the specific attributes you want. You can easily setup a model for training or modify an existing pretrained model to fine-tune.
diff --git a/docs/source/en/glossary.mdx b/docs/source/en/glossary.mdx
index a1edb53f95..4c984f389b 100644
--- a/docs/source/en/glossary.mdx
+++ b/docs/source/en/glossary.mdx
@@ -299,7 +299,7 @@ whole text, individual words).
### pixel values
-A tensor of the numerical representations of an image that is passed to a model. The pixel values have a shape of [`batch_size`, `num_channels`, `height`, `width`], and are generated from a feature extractor.
+A tensor of the numerical representations of an image that is passed to a model. The pixel values have a shape of [`batch_size`, `num_channels`, `height`, `width`], and are generated from an image processor.
### pooling
diff --git a/docs/source/en/main_classes/processors.mdx b/docs/source/en/main_classes/processors.mdx
index d37f8a1a40..5530720b1c 100644
--- a/docs/source/en/main_classes/processors.mdx
+++ b/docs/source/en/main_classes/processors.mdx
@@ -20,8 +20,8 @@ Processors can mean two different things in the Transformers library:
## Multi-modal processors
Any multi-modal model will require an object to encode or decode the data that groups several modalities (among text,
-vision and audio). This is handled by objects called processors, which group tokenizers (for the text modality) and
-feature extractors (for vision and audio).
+vision and audio). This is handled by objects called processors, which group together two or more processing objects
+such as tokenizers (for the text modality), image processors (for vision) and feature extractors (for audio).
Those processors inherit from the following base class that implements the saving and loading functionality:
diff --git a/docs/source/en/model_doc/beit.mdx b/docs/source/en/model_doc/beit.mdx
index 82e4a3a159..dea2522fb1 100644
--- a/docs/source/en/model_doc/beit.mdx
+++ b/docs/source/en/model_doc/beit.mdx
@@ -40,12 +40,12 @@ Tips:
- BEiT models are regular Vision Transformers, but pre-trained in a self-supervised way rather than supervised. They
outperform both the [original model (ViT)](vit) as well as [Data-efficient Image Transformers (DeiT)](deit) when fine-tuned on ImageNet-1K and CIFAR-100. You can check out demo notebooks regarding inference as well as
fine-tuning on custom data [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer) (you can just replace
- [`ViTFeatureExtractor`] by [`BeitFeatureExtractor`] and
+ [`ViTFeatureExtractor`] by [`BeitImageProcessor`] and
[`ViTForImageClassification`] by [`BeitForImageClassification`]).
- There's also a demo notebook available which showcases how to combine DALL-E's image tokenizer with BEiT for
performing masked image modeling. You can find it [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/BEiT).
- As the BEiT models expect each image to be of the same size (resolution), one can use
- [`BeitFeatureExtractor`] to resize (or rescale) and normalize images for the model.
+ [`BeitImageProcessor`] to resize (or rescale) and normalize images for the model.
- Both the patch resolution and image resolution used during pre-training or fine-tuning are reflected in the name of
each checkpoint. For example, `microsoft/beit-base-patch16-224` refers to a base-sized architecture with patch
resolution of 16x16 and fine-tuning resolution of 224x224. All checkpoints can be found on the [hub](https://huggingface.co/models?search=microsoft/beit).
diff --git a/docs/source/en/model_doc/cvt.mdx b/docs/source/en/model_doc/cvt.mdx
index a46ae68d58..873450cf83 100644
--- a/docs/source/en/model_doc/cvt.mdx
+++ b/docs/source/en/model_doc/cvt.mdx
@@ -32,7 +32,7 @@ a crucial component in existing Vision Transformers, can be safely removed in ou
Tips:
- CvT models are regular Vision Transformers, but trained with convolutions. They outperform the [original model (ViT)](vit) when fine-tuned on ImageNet-1K and CIFAR-100.
-- You can check out demo notebooks regarding inference as well as fine-tuning on custom data [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer) (you can just replace [`ViTFeatureExtractor`] by [`AutoFeatureExtractor`] and [`ViTForImageClassification`] by [`CvtForImageClassification`]).
+- You can check out demo notebooks regarding inference as well as fine-tuning on custom data [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer) (you can just replace [`ViTFeatureExtractor`] by [`AutoImageProcessor`] and [`ViTForImageClassification`] by [`CvtForImageClassification`]).
- The available checkpoints are either (1) pre-trained on [ImageNet-22k](http://www.image-net.org/) (a collection of 14 million images and 22k classes) only, (2) also fine-tuned on ImageNet-22k or (3) also fine-tuned on [ImageNet-1k](http://www.image-net.org/challenges/LSVRC/2012/) (also referred to as ILSVRC 2012, a collection of 1.3 million
images and 1,000 classes).
diff --git a/docs/source/en/model_doc/deformable_detr.mdx b/docs/source/en/model_doc/deformable_detr.mdx
index a0727bad1c..30683bce17 100644
--- a/docs/source/en/model_doc/deformable_detr.mdx
+++ b/docs/source/en/model_doc/deformable_detr.mdx
@@ -23,7 +23,7 @@ The abstract from the paper is the following:
Tips:
-- One can use [`DeformableDetrFeatureExtractor`] to prepare images (and optional targets) for the model.
+- One can use [`DeformableDetrImageProcessor`] to prepare images (and optional targets) for the model.
- Training Deformable DETR is equivalent to training the original [DETR](detr) model. Demo notebooks can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR).
 diff --git a/docs/source/en/model_doc/imagegpt.mdx b/docs/source/en/model_doc/imagegpt.mdx
index 8e6624b7aa..ec265d1488 100644
--- a/docs/source/en/model_doc/imagegpt.mdx
+++ b/docs/source/en/model_doc/imagegpt.mdx
@@ -49,7 +49,7 @@ Tips:
applied k-means clustering to the (R,G,B) pixel values with k=512. This way, we only have a 32*32 = 1024-long
sequence, but now of integers in the range 0..511. So we are shrinking the sequence length at the cost of a bigger
embedding matrix. In other words, the vocabulary size of ImageGPT is 512, + 1 for a special "start of sentence" (SOS)
- token, used at the beginning of every sequence. One can use [`ImageGPTFeatureExtractor`] to prepare
+ token, used at the beginning of every sequence. One can use [`ImageGPTImageProcessor`] to prepare
images for the model.
- Despite being pre-trained entirely unsupervised (i.e. without the use of any labels), ImageGPT produces fairly
performant image features useful for downstream tasks, such as image classification. The authors showed that the
diff --git a/docs/source/en/model_doc/levit.mdx b/docs/source/en/model_doc/levit.mdx
index 1ebe93ff3f..0a64471b34 100644
--- a/docs/source/en/model_doc/levit.mdx
+++ b/docs/source/en/model_doc/levit.mdx
@@ -53,11 +53,11 @@ Tips:
Techniques like data augmentation, optimization, and regularization were used in order to simulate training on a much larger dataset
(while only using ImageNet-1k for pre-training). The 5 variants available are (all trained on images of size 224x224):
*facebook/levit-128S*, *facebook/levit-128*, *facebook/levit-192*, *facebook/levit-256* and
- *facebook/levit-384*. Note that one should use [`LevitFeatureExtractor`] in order to
+ *facebook/levit-384*. Note that one should use [`LevitImageProcessor`] in order to
prepare images for the model.
- [`LevitForImageClassificationWithTeacher`] currently supports only inference and not training or fine-tuning.
- You can check out demo notebooks regarding inference as well as fine-tuning on custom data [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer)
- (you can just replace [`ViTFeatureExtractor`] by [`LevitFeatureExtractor`] and [`ViTForImageClassification`] by [`LevitForImageClassification`] or [`LevitForImageClassificationWithTeacher`]).
+ (you can just replace [`ViTFeatureExtractor`] by [`LevitImageProcessor`] and [`ViTForImageClassification`] by [`LevitForImageClassification`] or [`LevitForImageClassificationWithTeacher`]).
This model was contributed by [anugunj](https://huggingface.co/anugunj). The original code can be found [here](https://github.com/facebookresearch/LeViT).
diff --git a/docs/source/en/model_doc/maskformer.mdx b/docs/source/en/model_doc/maskformer.mdx
index c52fb184ec..4060cbab9a 100644
--- a/docs/source/en/model_doc/maskformer.mdx
+++ b/docs/source/en/model_doc/maskformer.mdx
@@ -32,8 +32,8 @@ Tips:
- If you want to train the model in a distributed environment across multiple nodes, then one should update the
`get_num_masks` function inside in the `MaskFormerLoss` class of `modeling_maskformer.py`. When training on multiple nodes, this should be
set to the average number of target masks across all nodes, as can be seen in the original implementation [here](https://github.com/facebookresearch/MaskFormer/blob/da3e60d85fdeedcb31476b5edd7d328826ce56cc/mask_former/modeling/criterion.py#L169).
-- One can use [`MaskFormerFeatureExtractor`] to prepare images for the model and optional targets for the model.
-- To get the final segmentation, depending on the task, you can call [`~MaskFormerFeatureExtractor.post_process_semantic_segmentation`] or [`~MaskFormerFeatureExtractor.post_process_panoptic_segmentation`]. Both tasks can be solved using [`MaskFormerForInstanceSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
+- One can use [`MaskFormerImageProcessor`] to prepare images for the model and optional targets for the model.
+- To get the final segmentation, depending on the task, you can call [`~MaskFormerImageProcessor.post_process_semantic_segmentation`] or [`~MaskFormerImageProcessor.post_process_panoptic_segmentation`]. Both tasks can be solved using [`MaskFormerForInstanceSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
The figure below illustrates the architecture of MaskFormer. Taken from the [original paper](https://arxiv.org/abs/2107.06278).
diff --git a/docs/source/en/model_doc/mobilenet_v1.mdx b/docs/source/en/model_doc/mobilenet_v1.mdx
index 73df368ed2..48627954ce 100644
--- a/docs/source/en/model_doc/mobilenet_v1.mdx
+++ b/docs/source/en/model_doc/mobilenet_v1.mdx
@@ -26,7 +26,7 @@ Tips:
- Even though the checkpoint is trained on images of specific size, the model will work on images of any size. The smallest supported image size is 32x32.
-- One can use [`MobileNetV1FeatureExtractor`] to prepare images for the model.
+- One can use [`MobileNetV1ImageProcessor`] to prepare images for the model.
- The available image classification checkpoints are pre-trained on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k) (also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes). However, the model predicts 1001 classes: the 1000 classes from ImageNet plus an extra “background” class (index 0).
diff --git a/docs/source/en/model_doc/mobilenet_v2.mdx b/docs/source/en/model_doc/mobilenet_v2.mdx
index ce3e19aea3..6b9dde63b8 100644
--- a/docs/source/en/model_doc/mobilenet_v2.mdx
+++ b/docs/source/en/model_doc/mobilenet_v2.mdx
@@ -28,7 +28,7 @@ Tips:
- Even though the checkpoint is trained on images of specific size, the model will work on images of any size. The smallest supported image size is 32x32.
-- One can use [`MobileNetV2FeatureExtractor`] to prepare images for the model.
+- One can use [`MobileNetV2ImageProcessor`] to prepare images for the model.
- The available image classification checkpoints are pre-trained on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k) (also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes). However, the model predicts 1001 classes: the 1000 classes from ImageNet plus an extra “background” class (index 0).
diff --git a/docs/source/en/model_doc/mobilevit.mdx b/docs/source/en/model_doc/mobilevit.mdx
index 1b73b1e439..c7de403a80 100644
--- a/docs/source/en/model_doc/mobilevit.mdx
+++ b/docs/source/en/model_doc/mobilevit.mdx
@@ -23,7 +23,7 @@ The abstract from the paper is the following:
Tips:
- MobileViT is more like a CNN than a Transformer model. It does not work on sequence data but on batches of images. Unlike ViT, there are no embeddings. The backbone model outputs a feature map. You can follow [this tutorial](https://keras.io/examples/vision/mobilevit) for a lightweight introduction.
-- One can use [`MobileViTFeatureExtractor`] to prepare images for the model. Note that if you do your own preprocessing, the pretrained checkpoints expect images to be in BGR pixel order (not RGB).
+- One can use [`MobileViTImageProcessor`] to prepare images for the model. Note that if you do your own preprocessing, the pretrained checkpoints expect images to be in BGR pixel order (not RGB).
- The available image classification checkpoints are pre-trained on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k) (also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes).
- The segmentation model uses a [DeepLabV3](https://arxiv.org/abs/1706.05587) head. The available semantic segmentation checkpoints are pre-trained on [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/).
- As the name suggests MobileViT was designed to be performant and efficient on mobile phones. The TensorFlow versions of the MobileViT models are fully compatible with [TensorFlow Lite](https://www.tensorflow.org/lite).
diff --git a/docs/source/en/model_doc/poolformer.mdx b/docs/source/en/model_doc/poolformer.mdx
index 1b5727311e..e047626261 100644
--- a/docs/source/en/model_doc/poolformer.mdx
+++ b/docs/source/en/model_doc/poolformer.mdx
@@ -28,7 +28,7 @@ The figure below illustrates the architecture of PoolFormer. Taken from the [ori
Tips:
- PoolFormer has a hierarchical architecture, where instead of Attention, a simple Average Pooling layer is present. All checkpoints of the model can be found on the [hub](https://huggingface.co/models?other=poolformer).
-- One can use [`PoolFormerFeatureExtractor`] to prepare images for the model.
+- One can use [`PoolFormerImageProcessor`] to prepare images for the model.
- As most models, PoolFormer comes in different sizes, the details of which can be found in the table below.
| **Model variant** | **Depths** | **Hidden sizes** | **Params (M)** | **ImageNet-1k Top 1** |
diff --git a/docs/source/en/model_doc/regnet.mdx b/docs/source/en/model_doc/regnet.mdx
index 1f87ccd051..a426ad8fa1 100644
--- a/docs/source/en/model_doc/regnet.mdx
+++ b/docs/source/en/model_doc/regnet.mdx
@@ -24,7 +24,7 @@ The abstract from the paper is the following:
Tips:
-- One can use [`AutoFeatureExtractor`] to prepare images for the model.
+- One can use [`AutoImageProcessor`] to prepare images for the model.
- The huge 10B model from [Self-supervised Pretraining of Visual Features in the Wild](https://arxiv.org/abs/2103.01988), trained on one billion Instagram images, is available on the [hub](https://huggingface.co/facebook/regnet-y-10b-seer)
This model was contributed by [Francesco](https://huggingface.co/Francesco). The TensorFlow version of the model
diff --git a/docs/source/en/model_doc/resnet.mdx b/docs/source/en/model_doc/resnet.mdx
index 3c8af6227d..ce1799e8d4 100644
--- a/docs/source/en/model_doc/resnet.mdx
+++ b/docs/source/en/model_doc/resnet.mdx
@@ -25,7 +25,7 @@ The depth of representations is of central importance for many visual recognitio
Tips:
-- One can use [`AutoFeatureExtractor`] to prepare images for the model.
+- One can use [`AutoImageProcessor`] to prepare images for the model.
The figure below illustrates the architecture of ResNet. Taken from the [original paper](https://arxiv.org/abs/1512.03385).
diff --git a/docs/source/en/model_doc/segformer.mdx b/docs/source/en/model_doc/segformer.mdx
index 5dc8da5d19..76a02c27f4 100644
--- a/docs/source/en/model_doc/segformer.mdx
+++ b/docs/source/en/model_doc/segformer.mdx
@@ -56,12 +56,12 @@ Tips:
- One can also check out [this interactive demo on Hugging Face Spaces](https://huggingface.co/spaces/chansung/segformer-tf-transformers)
to try out a SegFormer model on custom images.
- SegFormer works on any input size, as it pads the input to be divisible by `config.patch_sizes`.
-- One can use [`SegformerFeatureExtractor`] to prepare images and corresponding segmentation maps
- for the model. Note that this feature extractor is fairly basic and does not include all data augmentations used in
+- One can use [`SegformerImageProcessor`] to prepare images and corresponding segmentation maps
+ for the model. Note that this image processor is fairly basic and does not include all data augmentations used in
the original paper. The original preprocessing pipelines (for the ADE20k dataset for instance) can be found [here](https://github.com/NVlabs/SegFormer/blob/master/local_configs/_base_/datasets/ade20k_repeat.py). The most
important preprocessing step is that images and segmentation maps are randomly cropped and padded to the same size,
such as 512x512 or 640x640, after which they are normalized.
-- One additional thing to keep in mind is that one can initialize [`SegformerFeatureExtractor`] with
+- One additional thing to keep in mind is that one can initialize [`SegformerImageProcessor`] with
`reduce_labels` set to `True` or `False`. In some datasets (like ADE20k), the 0 index is used in the annotated
segmentation maps for background. However, ADE20k doesn't include the "background" class in its 150 labels.
Therefore, `reduce_labels` is used to reduce all labels by 1, and to make sure no loss is computed for the
diff --git a/docs/source/en/model_doc/swin.mdx b/docs/source/en/model_doc/swin.mdx
index e622acea26..0093d061dd 100644
--- a/docs/source/en/model_doc/swin.mdx
+++ b/docs/source/en/model_doc/swin.mdx
@@ -33,7 +33,7 @@ prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO
The hierarchical design and the shifted window approach also prove beneficial for all-MLP architectures.*
Tips:
-- One can use the [`AutoFeatureExtractor`] API to prepare images for the model.
+- One can use the [`AutoImageProcessor`] API to prepare images for the model.
- Swin pads the inputs supporting any input height and width (if divisible by `32`).
- Swin can be used as a *backbone*. When `output_hidden_states = True`, it will output both `hidden_states` and `reshaped_hidden_states`. The `reshaped_hidden_states` have a shape of `(batch, num_channels, height, width)` rather than `(batch_size, sequence_length, num_channels)`.
diff --git a/docs/source/en/model_doc/swinv2.mdx b/docs/source/en/model_doc/swinv2.mdx
index 9f91a265ed..576f1a142a 100644
--- a/docs/source/en/model_doc/swinv2.mdx
+++ b/docs/source/en/model_doc/swinv2.mdx
@@ -21,7 +21,7 @@ The abstract from the paper is the following:
*Large-scale NLP models have been shown to significantly improve the performance on language tasks with no signs of saturation. They also demonstrate amazing few-shot capabilities like that of human beings. This paper aims to explore large-scale models in computer vision. We tackle three major issues in training and application of large vision models, including training instability, resolution gaps between pre-training and fine-tuning, and hunger on labelled data. Three main techniques are proposed: 1) a residual-post-norm method combined with cosine attention to improve training stability; 2) A log-spaced continuous position bias method to effectively transfer models pre-trained using low-resolution images to downstream tasks with high-resolution inputs; 3) A self-supervised pre-training method, SimMIM, to reduce the needs of vast labeled images. Through these techniques, this paper successfully trained a 3 billion-parameter Swin Transformer V2 model, which is the largest dense vision model to date, and makes it capable of training with images of up to 1,536×1,536 resolution. It set new performance records on 4 representative vision tasks, including ImageNet-V2 image classification, COCO object detection, ADE20K semantic segmentation, and Kinetics-400 video action classification. Also note our training is much more efficient than that in Google's billion-level visual models, which consumes 40 times less labelled data and 40 times less training time.*
Tips:
-- One can use the [`AutoFeatureExtractor`] API to prepare images for the model.
+- One can use the [`AutoImageProcessor`] API to prepare images for the model.
This model was contributed by [nandwalritik](https://huggingface.co/nandwalritik).
The original code can be found [here](https://github.com/microsoft/Swin-Transformer).
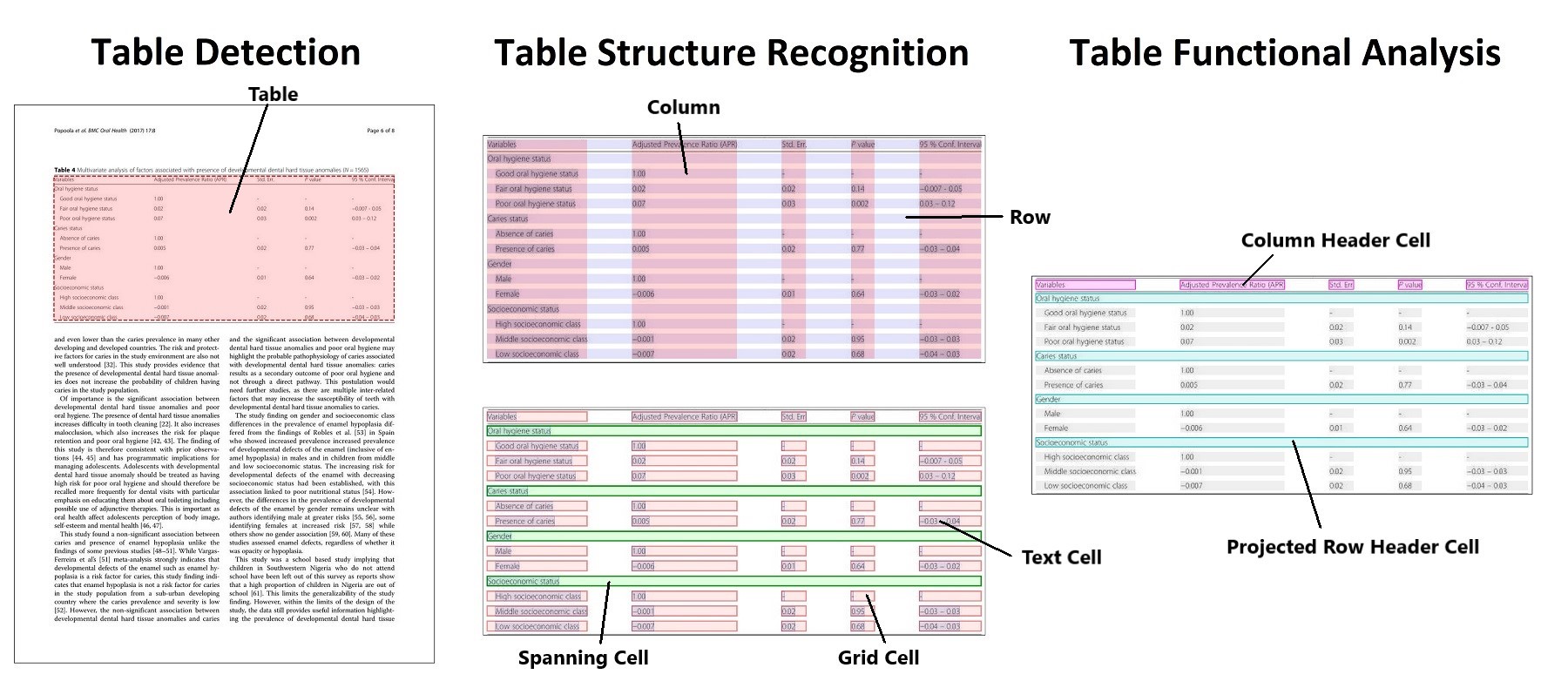
diff --git a/docs/source/en/model_doc/table-transformer.mdx b/docs/source/en/model_doc/table-transformer.mdx
index 793889ee32..862f4124c2 100644
--- a/docs/source/en/model_doc/table-transformer.mdx
+++ b/docs/source/en/model_doc/table-transformer.mdx
@@ -32,7 +32,7 @@ special customization for these tasks.*
Tips:
- The authors released 2 models, one for [table detection](https://huggingface.co/microsoft/table-transformer-detection) in documents, one for [table structure recognition](https://huggingface.co/microsoft/table-transformer-structure-recognition) (the task of recognizing the individual rows, columns etc. in a table).
-- One can use the [`AutoFeatureExtractor`] API to prepare images and optional targets for the model. This will load a [`DetrFeatureExtractor`] behind the scenes.
+- One can use the [`AutoImageProcessor`] API to prepare images and optional targets for the model. This will load a [`DetrImageProcessor`] behind the scenes.
diff --git a/docs/source/en/model_doc/imagegpt.mdx b/docs/source/en/model_doc/imagegpt.mdx
index 8e6624b7aa..ec265d1488 100644
--- a/docs/source/en/model_doc/imagegpt.mdx
+++ b/docs/source/en/model_doc/imagegpt.mdx
@@ -49,7 +49,7 @@ Tips:
applied k-means clustering to the (R,G,B) pixel values with k=512. This way, we only have a 32*32 = 1024-long
sequence, but now of integers in the range 0..511. So we are shrinking the sequence length at the cost of a bigger
embedding matrix. In other words, the vocabulary size of ImageGPT is 512, + 1 for a special "start of sentence" (SOS)
- token, used at the beginning of every sequence. One can use [`ImageGPTFeatureExtractor`] to prepare
+ token, used at the beginning of every sequence. One can use [`ImageGPTImageProcessor`] to prepare
images for the model.
- Despite being pre-trained entirely unsupervised (i.e. without the use of any labels), ImageGPT produces fairly
performant image features useful for downstream tasks, such as image classification. The authors showed that the
diff --git a/docs/source/en/model_doc/levit.mdx b/docs/source/en/model_doc/levit.mdx
index 1ebe93ff3f..0a64471b34 100644
--- a/docs/source/en/model_doc/levit.mdx
+++ b/docs/source/en/model_doc/levit.mdx
@@ -53,11 +53,11 @@ Tips:
Techniques like data augmentation, optimization, and regularization were used in order to simulate training on a much larger dataset
(while only using ImageNet-1k for pre-training). The 5 variants available are (all trained on images of size 224x224):
*facebook/levit-128S*, *facebook/levit-128*, *facebook/levit-192*, *facebook/levit-256* and
- *facebook/levit-384*. Note that one should use [`LevitFeatureExtractor`] in order to
+ *facebook/levit-384*. Note that one should use [`LevitImageProcessor`] in order to
prepare images for the model.
- [`LevitForImageClassificationWithTeacher`] currently supports only inference and not training or fine-tuning.
- You can check out demo notebooks regarding inference as well as fine-tuning on custom data [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer)
- (you can just replace [`ViTFeatureExtractor`] by [`LevitFeatureExtractor`] and [`ViTForImageClassification`] by [`LevitForImageClassification`] or [`LevitForImageClassificationWithTeacher`]).
+ (you can just replace [`ViTFeatureExtractor`] by [`LevitImageProcessor`] and [`ViTForImageClassification`] by [`LevitForImageClassification`] or [`LevitForImageClassificationWithTeacher`]).
This model was contributed by [anugunj](https://huggingface.co/anugunj). The original code can be found [here](https://github.com/facebookresearch/LeViT).
diff --git a/docs/source/en/model_doc/maskformer.mdx b/docs/source/en/model_doc/maskformer.mdx
index c52fb184ec..4060cbab9a 100644
--- a/docs/source/en/model_doc/maskformer.mdx
+++ b/docs/source/en/model_doc/maskformer.mdx
@@ -32,8 +32,8 @@ Tips:
- If you want to train the model in a distributed environment across multiple nodes, then one should update the
`get_num_masks` function inside in the `MaskFormerLoss` class of `modeling_maskformer.py`. When training on multiple nodes, this should be
set to the average number of target masks across all nodes, as can be seen in the original implementation [here](https://github.com/facebookresearch/MaskFormer/blob/da3e60d85fdeedcb31476b5edd7d328826ce56cc/mask_former/modeling/criterion.py#L169).
-- One can use [`MaskFormerFeatureExtractor`] to prepare images for the model and optional targets for the model.
-- To get the final segmentation, depending on the task, you can call [`~MaskFormerFeatureExtractor.post_process_semantic_segmentation`] or [`~MaskFormerFeatureExtractor.post_process_panoptic_segmentation`]. Both tasks can be solved using [`MaskFormerForInstanceSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
+- One can use [`MaskFormerImageProcessor`] to prepare images for the model and optional targets for the model.
+- To get the final segmentation, depending on the task, you can call [`~MaskFormerImageProcessor.post_process_semantic_segmentation`] or [`~MaskFormerImageProcessor.post_process_panoptic_segmentation`]. Both tasks can be solved using [`MaskFormerForInstanceSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
The figure below illustrates the architecture of MaskFormer. Taken from the [original paper](https://arxiv.org/abs/2107.06278).
diff --git a/docs/source/en/model_doc/mobilenet_v1.mdx b/docs/source/en/model_doc/mobilenet_v1.mdx
index 73df368ed2..48627954ce 100644
--- a/docs/source/en/model_doc/mobilenet_v1.mdx
+++ b/docs/source/en/model_doc/mobilenet_v1.mdx
@@ -26,7 +26,7 @@ Tips:
- Even though the checkpoint is trained on images of specific size, the model will work on images of any size. The smallest supported image size is 32x32.
-- One can use [`MobileNetV1FeatureExtractor`] to prepare images for the model.
+- One can use [`MobileNetV1ImageProcessor`] to prepare images for the model.
- The available image classification checkpoints are pre-trained on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k) (also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes). However, the model predicts 1001 classes: the 1000 classes from ImageNet plus an extra “background” class (index 0).
diff --git a/docs/source/en/model_doc/mobilenet_v2.mdx b/docs/source/en/model_doc/mobilenet_v2.mdx
index ce3e19aea3..6b9dde63b8 100644
--- a/docs/source/en/model_doc/mobilenet_v2.mdx
+++ b/docs/source/en/model_doc/mobilenet_v2.mdx
@@ -28,7 +28,7 @@ Tips:
- Even though the checkpoint is trained on images of specific size, the model will work on images of any size. The smallest supported image size is 32x32.
-- One can use [`MobileNetV2FeatureExtractor`] to prepare images for the model.
+- One can use [`MobileNetV2ImageProcessor`] to prepare images for the model.
- The available image classification checkpoints are pre-trained on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k) (also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes). However, the model predicts 1001 classes: the 1000 classes from ImageNet plus an extra “background” class (index 0).
diff --git a/docs/source/en/model_doc/mobilevit.mdx b/docs/source/en/model_doc/mobilevit.mdx
index 1b73b1e439..c7de403a80 100644
--- a/docs/source/en/model_doc/mobilevit.mdx
+++ b/docs/source/en/model_doc/mobilevit.mdx
@@ -23,7 +23,7 @@ The abstract from the paper is the following:
Tips:
- MobileViT is more like a CNN than a Transformer model. It does not work on sequence data but on batches of images. Unlike ViT, there are no embeddings. The backbone model outputs a feature map. You can follow [this tutorial](https://keras.io/examples/vision/mobilevit) for a lightweight introduction.
-- One can use [`MobileViTFeatureExtractor`] to prepare images for the model. Note that if you do your own preprocessing, the pretrained checkpoints expect images to be in BGR pixel order (not RGB).
+- One can use [`MobileViTImageProcessor`] to prepare images for the model. Note that if you do your own preprocessing, the pretrained checkpoints expect images to be in BGR pixel order (not RGB).
- The available image classification checkpoints are pre-trained on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k) (also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes).
- The segmentation model uses a [DeepLabV3](https://arxiv.org/abs/1706.05587) head. The available semantic segmentation checkpoints are pre-trained on [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/).
- As the name suggests MobileViT was designed to be performant and efficient on mobile phones. The TensorFlow versions of the MobileViT models are fully compatible with [TensorFlow Lite](https://www.tensorflow.org/lite).
diff --git a/docs/source/en/model_doc/poolformer.mdx b/docs/source/en/model_doc/poolformer.mdx
index 1b5727311e..e047626261 100644
--- a/docs/source/en/model_doc/poolformer.mdx
+++ b/docs/source/en/model_doc/poolformer.mdx
@@ -28,7 +28,7 @@ The figure below illustrates the architecture of PoolFormer. Taken from the [ori
Tips:
- PoolFormer has a hierarchical architecture, where instead of Attention, a simple Average Pooling layer is present. All checkpoints of the model can be found on the [hub](https://huggingface.co/models?other=poolformer).
-- One can use [`PoolFormerFeatureExtractor`] to prepare images for the model.
+- One can use [`PoolFormerImageProcessor`] to prepare images for the model.
- As most models, PoolFormer comes in different sizes, the details of which can be found in the table below.
| **Model variant** | **Depths** | **Hidden sizes** | **Params (M)** | **ImageNet-1k Top 1** |
diff --git a/docs/source/en/model_doc/regnet.mdx b/docs/source/en/model_doc/regnet.mdx
index 1f87ccd051..a426ad8fa1 100644
--- a/docs/source/en/model_doc/regnet.mdx
+++ b/docs/source/en/model_doc/regnet.mdx
@@ -24,7 +24,7 @@ The abstract from the paper is the following:
Tips:
-- One can use [`AutoFeatureExtractor`] to prepare images for the model.
+- One can use [`AutoImageProcessor`] to prepare images for the model.
- The huge 10B model from [Self-supervised Pretraining of Visual Features in the Wild](https://arxiv.org/abs/2103.01988), trained on one billion Instagram images, is available on the [hub](https://huggingface.co/facebook/regnet-y-10b-seer)
This model was contributed by [Francesco](https://huggingface.co/Francesco). The TensorFlow version of the model
diff --git a/docs/source/en/model_doc/resnet.mdx b/docs/source/en/model_doc/resnet.mdx
index 3c8af6227d..ce1799e8d4 100644
--- a/docs/source/en/model_doc/resnet.mdx
+++ b/docs/source/en/model_doc/resnet.mdx
@@ -25,7 +25,7 @@ The depth of representations is of central importance for many visual recognitio
Tips:
-- One can use [`AutoFeatureExtractor`] to prepare images for the model.
+- One can use [`AutoImageProcessor`] to prepare images for the model.
The figure below illustrates the architecture of ResNet. Taken from the [original paper](https://arxiv.org/abs/1512.03385).
diff --git a/docs/source/en/model_doc/segformer.mdx b/docs/source/en/model_doc/segformer.mdx
index 5dc8da5d19..76a02c27f4 100644
--- a/docs/source/en/model_doc/segformer.mdx
+++ b/docs/source/en/model_doc/segformer.mdx
@@ -56,12 +56,12 @@ Tips:
- One can also check out [this interactive demo on Hugging Face Spaces](https://huggingface.co/spaces/chansung/segformer-tf-transformers)
to try out a SegFormer model on custom images.
- SegFormer works on any input size, as it pads the input to be divisible by `config.patch_sizes`.
-- One can use [`SegformerFeatureExtractor`] to prepare images and corresponding segmentation maps
- for the model. Note that this feature extractor is fairly basic and does not include all data augmentations used in
+- One can use [`SegformerImageProcessor`] to prepare images and corresponding segmentation maps
+ for the model. Note that this image processor is fairly basic and does not include all data augmentations used in
the original paper. The original preprocessing pipelines (for the ADE20k dataset for instance) can be found [here](https://github.com/NVlabs/SegFormer/blob/master/local_configs/_base_/datasets/ade20k_repeat.py). The most
important preprocessing step is that images and segmentation maps are randomly cropped and padded to the same size,
such as 512x512 or 640x640, after which they are normalized.
-- One additional thing to keep in mind is that one can initialize [`SegformerFeatureExtractor`] with
+- One additional thing to keep in mind is that one can initialize [`SegformerImageProcessor`] with
`reduce_labels` set to `True` or `False`. In some datasets (like ADE20k), the 0 index is used in the annotated
segmentation maps for background. However, ADE20k doesn't include the "background" class in its 150 labels.
Therefore, `reduce_labels` is used to reduce all labels by 1, and to make sure no loss is computed for the
diff --git a/docs/source/en/model_doc/swin.mdx b/docs/source/en/model_doc/swin.mdx
index e622acea26..0093d061dd 100644
--- a/docs/source/en/model_doc/swin.mdx
+++ b/docs/source/en/model_doc/swin.mdx
@@ -33,7 +33,7 @@ prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO
The hierarchical design and the shifted window approach also prove beneficial for all-MLP architectures.*
Tips:
-- One can use the [`AutoFeatureExtractor`] API to prepare images for the model.
+- One can use the [`AutoImageProcessor`] API to prepare images for the model.
- Swin pads the inputs supporting any input height and width (if divisible by `32`).
- Swin can be used as a *backbone*. When `output_hidden_states = True`, it will output both `hidden_states` and `reshaped_hidden_states`. The `reshaped_hidden_states` have a shape of `(batch, num_channels, height, width)` rather than `(batch_size, sequence_length, num_channels)`.
diff --git a/docs/source/en/model_doc/swinv2.mdx b/docs/source/en/model_doc/swinv2.mdx
index 9f91a265ed..576f1a142a 100644
--- a/docs/source/en/model_doc/swinv2.mdx
+++ b/docs/source/en/model_doc/swinv2.mdx
@@ -21,7 +21,7 @@ The abstract from the paper is the following:
*Large-scale NLP models have been shown to significantly improve the performance on language tasks with no signs of saturation. They also demonstrate amazing few-shot capabilities like that of human beings. This paper aims to explore large-scale models in computer vision. We tackle three major issues in training and application of large vision models, including training instability, resolution gaps between pre-training and fine-tuning, and hunger on labelled data. Three main techniques are proposed: 1) a residual-post-norm method combined with cosine attention to improve training stability; 2) A log-spaced continuous position bias method to effectively transfer models pre-trained using low-resolution images to downstream tasks with high-resolution inputs; 3) A self-supervised pre-training method, SimMIM, to reduce the needs of vast labeled images. Through these techniques, this paper successfully trained a 3 billion-parameter Swin Transformer V2 model, which is the largest dense vision model to date, and makes it capable of training with images of up to 1,536×1,536 resolution. It set new performance records on 4 representative vision tasks, including ImageNet-V2 image classification, COCO object detection, ADE20K semantic segmentation, and Kinetics-400 video action classification. Also note our training is much more efficient than that in Google's billion-level visual models, which consumes 40 times less labelled data and 40 times less training time.*
Tips:
-- One can use the [`AutoFeatureExtractor`] API to prepare images for the model.
+- One can use the [`AutoImageProcessor`] API to prepare images for the model.
This model was contributed by [nandwalritik](https://huggingface.co/nandwalritik).
The original code can be found [here](https://github.com/microsoft/Swin-Transformer).
diff --git a/docs/source/en/model_doc/table-transformer.mdx b/docs/source/en/model_doc/table-transformer.mdx
index 793889ee32..862f4124c2 100644
--- a/docs/source/en/model_doc/table-transformer.mdx
+++ b/docs/source/en/model_doc/table-transformer.mdx
@@ -32,7 +32,7 @@ special customization for these tasks.*
Tips:
- The authors released 2 models, one for [table detection](https://huggingface.co/microsoft/table-transformer-detection) in documents, one for [table structure recognition](https://huggingface.co/microsoft/table-transformer-structure-recognition) (the task of recognizing the individual rows, columns etc. in a table).
-- One can use the [`AutoFeatureExtractor`] API to prepare images and optional targets for the model. This will load a [`DetrFeatureExtractor`] behind the scenes.
+- One can use the [`AutoImageProcessor`] API to prepare images and optional targets for the model. This will load a [`DetrImageProcessor`] behind the scenes.
 diff --git a/docs/source/en/model_doc/trocr.mdx b/docs/source/en/model_doc/trocr.mdx
index 90ff6aa902..3e3a6c1007 100644
--- a/docs/source/en/model_doc/trocr.mdx
+++ b/docs/source/en/model_doc/trocr.mdx
@@ -55,9 +55,9 @@ Tips:
TrOCR's [`VisionEncoderDecoder`] model accepts images as input and makes use of
[`~generation.GenerationMixin.generate`] to autoregressively generate text given the input image.
-The [`ViTFeatureExtractor`/`DeiTFeatureExtractor`] class is responsible for preprocessing the input image and
+The [`ViTImageProcessor`/`DeiTImageProcessor`] class is responsible for preprocessing the input image and
[`RobertaTokenizer`/`XLMRobertaTokenizer`] decodes the generated target tokens to the target string. The
-[`TrOCRProcessor`] wraps [`ViTFeatureExtractor`/`DeiTFeatureExtractor`] and [`RobertaTokenizer`/`XLMRobertaTokenizer`]
+[`TrOCRProcessor`] wraps [`ViTImageProcessor`/`DeiTImageProcessor`] and [`RobertaTokenizer`/`XLMRobertaTokenizer`]
into a single instance to both extract the input features and decode the predicted token ids.
- Step-by-step Optical Character Recognition (OCR)
diff --git a/docs/source/en/model_doc/videomae.mdx b/docs/source/en/model_doc/videomae.mdx
index f230ab4341..76e822ef8a 100644
--- a/docs/source/en/model_doc/videomae.mdx
+++ b/docs/source/en/model_doc/videomae.mdx
@@ -23,7 +23,7 @@ The abstract from the paper is the following:
Tips:
-- One can use [`VideoMAEFeatureExtractor`] to prepare videos for the model. It will resize + normalize all frames of a video for you.
+- One can use [`VideoMAEImageProcessor`] to prepare videos for the model. It will resize + normalize all frames of a video for you.
- [`VideoMAEForPreTraining`] includes the decoder on top for self-supervised pre-training.
diff --git a/docs/source/en/model_doc/trocr.mdx b/docs/source/en/model_doc/trocr.mdx
index 90ff6aa902..3e3a6c1007 100644
--- a/docs/source/en/model_doc/trocr.mdx
+++ b/docs/source/en/model_doc/trocr.mdx
@@ -55,9 +55,9 @@ Tips:
TrOCR's [`VisionEncoderDecoder`] model accepts images as input and makes use of
[`~generation.GenerationMixin.generate`] to autoregressively generate text given the input image.
-The [`ViTFeatureExtractor`/`DeiTFeatureExtractor`] class is responsible for preprocessing the input image and
+The [`ViTImageProcessor`/`DeiTImageProcessor`] class is responsible for preprocessing the input image and
[`RobertaTokenizer`/`XLMRobertaTokenizer`] decodes the generated target tokens to the target string. The
-[`TrOCRProcessor`] wraps [`ViTFeatureExtractor`/`DeiTFeatureExtractor`] and [`RobertaTokenizer`/`XLMRobertaTokenizer`]
+[`TrOCRProcessor`] wraps [`ViTImageProcessor`/`DeiTImageProcessor`] and [`RobertaTokenizer`/`XLMRobertaTokenizer`]
into a single instance to both extract the input features and decode the predicted token ids.
- Step-by-step Optical Character Recognition (OCR)
diff --git a/docs/source/en/model_doc/videomae.mdx b/docs/source/en/model_doc/videomae.mdx
index f230ab4341..76e822ef8a 100644
--- a/docs/source/en/model_doc/videomae.mdx
+++ b/docs/source/en/model_doc/videomae.mdx
@@ -23,7 +23,7 @@ The abstract from the paper is the following:
Tips:
-- One can use [`VideoMAEFeatureExtractor`] to prepare videos for the model. It will resize + normalize all frames of a video for you.
+- One can use [`VideoMAEImageProcessor`] to prepare videos for the model. It will resize + normalize all frames of a video for you.
- [`VideoMAEForPreTraining`] includes the decoder on top for self-supervised pre-training.
 >> import requests
>>> from PIL import Image
->>> from transformers import GPT2TokenizerFast, ViTFeatureExtractor, VisionEncoderDecoderModel
+>>> from transformers import GPT2TokenizerFast, ViTImageProcessor, VisionEncoderDecoderModel
->>> # load a fine-tuned image captioning model and corresponding tokenizer and feature extractor
+>>> # load a fine-tuned image captioning model and corresponding tokenizer and image processor
>>> model = VisionEncoderDecoderModel.from_pretrained("nlpconnect/vit-gpt2-image-captioning")
>>> tokenizer = GPT2TokenizerFast.from_pretrained("nlpconnect/vit-gpt2-image-captioning")
->>> feature_extractor = ViTFeatureExtractor.from_pretrained("nlpconnect/vit-gpt2-image-captioning")
+>>> image_processor = ViTImageProcessor.from_pretrained("nlpconnect/vit-gpt2-image-captioning")
>>> # let's perform inference on an image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
->>> pixel_values = feature_extractor(image, return_tensors="pt").pixel_values
+>>> pixel_values = image_processor(image, return_tensors="pt").pixel_values
>>> # autoregressively generate caption (uses greedy decoding by default)
>>> generated_ids = model.generate(pixel_values)
@@ -115,10 +115,10 @@ As you can see, only 2 inputs are required for the model in order to compute a l
images) and `labels` (which are the `input_ids` of the encoded target sequence).
```python
->>> from transformers import ViTFeatureExtractor, BertTokenizer, VisionEncoderDecoderModel
+>>> from transformers import ViTImageProcessor, BertTokenizer, VisionEncoderDecoderModel
>>> from datasets import load_dataset
->>> feature_extractor = ViTFeatureExtractor.from_pretrained("google/vit-base-patch16-224-in21k")
+>>> image_processor = ViTImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
>>> tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
>>> model = VisionEncoderDecoderModel.from_encoder_decoder_pretrained(
... "google/vit-base-patch16-224-in21k", "bert-base-uncased"
@@ -129,7 +129,7 @@ images) and `labels` (which are the `input_ids` of the encoded target sequence).
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
->>> pixel_values = feature_extractor(image, return_tensors="pt").pixel_values
+>>> pixel_values = image_processor(image, return_tensors="pt").pixel_values
>>> labels = tokenizer(
... "an image of two cats chilling on a couch",
diff --git a/docs/source/en/model_doc/visual_bert.mdx b/docs/source/en/model_doc/visual_bert.mdx
index dd722b919e..df8858b1fa 100644
--- a/docs/source/en/model_doc/visual_bert.mdx
+++ b/docs/source/en/model_doc/visual_bert.mdx
@@ -53,7 +53,7 @@ vectors to a standard BERT model. The text input is concatenated in the front of
layer, and is expected to be bound by [CLS] and a [SEP] tokens, as in BERT. The segment IDs must also be set
appropriately for the textual and visual parts.
-The [`BertTokenizer`] is used to encode the text. A custom detector/feature extractor must be used
+The [`BertTokenizer`] is used to encode the text. A custom detector/image processor must be used
to get the visual embeddings. The following example notebooks show how to use VisualBERT with Detectron-like models:
- [VisualBERT VQA demo notebook](https://github.com/huggingface/transformers/tree/main/examples/research_projects/visual_bert) : This notebook
diff --git a/docs/source/en/model_doc/vit.mdx b/docs/source/en/model_doc/vit.mdx
index 9b3a5a1e16..b71d85082c 100644
--- a/docs/source/en/model_doc/vit.mdx
+++ b/docs/source/en/model_doc/vit.mdx
@@ -40,7 +40,7 @@ Tips:
used for classification. The authors also add absolute position embeddings, and feed the resulting sequence of
vectors to a standard Transformer encoder.
- As the Vision Transformer expects each image to be of the same size (resolution), one can use
- [`ViTFeatureExtractor`] to resize (or rescale) and normalize images for the model.
+ [`ViTImageProcessor`] to resize (or rescale) and normalize images for the model.
- Both the patch resolution and image resolution used during pre-training or fine-tuning are reflected in the name of
each checkpoint. For example, `google/vit-base-patch16-224` refers to a base-sized architecture with patch
resolution of 16x16 and fine-tuning resolution of 224x224. All checkpoints can be found on the [hub](https://huggingface.co/models?search=vit).
@@ -67,7 +67,7 @@ Following the original Vision Transformer, some follow-up works have been made:
The authors of DeiT also released more efficiently trained ViT models, which you can directly plug into [`ViTModel`] or
[`ViTForImageClassification`]. There are 4 variants available (in 3 different sizes): *facebook/deit-tiny-patch16-224*,
*facebook/deit-small-patch16-224*, *facebook/deit-base-patch16-224* and *facebook/deit-base-patch16-384*. Note that one should
- use [`DeiTFeatureExtractor`] in order to prepare images for the model.
+ use [`DeiTImageProcessor`] in order to prepare images for the model.
- [BEiT](beit) (BERT pre-training of Image Transformers) by Microsoft Research. BEiT models outperform supervised pre-trained
vision transformers using a self-supervised method inspired by BERT (masked image modeling) and based on a VQ-VAE.
diff --git a/docs/source/en/model_doc/vit_mae.mdx b/docs/source/en/model_doc/vit_mae.mdx
index aeb19b96a1..4544237070 100644
--- a/docs/source/en/model_doc/vit_mae.mdx
+++ b/docs/source/en/model_doc/vit_mae.mdx
@@ -37,7 +37,7 @@ One can easily tweak it for their own use case.
- A notebook that illustrates how to visualize reconstructed pixel values with [`ViTMAEForPreTraining`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/ViTMAE/ViT_MAE_visualization_demo.ipynb).
- After pre-training, one "throws away" the decoder used to reconstruct pixels, and one uses the encoder for fine-tuning/linear probing. This means that after
fine-tuning, one can directly plug in the weights into a [`ViTForImageClassification`].
-- One can use [`ViTFeatureExtractor`] to prepare images for the model. See the code examples for more info.
+- One can use [`ViTImageProcessor`] to prepare images for the model. See the code examples for more info.
- Note that the encoder of MAE is only used to encode the visual patches. The encoded patches are then concatenated with mask tokens, which the decoder (which also
consists of Transformer blocks) takes as input. Each mask token is a shared, learned vector that indicates the presence of a missing patch to be predicted. Fixed
sin/cos position embeddings are added both to the input of the encoder and the decoder.
diff --git a/docs/source/en/model_doc/yolos.mdx b/docs/source/en/model_doc/yolos.mdx
index 185ee10c17..838517ea76 100644
--- a/docs/source/en/model_doc/yolos.mdx
+++ b/docs/source/en/model_doc/yolos.mdx
@@ -23,7 +23,7 @@ The abstract from the paper is the following:
Tips:
-- One can use [`YolosFeatureExtractor`] for preparing images (and optional targets) for the model. Contrary to [DETR](detr), YOLOS doesn't require a `pixel_mask` to be created.
+- One can use [`YolosImageProcessor`] for preparing images (and optional targets) for the model. Contrary to [DETR](detr), YOLOS doesn't require a `pixel_mask` to be created.
- Demo notebooks (regarding inference and fine-tuning on custom data) can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/YOLOS).
>> import requests
>>> from PIL import Image
->>> from transformers import GPT2TokenizerFast, ViTFeatureExtractor, VisionEncoderDecoderModel
+>>> from transformers import GPT2TokenizerFast, ViTImageProcessor, VisionEncoderDecoderModel
->>> # load a fine-tuned image captioning model and corresponding tokenizer and feature extractor
+>>> # load a fine-tuned image captioning model and corresponding tokenizer and image processor
>>> model = VisionEncoderDecoderModel.from_pretrained("nlpconnect/vit-gpt2-image-captioning")
>>> tokenizer = GPT2TokenizerFast.from_pretrained("nlpconnect/vit-gpt2-image-captioning")
->>> feature_extractor = ViTFeatureExtractor.from_pretrained("nlpconnect/vit-gpt2-image-captioning")
+>>> image_processor = ViTImageProcessor.from_pretrained("nlpconnect/vit-gpt2-image-captioning")
>>> # let's perform inference on an image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
->>> pixel_values = feature_extractor(image, return_tensors="pt").pixel_values
+>>> pixel_values = image_processor(image, return_tensors="pt").pixel_values
>>> # autoregressively generate caption (uses greedy decoding by default)
>>> generated_ids = model.generate(pixel_values)
@@ -115,10 +115,10 @@ As you can see, only 2 inputs are required for the model in order to compute a l
images) and `labels` (which are the `input_ids` of the encoded target sequence).
```python
->>> from transformers import ViTFeatureExtractor, BertTokenizer, VisionEncoderDecoderModel
+>>> from transformers import ViTImageProcessor, BertTokenizer, VisionEncoderDecoderModel
>>> from datasets import load_dataset
->>> feature_extractor = ViTFeatureExtractor.from_pretrained("google/vit-base-patch16-224-in21k")
+>>> image_processor = ViTImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
>>> tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
>>> model = VisionEncoderDecoderModel.from_encoder_decoder_pretrained(
... "google/vit-base-patch16-224-in21k", "bert-base-uncased"
@@ -129,7 +129,7 @@ images) and `labels` (which are the `input_ids` of the encoded target sequence).
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
->>> pixel_values = feature_extractor(image, return_tensors="pt").pixel_values
+>>> pixel_values = image_processor(image, return_tensors="pt").pixel_values
>>> labels = tokenizer(
... "an image of two cats chilling on a couch",
diff --git a/docs/source/en/model_doc/visual_bert.mdx b/docs/source/en/model_doc/visual_bert.mdx
index dd722b919e..df8858b1fa 100644
--- a/docs/source/en/model_doc/visual_bert.mdx
+++ b/docs/source/en/model_doc/visual_bert.mdx
@@ -53,7 +53,7 @@ vectors to a standard BERT model. The text input is concatenated in the front of
layer, and is expected to be bound by [CLS] and a [SEP] tokens, as in BERT. The segment IDs must also be set
appropriately for the textual and visual parts.
-The [`BertTokenizer`] is used to encode the text. A custom detector/feature extractor must be used
+The [`BertTokenizer`] is used to encode the text. A custom detector/image processor must be used
to get the visual embeddings. The following example notebooks show how to use VisualBERT with Detectron-like models:
- [VisualBERT VQA demo notebook](https://github.com/huggingface/transformers/tree/main/examples/research_projects/visual_bert) : This notebook
diff --git a/docs/source/en/model_doc/vit.mdx b/docs/source/en/model_doc/vit.mdx
index 9b3a5a1e16..b71d85082c 100644
--- a/docs/source/en/model_doc/vit.mdx
+++ b/docs/source/en/model_doc/vit.mdx
@@ -40,7 +40,7 @@ Tips:
used for classification. The authors also add absolute position embeddings, and feed the resulting sequence of
vectors to a standard Transformer encoder.
- As the Vision Transformer expects each image to be of the same size (resolution), one can use
- [`ViTFeatureExtractor`] to resize (or rescale) and normalize images for the model.
+ [`ViTImageProcessor`] to resize (or rescale) and normalize images for the model.
- Both the patch resolution and image resolution used during pre-training or fine-tuning are reflected in the name of
each checkpoint. For example, `google/vit-base-patch16-224` refers to a base-sized architecture with patch
resolution of 16x16 and fine-tuning resolution of 224x224. All checkpoints can be found on the [hub](https://huggingface.co/models?search=vit).
@@ -67,7 +67,7 @@ Following the original Vision Transformer, some follow-up works have been made:
The authors of DeiT also released more efficiently trained ViT models, which you can directly plug into [`ViTModel`] or
[`ViTForImageClassification`]. There are 4 variants available (in 3 different sizes): *facebook/deit-tiny-patch16-224*,
*facebook/deit-small-patch16-224*, *facebook/deit-base-patch16-224* and *facebook/deit-base-patch16-384*. Note that one should
- use [`DeiTFeatureExtractor`] in order to prepare images for the model.
+ use [`DeiTImageProcessor`] in order to prepare images for the model.
- [BEiT](beit) (BERT pre-training of Image Transformers) by Microsoft Research. BEiT models outperform supervised pre-trained
vision transformers using a self-supervised method inspired by BERT (masked image modeling) and based on a VQ-VAE.
diff --git a/docs/source/en/model_doc/vit_mae.mdx b/docs/source/en/model_doc/vit_mae.mdx
index aeb19b96a1..4544237070 100644
--- a/docs/source/en/model_doc/vit_mae.mdx
+++ b/docs/source/en/model_doc/vit_mae.mdx
@@ -37,7 +37,7 @@ One can easily tweak it for their own use case.
- A notebook that illustrates how to visualize reconstructed pixel values with [`ViTMAEForPreTraining`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/ViTMAE/ViT_MAE_visualization_demo.ipynb).
- After pre-training, one "throws away" the decoder used to reconstruct pixels, and one uses the encoder for fine-tuning/linear probing. This means that after
fine-tuning, one can directly plug in the weights into a [`ViTForImageClassification`].
-- One can use [`ViTFeatureExtractor`] to prepare images for the model. See the code examples for more info.
+- One can use [`ViTImageProcessor`] to prepare images for the model. See the code examples for more info.
- Note that the encoder of MAE is only used to encode the visual patches. The encoded patches are then concatenated with mask tokens, which the decoder (which also
consists of Transformer blocks) takes as input. Each mask token is a shared, learned vector that indicates the presence of a missing patch to be predicted. Fixed
sin/cos position embeddings are added both to the input of the encoder and the decoder.
diff --git a/docs/source/en/model_doc/yolos.mdx b/docs/source/en/model_doc/yolos.mdx
index 185ee10c17..838517ea76 100644
--- a/docs/source/en/model_doc/yolos.mdx
+++ b/docs/source/en/model_doc/yolos.mdx
@@ -23,7 +23,7 @@ The abstract from the paper is the following:
Tips:
-- One can use [`YolosFeatureExtractor`] for preparing images (and optional targets) for the model. Contrary to [DETR](detr), YOLOS doesn't require a `pixel_mask` to be created.
+- One can use [`YolosImageProcessor`] for preparing images (and optional targets) for the model. Contrary to [DETR](detr), YOLOS doesn't require a `pixel_mask` to be created.
- Demo notebooks (regarding inference and fine-tuning on custom data) can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/YOLOS).
 -`AutoProcessor` **always** works and automatically chooses the correct class for the model you're using, whether you're using a tokenizer, feature extractor or processor.
+`AutoProcessor` **always** works and automatically chooses the correct class for the model you're using, whether you're using a tokenizer, image processor, feature extractor or processor.
@@ -320,9 +320,9 @@ The sample lengths are now the same and match the specified maximum length. You
## Computer vision
-For computer vision tasks, you'll need a [feature extractor](main_classes/feature_extractor) to prepare your dataset for the model. The feature extractor is designed to extract features from images, and convert them into tensors.
+For computer vision tasks, you'll need an [image processor](main_classes/image_processor) to prepare your dataset for the model. The image processor is designed to preprocess images, and convert them into tensors.
-Load the [food101](https://huggingface.co/datasets/food101) dataset (see the 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub.html) for more details on how to load a dataset) to see how you can use a feature extractor with computer vision datasets:
+Load the [food101](https://huggingface.co/datasets/food101) dataset (see the 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub.html) for more details on how to load a dataset) to see how you can use an image processor with computer vision datasets:
@@ -346,17 +346,17 @@ Next, take a look at the image with 🤗 Datasets [`Image`](https://huggingface.
-`AutoProcessor` **always** works and automatically chooses the correct class for the model you're using, whether you're using a tokenizer, feature extractor or processor.
+`AutoProcessor` **always** works and automatically chooses the correct class for the model you're using, whether you're using a tokenizer, image processor, feature extractor or processor.
@@ -320,9 +320,9 @@ The sample lengths are now the same and match the specified maximum length. You
## Computer vision
-For computer vision tasks, you'll need a [feature extractor](main_classes/feature_extractor) to prepare your dataset for the model. The feature extractor is designed to extract features from images, and convert them into tensors.
+For computer vision tasks, you'll need an [image processor](main_classes/image_processor) to prepare your dataset for the model. The image processor is designed to preprocess images, and convert them into tensors.
-Load the [food101](https://huggingface.co/datasets/food101) dataset (see the 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub.html) for more details on how to load a dataset) to see how you can use a feature extractor with computer vision datasets:
+Load the [food101](https://huggingface.co/datasets/food101) dataset (see the 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub.html) for more details on how to load a dataset) to see how you can use an image processor with computer vision datasets:
@@ -346,17 +346,17 @@ Next, take a look at the image with 🤗 Datasets [`Image`](https://huggingface.
 -Load the feature extractor with [`AutoFeatureExtractor.from_pretrained`]:
+Load the image processor with [`AutoImageProcessor.from_pretrained`]:
```py
->>> from transformers import AutoFeatureExtractor
+>>> from transformers import AutoImageProcessor
->>> feature_extractor = AutoFeatureExtractor.from_pretrained("google/vit-base-patch16-224")
+>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
```
For computer vision tasks, it is common to add some type of data augmentation to the images as a part of preprocessing. You can add augmentations with any library you'd like, but in this tutorial, you'll use torchvision's [`transforms`](https://pytorch.org/vision/stable/transforms.html) module. If you're interested in using another data augmentation library, learn how in the [Albumentations](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_albumentations.ipynb) or [Kornia notebooks](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_kornia.ipynb).
-1. Normalize the image with the feature extractor and use [`Compose`](https://pytorch.org/vision/master/generated/torchvision.transforms.Compose.html) to chain some transforms - [`RandomResizedCrop`](https://pytorch.org/vision/main/generated/torchvision.transforms.RandomResizedCrop.html) and [`ColorJitter`](https://pytorch.org/vision/main/generated/torchvision.transforms.ColorJitter.html) - together:
+1. Normalize the image with the image processor and use [`Compose`](https://pytorch.org/vision/master/generated/torchvision.transforms.Compose.html) to chain some transforms - [`RandomResizedCrop`](https://pytorch.org/vision/main/generated/torchvision.transforms.RandomResizedCrop.html) and [`ColorJitter`](https://pytorch.org/vision/main/generated/torchvision.transforms.ColorJitter.html) - together:
```py
>>> from torchvision.transforms import Compose, Normalize, RandomResizedCrop, ColorJitter, ToTensor
@@ -370,7 +370,7 @@ For computer vision tasks, it is common to add some type of data augmentation to
>>> _transforms = Compose([RandomResizedCrop(size), ColorJitter(brightness=0.5, hue=0.5), ToTensor(), normalize])
```
-2. The model accepts [`pixel_values`](model_doc/visionencoderdecoder#transformers.VisionEncoderDecoderModel.forward.pixel_values) as its input, which is generated by the feature extractor. Create a function that generates `pixel_values` from the transforms:
+2. The model accepts [`pixel_values`](model_doc/visionencoderdecoder#transformers.VisionEncoderDecoderModel.forward.pixel_values) as its input, which is generated by the image processor. Create a function that generates `pixel_values` from the transforms:
```py
>>> def transforms(examples):
@@ -384,7 +384,7 @@ For computer vision tasks, it is common to add some type of data augmentation to
>>> dataset.set_transform(transforms)
```
-4. Now when you access the image, you'll notice the feature extractor has added `pixel_values`. You can pass your processed dataset to the model now!
+4. Now when you access the image, you'll notice the image processor has added `pixel_values`. You can pass your processed dataset to the model now!
```py
>>> dataset[0]["image"]
@@ -431,7 +431,7 @@ Here is what the image looks like after the transforms are applied. The image ha
## Multimodal
-For tasks involving multimodal inputs, you'll need a [processor](main_classes/processors) to prepare your dataset for the model. A processor couples a tokenizer and feature extractor.
+For tasks involving multimodal inputs, you'll need a [processor](main_classes/processors) to prepare your dataset for the model. A processor couples together two processing objects such as as tokenizer and feature extractor.
Load the [LJ Speech](https://huggingface.co/datasets/lj_speech) dataset (see the 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub.html) for more details on how to load a dataset) to see how you can use a processor for automatic speech recognition (ASR):
diff --git a/docs/source/en/quicktour.mdx b/docs/source/en/quicktour.mdx
index 7cfac04314..c0fcaa55cb 100644
--- a/docs/source/en/quicktour.mdx
+++ b/docs/source/en/quicktour.mdx
@@ -225,7 +225,7 @@ A tokenizer can also accept a list of inputs, and pad and truncate the text to r
-Check out the [preprocess](./preprocessing) tutorial for more details about tokenization, and how to use an [`AutoFeatureExtractor`] and [`AutoProcessor`] to preprocess image, audio, and multimodal inputs.
+Check out the [preprocess](./preprocessing) tutorial for more details about tokenization, and how to use an [`AutoImageProcessor`], [`AutoFeatureExtractor`] and [`AutoProcessor`] to preprocess image, audio, and multimodal inputs.
@@ -424,7 +424,7 @@ Depending on your task, you'll typically pass the following parameters to [`Trai
... )
```
-3. A preprocessing class like a tokenizer, feature extractor, or processor:
+3. A preprocessing class like a tokenizer, image processor, feature extractor, or processor:
```py
>>> from transformers import AutoTokenizer
@@ -501,7 +501,7 @@ All models are a standard [`tf.keras.Model`](https://www.tensorflow.org/api_docs
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
-2. A preprocessing class like a tokenizer, feature extractor, or processor:
+2. A preprocessing class like a tokenizer, image processor, feature extractor, or processor:
```py
>>> from transformers import AutoTokenizer
diff --git a/docs/source/en/task_summary.mdx b/docs/source/en/task_summary.mdx
index 9a3b1b48c4..697ee21df5 100644
--- a/docs/source/en/task_summary.mdx
+++ b/docs/source/en/task_summary.mdx
@@ -1101,24 +1101,24 @@ Class Egyptian cat with score 0.0239
Class tiger cat with score 0.0229
```
-The general process for using a model and feature extractor for image classification is:
+The general process for using a model and image processor for image classification is:
-1. Instantiate a feature extractor and a model from the checkpoint name.
-2. Process the image to be classified with a feature extractor.
+1. Instantiate an image processor and a model from the checkpoint name.
+2. Process the image to be classified with an image processor.
3. Pass the input through the model and take the `argmax` to retrieve the predicted class.
4. Convert the class id to a class name with `id2label` to return an interpretable result.
```py
->>> from transformers import AutoFeatureExtractor, AutoModelForImageClassification
+>>> from transformers import AutoImageProcessor, AutoModelForImageClassification
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
->>> feature_extractor = AutoFeatureExtractor.from_pretrained("google/vit-base-patch16-224")
+>>> feature_extractor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
>>> model = AutoModelForImageClassification.from_pretrained("google/vit-base-patch16-224")
>>> inputs = feature_extractor(image, return_tensors="pt")
diff --git a/docs/source/en/tasks/image_classification.mdx b/docs/source/en/tasks/image_classification.mdx
index a7362e10c4..2543db6d28 100644
--- a/docs/source/en/tasks/image_classification.mdx
+++ b/docs/source/en/tasks/image_classification.mdx
@@ -91,26 +91,26 @@ Now you can convert the label id to a label name:
## Preprocess
-The next step is to load a ViT feature extractor to process the image into a tensor:
+The next step is to load a ViT image processor to process the image into a tensor:
```py
->>> from transformers import AutoFeatureExtractor
+>>> from transformers import AutoImageProcessor
->>> feature_extractor = AutoFeatureExtractor.from_pretrained("google/vit-base-patch16-224-in21k")
+>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
```
-Apply some image transformations to the images to make the model more robust against overfitting. Here you'll use torchvision's [`transforms`](https://pytorch.org/vision/stable/transforms.html) module, but you can also use any image library you like.
+Apply some image transformations to the images to make the model more robust against overfitting. Here you'll use torchvision's [`transforms`](https://pytorch.org/vision/stable/transforms.html) module, but you can also use any image library you like.
Crop a random part of the image, resize it, and normalize it with the image mean and standard deviation:
```py
>>> from torchvision.transforms import RandomResizedCrop, Compose, Normalize, ToTensor
->>> normalize = Normalize(mean=feature_extractor.image_mean, std=feature_extractor.image_std)
+>>> normalize = Normalize(mean=image_processor.image_mean, std=image_processor.image_std)
>>> size = (
-... feature_extractor.size["shortest_edge"]
-... if "shortest_edge" in feature_extractor.size
-... else (feature_extractor.size["height"], feature_extractor.size["width"])
+... image_processor.size["shortest_edge"]
+... if "shortest_edge" in image_processor.size
+... else (image_processor.size["height"], image_processor.size["width"])
... )
>>> _transforms = Compose([RandomResizedCrop(size), ToTensor(), normalize])
```
@@ -213,7 +213,7 @@ At this point, only three steps remain:
... data_collator=data_collator,
... train_dataset=food["train"],
... eval_dataset=food["test"],
-... tokenizer=feature_extractor,
+... tokenizer=image_processor,
... compute_metrics=compute_metrics,
... )
@@ -266,14 +266,14 @@ You can also manually replicate the results of the `pipeline` if you'd like:
-Load a feature extractor to preprocess the image and return the `input` as PyTorch tensors:
+Load an image processor to preprocess the image and return the `input` as PyTorch tensors:
```py
->>> from transformers import AutoFeatureExtractor
+>>> from transformers import AutoImageProcessor
>>> import torch
->>> feature_extractor = AutoFeatureExtractor.from_pretrained("my_awesome_food_model")
->>> inputs = feature_extractor(image, return_tensors="pt")
+>>> image_processor = AutoImageProcessor.from_pretrained("my_awesome_food_model")
+>>> inputs = image_processor(image, return_tensors="pt")
```
Pass your inputs to the model and return the logits:
diff --git a/docs/source/en/tasks/semantic_segmentation.mdx b/docs/source/en/tasks/semantic_segmentation.mdx
index 069f312802..f1ab7ee0ea 100644
--- a/docs/source/en/tasks/semantic_segmentation.mdx
+++ b/docs/source/en/tasks/semantic_segmentation.mdx
@@ -90,12 +90,12 @@ You'll also want to create a dictionary that maps a label id to a label class wh
## Preprocess
-The next step is to load a SegFormer feature extractor to prepare the images and annotations for the model. Some datasets, like this one, use the zero-index as the background class. However, the background class isn't actually included in the 150 classes, so you'll need to set `reduce_labels=True` to subtract one from all the labels. The zero-index is replaced by `255` so it's ignored by SegFormer's loss function:
+The next step is to load a SegFormer image processor to prepare the images and annotations for the model. Some datasets, like this one, use the zero-index as the background class. However, the background class isn't actually included in the 150 classes, so you'll need to set `reduce_labels=True` to subtract one from all the labels. The zero-index is replaced by `255` so it's ignored by SegFormer's loss function:
```py
->>> from transformers import AutoFeatureExtractor
+>>> from transformers import AutoImageProcessor
->>> feature_extractor = AutoFeatureExtractor.from_pretrained("nvidia/mit-b0", reduce_labels=True)
+>>> feature_extractor = AutoImageProcessor.from_pretrained("nvidia/mit-b0", reduce_labels=True)
```
It is common to apply some data augmentations to an image dataset to make a model more robust against overfitting. In this guide, you'll use the [`ColorJitter`](https://pytorch.org/vision/stable/generated/torchvision.transforms.ColorJitter.html) function from [torchvision](https://pytorch.org/vision/stable/index.html) to randomly change the color properties of an image, but you can also use any image library you like.
@@ -106,7 +106,7 @@ It is common to apply some data augmentations to an image dataset to make a mode
>>> jitter = ColorJitter(brightness=0.25, contrast=0.25, saturation=0.25, hue=0.1)
```
-Now create two preprocessing functions to prepare the images and annotations for the model. These functions convert the images into `pixel_values` and annotations to `labels`. For the training set, `jitter` is applied before providing the images to the feature extractor. For the test set, the feature extractor crops and normalizes the `images`, and only crops the `labels` because no data augmentation is applied during testing.
+Now create two preprocessing functions to prepare the images and annotations for the model. These functions convert the images into `pixel_values` and annotations to `labels`. For the training set, `jitter` is applied before providing the images to the image processor. For the test set, the image processor crops and normalizes the `images`, and only crops the `labels` because no data augmentation is applied during testing.
```py
>>> def train_transforms(example_batch):
@@ -281,7 +281,7 @@ The simplest way to try out your finetuned model for inference is to use it in a
'mask': }]
```
-You can also manually replicate the results of the `pipeline` if you'd like. Process the image with a feature extractor and place the `pixel_values` on a GPU:
+You can also manually replicate the results of the `pipeline` if you'd like. Process the image with an image processor and place the `pixel_values` on a GPU:
```py
>>> device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # use GPU if available, otherwise use a CPU
diff --git a/docs/source/en/troubleshooting.mdx b/docs/source/en/troubleshooting.mdx
index ea0724cd4e..74346bccef 100644
--- a/docs/source/en/troubleshooting.mdx
+++ b/docs/source/en/troubleshooting.mdx
@@ -89,7 +89,7 @@ TensorFlow's [model.save](https://www.tensorflow.org/tutorials/keras/save_and_lo
Another common error you may encounter, especially if it is a newly released model, is `ImportError`:
```
-ImportError: cannot import name 'ImageGPTFeatureExtractor' from 'transformers' (unknown location)
+ImportError: cannot import name 'ImageGPTImageProcessor' from 'transformers' (unknown location)
```
For these error types, check to make sure you have the latest version of 🤗 Transformers installed to access the most recent models:
diff --git a/src/transformers/models/beit/modeling_beit.py b/src/transformers/models/beit/modeling_beit.py
index c1e91651d7..6062b87b15 100755
--- a/src/transformers/models/beit/modeling_beit.py
+++ b/src/transformers/models/beit/modeling_beit.py
@@ -49,7 +49,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "BeitConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "BeitFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "BeitImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "microsoft/beit-base-patch16-224-pt22k"
@@ -593,8 +593,8 @@ BEIT_START_DOCSTRING = r"""
BEIT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`BeitFeatureExtractor`]. See
- [`BeitFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`BeitImageProcessor`]. See
+ [`BeitImageProcessor.__call__`] for details.
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -769,7 +769,7 @@ class BeitForMaskedImageModeling(BeitPreTrainedModel):
Examples:
```python
- >>> from transformers import BeitFeatureExtractor, BeitForMaskedImageModeling
+ >>> from transformers import BeitImageProcessor, BeitForMaskedImageModeling
>>> import torch
>>> from PIL import Image
>>> import requests
@@ -777,11 +777,11 @@ class BeitForMaskedImageModeling(BeitPreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = BeitFeatureExtractor.from_pretrained("microsoft/beit-base-patch16-224-pt22k")
+ >>> image_processor = BeitImageProcessor.from_pretrained("microsoft/beit-base-patch16-224-pt22k")
>>> model = BeitForMaskedImageModeling.from_pretrained("microsoft/beit-base-patch16-224-pt22k")
>>> num_patches = (model.config.image_size // model.config.patch_size) ** 2
- >>> pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
+ >>> pixel_values = image_processor(images=image, return_tensors="pt").pixel_values
>>> # create random boolean mask of shape (batch_size, num_patches)
>>> bool_masked_pos = torch.randint(low=0, high=2, size=(1, num_patches)).bool()
@@ -1218,17 +1218,17 @@ class BeitForSemanticSegmentation(BeitPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, BeitForSemanticSegmentation
+ >>> from transformers import AutoImageProcessor, BeitForSemanticSegmentation
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/beit-base-finetuned-ade-640-640")
+ >>> image_processor = AutoImageProcessor.from_pretrained("microsoft/beit-base-finetuned-ade-640-640")
>>> model = BeitForSemanticSegmentation.from_pretrained("microsoft/beit-base-finetuned-ade-640-640")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # logits are of shape (batch_size, num_labels, height, width)
>>> logits = outputs.logits
diff --git a/src/transformers/models/beit/modeling_flax_beit.py b/src/transformers/models/beit/modeling_flax_beit.py
index 225fb280af..4a866584fb 100644
--- a/src/transformers/models/beit/modeling_flax_beit.py
+++ b/src/transformers/models/beit/modeling_flax_beit.py
@@ -102,8 +102,8 @@ BEIT_START_DOCSTRING = r"""
BEIT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`numpy.ndarray` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`BeitFeatureExtractor`]. See
- [`BeitFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`BeitImageProcessor`]. See
+ [`BeitImageProcessor.__call__`] for details.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
@@ -756,17 +756,17 @@ FLAX_BEIT_MODEL_DOCSTRING = """
Examples:
```python
- >>> from transformers import BeitFeatureExtractor, FlaxBeitModel
+ >>> from transformers import BeitImageProcessor, FlaxBeitModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = BeitFeatureExtractor.from_pretrained("microsoft/beit-base-patch16-224-pt22k-ft22k")
+ >>> image_processor = BeitImageProcessor.from_pretrained("microsoft/beit-base-patch16-224-pt22k-ft22k")
>>> model = FlaxBeitModel.from_pretrained("microsoft/beit-base-patch16-224-pt22k-ft22k")
- >>> inputs = feature_extractor(images=image, return_tensors="np")
+ >>> inputs = image_processor(images=image, return_tensors="np")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
```
@@ -843,17 +843,17 @@ FLAX_BEIT_MLM_DOCSTRING = """
Examples:
```python
- >>> from transformers import BeitFeatureExtractor, BeitForMaskedImageModeling
+ >>> from transformers import BeitImageProcessor, BeitForMaskedImageModeling
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = BeitFeatureExtractor.from_pretrained("microsoft/beit-base-patch16-224-pt22k")
+ >>> image_processor = BeitImageProcessor.from_pretrained("microsoft/beit-base-patch16-224-pt22k")
>>> model = BeitForMaskedImageModeling.from_pretrained("microsoft/beit-base-patch16-224-pt22k")
- >>> inputs = feature_extractor(images=image, return_tensors="np")
+ >>> inputs = image_processor(images=image, return_tensors="np")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
```
@@ -927,17 +927,17 @@ FLAX_BEIT_CLASSIF_DOCSTRING = """
Example:
```python
- >>> from transformers import BeitFeatureExtractor, FlaxBeitForImageClassification
+ >>> from transformers import BeitImageProcessor, FlaxBeitForImageClassification
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = BeitFeatureExtractor.from_pretrained("microsoft/beit-base-patch16-224")
+ >>> image_processor = BeitImageProcessor.from_pretrained("microsoft/beit-base-patch16-224")
>>> model = FlaxBeitForImageClassification.from_pretrained("microsoft/beit-base-patch16-224")
- >>> inputs = feature_extractor(images=image, return_tensors="np")
+ >>> inputs = image_processor(images=image, return_tensors="np")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
>>> # model predicts one of the 1000 ImageNet classes
diff --git a/src/transformers/models/conditional_detr/modeling_conditional_detr.py b/src/transformers/models/conditional_detr/modeling_conditional_detr.py
index 8860ff50b9..6ce8596592 100644
--- a/src/transformers/models/conditional_detr/modeling_conditional_detr.py
+++ b/src/transformers/models/conditional_detr/modeling_conditional_detr.py
@@ -153,8 +153,8 @@ class ConditionalDetrObjectDetectionOutput(ModelOutput):
pred_boxes (`torch.FloatTensor` of shape `(batch_size, num_queries, 4)`):
Normalized boxes coordinates for all queries, represented as (center_x, center_y, width, height). These
values are normalized in [0, 1], relative to the size of each individual image in the batch (disregarding
- possible padding). You can use [`~ConditionalDetrFeatureExtractor.post_process_object_detection`] to
- retrieve the unnormalized bounding boxes.
+ possible padding). You can use [`~ConditionalDetrImageProcessor.post_process_object_detection`] to retrieve
+ the unnormalized bounding boxes.
auxiliary_outputs (`list[Dict]`, *optional*):
Optional, only returned when auxilary losses are activated (i.e. `config.auxiliary_loss` is set to `True`)
and labels are provided. It is a list of dictionaries containing the two above keys (`logits` and
@@ -217,13 +217,13 @@ class ConditionalDetrSegmentationOutput(ModelOutput):
pred_boxes (`torch.FloatTensor` of shape `(batch_size, num_queries, 4)`):
Normalized boxes coordinates for all queries, represented as (center_x, center_y, width, height). These
values are normalized in [0, 1], relative to the size of each individual image in the batch (disregarding
- possible padding). You can use [`~ConditionalDetrFeatureExtractor.post_process_object_detection`] to
- retrieve the unnormalized bounding boxes.
+ possible padding). You can use [`~ConditionalDetrImageProcessor.post_process_object_detection`] to retrieve
+ the unnormalized bounding boxes.
pred_masks (`torch.FloatTensor` of shape `(batch_size, num_queries, height/4, width/4)`):
Segmentation masks logits for all queries. See also
- [`~ConditionalDetrFeatureExtractor.post_process_semantic_segmentation`] or
- [`~ConditionalDetrFeatureExtractor.post_process_instance_segmentation`]
- [`~ConditionalDetrFeatureExtractor.post_process_panoptic_segmentation`] to evaluate semantic, instance and
+ [`~ConditionalDetrImageProcessor.post_process_semantic_segmentation`] or
+ [`~ConditionalDetrImageProcessor.post_process_instance_segmentation`]
+ [`~ConditionalDetrImageProcessor.post_process_panoptic_segmentation`] to evaluate semantic, instance and
panoptic segmentation masks respectively.
auxiliary_outputs (`list[Dict]`, *optional*):
Optional, only returned when auxiliary losses are activated (i.e. `config.auxiliary_loss` is set to `True`)
@@ -1097,8 +1097,8 @@ CONDITIONAL_DETR_INPUTS_DOCSTRING = r"""
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values. Padding will be ignored by default should you provide it.
- Pixel values can be obtained using [`ConditionalDetrFeatureExtractor`]. See
- [`ConditionalDetrFeatureExtractor.__call__`] for details.
+ Pixel values can be obtained using [`ConditionalDetrImageProcessor`]. See
+ [`ConditionalDetrImageProcessor.__call__`] for details.
pixel_mask (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*):
Mask to avoid performing attention on padding pixel values. Mask values selected in `[0, 1]`:
@@ -1519,18 +1519,18 @@ class ConditionalDetrModel(ConditionalDetrPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, AutoModel
+ >>> from transformers import AutoImageProcessor, AutoModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/conditional-detr-resnet-50")
+ >>> image_processor = AutoImageProcessor.from_pretrained("microsoft/conditional-detr-resnet-50")
>>> model = AutoModel.from_pretrained("microsoft/conditional-detr-resnet-50")
>>> # prepare image for the model
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**inputs)
@@ -1687,25 +1687,25 @@ class ConditionalDetrForObjectDetection(ConditionalDetrPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, AutoModelForObjectDetection
+ >>> from transformers import AutoImageProcessor, AutoModelForObjectDetection
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/conditional-detr-resnet-50")
+ >>> image_processor = AutoImageProcessor.from_pretrained("microsoft/conditional-detr-resnet-50")
>>> model = AutoModelForObjectDetection.from_pretrained("microsoft/conditional-detr-resnet-50")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # convert outputs (bounding boxes and class logits) to COCO API
>>> target_sizes = torch.tensor([image.size[::-1]])
- >>> results = feature_extractor.post_process_object_detection(
- ... outputs, threshold=0.5, target_sizes=target_sizes
- ... )[0]
+ >>> results = image_processor.post_process_object_detection(outputs, threshold=0.5, target_sizes=target_sizes)[
+ ... 0
+ ... ]
>>> for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
... box = [round(i, 2) for i in box.tolist()]
... print(
@@ -1880,7 +1880,7 @@ class ConditionalDetrForSegmentation(ConditionalDetrPreTrainedModel):
>>> import numpy
>>> from transformers import (
- ... AutoFeatureExtractor,
+ ... AutoImageProcessor,
... ConditionalDetrConfig,
... ConditionalDetrForSegmentation,
... )
@@ -1889,21 +1889,21 @@ class ConditionalDetrForSegmentation(ConditionalDetrPreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/conditional-detr-resnet-50")
+ >>> image_processor = AutoImageProcessor.from_pretrained("microsoft/conditional-detr-resnet-50")
>>> # randomly initialize all weights of the model
>>> config = ConditionalDetrConfig()
>>> model = ConditionalDetrForSegmentation(config)
>>> # prepare image for the model
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**inputs)
- >>> # Use the `post_process_panoptic_segmentation` method of `ConditionalDetrFeatureExtractor` to retrieve post-processed panoptic segmentation maps
+ >>> # Use the `post_process_panoptic_segmentation` method of `ConditionalDetrImageProcessor` to retrieve post-processed panoptic segmentation maps
>>> # Segmentation results are returned as a list of dictionaries
- >>> result = feature_extractor.post_process_panoptic_segmentation(outputs, target_sizes=[(300, 500)])
+ >>> result = image_processor.post_process_panoptic_segmentation(outputs, target_sizes=[(300, 500)])
>>> # A tensor of shape (height, width) where each value denotes a segment id, filled with -1 if no segment is found
>>> panoptic_seg = result[0]["segmentation"]
>>> # Get prediction score and segment_id to class_id mapping of each segment
diff --git a/src/transformers/models/convnext/modeling_convnext.py b/src/transformers/models/convnext/modeling_convnext.py
index 44d34c833b..af4ec4e7f8 100755
--- a/src/transformers/models/convnext/modeling_convnext.py
+++ b/src/transformers/models/convnext/modeling_convnext.py
@@ -37,7 +37,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "ConvNextConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "ConvNextFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "ConvNextImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "facebook/convnext-tiny-224"
@@ -308,8 +308,8 @@ CONVNEXT_START_DOCSTRING = r"""
CONVNEXT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
diff --git a/src/transformers/models/convnext/modeling_tf_convnext.py b/src/transformers/models/convnext/modeling_tf_convnext.py
index 680c036e53..8906fa6b47 100644
--- a/src/transformers/models/convnext/modeling_tf_convnext.py
+++ b/src/transformers/models/convnext/modeling_tf_convnext.py
@@ -432,8 +432,8 @@ CONVNEXT_START_DOCSTRING = r"""
CONVNEXT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`np.ndarray`, `tf.Tensor`, `List[tf.Tensor]` ``Dict[str, tf.Tensor]` or `Dict[str, np.ndarray]` and each example must have the shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`ConvNextFeatureExtractor`]. See
- [`ConvNextFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`ConvNextImageProcessor`]. See
+ [`ConvNextImageProcessor.__call__`] for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
@@ -470,17 +470,17 @@ class TFConvNextModel(TFConvNextPreTrainedModel):
Examples:
```python
- >>> from transformers import ConvNextFeatureExtractor, TFConvNextModel
+ >>> from transformers import ConvNextImageProcessor, TFConvNextModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = ConvNextFeatureExtractor.from_pretrained("facebook/convnext-tiny-224")
+ >>> image_processor = ConvNextImageProcessor.from_pretrained("facebook/convnext-tiny-224")
>>> model = TFConvNextModel.from_pretrained("facebook/convnext-tiny-224")
- >>> inputs = feature_extractor(images=image, return_tensors="tf")
+ >>> inputs = image_processor(images=image, return_tensors="tf")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
```"""
@@ -561,7 +561,7 @@ class TFConvNextForImageClassification(TFConvNextPreTrainedModel, TFSequenceClas
Examples:
```python
- >>> from transformers import ConvNextFeatureExtractor, TFConvNextForImageClassification
+ >>> from transformers import ConvNextImageProcessor, TFConvNextForImageClassification
>>> import tensorflow as tf
>>> from PIL import Image
>>> import requests
@@ -569,10 +569,10 @@ class TFConvNextForImageClassification(TFConvNextPreTrainedModel, TFSequenceClas
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = ConvNextFeatureExtractor.from_pretrained("facebook/convnext-tiny-224")
+ >>> image_processor = ConvNextImageProcessor.from_pretrained("facebook/convnext-tiny-224")
>>> model = TFConvNextForImageClassification.from_pretrained("facebook/convnext-tiny-224")
- >>> inputs = feature_extractor(images=image, return_tensors="tf")
+ >>> inputs = image_processor(images=image, return_tensors="tf")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
>>> # model predicts one of the 1000 ImageNet classes
diff --git a/src/transformers/models/cvt/modeling_cvt.py b/src/transformers/models/cvt/modeling_cvt.py
index a76e681c3d..f1d6784051 100644
--- a/src/transformers/models/cvt/modeling_cvt.py
+++ b/src/transformers/models/cvt/modeling_cvt.py
@@ -35,7 +35,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "CvtConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "AutoFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "AutoImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "microsoft/cvt-13"
@@ -573,8 +573,8 @@ CVT_START_DOCSTRING = r"""
CVT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`CvtFeatureExtractor`]. See
- [`CvtFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`CvtImageProcessor`]. See [`CvtImageProcessor.__call__`]
+ for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
diff --git a/src/transformers/models/cvt/modeling_tf_cvt.py b/src/transformers/models/cvt/modeling_tf_cvt.py
index 448bfd2302..17880eaa9d 100644
--- a/src/transformers/models/cvt/modeling_tf_cvt.py
+++ b/src/transformers/models/cvt/modeling_tf_cvt.py
@@ -766,8 +766,8 @@ TFCVT_START_DOCSTRING = r"""
TFCVT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`np.ndarray`, `tf.Tensor`, `List[tf.Tensor]` ``Dict[str, tf.Tensor]` or `Dict[str, np.ndarray]` and each example must have the shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
@@ -808,17 +808,17 @@ class TFCvtModel(TFCvtPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, TFCvtModel
+ >>> from transformers import AutoImageProcessor, TFCvtModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/cvt-13")
+ >>> image_processor = AutoImageProcessor.from_pretrained("microsoft/cvt-13")
>>> model = TFCvtModel.from_pretrained("microsoft/cvt-13")
- >>> inputs = feature_extractor(images=image, return_tensors="tf")
+ >>> inputs = image_processor(images=image, return_tensors="tf")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
```"""
@@ -897,7 +897,7 @@ class TFCvtForImageClassification(TFCvtPreTrainedModel, TFSequenceClassification
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, TFCvtForImageClassification
+ >>> from transformers import AutoImageProcessor, TFCvtForImageClassification
>>> import tensorflow as tf
>>> from PIL import Image
>>> import requests
@@ -905,10 +905,10 @@ class TFCvtForImageClassification(TFCvtPreTrainedModel, TFSequenceClassification
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/cvt-13")
+ >>> image_processor = AutoImageProcessor.from_pretrained("microsoft/cvt-13")
>>> model = TFCvtForImageClassification.from_pretrained("microsoft/cvt-13")
- >>> inputs = feature_extractor(images=image, return_tensors="tf")
+ >>> inputs = image_processor(images=image, return_tensors="tf")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
>>> # model predicts one of the 1000 ImageNet classes
diff --git a/src/transformers/models/data2vec/modeling_data2vec_vision.py b/src/transformers/models/data2vec/modeling_data2vec_vision.py
index fad620e80b..75350eea33 100644
--- a/src/transformers/models/data2vec/modeling_data2vec_vision.py
+++ b/src/transformers/models/data2vec/modeling_data2vec_vision.py
@@ -48,7 +48,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "Data2VecVisionConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "BeitFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "BeitImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "facebook/data2vec-vision-base"
@@ -606,8 +606,8 @@ DATA2VEC_VISION_START_DOCSTRING = r"""
DATA2VEC_VISION_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`BeitFeatureExtractor`]. See
- [`BeitFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`BeitImageProcessor`]. See
+ [`BeitImageProcessor.__call__`] for details.
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -1146,17 +1146,17 @@ class Data2VecVisionForSemanticSegmentation(Data2VecVisionPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, Data2VecVisionForSemanticSegmentation
+ >>> from transformers import AutoImageProcessor, Data2VecVisionForSemanticSegmentation
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/data2vec-vision-base")
+ >>> image_processor = AutoImageProcessor.from_pretrained("facebook/data2vec-vision-base")
>>> model = Data2VecVisionForSemanticSegmentation.from_pretrained("facebook/data2vec-vision-base")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # logits are of shape (batch_size, num_labels, height, width)
>>> logits = outputs.logits
diff --git a/src/transformers/models/data2vec/modeling_tf_data2vec_vision.py b/src/transformers/models/data2vec/modeling_tf_data2vec_vision.py
index 5b4de28b7c..0a804aebd0 100644
--- a/src/transformers/models/data2vec/modeling_tf_data2vec_vision.py
+++ b/src/transformers/models/data2vec/modeling_tf_data2vec_vision.py
@@ -53,7 +53,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "Data2VecVisionConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "BeitFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "BeitImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "facebook/data2vec-vision-base"
@@ -849,8 +849,8 @@ DATA2VEC_VISION_START_DOCSTRING = r"""
DATA2VEC_VISION_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`np.ndarray`, `tf.Tensor`, `List[tf.Tensor]` ``Dict[str, tf.Tensor]` or `Dict[str, np.ndarray]` and each example must have the shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`BeitFeatureExtractor`]. See
- [`BeitFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`BeitImageProcessor`]. See
+ [`BeitImageProcessor.__call__`] for details.
head_mask (`np.ndarray` or `tf.Tensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -1397,17 +1397,17 @@ class TFData2VecVisionForSemanticSegmentation(TFData2VecVisionPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, TFData2VecVisionForSemanticSegmentation
+ >>> from transformers import AutoImageProcessor, TFData2VecVisionForSemanticSegmentation
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/data2vec-vision-base")
+ >>> image_processor = AutoImageProcessor.from_pretrained("facebook/data2vec-vision-base")
>>> model = TFData2VecVisionForSemanticSegmentation.from_pretrained("facebook/data2vec-vision-base")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # logits are of shape (batch_size, num_labels, height, width)
>>> logits = outputs.logits
diff --git a/src/transformers/models/deformable_detr/modeling_deformable_detr.py b/src/transformers/models/deformable_detr/modeling_deformable_detr.py
index c4a52d4257..e994854585 100755
--- a/src/transformers/models/deformable_detr/modeling_deformable_detr.py
+++ b/src/transformers/models/deformable_detr/modeling_deformable_detr.py
@@ -241,7 +241,7 @@ class DeformableDetrObjectDetectionOutput(ModelOutput):
pred_boxes (`torch.FloatTensor` of shape `(batch_size, num_queries, 4)`):
Normalized boxes coordinates for all queries, represented as (center_x, center_y, width, height). These
values are normalized in [0, 1], relative to the size of each individual image in the batch (disregarding
- possible padding). You can use [`~AutoFeatureExtractor.post_process_object_detection`] to retrieve the
+ possible padding). You can use [`~AutoImageProcessor.post_process_object_detection`] to retrieve the
unnormalized bounding boxes.
auxiliary_outputs (`list[Dict]`, *optional*):
Optional, only returned when auxilary losses are activated (i.e. `config.auxiliary_loss` is set to `True`)
@@ -1073,8 +1073,7 @@ DEFORMABLE_DETR_INPUTS_DOCSTRING = r"""
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values. Padding will be ignored by default should you provide it.
- Pixel values can be obtained using [`AutoFeatureExtractor`]. See [`AutoFeatureExtractor.__call__`] for
- details.
+ Pixel values can be obtained using [`AutoImageProcessor`]. See [`AutoImageProcessor.__call__`] for details.
pixel_mask (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*):
Mask to avoid performing attention on padding pixel values. Mask values selected in `[0, 1]`:
@@ -1603,17 +1602,17 @@ class DeformableDetrModel(DeformableDetrPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, DeformableDetrModel
+ >>> from transformers import AutoImageProcessor, DeformableDetrModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("SenseTime/deformable-detr")
+ >>> image_processor = AutoImageProcessor.from_pretrained("SenseTime/deformable-detr")
>>> model = DeformableDetrModel.from_pretrained("SenseTime/deformable-detr")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
@@ -1873,24 +1872,24 @@ class DeformableDetrForObjectDetection(DeformableDetrPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, DeformableDetrForObjectDetection
+ >>> from transformers import AutoImageProcessor, DeformableDetrForObjectDetection
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("SenseTime/deformable-detr")
+ >>> image_processor = AutoImageProcessor.from_pretrained("SenseTime/deformable-detr")
>>> model = DeformableDetrForObjectDetection.from_pretrained("SenseTime/deformable-detr")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # convert outputs (bounding boxes and class logits) to COCO API
>>> target_sizes = torch.tensor([image.size[::-1]])
- >>> results = feature_extractor.post_process_object_detection(
- ... outputs, threshold=0.5, target_sizes=target_sizes
- ... )[0]
+ >>> results = image_processor.post_process_object_detection(outputs, threshold=0.5, target_sizes=target_sizes)[
+ ... 0
+ ... ]
>>> for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
... box = [round(i, 2) for i in box.tolist()]
... print(
diff --git a/src/transformers/models/deit/modeling_deit.py b/src/transformers/models/deit/modeling_deit.py
index b741347d61..646b6b9a2a 100644
--- a/src/transformers/models/deit/modeling_deit.py
+++ b/src/transformers/models/deit/modeling_deit.py
@@ -44,7 +44,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "DeiTConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "DeiTFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "DeiTImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "facebook/deit-base-distilled-patch16-224"
@@ -433,8 +433,8 @@ DEIT_START_DOCSTRING = r"""
DEIT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`DeiTFeatureExtractor`]. See
- [`DeiTFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`DeiTImageProcessor`]. See
+ [`DeiTImageProcessor.__call__`] for details.
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -611,7 +611,7 @@ class DeiTForMaskedImageModeling(DeiTPreTrainedModel):
Examples:
```python
- >>> from transformers import DeiTFeatureExtractor, DeiTForMaskedImageModeling
+ >>> from transformers import DeiTImageProcessor, DeiTForMaskedImageModeling
>>> import torch
>>> from PIL import Image
>>> import requests
@@ -619,11 +619,11 @@ class DeiTForMaskedImageModeling(DeiTPreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = DeiTFeatureExtractor.from_pretrained("facebook/deit-base-distilled-patch16-224")
+ >>> image_processor = DeiTImageProcessor.from_pretrained("facebook/deit-base-distilled-patch16-224")
>>> model = DeiTForMaskedImageModeling.from_pretrained("facebook/deit-base-distilled-patch16-224")
>>> num_patches = (model.config.image_size // model.config.patch_size) ** 2
- >>> pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
+ >>> pixel_values = image_processor(images=image, return_tensors="pt").pixel_values
>>> # create random boolean mask of shape (batch_size, num_patches)
>>> bool_masked_pos = torch.randint(low=0, high=2, size=(1, num_patches)).bool()
@@ -721,7 +721,7 @@ class DeiTForImageClassification(DeiTPreTrainedModel):
Examples:
```python
- >>> from transformers import DeiTFeatureExtractor, DeiTForImageClassification
+ >>> from transformers import DeiTImageProcessor, DeiTForImageClassification
>>> import torch
>>> from PIL import Image
>>> import requests
@@ -732,10 +732,10 @@ class DeiTForImageClassification(DeiTPreTrainedModel):
>>> # note: we are loading a DeiTForImageClassificationWithTeacher from the hub here,
>>> # so the head will be randomly initialized, hence the predictions will be random
- >>> feature_extractor = DeiTFeatureExtractor.from_pretrained("facebook/deit-base-distilled-patch16-224")
+ >>> image_processor = DeiTImageProcessor.from_pretrained("facebook/deit-base-distilled-patch16-224")
>>> model = DeiTForImageClassification.from_pretrained("facebook/deit-base-distilled-patch16-224")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
>>> # model predicts one of the 1000 ImageNet classes
diff --git a/src/transformers/models/deit/modeling_tf_deit.py b/src/transformers/models/deit/modeling_tf_deit.py
index b7270abb65..1eca5a6239 100644
--- a/src/transformers/models/deit/modeling_tf_deit.py
+++ b/src/transformers/models/deit/modeling_tf_deit.py
@@ -52,7 +52,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "DeiTConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "DeiTFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "DeiTImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "facebook/deit-base-distilled-patch16-224"
@@ -614,8 +614,8 @@ DEIT_START_DOCSTRING = r"""
DEIT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`tf.Tensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`DeiTFeatureExtractor`]. See
- [`DeiTFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`DeiTImageProcessor`]. See
+ [`DeiTImageProcessor.__call__`] for details.
head_mask (`tf.Tensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -786,7 +786,7 @@ class TFDeiTForMaskedImageModeling(TFDeiTPreTrainedModel):
Examples:
```python
- >>> from transformers import DeiTFeatureExtractor, TFDeiTForMaskedImageModeling
+ >>> from transformers import DeiTImageProcessor, TFDeiTForMaskedImageModeling
>>> import tensorflow as tf
>>> from PIL import Image
>>> import requests
@@ -794,11 +794,11 @@ class TFDeiTForMaskedImageModeling(TFDeiTPreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = DeiTFeatureExtractor.from_pretrained("facebook/deit-base-distilled-patch16-224")
+ >>> image_processor = DeiTImageProcessor.from_pretrained("facebook/deit-base-distilled-patch16-224")
>>> model = TFDeiTForMaskedImageModeling.from_pretrained("facebook/deit-base-distilled-patch16-224")
>>> num_patches = (model.config.image_size // model.config.patch_size) ** 2
- >>> pixel_values = feature_extractor(images=image, return_tensors="tf").pixel_values
+ >>> pixel_values = image_processor(images=image, return_tensors="tf").pixel_values
>>> # create random boolean mask of shape (batch_size, num_patches)
>>> bool_masked_pos = tf.cast(tf.random.uniform((1, num_patches), minval=0, maxval=2, dtype=tf.int32), tf.bool)
@@ -917,7 +917,7 @@ class TFDeiTForImageClassification(TFDeiTPreTrainedModel, TFSequenceClassificati
Examples:
```python
- >>> from transformers import DeiTFeatureExtractor, TFDeiTForImageClassification
+ >>> from transformers import DeiTImageProcessor, TFDeiTForImageClassification
>>> import tensorflow as tf
>>> from PIL import Image
>>> import requests
@@ -928,10 +928,10 @@ class TFDeiTForImageClassification(TFDeiTPreTrainedModel, TFSequenceClassificati
>>> # note: we are loading a TFDeiTForImageClassificationWithTeacher from the hub here,
>>> # so the head will be randomly initialized, hence the predictions will be random
- >>> feature_extractor = DeiTFeatureExtractor.from_pretrained("facebook/deit-base-distilled-patch16-224")
+ >>> image_processor = DeiTImageProcessor.from_pretrained("facebook/deit-base-distilled-patch16-224")
>>> model = TFDeiTForImageClassification.from_pretrained("facebook/deit-base-distilled-patch16-224")
- >>> inputs = feature_extractor(images=image, return_tensors="tf")
+ >>> inputs = image_processor(images=image, return_tensors="tf")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
>>> # model predicts one of the 1000 ImageNet classes
diff --git a/src/transformers/models/detr/modeling_detr.py b/src/transformers/models/detr/modeling_detr.py
index b06453479f..478653ee63 100644
--- a/src/transformers/models/detr/modeling_detr.py
+++ b/src/transformers/models/detr/modeling_detr.py
@@ -148,7 +148,7 @@ class DetrObjectDetectionOutput(ModelOutput):
pred_boxes (`torch.FloatTensor` of shape `(batch_size, num_queries, 4)`):
Normalized boxes coordinates for all queries, represented as (center_x, center_y, width, height). These
values are normalized in [0, 1], relative to the size of each individual image in the batch (disregarding
- possible padding). You can use [`~DetrFeatureExtractor.post_process_object_detection`] to retrieve the
+ possible padding). You can use [`~DetrImageProcessor.post_process_object_detection`] to retrieve the
unnormalized bounding boxes.
auxiliary_outputs (`list[Dict]`, *optional*):
Optional, only returned when auxilary losses are activated (i.e. `config.auxiliary_loss` is set to `True`)
@@ -211,13 +211,13 @@ class DetrSegmentationOutput(ModelOutput):
pred_boxes (`torch.FloatTensor` of shape `(batch_size, num_queries, 4)`):
Normalized boxes coordinates for all queries, represented as (center_x, center_y, width, height). These
values are normalized in [0, 1], relative to the size of each individual image in the batch (disregarding
- possible padding). You can use [`~DetrFeatureExtractor.post_process_object_detection`] to retrieve the
+ possible padding). You can use [`~DetrImageProcessor.post_process_object_detection`] to retrieve the
unnormalized bounding boxes.
pred_masks (`torch.FloatTensor` of shape `(batch_size, num_queries, height/4, width/4)`):
Segmentation masks logits for all queries. See also
- [`~DetrFeatureExtractor.post_process_semantic_segmentation`] or
- [`~DetrFeatureExtractor.post_process_instance_segmentation`]
- [`~DetrFeatureExtractor.post_process_panoptic_segmentation`] to evaluate semantic, instance and panoptic
+ [`~DetrImageProcessor.post_process_semantic_segmentation`] or
+ [`~DetrImageProcessor.post_process_instance_segmentation`]
+ [`~DetrImageProcessor.post_process_panoptic_segmentation`] to evaluate semantic, instance and panoptic
segmentation masks respectively.
auxiliary_outputs (`list[Dict]`, *optional*):
Optional, only returned when auxiliary losses are activated (i.e. `config.auxiliary_loss` is set to `True`)
@@ -856,8 +856,7 @@ DETR_INPUTS_DOCSTRING = r"""
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values. Padding will be ignored by default should you provide it.
- Pixel values can be obtained using [`DetrFeatureExtractor`]. See [`DetrFeatureExtractor.__call__`] for
- details.
+ Pixel values can be obtained using [`DetrImageProcessor`]. See [`DetrImageProcessor.__call__`] for details.
pixel_mask (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*):
Mask to avoid performing attention on padding pixel values. Mask values selected in `[0, 1]`:
@@ -1243,18 +1242,18 @@ class DetrModel(DetrPreTrainedModel):
Examples:
```python
- >>> from transformers import DetrFeatureExtractor, DetrModel
+ >>> from transformers import DetrImageProcessor, DetrModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = DetrFeatureExtractor.from_pretrained("facebook/detr-resnet-50")
+ >>> image_processor = DetrImageProcessor.from_pretrained("facebook/detr-resnet-50")
>>> model = DetrModel.from_pretrained("facebook/detr-resnet-50")
>>> # prepare image for the model
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**inputs)
@@ -1410,7 +1409,7 @@ class DetrForObjectDetection(DetrPreTrainedModel):
Examples:
```python
- >>> from transformers import DetrFeatureExtractor, DetrForObjectDetection
+ >>> from transformers import DetrImageProcessor, DetrForObjectDetection
>>> import torch
>>> from PIL import Image
>>> import requests
@@ -1418,17 +1417,17 @@ class DetrForObjectDetection(DetrPreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = DetrFeatureExtractor.from_pretrained("facebook/detr-resnet-50")
+ >>> image_processor = DetrImageProcessor.from_pretrained("facebook/detr-resnet-50")
>>> model = DetrForObjectDetection.from_pretrained("facebook/detr-resnet-50")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # convert outputs (bounding boxes and class logits) to COCO API
>>> target_sizes = torch.tensor([image.size[::-1]])
- >>> results = feature_extractor.post_process_object_detection(
- ... outputs, threshold=0.9, target_sizes=target_sizes
- ... )[0]
+ >>> results = image_processor.post_process_object_detection(outputs, threshold=0.9, target_sizes=target_sizes)[
+ ... 0
+ ... ]
>>> for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
... box = [round(i, 2) for i in box.tolist()]
@@ -1588,24 +1587,24 @@ class DetrForSegmentation(DetrPreTrainedModel):
>>> import torch
>>> import numpy
- >>> from transformers import DetrFeatureExtractor, DetrForSegmentation
+ >>> from transformers import DetrImageProcessor, DetrForSegmentation
>>> from transformers.image_transforms import rgb_to_id
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = DetrFeatureExtractor.from_pretrained("facebook/detr-resnet-50-panoptic")
+ >>> image_processor = DetrImageProcessor.from_pretrained("facebook/detr-resnet-50-panoptic")
>>> model = DetrForSegmentation.from_pretrained("facebook/detr-resnet-50-panoptic")
>>> # prepare image for the model
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**inputs)
- >>> # Use the `post_process_panoptic_segmentation` method of `DetrFeatureExtractor` to retrieve post-processed panoptic segmentation maps
+ >>> # Use the `post_process_panoptic_segmentation` method of `DetrImageProcessor` to retrieve post-processed panoptic segmentation maps
>>> # Segmentation results are returned as a list of dictionaries
- >>> result = feature_extractor.post_process_panoptic_segmentation(outputs, target_sizes=[(300, 500)])
+ >>> result = image_processor.post_process_panoptic_segmentation(outputs, target_sizes=[(300, 500)])
>>> # A tensor of shape (height, width) where each value denotes a segment id, filled with -1 if no segment is found
>>> panoptic_seg = result[0]["segmentation"]
diff --git a/src/transformers/models/dpt/modeling_dpt.py b/src/transformers/models/dpt/modeling_dpt.py
index a16071607f..1f0cb869f4 100755
--- a/src/transformers/models/dpt/modeling_dpt.py
+++ b/src/transformers/models/dpt/modeling_dpt.py
@@ -52,7 +52,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "DPTConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "DPTFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "DPTImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "Intel/dpt-large"
@@ -651,8 +651,8 @@ DPT_START_DOCSTRING = r"""
DPT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`ViTFeatureExtractor`]. See
- [`ViTFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`ViTImageProcessor`]. See [`ViTImageProcessor.__call__`]
+ for details.
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -890,7 +890,7 @@ class DPTForDepthEstimation(DPTPreTrainedModel):
Examples:
```python
- >>> from transformers import DPTFeatureExtractor, DPTForDepthEstimation
+ >>> from transformers import DPTImageProcessor, DPTForDepthEstimation
>>> import torch
>>> import numpy as np
>>> from PIL import Image
@@ -899,11 +899,11 @@ class DPTForDepthEstimation(DPTPreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = DPTFeatureExtractor.from_pretrained("Intel/dpt-large")
+ >>> image_processor = DPTImageProcessor.from_pretrained("Intel/dpt-large")
>>> model = DPTForDepthEstimation.from_pretrained("Intel/dpt-large")
>>> # prepare image for the model
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
@@ -1052,17 +1052,17 @@ class DPTForSemanticSegmentation(DPTPreTrainedModel):
Examples:
```python
- >>> from transformers import DPTFeatureExtractor, DPTForSemanticSegmentation
+ >>> from transformers import DPTImageProcessor, DPTForSemanticSegmentation
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = DPTFeatureExtractor.from_pretrained("Intel/dpt-large-ade")
+ >>> image_processor = DPTImageProcessor.from_pretrained("Intel/dpt-large-ade")
>>> model = DPTForSemanticSegmentation.from_pretrained("Intel/dpt-large-ade")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
diff --git a/src/transformers/models/glpn/modeling_glpn.py b/src/transformers/models/glpn/modeling_glpn.py
index ebc148db66..acf8dea706 100755
--- a/src/transformers/models/glpn/modeling_glpn.py
+++ b/src/transformers/models/glpn/modeling_glpn.py
@@ -41,7 +41,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "GLPNConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "GLPNFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "GLPNImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "vinvino02/glpn-kitti"
@@ -464,7 +464,7 @@ GLPN_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
- [`GLPNFeatureExtractor`]. See [`GLPNFeatureExtractor.__call__`] for details.
+ [`GLPNImageProcessor`]. See [`GLPNImageProcessor.__call__`] for details.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
@@ -713,7 +713,7 @@ class GLPNForDepthEstimation(GLPNPreTrainedModel):
Examples:
```python
- >>> from transformers import GLPNFeatureExtractor, GLPNForDepthEstimation
+ >>> from transformers import GLPNImageProcessor, GLPNForDepthEstimation
>>> import torch
>>> import numpy as np
>>> from PIL import Image
@@ -722,11 +722,11 @@ class GLPNForDepthEstimation(GLPNPreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = GLPNFeatureExtractor.from_pretrained("vinvino02/glpn-kitti")
+ >>> image_processor = GLPNImageProcessor.from_pretrained("vinvino02/glpn-kitti")
>>> model = GLPNForDepthEstimation.from_pretrained("vinvino02/glpn-kitti")
>>> # prepare image for the model
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
diff --git a/src/transformers/models/imagegpt/modeling_imagegpt.py b/src/transformers/models/imagegpt/modeling_imagegpt.py
index 9d89251841..8a277e83c0 100755
--- a/src/transformers/models/imagegpt/modeling_imagegpt.py
+++ b/src/transformers/models/imagegpt/modeling_imagegpt.py
@@ -556,7 +556,7 @@ IMAGEGPT_INPUTS_DOCSTRING = r"""
If `past_key_values` is used, only `input_ids` that do not have their past calculated should be passed as
`input_ids`.
- Indices can be obtained using [`ImageGPTFeatureExtractor`]. See [`ImageGPTFeatureExtractor.__call__`] for
+ Indices can be obtained using [`ImageGPTImageProcessor`]. See [`ImageGPTImageProcessor.__call__`] for
details.
past_key_values (`Tuple[Tuple[torch.Tensor]]` of length `config.n_layers`):
@@ -679,17 +679,17 @@ class ImageGPTModel(ImageGPTPreTrainedModel):
Examples:
```python
- >>> from transformers import ImageGPTFeatureExtractor, ImageGPTModel
+ >>> from transformers import ImageGPTImageProcessor, ImageGPTModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = ImageGPTFeatureExtractor.from_pretrained("openai/imagegpt-small")
+ >>> image_processor = ImageGPTImageProcessor.from_pretrained("openai/imagegpt-small")
>>> model = ImageGPTModel.from_pretrained("openai/imagegpt-small")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
```"""
@@ -973,12 +973,12 @@ class ImageGPTForCausalImageModeling(ImageGPTPreTrainedModel):
Examples:
```python
- >>> from transformers import ImageGPTFeatureExtractor, ImageGPTForCausalImageModeling
+ >>> from transformers import ImageGPTImageProcessor, ImageGPTForCausalImageModeling
>>> import torch
>>> import matplotlib.pyplot as plt
>>> import numpy as np
- >>> feature_extractor = ImageGPTFeatureExtractor.from_pretrained("openai/imagegpt-small")
+ >>> image_processor = ImageGPTImageProcessor.from_pretrained("openai/imagegpt-small")
>>> model = ImageGPTForCausalImageModeling.from_pretrained("openai/imagegpt-small")
>>> device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
>>> model.to(device)
@@ -991,9 +991,9 @@ class ImageGPTForCausalImageModeling(ImageGPTPreTrainedModel):
... input_ids=context, max_length=model.config.n_positions + 1, temperature=1.0, do_sample=True, top_k=40
... )
- >>> clusters = feature_extractor.clusters
- >>> height = feature_extractor.size["height"]
- >>> width = feature_extractor.size["width"]
+ >>> clusters = image_processor.clusters
+ >>> height = image_processor.size["height"]
+ >>> width = image_processor.size["width"]
>>> samples = output[:, 1:].cpu().detach().numpy()
>>> samples_img = [
@@ -1124,17 +1124,17 @@ class ImageGPTForImageClassification(ImageGPTPreTrainedModel):
Examples:
```python
- >>> from transformers import ImageGPTFeatureExtractor, ImageGPTForImageClassification
+ >>> from transformers import ImageGPTImageProcessor, ImageGPTForImageClassification
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = ImageGPTFeatureExtractor.from_pretrained("openai/imagegpt-small")
+ >>> image_processor = ImageGPTImageProcessor.from_pretrained("openai/imagegpt-small")
>>> model = ImageGPTForImageClassification.from_pretrained("openai/imagegpt-small")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
```"""
diff --git a/src/transformers/models/levit/modeling_levit.py b/src/transformers/models/levit/modeling_levit.py
index a0d6f7ee09..bddd54cfb3 100644
--- a/src/transformers/models/levit/modeling_levit.py
+++ b/src/transformers/models/levit/modeling_levit.py
@@ -38,7 +38,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "LevitConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "LevitFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "LevitImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "facebook/levit-128S"
@@ -523,8 +523,8 @@ LEVIT_START_DOCSTRING = r"""
LEVIT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
diff --git a/src/transformers/models/maskformer/modeling_maskformer.py b/src/transformers/models/maskformer/modeling_maskformer.py
index 01ad3e6641..298d10879a 100644
--- a/src/transformers/models/maskformer/modeling_maskformer.py
+++ b/src/transformers/models/maskformer/modeling_maskformer.py
@@ -51,7 +51,7 @@ logger = logging.get_logger(__name__)
_CONFIG_FOR_DOC = "MaskFormerConfig"
_CHECKPOINT_FOR_DOC = "facebook/maskformer-swin-base-ade"
-_FEAT_EXTRACTOR_FOR_DOC = "MaskFormerFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "MaskFormerImageProcessor"
MASKFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
"facebook/maskformer-swin-base-ade",
@@ -192,10 +192,10 @@ class MaskFormerForInstanceSegmentationOutput(ModelOutput):
"""
Class for outputs of [`MaskFormerForInstanceSegmentation`].
- This output can be directly passed to [`~MaskFormerFeatureExtractor.post_process_semantic_segmentation`] or or
- [`~MaskFormerFeatureExtractor.post_process_instance_segmentation`] or
- [`~MaskFormerFeatureExtractor.post_process_panoptic_segmentation`] depending on the task. Please, see
- [`~MaskFormerFeatureExtractor] for details regarding usage.
+ This output can be directly passed to [`~MaskFormerImageProcessor.post_process_semantic_segmentation`] or or
+ [`~MaskFormerImageProcessor.post_process_instance_segmentation`] or
+ [`~MaskFormerImageProcessor.post_process_panoptic_segmentation`] depending on the task. Please, see
+ [`~MaskFormerImageProcessor] for details regarding usage.
Args:
loss (`torch.Tensor`, *optional*):
@@ -1462,8 +1462,8 @@ MASKFORMER_START_DOCSTRING = r"""
MASKFORMER_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
pixel_mask (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*):
Mask to avoid performing attention on padding pixel values. Mask values selected in `[0, 1]`:
@@ -1562,18 +1562,18 @@ class MaskFormerModel(MaskFormerPreTrainedModel):
Examples:
```python
- >>> from transformers import MaskFormerFeatureExtractor, MaskFormerModel
+ >>> from transformers import MaskFormerImageProcessor, MaskFormerModel
>>> from PIL import Image
>>> import requests
>>> # load MaskFormer fine-tuned on ADE20k semantic segmentation
- >>> feature_extractor = MaskFormerFeatureExtractor.from_pretrained("facebook/maskformer-swin-base-ade")
+ >>> image_processor = MaskFormerImageProcessor.from_pretrained("facebook/maskformer-swin-base-ade")
>>> model = MaskFormerModel.from_pretrained("facebook/maskformer-swin-base-ade")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> inputs = feature_extractor(image, return_tensors="pt")
+ >>> inputs = image_processor(image, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**inputs)
@@ -1741,19 +1741,19 @@ class MaskFormerForInstanceSegmentation(MaskFormerPreTrainedModel):
Semantic segmentation example:
```python
- >>> from transformers import MaskFormerFeatureExtractor, MaskFormerForInstanceSegmentation
+ >>> from transformers import MaskFormerImageProcessor, MaskFormerForInstanceSegmentation
>>> from PIL import Image
>>> import requests
>>> # load MaskFormer fine-tuned on ADE20k semantic segmentation
- >>> feature_extractor = MaskFormerFeatureExtractor.from_pretrained("facebook/maskformer-swin-base-ade")
+ >>> image_processor = MaskFormerImageProcessor.from_pretrained("facebook/maskformer-swin-base-ade")
>>> model = MaskFormerForInstanceSegmentation.from_pretrained("facebook/maskformer-swin-base-ade")
>>> url = (
... "https://huggingface.co/datasets/hf-internal-testing/fixtures_ade20k/resolve/main/ADE_val_00000001.jpg"
... )
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # model predicts class_queries_logits of shape `(batch_size, num_queries)`
@@ -1761,8 +1761,8 @@ class MaskFormerForInstanceSegmentation(MaskFormerPreTrainedModel):
>>> class_queries_logits = outputs.class_queries_logits
>>> masks_queries_logits = outputs.masks_queries_logits
- >>> # you can pass them to feature_extractor for postprocessing
- >>> predicted_semantic_map = feature_extractor.post_process_semantic_segmentation(
+ >>> # you can pass them to image_processor for postprocessing
+ >>> predicted_semantic_map = image_processor.post_process_semantic_segmentation(
... outputs, target_sizes=[image.size[::-1]]
... )[0]
@@ -1774,17 +1774,17 @@ class MaskFormerForInstanceSegmentation(MaskFormerPreTrainedModel):
Panoptic segmentation example:
```python
- >>> from transformers import MaskFormerFeatureExtractor, MaskFormerForInstanceSegmentation
+ >>> from transformers import MaskFormerImageProcessor, MaskFormerForInstanceSegmentation
>>> from PIL import Image
>>> import requests
>>> # load MaskFormer fine-tuned on COCO panoptic segmentation
- >>> feature_extractor = MaskFormerFeatureExtractor.from_pretrained("facebook/maskformer-swin-base-coco")
+ >>> image_processor = MaskFormerImageProcessor.from_pretrained("facebook/maskformer-swin-base-coco")
>>> model = MaskFormerForInstanceSegmentation.from_pretrained("facebook/maskformer-swin-base-coco")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # model predicts class_queries_logits of shape `(batch_size, num_queries)`
@@ -1792,8 +1792,8 @@ class MaskFormerForInstanceSegmentation(MaskFormerPreTrainedModel):
>>> class_queries_logits = outputs.class_queries_logits
>>> masks_queries_logits = outputs.masks_queries_logits
- >>> # you can pass them to feature_extractor for postprocessing
- >>> result = feature_extractor.post_process_panoptic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
+ >>> # you can pass them to image_processor for postprocessing
+ >>> result = image_processor.post_process_panoptic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
>>> # we refer to the demo notebooks for visualization (see "Resources" section in the MaskFormer docs)
>>> predicted_panoptic_map = result["segmentation"]
diff --git a/src/transformers/models/mobilenet_v1/modeling_mobilenet_v1.py b/src/transformers/models/mobilenet_v1/modeling_mobilenet_v1.py
index fedf27aed4..79c64dbaea 100755
--- a/src/transformers/models/mobilenet_v1/modeling_mobilenet_v1.py
+++ b/src/transformers/models/mobilenet_v1/modeling_mobilenet_v1.py
@@ -33,7 +33,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "MobileNetV1Config"
-_FEAT_EXTRACTOR_FOR_DOC = "MobileNetV1FeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "MobileNetV1ImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "google/mobilenet_v1_1.0_224"
@@ -285,8 +285,8 @@ MOBILENET_V1_START_DOCSTRING = r"""
MOBILENET_V1_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`MobileNetV1FeatureExtractor`]. See
- [`MobileNetV1FeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`MobileNetV1ImageProcessor`]. See
+ [`MobileNetV1ImageProcessor.__call__`] for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
diff --git a/src/transformers/models/mobilenet_v2/modeling_mobilenet_v2.py b/src/transformers/models/mobilenet_v2/modeling_mobilenet_v2.py
index d8b7f205c3..a47c5aebbe 100755
--- a/src/transformers/models/mobilenet_v2/modeling_mobilenet_v2.py
+++ b/src/transformers/models/mobilenet_v2/modeling_mobilenet_v2.py
@@ -43,7 +43,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "MobileNetV2Config"
-_FEAT_EXTRACTOR_FOR_DOC = "MobileNetV2FeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "MobileNetV2ImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "google/mobilenet_v2_1.0_224"
@@ -486,8 +486,8 @@ MOBILENET_V2_START_DOCSTRING = r"""
MOBILENET_V2_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`MobileNetV2FeatureExtractor`]. See
- [`MobileNetV2FeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`MobileNetV2ImageProcessor`]. See
+ [`MobileNetV2ImageProcessor.__call__`] for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
@@ -811,17 +811,17 @@ class MobileNetV2ForSemanticSegmentation(MobileNetV2PreTrainedModel):
Examples:
```python
- >>> from transformers import MobileNetV2FeatureExtractor, MobileNetV2ForSemanticSegmentation
+ >>> from transformers import MobileNetV2ImageProcessor, MobileNetV2ForSemanticSegmentation
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = MobileNetV2FeatureExtractor.from_pretrained("google/deeplabv3_mobilenet_v2_1.0_513")
+ >>> image_processor = MobileNetV2ImageProcessor.from_pretrained("google/deeplabv3_mobilenet_v2_1.0_513")
>>> model = MobileNetV2ForSemanticSegmentation.from_pretrained("google/deeplabv3_mobilenet_v2_1.0_513")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
diff --git a/src/transformers/models/mobilevit/modeling_mobilevit.py b/src/transformers/models/mobilevit/modeling_mobilevit.py
index fadfc4de30..e129fa2898 100755
--- a/src/transformers/models/mobilevit/modeling_mobilevit.py
+++ b/src/transformers/models/mobilevit/modeling_mobilevit.py
@@ -49,7 +49,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "MobileViTConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "MobileViTFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "MobileViTImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "apple/mobilevit-small"
@@ -692,8 +692,8 @@ MOBILEVIT_START_DOCSTRING = r"""
MOBILEVIT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`MobileViTFeatureExtractor`]. See
- [`MobileViTFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`MobileViTImageProcessor`]. See
+ [`MobileViTImageProcessor.__call__`] for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
@@ -1027,17 +1027,17 @@ class MobileViTForSemanticSegmentation(MobileViTPreTrainedModel):
Examples:
```python
- >>> from transformers import MobileViTFeatureExtractor, MobileViTForSemanticSegmentation
+ >>> from transformers import MobileViTImageProcessor, MobileViTForSemanticSegmentation
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = MobileViTFeatureExtractor.from_pretrained("apple/deeplabv3-mobilevit-small")
+ >>> image_processor = MobileViTImageProcessor.from_pretrained("apple/deeplabv3-mobilevit-small")
>>> model = MobileViTForSemanticSegmentation.from_pretrained("apple/deeplabv3-mobilevit-small")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
diff --git a/src/transformers/models/mobilevit/modeling_tf_mobilevit.py b/src/transformers/models/mobilevit/modeling_tf_mobilevit.py
index 41b9b313b0..ebfce88937 100644
--- a/src/transformers/models/mobilevit/modeling_tf_mobilevit.py
+++ b/src/transformers/models/mobilevit/modeling_tf_mobilevit.py
@@ -43,7 +43,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "MobileViTConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "MobileViTFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "MobileViTImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "apple/mobilevit-small"
@@ -811,8 +811,8 @@ MOBILEVIT_START_DOCSTRING = r"""
MOBILEVIT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`np.ndarray`, `tf.Tensor`, `List[tf.Tensor]`, `Dict[str, tf.Tensor]` or `Dict[str, np.ndarray]` and each example must have the shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`MobileViTFeatureExtractor`]. See
- [`MobileViTFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`MobileViTImageProcessor`]. See
+ [`MobileViTImageProcessor.__call__`] for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
@@ -1103,17 +1103,17 @@ class TFMobileViTForSemanticSegmentation(TFMobileViTPreTrainedModel):
Examples:
```python
- >>> from transformers import MobileViTFeatureExtractor, TFMobileViTForSemanticSegmentation
+ >>> from transformers import MobileViTImageProcessor, TFMobileViTForSemanticSegmentation
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = MobileViTFeatureExtractor.from_pretrained("apple/deeplabv3-mobilevit-small")
+ >>> image_processor = MobileViTImageProcessor.from_pretrained("apple/deeplabv3-mobilevit-small")
>>> model = TFMobileViTForSemanticSegmentation.from_pretrained("apple/deeplabv3-mobilevit-small")
- >>> inputs = feature_extractor(images=image, return_tensors="tf")
+ >>> inputs = image_processor(images=image, return_tensors="tf")
>>> outputs = model(**inputs)
diff --git a/src/transformers/models/perceiver/modeling_perceiver.py b/src/transformers/models/perceiver/modeling_perceiver.py
index 8ba049869c..7f12fb4ad5 100755
--- a/src/transformers/models/perceiver/modeling_perceiver.py
+++ b/src/transformers/models/perceiver/modeling_perceiver.py
@@ -768,7 +768,7 @@ class PerceiverModel(PerceiverPreTrainedModel):
Examples:
```python
- >>> from transformers import PerceiverConfig, PerceiverTokenizer, PerceiverFeatureExtractor, PerceiverModel
+ >>> from transformers import PerceiverConfig, PerceiverTokenizer, PerceiverImageProcessor, PerceiverModel
>>> from transformers.models.perceiver.modeling_perceiver import (
... PerceiverTextPreprocessor,
... PerceiverImagePreprocessor,
@@ -839,10 +839,10 @@ class PerceiverModel(PerceiverPreTrainedModel):
... )
>>> # you can then do a forward pass as follows:
- >>> feature_extractor = PerceiverFeatureExtractor()
+ >>> image_processor = PerceiverImageProcessor()
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> inputs = feature_extractor(image, return_tensors="pt").pixel_values
+ >>> inputs = image_processor(image, return_tensors="pt").pixel_values
>>> with torch.no_grad():
... outputs = model(inputs=inputs)
@@ -1266,17 +1266,17 @@ class PerceiverForImageClassificationLearned(PerceiverPreTrainedModel):
Examples:
```python
- >>> from transformers import PerceiverFeatureExtractor, PerceiverForImageClassificationLearned
+ >>> from transformers import PerceiverImageProcessor, PerceiverForImageClassificationLearned
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = PerceiverFeatureExtractor.from_pretrained("deepmind/vision-perceiver-learned")
+ >>> image_processor = PerceiverImageProcessor.from_pretrained("deepmind/vision-perceiver-learned")
>>> model = PerceiverForImageClassificationLearned.from_pretrained("deepmind/vision-perceiver-learned")
- >>> inputs = feature_extractor(images=image, return_tensors="pt").pixel_values
+ >>> inputs = image_processor(images=image, return_tensors="pt").pixel_values
>>> outputs = model(inputs=inputs)
>>> logits = outputs.logits
>>> list(logits.shape)
@@ -1407,17 +1407,17 @@ class PerceiverForImageClassificationFourier(PerceiverPreTrainedModel):
Examples:
```python
- >>> from transformers import PerceiverFeatureExtractor, PerceiverForImageClassificationFourier
+ >>> from transformers import PerceiverImageProcessor, PerceiverForImageClassificationFourier
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = PerceiverFeatureExtractor.from_pretrained("deepmind/vision-perceiver-fourier")
+ >>> image_processor = PerceiverImageProcessor.from_pretrained("deepmind/vision-perceiver-fourier")
>>> model = PerceiverForImageClassificationFourier.from_pretrained("deepmind/vision-perceiver-fourier")
- >>> inputs = feature_extractor(images=image, return_tensors="pt").pixel_values
+ >>> inputs = image_processor(images=image, return_tensors="pt").pixel_values
>>> outputs = model(inputs=inputs)
>>> logits = outputs.logits
>>> list(logits.shape)
@@ -1548,17 +1548,17 @@ class PerceiverForImageClassificationConvProcessing(PerceiverPreTrainedModel):
Examples:
```python
- >>> from transformers import PerceiverFeatureExtractor, PerceiverForImageClassificationConvProcessing
+ >>> from transformers import PerceiverImageProcessor, PerceiverForImageClassificationConvProcessing
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = PerceiverFeatureExtractor.from_pretrained("deepmind/vision-perceiver-conv")
+ >>> image_processor = PerceiverImageProcessor.from_pretrained("deepmind/vision-perceiver-conv")
>>> model = PerceiverForImageClassificationConvProcessing.from_pretrained("deepmind/vision-perceiver-conv")
- >>> inputs = feature_extractor(images=image, return_tensors="pt").pixel_values
+ >>> inputs = image_processor(images=image, return_tensors="pt").pixel_values
>>> outputs = model(inputs=inputs)
>>> logits = outputs.logits
>>> list(logits.shape)
diff --git a/src/transformers/models/poolformer/modeling_poolformer.py b/src/transformers/models/poolformer/modeling_poolformer.py
index b53c482da4..b659e25f05 100755
--- a/src/transformers/models/poolformer/modeling_poolformer.py
+++ b/src/transformers/models/poolformer/modeling_poolformer.py
@@ -34,7 +34,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "PoolFormerConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "PoolFormerFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "PoolFormerImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "sail/poolformer_s12"
@@ -302,8 +302,8 @@ POOLFORMER_START_DOCSTRING = r"""
POOLFORMER_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`PoolFormerFeatureExtractor`]. See
- [`PoolFormerFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`PoolFormerImageProcessor`]. See
+ [`PoolFormerImageProcessor.__call__`] for details.
"""
diff --git a/src/transformers/models/regnet/modeling_regnet.py b/src/transformers/models/regnet/modeling_regnet.py
index f317bf47d7..a95fafd984 100644
--- a/src/transformers/models/regnet/modeling_regnet.py
+++ b/src/transformers/models/regnet/modeling_regnet.py
@@ -37,7 +37,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "RegNetConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "AutoFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "AutoImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "facebook/regnet-y-040"
@@ -313,8 +313,8 @@ REGNET_START_DOCSTRING = r"""
REGNET_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
diff --git a/src/transformers/models/regnet/modeling_tf_regnet.py b/src/transformers/models/regnet/modeling_tf_regnet.py
index 8bbc37951a..fd36b2554f 100644
--- a/src/transformers/models/regnet/modeling_tf_regnet.py
+++ b/src/transformers/models/regnet/modeling_tf_regnet.py
@@ -35,7 +35,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "RegNetConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "AutoFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "AutoImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "facebook/regnet-y-040"
@@ -389,8 +389,8 @@ REGNET_START_DOCSTRING = r"""
REGNET_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`tf.Tensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
diff --git a/src/transformers/models/resnet/modeling_resnet.py b/src/transformers/models/resnet/modeling_resnet.py
index 7c3e176dcb..851cc3cecf 100644
--- a/src/transformers/models/resnet/modeling_resnet.py
+++ b/src/transformers/models/resnet/modeling_resnet.py
@@ -43,7 +43,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "ResNetConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "AutoFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "AutoImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "microsoft/resnet-50"
@@ -285,8 +285,8 @@ RESNET_START_DOCSTRING = r"""
RESNET_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
diff --git a/src/transformers/models/resnet/modeling_tf_resnet.py b/src/transformers/models/resnet/modeling_tf_resnet.py
index 4cf0d21ec7..483d5798e6 100644
--- a/src/transformers/models/resnet/modeling_tf_resnet.py
+++ b/src/transformers/models/resnet/modeling_tf_resnet.py
@@ -34,7 +34,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "ResNetConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "AutoFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "AutoImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "microsoft/resnet-50"
@@ -313,8 +313,8 @@ RESNET_START_DOCSTRING = r"""
RESNET_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`tf.Tensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
diff --git a/src/transformers/models/segformer/modeling_segformer.py b/src/transformers/models/segformer/modeling_segformer.py
index 0ce8dad2eb..c2fec27f0b 100755
--- a/src/transformers/models/segformer/modeling_segformer.py
+++ b/src/transformers/models/segformer/modeling_segformer.py
@@ -42,7 +42,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "SegformerConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "SegformerFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "SegformerImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "nvidia/mit-b0"
@@ -491,7 +491,7 @@ SEGFORMER_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
- [`SegformerFeatureExtractor`]. See [`SegformerFeatureExtractor.__call__`] for details.
+ [`SegformerImageProcessor`]. See [`SegformerImageProcessor.__call__`] for details.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
@@ -772,17 +772,17 @@ class SegformerForSemanticSegmentation(SegformerPreTrainedModel):
Examples:
```python
- >>> from transformers import SegformerFeatureExtractor, SegformerForSemanticSegmentation
+ >>> from transformers import SegformerImageProcessor, SegformerForSemanticSegmentation
>>> from PIL import Image
>>> import requests
- >>> feature_extractor = SegformerFeatureExtractor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
+ >>> image_processor = SegformerImageProcessor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
>>> model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> logits = outputs.logits # shape (batch_size, num_labels, height/4, width/4)
>>> list(logits.shape)
diff --git a/src/transformers/models/segformer/modeling_tf_segformer.py b/src/transformers/models/segformer/modeling_tf_segformer.py
index c6a8e00146..702730a6f1 100644
--- a/src/transformers/models/segformer/modeling_tf_segformer.py
+++ b/src/transformers/models/segformer/modeling_tf_segformer.py
@@ -37,7 +37,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "SegformerConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "SegformerFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "SegformerImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "nvidia/mit-b0"
@@ -568,8 +568,8 @@ SEGFORMER_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`np.ndarray`, `tf.Tensor`, `List[tf.Tensor]` ``Dict[str, tf.Tensor]` or `Dict[str, np.ndarray]` and each example must have the shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
@@ -835,17 +835,17 @@ class TFSegformerForSemanticSegmentation(TFSegformerPreTrainedModel):
Examples:
```python
- >>> from transformers import SegformerFeatureExtractor, TFSegformerForSemanticSegmentation
+ >>> from transformers import SegformerImageProcessor, TFSegformerForSemanticSegmentation
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = SegformerFeatureExtractor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
+ >>> image_processor = SegformerImageProcessor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
>>> model = TFSegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
- >>> inputs = feature_extractor(images=image, return_tensors="tf")
+ >>> inputs = image_processor(images=image, return_tensors="tf")
>>> outputs = model(**inputs, training=False)
>>> # logits are of shape (batch_size, num_labels, height/4, width/4)
>>> logits = outputs.logits
diff --git a/src/transformers/models/swin/modeling_swin.py b/src/transformers/models/swin/modeling_swin.py
index e33eddabf0..b304c6937f 100644
--- a/src/transformers/models/swin/modeling_swin.py
+++ b/src/transformers/models/swin/modeling_swin.py
@@ -43,7 +43,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "SwinConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "AutoFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "AutoImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "microsoft/swin-tiny-patch4-window7-224"
@@ -888,8 +888,8 @@ SWIN_START_DOCSTRING = r"""
SWIN_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -1053,7 +1053,7 @@ class SwinForMaskedImageModeling(SwinPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, SwinForMaskedImageModeling
+ >>> from transformers import AutoImageProcessor, SwinForMaskedImageModeling
>>> import torch
>>> from PIL import Image
>>> import requests
@@ -1061,11 +1061,11 @@ class SwinForMaskedImageModeling(SwinPreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/swin-base-simmim-window6-192")
+ >>> image_processor = AutoImageProcessor.from_pretrained("microsoft/swin-base-simmim-window6-192")
>>> model = SwinForMaskedImageModeling.from_pretrained("microsoft/swin-base-simmim-window6-192")
>>> num_patches = (model.config.image_size // model.config.patch_size) ** 2
- >>> pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
+ >>> pixel_values = image_processor(images=image, return_tensors="pt").pixel_values
>>> # create random boolean mask of shape (batch_size, num_patches)
>>> bool_masked_pos = torch.randint(low=0, high=2, size=(1, num_patches)).bool()
diff --git a/src/transformers/models/swin/modeling_tf_swin.py b/src/transformers/models/swin/modeling_tf_swin.py
index fdaefc0a3b..fc4b321fa0 100644
--- a/src/transformers/models/swin/modeling_tf_swin.py
+++ b/src/transformers/models/swin/modeling_tf_swin.py
@@ -47,7 +47,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "SwinConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "AutoFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "AutoImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "microsoft/swin-tiny-patch4-window7-224"
@@ -985,8 +985,8 @@ SWIN_START_DOCSTRING = r"""
SWIN_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`tf.Tensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
head_mask (`tf.Tensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -1321,7 +1321,7 @@ class TFSwinForMaskedImageModeling(TFSwinPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, TFSwinForMaskedImageModeling
+ >>> from transformers import AutoImageProcessor, TFSwinForMaskedImageModeling
>>> import tensorflow as tf
>>> from PIL import Image
>>> import requests
@@ -1329,11 +1329,11 @@ class TFSwinForMaskedImageModeling(TFSwinPreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/swin-tiny-patch4-window7-224")
+ >>> image_processor = AutoImageProcessor.from_pretrained("microsoft/swin-tiny-patch4-window7-224")
>>> model = TFSwinForMaskedImageModeling.from_pretrained("microsoft/swin-tiny-patch4-window7-224")
>>> num_patches = (model.config.image_size // model.config.patch_size) ** 2
- >>> pixel_values = feature_extractor(images=image, return_tensors="tf").pixel_values
+ >>> pixel_values = image_processor(images=image, return_tensors="tf").pixel_values
>>> # create random boolean mask of shape (batch_size, num_patches)
>>> bool_masked_pos = tf.random.uniform((1, num_patches)) >= 0.5
diff --git a/src/transformers/models/swinv2/modeling_swinv2.py b/src/transformers/models/swinv2/modeling_swinv2.py
index d0e86c1656..6f3aa61e1b 100644
--- a/src/transformers/models/swinv2/modeling_swinv2.py
+++ b/src/transformers/models/swinv2/modeling_swinv2.py
@@ -44,7 +44,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "Swinv2Config"
-_FEAT_EXTRACTOR_FOR_DOC = "AutoFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "AutoImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "microsoft/swinv2-tiny-patch4-window8-256"
@@ -968,8 +968,8 @@ SWINV2_START_DOCSTRING = r"""
SWINV2_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -1136,7 +1136,7 @@ class Swinv2ForMaskedImageModeling(Swinv2PreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, Swinv2ForMaskedImageModeling
+ >>> from transformers import AutoImageProcessor, Swinv2ForMaskedImageModeling
>>> import torch
>>> from PIL import Image
>>> import requests
@@ -1144,11 +1144,11 @@ class Swinv2ForMaskedImageModeling(Swinv2PreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/swinv2-tiny-patch4-window8-256")
+ >>> image_processor = AutoImageProcessor.from_pretrained("microsoft/swinv2-tiny-patch4-window8-256")
>>> model = Swinv2ForMaskedImageModeling.from_pretrained("microsoft/swinv2-tiny-patch4-window8-256")
>>> num_patches = (model.config.image_size // model.config.patch_size) ** 2
- >>> pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
+ >>> pixel_values = image_processor(images=image, return_tensors="pt").pixel_values
>>> # create random boolean mask of shape (batch_size, num_patches)
>>> bool_masked_pos = torch.randint(low=0, high=2, size=(1, num_patches)).bool()
diff --git a/src/transformers/models/table_transformer/modeling_table_transformer.py b/src/transformers/models/table_transformer/modeling_table_transformer.py
index ee675c0a4b..5fc0ccfe86 100644
--- a/src/transformers/models/table_transformer/modeling_table_transformer.py
+++ b/src/transformers/models/table_transformer/modeling_table_transformer.py
@@ -136,7 +136,7 @@ class TableTransformerModelOutput(Seq2SeqModelOutput):
@dataclass
-# Copied from transformers.models.detr.modeling_detr.DetrObjectDetectionOutput with Detr->TableTransformer,DetrFeatureExtractor->DetrFeatureExtractor
+# Copied from transformers.models.detr.modeling_detr.DetrObjectDetectionOutput with Detr->TableTransformer,DetrImageProcessor->DetrImageProcessor
class TableTransformerObjectDetectionOutput(ModelOutput):
"""
Output type of [`TableTransformerForObjectDetection`].
@@ -153,7 +153,7 @@ class TableTransformerObjectDetectionOutput(ModelOutput):
pred_boxes (`torch.FloatTensor` of shape `(batch_size, num_queries, 4)`):
Normalized boxes coordinates for all queries, represented as (center_x, center_y, width, height). These
values are normalized in [0, 1], relative to the size of each individual image in the batch (disregarding
- possible padding). You can use [`~TableTransformerFeatureExtractor.post_process_object_detection`] to
+ possible padding). You can use [`~TableTransformerImageProcessor.post_process_object_detection`] to
retrieve the unnormalized bounding boxes.
auxiliary_outputs (`list[Dict]`, *optional*):
Optional, only returned when auxilary losses are activated (i.e. `config.auxiliary_loss` is set to `True`)
@@ -797,8 +797,7 @@ TABLE_TRANSFORMER_INPUTS_DOCSTRING = r"""
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values. Padding will be ignored by default should you provide it.
- Pixel values can be obtained using [`DetrFeatureExtractor`]. See [`DetrFeatureExtractor.__call__`] for
- details.
+ Pixel values can be obtained using [`DetrImageProcessor`]. See [`DetrImageProcessor.__call__`] for details.
pixel_mask (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*):
Mask to avoid performing attention on padding pixel values. Mask values selected in `[0, 1]`:
@@ -1188,18 +1187,18 @@ class TableTransformerModel(TableTransformerPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, TableTransformerModel
+ >>> from transformers import AutoImageProcessor, TableTransformerModel
>>> from huggingface_hub import hf_hub_download
>>> from PIL import Image
>>> file_path = hf_hub_download(repo_id="nielsr/example-pdf", repo_type="dataset", filename="example_pdf.png")
>>> image = Image.open(file_path).convert("RGB")
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/table-transformer-detection")
+ >>> image_processor = AutoImageProcessor.from_pretrained("microsoft/table-transformer-detection")
>>> model = TableTransformerModel.from_pretrained("microsoft/table-transformer-detection")
>>> # prepare image for the model
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**inputs)
@@ -1357,24 +1356,24 @@ class TableTransformerForObjectDetection(TableTransformerPreTrainedModel):
```python
>>> from huggingface_hub import hf_hub_download
- >>> from transformers import AutoFeatureExtractor, TableTransformerForObjectDetection
+ >>> from transformers import AutoImageProcessor, TableTransformerForObjectDetection
>>> import torch
>>> from PIL import Image
>>> file_path = hf_hub_download(repo_id="nielsr/example-pdf", repo_type="dataset", filename="example_pdf.png")
>>> image = Image.open(file_path).convert("RGB")
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/table-transformer-detection")
+ >>> image_processor = AutoImageProcessor.from_pretrained("microsoft/table-transformer-detection")
>>> model = TableTransformerForObjectDetection.from_pretrained("microsoft/table-transformer-detection")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # convert outputs (bounding boxes and class logits) to COCO API
>>> target_sizes = torch.tensor([image.size[::-1]])
- >>> results = feature_extractor.post_process_object_detection(
- ... outputs, threshold=0.9, target_sizes=target_sizes
- ... )[0]
+ >>> results = image_processor.post_process_object_detection(outputs, threshold=0.9, target_sizes=target_sizes)[
+ ... 0
+ ... ]
>>> for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
... box = [round(i, 2) for i in box.tolist()]
diff --git a/src/transformers/models/trocr/processing_trocr.py b/src/transformers/models/trocr/processing_trocr.py
index 0e24afbf0b..4792d886e8 100644
--- a/src/transformers/models/trocr/processing_trocr.py
+++ b/src/transformers/models/trocr/processing_trocr.py
@@ -23,7 +23,7 @@ from ...processing_utils import ProcessorMixin
class TrOCRProcessor(ProcessorMixin):
r"""
- Constructs a TrOCR processor which wraps a vision feature extractor and a TrOCR tokenizer into a single processor.
+ Constructs a TrOCR processor which wraps a vision image processor and a TrOCR tokenizer into a single processor.
[`TrOCRProcessor`] offers all the functionalities of [`ViTImageProcessor`/`DeiTImageProcessor`] and
[`RobertaTokenizer`/`XLMRobertaTokenizer`]. See the [`~TrOCRProcessor.__call__`] and [`~TrOCRProcessor.decode`] for
diff --git a/src/transformers/models/van/modeling_van.py b/src/transformers/models/van/modeling_van.py
index bb9e2716d4..ec9b73f368 100644
--- a/src/transformers/models/van/modeling_van.py
+++ b/src/transformers/models/van/modeling_van.py
@@ -38,7 +38,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "VanConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "AutoFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "AutoImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "Visual-Attention-Network/van-base"
@@ -407,8 +407,8 @@ VAN_START_DOCSTRING = r"""
VAN_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all stages. See `hidden_states` under returned tensors for
diff --git a/src/transformers/models/videomae/modeling_videomae.py b/src/transformers/models/videomae/modeling_videomae.py
index a40b3881f7..bf6ca688fb 100644
--- a/src/transformers/models/videomae/modeling_videomae.py
+++ b/src/transformers/models/videomae/modeling_videomae.py
@@ -510,8 +510,8 @@ VIDEOMAE_START_DOCSTRING = r"""
VIDEOMAE_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_frames, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`VideoMAEFeatureExtractor`]. See
- [`VideoMAEFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`VideoMAEImageProcessor`]. See
+ [`VideoMAEImageProcessor.__call__`] for details.
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -581,7 +581,7 @@ class VideoMAEModel(VideoMAEPreTrainedModel):
>>> from decord import VideoReader, cpu
>>> import numpy as np
- >>> from transformers import VideoMAEFeatureExtractor, VideoMAEModel
+ >>> from transformers import VideoMAEImageProcessor, VideoMAEModel
>>> from huggingface_hub import hf_hub_download
@@ -605,11 +605,11 @@ class VideoMAEModel(VideoMAEPreTrainedModel):
>>> indices = sample_frame_indices(clip_len=16, frame_sample_rate=4, seg_len=len(videoreader))
>>> video = videoreader.get_batch(indices).asnumpy()
- >>> feature_extractor = VideoMAEFeatureExtractor.from_pretrained("MCG-NJU/videomae-base")
+ >>> image_processor = VideoMAEImageProcessor.from_pretrained("MCG-NJU/videomae-base")
>>> model = VideoMAEModel.from_pretrained("MCG-NJU/videomae-base")
>>> # prepare video for the model
- >>> inputs = feature_extractor(list(video), return_tensors="pt")
+ >>> inputs = image_processor(list(video), return_tensors="pt")
>>> # forward pass
>>> outputs = model(**inputs)
@@ -765,17 +765,17 @@ class VideoMAEForPreTraining(VideoMAEPreTrainedModel):
Examples:
```python
- >>> from transformers import VideoMAEFeatureExtractor, VideoMAEForPreTraining
+ >>> from transformers import VideoMAEImageProcessor, VideoMAEForPreTraining
>>> import numpy as np
>>> import torch
>>> num_frames = 16
>>> video = list(np.random.randn(16, 3, 224, 224))
- >>> feature_extractor = VideoMAEFeatureExtractor.from_pretrained("MCG-NJU/videomae-base")
+ >>> image_processor = VideoMAEImageProcessor.from_pretrained("MCG-NJU/videomae-base")
>>> model = VideoMAEForPreTraining.from_pretrained("MCG-NJU/videomae-base")
- >>> pixel_values = feature_extractor(video, return_tensors="pt").pixel_values
+ >>> pixel_values = image_processor(video, return_tensors="pt").pixel_values
>>> num_patches_per_frame = (model.config.image_size // model.config.patch_size) ** 2
>>> seq_length = (num_frames // model.config.tubelet_size) * num_patches_per_frame
@@ -942,7 +942,7 @@ class VideoMAEForVideoClassification(VideoMAEPreTrainedModel):
>>> import torch
>>> import numpy as np
- >>> from transformers import VideoMAEFeatureExtractor, VideoMAEForVideoClassification
+ >>> from transformers import VideoMAEImageProcessor, VideoMAEForVideoClassification
>>> from huggingface_hub import hf_hub_download
>>> np.random.seed(0)
@@ -968,10 +968,10 @@ class VideoMAEForVideoClassification(VideoMAEPreTrainedModel):
>>> indices = sample_frame_indices(clip_len=16, frame_sample_rate=4, seg_len=len(videoreader))
>>> video = videoreader.get_batch(indices).asnumpy()
- >>> feature_extractor = VideoMAEFeatureExtractor.from_pretrained("MCG-NJU/videomae-base-finetuned-kinetics")
+ >>> image_processor = VideoMAEImageProcessor.from_pretrained("MCG-NJU/videomae-base-finetuned-kinetics")
>>> model = VideoMAEForVideoClassification.from_pretrained("MCG-NJU/videomae-base-finetuned-kinetics")
- >>> inputs = feature_extractor(list(video), return_tensors="pt")
+ >>> inputs = image_processor(list(video), return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
diff --git a/src/transformers/models/vision_encoder_decoder/modeling_flax_vision_encoder_decoder.py b/src/transformers/models/vision_encoder_decoder/modeling_flax_vision_encoder_decoder.py
index 7042b2548d..5f9edbe7f9 100644
--- a/src/transformers/models/vision_encoder_decoder/modeling_flax_vision_encoder_decoder.py
+++ b/src/transformers/models/vision_encoder_decoder/modeling_flax_vision_encoder_decoder.py
@@ -86,8 +86,8 @@ VISION_ENCODER_DECODER_START_DOCSTRING = r"""
VISION_ENCODER_DECODER_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`jnp.ndarray` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using the vision model's feature extractor. For example, using
- [`ViTFeatureExtractor`]. See [`ViTFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using the vision model's image processor. For example, using
+ [`ViTImageProcessor`]. See [`ViTImageProcessor.__call__`] for details.
decoder_input_ids (`jnp.ndarray` of shape `(batch_size, target_sequence_length)`, *optional*):
Indices of decoder input sequence tokens in the vocabulary.
@@ -114,8 +114,8 @@ VISION_ENCODER_DECODER_INPUTS_DOCSTRING = r"""
VISION_ENCODER_DECODER_ENCODE_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`jnp.ndarray` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using the vision model's feature extractor. For example, using
- [`ViTFeatureExtractor`]. See [`ViTFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using the vision model's image processor. For example, using
+ [`ViTImageProcessor`]. See [`ViTImageProcessor.__call__`] for details.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
@@ -409,21 +409,21 @@ class FlaxVisionEncoderDecoderModel(FlaxPreTrainedModel):
Example:
```python
- >>> from transformers import ViTFeatureExtractor, FlaxVisionEncoderDecoderModel
+ >>> from transformers import ViTImageProcessor, FlaxVisionEncoderDecoderModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = ViTFeatureExtractor.from_pretrained("google/vit-base-patch16-224-in21k")
+ >>> image_processor = ViTImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
>>> # initialize a vit-gpt2 from pretrained ViT and GPT2 models. Note that the cross-attention layers will be randomly initialized
>>> model = FlaxVisionEncoderDecoderModel.from_encoder_decoder_pretrained(
... "google/vit-base-patch16-224-in21k", "gpt2"
... )
- >>> pixel_values = feature_extractor(images=image, return_tensors="np").pixel_values
+ >>> pixel_values = image_processor(images=image, return_tensors="np").pixel_values
>>> encoder_outputs = model.encode(pixel_values)
```"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
@@ -487,7 +487,7 @@ class FlaxVisionEncoderDecoderModel(FlaxPreTrainedModel):
Example:
```python
- >>> from transformers import ViTFeatureExtractor, FlaxVisionEncoderDecoderModel
+ >>> from transformers import ViTImageProcessor, FlaxVisionEncoderDecoderModel
>>> import jax.numpy as jnp
>>> from PIL import Image
>>> import requests
@@ -495,14 +495,14 @@ class FlaxVisionEncoderDecoderModel(FlaxPreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = ViTFeatureExtractor.from_pretrained("google/vit-base-patch16-224-in21k")
+ >>> image_processor = ViTImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
>>> # initialize a vit-gpt2 from pretrained ViT and GPT2 models. Note that the cross-attention layers will be randomly initialized
>>> model = FlaxVisionEncoderDecoderModel.from_encoder_decoder_pretrained(
... "google/vit-base-patch16-224-in21k", "gpt2"
... )
- >>> pixel_values = feature_extractor(images=image, return_tensors="np").pixel_values
+ >>> pixel_values = image_processor(images=image, return_tensors="np").pixel_values
>>> encoder_outputs = model.encode(pixel_values)
>>> decoder_start_token_id = model.config.decoder.bos_token_id
@@ -617,14 +617,14 @@ class FlaxVisionEncoderDecoderModel(FlaxPreTrainedModel):
Examples:
```python
- >>> from transformers import FlaxVisionEncoderDecoderModel, ViTFeatureExtractor, GPT2Tokenizer
+ >>> from transformers import FlaxVisionEncoderDecoderModel, ViTImageProcessor, GPT2Tokenizer
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = ViTFeatureExtractor.from_pretrained("google/vit-base-patch16-224-in21k")
+ >>> image_processor = ViTImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
>>> # load output tokenizer
>>> tokenizer_output = GPT2Tokenizer.from_pretrained("gpt2")
@@ -634,7 +634,7 @@ class FlaxVisionEncoderDecoderModel(FlaxPreTrainedModel):
... "google/vit-base-patch16-224-in21k", "gpt2"
... )
- >>> pixel_values = feature_extractor(images=image, return_tensors="np").pixel_values
+ >>> pixel_values = image_processor(images=image, return_tensors="np").pixel_values
>>> # use GPT2's eos_token as the pad as well as eos token
>>> model.config.eos_token_id = model.config.decoder.eos_token_id
diff --git a/src/transformers/models/vision_text_dual_encoder/modeling_flax_vision_text_dual_encoder.py b/src/transformers/models/vision_text_dual_encoder/modeling_flax_vision_text_dual_encoder.py
index aac1b0e8e9..6c6235f518 100644
--- a/src/transformers/models/vision_text_dual_encoder/modeling_flax_vision_text_dual_encoder.py
+++ b/src/transformers/models/vision_text_dual_encoder/modeling_flax_vision_text_dual_encoder.py
@@ -106,8 +106,8 @@ VISION_TEXT_DUAL_ENCODER_INPUTS_DOCSTRING = r"""
[What are position IDs?](../glossary#position-ids)
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
- a feature extractor (e.g. if you use ViT as the encoder, you should use [`ViTFeatureExtractor`]). See
- [`ViTFeatureExtractor.__call__`] for details.
+ an image processor (e.g. if you use ViT as the encoder, you should use [`ViTImageProcessor`]). See
+ [`ViTImageProcessor.__call__`] for details.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
diff --git a/src/transformers/models/vit/modeling_flax_vit.py b/src/transformers/models/vit/modeling_flax_vit.py
index 5d0527f5a7..0ba305e936 100644
--- a/src/transformers/models/vit/modeling_flax_vit.py
+++ b/src/transformers/models/vit/modeling_flax_vit.py
@@ -70,8 +70,8 @@ VIT_START_DOCSTRING = r"""
VIT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`numpy.ndarray` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`ViTFeatureExtractor`]. See
- [`ViTFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`ViTImageProcessor`]. See [`ViTImageProcessor.__call__`]
+ for details.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
@@ -565,17 +565,17 @@ FLAX_VISION_MODEL_DOCSTRING = """
Examples:
```python
- >>> from transformers import ViTFeatureExtractor, FlaxViTModel
+ >>> from transformers import ViTImageProcessor, FlaxViTModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = ViTFeatureExtractor.from_pretrained("google/vit-base-patch16-224-in21k")
+ >>> image_processor = ViTImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
>>> model = FlaxViTModel.from_pretrained("google/vit-base-patch16-224-in21k")
- >>> inputs = feature_extractor(images=image, return_tensors="np")
+ >>> inputs = image_processor(images=image, return_tensors="np")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
```
@@ -648,7 +648,7 @@ FLAX_VISION_CLASSIF_DOCSTRING = """
Example:
```python
- >>> from transformers import ViTFeatureExtractor, FlaxViTForImageClassification
+ >>> from transformers import ViTImageProcessor, FlaxViTForImageClassification
>>> from PIL import Image
>>> import jax
>>> import requests
@@ -656,10 +656,10 @@ FLAX_VISION_CLASSIF_DOCSTRING = """
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = ViTFeatureExtractor.from_pretrained("google/vit-base-patch16-224")
+ >>> image_processor = ViTImageProcessor.from_pretrained("google/vit-base-patch16-224")
>>> model = FlaxViTForImageClassification.from_pretrained("google/vit-base-patch16-224")
- >>> inputs = feature_extractor(images=image, return_tensors="np")
+ >>> inputs = image_processor(images=image, return_tensors="np")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
diff --git a/src/transformers/models/vit/modeling_tf_vit.py b/src/transformers/models/vit/modeling_tf_vit.py
index 8ce5420169..7fd664644e 100644
--- a/src/transformers/models/vit/modeling_tf_vit.py
+++ b/src/transformers/models/vit/modeling_tf_vit.py
@@ -41,7 +41,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "ViTConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "ViTFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "ViTImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "google/vit-base-patch16-224-in21k"
@@ -629,8 +629,8 @@ VIT_START_DOCSTRING = r"""
VIT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`np.ndarray`, `tf.Tensor`, `List[tf.Tensor]` ``Dict[str, tf.Tensor]` or `Dict[str, np.ndarray]` and each example must have the shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`ViTFeatureExtractor`]. See
- [`ViTFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`ViTImageProcessor`]. See [`ViTImageProcessor.__call__`]
+ for details.
head_mask (`np.ndarray` or `tf.Tensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
diff --git a/src/transformers/models/vit/modeling_vit.py b/src/transformers/models/vit/modeling_vit.py
index 2bf59866ef..1b937750c0 100644
--- a/src/transformers/models/vit/modeling_vit.py
+++ b/src/transformers/models/vit/modeling_vit.py
@@ -42,7 +42,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "ViTConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "ViTFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "ViTImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "google/vit-base-patch16-224-in21k"
@@ -481,8 +481,8 @@ VIT_START_DOCSTRING = r"""
VIT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`ViTFeatureExtractor`]. See
- [`ViTFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`ViTImageProcessor`]. See [`ViTImageProcessor.__call__`]
+ for details.
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -664,7 +664,7 @@ class ViTForMaskedImageModeling(ViTPreTrainedModel):
Examples:
```python
- >>> from transformers import ViTFeatureExtractor, ViTForMaskedImageModeling
+ >>> from transformers import ViTImageProcessor, ViTForMaskedImageModeling
>>> import torch
>>> from PIL import Image
>>> import requests
@@ -672,11 +672,11 @@ class ViTForMaskedImageModeling(ViTPreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = ViTFeatureExtractor.from_pretrained("google/vit-base-patch16-224-in21k")
+ >>> image_processor = ViTImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
>>> model = ViTForMaskedImageModeling.from_pretrained("google/vit-base-patch16-224-in21k")
>>> num_patches = (model.config.image_size // model.config.patch_size) ** 2
- >>> pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
+ >>> pixel_values = image_processor(images=image, return_tensors="pt").pixel_values
>>> # create random boolean mask of shape (batch_size, num_patches)
>>> bool_masked_pos = torch.randint(low=0, high=2, size=(1, num_patches)).bool()
diff --git a/src/transformers/models/vit_mae/modeling_tf_vit_mae.py b/src/transformers/models/vit_mae/modeling_tf_vit_mae.py
index 6ecec70623..ef5de25457 100644
--- a/src/transformers/models/vit_mae/modeling_tf_vit_mae.py
+++ b/src/transformers/models/vit_mae/modeling_tf_vit_mae.py
@@ -770,8 +770,8 @@ VIT_MAE_START_DOCSTRING = r"""
VIT_MAE_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`np.ndarray`, `tf.Tensor`, `List[tf.Tensor]` ``Dict[str, tf.Tensor]` or `Dict[str, np.ndarray]` and each example must have the shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
head_mask (`np.ndarray` or `tf.Tensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -830,17 +830,17 @@ class TFViTMAEModel(TFViTMAEPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, TFViTMAEModel
+ >>> from transformers import AutoImageProcessor, TFViTMAEModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/vit-mae-base")
+ >>> image_processor = AutoImageProcessor.from_pretrained("facebook/vit-mae-base")
>>> model = TFViTMAEModel.from_pretrained("facebook/vit-mae-base")
- >>> inputs = feature_extractor(images=image, return_tensors="tf")
+ >>> inputs = image_processor(images=image, return_tensors="tf")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
```"""
@@ -1121,17 +1121,17 @@ class TFViTMAEForPreTraining(TFViTMAEPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, TFViTMAEForPreTraining
+ >>> from transformers import AutoImageProcessor, TFViTMAEForPreTraining
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/vit-mae-base")
+ >>> image_processor = AutoImageProcessor.from_pretrained("facebook/vit-mae-base")
>>> model = TFViTMAEForPreTraining.from_pretrained("facebook/vit-mae-base")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> loss = outputs.loss
>>> mask = outputs.mask
diff --git a/src/transformers/models/vit_mae/modeling_vit_mae.py b/src/transformers/models/vit_mae/modeling_vit_mae.py
index 02bf80773d..39be66e691 100755
--- a/src/transformers/models/vit_mae/modeling_vit_mae.py
+++ b/src/transformers/models/vit_mae/modeling_vit_mae.py
@@ -612,8 +612,8 @@ VIT_MAE_START_DOCSTRING = r"""
VIT_MAE_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -677,17 +677,17 @@ class ViTMAEModel(ViTMAEPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, ViTMAEModel
+ >>> from transformers import AutoImageProcessor, ViTMAEModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/vit-mae-base")
+ >>> image_processor = AutoImageProcessor.from_pretrained("facebook/vit-mae-base")
>>> model = ViTMAEModel.from_pretrained("facebook/vit-mae-base")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
```"""
@@ -978,17 +978,17 @@ class ViTMAEForPreTraining(ViTMAEPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, ViTMAEForPreTraining
+ >>> from transformers import AutoImageProcessor, ViTMAEForPreTraining
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/vit-mae-base")
+ >>> image_processor = AutoImageProcessor.from_pretrained("facebook/vit-mae-base")
>>> model = ViTMAEForPreTraining.from_pretrained("facebook/vit-mae-base")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> loss = outputs.loss
>>> mask = outputs.mask
diff --git a/src/transformers/models/vit_msn/modeling_vit_msn.py b/src/transformers/models/vit_msn/modeling_vit_msn.py
index 43e9aa81a0..54be1afcc8 100644
--- a/src/transformers/models/vit_msn/modeling_vit_msn.py
+++ b/src/transformers/models/vit_msn/modeling_vit_msn.py
@@ -464,8 +464,8 @@ VIT_MSN_START_DOCSTRING = r"""
VIT_MSN_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -532,7 +532,7 @@ class ViTMSNModel(ViTMSNPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, ViTMSNModel
+ >>> from transformers import AutoImageProcessor, ViTMSNModel
>>> import torch
>>> from PIL import Image
>>> import requests
@@ -540,9 +540,9 @@ class ViTMSNModel(ViTMSNPreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/vit-msn-small")
+ >>> image_processor = AutoImageProcessor.from_pretrained("facebook/vit-msn-small")
>>> model = ViTMSNModel.from_pretrained("facebook/vit-msn-small")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
@@ -627,7 +627,7 @@ class ViTMSNForImageClassification(ViTMSNPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, ViTMSNForImageClassification
+ >>> from transformers import AutoImageProcessor, ViTMSNForImageClassification
>>> import torch
>>> from PIL import Image
>>> import requests
@@ -637,10 +637,10 @@ class ViTMSNForImageClassification(ViTMSNPreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/vit-msn-small")
+ >>> image_processor = AutoImageProcessor.from_pretrained("facebook/vit-msn-small")
>>> model = ViTMSNForImageClassification.from_pretrained("facebook/vit-msn-small")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
diff --git a/src/transformers/models/yolos/modeling_yolos.py b/src/transformers/models/yolos/modeling_yolos.py
index 62b03cfd4d..71c9ddb37e 100755
--- a/src/transformers/models/yolos/modeling_yolos.py
+++ b/src/transformers/models/yolos/modeling_yolos.py
@@ -53,7 +53,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "YolosConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "YolosFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "YolosImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "hustvl/yolos-small"
@@ -83,7 +83,7 @@ class YolosObjectDetectionOutput(ModelOutput):
pred_boxes (`torch.FloatTensor` of shape `(batch_size, num_queries, 4)`):
Normalized boxes coordinates for all queries, represented as (center_x, center_y, width, height). These
values are normalized in [0, 1], relative to the size of each individual image in the batch (disregarding
- possible padding). You can use [`~DetrFeatureExtractor.post_process`] to retrieve the unnormalized bounding
+ possible padding). You can use [`~DetrImageProcessor.post_process`] to retrieve the unnormalized bounding
boxes.
auxiliary_outputs (`list[Dict]`, *optional*):
Optional, only returned when auxilary losses are activated (i.e. `config.auxiliary_loss` is set to `True`)
@@ -573,8 +573,8 @@ YOLOS_START_DOCSTRING = r"""
YOLOS_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -756,7 +756,7 @@ class YolosForObjectDetection(YolosPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, AutoModelForObjectDetection
+ >>> from transformers import AutoImageProcessor, AutoModelForObjectDetection
>>> import torch
>>> from PIL import Image
>>> import requests
@@ -764,17 +764,17 @@ class YolosForObjectDetection(YolosPreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("hustvl/yolos-tiny")
+ >>> image_processor = AutoImageProcessor.from_pretrained("hustvl/yolos-tiny")
>>> model = AutoModelForObjectDetection.from_pretrained("hustvl/yolos-tiny")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # convert outputs (bounding boxes and class logits) to COCO API
>>> target_sizes = torch.tensor([image.size[::-1]])
- >>> results = feature_extractor.post_process_object_detection(
- ... outputs, threshold=0.9, target_sizes=target_sizes
- ... )[0]
+ >>> results = image_processor.post_process_object_detection(outputs, threshold=0.9, target_sizes=target_sizes)[
+ ... 0
+ ... ]
>>> for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
... box = [round(i, 2) for i in box.tolist()]
diff --git a/templates/adding_a_new_model/README.md b/templates/adding_a_new_model/README.md
index 4bb6663937..c8ee0ce667 100644
--- a/templates/adding_a_new_model/README.md
+++ b/templates/adding_a_new_model/README.md
@@ -186,14 +186,14 @@ wish, as it will appear on the Model Hub. Do not forget to include the organisat
Then you will have to say whether your model re-uses the same processing classes as the model you're cloning:
```
-Will your new model use the same processing class as Xxx (XxxTokenizer/XxxFeatureExtractor)
+Will your new model use the same processing class as Xxx (XxxTokenizer/XxxFeatureExtractor/XxxImageProcessor)
```
Answer yes if you have no intentions to make any change to the class used for preprocessing. It can use different
files (for instance you can reuse the `BertTokenizer` with a new vocab file).
If you answer no, you will have to give the name of the classes
-for the new tokenizer/feature extractor/processor (depending on the model you're cloning).
+for the new tokenizer/image processor/feature extractor/processor (depending on the model you're cloning).
Next the questionnaire will ask
-Load the feature extractor with [`AutoFeatureExtractor.from_pretrained`]:
+Load the image processor with [`AutoImageProcessor.from_pretrained`]:
```py
->>> from transformers import AutoFeatureExtractor
+>>> from transformers import AutoImageProcessor
->>> feature_extractor = AutoFeatureExtractor.from_pretrained("google/vit-base-patch16-224")
+>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
```
For computer vision tasks, it is common to add some type of data augmentation to the images as a part of preprocessing. You can add augmentations with any library you'd like, but in this tutorial, you'll use torchvision's [`transforms`](https://pytorch.org/vision/stable/transforms.html) module. If you're interested in using another data augmentation library, learn how in the [Albumentations](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_albumentations.ipynb) or [Kornia notebooks](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_kornia.ipynb).
-1. Normalize the image with the feature extractor and use [`Compose`](https://pytorch.org/vision/master/generated/torchvision.transforms.Compose.html) to chain some transforms - [`RandomResizedCrop`](https://pytorch.org/vision/main/generated/torchvision.transforms.RandomResizedCrop.html) and [`ColorJitter`](https://pytorch.org/vision/main/generated/torchvision.transforms.ColorJitter.html) - together:
+1. Normalize the image with the image processor and use [`Compose`](https://pytorch.org/vision/master/generated/torchvision.transforms.Compose.html) to chain some transforms - [`RandomResizedCrop`](https://pytorch.org/vision/main/generated/torchvision.transforms.RandomResizedCrop.html) and [`ColorJitter`](https://pytorch.org/vision/main/generated/torchvision.transforms.ColorJitter.html) - together:
```py
>>> from torchvision.transforms import Compose, Normalize, RandomResizedCrop, ColorJitter, ToTensor
@@ -370,7 +370,7 @@ For computer vision tasks, it is common to add some type of data augmentation to
>>> _transforms = Compose([RandomResizedCrop(size), ColorJitter(brightness=0.5, hue=0.5), ToTensor(), normalize])
```
-2. The model accepts [`pixel_values`](model_doc/visionencoderdecoder#transformers.VisionEncoderDecoderModel.forward.pixel_values) as its input, which is generated by the feature extractor. Create a function that generates `pixel_values` from the transforms:
+2. The model accepts [`pixel_values`](model_doc/visionencoderdecoder#transformers.VisionEncoderDecoderModel.forward.pixel_values) as its input, which is generated by the image processor. Create a function that generates `pixel_values` from the transforms:
```py
>>> def transforms(examples):
@@ -384,7 +384,7 @@ For computer vision tasks, it is common to add some type of data augmentation to
>>> dataset.set_transform(transforms)
```
-4. Now when you access the image, you'll notice the feature extractor has added `pixel_values`. You can pass your processed dataset to the model now!
+4. Now when you access the image, you'll notice the image processor has added `pixel_values`. You can pass your processed dataset to the model now!
```py
>>> dataset[0]["image"]
@@ -431,7 +431,7 @@ Here is what the image looks like after the transforms are applied. The image ha
## Multimodal
-For tasks involving multimodal inputs, you'll need a [processor](main_classes/processors) to prepare your dataset for the model. A processor couples a tokenizer and feature extractor.
+For tasks involving multimodal inputs, you'll need a [processor](main_classes/processors) to prepare your dataset for the model. A processor couples together two processing objects such as as tokenizer and feature extractor.
Load the [LJ Speech](https://huggingface.co/datasets/lj_speech) dataset (see the 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub.html) for more details on how to load a dataset) to see how you can use a processor for automatic speech recognition (ASR):
diff --git a/docs/source/en/quicktour.mdx b/docs/source/en/quicktour.mdx
index 7cfac04314..c0fcaa55cb 100644
--- a/docs/source/en/quicktour.mdx
+++ b/docs/source/en/quicktour.mdx
@@ -225,7 +225,7 @@ A tokenizer can also accept a list of inputs, and pad and truncate the text to r
-Check out the [preprocess](./preprocessing) tutorial for more details about tokenization, and how to use an [`AutoFeatureExtractor`] and [`AutoProcessor`] to preprocess image, audio, and multimodal inputs.
+Check out the [preprocess](./preprocessing) tutorial for more details about tokenization, and how to use an [`AutoImageProcessor`], [`AutoFeatureExtractor`] and [`AutoProcessor`] to preprocess image, audio, and multimodal inputs.
@@ -424,7 +424,7 @@ Depending on your task, you'll typically pass the following parameters to [`Trai
... )
```
-3. A preprocessing class like a tokenizer, feature extractor, or processor:
+3. A preprocessing class like a tokenizer, image processor, feature extractor, or processor:
```py
>>> from transformers import AutoTokenizer
@@ -501,7 +501,7 @@ All models are a standard [`tf.keras.Model`](https://www.tensorflow.org/api_docs
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
-2. A preprocessing class like a tokenizer, feature extractor, or processor:
+2. A preprocessing class like a tokenizer, image processor, feature extractor, or processor:
```py
>>> from transformers import AutoTokenizer
diff --git a/docs/source/en/task_summary.mdx b/docs/source/en/task_summary.mdx
index 9a3b1b48c4..697ee21df5 100644
--- a/docs/source/en/task_summary.mdx
+++ b/docs/source/en/task_summary.mdx
@@ -1101,24 +1101,24 @@ Class Egyptian cat with score 0.0239
Class tiger cat with score 0.0229
```
-The general process for using a model and feature extractor for image classification is:
+The general process for using a model and image processor for image classification is:
-1. Instantiate a feature extractor and a model from the checkpoint name.
-2. Process the image to be classified with a feature extractor.
+1. Instantiate an image processor and a model from the checkpoint name.
+2. Process the image to be classified with an image processor.
3. Pass the input through the model and take the `argmax` to retrieve the predicted class.
4. Convert the class id to a class name with `id2label` to return an interpretable result.
```py
->>> from transformers import AutoFeatureExtractor, AutoModelForImageClassification
+>>> from transformers import AutoImageProcessor, AutoModelForImageClassification
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
->>> feature_extractor = AutoFeatureExtractor.from_pretrained("google/vit-base-patch16-224")
+>>> feature_extractor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
>>> model = AutoModelForImageClassification.from_pretrained("google/vit-base-patch16-224")
>>> inputs = feature_extractor(image, return_tensors="pt")
diff --git a/docs/source/en/tasks/image_classification.mdx b/docs/source/en/tasks/image_classification.mdx
index a7362e10c4..2543db6d28 100644
--- a/docs/source/en/tasks/image_classification.mdx
+++ b/docs/source/en/tasks/image_classification.mdx
@@ -91,26 +91,26 @@ Now you can convert the label id to a label name:
## Preprocess
-The next step is to load a ViT feature extractor to process the image into a tensor:
+The next step is to load a ViT image processor to process the image into a tensor:
```py
->>> from transformers import AutoFeatureExtractor
+>>> from transformers import AutoImageProcessor
->>> feature_extractor = AutoFeatureExtractor.from_pretrained("google/vit-base-patch16-224-in21k")
+>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
```
-Apply some image transformations to the images to make the model more robust against overfitting. Here you'll use torchvision's [`transforms`](https://pytorch.org/vision/stable/transforms.html) module, but you can also use any image library you like.
+Apply some image transformations to the images to make the model more robust against overfitting. Here you'll use torchvision's [`transforms`](https://pytorch.org/vision/stable/transforms.html) module, but you can also use any image library you like.
Crop a random part of the image, resize it, and normalize it with the image mean and standard deviation:
```py
>>> from torchvision.transforms import RandomResizedCrop, Compose, Normalize, ToTensor
->>> normalize = Normalize(mean=feature_extractor.image_mean, std=feature_extractor.image_std)
+>>> normalize = Normalize(mean=image_processor.image_mean, std=image_processor.image_std)
>>> size = (
-... feature_extractor.size["shortest_edge"]
-... if "shortest_edge" in feature_extractor.size
-... else (feature_extractor.size["height"], feature_extractor.size["width"])
+... image_processor.size["shortest_edge"]
+... if "shortest_edge" in image_processor.size
+... else (image_processor.size["height"], image_processor.size["width"])
... )
>>> _transforms = Compose([RandomResizedCrop(size), ToTensor(), normalize])
```
@@ -213,7 +213,7 @@ At this point, only three steps remain:
... data_collator=data_collator,
... train_dataset=food["train"],
... eval_dataset=food["test"],
-... tokenizer=feature_extractor,
+... tokenizer=image_processor,
... compute_metrics=compute_metrics,
... )
@@ -266,14 +266,14 @@ You can also manually replicate the results of the `pipeline` if you'd like:
-Load a feature extractor to preprocess the image and return the `input` as PyTorch tensors:
+Load an image processor to preprocess the image and return the `input` as PyTorch tensors:
```py
->>> from transformers import AutoFeatureExtractor
+>>> from transformers import AutoImageProcessor
>>> import torch
->>> feature_extractor = AutoFeatureExtractor.from_pretrained("my_awesome_food_model")
->>> inputs = feature_extractor(image, return_tensors="pt")
+>>> image_processor = AutoImageProcessor.from_pretrained("my_awesome_food_model")
+>>> inputs = image_processor(image, return_tensors="pt")
```
Pass your inputs to the model and return the logits:
diff --git a/docs/source/en/tasks/semantic_segmentation.mdx b/docs/source/en/tasks/semantic_segmentation.mdx
index 069f312802..f1ab7ee0ea 100644
--- a/docs/source/en/tasks/semantic_segmentation.mdx
+++ b/docs/source/en/tasks/semantic_segmentation.mdx
@@ -90,12 +90,12 @@ You'll also want to create a dictionary that maps a label id to a label class wh
## Preprocess
-The next step is to load a SegFormer feature extractor to prepare the images and annotations for the model. Some datasets, like this one, use the zero-index as the background class. However, the background class isn't actually included in the 150 classes, so you'll need to set `reduce_labels=True` to subtract one from all the labels. The zero-index is replaced by `255` so it's ignored by SegFormer's loss function:
+The next step is to load a SegFormer image processor to prepare the images and annotations for the model. Some datasets, like this one, use the zero-index as the background class. However, the background class isn't actually included in the 150 classes, so you'll need to set `reduce_labels=True` to subtract one from all the labels. The zero-index is replaced by `255` so it's ignored by SegFormer's loss function:
```py
->>> from transformers import AutoFeatureExtractor
+>>> from transformers import AutoImageProcessor
->>> feature_extractor = AutoFeatureExtractor.from_pretrained("nvidia/mit-b0", reduce_labels=True)
+>>> feature_extractor = AutoImageProcessor.from_pretrained("nvidia/mit-b0", reduce_labels=True)
```
It is common to apply some data augmentations to an image dataset to make a model more robust against overfitting. In this guide, you'll use the [`ColorJitter`](https://pytorch.org/vision/stable/generated/torchvision.transforms.ColorJitter.html) function from [torchvision](https://pytorch.org/vision/stable/index.html) to randomly change the color properties of an image, but you can also use any image library you like.
@@ -106,7 +106,7 @@ It is common to apply some data augmentations to an image dataset to make a mode
>>> jitter = ColorJitter(brightness=0.25, contrast=0.25, saturation=0.25, hue=0.1)
```
-Now create two preprocessing functions to prepare the images and annotations for the model. These functions convert the images into `pixel_values` and annotations to `labels`. For the training set, `jitter` is applied before providing the images to the feature extractor. For the test set, the feature extractor crops and normalizes the `images`, and only crops the `labels` because no data augmentation is applied during testing.
+Now create two preprocessing functions to prepare the images and annotations for the model. These functions convert the images into `pixel_values` and annotations to `labels`. For the training set, `jitter` is applied before providing the images to the image processor. For the test set, the image processor crops and normalizes the `images`, and only crops the `labels` because no data augmentation is applied during testing.
```py
>>> def train_transforms(example_batch):
@@ -281,7 +281,7 @@ The simplest way to try out your finetuned model for inference is to use it in a
'mask': }]
```
-You can also manually replicate the results of the `pipeline` if you'd like. Process the image with a feature extractor and place the `pixel_values` on a GPU:
+You can also manually replicate the results of the `pipeline` if you'd like. Process the image with an image processor and place the `pixel_values` on a GPU:
```py
>>> device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # use GPU if available, otherwise use a CPU
diff --git a/docs/source/en/troubleshooting.mdx b/docs/source/en/troubleshooting.mdx
index ea0724cd4e..74346bccef 100644
--- a/docs/source/en/troubleshooting.mdx
+++ b/docs/source/en/troubleshooting.mdx
@@ -89,7 +89,7 @@ TensorFlow's [model.save](https://www.tensorflow.org/tutorials/keras/save_and_lo
Another common error you may encounter, especially if it is a newly released model, is `ImportError`:
```
-ImportError: cannot import name 'ImageGPTFeatureExtractor' from 'transformers' (unknown location)
+ImportError: cannot import name 'ImageGPTImageProcessor' from 'transformers' (unknown location)
```
For these error types, check to make sure you have the latest version of 🤗 Transformers installed to access the most recent models:
diff --git a/src/transformers/models/beit/modeling_beit.py b/src/transformers/models/beit/modeling_beit.py
index c1e91651d7..6062b87b15 100755
--- a/src/transformers/models/beit/modeling_beit.py
+++ b/src/transformers/models/beit/modeling_beit.py
@@ -49,7 +49,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "BeitConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "BeitFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "BeitImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "microsoft/beit-base-patch16-224-pt22k"
@@ -593,8 +593,8 @@ BEIT_START_DOCSTRING = r"""
BEIT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`BeitFeatureExtractor`]. See
- [`BeitFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`BeitImageProcessor`]. See
+ [`BeitImageProcessor.__call__`] for details.
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -769,7 +769,7 @@ class BeitForMaskedImageModeling(BeitPreTrainedModel):
Examples:
```python
- >>> from transformers import BeitFeatureExtractor, BeitForMaskedImageModeling
+ >>> from transformers import BeitImageProcessor, BeitForMaskedImageModeling
>>> import torch
>>> from PIL import Image
>>> import requests
@@ -777,11 +777,11 @@ class BeitForMaskedImageModeling(BeitPreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = BeitFeatureExtractor.from_pretrained("microsoft/beit-base-patch16-224-pt22k")
+ >>> image_processor = BeitImageProcessor.from_pretrained("microsoft/beit-base-patch16-224-pt22k")
>>> model = BeitForMaskedImageModeling.from_pretrained("microsoft/beit-base-patch16-224-pt22k")
>>> num_patches = (model.config.image_size // model.config.patch_size) ** 2
- >>> pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
+ >>> pixel_values = image_processor(images=image, return_tensors="pt").pixel_values
>>> # create random boolean mask of shape (batch_size, num_patches)
>>> bool_masked_pos = torch.randint(low=0, high=2, size=(1, num_patches)).bool()
@@ -1218,17 +1218,17 @@ class BeitForSemanticSegmentation(BeitPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, BeitForSemanticSegmentation
+ >>> from transformers import AutoImageProcessor, BeitForSemanticSegmentation
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/beit-base-finetuned-ade-640-640")
+ >>> image_processor = AutoImageProcessor.from_pretrained("microsoft/beit-base-finetuned-ade-640-640")
>>> model = BeitForSemanticSegmentation.from_pretrained("microsoft/beit-base-finetuned-ade-640-640")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # logits are of shape (batch_size, num_labels, height, width)
>>> logits = outputs.logits
diff --git a/src/transformers/models/beit/modeling_flax_beit.py b/src/transformers/models/beit/modeling_flax_beit.py
index 225fb280af..4a866584fb 100644
--- a/src/transformers/models/beit/modeling_flax_beit.py
+++ b/src/transformers/models/beit/modeling_flax_beit.py
@@ -102,8 +102,8 @@ BEIT_START_DOCSTRING = r"""
BEIT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`numpy.ndarray` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`BeitFeatureExtractor`]. See
- [`BeitFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`BeitImageProcessor`]. See
+ [`BeitImageProcessor.__call__`] for details.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
@@ -756,17 +756,17 @@ FLAX_BEIT_MODEL_DOCSTRING = """
Examples:
```python
- >>> from transformers import BeitFeatureExtractor, FlaxBeitModel
+ >>> from transformers import BeitImageProcessor, FlaxBeitModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = BeitFeatureExtractor.from_pretrained("microsoft/beit-base-patch16-224-pt22k-ft22k")
+ >>> image_processor = BeitImageProcessor.from_pretrained("microsoft/beit-base-patch16-224-pt22k-ft22k")
>>> model = FlaxBeitModel.from_pretrained("microsoft/beit-base-patch16-224-pt22k-ft22k")
- >>> inputs = feature_extractor(images=image, return_tensors="np")
+ >>> inputs = image_processor(images=image, return_tensors="np")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
```
@@ -843,17 +843,17 @@ FLAX_BEIT_MLM_DOCSTRING = """
Examples:
```python
- >>> from transformers import BeitFeatureExtractor, BeitForMaskedImageModeling
+ >>> from transformers import BeitImageProcessor, BeitForMaskedImageModeling
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = BeitFeatureExtractor.from_pretrained("microsoft/beit-base-patch16-224-pt22k")
+ >>> image_processor = BeitImageProcessor.from_pretrained("microsoft/beit-base-patch16-224-pt22k")
>>> model = BeitForMaskedImageModeling.from_pretrained("microsoft/beit-base-patch16-224-pt22k")
- >>> inputs = feature_extractor(images=image, return_tensors="np")
+ >>> inputs = image_processor(images=image, return_tensors="np")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
```
@@ -927,17 +927,17 @@ FLAX_BEIT_CLASSIF_DOCSTRING = """
Example:
```python
- >>> from transformers import BeitFeatureExtractor, FlaxBeitForImageClassification
+ >>> from transformers import BeitImageProcessor, FlaxBeitForImageClassification
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = BeitFeatureExtractor.from_pretrained("microsoft/beit-base-patch16-224")
+ >>> image_processor = BeitImageProcessor.from_pretrained("microsoft/beit-base-patch16-224")
>>> model = FlaxBeitForImageClassification.from_pretrained("microsoft/beit-base-patch16-224")
- >>> inputs = feature_extractor(images=image, return_tensors="np")
+ >>> inputs = image_processor(images=image, return_tensors="np")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
>>> # model predicts one of the 1000 ImageNet classes
diff --git a/src/transformers/models/conditional_detr/modeling_conditional_detr.py b/src/transformers/models/conditional_detr/modeling_conditional_detr.py
index 8860ff50b9..6ce8596592 100644
--- a/src/transformers/models/conditional_detr/modeling_conditional_detr.py
+++ b/src/transformers/models/conditional_detr/modeling_conditional_detr.py
@@ -153,8 +153,8 @@ class ConditionalDetrObjectDetectionOutput(ModelOutput):
pred_boxes (`torch.FloatTensor` of shape `(batch_size, num_queries, 4)`):
Normalized boxes coordinates for all queries, represented as (center_x, center_y, width, height). These
values are normalized in [0, 1], relative to the size of each individual image in the batch (disregarding
- possible padding). You can use [`~ConditionalDetrFeatureExtractor.post_process_object_detection`] to
- retrieve the unnormalized bounding boxes.
+ possible padding). You can use [`~ConditionalDetrImageProcessor.post_process_object_detection`] to retrieve
+ the unnormalized bounding boxes.
auxiliary_outputs (`list[Dict]`, *optional*):
Optional, only returned when auxilary losses are activated (i.e. `config.auxiliary_loss` is set to `True`)
and labels are provided. It is a list of dictionaries containing the two above keys (`logits` and
@@ -217,13 +217,13 @@ class ConditionalDetrSegmentationOutput(ModelOutput):
pred_boxes (`torch.FloatTensor` of shape `(batch_size, num_queries, 4)`):
Normalized boxes coordinates for all queries, represented as (center_x, center_y, width, height). These
values are normalized in [0, 1], relative to the size of each individual image in the batch (disregarding
- possible padding). You can use [`~ConditionalDetrFeatureExtractor.post_process_object_detection`] to
- retrieve the unnormalized bounding boxes.
+ possible padding). You can use [`~ConditionalDetrImageProcessor.post_process_object_detection`] to retrieve
+ the unnormalized bounding boxes.
pred_masks (`torch.FloatTensor` of shape `(batch_size, num_queries, height/4, width/4)`):
Segmentation masks logits for all queries. See also
- [`~ConditionalDetrFeatureExtractor.post_process_semantic_segmentation`] or
- [`~ConditionalDetrFeatureExtractor.post_process_instance_segmentation`]
- [`~ConditionalDetrFeatureExtractor.post_process_panoptic_segmentation`] to evaluate semantic, instance and
+ [`~ConditionalDetrImageProcessor.post_process_semantic_segmentation`] or
+ [`~ConditionalDetrImageProcessor.post_process_instance_segmentation`]
+ [`~ConditionalDetrImageProcessor.post_process_panoptic_segmentation`] to evaluate semantic, instance and
panoptic segmentation masks respectively.
auxiliary_outputs (`list[Dict]`, *optional*):
Optional, only returned when auxiliary losses are activated (i.e. `config.auxiliary_loss` is set to `True`)
@@ -1097,8 +1097,8 @@ CONDITIONAL_DETR_INPUTS_DOCSTRING = r"""
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values. Padding will be ignored by default should you provide it.
- Pixel values can be obtained using [`ConditionalDetrFeatureExtractor`]. See
- [`ConditionalDetrFeatureExtractor.__call__`] for details.
+ Pixel values can be obtained using [`ConditionalDetrImageProcessor`]. See
+ [`ConditionalDetrImageProcessor.__call__`] for details.
pixel_mask (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*):
Mask to avoid performing attention on padding pixel values. Mask values selected in `[0, 1]`:
@@ -1519,18 +1519,18 @@ class ConditionalDetrModel(ConditionalDetrPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, AutoModel
+ >>> from transformers import AutoImageProcessor, AutoModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/conditional-detr-resnet-50")
+ >>> image_processor = AutoImageProcessor.from_pretrained("microsoft/conditional-detr-resnet-50")
>>> model = AutoModel.from_pretrained("microsoft/conditional-detr-resnet-50")
>>> # prepare image for the model
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**inputs)
@@ -1687,25 +1687,25 @@ class ConditionalDetrForObjectDetection(ConditionalDetrPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, AutoModelForObjectDetection
+ >>> from transformers import AutoImageProcessor, AutoModelForObjectDetection
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/conditional-detr-resnet-50")
+ >>> image_processor = AutoImageProcessor.from_pretrained("microsoft/conditional-detr-resnet-50")
>>> model = AutoModelForObjectDetection.from_pretrained("microsoft/conditional-detr-resnet-50")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # convert outputs (bounding boxes and class logits) to COCO API
>>> target_sizes = torch.tensor([image.size[::-1]])
- >>> results = feature_extractor.post_process_object_detection(
- ... outputs, threshold=0.5, target_sizes=target_sizes
- ... )[0]
+ >>> results = image_processor.post_process_object_detection(outputs, threshold=0.5, target_sizes=target_sizes)[
+ ... 0
+ ... ]
>>> for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
... box = [round(i, 2) for i in box.tolist()]
... print(
@@ -1880,7 +1880,7 @@ class ConditionalDetrForSegmentation(ConditionalDetrPreTrainedModel):
>>> import numpy
>>> from transformers import (
- ... AutoFeatureExtractor,
+ ... AutoImageProcessor,
... ConditionalDetrConfig,
... ConditionalDetrForSegmentation,
... )
@@ -1889,21 +1889,21 @@ class ConditionalDetrForSegmentation(ConditionalDetrPreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/conditional-detr-resnet-50")
+ >>> image_processor = AutoImageProcessor.from_pretrained("microsoft/conditional-detr-resnet-50")
>>> # randomly initialize all weights of the model
>>> config = ConditionalDetrConfig()
>>> model = ConditionalDetrForSegmentation(config)
>>> # prepare image for the model
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**inputs)
- >>> # Use the `post_process_panoptic_segmentation` method of `ConditionalDetrFeatureExtractor` to retrieve post-processed panoptic segmentation maps
+ >>> # Use the `post_process_panoptic_segmentation` method of `ConditionalDetrImageProcessor` to retrieve post-processed panoptic segmentation maps
>>> # Segmentation results are returned as a list of dictionaries
- >>> result = feature_extractor.post_process_panoptic_segmentation(outputs, target_sizes=[(300, 500)])
+ >>> result = image_processor.post_process_panoptic_segmentation(outputs, target_sizes=[(300, 500)])
>>> # A tensor of shape (height, width) where each value denotes a segment id, filled with -1 if no segment is found
>>> panoptic_seg = result[0]["segmentation"]
>>> # Get prediction score and segment_id to class_id mapping of each segment
diff --git a/src/transformers/models/convnext/modeling_convnext.py b/src/transformers/models/convnext/modeling_convnext.py
index 44d34c833b..af4ec4e7f8 100755
--- a/src/transformers/models/convnext/modeling_convnext.py
+++ b/src/transformers/models/convnext/modeling_convnext.py
@@ -37,7 +37,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "ConvNextConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "ConvNextFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "ConvNextImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "facebook/convnext-tiny-224"
@@ -308,8 +308,8 @@ CONVNEXT_START_DOCSTRING = r"""
CONVNEXT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
diff --git a/src/transformers/models/convnext/modeling_tf_convnext.py b/src/transformers/models/convnext/modeling_tf_convnext.py
index 680c036e53..8906fa6b47 100644
--- a/src/transformers/models/convnext/modeling_tf_convnext.py
+++ b/src/transformers/models/convnext/modeling_tf_convnext.py
@@ -432,8 +432,8 @@ CONVNEXT_START_DOCSTRING = r"""
CONVNEXT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`np.ndarray`, `tf.Tensor`, `List[tf.Tensor]` ``Dict[str, tf.Tensor]` or `Dict[str, np.ndarray]` and each example must have the shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`ConvNextFeatureExtractor`]. See
- [`ConvNextFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`ConvNextImageProcessor`]. See
+ [`ConvNextImageProcessor.__call__`] for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
@@ -470,17 +470,17 @@ class TFConvNextModel(TFConvNextPreTrainedModel):
Examples:
```python
- >>> from transformers import ConvNextFeatureExtractor, TFConvNextModel
+ >>> from transformers import ConvNextImageProcessor, TFConvNextModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = ConvNextFeatureExtractor.from_pretrained("facebook/convnext-tiny-224")
+ >>> image_processor = ConvNextImageProcessor.from_pretrained("facebook/convnext-tiny-224")
>>> model = TFConvNextModel.from_pretrained("facebook/convnext-tiny-224")
- >>> inputs = feature_extractor(images=image, return_tensors="tf")
+ >>> inputs = image_processor(images=image, return_tensors="tf")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
```"""
@@ -561,7 +561,7 @@ class TFConvNextForImageClassification(TFConvNextPreTrainedModel, TFSequenceClas
Examples:
```python
- >>> from transformers import ConvNextFeatureExtractor, TFConvNextForImageClassification
+ >>> from transformers import ConvNextImageProcessor, TFConvNextForImageClassification
>>> import tensorflow as tf
>>> from PIL import Image
>>> import requests
@@ -569,10 +569,10 @@ class TFConvNextForImageClassification(TFConvNextPreTrainedModel, TFSequenceClas
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = ConvNextFeatureExtractor.from_pretrained("facebook/convnext-tiny-224")
+ >>> image_processor = ConvNextImageProcessor.from_pretrained("facebook/convnext-tiny-224")
>>> model = TFConvNextForImageClassification.from_pretrained("facebook/convnext-tiny-224")
- >>> inputs = feature_extractor(images=image, return_tensors="tf")
+ >>> inputs = image_processor(images=image, return_tensors="tf")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
>>> # model predicts one of the 1000 ImageNet classes
diff --git a/src/transformers/models/cvt/modeling_cvt.py b/src/transformers/models/cvt/modeling_cvt.py
index a76e681c3d..f1d6784051 100644
--- a/src/transformers/models/cvt/modeling_cvt.py
+++ b/src/transformers/models/cvt/modeling_cvt.py
@@ -35,7 +35,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "CvtConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "AutoFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "AutoImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "microsoft/cvt-13"
@@ -573,8 +573,8 @@ CVT_START_DOCSTRING = r"""
CVT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`CvtFeatureExtractor`]. See
- [`CvtFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`CvtImageProcessor`]. See [`CvtImageProcessor.__call__`]
+ for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
diff --git a/src/transformers/models/cvt/modeling_tf_cvt.py b/src/transformers/models/cvt/modeling_tf_cvt.py
index 448bfd2302..17880eaa9d 100644
--- a/src/transformers/models/cvt/modeling_tf_cvt.py
+++ b/src/transformers/models/cvt/modeling_tf_cvt.py
@@ -766,8 +766,8 @@ TFCVT_START_DOCSTRING = r"""
TFCVT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`np.ndarray`, `tf.Tensor`, `List[tf.Tensor]` ``Dict[str, tf.Tensor]` or `Dict[str, np.ndarray]` and each example must have the shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
@@ -808,17 +808,17 @@ class TFCvtModel(TFCvtPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, TFCvtModel
+ >>> from transformers import AutoImageProcessor, TFCvtModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/cvt-13")
+ >>> image_processor = AutoImageProcessor.from_pretrained("microsoft/cvt-13")
>>> model = TFCvtModel.from_pretrained("microsoft/cvt-13")
- >>> inputs = feature_extractor(images=image, return_tensors="tf")
+ >>> inputs = image_processor(images=image, return_tensors="tf")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
```"""
@@ -897,7 +897,7 @@ class TFCvtForImageClassification(TFCvtPreTrainedModel, TFSequenceClassification
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, TFCvtForImageClassification
+ >>> from transformers import AutoImageProcessor, TFCvtForImageClassification
>>> import tensorflow as tf
>>> from PIL import Image
>>> import requests
@@ -905,10 +905,10 @@ class TFCvtForImageClassification(TFCvtPreTrainedModel, TFSequenceClassification
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/cvt-13")
+ >>> image_processor = AutoImageProcessor.from_pretrained("microsoft/cvt-13")
>>> model = TFCvtForImageClassification.from_pretrained("microsoft/cvt-13")
- >>> inputs = feature_extractor(images=image, return_tensors="tf")
+ >>> inputs = image_processor(images=image, return_tensors="tf")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
>>> # model predicts one of the 1000 ImageNet classes
diff --git a/src/transformers/models/data2vec/modeling_data2vec_vision.py b/src/transformers/models/data2vec/modeling_data2vec_vision.py
index fad620e80b..75350eea33 100644
--- a/src/transformers/models/data2vec/modeling_data2vec_vision.py
+++ b/src/transformers/models/data2vec/modeling_data2vec_vision.py
@@ -48,7 +48,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "Data2VecVisionConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "BeitFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "BeitImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "facebook/data2vec-vision-base"
@@ -606,8 +606,8 @@ DATA2VEC_VISION_START_DOCSTRING = r"""
DATA2VEC_VISION_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`BeitFeatureExtractor`]. See
- [`BeitFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`BeitImageProcessor`]. See
+ [`BeitImageProcessor.__call__`] for details.
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -1146,17 +1146,17 @@ class Data2VecVisionForSemanticSegmentation(Data2VecVisionPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, Data2VecVisionForSemanticSegmentation
+ >>> from transformers import AutoImageProcessor, Data2VecVisionForSemanticSegmentation
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/data2vec-vision-base")
+ >>> image_processor = AutoImageProcessor.from_pretrained("facebook/data2vec-vision-base")
>>> model = Data2VecVisionForSemanticSegmentation.from_pretrained("facebook/data2vec-vision-base")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # logits are of shape (batch_size, num_labels, height, width)
>>> logits = outputs.logits
diff --git a/src/transformers/models/data2vec/modeling_tf_data2vec_vision.py b/src/transformers/models/data2vec/modeling_tf_data2vec_vision.py
index 5b4de28b7c..0a804aebd0 100644
--- a/src/transformers/models/data2vec/modeling_tf_data2vec_vision.py
+++ b/src/transformers/models/data2vec/modeling_tf_data2vec_vision.py
@@ -53,7 +53,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "Data2VecVisionConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "BeitFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "BeitImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "facebook/data2vec-vision-base"
@@ -849,8 +849,8 @@ DATA2VEC_VISION_START_DOCSTRING = r"""
DATA2VEC_VISION_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`np.ndarray`, `tf.Tensor`, `List[tf.Tensor]` ``Dict[str, tf.Tensor]` or `Dict[str, np.ndarray]` and each example must have the shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`BeitFeatureExtractor`]. See
- [`BeitFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`BeitImageProcessor`]. See
+ [`BeitImageProcessor.__call__`] for details.
head_mask (`np.ndarray` or `tf.Tensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -1397,17 +1397,17 @@ class TFData2VecVisionForSemanticSegmentation(TFData2VecVisionPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, TFData2VecVisionForSemanticSegmentation
+ >>> from transformers import AutoImageProcessor, TFData2VecVisionForSemanticSegmentation
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/data2vec-vision-base")
+ >>> image_processor = AutoImageProcessor.from_pretrained("facebook/data2vec-vision-base")
>>> model = TFData2VecVisionForSemanticSegmentation.from_pretrained("facebook/data2vec-vision-base")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # logits are of shape (batch_size, num_labels, height, width)
>>> logits = outputs.logits
diff --git a/src/transformers/models/deformable_detr/modeling_deformable_detr.py b/src/transformers/models/deformable_detr/modeling_deformable_detr.py
index c4a52d4257..e994854585 100755
--- a/src/transformers/models/deformable_detr/modeling_deformable_detr.py
+++ b/src/transformers/models/deformable_detr/modeling_deformable_detr.py
@@ -241,7 +241,7 @@ class DeformableDetrObjectDetectionOutput(ModelOutput):
pred_boxes (`torch.FloatTensor` of shape `(batch_size, num_queries, 4)`):
Normalized boxes coordinates for all queries, represented as (center_x, center_y, width, height). These
values are normalized in [0, 1], relative to the size of each individual image in the batch (disregarding
- possible padding). You can use [`~AutoFeatureExtractor.post_process_object_detection`] to retrieve the
+ possible padding). You can use [`~AutoImageProcessor.post_process_object_detection`] to retrieve the
unnormalized bounding boxes.
auxiliary_outputs (`list[Dict]`, *optional*):
Optional, only returned when auxilary losses are activated (i.e. `config.auxiliary_loss` is set to `True`)
@@ -1073,8 +1073,7 @@ DEFORMABLE_DETR_INPUTS_DOCSTRING = r"""
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values. Padding will be ignored by default should you provide it.
- Pixel values can be obtained using [`AutoFeatureExtractor`]. See [`AutoFeatureExtractor.__call__`] for
- details.
+ Pixel values can be obtained using [`AutoImageProcessor`]. See [`AutoImageProcessor.__call__`] for details.
pixel_mask (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*):
Mask to avoid performing attention on padding pixel values. Mask values selected in `[0, 1]`:
@@ -1603,17 +1602,17 @@ class DeformableDetrModel(DeformableDetrPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, DeformableDetrModel
+ >>> from transformers import AutoImageProcessor, DeformableDetrModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("SenseTime/deformable-detr")
+ >>> image_processor = AutoImageProcessor.from_pretrained("SenseTime/deformable-detr")
>>> model = DeformableDetrModel.from_pretrained("SenseTime/deformable-detr")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
@@ -1873,24 +1872,24 @@ class DeformableDetrForObjectDetection(DeformableDetrPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, DeformableDetrForObjectDetection
+ >>> from transformers import AutoImageProcessor, DeformableDetrForObjectDetection
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("SenseTime/deformable-detr")
+ >>> image_processor = AutoImageProcessor.from_pretrained("SenseTime/deformable-detr")
>>> model = DeformableDetrForObjectDetection.from_pretrained("SenseTime/deformable-detr")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # convert outputs (bounding boxes and class logits) to COCO API
>>> target_sizes = torch.tensor([image.size[::-1]])
- >>> results = feature_extractor.post_process_object_detection(
- ... outputs, threshold=0.5, target_sizes=target_sizes
- ... )[0]
+ >>> results = image_processor.post_process_object_detection(outputs, threshold=0.5, target_sizes=target_sizes)[
+ ... 0
+ ... ]
>>> for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
... box = [round(i, 2) for i in box.tolist()]
... print(
diff --git a/src/transformers/models/deit/modeling_deit.py b/src/transformers/models/deit/modeling_deit.py
index b741347d61..646b6b9a2a 100644
--- a/src/transformers/models/deit/modeling_deit.py
+++ b/src/transformers/models/deit/modeling_deit.py
@@ -44,7 +44,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "DeiTConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "DeiTFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "DeiTImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "facebook/deit-base-distilled-patch16-224"
@@ -433,8 +433,8 @@ DEIT_START_DOCSTRING = r"""
DEIT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`DeiTFeatureExtractor`]. See
- [`DeiTFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`DeiTImageProcessor`]. See
+ [`DeiTImageProcessor.__call__`] for details.
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -611,7 +611,7 @@ class DeiTForMaskedImageModeling(DeiTPreTrainedModel):
Examples:
```python
- >>> from transformers import DeiTFeatureExtractor, DeiTForMaskedImageModeling
+ >>> from transformers import DeiTImageProcessor, DeiTForMaskedImageModeling
>>> import torch
>>> from PIL import Image
>>> import requests
@@ -619,11 +619,11 @@ class DeiTForMaskedImageModeling(DeiTPreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = DeiTFeatureExtractor.from_pretrained("facebook/deit-base-distilled-patch16-224")
+ >>> image_processor = DeiTImageProcessor.from_pretrained("facebook/deit-base-distilled-patch16-224")
>>> model = DeiTForMaskedImageModeling.from_pretrained("facebook/deit-base-distilled-patch16-224")
>>> num_patches = (model.config.image_size // model.config.patch_size) ** 2
- >>> pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
+ >>> pixel_values = image_processor(images=image, return_tensors="pt").pixel_values
>>> # create random boolean mask of shape (batch_size, num_patches)
>>> bool_masked_pos = torch.randint(low=0, high=2, size=(1, num_patches)).bool()
@@ -721,7 +721,7 @@ class DeiTForImageClassification(DeiTPreTrainedModel):
Examples:
```python
- >>> from transformers import DeiTFeatureExtractor, DeiTForImageClassification
+ >>> from transformers import DeiTImageProcessor, DeiTForImageClassification
>>> import torch
>>> from PIL import Image
>>> import requests
@@ -732,10 +732,10 @@ class DeiTForImageClassification(DeiTPreTrainedModel):
>>> # note: we are loading a DeiTForImageClassificationWithTeacher from the hub here,
>>> # so the head will be randomly initialized, hence the predictions will be random
- >>> feature_extractor = DeiTFeatureExtractor.from_pretrained("facebook/deit-base-distilled-patch16-224")
+ >>> image_processor = DeiTImageProcessor.from_pretrained("facebook/deit-base-distilled-patch16-224")
>>> model = DeiTForImageClassification.from_pretrained("facebook/deit-base-distilled-patch16-224")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
>>> # model predicts one of the 1000 ImageNet classes
diff --git a/src/transformers/models/deit/modeling_tf_deit.py b/src/transformers/models/deit/modeling_tf_deit.py
index b7270abb65..1eca5a6239 100644
--- a/src/transformers/models/deit/modeling_tf_deit.py
+++ b/src/transformers/models/deit/modeling_tf_deit.py
@@ -52,7 +52,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "DeiTConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "DeiTFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "DeiTImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "facebook/deit-base-distilled-patch16-224"
@@ -614,8 +614,8 @@ DEIT_START_DOCSTRING = r"""
DEIT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`tf.Tensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`DeiTFeatureExtractor`]. See
- [`DeiTFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`DeiTImageProcessor`]. See
+ [`DeiTImageProcessor.__call__`] for details.
head_mask (`tf.Tensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -786,7 +786,7 @@ class TFDeiTForMaskedImageModeling(TFDeiTPreTrainedModel):
Examples:
```python
- >>> from transformers import DeiTFeatureExtractor, TFDeiTForMaskedImageModeling
+ >>> from transformers import DeiTImageProcessor, TFDeiTForMaskedImageModeling
>>> import tensorflow as tf
>>> from PIL import Image
>>> import requests
@@ -794,11 +794,11 @@ class TFDeiTForMaskedImageModeling(TFDeiTPreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = DeiTFeatureExtractor.from_pretrained("facebook/deit-base-distilled-patch16-224")
+ >>> image_processor = DeiTImageProcessor.from_pretrained("facebook/deit-base-distilled-patch16-224")
>>> model = TFDeiTForMaskedImageModeling.from_pretrained("facebook/deit-base-distilled-patch16-224")
>>> num_patches = (model.config.image_size // model.config.patch_size) ** 2
- >>> pixel_values = feature_extractor(images=image, return_tensors="tf").pixel_values
+ >>> pixel_values = image_processor(images=image, return_tensors="tf").pixel_values
>>> # create random boolean mask of shape (batch_size, num_patches)
>>> bool_masked_pos = tf.cast(tf.random.uniform((1, num_patches), minval=0, maxval=2, dtype=tf.int32), tf.bool)
@@ -917,7 +917,7 @@ class TFDeiTForImageClassification(TFDeiTPreTrainedModel, TFSequenceClassificati
Examples:
```python
- >>> from transformers import DeiTFeatureExtractor, TFDeiTForImageClassification
+ >>> from transformers import DeiTImageProcessor, TFDeiTForImageClassification
>>> import tensorflow as tf
>>> from PIL import Image
>>> import requests
@@ -928,10 +928,10 @@ class TFDeiTForImageClassification(TFDeiTPreTrainedModel, TFSequenceClassificati
>>> # note: we are loading a TFDeiTForImageClassificationWithTeacher from the hub here,
>>> # so the head will be randomly initialized, hence the predictions will be random
- >>> feature_extractor = DeiTFeatureExtractor.from_pretrained("facebook/deit-base-distilled-patch16-224")
+ >>> image_processor = DeiTImageProcessor.from_pretrained("facebook/deit-base-distilled-patch16-224")
>>> model = TFDeiTForImageClassification.from_pretrained("facebook/deit-base-distilled-patch16-224")
- >>> inputs = feature_extractor(images=image, return_tensors="tf")
+ >>> inputs = image_processor(images=image, return_tensors="tf")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
>>> # model predicts one of the 1000 ImageNet classes
diff --git a/src/transformers/models/detr/modeling_detr.py b/src/transformers/models/detr/modeling_detr.py
index b06453479f..478653ee63 100644
--- a/src/transformers/models/detr/modeling_detr.py
+++ b/src/transformers/models/detr/modeling_detr.py
@@ -148,7 +148,7 @@ class DetrObjectDetectionOutput(ModelOutput):
pred_boxes (`torch.FloatTensor` of shape `(batch_size, num_queries, 4)`):
Normalized boxes coordinates for all queries, represented as (center_x, center_y, width, height). These
values are normalized in [0, 1], relative to the size of each individual image in the batch (disregarding
- possible padding). You can use [`~DetrFeatureExtractor.post_process_object_detection`] to retrieve the
+ possible padding). You can use [`~DetrImageProcessor.post_process_object_detection`] to retrieve the
unnormalized bounding boxes.
auxiliary_outputs (`list[Dict]`, *optional*):
Optional, only returned when auxilary losses are activated (i.e. `config.auxiliary_loss` is set to `True`)
@@ -211,13 +211,13 @@ class DetrSegmentationOutput(ModelOutput):
pred_boxes (`torch.FloatTensor` of shape `(batch_size, num_queries, 4)`):
Normalized boxes coordinates for all queries, represented as (center_x, center_y, width, height). These
values are normalized in [0, 1], relative to the size of each individual image in the batch (disregarding
- possible padding). You can use [`~DetrFeatureExtractor.post_process_object_detection`] to retrieve the
+ possible padding). You can use [`~DetrImageProcessor.post_process_object_detection`] to retrieve the
unnormalized bounding boxes.
pred_masks (`torch.FloatTensor` of shape `(batch_size, num_queries, height/4, width/4)`):
Segmentation masks logits for all queries. See also
- [`~DetrFeatureExtractor.post_process_semantic_segmentation`] or
- [`~DetrFeatureExtractor.post_process_instance_segmentation`]
- [`~DetrFeatureExtractor.post_process_panoptic_segmentation`] to evaluate semantic, instance and panoptic
+ [`~DetrImageProcessor.post_process_semantic_segmentation`] or
+ [`~DetrImageProcessor.post_process_instance_segmentation`]
+ [`~DetrImageProcessor.post_process_panoptic_segmentation`] to evaluate semantic, instance and panoptic
segmentation masks respectively.
auxiliary_outputs (`list[Dict]`, *optional*):
Optional, only returned when auxiliary losses are activated (i.e. `config.auxiliary_loss` is set to `True`)
@@ -856,8 +856,7 @@ DETR_INPUTS_DOCSTRING = r"""
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values. Padding will be ignored by default should you provide it.
- Pixel values can be obtained using [`DetrFeatureExtractor`]. See [`DetrFeatureExtractor.__call__`] for
- details.
+ Pixel values can be obtained using [`DetrImageProcessor`]. See [`DetrImageProcessor.__call__`] for details.
pixel_mask (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*):
Mask to avoid performing attention on padding pixel values. Mask values selected in `[0, 1]`:
@@ -1243,18 +1242,18 @@ class DetrModel(DetrPreTrainedModel):
Examples:
```python
- >>> from transformers import DetrFeatureExtractor, DetrModel
+ >>> from transformers import DetrImageProcessor, DetrModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = DetrFeatureExtractor.from_pretrained("facebook/detr-resnet-50")
+ >>> image_processor = DetrImageProcessor.from_pretrained("facebook/detr-resnet-50")
>>> model = DetrModel.from_pretrained("facebook/detr-resnet-50")
>>> # prepare image for the model
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**inputs)
@@ -1410,7 +1409,7 @@ class DetrForObjectDetection(DetrPreTrainedModel):
Examples:
```python
- >>> from transformers import DetrFeatureExtractor, DetrForObjectDetection
+ >>> from transformers import DetrImageProcessor, DetrForObjectDetection
>>> import torch
>>> from PIL import Image
>>> import requests
@@ -1418,17 +1417,17 @@ class DetrForObjectDetection(DetrPreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = DetrFeatureExtractor.from_pretrained("facebook/detr-resnet-50")
+ >>> image_processor = DetrImageProcessor.from_pretrained("facebook/detr-resnet-50")
>>> model = DetrForObjectDetection.from_pretrained("facebook/detr-resnet-50")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # convert outputs (bounding boxes and class logits) to COCO API
>>> target_sizes = torch.tensor([image.size[::-1]])
- >>> results = feature_extractor.post_process_object_detection(
- ... outputs, threshold=0.9, target_sizes=target_sizes
- ... )[0]
+ >>> results = image_processor.post_process_object_detection(outputs, threshold=0.9, target_sizes=target_sizes)[
+ ... 0
+ ... ]
>>> for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
... box = [round(i, 2) for i in box.tolist()]
@@ -1588,24 +1587,24 @@ class DetrForSegmentation(DetrPreTrainedModel):
>>> import torch
>>> import numpy
- >>> from transformers import DetrFeatureExtractor, DetrForSegmentation
+ >>> from transformers import DetrImageProcessor, DetrForSegmentation
>>> from transformers.image_transforms import rgb_to_id
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = DetrFeatureExtractor.from_pretrained("facebook/detr-resnet-50-panoptic")
+ >>> image_processor = DetrImageProcessor.from_pretrained("facebook/detr-resnet-50-panoptic")
>>> model = DetrForSegmentation.from_pretrained("facebook/detr-resnet-50-panoptic")
>>> # prepare image for the model
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**inputs)
- >>> # Use the `post_process_panoptic_segmentation` method of `DetrFeatureExtractor` to retrieve post-processed panoptic segmentation maps
+ >>> # Use the `post_process_panoptic_segmentation` method of `DetrImageProcessor` to retrieve post-processed panoptic segmentation maps
>>> # Segmentation results are returned as a list of dictionaries
- >>> result = feature_extractor.post_process_panoptic_segmentation(outputs, target_sizes=[(300, 500)])
+ >>> result = image_processor.post_process_panoptic_segmentation(outputs, target_sizes=[(300, 500)])
>>> # A tensor of shape (height, width) where each value denotes a segment id, filled with -1 if no segment is found
>>> panoptic_seg = result[0]["segmentation"]
diff --git a/src/transformers/models/dpt/modeling_dpt.py b/src/transformers/models/dpt/modeling_dpt.py
index a16071607f..1f0cb869f4 100755
--- a/src/transformers/models/dpt/modeling_dpt.py
+++ b/src/transformers/models/dpt/modeling_dpt.py
@@ -52,7 +52,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "DPTConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "DPTFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "DPTImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "Intel/dpt-large"
@@ -651,8 +651,8 @@ DPT_START_DOCSTRING = r"""
DPT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`ViTFeatureExtractor`]. See
- [`ViTFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`ViTImageProcessor`]. See [`ViTImageProcessor.__call__`]
+ for details.
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -890,7 +890,7 @@ class DPTForDepthEstimation(DPTPreTrainedModel):
Examples:
```python
- >>> from transformers import DPTFeatureExtractor, DPTForDepthEstimation
+ >>> from transformers import DPTImageProcessor, DPTForDepthEstimation
>>> import torch
>>> import numpy as np
>>> from PIL import Image
@@ -899,11 +899,11 @@ class DPTForDepthEstimation(DPTPreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = DPTFeatureExtractor.from_pretrained("Intel/dpt-large")
+ >>> image_processor = DPTImageProcessor.from_pretrained("Intel/dpt-large")
>>> model = DPTForDepthEstimation.from_pretrained("Intel/dpt-large")
>>> # prepare image for the model
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
@@ -1052,17 +1052,17 @@ class DPTForSemanticSegmentation(DPTPreTrainedModel):
Examples:
```python
- >>> from transformers import DPTFeatureExtractor, DPTForSemanticSegmentation
+ >>> from transformers import DPTImageProcessor, DPTForSemanticSegmentation
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = DPTFeatureExtractor.from_pretrained("Intel/dpt-large-ade")
+ >>> image_processor = DPTImageProcessor.from_pretrained("Intel/dpt-large-ade")
>>> model = DPTForSemanticSegmentation.from_pretrained("Intel/dpt-large-ade")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
diff --git a/src/transformers/models/glpn/modeling_glpn.py b/src/transformers/models/glpn/modeling_glpn.py
index ebc148db66..acf8dea706 100755
--- a/src/transformers/models/glpn/modeling_glpn.py
+++ b/src/transformers/models/glpn/modeling_glpn.py
@@ -41,7 +41,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "GLPNConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "GLPNFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "GLPNImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "vinvino02/glpn-kitti"
@@ -464,7 +464,7 @@ GLPN_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
- [`GLPNFeatureExtractor`]. See [`GLPNFeatureExtractor.__call__`] for details.
+ [`GLPNImageProcessor`]. See [`GLPNImageProcessor.__call__`] for details.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
@@ -713,7 +713,7 @@ class GLPNForDepthEstimation(GLPNPreTrainedModel):
Examples:
```python
- >>> from transformers import GLPNFeatureExtractor, GLPNForDepthEstimation
+ >>> from transformers import GLPNImageProcessor, GLPNForDepthEstimation
>>> import torch
>>> import numpy as np
>>> from PIL import Image
@@ -722,11 +722,11 @@ class GLPNForDepthEstimation(GLPNPreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = GLPNFeatureExtractor.from_pretrained("vinvino02/glpn-kitti")
+ >>> image_processor = GLPNImageProcessor.from_pretrained("vinvino02/glpn-kitti")
>>> model = GLPNForDepthEstimation.from_pretrained("vinvino02/glpn-kitti")
>>> # prepare image for the model
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
diff --git a/src/transformers/models/imagegpt/modeling_imagegpt.py b/src/transformers/models/imagegpt/modeling_imagegpt.py
index 9d89251841..8a277e83c0 100755
--- a/src/transformers/models/imagegpt/modeling_imagegpt.py
+++ b/src/transformers/models/imagegpt/modeling_imagegpt.py
@@ -556,7 +556,7 @@ IMAGEGPT_INPUTS_DOCSTRING = r"""
If `past_key_values` is used, only `input_ids` that do not have their past calculated should be passed as
`input_ids`.
- Indices can be obtained using [`ImageGPTFeatureExtractor`]. See [`ImageGPTFeatureExtractor.__call__`] for
+ Indices can be obtained using [`ImageGPTImageProcessor`]. See [`ImageGPTImageProcessor.__call__`] for
details.
past_key_values (`Tuple[Tuple[torch.Tensor]]` of length `config.n_layers`):
@@ -679,17 +679,17 @@ class ImageGPTModel(ImageGPTPreTrainedModel):
Examples:
```python
- >>> from transformers import ImageGPTFeatureExtractor, ImageGPTModel
+ >>> from transformers import ImageGPTImageProcessor, ImageGPTModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = ImageGPTFeatureExtractor.from_pretrained("openai/imagegpt-small")
+ >>> image_processor = ImageGPTImageProcessor.from_pretrained("openai/imagegpt-small")
>>> model = ImageGPTModel.from_pretrained("openai/imagegpt-small")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
```"""
@@ -973,12 +973,12 @@ class ImageGPTForCausalImageModeling(ImageGPTPreTrainedModel):
Examples:
```python
- >>> from transformers import ImageGPTFeatureExtractor, ImageGPTForCausalImageModeling
+ >>> from transformers import ImageGPTImageProcessor, ImageGPTForCausalImageModeling
>>> import torch
>>> import matplotlib.pyplot as plt
>>> import numpy as np
- >>> feature_extractor = ImageGPTFeatureExtractor.from_pretrained("openai/imagegpt-small")
+ >>> image_processor = ImageGPTImageProcessor.from_pretrained("openai/imagegpt-small")
>>> model = ImageGPTForCausalImageModeling.from_pretrained("openai/imagegpt-small")
>>> device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
>>> model.to(device)
@@ -991,9 +991,9 @@ class ImageGPTForCausalImageModeling(ImageGPTPreTrainedModel):
... input_ids=context, max_length=model.config.n_positions + 1, temperature=1.0, do_sample=True, top_k=40
... )
- >>> clusters = feature_extractor.clusters
- >>> height = feature_extractor.size["height"]
- >>> width = feature_extractor.size["width"]
+ >>> clusters = image_processor.clusters
+ >>> height = image_processor.size["height"]
+ >>> width = image_processor.size["width"]
>>> samples = output[:, 1:].cpu().detach().numpy()
>>> samples_img = [
@@ -1124,17 +1124,17 @@ class ImageGPTForImageClassification(ImageGPTPreTrainedModel):
Examples:
```python
- >>> from transformers import ImageGPTFeatureExtractor, ImageGPTForImageClassification
+ >>> from transformers import ImageGPTImageProcessor, ImageGPTForImageClassification
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = ImageGPTFeatureExtractor.from_pretrained("openai/imagegpt-small")
+ >>> image_processor = ImageGPTImageProcessor.from_pretrained("openai/imagegpt-small")
>>> model = ImageGPTForImageClassification.from_pretrained("openai/imagegpt-small")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
```"""
diff --git a/src/transformers/models/levit/modeling_levit.py b/src/transformers/models/levit/modeling_levit.py
index a0d6f7ee09..bddd54cfb3 100644
--- a/src/transformers/models/levit/modeling_levit.py
+++ b/src/transformers/models/levit/modeling_levit.py
@@ -38,7 +38,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "LevitConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "LevitFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "LevitImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "facebook/levit-128S"
@@ -523,8 +523,8 @@ LEVIT_START_DOCSTRING = r"""
LEVIT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
diff --git a/src/transformers/models/maskformer/modeling_maskformer.py b/src/transformers/models/maskformer/modeling_maskformer.py
index 01ad3e6641..298d10879a 100644
--- a/src/transformers/models/maskformer/modeling_maskformer.py
+++ b/src/transformers/models/maskformer/modeling_maskformer.py
@@ -51,7 +51,7 @@ logger = logging.get_logger(__name__)
_CONFIG_FOR_DOC = "MaskFormerConfig"
_CHECKPOINT_FOR_DOC = "facebook/maskformer-swin-base-ade"
-_FEAT_EXTRACTOR_FOR_DOC = "MaskFormerFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "MaskFormerImageProcessor"
MASKFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
"facebook/maskformer-swin-base-ade",
@@ -192,10 +192,10 @@ class MaskFormerForInstanceSegmentationOutput(ModelOutput):
"""
Class for outputs of [`MaskFormerForInstanceSegmentation`].
- This output can be directly passed to [`~MaskFormerFeatureExtractor.post_process_semantic_segmentation`] or or
- [`~MaskFormerFeatureExtractor.post_process_instance_segmentation`] or
- [`~MaskFormerFeatureExtractor.post_process_panoptic_segmentation`] depending on the task. Please, see
- [`~MaskFormerFeatureExtractor] for details regarding usage.
+ This output can be directly passed to [`~MaskFormerImageProcessor.post_process_semantic_segmentation`] or or
+ [`~MaskFormerImageProcessor.post_process_instance_segmentation`] or
+ [`~MaskFormerImageProcessor.post_process_panoptic_segmentation`] depending on the task. Please, see
+ [`~MaskFormerImageProcessor] for details regarding usage.
Args:
loss (`torch.Tensor`, *optional*):
@@ -1462,8 +1462,8 @@ MASKFORMER_START_DOCSTRING = r"""
MASKFORMER_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
pixel_mask (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*):
Mask to avoid performing attention on padding pixel values. Mask values selected in `[0, 1]`:
@@ -1562,18 +1562,18 @@ class MaskFormerModel(MaskFormerPreTrainedModel):
Examples:
```python
- >>> from transformers import MaskFormerFeatureExtractor, MaskFormerModel
+ >>> from transformers import MaskFormerImageProcessor, MaskFormerModel
>>> from PIL import Image
>>> import requests
>>> # load MaskFormer fine-tuned on ADE20k semantic segmentation
- >>> feature_extractor = MaskFormerFeatureExtractor.from_pretrained("facebook/maskformer-swin-base-ade")
+ >>> image_processor = MaskFormerImageProcessor.from_pretrained("facebook/maskformer-swin-base-ade")
>>> model = MaskFormerModel.from_pretrained("facebook/maskformer-swin-base-ade")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> inputs = feature_extractor(image, return_tensors="pt")
+ >>> inputs = image_processor(image, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**inputs)
@@ -1741,19 +1741,19 @@ class MaskFormerForInstanceSegmentation(MaskFormerPreTrainedModel):
Semantic segmentation example:
```python
- >>> from transformers import MaskFormerFeatureExtractor, MaskFormerForInstanceSegmentation
+ >>> from transformers import MaskFormerImageProcessor, MaskFormerForInstanceSegmentation
>>> from PIL import Image
>>> import requests
>>> # load MaskFormer fine-tuned on ADE20k semantic segmentation
- >>> feature_extractor = MaskFormerFeatureExtractor.from_pretrained("facebook/maskformer-swin-base-ade")
+ >>> image_processor = MaskFormerImageProcessor.from_pretrained("facebook/maskformer-swin-base-ade")
>>> model = MaskFormerForInstanceSegmentation.from_pretrained("facebook/maskformer-swin-base-ade")
>>> url = (
... "https://huggingface.co/datasets/hf-internal-testing/fixtures_ade20k/resolve/main/ADE_val_00000001.jpg"
... )
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # model predicts class_queries_logits of shape `(batch_size, num_queries)`
@@ -1761,8 +1761,8 @@ class MaskFormerForInstanceSegmentation(MaskFormerPreTrainedModel):
>>> class_queries_logits = outputs.class_queries_logits
>>> masks_queries_logits = outputs.masks_queries_logits
- >>> # you can pass them to feature_extractor for postprocessing
- >>> predicted_semantic_map = feature_extractor.post_process_semantic_segmentation(
+ >>> # you can pass them to image_processor for postprocessing
+ >>> predicted_semantic_map = image_processor.post_process_semantic_segmentation(
... outputs, target_sizes=[image.size[::-1]]
... )[0]
@@ -1774,17 +1774,17 @@ class MaskFormerForInstanceSegmentation(MaskFormerPreTrainedModel):
Panoptic segmentation example:
```python
- >>> from transformers import MaskFormerFeatureExtractor, MaskFormerForInstanceSegmentation
+ >>> from transformers import MaskFormerImageProcessor, MaskFormerForInstanceSegmentation
>>> from PIL import Image
>>> import requests
>>> # load MaskFormer fine-tuned on COCO panoptic segmentation
- >>> feature_extractor = MaskFormerFeatureExtractor.from_pretrained("facebook/maskformer-swin-base-coco")
+ >>> image_processor = MaskFormerImageProcessor.from_pretrained("facebook/maskformer-swin-base-coco")
>>> model = MaskFormerForInstanceSegmentation.from_pretrained("facebook/maskformer-swin-base-coco")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # model predicts class_queries_logits of shape `(batch_size, num_queries)`
@@ -1792,8 +1792,8 @@ class MaskFormerForInstanceSegmentation(MaskFormerPreTrainedModel):
>>> class_queries_logits = outputs.class_queries_logits
>>> masks_queries_logits = outputs.masks_queries_logits
- >>> # you can pass them to feature_extractor for postprocessing
- >>> result = feature_extractor.post_process_panoptic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
+ >>> # you can pass them to image_processor for postprocessing
+ >>> result = image_processor.post_process_panoptic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
>>> # we refer to the demo notebooks for visualization (see "Resources" section in the MaskFormer docs)
>>> predicted_panoptic_map = result["segmentation"]
diff --git a/src/transformers/models/mobilenet_v1/modeling_mobilenet_v1.py b/src/transformers/models/mobilenet_v1/modeling_mobilenet_v1.py
index fedf27aed4..79c64dbaea 100755
--- a/src/transformers/models/mobilenet_v1/modeling_mobilenet_v1.py
+++ b/src/transformers/models/mobilenet_v1/modeling_mobilenet_v1.py
@@ -33,7 +33,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "MobileNetV1Config"
-_FEAT_EXTRACTOR_FOR_DOC = "MobileNetV1FeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "MobileNetV1ImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "google/mobilenet_v1_1.0_224"
@@ -285,8 +285,8 @@ MOBILENET_V1_START_DOCSTRING = r"""
MOBILENET_V1_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`MobileNetV1FeatureExtractor`]. See
- [`MobileNetV1FeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`MobileNetV1ImageProcessor`]. See
+ [`MobileNetV1ImageProcessor.__call__`] for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
diff --git a/src/transformers/models/mobilenet_v2/modeling_mobilenet_v2.py b/src/transformers/models/mobilenet_v2/modeling_mobilenet_v2.py
index d8b7f205c3..a47c5aebbe 100755
--- a/src/transformers/models/mobilenet_v2/modeling_mobilenet_v2.py
+++ b/src/transformers/models/mobilenet_v2/modeling_mobilenet_v2.py
@@ -43,7 +43,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "MobileNetV2Config"
-_FEAT_EXTRACTOR_FOR_DOC = "MobileNetV2FeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "MobileNetV2ImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "google/mobilenet_v2_1.0_224"
@@ -486,8 +486,8 @@ MOBILENET_V2_START_DOCSTRING = r"""
MOBILENET_V2_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`MobileNetV2FeatureExtractor`]. See
- [`MobileNetV2FeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`MobileNetV2ImageProcessor`]. See
+ [`MobileNetV2ImageProcessor.__call__`] for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
@@ -811,17 +811,17 @@ class MobileNetV2ForSemanticSegmentation(MobileNetV2PreTrainedModel):
Examples:
```python
- >>> from transformers import MobileNetV2FeatureExtractor, MobileNetV2ForSemanticSegmentation
+ >>> from transformers import MobileNetV2ImageProcessor, MobileNetV2ForSemanticSegmentation
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = MobileNetV2FeatureExtractor.from_pretrained("google/deeplabv3_mobilenet_v2_1.0_513")
+ >>> image_processor = MobileNetV2ImageProcessor.from_pretrained("google/deeplabv3_mobilenet_v2_1.0_513")
>>> model = MobileNetV2ForSemanticSegmentation.from_pretrained("google/deeplabv3_mobilenet_v2_1.0_513")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
diff --git a/src/transformers/models/mobilevit/modeling_mobilevit.py b/src/transformers/models/mobilevit/modeling_mobilevit.py
index fadfc4de30..e129fa2898 100755
--- a/src/transformers/models/mobilevit/modeling_mobilevit.py
+++ b/src/transformers/models/mobilevit/modeling_mobilevit.py
@@ -49,7 +49,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "MobileViTConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "MobileViTFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "MobileViTImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "apple/mobilevit-small"
@@ -692,8 +692,8 @@ MOBILEVIT_START_DOCSTRING = r"""
MOBILEVIT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`MobileViTFeatureExtractor`]. See
- [`MobileViTFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`MobileViTImageProcessor`]. See
+ [`MobileViTImageProcessor.__call__`] for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
@@ -1027,17 +1027,17 @@ class MobileViTForSemanticSegmentation(MobileViTPreTrainedModel):
Examples:
```python
- >>> from transformers import MobileViTFeatureExtractor, MobileViTForSemanticSegmentation
+ >>> from transformers import MobileViTImageProcessor, MobileViTForSemanticSegmentation
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = MobileViTFeatureExtractor.from_pretrained("apple/deeplabv3-mobilevit-small")
+ >>> image_processor = MobileViTImageProcessor.from_pretrained("apple/deeplabv3-mobilevit-small")
>>> model = MobileViTForSemanticSegmentation.from_pretrained("apple/deeplabv3-mobilevit-small")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
diff --git a/src/transformers/models/mobilevit/modeling_tf_mobilevit.py b/src/transformers/models/mobilevit/modeling_tf_mobilevit.py
index 41b9b313b0..ebfce88937 100644
--- a/src/transformers/models/mobilevit/modeling_tf_mobilevit.py
+++ b/src/transformers/models/mobilevit/modeling_tf_mobilevit.py
@@ -43,7 +43,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "MobileViTConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "MobileViTFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "MobileViTImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "apple/mobilevit-small"
@@ -811,8 +811,8 @@ MOBILEVIT_START_DOCSTRING = r"""
MOBILEVIT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`np.ndarray`, `tf.Tensor`, `List[tf.Tensor]`, `Dict[str, tf.Tensor]` or `Dict[str, np.ndarray]` and each example must have the shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`MobileViTFeatureExtractor`]. See
- [`MobileViTFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`MobileViTImageProcessor`]. See
+ [`MobileViTImageProcessor.__call__`] for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
@@ -1103,17 +1103,17 @@ class TFMobileViTForSemanticSegmentation(TFMobileViTPreTrainedModel):
Examples:
```python
- >>> from transformers import MobileViTFeatureExtractor, TFMobileViTForSemanticSegmentation
+ >>> from transformers import MobileViTImageProcessor, TFMobileViTForSemanticSegmentation
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = MobileViTFeatureExtractor.from_pretrained("apple/deeplabv3-mobilevit-small")
+ >>> image_processor = MobileViTImageProcessor.from_pretrained("apple/deeplabv3-mobilevit-small")
>>> model = TFMobileViTForSemanticSegmentation.from_pretrained("apple/deeplabv3-mobilevit-small")
- >>> inputs = feature_extractor(images=image, return_tensors="tf")
+ >>> inputs = image_processor(images=image, return_tensors="tf")
>>> outputs = model(**inputs)
diff --git a/src/transformers/models/perceiver/modeling_perceiver.py b/src/transformers/models/perceiver/modeling_perceiver.py
index 8ba049869c..7f12fb4ad5 100755
--- a/src/transformers/models/perceiver/modeling_perceiver.py
+++ b/src/transformers/models/perceiver/modeling_perceiver.py
@@ -768,7 +768,7 @@ class PerceiverModel(PerceiverPreTrainedModel):
Examples:
```python
- >>> from transformers import PerceiverConfig, PerceiverTokenizer, PerceiverFeatureExtractor, PerceiverModel
+ >>> from transformers import PerceiverConfig, PerceiverTokenizer, PerceiverImageProcessor, PerceiverModel
>>> from transformers.models.perceiver.modeling_perceiver import (
... PerceiverTextPreprocessor,
... PerceiverImagePreprocessor,
@@ -839,10 +839,10 @@ class PerceiverModel(PerceiverPreTrainedModel):
... )
>>> # you can then do a forward pass as follows:
- >>> feature_extractor = PerceiverFeatureExtractor()
+ >>> image_processor = PerceiverImageProcessor()
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> inputs = feature_extractor(image, return_tensors="pt").pixel_values
+ >>> inputs = image_processor(image, return_tensors="pt").pixel_values
>>> with torch.no_grad():
... outputs = model(inputs=inputs)
@@ -1266,17 +1266,17 @@ class PerceiverForImageClassificationLearned(PerceiverPreTrainedModel):
Examples:
```python
- >>> from transformers import PerceiverFeatureExtractor, PerceiverForImageClassificationLearned
+ >>> from transformers import PerceiverImageProcessor, PerceiverForImageClassificationLearned
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = PerceiverFeatureExtractor.from_pretrained("deepmind/vision-perceiver-learned")
+ >>> image_processor = PerceiverImageProcessor.from_pretrained("deepmind/vision-perceiver-learned")
>>> model = PerceiverForImageClassificationLearned.from_pretrained("deepmind/vision-perceiver-learned")
- >>> inputs = feature_extractor(images=image, return_tensors="pt").pixel_values
+ >>> inputs = image_processor(images=image, return_tensors="pt").pixel_values
>>> outputs = model(inputs=inputs)
>>> logits = outputs.logits
>>> list(logits.shape)
@@ -1407,17 +1407,17 @@ class PerceiverForImageClassificationFourier(PerceiverPreTrainedModel):
Examples:
```python
- >>> from transformers import PerceiverFeatureExtractor, PerceiverForImageClassificationFourier
+ >>> from transformers import PerceiverImageProcessor, PerceiverForImageClassificationFourier
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = PerceiverFeatureExtractor.from_pretrained("deepmind/vision-perceiver-fourier")
+ >>> image_processor = PerceiverImageProcessor.from_pretrained("deepmind/vision-perceiver-fourier")
>>> model = PerceiverForImageClassificationFourier.from_pretrained("deepmind/vision-perceiver-fourier")
- >>> inputs = feature_extractor(images=image, return_tensors="pt").pixel_values
+ >>> inputs = image_processor(images=image, return_tensors="pt").pixel_values
>>> outputs = model(inputs=inputs)
>>> logits = outputs.logits
>>> list(logits.shape)
@@ -1548,17 +1548,17 @@ class PerceiverForImageClassificationConvProcessing(PerceiverPreTrainedModel):
Examples:
```python
- >>> from transformers import PerceiverFeatureExtractor, PerceiverForImageClassificationConvProcessing
+ >>> from transformers import PerceiverImageProcessor, PerceiverForImageClassificationConvProcessing
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = PerceiverFeatureExtractor.from_pretrained("deepmind/vision-perceiver-conv")
+ >>> image_processor = PerceiverImageProcessor.from_pretrained("deepmind/vision-perceiver-conv")
>>> model = PerceiverForImageClassificationConvProcessing.from_pretrained("deepmind/vision-perceiver-conv")
- >>> inputs = feature_extractor(images=image, return_tensors="pt").pixel_values
+ >>> inputs = image_processor(images=image, return_tensors="pt").pixel_values
>>> outputs = model(inputs=inputs)
>>> logits = outputs.logits
>>> list(logits.shape)
diff --git a/src/transformers/models/poolformer/modeling_poolformer.py b/src/transformers/models/poolformer/modeling_poolformer.py
index b53c482da4..b659e25f05 100755
--- a/src/transformers/models/poolformer/modeling_poolformer.py
+++ b/src/transformers/models/poolformer/modeling_poolformer.py
@@ -34,7 +34,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "PoolFormerConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "PoolFormerFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "PoolFormerImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "sail/poolformer_s12"
@@ -302,8 +302,8 @@ POOLFORMER_START_DOCSTRING = r"""
POOLFORMER_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`PoolFormerFeatureExtractor`]. See
- [`PoolFormerFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`PoolFormerImageProcessor`]. See
+ [`PoolFormerImageProcessor.__call__`] for details.
"""
diff --git a/src/transformers/models/regnet/modeling_regnet.py b/src/transformers/models/regnet/modeling_regnet.py
index f317bf47d7..a95fafd984 100644
--- a/src/transformers/models/regnet/modeling_regnet.py
+++ b/src/transformers/models/regnet/modeling_regnet.py
@@ -37,7 +37,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "RegNetConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "AutoFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "AutoImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "facebook/regnet-y-040"
@@ -313,8 +313,8 @@ REGNET_START_DOCSTRING = r"""
REGNET_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
diff --git a/src/transformers/models/regnet/modeling_tf_regnet.py b/src/transformers/models/regnet/modeling_tf_regnet.py
index 8bbc37951a..fd36b2554f 100644
--- a/src/transformers/models/regnet/modeling_tf_regnet.py
+++ b/src/transformers/models/regnet/modeling_tf_regnet.py
@@ -35,7 +35,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "RegNetConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "AutoFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "AutoImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "facebook/regnet-y-040"
@@ -389,8 +389,8 @@ REGNET_START_DOCSTRING = r"""
REGNET_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`tf.Tensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
diff --git a/src/transformers/models/resnet/modeling_resnet.py b/src/transformers/models/resnet/modeling_resnet.py
index 7c3e176dcb..851cc3cecf 100644
--- a/src/transformers/models/resnet/modeling_resnet.py
+++ b/src/transformers/models/resnet/modeling_resnet.py
@@ -43,7 +43,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "ResNetConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "AutoFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "AutoImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "microsoft/resnet-50"
@@ -285,8 +285,8 @@ RESNET_START_DOCSTRING = r"""
RESNET_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
diff --git a/src/transformers/models/resnet/modeling_tf_resnet.py b/src/transformers/models/resnet/modeling_tf_resnet.py
index 4cf0d21ec7..483d5798e6 100644
--- a/src/transformers/models/resnet/modeling_tf_resnet.py
+++ b/src/transformers/models/resnet/modeling_tf_resnet.py
@@ -34,7 +34,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "ResNetConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "AutoFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "AutoImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "microsoft/resnet-50"
@@ -313,8 +313,8 @@ RESNET_START_DOCSTRING = r"""
RESNET_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`tf.Tensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
diff --git a/src/transformers/models/segformer/modeling_segformer.py b/src/transformers/models/segformer/modeling_segformer.py
index 0ce8dad2eb..c2fec27f0b 100755
--- a/src/transformers/models/segformer/modeling_segformer.py
+++ b/src/transformers/models/segformer/modeling_segformer.py
@@ -42,7 +42,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "SegformerConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "SegformerFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "SegformerImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "nvidia/mit-b0"
@@ -491,7 +491,7 @@ SEGFORMER_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
- [`SegformerFeatureExtractor`]. See [`SegformerFeatureExtractor.__call__`] for details.
+ [`SegformerImageProcessor`]. See [`SegformerImageProcessor.__call__`] for details.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
@@ -772,17 +772,17 @@ class SegformerForSemanticSegmentation(SegformerPreTrainedModel):
Examples:
```python
- >>> from transformers import SegformerFeatureExtractor, SegformerForSemanticSegmentation
+ >>> from transformers import SegformerImageProcessor, SegformerForSemanticSegmentation
>>> from PIL import Image
>>> import requests
- >>> feature_extractor = SegformerFeatureExtractor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
+ >>> image_processor = SegformerImageProcessor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
>>> model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> logits = outputs.logits # shape (batch_size, num_labels, height/4, width/4)
>>> list(logits.shape)
diff --git a/src/transformers/models/segformer/modeling_tf_segformer.py b/src/transformers/models/segformer/modeling_tf_segformer.py
index c6a8e00146..702730a6f1 100644
--- a/src/transformers/models/segformer/modeling_tf_segformer.py
+++ b/src/transformers/models/segformer/modeling_tf_segformer.py
@@ -37,7 +37,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "SegformerConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "SegformerFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "SegformerImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "nvidia/mit-b0"
@@ -568,8 +568,8 @@ SEGFORMER_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`np.ndarray`, `tf.Tensor`, `List[tf.Tensor]` ``Dict[str, tf.Tensor]` or `Dict[str, np.ndarray]` and each example must have the shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
@@ -835,17 +835,17 @@ class TFSegformerForSemanticSegmentation(TFSegformerPreTrainedModel):
Examples:
```python
- >>> from transformers import SegformerFeatureExtractor, TFSegformerForSemanticSegmentation
+ >>> from transformers import SegformerImageProcessor, TFSegformerForSemanticSegmentation
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = SegformerFeatureExtractor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
+ >>> image_processor = SegformerImageProcessor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
>>> model = TFSegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
- >>> inputs = feature_extractor(images=image, return_tensors="tf")
+ >>> inputs = image_processor(images=image, return_tensors="tf")
>>> outputs = model(**inputs, training=False)
>>> # logits are of shape (batch_size, num_labels, height/4, width/4)
>>> logits = outputs.logits
diff --git a/src/transformers/models/swin/modeling_swin.py b/src/transformers/models/swin/modeling_swin.py
index e33eddabf0..b304c6937f 100644
--- a/src/transformers/models/swin/modeling_swin.py
+++ b/src/transformers/models/swin/modeling_swin.py
@@ -43,7 +43,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "SwinConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "AutoFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "AutoImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "microsoft/swin-tiny-patch4-window7-224"
@@ -888,8 +888,8 @@ SWIN_START_DOCSTRING = r"""
SWIN_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -1053,7 +1053,7 @@ class SwinForMaskedImageModeling(SwinPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, SwinForMaskedImageModeling
+ >>> from transformers import AutoImageProcessor, SwinForMaskedImageModeling
>>> import torch
>>> from PIL import Image
>>> import requests
@@ -1061,11 +1061,11 @@ class SwinForMaskedImageModeling(SwinPreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/swin-base-simmim-window6-192")
+ >>> image_processor = AutoImageProcessor.from_pretrained("microsoft/swin-base-simmim-window6-192")
>>> model = SwinForMaskedImageModeling.from_pretrained("microsoft/swin-base-simmim-window6-192")
>>> num_patches = (model.config.image_size // model.config.patch_size) ** 2
- >>> pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
+ >>> pixel_values = image_processor(images=image, return_tensors="pt").pixel_values
>>> # create random boolean mask of shape (batch_size, num_patches)
>>> bool_masked_pos = torch.randint(low=0, high=2, size=(1, num_patches)).bool()
diff --git a/src/transformers/models/swin/modeling_tf_swin.py b/src/transformers/models/swin/modeling_tf_swin.py
index fdaefc0a3b..fc4b321fa0 100644
--- a/src/transformers/models/swin/modeling_tf_swin.py
+++ b/src/transformers/models/swin/modeling_tf_swin.py
@@ -47,7 +47,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "SwinConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "AutoFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "AutoImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "microsoft/swin-tiny-patch4-window7-224"
@@ -985,8 +985,8 @@ SWIN_START_DOCSTRING = r"""
SWIN_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`tf.Tensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
head_mask (`tf.Tensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -1321,7 +1321,7 @@ class TFSwinForMaskedImageModeling(TFSwinPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, TFSwinForMaskedImageModeling
+ >>> from transformers import AutoImageProcessor, TFSwinForMaskedImageModeling
>>> import tensorflow as tf
>>> from PIL import Image
>>> import requests
@@ -1329,11 +1329,11 @@ class TFSwinForMaskedImageModeling(TFSwinPreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/swin-tiny-patch4-window7-224")
+ >>> image_processor = AutoImageProcessor.from_pretrained("microsoft/swin-tiny-patch4-window7-224")
>>> model = TFSwinForMaskedImageModeling.from_pretrained("microsoft/swin-tiny-patch4-window7-224")
>>> num_patches = (model.config.image_size // model.config.patch_size) ** 2
- >>> pixel_values = feature_extractor(images=image, return_tensors="tf").pixel_values
+ >>> pixel_values = image_processor(images=image, return_tensors="tf").pixel_values
>>> # create random boolean mask of shape (batch_size, num_patches)
>>> bool_masked_pos = tf.random.uniform((1, num_patches)) >= 0.5
diff --git a/src/transformers/models/swinv2/modeling_swinv2.py b/src/transformers/models/swinv2/modeling_swinv2.py
index d0e86c1656..6f3aa61e1b 100644
--- a/src/transformers/models/swinv2/modeling_swinv2.py
+++ b/src/transformers/models/swinv2/modeling_swinv2.py
@@ -44,7 +44,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "Swinv2Config"
-_FEAT_EXTRACTOR_FOR_DOC = "AutoFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "AutoImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "microsoft/swinv2-tiny-patch4-window8-256"
@@ -968,8 +968,8 @@ SWINV2_START_DOCSTRING = r"""
SWINV2_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -1136,7 +1136,7 @@ class Swinv2ForMaskedImageModeling(Swinv2PreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, Swinv2ForMaskedImageModeling
+ >>> from transformers import AutoImageProcessor, Swinv2ForMaskedImageModeling
>>> import torch
>>> from PIL import Image
>>> import requests
@@ -1144,11 +1144,11 @@ class Swinv2ForMaskedImageModeling(Swinv2PreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/swinv2-tiny-patch4-window8-256")
+ >>> image_processor = AutoImageProcessor.from_pretrained("microsoft/swinv2-tiny-patch4-window8-256")
>>> model = Swinv2ForMaskedImageModeling.from_pretrained("microsoft/swinv2-tiny-patch4-window8-256")
>>> num_patches = (model.config.image_size // model.config.patch_size) ** 2
- >>> pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
+ >>> pixel_values = image_processor(images=image, return_tensors="pt").pixel_values
>>> # create random boolean mask of shape (batch_size, num_patches)
>>> bool_masked_pos = torch.randint(low=0, high=2, size=(1, num_patches)).bool()
diff --git a/src/transformers/models/table_transformer/modeling_table_transformer.py b/src/transformers/models/table_transformer/modeling_table_transformer.py
index ee675c0a4b..5fc0ccfe86 100644
--- a/src/transformers/models/table_transformer/modeling_table_transformer.py
+++ b/src/transformers/models/table_transformer/modeling_table_transformer.py
@@ -136,7 +136,7 @@ class TableTransformerModelOutput(Seq2SeqModelOutput):
@dataclass
-# Copied from transformers.models.detr.modeling_detr.DetrObjectDetectionOutput with Detr->TableTransformer,DetrFeatureExtractor->DetrFeatureExtractor
+# Copied from transformers.models.detr.modeling_detr.DetrObjectDetectionOutput with Detr->TableTransformer,DetrImageProcessor->DetrImageProcessor
class TableTransformerObjectDetectionOutput(ModelOutput):
"""
Output type of [`TableTransformerForObjectDetection`].
@@ -153,7 +153,7 @@ class TableTransformerObjectDetectionOutput(ModelOutput):
pred_boxes (`torch.FloatTensor` of shape `(batch_size, num_queries, 4)`):
Normalized boxes coordinates for all queries, represented as (center_x, center_y, width, height). These
values are normalized in [0, 1], relative to the size of each individual image in the batch (disregarding
- possible padding). You can use [`~TableTransformerFeatureExtractor.post_process_object_detection`] to
+ possible padding). You can use [`~TableTransformerImageProcessor.post_process_object_detection`] to
retrieve the unnormalized bounding boxes.
auxiliary_outputs (`list[Dict]`, *optional*):
Optional, only returned when auxilary losses are activated (i.e. `config.auxiliary_loss` is set to `True`)
@@ -797,8 +797,7 @@ TABLE_TRANSFORMER_INPUTS_DOCSTRING = r"""
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values. Padding will be ignored by default should you provide it.
- Pixel values can be obtained using [`DetrFeatureExtractor`]. See [`DetrFeatureExtractor.__call__`] for
- details.
+ Pixel values can be obtained using [`DetrImageProcessor`]. See [`DetrImageProcessor.__call__`] for details.
pixel_mask (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*):
Mask to avoid performing attention on padding pixel values. Mask values selected in `[0, 1]`:
@@ -1188,18 +1187,18 @@ class TableTransformerModel(TableTransformerPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, TableTransformerModel
+ >>> from transformers import AutoImageProcessor, TableTransformerModel
>>> from huggingface_hub import hf_hub_download
>>> from PIL import Image
>>> file_path = hf_hub_download(repo_id="nielsr/example-pdf", repo_type="dataset", filename="example_pdf.png")
>>> image = Image.open(file_path).convert("RGB")
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/table-transformer-detection")
+ >>> image_processor = AutoImageProcessor.from_pretrained("microsoft/table-transformer-detection")
>>> model = TableTransformerModel.from_pretrained("microsoft/table-transformer-detection")
>>> # prepare image for the model
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**inputs)
@@ -1357,24 +1356,24 @@ class TableTransformerForObjectDetection(TableTransformerPreTrainedModel):
```python
>>> from huggingface_hub import hf_hub_download
- >>> from transformers import AutoFeatureExtractor, TableTransformerForObjectDetection
+ >>> from transformers import AutoImageProcessor, TableTransformerForObjectDetection
>>> import torch
>>> from PIL import Image
>>> file_path = hf_hub_download(repo_id="nielsr/example-pdf", repo_type="dataset", filename="example_pdf.png")
>>> image = Image.open(file_path).convert("RGB")
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/table-transformer-detection")
+ >>> image_processor = AutoImageProcessor.from_pretrained("microsoft/table-transformer-detection")
>>> model = TableTransformerForObjectDetection.from_pretrained("microsoft/table-transformer-detection")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # convert outputs (bounding boxes and class logits) to COCO API
>>> target_sizes = torch.tensor([image.size[::-1]])
- >>> results = feature_extractor.post_process_object_detection(
- ... outputs, threshold=0.9, target_sizes=target_sizes
- ... )[0]
+ >>> results = image_processor.post_process_object_detection(outputs, threshold=0.9, target_sizes=target_sizes)[
+ ... 0
+ ... ]
>>> for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
... box = [round(i, 2) for i in box.tolist()]
diff --git a/src/transformers/models/trocr/processing_trocr.py b/src/transformers/models/trocr/processing_trocr.py
index 0e24afbf0b..4792d886e8 100644
--- a/src/transformers/models/trocr/processing_trocr.py
+++ b/src/transformers/models/trocr/processing_trocr.py
@@ -23,7 +23,7 @@ from ...processing_utils import ProcessorMixin
class TrOCRProcessor(ProcessorMixin):
r"""
- Constructs a TrOCR processor which wraps a vision feature extractor and a TrOCR tokenizer into a single processor.
+ Constructs a TrOCR processor which wraps a vision image processor and a TrOCR tokenizer into a single processor.
[`TrOCRProcessor`] offers all the functionalities of [`ViTImageProcessor`/`DeiTImageProcessor`] and
[`RobertaTokenizer`/`XLMRobertaTokenizer`]. See the [`~TrOCRProcessor.__call__`] and [`~TrOCRProcessor.decode`] for
diff --git a/src/transformers/models/van/modeling_van.py b/src/transformers/models/van/modeling_van.py
index bb9e2716d4..ec9b73f368 100644
--- a/src/transformers/models/van/modeling_van.py
+++ b/src/transformers/models/van/modeling_van.py
@@ -38,7 +38,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "VanConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "AutoFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "AutoImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "Visual-Attention-Network/van-base"
@@ -407,8 +407,8 @@ VAN_START_DOCSTRING = r"""
VAN_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all stages. See `hidden_states` under returned tensors for
diff --git a/src/transformers/models/videomae/modeling_videomae.py b/src/transformers/models/videomae/modeling_videomae.py
index a40b3881f7..bf6ca688fb 100644
--- a/src/transformers/models/videomae/modeling_videomae.py
+++ b/src/transformers/models/videomae/modeling_videomae.py
@@ -510,8 +510,8 @@ VIDEOMAE_START_DOCSTRING = r"""
VIDEOMAE_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_frames, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`VideoMAEFeatureExtractor`]. See
- [`VideoMAEFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`VideoMAEImageProcessor`]. See
+ [`VideoMAEImageProcessor.__call__`] for details.
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -581,7 +581,7 @@ class VideoMAEModel(VideoMAEPreTrainedModel):
>>> from decord import VideoReader, cpu
>>> import numpy as np
- >>> from transformers import VideoMAEFeatureExtractor, VideoMAEModel
+ >>> from transformers import VideoMAEImageProcessor, VideoMAEModel
>>> from huggingface_hub import hf_hub_download
@@ -605,11 +605,11 @@ class VideoMAEModel(VideoMAEPreTrainedModel):
>>> indices = sample_frame_indices(clip_len=16, frame_sample_rate=4, seg_len=len(videoreader))
>>> video = videoreader.get_batch(indices).asnumpy()
- >>> feature_extractor = VideoMAEFeatureExtractor.from_pretrained("MCG-NJU/videomae-base")
+ >>> image_processor = VideoMAEImageProcessor.from_pretrained("MCG-NJU/videomae-base")
>>> model = VideoMAEModel.from_pretrained("MCG-NJU/videomae-base")
>>> # prepare video for the model
- >>> inputs = feature_extractor(list(video), return_tensors="pt")
+ >>> inputs = image_processor(list(video), return_tensors="pt")
>>> # forward pass
>>> outputs = model(**inputs)
@@ -765,17 +765,17 @@ class VideoMAEForPreTraining(VideoMAEPreTrainedModel):
Examples:
```python
- >>> from transformers import VideoMAEFeatureExtractor, VideoMAEForPreTraining
+ >>> from transformers import VideoMAEImageProcessor, VideoMAEForPreTraining
>>> import numpy as np
>>> import torch
>>> num_frames = 16
>>> video = list(np.random.randn(16, 3, 224, 224))
- >>> feature_extractor = VideoMAEFeatureExtractor.from_pretrained("MCG-NJU/videomae-base")
+ >>> image_processor = VideoMAEImageProcessor.from_pretrained("MCG-NJU/videomae-base")
>>> model = VideoMAEForPreTraining.from_pretrained("MCG-NJU/videomae-base")
- >>> pixel_values = feature_extractor(video, return_tensors="pt").pixel_values
+ >>> pixel_values = image_processor(video, return_tensors="pt").pixel_values
>>> num_patches_per_frame = (model.config.image_size // model.config.patch_size) ** 2
>>> seq_length = (num_frames // model.config.tubelet_size) * num_patches_per_frame
@@ -942,7 +942,7 @@ class VideoMAEForVideoClassification(VideoMAEPreTrainedModel):
>>> import torch
>>> import numpy as np
- >>> from transformers import VideoMAEFeatureExtractor, VideoMAEForVideoClassification
+ >>> from transformers import VideoMAEImageProcessor, VideoMAEForVideoClassification
>>> from huggingface_hub import hf_hub_download
>>> np.random.seed(0)
@@ -968,10 +968,10 @@ class VideoMAEForVideoClassification(VideoMAEPreTrainedModel):
>>> indices = sample_frame_indices(clip_len=16, frame_sample_rate=4, seg_len=len(videoreader))
>>> video = videoreader.get_batch(indices).asnumpy()
- >>> feature_extractor = VideoMAEFeatureExtractor.from_pretrained("MCG-NJU/videomae-base-finetuned-kinetics")
+ >>> image_processor = VideoMAEImageProcessor.from_pretrained("MCG-NJU/videomae-base-finetuned-kinetics")
>>> model = VideoMAEForVideoClassification.from_pretrained("MCG-NJU/videomae-base-finetuned-kinetics")
- >>> inputs = feature_extractor(list(video), return_tensors="pt")
+ >>> inputs = image_processor(list(video), return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
diff --git a/src/transformers/models/vision_encoder_decoder/modeling_flax_vision_encoder_decoder.py b/src/transformers/models/vision_encoder_decoder/modeling_flax_vision_encoder_decoder.py
index 7042b2548d..5f9edbe7f9 100644
--- a/src/transformers/models/vision_encoder_decoder/modeling_flax_vision_encoder_decoder.py
+++ b/src/transformers/models/vision_encoder_decoder/modeling_flax_vision_encoder_decoder.py
@@ -86,8 +86,8 @@ VISION_ENCODER_DECODER_START_DOCSTRING = r"""
VISION_ENCODER_DECODER_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`jnp.ndarray` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using the vision model's feature extractor. For example, using
- [`ViTFeatureExtractor`]. See [`ViTFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using the vision model's image processor. For example, using
+ [`ViTImageProcessor`]. See [`ViTImageProcessor.__call__`] for details.
decoder_input_ids (`jnp.ndarray` of shape `(batch_size, target_sequence_length)`, *optional*):
Indices of decoder input sequence tokens in the vocabulary.
@@ -114,8 +114,8 @@ VISION_ENCODER_DECODER_INPUTS_DOCSTRING = r"""
VISION_ENCODER_DECODER_ENCODE_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`jnp.ndarray` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using the vision model's feature extractor. For example, using
- [`ViTFeatureExtractor`]. See [`ViTFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using the vision model's image processor. For example, using
+ [`ViTImageProcessor`]. See [`ViTImageProcessor.__call__`] for details.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
@@ -409,21 +409,21 @@ class FlaxVisionEncoderDecoderModel(FlaxPreTrainedModel):
Example:
```python
- >>> from transformers import ViTFeatureExtractor, FlaxVisionEncoderDecoderModel
+ >>> from transformers import ViTImageProcessor, FlaxVisionEncoderDecoderModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = ViTFeatureExtractor.from_pretrained("google/vit-base-patch16-224-in21k")
+ >>> image_processor = ViTImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
>>> # initialize a vit-gpt2 from pretrained ViT and GPT2 models. Note that the cross-attention layers will be randomly initialized
>>> model = FlaxVisionEncoderDecoderModel.from_encoder_decoder_pretrained(
... "google/vit-base-patch16-224-in21k", "gpt2"
... )
- >>> pixel_values = feature_extractor(images=image, return_tensors="np").pixel_values
+ >>> pixel_values = image_processor(images=image, return_tensors="np").pixel_values
>>> encoder_outputs = model.encode(pixel_values)
```"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
@@ -487,7 +487,7 @@ class FlaxVisionEncoderDecoderModel(FlaxPreTrainedModel):
Example:
```python
- >>> from transformers import ViTFeatureExtractor, FlaxVisionEncoderDecoderModel
+ >>> from transformers import ViTImageProcessor, FlaxVisionEncoderDecoderModel
>>> import jax.numpy as jnp
>>> from PIL import Image
>>> import requests
@@ -495,14 +495,14 @@ class FlaxVisionEncoderDecoderModel(FlaxPreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = ViTFeatureExtractor.from_pretrained("google/vit-base-patch16-224-in21k")
+ >>> image_processor = ViTImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
>>> # initialize a vit-gpt2 from pretrained ViT and GPT2 models. Note that the cross-attention layers will be randomly initialized
>>> model = FlaxVisionEncoderDecoderModel.from_encoder_decoder_pretrained(
... "google/vit-base-patch16-224-in21k", "gpt2"
... )
- >>> pixel_values = feature_extractor(images=image, return_tensors="np").pixel_values
+ >>> pixel_values = image_processor(images=image, return_tensors="np").pixel_values
>>> encoder_outputs = model.encode(pixel_values)
>>> decoder_start_token_id = model.config.decoder.bos_token_id
@@ -617,14 +617,14 @@ class FlaxVisionEncoderDecoderModel(FlaxPreTrainedModel):
Examples:
```python
- >>> from transformers import FlaxVisionEncoderDecoderModel, ViTFeatureExtractor, GPT2Tokenizer
+ >>> from transformers import FlaxVisionEncoderDecoderModel, ViTImageProcessor, GPT2Tokenizer
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = ViTFeatureExtractor.from_pretrained("google/vit-base-patch16-224-in21k")
+ >>> image_processor = ViTImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
>>> # load output tokenizer
>>> tokenizer_output = GPT2Tokenizer.from_pretrained("gpt2")
@@ -634,7 +634,7 @@ class FlaxVisionEncoderDecoderModel(FlaxPreTrainedModel):
... "google/vit-base-patch16-224-in21k", "gpt2"
... )
- >>> pixel_values = feature_extractor(images=image, return_tensors="np").pixel_values
+ >>> pixel_values = image_processor(images=image, return_tensors="np").pixel_values
>>> # use GPT2's eos_token as the pad as well as eos token
>>> model.config.eos_token_id = model.config.decoder.eos_token_id
diff --git a/src/transformers/models/vision_text_dual_encoder/modeling_flax_vision_text_dual_encoder.py b/src/transformers/models/vision_text_dual_encoder/modeling_flax_vision_text_dual_encoder.py
index aac1b0e8e9..6c6235f518 100644
--- a/src/transformers/models/vision_text_dual_encoder/modeling_flax_vision_text_dual_encoder.py
+++ b/src/transformers/models/vision_text_dual_encoder/modeling_flax_vision_text_dual_encoder.py
@@ -106,8 +106,8 @@ VISION_TEXT_DUAL_ENCODER_INPUTS_DOCSTRING = r"""
[What are position IDs?](../glossary#position-ids)
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
- a feature extractor (e.g. if you use ViT as the encoder, you should use [`ViTFeatureExtractor`]). See
- [`ViTFeatureExtractor.__call__`] for details.
+ an image processor (e.g. if you use ViT as the encoder, you should use [`ViTImageProcessor`]). See
+ [`ViTImageProcessor.__call__`] for details.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
diff --git a/src/transformers/models/vit/modeling_flax_vit.py b/src/transformers/models/vit/modeling_flax_vit.py
index 5d0527f5a7..0ba305e936 100644
--- a/src/transformers/models/vit/modeling_flax_vit.py
+++ b/src/transformers/models/vit/modeling_flax_vit.py
@@ -70,8 +70,8 @@ VIT_START_DOCSTRING = r"""
VIT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`numpy.ndarray` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`ViTFeatureExtractor`]. See
- [`ViTFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`ViTImageProcessor`]. See [`ViTImageProcessor.__call__`]
+ for details.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
@@ -565,17 +565,17 @@ FLAX_VISION_MODEL_DOCSTRING = """
Examples:
```python
- >>> from transformers import ViTFeatureExtractor, FlaxViTModel
+ >>> from transformers import ViTImageProcessor, FlaxViTModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = ViTFeatureExtractor.from_pretrained("google/vit-base-patch16-224-in21k")
+ >>> image_processor = ViTImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
>>> model = FlaxViTModel.from_pretrained("google/vit-base-patch16-224-in21k")
- >>> inputs = feature_extractor(images=image, return_tensors="np")
+ >>> inputs = image_processor(images=image, return_tensors="np")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
```
@@ -648,7 +648,7 @@ FLAX_VISION_CLASSIF_DOCSTRING = """
Example:
```python
- >>> from transformers import ViTFeatureExtractor, FlaxViTForImageClassification
+ >>> from transformers import ViTImageProcessor, FlaxViTForImageClassification
>>> from PIL import Image
>>> import jax
>>> import requests
@@ -656,10 +656,10 @@ FLAX_VISION_CLASSIF_DOCSTRING = """
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = ViTFeatureExtractor.from_pretrained("google/vit-base-patch16-224")
+ >>> image_processor = ViTImageProcessor.from_pretrained("google/vit-base-patch16-224")
>>> model = FlaxViTForImageClassification.from_pretrained("google/vit-base-patch16-224")
- >>> inputs = feature_extractor(images=image, return_tensors="np")
+ >>> inputs = image_processor(images=image, return_tensors="np")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
diff --git a/src/transformers/models/vit/modeling_tf_vit.py b/src/transformers/models/vit/modeling_tf_vit.py
index 8ce5420169..7fd664644e 100644
--- a/src/transformers/models/vit/modeling_tf_vit.py
+++ b/src/transformers/models/vit/modeling_tf_vit.py
@@ -41,7 +41,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "ViTConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "ViTFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "ViTImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "google/vit-base-patch16-224-in21k"
@@ -629,8 +629,8 @@ VIT_START_DOCSTRING = r"""
VIT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`np.ndarray`, `tf.Tensor`, `List[tf.Tensor]` ``Dict[str, tf.Tensor]` or `Dict[str, np.ndarray]` and each example must have the shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`ViTFeatureExtractor`]. See
- [`ViTFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`ViTImageProcessor`]. See [`ViTImageProcessor.__call__`]
+ for details.
head_mask (`np.ndarray` or `tf.Tensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
diff --git a/src/transformers/models/vit/modeling_vit.py b/src/transformers/models/vit/modeling_vit.py
index 2bf59866ef..1b937750c0 100644
--- a/src/transformers/models/vit/modeling_vit.py
+++ b/src/transformers/models/vit/modeling_vit.py
@@ -42,7 +42,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "ViTConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "ViTFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "ViTImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "google/vit-base-patch16-224-in21k"
@@ -481,8 +481,8 @@ VIT_START_DOCSTRING = r"""
VIT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`ViTFeatureExtractor`]. See
- [`ViTFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`ViTImageProcessor`]. See [`ViTImageProcessor.__call__`]
+ for details.
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -664,7 +664,7 @@ class ViTForMaskedImageModeling(ViTPreTrainedModel):
Examples:
```python
- >>> from transformers import ViTFeatureExtractor, ViTForMaskedImageModeling
+ >>> from transformers import ViTImageProcessor, ViTForMaskedImageModeling
>>> import torch
>>> from PIL import Image
>>> import requests
@@ -672,11 +672,11 @@ class ViTForMaskedImageModeling(ViTPreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = ViTFeatureExtractor.from_pretrained("google/vit-base-patch16-224-in21k")
+ >>> image_processor = ViTImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
>>> model = ViTForMaskedImageModeling.from_pretrained("google/vit-base-patch16-224-in21k")
>>> num_patches = (model.config.image_size // model.config.patch_size) ** 2
- >>> pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
+ >>> pixel_values = image_processor(images=image, return_tensors="pt").pixel_values
>>> # create random boolean mask of shape (batch_size, num_patches)
>>> bool_masked_pos = torch.randint(low=0, high=2, size=(1, num_patches)).bool()
diff --git a/src/transformers/models/vit_mae/modeling_tf_vit_mae.py b/src/transformers/models/vit_mae/modeling_tf_vit_mae.py
index 6ecec70623..ef5de25457 100644
--- a/src/transformers/models/vit_mae/modeling_tf_vit_mae.py
+++ b/src/transformers/models/vit_mae/modeling_tf_vit_mae.py
@@ -770,8 +770,8 @@ VIT_MAE_START_DOCSTRING = r"""
VIT_MAE_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`np.ndarray`, `tf.Tensor`, `List[tf.Tensor]` ``Dict[str, tf.Tensor]` or `Dict[str, np.ndarray]` and each example must have the shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
head_mask (`np.ndarray` or `tf.Tensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -830,17 +830,17 @@ class TFViTMAEModel(TFViTMAEPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, TFViTMAEModel
+ >>> from transformers import AutoImageProcessor, TFViTMAEModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/vit-mae-base")
+ >>> image_processor = AutoImageProcessor.from_pretrained("facebook/vit-mae-base")
>>> model = TFViTMAEModel.from_pretrained("facebook/vit-mae-base")
- >>> inputs = feature_extractor(images=image, return_tensors="tf")
+ >>> inputs = image_processor(images=image, return_tensors="tf")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
```"""
@@ -1121,17 +1121,17 @@ class TFViTMAEForPreTraining(TFViTMAEPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, TFViTMAEForPreTraining
+ >>> from transformers import AutoImageProcessor, TFViTMAEForPreTraining
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/vit-mae-base")
+ >>> image_processor = AutoImageProcessor.from_pretrained("facebook/vit-mae-base")
>>> model = TFViTMAEForPreTraining.from_pretrained("facebook/vit-mae-base")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> loss = outputs.loss
>>> mask = outputs.mask
diff --git a/src/transformers/models/vit_mae/modeling_vit_mae.py b/src/transformers/models/vit_mae/modeling_vit_mae.py
index 02bf80773d..39be66e691 100755
--- a/src/transformers/models/vit_mae/modeling_vit_mae.py
+++ b/src/transformers/models/vit_mae/modeling_vit_mae.py
@@ -612,8 +612,8 @@ VIT_MAE_START_DOCSTRING = r"""
VIT_MAE_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -677,17 +677,17 @@ class ViTMAEModel(ViTMAEPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, ViTMAEModel
+ >>> from transformers import AutoImageProcessor, ViTMAEModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/vit-mae-base")
+ >>> image_processor = AutoImageProcessor.from_pretrained("facebook/vit-mae-base")
>>> model = ViTMAEModel.from_pretrained("facebook/vit-mae-base")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
```"""
@@ -978,17 +978,17 @@ class ViTMAEForPreTraining(ViTMAEPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, ViTMAEForPreTraining
+ >>> from transformers import AutoImageProcessor, ViTMAEForPreTraining
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/vit-mae-base")
+ >>> image_processor = AutoImageProcessor.from_pretrained("facebook/vit-mae-base")
>>> model = ViTMAEForPreTraining.from_pretrained("facebook/vit-mae-base")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> loss = outputs.loss
>>> mask = outputs.mask
diff --git a/src/transformers/models/vit_msn/modeling_vit_msn.py b/src/transformers/models/vit_msn/modeling_vit_msn.py
index 43e9aa81a0..54be1afcc8 100644
--- a/src/transformers/models/vit_msn/modeling_vit_msn.py
+++ b/src/transformers/models/vit_msn/modeling_vit_msn.py
@@ -464,8 +464,8 @@ VIT_MSN_START_DOCSTRING = r"""
VIT_MSN_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -532,7 +532,7 @@ class ViTMSNModel(ViTMSNPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, ViTMSNModel
+ >>> from transformers import AutoImageProcessor, ViTMSNModel
>>> import torch
>>> from PIL import Image
>>> import requests
@@ -540,9 +540,9 @@ class ViTMSNModel(ViTMSNPreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/vit-msn-small")
+ >>> image_processor = AutoImageProcessor.from_pretrained("facebook/vit-msn-small")
>>> model = ViTMSNModel.from_pretrained("facebook/vit-msn-small")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
@@ -627,7 +627,7 @@ class ViTMSNForImageClassification(ViTMSNPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, ViTMSNForImageClassification
+ >>> from transformers import AutoImageProcessor, ViTMSNForImageClassification
>>> import torch
>>> from PIL import Image
>>> import requests
@@ -637,10 +637,10 @@ class ViTMSNForImageClassification(ViTMSNPreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/vit-msn-small")
+ >>> image_processor = AutoImageProcessor.from_pretrained("facebook/vit-msn-small")
>>> model = ViTMSNForImageClassification.from_pretrained("facebook/vit-msn-small")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
diff --git a/src/transformers/models/yolos/modeling_yolos.py b/src/transformers/models/yolos/modeling_yolos.py
index 62b03cfd4d..71c9ddb37e 100755
--- a/src/transformers/models/yolos/modeling_yolos.py
+++ b/src/transformers/models/yolos/modeling_yolos.py
@@ -53,7 +53,7 @@ logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "YolosConfig"
-_FEAT_EXTRACTOR_FOR_DOC = "YolosFeatureExtractor"
+_FEAT_EXTRACTOR_FOR_DOC = "YolosImageProcessor"
# Base docstring
_CHECKPOINT_FOR_DOC = "hustvl/yolos-small"
@@ -83,7 +83,7 @@ class YolosObjectDetectionOutput(ModelOutput):
pred_boxes (`torch.FloatTensor` of shape `(batch_size, num_queries, 4)`):
Normalized boxes coordinates for all queries, represented as (center_x, center_y, width, height). These
values are normalized in [0, 1], relative to the size of each individual image in the batch (disregarding
- possible padding). You can use [`~DetrFeatureExtractor.post_process`] to retrieve the unnormalized bounding
+ possible padding). You can use [`~DetrImageProcessor.post_process`] to retrieve the unnormalized bounding
boxes.
auxiliary_outputs (`list[Dict]`, *optional*):
Optional, only returned when auxilary losses are activated (i.e. `config.auxiliary_loss` is set to `True`)
@@ -573,8 +573,8 @@ YOLOS_START_DOCSTRING = r"""
YOLOS_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
- Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
- [`AutoFeatureExtractor.__call__`] for details.
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
+ [`AutoImageProcessor.__call__`] for details.
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
@@ -756,7 +756,7 @@ class YolosForObjectDetection(YolosPreTrainedModel):
Examples:
```python
- >>> from transformers import AutoFeatureExtractor, AutoModelForObjectDetection
+ >>> from transformers import AutoImageProcessor, AutoModelForObjectDetection
>>> import torch
>>> from PIL import Image
>>> import requests
@@ -764,17 +764,17 @@ class YolosForObjectDetection(YolosPreTrainedModel):
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
- >>> feature_extractor = AutoFeatureExtractor.from_pretrained("hustvl/yolos-tiny")
+ >>> image_processor = AutoImageProcessor.from_pretrained("hustvl/yolos-tiny")
>>> model = AutoModelForObjectDetection.from_pretrained("hustvl/yolos-tiny")
- >>> inputs = feature_extractor(images=image, return_tensors="pt")
+ >>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # convert outputs (bounding boxes and class logits) to COCO API
>>> target_sizes = torch.tensor([image.size[::-1]])
- >>> results = feature_extractor.post_process_object_detection(
- ... outputs, threshold=0.9, target_sizes=target_sizes
- ... )[0]
+ >>> results = image_processor.post_process_object_detection(outputs, threshold=0.9, target_sizes=target_sizes)[
+ ... 0
+ ... ]
>>> for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
... box = [round(i, 2) for i in box.tolist()]
diff --git a/templates/adding_a_new_model/README.md b/templates/adding_a_new_model/README.md
index 4bb6663937..c8ee0ce667 100644
--- a/templates/adding_a_new_model/README.md
+++ b/templates/adding_a_new_model/README.md
@@ -186,14 +186,14 @@ wish, as it will appear on the Model Hub. Do not forget to include the organisat
Then you will have to say whether your model re-uses the same processing classes as the model you're cloning:
```
-Will your new model use the same processing class as Xxx (XxxTokenizer/XxxFeatureExtractor)
+Will your new model use the same processing class as Xxx (XxxTokenizer/XxxFeatureExtractor/XxxImageProcessor)
```
Answer yes if you have no intentions to make any change to the class used for preprocessing. It can use different
files (for instance you can reuse the `BertTokenizer` with a new vocab file).
If you answer no, you will have to give the name of the classes
-for the new tokenizer/feature extractor/processor (depending on the model you're cloning).
+for the new tokenizer/image processor/feature extractor/processor (depending on the model you're cloning).
Next the questionnaire will ask